
Es un problema que viene sucediendo desde al menos el verano de 2023.

La infraestructura digital no la sostienen solo gigantes: también la apuntalan proyectos diminutos, mantenidos a ratos libres.

Un vídeo de la BBC nos recuerda cómo era mandar un texto a Londres desde Ámsterdam: con mucho ingenio (y dinero)
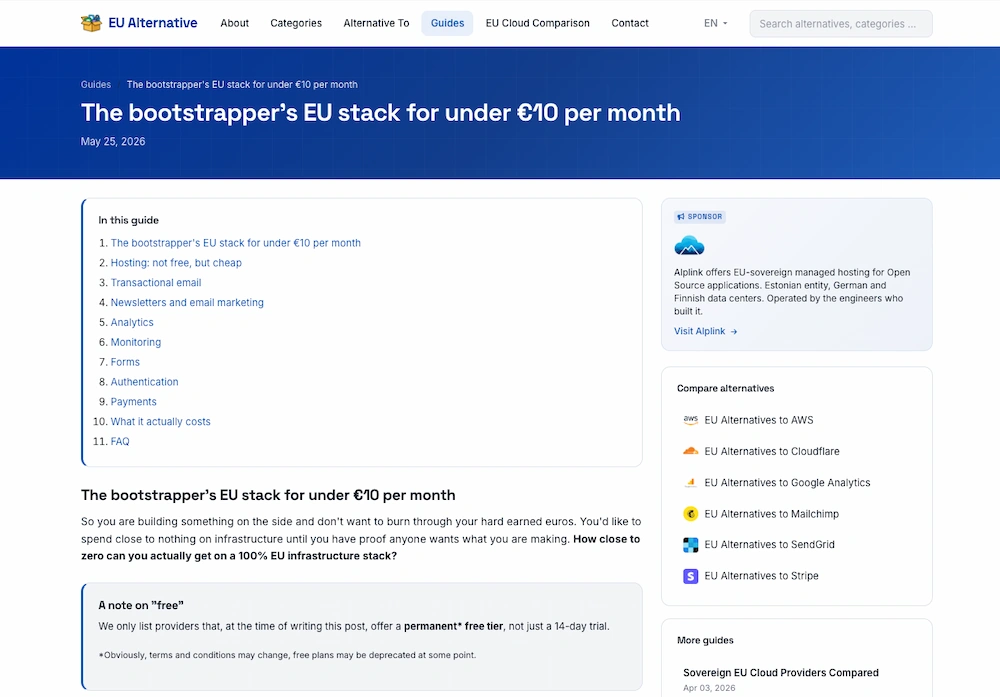
Montar tu imperio en internet cuesta menos de 10 euros al mes: 7 para el servidor y el resto, para esperar a que llegue el éxito.

Será una implantación paulatina de aquí a finales de año.

AIMC vuelve a los noventa con una encuesta de internautas, justo cuando el modem y el café eran más lentos que nuestras ganas de salir de casa.
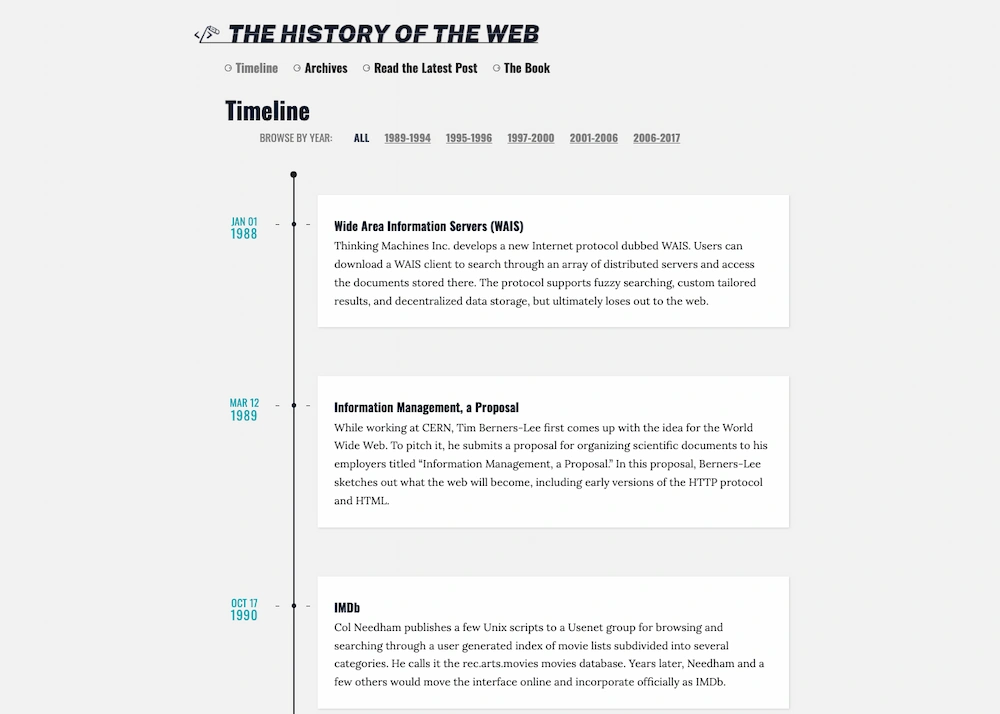
Una cronología muestra cómo la Web triunfó por accidente, entre banners horteras, guerras de navegadores y decisiones improvisadas.
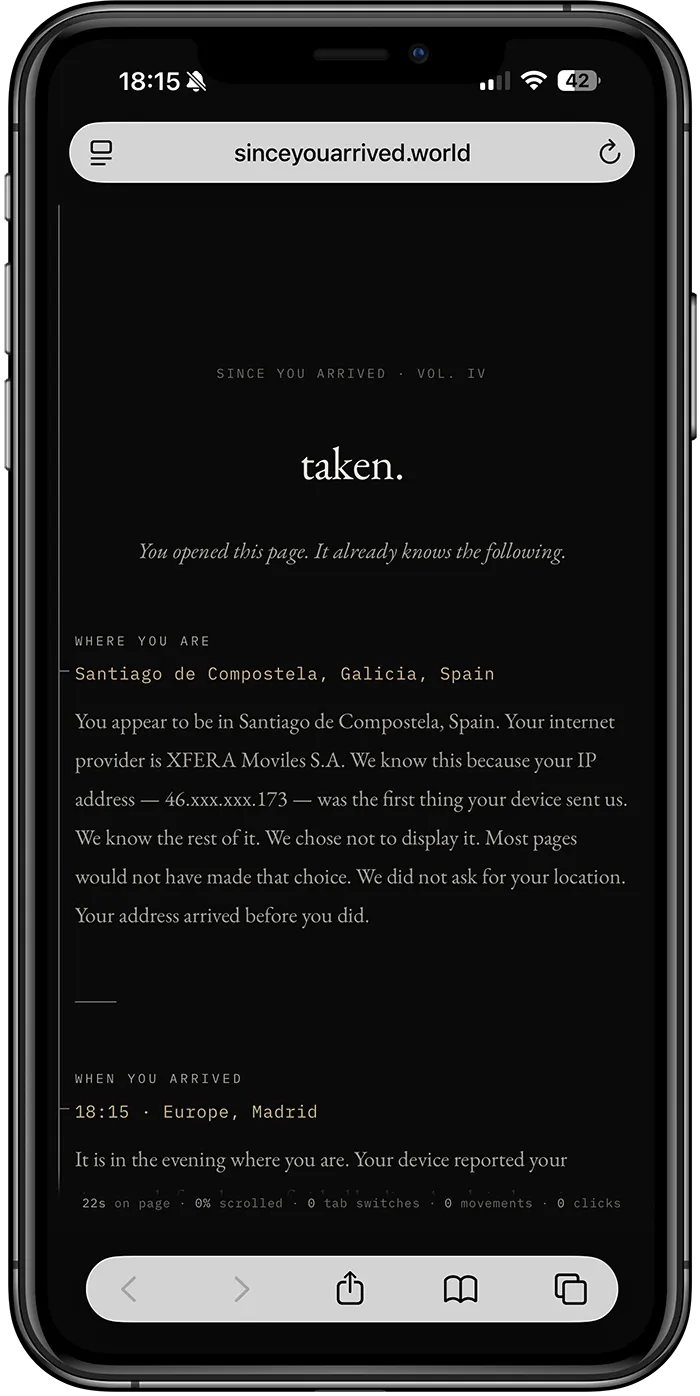
El mensaje es un poco catastrofista pero puede servir como herramienta para ver cómo configurar correctamente, o al menos intentarlo, los ajustes.

Han creado una copia de seguridad de Internet en Suiza, porque la neutralidad mola. Lo mejor: el archivo de IAs generativas.
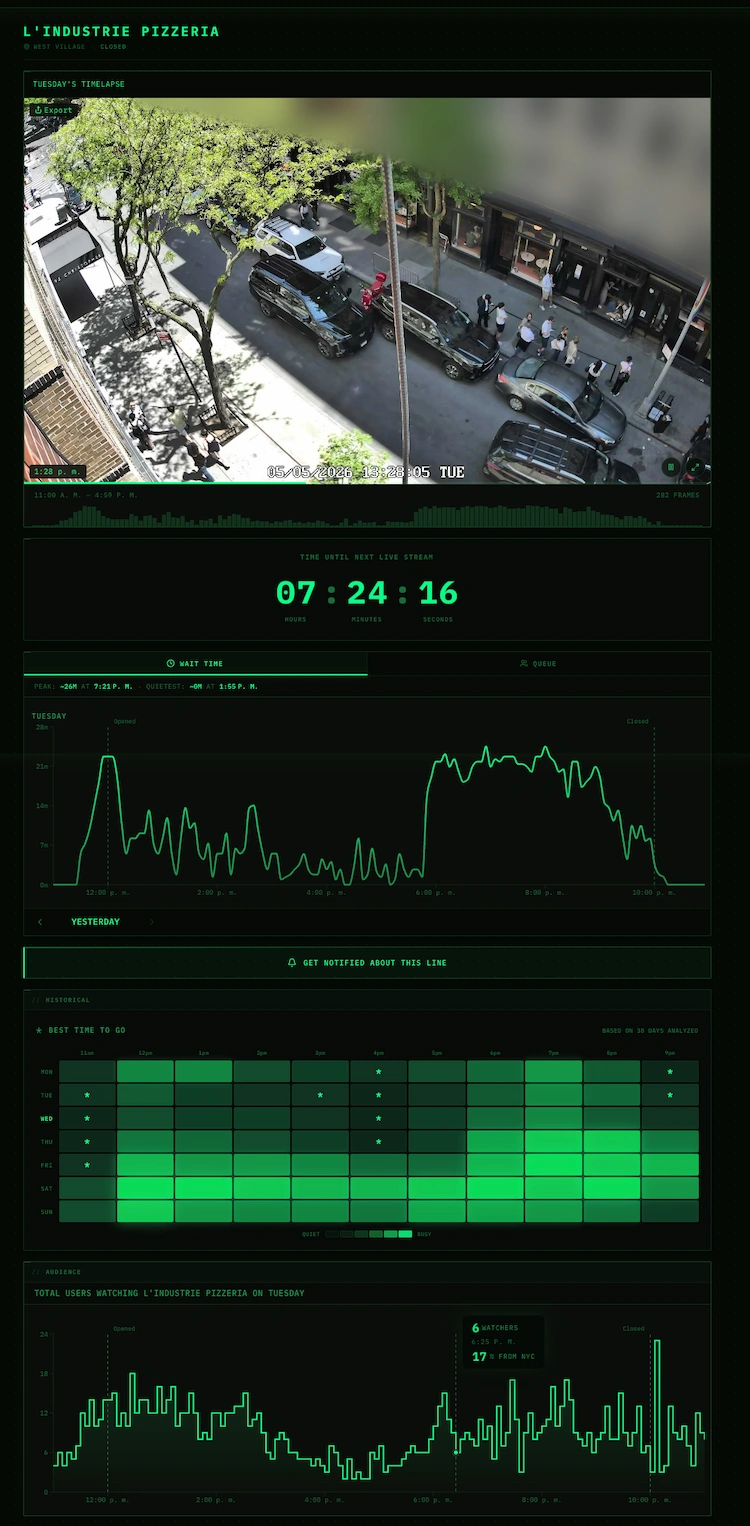
Unas cámaras, algo de visión artificial y una vieja fórmula matemática para ahorrar tiempo.

Tiene tres meses para lanzar otros 1.600 más.
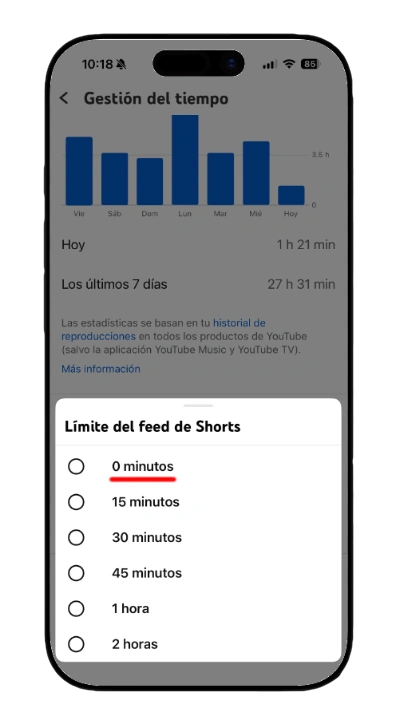
La plataforma permite, por fin, bloquear los vídeos cortos en móviles.

La red antes de las redes: 462.000 grupos donde se debatía de todo con pasión, ahora archivados para nostálgicos y curiosos.

Con el lanzamiento de hoy tiene en órbita 241 de los 1.615 que en principio tiene que haber lanzado para el 31 de julio de este año.

Publicar un correo y librarse de los buitres del spam aún tiene remedio.

Va, de nuevo, contra las promesas de respetar la privacidad de los usuarios, una y tantas veces rotas ya.

Como siempre habrá que ver cómo está implementado para poder terminar de formarnos una opinión.

La gran apuesta actual de la empresa es la inteligencia artificial… Hasta que vuelvan a cambiar de opinión.
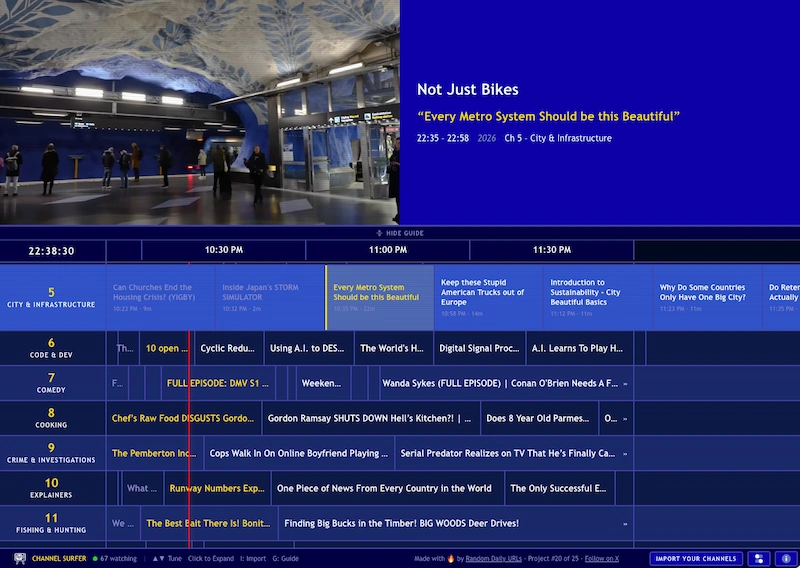
La nostalgia manda: 40 canales convierten YouTube en una tele con horarios, zapeo y la gloriosa imposibilidad de elegirlo todo.

Un texto imprescindible acerca de cómo todo ha ido a peor y sobre cómo podemos luchar contra ello.

Se une a un sitio similar que permite seguir los de cercanías.

Habrá que ver cómo funciona y si tiene efecto de tracción, pero parece una iniciativa más necesaria que nunca.

Se trata de un documento que recoge acciones ya en curso.

La sabiduría de las masas ahora precide hasta el apocalipsis: 20 a 1 a que hay hongo nuclear en marzo.

Un enorme índice de enlaces a recursos de todo tipo, organizado por categorías: inteligencia artificial, streaming, música, videojuegos y demás.

Un estudio de 200 canales y 800 vídeos revela 5 trucos para domar el algoritmo: emojis, cifras, dramas, preguntas y “así funciona”.

Un paseo por la web de hace 30 años sirve de excusa para coleccionar recuerdos.

Es el primero comercial del cohete y de los dieciocho que tiene contratados la empresa estadounidense.

La posibilidad de que la nueva Ley de Protección de Personas Menores de Edad en entornos digitales exija responsabilidades legales a directivos y dueños de redes sociales ha levantado ampollas.

Lo usará para lanzar un nuevo servicio basado en inteligencia artificial. Sí, otro.

Nos ponemos en modo abuelo Cebolleta y recordamos el momento histórico en que el equipo de la versión en español nos salvó de que se llenara de publicidad.
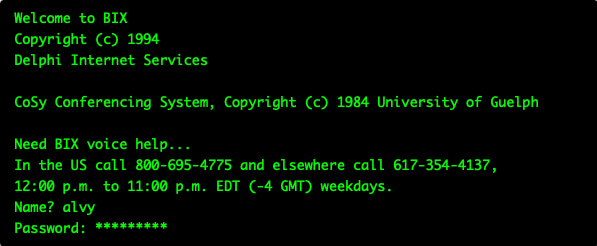
En 1994 Internet cabía en 80x25: un módem ruidoso, un emulador VT100 y un acceso a Gopher era todo lo que se necesitaba.

Alimenta a buscadores y también a la IA, pero prima el criterio humano: 25 años de neutralidad discutida pero bastante útil.

Esta idea propone orden y contexto para los rastreadores: las páginas clave primero, menos ruido y menos atribuciones «creativas», si el bot decide portarse bien.

La conectividad cayó a casi cero en 11 redes; desapareció el IPv6 y desde fuera se veía un 82% menos de Red. No fue un accidente.

Los bots han tomado Internet. Más del 50% del tráfico no es humano. ¡Quién iba a decir que las audiencias fantasma serían tan populares!

España es el Disneylandia de los vídeos basura generados por IA.

Las búsquedas de Google en 2025 muestran que el intelecto humano rivaliza con el de un cactus.

Hablamos de la nueva ley que en Australia impide a personas de menos de 16 años tener cuentas en estos servicios y de una iniciativa similar que el Gobierno de España quiere poner en marcha para 2026.

Navegar por dominios aparcados es como jugar a la ruleta del malware. El 40% de las veces acaban en phising y spam.

Fibra a 10 Gbps en casa:a (casi) la velocidad de la luz para descargar más cosas que nunca. ¿Quién dijo que 1 Gbps eran suficientes?

La Library of Time ofrece ser el arca de Noé de la web, rescatando calendarios y datos para que ni Marte se pierda la hora.

Tu navegador te conoce mejor que tu madre, individualizando tu herramienta de navegación entre millones.

Un error de configuración en Cloudflare convierte a internet en un desierto de errores 500.

Cloudflare Radar desnuda la web: Chrome triunfa, AWS sorprende y el dominio .su revive inesperadamente.

Ganar miles de millones con anuncios dudosos es fácil cuando ignoras todos los avisos. Las multas son calderilla en comparación.

El servicio será gratuito en todas las clases al menos en Iberia y en British Airways.

Muchas de las cosas que han hecho de la Red y de le tecnología cosas peores de lo que fueron.

Registro de aquella primera conexión en el cuaderno de utilización del IMP de UCLA A veces, como sucede cuando uno se pregunta cuál fue el primer ordenador de la historia, la respuesta depende de en qué términos se formule la pregunta, con...

Una vez más hemos visto como dependemos hasta extremos insospechados de cosas que están muy fuera de nuestro control.

Atlas de OpenAI llega para revolucionar el mercado de los navegadores: IA, respuestas en lenguaje natural y Chrome viéndolo desde la barrera.

Encuesta AIMC 2025: 30 minutos de preguntas sobre cómo navegas. Próxima parada: el futuro digital de España.

La Unión Europea quiere obligar a las plataformas de mensajería a incorporar tecnologías que analicen nuestras comunicaciones sin orden judicial ni nada parecido.

Un algoritmo genera libros al instante, poniendo a prueba la paciencia con zillones de páginas.

El sueño de la TV sin calidad: cientos de canales mediocres en un solo mosaico.
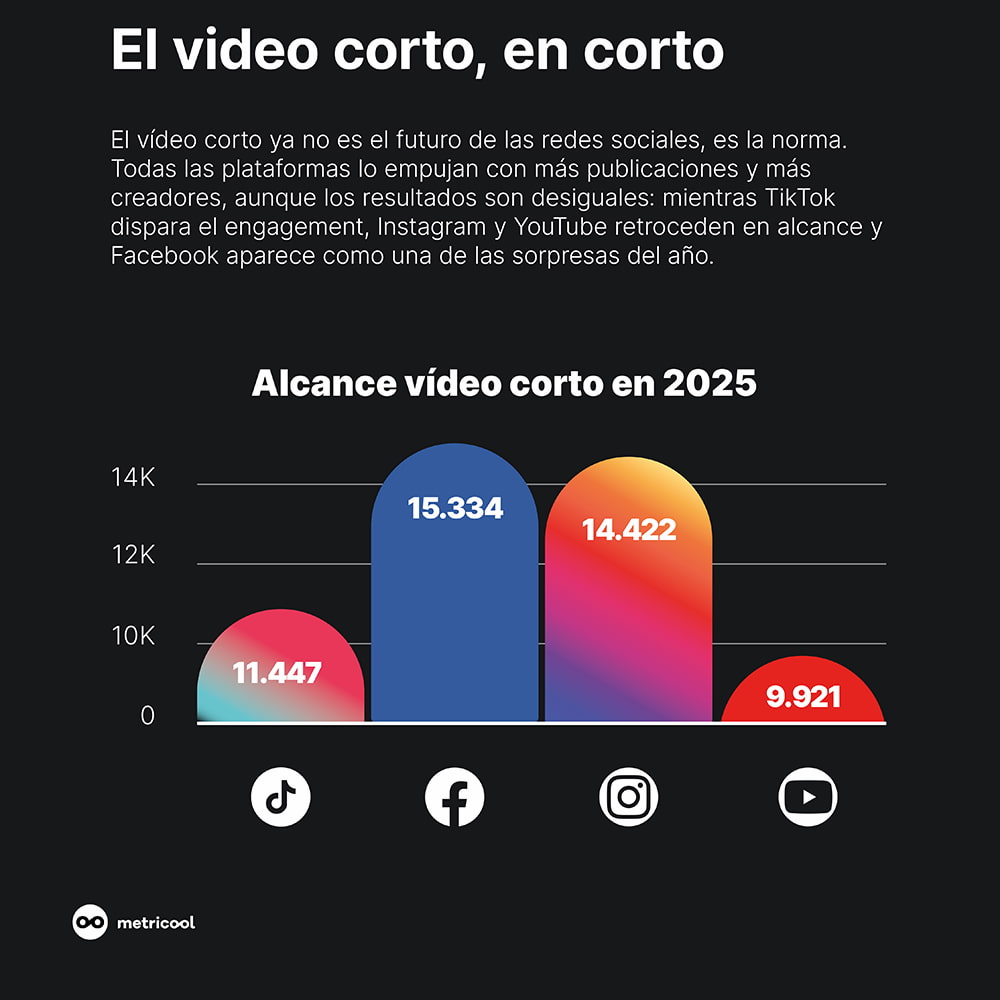
Bienvenidos al futuro: 3,75 segundos son ahora una eternidad en TikTok. Cebos y teasers mandan.

Tiene que lanzar más de 3.000 satélites más de aquí a finales de julio de 2026.

Uno de los máximos responsables de la explosión de los grandes modelos de lenguaje tiene una epifacnía.

IRC, el abuelo cascarrabias de las redes sociales, sigue vivo. Era el lugar para la charla global, ahora convertido en un rincón para los fieles.

Como siempre defiendo la idea de que las prohibiciones son contraproducentes; que hay que acompañar a los «nativos digitales» en este viaje.

Licencias RSL: el intento de poner orden en el caos de la IA. ¿Solución brillante o déjà vu de la sindicación de contenidos?

Los módems de antaño dialogaban en su propio idioma: pitidos y mucho ruido, como si fuera arte moderno.

AInnovación: el evento sobre IA, CMS y DXP. Madrid se llena de expertos y empresas tecnológicas con charlas y networking.

Un montón de normas hace que se acepten correos en formatos realmente alucinantes.

Si mucho mayor que no es lo suficientemente dramático, Unicode añade el ⋙. Ideal para discusiones donde el tamaño sí que importa.
¿Productividad? ¿Qué es eso? Con un millón de capturas web para mirar y perder el tiempo… El caos digital en su máximo esplendor. Igual hasta sales en la foto.

AOL se despide de su última reliquia: el módem. Sorprendente muchas personas aún lo usaban con sus sistemas operativos «viejos».
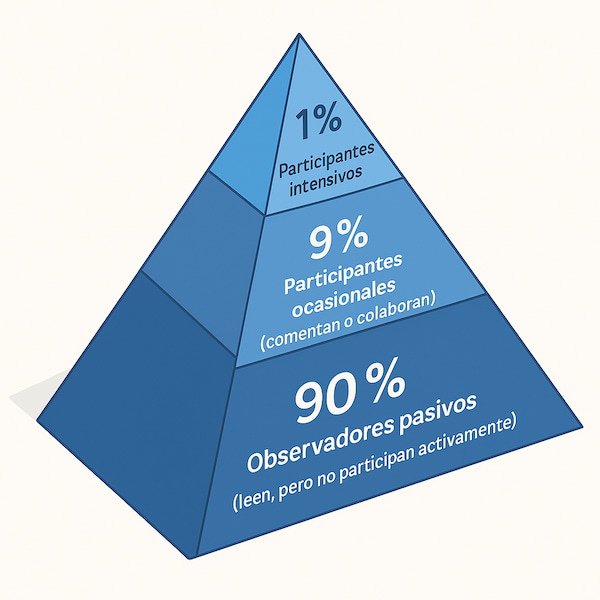
En el mundo digital el 1% grita y el 90% escucha en silencio. Los trolls y las opiniones falsas son el ruido de fondo.

Sarenet celebra 30 años con un nuevo data center en Bizkaia, apostando por la energía renovable y la soberanía tecnológica para pymes.

Del pique entre Márkov y Nekrasov a la IA moderna: cómo una idea de 1906 cambió el mundo, incluyendo el PageRank de Google.

Andrew Chan rastrea 1.000 millones de páginas web en 24 horas por 462 dólares, usando Redis.

La empresa de Jeff bezos tiene que lanzar unos 1.600 satélites en los próximos doce meses para no incumplir con sus permisos.

Al final se ha retractado ante la polémica creada por los cambios propuestos.

El futuro del rastreo web podría tener precio. Cloudflare planea que los gigantes tecnológicos paguen por husmear el contenido. El «error 402» como nuevo sheriff.

Para mí son una herramienta fundamental a la hora de guardar toda la información de interés que voy encontrando en Internet y, sobre todo, de poder recuperarla luego.
Google tiene códigos ocultos que eliminan la IA y los anuncios en los resultados.

El parque jurásico de los GIFs, donde la nostalgia se encuentra con el mal gusto digital de GeoCities. Terapia de choque visual en modo «canela fina».

La tabla periódica de emojis es la «ciencia exacta de lo subjetivo». ¿Quién diría que la risa es negativa? Bienvenidos a la era del sarcasmo digital.

Unas reflexiones ante la penúltima propuesta del gobierno de establecer sistemas técnicos de control de edad para regular el acceso a redes sociales y porno por parte de menores.
Pone fin a una carrera de casi 22 años, aunque lo cierto es que hace tiempo que había perdido gran parte de su relevancia.

Entender cómo los centros de datos no se quedan a oscuras durante un apagón es un ejercicio de fe en la redundancia y en los generadores gigantes.

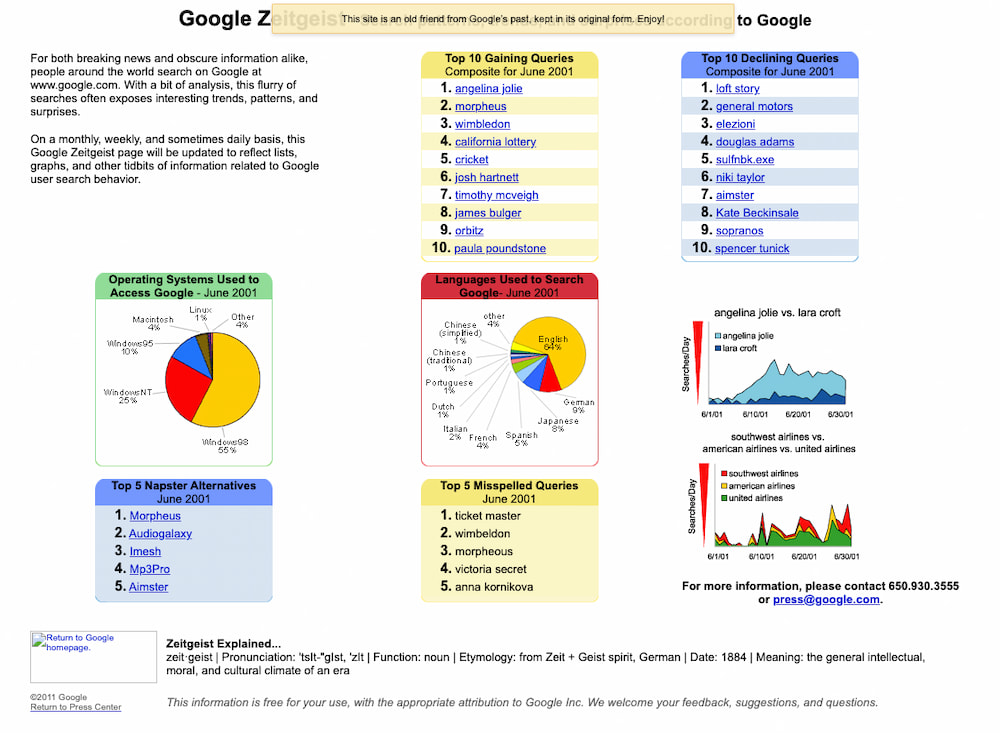
Google revela que lo más importante es ser, no ser indispensable. El zeitgeist: sonrisas, amor y fútbol… toda una sorpresa.

La campaña antipiratería de 2004, irónicamente, usó una tipografía pirata. Increíble pero cierto: sermonear sobre un «crimen» con otro «crimen».

Mensajes de error: el arte de no parecer un jeroglífico egipcio. Con claridad y alternativas los usuarios lo agradecen.
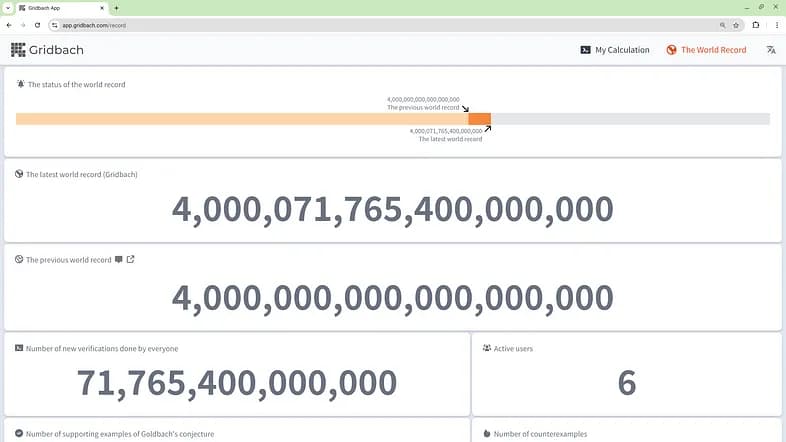
La conjetura de Goldbach, esa traviesa idea que resiste desde 1742, ha encuentrado en Gridbach un nuevo contendiente. Pero parece que los números siguen ganando.

Una visita en persona a las impresionantes instalaciones de Digital Realty en San Blas, Madrid.

El Grupo de Trabajo CSS y su text-wrap: pretty intentan lo imposible: que el texto no solo se lea, sino que también se vea bonito en la web.
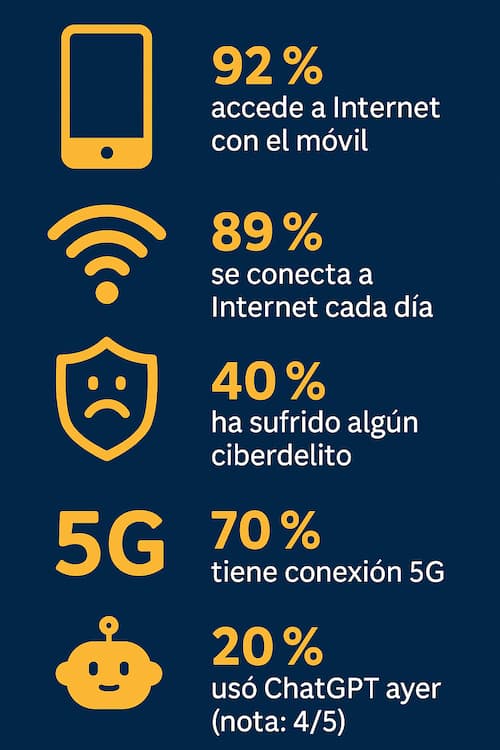
En el fascinante mundo de Internet en España, el móvil es rey, el 5G es su escudero fiel y la IA es la nueva vieja del visillo a la que todos escuchan.

Cuando los cables Ethernet fallan, un palillo puede obrar milagros. ¿Quién necesita alta tecnología?

Un rápido repaso de algunos detalles relevantes de la historia de la empresa que le permitieron arrancar el camino para convertirse en lo que es hoy en día.
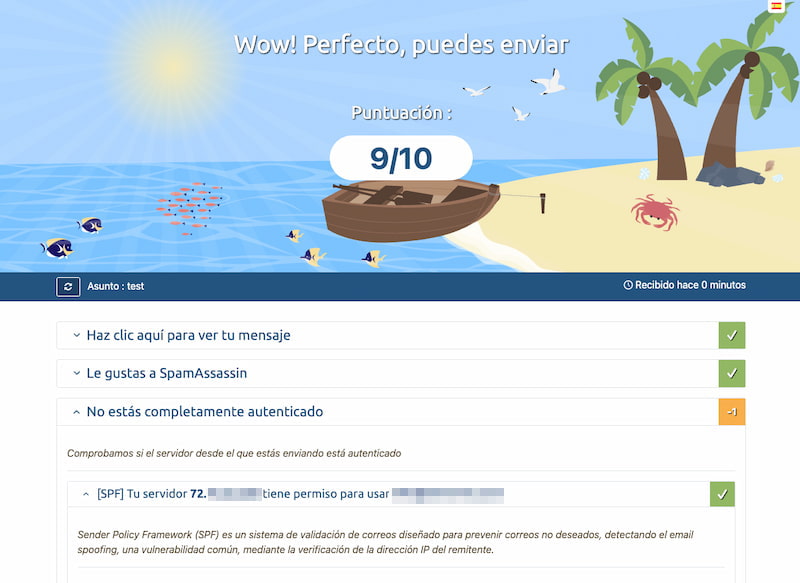
Mail-Tester ayuda a que los correos no sean considerados spam, evaluando detalles técnicos que probablemente ni entiendas, pero puedas mejorar..

Una crítica mordaz a las redes sociales que reflejan el abismo generacional entre adultos despistados y adolescentes atrapados por likes y emojis.
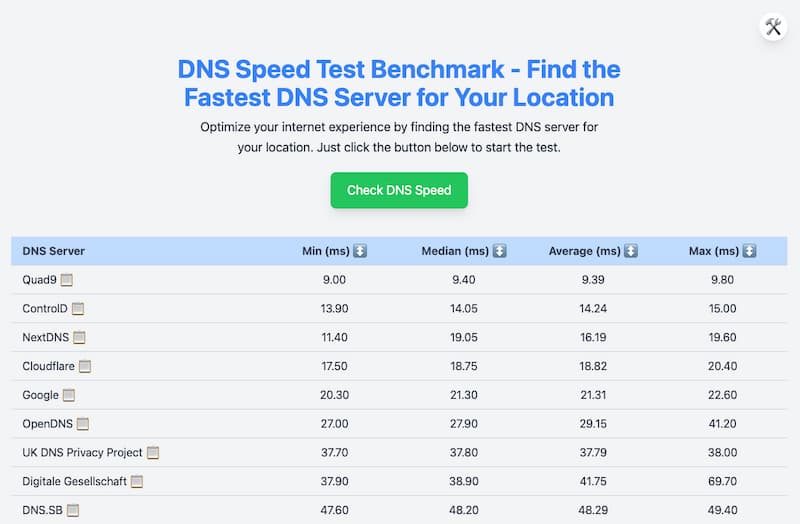
¿Tu DNS te hace esperar demasiado? DNS Speed Test Benchmark ayuda a encontrar el servidor más rápido y seguro para navegar sin estrés.

El que las generaciones más jóvenes hayan crecido rodeadas de ordenadores, teléfonos móviles y tabletas no hace que dominen su uso en absoluto.
Atajos de YouTube: el arte de navegar entre subtítulos y pantallas completas fotograma a fotograma sin tocar el ratón.
Skywriter facilita leer hilos de Bluesky, pero registrarse parece que está todavía «en construcción».
En YouTube la mayoría de los vídeos son más solitarios que un influencer en modo avión. Solo 41 visualizaciones promedio.

RSS, ese formato que se niega a morir, es el nuevo «invento cool» para evitar la infoxicación. A veces lo viejo es lo más moderno.
Un archivo de webs cuidadosamente etiquetadas y categorizadas para inspirar a diseñadores. Parece que la Helvetica bold sigue siendo la reina del baile digital.

Enviar un vídeo de un minuto al futuro parece fácil. Que en 2100 haya alguien para verlo y sepa abrir un MPEG4 ya es otro tema.
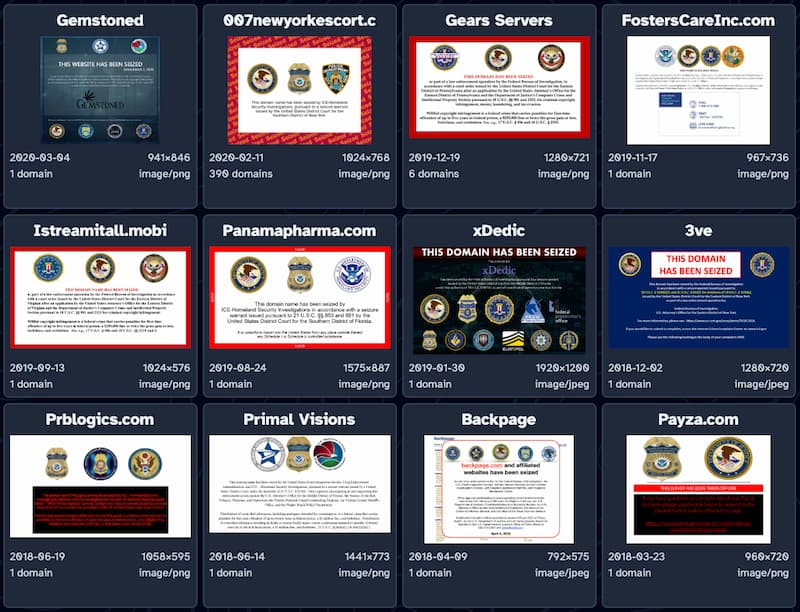
These Websites Have Been Seized es una fascinante recopilación de los carteles de «Este sitio web ha sido incautado» (o intervenido, o bloqueado… según se mire) a lo largo de los tiempos. Es lo que las autoridades estadounidenses plantifican en la...

Minimalismo educativo: esta web agrupa todas las etiquetas HTML, incluyendo pequeñas perlas de sabiduría. Perfecto para aprender y olvidar inmediatamente después.

Cancelar una suscripción o evitar compras y cargos inesperados: un deporte extremo en la era del diseño oscuro y la manipulación digital.

Meta prescindirá de los verificadores de datos, delegando la moderación en el público, lo que podría amplificar los bulos en los temas polarizados.

La enciclopedia libre en español ya supera los 2 millones de artículos. 26 millones de visitas diarias confirman su popularidad. Suma y sigue.
La nueva normativa que entra hoy en vigor no obliga a que sean sin coste.
Facebook e Instagram pasarán a confiar en la comunidad para verificar los datos de los contenidos de sus redes sociales. Los bots ya están afilando sus teclados para participar.

El legado digital resulta complicado. Compañías como Google, Facebook y Apple facilitan el proceso, pero no todo el contenido se hereda.
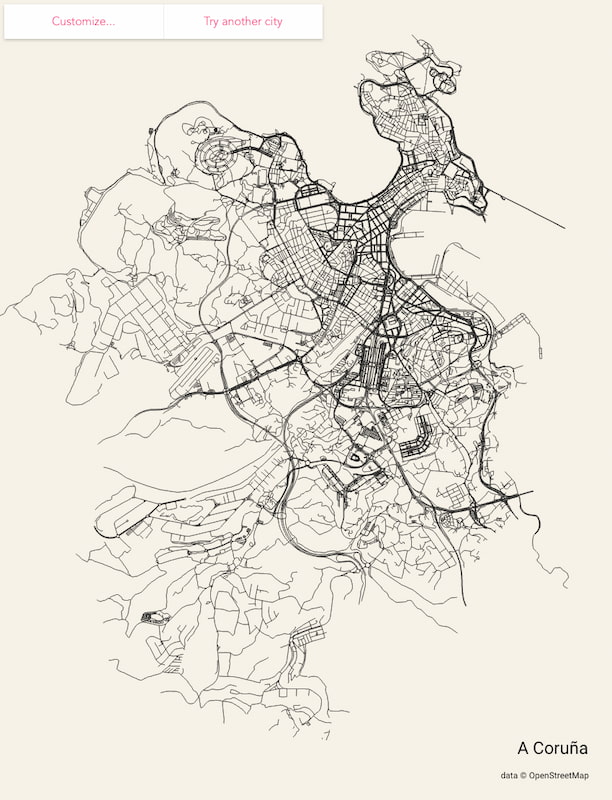
Un proyecto colaborativo dibuja las calles de 3.000 ciudades en una sola página, utilizando datos de mapas abiertos.
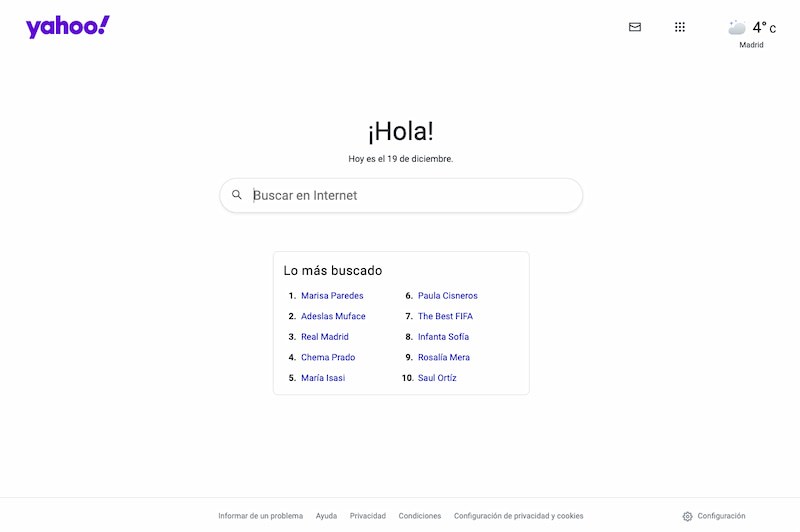
Yahoo España transforma su página en un espacio más limpio y directo, centrándose en servicios clave y dejando atrás el caos visual.
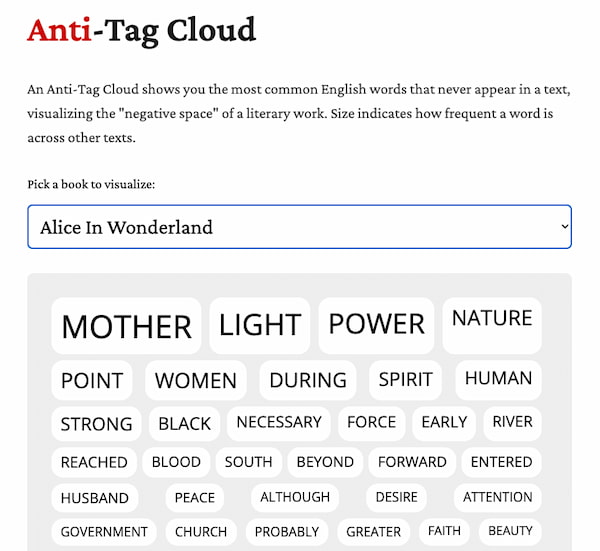
Esta página web procesa libros y destaca las palabras más raras, filtrando las comunes. Usa datos del Proyecto Gutenberg y Wiktionary.

Terra reflejó el boom de internet en España y la caída de las puntocom: especulación bursátil, servicios legendarios como su chat y un colapso que aún es toda una lección de historia.

Blastoff! A #LongMarch5B Y6 rocket with Yuanzheng-2 Y2 upper stage, has sent a group of new satellites for satellite internet services into orbit! The rocket lifted off at 6:00pm BJT on Dec. 16 from the #Wenchang Spacecraft Launch Site on the southern...

Un estudio revela que la electricidad usada por TikTok podría abastecer países pequeños. Una reflexión sobre prioridades.
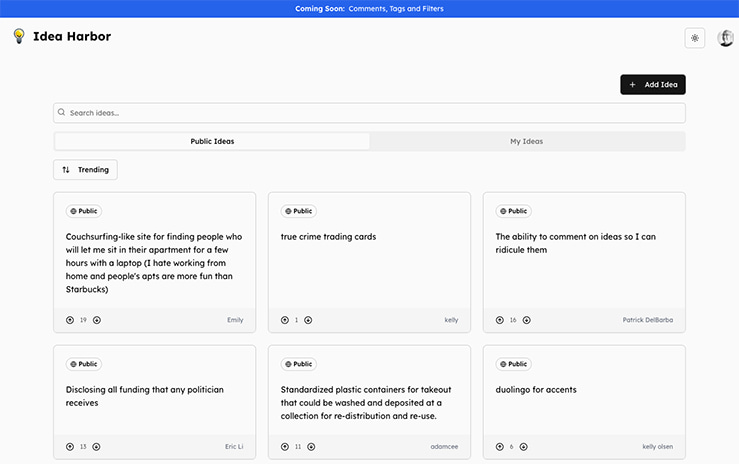
Una plataforma de ideas creativas que mezcla conceptos innovadores con un diseño simple y votaciones de los usuarios.

Los vídeos de YouTube etiquetados como IMG_XXXX muestran el costumbrismo digital en 5 millones de vídeos cortos, únicos y nostálgicos.

La lista de dominios de internet incluye marcas, términos genéricos y nombres exóticos que ofrecen alternativas únicas.
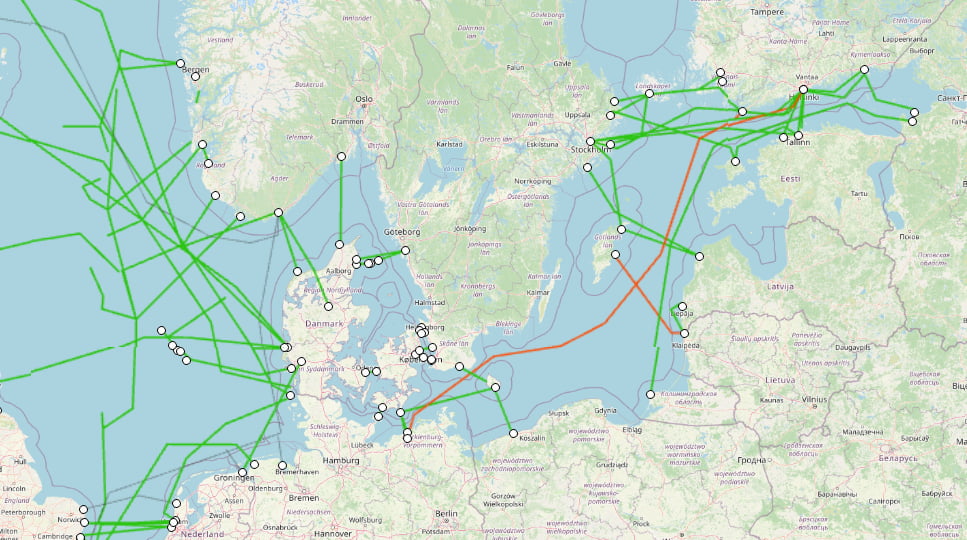
Europa alerta por daños intencionados en cables submarinos clave para las telecomunicaciones.

Un proyecto europeo que recopila alternativas de internet privadas y más sostenibles respecto a los servicios más populares de EE.UU.

Combina sonidos ambientales para relajarte con efectos personalizables en intensidad y duración, y compártelos.

Bluesky se va configurando como la alternativa más popular a Twitter. O al menos eso parece desde mi esquina de Internet. Aunque va por oleadas. La última ha sido causada por el cambio en la función de bloqueo, activado el miércoles...
A menudo es necesario descargar un audio o vídeo de Internet para, por ejemplo, utilizarlo en una presentación sin tener que depender de una conexión a Internet. Pero la inmensa mayoría de los sitios y redes sociales no incluyen una función...
Ofrece búsquedas útiles sin publicidad, aunque todavía es más lento y limitado que Google.

Rusia multó a Google por prohibir YouTube en el país y por ende «censurar» todo tipo de canales de contenido.

En 2004 JJ Merelo tuvo la idea –entonces revolucionaria– de organizar unas jornadas sobre Blogs y Medios en Granada. Era un momento en el que empezaban a aparecer los blogs en España –como por ejemplo Microsiervos– y aún no estaba clara...
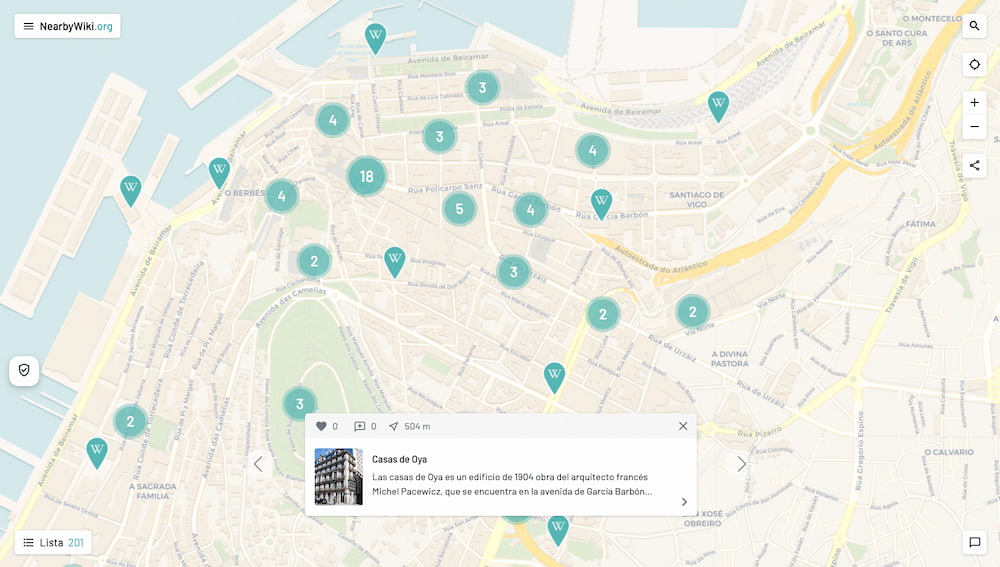
NearbyWiki es un curioso mashup de la gente de Hello World Digital que básicamente se describiría como Wikipedia + OpenStreetMap. De este tipo existen muchos, incluso a partir de las mismas herramientas, pero este destaca por la elegancia de su ejecución:...
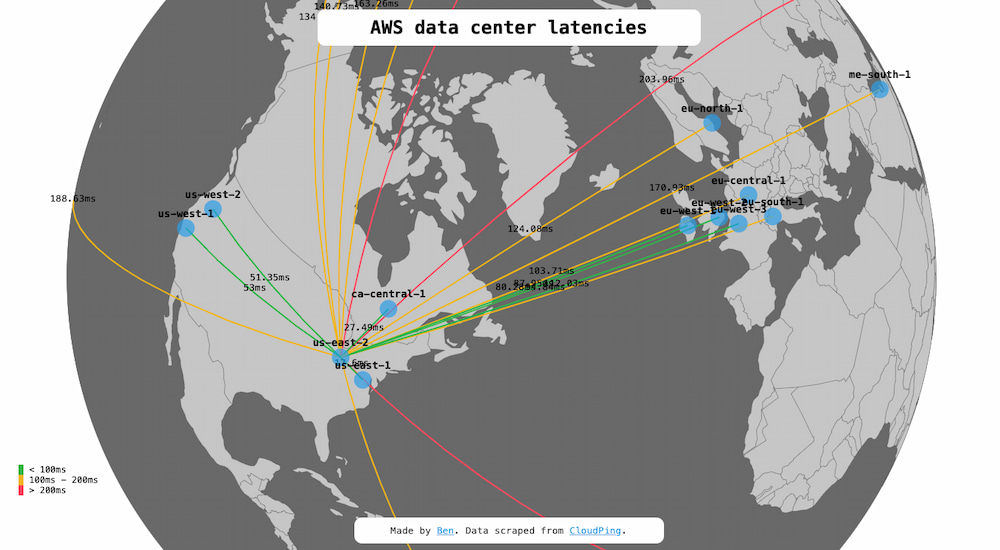
Con los datos en bruto de CloudPing el profesor Den Dicken ha desarrollado AWS data center latencies, donde se puede ver haciendo clics en los nodos de AWS la latencia o retardo que tienen las señales a otros nodos de la...

Se puede participar hasta el próximo domingo, 8 de diciembre: Navegantes en la Red:27ª encuesta a usuarios de Internet de la AIMC Como cada año, es la tradicional encuesta de la Asociación para la Investigación de Medios de Comunicación (AIMC), también conocida...
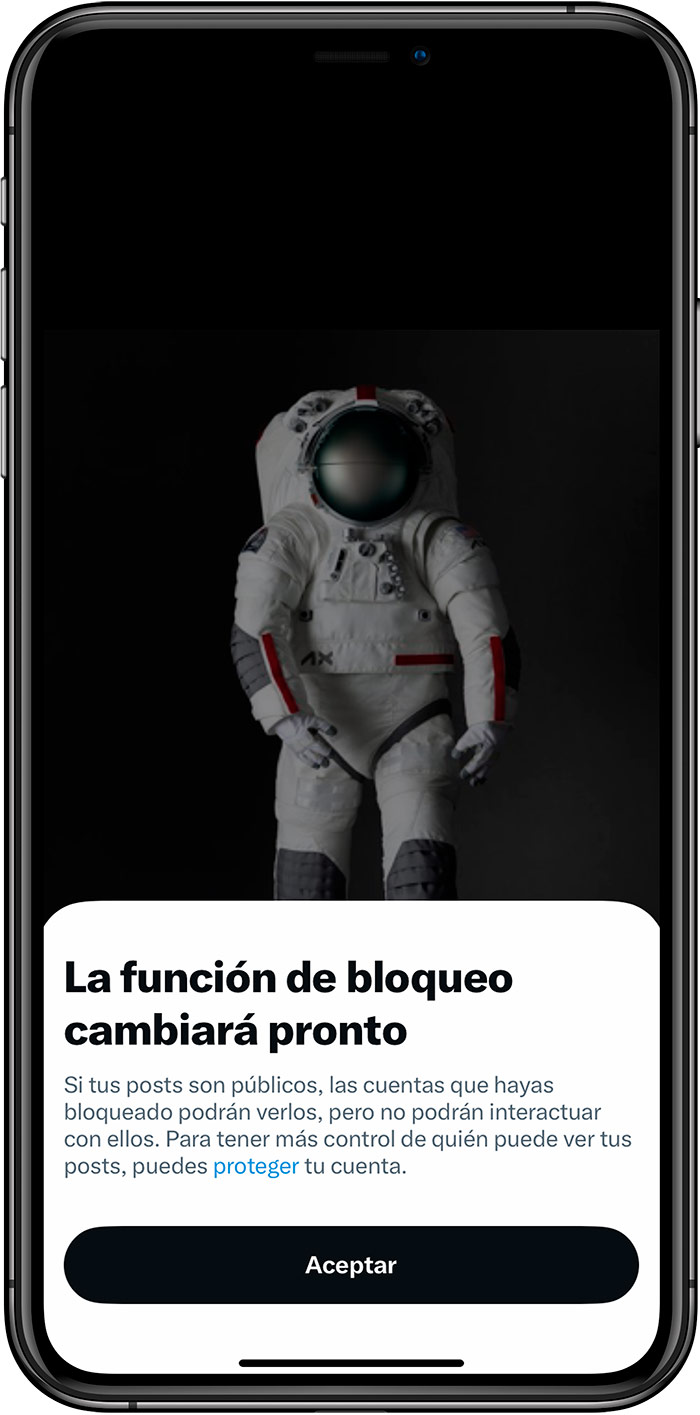
Ya lo habían anunciado hace algún tiempo pero ahora ya están saliendo avisos en la app: Twitter va a modificar la función de bloqueo haciéndola aún más inútil de lo que era. O al menos poniendo más fácil a las personas bloqueadas...

Loable e ímprobo este proyecto llamado WikiProject AI Cleanup con el que los wikipedistas esperan poder devolver un poco de brillo y esplendor a la enciclopedia libre. Un brillo que se ha visto empañado últimamente con demasiado contenido basura (spam IA)...
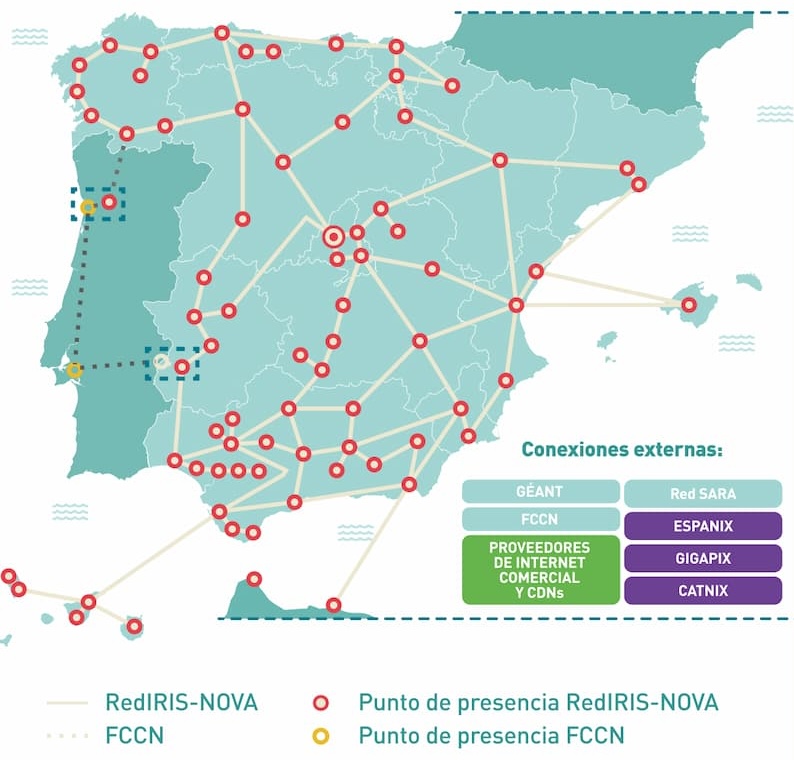
La gente de Digital Realty me encargó un artículo precioso, de esos que da gusto escribir: repasar desde el punto de vista de los centros de datos y la conectividad a nivel global la historia de internet en España. Así que...
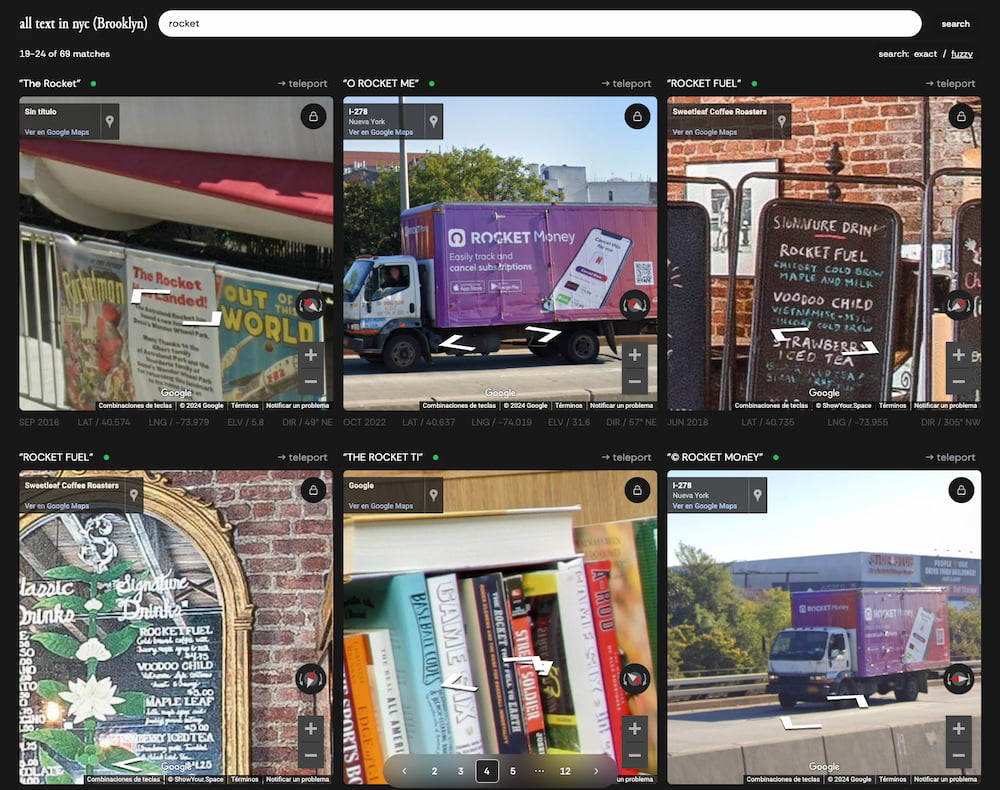
Me encanta la idea tras All text in NYC (Brooklyn) que consiste en utilizar los textos que aparecen en las fotografías callejeras de Google Maps como base de datos «buscable». Basta teclear una palabra (¡o número!) para ver cómo aparecen carteles,...
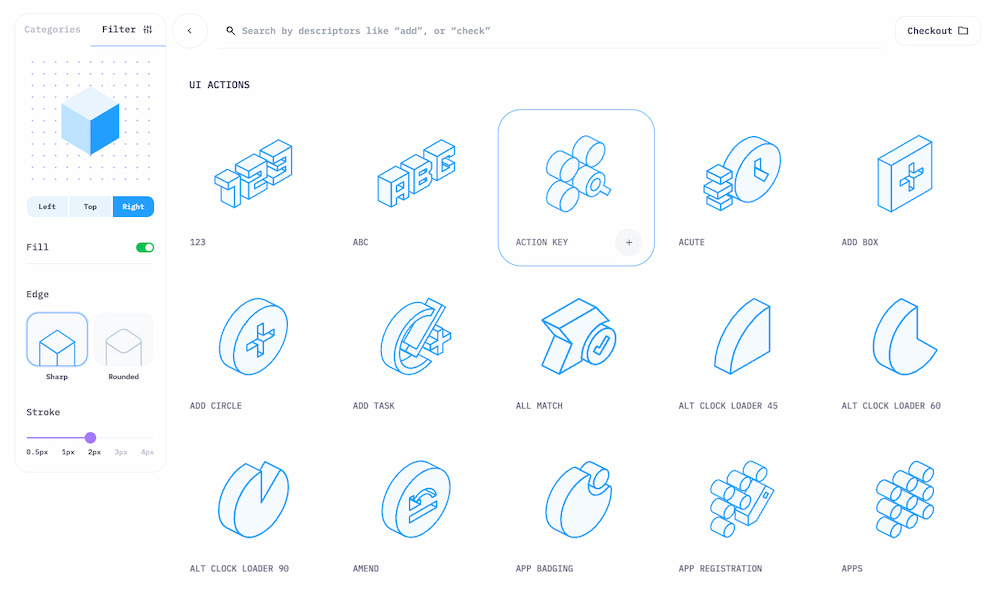
Yendo directos al grano y con unas cuantas opciones para crear variaciones, los Isocons son una extensa y a la par deliciosa colección de iconos isométricos para usar en cualquier diseño: páginas web, presentaciones, logotipos… Ya solo ver el primer pantallazo...

Algunos detalles de la historia de la tecnología son realmente curiosos, como la utilización de la @ (arroba) como separador en el correo electrónico, el formato de las URL o el de la \ (barra al revés) como separador de directorios....
En Neocities ya hay casi un millón de sitios web creados por gente que buscan un espacio donde expresar su creatividad y volcar sus contenidos sin limitaciones. Si te recuerda a Geocities es porque es un poco la misma idea de...
Dirigido a creadores de contenido en general, sin olvidar a los periodistas y editores de grandes medios, AInnovación es un encuentro que se celebrará el 10 de octubre de 2024 en la sede de Google Campus en Madrid. Está organizado por...
Buscadores de dominios hay muchos, pero me ha parecido interesante lo que propone Merklemap como buscador de subdominios. Esto quiere decir que escanea los servidores y busca todos los que tengan servicios asociados con un sitio web: Merklemap sirve para descubrir...

Uno de los artículos más populares que he escrito jamás es en el que hablo del verdadero origen de Internet. En él explico cómo esa idea que se ha extendido e instalado de que se trata de una red diseñada para sobrevivir...

I made a website. it's called "one million checkboxes dot com". it has one million checkboxes on it.checking a box checks it for everyone.that's it. have fun! pic.twitter.com/KBF4UqCMJc— nolen (@itseieio) June 26, 2024 Me ha encantado la historia que cuenta Nolen Royalty...

Estaría encantada de que los tuits de las personas a las que sigo o me sigue salieran de vez en cuando…– Ironia _____Foto de Maksym Kaharlytskyi en Unsplash...
Es difícil imaginar una web completamente en tipografía Courier, sagrada fuente monoespaciada donde las haya, pero Oskar Wickström ha hecho el ejercicio y ha creado The Monospace Web, donde explora esta artística curiosidad. Tal vez lo más interesante es que además...
Según cuentan todas las noticias, Pável Dúrov, el fundador y CEO de la popular aplicación de mensajería Telegram, fue detenido anoche en Francia nada más tocar tierra al bajar de su avión privado en Le Bourget. Al parecer el millonario venía de...

Estimado @OdonElorza2011:He leído con atención tu propuesta de «un twitter público gestionado por la UE». Y aunque entiendo tus argumentos y coincido contigo en que esto es —entre otras cosas— un cenagal de ruido y manipulación, discrepo radicalmente de tu planteamiento.Estos… https://t.co/rHR2UhnWgU—...

Despegue de la misión – SSST Un cohete Larga Marcha 6A ha puesto en órbita los 18 primeros satélites de la constelación china de acceso a Internet G60. G60 Starlink, que es como se la conocía al principio, de hecho. Así que...

Twiiter acaba de activar por defecto una opción que le permite usar tus datos para entrenar Grok, su IA. Para evitar esto que, insisto, se activa por defecto y sin avisar, puedes utilizar este enlace en un navegador web. Si por...

XKCD ya lo predijo A primera hora de esta mañana empezaron a saltar las noticias de problemas informáticos de todo tipo en todo el mundo en aeropuertos, aerolíneas, bancos, organismos públicos como el Osakidetza vasco o el Sergas gallego, pagos en cajeros...

El objetivo de la web debe ser empoderar a una sociedad equitativa, informada e interconectada. Históricamente, fue diseñada para facilitar la comunicación y el intercambio de conocimiento para todos. Para que la web continúe beneficiando a la sociedad, es esencial considerar...
ICQ en los 90 Nunca fui un gran usuario pero sé de parejas que se conocieron en ICQ, que hoy deja de funcionar después de casi 30 años. Tras varias ventas es ahora propiedad de la empresa rusa VK, que anima a...
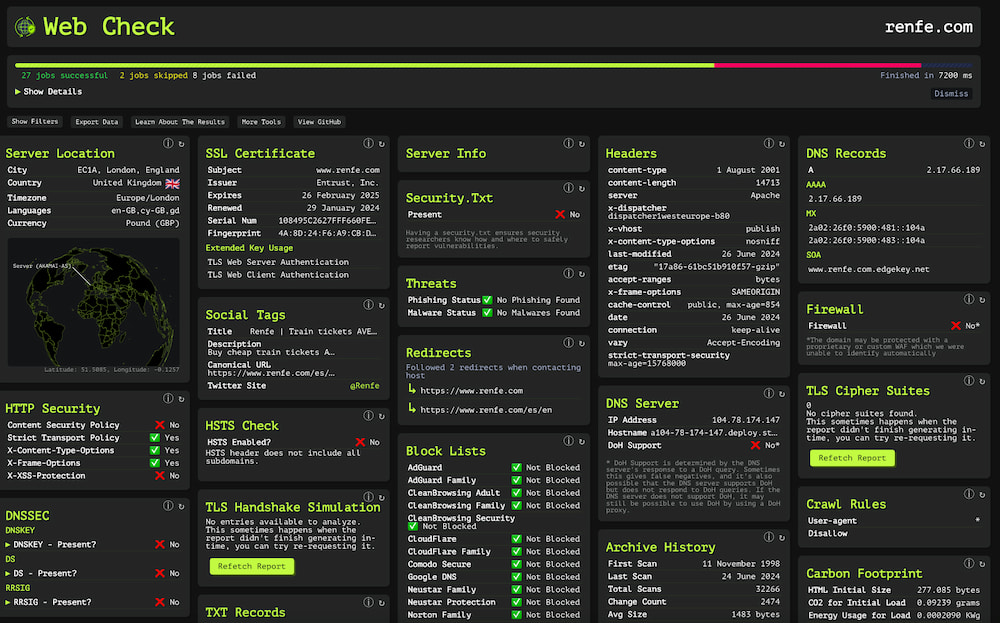
Web-Check es una especie de llave inglesa de la seguridad web, de esas para guardar y mirar de vez en cuando. Su finalidad es resumir en un pantallazo todo sobre la seguridad de un sitio web en particular. Es una especie...

Definición de bazofia según la RAE Ayer estaba leyendo una noticia que dice una cosa en el primer párrafo y la contraria en el siguiente. Y pensaba que había entendido algo mal… Hasta que llegué al final y vi una coletilla que...
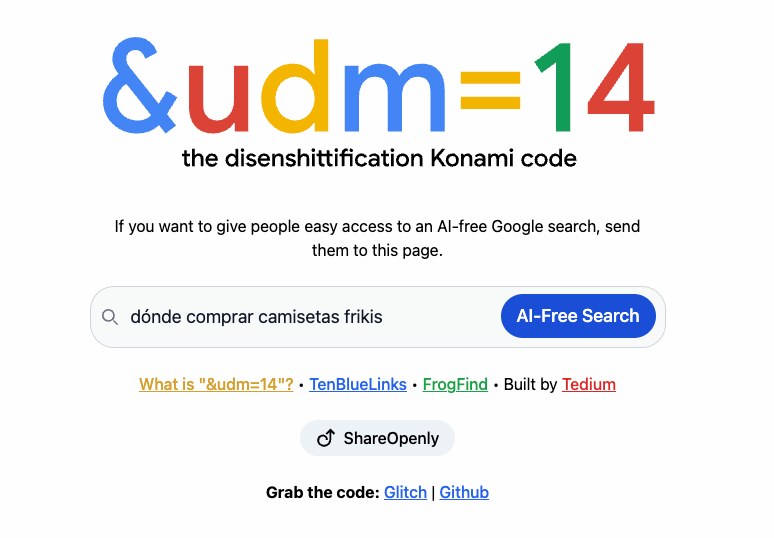
La gente de Tedium ha decido plasmar en una particular versión del más famoso buscador llamada &udm=14 su entendimiento de la «desmierdificación» de Google, gracias a un descubrimiento que hicieron hace poco: que si se añade el parámetro &udm=14 a la...

La Web se está volviendo hostil para los humanos. Se rastrea a los usuarios y se viola sistemáticamente su intimidad. Los resultados de las búsquedas están llenos de anuncios. Los robots nos envían spam constantemente. La IA generativa amenaza con convertir foros...

Guangyi Li ha recreado es una web esquemática cómo es su experiencia web hoy en día, lo cual incluye lo peor de lo peor, desde los anuncios fuera de lugar a los pop-ups abusivos, el disparo de las notificaciones, chats, ratings,...

Lunduke tiene un buen relato de esos para guardar en la Historia de Internet acerca de Por qué Firefox se llama Firefox. Es de esas típicas aventurillas que los más viejos del lugar hemos vivido y recordamos como en una neblina...
He visto una referencia a una Chuleta de JavaScript y en la misma página encontré otra sobre HTML y otra más sobre CSS. La diferencia respecto a tenerlas en un papel es que algunos detalles son interactivos, con las típicas utilidades...

ADSL apagada – Foto de Stephen Phillips - Hostreviews.co.uk en Unsplash Bueno, lo celebra de alguna que otra forma más. Pero es cierto que a partir de hoy, día en el que Telefónica cumple cien años, los usuarios domésticos de ADSL de...
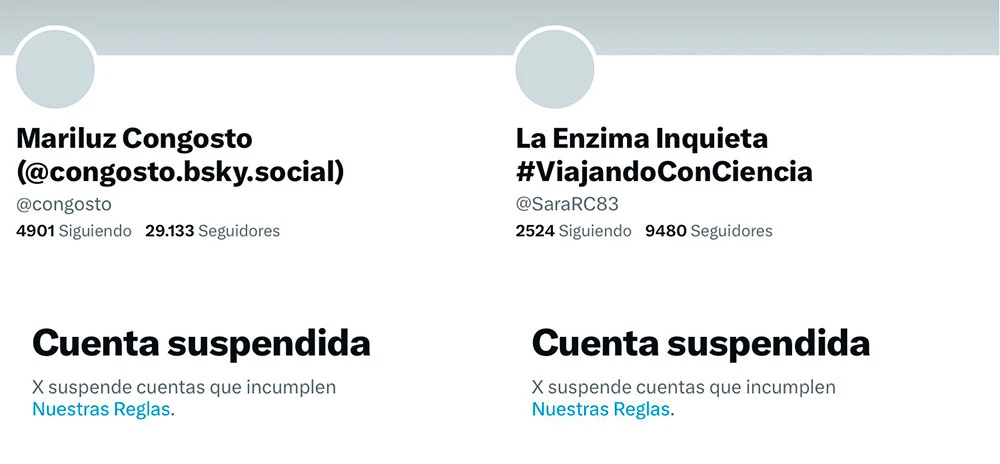
Dos de las muchas cuentas suspendidas Desde ayer por la tarde son continuos los tuits que hablan de una gran masacre de cuentas de Twitter en España. Al principio parecían afectadas sólo cuentas de divulgadoras e investigadoras. Pero con las horas también...
La decadencia de una web comienza cuando al comenzar enero no acierta a marcar el año* correcto en su pie de página. Obsérvalo en tus webs habituales cuando navegues por ahí y verás. _____* Curiosamente los avisos de copyright no necesitan indicar...
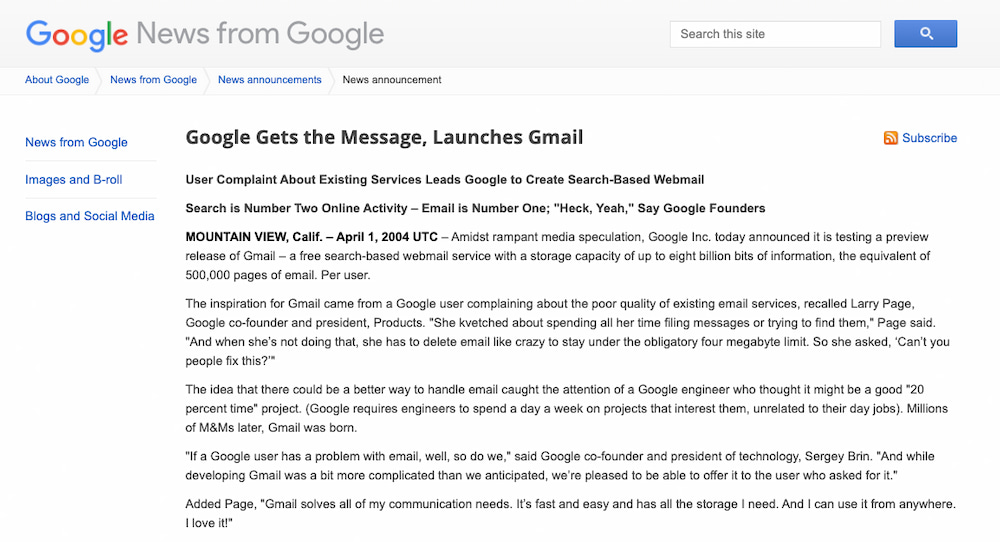
No fuimos pocos los que cuando hace hoy 20 años Google anunció Gmail pensamos que Google estaba de broma. Que fuera el April Fools o «día de los inocentes» del mundo angloparlante hacía sospechar. La nota de prensa además estaba escrita...
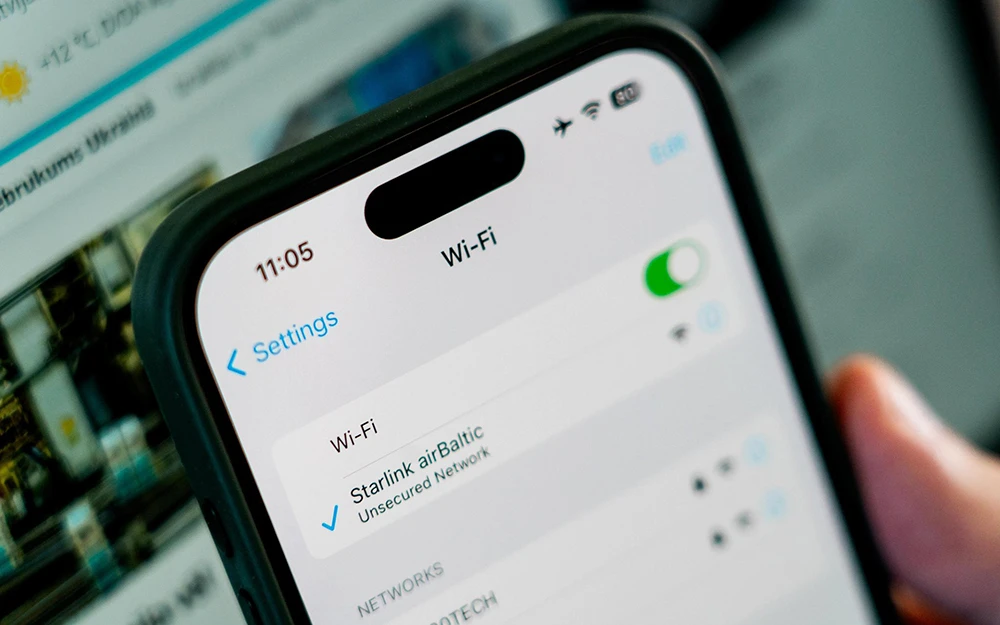
Starlink en versión airBaltic - Martin Gauss/airBaltic A principios de este año airBaltic anunció que ofrecerá conexión gratuita a Internet en sus vuelos utilizando el servicio de Starlink. Ahora acaba de hacer las primeras pruebas. La aerolínea está trabajando con SpaceX para...

Desde el departamento de core dumps o «cosas que tengo pendientes pero como no veo cuándo escribir sobre ello» dejo por aquí estos cinco artículos, sin orden ni concierto. Me gustaron los títulos y entradillas; los tenía hace tiempo por ahí...
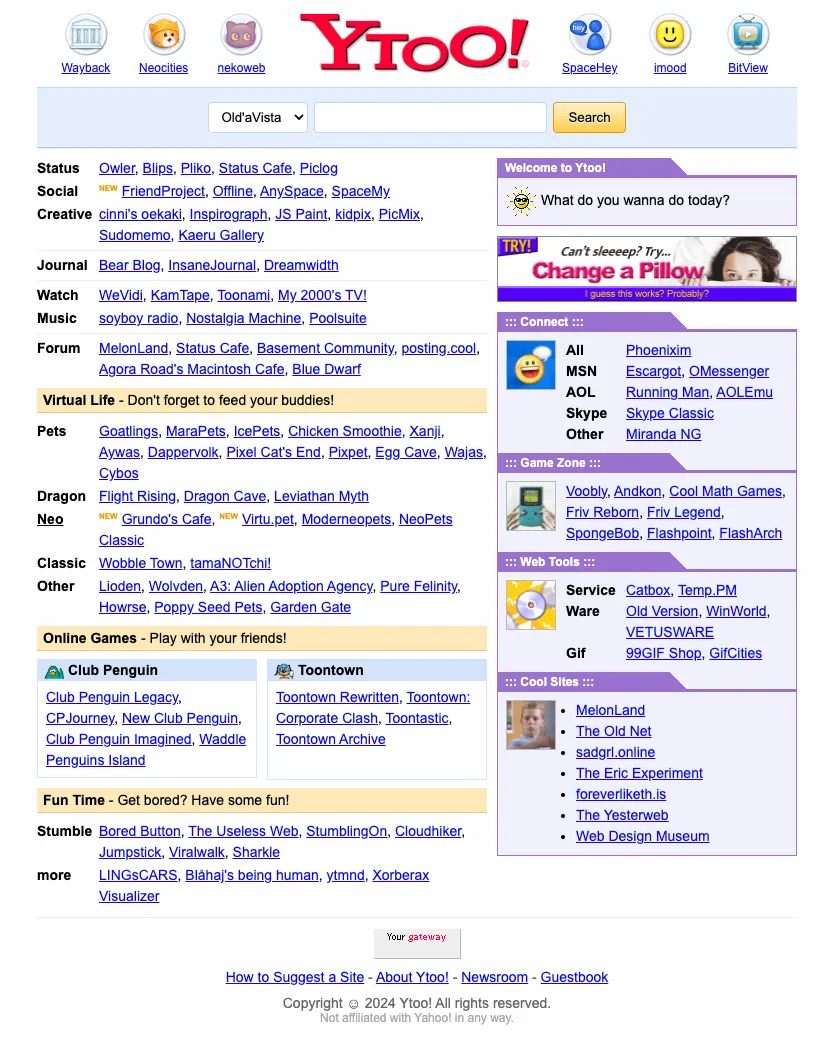
Ytoo! + Old’aVista ¡Qué ven mis ojos! Ytoo parte de la idea de crear algo nuevo con el look de un portal viejo. (Veremos lo que dura, abogados de Yahoo mediante). En palabras de VegBao, su creador: Ytoo! es algo más...
¿Están muertos los feeds RSS? ¡No! Cual irreductibles galos parecen resistirse con uñas y dientes a su desaparición. Tal y como comentábamos al hablar de redescubrir la experiencia de leer gracias a los RSS de los medios, blogs y diversos servicios,...

Esta mañana he estado en las instalaciones de IAAS asistiendo a la presentación Lyntia sobre su tecnología de la fibra óptica Hollow-Core. Han querido mostrarlo en vivo transmitiendo datos a de un datacenter a otro datacenter en la zona del Silicon...

Esta curiosa y minimalista página llamada URL Parts hace una sola y perfectamente: diseccionar las direcciones URL (Localizadores Uniforma de Recursos) que se usan en internet. Más específicamente, resulta útil en la Web para distinguir qué es qué. De este modo...

Del 12 al 17 de marzo, Tenerife se erige como el núcleo de la innovación tecnológica con la decimotercera edición de Tecnológica Santa Cruz. Este evento, pionero en España en el ámbito de las TIC, promete una agenda repleta de actividades...

Antes: ¿Se puede confiar en la Wikipedia?(2005) Ahora: Wikipedia ya no considera a CNET una «fuente generalmente fiable» tras su escándalo debido a la IA(2024) ¡Cómo ha cambiado el cuento! Antes los medios y expertos decidían si la Wikipedia era una fuente...
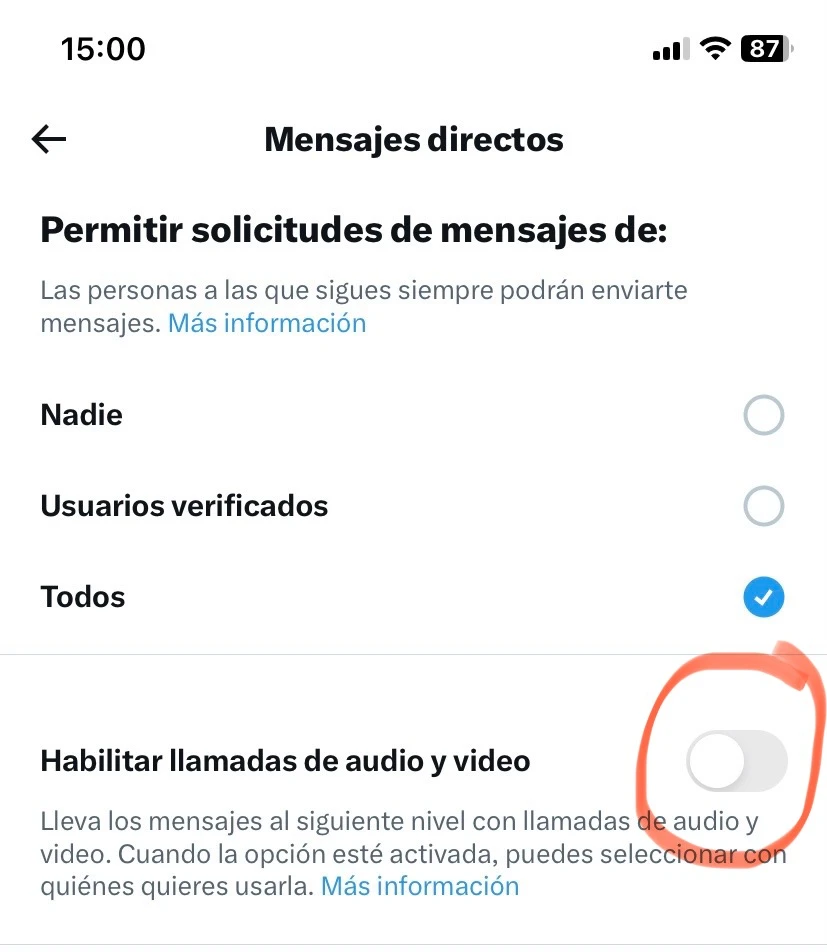
Desde hace unos días Twitter (también conocido como X) ha empezado a activar las llamadas de audio y vídeo para todo el mundo en Android e iOS. Antes era una opción sólo disponible para quienes pagaran una suscripción a uno de los...

En Minute Earth se traza un paralelismo entre los cambios de los vídeos de YouTube en los últimos tiempos y la evolución animal. ¿Por qué se parecen todos los vídeos de YouTube? Su conclusión es que YouTube, al igual que ocurre...
Hubo un tiempo en que los feeds RSS eran los que rulaban la Tierra. Pero por aquello de la irrupción de las redes sociales y, sobre todo, por el appificidio de Google Reader –al que simplemente apuñalaron traperamente– este formato de...

El otro día en la conferencia SPIE Photonics West celebrada en San Francisco el ingeniero de SpaceX Travis Breashears soltó algunos datos que fueron recogidos por PC Mag y que permite hacerse una idea de la capacidad actual de Starlink: 9.000...
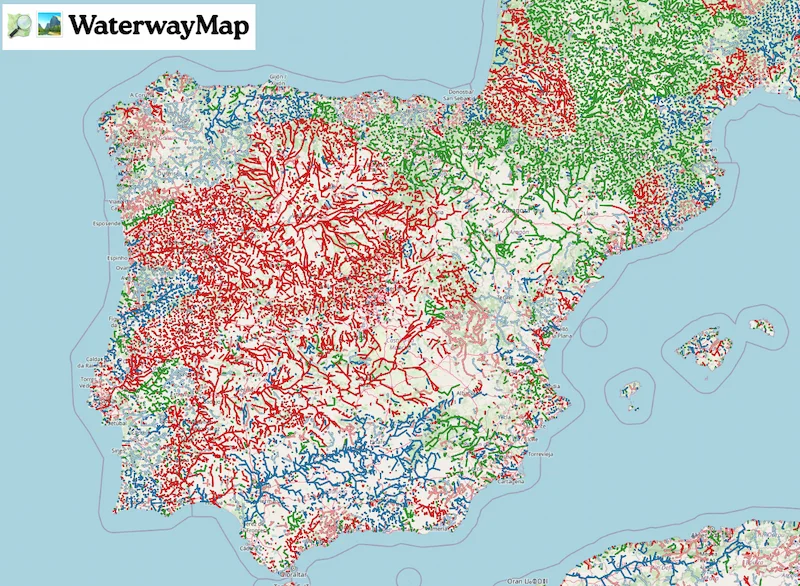
Vi un par de referencias a unos mapas peculiares que combinan datos que están en OpenStreetMaps pero normalmente no se muestran. Son datos sobre canales de agua (WaterwayMap) e infraestructuras de electricidad (Open Infrastructure Map). La cantidad de información, naturalmente, variaría...

Esta curiosa iniciativa llamada Old’aVista permite echar un vistazo a lo que era la Web primigenia con un motor de búsquedas con el aspecto del mítico AltaVista, el Google de la época de los 90. El diseño es el que usaba...

Quien más, quien menos, todo el mundo tiene la sensación de que de un tiempo a esta parte los resultados de Google han empeorado. Hasta no hace mucho se podía confiar en encontrar algo realmente útil en los diez primeros resultados,...

View of last night’s @Starlink satellite deployment, including the first six with Direct to Cell capabilities pic.twitter.com/tjrWMJfqH4— SpaceX (@SpaceX) January 3, 2024 El primer lanzamiento de SpaceX de 2024 ha sido de un lote de 21 satélites Starlink, lo que ya casi...
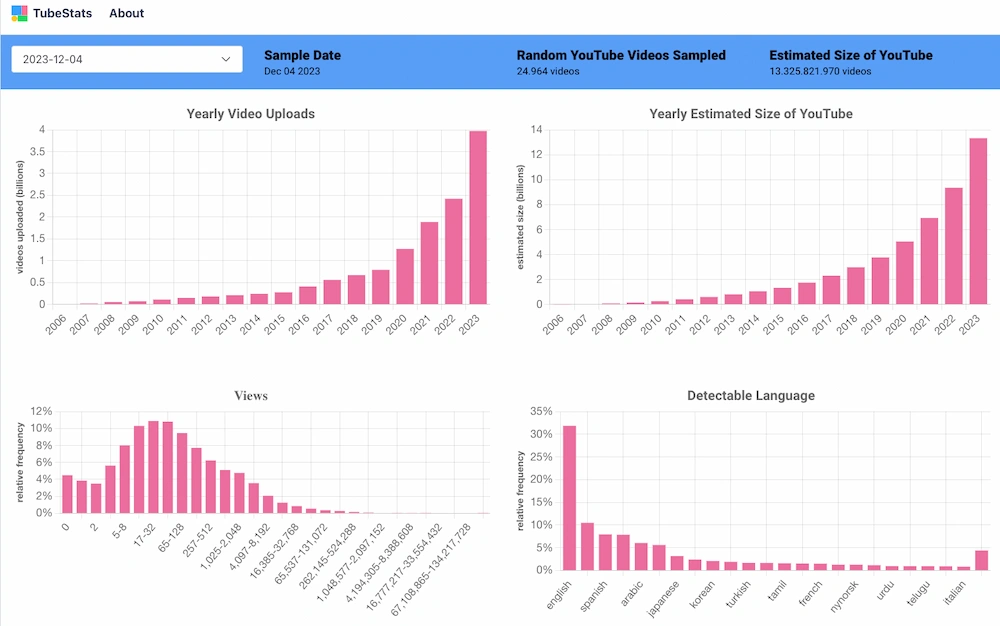
En la página de TubeStats se recopilan unas curiosas estadísticas sobre YouTube a partir de muestras recientes que permiten entender muchas cosas sobre el servicio tanto a largo plazo como a corto plazo, y que no se suelen ver cuando se...

Vista parcial de uno de los KuiperSat en órbita – Amazon Rajeev Badyal, el jefe del proyecto, publicaba hace unos días una foto en la que se ve, aunque parcialmente, uno de los dos satélites de prueba de la constelación Kuiper de...

Según informa Thierry Breton, el Comisario europeo de Mercado Interior y Servicios, la Comisión Europea ha abierto hasta cuatro procedimientos sancionadores a Twitter por no cumplir varios aspectos de la Ley de Servicios Digitales (DSA), en vigor desde este pasado verano. En...

Los apasionados de la cartografía Jay Foreman y Mark Cooper-Jones cuentan en este vídeo algunas curiosidades sobre la historia de los ccTLD o dominios de nivel superior geográficos, también llamados «dominios de primer nivel de los países» de internet. Con buen...
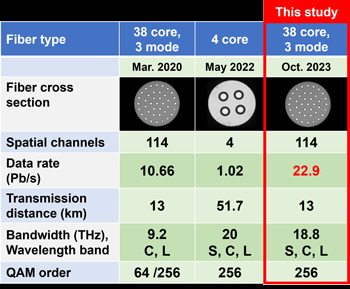
El Instituto Nacional de Tecnologías de la Información y Comunicaciones de Japón (NICT), en colaboración con la Universidad Tecnológica de Eindhoven y la Universidad de L’Aquila, ha logrado un avance significativo. Se trata de un nuevo récord mundial de 22,9 petabits...

Nos escribieron desde CertificadoElectronico.es animándonos a probar su servicio gratuito de emisión de certificados digitales en 48 horas con identificación mediante vídeo y sin necesidad de instalar nada en tu ordenador, móvil o tablet. Y sin necesidad incluso de salir de casa....

La vida pic.twitter.com/eRPMNaTS1K— El Hematocrítico (@hematocritico) November 26, 2023 Hace unas horas se nos ha muerto Miguel López. Que por su nombre en el MundoReal™ seguramente no te sonará. Pero si te digo que era El Hematocrítico y has estado en la...

Play like a girl: desafíos de las mujeres en la industria del juego y la tecnología. Por Marina Amores. Libros Cúpula (14 de junio de 2023). 240 páginas. Marina –ahora más conocida por estos pagos como @blissy– tuvo la suerte de que...

Mr. Internet: Cómo se relacionan la tecnología y el género y cómo te afecta a ti. Por Marta Beltrán. Next Door (27 de septiembre de 2023). 134 páginas. Aunque la tecnología, entendida en este libro básicamente como los campos de la informática,...

Se puede participar hasta el próximo domingo, 10 de diciembre: Navegantes en la Red:26ª encuesta a usuarios de Internet de la AIMC Como cada año, es la tradicional encuesta de la Asociación para la Investigación de Medios de Comunicación (AIMC), también conocida...

En AI Graveyard se reúnen los cadáveres de los proyectos de inteligencia artificial muertos y «discontinuados» que han dejado de existir. Y es que, al igual que el cementerio de productos Microsoft y el cementerio de Google parece claro que su...
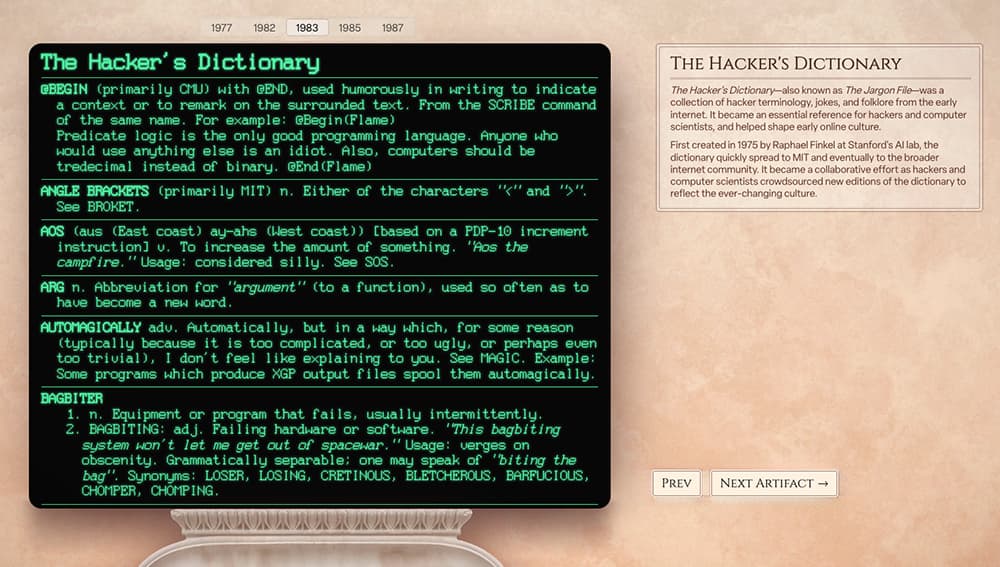
Neal Agarwal lo ha hecho de nuevo ya ha creado una guía fantástica llamada Artefactos de Internet que es una especie de museo de la internet viejuna organizado cronológicamente, con «artefactos» que no son más que pantallazos traídos del pasado, algunos...

El Archipiélago de Anguila, situado en el Caribe, es un conjunto de islas muy pequeño con apenas 14.000 habitantes. Pertenece a los territorios de ultramar del Reino Unido y pese a su reducida esencia, tiene asignado uno de los dominios de...

A veces hacer las preguntas correctas indagando machaconamente como un niño de cuatro años tiene su premio. En este caso encontré una presentación de Tony Finch titulado ¿De dónde viene la hora? que profundiza en el origen de algo tan corriente...

Hace unas horas el último Atlas V en su variante 501 ponía en órbita los KuiperSat-1 y KuiperSat-2, dos satélites de prueba del Proyecto Kuiper, su versión de Starlink. Los ha dejado en una órbita de 500 kilómetros de altitud con...

Que triquiñuelas para vender más y más caro en internet hay una infinita variedad ya lo sabíamos. Ahora parece que Amazon también los ha usado en forma de algoritmos de laboratorio para aumentar sus precios y conseguir mayores márgenes. El caso...

Chiqui en una imagen de 2017 – El País No recuerdo en qué sarao conocí a Chiqui. Quizás en el famoso WebDosBeta o a lo mejor en un Blogs y Medios –tengo fotos de él en muchas de sus ediciones– pero recuerdo...

Mario Tascón – Prodigioso Volcán Hoy nos hemos despertado con la tristísima noticia de la muerte de Mario Tascón con tan sólo 60 años. Demasiado pronto. Siempre es demasiado pronto. Pero a veces aún lo es más. No recuerdo exactamente cuándo conocí...

Como casi cualquier persona que ande metido en esto de la informática había oído hablar de los servicios en la nube que ofrecen Amazon, Google o Microsoft para desplegar ordenadores sin necesidad de adquirir máquinas. Incluso utilizo algunos servicios en mi trabajo...
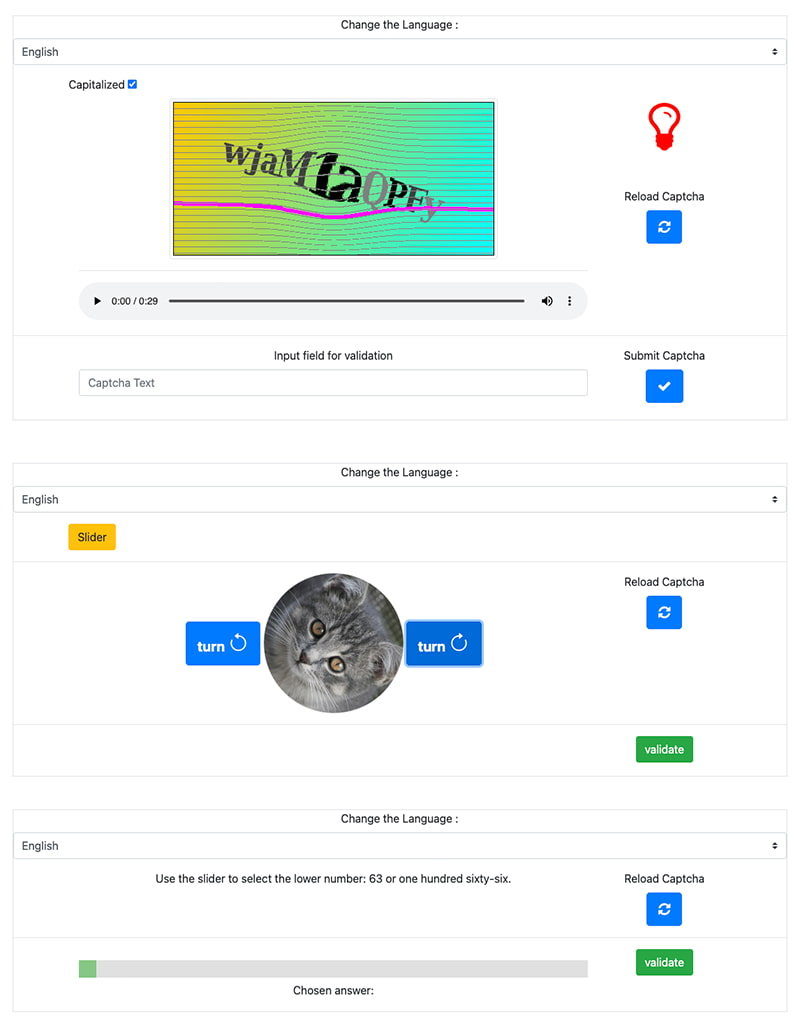
En el repositorio code.europa.eu gestionado por la Comisión Europea se puede acceder ya a EU-CAPTCHA (técnicamente ISA Action 2018.08 EU-Captcha), una iniciativa de la Comisión Europea. Consiste básicamente en tres tipos de captchas listos para utilizar en cualquier proyecto. El principal...

Jordi nos envió este vídeo y un enlace a Ibertex, videotex en España [actualización: por desgracia ya no existe], una lista donde se recogen diversas recreaciones de Ibertex entre los años 1991 y 1994. Este servicio era la versión española del...

Internet también está olvidando su pasado, literalmente– Shaminder Dulai En este artículo de opinión en DP Review titulado La Web que se pudre está eliminando nuestras fotos y vídeos Shaminder Dulai reflexiona acerca de cómo la descomposición o podredumbre de la...

Iedra se define como: (…) un buscador y explorador de palabras. Se puede entender como lo opuesto a un diccionario ordinario. En estos, se parte de una palabra para hallar su definición. En Iedra, se parte de una definición y se...
Bajo el dominio web Archive.Google hay cerca de de 2.300 páginas de Google (la empresa) a las que no se puede llegar de una forma obvia: el sitio no tiene «portada» y espeta un sonoro 404 si intentas entrar por la...

En la página Educational Sensational Inspirational Foundational (ESIF) Zach Leatherman recopila los documentos fundacionales del desarrollo web, por orden cronológico. En cierto modo me recordó un poco a la lista de los manifiestos sobre el ciberespacio y la tecnología que comencé...

Jeff Geerling ha actualizado con una prueba empírica los datos sobre la capacidad de las palomas mensajeras para transportar datos, recreando los clásicos experimentos colombófilos de 2003 y 2009. El resultado es que las palomas vuelven a ganar porque pueden transportar...

No enviábamos nada entre computadoras porque sólo teníamos una computadora. No enviábamos gráficos porque nadie tenía un terminal gráfico. No teníamos «Asunto» ni otros encabezados de correo. Pero rápidamente surgieron las convenciones. Limitábamos el tamaño de los mensajes porque el espacio...
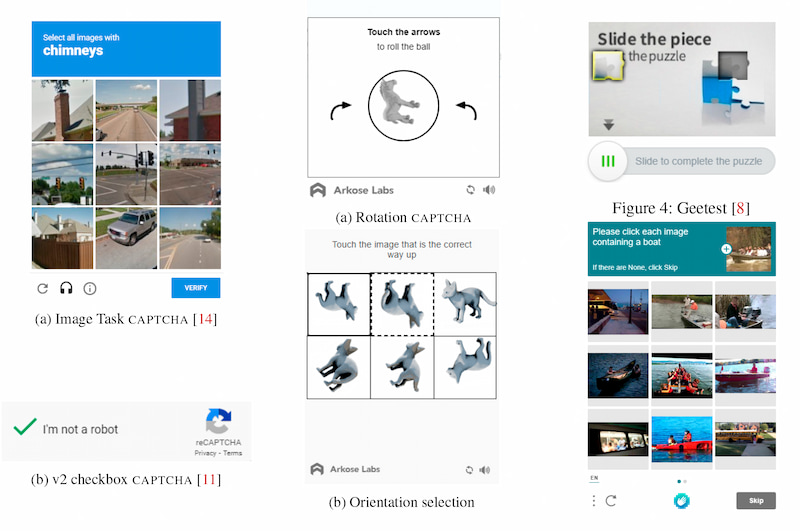
Es posible quedarse un poco ojiplático al ver los datos pero es hay que reconocer que se veía venir. En este trabajo titulado Un estudio y evaluación empírica de los CAPTCHAs modernos se dan datos acerca de que los bots ya...
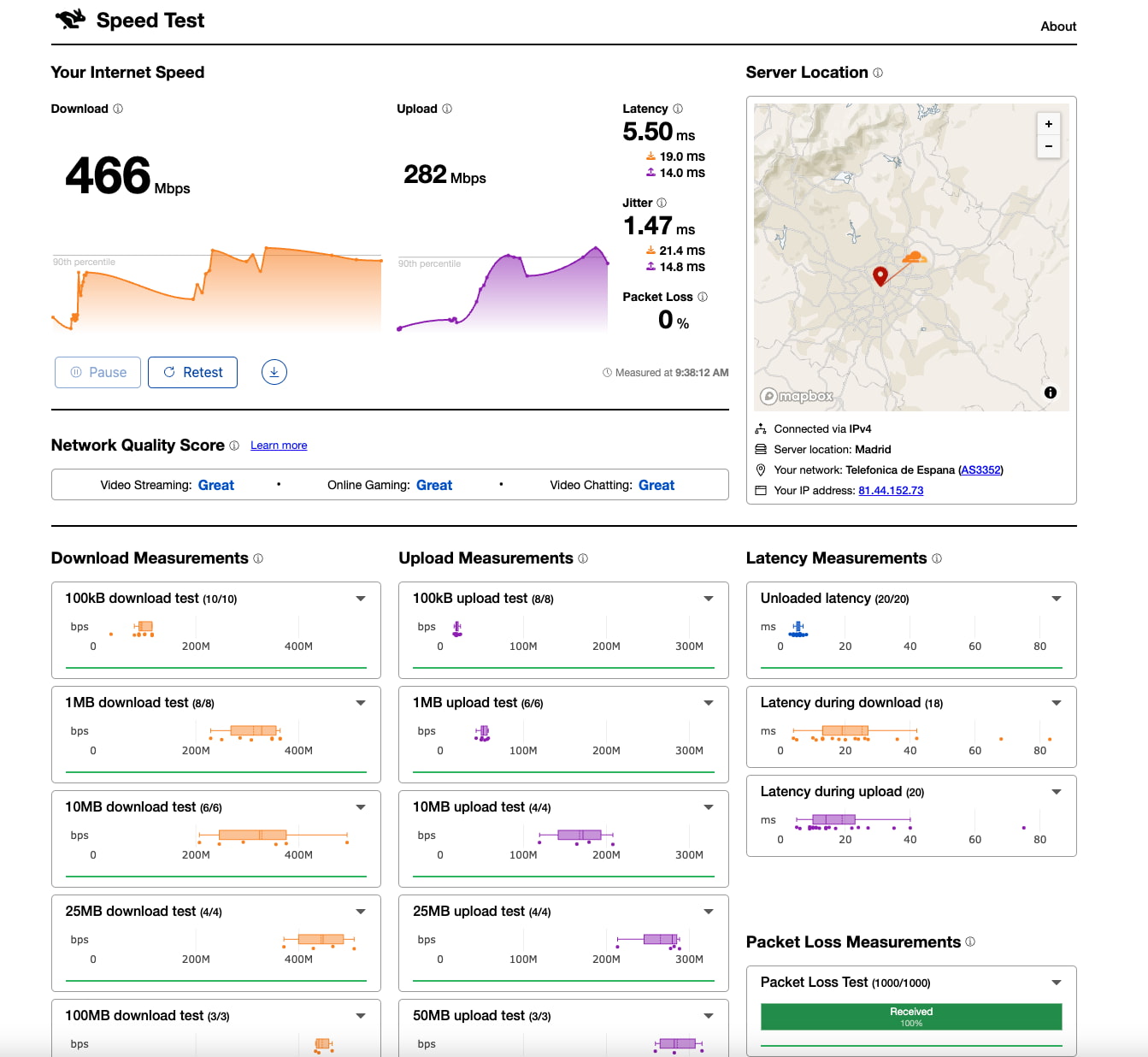
Me crucé con el Speed Test de Cloudflare, el clásico «test de velocidad de internet» que permite comprobar en un momento la calidad de la conexión a Internet: velocidad, latencia, jitter y otros datos útiles. Tan solo hay que visitar la...
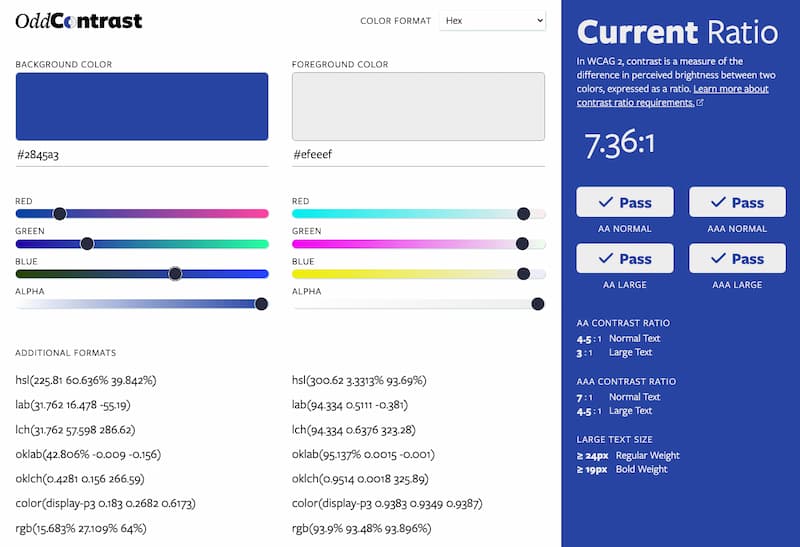
Uno de los factores que muchas veces se ignoran a la hora de tener en cuenta la accesibilidad web es el contraste de los colores elegidos para los fondos, textos y diversos elementos de los interfaces de la web. Tanto las...

