
Un descuento del 25 % lo deja en 374 euros, lo que es de agradecer en estos tiempos en lo que todo está carísimo porque la IA lo devora todo.

La tecnología corre hacia el futuro, pero sus iconos siguen anclados a 1984.

Las cifras que se manejan son descabelladas y como para asustar al más pintado.

Tras décadas de pensar mucho y hacer poco, la UE decide apoyar y mantener proyectos abiertos para la nube la, IA, los sistemas operativos y la ciberseguridad.
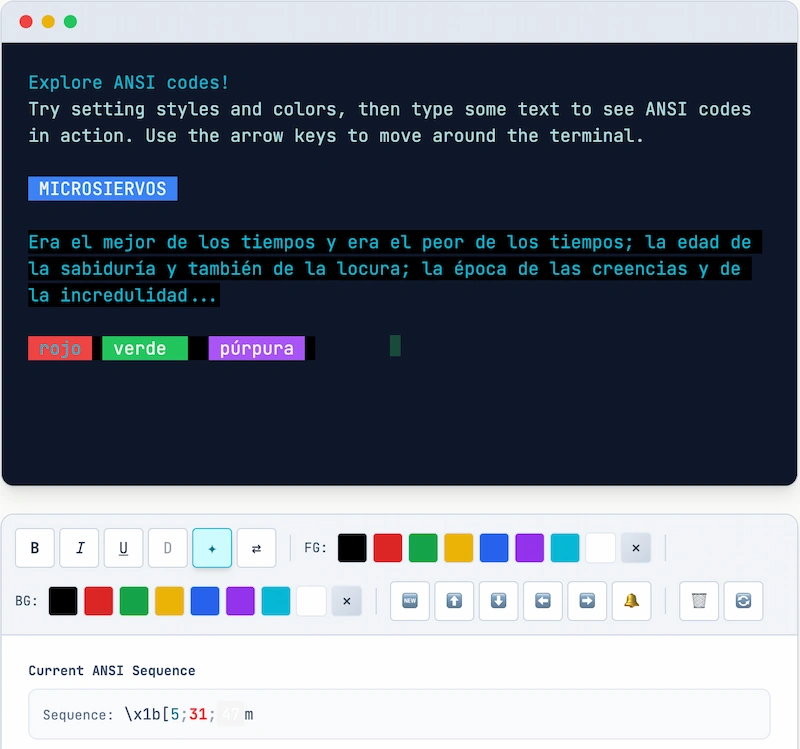
Códigos ANSI: como dar vida al terminal sin necesidad de un curso de arte moderno.
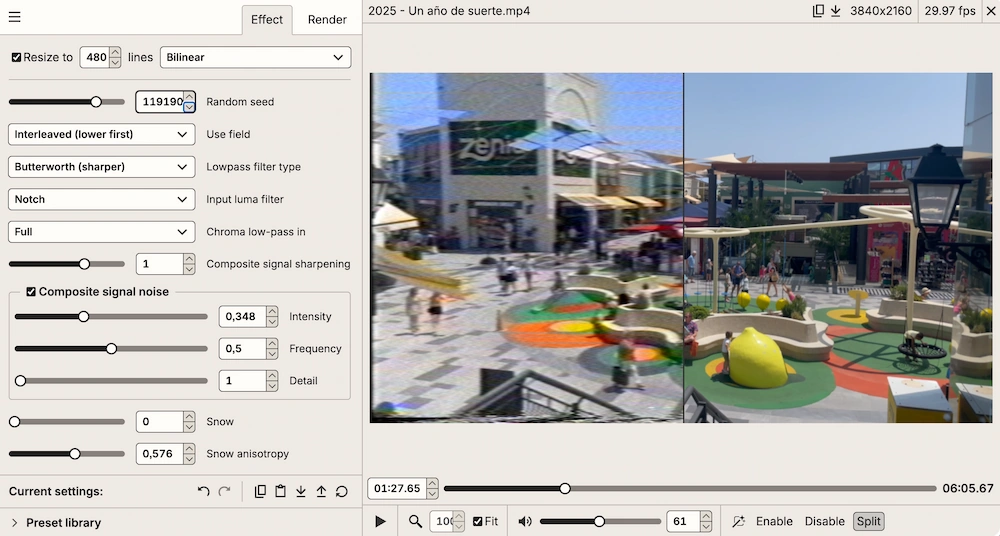
Convierte los vídeos modernos en el destino que podrían haber tenido en el pasado: parecer una cinta VHS de videoclub.
La infraestructura digital no la sostienen solo gigantes: también la apuntalan proyectos diminutos, mantenidos a ratos libres.
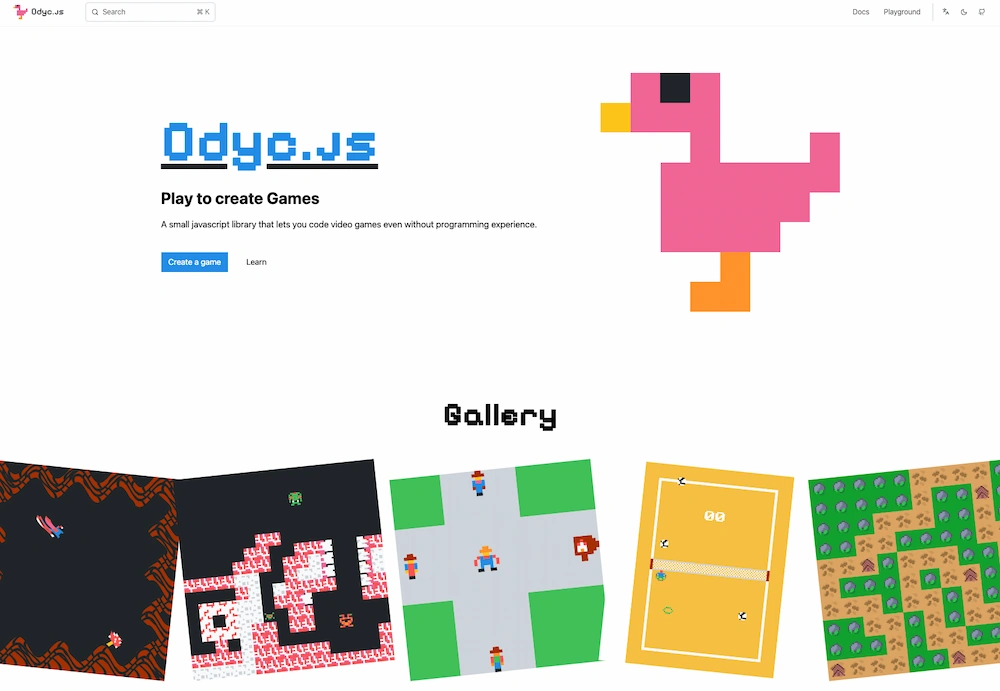
Odyc.js transforma a cualquier principiante en creador de videojuegos

Es una máquina recomendable para usarla con dispositivos con diferentes sistemas operativos y un volumen de impresión bajo.
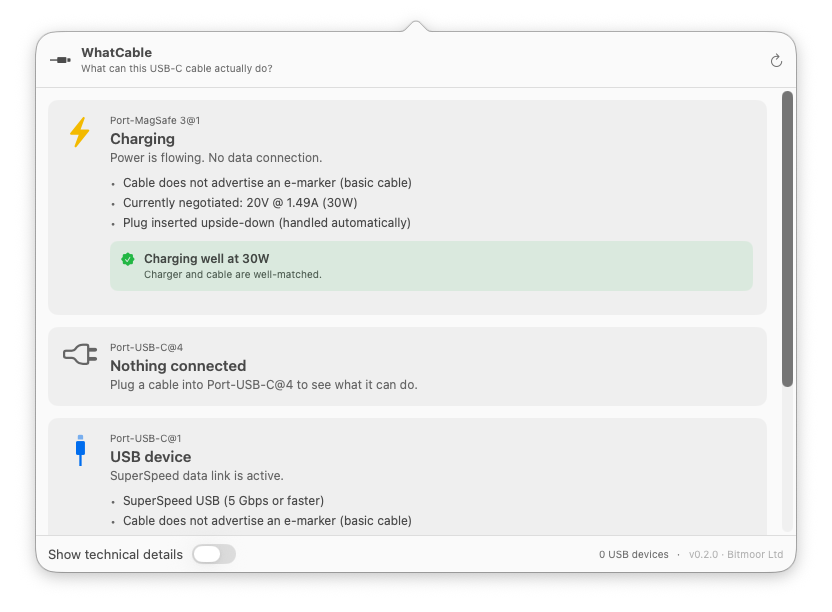
Qué cable es cuál y por qué a veces carga lento (spoiler: es por el cable)
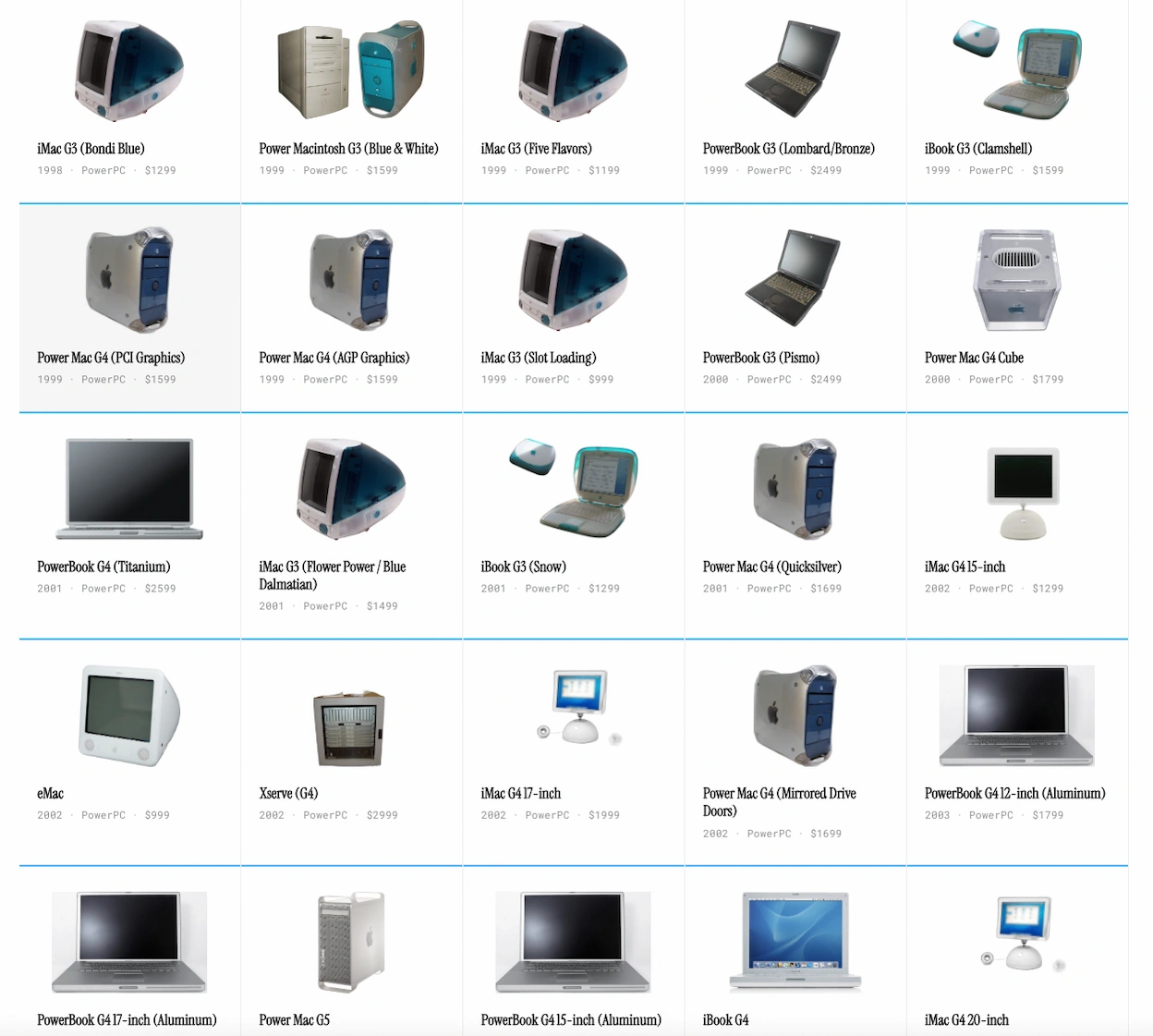
De la prehistoria del Lisa al MacBook Neo: 154 formas distintas de gastar dinero.

Sucede desde hace como un par de semanas.

Hablamos de la importancia de poder saber cómo funcionan ciertas aplicaciones que se meten en aspectos importantes de nuestras vidas.

La computación cuántica ya abre cerraduras de juguete y recibe premios. Pero las puertas serias aún le faltan muchísimos qubits.
nadie querría tener que utilizarla nunca pero es reconfortante saber que existe una opción si se tuercen las cosas.

Quizás algo ralentizada respecto a cuando fue formulada aún parece que siga básicamente en vigor.

Hacemos un breve repaso a la biografía del que se puede considerar como padre de la informática.

El QWERTY, un anacronismo ineficiente, reina gracias a la inercia colectiva. Sus rivales, pese a ser más rápidos y ergonómicos, son meras curiosidades para frikis.

Steve Jobs, Steve Wozniak y Ron Wayne registraron el acuerdo que establecía las bases de la empresa un uno de abril, aunque lo habían firmado el día antes.

Unos pequeños consejos para que no te pille el toro con eso de la pérdida de datos. O no mucho.

Se trata de una máquina de transistores cuya CPU pesa unos 40 kilos; de ahí lo de «personal.»

Gestiona miles de imágenes y tantas fototecas como quieras sin despeinarse.

La gran apuesta actual de la empresa es la inteligencia artificial… Hasta que vuelvan a cambiar de opinión.
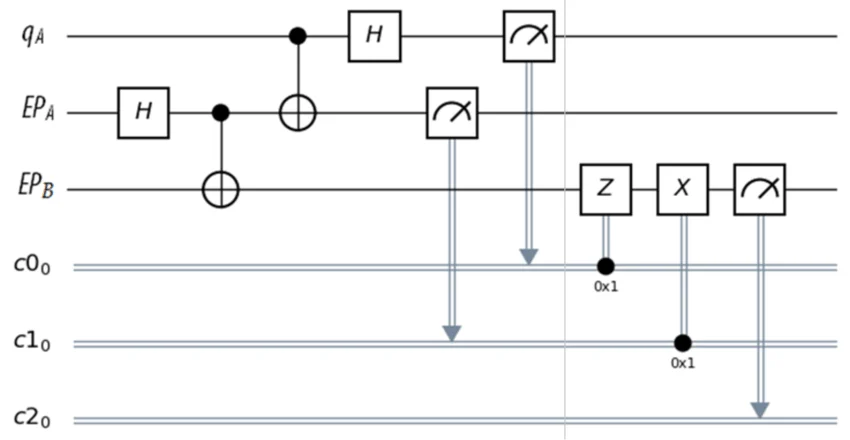
La ACM premia a dos pioneros por concebir hace 40 años la computación cuántica, hoy mitad promesa y mitad verbena marketiniana.

El resumen es que hay que aplicarlas siempre lo antes posible.

Un experimento visual convierte los matices de color en una tortura elegante, y enseña por qué hilar demasiado fino con los colores puede salir regular.

Apple presenta un portátil de entrada, que no de gama baja, que tiene muchos boletos para convertirse en un éxito.

Habrá que ver cómo funciona y si tiene efecto de tracción, pero parece una iniciativa más necesaria que nunca.

Una recreación de la realidad del ecosistema de software.

Una colección gigantesca de arte hecho con teclado: documentación, historia y herramientas para dibujar sin bits «modernos».
Hay que eliminar el contenido de un par de carpetas que de alguna manera ha resultado corrompido.

Se trata de un documento que recoge acciones ya en curso.
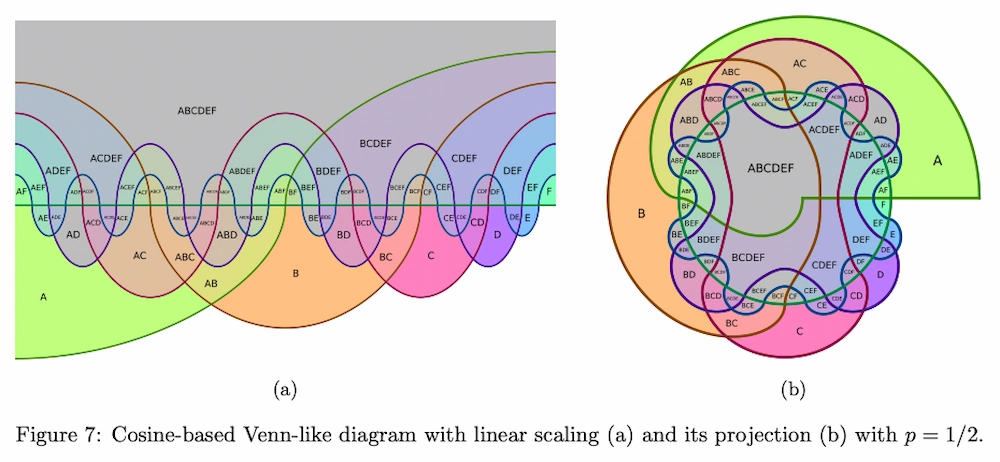
A pesar de que crezca su complejidad, estas curvas permiten mantener visibles regiones de hasta 8 o 9 conjuntos.

Un montaje consistente en una CPU de 16 bits con hojas de estilo: ejecuta demos y no requiere ni JavaScript, pero es lento como el hambre.

La enorme demanda para montar más y más centros de procesado de datos también les afecta.

Las máquinas ya no piden sintaxis, piden contexto.
Arte matemático sin píxeles: cuadrículas deceldas, funciones aleatorias y formas paramétricas, todo en CSS.

Informática doméstica y equipo musical callejero en el mismo trasto.

Es impresionantemente robusta y cómoda para personas de tamaño extra.

La idea es montar una plataforma de computación para inteligencia artificial en órbita formada por un millón de satélites.

Urbanismo en modo web: economía, recursos y multitudes, sin olvidarse del presupuesto municipal.

El despiece de decenas de formatos binarios byte a byte, con guía visual y código en varios lenguajes, para evitar aquello de resolverlo todo «a mano».

Quince recetas de laberintos: deterministas, aleatorias e híbridas, con paso a paso y resultados reconocibles y quizá discutibles.

Es el predecesor directo de Android, iOS y macOS, sin ir más lejos.

Nostalgia noventera en formato SimCity de 42 gigapíxeles

Tras 30 años, miles de ingenieros y miles de millones de euros después, ASML logró la tecnología para fabricar microchips avanzados en salas más limpias que los quirófanos.

Casi cabe en la cartera, con teclado y pantalla. Corre Lisp en un ESP32 y cuesta unos 30 dólares.

Más demanda, menos oferta porque se la han comido toda los centros de datos.

14 páginas que resumen a un coloso de 160 MFLOPS con 8 MB, 115 kW y regrigeración de freón líquido, que además servía de sofá y no fallaba.

La carrera armamentística por crear centros de procesos de datos cada vez más potentes en este campo es la causante de todo esto.

Un par de artículos y un vídeo acerca del estado de las cosas en el sistema operativo más utilizado del mundo.

El proceso está en marcha para que suceda lo mismo en algunos más.

Cuatro lecturas que no tienen desperdicio.

Europa quiere la independencia tecnológica, pero depende de chips y energía extranjeros. La soberanía digital es costosa y lenta, pero algo crucial.

Programar es más que teclear: es entender problemas, coordinar equipos y, a veces, odiar JavaScript. Todo un arte.

Los secretos del 6502: 3.510 transistores, sin CAD, y dibujado poco menos que a mano.

En 1973, Chile soñó con ser como Star Trek: un sistema cibernético con télex y estadísticas para gestionar la economía.

En Portugal, un museo rinde homenaje al ZX Spectrum, ese superordenador que ahora es una cápsula del tiempo de los 80.

Diseñar interfaces nunca fue tan fácil: conviertir vagas instrucciones en HTML funcional.

Juega a ser un dios de las partículas y pon a prueba tu GPU en un festival de caos y orden.

Una revista de programación en la que la brevedad es un arte y la periodicidad algo relativo.

Pegatinas que relatan historias que, con la obsolescencia, acaban en el olvido.

Hay otras once más para ver con el tema general la ciencia del futuro.

La auditoría de seguridad llevada a cabo en el Louvre tras el espectacular robo de hace unas semanas nos lleva a hablar de lo muy mal protegidos que estaban sus sistemas informáticos.

Atlas, el navegador que sueña con ser Chrome, aunque le faltan varias actualizaciones y un café.

El legado de los disquetes: ingeniería «vitage» con limpiadores ocultos y pegatinas traicioneras. Un manual que es pura arqueología digital.

Una vez más hemos visto como dependemos hasta extremos insospechados de cosas que están muy fuera de nuestro control.

El museo digital de microchips que nadie pidió, pero todos necesitábamos. De Zilog a Motorola, una fiesta de la mciroelectrónica.

La historia digital se escribe con Premios Turing: desde la programación estructurada hasta la IA. La crème de la crème de la informática.

Crear laberintos por el método Wilson: porque la vida no es lo suficientemente complicada. Caminos «justos», pero igual de liosos.

¿Proyecciones cartográficas o arte abstracto? Bostock y su galería D3 llevan los mapas a un nivel de creatividad geométrica inesperado.

Autómatas celulares en un universo de píxeles unidimensionales, que se adelantaron décadas al concepto de «vida artificial».

El hacker original: curiosidad infinita, humor contagioso y, por supuesto, Unix. Un legado que sigue inspirando.

Está pendiente de la aprobación por parte de las autoridades pertinentes.

Con más de 30 tipos de gráficos y un curso completo, esta web es el Disneylandia de la visualización de datos.

Tiene la mayoría de las funciones que necesita la mayoría de quienes tengan necesidad de un programa como este.

El Citizen Watch renace con sus míticos botones A/B/C/D. ¿Alguna vez cuatro botones fueron tan emocionantes?

Todo un museo de software freeware sin trampas, donde lo retro se mezcla con lo útil, en un viaje nostálgico por internet.
Un fallo hace que vaya creando ficheros temporales que nunca borra.

Python sigue dominando, pero la IA hace que preguntar sobre programación sea tan pasado de moda como el VHS.

Es importantísimo tener una estrategia de copias de seguridad bien planteada.

Como siempre defiendo la idea de que las prohibiciones son contraproducentes; que hay que acompañar a los «nativos digitales» en este viaje.

Un grupo de personas mantiene desinteresadamente proyectos críticos relacionados con la seguridad escritos en Go que quedan abandonados.
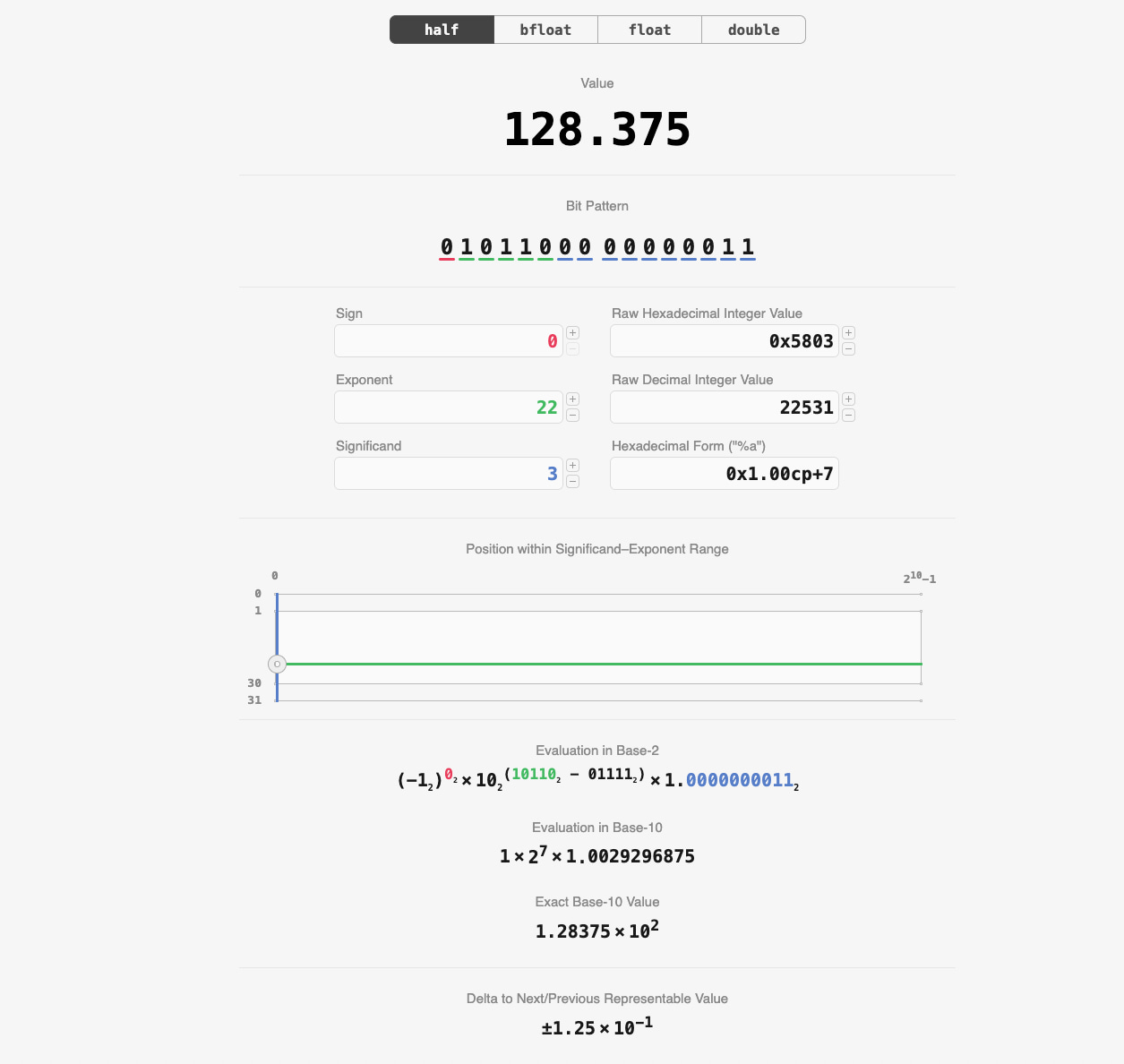
Coma flotante: la aritmética digital que permite infinitos, ceros con signo y NaN extravagantes en todo un espectáculo binario.

Unicode 17.0 incluye emojis surrealistas y un arsenal de 4.803 caracteres nuevos para lenguas que ni los políglotas más audaces pueden pronunciar.

Los módems de antaño dialogaban en su propio idioma: pitidos y mucho ruido, como si fuera arte moderno.

Daisy Bell, cantada por un IBM 7094 en 1961, marcó el inicio de la era de las voces artificiales. Su eco sigue resonando.

AInnovación: el evento sobre IA, CMS y DXP. Madrid se llena de expertos y empresas tecnológicas con charlas y networking.

Byte resucita digitalmente: un archivo de revistas con más páginas que un diccionario y más publicidad que un canal de teletienda.

En los 60, la visión del futuro era leer el periódico en la cama con un ordenador que costaba lo mismo que un alquiler en Londres.

La clase magistral de Jeff Erickson sobre algoritmos: gratis, extensa y perfecta para convertir problemas en simples ejercicios mentales.
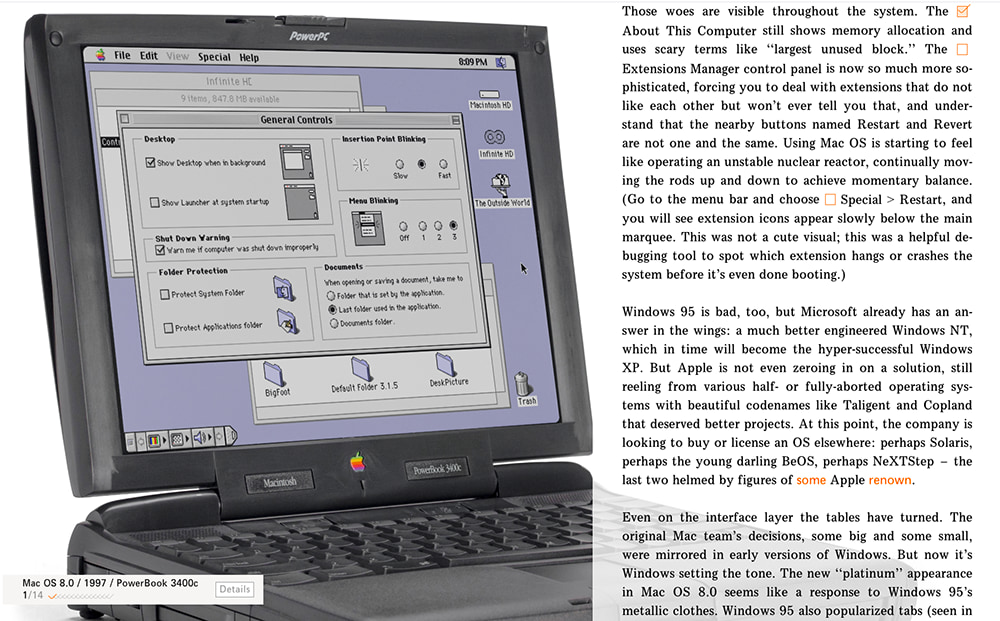
De los iconos de Susan Kare al Aqua de Jobs: 20 años de Ajustes de Mac donde el diseño pasó de lo sublime a lo caótico.

La nostalgia pixelada cobra vida. Un generador de alienígenas personalizados con más estilo que un desfile de moda galáctico.

Si mucho mayor que no es lo suficientemente dramático, Unicode añade el ⋙. Ideal para discusiones donde el tamaño sí que importa.

Apple-1: el santo grial de los ordenadores, ahora con un registro que documenta cada unidad de esta «chatarra» tan valiosa para los coleccionistas.

Google lanza Google Sans Code, una fuente para programadores con mejor legibilidad y de anchura variable. Gratis total.

No es barato pero su calidad de construcción y funcionalidades pueden justificar su precio para la persona adecuada.
Está disponible en inglés en una compra única para iOS, macOS y watchOS.
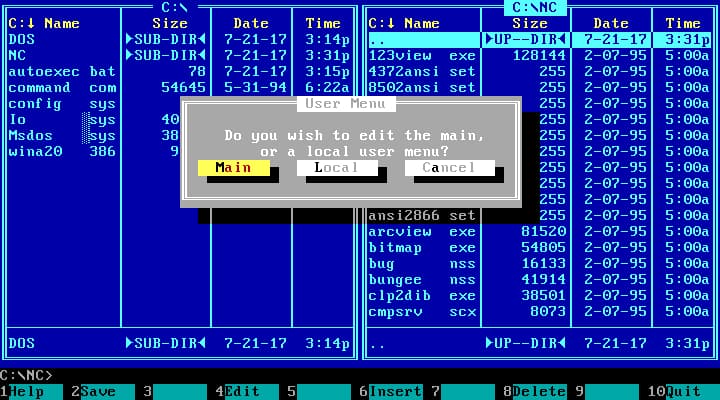
El arte de dibujar cajas con caracteres revive con los recuerdos de las interfaces gloriosas del DOS. ¿Quién necesita gráficos cuando existen las cajitas?

Tiene unas prestaciones impresionantes, aunque hay que pensar mucho si le vas a sacar todo el partido que puede dar.

Un teclado de 899 dólares de la serie Severance. En Kickstarter lo intentan, pero la cosa pinta complicada.

Samuel Antonio Jiménez da una explicación del origen de estas impresionantes máquinas sobre cómo fueron buscando soluciones a los desafíos que suponían.

Sumérgete en la nostalgia con pósteres binarios que desentrañan formatos antiguos y celebran los chascarrillos más frikis.

La arqueología digital desvela los lenguajes que se niegan a descansar en paz y aún inspiran a la programación moderna.
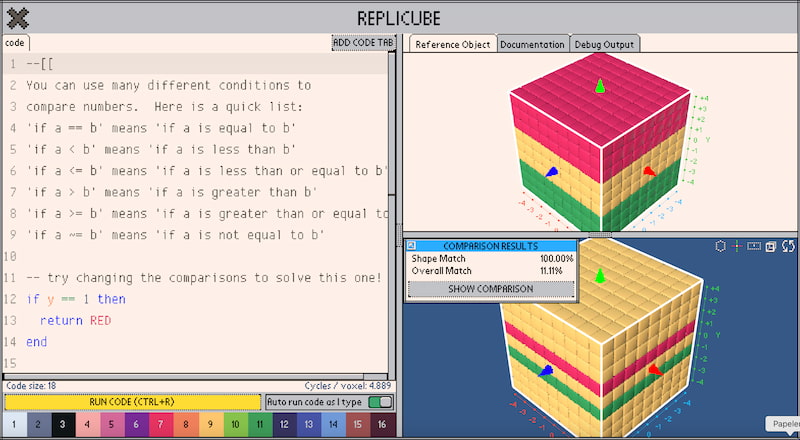
Replicube: cuando el código se convierte en un rompecabezas y los vóxeles en tu nuevo dolor de cabeza favorito.

Creer que la IA acelera el trabajo es como pensar que el café es un sustituto del sueño. Al final, los programadores pierden tiempo.

La complejidad computacional plantea preguntas filosóficas. Pero la IA no necesita superar la física, solo a los humanos.
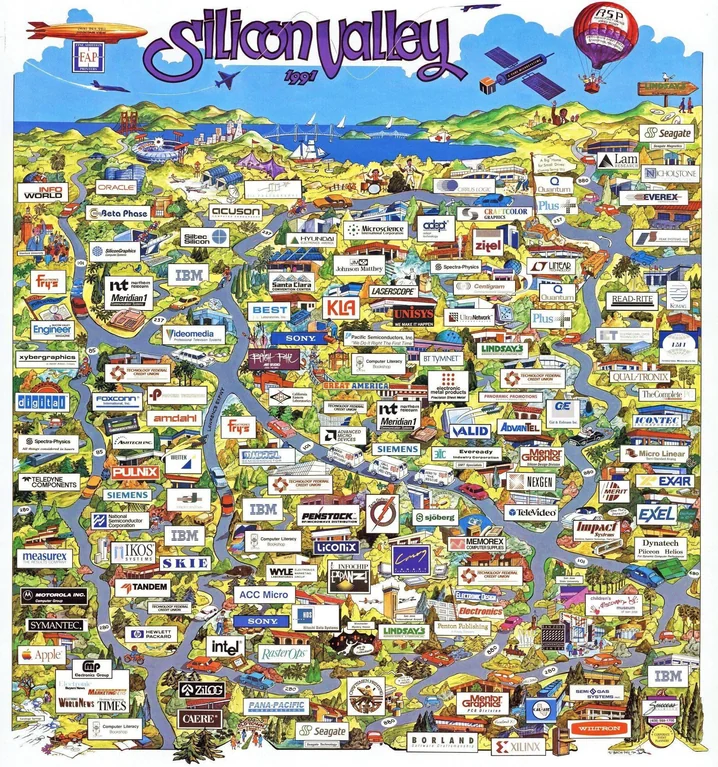
Un mapa de Silicon Valley en 1991 revela el panteón de empresas tecnológicas. Algunas brillan, otras se desvanecieron en la niebla.

Es un ordenador compacto que aunque tenga un procesador de hace ya unos años es perfectamente válido para la inmensa mayoría de los usos.
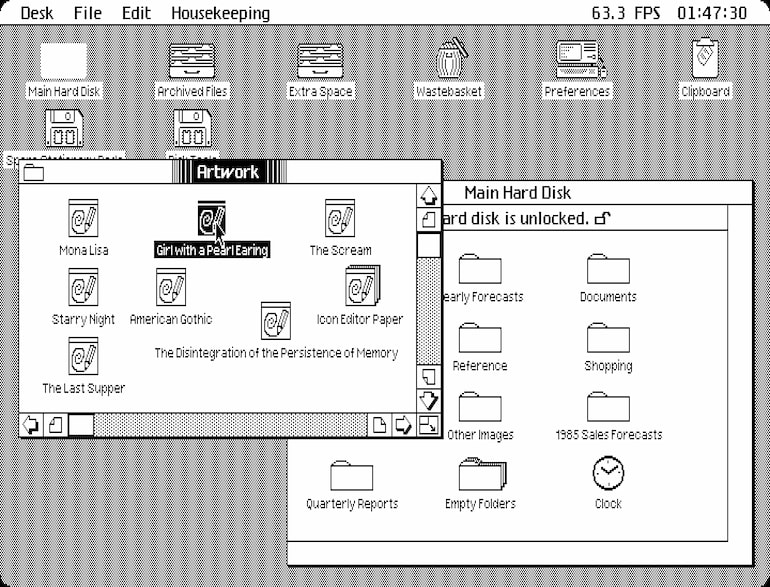
Cómo experimientar el Apple Lisa en un «regreso al pasado» con LisaGUI. Un nostálgico paseo virtual a la informática viejuna.

Su escaso peso y la duración de su batería lo hacen más que recomendable para su uso en entornos de ofimártica.

Este libbro recupera el fundamental trabajo de Betty Holberton, Kay McNulty, Marlyn Wescoff, Ruth Lichterman, Betty Jean Jennings, y Fran Bilas en poner en marcha el primer ordenador moderno.

Sus siete instrumentos podrán seguir trabajando en el estudio de la superficie y la atmósfera del planeta rojo.

Unicode: un viaje por un mar de bytes traicioneros y emojis que ocupan más espacio del que parece.
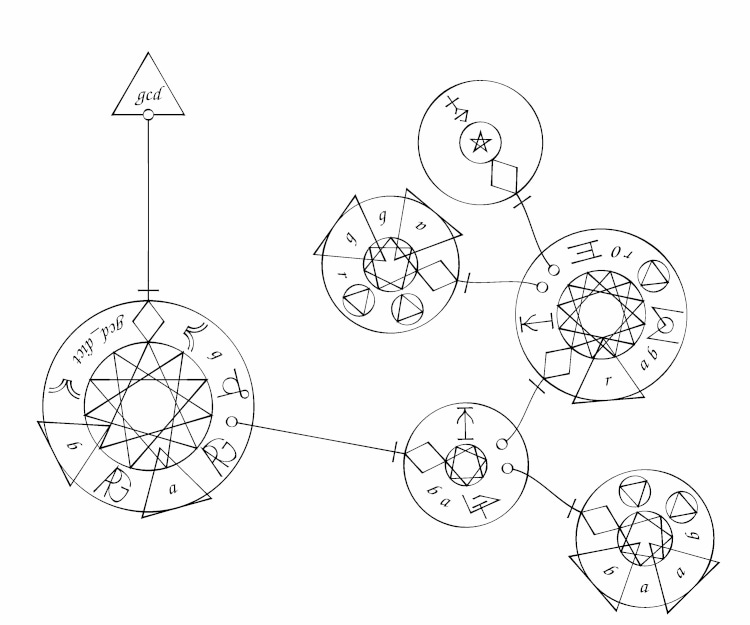
Mystical transforma el código en círculos mágicos, combinando programación y estética alquímica. Pero para hechiceros del software.

Ordenadores jubilados de todo el mundo se refugian en un museo en Cáceres, donde la historia de la computación vive un eterno déjà vu.

Aquellos días en que elegir un fondo sólido en Windows 7 era una técnica de ralentización: 30 segundos más por cada arranque. Aplausos.
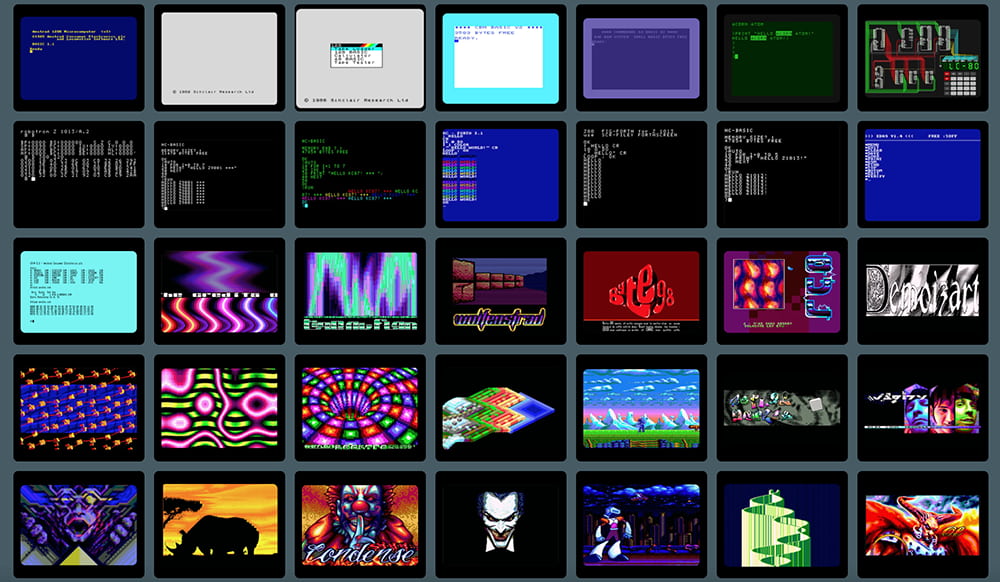
Emuladores que reviven la era dorada de los 8 bits pero sin los exasperantes tiempos de carga del pasado.
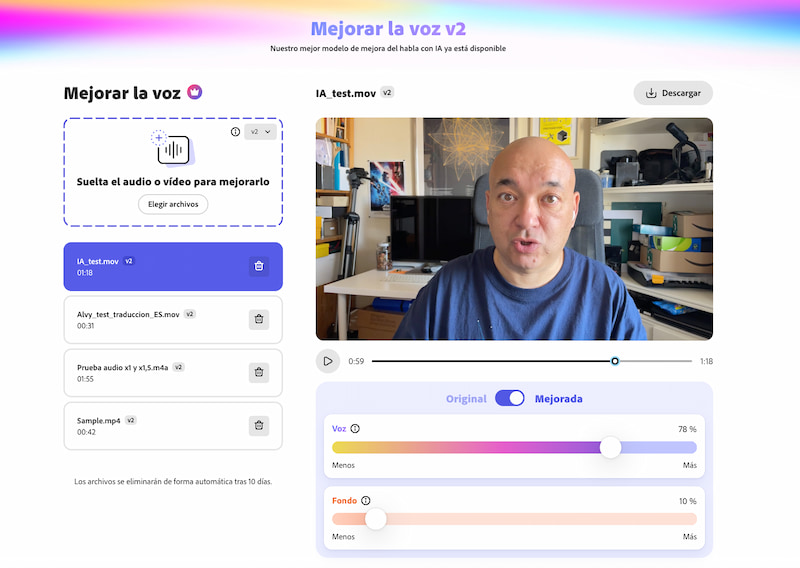
La IA de Adobe convierte audios de WhatsApp en charlas dignas. Gratis y sin registro, pero no esperes sonar como si grabaras en Abbey Road.

Réplicas modernas de ordenadores históricos, desde el PiDP-11 hasta el Whirlwind π, para sentirse como en la era de Turing.
Se puede celebrar el Día de la Tierra reciclando un ordenador viejo. No detendrá el cambio climático, pero al menos te sentirás útil por un par de minutos.
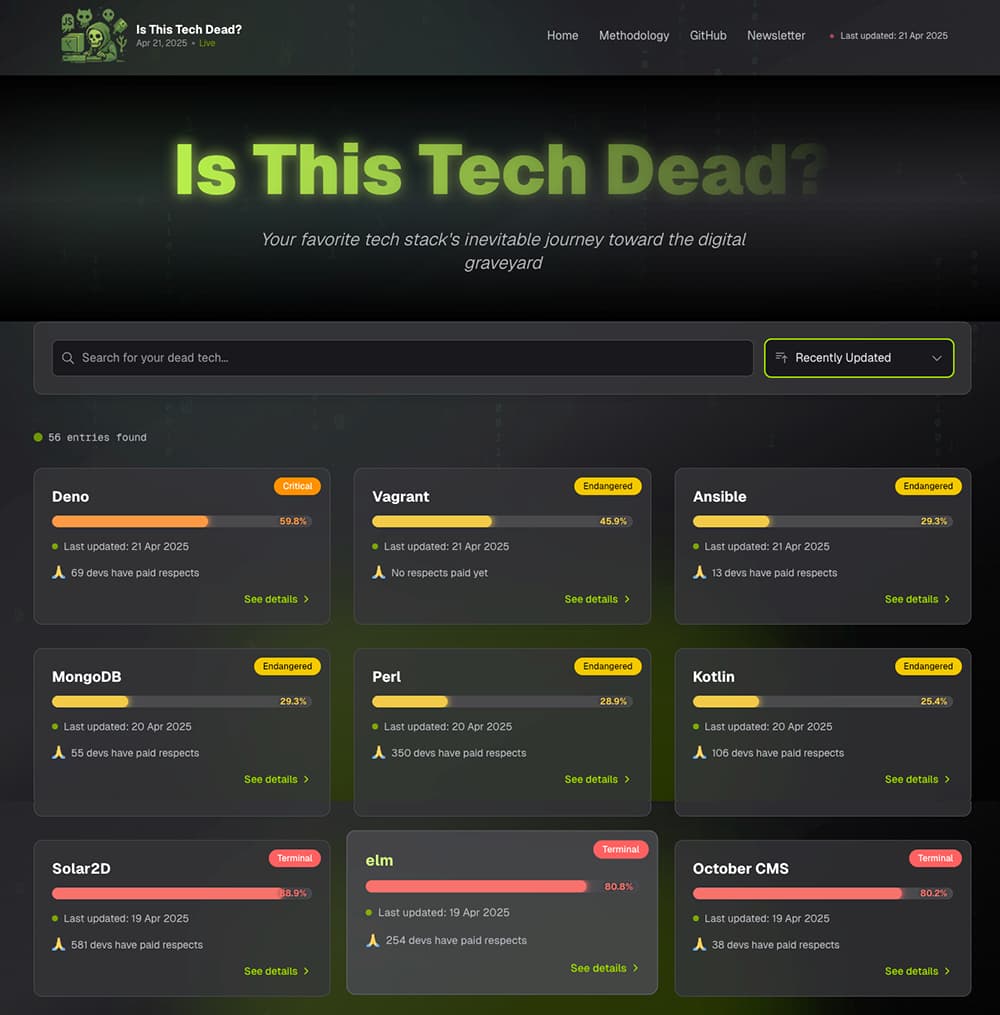
Bienvenidos al cementerio del software: 56 tecnologías que no sabe si ya se fueron o todavía están entre nosotros. Ni WordPress ni PHP resisten.

Cuando los cables Ethernet fallan, un palillo puede obrar milagros. ¿Quién necesita alta tecnología?

Un rápido repaso de algunos detalles relevantes de la historia de la empresa que le permitieron arrancar el camino para convertirse en lo que es hoy en día.

De un intérprete de Basic a tocar casi todos los palos de la informática.

Un mundo ideal: ordenadores reparables al estilo de los de las series de ciencia-ficción, con autonomía total y software libre. ¿El futuro? Quizás… Si no se estropean antes.
Hoy es el día de backup. Y ya sabes lo que se dice: Hay dos tipos de personas que usan ordenadores¹: aquellas que ya han perdido datos y aquellas que los van a perder. Yo ya he estado ahí. Así que...

La confusión con los crackers lleva décadas instaurada en los medios de comunicación y querer aclararlo es prácticamente una batalla perdida.

El soporte para teclados y monitores eran un lujo que había que programar con aquellas máquinas.

El que las generaciones más jóvenes hayan crecido rodeadas de ordenadores, teléfonos móviles y tabletas no hace que dominen su uso en absoluto.

VisuAlgo convierte el tedio de los algoritmos en un festival visual. 26 módulos para estudiantes que buscan entender mejor la programación.

Un cacharro retro que mezcla nostalgia con la complicación de un montaje electrónico. Ideal para programadores valientes y fans de lo vintage.

RSS, ese formato que se niega a morir, es el nuevo «invento cool» para evitar la infoxicación. A veces lo viejo es lo más moderno.

Wozniak recuerda sus días como creador del Apple II y critica la nube, la inteligencia artificial sin regulación y advierte del peligro de los deepfakes.
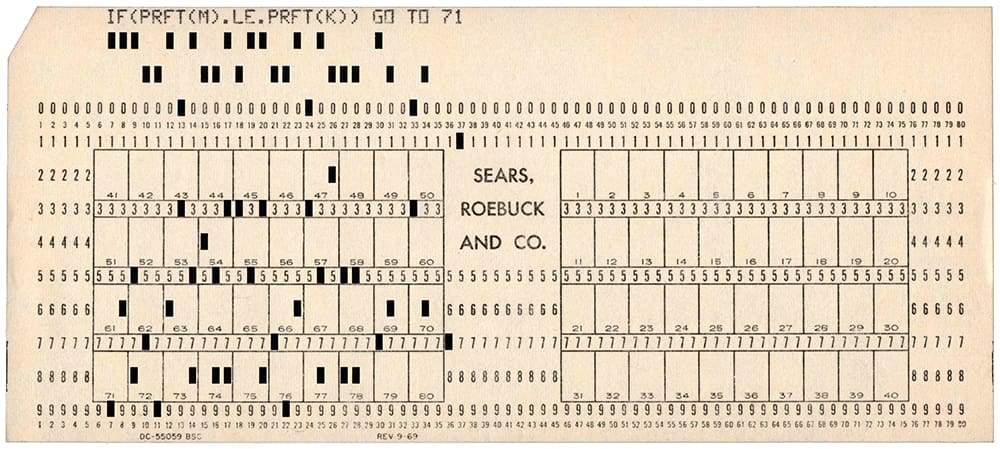
Antes de los discos duros y la nube, los programas venían en papel: 80 bytes por tarjeta perforada y millones de ellas para almacenar un giga.

Hablar está sobrevalorado. Dos IAs prefieren comunicarse con pitidos y tonos en el «modo Gibberlink». Eficiencia máxima, estética retro.

Olvídate de los dados trucados: este lanzamiento de una moneda cuántica es tan aleatorio que ni el universo sabe con anticipación qué saldrá.
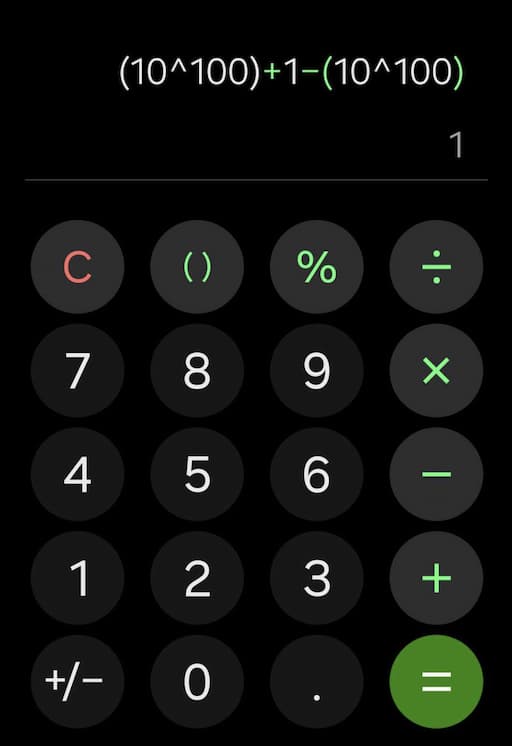
¿Sumar y restar? Fácil. ¿Hacerlo bien en binario, decimal y sin errores raros? Ahí empieza la odisea matemática de la calculadora de Android.
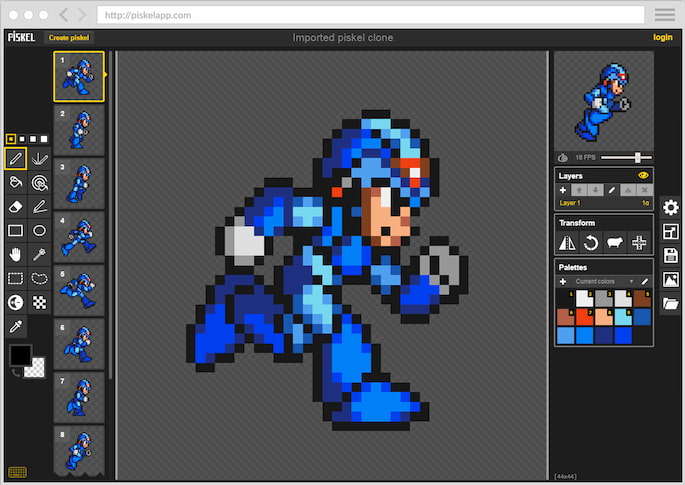
Una herramienta retro para diseñar sprites pixelados con animaciones, capas y paletas de colores. En los años 80 bastaba con un lápiz y 16 colores... y es igual pero más rápido y fácil

Tres de los sustos más gordos que nos hemos llevado cuando las cosas no han funcionado como estaba previsto.

Minimalismo educativo: esta web agrupa todas las etiquetas HTML, incluyendo pequeñas perlas de sabiduría. Perfecto para aprender y olvidar inmediatamente después.
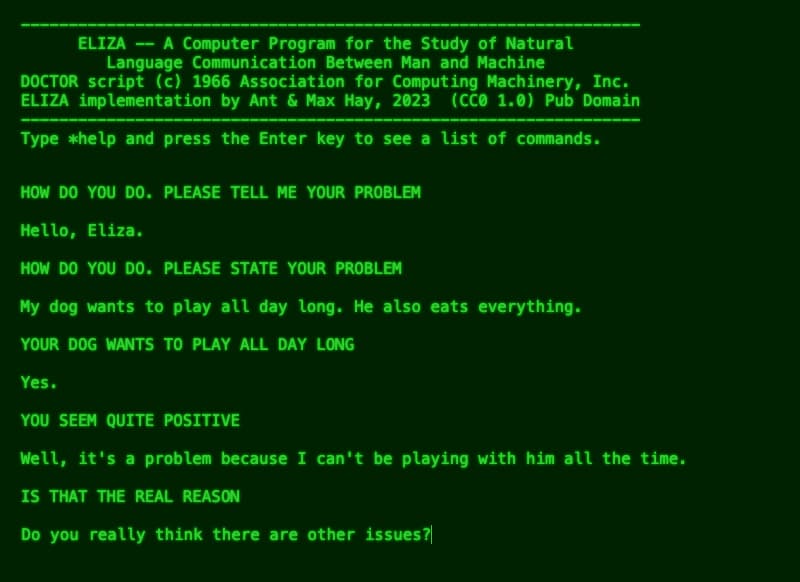
Una IA de los 60 llamada ELIZA demuestra que la gente ya atribuía emociones humanas a máquinas que apenas reformulaban preguntas.

Las «blinkenlights» son el entretenimiento geek por excelencia: un espectáculo técnico que no ayuda, pero siempre impresiona.
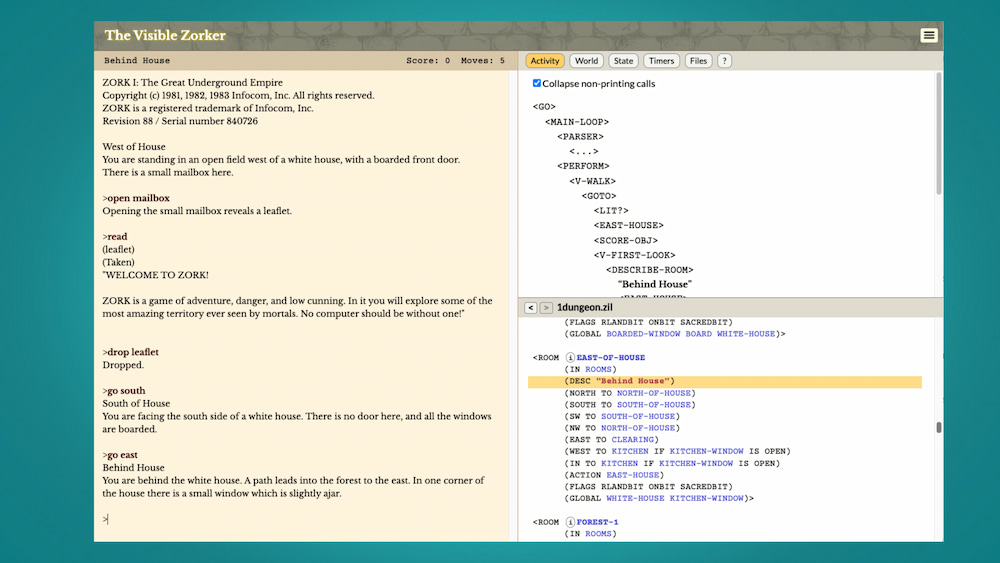
Zork I ya era difícil, pero ahora se puede complicar aun más viendo cómo su código fuente intenta que pierdas el juego.
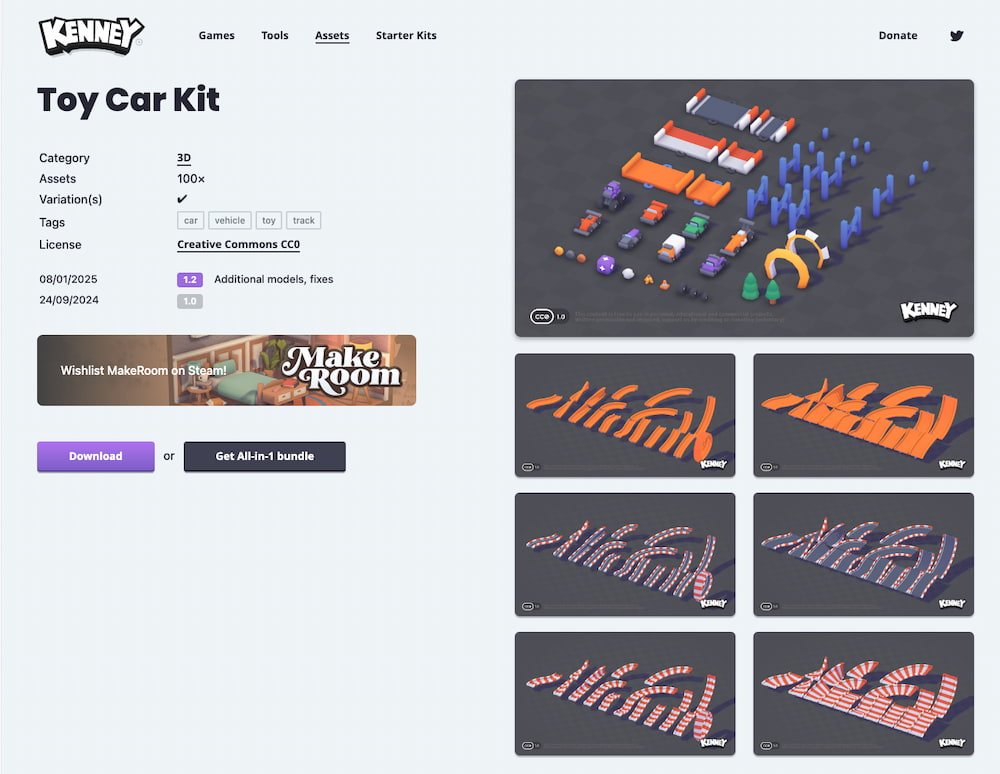
Una amplia colección de elementos 2D/3D gratuitos que facilita a programadores y diseñadores crear y probar videojuegos sin perder tiempo.

Sus logros fueron eclipsados por un injusto olvido histórico y la paranoia de la Guerra Fría.
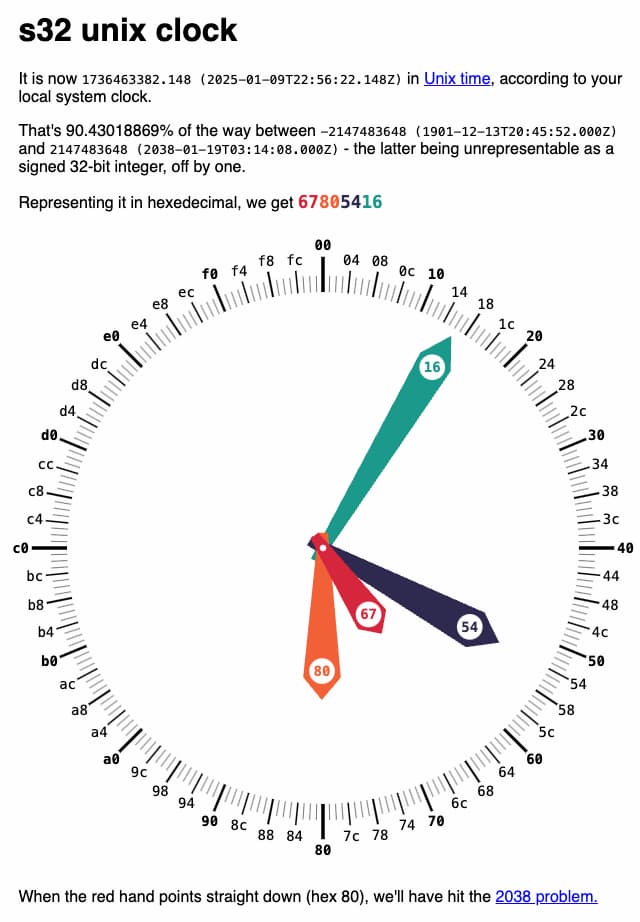
Un colorido reloj que convierte el tiempo Unix en algo más artístico antes de que llegue 2038, una historia que recuerda al «efecto 2000».

La saga de restaurar un Bendix G-15 revive el debate sobre cuál es el primer ordenador del mundo, con un toque de nostalgia geek.

Este libro explica desde la recursividad básica hasta los fractales, mostrando cómo usar esas técnicas en algoritmos y proyectos reales de programación.

Explorar Vintage Apple es como entrar en una librería de reliquias tecnológicas de Apple, con revistas Macworld escaneadas y tesoros de los 80.

Fue necesaria una compleja puesta a punto antes de que pudiera hacerlo.

Se me había pasado pero hace unos días fue anunciado el Raspbery Pi 500, una versión del famoso miniordenador educativo y para cacharreo en formato todo en uno, al estilo de los míticos Amstrad CPC, Commodore 64 o ZX Spectrum. Es...

Combina el encanto de la tecnología informática retro con características modernas, aunque su precio de 795 euros puede asustar.

El Altair 8800, lanzado hace 50 años, vendió más de 25.000 unidades, marcando el inicio del interés por los ordenadores en casa.

Una pareja crea un ordenador singular con 1.700 válvulas de vacío, diseño moderno de 8 bits y el espíritu de la retroinformática.

Estoy absolutamente enganchado a los vídeos en los que David de Usagi Electric, junto con algunos colegas, intentan devolver a la vida un ordenador de válvulas Bendix G-15 de 1956. Pero enganchado tipo The Expanse. Están en la lista Bendix G15...
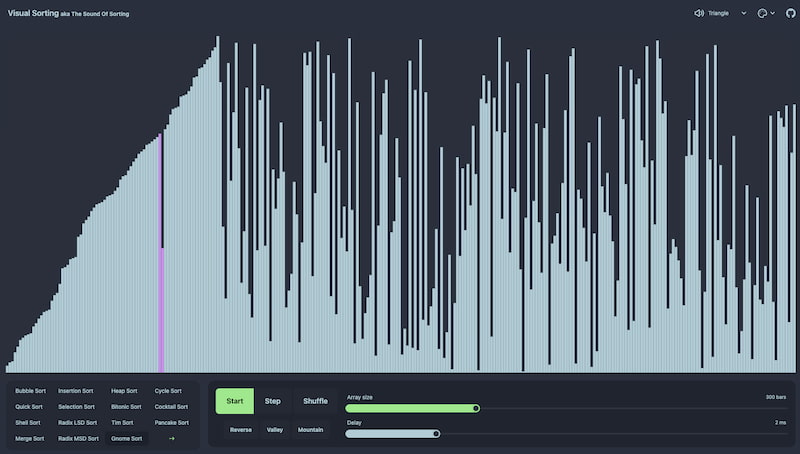
Cómo aprender sobre algoritmos de ordenación con una experiencia visual y sonora que combina interacción y código libre.

Susan Kare revolucionó el diseño digital con Chicago, ahora homenajeada en ChicagoKare.xyz

Esta semana ha muerto Thomas Eugene Kurtz, quien junto con John G. Kemeny diseñó en 1964 el lenguaje de programación Dartmouth BASIC, el primero de los cientos o miles de BASIC que hay a estas alturas. Kemeny falleció en 1992. El BASIC,...

Una web que combina los patrones del famoso autómata celular «el juego de la Vida» con música generativa, creando patrones sonoros únicos.
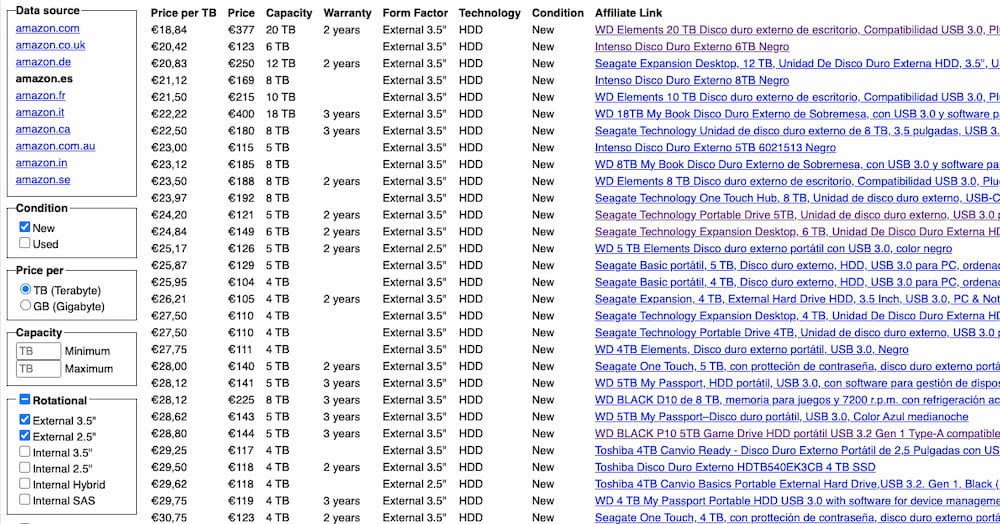
Una tabla ordenada por precio por terabyte muestra discos duros de Amazon y es filtrable por tipo y capacidad, sin anuncios.
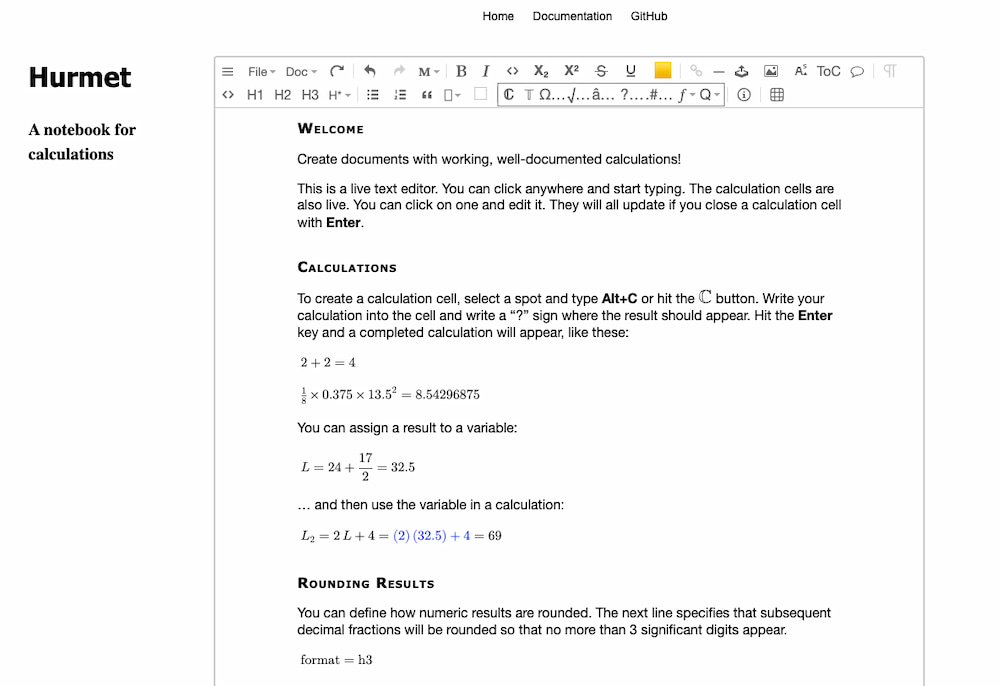
Me gusta la idea de Hurmet, que básicamente es un editor que calcula. Es fácil de usar y bastante potente, una especie de LaTeX simplificado que funciona según tecleas. Además hace que al realizar los cálculos los resultados sean correctos, algo...

La Open Source Initiative ha abierto una consulta pública acerca de la primera versión de la definición de «inteligencia artificial de código abierto». La idea es que todo el mundo esté más o menos de acuerdo en el de qué estamos hablando...

Este viejísimo minidocumental de 1968 es toda una joya de la arqueología informática. Muestra cómo era el Graphic 1, un equipo de los Laboratorios Bell que combinaba gráficos y música y que data de 1965. Era básicamente una consola que utilizaba...

Aunque teclear en sí mismo no es tan importante, teclear rápido sigue siendo una de las habilidades críticas para los desarrolladores, ya que reduce el tiempo invertido en una tarea tan insignificante como es teclear.– Uğur Erdem Seyfi Argumenta Uğur, diría...
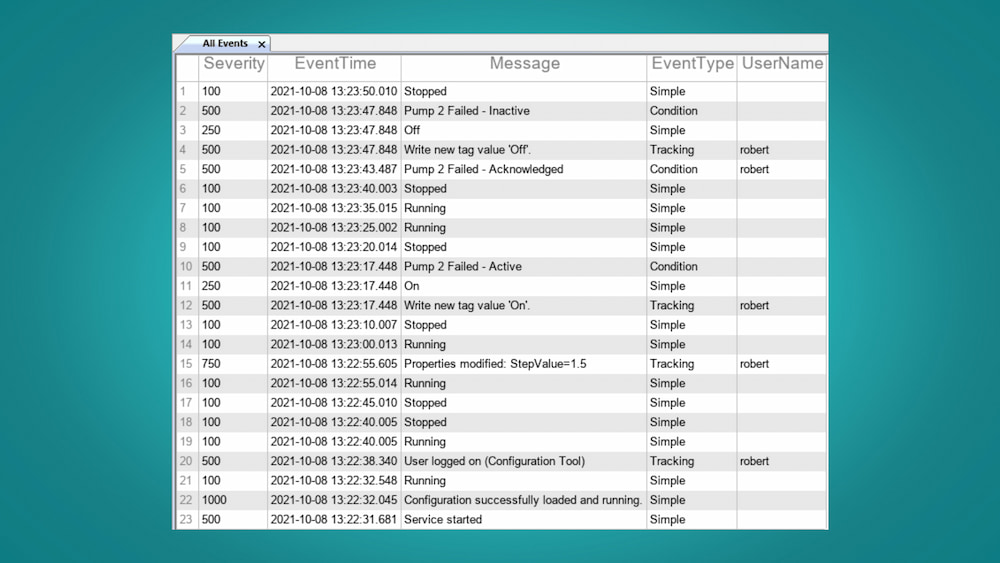
Rox Williams tiene una lista bastante precisa y bien definida de los mejores consejos para crear logs (registros), algo necesario en aplicaciones para depurarlas (debugear), cuando gestionan sistemas que trabajan con eventos, acciones o dispositivos externos. La clave suele ser empezar...

Un estudiante llamado Jan Strehmel decidió dedicar su tesis a analizar la relación entre la calidad del código abierto y la aparición en él de palabrotas y términos malsonantes. Tan intrascendente investigación demostraría de una vez por todas si incluir improperios...
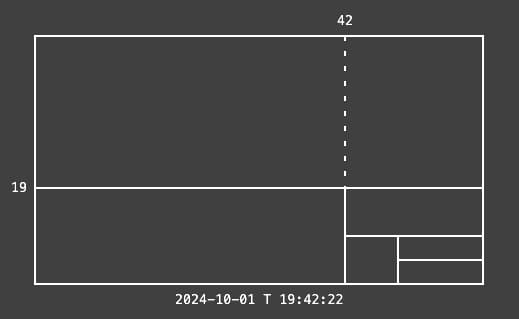
El Gridclock es un curioso reloj en el que la hora con minutos y segundo está representada como líneas que cruzan la pantalla. Está inspirado por el reloj Arvelie-Neralie de Devine Lu Linvega y por Hundred Rabbits. En la anotación del...
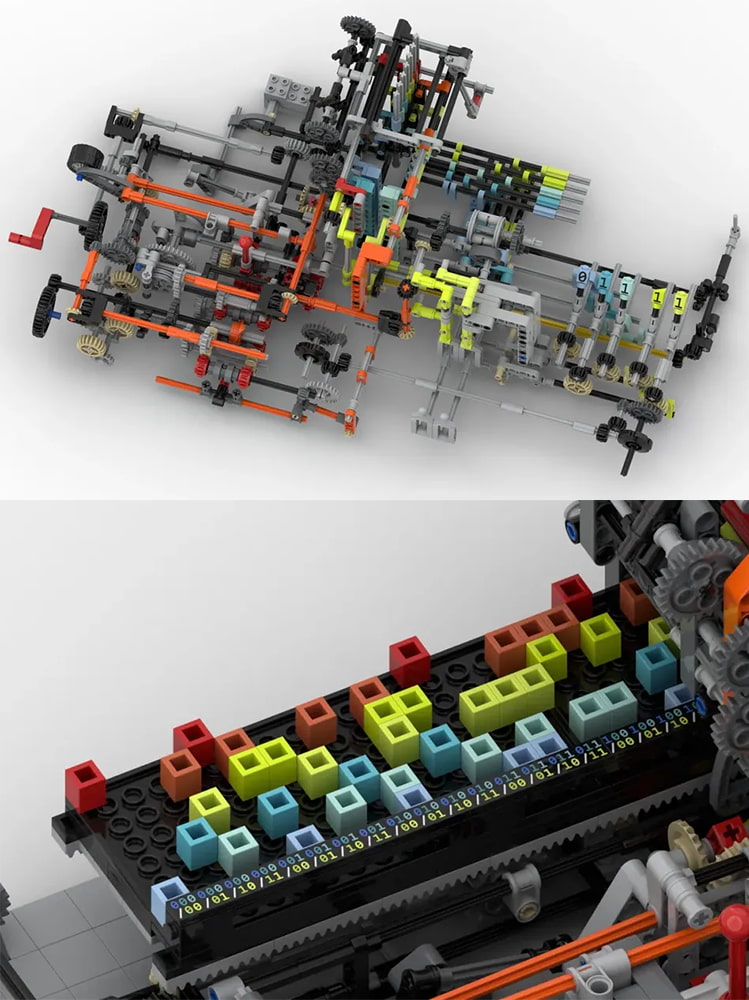
Combinando lo mejor de ambos mundos, o al menos de los mundos que nos gustan a nosotros, esta Máquina de Turing de LEGO aúna los orígenes de la informática con las sempiternas piezas de construcción de Lego. No es algo precisamente...
Dirigido a creadores de contenido en general, sin olvidar a los periodistas y editores de grandes medios, AInnovación es un encuentro que se celebrará el 10 de octubre de 2024 en la sede de Google Campus en Madrid. Está organizado por...

Según data la historia, el mítico Homebrew Computer Club se fundó el 5 de marzo de 1975. La primera reunión de hackers fue en el garaje de Gordon French en Menlo Park (California) y acudieron unas 30 personas interesadas en el...

Uno de los artículos más populares que he escrito jamás es en el que hablo del verdadero origen de Internet. En él explico cómo esa idea que se ha extendido e instalado de que se trata de una red diseñada para sobrevivir...

I made a website. it's called "one million checkboxes dot com". it has one million checkboxes on it.checking a box checks it for everyone.that's it. have fun! pic.twitter.com/KBF4UqCMJc— nolen (@itseieio) June 26, 2024 Me ha encantado la historia que cuenta Nolen Royalty...

Hace unas semanas se montó un cierto pollo cuando se hizo público que la NSA, la Agencia de Seguridad Nacional de los Estados Unidos, que es la responsable del monitoreo, recopilación y procesamiento global de información y datos para fines de...

Peter Jennings cuenta en primera persona la Historia de Microchess para el Kim-1, un programa de ajedrez de 1976 que ocupaba 1 KB y fue probablemente* el primer software comercial de la historia. Funcionaba originalmente en el Kim-1, un microordenador «montado»...

Hace ya un tiempo Michael Ravnitzky descubrió que en los archivos de la Escuela Nacional de Criptografía hay dos cintas de vídeo que contienen una charla de la almirante Grace Murray Hopper titulada Future Possibilities: Data, Hardware, Software, and People, Posibilidades futuras:...

Se ha escrito más ficción en Excel que en Word.– Dicho popular vía David Martínez _____Foto de Mika Baumeister en Unsplash...

La parte más conocida de este proyecto relacionado con los Sudokus se llama Super Sudoku, y lo creó Tom Nick para su abuela, que se quejaba de la escasa dificultad de los que encontraba en las revistas. Esto le llevó a...

No soy mucho de escribir sobre cacharros que no he probado. Pero dado que su versión original me pareció bastante impresionante he pensado que estaría bien mencionar que ASUS acaba de presentar la ROG Ally X, la versión actualizada de su...

Un escenario típico en el que se escucha el sonido en casa o en el coche incluye un software para reproducir el contenido, que tiene su regulador de volumen, el controlador general de volumen del sistema y finalmente unos altavoces externos...
XKCD ya lo predijo A primera hora de esta mañana empezaron a saltar las noticias de problemas informáticos de todo tipo en todo el mundo en aeropuertos, aerolíneas, bancos, organismos públicos como el Osakidetza vasco o el Sergas gallego, pagos en cajeros...

Enrico Tartarotti se pregunta en este vídeo ¿Qué ha sucedido con las interfaces de usuario? Es una reflexión sobre la evolución (o desinvolución, según se mire) de las últimas décadas, de cómo ha cambiado la forma visual en que nos comunicamos...

Este curioso chisme con cuya página me crucé el otro día es la Valve.Computer o Computadora de válvulas Es un curioso híbrido de máquina antigua de los años 50 utilizando válvulas de vacío (válvula termoiónica). Es obra de un entusiasta de...

Cuando me ofrecieron probar el teclado Trust GXT 867 Acira les dije que me parecía que no era el público objetivo para este teclado, que está pensado para quienes juegan mucho. Pero aún así me pidieron mis impresiones de usuario de...

He estado probando durante unas semanas un monitor Philips 27E1N1300AE. Es un monitor de 27 pulgadas LCD IPS en Full HD, lo que son 1.920 x 1.080 píxeles de resolución máxima en formato 16:9, y una frecuencia de refresco de 100...
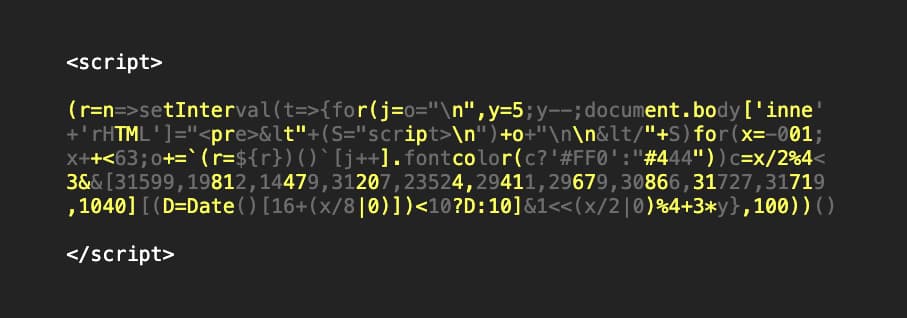
Martin Kleppe (@aemkei) ha dado a conocer una pequeña maravilla en JavaScript que ocupa tan solo 321 bytes y resulta visualmente llamativo: Qlock: un reloj en JavaScript que muestra la hora coloreando letras y símbolos del propio código fuente. Si no...

Inspirado por el trabajo de la bióloga Lynn Margulis, Jeffrey Ventrella ha creado este curioso y gozoso algoritmo visual llamado Clústeres. Es básicamente un micromundo de partículas, entidades ambiguas que pueden comportarse de una u otra manera según los parámetros preprogramados....
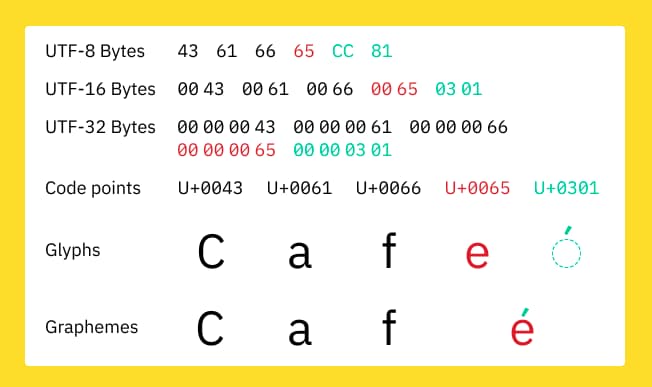
Hoy en día el 98% de los archivos de texto que se manejan en todo tipo de software estan codificados como UTF-8 (Unicode Transformation Format, 8-bit) una forma estándar de codificar caracteres en todas las formas de escritura, emojis incluidos. Hace...
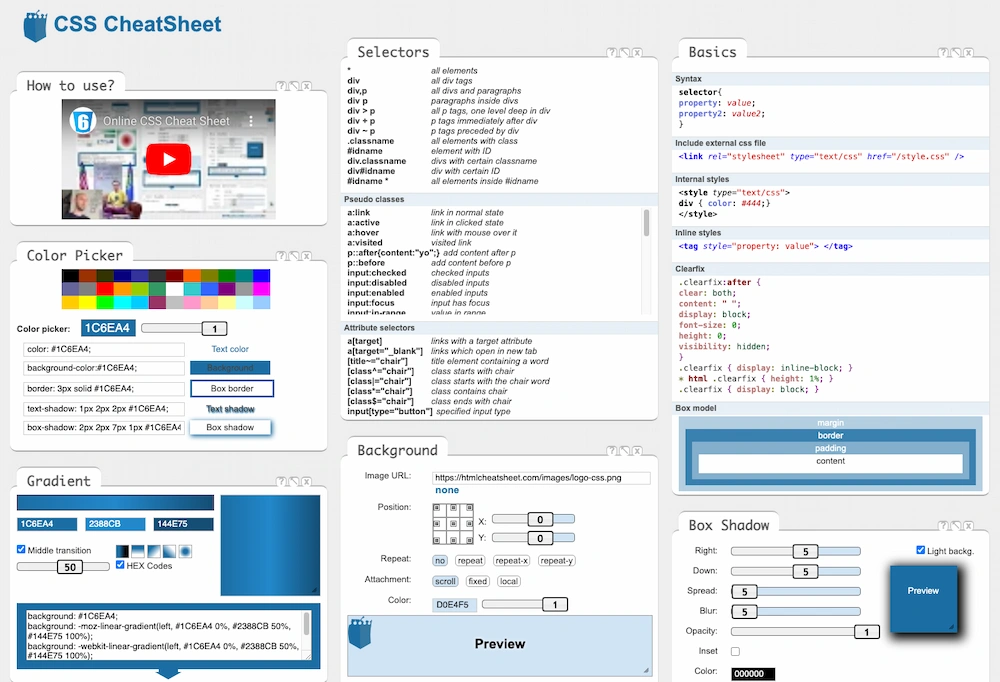
He visto una referencia a una Chuleta de JavaScript y en la misma página encontré otra sobre HTML y otra más sobre CSS. La diferencia respecto a tenerlas en un papel es que algunos detalles son interactivos, con las típicas utilidades...

Es más fácil escribir un programa incorrecto que comprender uno correcto. Los epigramas son «frases breves e ingeniosas, frecuentemente satíricas», algo así como «ocurrencias» o «frases agudas». Y hete aquí que a alguien se le ocurrió hace tiempo escribir (o recopilar) 120...
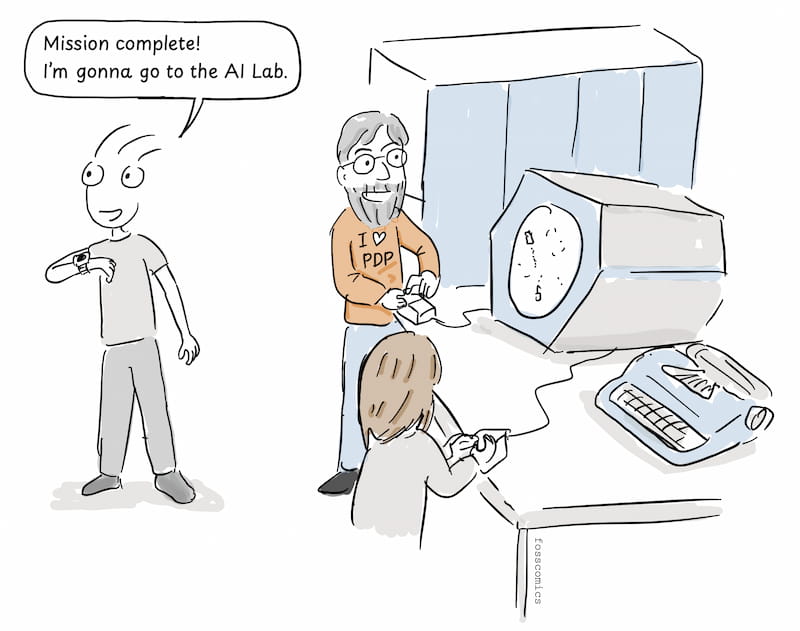
No conocía los Cómics de F/OSS, que están dedicados al software libre y abierto en desde diferentes puntos de vista (FOSS = Free and Open Source Software). Son obra de Joone Hur y se publican desde 2018, a un ritmo lento...

Este curioso maletín de WD llamado Ultrastar Transporter es una auténtica bestia pero con estilo en la que se pueden transportar 368 TB de datos en unidades SSD de una tacada. Te cabe media internet, por lo menos. Dicen que es...

Hacía mucho que no recomendábamos por aquí una camiseta interesante, y justamente me he cruzado con la Camiseta de la portada del Wired de junio de 1997, aquella maravilla de fondo blanco que mostraba el logo de Apple con una corona...

Los Pebble X Plus – Creative Desde hace unos años he tenido la oportunidad de poner a prueba sucesivas generaciones de los altavoces de sobremesa Pebble de Creative. Cada una que he ido probando se ha convertido en los que uso en...
Según alguien calculó el tamaño más grande posible representado en un archivo PDF sería un cuadrado que ocuparía unos 381 × 381 km (unos 145.000 km²), más o menos la mitad que la superficie de Alemania, una tercera parte de España...
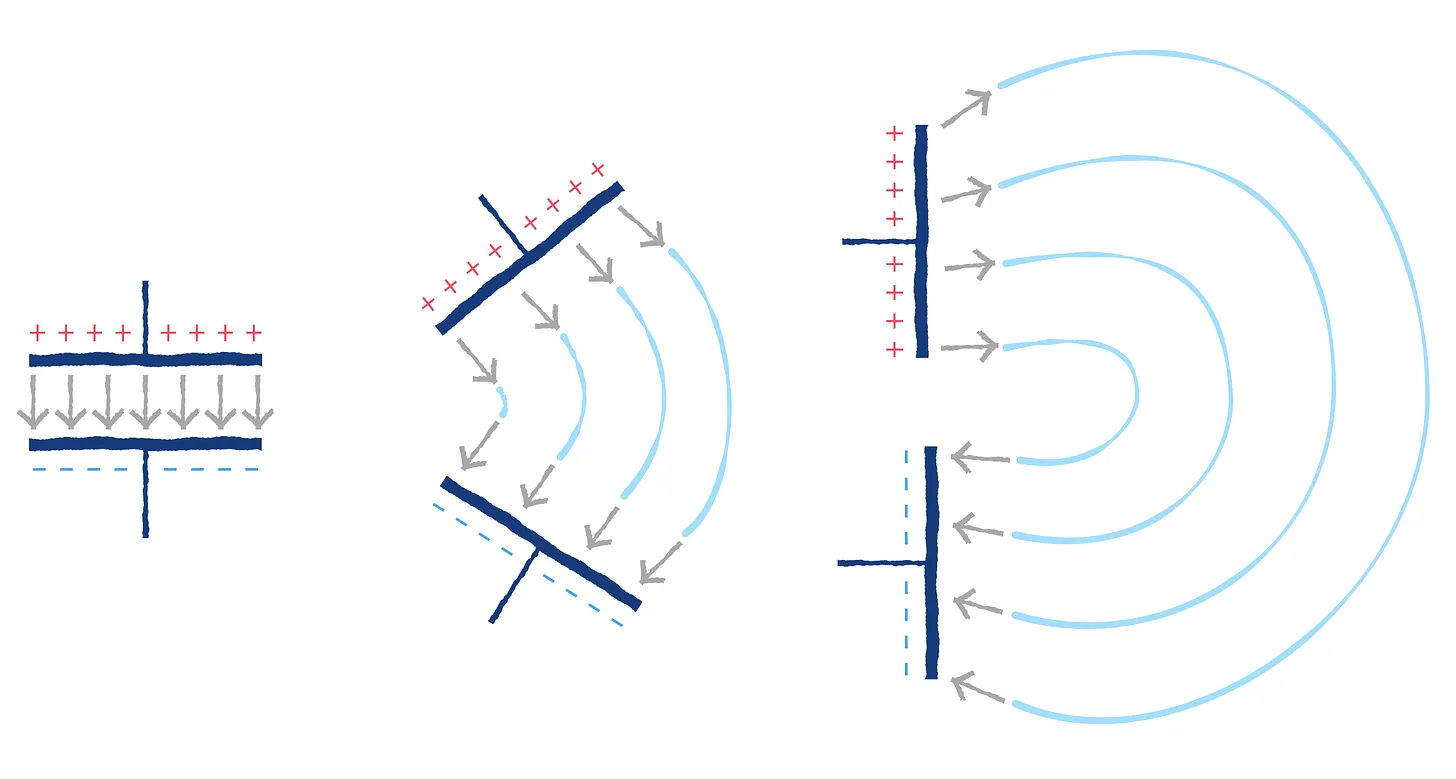
Me topé con este artículo muy divulgativo de Lcamtuf (Michal Zalewski) acerca de cómo funcionan las antenas de radio. Muy claro, fácil, entretenido y con las visualizaciones en imágenes y vídeos adecuadas para entenderlo todo. El artículo incluye explicaciones sobre la...

El Brewintosh de Kevin Noki, que es como ha llamado a esta creación, es una carcasa de Mac 128K meticulosamente recreada e impresa en 3D, que aloja un miniPC actual con un emulador de Mac, capaz de arrancar con disquetes o...
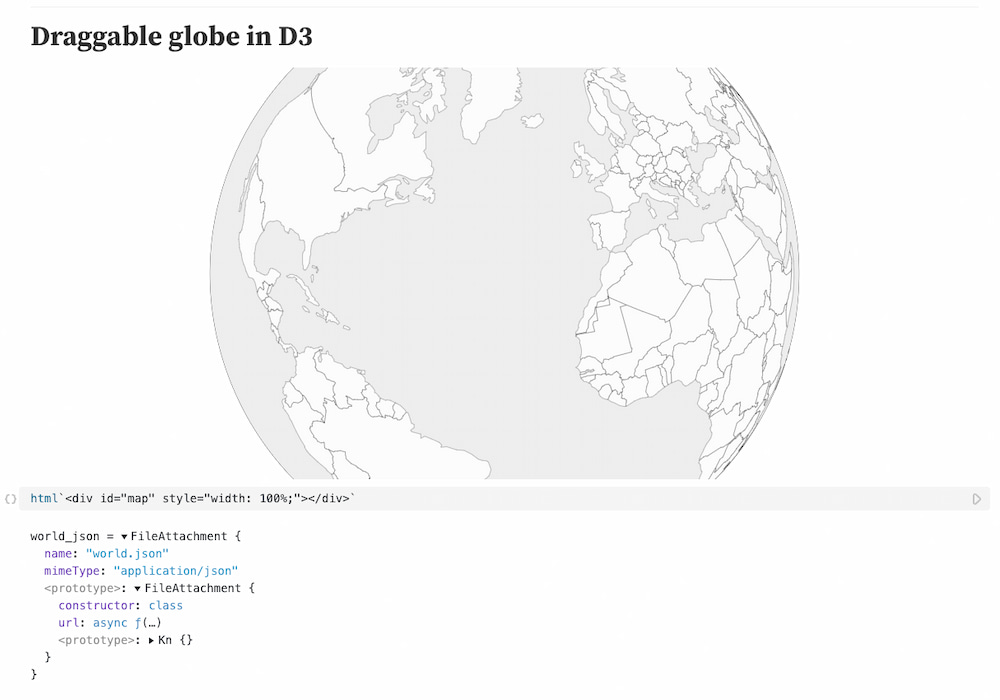
Este código de Michael Keith está creado con la librería JavaScript D3 y muestra muy básicamente un globo terrestre con todos los países. Se puede arrastrar con el razón, tiene zoom y otros detalles interesantes. Como puede verse el código es...
He estado probando una consola portátil para videojuegos ASUS ROG Ally. Y aunque no soy muy jugón –o aunque la vida no me da para serlo– resulta que ahora no me importaría nada tener una. La ROG (Republic Of Gamers) Ally...

No se puede negar que programadores y científicos tengan un fino sentido del humor. Un perfecto ejemplo sería este paquete/extensión creado por Hanno Rein y Patrick Bideault que sirve para añadir marcas de tazas de café a los documentos generados con...
El arquetipo del azar suele representarse con el lanzamiento de una moneda al aire. Es indiferente si cae sobre la palma de la mano, el suelo, si es un euro, una vieja peseta o un dracma: todos son sistemas físicos y...

¡Hola, soy Windows Defender! ¿Quieres actualizar? Bueno me actualizo automáticamente, pero como te metas… Ahí estoy yo, actualizándome siempre. Te miro, te observo, mientras carga la barra de progreso… 1% 2 3 4 5 6 7 8… Hasta el 100%. Y...

Aldo Cortesi es el creador de Binvis.io, una pequeña utilidad online que sirve para examinar «en colores» las tripas de cualquier archivos binario. Simplemente se elige el archivo en cuestión, que puede ser muy grande, y aparece una representación gráfica de...
Me ha gustado la idea de los Wizard Zines de Julia Evans (b0rk) como forma amena de aprender conceptos informáticos presentados de forma «alternativa»: HTML, Bash, DNS, Git… Por su aspecto naíf podría pensarse que estos cómic/revistas son «para niños» pero...

Parece que fue ayer pero hoy hace 40 años que Apple presentaba el Macintosh. Lo hizo dos días después¹ de emitir en la Super Bowl el ahora famoso anuncio dirigido por Ridley Scott que decía que la empresa iba a enseñarnos...

En su blog, Jessie Frazelle publicó una anotación titulada La vida de un byte de datos que a modo de cronología relata cómo era almacenar un byte entre los años 1951 y 2009, aunque luego lo amplía un poco hasta la...
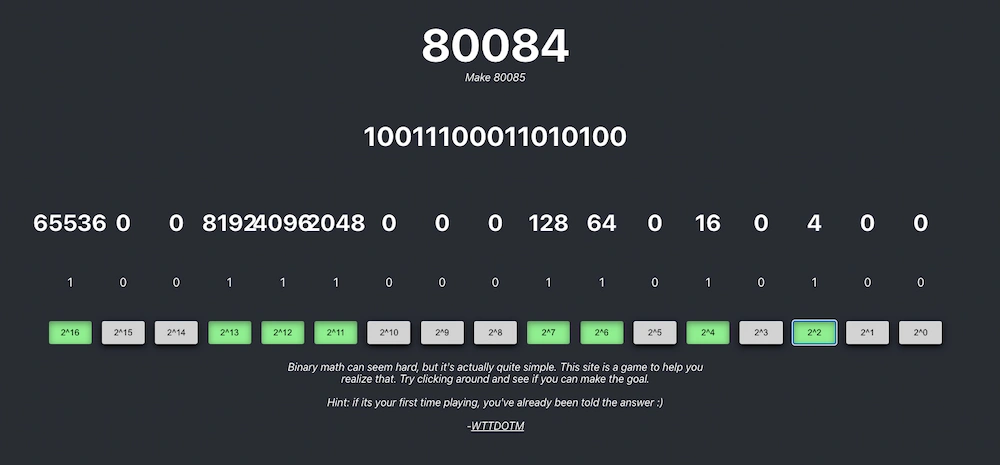
80085 es un número de 17 bits, compuesto de 1s y 0s de forma única. Las matemáticas de los números binarios pueden parecer complicadas al principio, pero cuando te acostumbras no lo son tanto. Jugando con Looo.lol se puede practicar para...

Acabamos de enterarnos de la muerte de Niklaus Wirth el pasado 1 de enero. Ha fallecido con 89 años de edad. Wirth fue el creador del lenguaje de programación Pascal, que si no recuerdo mal fue el segundo que aprendí después del...
WinWorld es una combinación de museo y comunidad virtual sobre el software retro, vintage y abandonado, incluyendo versiones previas y betas. Todo lo que hay en su extensa biblioteca se puede descargar, aunque no siempre es fácil hacerlo funcionar, pero ahí...

Me ha parecido buenísimo este vídeo que acompaña el artículo de Quanta Magazine titulado Complexity Theory’s 50-Year Journey to the Limits of Knowledge. («Cincuenta años del viaje de la teoría de la complejidad hasta los límites del conocimiento»). Es ameno y...

Acabo de enterarme de que este verano The Royal Mint, que es la versión británica de la Fábrica Nacional de Moneda y Timbre española, sacó unas monedas conmemorativas de Ada Lovelace, la primera persona de la historia en escribir un programa de...

Play like a girl: desafíos de las mujeres en la industria del juego y la tecnología. Por Marina Amores. Libros Cúpula (14 de junio de 2023). 240 páginas. Marina –ahora más conocida por estos pagos como @blissy– tuvo la suerte de que...

Mr. Internet: Cómo se relacionan la tecnología y el género y cómo te afecta a ti. Por Marta Beltrán. Next Door (27 de septiembre de 2023). 134 páginas. Aunque la tecnología, entendida en este libro básicamente como los campos de la informática,...
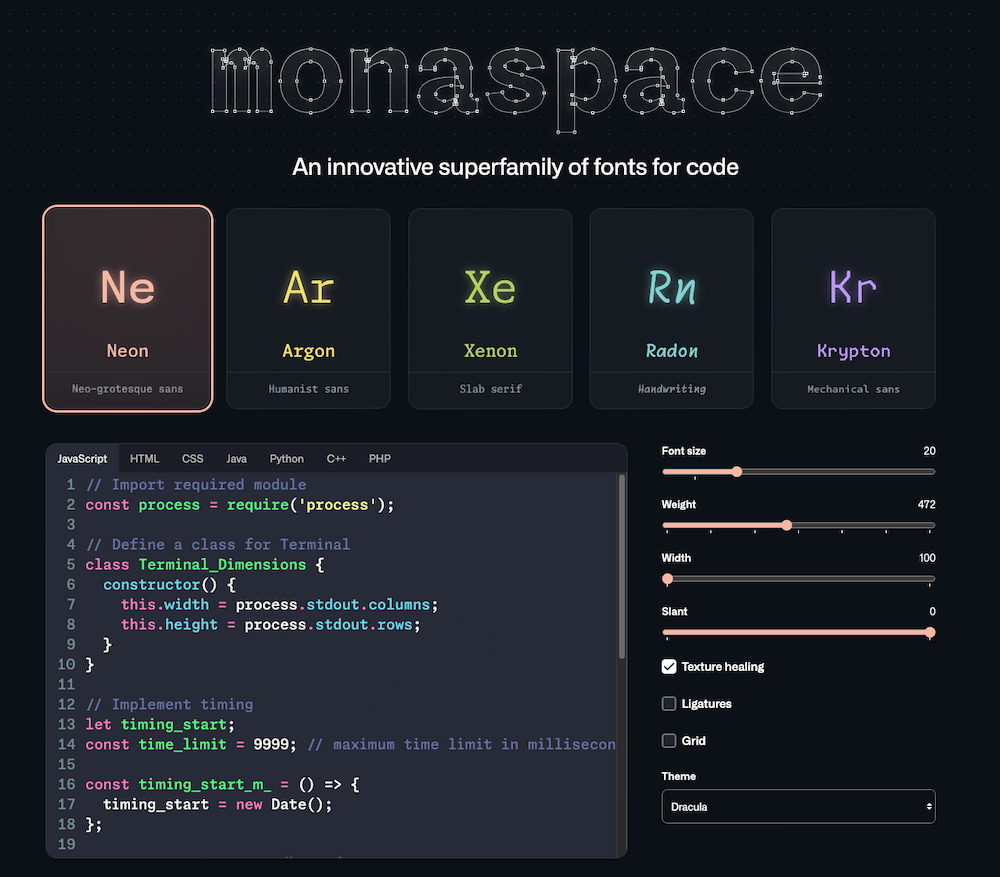
Monaspace es lo que llaman una superfamilia de tipografías monoespaciadas para trabajar con código en labores de programación y similares. Es un desarrollo de Github Next e incluye cinco fuentes diferentes cada una con un aspecto distinto: una estilo helvética, otra...

Encontré esta Visita virtual al Centro de Supercomputación de Barcelona, que no sé si es nueva o antigua, en la web del Barcelona Supercomputing Center. Está bien construida, con Matterport, y resulta muy fluida, de modo que con unos pocos clics...

Del departamento de «no me da la vida y se me acumulan los enlaces» llega el anuncio de la Raspberry Pi 5, que en realidad se produjo a finales de septiembre. Es una mejora de la 4, presentada en 2019. Aunque...
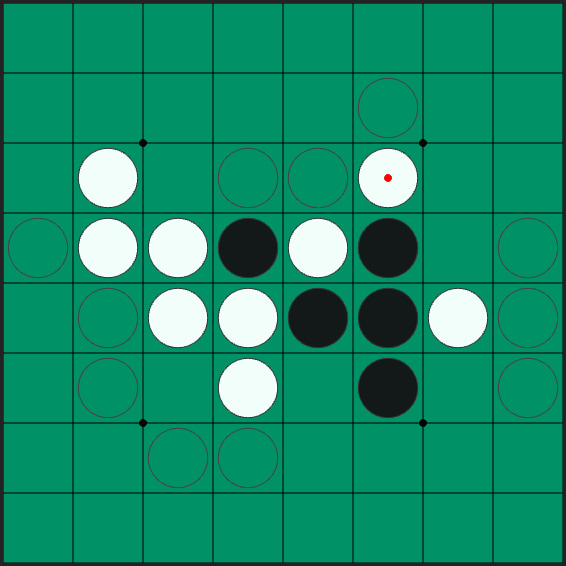
El clásico juego de estrategia del Othello, en algunos sitios también llamado Reversi o Yang, ya ha sido resuelto pese a lo inabarcable que parecía resultar computacionalmente. En total se había calculado que el Othello tenía unas 1058 posibles partidas y...

La nueva foto de Baby por su 75 aniversario – Universidad de Manchester El 21 de junio de 1948 el ordenador Manchester Small-Scale Experimental Machine o SSEM, del inglés máquina experimental de pequeña escala de Manchester, generalmente conocido como Baby, ejecutaba su...

En la web de Thomas Brase se cuenta de la impresionante aventura de arqueología tecnológica que es la restauración de un IMSAI 8080. Es una de esas joyas que como los Cray 1 o los Delorean han sobrepasado su función original...

He estado probando un ratón ergonómico vertical Verto de Trust. Aunque a primera vista parece un poco «ortopédico» lo cierto es que es muy cómodo de utilizar y en pocos días me he acostumbrado tanto a usarlo que ahora utilizar un ratón...

Russell Eveleigh ha creado este precioso visor hexadecimal para explorar manualmente cómo funciona eso de contar en diferentes bases, desde la base 2 (binario) a la 16 (hexadecimal) que tan común es en informática. El hardware está construido con una Raspberry...

No hay que complicarse mucho la vida para utilizar QX82 y crear videojuegos con aspecto ochentero; basta descargar el código de Github y ponerse manos a la obra. Lo interesante es que no se trata de un emulador ni una consola...

A veces hacer las preguntas correctas indagando machaconamente como un niño de cuatro años tiene su premio. En este caso encontré una presentación de Tony Finch titulado ¿De dónde viene la hora? que profundiza en el origen de algo tan corriente...
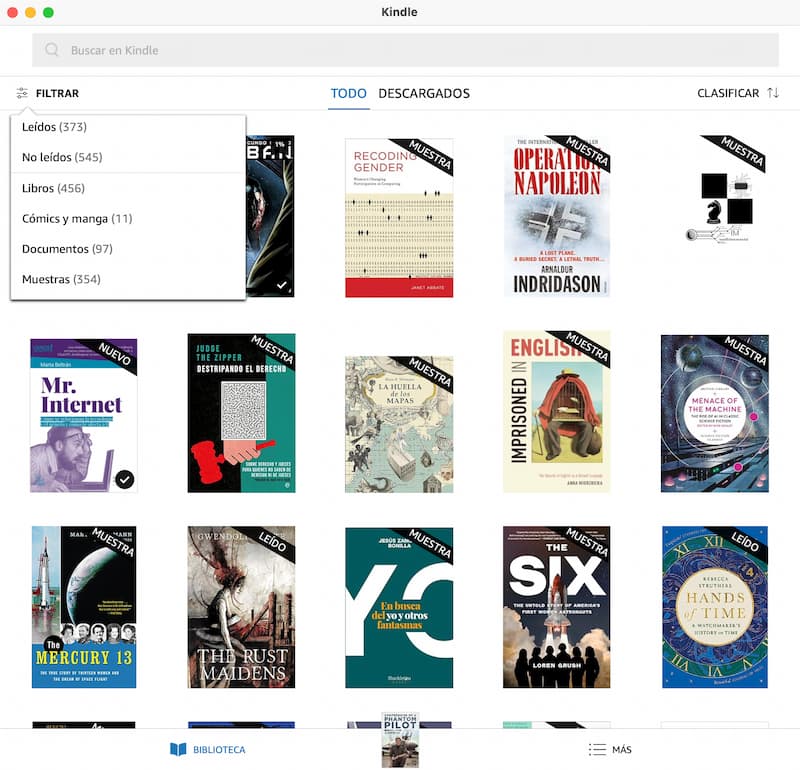
¡Por fin se puede filtrar la biblioteca como en un Kindle! Si usas Mac, tienes libros, documentos y cómics, o cualquier combinación de ellos en tu biblioteca Kindle, y los lees en el ordenador, corre, no andes, e instala la versión nueva...

Los otrora despejados armarios del centro de datos del CERN (Centro Europeo para la Investigación Nuclear) en Suiza han ido llenándose poco a poco durante los últimos años y ya han alcanzado un exabyte de capacidad de almacenamiento. Eso es equivalente...

Como casi cualquier persona que ande metido en esto de la informática había oído hablar de los servicios en la nube que ofrecen Amazon, Google o Microsoft para desplegar ordenadores sin necesidad de adquirir máquinas. Incluso utilizo algunos servicios en mi trabajo...

En este vídeo del canal Chornobyl Family puede disfrutarse del trabajo de seis meses de Alex y Michaela, dos entusiastas de la retroinformática de Ucrania y Eslovaquia. Llevan años visitado la Zona y han recopilado información sobre los ordenadores y equipos...

Está creación de DotEye es tan intranscendente como impresionante, aunque lo curioso es que se le pueden encontrar multitud de aspectos fascinantes que van desde el diseño a las matemáticas o la informática y la programación para gestionar cantidades ingentes de...

It’s an 8-bit world,and we’re 8-bit girls,it’s true,oh yeah!– The 8 Bit Girls Taylor y Amy han subido a su canal una creación musical con las 8 Bit Girls titulada La canción del 6502. Es un homenaje musical al mítico microprocesador...
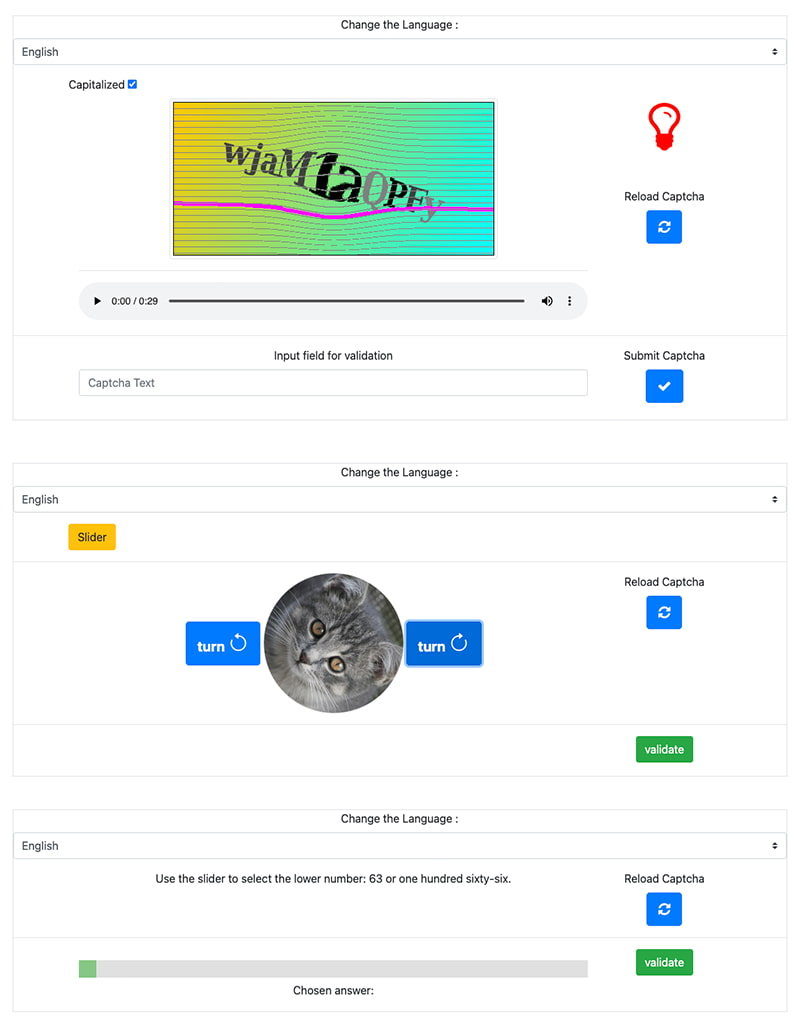
En el repositorio code.europa.eu gestionado por la Comisión Europea se puede acceder ya a EU-CAPTCHA (técnicamente ISA Action 2018.08 EU-Captcha), una iniciativa de la Comisión Europea. Consiste básicamente en tres tipos de captchas listos para utilizar en cualquier proyecto. El principal...
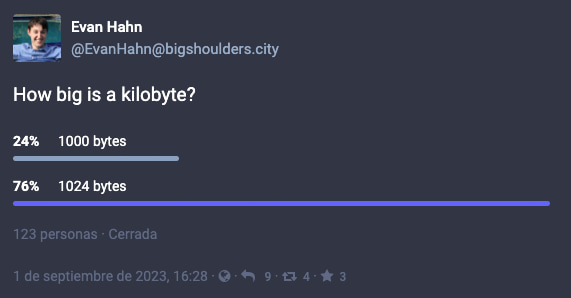
Evan Hahn revisó una cuestión de la que naturalmente ya hablamos por aquí hace más de 15 años, en forma de nota: cuál es el tamaño en bytes de los kilobytes, y por extensión de los megabytes, gigabytes, terabytes y demás....

Me ha gustado la forma en que en Exploring Exif el diseñador e ingeniero Harley Turan muestra el poderío de los metadatos del Formato de archivo de imagen intercambiable (Exif*); la conocida especificación de los archivos que salen de las cámaras...
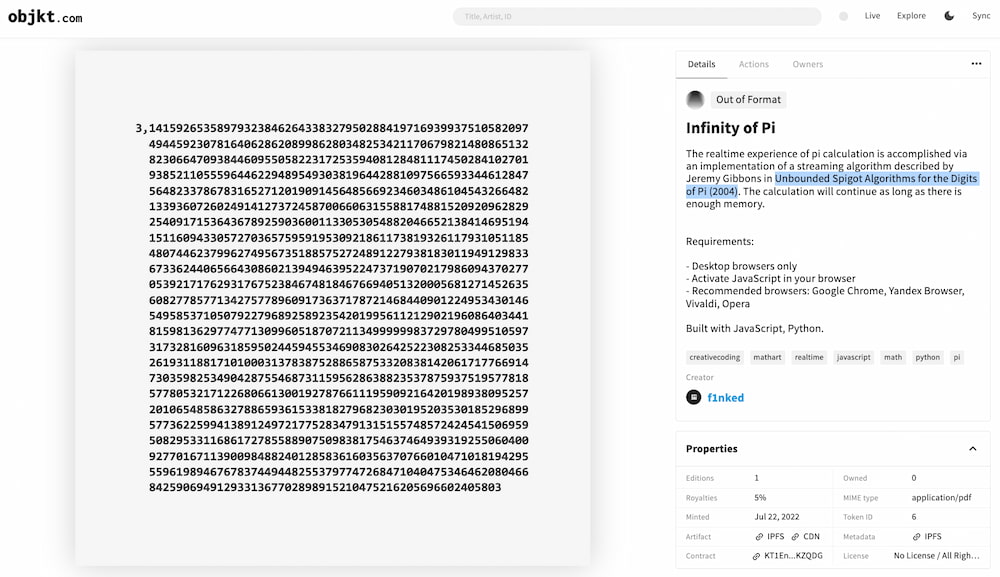
Infinity of Pi es una curiosa página que realiza un cálculo de pi (π) en tiempo real mediante un algoritmo descrito por Jeremy Gibbons. Lo más llamativo –al menos para mi, porque no me había cruzado nunca con esto– es que...

Allá por 2011 Steven Halim tuvo la idea de enseñar algoritmos usando animaciones. Junto con otras tres personas construyeron VisuAlgo, que lleva funcionando desde entonces, añadiendo algoritmos a un método educativo que consiste en que primero se mira, prueba y practica...

Javier de OSGeo nos escribió para contarnos que últimamente hay bastante preocupación en el mundo del software libre con la llamada Ley de ciberresiliencia (CRA), que de momento es una «propuesta de Reglamento sobre los requisitos de ciberseguridad de los productos...
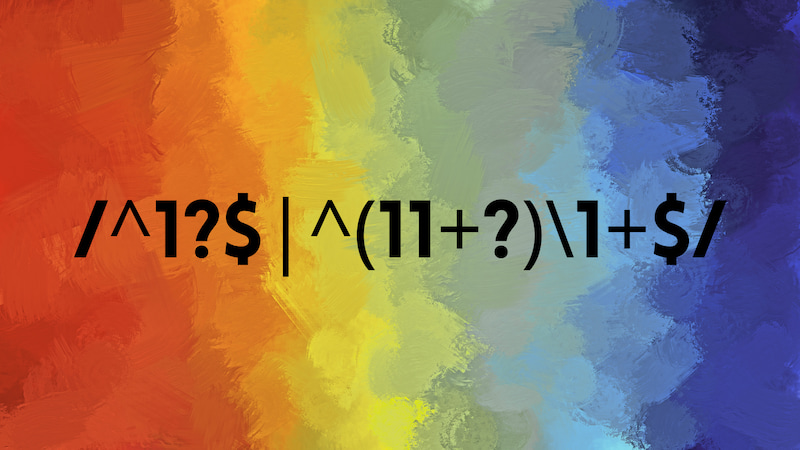
Esta regexp en Perl comprueba si un número es primo o no / Avinash Meetoo En los últimos meses descubrí un par de curiosidades sobre fórmulas para generar números primos y comprobarlos, entendiendo por «fórmulas» o bien una función matemática o bien...

No enviábamos nada entre computadoras porque sólo teníamos una computadora. No enviábamos gráficos porque nadie tenía un terminal gráfico. No teníamos «Asunto» ni otros encabezados de correo. Pero rápidamente surgieron las convenciones. Limitábamos el tamaño de los mensajes porque el espacio...
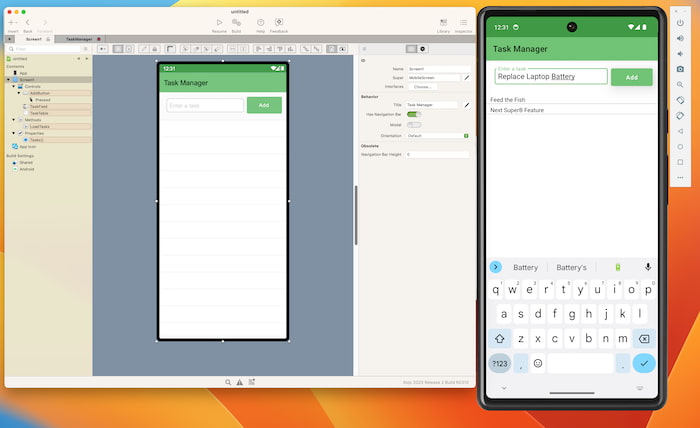
Xojo, el entorno de desarrollo + lenguaje de programación, se ha actualizado con el lanzamiento de Xojo 2023 Release 2 que incluye nuevas funciones, entre las que destaca la de crear directamente apps Android nativas, además de las apps iOS y...
Aristóteles. Lógica booleana. George Boole. Lógica proposicional. Lógica categórica. Lógica de predicados. El telar de Jacquard. Revolución Industrial. Tarjetas perforadas. Charles Babbage. Máquina de Diferencias. Tablas matemáticas. Computadoras humanas. Máquina Analítica. Ada Lovelace. Alan Turing. Von Neumann. Teoría de la información....

The Computer. A History from the 17th Century to Today. Por Jens Müller (autor) y Julius Wiedemann (redactor). Taschen (6 de junio de 2023). 472 páginas. Inglés, Italiano, y Español. La editorial nos envió amablemente un ejemplar de este libro para reseñar....

Alan Turing: El pionero de la era de la información. Por Peter Ross. Prólogo de José Manuel Sánchez Ron. Turner (22 de diciembre de 2020). 344 páginas. Traducción de Cristina Núñez Pereira. En inglés: aquí. En enero de 1937 Alan Turing publicaba...

