
La sabiduría de las masas ahora precide hasta el apocalipsis: 20 a 1 a que hay hongo nuclear en marzo.

Olvídate de los dados trucados: este lanzamiento de una moneda cuántica es tan aleatorio que ni el universo sabe con anticipación qué saldrá.

A todos nos ha sucedido eso de llegar a la parada del autobús, o el metro, y ver que según el póster informativo el tiempo medio de paso es de x minutos y pararnos a pensar: «estupendo, de promedio sólo tendré...
El arquetipo del azar suele representarse con el lanzamiento de una moneda al aire. Es indiferente si cae sobre la palma de la mano, el suelo, si es un euro, una vieja peseta o un dracma: todos son sistemas físicos y...

En este episodio de uno de nuestros canales favoritos, Numberphile, entrevistan al no menos admirado Marcus du Satoy acerca de las estratégicas matemáticas del Risk, uno de los arquetípicos juegos de mesa de la categoría de estrategia. TL;DR: ataca a muerte....

Una frase que se oye a menudo es esa de «¡Es imposible lograrlo! ¡Hay una posibilidad entre un millón!»* pero todos sabemos que pocos sucesos tienen exactamente esa probabilidad. Para hacernos una idea de cuán lejos están algunas cuestiones está ese...

En un reciente artículo, Mathieu Cesbron analiza Los números en los mitos de la creación y ¡sorpresa! El número 7 aparece mucho más mencionado de lo que cabría esperar, así, tal cual. Cesbron tomó unos 200 textos relativos a la creación...
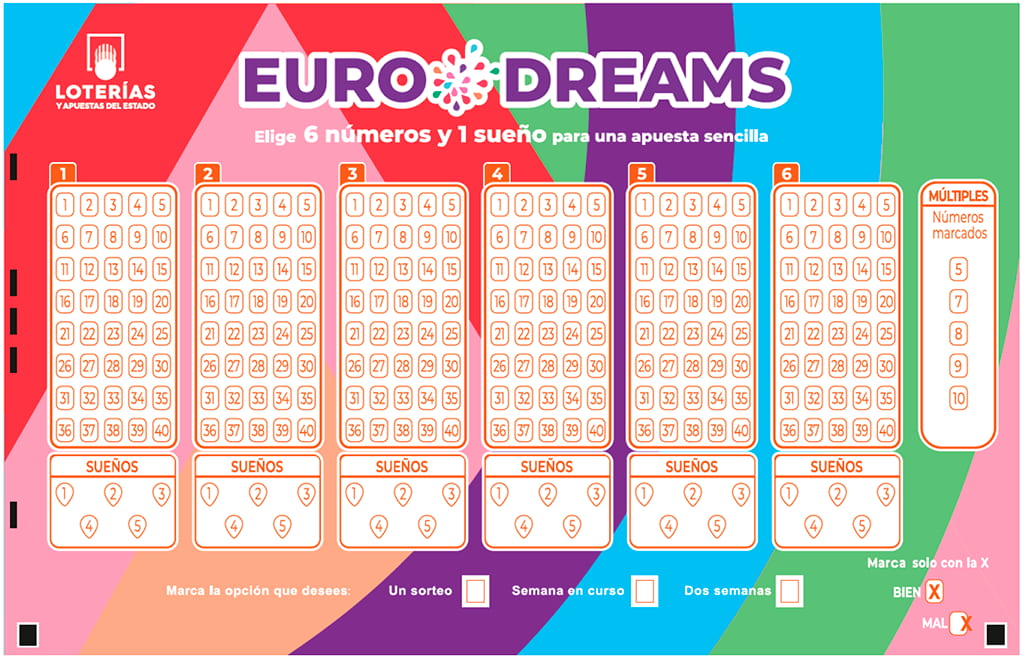
El organismo de Loterías y Apuestas del Estado lanza este 6 de noviembre una nueva variante de la lotería primitiva, la bonoloto y el Euromillones llamada Eurodreams. El juego es bastante sencillo de analizar, pero lo más interesante es la forma...
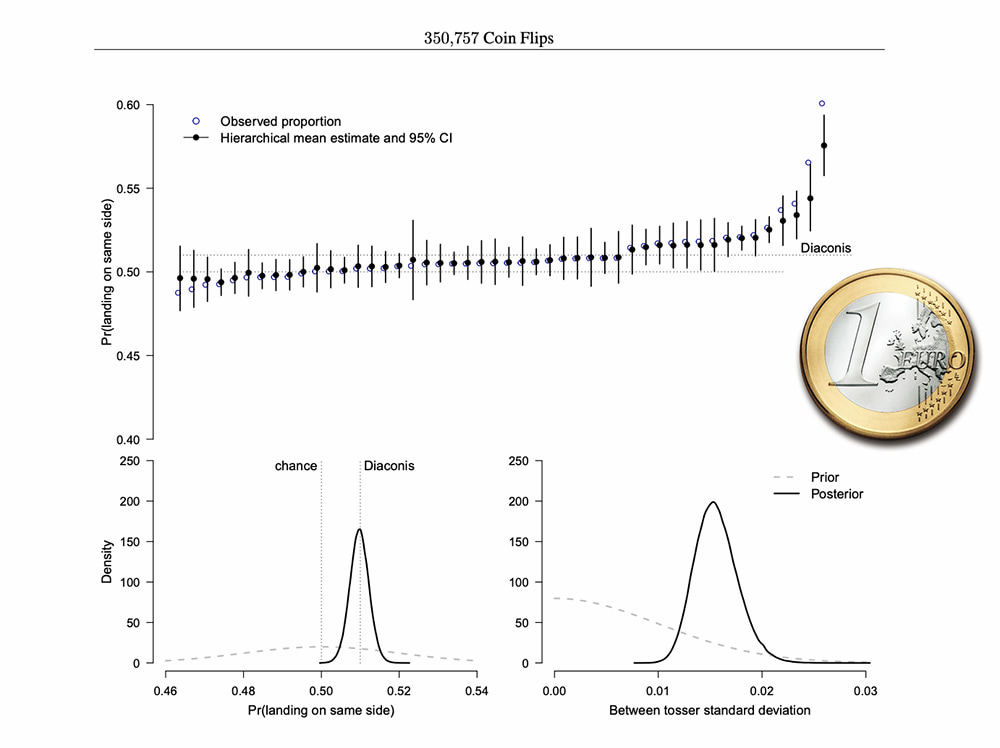
Un grupo de decenas de matemáticos se han pegado la currada de lanzar 350.757 monedas al aire y anotar los resultados para comprobar de qué modo «aterrizan» y cuál es el efecto físico del asunto, frente a la predicción matemática de...

Este fin de semana pude ver un par de documentales sobre el famoso caso del boleto millonario de Lotería Primitiva perdido y encontrado en A Coruña en 2012 que, aunque parezca imposible, a día de hoy todavía sigue coleando. Aquello sucedió...

Aleatoriedad: esa cosa que parece un sinsentido, pero resulta vital. Computadoras, tortugas y bonos del estado muestran su apasionante historia.

Qué gran alegría reencontrarme con The World Is Built On Probability (El mundo se basa en la probabilidad), un clásico de las matemáticas de Lev Tarasov publicado en 1984 (en ruso) por la legendaria editorial soviética MIR Publishers, que tenía unos...

He aquí una charla/entrevista de dos horas que no se hace larga, sino todo lo contrario. Es el episodio #71 de Kapital, un podcast de Joan Tubau, quien lleva cerca de dos años publicando material sumamente interesante tanto en forma de...

En este artículo de la National Library of Medicine unos investigadores explican cómo decidieron examinar hasta qué medida afectaba la aleatoriedad (o falta de ella) de algunos generadores de números aleatorios (RNGs) a las simulaciones de Monte Carlo, un método utilizado...
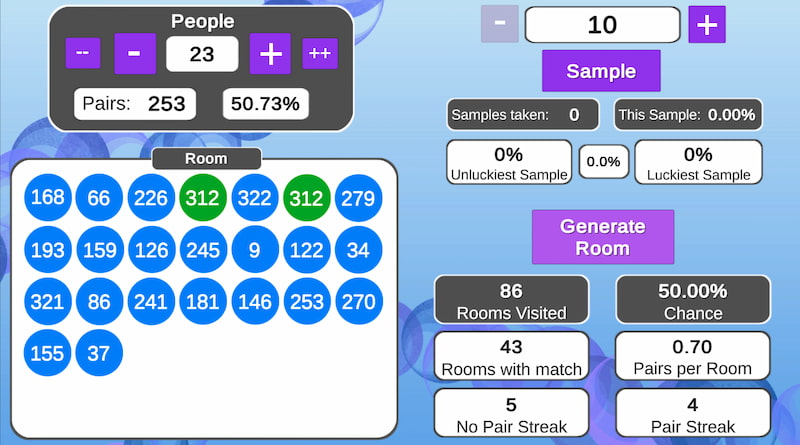
Para presentar la archiconocida paradoja del cumpleaños se suele hacer ver a la gente reunida en una clase cuántas personas hay –quizá 30 ó 40– y que un año tiene 365 días. Luego se pregunta si creen probable que dos personas...

John D. Cook tiene una serie de interesantes anotaciones sobre generadores de números aleatorios a las que se puede acceder bajo la etiqueta: RNG. Esto tiene aplicaciones tanto en criptografía como en muchas áreas de física y matemáticas, incluyendo las simulaciones....