Wikipedia, la enciclopedia libre, está en continua evolución. En el momento de escribir esto se están produciendo más de cien ediciones por minuto, lo cual es un ritmo bárbaro; inigualable diría yo en comparación con el de otro tipo de redacciones...

Alguien tuvo antaño la ingeniosa idea de reunir vídeos viejunos de YouTube y superponerles una máscara apropiada de televisor, además de realizar una metódica e ingeniosa clasificación temática. Parece que la idea triunfó y luego lo ha ido ampliando por décadas....
Twitter vestido de X Pues Elon Musk, en su infinita sabiduría, ha decidido que ahora Twitter se llama X. O puede que no. Es un nombre absolutamente genérico que tira por la borda 17 años de construcción de marca. 17 años en...
La web moderna es literalmente Satán y probablemente se comerá a tu primogénito si no hacemos algo al respecto, ¡y rápido!– No CSS Club,hiperboleando Me encontré por ahí varios sitios web técnicamente reivindicativos hasta el extremismo, a saber: El club del...
Hace bastantes meses, casi un año ya, decidí darle la oportunidad a Brave de convertirse en mi navegador habitual. Competía con Chrome, que había desbancado mucho antes a Firefox en mi equipo. El caso es que la excesiva lentitud del navegador...
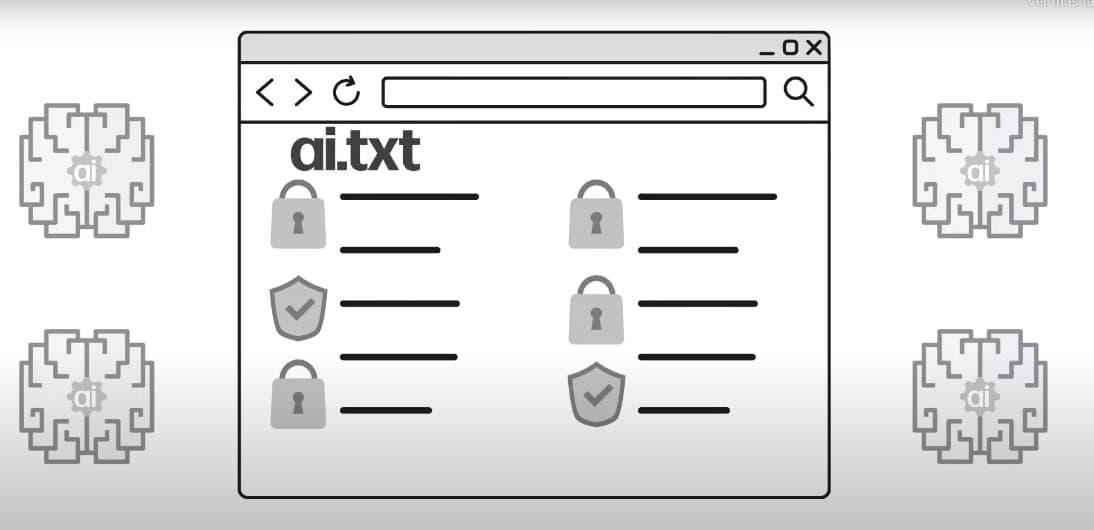
# AI.TXT # Spawning AI / Prevent datasets from using the following file types User-Agent: * Disallow: *.gif Disallow: *.jpg Disallow: *.png … Allow: *.txt Allow: *.pdf Allow: *.doc … Allow: *.css Allow: *.php Allow: *.sql Allow: / En Spawning tienen esta...
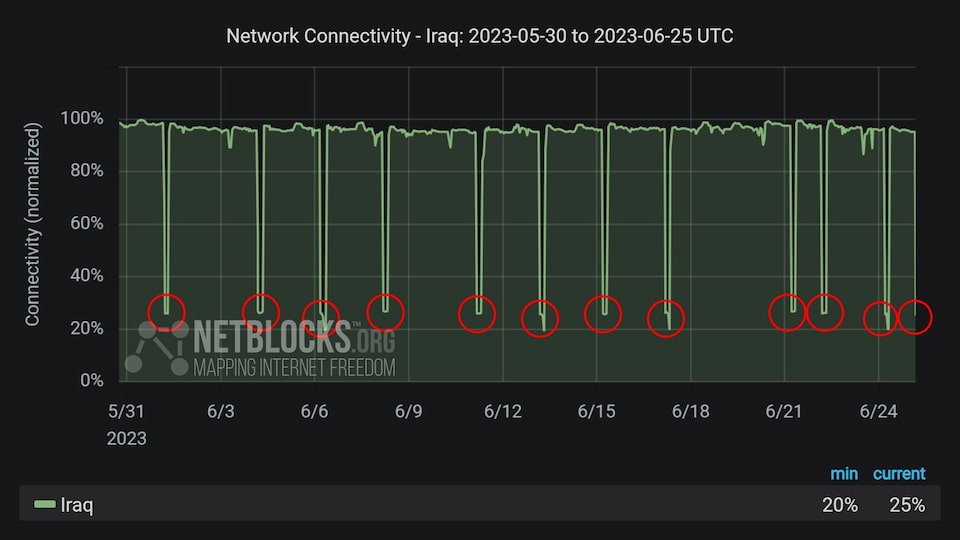
El análisis del tráfico de red en Irak de Netblocks muestra la coincidencia entre las caída de la conectividad en el país y las 3-4 horas que duran los exámenes finales previstos para los distintos días. Si se pierde agua, mejor cortar...
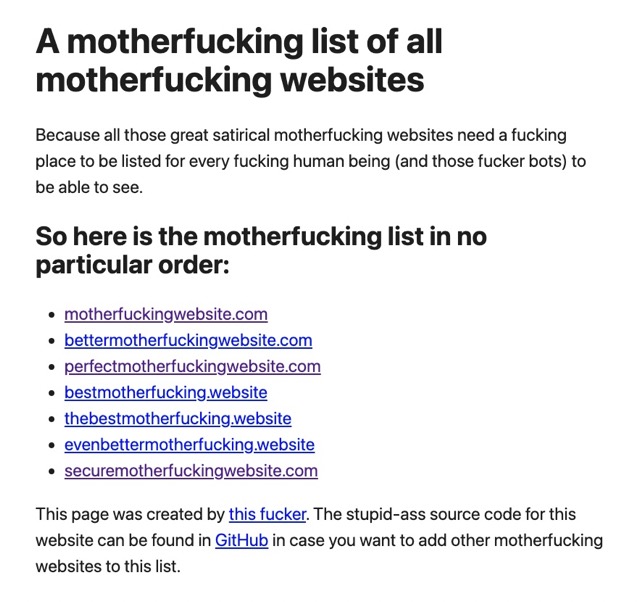
Sin paños calientes, A List of All Motherfucking Websites es una breve pero intensa selección de esos pequeños sitios web satíricos donde el factor común es el uso exhaustivo del término fucking para describir sus virtudes. Dependiendo del contexto y la...

Aunque lo normal es usar en el sistema operativo los DNS para que proporciona el proveedor de acceso a Internet, a veces es interesante probar otro por cuestiones de rendimiento, bloqueos o seguridad que pueden servir como buenas alternativas. Ahí van...

La norma dice: «Prohibidos vehículos en el parque». No Vehicles In The Park es una especie de juego creado por David Turner con una vuelta de tuerca muy curiosa. Básicamente consiste en contestar a 27 preguntas rápidas de tipo SÍ/NO respecto...
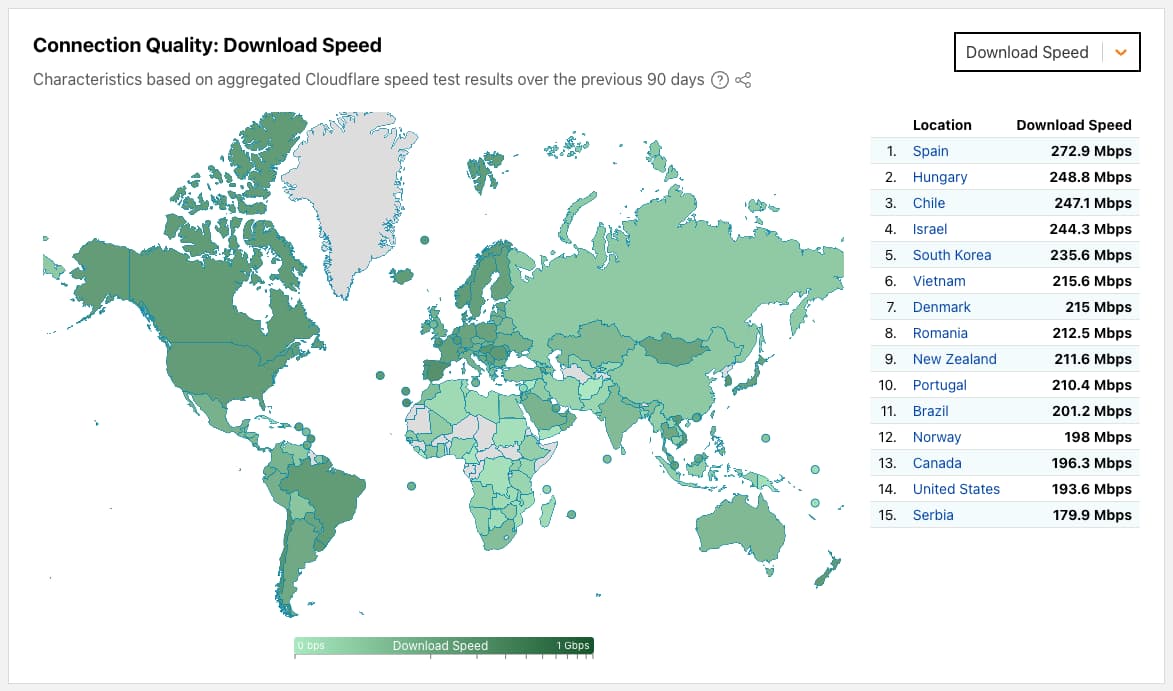
Por aquí somos muy críticos con las promesas de velocidad poco realistas y los anuncios rimbombantes de las compañías de telecomunicaciones, pero esta vez debemos congratularnos de aparecer como país como Top #1 mundial en cuanto a Velocidad de conexión a...
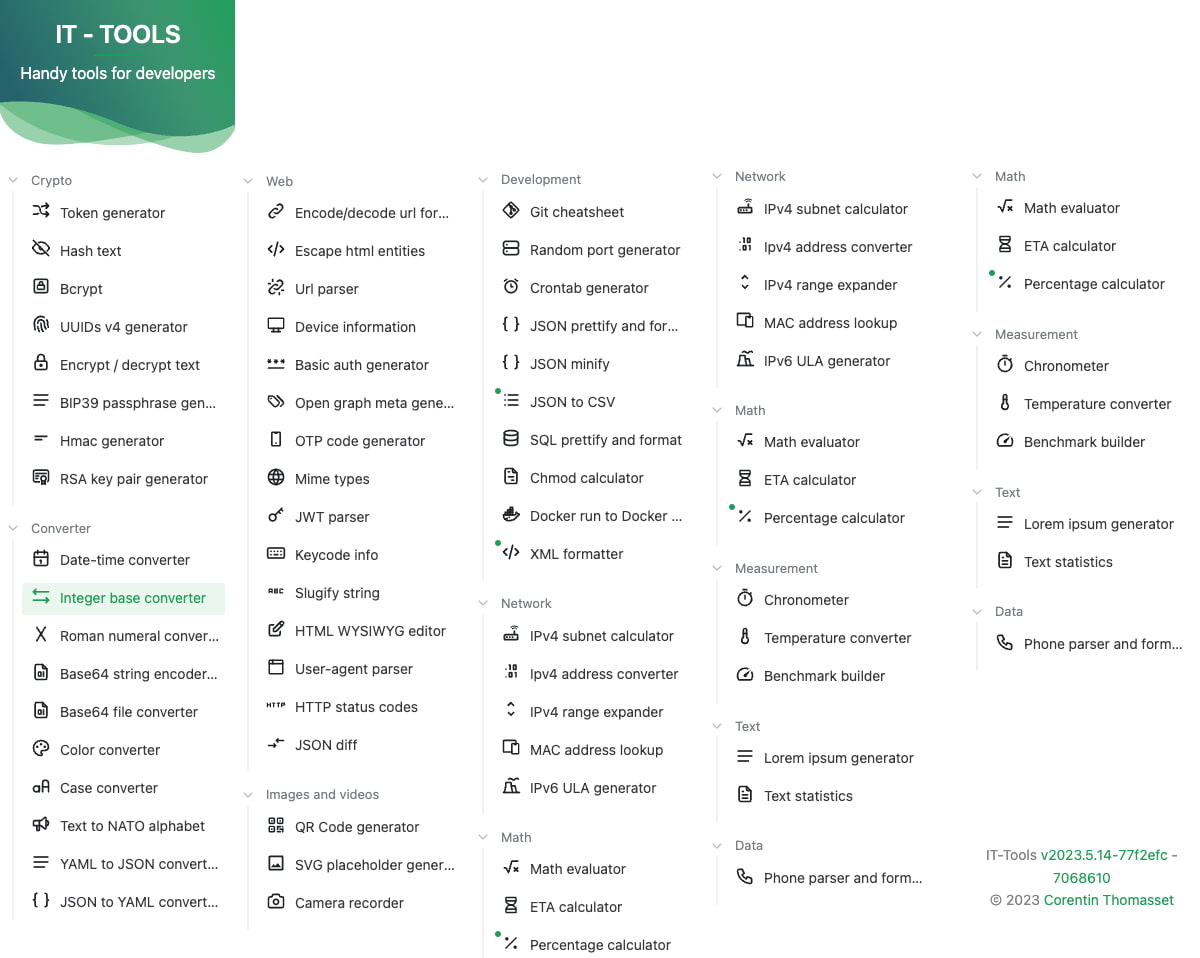
He contado unas 60 herramientas diferentes y a cual más interesante en IT Tools, una sorprendente página para guardar instantáneamente en Favoritos que resulta ser una auténtica navaja suiza de herramientas útiles para desarrolladores. Todas estas pequeñas utilidades están clasificadas en...
Me gusta el concepto detrás de DeArrow y he de decir que su ejecución tampoco está nada mal. Se trata de una extensión para navegadores (Chrome, Firefox, Edge y Opera) que reemplaza los títulos y miniaturas clickbait concebidos buscando el clic...
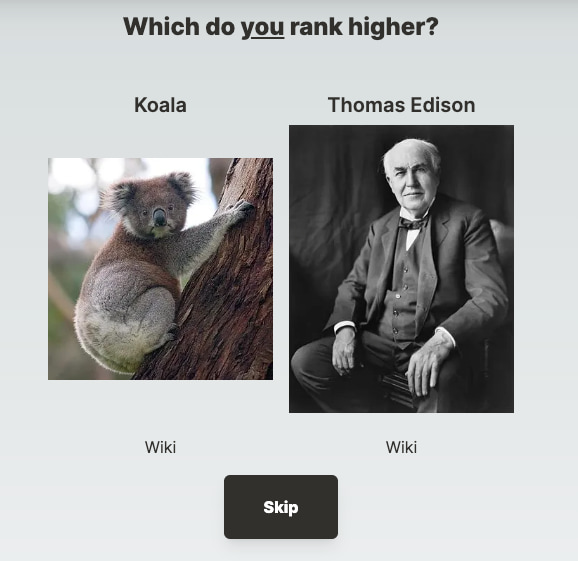
ELO Everything es un curioso sitio en el que se «juega» a valorar cosas como unas mejor que otras. Lo curioso es que no se trata sólo de personajes, u obras de arte o objetos comunes… Es una mezcla de todo....
Si te gustan los editores minimalistas te gustará Novel, pero incluso a quienes no le gusten los editores de este tipo –estilo Notion– apreciarán su función de autocompletar mediante inteligencia artificial, que básicamente escribe por ti de forma bastante coherente y...

En esta casa somos muy fanses del trabajo de Jaime Gómez-Obregón, así que, sin querer desmerecer ninguna otra, tenía muchas ganas de ver su charla Slow Tech: The JOY of missing out en el recientemente celebrado TEDxValència. Si sigues su trabajo,...
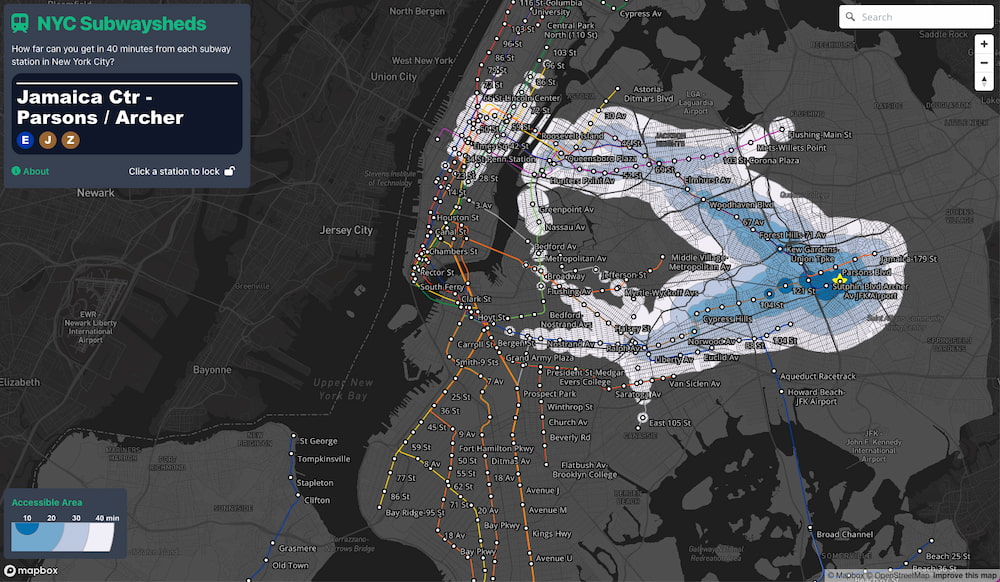
A nosotros puede que no nos resulte muy útil, pero la idea de NYC Subwaysheds está bien ejecutada: mostrar hasta dónde se puede llegar en 40 minutos partiendo de una parada cualquiera del metro de Nueva York en una gráfica de...
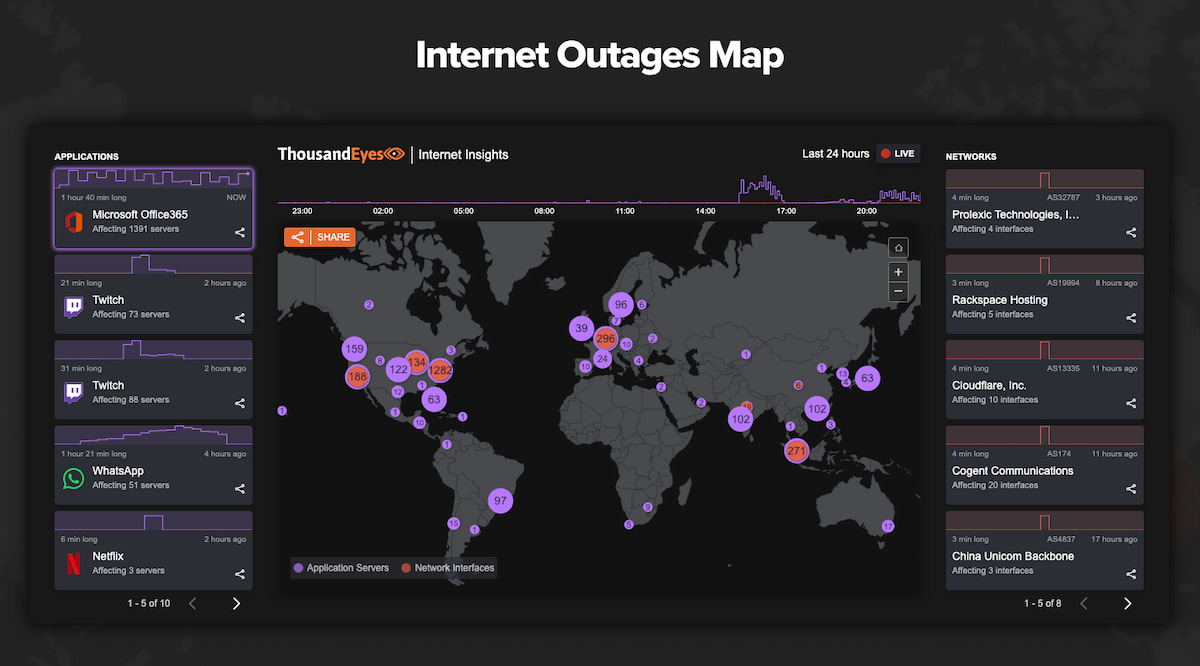
Este Mapa de Caídas de Internet de ThousandEyes muestra de un solo vistazo el estado de Internet en todo el mundo, especialmente de cortes y caídas de redes, ISPs y servidores en la nube. Esto incluye también las aplicaciones SaaS como...
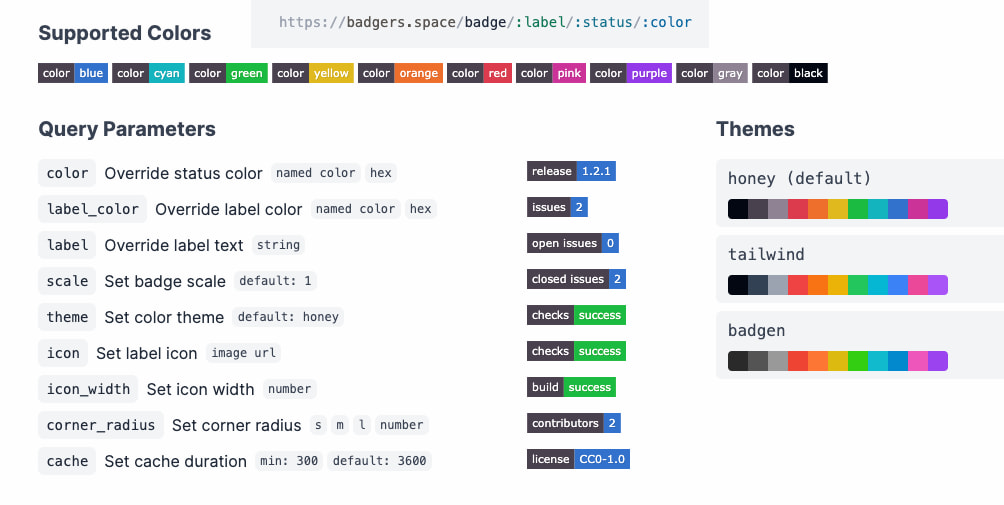
En algún sitio me encontré una referencia a SpaceBadgers, un generador de badges, algo que todo el mundo conoce pero para el que no he encontrado la traducción ideal al castellano (sería algo así como insignias*, placas, emblemas, chapas o incluso...

Google ha anunciado la puesta en marcha de ocho nuevos dominios de primer nivel: .dad, .phd, .prof, .esq, .foo, .zip, .mov y .nexus aprobados por la ICANN hace tiempo, dirigidos a quienes quieran crear con ellos sus proyectos web y apps....

En una entrevista en Spectrum, la revista del IEEE, Vinton Cerf reconoce tres errores que reconoce haber cometido en su carrera al impulsar diversas tecnologías de Internet, a saber: Pensar que 32 bits serían suficientes para todas las direcciones de Internet que...
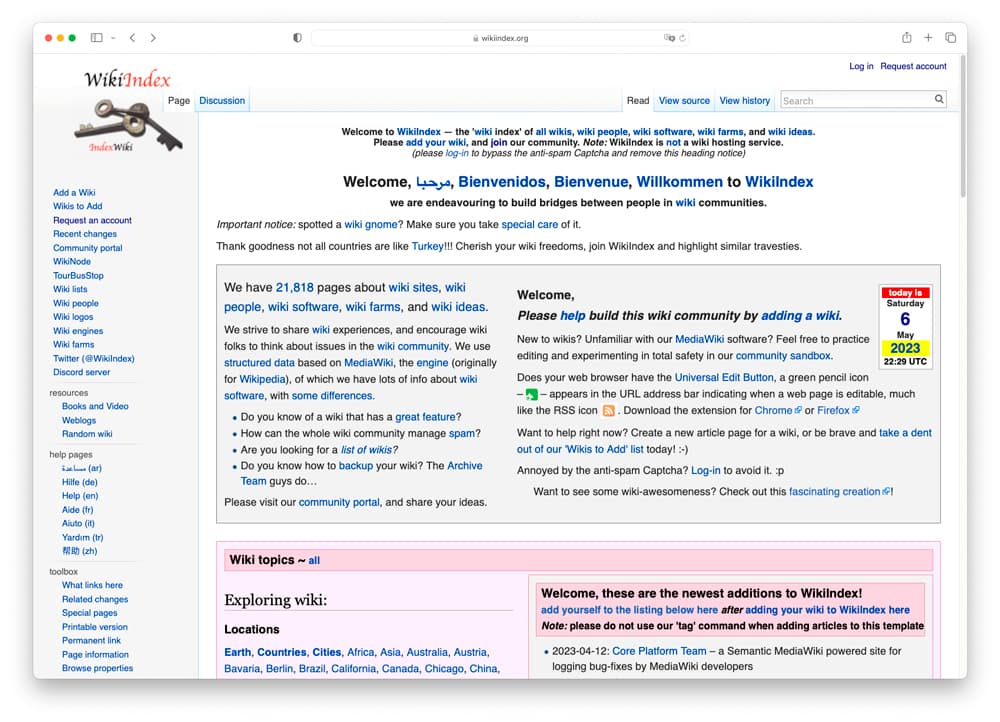
Me encontré por ahí WikiIndex que resulta ser un curioso sitio que no conocía acerca del universo de los wikis, incluyendo un índice de wikis, software para wikis, gente del mundo wiki y todo tipo de ideas relacionadas. En total tienen...
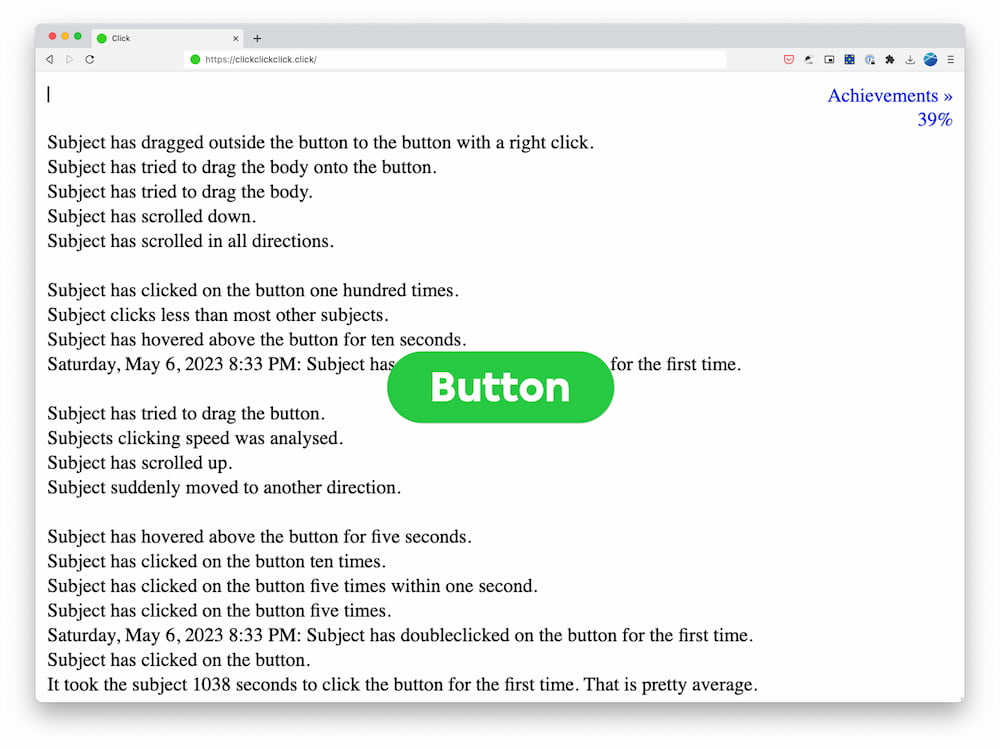
Clickclickclick.click es un curioso experimento de We Are Data, VPRO Medialab y Moniker que muestra cómo se analiza el comportamiento de los usuarios con el navegador presentándolo como un juego. Nada más empezar el navegador queda marcado con código que recoge...

Todo vuelve a cambiar: Cómo la Web3 revolucionará el mundo tal y como lo conocemos. Por Enrique Dans. Deusto (12 de abril de 2023). 248 páginas. Hace la pila de años que Enrique vive en el futuro, al menos en lo que...

Siguiendo la costumbre iniciada a principios de siglo, que año a año ha ido viendo cómo evoluciona España en este sentido, ya está disponible el informe Sociedad Digital en España 2023. Estos puntos, sacados del resumen ejecutivo, son los que ha...

WikiScroll apenas necesita explicación: es una colección de entradas de la Wikipedia con scroll infinito, que van apareciendo aleatoriamente (en random, como se dice hoy en día) a medida que te desplazas con el dedo o con el ratón por ellas....
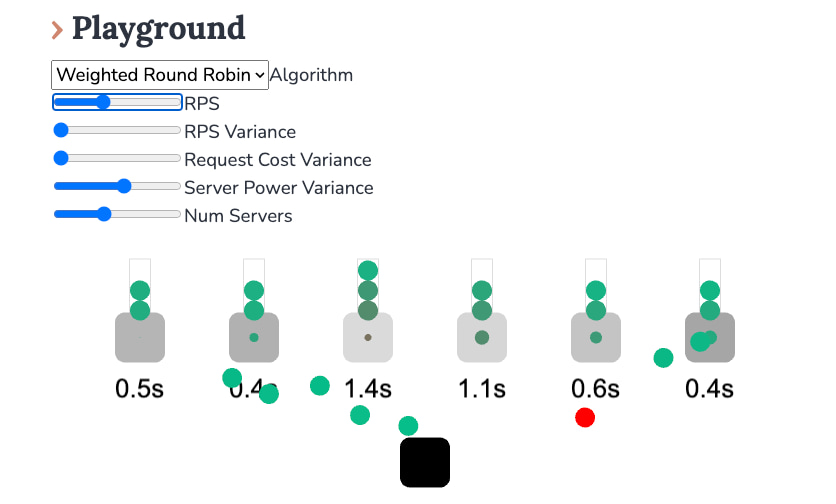
Me topé con un interesante artículo de Sam Rose que explica Cómo funciona el balanceo de carga en los servidores web. Este término técnico hace referencia a la forma en que los servidores donde se alojan las páginas web distribuyen el...
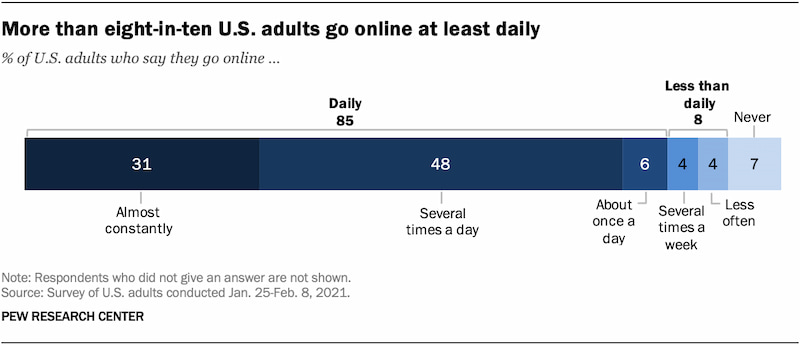
Unos 8 de cada 10 adultos se conectan a internet cada día. Y un 31% dicen estar «casi permanentemente conectados» durante ese periodo. Son datos de los Estados Unidos, pero podemos suponer que más o menos coincidirán con los de otros...

Kirby Ferguson ha publicado por fin la versión definitiva de Everything is a Remix (2023) como versión completa y actualizada de su trabajo documental entre 2010–2012 sobre el concepto de la remezcla. Es un documenta de una hora que combina lo...

Esta mañana un cohete LVM 3 –antes conocido como GSLV Mk3– despegaba del espaciopuerto de Sriharikota en India con 36 satélites de OneWeb a bordo. Tras el lanzamiento los 36 satélites se han separado correctamente de la etapa superior del cohete...

Si buscas RSS en Google lo primero que te aparece es una página del propio Google explicando cómo aplicar este estándar de sindicación de contenidos a sus servicios, luego una página del W3C, luego la Wikipedia y a continuación diversos blogs y...
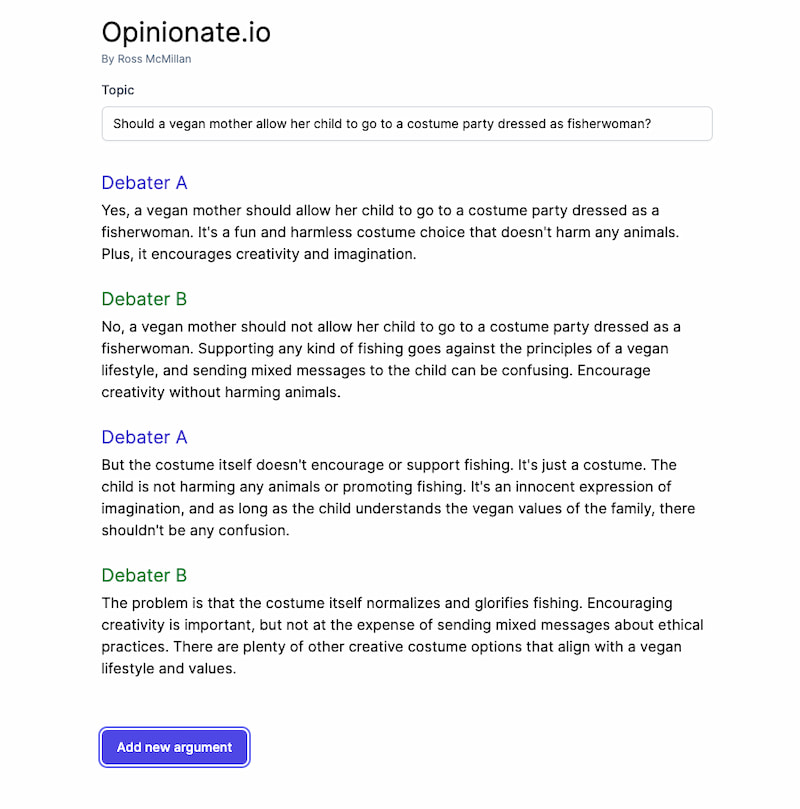
Tan maquiavélico como interesante y divertido, Opinionate.io de Ross McMillan hace uso de la tecnología de los modelos de lenguaje autorregresivos (supongo que usa GPT-3) para generar debates diametralmente opuestos. De este modo, basta plantear un tema y pulsar «Añadir argumentación»...

First Starlink v2 satellites reach orbit pic.twitter.com/0l08568mJ9— Elon Musk (@elonmusk) February 28, 2023 Esta pasada noche SpaceX ha lanzado el primer lote de satélites de segunda generación para su constelación Starlink de acceso a Internet. Aunque no son exactamente los que tenían...
La Lista pública de los sufijos es uno de esos curiosos recursos de Internet mantenido por voluntarios con paciencia y dedicación sobrehumanas para intentar poner un poco de orden en esta casa y que no esté todo hecho unos zorros. Se...

La semana pasada el Parlamento Europeo aprobaba prácticamente por unanimidad –el proyecto recibió 603 votos a favor, seis en contra y 39 abstenciones – la creación de la red de comunicaciones segura vía satélite IRIS². La primera vez que mencioné esta...

Se puede ver el carenado de las antenas de conexión vía satélite de este 777 de Qatar en lo alto del fuselaje a la altura de la segunda puerta – Wicho Hace unos días surgió en una conversación el asunto de que...
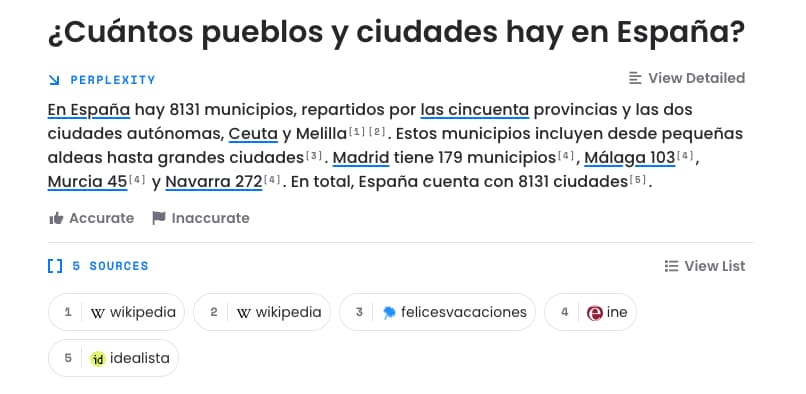
Perplexity AI es una de las más sorprendentes incorporaciones a la jauría de competidores que le están surgiendo a Google con esto de la popularización masiva de las aplicaciones de diversas inteligencias artificiales, especialmente las relacionadas con los modelos del lenguaje....

Ya se han publicado los últimos datos del tradicional estudio de Netcraft sobre el crecimiento de Internet. El resumen es que hay 1.132.268.801 sitios web en 270.967.923 dominios distintos que funcionan sobre 12.156.700 de servidores. Aunque son cifras enormes, en los...
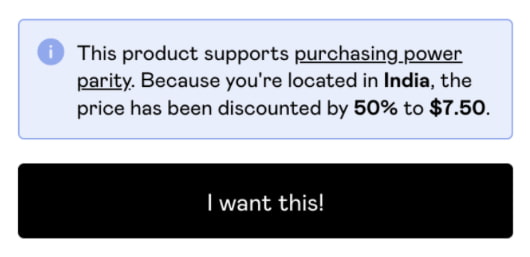
Me pareció muy interesante esta característica de Gumroad, la plataforma en la que se pueden vender ebooks, artículos, newsletters, podcasts y todo tipo de productos digitales (y no digitales). Consiste en aplicarles a los precios el factor de paridad de poder...
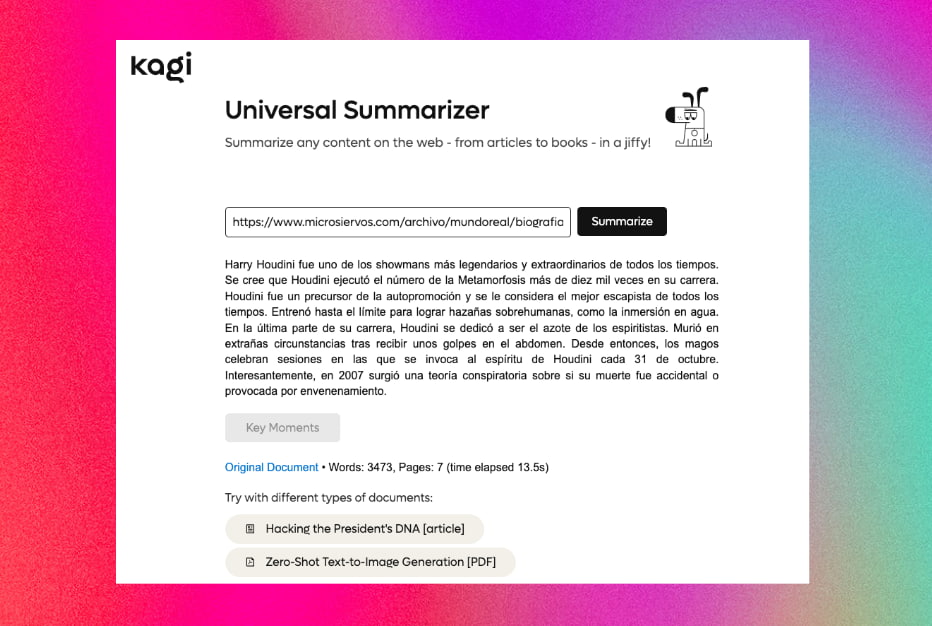
La gente de Kagi, que trabaja en un buscador sin publicidad y con versiones de pago ha lanzado un experimento llamado Kagi Universal Summarizer que es un «resumidor de páginas web». Simplemente introduces una dirección (URL) y te resume el contenido...
Lejos de ser ofensiva, la frase «explícamelo como si tuviera 5 años» es una forma divertida y popularizada en series y películas para pedir a alguien que te explique algo complejo de forma sencilla. En inglés se suele abreviar como ELI5...

Una pequeña muestra de la colección, con los GIF desanimados y el fondo eliminado para evitar daños visuales y respetar la salud de las personas fotosensibles. Hubo un tiempo en que los GIF rulaban la tierra, o más bien los territorios digitales...

Memorial de Tweetbot – Tapbots Pues ya está. Más de una semana después de haberse cargado de facto los clientes de terceras partes Twitter ha actualizado su acuerdo para desarrolladores con una cláusula que justifica lo que han hecho. Del Apartado II,...
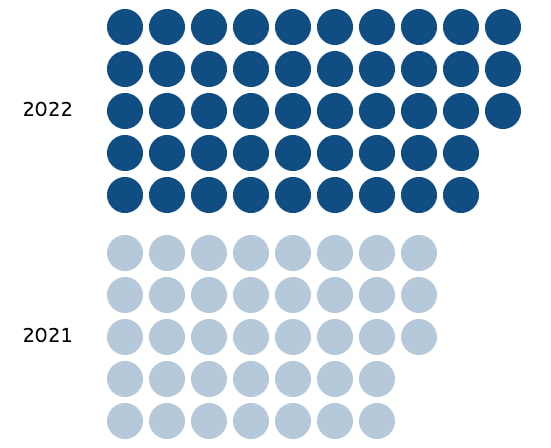
Tráfico de Internet (2022) a través de DE-CIX: 48 exabytes, un 25% más que en 2021 Según los últimos datos del operador de puntos de intercambio de Internet DE-CIX, durante 2022 se transmitieron más de 48 exabytes (EB) de datos a través...

Encontré Linkclump buscando extensiones que «hicieran cosas» con los hiperenlaces de las páginas web y se ha convertido en una de mis indispensables en el navegador. Básicamente permite abrir un montón de enlaces con solo seleccionarlos arrastrando con el ratón. Todo...
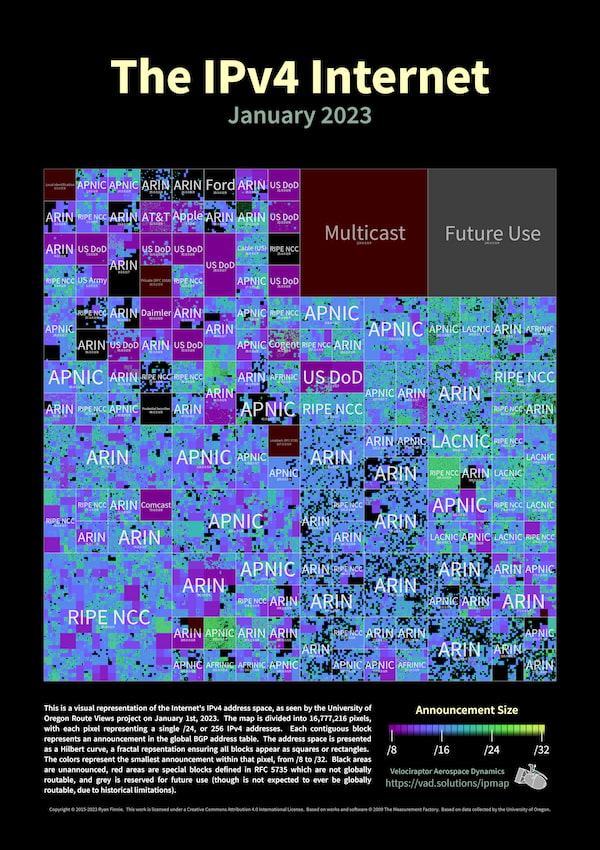
Este vistoso Mapa de Internet (2023) como espacio de direcciones IPv4 [clic para la versión ampliada a más resolución ] es una representación visual de la red según el proyecto Route Views de la Universidad de Oregón a fecha 1 de...

El Wobbly Clock de Christian es simplemente un reloj de manecillas flexibles. No hace nada más que dar la hora, eso sí, moviendo elásticamente la aguja del segundero cada 5 segundos. Una pequeña y relajante gozada sin más utilidad que esa...
Más de 72 horas después de que algunos clientes de terceras partes de Twitter dejaran de funcionar sigue sin haber respuesta oficial por parte de la empresa. Aunque unos mensajes filtrados de un grupo de Slack parecen indicar que está hecho a...
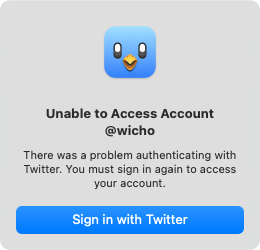
No hay ningún tipo de comunicación oficial de si ha sido a propósito o por accidente. Pero de lo que no hay ninguna duda es de que desde hace horas muchos de los clientes de terceros de Twitter no tienen acceso al...
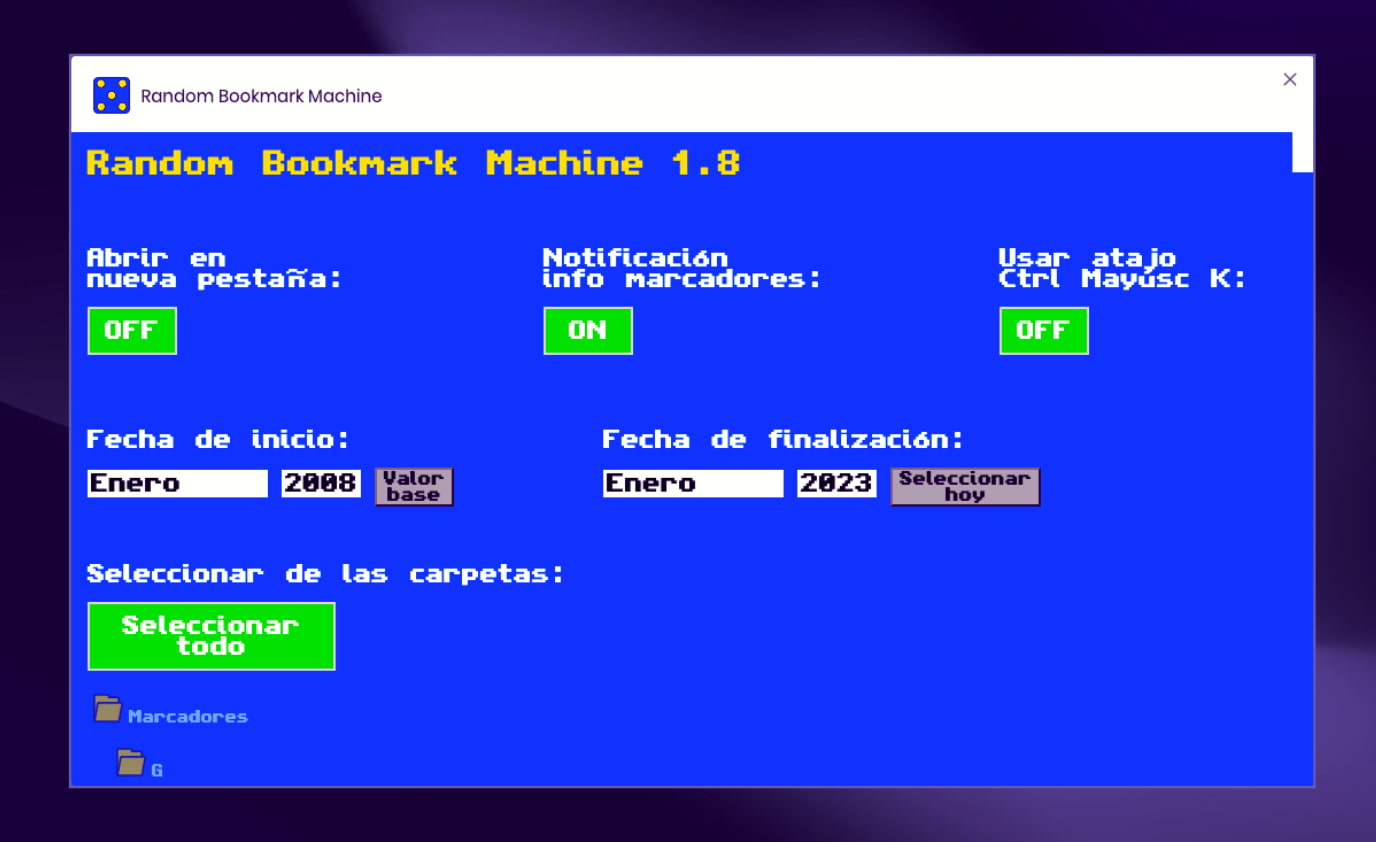
Llevo tiempo utilizando Random Bookmark Machine, una extensión para Chrome (y compatibles) que reemplazó a la que utilizaba anteriormente y había dejado de funcionar. Esta es la buena; he probado casi todas hasta llegar a ella. Básicamente sirve para saltar al...

Hace unos minutos un Falcon 9 de SpaceX ponía en órbita 54 satélites de la constelación Starlink de acceso a Internet. La órbita a la que van destinados, de 530 kilómetros de altitud y 43 grados de inclinación respecto al ecuador,...
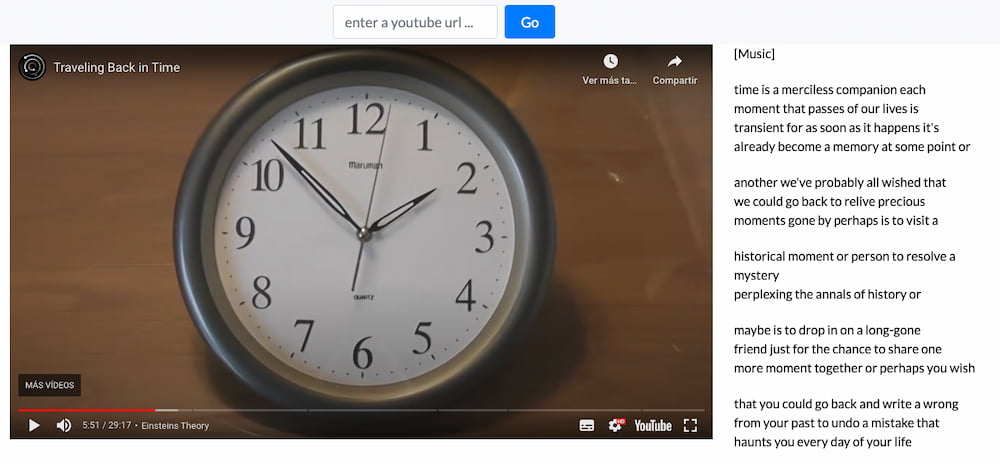
YouTube Transcript es una pequeña utilidad que extrae de YouTube las transcripciones del audio de los vídeos. La idea es sencilla y es algo que mucha gente tiene claro: es mucho más rápido leer que ver y escuchar los vídeos. Cuando...
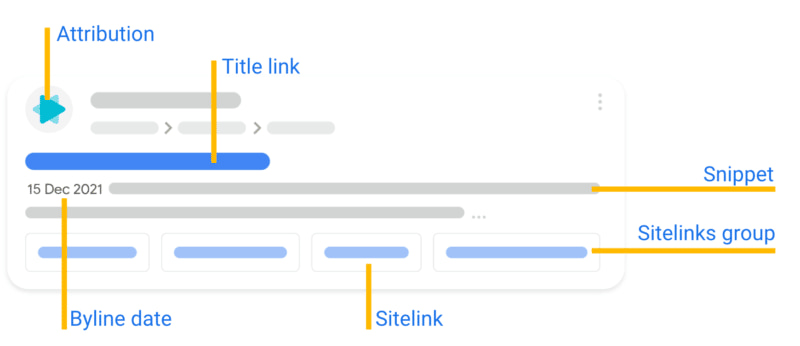
Una de las cosas más difíciles del trabajo en internet cuando se juntan equipos de diversas disciplinas u orígenes (por ejemplo, una agencia y los clientes, o programadores y diseñadores) es ponerse de acuerdo en la nomenclatura a utilizar. Tal vez...

Aunque son competencia indirecta de Starlink la pela es la pela y esta pasada noche un Falcon 9 de SpaceX ponía en órbita un lote de 40 satélites de la constelación de acceso a Internet de OneWeb. OneWeb tenía contratado el...

Twitter está sumido en el caos. Con la llegada de Elon Musk han sido fulminados de la compañía miles de empleados de todos los departamentos, una sangría importante que de un modo u otro pasará factura. Quienes hayan seguido la evolución de...

History is unfolding! We've deployed #BlueWalker3's 693-square-foot array, which is now the largest-ever commercial communications array in low Earth orbit.Read more about this important milestone here: https://t.co/4kupfxn3vO pic.twitter.com/KnE9CeWOCT— AST SpaceMobile (@AST_SpaceMobile) November 14, 2022 AST SpaceMobile, dentro de su objetivo de crear...

Llevo desde que se confirmó la compra de Twitter por parte de Elon Musk siguiendo el proceso como cuando sabes que va a ocurrir algo horrible pero no puedes dejar de mirar. Ha insultado a las personas que lo usan. Ha...

Jaime Gómez-Obregón, uno de nuestros hackers hiperactivos favoritos de la internet española, ha lanzado en unos pocos días un invento llamado SuperBOE. Es básicamente una versión más legible del BOE (Boletín Oficial del Estado) adaptada adecuadamente para Internet, es decir, aprovechando...
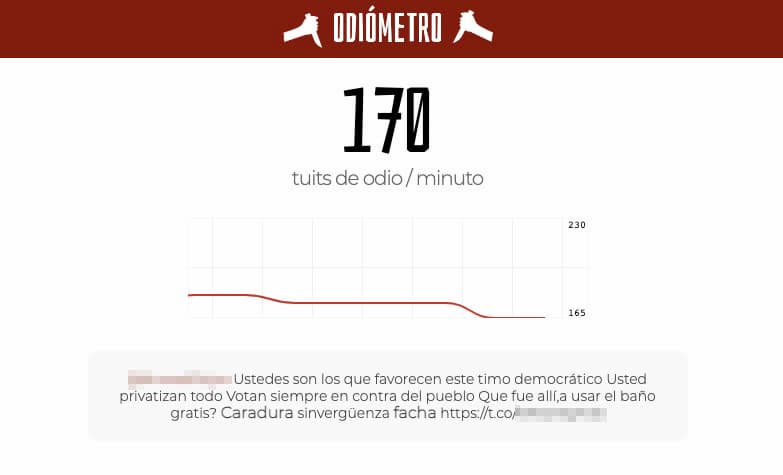
El Odiómetro es, tal y como se autodefine la página, «el espejo de nuestro odio». Lo ha creado Mikel Torres y es una visualización en tiempo real de todo tipo de insultos en castellano según se publican en Twitter, creada filtrando...

HotBot, AltaVista, Lycos, InfoSeek, Excite, Open Text, Point, A2Z, DejaNews, Aliweb, Pathfinder, El Indice, El Inspector de Telépolis, Linkstar, InfoMarket, 100hot, Electric Library, Accufind, Open Market, Magellan, WebCrawler. Si te suena alguno de estos nombres es que eres más viejo que...
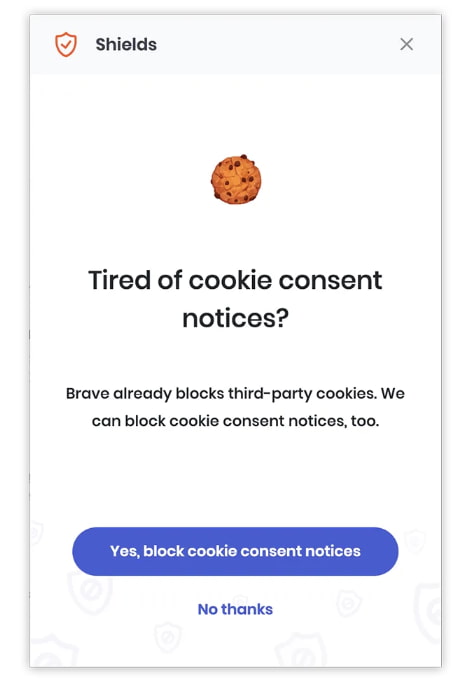
Si eres de quienes gustan de navegar tranquilamente y sin estridencias, apreciarás la nueva función que ya ha incorporado el navegador Brave –uno de los que presume de cuidar más la privacidad de los usuarios– para eliminar los avisos de consentimiento...

La fibra óptica es más rápida, más segura y sin duda más elegante que el cable telefónico, el coaxial de Ethernet o incluso que las ondas del wifi, que no llegan a todas partes y a veces lo hacen con interferencias....

Twitter está luchando por mantener a sus usuarios más activos -lo que llama «tuiteros de peso»- comprometidos con la plataforma, según documentos internos.– Sheila Dang vs. ¿Dónde se han ido los tuiteros, se pregunta la empresa que ha dejado florecer los movimientos...

Según publican en New Atlas unos investigadores de la Universidad Técnica de Dinamarca y de la Universidad de Chalmers han batido el récord de transmisión de datos situándolo en 1,84 petabits por segundo. Esto básicamente es casi el doble que todo...

Despegue de la misión – OneWeb Esta pasada noche NewSpace India Limited (NSIL), la división comercial de la ISRO, la agencia espacial india, ponía en órbita un lote de 36 satélites de acceso a Internet de OneWeb. Con él la empresa ya...

He de reconocer que jamás había oído esta historia de unas bragas que se vendían en Argentina con el nombre Internet. Bombachas, les dicen allí. Eran fabricadas por una empresa familiar que, para más recochineo, se llamaba Internet SRL. Propiedad de los...
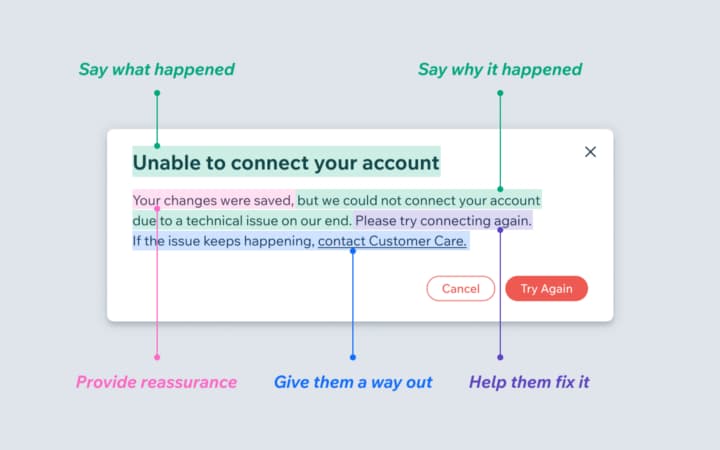
Rompamos gustosos aquí una lanza a favor del equipo de UX de Wix, el popular servicio de creación y alojamiento de páginas web, porque han corregido ni más ni menos que 7.643 mensajes de error para mejorar la vida de sus...

Se puede participar hasta el próximo domingo, 11 de diciembre: Navegantes en la Red:25ª encuesta a usuarios de Internet de la AIMC Es la tradicional encuesta de la Asociación para la Investigación de Medios de Comunicación (AIMC), también conocida como Navegantes en...

TVOnline.es es una de esas páginas que básicamente unifica en un solo sitio cientos de enlaces interesantes para que no pierdas el tiempo buscándolos; en este caso se trata de las emisiones de canales de televisión / TDT españoles en abierto...
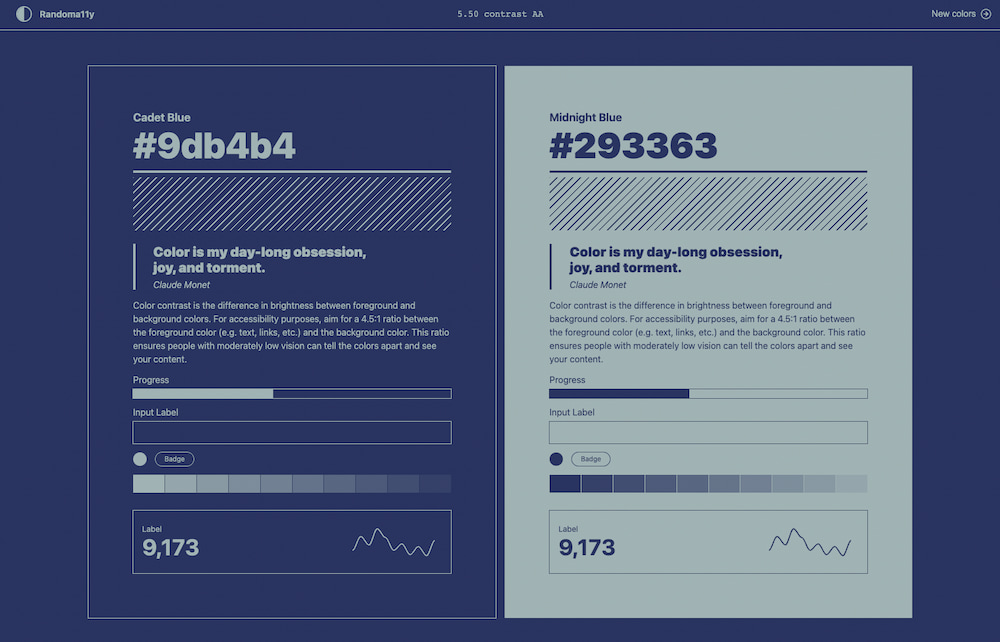
Randoma11y genera pares de colores apropiados para diseños que respetan la regla del contraste de color. El contraste de color es la diferencia de brillo entre los colores de primer plano y de fondo. Por motivos de accesibilidad hay que procurar...
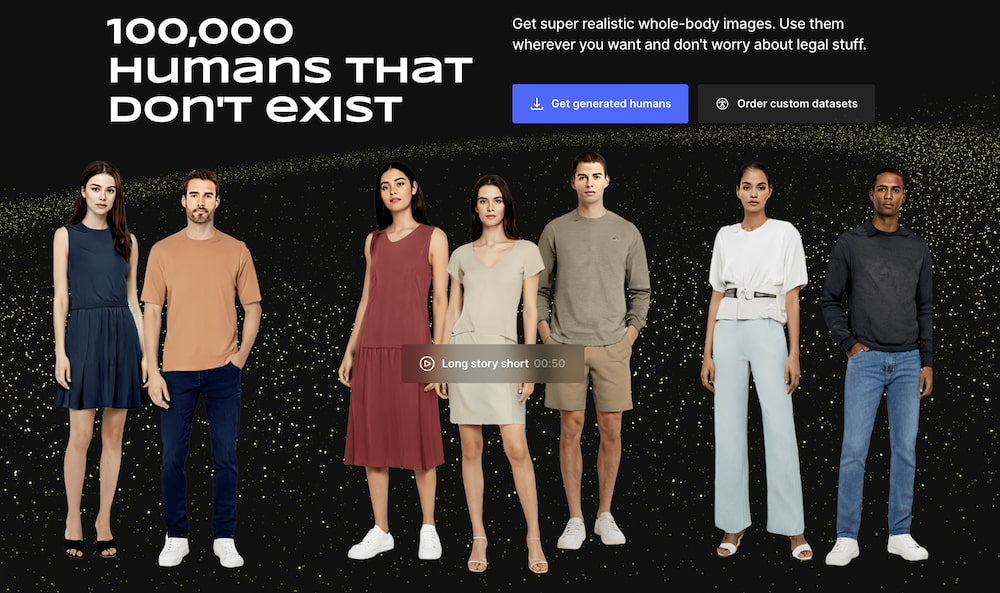
Me ha encantado 100.000 humanos que no existen tanto por el título como por lo ciberpunk que resulta. No son más que fotos generadas por algoritmos de IA de rostros y cuerpos humanos que, en esencia, «no existen». Es una especie...

Panel de salidas en el aeropuerto internacional de Los ángeles – Wicho El grupo de piratas informáticos –no, no son hackers, en todo caso ciberdelincuentes– conocido como Killnet lleva desde ayer atacando las webs de diversos aeropuertos de los Estados Unidos. La...

El Almanaque de la Web 2022 contiene 22 capítulos explicativos sobre los datos recogidos por el Archivo HTTP, que es el sitio en el que la gente del Archivo de Internet (Archive.org) guarda permanentemente los datos de la World Wide Web....

La buena gente de la Fundación Mozilla se ha currado un informe titulado Una investigación sobre la ineficiencia de los controles de usuario de YouTube que no deja muy bien a la plataforma de vídeos de Google. En esencia, la gente...

Un disco duro que tuvo mejores días – CC BY-SA 2.0 ES por Barney Livingston Periódicamente recuerdo a quien me lee la importancia de hacer copias de seguridad y aquello de que sólo hay dos tipos de personas que usan ordenadores, móviles,...
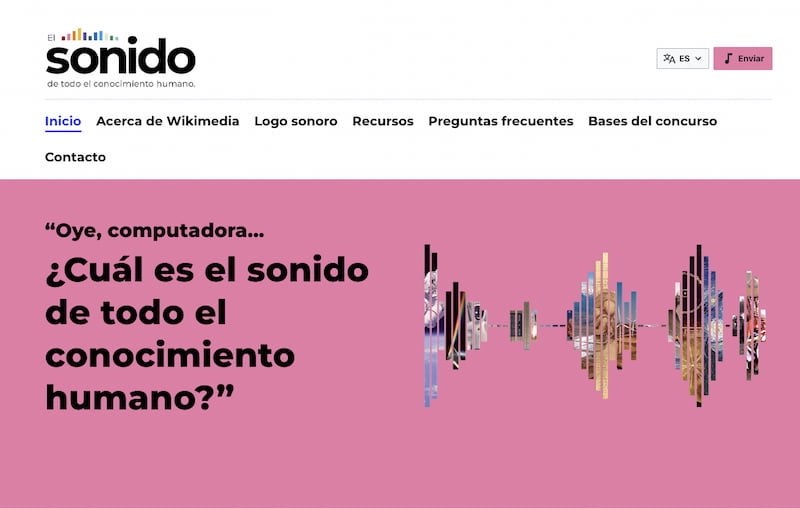
La Fundación Wikimedia ha organizado un concurso abierto para el logo sonoro de los proyectos Wikimedia. La idea es que exista un sonidillo breve y reconocible cada vez que se invoque a asistentes digitales que utilicen su información: «Hey, Google, ¿Cuándo...

El Unicode es probablemente el mejor invento desde el alfabeto romano y el código ASCII. Desde que unos ingenieros de Apple y Xerox lo inventaran allá por 1987 para facilitar la visualización de textos en diversos idiomas y lenguajes de símbolos...

Nos prometieron Marte, pero nos dieron Facebook… – Dr. Gernot Grömer,del Foro Espacial Austríaco(vía Remco Timmermans)...
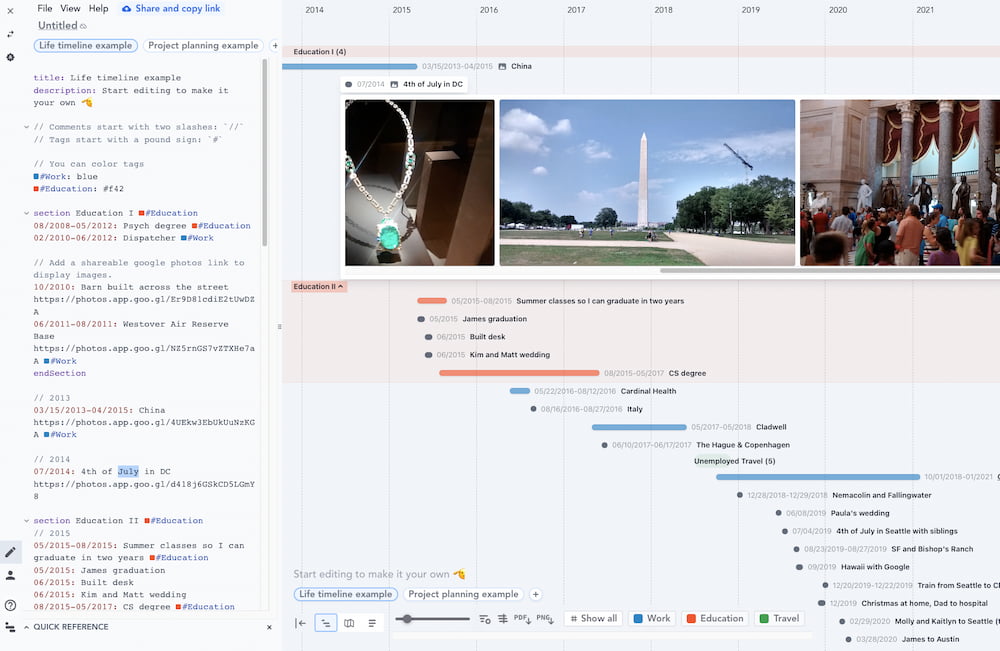
Markwhen tiene una pinta estupenda, aunque es de esas mini aplicaciones que necesitas probar con datos reales durante bastante tiempo para ver hasta qué punto encaja y resuelve lo que necesitas. Sirve para crear cronologías a partir de archivos de texto...
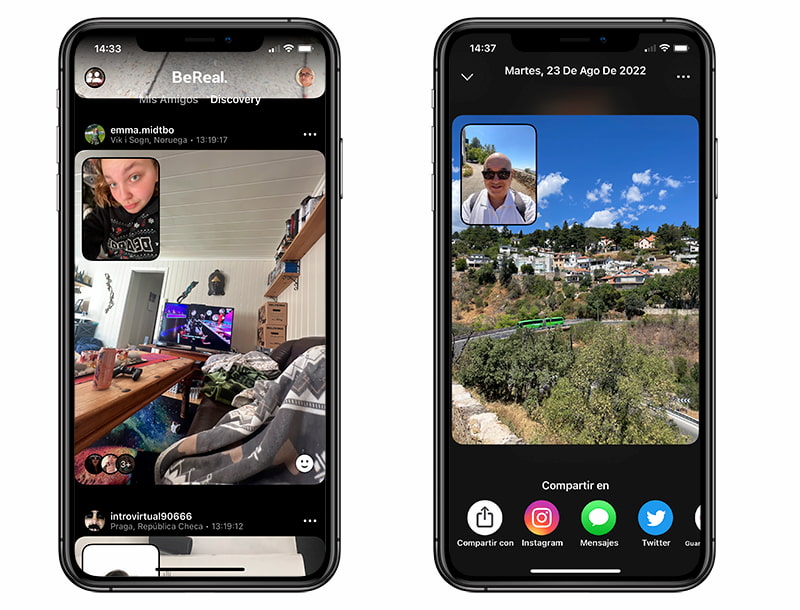
BeReal es la enésima red social de moda en la que se puede compartir con amigos y conocidos lo qué estás haciendo. La comunicación en su forma más pura. La diferencia es que se enfrenta a Instagram o Twitter, a estas...

Antenas Starlink instaladas en uno de los cruceros del grupo – Grupo Royal Caribbean Según una nota de prensa recién publicada el grupo Royal Caribbean usará Starlink para dar acceso a Internet en sus cruceros. Eso incluye todas las embarcaciones ya en...

La Web está ahora plagada de inescrutables banners de cookies que no parecen proporcionar ninguna funcionalidad, no cumplen con las normas de protección que se pretendían, utilizan «patrones oscuros» para empujar a los usuarios a dar su consentimiento a todas las...

Anoche, en una presentación en las instalaciones de SpaceX en Texas, Starbase, Elon Musk y Mike Sievert, director ejecutivo y presidente de T-Mobile en los Estados Unidos, anunciaban un acuerdo de ambas empresas para dar cobertura vía satélite a cualquier teléfono...
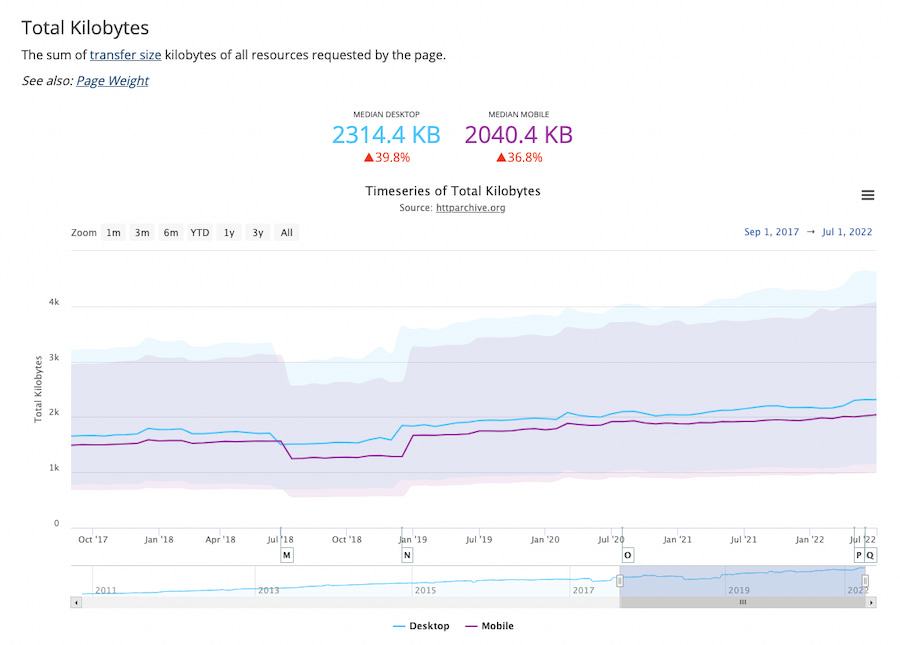
Del último informe sobre el Estado de la Web de HTTP Archive, una de las secciones de Archive.org, pueden extraerse algunos datos interesantes. El primero es que el tamaño/peso promedio de las páginas Web sigue aumentando como cada año: hemos pasado...

Con el lanzamiento de un lote de 52 satélites Starlink el pasado 10 de agosto, SpaceX superaba la barrera de los 3.000 satélites de la constelación de acceso a Internet puestos en órbita. Y desde entonces ya ha lanzado otros 46...

Me crucé con uno de los muchos vídeos que tiene Lord Draugr en su canal y como me gustó el estilo y, sobre todo, el contenido, acabé saltando de un a otro. Mi conclusión es que a este tío deberían darle...

Me encontré con pocas horas de diferencia el vídeo Nobody Shares Anymore de Mike Rugnetta y la anotación Las redes sociales y el fin de una era de Enrique Dans. Ambos hablan de cosas a las que llevo un tiempo dándole...
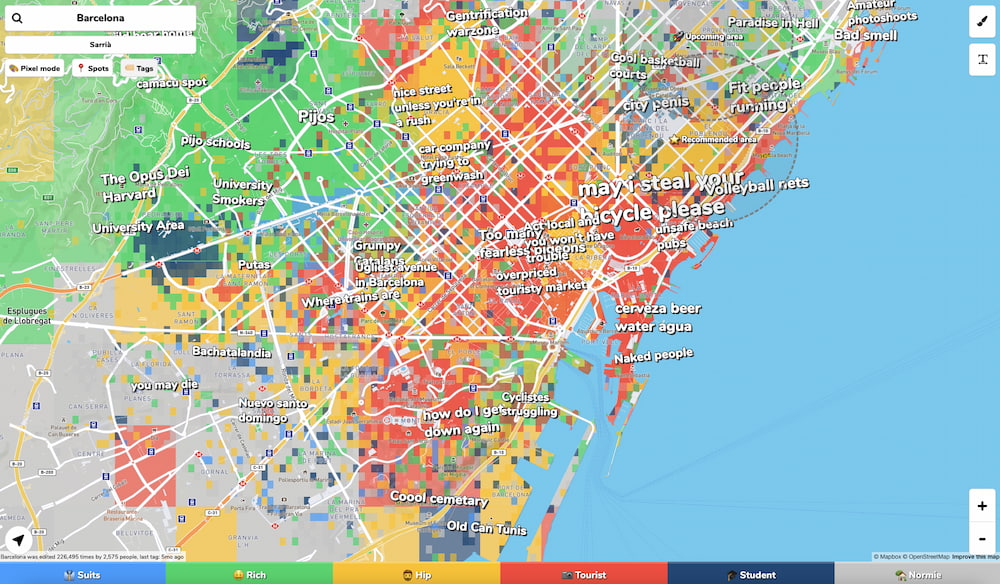
En Hoodmaps es la proverbial sabiduría de las multitudes la que le pone etiquetas a los mapas: busca la ciudad que te interese y verás cómo se define cada zona o barrio en función de lo que la gente opina de...
Ventana principal de la aplicación de Raindrop para macOS Hace más de diez años que Pocket es una herramienta imprescindible en mi trabajo. Tanto que algunos de esos años he estado en el 1% de las personas que más lo usan en...

Cotilleando los canales de paseos por ciudades que tanto me gustan me topé con este de Cámaras en vivo de diversos lugares del mundo de Magic Live. La peculiaridad es que es una selección curada de muy buena calidad por lo...

Craig Campbell nos documenta una revelación que ya nos temíamos, después de lo que vimos con los hiperenlaces: el 10% del primer millón de dominios más populares está MUERTO. Sin conexión. 404. Más muertos que el loro muerto de los Monty...
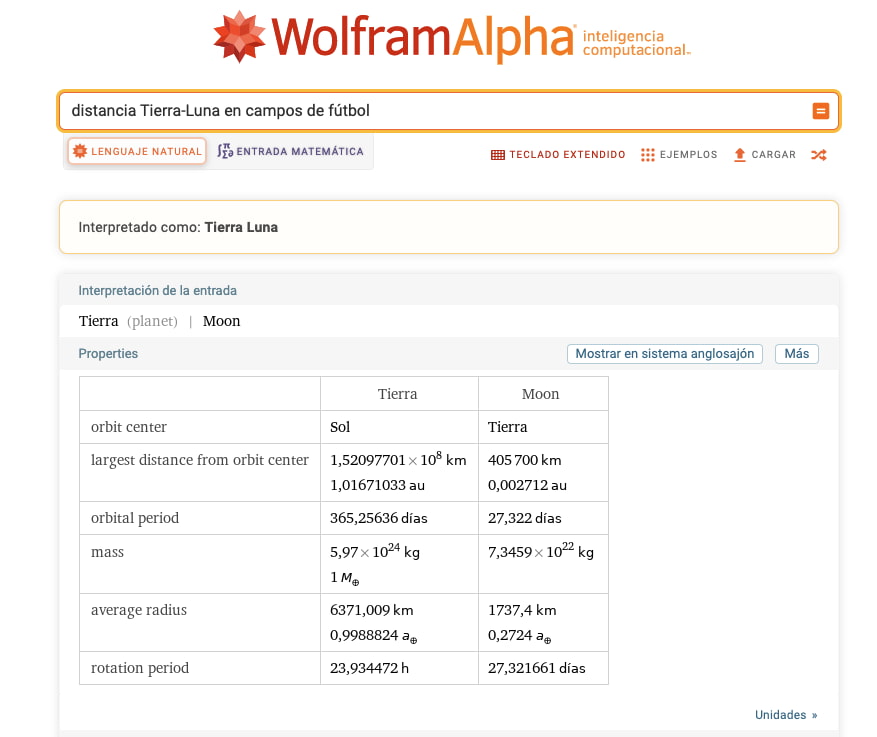
Han tenido que pasar unos cuantos años, pero por fin Wolfram Alpha está disponible en castellano. Sus creadores lo definen como inteligencia computacional aunque también puede entenderse como una recopilación de conocimientos a modo de calculadora/buscador. Básicamente preguntas cosas, interpreta lo...
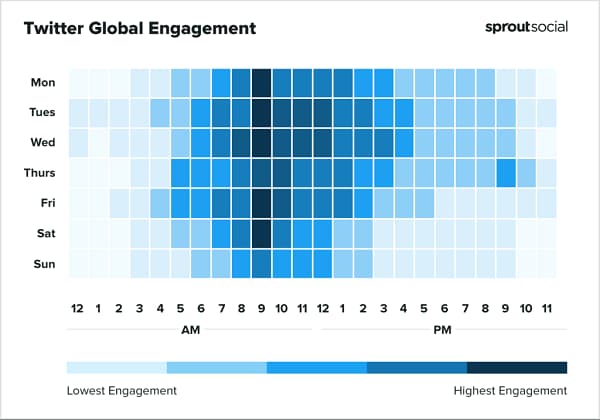
Según un estudio de la compañía especializada en redes sociales Sprout Social, el mejor momento para conseguir más interacciones al publicar en Twitter es cualquier día entre semana a las 10:00 de la mañana, excepto los jueves. Y los sábados también...
Cierta parte del SEO resulta ser un poco como el análisis técnico de la bolsa o las lecturas astrológicas: te las puedes creer o no, pueden tener un lejano poso de base científica (matemáticas o astrofísica) pero es difícil evaluar su...
Capture My Tweet es un servicio al que le das la dirección URL de un tuit y te monta una imagen bonita y con fondo, al tamaño que necesites, en un plis-plas. Con sus bordes redondeados, degradados de color de fondo...
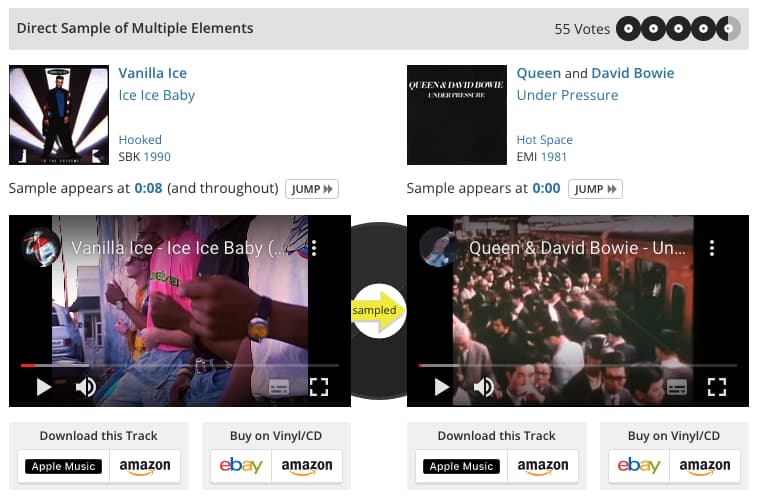
Si toda la música moderna te parece que suena igual es que en parte es igual. La proliferación desde hace ya más de medio siglo del Mellotron y los samples, por no hablar del Auto-Tune y otras trampas han convertido a...
Quienes aprecien las virtudes del minimalismo en el diseño y programación de sitios webs seguramente querrán echar un vistazo a PureCSS (o simplemente Pure), que son unos módulos CSS que apenas ocupan espacio (3,7 KB) y sirven para construir todo tipo...
Quienes usen Telegram saben que se añaden nuevas funciones frecuentemente, y que de hecho en eso es en lo que desataca frente a otras apps como WhatsApp, iMessage y otros programas de mensajería con los que compite. Aprovechando el anuncio de...

En este vídeo de la Fundación Long Now, esa que se preocupa por hacernos pensar a muy largo plazo, Adam Long desarrolla en cinco minutos cómo los marketroides se apoderaron hace más de un siglo de algunas de las narrativas en...
Los dominios son hoy en día tan escasos que difícil es encontrar una secuencia de unas pocas letras que tenga la dirección .com libre. Y como todo gran proyecto comienza por reservar un dominio y hacer unas camisetas, la idea de...
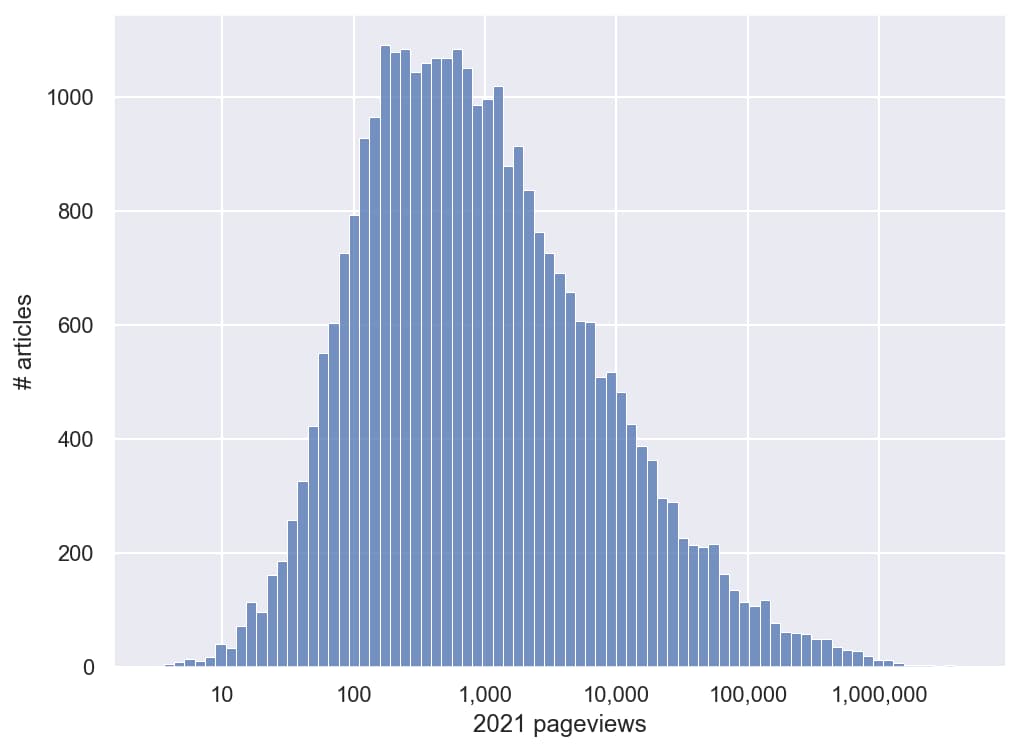
Colin Morris se enfrascó en una búsqueda del artículo menos visto en la Wikipedia. Al ser públicas las estadísticas, es fácil saber cuáles son los temas más populares, pero el extremo opuesto no es tan trivial. Eliminando las «páginas de desambiguación»,...
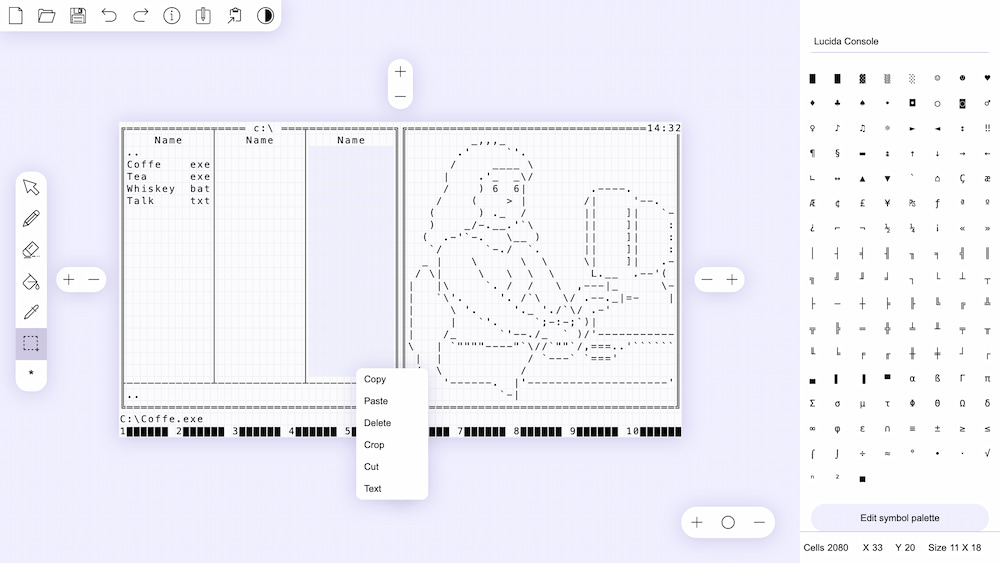
ASCII Art Paint es una encantadora y a la vez aberrante aplicación web para dibujar, pero sólo en el peculiar formato de los caracteres-como-píxeles del Arte ASCII. Lo mejor es que tiene una enorme cantidad de herramientas, dignas de un Photoshop,...
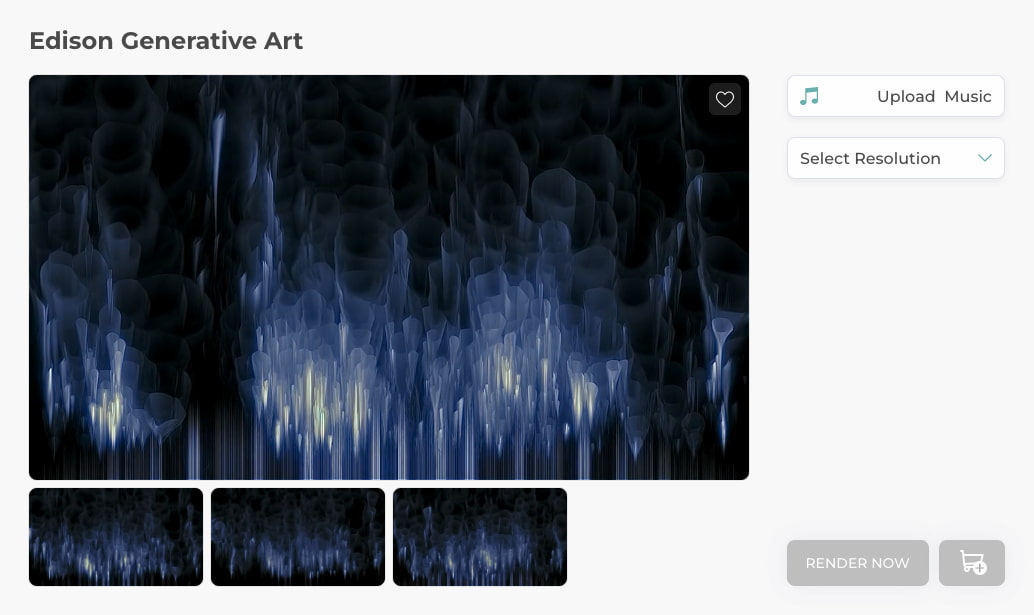
Doodooc es una curiosa herramienta medio musical, medio matemática, medio artística para generar imágenes animadas a partir de la música. Podríamos considerarlo un chisme con el que experimentar y probar con diferentes melodías, plantillas y resoluciones, quizá sólo por probar, quizá...

I hope that even my worst critics remain on Twitter, because that is what free speech means— Elon Musk (@elonmusk) April 25, 2022 Pues al final se ha salido con la suya y Elon Musk se ha comprado Twitter. Bueno, la junta...

Un Airbus A321 de Hawaiian Airlines en Maui – Wicho Con apenas unos días de diferencia Hawaiian Airlines y JSX se convertían en las dos dos primeras aerolíneas en anunciar que van a ofrecer conexión a Internet vía Starlink a bordo de...

Chris Anderson entrevistó ayer a Elon Musk en el marco del TED2020 y aunque buena parte de la entrevista versó sobre el futuro de Tesla otra buena parte acabó siendo sobre su reciente oferta pública de adquisición de Twitter, algo que...

Puesto de control de repostaje de un KC-46. Arriba, los monitores del sistema panorámico; abajo los del RVS - USAF/Cabo mayor Cody Dowell Una de las pocas que no vende todavía Amazon son lanzamientos espaciales. Por eso se ha tenido que comprar...

Do you want an edit button?— Elon Musk (@elonmusk) April 5, 2022 Hace unas horas saltaba la noticia de que Elon Musk se había comprado un 9,2% de las acciones de Twitter. Esto lo convierte en el mayor accionista individual de la...
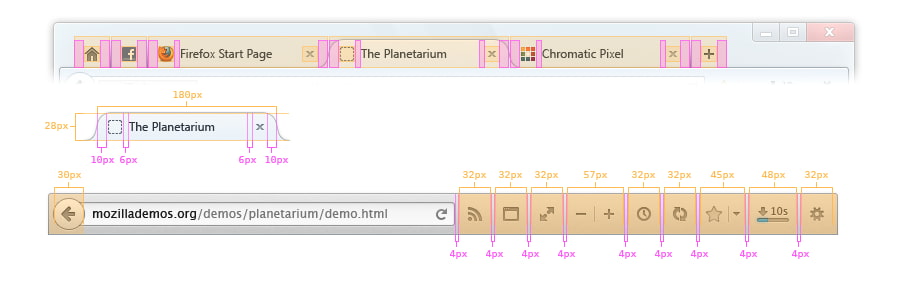
Este minucioso repaso explicado por MS_Y en una página de Github es todo un recorrido por la historia visual de la interfaz de usuario de Firefox, el navegador web que desarrollan la Corporación Mozilla y la Fundación Mozilla. Mozilla Firefox –también...

Leí en el blog de Archive.org que la buena gente del Museo de Historia de la Informática (CHM) de Silicon Valley consiguió hace relativamente poco salvar los archivos de CompuServe. Y la narración de la hazaña es totalmente de película, con...
Ahí van algunos artículos que recopilé sobre programación en HTML en los que se explican códigos y atributos útiles-pero-no-tan-conocidos para mejorar las páginas web. Cuestiones como evitar que en un formulario aparezcan palabras subrayadas porque se «dispara» el corrector ortográfico, cómo...
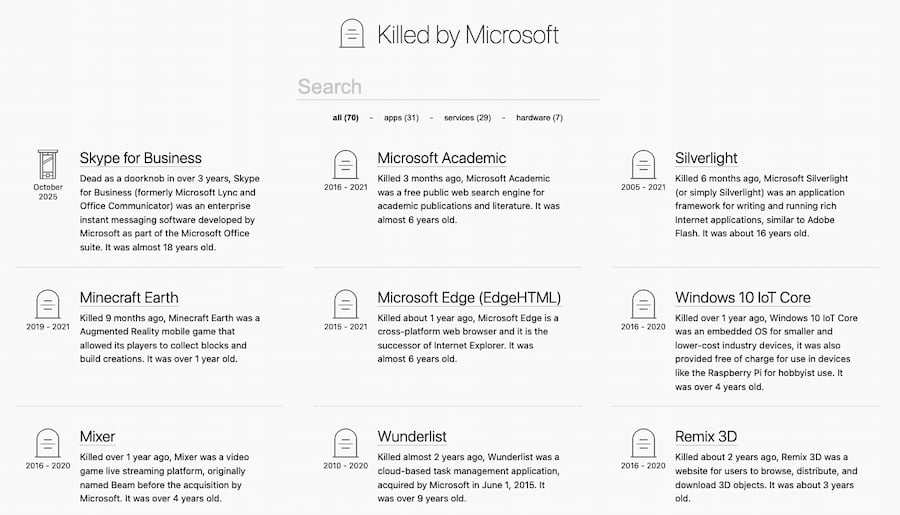
Todas las empresas esconden algún que otro «muerto» en sus armarios, y Microsoft no es la excepción. Quizá por eso y para que nadie se olvide Fabiano Riccardi y un montón de voluntarios llevan tiempo mantenido Microsoft Graveyard, el cementerio de...

Un cohete Soyuz-2.1b despegando de Vostochny con un lote de satélites OneWeb en marzo de 2021 – OneWeb Una de las muchas consecuencias de las sanciones impuestas a Rusia tras la invasión de Ucrania fue que OneWeb rompiera el contrato que tenía...

La latencia se conoce vulgarmente como retardo, aunque técnicamente sea una suma de retardos típica de la transmisión de paquetes en una red, o más en general la diferencia entre causa y efecto en diversos sistemas, ya sean una red de...

Según me he encontrado dando una vuelta por Twitter, la coalición Acción por la Justicia Algorítmica (AxJA) se ha creado para «desafiar la falta de control democrático, transparencia y rendición de cuentas en el uso y adquisición de sistemas de toma...

La noticias falsas (fake news) son una plaga de esta sociedad hiperconectada en la que vivimos. Y es algo que hay que recordar y tener muy presente siempre, aunque más quizás en estas primeras horas de la guerra de Rusia contra...
Estaba mirando unas fotos y usando el OCR del iPhone cuando me encontré con la necesidad de hacerlo desde el Mac. Pero no encontré una forma obvia ni directa, que parece que no existe a menos que instales un módulo o...

Increíble pero cierto: no sólo quedan 1,5 millones de personas que todavía pagan los servicios de AOL, sino que de todas ellas hay «unos pocos miles» que todavía lo utilizan para conectarse a través de módem (dial-up). Palabras literales de la...

Me ha parecido sumamente ingenioso lo que hace Drive & Listen, una web en la que puedes experimentar cómo es la conducción en otras ciudades del mundo. Utilizan vídeos de YouTube seleccionados a mano y los acompañan con emisoras de radio...

Impresión artística de un satélite OneWeb en órbita; tras el Brexit el Reino Unido está construyendo su propia constelación de acceso a Internet con OneWeb - OneWeb Cuentan en SpaceNews que la Unión Europea está dispuesta a construir a toda costa su...

Primero dijeron: Si no se adopta un nuevo marco de transferencia transatlántica de datos y no podemos seguir recurriendo a las CCE o a otros medios alternativos de transferencia de datos de Europa a Estados Unidos, es probable que no podamos ofrecer...

Este libro de pop-ups de los memes de Paper Paul es un proyecto artístico de alguien que aprecia los memes de internet y que cree que merece la pena mostrar cómo darles vidas animadas en el papel de las páginas de...

En la web del Unicode han actualizado con datos recientes los Emojis más usados, ordenados por frecuencia o, podríamos decir, popularidad. La típica lista poco útil pero que los frikis de los datos devoramos porque está llena de respuestas a preguntas...

Mitad en serio, mitad en broma, mitad como experimento,CodeCaptcha.io pone una idea sobre la mesa: un captcha –esas cajitas de «Demuestra que no eres un robot»– que en vez de textos ondulados o reconocer objetos en fotos como bicicletas o postes...

Con el lanzamiento de 49 satélites Starlink la pasada noche SpaceX ha superado la cifra de los 2.000 lanzados. En concreto va por los 2.042. Aunque teniendo en cuenta los que han dejado de funcionar y los que ya han sido...
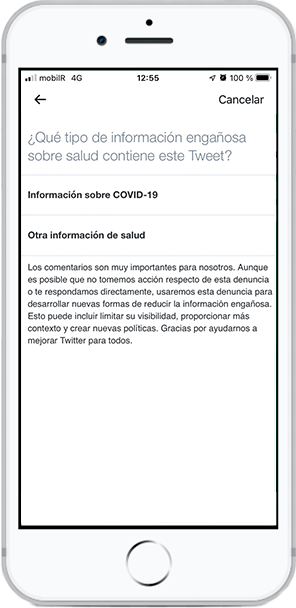
Non é sen tempo, que decimos en mi tierra. Pero por fin Twitter permite denunciar tuits específicamente por difundir información falsa sobre salud. Antes era complicado hacerlo porque realmente no había una categoría para hacerlo y había que ponerlos en el epígrafe...
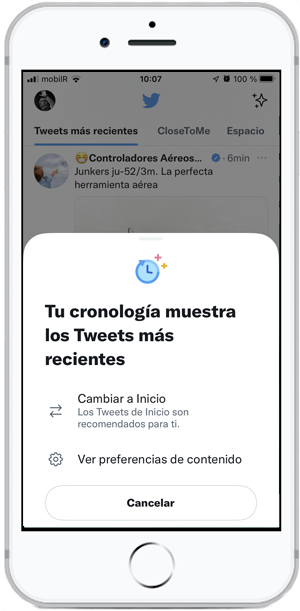
Durante años cuando alguien protestaba por lo que veía en Twitter mi respuesta fue que Twitter era aquello que hacíamos nosotros de él a la hora de escoger qué cuentas seguir. Pero desde que a Jack se le metió en los algoritmos...

Los primeros pasos de toda inteligencia artificial son difíciles. Quizá por eso Cheezam falla más que la web de Renfe*. Pero lo importante es el conceto. Así que servicio/app de ingenioso nombre parte de una idea genial: es como el Shazam...
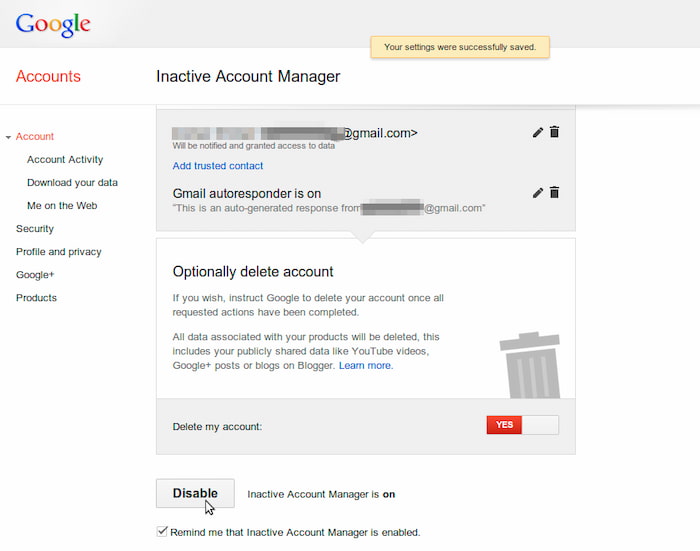
En Android Authority han hecho el ejercicio de comparar tres los servicios online más populares que ofrecen correo, mensajes, almacenamiento de fotos, documentos y demás y han llegado a la conclusión de que a la hora de morirse lo mejor es...

Han pasado casi dos años desde que comenzó la pandemia de la Covid-19. El mundo ha visto una y otra vez lo destructivas que pueden ser la desinformación y los bulos para la armonía social, la democracia y la salud pública; se...
«… y en la clase de Historia de hoy, niños y niñas, recordaremos cómo era conectarse a Internet a finales de los años 90.» Estaba yo quejándome hoy de que la velocidad de la fibra me oscilaba entre 350 y 400...

Todo esto del metaverso me cabrea mucho porque toda mi vida me han dicho que «está mal vivir en un mundo de fantasía» y que mis aficiones e intereses eran «escapismo malsano». Pero resulta que lo único que les enfadaba era...

La Web0 es la web descentralizada. En otras palabras: La Web0 es la Web3 sin todas las gilipolleces corporativas de la derecha libertaria de Silicon Valley.– Small Technology Foundationy cientos de otros firmantes Ahora que se habla tanto de la Web3...

Flip Clock, de Tanmay Makode. Para ver, disfrutar y maximizar. Un auténtico reloj de paletas a la antigua usanza. No hace gran cosa, pero da la hora exacta de forma elegante y fácil de ver. Recordemos que hace tiempo publicamos un...

code {display: inline; padding:2px;} El atajo de la semana son los Bangs de DuckDuckGo, simbolizados por el signo de exclamación ! como prefijo de una o varias letras. Es algo que parece haber «inventado» la gente del buscador DuckDuckGo buscar ser...

Al igual que Teruel o Bielefeld, muchos servicios y productos también «existen» aunque a veces no lo parezca o las conspiraciones o las modas se empeñen en mantenerlos un poco ocultos. Y es que no todo «viene de Estados Unidos» y...

Estuve hace algunas semanas en una charla/presentación sobre Culturas digitales, el libro del profesor José Luis Orihuela, cuyo inestimable legado en Internet ha venido volcando en eCuaderno desde hace más de dos décadas. De hecho @JLori es uno de los tuiteros,...
La Web está jodida. Esa es la triste situación en la que nos encontramos: se acabaron los días de la Web 1.0, en los que el humilde blog personal y los productos de la talla de GeoCities reinaban de forma suprema. En...