De cracker a hacker: tras algunas condenas, fugas y aislamiento, uno de los mayores hackers de todos los tiempos montó una consultora y enseñó ingeniería social a empresas y organismos.
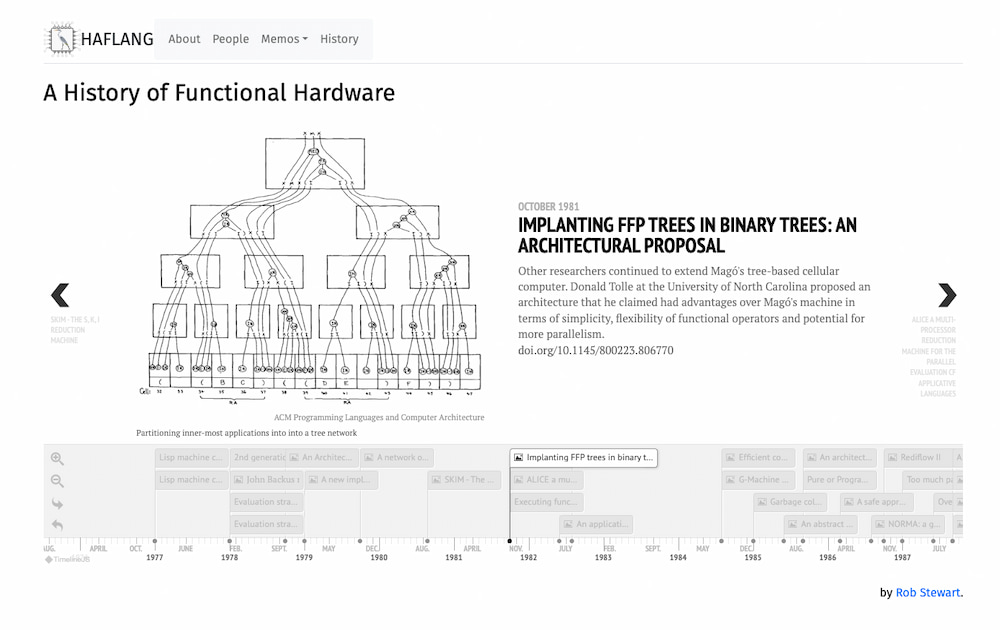
Quienes tengan como afición leer sobre la historia de la informática, los lenguajes y sus intríngulis encontrarán interesante A History of Functional Hardware, de Rob Stewart. Es básicamente una cronología del hardware funcional, máquinas cuyo hardware está diseñado específicamente para implementar...
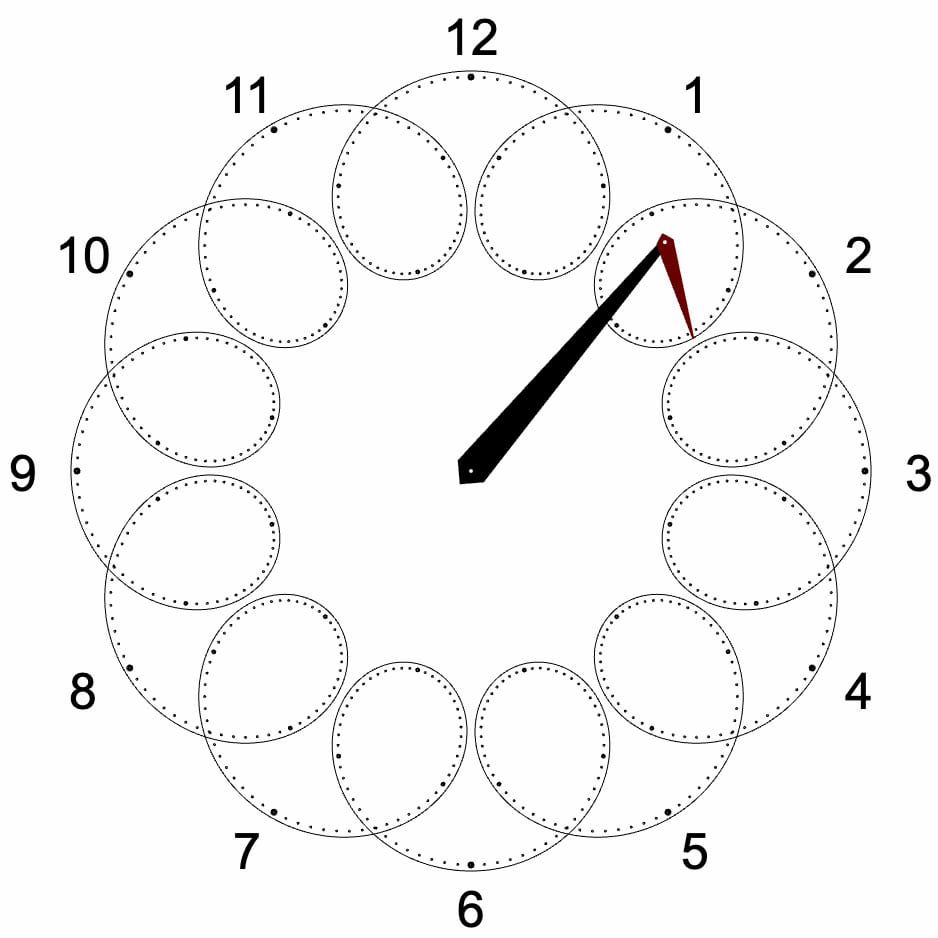
Sophie Houlden es una creadora de videojuegos que tiene en su web este interesante Reloj de epiciclos que emplea estas curiosas formas geométricas para marcar la hora exacta. Los epiciclos se «inventaron» en la época de los griegos para explicar los...
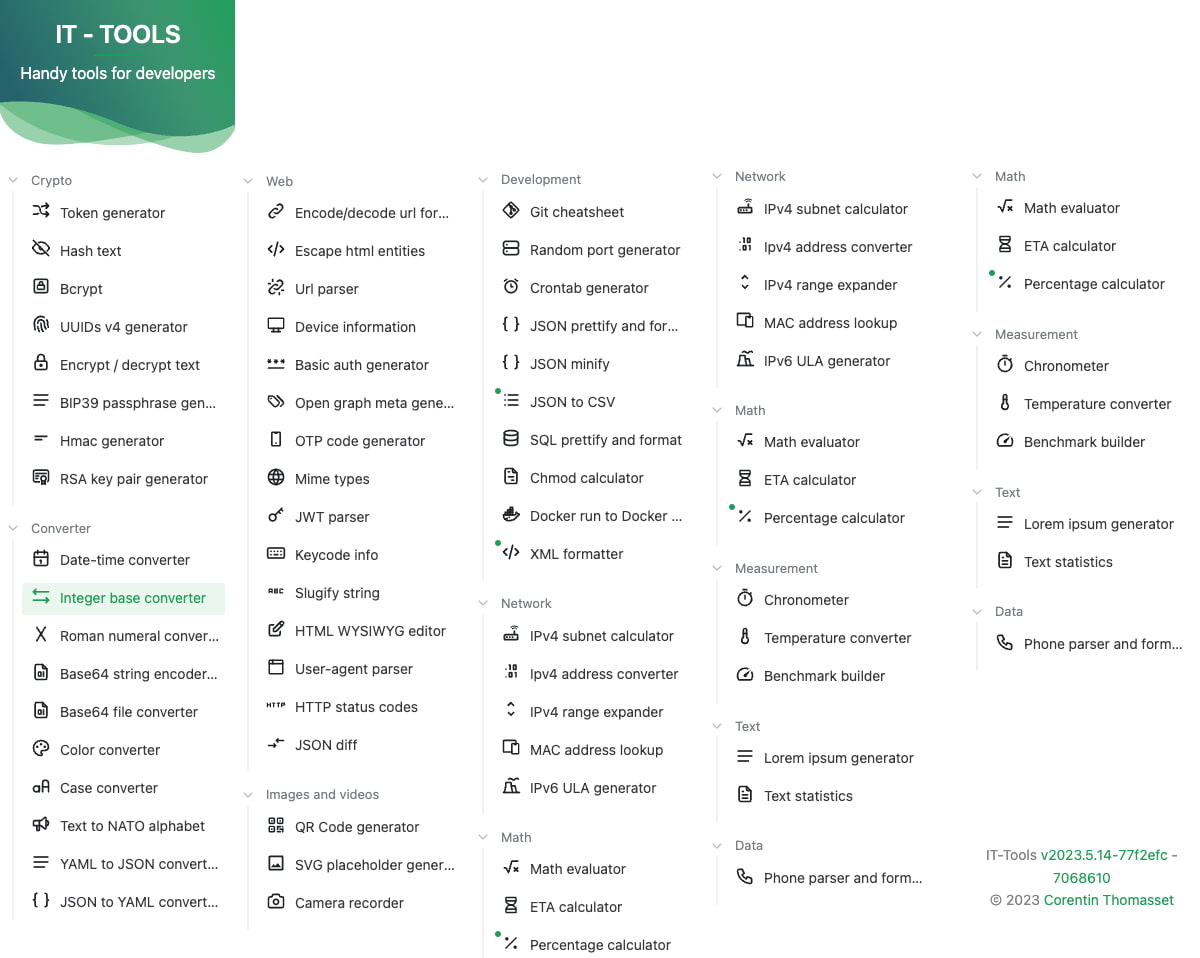
He contado unas 60 herramientas diferentes y a cual más interesante en IT Tools, una sorprendente página para guardar instantáneamente en Favoritos que resulta ser una auténtica navaja suiza de herramientas útiles para desarrolladores. Todas estas pequeñas utilidades están clasificadas en...
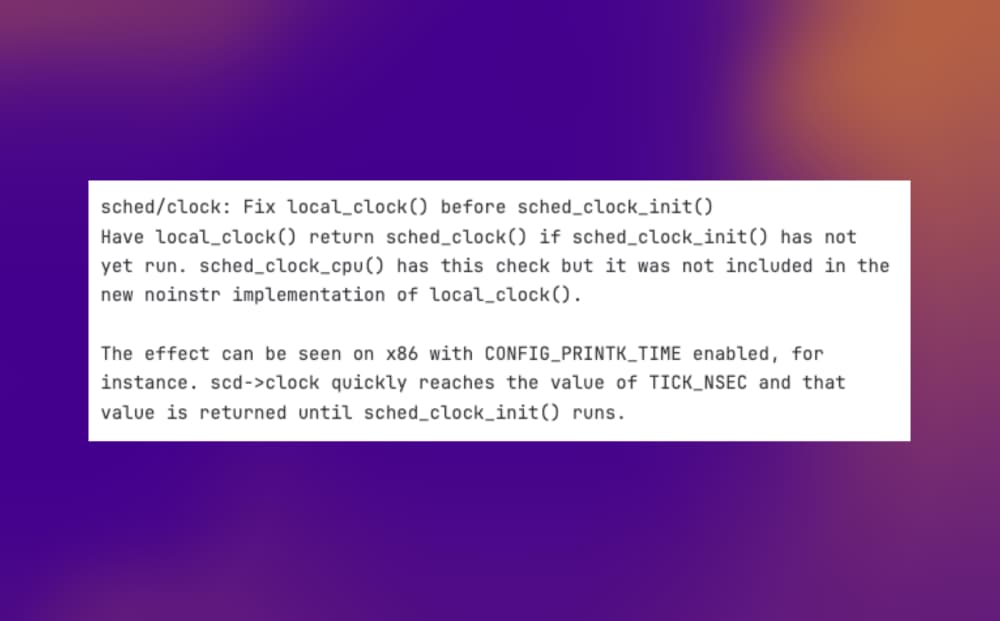
Richard WM Jones es un auténtico hacker del Linux que cuenta en su blog cómo pasó bastante tiempo investigando un extraño bug que hacía que Linux 6.4 se quedara colgado durante el arranque. El problema es que esto sólo sucedía una...
Si te gustan los editores minimalistas te gustará Novel, pero incluso a quienes no le gusten los editores de este tipo –estilo Notion– apreciarán su función de autocompletar mediante inteligencia artificial, que básicamente escribe por ti de forma bastante coherente y...

Estas pequeñas maravillas están en Miniatua, un sitio en el que un artesano se dedica a recrear en minaturas a escala 1:12 icónicos ordenadores antiguos, tanto reales como de ficción. Dónde esté esto, que se quiten los Funkos, claro. El W.O.P.R....

Este trabajo titulado El desensamblado completo de la ROM del Spectrum es como su propio nombre indica una documentación completa de los 16 KB de la ROM del Sinclair Spectrum, mítico microordenador familiar donde los haya de la época de los...

En esta casa somos muy fanses del trabajo de Jaime Gómez-Obregón, así que, sin querer desmerecer ninguna otra, tenía muchas ganas de ver su charla Slow Tech: The JOY of missing out en el recientemente celebrado TEDxValència. Si sigues su trabajo,...

Quienes sientan cierto interés por la evolución de las interfaces de usuario encontrarán interesante Evolution of the Scrollbar, donde Sébastien Matos recopiló algo más de una docena de barras de desplazamiento, es elemento imprescindible –o casi– de cualquier interfaz cuando hay...

No sé si me despedirán de Microsiervos por escribir esto, pero ahí está: la Comic Mono, una fuente creada por DTinth a partir de otra fuente llamada Comic Shanns ideada por Shannon Miwa, que básicamente es la Comic Sans pero «mejorada»...

Quédate con la cara de este entrañable tipo: Kevan Atteberry, un ilustrador que tiene en su haber el mérito (¿o demérito?) de haber creado a Clippy, el «asistente inteligente» de Office 97. Lo de «asistente inteligente» va entre comillas porque probablemente...

«Desde aquí se hackeó Protovision», dice @6502B, que ha recreado con cuidadoso y delicado detalle la habitación de David en Juegos de guerra (1983), mítica película para todos los hackers ochenteros donde las haya. Esta maqueta a escala 1:12 parece hecha...

Esta pequeña maravilla que muestran con todo tipo de detalles en Extreme Electronics se llama Pico Cray, un chisme que han encuadrado en la «computación distribuida a pequeña escala». Está diseñado con el elegante aspecto externo del Cray-1, incluyendo su fascinante...

Este precioso panel llamado The Analog Thing (abreviado: THAT) es una especie de ordenador analógico que se plantea como un equipo experimental con el que explorar otras formas de computación diferentes a la de los ordenadores digitales tradicionales que son los...

Ryo Ujiie, el director de tecnología de ispace, durante la presentación del informe sobre el accidente – ispace Un mes después de su intento fallido de alunizaje la empresa japonesa ispace ha hecho públicos los resultados de su investigación sobre el fallo....
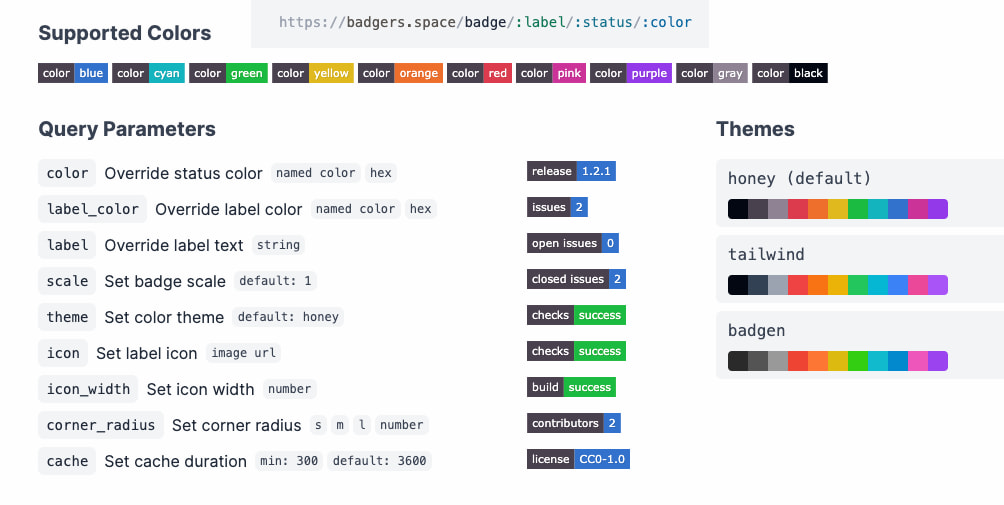
En algún sitio me encontré una referencia a SpaceBadgers, un generador de badges, algo que todo el mundo conoce pero para el que no he encontrado la traducción ideal al castellano (sería algo así como insignias*, placas, emblemas, chapas o incluso...

Cuando me voy de viaje y me llevo la cámara tengo la costumbre de copiar las tarjetas al final del día en el disco interno del ordenador. Pero desde que mac OS utiliza el formato APFS saber cuánto espacio hay libre en...
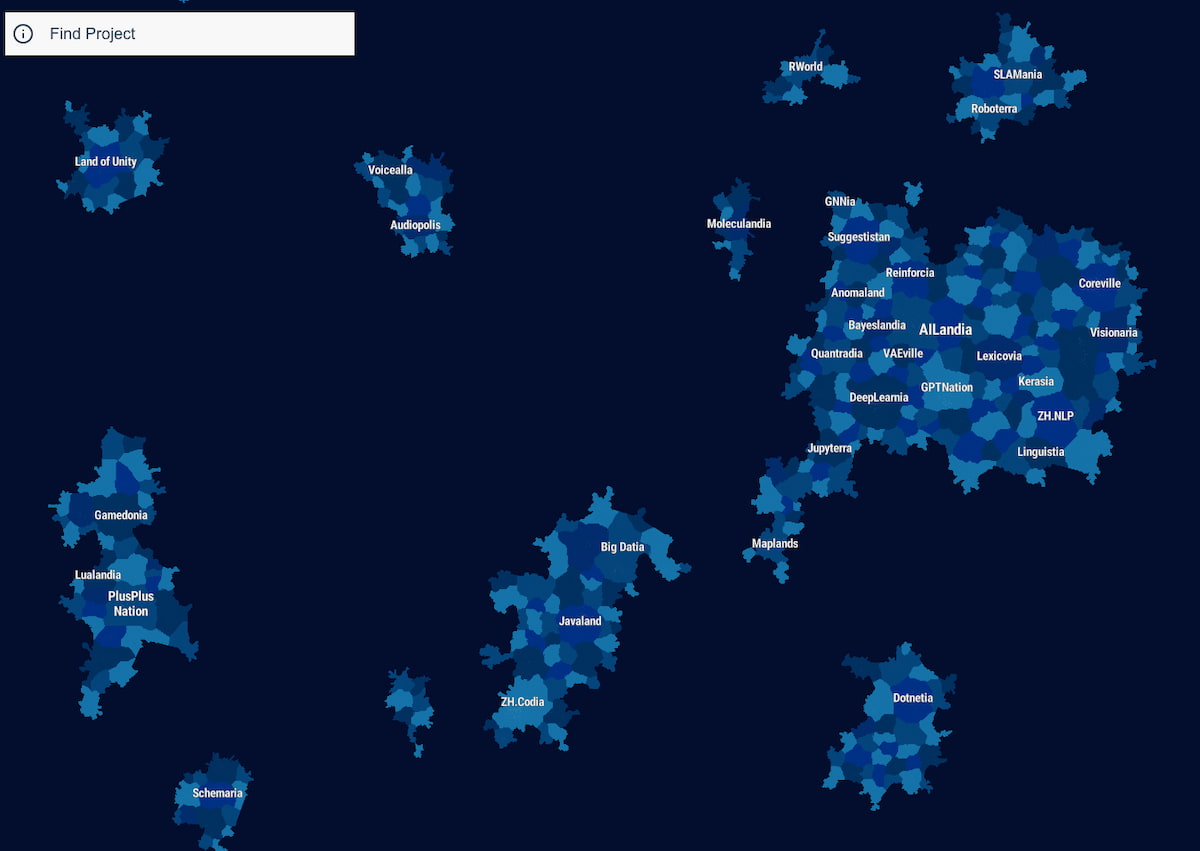
En este Mapa de GitHub aparecen más de 450.000 proyectos, a modo de islas de nombres míticos, organizados por áreas y tipos de software que se interpretan como países, y de los que hay más de 1.100. La idea es que...

El equipo de branding de Intel ha publicado con una licencia libre Intel One Mono, una tipografía clara y legible para quienes se pasan el día picando y leyendo código. Esto incluye caracteres bien diferenciados (0/O, 1/I/l…) y paréntesis, corchetes y...

El Museo virtual de las tarjetas de vídeo es poco más que el catálogo de la colección personal de Slaventus, un aficionado a este fascinante tipo de complementos en forma de placas de expansión que lleva desde 2011 atesorándolas, fotografiándolas y...
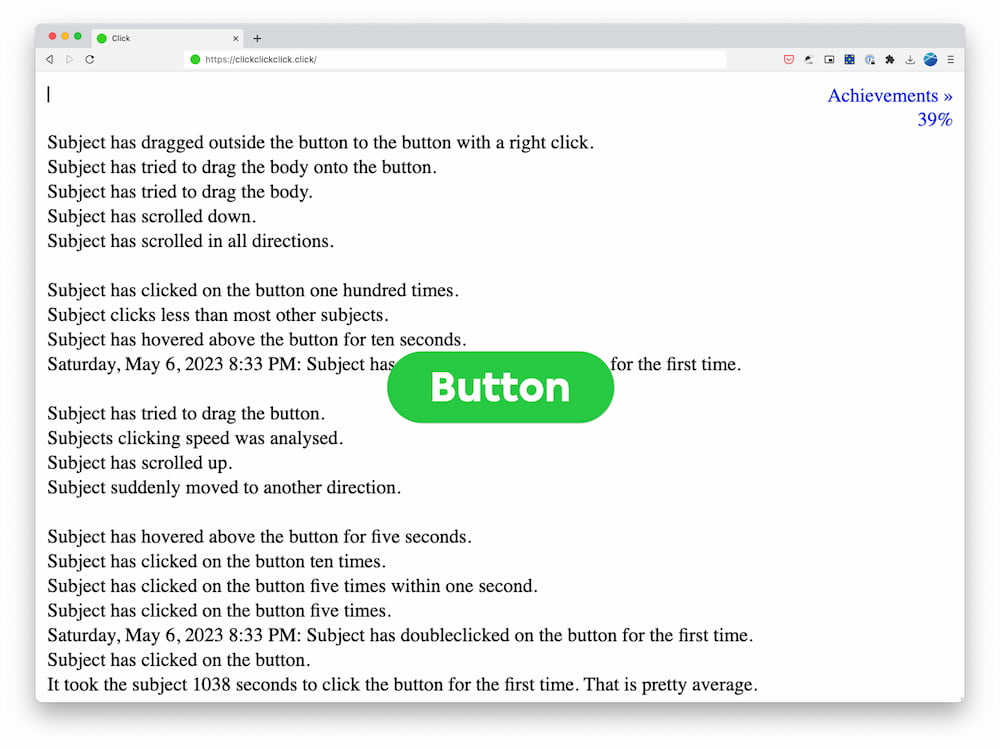
Clickclickclick.click es un curioso experimento de We Are Data, VPRO Medialab y Moniker que muestra cómo se analiza el comportamiento de los usuarios con el navegador presentándolo como un juego. Nada más empezar el navegador queda marcado con código que recoge...

Gran documento histórico el que ha publicado David Hoffman en su canal de YouTube: unas tomas del día a día de los vendedores de PCs y Macs en Fry's Electronics allá por 1995. Lo más importante no es tanto el look...
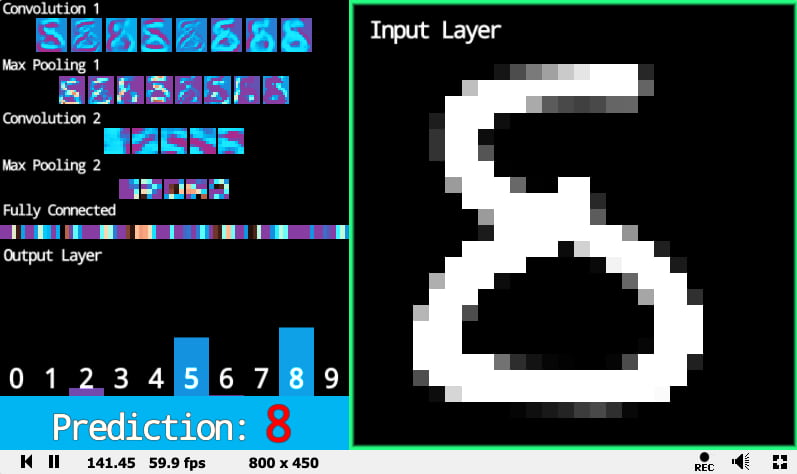
Este reconocedor de dígitos escritos a mano de @kishimisu tiene la peculiaridad de que muestra una visualización de lo que sucede en el código en tiempo real. Así, mientras el usuario dibuja un número en la capa de entrada (el recuadro...

En su misión por «inventar, romper y usar incorrectamente la tecnología», este divertidísimo hacker tuvo la genial idea de crear un sistema de reconocimiento visual capaz de interpretar sus gestos para convertirlos en pulsaciones de teclado. Como bien aclara al principio,...

Desde hoy está disponible para su descarga gratuita en varios formatos –o para leer en línea– el libro Make Something Wonderful (Haz algo maravilloso). Que no es una autobiografía de Steve Jobs al uso pero que habla de él en sus propias...
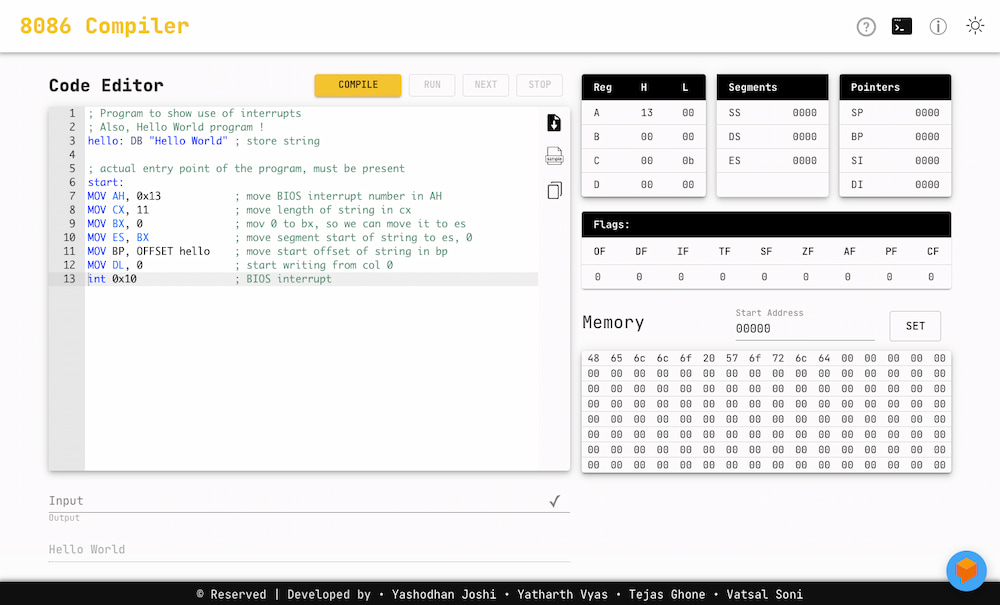
Funcional a la par que elegante, este Emulador de 8086 Emulator permite ejecutar programas escritos en ensamblador 8086, «compilándolo» a partir del código introducido en el editor… pero sin compilar. El asunto tiene un poco de truco, porque no es una...

La vida de la oficina en los 80s es una galería de fotos de Guru que datan de la década de 1980 y que muestra cómo eran entonces las oficinas, las gentes que las poblaban y los objetos que había en...
No sé mirando qué andaba por ahí cuando me sobrevino de repente un recuerdo: SideKick, el software aquel para PC que se arrancaba tecleando SK y se invocaba pulsando las dos teclas Mayúsculas a la vez. Era una utilidad de la...

Intel acaba de comunicar el fallecimiento de Gordon Moore, uno de los cofundadores de la empresa a los 94 años. Moore y Robert Noyce fundaron Intel en julio de 1968. Moore ocupó el cargo de vicepresidente ejecutivo hasta 1975, cuando se convirtió...

Bryan Braun, al que conocíamos de genialidades como Checkboxland tiene en su web los salvapantallas de After Dark recreados en CSS, que los más viejos del lugar recordarán porque fueron un superéxito de ventas en los 90. Y es que, sí,...

Me topé con este número de la mítica revista Byte de junio de 1981 perfectamente escaneado en la biblioteca de Archive.org. Hojearlo un poco me produjo una sensación muy particular, que no sé si será fácil de transmitir pero aun así...

En la web del Museo de historia de los ordenadores de Mountain View, California, tienen este escaneado de calidad en PDF del Manual del Apple-1 [PDF] que data de 1976. Sus amarilleadas páginas incluyen tanto el logo original de Apple –la...

No sabía que esto existía pero me parece tan divertido como absurdamente necesario: las condiciones Yoda (o Notación Yoda). Es un estilo de programación en el que las dos partes de una expresión, normalmente condicional, están escritas al revés. Funcionar funciona, y...
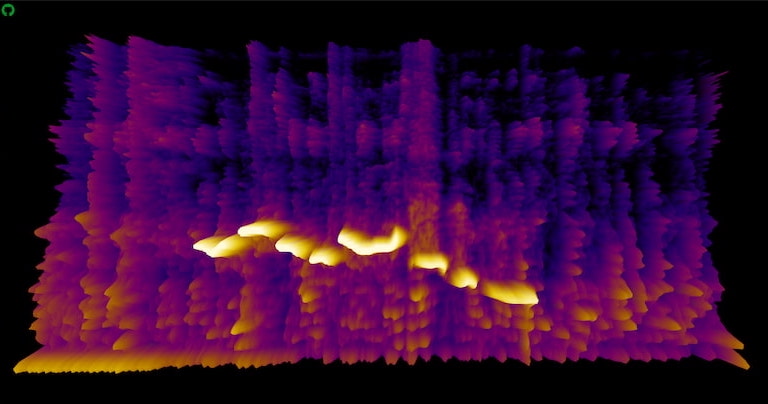
Tan sólo hay que visitar Spectrogram y darle permiso a la web para que pueda usar el micrófono del ordenador y generar un «espectrograma 3D» en tiempo real con el sonido de tu equipo. Las notas más agudas se ven arriba...
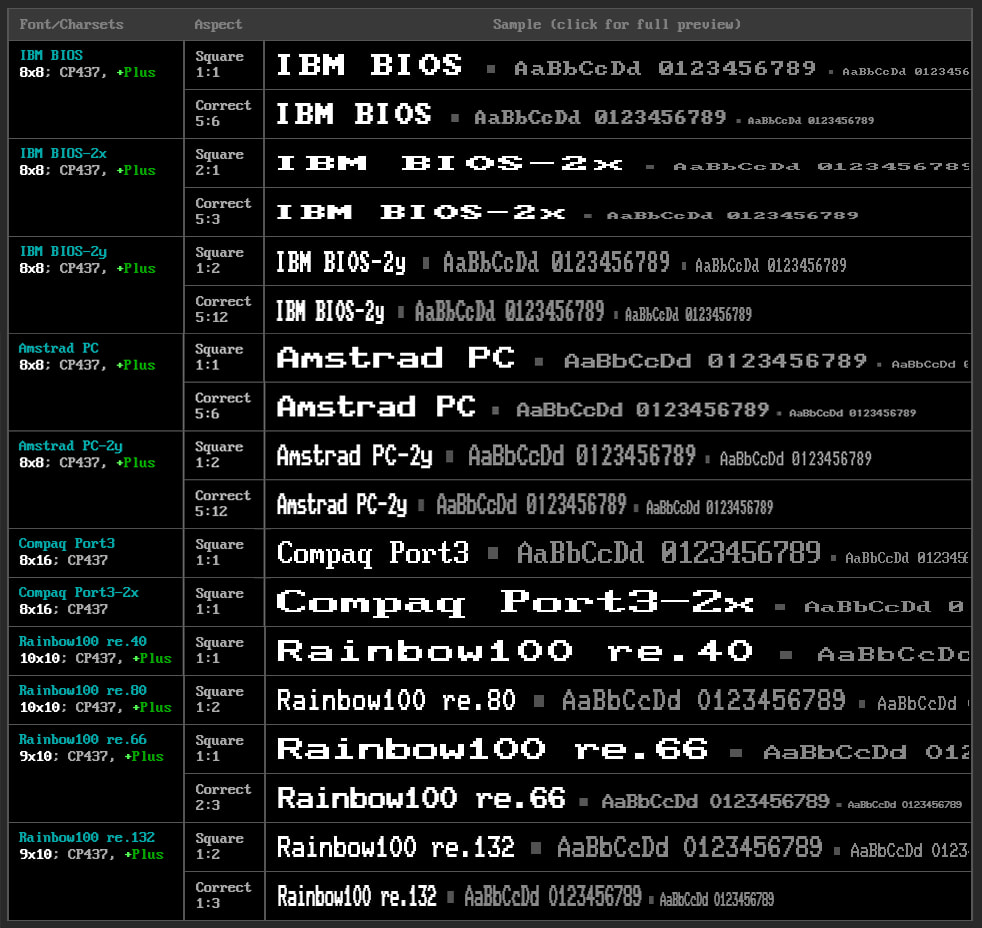
Menudo pedazo de colección han recopilado en The Ultimate Oldschool PC Font Pack, una página en la que se pueden encontrar los originales de las viejas fuentes pixeladas que se utilizaban en las pantallas de los ordenadores que funcionaban en «modo...

He estado probando unos altavoces Creative Pebble Pro que me han prestado. Son como el primo de Zumosol de los Pebble que llevo usando ya unos años, y cuestan como tres veces más. Pero las mejoras en calidad de sonido y, sobre...
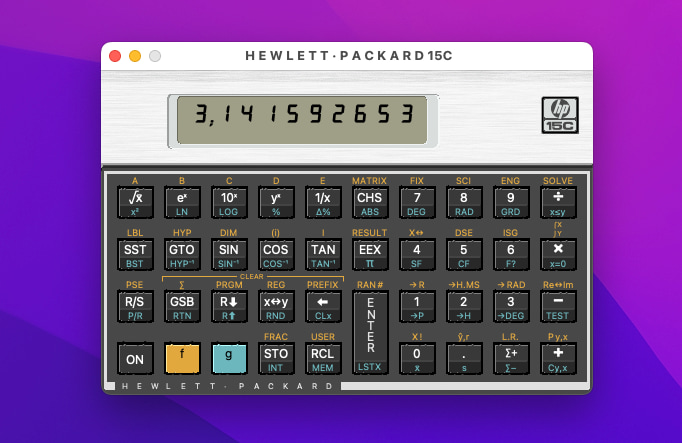
Desde el departamento de simuladores míticos y viejunos nos llega este Simulador de Calculadora HP-15C, en forma de aplicación para Windows, Mac y Linux. Este modelo, que recordarán los más viejos del lugar que sean «de ciencias», era el tope de...
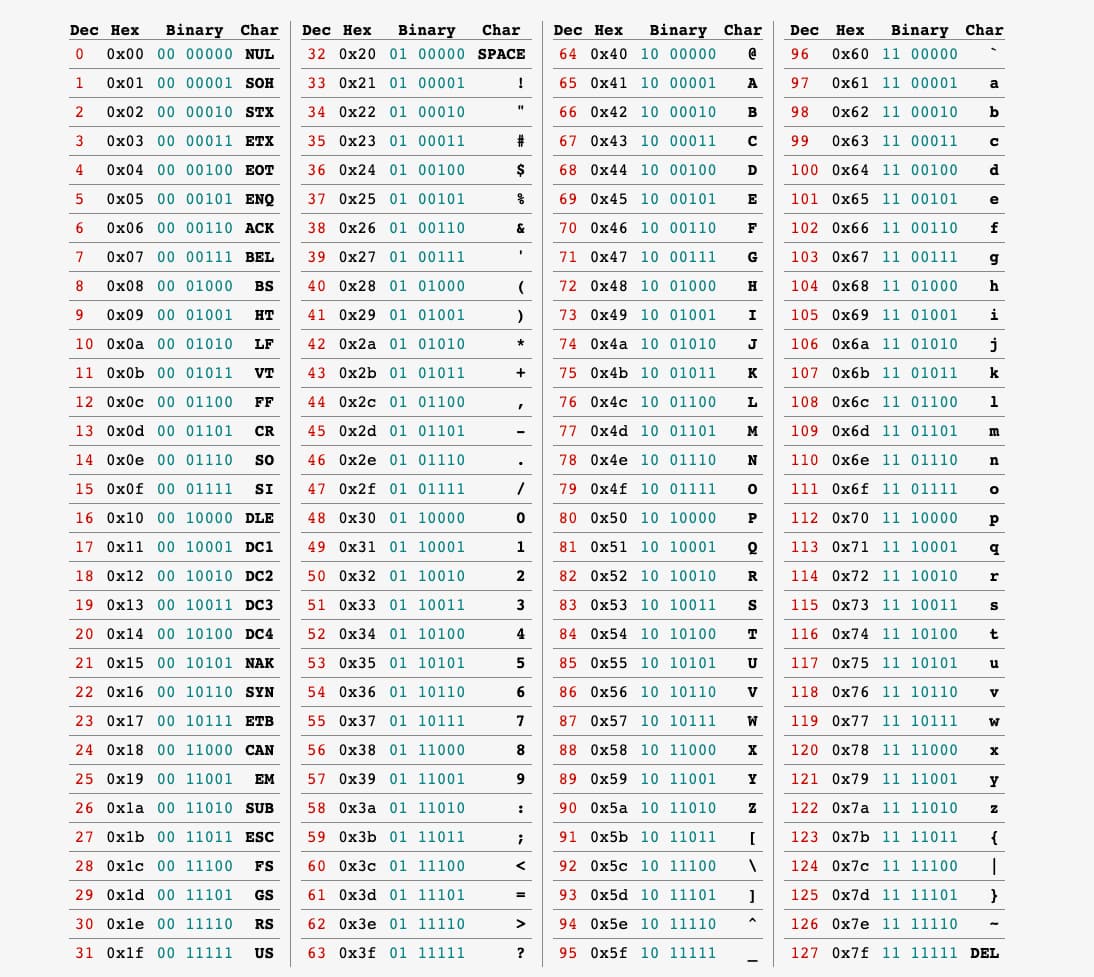
La fascinación que produce el código ASCII y sus orígenes no es desdeñable. Martin Tournoij, por ejemplo, tiene una página dedicada a la tabla ASCII y sus historias, donde explica un montón de detalles interesantes sobre este código tan conocido y...

El Zoo de Complejidad (Complexity Zoo) es una herramienta de referencia para teóricos de la informática y estudiantes, pero también puede venir bien a programadores, matemáticos, físicos y curiosos que se encuentre ocasionalmente con el concepto «clases de complejidad». Quién más...
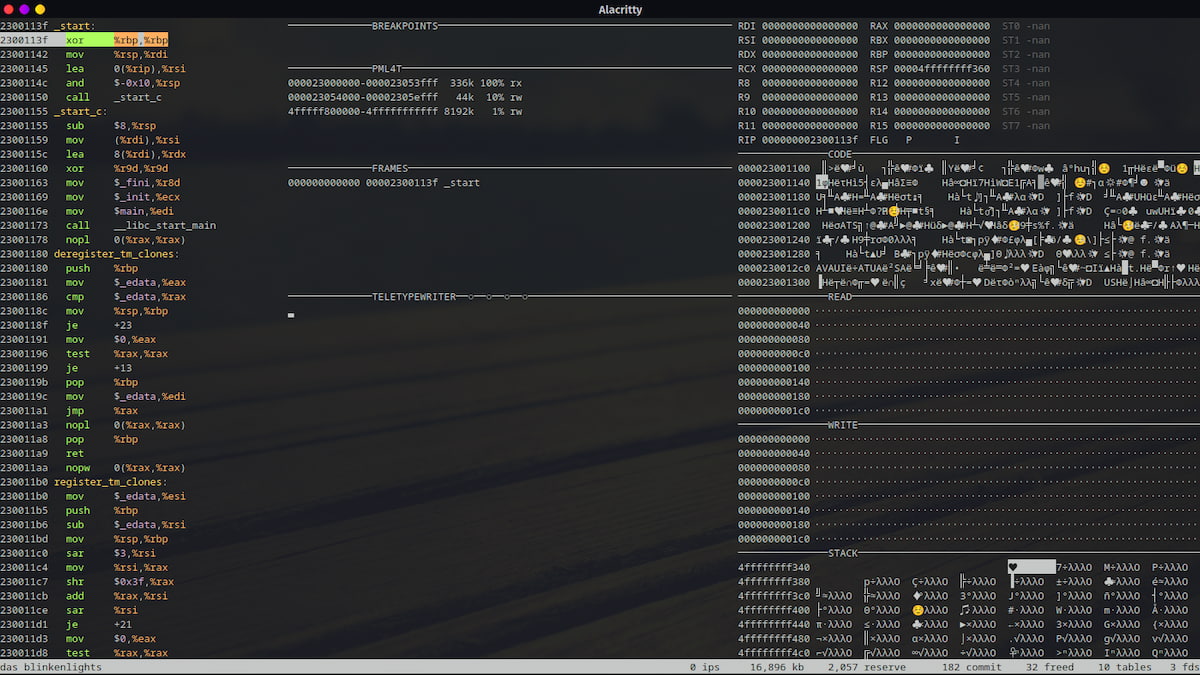
No tengo ni idea de lo útil o práctico que pueda ser esto, pero tiene mérito, con un punto gracioso por lo recursivo. Se trata de un emulador capaz de emularse a sí mismo y también a otros emuladores. Se llama...

En este estupendo tutorial titulado Cómo dibujar una cuerda en SVG con JavaScript de Stanko, a.k.a. Muffin Man, enseña todo el proceso de desarrollo desde que él y sus amigos pensaron en cómo harían para dibujar una cuerda –o maroma, cuestión...

En la semana anterior a las Navidades de 1947 los físicos estadounidenses John Bardeen y Walter Brattain, mientras trabajaban bajo la dirección de William Shockley en los Bell Labs, consiguieron crear el primer transistor, más concretamente el primer transistor de contacto...
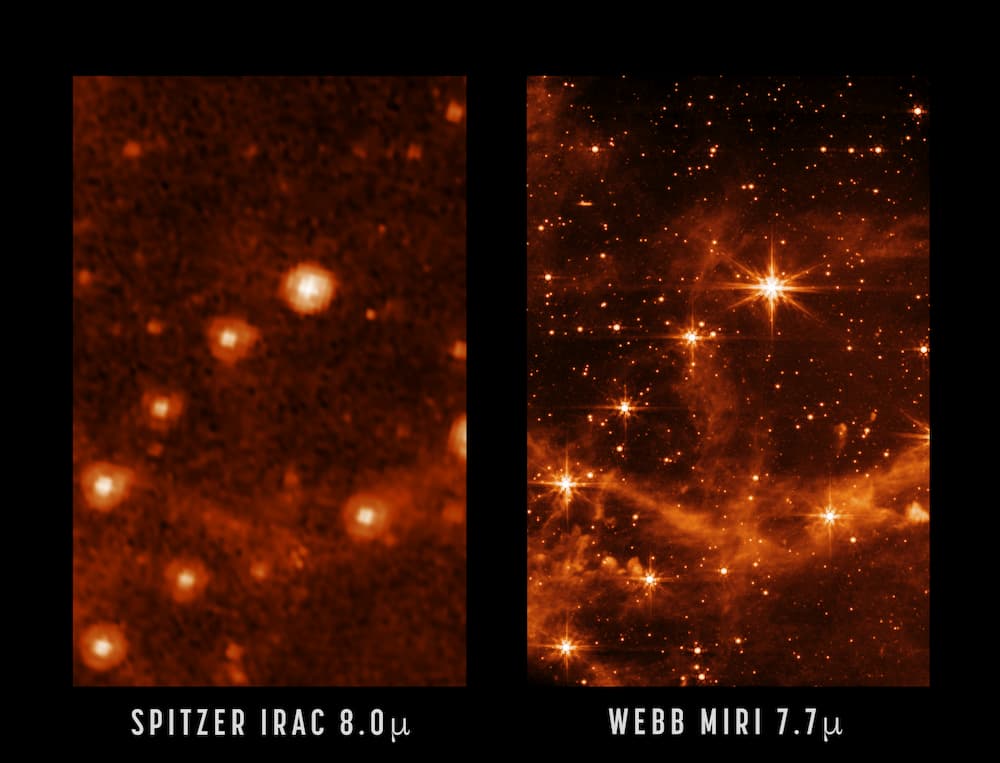
Se acerca el final de año y llega el momento de las recopilaciones. Así que hemos desempolvado algunos datos de la página de estadísticas para ver qué fue lo más popular del año pasado en Microsiervos. Estas son las cinco anotaciones más...
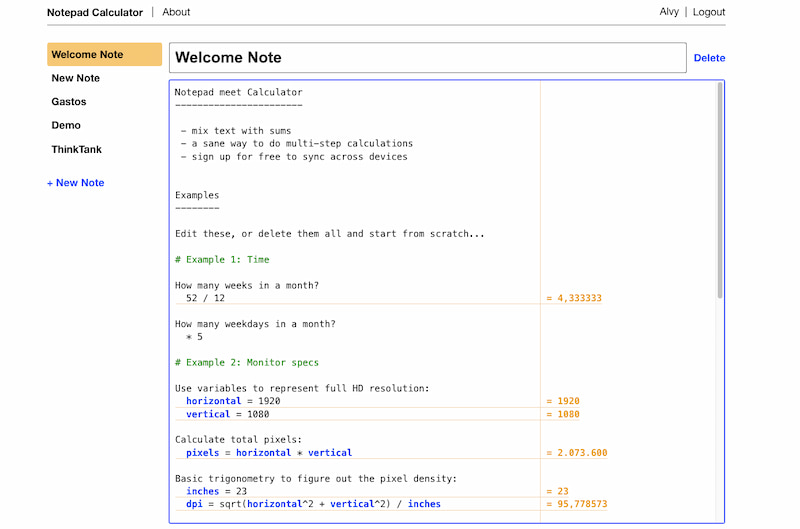
Si la calculadora del sistema operativo te parece un tanto limitada y no te apetece abrir una hoja de cálculo tal vez quieras probar Notepad Calculator. Es una especie de cruce entre aplicación de notas y calculadora: cuando haces operaciones, muestra...

A través de una reseña del libro “You Are Not Expected to Understand This”: How 26 Lines of Code Changed the World he llegado al artículo/proyecto que inspiró la obra. Se titula The Lines of Code That Changed Everything y en él...
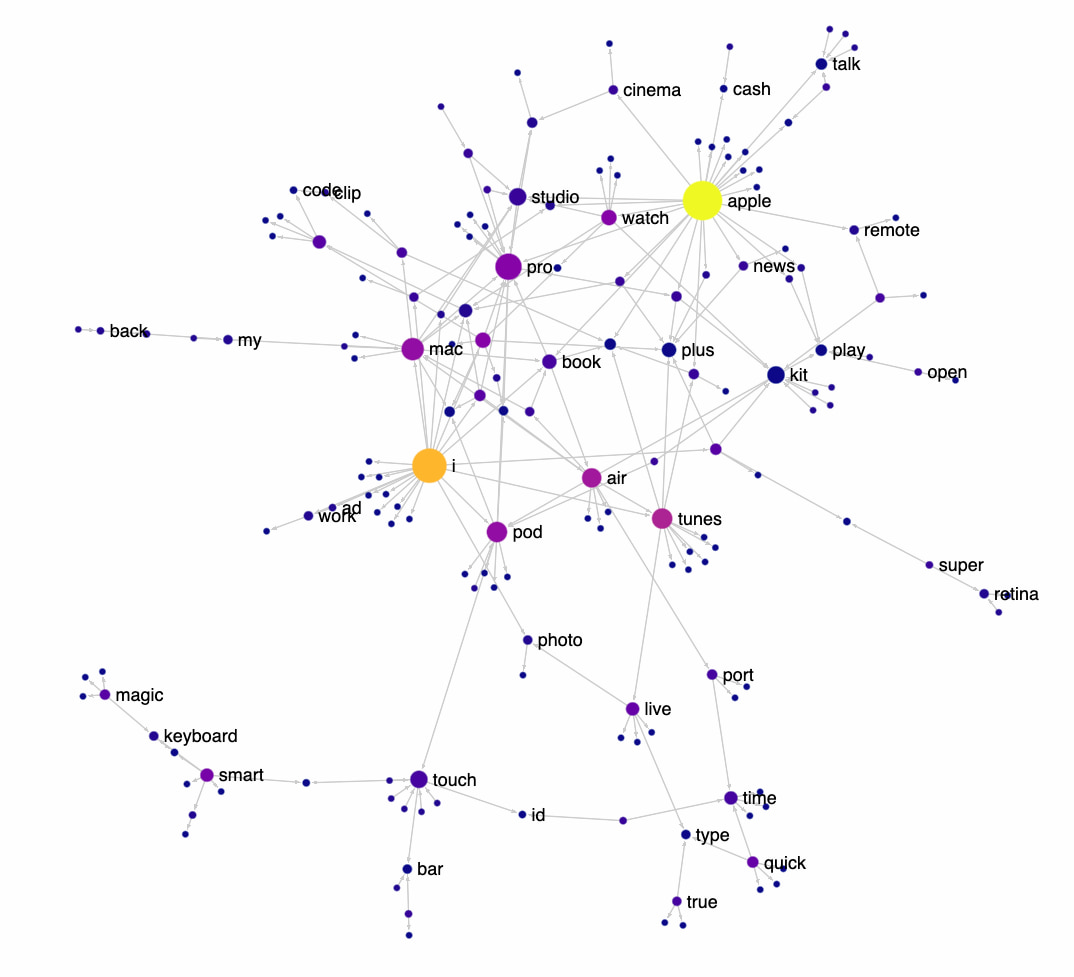
Nicolas Kruchten ha creado How Apple Names Things, una visualización interactiva de las marcas registradas de Apple que se corresponden con sus ordenadores, periféricos, dispositivos móviles y software. Se puede apreciar de un vistazo cómo las palabras favoritas de la compañía...
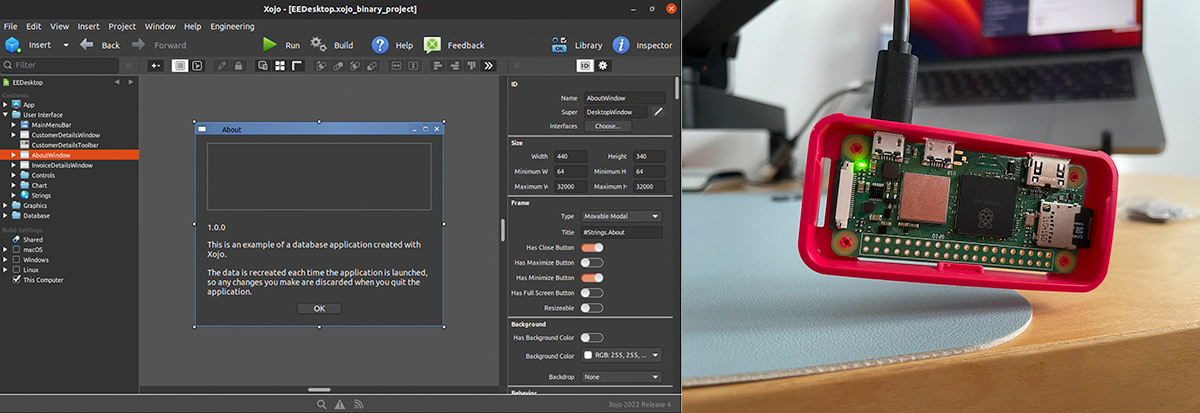
El entorno de desarrollo Xojo (IDE + lenguaje de programación) se ha actualizado con el lanzamiento de Xojo 2022 Release 4, que incluye 18 nuevas funciones, pero especialmente la posibilidad de compilar directamente para Linux ARM 64 (como AWS Graviton) y...

Este vídeo del humilde canal de YouTube de GlassTTY me ha parecido tan entretenido como educativo, porque demuestra dos cosas: lo mucho que se podía hacer con los pequeños primeros ordenadores familiares y cómo se puede divulgar de forma amena sobre...
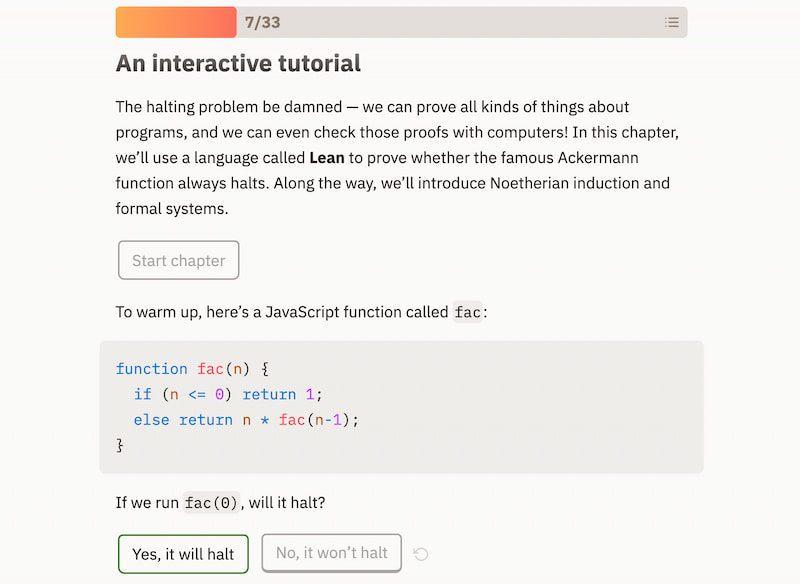
Esta pequeña joya se titula Los castores afanosos: una introducción interactiva a la teoría de la computación y es un curso muy bien armado sobre computación, con ejemplos fáciles de entender y seguir. El título, naturalmente, hace referencia a las máquinas...

Este impactante y fascinante Juego de la vida infinitamente recursivo del artista visual y programador Saharan es una especie de nueva dimensión del tradicional, porque explora una recursividad infinita en la que cada celda/píxel de la imagen es a su vez...

Shane Wighton, del canal Stuff Made Here, trabaja en proyectos tan largos como impresionantes. El último del que ha dado cuenta es la construcción de un mecanismo robótico para resolver puzles, pero puestos al tema, eligió la versión más difícil del...
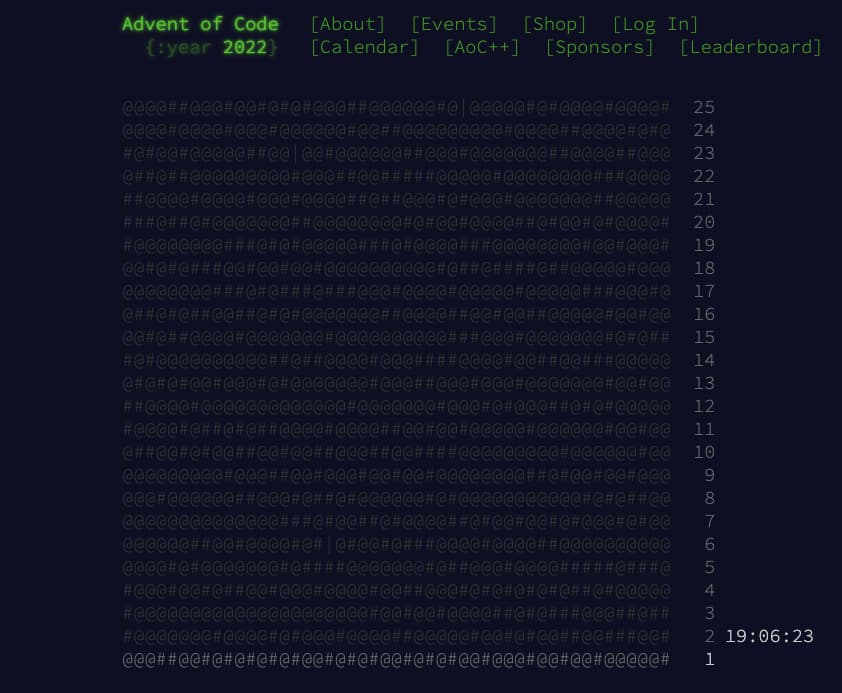
En Advent of Code 2022 se puede desde hoy acceder a un peculiar calendario de adviento, donde cada día en vez de un chocolate o regalo sorpresa hay un puzle lógico con problema de programación incluido. Cada línea de calendario representa...
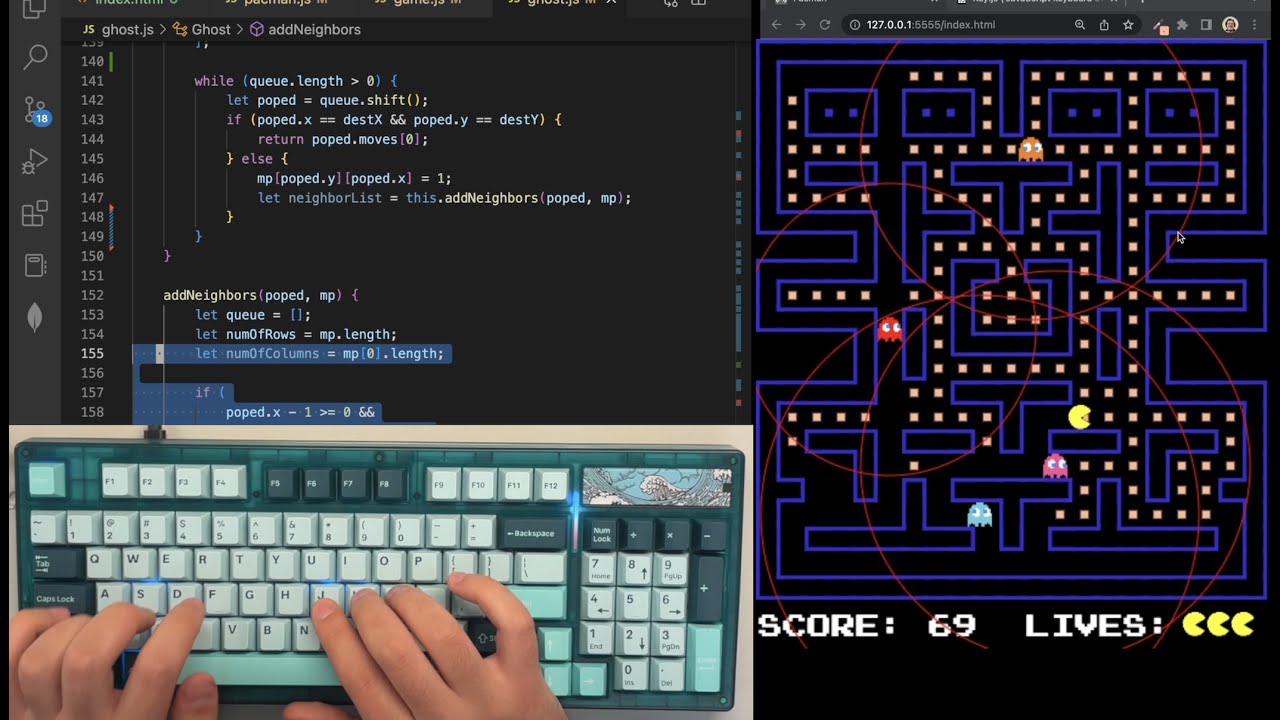
Servet Gulnaroglu tiene toda una colección de vídeos tan educativos como a la par de relajantes en su canal: cómo se programan diversos juegos sencillos, demos o páginas web usando poco más que JavaScript/HTML/CSS. Paso a paso y sin explicaciones. Este...
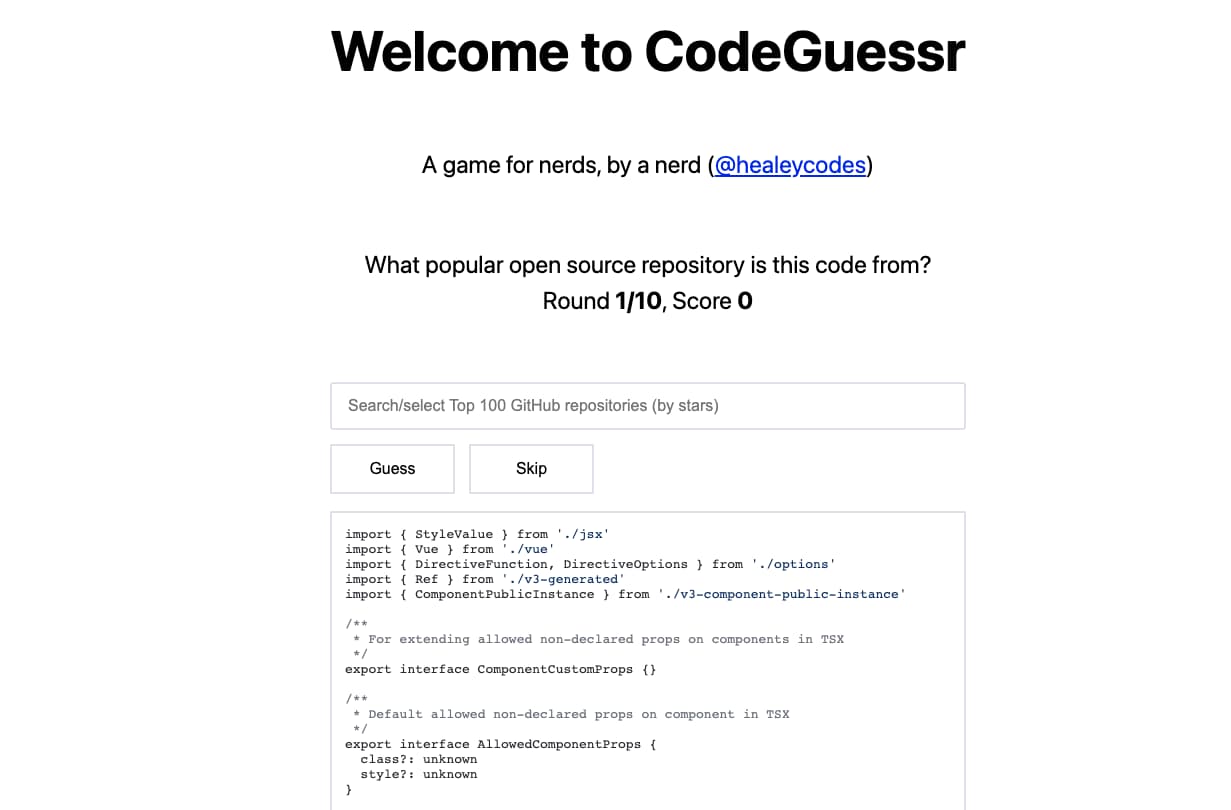
CodeGuessr se autocalifica como un juego para nerds, pero más bien suena a auténtica locura. Es como GeoGuessr pero en vez de adivinar lugares a partir de una foto hay que adivinar a qué proyecto de código abierto pertenecen unas cuantas...

Elevator Saga es un curioso juego que consiste en programar los ascensores de un edificio mediante JavaScript. Se muestran visualmente las plantas numeradas del edificio, los ascensores con sus indicadores y las personas que llegan al azar y quieren ir a...

Jack Rusher recopila vídeos sobre informática clásica y tiene esta interesante página llamada Demos clásicas de interfaces de usuario (1983-2002). Allí se recuerdan con fechas y algunos datos, clasificados por años y etiquetas, algunas de las primeras veces en que se...

Me topé con esta interesante charlita viejuna del canal Roguelike Celebration en la que Josh Ge de Grid Sage Games explica cómo crear un videojuego de mazmorras a la antigua usanza, pero con técnicas modernas. Así que si te gusta NetHack,...

No me imaginaba yo que en un humilde ratón de ordenador hubiera tanta tecnología avanzada, pero tal y como puede verse en este instructivo vídeo de Branch Education así es. Y eso que el vídeo está dedicado únicamente a uno de...
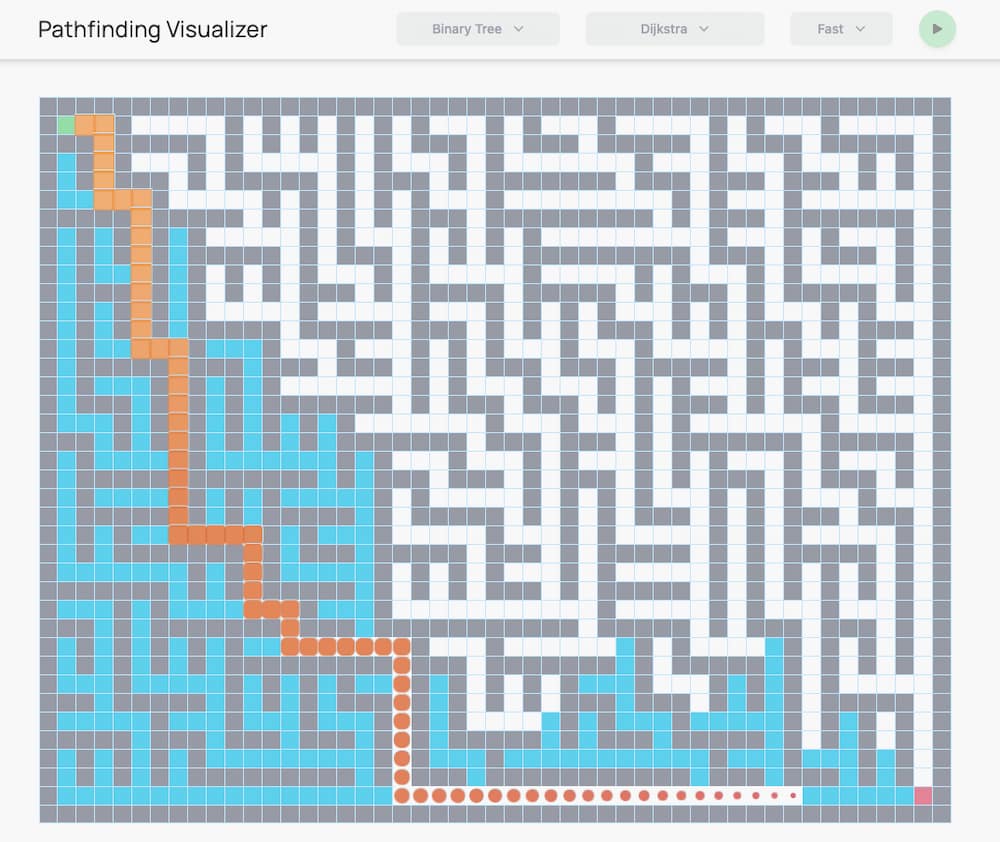
Esta curiosa visualización llamada Pathfinding Visualizer (algo así como «Visualizador de trayectorias») muestra cómo diferentes algoritmos resuelven un laberinto, tras generarlos de forma muy atractiva. En total se muestran cuatro algoritmos: Búsqueda en anchura (breadth first search) Búsqueda en profundidad (depth...

La fibra óptica es más rápida, más segura y sin duda más elegante que el cable telefónico, el coaxial de Ethernet o incluso que las ondas del wifi, que no llegan a todas partes y a veces lo hacen con interferencias....
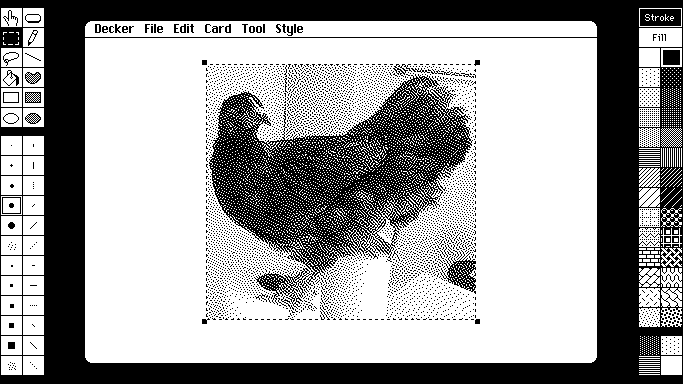
Esta preciosidad es Decker , una aplicación web para construir documentos interactivos de hipertexto. Gracias a su simplicidad se puede probar y aprender sobre la marcha y es que tiene un antecesor como inspiración inigualable: Decker está construido a partir del...

A finales de septiembre moría a con cien años de edad Kathleen Booth, una pionera británica de la informática, y autora del primer lenguaje ensamblador de la historia. Un lenguaje ensamblador es un lenguaje de programación de bajo nivel que sólo está...

Quienes tuvieran la suerte de vivir la época de la informática en la que la mejor forma de informarse eran las revistas en papel disfrutarán de la nostalgia que rezuma Computer Ads from the Past. Es una recopilación de anuncios míticos,...
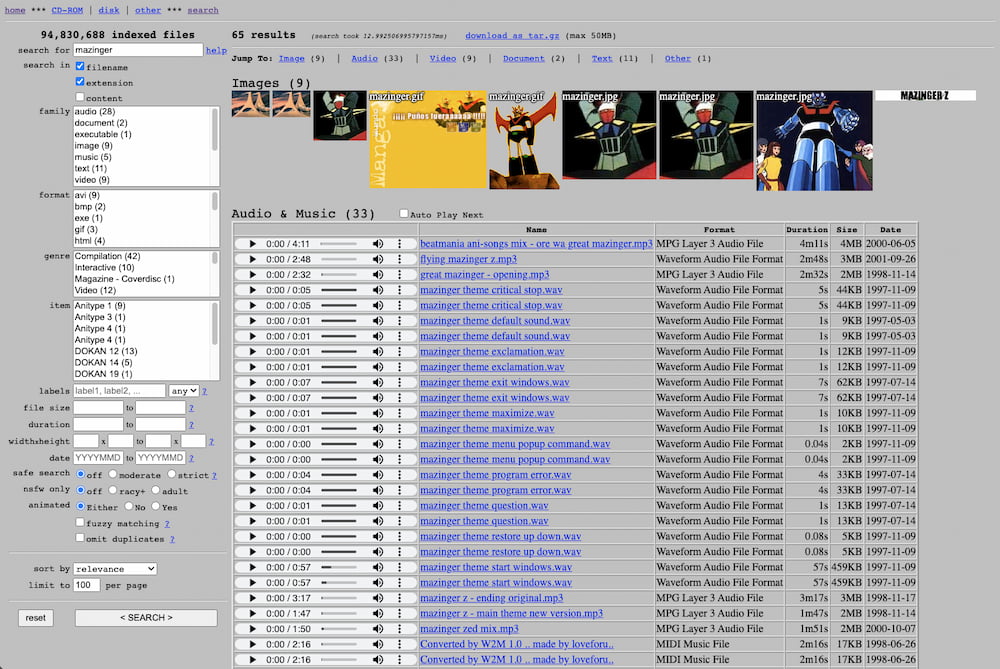
Discmaster es un experimento de Jason Scott, nuestro archivista geek y monocromo favorito y uno de los veteranos activistas de Archive.org. En su papel de personaje-casi-Diógenes de lo digital recopila todo lo que le llega, así como suena. Un día se...
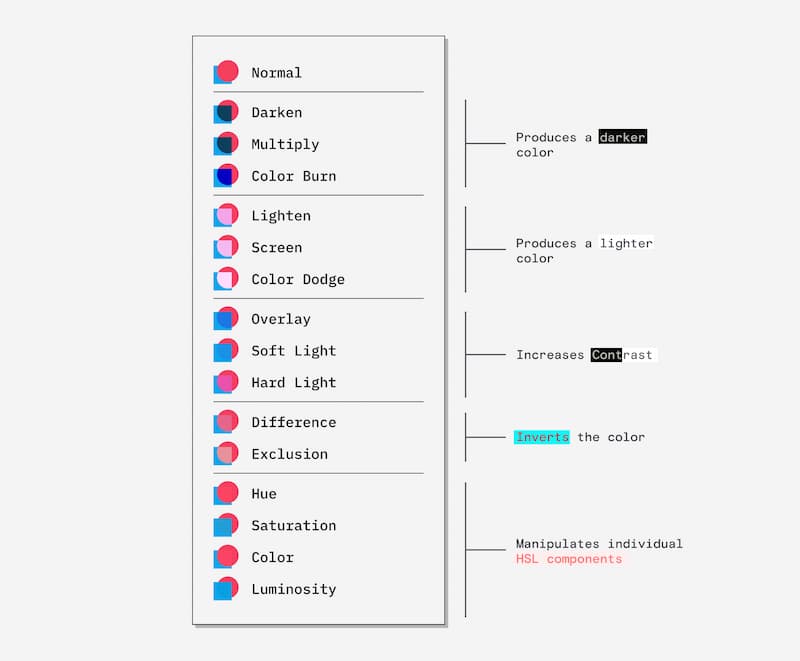
Si sientes curiosidad matemática por saber qué cálculos hay detrás de la fusión de colores por capas en Photoshop y otros programas de ilustración, Dan Hollick lo explica en este artículo: Blending Modes (modos de fusión). El resumen es que al...

En una enciclopedia temática a la antigua usanza, muy al estilo web «de los años 90», llamada Ex Astris Scientia un usuario llamado Will se entretuvo en preparar un artículo que recopila todos los tipos de ordenador de Star Trek, la...

Este pasado fin de semana he podido ver –más o menos– la exposición AI: More than Human, que explora la relación entre los seres humanos y la tecnología y la inteligencia artificial así como los más recientes avances tanto creativos como...

Esta genialidad de Sammyuri y un par de amigos es difícil de describir, pero básicamente se puede entender como un Minecraft 3D corriendo dentro de Minecraft sin mods ni similares. El gigantesco proyecto es un intrincado montaje de construcción de una...

Un disco duro que tuvo mejores días – CC BY-SA 2.0 ES por Barney Livingston Periódicamente recuerdo a quien me lee la importancia de hacer copias de seguridad y aquello de que sólo hay dos tipos de personas que usan ordenadores, móviles,...
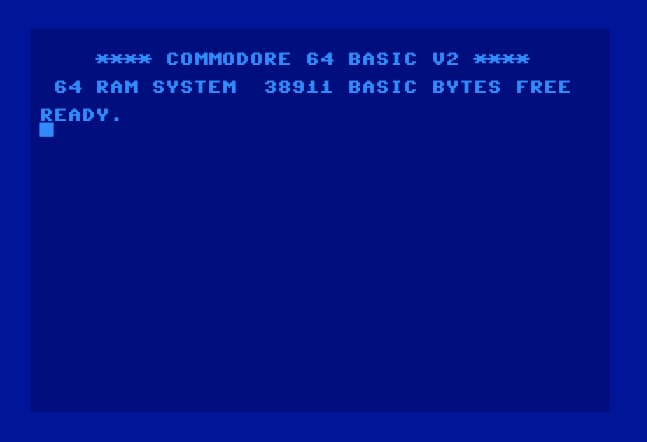
Momento retro para apreciar cómo era la programación cotidiana en el BASIC del C-64 de Commodore, con una explicación moderna y con ejemplos de Tomas Petricek acerca cómo era la experiencia de interactuación con un ordenador allá por los años 80....

El otro día me invitaron unos amigos a jugar a Moon (1110011), un juego de tablero en el que hay que manejar el rudimentario ordenador de una misión a la Luna y manipular con instrucciones lógicas y operadores los diversos registros...

La pionera Grace Murray Hopper dejó constancia de ello en el cuaderno de operaciones del ordenador Harvard Mark II.

El correo electrónico. Lo amas o lo odias, pero el hecho cierto es que ahí sigue, desde los inicios de Internet, y sigue siendo una herramienta vital para muchas personas cada día… aunque no todo el mundo tiene siquiera una dirección hoy...

En este vídeo de Linus Tech Tips prueban un PC nuevo-pero-viejuno de Nixsys con Windows 98, eso sí, con mucha calma, excepto la presentación que es más de risas. El caso es que Nixsys es una pequeña empresa de California que...

En el canal The Coding Train han hecho este curioso experimento consistente en programar en Basic un juego tipo «Serpiente» en un Apple II. De algún modo han conseguido una máquina restaurada y manuales, lo cual nos retrotrae a cómo se...

El núcleo de M74 – ESA/Webb, NASA & CSA, J. Lee y el equipo PHANGS-JWST. Gracias a J. Schmidt Después de años y años de retraso de su lanzamiento y seis meses de infarto después de él mientras se configuraba para funcionar...

Rachel Ignotofsky es una autora e ilustradora que tiene muchos superventas en su haber, entre ellos esta deliciosa Historia de los ordenadores que es una versión infantil de una de nuestras grandes aficiones: estudiar el origen de los ordenadores primitivos, antiguos...

Hunar Ahmad ha creado este colorido Juego de la vida con partículas, que recuerda mucho al Juego de la vida de Conway, aunque en vez de ser un bitmap en blanco y negro las formas que surgen tienen colores, movimientos más...
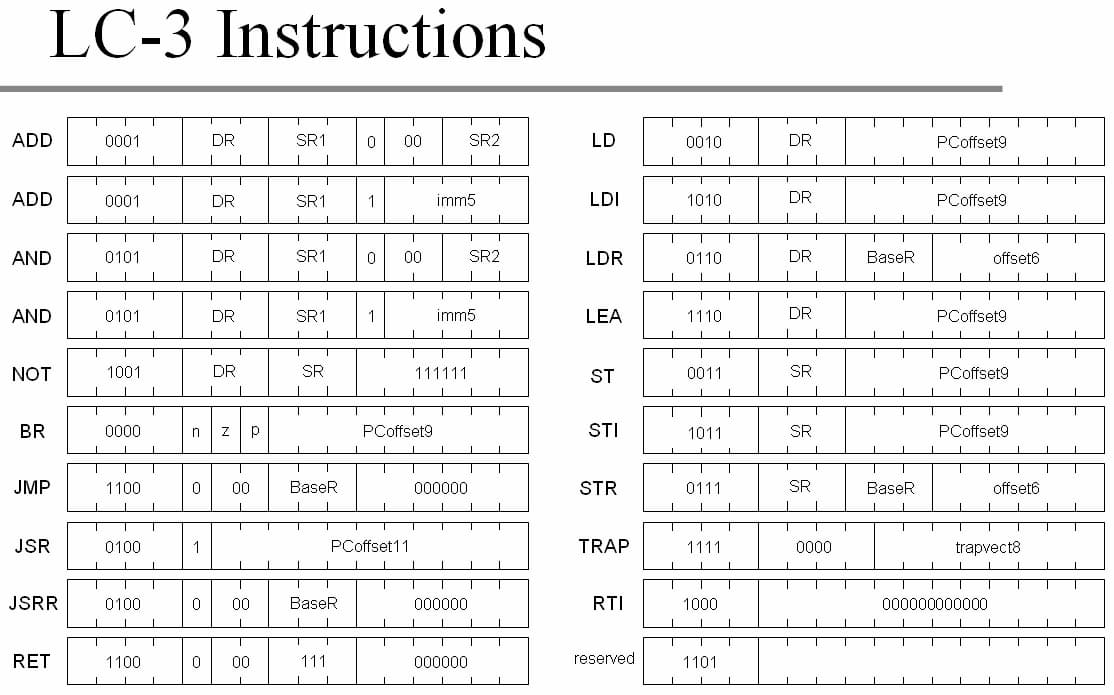
Este curioso proyecto es un intérprete de Forth para un ordenador muy básico, el LC-3 (Little Computer 3, un sistema educativo para niños) que explica cómo podría ser útil para programar en un mundo postapocalíptico en el que hubiera que introducir...
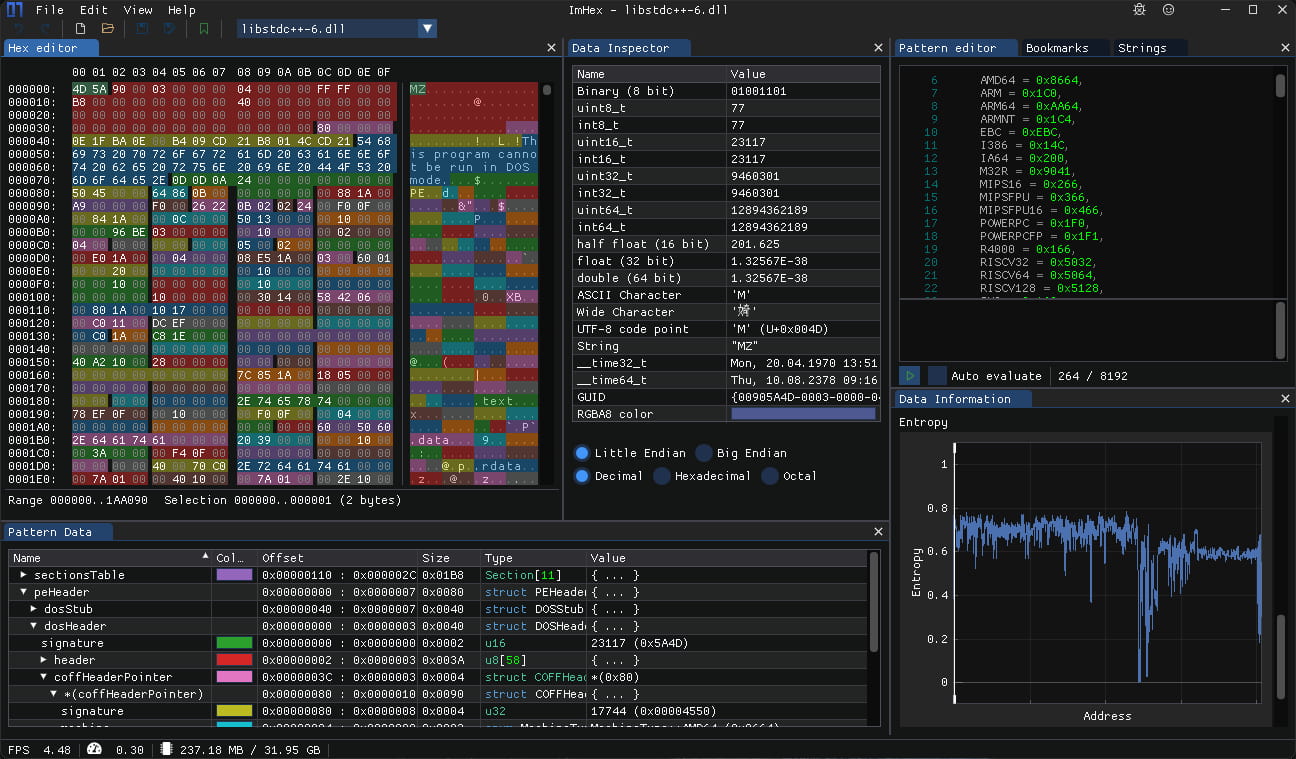
Recuerdo que en los del Commodore, el Spectrum, el PC y aquellos primeros ordenadores personales era habitual pasarse buena parte del día trabajando con un editor hexadecimal, una herramienta para editar ficheros «a pelo», byte a byte, casi como hacían en...

Un brillante equipo de mujeres, que estuvieron allí desde los primeros tiempos del JPL en 1936 y que eran conocidas como computadoras, fueron las responsables de hacer los cálculos de las ventanas de lanzamiento, las trayectorias, el consumo de combustible y otros...
Ventana principal de la aplicación de Raindrop para macOS Hace más de diez años que Pocket es una herramienta imprescindible en mi trabajo. Tanto que algunos de esos años he estado en el 1% de las personas que más lo usan en...

La buena gente de la revista Custom PC Magazine ha publicado Retrograde que es un especial de 100 páginas gratuito con una selección de buenos artículos de su sección Retrotecnología. Allí descubren a los jóvenes de hoy en día el hardware...

Este vídeo humorístico de Joma Tech sobre cómo es la dura preparación de un programador para una entrevista de trabajo tiene sus puntos, en especial porque muchos son ciertos –aunque sean un poco exagerados, vale, pero es humor– y más de...
Hace unos meses comentábamos el lanzamiento de Xojo 2022r1 con unas 220 mejoras en su entorno de desarrollo, con el que se pueden crear fácilmente aplicaciones nativas para Mac OS, Windows, Linux, Web, iOS y Raspberry Pi. Ahora se ha anunciado...

El Excel Formula Bot es un invento digno de admiración, porque la idea es preciosa, un uso de la inteligencia artificial para algo realmente útil a diario. En vez de tener que volverte loco en Excel mirando la Ayuda o probando...

La legendaria Pantalla azul de la muerte (BOsD, Blue Screen of Death) con la que se lamenta Windows cuando ya está en una situación terminal e irrecuperable es todo un clásico entre los clásicos. Aunque su gravedad depende de circunstancias un...
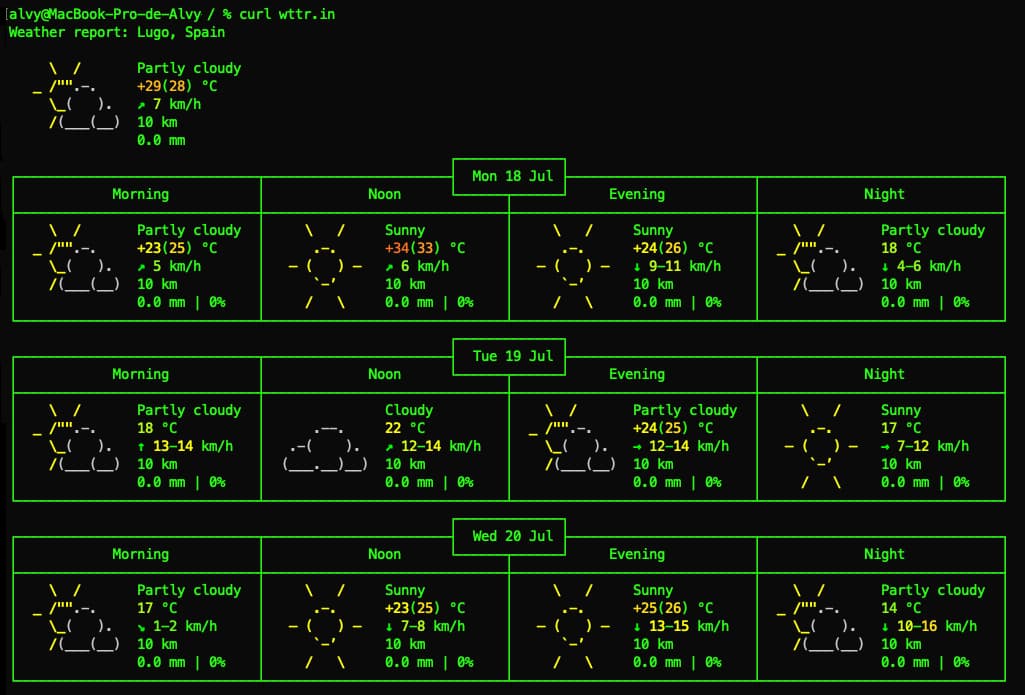
No me sabía yo este truco… Todo lo que hace falta para ver la predicción meteorológica en los próximos días de forma elegante pero retro es teclear en el terminal: curl wttr.in Quizá sea un poco lento –¡paciencia!– pero wttr.in extrae...

Alguien llamado kgsws tuvo la ingeniosa idea de hackear el código de Doom para que se pudiera ejecutar otro Doom dentro del propio juego. Esto añade un nivel de complejidad al famoso dicho «Doom se puede ejecutar en cualquier sitio» (calculadoras,...
Facundo Olano recopiló esta impresionante lista de papers o trabajos académicos sobre ingeniería del software con más de cien referencias. Hay dos versiones: una por temas (redes, criptografía, sistemas distribuidos, etcétera) y otra cronológica. Me he permitido extraer aquí unas cuantas...
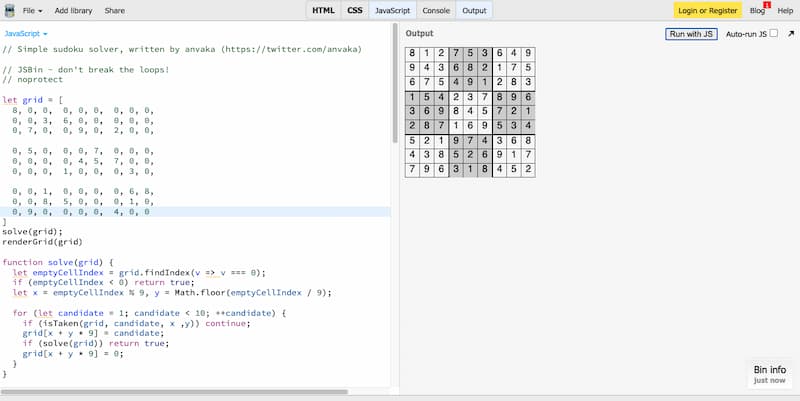
Revisando enlaces viejos me encontré con este programa para resolver sudokus escrito en JavaScript y creado por Andrei Kashcha. Seguramente su sencillez es su mayor virtud: son unas 80 líneas de código ligero, perfectamente estructurado en unas pocas funciones. Eso sí,...
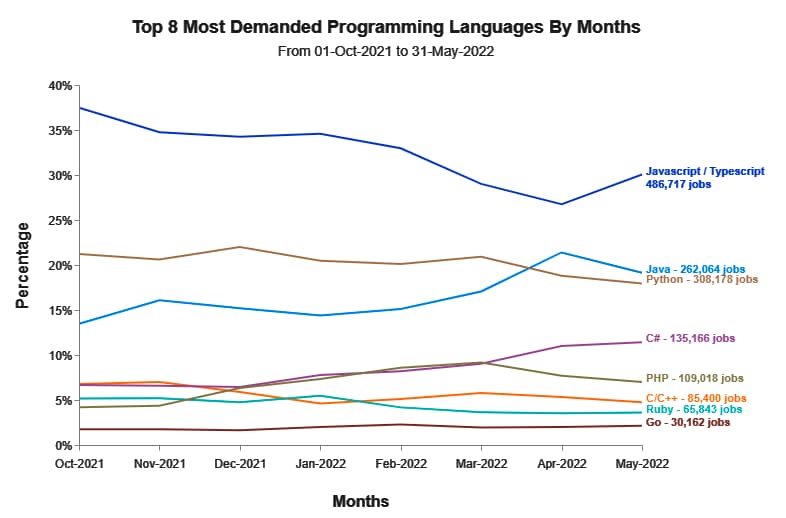
En DevJobsScanner han publicado la lista de los lenguajes de programación más demandados de 2022 (al menos del primer semestre, aunque estas cosas tienden a cambiar lentamente). La forma de elaborar la tabla es compleja pero interesante, porque refleja bien la...

El formato JPEG para comprimir las imágenes que vemos en Internet tiene ya muchos años, pero sigue siendo extremadamente útil porque proporciona una calidad razonable con imágenes que ocupan muy poco respecto a las originales. En este vídeo de Branch Education...

El gran Gregorio Naçu de C64 OS preparó esta infografía en el que el mítico procesador MOS 6502 se expone como si fuera el chip M2 de Apple –o algo mejor– en cualquiera de las presentaciones para público, desarrolladores y prensa...

Bryce Henderson ha creado esta visualización interactiva arbol de juego del tres en raya que muestra en un árbol ramificado de colores la evolución del juego dependiendo de los movimientos de los jugadores. Basta ir haciendo clics en el tablero para...

Diálogo de ajuste de página en Mac OS 9 – Apple A estas alturas no hay duda de que Mac OS X fue uno de los factores que contribuyó a salvar los Macintosh y, por tanto, a Apple cuando salió en 2001....
Quienes aprecien las virtudes del minimalismo en el diseño y programación de sitios webs seguramente querrán echar un vistazo a PureCSS (o simplemente Pure), que son unos módulos CSS que apenas ocupan espacio (3,7 KB) y sirven para construir todo tipo...
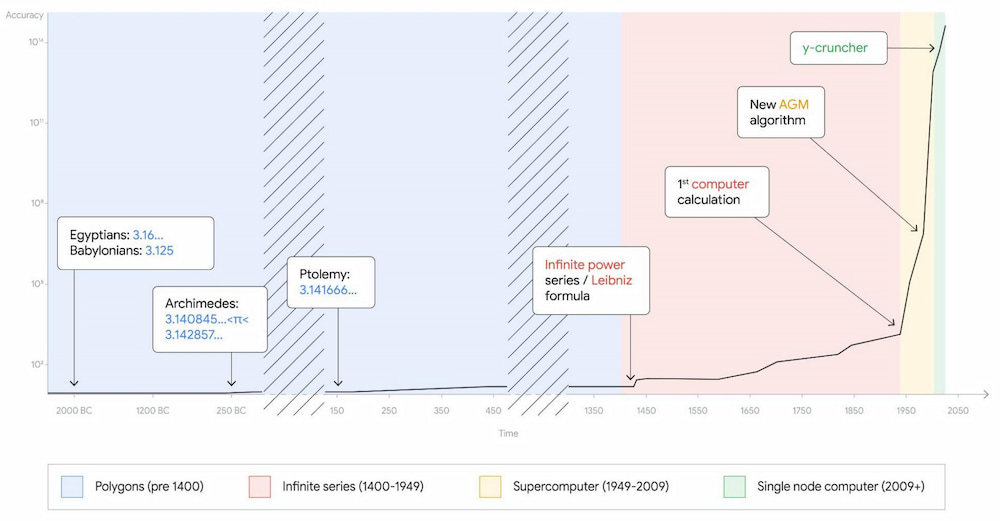
Tal y como cuentan en su propio blog, Google ha calculado 100 billones de dígitos de pi en Google Cloud («100 trillions» en inglés) utilizando el software y-cruncher de Alexander J. Yee, simplemente para demostrar que se puede hacer y que...

Sebastian Lage tiene este estupendo vídeo acerca de Chess AI*, que es un resumen en 30 minutos sobre la creación de un programa que juega al ajedrez desde cero. Está escrito en C# en el motor de Unity (el código está...
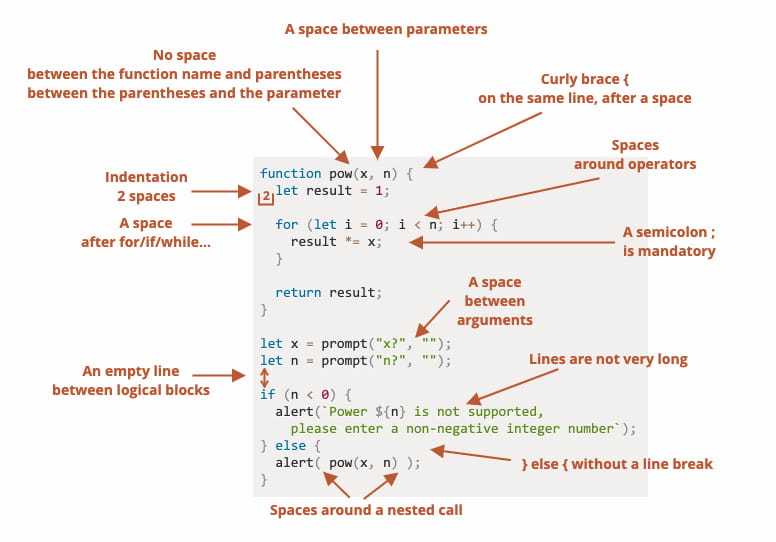
Como parte del interesante tutorial sobre JavaScript que comenté por aquí hace tiempo se puede encontrar este capítulo dedicado al Estilo al escribir código con algunos consejos sobre: Cómo indentar el código El uso de llaves, paréntesis y corchetes Los punto...

En el Laboratorio Nacional Oak Ridge de Estados Unidos se ha puesto en marcha el superordenador Frontier, una titánica computadora que ha subido directa a lo más alto del ránking Top500 de las supercomputadoras. Algunas de sus características técnicas más llamativas:...
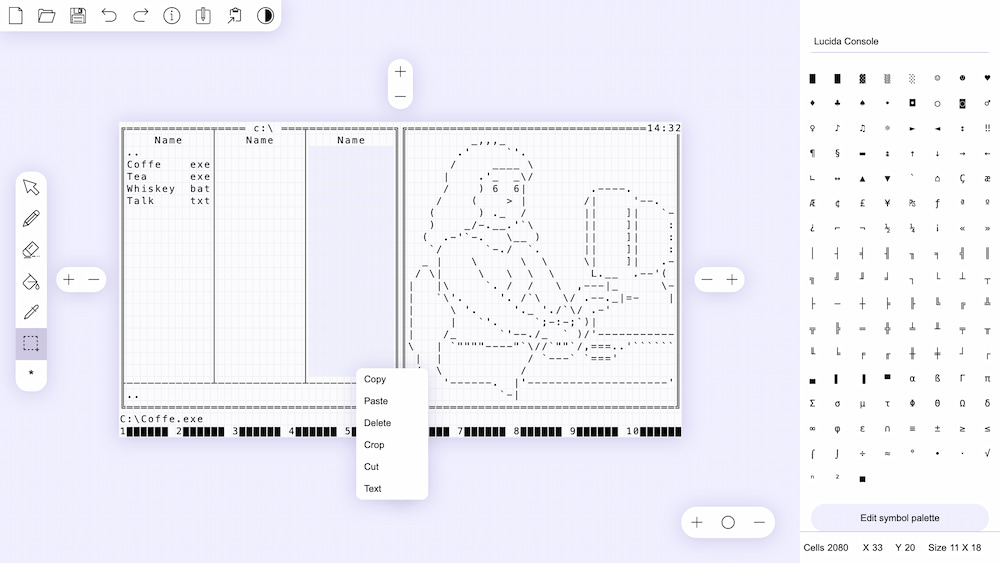
ASCII Art Paint es una encantadora y a la vez aberrante aplicación web para dibujar, pero sólo en el peculiar formato de los caracteres-como-píxeles del Arte ASCII. Lo mejor es que tiene una enorme cantidad de herramientas, dignas de un Photoshop,...

En el vídeo I found Katherine Johnson's actual calculations at NASA de Tibee se puede ver un pequeño análisis de la publicación de 1960 Determination of azimuth angle at burnout for placing a Satellite Over a Selected Earth Position de la...

Este perfil de Quanta sobre Leslie Lamport (1941-) nos presenta a un personaje importante de informática, aunque su nombre no resulte tan familiar como otros. Además del Premio Turing de 2013, este matemático tiene entre sus logros haber puesto las bases...
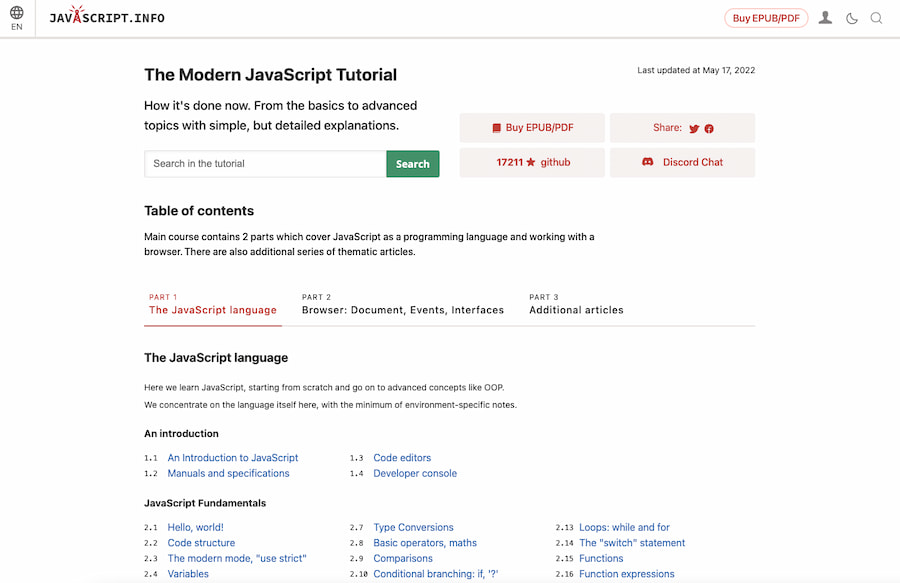
Ilya Kantor tiene en The Modern JavaScript Tutorial lo que denomina un tutorial sobre JavaScript moderno. Y es que JavaScript tiene ya unos cuantos añitos (surgió en 1995) y además de muchas variantes y versiones también los usos que se le...

Publicar código es tan fácil como utilizar una tipografía monoespaciada o usar la etiqueta <code>. También se podría hacer a mano, trabajando con cuidado los estilos, colores y tabulaciones. Pero si se necesita algo bonito para ilustrar en Code to Image...

La gente de Fireship hace una estupenda labor divulgativa en el terreno de la informática. El Canal de YouTube de Fireship tiene ya más de 1,3 millones de suscriptores, y con vídeos cortos bien producidos, de unos pocos minutos, explican lenguajes,...
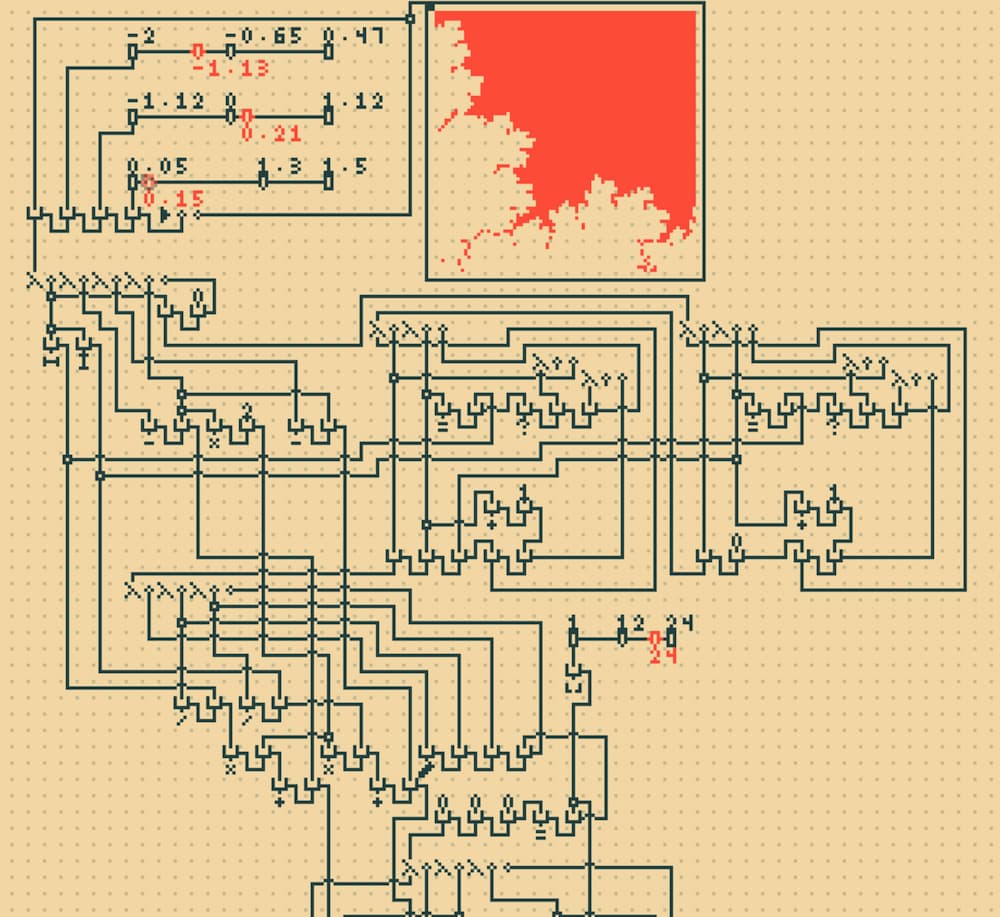
Este curioso lenguaje de programación inventado en el MIT se llama λ-2D (lambda 2D) y se define como «una exploración de los dibujos como lenguaje de programación, tomando ideas del cálculo lambda». Se parece a alguno de los otros poco explorados...

Un par de minutos para echar un vistazo al telar de Jacquard, el tátara-tátara-tárarabuelo de los telares modernos que guardan en una de las exposiciones del Museo Henry Ford de Innovación, que tiene una entretenida página web. Como ya hemos comentado...

El equipo de Somnolescent se pegó una buena currada para recopilar más de 700 muestras artísticas en Art Bits from HyperCard. Son clip-arts, iconos e imágenes propias del software de hipertexto que se incluía con los Macintosh de Apple en los...
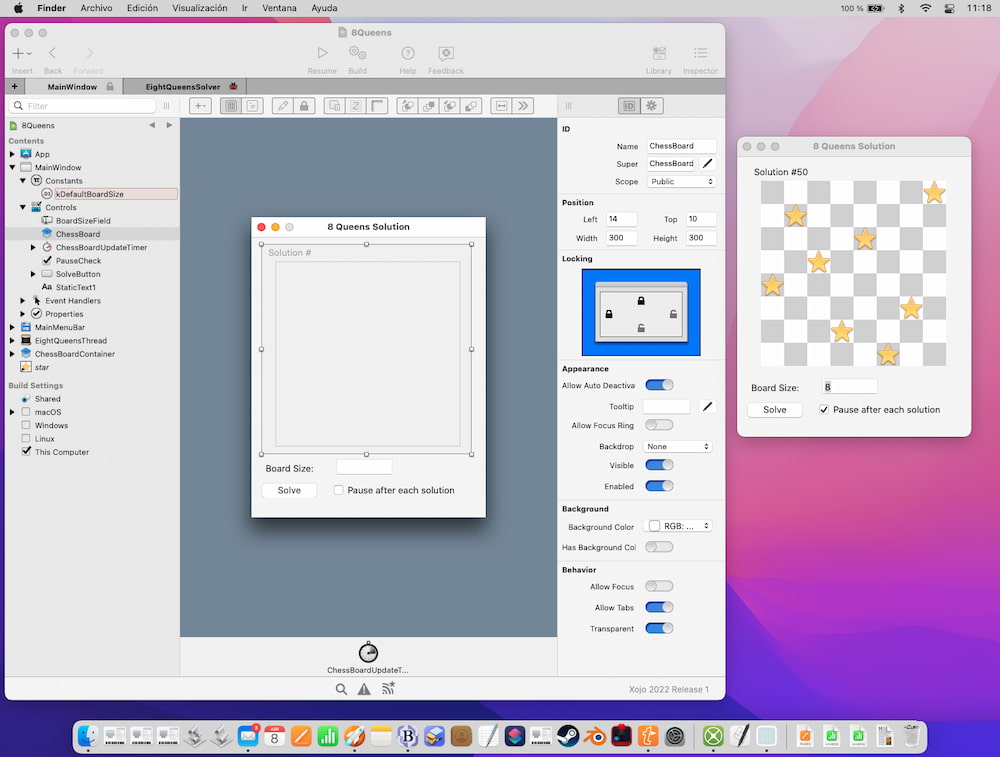
Me llegó una nota sobre el lanzamiento de Xojo 2022 Release 1, la actualización de este año del lenguaje + entorno de programación Xojo que tuve oportunidad de probar hace tiempo con bastante tranquilidad. Esta nueva versión mejora las anteriores pero...
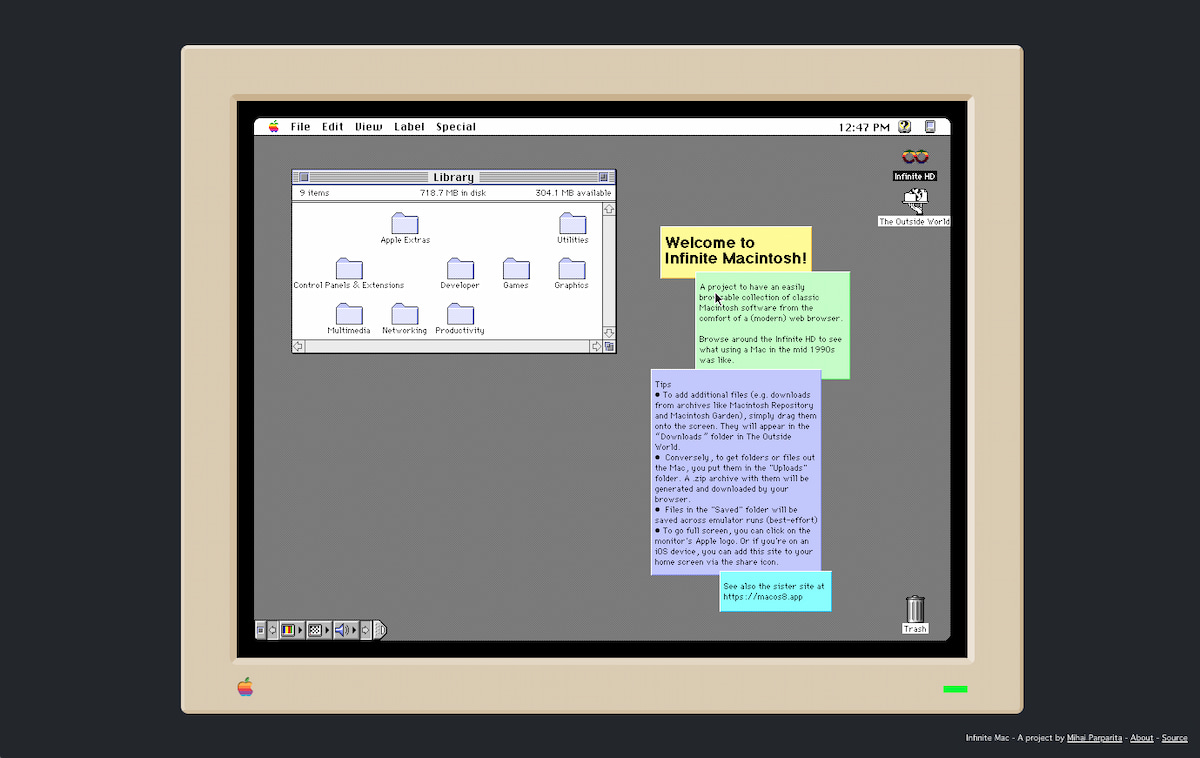
Este magnífico proyecto llamado Infinite Mac es una creación de Mihai Parparita y consiste en un emulador de Apple capaz de correr el Sistema 7 y 8 en el navegador, pero además acelerado para que su respuesta esté más acorde con...
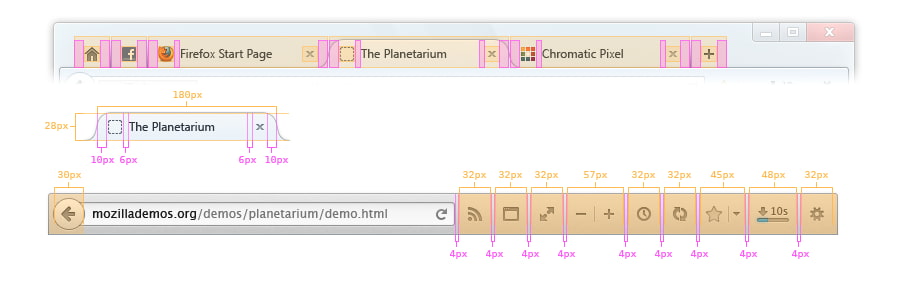
Este minucioso repaso explicado por MS_Y en una página de Github es todo un recorrido por la historia visual de la interfaz de usuario de Firefox, el navegador web que desarrollan la Corporación Mozilla y la Fundación Mozilla. Mozilla Firefox –también...
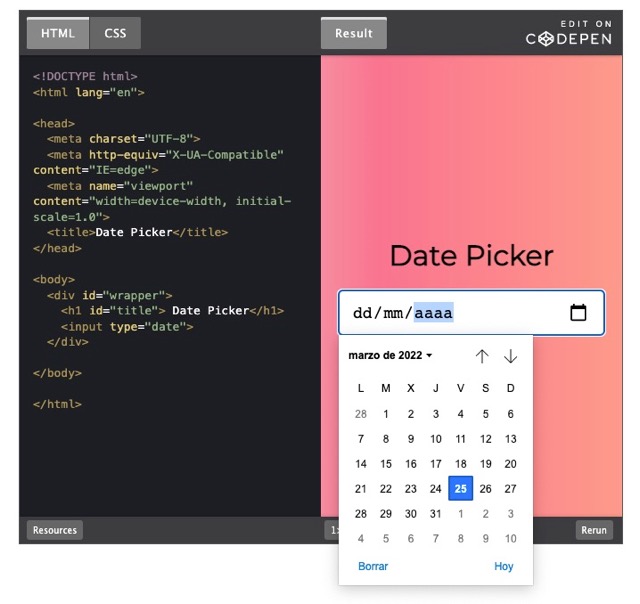
Ahí van algunos artículos que recopilé sobre programación en HTML en los que se explican códigos y atributos útiles-pero-no-tan-conocidos para mejorar las páginas web. Cuestiones como evitar que en un formulario aparezcan palabras subrayadas porque se «dispara» el corrector ortográfico, cómo...
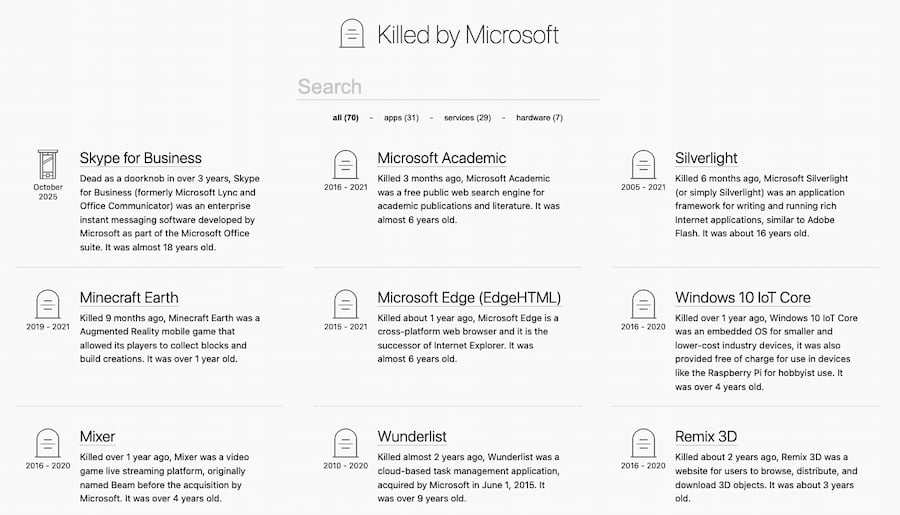
Todas las empresas esconden algún que otro «muerto» en sus armarios, y Microsoft no es la excepción. Quizá por eso y para que nadie se olvide Fabiano Riccardi y un montón de voluntarios llevan tiempo mantenido Microsoft Graveyard, el cementerio de...

Este pequeño ordenador llamado simplemente Penkesu Computer es una creación de Penk Chen, usando una Raspberry Pi Zero 2 W con piezas impresas en 3D, otras recicladas de una Gameboy Advance SP, una pantalla de 7 pulgadas y 1280x400 y un...

Sean Holloway ha creado estas espectaculares visualizaciones en ray tracing de agujeros negros según la relatividad general. Un trabajo a medio camino entre el arte, la ciencia y la programación. Traducido a lenguaje poco comprensible significa que se ha utilizado la...

A finales del año pasado me apunte como mecenas de 20 GOTO 10, un libro que hace unas semanas conseguía financiación. Pero aún llegas a tiempo de pedirlo si te interesa. La idea es contar la historia y el contexto social de...

Esta pequeña maravilla de Lucas Dul, un especialista en reparaciones de máquinas de escribir antiguas, se llama Proyecto Cyberdeck. Es una especie de ordenador retrofuturista, tan poco práctico que probablemente sería imposible trabajar con él más de un cuarto de hora…...

La latencia se conoce vulgarmente como retardo, aunque técnicamente sea una suma de retardos típica de la transmisión de paquetes en una red, o más en general la diferencia entre causa y efecto en diversos sistemas, ya sean una red de...
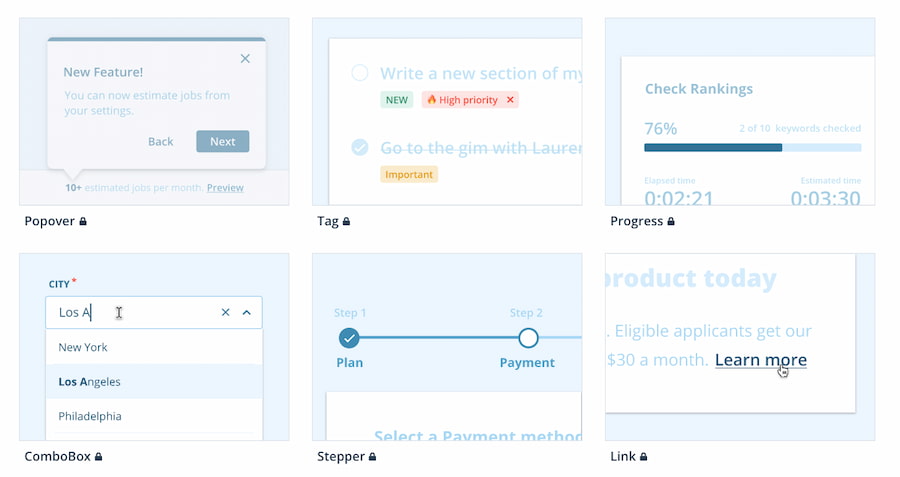
En el UI Components Handbook (Manual de los componentes de interfaces de usuario) un grupo de estudiantes y diseñadores de diversas empresas está recopilando ejemplos de los componentes de las UI de webs y apps, esto es, las diversas formas gráficas...
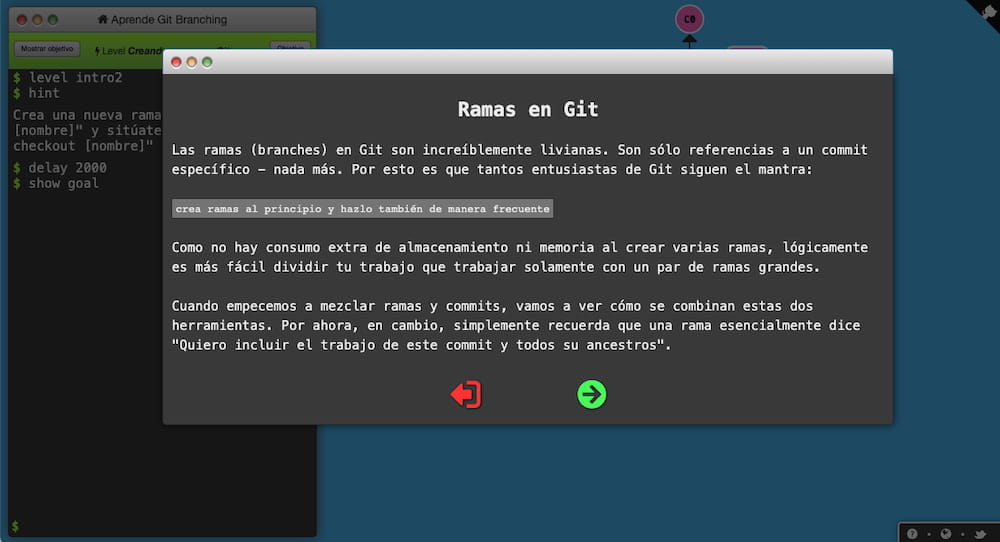
Learn Git Branching es un proyecto de @petermcottle, ingeniero de Instagram. Se trata de «una aplicación diseñada para ayudar a los principiantes a manejar los poderosos conceptos que hay detrás del trabajo con ramas (branches) en Git». Como tutorial interactivo y...