James de The Action Lab muestra en este vídeo cómo se puede construir el equivalente a un dado de seis caras pero con una pelota de ping-pong esférica, lo que los roleros llamarían un D6 esférico. Esto que en principio parece...
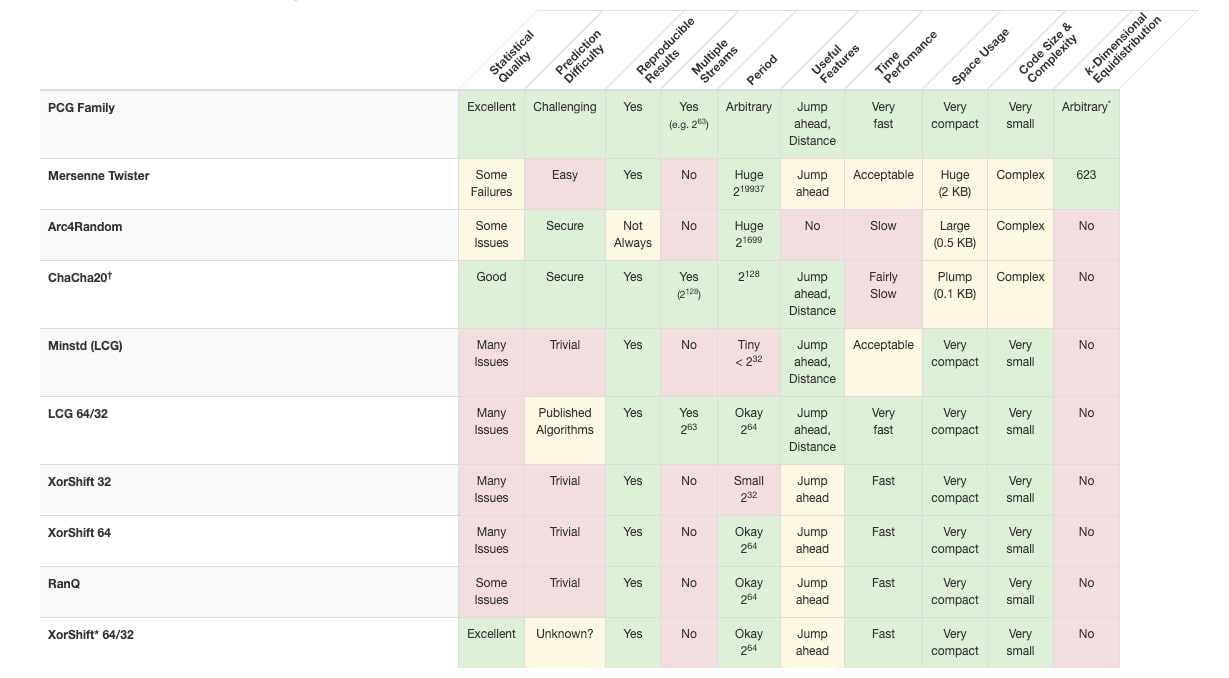
Generar números aleatorios no es fácil para los ordenadores, inherentemente deterministas. Por eso se trabaja en algoritmos que permitan generarlos cumpliendo con diferentes definiciones de aleatoriedad y a la vez ciertas premisas: que no requieran mucha memoria, que el código sea...

Dependiendo de la situación puedes elegir cómo enmarcar tu toma de decisiones. Depende de si la situación requiere elegir entre acciones o formarse una opinión en base a las evidencias.– Cassie Kozyrkovz Según Cassie Kozyrkovz, Jefa de Inteligencia de Decisión de...
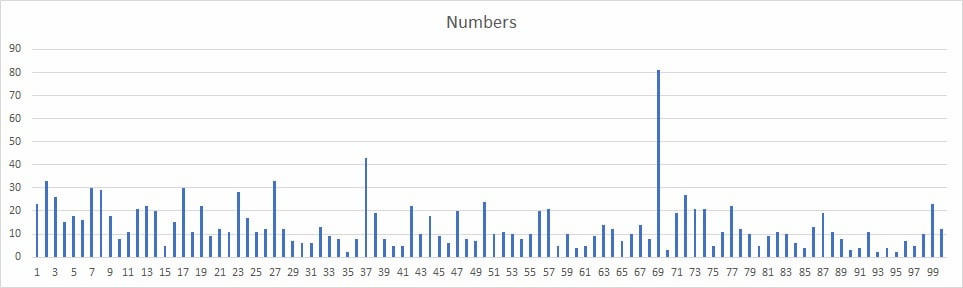
MahoganyForest pidió así como quien no quiere la cosa a un montón de gente de Reddit que eligieran un número entre 1 y 100. Tras ~1.300 respuestas este fue el resultado: 69, 37, 2, 27, 7, 17, 8, 23… En el...
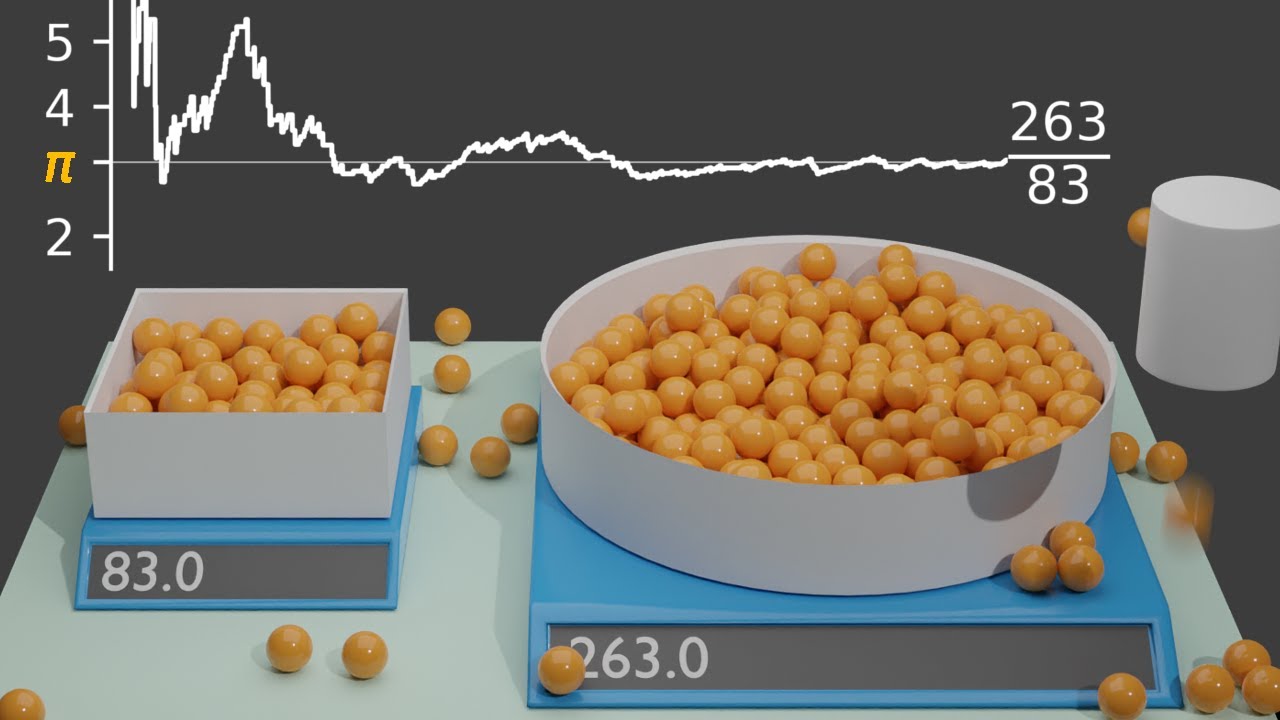
En el canal MarbleScience, que al parecer se dedica a hacer cosas divertidas con canicas, han construido esta Una simulación de Monte Carlo para calcular el valor de π. Al igual que otras de este tipo consiste en dejar actuar al...

Este es un vídeo de nivel frikismo máximo en el que se crea un laberinto diabólico en el famoso juego de simulación de parques de atracciones RollerCoaster Tycoon 2. La particularidad es que se trata de un laberinto imposible, no tanto...

Si un dado no te parece lo suficientemente aleatorio para generar un número al azar Brian Haidet, también conocido como AlphaPhoenix, tiene la solucuón para ti: un generador de números al azar que depende de la descomposición de partículas subatómicas, también...

Utilizando las herramientas de Observable HQ, muy potentes y siempre sorprendentes, he aquí una demostración visual denominada «Mathe Carlo».
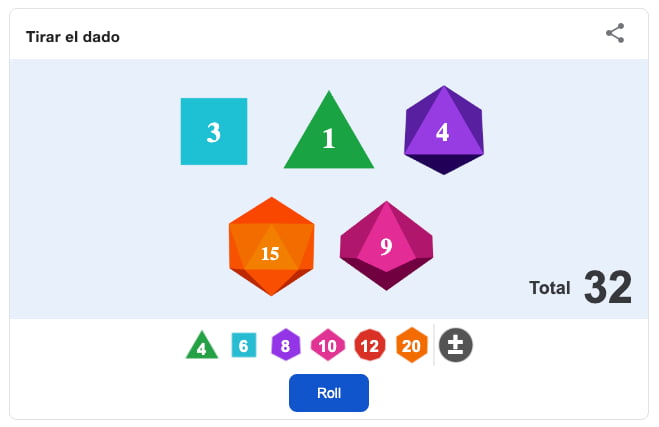
Si no hay dados a mano y necesitas hacer una tirada para algún juego o para alguna importante toma de decisión en la vida que quieras dejar en manos del azar, Google tiene una nueva función: Roll dice (Tirar el dado)....