Hay webs que hacen fáciles las tareas absurdamente complicadas; ScanYourPDF es una de ellas. Y es que todos hemos pasado alguna vez por el aberrante trámite por el que te envían un PDF que hay que imprimir, firmar físicamente, escanear y volver a enviar, sin que la opción lógica –firmarlo digitalmente, o añadir una firma escaneada y devolverlo– parezca ser suficiente.
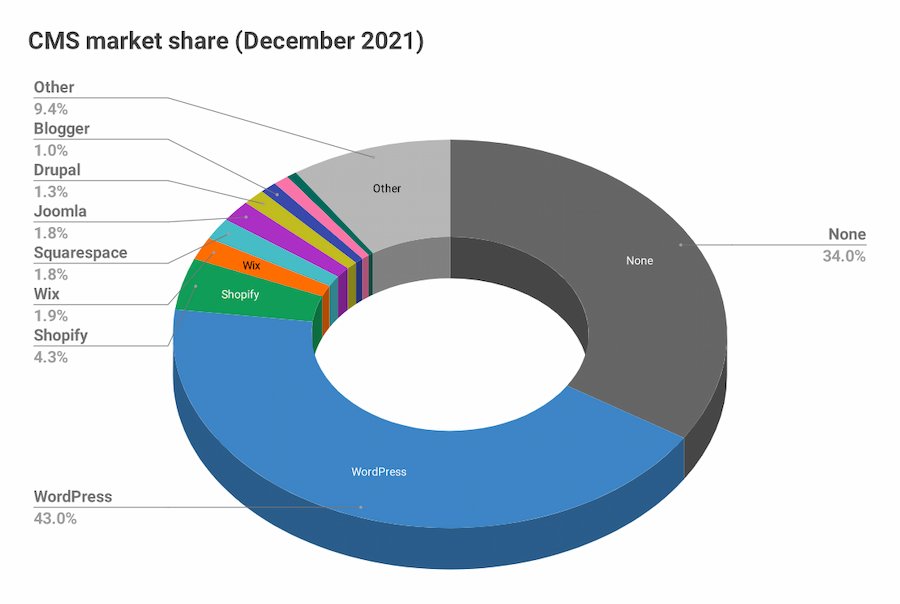
Joost de Valk ha publicado estos datos a diciembre de 2021 acerca del mercado de los CMS en Internet (Sistemas de Gestión de Contenidos). El resumen rápido es que WordPress es el #1 indiscutible (43%), seguido de «ninguno concreto» (sitios webs...

Sin mucha ceremonia, Amazon ha anunciado que retira Alexa tras 25 años de existencia. Alexa(.com) o Alexa Internet –que no hay que confundir con Alexa, la popular asistente digital, también de Amazon– era un sistema de medición de audiencias que se...
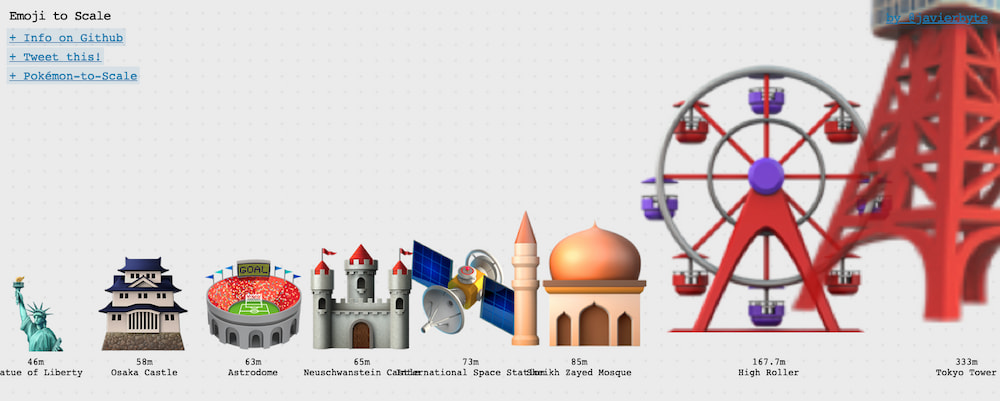
Emojis a escala es una ingeniosísima representación visual de todos los emojis comparados a la misma escala, de modo que las hormigas son más pequeñas y los rascacielos, torres y montañas mucho más grandes. Es una iniciativa de Javier Bórquez, autor...

La gente de HTTP Archive ha publicado su Almanaque de la Web de 2021, donde se analizan los datos recogidos durante todo el año acerca de las diversas plataformas, código y otras tendencias técnicas de las páginas que componen la World...
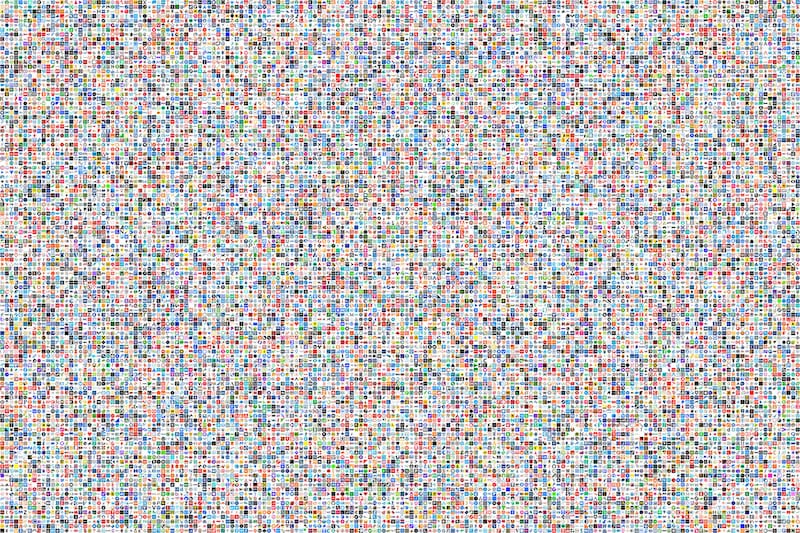
En este gigantesco mapa con 425.909 favicons se pueden ver los cientos de miles de iconos en bruto en los que Adam, Nathan y Patrick han basado un análisis detallado sobre el uso de los favicons. En total se corresponden a...
Ante la lenta adopción de IPv6 y en vista de que muchas organizaciones siguen solicitando direcciones IPv4 como si no hubiera un mañana, hay una propuesta haciendo las rondas por la IETF titulada Unicast Use of the Formerly Reserved 127/8, aunque todavía...

Ma ha parecido muy curioso lo que se cuenta en este trabajo, WikiContradiction: Detecting Self-Contradiction Articles on Wikipedia acerca de un algoritmo que han desarrollado para detectar contradicciones en el contenido de los artículos de la WikiPedia. Algo interesante porque igual...

En 1996 un profesor del MIT se preguntó cuál sería la «vida media» de una página o documento existente en la World Wide Web. Le preocupaba incluir citas en un trabajo y que luego desaparecieran con un triste Error 404: recurso no...

Si la nuestra es la generación de las mil caras, de las mil identidades digitales, el metaverso sería donde se juntan todas esas identidades. El lugar en el que se cruzan los caminos del mapa digital. Donde convergen nuestras versiones, la...

El Archivo de Internet ha actualizado este mes sus cifras, aprovechando que están de inventario y solicitando donaciones. Eso nos permite tener un conteo de la ingente cantidad de datos que mantiene digitalizados en sus servidores: 28 millones de documentos y...

Tarde, mal y a rastras el Gobierno de España ha adaptado a nuestro marco legal la directiva europea sobre propiedad intelectual. Esa que contiene los polémicos artículos 15 y 17, antes 11 y 13. Pero el consenso está en que se...
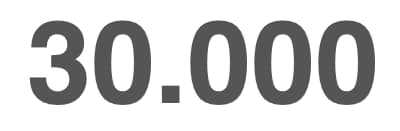
Hay gente que tiene muchos sueños y busca la fama. Pero la fama cuesta. Y tan complicado o más que conseguirla es medirla. Curiosamente, hay quien se ha atrevido a hacerlo para las redes sociales: el organismo regulatorio de la publicidad...

Esta curiosa miniserie alemana de cuatro episodios es de lo más geek que se puede encontrar ahora mismo en Netflix, y hay que reconocer que está entretenida y con buena producción [doblada al español –excepto el tráiler– incluyendo un curioso mix...

Me crucé con interesante y un poco viejuno pero atemporal artículo de Low-Tech Magazine titulado How to Build a Low-tech Website? (Cómo construir un sitio web de baja tecnología). En él se describe cómo crear páginas web para albergar en un...

Desde que hace más de 500 años Martín Lutero se agarrara un cabreo monumental y clavara sus Noventa y cinco tesis en la puerta de la puerta de las iglesias de Wittenberg a modo de manifiesto de declaraciones o propuesta de debate...

Se puede participar hasta el próximo domingo, 12 de diciembre: Navegantes en la Red:24ª encuesta a usuarios de Internet de la AIMC Es la tradicional encuesta de la Asociación para la Investigación de Medios de Comunicación (AIMC), también conocida como Navegantes en...

En la mañana del 14 de octubre de 2021 un cohete Soyuz-2.1b con una etapa superior Fregat-M lanzado desde el cosmódromo de Vostochni ponía en órbita el decimoprimer lote de satélites para acceso a Internet de OneWeb, formado por 36 unidades....

Bryan Braun tiene una obsesión tecnológica consistente en hacer cosas raras con checkboxes, que expone en un sitio llamado Checkboxland. Y es sin duda un gran hackeo, porque parte de la idea de usar algo para una finalidad totalmente diferente de...
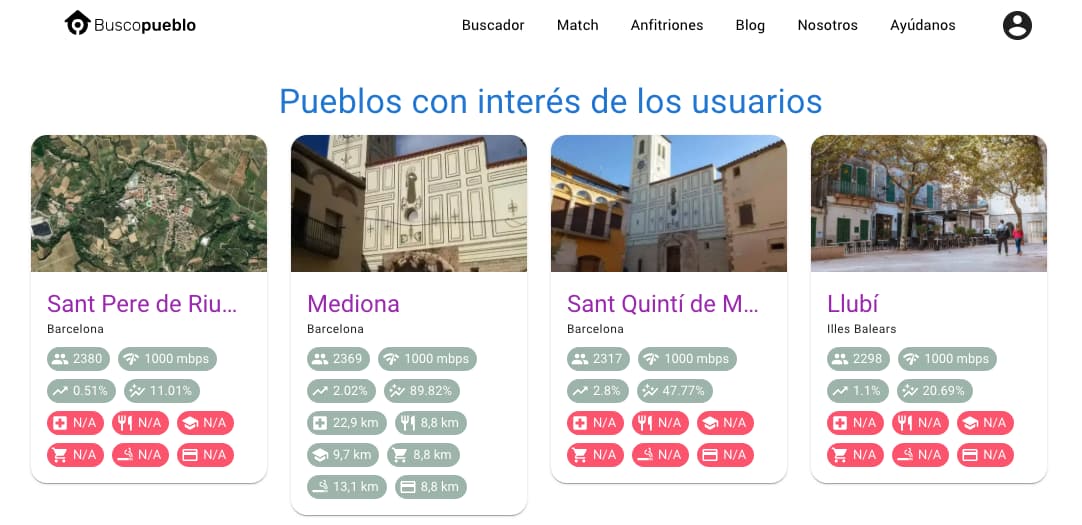
Se podría decir que BuscoPueblo es como un Idealista de la España vaciada, un buscador de territorios abandonados (o casi) o un Airbnb de lo rural. Lo interesante es que aunque Diego –que es su creador y quien nos lo ha...

Todavía resuenan en la red los ecos de los gritos en un vacío en el que nadie podía oír a nadie. Miles de millones de personas e influencers sorprendidas por la desaparición de Facebook y también de WhatsApp e Instagram –ambas...

En el estudio – Radio Coruña En las últimas semanas en Galicia está arreciando una campaña de smshing que afecta especialmente a las personas que tienen sus cuentas con Abanca. Sólo en la provincia de A Coruña hay 91 personas que se...
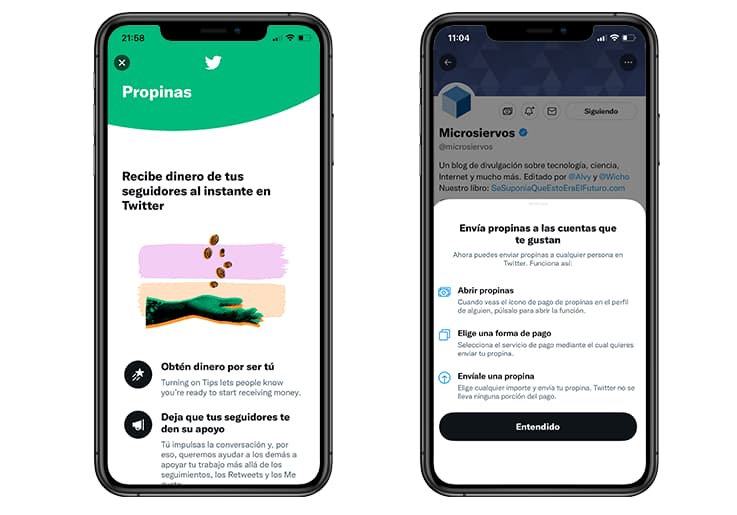
Twitter está activando la función Propinas en sus apps para iOS y Android en diferentes partes del mundo, algo que muchos esperaban como agua de mayo. En España y para iOS ya funciona, como hemos podido comprobar de primera mano en...

Should I Use A Carousel? responde con un simple y gran NO a la pregunta que todo diseñador web se ha hecho cuando se plantea montar una portada o página de aterrizaje. Sencillo, conciso y directo, sin paños calientes. Nada que...

En la Emojipedia han mostrado cómo serán algunos de los los nuevos emojis de Unicode 14.0, que ya han sido aprobados y llegarán en los próximos meses a los teléfonos móviles y todo tipo de apps y dispositivos. Forman parte de...

Apenas unas horas después de que SpaceX lanzara el primer lote de satélites para la segunda capa de su constelación Starlink para acceso a Internet la empresa británico–india OneWeb hacía el lanzamiento de su décimo lote de satélites, también para el...
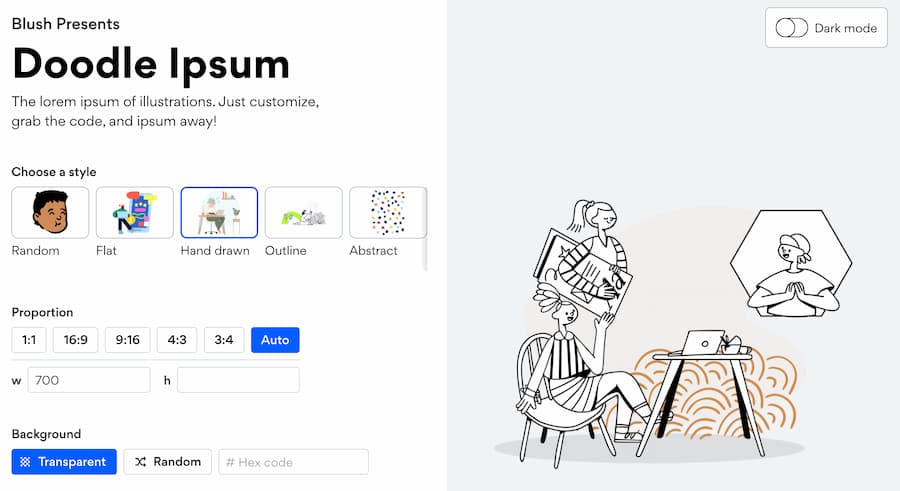
¡Qué buena la idea de Doodle Ipsum! Es básicamente un Lorem Ipsum de ilustraciones garabateadas, es decir, imágenes «de relleno» en diversos estilos que se pueden usar para bocetos y pruebas de diseño. Es una forma rápida de obtener un efecto...

Esta pasada noche un cohete Falcon 9 despegaba del Complejo de lanzamiento espacial 4E de la Base de la Fuerza Espacial de Vandenberg en California para poner en órbita 51 satélites Starlink. El lanzamiento marca el inicio de los lanzamientos de...
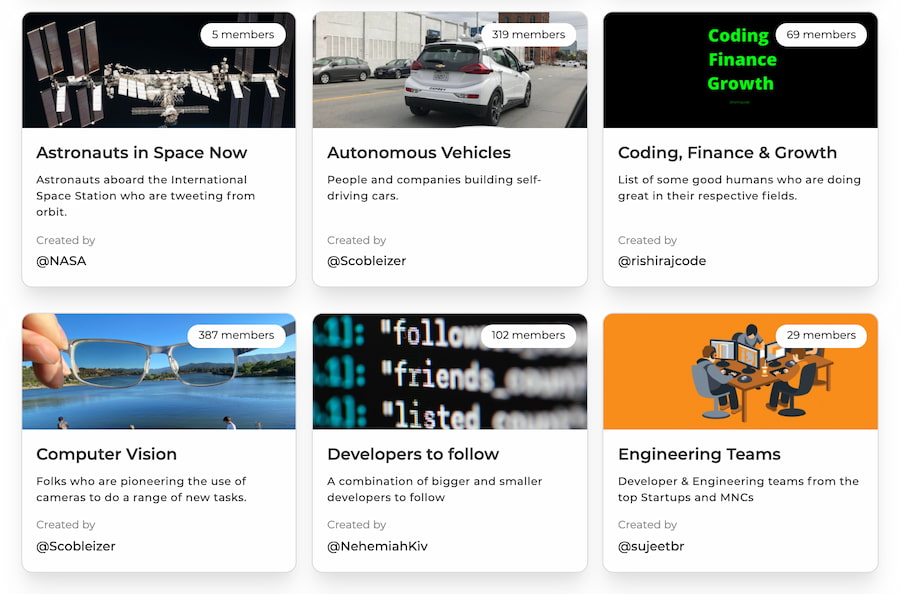
Por si te aburres de seguir siempre a las mismas cuentas de Twitter o quieres descubrir otras nuevas e interesantes más allá de las absurdas sugerencias de la propia app, Listr es una buena opción. Es una una sencilla lista de...

Este Generador de botones de Marko Denic es de esas páginas para guardar porque hace solo una cosa y la hace bien: generar código CSS para botones de páginas HTML. Más rápido y fácil, imposible. Todo lo que hay que hacer...

Mientras los seres normales y corrientes nos preguntamos ¿Por qué el cielo es azul? en el blog de Mozilla se han preguntado ¿Por qué los hiperenlaces son azules? Y la investigación de arqueología digital recorriendo los orígenes de la World Wide...

Сейчас группировка спутников #OneWeb на низкой околоземной орбите насчитывает 254 космических аппарата, планируется запуск сотен других. Сегодняшний запуск должен довести количество спутников OneWeb на орбите до 288 единиц.Но пока давайте посмотрим повтор пускаpic.twitter.com/2vdmUO7ygx— РОСКОСМОС (@roscosmos) August 21, 2021 La empresa angloindia OneWeb...

La gente de Archive.org recuperó el divertido contenido una antiquísima página llamada SewingAndEmbroideryWarehouse.com que ya no existe, aunque puede consultarse la versión guardada de 2014. ¿Notas algo peculiar a medida que avanzas en la página? Resulta que quién creó la página...
Este año el Archivo de Internet está celebrando su 25º aniversario, pues comenzó su andadura allá por 1996, al poco de crearse la World Wide Web. Desde entonces, tacita a tacita, ha guardado 70 petabytes de datos y más de 65...
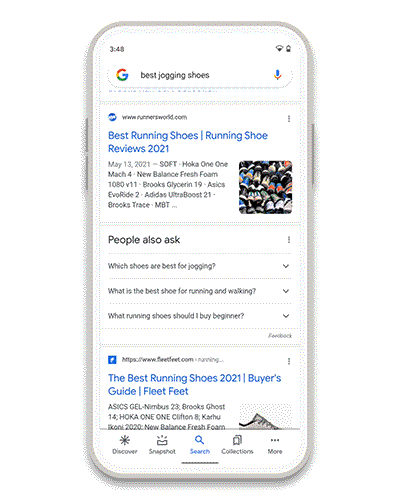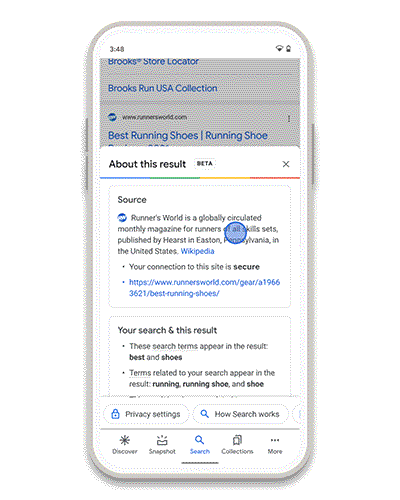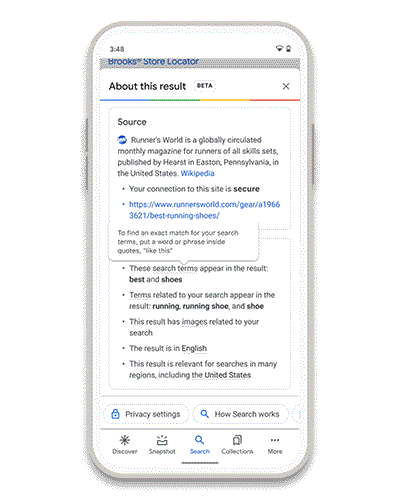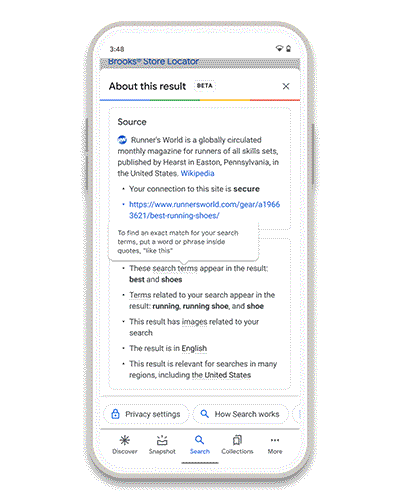
Una de las cuestiones que más inquieta a la gente acerca de los algoritmos, especialmente los que profundizan en la inteligencia artificial, es que las máquinas sean capaces de explicar sus decisiones. Esto será muy importante en el futuro, pero entender...
Muchas de las grandes empresas de Internet tienen una página –generalmente poco visible y nada fácil de encontrar– en la que te ofrecen como opción para gestionar tu privacidad solicitar una copia completa de los datos que tienen de ti. Hoy...

En este vídeo informativo Google explica cómo consigue que el algoritmo que proporciona los resultados de las búsquedas reaccione cuando se produce algún evento en momentos críticos, generalmente porque hay una emergencia o suceso grave o llamativo del que todo el...

Ha trascendido que dentro de los acuerdos que tienen las grandes compañías unas con otras Apple estaría almacenando a día de hoy más de 8 millones de terabytes (8 exabytes) en los servidores de Google, además de otras ingentes cantidades de información...

La antena de un terminal Starlink sobre el techo de una casa – Starlink La Subsecretaría de Telecomunicaciones (SubTel) del Ministerio de Transportes y Telecomunicaciones de Chile acaba de hacer público que el país será el primero de Latinoamérica en el que...

В честь пятого запуска «пять до 50» и доставки всех спутников в срок на головном обтекателе было размещено приветственное сообщение «Привет, Северный полюс», которое символизировало значительный прогресс компании #OneWeb в процессе покрытия территории Арктики pic.twitter.com/WFriyPYh5V— РОСКОСМОС (@roscosmos) July 1, 2021 Un cohete...

Seguro que esto es más viejo que una máquina de Turing a pedales, pero un tuit de Ramón –que siempre anda compartiendo enlaces interesantes– me lo recordó, y aunque hacía siglos que no pasaba por allí, bien merece la pena revisitarlo....

El software criptográfico PGP cumple hoy 30 años. La versión 1.0 se lanzó a las redes en 1991, una época en la que el software circulaba principalmente por listas de correo, las BBS (boletines electrónicos) y los servidores de FTP que servían...

Resultado de la votación en el Parlamento Europeo en la que se aprobó la DEMUD - vía Julia Reda No a la #LeyUribes. Contra la censura privada aprobada mediante real decreto ley, sin transparencia y sin debate previo. Movilización general, como en...

Suelo seguir con interés el informe sobra la Sociedad Digital en España. Esperaba el de 2020-2021 con especial interés por todo lo que trajo la pandemia de digitalización forzada y a marchas forzadas en muchos campos. Ya está disponible como Sociedad...
Пусковой день на космодроме #Восточный — 28 мая 2021 года.И ваши самые любимые ракурсы — всё в этом видео pic.twitter.com/MKcOivDzyJ— РОСКОСМОС (@roscosmos) May 28, 2021 Un cohete Soyuz-2.1b lanzó esta pasada noche un nuevo lote de 36 satélites de acceso a Internet...
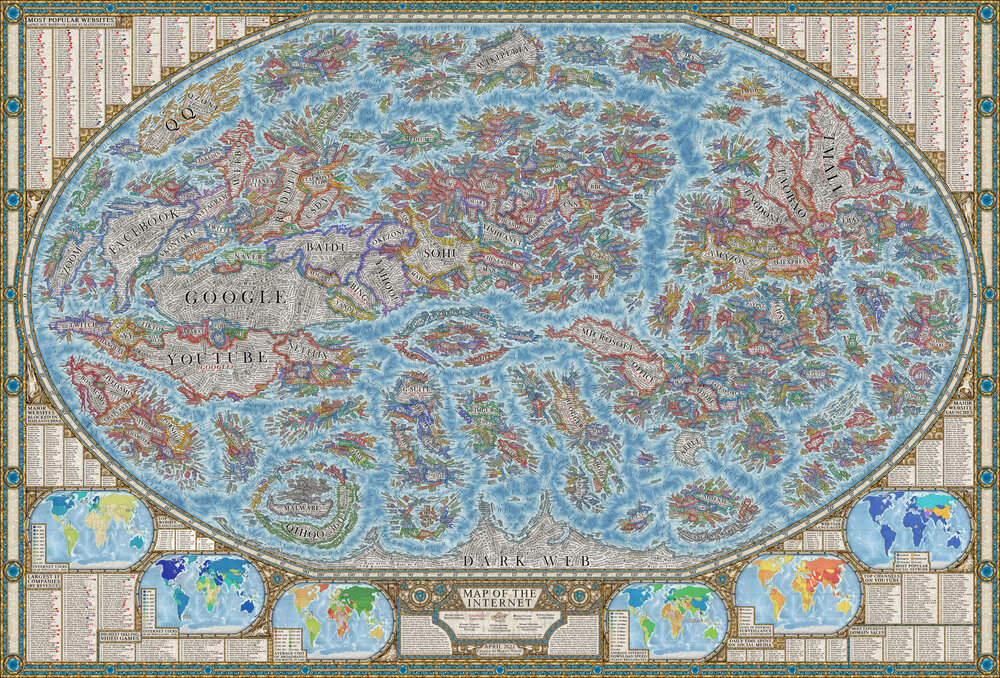
Este colorido mapa creado por Martin Vargic de Halcyon Maps es nueva versión de una de sus más grandes creaciones, el Mapa de Internet 2021 [aquí en alta resolución 9500 × 6500, 20 MB]. Dice que le ha tenido «entretenido» buena...
Hace casi una década que comentamos por aquí que «parecía buena idea que la Wikipedia se pudiera descargar en 10 GB», algo que la gente de proyecto Kiwix ha ampliado con habilidad en este tiempo a otros proyectos. De modo que...

Este cortometraje titulado The End es una gigantesca, estilosa y cuidada recopilación de imágenes de cine en formato cinemagraph, que vienen ser algo así como «GIF animados supervitaminados», tratados con esmero para limpiarlos de todo lo superfluo y concentrar la acción...
Hace unos días descubrí TinEye gracias a un hilo de Juan Carlos Muñoz. Se trata de una herramienta que te puede ayudar a dar con la autoría de cualquier imagen que veas por Internet y así poder dar los créditos pertinentes...
Can’t Unsee es un curioso examen de diseño con preguntas de tipo test en las que hay que elegir el diseño «más correcto». ¿Cómo? ¿Lo «más correcto»? ¿No se supone que la objetividad está obsoleta y que el hecho de que...
En BTW tienen una buena selección de landing pages (el término «páginas de aterrizaje» nunca cuajó), básicamente para echarles un vistazo e «inspirarse» cuando haya que crear una página web nueva de este estilo para un lanzamiento de algún nuevo producto,...

URL largas – Tus citas quedarán impresionadas por el tamaño de tus URLs. Y podrás olvidarte de dedicar tiempo a deletreárselas a la gente del trabajo: simplemente puedes gritar las URLs a pleno pulmón. Para quienes estén hartos de acortadores de direcciones...

Como seguramente ya sabéis quienes nos leéis, nuestro humilde blog surgió como un entretenimiento allá por 2003 para hablar sobre todo lo que nos encontrábamos por ahí al navegar por Internet: asuntos de ciencia y tecnología, gadgets, historia de la informática,...
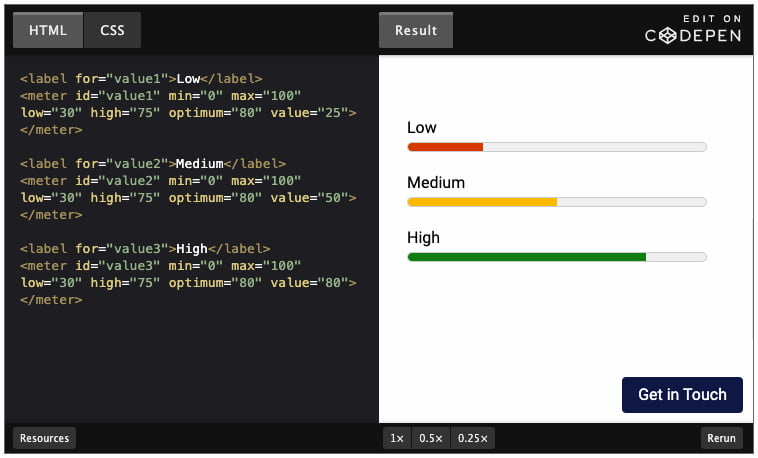
Algunos conocidos y otros no tanto, en HTML Tips Marko Denic explica unos trucos de HTML bastante interesantes. Y es que sucede que a menos que estés continuamente poniéndote al día sobre las incorporaciones al llamado lenguaje de la Web puede...

La Mona Lisa – Leonardo da Vinci He visto pasar esto y me parece buenísimo. Es la explicación un tanto delirante pero bastante correcta que le da QueerSamus a Jacobgalapagos de lo que es un NFT usando a la Mona Lisa como...

Es sabido que Bitcoin nació el 3 de enero de 2009 y que su creador fue alguien con pseudónimo de Satoshi Nakamoto, del que poco se sabe. También es un hecho cierto que el 26 de abril de 2011 Satoshi envió...

Un nuevo lanzamiento desde el cosmódromo de Vostochny ha puesto en órbita el sexto lote de satélites de la constelación que OneWeb está construyendo para dar acceso a Internet en cualquier lugar del mundo. De nuevo llevó a cabo el lanzamiento...

Ecosia es un buscador en el que las búsquedas se convierten en árboles plantados. Se autodefine como una web «más que neutra en CO₂» porque sus servidores utilizan «energía 200% renovable» es decir, que compensan toda la que consumen y otro...

Impresión artística de un lanzamiento de satélites Kuiper en un Atlas V – Amazon/ULA Además de SpaceX con su constelación Starlink y de la de OneWeb hay otro gran proyecto en marcha para llevar Internet a todas partes del mundo desde el...
Me encontré con el European Web Archive (Archivo Web Europeo) que aunque tiene pinta de ser algo «oficial» por el uso del look de la Unión Europea, banderita y color azul Pantone Reflex Blue típicos, es una iniciativa privada. Es una...

Llevo un tiempo siguiendo con curiosidad el asunto de los NFT. Pero desde la subasta por el equivalente a unos 65 millones de euros de Todos los días: los primeros 5.000 días de Beeple lo sigo más bien con una mezcla...

El nombre de Common Crawl es a la vez un proyecto y una organización sin ánimo de lucro que desde 2011 se dedica a rastrear la World Wide Web y generar un archivo abierto y accesible para que cualquier persona o...
Bruab Schrader publicó en su blog un curioso truco de baja tecnología que me pareció especialmente interesante por lo anti-intuitivo que resulta. Lo ha titulado simplemente Why All My Servers Have an 8GB Empty File y sirve para evitar uno de los...
Despegue del cohete – OneWeb Un cohete Soyuz-2.1b ha puesto en órbita un lote de satélites de OneWeb despegando desde el cosmódromo de Vostochny en la mañana del 25 de marzo de 2021. Con esto la empresa tiene ya 146 satélites en...
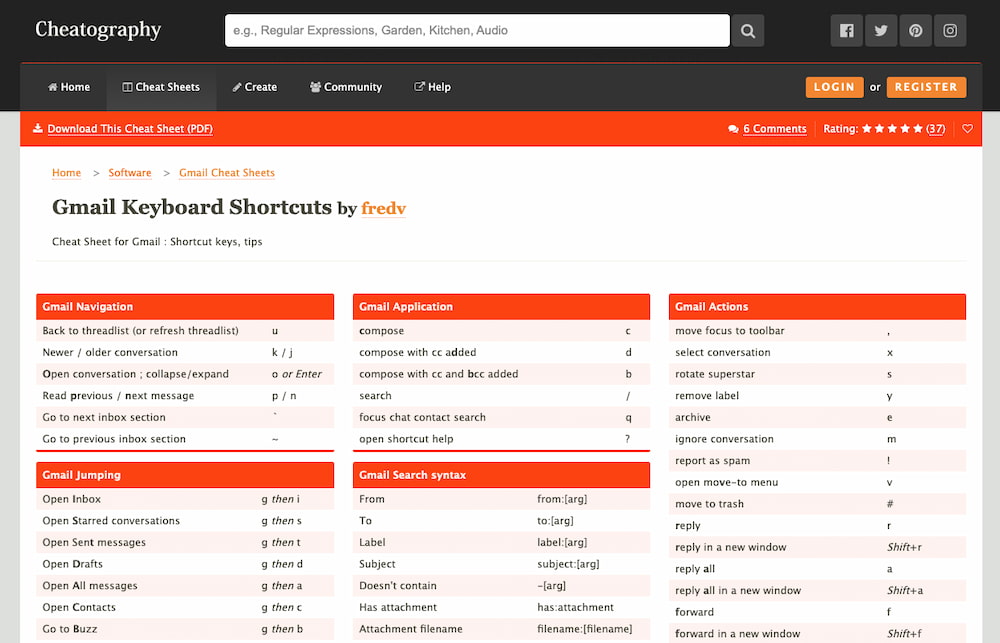
Bajo el lema «una chuleta para cada ocasión» Cheatography.com ofrece una gigantesca colección de prácticas «chuletas» –llámense apuntes, notas, resúmenes o atajos– que abarcan todo tipo de áreas del conocimiento. Estas son las categorías principales de las que cuelgan decenas y...
HowLongToRead.com es una curiosa web/calculadora que a partir del tamaño de un libro te dice cuánto se tarda en leerlo. El cálculo parte de una velocidad promedio de 300 palabras por minuto porque la gente suele leer entre 200 y 300...
Fastboard.io es una pequeña aplicación online que hace una sola cosa y la hace bastante rápido y bien. Es un espacio virtual a modo de pizarra, donde pueden dibujar y escribir varias personas de forma colaborativa en tiempo real, por ejemplo...

Ya se ha lanzado en pruebas beta el Internet Archive Scholar (Archivo de Internet Académico) gracias a los esfuerzos del equipazo multidisciplinar de Archive.org y diversas organizaciones y entidades que trabajan en el acceso abierto. Está disponible en varios idiomas, incluyendo...
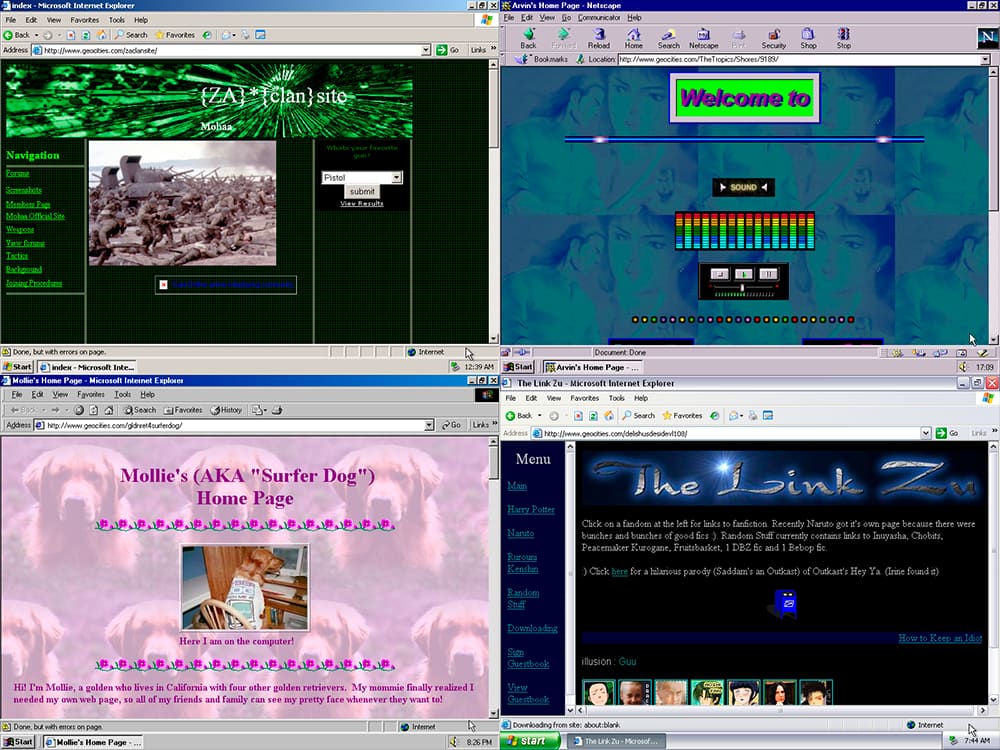
GeoCities era un sitio web surgido en 1994 en el que gente creaba y alojaba sus páginas personales. Como aquello de la World Wide Web era relativamente nuevo, lo divertido es que nadie tenía mucha idea de qué hacer o cómo...

Según ha calculado Kilian Arjona, el 90% de las emisiones de Twitch en español las ven tres personas o menos de promedio. Si la emisión tiene éxito, recibir las visitas de seis o más personas a lo largo del mes sitúa...

La colección de Iconos en Google Fonts incluye miles de iconos en cinco estilos distintos, todos ellos siguiendo las líneas de estilo Material Design de Google. Así que, ante la duda de ser más creativo y original o ir a lo...
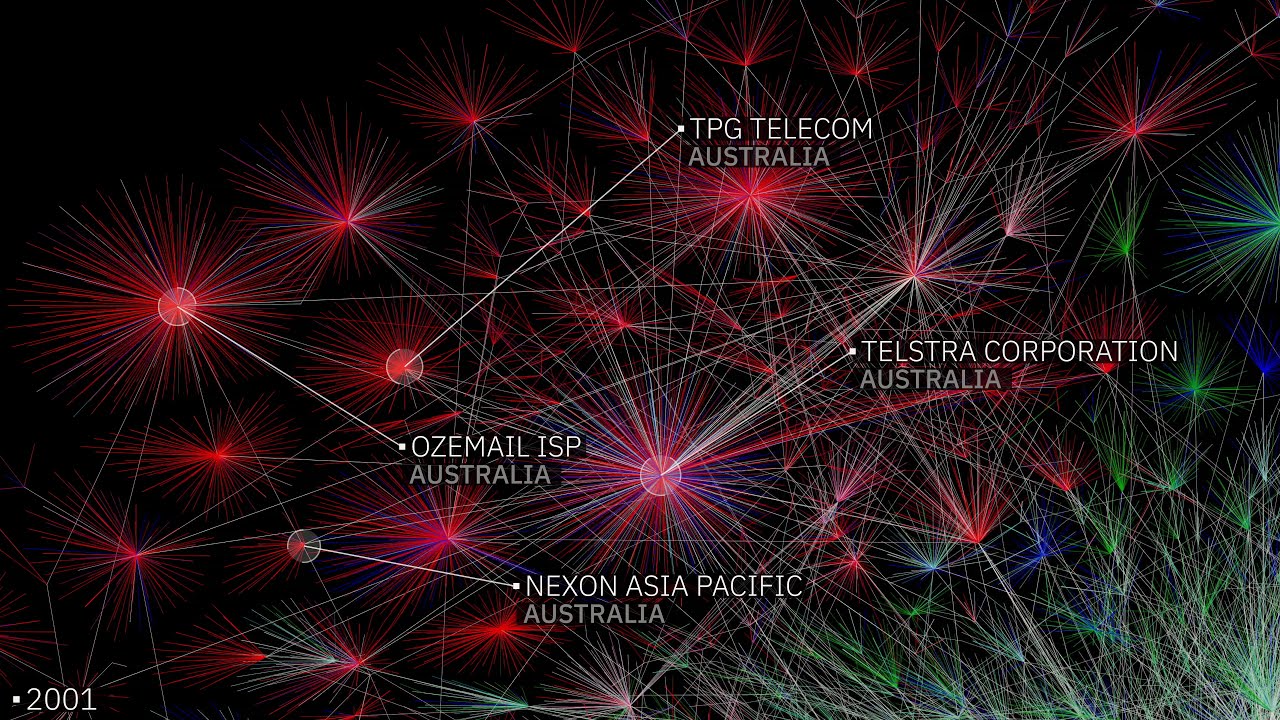
La gente del Proyecto OPTE lleva más de 17 años mapeando Internet y «dibujando líneas entre las conexiones de unos sitios y otros» como suelen decir. El resultado es una preciosa infografía animada de formas fractales en la que el paso...
@Karlicoss está llevando a cabo un interesante ejercicio que puede resultar en principio un tanto extraño, pero que tiene mucho sentido: trazar un mapa de su infraestructura de datos personales. Y es que hay gente peculiar a la que le gusta...
Nos avisaron por Twitter de que están empezando a llegar correos anunciando la disponibilidad en pruebas beta de kits y conexiones de Starlink para algunas zonas de España: 99 euros al mes + 499 euros del Kit, en una simple conversión...

En el segundo semestre de 2020 TikTok eliminó 9.499.881 cuentas de su servicio por incumplir las normas.

Clubpad es una de esas aplicaciones ingeniosillas para tener a mano y usar de forma comedida. Son básicament unos pocos efectos de sonido «de reacción» sumamente breves: risas, aplausos, jolgorio… Si estás en una sala de Clubhouse –el party-line de moda–...

IMissMyBar.com es una página web que recrea los sonidos y atmósfera de un bar, al mismo tiempo que permite escuchar listas de «música de locales» procedentes de Spotify. Básicamente son sonidos que te hacen compañía. En la página sólo se pueden...
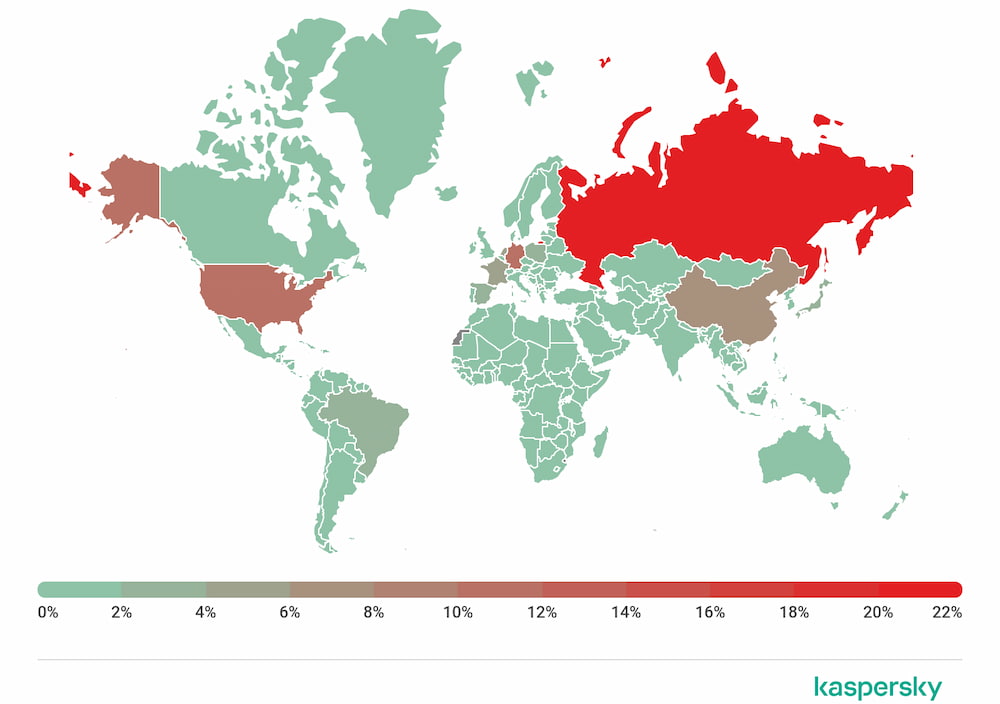
Los países que más spam enviaron en 2020 / Fuente: Kaspersky En SecureList de Kaspersky han publicado el informe anual sobre spam y phishing en 2020. Allí se puede ver a grandes rasgos el estado del spam a nivel mundial según captan...

Supercookie.me es un ingenioso método demostrado por Jonas Strehle (un programador de 20 años) para identificar el navegador que visita una web mediante una especie de «huella digital» imborrable. Lo hace utilizando algo tan aparentemente inofensivo como es el icono Favicon...
TextGradients.com hace una sola cosa y bastante bien: generar el código CSS de un degradado de color para un texto, como puede ser un titular o un destacado. No es que sea yo muy amante de los degradados –que probablemente son...

Según cuentan en Axios, Google está probando una tecnología que ya ha mostrado «señales prometedoras» de que podría servir para reemplazar a las cookies. Suena bien porque acabaría con los avisos de cookies y podría resolver algunas cuestiones relacionadas con la...
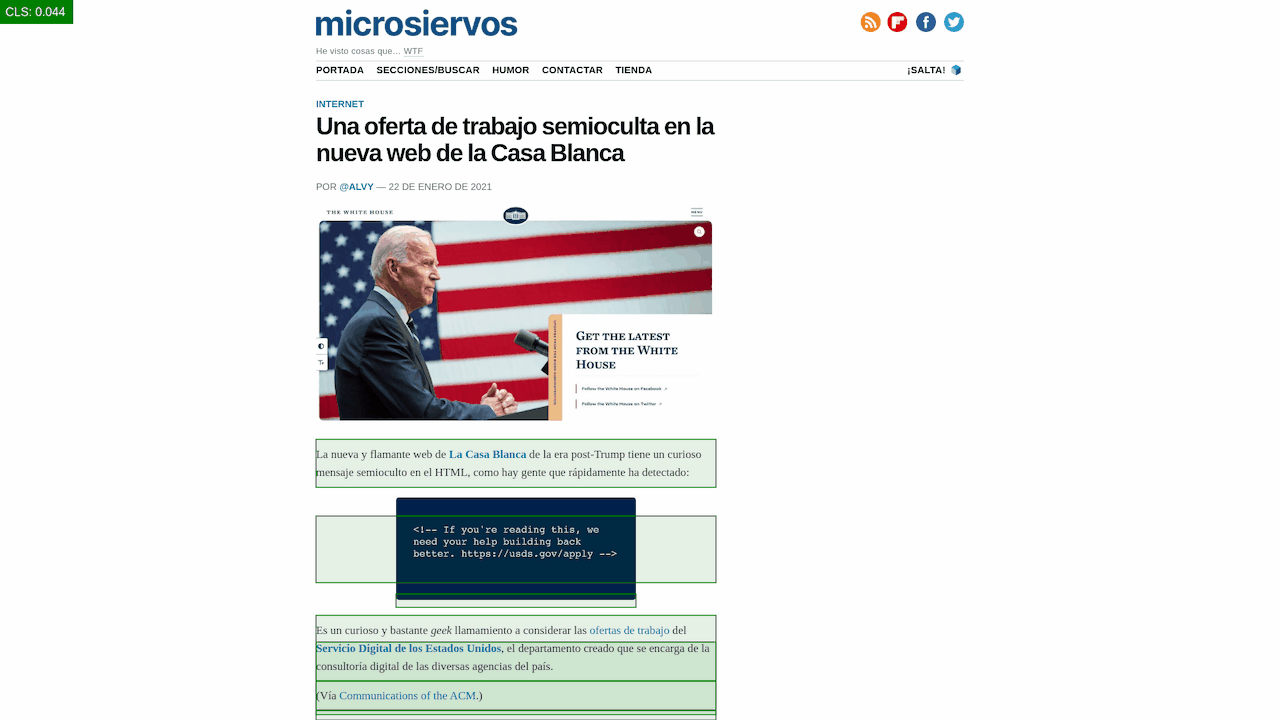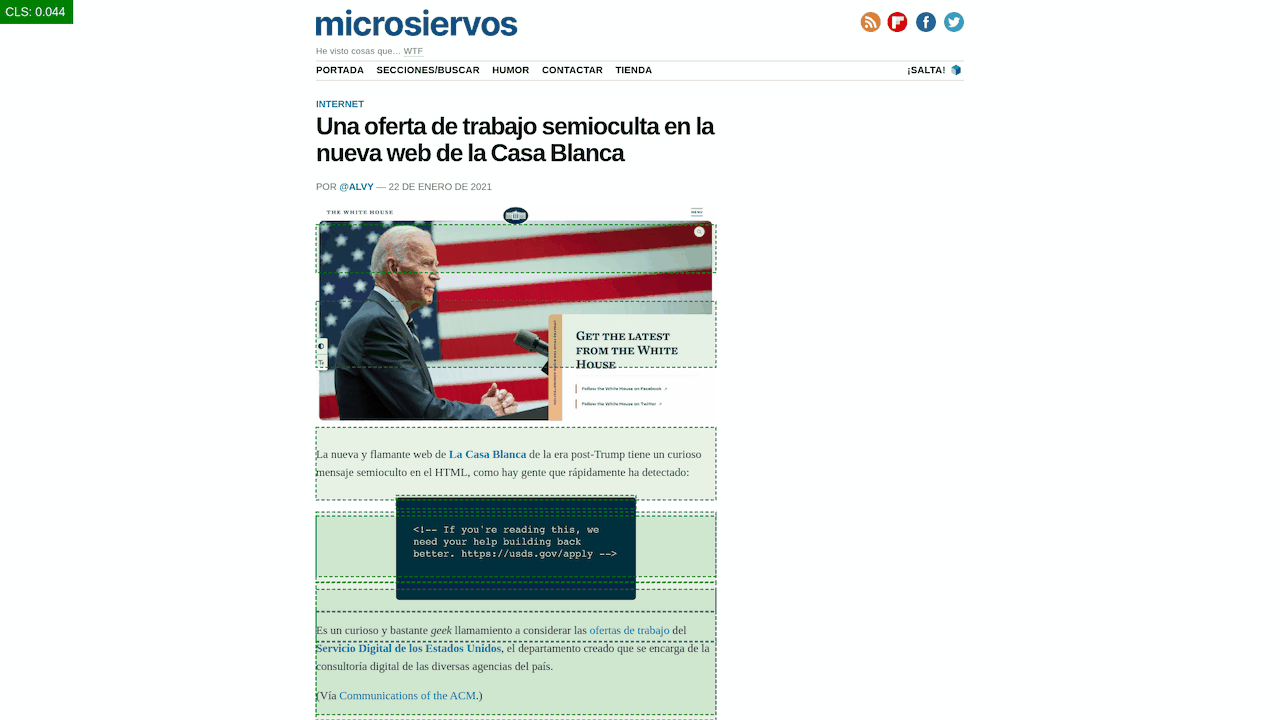
Con esta utilidad de Defaced llamada Layout Shift GIF Generator se puede generar un GIF animado que muestra cómo se cargan las páginas web tanto en dispositivos móviles (mobile) como en ordenadores(desktop). Tan sólo hay que teclear la URL completa, prefijo...

La nueva y flamante web de La Casa Blanca de la era post-Trump tiene un curioso mensaje semioculto en el HTML, como hay gente que rápidamente ha detectado: Es un curioso y bastante geek llamamiento a considerar las ofertas de trabajo...
El equipo de Prodigioso Volcán ha abierto en pruebas Clara. Se trata de un analizador de la claridad de textos en español que emplea técnicas para ayudar a escribir claro. También es un experimento en inteligencia artificial. Los textos pueden tener...

La Wikipedia celebra hoy su vigésimo aniversario. Poco más hay que decir a estas alturas acerca del que es, sin duda alguna, uno de los pilares de Internet tal y como la conocemos. Y del MundoReal™, porque, cada vez más, Internet...
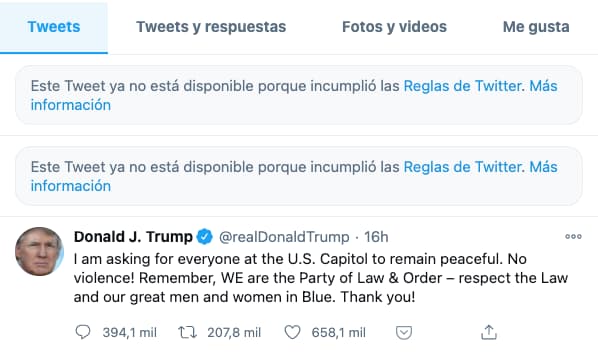
Que al mismísmo Presidente de los Estados Unidos le hayan restringido e incluso suspendido el uso de diversas cuentas redes sociales no es algo que se vea todos los días. Twitter, Facebook, Instagram, YouTube… Todo a raíz de que las usara...

Una de las cosas que se lleva 2020 pero que no echaremos de menos es Adobe Flash. A partir de hoy, 31 de diciembre de 2020, la empresa dejará de sacar actualizaciones para él y de distribuirlo. Aunque lo cierto es...
Existe una extensión de Chrome llamada Draftback creada por James Somers, un desarrollador que sintió curiosidad por el funcionamiento de Google Docs allá por 2014. Si se instala en el navegador al abrir cualquier documento de Google Docs aparece como un...
A cual más ingeniosa y original, las páginas que recopila 404pages.xyz son simplemente las tradicionales páginas de error 404 pero con una vuelta de tuerca – y cierto sentido del humor. Utilizando un botón para ir saltando al azar (o cambiando...
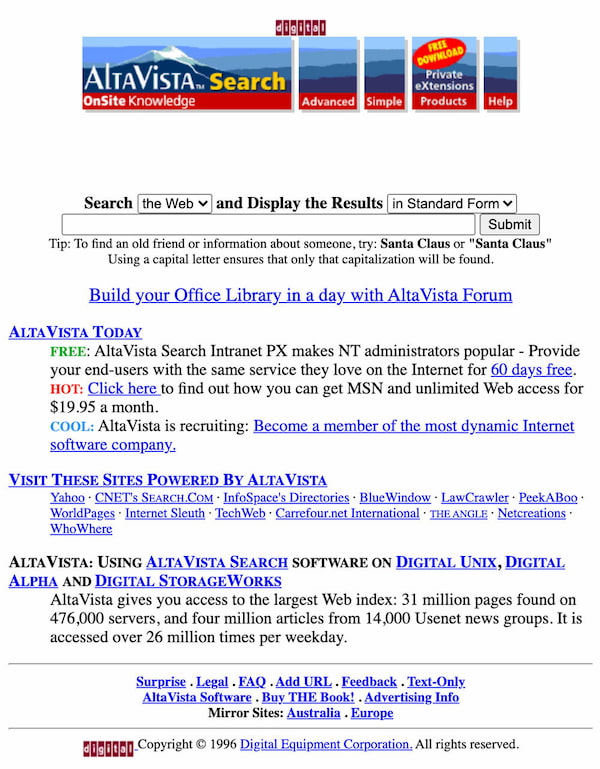
Estos días se cumplen 25 años de la entrada en funcionamiento de AltaVista, el primer y quizá más legendario motor de búsqueda de Internet… Lo que nos recuerda que no siempre existió Google para «encontrarlo todo». Ernie Smith ha publicado un...

Despegue de la misión – Roscosmos Algo más de ocho meses después de que la empresa se declarara en quiebra y cinco desde que el gobierno del Reino Unido junto con la operadora de telefonía Bharti Global se hicieran con su deuda...
El Mapa de la Red Telxius –la infrastructura de comunicaciones de la subsidiaria de Telefónica Infra– muestra por dónde circulan los datos de internet de la principal operadora de telecomunicaciones española. Y esto es sólo parte de la gigantesca red que...

El Archivo de Internet (Archive.org) que almacena copias de todo lo que se puede encontrar en la Red ha crecido notablemente durante 2020: de 40 a 65 millones de documentos (textos, imágenes, audio y vídeo).

La demanda de la FTC contra Facebook es
canela fina: La FTC alega que la empresa mantiene ilegalmente un monopolio de redes sociales a través de una conducta anticompetitiva.
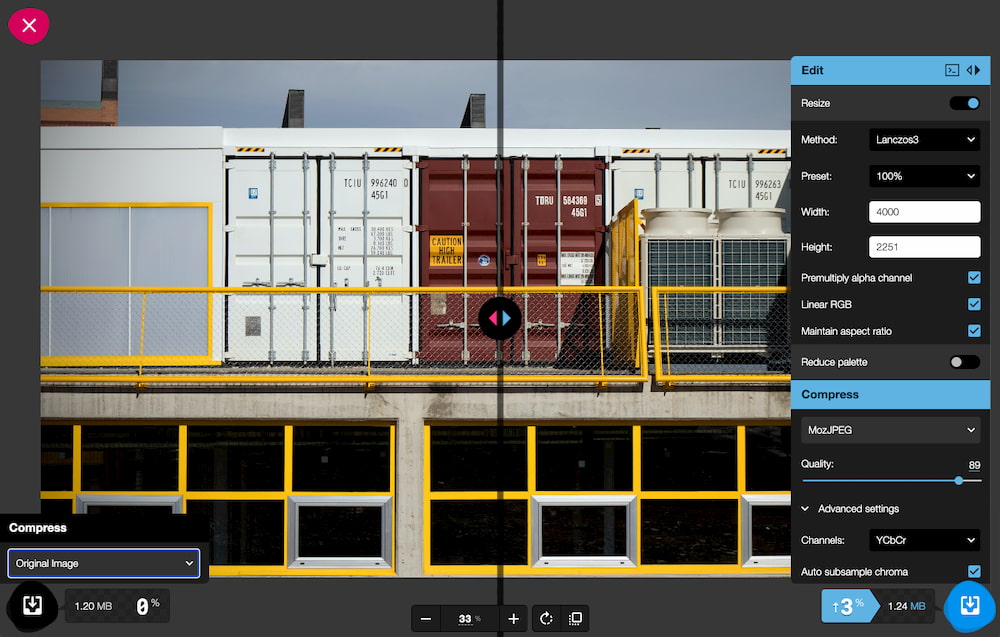
Google ha anunciado una renovación de Squoosh v2, su utilidad web «experimental» para convertir y comprimir imágenes de todo tipo desde el navegador. Desde que la descubrí hace ahora un par de años ha sido mi primera opción para reducir las...
Que en las redes sociales hay mucha mala leche y no menos troles y fake news circulando no es ninguna novedad. En algunos sitios eso se gestiona incluso de manera profesional e industrial, como hemos visto durante las campañas políticas. Ante...

3.357 ideas es una curiosa página similar a la típica lista de notas que tenemos muchas personas con ideas e inventos que estarían bien si existieran, y que se ofrecen para cualquiera que quiera usarlas. Aprovecho para recordar el importante pero...

En este vídeo que ha compartido Brett Batie se puede ver cómo es uno de los equipos de recepción de Starlink (antena + piezas de instalación + router + app) que permitirá conectarse a la red de satélites de la compañía...
En este vídeo Jessie Carabajal utiliza un analizador de espectro llamado Ekahau Sidekick conectado a su portátil para ver qué sucede con la velocidad del wifi casero al poner en marchas el microondas. Se puede ver el efecto en las transmisiones...
QueCovid.es es una remezcla de esas que deberían llevar tiempo inventados «oficialmente», pero que existe gracias a la iniciativa particular de unos estudiantes universitarios que han decidido montarlo y mantenerlo con sus limitados recursos. Básicamente muestra qué restricciones hay en cada...

Esta máquina es un servidor. ¡NO APAGAR! Dana ha reproducido la imagen de la pegatina que Tim Berners-Lee pegó al NeXT Cube en el que inventó la World Wide Web allá por 1990. Con esto se intentaba garantizar que ninguna persona...
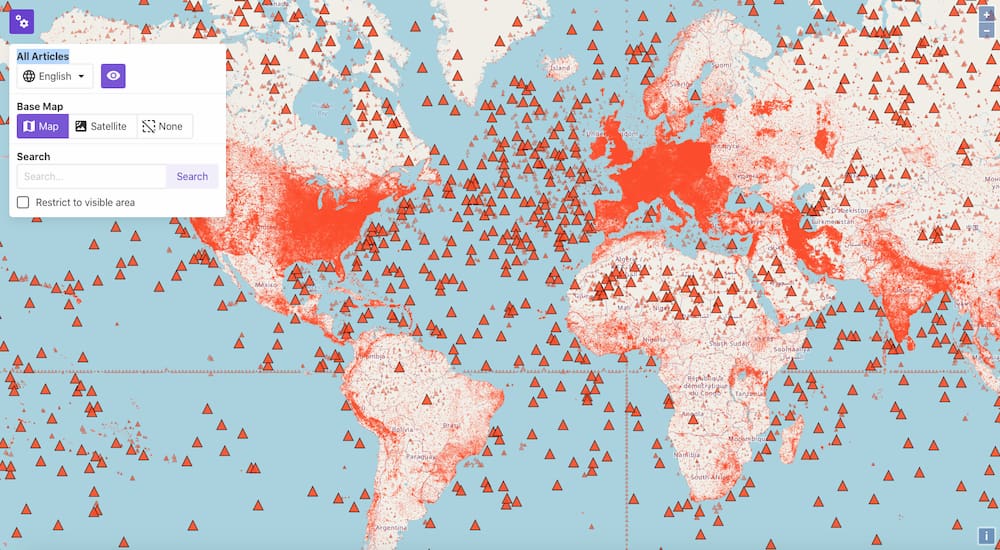
WikiMap es un proyecto de Louis Jencka que resulta sumamente curioso: muestra todos los puntos correspondientes a sitios geolocalizados en artículos de la Wikipedia + Wikidata. Es un mashup de datos de la propia Wikipedia con los mapas de OpenStreetMap. Los...

Se puede participar hasta el próximo domingo, 13 de diciembre: Navegantes en la Red:23ª encuesta a usuarios de Internet de la AIMC Es la tradicional encuesta de la Asociación para la Investigación de Medios de Comunicación (AIMC), también conocida como Navegantes en...
QR Menu Creator es un servicio de esos que hacen una sola cosa y la hacen fácil y bien: crear un menú de restaurante, una lista precios o similar y guardarla para que se puede acceder a ella con un código...

Este archivo inmenso, detallado y precioso sobre películas de cine y series de televisión que conocemos como IMDb, la sempiterna Internet Movie Database, nació tal y día como hoy hace 30 años. Su creador Col Needham arrancó el proyecto en el...
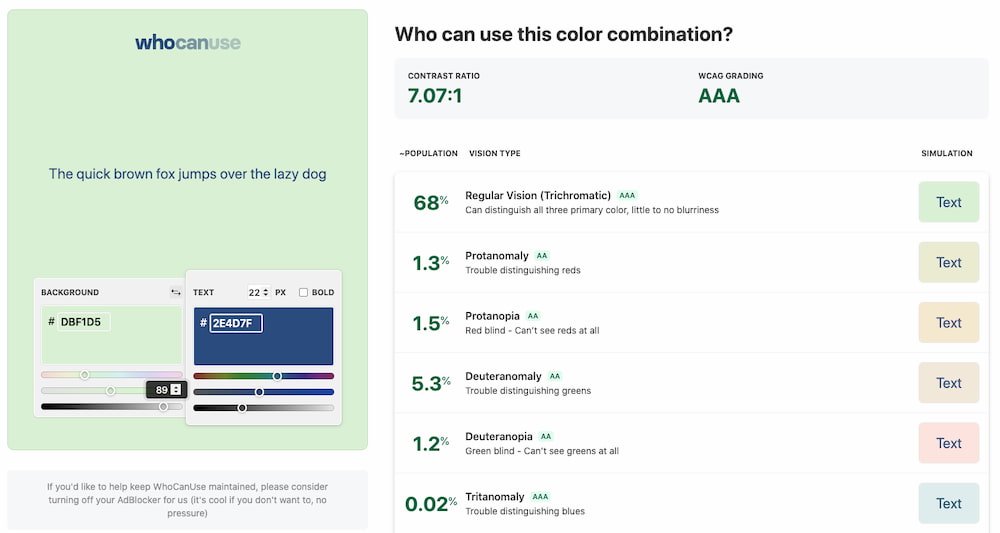
Who Can Use es una útil herramienta para comprobar si cierta combinación de colores en la web es visualmente accesible para todas las personas que puedan llegar a ella. Proporciona una calificación sobre lo adecuada que es una combinación o no...
Witeboard es uno de esos servicios que hacen una sola cosa y lo hacen bien: compartir una pizarra en blanco sobre la que varias personas pueden dibujar a la vez. Es un poco como Etherpad, CryptPad o Madpad pero con dibujos....
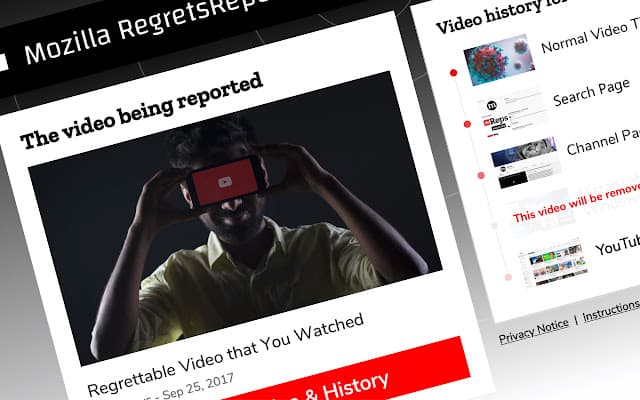
A través de un correo de la Fundación Mozilla me he enterado de la existencia de RegretsReporter. Es una extensión que sirve para denunciar y estudiar colectivamente vídeos falsos (fakes), conspiratorios, de odio, chungos, de actividades altamente peligrosas, etcétera a los...

Desde tiempos inmemoriales hackers y programadores han utilizado foo y bar como variables de ejemplo al escribir su código o hablar sobre él. Es lo que «técnicamente» llaman variables metasintácticas: algo para representar entidades desconocidas, sea eso lo que sea. Algo así...

El equipo del Internet Archive ha publicado algunas de las estadísticas de 2020 acerca de su labor como archivistas de la red. Una labor que por cierto va más allá de lo que está accesible en la World Wide Web y...
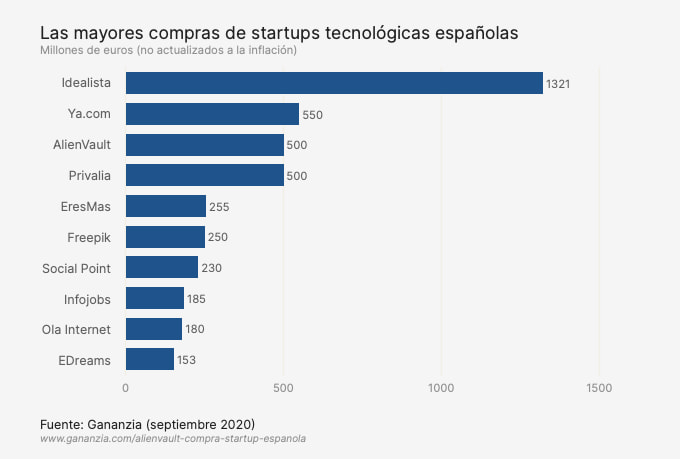
En Gananzia han actualizado su ránking de las mayores compras de startups españolas con la entrada de Idealista en el Top #1 tras la venta de la empresa al fondo sueco EQT Partners por 1.321 millones de euros. Esa cifra propia...

Hace unos meses Marcos abrió un hilo de Twitter explicando su sensación de que cada vez desaparecen más y más enlaces y contenido de URLs porque hay páginas que se cierran, cambian de dirección o simplemente se desvanecen. Si Ted Nelson...
El museo Winamp: nostalgia digital con skins que funcionan. Es como el tuning de coches, pero sin contaminar y más hortera.
WikiHist.html es un proyecto que básicamente consiste en una conversión de la Wikipedia de formato wikitexto (el lenguaje de marcado en el que se escribe) a HTML y a la vez conservando todas las revisiones del historial de cada artículo. Para...

Esta web llamada Signature Maker sirve para hacer una sola cosa: crear firmas de correo electrónico personalizadas. Por alguna extraña razón –que a mí se me escapa– esto suele ser considerado algo de lo más importante en la «imagen corporativa digital»...
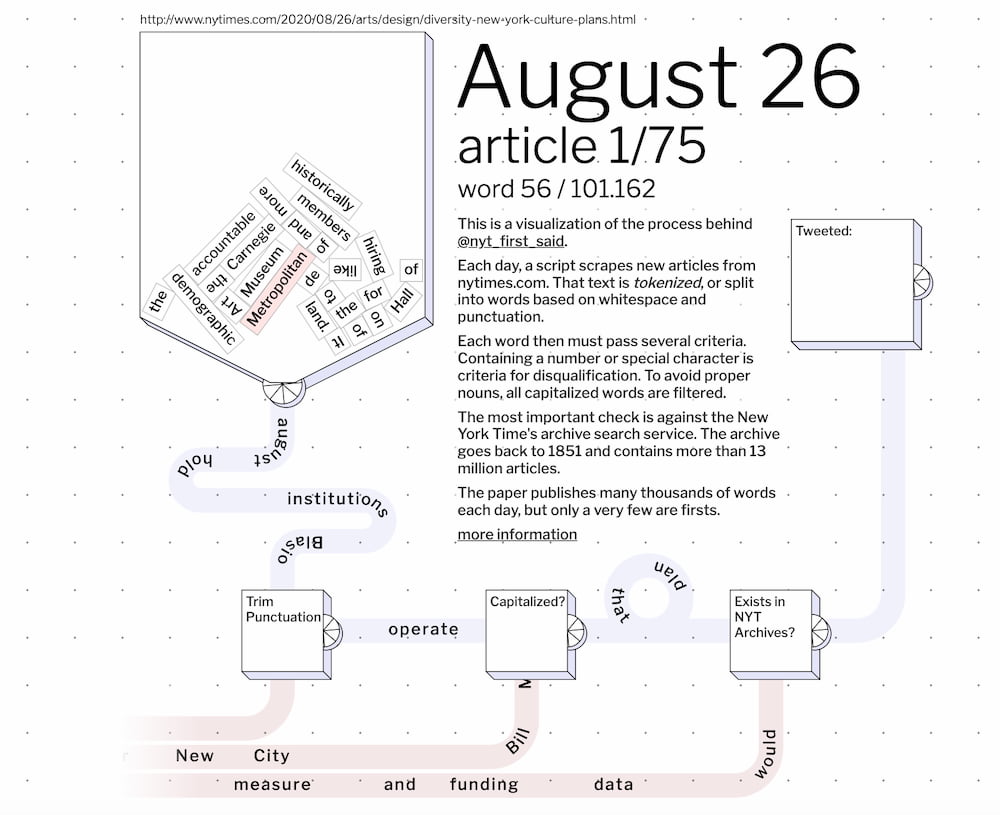
Bajo el nombre de New New York Times (NYT_first_said) existe una cuenta de Twitter que publica palabras que aparecen por primera vez en la historia en el diario The New York Times. Para ello las compara con los archivos históricos (13...

Bajo el nombre de Rainbow Hunt puede encontrarse lo que sus creadores denominan «el simulador de lluvia definitivo». Y es que, si hay simuladores de vuelo y de conducción, ¿por qué no de la naturaleza? Es la típica web relajante por...
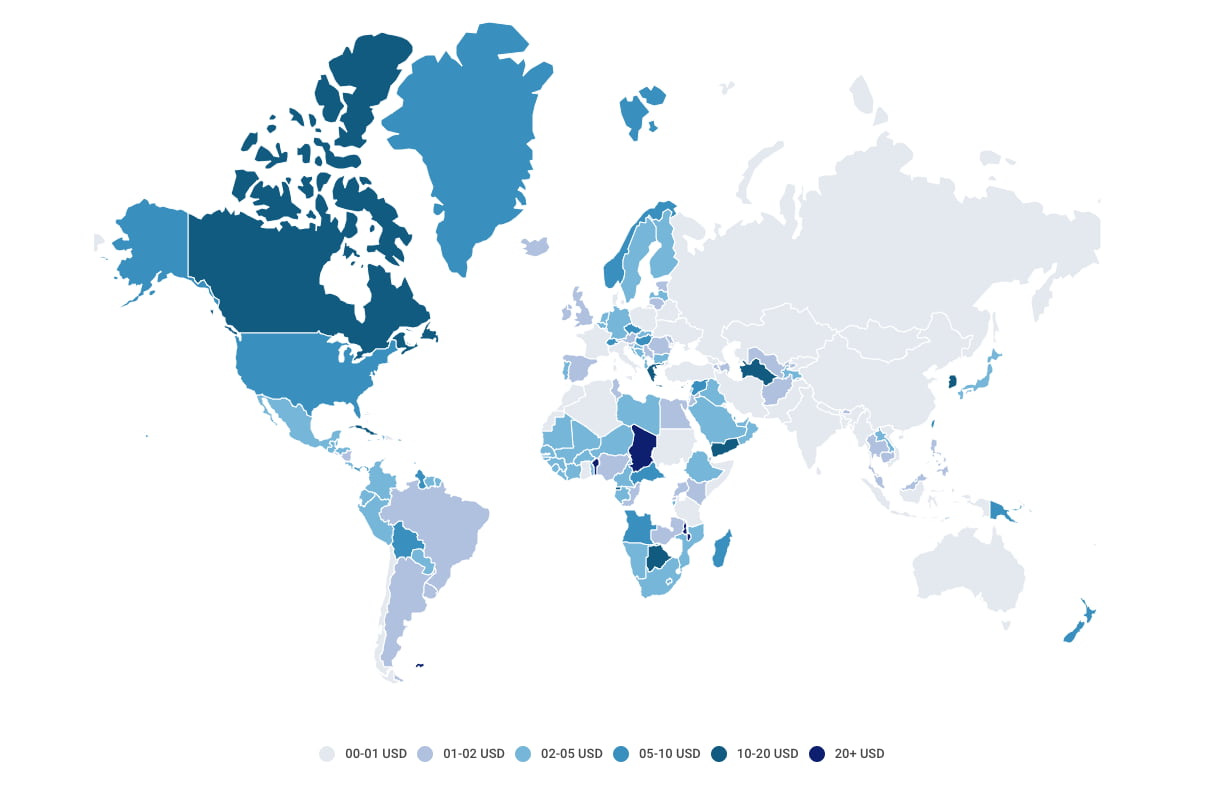
Esta infografía interactiva sobre el precio de un paquete de datos de 1 GB de la operadora Cable del Reino Unido se puede ver las diferencias de precio de la escencia de la conexión a Internet de unos países a otros....
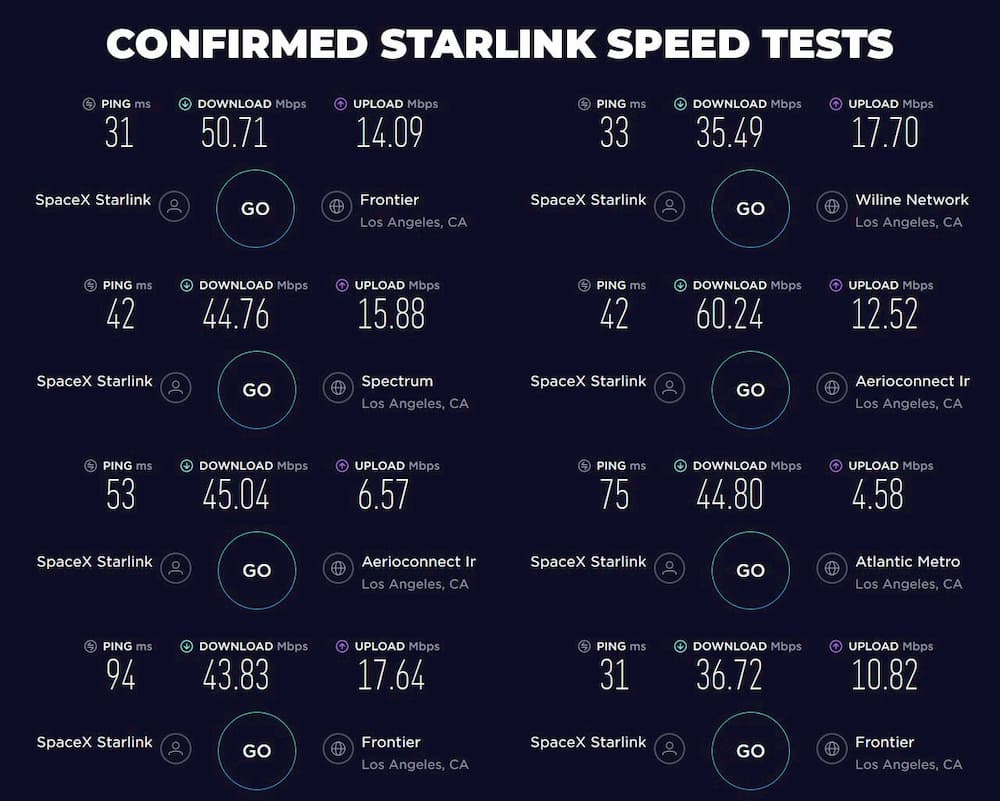
Impresión artística de satélites Starlink en órbita – SpaceX Desde hace unas semanas SpaceX ofrece la posibilidad de incorporarse como conejillo de indias a las pruebas de funcionamiento del acceso a Internet a través de sus constelación de satélites Starlink. Quienes se...

Una breve nota para informar de que la Fábrica Nacional de Moneda y Timbre (FNMT) lanza [al fin] una herramienta para solicitar el certificado digital desde cualquier navegador. Hasta ahora obtener ese certificado era un ejercicio en frustración para quienes no utilizaran...

Una Kravets, que trabaja en temas de CSS y desarrollo web en Google, ha grabado en vídeo para el canal de desarrolladores de Google Chrome las explicaciones que publicó hace unas semanas sobre 10 plantillas en CSS de una sola línea....

Imagen conceptual de una constelación de satélites - Ejército de los Estados Unidos La Comisión Federal de Comunicaciones (FCC) de los Estados Unidos acaba de aprobar la petición de Amazon de lanzar 3.236 satélites para acceso a Internet. Al estilo de las...
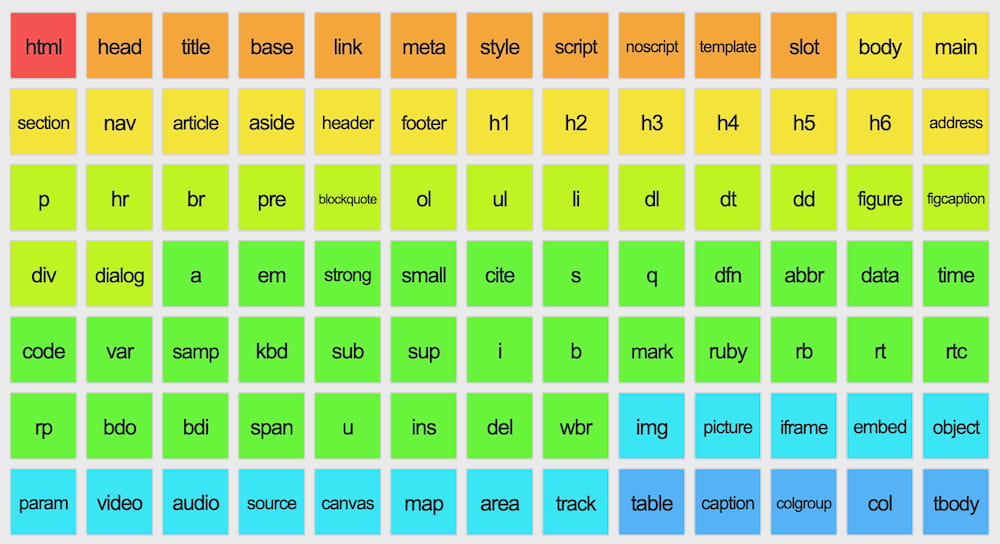
En un extraño crossover de esos que descolocan un poco he aquí AllTheTags.com: una especie de tabla periódica del HTML en el que cada elemento es una etiqueta del lenguaje de programación de páginas web. No es la primera ni la...

Con varias semanas de retraso SpaceX por fin ha podido llevar a cabo el décimo lanzamiento de satélites Starlink de serie. Aparte del número redondo este lanzamiento tiene la particularidad de que ha sido el primero en el que todos ellos...

He aquí una recreación de La joven de la perla, de Johannes Vermeer… … en CSS, obra de Louise Flanagan (@flangerhanger). Dice que ha necesitado unas 30 horas de trabajo (por amor al arte, claro), aprovechando su participación en el #100DaysOfCode....
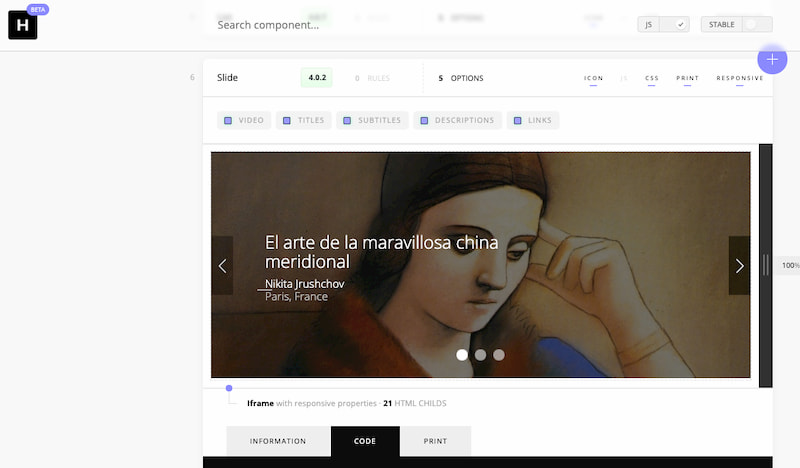
Salbatore nos escribió para contarnos que él y sus cinco hermanos –eso es devoción familiar por el código– han creado HTML.Systems que no es más que un repositorio de código HTML con componentes de interfaz de páginas HTML. En sus propias...

Seamos realistas. Estamos encerrados en casa.Y va a pasar tiempo hasta que podamos volver a viajar. Con WindowSwap puedes decorar cualquier pantalla de tu hogar al mismo tiempo que descubres mundo desde el confinamiento. O, más bien, descubres cómo se ve...
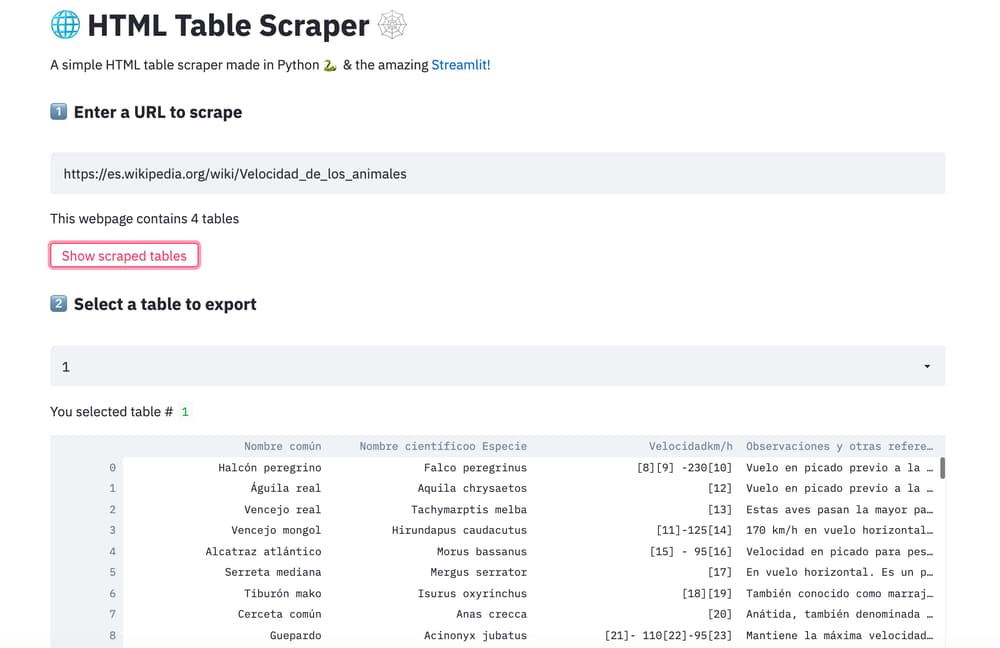
HTML Table Scraper es una aplicación de esas sencillas que hace una sola cosa y la hace bien: extraer datos de tablas de las páginas HTML y exportarlas como hojas de cálculo en formato CSV. Esto evita tener que hacer malabarismos...
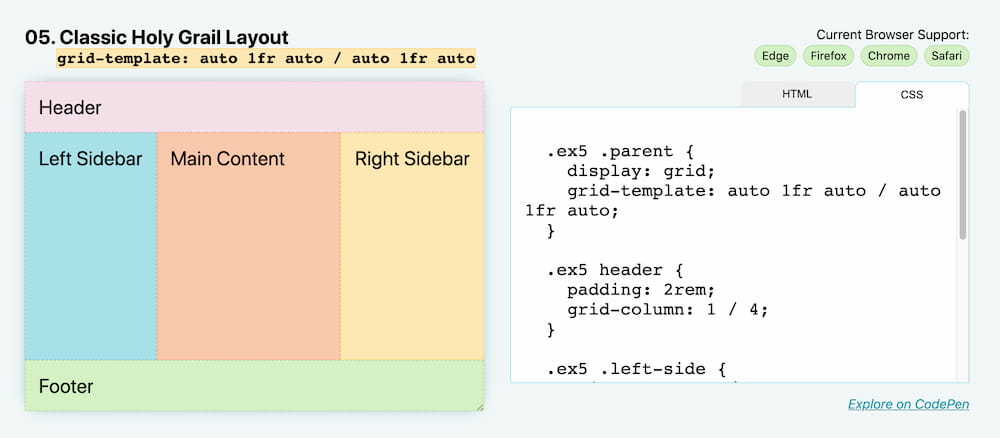
En 1-Line Layouts hay diez estupendas plantillas en CSS para conseguir mediante técnicas «modernas» (CSS Grid y flexbox entre principalmente) algunos de los efectos más clásicos de los diseños de páginas HTML+CSS con suma elegancia. Los ejemplos van desde el supercentrado...
Impresión artística de un satélite OneWeb en órbita - OneWeb Después de la quiebra de OneWeb, una de las empresas que están intentando crear una constelación de satélites para dar acceso a Internet, se ha producido ya la subasta de su deuda....

RSS Box es uno de esos sitios superútiles para quienes amamos los feeds RSS para seguir los contenidos que se publican en la web. Basta introducir el nombre de la cuenta de la que se quiere extraer la información y RSS...

Currando en digital – William Iven en Unsplash Acaba de ponerse en marcha en España la redacción de una carta de derechos digitales que se incorporará –si el impulso político para su creación dura lo suficiente– al Título X de la Ley...
Andaba buscando cómo hacer algo como esto cuando caí en que a alguien ya se le habría ocurrido antes y… efectivamente: Bookmark Shuffle es una extensión para Google Chrome que sirve para saltar con el navegador a un marcador al azar que...

Hace unos días que fue presentado el informe Sociedad Digital en España 2019 elaborado por la Fundación Telefónica. Es el informe antes conocido como La sociedad de la información en España que viene editándose desde 2012, así que ya tenemos unos...

El correo electrónico era algo mágico en los 90. Y entonces todo se fue a la mierda.– Rasmus Andersson HEY es una iniciativa de la gente de nuestro admirado Basecamp. Su portada es su manifiesto. Como mandan los cánones. Es un...
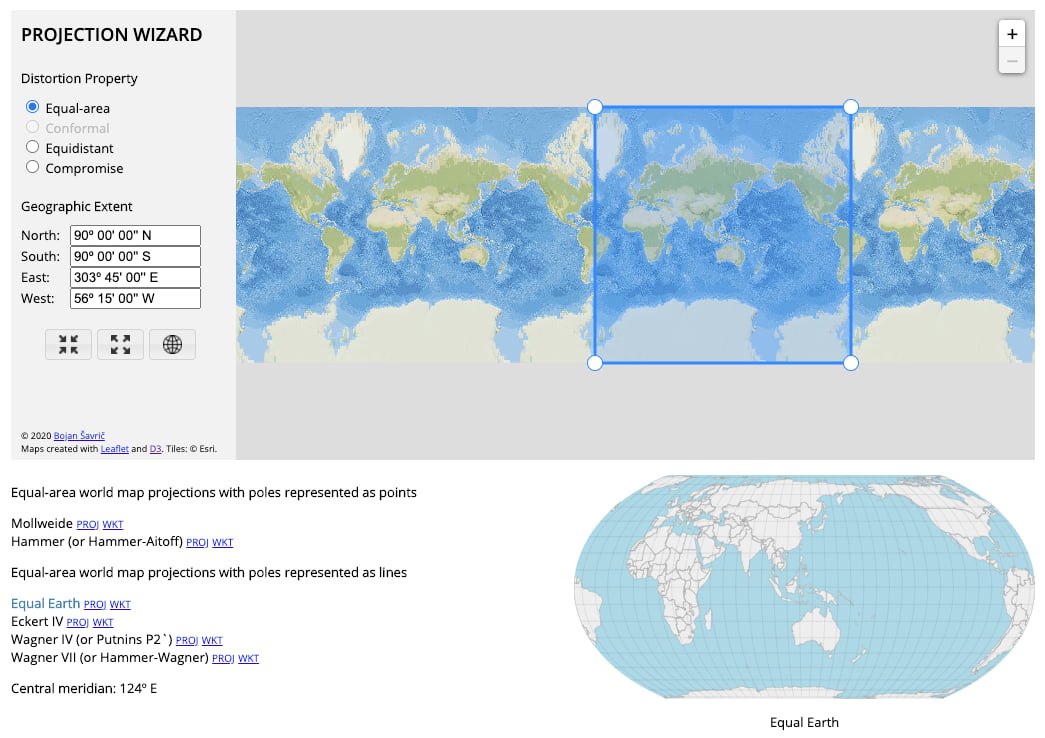
Projection Wizard intenta resolver algunos de los problemas de los mapas planos que matemáticamente nunca pueden representar la superficie de la esfera que es nuestro planeta. Lo mejor es que es un interactivo: basta mover y arrastrar los puntos sobre el...
En Smashing Magazine preguntaron a sus lectores qué extensiones utilizaban habitualmente en sus navegadores. El resultado fue una avalancha de más de 50, a cual más interesante. Lo único que se pedía es que no fueran «las típicas» sino más bien...
Este código CSS llamado new.css permite crear una web «moderna y adaptable (responsive)» en HTML con sólo incluirlo con un par de líneas en la cabecera de la página. Eso carga los 4,5 KB de código .css necesarios y ya está....
Con los nuevos tiempos llegan las «nuevas herramientas», como es el caso de Taskade, un «organizador del trabajo» con un aspecto bastante sencillo y directo concebido para teletrabajar en grupo. Muy apropiado para esta época de Zooms, Skypes y Hangouts Probarlo...

En los nuevos tiempos el teletrabajo es superior el trabajo de oficina: mucha gente puede hacer lo mismo con un portátil y un teléfono con la ventaja de no contagiarse de un virus potencialmente mortífero. Pero para quienes echan de menos...
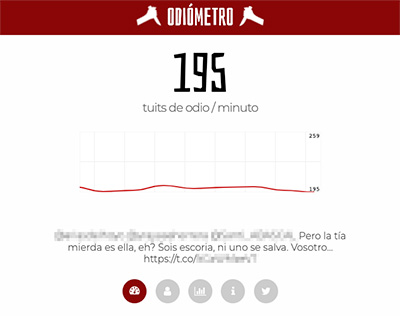
El espejo de nuestro odio. El Odiómetro es, como su propio nombre indica, un medidor del odio en Twitter. Una forma de cuantificar cuántos tuits de odio por minuto se emiten en la red social en castellano, buscando coincidencias con insultos,...

En Photocall.TV es tosco y directo, pero una de esas direcciones que es obligatorio guardar: las emisiones en directo de más de 1.000 canales de televisión nacionales e internacionales. Lo típico que necesitas cuando quieras ver algo concreto en cualquier canal...
This Meme Does Not Exist es una sección del sitio de memes Imgflip que genera memes mediante «inteligencia artificial». Es sabido que los memes pata negra se hacen «a mano», con el ingenio de quienes los crean con sus retorcidas y...

Successful deployment of 60 Starlink satellites confirmed pic.twitter.com/h3e6QmKRue— SpaceX (@SpaceX) April 22, 2020 Con el lote de 60 satélites Starlink puestos en órbita el 22 de abril de 2020 SpaceX ya ha lanzado 422 de éstos. La empresa aumenta así su ventaja...
Matt Reed decidió que tanta reunión por videoconferencia través de Zoom no era precisamente lo más productivo del mundo, de modo que decidió crear Zoombot, una especie de «gemelo digital» para hacerse pasar por él. El bot utiliza una especie de...

Ya hemos grabado otro podcast de Los Crononautas, «versión confinamiento». Está en la red en formato podcast como tercer episodio de la tercera temporada, a través de iVoox y también como descarga directa. Los Crononautas #S03E03: programa completo en iVoox [streaming] Los...
Los más jurásicos de Internet recordarán a YTMND como uno de esos sitios extremadamente frikis, rarunos y a la vez divertidos de principios de siglo XXI. Era una de esas comunidades de interneteros donde la gente creaba y compartía masivamente lo...
Ayer estuvimos grabando un episodio de Los Crononautas, versión confinamiento: cada cual en su casa y la videoconferencia Zoom en la de todos, para reírnos un poco y vernos los caretos. Ya está en la red en formato podcast como segundo episodio...
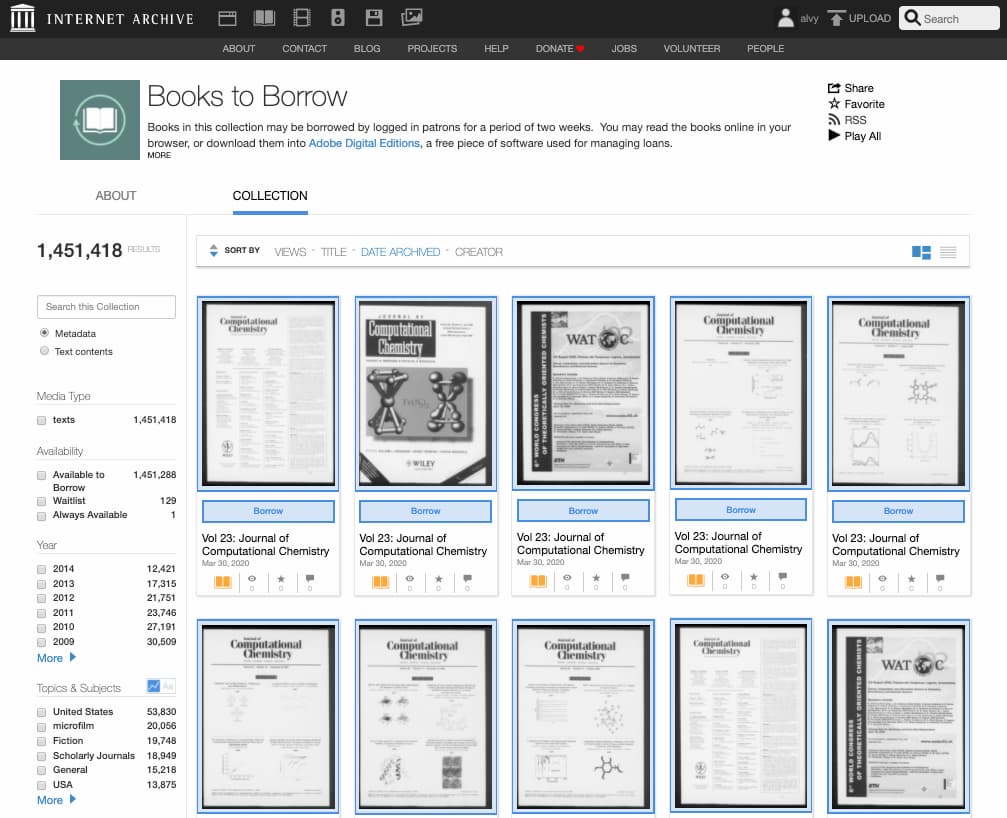
En la Biblioteca para préstamo de libros de The Internet Archive hay una gigantesca colección de libros escaneados que se pueden tomar prestados como si fuera una biblioteca física. En total hay 1.415.418 libros a día de hoy. Sí: 1,4 millones...
Impresión artística de un satélite OneWeb en órbita - OneWeb Tal y como adelantaba Bloomberg hace unos días OneWeb se ha declarado en bancarrota. Lo hace bajo el capítulo 11 de la Ley de Quiebras de los Estados Unidos, lo que quiere...

Despegue del cohete - Roscosmos Tras un lanzamiento sin problemas OneWeb ya ha establecido contacto con los 34 nuevos satélites puestos en órbita ayer. Fueron colocados en una órbita casi polar de 450 kilómetros de altitud. Usarán sus propulsores para subir a...

El cohete en la plataforma de lanzamiento - OneWeb Todo está listo en el Cosmódromo De Baikonur para que Arianespace lleve a cabo el lanzamiento del tercer lote de satélites de la constelación OneWeb de acceso a Internet. Está previsto para las...
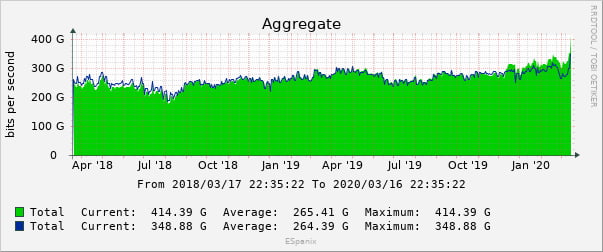
Al ver un tuit de Javier recordé que en stats.espanix.net se muestran las estadísticas del tráfico del punto neutro ESpanix de la internet española por el que se conectan todas las grandes telecos, proveedores de acceso y pequeños proveedores y organizaciones;...

La Smithsonian Institution, que se compone entre otras cosas de 19 museos, un zoológico y un complejo de investigación y educación acaba de lanzar la iniciativa Smithsonian Open Access. Se trata una plataforma donde están todos sus contenidos digitalizados, en en...
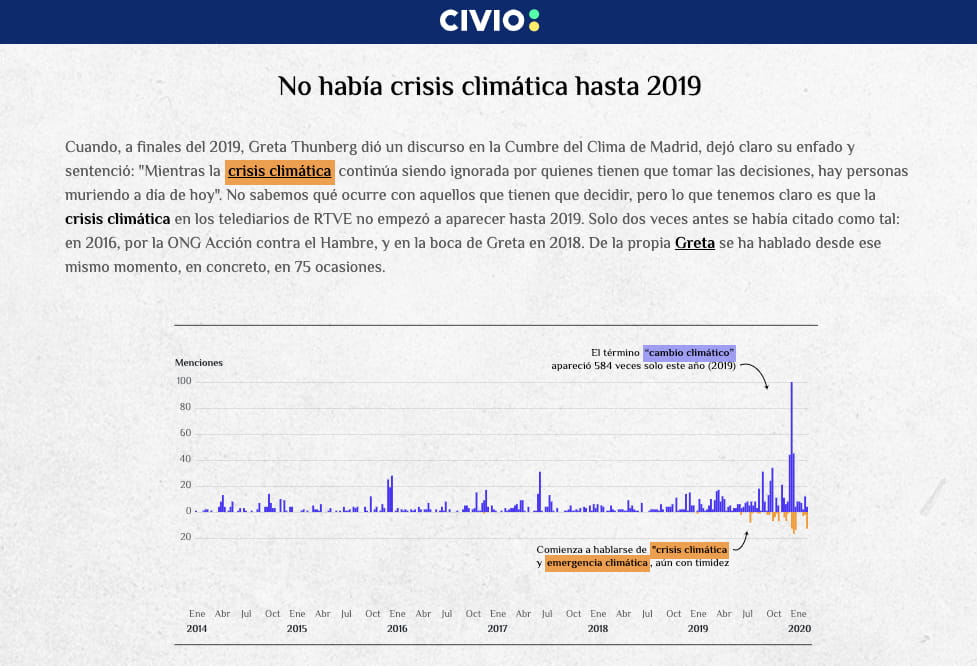
La gente de Civio ha dado a conocer Verba, un buscador sobre los contenidos textuales de los telediarios de RTVE desde 2014 hasta la actualidad. Es el resultado de la recopilación y adaptación en una aplicación de código abierto –publicada con...

SpaceX ha conseguido colocar en órbita 60 satélites más de la constelación Starlink de acceso a Internet. Con esto ya tiene 302 en órbita y aumenta su ventaja como operador del mayor número de satélites del mundo. Y como una de...

El Falcon 9 del lanzamiento Starlink anterior en la plataforma – SpaceX SpaceX tiene todo preparado en el Complejo de Lanzamiento 40 de cabo Cañaveral para lanzar un nuevo lote de satélites de su constelación Starlink de acceso a Internet. Con otros...
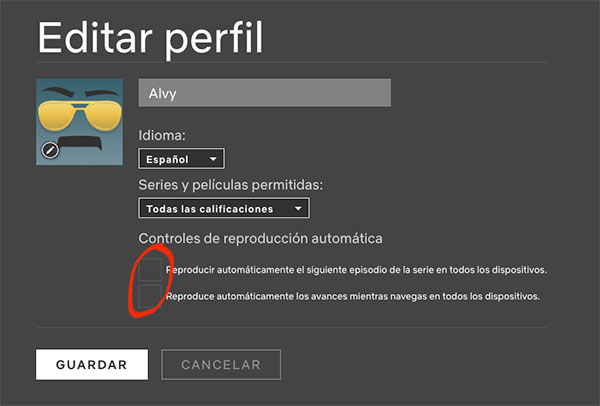
Ir a la web de Netflix y en el menú principal, elegir Administrar perfiles. Elegir el perfil de la persona a editar. Desmarcar las casillas «Reproducir automáticamente…» en el apartado Control de reproducción automática. De este modo te ahorras reproducciones innecesarias...

Despegue del cohete - Roscosmos Tal y como estaba previsto un cohete Soyuz-2.1b que despegó dede el Cosmódromo de Baikonur en la noche del 6 de enero de 2020 puso en órbita la primera tanda de 34 satélites de serie de OneWeb....

El cohete en la plataforma - Roscosmos Tras sucesivos aplazamientos en noviembre y diciembre de 2019 y otros dos en enero de 2020 todo parece estar listo por fin en el cosmódromo de Baikonur para el lanzamiento del primer lote de satélites...
Buscáis la fama, pero la fama cuesta. Y aquí es donde vais a empezar a pagar. Con sudor.– Fama (serie de televisión, 1982) Bruise Almighty se quejaba amargamente de que cuando hizo unas comprobaciones de sus cuentas sociales por motivos de...

Con algo más de una semana de retraso debido a que la meteorología no quería colaborar SpaceX ha hecho por fin el lanzamiento de la tercera tanda de satélites Starlink de serie. Han sido dejados en una órbita de 290 kilómetros...
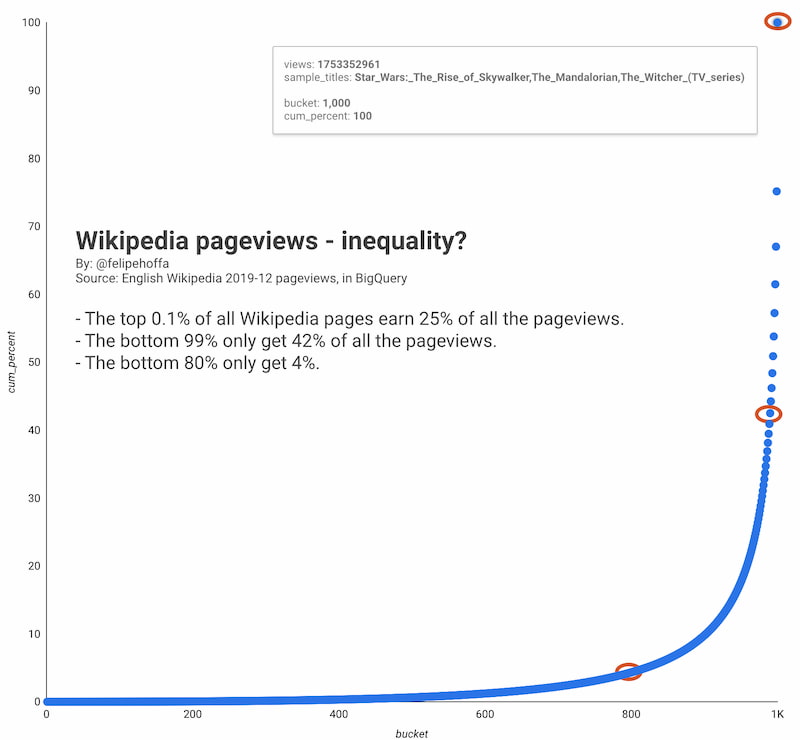
Todo el mundo ha oído hablar de un modo u otro de la Distribución de Pareto, de la «regla del 80-20» o el principio de Pareto y aquello de que en muchos ámbitos cuando una población o actos contribuyen a un...

Viviendo en el futuro: Claves sobre cómo la tecnología está cambiando nuestro mundo. Enrique Dans. Deusto, 2019. Hace diez años Enrique afirmaba en su primer libro que Todo va a cambiar. Pero en Viviendo en el futuro su argumento es que...
Google ha abierto oficialmente su buscador Dataset Search que hasta ahora había estado en beta. Se trata de un motor de búsqueda que ha indexado 25 millones de conjuntos de datos (datasets) con todo tipo de información: datos oficiales de los...
Una novedad reciente en el sector de los navegadores es Edge basado en Chromium (v79), que como es sabido es el código abierto genérico creado originalmente por Google para quienes necesitan desarrollar un navegador web. Como suele decirse, Microsoft al final...
DuckDuckGo Lite, que viene a ser una versión ligera, ultraminimalista y sin ningún tipo de publicidad de DuckDuckGo. Si este buscador ya se planteaba como «lo que era Google hace unos años», ahora es como el Google de 1998: limpio, rápido...
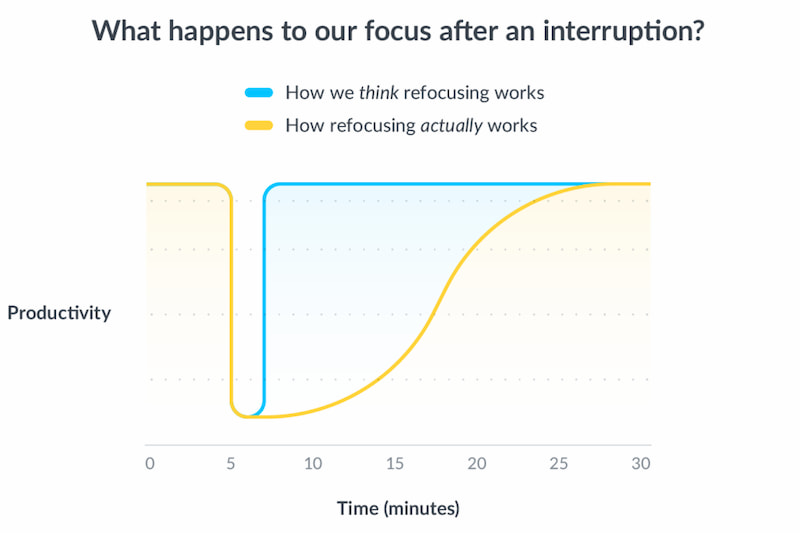
Mucha gente es cada vez menos amiga de las llamadas de voz, por no hablar de las reuniones en persona, de cara a trabajar eficientemente. Aunque con sus matices, se trata básicamente del fenóneno de la comunicación síncrona frente a la...