¿Qué cómo se depuran las aplicaciones? No se depuran, se escribe código sin errores. Pero no en JavaScript, porque nadie puede dominar JavaScript.– Jack BorroughsDesarrollador Senior de JavaScript He aquí el típico «humor de programadores» que sólo entenderán los informáticos, más...

En este vídeo de Nobel Tech se han entretenido en emular, grabar y montar en orden cronológico todos los sistemas operativos de los Macintosh de Apple, empezando en 1984 con el Sistema 0.97 (que oficialmente se dió a conocer como Macintosh...

Esta curiosidad de 0xdanelia llamada Regex Turing Machine es una demostración de cómo se puede utilizar el Notepad++ como sistema Turing completo utilizando las expresiones regulares y el comando buscar/reemplazar. En la imagen puede verse el código del castor afanoso, uno...

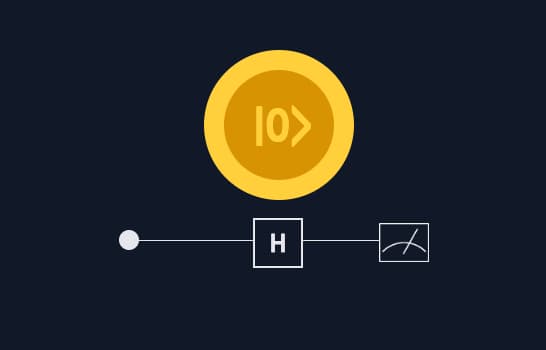
from qiskit import QuantumCircuit # Create a basic Bell State. qc = QuantumCircuit(2, 2) # 2 qubits, 2 bits qc.h(0) qc.cx(0, 1) # Measure and put the result into the two bits. qc.measure([0, 1], [0, 1]) # Display circuit. print(qc) En el...
La buena gente de 9to5Mac lanzó una pregunta al aire, o mejor dicho, a la mente colmena de Twitter: ¿Qué buen truco en los Mac debería conocer más la gente? El resultado es un gigantesco hilo de valiosos tuits con cientos...

En Thingverse tienen una detallada explicación acerca de cómo construir pieza a pieza esta caja torre retro para Raspberry Pi 4, de aspecto realmente encantador y con un decidido toque vintage. Lo que es la caja se imprime en 3D en...

Me parece muy importante lo que cuentan desde Civio en La Justicia impide la apertura del código fuente de la aplicación que concede el bono social. Básicamente han pedido que les dejen acceder a «las tripas» de BOSCO, el programa que...

Not gonna lie, I'm loving the Clustered-pi Zero build. Look at it! (just printing out more of the Cushions at the moment). Ordered some 90 degree micro USB connectors so the wires don't stick out the sides. https://t.co/AWk6oemZWP #raspberrypi #raspberrypizero2 @Raspberry_Pi pic.twitter.com/PjJzxWKiBy—...
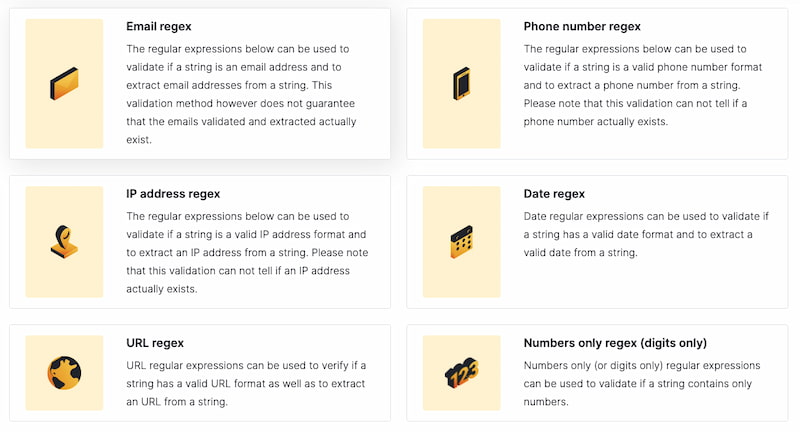
RegEx Library es una recopilación de la gente de UI Bakery en la que se pueden encontrar las expresiones regulares (RegEx) más comunes, incluyendo las que se suelen usar para la validación y extracción de datos de: Direcciones de correo Números...
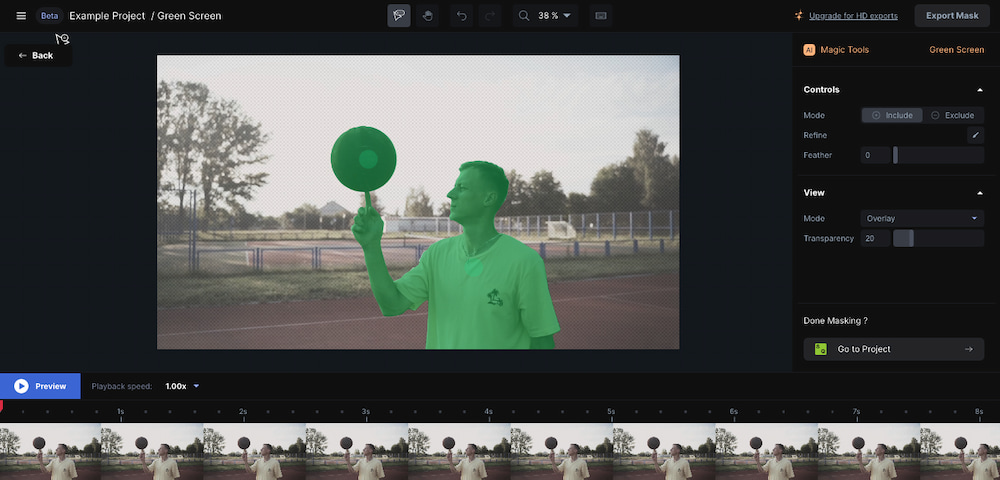
He estado echando un vistazo y haciendo algunas pruebas con Runway, un editor de vídeos que funciona directamente en el navegador web. Lo más destacado es que incluye algunos efectos muy resultones y fáciles de aplicar, entre ellos el croma verde...

Mitad en serio, mitad en broma, mitad como experimento,CodeCaptcha.io pone una idea sobre la mesa: un captcha –esas cajitas de «Demuestra que no eres un robot»– que en vez de textos ondulados o reconocer objetos en fotos como bicicletas o postes...
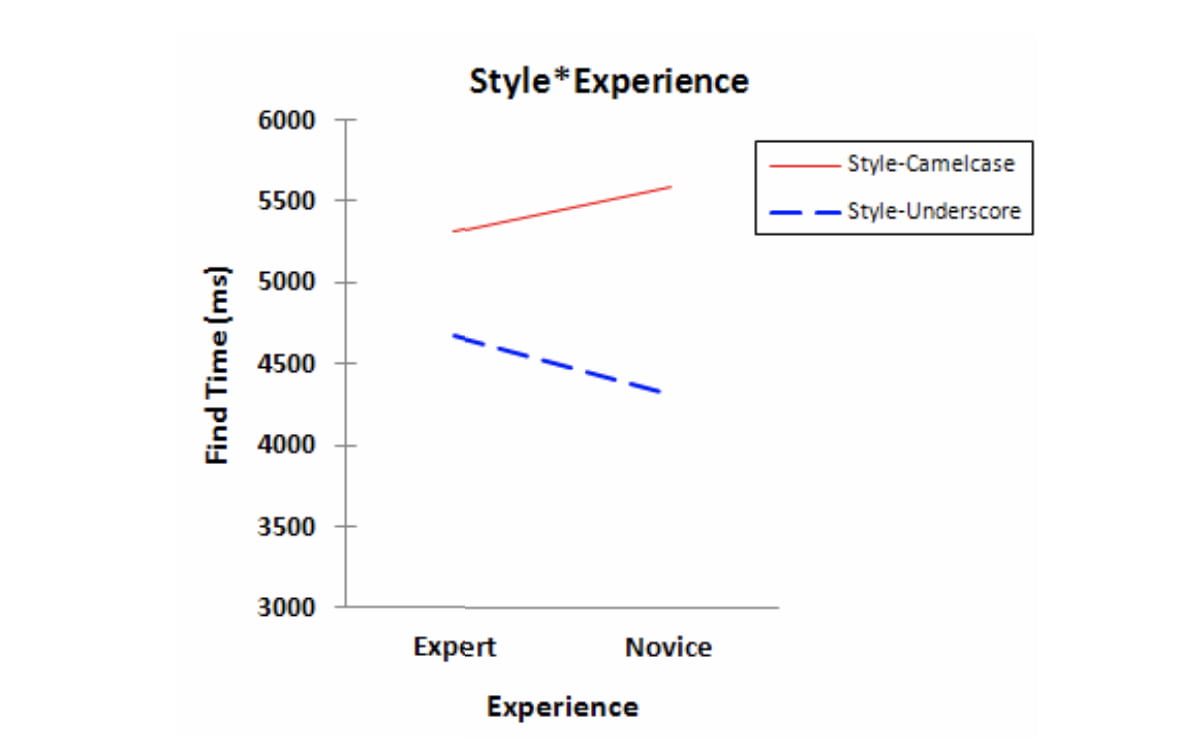
Un par de investigadores han tenido la santa paciencia de comprobar empíricamente si es más preciso y legible el código que utiliza palabras clave y variables escritas como PalabrasJuntas o espacios_subrayados (CamelCase vs. snake_case). Se puede leer aquí: An Eye Tracking...
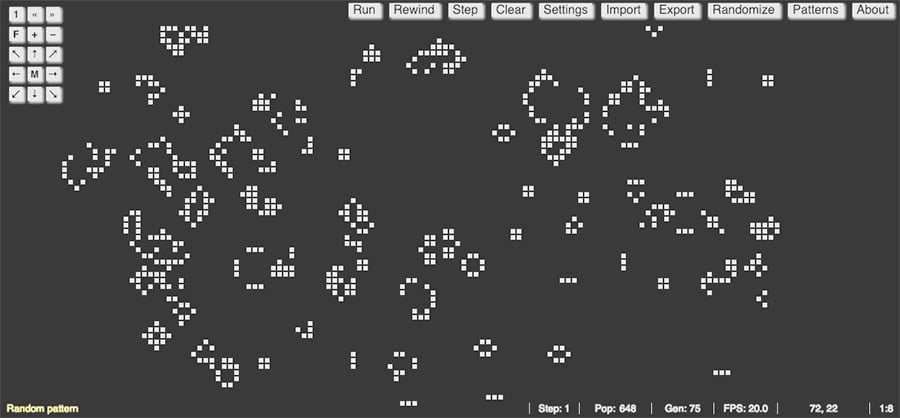
Está versión del Juego de la vida, llamada simplemente Game of Life de alguien que firma como Copy está escrita en JavaScript, de modo que se puede ejecutar directamente desde el navegador. En la parte de izquierda hay botones para centrar...
«… y en la clase de Historia de hoy, niños y niñas, recordaremos cómo era conectarse a Internet a finales de los años 90.» Estaba yo quejándome hoy de que la velocidad de la fibra me oscilaba entre 350 y 400...
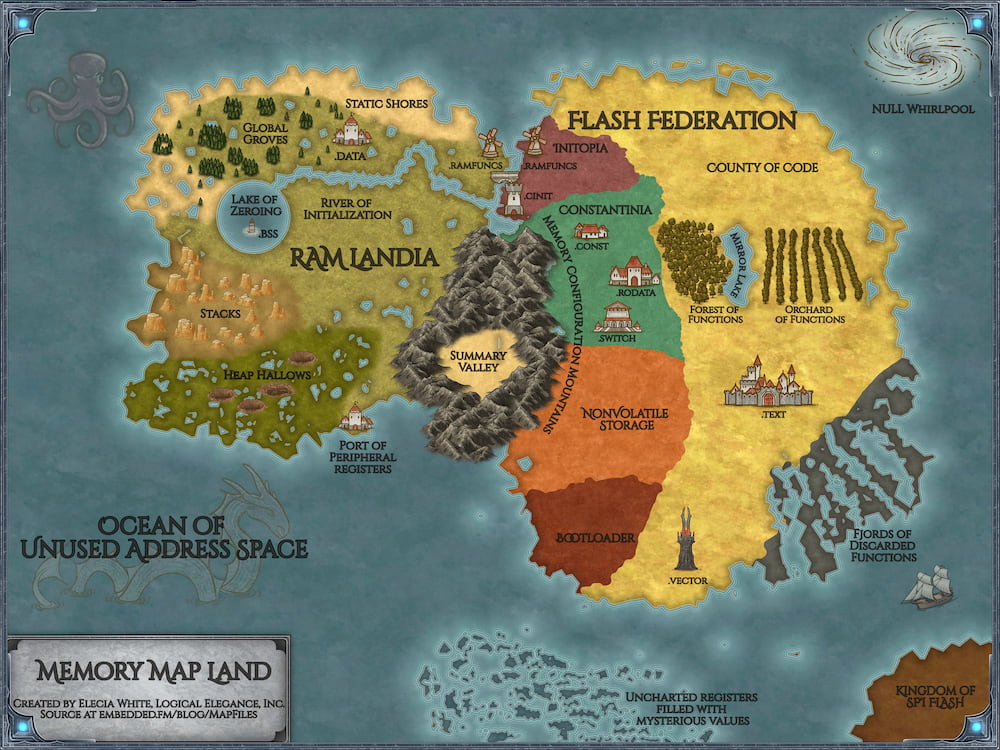
Elecia White es la creadora de Memory Map Land [zoom a la versión ampliada en Github], una artística representación de los mapas de memoria que se utilizan en el desarrollo de diferentes sistemas, especialmente microcontroladores. Es una curiosa forma de entender...

En el Laboratorio de Inteligencia Artificial del MIT (MITCSAIL) han desarrollado un sistema para diseñar y entrenar robots «blanditos» e inteligentes. Estos robots son puras formas geométricas, conjuntos de cuadrados flexibles que pueden adoptar diversas formas según un algoritmo evolutivo. Se...

Gregory Nacu es un hacker autodidacta que adora los ordenadores antiguos y se ha embarcado desde hace tiempo en la extenuante y apasionante tarea de crear un sistema operativo «moderno» para el Commodore 64, al que ha llamado, apropiadamente, C64 OS....
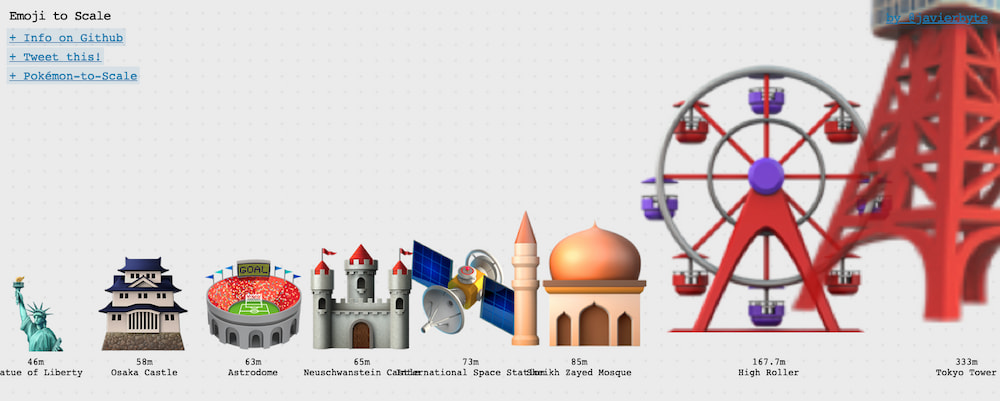
Emojis a escala es una ingeniosísima representación visual de todos los emojis comparados a la misma escala, de modo que las hormigas son más pequeñas y los rascacielos, torres y montañas mucho más grandes. Es una iniciativa de Javier Bórquez, autor...
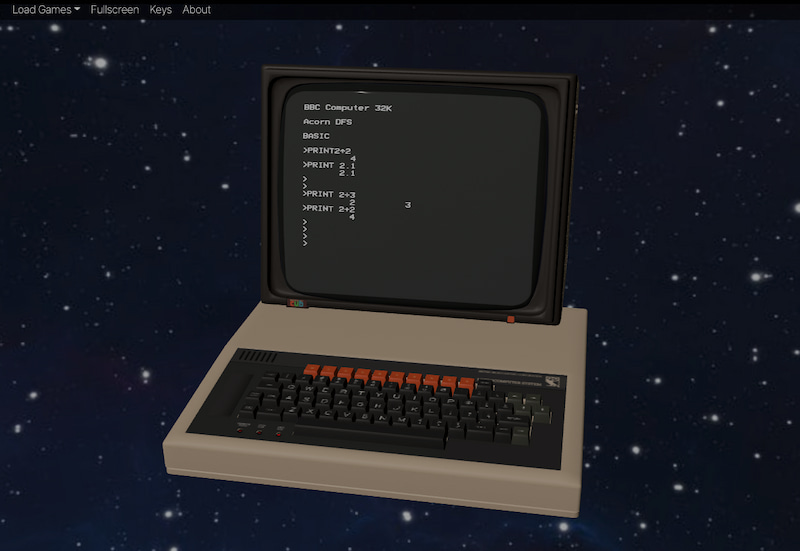
Este BBC Micro simulado en 3D llamado Virtualbeeb resulta bastante simpático porque (1) el intérprete Basic funciona perfectamente, (2) puedes moverlo en 3D para orientarlo como más te guste, (3) funciona a color y como bonus lleva incluidos cientos de juegos....

Según cuenta la BBC se ha sabido que a principios de noviembre se vendió un Apple I por 400.000 dólares en una subasta. El Apple I era el modelo original y primer ordenador Apple, diseñado por Wozniak y Jobs. Era básicamente...

Nos llega la noticia de que IBM ha presentado un procesador cuántico innovador de 127 qubits, «superando a los investigadores de Google y a los chinos», según dice la propia nota de prensa, «que hasta ahora habían realizado demostraciones con 60...
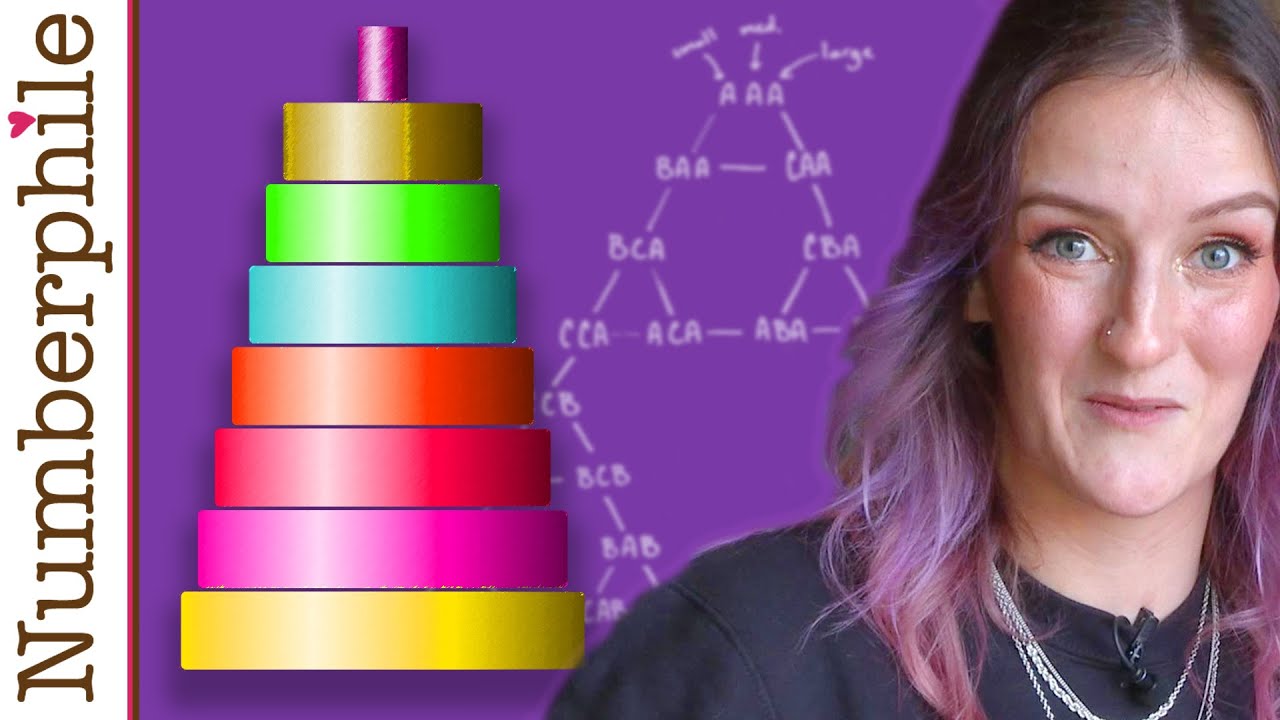
Ahí va una pequeña dosis de algoritmos, soluciones óptimas, bucles, paridad, crecimiento exponencial, caminos hamiltonianos y la curva de la punta de flecha de Sierpinski que es fractal. Pero parece un juego, con música incluso. El vídeo de Numberphile lo protagoniza...

Esta curiosa miniserie alemana de cuatro episodios es de lo más geek que se puede encontrar ahora mismo en Netflix, y hay que reconocer que está entretenida y con buena producción [doblada al español –excepto el tráiler– incluyendo un curioso mix...

Este precioso y didáctivo vídeo de Freya «Acegizmo» Holmér amenizado con relajante música de jazz es una explicación completa, matemática, geométrica y práctica de cómo funcionan las curvas de Bézier. Dado se utilizan para todo tipo de cosas en ilustración, tipografía...

En este fantástico, cuidadísimo y meticuloso videoclip producido por Apple se mezclan 45 años de «sonidos Apple» tan característicos y familiares que cualquiera que utilice un Mac y otros dispositivos de la compañía reconocerá con alguna parte de su cerebro reptiliano...
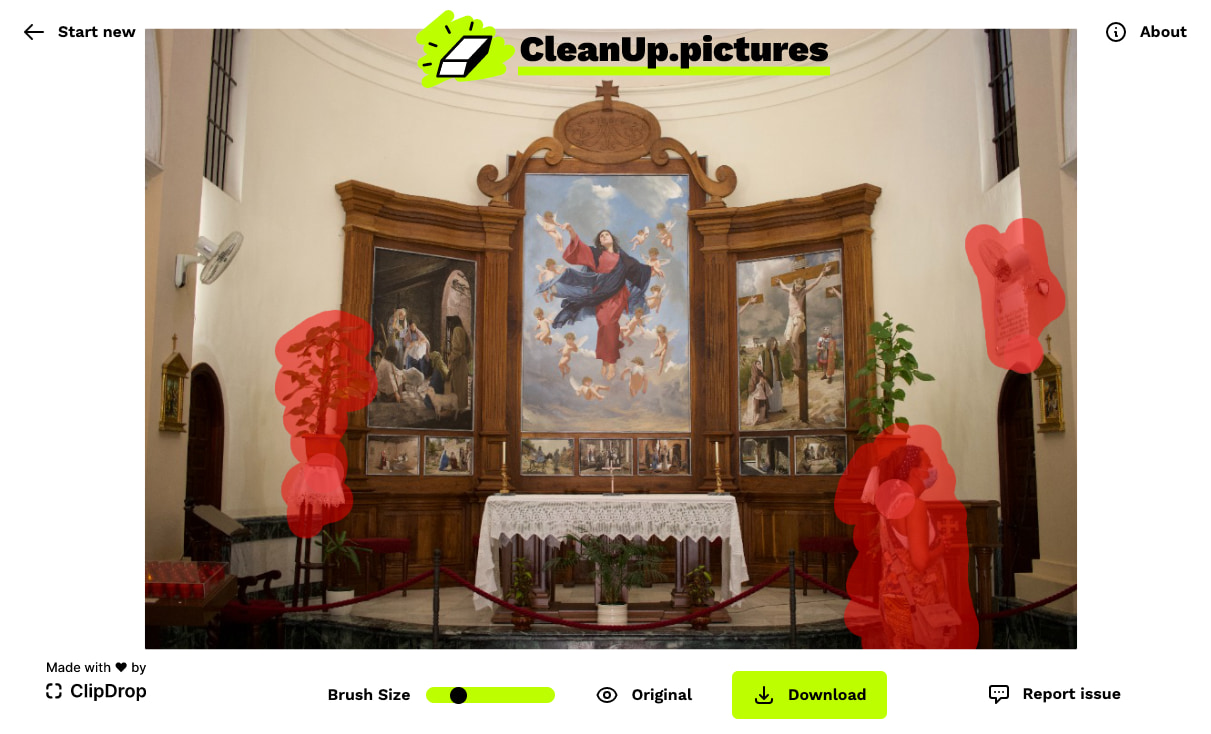
CleanUp.pictures hace una sola cosa y la hace estupenda y fácilmente: elimina objetos no deseados de las fotografías. Usarlo es tan fácil como arrastrar la foto sobre la zona de edición, bocetar en rojo la zona del objeto que se quiere...

Este vídeo es el tráiler de Turing Complete, un «juego sobre informática». La idea es espléndida: utilizar la forma de jugar típica de los juegos de puzles por niveles para ir añadiendo pasito a pasito diversas ideas sobre circuitos digitales. Así...

Bryan Braun tiene una obsesión tecnológica consistente en hacer cosas raras con checkboxes, que expone en un sitio llamado Checkboxland. Y es sin duda un gran hackeo, porque parte de la idea de usar algo para una finalidad totalmente diferente de...

Todavía resuenan en la red los ecos de los gritos en un vacío en el que nadie podía oír a nadie. Miles de millones de personas e influencers sorprendidas por la desaparición de Facebook y también de WhatsApp e Instagram –ambas...

¡Descubrimiento! He sabido de la existencia de la Vintage Computer Federation (VCF) a través de una de las charlas que organiza este grupo de usuarios amantes de las máquinas viejunas y del software de época. Está dedicada la evolución del juego...
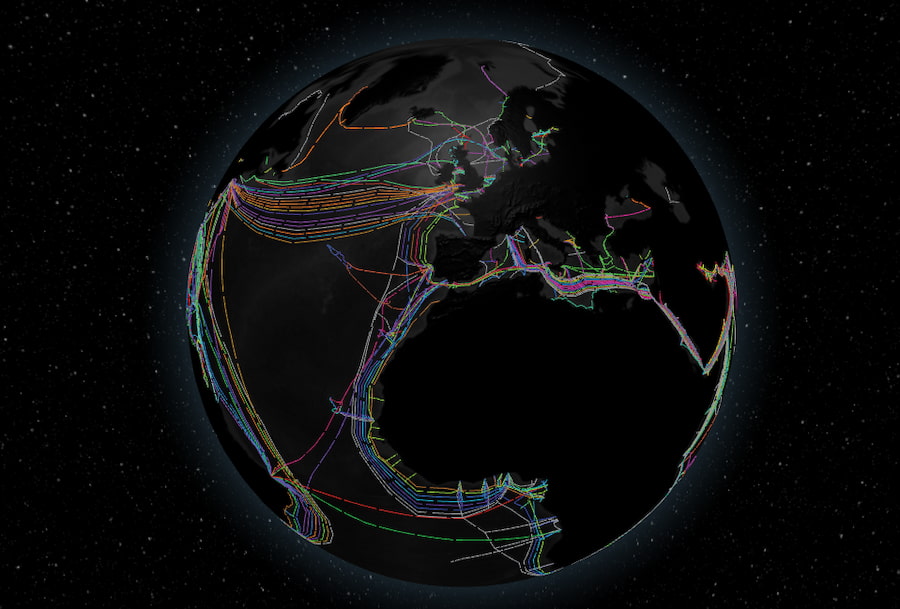
Es precioso globo terráqueo interactivo con cables submarinos es simplemente gozoso, tanto en lo visual como en lo táctil, porque puedes darle vueltas con el ratón, girarlo, hacer zoom y examinar las vías por las que circulan los bits en todas...

Los iconos del calendario de las apps suelen mostrar la tradicional y un poco obsoleta imagen del calendario de hojas diarias que se arrancan u hojean para marcar el transcurrir del tiempo y la fecha actual. Esta tradición from the past...

Este pasado fin de semana se celebró Naukas Bilbao 2021, que tras la cancelación del evento en 2020 marca un paso más de vuelta a la normalidad. A la normalidad normal, nada de nuevas normalidades. Yo tuve la oportunidad de dar...

Gracias a una anotación de Byran Lunduke acerca de las portadas de la revista Byte del artista Robert Tinney tuve un momento remember de aquellas ilustraciones que hoy nos parecerían casi «retrofuturistas», donde había mucha ilustración, imaginación y normalmente muy poco...

Todo lo que quiero es un agradecimiento por lo que hice. No quito nada a los que rompieron los códigos, pero no podrían haberlo hecho sin nosotras.Betty GilbertMiembro del Servicio Territorial Auxiliar (ATS)destinada en la Estación Y HMS Forest Moor The...

Hoy nos ha llegado la noticia del fallecimiento de Sir Clive Sinclair (1940-2021) a la edad de 81 años. Este venerable pionero de la informática tuvo un gran papel en la popularización de los primeros ordenadores familiares, en especial con el ZX...

The Royal Mint, que es el nombre de lo que viene siendo la «casa de la moneda» del reino unido, ha anunciado el lanzamiento de unas monedas de coleccionista en honor de Charles Babbage, el matemático y «padre de la computación...
Me ha llamado la atención 20 GOTO 10. Es un libro que cuenta la historia y el contexto social de los ordenadores, juegos y consolas retro de los 80 y los 90 del siglo XX. Pero lo hace utilizando números como 48K,...
Tras esta pantalla de un editor de código fuente se esconde una realidad más interesante: ofertas de empleo de tecnología para leer de forma disimulada mientras estás en el trabajo. La idea es, digámoslo claro, doblemente malévola porque si algo fastidia...
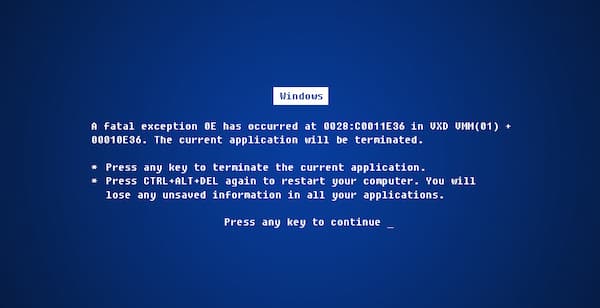
En línea con grandes éxitos como ¿Por qué los hiperenlaces azules son azules? David Plummer, un exingeniero de Microsoft y presentador del estupendo y recomendable Dave Garage nos cuenta todos los detalles sobre su investigación acerca de por qué las «pantallas...

Mezvan nos puso sobre la pista de Computer Engineering for Babies un curioso libro altamente geek que Chase Roberts, un informático e inventor ha creado y está moviendo en Kickstarter con bastante éxito. Según cuenta la idea le sobrevino al ver...
Para quienes gusten de las versiones viejunas de interfaces clásicas 7.css, XP.css y 98.css recrean de forma semántica el HTML utilizando las hojas de estilo (CSS), de modo que puedes programar interfaces que parezcan de Windows 98, XP o 7 en...

Javier nos escribió a raíz de un comentario sobre reducción de código a su mínima expresión para dejarnos un enlace a su Mandelbrot en ASCII art C++. Parte del mérito es lo bonito que queda (y eso que solo utiliza el...

Las dos imágenes del ejemplo que ha encontrado Sarah Jaime Lews tienen el mismo Neural Hash: 1e986d5d29ed011a579bfdea. Lo cual no debería ser posible porque se supone que variaciones de la imagen original en cuanto a objetos y contenido deberían generar un...
Flagpack es una completa colección de más de 260 banderas del mundo en diversos formatos listas de para descargar y utilizar. Vienen en tres tamaños: icono, mediano y grande. Están listas para usar con herramientas como Sketch, Figma, Adobe XD y...
Tenemos nuevo récord de cálculo de decimales de pi: 62 billones de decimales. Según cuentan en el departamento DAViS de la FHGR (Universidad de Ciencias Aplicadas de los Grisons, Suiza), bate el récord del mundo anterior que estaba en manos de...
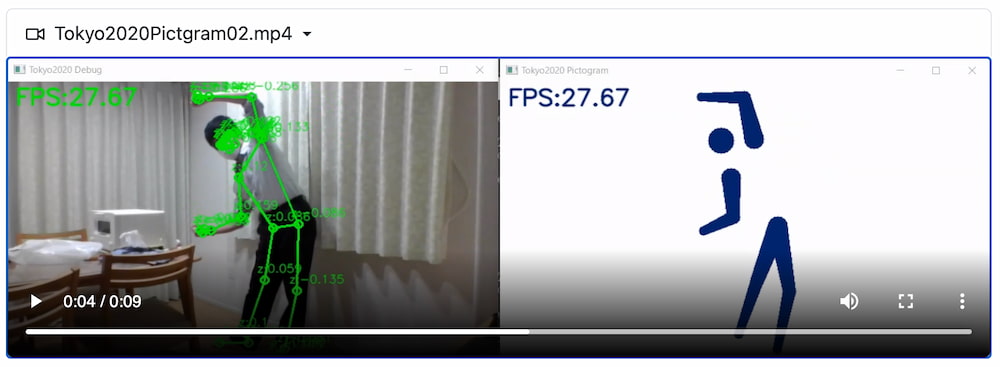
Uno de los grandes exitos de la inauguración de la ceremonia de inauguración de los Juegos Olímpicos de Tokio 2020 fue la presentación de los pictogramas: iconos animados muy estilosos y bien resueltos. Ahora esto mismo se puede hacer en casa...
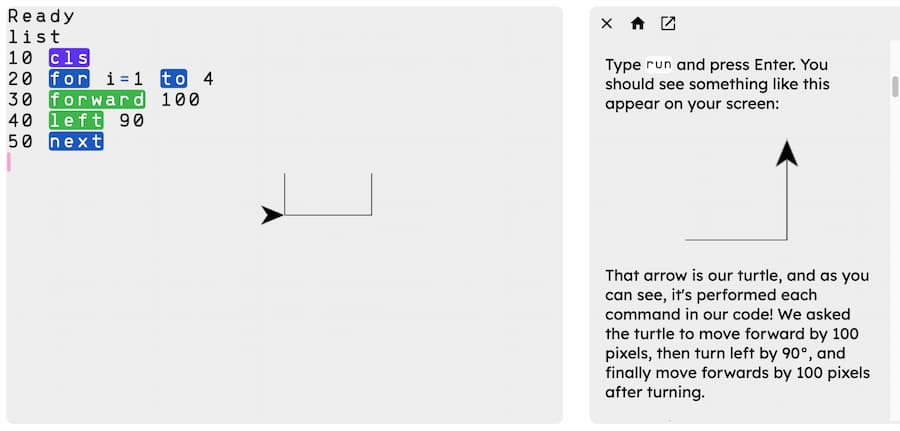
Atto es un Basic creado por James Livesey con el que se puede juguetear, hacer algunas cosas o simplemente recordar viejos tiempos. Funciona en el navegador y basta abrir la página en la que se aloja para empezar a hacer cosas....
Se me ocurrió tuitear una chorrada que me sucedió el otro día con la etiqueta #TúQueEresInformático, pero no tuve la precaución de ver si antes ya la había usado alguien para algo parecido. Naturalmente resulto ser un tópico tan típico que...

Apple es hoy en día la compañía más grande del mundo con una capitalización bursátil de 2,4 trillones de dólares. Pero todo tuvo un comienzo. Y cuando Apple salió a bolsa en Estados Unidos en diciembre de 1980, las autoridades del...
En la página de los Estándares ISO públicos sobre informática he contabilizado 735 documentos en total, que no son pocos para un sólo área del conocimiento. Los hay dedicados a lenguajes de programación, telecomunicaciones, seguridad y muchos más. En total la...

He estado un tiempo trasteando con un Dynabook Portégé X30L que muy amablemente me dejaron para probar. Soy de los que tiene la teoría de que siempre viene bien un segundo equipo como muleto por si necesitas reemplazar tu equipo principal...

Steve Wozniak, «Woz», uno de los mayores hackers de la historia y co-fundador de Apple, nos habla en este vídeo del canal de YouTube del Repair Preservation Group con sabias palabras acerca del derecho a reparar. Naturalmente, aprovecha para colar unas...

Este vídeo de Two Minute Papers me ha recordado a los viejos segmentos de Metrópolis de La 2 que disfrutábamos en los 80. Es una recopilación de los mejores trabajos en simulaciones físicas en animaciones 3D; un compendio del «estado del...
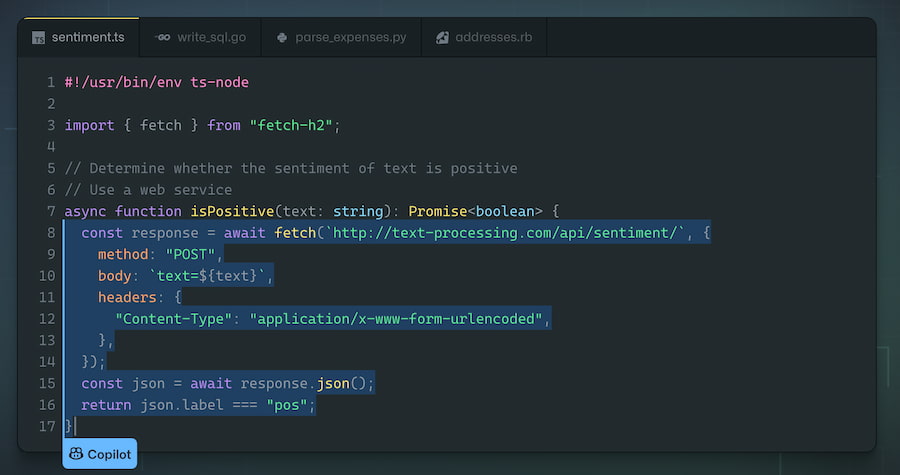
Nos escribieron algunos lectores para llamarnos la atención acerca de Copilot, una llamativa herramienta de GitHub/Microsoft que habíamos visto pasar el otro día y que sirve para generar código de programación a partir de un entrenamiento mediante inteligencia artificial. Llámalo «sugerencias»,...

Este divertido clip que vuelve a hacer las rondas estos días fue una idea de Josh Darnit. El «reto» consiste en escribir las instrucciones exactas para hacer un sandwich. Y muestra cómo algo supuestamente sencillo puede convertirse en algo tan complicado...

The Road to Conscious Machines: The Story of AI por Michael Wooldridge. Pelican 2020. 388 páginas. Quienes me sigáis mínimamente sabéis que protesto bastante por el tratamiento que se hace en general en los medios de la expresión inteligencia artificial. Entre...

Elliot Waite ha tenido la feliz idea de cruzar dos de los autómatas más simples y conocidos en uno solo: la Regla 30 de Wolfram y el Juego de la vida de Conway. El resultado es que cuando las células unidimensionales...

El software criptográfico PGP cumple hoy 30 años. La versión 1.0 se lanzó a las redes en 1991, una época en la que el software circulaba principalmente por listas de correo, las BBS (boletines electrónicos) y los servidores de FTP que servían...

Hace unos meses empecé a usar un MacBook Air de 2020 como mi ordenador principal. Se carga mediante USB-C, así que me tocó buscar un alimentador para llevar siempre conmigo. Y en el mundo del USB-C esto quiere decir que hay...
Llegué el otro día a Mastershot, que es una pequeña app web a modo de editor de videos con la particularidad de que funciona online, de modo que no tienes que bajarte una aplicación, instalar nada y está siempre disponible. Es...

Suelo seguir con interés el informe sobra la Sociedad Digital en España. Esperaba el de 2020-2021 con especial interés por todo lo que trajo la pandemia de digitalización forzada y a marchas forzadas en muchos campos. Ya está disponible como Sociedad...

El PiDP-11 – Oscar Vermeulen El PiDP-11, diseñado por Oscar Vermeulen, reproduce un PDP-11/70 de 1975 a escala 6:10. Bueno, reproduce la consola desde la que se encendía y apagaba y se podía hacer la depuración de programas examinando posiciones de memoria...
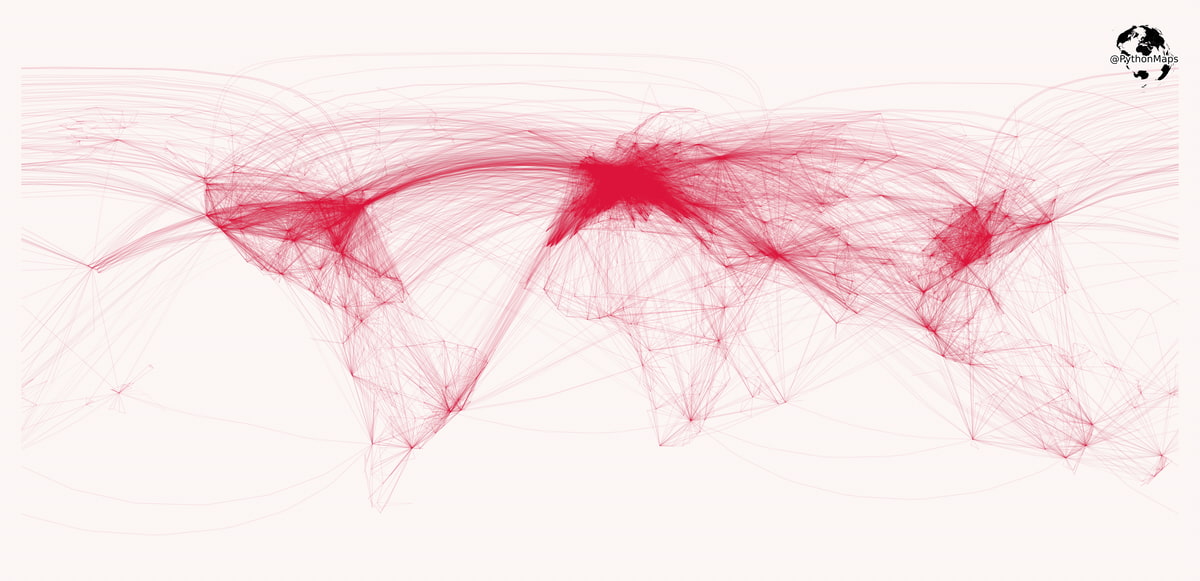
@PythonMaps es una maravilla de cuenta en la que se muestran visualizaciones de mapas temáticos creados a partir de datos: rutas aéreas, las emisiones de CO2 o los bosques más tupidos del planeta y muchos más, tanto propios como recopilados de...

John D. Cook tiene una serie de interesantes anotaciones sobre generadores de números aleatorios a las que se puede acceder bajo la etiqueta: RNG. Esto tiene aplicaciones tanto en criptografía como en muchas áreas de física y matemáticas, incluyendo las simulaciones....

Recuerdo que cuando se presentaron los chips de nodos de 3, 5 y 7 nm se traía siempre a colación los límites de la Ley de Moore porque esos tamaños para fabricar microchips parecían estar muy cerca de los «límites de...

Como seguramente ya sabéis quienes nos leéis, nuestro humilde blog surgió como un entretenimiento allá por 2003 para hablar sobre todo lo que nos encontrábamos por ahí al navegar por Internet: asuntos de ciencia y tecnología, gadgets, historia de la informática,...
Algunos conocidos y otros no tanto, en HTML Tips Marko Denic explica unos trucos de HTML bastante interesantes. Y es que sucede que a menos que estés continuamente poniéndote al día sobre las incorporaciones al llamado lenguaje de la Web puede...
Las apps que incorporan los conceptos de Realidad Virtual (RV) y Realidad Aumentada (RA) siguen creciendo día a día. Lo hacen incluso por encima del promedio del mercado de las apps, que pasó de 140.000 millones de descargas¹ en 2016 a...
Aunque iCloud, MacOS y Fotos (anteriormente iPhoto) son mayorcitos y deberían estar bastante libres de bugs, un fantasma recorre su código que hace que algunas veces las fotos simplemente no se sincronicen correctamente entre dispositivos. A mí me ocurre –y me...
La página Dev Fonts es un completo catálogo creado por @ImGaafar, con decenas de tipografías para usar en programación. Muestra cómo se ve el código y permite hacerse una idea rápida de cuán prácticas y legibles resultan; además se pueden filtrar...

Las cinco viñetas propuestas en el set – 20tauri/Lego 20tauri, la creadora del set de Lego de Mujeres de la NASA, vuelve a la carga, pero en este caso con la propuesta del set Women of Computing, Mujeres de la informática. Incluye...

El nuevo billete – Banco de Inglaterra El Banco de Inglaterra acaba de hacer público el diseño del nuevo billete de 50 libras esterlinas en el que Alan Turing acompañará a la reina Isabel II. Los detalles están en The new £50...

En la web de PCjs Machines el bueno de Jeff Parsons lleva años recopilando emuladores de sistemas antiguos, principalmente PCs, intentando que tanto su funcionamiento como su aspecto se asemejen lo más posible a los originales: imágenes pixelizadas en «fósforo verde»,...

Lou Ottens, the inventor of the cassette tape, died at age 94. pic.twitter.com/gmwlJjVWPd— rootbear (@_r00tbear) March 9, 2021 El 6 de marzo de 2021 fallecía a los 94 años de edad el ingeniero neerlandés Lou Ottens. Aunque su nombre no es precisamente...

Me crucé con una referencia a las -2000 líneas de código de Bill Atkinson [en la foto, el que sujeta el Macintosh] que está archivada Folklore.org y data de 1982. Es divertida y aunque conocía el contexto no la había visto...

Si quieres ver algo increíble prueba a jugar una partida de ajedrez rápida contra The Kilobyte’s Gambit de Matt Round, un ajedrez escrito en tan solo 1 KB de JavaScript. Con esa ínfima cantidad de código es capaz de anticipar 4...

Hace unos meses Félix Cantero me pidió que prologara su libro Inteligencia artificial y cultura pop. De la sinopsis del libro: «La inteligencia artificial está ya teniendo influencia en nuestras vidas (...) y en muchas cosas que probablemente ni imaginamos. Y es...

Betty Jennings (izquierda) y Frances Bilas, dos de las programadoras originales del ENIAC – U.S. Army Aunque el ENIAC está equipado con 18.000 tubos de vacío y pesa 30 toneladas, los ordenadores del futuro tan solo necesitarán 1.000 tubos de vacío y...

Este vídeo de Musiccombo es de esos que da gustirrinín pero ¡ojo! que lleva en su título un (probablemente dramatizado) Aviso: puede provocar ataques y convulsiones. Son ni más ni menos que 60 minutos de algoritmos ordenando valores de menor a...
En febrero de 2020 la Biblioteca Nacional de España (BNE) puso en marcha un proyecto con el objetivo de «asegurar la preservación y el acceso al videojuego». Casi un año después tiene unos 600 juegos catalogados. Pero gracias a la colaboración...

Una de las cosas que se lleva 2020 pero que no echaremos de menos es Adobe Flash. A partir de hoy, 31 de diciembre de 2020, la empresa dejará de sacar actualizaciones para él y de distribuirlo. Aunque lo cierto es...
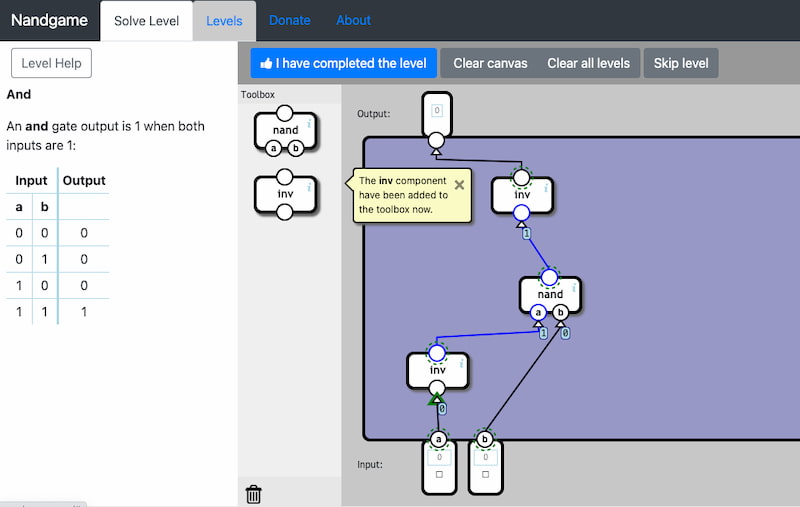
El objetivo de NandGame es llegar a construir un ordenador desde cero, para lo cual hay que empezar por lo básico: un poco de álgebra de Boole y puertas lógicas. En el juego hay que ir resolviendo los puzles lógicos nivel...
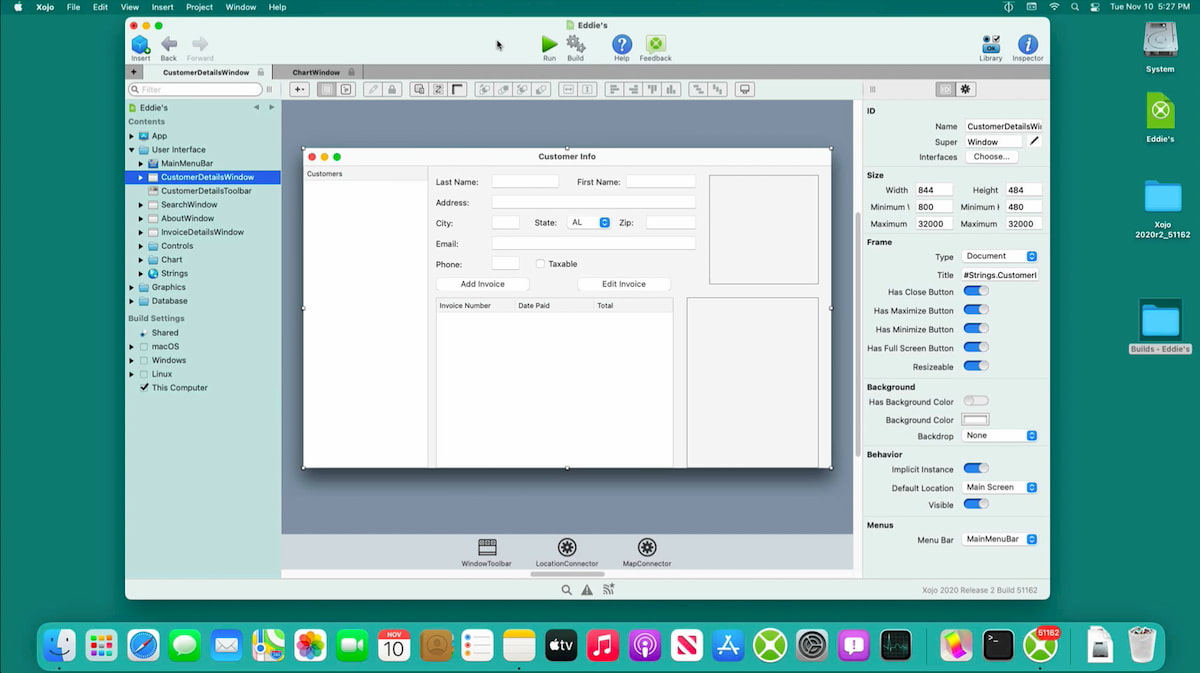
Estos días se ha lanzado Xojo 2020 Release 2, una actualización importante del lenguaje y entorno de programación Xojo. Para quien no lo conozca es un entorno con el que se pueden crear aplicaciones genéricas de todo tipo que luego se...

Este vídeo de Nostalgia Nerd resume varias décadas gloriosas acerca de un tema muy particular: el algoritmo/formato de compresión ZIP y por extensión otros que fueron muy populares por diversas razones en los años 90, como ARC, ZOO, ARJ y por...
macOS Big Sur en un MacBook Pro – Apple Desde hoy, 12 de noviembre de 2020, ya está disponible para su descarga macOS 11 Big Sur. Se trata de la actualización más relevante del sistema operativo de los Macintosh Apple desde que...
Para quienes el código de JavaScript les parezca un galimatías, o simplemente como referencia para tener a mano cual útil chuleta para no tener que estar mirando libros, Operator Lookup es una herramienta ideal. Basta un clic sobre el operador en...

Ya es oficial la tercera transición de plataforma de los Macintosh de Apple: del 68K al PowerPC a los procesadores Intel y ahora a ARM con la presentación de los tres primeros Mac basados en el nuevo procesador M1. Diseñado por Apple,...

La Raspberry Pi 400 es una nueva versión del famoso miniordenador educativo y para cacharreo en «formato teclado», todo en uno; una especie de Raspberry Pi «en formato Commodore», que decía Víctor. Además de su indudable atractivo por un diseño y...
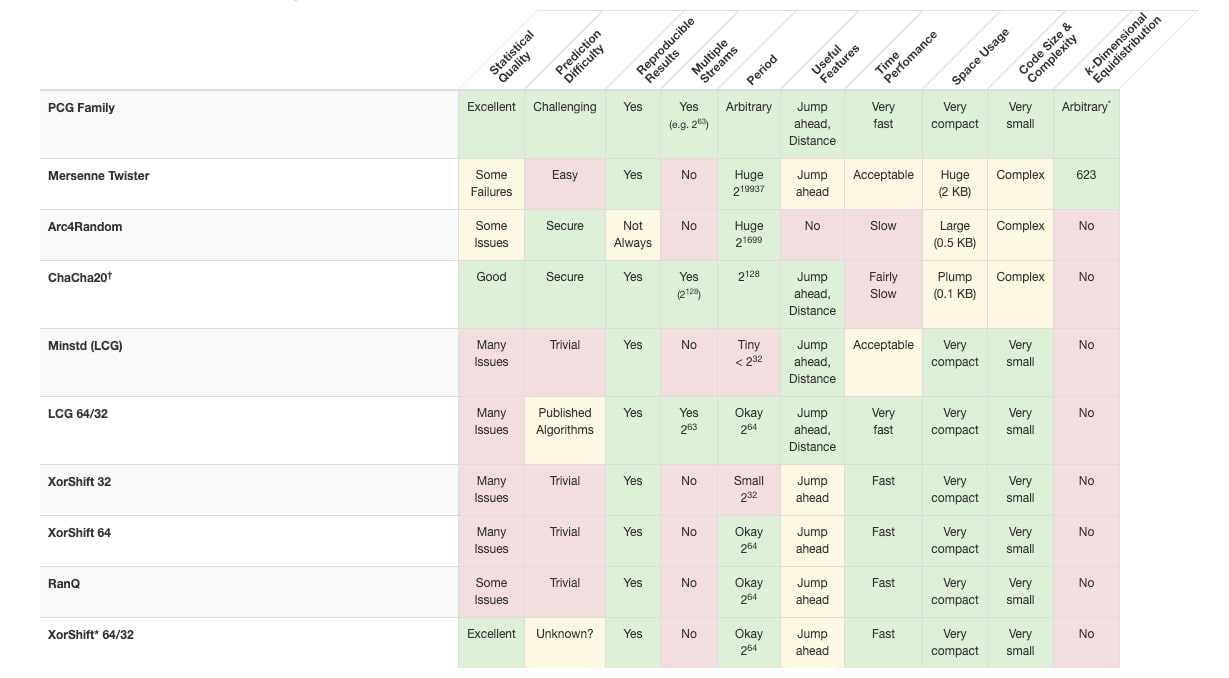
Generar números aleatorios no es fácil para los ordenadores, inherentemente deterministas. Por eso se trabaja en algoritmos que permitan generarlos cumpliendo con diferentes definiciones de aleatoriedad y a la vez ciertas premisas: que no requieran mucha memoria, que el código sea...

En el blog de Damien se analizan algunas Tipografías en 8 bits que además se pueden descargar para utilizar en cualquier diseño o proyecto. Están disponibles en TrueType y otros formatos, en tamaños normalmente de 7 píxeles de altura y 5-7...

En el siempre didáctico canal de Ben Eater, dedicado a la programación en lenguajes de bajo nivel, la electrónica de los procesadores y cosas así encontré este vídeo que muestra cómo es el código máquina resultante de compilar un sencillo programa...

Desde tiempos inmemoriales hackers y programadores han utilizado foo y bar como variables de ejemplo al escribir su código o hablar sobre él. Es lo que «técnicamente» llaman variables metasintácticas: algo para representar entidades desconocidas, sea eso lo que sea. Algo así...
Los más geeks están de fiesta porque el reloj del Tiempo Unix (también llamado Unix timestamp o tiempo POSIX) ha pasado hace nada la barrera de los 1.600.000.000, es decir 1.600 millones o 1,6 millardos, palabreja un tanto artificial que nadie...

Esta herramienta llamada Dungeon Map Doodler es un poco como el Adobe Illustrator de los mapas de juegos de rol: Partiendo de una hoja en blanco ofrece numerosas herramientas para dibujar caminos, pasadizos, estancias y estructuras, con herramientas que ciertamente competirían...
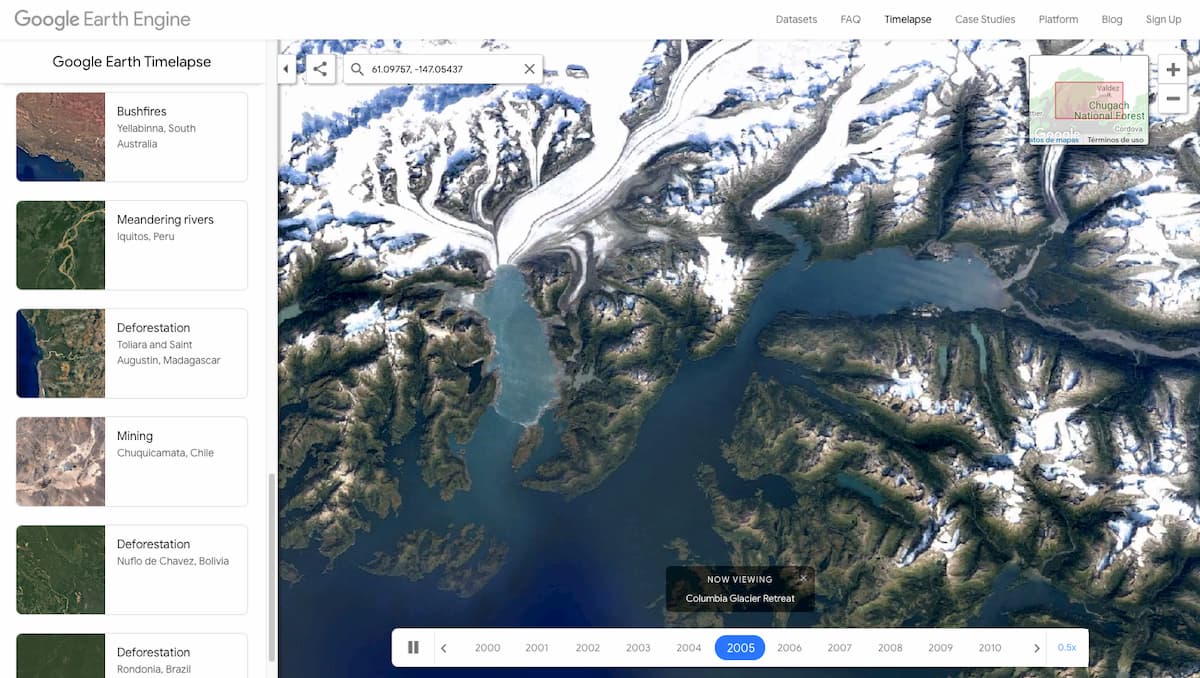
Utilizando el motor de Google Earth Engine han creado una página que guarda una colección de timelapses creados con Google Earth. Son como los timelapses fotográficos habituales pero de un fotograma al siguiente transcurre más o menos un año. Y las...
Salbatore nos escribió para contarnos que él y sus cinco hermanos –eso es devoción familiar por el código– han creado HTML.Systems que no es más que un repositorio de código HTML con componentes de interfaz de páginas HTML. En sus propias...

Esta simulación de fluidos en WebGL es una de esas páginas para perder el tiempo jugando con los botones: se pueden variar todo tipo de detalles y ver cómo se comportan, pulsando el botón Random Splats. Está creada por PavelDoGreat. El...

El equipo de Spectrum, la revista del IEEE ha hecho un gran trabajo con esta recopilación que hacen todos los años en una tabla interactiva: los lenguajes de programación más populares de 2020. Los datos provienen de 8 fuentes distintas que...
Estos mapas de ciudades tan aparentes no son de Google Maps; son de sitios que no existen: está generados mediante algoritmos por procedimientos con el Generador de Ciudades de ProbableTrain. Se trata de una técnica habitual para crear mundos, paisajes, o...
HTML Table Scraper es una aplicación de esas sencillas que hace una sola cosa y la hace bien: extraer datos de tablas de las páginas HTML y exportarlas como hojas de cálculo en formato CSV. Esto evita tener que hacer malabarismos...
Los Web Desktops es la denominación que Simone Marzulli ha dado a una cuidada selección de sitios web que parecen escritorios con diversas interfaces gráficas. Los hay que parecen Windows 1.0, está el conocido WebAmp que imita a WinAmp o una...

Este software que desarrolló Alex Bernstein, un empleado de IBM, allá por 1957, fue el primero en ser considerado un «software de ajedrez completo»: se jugaba en un tablero convencional de 8×8 y con todas las piezas. Aquí podemos ver a...

Face Depixelizer es un interesante invento (basado en otro llamado PULSE) que consiste en regenerar un rostro a partir de una imagen de pocos píxeles. Es algo así como el «sueño de los CSI» y de los guionistas de series y...
Slash\Escape es un juego conversacional de texto creado por Robin Lord, que tiene a las expresiones regulares (RegEx) como protagonistas. Una forma rara de enseñar algo complicado, pero también divertida. Y si manejarte con RegEx no es algo que te entre...
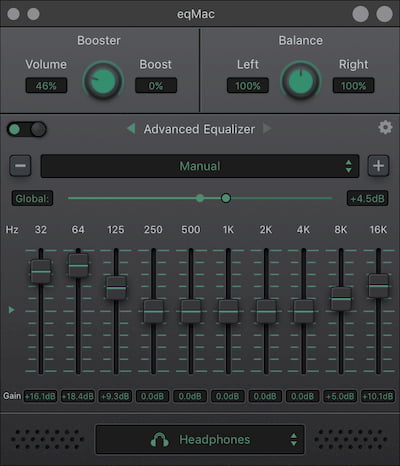
Una pequeña nota para recomendar EqMac para MacOS. Era algo que pasé tiempo buscando a falta de una solución «de sistema» y que hoy he tenido que actualizar manualmente he visto que se ha renovado de nuevo (antes se llamaba EqMac2)....

Hace unos días que fue presentado el informe Sociedad Digital en España 2019 elaborado por la Fundación Telefónica. Es el informe antes conocido como La sociedad de la información en España que viene editándose desde 2012, así que ya tenemos unos...
Mucho se habla de la supremacía cuántica computacional, ese momento en el que «un ordenador cuántico supera al mejor de los superordenadores convencionales resolviendo cierto tipo de problema», como decía Dominic Walliman. Sin embargo, sabemos poco de ella, especialmente cuántos qubits...

Descubrí medio de casualidad por ahí Processing, que se autocalifica como «lenguaje de programación para artistas visuales»: Processing es un software para bocetar y un lenguaje para aprender a programar en el contexto de las artes visuales. Desde 2001, Processing ha...

La colección de retrorecortables de Rocky Bergen Si tienes una impresora en color, un cúter, una regla metálica, pegamento y algún útil extra opcional como la parte roma de la hoja de un cuchillo o incluso piezas de Lego puedes hacer alguno...

Ken Shirriff, de quien conocemos otros proyectos como el estudio del chip de sonido de Space Invaders o el del Intel 8008 se ha entretenido explicar la ingeniería inversa del chip de sonido de la Game Boy Color, la famosa miniconsola...

Lo que se ve en este hackeo frankensteiniano es un Mac OS X Leopard (10.5) corriendo en emulación sobre un iPad Pro de 11" (2020) normal y corriente. Es algo que produce algo a medio camino entre la admiración por el...
La iniciativa colaborativa Folding@Home se está utilizando para investigar el COVID-19 y obtener información científica sobre posibles inhibidores del virus, sus moléculas y cómo actúan las proteínas según cómo se «doblen» en el espacio tridimensional. Es un esfuerzo colectivo que requiere...

En estos tiempos de coronavirus conceptos y objetoss cotidianos que dábamos por supuesto adquieren un valor incalculable (¿papel higiénico? ¿webcams? ¿harina? ¿mascarillas?) y resurgen profesiones y métodos que creíamos ya parte del pasado. En el mundo tecnológico estamos viendo por ejemplo...
Matt Reed decidió que tanta reunión por videoconferencia través de Zoom no era precisamente lo más productivo del mundo, de modo que decidió crear Zoombot, una especie de «gemelo digital» para hacerse pasar por él. El bot utiliza una especie de...

Esta pequeña joya titulada History of Icons recopila toda una historia de los iconos de las interfaces de usuario desde el principio de los tiempos jurásicos de la informática (1981) hasta hace unos años (2015 concretamente). Esta peculiar historia comienza de...

Who Invented the Computer? The Legal Battle That Changed Computing History por Alice Rowe Burks. Versión electrónica por Prometheus Books, 2002. 9,68€. 415 páginas. El 19 de octubre de 1973 el juez Earl R. Larson emitió el veredicto que ponía fin a...
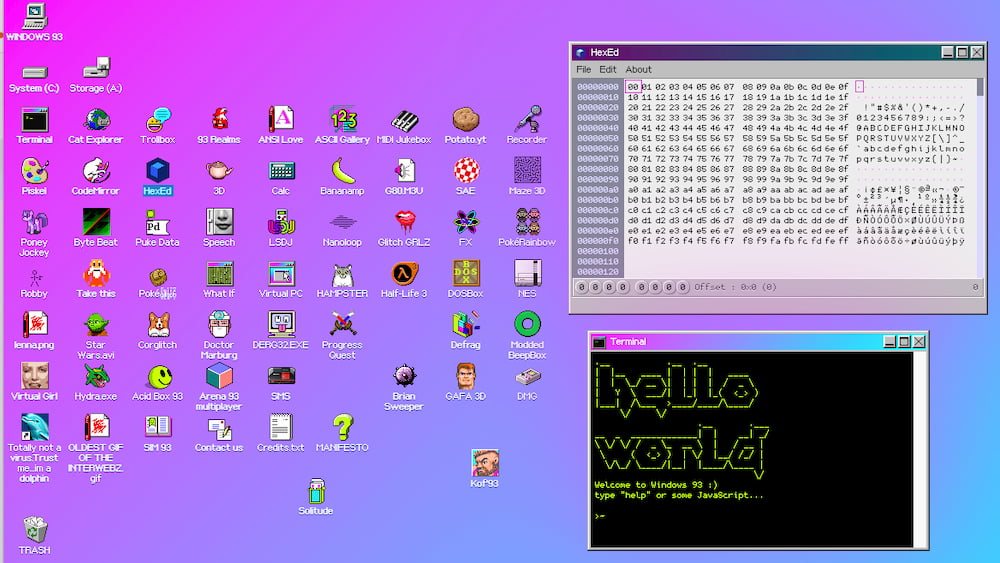
Windows93.net es un curioso entretenimiento experimental obra de Jankenpopp –un músico, artista y hacker– quien ha trabajado en su creación junto con un amplio elenco de hackers que han programado los diversos componentes, diseños, animaciones y música. Es difícil de explicar...

Llevo unas cuantas semanas ya leyendo Who Invented the Computer? The Legal Battle That Changed Computing History. Es un libro en el que se habla del juicio que que en 1973 determinó que John Vincent Atanasoff era el inventor del ordenador...
Larry Tesler Smiles at Whisper - Foto CC BY 2.0 Yahoo Acaba de fallecer Lawrence Gordon Tesler, más conocido como Larry Tesler. Mientras trabajaba como informático en el mítico Xerox PARC implementó, junto con Timothy Mott, las funciones de copiar y pegar...

Cuando después de la Segunda Guerra Mundial empezaron a llegar a la Unión soviética noticias acerca de los primeros ordenadores que iban entrando en servicio algunos científicos soviéticos vieron las enormes posibilidades de estas máquinas y pensaron en empezar a trabajar en...

Se ha dicho miles o millones de veces aquello de que cualquier teléfono móvil actual –en realidad ya desde hace años– es más potente que el ordenador de las naves del programa Apolo*, esas que nos llevaron a la Luna. Pero la...

Esta es la vibrante y emocionante historia de cómo Jonathan Morrison instaló 1,5 terabytes de RAM en su Mac Pro «para ver qué pasaba». La prueba de fuego consistía en abrir miles de pestañas en Chrome, una aplicación legendaria por su...

La Verea Direct Multiplier era un cacharro de unos 26 kilos de peso, 20 centímetros de largo, 13 de ancho y 17,5 de alto - Este ejemplar se lo regaló L. Leland Locke al Museo Smithsoniano Nacido en 1833 en Curantes, una...

Corría el año 1994 y Karl Sims, de la Thinking Machines Corporation, publicó un trabajo titulado Evolving Virtual Creatures [PDF]. En este vídeo del canal que lleva su nombre se puede disfrutar –con calidad muy de programa Metrópolis grabado en VHS–...

La historia de Jack Kilby y Robert Noyce, creadores del transistor: un desafío lógico y una guerra comercial con Japón por la RAM y los microprocesadores, porque innovar no incluye ganar el mercado.
Algunas personas, cuando se enfrentan a ciertos problemas de programación, dicen: “Ya sé. Usaré expresiones regulares”. Entonces tienen dos problemas.– Jamie Zawinski, ingeniero de Netscape (1997) – Me he aprendido la guía telefónica completa.– ¿De memoria?– No, comprendiéndola..– Chiste popular I...
DirtyMarkup, de la gente de 10 Best Design es un «embellecedor» de código que funciona prácticamente con un clic. Se pega el código en la página, se eligen algunas opciones –las que vienen por defecto no están mal– y con un...

JetBrains Mono es una tipografía libre y gratuita pensada para que quienes se dedican al desarrollo y pican código no tengan problemas de legibilidad. Naturalmente es monoespaciada; entre otros detalles están los que se suelen recomendar con ese fin: que se...

Viviendo en el futuro: Claves sobre cómo la tecnología está cambiando nuestro mundo. Enrique Dans. Deusto, 2019. Hace diez años Enrique afirmaba en su primer libro que Todo va a cambiar. Pero en Viviendo en el futuro su argumento es que...
Una novedad reciente en el sector de los navegadores es Edge basado en Chromium (v79), que como es sabido es el código abierto genérico creado originalmente por Google para quienes necesitan desarrollar un navegador web. Como suele decirse, Microsoft al final...

int x; // we want to find the minimum of x and y int y; int r; // the result goes here r = y ^ ((x ^ y) & -(x < y)); // min(x, y) En la página Bit Twiddling Hacks...
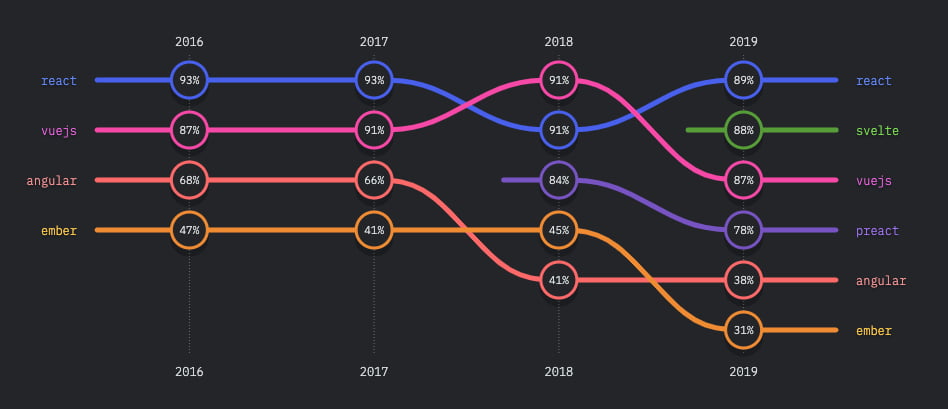
The State of JavaScript 2019 recoge como en otros años el estado del ecosistema de JavaScript, uno de los lenguajes que utilizan los navegadores web y que ya ha cumplido 24 años. El estudio lo hecho Sacha, Raphaël y Amelia y...

Visitar el Computer History Museum de Mountain View (California) debe ser toda una experiencia, pero gracias a YouTube puede ser todavía mejor: hacer la visita guiada con el legendario Steve Wozniak (Woz) de anfitrión contando jugosas batallitas de cada máquina de...

Un posible dispositivo basado en Snapdragon 7c - Qualcomm Otra de las novedades del Snapdragon Tech Summit de 2019 al que nos ha invitado Qualcomm son dos nuevas plataformas para ordenadores siempre encendidos y siempre conectados. Son dispositivos que beben del modo...

Erik Wiffin resume perfectamente en esta página web con el curioso nombre de 0.30000000000000004.com uno de los problemas de la representación matemática de los números en coma flotante que utilizan los ordenadores, o más bien los lenguajes que se usan los...
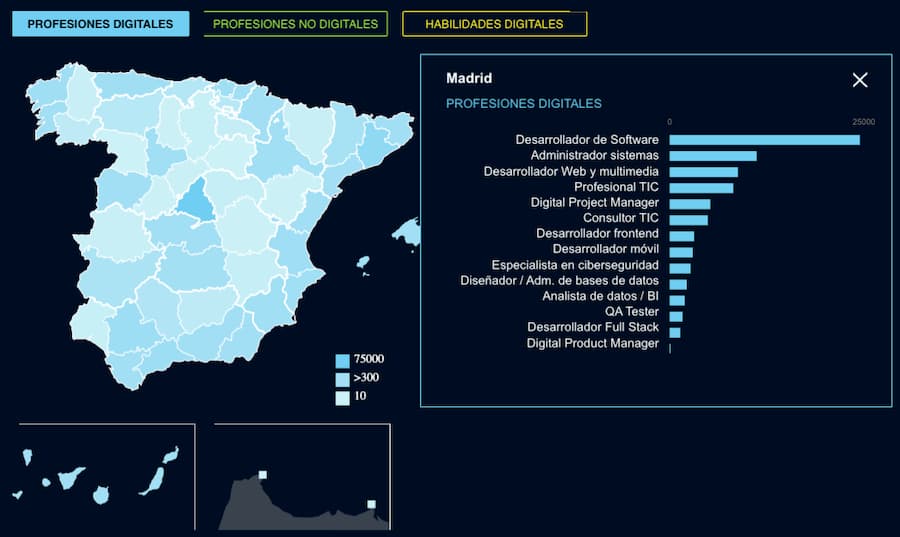
El Mapa del empleo es un análisis que han hecho en la Fundación Telefónica relativo a las profesiones digitales en España en la actualidad. Utiliza datos procedentes de las ofertas de InfoJobs y otras fuentes de los últimos 3 meses. Basta...

Luces, botones y… ¡acción! Este vídeo de arqueología informática de Living Computers muestra un chisme «históricamente significativo» restaurado y funcionando: un PDP-7. Es toda una joya y aunque sea increíble funciona. La máquina data de finales de los años 60; el...
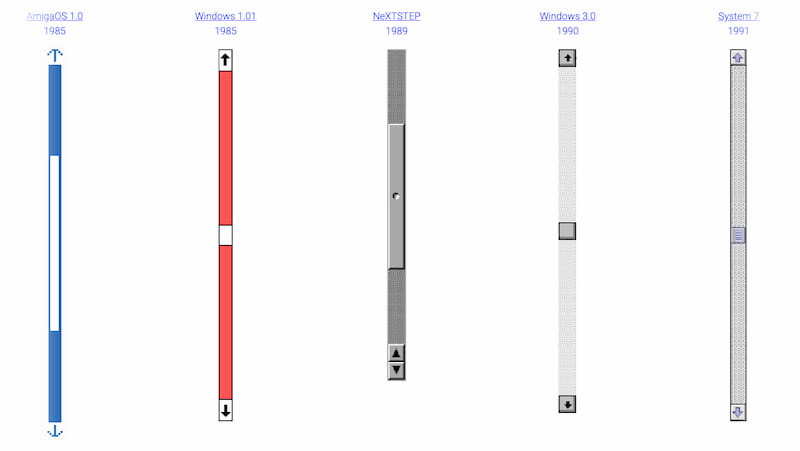
Sébastien Matos ha creado esta curiosa recopilación sobre la evolución de las barras de desplazamiento entre 1981 y 2015. Básicamente se ha recorrido algunas versiones de sistemas operativos con interfaces gráficas, no sólo MacOS y Windows sino también AmigaOS, NeXTSTEP y...

«HTML & CSS & JavaScript & Café & Lágrimas» Esta camiseta que está a la venta en TeeSpring bajo el epígrafe Website Ingredients es una idea de I Am Devloper, un informático que se toma la vida y el trabajo con...

Esta fotografía de un mapa del mundo construido con teclas de autoría desconocida que apareció hace tiempo MapPorn y otros sitios es una auténtica preciosidad. No hay por ningún lado datos sobre cuántas teclas lo componen –y hay una mezcla de...

Quantum Supremacy Using a Programmable Superconducting Processor(Google AI Blog) vs. On “Quantum Supremacy”(IBM Research Blog) Ampliando la noticia sobre el experimento de Google sobre «supremacía cuántica» en un ordenador con 53 qubits de hace un par de semanas, el paper ya se...
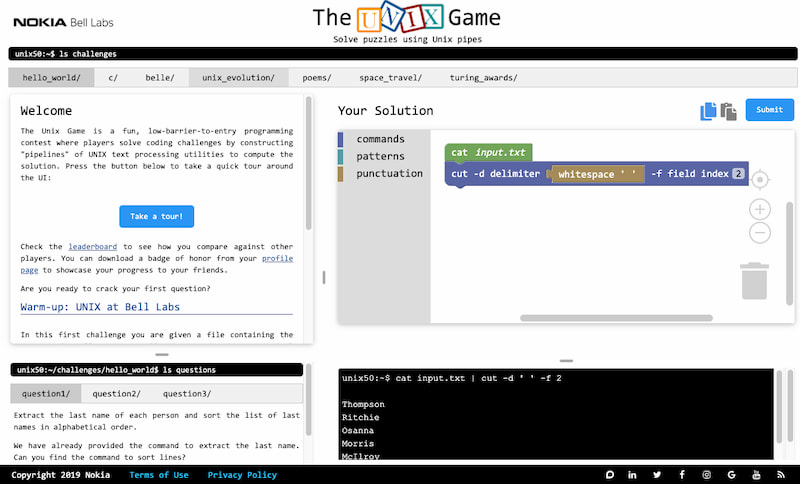
The Unix Game se define como (…) un divertido juego/concurso de programación para principiantes en el que hay que resolver retos de programación encadenando un pipeline de instrucciones de procesos UNIX que tratan los datos (textos) para dar con la solución....
Aprovecho este vídeo de Seeker que me ha parecido una muy buena explicación de la cuestión para anotar algunos enlaces acerca de un asunto que lleva unos días revoloteando: el trabajo que investigadores de Google y la NASA han llevado a...
En estos sarcásticos 30 segundos Jombo nos enseña cuál es la dura realidad de los tutoriales de programación en YouTube. Así, en general, de todos (generalización tan injusta como divertida). Como el locutor habla rápido, prueba a activar los subtítulos (el...
HEAD, del que existe una versión traducida al castellano (HEAD en castellano) es básicamente «una lista de todo lo que podría ir en la cabecera (head) de tu página web». Lo cual incluye elementos obligatorios, otros recomendables y otros opcionales (pero...
Este Generador de Mapas de Mundos de Fantasía de Azgaar es una auténtica preciosidad llena de detalles. Los mapas se generan mediante procedimientos, de modo que el azar permite una gran variación y que no haya dos mundos iguales. Nada más...

Este psicodélico y musical vídeo de Code Parade muestra complejos fractales generados a alta resolución que «reaccionan» al ritmo de la música. Más que una reacción es una acción, porque el código con el que se han generado lo que hace...

Sonic Ether se dedica a crear ambientaciones fotorrealistas para videojuegos en un proyecto que consiste en un shader llamado SEUS. Este vídeo de Minecraft creado su software que emplea técnicas de path tracing/ray tracing y texturas con todo tipo de detalles...

En los tiempos de los dinosaurios informáticos, para ganar velocidad en los discos duros era casi obligatorio utilizar programas desfragmentadores que recolocaban los datos almacenados en los diferentes sectores de modo que se tardara menos al acceder a los ficheros. Una...

Game of Life Cellular Automaton es un simulador del Juego de la vida de John H. Conway en el que se pueden dibujar directamente muchos de los patrones, figuras y «seres» más conocidos con solo elegirlos desde un menú e ir...
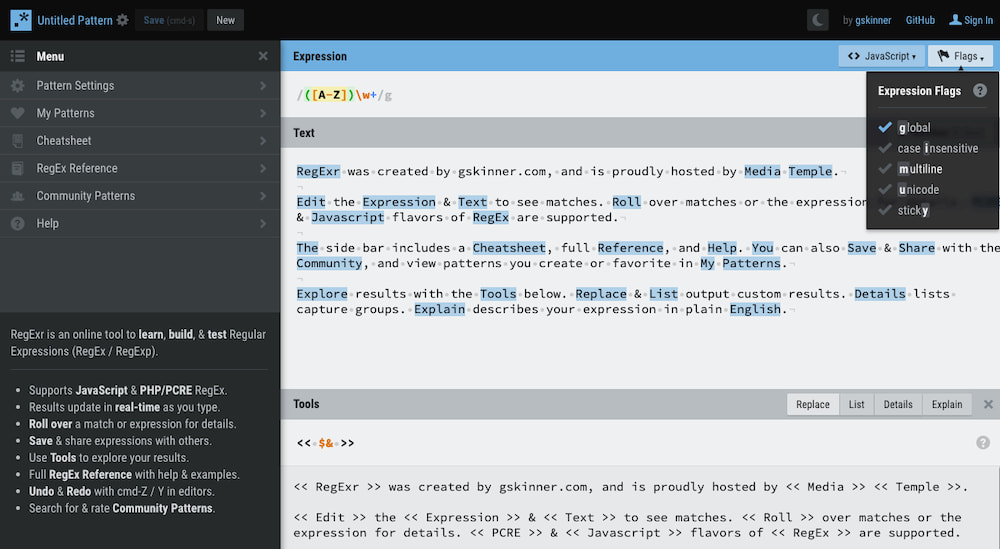
RegExr es una herramienta de gskinner para escribir y comprobar expresiones regulares, esas secuencias un tanto crípticas para los «no iniciados» en la programación, que se utilizan para buscar patrones en cadenas de caracteres. Por ejemplo, para validar una dirección de...
CryptPad es un proyecto de código abierto de la compañía francesa XWiki. Es una especie de suite como la de Google a la que cualquiera puede acceder online sin siquiera registrarse. Incluye procesador de textos, hoja de cálculo (en beta), editor...

Este año debido a eso de las vacaciones se nos pasó felicitar a todos los administradores de sistemas el último viernes de julio, como marca la tradición del Sysadmin Day. Pero para compensarlo he encontrado este divertido tráiler del Día de...
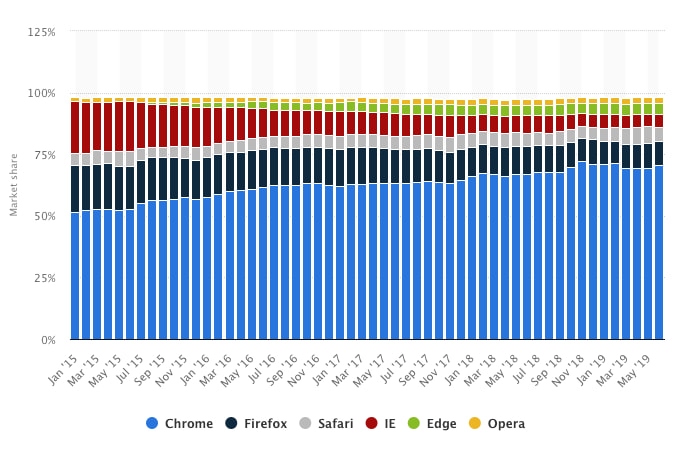
Estaba recordando los tiempos de Netscape y Explorer y cómo había ido evolucionando ese tipo de software desde 1994 cuando me encontré en Statista con un par de interesantes gráficos sobre cómo ha sido la evolución de la cuota de mercado...

Desde el mundillo de los foros del Spectrum llega ChesSkelet, un ajedrez mínimo que compite en tamaño con el mítico ZX-81 Chess, un software de ajedrez cuyo código cabía en 1 KB. En este caso no se trata de jugar bien...
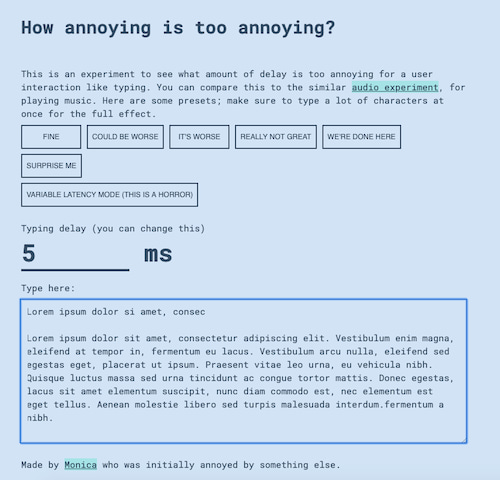
Este experimento de retardo de teclado programado por Monica Dinculescu permite entender táctilmente las diferencias entre tiempos de retardo –medidos en milisegundos– que puede haber al teclear. Esto se da tanto en una comunicación a distancia (usando un terminal, chat o...

El vídeo de Helmes que cuenta es historia hipercomprimida del desarrollo de software y la programación comienza en 1912 con Bertrand Russell y Alfred North Whitehead y sus trabajos sobre la la lógica formal y la teoría de tipos. Luego llegaron...

Simplificando un poco, y con permiso de las personas que se dediquen a la informática presentes en la sala, cualquier ordenador no es más que un conjunto más o menos enorme de interruptores que pueden estar abiertos o cerrados. La combinación...

El único ELEA 9003 que queda - Foto por Elisabetta Mori En los quince o veinte años posteriores a la Segunda Guerra Mundial hubo una ventana de oportunidad en la que los Estados Unidos no tenían por qué haberse convertido en la...

Hack es una fuente tipográfica de Source Foundry con licencia libre, disponible en formatos para OS X, Windows y Linux y con una versión TrueType para web, que se puede ver en acción en su playground. Tiene 1.500 caracteres y glifos...

for (int i = 0; i < foo; i++) { // ... } Me crucé con una viejísima pregunta acerca de por qué en programación se utilizan habitualmente las variables i y j en los bucles. En realidad se puede usar cualquier...

Gustavo no sha escrito para hablarnos de su modelo en miniatura impreso en 3D del Philips VG-8020, un ordenador MSX de los 80. Pero aunque por fuera tenga la forma un VG-8020 dentro lleva una Raspberry Pi 3 Model B+ con...

He estado probando unas bases Wi-Fi Lyra Trio de Asus que nos han prestado y he de decir que son unos de los dispositivos más fáciles de usar que haya probado jamás para montar una red inalámbrica que tenga que cubrir...

Teniendo en cuenta que actualmente se calculan unos 60 trillones de hashes SHA-256 por segundo para minar Bitcoin en todo el mundo, quizá no es aventurado afirmar que puede ser el «algoritmo más popular del mundo».– Matthew Weathers Me ha encantado...

Tras un proceso de recogida de propuestas en las que se recibieron 227.299 nominaciones para un total de TuringBillete50Libras.jpg científicos el Banco de Inglaterra acaba de anunciar que será Alan Turing quien figure en los nuevos billetes de 50 libras. Alan...
Me crucé con AmCharts que es una herramienta para generar código que a su vez genera gráficas de todo tipo en el terreno de la visualización de datos. Esto va desde los diagramas más simples (barras, tartas y demás) a los...

El Chess Programming Wiki (CPW) es un wiki dedicado a la programación del ajedrez. Esto incluye tanto información sobre algoritmos como acerca de detalles de los que normalmente no se comentan mucho al hablar de software de ajedrez: formas de representar...

En C++ Bitmap Library se recogen decenas de algoritmos «simples, robustos y optimizados» para imágenes bitmap de 24 bits, que además pueden portarse fácilmente a otros lenguajes porque son bastante autoexplicativos y están comentados. Son obra de Arash Partow, informático especializado...
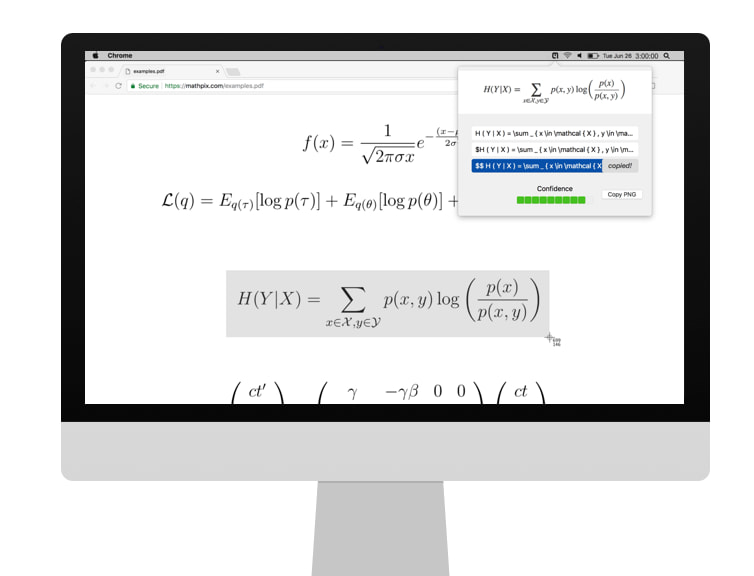
Mathpix [Mac OS, Windows, Linux] es una utilidad que sirve para convertir las ecuaciones que se ven en pantalla en código LaTeX, el lenguaje / sistema de composición de textos que todo el mundo utiliza para los trabajos científicos. Utilizarlo es...

De forma un tanto inesperada aunque no del todo sorprendente parece que el microordenador familiar C64 va a tener una «nueva vida» en forma de réplica del original. A escala 1:1 y con toda la funcionalidad del original (y más), un...

Ya está a la venta la Raspberry Pi 4 Model B, una nueva versión renovada del «ordenador en una placa de tamaño reducido» que es mucho más potente que las anteriores y mantiene un precio razonable (unos 35 dólares, algo más...

En este tutorial del Wall Street Journal Jon Cinkay, un experto en ergonomía, explica cómo se coloca correctamente una silla de trabajo, la mesa, la pantalla (o pantallas), el teclado y el ratón. Aunque se indican algunas medidas (en pulgadas, multiplicar...
Un equipo de Adobe Research y de la UC Berkeley han publicado un artículo acerca de una técnica para detectar manipulaciones faciales en Photoshop. Básicamente se aplica un algoritmo sobre una foto de una persona y confirma si ha sido manipulada...
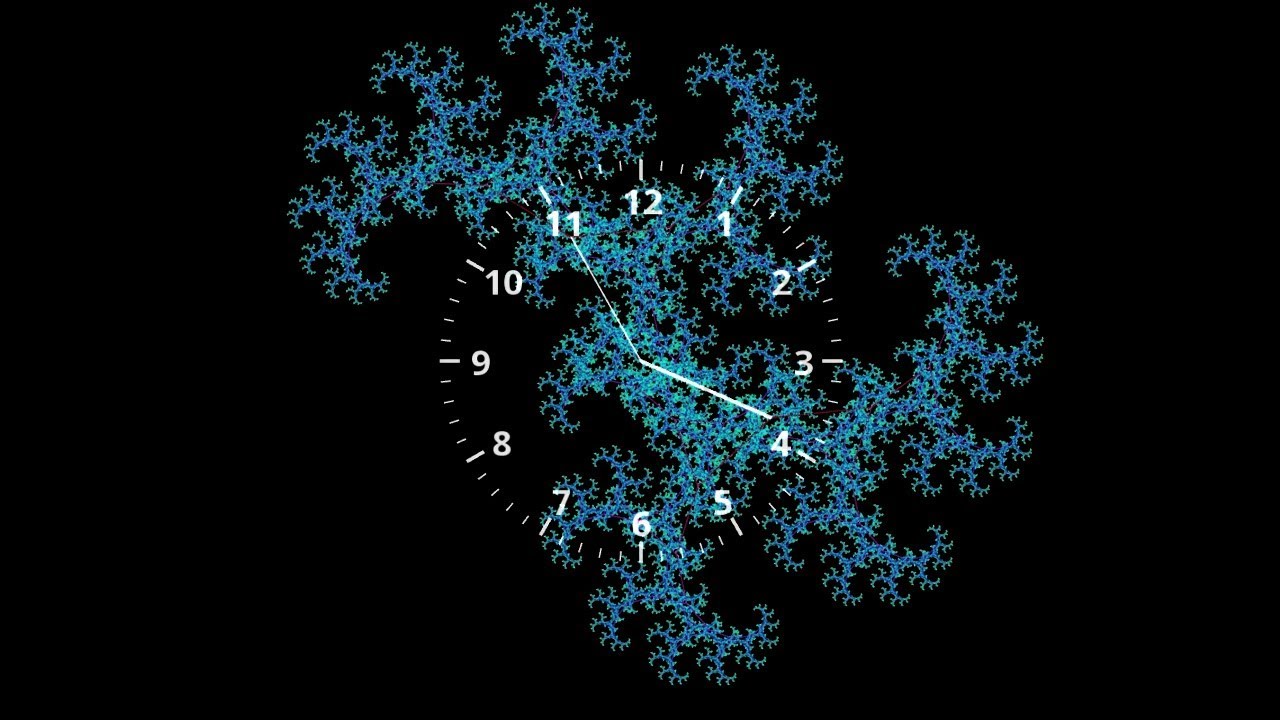
Las manecillas de este reloj son fractales: al final de cada una de ellas están copiadas y copiadas de nuevo de forma recursiva, pero cada vez un poco más pequeñas (al 70% en cada iteración, exactamente). Cuando las manecillas se mueven...

La gente de la Escuela Superior de Comunicación, Imagen y Sonido (CEV) nos ha avisado de que mañana jueves 13 de junio y la semana que viene realizarán unos «webinarios» o sesiones informativas online acerca de sus titulaciones oficiales. Allí se explican...

La vacalculadora (Cowculator) [manual en PDF] fue un curioso invento del que no se puede siquiera encontrar mucha información en Internet y que consiste en una especie de primitivo ordenador analógico para calcular cosas acerca de las vacas lecheras. Por suerte...

Nuestra admirada Ada Lovelace, la primera programadora de la historia, aunque mucho más allá de eso fue la primera persona en darse cuenta de los enormes cambios sociales que podían traer los ordenadores, busca hacerse un hueco en la Colección Científicos....

En la última Maker Faire un equipo de hackers enseñó este proyecto consistente en un circuito integrado gigante ideado para explicar a los más pequeños cómo funciona este tipo de componentes electrónicos. El montaje es una gigantesca placa de material acrílico...
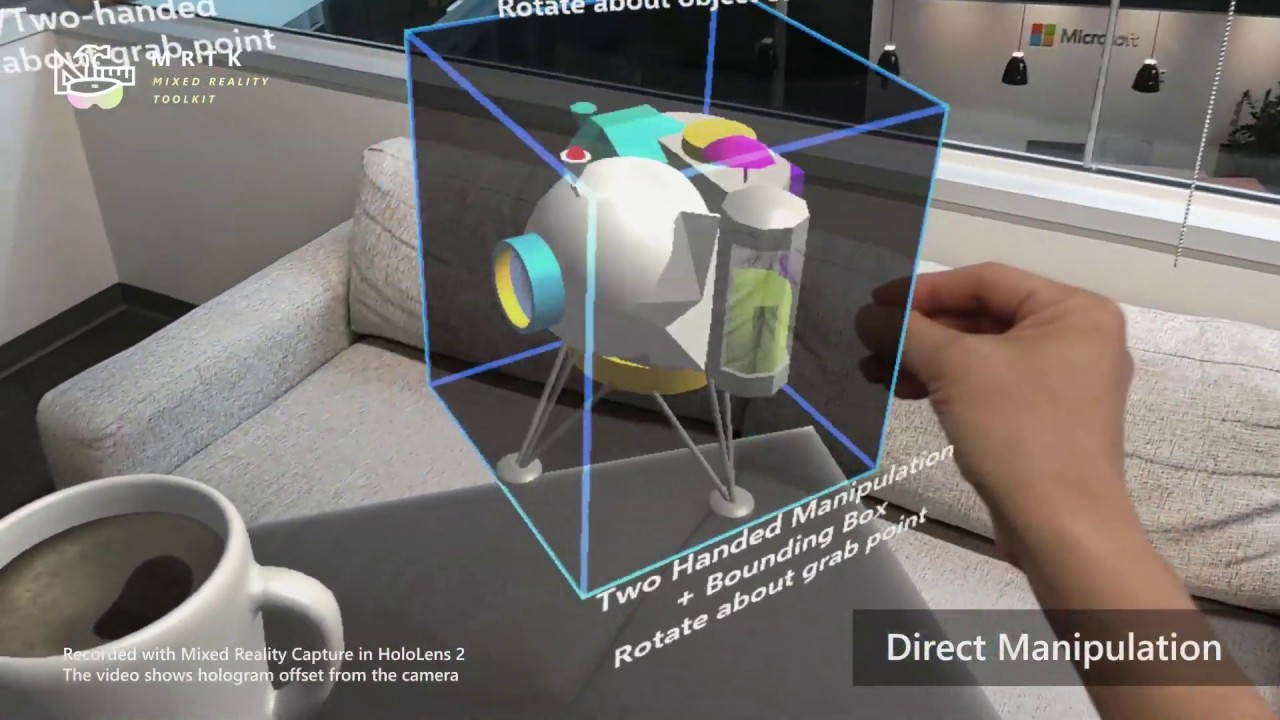
En este vídeo se puede ver el Mixed Reality Toolkit de Microsoft, una herramienta de software con distintos elementos de interfaz: botones, teclas, objetos 3-D y otros. El código está disponible en Github; funciona con el motor Unity 3D. De este...

Zoe ha inventado el WebTuner, una forma de hacer más cómodo (o no) algo tan habitual como cambiar de pestaña en el navegador. El invento es una rueda mecánica, como las de los mandos de sintonía de una radio analógica, que...

Esta maravilla de Omar Shehata titulada Unraveling the JPEG es un despiece absolutamente fascinante byte a byte de un fichero que contiene una fotografía JPEG con uno de los temas favoritos de Internet: un gato. Lo que ha hecho Shehata es...

The Augmentation of Douglas Engelbart (2019) es una documental de Daniel Silveira acerca de uno de los pioneros de la informática, visionario e inventor del ratón entre otras cosas. Fue una de las personas que realizó la primera demostración de una...

La evolución de las animación de imágenes generadas por ordenador (más conocidas simplemente como CGI) abarca ya tantas décadas como los ordenadores mismos. Se han usado en el mundo del entretenimiento para películas, series de televisión, documentales, videojuegos, anuncios y con...
Nuestro arqueólogo digital favorito, Jason Scott; ha subido a una zona de Github bajo el título de Historial Source el código fuente de diversas aventuras conversacionales de Infocom, la famosa expresa de software especializada en esos mundos imaginarios en los que...

Me encontré por ahí Redirect Path que es una sencilla extensión de Chrome que hace lo que cabría esperar: indicar de forma visible los saltos en forma de redirecciones que se han seguido hasta llegar a la página web que se...

Este pequeño cortometraje de animación 3D dirigido por Andy Goralczyk titulado Spring es tanto una pequeña historia de «fantasía poética» como una demostración de poderío. Está creado con Blender 2.8, la última versión del popular software de 3-D. Parte de la...

Tal y como cuenta Addy Osmani, ingeniero de Google Chrome, se está trabajando ya para incluir la carga diferida (lazy loading) de forma nativa en el navegador web a partir de la versión 75 (más o menos). Esta función es fácil...

Bajo el nombre de Lego Education Spike Prime Set el fabricante de juegos de piezas de construcción va a comercializar un kit educativo consistente en robots que se arman con piezas y que se pueden controlar programando en Scratch, el popular...

Microsoft y la Universidad de Washington están investigando y realizando demostraciones de un sistema automático para almacenar y recuperar datos en moléculas «fabricadas» con ADN. En un trabajo publicado en Nature Scientific Reports se explica en detalle sobre el proceso (Demonstration...

OpenDroneMap es un proyecto de código libre para procesar imágenes capturadas por drones y convertirlas en mapas. Esto que algo que suele hacerse con herramientas profesionales y normalmente caras, incluyendo nubes de puntos, ortofotos, modelos de elevación digital… Con este software...

Cuando los ordenadores modernos –ejem por lo de «modernos»– comenzaron a usarse para tareas civiles importantes como era ayudar en el control de tráfico aéreo la seguridad era la prioridad ante todo. En el año 1971 un ordenador especializado IBM 9020...
Este invento de la gente de Nvidia se llama GauGAN y básicamente es una herramienta estilo Paint que utiliza aprendizaje profundo para generar imágenes fotorrealistas (o artísticas) a partir de una paleta de palabras, colores y bocetos. Dicho en palabras llanas:...

Aprovechando el Día de pi se ha anunciado que Emma Haruka ha batido el récord de cálculo de dígitos de pi. En el blog de Google –donde trabaja– explica cuál ha sido su «receta» para conseguirlo. No es tarea trivial, porque...
¡Ah, el elusivo azar! Qué malos somos los humanos intentando emularlo. El caso es que me encontré con Not So Random («No tan aleatorio») es un experimento interactivo inspirado en el oráculo de Aaronson: el ordenador «adivina» qué teclas vas a...
Esta interesante herramienta llamada Polygonia Design Suite estaba originalmente pensada para crear diseños poligonales y patrones para plóteres de corte principalmente, pero también impresoras 3D. Ha ido creciendo y creciendo, hasta convertirse en un proyecto más allá del hobby. Sin duda...
En el vídeo, el navegador de la izquierda es un navegador Chrome normal y corriente; el de la derecha utiliza un sistema experimental de caché back/forward (bfcache) que hace que al usar los botones atrás/adelante del navegador la respuesta sea instantánea....

Lorenzo Herrera, un apasionado del cacharreo y una de esas personas que tuvieron como primer ordenador está detrás del Commodore PET Mini, una reproducción en miniatura de uno de los microordenadores más míticos de la historia. En concreto reproduce un PET...

¿Cómo reconoce una máquina un rostro? ¿Qué detalles concretos busca y cómo los distingue? ¿De qué depende que se pueda reconocer a una persona concreta entre miles en una fotografía? Son cuestiones que quien más quien menos se ha preguntado alguna...

Por alguna razón esté vídeo de la sección How It’s Made de Science Channel sobre el proceso industrial de fabricación de un portátil resulta extremandamente satisfactorio. Básicamente muestra el trabajo de montaje de los componentes de un portátil de gaming «cualquiera»...
MailtoLink.me es un elegante generador de enlaces mailto: viene a ser una forma intuitiva y sencilla a la par que bonita de preparar el código HTML la que se utiliza para abrir un correo con todos sus detalles. Esto es lo...

Clive Thompson repasa en un larguísimo artículo titulado The Secret History of Women in Coding para el New York Times la historia de las mujeres programadoras, desde Ada Lovelace y otras pioneras hasta nuestros tiempos, especialmente a cómo se ha ido...

Este sistema graba los datos de todos los componentes y le dice al ordenador principal de la Estación Espacial que «no está ardiendo» una vez por segundo, porque es muy importante no estar ardiendo en el espacio (…) Perdonadme que insista...
En Programming Fonts hay más de 50 fuentes tipográficas apropiadas para el uso en editores de código fuente. Cada una está enlazada con las páginas originales en las que pueden descargarse. Y lo mejor de todo: son gratis. Que no se...

Empantallados acaba de presentar el informe El impacto de las pantallas en la vida familiar, un estudio realizado por GAD3 para ellos que saca sus datos de una encuesta anónima a más de 1.400 hogares en los que hay hijos de menos...

La idea tras Script-8, una creación de Gabriel Florit, es interesante: un sitio en el que crear juegos retro al estilo de los 8 bits, en código abierto, con solo utilizar JavaScript. Los juegos se llaman, apropiadamente, cassettes y se pueden...

La inteligencia artificial es, en mi opinión, un término del que se abusa enormemente, ya que muy raramente se explica que hay que empezar por diferenciar entre la IA dura y la IA blanda. Una IA dura es la de un...
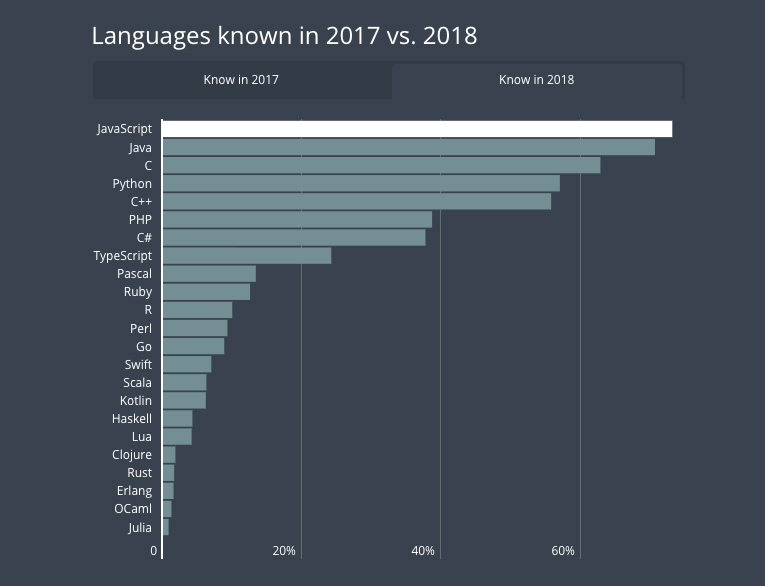
Entre las diversas «habilidades de los desarrolladores» se incluyen principalmente los lenguajes de programación que dominan. Según una encuesta de HackerRank en la que entrevistaron a unos 71.000 desarrolladores de más de 100 países, JavaScript ya es el lenguaje de programación...

En este vídeo de Vox Media se explica por qué las imágenes de los videojuegos están construidas con triángulos, aunque no se note, o al menos no la mayor parte de las veces. La razón es que para visualizar los objetos...
La geometría no euclidiana suele hacer que los objetos y formas geométricas se comporten de forma bastante rara, más que nada porque incumplen algunos de los postulados de los Elementos de Euclides: la suma de los tres ángulos de un triángulo...
Mariko Kosaka ha publicado en el área de desarrolladores de Google este interesante curso en cuatro partes titulado Un vistazo al interior de un navegador web moderno (en este caso: Chrome) en el que con dibujos explica lo que sucede entre...

El 27 de febrero de 2013 –200 días marcianos después de haber llegado a Marte– el ordenador A del rover Curiosity falló. Pero la misión pudo seguir adelante porque el vehículo dispone de dos ordenadores gemelos precisamente por si falla uno...
Desde el departamento de Maravillas de los cálculos en coma flotante nos llega esta sencilla y curiosa pregunta: ¿Qué resultado da como respuesta tu lenguaje de programación favorito a este cálculo? 9999999999999999,0 - 9999999999999998,0 = Las respuestas posibles van desde el 1...

Entre 1959 y 1989 la Unión Soviética intentó construir varias redes de ordenadores que conectaran todo el país, un poco al estilo de lo que la Arpanet estaba siendo para los Estados Unidos. Pero todos y cada uno de esos intentos...

La increíble mujer invisible es una charla de Lorena Fernandez en la que habla de las muchas mujeres que a lo largo de la historia han llevado a cabo trabajos o investigaciones extraordinarias. Especialmente en el campo de la ciencia y...

Del tuit de Jon Erlichman: Facebook – Febrero de 2004. Google Maps – Febrero de 2005. YouTube – Febrero de 2005. Twitter – Marzo de 2006. Waze – Mayo de 2006. Netflix en streaming – Febrero de 2007. Fitbit – marzo...

Codrops ha recopilado las demos más asombrosas de 2018, una lista que enlaza a un montón de experimentos visuales e interactivos con figuras 2D y 3D que funcionan directamente en el navegador. Al ser algo experimental se necesita un «navegador moderno»;...

Hoy en dia prácticamente no concebimos el uso de ordenadores si no es mediante interfaces gráficos con ventanas, iconos, ratón y puntero. Pero hace 50 años eran una idea revolucionaria que Douglas Engelbart y su equipo presentaron el 9 de diciembre...

Chris Anderson, conocido por haber sido durante mucho tiempo el director de Wired y por haber popularizado el concepto de la larga cola, hablaba hace unos días de cinco tecnologías que el creyó que lo iba a petar y estar en...

Las buenas noticias son que es bastante improbable que algún objeto del espacio exterior impacte contra la Tierra. Así que estamos seguros. Por ahora.– Gema Parreño Gema Parreño protagoniza este vídeo de Google en el que explica que se dedica a...
Aunque parezca de verdad esta recreación de un anuncio viejuno de revista de informática de papel (¡qué tiempos!) es cómo queda el recortable de Commodore 64 de Rocky Bergen. Basta descargar el PDF, imprimirlo en papel de buen gramaje y usar...
MarbleComplete es un poco difícil de explicar y resumir, pero básicamente podríamos decir es código para construir y simular circuitos de carreras de canicas con dibujos en código ASCII que tienen la propiedad de ser un sistema Turing completo. Según he...
En un artículo titulado Inside a super fast CSS engine: Quantum CSS (aka Stylo) uno de los ingenieros de Mozilla explicaba el año pasado cómo es por dentro un motor CSS desarrollado para Firefox, lo que llamaron Project Quantum. En la...

Esta encantadora maravilla para los ojos –y el tacto, supongo– combina lo mejor de dos mundos: Lego + Commodore. Se llama Brixty Four y es parte del Ideas Lego, donde la gente vota ideas de aficionados y si son muy populares...

Nos enviaron para probar una Unidad Dual USB Tipo C de 32 GB de SanDisk que básicamente un pendrive USB, de diseño sencillo y elegante aunque con algunas particularidades. El primero es que tiene dos conectores físicos: un USB Tipo A...

Aunque Logitech no lo pone en ningún sitio su mando a distancia R400 funciona sin problemas con un Mac y PowerPoint. Pero si lo quieres usar con Keynote la cosa se complica porque aunque los botones de avanzar y retroceder funcionan perfectamente...

Wave Function Collapse es un experimento de generación de escenarios mediante procedimientos mediante un algoritmo de cuántico nombre («colapso de la función de onda»). Se parece un poco a la Infinitown. Aunque al ser más bien monocroma y con patrones más...
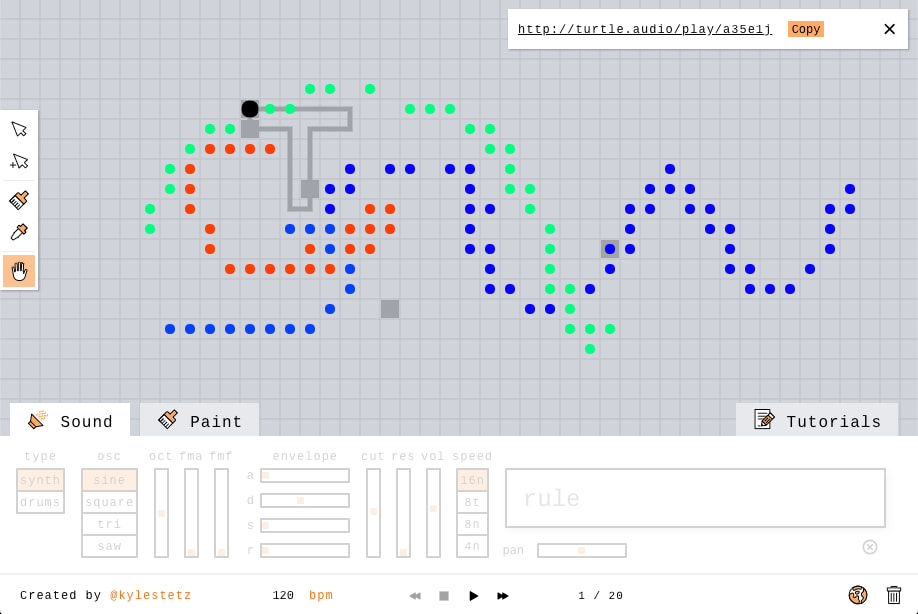
Turtle.Audio es una simpática creación de Kyle Stetz: una idea medio experimento, medio-auténtico lenguaje de programación musical-visual. Recuerda poderosamente al lenguaje Logo por aquello de la tortuga y las reglas simples. En la retícula de la pantalla se pueden dibujar notas...

Hasta ahora habíamos visto documentales dedicados a empresas de Silicon Valley, software –pero generalmente videojuegos– (Nibbler, Donkey Kong, Tetris) o sistemas operativos (Linux). Ahora Radley Olsen ha ido un paso más allá con Off the Tracks, un documental de entrevistas sobre...

Encontré este vídeo de Coding Tech donde Talia Gershon de IBM explica en un cuarto de hora bastantes cosas interesantes sobre computación cuántica. Me gustó sobre todo porque es fácil de entender y porque cubre todos los niveles. En la primera...

Puntero, cursor, flecha… De todas estas formas –y seguramente algunas más– se llama al indicador del ratón en la pantalla. Algo que nos ha acompañado desde 1968 cuando Engelbart lo dio a conocer al mundo en la madre de todas las...
Photopea es una creación de Ivan Kutskir, un programador de la República Checa que ha dedicado su «tiempo libre» (7.000 horas de nada, mientras estudiaba informática) a esta versión clonada de Photoshop que funciona en línea en el navegador web. Su...

[El vídeo empieza realmente en 03:50] Rob Pike es uno de los pioneros del software que trabajó en el Computing Science Research Group de los Laboratorios Bell en el desarrollo del sistema operativo Unix. Empezó en los tiempos más duro de...

En el siempre interesante The Microscopic Channel probaron a amplificar con un microscopio electrónico un antiguo Compact Disc con diversos niveles de aumentos. Los CD de música y los CD-ROM eran básicamente todos iguales (los DVD y Blu-rays son un poco...

Alan Turing fue una de las personas al frente del trabajo de intercepción de los mensajes cifrados de las fuerzas armadas alemanas llevados a cabo en Bletchley Park durante la segunda guerra mundial. Se estima que el éxito de ese trabajo permitió...

En Make a Website Hub han puesto al día y ampliado una de las chuletas favoritas de quienes utilizan software de Adobe: The Ultimate 2018 Adobe Creative Cloud Keyboard Shortcuts Cheat Sheet. Incluye atajos de teclado para Photoshop, Illustrator, Indesign, Premiere...

Me encontré por casualidad con uno de estos vídeos de microchips vistos a través de potentes microscopios y la verdad es que resultan fascinantes. Después de ver unos cuantos he seleccionado algunos de ellos que creo son más representativos de esta...

Paul Gardner Allen (1953-2018) fue un empresario, inversor y filántropo especialmente conocido por ser el cofundador de Microsoft junto con Bill Gates. Ambos se conocieron en la escuela Lakeside en su juventud y compartieron la pasión por los ordenadores; en ese...

Have you ever wondered how mirrors are possible in video games?(Turn sound on)pic.twitter.com/oMbXzPxXkD— Machinima (@Machinima) 6 de septiembre de 2018 En este vídeo que Machinima ha publicado en Twitter y Facebook se explican las tres formas que se suelen emplear en los...

Microsoft ha publicado bajo una licencia MIT/OSI y «para propósitos de referencia» el código fuente de MS-DOS 1.25 y 2.0 en Github, que básicamente son las mismas que ya publicaron en el Computer History Museum hace unos años, solo que en...

Nacida el 10 de diciembre de 1815, Ada Lovelace es considerada la primera programadora de la historia por su Nota G, un añadido a un artículo sobre la Máquina Analítica de Charles Babbage escrito por el ingeniero italiano Luigi Menabrea que ella...
Pyxel es código abierto y está en Github para quien quiera utilizarlo para crear en Python juegos retro al estilo más viejuno. Además, siguiendo aquella máxima que afirmaba que «las limitaciones son la fuente de la creatividad» Pyxel sólo permite pantallas...

Reemplazar una batería de Macbook Air paso a paso, un buen tutorial de IFixIt Hace unos días me llevé la desagradable sorpresa de encontrarme el Macbook Air «inflado»: la tapa cerraba mal y las teclas parecía que se fueran a salir; incluso...

Paper Programs podría considerarse una oda a la complejidad innecesaria, pero también es sumamente bonito, divertido y hackeable. Es un invento –por llamarlo de algún modo– de JP de Dynamicland. Funciona con un proyector, una cámara y hojas de impresora en...
Este curioso juego llamado JavaScript Equality Table Game sirve tanto para pasar un rato de diversión como para repasar / aprender las bases de JavaScript, en concreto el operador == (igualdad) y cómo lo gestiona el intérprete internamente. El operador ==...

Hace un tiempo contamos algo sobre la historia de General Magic, con motivo del documental que se estrenó sobre la compañía en el Tribeca Film Festival. Hoy me he topado con el vídeo de la primera demostración pública de Magic Cap,...

Este verano la compañía de computación cuántica Rigetti anunció sus avances en un chip de 128 qubits (récord), superando así al de 72 bits de Google. El chisme está compuesto de 16 pucks como el de la foto, conectados de forma...
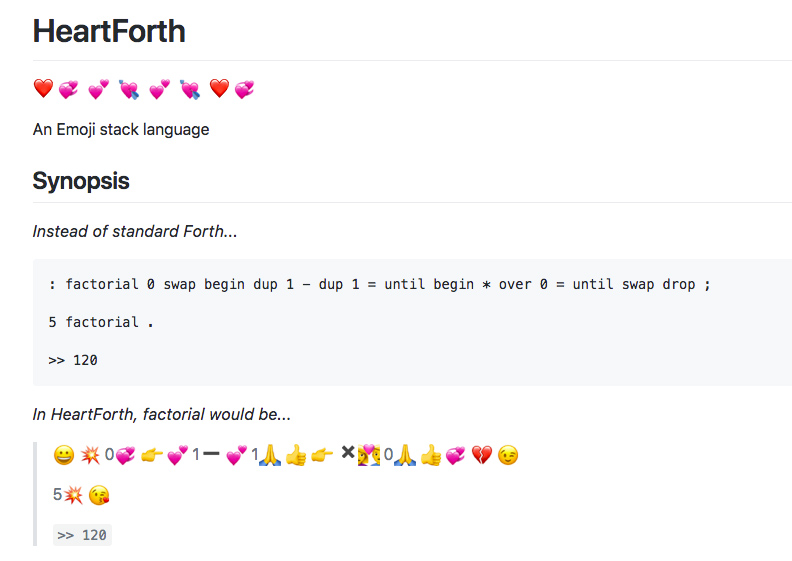
Desde el departamento de lenguajes de programación raros, raros nos llega esta mención al HeartForth, una idea de Neil Kandalgaonkar que básicamente se trata de una versión simplificada del Forth en la que las instrucciones han sido reemplazadas por los emojis...