Hace poco expresé mi sorpresa respecto al reciente fenómeno del joven de 16 años que ganó millones en la Copa del Mundo de Fortnite, hecho que algunos consideraban más rentable que deportes como el Tour de Francia, al menos en los...
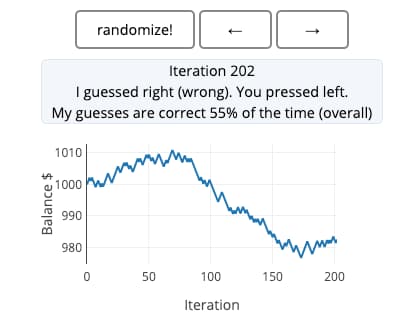
¡Ah, el elusivo azar! Qué malos somos los humanos intentando emularlo. El caso es que me encontré con Not So Random («No tan aleatorio») es un experimento interactivo inspirado en el oráculo de Aaronson: el ordenador «adivina» qué teclas vas a...

Todas las novelas y películas son iguales: el protagonista tiene un objetivo que conseguir. Pasa por muchas dificultades en su camino, y en algún momento parece que no vaya a ser capaz de lograrlo. Sin embargo, al final supera las dificultades...
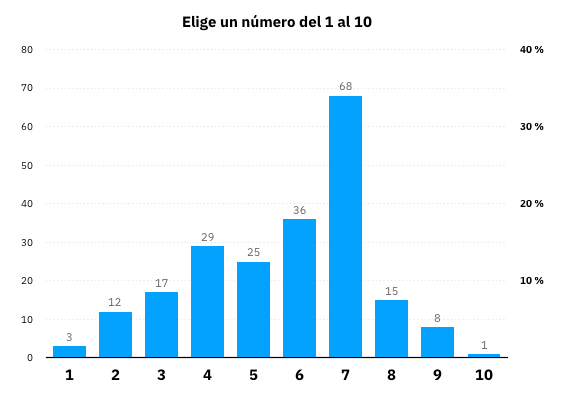
Alguien llamado RekkyRekReddit lanzó una pregunta a toda la gente que estaba conectada al servidor de su comunidad de videojuegos: que eligieran un número del 1 al 10. El gráfico muestra el resultado. El estudio no es que sea demasiado científico...

En los sorteos de ayer y hoy de dos loterías españolas distintas (el Cuponazo de la Once y la Lotería Nacional) el número ganador resultó ser el mismo, el 73073. ¿Cuál es la probabilidad de que ocurra esto? Realmente es un...

Esta elegante Máquina de Galton de Grand Illusions es una versión bastante simple y bien diseñada del experimento de Francis Galton con el que se puede enseñar cómo de las colisiones al azar de unas bolitas que caen alrededor de unos...

Charlando sobre la Aleatoriedad a partir de 64:00 En este episodio del podcast Los Crononautas #S02E23 estuvimos charlando sobre la aleatoriedad, algo a lo que en este blog le dedicamos una categoría temática completa, cosa que no hacemos con muchos temas. Puede...

Con el sugerente título de Experimentally generated randomness certified by the impossibility of superluminal signals un artículo publicado en Nature ($) describe un nuevo sistema que utiliza mediciones cuánticas para generar números aleatorios «certificados». En otras palabras: tienen la garantía de...
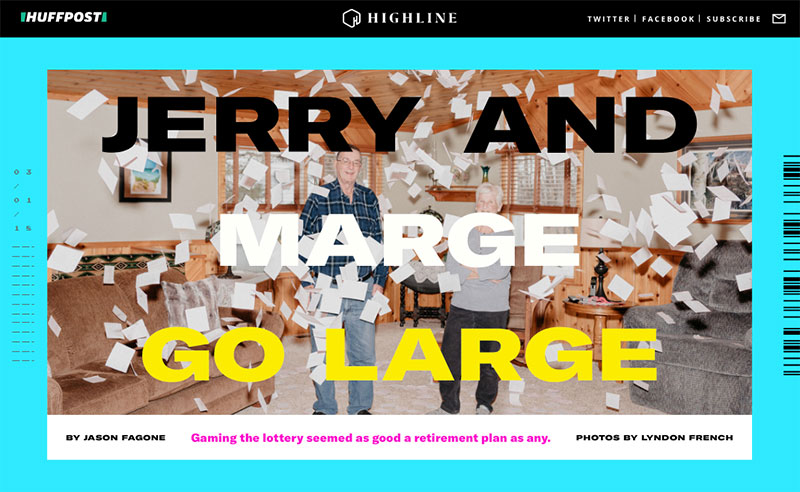
En el Huffington Post americano han publicado un larguísimo artículo de Jason Fagone sobre cómo una pareja de jubilados reventaron una de las loterías estadounidenses utilizando puramente análisis estadísticos. Son diez mil palabras, casi un pequeño libro, y la historia merece...

Según cuentan en BGR una señora de New Hampshire que ganó el superbote de la lotería Powerball estadounidense tiene que decidir entre salvaguardar su privacidad o cobrar un bote de 560 millones de dólares. La razón es que allí las reglas...
Encontré esta antigua pero sorprendente página con el Oráculo de Aaronson a través de una mención de pasada en un vídeo de las Infinite Series de PBS. Se trata de un simple entretenimiento consistente en pulsar las letras D y F...
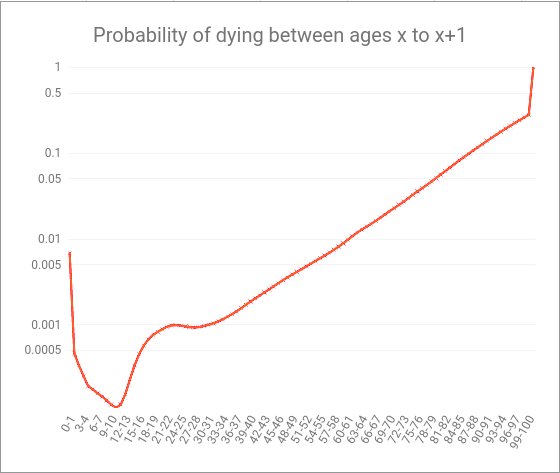
Me encontré en un tuit de @mezvan esta interesante gráfica sobre las probabilidades de morir a lo largo de la vida. Buscando algo más sobre su origen la vi mencionada en la ley de la mortalidad de Gompertz-Makeham y otros lugares....
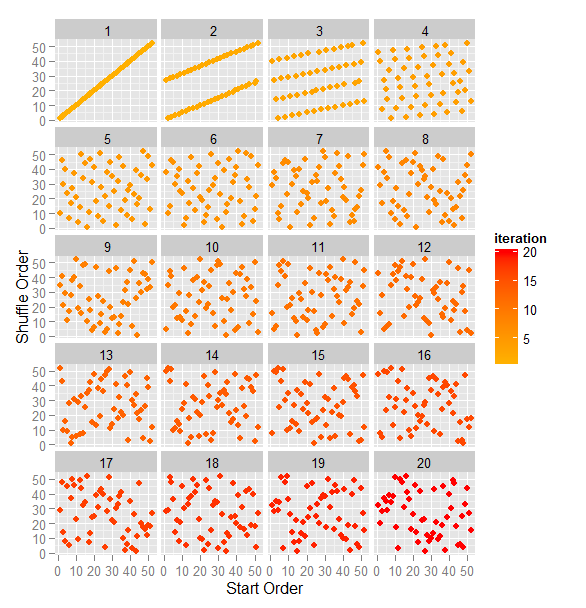
Las posiciones iniciales de los 52 naipes y cómo varían tras varias mezclas consecutivas / Stachyra Encontré un código de simulación para la mezcla americana de una baraja de naipes (escrito en R) bastante sencillo de entender y junto al que hay...

Driver, una creación de Dmitry Morozov, es un peculiar mecanismo interesante de observar –y un poco raro de escuchar– que ha sido calificado como una forma bastante complicada de generar números aleatorios. Según la descripción del autor: A todos los efectos...

Unos investigadores de la Universidad de Navarra han publicado un trabajo en el que analizan lo les sucede a 25.000 dados cuando se agitan al azar. El resultado es una ordenación bastante curiosa en forma de círculos concéntricos. Para que esto...

Tom Scott y el criptógrafo Nick Sullivan explican en este vídeo como la empresa Cloudflare –dedicada a servicios de contenidos y seguridad en Internet– utiliza en sus servidores varios métodos físicos, a cual más curioso y llamativo, para generar números aleatorios....
Los ordenadores necesitan números aleatorios para realizar todo tipo de tareas: simulaciones, juegos, criptografía, arte… Pero la forma de generarlos es puramente matemática, lo cual es un problema más que una ventaja: al cabo de un tiempo lo que parece aleatorio...

The Dice Lab es un curioso lugar en el que crean y fabrican dados para juegos de mesa. Tienen todos tipos de diseños, con prácticamente cualquier número de caras: 4, 6, 8, 10, 20, 30, 60… Incluso tienen dados de 3...
En la CNBC cuentan el curioso caso de un infiltrado que ha defraudado durante años a la Asociación de Loterías estadounidense, donde trabajaba como programador. Ahora se enfrenta a 25 años de prisión por haberse hecho ilegalmente con los premios de...