Alguien se ha entretenido en hacer un pequeño estudio acerca de las diferencias entre los diversos emojis de las tijeras según diversas «marcas» y su software. La verdad es que las diferencias son curiosas. Microsoft, Apple, Facebook, Google, WhatsApp… Todos tratan...
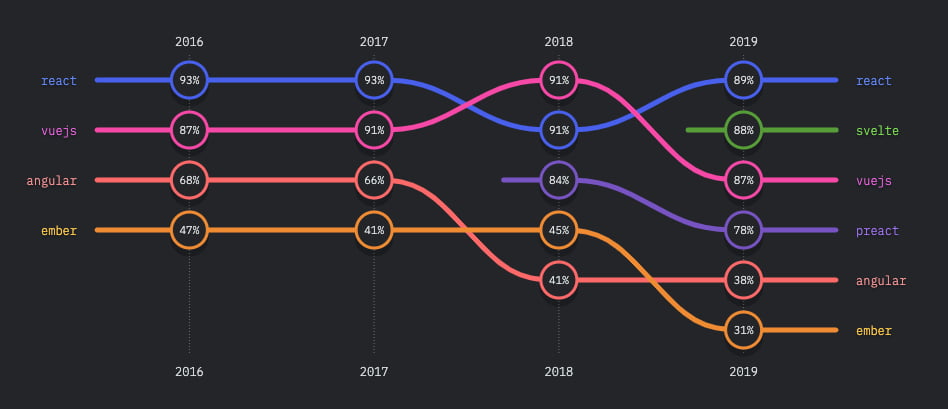
The State of JavaScript 2019 recoge como en otros años el estado del ecosistema de JavaScript, uno de los lenguajes que utilizan los navegadores web y que ya ha cumplido 24 años. El estudio lo hecho Sacha, Raphaël y Amelia y...
Utilizando varios de sus servicios de cartografía y mapas Google ha dado a conocer un dato interesante: ya ha mapeado el 98% de las zonas habitadas del planeta. Este dato se refiere a Google Earth, que utiliza imágenes aéreas y de...

Remove.bg hace un trabajo más que digno recortando retratos de forma rápida y precisa. Es una de esas aplicaciones que viene bien tener a mano, porque la tarea de eliminar un fondo y reemplazarlo por otro no siempre es fácil, aunque...
Yap llega de la mano de Gina Trapani, a la recordarán como fundadora de blogs como Lifehacker y otros proyectos. Es básicamente un chat minimalista con unas limitaciones muy peculiares y una principal característica: es efímero. O estás atento a lo...
Squirt.io, de Cameron Boehmer, es uno de esos inventos raros y curiosos que de vez en cuando aparecen por Internet. Es un «sistema» para leer cualquier página web más rápido y con más «concentración». Se instala como un bookmarklet arrastrando un...

El Contrato Para La Web es «un plan de acción global para que nuestro mundo en línea sea seguro y empoderador para todos y todas»: La Web se diseñó para unir a la gente y hacer que el conocimiento fuese accesible...
Me crucé con la página de Twitter Interests que es donde Twitter muestra la información sobre aquello que cree que te interesa, de cara a utilizarlo en la segmentación de la publicidad probablemente. También se pueden llegar a esos «intereses» desde:...

Emoji Storm es un experimento visual de Robert Lesser que consiste en una cascada visual de emojis en tiempo real procedentes de Twitter. También se puede cambiar de modo por «difuminar» que es más tranquilo. Es divertido verlo, y aunque no...
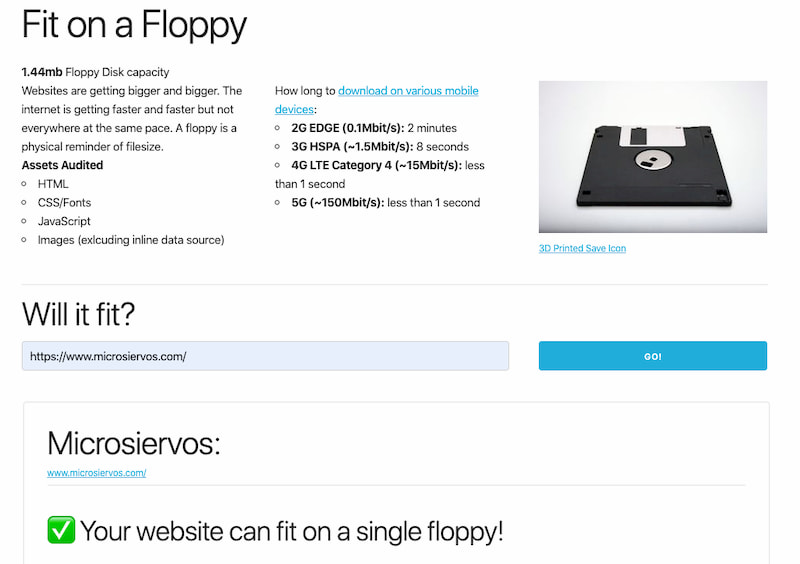
Fit on a Floppy es una página que responde a la pregunta de si tu web cabría en un disquete. Simplemente se escribe la URL y el sitio te lo calcula. El tamaño total de la página + imágenes asociadas deben...
En Best Meme of the Decade están haciendo una encuesta entre todo tipo de internautas para elegir el que podría considerase «el mejor meme de la década». La fórmula es sencilla: aparecen tres memes –no necesariamente relacionados– y eliges tu favorito....

Elimíname by DDR de Derecho de la Red es una práctica recopilación: todas las páginas de borrado de cuentas de servicios y apps de todo tipo. Si te hartas de la política de un servicio, te parecen abusivos los términos o...

Hace unos días el Centro de innovación Plexal británico invitó a Alan Kay y otros personajes de la cultura de Internet local a compartir sus vivencias personales de las décadas prodigiosas del nacimiento de Internet con motivo de las celebraciones por...

Este gráfico de Statista titulado «El arduo camino de los medios hacia el paywall» utiliza datos del estudio Digital News Report 2019 e indica básicamente el porcentaje de internautas encuestados que dijeron estar suscritos a alguna fórmula de suscripción o acceso...
Este truco que apuntó Ben Howdle para el navegador Chrome de Google (Windows, Linux, MacOS, Chrome OS) es muy práctico: consiste en activar un botón que normalmente es invisible y que llama Convertir página (Distill Page). Lo que hace es algo parecido...

Encontré Button Contrast Checker de la compañía portuguesa Aditus haciendo algunas comprobaciones sobre el contraste de textos, enlaces y botones de algunas páginas web. Es una herramienta gratuita y muy sencilla que audita si los botones de una web son accesibles,...
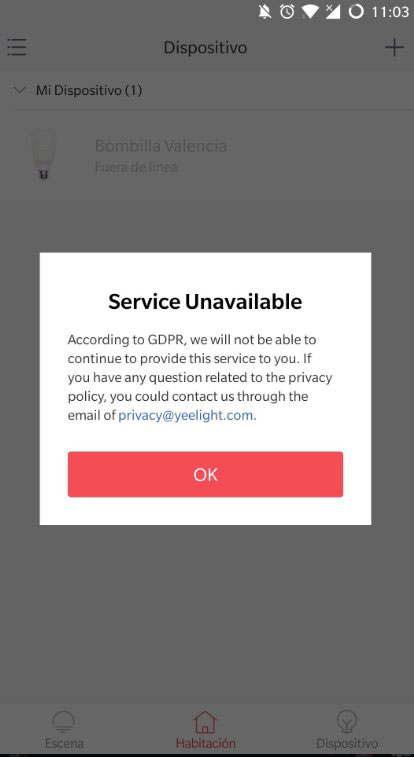
La entrada en vigor del Reglamento General de Protección de Datos (RGPD) ha hecho que recibiéramos decenas de correos para asegurarse de que queríamos que montones de empresas pudieran seguir manejando nuestros datos. Que hayamos tenido que dar el OK a innumerables...

Todo está listo en la Plataforma 40 de de Cabo Cañaveral para que SpaceX lance su segunda tanda de 60 satélites de la constelación Starlink para dar acceso a Internet en todo el mundo. Sería casi un lanzamiento rutinario más de...
Answer the Public es una curiosa herramienta en la que se puede escribir cualquier término y se obtiene una respuesta acerca de qué busca la gente en Internet acerca de dicho término. Puede servir para investigar o como sugerencia para saber...

Se puede participar hasta el próximo sábado, 9 de diciembre: Navegantes en la Red:22ª encuesta a usuarios de Internet de la AIMC Es la tradicional encuesta de la Asociación para la Investigación de Medios de Comunicación (AIMC), también conocida como Navegantes en...

La Sala 3420 del Edificio Boelter de la UCLA – Mark Sullivan Este año celebramos 50 años de la llegada de nuestra especie a la Luna, lo que sin duda es un hito histórico porque por primera vez poníamos los pies sobre...
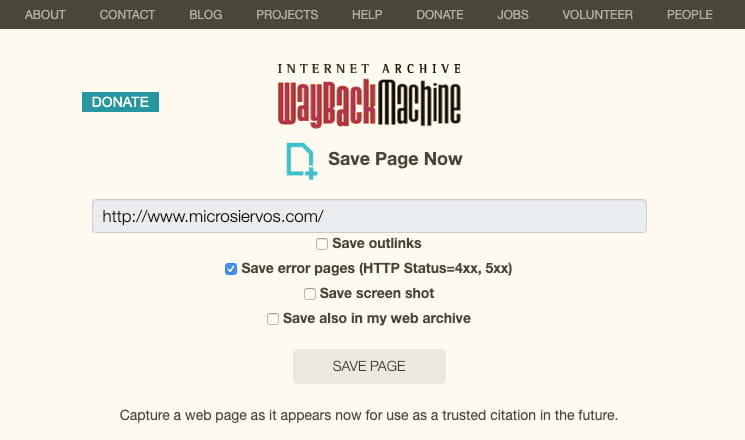
La Wayback Machine de Archive.org es uno de esos recursos que deberían ser considerados Patrimonio de la Humanidad de Internet, como poco. Sus arañas leen la World Wide Web de forma periódica archivando todo lo que encuentran para la posteridad. Casi...
Frecuentemente oímos muchas opiniones sobre CSS: que está roto, que es genial, o a veces ambas cosas a la vez (…) Es un poco como lo de: ¿esta imagen es un pato o un conejo? Dependiendo como lo mires, algo puede...
HEAD, del que existe una versión traducida al castellano (HEAD en castellano) es básicamente «una lista de todo lo que podría ir en la cabecera (head) de tu página web». Lo cual incluye elementos obligatorios, otros recomendables y otros opcionales (pero...

El vídeo explicativo de The Spinner [¡cuidadín!] es tan inquietante como perturbador: un servicio que ofrece influenciar subconscientemente a la persona que elijas mostrándole contenido en los sitios que suela visitar. Dicho así suena un poco peliculero, pero luego explican cómo...
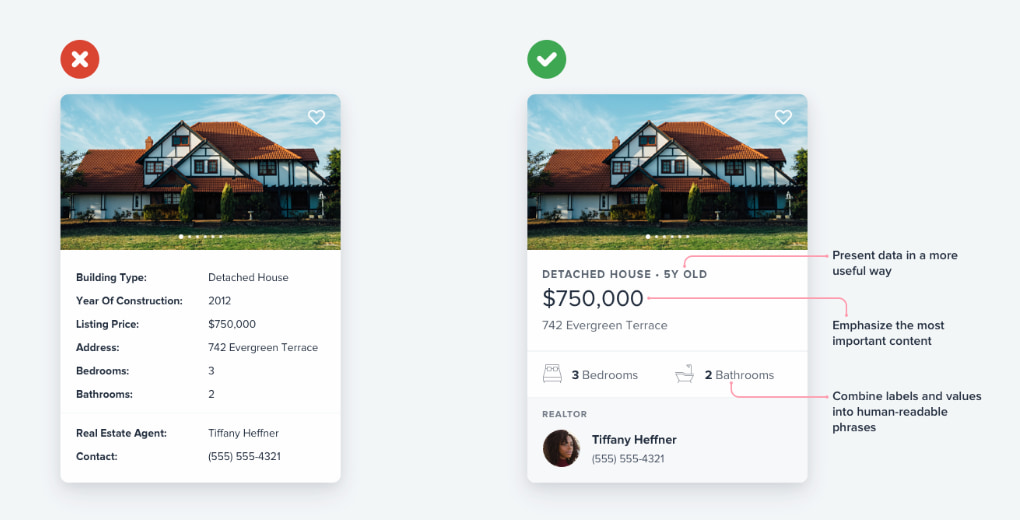
Steve Schoger y Adam Watham son los autores de Refactoring UI, que es un libro de diseño web sobre rediseño de interfaces de usuario. Técnicamente el término es refactoring, pero como no existe refactorización en castellano –aunque se usa para diseño...

Este curioso proyecto de Katja Trinkwalder y Pia-Marie Stute se llama accesoires for the Paranoid y es un proyecto medio artístico, medio tecnológico, medio irónico acerca de la seguridad de nuestros datos y la privacidad en el siglo XXI. Son pequeños...

Cuando surgieron los captchas mucha gente se preguntó si eran realmente necesarios; hoy con la invasión de spam en todas las formas y variantes son algo casi obligatorio para que muchos sistemas funcionen: sistemas de comentarios, formularios de compra, páginas de...
A raíz de un interesante hilo que publicó Borja Adsuara, Luis nos recomendó ToSDR (Terms of Service, Didn’t Read), una web que gestionan expertos que se leen los interminables textos legales de los diferentes servicios de internet para luego hacer un...

En esta economía de la atención y escándalos relacionados con la privacidad, la manipulación y las fake news en la que vivimos, un libro como El enemigo conoce el sistema (Debate, 2019) era sin duda necesario. En él Marta Peirano hace...
CryptPad es un proyecto de código abierto de la compañía francesa XWiki. Es una especie de suite como la de Google a la que cualquiera puede acceder online sin siquiera registrarse. Incluye procesador de textos, hoja de cálculo (en beta), editor...
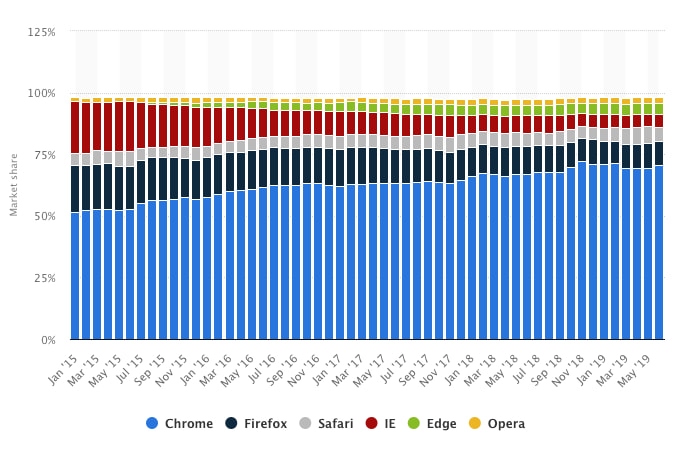
Estaba recordando los tiempos de Netscape y Explorer y cómo había ido evolucionando ese tipo de software desde 1994 cuando me encontré en Statista con un par de interesantes gráficos sobre cómo ha sido la evolución de la cuota de mercado...
Video Walks Around the World es una recopilación de 675 vídeo paseos (video walks) realizada pacientemente por Watercookerch utilizando Google My Maps. Son vídeos en los que simplemente la gente pasea por la calle grabando la vida cotidiana de las ciudades,...
Si no hay dados a mano y necesitas hacer una tirada para algún juego o para alguna importante toma de decisión en la vida que quieras dejar en manos del azar, Google tiene una nueva función: Roll dice (Tirar el dado)....
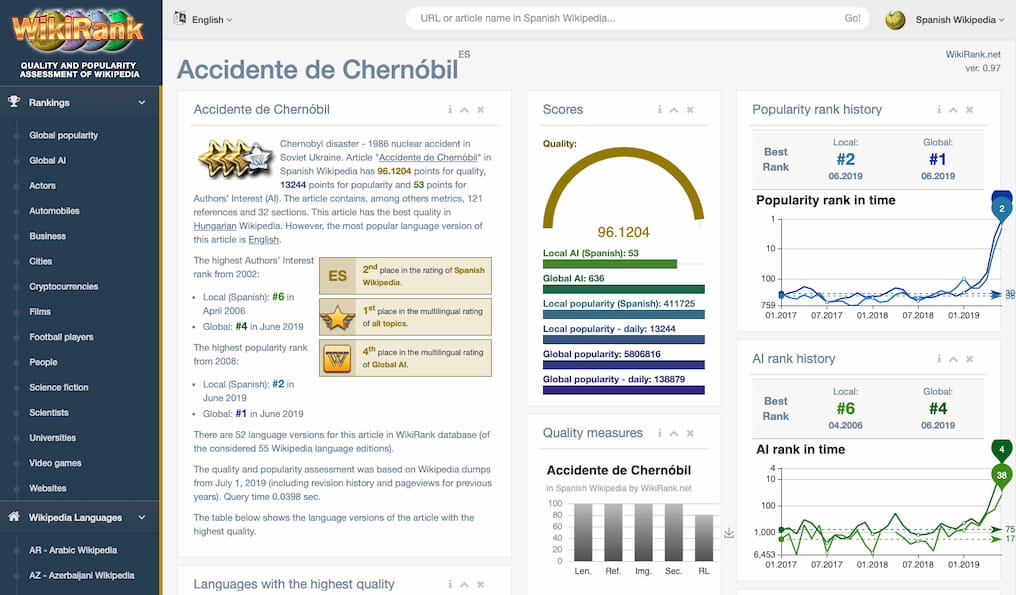
WikiRank es una maravilla de recurso estadístico acerca de los artículos de la Wikipedia. Su único pero es que el logo no es que sea horrible, es lo siguiente. Pero –temas visuales y de gustoscolores aparte– resulta totalmente impresionante: recopila varios...
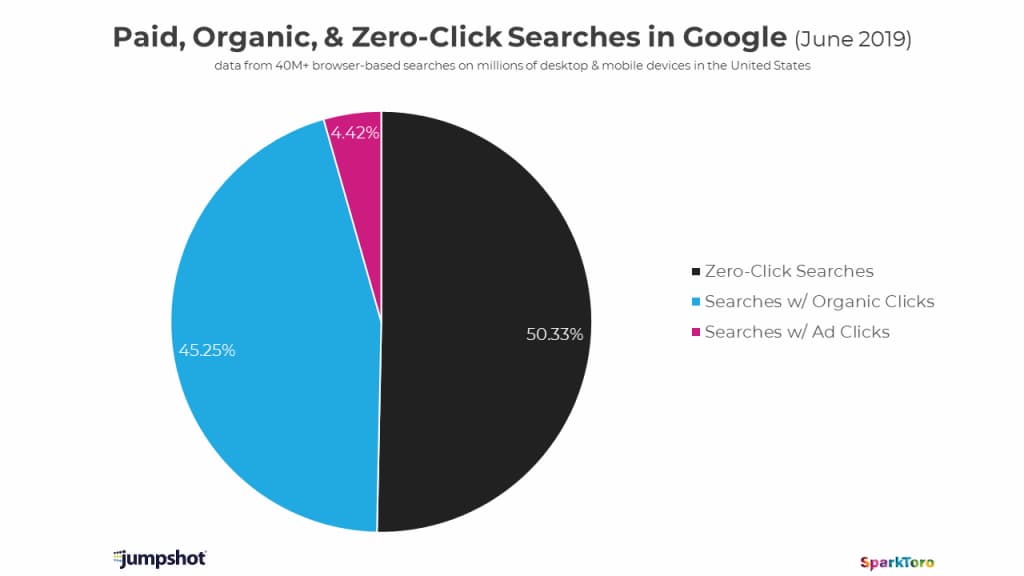
En un artículo de Rand Fishkin para SparkToro se incluye esta gráfica en la puede verse cómo según datos de los analistas de Jumpshot se ha superado el punto en que la mayor parte de las búsquedas en Google ya no...

Die With Me [iOS, Android] es una app medio real, medio artística, medio emo, obra de Dries Depoorter y David Surprenant. Lo que hace es conectarse con una sala de chat llena de gente que usa la misma app cuando al...
Desde hace unos días ya –por fin– se pueden regalar libros en formato Kindle en Amazon España. Para ello basta con localizar el libro que quieres regalar, localizar la opción Comprar para otros (a la derecha), decirle cuantos quieres regalar, y...

Nuevas apariciones estelares de las Venancia Lengüeta de la Internet moderna, las compañías más cotillas que «todo lo escuchan»: dispositivos, apps… Microsoft Contractors Hear Skype and Cortana Recordings(Tom’s Hardware) Apple contractors ‘regularly hear confidential details’ on Siri recordings(The Guardian) Google Admits Humans...
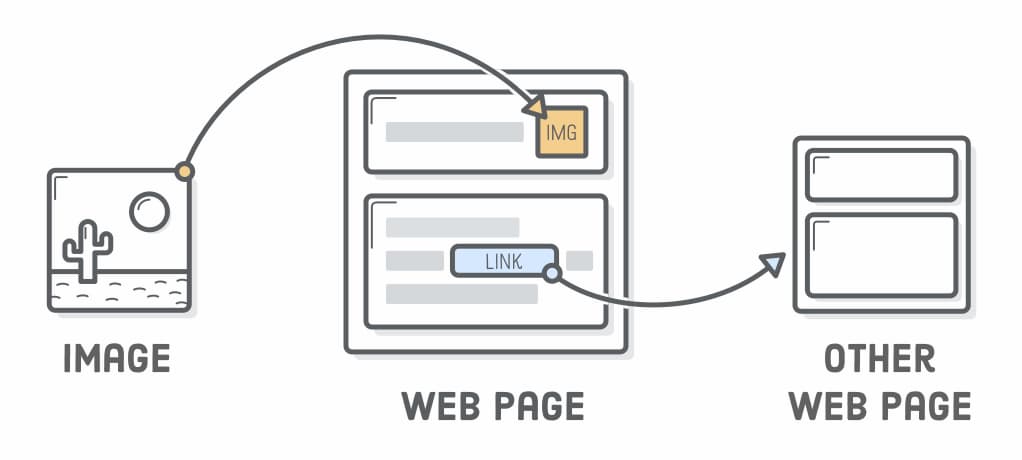
Bajo el título Interneting is Hard se publicó hace un tiempo un completo tutorial sobre algunas de las técnicas de creación de contenidos en HTML y CSS para la Web. Cómo tejer los mimbres más básicos de la red, vamos. Son...
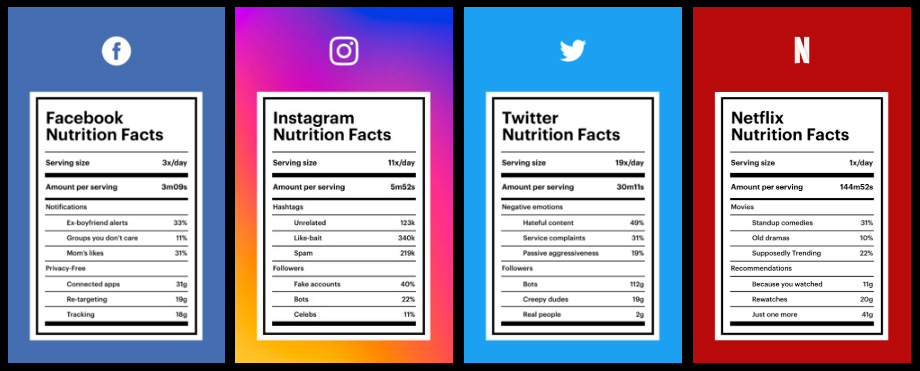
El mundo necesita una dieta tecnológica, y así es cómo los diseñadores pueden ayudar Esta especie de manifiesto de la gente de UX Collective, elegantemente presentado como una Dieta tecnológica, trata de combinar el diseño con la ética para hacer que...
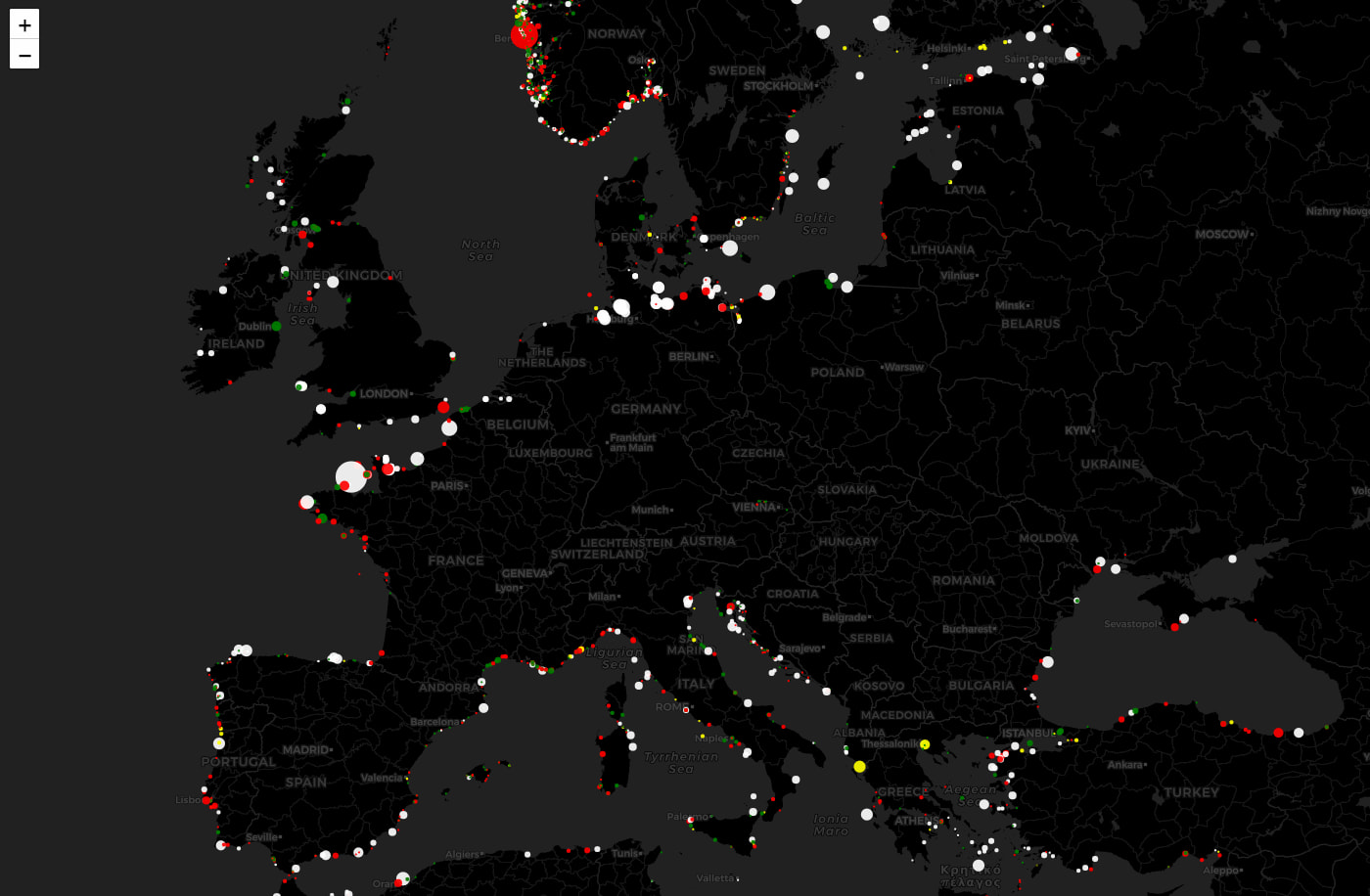
Es sabido que cada faro tiene un secuencia de destellos diferente, algo que técnicamente se denomina luz característica o apariencia. En esta web llamada Lighthouse Map muestra un mapa –principalmente de las costas de Europa– donde aparecen todos ellos, parpadeando del...
La Wayback Machine es junto con su papi Archive.org uno de mis megaproyectos favoritos de Internet, una auténtica joya, crème de la crème, probablemente una de las mejores iniciativas que junto a la Wikipedia hayan surgido en todas estas décadas. A...
YouGlish es una idea ingeniosa para aprender más sobre la pronunciación del inglés, muy en la línea de Forvo –un clásico entre nuestros favoritos– pero con una diferencia: las palabras se aprenden en el contexto de frases completas y los ejemplos...

Genius es un sitio de música en el que principalmente se recopilan letras de canciones, algo que comenzaron haciendo con canciones de rap, luego de hip-hop y hoy en día de cualquier estilo. En total tienen ya unos 25 millones de...

Parece que estos días los rediseños están de moda. Ahora ha sido Firefox quien ha hecho evolucionar (más que «cambiar») su marca para adaptarla a la línea de productos que ya no son sólo el navegador web sino muchos más. Con...
¡Ah, esas técnicas de YouTube con más trucos que la chistera de un mago! Miniaturas falsas, titulares con cebos/clickbait, caras de locos, profuso uso de emojis y similares… ¡Todo vale! En esta gráfica con las estadísticas de su canal que subió...

Los más viejos de lugar recordarán a Víctor Domingo (1956-2019) por su activismo en la red durante las últimas décadas: fue presidente de la Asociación de Internautas desde su creación en 1998 y uno de los primeros en reclamar la «tarifa plana...

Esta máquina llamada Quick Fix («Chute rápido») es una especie de invento medio en broma, medio en serio, medio crítica social sobre la «adicción a los seguidores y los likes» en las redes sociales. Es obra del artista Dries Depoorter. Equipada...
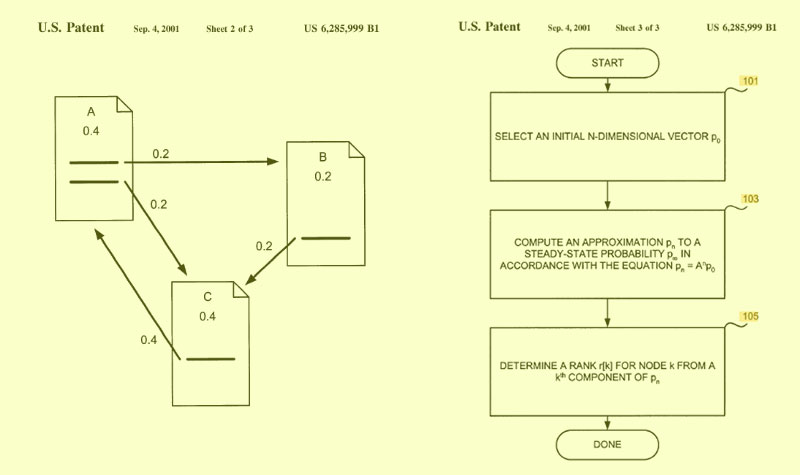
[Larry] Page se permitió una pequeña vanidad a la hora de poner nombre a la parte del sistema que calificaba los sitios web según los enlaces entrantes: lo llamó PageRank. Pero fue muy astuto; mucha gente asumió que el nombre se...

La pregunta que plantean en Today está en dólares, pero euro arriba o dólar abajo, viene a ser: ¿qué precio le pondrías al hecho de usar Internet el resto de vida? O más exactamente: ¿por cuánto dejarías de usar la red...

Después de actualizar el software de a bordo de los satélites y comprobar por tercera o cuarta vez que todo está bien SpaceX está lista para volver a intentar en lanzamiento de la primera tanda de 60 satélites Starlink. El primer...

De la nota informativa nº 74/2019 del Tribunal Constitucional: El Pleno del TC por unanimidad declara inconstitucional el Art. 58 bis. 1 de la Ley Electoral General que permite a los partidos políticos recopilar datos personales relativos a las opiniones políticas...

Como sardinas en lata comparados con Starman y su coche – Elon Musk A falta de la prueba estática del cohete que los pondrá en órbita SpaceX tiene todo listo para el lanzamiento de la primera tanda de satélites Starlink. Se trata...

En LiveScience dan una explicación a la imagen viral que está haciendo las rondas por internet como meme: una especie de foto en la que aparecen muchas cosas pero es imposible reconocer ninguna como un objeto concreto. Básicamente, es imposible nombrar...

Me encontré por ahí Redirect Path que es una sencilla extensión de Chrome que hace lo que cabría esperar: indicar de forma visible los saltos en forma de redirecciones que se han seguido hasta llegar a la página web que se...
Hace tiempo que había rumores al respecto pero al tener que solicitar los permisos pertinentes se ha confirmado: Amazon está dispuesta a entrar en el mercado del acceso a Internet vía satélite. El Proyecto Kuiper, según la documentación presentada por la...
PhotoSize es una de esas herramientas sencillas para hacer una tarea concreta que no viene mal tener por ahí guardada. Sirve para reducir el tamaño de las imágenes, y su particularidad frente a otras es que puede hacerlo «por lotes», es...
El agua (del latín aqua) era una sustancia cuyas moléculas estaban compuestas por dos átomos de hidrógeno y uno de oxígeno (…) Era una sustancia bastante común en la tierra y el sistema solar, donde se encontraba principalmente en forma de...

Escrito por Steve Crocker, aunque fruto de una conversación al respecto con Steve Carr and Jeff Rulifson., el 7 de abril de 1969 se publicaba el primer RFC. Titulado Host Software, software para el anfitrión, ese primer Request For Comments o Petición...

Smash es una herramienta de esas de «tener a mano» porque puede venir bien en momentos puntuales, o habrá para quien se convierta en habitual. Al igual que otras similares (WeTransfer, WeSendit) sirve para enviar archivos gigantescos a otras personas. Lo...

Tal y como cuenta Addy Osmani, ingeniero de Google Chrome, se está trabajando ya para incluir la carga diferida (lazy loading) de forma nativa en el navegador web a partir de la versión 75 (más o menos). Esta función es fácil...
Resultado de la votación - vía Julia Reda El Parlamento Europeo ha decidido, por 348 votos a favor y 274 en contra, adoptar el texto de la nueva versión de la Directiva sobre derechos de autor de la Unión Europea. La idea,...
El Soyuz-STB con una etapa superior Fregat que tenía que encargarse del lanzamiento de la primera tanda de satélites de OneWeb cumplió a la perfección con su misión e insertó los seis satélites en la orbita inicial prevista con una precisión...
En el vídeo, el navegador de la izquierda es un navegador Chrome normal y corriente; el de la derecha utiliza un sistema experimental de caché back/forward (bfcache) que hace que al usar los botones atrás/adelante del navegador la respuesta sea instantánea....

Mito #0: Si lees listas como estas no necesitas investigar.– UX Myths UX Myths recopila 34 mitos sobre experiencia de usuario, muchos de ellos relacionados con el diseño web y de aplicaciones (y algún que otro asunto relacionado). Expresiones, frases y...

Todo está listo en el espaciopuerto de Kourou para el lanzamiento de la primera tanda de satélites de OneWeb. Correrá a cargo de un Soyuz-ST, que es la variante de este cohete adaptada a las especificaciones de Arianespace. No es la...

La Asociación de Internautas, junto con la Plataforma en Defensa de la Libertad de Información (PDLI), la Asociación de Usuarios de Internet y la Asociación de Expertos Nacionales de la Abogacía Digital (ENATIC), así como los juristas Borja Adsuara Varela, Cecilia...
ThisAirbnbDoesNotExist.com es otro paso en la saga que podríamos denominar «salido de la imaginación de una inteligencia artificial». En este caso se trata de ofertas de alquiler de viviendas y pisos en Airbnb, incluyendo la ubicación, título, descripción, e incluso el...
MailtoLink.me es un elegante generador de enlaces mailto: viene a ser una forma intuitiva y sencilla a la par que bonita de preparar el código HTML la que se utiliza para abrir un correo con todos sus detalles. Esto es lo...

En La vida sin los gigantes tecnológicos (Gizmodo) la intrépida reportera Kashmir Hill cuenta cómo intentó eliminar de su vida completamente todo rastro de aplicaciones, servicios, aparatos, rastreo y datos de los cinco gigantes del mundo moderno. Al menos durante una semana....

Empantallados acaba de presentar el informe El impacto de las pantallas en la vida familiar, un estudio realizado por GAD3 para ellos que saca sus datos de una encuesta anónima a más de 1.400 hogares en los que hay hijos de menos...

Esta impresionante estatua es el Cristo Rey de Świebodzin y está en Polonia. Pesa unas 440 toneladas y mide 36 metros de altura (+3 metros de corona y otros 13 de pedestal). Me pareció gracioso descubrir que desde hace una década...
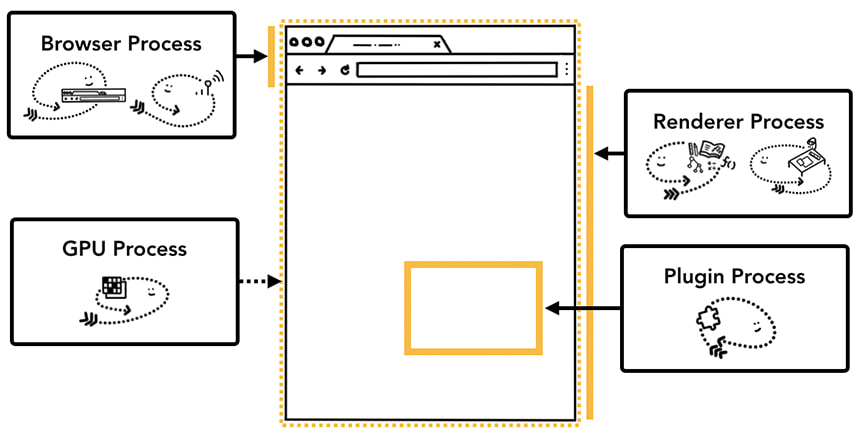
Mariko Kosaka ha publicado en el área de desarrolladores de Google este interesante curso en cuatro partes titulado Un vistazo al interior de un navegador web moderno (en este caso: Chrome) en el que con dibujos explica lo que sucede entre...

En Webflow hablan de 20 tendencias en diseño web para 2019 que dicen «definirán el diseño de webs y productos digitales» a lo largo del próximo año. Es muy visual y bien merece un vistazo. Algunos de los términos que usan...

Entre 1959 y 1989 la Unión Soviética intentó construir varias redes de ordenadores que conectaran todo el país, un poco al estilo de lo que la Arpanet estaba siendo para los Estados Unidos. Pero todos y cada uno de esos intentos...

Mi lavavajillas se abrió al terminar para secarse más fácilmente e hizo que se encendieran las luces inteligentes de la cocina sensibles al movimiento.Cualquier casa lo suficientemente avanzada es indistinguible de una casa encantada.– Richard Gaywood,programador resentido...

Del tuit de Jon Erlichman: Facebook – Febrero de 2004. Google Maps – Febrero de 2005. YouTube – Febrero de 2005. Twitter – Marzo de 2006. Waze – Mayo de 2006. Netflix en streaming – Febrero de 2007. Fitbit – marzo...

New on iOS! Starting today, you can tap to switch between the latest and top Tweets in your timeline. Coming soon to Android. pic.twitter.com/6B9OQG391S— Twitter (@Twitter) 18 de diciembre de 2018 La semana pasada Twitter anunciaba que comenzaba a desplegar en su...

El pasado mes de septiembre de 2018 el Parlamento Europeo votaba a favor de retomar los denostados artículos 11 y 13 del reglamento revisado sobre propiedad intelectual. Son, respectivamente, los artículos que permitirán a los editores cobrar por enlazar con las...

No deja de ser irónico que los plazos de los diversos trámites involucrados en su tramitación hayan llevado a que la nueva Ley Orgánica de Protección de Datos Personales y Garantía de los Derechos Digitales (LOPDGDD), que faculta a los partidos...

Hoy se aprobará en el Congreso el refuerzo de la Ley Sinde, que permitirá cerrar webs sin ningún tipo de control judicial en los procedimientos sancionadores. El juez, que se introdujo para calmar nuestro ánimos, se eliminará ahora porque saben que ya...

El canal de YouTube de Jaime Altozano está lleno de vídeos interesantísimos sobre música. Cosas como análisis de bandas sonoras, de canciones, de música clásica, o incluso el nuevo disco de Rosalía. Jaime ha tenido problemas a menudo con los filtros...

A finales de 1991 un grupo de investigadores, hartos de pegarse paseos hasta la cafetera instalada en la Sala Troyana (Trojan Room) del antiguo laboratorio de ordenadores de la Universidad de Cambridge, montaron una cámara que apuntaba a ella y escribieron...
Krisp es un software para MacOS que anda haciendo las rondas porque ha salido de beta y tiene tecnología de Nvidia detrás. Tiene una sola misión –y bastante llamativa– que es eliminar el ruido de fondo de las conversaciones realizadas en...
Squoosh es una herramienta de optimización de imágenes online, similar a otras ya existentes como TinyPNG. Tiene una interfaz del tipo «arrastrar y soltar» y es bastante fácil de utilizar. La típica utilidad que conviene tener siempre a mano porque es...

Desde 2017 el Mobile World Congress viene celebrando en Barcelona la Mobile Week Barcelona, un evento paralelo que tiene como objetivo convertirse en un espacio abierto de diálogo en torno al impacto de la tecnología digital en la sociedad. Involucra a toda...
Photopea es una creación de Ivan Kutskir, un programador de la República Checa que ha dedicado su «tiempo libre» (7.000 horas de nada, mientras estudiaba informática) a esta versión clonada de Photoshop que funciona en línea en el navegador web. Su...
Los hiperenlaces dan la sensación de ser un poco como bloques de Lego: unas piezas fundamentales en una red de conexiones muy complejas que existe en todas partes del mundo.– Margaret Gould Stewartdiseñadora de UX en YouTube y Facebook Esta nueva...

En esta perla concentrada de 5 minutos Brian Behlendorf explica algunas cuestiones de lo que puede suponer a largo plazo la tecnología blockchain de cara a construir la infraestructura de lo que denomina «la confianza como servicio». El lugar elegido es...

As we've been saying for a while, we are rethinking everything about the service to ensure we are incentivizing healthy conversation, that includes the like button. We are in the early stages of the work and have no plans to share right...

Se puede participar hasta el próximo 9 de diciembre: Navegantes en la Red:21ª encuesta a usuarios de Internet de la AIMC Es la tradicional encuesta de la Asociación para la Investigación de Medios de Comunicación (AIMC), también conocida como Navegantes en la...
En la lista 100 Websites That Shaped the Internet as We Know It la gente de Gizmodo ha hecho un esfuerzo por seleccionar todos esos sitios característicos de Internet que han hecho que la Web sea como la conocemos hoy en...
Intra (descargable en Google Play para Android) es una app de código abierto desarrollada por Jigsaw (una de las compañías de Google/Alphabet). Sirve para proteger el DNS de las conexiones, de modo que nadie pueda bloquearlo, censurarlo o modificarlo. Se instala...

Tom Scott cuenta en este estupendo vídeo la historia de lo que bien podría ser el primer «gran hackeo» de las telecomunicaciones, algo que sucedió en Francia en el siglo XVIII en lo que era la internet de palos y piedras...

Los gladiadores descubrieron que la Red podía ser un arma más poderosa que la espada.– Pepe Cervera Se nos ha ido, demasiado pronto, Pepe Cervera, casi más conocido por estos pagos interneteros como Retiario. Siempre se aprendían cosas de él y daba...

Google cumple 20 años estos días, en una fórmula que podría denominarse cumpleaños redefinido según la cual cuando no está muy claro si el día de la creación fue cuando se firmaron los papeles de la constitución de la empresa, de...
4/ So, we’re working on providing you with an easily accessible way to switch between a timeline of Tweets that are most relevant for you and a timeline of the latest Tweets. You’ll see us test this in the coming weeks.— Twitter...

Final vote for Parliament position on the copyright directive with #UploadFilters and #LinkTax: adopted. Parliament has failed to listen to citizens’ and experts’ concerns. #SaveYourInternet pic.twitter.com/gtGi6rg5kL— Julia Reda (@Senficon) 12 de septiembre de 2018 Aunque el plenario del Parlamento Europeo votó el...
Greg Sidelnikov, el «profe de JavaScript» y autor del CSS Visual Dictionary ha publicado Flexbox: el tutorial animado, un excelente resumen de las posibilidades de Flexbox para el diseño de contenidos web. Para el artículo ha hecho bueno aquello de que...

Hace unas semanas estuve en Avilés dando una charla sobre los nativos digitales –que no existen– y la forma en la que creo que la transformación digital de la sociedad y del mercado laboral influye en las oportunidades y búsqueda de empleo....

Este hackeril engendro de Joe Sondow se llama @EmojiTetra y es básicamente un bot de Tetris al que se juega vía Twitter. ¿Cómo? Cada tuit lleva incorporada una encuesta y votando se puede decidir si mover la pieza a la izquierda,...

Este mapa de la Dark Web de Hyperion Gray es … una visualización de los servicios .onion de Tor, a.k.a. servicios ocultos, a.k.a. la Dark Web («internet oscura»). Contiene 6.608 sitios revisados automáticamente por un rastreador en enero de 2018. Cada...
En un trabajo publicado por unos investigadores del University College y el Alan Turing Institute de Londres se cuantifica hasta qué punto los metadatos que incluyen los mensajes en las redes sociales pueden utilizarse para identificar usuarios concretos – sin siquiera...

Según datos de StatCounter el navegador web Chrome de Google tiene cerca del 59 por ciento del mercado de navegadores. "Gracias a que sus plug-ins funcionan limpiamente, a su facilidad de uso y a que está respaldado por Google no es...
Por Nacho Palou -
10 JUL 2018
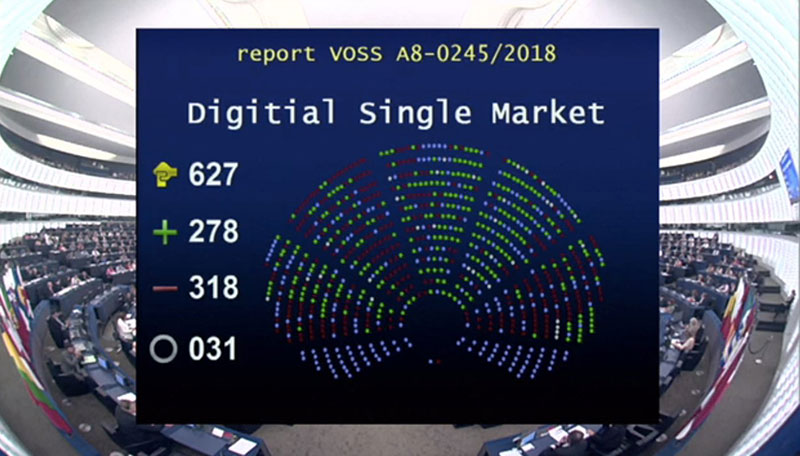
El plenario del Parlamento Europeo ha rechazado la propuesta de revisión revisión de la Directiva sobre derechos de autor de la Unión Europea que el Comité de Asuntos Jurídicos (JURI) había presentado. Esto incluye el rechazo de los Artículos 11 y...

Aunque este documental educativo de 9Gag sobre cómo funciona Internet se centra en Irlanda –por el acento y las coñas, supongo– en realidad es un poco una explicación universal, que comienza como todo el mundo sabe en las planicies de Australia....

Yesterday was the busiest day of the year in the skies so far and our busiest day ever. 202,157 flights tracked! The first time we've tracked more than 200,000 flights in a single day on https://t.co/krDfUYSbzK pic.twitter.com/ApCMHaVEQp— Flightradar24 (@flightradar24) 30 de junio...
Por Nacho Palou -
4 JUL 2018

El 5 de julio de 2018 al mediodía los 751 miembros del Parlamento Europeo están llamados a votar si aprueban o no el artículo 11 y el artículo 13 de la revisión de la Directiva sobre derechos de autor de la...
Trazando el perímetro del parque de El Retiro más o menos rápido sobre Google Earth arroja una superficie de 1,17 km². La cifra "oficial" es de 1,18 km² — así que bien. La posibilidad de medir distancias y áreas ha tardado en...
Por Nacho Palou -
26 JUN 2018

Si tu madre te dice que te quiere, verifícalo. Myriam nos ha hecho llegar un ejemplar de Verificación digital para periodistas, un libro que recoge técnicas y recursos gratuitos para la verificación de informaciones de todo tipo, imágenes incluidas, algo que...
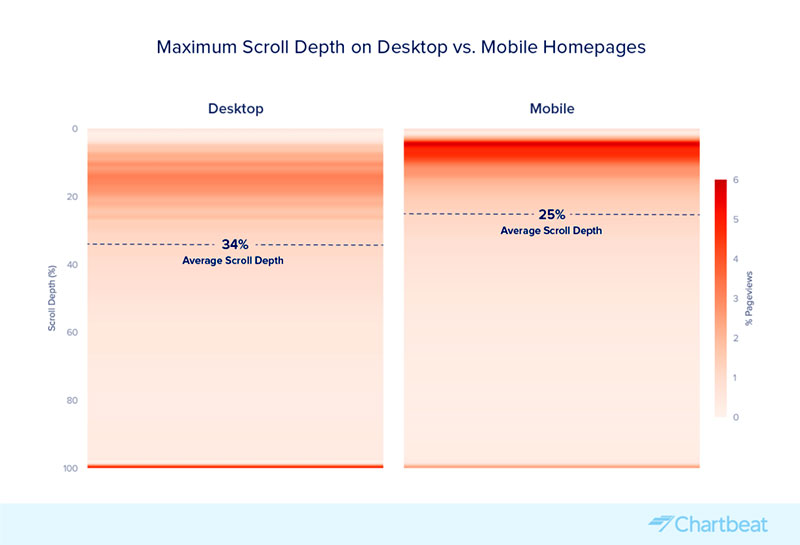
Chartbeat es una empresa y servicio de analíticas web que hace un gran trabajo –aquí lo usamos hace años durante una larga temporada– y que publica de vez en cuando análisis de los datos que obtiene de la medición de audiencia...
Lo contaba la eurodiputada Julia Reda vía Twitter, pero hay más detalles en These MEPs voted to restrict the internet in Europe today – but we’re not giving up: los Artículos 11 y 13 de la propuesta de revisión de la...

La extensión para el navegador web Chrome TrustedNews se basa en el Protocolo MetaCert de MetaCert y utiliza fuentes de datos independientes (como Snopes) y "políticamente objetivas" (sic) para medir la veracidad del contenido de las noticias. Es de los desarrolladores del...
Por Nacho Palou -
18 JUN 2018
Me preguntaron ayer así de repente que cuántos productos vendía Amazon. Cuántos productos distintos vende, porque las cifras de ingresos, pedidos, etcétera son más o menos fáciles de encontrar. Pero teniendo en cuenta que en la popular tienda electrónica se vende...
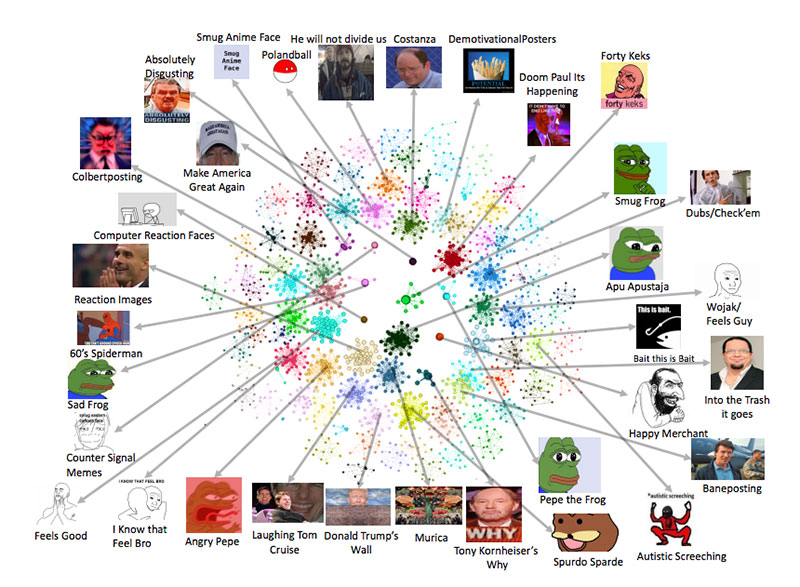
En un amplio estudio titulado On the Origins of Memes by Means of Fringe Web Communities (Sobre los orígenes de los memes a través de las comunidades web marginales) un grupo de investigadores de varias universidades han unido esfuerzos para investigar...

En España Internet se empezó a popularizar, aunque de rebote, gracias a InfoVía, que fue un intento por parte de Telefónica de poner en marcha un servicio similar a America OnLine o CompuServe, que a principios de los 90 tenían millones de...

¿Sabrías explicar el proceso de decisión de la UE? La @EU_Commission, el @Europarl_ES y el @EUCouncil tienen cada uno un rol importante. Descubre en este vídeo cómo se toman las decisiones ⇊ pic.twitter.com/wiPUlAOmH4— Jaume Duch (@jduch) 10 de junio de 2018 Para...
Quedan menos semanas para que el Parlamento Europeo vote la de propuesta Directiva sobre derechos de autor y la campaña #SaveYourInternet (Salva tu Internet) busca que no se apruebe su Artículo 13, dado que «dañaría a la cultura de Internet que...

«Robo de datos» y la importancia de la información personal a partir de 53:00 El otro día charlamos en el podcast de Los Crononautas #S02E27 acerca de la importancia de los datos personales y las consecuencias que puede tener esa captación o...

De impactante, claro y diáfano título, Ten Arguments For Deleting Your Social Media Accounts Right Now del pionero y visionario Jaron Lanier (Diez argumentos para eliminar tus cuentas de medios sociales ahora mismo) pasa a la lista de lecturas para el...
Según recoge TechCrunch Instagram utiliza tres criterios principales para determinar la cronología de contenidos de sus usuarios. Una información oportuna ahora que desde hace no mucho hay gente tiene la sensación de que se pierde más cosas en Instagram que antes,...
Por Nacho Palou -
4 JUN 2018
En las últimas semanas nuestros buzones de correo electrónico se han visto inundados de avisos de todo tipo acerca de la entrada en vigor del nuevo Reglamento General de Protección de Datos. Algunos de ellos innecesarios, otros equivocados (por no decir ilegales),...

Se ve que Oli Frost estaba un poco hasta las narices de que todo el mundo esté ganando usando y vendiendo sus datos personales así que los ha puesto en eBay empezando por 0,99 libras. Si alguien los quiere, lo vende...

Ahora que estamos en plena resaca post entrada en vigor del Reglamento General de Protección de Datos, también conocido como RGPD o GDPR por sus siglas en inglés, es un buen momento para reflexionar sobre la exposición que hizo el artista...
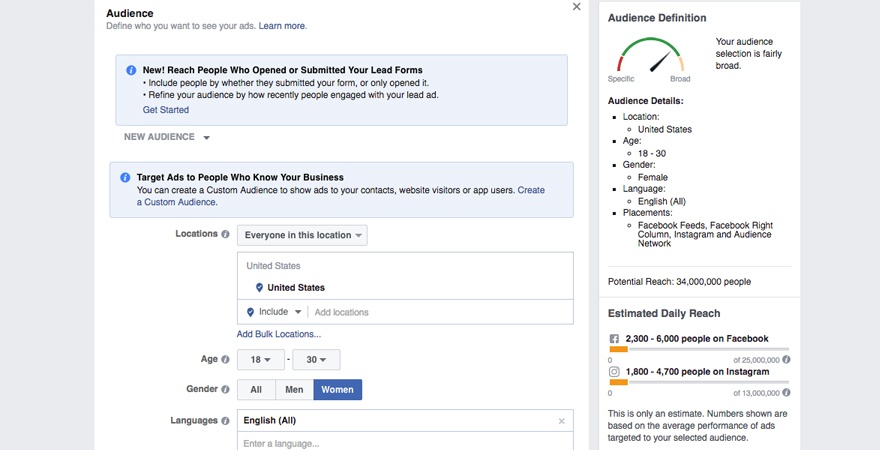
Chris Seline estaba sumamente interesado hace un par de años en trabajar en Reddit pero no suele ser fácil conseguir una entrevista allí – o para el caso en cualquier gran proyectos en donde sólo trabajan unas pocas decenas o cientos...
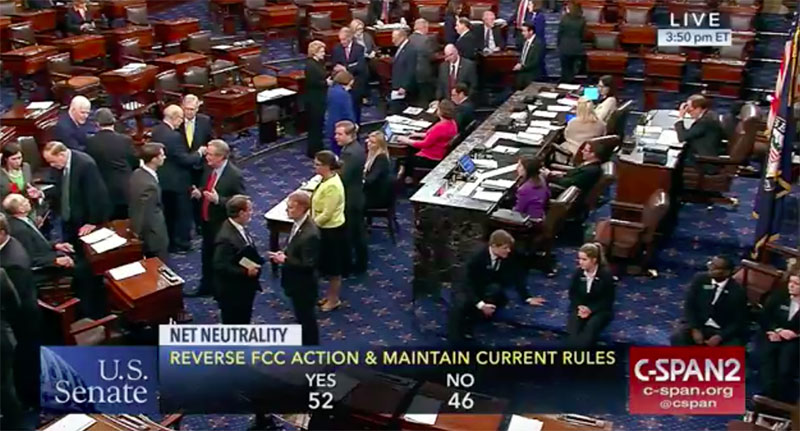
Aunque el partido republicano tiene la mayoría en el Senado de los Estados Unidos la mayoría ha votado en contra de la decisión de la administración Trump de terminar con la neutralidad de la red adoptada por la Comisión Federal de...
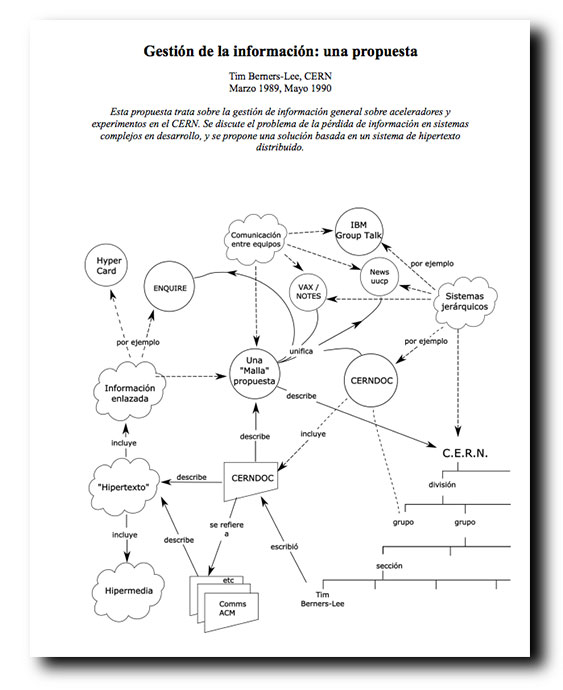
Carlos Menéndez de Datos a tutiplén nos envió una traducción del histórico documento de Tim Berners-Lee, el padre de la Web: el famoso Information Management: A Proposal que data de 1989. Con esto dice que suple «una carencia y una deuda...
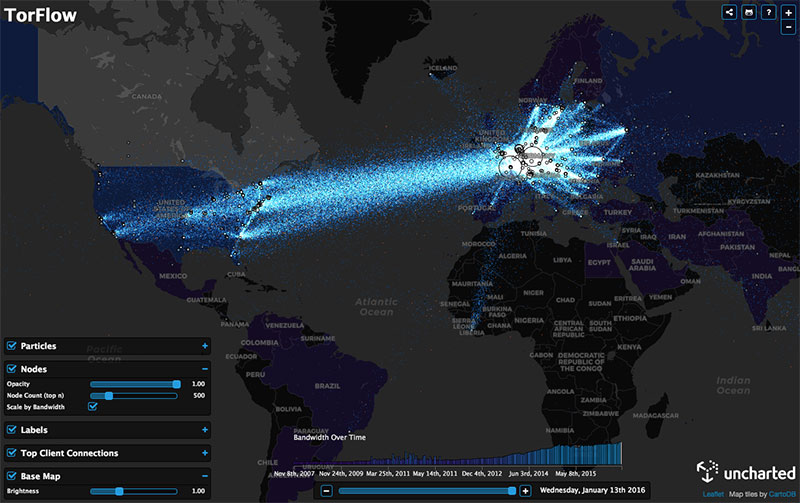
TorFlow es una representación en forma de mapa del tráfico de la red Tor, esa red superpuesta a Internet operada por voluntarios cuya principal característica es la búsqueda del anonimato mediante la ocultación del contenido a nivel incluso del encaminamiento de...

La mayoría de las personas leen a unas 200 palabras por minuto. Un acuerdo medio de condiciones de uso contiene casi 12.000 palabras. Esto quiere decir que serían necesarios unos 60 minutos de media para leer las condiciones antes de aceptarlas.–...

Less than 20 days till I land on Mars!— MarsPhoenix (@MarsPhoenix) 8 de mayo de 2008 En mayo de 2008 la sonda Phoenix de la NASA estaba en los últimos días de su viaje rumbo a Marte, donde donde tenía previsto aterrizar...

Una promoción limitada de la compañía aérea JetBlue, bautizada como Pie in the Sky, ofrece la posibilidad de hacer un pedido desde Los Ángeles a la pizzeria Patsy’s de Nueva York y que te la lleven a casa gratis. La promoción...
Por Nacho Palou -
4 MAY 2018

El 6 de agosto de 1991 Tim Berners–Lee, ahora Sir Tim Berners–Lee hacía pública la primera página web. Era parte de un proyecto suyo propuesto en marzo de 1989 que tenía como objetivo poder compartir información entre grupos y personas que...
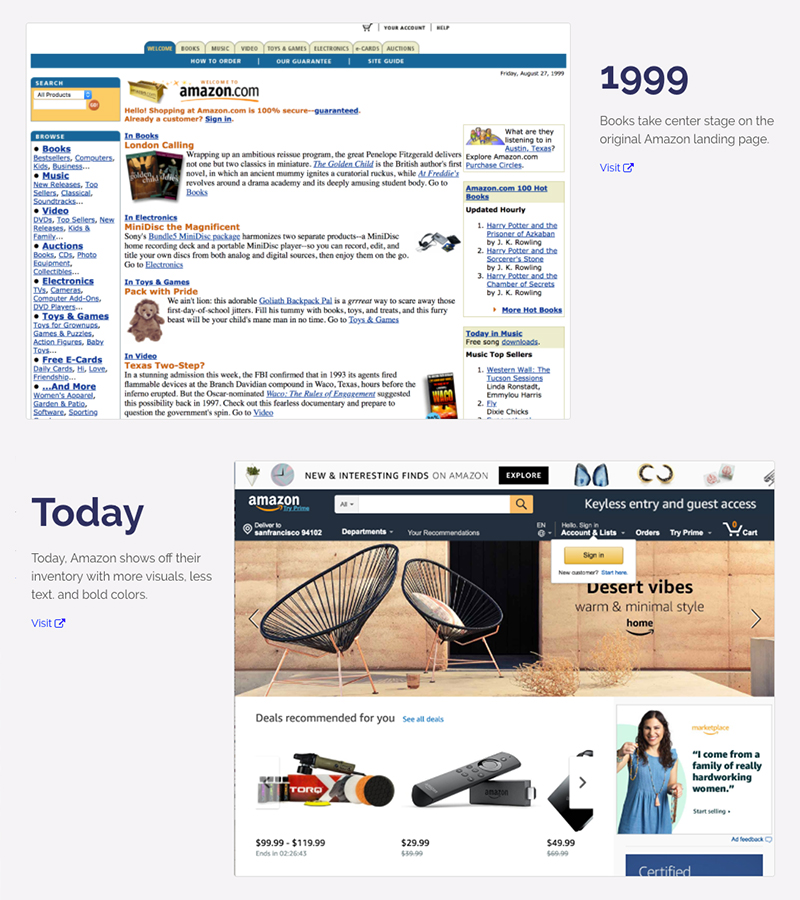
El equipo de Kapwing tiene en su web este Museo de Sitios Web donde analizan visualmente la evolución de diversas webs de contenidos, servicios y tiendas. Son una especie de máquina del tiempo que abarca desde 1995 hasta nuestros días, dos...
Los datos guían todo lo que hacemos. Usamos los datos para modificar los comportamientos de las audiencias.– lema de Cambridge Analytica ¿Por dónde íbamos? Ah, sí… Se pensaba que Cambridge Analytica accedió subrepticiamente a entre 30 y 50 millones de perfiles...
Vistas en su conjunto, hay cierta calidad surrealista, propia de David Lynch en esas imágenes. Pocas cosas podrían ser tan emocionantes como para evocar ese tipo de reacciones, nadie podría ser tan expresivo. Así que… ¿qué narices le pasa a esta...

Ted Nelson (1937) es el pionero de la informática que inventó el hipertexto. Con 80 años puede ver las cosas con tranquilidad y distancia, y habiendo vivido varias generaciones del mundo de la tecnología y la multimedia tiene los galones necesarios...

OpenSignal es una aplicación (Android, iOS) que utiliza datos de uso móvil anónimos (no datos personales) procedentes de dispositivos de millones de usuarios en todo el mundo. Esos datos se utilizan para analizar las conexiones móviles, conocer qué operadores ofrecen mejor...
Por Nacho Palou -
6 ABR 2018

Cloudflare anunció hace unos días la disponibilidad para todo el mundo del DNS 1.1.1.1, un servicio alternativo y gratuito de DNS que proporcionan habitualmente las operadoras y proveedores de acceso a Internet. Una de las principales ventajas del 1.1.1.1 es la...

En este vídeo de auténtica arqueología informática se muestra cómo era el proceso completo de arrancar un ordenador NeXT, su interfaz con su característico Dock y ventanas (heredadas del Macintosh y con iconos diseñados por Susan Kare y luego re-heredados por...
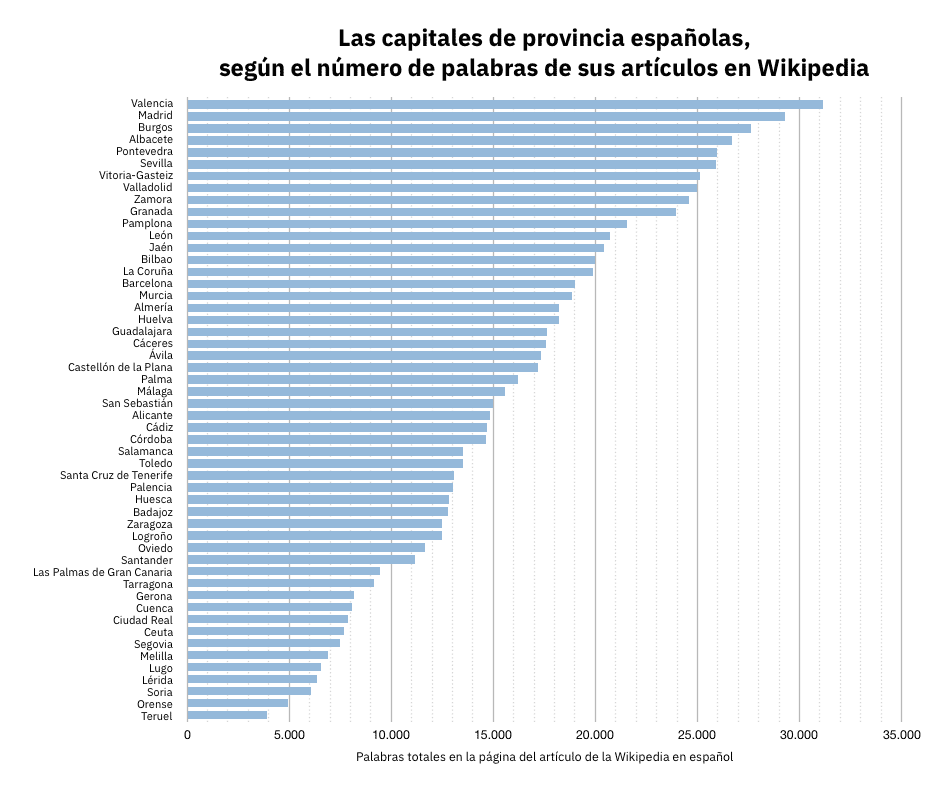
Me entretuve sacando estos datos: en el gráfico aparecen las 52 capitales de provincia españolas y cuánto hay escrito sobre ellas en Wikipedia. La fuente son las páginas de la propia enciclopedia; todas tienen una estructura bastante similar y en las...
Archive.org ha añadido unos 200 juegos procedentes de las antiguas máquinas de juegos y miniarcade, máquinas portátiles o maquinitas de entre los años de 1970 y de 1990, la mayoría de las cuales tenían pantallas LCD o fluorescentes — incluyendo Donkey...
Por Nacho Palou -
20 MAR 2018

Un cohete Soyuz con una etapa superior Fregat despegaba a las 18:10, hora peninsular española, del pasado 9 de marzo de 2018 para poner en órbita los cuatro últimos satélites de la constelación O3b para el operador SES. Los satélites O3b,...

Bajo el lema The web is under threat. Join us and fight for it la Fundación de la World Wide Web y su fundador e inventor Tim Berners-Lee hace un llamamiento para que en su 29º aniversario se puede «garantizar que...
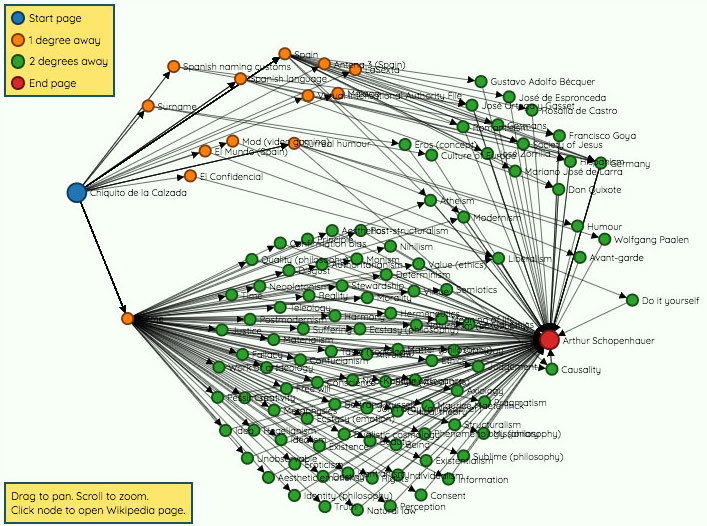
Six Degrees of Wikipedia lleva a la enciclopedia libre la teoría de Milgram de los seis grados de separación, que viene a decir que con eso de «un amigo de un amigo» estamos todos los habitantes del planeta conectados por unos...
Los vídeos de Layout Land son probablemente la mejor forma de pasar un rato aprendiendo sobre CSS, Flexbox y diseño web que hay actualmente. Son un admirable trabajo de Jen Simmons, una infatigable diseñadora de Mozilla que además es miembro del...
Después de reinventar los blogs con los hilos ahora va Twitter y reinventa los marcadores… con los marcadores. En la última actualización, que ya se está extendiendo por los tubos y por las aplicaciones para Android e iOS ahora es posible añadir...
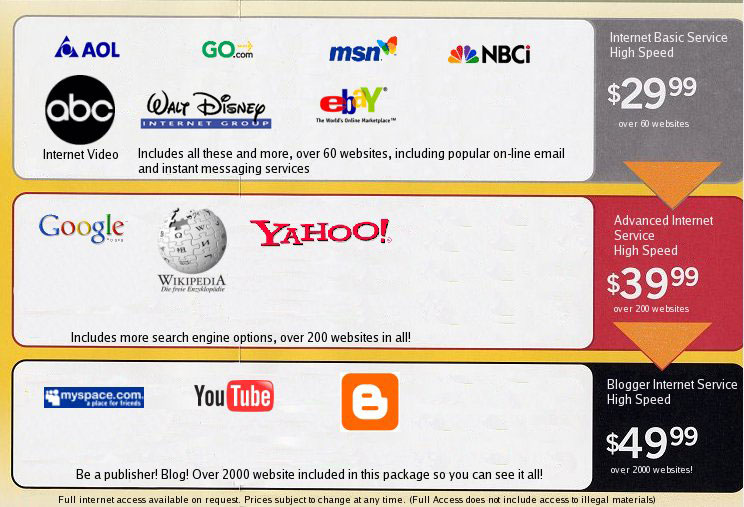
Le ha faltado tiempo a AT&T desde que la Comisión Federal de Comunicaciones (FCC) votara para abolir las normas que protegían la neutralidad de la red en los Estados Unidos el pasado mes de diciembre para empezar a ofrecer un programa...
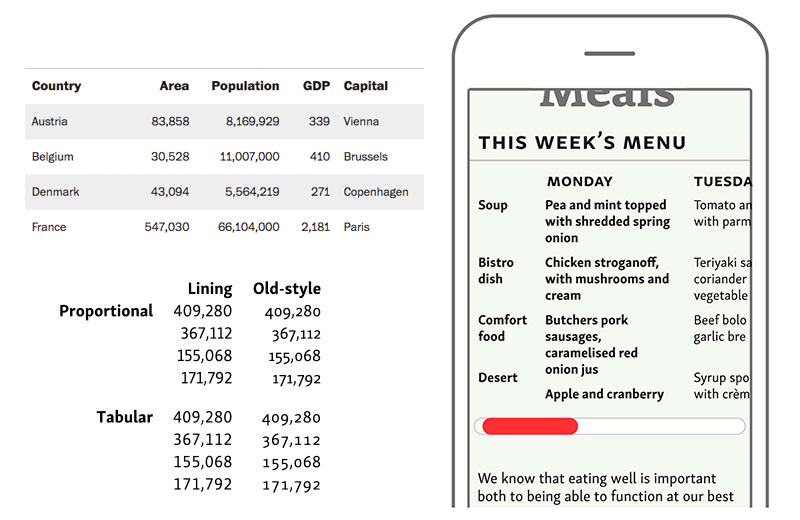
Richard Rutter ha publicado un muy completo artículo en A List Apart acerca del diseño de tablas en la web utilizando básicamente CSS y desde el punto de vista tipográfico. «Las tablas son para leerlas, no para mirarlas», es su máxima....

Declaración de Independencia del Ciberespacio(…) Estamos creando un mundo en el que todos pueden entrar, sin privilegios o prejuicios debidos a la raza, el poder económico, la fuerza militar, o el lugar de nacimiento.Estamos creando un mundo donde cualquiera, en cualquier...

Simple Print es una aplicación web que cumple eficazmente su función: produce a partir de artículos en la web archivos PDF limpios y optimizados para imprimir. Eso sí, sin imágenes, sin estilos y sin enlaces. Texto puro y duro. La herramienta...
Por Nacho Palou -
6 FEB 2018
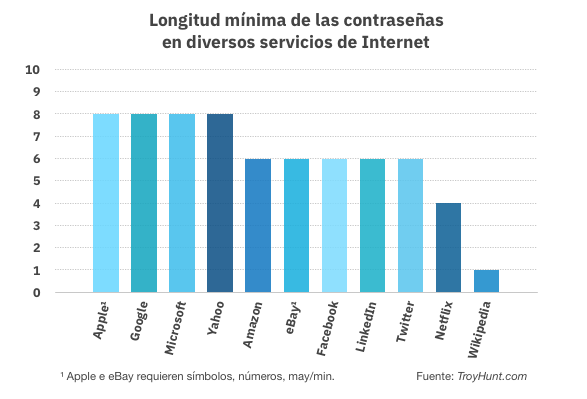
Todos sabemos que al elegir una contraseña para un servicio de Internet hay algunos consejos básicos que seguir: que no sea demasiado fácil de adivinar, que no sea la misma que en otros sitios, que no sea una palabra de diccionario...

Por favor desconéctate de internet. Esta es una revista offline de ensayos, ficción y poesía. Desactiva tu wifi para ver este número. Y por si alguien no sabe qué tiene que hacer para desconectarse de internet, que puede darse el caso,...
Por Nacho Palou -
6 FEB 2018

La aplicación web Population Estimator, de la NASA, calcula la cantidad de población y otros datos relacionados contenido dentro de una zona definida por el usuario sobre un mapa. La zona puede definirse usando dos herramientas, una de trazo libre (que...
Por Nacho Palou -
23 ENE 2018

Dejadme que os hable, hijos míos, acerca de los brutales días de las Guerras de Sindicación, RSS y Atom y RDF... [golpea el vaso en la barra] Un montón de programadores web escogieron bandos en aquellos días y nadie ha vuelto...

Uno de los más famosos videos virales de Internet es el conocido com BadDay.MPG. Hay quien incluso lo considera el «primer viral» como tal, pues data de 1997 (con permiso del Dancing Baby, que surgió en 1996). Pues bien, según cuentan...
En The Outline, We’d love to link you to this website but it’s impossible, Quería dar con la página (...) y empecé a hacer clics frenéticamente en cientos de redirecciones, pero viendo que cada redirección tenía indicaba la hora a la...
Por Nacho Palou -
11 ENE 2018

Sin ningún orden en particular: 8 Unsolved Science Mysteries From 2017 (National Geographic) The Best Books of 2017 (Kottke) 2017 in Pictures: The Best Science Images of the Year (Nature) The Best Products of 2017: Technology (Gear Patrol) The 10 Best...
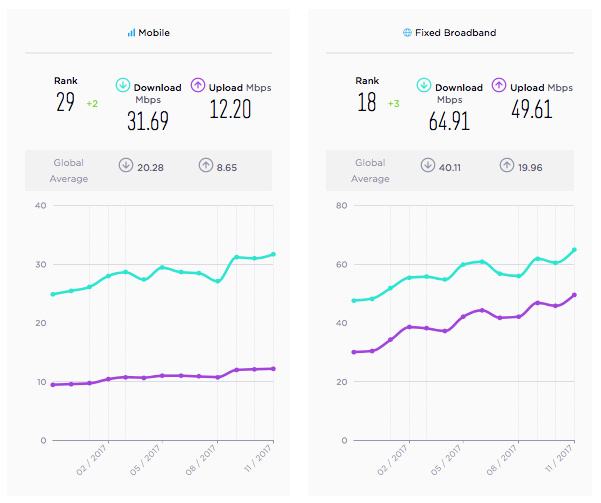
Según el Speedtest Global Index la velocidad promedio de internet creció más de un 30 por ciento en todo el mundo, llegando hasta los 40 megabits por segundo (Mbps) en conexiones terrestres y hasta los 20 Mbps en conexiones móviles. En...
Por Nacho Palou -
19 DIC 2017
La neutralidad de la red es un concepto básico del funcionamiento de Internet: todos los paquetes deben ser tratados igual independientemente de su destino y su origen. Pero tal y como había prometido Ajit Pai, el presidente de la Comisión Federal...
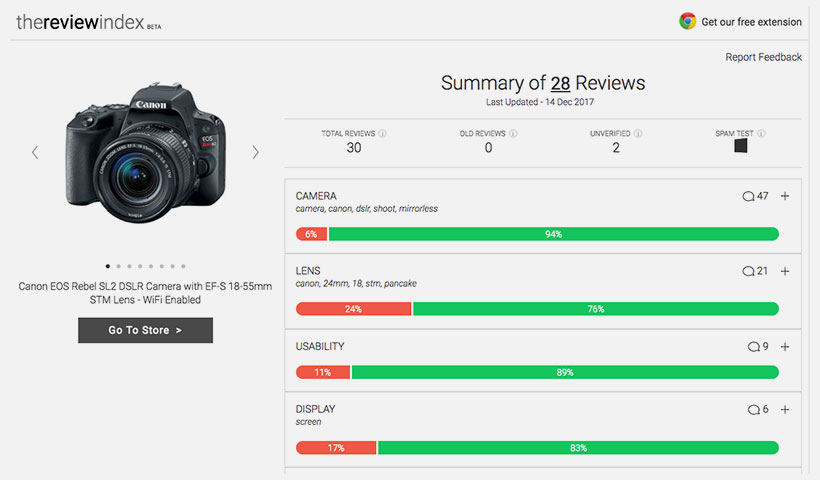
The Review Index es una herramienta que muestra todas posibilidades del análisis de datos semánticos y de unas buenas habilidades en cuanto a programación y uso de las APIs aplicadas a una buena idea. Es un servicio que básicamente extrae todas...
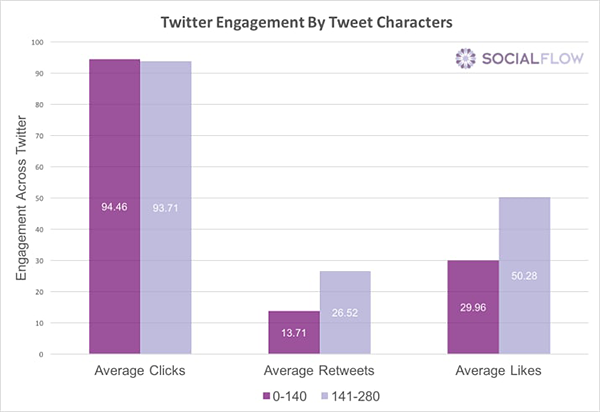
En BuzzFeed, Twitter Users Like Long Tweets More Than Short Ones,, SocialFlow analizó unos 30.000 tuits publicados entre el miércoles 29 de noviembre y el miércoles 6 de diciembre, contabilizando los clics, los reuits y los “me gusta“. Determinó que, de...
Por Nacho Palou -
11 DIC 2017

¿Cuánto cuesta una app? plantea una aproximación rápida y sencilla para quien haya tenido la proverbial genial idea y aspire a convertirla con ayuda de terceros en «algo que se coma el mundo». En otras palabras: es una forma casi instantánea...

Si no conoces a Calvin y Hobbes ya estás tardando: es una de las mejores tiras cómicas de las últimas décadas, un humor fino fino sobre un niño (Calvin) y su amigo imaginario (un tigre llamado Hobbes) cuya fantasía le lleva...
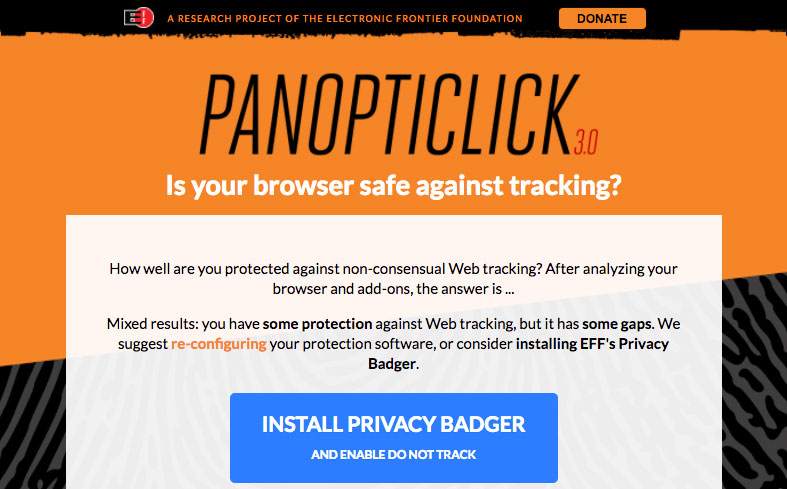
Panopticlick 3.0 es una versión totalmente renovada de la herramienta de la EFF (Fundación Frontera Electrónica) para concienciar a la gente sobre la cuestión de la privacidad en Internet y de paso dar algunas recomendaciones. La primera versión tiene ya algunos...

El pasado 27 de septiembre Los nativos digitales no existen sirvió como tema principal para inaugurar las Charlas #EnModoAvión, un ciclo de charlas sobre el impacto de la tecnología en la sociedad promovido por Cuatroochenta con la colaboración de la Universitat...

Ya se ha presentado Identidade Dixital, un proyecto de la Consellería de Cultura, Educación e Ordenación Universitaria de la Xunta de Galicia en el marco de la Estrategia gallega de convivencia escolar 2015-2020 con el que he tenido la suerte de...

Viktor Charyparn ha publicado un largo y muy interesante artículo con su punto de vista sobre el futuro de la nube y lo que vendrá más allá: The end of the cloud is coming. Como se puede ver por el título...

Eric Meyer es uno de los coautores de CSS: The Definitive Guide y el otro día publicó esta foto en Twitter con las tres últimas ediciones del libro. La cuarta es un pedazo de ladrillo de 1.016 páginas con, básicamente, «todo...
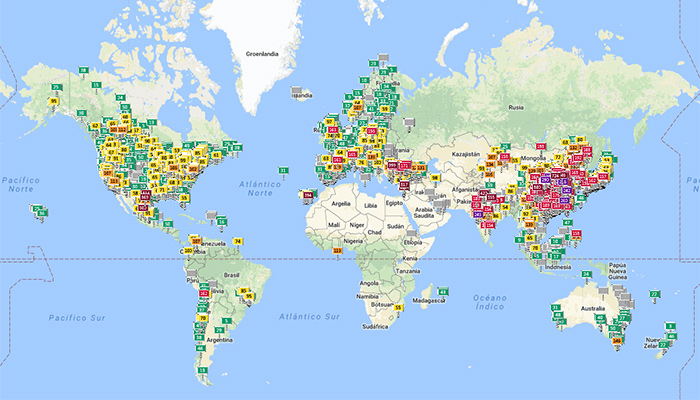
Air Pollution in the World es un mapa que muestra cuáles son los niveles de contaminación en todo el mundo, el índice de calidad del aire (ICA). El ICA se clasifica en seis niveles dependiendo de las mediciones de partículas en...
Por Nacho Palou -
13 NOV 2017

Desde Google Maps se puede ver el modelo del Halcón Milenario (o “Alcon” Milenario, wtf, antes de enviar la corrección) utilizado en las películas originales de Star Wars, a partir de 1977. “La emblemática nave, que aparece en varias de las...
Por Nacho Palou -
8 NOV 2017

Desde hace unas semanas algunas cuentas podían tuitear hasta 280 caracteres dentro de lo que Twitter consideraba una prueba piloto. Pero según se puede leer en Hoy Twittear es más fácil han decidido hacer de esa prueba piloto el estándar y extenderlo...

Marta Peirano explica en su charla en el Aquae Campus 2017 cómo las catedrales tecnológicas del siglo XXI están diseñadas para ocultar cosas y esconder el enorme poderío de las empresas que las controlan. Y para intentar que no pensemos en...
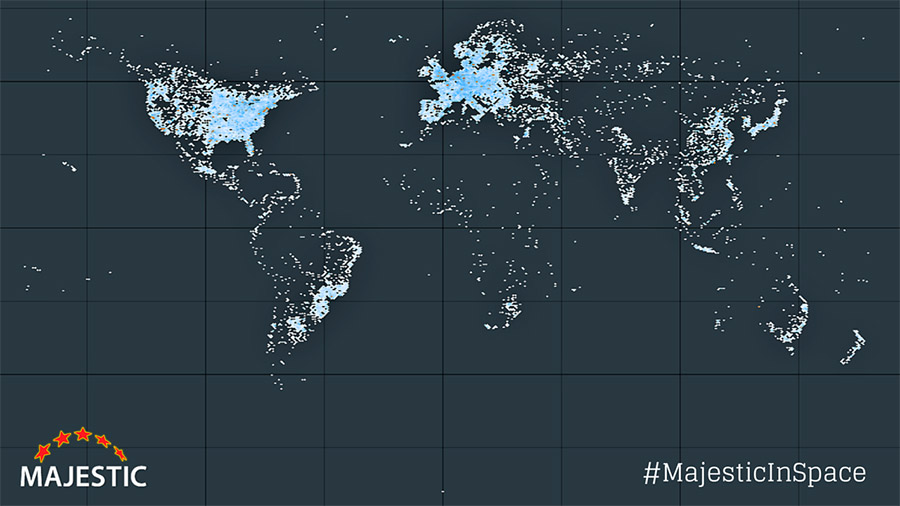
Cada punto simboliza uno de los centro de datos con servidores de Internet más representativos El efecto que se produce al representar los servidores de internet sobre la superficie del planeta (ojo: no están a escala) es básicamente un mapa del mundo,...

Access Mars es un “experimento” de realidad virtual vía web desarrollado por Goolge y por la NASA que permite “explorar en 3D una réplica de la superficie de Marte, tal cual la captó con fotografías digitales el rover Curiosity.” Las imágenes...
Por Nacho Palou -
23 OCT 2017

Mercurio, Venus, Ceres, Ío, Europa, Encélado, Titán, Plutón,... son algunos de los satélites y planetas que Google ha añadido a su mapas. Hasta ahora se podían visitar a través de Google Maps la Luna y Marte —además de la Estación Espacial...
Por Nacho Palou -
17 OCT 2017

Algunas de las preguntas a las que respondió Elon Musk en Reddit estaban relacionada con el acceso a Internet desde Marte. A una distancia máxima de 22 minutos-luz “navegar por la web puede ser un poco desesperante”, ya que eso significa...
Por Nacho Palou -
16 OCT 2017

El sábado pasado estuve en el estreno de Espacio Madresfera, la grabación del podcast de Madresfera con público en el Espacio Fundación Telefónica, un evento que tendrá periodicidad mensual. En esta ocasión el tema era «el lado menos amable de Internet»...

Mientras Puerto Rico se recupera de los daños causados por el huracán María, Alphabet (Google) ha recibido una “autorización experimental” de la FCC (el equivalente a la CMT, en España) para desplegar los globos de su proyecto Loon y ofrecer conexión...
Por Nacho Palou -
9 OCT 2017

Fotografía: Microsoft / Run Studios Con 6.600 km de longitud, hasta 3.350 metros de profundidad y 160 terabits por segundo de capacidad el cable submarino Marea —impulsado por Microsoft y Facebook y construido Telxius (filial del Telefónica)— es el cable submarino de...
Por Nacho Palou -
25 SEP 2017
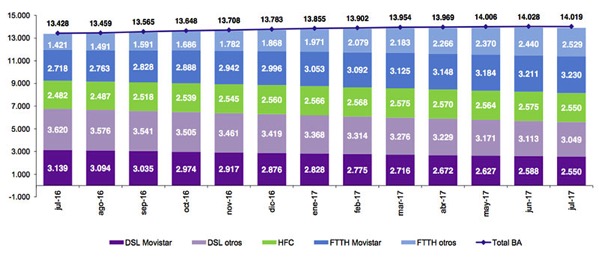
Según acaba de publicar la Comisión Nacional de los Mercados y la Competencia en julio de 2017 las líneas de fibra óptica superaron a las líneas ADSL por primera vez, con un total instalado de 5,7 millones de abonados para las...

El Ministerio de Energía, Turismo y Agenda Digital tiene en marcha una consulta pública con el objetivo de recabar propuestas e información relevante que quieran aportar los interesados para la elaboración de la Estrategia Digital para una España inteligente. El objetivo es...
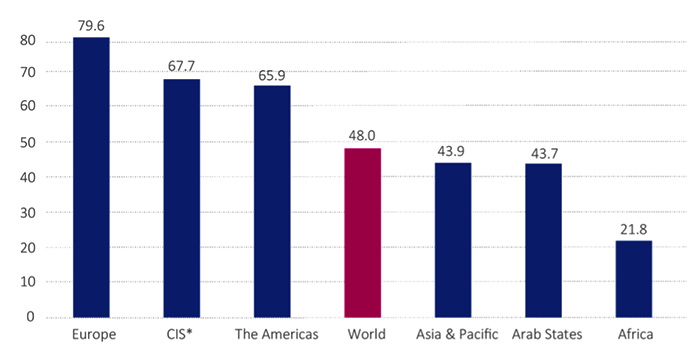
Porcentaje del uso de internet, por regiones en septiembre de 2017. Gráfico de ITU World Telecommunication Indicators Database. Para CIS (Rusia y antiguos estados de la URSS) los datos son calculados. Según el último informe de la Unión Internacional de las Telecomunicaciones...
Por Nacho Palou -
19 SEP 2017

En Time, Delta Plane Flew Straight Through Hurricane Irma and the Internet Couldn't Look Away, El vuelo 302 de Delta fue el último avión comercial que salió del Aeropuerto Internacional San Juan Luis Muñoz Marín de Puerto Rico el miércoles por...
Por Nacho Palou -
7 SEP 2017
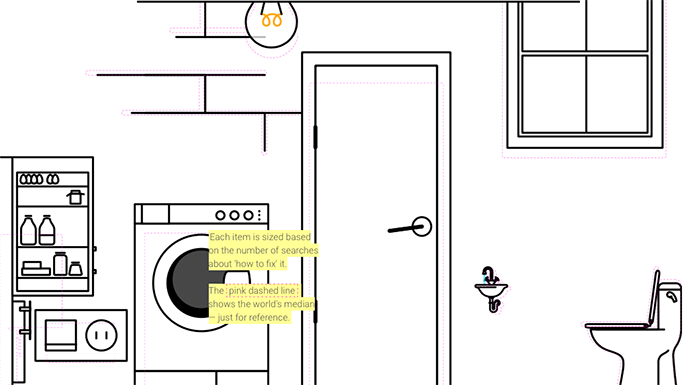
How To Fix a Toilet es un simpático ensayo visual de Xaquín G.V. en colaboración con Google News Lab. El proyecto explora qué búsquedas relacionadas con Cómo... arreglar, aprender o hacer cosas de todo tipo: desde cómo arreglar un ventana, una...
Por Nacho Palou -
6 SEP 2017

DeepL es un nuevo traductor de idiomas de los creadores de Linguee, que de momento tiene siete idiomas (incluyendo español, pero también inglés, francés, alemán entre otros) y cuya calidad –al menos tras unas cuantas pruebas rápidas variadas– es aparentemente muy...

Facebook ha mostrado un mapa del mundo creado con una nueva tecnología que combina fotografías de satélite de alta resolución (de DigitalGlobe) que luego se mejoran mediante algoritmos de inteligencia artificial y se filtran con los censos de población de cada...

En Motherboard, A Redditor Archived Nearly 2 Million Gigabytes of Porn to Test Amazon’s ‘Unlimited’ Cloud Storage, ¿Qué significa almacenamiento de datos "ilimitado" en la práctica? Los planes de almacenamiento de datos ilimitados ofrecidos por muchas compañías para promocionar su capacidad...
Por Nacho Palou -
26 AGO 2017
Al grano: Editar los tuits (estilo Telegram). Si en otras aplicaciones de mensajería privada/pública esto es perfectamente posible, ¿por qué no en Twitter?. O se podría permitir la edición durante los primeros 15 minutos tras su publicación (estilo Basecamp). O guardar...
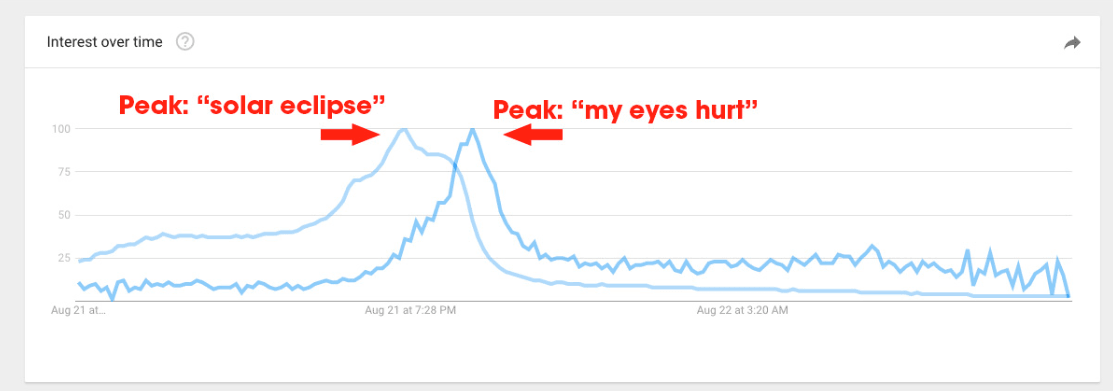
En The Next Web, People rushed to ask Google why their ‘eyes hurt’ after the solar eclipse, Mientras que las búsquedas para el término “eclipse solar” aumentaron gradualmente alrededor de las 17.30, se dispararon a las 18.25 y alcanzaron su pico...
Por Nacho Palou -
23 AGO 2017

En Great Big Story han recopilado varios de sus vídeos sobre virales y memes de Internet, lo que permite descubrir en diez minutos algunas de las historias detrás de esos vídeos que llevan desde los años 90 circulando por la red...
Hvper es un agregador rudo y supervitaminado, una mezcla en plan batiburrillo de todo lo que se publica y se lee por ahí, sin filtro ni criterio alguno excepto que es popular. Y quizá por eso funcione. Es una creación de...
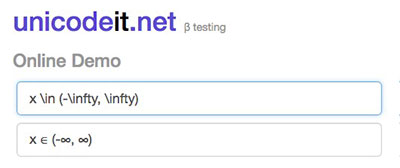
Unicodeit.net es una útil herramienta para todos aquellos que tengan que bregar con expresiones matemáticas en documentos de todo tipo. LaTeX es la herramienta más popular para editar documentación de tipo técnico y científico. Y Unicode el estándar de codificación de...
En este impresionante trabajo de la Share Foundation se analiza El tejido humano de Facebook, donde miles de empleados interactúan cada día. Los datos provienen directamente de LinkedIn: se rastrearon los perfiles de gente en cuyo perfil se indicaba que trabajan...
Versus es una herramienta muy útil para comparar directamente dos productos competidores del mismo segmento. Basta teclear los nombres separados por un «vs» (versus) para ver surgir los datos, ordenados en cómodos apartados. Versus tal vez no tenga toda la información...

Adobe ya había liquidado Flash a finales de 2015 sustituyéndolo por Adobe Animate CC, una herramienta de animación web para desarrollar contenido HTML5 que, de todos modos, era capaz de generar contenido en Flash. Pero según cuentan en Flash & The Future...
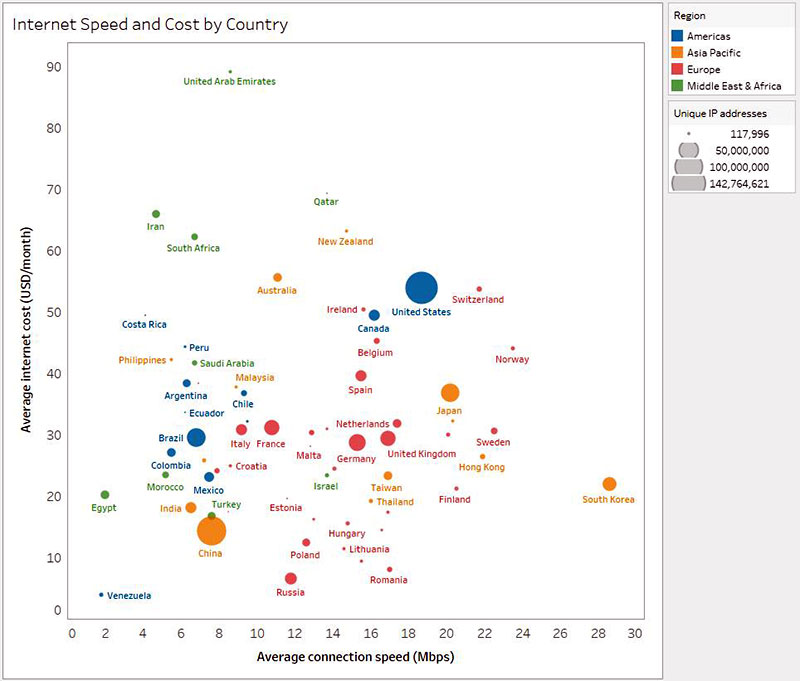
Según esta imagen el coste de una conexión a internet ADSL/cable, por encima de los 60 Mbps y sin límite de datos, como las que se comercializan mayoritarizamente en España, varía entre los 3 y los 52 euros mensuales. Esto no...
Vista de la Tierra desde la Cúpula de la ISS, observatorio y puesto de control de la Estación Espacial Internacional, cortesí de Google Street View. Desde ahora es posible recorrer la Estación Espacial Internacional en Google Street View y cotillear algunos de...
Por Nacho Palou -
21 JUL 2017

El Armstrong Flight Research Center (AFRC) de la NASA ha publicado en su canal de YouTube unos 300 vídeos históricos, clips y fragmentos de vídeo grabados en las últimas décadas. De entrada el AFRC tiene previsto incorporar unos 500 vídeos, en...
Por Nacho Palou -
19 JUL 2017

Charlie Deck de BigBlueBoo ha creado este Explorador fractal que hace buen uso de la potencia de los navegadores actuales para crear una visualización de fractales totalmente interactiva y extremadamente fina y ágil. Al arrancar se puede ver el conjunto de...

Interesante reflexión esta de Mike Loukides para el blog del Radar de O’Reilly: ¿Y si construimos la internet que siempre habíamos deseado? Viene a raíz de la batalla por la neutralidad de la red, pero va mucho más allá. Hastiado por...
La nueva aplicación de Copia de seguridad y sincronización de Google funciona en diferentes sistemas operativos de escritorio (MacOS, Windows) y permite hacer algo que mucha gente llevaba tiempo esperando: utilizar Google Drive para almacenar una copia de seguridad completa del...

Este vídeo de YouTube muestra la evolución de YouTube desde su nacimiento. Que manera más apropiada de hacerlo. Lejos quedan aquellos tiempos de 2005 en que apareció en la red. ¿Que cómo veíamos antes los vídeos? Never forget RealPlayer™. Si no...

Por estas fechas ya es habitual el Amazon Prime Day, una especie de híbrido entre el Black Friday, las rebajas de verano y los Reyes Magos. La hora mágica son las 00:00. Las ofertas aparecen y desaparecen junto con una cuenta...

Desde hace unos días Instagram ha ido desplegando una nueva opción de configuración relativa a los comentarios, con el objetivo de combatir a los trolls y a los spammers y la difusión de discursos de odio. Inicialmente disponible en inglés, ya está...
Por Nacho Palou -
3 JUL 2017
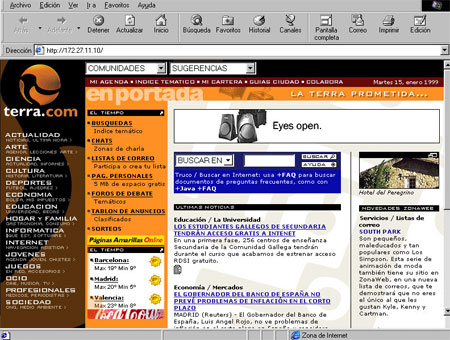
El portal Terra, icono máximo de la burbuja de internet en España, cierra su web tras dos décadas una historia marcada por grandes éxitos y no menos grandes fracasos.

El Centro Universitario de Formación e Innovación Educativa de la Universidade da Coruña ha organizado para este mes de julio el curso Docentes conectados, el reto de educar en la era digital, con estos objetivos: Facilitar un espacio rico de debate...

Cualquiera que haya hablado conmigo del asunto o que me haya leído en los últimos años –y en especial en los últimos meses– sabe lo que opino de los nativos digitales: simple y llanamente que Los nativos digitales no existen. Por...

Los comentarios en los artículos del New York Times son tan numerosos que sería misión imposible garantizar que las páginas tuvieran el aspecto respetable y calidad como les gustaría a los editores y anunciantes. De modo que la publicación tan solo abre...
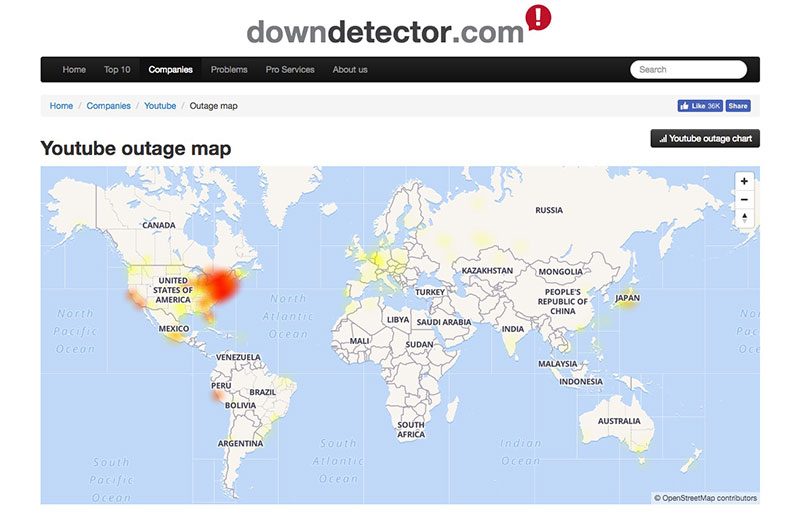
Down Detector (en español DetectorDeFallos.es o DownDetector.es) es un sistema de monitorización y alertas del tipo ¿Seré yo, maestro? que permite disipar rápidamente las dudas sobre si el problema de acceso lo tienes tú o es un problema global. La forma...

Páginas que muestran «lo que sucede en Internet en tiempo real» hay muchas; pero The Internet in Real Time es especialmente abundante en servicios; además de todos los clásicos incluye Uber, Airbnb, Bitcoin, Apple Pay, Booking, TripAdvisor… También es muy colorida...

El Govern ha aprobado un proyecto de ley con el que pretende regular lo que sucede con nuestras «posesiones» digitales cuando morimos. Pretenden que cualquiera pueda hacer un testamento en el que se incluyan nuestras comunicaciones electrónicas, nuestras cuentas en las redes...

A Susana Lluna y a mí nos invitaron a la tercera edición de PediaTIC para que explicáramos aquello de que Los niños no son nativos digitales, porque los niños no saben usar internet, aunque nos pueda parecer todo lo contrario, y...

Ya casi no es noticia dado que hace años que ha dejado de ser una empresa relevante en el mundo de Internet, a pesar de todo lo que fue… Pero se me hacía raro dejar pasar el hecho de que desde...
Sara Kendell once read somewhere that the tale of the world is like a tree. The tale, she understood, did not so much mean the niggling occurrences of daily life. Rather it encompassed the grand stories that caused some change in the...
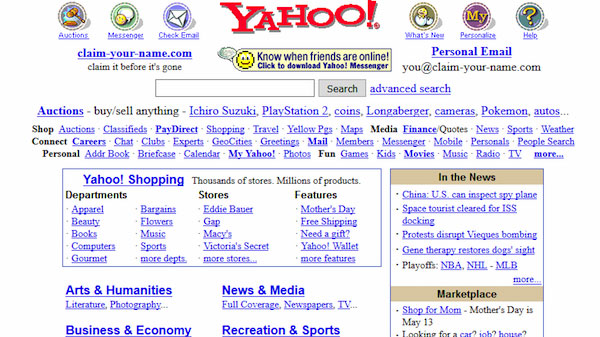
¡Preparen las gafas protectoras! El Web Design Museum atesora una recopilación de unos 800 diseños históricos de páginas de la World Wide Web. Nada mejor para recordar los viejos tiempos y disfrutar del horror de los diseños de la época, muchos...