Richard J. Ridel construyó esta máquina de Turing en madera, dispositivo para manipular símbolos sobre una cinta según unas reglas, que pese a su sencillez puede simular la lógica de cualquier ordenador – ingenio increíblemente importante aunque no muy práctico porque...

Sólo son unos pocos acordes, pero fácilmente identificables y muy característicos. Tras esta aparente simplicidad lo que pocas personas saben es todo el trabajo que llevan detrás, algo que desvela Matthew Bennet en este pequeño vídeo de los Microsoft Story Labs....

La Brand New Roman es una tipografía en la que cada letra es realidad una marca o producto bien reconocible. Ahí está la A de Adobe (y la a de Amazon), la G de Google o la M de Monster. La...

No sé si será la primera vez, pero desde luego que es muy notable la aparición de una publicación científica sobre el software utilizado para una película de ciencia ficción. Se titula Gravitational Lensing by Spinning Black Holes in Astrophysics, and...

Este pequeño proyecto de Throwboy buscaba algo de dinero para unos diseños muy peculiares: The Iconic Pillow Collection. La cosa escaló rápidamente y ahora que se la ido de las manos en vez de los 10.000 dólares que buscaba lleva 50.000...
En este vídeo de Jon Masters, ingeniero de Red Hat, se explica de forma técnica pero accesible –para quien tenga los conocimientos mínimos necesarios, claro– el problema que supone la nueva vulnerabilidad de seguridad llamada L1 Terminal Fault (L1TF) que permite...
Mike Bostrock tiene este algoritmo de Prim que trabaja sobre un conjunto de puntos aletatorios en el plano. Matemáticamente, el árbol recubridor mínimo (minimum spanning tree) es un grafo en forma de árbol que contiene todos los vértices – y los...

En Bootable CD + retro game in a tweet, Alok Menghrajani, ingeniero de seguridad en Square, explica con detalle cómo codificar una imagen ISO de disco (en formato CD-ROM) que puede inicializarse y desde el cual se puede ejecutar un vídeojuego...
Por Nacho Palou -
2 AGO 2018

Toshiba nos hizo llegar para pruebas un portátil Tecra Z50 de 15,6 pulgadas, que he estado utilizando junto con mis otros equipos durante unas cuantas semanas para ver su comportamiento en el día a día. Se trata de uno de los...

Hay un consenso más o menos generalizado en que el ENIAC es el primer ordenador de la historia, aunque le faltaban algunas cosas para terminar de parecerse a un ordenador actual, como por ejemplo que no podía cargar sus programas en...

El emperador Akihito de Japón ha anunciado que va a abdicar en su hijo Naruhito el 30 de abril de 2019. Entre otras cosas esto pondrá fin a la era Heisei y hará que el 1 de mayo de 2019 comience una...
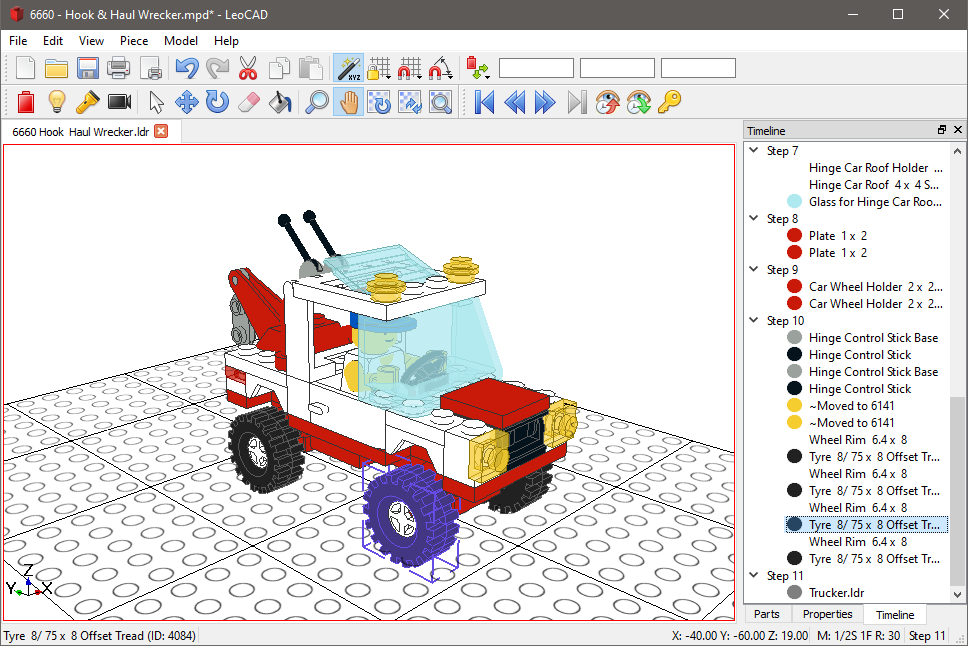
El programa para ordenador LeoCAD, disponible para macOS, Windows y Linux, permite construir modelos virtuales de Lego en 3D de forma parecida a cómo se haría en el mundo real y utilizando un catálogo de piezas que contiene más de 10.000...
Por Nacho Palou -
18 JUL 2018

Desde el Tribeca Film Festival llega el prometedor tráiler de General Magic, un documental sobre una de las más extrañas y a la vez desconocidas startups de Silicon Valley, sin la que no existirían muchas de las cosas que hoy damos...

En esta nueva entrega de los vídeos de los abuelos cebolleta de la informática se puede experimentar durante más de diez minutos la (literalmente) más tediosa forma de introducir un programa en el IBM 1401: girando ruedecitas y pulsando interruptores a...

Esta maravilla fabricada por Richard Brewster que muestran en Spectrum es una recreación del primer flip-flop (biestable), uno de los circuitos básicos más importantes de la electrónica digital, que ahora cumple un siglo. Tal y como indica su nombre, es un...
Holly Cummins ha terminado de publicar una serie de tres artículos titulada Cats, Qubits, and Teleportation: The Spooky World of … (Gatos, qubits y teleportación) en InfoQ en la que explica de forma breve y bastante concisa todo lo básico que...

Este mundo de criaturas matemáticas se llama Lenia (del latín lenis, «suave»). Según Bert Chan, su creador, Lenia es un autómata celular de estados continuos en un espaciotiempo continuo. Como en otros autómatas celulares surge en él toda una inesperada (bio)diversidad...

Roland Meertens ha ideado un método para pintar cuadros con colores usando números primos. Y la verdad es que el resultado –y el método– es la mar de interesante. Además en su web está el código para hacerlo y para comprobar...

Según datos de StatCounter el navegador web Chrome de Google tiene cerca del 59 por ciento del mercado de navegadores. "Gracias a que sus plug-ins funcionan limpiamente, a su facilidad de uso y a que está respaldado por Google no es...
Por Nacho Palou -
10 JUL 2018

En los años 80 la BBC y el gobierno británico tenían tan clara la importancia que iban a tener los microordenadores en el futuro que no sólo dedicaron montones de programas al asunto sino que también encargaron el diseño de un ordenador,...

El primer ordenador transportable de IBM, el IBM 5100, sólo "pesa 22 Kg y lo puedes enchufar en cualquier parte", una característica muy positiva en el contexto de un época en la que hacían falta varias personas para mover los ordenadores...
Por Nacho Palou -
3 JUL 2018
Trazando el perímetro del parque de El Retiro más o menos rápido sobre Google Earth arroja una superficie de 1,17 km². La cifra "oficial" es de 1,18 km² — así que bien. La posibilidad de medir distancias y áreas ha tardado en...
Por Nacho Palou -
26 JUN 2018

Desde enero se vienen publicando noticias un tanto llamativas sobre la escasez de GPUs de Nvidia, una de las marcas punteras y mejor valoradas del mundo de los PCs. Según se decía, la gente había hecho más pedidos de los que...
Una vez pasado por el compilador ya da igual, ¿no?– Winnie Quizá la mejor representación de este eterno debate del mundo de la programación sea la mítica escena de Silicon Valley en la que Richard confiesa «tener una ligera preferencia por...

En el mundo hay varios conjuntos musicales que se autodenominan orquestas de portátiles que usan ordenadores portátiles como pieza básica a la hora de interpretar música. Pero no usan portátiles con un programa que les permite funcionar como un sintetizador sino...

Me crucé con vídeo de una calculadora ternaria que muestra cómo operaba la máquina calculadora ternaria de Thomas Fowler, un artilugio construido en 1840 que basaba su funcionamiento en la base 3 (en vez de 2 del binario o el 10...

IBM ha anunciado que el superordenador Summit ya está en funcionamiento en el Laboratorio Nacional Oak Ridge. Con una potencia de cálculo de más de 200 petaflops duplica al que sería el siguiente de la lista, el Sunway TaihuLight que ocupa...

A Stefany Allaire este proyecto le sobrevino como una visión tras disfrutar de un vídeo de nuestro admirado 8-Bit Guy: The Gigatron TTL Computer without a Microprocessor. El Gigatron TTL es un ordenador «sin procesador» (CPU), que resulta bastante retro y...
Cuando algo fallaba en los primeros ordenadores generalmente era un problema de hardware y teníamos que buscarlo con un osciloscopio.– Carver Mead Carver Mead, venerable profesor del Caltech, tiene en su canal de YouTube una serie de vídeos titulada Perspectivas de...
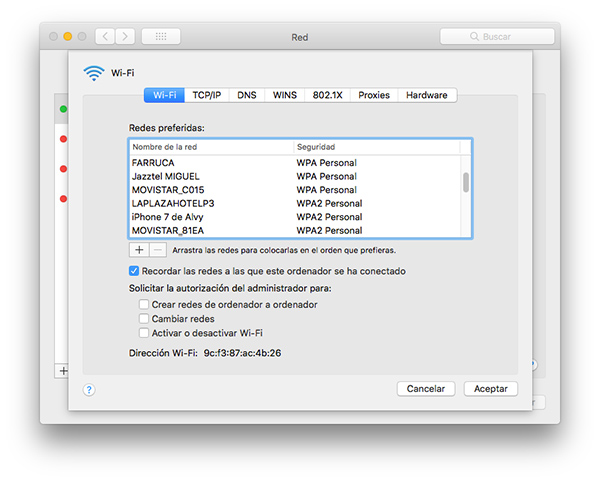
Esos lugares como el panel de las Redes preferidas del wifi, donde se almacenan recuerdos de viajes de negocios, vacaciones, o cafeterías a las que solías ir pero ahora ya no existen.– @MWichary El sábado pasado grabamos en persona el podcast...

Este vídeo de auténticos abuelos cebolletas de la informática muestra un mainframe 1401 de IBM en funcionamiento, compilando y ejecutando programas en lenguaje Fortran. Es una auténtica preciosidad llena de botones y lucecitas con sus tarjetas perforadas, su unidad de cinta...
Utilizando puertos serie RS-232 y velocidades que todavía se medían en baudios, estos terminales HP de la familia 264x que datan de los 70 y los 80 eran poco más que pantallas en blanco y negro capaces de mostrar caracteres ASCII...

Es un poco viejuno pero esta fábrica de coches a escala sigue siendo una fascinante demostración de lo que es posible construir con Lego y con un poco de programación en el lenguaje EV3Basic de los sensores y ordenadores Lego Mindstorm....
Por Nacho Palou -
21 MAY 2018

Kjetil Golid tiene una curiosa página llamada Generated.space (de los dominios .space de toda la vida ;-) donde experimenta con programación mediante procedimientos. El código se puede ver y descargar de Github. Entre los diversos «aparatos» generados matemáticamente hay marcianitos como...

Experiencia.De nuevo.Windows XP ha vuelto. Concebido como una renovación a nivel visual de Windows XP con el estilo, tipografía, paletas de color y reglas de interfaz propias de 2018, esta «Edición 2018 de Windows XP» fijo que triunfaría. Por desgracia no...

Si lo que cuentan en este vídeo funciona de verdad y es aplicable en el MundoReal™ se va a acabar aquello de que de dónde no hay no se puede sacar, al menos aplicado a la fotografía con poca luz. Según...
A la izquierda un archivo en formato Unix visto en el nuevo Notepad para Windows. A la derecha cómo se veía hasta ahora en Windows Notepad ese mismo archivo Unix. El Bloc de notas (Notepad) de Windows es un editor de texto...
Por Nacho Palou -
9 MAY 2018

Se suele decir que la historia la escriben los vencedores y probablemente por eso casi nadie sabe que el Reino Unido fue una gran potencia en los primeros años de la historia de la informática, justo después de la segunda guerra mundial....

El entrañable Profesor Brailsford narra para Computerphile una batallita de la prehistoria de la informática acerca del origen de términos como bit y por extensión los bytes y lo que técnicamente se denominan palabras. Curiosamente el término bit lo acuñó en...

En un reciente viaje a Londres descubrí por casualidad Message from the Unseen World, un homenaje del barrio de Paddington a uno de sus hijos más ilustres, Alan Turing, nacido allí el 23 de junio de 1912. Se trata de una...

Dorian Braun tiene un curioso artículo sobre el esotérico lenguaje de programación Befunge. Es una pequeña «monstruosidad» de la computación, que al igual que otros lenguajes como Brainfuck puede hacer muchas cosas pero haciéndolas complicadas. Como bien lo define en su...

Bajo el interesante título de The Surprising Creativity of Digital Evolution la gente de Improble Research –sí, los de los Premios Ig Nobel– ha recogido decenas de anécdotas e historias tan divertidas como reales sobre la «vida artificial» y los desvariados...

En este vídeo de Silicon Classics se muestra cómo era la SGI Indy, una de las primeras workstations de «gama baja» que Silicon Graphics intentó situar como el «equipo de entrada» para trabajar con CAD, vídeo y multimedia. Hablamos de la...

La supremacía cuántica es el momento en que un ordenador cuántico supera al mejor de los superordenadores convencionales resolviendo cierto tipo de problema.– Dominic Walliman Dicen que ese momento está a punto de llegar. O incluso que ya ha llegado. Para...

Ted Nelson (1937) es el pionero de la informática que inventó el hipertexto. Con 80 años puede ver las cosas con tranquilidad y distancia, y habiendo vivido varias generaciones del mundo de la tecnología y la multimedia tiene los galones necesarios...

Abril 2018 Breve y directo: Qubit Counter. Es una cronología de los hitos de la computación cuántica hasta nuestros días, medida en qubits. Desde cuando se realizó la primera demostracion experimental de computación cuántica de 2 qubits en Oxford (1998) hasta el...

En este vídeo de auténtica arqueología informática se muestra cómo era el proceso completo de arrancar un ordenador NeXT, su interfaz con su característico Dock y ventanas (heredadas del Macintosh y con iconos diseñados por Susan Kare y luego re-heredados por...

Los amantes del modding encontrarán interesante o cuando menos intrigante este PC Building Simulator (disponible en Steam, todavía en desarrollo), que es exactamente lo que parece: un simulador de construcción de PCs a medida. Se pueden elegir cajas, diseños y todo...

La unidad SSD ExaDrive DC100, de Nimbus Data tiene una capacidad 100 TB y se autoproclama como “la de mayor capacidad que se ha fabricado hasta la fecha”. En apenas un mes ese título se lo han disputado Nimbus Data (con...
Por Nacho Palou -
20 MAR 2018

En el canal de Matt Godbolt hay unos cuantos vídeos interesantes, pero este dedicado a cómo las CPUs optimizan diversas tareas comunes me pareció especialmente llamativo por lo claro y didáctico. Código incluido. En cinco ejemplos muestra con código en ensamblador...

He estado probando unos altavoces Creative Pebble que en lugar de por tener un montón de funciones se caracerizan por su sencillez, algo que es de agradecer. Disponibles en blanco o en negro los Pebble son un par de bolas de 11...
Los vídeos de Layout Land son probablemente la mejor forma de pasar un rato aprendiendo sobre CSS, Flexbox y diseño web que hay actualmente. Son un admirable trabajo de Jen Simmons, una infatigable diseñadora de Mozilla que además es miembro del...

En IEEE Spectrum, Build Your Own Altair 8800 Personal Computer, El Altairduino es un kit que proporciona una enorme cantidad de diversión. Es sorprendentemente divertido manejar un ordenador mediante interruptores en lugar de con clics de ratón. En serio, los primeros...
Por Nacho Palou -
28 FEB 2018

Literalmente 110% preciso. Y aún así los pantallazos que se ven en la primera parte son más creíbles que los de la mayoría de películas de Hollywood. Se le ha olvidado que después de arreglar el error y volver a compilar...

Un par de unidades PM1643 suman suficiente espacio como para almacenar de sobra toda la Wikipedia. Entera, con los históricos, las discusiones de los editores y en todos los idiomas, y también las imágenes y los vídeos de Wikimedia Commons. [Fuente: Size...
Por Nacho Palou -
22 FEB 2018
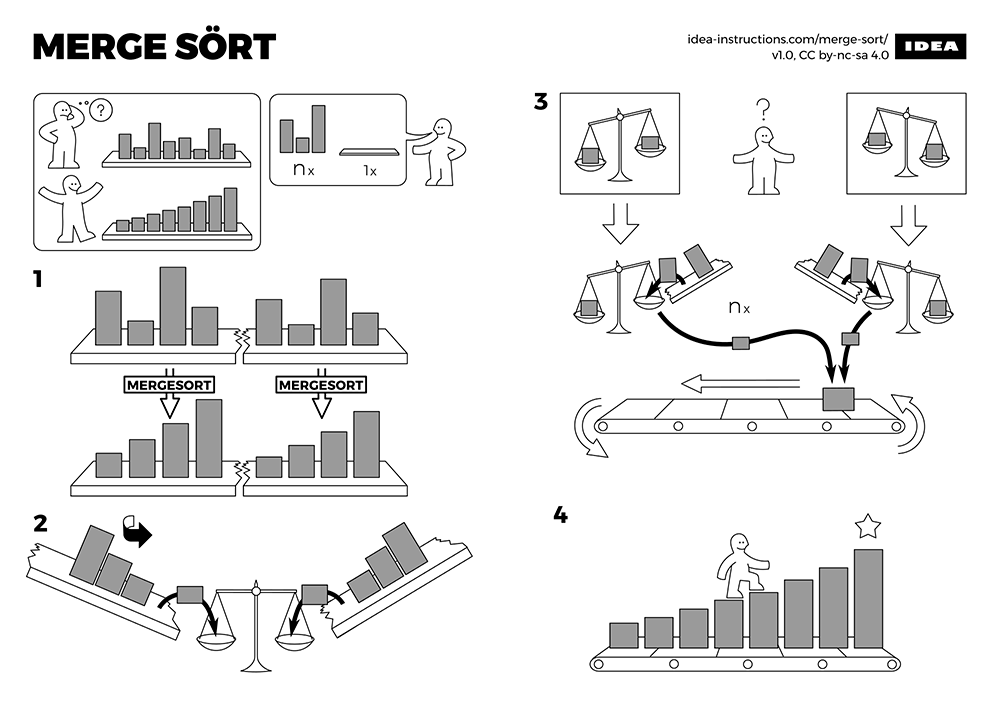
IDEA es la versión informático-didáctica de los manuales de instrucciones de Ikea. Si los famosos muñecos en blanco y negro son capaces de que puedas montar una litera Combo Stüva, un cabecero Brimmes o un lámpara Årstid, ¿por qué no ir...

Este pequeño vídeo de la Long Now Foundation cuenta unas cuantas cosas interesantes sobre la relevancia de Spacewar (1962) en la historia de los videojuegos y la informática. Los protagonistas son Steven Johnson (divulgador y teórico de los medios) entrevistado por...
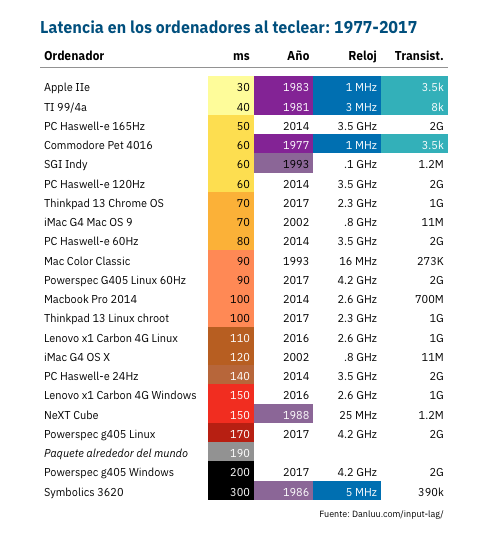
Los retardos (latencia) al teclear, en milisegundos. Cuanto más bajo, mejor Quienes hayan trabajado con ordenadores a lo largo de muchos años se habrán percatado –es difícil no hacerlo– de que por mucho que avance la tecnología los tiempos de respuesta son...

Tenía sesenta y uno. A lo largo de los años había golpeado mi cabeza una y otra vez contra el techo de cristal y ahora tenía otra cosa que jugaba en mi contra además de mi género – mi edad. Nadie...
Si la experiencia de usuario no es consistente en los diferentes canales los usuarios cuestionarán la credibilidad de la organización.– Jakob Nielsen Style Dictionary es un trabajo de Danny Banks, diseñador de UX en Amazon: un sistema para crear estilos multiplataforma...
Winamp2-js es una reimplementación que resucita el mítico Winamp 2.9 en HTML5 y Javascript, de modo que funciona en cualquier navegador. Y no lo hace nada mal: se pueden añadir al reproductor canciones MP3 simplemente arrastrándolas sobre la playlist, cambiar los...
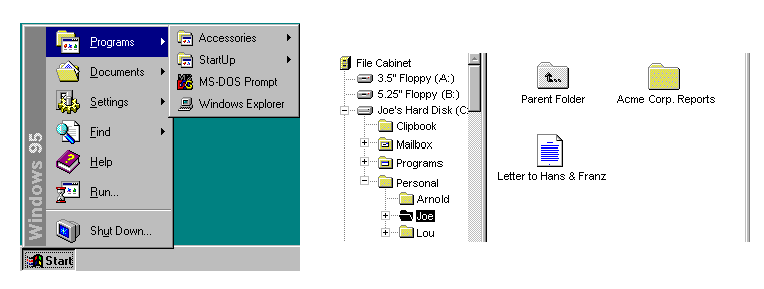
El nacimiento del menú Inicio Josh de Socket 3 encontró un viejo documento que había desaparecido de la web de Microsoft y que creyó que merecía la pena guardar para la posteridad – algo en lo que concordamos. Se titula The Windows...

Conecta los auriculares y disfruta de una experiencia sonora inmersiva. Este vídeo está grabado en el primer centro de computación IBM Q, donde científicos e ingenieros de IBM exploran ya las posibles aplicaciones que tendrán los ordenadores cuánticos. Los ordenadores cuánticos de...
Por Nacho Palou -
7 FEB 2018
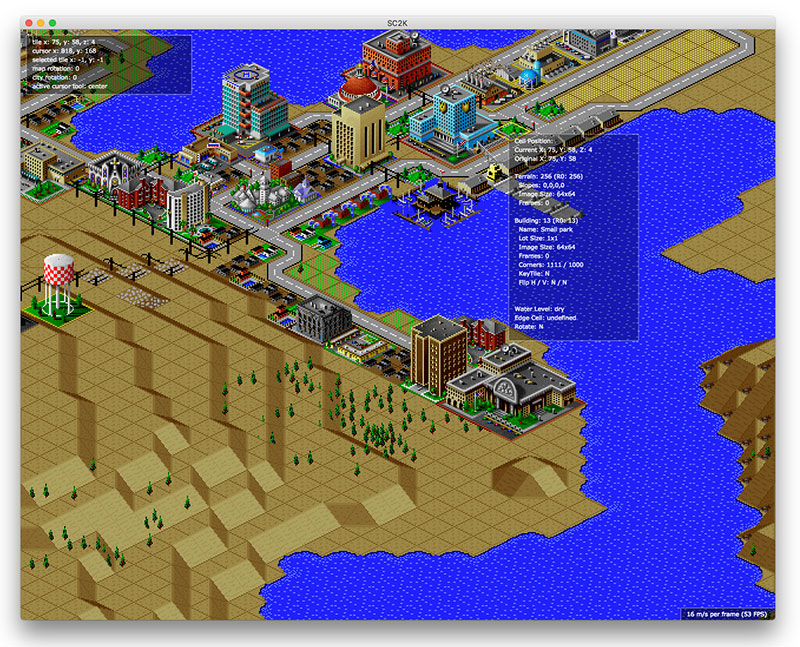
SimCity 2000 (1994) seguirá siendo durante mucho tiempo uno de los mejores videojuegos de simulación y estrategia de todos los tiempos. Y como demostración de la obsesión de muchos aficionados por continuar con este pequeño universo ahora ha surgido una especie...
Encontré esta antigua pero sorprendente página con el Oráculo de Aaronson a través de una mención de pasada en un vídeo de las Infinite Series de PBS. Se trata de un simple entretenimiento consistente en pulsar las letras D y F...

El DSKY, de display and keyboard, pantalla y teclado, era el interfaz que los astronautas del programa Apolo usaban para comunicarse con los ordenadores de a bordo de sus naves; nada que ver con los interfaces con pantallas táctiles de las...
Sepectre y Meltdown a partir de 81:00 Comienza y el año y el podcast Los Crononautas en el que colaboro semanalmente vuelve con su actividad habitual. En el episodio #S02E11 Martín Expósito y yo estuvimos charlando un poco del tema con el...

The Ultimate Apollo Guidance Computer Talk es una charla dedicada al Ordenador de Navegación del Apolo que dieron Christian Hessmann y Michael Steil en el 34º Chaos Communicacion Congress. En una hora hablan de su arquitectura, de su hardware, de sus...
Charles Babbage y Alan Turing asentirían orgullosos y sonrientes ante este ingenioso «invento». Se trata de una descripción de la forma mecánica de crear puertas lógicas utilizando únicamente placas y pernos articulados simples, del estilo de los que incluyen juegos de...
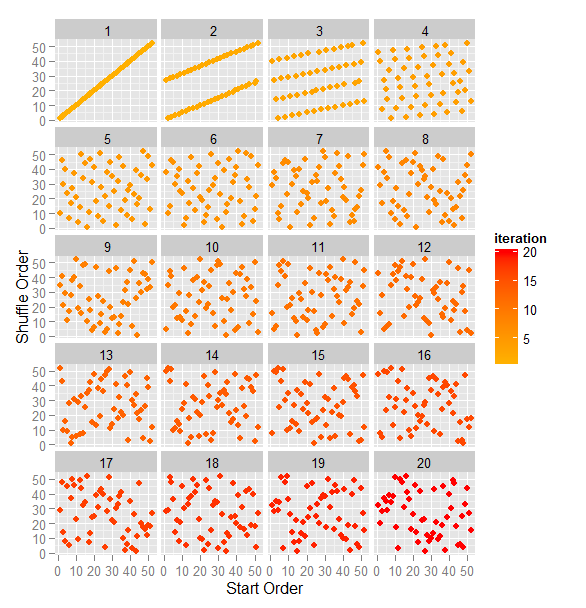
Las posiciones iniciales de los 52 naipes y cómo varían tras varias mezclas consecutivas / Stachyra Encontré un código de simulación para la mezcla americana de una baraja de naipes (escrito en R) bastante sencillo de entender y junto al que hay...

En Yanko Design, The keyboard of empowerment, Durante el tiempo que estuvo trabajando en Silicon Valley, Roya Ramezani hizo una observación bastante interesante: si bien el desequilibrio de género era evidente eso además tenía efectos en la forma en que las...
Por Nacho Palou -
5 ENE 2018

Vuelve el fantasma del «bug del Pentium» podría titularse esta historia. Los detalles son técnicamente un poco complicados (más info abajo), pero baste decir que es un SNAFU total para el comienzo de año de Intel: todos los procesadores que ha...

He estado evaluando el Toshiba Portégé X20W-D-10P, un portátil que se caracteriza por ser un ultraligero de tipo «2 en 1» que se puede utilizar como portátil convencional o en modo tableta, con solo girar la pantalla. Al ofrecer altas prestaciones...
Haz la prueba y compara la calidad de la síntesis de voz de este sistema llamado Tacotron 2 con el de Siri, Cortana o la entrañable «borracha de Google»: Tacotron 2: audio samples from natural TTS synthesis. La diferencia es tan...
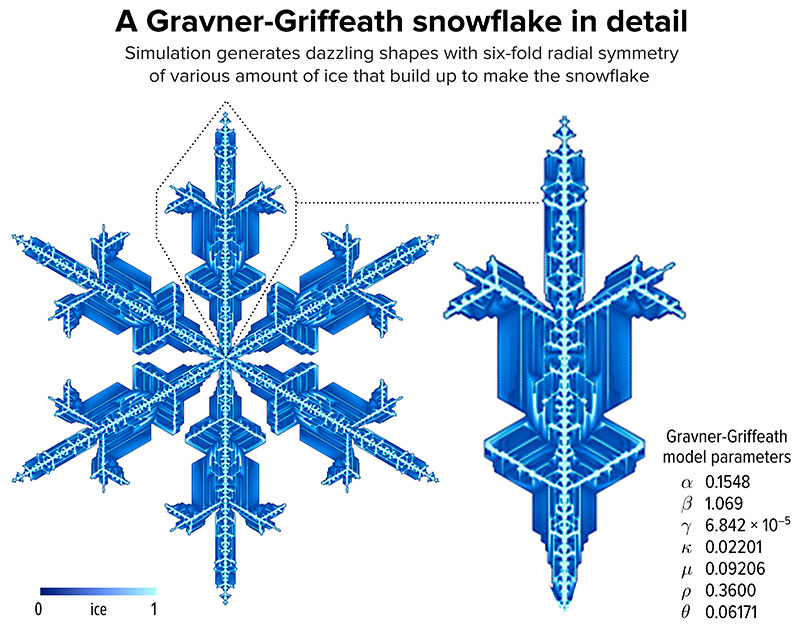
Krzywinski y Lever publicaron un precioso y bastante complejo artículo en Scientific American acerca de la creación de copos de nieve mediante modelos matemáticos. In Silico Flurries describe cómo utilizar un modelo que hace crecer estos intrincadas maravillas de la naturaleza...
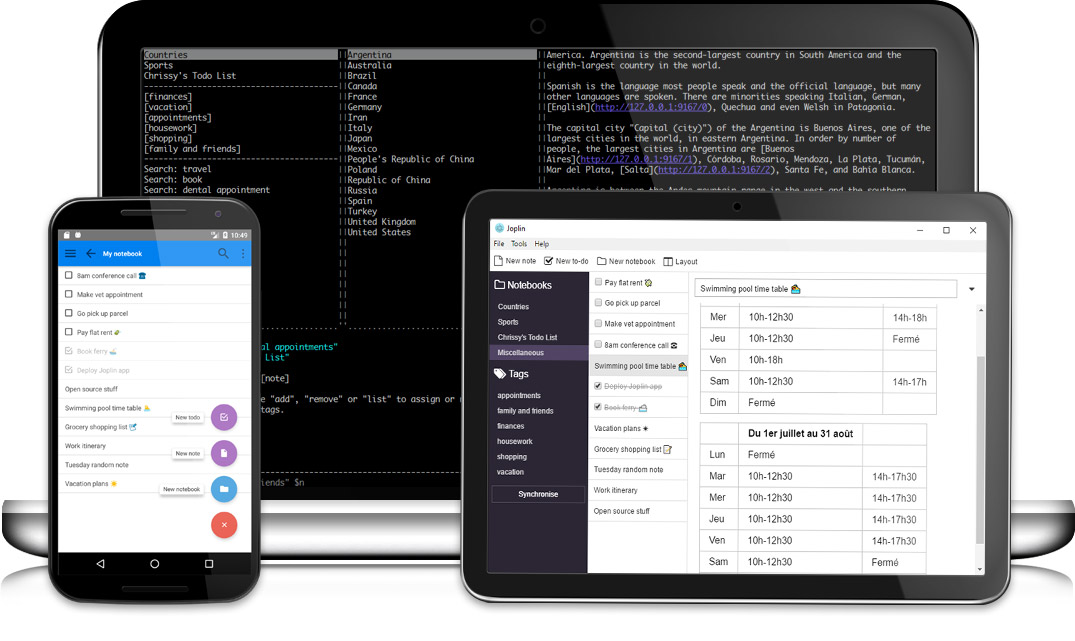
Joplin es una aplicación de notas, una especie de reencarnación mutante de Evernote o las Notas de Apple pero en versión gratuita y de código abierto – así que si por alguna razón no te gustan las anteriores puede ser una...

library(dplyr) library(ggplot2) seq(from=-10, to=10, by = 0.05) %>% expand.grid(x=., y=.) %>% ggplot(aes(x=(x+pi*sin(y)), y=(y+pi*sin(x)))) + geom_point(alpha=.1, shape=20, size=1, color="black")+ theme_void() Utilizando unas pocas funciones de R (el lenguaje de moda concebido como herramienta de análisis estadístico) Fronkonstin ha desarrollado la idea del...
Hoy ha salido a la venta el iMac Pro, el modelo de más alta gama que vende Apple y que viene potente: el modelo básico incluye 8 núcleos, 32 GB, 1 TB y pantalla 5K; en negro lado oscuro. Son 5.500...
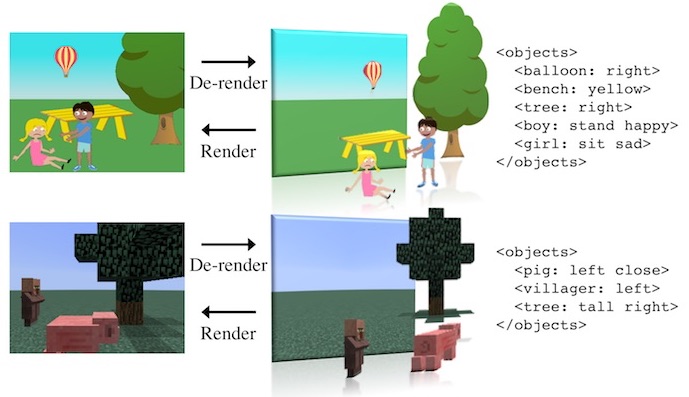
En el laboratorio de inteligencia artificial del MIT trabajan en algo llamado Neural Scene De-rendering («Desrenderizado de escenas mediante técnicas neuronales»). Básicamente consiste en obtener información de los objetos y lo que sucede en un fotograma 2D o una animación para...

Aunque no tengas talento para la pintura siempre que tengas Excel podrás pintar. — Tatsuo Horiuchi. Este señor se llama Tatsuo Horiuchi y es el Miguel Ángel del Microsoft Excel. Decidió convertirse en pintor una vez que se había jubilado, y ahora...
Por Nacho Palou -
5 DIC 2017

¿Cuánto cuesta una app? plantea una aproximación rápida y sencilla para quien haya tenido la proverbial genial idea y aspire a convertirla con ayuda de terceros en «algo que se coma el mundo». En otras palabras: es una forma casi instantánea...
TopoSketch es una herramienta que permite generar animaciones a partir de secuencias de fotogramas de un rostro, pero de una forma un poco «diferente». Básicamente se dibuja un garabato sobre una matriz de fotografías y el software genera la transición más...

Infinitown es un pequeño experimento en WebGL programado con Three.js, Blender y Unity. La ciudad es aleatoria y está creada mediante generación por procedimientos, como en muchos juegos y simulaciones. Primero se generan las manzanas y luego los edificios, coches y...

El pasado 27 de septiembre Los nativos digitales no existen sirvió como tema principal para inaugurar las Charlas #EnModoAvión, un ciclo de charlas sobre el impacto de la tecnología en la sociedad promovido por Cuatroochenta con la colaboración de la Universitat...

Alguien en el Laboratorio Nacional de Los Álamos –el mismo sitio donde está el superordenador Trinity– ha tenido la genial idea de crear unos módulos de supercomputación baratos llamados BitScope Cluster Modules con cientos de nodos en forma de racks con...

Ya se ha presentado Identidade Dixital, un proyecto de la Consellería de Cultura, Educación e Ordenación Universitaria de la Xunta de Galicia en el marco de la Estrategia gallega de convivencia escolar 2015-2020 con el que he tenido la suerte de...
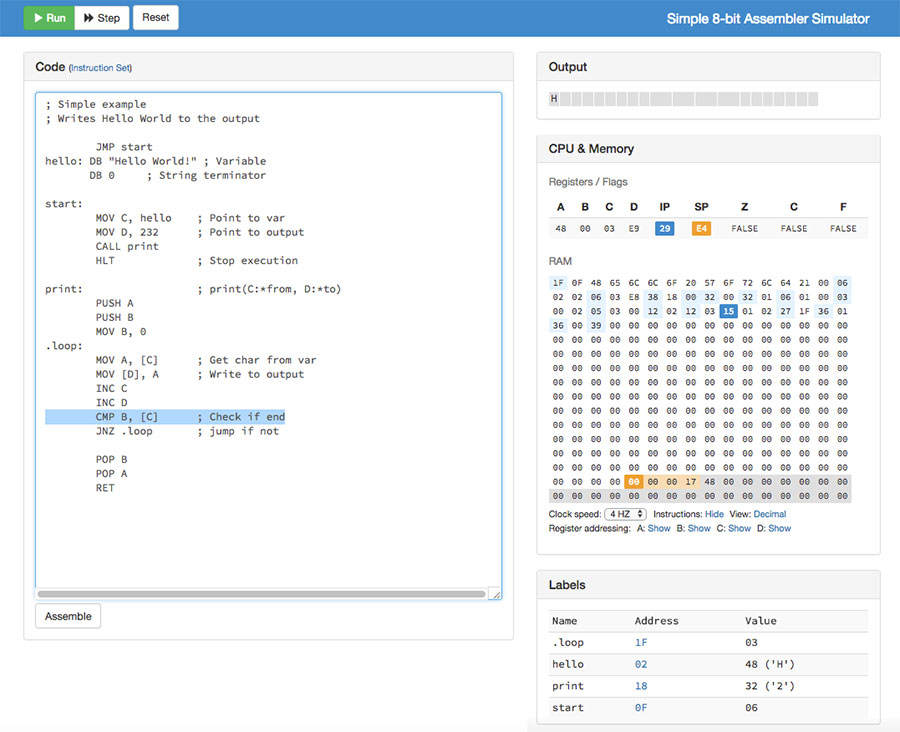
Este Simulador de ensamblador de 8 bits en JavaScript es una magnífica herramienta educativa para aprender y practicar las bases de uno de los lenguajes más cercanos al código máquina. Cada instrucción de ensamblador se traduce en un código ejecutable directamente...
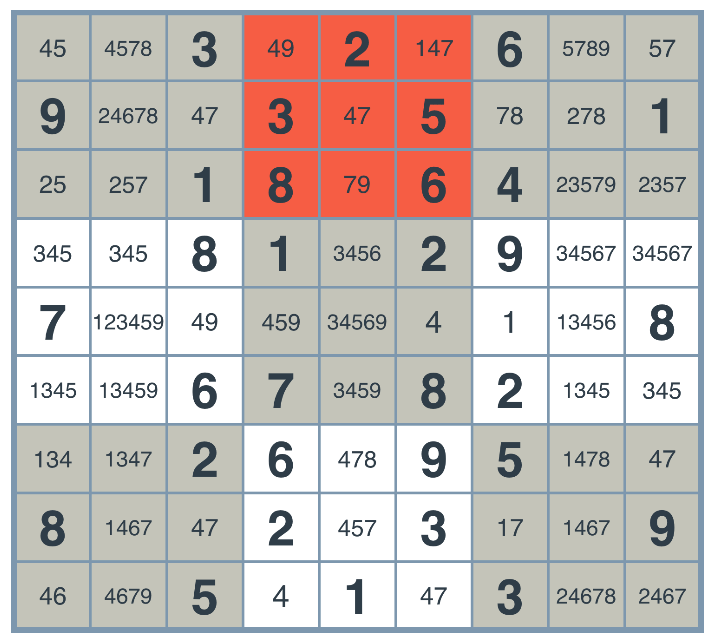
Aunque los populares sudokus se pueden resolver de muchas formas, que lo haga un ordenador no siempre es tan fácil como parece. En How To Win Sudoku Grant Bartel explica cómo funciona un método «típico de la inteligencia artificial» para hacerlo...

Scrollama [en Github] es una librería JavaScript de Russell Goldenberg para crear historias animadas en páginas dependientes del movimiento mediante scroll vertical al desplazarse por ellas. Esta técnica, que es bastante útil como elemento de ayuda a la «narración» de ciertas...

Viktor Charyparn ha publicado un largo y muy interesante artículo con su punto de vista sobre el futuro de la nube y lo que vendrá más allá: The end of the cloud is coming. Como se puede ver por el título...

Hace más de veinte años que no me conecto a CompuServe, pero me ha dado un puntito de nostalgia leer que el próximo 15 de diciembre de 2017 sus foros serán cerrados definitivamente y desaparecerán. Aunque he de reconocer que también...

Andrea Iacono publicó un buen artículo sobre los algoritmos de «vuelta atrás»: Backtracking Explained. Se trata de una estrategia normalmente recursiva para resolver problemas como los de los laberintos, la colocación de piezas y similares, en los que mediante una búsqueda...

Eric Meyer es uno de los coautores de CSS: The Definitive Guide y el otro día publicó esta foto en Twitter con las tres últimas ediciones del libro. La cuarta es un pedazo de ladrillo de 1.016 páginas con, básicamente, «todo...
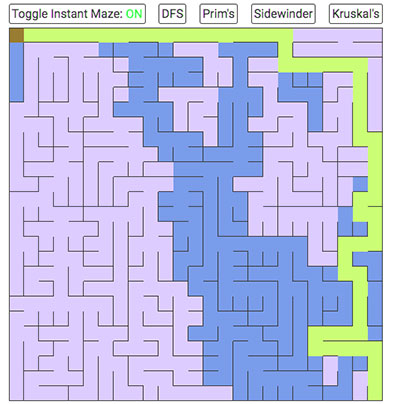
Este proyecto sobre laberintos primero los genera –utilizando varios «estilos», indicados arriba– y luego los resuelve de forma algorítmica, utilizando cuatro formas distintas (abajo): BFS (Búsqueda en anchura, Breadth First Search), DFS (Búsqueda en profundidad, Depth First Search), A* algoritmo de...

Me ha parecido muy interesante lo que plantea Reshma Saujani en esta charla (hay subtítulos en castellano) acerca del motivo por el que las mujeres «huyen» de las carreras relacionadas con la ciencia, tecnología, ingeniería o matemáticas. Según ella, y en...

No hay mal que por bien no venga. Así que Dimitry Tolmachyov, «constructor y emprendedor», decidió que como el consumo energético al tener funcionando máquinas minando bitcoins es tan enorme, qué mejor que usarlo para calentar su vivienda, situada en la...

Félix, que sabe que soy un gran fan de PowerPoint, me ha pasado el enlace a este vídeo de demostración de PowerPoint 1.0, cuando PowerPoint aún no era de Microsoft y sólo estaba disponible para Macintosh. Y es que PowerPoint fue...

PanLex es un proyecto de la Long Now Foundation consistente en construir la base de datos léxica más grande del mundo con la misión de «superar las barreras del lenguaje en favor de los derechos humanos, la información y las oportunidades.»...
En esta recopilación visual denominada Sorting Algorithms Revisualized se pueden observar de forma animada y colorida –como algunas otras veces ya habíamos visto por ahí– diversos algoritmos para ordenar conjuntos de datos en acción. Entre otras cosas aparecen el ordenamiento por...
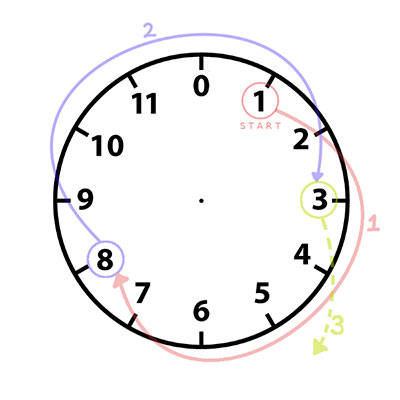
Los ordenadores necesitan números aleatorios para realizar todo tipo de tareas: simulaciones, juegos, criptografía, arte… Pero la forma de generarlos es puramente matemática, lo cual es un problema más que una ventaja: al cabo de un tiempo lo que parece aleatorio...

Mazeon tiene en su impresionante colección de pixel art una genial recopilación de ordenadores retro y consolas que vi pasar por un par de webs, incluyendo esta otra página de Retronator de otras temáticas. Entre ellas hay chismes como los viejos...
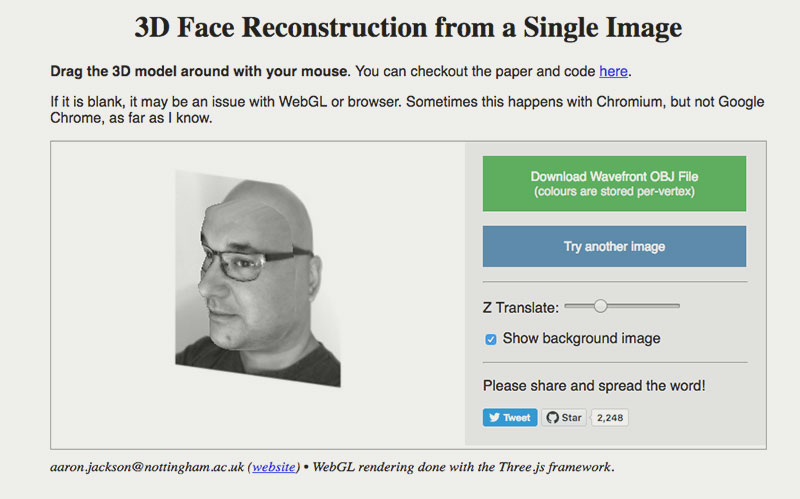
Esta demo permite probar cómo funciona el método de reconstrucción de rostros en 3D a partir de fotografías mediante una técnica llamada regresión volumétrica directa mediante redes neuronales convolucionales: 3D Face Reconstruction from a Single Image Para hacer funcionar la demo...

Este vídeo muestra el aspecto y funcionamiento del Mini Raspberry Pi Handheld Notebook, un mini-Pc con mini-pantalla y mini-teclado; algo apropiado para quienes sean fans de los Raspberry Pi, tengan manos pequeñas o simplemente disfruten con los retos de hackear gadgets...

IBM introdujo el primero modelo de ordenador portátil ThinkPad en 1992, en la época de windows 3.1. El modelo original (el 700c) lo diseñó Richard Sapper y se caracterizaba por su forma simple y funcional, minimalista “como una caja de puros...
Por Nacho Palou -
19 OCT 2017

Esta pequeña demostración permite ver cómo un algoritmo evolutivo en una red neuronal artificial permite a unos sencillos coches «aprender» a circular en un circuito de carreras. La evolución se produce a lo largo de varias generaciones, pero no son necesarias...

Esta curiosa fotografía procedente de un anuncio de Hewlett-Packard de 1972 tiene más de un detalle interesante, así que bien merece echarle un vistazo detallado. El primero es obviamente la camiseta de Joseph Fourier, el matemático y físico francés que inventó...

Me ha parecido muy interesante el artículo Your mind will never be uploaded to a computer del filófofo Jesús Zamora Bonilla en el que aborda la idea tan popular en la ciencia ficción y entre algunos iluminados de que en el futuro...
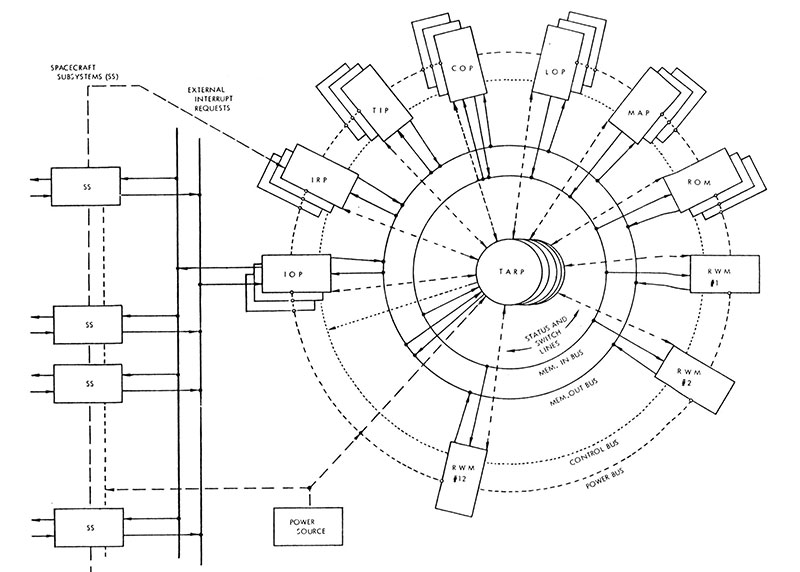
Buscando algo sobre los sistemas autorreparables de las sondas Voyager me encontré con From Sequencers to Computers de la NASA, que es el capítulo 5 del no menos interesante documento Computers in Spaceflight: The NASA Experience que hay en su web....

El Ministerio de Energía, Turismo y Agenda Digital tiene en marcha una consulta pública con el objetivo de recabar propuestas e información relevante que quieran aportar los interesados para la elaboración de la Estrategia Digital para una España inteligente. El objetivo es...

El amigo de 8-Bit Guy ha comenzado una serie en varias partes acerca de la historia de Commodore y el PET, el precursor de lo que luego serían el VIC-20, el C-64 y siguientes. Como bien afirma: (…) Cuando se habla...
Dominic Walliman, al que conocemos por sus brillantes resúmenes informativos y pósteres sobre matemáticas, física y otros campos del conocimiento ha publicado ahora el Mapa de la informática [zoom a la versión en alta resolución en Flickr]. Allí se puede ver,...

Las guerras del software, ahora en la realidad aumentada: ARCore vs. ARKit Google ha presentado ARCore, el kit de desarrollo de software para realidad virtual en Android. Es en cierto modo un «competidor directo» del ARKit de Apple, del que ya...

Literalmente al fondo del último cajón de un viejo archivador es donde el profesor Jim Miles encontró 148 documentos pertenecientes a Alan Turing que se corresponden al periodo que pasó en la Universidad de Manchester, entre 1949 y su muerte en...

Ser «el informático» es duro, especialmente si trabajas en el departamento de soporte técnico – sea en alguna nave de Star Trek o no. Es sin duda un trabajo sucio, pero alguien tiene que hacerlo, en este caso The Bitter IT...

El otro día de casualidad me topé con un ejemplo estupendo de cómo hacen uso algunas algunas app del reconocimiento facial. Obsérvese las diferencias cuando se añaden cuatro fotos a un tuit y luego se ve el resultado en la cronología de...

Un nanosegundo luz es una unidad de distancia, aunque con una particularidad: utiliza una unidad de tiempo muy pequeña (el nanosegundo) multiplicada por una velocidad muy grande en términos humanos (la de la luz). En este sentido es similar al año...

Este vídeo recuperado por el AT&T Tech Channel merece estar en los anales de la historia de la informática. Se trata ni más ni menos que de Claude Shannon, el «padre de la teoría de la información», demostrando cómo funciona una...
En el canal de 4096 hay unos cuantos vídeos interesantes sobre la evolución con el paso del tiempo de sistemas operativos, servicios y consolas. Ya publicamos hace tiempo la interesante Evolución de YouTube y ahora le ha tocado a Mac OS....
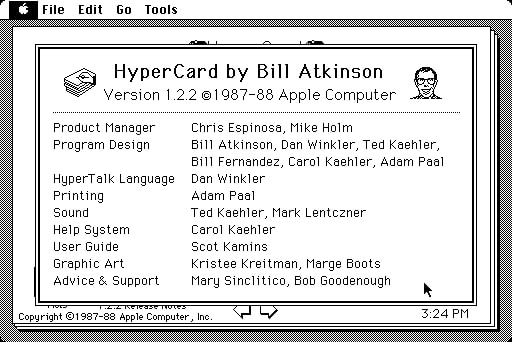
Chris Espinosa fue el empleado de Apple #08 y con 14 años ya trabajaba allá por 1976 en el famoso garaje de Steve Jobs. Participó junto con el no menos legendario Bill Atkinson en la creación de HyperCard, y estos días...

Crear de la nada nuevos personajes de anime, donde debido a la simplicidad de sus trazos muchos de ellos nos parecen «todos iguales» es complicado. Sin embargo, con un poco de habilidad y variando cada uno de los rasgos (pelos, ojo,...

Xieranmaya (con ayuda de su hermana Tian Qiong) explica en su página de Github cómo se pueden detectar y contar números primos con cualquier navegador web utilizando código CSS. La demo cuenta de 1 a 1000 y resalta en color rojo...

Lleva unos días haciendo las rondas la noticia acerca de dos bots creados por programadores de Facebook que supuestamente se pusieron a hablar entre ellos en un lenguaje que inventaron y que ni sus creadores podían entender. Según la noticia en cuestión...

The Home Of The Future: Year 1999 A.D. es un corto producido en 1967, año en el que la empresa cumplía 75 años, por la Philco-Ford Corporation en el que intentaban imaginar como sería el hogar del futuro, siendo el futuro...

Con las CPU/GPU más modernas se pueden obtener potencias de cálculo realmente asombrosas, hasta el punto de que tal y como ha calculado Carlos E. Perez usando componentes de AMD, concretamente una CPU Ryzen y una GPU Vega además de algo...
Sam Greydanus, un físico que investiga sobre aprendizaje profundo (deep learning) y neurociencia explica cómo se puede crear una red neuronal recursiva (RNN) para descifrar mensajes cifrados por la famosa máquina Enigma que utilizaron los alemanes durante la Segunda Guerra Mundial....
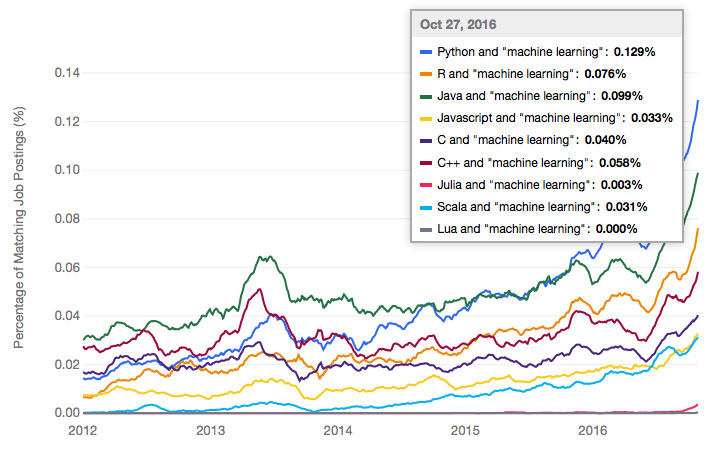
Python, R, Java, JavaScript y C. Al igual que en los 10 lenguajes más populares de programación que selección IEEE Spectrum a partir de una decena de fuentes, esta lista de Jean-François Puget de IBM, que procede de las búsquedas en...
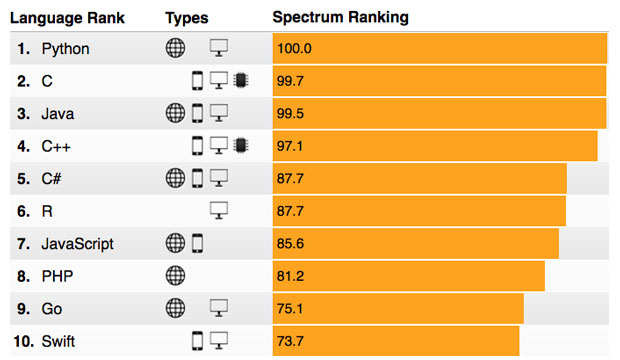
En The 2017 Top Programming Languages se muestra la lista que la revista IEEE Spectrum ha compilado a partir de diversas fuentes: concretamente 12 métricas de 10 publicaciones distintas, lo que abarcaba un total de 48 lenguajes. Python es el rey...

En Optimum Tech publicaron este interesante vídeo explicando el concepto de la lotería del silicio, que es como se suele llamar al hecho de que dos CPU (o Unidad de Procesamiento Gráfico">GPU) iguales sean en realidad ligeramente diferentes potencialmente en cuanto...

Esta unidad de almacenamiento llamada UHC-Silo Solid State Drive, de Viking, un fabricante especializado en memorias, ofrece la friolera de 50 terabytes en un factor de forma 3,5" estándar. Su velocidad de funcionamiento según las especificaciones es de 500/350 MBps en...

De las muchas leyendas que hay de la historia de la informática moderna una de las más conocidas es la de cómo Steve Jobs «robó» la idea de la interfaz gráfica de Xerox PARC. Y lo de «robó» va entre comillas...

Durante la pasada conferencia de desarrolladores Pycon de Portland (en septiembre hay otra en Cáceres) Jake Vanderplas hizo esta estupenda presentación que muestra herramientas y librerías para la visualización de datos con Python. Entre otras están Matplotlib (similar a Matlib) Seaborn...
La nueva aplicación de Copia de seguridad y sincronización de Google funciona en diferentes sistemas operativos de escritorio (MacOS, Windows) y permite hacer algo que mucha gente llevaba tiempo esperando: utilizar Google Drive para almacenar una copia de seguridad completa del...

El Centro Universitario de Formación e Innovación Educativa de la Universidade da Coruña ha organizado para este mes de julio el curso Docentes conectados, el reto de educar en la era digital, con estos objetivos: Facilitar un espacio rico de debate...

Cualquiera que haya hablado conmigo del asunto o que me haya leído en los últimos años –y en especial en los últimos meses– sabe lo que opino de los nativos digitales: simple y llanamente que Los nativos digitales no existen. Por...

Mundos Digitales es un congreso que se celebra en A Coruña dedicado a la animación, los efectos visuales, la realidad virtual, los videojuegos y la arquitectura. A él acuden algunos de los mejores profesionales de la industria de los contenidos digitales así...
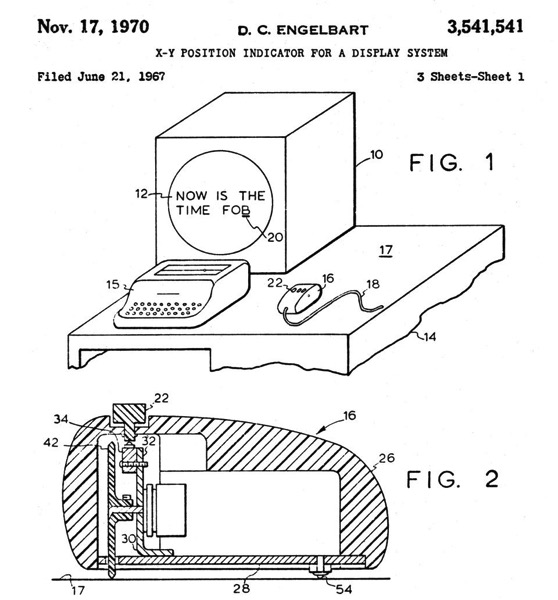
El 21 de julio de 1967 Douglas Engelbart solicitaba una patente bajo el nombre X-Y position indicator for a display system, patente que le fue concedida el 17 de enero de 1970: Un control para indicar la posición X-Y para ser...

Utilizando lo que vendrían a ser palos y piedras digitales en este vídeo de Udemy (una sitio tipo «academia por Internet, con vídeos») Christian nos enseña cómo escribir todo el código de un juego tipo Serpiente (Snake) en tiempo récord. Y...
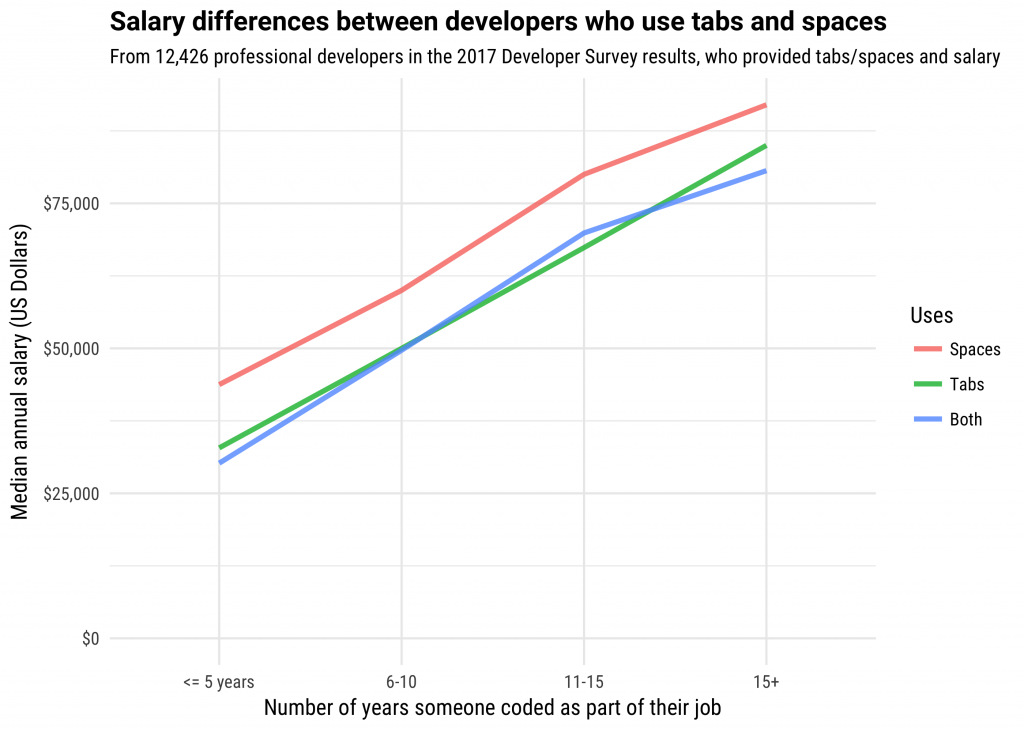
Esta conclusión no científica y más anecdótica que otra cosa podría poner fin el eterno debate entre si se deben indentar (sangrar) los bloques de código en programación usando espacios (¡y cuántos!) o usando tabuladores: los programadores que usan espacios para...
Por Nacho Palou -
16 JUN 2017
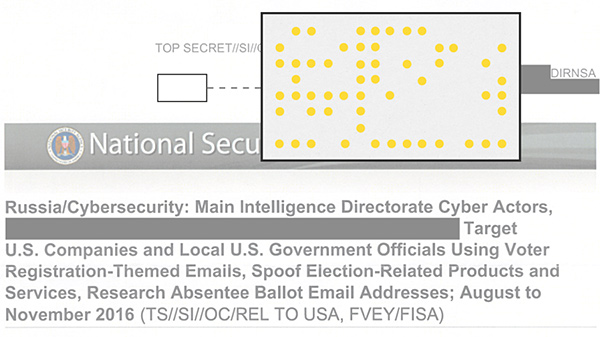
En Quartz, Computer printers have been quietly embedding tracking codes in documents for decades, En 2004, cuando las impresoras láser color todavía eran una novedad, la revista PCWorld publicó un artículo titulado Government Uses Color Laser Printer Technology to Track Documents....
Por Nacho Palou -
12 JUN 2017

Habíamos visto muchas variantes de Asteroides (1979), el mítico juego de Atari en el que nos dejábamos las monedas en los 80, pero ninguna tan espectacular como esta: un montaje en el que la pantalla está proyectada con láseres. La idea...

Este precioso juego llamado Turing Tumble está pensado como una especie de «computadora mecánica» con la que al jugar se aprende la lógica sobre cómo funcionan los ordenadores. Básicamente es una tabla inclinada de plástico con pernos, sobre los que se...
Dentro de cinco años habrá en internet más máquinas hablando entre sí (Machine-to-machine communication, M2M, conversaciones ilegibles para las personas) que personas usando móviles, tabletas y ordenadores para comunicarse con otras personas, según el informe Cisco's annual internet forecast, vía Quartz,...
Por Nacho Palou -
9 JUN 2017

La única misión del Generador de ciudades medievales de fantasía es la que indica su título. Se pueden elegir cuatro variantes: pueblo pequeño o grande, ciudad pequeña o grande. Esto influye en el tamaño final y la cantidad de detalles del...
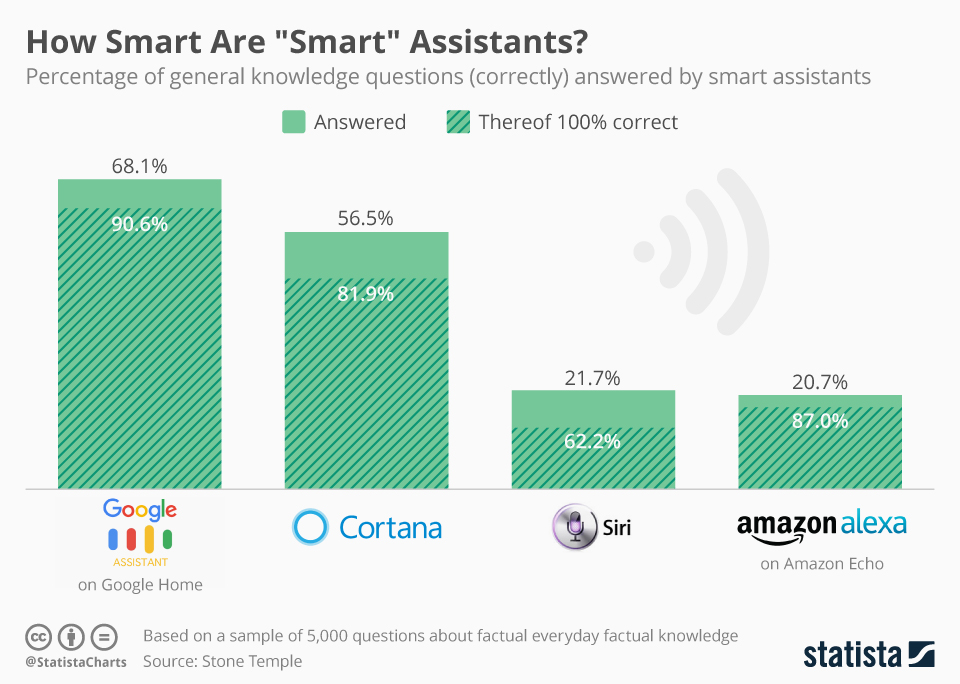
En color verde plano porcentaje de preguntas entendidas y contestadas, en verde con patrón porcentaje de esas respuestas que fueron correctas en su totalidad. En la agencia digital Stone Temple dispararon una batería de 5000 preguntas de asuntos cotidianos contra los cuatro...
Por Nacho Palou -
5 JUN 2017

El datacenter de Sarenet en el edificio de Tata Communications en el Parque Tecnológico de Bizkaia. El otro día dimos un paseo por las instalaciones que Sarenet tiene en el Parque Científico y Tecnológico de Bizkaia, muy cerca de Bilbao, dentro de...
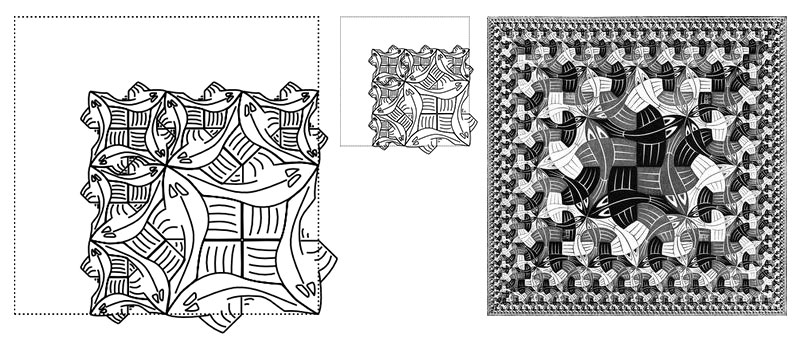
En las obras de M.C. Escher hay mucha matemática y geometría, pero un poco paradójicamente el propio Escher no se consideraba un gran conocedor de las matemáticas. Reconociendo sus propias limitaciones en más de una ocasión recurrió a la exploración autodidacta,...

Denostado por muchos, vilependiado por otros y blanco de infinidad de chistes, el conocido Windows Vista de Microsoft (2007-2010) fue durante largo tiempo ignorado por una parte importante de su público objetivo debido a sus más que visibles «problemas» de todo...

Desde hace ya algún tiempo la versión preliminar de Chrome Canary permite acceder a la que será una importante puesta al día del navegador Chrome. Está disponible para macOS, Windows (32 y 64 bits) y Android y suele añadir funciones nuevas...
Por Nacho Palou -
29 MAY 2017
Haciendo uso de emulación esa biblioteca de Alejandría conocida como Archive.org ha incorporado un nuevo emulador de Macintosh que puede correrse desde el navegador web, empaquetado con todo tipo de software que permite retrotraerse a los años 80 y 90. Entre...
Google ha recopilado en Quick, Draw! – The Data los datos de unos de sus experimentos en inteligencia artificial más divertidos: Quick, Draw! Si no lo has probado ya estás tardando. Los datos están publicados en Github e incluyen cada tipo...

En diciembre de 1974 Donald Sherman, afectado por el síndrome de Moebius que le impedía comunicarse por teléfono, fue capaz de pedir una pizza empleando un prototipo de ordenador a modo de prótesis vocal. El sistema, desarrollado por John Eulenberg y...
Por Nacho Palou -
16 MAY 2017
MalwareTech ha dado a conocer una web que recopila en tiempo real en un mapamundi los ataques del ransomware WannaCry a medida que se van sucediendo – también los de otros tipos de botnets. Además del mapa instantáneo hay versiones donde...
Alguna vez hemos explicado por aquí cómo se realiza la ingeniería inversa de microchips a partir de microfotografías que se examinan minuciosamente para recrear las conexiones entre sus miles de transistores y otros componentes. Es la forma más directa de recrear...

Microsoft trabaja en el desarrollo de un buscador de objetos y de personas en el MundoReal™, un sistema de inteligencia artificial y de aprendizaje automático que identifica e indexa todo lo que ven las cámaras, en tiempo real. De este modo,...
Por Nacho Palou -
11 MAY 2017
Estuve probando Duplicate Finder para macOS, una sencilla herramienta que encuentra archivos duplicados en el disco duro y que también forma parte de las utilidades de disco Disk Drill de Cleverfiles, el mismo desarrollador. Utilizarlo es sumamente sencillo: basta arrastrar y...

Vox Media publicó el año pasado este estupendo vídeo sobre cómo funcionan los «filtros de Snapchat», algo que la compañía llama «lentes Snapchat» y que hay quien lo llama «realidad aumentada» o términos futuristas similares. La respuesta está sacada directamente de...
Navegar y chatear todo es empezar, y con la nueva versión del navegador web de Opera además ambas cosas se pueden hacer a la vez, desde la misma aplicación. El navegador, aunque poco popular, cuenta con características brillantes y reconocidas a...
Por Nacho Palou -
10 MAY 2017

Cuando los hackers se reunen a pensar sobre «inventos raros» cualquier cosa es posible. Hace unos días el Equipo Liquid IT de Accenture Digital organizó lo que llaman La Semana Marciana, que básicamente es la presentación de proyectos originales con tecnologías...

A finales de julio y principios de agosto se celebrará en Los Ángeles el 44ª festival SIGGRAPH, un evento de unos cinco días en el que se combina la exhibición de nuevas técnicas en animación, interactivos, demos y gráficos con la...

En el Computer History Museum de Mountain View, California, han restaurado pacientemente un PDP-1, el primer ordenador construido por DEC allá por 1959. Los detalles sobre la restauración de esta increíble máquina son bastante sorprendentes y están resumidos en este vídeo...
El monitor LG 43UD79-B de 42,5 pulgadas LCD IPS y formato 16:9 tiene una resolución total 4K (3840 × 2160 píxeles) y diversas entradas HDMI (dos 4K a 30p y dos 4K a 60p), lo que le permite mostrar cuatro pantallas...
Por Nacho Palou -
3 MAY 2017

Random Sanity Project es un servicio web con un único objetivo: comprobar y garantizar que las secuencias de números aleatorios que se generan con todo tipo de software son realmente aleatorias. La forma de hacerlo es mediante una API a la...

En este vídeo se puede ver un trabajo realizado por expertos de la Universidad de Edimburgo y de Method Studios relativo al controlar mediante redes neuronales de los movimientos de los personajes de videojuegos en tiempo real de forma altamente realista....

La historia de Intel mucho de tecnología y mucho de Juego de Tronos. Gordon Moore y Robert Noyce inventaron junto con William Shockley el transistor en 1947. Una década después se fueron de los Bell Labs y fundaron Fairchild Semiconductor junto...

El ZX Spectrum Next es otro intento de recuperar la magia del ZX Spectrum, uno de los primeros «ordenadores familiares» que hace un par de días cumplió 35 años y que hizo las delicias de muchos de los informáticos más viejunos...

Datacamp ha utilizado el «formato tabla periódica» para recopilar cientos de recursos acerca de la ciencia de datos, lo cual incluye desde empresas a herramientas y software o blogs y foros. The Periodic Table of Data Science [zoom en versión detallada]...

2big Dock de LaCie saldrá a la venta este verano; es una especie de versión supervitaminada del LaCie 2big actual, que crecerá hasta versiones de 12, 16 y 20 TB. Eso son 20.000 GB (la equivalencia exacta depende de si eres...

Puede que las especificaciones del Pinebook no parezcan gran cosa, pero es que lo importante es su precio 89,99 dólares en versión con pantalla de 11 pulgadas y 99,99 dólares con 14 pulgadas. Su peso: 1 kg el pequeño, 1,2 kg...
¡Ay! ¡Si Alan Turing levantara la cabeza! Este hilarante vídeo de Tom Wildenhain muestra cómo PowerPoint es Turing completo y puede usarse computacionalmente como una máquina de Turing universal. Esto tiene curiosas, profundas y divertidas implicaciones a todos los niveles. No...
Una técnica que todos hemos experimentado en primera persona al visualizar ciertas infografías es el llamado scrollytelling, cuyo nombre es un juego de palabras que combina scroll («desplazamiento») con storytelling («contar historias»). En esencia el usuario interactúa con un contenido y...

Bob Taylor en el PARC Soy perfectamente consciente de que la Internet que disfrutamos en la actualidad es fruto del trabajo de muchísimas personas a lo largo de muchos años, pero si alguien puede optar al título de padre –al menos intelectual–...

Esta impresionante colección de pósteres minimalistas sobre formatos de archivo de Ange Albertini son tan informativos como claros – unas pequeñas maravillas del diseño. Cada póster describe con detalle un formato de archivo: JFIF/JPEG, PNG, GIF, WAV, TIFF, EXE, SWF, COM…...

Cuenta la historia que el Solitario de Windows lo inventó un becario que trabajaba en Microsoft. Y aquí está: se llama Wes Cherry y aquello sucedió en 1988, hace casi 30 años. En esta simpática mini entrevista de Great Big Story...
En The most popular open source projects on GitHub in each country Felipe Hoffa destaca cuáles son (o fueron, en 2016) los diez proyectos open source más populares dependiendo de las valoraciones que reciben y considerando cuál es su país de...
Por Nacho Palou -
12 ABR 2017

Esta tecnología para crear ciudades 3D tan bellas y colosales como detalladas se llama Apparence. Se basa en varias ideas: la generación de escenarios mediante procedimientos, la meticulosidad de los detalles, la variedad de objetos y ambientes y el trabajo interactivo...

Desde 2007 el The Geena Davis Institute on Gender in Media recopila datos e información acerca de los patrones de género que se dan en la industria del entretenimiento como películas y otras producciones para cine y televisión. El objetivo de...
Por Nacho Palou -
9 ABR 2017

Simon A. J. Winder dedicó hace tiempo cinco años (2009-2014) a la construcción de esta Calculadora a base de relés, un curioso ingenio electromecánico que hace de la computación algo más visible y a «escala humana», frente al oscurantismo de los...

Porque estamos en el Siglo XXI lo de tener dos monitores en el ordenador ya no se lleva. En su lugar Samsung está preparando un monitor doble que la coreana ha venido a llamar “doble full HD” (DFHD). Es básicamente el...
Por Nacho Palou -
7 ABR 2017

Este Mac Classic construido con Lego por Jannis Hermanns funciona, aunque no como un Mac de verdad. En cambio dispone de un microordenador Raspberry Pi Zero y una pantalla de tinta electrónica en la que muestra información como la hora, el...
Por Nacho Palou -
6 ABR 2017

L-Rod es una pantalla portátil pensada para servir como monitor externo para ordenadores e híbridos. Utiliza un único conector USB-C para la conexión de vídeo y la alimentación eléctrica. Según el ordenador al cual se conecte es posible usar dos pantallas...
Por Nacho Palou -
5 ABR 2017
Lluvias de meteoros vistas desde el espacio es una herramienta desarrollada por Ian Webster que representa visualmente cómo “se verían” desde el espacio las lluvias de meteoros más conocidas: las perseidas, leónidas, oriónidas,... o todas a la vez. Las lluvias de...
Por Nacho Palou -
27 MAR 2017

Existe una delgada línea entre el audio de una película porno y el audio es este vídeo de Lazy Game Reviews en el cual se saborea cada pieza y componente de un ordenador PC totalmente nuevo, precintado y a estrenar que...
Por Nacho Palou -
26 MAR 2017

Suena como una mezcla de algo mágico y digno de documental del cosmos infinito combinado con algún tipo de viaje con LSD alucinógeno. Pero es simplemente el sonido de arranque de Windows ralentizado a factor 40. Según cuentan en Boing Boing,...

Buzz Aldrin quiere ser recordado por algo más que por ser “el segundo hombre que pisó la luna”. Así que lleva un tiempo desarrollado un plan para colonizar Marte y establecer allí un asentamiento humano permanente. Sí, eso que no se...
Por Nacho Palou -
18 MAR 2017

Ken Shirriff se ha entretenido en diseccionar un microchip Intel 8008 (ojo: no confundir con el 8088) que curiosamente hoy 14 de marzo cumple exactamente 45 años (se puso a la venta en 1972). El trabajo es de una preciosa ingeniería...
Lo mejor de ambos mundos en esta obra sobre matemáticas para la informática, una magna obra de Lehman (Google), Thomson Leighton (MIT/Akamai) y Meyer (MIT). Disponible tanto en formato libro/PDF como en formato curso OpenCourseWare del Instituto de Tecnología de Massachusetts....

El NASA's Software Catalog es un catálogo de programas de software desarrollados y utilizados por la agencia espacial. Las aplicaciones cubren una gran cantidad de disciplinas técnicas y científicas: aeronáutica, astronáutica, electrónica, comunicaciones, procesado de datos, sistemas de propulsión, materiales, etc. En...
Por Nacho Palou -
6 MAR 2017

Tal día como hoy, un 5 de marzo pero de 1981 (hace la friolera de 36 años) se lanzaba al mercado británico el Sinclair ZX81, uno de los primeros microordenadores personales que pudo llegar a la gente corriente. Su precio era...
De unas reglas muy simples puede surgir algo muy complejo; en algunos autómatas celulares como el Juego de la vida esto se traduce en que de repente se convierten en una suerte de ordenador universal capaz de computar cualquier cosa. Como...

En Windows 98 Wrist Watch se detalla el desarrollo de un proyecto que combina el sistema operativo Windows 98 y un microordenador Raspberry Pi en un reloj de pulsera, en un smartwatch forrestwatch. El resultado es un reloj un poco aparatoso....
Por Nacho Palou -
3 MAR 2017

El pasado 24 de enero llegaba a las librerías el libro Los nativos digitales no existen, un libro coral que he coordinado junto con Susana Lluna. El objetivo del libro es concienciar a padres y educadores de que aunque es cierto que...

Ya está en línea el informe La Sociedad de la Información en España SiE[16, que con ésta alcanza ya las 17 ediciones. Algunas de sus cifras más destacables: El 80,6% de la población española usa Internet; el 98,4% en la franja...
YOLO (You Only Look Once, «sólo se mira una vez») es un algoritmo de visión artificial que detecta y clasifica objetos en tiempo real. Lo hace tan rápido que una tarjeta gráfica Nvidia Titan X es capaz de procesar entre 40...

¡Ah, el maravilloso mundo de la demoscene! Dwitter es uno de esos sitios donde pasarse un largo rato explorando, descubriendo y aprendiendo, en este caso sobre JavaScript, en su vertiente más visual con algunas imágenes asombrosas. Cada demo se ve en...

Esta visita virtual en 360 al CESGA (Centro de Supercomputación de Galicia) tiene algo de místico y mucho de ciencia ficción; quizá es por la relajante musiquilla de ambientación, quizá por la iluminación al estilo espacio profundo, quizá porque nuestra mente...

En NewScientist, AI learns to write its own code by stealing from other programs El sistema capaz de escribir código de programación llamado (PDF) DeepCoder, desarrollado por investigadores de Microsoft y de la universidad de Cambridge, puede resolver desafíos básicos como...
Por Nacho Palou -
23 FEB 2017

Led-it-go es un (PDF) proyecto de investigación que plantea la posibilidad de extraer información almacenada en un disco duro a través de led indicador de actividad; la luz que parpadea cuando el disco duro está escribiendo o leyendo datos, esa luz...
Por Nacho Palou -
23 FEB 2017

Este magnífico gráfico de Asymco representa 40 años de ordenadores personales, desde el Apple II a la Surface de Microsoft o el último mini-PC en forma de Raspberry Pi – todo lo cual incluye también las diversas plataformas como tabletas y...

Disk Drill 3 en acción sobre un iPhone He estado probando Disk Drill 3, la versión más reciente de esta utilidad de recuperación de archivos, que como novedad principal incluye ahora soporte para Android e iOS y para la recuperación de cosas...

Como parte de la apasionante restauración del Xerox Alto que está llevando a cabo pacientemente CuriousMarc (canal altamente recomendado) llegó el momento de probar algunos videojuegos de los 70, incluyendo un pinball y Astroroids, una fiel versión del clásico Asteroides. Los...

Genius Bar es como llama Apple a su servicio de soporte técnico dedicado a resolver dudas o problemas con los productos de Apple. Y este señor pensó que sería interesante plantarse en una tienda de Apple con un prototipo de Macintosh...
Por Nacho Palou -
15 FEB 2017

Gizmodo tiene este vídeo explicativo sobre cómo funcionan los diferentes tipos de teclados: mecánicos, de membrana, táctiles… Cada uno tiene un sonido ¡clic! característico, y sus ventajas y desventajas. En general los teclados mecánicos se consideran superiores: tienen buena velocidad de...
Hackr.io es un estupendo recurso de calidad que recopila cientos de cursos y también tutoriales sobre lenguajes de programación, siempre desde el punto vista de alguien que quiere aprender desde cero. Los usuarios envían –y votan– cursos o tutoriales preparados por...

El jugador de póker profesional Dong Kim se enfrenta en el Casino Rivers de Pittsburgh –a través de la pantalla– con Libratus, la inteligencia artificial que resultó victoriosa en el reto Brains vs. AI Libratus se ha enfrentado a un grupo de...

The 8-Bit Guy compró en eBay un Commodore 128 bastante hecho polvo (”probablemente el peor que he visto nunca”): la carcasa de plástico y las teclas estaban totalmente amarillentas y mugrientas, e incluso faltaba alguna que otra tecla — aunque en...
Por Nacho Palou -
3 FEB 2017

En Computerworld, Booted up in 1993, this server still runs -- but not for much longer, En 1993 Bill Clinton cumplía su primer año como presidente, se lanzaron Windows NT 3.1 y Parque Jurásico y Phil Hogan, arquitecto IT, encendió un...
Por Nacho Palou -
2 FEB 2017
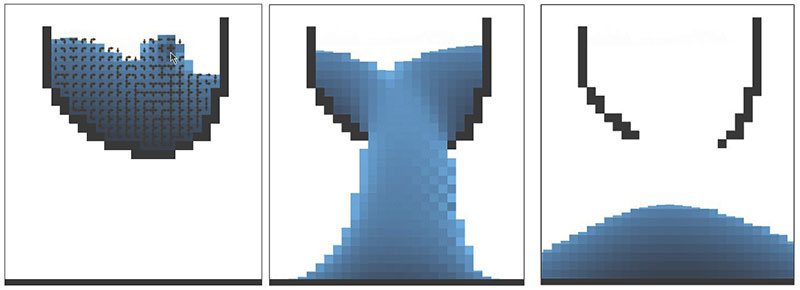
Este simulador de líquidos utilizando autómatas celulares es una forma de mostrar cómo actúan este tipo de creaciones matemáticas que tienen «comportamientos complejos a partir de reglas simples». Su creador es JGallant y está programado en Unity. Utiliza dos tipos de...

En el siempre excelente canal de Two Minute Papers resumen en cuatro minutos (eh, no es una ciencia exacta) el algoritmo que hay detrás de RAISR, una tecnología de la que ya hablamos hace un par de semanas y que Google...

Si te pasas por Sevilla antes del 1 de agosto de 2017 puedes aprovechar para darte una vuelta por la Casa de la Ciencia y visitar la exposición Érase una vez… la informática. Contiene más de 200 piezas de la colección...
Crear un algoritmo para jugar a Flappy Bird –el explosivo juego que surgió hace unos años y tuvo una vida tan intensa como efímera– es tarea casi trivial: obstáculos, distancias, saltos… Pero crear un algoritmo que aprenda por sí mismo a...
El amo del cotarro. ¡A ver quién lo supera! La forma en la que funcionan este reCaptcha, más conocido como «No soy un robot» es bastante curiosa: Google desarrolló un sistema que captura diversos datos sobre cómo se comportan las personas...

Print-A-Gif es un software en C# para imprimir GIF animados, con ayuda de ImageMagick (que hay que tener instalado) para el procesamiento de imágenes. Si eres de los que no entiendes ni papa de programación da un poco igual: en la...

Tal vez sea el avance definitivo: software de inteligencia artificial que aprende a escribir software de inteligencia artificial. El software autorreplicante. El reemplazo que nuestras limitadas mentes necesitan. En fin, si lo publican en el MIT Tech Review por algo será....

Tras el éxito de la Raspberry Pi, el mini-PC en una caja, Asus ha puesto a la venta la Tinker Board, una caja con exactamente el mismo formato y medidas pero equipada con un chip más potente y algunos extras, como...

Viva Amiga: The Story of a Beautiful Machine es un documental de una hora acerca del Commodore Amiga, una de las más estupendas máquinas surgidas en la década prodigiosa de los 80, diseñada para potenciar la creatividad y a los que...
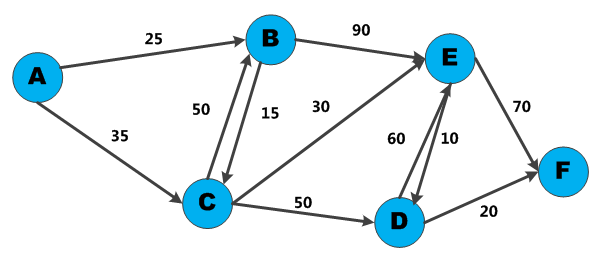
Dijkstra, Burbuja, Knapsack… Todos son términos relacionados con algoritmos de programación de algún tipo, pero también son los que surgen más frecuentemente en entrevistas de trabajo como parte de los tests que hay que superar. Que no todo es explicar cuál...
Este generador de planetas mediante procedimientos de Jarett Gross utiliza diversas variables para crear mundos pequeños, esféricos, teselados; se dirían de ficción. Entre las variables está la teselación (que es lo que más influye en la velocidad de cálculo) y el...

Con Toontastic 3D los niños de todas las edades pueden dibujar, crear animaciones y narrar sus propias aventuras; contar historias novedosas, realizar trabajos escolares y cualquier otra cosa que puedan imaginar. Todo lo que necesitan hacer es desplazar los personajes por...
Por Nacho Palou -
17 ENE 2017

El vídeo corresponde a una demo de Adobe Research, que explora el uso de un asistente digital tipo Siri (Adobe Sensei) aplicado a la edición de fotografías: «el reconocimiento de voz es capaz de entender el lenguaje natural del usuario para...
Por Nacho Palou -
17 ENE 2017
El navegador Neon de Opera es una interpretación “fresca y divertida” del navegador web Opera. Puede descargarse gratis para Mac y Windows. Neon usa la imagen de fondo del escritorio del sistema operativo del ordenador y la incorpora en la ventana...
Por Nacho Palou -
14 ENE 2017
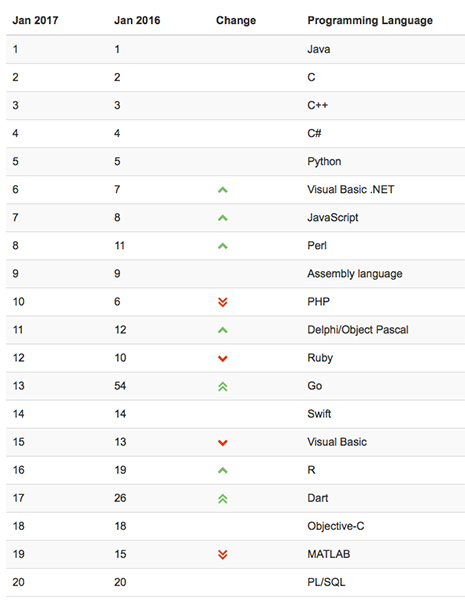
El lenguaje Go no es el más utilizado (por delante están los grandes clásicos: Java, C, Python, Perl, PHP,...) pero según el Tiobe Index el lenguaje de programación de Google ha disparado su popularidad en el último año, saltando nada más...
Por Nacho Palou -
12 ENE 2017

Una macrofotografía de un microchip, en hipercolor. Según GTD es un Pentium 4 de Intel, modelo que llegó al mercado a finales del año 2000. En el tumblr de Data-and-Vision puede disfrutarse alta resolución. (Vía Commodorez + Data-and-vision + MS-DOS5, etc.)...

La película Rogue One (2016) se sitúa cronológicamente justo antes del episodio IV de Star Wars que se filmó entre 1975 y 1976. Hay 40 años entre ambas películas, pero la narrativa de Rogue One hacía necesario recuperar a personajes de...
Por Nacho Palou -
10 ENE 2017

Cómo es un contrato de «Condiciones del Servicio» y cómo podría ser. Fuente: TNW En TheNextWeb lo tienen claro: It’s time for apps’ terms and conditions to ditch the legalese. Como ejemplo dicen que según un reciente informe aunque la mitad de...

El ordenador de Intel Compute Card mide 55 mm de ancho, 95 mm de largo y tiene 5 mm de grosor; es más o menos del mismo tamaño que una tarjeta de crédito (más o menos, y más gruesa) y la...
Por Nacho Palou -
9 ENE 2017

Este pequeño vídeo de Two Minutes Papers explica y muestra algunos ejemplos de una técnica denominada Voxel Cone Tracing que parece resolver uno de los problemas con la generación de imágenes por ordenador: el dotar de realismo a las escenas 3D...

La herramienta de Google Tilt Brush permite dibujar trazos que existen de forma tridimensional en un entorno de realidad virtual. Para explorar las posibilidades artísticas de este nuevo medio Google ha creado un grupo creativo multidisciplinar formado por más de sesenta...
Por Nacho Palou -
5 ENE 2017
Y se lo preguntas así, tal cual: Desde un ordenador, una tableta o un móvil en el que hay que iniciar sesión con la cuenta de Google — la misma que se tiene en el teléfono. Google devolverá como resultado de búsqueda...
Por Nacho Palou -
5 ENE 2017

En estos días en los que muchos «nativos digitales» van a recibir o ya han recibido un móvil o una tableta. Y el mito de los nativos digitales asomará de nuevo su cabeza con lo que nadie les contará cómo hacer...

Esta demostración denominada simplemente Wavenet TTS es una especie de avance de la línea que está siguiendo Google con DeepMind para mejorar la tecnología de síntesis de text-a-voz (TTS). Las voces actuales de Google, Siri (Apple) y Cortana (Microsoft) están bien...
Mini World Of Bits es una idea para medir la «capacidad de aprendizaje» de agentes capaces de interactuar con sitios web y aprender mediante técnicas de refuerzo. La idea consiste en estandarizar las pruebas de modo que los agentes reciben una...

LineForm, desarrollado por Ken Nakagaki, Sean Follmer, e Hiroshi Ishii, del Tangible Media Labs del MIT, es una ”interfaz cambiante” que ofrece nuevas posibilidades para representar información y datos abstractos (como el paso de corriente eléctrica o el resultado de una...
Por Nacho Palou -
21 DIC 2016

Este enfrentamiento sangriento entre 11.000 pingüinos y 4.000 “papanoeles” es una demostración del simulador de batallas épicas de Brilliant Games Studios y su poderoso sistema sistema de generación y animación de personajes virtuales. En total son 15.000 personajes renderizados moviéndose a...
Por Nacho Palou -
19 DIC 2016

Nate de Sparkfun se topó en un proyecto con un módem de 9600 bps y se preguntó de dónde provenía el número 9600 exactamente. Porque es un número «poco redondo» desde el punto de vista informático: si estaba relacionado con la...

En The Creators Project / Vice, Draw in 3D with the ‘Mental Canvas’ Illustration App, Mental Canvas (...) fusiona las necesidades de estética y estilo que necesita un ilustrador con el modelado 3D, dando como resultado ilustraciones con una maravillosa profundidad....
Por Nacho Palou -
14 DIC 2016

El uso combinado de un Bebop 2 de Parrot y de la tecnología de Pix4D permite crear modelos 3D de grandes edificios en apenas una horas. Desde la app Pix4Dcapture para móvil se selecciona sobre el mapa el edificio que se...
Por Nacho Palou -
14 DIC 2016
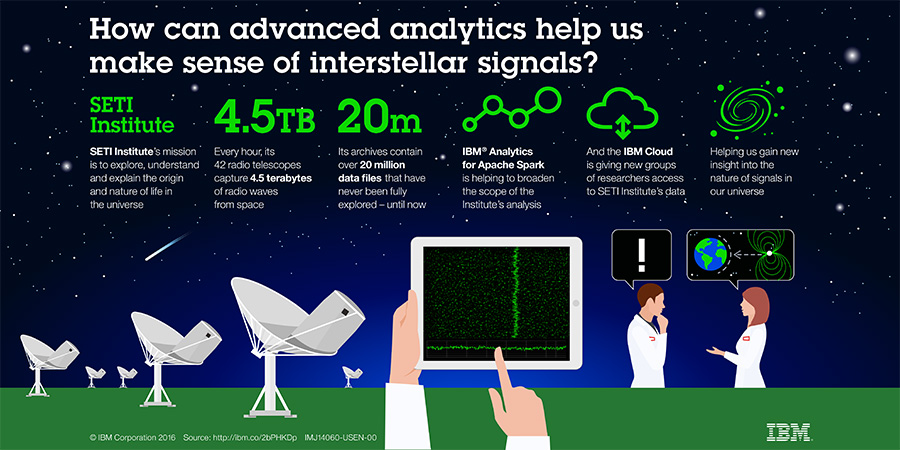
IBM ha publicado un pequeño estudio de caso titulado SETI Institute: expanding the parameters of the search for extra-terrestrial intelligence with advanced analytics en el que explica la tecnología de la marca que se está utilizando para actualizar el trabajo del...
Este emulador de Atari 2600 corre sobre Minecraft porque puede hacerse. Según Seth Bling que es su creador está hecho en un Minecraft «pelado», sin plugins o mods, utilizando unos 2.000 bloques de comandos, llamados así porque sirven para ejecutar comandos...
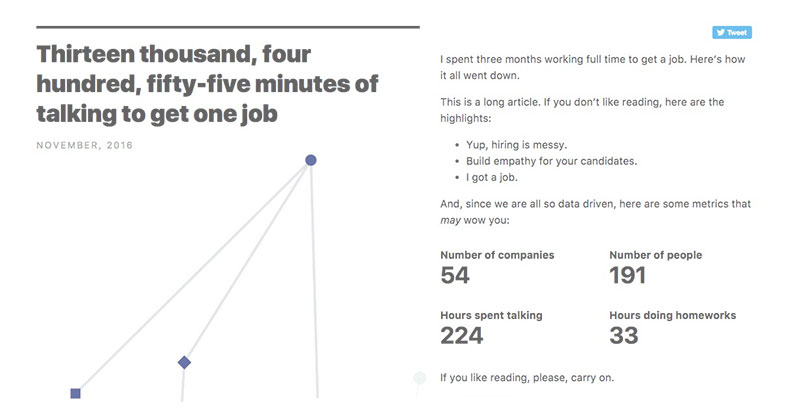
Jeff Kolesky convirtió su aventura de encontrar un nuevo trabajo en toda una labor de análisis detallado de datos. Anotó cuidadosamente todas sus llamadas de teléfono, reuniones y el tiempo dedicado al correo electrónico, sumó todas las horas y horas que...
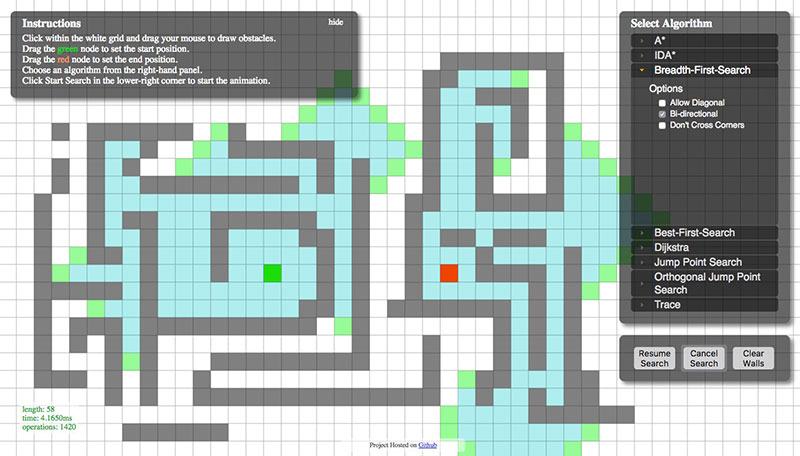
PathFinding contiene una explicación visual de diversos algoritmos para resolver laberintos. Basta dibujar los caminos y paredes haciéndolo tan sencillo o complicado como te apetezca y luego ver cómo laboriosamente se calcula el camino óptimo entre el punto verde y el...

Quienes trabajan con macOS habitualmente habrán experimentado de vez en cuando (es casi un ritual) el famoso crash de Apple Mail, la aplicación de correo. Ya sea porque no se cierra apropiadamente al salir, por algún «mensaje corrupto» que no llega...

El Barcelona Supercomputing Center ha anunciado la compra a IBM de un nuevo supercomputador MareNostrum 4 que será básicamente 12 veces más poderoso que el MareNostrum 3 que vienen utilizando hasta ahora y que está ubicado en la espectacular capilla de...

En TED-Ed han publicado una lección sobre cómo alfabetizar los volúmenes de una librería. El ejemplo es en realidad una metáfora para hablar de forma educativa sobre la eficiencia de diferentes algoritmos de ordenación, algo comúnmente utilizado en diversas tareas de...

Ah, los años de 1990: cibercafés, internet a 28 kilobit por segundos (no a 300.000, como ahora), pantallas con culo, modas y peinados cuestionables, gafas de realidad virtual y El cortador de césped,... De hecho, de todo lo que aparece en...
Por Nacho Palou -
29 NOV 2016

CSSreferenc.io es una guía visual de las propiedades más habituales de CSS. Pero en vez de ser el típico listado a lo bruto tipo W3C u O’Reilly esta guía está elegantemente diseñada, de modo que se pueda ver el resultado de...
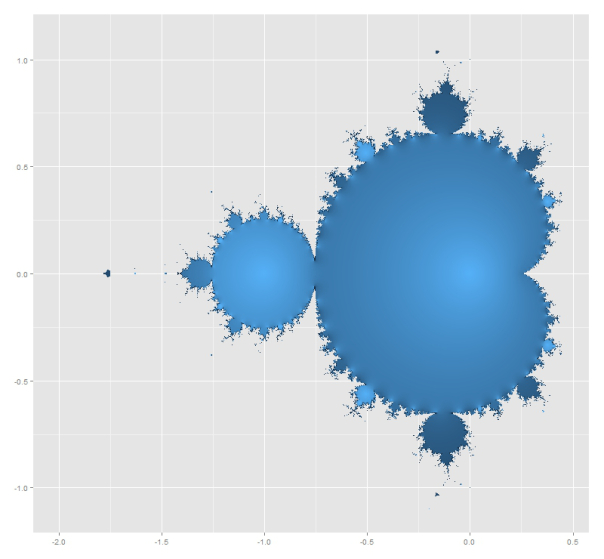
Muchas melodías y sonidos tienen algo de fractales, pero en The Sound Of Mandelbrot Set Antonio (que también escribe en Fronkonstin) explica algunos de sus experimentos con el conjunto de Mandelbrot para convertirlo en notas musicales. Los resultados pueden oírse en...
D3-force [código en Github] es un simulador de fuerzas entre partículas que utiliza un método denominado integración de Verlet para calcular los valores de la simulación – que no deja de ser una versión «simplificicada» de la realidad y cuya simplficación...

Eric Shull describió en esta página cómo funciona un código para generar islas de forma realista, mediante procedimientos, partiendo de algoritmos que trabajan con formas poligonales básicas. El resultado tiene cierto aspecto fractal debido al uso de la recursión; hay algunos...

La Máquina Big Hex es la antítesis de la miniaturización: un ordenador de 16 bits gigante diseñado para enseñar cómo funcionan estas máquinas por dentro. Cables, botones y luces dispuestos sobre un gigantesco tablero en el que decenas de módulos realizan...

Encontré gracias a @pickover este vídeo bastante asombroso (y viejo) de Phillip Bradbury que muestra a un gigantesco autómata del juego de la vida emulando el juego de la vida. Había oído hablar de algunas estructuras de este tipo hace años,...

Google Earth VR es la versión de Google Earth para utilizar con las gafas de realidad virtual Vive de HTC (y por extensión un ordenador capaz). Ofrece la posibilidad de «sobrevolar ciudades, contemplar las vistas desde lo alto de una montaña...
Por Nacho Palou -
17 NOV 2016

Estas preciosidades son los Backup Plus Portables de 5 TB de Seagate, un espacio de almacenamiento nada despreciable –hasta hace poco sólo al alcance de los administradores de sistemas y poco más– en un tamaño reducido (2,5 pulgadas) y peso ridículo...
Para unas cosas Google es la mayor inteligencia artificial que hará del mundo futuro un lugar mejor, pero para otras… … no sabe que media hora (0,5 horas) son 30 minutos. El menú ofrece «minutos», «horas» o «días», pero por defecto son...
Atlas Recall se autodefine como la memoria fotográfica de tu vida digital y podría considerarse así: la aplicación guarda copia de todo lo que en algún momento ha aparecido en la pantalla del ordenador o del móvil, y crea un índice...
Por Nacho Palou -
7 NOV 2016

Este vídeo tiene más años que la tana; es una demostración del funcionamiento de la Moniac, siglas de Monetary National Income Analogue Computer: «Computadora Analógica de Ingresos Nacionales Monetarios», una peculiar calculadora «de agua» que data de 1949 y que fue...

Los laberintos son sumamente interesantes de por sí, pero cuando se trata de generarlos de forma automática la cuestión se complica mucho más que cuando se diseñan «a mano». Recuerdo haber pasado días y días probando con diferentes algoritmos para crear...
PDF to JPG Online Converter es un servicio que realiza automáticamente la conversión de un PDF en un fichero de imagen JPEG. Esto es útil cuando la herramienta de edición de imágenes o composición que se está usando no permite abrir...

Habrá que dedicarle un rato a este informe que ha lanzado la Casa Blanca como visión global de los retos a los que se enfrentarán los Estados Unidos –y por extensión el reto de países– respecto a la inteligencia artificial (IA):...
Este simulador de autopista escrito por Silvan Mühlemann funciona directamente en el navegador – dice que escribió el código estando de vacaciones en España, para pasar el rato. Permite modificar diversos factores del tráfico rodado: la velocidad «objetivo» de los coches,...

Matt Zucker ha desarrollado un algoritmo llamado NoteShrink, con una excelente página explicativa sobre su funcionamiento, para limpiar y mejorar las imágenes escaneadas de apuntes escritos a mano. Además de eso, el resultado pasado por la compresión es mucho menor que...

Este vídeo muestra una alucinante tecnología del Ishikawa Watanabe Laboratory capaz de proyectar imágenes animadas sobre superficies flexibles, como materiales no rígidos o ropa, y que además estén en movimiento. El invento consta de dos partes: Para la proyección de imágenes...
Tron 2.0 es un estilo de mapas diseñado para Mapzen, una herramienta de mapas y cartografía abierta que permite personalizar la información visual sin apenas limitaciones. Pero lo más interesante no es la herramienta en sí sino el trabajo entre bambalinas...
La extensión TurboNote (disponible en español) para el navegador web Chrome (en Chrome Web Store) permite tomar notas y hacer apuntes directamente desde el navegador mientras se está visualizando un vídeo de YouTube, Vimeo, Ted, Facebook o Netflix, por ejemplo. Una...
Por Nacho Palou -
14 OCT 2016

“Estamos en 2016.” Y esto es lo que se siente al aprender JavaScript en 2016. ¡Ay! Una hilarante y historia de enredo real como la vida misma, escrita por Jose Aguinaga, inspirado por It’s the future. Indispensable a todos los programadores,...

Uno de los capítulos más curiosos de la historia de la informática se escribió, por increíble que parezca, a principios del siglo XIX en la Inglaterra victoriana. Charles Babbage concibió dos máquinas diseñadas para hacer cálculos. Una más limitada, la Máquina...

Hola, bienvenido a Paint. Según estos vídeos filtrados por WlakingCat, Microsoft tiene preparada una gran actualización de Paint, el programa de «dibujo» que se estrenó con Windows 1.0 en 1985 – y que desde entonces no ha cambiado demasiado. La versión...
Por Nacho Palou -
10 OCT 2016

No más tofu, Noto, es una nueva familia de fuente tipográfica digital que contiene unos 110.000 caracteres, cada símbolo Unicode existente, para acoger más de 800 lenguas, An open source font system for everyone — El proyecto Noto comenzó como una...
Por Nacho Palou -
7 OCT 2016

Esta lista preparada por Top Media incluye todo tipo de ordenadores altamente inútiles, disfuncionales o simplemente horrorosos. Entre ellos está el TI-99 de Texas Instruments, que solo podía escribir en mayúsculas; el telefonordenador E-m@ailer de Amstrad (¡del 2000!) que servía para «enviar...
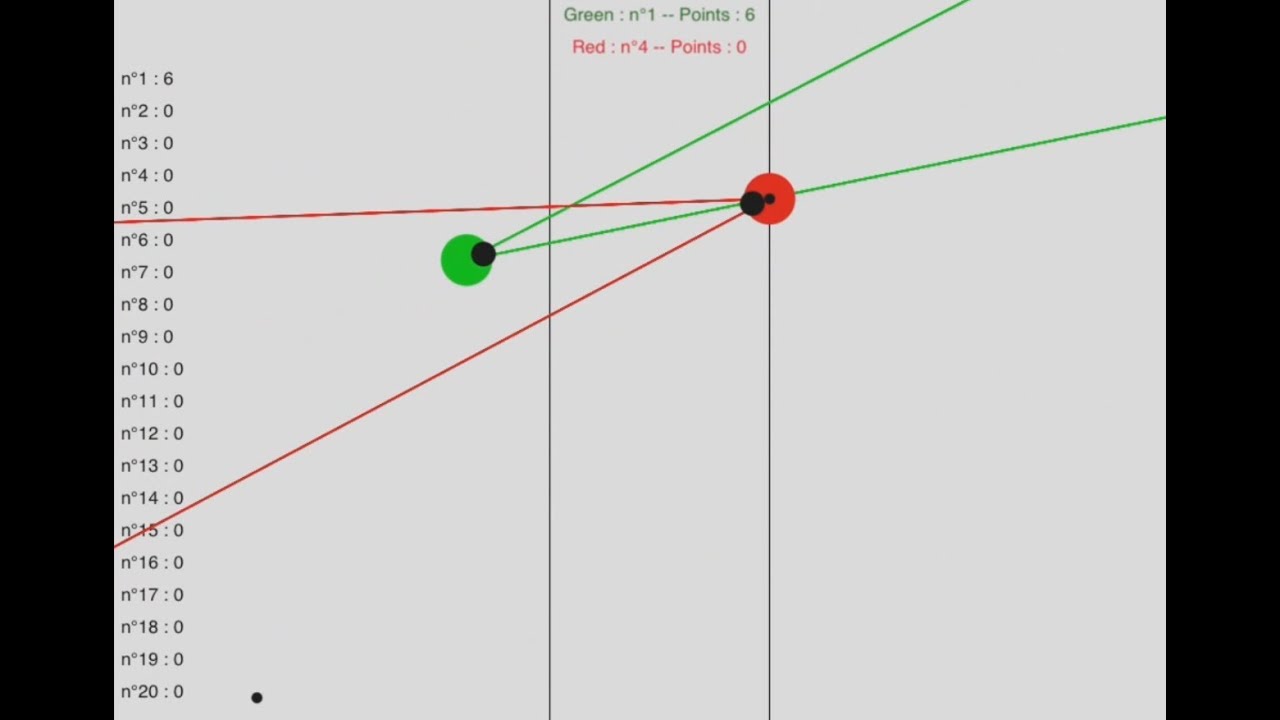
Lo más interesante de este vídeo es cómo muestra el potencial de los sistemas de aprendizaje basados en evolución de redes neuronales, que acaban aprendiendo a fuerza de ensayo-y-error mediante evoluciones aleatorias. En este caso se juega a ser Dios con...

Scribb, de la diseñadora multimedia Mylène Dreyer, es un sencillo videojuego que explora un interfaz mixto, que combina el uso del ratón y de trazos hechos con papel y rotulador. El jugador debe dibujar trazos y zonas negras con un rotulador,...
Por Nacho Palou -
29 SEP 2016

Este año se cumplen 50 años de la salida al mercado del Factor–P, el primer ordenador diseñado y construido en España de la historia. Claro que como suele suceder con estos cacharros antediluvianos todo depende de lo que estés dispuesto a...

No son vídeos, sino imágenes fijas convertidas a vídeo. Mientras que los ordenadores van a aprendiendo a reconocer objetos y escenas en fotografías, «entender el movimiento de los objetos y las escenas dinámicas es un problema intrínseco de la visión artificial», explican...
Por Nacho Palou -
28 SEP 2016

Pueblo Talaak / Sir Carma Espectacular y altamente recomendable el artículo de Matej «Retro» Jan en Retronator Magazine titulado Pixels and voxels, the long answer. Está dedicado a repasar la historia de los píxeles y los vóxeles en el arte y el...

De los creadores de la Sinclair ZX Spectrum Vega llega la Sinclair ZX Spectrum Vega Plus, una consola portátil que incluye pantalla en formato 4:3 para jugar sin problemas a los 1000 juegos clásicos para Spectrum que incluye. Pero también se...

Todos los que me conocéis sabéis que llevo años diciendo que los nativos digitales no existen; este pasado mes de julio hasta me dejaron contarlo en TEDxGalicia 2016. La premisa básica: que las niñas y niños que nacen rodeados de tecnología...

Si pudiera jugaría a videojuegos en un Atari. Y otras decenas de viejos anuncios de ordenadores en Vintage Computer and Videogames Ads, en 12 partes. Los hay serios y los hay aburridos y también los hay hilarantes, machistas, acertados, desafortunados y...
Por Nacho Palou -
27 SEP 2016
En First recording of computer-generated music – created by Alan Turing – restored, Investigadores neozelandeses han restaurado la grabación que registra la primera vez que se produjo música con un ordenador. Fue en 1951 usando un enorme aparato construido por el...
Por Nacho Palou -
27 SEP 2016

Se llama Daddy’s Car. Y dicen que se parece a alguna canción de los Beatles. Pero ha sido compuesta por una inteligencia artificial. A mi me gusta, pero lo cierto es que lo de los gustos musicales varía mucho de unas...
Este vídeo es una excelente demostración de cómo «pensar de otra forma» respecto a los tipos de tareas que realiza el software actual y el que podrían hacer en el futuro. Se trata de la edición de fotografías de rostros mediante...

Gavin de Tinkerings construyó este explorador de autómatas celulares, una máquina física y muy visual para ver en funcionamiento los autómatas celulares 1D más básicos. En su pantalla cada línea es un «momento» en la evolución de las «células»; la máquina...
A raíz del recientemente anunciado robo de datos de 500 millones de cuentas de Yahoo, que aún no está incluido y que se les saldrá de escala, no está de más darse una vuelta por World's Biggest Data Breaches. Incluye datos...
En The Neural Zoo, un blog del Asimov Institute, crearon un excelente y vistoso póster de las redes neuronales [aquí completo en alta resolución] que sirve a la vez de chuleta y de explicación resumida de cómo funcionan los diferentes tipos...
Doodle3D Transform es una app para el navegador web y para iPad y Android que convierte diseños y trazos hechos sobre papel en objetos 3D. El propósito de la aplicación es simplificar el diseño 3D para que resulte accesible a y...
Por Nacho Palou -
21 SEP 2016

Trasteando por ahí me he encontrado con The fsociety Keyboard, un teclado diseñado por AnonymouSmst que pretende ser mucho más que un teclado. Aparte de unas ruidosas teclas incorpora ledes programables para hacer efectos de iluminación, un joystick para simular un...

Una demo que muestra las posibilidades del programa Microsoft Actiongram, ya disponible en versión beta, que permite usar las HoloLens para crear contenido de realidad aumentada, vídeos que mezclan realidad y efectos y personajes virtuales. El vídeo recoge parte de la...
Por Nacho Palou -
13 SEP 2016

Disco duro Toshiba Canvio Premium (Mac) Capacidad 3 TB Interfaz datos USB 3.0 Conector USB Tipo A / C Alimentación vía USB Tamaño 10 x 7 x 1,5 cm Peso 295 g Versiones 1 TB / 2 TB / 3 TB...
A quienes les gusten los mapas que aparecen en las primeras páginas de libros como El señor de los Anillos, Dragonlance o incluso en la secuencia de introducción de Juego de tronos encontrarán apasionante echar un vistazo a este Fantasy map...
Boole, Babbage, Church, Zuse, Shannon, Lovelace, Leibniz, Turing, Wilkes, Jacquard, Minsky, Hopper, Thompson, von Neumann, Kurtz, Berners-Lee, Ritchie, Kay, Cerf, Moore, Pascal… Son algunos de los nombres de los pioneros, qué digo pioneros, genios y héroes, que bregaron en los duros...

La granja de renderizado que Pixar usó para la creación de Toy Story en 1995 tenía aproximadamente 1000 millones de transistores sumando los de todas las CPUs de los ordenadores Sun que la componían. La CPU A8 de un iPhone 6...

La NASA, en un giro inesperado de los acontecimientos, descubrió que las naves Apolo necesitaban software. Margaret Hamilton (1936-) salvó el día.
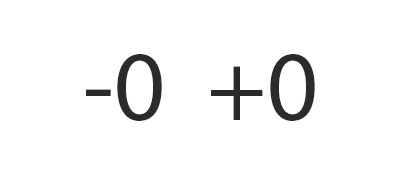
En la aritmética cotidiana el número cero no tiene signo, de modo que -0 y +0 son iguales: 0. Pero en informática se descubrió que sería útil tener ceros con signo («cero negativo» y «cero positivo») para ciertos cálculos. De este...

Stamp [OS X] es un programa de productividad (lo que antiguamente era un software de «macros») con el que se pueden crear snippets o «trozos» de texto para insertar en cualquier documento. Esto incluye principalmente textos repetitivos de correo electrónico, encabezados, trozos...

Aunque nunca fue un producto comercial Xerox fabricó unas 2000 unidades del Alto que se destinaron sobre todo para el uso interno de la empresa, aunque también se repartieron unos 500 a diversas universidades. Pero lo que hace importante al Xerox...

Javier «el Javo» nos envió una información sobre el Kansas Fest, un pequeño festival de una semana de duración donde se rememoran los tiempos de los inicios de Apple con aficionados de todas partes del mundo llevando sus Apple II y...
El Emulador de Amiga de Archive.org funciona con solo hacer un clic desde el navegador web; solo por eso merece la pena echarle un vistazo rápido. Allí están archivados para la posteridad miles de programas y juegos para el clásico y...

El juego Pokémon Go hace uso de la realidad aumentada combinando objetos virtuales —los personajes, pokémones y objetos del juego— sobre una imagen de vídeo del mundo real en el que aparecen. En la realidad virtual común los objetos virtuales y...
Por Nacho Palou -
6 AGO 2016

En este artículo titulado Reverse Turing Tests: Are Humans Becoming More Machine-Like? el filósofo John Danaher explica algunas ideas sobre el famoso Test de Turing y lo que supondría invertir la prueba, es decir: que un humano intente actuar como una...

La web Mark Maker hace uso del aprendizaje automático y de las redes neuronales para generar logotipos a saco, aplicando lo «aprendido» sobre logotipos por un ordenador. Como sea, el terminator de los diseñadores básicamente necesita que le des la marca...
Por Nacho Palou -
1 AGO 2016

Martes 15 [de agosto de 1843] Vi a AAL esta mañana y rechacé todas sus condiciones. – Charles Babbage El algoritmo de Ada: la vida de Ada Lovelace, hija de lord Byron y pionera de la era informática. James Essinger. Gibson Square,...

El New York Times publicó esta pieza sobre Lonnie Mimms, un coleccionista «profesional» amante los ordenadores. En su pequeño museo ha ido atesorando todo tipo de equipos principalmente de las décadas de los 70, 80 y 90. Muchísimos de ellos parecen...

Sencilla, elegante y geek a la vez, esta Code:deck es una baraja de naipes que utiliza código del mundo de la programación en unos naipes que se «autodefinen» en cada lenguaje. Es una idea un tanto enrevesada y autorreferente y solo...
Algo extraño y aberrante debió suceder hace poco en algún oscuro rincón de Google para que el otro día decidieran actualizar la versión 52.0.2xxx para OS X añadiendo por defecto el famoso Material Design que –como su propia definición dice– utiliza...