¿Es la creencia verdadera justificada un conocimiento? se preguntaba el filósofo Edmund Gettier hace medio siglo. ¿Sabemos cosas, conocemos cosas, es igual saber algo que conocerlo? Quizá esas cosas que simplemente sabemos no las conozcamos realmente; a lo mejor son ciertas...

Joe Hanson explica detalladamente en este episodio de It’s OK to be Smart qué es la suerte. O más bien, qué es lo que algunas personas consideran buena suerte o mala suerte y yendo un poco más allá por qué decimos...

Random Sanity Project es un servicio web con un único objetivo: comprobar y garantizar que las secuencias de números aleatorios que se generan con todo tipo de software son realmente aleatorias. La forma de hacerlo es mediante una API a la...
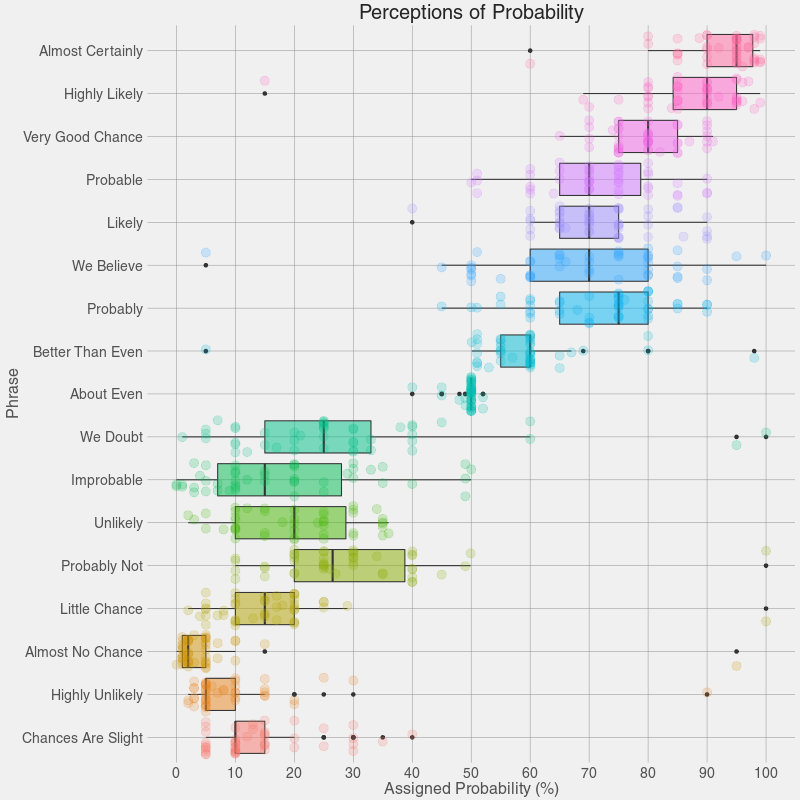
Perceptions of Probability es un trabajo de hace tiempo que Zonination presentó a los premios Information is Beautiful Awards. Básicamente consiste en preguntar a un grupo amplio de gente en qué probabilidad numérica (0-100%) creen que encajan diversos términos de los...

El jugador de póker profesional Dong Kim se enfrenta en el Casino Rivers de Pittsburgh –a través de la pantalla– con Libratus, la inteligencia artificial que resultó victoriosa en el reto Brains vs. AI Libratus se ha enfrentado a un grupo de...

Típica cola para comprar lotería en Doña Manolita – CC Barcex El pasado 22 de diciembre, aprovechando que coincidía con el día del Sorteo de Navidad, estuve hablando de lotería en el espacio que tenemos en Hoy por hoy A Coruña para...

Si piensas que gastas 20 euros en ahorrarte el disgusto que supondría que, no habiendo comprando el boleto, saliera el número premiado y todos tus compañeros se hicieran ricos menos tú, es posible que compense.– Florin DiacuCatedrático de MatemáticasUniversidad de Victoria...

Esta charla de Elie Bursztein en la Defcon 2016 muestra el funcionamiento con todo detalle de un curioso conjunto de dispositivos que él y un multidisciplinar grupo de hackers logró encontrar en el mercado negro. Se sabía su existencia, medio leyenda,...

Por aquí ya hemos hablado alguna vez de Persi Diaconis, un matemático de Stanford más conocido por sus trabajos sobre el azar y la aleatoriedad en objetos comunes, tales como las monedas, los dados o las barajas de naipes. Dos de...

BoltKey ha hecho un curioso experimento que –al menos para mí– ha vuelto a dejar muy claro que el concepto azar es elusivo, o que al menos los humanos no tenemos nada que hacer como generadores de azar. Multiclick permite a cualquiera...

Hace poco han cambiado las normas de Euromillones, la lotería tipo «loto» que une a nueve países de la zona europea a modo de federación de juego. Entre los cambios principales puestos en marcha a partir de septiembre de 2016 hay...
La Powerball estadounidense ha ido acumulando bote tras bote en los últimos meses, hasta el punto de que se están sorteando 1400 millones de dólares para quien tenga la suerte de acertar la combinación ganadora. (Eso son unos 1300 millones de...
Ya hemos comentando aquí que los seres humanos no somos muy buenos en ciertas técnicas matemáticas (calcular probabilidades, entender los grandes números o el crecimiento exponencial). Pues bien: tampoco somos muy buenos generando secuencias de números al azar. Dos minutos bastan...
¿Te imaginas jugar a una lotería en la que tu número es el mismo que el de todos tus vecinos, pero solo resultas premiado si has apostado? Al parecer es cómo funciona la Nationale Postcode Loterij, una lotería de carácter no lucrativo...
Peter Norvig, ex-Google, explica en un extenso artículo con código en Python cómo crear simulaciones para entender algunos de los problemas y paradojas clásicas de la matemática probabilística. En concreto emplea ejemplos con dados, fechas de nacimiento, cuestiones sobre el nacimiento...
Andrew Lloyd se preguntó qué pasaría si se apuntaba a 1000 concursos y sorteos de esos que aparecen en las tiendas, revistas, periódicos y televisión. ¿Cuántos ganaría? ¿Cuánto tiempo necesitaría? ¿Merecería la pena? Aprovechando las circunstancias grabó su experiencia en vídeo;...
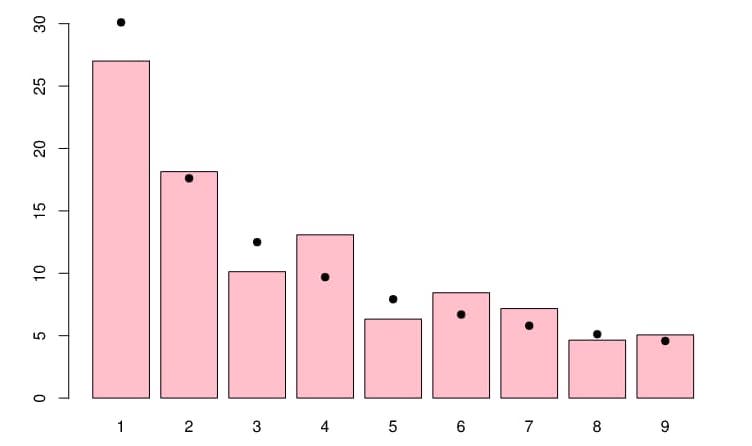
Este gráfico muestra las veces que aparecen los números del 1 al 10 en diversos libros publicados en inglés a lo largo de los dos últimos siglos. Está expresado (diría yo) en porcentajes sobre el total de todas las palabras contenidas...
Pulsando al azar el botón/enlace Página aleatoria de la Wikipedia y anotando y clasificando los resultados manualmente se obtuvo el gráfico de la imagen, que muestra a las claras qué áreas del conocimiento humano están más representadas en la enciclopedia libre....
Dos personas están en un gran estadio lleno de gente, se separan y se pierden. Quieren encontrarse la una a la otra, pero no han acordado nada de antemano; la única forma que tienen de localizarse es deambular buscándose. Tal vez...
Hablando de fascinantes historias de aleatoriedad Charles Oberon recuperó la historia aquella de cuando medio mundo se volvió loco porque sus iTunes (puede ser que incluso los iPod) reproducían canciones en modo aleatorio que parecía poco aleatorio: Apple tuvo que desarrollar un...

Persi Diaconis es un conocido e interesantísimo matemático que como otros fue en una época anterior mago profesional y que plantea en este vídeo de Numberphile una curiosa cuestión sobre monedas y aleatoriedad. Su área de especialización es el azar y...
Cuando de juegos de azar se trata es importante que todos los elementos que los componen (dados, bolas, naipes) sean iguales. Sin embargo el bueno de Mark Frauenfelder descubrió algunas curiosidades pesando los naipes con una balanza de alta precisión (0,01 g)...
Esta app para iPhone llamada apropiadamente Am I Going Down? utiliza información pública sobre aerolíneas, modelos de avión, rutas, etcétera para calcular la probabilidad de un accidente de avión. Si hay huevos la puedes usar antes de embarcar. Eso sí: aunque...
Un grupo de matemáticos de la Universidad de Alberta han dado con un un algoritmo imbatible al póker (variante Texas Hold'em) como se puede leer en Science (Texas Hold 'em poker solved by computer), Scientific American (Game Theorists Crack Poker), Spectrum...
La aversión al riesgo es la forma en que economistas, matemáticos y psicólogos explican fenómeno muy común que en cierto modo desafía a la lógica. Más o menos dice así: cuando actuamos en términos económicos y de juegos las personas tendemos...
Los españoles gastamos tanto dinero en la Lotería de Navidad que la cifra equivale al 0,3 por ciento del Producto Interior Bruto (PIB) del país. Además, se ha calculado que si el Gordo cae concentrado en una provincia determinada su PIB aumenta...