WLRD (antes conocida como eeGeo) es una empresa que se dedica a los mapas, más concretamente a la apasionante y complicada tarea de hacer que mapas y callejeros se puedan entender claramente. Su planteamiento es simple: a partir de los datos...
Dentro de cinco años habrá en internet más máquinas hablando entre sí (Machine-to-machine communication, M2M, conversaciones ilegibles para las personas) que personas usando móviles, tabletas y ordenadores para comunicarse con otras personas, según el informe Cisco's annual internet forecast, vía Quartz,...
Por Nacho Palou -
9 JUN 2017
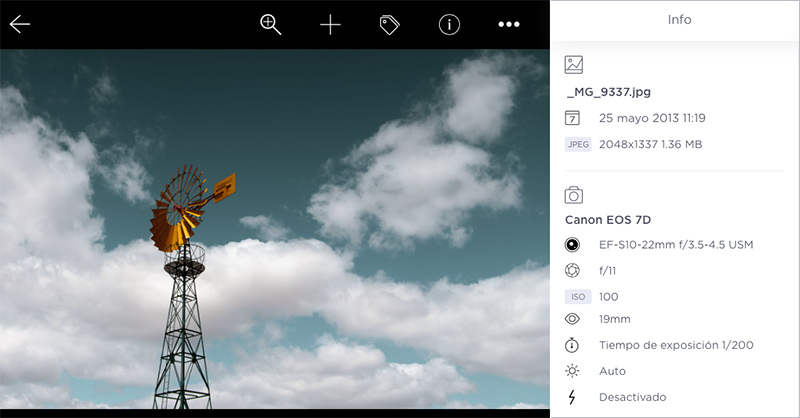
Irista es un servicio online de Canon para guardar y organizar fotografías, independientemente de dónde se encuentren almacenadas: en Flickr, en Facebook, en el disco duro del ordenador o en el móvil. Eso sí, sólo fotografías, no vídeos. Las fotografías guardadas...
Por Nacho Palou -
6 JUN 2017

El datacenter de Sarenet en el edificio de Tata Communications en el Parque Tecnológico de Bizkaia. El otro día dimos un paseo por las instalaciones que Sarenet tiene en el Parque Científico y Tecnológico de Bizkaia, muy cerca de Bilbao, dentro de...

Me encontré en IAmPuzzlr con una simpática infografía sobre Las leyes y efectos de Internet (Streissand, Poe, Cunningham…) donde se mencionaba la Constante de Wadsworth, que viene a definirse así: El primer 30% de cualquier vídeo no contiene ningún tipo de...
En inglés, la Lista de listas de listas de Wikipedia contiene una amplia lista de listas que contienen listas, tal y como su nombre indica. El artículo en sí tiene forma de lista e incluye las más interesantes listas de listas,...
A diferencia de la mayoría de supermercados online (incluyendo el de Amazon), Ulabox ofrece la posibilidad de comprar productos frescos de mercado a través de internet: carne, pescado, verduras..., además de refrigerados y congelados. He tenido ocasión de probar algunos de...
Por Nacho Palou -
29 MAY 2017

Desde hace ya algún tiempo la versión preliminar de Chrome Canary permite acceder a la que será una importante puesta al día del navegador Chrome. Está disponible para macOS, Windows (32 y 64 bits) y Android y suele añadir funciones nuevas...
Por Nacho Palou -
29 MAY 2017
Antes de que se desencadenara el conflicto en el 2011, Siria era una sociedad moderna y dinámica. Muchos de los ciudadanos sirios tenían una vida similar a la tuya, y la música, la moda y el deporte eran algunos de los...
Por Nacho Palou -
24 MAY 2017

Hacienda se pone seria con grandes youtubersy éstos se marchan de España vs. Solo 1 de cada 10 youtubers españolesvive en exclusiva de su canal ¡Vaya! Quizá es que como decían en otro artículo es que sólo son «millonarios en clics»....

Hoy 17 de mayo se celebra el Día de Internet, así que es un día de gran regocijo. Draw my Life en Español lo celebra con una explicativa breve historia acerca de la más increíble red mundial de comunicaciones, que digo,...
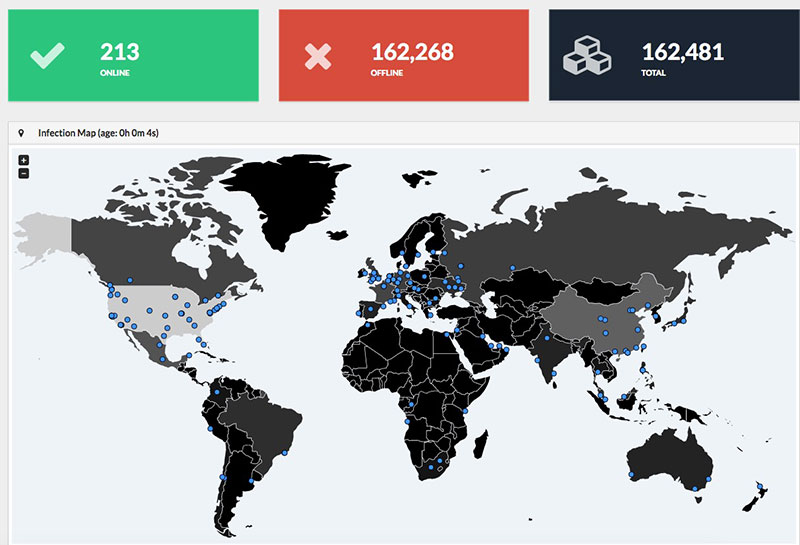
MalwareTech ha dado a conocer una web que recopila en tiempo real en un mapamundi los ataques del ransomware WannaCry a medida que se van sucediendo – también los de otros tipos de botnets. Además del mapa instantáneo hay versiones donde...
Los colores más populares situados en una rueda de color (tono/saturación) En The Colors Used by the Ten Most Popular Sites Paul Hebert desgrana los colores más utilizados en los diez sitios web más populares (de Google a Twitter, pasando por Facebook...

Google Maps es para encontrar los sitios. Google Earth es para perderse.– Gopal Shah, jefe de producto / Google Earth En este episodio de Nat and Friends se explica con bastante detalle cómo se crean las imágenes de Google Earth –...
Igual pero mejorado. Así es como es el nuevo diseño de YouTube, más limpio y minimalista que el conocido hasta ahora. De momento el nuevo diseño no está implementado de forma general, pero es posible activarlo y empezar a disfrutarlo desde...
Por Nacho Palou -
3 MAY 2017
Twitter Text Splitter es una sencilla herramienta en la que basta pegar cualquier texto para que sea cómodamente «troceado» en tuits de 140 caracteres, coincidiendo elegantemente con los finales de palabras. Una vez pegado en la primera caja el párrafo completo...
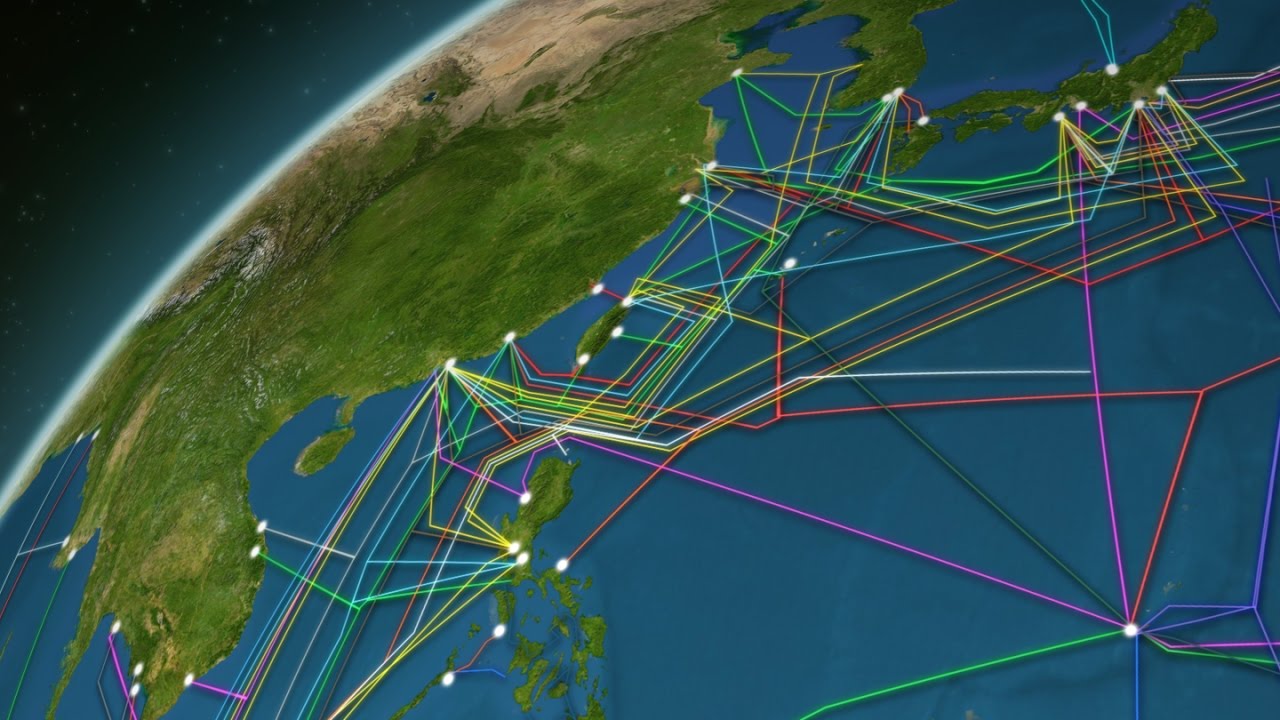
Business Insider ha actualizado con esta animación y algunos datos interesantes sobre los 900.000 km de cables submarinos que transportan las comunicaciones del planeta, incluyendo todo lo relacionado con Internet. Y es que aunque la red global también cuenta con el...

El Centre for Computing History tiene este interesante documento de más de una hora sobre el trabajo de Jim Boulton, arqueólogo digital. Uno de sus proyectos para la exposición 64 bits, que acaba de terminar, fue recrear la historia de Internet...

Font Map es una web creada por el estudio de diseño IDEO que sirve para encontrar tipografías «similares». Tiene un lado bueno/malo a la vez: sólo incluye las tipografías de Google Fonts. De este modo se pueden comparar sólo las tipografías...
Una técnica que todos hemos experimentado en primera persona al visualizar ciertas infografías es el llamado scrollytelling, cuyo nombre es un juego de palabras que combina scroll («desplazamiento») con storytelling («contar historias»). En esencia el usuario interactúa con un contenido y...
Photofeeler es una puesta en práctica bastante resultona de la forma científicamente correcta de elegir una imagen de perfil para las redes sociales, esa «maldición» de la que hablábamos el otro día. Este servicio lleva a la práctica algunas de esas...

En un sesudo trabajo de un grupo de psicólogos titulado Choosing face: The curse of self in profile image selection se pidió a varios participantes que cedieran una docena de fotos de perfil para redes sociales y a continuación que eligieran...

Bob Taylor en el PARC Soy perfectamente consciente de que la Internet que disfrutamos en la actualidad es fruto del trabajo de muchísimas personas a lo largo de muchos años, pero si alguien puede optar al título de padre –al menos intelectual–...

Al parecer YouTube tiene “en secreto” un modo nocturno con cual se puede cambiar el habitual fondo blanco por un fondo negro, más apropiado para ver vídeos en la oscuridad. La opción se puede activar desde el navegador web Chrome siguiendo...
Por Nacho Palou -
17 ABR 2017

Bill Gates dice estar “entusiasmado con el potencial que ofrece la realidad virtual”. Tanto que tiene una edición de su blog Gates Notes en la plataforma Samsung VR donde comparte sus experiencias e ideas en forma de vídeos de 360° dedicados...
Por Nacho Palou -
12 ABR 2017
Esta extraña pero curiosa lista se corresponde a las preguntas más preguntadas a Google cada mes. En total llega a las mil consultas más habituales, que aunque naturalmente es algo que cambia con el tiempo y con los países. Pero sin...
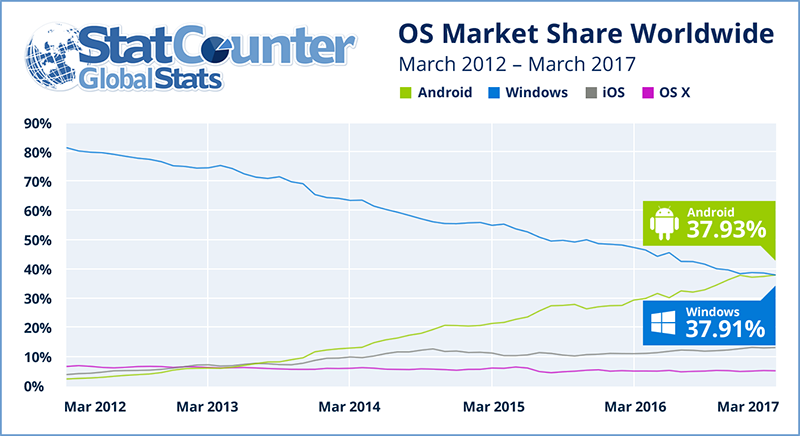
En TechInsider, Google's Android just overtook Windows to become the No. 1 platform for getting online, Windows de Microsoft ya no es el sistema operativo dominante en el mundo, una posición que mantenía desde los años de 1980. Windows ha sido...
Por Nacho Palou -
4 ABR 2017

Tipografía web mejor para una Web mejor Esta es la premisa es la que se basa el curso Better Web Type desarrollado por Matej Latin. Son diez lecciones y tutoriales que se reciben por correo electrónico periódicamente con temas que cubren...
Por Nacho Palou -
24 MAR 2017

No se le pueden pedir peras al olmo, y eso es así. Al menos de momento. Pero la app Univers (por ahora para iOS) tiene el mérito de ofrecer las herramientas necesarias para crear una página web “en minutos”, incluyendo el...
Por Nacho Palou -
23 MAR 2017
Algunas veces, cuando estoy mirando una página web, desearía que saliera una especie de ventana desde la parte de arriba de la pantalla, oscureciendo todo lo que estoy intentando leer, para contarme cómo suscribirme un boletín en el que no esté...
SpaceX, la compañía espacial de Elon Musk, ha solicitado oficialmente a la FCC permiso para lanzar 11.943 satélites de órbita baja con idea de crear una gigantesca red que rodee nuestro planeta y proporcione comunicaciones de banda ancha en cualquier lugar...
O eso es lo que dice la descripción de TXT.FYI, un sistema de publicación en el cual no hay más que escribir, publicar y listos — el texto queda online. Sin crear cuenta, sin contraseñas, ni códigos de seguimiento ni de...
Por Nacho Palou -
16 MAR 2017

The Internet Warriors es un documental producido por el diario The Guardian (en inglés, subtitulado) en el cual aparecen algunos trolls de internet en persona, ¿Por qué tanta gente utiliza internet para acosar y para amenazar a los demás, llevando hasta...
Por Nacho Palou -
15 MAR 2017
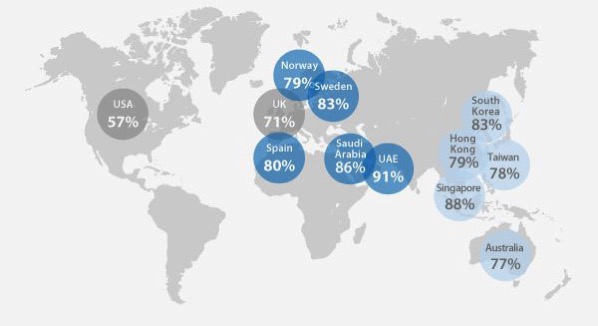
Los 10 mercados con más penetración de smartphones + USA y UK para comparar Como complemento al informe La Sociedad de la Información en España SiE[16 resulta interesante echar un ojo a Tendencias de internet, estadísticas y datos en los Estados Unidos...
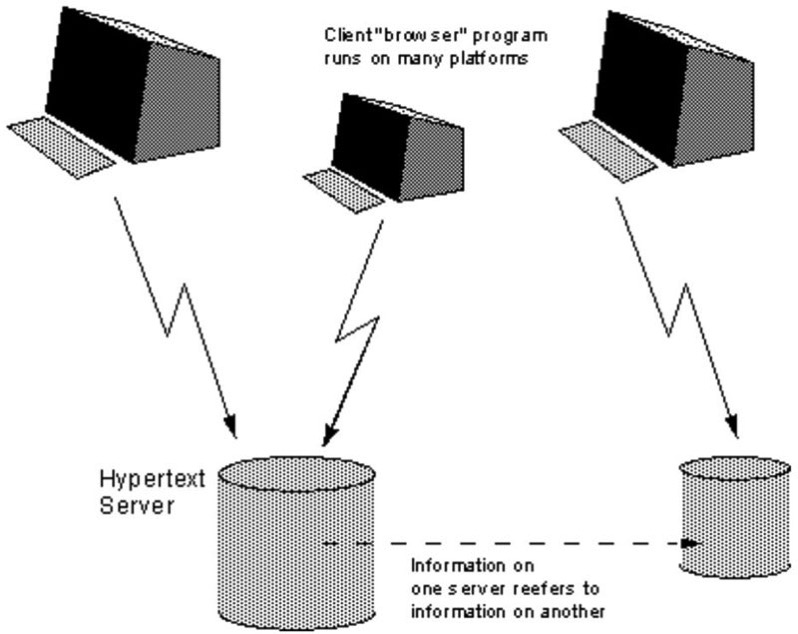
En el día en el que se cumplen 28 años de que Tim Berners–Lee presentara su primera propuesta de lo que terminaría siendo la web que hoy conocemos su creador escribe en The Guardian acerca de tres cosas que hay que...

El nuevo reCaptcha de Google es una especie de «captcha sin captcha», una forma de distinguir si quien quiere acceder a un servicio o página es un ser humano o un robot pero sin mostrar un «reto» para comprobar su humanidad...
En /r/Futurology (una interesante sección del agregador Reddit) han planteado una Iniciativa sobre la calidad de las fuentes (SQI). Básicamente lo que hace es añadir un icono de color junto con los enlaces de las noticias que se seleccionan. Cuando no...

Perspective es una herramienta de Google que utiliza el aprendizaje máquina para “conocer” y puntuar el tono y el impacto que tiene un texto en una conversación, en un tuit o en un comentario. La idea es que los desarrolladores y...
Por Nacho Palou -
6 MAR 2017
La Fundación Mozilla ha anunciado la adquisición de Pocket, más exactamente de Read It Later, Inc. (nombre de la empresa y originalmente de la aplicación de 2010, que sería posteriormente renombrada a Pocket en 2012). También consiguió muchas menciones como «mejor...

Ya está en línea el informe La Sociedad de la Información en España SiE[16, que con ésta alcanza ya las 17 ediciones. Algunas de sus cifras más destacables: El 80,6% de la población española usa Internet; el 98,4% en la franja...
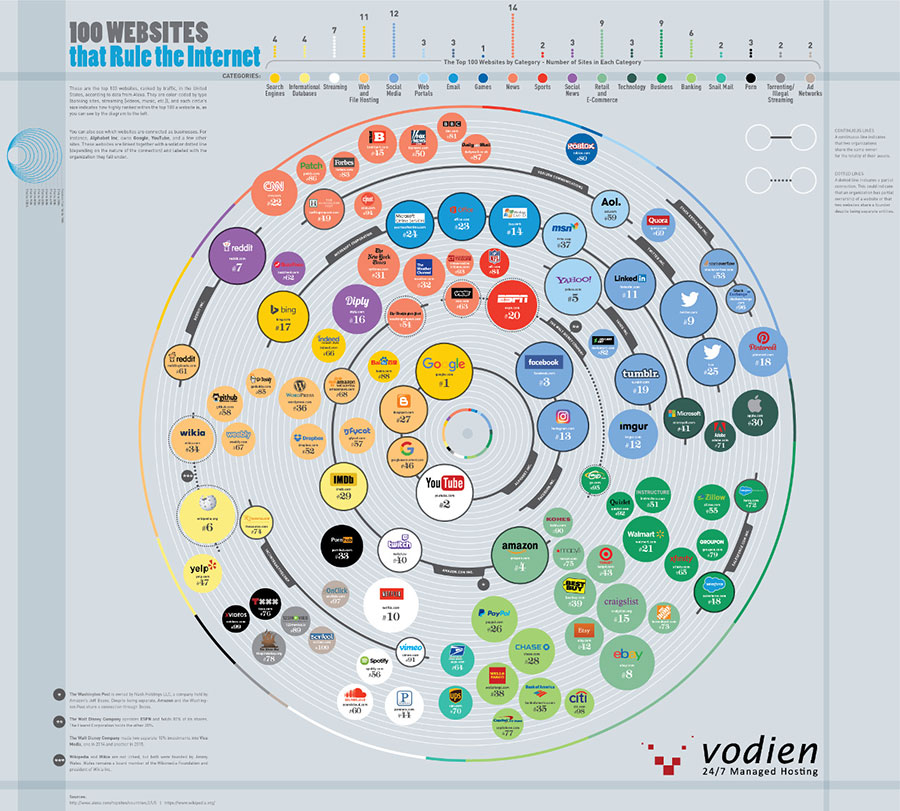
Los 100 sitios más visitados de Internet, según Alexa. [Zoom para ver los detalles] Ya sabemos que el ranking Alexa no es gran cosa en cuanto a fiabilidad y precisión en el detalle de sus datos, pero a grandes rasgos separa a...
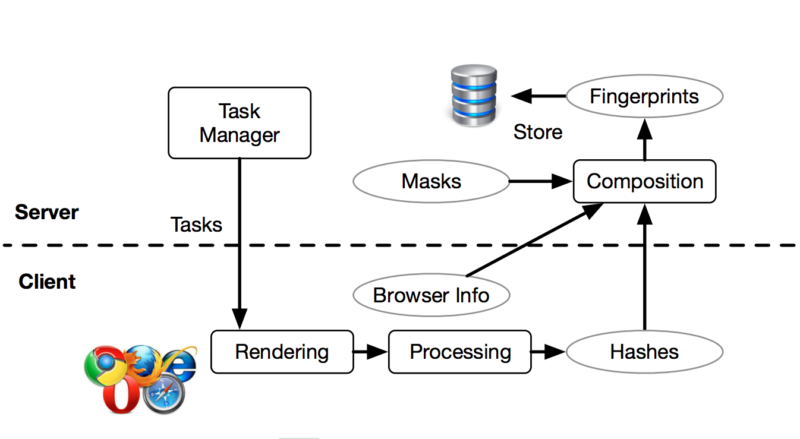
Ars Technica da cuenta del trabajo de unos investigadores que han desarrollado un método efectivo al 99% para identificar a un usuario que navega por la web aunque utilice diferentes navegadores en un mismo ordenador. Esto normalmente se hace a través...
Este gráfico de Business Insider con datos recopilados por Statista (a partir de las cifras dadas por las compañías) compara el crecimiento de las principales redes sociales (Facebook, Instagram, Snapchat y Twitter) y de las aplicaciones de mensajería WhatsApp y Messenger...
Por Nacho Palou -
13 FEB 2017

Colors of Control en el grupo Control Panel de Flickr (C) Mя.Møпstɛr Control Panel es un grupo de Flickr dedicado a los paneles de botones, indicadores y lucecitas de todo tipo de artefactos, desde ordenadores a centrales nucleares o centrales geotérmicas. Este...
Vive un Internet Seguro es una iniciativa de Google y la OCU que recopila consejos y recomendaciones que cubren todos los aspectos de la seguridad y privacidad en Internet. Ahí se puede aprender fácilmente desde cómo proteger un router a gestionar...

Un par de investigadores del Departamento de Informática de la University College London han publicado un interesante trabajo sobre bots en Twitter que han titulado The ‘Star Wars’ botnet with 350K+ Twitter bots. Allí se relata, diría que de forma un...

What Comes is the Future es un documental de Matt Griffin, creador de Bearded trata de resumir en una hora decenas de conversaciones con figuras históricas de la World Wide Web, comenzando por el llamado «padre de la Web» (Tim Berners-Lee)...
El navegador Neon de Opera es una interpretación “fresca y divertida” del navegador web Opera. Puede descargarse gratis para Mac y Windows. Neon usa la imagen de fondo del escritorio del sistema operativo del ordenador y la incorpora en la ventana...
Por Nacho Palou -
14 ENE 2017

Creo que no hemos visto visto más que la punta del iceberg. El potencial de lo que internet puede hacer a la sociedad, tanto en lo bueno como en lo malo, es inimaginable. Estamos en la cúspide de algo que será...
Por Nacho Palou -
14 ENE 2017
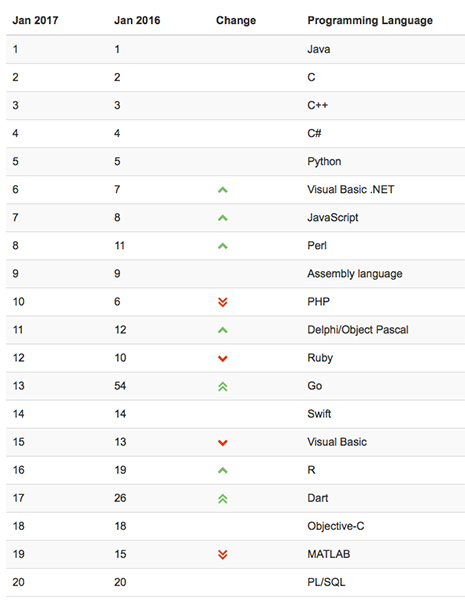
El lenguaje Go no es el más utilizado (por delante están los grandes clásicos: Java, C, Python, Perl, PHP,...) pero según el Tiobe Index el lenguaje de programación de Google ha disparado su popularidad en el último año, saltando nada más...
Por Nacho Palou -
12 ENE 2017

Lo cuenta Google como quien no quiere la cosa en Google+ Hangouts API Support FAQ: a partir del 25 de abril de 2017 la API de Hangouts dejará de funcionar, con lo que las aplicaciones de terceras partes que complementan el funcionamiento...

Cómo es un contrato de «Condiciones del Servicio» y cómo podría ser. Fuente: TNW En TheNextWeb lo tienen claro: It’s time for apps’ terms and conditions to ditch the legalese. Como ejemplo dicen que según un reciente informe aunque la mitad de...

En estos días en los que muchos «nativos digitales» van a recibir o ya han recibido un móvil o una tableta. Y el mito de los nativos digitales asomará de nuevo su cabeza con lo que nadie les contará cómo hacer...
Cada notificación irrelevante que envías daña gradualmente tu marca. ¿Quieres realmente quieres que sea conocida como esa empresa molesta que envía basura a los usuarios simplemente para atraer más visitas? Los usuarios merecen algo más.– John Saito, diseñador UX de Dropboxex-Google,...

Opine lo que opine la gente acerca de Internet, lo cierto es que Adam el del entretenidísimo Adam Ruins Everything (en TruTV) desmonta en dos minutos algunos mitos acerca de lo mala que es Internet. Como por ejemplo que «la gente...

Facebook no es gratis. Pagas por usarlo: con tu identidad Al menos eso opina Adam Conover, que parodia el comportamiento a lo «gran hermano» de Facebook en un sketch de Adam Ruins Everything (TruTV), una serie divulgativa sobre ideas falsas que...

Cuando se trata de mover una gran cantidad de datos a través de internet el proceso puede ser largo y lento, incluso utilizando conexiones rápidas: «mover petabytes o exabytes [miles de terabytes o miles de petabytes, respectivamente] de archivos gráficos, registros...
Por Nacho Palou -
1 DIC 2016

Webverse es una visualización interactiva de la World Wide Web que ha creado Owen Cornec con motivo del 20º aniversario del Internet Archive, que guarda copias no solo de la web sino de buena parte de otros servicios de Internet (como...
La actualización de este año del Google Earth Timelapse (se presentó en 2013) ha añadido nuevos petabytes de datos a un proyecto ya de por sí espectacular. Se trata de un estupendo trabajo que utiliza el motor de cartografía de Google...

Ah, los años de 1990: cibercafés, internet a 28 kilobit por segundos (no a 300.000, como ahora), pantallas con culo, modas y peinados cuestionables, gafas de realidad virtual y El cortador de césped,... De hecho, de todo lo que aparece en...
Por Nacho Palou -
29 NOV 2016
Tweet Mashup es el chascarrillo de moda: es una tontá que básicamente examina las cronologías de dos cuentas cualesquiera y busca un punto de enlace, normalmente consistente en varias palabras –al estilo cadenas de Markov–. El resultado es sintácticamente correcto la...
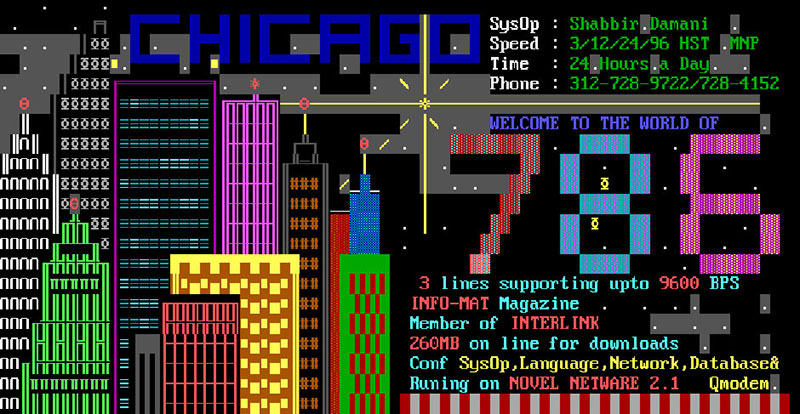
A quien le apetezca un viajecito al pasado de los buenos, a la época de las retrocomunicaciones, al mundo en el que las velocidades de conexión se medían en baudios en vez de en megas le encantará este artículo de The...

Foto de familia de los ganadores – Fátima Cruz Estos de la foto son los ganadores de los Premios Bitácoras 2016, los premios decanos de la blogosfera española, que con la de 2016 llevan ya doce ediciones: Premio Mejor Blog de Viajes:...

Telegrap.ph Eso es todo lo que hay que teclear para publicar una nota en la nueva plataforma de la gente de Telegram, la app de mensajería «para esa gente rara que no usa Whatsapp». Tras escribir un título, un nombre y...
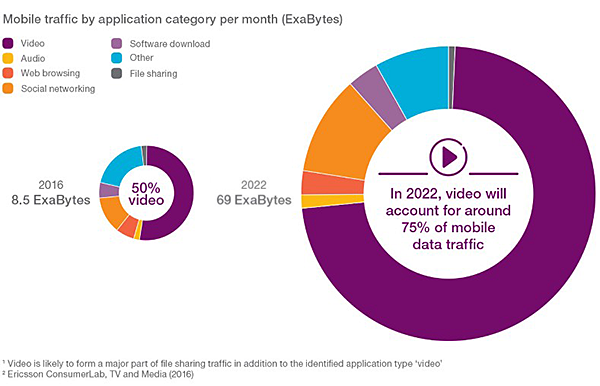
El tráfico de datos global ha crecido un 50 por ciento en un año. En España la mayor parte del tráfico de datos móviles corresponde a las aplicaciones de Facebook (primero), YouTube, WhatsApp, Instagram y Twitter (excluyendo sus versiones web) según el...
Por Nacho Palou -
21 NOV 2016

Se puede rellenar hasta el próximo 11 de diciembre: Navegantes en la Red:19ª encuesta a usuarios de Internet de la AIMC Se trata de la ya tradicional encuesta de la Asociación para la Investigación de Medios de Comunicación (AIMC), también conocida como...
Para unas cosas Google es la mayor inteligencia artificial que hará del mundo futuro un lugar mejor, pero para otras… … no sabe que media hora (0,5 horas) son 30 minutos. El menú ofrece «minutos», «horas» o «días», pero por defecto son...
Anda el personal un tanto soliviantado bajo el hashtag #SinMemesNoHayDemocracia a causa de una propuesta no de ley del gobierno español que pretende regular (más) el uso de imágenes ajenas, en especial en lo que se refiere a compartirlas en redes sociales...
Un equipo de Mozilla se ha embarcado en la aventura del Coral Project, (…) para mejorar la forma en que los periodistas y las comunidades se relacionan con los sitios web. Un conjunto de herramientas libres y de código abierto para...
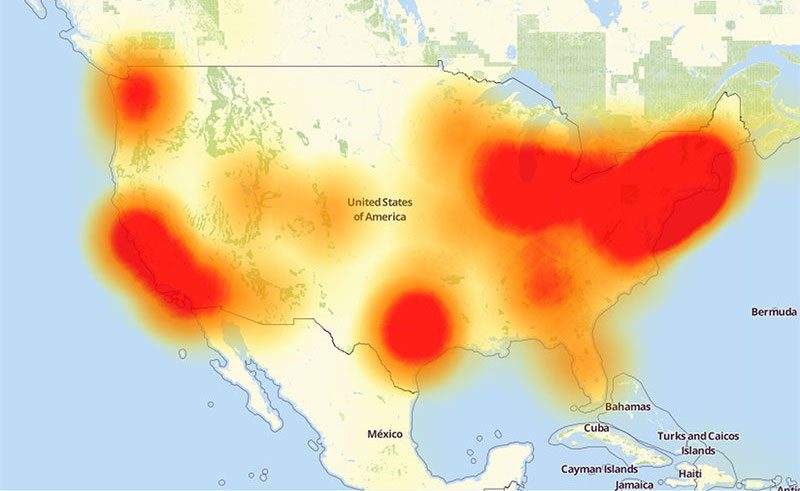
Ayer un montón de sitios de buena parte de Internet mordieron el polvo al fallar los DNS de Dyn, uno de los grandes proveedores de la red. Al caer los DNS también cayeron un montón de webs conocidas (Twitter, Spotify, Paypal,...
Internet es maravillosa por inventos como Napflix. Se trata de un servicio de entretenimiento medio en broma medio en serio: una especie de parodia de Netflix para disfrutar de la mejor siesta posible mirando a la pantalla. El contenido de Napflix,...

Quora, la comunidad de preguntas y respuestas sobre todo tipo de ramas del conocimiento tiene como misión Compartir y ampliar el conocimiento mundial. A partir de hoy también está disponible en español (la primera versión que plantean en otro idioma) con...
La extensión TurboNote (disponible en español) para el navegador web Chrome (en Chrome Web Store) permite tomar notas y hacer apuntes directamente desde el navegador mientras se está visualizando un vídeo de YouTube, Vimeo, Ted, Facebook o Netflix, por ejemplo. Una...
Por Nacho Palou -
14 OCT 2016
La nueva función de búsqueda de colores de Google permite también hacer conversiones de RGB —como (255,0,255)— a Hexadecimal —como #FF00FF, muy utilizada en la web— y al revés. Vía Android Police....
Por Nacho Palou -
10 OCT 2016
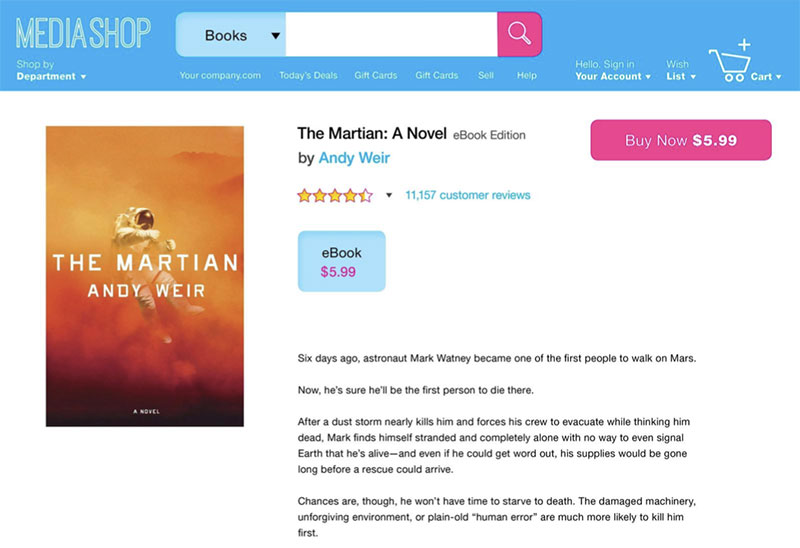
Aaron Perzanowski y Chris Jay Hoofnagle, dos profesores de leyes estadounidenses, han escrito un trabajo titulado What we buy when we buy now [PDF], Lo que compramos cuando compramos ahora, en el que analizan lo que realmente estamos adquiriendo cuando compramos...

Si nos cuentan algo de viva voz es posible que desconfiemos si nos suena un poco raro. Pero ante un «lo leí en el periódico» o un «lo vi en la televisión» nuestro sentido crítico tiende a desaparecer. Y si es...

Dice el autor que actualiza esta lista frecuentemente, pero si se vuelve muy popular es probable que se tomen contramedidas para evitar accesos no autorizados. La página en la que está recopilando las contraseñas se llama A Map Of Wireless Passwords...

PostCrimes es herramienta de protesta creada por Mozilla que permite crear una postal «ilegal» a modo de selfie simulado y enviársela a los miembros del Parlamento Europeo de tu país. ¿Por qué? Porque debido a las libertades a la denominada libertad...

Todos los que me conocéis sabéis que llevo años diciendo que los nativos digitales no existen; este pasado mes de julio hasta me dejaron contarlo en TEDxGalicia 2016. La premisa básica: que las niñas y niños que nacen rodeados de tecnología...

La app de meteorología Dark Sky comenzó como un proyecto de financiación colectiva. Cuando salió en 2013 se consideró como la mejor app de meteorología para móviles de todos los tiempos, a pesar de sus limitadas funciones y disponibilidad de entonces...
Por Nacho Palou -
26 SEP 2016

En Fayerwayer: Facebook mintió sobre la audiencia y las métricas de sus videos durante dos años. En consecuencia quienes pagaron por anuncios publicitarios basándose en esos datos de audiencia están contentitos: Según The Wall Street Journal Facebook habría inflado el alcance...
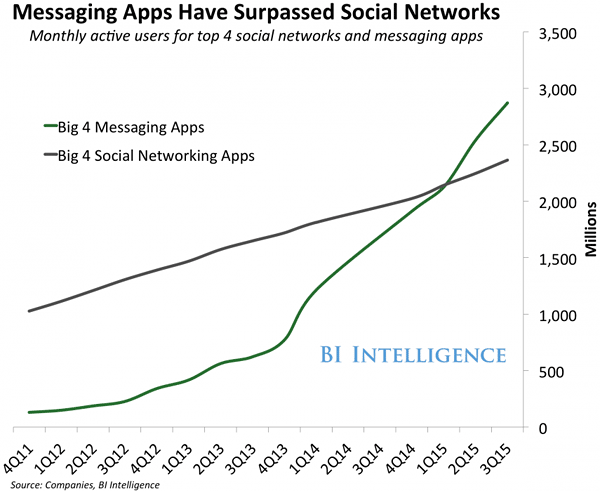
Las aplicaciones de mensajería «que otrora fueron simples servicios para el intercambio de mensajes, imágenes, vídeos y gif animados, se han convertido en ecosistemas en expansión con sus propios desarrolladores, apis y aplicaciones.» Tienen mayor capacidad que las redes sociales para...
Por Nacho Palou -
20 SEP 2016
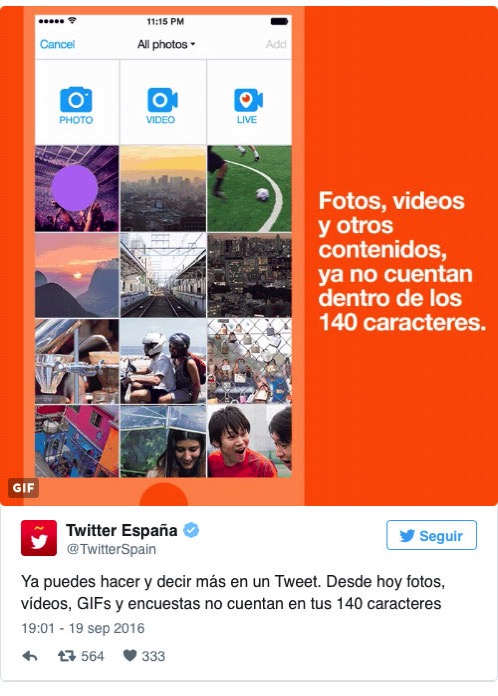
Ya lo habían anunciado hace algún tiempo pero ahora ya hay fecha: a partir del 19 de septiembre de 2016 Twitter irá cambiando paulatinamente la forma en la que cuenta los caracteres de los tuits. Así, cuando tu cuente resulte agraciada:...

Tras unos meses en funcionamiento, el plan de Nueva York para cambiar las cabinas de teléfono por redes wifi —que ofrecen conexiones de 1,3 Gbps en un radio de 50 metros de forma gratuita— se ha topado con un imprevisto: los...
Por Nacho Palou -
15 SEP 2016
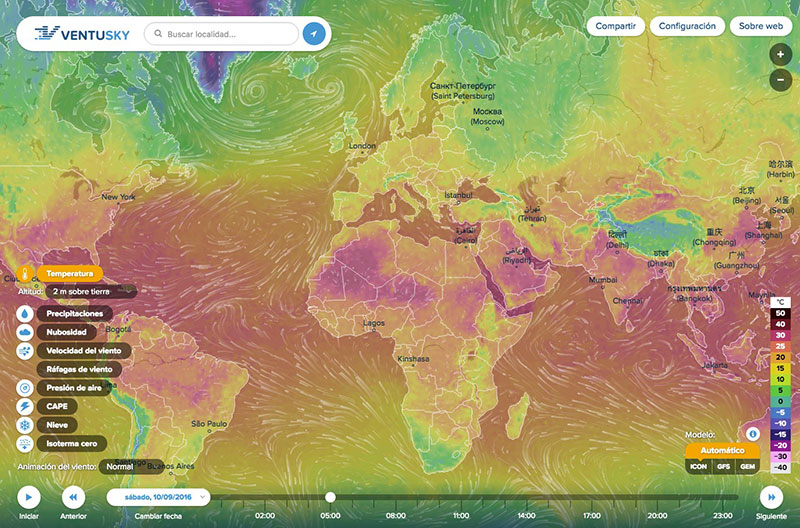
VentuSky es una aplicación de InMeteo, una compañía Checa que se dedica al estudio del clima. Es algo así como la clásica aplicación de «el tiempo» atmosférico, pero a lo bestia: la información se muestra a nivel global para todo el...
Esta imagen muestra Todas las cuentas verificadas de Twitter [Gigapan, zoom] y la relación que existe entre ellas. Pero curiosamente no lo ha creado nadie de Twitter, sino Luca Hammer. Hammer es un experto en creación de visualizaciones de datos. La...
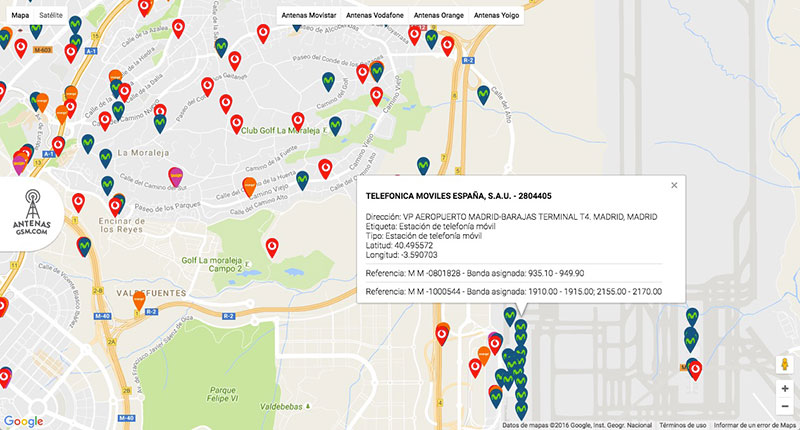
AntenasGSM.com es un mapa de las más de 60.000 antenas GSM que hay en toda España que mejora la inútil información que para variar tiene el Ministerio de Industria y Fomento en su web. El creador de esta página extrajo los...

Lo llamé @ Cafe y, colega, la gente no tenía ni idea de lo que significaba el símbolo ese.– Glenn McGinnisFundador del @ Cafe (1995) Corrían tiempos de cambios en el invierno de 1995… La Web se había inventado hacía poco...

Gestionar el servicio de almacenamiento y distribución de vídeos más grande del mundo no es tarea fácil, especialmente teniendo en cuenta los millones de usuarios que lo utilizan cada día, los millones de horas de grabaciones que se suben para distribuir y la gran variedad de formatos en los que se graban y luego distribuyen.
Benditos FAQ: ¿Cómo elijo no compartir la información de mi cuenta WhatsApp para mejorar mi experiencia respecto a los productos y publicidad en con Facebook? Esto funciona tanto cuando aparece el nuevo contrato de Términos y condiciones –ese que todo el...
We didn't start the fire It was always burning Since the world’s been turning We didn't start the fire No we didn't light it But we tried to fight it Si te sabes la letra de la canción, casi no necesitas...

En Frame han realizado un buen trabajo preparando un repaso histórico a los videoblogs de YouTube, y por ende al fenómeno youtuber, desde una perspectiva histórica (dando por válido «historia» = algo más de diez años). El vídeo comienza con personajes...

El uso mensual que hace el español medio del móvil se ha cifrado recientemente en 91 minutos de llamadas de voz, 7 SMS y 882 MB de datos transferidos. La caída a plomo de los SMS está relacionada con el uso...
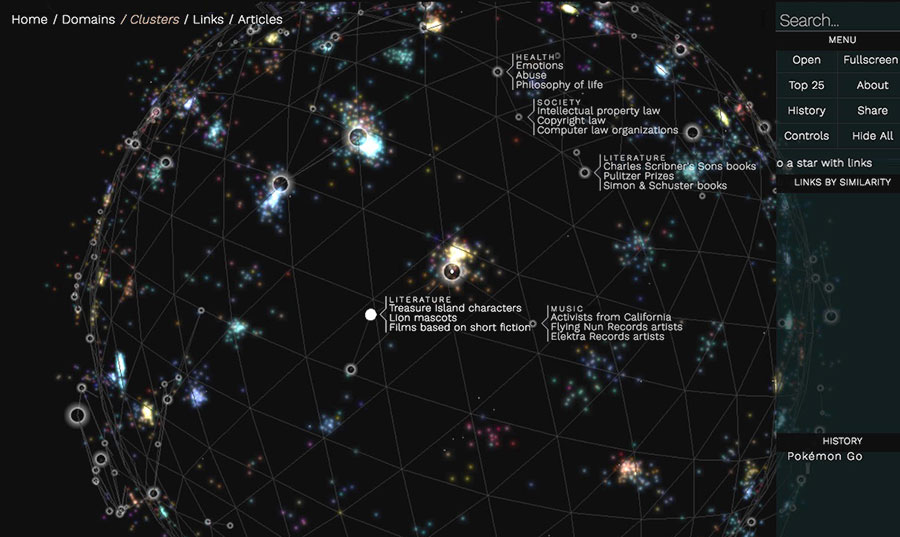
Wikiverse es una de esas visualizaciones bonitas y entretenidas, que muestra los contenidos de la Wikipedia (hasta 250.000 artículos, en inglés) en una suerte de «universo esférico» con el que se puede interactuar con el ratón y el teclado. Los artículos...
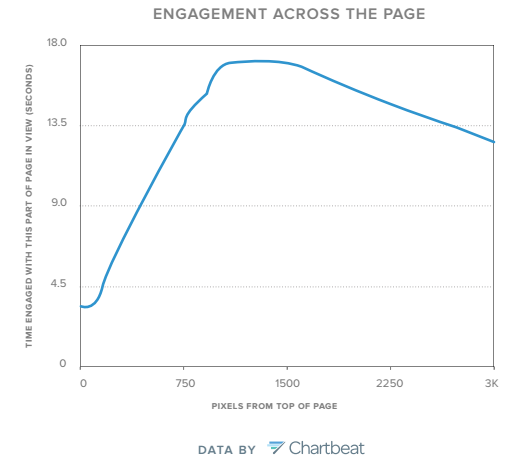
La gente que ha desarrollado Chartbeat –un servicio que permite ver en tiempo real las métricas básicas de las páginas web, como el número de visitantes simultáneos, tiempo duran las visitas, velocidad de carga, etcétera– ha publicado un pequeño análisis sobre la...
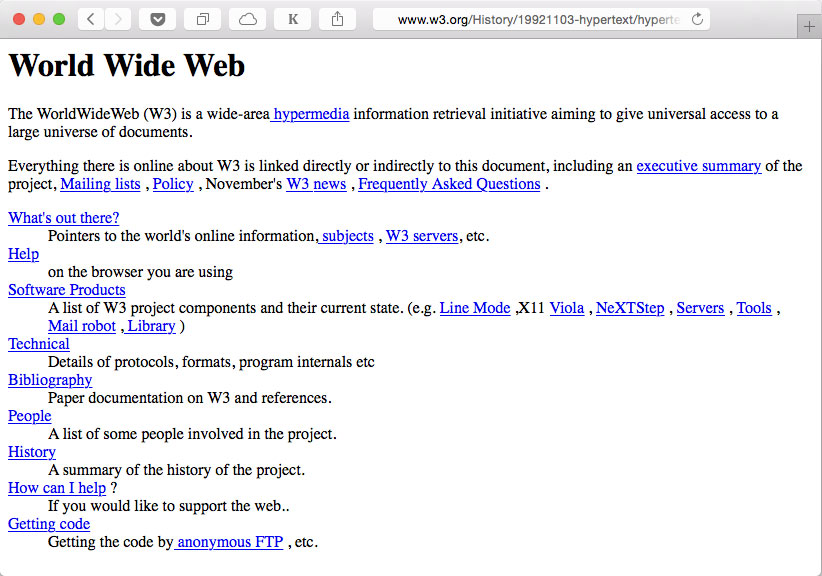
No ha estado en línea todos estos años, pero el 6 de agosto de 1991 Tim Berners–Lee, ahora Sir Tim Berners–Lee hacía pública la primera página web. Se trataba de un proyecto para poder compartir información entre grupos y personas que...

La web Mark Maker hace uso del aprendizaje automático y de las redes neuronales para generar logotipos a saco, aplicando lo «aprendido» sobre logotipos por un ordenador. Como sea, el terminator de los diseñadores básicamente necesita que le des la marca...
Por Nacho Palou -
1 AGO 2016

Connor Flood ha sido el encargado de un proyecto apasionante en las tripas de Wolfram Alpha, ese poco conocido «motor de conocimiento» con aspecto de buscador pero que cuenta con gigantescas bases de datos estructuradas y con el cerebro de Mathematica,...

Ha pasado ya casi un mes, pero Facebook acaba de hacer público que el 28 de junio de 2016 tenía lugar el primer vuelo del primer prototipo de su dron Aquila, diseñado para llevar el acceso a Internet a lugares remotos....
Algo extraño y aberrante debió suceder hace poco en algún oscuro rincón de Google para que el otro día decidieran actualizar la versión 52.0.2xxx para OS X añadiendo por defecto el famoso Material Design que –como su propia definición dice– utiliza...

Número de móviles vendidos en un par de minutos, en todo el mundo. Una cosa queda clara: el uso del móvil no muestra signos de deceleración e incluso entre la población con menos recursos está aumentando el acceso a los móviles, la...
Por Nacho Palou -
18 JUL 2016

Hemos mencionado en unas cuantas ocasiones el artículo As we may think, de Vannevar Bush. Publicado en julio de 1945 en la revista The Atlantic Monthly el autor habla en él del memory extender, que él mismo bautiza como Memex. Se trata...
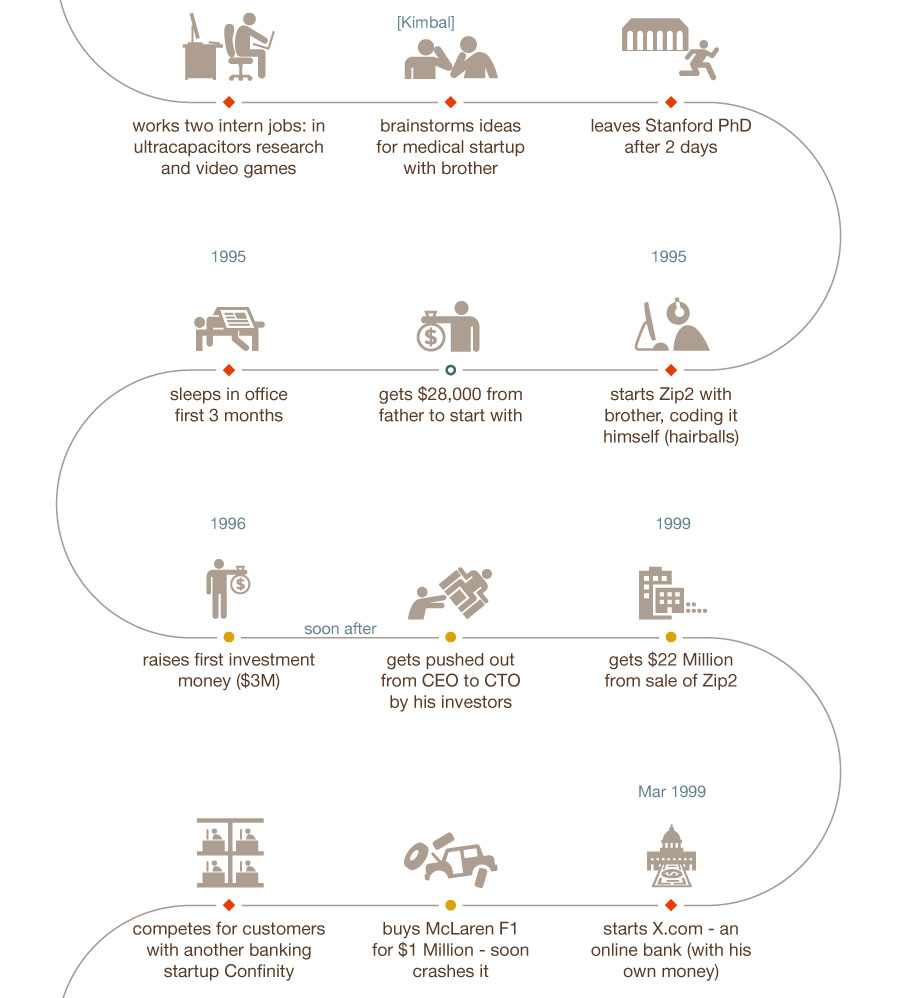
Me gustaría morir en Marte, pero no del impacto.– Elon Musk How Elon Musk Started es una gigantesca infografía de Anna Vital para Business Insider en la que se puede recorrer en zig-zag la vida de Elon Musk en tan solo...

Estrella del rock, trabajadora tecnológica, programadora y científica: 4 de los 100 nuevos próximos «femmojis» que el Unicode Consortium propuso hace poco y ya han sido aprobados. Estarán disponibles en 4 tonos de piel y busca principalmente que existan todas las...

El vídeo que muestra muchos populares virales que seguramente ya habrás visto, y no solo en Internet: una compañía especializada se los «coló» a los medios de comunicación de todo el mundo a modo de «experimento». Gente como ellos son los...
Zack Bloom ha escrito una anotación sobre La historia de las URL: Dominio, protocolo y puerto donde se desentrañan las fechas claves y cómo surgieron cada una de las partes del formato de estas direcciones, del estilo https://www.microsiervos.com [Curiosamente se suele...

El Dodocool AC750 es un dispositivo que extiende el alcance del wifi repitiendo la señal del router para hacer que llegue más allá o para que llegue con más potencia — y por tanto con más velocidad de conexión. Tanto la...
Por Nacho Palou -
6 JUL 2016
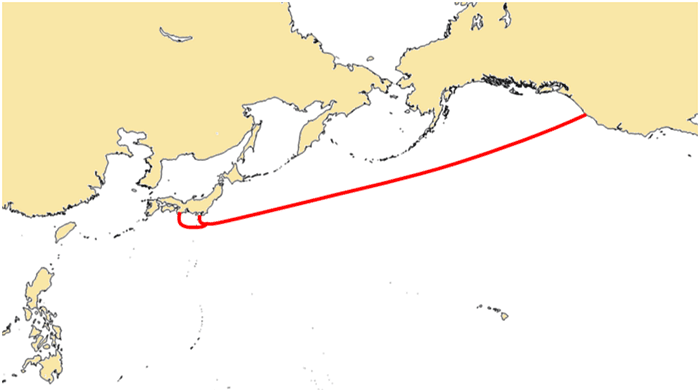
Hoy entra en servicio el cable submarino del consorcio Faster. Este cable es, precisamente, el más capaz (o el más 'veloz') de su clase: puede transmitir 60 Terabits por segundo a lo largo de los 9000 km de longitud, la distancia...
Por Nacho Palou -
30 JUN 2016

Me pareció muy interesante el artículo de Tech Insider This Russian technology can identify you with just a picture of your face que habla de FindFace, una app rusa que todavía no se puede conseguir fuera del país. [No confundir con...
A las vacas de los Picos de Europa poco les importan las cámaras de Google Street View Google ha anunciado nuevos paseos 360º por parajes y lugares icónicos de España. Hay algunos de monumentos y zonas peatonales de las ciudades, como la...
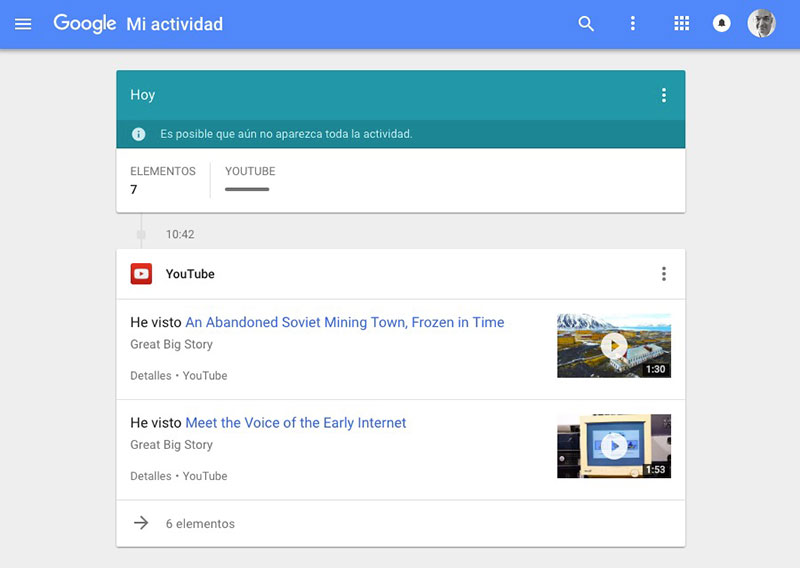
Mi actividad en Google (myactivity.google.com) recopila en una única página todo lo que Google y sus servicios asociados «saben sobre ti»: YouTube, Gmail, ubicaciones… En otras palabras: qué datos declara públicamente que guarda sobre lo que haces en tu navegación por...

Este entrañable señor es Elwood Edwards y es la voz que decía aquello de Welcome! You’ve got mail en el software de America Online (AOL) que tan popular fue en los 90 – ciertamente más en Estados Unidos y Latinoamérica que...

Searches, de Ishac Bertran, es una colección de seis libros que contienen las búsquedas realizas en Google entre 2010 y 2015. La idea surgió cuando a finales de 2015 Google sugirió a Ishac que comprobara sus preferencias de privacidad y descubrió...
Por Nacho Palou -
22 JUN 2016
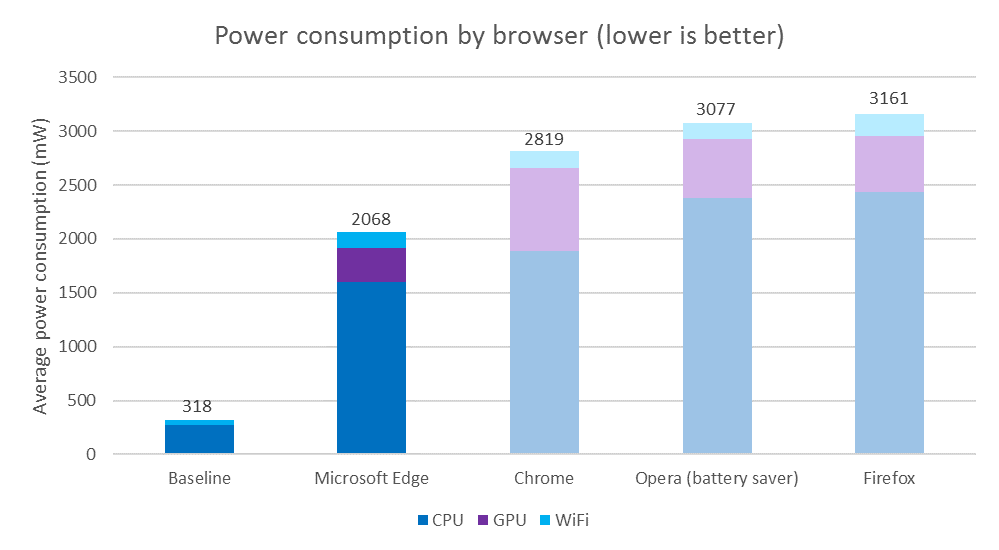
Que el navegador web Chrome de Google reduce significativamente la duración de la batería de los ordenadores portátiles es algo ya conocido — y hasta ahora no solucionado del todo. También se sabía que el navegador web que gasta menos batería...
Por Nacho Palou -
20 JUN 2016
La nueva versión de Google Fonts (fonts.google.com) tiene más o menos las mismas colecciones que la que se lanzara hace ya más de cinco años pero con un aspecto renovado y mucho más funcional. Utiliza el estilo Material Design minimalista y...

Una recopilación de Mental Floss con imágenes y explicaciones para pasar el rato con datos curiosos sobre internet. ¿El dominio más antiguo? ¿La contraseña más popular? ¿Facebook haciendo su aparición en numeros casos de divorcio?
Timeglobe no es perfecto pero es un buen intento: combina datos de la Wikipedia y DBpedia para mostrar diferentes eventos de la historia en los que lugares en los que sucedieron.
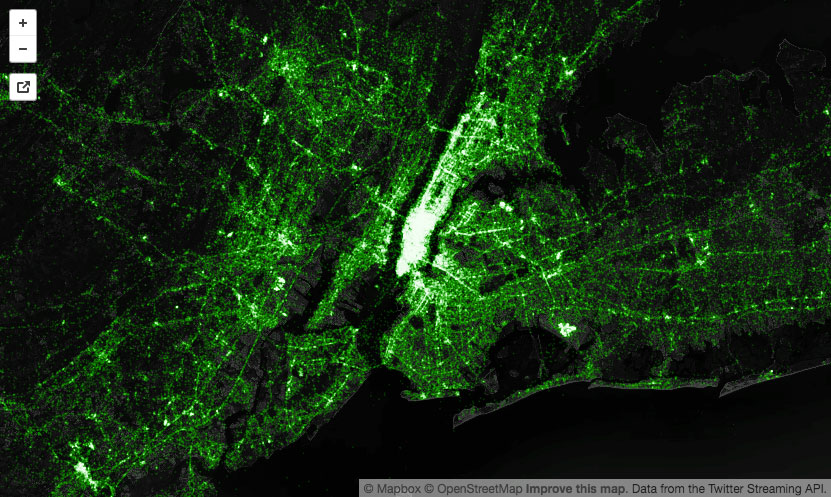
Este autodenominado Mapa detallado de los tuits de todo el mundo («el que más») se realizó hace un par de años y requirió una enormidad de datos. En concreto se capturaron unos 120 tuits geolocalizados por segundo (a razón de 3...
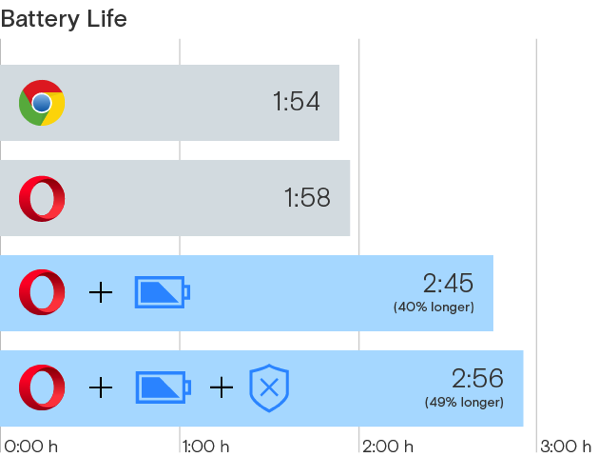
Con tanta parafernalia en las páginas web y también en los navegadores web resulta que buena parte de la batería de un ordenador portátil se consume durante la navegación por internet. Como medida Opera Software ha incorporado una opción de bajo...
Por Nacho Palou -
8 JUN 2016
Lo And Behold: Reveries of the Connected World es un documental de Werner Herzog sobre Internet y lo que supone vivir en un mundo conectado que se estrena el 19 de agosto de 2016. Según cuentan en Wired, donde ya han...

Lo de entonces no eran emojis, pero eran el equivalente de la época: expresiones gráficas que se utilizaban como forma de comunicación y para decorar tarjetas de felicitación, pancartas y pósteres, señales,... y el comienzo de la que se considera una...
Por Nacho Palou -
1 JUN 2016
Cuatro sherpas ascendieron el Everest hasta la cima portando cámaras de 360° sobre sus cabezas, El arriesgado desafío es parte del #Project360 del fabricante suizo de equipo de montaña Mammut, un ambicioso proyecto que empareja a montañeros expertos como cámaras de...
Por Nacho Palou -
30 MAY 2016
Terrapatern es una curiosa herramienta que todavía está en versión alfa, quizá porque ni siquiera sus creadores son conscientes de hasta dónde puede llegar su potencia y utilidad. Se trata de una especie de buscador de imágenes similares que utiliza los...
Techmoan es un curtido youtuber que hace reseñas de equipos de audio y de vídeo, de gadgets curiosos y también de tecnologías obsoletas, como casetes o tocadiscos. Tecnologías retro. Tecnologías superadas. Vintage. Los vídeos de Techmoan suman 60 millones de visualizaciones;...
Por Nacho Palou -
23 MAY 2016
Paper Planes es uno de esos experimentos de Google que hay que probar con un móvil (la URL corta es g.co/IOplanes. Sirve crear y lanzar avioncitos de papel y al mismo tiempo ver acompañado de relajante música los aviones que se...
En el blog de Google, Introducing Spaces, a tool for small group sharing Compartir en grupo no es fácil. Tener a todos los amigos en la misma aplicación puede ser un reto. Compartir cosas implica normalmente saltar entre aplicaciones y copiar...
Por Nacho Palou -
17 MAY 2016
Propuesta de Michael Flarup. Debe ser un poco incómodo estar estos días en los zapatos de Ian Spalter, director creativo de Instagram. Ian es el responsable del cambio de logo de Instagram, tan criticado por tantos e incluso en algún caso llegando...
Por Nacho Palou -
16 MAY 2016
Este Billboard Top 100 de Polygraph es una recopilación de las últimas seis décadas de la música pop entendida como listas del Top 5 mensuales. Parte de la gracia es que es interactiva: tras elegir el año y mes en la...
Garajonay, La Gomera (CC) Josevi11 / Wiki Loves Earth @ Wikimedia La asociación Wikipedia España de la que dependen proyectos como Wikipedia, Wikiquotes o Wikimedia Commons ha puesto en marcha durante este mes de mayo Wiki Loves Earth 2016, un concurso fotográfico...
Dailight Hours Explorer es un interactivo que calcula y muestra al instante las horas de luz que hay al en cada lugar del mundo. Basta mover el indicador de Latitud y elegir la fecha en cuestión; junto al globo terráqueo (que...
No me había percatado de ello porque siempre uso Twitter desde Tweetbot, pero hace un par de días tuve que entrar a través de la web y caí en la cuenta de que que mi cuenta tenía ya activada la opción...
La semana pasada participé en Innova Bilbao 2016 con una charla titulada «¿Nativos digitales?» en la que insistí, una vez más, en que los nativos digitales, esos que se supone que por haber nacido a partir de 1990 o así tienen superpoderes...
GapFinder es un pequeño experimento muy interesante: recomienda qué artículos de la Wikipedia de un idioma convendría traducir a otro, teniendo en cuenta principalmente su popularidad (medida en «páginas vistas») en la enciclopedia original. Los datos relativos a los idiomas se...
La Ley de Poe dice que «en la ausencia de un guiño o indicación que lo aclare, es difícil o imposible distinguir entre una postura ideológica extrema y la parodia de esa misma postura». Este vídeo, para mí, es un claro...
Desde El Correo me han invitado a participar en Innova Bilbao 2016, donde el viernes 15 de abril a las 16:00 daré una charla en la que hablaré sobre los famosos nativos digitales y de cómo asumir que no existen es importante...
Bit Bonkers es un proyecto de visualización en WebGL de la blockchain, que en palabras fáciles de entender sería una especie de «libro de registro o base de datos donde se apuntan todas las transacciones – con la peculiaridad de que...
Vox Media tiene una pequeña pieza en vídeo sobre los tubos neumáticos, que se inventaron hace ya 150 años «para transportar correo, objetos, gatos y gente» y tuvieron gran utilidad. En Nueva York o París había grandes red a finales del...
Los Chatty Maps son detallados callejeros de Londres, Barcelona, Madrid, Nueva York y Boston. La idea es mostrar los lugares con menos contaminación acústica: con poco ruido, tráfico rodado y a ser posible con «sonidos de la naturaleza». En su confección...
Ya disponible el informe de la Fundación Telefónica sobre la sociedad de la información en España en 2015, resumido en este vídeo y en estos datos: Internet está en el día a día 27,1 millones de personas, lo que representa el...
«Internet hará que todas esas cosas malas desparezcan» Deberían regalarlo al empezar la educación secundaria. (Vía Practical Developer.)...
Esta simulación de Internet dicen que es la más grande hasta el momento, tan grande, tan grande que está a escala 1:1: unos 60.000 AS (Sistemas Autónomos, las instalaciones que suelen tener los proveedores de acceso y alojamiento) y 500.000 de...
La línea roja alrededor de Gibraltar indica la existencia de una disputa territorial oficial... al menos cuando se mira desde este lado. En Popular Science, Google Maps Moves The World's Borders Depending On Who's Looking, Ethan R. Merel [el autor del estudio...
Por Nacho Palou -
31 MAR 2016
Soy muy fan de las clases de microbiología que Ignacio López–Goñi da a través de Twitter com la etiqueta #microMOOC y que luego recopila en Storify; un montón de información interesante y relevante en píldoras de 140 caracteres con sus correspondientes ilustraciones...
Una de las aplicaciones más curiosas de los vídeos 360° es la de mostrar cómo son realmente algunos lugares con un realismo enorme: «como si estuvieras allí». En este ejemplo se puede ver en pantalla o con unas gafascartón de esas...
Nosotros no somos nativos digitales, somos la generación Tuenti. – Claudia Dans Nacida en los 90, Claudia Dans recuerda haber vivido siempre conectada desde que tiene uso de razón y lleva años blogueando, así que cae de pleno dentro del supuesto grupo...
Hoy, 21 de marzo de 2016, Twitter cumple 10 años. Si allá por marzo de 2007, cuando abrí mi cuenta de Twitter, me hubieran preguntado si creía que el servicio tenía mucho futuro creo que habría dicho que no parecía gran...
En su cuenta Instagram, King Blotto III —diseñador y calígrafo y entusiasta de los estilógrafos— comparte vídeos cortos, de unos pocos segundos, que recogen y muestran de cerca el trazado de caligrafías y de dibujos usando estilográficas. Además de la precisión...
Por Nacho Palou -
21 MAR 2016
Miniatur Wunderland, el país de las maravillas en miniatura, tiene el título de ser la maqueta con el trazado de tren más largo del mundo con 15 km de vías. En toda la instalación hay hasta 200 000 ciudadanos pintados y...
Por Nacho Palou -
18 MAR 2016
El amo del tiempo. Como el famoso «relojero de la Puerta del Sol» pero a lo bestia. Se llama Judah Levine y es el creador del software y quien puso en marcha el servidor original de la «hora oficial» que se...
En Mapping the Online World puede leerse sobre cómo la gente de Nominet ha creado un mapamundi [JPEG] en el que cada país tiene un tamaño proporcional a su número de registros de dominios. Resulta curioso que algunos tan llamativos como...
TL;DR: 100 abreviaturas de Internet. Y algunas del MundoReal™. (Vía Taxi.)...
Instant Logo Search es un gigantesco archivo de logotipos e isotipos de las marcas más conocidas que se pueden buscar y descargar libremente. Basta teclear el nombre, elegir el formato y arreando. (Eso sí: ojo al usarlos que luego cada marca...
En Fusion, We calculated the year dead people on Facebook could outnumber the living, Facebook tiene 1500 millones de usuarios (...) y millones de ellos ya están muertos. A menudo, cuando alguien muere, sus allegados convierten sus perfiles en mausoleos, en...
Por Nacho Palou -
8 MAR 2016
Go Fucking Work es una extensión de Chrome que hace una sola cosa pero la hace bien: redirigir los sitios improductivos de Internet a «pósteres motivadores» que con un lenguaje vehemente y florido animan a retomar el duro trabajo. Así que...
En MIT Technology Review, Google Unveils Neural Network with “Superhuman” Ability to Determine the Location of Almost Any Image, Tobias Weyand, especialista en visión artificial en Google y un par de sus colegas han desarrollado un software capaz de determinar dónde...
Por Nacho Palou -
7 MAR 2016
He estado unos días probando la SarenetApp, app para iOS y Android que facilita a los clientes de la veterana empresa de comunicaciones de una forma de hablar más barato o incluso gratis, a través de wifi o la red de...
El pasado 5 de marzo de 2016 fallecía Ray Tomlinson, uno de los ingenieros a los que se puede incluir en el grupo de los que crearon Internet. De hecho Tomlinson fue el creador de la primera killer app de Internet, pues...
A raíz de El problema de obesidad de la Web: el futuro de los medios online, Kalev Leetaru se refería a los navegadores web como «hazañas de la ingeniería, capaces de ejecutar sistemas operativos completos, como Windows XP». Desde 7 classic...
Por Nacho Palou -
4 MAR 2016
Según el Índice de la Economía y la Sociedad Digitales (DESI) elaborado por la Comisión Europea sólo un 54% de los españoles posee competencias digitales básicas y, en general, obtenemos un 0,52 sobre 1 en la puntuación de los cinco aspectos que...
Facebook acaba de publicar los datos de su estudio de acceso a Internet en todo el mundo en 2015, cuyos resultados se pueden leer en State of Connectivity 2015: A Report on Global Internet Access. El resumen es que entre 2014,...
En How you can use Facebook to track your friends’ sleeping habits, Søren Louv-Jansen explica de qué manera es posible conocer cuáles son los hábitos de sueño de los amigos y contactos de Facebook; al menos, es verdad, averiguar los hábitos...
Por Nacho Palou -
1 MAR 2016
Las interfaces web responsive son aquellas que adaptan su presentación de acuerdo con el tamaño de la pantalla o si se miran desde un móvil, un ordenador o un tablet, por ejemplo. Resizer es una herramienta de Google para ver y...
Por Nacho Palou -
29 FEB 2016
Facebook también tiene un departamento de investigación con un blog donde publica eventualmente diversas curiosidades que van descubriendo y avances que realizan. Una de ellas tiene que ver con la famosa teoría de los seis grados de separación, algo que como...
El Google Play Market Retro, la App Store Retro y también la Mac App Store Retro son las versiones estilo PC con MS-DOS de finales de los años 1980 y principios de los 1990. No es sólo que la estética se...
Por Nacho Palou -
19 FEB 2016
Los próximos 25 y 26 de febrero de 2016 se celebra la sexta edición de Comunica2, el congreso internacional sobre redes sociales que organiza la Universidad Politécnica de Valencia. Hay un interesante programa con multitud de charlas y talleres sobre nuevos...
El superexperto en seguridad Bruce Schneier ha anunciado la edición de este año de su Estudio global sobre productos de cifrado, una ambiciosa, extensa y diría que muy completa -si no «la más completa»- recopilación sobre las tecnologías de vanguardia en...
Ciencia en Redes 2016, una jornada para periodistas, investigadores, comunicadores, museógrafos e instituciones y empresas dedicadas a la ciencia y el I+D+i, tendrá lugar el jueves 28 de abril de 2016 en La Casa Encendida, en Madrid. Como en años anteriores una...
A leer sobre el software de Autosdesk utilizado por la impresora 3D «de juguete» de Mattel recordé la aplicación online Tinkercad, también de Autosdesk — de su catálogo de aplicaciones 3D gratuitas. Tinkercad funciona directamente en un navegador web moderno (Windows,...
Por Nacho Palou -
15 FEB 2016
He aquí una recopilación en un solo vídeo de muchas de esas cosas que dan gustirrinín al verlas –algo que seguramente será una forma leve de TOC–muchas de las cuales hemos publicado por aquí en el pasado. (Sorprendentemente muchas, de hecho.)...
En esta visualización se convierten en una gráfica matemática y colores los detalles del handshake que da inicio a una comunicación vía modem acústico. Uno de los ejes es el temporal y el otro el de las frecuencias. Ruiditos que retrotraen...
Al final los rumores se han confirmado, y tal y como se puede leer en Never miss important Tweets from people you follow, Twitter ha empezado a activar poco a poco la función de ver los tuits más populares de la gente...
Me gusta la idea de esta navegación estilo Google Maps para el catálogo Ikea, una lista de productos tan amplia como largas y tortuosos son los laberintos de sus tiendas. Al menos como forma alternativa estaría bien verlo en otras tiendas...
La imagen publicada por Jan Koum hace unos días resume algunas de cifras relacionadas con WhatsApp. Además de las que dan título a esta anotación (mil millones de usuarios activos al mes y 42 000 millones de mensajes al día) hay...
Por Nacho Palou -
8 FEB 2016
De las profundidades de Internet llega esta especie de Google de «Los Simpsons» llamado Frinkiac. En total almacena más de tres millones de fotogramas de todas las temporadas de los populares personajes, adecuadamente asociadas con palabras descriptivas, de modo que se...
Max Braun en Medium, My Bathroom Mirror Is Smarter Than Yours sobre la fabricación artesanal de un espejo para el cuarto de baño que funciona con Android y que muestra información —como la previsión meteorológica—, la hora o notificaciones directamente delante...
Por Nacho Palou -
3 FEB 2016
Mi página personalizada de Vídeos del momento al entrar en Youtube. Más o menos. Ojos abiertos y saltones. Boca abierta con cara entre el asco y el asombro. Mirada perdida como de locos. Ese parece ser el look de los años 10,...
El rover marciano Curiosity ha compartido en su página de Facebook una imagen de vídeo en la que capta todo lo que hay a su alrededor, 360° que incluyen el paisaje marciano y la propia sonda. Técnicamente no es la mejor...
Por Nacho Palou -
1 FEB 2016
Hace unos meses, debido a un error por parte de Google, Sanmay Ved se convirtió en el hombre que fue dueño de google.com durante un minuto; del dominio, por supuesto. Fue el pasado mes de ocutbre, cuando casi de casualidad Sanmay andaba...
Por Nacho Palou -
1 FEB 2016
Esta práctica chuleta de Mainstreethost incluye en una sola imagen las dimensiones de todas las imágenes que habitualmente tienes que preparar y subir a las redes sociales para dejarlas niqueladas y visualmente perfectas: 2016 Social Media Image Size Cheat Sheet. Se...
I Love IMG (de los creadores de I Love PDF) es un servicio web para realizar algunas modificaciones rápidas de formato en archivos de imágenes: comprimir, redimensionar, recortar… Se puede usar desde cualquier navegador y dispositivo, lo cual resulta cómodo y...
Hoy en día un guerrero Masai africano con un teléfono móvil tiene mejor capacidad de comunicación de la que tenía el Presidente de los Estados Unidos hace 25 años. Y si se trata de un teléfono inteligente con acceso a Google también...
En AsapScience, un vídeo con algunos datos sobre la ciencia de los troles de internet. Los datos proceden de un estudio sobre 1200 usuarios de Internet, de los cuales un 5,6 por ciento declararon abiertamente ser troles. Las definiciones varían un...
TorFlow es una visualización de Tor, la famosa red de anominato que «a vista de satélite» se parece un poco a los aviones que recorren los continentes, el tráfico de internet convencional y algo parecido. Los paquetes de datos van de...
Tracing You es un proyecto de Benjamin Grosser de esos de tipo «inquietante»: si se le da bien verás aparecer la foto del lugar en el que estás físicamente en plena pantalla, junto con las de los demás visitantes. ¿Cómo se...
La gente de Cushion realizó un interesante ejercicio en el que desglosaron los costes a la hora de crear y mantener una aplicación web a lo largo del tiempo. Se utilizaron a sí mismos como ejemplo; venden su aplicación para que...
A los tradicionales 801.11a/b/g/n y el más moderno ac, con velocidades entre 54 y 800 Mbps, se unirán pronto otros estándares Wi-Fi que están por llegar pero para los cuales han empezado a aparecer algunos dispositivos entre los fabricantes. Todos ellos...
Desde el Departamento del doctor Sánchez Ocaña, En The Information, Facebook’s Android Contingency Planning, Facebook trabaja en secreto en una serie de medidas de contingencia para mantener sus aplicaciones funcionando en dispositivos y teléfonos Android sin depender de Google; sin tener...
Por Nacho Palou -
7 ENE 2016
La vida es corta: no veas mierdas– BAGmovies El lema de BAGmovies deja claro su misión: recomendar las mejores series de televisión y películas dado que el tiempo del que disponemos en nuestras limitadas vidas es demasiado breve. Lo dicen con...
En Flowing Data recopilaron su selección anual de los mejores proyectos de visualización de datos del año. Puede verse un resumen de ellos aquí: 10 Best Data Visualization Projects of 2015. Cada uno es bastante distinto del anterior y de todos...

Sin ningún orden en particular, ahí van: 1. El día de Regreso al Futuro El futuro era esto: 21 de octubre de 2015. Así que lo celebramos con algo más de una docena de anotaciones con comentarios de la trilogía Regreso al...
La web Goldilocks muestra de forma interactiva los datos y la información procedente del Planetary Habitability Laboratory y en concreto de su Catálogo de Exoplanetas Habitables. De hecho, el término Goldilocks se refiere en astrobiología precisamente a los planetas extrasolares que...
Por Nacho Palou -
22 DIC 2015
¿Cómo activar JavaScript en un navegador web?«JavaScript está desactivado o no funciona en tu navegadorEste sitio requiere JavaScript para funcionar correctamente» Sublime.– @SancasDev No hace falta siquiera tener que usar Internet Explorer para disfrutar de la «pescadilla que se muerde la cola»...
Finales de diciembre: época para rememorar. En este caso de la mano de Live a year in 4 minutes de la Fundación Wikimedia, que muestra de una forma extremadamente bella y elegante lo más relevante en la enciclopedia libre que editamos...

Del informe El año en búsquedas 2015 y las listas más populares que ha publicado Google aprendimos este año que: La gente ya no busca «sexo» ni «porno» en internet, es más popular y relevante en el buscador la «Copa del...
En Creative Market, Las diez confesiones de un adicto a Internet: Desconfío de los lugares en los que no hay wifi Utilizo los servicios de mensajería para hablar con quienes tengo al lado Me pongo agresivo si el wifi va lento...
Los que tengan conexiones de banda ancha bien capaces y ordenadores o televisores inteligentes potentes apreciarán que la NASA esté publicando ya en Ultra HD los vídeos de los lanzamientos de las últimas misiones. Esto quiere decir 2160p60 que son 4K...
El Plume Air Report se describe como el primer mapa mundial del aire. Recopila información sobre los niveles de contaminación, de gases y partículas en suspensión en 40 países; o mejor dicho, en algunas ciudades de 40 países — por ejemplo,...
Por Nacho Palou -
10 DIC 2015
Hiperespacio – el eslabón perdido entre las páginas personales y Microsiervos allá por 1999 Toda una experiencia rememorar con Oldweb.today cómo era navegar en épocas remotas de la Web: basta elegir el navegador web, el sistema operativo y la dirección de la...
El Speedtest de Ookla que se utiliza para medir la velocidad de la conexión de Internet se ha actualizado: desde hace un tiempo está en pruebas beta en una versión que no requiere utilizar Flash, lo cual es todo un avance....
En el blog de Adobe, Adobe News, Flash, HTML5 and Open Web Standards, Actualmente los estándares abiertos como HTML5 han madurado lo suficiente como para igualar las capacidades de Flash. Nuestros clientes han manifestado su deseo de que la aplicaciones de...
Por Nacho Palou -
2 DIC 2015

Un anuncio de Microsoft cantando por la paz en la tierra frente a una Apple Store subida como vídeo en YouTube (Google). Que no se diga....
Y con la de 2015 van once ediciones de los Premios Bitácoras, los decanos de la blogosfera hispana, que en esta ocasión han tenido estos ganadores: Premio Mejor Blog de Salud e Innovación Científica: Lucía, mi Pediatra. Premio Mejor Blog de...
Debemos crear un mundo en que todo ser humano pueda gratuitamente acceder a la suma de todo el conocimiento humano. En esta miniconferencia de TEDxLeon el profesor Jorge Sierra (a.k.a. Lucien Legrey), presidente de Wikimedia España (la fundación que está detrás...
Las luchas por subir el volumen en la música comercial acabaron gracias a la normalización del sonido en las plataformas digitales, especialmente en YouTube.
Se puede rellenar hasta el próximo 13 de diciembre: 18ª encuesta a usuarios de Internet de la AIMC Se trata de la ya tradicional encuesta de la Asociación para la Investigación de Medios de Comunicación (AIMC): Esta encuesta no tiene ningún carácter...
Sitios en los que has estado con tu iPhone Frequent Locations" title="iPhone > Frequent Locations" /> iOS > Ajustes > Privacidad > Localización > Servicios del Sistema [abajo] > Ubicaciones Frecuentes [hacia el centro] > Historial Funciona en los iPhone, si tenías...
iTunes Terms and Conditions: The Graphic Novel es el acuerdo legal íntegro que se supone que aceptas al utilizar iTunes —o que no has leído pero que igualmente aceptas— convertida en una suerte de cómic al estilo de las novelas gráficas...
Por Nacho Palou -
4 NOV 2015
Hace unos meses en Hopes&Fears, I used a 56K modem for a week and it was Hell on Earth, En 2015 nada funciona con un módem de 56K. Facebook hace el intento pero acaba mostrándose como un revoltijo de enlaces y...
Por Nacho Palou -
3 NOV 2015
Los vídeos en resolución 4K y a 360 grados en YouTube son cada vez más abundantes y cada vez más espectaculares, aunque ponen a prueba la capacidad del navegador web, del ordenador y de la conexión a Internet — sobre todo...
Por Nacho Palou -
2 NOV 2015
Versión TL;DR: los políticos se han vuelto a bajar los pantalones con las telecos y no han aprobado ninguna de las enmiendas mediante las que se pretendía asegurar la neutralidad de la red. Vaya sopresa. Así, tal y como cuenta Pablo Romero...
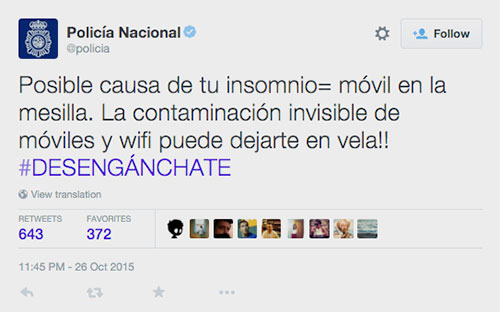
Alguien en la cuenta oficial en Twitter de la @Policia (Policía Nacional) la ha liado parda en un absurdo intento de curar la «adicción» a los móviles e internet al asociarlos al insomnio y la «contaminación invisible» de los teléfonos móviles...
Esta semana asistimos a la puesta de largo de Netflix en España, un servicio que en EE UU puso de moda a finales de los 90 la denominada «tarifa plana de videoclub» originalmente con DVD físicos y posteriormente a través de...
Esto ha sido parte parte de mi proyecto personal de este verano: la elaboración de una lista de cortometrajes sobre viajes en el tiempo que permitiera disfrutarlos en Internet de forma cómoda. Está disponible en dos formatos: YouTube y Vimeo (todavía...
Pablo 2.0, de la gente de Buffer es una sencilla herramienta para combinar imágenes y textos (frases, citas y pensamientos) con idea de subirlos a las redes sociales. Se sube la imagen, se escribe o pega el texto, se elige el...
¿Abrir enlaces en la misma ventana del navegador, en una ventana nueva o en la ventana del navegador de otra persona? La extensión Shove para el navegador web Chrome abre “por la fuerza” una URL en la pestaña del navegador de...
Por Nacho Palou -
9 OCT 2015
En Business Insider, This guy bought 'Google.com' from Google for one minute, Era tarde y Sanmay Ved andaba por Google Domains, el servicio de compra de dominios de Google, cuando se dio cuenta de que el dominio google.com estaba libre: al consultar...
Por Nacho Palou -
1 OCT 2015
LibraryOfBabel.info es una recreación «estilo Internet» de la grandiosa Biblioteca de Babel imaginada por Jorge Luis Borges y publicada como uno de los cuentos del recopilatorio Ficciones (1944/2012). El universo, la biblioteca En versión original la biblioteca es «otra forma de...
Seguro que os ha pasado que cuando se habla de leyes que regulan la retención de datos de usuarios y esas cosas alguien os ha dicho aquello de «a mí me da igual, total no hago nada malo»… Pues se equivoca...
The Waiting Wall es un experimento medio artístico medio tecnológico medio social que han instalado en una estación de metro con motivo del Festival Digital de Brighton. Básicamente es un panel al que la gente envía desde Twitter o una página...
Tom Scott explica los tecnicismos de por qué poner http://a/%%30%30 en la barra de direcciones de Chrome, o incluso pasar el ratón por encima (mouseover) «casca» el programa, cerrándolo inevitablemente. Seguro que lo arreglan pronto, pero como curiosidad no está nada...
En enero de este año Telegram, «el servicio de mensajería que llegó del frío», una especie de Whatsapp que funciona tanto en móviles como tabletas y web, enviaba 1.000 millones de mensajes de texto diarios. En mayo ya enviaba 2.000 millones...
Bill Nye (the Science Guy) explica cómo se las apañará nuestro cerebro para «procesar toda la información resultante cuando todo esté conectado a Internet». Y lo explica utilizando emojis — el «lenguaje de las cosas». De modo que aunque se podría...
Por Nacho Palou -
22 SEP 2015
Maps.Wikimedia.org es la dirección web para acceder a los mapas de la Fundación Wikimedia, más conocida por ser la organización sin ánimo de lucro que gestiona la Wikipedia y con la que cientos de miles de voluntarios de Internet colaboran. Tal...
Hubo un tiempo en que el patio de las «búsquedas en Internet» estaba más competido: un tiempo en el que dinosaurios como AltaVista, Excite, HotBot, InfoSeek, Fast, WebCrawler y Lycos dominaban la superautopista de la información antes de que llegara Google...
Nueva York, Londres, Hong Kong y Los Angeles son las ciudades en las que se puede explorar de forma visual la actividad y el uso colectivo de las redes móviles: las llamadas que se realizan, el envio de mensajes de SMS...
Por Nacho Palou -
9 SEP 2015
StarCraft es uno de los juevos más veteranos y populares y alguien se ha tomado la molestia —y la gran tabajera— de trasladar la versión original del juego al lenguaje HTML y JavaScript de tal moco que el juego funciona directamente...
Por Nacho Palou -
8 SEP 2015
Scott Kelly: Un saludo a mis amigos que vienen en la #Soyuz @Astro_Andreas y @Volkov_ISS y al cosmonauta kazajo A. Aimbetov al que aún no conozcoSergey Volkov: Gracias!!! Hola desde el módulo de al lado! Todos hemos hecho esto de enviarle un...
Tal día como hoy en 1995 Telefónica anunciaba la entrada en funcionamiento de InfoVía en fase de pruebas, aunque su entrada en servicio oficial no se producía hasta el 15 de diciembre de ese mismo año. InfoVía era un intento, que llegaba...
Izquierda, mal; derecha, bien (Google dixit) En Google Webmaster Blog, Mobile-friendly web pages using app banners, A partir del 1 de noviembre, las páginas que muestren un interstitial que oculte una parte importante del contenido de la web para ofrecer instalar una...
Por Nacho Palou -
2 SEP 2015
En realidad pueden ser latas de cerveza como pueden serlo de cualquier refresco, pero las latas de cerveza son más bonitas y mucho más interesantes que ninguna otra. Como sea, para el caso que nos ocupa lo importante es que la...
Por Nacho Palou -
31 AGO 2015

Vox Media publicó este vídeo con consejos para mejorar la señal Wi-Fi en casa; en él aprovecha una de las visualizaciones sobre el wifi casero de Jason Cole, que ya comentamos por aquí hace tiempo. Básicamente son cinco los detalles a...
Code Rush (David Winton, 2000) es un documental sobre los ingenieros de Netscape a finales de los 90, cuando en plena Guerra de los Navegadores una de las empresas puntocom más emblemática, Netscape, decidió crear la Fundación Mozilla para que gestionara...
Sí, es una hora y pico entre charla y preguntas, pero merece mucho la pena, ya que explica como la ley de enjuiciamiento criminal española por fin se pone al día con lo que se refiere a enfrentarse a delitos informáticos...
… te hace sentir pequeñín, pequeñín: How Much Data is in the Cloud?...
Si andas aburrido puedes pegarle unos cuantos clics a RandomUsefulWebSites, un pequeño proyecto que con un clic te lleva de un salto al azar a alguna web «útil», lo cual incluye conversores, listas, calculadoras, sitios complementarios a las tiendas de comercio...
Lo habían anunciado hace unas semanas a los desarrolladores, pero ahora ya es oficial. Según se puede leer en Eliminamos el límite de 140 caracteres de los Mensajes Directos: Si has revisado tus Mensajes Directos hoy, probablemente te hayas dado cuenta de...
Larry Page y Sergey Brin han anunciado como sorpresa de verano la creación de Alphabet, una especie de empresa-paraguas que aglutinará diversas propiedades, la mayor de las cuales será Google. En su «web corporativa» abc.xyz. Así que ahora el alfabeto podría...
Si en las últimas semanas has observado que los resultados de Wikipedia aparecen «un poco más abajo» en Google quizá no sea solo una sensación tuya. Los expertos de SimilarWeb, un sitio especializado en análisis de tráfico web, optimización, SEO y...
Quien esté aburrido de ver reposiciones de series y películas de hace décadas en televisión puede aprovechar una horita libre para echar un vistazo a Ulterior States, un proyecto de Tomer Kantor / IamSatoshi en el que se entrevista a decenas...
La empresa de software SAP encargó a Information if Beautiful esta infografía interactiva titulada The Internet of Things: a Primer. Además de una descripción general se incluyen datos de todo tipo sobre los últimos estudios al respecto. Para el año 2020...
Tras darte una vuelta por varios sitios populares de la Web todas estas empresas te estarán «siguiendo» Según Monday Note si cargas 20 portadas de sitios conocidos de Internet te rastrean unos 500 trackers en total, entendiéndose por tracker elementos del tipo...
Aunque utiliza datos de 2013, este Mapa del mundo conectado permite apreciar de un vistazo qué zonas de planeta están más conectadas y cuáles menos: cuanto más oscuro, más porcentaje de gente conectada, cuanto más claro, más aislamiento. Además de eso...

«Bienvenido a CompuServe: el servicio de información más grande del universo (conocido)» Técnicamente era correcto que en 1988 CompuServe se anunciara dignamente como el servicio de información más grande del universo (conocido): contaba ni más ni menos que con unos 380.000 suscriptores....
HowDNS.works explica con monigotes en varias páginas de viñetas cómo un proceso tan aparentemente trivial como es ir a una web requiere toda una serie de consultas e interacciones con el llamado Sistema de Nombres de Dominio. Que menos mal que...
Nacidos para anular el spam, distinguir a los bots de los humanos e impedir que los automatismos hicieran «cosas malas» surgieron los captchas… Y en aquel momento parecían una buena idea. Pero al poco empezaron los primeros problemas: que si fallos...
Bajo el curioso título de The Random User nos encontramos con una obra artístico-técnica que en palabras de su creador, Arturo Melero de Monobo consiste en: Un ratón vintage intervenido que navega por internet aleatoriamente, sin control. Un usuario especial que...
Exportify sirve para exportar todas tus listas de canciones a formato listas de texto separadas por comas (.csv) – algo que por alguna extraña razón Spotify no facilita en la gestión de tu propia cuenta. Ese formato se puede importar directamente...
Face Off [iOs] es una curiosa app para iOS que sirve para obtener una respuesta rápida respecto a qué selfies quedan mejor como avatares. Basta arrancarlo y conectarse con la cuenta de Facebook, de donde tomará el avatar actual y alguno...
Efectivamente, teléfono es más corto. Pero… Mira los datos. Es una excelente gráfica de Luke Wroblewski que encontré vía @minid....
Seguramente alguna vez te ha pasado algo parecido a esto: abrir la galería de fotos del móvil para buscar una fotografía que quieres utilizar o enseñar a alguien y acabar rindiéndote con un “bueno, pues ahora no la encuentro”. La app...
Por Nacho Palou -
7 JUL 2015
En Fast Co. Design, Love MS Paint? Here's VR Paint, El último proyecto de realidad virtual de Microsoft Research Labs se llama Semantic Paint. Basado en la tecnología Kinect, Semantic Paint recrea en virtualmente y en 3D la habitación en la...
Por Nacho Palou -
2 JUL 2015
¿Quién da la vez, por favor? Vayan accediendo de uno en uno a MostExclusiveWebsite.com, la página en la que hay que hacer cola para poder entrar porque sólo puede ser visitada por una persona durante un minuto, mientras que el resto...
Por Nacho Palou -
2 JUL 2015
Los partidos de la oposición la rechazan, igual que lo hacen la mayoría de los ciudadanos, la ONU ha urgido al Gobierno a retirarlas... Pero mañana, 1 de julio de 2015, entran en vigor en España la Ley de Seguridad Ciudadana y...
Manual del ciberactivista: teoría y práctica de las acciones micropolíticas. Javier de la Cueva. Bandaàparte Editores, 191 páginas. No sé muy bien si Javier sabía muy bien donde se metía con la Demanda contra el canon; no sé si su postura...
Pulsando al azar el botón/enlace Página aleatoria de la Wikipedia y anotando y clasificando los resultados manualmente se obtuvo el gráfico de la imagen, que muestra a las claras qué áreas del conocimiento humano están más representadas en la enciclopedia libre....
La resolución de los nuevos vídeos grabados desde la Estación Espacial Internacional tienen tal calidad de ampliación óptica y resolución que puede verse hasta el tráfico en movimiento. Debido al desplazamiento relativo de la Tierra y la EEI incluso la perspectiva...
Según el acta del jurado: «El jurado ha valorado el importante ejemplo de cooperación internacional, democrático, abierto y participativo, en el que colaboran desinteresadamente miles de personas de todas las nacionalidades, que ha logrado poner al alcance de todo el mundo el...
Ya tenemos fechas para EBE15, que se celebrará en Sevilla el 20, 21 y 22 de noviembre de 2015. Esta es la décima edición de Evento Blog España. ¡Quién nos lo iba a decir cuando en 2006 nos juntamos algo más...
La FTC, la Federal Trade Commission —algo así como nuestra Comisión Nacional de los Mercados y la Competencia— ha iniciado el primer caso de investigación de un proyecto de financiación colectiva con cargos por estafa. Según la FTC el acusado anunció en...
Por Nacho Palou -
15 JUN 2015
En TNW News, The New York Times wisely blocks staff from viewing its desktop homepage, El personal del The New York Times ha recibido un email en el que se les comunica el bloqueo a la página web del The New...
Por Nacho Palou -
14 JUN 2015
Cuando leí que Movistar iba a triplicar la velocidad de transferencia de las conexiones domésticas de fibra me recordó a los viejos tiempos en los que te «subían» el ADSL de 512 Kbps a 1 Mbps, luego a 2 o 3,...
Agar.io es un vicioso –que digo vicioso, viciosísimo– juego multijugador que hace bueno aquello de que el pez grande se come al chico: está diseñado para acabar con tu productividad, así que aprovecha que es viernes y empieza el fin de...
En Twitter Developers, Removing the 140 character limit from Direct Messages, se anuncia que en el mes de julio los mensajes directos de Twitter dejarán de tener el límite de 140 caracteres. En los tuits, sin embargo, se mantendrá esa longitud máxima...
Por Nacho Palou -
12 JUN 2015
Puedes evitar la realidad, pero no puedes evitar las consecuencias de evitar la realidad.– Ayn Rand Me quedé con esta frase de la escritora Ayn Rand de la charla Ashkan Fardost en su charla TED sobre la Internet de las cosas:...

50 de las páginas 404 más creativas de la web es un artículo que recopila cincuenta de las ideas más creativas sobre páginas de error «no encontrado» de toda la Web, más conocidas como «errores 404». Junto a cada imagen hay...

VidStatsX mantiene esta lista con los 200 canales de YouTube con más suscriptores que bien merece un repaso: Los marcados con # son temáticos (música, juegos, deportes…) el resto es más interesante y son de videobloggers o empresas de contenidos. El...
Sebastien Gabriel, del equipo visual de Google Chrome, en Redesigning Chrome for Android. Part I, Los tres principios de Chrome ilustrados¹. De izquierda a derecha: velocidad, simplicidad y seguridad.Y uno adicional y que quizás sea el más importante en lo que...
Por Nacho Palou -
8 JUN 2015
En Google Chrome Blog, Better battery life for your laptop, El uso de Adobe Flash supone un mayor consumo de la batería del portátil, de modo que estamos trabajando con Adobe para reducir el consumo de energía al utilizar Flash parando...
Por Nacho Palou -
5 JUN 2015
En Wired, Google's Ingenious Plan to Make Apps Obsolete, Los guiños hacia la web durante la conferencia Google I/O fueron demasiados como para enumerarlos todos; impregnaron la presentación. Google Fotos facilita compartir imágenes directamente desde la web. Polymer permite desarrollar aplicaciones web...
Por Nacho Palou -
4 JUN 2015
Pues después de años de rumores ya es oficial: De una entevista de Ángel Jiménez y Javier López con con Reed Hastings, creador y presidente de Netflix: El precio rondará los 8 euros al mes No estarán, al menos la principio, series...
Un grupo de investigadores españoles han creado Oko, un marco de fotos digital que se conecta a Internet y en el que se pueden ver fotos como en los marcos de toda la vida o utilizar para la visualización de mensajes,...
2015 Internet Trends Report de Kleiner Perkins Caufield & Byers Si andas metido en Internet o te interesa aprender más su mercado, las tendencias o el futuro, te vendrá bien dedicar un buen rato a analizar el 2015 Internet Trends de...
En CNet, Mozilla overhauls Firefox smartphone plan to focus on quality, not cost Mozilla ha renovado su proyecto de móviles con sistema operativo Firefox OS al percatarse de que apostar por teléfonos de muy bajo precio no es suficiente para competir...
Por Nacho Palou -
1 JUN 2015
Desde MIOTtech nos llegó un tuit acerca de su MIOT, un «contador social», un panel informativo a la antigua usanza –de hecho combina madera, aluminio y metacrilato con un display mecánico– que muestra en tiempo real algunas métricas provenientes de Internet,...
Para una explicación más a fondo de esto, recomiendo Memecracia de Delia Rodríguez, un libro que no en vano se subtitula «Los virales que nos gobiernan», disponible en Amazon tanto en ebook para Kindle como en formato árboles muertos. Pero este...
Puedes usar un ratón, el dedo o una tableta con lápiz digital: la cuestión es dibujar el círculo más perfecto posible a mano alzada. Ve a Circular y haz la prueba para comprobar la «redondez» de tu creación. La puntuación total...
La gente de Delta Airlines ha conseguido combinar la seriedad necesaria en un vídeo de seguridad a bordo con un toque de humor, en este caso tirando de memes de Internet. Lo cual, como puede verse, quiere decir que el vídeo...
En la Chrome Web Store, la extensión para Chrome Google Tone aprovecha los altavoces y el micrófono del ordenador para transmitir información entre ordenadores próximos, es decir, que funciona siempre y cuando unos y otros ordenadores puedan oirse entre sí. Los...
Por Nacho Palou -
20 MAY 2015
Aunque tardé en entrar por el aro desde hace algún tiempo soy muy fan de los libros en formato electrónico, aunque sin dejar de lado, eso sí, los que vienen en formato árbol muerto. Pero aunque tienen muchas ventajas, siguen teniendo,...
Con millones de ordenadores, dispositivos y servidores de todo tipo conectados, la Red es una auténtica bestia energética que absorbe una buena parte de los recursos de todo el planeta. En este vídeo de SciShow se analiza cuánta energía consume Internet,...
El proyecto de identificación de imágenes de Wolfram es capaz de identificar el contenido de una imagen: basta con arrastrar un fotografía y Wolfram sabrá lo que es (o quién es cuando la imagen es de un rostro conocido, por ejemplo)...
Por Nacho Palou -
19 MAY 2015
¡Cuidado que vicia! Film Hunt es una estupenda base de datos que ha extraído la información de las «puntuaciones del público» de la IMDb en diversas categorías: ciencia-ficción, crimen comedia... Es básicamente un resumen de lo mejor del o mejor del...
La Histropedia es una herramienta para jugar con las cronologías o timelines creándolas desde cero o remezclando las ya existentes. Una buena forma de entender cómo funciona es cargar los datos de alguno de los ejemplos que contiene, extraídos en su...
En horizontal, cuántos píxeles baja el visitante; en vertical el porcentaje de gente.Una de cada cuatro baja antes de que cargue la página. «Estar arriba» no garantiza ser visto. LukeW dedicó su artículo The is no fold a examinar los datos sobre...
Desde hoy cualquier persona que disponga de un establecimiento o local comercial o de un negocio puede utilizar Maps Connect para darlo de alta en Apple Maps, de tal modo que aparezca en las búsquedas y en los mapas. Si el...
Por Nacho Palou -
15 MAY 2015
En TestTube se puede activar el nuevo diseño del reproductor de YouTube junto con otros elementos del diseño del servicio. Basta pulsar el botón de la parte inferior de la página para que a partir de ese momento se use un...
Desde hace algunos meses existe en la red un nuevo proyecto llamado ePolitic que es una especie de cruce supervitaminado entre LinkedIn y la Wikipedia: el contenido son los currículums en formato de datos abiertos: pueden añadir información editores, los propios...
CNN ha publicado unos datos dejando claro que la banda ancha claramente no llega a todo el mundo, pero lo sorprendente es que ni siquiera en Estados Unidos. Según los resultados trimestrales de AOL el número de suscriptores al servicio que...
Manolo nos envió un enlace al Pretenciosómetro (pretentious-o-meter.co.uk), un sitio web que ofrece un resumen rápido de la valoración de las películas según los críticos y según el público: (…) Básicamente lo que hace es comparar la nota que los críticos...
Uno de los frente abiertos en los Estados Unidos en la lucha por los derechos de los usuarios frente a la protección de la propiedad intelectual es en la lucha que mantiene la Electronic Frontier Foundation contra los fabricantes de automoción. Se...
Guarda esta útil página: separator.mayastudios.com ¡Fácilmente! Si tu navegador no lo hace, guarda esta página y desde allí podrás y arrastrar separadores vacíos ( | ) donde te haga falta. Puedes añadirlos tanto como separadores verticales en la barra del navegador como horizontales en...
Madrid y el Paseo de la Castellana vistos en 1956 y en la actualidad desde la misma posición A raíz de una vieja anotación que publicamos acerca de El crecimiento de Madrid Javier nos escribió hace ya bastante para enseñarnos un proyecto...
El Mapa de los cables submarinos del mundo (2015) de Telegeography vuelve como cada año, esta vez incluso con espónsor y un diseño artístico renovado que lo convierten un una auténtica obra de arte. La información está actualizada respecto a ediciones...
Si todos los sitios web de las startups¹ te parecen iguales es porque lo son. Como demostración, este Generador Aleatorio de Webs para Startups incluye todo lo necesario: nombres de producto inventados, lenguaje marketroide, fotos inspiradoras… Simplemente recarga la página con...
Country Codes of the World [aquí con más detalle, PDF] es una preciosa infografía / póster de John Yunker, actualizada con los más de 260 dominios de internet de primer nivel de todo el mundo, la mayor parte de los cuales...
Ordenados por «importancia»: países, personas, estrellas pop y teoremas matemáticos The Open Wikipedia Ranking es una interesante herramienta con la que jugar a ordenar las cosas por importancia. Aunque lógicamente el problema es definir «qué es la importancia» habría diversos criterios para...
Jeff Jarvis adelantó una noticia sonada para el entorno periodístico y de Internet en Whither news?, que dice así: Google firma un pacto de amistad con editores europeos Google necesita amigos en Europa. Y puede que finalmente los haya encontrado. Mañana, Google...
TICbeat da en clavo sobre el DNI-e: «Desgraciadamente, no hay un motivo único al que achacar el fracaso de esta tecnología, sino que son múltiples las causas». Alguien con ánimo y tiempo podría debatir sobre esto; hay unos 40 millones de DNI-e...
Your life on earth, o cómo el mundo y tú habéis cambiado desde que naciste. Averigua cómo, desde que naciste, tu vida ha progresado; cúantas veces ha latido tu corazón o qué distancia has recorrido a través del espacio. Conoce cómo...
Por Nacho Palou -
26 ABR 2015
El World Air Quality Index es un interesante mashup en el que se combinan mapas de Google con datos públicos de diversas ciudades de todo el planeta respecto a la calidad del aire que se respira. Los valores están expresados en...
La página Emojitracker hace un seguimiento en tiempo real de qué emojis se están enviando en tuits, a cada instante, a través de Twitter —y mantiene un contador para todos y cada uno de ellos, ordenados desde el más utilizado al...
Por Nacho Palou -
24 ABR 2015
Jennifer Golbeck ha detectado que la Ley de Benford -tan fascinante como carente de «sentido común»- también se aplica a las redes sociales y que eso puede tener interesantes aplicaciones prácticas. Puede leerse el trabajo completo en Arxiv: Benford's Law Applies...
La forma de descargarlo es ir a Google History, desplegar el menú de Preferencias (rueda), elegir Descargar y seguir las instrucciones. Pero… Hay tres razones para descargar tu historial de búsquedas en Google: (1) quieres comprobar lo que Google sabe de...
Alguien se entretuvo en hacer un análisis real, sobre el terreno, de Google+ y se descargó ni más ni menos que 516.246 «perfiles personales» públicos de la red social de Google. El resultado: el 90 por ciento de la gente que ha...
El proyecto Twin Strangers (Desconocidos gemelos) es tan divertido como inquietante: tres amigos deciden encontrar a sus «otros yos» utilizando las redes sociales. Sí: sus dobles de aspecto con gran parecido. doppelgängers prácticamente. Todo comienza publicando las fotos y rastreando las...
Google ha añadido una nueva función que permite localizar la posición física del teléfono inteligente en el mapa con solo teclear find my phone («encuentra mi teléfono») en el buscador. Eso sí, de momento hay que hacerlo en la versión internacional...
Este texto de referencia y estudio es muy interesante: Animation Principles for the Web y merece un hueco en los marcadores para consultarlo de vez en cuando. Básicamente condensa en una docena de escenas animadas (GIFs, para más mérito) las principales...