Los disquetes no van a durar para siempre. Pero no me da pena: yo tampoco duraré para siempre.– Tom PerskyFloppyDisk.com Este buen hombre gestiona FloppyDisk.com y cuenta en este videoreportaje de Great Big Story cómo ya bien entrado el siglo XXI...

Hemos mencionado en unas cuantas ocasiones el artículo As we may think, de Vannevar Bush. Publicado en julio de 1945 en la revista The Atlantic Monthly el autor habla en él del memory extender, que él mismo bautiza como Memex. Se trata...

En 2011 Motorola nos dejó ver y probar el Motorola Atrix, el teléfono que se convertía en ordenador portátil conectándolo a un portátil tonto, una pantalla y un teclado sin procesador, ni disco duro, ni baterías. Un producto interesante que no...
Por Nacho Palou -
15 JUL 2016
C++ Quiz: are you a code guru? Este test creado por los desarrolladores de PVS-Studio utiliza código de proyectos reales en los que se encontraron errores de programación de todo pelaje. Si sabes C++ y te consideras razonable bueno quizá quieras...

De algún modo acabé atrapado en un pliegue de YouTube con decenas de videos dedicados a hacer divisiones por cero en calculadoras mecánicas y ver qué pasa. Vídeos de hasta diez horas en los que máquinas electromecánicas permanecen en un bucle...
Por Nacho Palou -
12 JUL 2016

Con más de 100 millones de líneas de código, 90 ordenadores y módulos de control y un total de 50 kilos de electrónica, cables y sensores, un coche de lujo moderno se puede considerar un superordenador personal. La imagen representa el...
Por Nacho Palou -
12 JUL 2016
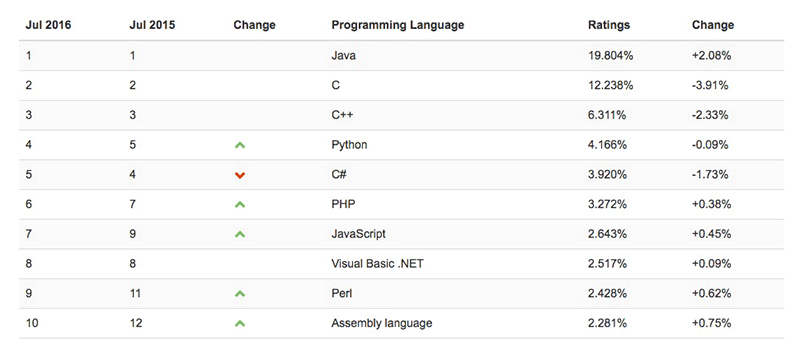
El ránking TIOBE es un indicador de la popularidad de los diversos lenguajes entre la comunidad de programadores. En la tabla de este mes se ha colado de forma inesperada un viejo conocido en el puesto #10, superando a Ruby, Swift...

En el Communications of the ACM han dedicado un artículo al gigantesco repositorio de software que gestiona Google. Una especie de gigantesco sistema monolítico con 1.000 millones de archivos en su interior, en el que cada día miles de desarrolladores hacen cambios sobre todo el software que utiliza la compañía

He aquí una recopilación de todos los sonidos de arranque de Windows, desde la versión 3.1, la primera con sonido, a Windows 10, que vuelve a no tener sonido. Hicieron el montaje en Mashable hace ya tiempo. Algunos son tan populares...

Este es el nuevo modelo del proyecto One Laptop Per Child, que empezó con aquello del «ordenador de 100 dólares» y ya va por 230 dólares (aunque sean «australianos»). Se llama Infinity One y es todo un señor portátil pero más...

En la web de Proyecto Bloks Google describe su idea de una plataforma de hardware abierta para que los diseñadores puedan crear una experiencia de «programación tangible» para los pequeños estudiantes. Esto incluye piezas físicas parecidas a las de las construcciones...

El vídeo muestra y explica con detalle cómo funciona una unidad de cinta magnética IBM 729, antecesor de los discos duros que utilizaba cintas magnéticas de varios cientos de metros para almacenar la información. Una cinta de media milla (unos 730...
Por Nacho Palou -
30 JUN 2016
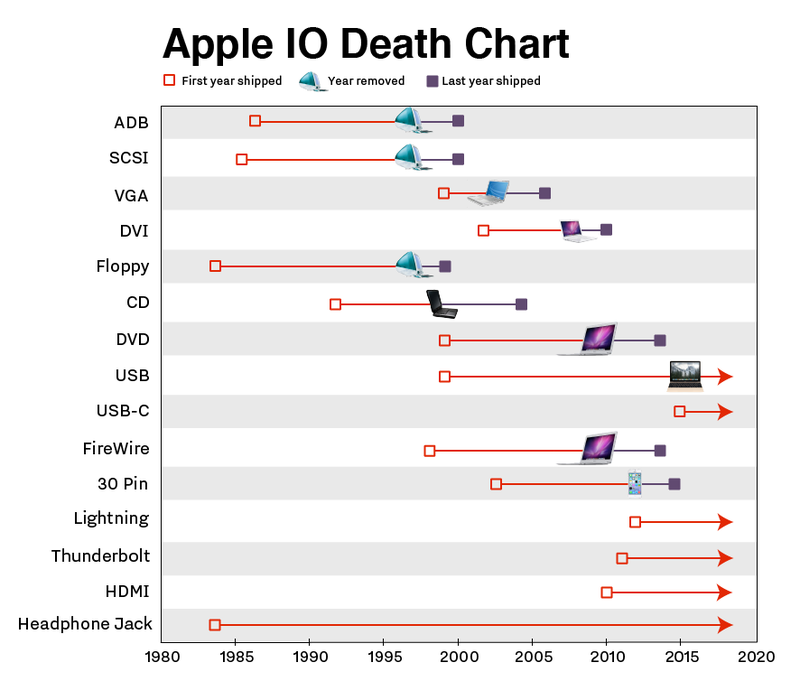
No nos hacemos a veces idea de lo efímeros que son los «estándadares» (comillas intencionadas) que utilizamos cada día. La tabla que han recopilado en The Verge, The ultimate Apple I/O death chart permite hacerse una buena idea del panorama en...

En Motherboard, Researchers Make Malware That Steals Data by Spinning Your Computer's Fans, Investigadores de la universidad Ben Gurion de Israel describen un ataque informático dirigido contra ordenadores aislados que normalmente no resultan accesibles ni tienen conexión (...) el método aplicado...
Por Nacho Palou -
29 JUN 2016

La hora del código de Code.org, anima a los niños se introduzcan en la programación desde temprana edad. Los cursos son gratuitos y se completan vía web, a través de tutoriales y lecciones disponibles también en español. Para los cursos de...
Por Nacho Palou -
29 JUN 2016

El PocketCHIP (49 dólares) es un pequeño ordenador de tamaño minúsculo construido sobre la placa CHIP que es a su vez un PC de 9 dólares y uno de los más baratos del mundo. Pese a su tamaño, lleva de todo:...
Los que utilizan la línea de comandos de Linux de forma ocasional encontrarán útil TLDR Pages, una sencilla web en la que se pueden consultar todas las páginas del manual («Man») de forma simplificada –pero completa– y a la vez con...

Nuestro admirado 8-Bit Guy nos recuerda cómo era la época en la que el almacenamiento externo de los ordenadores «familiares» se hacía en cintas de casete. Esto fue antes de la popularización de los disquetes flexibles y después del uso de...
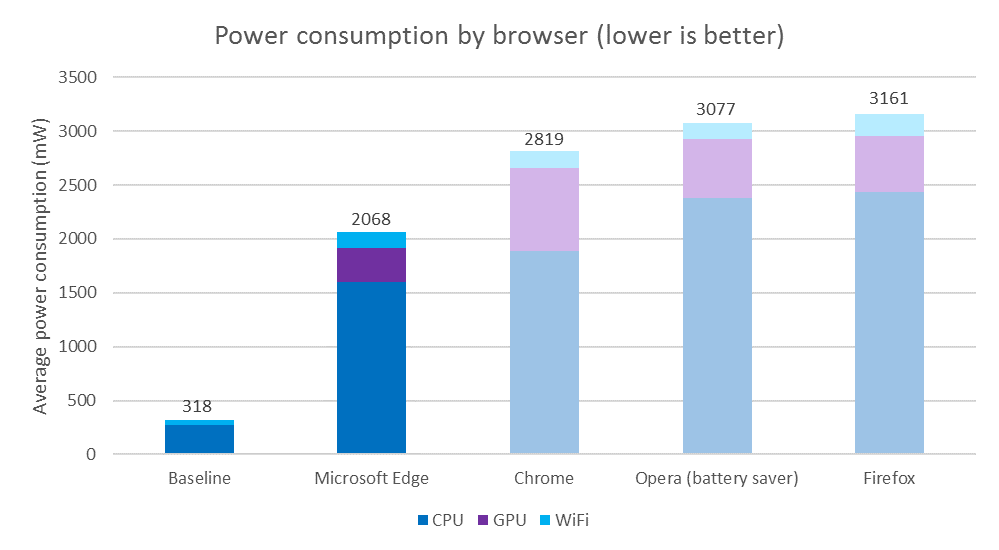
Que el navegador web Chrome de Google reduce significativamente la duración de la batería de los ordenadores portátiles es algo ya conocido — y hasta ahora no solucionado del todo. También se sabía que el navegador web que gasta menos batería...
Por Nacho Palou -
20 JUN 2016

El Smart Boy Developer Kit comenzará a enviarse en diciembre pero ya está a la venta y se puede reservar por 60 dólares. Se trata de un ingenioso kit de desarrollo para utilizar y crear juegos compatibles Game Boy a partir...
Cómo cambiar en diez segundos y con dos comandos el tipo de archivo de captura por defecto en OS X (JPEG, PNG, PDF…)

Remix OS 2.0 es una versión de Android para ordenadores con procesadores Intel x86, ordenadores PC y Mac y además es gratuita. No se trata de un entorno en el que ejecutar aplicaciones Android —como hace la extensión ARC Welder para...
Por Nacho Palou -
15 JUN 2016

Este extraño cortometraje experimental se titula Sunspring. Es una idea de Oscar Sharp (cineasta) y Ross Goodwin (tecnólogo) que partió del reto de crear una «máquina capaz de escribir guiones». Con ideas basadas en las redes neuronales crearon Jetson, un software...
El voto electrónico es uno de esos animales mitológicos que se suelen usar como ejemplo de un futuro mejor porque «suena bien» pero sobre el que casi todos los expertos te dirán ¡No! ¡Eso es lo único que no debería ser...
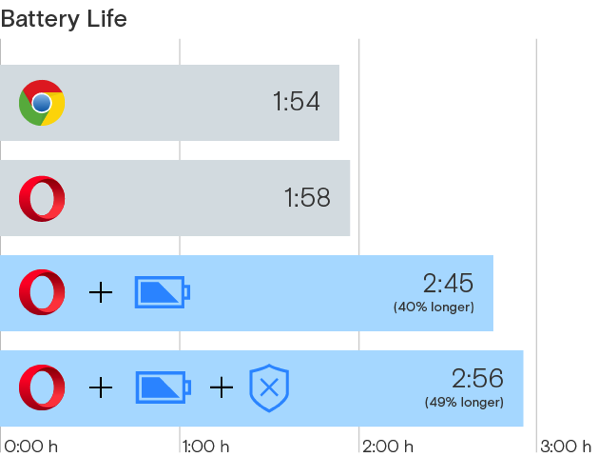
Con tanta parafernalia en las páginas web y también en los navegadores web resulta que buena parte de la batería de un ordenador portátil se consume durante la navegación por internet. Como medida Opera Software ha incorporado una opción de bajo...
Por Nacho Palou -
8 JUN 2016

El iPad Pro de 9,7 pulgadas con el teclado Smart Keyboard. El iPad Pro de 9,7 pulgadas contiene la tecnología y la capacidad del iPad Pro en el formato, tamaño y peso, del iPad Air 2. Esto significa, por una lado, potencia...
Por Nacho Palou -
8 JUN 2016

La gente de la firma de seguridad Pen Test Partners se percató de la particular manera que tiene el ordenador del Mitsubishi Outlander PHEV de conectarse con la app en el móvil del usuario: en lugar de usar el habitual método...
Por Nacho Palou -
7 JUN 2016
El proyecto Magenta del Google Brain Team utiliza sistemas de aprendizaje máquina o aprendizaje automático para crear obras artísticas, como por ejemplo música. La del vídeo es la primera composición musical compuesta por una red neuronal, un sistema informático expuesto a...
Por Nacho Palou -
7 JUN 2016
La app para iPhone Ipsum — Chat with your Journal de Samir Ghobril sirve para lo que se indica en su nombre, para hablar con tu diario. Respecto a un diario convencional Ipsum funciona de forma parecida a un servicio de...
Por Nacho Palou -
6 JUN 2016

Explosión del primer Ariane 5 – ESA El 4 de junio de 1996 el primer Ariane 5 tenía que haber puesto en órbita las cuatro sondas de la misión Cluster, pero en lugar de eso explotó a los 37 segundos de despegar....

El Megaprocesador es un proyecto de geek loco de James Newman, que lleva años trabajando en ello simplemente porque (a) le da la gana y (b) ha pensado que «hacer grande lo pequeño» y mostrarlo con luces puede ayudar a mucha...

Lo de entonces no eran emojis, pero eran el equivalente de la época: expresiones gráficas que se utilizaban como forma de comunicación y para decorar tarjetas de felicitación, pancartas y pósteres, señales,... y el comienzo de la que se considera una...
Por Nacho Palou -
1 JUN 2016
El estado de una copia de seguridad es desconocido hasta que intentas restaurarla.– nixCraft(vía Johathan McDowell)...
La NesPi es un híbrido tan simpático como entrañable, surgido del cruce entre piezas de Lego, la Nintendo Entertainment System (NES) del año 85 y los modernos Raspberry Pi, uno de los ordenadores pequeños más populares y baratos entre los aficionados...
En el siempre apasionante Juego de la vida de John H. Conway se fueron descubriendo con el paso del tiempo espectaculares construcciones: deslizadores, supernaves, cañones… Nombres todos ellos para dar a entender la función y propiedades que «aparentes» pequeñas figuras podían...
No hay nada más permanente que un apaño temporal.– Kyle Simpson(vía Programming wisdom)...
Esta colección de fotografías de viejas computadoras provienen de imágenes originales tomadas por Docubyte en el Museo Nacional de Computación de Bletchley Park (Reino Unido), posteriormente retocadas por Ink. Son gigantescos mainframes muy sexys y vintage para los estándares de una...
99 pequeños bugs en el código99 pequeños bugs en el códigoElimina uno, parchéalo117 pequeños bugs en el código – @irqed Dedicado, con cariño, a todos los programadores que nos leen. (El vídeo, vía Carlos Menéndez)....
Los primeros servidores de Google estaban montados en racks de corcho; básicamente eran la placa base del ordenador, discos y ventiladores. Con el tiempo llegaban a combarse por el centro debido a su propio peso. Ahora que Google es una empresa...
Este vídeo de Explanimator, un canal de New Scientist, explica qué es la información y aborda cuestiones como si existe o no existe independientemente de que alguien la esté observando, la paradoja del demonio de Maxwell y la presencia al respecto...
Aunque ya hacía meses que se puede acceder a WhatsApp con el ordenador usando un navegador ahora se puede hacer desde sendas aplicaciones para OS X 10.9 y superiores y para Windows 8 y superiores, tal y como se puede leer...
Este vídeoclip está creado con Oscilloscope, una aplicación para OS X, Linux y Windows cuyo código fuente también se puede descargar para reutilizar. Basta arrastrar encima un fichero de audio para que realice interesantes cabriolas musicales. Las imágenes proceden de una...
Hypertext: an Educational Experiment in English and Computer Science at Brown University es un pequeño documental realizado en 1976 sobre un sistema de hipertexto utilizado en la Universidad Brown a finales de los 60 y principios de los 70 para dar...
Steven Sinofsky, ex presidente de la división Windows en Microsoft, cuenta en My Tablet Has Stickers cómo el iPad Pro de 9,7" ha reemplazado a todos sus otros ordenadores, portátiles y de sobremesa, Cuando recibí el nuevo iPad Pro 9,7 decidí...
Por Nacho Palou -
4 MAY 2016
En este vídeo de Filmmaker IQ John Hess explica todo lo que hay detrás de los CGI o imágenes generadas por ordenador principalmente en el cine. Como sabiamente dice en el fondo todo son matemáticas aplicadas a las coordenadas de los...
SAM, de Sample Analysis at Mars, Análisis de Muestras en Marte, es uno de los instrumentos del rover Curiosity, que lleva desde el 6 de agosto de 2012 explorando Marte; de hecho SAM representa más de la mitad de la carga útil...
En el canal de 8-Bit Guy se puede encontrar este vídeo sobre la restauración de un viejo Apple IIc de hace más de 30 años: es de esos muy detallados que además da gustirrinín por la calma, orden y el buen...
Quienes hayan sufrido un desastre de datos sabrán que aunque las probabilidades de recuperar archivos arrojados a la papelera o discos formateados es más bien baja, existir existen. Esto es porque los sistemas operativos normalmente no borran machacando los 0s y...
El Proyecto AAduino es una versión modificada del Tiny328 que tiene el mismo tamaño que una pila de tipo AA, el tamaño de pila normal y corriente que usa el transistor de la abuela. Ingeniosamente, el AAduino cabe perfectamente en el...
Por Nacho Palou -
22 ABR 2016
La semana pasada participé en Innova Bilbao 2016 con una charla titulada «¿Nativos digitales?» en la que insistí, una vez más, en que los nativos digitales, esos que se supone que por haber nacido a partir de 1990 o así tienen superpoderes...
Tal y como era previsible la historia del tipo llamada Marco Marsala que formateó un servidor y a miles de clientes con un “rm -rf” y pidió ayuda en un foro ha resultado ser falsa. Era un viral publicitario para la...
Minipunto para quienes dijeron «disco duro». Se trata del IBM 3380, una unidad de 2 GB cuyo precio rondaba los 100.000 dólares en 1981 (que serían unos 260.000 dólares de hoy en día). Su tiempo de respuesta era unos 16 milisegundos,...
Desde El Correo me han invitado a participar en Innova Bilbao 2016, donde el viernes 15 de abril a las 16:00 daré una charla en la que hablaré sobre los famosos nativos digitales y de cómo asumir que no existen es importante...
Desarrollado por el Autonomous Systems Laboratory de Stanford, el algoritmo está diseñado para que vehículos robotizados que se mueven a gran velocidad, caso de cuadricópteros, determinen su ruta y sus movimientos en tiempo real evitando obstáculos que pueden surgir e interponerse...
Por Nacho Palou -
6 ABR 2016
Para celebrar el 40º aniversario de Apple los ilustradores de Wired han trabajado en una gigantesca imagen que contiene todos los productos puestos a la venta por la compañía en una sola imagen: All of Apple’s Products Ever, in One Glorious...
Hoy, 1 de abril de 2016, se cumplen 40 años de la fundación de Apple –una buena humorada hacerlo un 1 de abril– así que me ha parecido un buen momento para rescatar este vídeo en el que sale Steve Wozniak,...
Atari Computer Concepts, vía Coudal, reúne ilustraciones de bocetos, diseños e ideas para ordenadores Atari que no llegaron a ser. La mayoría de los dibujos están hechos a principios de los ochenta y son obra de Regan Cheng, entonces jefe de...
Por Nacho Palou -
31 MAR 2016
La línea roja alrededor de Gibraltar indica la existencia de una disputa territorial oficial... al menos cuando se mira desde este lado. En Popular Science, Google Maps Moves The World's Borders Depending On Who's Looking, Ethan R. Merel [el autor del estudio...
Por Nacho Palou -
31 MAR 2016
Olo es una impresora 3D portátil, de pequeñas dimensiones y peso (780 gramos) que utiliza el teléfono móvil como parte esencial para funcionar e imprimir objetos. Así que más que una impresora 3D Olo es un accesorio que convierte el móvil...
Por Nacho Palou -
28 MAR 2016
Sean Follmer del MIT habla en esta charla de cómo hemos evolucionado con nuestras herramientas y de cómo estas han evolucionado con nosotros, adaptándose a nuestros cuerpos, a nuestras necesidades, en especial a nuestras manos, desde las primeras lascas a cosas...
La gente de Toshiba nos envió hace tiempo una unidad de pruebas del Canvio AeroMobile, una unidad SSD de almacenamiento «inalámbrica» que se puede utilizar a modo de disco duro externo o conectándose a ella vía wifi. Y aunque la principal...
Si por alguna razón tienes un montón de tarjetas microSD a mano puedes unirlas todas ellas mediante este adaptador 10 × microSD convirtiéndolas en… ¡tachán! una unidad SATA SSD de 2,5". Pero eso sí: esto es como pedirle cosas al genio...

Con 79 años nos ha dejado el ingeniero químico Andrew Grove, a quien se considera «el primer empleado» de Intel Corporation. Fue contratado personalmente por los fundadores de la compañía, Robert Noyce y Gordon Moore cuando, los tres dieron el salto...
Cargador MagSafe de 45 vatios falso (izquierda) y cargador original MagSafe de 60 vatios (derecha) En MacRumors, MacBook Charger Teardown Highlights Dangers of Counterfeit Adapters, A pesar de que exteriormente el cargador falso parece auténtico (...) cuando se abre es cuando se...
Por Nacho Palou -
23 MAR 2016
El micro:bit es un ordenador minúsculo con el que se puede aprender a programar. Lo reciben gratis en el colegio todos los niños de Inglaterra, Escocia, Gales e Irlanda del Norte cuando tienen 12 años. Externamente tiene 25 ledes y diversos...
Nosotros no somos nativos digitales, somos la generación Tuenti. – Claudia Dans Nacida en los 90, Claudia Dans recuerda haber vivido siempre conectada desde que tiene uso de razón y lleva años blogueando, así que cae de pleno dentro del supuesto grupo...
No tengo muy claro que esto no tenga que ir en WTF, pero… Los juzgados gastan un 30 % más de papel desde la orden de «papel cero» – La falta de un sistema completo de gestión informática obliga a imprimir...
Con todos vosotros los Green, una pareja de geeks británicos de los 80, que nos muestran lo «sencillo» que era conectarse a Prestel, una especie de videotexto interactivo británico, usando su ordenador y su módem y cómo enviar correos electrónicos a...
El amo del tiempo. Como el famoso «relojero de la Puerta del Sol» pero a lo bestia. Se llama Judah Levine y es el creador del software y quien puso en marcha el servidor original de la «hora oficial» que se...
Viejo vídeo de hace más de un año en el que se ve cómo un chorro de agua de alta presión es capaz de cortar el resistente metal de un portátil sin mayor problema y sin apenas causar desperfectos más allá...
AlphaGo, el software para jugar al go de Google ya ha vencido en el match contra el campeón humano Lee Sedol al haber ganado cuatro de las cinco partidas. Las victorias fueron por lo general bastante aplastantes y contundentes: 1-0, 2-0,...

Las AlphaSmart (1993-2013) fueron un conjunto de máquinas procesadoras de texto, una especie de híbrido entre los ordenadores portátiles y las máquinas de escribir, pero con la limitada capacidad de los procesadores y pantallas de hace dos décadas. ¿Te gusta su...
En el documental Graphic Means, previsto para la primera de 2017, la diseñadora Briar Levit explora la evolución y los procesos de diseño utilizados por los diseñadores gráficos entre 1950 y 1990, Mis conocimientos sobre la producción gráfica anterior a la...
Por Nacho Palou -
13 MAR 2016
Mañana viernes se pone a la venta el Samsung Galaxy S7 que se ofrece en dos sabores: el normal, con pantalla plana de 5,1 pulgadas y el Edge, que con pantalla de 5,5 pulgadas curvada en los bordes. Este último, el...
Por Nacho Palou -
10 MAR 2016
Code es un medio-trivial medio-juego-de-cartas formado por cuatro mazos de tarjetas sobre cuatro temas relacionados con la programación. Y como en todo gran entretenimiento, aquí se aprende mientras se juega. Eso sí: demostrando estos conocimientos ligar no vas a ligar mucho...
Según cuentan en Man hacks Tesla firmware, finds new model, has car remotely downgraded, Jason Hughes accedió al sistema operativo de su coche eléctrico Tesla P85D y descubrió algo interesante: una referencia a un modelo P100D. Esto es, una variante o...
Por Nacho Palou -
9 MAR 2016
Si llamas a Lockheed Martin con intención de comprar un F-35 mejor que tengas preparados los 200 millones de dólares que cuesta cada unidad. Un poco a lo Windows y un mucho a lo WTF, The F-35 Has Big Radar Problems and...
Por Nacho Palou -
9 MAR 2016
En Fusion, We calculated the year dead people on Facebook could outnumber the living, Facebook tiene 1500 millones de usuarios (...) y millones de ellos ya están muertos. A menudo, cuando alguien muere, sus allegados convierten sus perfiles en mausoleos, en...
Por Nacho Palou -
8 MAR 2016
Este invento se llama HotPlug y básicamente resuelve una situación con la que suelen encontrarse los fuerzas y cuerpos de seguridad de todos los países: una escena de algún crimen en la que hay un ordenador de sobremesa enchufado que ha...
En MIT Technology Review, Google Unveils Neural Network with “Superhuman” Ability to Determine the Location of Almost Any Image, Tobias Weyand, especialista en visión artificial en Google y un par de sus colegas han desarrollado un software capaz de determinar dónde...
Por Nacho Palou -
7 MAR 2016
A raíz de El problema de obesidad de la Web: el futuro de los medios online, Kalev Leetaru se refería a los navegadores web como «hazañas de la ingeniería, capaces de ejecutar sistemas operativos completos, como Windows XP». Desde 7 classic...
Por Nacho Palou -
4 MAR 2016
Raúl nos contó esta deliciosa anécdota informática tras compartir por Twitter un pantallazo en el que una de las cosas más llamativas era el peculiar uso de las letras Ñ delante de las variables en un código de aspecto viejuno: Soy...
En Force Push A Car los chicos de Film Riot explican con cierto detalle qué efectos especiales utilizan y cómo los aplican para completar un simpático microcorto de algo menos de dos minutos de duración. En total apenas suman cinco segundos...
Por Nacho Palou -
1 MAR 2016
En How you can use Facebook to track your friends’ sleeping habits, Søren Louv-Jansen explica de qué manera es posible conocer cuáles son los hábitos de sueño de los amigos y contactos de Facebook; al menos, es verdad, averiguar los hábitos...
Por Nacho Palou -
1 MAR 2016
Las interfaces web responsive son aquellas que adaptan su presentación de acuerdo con el tamaño de la pantalla o si se miran desde un móvil, un ordenador o un tablet, por ejemplo. Resizer es una herramienta de Google para ver y...
Por Nacho Palou -
29 FEB 2016
Una Calculadora Millionaire construida por Egli (circa 1910) / (CC) Ezrdr @ Wikimedia Cliff grabó para Numberphile este vídeo en el que enseña una calculadora mecánica que compró por unos ridículos 70 dólares hace varias décadas: es de fabricación suiza y se...
Macworld (abril 1984) [versión HTML, PDF, texto, ePub, Kindle] En el Archivo de Internet está guardada para la eternidad una copia del primer número de la revista Macworld, que se lanzó hace ahora 32 años de forma simultánea al Macintosh de Apple....

Me ha sorprendido que nunca hayamos hablado aquí de Computer Perspective, un vídeo creado por el estudio de Charles y Ray Eames sobre una exposición con el mismo título patrocinada por IBM que trata de la evolución de los ordenadores desde...
El Google Play Market Retro, la App Store Retro y también la Mac App Store Retro son las versiones estilo PC con MS-DOS de finales de los años 1980 y principios de los 1990. No es sólo que la estética se...
Por Nacho Palou -
19 FEB 2016

Este vídeo que ha sido recuperado recientemente muestra cómo era la máquina diferencial #2 de Babbage que estaba instalada en el Computer History Museum de Mountain View, California. Es básicamente una versión remasterizada de un vídeo de 2012, algo que se...
The Malware Museum de Mikko Hypponen, en Archive.org, recopila algunos de los programas maliciosos, normalmente virus informáticos que se propagaban en los años 1980 y 1990 por los PC con sistema operartivo MS–DOS — aunque se echa de menos alguno mítico...
Por Nacho Palou -
18 FEB 2016
Cuenta un viejo chiste –no recuerdo si era un relato o una viñeta– que Un niño de corta edad y un perro están jugando al ajedrez. A medida que la partida avanza un curioso que rondaba por allí consigue ver lo que...
El superexperto en seguridad Bruce Schneier ha anunciado la edición de este año de su Estudio global sobre productos de cifrado, una ambiciosa, extensa y diría que muy completa -si no «la más completa»- recopilación sobre las tecnologías de vanguardia en...
A leer sobre el software de Autosdesk utilizado por la impresora 3D «de juguete» de Mattel recordé la aplicación online Tinkercad, también de Autosdesk — de su catálogo de aplicaciones 3D gratuitas. Tinkercad funciona directamente en un navegador web moderno (Windows,...
Por Nacho Palou -
15 FEB 2016
En The Guardian publican un artículo en el que explican los resultados de un estudio llevado a cabo por investigadores sobre el repositorio de código GitHub en el que han concluido que las mujeres son mejores programando, al menos si se...
Una deliciosa forma de enseñar a los niños sobre computadoras es una charla de Linda Liukas en la que habla de la belleza que ve en la programación y de cómo los padres no deberíamos, jamás, decirles a nuestros hijos que...
A estas alturas todos estamos más que acostumbrados a usar interfaces gráficos de usuario con ventanas, iconos, ratón y un puntero, pero en los 70 eran una idea revolucionaria. Este vídeo es de una calidad más bien lamentable, pero muestra distintas...
En esta visualización se convierten en una gráfica matemática y colores los detalles del handshake que da inicio a una comunicación vía modem acústico. Uno de los ejes es el temporal y el otro el de las frecuencias. Ruiditos que retrotraen...
He estado usando un monitor AOC G2460VQ6 como pantalla principal de mi portátil durante las últimas semanas, reemplazando al que venía usando hasta ahora que era un modelo más grande pero antiguo (de otra marca). Se trata de un monitor LED...
Un petabyte unos son 1000 terabytes (o 1024, dependiendo de si eres un pedante o un geek) y aunque tradicionalmente ha sido una cantidad mítica de almacenamiento, lejos del alcance de los mortales, comienza a estar dentro del rango de lo abarcable:...
El rocódromo Brooklyn Boulders se convirtió en un videojuego experimental de escalada artificial con una idea de Randori, una pequeña empresa dedicada a los videojuegos. La idea es sencilla: se proyectan números, pistas y objetivos sobre la pared y los escaladores...
1. Desinstala la app de Facebook * * * En The Guardian, Uninstalling Facebook app saves up to 20% of Android battery life, El usuario de Reddit pbrandes_eth descubrió que con las aplicaciones Facebook y Facebook Messenger desinstaladas el resto de...
Por Nacho Palou -
1 FEB 2016
Con algunas piedras y palos se computaba mejor que con estas joyitas. Resulta que en Computing hicieron una recopilación de los diez peores microordenadores de la historia incluyendo modelos de todos los pelajes: máquinas familiares para jugar, supuestos ordenadores para negocios,...
Fascinado desde sus días de colegio en Harvard por los misterios de la inteligencia y el pensamiento humanos, el profesor Minsky no veía diferencia entre los procesos mentales de las personas y de las máquinas. A partir de 1950 comenzó a...
Adam y Jaime demuestran la diferencia entre el procesamiento lineal (dibujando un muñeco con un robot que dispara pintura) y el procesamiento en paralelo haciendo lo mismo pero con un millar de tubos que disparan a la vez. Tan divertido como...
En la EPFL suiza han montado una instalación artística llamada Sol.id que combina un poco de arte con diseño mediante ordenador e ingeniería. El resultado es que los rayos del sol se reflejan en varias placas metálicas para homenajear a cuatro...
He estado probando desde hace algunas semanas el disco duro Canvio Connect II, un modelo portátil de Toshiba de 2 TB (disponible en varias capacidades) que ofrece buenas prestaciones en tan solo 230 gramos de peso. La unidad es un disco...
Los ordenadores del Proyecto GIMPS (Great Internet Mersenne Prime Search) han descubierto el mayor número primo conocido hasta la fecha, un primo de Mersenne de la forma M = 2n - 1 en el que n también es primo. El número en...
Rick Chan dio con un IBM PS/2 Modelo 30 de ~1990, con procesador 286 a 10 MHz, 1MB de RAM y MS-DOS 5 y totalmente nuevo, sin desempaquetar desde que salió de la fábrica hace un cuarto de siglo. El unboxing...
Por Nacho Palou -
19 ENE 2016
(Sobra decir que si aún no has visto la película igual te interesa no ver este vídeo por si te destripa alguna escena o trama. Claro que si todavía no has visto la película es porque probablemente te da bastante igual.)...
Por Nacho Palou -
15 ENE 2016
Apple sobre la función Night Shift en iOS 9.3, Numerosos estudios demuestran que la exposición a luz azul al anochecer puede afectar a tus ritmos circadianos y dificultar la conciliación del sueño. La función Night Shift utiliza el reloj y la...
Por Nacho Palou -
14 ENE 2016
Asymco hizo circular este cuadro resumen en el que se enumeran las plataformas microinformáticas más relevantes a lo largo de las últimas décadas, en función de sus ventas/instalaciones. [Por desgracia los colores de la leyenda del gráfico son muchos y un...
«¡Al ordenador se le ha olvidado mi contraseña!» En Upvoted, en versión viñetas animadas y a todo color… IT Workers Share the Most Idiotic Things Non-Techies Have Told Them. Una recopilación de burradas aportadas por informáticos de todo el mundo, pronunciadas por...
La gente de Cushion realizó un interesante ejercicio en el que desglosaron los costes a la hora de crear y mantener una aplicación web a lo largo del tiempo. Se utilizaron a sí mismos como ejemplo; venden su aplicación para que...
Digo al parecer porque ni siquiera he hecho el ademán de comprobarlo: la aplicación para iOS Moonlight (gratuita, en la App Store) requiere para funcionar un ordenador PC con tarjeta gráfica Nvidia. Moonlight utiliza la función GameStream que incorporan estas tarjetas....
Por Nacho Palou -
6 ENE 2016
Star Citizen es un ambicioso juego de simulación espacial del creador del mítico Wing Commander. Básicamente es un gigantesco universo en el que los jugadores pueden explorar galaxias, sistemas y planetas; naturalmente también hay estaciones especiales, combates y lo demás como...
De un universo multicolor con todo tipo de plataformas para los smartphones a una realidad bicolor donde Android y iOS se comen todo el pastel – dejando unas migajillas a Windows Phone. Los datos proceden de la Wikipedia. Bonus – De...
1. ¿Qué?2. ¿Por qué?3. ¿Cómo?4. Imposible.5. Oh.- Daryl Ginn(Via Jonathan McDowell)...

Ada Lovelace (1815-1852), la dama que prefirió los números a los poemas, y acabó escribiendo el primer algoritmo de la historia.
Aprovechando el tirón del anuncio de Google de que tienen un ordenador cuántico 100 millones de veces más potente que uno convencional –más o menos– la gente de In a Nutshell ha publicado este vídeo divulgativo sobre la computación cuántica, los...
El «ordenador cuántico» de Google, la NASA y la USRA recibió ayer otro pequeño impulso por parte de Google con un evento en el que se presentó un trabajo sobre su espectacular progreso. Pero entender los detalles de la computación cuántica...
Hiperespacio – el eslabón perdido entre las páginas personales y Microsiervos allá por 1999 Toda una experiencia rememorar con Oldweb.today cómo era navegar en épocas remotas de la Web: basta elegir el navegador web, el sistema operativo y la dirección de la...
Apple ha anunciado que su lenguaje de programación Swift ha pasado a a ser de código abierto. Toda la información está en Swift.org y los repositorios en github.com/apple. También hay una nueva web completa dedicada al lenguaje (Swift.org) en la que los...
En el blog de Adobe, Adobe News, Flash, HTML5 and Open Web Standards, Actualmente los estándares abiertos como HTML5 han madurado lo suficiente como para igualar las capacidades de Flash. Nuestros clientes han manifestado su deseo de que la aplicaciones de...
Por Nacho Palou -
2 DIC 2015
Durante años el checo Jakub F se dedicó a distribuir ilegalmente por internet software y contenidos de empresas como Microsoft, Sony Music o la Fox. Hasta que le pillaron. The Story of my Piracy (con subtítulos en inglés) es el vídeo...
Por Nacho Palou -
1 DIC 2015

Tenía por ahí guardada la página de enjalot en bl.ocks.org que es una joyita de esas en las que perderse durante largas horas: algoritmos, construcciones geométricas, visualizaciones matemáticas… ¡Cuidado que engancha! Todos los gráficos y el código están en bl.ocks.org que...
Star Wars Spoiler Blocker es una extensión para el navegador web Chrome que bloquea una página o contenido web si detecta que contiene algún spoiler de Star Wars: El despertar de la Fuerza. Basta con instalar la extensión en el navegador...
Por Nacho Palou -
30 NOV 2015
NeuralTalk es un software de Andrej Karpathy, una red neuronal de esas que identifican objetos en las fotos y los «explican» con lenguaje normal y corriente, solo que ha sido modificado para recoger las imágenes de una webcam. El resultado a...
El precio oficial de un cargador de corriente Magsafe Apple para los MacBook Pro es de 89 euros; más caro que algunos artilugios de otro tipo e incluso que algunos ordenadores. De hecho no tiene la menor gracia cuando el perro mordisquea...

La Raspberry Pi Zero es tan barata (5 dólares, ~5 euros) que probablemente es el ordenador más económico del mundo. Es tan barato, tan barato que lo están regalando con algunas revistas – como antiguamente regalaban CD-ROMs, vamos. La placa base...
En Business Insider, A programmer wrote scripts to secretly automate a lot of his job — and email his wife and make a latte, Uno de sus scripts compone un mensaje con el texto «sigo en el trabajo» + «algún motivo» elegido...
Por Nacho Palou -
24 NOV 2015
Dos vistas del Pamiatnik Klaviature de Ekaterimburgo Joan nos escribió para contarnos que un amigo suyo había estado recientemente en Ekaterimburgo, donde se encontró con el monumento al teclado que hay a orillas del río Iset. Se trata de una instalación...
En Fast Co. Design, How Apple Is Giving Design A Bad Name, Los productos de Apple, especialmente aquellos que hacen uso de iOS, su sistema operativo móvil, ya no siguen los conocidos y bien establecidos principios de diseño que Apple desarrolló...
Por Nacho Palou -
11 NOV 2015
El vídeo —con sus imperfecciones— está capturado directamente de las gafas Samsung Gear VR usadas para probar la aplicación Oculus Arcade. La aplicación Oculus Arcade, todavía en versión beta, permite usar gafas de ralidad virtual como estas de Samsung o las...
Por Nacho Palou -
11 NOV 2015
Grand Theft Auto V (Windows, PS3/4, Xbox 360/One) lleva años sido todo un éxito de críticas, popularidad y premios de la industria de los videojuegos. Uno de los aspectos más cuidado del juego son sin duda los gráficos y la cinemática....
Star Wars: Building a Galaxy with Code, un tutorial online gratuito de Corde.org diseñado para que enseñar a los más jóvenes conceptos de programación mediante el desarrollo de sencillos videojuegos protagonizados por personajes de Star Wars. “Building a Galaxy with Code”...
Por Nacho Palou -
10 NOV 2015
En Tesla will restrict Autopilot mode to stop people “doing crazy things”, ArsTechnica recoge algunos detalles dados por Elon Musk respecto al piloto automático de Tesla que una reciente actualización habilitó en unos 40 000 vehículos que, juntos, recorren más de...
Por Nacho Palou -
5 NOV 2015
iTunes Terms and Conditions: The Graphic Novel es el acuerdo legal íntegro que se supone que aceptas al utilizar iTunes —o que no has leído pero que igualmente aceptas— convertida en una suerte de cómic al estilo de las novelas gráficas...
Por Nacho Palou -
4 NOV 2015
El dron del vídeo vuela por sí mismo de forma autónoma —le sigue de cerca un modelo teledirigido, controlado por un humano— esquivando los árboles que se encuentra por el camino gracias al sistema de detección de obstáculos desarrollado por Andrew...
Por Nacho Palou -
3 NOV 2015
Del 1 al 5 de noviembre puede verse en YouTube en exclusiva CodeGirl, un documental sobre un grupo de chicas de secundaria que participa en un concurso de programación para mejorar la comunidad en la que viven mediante el uso de...
El sistema desarrollado por investigadores de la Universidad de Hong Kong y Microsoft Research autocompleta los trazos de las ilustraciones dibujadas a mano que forman parte de una animación. Es decir, el ilustrador dibuja un fotograma de inicio y el fotograma...
Por Nacho Palou -
29 OCT 2015
Aprobada en 1998, la Digital Millennium Copyright Act es una ley estadounidense que, entre otras cosas, protege al software propietario prohibiendo su copiado y modificación, o al menos la de los sistemas de protección que incorpore. Una de las cosas que protege...
En Popular Mechanics han recopilado once vídeos que muestran cómo han evolucionado las calculadoras a lo largo de los tiempos. Pueden verse todos ellos en 11 Calculators That Show How Far Computing Has Come in the Past 2,000 Years. La selección...
Ordenador + vídeo + cámara + agenda + wifi + mp3 + discman = smartphone (150 gr.) Más o menos así es la ecuación hoy en día. (Imagen viejuna vía C:\>.)...
Probablemente lo más llamativo de la función de conducción asistida de Tesla (aparte de que se sirva aún en «versión beta») es que se trata de una capacidad adquirida por el vehículo a través de una actualización de software. Es decir,...
Por Nacho Palou -
27 OCT 2015
Para los frikis del espacio y de la informática, este documental de los años 60 sobre el Apollo Guidance Computer, el ordenador que llevó a las misiones Apolo a la Luna y de vuelta a la Tierra con mucha menos potencia...
El vídeo de Magic Leap no se ha logrado mediante «montajes ni con efectos especiales», sino que está «grabado directamente». Se supone que «grabado directamente» a través de la tecnología de realidad aumentada de Magic Leap, de la cual aún no...
Por Nacho Palou -
26 OCT 2015

Nacido en 1881 en Moscú, Emmanuel Goldberg se doctoró en química en la Universidad de Leipzig en 1906, ya que había fijado su residencia en Alemania para huir del antisemitismo rampante en Rusia. El 1917 empezó a trabajar para Carl Zeiss, donde,...
Julia Evans y Kamal Marhubi, que trabajan en Google, prepararon este curioso test sobre computación que resulta a la vez muy didáctico y aclaratorio. Básicamente consiste en adivinar cuán rápido es un ordenador actual calculando cuántos cálculos de distintos tipos puede...
Nos enviaron desde SanDisk muy amablemente una unidad de pruebas del SanDisk Extreme 500 Portable SSD, una Unidad de Estado Sólido (SSD) o «disco de memoria» de 240 GB, que también existe en versión 120 GB. Este tipo de unidades son...
En el artículo (en PDF) Real-time Expression Transfer for Facial Reenactment un grupo de investigadores de Stanford explican su método para transferir las expresiones faciales de una persona a otra persona — en vídeo y en tiempo real. El principio es...
Por Nacho Palou -
20 OCT 2015
Blender es un software para la creación de objetos 3D, renderings y animaciones con unas posibilidades asombrosas. Funciona en Windows, OS y Linux [página de descarga] y además es gratuito y libre. Lleva años utilizándose en todo tipo de trabajos y...
Peter Norvig, ex-Google, explica en un extenso artículo con código en Python cómo crear simulaciones para entender algunos de los problemas y paradojas clásicas de la matemática probabilística. En concreto emplea ejemplos con dados, fechas de nacimiento, cuestiones sobre el nacimiento...
USB killer v2.0, No te preocupes por el portátil, seguramente volverá a funcionar después de cambiar la placa base. ¿Alguien tiene un MacBook Pro para probar? Hace unos meses surgió la historia de una unidad USB maliciosa que podía freír un...
Por Nacho Palou -
14 OCT 2015
Cataloging the World: Paul Otlet and the Birth of the Information Age, de Alex Wright (Oxford University Press, 2014). Nacido el 23 de agosto de 1868 en una acomodada familia belga, a Paul Otlet desde pequeño le obsesionaba el orden. En...
Lovelace & Babbage: Ada Lovelace, Charles Babbage, y la máquina analítica en Lego Desde hace algunos años el segundo martes de octubre es el día de Ada Lovelace, que en 2015 cae en el 13 de octubre. Por lo general se considera...
Amazon no se anda con minucias: si necesitas capacidad de almacenamiento y transferencia a lo bestia basta con contratar dentro de su sección AWS (Amazon Web Services) el nuevo Amazon Snowball («Bola de nieve»). Al hacer esto Amazon te envía cómodamente...
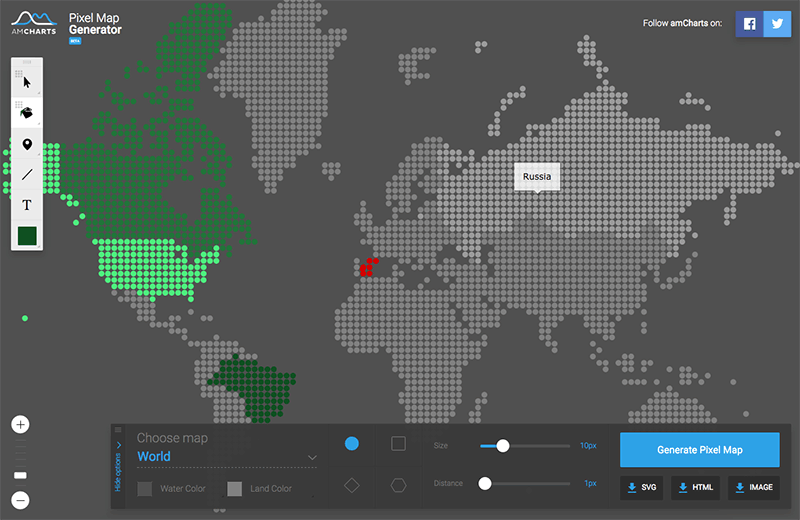
En AmCharts son unos auténticos artesanos del JavaScript/HTML5; una de sus múltiples maravillas es el que llaman Pixel Map Generator, una herramienta con la que crear preciosos mapas y personalizarlos sin salir del navegador. Primero se elige un tamaño y forma...
Si necesitas una librería para montar un carrusel de imágenes fácilmente con HTML/CSS prueba Slick: es sencillamente de lo mejorcito, más flexible y completo que encontrarás. Ni siquiera hace falta saber mucho de programación ni tocar demasiado código para usarlo. La...
He estado probado como monitor principal en las últimas semanas el BDM3270QP que amablemente nos hizo llegar Philips este verano. Se trata de un llamativo modelo de 32 pulgadas en Quad HD, es decir hasta 2560 × 1440 píxeles como resolución...
Baxter de Rethink Robotics es un robot que lleva ya tiempo mostrando sus habilidades. A simple vista no resulta especialmente espectacular ni por su aspecto ni en sus tareas y habilidades; incluso resulta hasta cómico haciendo algo tan simple como doblar...
Por Nacho Palou -
6 OCT 2015
Bodhi Priyantha, Ranveer Chandra y Anirudh Badam son algunos de los investigadores de Microsoft empeñados en alargar la duración de las baterías de los gadgets de forma ingeniosa. Interesante aproximación al problema de la duración de las baterías en ordenadores, tablets, móviles...
Por Nacho Palou -
5 OCT 2015
Imagen: Hitachi / Fast Company En Fast Company, Hitachi Says It Can Predict Crimes Before They Happen, No se trata de unos trillizos de mutantes psíquicos como en The Minority Report, pero Hitachi asegura que su sistema puede predecir dónde y cuándo...
Por Nacho Palou -
30 SEP 2015
Con tanto iPhone y tanto iOS 9 y tanto Apple Watch había pasado un poco desapercibido el lanzamiento de hoy de OS X 10.11 «El Capitán». Así que si tienes un Mac ve haciendo una copia de seguridad como los cobardes...
Imágenes infrarrojas de M42, nebulosa de Orión. NASA. En Adobe Conversations, How Photoshop Helps NASA Reveal the Unseeable, [Para obtener las imágenes en color] básicamente cojo la información de las imágenes en escala de grises correspondientes a distintas partes del espectro infrarrojo...
Por Nacho Palou -
29 SEP 2015
Los automóviles de lujo están entre las máquinas más sofisticadas que existen, con 100 millones o más de líneas de código de programación. Compara esa cifra con los 60 millones de líneas de código de todo Facebook o con los 50 millones...
Por Nacho Palou -
28 SEP 2015
Google ha publicado este buen vídeo divulgativo sobre aprendizaje automático (Machine Learning) y aprendizaje profundo (Deep Learning) en redes neuronales artificiales. Si todos estos términos te suenan raros tal vez te queden un poco más claro tras ver las explicaciones. Por...
Tom Scott explica los tecnicismos de por qué poner http://a/%%30%30 en la barra de direcciones de Chrome, o incluso pasar el ratón por encima (mouseover) «casca» el programa, cerrándolo inevitablemente. Seguro que lo arreglan pronto, pero como curiosidad no está nada...
En The Verge, Pico Cassettes are retro game cartridges for your phone, La naturaleza física de los cartuchos, que recuerdan a los de las videconsolas Game Boy [Famicom Mini en el original], sirve para algo más que invocar a la nostalgia,...
Por Nacho Palou -
22 SEP 2015
En Visualizing map distortion Mike Bostock y su equipo tienen una visualización interactiva del globo terráqueo en diversas proyecciones cartográficas. Basta elegir el tipo de proyección en el menú desplegable y moverse con el ratón para entender cómo se ve (izquierda)...
De todas las reseñas que he visto por ahí esta de DetroitBorg me ha parecido bastante completa: basta dedicar 15 minutos para entender las principales novedades en la interfaz y las funciones principales del sistema que se han mejorado: búsquedas, notificaciones,...
C. Liam Brown ha creado una calculadora para «Hundir la flota», el popular juego de los barquitos al que todos hemos jugado de pequeños – ya sea en versión piezas de plástico o con lápiz y papel. Se puede probar o...
Erle-Spider es un dron con patas, con seis patas en concreto1, que puede desplazarse de forma autónoma. Tiene 45 minutos de autonomía, se controla desde el teléfono móvil —vía Bluetooth, wifi o 3G— y es OpenSource «en la medida de lo...
Por Nacho Palou -
14 SEP 2015
Si te indigna que la tinta de impresora original sea uno de los líquidos más caros del planeta y como usuario final odias que te mientan sobre los «cartuchos vacíos» imagina cómo se sentirá la gente que se dedica profesionalmente al...
Palette es un cojunto de controles físicos que permiten a los fotógrafos editar las fotografías manipulando una serie de diales y botones — en un recorrido inverso en el que los controles virtuales propios de los programas de edición dejan de...
Por Nacho Palou -
9 SEP 2015

Esta explicación de cómo funciona un generador de escenarios mediante procedimientos (estilo Dragones y Mazmorras) es un estupendo ejemplo de cómo utilizar algoritmos para crear contenidos automáticamente y de forma «realista» en vez de tener que hacerlo a mano. La técnica...
Tal día como hoy en 1995 Telefónica anunciaba la entrada en funcionamiento de InfoVía en fase de pruebas, aunque su entrada en servicio oficial no se producía hasta el 15 de diciembre de ese mismo año. InfoVía era un intento, que llegaba...
Todavía hoy los gráficos pixelados siguen resultando atractivos para mucha gente, especialmente para aquellos que vivieron el inicio de los gráficos por ordenador, e incluso son “objeto” de culto — y a otras muchas personas les causarán la risa. El vídeo...
Por Nacho Palou -
3 SEP 2015
Lo habían anunciado en junio, pero desde hoy, 1 de septiembre de 2015, es efectivo: Google Chrome va a empezar a poner en pausa de forma automática contenido en Flash que no sea central para el contenido de la página que...
El vídeo Autonomous Drifting using Machine Learning del MIT Aerospace Controls Lab muestra la progresión del aprendizaje automático de un ordenador aplicado al control de un coche teledirigido que patina sobre el suelo. A partir de ahí y gracias al aprendizaje...
Por Nacho Palou -
1 SEP 2015
No es por dar envidia, pero... Este hacker se ha construido una GPU especial para poder controlar 6 monitores 4K con un Mac Pro 2013 (que normalmente solo funciona con hasta 3 mediante el conector Thunderbolt). El resultado es un superescritorio...
– ¡Pf, tío, qué lento es este trasto! Pensé que con 3,2 GHz y 12 GB de RAM iría más rápido…– Ya verás… ¡Algún día tendremos PCs cien veces más potentes y todo cargará más rápido! Esta tira de CommitStrip.com ilustra una...
A este paso al manejar el ordenador va a parecer que en vez de usar el ratón y el teclado estamos utilizando el poder de la Fuerza para cada pequeño gesto. Esta demostración está realizada con el sensor Leap y una...
El programa ganador del concurso de programación en 1 KB de Assembly 2015 fue BLCK4777 de p01/ribbon. En total, 1023 bytes, técnicamente dentro de los 1024 bytes del KB permitido¹. El resto de participantes también eran muy buenos; mucho fractal sobre...
The Code (2001, Hannu Puttonen) [subtítulos en castellano] es un documental clásico sobre la historia del Linux narrada por sus protagonistas. Entre los entrevistados --ya hace un par de décadas- están naturalmente el ideólogo tras el concepto del software libre, rms...
Aunque es bastante desconocido el Programma 101 se puede considerar el primer ordenador de sobremesa comercial del mundo. Fabricado por Olivetti en los Estados Unidos a partir de 1965 según un diseño de Pier Giorgio Perotto hoy en día lo consideraríamos...
Sí, es una hora y pico entre charla y preguntas, pero merece mucho la pena, ya que explica como la ley de enjuiciamiento criminal española por fin se pone al día con lo que se refiere a enfrentarse a delitos informáticos...

The iBook Guy ha comenzado un serial que merece nuestra atención y probablemente la de cualquiera interesado en la historia del diseño y la imagen digital: los gráficos de ordenador de la vieja escuela. Cada episodio incluye subtítulos en inglés y...
Algunos de los primeros usuarios en recibirlo no están muy contentos con la selección de juegos incluidos ni con los controles, pero aún así el ZX Vega resulta un cacharro intrigante. Se trata de un ZX Spectrum reencarnado en una especie...
Este trailer muestra algunos de los personajes que aparecerán en Revolucionarios, una serie documental para Internet que podrá verse en KQED (un canal de televisión pública de California) y más cómodamente en el resto del mundo a través del siempre recomendable...
¿Cuánta información cabía en un diskette de 3½? ¿Qué vídeo musical venía con Windows 95? ¿Dónde se compraban los CD-MIX? Y así hasta 25 preguntas para ver cómo andas de conocimientos acerca de informática viejuna, o cuán viejuno eres, en El...
En Business Insider han hecho una encuesta entre varios cientos de sus lectores para averiguar cuáles se consideran las mejores universidades en ciencias de la computación e informática en Estados Unidos, entendiendo como tales las que se consideran más valiosas para...
Una de los programas más odiados de Apple, y probablemente con muchos motivos, es iTunes. Parte de la culpa de esto es que lo que nació como un programa para gestionar música con el tiempo fue recibiendo añadidos para gestionar iPods,...
Aunque no es un hecho muy conocido el primer ordenador comercial de la historia fue fabricado en el Reino Unido. Y lo que hace la historia aún más sorprendente es que fue construido a instancias de J. Lyons & Co., una...
La gente de Moby Motion ha preparado estos vídeos a alta definición y 60 FPS como demostraciones de simulaciones físicas realistas: son básicamente torres de palitos que caen por la fuerza de la gravedad cuando otros objetos colisionan con ellas. Quizá...
Es bien sabido que el tipo que inventó la famosa y mil veces mencionada por todas partes «interfaz del ordenador de Minority Report» se llama John Underkoffler y que su trabajo consiste en… inventar interfaces reales de ordenador en la empresa...
Una de las mejoras de OS X Yosemite 10.10.4 es la «Mejora de la fiabilidad de la actualización de las fototecas de iPhoto y Aperture a Fotos»… Algo que en mi caso llega un poco tarde, ya que durante la migración...
Esa preciosidad es una Breve historia visual del código abierto, que aunque un poco antigua (2013) sigue siendo igual de válida: muestra en una sola imagen la evolución de los 16 principales lenguajes de programación de código abierto desde 1993 y...
Bajo el curioso título de The Random User nos encontramos con una obra artístico-técnica que en palabras de su creador, Arturo Melero de Monobo consiste en: Un ratón vintage intervenido que navega por internet aleatoriamente, sin control. Un usuario especial que...

Últimamente se habla mucho de los peligros de la inteligencia artificial: que si los coches autónomos, los drones, los algoritmos que controlan los mercados… Más de uno está realmente acojonado. Y en esta entrega de Computerphile Rob Miles explica algunas de...
Seguramente alguna vez te ha pasado algo parecido a esto: abrir la galería de fotos del móvil para buscar una fotografía que quieres utilizar o enseñar a alguien y acabar rindiéndote con un “bueno, pues ahora no la encuentro”. La app...
Por Nacho Palou -
7 JUL 2015
Según Ustun Ozgur, experto en el tema, esto es lo que hay que leer y empollar para convertirse en un gran programador JavaScript: JavaScript: The Good Parts JavaScript: The Definitive Guide Secrets of the JavaScript Ninja Javascript Allongé You Don’t Know...
The Thrilling Adventures of Lovelace and Babbage es una edición en papel del comic de culto 2dGoggles sobre dos grandes pioneros de la computación: la primera programadora (Ada Lovelace) y el creador de la Máquina diferencial (Charles Babbage). La legendaria Maquina...
En Google publicaron un artículo divulgativo acerca de sus progresos en inteligencia artificial aplicados a la clasificación automática de imágenes y al reconocimiento de voz. Se trata de una curiosa idea basada en las redes neuronales de las que hemos hablado...
Paul Ford ha publicado en Bloomberg The Code, el mega-artículo del mes; si te interesan los ordenadores y la programación ya estás tardando en leerlo. Cubre un montón de aspectos e historias desde un poco de vista realmente divulgativo y con...
Las redes neuronales son una de las más comunes formas de aprendizaje para el software; en el vídeo se explica cómo se creó MarI/O, un software de este tipo diseñado para superar niveles del mítico Super Mario World. Este tipo de...
Cuando leí que Movistar iba a triplicar la velocidad de transferencia de las conexiones domésticas de fibra me recordó a los viejos tiempos en los que te «subían» el ADSL de 512 Kbps a 1 Mbps, luego a 2 o 3,...
Halt and Catch Fire, conocida por el nemónico HCF, fue en origen una instrucción ficticia en código máquina que se decía estaba siendo desarrollada por IBM para su uso en sus computadoras System/360 (…) se refiere a una instrucción en código...
Ya le iba tocando, pero por fin desde hace unos días está disponible Tweetbot 2.0 en la App Store, una actualización gratuita para los que ya tenemos una licencia, 12 euros para nuevos compradores. La diferencia fundamental está en el rediseño...
En este episodio de Computerphile se hace una visita guiada al Museo de la Informática de Cambridge (Reino Unido) y se repasan algunas de sus máquinas. Es prácticamente como estar allí con un guía; el vídeo no tiene subtítulos pero lo...
Sebastien Gabriel, del equipo visual de Google Chrome, en Redesigning Chrome for Android. Part I, Los tres principios de Chrome ilustrados¹. De izquierda a derecha: velocidad, simplicidad y seguridad.Y uno adicional y que quizás sea el más importante en lo que...
Por Nacho Palou -
8 JUN 2015
Fotografía: Aloysius Low/CNET En Cnet, Microdia crams 512GB into a microSD card, out in July, Has leído bien, 512 GB — más del doble que la tarjeta micro SD de 200 GB que SanDisk anunció en marzo durante el MWC. La capacidad...
Por Nacho Palou -
8 JUN 2015
En Google Chrome Blog, Better battery life for your laptop, El uso de Adobe Flash supone un mayor consumo de la batería del portátil, de modo que estamos trabajando con Adobe para reducir el consumo de energía al utilizar Flash parando...
Por Nacho Palou -
5 JUN 2015
En Wired, Google's Ingenious Plan to Make Apps Obsolete, Los guiños hacia la web durante la conferencia Google I/O fueron demasiados como para enumerarlos todos; impregnaron la presentación. Google Fotos facilita compartir imágenes directamente desde la web. Polymer permite desarrollar aplicaciones web...
Por Nacho Palou -
4 JUN 2015
En CNet, Mozilla overhauls Firefox smartphone plan to focus on quality, not cost Mozilla ha renovado su proyecto de móviles con sistema operativo Firefox OS al percatarse de que apostar por teléfonos de muy bajo precio no es suficiente para competir...
Por Nacho Palou -
1 JUN 2015
MalMath [Android] es una calculadora en forma de app que resuelve ecuaciones pero las explica paso a paso. Incluye detalles, gráficas y hasta un «generador de problemas» para practicar, con varios niveles de dificultad. Dicen que es una herramienta ideal «para...
Screentendo, de Aaron Randall, es una aplicación para OS X que funciona de forma parecida a un capturador de pantalla: permite seleccionar un área de la pantalla del ordenador, o de una imagen, y automáticamente la convierte en un nivel ‘jugable’...
Por Nacho Palou -
27 MAY 2015
Igual que el fabricante de tractores John Deere, ahora General Motors dice que los que compran un coche de la marca no son dueños del coche sino de una licencia para usarlo, tal y como se puede leer en GM: That...
En la KAUST (King Abdullah University of Science and Technology) de Arabia Saudita compraron un superordenador Cray XC40 y fueron grabando todos los pasos de su instalación. Este equipo es de esos chismes que realmente ocupan una habitación y necesitan refrigeración...
En la Chrome Web Store, la extensión para Chrome Google Tone aprovecha los altavoces y el micrófono del ordenador para transmitir información entre ordenadores próximos, es decir, que funciona siempre y cuando unos y otros ordenadores puedan oirse entre sí. Los...
Por Nacho Palou -
20 MAY 2015
1. Cierra Chrome * * * En The Next Web, Why I’m breaking up with Google Chrome, Al principio me negaba a aceptarlo. Pero ahora tengo que admitirlo — el Chrome estable y ágil que conocía es un recuerdo lejano. Conforme...
Por Nacho Palou -
20 MAY 2015
El proyecto de identificación de imágenes de Wolfram es capaz de identificar el contenido de una imagen: basta con arrastrar un fotografía y Wolfram sabrá lo que es (o quién es cuando la imagen es de un rostro conocido, por ejemplo)...
Por Nacho Palou -
19 MAY 2015
El NASA's Software Catalog es un amplio catálogo de productos de software y desarrollos con un amplio espectro de aplicaciones técnicas de todos los colores, desde cómo lanzar un cohete a procesar datos o imágenes obtenidas por instrumentos a bordo del...
Por Nacho Palou -
17 MAY 2015
El Samsung SSD Portátil T1 es una unidad externa de almacenamiento de tipo SSD concebida como sustituta a los discos duros portátiles. El tipo de almacenamiento que utiliza es similar al de las tarjetas de memoria y pendrives, lo que significa...
Por Nacho Palou -
8 MAY 2015
Si la Raspberry Pi, más conocida como «el ordenador de 25 dólares» (aunque luego sean unos 50€) ha sido un gran exitazo de los últimos tiempos y ha dado lugar a todo tipo de proyectos y cosas divertidas, el pequeño Chip...

Osborne 1 en OldComputers.net 5 Tech Firsts That Changed the World es una selección de modelos iniciales de gadgets que «sin ser tal vez los mejores» ni los más conocidos, «sí tuvieron un destacado impacto en nuestras vidas y establecieron las bases...
Por Nacho Palou -
5 MAY 2015
Un usuario entrando en una tienda de aplicaciones para móviles. En MIT Technology Review, The Truth About Smartphone Apps That Secretly Connect to User Tracking and Ad Sites, Vigneri y su equipo descargaron más de 2000 aplicaciones gratuitas de 25 categorías diferentes...
Por Nacho Palou -
5 MAY 2015
Esta anotación de Fayerwayer explica muchas cosas misteriosas que le han estado sucediendo a mi Mac últimamente… Problemas de conexión con Wi-Fi en OS X 10.10.3 – De acuerdo a una interesante cantidad de usuarios en los foros de Apple, la...
Guarda esta útil página: separator.mayastudios.com ¡Fácilmente! Si tu navegador no lo hace, guarda esta página y desde allí podrás y arrastrar separadores vacíos ( | ) donde te haga falta. Puedes añadirlos tanto como separadores verticales en la barra del navegador como horizontales en...
En Digital Trends, Say goodbye to Micro$oft — the new Microsoft is all about openness, Hasta ahora, las versiones ‘beta’ de Windows tenían una duración muy limitada y estaban abiertas a administradores de hardware y profesionales que lo solicitaban y firmaban acuerdos...
Por Nacho Palou -
1 MAY 2015
Que la publicidad en aplicaciones gratuitas devora la batería del móvil es algo de sobra conocido, pero no viene mal recordarlo y más aún cuando se tienen datos concretos tras comparar el consumo de batería y del tráfico de datos que...
Por Nacho Palou -
25 ABR 2015
En la última década se ha hablado tanto de la «piratería de contenidos» como la música, las películas o los libros que encontrar esta infografía sobre la «piratería» de software me resultó casi entrañable: Annual Software Piracy. Los tamaños asignados a...
{Aviso: leer este artículo completo puede hacerte estallar la cabeza.} Matrix. El cerebro en una cubeta. Descartes, Platón y sus disquisiciones filosóficas. La Holocubierta de Star Trek. Los Sims. El cerebro humano. La teoría computacional de la mente. La capacidad de...
En Quartz, algunos datos de la encuesta anual que hace Stack Overflow entre desarrolladores —casi 22.000 de todo el mundo este año— para conocer su perfil, intereses, ocupación, estado laboral, satisfacción, demografía... y desentrañar el misterio de si los desarrolladores son...
Por Nacho Palou -
13 ABR 2015
Este «ordenador», llamado M^3 (Michigan Micro Mote) dicen que es del tamaño de un grano de arroz; más exactamente mide 2 mm de largo por 1 mm de ancho y 0,4 mm de alto. Desde luego no es un ordenador como...
Vale, es verdad que no se aprende a editar fotografías en cinco minutos, pero tampoco es neurocirugía — especialmente cuando se trata de hacer ediciones para todos los públicos, sencillas, rápidas y en muchas ocasiones con aplicaciones móviles, mucho más simples...
Por Nacho Palou -
9 ABR 2015
El Intel Computer Stick es un ordenador «completo» reducido al tamaño de un pendrive: 10 cm de longitud. Se vende por 150 dólares (~140 euros) y lleva preinstalados Windows 8.1 o Linux, a elegir. Incluye wifi, Bluetooth, una ranura microSD, un...
Swoosh para Android (2,21€, en Google Play) convierte el móvil en un sensor de movimientos que sirve —por ahora sólo— para pasar las diapositivas de una presentación haciendo un simple gesto en el aire con la mano. Swoosh funciona con ordenadores...
Por Nacho Palou -
6 ABR 2015
Aunque los emuladores y las ROM de videojuegos antiguos que hay en Internet permiten jugar a éstos en el ordenador e incluso directamente en el navegador web —para quienes gusten de los videojuegos clásicos, pixelados y con un puñado de colores,...
Por Nacho Palou -
6 ABR 2015
Aunque Windows XP (2001) ya ni siquiera tiene soporte técnico desde hace un año (2014), según las estadísticas de Net Applications sigue teniendo más instalaciones que Windows 8.1, con un 14 por ciento de cuota de mercado. En la lista global, Windows...
Flipboard para Android funcionando en OS X. Para ejecutar aplicaciones de Android en Windows, Mac y Chrome OS es necesario instalar la extensión ARC Welder en el navegador Chrome. También es necesario obtener las aplicaciones Android como archivos APK y descargarlos al...
Por Nacho Palou -
3 ABR 2015
Después de probar la aplicación Adobe Comp (gratis, iPad) me ha parecido una herramienta muy poderosa para bocetar diseños de todo tipo, desde páginas web a diseños impresos, interfaces de aplicaciones e incluso tarjetas de visita. Se comienza eligiendo un lienzo...
Por Nacho Palou -
30 MAR 2015
Lo confieso: no puedo evitar dedicar diez minutos a ver este vídeo de Tom Scott de Computerphile cada vez que me cruzo con él. Es un perfecto ejemplo de la complicación que en la práctica puede llegar a suponer algo aparentemente...
Para demostrar el poderío del lenguaje Wolfram y algunos de los conjuntos y bases de datos de conocimientos que maneja (como mapas, datos demográficos, textos…) su web incluye unos cuantos ejemplos «del tamaño de un tuit»: 140 caracteres. Están todos en...
No soy un experto, pero diría que este método para tomar el control de un ordenador o para robar información contenida en un ordenador que no está conectado a Internet no parece muy práctico, aunque sí resulta muy curioso. En Wired,...
Por Nacho Palou -
23 MAR 2015
Ken Shirriff es un ingeniero que compartió una historia interesante. Se enteró de que en el Museo de Historia de los Ordenadores había un equipo IBM 1401 funcional; en su día se fabricaron unas 20.000 unidades y se alquilaban a las...

En Calligraphr [antes: MyScriptFont] puede encontrarse todo lo necesario para crear una tipografía de tipo «escritura manual» (script). Puedes crear una versión básica en diez minutos con la ayuda de una impresora/escáner, un rotulador y un mínimo de paciencia. Antes de...
De la completísima infografía que publican en Compass sobre cómo pagar el salario de los programadores (How Much Should You Pay Your Engineers?) me quedo con la sección que indica cuánto pagar a la gente según sus habilidades y conocimientos. Dale...
Aunque juntos suman el tamaño equivalente a un monitor de algo más de 30 pulgadas, en realidad este monitor Brilliance Two-in-One de Philips está formado por dos pantallas individuales de 19 pulgadas cada una. Las especificaciones no son nada del otro...
Por Nacho Palou -
18 MAR 2015
En Quartz, Microsoft is scrapping Internet Explorer, El fin está cerca para el navegador web Internet Explorer. Ayer Chris Capossela, director de márketing de Microsoft, confirmó que el nuevo navegador web de Windows —anunciado en enero con el nombre clave Spartan— no...
Por Nacho Palou -
17 MAR 2015
I Love PDF ha renovado sus herramientas para hacer más sencilla la vida de cualquiera con un ordenador por cuyas manos pasen archivos PDF – que al final somos la mayoría, claramente. Entre estas herramientas están funciones para convertir de PDF...
Alguien en Creative Live tuvo la genial idea de rescatar un Mac OS 8 e instalar el software para que ocho afamados diseñadores se enfrentaran a algunas sencillas tareas de retoque fotográfico. ¿Podrían conseguirlo? El resultado es un vídeo entre el...
IBM tiene un tumblr con un estilo algo diferente al que uno se podría esperar de un «gigante azul» haciendo microblogging; se llama simplemente IBMblr....
Hecho #1: Bajo el capó la mayor parte del software que utilizas a diario (como Mac OS X o Facebook) incluye un terrorífico número de hackeos y apaños que malamente encajan para que la cosa funcione «como un todo». Sería como desmontar...
Esta infografía de 7DayShop.com no es especialmente cruel pese a su título, sino más bien histórica y educativa. Recopila los grandes errores de Apple en el desarrollo de tecnologías y productos, algo que a veces pasó desapercibido y otras no tanto....
La historia del USB asesino la cuentan en USB Killer, vía Hack A Day, y se resume en que alguien robó una unidad USB (un pendrive) y lo conectó a su ordenador para ver qué contenía. Al rato el ordenador estaba...
Por Nacho Palou -
12 MAR 2015
Prometiendo lo mejor de ambos mundos la nueva app de Google para iOS, Google Calendar [descargable en la App Store], es el equivalente de la versión Android e integra todas las funciones del popular servicio para organizarse los días. Entre otras...
En The New York Times, Did a Human or a Computer Write This?, Una sorprendente cantidad de todo lo que leemos no ha sido escrito por personas, sino que está redactado por algoritmos informáticos. ¿Sabrías distinguir unos textos de otros? El...
Por Nacho Palou -
11 MAR 2015
Se considera que el milenario juego del Go guarda más parecido con el pensamiento humano que el ajedrez, razón por la cual una app para un smartphone decente puede ganar a cualquier humano al ajedrez y en cambio los jugadores programados...
Señales de que eres un mal programador vs. Señales de que eres un buen programador (Vía Software Engineering Tips.)...
El Universal Foldable Keyboard de Microsoft es un teclado ligero y compacto que conserva un tamaño de teclas razonable; y es universal —al menos en lo que al universo de los dispositivos móviles se refiere— compatible con los sistemas operativos móviles...
Por Nacho Palou -
3 MAR 2015
Pocas veces se tiene la oportunidad de tener acceso un equipo verdaderamente puntero en algún aspecto, así que cuando nos ofrecieron amablemente para probar durante unas semanas una unidad del nuevo Toshiba P50t, que incorpora una pantalla Ultra HD 4K, no...
Hace unas semanas estuve hablando un buen rato con Piergiorgio Sandri, un redactor de La Vanguardia, acerca de Apple y Microsoft y acerca de Steve Jobs y Bill Gates. Nuestra charla ha quedado reducida a apenas un par de frases en Jobs...
Con Astropad, un invento de un par de ex ingenieros de Apple, basta instalar algo de software y una app para que el iPad se comporte como una tableta gráfica de las de toda la vida. Y una vez preparado, ¡a...
En Creative Bloq, First real alternative to Photoshop launched... and it's free!, Affinity Photo, disponible para Mac en versión beta gratuita [durante 10 días], no se conforma con ser una copia de Photoshop o una versión reducida de éste, sino que...
Por Nacho Palou -
12 FEB 2015
First web page viewed by «first» browser via c.1965 modem and terminal: La primera página web de la historia vista por el Line Mode Browser de Nicola Pellow… Pero desde un teletipo ASR-33 conectado a un sistema remoto que corre Solaris...
Este cerebro computerizado electrónico era capaz de (atención) sumar, restar, multiplicar y memorizar. Desde luego, comparado con los ordenadores modernos no era gran cosa; pero también es cierto que su precio era de tan solo 5 dólares, que hoy en día...
Al principio no había nada más que el teclado... Bueno, y también tarjetas perforadas y tubos de vacío.- Dave Wiskus Convivimos cada día con cientos de ellas y en muchos casos no nos damos apenas cuenta de que están ahí - aunque...
Ah, los teclados mecánicos. El teclado OneBoard PRO+ de Acooo (~250 euros) vuelve a poner en tus dedos el tacto que deberían tener todos los teclados de ordenador —pero que ninguno tiene ya. Pero además el OneBoard PRO+ esconde en su...
Por Nacho Palou -
5 FEB 2015

Disculpa este modelo tan burdo… no me dio tiempo a construirlo a escala.– Doc BrownRegreso al futuro Por diversas razones, muchas representaciones gráficas con las que convivimos habitualmente no están «a escala» sin que ello nos suponga ningún problema. Por ejemplo:...
Seguro que te ha pasado alguna vez: tienes varias pestañas abiertas y en alguna de ellas se está reproduciendo algún contenido ‘que suena’, caso de un vídeo o música. Y para detener el sonido tienes que quitar el volumen del ordenador...
Por Nacho Palou -
4 FEB 2015
Aunque servicios como Dropbox o Drive facilitan enormemente transferir archivos entre dispositivos, en ocasiones puede ser necesario o preferible transferir archivos directamente entre dispositivos como ordenadores, móviles o tablets. Una opción sencilla es recurrir a aplicaciones como AirDisk Pro (para iPhone...
Por Nacho Palou -
3 FEB 2015
En el blog de Google Maps, Google Earth Pro is now free, Google Earth Pro tiene las mismas funciones, facilidad de uso e imágenes de Google Earth junto con herramientas avanzadas que permiten medir edificios en 3D [por ejemplo, ver cómo...
Por Nacho Palou -
2 FEB 2015
Desde el Departamento Éramos-pocos-y-parió-la-abuela, la compañía Vivaldi ha desarrollado un navegador web dirigido especialmente para los power users. Así que no aspira a competir con los navegadores para todos los públicos como Safari o Chrome sino a un público menor y...
Por Nacho Palou -
28 ENE 2015
{Dentro vídeo estilo Metrópolis de La 2} Crear bacon altamente realista. Peinar a los muñecos. O «hacer la ola» con una multitud en un estadio. Se trata de una demo de Houdini 14, una herramienta especializada a la que se han añadido...
El Kindle Textbook Creator de Amazon es una herramienta parecida al iBooks Author de Apple, destinada a profesores y docentes para crear de forma gratuita y fácil libros educativos en formato electrónico. La herramienta permite convertir documentos en formato PDF (sólo...
Por Nacho Palou -
24 ENE 2015

Para los que les guste Windows en este vídeo del Wall Street Journal pueden ver un adelanto de su aspecto y algunas de sus funciones. La interfaz pretende ofrecer más opciones a los usuarios – aunque como puede verse eso no...
Mikael Hvidtfeldt Christensen de Syntopia explica en un excelente artículo titulado Path Tracing 3D Fractals algunas cuestiones y ejemplos sobre la técnica del ray-tracing o trazado de rayos para generar imágenes por ordenador empleando fractales a modo de ejemplo. Entre las...
Robert nos hizo llegar un enlace a su Tabla periódica de de los elementos HTML (que actualiza una idea antigua que ya no existe). Básicamente contiene todos los elementos a título individual y también una serie de botones en la parte...

Imagina que viajaras en el tiempo 200 años hasta el pasado. ¿Sería posible para un científico experto en diversas áreas tecnológicas construir un ordenador completamente desde cero en menos de 20 años? – Quora Esta pregunta y otras similares (como la...
La estudio de diseño alemán Cruved/Labs ha hecho su propia interpretación del Macintosh original (vía Designboom) de 1984 en 2015, 31 años después, La base tecnológica del Macintosh de Cruved/Labs es el MacBook Air actual de 11 pulgadas, aunque con la...
Por Nacho Palou -
14 ENE 2015
Acceso a OS X desde el iPhone 6 Plus La extensión de Google Chrome Remote Desktop permite controlar cualquier ordenador PC o Mac desde dispositivos móviles iOS (iPad, iPhone) y Android —para el que ya existía. Es totalmente gratis y va bastante...
Por Nacho Palou -
14 ENE 2015
Gary Kovacs, exCEO de Mozilla (vídeo), El mayor desafío ahora es lograr que los consumidores sean más inteligentes. Usuarios inteligentes en lugar de dispositivos inteligentes. Los consumidores deben aprender a tener el control de su vida online. Hay muchas herramientas para...
Por Nacho Palou -
13 ENE 2015
Al parecer hay por ahí un bot que se ha dedicado a comprar drogas y hasta obtener un pasaporte falso. El caso es que unos programadores lo soltaron para pruebas con un presupuesto de 100 dólares a la semana (en bitcoin) que...
The imitation game (Descifrando Enigma) (Morten Tyldum, 2014). Benedict Cumberbatch, Keira Knightley. El trabajo de Alan Turing en Bletchley Park, en especial entre 1939 y 1941, mientras desarrollaba lo bomba criptográfica que permitió descifrar los mensajes codificados con las máquinas Enigma...
En GigaOM, Chromebooks can now run Linux in a Chrome OS window, Esto es guay: a partir de ahora los usuarios de Chromebook pueden ejecutar su distribución favorita de Linux directamente en una ventana de Chrome OS. François Beaufort ha anunciado...
Por Nacho Palou -
2 ENE 2015
En The Daily Beast, New U.S. Stealth Jet Can’t Fire Its Gun Until 2019, A pesar de que el Joint Strike Fighter, o F-35, supuestamente llegará a los Marines este año y a la Fuerza Aérea en 2016, el software del...
Por Nacho Palou -
2 ENE 2015
Tal y como deja ver Eric Scott Hunsader en este gráfico, la velocidad de la información no es infinita y la de los reguladores del mercado bursatil en cambio es tremendamente lenta. Como ejemplo, este ejemplo en el que las operaciones...
Esta interesante simulación de un doble péndulo creado en Python está realmente lograda y resulta muy instructiva. Un doble péndulo no es más que un péndulo simple del que cuelga otro péndulo y sobre el que influyen la gravedad y otras...
Como parte de una gigantesca infografía sobre superordenadores en el bolsillo encargada por Fonebank a partir de datos de decenas de fuentes, me quedo con este dato: Si el iPad 2 hubiera existido en 1988 habría sido el ordenador más poderoso...
Hace un tiempo Toshiba nos envió una de sus nuevas unidades de disco duro externo de alta capacidad, un Canvio Desktop en su versión de 4 terabytes (las hay de 4 y 5 TB, en dos colores). Ha estado conviviendo con...
Una sola línea de JavaScript, moveForward(100); se considera la primera –y de momento única– línea de software escrita por un presidente de los Estados Unidos. Lo hizo Obama el otro día «para completar el dibujo de un cuadrado» en una clase...
A raíz de la nota acerca de los mejores lenguajes de programación para principiantes nos dice Daniel que CodinGame (…) es de lejos la mejor página que he encontrado para aprender a programar y además lo hace mediante retos en forma...
Business Insider ha dedicado un artículo dirigido a todos aquellos que quieran aprender a programar. Su conclusión es que los mejores lenguajes de programación para principiantes son: Un lenguaje de arrastrar-y-soltar para familiarizarse con algunos conceptos (Blocky, Code Studio) Python, por...
El próximo jueves 11 de diciembre las tiendas Apple de todo el mundo —incluyendo las 11 tiendas en España— organiza talleres gratuitos para enseñar a programar a niños a partir de 6 años. El taller tiene una hora de duración y está...
Por Nacho Palou -
5 DIC 2014
El fotógrafo Kevin Twomey lleva años fotografiando la colección de calculadoras electromecánicas de Mark Glusker. Pero en lugar de fotos al uso las fotografían sin sus cubiertas, de tal forma que se pueden ver, al menos parcialmente, los deliciosamente complicados mecanismos...

Ni más que ni menos que Jim Parsons, más conocido como Sheldon Cooper, nuestro científico incomprendido favorito que durante años ha estado ocupado el mismo hueco del sillón de su apartamento en The Big Bang Theory. Lo va a tener difícil...
Si pensabas que no podía haber nada más repelente que Hello Kitty o más pasteloso que los unicornios rosas ¡cuidado! La Barbie informática ha estado acechando por ahí en forma de libro titulado Barbie: puedo ser ingeniera informática. Y vaya libro:...
A finales del siglo XIX, Albert Michelson –el mismo que calculó la velocidad de la luz junto con Morley– inventó esta máquina que llegó a comercializarse y tenía la capacidad de sumar 20 sinusoides (y en otra versión hasta 80) y...
En la BBC, Microsoft fixes '19-year-old' bug with emergency patch Investigadores de IBM detectaron el fallo el pasado mes de mayo, aunque no se ha hecho público hasta tener una solución ya que afecta a todas y cada una de las versiones...
Por Nacho Palou -
13 NOV 2014
Del 3 al 7 de noviembre en la Escuela de Ingeniería y Arquitrectura de la Universidad de Zaragoza: Retromañía 2014, el evento anual sobre retroinformática. Este año hay una exposición «XXX Aniversario del Apple Macintosh», el Torneo de XXX aniversario Tetris,...
Con 534 productos en total, este póster cubre desde el Apple I al último iMac 5K, desde el BASIC a Yosemite, del Apple Writer a Pages. Lo han llamado The Insanely Great History of Apple 3.0 – toda una historia de...

Leonard Kleinrock, uno de los pioneros de Internet, nos enseña en este video vídeo el primer aparato que conectó Internet: un «procesador de mensajes de interfaz» (IMP) –hoy en día popularizado como router– que se instaló en el ordenador principal de...
En marzo de 1953 sólo existían 53 kilobytes de RAM en todo el planeta Tierra. Un portátil corriente de hoy en día tiene cien mil veces más RAM de la que tenía todo el planeta hace menos de un siglo. [Fuente: Turing's...

El mítico Commodore 64 (CC) Evan-Amos @ Wikimedia Commons ¡Ah, el Commodore 64! Aquel microordenador que rompió moldes y pegó tan fuerte que figura en el libro Guinness de los Récords como el ordenador que más unidades del mismo modelo ha vendido...
The Math Kid explica cómo se dibuja un círculo en una retícula cuadrada que básicamente es como se han dibujado los círculos en las pantallas de píxeles cuadrados de toda la vida – si alguna vez has programado seguramente te suene....
¡Eh, que es ciencia! Se trata de una una simulación del DEM Research Group que permite predecir cómo se dañarán docena y pico de peras metidas en una caja –no sabemos si variedad de agua o conferencia– durante su transporte, debido...
De momento el equipo detrás de Transcense busca financiación colectiva para desarrollar su proyecto: una aplicación para móviles que aspira a que las personas que oyen y desconocen el lenguaje por signos y las personas que son sordas o que tienen...
Por Nacho Palou -
15 OCT 2014
Bricolabs, un taller que reune semanalmente a todos aquellos que quieran colaborar en el diseño, construcción y pruebas de todo tipo de aparatos y gadgets, propuestos por los propios participantes y al estilo de otros HackerSpaces y FabLabs del mundo, en...
Celebrado el martes de «en medio» de cada mes de octubre, el día de Ada Lovelace, en honor a quien se considera la primera programadora de la historia, tiene como objetivo aumentar el reconocimiento de las mujeres en ciencia, tecnología, ingeniería...
SmallPDF comprime archivos PDF no veas qué bien. Archivos de varios MB los deja en un 10% de su tamaño, a calidad más que razonable. Y además junta varios en un mismo archivo y sabe muchos más trucos con los archivos...
Normalmente utilizamos números de versión (8.0.1, 8.0.2…) para referirnos a las pequeñas mejoras y arreglos que se introducen en el software de versión en versión. Cuando estos cambios se hacen únicamente para evitar un problema concreto, por ejemplo un agujero de...

La gente de Tested ha estado probando la nueva versión de Windows denominada Windows 10 Technical Preview, que se puede descargar e instalar [~4 GB] pero que «no está recomendada para máquinas en producción hoy en día» debido a que es...
¡Ah, qué tiempos aquellos en los que un píxel era un píxel! (…) Nuestra misión es honrar a aquellas creaciones pixeladas que diseñamos desde hace 18 años, a pesar de las limitaciones de ResEdit [la aplicación que se usaba para estas...
En FP, Why Big Data Missed the Early Warning Signs of Ebola, La primera alerta pública internacional sobre la epidemia inminente no procedió de la minería de datos ni de los medios sociales, sino a través de canales más tradicionales: un artículo...
Por Nacho Palou -
29 SEP 2014
Hace un par de años Ishac Bertran dio a conocer su propuesta para hacer más natural el intercambio de contenidos y entre dispositivos, simplemente aproximando el móvil al ordenador arrastrando elementos entre ellos. Es lo que hace precisamente el proyecto THAW...
Por Nacho Palou -
19 SEP 2014
TextMechanic es una de esas herramientas que conviene tener a mano, un buen compañero para toda persona que trabaje con textos. Es un servicio web que hace muchas de las funciones que suelen estar disponibles en los editores de texto, y algunas...
Al consejo del otro día de como desactivar la reproducción automática de vídeos en Facebook desde el ordenador se le puede añadir este para hacer lo mismo en iOS: Basta con ir a Ajustes -> Facebook -> Ajustes -> Auto-play-> Off...
¡Snif! Aunque no encontrado una declaración oficial de IDG (el grupo editorial al que pertenece) el pasado 10 de septiembre –justo al día siguiente del evento de presentación del iPhone 6 de Apple– se conoció a través de Twitter y de...
En Exploring Data, La Red de Inflencias entre los Lenguajes de Programación en su edición 2014. En esta visualización creada por Ramiro Gómez en la lista de este año los que cortan el bacalao son los clásicos entre los clásicos: Lisp,...
TuesdaysAndFridays vende esta réflex Alfa, disponible en modelos Canon, Nikon, Sony, o sin marca, y en capacidades de 4 y 8 GB, ya que en realidad el objetivo es una memoria USB. Que sí, que no es muy práctica, que los...
Blockly es un lenguaje de programación para niños que funciona vía web y con una interfaz gráfica. Se programa arrastrando y soltando piezas y ni siquiera hay que teclear. Además de este y otros similares están todos los recursos de Code.org,...
Si OS X se necesita desplegar las subcarpetas de una carpeta se puede hacer seleccionándolas todas (Comando-A) y simplemente pulsando Cursor derecha. Si se repites la operación de nuevo (Comando-A, derecha, Comando-A…) se van desplegando más y más hasta el último...
Una buenísima noticia para cualquiera que esté interesado en la historia de los hackers españoles: Hackstory, el impresionante trabajo de Mercé Molist que recopilando su historia, está ya disponible para su descarga como libro electrónico en multitud de formatos. La descarga es...
En azul: duración de las partidas aleatorias en simulación;en marrón: partidas reales entre maestros La curiosidad llevó a @BillAutomata –que personalmente dice no ser un gran jugador– a preguntarse cuán diferente sería normalmente una partida de ajedrez completamente aleatoria frente a las...
Watson, el famoso superordenador de IBM, dejó hace tiempo los concursos contra humanos para dedicarse a temas más relevantes, como el trabajo en investigación médica y sectores del conocimiento especializados. Aunque todavía no esté claro qué parte de lo que lee «entiende»,...
El problema matemático del viajante (en inglés: Travelling Salesman Problem, TSP) es un clásico en el mundo de los algoritmos: encontrar la ruta más corta posible que visite cada ciudad una sola vez en un mapa, regresando a la ciudad de...
Dropbox Pro 1 TB 9,99€ / mes Lento Accesible desde cualquier parte No ocupa espacio físico No necesita enchufe/cable Backups seguros Al alcance de la NSA WD Portable 1 TB 59,99€ / hasta que se rompa Muy rápido / USB 3.0...
GitLive utiliza la API de GitHub, el famoso repositorio del sistema de control de versiones Git -especialmente popular en proyectos de código abierto y software libre- para mostrar qué está haciendo la gente de la comunidad, especialmente colaborando e interactuando de...
Aparte de una cama sin bichos sólo hay dos cosas que considero imprescindibles en un hotel: una ducha con una buena presión de agua y Wi-Fi, a ser posible gratuita; de hecho la disponibilidad de esta es uno de los criterios...
Microsoft Word para Mac existía desde 1985; fue la primera versión de esta aplicación con interfaz gráfico Tal día como hoy, el 1 de agosto de 1989, Microsoft sacaba al mercado Microsoft Office, el paquete ofimático que junto con Windows terminaría por...
Merece la pena dedicar veinte minutos a repasar este trocito de historia del diseño y la informática que fue el desarrollo de Illustrator, el primer programa en en 1987 comercializó Adobe tras haberse dedicado únicamente al lenguaje PostScript para impresoras. Illustrator...
Los algoritmos son uno de los componentes más importantes de cualquier campo de la ciencia, pero especialmente la matemática y la informática. En un excelente trabajo titulado Visualizing Algorithms al que Mike Bostock debe haber dedicado días –si no semanas– se...

Fue un cambio que nadie vio venir: la idea de que podríamos tomar un libro, una pintura o una canción y enviarla a través de hilos, cables o incluso el aire hasta el otro lado del mundo – de modo que...
Los fans que están detrás de The HAL Project llevan cinco años recreando los elementos visuales del famoso ordenador de 2001: Una odisea del espacio. Su creación cuenta con todo tipo de detalles: animaciones, colores y tipografías idénticas a las del...
Nunca he sido demasiado «jugón», pero no tardaré mucho en ver Video Games: The Movie en cuanto salga, un documental sobre la historia de los videojuegos, quienes los hacen, y quienes los juegan. El estreno está previsto para el 15 de...
En Ars Technica, The history of Android: The endless iterations of Google’s mobile OS, Las primeras versiones de Android no fueron muy populares, y hasta la versión 4.0 del sistema operativo sólo se podían hacer capturas de pantallas utilizando el entorno...
Por Nacho Palou -
17 JUN 2014
71 series data modems, 1974 Aparte de su colección de hardware y software el Computer History Museum dispone de montones y montones de folletos que van desde la década de los 50 hasta principios de los 80. En Selling the Computer Revolution...

En esta historia de 2010, titulada Zip Files All The Way Down (Vía Kottke) Russ Cox de los Bell Labs cuenta cómo indagar sobre el curioso problema de si es posible crear un fichero .zip que se contenga a sí mismo,...
Jennifer in Paradise, John Knoll En The Guardian, Jennifer in paradise: the story of the first Photoshopped image se cuenta la historia de esta fotografía, tomada por John Knoll en 1987 a su entonces novia Jennifer, que es la imagen que se...
Por Nacho Palou -
16 JUN 2014
La World Wide Web es, sin duda alguna, la cara más popular de Internet, tanto que para mucha gente la Web es Internet, o viceversa. Pero aunque no hay duda de que su desarrollo sale de la propuesta que Tim Berners-Lee...
La primera parte de la secuencia está grabada con una cámara SLR convencional; la segunda parte a medida que aumenta el factor de ampliación proceden de un microscopio electrónico (SEM). El interior del chip se ve bastante bien porque es un...
… Y mira que al popularizador de la singularidad tecnológica le hubiera gustado. Su conversación con ese chatbot hablador que se presentó a un test de Turing y supuestamente «piensa» o «es inteligente» fue más o menos algo así: Pregunta: Vivo en...
Este es el interfaz con el que Eugene Goostman se relaciona con el mundo Aún cuando nosotros mismo no tenemos muy claro qué es la inteligencia juzgar si un programa de ordenador es inteligente no es nada complicado, y a pesar de...
¿De qué estamos hechas las personas? Una guía básica para desarrolladores web, desde el <head>> hasta el </body>. (Vía System Comic + I Love Charts + Rosscott.)...
Codebases es una infografía que muestra el total de líneas de código de programas y «otras entidades» que se ejecutan como software de un modo u otro.
Con datos de GitHub y Stack Overflow (ejes horizontal/vertical) se ha creado este gráfico interactivo de «popularidad» de los lenguajes de programación actuales. Teóricamente –si dibujas la diagonal imaginaria desde el 0– cuando más arriba y a la derecha esté un...
Como parte de sus funciones de cuantificación personal el Samsung Galaxy S5 dispone de un pulsómetro en la parte posterior, un sensor en el que se coloca el dedo para medir las pulsaciones cardiacas. Su funcionamiento es similar al de un...
Por Nacho Palou -
14 MAY 2014

Los lectores más veteranos recordarán haber realizado –o intentado– esta operación consistente en desmontar un Mac original para hacer algún tipo de reparación, ampliación o mejora. Y digo intentar porque en este Mac (un Mac Plus exactamente) ni los tornillos eran...
El ingrediente secreto para que el proceso termine bien Hace unos días, tras un desafortunado incidente con mi ordenador, me vi obligado a tirar de Time Machine, probablemente el mejor invento de la humanidad en mucho tiempo, para restaurar el contenido de...

En este reportaje de Tested diversos expertos explican cómo se construye un superordenador, incluyendo una visita al Centro de Supercomputación Avanzada de Texas, cómo se crean las listas y rankings y hasta dónde podrán llegar en cuanto a velocidad. Para que...
BASIC en un Spectrum Tal día como hoy, pero en 1964, un ordenador del Dartmouth College ejecutaba por primera vez un programa escrito en BASIC, un lenguaje de programación diseñado por John Kemeny y Thomas Kurtz. Su idea era crear un lenguaje...
En el vídeo se ve y se explica paso a paso el proceso para «transferir» una fotografía impresa con una impresora convencional de inyección de tinta en superficies como madera. Básicamente se imprime la imagen invertida (especialmente si tiene texto) sobre...
Por Nacho Palou -
30 ABR 2014
¿Recuerdas aquella historia del año pasado en la que se desveló que el código secreto nuclear de los misiles de los silos americanos había sido ‘00000000’ durante 20 años? Ahora la gente de la CBS ha tenido acceso al interior de...
Ya hemos mencionado en algunas ocasiones Hack Story, el wiki en el que Mercé Molist ha ido recopilando la historia de los hackers españoles. Pero si quieres una introducción al tema, incluyendo una explicación de por qué no se debe usar el...
Real como la vida misma, vía @miuirom....
Por ahora es poco más que una demostración llevada a cabo durante el Pilot Innovation Day en Adventia, la escuela de formación de pilotos, pero tal y como se puede leer en La primera escuela de pilotos del mundo en volar...
A partir de hoy, 8 de abril de 2014, y unos doce años y medio después de su presentación, Microsoft deja de actualizar Windows XP y también de darle soporte, a menos que tengas un contrato de mantenimiento, en cuyo caso...
Europe in 8 Bits - Trailer de Javier Polo en Vimeo. El vídeo corresponde a la secuencia de inicio del documental Europe In 8 Bits de Javier Polo realizado en 2012 y dedicado a la música interpretada con los chips de...
Por Nacho Palou -
7 ABR 2014
Es ligeramente diferente al original, y si consigues pasar 255 columnas habrás terminado el juego, pero Flappy Bird ZX me parece una de las versiones con más gracia del popular juego para móviles, en especial si la juegas en un emulador...
Yo era del Commodore 64, pero no he podido evitar una cierta nostalgia al ver el vídeo de este emulador de ZX Spectrum cargando el logo de Google desde una cinta; hay también una versión real de esto. Y, como siempre...
Microsoft ha puesto a disposición del público en el Museo de Historia de la Computación el código fuente original de MS-DOS 1.1 (1982), 2.0 (1983) y Word para Windows (1990). Como curiosidad: la primera versión de MS-DOS ocupaba tan solo 12...
Sigue habiendo mucho debate sobre si es mejor trabajar con un monitor gigantesco o dos algo más pequeños: si más superficie útil te hace más eficiente y productivo, si es bueno o malo ergonómicamente hablando o si poder tener más ventanas...

En aquellos días del amanecer del segundo año de la segunda década del tercer milenio, descendió una gran oscuridad sobre la conectividad a internet de las gentes del 276 de Ferndale Srt. Durante años, aquellas felices gentes habían disfrutado en sus...
iBetterCharge [OS X, Windows] resuelve un problema tonto que le sucede a mucha gente: olvidar cargar el móvil cuando es posible y conveniente, algo que está penalizado con la muerte de la batería en el momento más inoportuno horas después. La...
10 megas –tan siquiera gigas– por el módico precio de 3.398 dólares es esta irresistible oferta de XComp de allá por 1980. A precios actuales, según la CPI Inflation Calculator, serían la friolera de 9.646,20 dólares… Y total para que no...
Gigawipf creó una versión de Tainted Love interpretada por 13 disketeras y un disco duro y la subió a su canal de YouTube como Floppy Music | Soft Cell - tainted love (13 fdd + 1 hdd)… Pero lo mejor es...
Los programadores y gente aficionados al mundo de la información y los datos harán bien en estar al tanto del lanzamiento del lenguaje Wolfram, creado por el hiperactivo e insaciable autor de Mathematica, autor de profundas e intrigantes nuevas teorías y...
Apple ya ha corregido el bug 'gotofail' incorporando el parche en la actualización a la versión 10.9.2 de OS X. Si no te ha aparecido ya el aviso automático se puede forzar la descargar con Menú Apple > Actualización de Software o...
Actualización (mayo de 2019) – El artículo de la revista original ya no está disponible, pero este es un buen equivalente: The Linux Filesystem Explained. Buena referencia de un nivel muy, muy sencilla para todos los que estén aprendiendo Linux o los...
El inventor del combo de teclas más famoso de todos los tiempos (Control-Alt-Delete en los PC) habla de cómo programarlo fue cosa de 5 minutos porque los desarrolladores estaban un poco hartos y necesitaban un hackeo rápido para reiniciar el PC...
The Flippy Disk Thing es un artículo del arqueólogo digital Jason Scott dedicado a uno de los más entrañables sistemas de almacenamiento del que disfrutamos algunos en la época de los 80 y hasta los 90 – aunque en realidad se...
En este vídeo de National Geographic, con las consiguientes dosis de guionización y dramatización propias del programa ese de la casa de empeños de Detroit o del explorador «behind the musgo», se cuenta algo sobre la historia de una cápsula del...
Paul Thurrott en What the Heck is Happening to Windows? Lo cierto es que el Windows 8.1 Update 1 no es precisamente una actualización trascendental, y aunque trae muchos pequeños cambios en Windows tampoco añade ninguna característica importante [...] Anteriormente dije de...
Por Nacho Palou -
10 FEB 2014
Hace poco se cumplían 70 años desde que por primera vez un ordenador Colossus, uno de los candidatos a ser el primer ordenador de la historia, consiguiera descifrar mensajes codificados con las máquinas Lorenz que usaban las fuerzas armadas alemanas. Este...
No sé bien cómo llegué a Programmers at Work, pero me hizo especial ilusión, porque es la versión en Internet del libro de entrevistas de 1986 en que Susan Lammers recopiló entrevistas con los míticos genios de la época: desde Dan Bricklin...
Todos los que recordamos la época de los 8 bits con cariño veremos este vídeo con una cierta nostalgia, errores de carga desde cinta incluidos. (Vía Wired)....
Origami es un plug-in desarrollado por el equipo de diseño de Facebook para la aplicación Quartz Composer de Apple (gratuita) destinada originalmente al diseño de gráficos animados a la que Facebook le ha encontrado una nueva utilidad —modificándola con su extensión Origami—...
Por Nacho Palou -
4 FEB 2014
El ganador del Concurso Internacional de Código C ofuscado en 2013 de 2013 fue 8086tiny: an IBM PC emulator, apodado «el emulador de PC más pequeño del mundo». Su tamaño normal es de unos 25 KB y emula un PC-XT con...
En Which Internet Browser Will Make Your Battery Last Longer?, Para comprobar qué navegador gasta menos batería he comparado Internet Explorer, Firefox, Chrome y Opera en Windows 8.1 con tres ordenadores distintos: un viejo HP Pavilion dv7, una tableta Toshiba Encore 8"...
Por Nacho Palou -
29 ENE 2014
Keywasher de Coudal Partners en Vimeo....
Por Nacho Palou -
29 ENE 2014
En lo que al hardware se refiere el Bluetooth ZX Spectrum no será más que un teclado Bluetooth convencional, lo cual es bastante WTF porque no recuerdo yo que el teclado de goma del ZX Spectrum fuera especialmente cómodo, sino más...
Por Nacho Palou -
29 ENE 2014
Según Will Water Be Your Next Printer Ink? el 40 por ciento de los documentos impresos en entornos de oficina se utilizan sólo una vez, lo que supone un desperdicio tanto de tinta de impresora como, sobre todo, de papel. La...
Por Nacho Palou -
29 ENE 2014
Microsoft SkyDrive pasará a llamarse Microsoft OneDrive En The OneDrive Blog, Cambiar el nombre de un producto tan apreciado como SkyDrive no ha sido fácil. Pero creemos que el nombre nuevo, OneDrive, transmite el valor que queremos ofrecerte y representa mejor nuestra...
Por Nacho Palou -
27 ENE 2014
Vídeo oficial de Apple para celebrar que el Macintosh cumple 30 años. ¿Quién no recuerda a estas alturas el mítico anuncio de Ridley Scott de aquel 24 de enero de 1984? Pues estuvo a punto de no emitirse, tal era la...
Fallos anuales (%) que requieren cambiar los discos duros. Con casi 30.000 discos duros convencionales de las marcas Seagate, Hitachi, Western Digital, Toshiba y Samsung —con distintas capacidades y velocidades de giro— funcionando en sus máquinas, Backblaze Storage Pod ha publicado datos...
Por Nacho Palou -
23 ENE 2014
El Independent JPEG Group ha publicado la nueva Libjpeg 9.1 que incluye básicamente las funciones para codificar y decodificar imágenes JPEG. En la práctica esto significa una ligera renovación del estándar de compresión de imágenes –al que han dado en llamar...
Interesante reflexión de Harry McCracken en Time: Todo el mundo parece tener una marcada opinión sobre lo que Apple debería hacer. Y un porcentaje sorprendentemente grande de esas personas que comparten con los demás sus reflexiones lo hacen no como una sugerencia...
He pasado algunas semanas probando una tableta Surface 2 que amablemente nos prestó Microsoft; es una renovada versión de la original a la que denominan en su web como «Más fina. Más poderosa». Habiendo probado el año pasado la Surface RT...
Preparados para la nueva normativa - Foto de Paco López Hoy se cumple una semana de la entrada en vigor de la nueva normativa que permite a las aerolíneas españolas solicitar de la Agencia Estatal de Seguridad Aérea el permiso para autorizar...
Un de los adaptadores de Finsix – Foto vía Venturebeat No estará disponible hasta mediados de año, puede que más tarde en el caso de la versión europea, pero si como dice el fabricante el precio va a ser similar al del...
Probablemente sería más fácil de entender si estuviera escrita en klingon, pero lo que quiere decir la «Resolución de 20 de diciembre de 2013, de la Dirección de la Agencia Estatal de Seguridad Aérea, por la que se establecen los requisitos operacionales...
E.T. para Atari 2600, el juego que se ganó a pulso el título de ser probablemente el peor de la historia Al principio se me pasó porque leí las noticias al respecto de medio lado y lo confundí con la colección de...
Kingston ha lanzado este pendrive de memoria Flash de 1 TB, llamado cariñosamente HyperX Predator. Y no solo el nombre acojona, también los 1.300 dólares que cuesta (unos 950 euritos, casi a euro el gigabyte). Los que somos más viejunos y...
Ya se pueden revivir con un clic los viejas eras de la edad dorada de la informática gracias a Amiga 500 Emulator, que carga una versión del mítico microordenador «familiar» de Commodore con algunos extras. Tan solo hace falta visitarlo con...
Alguien, cuyo nombre mantendré en el anonimato, me acusó una vez de ser algo psicópata por enrollar el cable del cargador de mi portátil en las patitas que este tiene al efecto para evitar que se enrolle con el resto de...
File Extensions por Randall Munroe Ahora tendría que hacer uno parecido según la red social en la que te encuentres una información, quizás basándose en su mapa de las comunidades en línea....
Según en qué esquina del planeta estés y cómo le de a Google, es posible que hoy hayas visto el Doodle –el dibujito– que le dedican a Grace Murray Hopper en el 107 aniversario de su nacimiento. Grace Murray Hopper, que...
Utilizando una impresora 3D convencional es posible imprimir mapas y planos con relieves y texturas que ayuden a las personas con discapacidad en la vista a entender y familiarizarse con intersecciones difíciles para ellos, como algunas rotondas en las que el...
Por Nacho Palou -
9 DIC 2013
Google Compute Engine abierto al «público en general» con más poderío, soporte 24/7 y un SLA del 99,95%. A competir con el EC2 de Amazon a muerte – y bajando los precios un diez por ciento para empezar. Hoy en día, quien...
Visual.ly ha producido Origins of Common UI Symbols, una infografía basada en el artículo The Secret Histories of Those @#$%ing Computer Symbols de Wired. Básicamente es una pequeña historia de algunos de los más icónicos símbolos que se han convertido en...
Es la consecuencia de las sucesivas compresiones con pérdida que sufre el vídeo original alternativamente, cuando YouTube lo recibe y almacena y cuando se descarga y guarda en otro archivo en el ordenador. No es hacer copias — la copia digital...
Por Nacho Palou -
4 DIC 2013
Morgan Freeman por Kyle Lambert. Espectacular retrato de Morgan Freeman pintado por Kyle Lambert en un iPad Air, con 285 000 trazos hechos con los dedos, la app Procreate y 200 horas de trabajo — a partir de una fotografía de Scott...
Por Nacho Palou -
3 DIC 2013
Esta pequeña perla gráfica muestra cómo ha crecido con el paso de los años la velocidad máxima que cada año marcan las supercomputadoras más poderosas del mundo: Fastest supercomputers (Science News). La mayor bestia del cálculo hasta el momento sigue siendo...
Reproducción de una bombe británica, equivalente a 36 Enigmas de 3 discos - CC Sarah Hartwell Durante la segunda guerra mundial el Reino Unido y los Estados Unidos utilizaron varios centenares de dispositivos electromecánicos conocidos como «bombe» para descifrar los mensajes alemanes...
3D Heart Models Help Save Children’s Lives, Justin Ryan es un artista convertido en ingeniero biomédico que utiliza su habilidad para hacer un modelo tridimensional del corazón de un niño que necesita cirugía [...] el modelo es una réplica exacta del...
Por Nacho Palou -
2 DIC 2013
Yusuke Endoh creó este simulador de dinámica de fluidos en ASCII, un programa bastante ofuscado según cuenta, programado en C para un compilador C99. Adornado conveniente con música clásica se convierte claramente en algo que solo se puede calificar de épico....
Es una especie de Raspberry Pi pero en bonito. Se llama Kano y su colorido aspecto llama poderosamente la atención. En el kit básico va una Raspberry Pi modelo B, el sistema operativo en una tarjeta SD de 8 GB (una...
Depende de cómo lo mires. Me sorprendió encontrarme por ahí con SpeedTree, que al parecer es una herramienta puntera en la creación de árboles artificiales. Se utiliza en modelado 3-D para arquitectura, videojuegos y creación de escenarios y efectos especiales. Un...
Clic para ampliar. La de arriba es una comparación no científica entre utilizar aplicaciones móviles para medir la actividad física en el iPhone 5s (en rojo) y utilizar el accesorio FitBit Zip (en azul) que sirve para eso; cuando lo llevas encima,...
Por Nacho Palou -
18 NOV 2013
ATTN @JetBlue Pilots: PED Policy Now Effective! The first B6 flight to allow gate2gate was 2302 JFKBUF @ 1630 pic.twitter.com/jbHtwWSCA5— HelloJetBlue (@HelloJetBlue) November 1, 2013 Siguiendo los pasos marcados por la reciente decisión de la Autoridad Federal de Aviación de los Estados...
En Art of the Title se dedican a analizar títulos de crédito de videojuegos. Según cuentan ellos mismos con el vídeo A Brief History of Video Game Title Design intentan ilustrar como el lenguaje de cine ha influido en los videojuegos,...
Desde principios de los 80 y hasta principios de los 90 España fue una gran potencia en el desarrollo de videojuegos, tal y como se puede leer en Ocho Quilates: Una historia de la Edad de Oro del software español. Pero las...
Esta bestial creación de Panasonic es una tableta con pantalla de 20 pulgadas y 3840 × 2560 de resolución, más allá del Ultra HD que empieza a ponerse de moda en los televisores de gran formato. Como excusa para hacerte con...

El juego de la vida de Conway. (Salta a 01:10 si ya conoces las reglas) En el peculiar mundo computacional de los autómatas celulares el juego de la vida de John H. Conway ocupa un lugar destacado y por méritos propios....
El XXX aniversario del MSX es uno de los temas de este año RetroMañía 2013, el evento anual de la asociación RetroAcción sobre retroinformática, tendrá lugar este año del 4 al 8 de noviembre de 2013 como parte de las actividades de...
Este curioso vídeo muestra el trabajo de una empresa llamada Vicarious que trabaja en el campo de la inteligencia artificial, intentando hacer que los ordenadores «piensen» como los humanos. Uno de los primeros retos que se plantearon fue superar una de...
Elite en JMESS Además de guardar un archivo histórico de la pinta que tenían las páginas web en the Wayback Machine en The Internet Archive se pueden encontrar archivos de audio, grabaciones de música en directo, libros, películas… Y desde ya un...
Evernote, imprescindible para mi En RTVE.es me pidieron que escribiera algo sobre cómo me organizo para gestionar toda la información que pasa por mis manos y qué aplicaciones y gadgets uso para eso. El resultado es la pieza titulada Cómo estudiar con...
Mucho Mega, un corto de Raúl Navarro con Gabriel Salas e Iggy Rubin emitido en la sección Router 66 del programa Torres y Reyes de La 2. (Gracias, Maqui)....
El logo de Android nació en 2007 y es obra de Irina Blok, que entonces trabajaba como diseñadora en Google, Who Made That Android Logo? — A Blok y a su equipo de diseño se les pidio que crearan una imagen...
Por Nacho Palou -
15 OCT 2013
Si eres de los que tiene la sana costumbre de ponerle nombres propios a los servidores, equipos informáticos personales, unidades de disco y demás –eso de «Mi PC» o «HDD» queda un poco viejuno ya– te vendrá bien Hostnames una lista...
Pulsa para ampliar La historia de Android, el sistema operativo diseñado originalmente para cámaras digitales y que hoy es el más utilizado en los teléfonos móviles (que irónicamente cada vez son más cámara de fotos que otra cosa) y que compró Google...
Por Nacho Palou -
10 OCT 2013
La Busycom Handy-LE es uno de los objetos incluidos en esta lista - Foto por Nigel Tout Como cualquier otra lista de este estilo hay cosas discutibles como por ejemplo los Beats, y otros erróneamente identificados como el Commodore Educator 64 que...
Para los nostálgicos de la sala, Cloudpaint, una versión en línea completa del mítico MacPaint con el que muchos empezamos a alucinar con los Macintosh y a comprender que el futuro estaba en los interfaces gráficos de usuario. ¡Qué tiempos aquellos...
HTTPflies es bonito: códigos de error como si fueran una colección de mariposas. Además son SVG (gráficos vectoriales) y la historia del cómo se hizo, surgiendo de un chiste es simpática y entretenida....
Mientras que un puntero para pantallas táctiles se limita a servir como sustituto de los dedos, un lápiz digital como el Intuos Creative Stylus de Wacom (99,90 euros) es un puntero más sofisticado que se conecta con el iPad por Bluetooth...
Por Nacho Palou -
9 OCT 2013
Eso no puede suceder Eso no sucede en mi máquina Eso no debería suceder ¿Por qué sucede eso? ¡Oh, ya veo! Pero… ¿cómo podía funcionar antes? (Desde el pasado vía Plasmasturm.)...

Tenía por ahí guardada esta conferencia del 25C3 (el congreso del Chaos Computer Club de 2008) en la que Michael Steil explicó prácticamente todo lo que se puede explicar sobre el C-64 en 64 minutos y 256 «diapositivas». Un trabajo impresionante....
Sabía que Apple vende iPhones probablemente tan deprisa como puede fabricarlos, pero aún así me sorprendieron los datos que se pueden leer en Listen Up Apple-Haters: IPhone Sales Eclipse Microsoft and Amazon Revenue. Según ese artículo si el iPhone lo vendiera una...
Con todo lo WTF que es la película «Objetivo la Casa Blanca» resulta que contiene la que es probablemente la escena del tipo personas delante de un ordenador más realista que se haya visto nunca en el cine. — La contraseña es¹...
Por Nacho Palou -
30 SEP 2013
Un Floppy ROM con un programa para llevar el libro mayor de una contabilidad Soy lo suficientemente viejuno como para haber usado cintas de casette para almacenar programas, pero no como para haber usado nunca un Floppy ROM, que es como el...
¿Cómo es el centro de proceso de datos del CERN donde están alojado el Gran Colisionador de Hadrones y otros cientos de proyectos científicos y tecnológicos? La gente de Computerphile tuvo acceso al interior de ese datacenter y nos explica todas...
// // Querido mantenedor del código: // // Una vez hayas intentado 'optimizar' esta rutina // y te hayas dado cuenta del terrible error que has // cometido, por favor incrementa el contador que hay // debajo a modo de aviso para...
Source Code Pro Igual que con los editores de texto, esto es poco menos que para provocar una guerra de comentarios, pero en What are the best programming fonts? hay una recopilación de tipos de letra monoespaciados votados por los usuarios de...
Este «cluster Beowulf» de Raspberry Pi es la solución que Joshua Kiepert encontró al desarrollar su trabajo en la universidad. Teniendo en cuenta que cada ordenador en miniatura cuesta unos 30 o 40 euros, las 33 cajitas que hay dentro de...
El AGC (Apollo Guidance Computer) era un primitivo ordenador que se utilizaba para guiar a las naves de las misiones Apolo en sus viajes hacia la Luna. Tenía tan solo 2 KB de memoria RAM (de 16 bits), funcionaba a 2...
Tras efecuar la rotación, los puntitos blancostienen un color «indeterminado» ¿Cómo solucionarlo? Girar imágenes ideales cualquier ángulo es matemáticamente fácil, pero… ¿Qué pasa cuando se trata de píxeles cuadradotes? Este entretenido artículo de Data Genetics explica algunos de los problemas y soluciones...
Entiendo perfectamente lo que quiere reflejar Intel con esta imagen, y de hecho hace muchos años que mi ordenador es un portátil, pero lo que no consigo dominar es lo de tener la mesa ordenada… Aunque juro que lo intento y...
En este video y en estas fotografías de Steve Jurvetson aparece el ordenador (supuestamente) cuántico D-Wave como los adquiridos por Google o la Nasa. El vídeo es un poco decepcionante porque el D-Wave no es más que una caja con algunas...
Por Nacho Palou -
22 AGO 2013
Queridos niños. hubo una época en la que los píxeles eran del tamaño de puños y las paletas apenas tenían colores…– El Abuelo Cebolleta Informático Gente como la que gestiona 16c, el Archivo de Arte ANSI/ASCII Dieciséis Colors, está haciendo una...
Si conoces Stack Overflow en inglés no se te hará difícil de entender EntreDesarrolladores.com, una idea similar con un diseño prácticamente igual, en la que los desarrolladores participan en formato «preguntas y respuestas» consiguiendo votos y popularidad a cambio de nada....
La gente suele pensar en rms como en el filósofo del que surgió la idea y en mi como el ingeniero que fue capaz de ponerla en práctica.– Linus Torvalds No habíamos mencionado por aquí hasta ahora un «documento histórico» titulado...