El agraciado oso amarillo, un disfraz habitual en estos casos en China(Foto: ChinaNews.com) El afortunado ganador del premio equivalente a unos 65 millones de euros en la lotería China de la provincia de Shanxi acudió a una rueda de prensa disfrazado de...

¿Qué es la aleatoriedad? ¿Cómo podemos saber que un algo, como una secuencia, un lanzamiento de dados o un proceso es verdaderamente aleatorio? ¿Y si simplemente parece aleatorio pero no lo hemos observado con suficiente cuidado, o durante suficiente tiempo como...
Lo más bonito de estas explicaciones matemáticas es cuando la zona de los valores obtenidos en el «experimento» («Actual») van coincidendo lenta pero inexorablemente con los valores esperados («Expected») de forma milimétricamente precisa. La visualización es de Victor Power y muestras...
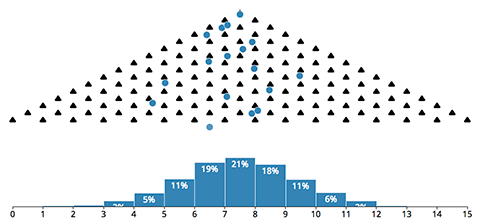
En probabilidad, el Teorema del límite central viene a decir que En condiciones muy generales, si Sn es la suma de n variables aleatorias independientes, entonces la función de distribución de Sn «se aproxima bien» a una distribución normal (también llamada...
Este artículo se publicó originalmente en Cooking Ideas, un blog de Vodafone donde colaboramos semanalmente con el objetivo de crear historias que «alimenten la mente de ideas». Imagina que estás un día cualquiera leyendo a tus colegas en Twitter o repasando...
¿Y por qué? . . . Aleatoridad no es lo mismo que uniformidad. Y resulta que del mismo modo que nos cuesta mucho generar mentalmente una serie de valores realmente aleatorios, los seres humanos no somos demasiado buenos juzgando la aleatoriedad....
Unos tipos intentaron ganar en México la Loto (allí llamada Revancha) mediante una idea la mar de ingeniosa a la par que compleja y arriesgada- casi de guión de película de suspense. La idea surgió de quienes eran los responsables subcontratados para...
Tenía por ahí guardado para revisar este episodio de Redes titulado Descifrar las probabilidades en la vida , donde Punset entrevista a Amir Aczel (autor de Chance: A Guide to Gambling, Love, the Stock Market, and Just About Everything Else) acerca...
En Yorokobu tienen una recopilación estupenda de Los mejores logos según los Premios Brand New, que algo saben del tema. La verdad es que son todos una maravilla....
¿Existe el azar? ¿Y la causalidad? ¿Y si todo es determinista, qué es el azar? ¿No sería el indeterminismo prueba de nuestro desconocimiento? ¿Cómo afecta esto al determinismo? ¿Es la física cuántica no determinista? ¿Son los sucesos probabilísticos no deterministas? ¿Qué es...
Aciago día hoy martes y 13, creen muchas personas. ¿No tanto? He aquí un ejemplo la mar de curioso que nos envió Carlos Adán. Carlos es conocido por haber participado en algunos concursos televisivos; de hecho es el protagonista del mítico vídeo...

Tienen una vida y se la van a jugar. Primero fue el libro, que parecía casi el guión de una película, y ahora es… la película. La Fabulosa Historia de Los Pelayos ha sido llevada a la gran pantalla y se...
Este año el tradicional sorteo de la Lotería de Navidad tiene algunas novedades respecto a años anteriores. Básicamente consisten en que en vez de 85.000 números distintos habrá 100.000. También los diversos premios se repartirán de forma un tanto diferente. Se...
Investigadores de la Universidad Rovira i Virgili (URV) pueden conocer el voto de un juez del Tribunal Supremo de EE.UU. a partir de las decisiones que tomen los otros ocho miembros del tribunal con una probabilidad de éxito del 83%. El...
Cuatro años ha tardado la justicia española en poder confirmar lo que en su día clasificamos por aquí como de matemáticamente improbable por no decir im-posi-ble, es decir, lo que era palmario. La afirmación en cuestión era: En los últimos 15...
En @markov_bible se van publicando twitts de 140 caracteres con «pasajes» de la Biblia en formato cadenas de Markov – básicamente textos cuasi-aleatorios. El señor Markov era un profesor de matemáticas que inventó este instrumento numérico capaz de generar textos al...
Un trabajo de referencia realmente excelente. Pero una pena que con tanto número al azar no los hayan ordenado, para que fuera más fácil encontrar los que estás buscando. Me ha gustado mucho el libro, aunque recomiendo leerlo en la versión en...

Este entretenido vídeo muestra en diez minutos –y de forma muy divulgativa– cómo funcionan los dados no-transitivos, un «paradójico» juego de azar en el que se utilizan tres dados con sus caras marcadas con números del 1 al 6, pero de...

Actualización: Las normas y condiciones de este juego de azar cambiaron a lo largo del tiempo. Se pueden consultar las nuevas tablas de probabilidades matemáticas actualizadas en los enlaces: Euromillones 5/50 + 2/12 (septiembre de 2016) Resulta que a partir del próximo...
(…) La emocionante aventura de un grupo de jóvenes con pocas perspectivas de futuro a los que se les presenta la gran oportunidad: cambiar su suerte y disfrutar de una aventura que se convertirá en un modo de vida absolutamente a contracorriente,...

Cracking the Scratch Lottery Code es un artículo de lectura obligada para los amantes de los juegos de azar y su particular relación con la matemática, la estadística e incluso el diseño de juegos, el lavado de dinero y otras actividades similares....
He aquí una idea de esas sencillamente geniales que ganó un concurso publicitario llamado The Fun Theory para Volkswagen en Suecia, explicada en un vídeo simpático y descriptivo a la vez. Consistía en colocar en una calle una cámara de tráfico...
Tal y como cuentan en muchos periódicos, por ejemplo en Los Angeles Times (Hay Jackpot for Lost lottery numbers) el martes pasados los números ganadores del Mega Millions estadounidense fueron casi, casi, los números de Hurley en Perdidos (Lost). El sorteo...
En el sorteo de ayer sábado de la Lotería Primitiva española resultaron ganadores 47 personas con el premio máximo de 6 aciertos. ¡Wow! Los pobres se llevarán únicamente unos 60.000 euros cada uno, frente a los 2 ó 3 millones de euros...
En Gizmodo citan un trabajo publicado en arXiv titulado Twitter mood predicts the stock market. En él unos informáticos explican que si se analizan los de mensajes de Twitter a gran escala, en busca de ciertas palabras clave que permiten el «estado...
Curiosos estos dos datos que vi en La Ciencia y sus Demonios: En el 60% de las ocasiones en que hay una tanda de desempate en un partido de fútbol, la victoria es para el equipo que lanza el primer penalti. En...
Cuando te enfrentes a un dilema, simplemente lanza una moneda al aire. Funciona. Pero no porque con eso se decida la cuestión, sino porque durante el breve momento en que la moneda está suspedida en el aire, de repente descubres lo...
Curioso el efecto que explica este artículo: La posición de los ojos predice el número que tienes en mente. Al parecer tomaron un grupo de sujetos y les pidieron que pensaran números al azar entre el 1 y al 30. Grabando en...
Interesante todo lo que cuenta Migui en Primeras evidencias de que los procesos cuánticos generan números verdaderamente aleatorios, una traducción libre de First Evidence That Quantum Processes Generate Truly Random Numbers de Cristian Calude (Universidad de Auckland de Nueva Zelanda) donde se...
– Cariño, cariño, ¡he acertado un pleno al 15 en la quiniela!– ¡Guau! Voy a hacer las maletas que nos vamos a dar la vuelta al mundo con el yate que nos vamos a comprar…– … Pues no vayas tan deprisa, que...

Desde tiempos inmemoriales el hombre ha intentado domeñar al azar. Si el destino estaba escrito en los dados ¿por qué no leerlo con antelación? Y si no está escrito, ¿podríamos con nuestro libre albedrío influenciarlo a nuestro favor? Cuando además hay...
Alguien se dedicó tras los últimos incidentes a calcular las probabilidades matemáticas de que te toque ir en un avión en el que se produzca un incidente terrorista (el cálculo es «con origen o destino en Estado Unidos») y concluyó que (…)...
Hay gente que es capaz de hacer arte geométrico con billetes de metro, tarjetas de visita o cajas de cerillas. En Tapecraft hay una colección preciosa de Happy Monkey de lo que se puede hacer con cinta adhesiva y rotuladores fosforitos....
El mayor premio de la historia de la Quiniela (9,1 millones de euros) lo ganaron futbolistas. Otro colectivo que no alcanza a entender que si formas parte del espectáculo, ya seas árbitro o jugador, no deberías siquiera plantearse participar en las apuestas...
Money for Nothing: One Man's Journey Through the Dark Side of Lottery Millions. Edward Ugel. HarperBusiness. 2007. Esperaba otra cosa de este libro: cuando lo vi mencionado por ahí parecía una entretenida recopilación de historias de gente a la que le...
Literalmente y sin problemas: Cómo ganar a la ruleta. Uno de los pasos es un poquillo complicado, pero por lo demás resulta matemáticamente seguro. § BuzzFeed...
Curiosa lista la que han recopilado en Body by Science, titulada apropiadamente Dirty Dozen for Black Swan Avoidance [el blog ya no existe]. Básicamente consiste en evitar situaciones del estilo «cisne negro»: aquellas en la que el resultado es altamente impredecible...
Azar y libertad, del matemático y divulgador Carlo Frabetti, es la continuación de Determinismo y libertad, en donde se exploran diversas cuestiones sobre conceptos como el libre albedrío, el determinismo y el azar. El primer artículo dio lugar a un muy interesante...
Una lotería con truco en El País cuenta la historia de lo nunca visto: cómo una lotería catalana llamada Combi 3, variante de la Lotto 6/49, estaba tan mal diseñada que favorecía a los jugadores. El problema principal de esa versión es...