Helo ahí: un viejo cuaderno de hojas seguramente un poco amarillentas, pero… esta es la portada del folleto original de Internet [PDF] que explicaba cómo era la red en sus primeros años. Por aquella época todavía se llamaba Arpanet y era...
… Todo el mundo terminaría las conversaciones con su nombre, teléfono, fax, cargo, dirección postal y cinco minutos de rollo legal; la gente recibiría «con copias» de mensajes que no son para ellos y te llegarían al cúbiculo tipos para darte...
Las apps de moda son Meerkat y Periscope. Sirven para retransmitir vídeo en tiempo real a amigos al estilo red social; aunque también se puede «emitir en público» como quien lo hace por radio o televisión. Son una especie de Twitter...
Tu sitio web debe de ser fácil de usar incluso para una persona borracha. * * * Y basándose en este principio del diseño web desde The User is Drunk Richard, experto en interfaces y en usabilidad —y en combinados—, se emborracha...
Por Nacho Palou -
30 MAR 2015
TRAVIC es un proyecto de la Universidad de Friburgo y geOps a modo de mashup con los datos abiertos procedentes de los mapas de OpenStreetMap y de más de 200 agencias y empresas de transporte público de todas partes del mundo...
WhatIsthisThingCalled.com plantea preguntas en forma de fotografías y vídeos y respuestas a través de disqus. La gente puede ver las imágenes de objetos cotidianos –o no tanto– que se van publicando, deja su opinión, buen saber o enlaces y si hay...
Quienes disponemos de fibra óptica en casa o en la oficina y estábamos esperando algún aumento de velocidad –que ya tocaba– estamos de suerte, porque la información se está filtrando a partir de hoy: Movistar no solo duplicará sino que triplicará hasta...
En Quartz, Microsoft is scrapping Internet Explorer, El fin está cerca para el navegador web Internet Explorer. Ayer Chris Capossela, director de márketing de Microsoft, confirmó que el nuevo navegador web de Windows —anunciado en enero con el nombre clave Spartan— no...
Por Nacho Palou -
17 MAR 2015
En ocasiones el final no es nada dramático: no hay un ¡bang! ni se oyen lamentos, tan solo un error de conexión (…) Cuando desconectaron el servidor ciertas partes del mundo comenzaron a desaparecer poco a poco: la textura de los...
IBM tiene un tumblr con un estilo algo diferente al que uno se podría esperar de un «gigante azul» haciendo microblogging; se llama simplemente IBMblr....
Prometiendo lo mejor de ambos mundos la nueva app de Google para iOS, Google Calendar [descargable en la App Store], es el equivalente de la versión Android e integra todas las funciones del popular servicio para organizarse los días. Entre otras...
En Harvard Business Review, Where the Digital Economy Is Moving the Fastest, vía Bill Gates, en referencia al Digital Evolution Index, un estudio periódico que analiza el desarrollo digital de medio centenar de países, incluyendo España —aquellos que albergan a la...
Por Nacho Palou -
10 MAR 2015
Estoy utilizando un software que se llama Netscape que es conocido como «navegador web», es poderoso pero sencillo a la vez y lo recomiendo para Internet... Aquí tenemos a Yahoo, que ordena enlaces por categorías [aparece una pantalla de texto] (...)...
Every User es una especie de experimento de Plummer Fernandez que básicamente publica todos los usuarios de Twitter uno por uno, desde el más antiguo al más reciente. La forma en que funciona es así: cada dos minutos, más o menos,...
Alguien en The Daily Conversation se entretuvo en recopilar los mejores 101 vídeos de YouTube de los últimos diez años, quizá por su popularidad, quizá por su poderío o porque marcaron un momento clave en algún aspecto. De modo que, como...
En Forbes, Microsoft Is The New Google, Google Is The Old Microsoft, La publicidad y el buscador se han convertido en el Windows y Office de Google. Ambos productos están siendo devorados por una publicidad dirigida cada vez más a los medios...
Por Nacho Palou -
19 FEB 2015
La Asociación Española de Comunicación Científica, de la que soy miembro, organiza por cuarto año consecutivo la jornada Ciencia en Redes, que se celebrará el próximo 28 de mayo de 2015 en La Casa Encendida, en Madrid. Como siempre, aspiramos a contar...
WikiGalaxy es un proyecto de Owen Cornec que deja navegar por los 100 000 artículos más populares de la Wikipedia en inglés de 2014 como si fueran una galaxia. Cada página es una estrella, con las páginas relacionadas representadas por estrellas...

Flipboard ya se puede usar desde la Web además de como app, formato en el que ha alcanzado una inusitada popularidad en los últimos años. Con financiación en el bolsillo y un buen equipo trabajando tras las bambalinas ésta era una...
El libro Networks of New York: An Internet Infrastructure Field Guide de Ingrid Burrington, vía Laughing Squid, es una guía de campo visual qué explica qué son algunas de las infraestructuras y aparatos que hay repartidos por la ciudad de Nueva...
Por Nacho Palou -
9 FEB 2015

Entre BBS ochenteros y herramientas «guays explica sus viajes mochileros por Asi y una obsesión: espiar el cosmos.
Maurits Martijn en Medium, Quizá no es buena idea que leas esta historia usando un wifi público, Vamos a un tercer café. La última petición que le hago a Slotboom es que me muestre lo que él haría si en realidad quisiera...
Por Nacho Palou -
7 FEB 2015

Disculpa este modelo tan burdo… no me dio tiempo a construirlo a escala.– Doc BrownRegreso al futuro Por diversas razones, muchas representaciones gráficas con las que convivimos habitualmente no están «a escala» sin que ello nos suponga ningún problema. Por ejemplo:...
Seguro que te ha pasado alguna vez: tienes varias pestañas abiertas y en alguna de ellas se está reproduciendo algún contenido ‘que suena’, caso de un vídeo o música. Y para detener el sonido tienes que quitar el volumen del ordenador...
Por Nacho Palou -
4 FEB 2015
Más allá de las listas y las listas de listas, en la Wikipedia hay una página con listas de listas de listas. Anteriormente: Las mejores 100 listas de todos los tiempos según el New York Times. (Vía I can programming.)...
Desde el Departamento Éramos-pocos-y-parió-la-abuela, la compañía Vivaldi ha desarrollado un navegador web dirigido especialmente para los power users. Así que no aspira a competir con los navegadores para todos los públicos como Safari o Chrome sino a un público menor y...
Por Nacho Palou -
28 ENE 2015
«Te lo repito, mamonazo: ¿Hablan inglés en ‘Qué’?» En PlayPhrase.me hay literalmente miles de vídeos de frases de más de 160 películas para que puedas practicar el inglés normal y corriente escuchando cómo lo pronuncian diferentes actores. Star Trek, El club de...
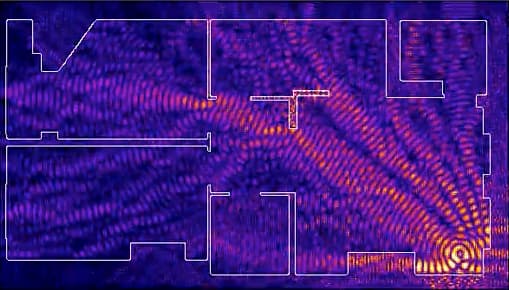
¿Sabes eso de que el wifi de tu casa llega perfectamente a un rincón en cierta habitación pero cuando estás en tu esquina favorita del sofá simplemente se desploma? Es debido a que el wifi es una radiación electromagnética a la...

Cuando se trata de mostrar grandes cantidades de información en una web, ya sean productos de una tienda, resultados de una búsqueda o anuncios en una web de empleo, tradicionalmente se ha venido utilizando un recurso de interfaz conocido como paginación...
Esta pizarra borrable con su rotulador es la encarnación física de un meme de Internet, en este caso el famoso Batman abofetenado a Robin. La idea es usarlo en casa o en la oficina como borrador rápido – aunque como desventaja...
Año nuevo (más o menos), así que la Fundación Telefónica acaba de publicar su informe La Sociedad de la Información en España 2014, que se puede descargar en PDF y EPUB, aunque está resumido en el vídeo de arriba. En Informes...
La brillante viñeta Watching someone use a computer deliciosamente adaptada al cine mudo en esta animación de Guy Collins: The Scrollwheel....
Por Nacho Palou -
20 ENE 2015
Robert nos hizo llegar un enlace a su Tabla periódica de de los elementos HTML (que actualiza una idea antigua que ya no existe). Básicamente contiene todos los elementos a título individual y también una serie de botones en la parte...
Este fantástico viaje al pasado se llama Olduse.net: consiste en una recreación de cómo era la red USENET hace exactamente 30 años. Para ello hace tiempo se puso en marcha un servidor llamado nntp.olduse.net donde se hacían aparecer los mismos contenidos...
Aunque en el vídeo de Obama explicando lo importante que es el ancho de banda para los ciudadanos menciona París como ejemplo de ciudad extrajera con conexiones potentes, lo cierto es que en Europa el estado de la industria de las...
Por Nacho Palou -
15 ENE 2015
A Teenager’s View on Social Media «escrito por un auténtico quinceañero/adolescente» es una anotación realista sobre cómo ven el mundo de las redes y medios sociales actuales los jóvenes – al menos desde los Estados Unidos, que es desde donde escribe...
Acceso a OS X desde el iPhone 6 Plus La extensión de Google Chrome Remote Desktop permite controlar cualquier ordenador PC o Mac desde dispositivos móviles iOS (iPad, iPhone) y Android —para el que ya existía. Es totalmente gratis y va bastante...
Por Nacho Palou -
14 ENE 2015

En este didáctico vídeo el presidente de los Estados Unidos explica una infografía guardada en su tableta para mostrar porqué es importante que las ciudades de un país cuentan con una buena infraestructura y un ancho de banda suficiente como para...
Tan grande es el éxito de Kickstarter, el servicio de financiación colectiva pensado para inventores y creadores de proyectos, que recientemente se ha sabido que durante el año 2014 ha ingresado 850 euros por minuto: unos 420 millones de euros en todo...
En este vídeo –que podríamos considerar un poco Pr0n para sysadmins– se puede contemplar el nacimiento de Skynet cómo es un datacenter de Google por dentro, con sus racks, servidores y sistemas de refrigeración. (Puedes usar la regla de saltarte el...
Cómo GitHub utiliza GitHubpara documentar GitHub Enrevesado pero práctico a la vez. Es otro nivel respecto a minucias como usar Wikipedia para explicar la Wikipedia y similares....
GMB Akash — Crossing the Waterways in Bangladesh The Art of Saving a Life es una iniciativa de la «Bill & Melinda Gates Foundation» que defiende las vacunas como uno de los mayores avances de la humanidad, Las vacunas salvan millones de...
Por Nacho Palou -
8 ENE 2015
Al parecer hay por ahí un bot que se ha dedicado a comprar drogas y hasta obtener un pasaporte falso. El caso es que unos programadores lo soltaron para pruebas con un presupuesto de 100 dólares a la semana (en bitcoin) que...
Clic para ampliar Data Never Sleeps 2.0, una imagen que resume una parte de la información que se genera en Internet cada minuto, incluyendo, 277.000 tuits, 350.00 fotos con WhatsApp, 240 millones de mensajes de correo electrónico, 4 millones de búsquedas en...
Por Nacho Palou -
5 ENE 2015
El directorio de Yahoo, que durante años antes de la existencia de Google fue uno de los puntos de partida para navegar y encontrar nuevas páginas en la Web ha sido cerrado retirado oficialmente a 1 de enero de 2015, tal...
The Internet in Real Time es tan vertiginoso que asusta. Parafraseando a lo que decían en MetaFilter: «en lo que has tardado en leer estas líneas se han publicado más de 200.000 estados en Facebook, 20.000 tuits y se han descargado...
Forgotify parte de un dato impactante y una idea curiosa. El dato es que existen más de 4 millones de canciones en Spotify que nunca, jamás, nadie ha escuchado. Y eso que hay 40 millones de usuarios dale que te pego...
A partir de modelos estadísticos de las búsquedas, información social y otros indicadores la gente de Bing se lanza a la piscina de las predicciones para el año 2015. Éstas se refieren a temas como la moda, los deportes o las...
Por Nacho Palou -
18 DIC 2014
Una desigual pelea contra el Internet Explorer de Microsoft, una serie de malas decisiones en cuanto a la dirección en la que desarrollarlo, y una lamentable gestión por parte de AOL tras comprarlo hicieron que Netscape Navigator fuera perdiendo relevancia como navegador...
AEDE, la Asociación de Editores de Diarios Españoles, presiona al gobierno de España para que modifique la Ley de Propiedad Intelectual de tal forma que se establece un canon irrenunciable para agregadores y sitios como Google News que quieran incluir «fragmentos...
Tenemos >Internet hecho un estercoler y la World Wide Vac es la aspiradora virtual que analiza y limpia el buzón de correo para dejarlo limpio de polvo digital, Internet se ha convertido en nuestro segundo hogar, pero la gente sólo limpia...
Por Nacho Palou -
4 DIC 2014
El 60% de los dispositivos conectados a Internet son ya teléfonos móviles y tabletas, desde los que se mueve más del 25% de todo el tráfico de Internet. En general es un mundo de móviles, y sus pantallas son los que...
Por Nacho Palou -
3 DIC 2014
RadiumOne: The Light and Dark of Social Sharing En VentureBeat, Dark social: Facebook is less than one-third of all social sharing, Según el estudio RadiumOne: The Light and Dark of Social Sharing realizado entre 9000 personas, el 59% comparte contenidos online a...
Por Nacho Palou -
2 DIC 2014
Gizmodo publicó un intensa anotación dedicada a cómo enfrentarse a la inevitable situación de explicarle a la familia –como «entendido en ordenadores», ejem– qué es eso de la neutralidad de la red, en su caso jugando con el chiste de que será...
Population.io está haciendo las rondas estos días; es una herramienta para calcular tu «lugar» entre los 7.000 millones de habitantes que somos en el planeta Tierra. Simplemente escribes la fecha y país de nacimiento, si eres hombre o mujer y ¡listo!...
Y con esta van diez ediciones de los Premios Bitácoras, lo decanos de la blogosfera española, que en la edición de 2014 han tenido estos ganadores: Premio Mejor Blog del Público: Cuentos infantiles cortos. Premio Mejor Twitter: Policía Nacional, @policia. Premio...
Criando HTMLeros desde la tierna cuna. Una idea que tuvo un diseñador web y acabó en las estanterías virtuales de Think Greek: HTML for babies. «Porque nunca se es lo suficientemente joven como para validar bajo los estándares del W3C.»...
Más limpio, más bonito y más atractivo. Siguiendo el enlace de Archive.org v2 se puede probar la nueva versión de la web de Archive.org. Estamos hablando del auténtico «archivo de Internet», que se remota años y años en la historia de...
Según Information Geographies, The Geographically Uneven Coverage of Wikipedia, el origen de más de la mitad de todos los artículos que hay en la Wikipedia, en todos los idiomas, se concentra dentro del área rodeada por ese circulo rojo, que representa...
Por Nacho Palou -
12 NOV 2014
Del hombre al que primero le parecía bien espiar los correos y ordenadores de todo el planeta; del premio Nobel de la Paz en cuya mano está el botón rojo del mayor arsenal de armas de destrucción masiva del mundo; del...
En BusinessWeek, Non-White Emoji Are Finally Coming, Hasta ahora la gente que no tiene la piel blanca tenía un pequeño problema a la hora de añadir emojis a sus mensajes de texto (porque) no había ninguna opción para enviar una cara...
Por Nacho Palou -
6 NOV 2014
En The Internet Archive hay una recopilación de más de 900 juegos de tipo arcade clásicos, de los de toda la vida desarrollados entre los años 70 y 90 del siglo pasado: The Internet Arcade. Lo mejor es que funcionan a...
Por Nacho Palou -
3 NOV 2014
Con una asistencia más bien escasa los partidos políticos españoles presentes en el Congreso acaban de dar el paso final en el parlamento para que la reforma de la Ley de Propiedad Intelectual pueda entrar en vigor, algo que sucederá el...

Leonard Kleinrock, uno de los pioneros de Internet, nos enseña en este video vídeo el primer aparato que conectó Internet: un «procesador de mensajes de interfaz» (IMP) –hoy en día popularizado como router– que se instaló en el ordenador principal de...
Este vídeo de Mario Kart 8 es un excelente ejemplo del formato de visualización a 60 fps en alta resolución en Youtube, que acaba de estrenarse. Esto es el doble de fotogramas por segundo de lo habitual (también funciona con 48)....
Ahora es posible enviar mensajes a la gente cuando hayas muerto, aunque básicamente tendrás que escribirlos antes de tan triste suceso e interactividad no tendrán mucha, la verdad. Este es el servicio que ofrece Death Switch –y no es el primero–...
Alice y su marido celebraron su sexto aniversario y como «regalo» (cágate lorito) ella le devolvió otro «regalo» que le había hecho él seis años antes: un análisis de su intercambio de mensajes de chat durante la época en que fueron novios:...
Mark Zuckerberg, fundador de Facebook,y su esposa Priscilla Chan donan25 millones de dólares para combatir el Ébola vs. Especuladores venden los dominios Ebola.comy Ebola.es con precios de salida de150.000 dólares y 5.000 euros...
Primer mapa de la cobertura 4G en España / Fuente: CNMCblog.es Desde el blog de la Comisión Nacional de los Mercados y la Competencia, el Mapa de la cobertura 3G y 4G en España que está muy bien pero –todo sea dicho–...
Si términos como UNIVAC, VAX, X.25, EU-net, UUCP o DECnet no te suenan a chino es porque igual conociste los tiempos gloriosos de RedIRIS, el IFIC y el CIEMAT. Para hacerse una idea de lo pequeñita que era, en 1992 había...
(Número de sitios web / hostnames en Internet – septiembre 2014) La gente de Netcraft escanea periódicamente la Web para comprobar cuántos dominios hay registrados, cuántos tienen servidores web activos, cuál es su estado y guardar un histórico para las estadísticas. Pues...
Memoria. Capacidad de disco duro. Gigahercios de procesador. Magnitudes todos ellas que nunca jamás serán «suficientes», como le sucede al popular «ancho de banda», técnicamente conocido como velocidad de transferencia de datos. Por eso celebramos esta noticia/rumor que dice que Telefónica retará...
TextMechanic es una de esas herramientas que conviene tener a mano, un buen compañero para toda persona que trabaje con textos. Es un servicio web que hace muchas de las funciones que suelen estar disponibles en los editores de texto, y algunas...
Al consejo del otro día de como desactivar la reproducción automática de vídeos en Facebook desde el ordenador se le puede añadir este para hacer lo mismo en iOS: Basta con ir a Ajustes -> Facebook -> Ajustes -> Auto-play-> Off...
Este mapa creado por John Matherly del buscador Shodan muestra cada dispositivo conectectado a Internet (en realidad, la ubicación de cada IP) por todo el mundo. El color azul representa las zonas con menos densidad de dispositivos; el rojo las zonas...
Por Nacho Palou -
16 SEP 2014
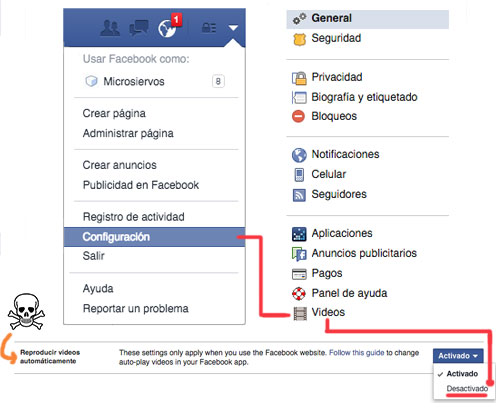
Si eres de los que echas pestes cada vez que entras en Facebook y ves cómo los malditos vídeos se reproducen solos sin que lo hayas solicitado, y para colmo te pierdes cuando intentas ver si hay alguna forma de detener esa...
TL;DR: Si se ingresa menos de 9.000 euros al año, no hay problema. Pero si se trata de los únicos ingresos y son regulares (aunque totalicen menos) entonces también hay que darse de alta como autónomo. Interesante el análisis detallado que han...
Las mentes inquietas de Juan Ignacio Pérez y sus secuaces de la Cátedra de Cultura Científica de la Universidad del País Vasco han puesto un nuevo invento para seguir adelante con su empeño de ayudar en todo lo posible con la...
Como cada año, ya tenemos aquí el Mapa de los cables submarinos 2014 de Telegeography, una auténtica preciosidad con datos procedentes de todas partes del globo. En la península ibérica destaca la cantidad de conexiones se salen de Lisboa, estratégicamente situada,...
La gente de The Internet Archive ha anunciado que han añadido ni más ni menos que 14 millones de imágenes antiguas al archivo de The Commons. Estas imágenes no tienen propietario conocido de sus derechos y se suman así a otros...
Dropbox Pro 1 TB 9,99€ / mes Lento Accesible desde cualquier parte No ocupa espacio físico No necesita enchufe/cable Backups seguros Al alcance de la NSA WD Portable 1 TB 59,99€ / hasta que se rompa Muy rápido / USB 3.0...
GitLive utiliza la API de GitHub, el famoso repositorio del sistema de control de versiones Git -especialmente popular en proyectos de código abierto y software libre- para mostrar qué está haciendo la gente de la comunidad, especialmente colaborando e interactuando de...
En este gráfico de la RIAA se puede ver claramente cómo ha sido la evolución de los ingresos de los años 80 a esta parte en el mundo de la música, dividiendo los totales entre los diferentes tipos de ingresos y...
Captura+Photoshop= El 40% de los whatsapps y SMS usados en juicios son falsos, según la Asociación de Internautas. En la página explican cómo utilizar software específico para simular que se envían SMS o whatsapps falsos; la realidad podría ser incluso mucho más...
Aparte de una cama sin bichos sólo hay dos cosas que considero imprescindibles en un hotel: una ducha con una buena presión de agua y Wi-Fi, a ser posible gratuita; de hecho la disponibilidad de esta es uno de los criterios...
24 horas de sonido de fondo del motor del Enterprise de Star Trek. Y de un destructor imperial. Y del Halcón Milenario y de la Estrella de la muerte. Para trabajar con tranquilidad en un buen «ambiente»....
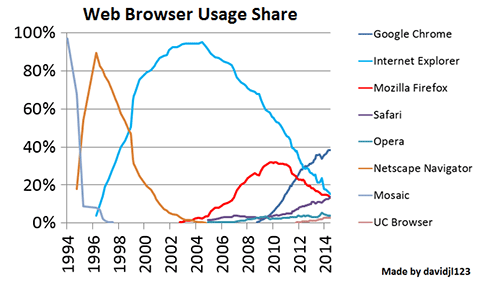
Este gráfico de davidjl123 muestra lo que han sido las cuotas de mercado de los navegadores web en los últimos 20 años, de 1994 a esta parte. Lo que comenzó siendo un monopolio al 100% de NCSA Mosaic, el primer navegador,...
Según un reciente estudio de YouGov entre los británicos, un 65 por ciento de la gente considera que los autores de la Wikipedia son más fieles a la verdad que los periodistas tradicionales. Exploran en profundidad este dato en CuartoPoder: La...
La reforma de la Ley de Propiedad intelectual, que incluye entre otras cosas la polémica tasa Google, que en realidad tendría que llamarse tasa AEDE, fue aprobada ayer en la Comisión de Cultura del Congreso. Será ahora remitida al Senado para su...
En El Androide Libre y en Omicrono cuentan las nuevas condiciones que exigirá la Comisión Europea a las tiendas de apps para proteger a los más débiles. Lo que se pretende es evitar que la gente se sienta defraudada al comprar aplicaciones...
Y si lo que usted quiere es tuitear sobre lo que el gobierno le está haciendo a su pueblo, entonces lo que necesita es suscribirse al «Paquete Revolucionario» por tan solo $19,95. Los chicos de College Humor ponen los puntos sobre...
Uso de actividades sociales en los smartphones; porcentaje sobre el total de usuarios de smartphone entrevistados pare el estudio Un año más la Fundacion Orange ha publicado su informe sobre el desarrollo de la Sociedad de Información en España, el Informe eEspaña...
¿Que qué hago en el mundo exterior? En mi casa no hay Internet y no veía la luz del sol desde que conectaba por módem en el 96... Resulta que es altamente recomendable. Impactante el momento cumbre del vídeo y sus...
La FCC aprueba 1.000 millones de dólares anuales de inversión para llevar Wi-Fi a todas las escuelas estadounidenses vs. Expertos españoles reclaman extremar las precauciones con el Wi-Fi y restringir su uso en las escuelas y espacios públicos...
De Grathio: Pestaña: Métrica relativa a la dificultad de resolución de un problema, calculado según el número de pestañas del navegador abiertas cuando se resuelve. Ej. «Un problema de 19 pestañas». Digno de geekcionario, sin duda....
Startupxplore se ha renovado; es una interesante y necesaria iniciativa de la que ya hablamos a principios de año y nos pareció muy interesante. Ahora han completado la información con Los principales inversores en empresas de reciente creación (startups) en España,...
NSA: Aquí abajo se espía. Los activistas de la Electronic Frontier Foundation, Greenpeace y el Tenth Amendment Center hicieron volar un dirigible de 50 metros sobre el centro de proceso de datos que la Agencia de Seguridad Nacional estadounidense tiene en...
Cuando la combinación de las ciudades inteligentes y el movimiento Open Data facilita a la gente datos públicos sobre lo que ocurre en la ciudad suceden cosas interesantes. En Nueva York, por ejemplo, un grupo de programadores llamado Wolves in the...
Un pequeño y brillante cortometraje de los tres hermanos noruegos HigtonBros sobre la «autoimpuesta esclavitud» y la forma en que algunas personas viven su propia realidad y la de los demás en ese peculiar y etéreo mundo llamado «las redes sociales»....
¡Ding! Ahí va una estrella junto a un tuit. Porque es divertido. Para leerlo más adelante. Porque parece importante. Porque se está de acuerdo. Para discutirlo luego. Porque hace «sentirse especial». Porque tienen vídeo o fotos. Porque es emotivo. Porque es...
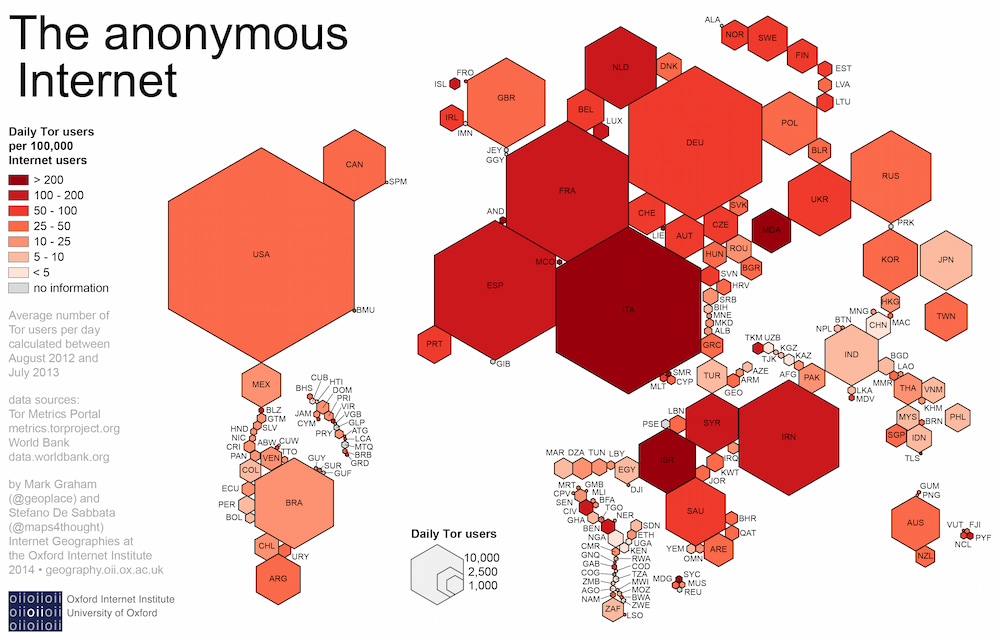
Tor es un sistema de comunicaciones cifradas que protege la comunicación entre el ordenador del usuario y el servidor al que accede, para garantizar que la navegación por Internet es totalmente segura y privada, sin que quede registro de los sitios...
Por Nacho Palou -
24 JUN 2014
Tamaños y formatos adecuados para las imágenes de Twitter. The Ultimate Guide to Using Images in Social Media reúne las recomendaciones acerca de los formatos y tamaños que deben tener las imágenes según a qué servicio o red se vayan a enviar:...
Por Nacho Palou -
23 JUN 2014
Timothy Lee recopiló en 40 maps that explain the internet varias decenas de interesantes mapas relacionados con Internet, muchos de los cuales hemos mencionado alguna vez por aquí. Están desde los más antiguos mapas sobre el origen de Internet a los...
Emojipedia.org Sorprendentemente (o no), este sitio existe. Entre otras cosas podemos descubrir allí que el mes de julio que viene se añarirán nuevos emojis al estándar Unicode 7.0, que la famosa «flamenca del vestido rojo» en realidad ni es flamenca ni...
Hay montones y montones de vídeos grabados por drones en YouTube, pero en TravelByDrone se dedican a recopilar aquellos que tienen interés para ver posibles destinos turísticos. Puedes usar el mapa para navegar por ahí o el buscador de la parte...
Algo importante cuando estás desasrrollando una web es comprobar que se vea bien en todos los navegadores, sistemas operativos y dispositivos posibles. Pero para ahorrar el trabajo de tener que ir uno por uno haciendo las pruebas existen servicios como BrowserStack...
En lo que de otro modo podría ser considerado una «extraña situación» los Marshal de los Estados Unidos han sacado a subasta 29.656,51306529 bitcoins que al cambio actual (unos 600 dólares por bitcoin) serían algo así como 18 millones de dólares. Aunque...
La World Wide Web es, sin duda alguna, la cara más popular de Internet, tanto que para mucha gente la Web es Internet, o viceversa. Pero aunque no hay duda de que su desarrollo sale de la propuesta que Tim Berners-Lee...
Si me llegan a decir en 2011 que veríamos al bitcoin junto con el resto de monedas como el dólar o el euro en Google Finanzas o Yahoo Finanzas, no me lo creo – por no hablar de la cotización, claro....
— Este vídeo cambiará tu vida, te ahorrará dinero, mantendrá tu tarjeta de crédito segura y protegerá tu identidad online.— ¿Y cómo has subido el vídeo a Internet, con la mente?— No, con la tostadora....
Por Nacho Palou -
12 JUN 2014
Una sentencia relacionada con el llamado «derecho al olvido» pretende que por ley se haga algo que en la práctica va a resultar imposible: ignorar la existencia de ciertos contenidos en la red (¿te suena esa situación?) El caso es que...
Todos los que lleváis leyéndome algún tiempo sabéis que la expresión «nativo digital» me saca de mis casillas porque me niego a creer en que los niños y adolescentes actuales sean tal cosa. No discuto que tienen una naturalidad a la hora...
No es un ejercicio científico, pero ahí quedan las curiosidades encontradas por Avast Virus Lab tras analizar una muestra de las contraseñas utilizadas por hackers, Hackers use weak passwords just like the rest of us — Comparando los resultados de los gráficos...
Por Nacho Palou -
10 JUN 2014
¡Oh, la humanidad! Alguien se ha entretenido en realizar algunos cálculos de servilleta con motivo de que el vídeo de la pegadiza «Gangnam Style» (2012) alcanzara los 2.000 millones de visualizaciones en YouTube hace poco. Si tiene una duración de 4 minutos...
Last Week Tonight with John Oliver (HBO): Net Neutrality son 13 minutos hilarantes pero a la vez tremendamente serios en los que este presentador da cera al gobierno de los Estados Unidos y a operadoras como Comcast y Verizon acerca de...
Unos 90 segundos de Internet The Internet in Real-Time es un sitio que tiene como único objetivo ir llevando una cuenta de la cantidad de información que se mueve en Internet desde el momento en el que te conectas a él: horas...
La relación entre la puntuación que la gente otorga en las reseñas que escribe sobre productos y cuán útiles resultan
Porcentajes de tuits según el idioma seleccionado por los usuarios según un gráfico creado por Gnip, Inc: Inglés. Japonés. Español. Portugués. Indonesio. Árabe. Francés. Turco. Ruso. Coreano. (@conradhackett vía RT de @airamzr)....
Varios motivos han hecho que en las últimas semanas se hable mucho en España de lo que se puede decir y qué no se puede –o debe– decir en Twitter y similares. Estos son unos enlaces sobre el tema que me he...
El primer sitio web en el crawler de Moebio Santiago nos escribió para hablarnos de First Site and Beyond un crawler visual de la web, o lo que es lo mismo, un sitio que permite ir recorriendo la web haciendo clic en...
No soy nada futbolero, pero me encanta esta visualización interactiva de la final de la Champions League de 2014 entre el Atlético de Madrid y el Real Madrid construida a base de tuits geolocalizados que contenían las palabras clave relevantes. Real...
Una gráfica que muestra las aplicaciones de mensajería instantánea más utilizadas en cada país: Whatsapp, Facebook Messenger, Line, etc.
#Morganfire02 el 2 de abril de 2014#Morganfire02 el 18 de mayo de 2014 El 8 de septiembre de 2013 se produjo un incendio en la cumbre del Monte Diablo, en los Estados Unidos. Para intentar entender las consecuencias de este y cómo...
Con motivo del Día de Internet 2014 celebrado el pasado sábado nos pidieron en RTVE.es que echáramos la vista atrás –y hacia adelante– para repasar las últimas décadas de Internet e imaginar cómo podría ser su futuro lejano. De modo que hicimos...
Tal y como explican en The Connectivist en 1992 eran un millón pero para 2020 serán 50.000 millones de aparatos los que estarán conectados a Internet, desde teléfonos móviles a las ruedas de tu coche o las bombillas de casa. Básicamente...
Ramiro Gómez creó esta visualización sobre la evolución de los usuarios de Internet en el mundo, por países donde el eje vertical muestra el número de usuarios, el horizontal el PIB y el tamaño de los círculos el número de habitantes....
Filtrar por antigüedad. Esto permitiría eliminar los vídeos viejunos que quizá fueron interesantes en su día pero que ya no tienen nada de actual. Filtrar por calidad. Para eliminar los píxeles como puños y dejar solo los vídeos de calidad 480...
Aunque parezca un poco lioso, quédate con esta idea: Todos los datos deben ser tratados por igual. (Vía Geeks Are Sexy.)...
7 3 8 FavouriteNumber.net se creó para que la gente votara su número favorito. Ganó el 7, seguido del 3 y el 8, tras unos 44.000 votos. Actualización (2021) – La web ya no existe, pero estos fueron los resultados....
+1: los del volcán y la Fundeu (Fundación del español urgente = Para Qué Esperar a que la Real Academia Se Pronuncie Sobre Algo) han creado esta elegante infografía con 30 abreviaturas para sobrevivir en Twitter. Enséñasela a tu madre y...
What’s New With NCSA Mosaic, versión abril de 1994. Una de las más clásicas páginas de toda internet. Con el HTML más básico y puro que puedas imaginar, e interesantes novedades de la época como… [el 95% de los enlaces ya están...
En junio de 2008 Promusicae, Sony BMG Music Entertainment S.A, Universal Music Spain S.A., y Warner Music Spain S.A. denunciaron a Pablo Soto reclamándole 13 millones de euros al entender que había desarrollado sus aplicaciones para intercambio de archivos mediante redes P2P...
Según esta sentencia (en inglés) del Tribunal de Justicia de la Unión Europea la Directiva 2006/24/CE, de Retención de Datos [PDF], es contraria al derecho de la Unión y, por tanto, no válida. El TJUE reconoce que la retención de datos es...
Por Nacho Palou -
8 ABR 2014
A veces esto de estar en la Unión Europea tiene sus ventajas. Hoy el Parlamento Europeo ha votado apoyar la iniciativa Connected Continent de Neelie Kroes, iniciativa que entre otras cosas incluye asegurar la neutralidad de red y la eliminación de las...
En inglés tiene un juego de palabras más gracioso: Internet Tube. Es a la vez mapa del metro (tube) y mapa de los tubos o cables submarinos de fibra óptica que llevan la información de un lado a otro del planeta,...
Apenas uno días después de que un juez denegara la petición de cierre de Goear.com por parte de la Comisión Sinde-Wert por considerarlo una medida desproporcionada se ha sabido que la Secretaría de Estado de Cultura recurrirá el auto judicial en cuestión,...
Pocas cosas nos gustan aquí más que los mapas, o que Internet, de modo que no podemos sino alegrarnos de que la gente de Halcyon Maps haya combinado estas dos querencias en una de sus más conocidas obras que a partir...
Lo cuenta con todos los detalles que puede David Bravo en Denegada judicialmente la primera orden del Ministerio de Cultura de cierre de una página web. Pero el resumen es que la Comisión Sinde-Wert pidió el cierre de Goear porque se habían...
Un poco de peras vs manzanas como excusa para ver en el mismo vídeo a dos máquinas poderosas e impresionantes: el RB7 (2011) del equipo de Fórmula 1 de RedBull y un F/A-18 Hornet de la Fuerza Aérea australiana....
Por Nacho Palou -
19 MAR 2014
«Dios mío! ¡Han matado los subrayados! ¡Hijos de *&%$…! ¡El infierno se ha congelado! ¡El apocalipsis se acerca! Discreta y sigilosamente, el mismísimo Google ha eliminado el subrayado de los enlaces de los resultados de búsqueda. Que hayan adaptado esta práctica de...

En aquellos días del amanecer del segundo año de la segunda década del tercer milenio, descendió una gran oscuridad sobre la conectividad a internet de las gentes del 276 de Ferndale Srt. Durante años, aquellas felices gentes habían disfrutado en sus...
¡Oh! Resulta que todos esos «extraños que se besan ardientemente por primera vez» en First Kiss no son tan extraños: son actores, actrices y modelos… Y la película es un anuncio de ropa, tal y como explica Slate. También en The...
Portada de la propuesta de Tim Berners-Lee Hoy, 12 de marzo de 2014, se cumplen 25 años exactos desde que Tim Berners-Lee le propusiera a su jefe en el CERN la creación de un sistema que permitiera compartir información entre los distintos...
El directorio de Yahoo, estilo retro pero funcionando hoy en día. Cuál ha sido mi sorpresa al verlo… Como reencontrarte en la calle con un viejo amigo....
En Time, 1 World Trade Center: Time's View From The Top Of NYC, una panorámica interactiva de 360º de las vistas desde lo alto del edificio de 104 plantas One World Trade Center, «oficialmente» el edificio más alto de EE UU...
Por Nacho Palou -
7 MAR 2014
El gráfico interactivo Hungry Tech Giants recopila quince años de adquisiciones por parte de algunas de las empresas tecnológicas más poderosas y más voraces: Apple, Amazon, Google, Yahoo y Facebook. Facebook se lleva la palma con los 19.000 millones pagados por...
Por Nacho Palou -
5 MAR 2014
¡Alehop! ¡Alehop! ¡Ah, si teletransportarse fuera así de fácil! Jim Andrews creó este sencillo código que permite ir saltando de lugar en lugar a través de las fotos de Google Street View. Tan solo hay que hacer clic en el botón...
El 57 por ciento del tráfico de Internet que circula por Estados Unidos pasa en algún momento por conexiones wifi. Y ese porcentaje sigue creciendo. [Fuente: Cisco + The Wall Street Journal ($), vía parislemon.)]...
El acceso a CompuServe, en 1985, costaba 6 dólares por hora a 300 baudios, o 12 dólares por un acceso a 600 baudios. 3500 veces esta velocidad hacen un megabit/segundo. [Fuente: @eduo]...
La semana pasada tuve el honor de impartir la charla de clausura de la ceremonia de entrega del concurso Tesis en 3 Minutos de la Universidad Pública de Navarra. Este concurso, que tiene categorías para tesis, trabajos de fin de máster...
Es como si vives en una tribu que ha ido prosperando, creciendo y conquistando territorios. En un momento dado la tribu la forman 6.000 nativos y todo va estupendamente (…) Pero, de repente, un buen día el jefe de la tribu convoca...
Mediante una combinación del trabajo realizado por decenas de empresas y agencias –entre ellas Vizzuality– y herramientas de la colección de Google Maps y Google Earth, Global Forest Watch muestra el estado de los bosques del mundo «casi en tiempo real»....
La Asociación de la Prensa de Madrid mantiene una lista de Nuevos medios lanzados por periodistas desde una fecha aproximada al «comienzo de la crisis» (enero 2008) hasta la actualidad. Todos ellos proceden del Informe Anual de la Profesión Periodística, 2013. En...
Como viene siendo tradición desde su primera edición, antes de arrancar la de 2014 de iRedes, el Congreso Iberoamericano sobre Redes Sociales, se ha presentado la cuarta versión de su mapa de redes sociales, que incluye aquellas con al menos 10.000...
María González, directora jurídica de Google España, en una estupenda entrevista a Hoja de Router: P: ¿Google considera que los medios de comunicación tienen derecho a que se les pague una cuota por aparecer en Google News? R: Todos los editores y...
El otro día surgió la cuestión de cómo analizar las visitas que había tenido una página web concreta a lo largo del tiempo. Es un dato trivial para cualquier sistema de analítica web; por ejemplo el popular Google Analytics. Pero como cada...
Los 19.000 millones de dólares en efectivo y acciones en los que está valorada la compra de Whatsapp por parte de Facebook superan el presupuesto de la NASA para 2014, cifrado en 17.650 millones de dólares.[Fuente: @CarolynPorco]...
El Consejo de Ministros de hoy ha aprobado remitir a las Cortes el proyecto de ley mediante el que se pone al día la Ley de Propiedad Intelectual; de hecho el mismo ministro Wert compareció después del Consejo para informar de ello…...
Utilizando datos de Alexa (de 2011) este enorme Mapa de Internet –más exactamente, mapa de la World Wide Web– representa con círculos de tamaños relativos la audiencia los distintos dominios por los que navegan los internautas. En otras palabras: si tu...
Pasito a pasito la velocidad promedio de las conexiones de Internet en España ha aumentado un 42 por ciento en el último año, según un informe de Akamai. En la imagen somos la línea azul claro, que pasa de unos 2...
Lower Hutt, Nueva Zelanda. Un bosque denso de marismas habitado por maoríes y europeos llegados a aquellas tierras en el siglo XIX. Parte de El Señor de los Anillos se rodó allí. Pero lo mejor de Lower Hutt es que está...
Clic para ver entero Tomando como base el mapa de las comunidades en línea de XKCD y aplicándole el estilo de los mapas de National Geographic Martin Vargic ha creado lo que llama el Mapa de Internet 1.0, una cosa realmente preciosa...
Con Google Street View y desde la comodidad del sofá, se puede hacer una visita a la Antártida y llegar al mismísimo Polo Sur, donde por lo visto hay un palo (un orbe pulido sobre un poste estriado) rodeado por las...
Por Nacho Palou -
31 ENE 2014
What Happened To The New Internet?, Una Internet nueva planteada como un Elysium online: un lugar seguro para desarrolladores e inversores y líderes del pensamiento; un hogar nuevo creado por la élite de Internet para la élite de Internet. Financiada por...
Por Nacho Palou -
30 ENE 2014
Cuando hablo de la historia de los blogs siempre menciono la página Justin's Links from the Underground como la precursora en publicar enlaces en forma cronológica inversa, justo como hacían los primeros blogs. Claro que entonces publicar en la web no...
El tiempo promedio dedicado a Facebook es de 17 minutos al día por usuario de esa red social. Facebook no proporciona información indivudal sobre el tiempo dedicado, pero esta herramienta online de Time lo calcula analizando las fechas y horas de...
Por Nacho Palou -
28 ENE 2014
De la mano de los los creadores del estupendo Spain Startup Map del que hablamos el año pasado por aquí llega un infografía en tiempo real sobre el estado de la cuestión: A View of the Spanish Startup Community, que básicamente...
Pepe y los piratas[«A ver qué novelista que no sea un demagogo o un cretino se resiste a que lo lean más, en lugares donde el libro de papel no llega por diversas razones.» Arturo Pérez Reverte, 2009] vs. Ese fulano (quizás...
Microsoft SkyDrive pasará a llamarse Microsoft OneDrive En The OneDrive Blog, Cambiar el nombre de un producto tan apreciado como SkyDrive no ha sido fácil. Pero creemos que el nombre nuevo, OneDrive, transmite el valor que queremos ofrecerte y representa mejor nuestra...
Por Nacho Palou -
27 ENE 2014
La gente de Incapsula publicó esta curiosa infografía acerca del Tráfico de robots en Internet durante 2013. El resultado: que entre pitos y flautas los no-humanos ya superan claramente a los seres humanos en cuanto a tráfico; concretamente 61,5% vs. 38,5%....
Después de que investigadores de Princeton publicasen el estudio que afirmaba que Facebook habrá perdido el 80% de su pico de usuarios en 2017, desde Facebook han hecho su propio estudio «basado en análisis científicos robustos». Debunking Princeton, La gráfica de...
Por Nacho Palou -
24 ENE 2014
Una sentencia obliga a cortar Internet a un usuario gallego por descargar archivos en redes P2P vs. R asegura que no cortará la conexión al usuario sancionado por descargarse archivos y además Enrique Dans: «Las discográficas han intentado crear un clima de...
Frecuencia de búsquedas en Google para MySpace y Facebook según Google Trends. Google Trends ya se ha utilizado antes con buenos resultados para hacer el seguimiento de epidemias como la Gripe A Raro: El departamento de Mecánica e Ingeniería Aeroespacial de Princeton...
Por Nacho Palou -
23 ENE 2014
El Independent JPEG Group ha publicado la nueva Libjpeg 9.1 que incluye básicamente las funciones para codificar y decodificar imágenes JPEG. En la práctica esto significa una ligera renovación del estándar de compresión de imágenes –al que han dado en llamar...
Sightsmap utiliza el posicionamiento o la información relativa a la ubicación contenida en las fotografías enviadas a Google Maps y Google Earth a través de Panoramio para dibujar un mapa de las ciudades y de los lugares más fotografiados en todo...
Por Nacho Palou -
21 ENE 2014
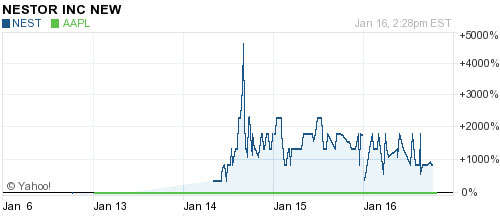
Subidón de valor de las acciones de NEST Hace unos días Google anunciaba la compra de Nest Labs, la empresa fundada por Tony Fadell y Matt Rogers, dos antiguos empleados de Apple, que fabrica un termostato revolucionario. Con esto una pequeña empresa...
¿Existirá el Pantone Tauntaun? Igual que el de la NASA el perfil de Star Wars en Instagram hace trampas porque las fotos que sube no están hechas con un móvil; de hecho los móviles, y mucho menos con cámara y conexión a...
La Fundación Telefónica acaba de publicar su informe La Sociedad de la Información en España 2013, que se puede descargar en PDF y EPUB, aunque para los más impacientes tienen el vídeo que está aquí arriba. Puntos a destacar de este...
Las tres cosas que aprendí que repiten insistentemente todos los instaladores de fibra óptica de Movistar cuando vienen a casa o a tu oficina a instalarte las conexiones de 100 Mbps: «Por wifi no pruebes la velocidad que va muy lento». Completamente...
A pesar de su empeño de meternos Google + hasta en los termostatos (todo se andará) de vez en cuando Google sigue haciendo cosas bien. En este caso, incorporar en un sitio visible a su búsqueda de imágenes un filtro según...
El año en que lo conectamos todo vs. La Internet de las cosas es increíblemente insegura – Y a menudo no hay forma de parchearla...
La Comisión Europea está recogiendo opiniones acerca de una futura reforma de los derechos de autor hasta el próximo 5 de febrero de 2014, incluida la cuestión de si hay que hacerla o no. Para ello es necesario leer la información y...
Unos 2.000 millones de personas usamos Internet. Otros 5.000 millones, no. Es un gráfico del siempre instrutivo Horace Dediu / Asymco....
24 horas en un depósito de remolques de UPS en Nueva York [aviso: la música es Rudolph The Red Nosed Reindeer] Estas navidades Amazon volvió a batir su propio récord de ventas, llegando a vender el pasado 2 de diciembre, en el...
Un servicio llamado Skybox comenzará a ofrecer pronto imágenes HD de la Tierra, tomadas desde 24 satélites a 600 kilómetros de altitud, según cuenta The Atlantic. La resolución parece ser de un metro por píxel y por las explicaciones que dan...

Flickr ha anunciado una nueva función que permite incrustar fotografías e imágenes en cualquier otra web. Aunque esto se podía hacer antiguamente de forma un tanto rudimentaria los más viejos del lugar recordarán que ya hubo algún armegedón en que que...
La Biblioteca Británica ha publicado en Flickr una gigantesca colección de más de un millón de imágenes de dominio público procedentes de los siglos XVII, XVIII y XIX, completamente catalogadas y clasificadas con etiquetas, palabras clave y descripciones perfectamente «buscables». Son...
Gruber sugirió en compañía de otros una propuesta tan ingeniosa como maléfica: ante las apps insistentes que se pasan el día pedigüeñando que por favor las votes o escribas una reseña positiva en las tiendas, hacer lo siguiente: Ir a la...
Hay cosas que despiertan pasiones pero que algunos no podemos aspirar a comprender: los vídeos de las youtubers famosas, las señoras que cuidan a más de cinco gatos en su casa o los GIF animados que pueblan innumerables webs. Los amantes...
Es la consecuencia de las sucesivas compresiones con pérdida que sufre el vídeo original alternativamente, cuando YouTube lo recibe y almacena y cuando se descarga y guarda en otro archivo en el ordenador. No es hacer copias — la copia digital...
Por Nacho Palou -
4 DIC 2013
Y con esta van ya nueve ediciones de los premios decanos de la blogosfera española. En la edición de 2013 han resultado ganadores: Premio Mejor Blog del Público: Blog Vilma Núñez. Premio Premio Especial del Jurado: Error500. Premio Mejor Twitter: Barbijaputa...
Fuente: Quartz. Aumentan especial y espectacularmente las horas de vídeo y los tuits que se producen cada minuto en 2013. Fuente: A snapshot of one minute on the internet, today and in 2012. Relacionado: ¿Cuánta gente accede a Facebook en un minuto?...
Por Nacho Palou -
29 NOV 2013
Telegeography lleva años creando un mapa de los cables submarinos de comunicaciones que, junto con las conexiones vía satélite, forman una parte importantísima del sistema nervioso de nuestra sociedad. La versión de 2013, con un delicioso diseño retro, está disponible en...
Llamadme Christopher. En Wired, Christopher Fry, el ingeniero que mató a la ballena de Twitter, La ballena de error de Twitter es cosa del pasado. De hecho la quitamos este verano y su imagen no está ya en los servidores de...
Por Nacho Palou -
26 NOV 2013

En este vídeo de YouTube la gente de Computerphile y empleados de YouTube explican cómo funcionan los vídeos de YouTube. Si la definición te parece «un poco circular» espera a experimentar el desconcierto cuando veas los circulitos del buffering que indican...
En The Assassination Market está en marcha de forma anónima y aparentemente más en serio que en broma un mercado de asesinatos: la implementación de un modelo teórico que combina criptografía, anonimato y mercados con dinero «real» a través de bitcon en...
Más momentos históricos en Histagrams....
Por Nacho Palou -
19 NOV 2013
La gente de Maptimize ha puedo en línea esta pequeña aplicación llamada One Million Tweet Map como muestra de poderío: básicamente muestra en tiempo real hasta un millón de tuits capturados desde la manguera de la línea temporal global de Twitter....
NanoBite subió un vídeo con un irónico «Por fin YouTube es un servicio completamente funcional programado por gente muy competente» – explicando con ejemplos reales que «ya no le faltan botones que pulsar ni funcionalidades ni nada de nada» como cabría...
Tuuu, pó pi pó pópó pi pó pó pi Qui puóóóórr cu ri uóóór Piiiriiiriii póóhh whiiii… Los más viejos del lugar recordarán este sonidito como algo cotidiano y le retrotraerá a la edad de piedra de las telecomunicaciones: era el...
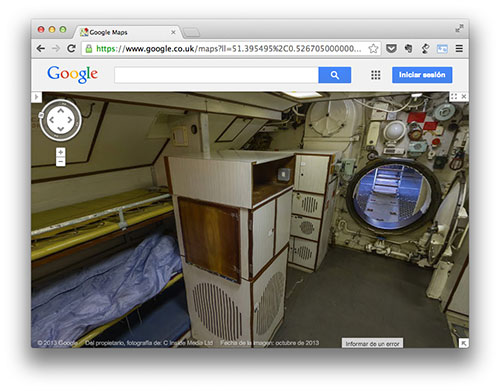
Interior del HMS Ocelot No es lo mismo que meterse dentro de un submarino real, lo que resulta bastante claustrofóbico, y eso que los dos que visité estaban convertidos en museos; no quiero pensar lo que puede ser estar bajo la superficie...
♪♫ Todo el día aquí sentado, esperando a que llegue el momento adecuado para empezar a trabajar ♫♪♪...
Por Nacho Palou -
5 NOV 2013
Evernote, imprescindible para mi En RTVE.es me pidieron que escribiera algo sobre cómo me organizo para gestionar toda la información que pasa por mis manos y qué aplicaciones y gadgets uso para eso. El resultado es la pieza titulada Cómo estudiar con...
Parece Juegos de Guerra pero es el ciberespacio en plena ebullición. Hasta ahora habíamos visto visualizaciones de los ciberataques DDoS casi como un videojuego y mucha gente incluso se plantea si este tipo de disrrupciones son más una forma de desobediencia...
Mucho Mega, un corto de Raúl Navarro con Gabriel Salas e Iggy Rubin emitido en la sección Router 66 del programa Torres y Reyes de La 2. (Gracias, Maqui)....
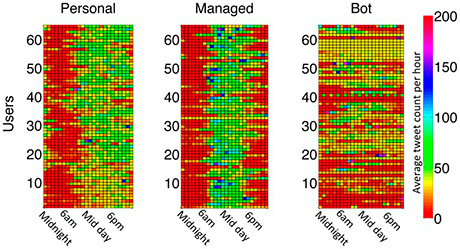
Gabriela Tavares y Aldo Faisal publicaron un sesudo trabajo con el impactante título de Scaling-Laws of Human Broadcast Communication Enable Distinction between Human, Corporate and Robot Twitter Users que Jack Schofield tuvo a bien resumir extrayendo este excelente gráfico. Básicamente trataban...
Desde la página Museo Lamborghini en Google+....
Por Nacho Palou -
17 OCT 2013
Arqueología 2.0 de la buena: era un trabajo sucio pero alguien tenía que encontrar rebuscando, rebuscando, la primera vez que se usaron originalmente en Twitter el @nombre para enviar una respuesta personal, el primer #hashtag (de Chris Messina, uno de los...
Se puede rellenar hasta el próximo 8 de diciembre: 16ª encuesta a usuarios de Internet de la AIMC Es la tradicional encuesta de la Asociación para la Investigación de Medios de Comunicación (AIMC), decimosexta edición: Esta encuesta no tiene ningún carácter comercial:...
Pues depende. Del momento y de los países. En Bots vs. Wikipedians se puede ver en vivo esa lucha a muerte entre unos y otros; la cuestión aquí no es la calidad sino quiénes editan más. Los bots de la Wikipeda...
En el Facebook Security Simulator tienes 20 segundos para comprobar las opciones de seguridad y privacidad en Facebook antes de que cambien. Y antes de que vuelvan a cambiar otra vez....
Por Nacho Palou -
15 OCT 2013
El mapa de Information Geographies Internet Population and Penetration, representa el tamaño de los países según la penetración de Internet y al número total de usuarios de Internet que hay en cada país —con datos del Banco Mundial de 2011. El...
Por Nacho Palou -
15 OCT 2013
O a eso aspira Seene (iOS, gratis), que funciona de la misma forma que Instagram pero hace fotos con cierta tridimensionalidad que se aprecia según se mueve el móvil, de igual manera que el efecto de paralelaje de iOS 7. Sin...
Por Nacho Palou -
14 OCT 2013
Al fin he tenido la ocasión de probar el Goodspeed de Uros, un gadget pensado para poder conectarte a Internet con el móvil, el tablet o el ordenador cuando estás en el extranjero sin necesidad de arruinarte con el clavo de las...
Después de recibir en un mismo día las notificaciones de que un juzgado archivaba el caso contra un cliente suyo mientras que la Sección Segunda de la Comisión de la Propiedad Intelectual, más conocida como Comisión Sinde-Wert, consideraba que su sitio web...
En el artículo All Is Fair in Love and Twitter sobre el origen del nombre para Twitter, vía Business Insider. [Evan] Williams sugirió en tono de broma llamar al proyecto «Friendstalker» (acosador), pero resultaba demasiado espeluznante. [Noah] Glass se obsesionó, hojeando un...
Por Nacho Palou -
9 OCT 2013
HTTPflies es bonito: códigos de error como si fueran una colección de mariposas. Además son SVG (gráficos vectoriales) y la historia del cómo se hizo, surgiendo de un chiste es simpática y entretenida....
En Quartz, China has more internet monitors than soldiers China cuenta con dos millones de personas que trabajan como supervisores online según un informe (enlace en chino) de la semana pasada publicado por el medio estatal The Beijing News; una cifra que...
Por Nacho Palou -
8 OCT 2013
Buscar en Google es muy fácil, pero buscar en Google como un Jedi y encontrar los que se busca de forma más rápida y certera tampoco es mucho más difícil, sobre todo con esta chuleta: Comillas (“”) hace una búsqueda exacta...
Por Nacho Palou -
8 OCT 2013
Siguiendo los pasos que se indican en el vídeo y que se explican en Cola Can Battery se puede obtener algo de electricidad con una lata de refesco y una moneda; poca cosa, eso sí —algo más de 0,5 voltios añadiendo...
Por Nacho Palou -
8 OCT 2013

El experto en seguridad es un héroe tan mítico que hasta existen memes sobre él. Publicó la biblia de la criptografía aplicada («Applied Cryptography») y se dedica a labores de consultoría.
Caos organizado en un almacén de Amazon - La foto es de Matt Cardy y está en What It Looks Like Inside Amazon.com Con el enorme volumen de negocio de Amazon y la cantidad de pedidos que tiene que procesar cada día...
Un año más vuelven a la carga los Premios Bitácoras, que este año celebran su novena edición. Ya está en marcha la fase de nominaciones, en la que hasta el 15 de noviembre cualquier usuario registrado de Bitácoras.com puede nominar a...
Con todo lo WTF que es la película «Objetivo la Casa Blanca» resulta que contiene la que es probablemente la escena del tipo personas delante de un ordenador más realista que se haya visto nunca en el cine. — La contraseña es¹...
Por Nacho Palou -
30 SEP 2013
Una interesante visualización sobre Foursquare, que muestra los check-ins de la gente como una película en la que el tiempo está comprimido. Cada tipo de lugar tiene un color distinto. Lo verde se asocia con la comida: se ve que a...
El Handbook for New Employees de Valve resume los principios y los objetivos de la compañía para que sirvan como guía para los empleados, los que «con sus ideas, talento y energía harán que Valve siga brillando en el futuro», Gracias...
Por Nacho Palou -
26 SEP 2013
Line Mode Browser 2013 es un emulador que permite experimentar (o rememorar) en un navegador web actual cómo era navegar por la web primigenia con un navegador de la época de los dinosaurios. Tengan mucho cuidado ahí fuera. Aunque el navegador...
Por Nacho Palou -
26 SEP 2013
Dustin Curtis en What I would have written. Esto es lo peor de Twitter, es lo que puede haber destruido mi mente para siempre: me encuentro caminando por la calle y por cada puta cosa que pienso me pregunto: “¿Cómo podría encajar...
Por Nacho Palou -
26 SEP 2013
Canva no es una herramienta de diseño para diseñadores, pero sí permite que cualquiera sin muchos conocimientos de diseño pueda hacer imágenes, invitaciones, carteles o presentaciones decentes, fácil y rápidamente y con resultados más que suficientes para andar por casa. Para...
Por Nacho Palou -
23 SEP 2013
Los dos años de cárcel que sugería la Memoria de la Fiscalía General del Estado de 2012 [PDF 12,6 MB] para […] quien con ánimo de lucro y en perjuicio de tercero, reproduzca, plagie, facilite el acceso, distribuya o comunique públicamente, en...
¿Puede Google solucionar el tema de la muerte? Luego dicen que las empresas tecnológicas crean mucho hype… (bombo), pero anda que algunas portadas de revistas… En fin, el artículo no está nada mal: Google vs. Death en Time....
Ya lo decía hace unos días Sergio Carrasco a raíz de las dos resoluciones que en el mismo día condenaban y absolvían al titular de una web de enlaces: La Sección Segunda se saltará la Ley en sus resoluciones hasta que se...
The Price Geek calcula el precio al que puedes vender o comprar todo tipo de gadgets de segunda mano, incluyendo teléfonos móviles, videoconsolas, tabletas, cámaras, ordenadores,... Para calcularlo Price Geek revisa los precios de pujas recién cerradas y de pujas próximas...
Por Nacho Palou -
17 SEP 2013

ColourCo.de es una de esas herramientas interesantes para jugar y entretenerse con los colores, por si a alguien le está resultado complicado eso de inspirarse. Tiene tantas opciones que la mitad no sabría decir ni para qué sirven… ¡Pero producen resultados...
España, 2 de septiembre de 2013. El abogado David Bravo recibe dos notificaciones: La Sección Segunda de la Comisión de Propiedad Intelectual, más conocida como Comisión Sinde-Wert, formada por funcionarios a los que no se les exige ser jueces, decide que el...
Todos los bits deben ser tratados por igual.– la definición más simple de la Neutralidad de la Red He aquí una bonita y sencilla cronología de información importante: What is Net Neutrality: A Timeline, donde pueden verse algunos de los hitos...
Hace algún tiempo mencioné la propuesta conceptual de un navegador web minimalista y contextual llamado Flaps. A raíz de aquello intercambié algunos mails con su autor, Ishac Bertran, respecto a la necesidad de reinventar los navegadores web, especialmente en teléfonos y...
Por Nacho Palou -
10 SEP 2013
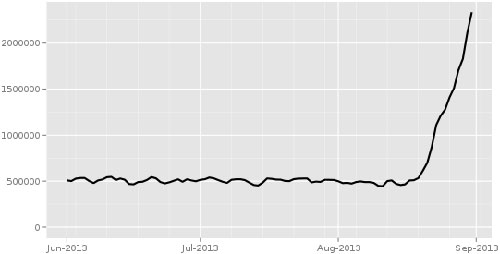
Usuarios diarios conectados a TOR desde todo el mundo Del departamento de enlaces que me fui encontrando durante las vacaciones, la gente de TOR, el conocido anonimizador de tráfico en Internet, ha detectado un enorme aumento de usuarios hacia finales del mes...
Juan José, el administrador de una web de enlaces a descargas de música, vio como tanto un proceso civil y otro penal iniciados contra él eran archivados al entender los jueces, como en otras tantas otras ocasiones ya, que las webs de...
John Beieler ha recopilado cuándo y dónde se han producido protestas en todo el mundo en los últimos 34 años, entre 1979 y 2013, y ha colocado esa información sobre un mapa que muestra 250 millones de esas protestas a lo...
Por Nacho Palou -
26 AGO 2013
Listen to Wikipedia emite el sonido de un instrumento instrumental según se modifica la wikipedia: de timbre cuando se añade una entrada o de cuerda cuando se borra. El tono de la nota varía según el volumen de la edición. Los...
Por Nacho Palou -
26 AGO 2013
Con el software adecuado, un poco de hardware Arduino y nos electrodos, unos estudiantes han creado Pavlov Poke, un cacharro que suelta descargas eléctricas al usuario cada vez que visita Facebook. Es una forma un tanto bestiaja de crear un condicionamiento...
No es que el estudio sea rigurosamente matemático, pero la gente de Netcraft que algo sabe de esto ha cruzado algunos datos públicos con curiosos resultados, tal y como se puede ver en el artículo que han publicado en su blog:...
Just Delete Me es básicamente una recopilación de enlaces que te dirigen directamente a la opción para borrar las cuentas que tengas en diversos servicios web: Facebook, Google, Dropbox, Yahoo, Hotmail,… El código de color que acompaña a cada enlace indica...
Por Nacho Palou -
22 AGO 2013
Según Phys.org Google estaría preparando un sistema con el que sabría cuándo alguien mira un anuncio en Internet o en el MundoReal™ Sería algo parecido al actual modelo publicitario de «pago por clic» en el que el anunciante paga cuando alguien pulsa...
Por Nacho Palou -
19 AGO 2013

La gente de Computerphile nos da un pequeño paseo por el edificio, los corredores y la habitación del CERN en Suiza en la que Tim-Berners Lee inventó la World Wide Web; incluyendo una imagen del primer servidor, el legendario NeXT Cube....
Si conoces Stack Overflow en inglés no se te hará difícil de entender EntreDesarrolladores.com, una idea similar con un diseño prácticamente igual, en la que los desarrolladores participan en formato «preguntas y respuestas» consiguiendo votos y popularidad a cambio de nada....
451 Unavailable: Site Blocked for Legal Reasons es una propuesta de código de error HTTP con un mensaje asociado cuando el contenido de un sitio web no pueda mostrarse por «razones legales». Ideal para países con censura y similares. (Vía MeFi.)...
Cortesía de la gente de The Pirate Bay: PirateBrowser = Tor + Firefox + FoxyProxy + configurado Se puede descargar directamente desde su página oficial o a través de este enlace magnet o fichero torrent. De momento solo Windows. La idea...
Según un análisis sobre más de 25 millones de sesiones de navegación en todo el mundo, se sabe que no hay ninguna parte de una página web que realmente vea el cien por cien de los visitantes; muchos comienzan a desplazarse...
Desde el departamento de No-hacía-falta-tanta-ciencia-pa-eso llega Social Influence Bias: A Randomized Experiment, un trabajo publicado en Science acerca de los usuarios de los servicios de noticias sociales (y casi total seguridad a Reddit que es el que parece que usaron como fuente...
I am very happy to say that as of tomorrow I will be leading Flickr efforts at Yahoo. Amazing beautiful challenge. http://t.co/EhJbHIaxxH— Bernardo Hernandez (@BernieHernie) August 6, 2013 Tras comprarlo en 2005 Yahoo básicamente procedió a olvidarse de Flickr, un sitio que...
No habría adivinado jamás que los artículos de moda son la categoría en la que los españoles nos gastamos más en compras en línea, y me sorprende bastante también el quinto puesto de los artículos de segunda mano, aunque quizás con...
Filtrando la hastagrea Soy muy fan de Tweetbot como cliente de Twitter y de hecho es el que uso en mi Mac y en iOS a pesar de que las tres licencias hay que comprarlas por separado. Pero soy aún más fan...
Two Energy Futures muestra dos posibles futuros, El primero es un futuro alimentado por los combustibles fósiles, que es hacia el que nos dirigimos (…) un futuro de cambio climático fuera de control y de sufrimiento humano generalizado. El segundo es...
Por Nacho Palou -
26 JUL 2013
Una calculadora tan práctica como a veces un poco cruel o tristemente realista: todo depende de cómo se mire. Se llama simplemente See Your Folks (Ver a tus padres) y con cuatro datos sobre dónde vives, cuántas veces visitas a tus...
Llevo años diciendo a propios y a extraños que eso de los nativos digitales es una chorrada y que estos no existen, que el que un niño haya nacido rodeado por ordenadores, smartphones o tablets no garantiza que sepa usarlos. Juan...
Tubos: De cómo seguí un cable estropeado y descubrí las interioridades de Internet. Andrew Blum. Español, 272 páginas. Edición Kindle en Inglés. Un día la conexión a Internet de la casa del autor dejó de funcionar, y cuando al día siguiente...
Startup Universe es una base de datos que utiliza la información recopilada por Crunchbase a lo largo de varios años para visualizar de forma interactiva más de 29.000 empresas tecnológicas de reciente creación (startups) 34.000 fundadores de estas empresas y 12.000...
La CMT lo titula apropiadamente Cuota de mercado móvil: acortando distancias. Es decir: Movistar y Vodafone bajando, los demás subiendo: Orange, Yoigo y los OMVs....
Todos estos botones tan… ejem, distintos… son de la misma web. Mala idea. Me gustó cómo Brad Fost plantea el inventario de interfaz de una web: una recopilación sistemática de todos los iconos, botones y elementos gráficos y textuales que se utilizan...
Este artículo originalmente en Cooking Ideas, un blog de Vodafone sobre historias que «alimentan la mente de ideas». La foto de Jimmy Wales aparece en los banners que la Wikipedia coloca cada año para recaudar dinero para su proyecto. Junto a...
¿Dónde están esos mensajes avisando de que WhatsApp va a ser de pago cuando se les necesita? Vale, no iban a servir de nada, y en cualquier caso lo que decían de que WhatsApp iba a empezar a cobrar por los mensajes...
El decreto número 0157 del 9 de julio de 2013 del Ministerio de Cultura francés pone fin a la aventura de la ley Hadopi, aquella que pretendía luchar contra las descargas no autorizadas en Internet llegando al extremo de cortar la conexión...
En 1977 aún era posible dibujar un mapa que se podía captar de un vistazo de Arpanet, la red creada con el fin de facilitar a los colaboradores de la Agencia de Proyectos de Investigación Avanzados de Defensa el acceso a ordenadores,...
A ratos parece un poco un anuncio de Duck Duck Go, pero merece la pena echarle un ojo a este vídeo de una charla de Gabriel Weinberg, el fundador del buscador que es lo que era Google hace unos años en...
How Google is Killing Organic Search: 13% Éste es el porcentaje del espacio de la página de Google que ocupan los resultados orgánicos [de verdad] al buscar “taller mecánico” en un portátil con pantalla de 13 pulgadas. El resto son todo...
Por Nacho Palou -
3 JUL 2013
En 1969 Internet conectaba cuatro ordenadores. Cuatro. Aunque entonces se llamaba Arpanet.En 1984 pasó a llamarse Internet porque conectaba 1000 dispositivos. En 1998 superaba las cifras de 50 millones de usuarios y 25 millones de servidores. En 2009 enlazaba 440 millones...
Por Nacho Palou -
2 JUL 2013
Esta megahiperinfografía de Information is Beautiful Studio para BBC World titulada Bytesized pone en contexto el tamaño de la información de unos órdenes de magnitud a otros. En la gigantesca imagen vemos desde lo que podemos almacenar en discos, cintas y...
Hoy es el día en el que la segunda limpieza de primavera de Google se va a llevar por delante a Google Reader. Así que si no lo has hecho ya, apenas te quedan unas horas para hacer una copia de...
AltaVista en los viejos buenos tiempos de 1996 Hace años que dejó de ser relevante, pero a partir del 8 de julio Yahoo da el carpetazo definitivo a AltaVista, el primer buscador que muchos llegamos a utilizar con asiduidad a mediados-finales de...
No es fácil protegerse de PRISM teniendo en cuenta que la mayor parte de los servicios de Internet están en Estados Unidos y éstos han vendido completamente la información a agencias de inteligencia como la NSA (cosa que ya sabíamos por...
The World, Traced by Airport Runways es un mapa del mundo en el que sólo están representadas las pistas de aterrizaje que existen por todo el planeta —o al menos lde os más de 45.000 registrados en la base de datos...
Por Nacho Palou -
27 JUN 2013
En Baynote, Big Brother is a Technology Company. En VentureBeat, How Google, Yahoo, Apple, Facebook, and Amazon track you — Google, Facebook y Yahoo dependen en gran parte de los ingresos por publicidad. Amazon y Apple venden productos, pero también recogen...
Por Nacho Palou -
27 JUN 2013
Evolución del número de hogares con conexión a Internet de banda ancha en España y Europa 700.000 ciudadanos más que se han incorporado a uso de Internet en 2012 ponen ya a casi el 70% de la población española como usuario habitual...
En Esty han puesto a la venta La Internet, una réplica perfecta como la que se guarda en las oficinas de Reynholm Industries. Tiene su botón de encendido y apagado que nadie debe tocar so pena de sumir al mundo en...
Lupeon es a la impresión 3-D lo que los Workcenter son a la impresión en papel y las fotocopias: un sitio al que envías los modelos diseñados con tu ordenador y ellos se encargan de imprimirlos en material físico y hacértelos...
Distribución de dispositivos Android, BlackBerry y iPhone en Barcelona. Distribución de dispositivos Android, BlackBerry y iPhone en Madrid. Mobile Devices + Twitter Use es un mapa dibujado con 280 millones de tuits en los que es posible conocer la ubicación y el...
Por Nacho Palou -
20 JUN 2013
Fanático. Negacionista. Catador. Novato. Merodeador. Pedante. Fantasma. Camaleón. Preguntón. Confidente. Inseguro. La verdad es que casi ninguna suena muy positiva que digamos. Más detalles en: ¿Cuál es tu personalidad en redes sociales? según un estudio de First Direct y el departamento de...
Desde el departamento de Disquisiciones filosóficas desde las profundidades llega este artículo: On “Geek” Versus “Nerd”, donde el amigo Burrsettles descompone con todo detalle una de las cuestiones linguísticas y de fondo sobre estos términos sociales, un poco a lo Hacker...
Los obsesionados con hacer check-in, check-in, check-in allí donde pisan con Foursquare ahora pueden recibir otra dosis de cuantificación visual con la preciosa Foursquare Time Machine. Se trata de una peculiar «máquina del tiempo» donde se muestran visualmente todos los puntos...

Este artículo se publicó originalmente en Cooking Ideas, un blog de Vodafone donde colaboramos semanalmente con el objetivo de crear historias que «alimenten la mente de ideas». Twitter es sin duda uno de los grandes éxitos de los últimos años: más...
En Phys.org, Spanish police leverage Twitter to fight crime, La Polícia Nacional española ha creado un ejército de más de medio millón de seguidores en Twitter que contribuye en la persecución de la delincuencia y del tráfico de drogas través del contacto...
Por Nacho Palou -
12 JUN 2013
El el blog de Google apuntan a un dato de un estudio que la compañía ha encargado al Lawrence Berkeley National Laboratory respecto a cuánto podría ahorrarse en energía si la gente que usa ordenadores en las oficinas (unos 86 millones...
Si naciste el 7 de noviembre te concibieron (probablemente) en San Valentín La calculadora gráfica BabyMaking muestra, como su propio nombre indica, el momento más probable en que se hizo un bebé (siempre «aproximadamente») simplemente restando 9 meses a las fechas de...
Para quienes gusten de explorar las famosas novelas del mundo de George R. R. Martin, ahora convertidas en la serie del momento, este mapa interactivo de Juego de Tronos funciona un poco «a lo Google Maps»: se puede mover el contenido...
Porque al que tiene, le será dado y tendrá más;y al que no tiene, aun lo que tiene le será quitado.– Mateo 25:14-30 Según dicen por ahí, concretamente en VentureBeat, resulta que es relativamente fácil –aunque quizá algo carillo– manipular el...
Según las cuentas oficiales hay 35.271 personas en España que han donado 488.273 dólares (unos 375.000 euros) en la campaña internacional de financiación de la Wikipedia de 2012 – lo cual nos sitúa en el Top 10 mundial, a razón de...
Porcentaje de respuestas afirmativas a la pregunta «¿Has sido alguna vez rechazado para un trabajo a causa de comentarios o fotografías publicadas online/en redes sociales?» Facebook costing 16-34s jobs in tough economic climate — Uno de cada diez jóvenes de entre 16...
Por Nacho Palou -
4 JUN 2013
Usar como reader para leer los feeds RSS una aplicación como NetNewsWire, mi favorita de todos los tiempos tiene muchas ventajas: te almacena los feeds, puedes marcar los que quieres leer luego, crear una plantilla para publicar una anotación «vía xyz…»...
Al poco de estrenar el ordenador que uso ahora, un MacBook Air de 13", me llevé un buen susto porque trabajando en un lugar en el que no podía enchufarlo a la corriente se quedó sin batería en poco más de una...
Tal día como hoy, un 27 de mayo, pero de hace exactamente diez años (en 2003) un chaval por aquel entonces de 19 años llamado Matt Mullenweg anunciaba públicamente a todo el mundo la primera versión «oficial» de WordPress (0.71-gold). Esa...
@VickyBol pasó un enlace a Kickstarter en 2012, un espléndido resumen de las cifras que maneja Kickstarter, el popular servicio de financiación colectiva que mencionamos habitualmente relacionado con diversos proyectos. Visualmente además es una gozada. En total durante el año pasado…...
Se nos está yendo de las manos... Aquí no se han ponderado adecuadamente los derechos a proteger, y menos se ha comparado con otros casos— Sergio Carrasco (@sergiocm) 20 de mayo de 2013 Algunos enlaces con análisis por parte de los que...
Distributed Denial of Service Actions and the Challenge of Civil Disobedience on the Internet, una tesis de Molly Saunders que examina la relación de los ataques distribuidos de denegación de servicio (DDoS) y el activismo político, (vía Schneier). Internet sirve como medio...
Unas frases de un estudio del Pew Research Center y el Berkman Center for Internet and Society (vía Buzzfeed): Entre los grupos de quinceañeros muchos expresaron su falta de entusiasmo por Facebook. No les gusta que cada vez haya más adultos en...
Este artículo se publicó originalmente en Cooking Ideas, un blog de Vodafone donde colaboramos semanalmente con el objetivo de crear historias que «alimenten la mente de ideas». Todos conocemos los contenidos virales porque inundan nuestros buzones, las páginas de Internet que...
¡Albricias! Los fans del yo cuantificado estamos de suerte – es lo que tiene guardar datos simplemente por el placer de guardarlos: a veces luego suceden cosas interesantes con ellos. En este caso la popular app para marcar por dónde andas...
Dice un juez que Airbnb es ilegal en Nueva York: hay una ley allí, similar a la que se está planteando para España, que prohibe los alquileres de «menos de 29 días». El objetivo es evitar que las casas particulares se...
El gráfico prácticamente habla por sí solo (y la escala es logarítmica): según NetCraft el crecimiento de Amazon Web Services ha sido de de más de un 30 por ciento en los últimos ocho meses. Los servicios en la nube de...
Por si la denostada Ley Lassalle nos parecía poco, el gobierno sigue adelante con su empeño de criminalizar los enlaces y cualquier dispositivo o software que permita saltarse un sistema anti copia, aunque sea para ejercer nuestro derecho a copia privada, derecho...
La Wikipedia en Español ya ha superado el millón de artículos. ¡Felicidades a todos!...
¡Jo, cómo ha cambiado el cuento! La verdad es que vista así gráficamente, la evolución desde la Web primigenia desde su limitado hipertexto en modo texto y monocromo a lo que disfrutamos cada día con páginas interactivas, multitáctiles y adaptables en...
Irónicamente titulado Cómo enfocarse en la era de la distracción lo normal es que quien vea esta infografía de Visua.ly ni siquiera termine de leerla completa. ¿Apostamos?...
La gente de Twitter en el Reino Unido organizó un evento llamado #Twitter4Brands acerca del uso de las redes sociales orientadas as las campañas publicitarias y las ventas a través de comercio electrónico. Allí se presentó un estudio de Deloitte comparando...
Este artículo se publicó originalmente en Cooking Ideas, un blog de Vodafone donde colaboramos semanalmente con el objetivo de crear historias que «alimenten la mente de ideas». Hoy en día son muchos los que se quejan de la falta de privacidad...
'Deleted' Snapchat photos saved in phone data, can be examined as evidence — La aplicación guarda las fotos en el teléfono [para poder mostrarlas] —según Richard Hickman, forense informático— aunque [Snapchat] diga que se borran a los pocos segundos ni siquiera se...
Por Nacho Palou -
13 MAY 2013
Dubai en 1984 (arriba) y en 2012. Timelapse es una web de la publicación Time, en colaboración con Google y la USGS, que permite viajar en el tiempo 30 años a través de imágenes aéreas y de satélite de la superficie de...
Por Nacho Palou -
13 MAY 2013
Bolid.es representa la caída de casi 35.000 meteoroides, principalmente de los 1045 de ellos de los cuales se tiene constancia que fueron vistos durante su entrada en la atmósfera. La mayoría de los cuerpos encontrados y observados se concentran en Europa,...
Por Nacho Palou -
13 MAY 2013
El último medio invento medio juego, medio gansada de Internet se llama Social Roulette. Se supone que es como la ruleta rusa pero con tu cuenta de Facebook: te registras y le dejas tu contraseña con los permisos activados; tras cada...
Esta página muestra en tiempo real los cambios recientes en la Wikipedia, superpuestos en un mapa del mundo. Es un tanto estremecedor ver la velocidad e imaginar la magnitud del trabajo, especialmente cuando se hace de una forma un tanto caótica...
¿Y para qué queremos aprender y memorizar cosas si basta con ir a Google para encontrarlas? Este vídeo explica algunas cuestiones interesantes sobre los efectos que podría estar teniendo Internet sobre nuestra memoria y nuestra capacidad de atención. ¿A que te...
«Según Reddit» dentro de ese círculo colocado sobre un planisferio vive más gente que fuera de él: ahí se concentran unos 3,7+ millardos de personas, más de la mitad de la población mundial. Al parecer también están ahí el 99,9% de...
Por Nacho Palou -
7 MAY 2013
«Síguenos en Facebook y vacunaremos a cero niños contra la polio» De la campaña Likes Don't Save Lives de Forsman & Bodenfors para Unicef Suecia, Hoy es más fácil que nunca apoyar una buena causa — todo lo que tienes que...
Por Nacho Palou -
6 MAY 2013
El problema con los archivos y las bibliotecas a largo plazo es que suelen acabar consumidos por el fuego en espectaculares incendios propiciados por problemas en los gobiernos de cada época. Echa un vistazo a la historia. Por aquí somos muy...
Este artículo se publicó originalmente en Cooking Ideas, un blog de Vodafone donde colaboramos semanalmente con el objetivo de crear historias que «alimenten la mente de ideas». La frontera entre nuestro yo y nuestro yo digital sigue difuminándose y volviéndose cada...
FlavorWire hablando acerca del Streamageddon, en el que han desparecido 1.800 películas y series de su vasto catálogo porque han caducado los acuerdos o derechos de comercialización que tenían: Aún a riesgo de que suene infantil: se supone que esto es...
Al parecer algunos suscriptores de la revista Forbes han recibido un ejemplear impreso que funciona como un punto de acceso wifi con conexión a Internet, durante 15 días, a través de un router colocado en un encarte de la publicación. Puede ser...
Por Nacho Palou -
30 ABR 2013
Which Creative Commons licence is right for me?(CC) CCI & Creative Commons Australia. Según las respuestas Sí / No dadas a las preguntas puedes averiguar rápidamente qué licencia Creative Commons se ajusta mejor a tu obra (escrita, fotográfica, sonora, audiovisual,...) según lo...
Por Nacho Palou -
29 ABR 2013
Si tienes un servidor de algún tipo, mejor que no te suceda nunca esto: un ataque DDoS, uno de los más letales que hay en la Red. Básicamente consiste en la saturación de un servidor (en el vídeo, a la derecha:...
En RTVE.es, mis impresiones sobre Facebook Home tras haberlo probado en un Samsung Galaxy Note II, uno de los pocos teléfonos Android en los que de momento se puede instalar. Facebook Home hace lo que promete y lo hace razonablemente bien, pero...
Por Nacho Palou -
26 ABR 2013
Hala, ¡arreglada! _____(CC) Traducido y adaptado de Geeks Are Sexy + Wikipedia...
Carbon Date de Hany SalahEldeen y Michael Nelson es una herramienta que permite conocer con cierta aproximación la edad de un sitio web, o al menos el registro o el contenido más antiguo que se publicó en ella y del quedó constancia...
Por Nacho Palou -
23 ABR 2013
Si tienes hijos o trabajas con niños y/o adolescentes, no te puedes perder Adolescentes y redes sociales, un vídeo que aborda este delicado tema con mucha ecuanimidad sin caer en el mensaje apocalíptico que muchas veces se le asocia. Al contrario,...
Zenith y The Cocktail Analysis acaban de publicar la quinta oleada de su observatorio de redes sociales, con especial énfasis este año en cómo estamos reaccionando los usuarios a la presencia de las marcas en estas. Facebook, Twitter y los móviles...
En marzo de 2012 Promusicae denunció a Enrique Dans por entender que este había atentado contra el honor de la entidad por este párrafo de la entrada Siete motivos por los que el caso SGAE es mucho más que la propia...
¡Sencillamente genial! Tras el largo y detallado título de Do Not Touch – Celebrate the nearing end of the humble computer cursor hay una especie de experimento social y un videoclip. Primero se pide a la gente que siga las instrucciones...
Un interesante punto de vista sobre Bitcoin en GurusBlog, bastante bien explicado: Guru Huky su Opinión sobre Bitcoin (¡gracias Furilo por la pista). Bitcoin es un sistema de pagos peer to peer que permite a cualquiera pagar a quién sea por internet...
Google ha añadido una curiosa pero acertada función desde la que sus usuarios pueden indicar qué desean que suceda con su cuenta de Google en el caso de que ésta permanezca inactiva de forma prolongada —porque ya no la utilices o porque...
Por Nacho Palou -
12 ABR 2013
A estas alturas de la película, con tanta tienda de comercio electrónico activa, ventas millonarias y nuevos negocios en línea floreciendo cada día daba ya por superado el famoso miedo a comprar con tarjeta de crédito en Internet - para mi y...
Hace unos días me llamaron del programa Bos Días la Televisión de Galicia para pedirme mi opinión sobre la Ley Lassalle, y aunque intenté que hablaran del tema con un abogado, que seguro que sabría más que yo del tema, insistieron...
A Javier Pastor se le ocurrió ir tecleando en Google «tengo xx años y» y grabar un vídeo con las sugerencias de Google para completar esa pregunta. Las sugerencias que van saliendo en Tu vida según Google van de lo hilarante...
P: ¿Es aceptable para el Consejero Delegado de una empresa de reciente creación con unos 50 empleados ir con sandalias o chanclas a la oficina? R: Sí, porque siendo el jefe eres quien decide cuál es el «tono» y la cultura corporativa,...
Más sobre el jodido 0,0000000000000000001 por ciento del que hablaba Cory Doctorow hace unos días y que está consiguiendo que gobiernos de todo el mundo legislen acerca de Internet por y para ellos en lugar de quien en realidad le da vida...
¡Que quitan el Messenger! Creo que pocos servicios de Internet generaron a lo largo de su vida tantos correos encadenados afirmando –falsamente– que se cerraba o que se iba a volver de pago como Microsoft Messenger. Claro que eso se hizo realidad,...
No sé, igual soy un poco rarito, pero de verdad que este vídeo hace que no me apetezca nadita probar Facebok Home: Claro que igual es porque no sé escoger bien a mis amigos: Lo del Facebook Home queda muy mono cuando...
Om Malik, Why Facebook Home bothers me: It destroys any notion of privacy, El GPS del teléfono puede enviar información constante a los servidores de Facebook [«infractor reincidente en cuestiones de privacidad»], indicando tu paradero en todo momento.De modo que si tu...
Por Nacho Palou -
5 ABR 2013
How Far is it to Mars? es una brillante represetación gráfica —usando píxeles como unidad de referencia— de la enorme distancia que nos separa de Marte, destino previso para la década de 2030 y que requiere unos 150 días de viaje...
Por Nacho Palou -
4 ABR 2013
En este peculiar Juego de tronos que es Internet lo que se acerca no es el invierno sino la fibra y los Salvajes de más allá del Muro son más bien los trolls. Así que la gente de College Humour se...
Este artículo se publicó originalmente en Sin vuelta de hoja, un blog de MásMóvil donde colaboramos semanalmente con el objetivo de contar cosas sensatas y relajantes relacionadas con la tecnología y la ciencia. A continuación he recopilado algunos enlaces que hacen...
Un vídeo de BuzzFeed inspirado en esta colección de imágenes de comida representando 200 Calorias. Es curioso ver por ejemplo que —en lo que a la ingesta pura y dura de calorías se refiere (sin considerar grasas ni otra cosas)— aporta...
Por Nacho Palou -
27 MAR 2013

La idea del proyecto Hello Europe es sencilla: instalar gigantescos paneles de dos metros de altura en diversas ciudades de toda Europa que estén conectados de modo que la gente pueda hablar de un lado a otro – como si fueran...
Estábamos tuiteando @luisete, @VicenteAlfonso, @davidgamez y yo sobre qué hacer cuando cierre Google Reader y cómo Reeder, Feedly o NetNewsWire, entre otros, tendrán que desarrollar sus propios servicios de sincronización. En medio de la conversación surgió el asunto de por qué Google...
Según los datos que he obtenido a partir de 39 servicios y APIs de Google —que van desde el efímero "Google Lively" (un chat animado en 3D presentado el 9 de julio de 2008 y sacrificado sólo 175 días después, el...
Por Nacho Palou -
25 MAR 2013
Tal y como todos los que sabían un poco del tema auguraban la Ley Sinde ha resultado ser un fracaso, lo que no quita para que nunca debiera haber sido aprobada. Así que ahora el gobierno de España, presionado básicamente por la...
Tal y como estaba previsto hoy ha sido aprobada en el consejo de ministros la reforma de la Ley de Propiedad Intelectual conocida como Ley Lassalle, todo un asalto a muchas de nuestras libertades con la excusa de proteger la propiedad intelectual....
Foursquare check-ins show the pulse of New York City and Tokyo de Foursquare en Vimeo. Watch: Four Days Of Foursquare Check-Ins In One Minute — En estos mapas de Nueva York y Tokio cada punto representa un único «check-in» en Foursquare y...
Por Nacho Palou -
22 MAR 2013
TusSeries cierra, en breve también este anuncio desaparecerá Los jueces han dicho una y otra vez que en España enlazar no es delito, y por eso nació el engendro de la Ley Sinde, para poder ir contra según qué sitios web sacándose...
K.P. Kaiser se ha construido un chisme con Arduino que sirve para medir la frecuencia cardíaca durante ciertas actividades, como pueden ser meditar o navegar por la web. Tal y como dicen en Hack-a-day que es donde lo vi, lo curioso...
La popular plataforma de vídeos YouTube ha alcanzado los 1.000 millones de usuarios únicos mensuales; eso quiere decir que más o menos la mitad de la gente que navega por Internet pasa por allí a ver algún vídeo cada mes, aunque...
Google replica a Evernote, Con Google Keep puedes anotar rápidamente ideas, organizar listas y e incluir fotos e información. Las notas se guardan en Google Drive y se sincronizan con todos tus dispositivos blablabla… A ver cuánto dura éste....
Por Nacho Palou -
21 MAR 2013
El gráfico muestra cómo ha evolucionado en los últimos años la cantidad de enlaces que diversas entidades han solicitado a Google que elimine de su buscador: 51 millones de enlaces en todo 2012; ni más ni menos que 4 millones a...
Aunque no seamos muy conscientes de ello dependemos bastante de unos 900.000 kilómetros de cables submarinos que rodean nuestro planeta y que usamos para llevar todo tipo de comunicaciones, entre ellas las de voz y en especial las de datos que...
Al parecer y según Intel, cada minuto se hacen 227.000 logins en Facebook. En todo Internet, en un minuto, se transfieren 640.000 GB de información, se conectan por primera vez 1.300 móviles, se publican 6 artículos en la Wikipedia, se envían...
Por Nacho Palou -
20 MAR 2013
Cuando el gobierno de España se inventó la Ley Sinde, a instancia de la industria de contenidos y duramente presionado por el gobierno de los Estados Unidos, los que saben de todo esto dijeron que no serviría de nada y que lo...
¿Te has preguntado alguna vez cómo es Internet? ¿Cómo se interconectan unos servidores y unas redes unas con otras? La gente de Peer 1 Hosting ha creado esta app con un alucinante Mapa de Internet [iOS, Android] que arroja un poco...
Algunas alternativas a Google Reader —y mi opinión sobre la puñalada de Google a sus «leales seguidores»—, en RTVE.es: Google Reader cierra, pero hay vida más allá de Google. Afortunadamente, porque como se oye por ahí... ¿Cómo se puede confiar en alguien...
Por Nacho Palou -
14 MAR 2013
«Siete álbumes de fotos que ilustran las actividades diarias de mi gato. Pulsa "Me gusta" si crees en Jesús y no quieres ir al infierno.» En According to Devin, redes y medios sociales explicados con gatos, vía Geeks rre Sexy. Similar: Redes...
Por Nacho Palou -
14 MAR 2013
Wide Web World es un mini proyecto personal de Paul Wex: él mismo compuso la música, planificó las tomas y grabó las imágenes. Todo ello sin salir de casa. ¿El truco? No son tomas reales: están creadas a partir de las...
Según se puede leer en A second spring of cleaning el próximo 1 de julio de 2013 Google Reader pasará a mejor vida. Personalmente no lo usaba como tal sino a través de su API para sincronizar mis feeds entre varias...
Divertida historia esta de Curtis Woodhouse, boxeador y cazador de troles de Internet en su tiempo libre según su perfil de Twitter. En Deadspin, Warning: If You Troll A Professional Boxer On Twitter, He Might Show Up At Your House, Curtis Woodhouse,...
Por Nacho Palou -
13 MAR 2013
Your Twitter Archive is now avail. in: Dutch, Farsi, Finnish, French, German, Hebrew, Hindi, Hungarian, Malay, Norwegian, Polish, & Spanish.— Twitter (@twitter) 11 de marzo de 2013 Aunque algunos ya lo habíamos conseguido mediante el sencillo truco de poner el idioma de...
En RTVE.es, El tráfico global de correo electrónico desvela potenciales choques de civilizaciones: al analizar el tráfico de correo de Yahoo los investigadores han podido comprobar que el flujo de emails es consistente con la tesis «Choque de civilizaciones» de Samuel...
Por Nacho Palou -
8 MAR 2013
¡Gran truco! Escribes un par de valores sobre el mismo tema. Seleccionas la segunda celda. Arrastras desde la esquina inferior derecha manteniendo pulsado la tecla Control (Opción en Mac OS X) y el resto de datos los rellena Google «inteligentemente» con...
Si hay dos temas de los que escribo de forma recurrente son el del verdadero origen de Internet, que no fue concebida como una red de ordenadores capaz de sobrevivir a un ataque nuclear, y de los famosos nativos digitales, que no...
Quizá prefieras no leer esto si eres una persona sensible y fácilmente impresionable, no te gusta el humor negro o te molestas fácilmente por las cosas raras que gente a la que no conoces de nada hace en Internet. Resulta que...
Google está utilizando una variante de baja tecnología de su método de creación de imágenes para Street View para añadir las fotos inmersivas de lugares como estaciones de esquí, estadios o lugares turísticos. En Trend It Up –el blog de Sony...
El nombre ya impone, y la idea no está nada mal, la verdad sea dicha: The Terrainator permite elegir una zona del mapa a partir de Google Maps y utilizando los datos de diversas fuentes oficiales obtener datos de elevación para...
Como previo al III Congreso Iberoamericano sobre Redes Sociales ya tenemos aquí la tercera actualización de su mapa de redes sociales, disponible con todo lujo de detalles y en versión interactiva y pasa su descarga en Presentación de la tercera versión...
Santiago Ortiz ha captado la esencia de cómo convertir un montón de datos relacionados en una animación interactiva visualmente atractiva, fácil de entender e informativa a la vez. En la página que ha programado se recogen las conversaciones públicas de los...
Me he encontrado con la idea de Wikipedia Zero en una anotación de The Red Ferret Journal. Se trata de una interesante iniciativa surgida el año pasado consistente en facilitar a la gente de países en desarrollo el acceso gratuito total a...
Este artículo se publicó originalmente en Trend It Up, un blog de Sony Mobile donde colaboramos con anotaciones sobre el mundo de las tendencias combinadas de la tecnología, el diseño y las artes. Hay proyectos de esos que surgen de vez...
Similar a los ubicuos botoncitos para «conectarse» a diferentes servicios con la cuenta de Twitter o de Facebook, ahora Google ha anunciado que ha comenzado a ofrecer sus credenciales a través del botón de conexión con Google+. El sistema se plantea...
La gente de Code.org rodó este mini-testimonial con todo un elenco de superestrellas geek para concienciar a la gente de que a nivel mundial hay escasez de informáticos; también quieren que cale la idea de que enseñar a programar es mucho...
¿Cansado de tu avatar? En Self Portrait [Facebook] puedes conseguir una versión mejorada en forma de dibujo, retoque o caricatura, dibujada por alguien de cualquier lugar del mundo, con la condición de que tú devuelvas el mismo favor dibujándole a él...
El dato: 6 de cada 10 usuarios no completan el proceso de compra en las tiendas de Internet. Hasta ahora se pensaba que quien fuera capaz de mejorar de forma consistente esas cifras, aunque sea en tan solo un 2 por...
Aunque lo propio sería que estuvieran disponibles en línea, hace unos meses que Twitter anunció que ofrecería a sus usuarios la posibilidad de descargar un archivo con todos sus tuits, lo que nos permitiría ir más allá del límite de 3.200...
Retomando las buenas costumbres de rankear todo lo rankeable, la gente de CodeSyntax presentó hace algunas semanas un proyecto interesante, NiagaRank. Básicamente se trata de un agregador de noticias, artículos de blogs y enlaces interesantes que la gente comparte por Twitter....
Este artículo se publicó originalmente en Cooking Ideas, un blog de Vodafone donde colaboramos semanalmente con el objetivo de crear historias que «alimenten la mente de ideas». Los artículos en Wikipedia referidos a los accidentes geográficos ‘dibujan’ en gran medida un mapa...
Por Nacho Palou -
20 FEB 2013
Este artículo se publicó originalmente en Sin vuelta de hoja, un blog de MásMóvil donde colaboramos semanalmente con el objetivo de contar cosas sensatas y relajantes relacionadas con la tecnología y la ciencia. Todos los conductores saben que el precio de...
Detalle de Web trend map 2007, un gráfico que refleja como se conectan entre si algunos de los sitios más populares Si el número de Bacon de un actor es el número de actores a través de los que se le puede...
Este mapa global de las startups tecnológicas [ojo: puede ir un poco lento] tiene algunos detalles interesantes, como que usando Google Maps permite localizar empresas según regiones, países y ciudades. En Iberia se listan en total 367: unas cien en portugal,...
Publiqué algo sobre Shopkick y la fidelización de clientes convertida en un juego para el teléfono móvil en el blog de ideas y experiencias en comercio electrónico de SEUR. Esta gente de Shopkick tuvo la idea de fomentar las visitas a...
Este artículo se publicó originalmente en Cooking Ideas, un blog de Vodafone donde colaboramos semanalmente con el objetivo de crear historias que «alimenten la mente de ideas». Muchos avances tecnológicos se equilibran con ciertos retrocesos en otras áreas, a veces propiciados...