How to Coil Cables es un vídeo –está en inglés pero da igual– que enseña un par de técnicas para enrollar cables de todo tipo de tal forma que no se enreden cuando los quieras desenrollar y, sobre todo, para no...
Este artículo se publicó originalmente en Cooking Ideas, un blog de Vodafone sobre historias que «alimentan la mente de ideas». Los ordenadores son cada vez más hábiles en el procesamiento del lenguaje natural, en las traducciones y en el análisis de...
A todos nos ha tocado ordenar una colección de revistas, libros, discos, un mazo de cartas, etc. Cuando son pocos da más o menos igual el método que sigas para ordenarlos, aunque cuando el número de cosas a ordenar crece sí...
Según un sesudo estudio de los ingenieros de Microsoft, las tres teclas más utilizadas en los teclados de ordenador son, por este orden, 1. La barra espaciadora, 2. La letra E y 3. La tecla de Retroceso. Al dato añadieron que además...
1979 – Disco duro con 250 MB de capacidad, 250 Kg de peso y un coste de decenas de miles de euros. 2013 – Tarjeta micro SD con 16 GB de capacidad (64 veces el disco duro de 1979) con un...
Por Nacho Palou -
29 JUL 2013
A sus 97 años este entrañable abuelito Hal Lasko todavía utiliza el Paint de Windows 95 para crear preciosas composiciones visuales de colores en 8 bits....
La memoria SanDisk Connect Wireless Flash Drive es similar a un pendrive o a una memoria USB de las de toda la vida, pero cambia la conexión USB para el acceso a los datos y contenidos por una red wifi propia....
Por Nacho Palou -
23 JUL 2013
Llevo años diciendo a propios y a extraños que eso de los nativos digitales es una chorrada y que estos no existen, que el que un niño haya nacido rodeado por ordenadores, smartphones o tablets no garantiza que sepa usarlos. Juan...
Tubos: De cómo seguí un cable estropeado y descubrí las interioridades de Internet. Andrew Blum. Español, 272 páginas. Edición Kindle en Inglés. Un día la conexión a Internet de la casa del autor dejó de funcionar, y cuando al día siguiente...
Los equipos de David Lightman y el WOPR El otro día hablábamos de la tecnología de Juegos de guerra, una de nuestras películas preferidas de todos los tiempos. En ella David Lightman estaba a punto de desatar una guerra termonuclear global por...
Douglas Engelbart en 2008 por Alex Handy Al parecer trabajar con él resultaba un tanto complicado por su «talibanismo» a la hora de defender sus ideas, hasta el punto de que aunque patentó el ratón para ordenador junto con Bill English sus...
Estuve el otro día repasando Juegos de guerra, una de nuestras películas geek favoritas y la verdad es que aguanta el paso del tiempo dignamente. Hay algunas cosas un tanto irrisorias hoy en día, como el acoplador acústico, las cabinas telefónicas...
¡Fortran da miedo! No están todos, ni tampoco hay que tomárselo demasiado en serio, pero en ¿Qué intentaba arreglar cada lenguaje de programación? hay recogidos los motivos que llevaron a la creación de muchos lenguajes de programación, por lo general para intentar...

Cuentan las crónicas que un ordenador llamado The Manchester Baby fue el primero en ejecutar un programa que estaba almacenado en una memoria electrónica – un matiz relevante en este tipo de historias porque sigue sin estar muy claro cuál fue...
Si eres de los que siempre ha querido pasarse por alguna de las Maker Faire que organiza la revista Make, esta llega ahora a España en su versión Mini Maker Faire, que es la marca bajo la que estas ferias se...
mOwayduino, el robot basado en Arduino dotado de diversos sensores y programable en varios lenguajes de Minirobots, ya está en Indiegogo. Aspiran a conseguir 50.000 dólares de aquí al 1 de agosto de 2013 para poder lanzarlo al mercado; a ver...
… al menos para este programador, que ha decidido que para qué necesitas oficina, casa o garaje si puedes montártelo en una tienda de campaña con un portátil y una conexión de datos decente. El proyecto se llama Blockie.io y la...
Nipple Y todo lo demás se aprende. Puede que ni el pezón sea intuitivo. Así que no existen interfaces intuitivas, ni de ordenador ni de otro tipo. Como mucho, menos engorrosas. En The Only Intuitive Interface Is The Nipple. ¡Gracias Ishac Bertran!...
Por Nacho Palou -
10 JUN 2013
Desde Minirobots nos han escrito para hablarnos de mOwayduino, su proyecto para lanzar al mercado un pequeño robot basado en Arduino dotado de diversos sensores y programable en varios lenguajes. Tiene sensores de proximidad, de luz, para seguir líneas, micrófono y...
Usar como reader para leer los feeds RSS una aplicación como NetNewsWire, mi favorita de todos los tiempos tiene muchas ventajas: te almacena los feeds, puedes marcar los que quieres leer luego, crear una plantilla para publicar una anotación «vía xyz…»...
Al poco de estrenar el ordenador que uso ahora, un MacBook Air de 13", me llevé un buen susto porque trabajando en un lugar en el que no podía enchufarlo a la corriente se quedó sin batería en poco más de una...

Quien más quien menos haya trabajado en el campo de la programación se habrá cruzado sin duda con algún ejemplar de los libros de animales de O'Reilly. Las portadas de la famosa editorial son una especie de gigantesco zoológico, a veces...
En Firebox, por unos 20 euros (4 GB)....
Por Nacho Palou -
28 MAY 2013
Aplicar la realidad aumentada al mantenimiento de los coches, como hacen estas gafas de BMW de hace ya unos años, fue uno de los primeros ejemplos prácticos de realidad aumentada. Otro ejemplo similar pero más asequible sería esta aplicación de demostración...
Por Nacho Palou -
28 MAY 2013
Ambientado en los pseudo-80 (sublime definición) este impresionante trabajo gráfico de Brian Sørensen aprovecha para insertar algunos equipos e iconos de la infancia de la informática: un Commodore 64 tan real como es posible, un IBM PC, un datassette… Indispensable revivirlo....
«Caras» en el extremo oriental de Rusia La pareidolia es ese fenómeno que nos lleva a reconocer formas reconocibles en sitios donde no las hay y ver, en especial caras. Pero lo bueno es que si se le aplica un algoritmo de...
Un año más, la feria + conferencia SIGGRAPH reunirá de nuevo a expertos de distintas disciplinas en el campo de las imágenes generadas por ordenador. Aquí pueden verse un pequeño avance de lo que podrá disfrutarse allí este año. Entre otras...
Kepler-76b en Exoplanet Exoplanet, una aplicación escrita por Hanno Rein, un astrofísico, y disponible para iPhone e iPad, es una magnífica opción para mantenerte al día de todas las novedades sobre planetas extrasolares que se producen casi cada semana. Incluye una base...
International Space Station making laptop migration from Windows XP to Debian 6 -- La Estación Espacial ha decidido cambiar docenas de portátiles con Windows XP al sistema basado en Linux Debian. Windows X-P, ahm. Relacionado: Unix / Linux es el ancestro común...
Por Nacho Palou -
13 MAY 2013
En mis tiempos de estudiante las placas de circuitos impresos se hacían con adhesivos o rotulador Edding y baños de ácido, así que The Othermill es otro clavo en el ataúd de mi juventud: es una pequeña fresadora doméstica, de escritorio,...
Por Nacho Palou -
10 MAY 2013
Ni Creative Suite 6 ni CS5 ni nada de nada: lo que necesitamos en nuestros ordenadores es Adobe Milagro™, una versión con funciones para resolver todos los problemillas cotidianos a los que se enfrentan diseñadores y artistas digitales de mal vivir....
David Pogue es un tipo tan majo como parece en el vídeo; tuve la suerte de conocerle en los 90 en la época de Macworld (él escribía una columna en la edición americana). Desde entonces se ha dedicado a divulgar y...
Al parecer algunos suscriptores de la revista Forbes han recibido un ejemplear impreso que funciona como un punto de acceso wifi con conexión a Internet, durante 15 días, a través de un router colocado en un encarte de la publicación. Puede ser...
Por Nacho Palou -
30 ABR 2013
Así de espectacular y de realista pueden llegar fluidos como el agua generados por ordenador, destinados a videojuegos, gracias a un nuevo algoritmo de simulación de líquidos denominado «Position Based Fluids» desarrollado por el fabricante de procesadores gráficos Nvidia. Vía Mashable....
Por Nacho Palou -
25 ABR 2013
John Underkoffler diseñó la interfaz del ordenador que aparecía en la película Minority Report y actualmente desarrolla y vende software similar al que se podía ver en los ordenadores de Minority Report. En el vídeo se puede ver una demo del...
Por Nacho Palou -
24 ABR 2013
En TechCrunch, sobre «la muerte del PC» que tanto se ha nombrado tras las últimas cifras de ventas de ordenadores en el mundo, Muchos tratan de hacernos creer que la disminución de las ventas de ordenadores nuevos significa que éstos están siendo...
Por Nacho Palou -
23 ABR 2013
¿Sabes esos largos contratos cuando estrenas un software que nadie lee? ¿La denominada mayor mentira jamás contada? Dicen en OMG que hace una década, medio de cachondeo medio en serio una compañía incluyó en la licencia un «premio sorpresa» de 1.000 dólares...
Si tienes hijos o trabajas con niños y/o adolescentes, no te puedes perder Adolescentes y redes sociales, un vídeo que aborda este delicado tema con mucha ecuanimidad sin caer en el mensaje apocalíptico que muchas veces se le asocia. Al contrario,...
Cualquiera que se haya puesto a programar un poco sabe que esto es real como la vida misma. Bueno, real como la vida misma salvo en la parte de los requisitos, que todos sabemos que son los padres. (Vía @1Pr0grammer)....
Uno de los fundadores de Android, Andy Rubin, citado en PCWorld — Android founder: We aimed to make a camera OS, La misma plataforma, exactamente el mismo sistema operativo que construimos [en 2004] para cámaras de fotos, se convirtió en Android para...
Por Nacho Palou -
17 ABR 2013

Desde el departamento de los mundos viejunos informáticos nos llegan hoy los ecos de este vídeo de época del IBM 305 RAMAC. Fue el primer ordenador comercial con disco duros parecidos a los de hoy en día (cabeza móvil y magnéticos)....
Paul Allen y Bill Gates, los fundadores de Microsoft, y unos cuantos cacharrosAllen y Gates con más o menos los mismos cacharros en 2013 Una foto clásica de la historia de los ordenadores, reproducida en el Living Computer Museum de Allen,...
Si manejas datos en Excel que puedan de algún modo geolocalizarse sobre un mapa, como estadísticas de población, ventas por regiones, ciudades o cuestiones similares te interesará echar un vistazo a GeoFlow. Se trata de un proyecto de Microsoft que actúa...
Según IDC en el primer trimestre de 2013 la cantidad de PCs enviados por los fabricantes a sus canales de distribución bajó un 13,9 por ciento respecto al mismo trimestre de 2012, casi el doble del 7,7 por ciento previsto. La culpa...
Representación artística de la Pioneer 11 en el espacio En 1980 algunos científicos que trabajaban con los datos de las sondas Pioneer 10 y 11 se dieron cuenta de que estas estaban frenando algo más despacio de lo previsto por la ley...
Como todos los 31 de marzo, hoy es el Día internacional de las copias de seguridad. Además de que hagas un backup completo de todos tus datos ya mismo para celebrarlo, hay algunos consejos e ideas al respecto en World Backup...
The Touch es una aplicación para Mac (con versión para iPad) que permite editar fotografías y vídeos en Lightroom y Final Cut Pro X mediante gestos realizados tanto con en el trackpad / Magic Trackpad como desde la pantalla del iPad....
Por Nacho Palou -
26 MAR 2013
Estábamos tuiteando @luisete, @VicenteAlfonso, @davidgamez y yo sobre qué hacer cuando cierre Google Reader y cómo Reeder, Feedly o NetNewsWire, entre otros, tendrán que desarrollar sus propios servicios de sincronización. En medio de la conversación surgió el asunto de por qué Google...
La tinta de impresora es más cara que la sangre humana; actualmente va a unos 70 céntimos el mililitro frente a 40 que cuesta la sangre, 10 la penicilina o 2 céntimos el petróleo. Una curiosidad que no por conocida resulta...
Una ínfima parte de la colección Cabrinety; en total ocupa más de 400 metros de estanterías en la Biblioteca de la Universidad de Stanford Durante su corta vida Stephen M. Cabrinety llegó a acumular una enorme colección de programas, hardware, periféricos, consolas...
Probablemente con años de retraso, en mi trabajo del MundoReal™ estamos empezando a trastear con Processing, un lenguaje de programación basado en Java que tiene como objetivo enganchar a gente que no tiene ni idea de programar en esto de la...
Dell dejó ver en la conferencia de arte y tendencias SXSW su nuevo modelo portátil Dell XPS 18. Básicamente es una tableta de 18 pulgadas Full-HD con teclado y ratón inalámbricos. Corre Windows 8 y su peso –todo incluido– es de...
La cuota de mercado es insuficiente, las ventas están siendo pobres y hasta Samsung está retirando algunas tabletas Windows RT en algunos países porque no se cumplen las previsiones. Según Wired, Microsoft tiene un problema pero todavía está a tiempo de...
Este artículo se publicó originalmente en Sin vuelta de hoja, un blog de MásMóvil donde colaboramos semanalmente con el objetivo de contar cosas sensatas y relajantes relacionadas con la tecnología y la ciencia. Cuando rellenar formularios a través del navegador web...
Ocho Quilates: Una historia de la Edad de Oro del software español. Jaume Estevez Gutiérrez. Web: www.ochoquilates.com; @ochoquilates en Twitter. La celebración de RetroMadrid 2013 y su homenaje a La Abadía del Crimen es la excusa perfecta para recomendar la lectura...
Grandes máquinas nunca mueren. 8, 9 y 10 de marzo, Madrid. Si no tienes nada mejor que hacer en un fin de semana frío y lluvioso, los espacios culturales del Matadero son un sitio mejor que cualquier otro, porque se celebra...
El Levitating Wireless Computer Mouse de momento no es más que una idea y puede que nunca llegue a ser un producto real, pero ahí queda una idea tan chula como por ahora improbable. Según su autor este ratón evitaría el...
Por Nacho Palou -
8 MAR 2013
Si hay dos temas de los que escribo de forma recurrente son el del verdadero origen de Internet, que no fue concebida como una red de ordenadores capaz de sobrevivir a un ataque nuclear, y de los famosos nativos digitales, que no...
Un mismo modelo impreso en 3D a distintas escalas Como constructor empedernido de maquetas de Airfix, Marchbox, Esci, Italeri, Tamiya y similares, fundamentalmente de aviones, llevaba tiempo pensando en lo útil que podrían ser las impresoras 3D para este tipo de afición....
Applied Design es una nueva exposición del MoMA que busca explorar como el diseño nos ayuda a responder a los cambios en casi cualquier aspecto de nuestras vidas buscando facilitar nuestra interacción con las cosas. Esto, en opinión de los responsables...
No es la más práctica del mundo por su tamaño, pero esta memoria USB hecha con un controlador Nintendo NES mola todo. Las hay también hechas con cartuchos de Game Boy Advance, los dos modelos en distintas capacidades de 8 a...
Vale, no es un holograma de verdad sino más bien una pantalla volumétrica que recrea el efecto de estar observando un objeto tridimensional. Es el resultado de colocar cuatro trozos de plexiglás sobre una pantalla LCD convencional situada en horizontal. Cómo...
Por Nacho Palou -
4 MAR 2013
Como todos los que nos dedicamos a esto de la informática sabemos, el Virus Venn Diagram de XKCD lo clava y es real como la vida misma. Al hilo de esto, Una docena de preguntas que me han hecho siendo informático...
La gente de Code.org rodó este mini-testimonial con todo un elenco de superestrellas geek para concienciar a la gente de que a nivel mundial hay escasez de informáticos; también quieren que cale la idea de que enseñar a programar es mucho...

Este artículo se publicó originalmente en Trend It Up, un blog de Sony Mobile donde colaboramos con anotaciones sobre el mundo de las tendencias combinadas de la tecnología, el diseño y las artes. Quien pase sus días con lenguajes de programación...
En el Computer History Museum de Mountain View han conseguido que el código fuente de Photoshop 1.0 sea considerado «una gema digna de exposición» y lo está ofreciendo para su descarga y análisis, así como para curiosos y coleccionistas. Este software...
Alguien ha tenido el humor de crear unos subtítulos para el típico sonido de un módem cuando se estaba conectando: Tuuu, pó pi pó pópó pi pó pó piQui puóóóórr cu ri uóóórPiiiriiiriii póóhh whiiiianhô anhô wiiiitchaaaaahhh puaaaoooooaaahhhhhprããããa uãuããsshhhhhhshshhhhhhh No es que...
Desde el departamento de Esto ya lo he vivido yo, el E-inkey Keyboard Concept es un teclado en el que cada una de sus teclas es una pantalla de tinta electrónica, de modo que el símbolo que aparece ellas puede cambiar...
Por Nacho Palou -
1 FEB 2013
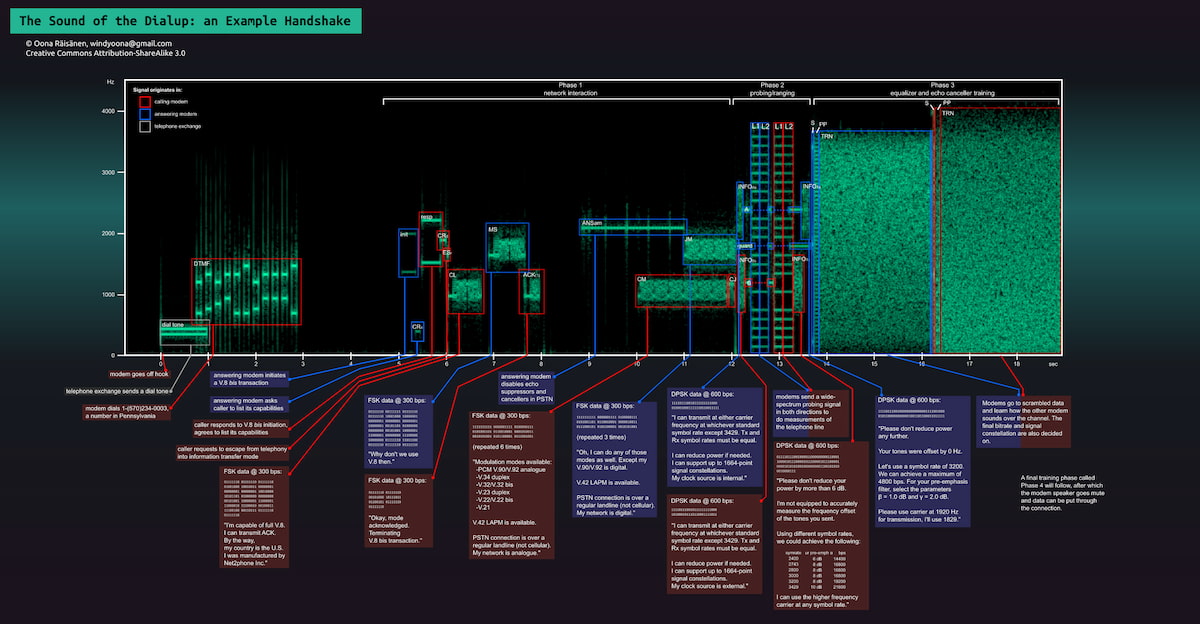
Esta preciosa y detallada infografía [también como PNG 2500x1300] creada por Oona Räisänen muestra las diversas fases del handshaking de los módems, el «intercambio de saludos» técnico entre un dispositivo y otro a través de líneas telefónicas analógicas: The sound of...
¡Mundo viejuno informático! Estos días la hoja de cálculo Lotus 1-2-3 cumple 30 años y Dan Bricklin, uno de sus creadores, lo recuerda con un profuso artículo: 30 years since Lotus 1-2-3. Como los más viejos del lugar recordarán antes de...
Basta con poner en la barra de direcciones del navegador, data:text/html, <html contenteditable> Para que la página en blanco del navegador web se convierta en un espacio en el que escribir texto y tomar notas. En los comentarios de la anotación...
Por Nacho Palou -
30 ENE 2013
Microsoft redime algunos de sus pecados con este emotivo anuncio (¿de qué me suena a mi?) orientado a los niños de los 80 con un montón de referencias geeks que emocionarán a todo aquel que utilizara módems con lucecitas, tamagotchis y...
Ashton Kutcher como Steve Jobs intentando convencer a Josh Gad como Steve Wozniak de que la gente querrá comprar un ordenador cuando sepa que lo quiere. Este es el primer clip oficial de jOBS, la película sobre la vida de Steve...
Moves for iPhone, Moves automaticamente registra cualquier paso, pedalada o zancada que des. La app siempre está activa, no necesitas iniciarla o detenerla. Simplemente mantén el móvil en el bolsillo o en la bolsa. Moves utiliza una combinación de datos referentes al...
Por Nacho Palou -
25 ENE 2013
La Samsung Galaxy Camera es un producto curioso. Es un cruce entre una cámara compacta y un teléfono Android. O es un teléfono Android con una cámara supervitaminada pero que no hace llamadas. Probablemente la Samsung Galaxy Camera (SGC) es un...
Por Nacho Palou -
24 ENE 2013
El periodo de prueba de Chocolat ha terminado :(Todo funcionará como hasta ahora,sólo que el tipo de letra ha sido cambiado a Comic Sans.Compra Chocolat Ingenioso, divertido, y sobre todo infalible sistema de protección el que han incorporado los programadores de Chocolat...

Aunque es difícil responder a la pregunta de cual fue el primer ordenador de la historia, prácticamente nadie discute que los orígenes de las máquinas programables se pueden llevar hasta el telar de Jacquard. Claro que para que las cosas se...
Los tablets son turismos y los PC son camionetas, Steve Jobs comparaba la transición desde el ordenador de sobremesa y el ordenador portátil hacia los tablets como lo fue el paso desde las camionetas a los turismos. Las camionetas disminuían en popularidad...
Por Nacho Palou -
23 ENE 2013
Tal y como prometio, Kim Dotcom vuelve a la carga con Mega, el servicio que está llamado a suceder a Megaupload. Más de un millón de usuarios registrados en poco más de dos días y un dimensionamiento un tanto escaso ante...
The Trend Against Skeuomorphic Textures and Effects in User Interface Design se refiere a la técnica de hacer que las interfaces gráficas de sistemas operativos y de aplicaciones imiten la apariencia de objetos reales con texturas (de metal, piel o madera, por...
Por Nacho Palou -
21 ENE 2013
ARR, pt. 2 por Marcin Wichary Es una pena que no tenga absolutamente ningún enlace, igual que tampoco los tiene la página correspondiente del Museo de la Tecnología de Varsovia, pero el este álbum de fotos de su sección dedicada a la...
En TICbeat, IBM vuelve a liderar el ranking de patentes de la industria de la tecnología de la información: En total, IBM ha registrado 6.478 patentes durante 2012, lo que pone a la compañía por delante de Samsung (5.081) y Canon (3.174),...
De la nota de prensa de Microsoft, Windows 8 alcanza 60 millones de licencias vendidas -- Las ventas acumuladas de Windows 8, que incluyen tanto actualizaciones como ventas para dispositivos nuevos, marcan una trayectoria de ventas similar a la experimentada por Windows...
Por Nacho Palou -
9 ENE 2013
Dos años y medio de uso del ordenador - Marcin Ignac Ahora que está de moda esto del «yo cuantificado», sólo falta completarlo con cosas como estos gráficos creados por Marcin Ignac de su uso del ordenador a lo largo de dos...
Cuando el arte y la genialidad del código bien programado se unen suceden cosas maravillosas. En esta recopilación en vídeo de PBS Off Book pasan a toda velocidad un montón de ejemplos de cómo programadores-artistas crean verdaderos mundos digitales, visualizaciones imposibles...
Cada diez años se ha multiplicado por mil la velocidad de estos superordenadores. La nueva versión de la supercomputadora Mare Nostrum estará entre las doce más poderosas de Europa. En modelos predictivos sobre extracción de petróleo el Mare Nostrum «acertó» 6 de...
Bruce sterling en Why It Stopped Making Sense to Talk About 'The Internet' in 2012: En 2012 cada vez tenía menos sentido hablar de «Internet», «los PCs», «teléfonos», «Silicon Valley», o «los medios», y cada vez más estudiar Google, Apple, Facebook, Amazon...
Alejandro Suárez resume y comenta La vida de Steve Jobs en nueve frases que este pronunció a lo largo de su vida: La innovación es lo que distingue a un líder y a un seguidor. No me interesa ser el hombre más...
El ioSafe es tan vistoso como poderosamente resistente: es un modelo anti-incendios y resistente al agua. Eso quiere decir que podría aguantar un fuego de unos 800°C durante 30 minutos o pasar a un metro de profundidad durante 72 horas. Su...
Del mismo modo que con VMWare o Parallels es posible ejecutar Windows en ordenadores Mac, con BlueStacks puedes ejecutar aplicaciones Android en Mac OS X. BlueStacks también está disponible, desde hace algún tiempo, para ordenadores PC con Windows. Las aplicaciones se...
Por Nacho Palou -
28 DIC 2012
Utilizando un ordenador para controlar la posición horizontal y vertical de un imán situado bajo la superficie de la mesa, se trasladan al dibujo a mano alzada sobre papel métodos del diseño asistido por ordenador [...] Además de poder trazar con...
Por Nacho Palou -
26 DIC 2012
Probablemente no son muy prácticos, porque a la mínima que te descuides te bloquean el puerto USB de al lado, y si es la de un modelo de avión que lleve los estabilizadores en la parte alta de la deriva lo...
Mercado global de sistemas operativos para informática personal entre 1975 y 2012 (estimación), según KPCB. ZDNet, citando a Goldman Sachs en Windows has fallen behind Apple iOS and Google Android, Si en el año 2000 los ordenadores personales (PC) eran los aparatos...
Por Nacho Palou -
13 DIC 2012
Primera unidad del Setun A finales de los años 60 el gobierno de la Unión Soviética tomó la decisión de que todos los desarrollos en el campo de la informática debían centrarse en copiar el IBM 360 para así poder asegurarse la...
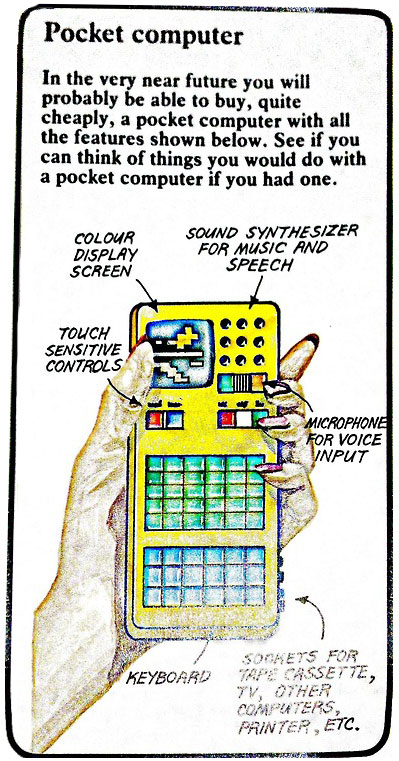
En un libro para niños sobre ordenadores publicado allá por los 80 del siglo pasado (que en realidad ya son del milenio pasado) imaginaban así un futuro ordenador de bolsillo: En un futuro cercano probablemente podrás comprar, muy barato, un ordenador...
Los físicos e informáticos llevan tiempo trabajando con la supercomputadora Mira para recrear la historia de nuestro universo con cierto nivel de detalle dentro de las posibilidades de este tipo de modelos matemáticos y la potencia del hardware y el software...
En Wired Danger Room, 3-D Printed Gun Only Lasts 6 Shots. Un paso más hacia lo de fabricar armas de fuego que te puedes descargar de internet [y materializar con una impresora 3D]. Los armeros probaron un rifle parcialmente impreso en...
Por Nacho Palou -
4 DIC 2012
Un MacBoo Pro desmontado y funcionando sumergido en aceite mineral (vía 512 pixels). El aceite funciona como refrigerante, igual que el agua y de forma mucho más efectiva que el aire —los ventiladores del ordenador extraen el aire calentado por componentes...
Por Nacho Palou -
4 DIC 2012
Desde hace años en la NASA tienen medianamente claro que Internet, los blogs, y las redes sociales son una estupenda herramienta para hacer llegar su trabajo al público en general sin tener de pasar por el filtro de los medios tradicionales,...
Este es un trabajo de esos en los que a cualquiera nos hubiera encantado participar: contrataron a la gente de xRez Studio para realizar una giga-foto de la Máquina Diferencial de Babbage expuesta en el Museo de Historia de la Informática...

10 PRINT CHR$(205.5+RND(1)); : GOTO 10, editado por MIT Press, es una obra colectiva con el curioso título de una línea de programa BASIC del Commodore 64. Los más viejos del lugar recordarán que en aquellos ordenadores parte de los juegos...
Black Friday Report 2012 de IBM (datos para EE UU), Ventas sociales: los compradores procedentes de redes sociales como Facebook, Twitter, LinkedIn y YouTube generaron el 0,34 por ciento de todas las ventas online durante el Viernes Negro, una disminución de más...
Por Nacho Palou -
26 NOV 2012
¿Qué pasaría si adoptáramos el uso de herramientas colaborativas de código abierto similares a Git para la creación de leyes de tal forma que los ciudadanos pudiéramos seguir el proceso de elaboración de estas e incluso participar en él? Pues según...
Siguiendo una sencillas instrucciones de pre tecnología te puedes montar un soporte para el ordenador portátil en un periquete con la caja de la pizza de anoche. Lo más importante: que no haya restos de pizza en el interior de la...
Por Nacho Palou -
21 NOV 2012
Patrick Blampied decidio aprovechar las piezas de un viejo Powerbook 100 y la carcasa de un más viejo todavía Macintosh Portable (a.k.a. «arrastrable») para crear un híbrido corriendo Mac OS X que funciona. Lo más complicado dice que fue montar la...
Hasta ahora Nokia Here, el servicio de mapas de Nokia, se podía utilizar en iPhone y Android, y desde cualquier ordenador, desde el navegador web. Y desde hoy además está disponible también como aplicación para iOS (iPhone,iPod Touch y iPad). La aplicación,...
Por Nacho Palou -
20 NOV 2012
Una de las consecuencias de la «iOSificación» cada vez mayor de Mac OS X, o de la convergencia entre este y el sistema operativo de los dispositivos móviles de Apple, es que algunas cosas que antes podíamos controlar con más detalle...
(Unidades vedidas anualmente, en millones) Teléfonos móviles (en #00A550) vs. ordenadores personales (#FF00FF) Benedict Evans, En 2012 la gente habrá comprado: 350 millones de ordenadoresEntre 625 y 650 millones de dispositivos iOS y Android [smartphones y tablets]1.700 millones de teléfonos móviles...
Por Nacho Palou -
20 NOV 2012
En la última semana larga he tenido ocasión de probar el iPad Mini de Apple. Mi impresión es que reproduce con bastante fidelidad la experiencia de uso del iPad, aunque evidentemente los elementos en pantalla ven reducido su tamaño respecto al...
Por Nacho Palou -
16 NOV 2012
En TechCrunch, Ballmer se refirió al ecosistema Android como "salvaje", "sin control" y susceptible al malware [software malicioso]. En The Loop, Y esto lo dice el hombre que está al cargo del sistema operativo más infectado de virus y de malware del...
Por Nacho Palou -
16 NOV 2012
Vista parcial del superordenador Titán - Laboratorio Nacional Oak Ridge Un diseño híbrido que combina CPUs tradicionales y procesadores gráficos han permitido a Titan, el ordenador del Laboratorio Nacional Oak Ridge antes conocido como Jaguar ahora convenientemente modernizado, hacerse con el puesto...
Flaps de Ishac Bertran en Vimeo. Flaps es la representación conceptual de navegador web propuesto por el diseñador Ishac Bertran, Flaps: fast and contextual browsing es un navegador web a pantalla completa cuya infraestructura visual es mínima, la interfaz para la...
Por Nacho Palou -
12 NOV 2012

Este artículo se publicó originalmente en Cooking Ideas, un blog de Vodafone donde colaboramos semanalmente. Las pantallas táctiles capacitivas —las que funcionan por contacto, sin necesidad de hacer presión— se basan en la propiedad del cuerpo humano para conducir la electricidad....
Por Nacho Palou -
7 NOV 2012
El servicio de sincronización remota y almacenamiento en la nube Cubby actualiza las aplicaciones web y de escritorio (al parecer no las apps móviles; sigue sin ser posible enviar archivos a Cubby desde éstos) y se abre a todos los públicos, sin...
Por Nacho Palou -
6 NOV 2012
Aunque se podía acceder vía web a los contenidos guardados en Pocket, el servicio antes conocido como read It Later, ahora existe Pocket Mac OS X como aplicación nativa. Por si no conoces el servicio, la idea es que se pueden...
Al final me da a mi que si algún día acabamos teniendo oficinas sin papel será por aburrimiento, más que otra cosa. Mientras tanto, servicios como OfficeDrop pueden servir para automatizar algunos procesos o ayudarnos a evitar trastear con papeles: se...
Cómo acceder desde el móvil a páginas web abiertas en el ordenador y viceversa, utilizando los navegadores web Safari o Chrome utilizando la función que permite ver las páginas web abiertas en otros navegadores web del mismo usuario; y con la...
Por Nacho Palou -
5 NOV 2012
John Pultorak dedicó, hace ya tiempo, cuatro años a construir —en el sótano de su casa— una réplica funcional del ordenador de guiado (AGC, Apollo Guidance Computer) utilizado en las misiones Apolo. Este ordenador guiaba a las naves Apolo en su...
Por Nacho Palou -
5 NOV 2012

Detrás el absurdo, casi imposible, atractivo exterior de Megan Fox se esconde un profundo amor por la biología marina… Esta peliculita de Acer/Intel tiene su aquel: una Megan Fox «reconvertida» haciendo de nerd e investigando las formas de comunicación con los...
Horace Dediu en The omnivorous app, El software rara vez se percibe como el activo de valor fundamental de un negocio. Pero no nos equivoquemos: Apple, Google, Microsoft, Facebook y Amazon son todas empresas de software. Cada una "monetiza" o integra el...
Por Nacho Palou -
29 OCT 2012
Windows 8 es un sistema operativo atractivo y para múltiples dispositivos, y es el cambio más radical del sistema operativo de Microsoft desde Windows 95. Windows 8 está a la venta como actualización para versiones anteriores de Windows (Windows XP, Windows...
Por Nacho Palou -
26 OCT 2012
Ross Hilbert creó estas preciosas Ventanas fractales de tonos Escherescos con su generador de fractales, el Fractal Science Kit [Windows]. Aunque el resultado para el común de los mortales son unas curiosas ventanas infinitas encadenadas, matemáticamente se trata de un «conjunto...
Más o menos. Cassete philips (cc) raulrodlin En New Scientist, Cassette tapes are the future of big data storage. Aunque los discos duros han sido tradicionalmente la bestia de carga del almacenamiento masivo, próximamente podrían ser sustituidos por un nuevo tipo de...
Por Nacho Palou -
24 OCT 2012
Un nuevo documento con una propuesta de recomencación del W3C denominada High Resolution Time propone mejorar la precisión actual de las mediciones del tiempo en JavaScript, hasta ahora en milisegundos, pasando a usar microsegundos (milésimas de milisegundos). De esta forma, los programas...
Los nuevos iPad (de 4ª generación, desde 499€) y iPad Mini (desde 329€) se podrán adquirir a partir de este viernes 26 de octubre, con fechas de entrega y a partir del 2 de noviembre. El 26 de octubre es el...
Por Nacho Palou -
24 OCT 2012
Al parecer para muchos usuarios existe cierta confusión y desconocimiento de las diferencias entre Windows 8 y Windows 8 Pro y Windows RT. La confusión se debe sobre todo a que tienen la misma apariencia (al menos a simple vista) y el...
Por Nacho Palou -
23 OCT 2012
Shapeways es uno de esos servicios tipo los Work Center pero para imprimir objetos en 3D: envías el modelo y obtienes el objeto material en plástico, cerámica, acero o vidrio, entre otros materiales. El vídeo muestra las posibilidades que ofrece la...
Por Nacho Palou -
19 OCT 2012
Desde hace nada está disponible en la App Store la versión final de TweetBot, mi cliente favorito para Twitter tanto en iOS como en Mac OS X con diferencia. Como comenté cuando salió la alfa para Mac OS, y después de...
Where the Internet lives es una visita fotográfica por algunos de los centros de proceso de datos de Google en los que se puede ver cómo se montan, quienes trabajan en ellos, y en qué lugares deciden ponerlos. Pr0n geek pero...
Bill Gates en 1984: una portada viejuna de Time con el «boss» de protagonista. La encontré en la galería de X-Ray Delta One en Flickr....
Recientemente he tenido ocasión de ver y probar el sistema operativo BlackBerry 10, la apuesta de RIM (fabricante de los productos BlackBerry) que debería ver la luz en los primeros meses del próximo año. BlackBerry aspira a ser la tercera vía,...
Por Nacho Palou -
10 OCT 2012
Estos días los ordenadores portátiles ThinkPad cumplen 20 años. El ThinkPad original fue desarrollado por IBM, y se comenzó a comercializar en 1992. En el año 2005 IBM vendió su negocio de ordenadores portátiles a Lenovo, quien desde entonces ha continuado...
Por Nacho Palou -
8 OCT 2012
Creado a modo de tributo a Steve Jobs esta recreación de un iPod original escrita en HTML5 y CSS3 por Pritesh Desai de Inventika Solutions es bastante impresionante. La explicación de cómo y por qué está en 1000 songs in your...
Desde las profundidades de las interwebs llega la Versión Honesta del anuncio publicitario de Explorer 9. Un navegador «más guay» (según dijo un tipo cualquiera) y «sorprendentemente malo para ver porno» (segun otro). Una superproducción de la siempre divertida gente de...
En el lector de feed pillé a estas dos entradas muy juntas, haciendo manitas. Is Twitter Shooting Itself In The Foot Focusing 100% On Ads? El mismo día que Twitter enfada a sus usuarios estrenando su mecanismo de encuestas publicitarias veía la...
Por Nacho Palou -
4 OCT 2012
Durante el año pasado por primera vez se vendieron más smartphones que ordenadores, una tendencia que previsiblemente seguirá empequeñeciendo en proporción el parque informático de ordenadores de sobremesa y portátiles en los próximos cuatro años (gráfica 2005-2011, gráfica de previsión hasta...
Por Nacho Palou -
3 OCT 2012
Cybercaronte nos escribió para contarnos que este verano se hizo la típica escapadita que yo llevo preparando años pero no termino de hacer: una visita a Bletchley Park (Inglaterra), el lugar cuna de criptoanalistas y rompecódigos durante la II Guerra Mundial....
Esta regla lineal calibrada en píxeles (escala 150 ppi) es una de las muchas herramientas curiosas disponibles en UI Stencils para bocetar a tamaño real páginas web o aplicaciones; tiene guías para los tamaños / resoluciones (vertical y horizontal) más comunes...
Por Nacho Palou -
3 OCT 2012
La aplicación Sherpa (gratuita) es un asistente por voz para Android que permite dirigirse al teléfono con lenguaje natural para solicitar información o para que realice determinadas tareas. Por ejemplo llamar por teléfono a alguien, enviar un mensaje, programar una cita...
Por Nacho Palou -
2 OCT 2012

Estuvimos ayer en la inauguración del Little Apple Museum de Madrid, un pequeño rincón para los amantes de la informática y la tecnología, donde poder admirar y ver algunos de los primeros ordenadores de Apple. El museo se abre el próximo...
Google Play, la tienda de aplicaciones para el sistema operativo Android, suma 675.000 aplicaciones y acumula un total de 25.000 millones de descargas, una cifra que —bonita comparación— «es más del doble de la distancia, en millas, recorrida por la sonda...
Por Nacho Palou -
27 SEP 2012
La nueva herramienta Nokia Xpress Web App Builder es un asistente online (funciona directamente en el navegador web) destinado al desarrollo de aplicaciones para la plataforma Series 40 (o S40), la utilizada por los smartphones de entrada de Nokia, incluyendo la...
Por Nacho Palou -
26 SEP 2012
Me gustó la idea del Evernote Smart Notebook by Moleskine y estaba deseando probarla, lo que he tenido ocasión de hacer gracias a @evernote_es Esta Moleskine está diseñada específicamente para funcionar con Evernote, el conocido servicio que permite guardar notas y...
Por Nacho Palou -
24 SEP 2012
Según The App Date, uno de cada cuatro españoles usa a diario aplicaciones en móviles, tabletas o televisores —el doble que a principios de año. En total 12 millones de usuarios se descargan en España 2,7 millones de aplicaciones cada día....
Por Nacho Palou -
17 SEP 2012
Mi casa es bastante larga y, como no podía ser de otro modo, el punto en el que entra la conexión a Internet en ella está en uno de los extremos, con lo que tener conexión en toda la casa exige pasar...
Algunos conceptos de lo que han dado en denominar Análisis de Redes Urbanas, en las que cabe de todo: desde las personas, medios de comunicación, transportes… Gracias a estos análisis se pueden mejorar las ciudades y entender cómo debe ser el...
El tablet con pantalla de 7 pulgadas y sistema operativo Android 4.1 (Jelly Bean) Google Nexus 7 se puede comprar en Google Play desde España (excepto al parecer en Ceuta, Melilla y Canarias) por 199 euros con 8 GB de memoria...
Por Nacho Palou -
27 AGO 2012
Quark DesignPad Preview permite crear prototipos maquetas directamente en el iPad, de forma similar a como se hacen directamente en QuarkXPress. Los prototipos se pueden compartir como imágenes directamente desde la aplicación, por Twitter o correo electrónico. Ahora, para poder desarrollar...
Por Nacho Palou -
23 AGO 2012
Este artículo se publicó originalmente en Ciencia, el suplemento de El Correo donde colaboramos habitualmente. Hace unas semanas Mikel Agirregabiria, @agirreagabiria, físico y educador, responsable de Innovación Educativa de Vizcaya en el Gobierno vasco y bloguero de pro desde hace años,...
Patricio Palladino escribió acerca de cómo se puede recrear cualquier JavaScript a partir de ocho caracteres distintos, más concretamente ()[]{}!+ El resultado es un código en cierto modo minimalista pero que está muy lejos de ser óptimo; más bien algo bastante...
The Byte Cellar por Blake Patterson. Clic para ver en grande y convenientemente etiquetado Yo aún conservo un Macintosh SE/30 en el trastero con 2,5 MB de RAM (sí, megabytes) y dos disketeras de 1,44 que probablemente aún funcione… Y es cierto...
Resulta que de las 650.000 aplicaciones distintas que hay en la App Store de Apple un estudio ha mostrado que el 60 por ciento, es decir unas 400.000, no han sido descargadas nunca jamás. El dato es tan extraño como inquietante, porque...
Por si alguien no se ha enterado todavía, Apple ha lanzado hoy la más reciente versión de OS X, la 10.8, bautizada como Mountain Lion, con apenas una semana para cumplir la promesa de hacerlo en este mes de julio. Disponible por...
Views of the Sky es una sencilla visualización 3-D del cielo estrellado y las constelaciones, a partir de datos extraídos de la Wikipedia, usando JavaScript + HTML (canvas). Los lo envió Santiago para compartirlo con todos. Elegante y bonito....
Noisy Typer - a typewriter for your laptop. por Theo Watson en Vimeo. Del departamento de chorradas variadas, Noisy Typer, una aplicación que reproduce los sonidos de una máquina de escribir cuando tecleas en tu Macintosh. Para los nostálgicos de la...
Un año más en Lifehacker han hecho sus listas de de aplicaciones recomendadas para Android. iPad. iPhone. Linux. Mac OS X. Windows. La mayoría son gratuitas, aunque las hay en versión light o que ofrecen servicios «freemium», y algunas son de pago...
Plato de un disco duro - Foto CC por Jesse! S? Uno de los problemas de la industria nuclear es no sólo gestionar los residuos que genera a corto plazo sino el hacerlo de forma que dentro de miles o millones de...
Gauntlet Keyboard de Jiake Liu en Vimeo. Gauntlet, el teclado guante, se viste en una mano y conecta por Bluetooth con el móvil o el tablet. En el vídeo no se aprecia bien, pero se supone que tocando las letras situadas...
Por Nacho Palou -
16 JUL 2012
Este artículo se publicó originalmente en Cooking Ideas, un blog de Vodafone donde colaboramos semanalmente. En unas cuantas ocasiones nuestra confianza en la tecnología y en que la dominamos perfectamente ha estado a punto de tener graves consecuencias, tan graves como que...
Desde ayer está disponible para descarga de forma gratuita una versión alfa del esperado, al menos para los que ya lo usamos en iOS, TweetBot for Mac. Esta alfa requiere Mac OS X 10.7 o posterior, aunque ya advierten que la...
Una computadora puede ser llamada «inteligente» si logra engañar a una persona haciéndole creer que es un humano.- Alan Mathison Turing23 de junio de 1912 - 7 de junio de 1954...
Aunque me gusta el tablet Surface de Microsoft ese teclado físico se antoja un poco dependencia del pasado –como también lo son el lápiz o puntero, el escritorio por debajo de Metro, la compatibilidad con las aplicaciones antiguas, la versión con...
Por Nacho Palou -
21 JUN 2012
Los amantes de los dibujos pixelados, las paletas de colores limitadas y los efectos de sonido básicos pero interesantes disfrutaran con este mini-documental que examina con nostalgia el arte en la época de los microordenadores de 8 bits: Evolution of 8-Bit...
El programa Reflection (para OS X y Windows, ~12 euros; versión de prueba gratuita) sirve para replicar la pantalla de los iPhone o iPad (ultimas generaciones) en ordenadores PC o Mac. Reflection utiliza la función AirPlay de iOS y funciona del...
Por Nacho Palou -
11 JUN 2012
La agresión ocular por una interfaz pixelada y que ya hace 12 años resultaba poco sofisticada es el precio a pagar por utilizar un Office "de verdad" en el iPad. CloudOn permite utilizar una versión "virtualizada" de Office directamente en el iPad....
Por Nacho Palou -
8 JUN 2012

La aplicación on{X} de Microsoft –de momento disponible para teléfonos Android– sirve para automatizar acciones en el teléfono móvil creando reglas o macros. Es decir, permite ejecutar acciones a partir de una secuencia de instrucciones condicionadas. Por ejemplo, se puede programar...
Por Nacho Palou -
6 JUN 2012
La aplicación para iPad Leonardo da Vinci: Anatomy [iTunes, 10,99 €] recopila 268 páginas de notas y dibujos en alta resolución que Leonardo realizó durante sus estudios de la anatomía humana y de algunos animales. La resolución de las imágenes y...
Por Nacho Palou -
1 JUN 2012

Los hackers originales del MIT eran unos tipos a los que les apasionaba saber todo lo posible de las máquinas que usaban por el placer de saberlo, y si para saber algo más había que saltarse alguna norma pues no tenían ningún...
Diego nos contó que ha lanzado este tutorial: HTML5Rubik. Básicamente es una explicación paso-a-paso de cómo construir un cubo de Rubik interactivo empleando únicamente CSS3 y JavaScript. Funciona en cualquier «navegador web moderno» y también en iPhone/iPad y dispositivos Android....
CPUs con Linux, conectores USB, Wi-Fi, memoria… < 150€ FXI Cotton Candy 62€ AllWinner A10 39€ APC VIA 20€ Raspberry Pi … ¿quién da más?...
Este vídeo del festival SIGGRAPH 2012 muestra algunos de los avances técnicos de los últimos tiempos en generación de imágenes por ordenador, simulaciones 3-D, materiales, partículas, tratamiento de imágenes… Una auténtica maravilla en la que a veces es difícil distinguir lo...
Ayer tuve ocasión de asistir a una demostración de Apple centrada en videojuegos y nuevas aplicaciones que saldrán en los próximos meses, y también de aplicaciones para la creación de contenidos. Aparte de ver y probar novedades aún en desarrollo -como...
Por Nacho Palou -
22 MAY 2012
Hace algún tiempo me llamó mi buen amigo Jorge -un veterano en esto de la tecnología y junto a quien he trabajado en más de una ocasión- para contarme que se había embarcado en una nueva aventura. Lo que tenía muy...
Este artículo se publicó originalmente en Cooking Ideas, un blog de Vodafone donde colaboramos semanalmente. Hace ya algún tiempo Google anunció el proyecto Android@Home, que consistía básicamente en utilizar el sistema operativo Android para controlar distintos aspectos de una vivienda a través...
Por Nacho Palou -
16 MAY 2012
No es sin tiempo, pero Apple ha publicado al fin una herramienta específica para eliminar Flashback, el malware más extendido para Mac OS de los últimos años. Flashback en acción. El icono recuadrado puede cambiar según la variante del virus y a...
No, niños, no es un trailer de Saw VII ni de Rec 4… No hace tanto, algo más de una década, así avisaba el Gobierno a los ciudadanos de lo chunga que iba a ser la llegada del año 2000 para...
De nombre extraño y misteriosamente sonoro, Hartverdrahtet fue el ganador del concurso PC 4kB. En ese concurso de programación el software presentado deben ocupar 4 KB de código fuente como máximo. El original funciona en Windows XP/Vista/7 y de su ejecución...

El problema del viajante es un clásico de las matemáticas y la teoría de la computación: consiste en encontrar la ruta óptima para visitar varias ciudades, recorriendo la menor distancia posible, sin repetir el paso por ninguna de ellas. El problema...
Plasta en WhatsApp Lo de que hemos leído y comprendido y aceptamos las condiciones de uso de los servicios que usamos en Internet debe andar ahí, ahí con aquello de que «sí, soy mayor de edad en el lugar en el que...
Este artículo se publicó originalmente en La Voz de Galicia, donde colaboramos habitualmente. Esta es la versión sin límites de espacio y con enlaces. Este año se cumplen 40 años de la publicación del artículo «Autómatas auto-reproducibles con intercambio mínimo de información»,...

En el corazón de un ordenador, de cualquier tipo de ordenador, todo lo que hay son números. John Graham-Cumming repasa en The Greatest Machine That Never Was, una charla TEDx en el Imperial College, la historia de Máquina Analítica, un diseño...
Para quienes usamos para el cine-en-casa más el ordenadador que el sintonizador del televisor, VLC Remote [App Store, gratis/3,99€] es una auténtica bendición. Combina lo mejor del reproductor VLC 2.0 con la comodidad del control remoto a través del iPhone. Aunque eso...
La última actualización de SkyDrive, el servicio de disco duro virtual de Microsoft, trajo muchas funcionalidad útiles -a lo Dropbox- y aplicaciones específicas para Mac, Windows e iOS. Peeeero -siempre hay un pero- por el camino redujo el espacio que ofrecía...
Por Nacho Palou -
27 ABR 2012
Cuando se escribe y edita texto para la web es inevitable utilizar etiquetas del lenguaje HTML. Por ejemplo <a href... para colocar un enlace, <strong> para poner texto en negrita o <ul><li>... para componer una lista. Probablemente sabes de sobra el engorro...
Por Nacho Palou -
19 ABR 2012

The Solar System: Explore Your Backyard es una aplicación para Windows que con casi toda seguridad conseguirá financiar su desarrollo en unos días: es una increíble visualización de nuestro planeta y «los alrededores» – que si uno tiene algo de visión...
Manzanas usadas es un sitio para comprar y vender equipos usados en cinco minutos, desarrollado por la gente de BlogOff / Adama Web....
Cubby puede considerarse una alternativa al popular Dropbox o a SkyDrive -entre otros servicios de disco duro virtual-, y funciona de forma similar a éstos. Pero Cubby tiene dos interesantes características a destacar: En Cubby cualquier carpeta del disco duro puede convertirse...
Por Nacho Palou -
13 ABR 2012
Spatially aware devices de Ishac Bertran en Vimeo. El vídeo Spatially aware devices de Ishac Bertran esboza su propuesta para mejorar -o hacer más natural- el intercambio de contenidos y elementos entre múltiples dispositivos, caso de un ordenador y un teléfono móvil...
Por Nacho Palou -
13 ABR 2012
No sin tiempo, desde hace unas horas estás disponibles a través de Actualización de software sendas actualizaciones de Java para Mac OS X 10.6 Snow Leopard y Mac OS X 10.7 Lion que según dice la propia Apple «eliminan la mayoría de...
Si las estimaciones de Doctor Web son correctas, y todo parece indicar que sí lo son, con unos 650.000 ordenadores infectados en todo el mundo Flashback es el malware más extendido para Macintosh desde los lejanos tiempos de nVIR. Pero a diferencia...
Ya que hoy es el Día Internacional de las Copias de Seguridad, algunas de las #patochadasinformaticas que nos habéis enviado relacionadas con el tema: Bluntman: Se que es difícil de creer, y no me lo creería si no lo hubiese vivido, pero...
Hoy 31 de marzo es el día internacional designado como Día del Backup o de las Copias de seguridad: sí, esas que siempre se nos olvida hacer y de las que solo nos acordamos cuando ya lo hemos perdido todo. Muchos encuentran...
El tablet Courier fue una idea desarrollada por Microsoft que se dejó entrever en forma de demostración / prototipo hace un par de años. Pero entonces la llegada del iPad puso un poco patas arribas muchos proyectos de tablets como éste y...
Por Nacho Palou -
28 MAR 2012
See Through 3D Desktop, de Jinha Lee en Vimeo. Combinando una pantalla transparente, un entorno gráfico en 3D y la detección de gestos y movimientos -algo que Microsoft, como demuestra Kinect, domina sobradamente- Jinha Lee y Cati Boulanger, del Microsoft Applied Sciences...
Por Nacho Palou -
26 MAR 2012
50x: la cagamos.40x: la cagaste.30x: pregúntale a ese otro.20x: vale.- @DanaDanger...
Llevo unas semanas con un Monitor Brilliance LED 241P3 de 24" que nos envió amablemente Philips para probar, usándolo como segundo monitor junto a mi iMac. Es un periférico interesante del que el fabricante destaca sus colores naturales y el ahorro...
Todos hemos hecho lo que el tipo de este vídeo cuando un ordenador no hace lo que queremos… Más de una vez. Menos mal que, por lo general, los ordenadores no responden como este ;-) (Del departamento de enlaces que el...
The Computer Magazine Archives, una sección de Archive.org en la que hay ejemplares de revistas antiguas, obsoletas pero todavía entrañables como Amiga World, 80 Micro, Commodore World, Format, Enter, RUN Magazine, ZX Computing y muchas más. Se pueden descargar en PDF,...
Ordenador analógico AMF 665/D Hay una cierta cantidad de sitios web en los que se pueden ver colecciones de ordenadores de todos los tiempos, pero me ha gustado especialmente Old Computer Museum por la cantidad de ordenadores analógicos que tiene su dueño....
El verdadero arte ASCII será siempre el creado a mano, pero para echarse unas risas asciifi | all the images lo hace de forma automática con aquellas imágenes que le tiras encima, aunque se pueden ajustar parámetros como el ancho de la...
He aquí un curioso y marchoso montaje hecho con Gource, ffmpeg y x264 a partir de los datos de la actividad de los desarrolladores que han participado en el código fuente del reproductor multimedia y multiplataforma VLC, del que el otro...
Roberto nos escribió para comentarnos la existencia de blank, un pincho USB incrustado en un corcho diseñado por hum que además tiene la coña de que se «guarda» en una botellita de cristal. La verdad es que no se si será...
Ya está disponible la nueva versión del famoso reproductor multimedia para Mac OS X: VLC 2.0. También para Windows, Linux y otros sistemas....
Por ejemplo, mover objetos en una fotografía olvidándote de tener cuidado con el fondo, que se adaptará automáticamente como por arte de magia. Una interesante función que dicen estará incluida en la próxima versión del popular software de retoque fotográfico. Lo...
Todo comenzó con un par de inocentes tuits… Creía que el día que vi a alguien sumar las columnas de Excel con una calculadora lo había visto todo… Pero no, hay cosas peores :S— Wicho (@wicho) febrero 9, 2012 Como por ejemplo...
La opción AirPrint de iOS permite, en teoría, imprimir directamente desde dispositivos iOS (iPhone, iPad y iPod Touch) en impresoras inalámbricas. Digo en teoría porque yo nunca lo he conseguido a pesar de que debería poder en la HP Wireless que tenemos...
Por Nacho Palou -
6 FEB 2012
Una interesante animación con un montón de datos extraídos de la 12ª edición del Informe de La Sociedad de la Información en España, con comparaciones con los de 2010 para que veamos cómo van cambiando las cosas. Queda mucho por hacer,...
The German de Nick Ryan en Vimeo. The German, de Nick Ryan es un corto irlandés sobre la II Guerra Mundial que relata la persecución de un piloto inglés a un piloto alemán, primero por aire y después a pie, por tierra....
Por Nacho Palou -
30 ENE 2012
Si usas Safari y eres de los que estás más que preocupado y mosqueado con el empeño de Google de colarnos Google+ hasta en la sopa queramos o no, lo que está resultando bastante polémico, ya tienes disponible para descargar la extensión...
Visto el tamaño que tenían los componentes de aquella época, no es nada de extrañar esta anécdota que cuenta un lector de The Next Web en How one man got lost in a computer, and other tales from the forgotten days of...
Esto que se ve en la foto, y ojo al señor que se ve detrás para que os hagáis una idea del tamaño del invento, es un módulo de 4 KB de memoria fabricado por IBM allá por 1954 que se...
Sacado de The rise and fall of personal computing: en el eje horizontal, años, en el eje vertical, unidades puestas en el mercado cada año según las cifrasd e Gartner (ojo que la escala es logarítmica) de distintas plataformas a lo...
Es lo más parecido al cielo de los geeks. Así a ojo es difícil calcular cuántas pantallas tiene Robert Scoble en su puesto de trabajo, por no hablar del tamaño. El conocido bloguero y exevangelizador de Microsoft además parece totalmente asimilado...
El pasado viernes tuve la oportunidad de entrevistar a Nicholas Negroponte junto con Javier Barrera (@juanlarzabal), quien hacía lo propio para El Ideal y ha publicado algunas de las respuestas en «En el Sacromonte me he sentido como en casa».. Siendo un...
IBM ha conseguido reducir a 12 átomos los necesarios para almacenar 1 bit (en cualquier de sus dos estados, "1" ó "0"). La cantidad de átomos utilizados repercute directamente en el tamaño físico de la memoria y por tanto permite guardar...
Por Nacho Palou -
16 ENE 2012

Entre hoy y mañana se está celebrando en Granada la edición de 2012 de la Conferencia Internacional de Software Libre junto con Más Digital, un evento paralelo que reúne toda una serie de actividades adicionales. El software libre es aquel que permite...
Un Programma 101 en el National Museum of Computing - (cc) AlisonW Decidir cual fue el primer ordenador del mundo es algo bastante complicado, pues para empezar hay que ponerse de acuerdo en qué entendemos por ordenador. Así, todo depende de si...
I've got the power! Unos escolares hacen una demostración durante el XVI Día de la Ciencia en la Calle Gracias al uso cada vez extendido de las TIC en las aulas cada día hay más posibilidades de hacer llegar las actividades que...
Si echas de menos ver como se reiniciaban versiones antiguas del sistema operativo de los Mac, de Windows, un NeXT, o incluso cosas más raras como Rhapsody, The Restart Page tiene hasta 17 secuencias de reinicio para que se te salte...
How It Works...The Computer es un a estas alturas entrañable libro de 1971, reeditado en 1979, que intenta contar cómo funcionan los ordenadores, con perlas como la del título de esta anotación o como otra en la que dice que las...
Todo lo que veíamos en nuestro pabellón del CES era gente de Atari con la boca abierta, diciendo: «¿Cómo pueden hacer estos de Commodore todo eso por 595 dólares?» Una pausa para un poco de retroinformática mítica: Historia de la Tecnología:...
Según All About Windows Phone en la tienda de aplicaciones Windows Phone Marketplace ya hay 50.000 aplicaciones, una décima parte de las que existen en la App Store de Apple (500.000). El Android Market suma ahora 380.000 aplicaciones. De modo que...
Por Nacho Palou -
28 DIC 2011
El de la foto es un prototipo operativo de teléfono móvil con sistema operativo Android y procesador Intel. En su última versión de este procesador, de apellido Medfield, el último de los vástagos Atom de Intel parece capaz de competir con...
Por Nacho Palou -
21 DIC 2011
Cuando se anunció el iPad hace ahora casi dos años, Eric Schmidt, entonces CEO de Google, afirmó «no encontrar diferencias entre un teléfono grande y un tablet». Aunque ya parece haberlas encontrado porque da a entender que Google sacará su propio tablet...
Por Nacho Palou -
20 DIC 2011
Presentado por Xerox en 1981, el Xerox 8010 Information System, más conocido como Star, fue el primer ordenador comercial de la historia en incorporar un interfaz con ventanas, iconos, ratón y puntero: Pero el Star, como se puede ver en este vídeo...
City Fireflies v0.2 por Victor Diaz en Vimeo. City Fireflies es una instalación creada por el colectivo de creación digital Uncoded.es que consiste en una pantalla LED de 15×10 metros instalada en la plaza del Medialab Prado en Madrid. El objetivo del...
Ayer se vendió en una subasta en Sotheby's por un total de 1.594.500 dólares el contrato mediante el que Steve Jobs, Steve Wozniak y Ron Wayne fundaron Apple el 1 de abril de 1976. Jobs, en especial con su reciente fallecimiento,...
The Animals House of the Rising Sun Old School Computer Remix es una versión de todo un clásico, House of the Rising Sun de The Animals, interpretada por Un scanner HP Scanjet 3P controlado por un ordenador con Ubuntu v9.10 y...
Un LEO I - LEO Computers Society Construído por J. Lyons & Co., algo así como la versión británica de los MacDonalds, el ordenador conocido como LEO I, de Lyons Electronic Office I, el primer ordenador comercial de la historia, entraba en...
Mmm… Repasemos las noticias de hoy, a ver… clic, clic… Investigadores alertan que las impresoras se pueden hackear para que ardan en llamas (Fayerwayer) Pse, lo habitual, nada alarmante. Ilustrativa foto, por cierto…...
En Slashdot cuentan que Atos, una gran empresa europea de tecnología (con 74.000 empleados y 5.000 millones de dólares de facturación) ha decidido prescindir del correo electrónico de aquí a 18 meses. ¡Prohibido enviar un solo correo! Al parecer han calculado que...
El New York Times publicó en su sección de Ciencia un bonito esquema de la máquina analítica de Babbage, considerada uno de los primeros ordenadores del mundo… si no fuera porque nunca llegó a ser construido, pues la tecnología de la...
Del 7 al 11 de noviembre, en Zaragoza, RetroMañía 2011 celebrará su quinta edición, en la Escuela de Ingeniería y Arquitectura (EINA). El acceso es libre, así que todos los aficionados a la informática retro, los videjuegos clásicos, el software viejuno...
Contar la historia de Internet en 8 minutos es cuando menos complicado, y hay algunas cosillas en este vídeo que me han llamado la atención, como por ejemplo la fecha en la que dicen que se envió el primer correo electrónico,...
John McCarthy, más conocido por ser el creador del lengaje de programación Lisp y del término inteligencia artificial, falleció ayer en California, a los 84 años. Este veterano pionero de la informática moderna trabajó durante décadas en Stanford, el M.I.T., Darmouth y...
Este próximo miércoles 26 de octubre, de 12.00 a 13.30 en Madrid (recinto IFEMA, Auditorio 5) participaré a las 13.30 en una mesa redonda que se ha organizado como homenaje a Steve Jobs. Tendrá lugar dentro del marco del evento Ecomm-Marketing,...
Uno de los aspectos más interesantes del iPad 2 que mencioné cuando lo probé en su día, es la posibilidad de contectarlo a cualquier televisor o pantalla con conector HDMI. De este modo se puede reproducir en el televisor todo aquello...
Por Nacho Palou -
24 OCT 2011
El denostado GO TO hace su primera aparición en el manual Trasteando por Bitsavers @eduo se encontró con el manual [PDF 2,1 MB] del Dartmouth BASIC, el primer BASIC de la historia, creado en 1964 por por John Kemeny y Thomas Kurtz...

El IBM 350, presentado el 13 de septiembre de 1956, fue el primer disco duro de la historia. Con una capacidad de unos 4,4 MB totales en sus 50 platos de dos caras, harían falta unos 232 de estos para igualar...
La aplicación Bamboo Paper de Wacom para iPad (gratuita) permite utilizar el iPad como un cuaderno de papel. Se puede utilizar con el dedo o con cualquier lápiz o puntero específico para usar con el iPad. En combinación con el lápiz...
Por Nacho Palou -
17 OCT 2011
Dicen que las desgracias nunca vienen solas, y a la muerte de Steve Jobs de la semana pasada se ha añadido estos días la de Dennis Ritchie, otro de los grandes de la informática. Tenía 70 años y pertenecía a la generación...
Boing Boing Google Wired y muchos más… Larga vida a Steve – Fayerwayer Steve Jobs: su vida en 25 vídeos – Pixel y Dixel Gracias Steve, eres pura inspiración – Digitalismo Blogpocket Los medios: NY Times, El País, The Guardian… –...
Por mucho que supiéramos que esto iba a pasar –más bien temprano que tarde– y que hoy no podamos dejar de mencionar la muerte de Steve Jobs, preferimos con mucho recordar su vida y sus increíbles logros en Steve Jobs: el...
Las Adobe Touch Apps son un conjunto de seis aplicaciones específicamente desarrolladas para tablets iPad y Android. Presentadas ayer por Adobe durante la conferencia MAX 2011 se pueden considerar versiones tablets de los conocidos programas incluidos en los paquetes Adobe Creative...
Por Nacho Palou -
4 OCT 2011
Imagen por @breko 1985: Colores chillones, aspecto alicatado. Las aplicaciones pueden ejecutarse como un pequeño mosaico o a pantalla completa. Las ventanas no se pueden cambiar de tamaño ni mover libremente. 1986 - 2011: Un cuarto de siglo revolviendo el diseño de...
Por Nacho Palou -
28 SEP 2011
Alberto nos escribió para contarnos algo sobre la competición internacional de inteligencia artificial en StarCraft, donde los participantes crean bots que juega a competir en StarCraft, el clásico juego de Blizzard. Los programas se envían –el código es público– y compiten...

No me queda muy claro si lo de «hecho a mano» se refiere al anuncio o al ordenador, pero bien podrían ser ambas cosas… ¿Quién no se acuerda del mítico microordenador Dragon? «¡El futuro en tus manos!» «¡Con OS9!» Y que...
Si el Macbook Air fuera tan ineficiente como los ordenadores de 1991, la batería duraría 2,5 segundos. [Fuente: The Atlantic.]...
Desde hace tiempo la búsqueda por voz está disponible en aplicaciones de Google para móviles como iPhone o Android. Esto permite introducir la palabra o secuencia de texto a buscar dictándola, sin necesidad de teclearla. Y funciona bastante bien. Ahora también...
Por Nacho Palou -
30 AGO 2011
IBM está construyendo el sistema de almacenamiento de datos más grande que se conoce: 120.000.000 de gigabytes o 120 petabytes para abreviar y para que la cifra quepa en Twitter. Tiene al menos 8 ó 10 veces más capacidad que los actualmente...
Por Nacho Palou -
29 AGO 2011

«Aunque tú lo uses veinte veces al día, la mayor parte de la gente no lo usa jamás». Y es que los conocimientos sobre las funciones del software que manejamos cada día siguen en los niveles de siempre: según expertos de...
(Imagen: DestroySites.com) ...para su supervivencia, claro. El equipo de seguridad de Google, formado por unas 250 personas repartidas en distintas oficinas del mundo, se dedica a evaluar riesgos, establecer medidas y resolver cualquier incidente que pueda afectar a sus servicios, plataforma y...
Por Nacho Palou -
23 AGO 2011
El área de Ajedrez por Ordenador en la web del Computer History Museum bien merece un buen repaso: tiene fotografías históricas, textos que explican las diversas épocas y documentos tales como partidas anotadas. Los ingenios mecánicos e informáticos comenzaron a jugar...
Por Sergio Periotti § @franiglesias_, @sebitauma y @miguelsola69 Como cualquiera que me haya oído hablar del tema en alguna ocasión, me siento enormemente afortunado de que en el colegio se empeñaran en enseñarme a pensar, por lo que me siento enormemente identificado...
Tutorial paso a paso para copiar la música del iPod al PC [Windows], aunque el título original es un poco más florido, cortesía de Ellimis@reddit. Otras alternativas –algunas de las cuales funcionan también con los iPhones y los iPod Touch– son...
Puedes usarlo pidiendo imágenes en URL al tamaño que necesites al estilo http://placehold.it/350x309 (basta cambiar los números); también con una etiqueta HTML img src del mismo modo. Se llama Placehold.it y como idea está genial. Lo vi pasar por Genbetadev, donde...
Mundo Hacker TV, que nació en la radio para luego saltar a la televisión por Internet a través de Globbtv, ahora va a poder llegar al gran público en Telecinco a través de Nosolomúsica. Será con cuatro programas especiales que se emitirán...
Debido a algún problema relacionado con el suministro eléctrico, el servicio «en nube» EC2 de Amazon (Amazon Elastic Compute Cloud) ha mordido el polvo hacia las 20.00 hora española, provocando una caída total de los sistemas y arrastrando con ello a miles...
En la competición de programación JS1k se pueden crear demos, entretenimientos y juegos con la única limitación de usar como máximo 1 KB de JavaScript. Eso no es gran cosa, pero se pueden hacer grandes cosas, como pueden atestiguar todos los...
Tecnologías de los 80 vs Tecnologías de hoy: Infografía es un curradísimo vídeo de los chicos de Xataka que repasa las enormes diferencias entre los cacharros que usábamos en la década de los 80 y los que usamos ahora. Los que...
Hay que reconocer que no suena nada mal el dato de que Apple ha vendido más de un millón de copias de OS X Lion en las 24 primeras horas tras el lanzamiento, pero es una cifra que simplemente palidece en comparación...
Hace poco más de un año desde que Apple lanzara el iPad, pero durante el pasado trimestre ya consiguió pasar a los Macintosh, que ya tienen 27 años, en ingresos. En el trimestre en cuestión Apple vendió 9,25 millones de iPads por...
Después de inversiones millonarias para introducir –a menudo con calzador– las TIC en el aula, Al otro lado de las TIC es un estudio que mediante cientos de entrevistas con profesores, alumnos, docentes TIC, y personajes de reconocido nombre en este...
La mayoría del tráfico en Internet en 2015 será vídeo. Para entonces serían necesarios cinco años para ver la cantidad de vídeo que va a transmitirse a través de las redes globales cada segundo. [Fuente: The Dawn of the Zettabyte Era]...
Ayer hablábamos de que se calcula que en 2011 se generarán y almacenarán 1,8 Zettabytes más de información, una cantidad enorme y difícilmente comprensible. Pero tendremos que irnos haciendo a la idea, porque por ejemplo en Cisco calculan que será en 2015...
¿Es buen momento para comprar tal portátil o determinada cámara? Variaciones en el precio o el ciclo de vida del producto -por ejemplo, si ya tiene sustituto en el horizonte- pueden sembrar dudas sobre si es el momento adecuado para comprar...
Por Nacho Palou -
21 JUN 2011
Un IBM 704, uno de los primeros ordenadores comercializados por IBM Hoy se cumplen cien años de la fundación de la Computing-Tabulating-Recording Company (C-T-R), la empresa que luego se convertiría en IBM, por lo que hemos hecho un mínimo resumen de este...

Para salivar: un iMac abriendo todas las aplicaciones del sistema a la vez, excepto un par de las pequeñas porque arrancan a pantalla completa. La clave es el disco SSD de 256 GB incorporado; aparte de eso se trata del iMac...
No tenemos ni idea de si esta oferta de trabajo es actual, antigua o si sigue en pie, pero nos la pasaron por correo como altamente creativa y ciertamente que lo es: simbiotica.es/oferta Casi a la altura de las mejores ofertas de...
¿10 millones de dólares por 128 qubits? No sé yo. Lo último que recuerdo es que hace años D-Wave admitió que su invento (llamado por entonces «Sistema Orión») no era una computadora cuántica. Al parecer han conseguido publicar un artículo en...
Este Handcrafted Fire-Colored Cat-5 Cable Flogger debería estar colgado de la pared de todo BOFH que se precie, para que los lusers se lo piensen la próxima vez que vengan con aquello de que «pero yo no le hice nada» o...

Un montaje que enseña desarrollos curiosos realizados por programadores de todo el mundo para la tecnología Kinect de Microsoft en estos últimos meses; en riguroso orden de aparición tal y como aparecen en el vídeo montado y publicado por jcl5m: Raw...
La cantidad de información que los aproximadamente 27 millones de servidores «de negocios» que existen en Internet procesan cada año es de unos 9,5 zettabytes. La magnitud del dato es casi incomprensible: un zettabyte equivale a 1.000 exabytes, 1.000.000 de petabytes o...
Universe Sandbox es un simulador interactivo para Windows, en el que los ingredientes son estrellas, planetas y un toque de gravedad. El resultado es que se puede «jugar» a crear sistemas solares y ver los efectos de modificar sus masas y...
La unión perfecta entre la música con ritmo y la cultura tecnológica....
The WebGL Globe es un medio experimento de Google a modo de plataforma geográfica de visualización de datos: permite crear globos en los que se visualicen datos de todo tipo. Como dicen por ahí, un nunca más apropiado «Hack the planet!»...
Por unas cosas o por otras al cabo del año pasan por mis manos un montón de Macintosh de todos los tipos que me encargo de poner a andar o de reciclar para pasárselos a un usuario distinto, y en todos ellos...
La aplicación Qwiki para iPad [enlace a iTunes, gratuita] está diseñada para servir información en forma de experiencia especialmente adecuada para su uso desde tablets y dispositivos móviles -hay versiones para iPhone y Android e desarrollo. Aunque los contenidos de Qwiki...
Por Nacho Palou -
4 MAY 2011
En ILearnedToProgram.com la gente cuenta cómo y porqué aprendió a programar, en una sucesión casi infinita de evocadores mensajes cada vez que se recarga la página. (Vía ReadWriteWeb.)...
El teclado Cool Leaf de Minebea surgió –como aquellos Optimus Keyboard y Optimus Tactus– como una idea conceptual: un teclado de ordenador que existía sólo en una superficie táctil, similar a como es en la pantalla táctil de un smartphone o...
Por Nacho Palou -
26 ABR 2011
350 millones de licencias de Windows 7 ha vendido Microsoft en 18 meses, desde que la última versión de su sistema operativo para ordenador viera la luz a finales de 2009. Esto son unas 7 copias de Windows 7 cada segundo. Aunque...
Por Nacho Palou -
25 ABR 2011
Desde el departamento de Definitivamente hay gente que tiene mucho tiempo libre llegan estas 1.900 líneas de código C (y un poquito de ensamblador) para explicar la película Origen como si fuera un programa informático: si se ejecuta el programa, se...
Ah, cifras grandes. ¡Cuánto nos gustan! Ayer Google anunció que se habían alcanzado los 3.000 millones de descargas desde el Android Market, catálogo que suma ya 350.000 aplicaciones. Cada trimestre del año se activan unos 30 millones de terminales Android. Y en...
Por Nacho Palou -
15 ABR 2011
La aplicación para iPhone desarrollada por Jeremie Francone y Laurence Nigay del IIHM del Laboratorio de Informática de Grenoble utiliza la cámara frontal de estos dispositivos para simular el efecto 3D en pantalla. El efecto también se puede reproducir en el...
Por Nacho Palou -
12 ABR 2011
Salvo error u omisión la ley actualmente vigente en España al respecto permite hacer hasta tres copias de seguridad de los discos que compremos, algo que además en los últimos años tiene cada vez más sentido a la hora de poder poner...
Shell-sort with Hungarian (Székely) folk dance ilustra de forma gráfica (y un tanto pintoresca, todo hay que decirlo) el algoritmo de ordenamiento Shell, en el que se comparan elementos separados por un espacio de varias posiciones que cambian de lugar si...
No están todas, en especial dado que cada vez salen más ordenadores haciendo más cosas (muchas veces descabelladas) en cada vez más películas, pero en Access Main Computer File hay capturas de pantalla de los interfaces de ordenador usados en un...
Tal vez su nombre no te suene, pero seguro que has visto sus trabajos: Mark Coleran es el diseñador de una buena parte de las interfaces gráficas de ordenadores y otros aparatos que se ven en las películas de Hollywood. Entre...
Anillo modelado con la impresora 3D de Veloso Espectacular la resolución y precisión que logra la impresora 3D artesanal construida por Veloso, capaz de modelar formas de hasta 50 micrones. Eso sí, la tarea requiere su tiempo: 3,5 cm por hora. El...
Por Nacho Palou -
4 ABR 2011
Este artículo se publicó originalmente en Cooking Ideas, un blog de Vodafone donde colaboramos semanalmente. Además del sistema operativo Android, la pasada edición del Mobile World Congress tuvo otra tecnología protagonista por omnipresente: la del tablet iPad. Y no precisamente porque Apple...
Por Nacho Palou -
4 ABR 2011
Aunque para muchos es un perfecto desconocido, Paul Baran inventó una de las técnicas básicas para las redes de comunicaciones que usamos hoy en día, la conmutación de paquetes. Su trabajo al respecto, pensado para el diseño de redes de comunicaciones capaces...

Este artículo se publicó originalmente en Cooking Ideas, un blog de Vodafone donde colaboramos semanalmente con el objetivo de crear historias que «alimenten la mente de ideas». Hay muchas cosa sobre el diseño de webs que generan encendidos debates, pero una...
Según acaba de publicar El Mundo en La Audiencia Nacional anula la normativa que regula el canon digital la Sala de lo Contencioso-Administrativo de esta ha declarado nula la orden ministerial PRE/1743/2008 que regula el canon digital desde el 1 de julio...
El ‘zoo’ Mac OS X al completo: Cheetah/Puma (2001), Jaguar, Panther, Tiger, Leopard, and Snow Leopard (2010)...
Por Nacho Palou -
24 MAR 2011
Pocas labores hay tan ingratas como tener que trabajar con formularios HTML, así que se agradece las pistas que The Current State of HTML5 Forms proporciona: cómo funcionan los nuevos tipos de entradas de datos, qué navegadores los soportan, cómo gestionar...
La Gray Area Foundation y el artista Nik Hansellman crearon para Waze estas visualización de cómo es el tráfico un día cualquiera en la ciudad de Los Ángeles a partir de la información pública compartida por los usuarios mediante crowdsourcing. En...
PRESS PLAY ON TAPE es una «banda revival del Commodore 64», que con un apropiado nombre TODO EN MAYÚSCULAS y una web que evoca la pantalla del viejo ordenador de los 80. Allí hay algunos vídeos geniales, como esta interpretación de...
De entre todos los sectores industriales afectados por el terremoto de Japón, el tecnológico será uno de los que más se harán notar en todo el mundo. No sólo de allí llegan numerosos bienes de consumo, también desde aquel país salen gran...
Por Nacho Palou -
17 MAR 2011
Todavía hay gente como Bob desarrollando juegos y programas para el ZX-81, que recientemente celebró su 30º aniversario. Empezó a retro-desarrollar para el Spectrum, pero pensó que 48 KB eran demasiada RAM y se pasó al ZX-81 que solo tenia 1 KB...
Menos mal que ya queda menos para el verano… (Vía AppleWeblog.)...
Pegman, el hombrecillo de Google Street View, recibe ese nombre por su parecido con una pinza para la ropa (clothes peg) En Street View: Explore the world at street level Google ha reunido todos los recursos relacionados con Street View, el servicio...
Por Nacho Palou -
15 MAR 2011
Quién sabe si a veces los técnicos hacen uso de una ruleta de la fortuna como la de la foto, encontrada en alguna recóndita cueva llena de frikis… aunque a veces la Solución Universal (#1) sea suficiente, a lo I.T. Crowd. Si...

Digital natives – CC Thomas Angermann Este artículo se publicó originalmente en Cooking Ideas, un blog de Vodafone donde colaboramos semanalmente con el objetivo de crear historias que «alimenten la mente de ideas». Marc Prensky acuñaba en 2001 la expresión «nativo digital»...
El icono de los anillos entrelazados en el iPad (detrás) indica que está conectado a Internet a través de la conexión 3G del iPhone. Muchos echábamos de menos en el iPhone poder compartir la conexión 3G del móvil a través de WiFi...
Por Nacho Palou -
10 MAR 2011
El Windows Phone Marketplace, que va camino de contabilizar las 10.000 aplicaciones para teléfonos con Windows Phone 7, añade la posibilidad de que los desarrolladores ofrezcan versiones de prueba de sus aplicaciones antes de tener que decidir si se paga por ellas...
Por Nacho Palou -
10 MAR 2011
Las secciones y contenidos de Zite se eligen en base a los gustos y preferencias de lectura del usuario. Si tienes un iPad probablemente ya conozcas la aplicación Flipboard –una de las más populares, nombrada "aplicación del año" por Apple– que lo...
Por Nacho Palou -
9 MAR 2011
Tras el enfrentamiento con Apple por la ausencia de Flash en dispositivos iOS (iPhone, iPod, iPad) Adobe “se une al enemigo” con el desarrollo de Wallaby (Mac, Windows), una aplicación en desarrollo que convierte archivos FLA de Adobe Flash Professional CS5 a...
Por Nacho Palou -
8 MAR 2011
Fractal Lab es como tener un fractal en las manos con una lupa infinita y un montón de pinturas; una herramienta impresionante para la exploración de fractales matemáticos. Funciona a través del navegador; sólo hace falta instalar la última versión de...
En la web del New York Times tienen este Piedra, papel, tijera contra un ordenador que incorpora algo de inteligencia artificial – o como se le pueda llamar a eso. La idea es que el programa incluye 200.000 partidas jugadas contra...
… y la mano amiga que le dará la puntilla será la de Microsoft, que ha lanzado una curiosa campaña para erradicar del mapa de la web al vetusto navegador: diez años tiene ya el código de la critarurita, que se...
Se acabaron los ejercicios fútiles de rumorología que invariablemente anteceden a cualquier presentación de Apple. Después de un Mobile World Congress plagado de tablets, sobre todo con sistema operativo Android 3.0 Honeycomb, mueve ficha el iniciador del fenómeno tablet cuando aún...
Por Nacho Palou -
2 MAR 2011
Este artículo se publicó originalmente en Cooking Ideas, un blog de Vodafone donde colaboramos semanalmente con el objetivo de crear historias que «alimenten la mente de ideas». Si hay un tipo de personaje apasionante en el mundo de la tecnología ese...
Hace unos días un compañero al que llamaremos Bichos para mantener su identidad en el anonimato se me acercó a primera hora de la mañana para preguntarme si podía echarle un ojo a un disco duro en el que tenían que estar...
¿Y tú, cómo pones las llaves cuando programas? { Whitesmith, GNU, BSD/Allman, Kernighan & Ritchie / Kernel } En el fondo se trata un poco de una pregunta-trampa porque todo el mundo sabe que obviamente lo correcto es…...
Primal Chaos es una página de visualizaciones relativas a los números primos y a la forma en que están distribuidos entre los números naturales. Las imágenes son muy bonitas, pero no contienen nada matemáticamente relevante aparte de eso. Todo comenzó para...
An Update is Available for Your Computer por Sticky Comics Linux: – “Guay, ¡más cosas gratis!”Windows: – “¡Otra vez no!”Mac: – “¡Oh! ¡Sólo 99 euros!” (Vía Geek are Sexy.)...
Por Nacho Palou -
25 FEB 2011
Los nuevos MacBook Pro de Apple aterrizaron ayer un poco por sorpresa, tal ve para ir despejando y caldeando el ambiente de cara a la presentación el iPad dos la semana que viene. Las novedades no son muy numerosas aunque los...
Motorola XOOM, 10 pulgadas y Android 3.0. Y sin Adobe Flash “hasta primavera”. El tablet Motorola XOOM estará disponible desde mañana 24 en EE UU con la operadora Verizon. Es el primero que sale con sistema operativo Android 3.0 Honeycomb. Y curiosamente...
Por Nacho Palou -
23 FEB 2011
Nomad Brush + iPad de Don Lee en Vimeo. El Nomad Brush es un pincel para dibujar sobre pantallas táctiles como la del iPad. A diferencia del lápiz electrónico del HTC Flyer el Nomad Brush es analógico. Está fabricado con fibras naturales...
Por Nacho Palou -
22 FEB 2011
El año pasado se decía que en 2011 se venderían más 'smartphones' que ordenadores y, ¡anda! si ya estamos en 2011. Y, según la consultora IDC, ya ocurre que se venden más teléfonos inteligentes que ordenadores. En volúmenes la diferencia no es...
Por Nacho Palou -
21 FEB 2011
Olá con la nueva versión de Google Public Data Explorer surjan muchos Hans Rosling que hagan más fácil entender el mundo en que vivimos. No en vano se trata de una herramienta basada en Gapminder, cuya tecnología adquirió Google hace años,...
Pixelfari es una versión «tuneada» de Safari para Mac OS X completamente funcional salvo por el pequeño detalle de la ínfima resolución y sus gráficos de 8 bits. Deliciosamente retro. Y no es por darle ideas malvadas a nadie, pero dado...
– ¿Cuántos programadores de Microsoft hacen falta para cambiar una bombilla?– Ninguno. Simplemente redefinen oscuridad como el «nuevo estándar».– popular chiste informático Hoy la gente de Mozilla publicó una dura anotación llena de detalles y estadísticas acerca de cómo se comporta...
Agencias, diseñadores de webs y webmasters puede que encuentren útil en estos tiempos salvajes que corren la idea de CSS Killswitch. Se trata básicamente de incorporar en las hojas de estilo del sitio que se ha diseñado una llamada a un fichero...
Lo retro/vintage parece estar de moda: le instalamos software a las cámaras de alta resolución para que las fotos parezcan tomadas con una Lomo; los 8 bits causan sensación e incluso se hacen películas sobre ello… De ahí que resulte (¡ejem!)...
El C-64x es una recreación del Commodore 64 de toda la vida con su aspecto de teclado gigante pero con un PC en el interior. Va equipado con un procesador Atom Dual Core 525, una tarjeta Nvidia Ion2, 2 GB de...
Este artículo se publicó originalmente en Cooking Ideas, un blog de Vodafone donde colaboramos semanalmente. Google como aplicación móvil integra funciones no disponibles de momento en la versión web (detrás): búsqueda por imagen (Goggles) y la búsqueda por voz que ahorra teclear...
Por Nacho Palou -
10 DIC 2010
Sir Maurice Wilkes, uno de los pioneros británicos en el campo de la informática, y líder del equipo de diseñó y construyó el EDSAC, acaba de morir a los 97 años. Hoy en día su nombre probablemente sólo nos suena a los...
10 consejos para la resolución de problemas técnicos inexplicables, o cómo desentrañar los expedientes X de la tecnología: simplificación, pruebas metódicas, reflexión, buscar en el lugar adecuado, pedir ayuda… Toda una serie de interesantes consejos en el blog de Manuel Pereira....
Lo estábamos esperando desde mayo de este año, cuando Verica Trstenjak, Abogado General de la Unión Europea, emitió una opinión que decía literalmente que «el canon por copia privada sólo puede gravar los equipos, aparatos y materiales de reproducción digital que presumiblemente...

All About Polymorphics es una película promocional para TRW Inc. es alucinante, pues plantea ya en 1959 un sistema que utilizaría distintos tipos de «cajas de computación» situadas por distintos lugares y conectados mediante una red de comunicaciones capaz de reconfigurarse...
Después de que en los últimos años se hayan construido distintas partes de ella y comprobado su funcionamiento en el MundoReal™, parece claro que la máquina analítica de Charles Babbage podría haber sido el primer ordenador de la historia. Sólo que a...

Alberto nos recomendó un viejuno pero todavía curioso artículo de la Wikipedia en donde se explica que un número primo ilegal es un número primo que contiene información que está prohibida poseer o distribuir, aunque esto depende de las leyes de cada...
Desde hace mucho tiempo en mi bolsa del ordenador no falta un módem USB 3G, que en innumerables ocasiones me ha sacado de un apuro, ya sea en sitios en los que la carencia de Wi-Fi abiertas es manifiesta, o en saraos...
En el mundo de la informática no es nada raro ver como una idea se adelanta a su tiempo, ya sea porque la tecnología todavía no está lo suficientemente avanzada como para hacerla práctica, ya sea porque no ofrece ventajas lo suficientemente...
Tiene su mérito: PS-HTTPD es un servidor web simplificado escrito en Postscript, el «lenguaje de las impresoras». Es como hacer que un microondas sirva para reproducir música: tan poco práctico como divertido. Un gran hackeo. (Vía CyberHades.)...
Starring the Computer es una detallada lista de películas y episodios de series de televisión en los que aparecen todo tipo de ordenadores. No es que todos tengan un papel protagonista (son más bien also starring) pero lo interesante es que...
VLC Media Player para iPad. Apenas tiene botones y es la caña....

Acongojante es poco: la gente del proyecto Visual 6502 ha creado una simulación de la mítica CPU de MOS Technology de los años 70, pero no una simulación cualquiera: lo han hecho a partir de microfotografías de del chip, recreando los...
Si la tabla periódica de magdalenas que Agus le hizo a Johnny te gustó, esta tarta que Esther encargó para un afortunado Javier te hará saltar las lágrimas de la emoción: El 80's cake es una de las creaciones de Pedacitos de...
Tras haber dominado el mercado de los navegadores web durante años, después de haber conseguido sacar de ese mismo puesto al otrora poderosísimo Netscape, Microsoft ha tenido que ver en los últimos años como poco a poco la cuota de mercado de...
Making Future Magic: iPad light painting por Dentsu London en Vimeo. El vídeo de Dentsu London y BERG explica la ingeniosa técnica desarrollada para pintar con luz utilizando un iPad, logrando textos y objetos tridimensionales que parecen flotar en el aire como...
Por Nacho Palou -
15 SEP 2010
NoReplyAll, un módulo para Outlook que desactiva los botones Reply All (Contestar a todos) y Forward (Reenviar). Lo del Reply All puede tener sentido. Lo del Forward es cruel. Lo de que esté diseñado específicamente para Outlook es deliciosa y doblemente cruel....
Hoy es el 256º día del año, de modo que –apropiadamente– se celebra el Día del programador. Según parece en Rusia además consiguieron que fuera oficialmente un día festivo para quienes se dedican a ello como profesión....
4*-/%>:+:i.1e6 es un programa escrito en el lenguaje de programación J que calcula π con una precisión de cinco decimales. tiene su mérito porque sólo usa 14 caracteres/bytes. La circular constante también se puede calcular con un programa de 52 bytes en...
Este artículo se publicó originalmente en Cooking Ideas, un blog de Vodafone donde colaboramos semanalmente con el objetivo de crear historias que «alimenten la mente de ideas». Los ordenadores son para hacer... cosas de ordenadores. Comunicarse, hacer las cuentas, escribir, programar, banalidades...
Toni del Castillo ha puesto en la App Store iDraw Pixels, una deliciosa aplicación que sólo sirve para dibujar píxeles gordos, convirtiendo al iPad en una especie de máquina del pasado o en un objeto decorativo al colocarlo sobre su dock....
HTML5 Elements, otra forma de ver el HTML nuestro de cada día, a lo tabla periódica. Incluyendo, apropiadamente, el elemento table. (¡Gracias, Roberto!)...
Lenta. Confusa. Vacía. Incómoda. Difícil de usar. Aislada. Llena de Spam. Y parece más una tienda que una reunión de amigos. Eso es lo que opino de Ping, la red social que presentó Apple como parte de iTunes 10: Decepcionante....
Los servidores de Microsoft reciben entre 7.000 y 9.000 ataques diferentes desde Internet durante cada segundo del día. La mayor parte procede de script kiddies sin demasiados conocimientos, que eligen atacar a un coloso para iniciar sus andanzas (¡tsk, tsk!) Curiosamente, muchos...
Este artículo se publicó originalmente en Cooking Ideas, un blog de Vodafone donde colaboramos semanalmente con el objetivo de crear historias que «alimenten la mente de ideas». A principios de 2005 se anunciaba la iniciativa OLPC (One Laptop Per Child, «Un...
Dicen que las limitaciones son la fuente de la creatividad, y en este caso todo eran limitaciones para un gran hacker. La imagen de arriba es de ZX-81 Chess, el que algunos consideran el mejor programa de ordenador jamás escrito. Y...
Desde hace unos meses estoy utilizando Zinio para leer algunas de mis revistas favoritas en el iPad. Zinio consiste en un quiosco de prensa virtual desde el que se puede acceder a numerosas publicaciones electrónicas, incluyendo revistas, libros o catálogos. Las...
Por Nacho Palou -
18 AGO 2010
Read It Later es una altamente recomendable aplicación que existe en versión gratuita pero bien vale los pocos euros que cuesta la versión de pago. Es el santo grial del procrastinador: un sistema automatizado para marcar páginas para «leer leer luego»,...

Mientras María Jesús y su Acordeón animaba el verano con El baile de los pajaritos y estaba a punto de estrenarse En busca del Arca perdida, los geeks de la época podían comprar el caluroso 12 de agosto de 1981 el...
Este USB de 7 puertos que venden en ThinkGeek soluciona uno de los problemas más típicos de los equipos actuales: tener un montón de chismes enchufados y consumiendo cuando en realidad no es necesario. De modo que aquí, además de poder...
Hay una fina línea que separa la ciencia de la paja mental. Las pseudociencias pretenden usar y estar cerca de la ciencia para parecer «serias»; a veces la ciencia parece más bien ciencia-ficción y en general suele ser muy entretido leer...

Por Lektu Desde que FORTRAN, Lisp y COBOL hicieron su aparición a principios de los 50, hasta nuestros días, se han desarrollado miles de lenguajes de programación cubriendo todos los nichos imaginables, desde la aviónica militar a la enseñanza de la programación...
30 JUL 2010
Una «humilde colección» de procesadores y alguna que otra placa madre con más de mil tipos diferentes de CPUs, incluyendo tanto procesadores de era Soviética como del mundo occidental –Intel básicamente– desde la década de los 70 hasta la actualidad. (Vía...
Parece que fue ayer, pero hace ahora 25 años, una demo con una pelota rebotando por la pantalla nos dejaba a todos los que apreciábamos la tecnología completamente asombrados y con la mandíbula por los suelos, deseando echar mano de esa maravilla...
Éste y otros increíbles 29 y altamente frikis anuncios de ordenadores y accesorios prehistóricos de los 70 y 80 en 30 Old PC Ads That Will Blow Your Processor. Incluyen personajes como Isaac Asimov, precios desorbitados para la RAM y los...
La página de casos prácticos de Real Flow tiene un montón de vídeos e información en forma de entrevistas sobre cómo la gente usa este software -tecnología española que lleva 12 años en el mundo de los efectos visuales- en películas...
Bueno, al menos todos los títulos del catálogo de Libranda, la plataforma de distribución de libros electrónicos de las principales editoriales españolas, que son compatibles con mi lector de libros electrónicos… Que en estos momentos, y por todo lo que se, se...
Curiosos cristales de colores: pseudocubos generados con 73 lineas de código Context Free es un programa que genera imágenes matemáticas: recursivas, fractales, con patrones, aleatorias o cualquier otra cosa que se te ocurra, a partir de un lenguaje de programación diseñado especialmente...
Desde hace algún tiempo le cuento a todo aquel que me pregunta que opino que no debería haber clases de informática en los colegios como asignatura aparte, igual que no hay clases de lápiz, y que en mi opinión la informática tendría...
8-bit City recopila mapas de algunas ciudades creados en 8 bits, al estilo de los videojuegos clásicos. Pero no están dibujados a mano, sino mediante un sistema especialmente programado para ello que utiliza los datos públicos de OpenStreetMap para crear las...
Cada vez hay más y más aplicaciones de realidad aumentada gracias a los móviles cada vez más potentes de los que disponemos, permanentemente conectados a Internet, aunque la mayoría de ellas están pensadas para ofrecer información actual sobre restaurantes, cajeros automáticos, puntos...
Fotografía: Sandra Pompe / Control. Más fotos. El videojuego Pac-Man (o Comecocos) fue diseñado por Tōru Iwatani (arriba en la imagen mostrando los bocetos originales del juego) a principios de los años 80. § Kottke....
Por Nacho Palou -
24 JUN 2010
Desde el departamento Yo es que soy más de acceder a las fotos de Picasa por línea de comandos nos cuentan que Google permite acceder a algunos de sus servicios por esta vía con GoogleCL. Blogger, Calendar, Contacts, Docs, Picasa y...
Por Nacho Palou -
23 JUN 2010
The Art of Analog Computing por meltmedia en Vimeo. Un simpático vídeo que representa las herramientas e interfaces digitales que usamos a diario en forma analógica. Atención a los timelines de Twitter y al spam ;-) (Vía, paradójicamente digital, Clipset)....
iMac, año 2000iPhone 4, año 2010 Sistema operativoMac OS 9.0.4iOS 4.0 Procesador500 MHz PowerPC G3 CPU,Memoria de 128MB1 GHz ARM A4 CPU,memoria de 512 MB GráficosATI Rage 128 Pro,memoria de 8MB8 millones de triángulosPowerVR SGX 535,memoria del sistema28 millones de triángulos...
Por Nacho Palou -
21 JUN 2010
Válida para cualquier ordenador o dispositivo que acepte un teclado USB The USBTypewriter™ es un accesorio de estos que no necesitan más justificación para existir que la de que hay que hacerlos porque es posible hacerlos. Una ya terminada se puede...
Monster Chess usa más de 100.000 piezas de Lego de varias series: 37.612 en el tablero de 14,5 metros cuadrados, 17.114 en las piezas, 17.748 en las bases robotizadas que permiten mover estas, 22.688 en los mosaicos y 1.853 en la...
Stick with me, baby!, simpáticas pegatinas para colocar sobre el característico logo de los MacBook....
Por Nacho Palou -
11 JUN 2010
Impresionante trabajo de unos estudiantes de un colegio japonés: (Nos llegó bit a bit desde TokyoMango, a dónde lo envió Kazu Y, vía Boing Boing). Post-its en "stop-motion", incluido el making of. 8-bit trip, juegos retro en stop motion con Lego, un...
Este artículo se publicó originalmente en Cooking Ideas, un blog de Vodafone donde colaboramos semanalmente con el objetivo de crear historias que «alimenten la mente de ideas». Jakob Nielsen es uno de los expertos en usabilidad más reconocido de Internet, que publica...
Si Escher levantara la cabeza, sin duda disfrutaría diseñando escenarios como estos que se pueden ver en el vídeo de New Scientist. Es un software creado por Tai-Pang Wu de la Universidad China de Hong Kong: es capaz de renderizar imágenes...
Tan aplastante como el dominio de Windows en otros entornos es el de Linux en las supercomputadoras del mundo. Es otro gráfico de la BBC, que encontré en OMG! Ubuntu! a raíz del que crearon para la lista de los Top...
In graphics: Supercomputing superpowers, de la BBC, muestra cómo están repartidos los equipos de supercomputación por el mundo, algo así como el mapa de las superpotencias de la supercomputación. Los datos provienen de la lista original del famoso Top 500 de...

«Unos ingenios excitantemente mecánicos», según describe Cory de Boing Boing, y no se puede estar más de acuerdo con él. Se trata de un pequeño documental dividido en siete partes (se puede seguir en la columna de vídeos relacionados en YouTube)...
No he tenido tiempo más que de echarle un vistazo por encima, pero el texto History of NSA General-Purpose Electronic Digital Computers [PDF 3,1 MB] de Samuel S. Snyder sobre los ordenadores de la NSA entres 1950 y diciembre de 1963 tiene...
How Fanboys See Operating Systems en MakeUseOf.com...
Por Nacho Palou -
14 MAY 2010
En la presentación del iPad, Steve Jobs dijo que no tenía claro si existía un hueco en el mercado para un dispositivo como este, pero también señaló que, de existir, el iPad era el mejor producto en el segmento, aunque, por otra...
Cuando a principios de los noventa se creó la web, que ahora es sin duda el más popular servicio de Internet, sus capacidades multimedia iban poco más allá de insertar imágenes en las páginas. La interactividad tampoco era gran cosa y apenas...
Comparando la organización de los sistemas que controlan los procesos que tienen lugar en un organismo vivo y en un ordenador, investigadores de la Universidad de Yale tratan de explicar por qué los ordenadores tienden a funcionar mal más a menudo que...
Por Nacho Palou -
4 MAY 2010
Ahora que hasta Sony, inventor de los diskettes de 3,5 pulgadas, el último en ser utilizado masivamente en los ordenadores, va a dejar de fabricarlos, en la BBC han seguido las instrucciones que Randy Sarafan da en su libro 62 Projects to...
Apple - Newton “Cadillac” Prototype, foto (cc) splorp A raíz del prototipo de iPhone de cuarta generación supuestamente perdido por un ingeniero de Apple, el mural de Flickr Apple Prototypes recopila decenas de prototipos de productos de Apple que nunca vieron la...
Por Nacho Palou -
21 ABR 2010
N.Konstantinov y un grupo de matemáticos utilizaron la técnica de stop-motion para generar Kitten, esta película de animación con un gato como protagonista que probablemente sea una de las primeras de la historia en que participó un ordenador. No está claro...
Clic en la imagen para ampliar Para lo poco que se puede escribir en un tweet, 140 caracteres, es sorprendente la cantidad de información «oculta» que viaja con cada uno de ellos, como se puede ver en la ilustración Map of a...
Lo que en el vídeo de arriba parecen un par de ventanas con muy buenas y variadas vistas son dos pantallas planas de 46 pulgadas. Ambas están conectadas a un ordenador y controladas con el programa Winscape (Mac OS X). Conforme...
Por Nacho Palou -
19 ABR 2010
Hoy sale a la venta en todo el mundo Creative Suite 5 de Adobe, aproximadamente año y medio después de la versión anterior, puesta a la venta en octubre de 2008. Esta nueva versión, según la edición que se compre de las...
Sin sorpresas en la respuesta, Gráfico: SixRevisions. Los resultados obtenidos en las mediciones de SixRevisions sobre el rendimiento de los principales navegadores web evidencia que hay dos tipos de navegadores web: Internet Explorer y todos los demás. A cuento: Cómo se ve...
Por Nacho Palou -
8 ABR 2010
Smart Design's iPad ... Circa 1989 en Fast Company / Imagen: Fast Company Un curioso e interesante artículo en Fast Company respecto a los primeros prototipos de tablet desarrollados en un proyecto de treinta días de duración encargado por Apple en...
Por Nacho Palou -
30 MAR 2010
La función de los adaptadores Powerline AV 200 de Netgear es convertir la instalación eléctrica de la vivienda en una red local de datos para disponer de conexión a Internet en cualquier enchufe. De este modo se utilizan los enchufes eléctricos...
Por Nacho Palou -
29 MAR 2010

A Turing Machine es una Máquina de Turing hecha realidad. Su creador pensó que sería divertido construir físicamente la máquina teórica concebida en la mente del pionero de la computación Alan Turing y se puso manos a la obra. Hablé algo...
Esta es una de las animaciones que Pedro M. Cruz tiene en Traffic in Lisbon condensed in one day y que recogen el tráfico en Lisboa a lo largo de un día de octubre de 2009 en poco más de un...
Steve Jobs Cut Out por Jay Hauf Esta plantilla, unas tijeras, un poco de pegamento, y algo de maña y paciencia dan como resultado este Steve Jobs «cabecicubo», completo con sus reglamentarios jersey negro de cuello vuelto y vaqueros y un iPhone...
Después de ver Safari dentro de Safari Sebastián (¡gracias!) nos envió un enlace con un truco para abrir el navegador Firefox dentro del navegador Firefox. En este caso no tiene el encanto de la dificultad de dibujar la interfaz completa de...
Por Nacho Palou -
22 MAR 2010
Todo un ejemplo de autorreferencia, Un buen navegador debería ser capaz de interpretarse a sí mismo. La versión del navegador Safari que aparece dentro de mi navegador Safari es una versión desarrollada por completo con HTML y CSS3. Sólo funciona en navegadores...
Por Nacho Palou -
18 MAR 2010
Salvo que tengas la mirada sucia, la navegación en “modo incógnito” del navegador web Google Chrome está pensada para cuando desees navegar sin dejar rastro (por ejemplo, al buscar información para preparar cumpleaños y regalos sorpresa). Cuando navegues en este modo, las...
Por Nacho Palou -
15 MAR 2010
Vale, reconozco que quizás haya que ser bastante geek de la informática para disfrutarlo, pero si lo eres este vídeo es un rato curioso. En él se puede ver en acción una herramienta llamada ICU64 (que se puede leer como I...
Seguro que más de uno y más de dos de los que leéis Microsiervos os habréis ganado esta insignia de Family Tech Support (Soporte técnico familiar) por Nerd Merit Badges. Con creces. (Vía Neatorama). Busca la tecla socorro, cosas de los...
La aplicación DssBH (Distortion of the stellar sky by a Schwarzschild black hole, para Windows y Linux) simula cómo se vería el espacio entorno a un agujero negro de Schwarzschild, la región simétrica y esférica contenida dentro de los límites de...
Por Nacho Palou -
12 FEB 2010
Vodafone ofrece con el netbook Samsung N130 una solución completa de conectividad móvil: ofrece el pequeño portátil desde 19 euros vinculado a una conexión 3G con permanencia de 24 meses, lo que hace que el precio total sea de 955 euros;...
Por Nacho Palou -
10 FEB 2010
Vodafone 360 es un servicio de la operadora Vodafone que unifica los contactos personales y las redes sociales a través del teléfono móvil y del ordenador. De este modo desde el teléfono se puede conocer el estado de, por ejemplo, los contactos...
Por Nacho Palou -
1 FEB 2010
Bastó con que a principios de este mes se filtrara la información de que Apple había reservado un local en San Francisco para el próximo día 27 para que la máquina de rumores se pusiera a funcionar a todo ritmo, ayudada sin...
Comfort Lapdesk for Notebooks, de Logitech | Si tienes un portátil probablemente alguna vez te habrás visto en la necesidad de colocar un libro o un cojín entre éste y las piernas para aislarte del calor que desprende el ordenador. Precisamente...
Por Nacho Palou -
25 ENE 2010
Mouse pointer track recoge el camino recorrido por el puntero del ratón de Anatoly Zenkov durante una sesión de trabajo de tres horas en Photoshop, interrumpida por un par de pausas de café que se corresponden a los dos puntos más...
Realism in UI Design es un breve pero interesante análisis spbre los símbolos en las interfaces de usuario. Cada símbolo representa una idea o concepto, y para que sean efectivos deben estar en un punto medio entre la imagen real de...
Disponible en negro y rojo, la funda BookBook está pensada para los MacBook y MacBook Pro, pero seguro que cualquier otro portátil de dimensiones similares se encontraría a gusto dentro de ella. El interior es de un tejido suave para proteger...
El curso iPhone Application Development de la Universidad de Stanford está disponible gratuitamente en forma de vídeos y presentaciones en iTunes (enlace iTunes). El curso dura en total 10 semanas y cubre todos los aspectos de programación con el iPhone SDK (para...
Por Nacho Palou -
21 ENE 2010
CentennialMerchant vende estos discos duros externos en Etsy en capacidades de 320, 500 y 640 gigas, para lo que monta mecanismos Samsung dentro de viejas cintas VHS, aunque si eres medianamente mañoso no puede ser muy complicado montar uno con cualquier...
Todo empezó con las informaciones que decían que Apple había reservado sitio para un evento en el Yerba Buena Center for the Arts de San Fancisco el próximo 27 de enero, pero en realidad no había confirmación por parte de la empresa…...
Tras las optimistas predicciones de mediados del siglo XX acerca de los avances en cerebros electrónicos e inteligencia artificial, lo cierto es que no hay nada que realmente nos pueda hacer pensar que hoy en día estamos más cerca de conseguir crear...

Si hay una forma de revivir un chisme de baja tecnología en otro de alta tecnología, este es un magnífico ejemplo: cómo convertir una vieja máquina de escribir Smith Corona de los años 40 en un teclado USB y conectarla a...

No sucedió nada realmente de importancia cuando el calendario cambió del año 1999 al 2000, pero… qué mal lo pasó mucha gente pensando en las consecuencias. Y cuánto tiempo y dinero costó a la industria revisar y corregir el problema del...
Por cortesía de Christian, que nos pasó el enlace hace ya unos días, 8-bit Chrsitmas de Rush Coil, una colección de villancicos tradicionales en 8 bits para amenizar las celebraciones de estos días. Aunque quizás tengas que explicarle a tus más...
Steve Jobs durante la presentación del MacBook Air en 2008. Fotografía de Matthew Yohe, Wikipedia.Steve Jobs ha sido nombrado CEO del año por la revista Harvard Business Review por “incrementar en 150.000 millones el valor en bolsa de Apple, en los últimos...
Por Nacho Palou -
22 DIC 2009
Esta semana el Ministerio de Educación y Microsoft firmaron un acuerdo marco mediante el que la segunda pone a disposición de los centros educativos que aún son competencia del Ministerio un paquete con las últimas versiones de su software a un precio...
La gente de Multitouch Barcelona creó este simpático vídeo sobre lo que sucede entre bastidores en el interior de nuestros queridos ordenadores… una especie de «interfaz humana» llamada Hi, de lo más curiosa y divertida. (Vía CyberHades.)...
En La historia informática en documentos PDF hay un enlace a Historic Documents in Computer Science, una pequeña recopilación hecha por Karl Kleine, profesor de la Universidad de Ciencias Aplicadas de Jena (Alemania), de documentos importantes en la historia de la informática,...
El Nokia Booklet 3G, que la finlandesa califica como miniportátil, se sitúa en cuanto a tamaño y prestaciones por encima de los netbooks y por debajo de los portátiles; sin embargo, se podría decir que es el auténtico netbook, ya que...
Por Nacho Palou -
25 NOV 2009
Vintage computing '67 Esta imagen forma parte del álbum Chicks 'n' Computers, que igual que el de Vintage Computer o el de Vintage Electronics es uno de los que mantiene el autor de Retrospace, un blog dedicado a estudiar cuando la cultura...
Según un estudio recientemente publicado de Panda Labs, una empresa dedicada al desarrollo de herramientas para la detección y desinfección de virus y otros programas maliciosos para ordenadores España es el primer país del mundo en cuanto a ordenadores infectados, con ni...
Más de uno se sentirá identificado con esta estampa del ingrato trabajo de ser el soporte técnico de la familia que publicaron en Slashdot: Desde que aprendí a manejar ordenadores muy jovencito he sido el técnico de soporte de toda la familia:...
A New Theory of Awesomeness and Miracles es un fascinante artículo que proviene de una conferencia de Jaime Bridle sobre juegos y estrategia, en el que se describe la construcción de MENACE, una increíble «máquina» ideada por el profesor Donald Michie,...
En Cuando los bugs terminan en explosiones contaron hace tiempo cómo errores de programación acabaron liándola parda en algunas misiones espaciales. El Mariner 1, el Ariane 5 y el Mars Climate Orbiter sucumbieron en forma de costosos fuegos artificiales debido a bugs...
Con los valores de Apple rondando los 200 dólares por acción, Ronald Wayne debe estar tirándose de los pelos, si acaso aún le queda alguno, Ronald Gerald Wayne es el tercer y poco conocido fundador de la empresa de ordenadores Apple, junto...
Por Nacho Palou -
30 OCT 2009
ABTests.com¹ es un interesante repositorio de pruebas A/B, una forma de análisis de efectividad que suele usarse a modo de ensayo-y-error para mejorar las páginas web en cuestiones de interfaz de usuario y usabilidad, así como en campañas publicitarias y similares....
O al menos “todas aquellas aplicaciones populares y disponibles online para descarga”. El funcionamiento de la página Ninite es simple como el mecanismo de un chupete –lo cual no quiere decir que no sea genial: se marcan las aplicaciones a instalar...
Por Nacho Palou -
29 OCT 2009
Cuando los griegos clásicos hablaban de la hibris se referían a un orgullo o confianza en uno mismo exagerados que con frecuencia tenía como consecuencia un merecido castigo, y lo cierto es que es algo que se me viene a la mente...
Logotipo de Windows 7 en Sietes Apenas dos años y medio después de sacar al mercado el problemático Windows Vista Microsoft ha puesto hoy a la venta en todo el mundo Windows 7, del que ya escribimos en su momento cuando salió...
<BLINK> No conocía esta historia, pero en The Origins of the <Blink> Tag cuentan en palabras de sus protagonistas cómo fue concepción de unos de los más aberrentes inventos incorporados en el lenguaje HTML de las páginas web, tan solo superado –tal...
Apple superó ayer durante unas horas, al abrir los mercados, la barrera de los 200 dólares por acción, alcanzando así un nuevo récord de capitalización bursátil: 178.000 millones de dólares (eso es más que Google). Probablemente los buenos resultados que presentó...
TidBITS ha cumplido 1.000 números, lo cual para un boletín semanal quiere decir que lleva más de 19 años publicándose. Este legendario boletín electrónico creado por Adam y Tonya Engst arrancó en 1990, y ha sido un punto de referencia sobre el...
De Windows 1.0 (1985)... A Windows 7 (2009) En un recorrido visual de 24 años por las cajas de Windows, desde que era sólo un entorno operativo hasta que alcanza la edad para beber en EE UU y se convierte en un...
Por Nacho Palou -
19 OCT 2009
A un estudiante finlandés llamado Cessu se le ocurrió probar qué sucedería si convirtiera los registros de una CPU en notas musicales, algo que dicen podría denominarse auralización. Lo primero que hizo fue reducir un poco el frenético ritmo de la...
Conector VGA (~ 1987) en un Vaio X de 2009 Esto es lo que sucede cuando sigues utilizando tecnologías obsoletas –como esa salida de vídeo VGA de 1987, literalmente del siglo pasado–, en tus portátiles ultrafinos, ultramodernos y ultracaros de última generación....
Por Nacho Palou -
14 OCT 2009
La inmerecida fama de los «hackers»,La Voz de Galicia 11 de octubre de 2009. A pesar de que el término se asocia con la piratería informática, el grupo nació en el MIT a principios de los sesenta intentando optimizar un primitivo ordenador...
Jacquard's Web: How a Hand-Loom Led to the Birth of the Information Age. James Essinger Oxford University Press. Inglés. 2007. En 1801 Joseph Marie Jacquard presentó el telar que lleva su nombre, aunque sería más apropiado decir que lo que presentó...
El Computer History Museum es uno de esos sitios que tengo que visitar sí o sí, pero por ahora he tenido que contentarme siempre con galerías de imágenes de gente que ha podido pasarse por allí. En este caso se trata de...
La formación de la Open Android Alliance –el grupo oficial es Open Handset Alliance– es una suerte de adiós expresada por algunos de los más valiosos desarrolladores con que cuenta la plataforma Android, quienes ya no incluirán las aplicaciones de Google en...
Por Nacho Palou -
30 SEP 2009
Esta anotación fue publicada originalmente en La Voz de Galicia, diario en el que nos han fichado como colaboradores para publicar una página sobre tecnología, ordenadores, Internet y esas cosas en la sección de Sociedad. Una ley que cambió el mundo,La Voz...
Mientras media humanidad espera el rumoreado tablet de Apple -que en mi opinión no veremos al menos hasta la Macworld Expo de enero de 2010- o poderle poner las manos encima al CrunchPad, en Gizmodo se descuelgan con este vídeo en el...
Gene Roddenberry (1921 - 1991), creador de la serie Star Trek, tuvo unos de los primeros ordenadores Macintosh 128 que se fabricaron. Fue un regalo que le hizo Apple en 1986. Ese ordenador saldrá a subasta y se calcula que puede llegar...
Por Nacho Palou -
18 SEP 2009
Ya que no estábamos por aquí para dar la noticia de la llegada de la televisión, nos alegramos de poder anunciar la puesta en marcha de Telebisión, un programa pasado en XBMC para gestionar y visualizar en el televisor contenidos de...
Por Nacho Palou -
17 SEP 2009

Hace más de 25 años, Richard Stallman, uno de los héroes de la tecnología moderna, definió una forma de entender el software a partir de unas libertades básicas. Algo que ha llegado hasta nuestros días revolucionando la industria informática. Si todo...
Esta Chocolate Bar HDD USB Case es absolutamente genial para reutilizar cualquier disco duro o unidad SSD SATA de 2,5 pulgadas que uno tenga perdida por ahí. Cuesta sólo unos 13,5 euros, aunque sospecho que los gastos de envío iban a...
Ver vídeo: Handheld Projector DemoHandheld Projector Demo [YouTube 6:57] Andrés nos pasó un enlace a este vídeo en el que se ve una demostración de un sistema desarrollado en la Universidad de Toronto en el que mediante un proyector que se maneja...
La campaña lanzada por John Graham-Cummig para pedir una disculpa oficial del gobierno británico a Alan Turing por como fue tratado al salir a la luz su condición de homosexual ha dado sus frutos con una carta del primer ministro Gordon Brown...
Aunque en efecto la mayoría de las mejoras de Mac OS X 10.6, más conocido como Snow Leopard, no están a la vista, una de las que sí se ven y son más aparentes es un Exposé muy mejorado respecto a versiones...
Me recomendaron como disco duro externo estas unidades de Western Digital llamadas My Book que por lo que he probado van muy bien. Se venden en diversas capacidades: las de 1 y 2 TB salen a algo más de 100 euros...
Me ha parecido muy curioso este vídeo en el que se ve la evolución del wiki wiki.tudelft.nl utilizado en la Universidad de Tecnología de Delft desde que se lanzó a finales de 2004 hasta que sobrepasa las 10.000 páginas. En el...
Despúes de un primer rechazo a mediados de junio al fin Apple ha aprobado C64, el emulador de Commodore 64 para iPhone escrito por Manomio, al parecer después de que haya sido eliminada la opción de ejecutar BASIC en él (no, yo...
Ver vídeo: Ivan Sutherland's Sketchpad 1963Ivan Sutherland : Sketchpad Demo (1/2) y (2/2) [YouTube 10:34 + 10:29] La realización del vídeo y la naturalidad de las personas que salen en él dejan bastante que desear, pero este clip es muy interesante porque...
Esta página fue publicada originalmente La Voz de Galicia, diario en el que nos han fichado como colaboradores para publicar una página sobre tecnología, ordenadores, Internet y esas cosas en la sección de Sociedad. Apple se prepara el futuro,La Voz de Galicia...

A PES le llevó unos tres meses de trabajo terminar este vídeo en stop motion en el que homenajea a clásicos de la era de los 8 bits como Centipede, Frogger, Asteroids, Space Invaders y el Comecocos, AKA Pac Man. En...
Alan Turing fue una de las figuras clave en el trabajo de Bletchley Park para descifrar los códigos utilizados por el ejército alemán durante la segunda guerra mundial, algo que como poco contribuyó a acortar en algunos meses la guerra. Antes de...
El superordenador JUGENE, construido por IBM en el Jülich Research Centre (Alemania), es capaz de realizar 1.000 billones de operaciones de coma flotante por segundo, es decir un PetaFLOPS o 1015 FLOPS. FLOPS es el acrónimo de Floating point Operations Per...
Por Nacho Palou -
31 AGO 2009
From Sand to Silicon: the Making of a Chip es una divulgativa página de Intel en la que se pueden ver un montón de imágenes «paso a paso» de cómo se construyen los chips… al menos los de Intel. (Nos lo...
Desde 2001 Gordon Bell, un investigador de Microsoft, está llevando a cabo un proyecto llamado MyLifeBits en el que está almacenando digitalmente toda la información que genera a diario con la ayuda de toda una serie de dispositivos como un escáner de...