Las probabilidades de acertar la lotería son de una entre 14 millones. Las probabilidades de que un hombre de edad media muera durante el próximo año por cualquier causa son de una entre mil. Se puede calcular que también hay una probabilidad...
Sergio nos envió un enlace a esta curiosa noticia y altamente sorprendente noticia: La lotería búlgara repite la misma combinación en dos sorteos consecutivos. Al parecer esa lotería es parecida a la Loto española, pero se juega eligiendo 6 números entre 42....
Al parecer si una cartera perdida lleva en su interior fotos de bebé la probabilidad de que sea devuelta a su dueño se multiplica por más de cinco respecto a una cartera que no lleve fotos. Frente al 15 por ciento que...
El otro día le cayó encima un meteorito a un chaval Alemán; por suerte sólo le hirió en la mano, pero al impactar contra el suelo dejó un pequeño cráter de casi medio metro de diámetro. Hay más detalles en Meteorite Strikes...
Una visualización de la Ley De Benford / Daniel A. Becker Random Walk es un impresionante y detallado trabajo de representación visual del azar en muchas de sus apariciones en el mundo de la matemática y la física. Es un trabajo de...
La historia de la Dice-o-Matic II, una compleja máquina que lanza dados, es realmente curiosa: creada por la gente de GamesByEmail.com, una web en la que se juega al Backgammon, Gambit y otros juegos de tablero, se utiliza como generador aleatorio...
Increíble pero cierto esto que nos envía Pablo: hace unos días en Argentina hubo gente que ganó a la lotería haciendo sus apuestas… conociendo el número ganador, aprovechándose del cambio de hora entre dos zonas del país que están en diferentes husos...
Xabier nos hizo llegar un enlace a esta curiosa noticia: El Athletic se ve obligado a dar explicaciones ante la gran confusión generada por el sorteo donde se explica la controversia que se ha generado en torno al sorteo del número limitado...
Es azar, no lo llames telepatía es una anotación que preparó Eugenio junto con un grupo de alumnos: trabajaron para entender el factor del azar en la baraja Zener, mediante un análisis estadístico. La conclusión del análisis es que los parapsicólogos...
En una anotación altamente interesante titulada El trabajo mata más que la guerra: más posibilidades matemáticas de morir se hace referencia a estudios numéricos acerca de las causas de las muertes entre la población. Una de las conclusiones es que al parecer...

Los HotBits son números verdaderamente aleatorios generados mediante un proceso inherentemente azaroso de las leyes de la naturaleza: el fenómeno cuántico del decaimiento.

Tan apasionante como antigua es esta historia del New York Times que recuperó J-Walk de la hemeroteca (1992) y que se titula algo así como El grupo que invirtió 5 millones de dólares para ganar a la lotería. En ella se cuenta...
Este simulador de Lotería primitiva [Flash] proviene de una página para aprender a diseñar en Flash, pero también sirve para entender de forma práctica lo complicado que puede ser acertar en este juego de azar. Aunque esta variante no es igual que...
La extraña historia de Donald Peters, un hombre de 79 años de Connecticut que compró su tradicional billete de lotería como hacía siempre, con tan buena suerte que fue agraciado con 10 millones de dólares, pero con tan mala suerte que murió...
Interesante la charla de Dan Gilbert en TED (2005) que se titula Exploring the frontiers of happiness (Explorando las fronteras de la felicidad), donde a partir del concepto de valor esperado o «esperanza matemática» popularizado y adecuadamente definido por Daniel Bernoulli...
Un meteorito impactó contra un almacén en Nueva Zelanda, causando un incendio que destruyó el edificio. La única víctima leve fue un hombre que estaba en su interior y tuvo que ser atendido de un corte. Si ya es difícil que te...
Una historia real, con moraleja: El dueño de un bar que normalmente frecuento eliminó de su mobiliario las máquinas recreativas tipo B [tragaperras] hace un par de años (…) le pregunté el porqué de dicha decisión y su respuesta fue (…) que...
MindHacks resume en Why are people reluctant to exchange lottery tickets? este curioso efecto psicológico que estudiaron un par de expertos y sobre el que publicaron un trabajo completo (Another look at why people are reluctant to exchange lottery tickets) donde de...
En el reciente MAD #494 se incluía una divertidísima sátira sobre Las 50 peores cosas de Internet, que incluía –cómo no– a los casinos de juego online, con una descripción de «traca»: #8 - Los casinos online – «Aunque podemos ver tus...
Me encantó cuando la leí en el libro de Taleb en Los Cisnes Negros, así que no me resisto a publicarla ahora que la he reencontrado por casualidad en un blog: La paradoja del pavo – Un pavo es alimentado durante mil...
Gustavo y Mauricio me escribieron cada uno por su lado para contarme el restultado de este curioso sorteo en la loto de Chile, sabedores de lo mucho que me gusta el tema. Resulta que en la Loto de Chile se eligen seis...
Los números aleatorios generados por ordenador utilizando las funciones habituales de los diversos lenguajes de programación son en realidad pseudo-aleatorios. Más o menos se conoce cuales de estas funciones son mejores, peores o cuales fallan a veces. En la práctica se usan...
Azar en su más pura esencia: Fórmulas de echar a suertes recopiladas en la Wikipedia. Hay qué ver qué compendio de sabiduría es esto de Internet....
Interesante: Si se lanzan cuatro monedas al azar, incluso si en vez de lanzarlas se tiran apuntando, la probabilidad de que las cuatro monedas queden formando los vértices de un cuadrado es cero.Sucede algo parecido si se lanzan dos dos palillos al...
Bucles descubrió a través del programa divulgativo Alterados por Pi una interesante referencia a los dados no transitivos. Son dados con puntuaciones diseñadas especialmente de modo que tienen la siguiente curiosa propiedad, por ejemplo estos dados de Efron propuestos por Bradley Efron:...
21: Blackjackde Robert Luketic, con Jim Sturgess y Kevin Spacey. Estuve viendo 21: Blackjack con ganas tras haberme leído diversos los libros sobre el tema de los hackers del MIT que «ganan a los casinos al Blackjack», y aunque sabía que...
Si le pides a un grupo de gente que lance monedas al aire y anote los resultados, y a otro grupo que imagine que lanza monedas al aire y anote los resultados, suele ser fácil distinguir una cosa de la otra: las...
Un completo y muy interesante artículo publicado hoy en Soitu: ¿Qué hay en juego con las apuestas deportivas? explica cómo van a ser las nuevas casas de apuestas deportivas «a la inglesa» que empezarán a funcionar en los próximos días en España....
Nano nos recordó que en unas semanas se estrena en EE.UU. 21, que es la esperada película sobre el equipo del M.I.T que contaba cartas para ganar al BlackJack. El trailer que se está emitiendo en algunos cines españoles y que también...
Analizar el resultado de las elecciones a toro pasado como hacen los tertulianos es tan aburrido como trivial; mucho más curioso es analizar cómo las predicciones y sondeos anteriores a las elecciones se aproximaron a la realidad mediante diferentes métodos. Sondeos previos...
El número de formas distintas en que puede mezclarse una baraja francesa (póker) de 52 cartas es exactamente 52 × 51 × 50 × ... 3 × 2 × 1, también llamado factorial de 52. Eso son más de 8 × 1067...
JuegosdeIngenio.org «sorteó» un premio máximo de un millón de dólares bajo una curiosa fórmula: cualquier persona podía pedir la cantidad de tickets que deseara –totalmente gratis– sin límite alguno. Entonces al azar se eligiría un ticket y el afortunado se llevaría un...
El mayor premio de la historia de Estados Unidos en una tragaperras fue de más de diez millones de dólares que se habían acumulado como «bote» durante años, a cambio de una moneda de cinco centavos. Sucedió en Atlantic City y la...
En realidad todos los números son igual de probables pero… Tal y como cuentan en 20 Minutos según datos que se han oído también en otros sitios, parece que para el tradicional Sorteo Extrordinario de Navidad de este año las terminaciones en...
A falta de π para el Sorteo de Navidad, bienvenido es π redondeado. El 31415 lo vendían en Sevilla pero se agotó hace semanas (Zifra intentó conseguirme uno sin éxito). El 31416 lo busqué en la web de la ONLAE y...
Lo encontró Iridium en Sevilla. Es tan probable que sea el Gordo como cualquiera de los otros 84.999 números que se pondrán en juego esta navidad en la Lotería Nacional. Curiosamente este año se emitirían billetes de Lotería de Navidad por...
Pattern Analysis of MegaMillions Lottery Numbers es un interesante artículo que analiza estadísticamente los sorteos de la lotería MegaMillions estadounidense, el equivalente a la Lotería Primitiva española, o más bien al Euromillones europeo. El autor examina datos históricos buscando patrones a ver...
The Absolute Poker Cheating Scandal Blown Wide Open es una anotación de Freakonomics en la que se expone el resumen de varios artículos de Steven D. Levitt y algunos hilos en un foro acerca de las trampas en el póquer online. Para...