Este documental cuenta la historia en el MundoReal™ de los fundadores del polémico The Pirate Bay. Está protagonizado por ellos mismos en persona y dirigido por Simon Klose. Entre 2009 y 2010 y tras los oportunos recursos sus responsables fueron sentenciados...
¡Qué bueno! En el Multicolr Search Lab de MulticolorEngine se pueden elegir hasta cinco colores en una paleta para buscar imágenes con tonalidades semejantes en más de 10 millones de fotografías con licencia libre Creative Commons que hay en los vastos...
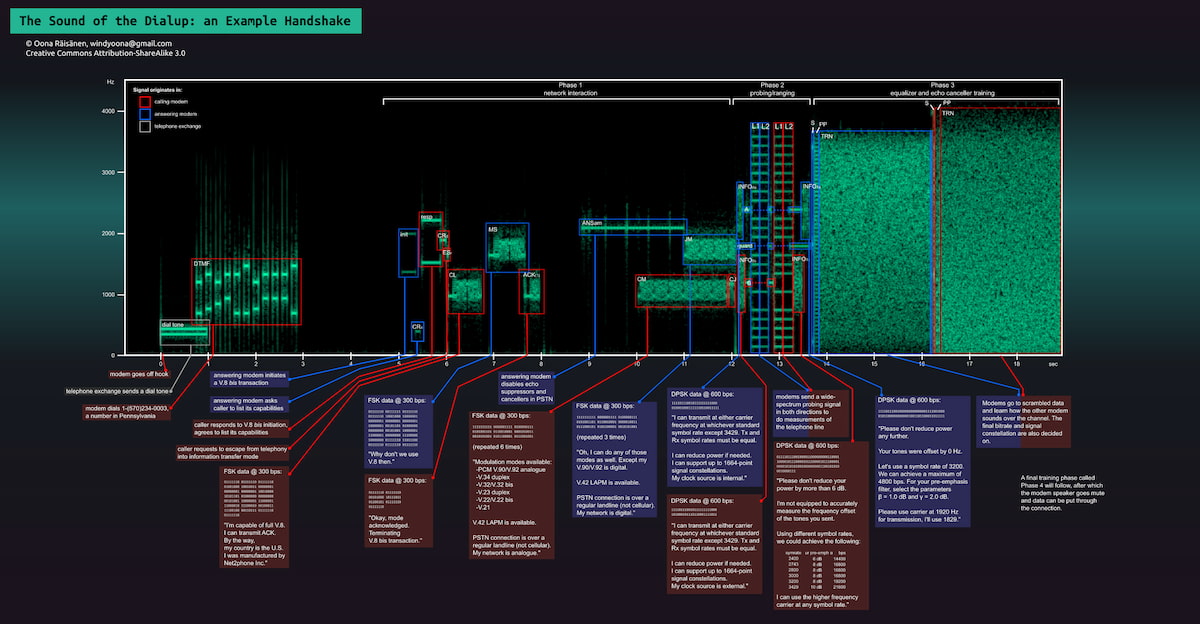
Esta preciosa y detallada infografía [también como PNG 2500x1300] creada por Oona Räisänen muestra las diversas fases del handshaking de los módems, el «intercambio de saludos» técnico entre un dispositivo y otro a través de líneas telefónicas analógicas: The sound of...
De achterkant van het Internet, que se traduce por algo así como «la parte de atrás de Internet», es una curiosa pieza con música de Nathan Shirley adaptada al ritmo de los LEDs parpadeantes de uno de los centros de datos...
[modo abuelo cebolleta on] Los gif animados son solo una de las 6 cosas inolvidables del Internet 1.0 que nos recuerda Kid A, el álter ego de @Josuedric, en esta tira cómica… Aunque creo que en realidad no echo de menos...
Aunque surgieron un poco por accidente uno de los componentes fundamentales de la estructura física actual de Internet son los puntos en los que los distintos operadores conectan sus redes entre si. En ellos cada uno de los operadores y proveedores de...
Basta con poner en la barra de direcciones del navegador, data:text/html, <html contenteditable> Para que la página en blanco del navegador web se convierta en un espacio en el que escribir texto y tomar notas. En los comentarios de la anotación...
Por Nacho Palou -
30 ENE 2013
La tira cómica Instagram Vs. Vine representa perfectamente qué es Vine: un Instagram con vídeos de seis segundos de duración. Sin embargo en mi opinión Vine no tiene ni la mínima parte de atractivo que tuvieron Instagram o Twitter cuando salieron....
Por Nacho Palou -
29 ENE 2013
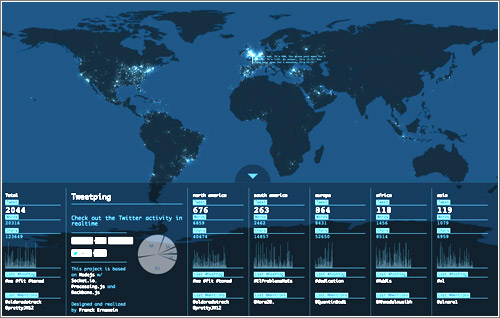
Si nuestro planeta apenas es una mota de polvo en el vacío del cosmos, nuestros insignificantes tuits son como gotas de agua en el océano: esa es al menos la sensación que queda tras echar un vistazo a Tweet ping, una...
Según el propio Kim Dotcom: Top 5 #Mega traffic countries (week 1): Spain, Brazil, France, Netherlands & New Zealand.— Kim Dotcom (@KimDotcom) 26 de enero de 2013 Justo en la misma semana en la que el presidente de la Motion Picture Ass....
Este soy yo con gafas – aunque nunca me he puesto esas gafas. Los que quieran hacer una buena web que realmente aproveche la tecnología que tenemos en nuestros equipos pueden ir inspirándose en Ditto. Utilizando una tecnología no demasiado compleja...
Los tablets son turismos y los PC son camionetas, Steve Jobs comparaba la transición desde el ordenador de sobremesa y el ordenador portátil hacia los tablets como lo fue el paso desde las camionetas a los turismos. Las camionetas disminuían en popularidad...
Por Nacho Palou -
23 ENE 2013
¡Albricias! He aquí una solución a ciertos problemas de aparcamiento tan ingeniosa que la explicación cabe en una frase: Poder enviar mensajes de forma anónima a los propietarios de coches usando su matrícula como dirección de envío. El servicio se llama...
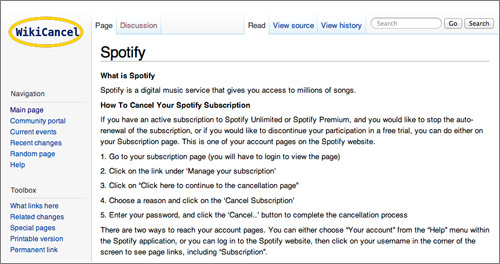
WikiCancel es el Santo Grial de los clientes descontentos; hace fácil lo que tradicionalmente es una misión imposible, el viaje épico hasta la cancelación de una cuenta de un servicio de Internet o de una empresa de telefonía. La idea es...
Con mucha suerte.Porque solo funcionan si se tiene mucha suerte. How To Make That One Thing Go Viral. Para enseñar al jefe en caso de que todo lo demás no funcione. De la gente de Upworthy....
Tal y como prometio, Kim Dotcom vuelve a la carga con Mega, el servicio que está llamado a suceder a Megaupload. Más de un millón de usuarios registrados en poco más de dos días y un dimensionamiento un tanto escaso ante...
Esta imagen de la ciudad de Madrid —que parece la típica fotografía de la Tierra tomada de noche desde el espacio— está formada por los últimos 500 millones de check-ins hechos por los usuarios de Foursquare. El mapa completo, mundial, se...
Por Nacho Palou -
21 ENE 2013
Según explica Stewart Butterfield, cofundador de Flickr, Porque el tipo que tenía el dominio flicker.com no quería venderlo, y a nosotros nos encantaba ese nombre [en español: el titilar o parpadear de una luz]. Lo de quitar la letra “e” fue idea...
Por Nacho Palou -
18 ENE 2013
En Wired, Instagram User Numbers Down; Updated Terms of Service in Effect This Week. Instagram tuvo un final de año accidentado después de anunciar sus nuevos términos de uso. Muchos usuarios los interpretaron [sic] como que Instagram podría vender sus fotos e...
Por Nacho Palou -
16 ENE 2013
Un estudio realizado entre jóvenes de 13 a 25 años revela que a pesar de que al 55 por ciento de los usuarios entre 13 y 18 años y al 52 por ciento en el tramo entre los 19 y 25 años...
Por Nacho Palou -
14 ENE 2013
Terremotos. Volcanes. Tsunamis. Erupciones volcánicas. Incendios. Olas de calor. Accidentes de avión. Alertas de polución medioambiental. Tormentas de Nieve. Accidentes de tráfico. Epidemias. Riegos biológicos. Inundaciones. Condiciones climáticas extremas. Huracanes. Tifones. Muertes masivas de animales (!) Asteroides que se aproximan a...
Un resumen rápido en vídeo de la 13ª edición de este infiorme, aunque el texto completo se puede consultar en línea en La Sociedad de la Información en España 2012....
En Geeks are Sexy, Bad blogger: 10 things bloggers need to stop doing, like, yesterday. Resumen rápido de diez cosas que los bloggers deberían dejar de hacer: Utilizar "clic aquí" como texto para un enlace. Utilizar la palabra "Enlace" como texto para...
Por Nacho Palou -
9 ENE 2013
The lottery of life, dónde es mejor nacer en 2013 El índice de calidad de vida relaciona los resultados de encuestas acerca de la satisfacción personal de los ciudadanos y lo felices que se sienten con su vida. La riqueza ayuda...
Por Nacho Palou -
9 ENE 2013
Microsoft ya había anunciado que durante el primer trimestre de este año cerraría el veterano Microsoft Messenger y trasladaría a todos sus usuarios a su servicio hermano (adquirido en en 2011) Skype. Y según The Next Web ya habría fecha para...
Por Nacho Palou -
9 ENE 2013
How to stop piracy: 1 Create great stuff 2 Make it easy to buy 3 Same day worldwide release 4 Fair price 5 Works on any device— Kim Dotcom (@KimDotcom) enero 7, 2013 No siempre estoy de acuerdo con las cosas que...
Bruce sterling en Why It Stopped Making Sense to Talk About 'The Internet' in 2012: En 2012 cada vez tenía menos sentido hablar de «Internet», «los PCs», «teléfonos», «Silicon Valley», o «los medios», y cada vez más estudiar Google, Apple, Facebook, Amazon...
Flickr quiere aprovechar de la debacle de Instagram para enviar un recordatorio de su existencia. Y lo hace dando tres meses gratis a sus usarios de Flicker Pro, que verán ampliado con este tipo adicional la duración de su período de...
Por Nacho Palou -
28 DIC 2012

YouTube ha recopilado lo más popular que pasó por sus tubos en un solo vídeo en el que aparecen todas las creaciones y descubrimientos de este año, desde PSY al Call me maybe, Minecraft y tantas otras piezas populares y memes....
Citas de cine adaptadas a los tiempos modernos: una ingeniosa colección de frases y citas de la conocida base de datos de cine IMDB que aparecen cuando se intenta acceder a alguna página que no existe en esa web. Naturalmente –como...
iPad 1.795 | Kindle 250 | Nexus 100 | Surface 36 Me gustaría ver cómo recopilaron estos datos, que se supone que recogen los tuits que dicen «primer tuit desde mi [loquesea]» en Nochebuena de 2012… Pero lo cierto es que me...
En la World Wide Web se crean -pero también se destruyen- millones de páginas cada día. En WorldWideWebSize.com suman las páginas que han rastreado los grandes motores de búsqueda de Google, Bing y Yahoo y restan las que se solapan porque son...
En aquellos primeros días, ninguno de nosotros tenía ni idea de en qué se iba a convertir. Yo tenía una visión, y acerté en mucho. Pero lo que no vi fue la parte social, que mi madre de 99 años usaría Internet...
El 23 de abril de 2005 Julio Alonso publicaba una anotación titulada SGAE = ladrones por la que recibió un burofax de los abogados de la sociedad que decía que la anotación «resulta injuriante para el buen nombre de la SGAE y...
Instagram, Debido a los comentarios recibidos, hemos modificado la sección sobre publicidad volviendo a la versión original; la misma que teníamos cuando lanzamos el servicio en octubre de 2010. Puedes ver el cambio aquí. Demasiado tarde. Vamos a tomarnos algo de tiempo...
Por Nacho Palou -
21 DIC 2012
En Twitter, Tom Anderson sobre Instagram, Temer por el cambio en las condiciones de uso de Instagram es ridículo… No señor, no es una cuestión de temer nada, es la gran falta de respeto que son los nuevos términos de uso hacia...
Por Nacho Palou -
20 DIC 2012
Oh, sí: ahora tengo una bonita colección de 500 momentos fotografiados con tonos absurdos y una resolución inferior a la que tenían los mejores ordenadores de 1988....
Por Nacho Palou -
20 DIC 2012
Moss tenía una forma un tanto peculiar de avisar a Emergencias por correo electrónico cuando se encontraba con un incendio en la oficina, pero la realidad nuevamente supera a la ficción: Los bomberos londineses aceptarán avisos de emergencias a través de...
Anil Dash, The Web we Lost. La industria y la prensa tecnológica han tratado el surgir de las redes sociales mil millonarias y la ubicuidad de las aplicaciones en smartphones como una victoria absoluta para las personas comunes. Rara vez mencionan lo...
Por Nacho Palou -
20 DIC 2012
Hacía ya algún tiempo que habían dicho que estaban en ello, pero al fin Twitter ha anunciado de forma oficial que ya disponen de una opción para que cada uno de nosotros se descargue todos sus tuits, tal y como cuentan en...
Este museo solo existe en Internet, y también está dedicado a cosas que prácticamente solo existen en Internet: The Big Internet Museum. Entre tecnologías del pasado, servicios obsoletos y memes diversos hay una buena dosis de humor e historia recopilados durante...
Por fin, tras varias semanas de espera e incertidumbre, está disponible la aplicación de los Mapas de Google para iPhone (y iPad) en la App Store. En RTVE.es, disponible la aplicación de Mapas de Google para iPhone....
Por Nacho Palou -
13 DIC 2012
En la oficina, escuchando la música del ordenador de casa. Hay aplicaciones como LogMeIn que permiten acceder de forma remota desde el iPhone o desde iPad al escritorio del ordenador, y utilizarlo casi como si estuvieras sentado delante de él, aunque todo...
Por Nacho Palou -
12 DIC 2012
Google60, búsquedas en Internet al estilo Mad Men simula el funcionamiento de un ordenador de los años 60 del siglo pasado para hacer búsquedas en el Google actual. Incluye la entrada de los términos a encontrar codificando una tarjeta perforada y...
Por Nacho Palou -
12 DIC 2012
The Real Thing de Union HZ en Vimeo. Yo que soy más de fotografía encuentro delicioso el vídeo The Real Thing, que es como una secuencia de magníficas fotografías en movimiento — y admito que el coche también tiene su atractivo: un...
Por Nacho Palou -
10 DIC 2012
Aunque al parecer Instagram ha capado la opción de publicar las fotos directamente en Twitter (ahora hay que seguir el enlace a Instagram para verlas) ha tardado poco en propagarse por Internet la forma en la que poder seguir haciéndolo, independientemente...
Por Nacho Palou -
10 DIC 2012
Este artículo estaba escrito para ser publicado en La Voz de Galicia, diario con el que colaboramos de forma habitual, pero al final por cosas de que el papel no es infinitamente estirable no ha cabido, así que la recuperamos aquí. Tras...
Resulta fascinante quedarse embobado mirando esta simulación estadística de nacimientos y defunciones en tiempo real. Aunque se aplica únicamente a los Estados Unidos, bien podría hacerse con cualquier otro país. Tic, tac, tic, tac, tic… Esta visualización de cómo acontecen las...
En RTVE.es, Google pide a los usuarios que reclamen que la Web sea libre y abierta, Google Take Action ofrece la posibilidad de expresar estar en contra de cualquier tipo de regulación o control gubernamental sobre Internet. «Los gobiernos no deberían determinar...
Por Nacho Palou -
7 DIC 2012
No recuerdo haber visto pasar en su momento este estudio sobre redes sociales en España realizado por The Cocktail Analysis, 4ª Oleada Observatorio de Redes Sociales: Las marcas empiezan a encontrar límites. Tiene ya unos meses, pues fue publicado en abril...
Concebidas como un complemento al copyright tradicional para aquellos creadores que tienen claro que quieren compartir sus obras aún reservándose el derecho a que se reconozca su autoría, las licencias Creative Commons cumplen la semana que viene diez años desde su...
En What If de XKCD, ¿Cuánto espacio físico ocupa Internet? Una forma de calcular cuánto espacio físico ocupa la información almacenada en internet es comprobar cuándo espacio de almacenamiento hemos comprado los seres humanos. Se fabrican alrededor de 650 millones de discos...
Por Nacho Palou -
5 DIC 2012
Ante una reunión de la Unión Internacional de Telecomunicaciones en la que se pretende abordar el tema de la regulación de Internet Vinton Cerf, uno de los que sí pueden decir que es uno de los padres de Internet, ha publicado esta...
Clic para ver en grande John Atkinson de Wrong Hands nos ha calado perfectamente con su viñeta Procrasti-Nation, que con su permiso hemos traducido al español tras haberlo procrastinado convenientemente… Claro que él también procrastinó lo suyo antes de contestarnos para decirnos...
Desde hace años en la NASA tienen medianamente claro que Internet, los blogs, y las redes sociales son una estupenda herramienta para hacer llegar su trabajo al público en general sin tener de pasar por el filtro de los medios tradicionales,...
Crecimiento del año 3 al 4 de algunas redes sociales - clic para ver la imagen completa Social Media Statistics es una infografía que intenta hacer un pantallazo del estado actual en cuanto a tamaño y crecimiento de las principales redes sociales*....
Esta semana se ha anunciado la disponibilidad en España de Joyn, un servicio de mensajería móvil habitualmente descrito como el WhatsApp de las operadoras y en la que actualmente participan en nuestro país Movistar, Vodafone y Orange. Joyn permite chatear (enviar y...
Por Nacho Palou -
30 NOV 2012
En azul, las búsquedas de www.google.com en Google; en rojo las de www.yahoo.com Si según dice el propio Google la gente busca cada vez más www.google.com en Google, ¿alguien me puede decir cómo seguimos diciendo que os nativos digitales ya nacen sabiendo...
World Life Expectancy Map es un interactivo con los datos sobre esperanza de vida (el número de años que sería «normal» vivir) en los diversos países del mundo. A día de hoy, y según las listas oficiales, la mayor es de...
Evernote Clearly es una nueva extensión de Evernote de momento disponible para el navegador web Chrome. Si conoces Readability funciona de forma parecida: al pulsar el icono de la extensión se extrae el contenido de una página web, por ejemplo una...
Por Nacho Palou -
28 NOV 2012
Productos relacionados con Apocalipsis Z en Amazon España Cogiendo la información acerca de qué productos suele comprar la gente junto con otros en Amazon Yasiv proporciona una forma gráfica de navegar por esta red de productos. Para ello, basta con teclear el...
Se puede rellenar hasta el próximo 9 de diciembre: Encuesta a usuarios de Internet de la AIMC Es la tradicional encuesta de la Asociación para la Investigación de Medios de Comunicación (AIMC), decimoquinta edición: Esta encuesta no tiene ningún carácter comercial: se...
Black Friday Report 2012 de IBM (datos para EE UU), Ventas sociales: los compradores procedentes de redes sociales como Facebook, Twitter, LinkedIn y YouTube generaron el 0,34 por ciento de todas las ventas online durante el Viernes Negro, una disminución de más...
Por Nacho Palou -
26 NOV 2012
Aunque el consejo general suele ser no usar mensajes automáticos de respuesta en el correo electrónico porque pueden (1) volverse locos, (2) hartar a los interlocutores y (3) revelar información que quizá no habría que facilitar a según qué personas/entidades, hay que...
¿Qué pasaría si adoptáramos el uso de herramientas colaborativas de código abierto similares a Git para la creación de leyes de tal forma que los ciudadanos pudiéramos seguir el proceso de elaboración de estas e incluso participar en él? Pues según...
Foto de familia de los premiados Anoche en La Casa Encendida se celebró la ceremonia de entrega de los Premios Bitacoras.com 2012, que en sus distintas categorías fueron a parar a: Premio Mejor Blog del Públicoy Personal: Yo fui a EGB Premio...

Llevo años diciendo que eso de los nativos digitales, esos que no existen, no es más que una disculpa por parte de muchos padres y educadores para mirar hacia otra parte en lo que se refiere a la educación de niños...
Enrique Dans estuvo ayer reunido con directivos de Telecinco, y también con el bloguero y comunicador Pablo Herreros, protagonista de la última polémica en torno a la querella que la cadena ha presentado contra el periodista, en la que le piden 3,7...
LINE solo tiene un añito de antigüedad, pero llega desde Asia como un producto perfectamente terminado y funcional: mensajería de tipo chat, llamadas de voz gratuitas, envío de fotos, vídeos, música, timeline estilo Twitter/Facebook… Pero lo mejor de todo es que explota...
Al principio la gente se partía de la risa porque se subastaban riñones. Superados esos problemillas típicos de las empresas jóvenes, ahora eBay es un negocio megamillonario que sobrevivió a la crisis de las puntocom con creces. Estos días eBay cumple...
¿Qué hace que una empresa sea revolucionaria? Que sus innovaciones obliguen a otras empresas a cambiar de rumbo. Y estás son las 50 empresas revolucionarias en 2012, según los editores del MIT Technology Review....
Por Nacho Palou -
21 NOV 2012
Hasta ahora Nokia Here, el servicio de mapas de Nokia, se podía utilizar en iPhone y Android, y desde cualquier ordenador, desde el navegador web. Y desde hoy además está disponible también como aplicación para iOS (iPhone,iPod Touch y iPad). La aplicación,...
Por Nacho Palou -
20 NOV 2012
FullTextRSSFeed es de lo mejorcito que me he encontrado últimamente como solución al tradicional problema de los feeds cortados o incompletos: como resumen en la página, es rápido, es gratis, se refresca constantemente, funciona con cualquier agregador, elimina los anuncios publicitarios y...
Adiós intermediarios: Vimeo, la popular plataforma de vídeos de autor, artísticos y con un toque especial, apuesta por ser una de las vías más directas entre creadores de películas, cortometrajes y otros experimentos audiovisuales al añadir en su «videoclub» herramientas para...
Desde los Google Labs llega otro experiento de estos que combinan fuerza bruta y elegancia: 100.000 estrellas. Es una representación visual de nuestro vecindario cósmico, muy resultona sobre todo vista a pantalla completa en una pantalla gigante. S esas 100.000 estrellas...
— ¿En qué trabajas? — Pues mira, soy escritor — ¡Vaya!, ¡eso es genial! ¿Y qué escribes? — Escribo en Internet — Ahm,... ¿entonces eres además estudiante o dependiente o algo de eso? — NO, MALDITA SEA. SOY ESCRITOR La de...
Por Nacho Palou -
15 NOV 2012
En los Sandia National Laboratories 500 ordenadores personales ejecutan un software de simulación que recrea la existencia de 300.000 teléfonos Android que se pasan el día haciendo cosas de teléfono móvil e interactuando entre sí, enviandose mensajes, y accediendo a Internet....
Por Nacho Palou -
14 NOV 2012
Hice una pequeña recopilación de algunos de mis servicios de información apocalípticosfavoritos: desde los que te informan de los terremotos a través de un feed RSS a los que te permiten seguir lo que sucede durante los terremotos, huracanes o tsunamis en...
Este artículo se publicó originalmente en Cooking Ideas, un blog de Vodafone donde colaboramos semanalmente con el objetivo de crear historias que «alimenten la mente de ideas». Si eres de los que no puede resistirse a las compras por impulso, mejor...
Según un estudio realizado por un profesor de informática, los visitantes de una web comienzan a irse de la página si un vídeo tarda más de dos segundos en arrancar. A partir de ahí, cada segundo de más que tarde en reproducirse...
Flaps de Ishac Bertran en Vimeo. Flaps es la representación conceptual de navegador web propuesto por el diseñador Ishac Bertran, Flaps: fast and contextual browsing es un navegador web a pantalla completa cuya infraestructura visual es mínima, la interfaz para la...
Por Nacho Palou -
12 NOV 2012
papertoilet.com En lo que debe ser algo así como la antítesis de StumbleUpon, el sitio que intenta ayudarte a encontrar sitios web que te puedan resultar interesantes, The Useless Web no tiene otro propósito que llevarte a una web inútil tras otra....
Con muchas más prisas que otros temas más urgentes el gobierno parece dispuesto a sacar adelante una reforma de la Ley de Propiedad Intelectual modificándola por Real Decreto-Ley. Piratas de Cataluña ha obtenido una copia del borrador que maneja el gobierno, y...

Quién más, quien menos, alguna vez puede que te hayas quedado sin combustible por despiste o por calcular mal; habrás acabado miserablemente tirado en medio de la calle, quizá por no saber cuál era la distancia que realmente podía recorrer tu coche...
En el nombre del FSM… ¡Qué peligro! Alguien ha tenido la genial idea de crear un vestido de muestra tuits sobre un tejido fabricado con bombillas LED, todo en tiempo real. Y yo no puedo sino imaginarme que va a ser...
El servicio de sincronización remota y almacenamiento en la nube Cubby actualiza las aplicaciones web y de escritorio (al parecer no las apps móviles; sigue sin ser posible enviar archivos a Cubby desde éstos) y se abre a todos los públicos, sin...
Por Nacho Palou -
6 NOV 2012
Aunque se podía acceder vía web a los contenidos guardados en Pocket, el servicio antes conocido como read It Later, ahora existe Pocket Mac OS X como aplicación nativa. Por si no conoces el servicio, la idea es que se pueden...
Cómo acceder desde el móvil a páginas web abiertas en el ordenador y viceversa, utilizando los navegadores web Safari o Chrome utilizando la función que permite ver las páginas web abiertas en otros navegadores web del mismo usuario; y con la...
Por Nacho Palou -
5 NOV 2012
La última exposición de Leonardo da Vinci en Madrid, que pude visitar a principios de este año, me pareció una maravilla, y me permitió descubrir los curiosos Códices Madrid que se guardan en la Biblioteca Nacional tras una rocambolesa historia sobre...
Para refrescar un poco las lecciones que todos recibimos en el parvulario de Internet escribí El tiempo de carga es el gran olvidado en el universo del comercio electrónico en el blog de ideas y experiencias en comercio electrónico de SEUR. Allí...
Legible, minimalista y elegante. Wikipedia ha rediseñado completamente su versión móvil (en RTVE.es). Un diseño web adaptativo con criterio y acierto, para uno de los sitios más populares de la Web. Si entras con un dispositivo móvil lo verás automáticamente; también...
Para días como hoy, en los que algunas páginas web no funcionan, el correo va de aquella manera y no sabes muy bien qué demonios está pasando y si un huracán ha tumbado algún centro de datos o roto los cables de...
La consecuencia extrema del Efecto de desinhibición en línea resumida y expresada visualmente y de forma coloquial (muy coloquial) en esta gran teoría conocida como Greater Internet Fuckwad Theory....
Por Nacho Palou -
30 OCT 2012
Uno de esos servicios prácticos y con un mnemónico fácil de recordar: Loads.in calcula en cuánto tiempo carga tu web; basta usar/guardar una dirección del tipo microsiervos.loads.in para que al llamarla realice el cálculo. El resultado es del tipo realista, mostrando...
Antenas de telefonía móvil - Foto CC por Joe Ross Aún después de comprobar en mi propia cuenta corriente que la nueva normativa de la Unión Europea que rebaja el precio de los datos en roaming no hace que deje de ser...
DuckDuckGo es lo que era Google hace unos años. Se trata de un buscador genérico, que respeta la privacidad por encima de todo, donde se busca la relevancia, destacar lo que realmente es importante (sitios oficiales, definiciones, términos relacionados) y la...

Carolina de Clipset estuvo en la gigantesca nave que Amazon España ha inaugurado en San Fernando de Henares (Madrid): una especie de tienda de chuches para adultos y a lo bestia, con cientos de estanterías llenas de productos, donde sobre todo...
Meeeeeeegaaaaaaaa!!!— Kim Dotcom (@KimDotcom) octubre 18, 2012 Mientras se desentraña el embrollo legal alrededor del cierre de Megaupload, lo que sin duda llevará años, Kim Dotcom no se está quieto y anuncia que ya tiene pensados los detalles de un nuevo servicio...
Desde hace nada está disponible en la App Store la versión final de TweetBot, mi cliente favorito para Twitter tanto en iOS como en Mac OS X con diferencia. Como comenté cuando salió la alfa para Mac OS, y después de...
Frank La Rue, relator de la ONU sobre Libertad de Expresión, en el V Congreso Mundial de los Derechos de la Infancia y la Adolescencia: Así como es un espacio abierto, internet tiene sus contaminantes. Pero proteger a los niños de esos...
Aberrantes para unos, elementos indispensables de la historia de Internet para otros, desde su invención los GIF animados han despertado todo tipo de sentimientos: entre el odio y la admiración artística. Lo que fuera una idea original de CompuServe como formato...
Where the Internet lives es una visita fotográfica por algunos de los centros de proceso de datos de Google en los que se puede ver cómo se montan, quienes trabajan en ellos, y en qué lugares deciden ponerlos. Pr0n geek pero...
Mapping The Entertainment Ecosystems of Apple, Microsoft, Google & Amazon muestra de forma visual la disponibilidad que tienen en todo el mundo los ecosistemas de entretenimiento de Amazon, Apple, Google y Microsoft, específicamente contenidos digitales de música, películas, programas de televisión,...
Por Nacho Palou -
17 OCT 2012
No contentos con el varapalo que sufrió el tratado ACTA en su votación en el Parlamento Europeo, cuando fue rechazado con un 92 por ciento de los votos en contra, la Comisión Europea y los gobiernos de los países miembros de la...
¿Cansado de los tonos pastel de los Mapas de Google? Estos Mapas de Stamen son una alternativa: con datos procedentes de OpenStreetMap también juegan con los estilos y colores; desde un mapa de terreno más o menos convencional a una versión...
How do they Make Money? responde a la pregunta que mucha gente se hace tras ver ciertos servicios o empresas de Internet: «La idea está muy bien, pero… ¿cómo ganan dinero?» El planteamiento es perfecto porque es a la vez simple...
Sencillamente hipnotizante: cientos de trenes circulando con total precisión por las entrañas de una de las ciudades más pobladas del planeta. (Vía @douglascoupland.)...
Si te dedicas a Internet y sólo tuvieras unos minutos para ver un vídeo a lo largo del día de hoy, harías bien en que fuera este mini-documental sobre diseño web. Es de PBS DigitalStudios y forma parte de la segunda...
Un simpático vídeo en el que Eran Amir utiliza pintura gris —también sobre él mismo— para para grabar en blanco y negro con una cámara en color....
Por Nacho Palou -
11 OCT 2012
Me llamó mucho la atención el inicio de la producción de la película Iron Sky hace ya un par de años. El proyecto comenzó sin muchos recursos y financiándose sobre la marcha, incluso con aportaciones de particulares o "vendiendo" el acceso...
Por Nacho Palou -
10 OCT 2012
50€ apenas dan para 15 megas de subida y los de bajada ni mueven el contador Hace unos días, aprovechando que estaba de viaje en Bélgica, decidí utilizarme a mi mismo como conejillo de indias para probar la nueva normativa en vigor...
Antes vs. Ahora Tal y como comentan en AppleInsider, los desastrosos mapas de iOS 6 siguen experimentando cambios y mejoras sin que la compañía esté dándole demasiada publicidad al hecho – simplemente trabajando «por detrás» mientras se fustiga en silencio....
Creado a modo de tributo a Steve Jobs esta recreación de un iPod original escrita en HTML5 y CSS3 por Pritesh Desai de Inventika Solutions es bastante impresionante. La explicación de cómo y por qué está en 1000 songs in your...
La función de vista de calle (Street View) fue una pérdida vinculada a la desaparición de la aplicación Google Maps, ya que hasta ahora no estaba disponible en la versión web de los mapas de Google. Hasta ahora, que Street View...
Por Nacho Palou -
4 OCT 2012
¡Estoy indignado! No porque @MarsCuriosity use foursquare –todo lo contrario, llevo años diciendo que me parece brillante el uso que la NASA está haciendo de las redes sociales– sino porque me parece increíble que le vayan a dar la alcaldía de...
En el lector de feed pillé a estas dos entradas muy juntas, haciendo manitas. Is Twitter Shooting Itself In The Foot Focusing 100% On Ads? El mismo día que Twitter enfada a sus usuarios estrenando su mecanismo de encuestas publicitarias veía la...
Por Nacho Palou -
4 OCT 2012
Durante el año pasado por primera vez se vendieron más smartphones que ordenadores, una tendencia que previsiblemente seguirá empequeñeciendo en proporción el parque informático de ordenadores de sobremesa y portátiles en los próximos cuatro años (gráfica 2005-2011, gráfica de previsión hasta...
Por Nacho Palou -
3 OCT 2012
Ars Technica ha publicado los datos de septiembre de 2012 de sus estudios de mercado sobre navegadores web que incluyen datos y gráficas muy interesantes y fáciles de comprender. Tal y como destaca John Gruber del blog Daring Fireball, con datos...
Un homenaje a los escritores de la serie, a la cultura libre y a todos lo que crearon Lostpedia con sus más de 7000 artículos. A falta de Perdidos bueno es recuperar los guiones y visualizarlos de forma artística de una...
Historia de Slashdot - clic para ver entero Slashdot, uno de los sitios de referencia en Internet durante muchos años para los aficionados a la tecnología –fundamental pero no exclusivamente– cumple hoy 15 años. A lo largo de este tiempo se han...
Este gigantesco panorama 3-D en ultra-alta resolución de las pirámides de Guiza impresiona pero de verdad. Es además todo un ejemplo de cómo combinar tecnología y fotografía para lograr un resultado impactante: se pueden realizar movimientos, zoom, cambios de posición... parece...
En uno de los muchos experimentos de los Google Labs con el navegador web Chrome, para mostrar su potencia y todo lo que es capaz de hacer, prepararon este Globo terráqueo con nubes, donde se combinan imágenes de la NASA, los...
A propuesta de los gobiernos de Alemania, Bélgica, España, los Países Bajos y el Reino Unido el proyecto The Clean IT ha recibido 400.000 euros para redactar una serie de principios y buenas prácticas que aplicar para la lucha y prevención del...
Ya hemos hablado en unas cuantas ocasiones de que si el espacio representa para la mayoría de nosotros lo inexplorado es porque muchas veces no nos acordamos de que en realidad hay una gran parte de nuestro planeta que aún no...
Este es su aspecto: lo llaman Google Maps Business Photos y me parece que tardaremos bastante en verlo por aquí(*). Fotos inmersivas de 360 grados para que la gente pueda ver el aspecto interior de un restaurante, un hotel o una...
Hoy se estrena en la Red eldiario.es, un nuevo medio completamente digital y de contenidos principalmente políticos detrás del cual está un equipo dirigido por Ignacio Escolar, más conocido por haber sido uno de los fundadores del diario Público y sobre...
A Santiago le llamó la atención el artículo del New York Times titulado Define Gender Gap? Look Up Wikipedia’s Contributor List en el que se explora la diferencia de sexos existente entre los editores de la Wikipedia. Según el artículo, que...
YouTube en el iPhone Después del anuncio por parte de Apple de que dejaría de incluir su propia aplicación para YouTube en iOS 6 era sólo cuestión de tiempo que Google sacara una aplicación propia, lo que acaba de suceder, justo a...
Un año más ya están aquí los premios Bitácoras, que este año cumplen su octava edición, con 20 categorías que se pueden votar de aquí hasta el 9 de noviembre. De los votos de los usuarios saldrán 3 finalistas por categoría...
Lo cuenta David Bravo en La Comisión Sinde desde dentro: los desmanes son para el verano, pero en resumen: La Sección Segunda de la Comisión de Propiedad Intelectual insiste en realizar sus comunicaciones vía electrónica aún a pesar de que el sistema...
Algunos conceptos de lo que han dado en denominar Análisis de Redes Urbanas, en las que cabe de todo: desde las personas, medios de comunicación, transportes… Gracias a estos análisis se pueden mejorar las ciudades y entender cómo debe ser el...
En TechCrunch, Atari cumple 40 años y lleva ocho de sus juegos clásicos más conocidos al navegador web [trasladados a] lenguajes HTML5 y CSS3. Atari planea sumar hasta 100 juegos a este catálogo en los próximos meses. Microsoft anda por medio para...
Por Nacho Palou -
31 AGO 2012
Todos sabemos que eso de que «he leído, entiendo y acepto las condiciones de uso» de cualquiera de los múltiples servicios que usamos en Internet es probablemente la mentira que más se repite en esta, en dura pugna con la de...
Este artículo se publicó originalmente en Cooking Ideas, un blog de Vodafone donde colaboramos semanalmente. Seguro que cuando allá por 1995 Ivan Goldberg se inventó a modo de broma el «Síndrome de adicción a Internet» en una lista de correo de...
Marcar un tuit como equivocado A todos nos hemos pasado que hemos lanzado un tuit con un URL equivocado, en el que hemos matado a alguien que todavía goza de buena salud, o en el que damos una información que luego comprobamos...
Este artículo se publicó originalmente en Ciencia, el suplemento de El Correo donde colaboramos habitualmente. Hace unas semanas Mikel Agirregabiria, @agirreagabiria, físico y educador, responsable de Innovación Educativa de Vizcaya en el Gobierno vasco y bloguero de pro desde hace años,...
La sincronización de Chrome, el popular navegador de Google, suele resultar muy práctica. Pero le encontré algunas limitaciones cuando se usa con varios ordenadores y dispositivos, entre ellas un conflicto típico difícil de resolver: cambios que hiciste que no quieres que...
Model del rover ExoMars que se pudo ver en año pasado en el Pabellón Espacial de ILA - ESA/M. Pedoussaut La DLR, la Agencia Espacial Alemana, y la ESA han convocado su segundo SpaceTweetup conjunto, que en esta ocasión se celebrará en...
Pues eso, que los chicos de Google no saben estarse quietos y acaban de lanzar Handwrite, una forma de buscar escribiendo con los dedos en la pantalla de tu dispositivo móvil en lugar de usar el teclado virtual. Por ahora es...
Datos de Twitter en España en 2012 Ya está disponible para su descarga el informe Informe eEspaña 2012 de la Fundacion Orange sobre el desarrollo de la Sociedad de Información en España, con un montón de información, entre ella que: España ocupa...
He aquí un bonito «concepto» de estación Wi-Fi callejera, un diseño de Mathieu Lehanneur: en un parque soleado, con sombra, pantalla gigante, tomas eléctricas para cargadores… … e incluso asientos estilo pupitre en los que cómodamente sentarse para recibir el Wi-Fi,...
El «Político»: un plasta que goza de su mejor momento en tiempos de crisis The Many Faces of the Internet User de Flowtown simplifica en siete tipos la fauna de Internet, que según Jerry de I Can Has Internets además conviene evitar....
Signing up for Twitter ;-)— Wicho (@wicho) marzo 21, 2007 Hace algún tiempo escribía sobre lo complicado –o imposible– que es recuperar tu primer tuit si llevas escritos más de 3.200, que es el límite que impone el API del servicio en...
Desde ayer está disponible para descarga de forma gratuita una versión alfa del esperado, al menos para los que ya lo usamos en iOS, TweetBot for Mac. Esta alfa requiere Mac OS X 10.7 o posterior, aunque ya advierten que la...
Muchos confirmarán que esta lista que publicó Update or Die es tan real como la vida misma. [Al parecer proviene de un artículo de The Wall que ha desaparecido (?)]. En cualquier caso, estas son las 20 «mentiras» más habituales en Facebook,...
Con un contundente resultado de 478 votos en contra, 39 a favor, y 165 abstenciones, el Parlamento Europeo ha dicho hoy que no al tratado ACTA: European Parliament rejects ACTA. El Anti-Counterfeiting Trade Agreement, o Acuerdo Comercial Anti Falsificación, venía siendo...
Me acaban de pasar una noticia de última hora… O, para aquellos de ustedes que usen Twitter, «eso de lo que llevamos días hablando».– Broken news,CC por Rob Cottingham,usada con permiso...
Real-time geolocated tweets es un experimento en forma de mashup (Google Maps + Twitter) bastante resultón. Muestra tuits en tiempo real sobre los mapas, y funciona razonablemente bien cuando haces zoom en distintas zonas. Si acaso se antoja un tanto escaso...
El comité de Mercado Internacional, INTA, del Parlamento Europeo le ha dado hoy otro buen golpe al tratado ACTA, el Anti-Counterfeiting Trade Agreement, o Acuerdo Comercial Anti-Falsificación. Con los votos a favor de Socialistas, Liberales, Verdes y la Izquierda Unitaria, se ha...
Este artículo se publicó originalmente en Cooking Ideas, un blog de Vodafone donde colaboramos semanalmente con el objetivo de crear historias que «alimenten la mente de ideas». La Web lleva ya más de 20 años funcionando, pero para algunas cosas… ¡parece...
Gracias a lo que cuenta David Bravo en Llega el primer caso a la Comisión Sinde: por qué es más peligrosa de lo que parecía ya sabemos el primer nombre de un sitio web español que tiene que enfrentarse con los...
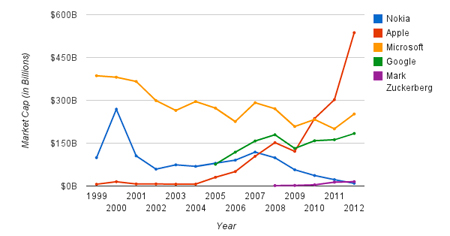
Para que luego digan que no hay «gente valiosa». Aunque estos cálculos son siempre muy relativos, resulta que, tal y como publica Wired, el valor de las acciones que posee Matt Zuckerberg de Facebook está en torno a los 15.100 millones...
Por si había pocas celebraciones -así, en general- llega una nueva, sin duda la más interesante para nuestros lectores y sus respectivas versiones 2.0 también conocidas como mini-,o descendencia o, más popularmente, hijos: el Día de los padres geeks, los apasionados...
.barcelona .bbva .bcn .catalonia .eus .gal .lacaixa .madrid .mango .movistar .seat .sener .telefonica .terra .zara En total son 15 dominios solicitados por empresas, entidades y organizaciones diversas. El más largo es .telefonica; los más cortos .gal y .eus. Solo telefónica se ha...
¿Conoces Yandex, Mail.Ru o Baidu? Tal vez deberías: son los sitios más populares de Internet que la gente visita en Rusia, los países de Europa del Este y China. En otros lugares dominan Facebook, Yahoo o –mayoritariamente– el gigantesco Google. En...
Desde el departamento de yo-ya-he-vivido-esto nos llega la versión humorística de UCB Comedy sobre uno de los problemas habituales de algunos servicios de Internet: lo porculeros que son a la hora de obligarte a elegir una contraseña. Relacionado: La razón por...
Ayer los comités de Industria, Asuntos Legales, y Libertades Civiles del Parlamento Europeo votaban su posición respecto al tratado ACTA, el Anti-Counterfeiting Trade Agreement, o Acuerdo Comercial Anti-Falsificación, y los tres votaron que no lo van a apoyar. Su voto, igual que...

Los hackers originales del MIT eran unos tipos a los que les apasionaba saber todo lo posible de las máquinas que usaban por el placer de saberlo, y si para saber algo más había que saltarse alguna norma pues no tenían ningún...
Los comités de Industria, Asuntos Legales, y Libertades Civiles votan mañana en el Parlamento Europeo acerca del tratado ACTA, el Anti-Counterfeiting Trade Agreement, o Acuerdo Comercial Anti-Falsificación, un tratado que sobre el papel, tiene como objetivo luchar contra el tráfico y la...
Un auto fechado el 11 de mayo pero comunicado el 28 a las partes entiende que no hay motivos suficientes para suspender la aplicación del Reglamento de la Ley Sinde-Wert, y que en todo caso será su aplicación y no el reglamento...
Patricia Fernández de Lis y alguno de sus secuaces de la sección de ciencia del desaparecido diario Público anuncian su vuelta con Materia, «una nueva web de noticias de ciencia, medio ambiente, salud y tecnología, que estará online en el verano...
Ayer tuve ocasión de asistir a una demostración de Apple centrada en videojuegos y nuevas aplicaciones que saldrán en los próximos meses, y también de aplicaciones para la creación de contenidos. Aparte de ver y probar novedades aún en desarrollo -como...
Por Nacho Palou -
22 MAY 2012
«Despersonalizando» Twitter Estos días se ha estado hablando de como Twitter es capaz de guardar un registro de los sitios que visitas sólo con que estos tengan instalado el botón para tuitear la página en cuestión o si tiene instalado alguno de...
Quienes gusten de aumentar su nivel de adrenalina y ansiedad mediante emociones fuertes no tienen más que seguir a @PrimaRiesgoBot, un bot de Twitter que cada 10 minutos pía con el valor del diferencial de deuda entre los bonos alemanes y...
Facebook sale a bolsa. El New York Times ha preparado un espléndido interactivo en el que se compara el volumen de la operación con el de otras empresas del sector tecnológico en las últimas décadas. El tamaño de los círculos y...
Hace algún tiempo me llamó mi buen amigo Jorge -un veterano en esto de la tecnología y junto a quien he trabajado en más de una ocasión- para contarme que se había embarcado en una nueva aventura. Lo que tenía muy...
En los Estados Unidos ya se habían publicado algunas sentencias que decían que una dirección IP no identifica a una persona, como en el caso de la demanda Hard Drive Productions contra 90 personas por descargarse una de sus películas, una similar...
Este artículo se publicó originalmente en La Voz de Galicia, donde colaboramos habitualmente. Esta es la versión sin límites de espacio y con enlaces. Antón Reixa, recién elegido como nuevo presidente de la SGAE, realizaba el pasado mes de marzo unas declaraciones...
Desde ayer en los Países Bajos se han convertido en el primer país europeo en incorporar la neutralidad de la Red en una ley. Según se puede leer en Netherlands first country in Europe with net neutrality los puntos más importantes...
Hacer algunas semanas Read It Later se cambió de nombre a Pocket. Por aquí habíamos publicado una reseña completa hace tiempo; para mi gusto es el mejor lector de contenidos en diferido para tabletas, una de esas app que es obligatorio...
Plasta en WhatsApp Lo de que hemos leído y comprendido y aceptamos las condiciones de uso de los servicios que usamos en Internet debe andar ahí, ahí con aquello de que «sí, soy mayor de edad en el lugar en el que...
Puede resultar extraño encontrar en la Wikipedia –donde tanta información precisa hay sobre hechos– que también haya una lista de todo lo que va a suceder, pero ahí está. Más exactamente, hay tres cronologías del futuro a cual más interesante: Timeline...
Cube es un juego planteado para explorar algunas de las posibilidades de Google Maps. Consiste en mover la bolita por el mapa como en los juegos de laberintos, hasta llegar al objetivo. El escenario es el MundoReal™, y hay diversas tareas...
MillionShort sirve para dos cosas: comprobar cómo serían las búsquedas cotidianas si carecieran de relevancia y –con un poco de suerte– para encontrar «pequeñas joyitas». Lo que hace es buscar como se hace normalmente en Google, pero eliminar el primer millón...
Tarde, mal, y a rastras, van llegando las opciones autorizadas para ver series, películas, y documentales en línea en España. Con la reciente apertura a todo el mundo de Youzee, que hasta el momento sólo estaba disponible por invitación, Antonio Delgado...
La última actualización de SkyDrive, el servicio de disco duro virtual de Microsoft, trajo muchas funcionalidad útiles -a lo Dropbox- y aplicaciones específicas para Mac, Windows e iOS. Peeeero -siempre hay un pero- por el camino redujo el espacio que ofrecía...
Por Nacho Palou -
27 ABR 2012
Cuando se escribe y edita texto para la web es inevitable utilizar etiquetas del lenguaje HTML. Por ejemplo <a href... para colocar un enlace, <strong> para poner texto en negrita o <ul><li>... para componer una lista. Probablemente sabes de sobra el engorro...
Por Nacho Palou -
19 ABR 2012
La respuesta corta es: realmente grande. Porque Amazon, además de vender libros y cacharritos y toda suerte de objetos a través de su tienda online, dispone de una de las mayores plataformas en Internet que revende a terceras partes como un proveedor...
Por Nacho Palou -
19 ABR 2012
Lo mejor de todo es que «funciona»: Google BBS. (¡Gracias Jose! También lo vimos en Boing Boing.)...
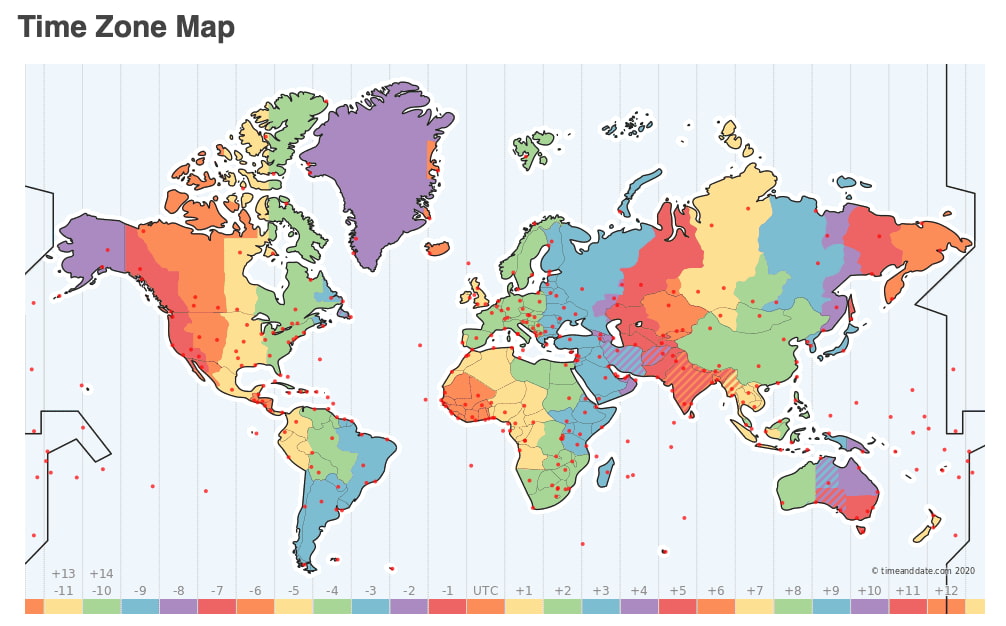
Hemos recomendado varias veces TimeAndDate.com como uno de los mejores sitios en los que encontrar datos, información y utilidades para lidiar con los calendarios y la hora en cualquier parte del mundo y en cualquier instante o época la hora. Entre...
El documental Liberad la Red [Free the network, 30 min. Inglés subtitulado en español] repasa los eventos de la ocupación de Wall Street el pasado mes de septiembre. Pero está planteado desde el punto de vista de Isaac Wilder y de...
Por Nacho Palou -
13 ABR 2012
Un año más vuelven las jornadas decanas sobre esto «del Internet» en España, las Jornadas Blogs y Medios de Granada. En las IX Blogs y Medios el lema escogido es Internet es el pasado. El futuro es el Periodismo: Nuevas formas de...
Si las estimaciones de Doctor Web son correctas, y todo parece indicar que sí lo son, con unos 650.000 ordenadores infectados en todo el mundo Flashback es el malware más extendido para Macintosh desde los lejanos tiempos de nVIR. Pero a diferencia...
Resulta que Facebook ha comprado Instagram por 1.000 millones de dólares. Aunque adquirir por cifras millonarias empresas cuyas fórmulas de ingresos –por no hablar de beneficios– son prácticamente desconocidas y recuerde a otros tiempos, también da lugar a datos curiosos: Resulta que...
Nunca descargar el más completo repositorio sobre todo el conocimiento de la humanidad estuvo a tan pocos clics. ¡Nunca se sabe cuándo vas a poder necesitarlo! Wikipedia completa / español [10 GB / OpenZIM, torrent] Wikipedia completa / inglés [10 GB /...
Hoy entra en vigor el Real Decreto-ley 13/2012, de 30 de marzo, por el que se transponen directivas en materia de mercados interiores de electricidad y gas y en materia de comunicaciones electrónicas, que básicamente traspone parte de la normativa europea más...
Este artículo se publicó originalmente en La Voz de Galicia, donde colaboramos semanalmente. Esta es la versión sin límites de espacio y con enlaces. Un año más la Asociación de Internautas ha publicado su estudio sobre las conexiones ADSL en la Unión...
Show My Street es una versión ligera y rápida de los mapas de Google + Street View: basta empezar a teclear la dirección para ver cómo el mapa se va centrando y cómo las imágenes aparecen en menos que canta un...
Convencida del enorme potencial de las llamadas herramientas 2.0 la Asociación Española de Comunicación Científica –de la que soy miembro– convoca Ciencia en Redes, un evento destinado a periodistas, investigadores, comunicadores, museógrafos e instituciones y empresas dedicadas a la ciencia y el...
Leo, aunque mentiría si dijera que con asombro a tenor de lo que vienen haciendo en los últimos años, que Promusicae ha interpuesto una denuncia contra Enrique Dans ya que entiende que ha atentado contra el honor de la entidad. El origen...

¡Autorreferente al límite! Tal y como cuentan en Motherboard, Eric Moneypenny intentó crear un «proyecto de financiación colectiva» en el sitio de moda, KickStarter, para comprar el propio KickStarter. Su idea era conseguir 19 millones de dólares. Dicha idea fue fulminantemente decapitada....
Desde hace años SeatGuru es un sitio de visita obligado a la hora de planear un viaje en avión, en especial si este es un poco largo, para poder escoger el mejor asiento posible. Allí se encuentran más de 700 esquemas de...
Está a punto de arrancar la segunda edición de iRedes, el congreso iberoamericano sobre redes sociales, en el que se presentará la segunda versión del Mapa de las Redes Sociales en Iberoamérica. La idea es mostrar las principales redes sociales que...
No tiene mayor utilidad, pero sí su coña: Chirp Clock se dedica a buscar entre los miles de tuits que pasan cada segundo por Twitter y muestra la hora actual destacándola en aquellos que la mencionan, tal y como se ve...
El artículo 404 –no es broma– del vigente Código Penal en España, titulado «De la prevaricación de los funcionarios públicos y otros comportamientos injustos» dice que: A la autoridad o funcionario público que, a sabiendas de su injusticia, dictare una resolución arbitraria...
32 cuentas de Twitter absurdas y divertidas es una recopilación de @Manz de exactamente eso, 32 cuentas de Twitter que no te puedes tomar muy en serio, pero que son sin duda parte de la gracia de este servicio. Todas ellas...
Este artículo se publicó originalmente en Cooking Ideas, un blog de Vodafone donde colaboramos semanalmente con el objetivo de crear historias que «alimenten la mente de ideas». Quienes lleven más tiempo en Internet recordarán que algunas de las primeras preocupaciones de...
Al parecer los alemanes tienen un problema con la puntualidad de los trenes que «llegan demasiado tarde, por desgracia bastante a menudo». De modo que se les ha ocurrido crear esta página de seguimiento en tiempo real donde pueden verse los...
Todo un detallado estudio de Delia Rodríguez sobre uno de los fenómenos grandes de la memética de este año....
Este artículo se publicó originalmente en La Voz de Galicia, donde colaboramos semanalmente. Esta es la versión sin límites de espacio, con enlaces, y convenientemente actualizada. El Tribunal Supremo no se ha pronunciado todavía sobre las dos solicitudes de suspensión cautelar del...
Aprovechando que estos días estará en Galicia para participar en #NeThinking2012, que se celebra en la Isla de San Simón entre esta tarde y mañana, Antonio Delgado ha convocado la primera #Redada en Galicia. Bajo el título #Redada Santiago de Compostela 1:...
Aunque cada vez hay más países que se están descolgando y que afirman que no ratificarán el tratado ACTA nunca hay que despreciar el poder de los lobbies estadounidenses y de su gobierno, así que no está de más repasar este...
De la entrevista a Viviane Reding, primera vicepresidenta de la Comisión Europea y comisaria europea de Justicia, Derechos Fundamentales y Ciudadanía que publica El País bajo el título «Europa vive el peligro de un retroceso democrático» (las negristas son mías): P. ¿Es...
Dado que el Tribunal Supremo no ha concedido la suspensión cautelar del reglamento de la conocida como ley Sinde-Wert que solicitaban la Asociación de Internautas por un lado y la Red de Empresas de Internet (REI) y la Asociación Española de la...

He sido amablemente invitado por AGAPI, la Asociación Gallega de Productoras Independentes, a participar en un taller-debate sobre el tema de las descargas no autorizadas dentro de la jornada A obra Audovisual, propiedade intelectual e contexto dixital que se celebra hoy en...
El diario The Wall Street Journal, en su artículo Google's iPhone Tracking, Web Giant, Others Bypassed Apple Browser Settings for Guarding Privacy acusa y muestra evidencias de que Google y otras compañías de publicidad móvil han estado ignorando la configuración de la...
Por Nacho Palou -
17 FEB 2012
Reír para no llorar: La UNESCO no quiere a nadie de WikiLeaks en su conferencia sobre WikiLeaks, tal y como explican en Fayerwayer. Al parecer se trata de un evento que ha organizado la UNESCO sobre lo que suponen las informaciones que...
Igual que hizo en su momento la Asociación de Internautas, la Red de Empresas de Internet (REI) y la Asociación Española de la Economía Digital (adigital) han presentado un recurso ante el Tribunal Supremo contra la Ley Sinde-Wert. Y también igual que...
CruiseWise es un buscador de cruceros. Así de simple. Me pareció bien resuelto en cuanto a interfaz y comodidad de uso, que es lo que se le puede pedir a este tipo de servicios: rapidez y facilidad para ir mirando, buscando...
Una vez más una sentencia, en este caso de la Audiencia Provincial de Álava, confirma que enlazar a descargas o a archivos en streaming es legal: La Audiencia Provincial de Alava acuerda el sobreseimiento libre del caso Cinetube. El auto dice, y...
Este artículo se publicó originalmente en La Voz de Galicia, donde colaboramos semanalmente; esta es la versión con enlaces. Sobre el papel el Anti-Counterfeiting Trade Agreement, o Acuerdo Comercial Anti-Falsificación, tiene como objetivo luchar contra el tráfico y la venta de falsificaciones...
Tras algunos años en producción financiada muy en parte de forma independiente, a base de donaciones de particulares, la película Iron Sky se proyectará este fin de semana en el Festival de Cine de Berlín, la Berlinale. En 1945 los nazis...
Por Nacho Palou -
9 FEB 2012
Los miembros de Red S@stenible, autores del texto A partir de hoy, Red y Libertad, vuelven a la carga, dispuestos dialogar con el gobierno para conseguir «una solución dialogada y dialéctica acerca de los retos que la sociedad de la información está...
Social Media Explained a la @ThreeShipsMedia, de douglaswray Twitter: Me estoy comiendo un #donut Facebook: [Me gusta] donut Foursquare: Aquí es donde como donuts Instagram: Foto envejecida de mi donut YouTube: Aquí estoy comiéndome un donut Pinterest: Receta para donuts LastFM: Escuchando...
Por Nacho Palou -
7 FEB 2012
Este es el final del camino, amigos. La decisión no ha sido fácil, pero hemos decidido cerrar voluntariamente. Hemos luchado durante años por nuestro derecho a comunicarnos, pero ha llegado el momento de pasar página. Ha sido la experiencia de una...
Rolod_zeo nos ha escrito para contarnos que debido al gran número de quejas de sus ciudadanos acerca de la diferencia entre la velocidad que se oferta en las conexiones de banda ancha y las que estas dan en realidad la Unión Europea...
Este artículo se publicó originalmente en La Voz de Galicia, donde colaboramos semanalmente; esta es la versión con enlaces. Hace unos días un amigo comentaba en una charla de sobremesa que en su opinión el libro electrónico iba a acabar con las...
La industria del copyright movió un dedo y se enviaron cartas advirtiendo de acciones legales. Cuando las cartas se ignoraron, la industria movió un dedo y se interpusieron las acciones judiciales. Cuando los jueces resolvieron en favor de denunciados y demandados, la...
Me pareció genial la idea, pero sobre todo la implementación, de TweetTrendings: una web que explica lo que hay detrás de cada Trending Topic (los «temas del momento») en Twitter. Puede participar cualquiera: basta con identificarse con la cuenta de Twitter...
Lo puedes comprobar en relación al porcentaje de usuarios utilizando la herramienta Browser Size de Google. Ese porcentaje de usuarios lo es en relación a los datos que tiene Google respecto a los tamaños de ventana que utilizan los usuarios de...
Por Nacho Palou -
31 ENE 2012
Este artículo se publicó originalmente en La Voz de Galicia, donde colaboramos semanalmente; esta es la versión con enlaces. Tras intentarlo antes con Orkut, lanzado en enero de 2004 y que sólo ha conseguido cierto éxito en Brasil y la India, y...
Una interesante animación con un montón de datos extraídos de la 12ª edición del Informe de La Sociedad de la Información en España, con comparaciones con los de 2010 para que veamos cómo van cambiando las cosas. Queda mucho por hacer,...
Nadie hace ni caso a esos anuncios, pero son molestos de narices, así que la técnica que explican en este vídeo resulta de lo más práctica. Resulta un poco irónico que el propio vídeo incluya anuncios, pero… es lo que hay...
¿Que qué hace Paulo Coelho en la portada de The Pirate Bay? Él mismo lo explica en Promo Bay: The Pirate Bay pone hoy en marcha un nuevo e interesante sistema para promocionar las artes.¿Tienes una banda? ¿Eres un productor de...
Uno desaparece, cuatro resurgen con fuerza. El efecto hidra. (Vía Fayerwayer.)...
Si usas Safari y eres de los que estás más que preocupado y mosqueado con el empeño de Google de colarnos Google+ hasta en la sopa queramos o no, lo que está resultando bastante polémico, ya tienes disponible para descargar la extensión...
Entre otras cosas, y según recogen en 8 Crazy Things IBM Scientists Have Learned Studying Twitter: Cada segundo, hay 10 tuits que mencionan Starbucks Lady Gaga gana seguidores más rápidamente de lo que Twitter añade nuevas cuentas. IBM puede predecir el tiempo...
Por Nacho Palou -
26 ENE 2012
La historia de las cadenas user-agent de los navegadores, explicada en WebAIM; breve e intensa, en estilo bíblico y bastante completa aunque viejuna (es de 2008), aunque al menos llega hasta Chrome. El final es tan apocalíptico como la situación en...
Google Public Alerts es una nueva función añadida en Google Maps que indica aquellas zonas para las que hay activada algún tipo de alerta por cuestiones tales como terremotos, huracanes, inundaciones o de otro tipo. Las fuentes son las agencias estadounidenses...
Por Nacho Palou -
26 ENE 2012
Megaupload en Vía V de Marcus Fernandez en Vimeo. Anoche estuve en Vía V de V Televisión hablando con Fernanda Tabarés y Pancho Casal (@panchocasal) de Continental Producciones sobre si y cómo afecta al tema de las descargas no autorizadas el cierre...
Este artículo se publicó originalmente en Cooking Ideas, un blog de Vodafone donde colaboramos semanalmente. El "crowdfunding" o la financiación colectiva o en masa es una fórmula que permite respaldar económicamente ideas o proyectos a partir de un amplio número de aportaciones...
Por Nacho Palou -
25 ENE 2012
Focus on the User es una iniciativa de ingenieros de Facebook, Twitter y MySpace (!) que trata de resolver el hecho de que en lo que a web social se refiere Google sólo considera perfiles de Google+ y no de otras...
Por Nacho Palou -
24 ENE 2012
Este artículo se publicó originalmente en Cooking Ideas, un blog de Vodafone donde colaboramos semanalmente con el objetivo de crear historias que «alimenten la mente de ideas». A estas alturas todo el mundo debería saber que lo que se escribe en...
Esta mañana estuve en Voces de Galicia de Radio Voz hablando del cierre de Megaupload con Manuel Cristóbal (@manuxcristobal), Marcus Fernández (@marcusfernandez), Víctor Salgado (@abonauta) e Isidoro Valerio (@IsidoroValerio). Le dimos al tema durante casi 50 minutos, y aún así quedaron temas...
Este fin de semana Blogalia, la primera plataforma de alojamiento de blogs en español, ha cumplido diez años. Sí, nació en 2001 porque Víctor R. Ruiz (@vrruiz) tuvo un sueño, mucho antes de que muchos hubiéramos oído hablar de la cosa esa...
Este artículo se publicó originalmente en La Voz de Galicia, donde colaboramos semanalmente, con el título No servirá de nada, las redes P2P funcionarán igual; esta es la versión sin límites de espacio y con enlaces. Si me atengo a lo que...
Según se puede leer en SOPA and PIPA dead – for now tanto Lamar Smith, promotor de SOPA, como Harry Reid, promotor de PIPA, han decidido aparcar la tramitación de ambas leyes. Las causas que apuntan son varias, aunque parten de las...
El popular servicio de descargas MegaUpload, con sede en Hong Kong, está cerrado y varios de sus responsables arrestados acusados de piratería, según cuenta el Wall Street Journal. Las cuatro personas detenidas se encontraban físicamente en Auckland (Nueva Zelanda) y serían...
Parte de una infografía explicativa sobre estas leyes, clic para ver entera Hay poco que los ciudadanos de otros países podamos hacer para oponernos a SOPA y PIPA, pero eso no quiere decir que no deba importarnos, como dice Michael Geist en...
OSM 2008: A Year of Edits de ItoWorld en Vimeo. Aunque el vídeo es bastante viejuno, de 2008, lo encontré documentando el artículo OpenStreetMap, la alternativa libre que compite con Google Maps como servicio de mapas y geolocalizaciones. La iniciativa OpenStreetMap, de...
Por Nacho Palou -
17 ENE 2012
Este artículo se publicó originalmente en Cooking Ideas, un blog de Vodafone donde colaboramos semanalmente con el objetivo de crear historias que «alimenten la mente de ideas». Nos pasamos el día conectados y compartiendo pequeños instantes con los amigos y conocidos...
Este artículo se publicó originalmente en Cooking Ideas, un blog de Vodafone donde colaboramos semanalmente con el objetivo de crear historias que «alimenten la mente de ideas». Esa es la frase lapidaria que me contó un amigo que le decía un...
Empezando por una imagen transparente y buscando en Google Imágenes usando la función «imágenes relacionadas» van apareciendo imágenes ligeramente distintas pero cambiantes en cada interacción. Sebastián Schmieg se entretuvo en recopilar 2.951 de ellas y montarlas en un vídeo, al que...
Según una empresa de consultoría que asesora a las operadoras móviles, el uno por ciento de los usuarios de telefonía móvil consume la mitad del ancho de banda disponible… y la cifra sigue subiendo. En total analizaron durante 24 horas el...
Las licencias Creative Commons permiten conectar al autor directamente con su audiencia, impulsan la co-creación y la co-producción, además permiten que la obra se comparta de modo que alcancen el mayor número de espectadores. Disfrutaremos del mejor cine durante el fin...
Paper Browser son plantillas en papel listas para descargar e imprimir. Reproducen la ventana del navegador web con rejillas y guías para diseñar páginas web en distintos anchos (800, 960, 1024 píxeles), reservando el espacio ocupado por las barras de herramientas...
Por Nacho Palou -
12 ENE 2012
I've got the power! Unos escolares hacen una demostración durante el XVI Día de la Ciencia en la Calle Gracias al uso cada vez extendido de las TIC en las aulas cada día hay más posibilidades de hacer llegar las actividades que...
Ley Sinde, SOPA, PIPA, el derecho al olvido y al perdón en Internet… Unas reflexiones de la abogado Paloma LLaneza sobre temas legales e Internet, que sobre todo en el ámbito de la propiedad intelectual van a dar mucho que hablar...
La recopilación de la lista original de #ComparteCultura es obra de @kurioso y está en #ComparteCultura. P2P La mejor forma de ejercer tu derecho a compartir con otros usuarios de la red es el P2P (Peer-to-Peer). El P2P sirve para intercambiar...
Mapnificient sigue ampliando su cobertura y ya puede usarse también en Madrid. La idea sigue siendo la misma: elegir un lugar cualquiera de la ciudad y visualizar fácilmente con un deslizador la zona que se puede explorar, andando o en transporte...
Dentro de los muchos problemas que tiene, uno de los aspectos más criticados de la Ley Sinde-Wert es que una comisión administrativa, en concreto la Sección Segunda de la Comisión de Propiedad Intelectual, puede decidir el cierre de una página web sin...
Por Drew de Toothpaste for Dinner, vía Miss Cellania....
Por Nacho Palou -
5 ENE 2012
Del estudio «Infracciones al copyright en el internet: el marco legal existente es suficiente» [nota de prensa en PDF 40 KB] publicado en conjunto por el Instituto de Propiedad Intelectual y el gobierno suizo, que afirma que que aunque internet haya cambiado...
History of Life - Department of Geoscience. University of Wisconsin-Madison Lo que conocemos y aventuramos sobre el origen y evolución de la vida en el planeta Tierra presentado en forma de reloj de 24 horas. En esta representación, a lo largo de...
Por Nacho Palou -
2 ENE 2012
En el último consejo de ministros del año, y a pesar de aquello que había dicho Mariano Rajoy de que «hablarían con todas las partes implicadas antes de tomar una decisión», ha aprobado el reglamento de la Ley Sinde [PDF 2,4 MB],...
Parte de la infografía explicativa, clic para ver entera Qué es SOPA y por qué es un peligro para ti, la versión estadounidense de nuestra Ley Sinde explicada muy clarita con unas cuantas ilustraciones… De Mafalda, claro ;-) (Vía clipset)....
Clic para ver en grande Creo que Antonio Ortiz y yo nunca nos hemos parado a hablar del tema, pero puedo suscribir casi por completo su algoritmo definitivo para la compra de un libro en edición electrónica, con la salvedad de que...
Hay que ser un poco geek para apreciar en profundidad la belleza de esto: Gareth Lloyd y Tom Martin descargaron todos los artículos de Wikipedia (30 GB), extrajeron los que tenían georeferencias (420.000) y se quedaron con los que incluían fechas...
Sencillamente genial esta anotación en Fronteras dedicada a territorios que están situados muy, muy, muy lejos de la «ubicación principal» de sus diversos países «de origen» sobre el mapa, tales como islas lejanas y tierras de ultramar: A diez mil kilómetros...
En junio de 2008 Promusicae, Sony BMG Music Entertainment S.A, Universal Music Spain S.A., y Warner Music Spain S.A. denunciaron a Pablo Soto reclamándole 13 millones de euros al entender que había desarrollado sus aplicaciones para intercambio de archivos mediante redes P2P...
Youzee es un servicio de videoclub online para alquilar películas y series. De momento funciona a través del navegador web y mediante invitación, pero a partir del año que viene –en cuestión de semanas, como quien dice– estará disponible para todo...
Por Nacho Palou -
16 DIC 2011
Como todos los años, Google acaba de publicar lo más buscado del año 2011 en España, que viene siendo: Elecciones 2011. Bankia. Atrapa Un Millón. Whatsapp. Dieta Dukan. Juego de Tronos. iPhone5. Supervivientes 2011. El Barco. Gadaffi. Hay un total de...
Igual que muchos otros que teníamos ya una cuenta en Amazon.com, al ir a realizar mi primera compra de un ebook Kindle en español en Amazon España me encontré con un mensaje que me decía que para ello tenía que transferir mi...
Una curiosa idea con Google Maps, de Iacopo Boccalari. (Vía Wwwhat's new?)...
Así, como suena, uniendo tradición y modernidad: QR-Countdown. Actualización (27 de junio de 2023) – El enlace por desgracia desapareció....
Wikistream muestra cómo se actualiza la Wikipedia en tiempo real. Las dos iniciales son el idioma, por ejemplo [es] = español; el numerito de la derecha indica cuántos caracteres se han añadido o borrado en cada edición. Pulsando la P se...
Ahora Google muestra gráficas de ecuaciones matemáticas cuando identifica que un término de búsqueda es una ecuación. Basta teclearlas en la caja de búsqueda. (Vía Wwwhat's new?)...
Un montón de cajas y gentecilla por ahí. What it Looks Inside Amazon.com, en Buzzfeed, con unas impresionantes fotos de Matt Cardy para Getty Images. Mmmm… ¿Dónde habré visto yo esto antes? Ah, sí… En busca del Arca perdida (Steven Spielberg,...
A través de Engadget descubrí un ingente recurso: los más de 60 millones de artículos de 300 años de periódicos que la Biblioteca Británica tiene a disposición de todo el mundo en una web llamada The British Newspaper Archive. Buscar es...
Shoghi (¡gracias!) nos envió un enlace en cierto modo autorreferente y un tanto paradójico a la «máquina del tiempo» Wayback Machine de Archive.org, que como bien es sabido guarda copias de toda la Web desde las épocas más remotas – interneteramente...
En Slashdot cuentan que Atos, una gran empresa europea de tecnología (con 74.000 empleados y 5.000 millones de dólares de facturación) ha decidido prescindir del correo electrónico de aquí a 18 meses. ¡Prohibido enviar un solo correo! Al parecer han calculado que...
Google homenajea hoy con su doodle –con el que por cierto se puede y debe jugar– la publicación en 1951 de Los astronautas, el primer libro de Stanislaw Lem en ver la luz, aunque era en realidad la tercera novela que...
Estuve probando un poco SocialBro, una herramienta bastante potente para el análisis de comunidades en Twitter. Se trata de una aplicación multiplataforma que corre sobre Adobe AIR tanto en Windows como Mac, Linux o alternativamente en el navegador Chrome. Basta descargarlo,...
Un curioso tuit que aprovechándose de un bug (¿o feature?) de funcionamiento de Twitter consiguió meter 1.680 caracteres en un solo mensaje, tal y como pueden verse en la cuenta de @chroman. [Actualización: Nos corrigen que el original procede de @wkpn...
Europa coloreada por tuits Una semana de tuits geolocalizados obtenidos a través de la API de de Twitter analizados con un detector automatizado de idiomas (por lo que lógicamente puede haber errores), convenientemente masajeados, y el resultado es Language communities of Twitter,...
Impresionante este montaje musical de Gilad Chehover (batería), Guy Bernfeld (bajo) y Or Paz (guitarra), The Gag Quartet, junto con un amplio equipo de artistas y animadores, que han juntado más de 40 memes de Internet en una sola canción. Aunque...
Google y Facebook –igual que muchos otros servicios que usamos en Internet– saben un montón acerca de nosotros, probablemente mucho más de lo que nos damos cuenta. Usan esa información para intentar adivinar qué es lo que nos interesa ver cuando...
Contar la historia de Internet en 8 minutos es cuando menos complicado, y hay algunas cosillas en este vídeo que me han llamado la atención, como por ejemplo la fecha en la que dicen que se envió el primer correo electrónico,...
Tuve una de las primeras invitaciones que rularon por aquí para usar Google+, y lo hice con ganas para ver de qué iba hasta que me suspendieron la cuenta por poner Javier Pedreira (Wicho) como nombre. Imagino que el problema es el...
What's UP?! es una aplicación desarrollada por User Interface Design GmbH que sirve para ver los temas del momento (AKA trending topics) globales de Twitter, tanto los que están vigentes en tiempo real, como los del pasado. Los representa mediante círculos,...
The Deleted City es un proyecto de Richard Vijgen, que ha reconstruido una visualización del legendario servicio de alojamiento de páginas web Geocities (RIP, 1995-2009) a partir de la copia de seguridad de 650 GB que se hizo antes del cierre....
Como filtro, filtro, no parece que sea gran cosa, pero desde luego es original: el CAPTCHA de las resistencias electrónicas: basta con igualar con los controles móviles el valor en ohmios de la resistencia que se ve en la imagen. La...
Este artículo se publicó originalmente en Cooking Ideas, un blog de Vodafone donde colaboramos semanalmente. Uno de los grandes problemas de la investigación espacial es que a menudo es difícil comunicar sus logros al público, lo que unido a la impresión de...
Hace tiempo que tengo asumido que los que seguimos usando Foursquare somos una minoría aún dentro del frikismo de los que usamos a diario cosas como Twitter o Instagram, pero he de reconocer que aún así me ha sorprendido bastante esta animación:...
Tras languidecer durante años en las manos –o quizás mejor zarpas– de Yahoo, que lo compró en 2005, Delicious fue vendido hace unos meses a AVOS, una empresa creada por Chad Hurley y Steve Chen, los fundadores de YouTube. Desde ayer, tal...

(…) Soy un operador financiero, a mí no me preocupa la crisis. Si veo una oportunidad para ganar dinero, voy a por ella. Nosotros, los brokers, no nos preocupamos de cómo arreglar la economía o de cómo arreglar esta situación. Nuestro trabajo...
Infografía "viva" que muestra de forma animada cálculos de datos sobre el crecimiento y utilización de Internet en todo el mundo en función del tiempo que transcurre desde que se abre la página State of the Internet 2011, Algunos números que...
Por Nacho Palou -
27 SEP 2011
Este fin de semana se celebró la entrega de premios de los Tweets Awards España, que premia a los mejores profesionales del mundo online y a los tuiteros más involucrados en la popular red social. Los premios fueron votados por el...
El estudio Global Game Download de Pando Networks analiza la fiabilidad y velocidad de conexión a Internet de países de todo el mundo, 224 para ser exactos que suman 27 millones de descargas realizadas desde 20 millones de ordenadores. En el...
Por Nacho Palou -
23 SEP 2011
Kiva es una de las empresas pioneras en el campo de los microcréditos: pequeñas aportaciones de muy poco dinero (menos de 20 euros) que enviadas a la persona adecuada en el lugar justo pueden cambiar vidas: comprar semillas, criar unas gallinas,...
Tras años de espera -mi primer pedido a Amazon.com es de septiembre de 1996 y creo que desde entonces estoy enganchado- desde hace un minuto por fin está en funcionamiento Amazon.es. Así que por fin los que nos dedicábamos a hacer...
Una de las cosas acerca de los libros electrónicos de la que la mayoría de la gente parece no haberse dado cuenta es de que estos son la primera cosa aparte del aire de la que podremos tener tantos como queramos. Piensa...
En el enésimo capítulo del culebrón que está viendo como Yahoo sigue el camino de AltaVista hacia el cementerio de los viejos grandes buscadores de Internet, Carol Bartz, su directora ejecutiva fue despedida por Roy Bostock, el presidente de la compañía, por...
El equipo del acortador de direcciones Bitly publicó un breve pero interesante análisis sobre la vida de los enlaces y la atención que la gente les presta. Básicamente consistía en analizar los enlaces acortados a diversos tipos de contenidos, publicados en...
Adiós a la productividad de este lunes. La aplicación web Eyes on the Solar System de la NASA permite recorrer el Sistema Solar en 3D libremente, en cualquier dirección y ver modelos tridimensionales de los numerosos objetos que contiene (desde el...
Por Nacho Palou -
5 SEP 2011
Place Pulse, del M.I.T., es más profundo de lo que parece a simple vista. Básicamente sirve para elegir mediante crowdsourcing, en plan binario y fotográfico, los lugares más atractivos o peligrosos de diferentes ciudades. Pero por detrás hay redes de percepción...
S119-E-009793: La Estación Espacial Internacional con todos sus paneles solares Desde que en marzo de 2009 los tripulantes de la misión STS-119 de la NASA instalaran el último juego de paneles solares en la Estación Espacial Internacional esta es el segundo objeto...
Desde hace tiempo la búsqueda por voz está disponible en aplicaciones de Google para móviles como iPhone o Android. Esto permite introducir la palabra o secuencia de texto a buscar dictándola, sin necesidad de teclearla. Y funciona bastante bien. Ahora también...
Por Nacho Palou -
30 AGO 2011

«Aunque tú lo uses veinte veces al día, la mayor parte de la gente no lo usa jamás». Y es que los conocimientos sobre las funciones del software que manejamos cada día siguen en los niveles de siempre: según expertos de...
Después de 14 años y haber publicado unas 15.000 anotaciones, es hora de que diga adiós a Slashdot (…) A partir de ahora podréis seguirme como @cmdrtaco en Twitter O Rob Malda en Google+. Steve Jobs se va de Apple, CmdrTaco se...
Apenas un par de semanas después de incorporar la posibilidad de subir directamente imágenes a Twitter sin la necesidad de usar ningún servicio externo –aunque estos siguen funcionando– ahora el servicio incorpora galerías de imágenes de los usuarios: Estas incorporan tanto las...
Mapnificent es una inteligente forma de usar los mapas de Google «al revés»: basta indicar dónde estás para que te indice cuán lejos puedes llegar usando el transporte público variando el tiempo de que dispones con un sencillo deslizador. Los datos...
En una jugada que tiene bastante sentido Foursquare acaba de anunciar que ha añadido eventos a su base de datos. Así, en lugar de tener que crear un sitio nuevo para dejar claramente indicado que estás, por ejemplo, en un concierto en...
World map of Flickr and Twitter locations: Uso de Flickr y Twitter en el mundo - Eric Fischer Desde hace algún tiempo, siempre que doy una charla y menciono Twitter no dejo de comentar como a veces las redes sociales hacen como...
Puedes usarlo pidiendo imágenes en URL al tamaño que necesites al estilo http://placehold.it/350x309 (basta cambiar los números); también con una etiqueta HTML img src del mismo modo. Se llama Placehold.it y como idea está genial. Lo vi pasar por Genbetadev, donde...
Con C64 Yourself puedes convertir una foto tuya o cualquier imagen en general al estilo bitmap de baja resolución de los C-64, con sus características limitaciones de colores y todo lo demás. El funcionamiento de la página está estupendamente resuelto y...
José Luis nos pasó un enlace a GeaCron, un mapamundi interactivo que tiene la peculiaridad de contener la información temporal sobre las fronteras mundiales, de modo que basta teclear la fecha o usar los botones para ver qué países era cual...
Debido a algún problema relacionado con el suministro eléctrico, el servicio «en nube» EC2 de Amazon (Amazon Elastic Compute Cloud) ha mordido el polvo hacia las 20.00 hora española, provocando una caída total de los sistemas y arrastrando con ello a miles...
… que era la primera página de la World Wide Web.
Puedes teclear cualquier dirección del mundo, como en Google Maps, en Rorschmap y alucinar un poco: es una curiosa página que creará un simpáctico efecto visual con las imágenes aéreas a modo de caleidoscopio – o algo parecido. Es como ver...
Pósteres de propaganda de los «social media», una idea con encanto de Aaron Wood....
Hace unos días se me ocurrió que me vendría bien recuperar mi primer tuit para una charla que estoy preparando. Pero tras varios días de búsquedas por la web adelante y de preguntarlo en el propio Twitter, resulta que no es necesariamente...
Tecnologías de los 80 vs Tecnologías de hoy: Infografía es un curradísimo vídeo de los chicos de Xataka que repasa las enormes diferencias entre los cacharros que usábamos en la década de los 80 y los que usamos ahora. Los que...
Estaba buscando el dato de cuantas fotos se suben a diario a Flickr y me encontré con esta infografía que muestra el contenido que se sube a diario a algunos de los sitios más populares de la famosa web 2.0 esta: How...
WordItOut es uno de esos servicios que alguna vez hemos mencionado que sirven para convertir textos en «nubes de palabras» según su frecuencia; en este caso resulta que WordItOut es especialmente personalizable y admite muchísimas variaciones en el aspecto de los...
Jorge, de la popular serie Malviviendo, lleva años peleándose con YouTube y el famoso «contador de visualizaciones»; se ha convertido en un pozo de sabiduría al respecto y nos ha contado por correo un montón de cosas que añadir a lo que...

¿Muestra el contador de YouTube el número de gente que ha visto completo un vídeo? ¿O tan solo los que han pulsado play independientemente de que abandonen la reproducción a los pocos segundos? Siempre sospeché que era lo primero, pero la confirmación...
Rayitas verdes, rayitas rojas, rayitas negras… son las indicaciones del estado de tráfico en Google Maps, una función que existe desde hace tiempo en otros países y que ahora ha llegado a algunas ciudades de España, como Madrid, Barcelona, Zaragoza y...
La sentencia desestima la demanda de SGAE contra la página de enlaces indice-web.com y se convierte en «la primera sentencia firme en vía civil dictada en nuestro país que declara que las páginas de enlaces a redes P2P o a webs de...
Evolución de las condiciones de privacidad de Facebook, sólo una parte de sus condiciones de uso. [Fuente: Facebook Privacy: A Bewildering Tangle of Options. Vía Más allá de la LOPD: privacidad en las redes sociales y normativa en el entorno online,...
An In-Depth Look Inside the Twitter World es un análisis sobre cómo se comportan los usuarios de Twitter, que condensó estupendamente David McCandless en esta infografía del tipo «Si Twitter fuera un país de cien habitantes…» El resumen es que cada...
Organizational Charts, una divertida viñeta de Manu Cornet. § Business Insider....
Por Nacho Palou -
30 JUN 2011
Clic para ver completo Incluyendo todo tipo de información digital, desde la procedente de duplicar información ya existen, como en el caso de copiar un DVD, a la contenida en un tuit, la cantidad de información digital que se acumula en el...
Por Nacho Palou -
29 JUN 2011
Tras leer la historia de Google en In The Plex de Steven Levy me quedó claro que si hasta ahora el gigante de las búsquedas no ha sabido colocarse en el mercado de las redes o productos sociales es porque en la...
Kilodays permite calcular fácilmente cuántos kilodías (versión pedante de K) han transcurrido desde una fecha señalada, por ejemplo tu cumpleaños o cualquier otra. Así medio de casualidad descubrí que el Macintosh original cumplió hace algo más de una semana la cifra...
En este año 2011 ya ha sucedido que se venden más smartphones que ordenadores, que hay más gente accediendo a Internet desde un iPad que desde un ordenador Linux y que cada minuto se activan más dispositivos móviles que bebés nacen...
Por Nacho Palou -
21 JUN 2011
Casi 100.000 tweets, 700.000 estados de Facebook puestos al día, 170.000.000 correo enviados (la mayoría spam), 700.000 búsquedas, 12.000 nuevos anuncios en Graigslist, 13.000 descargas de apps para iPhone, 20.000 posts en Tumblr, 70 nuevos dominios registrados… Es un resumen visual...
Cuando por aburrimiento ya habíamos agotado hace años todas nuestras elucubraciones acerca de por qué las imágenes de previsualización de los vídeos de YouTube seguían –aun habiendo entrado ya la segunda década del siglo XXI– mostrando píxeles como puños van y...
¿Puedo ser tu amigo? ¿Me dejas escribir en tu escaparate? Permíteme que te enseñe mis fotos privadas… ¡Voy a seguirte, voy a seguirte! Las situaciones serían tan ridículas que han dado hasta para un argumento de una ópera en Londres, Two...
Esta historia tiene por protagonistas algunos conceptos que a mucha gente le sonarán extraños y futuristas: dinero virtual, matemáticas avanzadas, criptografía segura y unas reglas económicas diferentes a las que conocemos (…) Las bitcoins son unas peculiares «monedas hechas de bits»...
Tercer teaser de la película Iron Sky, la película sobre el regreso de los nazis que en 1945 huyeron de la Tierra para esconderse en la cara oculta de la Luna. La película ya tiene además fecha de estreno, el 4...
Por Nacho Palou -
13 MAY 2011
Evolution of Readers (CC) John Blyberg en Flickr Este artículo se publicó originalmente en Cooking Ideas, un blog de Vodafone donde colaboramos semanalmente con el objetivo de crear historias que «alimenten la mente de ideas». Durante muchos años las editoriales han visto...
La cantidad de información que los aproximadamente 27 millones de servidores «de negocios» que existen en Internet procesan cada año es de unos 9,5 zettabytes. La magnitud del dato es casi incomprensible: un zettabyte equivale a 1.000 exabytes, 1.000.000 de petabytes o...
Era un secreto a voces estos últimos días, pero por fin es oficial: Microsoft to Acquire Skype. En un acuerdo valorado en 8.500 millones de dólares, un poco más de 5.900 millones de euros, la empresa de Redmond se hace con Skype,...
Si aún sueñas con desarrollar una carrera relacionada con el espacio, este diagra de flujo de Good, What is the Ideal Space Career for You? te ayuda a dilucidar tus posibilidades, o cuál es la mejor de las opciones para ti....
Por Nacho Palou -
9 MAY 2011
La aplicación Qwiki para iPad [enlace a iTunes, gratuita] está diseñada para servir información en forma de experiencia especialmente adecuada para su uso desde tablets y dispositivos móviles -hay versiones para iPhone y Android e desarrollo. Aunque los contenidos de Qwiki...
Por Nacho Palou -
4 MAY 2011
Por poco interés que uno tenga en el tema, seguro que todos hemos oído hablar del PageRank, que, simplificando un poco las cosas, es una valoración de 0 a 10 que Google otorga a las páginas web que indexa. Como imagino que...
Quino nos estuvo contando algunas cosas de Trickon cuando era solo un proyecto, y verlo ahora ya más «crecidito» es todo un gustazo: es un híbrido entre red social y «formato interactivo especializado» sobre deportes extremos, con un montón de secciones...
Todos los estereotipos de Facebook reunidos en un solo vídeo: la amiga a la que le gusta todo; el amante de las letras de canciones; la princesa que no deja de hacerse autorretratatos; el comidógrafo que no hace más que fotos...
ShowYou es caballo ganador: una aplicación gratuita para iOS que permite ver en el iPad con absoluta comodidad todos los vídeos que enlazan y comparten tus colegas de las redes sociales. ¿No estaban los tablets hechos para matar ratos? Pues esta...
Quijotipsum es como Lipsum, el generador de Lorem Ipsum, pero con el Quijote. ¿Alcanzará la misma popularidad? Los siglos lo dirán. (¡Gracias Pablo!)...
Estados Unidos – En la web de la Casa Blanca el gobierno de los EE UU ha puesto una página llamada Federal Taxpayer Receipt que dice a cualquiera que viva allí en qué se emplea el dinero de sus impuestos estatales....
CrimeMapping puede servir simplemente para cotillear qué pasa por los alrededores o tal vez para elegir casa en un lugar tranquilo: es una capa informativa sobre los delitos en distintos puntos de las ciudades creada a partir de la información pública...
Este artículo se publicó originalmente en Cooking Ideas, un blog de Vodafone donde colaboramos semanalmente con el objetivo de crear historias que «alimenten la mente de ideas». Aquí el que no corre, vuela, y estamos en Internet donde esos que vuelan...
Google Street View de Sehsucht™ en Vimeo. Google Street View de Sehsuch es un bonito vídeo que recrea un viaje por el mundo a través de Google Street View. Tan bueno como el video resultante son los vídeos que muestran cómo fue...
Por Nacho Palou -
12 ABR 2011
Este Mapa de Internet 2011 de Peer 1, una empresa del ramo, existe en versión «interactiva» (aunque de interactiva tiene poco, más bien sería ˜versión con zoom» y muestra las conexiones entre los diferentes nodos de Internet. Utiliza los datos topológicos...
Si tienes a mano un navegador compatible con WebGL -como Chrome o Firefox- puedes probar Cycleblob, un juego de carreras de motos de luz tipo Tron que tiene el mérito de estar completamente desarrollado con lenguajes abiertos como WebGL y HTML5, sin...
Por Nacho Palou -
7 ABR 2011
Uso de Twitter y cómo lo ve la gente es una reflexión (o irreflexión) de Fernand0 acerca de cómo usar Twitter, del que en realidad cada uno puede y debe hacer un sayo, con un par de enlaces a otras entradas similares...
Para probar el botón +1 de Google (a.k.a. «Me gusta»), que de momento sólo funciona en Google.com/inglés, basta usar una cuenta Google que tenga un perfil público y unirse cual cobaya al experimento de laboratorio. El nombre elegido para esta nueva...
Esta tarde y mañana durante todo el día participaré en el encuentro #NeThinking en la isla de San Simón, invitado por la Fundación Illa de San Simón y por su coordinador, Nacho de la Fuente. La idea es «conversar sobre nuestros modos...
Aunque para muchos es un perfecto desconocido, Paul Baran inventó una de las técnicas básicas para las redes de comunicaciones que usamos hoy en día, la conmutación de paquetes. Su trabajo al respecto, pensado para el diseño de redes de comunicaciones capaces...

Este artículo se publicó originalmente en Cooking Ideas, un blog de Vodafone donde colaboramos semanalmente con el objetivo de crear historias que «alimenten la mente de ideas». Hay muchas cosa sobre el diseño de webs que generan encendidos debates, pero una...
Un grupo de investigadores del International Computer Science Institute de San Diego se propuso averiguar cuanto dinero podía ingresar un spammer al día, para lo que dejaron que ocho ordenadores se infectaran de un virus que los convetía en miembros de una...
Altamente recomendable para todos aquellos interesados en escribir lo mejor posible en estos nuevos (o ya no tanto) inventos que son los blogs, Twitter, y similares, Estilo: manual para nuevos medios es un proyecto que ha puesto en marcha la Fundéu BBVA,...
En abril y diciembre de 2008 los juzgados de instrucción números 1 y 4 respectivamente ordenaban el archivo de los casos contra IndiceDonkey y contra Spanishare al concluir que un enlace no es un acto de comunicación pública. Esta semana, con apenas...
Pocas labores hay tan ingratas como tener que trabajar con formularios HTML, así que se agradece las pistas que The Current State of HTML5 Forms proporciona: cómo funcionan los nuevos tipos de entradas de datos, qué navegadores los soportan, cómo gestionar...
Pixelhead (cc) Martin Backes Por si se cruzan con Pegman, con algún instagramer compulsivo, para evitar aparecer por Facebook o porque temen encontrarse con algún gran hermano, ahora que son familia numerosa. La máscara de camuflaje Pixelhead es un proyecto de Martin...
Por Nacho Palou -
22 MAR 2011
Durante la gran migración de invierno de Twitter el "mayor desafío al que se ha enfrentado" el servicio –necesario para incrementar su uptime o funcionamiento sin interrupciones–, hubo que copiar todos y cada uno de los tweets escritos a lo largo de...
Por Nacho Palou -
22 MAR 2011
twttr sketch: un primer boceto de cómo podía ser twttr (CC) Jack Dorsey A Twitter le llevó 3 años, dos meses y un día llegar a los primeros mil millones de tweets. Menos de dos años después de alcanzar ese hito, los...
RDTN.org es una versión colaborativa de un mapa de Japón en el que la gente mide las dosis de radiación de su localidad y las sube a la web, visualizándose sobre Google Maps. Se parece a la versión de TargetMap excepto...
Curiosity and Need to Know es una visualización con las visitas a los términos relacionados con la catástrofe de Japón en la Wikipedia. Puede verse cómo el interés inicial por la escala Richter o la zona de Sendai pasan a ser...
Tras el correspondiente periodo de pruebas posterior a su lanzamiento el pasado 26 de noviembre, el satélite Hylas 1 está listo ya para entrar en funcionamiento. Impresión artística del Hylas 1 en órbita De hecho, en esta fase de pruebas ha demostrado...
Aunque ya hace algún tiempo que se podía usar Twitter mediante una conexión cifrada mediante el protocolo HTTPS, había que acordarse de hacerlo yendo a https://www.twitter.com/ en lugar de a la dirección habitual (ojo con la s antes de los dos puntos)....
Pegman, el hombrecillo de Google Street View, recibe ese nombre por su parecido con una pinza para la ropa (clothes peg) En Street View: Explore the world at street level Google ha reunido todos los recursos relacionados con Street View, el servicio...
Por Nacho Palou -
15 MAR 2011
Afortunadamente, lejos quedan los tiempos en los que la web estaba llena de sitios que sólo funcionaban con Internet Explorer y Windows, aunque haberlas aún las hay. Pero por si quieres seguir usándolo, o no te queda otro remedio, ya está disponible...

Digital natives – CC Thomas Angermann Este artículo se publicó originalmente en Cooking Ideas, un blog de Vodafone donde colaboramos semanalmente con el objetivo de crear historias que «alimenten la mente de ideas». Marc Prensky acuñaba en 2001 la expresión «nativo digital»...
WeatherSpark es la antítesis de la simplicidad y del saber «qué tal tiempo hará mañana» con una frase: es una web con infinidad de datos y gráficos sobre climatología: temperaturas, nubes, precipitaciones… incluso datos detallados de presión atmosférica, dirección y velocidad...
El jugón. La «coordinadora de eventos». El marketroide desesperao. El que etiqueta las fotos con el culo. El pesao acosador. El que está todo el día haciendo tests. El pasivo-agresivo («que publica insultos rimbombantes sin mencionar a nadie por su nombre...
Estuve probando WatchMouse, un servicio de monitorización de sitios web avanzado y muy completo. Este tipo de servicios los utilizan los webmasters y administradores de sistemas para diversas tareas, pero principalmente para comprobar que sus sitios web funcionan correctamente, controlar los...
Las secciones y contenidos de Zite se eligen en base a los gustos y preferencias de lectura del usuario. Si tienes un iPad probablemente ya conozcas la aplicación Flipboard –una de las más populares, nombrada "aplicación del año" por Apple– que lo...
Por Nacho Palou -
9 MAR 2011
Hoy se ha hecho público que, en aplicación de lo que dice la sentencia del Tribunal de Justicia de la Unión Europea acerca de que la forma en la que se aplica el canon digital en España es ilegal, la Sección 15...
Un grupo estadounidense llamado IIPA (Alianza Internacional de la Propiedad Intelectual) en el que están asociaciones como la BSA (Software), RIAA (Discográficas) y similares ha presentado su 25º informe anual en el aparecen los 40 países más «piratas» del mundo. Otros años...
Tras meses de retrasos el transbordador espacial Discovery inició la semana pasada su última misión, la STS-133. El vídeo de arriba capta el momento del despegue visto desde un avión que pasaba "cerca" de la base de lanzamiento en su vuelo...
Por Nacho Palou -
28 FEB 2011
Time.is: por si no tienes un reloj a mano o dudas de lo que indica. Con precisión atómica, pero sobre todo… ¡Fácil de recordar! (Vía The Presurfer.)...
Las malas noticias son que en Gmail se han borrado entre 150.000 y 500.000 cuentas de correo por algún tipo de problema técnico, incluyendo los mensajes, ficheros vinculados, carpetas, etiquetas y demás… Las buenas noticias son que los ingenieros de AGoogle ya...
The Internet Wishlist: si tienes un deseo respecto a algún tipo de «invento» que se pudiera hacer realidad relativo a Internet, basta que lo comentes a los cuatro vientos en Twitter con la etiqueta #theiwl; si eres desarrollador y andas corto...
Google Forecloses On Content Farms With «Farmer» Algorithm Update es un artículo del siempre recomendable Search Engine Land donde se explica cómo el cambio de algoritmo que ha hecho Google hoy afectará al ~12 por ciento de los resultados de búsqueda, de...
Motorola XOOM, 10 pulgadas y Android 3.0. Y sin Adobe Flash “hasta primavera”. El tablet Motorola XOOM estará disponible desde mañana 24 en EE UU con la operadora Verizon. Es el primero que sale con sistema operativo Android 3.0 Honeycomb. Y curiosamente...
Por Nacho Palou -
23 FEB 2011
Una vez más un caso contra una web de enlaces se resuelve con la absolución de los procesados, en este caso los responsables de FenixP2P, tal y como se puede leer en la sentencia del Juzgado de lo Penal Nº 1 de...
De la entrevista al diputado del PP José María Lassalle en 20minutos.es publicada como Lassalle: «La ley Sinde ha puesto las bases para una nueva Ley de Propiedad Intelectual»: Ustedes han defendido la "doble intervención judicial". Los críticos con el texto argumentan...
Olá con la nueva versión de Google Public Data Explorer surjan muchos Hans Rosling que hagan más fácil entender el mundo en que vivimos. No en vano se trata de una herramienta basada en Gapminder, cuya tecnología adquirió Google hace años,...
– ¿Cuántos programadores de Microsoft hacen falta para cambiar una bombilla?– Ninguno. Simplemente redefinen oscuridad como el «nuevo estándar».– popular chiste informático Hoy la gente de Mozilla publicó una dura anotación llena de detalles y estadísticas acerca de cómo se comporta...
Como era previsible, y a pesar de las protestas y movilizaciones, la Ley Sinde ha superado hoy su último trámite parlamentario con su votación en el Congreso. Con los 323 votos a favor de PSOE, PP y CiU, una abstención, y los...
Este Mapa de las conexiones en Tuenti muestra cómo se conectan los amigos de la popular red social española entre sí: las zonas rojas indican enlaces con más «conexiones» y las de colores como amarillo y verde las que tienen un...
Personal Blocklist es una ingeniosa idea de Google para mejorar la calidad de sus resultados de búsqueda, que tanto habían sido criticados últimamente. Se trata de una extensión para Chrome que simplemente bloquea los resultados que contengan una cadena de término...
Google no ofrece horóscopos, ni consejos sobre finanzas, ni chat.Nuestra filosofía / Google, circa 2006 Hace cinco años, se nos hacía extraño que un (¡ejem!) buscador pudiera atreverse a ofrecer servicios de contenidos especializados. Se ve que ni ellos mismos lo...
Desde mañana lunes 14 y hasta el jueves se celebra en Barcelona el Mobile World Congress (MWC). Se trata del mayor evento -entre feria y congreso- dedicado a las comunicaciones móviles. Tablets y los superteléfonos serán los grandes protagonistas de esta edición...
Por Nacho Palou -
13 FEB 2011
Tal y como estaba pactado, la Ley Sinde, en una versión ligeramente maquillada, ha vuelto a ser incluida en la Ley de Economía Sostenible con 244 votos a favor y con sólo 12 en contra, los de ERC, ICV, CC, PNV, Partit...
Este artículo se publicó originalmente en Cooking Ideas, un blog de Vodafone donde colaboramos semanalmente con el objetivo de crear historias que «alimenten la mente de ideas». Inmersos en las redes sociales, las costumbres de muchos han cambiado radicalmente en los...
EL objetivo principal de la Ley Sinde es, al menos sobre el papel, poder cerrar rápida y fácilmente las llamadas webs de enlaces, algo que la industria audiovisual cree que servirá como remedio mágico para hacer desaparecer los últimos años de evolución...
La versión revisada de la ley Sinde que han pactado PSOE, PP y CiU sigue siendo igual de mala que la anterior, según opinan abogados expertos en estos temas, sobre todo por dejar, digan lo que digan los políticos para justificarse, a...
Me resulta la mar de curioso que Google haya tomado la decisión de filtrar ciertos términos como uTorrent, BitTorrent, o MegaUpload en las sugerencias de búsqueda y en los resultados de búsqueda instantánea, aunque al menos por ahora no en los resultados...
Agencias, diseñadores de webs y webmasters puede que encuentren útil en estos tiempos salvajes que corren la idea de CSS Killswitch. Se trata básicamente de incorporar en las hojas de estilo del sitio que se ha diseñado una llamada a un fichero...
Fui muy escéptico respecto a la reunión que organizó Álex de la Iglesia para intentar dialogar sobre la Ley Sinde, pero he de reconocer que por el camino ha demostrado que al menos él tenía ganas de intentar llegar a un entendimiento....
Microsoft, la Fundación Mozilla y Google, entre otros, se han puesto de acuerdo en incorporar una nueva función en sus navegadores web llamada «cabecera Do-Not-Track» (No-hacer-seguimiento), relacionada con la privacidad y el rastreo o seguimiento que los sitios web hacen de...
Tal y como nos temíamos, el PP y el PSOE han pactado esta misma tarde, casi en el último momento, una nueva versión de la Ley Sinde que será aprobada en el Senado sin ningún problema, ya sea mediante la abstención del...
A modo de homenaje del estándar Robots.txt, un grupo de humanos ha creado Humans.txt, para mostrar de forma rápida y simple quiénes son las personas de carne y hueso que están detrás de una página web. (Vía Quora.)...
If It Were My Home es un comparador de países. Eliges el país en que vives, eliges otro distinto y listo: aparece un mapa para que puedas comparar los tamaños relativos y luego toda una serie de datos demográficos y económicos...
La gente de 101.es ha actualizado el vídeo que hicieron el año pasado sobre el estado de las redes sociales en España para reflejar los datos de 2010, aunque como es inevitable ya hay datos desfasados en el propio vídeo, como...
La Wikipedia cumple hoy diez años. ¡Felicidades a todos!...
El que el Congreso rechazara aprobar la Ley Sinde antes de las vacaciones de navidad fue todo un regalo de reyes anticipado. Pero con la vuelta de la actividad política podríamos ver cómo la resucitan en el Senado y nuestros representantes...
Google ha calculado que hay unos 5 millones de terabyes de datos en Internet, de los cuales sólo ha indexado un 0,04 por ciento. Se podría meter toda Internet en unos 200 millones de discos Blu-Ray. 18 Fun Interesting Facts You Never...
Este artículo se publicó originalmente en Cooking Ideas, un blog de Vodafone donde colaboramos semanalmente con el objetivo de crear historias que «alimenten la mente de ideas». El otro día charlé por correo con un lector sobre un tema pseudocientífico, al...
Desde hace unas horas está disponible en la App Store (iTunes) la revista digital iMAG Magazine para tablets. Inicialmente está disponible para iPad. Se trata de la primera revista nativa digital de este tipo en español. Trata temas de estilo de vida,...
Por Nacho Palou -
23 DIC 2010
A pesar de que a menudo se intenta presentar, de forma interesada, el asunto de las descargas a través de Internet como la defensa a ultranza de la gratuidad absoluta de todos los contenidos frente al derecho de sus autores de cobrar...
David Bravo hace esta Síntesis de la Ley Sinde: La industria del copyright movió un dedo y se enviaron cartas advirtiendo de acciones legales. Cuando las cartas se ignoraron, la industria movió un dedo y se interpusieron las acciones judiciales. Cuando los...
Si nadie lo evita, el gobierno conseguirá que mañana la Ley Sinde pase por el Congreso sin modificaciones y sin debate, sólo con un breve trámite en su Comisión de Economía. Es esa ley que con la excusa de defender los derechos...
Las menciones al Telex, el fax y el correo electrónico en millones y millones de libros entre 1970 y 2008, cortesía de Ngram Viewer, una nueva herramienta de Google que utiliza los datos en bruto en las publicaciones para proporcionar gráficos...
Wikipedia 10K Redux es un trabajo de arqueología digital de Joseph Reagle, que ha sido capaz de reconstruir las primeras 10.000 ediciones de la Wikipedia. En su blog explica un poco cómo hizo la reconstrucción y en qué consistieron esas ediciones. Entre...
Al parecer nuestros temores sobre el cierre de Delicious eran un tanto exagerados, ya que según cuenta What’s Next for Delicious?, la única entrada que hay ahora mismo en su blog, Yahoo! no va a cerrar el servicio sino que planea venderlo....
Justo acaban de cumplirse cinco años de la compra por parte de Yahoo! del servicio para guardar y compartir marcadores del.icio.us cuando, tras la ronda de despidos de ayer, se confirma que Yahoo! va a cerrar del.icio.us, entre otros de sus productos,...
Tal y como se puede leer en El Congreso aprobará de forma exprés la «Ley Sinde» la intención del ejecutivo español es tramitar la Ley de Economía Sostenible en una reunión de la Comisión de Economía el próximo martes. Esta Comisión está...
Visualizing Friendships de Paul Butler El gráfico de arriba, Visualizing Friendships de Paul Butler, responde a su curiosidad por saber “cómo la geografía y las fronteras influyen en la relación entre personas”. Quería lograr una imagen que “revelase qué ciudades del mundo...
Por Nacho Palou -
14 DIC 2010
Vale, en realidad no estaba hablando de Internet porque el término todavía no se había popularizado, y de hecho la Web todavía no existía como tal cuando se grabó esta entrevista para «El Mundo de las Ideas» de Bill Moyers, pero...
Este artículo se publicó originalmente en Cooking Ideas, un blog de Vodafone donde colaboramos semanalmente. Google como aplicación móvil integra funciones no disponibles de momento en la versión web (detrás): búsqueda por imagen (Goggles) y la búsqueda por voz que ahorra teclear...
Por Nacho Palou -
10 DIC 2010
Operating System Market Share / NetMarketShare Me ha sorprendido leer que el iPad generará más del 2% del tráfico web en 2011, en EE UU. Aunque parezca poco un 2% es una barbaridad del tráfico porque Windows ocupa casi el 91%, de...
Por Nacho Palou -
9 DIC 2010
El recorrido de Spirit si hubiera partido de la Puerta del Sol en Madrid BBC Dimensions es un curioso sitio en el que puedes comparar el tamaño de ciertos lugares, eventos y cosas con la zona en la que vives. Para ello...
Un genial artículo de Víctor R. Ruiz acerca de lo que ha sucedido en torno al #manifiesto contra la Ley Sinde ahora que se acaba de cumplir un año de su aparición: Primer aniversario del #manifiesto (+ #cablegate) Y resulta que además,...
Esto de los aniversarios nunca es una ciencia exacta -respecto a quién, ni a cuándo, ni a dónde-, pero en cualquier caso me pareció simpática esta rememoración de los primeros pasos en el uso del correo electrónico en España: El hombre que...
Por Nacho Palou -
2 DIC 2010
Symbian (Nokia en su mayor parte) es el sistema operativo móvil más utilizado en el mundo, pero su popularidad no se reparte por igual: triunfa en África, Asia y América del Sur, mientras que apenas existe en América del Norte y...
Por Nacho Palou -
1 DIC 2010
Con toda la que está cayendo últimamente con el tema de la neutralidad de la red, es una magnífica noticia que se ponga en marcha Red Neutral, con la idea de convertirse en una página donde se recopila información acerca de la...
Los ciudadanos y las empresas usuarias de Internet adheridas a este texto manifestamos: Que Internet es una Red Neutral por diseño, desde su creación hasta su actual implementación, en la que la información fluye de manera libre, sin discriminación alguna en función...
Mañana, según prometieron en su momento los partidos que votaron en contra de la moción a favor de la neutralidad de la red que había sido presentada por el Partido Popular, este tema debería volver al Senado. Habrá qué ver qué tipo...
Confieso que no había oído hablar de Alejandro Piscitelli hasta que lo vi en el programa de EBE10 como responsable de la conferencia de clausura del evento, aunque automáticamente lo di por bueno si los organizadores lo habían invitado. Pero me dejó...
La semana pasada Apple presentó su nuevo Apple TV (119 euros) y comenzó a ofrecer películas en alquiler y venta a través de iTunes, lo que es parte esencial del nuevo Apple TV. El nuevo Apple TV poco tiene que ver...
Por Nacho Palou -
19 NOV 2010
Como era previsible, la moción a favor de la neutralidad de la red que había sido presentada por el Partido Popular ha sido rechazada por los 121 votos en contra de todos los grupos parlamentarios salvo el de este, que emitió los...
Dos senadores del PP por Castilla y León defienden esta semana en el Senado una moción que insta al gobierno a modificar la normativa española en materia de Sociedad de la Información de tal forma que se garantice el cumplimiento del principio...
La semana pasada Google sorprendió a todo el mundo -a sus empleados los primeros- con una paga extra de 1.000 dólares para cada una de las personas a las que tiene en nómina, más un 10% de incremento salarial. Durante la conferencia...
Por Nacho Palou -
16 NOV 2010
Mañana martes comienza la cuarta edición de FICOD, el Foro Internacional de Contenidos Digitales impulsado por el Ministerio de Industria, Turismo y Comercio y por la Secretaría de Estado de Telecomunicaciones a través de la entidad Red.es. La inscripción en FICOD...
Por Nacho Palou -
15 NOV 2010
Aunque arriesgada, la apuesta de la Xunta de Galicia por Conexións, un programa de divulgación sobre los últimos avances en el conocimiento, la tecnología, la investigación y la innovación en Galicia cuya primera temporada se comenzó a emitir el pasado mes de...
mapmyfollowers te permite ver sobre un mapa de dónde son tus followers, aunque si tienes muchos el límite máximo que muestra son 1.000, pero puedes escoger qué 1.000 quieres ver. De paso también te enseña una nube con las palabras más...
Harto de soportar capullos, Adam de Lifehacker preparó su respuesta estándar y la añadió a la colección de «textos expandidos» (los «macros», de toda la vida, vamos) que tiene instalados en el ordenador, de modo que cuando teclea ,capullo en cualquier mensaje...
Feedly nació como una especie de «Flipboard pero para Firefox», aunque con el tiempo ha acabado siendo un servicio web de pleno derecho, una gran alterantiva al mismísimo Google Reader. También existe como app para dispositivos móviles. Permite añadir feeds (acepta...
Los usuarios «de a pie» de foursquare vamos a tener cuando menos complicado poder conseguir la insignia de NASA Explorer con la que se ha hecho hoy Douglas Wheelock al hacer check-in allí arriba: One small step for man, one giant check-in...
Los legos en la materia nos despertamos ayer con la alegría de los primeros titulares que aseguraban que el tribunal de Justicia de la Unión Europea había declarado ilegal el canon digital que se aplica en España a dispositivos electrónicos y soportes...
El cachondeo y desconcierto con el tema de las direcciones IPv4 que se iban a agotar pero que nunca se agotaban ha dado un giro inesperado. Esta pesadilla lleva años atormentando a los administradores de redes en sus peores sueños y ahora...
Lo estábamos esperando desde mayo de este año, cuando Verica Trstenjak, Abogado General de la Unión Europea, emitió una opinión que decía literalmente que «el canon por copia privada sólo puede gravar los equipos, aparatos y materiales de reproducción digital que presumiblemente...
13ª Encuesta Navegantes en la Red por Navegantes en la Red en Vimeo. Desde hoy está en marcha la 13ª encuesta AIMC a usuarios de Internet, una encuesta sin carácter comercial que se realiza con el único objetivo de seguir profundizando en...
Alertan de que el sistema actual de direcciones IP de Internet se agotará en 2012 (El Mundo, 2010) Las direcciones IPv4 se agotarán a comienzos de 2011 (ALT1040, 2010) Las direcciones IPv4 de Internet se agotarán en 2010 (Eliax.com, 2007) ICANN prevé...
Actualización (2016) – WizardRSS murió pero el Full-Text RSS 3.6 de FiveFilters realiza el mismo trabajo. Desde el departamento de cómo-no-habían-inventado-esto-antes llega WizardRSS, un servicio minimalista que lo único que hace es crear un feed RSS «completo» para aquellos sitios que tienen...
La gente de Creative Commons ha lanzado esta propuesta de símbolo para el Dominio Público que permitirá a todo el mundo identificar rápida y fácilmente obras de todo tipo que estén libres de copyright porque sus autores así lo hayan decidido...
ZumoCast habilita la emisión en streaming de los contenidos multimedia -vídeos, películas y música- almacenados en el ordenador para poder acceder a ellos -sin necesidad de descargarlos- desde cualquier otro ordenador vía web, dispositivos con navegador web o desde dispositivos iOS...
Por Nacho Palou -
11 OCT 2010
Online Communities 2 por Randall Munroe Me encanta esta actualización del mapa de las comunidades en línea de XKCD, con un montón de detalles hilarantes -hay que verlo en grande para apreciarlo al cien por cien- como por ejemplo el Desierto de...
La web de Facebook sirve 690.000 millones de páginas a sus visitantes cada mes, lo que supone el 9,5 por ciento del tráfico de Internet mundial, un poco más que el de Google, según algunas fuentes. Cuenta con al menos seis gigantescos...
Llevábamos meses esperando a que Benito, José Luis y Luis dieran el pistoletazo de salida definitivo para EBE10 con la apertura del proceso de preinscripción, lo que por fin ocurrirá esta mañana a las 10 (hora de España, UTC +1). Este año...
Ante la inminente puesta en práctica en Francia de la Ley de los tres avisos dentro de unos días, las «multinacionales del copyright» ya afilan sus cuchillos: están enviando más de 10.000 denuncias diarias a los ISP y a las autoridades para...
No me había fijado hasta ahora que cuando dejas de seguir a alguien en Twitter el nombre de la página con la que se lleva a cabo esa acción se llama twitter.com/friendship/destroy. ¡Tan explícito como cruel!...
Pues bastante reales, la verdad sea dicha, Desde hace algo más de un año en casa tengo la conexión de fibra de 50Mb/3Mb (bajada/subida) de ONO que actualmente la operadora publicita como "velocidad real". Precisamente ese fue el argumento con el que...
Por Nacho Palou -
24 SEP 2010
Alguien con tiempo libre se entretuvo en crear Inframutt, un buscador que es como Google pero al revés: proporciona los resultados menos relevantes para cada búsqueda que se hace. Esto tampoco es una ciencia exacta, y alguna vez lo he visto...
De muy poco han servido las protestas contra la llamada Ley Sinde, que camuflada dentro de la Ley de Economía Sostenible busca sustraer al poder judicial la potestad de cerrar sitios web y dejarla en manos de una comisión cuyos miembros están...
Así, el capítulo de la captura de datos «por error» de las redes Wi-Fi abiertas que se iban encontrando los coches de Google Street View va a acabar en España sin que la fiscalía actúe contra la empresa. La Fiscalía de Guipúzcoa,...
Un vídeo que comienza con un tal Barack Obama diciendo que Internet es quizá la red más abierta de la historia y que deberíamos conservarla así: Y aunque la referencia a la censura que aparece en él pueda parecer un poco fuerte,...
"El riesgo de tener un PowerBook se evita con una pegatina de Dell."Technology Protection, de Tobias Lunchbreath. Home Security Innovations for Modern Living (Medidas de seguridad caseras para la vida moderna) en Core77 es una divertida tira cómica con sugerencias asequibles para...
Por Nacho Palou -
20 SEP 2010
Transformers de repey815 en Vimeo. Más corta, más barata, menos aburrida y sin rastro de Megan Fox, este corto de Transformes es mucho mejor que el largometraje de Michael Bay y su secuela juntas. Está supuestamente grabado con cámaras réflex baratas con...
Por Nacho Palou -
20 SEP 2010
Este martes 21 de septiembre de 2010, se acaba el plazo para que los grupos parlamentarios puedan aportar sus enmiendas a Ley de Economía sostenible y, con ella, la Disposición Final Segunda (anteriormente Disposición Final Primera) o "Ley Sinde" que ataca los...
En Seemyfun publicaron algunos experimentos interneteros sobre nombres de dominios. En uno de ellos se comprobó que aunque –como era predecible– todos los dominios .com de cuatro letras (A-Z) están ya registrados hace tiempo, más del 80% de los dominios de tres...
Este gráfico representa los colores dominantes en los cien sitios más populares de la web, compilado por COLURlovers, donde querían ver si hay algún color dominante entre ellos o bien si los mismos tipos de sitios compartían esquemas de color: The Most...
Guillermo Álvarez nos hizo llegar un enlace a gNewsInstant.com, un proyecto que acaba de la lanzar en la línea de la fiebre de lo instantáneo inaugurada por Google Instant. El sistema es una caja que busca y filtra los contenidos de...
Tras haber dominado el mercado de los navegadores web durante años, después de haber conseguido sacar de ese mismo puesto al otrora poderosísimo Netscape, Microsoft ha tenido que ver en los últimos años como poco a poco la cuota de mercado de...
Según Cisco, a lo largo de este año el 40 por ciento del tráfico mundial en Internet será consumido en la visualización y descargas de vídeo. En 2014 "la suma de todas las formas de vídeo (TV, VoD, video por Internet y...
Por Nacho Palou -
15 SEP 2010
Greg’s Cable Map es un curiosísimo e informativo mapa de los cables submarinos de comunicaciones que unen unos países con otros. A diferencia de otros mapas submarinos estáticos que también son preciosos y hemos comentado alguna vez por aquí, éste es...
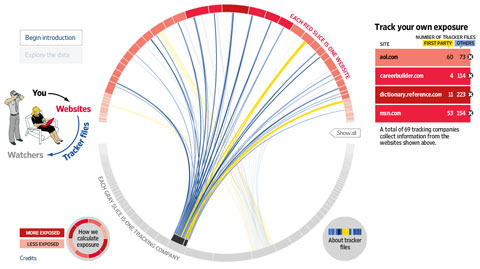
What They Know es un interesante trabajo interactivo del Wall Street Journal: reune en una sola página toda la información que los numerati de Internet recopilan sobre ti cuando navegas por la web, por usar el término de Stephen Baker para...
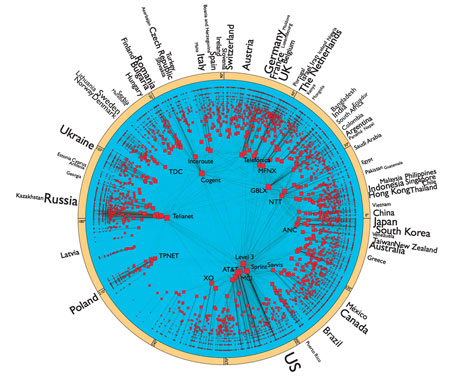
En este plano hiperbólico de Internet que han creado investigadores de la Universidad de Barcelona los cuadraditos rojos son los sistemas autónomos de las grandes empresas y telecos; las líneas son sus conexiones –repestando las distancias físicas reales que hay entre...
Google Genie es lo más parecido que encontrarás a una sala de teletransporte: un botón de salto entre puntos aleatorios de Google Street Views en los continentes que marques en el menú. Es como la Página aleatoria de la Wikipedia o...
CodeOrgan es una simpática web que convierte cualquier página web en música. En el «análisis de la web» básicamente se utiliza el código HTML de la página: se extraen todas las letras entre la A y la F, que se corresponden...
Lenta. Confusa. Vacía. Incómoda. Difícil de usar. Aislada. Llena de Spam. Y parece más una tienda que una reunión de amigos. Eso es lo que opino de Ping, la red social que presentó Apple como parte de iTunes 10: Decepcionante....
The Web 2.0 Summit Points of Control Map es un precioso interactivo sobre la Web 2.0 y las diversas categorías de servicios que ofrece hoy en día Internet en diversas áreas. Aparecen muchas empresas y servicios categorizados en un mapa a...
◣◤◢◥◣◤◢◥◣◤◢◥◣◤◢◥ ◤◢◥◣◤◢◥◣◤◢◥◣◤◢◥◣ ◣◤◢◥◣◤◢◥◣◤◢◥◣◤◢◥ ◤◢◥◣◤◢◥◣◤◢◥◣◤◢◥◣ ◣◤◢◥◣◤◢◥◣◤◢◥◣◤◢◥ ◤◢◥◣◤◢◥◣◤◢◥◣◤◢◥◣ Originales patrones e imágenes Unicode para Twitter, recopiladas apropiadamente en @l_I__I_l, la cuenta de LIIL. (¡Gracias, David!)...
Ikimap es un potente pero sencillo servicio para la creación de mapas personalizados a partir de cartografías ya existentes, con el objetivo de compartirlos con los demás o embeberlos en otras páginas web, como se hace con los vídeos de YouTube....
Icons of the Web es un increíble trabajo de recopilación de cientos de miles de iconos correspondientes al primer millón de sitios web según el ránking de Alexa, que para medir audiencias igual no es gran cosa pero para este tipo...
Read It Later es una altamente recomendable aplicación que existe en versión gratuita pero bien vale los pocos euros que cuesta la versión de pago. Es el santo grial del procrastinador: un sistema automatizado para marcar páginas para «leer leer luego»,...
Hay una fina línea que separa la ciencia de la paja mental. Las pseudociencias pretenden usar y estar cerca de la ciencia para parecer «serias»; a veces la ciencia parece más bien ciencia-ficción y en general suele ser muy entretido leer...
Hace unos días escribía para La Voz de Galicia en forma general acerca de los problemas legales que puede suponer para Google haber almacenado datos obtenidos de redes Wi-Fi abiertas aunque fuera supuestamente sin mala intención y con la idea de elaborar...
Bueno, al menos todos los títulos del catálogo de Libranda, la plataforma de distribución de libros electrónicos de las principales editoriales españolas, que son compatibles con mi lector de libros electrónicos… Que en estos momentos, y por todo lo que se, se...
Sobre el papel el Anti-Counterfeiting Trade Agreement, o Tratado de Negocios Anti Falsificaciones, que está siendo negociado entre los Estados Unidos y Australia, Canadá, Corea del Sur, Japón, Marruecos, México, Nueva Zelanda, Singapur, la Unión Europea, y algún país más, tiene como...
Independientemente de que los motivos que llevaron a Google a almacenar información recogida de redes wifi abiertas por los coches que recorren el mundo tomando las imágenes para su servicio Street View - en el que se pueden ver fotos a pie...
Una selección de vídeos en YouTube con resolución 4K (4096 × 2304 píxeles o 2304p), la resolución más alta disponible en vídeo y la perfecta si tienes una pantalla de unas 300 pulgadas. Esa resolución sólo se muestra en el reproductor de...
Por Nacho Palou -
12 JUL 2010
La movilización ciudadana para pedir a los eurodiputados que firmaran una declaración escrita contra los peores aspectos del tratado ACTA ha tenido tal éxito que el presidente del Parlamento Europeo se ha visto obligado a ampliar el plazo hasta el próximo 9...
El Anti-Counterfeiting Trade Agreement, o Tratado de Negocios Anti Falsificaciones, que está siendo negociado desde 2008 entre los Estados Unidos y Australia, Canadá, Corea del Sur, Japón, Marruecos, México, Nueva Zelanda, Singapur, la Unión Europea, y algún país más, tiene como...
Hace unos días Jorge Casanova, de La Voz de Galicia, se pasó por casa para hablar durante un buen rato conmigo y con mi familia acerca del uso que hacemos de Internet y las nuevas tecnologías. Hizo lo mismo con los Pérez...