Un 25 de agosto, pero de 1991 -hace ahora exactamente 18 años- el finlandés Linus Torvalds enviaba un humilde mensaje a Internet anunciando al mundo el proyecto en el que llevaba varios meses trabajando en sus ratos libres: un sistema operativo...

Absolutamente impresionante este vídeo creado con la técnica stop motion con piezas de Lego y su correspondiente musiquilla ratonera que homenajea a los juegos de los tiempos de los 8 bits con los que muchos hicimos nuestros primeros pinitos con esto...
Nunca se sabe cuándo vas a necesitar el código de una doble flecha a la izquierda o una cuádruple integral, así que conviene tener esta Tabla Unicode interactiva siempre a mano. Se puede navegar cómodamente por los simbolitos y luego ver...
Lektu me pasó este apasionante artículo: Superstitions donde se habla sobre las supersticiones en los MMOG, estudiadas desde el punto de vista psicológico y del comportamiento de la gente real, mediante entrevistas y encuestas. Gente que jugaba a World of Warcraft,...
Hace unos días cayó en mis manos una impresora multifunción Canon y si bien sabía que con Mac OS X no tendría ningún problema para utilizarla como impresora compartida en red (para los despistados: Preferencias del Sistema -> Compartir -> Compartir Impresora)...
La Mario Competition 2009 es un concurso para programas de ordenador «inteligentes» que sean capaz de jugar a una versión modificada de Super Mario Bros llamada Infinite Mario Bros que tiene la ventaja de ser parecida al original y con infinitos...
Este programa en C de Daniel Vik genera los dígitos de π, y tiene un aspecto deliciosamente autorreferente: Lo encontré buscando por ahí los programas más cortos que generan los dígitos decimales de π con precisión arbitraria. Cualquier lenguaje de programación valdría....
En Cult of Mac captaron bien la sutil diferencia: vs. (Vía Bitelia.)...
Vi pasar por reddit que PC Plus publicó un artículo muy divulgativo sobre cómo se resuelven algunos problemas geométricos mediante algoritmos: Solve computational geometry problems [PDF]. Por lo general esos algoritmos del campo de la geometría y la topología son programados...
Las dos principales características que incorpora la versión 2.8 Gold de Skype para Mac son son el Skype Access y la posibilidad de compartir la pantalla. Empezando por lo último –lo más interesante–, la opción de Pantalla Compartida permite que el usuario...
Por Nacho Palou -
21 JUL 2009
Steven Leckart y Jason Lee crearon esta imagen de cómo un geek puede combinar las redes sociales, el blogging y el entretenimiento digital para mantener una adecuada vida geek equilibrada. En total son nueve horas al día que incluso incluyen hora...

Por ahora no es más que un anuncio para las cartas certificadas electrónicas del sistema postal francés, y menos mal, porque si fuera un producto real de Apple no habría átomos suficientes en el universo para escribir su precio ;-P...
Esta página fue publicada originalmente La Voz de Galicia, diario en el que nos han fichado como colaboradores para publicar una página sobre tecnología, ordenadores, Internet y esas cosas en la sección de Sociedad. ">El cuento de nunca acabar,La Voz de Galicia...
No es que pudieran quedar muchas dudas sobre ello tras todo el esfeurzo realizado en los últimos años por Google para desarrollar un más que competente conjunto de aplicaciones basadas en la web, y menos aún tras la presentación de Google Chrome...
VLC es un pequeño programa que resuelve de una tacada muchas de las grandes preguntas que se hacen los usuarios: ¿con qué programa puedo ver cómodamente una película de esas que me he bajado por Internet? ¿Y si está en inglés...
Comprobando los datos del día del Excelversario (tal y como lo bautizó Treegom, el lector que nos puso sobre la pista) descubrimos una historia bastante curiosa. Si se comprueba la fecha en Excel efectivamente hoy marca el valor 40.000, el «número de...

HP Calculator Software, toda una idea: por 10 dólares se puede revivir la experiencia –y disfrutar de la practicidad– de las míticas calculadoras científicas de Hewlett-Packard en el iPhone / iPod Touch; también existe una versión como aplicación para Windows. Un...
Toledo Nanochess es un pequeño programa que juega al ajedrez. Tan pequeño que ocupa menos de 2 KB. Existen algunas variantes que tienen hasta modo gráfico, e incluso hay otra escrita en menos de 4 KB de JavaScript, superando al mítico...
La próxima actualización del programa de correo electrónico Microsoft Outlook retrocede otros cuantos años al pasado, diez para ser exactos. Después de que la versión 2007 de Outlook prescindiese de utilizar el motor HTML de Internet Explorer para pasar a tirar del...
Por Nacho Palou -
24 JUN 2009
Fue The Wall Street Journal quien hace unos días dio la noticia de que Steve Jobs habría recibido hace dos meses un trasplante de hígado en Jobs Had Liver Transplant, pero se trataba de una noticia sin confirmar hasta hace apenas unas...
Me encontré este vídeo en Commodore 64 rechazada de la App Store, un enlace que nos envió Juanjillo en el que se habla de que Apple no parece dispuesta a aceptar para su tienda de aplicaciones un emulador de Commodore 64, algo...
Un estupendo artículo en la serie de informática histórica de Macluskey en El Cedazo, en esta ocasión sobre el lenguaje COBOL, que fue creado en 1959 y todavía se usa hoy en día. Como bonus hay enlaces a otra anotación con...
Si necesitas calzar tu camión para que no se vaya cuesta abajo y no tienes una piedra o una cuña a mano, siempre puedes utilizar un ThinkPad T400s, como hicieron los chicos de Slash Gea, que lo pisaron con un camión...
Por Nacho Palou -
20 JUN 2009
La realidad aumentada permite incorporar información adicional al MundoReal™ a través de imágenes, vídeos o en tiempo real. La entrada Georeferenciando panorámicas del Blog de IDEE explican el funcionamiento y la mecánicas detrás de The Marmota Project, que combina fotografías reales con...
Por Nacho Palou -
18 JUN 2009
Entrañable anuncio de televisión de 1956, protagonizado por la computadora UNIVAC I, uno de los primeros ordenadores que se puso a la venta comercialmente. Tan potente, tan potente, que aquellos tubos de vacío del «gigantesco cerebro electrónico» te rellenaban casi por...
Breadbox64 en funcionamiento No es que tenga una gran utilidad que digamos, pero para los que recordamos con cariño la época dorada de los ordenadores personales de 8 bits y que aún nos emocionamos al ver Hey Hey 16K Breadbox64, un cliente...
Diez de los más poderosos superordenadores de todos los tiempos de imponente aspecto, como el Connection Machine CM-5 de la Thinking Machines Corporation de la foto. Este era tan fotogénico que lo usaron en algunas escenas de Parque Jurásico; otros como...
Aunque Gmote aún está un poco verde, más o menos funciona y es una aplicación muy interesante que permite convertir terminales Android en un control remoto para el ordenador. Esta función es interesante para, por ejemplo, ver películas, escuchar música o acceder...
Por Nacho Palou -
10 JUN 2009
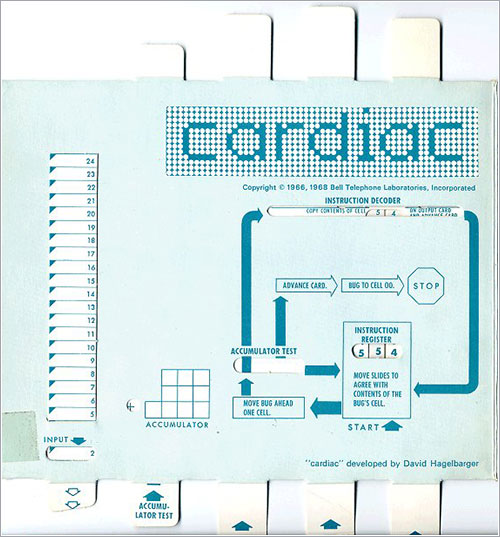
Aunque a estas alturas todos tenemos claro que no es necesario tener ni idea de cómo funciona un ordenador ni de programación para usar uno, a finales de los años 60, cuando los ordenadores empezaban a hacerse un hueco en el MundoReal™...
Hace apenas unas horas que ha arrancada la Conferencia Mundial de Desarroladores de Apple (WWDC) de 2009 en la que las estrellas serán Mac OS X 10.6, conocido como Snow Leopard, y la nueva versión 3.0 del software del iPhone. Hemos...
Desde Chromium Developer se pueden descargar las primeras versiones aún en desarrollo del navegador Chrome de Google para ordenadores Mac OS X y Linux, en inglés....
Por Nacho Palou -
8 JUN 2009
Una lista. Y de ordenadores personales de los primeros tiempos. Irresistible, por supuesto. Dawn of the Personal Computer: From Altair to the IBM PC da un repaso a algunas de las máquinas de las colecciones de Eric Klein y del Computer History...
Places Directory es otra de esas brillantes aplicaciones que nacen en Google del 20 por ciento del tiempo del que los desarrolladores de la compañía disponen para dedicar a proyectos de libre elección. La aplicación –disponible también desde el Android Market–...
Por Nacho Palou -
4 JUN 2009

No es que sea un derroche de acción y entretenimiento, pero este vídeo en el que K.C. (AKA Phreakmonkey) usa un acoplador acústico Livermore Data Systems "Model A" me resulta realmente interesante por la descripción que hace del cacharro en cuestión:...
Colossus por Rich Aunque son pocas, y la última está incluso desenfocada y subexpuesta, estas fotos del Colossus reconstruido de Bletchley Park me han recordado las ganas que tengo de visitar el museo que allí tienen. Bletchley Park fue el lugar principal...
Historia épica: Los tormentosos años 90: La guerra de los PC. Es un elaboradísimo ensayo –de hecho, es sólo la primera parte– escrito por Macluskey en El Cedazo. Es una gran visión personal de la época, en el que los protagonistas...
Es interesante ver esta vista nocturna de una ciudad creada mediante una versión extrema de programación por procedimientos. A diferencia de otras técnicas que podrían usarse para crear algo así, en la que se construirían diversos objetos en 3-D, texturas y...
Una conversación acerca de cómo los epidemiólogos usan distintas herramientas y modelos informáticos para intentar entender cómo se extienden las enfermedades llevó a Jer Thorp a preguntarse si no habría información en las redes sociales que todos usamos a diario que permitiera...
Navegando por el Android Market -la aplicación del sistema Android que permite acceder y descargar aplicaciones- me llamó la atención que una llamada Keep Android Open Petition era de las más populares. El programa, abreviado Tether Petition, es para adherirse a la...
Por Nacho Palou -
12 MAY 2009
Hace tiempo que uso WhatSize de ID-Design para analizar los contenidos de los discos duros y ver qué es lo que está ocupando más espacio cuando toca averiguar a dónde han ido a parar todos esos gigas que el disco traía de...
... Alguien dedicó su tiempo a buscar en Google Maps formas que representen todas las letras del abecedario en el estado de Victoria, en Australia. (Vía Trash.)...
Por Nacho Palou -
2 MAY 2009
Swine Flu Map muestra los casos de gripe porcina registrado por todo el globo, pudiendo filtrarse según sean casos confirmados, sospechosos o finalmente negativos. Pulsando sobre los puntos se amplía algo de información sobre cada caso. Aunque en España sólo aparece...
Por Nacho Palou -
29 ABR 2009
Pues si. El Navegador Ópera, el más innovador de los navegadores que son ignorados por la masa, cumple ahora 15 años ¡Felicidades!...
Por Nacho Palou -
29 ABR 2009
Según se puede leer en Flickr users make accidental maps David Crandall, Lars Backstrom, Daniel Huttenlocher y Jon Kleinberg del departamento de Ciencias de la Computación de la Universidad de Cornell han cogido los datos de geolocalización de unos 35 millones de...
PC World ha publicado una galería de fotos sobre la historia de Sun, la legendaria compañía informática recientemente adquirida por Oracle. Entre las diversas curiosidades históricas de Sun Microsystems destacan algunas como Su nombre, Sun, era originalmente un acrónimo de Stanford...
Los ingenieros de IBM consideran que han programado un ordenador que es «suficientemente inteligente» como para competir contra los humanos en el clásico programa de preguntas y respuestas de la televisión norteamericana. Al más puro estilo de los concursos televisivos, Jeopardy!...
Este estilo de computación cada vez más popular permite utilizar vastos recursos informáticos de forma relativamente sencilla, pagando sólo por lo que se utiliza realmente. Con más ventajas que inconvenientes está cambiando la forma en que se desarrollan las nuevas aplicaciones....
La webcam recoge los movimientos de cabeza del usuario, y el programa Enable Viacam los convierte en movimientos del puntero del ratón por la pantalla. Enable Viacam (abreviado como eViacam) es un programa para Windows y Linux que permite mover el puntero...
Por Nacho Palou -
27 ABR 2009
José Ramón nos pasó el enlace a la web del Museo de Informática García Santesmases, que situado en los pasillos de la Facultad de Informática de la Universidad Complutense de Madrid expone máquinas desarrolladas en la Complutenes entre los años 1950 y...
Informática en Ensidesa: los orígenes de la informática en España, que nos hizo llegar muy amablemente Fernando, su autor, es una detallada historia del jurásico de la informática en España, de los tiempos en los que de hecho ni siquiera existía...
Empezando por el primero que utilizó la metáfora del escritorio de trabajo, el Xerox 8010 Star (1981) Y muchos de los que vinieron después recopilados en Operating System Interface Design Between 1981-2009 (vía Digg). Uno de mis favoritos de todos los tiempos...
Por Nacho Palou -
21 ABR 2009
Intel 8086 y Core i7 A Brief History of CPUs: 31 Awesome Years of x86 es un repaso a la evolución de los procesadores de la familia Intel x86, clónicos y derivados, que hoy en día están en la inmensa mayoría de...
ScreenCastle (requiere Java) es una aplicación que permite graba screencasts directamente desde el navegador y guardarlas online. Un screencast es un vídeo en el que quedan registrados la pantalla del ordenador, y opcionalmente audio, con los movimientos del ratón y las acciones...
Por Nacho Palou -
14 ABR 2009
Estaba empezando a leer Zero, un libro de Charles Seife sobre el número cero, cuando me encontré con la curiosa historia geek de este buque de guerra, el USS Yorktown (CG-48). Puesto en funcionamiento a principio de los 80, contaba con...
¡Tiembla procrastinación! SelfControl es una aplicación (OS X) que bloquea el acceso a sitios de Internet durante un tiempo determinado, lo que puede ayudar a concentrarse en el trabajo, “eso que se hace cuando no se está distraído con Internet”. Por...
Por Nacho Palou -
7 ABR 2009
La sección myMoleskine, de la página web del fabricante de las Moleskine, permite crear hojas para encartar en las míticas libretas. Hay tres herramientas según el tipo de hoja que se quiere producir: contenido de texto y/o fotos, plantillas para contactos...
Por Nacho Palou -
1 ABR 2009
No le había prestado demasiada atención a la historia del cracker detenido ayer en Jerez de la Frontera más allá del detalle curioso de que por lo visto se dedicaba especialmente a fisgonear e las vidas digitales de personas famosas y a...
Cuando a Tomás Pollak le robaron su portátil estuvo durante algún tiempo pendiente de intentar cazarlo conectado a Internet aprovechando que algunos de los sitios a los que se conectaba el navegador instalado por defecto eran de su propiedad, por lo que...
Esta página salió en la edición del domingo pasado de La Voz de Galicia, diario en el que nos han fichado como colaboradores para publicar una página sobre tecnología, ordenadores, Internet y esas cosas en la sección de Sociedad. Internet en todos...
Todos los días nos encontramos noticias sobre las nuevas tecnologías en los medios de comunicación que las culpan de todos los males del mundo -y alguno más- cuando muchos sabemos que Internet, los teléfonos móviles, los videojuegos, y ni tan siquiera la...
Este era el aspecto de un «ordenador portátil» de 1982: la pantalla era de una sola línea de unos pocos caracteres, como las calculadoras. El chisme podía contectarse a un teléfono mediante un acoplador acústico con ventosas, algo un tanto aparatoso....
The Ctrl+Alt+Del Tool: Se ve que algún usuario de Windows no pudo resistir más el pasarse el día haciendo el saludo de los tres dedos ;-) (Vía Gizmodo.)...
Aún en esta época de agendas digitales y teléfonos ultrasofisticados -o quizás precisamente por eso- las Moleskine siguen teniendo un encanto que hace que se sigan vendiendo a montones, y ahora puedes tenerlas en tu ordenador en un par de colecciones distintas:...

Esto es un auténtico modding con estilo: un MacBook en el que una manipulación a fondo del equipo permite convertir la manzanita transparente en una segunda pantalla LCD en la que mostrar diversas cosas: un salvapantallas, la webcam o el visualizador...
Una de las áreas en las que la técnica va muy por detrás de los deseos y aspiraciones de los usuarios es la de las baterías, pues a pesar de los avances que ha habido seguimos encontrándonos con que estas tardan un...
Interesante a la par que entrañable esta recopilación de interfaces: Operating System Interface Design Between 1981-2009. Aunque la primera interfaz gráfica moderna fue la del Xerox Alto (1973) el artículo abarca todas las décadas posteriores con bastante detalle e imágenes. Además...
Lo de arriba es The Cactus Dome, el sarcófago de hormigón abovedado construido entre 1977 y 1980 en la isla de Runit, en las Islas Marshall (ver en Google Maps). Tiene 107 metros de diámetro y contiene cerca de 85.000 metros...
Por Nacho Palou -
11 MAR 2009
Calculadora Iskra 12 con tubos nixie Sergei Frolov mantiene en Soviet Calculators Collection un museo en línea en el que recoge (por ahora) 157 modelos de calculadoras soviéticas, desde antiguos modelos mecánicos a manivela a las electrónicas, pasando por modelos electromecánicos de...
Hace algún tiempo Enrique Dans escribía en Los hombres tranquilos acerca de una entrevista que Fortune le hacía a Bill Watkins, en aquel momento CEO de Seagate Technology, uno de los principales fabricantes de discos duros, en la que el señor Watkins...
Estos días anda haciendo las rondas de blogs y demás medios digitales un vídeo de Microsoft en el que se ve cómo conciben la informática en 2019 (creo que el primer sitio en el que lo vi fue en La Brújula Verde):...
Piet es un lenguaje de programación inventado por David Morgan-Mar, ligeramente viejuno pero altamente curioso. Su nombre es un homenaje al neoplasticista Piet Mondrian porque los resultados que produce tienen cierta belleza matemática que se asemeja a los cuadros del artista holandés....
Esta página salió en la edición del domingo pasado de La Voz de Galicia, diario en el que nos han fichado como colaboradores para publicar una página sobre tecnología, ordenadores, Internet y esas cosas en la sección de Sociedad. El peligro de...
Como sabiamente rescató J-Walk… … en 1986 podías dominar el mundo si tenías el módem adecuado. Este momento retro viene porque se encontró por ahí con un ejemplar de PC Plus de 1986, donde las grandes novedades eran las tarjetas gráficas...
Hoy mismo arranca en el Campus de Reina Mercedes de la Universidad de Sevilla Imaginática 2009, unas jornadas de libre asistencia para universitarios, institutos y ciudadanos en general que durante toda la semana, y bajo el lema «Bienvenidos a la Informática del...
Why is the DOS path character «\»? es un breve relato en primera persona de Larry Osterman, veterano programador de Microsoft, sobre por qué decidieron utilizar la barra invertida \ como separador de directorios en vez de / allá por los tiempos...
ANIM 01 [codeco] por Esferobite-DSK [2 min]. Los chicos de Esferobite-DSK vuelven a la carga con su transposición de lo digital a lo analógico en este simpático vídeo que recrea los juegos de 8 bits a los que muchos hemos jugado, pero...
Welcome to Macintosh. Un documental de Robert Baca y Josh Rizzo (2008). Siempre entrañable como casi cualquier pasaje de la historia antigua de Apple Computer, este documental es una recopilación enlazada de entrevistas con algunos protagonistas de la época y otros...
Apple ha publicado una versión beta de su navegador Safari 4 (Mac, PC), con motor Nitro. Según Apple es más de 4 veces más rápido ejecutando JavaScript que su antecesor. Algunas características que de entrada resultan interesantes: Top Sites: muestra en...
Por Nacho Palou -
25 FEB 2009

Los clientes de Apple son los más felices con sus ordenadores dice una encuesta que han hecho....
Colección de camisetas RetroGames de Imprenta Digital Plus Ideales para los que tenemos ya una edad y recordamos con cariño los tiempos de los 8 bits (escasos) mientras tarareamos Hey Hey 16K. (Gracias por la pista Gominitas.) Camisetas de fantasmas Pac-Man, que...
Representación en fromato Google Earth (visible en el programa o vía web con el plug-in) del choque entre satélites artificiales que sucedió el martes de la semana pasada a unos 780 kilómetros de altura sobre Siberia, y en el cual resultaron...
Por Nacho Palou -
16 FEB 2009
KEEP son las siglas en inglés de Keeping Emulation Environments Portable, un proyecto europeo dotado con unos cuatro millones de euros, que busca crear el «emulador universal», un desarrollo que sea capaz de abrir y reproducir formatos de archivo obsoletos y otros...
Por Nacho Palou -
16 FEB 2009
Esta página salió en la edición del domingo pasado de La Voz de Galicia, diario en el que nos han fichado como colaboradores para publicar una página sobre tecnología, ordenadores, Internet y esas cosas en la sección de Sociedad. Datos a buen...
Desde Cyberhades nos recomendaron Tech Titans Building Boom de la prestigiosa IEEE Spectrum donde se cuentan los esfuerzos de gigantescas compañías como Amazon, Google, Microsoft y Yahoo para construir gigantescos datacenters. Estos enormes centros son calificados como la encarnación de la...
Dice Cory de Boing Boing que siempre soñó con escribir este titular, Slashdot slashdots Slashdot: allí se cuenta cómo el popular sitio de noticias para geeks se «tumbó» a sí mismo el otro día y estuvo más de una hora caído debido...
En Tu Experto cuentan que Windows 7 tendrá cinco versiones diferentes las cuales se antojan demasiadas, dado que la confusión que generan entre quienes van a comprarlo fue precisamente una de las críticas que se hizo de Windows Vista. Por el lado...
«Marte tiene dos lunas, el doble de las que tiene tu planeta.» WTF? Google Mars, que va incluido como parte del nuevo Google Earth 5, permite chatear con un marciano de nombre Meliza. Meliza está empeñado en que Marte es más guay...
Por Nacho Palou -
4 FEB 2009
Esta página salió en la edición del domingo pasado de La Voz de Galicia, diario en el que nos han fichado como colaboradores para publicar una página sobre tecnología, ordenadores, Internet y esas cosas en la sección de Sociedad. La gripe de...
(Vía Look At This...) ¡Hay que ver lo que nos gustas los generadores de cosas en general!...
Por Nacho Palou -
1 FEB 2009
Dos desarrollos interesantes para Google Earth en HeyWhatsThat, vía Google Earth Blog. Eclipses – animaciones de los eclipses de sol del pasado 26 de enero y del próximo 21 de julio, que será total y visible desde el Pacífico Sur. La...
Por Nacho Palou -
29 ENE 2009
«Bienvenido al ahora»: Plug into now. Los distintos gráficos contienen o informan sobre eventos que están sucediendo y representan la contabilidad a nivel mundial de consumo y producción de bienes (coches, casa, huevos, vasos de papel...) en base a datos estadísticos a...
Por Nacho Palou -
26 ENE 2009
Tal día como hoy en 1984 Apple presentaba el Macintosh al mundo después de aquel famoso anuncio que decía que la empresa iba a enseñarnos enseñarnos por qué 1984 no iba a ser como 1984 y demostrando fehacientemente desde entonces que...
La pelea de siempre, en formato de corto de alta resolución y con unos fenomenales efectos especiales. Merece la pena verlo en alta resolución, pero también está en un más accesible y rápido formato YouTube. (Vía TickleBooth.)...
Por Nacho Palou -
24 ENE 2009
Este artículo ha sido también publicado originalmente, en versión ligeramente resumida, en la sección de Ciencia y Tecnología de Público, bajo el título Windows 7: un buen comienzo.Nos echó una mano con las pruebas técnicas nuestro amigo Carlos.- por Carlos Chenel,...
Un momento de nostalgia informática en plan recortable para cortar y montar mientras escuchas Hey Hey 16K: Foldskool Heroes Series 3 por Marshall Alexander (Los vio Santiago en MacKinando.) Juegos «Game & Watch» para iPod Touch e iPhone, recordando consolas retro. Juegos...
Haciendo bueno aquello de que una imagen vale más que mil palabras llega… La guerra de los navegadores (2002-2008), una infografía muy explícita creada por BovingdonBug de Pixel Labs, donde el ancho de las banderas en la zona de 2008 indica...
Esta es una pequeña pieza de opinión que me pidió La Voz de Galicia sobre el que Steve Jobs haya anunciado que deja la empresa en manos de Tim Cook al menos hasta el verano. Salió en la página 28 junto con...
15.30 - Enfilando el rio Hudson buscando el amaraje para minimizar el impacto. Con los datos de la posición del vuelo 1549 que ayer por la noche (hora española) terminó con el Airbus flotando en el rio Hudson, en Nueva York, Google...
Por Nacho Palou -
16 ENE 2009
El próximo 28 de enero tendrá lugar el Adobe CS4 Tour en Madrid como seminario de presentación y con motivo del lanzamiento de la nueva versión de Creative Suite. En Barcelona la presentación tendrá lugar dentro de la feria Graphispag Digital 2009...
Por Nacho Palou -
15 ENE 2009
Esta página salió en la edición del domingo pasado de La Voz de Galicia, diario en el que nos han fichado como colaboradores para publicar una página sobre tecnología, ordenadores, Internet y esas cosas en la sección de Sociedad. Los programas de...
Esta página salió en la edición del lunes pasado de La Voz de Galicia, diario en el que nos han fichado como colaboradores para publicar una página sobre tecnología, ordenadores, Internet y esas cosas en la sección de Sociedad. Tecnología para el...

Flipping Typical es una página web en la que puedes teclear cualquier texto y comprobar cómo se vería en todas las tipografías que tengas instaladas en tu ordenador, interesante y útil a la vez. Apropiadamente, este microservicio tiene un WTF en...
Living Room 2 No conocía hasta ahora los trabajos hechos con SunFlow, un sistema de renderizado para crear imágenes con calidad fotográfica, algunas de las cuales son difíciles de distinguir de la realidad. En la web del proyecto hay una galería de...
Google ha actualizado las imágenes 3-D de todo Nueva York en Google Earth con edificios tridimensionales a los que se aplican texturas foto-realistas para lograr un efecto casi de fotografía. Para apreciar la calidad de las imágenes basta arrancar el programa,...
Ya existe versión para Mac del plugin de Google Earth –disponible para Windows desde hace unos meses. Esta extensión (para Safari 3.1+ y Firefox 3.0+ sobre OS X en PowrPC o Intel; Firefox e Internet Explorer 6 y 7 para Windows) permite...
Por Nacho Palou -
10 DIC 2008
Esta página salió en la edición del domingo pasado de La Voz de Galicia, diario en el que nos han fichado como colaboradores para publicar una página sobre tecnología, ordenadores, Internet y esas cosas en la sección de Sociedad. La madre de...
Igor Ostrovsky es un desarrollador de Microsoft que trabaja en computación en paralelo; escribió una interesante anotación titulada Numbers that cannot be computed donde describe un fenómeno curioso, los números que no son computables. El asunto dista de ser trivial, pero allí...
En la portada de Artificial Intelligence: A Modern Approach aparecen un montón de curiosos elementos, entre ellos… el propio libro, del que se ve la portada. Son geniales todos los detalles de los otros elementos de la composición, que van desde...
Me encontré con un buen grupo de siervos de Bill cuyas vicencias técnicas están agrupadas en Geeks.ms, de tagline «Todo lo que los geeks de Windows y .Net tienen que contar». Es una comunidad bastante completa con su planet de blogs, los...
La mayor potencia de supercomputación se concentra en los Estados Unidos; después están Francia, Alemania y Japón. El gráfico muestra el número de superordenadores y el tamaño de los círculos su potencia en teraflops. Es una infografía original del New York...
Este concepto de ordenador llamado SGI Molecule, tal y como cuenta Wired, es una idea de Silicon Graphics sobre cómo meter 10.000 núcleos en una CPU de tamaño personal. Es capaz de ejecutar 40 veces más hilos de ejecución que un...
Tal y como cuentan en Alley Insider, la clásica revista informática PC Magazine americana, con la que tantas cosas sobre ordenadores aprendimos (comenzó a publicarse en 1982), dejará de editarse en papel a partir del próximo mes de enero. Aunque la...
Definitivamente, este tipo de icono para la opción ‘Guardar...’ es el único disco de 3,5 pulgadas que veo desde hace como diez años –Apple dejó de utilizar la disquetera con los G3 “pitufo” en 1999. When Will the Floppy Disk Die as...
Por Nacho Palou -
19 NOV 2008
Dentro del Proceso de Bolonia, del que España forma parte, y que pretende unificar las titulaciones universitarias en los países miembros de la Unión Europea, uno de los pasos es el de regular qué competencias ha de tener cada carrera en sus...
Esta imagen que nada tiene de fake y que bien podría haber entrado en los anales de los WTF se queda en mera curiosidad histórica: data de 1981 y es una foto más entre los diez millones de imágenes de la...
Aunque Adobe alguna vez ha afirmado que habría una versión de Flash para el iPhone “algún día”, el artículo Why Apple Won't Allow Adobe Flash on iPhone de GadgetLab explica los motivos por los que es mejor irse olvidando de que eso...
Por Nacho Palou -
18 NOV 2008
Explicados con esquemas, como para niños de cuatro años (niños que sepan algo de inglés): Things Caches Do. Con los impertérritos y siempre dispuestos Alice y Bob como protagonistas. (Además he aprendido que se dice el caché web y no la...
¡Islandia funciona sobre Mac OS X! (CC) coggodblog en Flickr Cult of Mac escribió sobre un avistamiento del símbolo Comando en una carretera de Islandia. Podría haber sido (o es) un excelente WTF, pero la regla #1 de los WTFs dice que...
Hard drive sounds, colección de sonidos producidos por discos duros que tienen algún tipo de problema o que simplemente no lo van a conseguir; si tu disco duro suena de algún modo parecido a estos, mejor haz una copia de seguridad cuanto...
Por Nacho Palou -
12 NOV 2008
Esta página salió en la edición del domingo pasado de La Voz de Galicia, diario en el que nos han fichado como colaboradores para publicar una página sobre tecnología, ordenadores, Internet y esas cosas en la sección de Sociedad. La conquista de...
Con tan amenazador aspecto, ha de ser descagarda de inmediato: Magic Number Machine, sólo para Mac OS X. Quien use Windows habrá de esperar a la Calculadora de Windows 7 para poder saborear algo con 25 dígitos de precisión y tantos...
Mi amigo Antonio, después de usar durante años una conexión a Internet gratis de aquellas de Terra vía módem, decidió que ya era hora de incorporarse al siglo XXI y poner una conexión de banda ancha en su casa, en especial para...
The Sheep Market fue un experimento llevado a cabo por Aaron Koblin en 2006, con resultados medio artísticos medio del mundo de la computación distribuida (o algo así). La prueba consistió en ofrecer dos centavos de dólar a cada persona que le...
Adobe Photoshop CS4: As real as it gets en Getting real software interface Después de seguir el camino inverso Tweet de Francisco > Su web > Maestro Alberto > digital inspiration > John Nack, quien a su vez o recibió de Lori...
Encyclopedia es un lector offline de la Wikipedia para iPhone y iPod Touch, que por el precio de 6 euros me parece una de las mejores aplicaciones posibles para instalar en el pequeño gadget y multiplicar su utilidad. No sólo permite...
Commodore BASIC para Mac OS X, Linux y Windows, una versión para ordenadores modernos de ese lenguaje que tantas mentes dañó (¡así nos hemos quedado!) que se puede ejecutar directamente desde la consola para recordar viejos tiempos. (Vía Lifehacker.) JJSpeecy, un...
Cuando son los propios usuarios los que tienen que reconstruir a base de pegatinas, letreros y flechas, la lamentable interfaz de un cajero automático de un párking, es señal de que alguien no hizo demasiado bien su trabajo. En UseLog (¡gran...
Se ha puesto de moda denigrar los ordenadores del pasado con frases como «volamos a la Luna con menos potencia de cálculo de la que tengo en mi reloj» o «¿puedes creer que todo el programa Apolo cabía en solo 36K de...
Hoy es el 25º aniversario de Microsoft Word… ¿Felicidades?– JamalDols en Twitter(Aunque en realidad Word fue publicado el 25 de octubre de 1983, el «conceto» del mensaje es lo que importa.)...
Interactive map of Linux kernel, una mapa detallado de «cómo funciona Linux por dentro», ideal para quienes están aprendiendo. Se puede navegar con el ratón (rueda = zoom) o mediante los controles de la ventana; los diferentes detalles están convenientemente hiperenlazados....
Esta mañana casi todos los diarios recogían la noticia de la condena a R.A.G. por haber escrito un crack que permitía saltarse la protección anti copia del programa Presto y así poder copiarlo y usarlo sin pagarlo y por distribuir este crack...
Esta es la cuarta página que publicamos en La Voz de Galicia, diario en el que hemos sido amablemente invitados a publicar una página sobre tecnología, ordenadores, Internet y esas cosas en la sección de Sociedad todos los domingos. Vista, el gran...
3M MPro 110 | El microproyector de bolsillo de 3M tiene un tamaño similar al de un mando a distancia mediano, cabe en la palma de la mano y pesa apenas 150 gramos. Utiliza tecnología de iluminación LED en lugar de...
Por Nacho Palou -
22 OCT 2008
FullScreen Plasma, uno de los diversos, bellos y visualmente potentes experimentos con JavaScript de Thiemo Mättig, que muestran hasta dónde se puede llegar con este lenguaje de programación....
Cuando J. Presper Eckert y John Mauchly, los diseñadores del ENIAC, decidieron abandonar la Universidad de Pennsylvania para fundar su propia empresa dedicada a construir y vender ordenadores su primera venta, que también fue la primera venta de un ordenador comercial de...
Panorámica interactiva geoposicionada en Google Maps realizada por Iñaki Rezola desde el Cerro de Santa Catalina, en Gijón. 360 Cities geoposiciona imágenes panorámicas interactivas con 360 grados de visión que puede verse directamente desde Google Earth y Google Maps. Panorámicas en la...
Por Nacho Palou -
15 OCT 2008
Teníamos programada esta reflexión twittera de Antonio Delgado como frase del día del próximo 10 de noviembre, cuando tendría que haberse inaugurado el SIMO: El SIMO de este año va a tener menos gente que un Blogs & Beers en Madrid. Pero...
Logstalgia (a.k.a. ApachePong) es un software para visualizar el fichero de logs que registra loas peticiones de los visitantes al servidor web como si fuera Pong, el más retro de los juegos retros, considerado como el primer «videojuego moderno» de la...
Hacerse pasar por humano se considera la prueba última de la inteligencia artificial para una computadora, de modo que seis programas van a intentar de nuevo superar el resto, más conocido como Test de Turing a partir del próximo domingo, en la...
Estos días he tenido que «reanimar» el MacBook de una amiga que se quedó lelo durante una copia de archivos entre un iPod, un pincho USB y su disco duro interno y luego se negaba a arrancar, y también tuve que recuperar...
Hemos sido amablemente invitados a publicar una página sobre tecnología en la sección de Sociedad de La Voz de Galicia todos los domingos. Esta es la segunda. La lenta carrera de la banda ancha,La Voz de Galicia 5 de octubre de 2008....
Por fin un verdadero avance en el mundo de las pantallas: un híbrido de pantalla con… otra mini-pantalla incorporada. El monitor principal LCD tiene 22" y su pequeño satélite, que puede ubicarse en diversas posiciones, 7". La idea es que en...
Arte visual a partir de la matemática intrínseca de la música, creada por Glenn Marshall con Processing, un lenguaje de programación open source que suelen emplear los artistas que trabajan con imágenes, animación y entornos interactivos especialmente visuales. (~~ FlowingData ~~)...
Ojo, esta anotación es extremadamente peligrosa para la productividad. Juegos Flash por XKCD [Original en inglés] Randall Munroe tiene toda la razón del mundo con esto… Y por si lo dudas: Juego flash: Boomshine Reflections Bloons: un juego fácil y divertido, el...
Es toda una suerte que BlogOff esté nuevamente de vuelta en la blogosfera; es un muy interesante y divulgativo blog sobre informática, que tuvo un parón temporal pero que renace con fuerza, con un toque de profesionalización. Entre las novedades hay un...
Martín Varsavsky ha anunciado que el próximo lunes, 13 de octubre se celebrará la II edición del Facebook Developer’s Garage en Madrid, una jornada para desarrolladores que contará con la presencia estelar de Mark Zuckerberg, fundador de Facebook. En Flickr hay fotos...
Desde el pasado domingo hemos empezado a publicar una página sobre tecnología en la sección de Sociedad de La Voz de Galicia que iremos publicando también en Microsiervos unos días después de que salgan en La Voz. Esta es la primera de...
Pandora es un proyecto desarrollado por varios hackers y la comunidad GP32X: un híbrido entre ordenador y consola portátil, completamente open-source que entre otras cosas incorpora conexiones inalámbricas Wi-Fi y Bluetooth. Entre sus características se incluyen dos ranuras para memoria de...
Sorting Algorithm Animations muestra visualmente cómo funciona diversos algoritmos de ordenación de datos. Al pulsar en los iconos verdes, se ponen en marcha. Cada algoritmo se prueba con un conjunto de datos aleatorio, otro que está poco desordenado, otro inverso y...
En plena crisis con muchos de los bancos más importantes del mundo en quiebra y los inversores sin saber qué hacer, el momento WTF del día fue un bug ocurrente en alguno de los sistemas de la bolsa que mandó las acciones...

Estoy indagando desde hace tiempo sobre el origami, el arte japonés de la papiroflexia, a raiz de una apasionante presentación de Robert Lang en TED, que me dejó totalmente impactado por los avances en «origamis modernos» que allí explicó que ha...
net.unix-wizardsFecha: 27 Sept, 1983, 7:35 pmVoy a escribir un sistema de software compatible Unix que llamaré GNU (GNU’s Not Unix: «GNU no es Unix») para ofrecerlo de forma libre a cualquiera que quiera usarlo. Cualquier contribución en forma de dinero, programas y...
Oracle nos ha invitado a visitar el Oracle OpenWorld 2008, su conferencia anual de usuarios y desarrolladores, en la que las cifras son sorprendentes: Han sido necesarias 45.000 horas de trabajo para prepararla. Hay 3.639 personas de la organización encargándose de que...

Visualmente es un encanto, y parece que en eso se quedó: en siluetear el aspecto de 64 formatos de almacenamiento de datos que no lo consiguieron, incluyendo el Minidisc, los disquetes, las cintas de audio magnéticas, el Jaz de IOmega, el...
Port Knowledgebase es una completa lista de los puertos TCP y UDP más comunes que se suelen verse en Internet. Entre los más conocidos están los típicos 80, 23, 21 y 25 (HTTP/Web, Telnet, FTP y correo) pero la lista completa va...
Ignasi de PS3GRID-GPUGRID nos escribió para contarnos que están reclutando voluntarios para unirse a su red de computación distribuida. Esta red tiene la particularidad de que utiliza la potencia «sobrante» de las consolas PlayStation3 de Sony y de las tarjetas gráficas Nvidia...
Learn Experiment es un experimento de aprendizaje que Jaime ha montado en su sitio web y que invita a probar a quien esté interesado en el e-learning. Consiste en aprender la equivalencia entre caracteres japoneses kanji y castellano, como si fuera...
Estuve probando Xtorrent que es un cliente P2P para Mac bastante interesante, realmente bonito en cuanto a interfaz y aparentemente bastante rápido y eficieente. Destacaría todo esto: Lo mejor El diseño e interfaz estilo iTunes, muy «Mac» lo hacen fácil de utilizar...
My Documents Laptop Sleeve es una ingeniosa funda de neopreno para llevar el portátil. A la venta en una de nuestras tiendas favorita, ThinGeek, por unos 30 dólares. Incluye un pin con la forma del cursor –aunque aparentemente lo que no...
Por Nacho Palou -
6 SEP 2008

Este artículo ha sido también publicado originalmente, con ligeras modificaciones, en la sección de Ciencia y Tecnología de Público, bajo el título «Chrome: sencillez y compatibilidad frente a años de experiencia». Con la llegada de Chrome el usuario final tiene una...
Google Chrome es el nuevo navegador web de Google, que ya se puede descargar para probar, de momento sólo en versión beta para Windows, y en castellano (próximamente también para Mac y Linux). Se descarga e instala muy fácilmente y su principal...
Esta preciosa creación llamada Blue Cells es una interpretación en Flash del basada en los célebres autómatas celulares del Juego de la Vida de Conway. Ha sido creado por Grant Robinson, quien también tiene otra versión más colorida llamada Heatmap. Las...
El equipo de 3M nos invitó amablemente a que probáramos uno de sus filtros de privacidad para portátiles y monitores LCD. Consiste en una lámina de plástico ligeramente oscurecida, que únicamente se muestra trasparente (más bien traslucido) cuando se mira totalmente...
Por Nacho Palou -
1 SEP 2008
Los números aleatorios generados por ordenador utilizando las funciones habituales de los diversos lenguajes de programación son en realidad pseudo-aleatorios. Más o menos se conoce cuales de estas funciones son mejores, peores o cuales fallan a veces. En la práctica se usan...
Rescuetime es una aplicación que hace un seguimiento detallado de a qué se dedica el tiempo con el ordenador, con el objetivo de generar informes y así «optimizar el tiempo» en cosas más útiles que procrastinar, ir saltando de web en web...
Un par de largos e interesantísimos artículos a modo de «biografía corporativa» de Atari en Gamasutra, escritos por el historiador de los videojuegos Steve Fulton: Atari: The Golden Years – A History, 1978-1981 The History of Atari: 1971-1977 ( Vía /|\...
Pensé que había perdido un montón de mensajes de correo por un cambio que hice de POP3 a IMAP en mi buzón habitual de correo, pero resulta que, gracias a Jobs, no. En Apple Mail me aparecían algunas carpetas (buzones) «aparentemente vacías»...

Interesante esta charla de Kevin Kelly, visionario y fundador de Wired, en TED: Predicting the next 5,000 days of the web [inglés, 20 min.] sobre el futuro de la Web, donde abunda en algunas de las ideas que ha desarrollado en...
La cultura geek, en el diario La Vanguardia: Unos dirán que el geek más célebre es Bill Gates y otros sostendrán que se trata de una contracultura surgida en la universidad (…) Si los hippis querían volver a la naturaleza y los...
Al cierre de la bolsa a día de ayer, Apple superó en valor a Google (en cuanto a capitalización bursátil se refiere, que es lo que suele utilizarse para comparar esto). O más bien habría que decir «vuelve a valer más...
Agentes de Sébastien Chevrel, o cómo ver emerger comportamientos complejos surgidos de las interacciones entre agentes que siguen unas reglas muy simples....
Fernando Acero explica en un artículo publicado por Kriptópolis el n-éstimo problema de seguridad de Windows Vista, que parece ser especialmente relevante y con profundas implicaciones: ¿La puntilla para Vista?. Hay más detalles en inglés en la historia de SearchSecurity.com Windows Vista...
Se pueden construir puertas lógicas que apliquen el algebra booleana con casi cualquier cosa capaz de funcionar en plan binaro;. En su página personal Neil Fraser muestra Domino Logic, construcciones de las puertas OR, AND y XOR con piezas de dominó,...
Brillante hackeo con JavaScript y CSS, bien explicado en anieto2k: Cómo detectar el sexo de tus visitantes con su historial de navegación. El código original se llama SocialHistory.js y se basa en un hackeo tremendamente ingenioso: utilizando técnicas de programación en JavaScript...

Este vídeo es tan acojonante que ha dejado flipados hasta a los expertos en estas cosas, tan futurista e increíble que ni siquiera Jack Bauer soñaría con tener algo parecido en la séptima temporada de 24: Video Earth (Google Earth +...
Extensa colección que recopila decenas de tutoriales, técnicas y trucos para trabajar Illustrator en Vector Illustration: 60+ Illustrator Tutorials, Tips and Best Practices....
Por Nacho Palou -
24 JUL 2008
Preguntándose qué hay de cierto o de leyenda en el dicho aquel de que una imagen vale más que mil palabras, José Muelas decidió darle una vuelta: partió de ciertas premisas y de las bases de la Teoría de la Información de...
Esta mañana estuvimos en la presentación de Blinko, una nueva red social pensada especialmente para móviles que por ahora está en beta cerrada, en la que pudimos escuchar una charla de David Weinberger, uno de los autores de The Cluetrain Manifesto, sobre...
Decidir cual fue el primer ordenador del mundo es algo un poco más complicado de lo que podría parecer a primera vista, ya que como comentábamos ya hace algún tiempo todo depende en realidad de cómo definas ordenador. Así, la respuesta podría...

Detalle de un depósito de gas en el puerto de Barcelona. A la derecha con las nuevas imágenes. Buenas noticias: algunas de las principales ciudades del litoral catalán, y toda la línea de costa entre Barcelona y Palamós, han recibido una actualización...
Por Nacho Palou -
14 JUL 2008
7 funcionalidades ocultas de Firefox 3, o al menos tal vez algunas de ellas son desconocidas por muchos. Aunque precisamente el truco de duplicar una pestaña con todo su historial de navegación, que no conocía y puede ser interesante, de momento no...
Por Nacho Palou -
12 JUL 2008
Seguramente harto de oir una y otra vez la historia / medio-leyenda de que el logotipo de Firefox aunque parece un zorro es un panda rojo, y dado que en inglés firefox puede aplicarse a ambos bichos, el biólogo Copépodo realizó...
Me ha hecho gracia encontar este conjunto de tipos de letra porque hace ya unos cuantos años el tipo de letra GoodDog Cool me parecía bastante simpática –pero con el tiempo le había perdido la pista. Más en Freeware fonts en...
Por Nacho Palou -
8 JUL 2008
Mini vMac DS corriendo el Sistema 6; foto de Synaesthesia Mini vMac DS R3 es un emulador de Macintosh que puede ejecutar el Sistema 6 de los viejos Macintosh de Apple en una tarjeta DS Flash en la consola Nintendo DS. Descubrieron...
En realidad no había ningún récord que batir porque nunca antes se había contabilizado de forma oficial, pero según certifican desde Guinness World Records Firefox 3 ha conseguido 8.002.530 descargas entre las 18:16 UTC del 17 de junio de 2008 y las...
La vida se parece cada vez más a Minority Report: UbiqWindow es la empresa japonesa creadora de la tecnología, que proyecta imágenes del ordenador en mitad de la habitación y permite interactuar con ellas. La verdad es que con Google Earth...
En apenas cinco días dos cambios importantes en Microsoft, la retirada del mercado de Windows XP hoy mismo y la retirada del día a día de la empresa de su cofundador Bill Gates el pasado viernes: Microsoft deja de distribuir el sistema...
Reciclando informática retro de esta que está obsoleta hasta para los currantes del ramo: cómo hacer un portalápices con disquetes de 3 1/2", rescatado del siempre recomendable Instructables.com. (Vía LifeHacker.)...
El poder de los GIF animados, aplicado a la explicación que da la Wikipedia del Efecto 2038 a.k.a. «problema del 2038». Es algo parecido al Problema del año 2000 que ya tuvimos la suerte de vivir y sobrevivir. Tiene que ver...
10 Free MS Word Alternatives You Can Use Today recopila una decena de programas para edición de textos compatibles con el formato .doc de Microsoft Word. La selección incluye programas para instalar en el ordenador (como OpenOffice o Neo Office) o que...
Por Nacho Palou -
25 JUN 2008
Los Apollo están disponibles en 160, 250, y 320 GB de capacidad. La familia Apollo de Imation son discos duros portátiles de alta capacidad. Destaca sobre todo por su ligereza (apenas 160 gramos) y buen aspecto. Transmite la sensación de aguantar bien...
Por Nacho Palou -
25 JUN 2008
¡Venimos a visitaros en son de paz y con buena voluntad! Un robot no debe dañar a un ser humano o, por su inacción, dejar que un ser humano sufra daño.Los robots han visto cosas que vosotros no creeríais.Los robots son sus...
Por Nacho Palou -
19 JUN 2008
Por aquí no usamos mucho Windows Vista, pero nos apiadamos de quienes tengan que hacerlo. Aun así, creemos que es de justicia mencionar esta recopilación orientada a sus sufridos usuarios, titulada: 10 trucos para hacer Windows Vista más rápido que es una...
Ya está disponible para descarga Skype 4 beta para Windows, la nueva versión del popular software de comunicaciones a través de Internet. En esta versión dicen que se han concentrado en mejorar las videollamadas, que funcionan a pantalla completa, y la...

Aspecto de los servidores de Archive.org en 2007 – Foto (CC) MysteryBee O’Reilly publica una extensa entrevista con el responsable de tecnología de Archive.org, uno de los proyectos más apasionantes de todo la Internet y su «repositorio histórico» de facto. Se titula...
Vástago del matrimonio formado por un lector de tarjetas tipo “731 en 1” y del lector USB de discos duros internos: lector de discos duros internos y tarjetas CompactFlash vía USB 2.0. Portátil, ligero y por apenas 15 euros. (Vía Engadget.)...
Por Nacho Palou -
18 JUN 2008
Hoy a partir de las 19:00, hora de España (GMT +2), estará disponible para su descarga la versión definitiva de Firefox 3 y la Fundación Mozilla se ha planteado celebrarlo estableciendo un récord de descargas en 24 horas tal y como cuentan...
$ # % {} * [] ~ & <> Vi pasar por Coding Horror las diversas y exóticas formas con que se conocen en inglés a todos los signos especiales que suelen usar los programadores, que aunque son signos ortográficos convencionales, los...
Toochr es una idea tan sencilla como elegante: un directorio web «editado por humanos» de sitios, servicios web optimizados y aplicaicones para iPhone y iPod Touch. Basta con comenzar a navegar por www.toochr.com desde la pantalla del iPod Touch/iPhone para descubrir...
Todavía no he terminado de verlo, así que haré la reseña completa cuando lo haya hecho, pero por lo que he visto hasta ahora el documental The machine that changed the world de WGBH Boston y BBC TV es tan bueno como...
Ahora que los ordenadores ya vienen en su inmensa mayoría sin disketera a menos que la pidas expresamente, y eso suponiendo que exista la opción, este vídeo viene a reivindicar la utilidad de estos cuasi olvidados dispositivos....
Emerging Applications of P2P Technologies es un Wiki donde se puede participar incluyendo en las diversas categorías ejemplos y explicaciones de usos legítimos de las tecnologías P2P. En la lista hay todas esas cosas y alguna más: Distribución de películas de alquiler...
Una de nuestras películas favoritas de todos los tiempos, la mítica Juegos de Guerra, está de aniversario y cumple 25 años estos días. Lo mencionan Slashdot y Barrapunto: WarGames and the Great Hacking Scare of 1983 «Juegos de guerra» cumple 25...
En una de las últimas actualizaciones de imágenes en Google Earth se han incluido imágenes recientes de Birmaia / Myanmar, país que recientemente fue asolado por el ciclón Nargis. De modo que aparte de las imágenes tomadas en su momento por...
Por Nacho Palou -
3 JUN 2008
Todo lo que tiene que ver con la Singularidad Tecnológica es a la vez tan fascinante como controvertido, un caso interesante de «futurología» muy entretenida para los que les guste dejar volar la imaginación respecto a los avances de la técnica,...
En ZDNet han publicado Annoying software: a rogues’ gallery que es una recopilación visual del software de las últimas décadas que resulta irritanemente «molesto» por diversas razones, incluyendo que se intenta autoinstalar, te cambia la configuración del equipo, te insistetodo el rato...
A raíz del comentario que hacía el otro día acerca de cómo ha evolucionado Microsoft Flight Simulator con los años en la anotación sobre el vídeo Aerosoft Grand Madrid Barajas, José Manuel de Sandglass Patrol nos ha pasado un gif animado...
Digsby resultará útiles a quienes sean muy aficionados a chatear y a las redes sociales, cuantas más mejor. Es un programita que se descarga gratis y sirve para agrupar en un solo sitio las cuentas de mensajería de Yahoo, ICQ, AOL/AIM, Google...
Un ordenador ILLIAC II de la Universidad de Illinois (1962) Para amantes de la prehistoria informática, la página de John Kopplin titulada An Illustrated History of Computers (2002) es un estupendo resumen visual en cuatro partes donde pueden verse en plan rápido...
Glosario gráfico: Cursiva — La clave para distinguir una verdadera cursiva de una falsa cursiva es que la letra a minúscula de las cursivas es siempre similar a la que se escribe a mano y nunca tiene el aspecto de gancho...
Por Nacho Palou -
16 MAY 2008
Tom Castro, un lector del blog, nos envió una captura de pantalla de una curiosa formación geográfica visible en las imágenes aéreas de Sigpac (Sistema de Información Geográfica del Ministerio de Agricultura y Pesca, similar a Google Maps), para preguntar si sabíamos...
Por Nacho Palou -
16 MAY 2008
JBL On Stage IIIp para iPod/iPhone. Hace meses pude oir en un par de sitios esta base de altavoces JBL On Stage y me pareció que sonaba muy bien, de modo que aprovechando un viaje y eso de que el dólar...
El que para mi es sin duda el mejor client de BitTorrent para Mac acaba de actualizarse: Transmission 1.2. Funciona sobre Mac OS X 10.4.11 pero recomiendan 10.5; también hay algunas versiones Linux. Los cambios de esta actualización «relevante» incluyen: Soporte...
Meshlium es un nuevo proyecto a modo de red «sensorial» inalámbrica, un tipo de redes mesh, diseñadas para investigación y con fines educativos. Está construido además con hardware y código abiertos. Es obra de Libelium, una empresa spin-off de la Universidad...
Aunque hay un montón de servicios, utilidades y sitios que permiten descargarse los vídeos de YouTube, por no hablar de recatarlos de la caché del navegador, el bookmarklet que se puede instalar en Download YouTube Videos as MP4 Files es lo más...
Estado en el que estaba el disco duro Seagate de 400 MB que iba a bordo del Columbia y cuyos datos ahora han sido recuperados. Fotos NASA. Más de cinco años después del accidente del Transbordador Espacial Columbia, ingenieros de la NASA...
Por Nacho Palou -
8 MAY 2008
Hoy se cumplen 10 años de la presentación del primer iMac, el ordenador que junto con el iPod que llegó tres años más tarde, marcó el resurgir de Apple cuando muchos, incluido Michael Dell, quien luego tuvo que comerse sus palabras, la...
Holden: Está usted en un desierto, caminando por la arena cuando, de repente (…) Mira hacia abajo y ve un galápago que se arrastra… Leon: ¿Un galápago? ¿Qué es eso? Holden: ¿Sabe lo que es una tortuga? Leon: Claro. Holden: Pues lo...
Cory Doctorow, uno de los autores de Boing Boing , dice vivir y morir dentro de su correo electrónico y que tiene almacenados más de un millón de correos electrónicos desde 1991… a pesar de lo cual asegura que su bandeja de...
Hans Reiser es un programador de la comunidad open source, más conocido por ser el autor del Sistema de Archivos Reiser (ReiserFS) que en se utiliza en Linux… Un día, su ex-mujer desapareció en «extrañas circunstancias». Desde 2006 ha estado encarcelado de...
Adobe TV (requiere Flash, en inglés) es un repositorio de vídeos divulgativos, a modo de tutoriales y explicaciones visuales, con los productos de Adobe Creative Suite 3 como protagonistas. Aunque lleva poco tiempo online los contenidos van creciendo cada día —se...
Por Nacho Palou -
21 ABR 2008
Amanece en la Puerta de Alcalá (Madrid).Arriba el nuevo control horario que modifica la iluminación entre día y noche. Ya es posible descargar la versión versión 4.3 beta de Google Earth. No hay grandes cambios respecto a la versión actual (para eso...
Por Nacho Palou -
16 ABR 2008
Las entrañas del coloso, vistas por sí mismo: Google Datacenters. (Vía FayerWayer)...
Mactab de Other Designs Slick Laptop Designs and Concepts es una preciosa recopilación de ordenadores portátiles ultradelgados, a cual más bonito. Algunos son conceptos y otros reales....

Alguien recibió un cheque de Donald Knuth por 10,24 dólares, al haber encontrado cuatro erratas en su mítico libro sobre programación The Art of Computer Programming a.k.a. La Biblia del Programador. La simpática gratificación geek que Knuth ofrece a sus lectores...

Hoy ando por Londres y como buen aerotrastornado intentaré aprovechar unas horas libres que tengo para retratar algunos aviones en el aeropuerto de Heathrow, en especial alguno de los Airbus A380 de Singapore Airlines con los que la aerolínea acaba de...
El ZPC-GX31 de Cybernet es un PC todo-en-uno, que lleva todo lo que es «el ordenador» en el teclado. Es el teclado. En cierto modo los portátiles son algo parecido, y el prehistórico C-64 hasta se le da un aire, asi...
The Internet Will End in 30 Years! anuncia el fin de Internet dentro de 30 años, debido al famoso bug/problema del año 2038 que viene a indicar el fin de los tiempos en Unix y otros sistemas operativos, algo similar pero distinto...
Varias pantallas en el elegante escritorio de Andrew. Parece que sí. Excusa perfecta para salir pitando a la tienda a por una pantalla adicional. El dato proviene de un estudio de la Universidad de Utah: Bigger Computer Monitors = More Productivity –...
Aunque el concepto de versión beta hace años que perdió su significado original, ver que se lanza la versión «alfa» de Firefox 4 cuando a día de hoy sólo se ha llegado hasta la «beta 3» de Firefox 3 (y en varios...
Aurelio nos recomendó que probásemos la extensión Taboo para Firefox. La he instalado esta mañana y ya se ha convertido en imprescindible (así, del tirón) porque se ajusta perfectamente a mi forma de procrastinar la lecturas de anotaciones o páginas o para...
Por Nacho Palou -
11 MAR 2008
Notengoenie.com es un servicio web minimalista de Korochi que resultara util para quienes se encuentren ante la dificil tarea de teclear con enies y acentos en un teclado sin enies ni acentos. Como funciona? Basta ir a esa pagina web para copiar-y-pegar....
De momento lo único que realmente me gusta de Firefox 3 (pero me gusta bastante y no me suena haber visto comentado por ahí) es la reinterpretación de la clásica opción de incrementar o reducir texto de la página (Ver >...
Por Nacho Palou -
4 MAR 2008
Mapping the Internet: Domains Names & Nameservers de Matthew Zook es un archivo KML para Google Earth que geoposiciona los TLD (Top Level Domain, la "extensiones" de los dominios que dependen del país que los otorga o del destino de uso...
Por Nacho Palou -
3 MAR 2008
Igual esto es más viejo que quéseyo, pero acabo de descubrir que en el Mac OS X hay algunas funciones Deshacer (Comando+Z) para ciertas funciones del Finder de las que se suelen ejecutar con el ratón, tales como: Mover archivos de una...
El Atlas del Espacio para Google Earth se inició con motivo de la convocatoria del Wirefly X PRIZE Cup de 2006, y actualmente reúne y posiciona todo tipo de información relacionada con el espacio: centros espaciales, asociaciones astronómicas, museos, bases de lanzamiento...
Por Nacho Palou -
25 FEB 2008
Sorprendiendo a propios y extraños Microsoft anunciaba ayer en una rueda de prensa en la que tomaron parte Steve Ballmer y Ray Ozzie que a partir de ahora la empresa dará un giro radical a su estrategia y que sus productos mejorarán...
Qué maravilla de simulador de objetos y leyes físicas en 2-D. Lo ha creado Emil Ernerfeldt, un estudiante sueco y se llama Phun (juego de palabras con fun, «divertido»). Incluye gravedad, fluidos y un montón de opciones para crear pequeños mundos...
La mayor desventaja de usar las betas de Firefox 3 es, en mi opinión, el que al arrancar desactiva las extensiones que estuvieran instaladas en la versión 2.x y como por lo general estas todavía no están actualizadas para trabajar con Firefox...
Aperture 2, nueva interfaz simplificada. He estado probando un poco el nuevo Aperture 2 y realmente me ha gustado, mucho más que la versión anterior que no acabó de convencerme del todo porque parecía un poco elemental. Ya entonces sin embargo el...
Por Nacho Palou -
13 FEB 2008
Me encontré en Hexadecimal Time and Geo Coordinates (una curiosa imagen de Flickr) ciertas explicaciones sobre el tiempo hexadecimal, una extraña propuesta para pasar el sistema de tiempo a base 16 (hexadecimal). En ese sistema día se dividiría en 10 (dieciséis)...
Esta es la historia de un tipo que compró hace poco un Apple IIc en eBay. El que fuera uno de los más míticos modelos de ordenadores Apple fue adquirido originalmente por alguien en 1988 y guardado con todo cariño. La...
Naaaah. Va a ser como un muerto guiando a un ciego.– Dave Winer Microsoft lanza una oferta por Yahoo! – 44.600 millones de dólares....
Luis ha recopilado en Cantidad de información una lista con la cantidad de información que puede incluirse en los distintos tipos de mensajes, soportes y medios de almacenamiento. La lista va desde el más simple bit para las decisiones binarias a los...
Tarjeta de visita para sufridos informáticos, una dura profesión; pueden ser repartidas tras escuchar los problemas de los pobrecitos usuarios con sus ordenadores: (Esta se la regalaron a araque y habrían de ser producidas en cantidades industriales como alivio para el gremio.)...
En cualquier momento pueden entrar en vigor las nuevas tarifas del canon digital que el mes pasado nuestros políticos decidieron mantener vigente al rechazar una enmienda que proponía su revisión para dentro de un año, así que es el momento de aprovechar...
Tal y como se dio a conocer hace algunos días y ha circulado por ahí, SETI@home está buscando nuevos voluntarios. Este popular proyecto fue uno de los primeros en popularizar la idea de computación distribuida: la utilizacion de un gran número de...
Sun ha comprado MySQL por 1.000 millones de dólares. Lo cuenta el CEO de Sun Microsystems en su blog. MySQL es uno de los sistemas de gestión de bases de datos relacionales más populares del mundo, desarrollado como software libre. También es...
Recopilado por un grupo de aficionados de la comunidad de Google Earth (tómese su fiabilidad en consecuencia), el archivo SAM site overview (.kml, unos 6 MB), posiciona en el mapa casi 1.400 bases de lanzamiento de misiles tierra-aire repartidos por el...
Por Nacho Palou -
15 ENE 2008
¡Qué gran verdad! ¿Por qué algunos programadores se preocupan hasta el paroxismo por controlar que las cuentas de correo de los formularios estén correctas mientras en el mismo formulario puedes inventarte teléfonos, colocar una misma letra mil veces en el nombre, inventarte...
Cool Computer Casings: una recopilación de trabajos artísticos a la par que prácticos de Shirley Two Feathers con cajas de ordenadores que pasaron por un modding tan bello como en cierto modo extremo....
Cómo mantener el escritorio limpio y sin cables… … escondiendo los cables debajo de la mesa. Explicación completa en Decluttered. Materiales: menos de 25 €. (–––––– Signal vs. Noise.)...
Cada vez que Apple actualiza sus modelos de gama alta acudo ritualmente –como tantos otros– a la Apple Store España para jugar un rato a configurar el modelo de Mac más completo posible: el mega-Mac Prosaurius Rex, la bestia más cargada y...
Clic en «Play» para empezar. Clic y arrastrar para darse una vuela. Super Computer Timelapse [Flash] es un vídeo de time-lapse sobre el proyecto de construcción de un superordenador. Además de interesante de por sí, está montado con la tecnología de realidad...
Para poner un poco de orden en la decepcionante última versión de su sistema operativo y tras el famoso lío de versiones y «sabores», Microsoft ha decidido que Windows Vista estará a partir de hoy disponible en cuatro ediciones diferentes: Windows Vista...
La semana pasada, harto de versiones cada vez peores de Firefox 2, al menos bajo Mac OS X Leopard, y en especial de la actualización 2.0.0.11 del navegador, que es poco menos que insufrible, pensé que poco podía perder probando Firefox 3...
Nada menos que 8.000 dólares el galón —o 1.400 euros por litro. Que es por lo que en el caso de impresoras domésticas de gama baja puede salir más rentable cambiar la impresora que reponer la tinta: HP finds formula to turn...
Por Nacho Palou -
19 DIC 2007
Alabados sean Rosyna de Unsanity y Merlin de 43 folders por haber publicado la solución al bug más porculero de todos los que he venido sufriendo en el último año en mi Mac. El caso es que llevaba desde antes del verano...
El disco duro portátil Little Disk de LaCie es una opción a tener en cuenta para transportar cantidades medianas de información (hasta 60GB) de forma cómoda y fiable y a precio asequible. Pero es esencialmente un producto víctima de su diseño. LaCie...
Por Nacho Palou -
17 DIC 2007
El rendimiento de los ordenadores se mide en FLOPS: «operaciones de punto flotante por segundo», que viene a ser como dividir dos números con bastantes decimales u operaciones parecidas. Como los ordenadores son muy rápidos es común hablar de megaFLOPS (millones de...
No es lo mismo ordenar que ordenar: La de la izquierda es una ordenación alfabética «natural», como la del explorador de Windows, la de la derecha la típica ordenación «Asciibética» de la mayoría de los lenguajes de programación (por ej. Arrray.Sort() en...
Tal y como puede verse aquí: Me sucedió hoy instalando un Macbook Pro recien comprado, que venía con 10.4 y el disco del 10.5 para actualizar. Después de las dos horas largas de instalación desde el DVD al comprobar «Actualizar Software» aparecieron...
Llega con un poco de retraso porque fue este pasado mes de agosto cuando el mítico Commodore 64 con el que muchos nos iniciamos en esto de la informática cumplía 25 años, pero la galería de imágenes que publica Wired en Gallery:...
Interesante la idea de Google Chart API, pensado como una herramienta para desarrolladores y webmasters, aunque es tan simple que casi, casi, podría usarla un niño de cuatro años.
Texto de la etiqueta: “Este ordenador es un servidor ¡NO APAGAR!” Este NeXTcube de Berners-Lee fue el primer servidor web. Se utilizó también para programar el primer navegador web, llamado precisamente WorldWideWeb, en 1990. En la Navidad de aquel año, Berners-Lee...
Por Nacho Palou -
3 DIC 2007
Desde el Flight Simulator 1.0 de 1982 (cumplió 25 años este mes de noviembre), a la izquierda, al Silent Hunter 4: Wolves of the Pacific (derecha). Todo un avance que se puede ver de un vistazo en esta galería de capturas....
Por Nacho Palou -
1 DIC 2007
Decoding the Universe: How the New Science of Information Is Explaining Everything in the Cosmos, from Our Brains to Black Holes. Charles Seife. Inglés. 298 páginas. Apasionante este libro que desarrolla muchas de las ideas de la Teoría de la Información...
1. Impresión aparente. 2. Aumentado el contraste, aparecen los puntitos amarillos codificados. 3. El código, descifrado. Yellow Peril muestra cómo funciona el código «invisible» que el gobierno norteamericano sugirió «persuasivamente» hace años que incluyeran de serie los fabricantes de impresoras, algo que...
Box2DFlashAS3 es una demostración en Flash del poderío de las liberías Box2D, un motor de objetos que respetan las leyes físicas especialmente para juegos 2-D. Basta arrastrar los objetos con el ratón, y moverse con el cursor izquierda o derecha para...
Los dominios de primer nivel de Internet más consultados. (ICANN) Es bueno ser Rey, pero es mejor ser root en un Root Server. De ese modo es como cuentan en el blog de la ICANN que han obtenido este gráfico. Con una...
Módem USB Huawei E272 Vodafone. Vodafone nos ha prestado otro de sus módems USB 3G para probar, en este caso el Huawei E272. Se trata de un modelo desarrollado específicamente para Vodafone por Huawei Technologies, por lo que a diferencia del...
Markoff recoge en Adding Math to List of Security Threats las explicaciones de Adi Shamir (más conocido por ser la «S» de RSA) relativas a ciertos potenciales problemas de seguridad global. Al parecer errores en los chips que realizan cálculos numéricos, parecidos...
Actualmente se cuentan en el catálogo de exoplanetas 221 planetas situados fuera del Sistema solar. El catálogo recoge planetas y cuerpos-tipo-planeta extrasolares que orbitan estrellas más o menos cercanas —teniendo en cuenta en astronomía el concepto de “cercano” adquiere una nueva dimensión...
Por Nacho Palou -
20 NOV 2007
Para quienes quieran vivir «livin' la vida loca» ya está disponible para descarga Firefox 3 Beta 1, una versión recomendada solo para desarrolladores y aquellos que quieran hacer de conejillos de indias. De hecho desde Mozilla se pide que enlacemos con Firefox...
JJ de la Universidad de Granada está haciendo un experimento de computacion distribuida. Aunque ya tiene algunos resultados le vendría bien obtener más datos. Se puede ayudar con un par de clics: Ayudilla experimento computación distribuida – Llevo haciendo desde hace una...
Esto sí que sería un avance de verdad: Poder FTPear a la tarjeta SIM de los teléfonos móviles. Situación: llegas a la oficina, tienes el Bluetooth activado y con cualquier cliente de FTP puedes subirte, sin cables, lo que necesites para llevar...
Me crucé con Muerte a las barras de desplazamiento con look Aqua y siempre que veo un título de ese estilo me hace gracia. Me recordó a odios clásicos como Muerte a la Comic Sans. Es expresión es relativamete habitual en el...
Tony Sale y su equipo, en 1994, reconstruyendo Colossus.Foto (GFDL): MaltaGC para Wikimedia Commons Un grupo de aficionados a la criptografía, los ordenadores y las máquinas antiguas terminó de reconstruir Colussus, que a veces ha sido considerado el primer ordenador del mundo....
Se titula Aplicaciones del cálculo en congruencias pero es otra forma de decir Cómo calcular el número/letra de control de una Cuenta Corriente, el DNI/NIF o el ISBN. (Existe otro divertido que no está aquí que es el CIF de las empresas.)...
Con la nueva versión de Google Earth se incluyen nuevas capas de datos (o se incluyen por defecto las otrora opcionales) y se reorganizan un poco las que ya existían y las últimas capas añadidas hace unos pocos meses, aunque realmente ya...
Por Nacho Palou -
14 NOV 2007
Android es la nueva plataforma de Google para aplicaciones móviles, un conjunto de herramientas y aplicaciones que conforman un sistema operativo para teléfonos móviles y otros gadgets, basada en software libre. Hay una buena explicación sobre qué es Android en Dirson, también...
Cyborgs: the future for humans es el título de la conferencia de Kevin Warwick, profesor de la Universidad de Reading, que impartirá el próximo viernes 16 de noviembre en Madrid. Esta conferencia se enmarca dentro de las Jornadas de Informática de la...
El Ventanal de Rosa es el nuevo blog de Rosa Mª García, más conocida por ser la presidenta de Microsoft Ibérica. Hoy nos invitó a unos cuantos blogueros a comer para contárnoslo pero sobre todo para preguntarnos cosas y compartir un...
Project Euler es una web de problemas numérico-lógicos y de programación que lleva el nombre del famoso matemático. Allí se proponen retos que supongan pensar «con algo más que una mente puramente matemática», de modo que para resolver el problema haga...
En HyperSpace - The «instant on» embedded OS hablan de una idea interesante: sistemas operativos ligeros que necesitan sólo unos pocos segundos para arrancar y estar funcionando. El problema es que los arranques de los ordenadores actuales son lentos –a cada año...
Otra colección de fotos de ordenadores, en este caso no de ordenadores malosos sino de viejas glorias de la informática reunidas en la décima edición del Vintage Computer Festival en Gallery: Ancient Marvels Abound at Vintage Computer Festival: Un LINC de 1962...
The Top 10 Evil Computers que puede hojearse como fotogalería muestra los ordenadores más malos malosos de la historia de la ciencia-ficción, incluyendo a HAL 9000 de 2001: Una Odisea del Espacio, Nomad (de Star Trek), el ordenador de Superman III,...
QEDWiki es la herramienta de IBM para programadores que quieran crear mashups, con toques de wiki. En la página hay tantos acrónimos raros que para entenderlo es mejor ver el vídeos de demostración de su web. En cierto modo es parecido a...
La Sierra Madrileña en relieve. Maps-For-Free ofrece mapas de elevación (relieve) sobre los conocidos Google Maps, con la idea de ir añadiendo otro tipo de capas y servir de ejemplo de cómo crear nuevas aplicaciones con toda esa información. Para mirar los...
Ordenador analógico GPS (1950) para resolver problemas industrialesFoto © Mark Richard, Core Memory Project Core Memory Project en un trabajo artístico y un libro de fotografías de Mark Richards con John Alderman, que muestra con vivos colores cómo eran los antiguos ordenadores...
Ingeniosa forma de reclutamiento de programadores cerebritos. (z = Asia Pacific Headhunter / Digg)2...
En Infinite Recursion with Screen Sharing Glenn Fleishman pone un buen ejemplo de recurrencia que capturó en ordenador, con una combinación del Screen Sharing / Remote Desktop de Leopard con VNC y Timbuktu Pro, de modo que un ordenador veía la...
AppleInsider hace en Road to Mac OS X Leopard: System Preferences un repaso de como ha evolucionado la forma de controlar el comportamiento de muchas funciones en el sistema operativo de los Macintosh desde 1984, cuando las Preferencias del Sistema eran un...
pForm es un generador de formularios en HTML. Considerada la Siberia de diseñadores, programadores y htmleros, la codificación en HTML de estas indispensables páginas web recobra una nueva luz gracias a este servicio gratuito: permite generarlos de forma visual en cuestión...
Mientras procrastinamos escribir una reseña medio decente entre los tres sobre Leopard (Mac OS X 10.5), he aquí una colección de enlaces que pueden ser útiles para quienes ya han actualizado su Mac o para quienes se lo están pensando: La mejor...
Así es cómo el nuevo OS X Leopard representa los ordenadores Windows en el entorno de red. Sí, eso es una pantalla azul de la muerte. Con dos cojones. (Nos lo contó anticipadamente Rafa Espada y ahora ya lo hemos visto...
Por Nacho Palou -
30 OCT 2007

Hidden Histogram Picture Maker es un generador de aquellas imágenes tan curiosas que empleando una técnica esteganográfica parecen indiferentes aunque en realidad sus histogramas ocultan la verdadera imagen. Como por ejemplo… El Titanic En los programas de tratamiento de imágenes se pueden...
¡Ah, qué tiempos aquellos…! Es una foto del Museo Informático DigiBarn, un curioso cruce entre granja de animales y «no-museo» informático, donde se exhiben todo tipo de ordenadores prehistóricos. Está situado en las montañas de Santa Cruz, al norte de California. Lo...
En este mismo instante, con la salida a la venta de Mac OS Leopard, el sistema operativo clásico de los Macintosh deja de existir para Apple: Do Classic applications work with Mac OS X 10.5 or Intel-based Macs?Classic applications do not work...
La interrobang, un nombre propio que tal vez podría traducirse como interroclamación (interrogación + exclamación) es un híbrido entre exclamación e interrogación, así ‽ Aunque, visto de otro modo, bien podría llamarse… exclamagación. Investigando un poco encontré emoticonos vs interrobang, todo un...
Dos de los más populares nombres de variables en programación son foo y bar, a veces acompañadas de foobar. Provienen de una expresión del inglés, de la época de la Segunda Guerra Mundial: FUBAR. Son las iniciales de Fucked Up Beyond All...
La máquina de Turing (2,3) de dos estados y tres colores.Se ha demostrado que es de tipo «Universal» El premio sobre una pequeña Maquina de Turing (2,3) ofrecido por Stephen Wolfram ya tiene ganador oficial: Alex Smith, un estudiante de veinte años...
Una idea bastante ingeniosa que permite convertir los discos duros convencionales en discos duros externos USB 2.0. De este modo te evitas lidiar con instalaciones de discos internos adicionales que suelen ser un rollo —y no son siempre posibles como es...
Por Nacho Palou -
22 OCT 2007
Entrañable… [||||||| 73% |||||||————] Barras de Progreso: Las barras de progreso son compañeras de soledad delante de nuestras pantallas. Nos quedamos embobados mirando cómo se rellenan los cuadritos que faltan. «Podría hacer otra cosa, pero… es que ya casi va por el...
Un artículo publicado por la Universida de Riverside (California), titulado UC Riverside Research Leads to Self-Improving Chips with Speed «Warping» da cuenta de una idea que podría suponer un avance de «velocidad factorial» sobre la potencia de cálculo de los ordenadores del...
Vodafone Mobile Connect Módem USB HSPA/3G/EDGE/GPRS. Hace unas semanas Vodafone nos prestó su nuevo módem USB HSPA, así que después de haber hecho las pruebas pertinentes, este es nuestro análisis de su funcionamiento bajo Mac OS X. El kit El equipo...
Con la calculadora de consumo de energía se puede saber más o menos cuál es el coste anual de la energía consumida por algunos ordenadores Apple funcionando de forma continua. También calcula el ahorro que supone la activación de Economizador (en...
Por Nacho Palou -
20 OCT 2007
Moway, el mini-robot programable es un curioso artilugio del tamaño de un teléfono móvil que tiene ruedas y sensores y se puede programar a través de un cable USB con el ordenador. Está diseñado para lo que llaman robótica colaborativa: varios...
Foto-galería: Ordenadores prehistóricos, muchos de los cuales funcionaban, literalmente, «con radiocassette». ( ...- .. .- -.-. .-.. .. .--. ... . -) * «Rular» es un verbo rulante, véase....
Una nueva «lista a la que no podemos resistirnos», en este caso de diez «secretos» que deberías conocer si piensas en dedicarte profesionalmente a la informática, traducido y resumido de Sanity check: 10 dirty little secrets you should know about working in...
IconFinder es un buscador de iconos gratis: simplemente escribes algo como camera y aprece una selección de iconos para personalizar el escritorio y dejar atrás las aburridas imágenes de siempre. Están todos en formato PNG y en general parecen de gran calidad....
Resumen muy resumido del artículo Why I Won't Buy an iPhone de Arik Hesseldahl para BusinessWeek, quien dice que a pesar de que opina que el iPhone es extraordinario y que representa un significativo paso adelante en el desarrollo de los dispositivos...
¿Qué hacer con veintitantos Macintosh II que tienes muertos de risa en tu almacén? Pues convertirlos en un (in)cómodo sofá para maqueros, como han hecho en la Mac Store de Maryland Heights en Missouri, Estados Unidos: Al precio que iban los Macintosh...
Electronic Brains: Stories from the Dawn of the Computer Age. Mike Hally. Granta Books, 3 de abril de 2006. Inglés. 304 páginas. ISBN: 1862078394. Web del autor: Mike Hally -- Journalist and Photographer. Este libro surge de la investigación realizada por el...
Al parecer, en Excel 2007, multiplicar 850 × 77,1 da como resultado 100.000 (en vez de 65.535 que es lo correcto). Sucede con otras multiplicaciones similares. Y debe ser un bug porque en la lista de features no viene indicado. Es un...
20 síntomas de que podrías ser un Geek en Picando Código, traducidos del original 20 Signs You Might Be A Geek de Kludge. (Vía PuntoGeek.) Actualización: Y ya que estamos... Tim Berners-Lee: no a la estúpida cultura geek masculina (ALT1040), donde...
1 GB de almacenamiento hace 20 años y 1 GB hoy en día… casi no han cambiado las cosas ni nada: El giga de hoy en día, por si no lo ves, es la tarjeta SD que está entre el pulgar y...
Habría que crear una categoría honorífica en los Premios Darwin para aquellos imbéciles que aunque no mueren realizando actos estúpidos (mejorando así el acervo genético global) acaban en una prisión del tipo toma-mi-culo-y-que-te-aproveche. Un gran candidato sería este tipo que [supuestamente] dicen...
Windows vs. Mac, vi vs. emacs… y a estas alturas todavía C vs C++. Habría que añadir los siguientes párrafos a la definición de flamazo. Sucedió en una lista de correo, comparando el lenguaje C con el C++, respondiendo a provocaciones previas,...
El 19 de septiembre de 1982 a las 11:44, hora de la costa este de los Estados Unidos, las 17:44 hora de España, Scott Fahlman proponía en medio de una serie de mensajes medio en serio y medio en broma el uso...
Hoy 13 de septiembre de un año común no-bisiesto es el día 256 del año y se celebra el Día del Programador. La página web que intenta hacer oficial esta fiesta no-oficial es ProgrammerDay.info. Al igual que con el Día de...

Explaining the JPEG Algorithm es una página que explica completamente y de forma gráfica cómo funcionan las ubícuas imágenes JPEG que se usan en la Web y las cámaras digitales, con especial énfasis en la parte matemática. Este tipo de compresión...
The Complete History of Lemmings repasa la historia del popular juego de mano de sus creadores, incluyendo imágenes de las diversas fases de su creación y muchas anécdotas. La primera idea surgió en 1989 y entre todas las curiosidades del juego...
El Seam Carving o Retarget es un algoritmo que cambia de tamaño las imágenes sin afectar al contenido y que se pudo ver en demostración en Siggraph 2007. Soluciona un típico problema de los crops o recortes que es que si...
Google Earth 4.2, además de servir como simulador de planetario con imágenes, también puede funcionar como un rudimentario simulador de vuelo para sobrevolar las imágenes de superficie y estructuras tridimensionales de una manera adicional al habitual “modo superman”. Aproximación a la Ciudad...
Por Nacho Palou -
4 SEP 2007
Con esto de las vacaciones casi se me pasa, pero un mes de agosto de hace 25 años se ponía a la venta el Commodore 64, uno de los microordenadores más populares de la historia y con el que muchos de los...
Una anécdota medio matemática, medio informática, extraída también de The Music of the Primes, el libro Marcus du Sautoy. A principios de los 70, los matemáticos Zagier y Bombardi hicieron una apuesta relativa a la hipótesis de Riemann en la que ambos...
Google Earth 4.2 es una actualización significativa del popular programa de Google para explorar el planeta con imágenes aéreas y de satélite. Tal y como cuentan en Google Earth 4.2: novedades ahora se puede mirar al cielo y utilizar el programa también...
Importante: ver actualización al final Hasta la NASA se equivoca con su datos y a veces las consecuencias son insospechadas. El famoso bug del «efecto 2000» que se produjo al cambiar de 1999 a 2000 afectó a los datos climáticos en bruto...
Ya hace algún tiempo que se pueden geolocalizar las fotos que se suben a Flickr desde la opción Mapa del Organizador, pero a mi modo de ver esta función tiene dos problemas:Por un lado, usa los mapas de Yahoo, que en general...
¡Nunca se sabe cuándo se va a necesitar uno! En la web del servicio Quantum Random Bit Generator se ofrece un generador de bits aleatorios realmente aleatorios y no pseudoaleatorios como suelen ser los generados por ordenador. La fuente aleatoria se llama...
18 atajos de teclado imprescindibles para Photoshop que nunca vienen mal si usas el popular programa de Adobe. (Vía Tropiezos en la red.) 200 atajos de teclado productivos, para Jedis del teclado. Atajos de teclado de NetNewsWire, el lector RSS para Mac...
Estas matrioskas con toque geek son unas muñecas muy especiales llamadas bit, byte, kilobyte, megabyte, gigabyte y terabyte. Son una obra artística de Art Lebedev. (Vía PuntoGeek.)...
Google Earth Blog es un blog no-oficial de Frank Taylor que ahora tiene versión en Español. Está dedicado a todo lo que tenga que ver con Google Earth, el software de imágenes por satélite de Google que tiene todo tipo de...
El Hutter Prize for Compression of Human Knowledge es un peculiar reto medio informático medio matemático propuesto por Marcus Hutter, Matt Mahoney y Jim Bowery, quienes tienen 50.000 euros esperando como premio para quien consiga comprimir sin pérdidas un archivo que contiene...
Los códigos HTML que ofrecen YouTube y Google Video para «incrustar/insertar» los vídeos (embed) en otras páginas web no validan XHTML. Aunque validar en XHTML esté a veces sobrevalorado, no viene mal que las páginas con vídeos incrustados validen también correctamente. Además...
Klondike Solitaire Online, para jugar vía web al «Solitario». El popular Solitario incluido en las versiones modernas de Windows es una de las muchas versiones de este tipo de juegos de cartas y se llamaba originalmente Klondike, en inglés Patience o también...
Alguna vez hemos hablado por aquí de los efectos drostes escherianos y enlazado algunas fotos e imágenes curiosas de este efecto visual autorreferente. Roberto encontró algunos enlaces más en Flickr donde se detallan las técnicas a usar e hizo una traducción al...
The Strangest Sights in Google Earth, una recopilación de algunos de los lugares, objetos y momentos más raros y curiosos que pueden econtrarse hasta ahora en Google Earh: barcos y camiones accidentados; elefantes corriendo por la sabana africana; figuras gigantes o un...
Por Nacho Palou -
30 JUL 2007
Siete superordenadores poderosos conocidos publicamente recopilados en Top 7 Most Powerful Supercomputers in the World (Publicly Known); y unos cuantos enlaces para perderse un buen rato leyendo al respecto. Blue Gene/L, Lawrence Livermore National Laboratory. Red Storm, Sandia National Laboratories. BGW (Blue...
Por Nacho Palou -
25 JUL 2007
Ya se que este ordenador puede estar perfectamente protegido por un cortafuegos instalado en otra máquina del que la copia local de Windows no tiene ni idea, pero me parece que la imagen no deja de tener su gracia en este mundo...
The Best 80 Photoshop Text Effects on the Web es una recopilación de tutoriales para crear efectos de texto utilizando Photoshop. En algunos casos se incluyen archivos de las acciones o los originales utilizados en el tutorial. (Vía del.icio.us/popular.)...
Por Nacho Palou -
23 JUL 2007
Keyboard Shortcuts: 200 productive keyboard hotkeys es la recopilación definitiva para convertirse en un Jedi del teclado, alguien capaz de usar el ordenador sin (apenas) tener que echar mano del ratón. La lista es para Windows, pero sustituyendo Comando por Control y...
No había visto las nuevas capas de NASA en Google Earth hasta que las he visto mencionadas en el Lat Long Blog; NASA in Google Earth. Estas nuevas capas añaden fotografías de la Tierra tomadas desde el espacio por astronautas e imágenes...
Por Nacho Palou -
22 JUL 2007

Me encanta poder dar un como titular como éste. Ha sido una de las cuestiones que relacionada con teoría de juegos e informática que desde siempre me ha parecido intrigante y apasionante. Hace un par de años ya comenté de pasada...
AJAX, ASP, ASP, AVS, AWS, CGI, CMYK, CNAME, CPC, CPM, CRAP, CRON, CRUD, CSC, CSRF, CSS, CTR, CVS, DBMS, DHTML, DNS, DOM, DTD, FAQ, FLA, FTP, GIF, GUI, HTML, HTTP, HTTPS, ICANN, IIS, IP, JPEG, JS/, JSP, MID, PHP, PNG, PPC, PR,...
Aunque parezca increíble, el sonido de arranque (¡Doooong!) de los Mac no se puede desactivar. Ni siquiera aunque estén enchufados unos auriculares a la salida de cascos, truco de baja tecnología que funcionaba en los modelos más viejos. Este «sonoro problema» durante...
Estaba importando viejos CDs de música en iTunes cuando empecé a tener problemas por una especie de «error en el archivo iTunes Library», lo cual me resultó bastante raro. Aunque al principio pensé que podía ser que al leer los discos compactos...
«Error en este diálogo» Sinner nos envió esta pantalla con la que se topó el otro día, un error autorreferente de Microsoft Internet Explorer (corriendo bajo Virtualbox en Debian). Más que un error parece un chiste. Actualización (16 de julio de 2007):...
En el pasado Adobe Live una de las funciones estrella en las presentaciones de Photoshop CS3 era la nueva función para fusionar capas. Esta función permite entre otras cosas crear panorámicas a partir de dos o más fotos de forma increiblemente fácil...
Por Nacho Palou -
5 JUL 2007
Sorting Algorithms es una demostración visual de cómo funcionan más de una docena de algoritmos de ordenación. Para programadores también se incluye el código fuente en Java de todos ellos....
Con un titular a medio camino entre algo publicado por D.C. Comics o los panfletos repartidos por el chiflado de Conspiración llega Military Running a Parallel Earth Simulator. Allí se se enlazan a curiosas historias, una titulada literalmente Los militares están simulando...
Antonio, repasando su colección de Muy Interesante, se encontró con esta proposición de Pedro G. Gans en la desaparecida sección ¡Qué idea! de la revista:Como me decía Antonio, ahora cualquiera identificaría este aparato con un portátil, pero es que esta idea fue...
Se publicó por fin la versión 3 de la GNU General Public License, una de las licencias de software libre pioneras y más populares del panorama actual, madurada tras más de quince años desde que se publicara la versión 2 (GPL v2)...
Inside the Intenet Archive es un antiguo pero no por ello menos interesante artículo sobre las interioridades de The Internet Archive (más conocido como Archive.org) – a veces llamado «la Biblioteca de Alejandría de la Web» o también «la mayor colección de...

Binary marble adding machine sería algo así como un prototipo de ordenador de los Picapiedra y todo un ejemplo de ingenio: una máquina capaz de sumar números en binario, que funciona con canicas y está construida en madera, tal y como...
Confirmando las teorías conspiranoicas que a todo el mundo le vienen a la mente cada vez que la impresora enciende la luz de «cartucho de tinta vacío»… Study: Inkjet printers are filthy, lying thieves – Se trata de un estudio de TÜV...
El próximo jueves 21 de junio Adobe organiza la Adobe Live 2007 un evento dirigido a profesionales de la industria gráifca, el desarrollo web, la publicidad, el vídeo y la fotografía digital. Este año el gran protagonista es el producto de Adobe...
Por Nacho Palou -
14 JUN 2007
Desde la prehistoria informática nos llega en modo condensado una bonita narración: A Potted History of WordStar (Una historia condensada de WordStar), las peripecias del que fuera uno de los primeros programas de tratamiento de textos con los que tanta y...
Ya está disponible la versión final de NetNewsWire 3.0, el agregador de noticias «oficial» de Microsiervos, NetNewsWire 3.0 for Mac. Las novedades que destaca NewsGator de esta nueva versión son:Integración con Spotlight, Agenda, iCal, iPhoto, Growl, Twitterific y más.Nueva apariencia, nuevas vistas,...
Apple II – Apple Inc. Hoy se cumplen 30 años de la puesta a la venta del Apple II, el ordenador que por primera vez demostró que el público en general podía tener interés en tener un ordenador en su casa. Y...
Nacho y yo estamos en el Google Developer Day 2007 que se está celebrando en Madrid y otras ciudades del mundo de forma simultánea. Hay unos quinientos programadores y muchos ingenieros de Google que están enseñando algunas de las novedades que se...
Trompa dibujada en Illustrator por Yukio Miyamoto Igual que los dibujos técnicos de Makoto Ouchi los dibujos técnico-artísticos de Yukio Miyamoto demuestran su maestría, su habilidad y su profundo conocimiento de las herramientas y las posibilidades del software de dibujo vectorial...
Por Nacho Palou -
23 MAY 2007
La noticia llega de Suiza: A mighty number falls, describe cómo gracias a tres clusters de tres instituciones diferentes (el EPFL, la Universidad de Bonn y NTT en Japón) se ha completado una «monstruosa secuencia de cálculos» para hallar los factores primos...
How does Gates shape up as a seer? es un recopilación de diversas «predicciones» que hizo Bill Gates, fundador de Microsoft, a lo largo de las últimas décadas, en discursos, conferencias, entrevistas y publicaciones diversas, incluyendo su libro Road to the Future....
David Troy ha creado dos de los mashups más adictivos de los últimos tiempos con flickrvision, que te permite ir viendo en qué lugares del mundo están hechas las fotos que se van subiendo a Flickr, y con twittervision, que te permite...
A los más viejos del lugar sin duda esta anotación les traerá una pizquita de nostalgia, pues esta semana John Nack, el responsable de producto senior de Adobe Photoshop, confirmaba en su blog que Macromedia FreeHand ya no recibirá más actualizaciones: FreeHand...
Esta máquina de Turing tiene dos estados y tres colores.¿Es universal o no? La demostración se paga a 25.000 dólares Seguramente ni el propio Stephen Wolfram ni su equipo han podido resolver este problema durante los últimos años, de modo que ahora...
La última vez que estuve en Londres en las cercanías del Tower Bridge estaba instalado The Weee Man, una escultura que intenta concienciar a la gente de la cantidad de basura electrónica y eléctrica que genera al cabo de su vida, pero...
Ayer, Barrapunto… Según Microsoft, Linux tiene calidad porque viola sus patentes: Microsoft ha anunciado que los usuarios del software libre (…) violan como mínimo 235 patentes de Microsoft, si bien no mencionan cuáles son. Microsoft está amenazando a los usuarios finales de...
El cerebro humano tiene un nivel de complejidad tremendo, pero es algo que podríamos llegar a entender y manejar prácticamente en su totalidad. Una de las formas de verlo es que el «diseño» del cerebro humano está descrito en unos 20 megabytes...
El Hotmail «de siempre» se llama ahora Windows Live Hotmail oficialmente, es la nueva versión del correo gratuito de Microsoft con novedades en todas estas áreas: 2 GB de espacio para los mensajes Mejoras en seguridad Diseño e interfaz renovados Más rápido...
Estuve probando Quomon, que se basa en una idea muy simple: dejas una pregunta y otro usuario, experto en el tema, te responde al cabo de un tiempo. La temática general de Quomon es «tecnologías de la información», lo cual centra un...
Andaba buscando otra cosa y me encontré Drive-in, una utilidad que sirve para crear imágenes completas de cualquier DVD en el disco duro del Mac para uso personal, con «calidad total». El resultado es una especie de «imagen» del DVD que se...
Un aspecto divertido del simulador de vuelo X-Plane (Mac, Windows y Linux; ya lo mencionamos hace tiempo) es que permite jugar a aterrizar el transborador espacial Discovery en la pista de la base Edwards, en el desierto de California. En el juego...
Por Nacho Palou -
24 ABR 2007
No puedes decir... Esa foto es Photoshop total... Ni nada parecido, sino que tienes que decir Esa foto está manipulada con el programa Adobe® Photoshop®. Según Proper use of the Photoshop trademark vía A Welsh View....
Por Nacho Palou -
23 ABR 2007
Hoy se cumplen 25 años de la puesta a la venta del primer modelo de ZX Spectrum, uno de los ordenadores personales más populares de todos los tiempos, con el que muchos de los que hoy nos dedicamos a esto de la...
En versiones online [requiere Flash] y salvapantallas para Mac y Windows: Polar Clock v2. (Vía Information Aesthetics.)...
Por Nacho Palou -
21 ABR 2007
¡Niños, no intentéis esto en casa! Subliminal Message para Mac OS X y Windows es un inquietante y WTFquiano programa que sirve para mostrar mensajes subliminales en la pantalla de tu propio ordenador, como texto o imágenes. Estos mensajes pueden tener una...
En el departamento de aumento-de-la-productividad y lucha contra la sobredosis de información estábamos estos días investigando el efecto de quitar los iconos de notificación de «nuevos mensajes» de diversos programas, especialmente del correo electrónico y el agregador de feeds rss. Aparentemente este...
TutorialLab es una nueva web recién lanzada cuya idea es ofrecer tutoriales en vídeo gratis a todo el mundo, pequeños cursos sobre técnicas diversas, desde Excel a Photoshop, hojas de estilo CSS o Flash Vídeo. El formato también permite a los lectores...
A los pocos días de estar en manos de sus primeros compradores el Apple TV ha demostrado ser un cacharro la mar de «hackeable» y poco cerrado, lo que podría tirar por tierra muchas de las pegas que le puse cuando Steve...
Apple y EMI, una de las grandes discográficas del mundo, han convocado un acto para dentro de una hora en las oficinas de EMI en Londres al que asistirá el propio Steve Jobs y en el que van a desvelar una «sorprendente...
YMMV, que se decía antiguamente (Your Mileage May Vary, en referencia a que con la misma gasolina coches parecidos e incluso iguales pueden recorrer distancias distintas dependiendo de factores incontrolables). ¿A qué velocidad te mueves en en Internet? es un interesante artículo...
El Directorio de APIs de Programmable Web ha alcanzado ya las 400 referencias. Se pueden ver organizadas por Categorías, de las cuales existen más de cincuenta. Las más populares son Mapas, Referencia e Internet. Las APIs son un conjunto de especificaciones para...
Creo que no sorprendió a nadie que las reuniones entre las entidades gestoras de derechos de autor y los fabricantes de dispositivos electrónicos cuyos productos se verán gravados por el nuevo canon digital terminaran sin ningún tipo de acuerdo. Lo que ya...
La semana pasada tuve la oportunidad de visitar durante un rato CeBIT, una macro-feria de informática que se celebra todos los años en la ciudad alemana de Hannover, por cortesía de Samsung, que nos llevó allí a tres bloggers y a algunos...
Esto hace tiempo que quería probarlo desde que me lo comentó un amigo hace algunos años: hacer que el ordenador monitorice la presencia del teléfono móvil con Bluetooth para que haga cosas según si lo encuentra o no. Tal vez el ejemplo...
Por Nacho Palou -
20 MAR 2007
Apasionante cien por cien: ¿Sueñan los androides con ovejas eléctricas? es un resumen en castellano de Enrique Dans sobre el no menos interesante Can Operating Systems tell if they're running in a Virtual Machine? donde se habla de las restricciones legales...
Diez pasos para plantear una duda informática son los diez pasos que por desgracia nadie que tenga una duda informática va a seguir para plantearla, lo cual creará sin duda cabreos y confusión entre los candidatos a responder las preguntas. Tal vez...
Si no te gusta que tu carpeta predefinida de descargas se llene con cientos de archivos de todo tipo mezclados, Download Sort es una extensión para Firefox te evitará tener que especificar a mano dónde quieres descargar algunos de esos archivos o...
Seismac es un salvapantallas para los MacBook y MacBook Pro que disponen de sensores de movimiento, que convierte el ordenador en un sismógrafo capaz de detectar temblores de tierra y terremotos de todo tipo. Mi iBook es viejo y no tiene sensores,...
Soundstream es un salvapantallas para Mac OS X simpático e ingenioso, esas grandes cualidades que debe tener todo salvapantallas: los motivos luminosos de colores de la pantalla cambian y mueven según el sonido ambiente que recoge el micrófono del ordenador. Así las...
Seguro que habrás observado que al hacer una fotografía desde el suelo hacia la parte superior de un objeto alto (inclinando la cámara), como por ejemplo un edificio, el resultado es que el sujeto fotografiado presenta una perspectiva exagerada: las líneas verticales...
Por Nacho Palou -
26 FEB 2007
Virtual Globe es una aplicación para visualizar el globo terrestre en tres dimensiones, combinando datos de elevación con imágenes aéres y de satélite. Es muy similar a Google Earth, tanto por la forma de funcionar (las imágenes y datos topográficos se descargan...
Por Nacho Palou -
24 FEB 2007
Jugando a reordenar las letras:Microsoft Vista = Fascist Motor VIY hay más anagramas de «Microsoft Vista», descubiertos por Isaac, como It's Visa comfort (debe ser por el precio)....
Divertido post en FayerWayer protagonizado por Seti@home el proyecto que consiste en repartir entre voluntarios paquetes de señales recibidas por varios radiotelescopios para que sus ordenadores las procesen en los tiempos muertos —al menos como salvapantallas es bonito. El objetivo es encontrar...
Por Nacho Palou -
22 FEB 2007
Más claro imposible, ¿no? (Gracias, Alejandro.)...
NetNewsWire 3.0d46: sneak-peek release es una versión previa de la nueva actualización 3.0 NetNewsWire, que es mi programa favorito para leer feeds RSS en Mac OS X. Ojo: esta versión ni siquiera es una beta, así que puede fallar más que una...
Colosal WTF!!!! Más de nueve megabytes de parche para actualizar el «sistema del horario de verano» en Mac OS 10.4.8. En los ordenadores con Mac OS X 10.3 el parche ocupa sólo 4 MB. Comparativamente, los 81 MB de Java o los...
He terminado de actualizar la anotación acerca del Sistema de Computación Cuántica Orion, la computadora cuántica que D-Wave presentó el otro día. Ahora que ha pasado el ruido mediático y tras hacer el seguimiento a decenas y decenas de enlaces y noticias...
Software Wars, creado por Steven Hilton, es una visualización general de cómo van las guerras del software del siglo XXI, «la batalla épica entre el software libre y el open source contra el imperio Microsoft». Se podrían discutir un poco los...
Impresionante FromLostToTheRiverismo que le ha soltado la más reciente versión de Democracy nada más instalarla a Manu: Si a pesar de todo quieres saber algo más de esta nueva versión, Cory Doctorow habla de ella en Democracy Player gets even better. Chasque...
Bipbip.puntoOrg es una nueva web a modo de portal creada por la Fundación Bip Bip para ofrecer a las ONG información y acceso real a las nuevas tecnologías. Resumen su misión en estos tres puntos: Explicar cuáles son las tecnologías que pueden...
Dejemos de lado el hecho de que los usuarios no los queremos y que como mucho los toleramos si no son demasiado restrictivos y que la industria debería tomar nota e ir por otro sitio, pero según se puede leer en Blu-Ray...
Avances en la construcción de cerebros artificiales, según explica Enrique Dans: Un verdadero cerebro artificial – En el artículo Building the Cortex in Silicon del MIT Technology Review se cuenta cómo un grupo de científicos en Stanford que trabajan en ese enigmático...

¿Ha probado a abrirlo? Un auténtico momento BOFHer medieval ¿Qué hacian en la edad media los monjes cuanto tenían problemas con sus «nuevos» sistemas de escritura? Llamaban al Soporte Técnico de los Libros [subtítulos en inglés y danés para el noruego...
Sin palabras me he quedado al leer sobre el sistema de computación cuántica llamado Orion que la compañía canadiense D-Wave presentará la semana que viene al público. La descripción técnica está llena de términos que asombran a la vez que asustan un...
El hacker y las hormigas. Versión 2.0. Rudy Rucker. Ómicron 2006. ISBN: 849657525X. En inglés: Hacker and the Ants. Jerzy Rugby es un hacker en el sentido tradicional de la palabra que trabaja como programador en GoMotion, donde su ocupación es desarrollar...
The programmer hierarchy muestra visualmente la estructura jerárquica de los programadores informáticos en diferentes lenguajes, con un toque de humor y autocrítica. La flecha indica «se consideran a si mismos superiores a…» Los programadores en LISP y Ensamblador ocupan lo más alto...
Si utilizas algo como Apple Remote Desktop o VNC para controlar la propia máquina en que se está ejecutando, lo que se ve es esto. Algo parecido a cuando enfocas una cámara de vídeo conectada a una televisión a la propia...
Después de varios meses de versiones beta disponible para descarga, Adobe presenta la versión final de Adobe Photoshop Lightroom que estará disponible a finales de febrero en inglés (de momento no habrá versión en español); hasta entonces las versiones betas se mantienen...
Por Nacho Palou -
29 ENE 2007
Noruega declara ilegal iTunes — La cuestión radica en que los contenidos que se compran legalmente en iTunes sólo funcionan en el reproductor del mismo nombre y en los dispositivos iPod de Apple, cuando una canción pagada tendría que ser compatible con...
Por Nacho Palou -
25 ENE 2007
En cuatro sencillos pasos puedes mejorar el aspecto de tus fotografías dándoles colores más brillantes y luminosos.Foto original a la izquierda, ajustada siguiendo el tutorial a la derecha.La fotografía del ejemplo es el típico caso de cámara deslumbrada por un exceso de...
Por Nacho Palou -
24 ENE 2007
Un poco de historia reciente de la informática: cómo un programador de Microsoft inventó la API de XMLHTTP, la incorporó en Explorer 5 y cómo luego pasaría a estandarizarse y convertirse en uno de los pilares técnicos de la Web 2.0 y...

The History Of Hacking es un gran documental educativo a la par que histórico que en su día emitió Discovery Channel en castellano. Trata sobre la historia de los hackers, empezando por los phreakers o hackers telefónicos como John Draper (Captain...
Ya se puede descargar Google Earth, versión 4, el popular programa de Google para visualización de imágenes aéreas y de satélite de ciudades y cualquier lugar del mundo «volando como si fueras Supermán». Algunas de las novedades que incluye esta nueva versión,...
Estaba esperando a conocer más detalles del Apple TV porque en casa quiero montar algún tipo de centro multimedia para sustituir al vídeo, que se nos murió hace más de un año, al equipo de música, que tenemos arrinconado y sin conectar...
No se si como se decía antes de que empezara la keynote de Steve Jobs hoy en la Macworld Expo 2006 habrá sido la presentación de la década o no, pero tras anunciar algunas cifras -2.000 millones de canciones- y contenido nuevo...
En un par de horas comienza la conferencia inaugural de Steve Jobs en la Macworld Expo de San Francisco, y si normalmente ya es algo que todos los maqueros esperamos ansiosamente, las expectativas para la de este año están por las nubes....
Por fin he tenido oportunidad de acabar de ver El mundo según Google, un documental recientemente emitido en el canal Odisea que trata de Google en el que directivos e investigadores de la empresa hablan de ella, de lo que están haciendo,...
Casi un año después de la salida de los primeros Macintosh con procesador Intel, Adobe se lo sigue tomando con calma para sacar de una vez una versión universal de sus aplicaciones que pueda aprovechar toda la potencia de estos nuevos procesadores,...
Aunque no utilizo Windows XP más que para lo imprescindible (básicamente, comprobar HTML y CSS) sí que debo reconocer que el software Parallels, que permite ejecutar Windows sobre ordenadores Mac con procesador Intel, es de los programas que más gratamente me ha...
Por Nacho Palou -
13 DIC 2006
La extensión FxIF (OS X, Windows) para el navegador Firefox extiende la información que proporciona la opción “Propiedades” del menú contextual que se muestra al pulsar con el botón derecho sobre una imagen (Ctrl+clic en Mac con ratones de un botón) con...
Por Nacho Palou -
11 DIC 2006
Interesante anotación en La Singularidad Desnuda sobre la posibilidad de que algún sistema, como podría ser Google, pudiera superar el Test de Turing en un futuro cercano. El razonamiento tiene que ver con el hecho de que los buscadores como Google parecen...
Desde hace un par de meses Adobe ofrece una serie de cursos y seminarios online vía web utilizando su tecnología Adobe Connect. Los seminarios retransmitidos en directo, permiten la asistencia de los oyentes desde cualquier lugar, vía web en la ventana del...
Por Nacho Palou -
4 DIC 2006
Stellarium es un programa gratuito de código abierto. Es capaz de mostrar un cielo realista en 3D, tal como se aprecia a simple vista, con binoculares o telescopio.Tiene un catálogo de unos 120.000 objetos y está disponible en español (y otros muchos...
Por Nacho Palou -
3 DIC 2006
Como por ejemplo...Vaya... ¡Oops! Esto no lo hacía antes... Hmmm, qué raro... Tal vez haciendo esto...Y unas cuantas más en 101 Things you do NOT want your System Administrator to say. (Vía Populicio.us.)...
Por Nacho Palou -
1 DIC 2006
¡Ah, El maravilloso mundo de los simuladores de tráfico. En esta ocasión encontré esta referencia a el paso de la muerte que en realidad se llama técnicamente Multiagent Traffic Management: A Reservation-Based Intersection Control Mechanism [Applet Java]. Simplemente haz clic y elige...
Divertido comando para ejecutar en la aplicación Terminal de Mac OS X: say hello y otros más o menos útiles en Ten OS X Command Line Utilities you might not know about. Capturas de DVD en Mac OS XSolucionar problemas de arranque...
Por Nacho Palou -
24 NOV 2006
The Top Ten Things I Love Most About Woz es una encantadora lista que escribió nuestro admirado Guy Kawasaki sobre nuestro no menos admirado «Woz», Steve Wozniak, legendario hacker y creador de los primeros ordenadores Apple entre otras cosas. Le pedí permiso...
Mi iMac me avisó hoy de que estaba disponible la actualización del firmware iMac EFI Firmware Update 1.1 que está recomendada para todos los iMac Intel que corran Mac OS X 10.4.6 o superior. El procedimiento de instalación del firmware es: Bajarte...
Para cuando tengas una horita libre, un documental de la BBC sobre un juego que a lo mejor te suena y al que a lo mejor jugaste alguna vez, Tetris, y su autor, Alexey Pazhitnov: BBC >> Tetris - From Russia With...
Hacer una lista de los peores fracasos en cualquier campo es algo profundamente personal que tiene mucho que ver con las experiencias de cada uno, así que seguro que si todos nos ponemos a hacer nuestras listas de los peores fracasos de...
Si utilizas una pantalla LCD o TFT («plana» o de un portátil) puede interesarte activar ClearType, la tecnología de Windows XP que mejora notablemente la visualización de texto en pantalla (cualquier tipo de texto) que se agradece especialmente navegando la web (y...
Por Nacho Palou -
26 OCT 2006
A través de ThinkWasabi encontré un pequeño programa para Mac, gratuito, que facilita enormemente la tarea de pasar archivos entre varios ordenadores de una misma red local. DropCopy se muestra como un pequeño círculo que se puede colocar en cualquier parte del...
Por Nacho Palou -
25 OCT 2006
La encuesta informal que publicamos ayer sobre la gente que usaba Spectrum, Commodore, Amstrad y demás dió como resultado (interpretable) lo que más o menos se podía suponer: que el Spectrum fue bastante más popular que otros ordenadores y que más o...
Gracias al atajo publicado por el Dr. Wasabi hemos podido descargar la versión 2.0 final del navegador Firefox (sin variaciones respecto a la última RC3) con unas horas de adelanto respecto a la fecha de lanzamiento oficial que es mañana 24 octubre....
Por Nacho Palou -
23 OCT 2006
iWoz. Computer Geek to Cult Icon: Getting to the Core of Apple's Inventor. Steve Wozniak y Gina Smith. W W Norton & Co Ltd, 25 de septiembre de 2006. ISBN: 0393061434. Inglés. Tenía muchas ganas de leer esta autobiografía de Steve Wozniak,...
Angeloso publicó una curiosa Historia del Spectrum y de Sir Clive Sinclair y se preguntaba desde PlanetaTortuga.com por cuál habrá sido la trayectoria informática de la gente proveniente de los míticos tiempos de los Commodore, los Spectrums y los Amstrad, los más...
Internet Explorer 7 para Windows, la nueva versión del navegador web más usado del mundo, ya se puede descargar desde la web de Microsoft, así que los amantes del riesgo pueden pasar un día entretenido. Los requerimientos son pocos: tener instalado Windows...
Según cuentan en ComputerWorld, más del sesenta por ciento de los directores de informática de empresas estadounidenses dijeron en una reciente encuesta que todavía usan activamente el lenguaje COBOL en algunos de sus sistemas, y, lo cual es todavía más asombroso, también...
HawkWings es un blog decidado exclusivamente a la aplicación Mail de Apple, cariñosamente conocida como Mail.app. No hubiera pensado que existiera tal grado de especialización ni un blog dedicado a una aplicación tan común y corriente, pero en cierto modo tiene...
Convert HTML to Javascript Include Source es una página que puede resultar útil para programadores de páginas web. Lo que hace es que convierte un trozo de código HTML cualquiera a una función document.write de Javascript que se puede incluir a su...
Esta lista que publicó originalmente The Enquirer en 2006 está pensanda en los «pirados» por leerlo todo sobre la historia de la industria de la informática, las empresas y sus protagonistas. Es una selección que combina algunos títulos bastante recientes con...
Mat! de Other Films nos envió esto que suena interesante: 8 BIT es un documental de realización totalmente independiente y con vocación artistica (se estrenara el proximo 7 de Octubre en el moma de Nueva York) que se adentra en la relación...
Como cada 29 de septiembre, la LSPM cumple años. Esta vez es toda una década, un tiempo casi infinito en Internet. Digamos que en «años-perro» de esos que valen ×7, esa lista de correo debería estar ya jubilada, pero mírala, ahí sigue....
Desde hoy está disponible para descarga el Adobe Photoshop Lightroom beta 4, el programa fotográfico antes conocido como Adobe Lightroom a secas. Con esta versión los desarrollos de Lightroom para Mac y Windows se ponen a la par después de unos meses...
Por Nacho Palou -
25 SEP 2006
¡Cuidado! Me llegó un curioso virus (o algo parecido) por correo. Se hace pasar por un envío de un amigo desde YouTube, con nombre de atractiva modelo. En el From: pone YouTube, y va dirigido a tu nombre real. No hay más...
Si no nos avisa Martín se nos hubiera pasado totalmente, pero resulta que el 13 de septiembre (el 12 en el caso de los años bisiestos) es el día 28 del año, motivo por el que se celebra en él el Día...
IBM 305 en el arsenal Red River del ejército de los Estados Unidos. Las dos unidades que se ven en primer plano son dos discos duros 350; al fondo están la consola 380 y la unidad de proceso del 305. Con un...
Mi PowerBook 15 era de los afortunados potenciales a la combustión espontánea, de modo que solicité el reemplazo de la batería en Apple –siguiendo las indicaciones del «Importante aviso de seguridad» que me llegó por mail. El proceso bien y la respuesta...
Por Nacho Palou -
7 SEP 2006
El humor sandwichero de xkcd....
Para un trabajo que estoy terminando de desarrollar necesito recopilar preguntas y dudas típicas sobre el funcionamiento del correo electrónico, especialmente entre los usuarios principiantes y novatos. Agradeceré todas las preguntas de este estilo que pueda recibir, sobre todo si son realmente...
Los casos de ordenadores entrando en combustión espontánea que han ido apareciendo este verano podrían estar relacionados finalmente con varios millones de baterías fabricadas por Sony para Apple, Dell, y otros fabricantes queEn ciertas condiciones presentan un elevado riesgo de sobreclentarse o...
Muerte, muerte, muerte: Muerte a Bloq Mayúsculas – Pieter Hintjens ha iniciado una campaña para difundir su opinión de que la tecla de Bloqueo Mayúsculas está obsoleta, no es necesaria y encima es la causante de numerosos fallos y malentendidos. Dice que...
Los ha encontrado Salva y están en PixelGirl Presents: Star Trek: f I Were A Thief In The 24th Century, una colección de 105 iconos sobre todas las series de Star Trek incluyendo algunos realmente rebuscados, propios de los trekkies más frikis...