Tras ver cómo quedó el bate de Martin Prado, de los Braves, al arrojarlo después de batear, el comentarista no puede sino exclamar: «esto no volverá a suceder ni en cien años». Aunque lo cierto es que practicando, practicando… El vídeo...

El físico Michael Berry realizó una afirmación acerca de los cálculos para acertar con precisión cuál sería el resultado de un choque de bolas de billar. Partió de la idea de que se conocían con precisión la masa de las bolas...

¿Puedes perder todo tu dinero en el casino y echarle la culpa a la química de tu cerebro y a las medicinas que te recetaron? Aparentemente sí. Leyendo El cisne negro: el impacto de lo altamente improbable de Nassim Taleb me...
Klondike Solitaire Online, para jugar vía web al «Solitario». El popular Solitario incluido en las versiones modernas de Windows es una de las muchas versiones de este tipo de juegos de cartas y se llamaba originalmente Klondike, en inglés Patience o también...
Todos los vídeos de YouTube tienen un código único al estilo SIvp8xmvAyc. Son combinaciones únicas al azar de once letras y números que, de seguir así, algún día se agotarían, como las matrículas. En ¿Cuántos vídeos caben en Youtube? hacen un repaso...

En Póquer-Red cuéntan la última victoria humana sobre las máquinas, en este caso al Póquer con Límite (Limit Hold’em). Laak, Eslami vs. Polaris: victoria humana – Los profesionales Phil Unabomber Laak y Ali Eslami lograron derrotar al superbot de póquer Polaris en...
…Así que si te montas en avión (¡en una compañía de primera!) con un boleto de los Euromillones en el bolsillo, tienes doce veces más posibilidades de morir en un accidente que de aterrizar millonario.– interesante apreciación probabilísticaque nos envió Jesús por...
Ponder This es una sección del área de investigación de la web de IBM donde se publica un puzzle o reto matemático cada mes. Pasado ese plazo dan la solución. Como premio honorífico también se publican nombres de todos los que resolvieron...
K73 nos envió este texto que podría ser una especie de mini-relato improvisado, inspirado tras darse una vuelta por la sección de azar del blog… Me gustó y le pedí permiso para reproducirlo aquí. Viviendo del casino: un sistema para ganar siempre...
Por no decir im-po-si-ble… Un tipo con suerte – «En los últimos 15 años me han tocado aproximadamente 50 premios de juegos de azar, como la lotería, la Bonoloto o el cupón de la Once. Y en toda mi vida me habrán...
La probabilidad en el póquer convencional de obtener una escalera real (una escalera de color al As: 10-J-Q-K-A) de «primeras dadas», es decir, nada más repartir, es de una entre 649.740. Esto se refiere al juego con toda la baraja (52 naipes)...
Ayer en la Lotería Primitiva española los seis números ganadores fueron 1-2-4-8-9-24 (ccomplementario, 48; reintegro, 4). Se jugaron 18 millones de apuestas al precio de un euro cada una. Como la probabilidad de acertar los seis números es de una entre...
Un grupo formado por el diez por ciento de los jugadores de loterías son los que compran casi el setenta por ciento de los boletos. El dato es de un estudio de la Universidad de Duke (en el 2000, en Estados Unidos),...
Como recuerda J-Walk, este artículo de SmartMoney es de hace más de cinco años, pero todavía bastante válido e igual de impactante: Ten Things the Gaming Industry Won’t Tell You. Sin duda puede aplicarse sin problemas tanto a la industria del juego/apuestas...
Stephen Dubner explica en el blog de Freakonomics que según sus datos entre el 30 y el 70 por ciento de los premios de las loterías no se cobran porque no los reclama nadie, al menos en Estados Unidos. Este dato podría...
Lo que muestra este gráfico son las frecuencias de aparición de los números de la loto, en concreto todos los números de la Lotería Primitiva y la Bonoloto en España desde 1988 hasta 2006. Cada color representa una bola numerada, del 1...
De entre todas las curiosidades numéricas y probabilísticas del pasado sorteo de la Lotería de Navidad una no pasó desapercibida para los periódicos: tal y como cuentan en La Razón en el artículo El colmo de la suerte: dos sevillanos se llevan...
Olalla nos escribió para contarnos una curiosidad sobre el Sorteo de Navidad 2006 de la Lotería Nacional que se ha celebrado hoy: dos de los grandes premios, un cuarto y un quinto, son el mismo número escrito al revés: 47272 y 27274....
Estaba revisando ayer What Shape is a Snowflake?, el precioso libro de Ian Stewart, cuando me crucé con una de las cuestiones interesantes que trata al hablar de los sistemas caóticos, aunque lo hace muy por encima. Esto es más o menos...
Joseph Jagger es más conocido como «el hombre que saltó la banca en Montecarlo» En 1873 contrató a seis personas para anotar metódicamente los números de seis de las ruletas del Casino Beaux-Arts. Estudiando dichos números, descubrió que una de las ruletas...
Ayer vi que el Canal de Historia, sin duda uno de mis favoritos (disponible en plataformas digitales) emitirá el próximo domingo 26 de noviembre a las 15.00 el documental La buena fortuna de los García-Pelayo que trata sobre la legendaria familia García-Pelayo...
ACid me recordó por correo que la semana pasada tampoco nadie acertó el bote de 150 millones de euros que había en el sorteo de Euromillones. Eso quiere decir que esta semana el bote acumulado para el primer premio podría entregar a...
… O es que tienes mucha, mucha, mucha, mucha suerte o es que le has robado el boleto con premio a algún ancianito despistado. Al menos eso sucede en Canadá, según el artículo de la CBC Luck of the Draw. Al parecer...
Alejandro resumió en Discriminación alfabética el curioso error matemático en que (increíblemente) todavía se cae en muchas situaciones cuando se realizan sorteos que implican a un gran número de personas: el «sorteo alfabético». Normalmente se elige una letra (o dos) del bombo,...
Detienen a dos directivos de la compañía de apuestas Bwin – Dos dirigentes de la empresa de apuestas por internet Bwin [anteriormente Bet and Win], Manfred Bodner y Norbert Teufelberger, fueron detenidos el viernes cerca de Niza e ingresaron ayer, provisionalmente, en...
Un correo esta mañana decía así: Asunto: Estafa en los casinos?Hola mi experiencia en los casinos es muy corta pero muy dura en dos semanas he perdido 12.000 euros. Todo iba bien al principio utilizaba la tecnica de doblar la apuesta cuando...
Si eres tan listo, ¿por qué no eres rico? Un matemático invierte en la bolsa. John Allen Paulos. Tusquets. 2005 ISBN: 483109700. Español. Título Original (inglés): A Mathematician Plays the Stock Market. 256 páginas. Este libro de John Allen Paulos describe exactamente...
Esto sí que me ha sorprendido: Cory Doctorow cuenta en Boing Boing que los números suelen comenzar más frecuentemente por «1» que por cualquier otro dígito. Así como suena. Una teoría matemática llamada Ley de Benford predice que en un conjunto...
Ir a GoogleTeclear el 20085 (el número del Gordo de Navidad)Pulsar Voy a tener suerte.Comprobar cómo realmente era un número chungo.Ahora San Google, por favor te pedimos, a ver si pudiera ser para el Sorteo de El Niño que salga el...
La probabilidad de morir en un salto en paracaídas es aproximadamente de una entre 100.000. Más o menos la misma de que te toque el Gordo en la lotería hoy (una entre 85.000). Actualización: Pues como cabía esperar, ni lo uno ni...
¿Se acerca la realidad a la ficción? ¿Es Perdidos algo más que una serie de televisión? Los números de Hurley casi salen en la Lotto de Irlanda el pasado 19 de noviembre, pues la combinación ganadora fue 4, 8, 15, 16, 23,...
Uno de los artículos que más me gustó de la revista Wired de septiembre es On the Internet, Nobody Knows You're a Bot. Cuenta cómo expertos en software y juegos, más específicamente poker online, diseñan bots (robots) que juegan en las salas...
Edmundo de ALT1040 recupera una historia clásica que alguna vez hemos comentado de pasada por aquí: un juego de televisión de los años 80 que permitió a un concursante ganar mucho dinero gracias a su ingenio, sin trampas. Lo hizo reconociendo el...
Los tréboles de cuatro hojas son una mutación genética. Según los expertos, la probabilidad de encontrar un «trébol de la suerte» de forma natural entre otros tréboles normales de tres hojas es de aproximadamente una entre 10.000. (Vía Ask Yahoo.)...
Hoy se estrelló un avión de pasajeros en Guinea Ecuatorial (85 muertos); y el mismo día también se estrelló un hidroavión en Costa Rica (7 muertos). E incluso creo que hace muy poco hubo otro accidente importante en Asia, aunque no lo...
Algo raro ha pasado con ONLAE.com que se supone que era el dominio de la La Organización Nacional de Loterías y Apuestas del Estado. Ahora aparece este mensaje: This directNIC Free Hosting account has been terminated due to a violation of the...
¡Qué bueno! En el episodio de CSI que están emitiendo ahora mismo (No More Bets, cuarta temporada) el caso trata de unos tipos que ganan jugando a la ruleta con un ordenador en el zapato, y como no podía ser de otra...
La revista Consumer ha publicado Loterías: probabilidades de que toquen, un artículo en el que se hace un repaso a las diversas Loterías del Estado, las probabilidades de acertar y algunas otras curiosidades. Loterías: probabilidades de que toquen - Cada español se...
«Los Fabulosos Pelayos» se están dedicando ahora al póquer por Internet - se ve que hace tiempo dejaron las ruletas de los casinos. Ya contaban algo al respecto al final de su libro autobiográfico, y Tomás nos ha pasado una reciente entrevista...
Un par de geeks de Stanford y Cornell han inventado un sistema que permite a un ordenador ver las cartas de una bajara «desde la parte de atrás». Un ordenador maneja una cámara y un proyector, que ilumina la escena. Los rayos...
Uno nunca sabe cuándo va a necesitar un buen generador de números aleatorios, así que conviene tener Random.org apuntado por ahí. Por otro lado, en una nota de ForeverGeek titulada Pi Is Not The Best Random Number Generator se menciona un estudio...