El 8 de diciembre de 1968, durante la Fall Joint Computer Conference, Douglas Engelbart y su equipo dejaron asombrados a propios y extraños con una demostración del oNLine System, el primer sistema informático que hacía uso de un interfaz WIMP. Con...
Buscando herramientas para optimizar el disco duro y hacer copias de seguridad encontré Carbon Copy Cloner para Mac OS X que es una sencilla herramienta para crear copias completas de un disco, incluyendo las carpetas del sistema y las aplicaciones, en discos...
Estos son dos artículos que encontré interesantes en los últimos ejemplares de Investigación y Ciencia, aunque creo que en la web sólo están disponibles completos para leer en inglés (para suscriptores): The Science behind Sudoku, explica algunos temas matemáticos relevantes, incluyendo lo...
Con un procesador Intel 8088 a 4,77 MHz y una configuración base de 16 KB de memoria RAM -las disketeras eran opcionales- hoy hace 25 años que se ponía a la venta el modelo 5150 de IBM, más conocido como IBM PC....
Impresionantes demos en vídeo procedentes del TED sobre una interfaz que al permitir al ordenador procesar información de múltiples puntos de la pantalla táctil de forma simultánea se puede utilizar con las dos manos y varios dedos a la vez, creando...
Todos los que en nuestro trabajo tenemos que solucionar problemas de los usuarios con sus ordenadores o con la informática en general estamos más que acostumbrados a que de vez en cuando nos lleguen mensajes o peticiones sin demasiado sentido que hay...
El spam es un auténtico coñazo, pero el proyecto Spam Plants de Alex Dragulescu intenta sacar algo bonito de él analizando el contenido de lotes de esos mensajes y convirtiéndolos en una especie de plantas generadas por ordenador, aunque a mi me...
Pues parece que el calor Dell verano sigue jugando malas pasadas a propietarios de ordenadores que acaban convertidos en bolas de fuego. Pero no es una «feature» exclusiva de los Dell, sino un problema cada vez más común entre los ordenadores portátiles...
Por Nacho Palou -
3 AGO 2006
La teoría de la aplicación experimental Photosynth de Microsoft suena bastante bien:Partiendo de una colección de fotos tomadas en un mismo lugar o a un mismo objeto analiza las similitudes de éstas y las muestra en la forma de un entorno tridimensional.De...
Por Nacho Palou -
2 AGO 2006
¡Ah!, la Wikipedia, esa fuente creciente de información donde cuando entras puedes tardar horas en volver a salir... Trasteando un poco encontré una tabla comparativa de sistemas operativos: información general, tecnica y del entorno gráfico de los SO más populares. La definición...
Por Nacho Palou -
1 AGO 2006
Ultimo viernes de julio, así que hoy es el System Administrator Appreciation Day o Día de Mostrar Aprecio a tu Administrador de Sistemas –y conviene mucho mostrarle aprecio a tu administrador de sistemas de vez en cuando. Y ¡felicidades! si es tu...
Por Nacho Palou -
28 JUL 2006
Malas noticias para Nicholas Negroponte y su proyecto OLPC, el portátil de 100 dólares para niños de países en vías de desarrollo, ya que el Ministerio de Educación de India acaba de rechazar categóricamente entrar en el proyecto, al que califica de...
Calendarios chinos, mayas y lunares, sistemas de cifrado, espirales de números primos, stegonografía, criptosistemas, conversores de gráficos, destructores de datos, factorizadores, autómatas celulares, tiempo fractal, calculadores de frecuencias, conversión de fechas… ¡Demasiadas palabras interesantes juntas! Un montón de software para Windows y...
Firefox Cheat Sheet, recopilación de las combinaciones de teclas y atajos de teclado y de ratón para manejar Firefox. Incluye algunos trucos extras e información sobre la configuración del navegador. «Chuleta» para Google«Chuleta» para Movable Type...
Por Nacho Palou -
26 JUL 2006
¿Por qué al calendario de Unix en septiembre de 1752 le faltan 11 días? (Compruébalo primero tecleando cal 9 1752). September 1752 S M Tu W Th F S 1 2 14 15 16 17 18 19 20 21 22 23 24...
¡Ya era hora! Casi un año después de presentar el Mighty Mouse (AKA Súper Ratón) Apple ha sacado por fin el Mighty Mouse inalámbrico… justo cuando el ratón Trust que venía usando acaba de cascar. Apple Store, allá voy. Actualización 31 de...
(¡Por fin un uso doblemente adecuado para la frase!) 2001: A Space Odyssey Icons es una pequeña pero esmerada colección de iconos sobre la mítica película de Stanley Kubrik, 2001: Una Odisea del Espacio. Vienen ya listos para copipastear, en formatos preparados...
Cada vez que se hace una lista sobre el uso de Internet y tecnologías similares España suele quedar a la cola cuando se trata de algo bueno, aunque escala puestos rápidamente cuando la lista trata un tema chungo, como por ejemplo el...
El hardware es prehistórico, aunque mola mucho, pero los conceptos acerca de generadores de ondas, forma de estas, envolventes, muestreos y similares son aún completamente válidos en este documental de introducción a la música electrónica: Discovering Electronic Music Part 1, Part 2,...
54 iconos de la serie Lost (Perdidos) para Mac diseñados por Lard Designs. Inapropiada cantidad porque deberían haber sido 42, pero bueno. Aun así están muy bien. Incluyendo la carpeta con la estatuilla de la virgen, que debe ser la de «ayuda...
Adobe Lightroom Beta, programa específico para la organización y tratamiendo de fotogradías ya está disponible para Windows. Lightroom, del ya hemos hablado por aquí en anteriores ocasiones (hasta ahora sólo estaba disponible para Mac OS X), está actualmente disponible públicamente en beta...
Por Nacho Palou -
20 JUL 2006
Después de casi dar por perdida la batalla contra el spam decidí buscar algún software adicional para Mac OS X que resultara más inteligente que los filtros del Apple Mail, que definitivamente funcionan fatal y con el tiempo se vuelven tontos y...
BBS: The Documentary. DVD (2005). Jason Scott. Inglés. (Subtítulos en inglés). 40 dólares (pack 3 DVDs). Licenciado como Creative Commons, descargable en torrents y disponible en YouTube. Hace tiempo descubrí esta pequeña joya de documental y tras leer sobre ella y...
De vuelta a 1972: PongSaver, el salvapantallas de Pong para Mac OS X. ¡Y de paso marca la hora! (Vía Applesfera.) Actualización (14 de julio de 2006): Buro Vormkrijgers, los fabricantes del Reloj pong de pared también tienen una versión en salvapantallas...
Cuando Wired (la revista) nació, a principios de los 90, todavía no existía la Web. Luego pasaron años hablando de Internet y el ciberespacio, bajo la paradójica situación de que ni ellos mismos tenían web – de hecho fueron bastante criticados por...
El super-ratón moderno de Apple es tan cómodo que cuando te acostumbras ya no hay vuelta atrás, especialmente por la ruedecita (bola) central para hacer el desplazamiento por las ventanas. El problema es que con el tiempo se acaba ensuciando y el...
He visto cosas que no creeríais, como esta colección de Iconos Blade Runner para Mac OS X en Pimley's Projects. Son sólo cinco pero muy bien realizados. Me gustaron especialmente el unicornio y la pistola de Deckard. Están en formato para Mac...
Es oficial, fin del soporte técnico para Windows 98 y Windows Me desde hoy, aunque el contenido del soporte técnico en línea seguirá disponible. La propia empresa lo explica así:Microsoft está retirando el soporte para estos productos porque se encuentran desactualizados y...
Un truco viejo pero útil para reproducir películas con QuickTime Player a pantalla completa sin necesidad de pagar la versión QuickTime Pro como se explica en Full screen for free. Abre el Editor de Scriptsescribe (o copia y pega este script) tell...
Por Nacho Palou -
11 JUL 2006
Esto sí que son, literalmente hablando, memory sticks: Wooden Memory SticksEl estudio de diseño OOOMS del que proceden tiene por cierto un portfolio de ideas-productos que merece la pena ver. Y su propia interpretación sobre qué es un blog –no se puede...
Por Nacho Palou -
10 JUL 2006
Apple Transparent Display Concept es un bonita idea de un Mac que cuando está apagado es casi transparente –recomendado ver la imagen a tamaño original con la opción de Flickr «See different sizes» (Enviado por Asier –a quien también le gustaría tener...
Por Nacho Palou -
7 JUL 2006
CoverFlow es un programita para Mac OS X Tiger, que crea un catálogo visual con las portadas de los álbumes de música que tienes en tu librería iTunes. En el primer arranque hace la recopilación trayéndose las imágenes de Internet. La interfaz...
Comienza un lunes de un mes largo, caluroso y aburrido. Qué mejor que empezar la mañana con una broma a los compañeros de oficina. Especialmente recomendable si has sido de los primeros en llegar. Desmonta con cuidado las teclas de sus teclados...
Nacho Escolar escribe en su artículo Canon digital: el unánime absurdo, entre otras cosas, acerca del hecho de que la recién aprobada Ley de Propiedad Intelectual establece por ley (antes era un acuerdo entre los fabricantes de soportes y la SGAE) un...
El artículo One Cheap Desktop for All de Wired me recordó una anotación de Juan sobre el ordenador de 150 dólares que Yellow Sheep River va a poner a la venta basándose en «una iniciativa empresarial rentable sin necesidad de ayudas públicas»...
Voy a denominar a ésta la Semana de las Soluciones Técnicas Absurdas, literalmente: Si el disco externo LaCie Brick no se monta en el iMac al arrancar y te pega un susto de muerte, la solución es: 1. Abrir Utilidad de Discos...
El País publica hoy la segunda parte de la entrevista que le hizo Mercè Molist a Kevin Mitnick, titulada Los mejores consejos de un 'superhacker', en la que Mitnick explica las precauciones básicas que debe tomar el propietario de un ordenador. (Gracias,...

Conway: el genio que hizo que los nerds perdieran horas estudiando patrones simples y complejos.
He aquí una explicación rápida y sencilla, paso-a-paso, sobre cómo cifrar archivos en Mac OS X para mantenerlos en secreto. La idea es crear un volumen de disco «cifrado» con el programa Utilidad de Discos que va incluido con el sistema (carpeta...
Un poco de especulación sin fundamento para pasar el rato: Microsoft fue fundada el 4 de abril de 1975, Bill Gates nació el 28 de octubre de 1955… y acaba de anunciar que se retira del día a día de la empresa.Apple...
Si tienes interés por ver qué le contó Bill Gates a sus empleados sobre su decisión de dejar el día a día de la compañía para pasar a dedicarse fundamentalmente a su fundación el texto del correo electrónico está disponible en Bill...

Microsiervos (Microserfs). Douglas Coupland. 1995. Harper Collins. Publicado en castellano en 1996 por Ediciones B, Grupo Z. ISBN 84-406-6646-2. Traducido por J.G. López Guix y C. Francí. Existe una segunda edición de bolsillo, mejorada y revisada, también en Ediciones B (ambas...
Con el objetivo de dedicarse plenamente a la dirección de la fundación benéfica que creó junto con su mujer Bill Gates anunciaba ayer que irá abandonando poco a poco sus responsabilidades en Microsoft, empezando por el puesto de Chief Software Architect, que...
En la sección ofertas de trabajo para geeks del Wiki entró una nueva oferta para un bioestadístico así que si conoces alguno, avísale. Conozco personalmente a la gente de la empresa en cuestión y tienen muy buen ambiente y un jefe estupendo,...
Tronik de Impacto6 tiene algunos proyectos para construir máquinas arcade de videojuegos, sobre los que ha publicado una serie de explicaciones y fotos paso a paso, como las de Interceptor, una cabina de simulación, que elevan el concepto de «bricomanía» a un...
Dos nuevas betas recién salidas del horno para jugar:Por un lado, la primera beta de Flock, el navegador basado en Mozilla que integra el acceso a sitios como de.icio.us, Flickr y Photobucket, un lector de feeds RSS, y que además sirve como...
Tal día como hoy, 14 de junio, pero de 1951, hace exactamente 55 años, el ordenador UNIVAC I entraba en funcionamiento en la oficina del Censo de los Estados Unidos. El UNIVAC I (siglas de Universal Automatic Computer) estaba construido con 5.200...
El horror de todo geek: los amigos con problemas informáticos. Me lo recordó esta historia que vi en el diario Qué de Madrid hoy, que en realidad viene a dar otros datos sobre el tema: Cuando hay un problema informático las empresas...
La colección de widgets de beon tiene la particularidad de que sus componentes funcionan por sí solos, de modo que para consultarlos y utilizarlos directamente desde el escritorio no es necesario instalar ningún motor tipo Yahoo! Widgets (aka Konfabulator) o el Dashboard...
Por Nacho Palou -
13 JUN 2006
Durante una auditoría de seguridad informática en una empresa que se dedica a conceder créditos en la que los responsables de ésta se mostraron especialmente preocupados por el factor humano y lo fácilmente que en el pasado sus empleados habían revelado claves...
Igual que se cuenta que uno siempre recuerda su primer coche, nosotros los geeks siempre recordamos nuestro primer ordenador. Si en tu caso fue un Commodore (C64, VIC-20, Amiga…) y ahora usas un Macintosh, Think Commodore seguro que te interesa, ya que...
Si utilizas la apllicación Apple Mail para el correo electrónico y quieres aprovechar la superficie de pantalla de los monitores panorámicos como los que llevan los iMac puedes optar por visualizar la aplicación en horizontal con tres paneles verticales con el plgin...
Por Nacho Palou -
5 JUN 2006
Jack PC es, literalmente, un PC del tamaño de un enchufe, que puede empotrarse en la pared. Jack PC – Se trata de un Pocket PC capaz de instalarse sustituyendo a cualquier toma estándar de la pared (enchufe, antena, red, etc.). Microprocesador...
Sing that iTune! 3.0 es un widget fenomenal: si hay música sonando en iTunes se descarga y muestra en el dashboard la letra de la canción y la imagen de la portada del álbum. Si se quiere tanto la imagen como la...
Por Nacho Palou -
2 JUN 2006
How To Backup Your Mac Intelligently tiene una colección de consejos, algunos más ingeniosos que otros, sobre cómo hacer una copia de seguridad de todo lo que hay en tu Mac. En este mundo moderno de la vida digital donde cada mes...
¡Múltiples historias de terror podrían insertarse aquí en un lunes por la mañana! Eduardo hizo una buena traducción de la excelente anotación: How Not to Lead Geeks: Cómo no tratar a los geeks en el trabajo Subestimar el entrenamiento. No dar reconocimiento....
Paul Stamatiou hace una selección de los siete mejores grupos de Flickr para «techies» en Top 7 Techie Flickr Groups en la que seguro que encuentras más de uno que te guste (si es que no eres ya miembro de alguno de...
Otro ingenioso uso para los sensores de movimiento de los portátiles de Apple, el SmacBook Pro te permite cambiar de escritorios dándole guantazos al portátil. El vídeo es muy aclaratorio: (Gracias, Luis.) MacSaber: Cómo convertir un Mac en un Sable Láser de...
Esta lista publicada por la edición norteamericana de PC World es brutal: [ALT1040] – PC World arma una lista de los 25 peores productos tecnológicos de todos los tiempos. Los cinco peores:AOLRealPlayer, de RealNetworksSoftRAM, de SyncronysMicrosoft Windows MilleniumCDs musicales de Sony BMG...
The broken laptop I sold on ebay. (Algunas fotos [+18, NSFW]) La ironía/sarcasmo que hay detrás de todo esto es increíble. (¡Prueba primero a leer la historia! Está en inglés pero no es muy difícil.) Se trata del «supuesto blog personal» de...
SELECT * FROM consejillos WHERE nivel = “novatos”; Chuleta para MySQL...
MacSaber utiliza los sensores de movimiento que llevan algunos de los portátiles Apple para convertirlos en sables láser, al menos en apariencia… y con un poco de imaginación. Instalas el programa y entonces a medida que agitas el portátil emite el tradicional...
Apple ha presentado hoy los nuevos portátiles que sustituyen a los iBook en su gama y… ¡Sorpresa, se llaman MacBook! ;-) El comunicado de prensa (todavía en inglés) está en Apple Unveils New MacBook Featuring Intel Core Duo Processors, la página de...
La extensión TinyUrl Creator para Firefox incorpora la función del servicio web TinyURL directamente en el menú contextual del navegador. Más cómodo imposible.
Por Nacho Palou -
13 MAY 2006
Versión final de NetNewsWire 2.1, el mejor lector de feeds RSS para Mac. Imprescindible para los MacIntel (ahora NNW es binario universal). Las características principales a destacar son las mismas que las comentadas en la anotación NetNewsWire 2.1b16: beta pública una veintena...
Por Nacho Palou -
10 MAY 2006
Aquí va un truco de captura de pantalla en Mac OS X que aprendí no recuerdo dónde porque fue hace algún tiempo –de hecho tenía idea de haberlo puesto ya– que permite capturar en una imagen elementos independientes que haya en pantalla,...
Por Nacho Palou -
10 MAY 2006
Emilio nos invitó amablemente a probar la aplicación infoscape (blog) que está desarrollando en sus ratos libres. Aunque por aquí utilizamos ordenadores Macintosh también hay algún PC con Windows disponible para pruebas y comprobaciones y en uno de ellos instalé la versión...
Por Nacho Palou -
10 MAY 2006
Suena el teléfono en casa; es una amiga que necesita de una sesión de soporte técnico:-Mira, es que tengo que hacer un trabajo en PowerPoint y quiero hacer que suenen unas cosas cuando haga clic en un botón, pero no me funciona...
Si cada vez generas más y más material digital que quieres conservar, ¿cómo harás para guardar una copia de seguridad de más de 100 gigabytes de datos cada año, durante los próximos 50 años? Mark Pilgrim cuenta un reciente crash de disco...
Hubo un tiempo en que las estaciones de trabajo Silicon Graphics rulaban la tierra. Hoy SGI declara bancarrota según cuenta el Wall Street journal. Se apunta al temido «chapter 11» de la legislación norteamericana, que viene a ser lo que aquí conocemos...
Para variar, un artículo que habla bien de los hackers, titulado precisamente ¿Qué tenemos que agradecer a los hackers? Unas pistas: videojuegos, música generada por ordenador, el ordenador personal, una «cosilla» llamada Internet… (Vía Port 666.) The New Hacker's Dictionary, Third Edition;...
Mientras el proceso que terminará por poner un MacBook Pro en mis manos sigue sus pasos (después de todos estos meses sigo odiando el nombre), estos días tuve la oportunidad de volver a trastear un rato con uno de ellos, en este...
Wired publica Apple Heroes and Villains, donde están todos los que deben estar: desde los «fálsos ídolos» a los verdaderos villanos, lo héroes y los cabezas de turco de la historia de Apple… Incluyendo algunos que fueron villanos durante una época y...
Selling the Computer Revolution es una colección de cientos de folletos de ordenadores ya desaparecidos, que se pueden buscar por tipo, marca o década, a partir de los años 50. Ideal para saber cómo se las arreglaban para vender un UNIVAC, descubrir...
Briblo es un salvapantallas que va haciendo caer piezas de LEGO en la pantalla. Se pueden mover con el cursor (lo cual no desactiva el salvapantallas, pero el ratón o cualqier otra lo hará). Funciona en Mac OS X y en Windows....
¿Cómo generas una nube de cientos de millones de tags? ¿O cómo guardas 1.400 millones de posts en una base de datos? O'Reilly Radar está recopilando una serie de historias sobre «batallitas» con bases de datos gigantescas en servicios de nueva generación...
Llevo un par de semanas probando FlickrExport (Mac OS X) y la verdad es que va muy bien aunque presenta cierta inestabilidad a veces. También Flickr se sigue atascando a veces mientras subes fotos, pero bueno. Creo que definitivamente es de lo...
Hoy se anunció un nuevo blog: Applesfera, de la fábrica de Weblogs, S.L.. Bienvenidos al blog de Apple – Como ya habrás adivinado en este blog encontrarás todo lo relacionado con los productos y servicios del universo Apple: Mac OS, iPod, portátiles,...
Cómo sacarle el máximo a tu Mac, segunda parte es una especie de «curso para principiantes de Mac OS X» bastante útil si estás empezando con un Mac, porque resume los atajos de teclado más importantes. Además, Diego (Minid) lo cuenta con...
Un montón de fotos de las instalaciones en el campus de Microsoft donde se desarrolla el software para Mac. Por ahí acumulan muchas Mac de todos los tipos y colores, incluyendo una colección de 150 Mac minis perfectamente alineados.Suman un montón de...
Por Nacho Palou -
21 ABR 2006
Hace unas semanas el pequeño iBook 12" que tenemos en casa empezó a perder la batería. Cada vez duraba menos y finalmente perdió hasta el reloj interno y no podía funcionar sin estar enchufado a la corriente. Algo que era bastante extraño...
¡Momento de despiste tecnológico! Mientras mandaba un fax con la impresora-escáner-fax-copiadora de la oficina tecleé el número de fax y pulsé el botón de OK. Pero el cacharro estaba en modo «fotocopiar». De modo que la máquina obedientemente se puso a hacer...
Sellos de distintos países que honran personajes e inventos claves relacionados con la informática: Computers on Stamps.Si, Bill también tiene uno. Mi favorito es éste de Indonesia: Y2K bug, ¡qué auténtico!...
Por Nacho Palou -
18 ABR 2006
En Apple Mail: Mayúsculas-Comando-U En NetNewsWire: Comando-K Problema resuelto. Tiempo estimado: 5 segundos....
Cuando Apple anunció que se pasaba a procesadores Intel una de las primeras preguntas que surgieron fue la de si iba a ser posible instalar Windows en esas máquinas. Phil Schiller dijo entonces que aunque no lo iban a soportar, tampoco lo...
Ya es oficial: instala Windows XP en tu Mac (con procesador Intel):Apple incluirá en la próxima versión de Mac OS X, Leopard, la tecnología que permitirá instalar y ejecutar el sistema operativo Windows XP en tu Mac. Puedes descargar la beta pública...
Por Nacho Palou -
5 ABR 2006
En CNN, BillG cuenta cómo es su mesa de trabajo: How I Work: Bill Gates. Si echas un vistazo a esta oficina, verás que no hay mucho papel. En la mesa tengo tres pantallas, sincronizadas con el mismo escritorio. Puedo arrastrar cosas...
En general para instalar una aplicación en OS X basta con copiarla al disco duro del ordenador –a la carpeta Aplicaciones por ejemplo. Sin embargo al ejecutarlas esas aplicaciones pueden crear carpetas y/o archivos auxiliares (para las preferencias por ejemplo) que no...
Por Nacho Palou -
4 ABR 2006
Esto del spam está alcanzando proporciones desorbitadas. Últimamente los «malos» spammean el buzón que usamos para recibir mensajes sobre las anotaciones del blog, este fin de semana llegaron cientos. Además utilizan el formulario de «enviar a un amigo» para enviar spam a...
Apple ha decidido no organizar ningún tipo de acto ni presentación de producto para celebrar su 30 aniversario, a pesar de lo que algunos esperaban, pero muchos de los sitios que siguen la empresa de la manzana sí han ido publicando cosas...
No todos lo días se cumplen 30 años. ¡Felicidades, Apple!...
Si hay alguien que debe tener una cierta idea de por dónde pueden ir los tiros con esto de la web es precisamente quien la inventó, Sir Tim Berners-Lee, quien hace unos días impartió una conferencia al respecto en el Oxford Internet...
Esta semana se presentó en Santiago de Compostela el proyecto de construcción del superordenador «Finis Terrae», una máquina que cuando esté terminada al «módico» precio de 60 millones de euros contará con 18 terabytes de memoria y unos 2.500 procesadores. Según cuenta...
La vena nostálgica de Alvy de ayer con la Killer List of Video Games y Marble Madness me recordó que tenía guardados por ahí unos enlaces a una serie de anotaciones de Boja sobre el emulador MAME (que por cierto también podría...
Se acerca el 30º aniversario de Apple Computer, que es mañana 1 de abril, y empiezan a aparecer vídeos y otras cusiorisadades. ALT1040 reseñó dos muy buenos: Un recorrido por la era moderna de Apple que realmente es precioso, y con una...
A ver si sacamos un ratillo para instalar algo así en el sótano: ILM's Datacenter – La revista Computer Graphics World ha podido echar un vistazo al interior del datacenter de Industrial Light and Magic después de que se trasladaran de San...
El próximo día 1 de abril Apple cumple 30 años. Wired News ha preparado una gallería de todos los sistemas operativos desarrollados o utilizados para los ordenador de la compañía: Apple OS GalleryOtros especiales en Wired con motivo del 30 aniversario: Apple...
Por Nacho Palou -
30 MAR 2006
En una entrevista a Steve Ballmer, CEO (Presidente y Consejero Delegado) de Microsoft:P.: ¿Tiene usted un iPod? R.: No, no tengo. Y mis hijos tampoco. En muchos aspectos mis hijos están tan mal criados como muchos otros, pero al menos en este...
Por Nacho Palou -
30 MAR 2006
Me instalé Bye, Bye Dashboard que lo único que hace es eliminar el Dashboard de Mac OS X, un chisme curioso y llamativo pero que apenas uso, la verdad. Esta utilidad funciona bien y la máquina se nota un poco más rápida,...
Hoy se cumplen cinco años desde que saliera Cheetah, la primera versión pública de Mac OS X. Eduardo hace un breve repaso de su historia en Una breve historia del Mac OS X; John Siracusa publica en Ars Technica Five years of...
Desde hace meses venía sufriendo un bug que hacía que en varios iMac corriendo diversas versiones de Mac OS X el sonido no funcionara, pero únicamente en las películas Flash y similares, incluyendo los Google Vídeo, YouTube y todo ese tipo de...
Si estás tentado de instalar Windows XP en tu Macintosh con procesador Intel Core ahora que ya se sabe como hacerlo, Dual Booting XP es un wiki en el que se va recopilando la información acerca de los distintos parches disponibles, drivers...
Es una lástima que la calidad de imagen y sonido no sean mejores, pero en cualquier caso el documental de 1972 Computer Networks: The Heralds of Resource Sharing no tiene desperdicio. En él pioneros de Internet como J. C. R. Licklider,...
Brent Simmons acaba de anunciar la beta pública de NetNewsWire 2.1b16 para Mac OS X. Es la primera beta de la esperada versión 2.1. NetNewsWire del que he hablado más de una vez es mi agregador de feeds RSS favorito: es muy...
Aunque los parámetros de importación que vienen configurados por defecto en iTunes producen archivos de audio comprimidos con una buen relación entre tamaño y calidad en A Recording Engineer's Guide to the Secrets of iTunes and iPod se mencionan un par de...
Por Nacho Palou -
17 MAR 2006
ChessBrain aspira a ser el mayor ordenador de ajedrez del mundo. Es un «superordenador virtual» que funciona de forma distribuida en miles de ordenadores de Internet a la vez, algo pareceido a cómo funcionan SETI@Home y similares. Es un proyecto que...
Nacho escribió hace algún tiempo acerca del concurso que había en marcha para conseguir instalar Windows XP en uno de los nuevos Macintosh con procesador Intel de tal forma que el usuario pudiera escoger a la hora de encender el ordenador qué...

World of M.U.L.E. es una viejísima y desactualizada (pero completa) página dedicada a M.U.L.E., uno de los más legendarios y míticos videojuegos de estrategia multijugador que acapararon las listas de éxitos de los 80. Disponible para Commodore, Atari y otras plataformas,...
Por lo visto los modelos del OLPC, el famoso ordenador de 100 dólares del MIT, que Martín Varsavsky fotografió hace poco no eran los candidatos al diseño final sino prototipos o incluso maquetas, pues aparecen como «imágenes conceptuales» en en la web...
La Petite Claudine en El País: «Nuestros representantes políticos son analfabetos en el medio digital».P. ¿Qué opina sobre la reforma de la ley de Propiedad Intelectual?Como cualquier persona en su sano juicio, opino que es una barbaridad: establece que el usuario de...
La anotación de Alvy sobre Feed Your Reader me recordó lo poco intuitivo y complicado que resulta escoger aplicaciones por defecto para los diferentes protocolos de Internet en Mac OS X, tanto en la versión 10.3 (Jaguar) como en la versión 10.4...
Esto sí que es retro: Punched Cards, todo tipo de información histórica sobre las tarjetas perforadas. Tal y como cuentan en el artículo De tarjetas perforadas de Tecnología Obsoleta: Hay que reconocer como prodigiosas la infinidad de aplicaciones que llegó a tener...
Podquerón es el podcast del Grupo de Usuarios Macintosh de Málaga y la Costa del Sol (GUM/Málaga). Está dedicado a «las novedades en torno al Mac, Internet y el mundo de la tecnología y los gadgets». Después del «episodio piloto» (Podquerón...
Por Nacho Palou -
10 MAR 2006
IBM dejara de utilizar Windows a nivel corporativo – IBM ha cancelado su contrato con Microsoft a partir de Octubre de este año. Esto significa que IBM no usará Windows Vista para sus ordenadores de escritorio. A partir de Julio, los empleados...
Una cosa muy buena del mando a distancia que llevan los nuevos Mac es que no sólo tiene utilidad con el FrontRow –que todo sea dicho, en un entorno de trabajo se usa más bien poco. En Beyond the Front Row with...
Por Nacho Palou -
8 MAR 2006
Una amplia explicación en la Stanford Encyclopedia of Philosophy sobre uno de los asuntos más interesantes y profundos de la informática y la inteligencia artificial: The Turing Test, la propuesta planteada por Alan Turing hacia 1950 relativa a cómo decidir o considerar...
Endo es un nuevo agregador de feeds RSS creado por Adriaan, el autor de Ecto (nuestro editor de weblogs favorito), así que es obligatorio probarlo. Al parecer es bastante potente gracias a la función agrupación inteligente. Funciona sólo bajo Mac OS X...
Tenía pendiente escribir una pequeña guía de cómo copiar DVDs con Mac OS X, pero como es habitual estaba procrastinando un poco el tema, hasta que leí en Y viva el canon que nuestros «queridos» políticos han decidido ceder a las presiones...
Tengo marcado en la agenda iCal de Mac OS X que me avise todos los días 30 de cada mes porque es lo que denominamos el día del backup: una vez al mes hacemos una copia de seguridad completa de todo lo...
Martín Varsavsky estaba hace un par de días en el MIT, justo cuando estaban decidiendo el diseño final del ordenador de 100 dólares que pretenden hacer llegar a todos los niños de los países con menos medios, el OLPC, y recibió permiso...
Todos hemos leído en alguna ocasión una de esas historias de un portátil atropellado o que se cae desde el techo de un coche cuando el dueño arranca si acordarse de recoger el portátil y de cómo el portátil no sufre ni...
Un amigo me ha traído hoy un MacBook Pro a 2 GHz, recién llegado de la AppleStore, para que le configurara unas cosas, así que tuve la oportunidad de trastear con el cacharro unos 15 ó 20 minutos. Unas primeras observaciones sobre...
En mi trabajo del MundoReal™ utilizamos a menudo vídeos como apoyo en las exposiciones que hacemos. Ya hace tiempo que hemos dejado de usar vídeos de cinta y que nos hemos pasado a los reproductores de DVD «de todo a cien», y...
Les faltan mejores explicaciones de lo que sale en cada foto, pero este set de fotos en Flickr del Computer History Museum de Mountain View es muy interesante. Por destacar unas cuantas fotos, hay un Apple I, un Cray-1 en el que...
Ciertamente la computación cuántica es un poco difícil de entender: Un ordenador cuántico que funciona mejor cuando está apagado – Incluso para el loco mundo de la mecánica cuántica esto resulta chocante. Un programa para ordenador cuántico ha producido un resultado sin...

La frase de hoy estaba dedicada a la solución de soporte técnico más efectiva del mundo. Es la que usan los geeks de IT Crowd cada vez que suena el teléfono. Departamento técnico, ¿dígame? ¿Ha probado a apagarlo y encenderlo? Elías...
Quizás es que Apple no tuvo mucho tiempo de reaccionar e introducir una seguridad más fuerte en Mac OS X 10.4.5 para Intel respecto a la de la versión 10.4.4, pero apenas una semana después de su publicación Maxxuss ya se las...
Christopher Breen cuenta en Tale of a shifty shuffle como hace poco dos usuarios que estaban intercambiando archivos usando un iPod Shuffle como disco USB vinieron a pedirle ayuda para recuperar los datos que este contenía después de que el Shuffle dejara...
Este salvapantallas seguro que le encanta a Wicho: Holding Pattern. Lo que hace es convertir la pantalla en una ventanilla de avión cuando no se está usando, y vas viendo pasar las nubes y todo eso, con diversas fotos y fondos en...
El otro día desayunando con nuestro amigo Pedro comentamos el tema de la fotografía HDR (o HDRI, High Dynamic Range Imaging), una técnica de procesamiento de fotografías con la que se obtienen imágenes que incluyen una amplia gama de niveles de exposición...
Por Nacho Palou -
22 FEB 2006
A raíz de la aparición del troyano/gusano latestpics.tgz, alias OSX/Leap-A, alias Oompa/Loompa, Juan de Dios Santander ha hecho una lista de malware para Mac OS X. Afortunadamente la lista sólo tiene cuatro miembros, y ninguno de ellos es capaz de ejecutarse por...
Apenas un par de días después de que en OSx86 Project saliera publicada la noticia de que Maxxuss había conseguido saltarse las protecciones de Mac OS 10.4.4 para Intel e instalarlo en un ordenador con un procesador x86 genérico Apple los ha...
Todavia está muy verde como para que sirva realmente para nada, pero la gente de Mactel-Linux ha conseguido hacer arrancar un iMac con procesador Intel con un Gentoo Linux modificado desde un disco duro USB. Mientras tanto Windows XP y Vista siguen...
Se confirma que anda por ahí suelto un troyano, que no virus, para Mac OS X, latestpics.tgz, que se hace pasar por una serie de capturas de pantalla de Mac OS X 10.5. Andrew Welch de Ambrosia Software fue quien dio la...
En septiembre del año pasado una relativamente desconocida empresa japonesa llamada ACCESS que hace software para teléfonos móviles se hacía con PalmSource, la empresa encargada de desarrollar el Palm OS, arrebatándole la compra a la propia Palm por haber ofrecido unos millones...

Ya está disponible Camino 1.0, un navegador de código abierto basado en Mozilla, igual que Firefox, pero en el caso de Camino especialmente pensado para usuarios de Macintosh. Es una aplicación universal, es decir, que corre tanto en Macintosh con procesador PowerPC...
Nueva versión beta del software Adobe Lightroom que ya comentamos por aquí en su día. La versión Beta 2 ahora está compilado también para los Mac con procesador Intel....
Por Nacho Palou -
15 FEB 2006
El padre de Alexander Randall V era amigo de la infancia de J. Presper Eckert, quien junto con John Mauchly fue uno de los creadores del ENIAC, que tanto si lo consideras el primer ordenador del mundo como no fue en cualquier...
El hacker conocido como Maxxuss, quien ya había conseguido desproteger las versiones anteriores para desarrolladores, dice haber conseguido saltarse las protecciones que Apple e Intel han incorporado a la versión de Mac OS 10.4.4 que viene con los nuevos Macs con procesador...

Documento histórico: desde la máquina del tiempo, hace 30 años ahora, la carta original de Bill Gates, enviada a los aficionados del Homebrew Computer Club pidiéndoles que por favor «no le roben» copiándose el BASIC para el Altair. Algunos párrafos son...
CNET publicó hace unos días A brief history of hard drives, un recorrido visual por la historia de los discos duros que además de las imágenes incluye pequeños textos con datos curiosos como la relación kilogramo/gigabyte de alguna de aquellas unidades....
En Mac OS X, como otros sistemas operativos comerciales, en principio no se pueden hacer capturas de pantalla directamente desde el sistema cuando se está reproduciendo un DVD. Se supone que por rollo de cuestiones legales –aunque parece que nadie haya copiado...
Por Nacho Palou -
10 FEB 2006
Una de las mejores cosas que tenía Mac OS 9 para los usuarios de portátiles, si no la mejor, era el Gestor de Localizaciones, un panel de control que permitía definir distintos lugares en los que ibas a usar tu Mac y...
Ya teníamos una máquina en diferencias según el diseño de Charles Babbage construida con piezas de Meccano, a la que ahora hay que añadirle una construida con piezas de Lego Technic: LEGO Difference Engine. ¡El LEGO lo puede todo! (Vía Boing Boing.)...
Cuando andas por ahí a la caza de redes WiFi abiertas el menú AirPort de Mac OS X no sirve para mucho porque aunque cuando lo pinchas te muestra las redes que detecta no te dice si están abiertas o no hasta...
El principio del overclock es tan simple como efectivo: aumentando la frecuencia de funcionamiento de un procesador aumenta el número de instrucciones que procesa cada segundo y por tanto el rendimiento –aunque también aumentan la temperatura y la inestabilidad de los componentes....
Por Nacho Palou -
2 FEB 2006
Un par de páginas del mítico MacInTouch que pueden ser útiles si estás pensando en comprarte un Mac Intel: Rosetta Compatibility: PowerPC Applications on Intel Macs – una lista de aplicaciones nativas PowerPC que deberán interpretarse a través de Rosetta para ejecutarse...
Por Nacho Palou -
2 FEB 2006
Demostración práctica, en Presentation Zen: (Vía Jeremy Zawodny's blog.)...
No había visto esto mencionado en ningún sitio, pero por lo visto no hay manera de crear un disco externo de arranque que funcione tanto en Macintosh con procesador PowerPC como con los nuevos Macintosh basados en procesadores Intel, según cuenta Jonathan...
Igual a este gráfico que mide el número de usuarios de uno de los servicios de un servidor Mac OS X Server no le venía mal un pequeño redondeo de los resultados: Porque me da que no me van a vender licencias...
La ONU ha anunciado en el foro de Davos que firmará a través del Programa de las Naciones Unidas para el Desarrollo un acuerdo con Nicholas Negroponte del MIT y la ONG One Laptop per Child para trabajar junto con gobiernos y...
Cuando a un ordenador con Mac OS X instalado le da por no arrancar y se queda en una pantalla gris o azul justo cuando tenía que mostrar la ventana de inicio de sesión o el Finder muchas veces es posible arreglarlo...
Y sólo de momento la recompensa ya asciente a más de 6.700 dólares. Windows XP on an Intel Mac es un concurso en el que ganada quien primero presente las instrucciones necesarios para conseguir que un MacIntel pueda tener instalados un Windows...
Por Nacho Palou -
26 ENE 2006
NetNewsWire es nuestro lector de canales RSS preferido, y no dejamos de recomendarlo como una herramienta estupenda para estar al tanto de las noticias que te interesan con un mínimo de esfuerzo y sin la necesidad de acudir a un agregador en...
Va de cumpleaños hoy la cosa:Cumpleaños infeliz: 20 años de virus – Este mes se cumplen 20 años de la aparición del primer virus informático. Fue durante las primeras semanas del año 1986 cuando se descubrió que el primer virus, llamado Brain,...
Por Nacho Palou -
24 ENE 2006
Los dos patitos, 22 años, le caen hoy a los ordenadores Macintosh desde que se presentaran el 24 de enero de 1984, tal y como nos recuerda el Calendario Geek. Y recuerda: «nunca confíes en un ordenador que no puedes levantar»....
Por Nacho Palou -
24 ENE 2006
Según cuenta Hardmac en Why we have no official info on the MacBook Pro's battery life Apple organizó la semana pasada una presentación de sus nuevos productos en París y a la pregunta de por qué no hay datos todavía sobre la...
Hace un par de años Bill Gates prometió que iba a resolver el problema del spam, lo cual, se mire como se mire, no ha conseguido… a menos claro que consideres que para resolver el susodicho problema no sea necesario acabar con...
Este año Apple cumplirá su 30 aniverario y Thank You Steve! es un sitio web preparado para celebrar la ocasión. El lanzamiento oficial está programado para este viernes 27 de enero.«Steve» es por Steve Jobs y Steve Wozniak. El sitio incluye de...
Por Nacho Palou -
23 ENE 2006
Hay emuladores de Commodore 64 para muchas plataformas, pero si te encuentras con que no tienes ninguno a mano y te da un ataque de nostalgia c64s.com pone un emulador escrito en Java dentro de tu navegador sin necesidad de instalar nada....
De la nota de prensa de Apple, que esta semana comunicaba los resultados financieros del último trimestre de 2005, aunque por cosas contables de los Estados Unidos en realidad es el primer trimestre de su año fiscal 2006:Apple ha anunciado los resultados...
La gente de Podbrix hace ediciones limitadas de productos que mezclan los Legos con los iPods y/o cosas relacionadas con el mundo de los Macintosh, como por ejemplo esta figura de Lego modificada para parecerse a Steve Jobs vestido de keynote con...
Por si no fuera suficiente con su reciente cambio de logotipo y eslogan Intel acaba de anunciar que abandona el nombre Pentium, así que en lugar de un Intel Pentium 4 Dual Core ahora los maqueros podremos decir que nuestros nuevos Macs...
Según cuenta el programador de Mozilla Josh Aas en en el artículo Firefox for Intel Macs planned for March si todo va bien está previsto que en marzo esté disponible el navegador Firefox nativo para los Mac con procesador Intel, a falta...
Por Nacho Palou -
16 ENE 2006
Hace unos nueve años, poco después de que Steve Jobs, actuando como iCEO de Apple, hubiera anunciado la cancelación del programa de Macintosh clónicos y su intención de colaborar más de cerca con Microsoft, Michael Dell decía esto sobre la empresa de...
Continúa la búsqueda de cualquier nueva información acerca de los nuevos Macs que Apple presentó el martes de esta semana en la Macworld de San Francisco mientras esperamos a poder ponerle las manos encima a uno. Por un lado, a través de...
Esta es una de esas reglas no escritas pero que merece estar escrita en algún lado. Se aplica a quienes trabajan en informática e Internet, y viene a decir algo así como: La regla de los viernes – Los viernes nunca, jamás,...
Esto debe ser algún tipo de récord, porque aún no habían pasado 24 horas de la keynote de Steve Jobs del pasado martes en la que presentó el nuevo iMac con procesador Intel Core Duo y el MacBook Pro (argh!) cuando Leander...
¡Qué bueno! Instalando el módulo Flip4Mac es posible reproducir vídeo y música en los formatos WMV y WMA directamente en QuickTime, sin tener que utilizar el Windows Media Player ;-) Mucho más cómodo -probablemente también para Microsoft que ya se puede ahorrar...
Por Nacho Palou -
12 ENE 2006
Además de los nuevos MacBook Pro recién presentados en Macworld San Francisco todavía es posible adquirir los portátiles PowerBook G4 «de toda la vida», así que tal vez si estás pensando en adquirir alguno de estos portátiles o cambiar el actual por...
Por Nacho Palou -
12 ENE 2006
The Wizard Who’s Woz es una entrevista al mítico hacker y fundador de Apple Steve Wozniak, realizada por David Pescovitz para la revista Forefront. Wozniak habla de algunas de las historias más comentadas de su vida, como sus legendarias bromas y proyectos...
Con seis meses de antelación sobre lo anunciado inicialmente por Steve Jobs en la WWDC de 2005 ya tenemos aquí los dos primeros Macintosh con procesadores Intel, el nuevo iMac y el espantosamente llamado MacBook Pro. Personalmente, estaba convencido de que Apple...
Brillante observación: Geek humour - El día en que Apple presentó sus primeros ordenadores con procesador Intel, cerró el día cotizando en bolsa a 80,86 dólares la acción.(Vía Technorati.)...
Por Nacho Palou -
11 ENE 2006
Google Earth para Mac OS X ya es oficial: Google Earth in a Mac world (PC too). En la página de descarga de Google Earth se indican los requisitos mínimos:Mac OS X (10.4). Procesador a 500MHz. 256MB de RAM. 400MB de disco...
Actualización 22:00: Los precios son:1.339 euros para el iMac 17".1.749 para el iMac de 20".2.089 para el MacBook Pro a 1,67 GHz.2.599 para el MacBook Pro a 1,83 GHz. La keynote ya está disponible en Macworld San Francisco 2006 Keynote Address. (Gracias,...
Tres divertidos vídeos, al menos para los maqueros, con el audio de la presentación de Microsoft Windows Vista por parte de Bill Gates en el CES [ojo, enlace con musiquita encendida por defecto] montado sobre imágenes de Mac OS X: Re-Introducing the...
Ya faltan menos de 24 horas para una de las presentaciones más esperadas de la historia de Apple, y en Joy of Tech van calentando motores con What's behind a Steve Jobs keynote, una ilustración que muestra lo que realmente hay tras...
El lunes de la semana que viene arranca la Macworld Expo de San Francisco, probablemente el evento más esperado de todo el año por los usuarios de Macintosh. Como es habitual será Steve Jobs el que la abra con una de sus...
Vaya rumor. Steve Ballmer deja su puesto de CEO de Microsoft, y el ex-presidente Bill Clinton ocupa el cargo como presidente de Microsoft.Lo mejor de este rumor no es que sea cierto o no que Ballmer se vaya, sino que de ser...
Leí sobre lo siguiente en algún sitio hace tiempo, y con el tiempo he comprobado que es una gran verdad y que funciona. La historia original estaba aplicada a empresas en las que el equipo directivo le pedía trabajos a los programadores,...
Public Computer Crashes es un grupo de Flickr dedicado a recoger fotografías de ordenadores instalados en lugares públicos que se quedan colgados y dan errores que todo el mundo puede ver. (Vía Cyberlatam.) Los ordenadores son peligrosos.El HTML es peligroso....
Todo un clásico que encontré por ahí perdido en el disco: ¿Qué es un ordenador personal? Permítanme contestar con la analogía entre la bicicleta y el cóndor. Hace unos cuantos años, leí un estudio –creo que en el Scientific American– sobre la...
Aunque la presentación oficial se producirá la semana que viene en el CES [ojo, enlace con musiquita encendida por defecto] Intel acaba de confirmar que tras 37 años con el mismo logotipo y 16 años con el eslogan «Intel Inside» se dispone...
Tras el anuncio de que Apple se pasaba a procesadores Intel he pasado por meses de duro y desgarrador debate interno acerca de qué hacer al respecto, pero al fin hoy he puesto fin a ese debate al tomar la decisión que...
Referenciado por Eduardo he encontrado un Decálogo del mundo de la Informática que publicó Punto y Aparte a modo de resumen imprescindible para los no-geeks: Aquí os expongo diez cosas básicas que cualquier individuo «de a pie» debería conocer, antes de dar...
Una supuesta compra de Opera por parte de Microsoft aún no confirmada pero que empieza a oirse por todas partesMicrosoft Buys Out Opera — En una reciente conversación con uno de nuestras fuentes internas en Microsoft reveló que ésta ha comprado Opera...
Por Nacho Palou -
23 DIC 2005
Diez programas imprescindibles para Mac OS X. Ya uso cuatro de los diez y he probado alguna vez otros tres o cuatro, así que miraré los dos o tres que me quedan, siempre se descubren cosillas interesantes. 10 for X — Un...
Qué fácil es criticar el código de los demás (a veces): The Daily WTF es un blog donde aparecen fragmentos de código que envían otros programadores a través de su foro. ¿Y qué es lo divertido? Que estos fragmentos de código son...
He actualizado la anotación de la prueba del LaCie Brick con la lista de precios recomendados de la gama, incluyendo los portátiles. Por supuesto, estos precios pueden cambiar de distribuidor a distribuidor y bajar con el tiempo, así que antes de decidirte...
La página de Microsoft Internet Explorer 5 for Mac cuenta que la empresa dejará de dar soporte para IE para Macintosh el 31 de diciembre de 2005 y que dejará de distribuirlo a través de Mactopia, su sitio web dedicado a sus...
Bill es bueno: Time elige «personajes del año» a Bill y Melinda Gates y al cantante Bono por «buenos samaritanos» - El semanario estadounidense Time ha elegido «personajes del año 2005» al multimillonario fundador del gigante de la informática Microsoft, Bill Gates,...
Por lo visto el Defensor del Menor de la Comunidad de Madrid está difundiendo datos de lo dañinos que son los videojuegos y las adicciones que crean, pero como es habitual en estos casos lo está haciendo de una forma totalmente genérica,...
El invitado de esta semana en NerdTV es Douglas Engelbart, el hombre que inventó en ratón y uno de los que más influyó en que la forma habitual de entenderse hoy en día con los ordenadores sea mediante interfaces WIMP. Como siempre...
Si tienes un Macintosh con un procesador PowerPC G4 o PowerPC G5, BeatnikPad ofrece versiones optimizadas de Firefox 1.5 para cada uno de esos procesadores:G4-optimized Firefox 1.5 released.G5-optimized Firefox 1.5 released. Actualización: Alex nos pasa un enlace a Dopar Firefox, una anotación...
Xyle scope una aplicación (OS X) que destripa las páginas web que visitas mostrándolas a la izquierda como un navegador web normal (el motor de visualización es Safari) y a la vez mostrando a la derecha todos los detalles sobre cómo está...
Por Nacho Palou -
12 DIC 2005
Si hace unos días descubríamos que los discos duros LaCie Brick con forma de pieza de Lego realmente existen, poco después nos llevamos la alegría de que LaCie se ofreciera a enviarnos uno para que lo probáramos, cosa que hicimos encantados....
Por lo visto es una versión no oficial pero más o menos funciona. Dirson ha publicado varios enlaces desde los que descargarlo [~12,5MB] en Google Earth para Mac OS X....
Por Nacho Palou -
9 DIC 2005
Aunque desde principios de este año Roxio ya distribuía una versión con Toast 7 Titanium, DivX.com acaba de publicar una versión de DivX 6 para Mac OS X que te puedes descargar sin necesidad de comprar Toast, DivX 6 for Mac. Esta...
Cuando se trabaja en proyectos informáticos hay un valor conocido como el uptime o tiempo que un ordenador (o sistema, o sitio web en general) ha estado funcionando sin interrupciones. No estoy del todo seguro de cuál es la traducción más...
Casi mes y medio después de que se hiciera público el fiasco del sistema DRM de Sony la empresa por fin ha sacado un desinstalador en condiciones que sustituye al anterior desinstalador que funcionaba a través de una página web y que...
Al menos para los editores del New Oxford American Dictionary, podcast es la palabra del año 2005 en los Estados Unidos, por delante de palabras como gripe aviar, reggaeton o incluso sudoku. Los detalles, en 'Podcast' Is the Word of the Year....
Hoy hace exactamente seis meses que Steve Jobs anunciaba en la WWDC que Apple «se pasaba al lado oscuro» y que abandonaba los procesadores PowerPC para pasarse a procesadores Intel. Esto provocó, lógicamente reacciones muy airadas por parte de los usuarios a...
Durante años hubo un jardín de iconos en 2D frente a las instalaciones de investigación y desarrollo Apple en Cupertino, aunque ahora ya no está porque en 1998 fue desmontado, supuestamente para restaurarlo, y en la práctica nunca lo volvieron a montar....
Tras obtener la aprobación de sus respectivas juntas de accionistas y los correspondientes permisos y vistos buenos de las agencias gubernamentales implicadas en el proceso Adobe anunciaba esta semana en Adobe's Acquisition of Macromedia Expected to Close on December 3, 2005 que...
Ya está disponible la versión definitiva de Firefox 1.5....
Nuestros trabajos en el MundoReal™ han hecho que no hayamos tenido tiempo ni de mencionar esto, pero por si aún queda algún lector de Microsiervos que no se haya enterado, si has comprado alguno de los discos incluidos en CD’s Containing XCP...
Según el Calendario Geek, mañana 29 de noviembre hará exactamente 30 años desde que Bill Gates utilizara el nombre «Microsoft» (escrito así, hasta entonces se había escrito «Micro-soft») en una carta enviada a Paul Allen para referirse a la asociación entre ambos....
Durante unos días tuve que trabajar en una oficina en el que no había conexión a Internet instalada, lo que supuso una oportunidad excelente de probar la tarjeta PCMCIA UMTS/3G de Movistar en el MundoReal™. Como ya conté en su momento, Movistar...
No es nuevo pero mirando cosillas sobre el Mac mini me encontré este modding mackero: Cómo construir un Halcón Milenario de Star Wars con un Mac Mini dentro, por unos 20 dólares que es lo que cuesta la maqueta: Millennium Falcon Mac...
Hace tiempo que se lanzó la propuesta y era todo un reto, y ya hay un prototipo. Ya es una realidad. Ordenadores portátiles a 100 dólares. Laptop 100 es un proyecto poderoso del MIT que ya anuncié en abril pasado. Lo acaba...
Firefox 1.5 RC3 ya está disponible para descarga. Si utilizas alguna versión 1.5 anterior a la RC3 Firefox se actualiza automáticamente (como ha sido mi caso) y simplemente tienes que permitir el reinicio del navegador para disfrutarla. También está disponible en español...
Por Nacho Palou -
18 NOV 2005
Como curiosidad curiosa: si ya has descargado la última actualización del sistema del OS X ya tienes en tu Mac la primera aplicación compilada para procesadores Intel y PowerPC.Lo que en The Apple Blog interpretan como que los Mac con procesador de...
Por Nacho Palou -
17 NOV 2005
¿Eres el más geek? Técnicamente lo han llamado Concurso de Geekipollas. Suena un poco peyorativo, pero en realidad resulta que es el nombre del blog. Es un concurso planteado sin ánimo de ofender, sino para divertirse con la geekipollez propia cuando roza...
En History's Worst Software Bugs de Wired están todos: Fallo de la sonda Mariner I (1962).Oleoducto soviético -> explosión no nuclear más grande de la historia (1982): Farewell Dossier, CIA slipped bugs to Soviets.Radiaciones letales en el Therac-25, un dispositivo médico (1985-1987).Gusano...
...¡veo muertos!Curioso, no sabía o no recordaba que tenía un Communicator por ahí en una carpeta con aplicaciones para Mac OS 9, la cual por cierto me ha parecido apropiado renombrar como cementerio de elefantes. ¡Hey también hay un Internet Explorer 5!,...
Por Nacho Palou -
7 NOV 2005
Me ha gustado la pequeña aplicación para OS X RSS Menu que coloca un minilector de feeds en el menú superior a modo de acceso super-rápido a unos cuantos feeds imprescindibles. (Vía RSS Haciendo facil lo simple.)...
Por Nacho Palou -
6 NOV 2005
Mi copia de Firefox todavía no ha dicho ni «mú» al respecto, pero desde esta mañana ya está disponible Firefox 1.5 RC 1, una nueva versión algo menos beta que la anterior y más cercana a lo que debería ser la versión...
Acaba de salir la actualización a Mac OS X 10.4.3. Según cuenta Forever Geek hay bastantes mejoras pequeñas, sobre todo en la velocidad de Spotlight y Exposé, aparte de eso hay mejores en AirPort y Bluetooth, soporte para cámaras en formato RAW,...
A diferencia de lo que ocurre con la Oficin@ Movistar 3G y los Macintosh, que no soporta el uso de tarjetas PCMCIA bajo Mac OS X, Vodafone menciona específicamente en su web que sus tarjetas Vodafone Mobile Connect 3G funcionan con Mac...
Hice 77, 78 y con gran esfuerzo y concentración, 84: World Mouseclicking Competition. A ver cuántos clics eres capaz de hacer con el ratón en diez segundos. Hay quien pasa de 100. (Vía Tecnochica.)...
Según el Calendario Geek ayer día 28 de octubre Bill Gates cumplió 50 años. Lo vi hoy de casualidad revisando cuando añadía unos eventos de noviembre. No parece que muchos medios hayan informado de la onomástica. También hace poco Microsoft cumplió 30....
Una Usuaria Anónima (UA) entra en mi despacho y sin ponerme en antecedentes ni nada parecido me suelta: UA: Tienes que mirar lo de las búsquedas en el programa de visitas.Yo: ¿Podrías ser más específica?UA: No. Relacionado: Pero yo no le hice...
En mi trabajo del MundoReal™ ya hace algún tiempo que somos los suficientes como para que casi todas las semanas haya alguien de viaje o en algún sitio con conectividad reducida o inexistente, por lo que llevaba algún tiempo queriendo probar una...
Ya que en la mayoría de nuestra lista top 10 de películas geek los ordenadores juegan un papel muy importante, conviene no olvidar que en la mayoría de las ocasiones en las que aparece un ordenador en una película Hollywood mete la...
En Así empezó todo «esto» Kirai hace un repaso rápido a los orígenes de la era informática y a algunos de los pioneros: Charles Babbage, Alan Turing y Leibnitz....
Flock, el nuevo navegador basado en Gecko que comentábamos hace unos días ya está disponible para descarga en versión beta (versión 0.4.8, unos 10MB). Luis nos avisaba de que en Dobleclic.org ya hay una pequeña reseña y Alex también lo cuenta desde...
Por Nacho Palou -
21 OCT 2005
Si tuviera que nombrar en una lista rápida cinco de esos pequeños programas shareware o gratuitos que casi invariablemente utilizo a diario y que considero «imprescindibles» diría estos (ordenados sin criterio): Transmit, un excelente cliente FTP. 29,95 dólares [~25 euros]ecto, aplicación local...
Por Nacho Palou -
20 OCT 2005
Unos cuantos artículos y entrevistas de estos días que se me van acumulando sin poder echarles nada más que un ojo pero que parecen tener buena pinta:David Bravo, en El País, sobre la creación de Comisión Antipitarería gubernamental y sobre el borrador...
Si llevas algunos años usando Macintosh seguro que recuerdas las míticas tostadoras volantes del salvapantallas After Dark. Hace años que Berkeley Systems, la empresa que lo vendía, cerró, y aunque ahora infinisys vende una versión actualizada llamada After Dark X + Fish...
La EFF ha publicado DocuColor Tracking Dot Decoding Guide que es una guía para decodificar los códigos ocultos en las Xerox DocuColor, uno de los equipos multifunción (impresora / fotocopiadoras / fax) láser color de Xerox. Esos códigos son una matriz de...
Tal y como cuentan en Techworld, Intel ha superado la barrera de los 1.000 millones de transistores por chip en un modelo experimental del que ya existen algunas unidades y que pronto entrará en producción. Intel breaks one billion transistor barrier -...
Al parecer en el renovado iMac G5 el módem 56K de toda la vida ha pasado a ser un componente opcional. Apple ha sido a lo largo de su historia una de las empresas que más ha arriesgado matando tecnologías obsoletas. Fue...
Si diseñar un microchip ya tiene que ser complicado, colar en el diseño un dibujo o un mensaje es para nota, pero es algo que por lo visto los ingenieros responsables de su diseño llevan haciendo casi cuarenta años, como descubrió Michael...
Hace algún tiempo publicamos un truco para acelerar Firefox que funciona bien, pero que implica trastear con el fichero de configuración, operación no muy complicada pero que puede no ser del gusto de todo el mundo. Si quieres probar el truco en...
Dan Gillmor hace un rápido análisis de la lista de pagos, multas y arreglos tanto judiciales como extrajudiciales a los que ha llegado Microsoft en los últimos años para arreglar su «problemilla» como tras ser acusado de monopolio en 1998. La lista...
En Juegos de guerra David Lightman, el personaje interpretado por Matthew Broderick, está a punto de provocar la Tercera Guerra Mundial en su empeño de echar una partida a un nuevo juego de ordenador al ponerse a trastear sin darse cuenta con...
Si ayer fue el día de la «compra de weblogs», hoy es el día de los «concursos de weblogs». Con este van dos en los que estamos nominados, lo leí hoy en el blog de PC actual. Se trata de los XIII...
Disponible la versión beta 2 de Firefox 1.5, más o menos un mes después de la versión beta 1. Dada la «inestabilidad» de la actual 1.0.7 sobre Mac OS X tampoco se pierde nada probando esta versión beta. De hecho en todo...
Por Nacho Palou -
7 OCT 2005
He pasado un rato divertido con MapBuilder, una herramienta vía web que sirve para crear los típicos mapas de GoogleMaps en los que hay cosas marcadas e información relacionada con la marca. En el caso del mapa de prueba he marcado en...
Por Nacho Palou -
5 OCT 2005
Según el Calendario Geek, hace exactamente 14 años, un 5 de octubre tal y como hoy, aparecía este mensaje en Internet: ¿Echas de menos los días de minix-1.1, cuando los hombres eran hombres y escribían sus propios controladores de dispositivos? ¿Estás sin...
Estoy probando TextExpander que es un panel de control para Mac OS X muy práctico: sirve para crear atajos para textos, como los antiguos «macros», abreviaturas que te inventas y que puedes activar en cualquier aplicación: en tu editor de texto,...
¡Hmmmm! ¡Iconos y Futurama en la misma frase!: Futurama Vol. 1(Vía r00lz.) FamFamFam: iconos gratis total¡Favicons!Iconos: la historiaIconos, enlaces a sitios y colecciones de iconos.GUIdebook, un bonito sitio que reúne iconos y otros elementos de interfaces gráficos.Futurama TaglinesCuriosidades matemáticas en Futurama...
Por Nacho Palou -
30 SEP 2005
La LSPM (Lista de Soluciones Planeta Mac) es ya todo un clásico en el círculo de los mackeros españoles. Es una lista de correo que funciona a modo de comunidad Macintosh o MUG. Hoy la LSPM está de celebración, y no muchos...
...sobre todo si están hechas en uno de tus sitios web y tu producto es el que sale perdiendo como sucede en Windows Marketplace cuando comparas Explorer y Firefox: (Gracias, dapobe; no te enfades, Eneko ;-)...
iCon. Steve Jobs: The Greatest Second Act in the History of Business. Jeffrey S. Young y William L. Simon. Wiley, 13 de mayo de 2005. ISBN: 0471720836. Inglés. [ver similares] Egoísta, manipulador, caprichoso, sin problemas para apropiarse de las ideas o el...
WebDosBeta tendrá lugar dentro de un mes en Madrid: Six Apart, el Instituto de Empresa y eConozco organizan WebDosBeta, una jornada sobre blogs, sindicación, podcasts, AJAX, APIs, redes sociales, folksonomías, internet móvil... (añada su «buzzword» preferido™). Se celebrará el lunes 24 de...
Microsoft celebró ayer su 30º cumpleaños en una gran fiesta a la que asistieron 16.000 empleados. (Intentando buscar la fecha exacta de su fundación para el Calendario Geek no he conseguido dar con ella. Hay cronologías que varían casi entre enero y...
Convocatoria interesante en Sevilla: Computación no convencional - Del 3 al 7 de Octubre se celebrará en Sevilla la cuarta edición del congreso International Conference on Unconventional Computation. El ámbito del congreso abarca todas las áreas de computación no convencional, tanto a...
Espoleada por la necesidad de poder enfrentarse a la rapidez con la que hacen las cosas empresas como Google u otras que distribuyen o actualizan sus productos a través de Internet Microsoft se reestructura, como cuenta Enrique Dans:La reorganización pretende agilizar la...
Hey Hey 16K es una divertida animación en Flash (y en inglés, pero con subtítulos en plan karaoke) que homenajea a los ordenadores como el ZX Spectrum o el Commodore 64, con los que muchos empezamos en esto de la informática con...
Convocatoria interesante. Añadida al Calendario Geek de octubre: Bajo el lema «Libertad en Construcción Permanente» la sexta edición del Hackmeeting se celebrará este año en el recinto ferial de Mercadal (Menorca) durante los días 21, 22 y 23 de Octubre. El hackmeeting...
Tras algo más de una jornada utilizando el Mighty Mouse de Apple ya más o menos empiezo a costumbrarme a echar mano (o dedo) a los botones adiciones de los cuales carecía hasta ahora. Aún así todavía se me olvida que ciertas...
Por Nacho Palou -
21 SEP 2005
Sin duda la noticia de esta Apple Expo es que finalmente no hubo ninguna noticia importante por parte de Apple -a menos que consideres que una actualización de los servicios que ofrece en .mac lo es- tras la cancelación de la conferencia...
Con la conexión segura (cifrada) de Google del servicio llamado Google Secure Access se garantizan conexiones a Internet más seguras partiendo de un planteamiento bastante básico: un programa cliente necesario que hay que instalar en el ordenador (y que de momento sólo...
Por Nacho Palou -
20 SEP 2005
La linguística no es mi especialidad, lo de la doble negación a veces suena extraño, etc. pero lo que viene a continuación es bastante fácil de entendener creo yo. Bill Gates en una entrevista contesta a una pregunta haciendo referencia al famoso...
¡Ah! Esa gran verdad: El 79% de los responsables informáticos cree que los empleados son «peligrosos» - Un estudio ha revelado que el 79% de los responsables informáticos cree que los empleados ponen en peligro a sus empresas al no hacer un...
John Calhoun, además de programar multitud de juegos para Mac en los 90, construye máquinas arcade para jugar con el emulador MAMEAdemás de algunas otras manualidades ya conocidas como el marco de fotos digital y el Mac-Aquarium. (Vía digg.)...
Por Nacho Palou -
15 SEP 2005
Adaptación libre de 11 Signs You've Got an Old Computer: 11 señales de que tu ordenador está viejo: 11. Tiene luces parpadeantes (bombillas, no LEDs). 10. El diccionario por omisión es «castellano antiguo». 9. La protección antiruidos es de cemento armado. 8....
Entre la broma, el esperpento y el horror, no sabemos bien qué pensar: Bill Gates y Steve Jobs cantan su historia en el musical «Nerds» — La obra, que se estrena el 20 de septiembre, forma parte de las representaciones del Festival...
Barrapunto siempre ha sido un sitio de referencia que hemos recomendado con todas nuestras fuerzas, y enlazado hasta la saciedad porque está lleno de artículos interesantes, geeks, frikis de todos los colores y además gestionado por varios editores y amiguetes nuestros (foto...
Geeks. Hay quien se pregunta si los geeks dominarán el mundo o si ser geek está de moda. Es un artículo titulado Ancient Geek en el Toronto Star, que en Barrapunto está traducido completo al castellano como ¿Está de moda ser geek?...
A finales de este mes tendré la suerte de irme unos días al sur, invitado por JJ de la Universidad de Granada para impartir una parte del curso titulado Curso de Arquitectura de la Información, Construcción Avanzada de Sitios Web, 2ª Edición....
En mi trabajo del MundoReal™, los Museos Científicos Coruñeses, hasta ahora hemos estado utilizando el viejo método de «pásaselo al webmaster» para gestionar y actualizar nuestra web, pero ya hace tiempo que se nos viene quedando corto, así que estamos buscando un...
Cyan Worlds, la empresa responsable de Myst y sus secuelas está a punto de cerrar sus puertas. Tal y como cuenta uno de sus empleados en Time of your life ya han despedido a la mayoría de la plantilla, así que parece...
Uno de los más destacados ingenieros de la compañía le dice a Steve Ballmer, CEO (Presidente y Consejero Delegado) de Microsoft, que deja su trabajo para irse a otra empresa. Desde hace tiempo Google está llevándose a mucha gente de Microsoft. Los...
El Homebrew Computer Club (Club de los Ordenadores Caseros) empezó a celebrar sus reuniones en marzo de 1975. En estas reuniones sus miembros compartían ideas y hardware y software hechos por ellos mismos, y sin duda tienen un lugar especial en la...
Basada en el libro Fire in the Valley: The Making of The Personal Computer, la película Pirates of Silicon Valley cuenta la historia de los principios de Apple y Microsoft y sale ahora en DVD; en español está en VHS, pero no...
En otro paso importante del proceso, los accionistas de Adobe y Macromedia han aprobado la compra de la segunda por parte de la primera, aunque ahora le estén llamando fusión a operación: Adobe, Macromedia Shareholders Give Merger High Five. Ahora sólo queda...
Si usas un portátil seguro que al cabo de un tiempo empezarás a preguntarte por el estado de la batería y si esta es capaz de mantener la carga adecuadamente. Si tu portátil es un PowerBook o un iBook con Mac OS...

Actualización (2023) – El wiki hace años que ya no existe, así que se han quitado los enlaces dado que no funcionan. El Calendario Geek del Wiki ya tiene 56 entradas, la mayoría escritas por lectores del Wiki de Microsiervos. Eso supone...
El Correo Gallego publica cada día los resultados de una encuesta que hace en su web; la de ayer me pareció cuando menos curiosa:¿Justifica usted el pirateo informático para abaratar el coste de los programas? Sí: 93,9%No: 6,1%Creo que la pregunta tendría...
Todos los últimos viernes de julio, como hoy, se celebra el System Administrator Appreciation Day que en castellano sería algo así como Día de Mostrar Aprecio a tu Administrador de Sistemas. Así que si eres algún tipo de administrador de sistemas, centralitas,...
Razorbuzz nos envía un enlace a unas muy bonitas fotos de una visita a las oficias de Adobe en San José, California, vía Double Viking....
En 1987 los discos duros eran muy caros y el sistema operativo NeXTstep necesitaba unos 200 MB de disco. Un disco duro de esa capacidad costaría miles de dólares, de modo que para el NeXT Cube se optó por la entonces emergente...
Por Nacho Palou -
27 JUL 2005
Como cuenta edmz, hay mucho «listillo» suelto. Mejor recordar esto sobre eMule: Descargar emule es gratis - Que quede muy claro: eMule es completamente gratuito. Puedes bajarlo sin pagar por el programa ni por el acceso a la red p2p (…) [Algunos]...
El Amiga fue presentado tal día como hoy hace 20 años por Commodore, y aunque en su momento era una máquina muy avanzada que gozó de mucha y merecida popularidad, hoy en día la plataforma apenas sobrevive en la forma del AmigaOne......
Había pensado estar desconectado durante las vacaciones, pero en previsión de un acontecimiento del que estamos pendientes en mi trabajo en el MundoReal™ al final he decidido que va a ser mejor que tenga alguna forma de conectarme a Internet durante ese...
Microsoft acaba de anunciar oficialmente que la próxima versión de Windows, hasta ahora conocida por su nombre en código Longhorn, se llamará Microsoft Windows Vista y que estará en el mercado en la segunda mitad de 2006... si no se vuelve a...
Desde el programa Google Earth es posible guardar en un archivo diversa información relativa a una localización o vista concreta, de modo que además de poder volver en cualquier momento al mismo punto también es posible (y esto es lo divertido) compartir...
Por Nacho Palou -
22 JUL 2005
Este es el salvapantallas definitivo. Como buen fan de Star Trek levaba tiempo esperando algo como esto, y por fin lo he encontrado y además es totalmente genial. System 47 es un salvapantallas que convierte por un rato tu ordenador en...
Para manejar el ordenador con ambas manos el TactaPad es una versión primitiva de a los guantes con los que John Anderton maneja su ordenador. De momento no pasa de ser una idea o como mucho un prototipo, pero la idea es...
Por Nacho Palou -
19 JUL 2005
José Luis nos escribe para recordarnos que estos días también cumple diez años el formato mp3 y que ha escrito un artículo al respecto en su Glosario de Tecnología Informática. Como tiene problemas con su proveedor de acceso y por lo visto...
El impresionante teclado del que hablábamos el otro día podría estar en el mercado en cosa de un año por unos 200 ó 300 dólares si las negociaciones que tienen abiertas con distintos fabricantes dan su fruto, al menos según dice Artemy...
En el Optimus keyboard cada tecla muestra exactamente la función que cumple si se pulsa en ese momento. A la izquierda cuando se está utilizando con Photoshop y a la derecha el mismo teclado a cuando se está jugando al Quake. ¡Hmmm!...
Por Nacho Palou -
14 JUL 2005
Turing Machine es una demostración más de que el Lego lo puede todo, pues en este caso ha sido utilizado para construir una máquina de Turing. Absolutamente «im prezionante». (Vía Boing Boing.) Turing sobre raíles, una máquina de Turing implementada con trenes...
La BBC cuenta en Key hacker magazine faces closure que Phrack, la mítica revista de y para hackers y phreakers desaparece tras casi veinte años de publicación con su número 63, número será editado en tapa dura y que seguro que se...
Sven Jaschan, el joven alemán que en mayo del año pasado se confesó autor del gusano Sasser que puso fuera de servicio a miles de ordenadores en todo el muno, acaba de ser condenado a 21 meses de cárcel y 30 horas...
Por 648 votos en contra y 14 a favor, y para alegría de muchos, el Parlamento Europeo rechaza las patentes de software. Al parecer los políticos han decidido rechazar la ley porque en su forma actual no convencía a nadie... como si...
Una curiosa forma de pintar, con resultados espectaculares: Context Free Design Grammar[A] very simple programming language for generating pictures. You write a text file as an input (a .cfdg file), and it spits out a beautiful graphic up to 1000 megapixels (a...
Por Nacho Palou -
6 JUL 2005
Al parecer están reconstruyendo el mítico garaje de Hewlett-Packard, situado en Palo Alto, una de las ciudades del Silicon Valley de California. En la foto del artículo se puede ver cómo era el lugar donde Bill Hewlett y Dave Packard diseñaron los...
Ayer leí una reseña en Slashdot, Our Brains Don't Work Like Computers, sobre un trabajo publicado en Proceedings of the National Academy of Sciences por un psicolingüista de la Universidad de Cornell: New Cornell study suggests that mental processing is continuous, not...
Un «Hello World» es lo único que hace normalmente el primer programa escrito en el lenguaje de programación que se está aprendiendo y The Hello World Collection recopila el código necesario para programar eso en unos 190 lenguajes de programación: Basic (¡ah!),...
Por Nacho Palou -
30 JUN 2005
Stupid Computer Tricks! recoge en fotografías lo mejor de las cafradas que los usuarios incompatibles con la tecnología hicieron a sus máquinas durante los ocho años que Rod Shelley trabajó en el departamento de soporte de una tienda de ordenadores. Cualquiera que...
Google Earth, el programa antes conocido como Keyhole, ahora es gratuito (ya no hay versión de prueba limitada) aunque las opciones más poderosas se quedan para las versiones de pago (Plus y Pro) o como extras con coste adicional para la versión...
Por Nacho Palou -
28 JUN 2005
Un compañero mío ha tenido problemas para conectarse a la red Wi-Fi de la sala VIP de Iberia del Aeropuerto de Barajas en las últimas ocasiones en las que ha intentado usarla. Su ordenador es un PowerBook G4 con Mac OS X...
La Corte Suprema de los Estados Unidos ha fallado hoy en el caso MGM Studios, Inc. v. Grokster, Ltd., y lo ha hecho en favor de MGM y los otros 27 estudios que se habían personado en el caso. Las reacciones por...
Think Secret publica en A first look at Apple's Intel Mac (with photos) una pequeña descripción y fotografías de los Apple Development Platform ADP2,1, que son los Macintosh con un Pentium a 3,6 GHz que Apple está vendiendo a sus desarrolladores para...
El programa Audio Hijack (OS X, unos 12 euros) sirve para capturar el sonido procedente de cualquier aplicación. Es decir, permite grabar en un archivo AIFF cualquier audio que suene en tu ordenador, venga de archivos Flash, conversaciones vía Skype, películas o...
Por Nacho Palou -
22 JUN 2005
Andrew Orlowski de The Register explica en Taking Osborne out of the Osborne Effect que el efecto Osborne del que tanto se ha hablado desde que Apple anunció que se pasaba a procesadores Intel en realidad no existió, al menos no tal...
Jack Kilby el inventor del circuito integrado, sin el que nuestro mundo no sería el que es, acaba de fallecer a los 81 años víctima de un cáncer: Microchip Pioneer Jack Kilby Dies at 81. (Vía Boing Boing.)...
Al menos el bug detectado el mes pasado sobre que Netscape podía «romper» IExplorer ha quedado solucionado por parte de Netscape: Netscape 8 update for XML rendering....
Por Nacho Palou -
20 JUN 2005
Este artículo fue publicado originalmente el 7 de diciembre de 1997 en el periódico El Ideal Gallego; en esta revisión me he limitado a añadir algunos enlaces....
La Vanguardia publica hoy una entrevista con Richard Stallman, el conocido hacker y defensor del software libre, titulada “Bill Gates está espiándote”. Es tan peculiar como tiene fama de serlo el propio RMS. (Gracias, GgarfielD.) Actualización (15 de junio de 2006): Por...
Hace un par de días comenzó a circular el rumor de que la versión previa de Mac OS X para Intel que Apple está dando a sus desarrolladores está ya en las redes P2P, y hasta hay un vídeo al que no...
El PDM sigue dando sus frutos: jwz se ha pasado a Mac. La gota que colmó el vaso en su caso fue que le resultó imposible bajo Linux usar correctamente una tarjeta de sonido que se había comprado, de modo que se...
Pregunta: Bueno, a ver, mi pregunta es que si yo tenía un mensaje de correo en el Outlook que he borrado, y luego además me he ido a la carpeta de Elementos borrados y le he dicho «Eliminar correo borrado» y luego...
La anotación If some Software Developers built houses? de UI Hall of Shame le da un buen palo a algunos programadores en lo que a su habilidad para diseñar interfaces de usuario se refiere comparándola con lo que pasaría si diseñaran casas,...
Después de haber trabajado en un periódico soy consciente de que lo mismo estas declaraciones han sido sacadas de contexto y hay que tomarlas con cierta precaución, pero según cuenta La Voz de Galicia en El Gobierno condiciona a una mayor seguridad...
Una de las piezas fundamentales en la transición de Apple a procesadores Intel es Rosetta, un software que permitirá a los nuevos Macintosh con procesadores x86 ejecutar programas escritos para PowerPC. Aunque Steve Jobs no dio ningún dato al respecto durante la...
Diez añitos cumple hoy el lenguaje PHP. It has been 10 years since Rasmus released the first version of PHP. To everyone that has helped to shape PHP into what it is today; from the people developing the core and extensions, documentors,...
El autor del documental sobre la historia de las BBS en DVD del que hablábamos hace unos días cuenta en Why the BBS Documentary is Creative Commons por qué aún a pesar de que le ha llevado cuatro años terminarlo ha decidido...
Operating System Sucks-Rules-O-Meter hace búsquedas periódicas en Altavista en las que cuenta cuantas veces aparece el nombre de un sistema operativo unido a la palabra «rocks» (mola) o «sucks» (no mola) y hace un gráfico con los resultados. El más popular en...
A pesar de lo increíble que nos parecía hace apenas cinco días, ha pasado. Después de años ensalzando las virtudes del PowerPC y de los procesadores RISC, Steve Jobs anunciaba ayer que Apple va a abandonar la arquitectura PowerPC para pasarse a...
Enrique se compró un Mac-mini: Im-pre-sio-nan-te: Estoy completamente impresionado (...) Me ha parecido, simplemente, otra dimensión (...) Desempaqueté todo, puse los componentes de la única manera posible en la que podían encajar, y le dí al botón (...) Pero lo que más...
Por lo general la WWDC de Apple no es un evento que genere demasiado interés incluso dentro del mundo de los «maqueros», salvo por la posibilidad de que la empresa anuncie algún tipo de hardware nuevo o la actualización de los modelos...
En las páginas de soporte de Microsoft hay una extensa nota dedicada a un problema curioso y divertido: Problemas de reproducción y de protección contra copia cuando se intenta reproducir la película en DVD de Blancanieves y los siete enanitos[...] Windows XP...
Por Nacho Palou -
6 JUN 2005
Esta noticia aparece periódicamente, aunque esta vez C/Net parece tenerlo muy claro, hasta el punto de que en Apple to ditch IBM, switch to Intel chips dicen que fuentes que conocen bien la situación afirman que Steve Jobs va a anunciar ese...
Un articulo poco técnico sobre la infraestructura que mantiene en funcionamiento la web de BBC News, una web que llega a alcanzar en sus días pico más de 4 millones de usuarios y 50 millones de impresiones de página: The BBC News...
Este artículo es otro de los que escribí hace años para El Ideal Gallego como parte una serie más o menos regular que pretendía ir contando a los lectores qué era eso de Internet de lo que se empezaba a hablar tanto...
¿Qué se puede hacer con una rana muerta que no sea sopa? Por ejemplo, un servidor web: Frog with Implanted WebserverLa rana está suspendida en un cubo de cristal relleno de formaldehído y tiene un cable ethernet conectado por el abdomen al...
Por Nacho Palou -
1 JUN 2005
Keyhole ha sido adquirido por Google y ahora se llama Google Earth. Hace poco que añadieron imágenes de satélite de España además del resto del mundo, lo cual lo hacía más interesante. Ahora a los usuarios registrados nos han mandado por...
Esto es bastante jurásico y mítico a la vez, la disección línea a línea del código de Sargon II, un viejísimo programa de ajedrez que tiene ya veinte años y cabía en 8 KB -la capacidad de muchos cartuchos de juegos- y...
Jorge es un lector que nos pregunta por correo algo curioso que mejor trasladar a una anotación para que así reciba diversas recomendaciones: Soy estudiante de segundo curso de Ingeniería Informática y paradójicamente no tengo ningún libro de informática en mi biblioteca....
Un artículo sobre el famoso sonido que hacen los Mac al arrancar —si todo va bien: The Mac Startup SoundIt's a C Major chord, played with both hands stretched out as wide as possible [...] I wanted something really fat, heavy bass,...
Por Nacho Palou -
27 MAY 2005
Al instalar el nuevo Netscape 8 puede suceder (como ha sido mi caso con un Windows XP) que Internet Explorer deje de visualizar documentos XML —como los feeds RSS. En IEBlog cuentan la solución en dos pasos y el primero de ellos...
Por Nacho Palou -
26 MAY 2005
Foxylicious — Una extensión para Firefox que sincroniza los favoritos guardados en del.icio.us y los favoritos del navegador. del.icio.us Cómo hacer un backup de Del.icio.us Del.icio.us loader...
Por Nacho Palou -
26 MAY 2005
Este artículo fue publicado por primera vez en El Ideal Gallego del 20 de abril de 1997, y las recientes menciones de textfiles.com y del documental sobre la historia de las BBS me han animado a desempolvarlo, actualizarlo un poco, y...
Aunque en España nunca gozaron de tanta popularidad como en los Estados Unidos, a pesar de haber existido unas cuantas bastante conocidas, las BBS fueron el primer medio que permitió al público en general comunicarse en línea, mucho antes de la popularización...
El otro día tuve que instalar un Windows 98 y al descargar las correspondientes actualizaciones me sorprendió ver que Windows es capaz de contar milésimas de bit (o así, no he contado los ceros): Errores bizarros peculiares...
En Mac OS 10.4 Tiger se puede anular la tecla de Bloqueo Mayúsculas (Caps Lock) del siguiente modo: Abrir Preferencias del SistemaElegir Teclado y RatónElegir Teclas de ModificaciónElegir Sin Acción para la Tecla de Bloqueo de MayúsculasSi no fuera porque sirve para...
Vía The Unofficial Apple Weblog descubro que Kernel Panic ha creado un álbum en Flickr llamado Home Page con una historia visual de la página principal de Apple similar a los que hemos creado de Microsiervos. El artículo de TUAW también incluye...
No le vendría mal rediseñarlo un poco para que dejara de ser un tocho tan largo, pero Evan Koblentz, el editor de Computer Collector Newsletter acaba de publicar un interseante y muy trabajado artículo sobre la evolución de los PDA de 1975...
Antes se decía que uno siempre se acuerda de su primer coche, y supongo que a los geeks nos pasa lo mismo con nuestro primer ordenador, en mi caso un Commodore 64, así que me sorprendió muy agradablmente descubrir que aún hoy...
Supongo que es absolutamente adecuado que en el Día das Letras Galegas salga al público Chintófano, un "widget" para Dashboard que permite consultar el Diccionario da Real Academia Galega: ¿Alguien conoce "widgets" para las demás lenguas que se hablan en España? (Gracias,...
¿Quién no tiene pilas de diskettes y/o archivos creados con versiones antiguas de programas que las actuales no reconocen? ¿O creados con aplicaciones que ya no existen? OldVersion.com pretende recopilar versiones antiguas de programas y utilidades para que quien necesite una pueda...
Xosé Castro es un traductor e intérprete en cuya web hay unos cuantos artículos muy interesantes, como por ejemplo el Diccionario de burradas del Español, de lo que esto es sólo una pequeñísima muestra:Tráeme el fli de limpiar los hornos. (aerosol, spray)Le...
Si alguna vez te has preguntado por qué demonios el filtro que se utiliza en Photoshop y otras aplicaciones similares para enfocar imágenes se llama máscara de desenfoque, en el artículo Behind the Unsharp Mask: The Secret World of Sharpening de EarthBound...
Hoy hace dos semanas que instalé Mac OS X 10.4 a.k.a. Tiger en mi PowerBook por el viejo método de «los dos cojones y medio cerebro» y la verdad es que la experiencia ha sido positiva, bastante más que en el caso...
No está del todo claro el alcance que puede tener esto, pero si usas Safari 2.0 con Mac OS X 10.4 y no has tocado los ajustes por defecto, podrías encontrarte con que una página web diseñada a tal efecto puede descargar...
Esta es otra anotación que seguro que le encanta a Alex, y es que vista la ficha de "Ella Enchanted" en la web de Yelmo Cineplex, algo me dice que al programa de traducción automática que usan aún le faltan por lo...
Ya no es novedad porque hace años que esto es posible, pero una vez en marcha la campaña de la declaración de Hacienda de este año, me conecté a los servidores de la Agencia Tributaria utilizando la opción "Programa de ayuda en...
Las películas y series de ciencia ficción nos tienen tan acostumbrados a que las naves espaciales tengan unos ordenadores tan potentes que resulta cuando menos soprendente descubrir que la mayoría de los cohetes tienen menos potencia de cálculo que cualquier consola portátil...
Revolution in The Valley. Andy Hertzfeld. O'Reilly, 1 de diciembre de 2004. ISBN: 0596007191. Inglés. 320 páginas. Andy Herzfeld es uno de los creadores del Macintosh original y lleva años recopilando historias acerca de su nacimiento en el weblog Folklore.org, cuyo contenido...
La famosa historia del Reto / Concurso de Compresión de Ficheros, en el que un tipo reclamó los 5.000 dólares tras haber logrado comprimir un fichero de contenido totalmente aleatorio: The $5000 Compression Challenge. I will attach a prize of $5,000 to...
Uno nunca sabe cuándo va a necesitar un buen generador de números aleatorios, así que conviene tener Random.org apuntado por ahí. Por otro lado, en una nota de ForeverGeek titulada Pi Is Not The Best Random Number Generator se menciona un estudio...
Odialas o ámalas, las 40 empresas líderes en tecnología e innovación para Wired en The Wired 40. En el número uno, Apple; entre las que se quedaron fuera por los pelos, Inditex....
John Gruber de Daring Fireball está recopilando pequeños detalles de Tiger que son nuevos o distintos de versiones anteriores y que no han sido recogidos en las listas de nuevas características de Apple en Tiger Details; también hay un feed RSS....
Tiger ya a la venta --hoy deberían llegar llegaron nuestras licencias. Si piensas instalártelo ya puedes ir eligiendo y descargando los widgets para el dashboard que vas a utilizar, acciones para automator y extensiones para spotlight. Si no puedes esperar para utilizar...
Por Nacho Palou -
29 ABR 2005
No había leído este artículo de hace un par de días Microsoft to add 'black box' to WindowsMicrosoft [...] is adding the PC equivalent of a flight data recorder to the next version of Windows, in an effort to better understand and...
Por Nacho Palou -
28 ABR 2005
Acabo de instalar Mac OS X 10.4 Tiger (que no se enteren en Apple) sobre un Mac OS X 10.3.9 sin ningún problema y por ahora todo parece funcionar sin mayor problema. La mayor curiosidad por ahora es que al activar por...

Hoy 27 de abril el ratón cumple años(*). En 1963 Douglas Engelbart del Stanford Research Institute lo presentó en una demo del oN-Line System (NLS). Años después, en 1970, recibiría la patente US3541541 titulada «Indicador de posición X-Y para un sistema...
Por lo visto Microsoft Windows cumple hoy 20 años. Según el artículo de la Wikipedia Historia de Windows:La interfaz gráfica fue creada imitando el Mac OS de Apple.Entonces, ¿por qué usar una copia cuando se puede usar el original, que además funciona?...
The New Hacker's Dictionary, Third Edition. Eric. S.Raymond. The MIT Press. 1996 (1993). ISBN: 0262680920. Inglés. 547 páginas. Weblog de Eric S. Raymond. Esta tercera edición del Diccionario del Hacker es sin duda referencia obligada para todos los hackers como para...
Un repaso histórico sobre los hackers, desde el M.I.T. de los 1950 hasta los microordenadores y los videojuegos, con ética hacker incluida, por si faltaba épica.
David Clark, un ingeniero inglés que nunca tira una revista a pesar de las broncas que seguro que eso le ha acarreado en casa, ha encontrado entre su coleccion un ejemplar del número del 19 de abril de 1965 de Electronics en...
Mientras esperamos que Tiger entre por nuestras puertas, Apple ha montado una página en la que detalla las más de 200 prestaciones nuevas de la próxima revisión del Mac OS: ver todas las prestaciones de Mac OS Tiger. Por ahora redirige a...
A mi, al menos, la noticia me ha pillado totalmente por sorpresa: Adobe compra Macromedia por 2.623 millones. Nota oficial de Adobe: Adobe to acquire Macromedia. Es quizás demasiado pronto para especular con qué puede significar esto, pero me da que como...
Lo de dar soporte a usuarios de ordenadores es una fuente inagotable de anécdotas más bien curiosas. Hace unos días Bob entró en mi despacho con un disco duro portátil en la mano y me dijo:Se volvió a estropear, pero yo no...
De los creadores de Corrector Gramatical de «lenguaje natural» ;)...
Por Nacho Palou -
14 ABR 2005
Hace unos meses empezaron a instalar monitores en los autobuses urbanos de mi ciudad para amenizar el viaje a los pasajeros y sobre todo, imagino, para ganarse unas pelillas con los anuncios que van intercalados entre videoclips varios y noticias más caducadas...
La publicación en 1949 de "A Mathematical Theory Of Music" convenció a Harry Olsen y Hebert Belar, dos ingenieros de la RCA, de que se podrían generar grandes éxitos musicales automáticamente usando ordenadores, idea que vendieron a los directivos de la RCA...
Pues eso, que Apple por fin ha fijado como fecha para la salida de Mac OS X v10.4 «aka» Tiger el próximo 29 de abril. La web de Apple España todavía no dice nada, pero en la de Apple USA ya cuentan...
Jon Lech Johansen, la más conocida de las personas a las que debemos agradecer el poder hacer copias de seguridad de nuestros DVDs, habla en Slyck de sus puntos de vista sobre los sistemas DRM, el origen de de de_CSS, las discográficas...
Hit the road, Mac incluye sugerencias, tanto en cuanto a equipos y accesorios como servicios recopiladas por colaboradores y lectores de Macworld en cuanto a viajar con ordenadores y lo que eso supone. Viajar en la era digital.Mis gadgets habituales....
Si hace algún tiempo hablábamos de nombres de producto poco afortunados, una anotación de hoy en TUAW, What kind of iPod do I have?, acerca de los distintos iPods que existen, todos con el mismo nombre, me recordó que Apple lleva años...
Jeff Dean de Google habla de lo que supone poder ofrecer unas búsquedas de calidad en Google: A Behind-the-Scenes Look, un programa de la televisión de la Universidad de Washington. (Vía Slashdot.)...
¿Quien dijo que los Macintosh sólo servían para diseñadores y artes gráficas? Museos Coruñeses: ...más de 150 Mac. Algún Macintosh más de mc2 en Macs@Work; espero ir añadiendo más en los próximos días....
Un compañero me comentaba hace un rato Oye, que el ordenador me está diciendo no se qué del network, y seguro que es cosa vuestra.Cuando le pregunté si podía ser algo más específico me dijo que no, que ya no se acordaba,...
Ranchero Software acaba de montar un par de páginas de recursos adicionales para dos de nuestras aplicaciones de cabecera, NetNewsWire (lector/agregador de feeds RSS/XML) y MarsEdit (editor de blogs): NetNewsWire resources y MarsEdit resources. (Vía The Unofficial Apple Weblog.)...
En la anotación Return of the Mac de Slashdot hay una interesante discusión acerca de la importancia que puede tener el hecho de que cada vez más hackers se estén pasando a Mac OS X, basada en lo que cuentan enReturn of...
Jeff Hawkins, el creador de la Palm Pilot, ha fundado Numenta, una empresa que tiene como objetivo desarrollar un nuevo tipo de memoria para ordenador basado en el neocórtex humano, poniendo en práctica algunas de las ideas expresadas en On Intelligence. (Vía...
Aunque Apple no ha anunciado la fecha en la que va a publicar la próxima gran revisión de su sistema operativo, Mac OS X 10.4 Tiger, y se limita a decir que en el primer semestre de 2005, Amazon lo está ofreciendo...
The Birth of the Notebook [PDF 1,4 MB], un interesante artículo de Cristopher Null para Mobile PC sobre el nacimiento de los ordenadores portatiles. (Vía Boing Boing.)...
Basándome en el mini-tutorial 6600, T-Mobile and Mac :-) añadí una conexión en el PowerBook con Mac OS X 10.3 que me permite tener acceso a Internet desde cualquier sitio donde haya cobertura GPRS (aka «en toda España» [fuente]) a través de...
Por Nacho Palou -
22 MAR 2005
GUIdebook: Icons timeline, con ilustraciones de los iconos más tradicionales y llamativos de casi todos los sistemas operativos a medida que fueron evolucionando: desde el Lisa al Mac OS X, pero también todos los de Windows y NeXT, OS/2, BeOS y...
1000bit, un sitio dedicado a los ordenadores antiguos, tiene una curiosa colección de casi 200 anuncios de estos maquinillos; el de Data General de 1982 de la señorita con el pañuelo al cuello no tiene desperdicio....
Llevaba algún tiempo buscando una utilidad que me permitiera controlar iTunes sin necesidad de tener abierta la ventana de éste ni hacerlo a través del Dock, y el otro día di con ella gracias a la anotación What's in your menubar? de...
Error10, una colección de errores del Mac OS cuando menos curiosos... que no necesariamente útiles ni aclaratorios. Actualización (6 de marzo de 2005, Alvy): Encontré en mi disco duro estos dos, muy antiguos (circa Sistema 7) pero simpáticos: una errata en la...
El Macintosh se ha quedado huérfano de padre tras fallecer ayer, víctima de un cáncer a los 61 años, Jef Raskin, quien fue el empleado número 31 de Apple y el que tuvo la idea original de un ordenador que tendría que...

La revistsa Computer Hoy dedica 23 páginas, más portada y editorial ("El secreto de la caja mágica") al mundo Apple en su número 167. Olvídate de los virus. Trabaja sin cuelgues. Usa los mejores programas… y disfruta de tu PC. En...
Buscando algún icono con el que reemplazar ese espantoso que viene por defecto en el disco duro en OS X, que parece un trasto de hace quince años, encontré algunos sitios chulos llenos de iconos (algunos gratis y otros de pago)...
Por Nacho Palou -
18 FEB 2005
Han tardado casi un año más que Boeing, pero en Airbus también se han dado cuenta de que el dinero protege a los aviones de las interferencias: Presentan un sistema para usar móviles y ordenadores en aviones. Eso sí, Airbus ha aprovechado...
Si los hackers originales eran todos miembros del Tech Model Railroad Club del MIT, el que la gente de Monochrom haya montado una máquina de Turing usando un tren en miniatura es algo así como el meta-hackeo máximo o la über-geekada del...
La gente de PC Stats ha visitado la fábrica de placas madre de Gigabyte en Taiwán y lo han documentado con un montón de fotografías: How Motherboards Are Made: A Gigabyte Factory Tour, así que aunque sepas poco inglés creo que podrás...
¿Quién se acuerda a estas alturas de eWorld, Pippin o del Mac TV? Thomas Hormby recoge en Top 10 Apple Flops los que considera peores productos e ideas de Apple, aunque en realidad son 9 porque la lista incluye la versión 6...
Ayer llegó el pequeñín de la familia, el Mac Mini. La verdad es que es una auténtica monada (fotos en Flickr). Le he puesto un teclado y ratón inalámbricos de Apple y una pantalla plana LG, y va de miedo, aunque estoy...
Si quieres instalar Mac OS X en tu PC puedes probar PearPC, un emulador de la plataforma PowerPC) y seguir estas instrucciones, Installing OS X on a PC. Si algún valiente se atreve que nos cuente si funciona ;-)...
Por Nacho Palou -
2 FEB 2005
Tras el vídeo de la presentación del Macintosh en 1984, seguimos con el tema de la arqueología maquera, pues Pixel nos pasa un enlace a una anotación en su blog acerca de un folleto de Apple titulado "Who needs a computer anyway"...
Hoy se cumplen 21 años de la presentación oficial del Macintosh, así que ya es mayor de edad en su país de origen Por ahí anda un vídeo de la presentación de Jobs, The lost 1982 video, pero el servidor ha sido...
Si tras la presentación de Steve Jobs en la Macworld Expo de la semana pasada pensaste en lo bien que podría hacer el Mac mini de grabador de video digital (DVR), échale un ojo a Mac HTPC - The Mac mini HTPC,...
Hace unos días Alvy comentaba lo bien pensado que está MarsEdit, pues es capaz de recuperar tu trabajo no guardado en el caso de un cuelgue o de que se vaya la luz, pero en eso no es sino la excepción que...
Paul Nixon ha preparado la bonita inforgrafía Apple's Tipping Point: Macs For The Masses para visualizar la estrategia de Apple con el lanzamiento del iPod Shuffle y el Mac Mini"....
Por Nacho Palou -
13 ENE 2005
Nuestro gozo en un pozo, habiamos preparado hasta las palomitas, gran evento el de hoy... pero parece que ni Apple ni Macworld Expo retransmiten en directo por Internet la conferencia inaugural (ketnote) de Steve Jobs, que es dentro de unas horas. Según...
No es oficial, no está soportado y blah blah blah, pero si no te funciona, basta con que dejes los parámetros como estaban para deshacer los cambios: Abre una ventana o pestaña nuevas. Teclea "about:config" (sin las comillas) y retorno. Busca la...
Si has almacenado muchos favoritos en del.icio.us sería bueno que pensaras de vez en cuando en hacer una copia de seguridad. Porque... ¿A que sería un fastidio perderlos todos? Esto es tan sencillo como poner esta URL en el navegador: http://del.icio.us/api/posts/all Tecleas...
Una anotación de Mark Frauenfelder en BoingBoing acerca de cómo a su mujer le ha sido imposible pagar una multa que le pusieron a pesar de haberlo intentado en varias ocasiones porque el agente que se la puso olvido poner la fecha...
Garrett Birkel ha publicado una versión comentada y anotada de In The Beginning Was The Command Line, el conocido ensayo de Neal Stephenson, con el permiso de éste: The Command Line in 2004. Si aún no lo has leido, hay una traducción...
La Thinking Machine 4 es una máquina de ajedrez en Java, que tiene la particularidad de mostrar visualmente lo que está «pensando» el ordenador. Mientras que tú sencillamente echas un vistazo, calculas algunas líneas de juego y mueves, los miles de líneas...
Todo el software del mundo debería estar tan bien diseñado como MarsEdit, el editor de blogs para Mac OS X de Ranchero Software. Si se te cierra la aplicación debido a un crash, todo lo que estabas escribiendo queda guardado. Al arrancar...
O los implantes mamarios llevan un chip (y nosotros sin saberlo) o alguien ha metido las patas al traducir esta noticia: El chip de silicona, el invento más influyente de los últimos 50 años. ¿O es que en Silicon Valley llevan años...
The Dream Machine. J. C. R. Licklider and the Revolution That Made Computing Personal. M. Mitchell Waldrop. Penguin Books, agosto de 2002. Inglés. Aunque J. C. R. Licklider no es el autor directo de ninguno de los avances fundamentales en el campo...
Koders es un útil sitio para programadores en el que es fácil encontrar código ya escrito, en muchos de los lenguajes de programación más populares. En sus páginas explican cómo funciona la idea: «Koders facilita a los desarrolladores la tarea de encontrar...
Virtual Apple es un emulador en línea de un Apple II que cuenta con unas 1100 imágenes de disco con software para esta máquina al que se accede mediante un emulador escrito en Active X... por lo que sólo funciona con Internet...
Es una bonita historia para Navidad: The Graphic Calculator Story. Narra las aventuras de Ron Avitzur durante la creación de la Calculadora Gráfica, originalmente NuCalc, que formó parte de las aplicaciones incluidas en más de 20 millones de Macintosh PowerPC, en el...
Y menos mal que no elegí "instalación completa" porque sólo quería el controlador de la impresora, sin programas adicionales...En lo que tardé en hacer la captura ya se habían copiado unos 1000+ archivos....
Por Nacho Palou -
22 DIC 2004
El ingenio y la habilidad de alguna gente es absolutamente sorprendente. Al tipo que se ha currado un ordenador universal con Lego hay que añadir a Tim Robinson, que ha construido una Máquina en Diferencias de Charles Babbage, un Analizador Diferencial de...

Hoy instalé la ampliación de RAM en mi nuevo iMac G5 de 20" — una auténtica bestia corriendo a 1,8 GHz. Los que se quejan de que la memoria base de 256 MB con que Apple sigue vendiendo los equipos de...
En Fark.com han organizado uno de sus famosos concursos de Photoshopeado en el que el tema es What if the Mac really was a cult? Imprescindible para maqueros ;-)...
Ahí va un truco impresionantemente útil para iTunes (aunque seguro que para variar soy el último idiota en descubrirlo) que he leído en la edición en papel de Playlist: Guía del iPod, una buenísima guía que ha publicado recientemente la gente de...
No te pierdas How It Works... The Computer. Se trata de dos ediciones, de 1971 y 1979, de este libro que intenta explicar lo que son -eran- los ordenadores, escaneadas y puestas en línea....
Este curioso personaje tiene un objetivo en su vida: crear un archivo digital de todas las canciones que existen. Sencillamente, por si llega el fin del mundo y hay que preservarlas. "(...) Hasta ahora su archivo de música rivaliza con la tienda...
El largamente esperado Delicious Library ya está disponible. Es un software exclusivo para Mac OS X ($40, con versión de prueba gratuita) [descarga .dmg 10 MB] que permite organizar tu librería, videoteca y discoteca -- todo a la vez y con una...
PowerBook G4 15 SuperDrive Nada más sacarlo de la caja y encenderlo ya tiene conexión WiFi (802.11g) y puedes conectarlo por FireWire 800 directamente a otro Mac para transferir todos los datos y tenerlo listo para trabajar en minutos. También se conecta...
Por Nacho Palou -
3 NOV 2004
BusinessWeek publica un artículo acerca de Steve Jobs en The Great Innovators, la serie sobre grandes innovadores que está publicando con motivo de su 75 aniversario: Steve Jobs: He Thinks Different.More than anyone else, he brought digital technology to the masses....
danamania, una geek australiana a la que le encanta exprimir viejos macs al máximo cuenta como ha instalado Mac OS X Panther en un Macintosh Centris 650, una máquina que monta un Motorola 68040 a 25 MHz. Lo ha hecho instalando PearPC...
Talk time: Jef Raskin es una breve entrevista que publica The Guardian con uno de los creadores del Macintosh, en la que éste no se corta un pelo:Perhaps the longest surviving legacy of your original design is its "appliance" nature. Has this...
Un curioso artículo de Wikipedia sobre los tipos utilizado por Apple a lo largo de su historia, desde la a Motter Tektura del logo de 1975 a la Myriad Pro....
Por Nacho Palou -
21 OCT 2004
OSXplanet es un software de escritorio "vivo" de Gabriel Otte para Mac OS X que descubrí a través de Dan Gillmor. Está basado en el open source Xplanet nativo de Linux/FreeBSD, también para Windows, que a su vez se está inspirado...
... dijo un empleado de Microsoft en su weblog: Resulta que ahora tengo GMail, la Toolbar de Google, la Deskbar de Google y Google Desktop. Para buscar en la ayuda de MSDN uso Google. En casa, todos mis ordenadores tienen Google como...
Un equipo de la Southampton University ganó el concurso de programación The Iterated Prisoner's Dilemma Competition, celebrado con motivo del 20º aniversario del Dilema del Prisionero, con una estrategia que superó a la clásica ganadora de toda la vida, tit-for-tat, considerada invencible....
Alexburke lo cuenta en How To Cost Microsoft Money: cómo consiguió 150 copias físicas de CD-ROMs del SP2 de Windows XP en modalidad “gratis total” con solo pulsar el botón ATRáS y RECARGAR 150 veces en su navegador. ¡Y con fotos! (Visto...
En una sala de chat: <Sonium> someone speak python here? <lucky> HHHHHSSSSSHSSS <lucky> SSSSS <Sonium> the programming language Esta es una de las últimas (y muy graciosas) estupideces / chistes que se pueden encontrar entre los miles de citas de la QDB...
Para celebrar la emisión de nuevos capítulos del serial radiofónico de La Guía del Autoestopista Galáctico la BBC ha puesto en línea una versión actualizada del clásico juego de aventuras de Infocom basado en la trilogía de libros original. Aunque esta versión...
Computer Stupidities, una de esas recopilaciones de anécdotas y frases gloriosas de las personas en continua lucha contra las máquinas.From a Windows 95 user: Customer: "I think my computer doesn't know what it is doing."Tech Support: (pause) "Why? What is the problem...
Por Nacho Palou -
21 SEP 2004
Así era Google por dentro hace seis años y cómo se calcula que es hoy....
Por Nacho Palou -
20 SEP 2004
Puedes ver y votar el aspecto de los diagramas de redes proporcionados por cualquier usuario que quiera participar en las distintas categorías de redes: grandes, pequeñas y domésticas. Un buen sitio para ver qué hacen otros y aprender....
Por Nacho Palou -
16 SEP 2004
Después de utilizarlo un tiempo, CSSEdit (Mac OS X) es sin duda el editor CSS que más me gusta: sencillo, completo, rápido y eficaz –incluso previsualizando, y también es bonito y barato, unos 20€. StyleMaster (Mac OS X y Windows) es ligeramente...
Por Nacho Palou -
16 SEP 2004
Es demasiado bueno como para ser cierto, así que seguramente se quedará en vaporware, pero sería estupendo que QuickTransit, el producto del que habla este artículo de Wired, llegara a convertirse en un producto comercial. Este software, al menos según dice su...
Microsoft apenas acaba de hacer pública la actualización SP2 de Windows XP, que se supone más segura y menos vulnerable que versiones anteriores, pero parece ser que ya se han descubierto agujeros en ella....
Como maquero empedernido, he de reconocer que Dan de MisterBG ha clavado el ciclo de producto de Apple. [vía Cult of Mac]...
Esta semana, en concreto el pasado 7 de junio, se cumplieron 50 años de la muerte de Alan Turing, hecho que ha quedado prácticamente eclipsado a causa de la conmemoración del desembarco de Normandía, en el que Turing tuvo mucho que ver...
Ayer a primera hora de la mañana el tráfico aéreo con destino u origen en el Reino Unido se vió afectado por un problema con los ordenadores que gestionan los centros de control aéreo que obligó a reiniciar el sistema, con el...
Tras diez años de trabajo y coincidiendo con los actos que conmemoran el 60 aniversario del Día D se ha puesto en funcionamiento en Blechtley Park una reconstrucción de un Colossus Mk2, el dispositivo utilizado por los servicios de inteligencia británicos durante...
Me encantan las cronologías (timelines): algunas tienen un tremendo valor por la información y otras por la forma gráfica de presentarlas. Esta Historia del UNIX destaca principalmente por la información, y explora todas las versiones de UNIX desde 1994 1969 hasta 2004...
En la línea de la anotación de Alvy acerca de la reproducción de Lemmings en DHTML, también está WebSE, una simulación de un Macintosh SE con el Sistema 7 desarrollada en Flash. Incluye joyas como MacWrite 1.0 y MacDraw 0.9.4, así como...
Un bonito sitio que reúne iconos y otros elementos de interfaces gráficos (GUI) de distintos sistemas operativos: Mac OS, Windows, BeOS, RH Linux,......
Por Nacho Palou -
17 MAY 2004
Hay geeks y ultra-geeks. Fanáticos del software libre y ultrafanáticos del software libre... Para comprobarlo, échale un vistazo a las fotos del post titulado Auténtica Boda Geek en Mundo Ismaeliano (segundo post ahora mismo -- no hay permalinks): Escenario: una boda en...
Absolutamente elegante, sencilla y práctica: 4096 Color Wheel....
Sobre todo en las pantallas de los aeropuertos. Actualización: Jonan de Pixel y Dixel también nos recuerda que por otra parte Windows es peligroso en las terminales de autobús....
>Hello, Alice ALICE: Hi there! >How are you doing? ALICE: I'm doing great, how about you? >Well, a typical day at work ALICE: Interesting. How old are you? >I'm 36 ALICE: Oh, you were born in the 20th century! >How old are...
Boeing ha hecho un descubrimiento sorprendente: el dinero protege los sistemas de vuelo de los aviones de las dañinas interferencias de las redes WiFi. A partir de abril los pasajeros de varios vuelos internacionales de Lufthansa con origen en Alemania podrán tener...
Dedicado a todos esos administradores de sistemas incomprendidos que hay por el mundo… Elige no tener vida. Elige no tener cuidado. Elige no tener familia. Elige un ordenador jodidamente grande, elige discos en array del tamaño de una lavadora, racks de módems,...
Por lo visto se ha hecho real, oficialmente, el viejo chiste de llamar «2.0» a los descendientes de los geeksA self-described engineering geek has taken a software approach to naming his newborn son [...] Jon Blake Cusack 2.0Según cuentan diversos medios....
Por Nacho Palou -
4 FEB 2004
El ultimo juguete que le he puesto a mi iMac se llama EyeTV USB. Es un digitalizador de vídeo que incluye sintonizador de televisión. Sirve básicamente para ver la televisión y grabar vídeo en el disco duro y también tiene una entrada...
Gates, cofundador y presidente de Microsoft, será investido con el título de Sir (KBE) por la reina Isabel, en «reconocimiento a su aportación empresarial en Gran Bretaña».All I know about the ceremony is what I saw on Monty PythonAfirmó Bill Gates al...
Por Nacho Palou -
27 ENE 2004
Hoy se cumplen veinte años de la presentación del primer Macintosh.Hello, I am Macintosh. Never trust a computer you cannot lift... I'm glad to be out of that bag.Puede que hoy por hoy la cuota de mercado de Apple no sea espectacular,...
Owen Linzmayer, autor entre otros de The Mac Bathroom Reader [ver similares], selecciona para Wired los veinte Macs más significativos en los veinte años de historia de este maquinillo. Sólo dos de la docena o así de Macs que he tenido hasta...
El próximo día 24 de enero se cumple el 20 aniversario desde que se lanzase el ordenador Macintosh en 1984. Con motivo de tal celebración Apple reedita su ya famoso anuncio 1984 con una pequeña modificación: la corredora lleva en su cintura...
Por Nacho Palou -
7 ENE 2004
Tras el primer trimestre de la historia de Microsoft en el que sus beneficios no han crecido, Charlie Demerjian postula en este artículo de The Inquirer que se está produciendo un gran cambio en la industria de las TI en el que...
The Faces in Front of the Monitors recoge una colección de fotografías de muchos de los personajes más conocidos de la historia de Internet y de los ordenadores. [vía Slashdot]...
John Paczkowski ha recopilado en First Computers unas cuantas historias sobre la gente de Silicon Valley y sus primeros ordenadores. La fauna es de lo más variada: Osbornes, Commodores 64, 286s, Altair... las historias personales sobre estos cacharros (¡y sus precios!) son...
Hace años que la NASA publica la imagen astronómica del día acompañada de una breve explicación escrita por un astrónomo profesional en Astronomy Picture of the Day, pero si eres usuario de Macintosh, hay una pequeña utilidad donationware llamada APOD Grabber que...
Aún a pesar de que esta noticia no salió el 1 de abril, equivalente anglosajón del día de los Santos Inocentes, y de que no tiene su origen en una coña de The Onion, me resulta prácticamente increíble, aún cuando tanto la...
Ya es oficial: Big Mac, el superordenador construido por Virginia Tech a base de 1.100 Power Macintosh G5 es el tercer ordenador más rápido del mundo, a una fracción del coste de los dos que lo anteceden y del de muchas máquinas...
El artículo 20 años infectando computadoras publicado esta semana en el sitio de la BBC cuenta: Los virus informáticos cumplen este lunes 20 años de andanzas, causando dolores de cabeza a todo tipo de usuarios de computadoras. Sin embargo el concepto de...
Por Nacho Palou -
13 NOV 2003
Como geek profesional llevo muchos años destripando máquinas simplemente para ver cómo son por dentro, para ver qué falla en ellas, cambiarles algún componente o realizar alguna ampliación -aún recuerdo cómo sudaba cuando instalé 2 MB de RAM que costaron algo así...
Después de haber obtenido el visto bueno de las autoridades competentes y de llegar a sendos acuerdos extrajudiciales para terminar con dos demandas interpuestas contra la operación anunciada en junio de este año, ésta dio ayer su último paso al obtener la...
Your Sky, un planetario interactivo vía web similar a Voyager o StarryNight (algo más limitado) pero muy rápido (nada de applets), lo suficientemente completo y con la ventaja de estar disponible desde cualquier ordenador -con conexión. Funciona bastante bien y se configura...
Por Nacho Palou -
6 OCT 2003
Impresionante el montón de ordenadores PowerMac G5 conectados para el Terascale Project: 1.100 máquinas en total. Combining the power of 1,100 Apple computers, the Terascale Cluster project is bringing Virginia Tech to the forefront in the supercomputing arena. Algunas imágenes del proyecto....
Por Nacho Palou -
22 SEP 2003
Cortesía de Pablo, un curioso mensaje de error de Windows 2000, explicado –supuestamente– en la Knowledge Base de Microsoft: «Su contraseña debe tener por lo menos 18770 caracteres y no puede ser igual que ninguna de las 30689 contraseñas previas. Escriba una...
¿Te imaginas montar un servidor web en una máquina de 1986 (no, no se trata de un error, realmente es de 1986) con 4 MB de RAM, procesador a 8 MHz, dos disketeras, y sin disco duro? ¿Imposible? Pues esa es precisamente...
Tareas hercúleas en el Google Code Jam 2003: «(...) We have some serious problems and we'd like to share them with people who are motivated by that kind of challenge. So, you're invited to take part in the Google Code Jam 2003,...
Este artículo de Wired cuenta cómo una vez obtenido el permiso de Steve Wozniak y ante la callada de Apple al respecto Vince Briel está a punto de empezar a fabricar y vender una serie limitada de réplicas del Apple I. Cuestan...
A raíz de mi comentario sobre el libro A computer called LEO, que trata del primer ordenador de oficina del mundo, alguien nos escribió para preguntarnos cuál fue el primer ordenador del mundo, y aunque la pregunta parece sencilla, en realidad tiene...
A computer called LEO: Lyons Tea Shops and the World's First Office Computer. Georgina Ferry. Fourth Estate. 2003. ISBN: 1841151858. (Inglés). 240 páginas. Este libro cuenta la sorprendente y desconocida historia de cómo Lyons, una empresa inglesa fundamentalmene conocida por su cadena...
Si tienes un Macintosh, probablemente alguna vez hayas visitado MacInTouch, la publicación que Ric Ford mantiene, de una forma u otra desde hace casi una década. Nació como fue una revista independiente en 1985, un par de años después se integró con...
PrintBrush es una impresora de nueva tecnología, parecida a aquellos escáneres de mano que detectaban el movimiento cuando los desplazabas por el papel. Solo que este gadget, cuando lo mueves, imprime. Realmente ingenioso. (Vía jwz.)...
...realmente quiere decir cuando se refiere, por ejemplo, al significado de estándares "Standards" - (1) (n, pl.) - What Microsoft thinks should be the defined baseline for computing and networking protocols. (2) (n, pl) - Microsoft's inserting of proprietary code into computing...
Por Nacho Palou -
11 JUN 2003
En DiarioRed.com se habla por fin sobre la propagación del que probablemente el «gusano de envío masivo» que comenté el otro día. Los síntomas coinciden con un tal Win32/Bugbear.B (Tanatos.B) según EnciclopediaVirus.com, excepto porque a mi no me llegaban ficheros adjuntos: Una...
VA Linux está subiendo en bolsa (Nasdaq: LNUX) un 50, 60… 70% hoy. Y no por algo que haya hecho sino por algo que ha dicho Microsoft. Al parecer se ha filtrado un memorandum interno de Microsoft en el que Steve Ballmer...
01010101 01101110 00100000 01100011 01101111 01101110 01110110 01100101 01110010 01110011 01101111 01110010 00100000 01100010 01101001 01101110 01100001 01110010 01101001 01101111 00101101 01110100 01100101 01111000 01110100 01101111 00101110...
Encontré finalmente en Col's Random Sentence Generator una explicación (y código fuente) de Colin Frayn sobre un algoritmo que genera frases aleatorias parecidas a la del virus/gusano/troyano comentado ayer. Que por otro lado sigo sin identificar (y no ha vuelto a enviar...
Hoy recibí dos emails muy extraños. Estoy casi seguro que eran de un gusano (o virus-gusano). No se si será conocido o nuevo, pero nunca jamás había visto nada igual, y mira que recibo cientos de spams diarios en varias cuentas. Esos...
Vía pjorge.com, una demo genial de cómo una página web puede hacer cosas físicas a tu ordenador (sólo Windows – por suerte)....
Vía Sablog, explicación visual de por qué no conviene tener un conejo como mascota en una casa geek: Naugthy Bunny. Salvamos a un conejo. Lo encontramos en un parking la semana pasada. No deberíamos habernos preocupado por él. Ya no tenemos el...
Vía Dive into mark, siete palabras en cinco líneas de HTML que cuelgan Internet Explorer para Windows –aunque esté actualizado con todos los parches habidos y por haber– así como Outlook y cualquier otro software que lleve el motor HTML de Microsoft...
[Modo irónico ON] Es gracioso leer Las causas judiciales de Madrid se podrán consultar por Internet: 28 de abril de 2003 - Las causas judiciales de Madrid se podrán consultar por Internet - El Plan de Informática, impulsado por la Consejería de...
Hoy me puse a actualizar un Power Mac G4 para instalarle desde cero un Mac OS X Jaguar (10.2). Usé la última versión que compré en enero (hace dos meses) y tras la instalación completa, que fue muy bien, se conectó a...
En el MIT un par de estudiantes graduados compraron algunos discos duros usados en eBay y se dedicaron a recuperar la información que había o que hubo en ellos alguna vez. Y por lo visto encontraron demasiadas cosas, según cuentan. Influidos por...
Por Nacho Palou -
17 MAR 2003
Un artículo sobre computación cuántica divulgativa en castellano, El Ordenador Insuperable. El autor es David Deutsch, el amo del tema. Es el autor de uno de los libros que más me han impactado en los últimos años: The Fabric of Reality: The...
El Teorema del Salario de Dilbert establece lo siguiente: Los ingenieros y los científicos nunca pueden ganar tanto como los ejecutivos o los comerciales La demostración matemática parte de dos postulados de dominio popular: Postulado número 1: Knowledge is Power (El Conocimiento...
Parece que por ahí, en alguna tienda especializada, identifican cualquier cacharrillo que sirva para conexiones inalámbricas como Bluetooth, incluso si en realidad son dispositivos Wi-Fi o IEEE 802.11x que aunque es una tecnología similar (pero superior) es incompatible con aquella. El motivo...
Por Nacho Palou -
18 DIC 2002
Hace tiempo que perdí la cuenta del número de combinaciones 'usuario y contraseña' que utilizo habitualmente, las cuales guardo principalmente en la memoria (en la neuronal) o apuntados por ahí con cifrados mentales rápidos para no tener que memorizarlas pero que me...
Por Nacho Palou -
8 NOV 2002
Por ahí andan un par de noruegos mosqueados con HP porque, según cuenta el periódico noruego Aftenposten [hottentotten], desde hace una semana lo que escribe uno de ellos con su teclado inalámbrico aparece en la pantalla del otro que resulta que tiene...
Por Nacho Palou -
6 NOV 2002
Hablando de compras «loser» este juguetito de Apple posiblemente sea uno de los trastos que hacen honor a la definición. Un PowerBook G4 Titanium a 1GHz, con MacOS X, tostadora de discos DVD, pantalla de 15 pulgadas y amigo de casi todos...
Por Nacho Palou -
6 NOV 2002
Resulta que hace años, como los sistemas de almacenamiento eran escasos y caros, comprimíamos las cosas al guardarlas para archivar, sencillamente para ahorrar en disquetes o cartuchos. Lo cual no sería un problema si no fuera porque la mayor parte de esos...
¡Recuperado el Mac! Al instalar el 7.5.5 en inglés sobre el 7.0 en español y probar con la utilidad 'Primera Ayuda' (que incluye Apple para recuperar discos estropeados) el disco duro principal ha aparecido como por arte de magia y decenas de...
No se trata de un exorcismo, pero casi. Hace tiempo que decidí intentar recuperar todo lo que había en mis trastos antiguos (léase: ordenadores viejos) antes de que el paso del tiempo los deteriore más allá de toda posibilidad imaginable de recuperación....
Ahí va un pequeño truco para incrementar (sin compartir) el nivel de participación (Participation Level) de Kazaa Lite. Por lo que sé al respecto (que no es mucho) hay al menos un par de formas distintas a esta de hacerlo. Con esta...
Por Nacho Palou -
12 OCT 2002
Así que éste es el portátil [más fotos] que el FBI confiscó al célebre hacker Kevin Mitnick cuando éste fue detenido en 1995 (tras lo cual pasó cinco años entre rejas) y está a la venta en eBay. Se entrega junto con...
Por Nacho Palou -
3 OCT 2002

Sólo para los más microsiervos del lugar: Create Your Own O'Reilly Cover. Sirve para crear tus propios libros con portada «versión O’Reilly». Elige el dibujo, escribe los textos y listo, ya puedes descargar el archivo gráfico para la posteridad. Actualización (2006):...
Todo un clásico: el documento para identificar a tu administrador de sistemas entre la variada fauna informática que puebla las empresas: Know your System Administrator....
Protect your Macintosh. Bruce Schneier. Peachpit Press. 1994. ISBN: 1566091012. Inglés. 316 páginas. En su día fue un gran libro de referencia para los usuarios de Macintosh y responsables de sistemas interesados por los temas de seguridad. Describe técnicas de cifrado de...