The Eudaemonic Pie: The bizarre true story of how a band of physicists and computer wizards took on Las Vegas. Thomas A.Bass. Houghton Mifflin. 1985. ISBN: 0395353351. Inglés. 330 páginas. Web sobre el libro, por Thomas A. Bass Este libro también...
En la Bonoloto de ayer hubo dos acertantes de primera categoría (6) que se llevaron 170.307,11 euros cada uno, pero sólo hubo un acertante de 5 + Complementario que se llevó exactamente la misma cantidad (Bonoloto en la ONLAE). 1ª (6 Aciertos)...
En el sorteo de La Primitiva de ayer sábado no hubo acertantes de 6, de modo que se ha generado un bote de 15.950.946,43 euros (casi 16 millones) que no está nada mal. Todavía no se sabe cuándo se pondrá en juego....
Tal y como mencionan en Wired en el artículo Shoe helps gambler cheat at roulette, han detenido a un jugador húngaro que utilizaba en los casinos un ordenador escondido en el zapato para «adivinar» dónde iba a caer la bola en la...
Buenísima idea... Online Poker Googlebomb:Enlaza a este artículo de la Wikipedia con las palabras: Online Poker — Este es otro esfuerzo para desalentar a los blogspammers.(Vía ALT1040.)...
Tardó veinte meses y costó vidas, pero al fin ha salido el famoso 53 de la Lotto italiana en Venecia: Sale en Venecia el ansiado número 53 de la lotería italiana, tras veinte meses de espera....
a1f0n50 nos ha escrito para contarnos que la campaña teaser (misteriosa) de El Gordo Más Gordo que hay estos días en televisión en toda España (con unos actores imitando a Epi y Blas) no es otra que la de una nueva versión...
Sencillamente, asombroso: Italia sucumbe a la maldición del número 53 (€) — La «negativa» de un guarismo de la Lotto a salir premiado desencadena una ola de suicidios, asesinatos y ruinas. [El Mundo] El mal fario del 53 — Una lotería causa...
Yabu va a hacer un divertido experimento cuántico relacionado con la Loto, lo cuenta en El Gordo de Schrödinger. Tomamos un boleto de El Gordo de la Primitiva, rellenado al azar. Lo introducimos en una caja vacía en mi casa, y la...
Según la Wikipedia, hablando de la lotería (lottery): Algunos Estados la prohiben, mientras que otros la apoyan, hasta el punto de que se organizan loterías nacionales. La definición de la Wikipedia en castellano (lotería) no es gran cosa, y dice que En...
Wicho ya avisó: «¿Volverán a tener suerte este año?». El Pez cree que Sort Es Bona Si La Bolsa Sona. Podía pasar. Simplemente porque allí venden más. Yo a falta de un análisis más detallado recomiendo el que hice el año pasado:...
Por lo visto desde el pasado sábado la administración de lotería de La Bruixa d'Or ya agotó toda su lotería de Navidad: Xavier Gabriel, su dueño, ha explicado que puso a la venta esta lotería el pasado 7 de julio y que...
El 18. Para mañana. A ver si toca....
El Tribunal Supremo ha terminado por dar la razón a los Pelayos en un largo contencioso de sentencias y recursos relativas a la prohibición que pesaba sobre ellos a entrar en el Casino Gran Madrid después de que ganaran astronómicas sumas de...
Los aficionados a los juegos de rol conocen más variaciones de los dados que nadie, porque en juegos como Dragones y Mazmorras se utilizan dados de 4, 6, 8, 12 o incluso 20 caras (representados como D4, D6, D8, D12 o D20)....
Muy prometedor este nuevo Diario Online de un jugador de Internet Poker, que aunque solo tiene una anotación en el diario ya ofrece una estupenda guía para aprender a jugar al Texas Hold'em (también conocido como Sin Límite de Texas) y también...
Ana, una amable lectora, me escribió por correo al detectar un error en los cálculos probabilísticos del viejo artículo sobre la Lotería Primitiva. En dicho artículo se afirmaba que la probabilidad de acertar el premio de cuarta categoría (4 aciertos) era de...
Exactamente al revés que aquel mítico anuncio publicitario: Un hombre gana 270.600 dólares al apostarse los ahorros de toda su vida – Ashley Revell, de 32 años, londinense, había liquidado todas sus posesiones para obtener fondos para lo que sería su «acto...
Ha sido calificado de Cibergolpe, Aventura de James Bond, Complot y hasta de Sofisticada estafa millonaria. Esta mañana el anzuelo de David Readman capturaba la noticia geek del mundo de la ruleta y los casinos: Un móvil con láser y ordenador tima...
Un señor se llevó más de 20 millones de euros en el sorteo de Euromillones del viernes pasado, lo cual no está nada mal. Al parecer es un récord histórico en cuanto a premios en España: El mayor premio de la lotería...
Actualización: Las normas y condiciones de este juego de azar cambiaron a lo largo del tiempo. Se pueden consultar las nuevas tablas de probabilidades matemáticas actualizadas en los enlaces: Euromillones 5/50 + 2/11 (mayo de 2011) Euromillones 5/50 + 2/12 (septiembre de...
Alfonso, un amable lector de Microsiervos, nos ha hecho llegar por correo electrónico una jugosa información sobre el inminente lanzamiento de Euromillones, un nuevo juego de la ONLAE, parecido a la Lotería Primitiva pero que se realizará junto con otros países: Francia...
Parece que el Gordo de Navidad siempre toca en Sort, Lleida, en la administración La Bruixa d'Or (La Bruja de Oro). En realidad puede que no sea tan extraño que siempre toque ahí. En el sorteo de Navidad sólo hay 66.000 números...

Cuando la física y la matemática dijeron que no se podía ganar, los Pelayos dijeron «sujétanos el cubata» y se llevaron un millón y medio de euros.
Positively Fifth Street: Murders, Cheetahs, and Binion's World Series of Poker. James McManus, 2003. Inglés.Póker Sin Límite de Texas (Texas Hold'em): Reglas Se juega con una sola bajara, sin comodines. El orden de las manos ganadoras es el tradicional: escalera de color,...
Cuentan los periódicos la fiebre en Italia por la SuperEnalotto, en la que tras 44 semanas consecutivas se ha acumulado un bote (jackpot) de 63 millones de euros, perspectiva ante la cual los italianos (y muchos otros europeos) se están volviendo locos...
Un sorteo del mes pasado en la Loto española, con resultados anómalos: Sorteo 23. Sábado 7 de junio de 2003. Recaudación: 24.156.996,00 € (a 1 € por apuesta). Bote: 6.237.837,34 € Combinación Ganadora: 4-6-13-23-33-43, C: 31, R: 2 6 aciertos . ....
Esta historia lleva unos días circulando y seguramente durará algunas semanas más. He preferido esperar unos días antes de publicar algo para ver y valorar reacciones y contra-reacciones. Como mago aficionado «en prácticas» que soy, la historia en sí no ha podido...
Bringing Down the House: The Inside Story of Six MIT Students Who Took Vegas for Millions. Ben Mezrich. 2002. Este esperado libro fue adelantado en un número reciente de la revista Wired bajo el atractivo título Hacking Las Vegas. El título de...

Fooled by Randomness: The Hidden Role of Chance in the Markets and in Life. Nassim Nicholas Taleb. 2001. En español: ¿Existe la suerte? Las trampas del azar. A medio camino entre las finanzas y las mátemáticas, este curioso libro de un...
El azar influye en muchos factores de la vida, especialmente en algunos como el comportamiento de los mercados, la bolsa, y las inversiones. Casi cualquier hecho o comportamiento se puede modelar y tratar en base a una suma de factores conocidos y...
Un clásico que tiene mucho que ver con los eudaemons (y por extensión con el grupo de los eudaemons atacan de nuevo en Las Vegas), un artículo en Wired titulado Cracking Wall Street. Imagina que pudieras discernir las tendencias del mercado, acelerando...
Estos nuevos Robin Hoods («robo a los ricos, me lo quedo yo») recuerdan al grupo de eudaemons descrito en The Eudaemonic Pie y aunque se les parecen mucho son del MIT. En Wired publican este mes Hacking Las Vegas, donde se describe...

Este análisis matemático de la Lotería Primitiva en España explica cómo la elección de «números no-favoritos» y el «efecto bote» pueden aumentar las probabilidades de obtener más dinero en los premios mayores.