Nuestro admirado proyecto, que recopila todo el saber de la humanidad, en el que lo más popular es Harry Potter y en el que la biografía de Darth Vader es más larga que la de George Washington nos alumbra con nuevas dosis...
Esta semana, de jueves 1 de julio a sábado 3, se celebra en el Hotel Silken Ciudad de Gijón el ESET Foro Internet Meeting Point 2010. Es la tercera edición, o más bien el descendiente, de aquel modesto pero muy interesante BlogAsturias...
Con la instalación del iOS 4 en los iPhone y iPod Touch se activa por defecto -porque el usuario lo acepta en los términos del nuevo sistema operativo- la opción que permite a Apple obtener información personal y sobre la posición...
Por Nacho Palou -
23 JUN 2010
Ver infografía completa. How The World Spends Its Time Online, una bonita infografía de VisualEconomics con datos de Nielsen sobre a qué dedican el tiempo los usuarios cuando acceden a Internet. En España casi el 80% de los usuarios acceden a redes...
Por Nacho Palou -
22 JUN 2010
Si no te gustó el «Me gusta» de Facebook en el MundoReal™ siempre puedes aprovechar para hacerte con el sello de caucho No me gusta y estrenarlo....
Por Nacho Palou -
22 JUN 2010
Sello de caucho “Me gusta” a lo Facebook, vía The Raw Feed....
Por Nacho Palou -
14 JUN 2010
No soy un gran usuario de Facebook, con lo que no he tenido que sufrir todas las cosas que se mencionan en este vídeo de Cenicero Total, pero suscribo y comprendo gran parte de lo que dicen... En especial la número 1,...
Por fin después de tantas espera los usuarios espñoles de Android podemos acceder a las funciones de Google Maps Navigation (navegador GPS) y de búsquedas y dictado por voz, tanto para realizar búsquedas dictando palabras o frases como para redactar emails o...
Por Nacho Palou -
9 JUN 2010
La cruzada contra Flash no es sólo cosa de Steve Jobs, aunque sea éste quien más abierta y claramente lo ha expresado, En realidad a Google tampoco le gusta Flash. Un sitio hecho sólo con Flash está muerto a efectos de SEO...
Por Nacho Palou -
5 JUN 2010
Viejuno pero curioso e interesante: si se ponen dos latas de Coca-Cola –una normal y otra light– en un recipiente con agua, la primera se hundirá como una piedra, mientras que la segunda flotará, El azúcar es mucho más denso que...
Por Nacho Palou -
31 MAY 2010
Hoy se ha prolongado el plazo para que los grupos parlamentarios puedan aportar sus enmiendas a Ley de Economía sostenible y, con ella, la Disposición Final Segunda (anteriormente Disposición Final Primera) que ataca los derechos fundamentales en Internet en favor de lobbies...
A muchos Usenet os sonará a chino, pero para los que llevamos unos años en Internet representa algo así como el antepasado de foros y grupos de discusión como los grupos de Google, a través de los que de hecho se puede...
La EFF (Eletronic Frontier Foundation), la entidad sin ánimo de lucro con más reputación en Internet en lo relativo a la defensa de los derechos de los internautas, ha publicado los resultados de un estudio titulado ¿Cuán único es realmente tu navegador...
La web andro.tv da acceso al streaming de la emisión de algunos canales de televisión (CCN+, Cuatro y Telecinco, entre otras). La calidad es bastante razonable, aunque en ocasiones puede interrumpirse la señal. § and.roid.es Vodafone Live TV!, plataforma de televisión...
Por Nacho Palou -
19 MAY 2010
IS Parade es la típica tontería con la que puedes perder un buen rato, en este caso mirando embobado como tus seguidores en Twitter -o los de cualquier otro usuario- desfilan por tu monitor representados por muñequitos que van tocando instrumentos,...
Hoy descubrí este término en alemán, que significa algo así como «máximo accidente creíble» o «peor escenario posible». En coloquial debe ser «gran metedura de pata», «pa’ habernos matao», «gran cagada» o similar. Como por ejemplo en Debido a un error de...
Después de ver la intro de los dibujos animados de Spiderman de 1967, Anthony Calzadilla pensó que podría hacer una animación igual de básica utilizando sólo CSS3, JavaScript y HTML5. Dicho y hecho. Explica cómo en Pure CSS3 Spiderman Cartoon w/...
Por Nacho Palou -
6 MAY 2010
¡Advertencia! Ponte las gafas de sol antes de probar esto para evitar daños oculares. Geocitiesizer es toda una joya para los arqueólogos web: convierte cualquier página web de las actuales al viejuno estilo de las primeras web de Geocities en los...
El caos generalizado causado por el cierre casi completo del espacio aéreo europeo a causa de las cenizas procedentes del volcán Eyjafjalla ha puesto a prueba la capacidad de gobiernos, aerolíneas, y sistemas de gestión de control del espacio aéreo. Algunos de...
Después de dos años y medio de negociaciones secretas, hoy se ha hecho público el borrador del texto que es estos momentos se maneja para el tratado ACTA. Sobre el papel el Anti-Counterfeiting Trade Agreement, o Tratado de Negocios Anti Falsificaciones, que...
Cap·Man, Akihabara Akihabara, HTML5 is my Arcade now es un conjunto de librerías, herramientas y rutinas diseñadas para desarrollar con JavaScript y algo de HTML5 juegos pixelados, propios de la era de los 8 y 16 bit. No tiene nada que ver...
Por Nacho Palou -
21 ABR 2010
Clic en la imagen para ampliar Para lo poco que se puede escribir en un tweet, 140 caracteres, es sorprendente la cantidad de información «oculta» que viaja con cada uno de ellos, como se puede ver en la ilustración Map of a...
Ver vídeo: Uso de las redes sociales en España y resto del mundoUso de las redes sociales en España y resto del mundo [~4 min.] Un interesante vídeo sobre el tema elaborado por cientouno. Las fuentes de los datos -fundamentales- están al...
Sin sorpresas en la respuesta, Gráfico: SixRevisions. Los resultados obtenidos en las mediciones de SixRevisions sobre el rendimiento de los principales navegadores web evidencia que hay dos tipos de navegadores web: Internet Explorer y todos los demás. A cuento: Cómo se ve...
Por Nacho Palou -
8 ABR 2010
Con el objetivo de abrir las mentes de los ministros de Telecomunicaciones y Sociedad de la Información de la Unión Europea, que se reunen en el marco de la Presidencia Española de la Unión Europea del 18 al 20 de abril,...
…y te diré quien eres, al menos según Twitter Job Description by Date Joined por Damian Damjanovski. A mi me pilla un poco por delante de los fururistas/innovadores. (Vía, de forma totalmente apropiada, un RT de @amartino de un tweet de...
La función de los adaptadores Powerline AV 200 de Netgear es convertir la instalación eléctrica de la vivienda en una red local de datos para disponer de conexión a Internet en cualquier enchufe. De este modo se utilizan los enchufes eléctricos...
Por Nacho Palou -
29 MAR 2010
Después de ver Safari dentro de Safari Sebastián (¡gracias!) nos envió un enlace con un truco para abrir el navegador Firefox dentro del navegador Firefox. En este caso no tiene el encanto de la dificultad de dibujar la interfaz completa de...
Por Nacho Palou -
22 MAR 2010
Todo parece indicar que el Consejo de Ministros aprobará hoy viernes en Sevilla, en pleno puente de San José, como quien no quiere la cosa, ese engendro llamado «Ley de Economía Sostenible», que incluye la conocida como «Ley Sinde», que permitirá el...
Todo un ejemplo de autorreferencia, Un buen navegador debería ser capaz de interpretarse a sí mismo. La versión del navegador Safari que aparece dentro de mi navegador Safari es una versión desarrollada por completo con HTML y CSS3. Sólo funciona en navegadores...
Por Nacho Palou -
18 MAR 2010

Aunque cada vez somos más las personas que utilizamos Internet a diario, este vídeo de IBM habla de lo que puede representar para nosotros y el planeta que cada vez haya más cosas de todo tipo como sensores de temperatura, de...
Según Daniel Ek, CEO de la empresa sueca Spotify, Algunos días Spotify consume más ancho de banda de Internet que toda la capacidad que tiene Suecia como país Afortunadamente Spotify funciona por P2P –intercambiando paquetes de datos entre ordenadores de usuarios particulares...
Por Nacho Palou -
16 MAR 2010
Numerosos abogados llevan años diciéndolo, y muchos sin tener ni idea de leyes no entendíamos que se pudiera pensar otra cosa. Tampoco es ni con mucho la primera en este sentido, pero la sentencia [PDF 262 KB] en la que D. Raúl...
Varios países, entre ellos los miembros de la Unión Europea, llevan desde 2008 negociando el tratado ACTA, o Anti-Counterfeiting Trade Agreement, a instancias de los Estados Unidos. Este tratado, al menos en teoría, tiene como objetivo el luchar contra la fabricación, tráfico,...
Hace unos días fue noticia el caso de un matrimonio surcoreano arrestado por la policía de su país tras permanecer varios meses huido después de que su hija de tres meses muriera de inanición. Al parecer, apenas la cuidaban y solo le...
Mediante un acuerdo entre la editorial de Popular Science y Google los 137 años del archivo de la revista, convenientemente pasados por un sistema de reconocimiento óptico de caracteres, están disponibles en línea: Una de las múltiples apariciones de Nikola Tesla en...
What do you suggest? por Simon Elvery es un fascinante experimento que a partir de una término de búsqueda que le des o de uno que escoja al azar te va mostrando con qué otras palabras lo han ido asociando otros...
Un interesante vídeo elaborado por Jesse Thomas con algunos de los asombrosos números de la Internet actual: JESS3 / The State of The Internet por Jesse Thomas en Vimeo. Ojo, de todos modos, que los billones que salen en el vídeo son...
La infografía Google facts and figures recoge algunos de los datos y cifras más relevantes relacionadas con Google: cronología, tráfico y cifras las búsquedas, empleados, dinero......
Por Nacho Palou -
1 MAR 2010
Esta semana ha causado sorpresa la sentencia de un juez italiano que condenaba a seis meses de cárcel a tres ejecutivos de Google por la publicación en YouTube de un vídeo en el que alumnos de un centro educativo de Turín sometían...
Según un análisis de 2,8 millones de tweets [que pueden ser pocos teniendo en cuenta que se envían casi 50 millones cada día] sólo la mitad están en inglés. Los cinco idiomas más utilizado son –después del inglés–, japonés, portugués, malayo y...
Por Nacho Palou -
25 FEB 2010
El Anti-Counterfeiting Trade Agreement, o Tratado de Negocios Anti Falsificaciones, que está siendo negociado desde 2008 entre los Estados Unidos y Australia, Canadá, Corea del Sur, Japón, Marruecos, México, Nueva Zelanda, Singapur, la Unión Europea, y algún país más, tiene como objetivo...
La próxima vez que veas la ballena de Twitter –o que la API te devuelva un error–, acuérdate de esto: De media, en 2007 se generaban 5.000 tweets al día; en 2008 ya eran 300.000 y en 2009 creció hasta los 2,5...
Por Nacho Palou -
22 FEB 2010
Visualizador de cómo funciona el protocolo BitTorrent para el intercambio de archivos por P2P. Probablemente es un poco viejuno y probablemente cómo funciona el P2P es algo conocido por muchos, pero el visualizador tiene cierto efecto hipnótico y es preciso en...
Por Nacho Palou -
22 FEB 2010
He aquí un sencillo vídeo de los chicos de ADNstream para explicar, una vez más, la importancia de la neutralidad de la red: Es especialmente relevante ahora que Miguel Sebastián parece dispuesto a convertirse en el ministro de Telefónica en lugar...
El que Facebook aumente la edad mínima para abrir una cuenta hasta los 14 años no va a servir para evitar que menores que no los tengan las sigan abriendo, igual que no lo ha evitado en otras redes sociales, así que...
Para muchos usuarios Google -el buscador- es sinónimo de Internet y les sorprende descubrir que en realidad es solo un servicio que a su vez funciona sobre solo una parte de la web, pues existen sitios como Tuenti que, en este caso...
Please Rob Me es un curioso servicio que evidencia en clave de humor uno de los riesgos que supone hacer eso que está tan de moda en Internet: informar pública y continuamente dónde estamos tomado café. Es habitual ver pasar esos...
Por Nacho Palou -
18 FEB 2010
El que Sebastián no vea mal la posibilidad -lanzada hace unos días por el presidente de Telefónica, César Alierta- de cobrar a los buscadores por el uso que hacen de las redes de la operadora pone de manifiesto lo poco que le...
Vodafone ofrece con el netbook Samsung N130 una solución completa de conectividad móvil: ofrece el pequeño portátil desde 19 euros vinculado a una conexión 3G con permanencia de 24 meses, lo que hace que el precio total sea de 955 euros;...
Por Nacho Palou -
10 FEB 2010
Vale, las generalizaciones suelen ser injustas, pero visto lo visto, esta Carta de adhesiones políticas a la libertad en Internet se aproxima mucho a la realidad. Demasiado de hecho para lo que sería de desear. (Vía El Incordio)....
La aplicación online Sketchpad es similar a otras aplicaciones de dibujo existentes que funcionan directamente en el navegador web. La diferencia de Sketchpad es que está completamente desarrollada en el lenguaje HTML5 y no recurre a tecnologías como Flash, que requieren...
Por Nacho Palou -
8 FEB 2010
ISS desde la ISS, foto de @Astro_Jose Imágenes como la de arriba se pueden ver pasar por Twitter enviadas directamente por los usuarios este servicio @Astro_Jose y @Astro_Soichi, que han formado o forman parte de la tripulación de la Estación Espacial Internacional....
Por Nacho Palou -
5 FEB 2010
Vodafone 360 es un servicio de la operadora Vodafone que unifica los contactos personales y las redes sociales a través del teléfono móvil y del ordenador. De este modo desde el teléfono se puede conocer el estado de, por ejemplo, los contactos...
Por Nacho Palou -
1 FEB 2010
Cuando el gobierno presentó el texto de la Ley de Economía Sostenible que iba a remitir a los correspondientes órganos consultivos para luego someterlo a trámite en las Cortes una de las cosas que aseguró Francisco Caamaño, el ministro de justicia, fue...
Aunque los tripulantes de la ISS disponían ya de acceso a correo electrónico, telefonía sobre IP, y videoconferencias con algunas limitaciones, hasta ahora no tenían acceso a la web. Pero desde esta misma semana, gracias a una actualización de software recién instalada...
El curso iPhone Application Development de la Universidad de Stanford está disponible gratuitamente en forma de vídeos y presentaciones en iTunes (enlace iTunes). El curso dura en total 10 semanas y cubre todos los aspectos de programación con el iPhone SDK (para...
Por Nacho Palou -
21 ENE 2010
Bill no sólo es listo, sabio, amable y bueno, sino que ahora cualquiera puede cumplir su sueño de pedirle que sea su «amigo» aunque sea al estilo follower, en Twitter: @BillGates. Se estrenó con el Hello World! de rigor. Y no...
La Comisión Nacional de la Competencia, adscrita al Ministerio de Economía, hacía ayer público un informe sobre las entidades de gestión de derechos de autor (AGEDI, AIE, AISGE, CEDRO, DAMA, EGEDA, SGAE y VEGAP) que las deja realmente mal paradas, y no...
Tal y como estaba previsto finalmente se hizo público el texto de la Ley de Economía Sostenible aprobado por el consejo de ministros, texto que incluye una disposición final primera diseñada para luchar contra las descargas no autorizadas de contenidos con derechos...
La aplicación Kindle for iPhone (o iPod Touch) de Amazon permite leer los libros electrónicos en formato para el lector Kindle sin necesidad de disponer de uno. Esta aplicación ha sido de momento lo más interesante que he visto respecto a los...
Por Nacho Palou -
18 ENE 2010
Allan Ellis, fundador de Oink.cd, absuelto de la acusación de compartir música ilegalmente en Internet. El popular tracker de torrents llegó a tener 200.000 usuarios registrados y a facilitar 21 millones de descargas P2P. El sitio fue cerrado por la policía en...
Además de la base WiFi para módems 3G USB, Vodafone comercializa un MiFi modelo 2352 que también hemos tenido ocasión de probar y que amplía las opciones entre las que pueden elegir sus clientes de acceso 3G. El MiFi 2352 se...
Por Nacho Palou -
15 ENE 2010
Consideramos imprescindible la retirada de la disposición final primera de la Ley de Economía Sostenible por los siguientes motivos: Viola los derechos constitucionales en los que se ha de basar un estado democrático en especial la presunción de inocencia, libertad de expresión,...
Después de todo lo que se ha escrito desde que se conoció la Disposición Final Primera de Ley de Economía Sostenible y el más que temible efecto que podría tener sobre las libertades básicas en Internet estaba escribiendo algo similar a esto...
Aunque no es nada común, había un gran interés entre la comunidad de usuarios de Internet por el Consejo de Ministros de ayer, ya que estaba previsto que de él saliera el texto definitivo de la Ley de Economía Sostenible (LES). Este...
Desde el principio de los tiempos Vodafone ha apostado fuertemente –probablemente más ninguna otra operadora– por el acceso a Internet a través de conexión 3G, tanto desde el móvil como desde el ordenador. Actualmente cuenta con una amplia oferta de productos...
Por Nacho Palou -
8 ENE 2010
De nuevo estamos hablando de información publicada en un artículo de El País en lugar de información oficial, pero según se puede leer en Las 'webs' de descargas se podrán cerrar en un mes con orden judicial el gobierno estaría dispuesto a...
geek,+--nerds vs nerds,+--geek(los -- eliminan un término de la búsqueda en el Tagmash de LibraryThing:) Hay una explicación mucho más detallada en Geek y nerd, una de las primeras anotaciones que publicamos en Microsiervos allá por julio de 2003. El diagrama de...
Issuu.com, el servicio online que permite la publicación de medios digitales, ha lanzado una versión aún beta para acceder a los contenidos a través del teléfono móvil. Inicialmente disponible para la plataforma Android, en breve habrá también una aplicación para el...
Por Nacho Palou -
22 DIC 2009
Desde hace una semana algunos usuarios están informando de que la velocidad de descarga desde los populares servicios de almacenamiento de archivos Megaupload y RapidShare ha descendido «drásticamente». Hay más detalles en el hilo de ADSL Zone Megaupload y Rapidshare son tortugas...
Este vídeo representa los accesos a 15 de los servidores de la web del new York Times el pasado 25 de junio, el día de la muerte de Michael Jackson: En amarillo se muestran los accesos a la web desde ordenadores,...
Una ingeniosa y efectiva forma de presentar imágenes con efecto 3D presentando varias imágenes con distinta perspectiva, pero utilizando sólo lenguaje CSS para hacer la transición: CSS 3D Meninas. Vía Manu Contreras, vía Juan Diego Polo. Mucho más elegante, natural y...
Por Nacho Palou -
16 DIC 2009
Podemos discutir el tema de los derechos de autor hasta la saciedad, y sin duda es un debate que hay que afrontar, en especial en la era de un mundo perfectamente copiable, pero creo que a algunos hay que explicarles antes...
360 es un servicio de Vodafone diseñado para unificar los contactos y las redes sociales en un único lugar accesible a través del teléfono móvil o del ordenador, mediante un servicio web que además sincroniza los contenidos del teléfono. Después de...
Por Nacho Palou -
15 DIC 2009
Gráfico interactivo con el histórico de popularidad de los navegadores web según datos estadísticos de W3.org desde enero de 2002, donde entre otras cosas se aprecia la continua pérdida de presencia de Internet Explorer, en cualquiera de sus versiones, y el...
Por Nacho Palou -
15 DIC 2009
Modelos de negocio: Cómo ganar dinero en un mundo perfectamente copiable (y su segunda parte) es probablemente uno de los mejores artículos de este año sobre el tema, por no decir de la década –a la altura diría del mítico Por favor,...
Esta mañana tuvimos una nueva reunión sobre el #manifiesto, esta vez con Estéban González Pons, Carlos Floriano y otros responsables del Partido Popular. En el grupo no sólo estábamos bloggers, también periodistas, creadores de contenidos en diversos campos, músicos aficionados, autores...
Esta mañana estuve junto a algunos colegas que apoyan el #manifiesto reunido con Gaspar Llamazares de Izquierda Unida. La reunión fue a invitación de su grupo parlamentario. Al igual que a la reunión con el Ministerio de Cultura acudimos cada cual a...
Después de estos cuatro días en los que casi todo el mundo ha estado de puente quizás convenga recordar que a pesar de toda la repercusión en medios que las movilizaciones contra la disposición final primera de la Ley de Economía Sostenible...
La inclusión de una disposición adicional primera en la Ley de Economía Sostenible presentada por el Gobierno de José Luis Zapatero el viernes de la semana pasada destinada a luchar contra las descargas a través de Internet de material sometido a derechos...
En La dirección de correo electrónico un primer filtro en la selección de personal se cuentan cosas interesantes de un estudio de Kevin Tamanini, un psicólogo especializado en recursos humanos. Su análisis tiene que ver con cómo la dirección de correo electrónico...
El rechazo frontal a la creación de un comité de expertos que podría decidir el cierre de una web sin que mediara decisión judicial alguna está por todas partes, pero aquí van algunos enlaces que he podido ver hoy y que me...
Bonito número han elegido para el servicio de DNS oficial de Google, ese que se pone en la configuración de red del equipo y que en las conexiones Internet convierte los xyz.com en números IP como 108.42.23.16. Técnicamente parece igual que los...
Ayer en Microsiervos publicamos como hicieron tantos sitios el Manifiesto en defensa de los derechos fundamentales en Internet, al que se sumaron miles de Internautas con una velocidad asombrosa, en un impresionante efecto que la verdad es que hacía mucho que no...
Cuando José Luis Rodríguez Zapatero anunció que iba a presentar una Ley de Economía Sostenible para ayudar a sacar el país de la crisis económica actual no creo que ningún usuario de Internet español se haya imaginado la que se iba a...
Esta semana el Parlamento Europeo probó el llamado Paquete de Telecomunicaciones un conjunto de normas destinado a unificar el mercado entre los 27 países miembros. Uno de los aspectos que más polémica ha desatado durante su trámite ha sido el de la...
Ante la inclusión en el Anteproyecto de Ley de Economía sostenible de modificaciones legislativas que afectan al libre ejercicio de las libertades de expresión, información y el derecho de acceso a la cultura a través de Internet, los periodistas, bloggers, usuarios,...
Las fotografías del Emperador Guillermo II de Alemania (1859 - 1941) pueden verse en la web del Huis Doorn Photo collection. La colección completa consta de unas 12.000 fotografías, de las cuales unas 5.500 pueden verse online y muchas de ellas...
Por Nacho Palou -
30 NOV 2009
Ya mencionamos hace unos meses los serios problemas legales que su ponía para Mininova, el conocido sitio de intercambio de archivos P2P, una sentencia judicial como resultado de una denuncia de BREIN (Bescherming Rechten Entertainment Industrie Nederland), algo así como la SGAE...
Tal y como estaba previsto, esta mañana el Parlamento Europeo aprobó por 510 votos a favor, 40 en contra y 24 abstenciones el controvertido Paquete de Telecomunicaciones, con lo que ahora los países miembros tienen hasta mediados de 2011 para adaptar sus...
Como cualquier otra lista esta es matizable, pero para los organizadores de los Webby Awards, estos son los diez momentos más relevantes de la historia de Internet en esta década: Craiglist comienza a expandirse fuera de San Francisco (2000), empezando a comerse...
Según un estudio recientemente publicado de Panda Labs, una empresa dedicada al desarrollo de herramientas para la detección y desinfección de virus y otros programas maliciosos para ordenadores España es el primer país del mundo en cuanto a ordenadores infectados, con ni...
El anuncio por parte del ministro de Industria, Miguel Sebastián, de que a partir del 2011 el acceso a Internet de banda ancha será un servicio universal en España debería ser a priori motivo de alegría, pero lo cierto es que le...
Aunque desde el verano de 2005 es posible compartir archivos a través del protocolo BitTorrent sin necesidad de utilizar un tracker, que es un ordenador que centraliza la información acerca de qué clientes están compartiendo un archivo determinado en esa red, esta...
Land Mass and Population Size By Country, es una selección de varios países para los que se muestra visualmente la relación entre la superficie que ocupan y el número de personas que los habitan. Se echa de menos que no haya...
Por Nacho Palou -
16 NOV 2009
Mapa de la red IP de Telefónica Para los más geeks de la casa, Longhaul Network Maps reúne un poco de pr0n duro en forma de mapas de redes IP de distintos proveedores de acceso de todo el mundo, incluyendo tanto redes...
Puesta en marcha por la administración Bush en 2007 la negociación del tratado ACTA (Anti-Counterfeiting Trade Agreement) en teoría tiene como objetivo luchar contra las falsificaciones de todo tipo y su tráfico y venta. Hay unos cuarenta países involucrados en su negociación,...
Cam, TeleSync, VHS-Screener, VHS-Rip, TeleCine, DVD-Screener, DVD-Rip, DVD-R, DVD, ISO, NRG, BIN, CUE, MDF, MDS, BR-Rip, TV-Rip, DVB-Rip, HDTV-Rip, PDTV-Rip, DSR-Rip, LD-Rip, R5-Rip, Workprint/WP, DivX, Xvid, AVI, VídeoCD, VCD, Súper VídeoCD, SVCD, CVCD, KVCD, RAT-DVD, MP3, WAV, AAC, AC3, RA, OGG, Subbed,...
Esta tarde se reunía el comité de conciliación que se está encargando de buscar un texto aceptable para el Parlamento Europeo y el Consejo de la Unión Europea del Paquete de Telecomunicaciones que regirá el funcionamiento, entre otras cosas, de Internet en...
Ver vídeo: World Battleground The Google Story [2:13] Lleva ya unos días por ahí, con lo que es algo viejuno en términos blogosféricos, pero este vídeo con la historia de la empresa montado por gente de Google en el Reino Unido no...
ABTests.com¹ es un interesante repositorio de pruebas A/B, una forma de análisis de efectividad que suele usarse a modo de ensayo-y-error para mejorar las páginas web en cuestiones de interfaz de usuario y usabilidad, así como en campañas publicitarias y similares....
O al menos “todas aquellas aplicaciones populares y disponibles online para descarga”. El funcionamiento de la página Ninite es simple como el mecanismo de un chupete –lo cual no quiere decir que no sea genial: se marcan las aplicaciones a instalar...
Por Nacho Palou -
29 OCT 2009
Internet sin neutralidad de Red por quink Es quizás un poco exagerada, pero esta ilustración deja bastante claro en lo que se puede convertir una Internet en la que no esté en vigor la neutralidad de la red y en la que...
Internet Speeds and Costs Around the World [jpeg 410 KB] Circulan por ahí diversos enlaces a este gráfico en el que se supone que están representados los primeros veinte países del mundo según la calificación de la Information Technology & Innovation Foundation,...
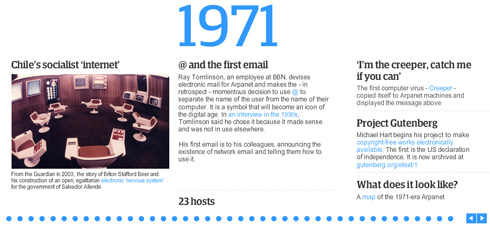
The Guardian ha publicado A people's history of the internet, una cronología de los últimos 40 años de Internet partiendo de las experiencias compartidas por sus lectores. Con toda la información que recibieron crearon un pequeño «documental interactivo» que incluye datos...
Teníamos pendiente publicar una reseña de Bubok desde que vio la luz… pero lo fuimos procrastinando y no llegamos a probarlo personalmente en profundidad, aunque la idea nos pareció genial y su evolución ha sido espectacular. Así que pedimos a una autora...
Accident Depiction es una herramienta de dibujo online para crear un esquema de accidente de tráfico con total facilidad: no hace falta saber dibujar, ¡hasta un niño de cuatro años podría hacerlo! Primero se sitúan las «piezas» que componen los carriles...
Representación gráfica de la sección superior del cohete Atlas en rumbo de colisión con la Luna. Detrás la sonda LCROSS observará el impacto, y cuatro minutos después terminará igual. Imagen NASA En un ejemplo más de si no lo consigues, prueba con...
Por Nacho Palou -
8 OCT 2009
Adaptando las verdades ocultas en las sugerencias de Google encontré que hay casi 1.300 millones de resultados para “Google es search”, una definición tan estúpida que parece una campaña de márketing, Pero la que de verdad me gustó es la no existencia...
Por Nacho Palou -
7 OCT 2009
Aunque la República Federal de Yugoslavia desapareció en 2003 –cuando ya sólo estaba formada por Serbia y Montenegro tras la separación de Eslovenia, Croacia, Macedonia y Bosnia-Herzegovina– hasta el año 2006 en que Montenegro proclamó su independencia el ICANN –la entidad que...
Por Nacho Palou -
30 SEP 2009
Google Acquisitions and Investments [clic/zoom para ver detalles] resume de forma gráfica las compañías que Google ha ido adquiriendo en sus once años de vida, así como los acuerdos estratéticos. Por ahí están Panoramio, Keyhole, que allá por 2005 se convirtió...
Un auto de la Audiencia Provincial de Murcia ordena reabrir de nuevo el caso contra el sitio de intercambio de enlaces P2P Elitedivx, a instancias de un recurso de la acusación ante el auto de sobreseimiento dictado en el verano de 2008...
El presidente Barack Obama había mencionado durante su campaña electoral su intención de apoyar la neutralidad de Internet, el principio que dice que todo el tráfico que circule por esta debe ser tratado igual independientemente de de qué tipo sea y de...
Esta anotación fue publicada originalmente en La Voz de Galicia, diario en el que nos han fichado como colaboradores para publicar una página sobre tecnología, ordenadores, Internet y esas cosas en la sección de Sociedad. Los varios cumpleaños de Internet,La Voz de...
No están todos los que fueron pero sí que son todos los que están; se trata de una Cronología de los buscadores de Internet publicada por Search Engine Journal, que aunque se remonta a la época del Proyecto Xanadú y más...
Real-time Web Monitor es un servicio de Akamai que mide las condiciones de funcionamiento de Internet alrededor del mundo en tiempo real durante las 24 horas del día. Con esa información se pueden seguir las zonas del mundo en las que...
Contundente respuesta… aunque sea una simple encuesta web de fiabilidad muy relativa. Según esto, un 12 por ciento de los lectores de ElPaís.com estarían dispuestos a pagar, frente a un 86 por ciento que no pagaría por contenidos de calidad en...
Unos grandes admiradores de la belleza de Helvética crearon diversos temas alternativos y minimalistas para diversos servicios web, que mejoran su aspecto y se hacen apetecicles sólo de verlos: Helvetireader, para Google Reder, de Jon Hicks Helvetical, para Google Calendar, de...
Aunque el 29 de Marzo de 2006 el Juzgado de Instrucción nº8 de Alicante había acordado el sobreseimiento libre y archivo de las actuaciones contra Naiadadonkey.com al final esa resolución fue anulada al determinarse que el tribunal en cuestión no era competente,...
Del mismo modo que servicios como Panoramio pueden mostrar sobre un mapa el lugar donde se hizo una fotografía, el Mapa dibujado de Madrid muestra en Google Maps la localización geográfica de la escena que aparece representada entre los trazos rápidos...
Por Nacho Palou -
3 SEP 2009
Esta visualización muestra 11.000 mensajes de «buenos días» en Twitter (en distintos idiomas) a lo largo de un periodo de 24 horas. Cada bloque es un tweet, los verdes son madrugadores, los naranjas sobre las 9 de la mañana, los rojos...
Mientras la junta extraordinaria de accionistas de Global Gaming Factory X aprobaba la compra de The Pirate Bay con la idea de convertirlo en un sitio de pago, suponiendo, eso sí, que consigan la financiación necesaria y que la investigación a la...
Ayer a última hora de la mañana la empresa que alojaba a The Pirate Bay, recibía una comunicación de un tribunal que le decía que de no cerrar el acceso al sitio se enfrentaba a una multa de hasta 500.000 coronas suecas...
Si tienes curiosidad por saber cuántas personas hay ahora mismo en el espacio, lo puedes consultar aquí: How Many People Are In Space Right Now? En el momento de escribir esto hay seis, todos ellos en la Estación Espacial Internacional (ISS), de...
Por Nacho Palou -
24 AGO 2009
Personas, un trabajo de Aaron Zinman, forma parte de la exposición Metropath(ologies) que está en el Museo del M.I.T. A partir de un nombre y un apellido analiza los datos que encuentra en la web mediante algoritmos semáticos, para crear unas...
Igual esto es más viejo que el TBO o bien conocido, pero lo he descubierto ahora y me ha parecido interesante: cómo enlazar a un momento concreto de un vídeo de YouTube. Basta como indicar el minuto / segundo a continuación del...
Por Nacho Palou -
20 AGO 2009
New Scientist publicó la fotogalería Exploring the exploding Internet sobre el crecimiento de Internet: los cables submarinos, las direcciones de Internet, el tráfico y el número de usuarios. Esta me pareció especialmente interesante, un «censo» de Internet basado en pings a...
The Pirate Bay ha publicado un torrent de todos los torrents almacenados en Pirate Bay en previsión de que con el próximo cambio de dueños sucedan cosas chungas, y al menos la gente pueda hacer algo con ellos. Ese meta-torrent ocupa 21...
No sé si esto será nuevo o no, porque me lo encontré de casualidad, pero en Google Images además de seleccionar fotos pequeñas/medianas/grandes se puede elegir «Más grande que…» para visualizar imágenes de hasta 70 megapíxeles. Buscando megafotos entre otras cosas...
Your World of Text es la típica buena-y-simpática-idea que acabó descarriada: un gran panel en el que cualquiera puede escribir cualquier cosa. Basta ir haciendo scroll por la gigantesca matriz de letras y dejar huella tecleando algo de texto. El resultado...
How Many Nukes Will Destroy the World? | Information Is Beautiful Lo de arriba es una representación visual del número de bombas atómicas “de las gordas” que son necesarias para extinguir la raza humana. Cada bomba del gráfico representa unas mil...
Por Nacho Palou -
12 AGO 2009
Esta página fue publicada originalmente La Voz de Galicia, diario en el que nos han fichado como colaboradores para publicar una página sobre tecnología, ordenadores, Internet y esas cosas en la sección de Sociedad. Microsoft se hace con Yahoo! por la puerta...
Wikipedia en Español acaba de alcanzar el hito de los 500.000 artículos publicados. El proyecto global arrancó en 2001 y la versión en español lo hizo en mayo del mismo año. Eso quiere decir que en unos 3.000 días se han...
Interactive 360° panoramic of Stonehenge (tamaño completo), panorámica en Flash del monumento prehistórico de Stonehenge. La vista de 360 grados se maneja con el ratón o con las flechas del teclado. Las tecla Control (Comando en Mac) y Mayúsculas acercan o...
Por Nacho Palou -
30 JUL 2009
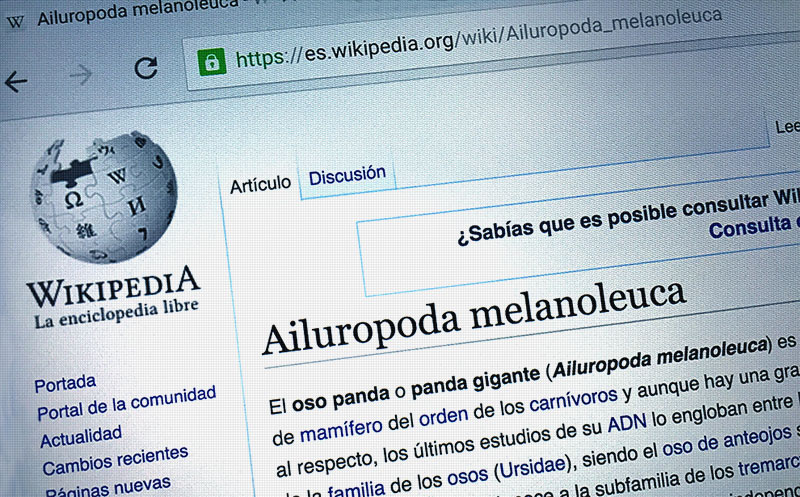
Este artículo se publicó originalmente en La Linterna del Traductor, una nueva revista de la Asociación Española de Traductores, Correctores e Intérpretes, donde estrenaron una sección dedicada a la tecnología y para la que me pidieron amablemente una contribución sobre el...
Desde luego no se está vendiendo como tal cosa, pero el acuerdo de «colaboración» entre Microsoft y Yahoo! se parece sospechosamente a una compra por parte de la primera del activo más importante de la segunda, que es el tráfico que genera...
Varias ideas de imágenes foto-realísticas –impresas en láminas de plástico– para decorar la puerta del garaje recopiladas en My other car's a jet... Or how to turn a garage door into a work of art, vía John Nack. Se puede comprar...
Por Nacho Palou -
27 JUL 2009
En HelpINeedHelp.com («Ayuda, necesito ayuda») venden remedios para pequeños problemas cotidinanos empaquetados de una forma realmente original. La caja de «Ayuda, me he cortado» contiene tiritas, la de «Me duele todo el cuerpo» unas píldoras de ibuprofeno. Los venden en tiendas...
Esta página fue publicada originalmente La Voz de Galicia, diario en el que nos han fichado como colaboradores para publicar una página sobre tecnología, ordenadores, Internet y esas cosas en la sección de Sociedad. Google y Microsoft se enfrentan por el negocio...
Las dos principales características que incorpora la versión 2.8 Gold de Skype para Mac son son el Skype Access y la posibilidad de compartir la pantalla. Empezando por lo último –lo más interesante–, la opción de Pantalla Compartida permite que el usuario...
Por Nacho Palou -
21 JUL 2009
Cuando Global Gaming Factory X anunció que había alcanzado un acuerdo para la adquisición de The Pirate Bay dijo que uno de sus objetivos era buscar un modelo de negocio viable para el sitio que permitiera a los dueños de los derechos...
Steven Leckart y Jason Lee crearon esta imagen de cómo un geek puede combinar las redes sociales, el blogging y el entretenimiento digital para mantener una adecuada vida geek equilibrada. En total son nueve horas al día que incluso incluyen hora...
Hace 153 años nacía Nikola Tesla; Google ha cambiado su logo a una poderosa e impactante bobina Tesla en plena acción en un entrañable homenaje al «hombre que inventó el Siglo XX». (¡Gracias Miguelo y Zarce por el aviso!) Tablero de...
No es que pudieran quedar muchas dudas sobre ello tras todo el esfeurzo realizado en los últimos años por Google para desarrollar un más que competente conjunto de aplicaciones basadas en la web, y menos aún tras la presentación de Google Chrome...

Por si a estas hora aún queda alguien en el universo conocido que no se haya enterado: Algo más de cinco años después de que Gmail fuera presentado en público -un uno de abril ni más ni menos, lo que nos hizo...
En España ya se han producido unas cuantas sentencias absolutorias en juicios contra sitios que proporcionaban enlaces a archivos de redes P2P como por ejemplo los de Spanishare, Sharemula, o eliteDivX, por citar algunos. El único caso en el que ha habido...
En la web de Iberia es imposible hacer el «auto check-in online» si usas Firefox bajo un sistema operativo que no sea Windows aunque tengas instalado un lector de archivos PDF, ya que esta se empeña en no detectarlo si no es...
CompuServe shuts down: Tras una larga agonía, el CompuServe que conocimos está ya casi totalmente cerrado, aunque su sistema de correo –tan primitivo que las direcciones estaban formadas por dos grupos de números– todavía funcionan y seguirán siendo gratuitas para sus...
Resulta cuando menos chocante, pero no parece que se trate de una broma del April Fools cambiada de fecha ni nada parecido sino que va en serio: Hay un acuerdo por el que The Pirate Bay ha sido vendido por sus creadores...
Horror Movie Shower Curtain a la venta en Think Geek. Como complemento, la alfombra para los pies va a juego. (Vía The UberReview.)...
Por Nacho Palou -
30 JUN 2009
El Google Apps Status Dashboard es una página que muestra información en tiempo real acerca del estado de los distintos servicios que ofrece Google. Desde hoy está disponible en 24 idiomas, incluyendo el español. Es muy útil para consultarla en el...
Por Nacho Palou -
26 JUN 2009
Esta página fue publicada originalmente La Voz de Galicia, diario en el que nos han fichado como colaboradores para publicar una página sobre tecnología, ordenadores, Internet y esas cosas en la sección de Sociedad. La revolución de las comunicaciones,La Voz de Galicia...
La próxima actualización del programa de correo electrónico Microsoft Outlook retrocede otros cuantos años al pasado, diez para ser exactos. Después de que la versión 2007 de Outlook prescindiese de utilizar el motor HTML de Internet Explorer para pasar a tirar del...
Por Nacho Palou -
24 JUN 2009
Igual que el año pasado en su encarnación original como BlogAsturias, este año el Foro Internet Meeting Point ha sido una experiencia muy gratificante, y aunque me ha encantado volver a ver a un montón de gente y conocer a otra nueva,...
¡Aleluya! Un verdadero avance en hacer la vida más fácil a quienes cierran pestañas y ventanas para justo un instante después arrepentirse: Deshacer Cerrar Ventana en Firefox, superando incluso al indispensable Deshacer Cerrar Pestaña. Disponible en la nueva versión Firefox 3.5 RC2...
Este es un pequeño artículo que me pidieron en La Voz de Galicia para apoyar la información sobre la concesión del premio Príncipe de Asturias de Investigación Científica y Técnica a Martin Cooper y Raymond Tomlinson.La noticia completa está en Los padres...
Estos últimos días, Twitter se ha convertido en uno de los principales canales de comunicaciones a través del que los iraníes pueden enviar información sobre los disturbios en aquel país -que se iniciaron tras las acusaciones de fraude en las elecciones del...
Por Nacho Palou -
17 JUN 2009
Después de haber tenido que explicar en más de una ocasión que Google o la web no son Internet la verdad es que no me sorprende nada que tras preguntarle a más de 50 personas de diferentes edades y perfiles qué...
Breadbox64 en funcionamiento No es que tenga una gran utilidad que digamos, pero para los que recordamos con cariño la época dorada de los ordenadores personales de 8 bits y que aún nos emocionamos al ver Hey Hey 16K Breadbox64, un cliente...
¡Arrepentíos, tuiteros, el fin de Twitter se acerca! Cuando los creadores de Twitter pusieron en marcha el servicio decidieron que cada «tuit» tenía que tener un identificador único que permitiera localizarlo y hacer cosas más o menos interesantes con él. Por algún...
Web development timeline since 1990 por Felpe Micaroni Lalli La historia de la web en formato de línea temporal. Ahora la cosa sería convertir esa imagen en un mapa que enlazara con las definiciones correspondientes....
En la noche de las recientes elecciones europeas no estaba confirmado del todo, y desde entonces se me había pasado el tema, pero efectivamente se ha confirmado que Pirat Partiet obtiene 1 escaño en el Parlamento Europeo, menos de un mes después...
Jamoral estuvo buceando hace tiempo en la completa y práctica Hemeroteca de La Vanguardia para encontrar las primeras menciones a la palabra «Internet» en el diario. La más antigua la encontró en un artículo data de 1990 titulado Juzgado por colocar un...
Hoy mismo, a instancias del grupo socialista, el Consejo Constitucional francés, equivalente al Tribunal Constitucional de otros países, se pronunciaba sobre la controvertida ley Hadopi que pretende regular las descargas de Internet en el país galo mediante un sistema de respuesta graduada...
Desde Chromium Developer se pueden descargar las primeras versiones aún en desarrollo del navegador Chrome de Google para ordenadores Mac OS X y Linux, en inglés....
Por Nacho Palou -
8 JUN 2009
Con motivo del 40 aniversario de la llegada del Apolo XI a la Luna, radioaficionados y voluntarios de todo el mundo están organizando el proyecto Echoes of Apollo, World Moon Bounce Day (Día mundial de rebotes en la Luna). La idea es...
Por Nacho Palou -
4 JUN 2009
Visualizador de exoplanetas que utiliza Google Earth en el navegador (requiere plugin), incluye algo de información sobre lo poco que se sabe de los exoplanetas o planetas fuer del Sistema Solar y se adorna de una interfaz estilo pantallas de la...
Por Nacho Palou -
4 JUN 2009
internetmap005, Internet vista por un escritor de 30 años A Kevin Kelly, uno de los fundadores de Wired, se le ocurrió que podía ser interesante pedirle a la gente que dibuje como ve Internet en su mente -a nivel conceptual, no técnico-...
Si accedes al dominio BooneOakley.com no llegas a una páginas web como cabría esperar, sino a un vídeo en YouTube –que por supuesto es el motivo por el que querrías visitar este dominio. Aprovechando funciones de YouTube como la inclusión de...
Por Nacho Palou -
2 JUN 2009
Ya se puede probar Bing, el nuevo motor de búsqueda de Microsoft, sobre cuyo planteamiento escribimos hace unos días. Pero, un momento, yo ya he vivido esto antes… Si no fuera porque sabes que es de Microsoft podrías jurar que es...
Esta semana Pablo Soto participó en un encuentro digital en El Mundo en el que respondió a unas cuantas preguntas que le fueron haciendo los internautas sobre el juicio que acaba de protagonizar -involuntariamente, claro está- en el que la industria discográfica...
¿Podría alguien llegar a ganar la partida de las «noticias noticiosas» combinando lo que se puede leer en los tweets que publica la gente en Twitter con el criterio de editores homanos? He aquí un ejemplo: a las 10:24 hora de...
Esta página fue publicada originalmente La Voz de Galicia, diario en el que nos han fichado como colaboradores para publicar una página sobre tecnología, ordenadores, Internet y esas cosas en la sección de Sociedad. Juicio a las redes P2P,La Voz de Galicia...
Una bonita forma de visualizar de dónde proceden geográficamente los twitts públicos o los de de tus contactos (requiere identificarte con tu cuenta). También puede colocarse como salvapantallas (Windows y próximamente Mac): TwittEarth. (Vía Information Aesthetics, donde hay más visualizadores de...
Por Nacho Palou -
27 MAY 2009
Me encontré esto por casualidad en Google y no sé si es nuevo o parte de las nuevas funciones de búsqueda que incorporaron recientemente (o incluso de antes), pero me pareció muy interesante: si buscas el nombre de un personaje relevante,...
Curioseando desde el terreno marcado por pruebas de bombas en Google Maps, Fer se encontró esta curiosa imagen del Coronel Sanders, el pollo del logotipo del Kentucky Fried Chicken. Justo al lado de la “Extraterrestrial Haighway” (WTF!) (¡Gracias Fer!)...
Por Nacho Palou -
25 MAY 2009
Cuando se habla del origen de la World Wide Web normalmente se menciona a Tim Berners-Lee y quizás a Robert Cailliau, a Ted Nelson, a Douglas Engelbart, y a Vannevar Bush como aquellos cuyas ideas fueron evolucionando o sirviendo de inspiración para...
Así queda el paisaje tras años de pruebas de bombas atómicas y convencionales: Area S4 en Google Maps. La zona está situada en Nevada. En Wikimapia están etiquetados e identificados los cráteres y cráteres inversos (supongo que este tipo de formaciones tendrán...
Por Nacho Palou -
21 MAY 2009
Hoy a las 11:30 comienza en Madrid el juicio contra Pablo Soto y su empresa MP2P Technologies, que ha publicado herramientas como Piolet, Omemo y Blubster que funcionan con tecnología P2P y que permiten a sus usuarios intercambiar archivos de forma rápida...
ShopSavvy es una aplicación disponible para Android -y en breve también para iPhone. Utilizando la cámara del móvil lee códigos de barras de los productos, los identifica y muestra un listado comparativo con los precios que tienen para ese artículo en...
Por Nacho Palou -
19 MAY 2009
Por fin se abrió el esperado Wolfram Alpha, la última criatura de Wolfram Research, la empresa más conocida por su revolucionario software Mathematica. Wolfram Alpha no es un nuevo Google, ni acabará con Google. Que no cunda el pánico. Wolfram Alpha...
Un recorrido a los últimos 210 años -y una previsión a 10 años vista- sobre la vía de comunicación o información más utilizada, desde el mercado local de 1800, con encuentros en el MundoReal™, hasta el auge de la comunicación digital...
Por Nacho Palou -
14 MAY 2009
Al final Nicolas Sarkozy se ha salido con la suya y hoy mismo el Senado aprobaba por 189 votos contra 14 el texto de la ley Hadopi que ayer había votado la Asamblea Nacional por 296 votos a favor frente a 233...
Esta página fue publicada originalmente La Voz de Galicia, diario en el que nos han fichado como colaboradores para publicar una página sobre tecnología, ordenadores, Internet y esas cosas en la sección de Sociedad. ">EE.UU. llama pirata a medio mundo,La Voz de...
Una conversación acerca de cómo los epidemiólogos usan distintas herramientas y modelos informáticos para intentar entender cómo se extienden las enfermedades llevó a Jer Thorp a preguntarse si no habría información en las redes sociales que todos usamos a diario que permitiera...
Navegando por el Android Market -la aplicación del sistema Android que permite acceder y descargar aplicaciones- me llamó la atención que una llamada Keep Android Open Petition era de las más populares. El programa, abreviado Tether Petition, es para adherirse a la...
Por Nacho Palou -
12 MAY 2009
Aerial Virtual tour of New York, una aplicación online que permite hacer un recorrido áereo virtual sobre la ciudad de Nueva York, con espectaculares imágenes de la ciudad (fotografías de Oleg Gaponyuk y Andrei Zubets), información sobre sitios interesantes y una...
Por Nacho Palou -
12 MAY 2009
Ya sabemos que el que una cosa suceda después de otra no quiere decir que estén relacionadas (Post hoc ergo propter hoc) pero no deja de ser curioso que en las tres semanas posteriores a la publicación de la sentencia condenatoria a...
Live Ships Map es un mashup creado con Google Maps con la posición de los barcos comerciales que navegan por el mundo. Todos ellos incorporan, desde hace tiempo, y de forma parecida a como sucede en los aviones, un transpondedor que...

Un pequeño vídeo hecho por la gente de Google para dar envidia al resto de los trabajadores del universo conocido que se arrrastran a sus grises cubículos cada día. Muestra en tono divertido cómo está construido y todos los entretenimientos y...
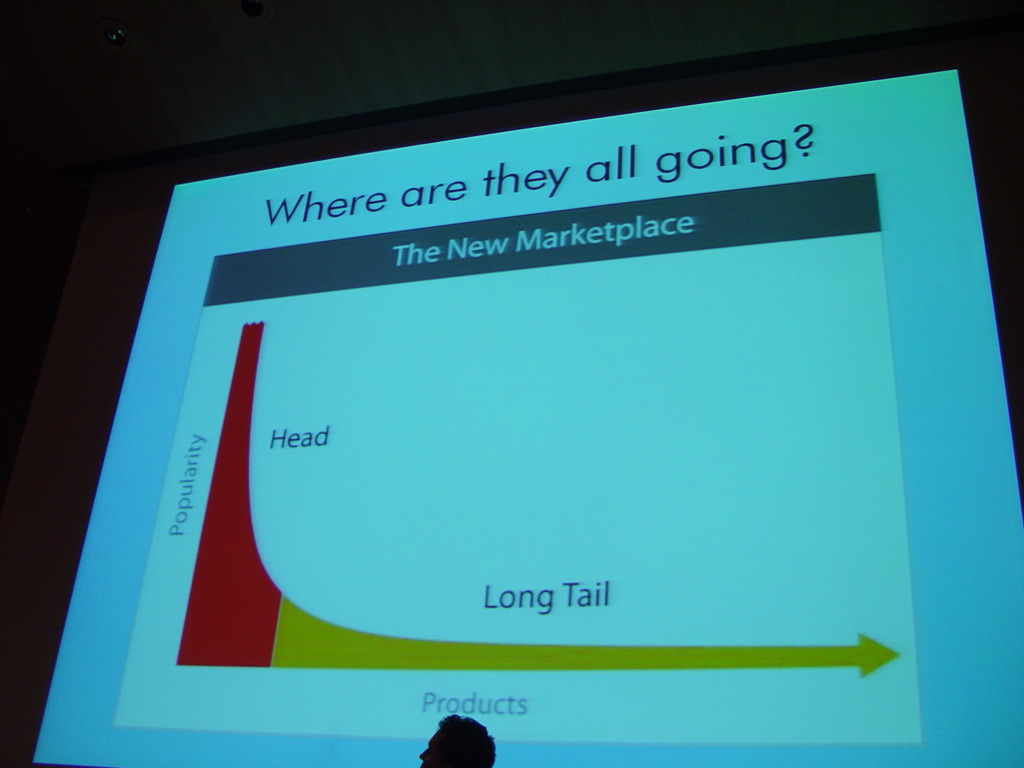
Hace ahora cinco años Chris Anderson publicó un artículo titulado The Long Tail en la revista Wired, cuyo destino dirige desde hace casi una década. Este físico de carrera pero divulgador y periodista de profesión había observado, al más puro estilo...
Una petición de los eurodiputados Rebecca Harms y Alexander Alvaro, ambos alemanes, para que se cambiara el orden en la votación que hoy tuvo lugar en el plenario del Parlamento Europeo tuvo como efecto que este aprobara por 407 votos a favor,...
Esta página fue publicada originalmente La Voz de Galicia, diario en el que nos han fichado como colaboradores para publicar una página sobre tecnología, ordenadores, Internet y esas cosas en la sección de Sociedad. El imparable declive de Yahoo!,La Voz de Galicia...
El plenario del Parlamento Europeo vota este miércoles 6 de mayo a las 12 del mediodía el Paquete de Telecomunicaciones, que es el conjunto de directivas que, de ser aprobadas, y una vez traspuestas a los sistemas legales de los países miembros,...
Como suele suceder con muchos conceptos de Internet, no existe una definición al gusto de todos de lo que es un podcast. Una definición que abarque los principales conceptos diría que un podcast básicamente consiste en archivos de audio de algún tipo...
Las folksonomías suelen existir como algo desorganizado y un poco caótico que la gente va creando y haciendo evolucionar a su libre albredrío, aunque el resultado de la clasificación mediante etiquetas o tags resulte tremendamente útil para localizar y enlazar objetos (fotos,...
Este listado de formatos de las peliculas de Internet habla de todas esas siglas y nombres que se utilizan en los nombres de archivo que hay en las redes que comparten películas, algo un tanto críptico pero que el artículo aclara con...
Mmoro.ca dijo: No puedes considerarte un buen geek si usas más el ratón que el teclado. Y publicó una lista de cómo conseguir nuevos superpoderes lamada: Twitter Accesskey: métodos de acceso rápido para Twitter que permiten utilizar la web del popular programa...
El Paquete de Telecomunicaciones, que es el conjunto de reglas que entre otras cosas regirán el funcionamiento de Internet en los próximos años en los países miembros de la Unión Europea, sigue su tramitación en las instituciones europeas, y la cosa no...
Me pareció excelente la descripción que publicó Jesús Encinar sobre por qué la información cada vez es mejor aunque paradójicamente cada vez tiene más ruido. Partiendo del problema conocido de la superabundancia informativa hace un resumen gráfico excepcional del factor «señal vs....
Swine Flu Map muestra los casos de gripe porcina registrado por todo el globo, pudiendo filtrarse según sean casos confirmados, sospechosos o finalmente negativos. Pulsando sobre los puntos se amplía algo de información sobre cada caso. Aunque en España sólo aparece...
Por Nacho Palou -
29 ABR 2009
Pues si. El Navegador Ópera, el más innovador de los navegadores que son ignorados por la masa, cumple ahora 15 años ¡Felicidades!...
Por Nacho Palou -
29 ABR 2009
Akamai publica en su web un informe llamado State of the Internet donde se muestran entre otras cosas el ritmo de adopción de la banda ancha en los diversos países del mundo. En Europa un 70% de las conexiones son de...
Desde hace unos años la tecnología Wi-Fi para la transmisión de datos de forma inalámbrica se está imponiendo frente a las conexiones por cable y cada vez es más habitual, si no de rigor, que ordenadores portátiles, teléfonos avanzados, agendas digitales, consolas...
Este estilo de computación cada vez más popular permite utilizar vastos recursos informáticos de forma relativamente sencilla, pagando sólo por lo que se utiliza realmente. Con más ventajas que inconvenientes está cambiando la forma en que se desarrollan las nuevas aplicaciones....
Newsmap.jp es la nueva dirección de Newsmap, un visualizador de las noticias que pasan por Google News, arrebatador por su estilo y colorido, que permite personalizar los temas y regiones y mostrar los titulares en un mural donde lo más grande...
La pertenencia del juez Tomas Norström, que fue quien dictó la sentencia que condenaba a un año de cárcel y a pagar una multa de 2,7 millones de euros a los cuatro responsables de The Pirate Bay, a diferentes grupos que defienden...
Los fondos son aún muy escasos -un conteo rápido me da que no pasa de los 1.400 artículos- pero desde ayer está en funcionamiento la Biblioteca Digital Mundial, un proyecto liderado desde la Biblioteca del Congreso de los Estados Unidos y que...
Los resultados de la votación de los mayores logros de la NASA (en la tierra) reflejan un poco lo importante que es para el público que los estudios científicos tengan aplicaciones prácticas “tangibles” –como lo son el uso del GPS o conocer...
Por Nacho Palou -
22 ABR 2009
Stephen Hawking en Google News Timeline Google News Timeline es un nuevo experimento de Google Labs en el que puedes introducir una búsqueda y ver las menciones que se han hecho de ese término agrupadas por día. Se pueden acotar las búsquedas...
Alguién personalizó uno de los servicios de búsquedas de Google para convertirlo en un Buscador de Torrents, algo que no era demasiado difícil… pero ha recobrado cierta notoriedad. Los resultados llevan a páginas que alojan los torrents de las redes P2P...
Agujero de la capa de ozono sobre la Antártida. Sept. 2008. Fuente: Earth Observatory, NASA.Hasta mañana se puede votar cuál es el mayor logro de la NASA en sus vías de investigación dedicadas al planeta Tierra. Se pueden votar un máximo de...
Por Nacho Palou -
20 ABR 2009
En Sicrono hicieron una traducción breve pero suficiente de nueve reglas esenciales para cualquiera que vaya a informar sobre un hecho o evento, recogidas y ampliadas en el artículo Citizen Journalism Publishing Standards, en The Huffington Post. Me gustó especialmente la recomendación...
Por Nacho Palou -
18 ABR 2009
Un hilarante vídeo de CollegeHumor al ritmo de We didn't start the fire sobre la calidad de los comentarios en general a poco que se líe la cosa. No tiene subtítulos, pero se puede seguir por el texto de los propios...
Tal y como adelantaba Peter S. Kolmisoppi por Twitter, la sentencia en el juicio que se seguía contra él y los otros tres responsables de The Pirate Bay es condenatoria. El Museo Nacional de Ciencia y Tecnología de Suecia acaba precisamente de...
En su momento ya comenté que el nombramiento de Ángeles González-Sinde, como ministra de cultura no me parecía muy adecuado por su vinculación a la industria audiovisual, lo que la convertía en juez y parte, pero también comentaba que me gustaría estar...
Free Music Archive es un repositorio de música de calidad libre y gratuita. El archivo está inspirado en movimientos como los de las licencias Creative Commons o el concepto del software abierto a desarrolladores. La música disponible puede descargarse legalmente. Su...
Por Nacho Palou -
14 ABR 2009
ScreenCastle (requiere Java) es una aplicación que permite graba screencasts directamente desde el navegador y guardarlas online. Un screencast es un vídeo en el que quedan registrados la pantalla del ordenador, y opcionalmente audio, con los movimientos del ratón y las acciones...
Por Nacho Palou -
14 ABR 2009
KuvE, el ex-webmaster de Infopsp, nos escribió para comentarnos que David Bravo había publicado una entrevista con él en la que hablan del caso de InfoPSP y del acuerdo al que llegó para declararse culpable aún cuando todas las sentencias anteriores en...
Me extrañó mucho oír en el telediario hace un par de días que el responsable del sitio Infopsp había sido condenado a un hombre a seis meses de prisión y al pago de una multa de 4.900 euros por lucrarse mediante su...
La semana pasada el gobierno francés, al forzar una votación a última hora de la noche cuando sólo había presentes 16 diputados de los 577 que forman parte de la Asamblea Nacional, conseguía que esta aprobara por 12 votos a favor y...
Esta página salió en la edición del domingo pasado de La Voz de Galicia, diario en el que nos han fichado como colaboradores para publicar una página sobre tecnología, ordenadores, Internet y esas cosas en la sección de Sociedad. Llamadas gratis a...
Pocas veces un ministro de un gobierno ha causado una reacción tan fuerte antes de haber jurado su cargo como Ángeles González-Sinde, presentada hoy por el presidente José Luis Rodríguez Zapatero como su próxima ministra de cultura: Ángel Gabilondo, Trinidad Jiménez y...
¡Tiembla procrastinación! SelfControl es una aplicación (OS X) que bloquea el acceso a sitios de Internet durante un tiempo determinado, lo que puede ayudar a concentrarse en el trabajo, “eso que se hace cuando no se está distraído con Internet”. Por...
Por Nacho Palou -
7 ABR 2009
Plaza de Toros de Madrid y calle Alcalá, 2007 ¿Puede haber algo mejor que Google Maps/Earth? Pues depende. Muy agradecidos estamos a NeOscape por habernos enviado un enlace a Nomecalles (Nomenclator Oficial y Callejero), una especie de Google Maps de Madrid creado...
Who Protects The Internet? es un interesantísimo artículo de Popular Science que describe el trabajo de quienes protegen físicamente los cables submarinos por los que circula Internet en todo el planeta. Está llena de datos e historias interesantes, como la de...
Esta página salió en la edición del domingo pasado de La Voz de Galicia, diario en el que nos han fichado como colaboradores para publicar una página sobre tecnología, ordenadores, Internet y esas cosas en la sección de Sociedad. Veinte años de...
Telefónica acaba de anunciar el lanzamiento de TerraGiga, su servicio de almacenamiento en Internet, con capacidades de 5, 10, 20 y 100 gigas. La opción de 5 gigas es gratuita durante un año, aunque esa gratuidad es a cambio de que el...
Átomo de carbono de una molécula de azúcar del ADN humano. Nanoreisen (disponible en español) es “un viaje virtual al descubrimiento del micro y del nano cosmos”: comienza a escala humana normal y llega a valores de femtómetros, 10-15 metros (un...
Por Nacho Palou -
29 MAR 2009
Al mismo tiempo que el Comité de Mercado Interno y Protección del Consumidor (IMCO) de la Unión Eorupea está procediendo a una segunda lectura del Paquete de Telecomunicaciones, un conjunto de normas que para muchas personas contiene lenguaje preocupante en lo que...
Si el otro día hablábamos de los mayores peligros para Internet que habían compilado en Wired, Celia nos recuerda que en el Parlamento Europeo se está procediendo ahora mismo a la segunda lectura de llamado Paquete de Telecomunicaciones, y que en opinión...
Anoche se montó un cierto revuelo con la publicación en Twitter Confirms Paid Pro Accounts On The Way de que la empresa confirmaba que estaría pensando en crear cuentas de pago, aunque sin especificar qué ofrecerían estas cuentas «pro». Pero en realidad,...
PIA10588: Tormenta azul en Saturno - NASA/JPL/Space Science Institute La NASA y Microsoft acaban de anunciar que WorldWide Telescope, el telescopio virtual de la segunda, incorporará más de 100 terabytes de imágenes procedentes del Planetary Data System de la agencia, un repositorio...
Hace unos días, hablando de la posibilidad de que se promulguen leyes que de alguna forma regulen y penalicen el uso de las redes P2P, comentábamos que aparte de los problemas legales que puede suponer esto la tecnología simplemente se pondría por...
Traduzco, resumo y adapto de Top Internet Threats: Censorship to Warrantless Surveillance, una lista de los mayores peligros para Internet publicada recientemente en Threat Level: Escuchas gubernamentales sin autorización. Esto algo que empezó a suceder en los Estados Unidos después de los...
Los amantes de las estadísticas absurdas estamos de suerte: Bookscraper, de los laboratorios del Times Online es una herramienta que sirve para comparar palabra por palabra algunas de las grandes obras de la literatura clásica y ver cuánto coinciden. En esta...
La revista Quo me invitó a participar en Blogbate, una nueva sección abierta a cualquiera que tenga un blog, algo que opinar y ganas de participar. No son exposiciones de expertos ni nada parecido, sino de gente corriente que quiere exponer su...
Por Nacho Palou -
24 MAR 2009
...esto es un poco el diagrama de lo que sucede cuando pides una página web, BigHTTPGraph por Alan Dean....
Por Nacho Palou -
23 MAR 2009
La primera mención a Google en el diario La Vanguardia data de hace exactamente diez años. Tal y como descubrió Pere Rovira en la Hemeroteca de la Vanguardia, tuvo lugar en marzo de 1999. Era una minireseña en la sección El...
Aviones en vuelo en LocalizaTodo.com Vorian nos pasó el enlace a LocalizaTodo, un mashup que muestra sobre los mapas de Google Maps y Google Earth la posición de diferentes recursos tales como aviones en vuelo, barcos y regatas, estaciones meteorológicas, avisos de...
Por Nacho Palou -
23 MAR 2009
Este es un breve análisis que me ha pedido La Voz de Galicia sobre las leyes «de tres avisos» que se están implantando o estudiando en distintos países. Dudas razonables a la hora de legislar las descargas en la Red La Voz...
Microsoft WorldWide Telescope en la web Microsoft acaba de anunciar un cliente web en versión alfa para su WorldWide Telescope, con el que se puede acceder a la mayoría de las funciones de la citada aplicación sin necesidad de instalar nada salvo...
Todos los días nos encontramos noticias sobre las nuevas tecnologías en los medios de comunicación que las culpan de todos los males del mundo -y alguno más- cuando muchos sabemos que Internet, los teléfonos móviles, los videojuegos, y ni tan siquiera la...
Google ha anunciado hoy tres nuevas funciones en el apartado dedicado a Marte de Google Earth: Por un lado, hay una nueva capa con mapas históricos al estilo de los que hicieron Giovanni Schiaparelli, Percival Lowell a finales del siglo XIX y...
Propuesta de Tim Berners-Lee en el CERN (marzo de 1989)Tras leerla, su jefe Mike Sendall escribió al margen:«Una idea vaga, pero interesante…» y le permitió continuar Estos días se cumplen veinte años de la propuesta de Tim Berners-Lee para crear un sistema...
Esta página salió en la edición del domingo pasado de La Voz de Galicia, diario en el que nos han fichado como colaboradores para publicar una página sobre tecnología, ordenadores, Internet y esas cosas en la sección de Sociedad. Las P2P, en...
Lo de arriba es The Cactus Dome, el sarcófago de hormigón abovedado construido entre 1977 y 1980 en la isla de Runit, en las Islas Marshall (ver en Google Maps). Tiene 107 metros de diámetro y contiene cerca de 85.000 metros...
Por Nacho Palou -
11 MAR 2009
Mientras el gobierno francés sigue empeñado en sacar adelante su ley de los tres avisos mediante la que pretende evitar que los usuarios se descarguen contenidos de Internet protegidos por derechos de autor usando redes P2P, el equivalente noruego a Radio Televisión...
Evan Williams: How Twitter's spectacular growth is being driven by unexpected uses Evan Williams (ev en Twitter), uno de los fundadores de Twitter, dio una charla en las conferencias TED de este año en la que habla del enorme éxito del...
Con un interfaz que cualquiera que haya usado Google Maps podrá usar sin ningún tipo de problema, Iceman Photoscan es un proyecto que permite echar un vistazo a través de Internet a Ötzi, el hombre de hielo, con una resolución y detalle...
Llevo algunos días probando la beta de FairShare, un servicio muy intersante que se abrió al público ayer y que sirve para hacer un seguimiento de la utilización de los contenidos de tu blog en otros blogs y lugares de la...
Esta página salió en la edición del domingo pasado de La Voz de Galicia, diario en el que nos han fichado como colaboradores para publicar una página sobre tecnología, ordenadores, Internet y esas cosas en la sección de Sociedad. El peligro de...
Reconstructing the structure of the world-wide music scene with Last.fm, representación visual del entramado de las relaciones musicales, al estilo de los mapas de nodos de Internet, con datos de uso del servicio Last.fm. Los circulos representan grupos y artistas, el...
Por Nacho Palou -
2 MAR 2009
La ICANN publicó este gráfico donde se explica cuántos dominios de primer nivel existen. Los dominios de primer nivel son, para entendernos, la parte final de las direcciones de Internet que se ven en el navegador web; por ejemplo .es estaría...
Hoy mismo arranca en el Campus de Reina Mercedes de la Universidad de Sevilla Imaginática 2009, unas jornadas de libre asistencia para universitarios, institutos y ciudadanos en general que durante toda la semana, y bajo el lema «Bienvenidos a la Informática del...
Llevo unas semanas dando unas sesiones de formación a varios grupos de profesores sobre esto de la tan traída y llevada Web 2.0, redes sociales, y demás, y una de las cosas en las que hago especial hincapié es en cuanto debemos...

YouShouldHaveSeenThis.com recopila las 99 meme-chorradas de Internet que todo el que no haya estado muerto o encerrado en una cueva sin conexión durante el último lustro debería haber visto. La mayor parte de los enlaces son youtubes tan breves como impactantes,...
Esta página salió en la edición del domingo pasado de La Voz de Galicia, diario en el que nos han fichado como colaboradores para publicar una página sobre tecnología, ordenadores, Internet y esas cosas en la sección de Sociedad. La vida social...
Apple ha publicado una versión beta de su navegador Safari 4 (Mac, PC), con motor Nitro. Según Apple es más de 4 veces más rápido ejecutando JavaScript que su antecesor. Algunas características que de entrada resultan interesantes: Top Sites: muestra en...
Por Nacho Palou -
25 FEB 2009
Google Analytics vs XiTi: cómo miden el origen de las visitas es un interesante artículo comparativo sobre cómo dos herramientas de métricas web (medición de visitas) hacen su trabajo. En él se sugiere que los datos de Google Analytics están sesgados a...
Interesante dato: El 85% de las reclamaciones de telecomunicaciones fue favorable a los usuarios durante 2008, según datos de la Oficina de Atención al Usuario de Telecomunicaciones. Eso es casi un pleno: reclamación que llega, reclamación a favor del consumidor. Esa oficina...
Mi «yo» como «Homo erectus», hace 1,8 millones de años. Devolve Me modifica tu imagen actual para adaptarla al look que se llevaba hace hasta 3,7 millones de años. Basta con subir una fotografía tipo carnet, aplicar la máscara de cara (haciendo...
Por Nacho Palou -
12 FEB 2009
¡Altamente circular! False Fact On Wikipedia Proves Itself traducible como Un hecho falso en la Wikipedia se demuestra a sí mismo cuenta una curiosa historia cíclica sobre la popular enciclopedia. Al parecer alguien editó «vandálicamente» el nombre (realmente largo) de un nuevo...
Trasteando un rato por Neoformix me topé con una curiosa aplicación desarrollada en Java llamada Twitter Venn que hace diagramas de Venn con dos o tres términos que se le indican y muestra los tweets en los que se habla de cada...

Los HotBits son números verdaderamente aleatorios generados mediante un proceso inherentemente azaroso de las leyes de la naturaleza: el fenómeno cuántico del decaimiento.
Dice Cory de Boing Boing que siempre soñó con escribir este titular, Slashdot slashdots Slashdot: allí se cuenta cómo el popular sitio de noticias para geeks se «tumbó» a sí mismo el otro día y estuvo más de una hora caído debido...
Tal vez por ser de los más primarios el tema de la «velocidad» de las páginas web y su «peso» sigue siendo infravalorado por muchos. Pero encontré (víaa reddit) un antiguo y revelador ejemplo que Greg Linden publicó hace un par de...
Es bien sabido que aquí nos encantan las listas y las guías y tutoriales del estilo «Cómo hacer…» (en inglés: HOWTOs), de modo que esta hilarante recopilación de Las 11 guías de «Cómo hacer» más innecesarias de toda la web nos parece...
Adelantándose a San Valentín que es dentro de unos días, la gente de ShirtCity ha plasmado en una camiseta el sueño de algunos geeks....
(Vía Look At This...) ¡Hay que ver lo que nos gustas los generadores de cosas en general!...
Por Nacho Palou -
1 FEB 2009
Unas interesantes reflexiones sobre conductas, refuerzos castigos, experimentos con ratones y el uso que las personas hacemos de los servicios Internet, procedente de una presentación sobre «sistemas de descubrimiento que enganchan», en el blog de Jesús Encinar: El email, como las tragaperras,...
«Bienvenido al ahora»: Plug into now. Los distintos gráficos contienen o informan sobre eventos que están sucediendo y representan la contabilidad a nivel mundial de consumo y producción de bienes (coches, casa, huevos, vasos de papel...) en base a datos estadísticos a...
Por Nacho Palou -
26 ENE 2009
Con motivo de su 10º aniversario y aprovechando que en estos días van a presentar resultados, el Correo Digital ha publicado un especial titulado Google: ¿Ángel o demonio? donde se puede encontrar una cronología y un montón de información sobre la...
Esta página salió en la edición del domingo pasado de La Voz de Galicia, diario en el que nos han fichado como colaboradores para publicar una página sobre tecnología, ordenadores, Internet y esas cosas en la sección de Sociedad. El mundo en...
{ Nota: Esta anotación habla de un proyecto relacionado con Strands, que es una de las empresas en que participo como consejero. Ver Full Disclosure } Ya está en el aire Actibva Predicciones que es la forma que toman en la...
Una web oficial donde buscar la gasolina más barata: lo interesante es que es «oficial», depende del Ministerio de Industria; además los precios de los carburantes actualizan cada hora y los resultados aparecen ordenados automáticamente de más barato a más caro. Lo...
Si tienes curisidad por echar un ojo a la ceremonia de investidura del nuevo presidente de EE UU –que tendrá lugar hoy marte 20 a las 16.30 GMT (+1 hora oficial en España) tienes varias opciones. 5 Best Ways to Watch the...
Por Nacho Palou -
20 ENE 2009
Haciendo bueno aquello de que una imagen vale más que mil palabras llega… La guerra de los navegadores (2002-2008), una infografía muy explícita creada por BovingdonBug de Pixel Labs, donde el ancho de las banderas en la zona de 2008 indica...
15.30 - Enfilando el rio Hudson buscando el amaraje para minimizar el impacto. Con los datos de la posición del vuelo 1549 que ayer por la noche (hora española) terminó con el Airbus flotando en el rio Hudson, en Nueva York, Google...
Por Nacho Palou -
16 ENE 2009
49 Amazing Social Media, Web 2.0 And Internet Stats es una interesante recopilación de datos curiosos, medio útiles medio inútiles, sobre algunos servicios de Internet y en especial servicios que se pueden encuadrar en la Web 2.0. Como siempre sucede con estas...
La Ley de Moore –que originalmente establecía que el número de transistores que caben en un circuito integrado se duplica aproximadamente cada 18 meses– también es aplicable al crecimiento físico de Internet. Internet Growth Follows Moore's Law Too – Investigadores chinos han...
Por Nacho Palou -
15 ENE 2009

Preciosa esta Historia de Internet en formato documental animado, contada con iconos, que abarca desde finales de los años 50 hasta nuestros días – además narrada en perfecto inglés británico. (Vía MeFi.) Relacionado: La NSF y el nacimiento de Internet, en...
TorrentFreak acaba de publicar su ya tradicional lista de los mejores 10 sitios para buscar torrents del año, Top 10 Most Popular Torrent Sites of 2008, y que son: The Pirate Bay, con una media de más de 25 millones de personas...
El Web Design Sketchbook es un bonito cuaderno para hacer bocetos de diseños de aplicaciones y páginas web....
Por Nacho Palou -
28 DIC 2008
Physical Internet es el nombre de este simulador físico de Internet, donde mediante canicas que ruedan se revela el funcionamiento de la red y su magia al transmitir la información en forma de paquetes que llegan a su destino a través...
Ya existe versión para Mac del plugin de Google Earth –disponible para Windows desde hace unos meses. Esta extensión (para Safari 3.1+ y Firefox 3.0+ sobre OS X en PowrPC o Intel; Firefox e Internet Explorer 6 y 7 para Windows) permite...
Por Nacho Palou -
10 DIC 2008
Madrid, 1831 es un mapa de la colección de David Rumsey superpuesto adecuadamente con las imágenes aéreas actuales de la ciudad proporcionadas por Google Maps / Google Earth, al que se pueden acceder con el navegador cómodamente. Yo ya había probado...
Revolución Digital: el impacto de las nuevas tecnologías es un reportaje de Informe Semanal que se emitió ayer y se grabó durante las últimas semanas, aprovechando la visita de algunos de los protagonistas que en él aparecen al pasado FICOD. Describe...
Una vez más, y ya van unas cuantas, un caso contra un sitio de intercambio de enlaces termina con el sobreseimiento de este: "Si no es delito, no es delito": Se sobreseen las actuaciones seguidas contra la página de elinks Spanishare. De...
Cory Doctorow ha hecho un llamamiento a los creadores de contenidos, empresas, webmasters y particulares que crean, remezclan y publican en Internet: textos, fotografías, vídeos, música. La encuesta es un poco larga y pesada (tal vez entre 20 y 30 minutos) y...
Esta página salió en la edición del domingo pasado de La Voz de Galicia, diario en el que nos han fichado como colaboradores para publicar una página sobre tecnología, ordenadores, Internet y esas cosas en la sección de Sociedad. La neutralidad de...
Esta página salió en la edición del domingo pasado de La Voz de Galicia, diario en el que nos han fichado como colaboradores para publicar una página sobre tecnología, ordenadores, Internet y esas cosas en la sección de Sociedad. ¿Podemos fiarnos de...
Esta semana arranca el FICOD 2008 en Madrid; es su segunda edición y se celebra durante los días 25, 26 y 27 de noviembre; ya hay varios miles de personas inscritas (la inscripción es gratuita.) Entre los contenidos que a priori me...
Desde hoy viernes y hasta el domingo se celebra en el Palacio de Congresos de Madrid [mapa] la II Edición del Congreso de Webmasters, con un montón de ponencias y talleres. Yo participaré en la ponencia Casos de éxito: Microsiervos, Tuenti y...
The Internets: apropiadas viñetas para los innumerables acrónimos de la jerga de la Red, , con licencia para usar y compartir libremente a cambio de un enlace y la cita adecuada, surgidas desde las profundidades de esa increíble serie de tubos...
Esta imagen que nada tiene de fake y que bien podría haber entrado en los anales de los WTF se queda en mera curiosidad histórica: data de 1981 y es una foto más entre los diez millones de imágenes de la...
Aunque Adobe alguna vez ha afirmado que habría una versión de Flash para el iPhone “algún día”, el artículo Why Apple Won't Allow Adobe Flash on iPhone de GadgetLab explica los motivos por los que es mejor irse olvidando de que eso...
Por Nacho Palou -
18 NOV 2008
Después de resistirse con uñas y dientes a una oferta de compra por parte de Microsoft en la que esta ofrecía 33 dólares por cada acción de Yahoo! mientras que él insistía en un mínimo de 37 dólares, lo que le costó...
Explicados con esquemas, como para niños de cuatro años (niños que sepan algo de inglés): Things Caches Do. Con los impertérritos y siempre dispuestos Alice y Bob como protagonistas. (Además he aprendido que se dice el caché web y no la...
En estos momentos arrancan las IV Jornadas de Informática de la Universidad Europea de Madrid, en las que bajo el tema «Web 2.0: Tecnología, Sociedad y Comunicación» desde hoy y hasta el viernes distintas personas relacionadas con la web 2.0 y su...
WikiMapia es un curioso crossover entre Google Maps y un wiki; sirve para taggear con descripciones las diversas zonas de los mapas, de modo que los barrios, parques, edificios públicos y demás puedan verse a simple vista, cosa que no siempre...
Supervivencia en el Titanic por clase de pasajero y sexo Many Eyes es una web patrocinada por IBM que sirve para explorar visualmente diversos conjuntos de datos que cuentan en forma de gráficos la misma historia, pero como suele suceder, de formas...
The Sheep Market fue un experimento llevado a cabo por Aaron Koblin en 2006, con resultados medio artísticos medio del mundo de la computación distribuida (o algo así). La prueba consistió en ofrecer dos centavos de dólar a cada persona que le...
Me pareció gracioso que sucediera esto, pero en cierto modo era inevitable: el cambio de la URL de portada en la Wikipedia en español. Resulta que la dirección de la portada anterior era es.wikipedia.org/wiki/Portada. Pero en realidad la coletilla /wiki/xyz se utiliza...
Esta página salió en la edición del domingo pasado de La Voz de Galicia, diario en el que nos han fichado como colaboradores para publicar una página sobre tecnología, ordenadores, Internet y esas cosas en la sección de Sociedad. La importancia de...
32 Nearby Stars es una representación espacial de 32 estrellas cercanas al Sol, situadas a no más de 14 años luz del Sistema Solar –cada recuadro representa un año luz. Con el ratón se puede rotar el plano, también colocándolo sobre...
Por Nacho Palou -
3 NOV 2008
Por Nacho Palou -
3 NOV 2008
Utilizando la API de Google Street View es posible recorrer rutas como si se fuera conduciendo -o navegando. Un ejemplo es A Street View Drive Through Madrid -aunque es posible recorrer cualquier otra ruta donde hata Stree View simplemente indicando la...
Por Nacho Palou -
1 NOV 2008
Esta página salió en la edición del domingo pasado de La Voz de Galicia, diario en el que hemos sido amablemente invitados a publicar una página sobre tecnología, ordenadores, Internet y esas cosas en la sección de Sociedad. Adiós a los discos,La...
El año pasado, durante la tramitación en las Cortes de la Ley de Medidas de Impulso de la Sociedad de la Información, más conocida como LISI, hablamos en varias ocasiones, como por ejemplo en La LISI y sus «autoridades competentes», de como...
Tal y como adelantaba Dirson, el nuevo Google Street View ya está disponible para España en Google Maps. Entre las ciudades agraciadas con fotos callejeras tomadas a pie de calle se encuentran Madrid, Barcelona, Sevilla y Valencia, de momento. El visor...
El libro Atlas of Cyberspace de Rob Kitchin y Martin Dodge es un precioso trabajo que contiene más de 300 imágenes a todo color que ilustran la infraestructura y funcionamiento de Internet y sus servicios y su evolución a lo largo de...
Deckerix recopiló pacientemente un mes completo de spam para poder hacer este gráfico que indica el tipo de basura electrónica que se puede recibir al cabo de 30 días, en unos 650 correos. Más de la mitad fueron medicamentos, y el...
Crossumer Claves para entender al consumidor español de nueva generación. Víctor Gil y Felipe Romero. Ediciones Gestión 2000, 2008. 250 páginas. ISBN: 9788498750010. Web del libro. Blog de Víctor: insightsblog.com. Blog de Felipe: divergencias. La editorial nos envió un ejemplar por...
En pqpq se plantean dicotomías, dilemas o versus para que los lectores dejen su opinión al respecto, de forma breve. Funciona como un blog y trata temas diversos, tanto intranscendentes como cotidianos, de diseño, políticos, entretenimiento u otros. Está todo montado con...
Aunque algunos quiosqueros le den la vuelta a los periódicos para que los paseantes no puedan cotillear los titulares sin pagar, ahora existe una buena alternativa: Kiosko.net, una página donde todos los días aparecen las principales portadas de los diarios españoles...
Gina Trapani de LifeHacker hizo una encuesta rápida e informal entre sus lectores para saber qué opinaban sobre OpenID: si todavía lo encontraban confuso o difícil de usar y esas cosas. El resultado es un tanto decepcionante y muestra que aunque la...
Panorámica interactiva geoposicionada en Google Maps realizada por Iñaki Rezola desde el Cerro de Santa Catalina, en Gijón. 360 Cities geoposiciona imágenes panorámicas interactivas con 360 grados de visión que puede verse directamente desde Google Earth y Google Maps. Panorámicas en la...
Por Nacho Palou -
15 OCT 2008
Esta es la tercera página que publicamos en La Voz de Galicia, diario en el que hemos sido amablemente invitados a publicar una página sobre tecnología en la sección de Sociedad todos los domingos. La revolución de los usuarios,La Voz de Galicia...
La semana pasada Isidoro Valerio me invitó a participar en una tertulia en Radio Voz sobre la operación Carrusel, una operación contra la pornografía infantil que se saldó con la detención de 121 personas que usaban Internet para intercambiar este tipo de...
Me llamaron de Radiocable para hablar un poco del extraño y preocupante interés que están mostrando algunos políticos en regularizar los blogs y crear un registro europeo de blogs en el que figurarían datos sobre la identidad del autor, sus intereses políticos...
Hace unos meses, Microsoft lanzaba una oferta para adquirir Yahoo por unos 45.000 millones de dólares, a 31 dólares la acción. Yahoo se negó a acceder a la operación, afirmando que la compañía valía mucho más, que era una oferta indignante, bla...
Logstalgia (a.k.a. ApachePong) es un software para visualizar el fichero de logs que registra loas peticiones de los visitantes al servidor web como si fuera Pong, el más retro de los juegos retros, considerado como el primer «videojuego moderno» de la...
Hemos sido amablemente invitados a publicar una página sobre tecnología en la sección de Sociedad de La Voz de Galicia todos los domingos. Esta es la segunda. La lenta carrera de la banda ancha,La Voz de Galicia 5 de octubre de 2008....
No es como esperaba, pero sí bastante ingenioso: Youtube, Now in Super HD. (Vía Rosa J.C.)...
Por Nacho Palou -
2 OCT 2008
Turismo recibido neto – El tamaño de cada país representa los viajes turísticos hechos a cada territorio menos los hechos desde cada uno de esos territorios a cualquier otro lado. The Atlas of the Real World (Atlas del MundoReal™) representa los países...
Por Nacho Palou -
2 OCT 2008
Martín Varsavsky ha anunciado que el próximo lunes, 13 de octubre se celebrará la II edición del Facebook Developer’s Garage en Madrid, una jornada para desarrolladores que contará con la presencia estelar de Mark Zuckerberg, fundador de Facebook. En Flickr hay fotos...
Hacer ingeniería inversa de «cómo funciona Google por dentro» es casi un deporte olímpico de la Red: las teorías que circulan por ahí, incluso en círculos supuestamente serios, son tan extravagantes como asombrosas. Así que si hablamos de Google AdSense, donde además...
En plena crisis con muchos de los bancos más importantes del mundo en quiebra y los inversores sin saber qué hacer, el momento WTF del día fue un bug ocurrente en alguno de los sistemas de la bolsa que mandó las acciones...
The Conversation Prism es otra forma de visualizasr los servicios de la Web 2.0, actualizado con datos recientes. También en Flickr se puede ver con algunos añadidos de los usuarios. Sus creadores lo definen como una representación viviente de los Medios...
Windows on Earth es un simulador que permite observar la superficie de la Tierra como si se mirase a través de alguna de las ventanas de la Estación Espacial Internacional (ISS), a 360 kilómetros de altura. Funciona directamente en el navegador;...
Por Nacho Palou -
29 SEP 2008
El traductor de idiomas de Google ha incorporado catalán-español y español-catalán a su repertorio. → El traductor d’idiomes de Google ha incorporat català-castellà i castellà-català al seu repertori. → El traductor de idiomas de Google ha incorporado catalán-castellano y castellano-catalán a su...
Deletionpedia recopila fragmentos del «conocimiento» humano que la Wikipedia no supo apreciar: contiene unas 63.500 entradas que fueron borradas de la Wikipedia en inglés, lo cual incluye algunas tan aparentemente absurdas como la lista de películas en las que aparecen monos o...
For legal aid, press 1. For tech support, press 2.Citando la prueba A de la acusación, su cuenta en Twitter, «@atracador Estoy en el coche con el dinero y los rehenes. ¿Dónde andas?» Sin llegar a estos extremos, esta viñeta me recordó...
David Bravo y Javier de la Cueva nos dan hoy una estupenda noticia en Resolución final del caso Sharemula. La Audiencia de Madrid es rotunda: las webs de enlaces a redes P2P no son delito. En efecto, el famoso caso contra Sharemula,...
Port Knowledgebase es una completa lista de los puertos TCP y UDP más comunes que se suelen verse en Internet. Entre los más conocidos están los típicos 80, 23, 21 y 25 (HTTP/Web, Telnet, FTP y correo) pero la lista completa va...
Antes del verano, justo cuando el Parlamento Europeo estaba a punto de irse de vacaciones, se montó una cierta polémica porque el europarlamentario británico Malcolm Harbour introducía tres enmiendas en el conocido como Paquete de Telecomunicaciones que podían ser potencialmente negativas para...
En este mapa llamado World Web Map cada país ha sido sustituido por un sitio web de Internet de «tamaño equivalente» (con datos de 2007), lo cual permite hacerse una idea de cuán grandes son ciertos sitios web en comparación con...
Searchme es un buscador bastante chulo; funciona razonablemente bien como buscador, pero es digno de destacar básicamente por su estética y su interfaz... que en realidad es más bonita que práctica. Si eres usuario de iTunes y/o de Mac OS X...
Por Nacho Palou -
15 SEP 2008
Selver me recomendó echar un vistazo a Connexions, un proyecto que intenta acercar material educacional de todos los niveles de manera libre y gratuita a la gente. Se basa en desarrollar «módulos» educativos, en que la educación sea modular y no lineal....
Learn Experiment es un experimento de aprendizaje que Jaime ha montado en su sitio web y que invita a probar a quien esté interesado en el e-learning. Consiste en aprender la equivalencia entre caracteres japoneses kanji y castellano, como si fuera...
"Ver todo el universo conocido", el botón más chulo nunca antes visto en una aplicación Flash. El proyecto 4D2U (requiere Flash, en inglés y japonés), desarrollado por el Observatorio Astronómico de Japón, contiene en la ventana del navegador la jerarquía de todo...
Por Nacho Palou -
12 SEP 2008
Los cinco minutos de curiosidad genealógica de hoy pueden perderse adecuadamente en World Names Profiler, una sencilla página que muestra en qué países son más comunes los apellidos que escribas. No funciona con acentos ni eñes, así que mejor usar ASCII limpito....
Google News Archive es un nuevo buscador de Google sobre el texto completo de periódicos antiguos, algo tremendamente interesante porque pone una nueva vasta recopilación de información textual al alcance de todos. Si bien algunos grandes periódicos tienen sus hemerotecas digitalizadas y...
Porque no todos los caracteres son fáciles de teclear ni recordar, y porque ni la web es una máquina de escribir ni los blogs tampoco, viene de perlas CopyPasteCharacter, que conviene tener a mano. En Mac: Seleccionar, ⌘C y ⌘V y...
Google cumple diez años y Dirson ha creado una encuesta para ver qué opinan sus lectores respecto a cómo ven a Google, en total siete sencillas preguntas: La mejor herramienta para usuarios creada por Google El mayor fracaso en las herramientas creadas...

Helo aquí: Chrome. Si en el navegador de Google se teclea about:internets aparecen dibujada una series de tubos en 3-D en la pantalla. Es una parodia sobre la desafortunada afirmación de que Internet es como una serie de tubos que popularizó...

Este artículo ha sido también publicado originalmente, con ligeras modificaciones, en la sección de Ciencia y Tecnología de Público, bajo el título «Chrome: sencillez y compatibilidad frente a años de experiencia». Con la llegada de Chrome el usuario final tiene una...
Google Chrome es el nuevo navegador web de Google, que ya se puede descargar para probar, de momento sólo en versión beta para Windows, y en castellano (próximamente también para Mac y Linux). Se descarga e instala muy fácilmente y su principal...
Esto va en serio. No es un simulacro. Y para todos los que piensen que pueden evitar la tormenta, tengo noticias para ellos: puede que sea el mayor error que cometan en sus vidas (…) Esta es la madre de todas...
Ejemplo de vídeo del programa Top Gear subtitulado en español, inglés, francés, alemán, italiano y japonés –a elegir. Desde ahora al subir un vídeo a YouTube es posible acompañarlo con subtítulos en uno o más idiomas, hasta 120 en un mismo vídeo,...
Por Nacho Palou -
29 AGO 2008
NSF and the Birth of the Internet [Flash, inglés] es una infografía interactiva de la National Science Foundation (NSF) que narra con pequeños vídeos, imágenes y textos, la historia de Interneta a lo largo de las cinco últimas décadas, desde los...
Vía Rosa J.C. llegué hasta este Listado de Marcas blancas, que es el mismo o similar a algunos que circulan por correo desde hace tiempo. Viene a resumir en una tabla qué marcas «conocidas» están detrás de los productos de marca blanca...
Mauro Entrialgo lo clava una vez más en Interneteo y Aparatuquis del 3 de marzo de 2007 (Davidgp no fue nada idiota al pillar esto en Escolar.) Intercrastinación ilustrada, Blogs contaminantes, Auto-soporte técnico, Ya están aquíííí… nueva invasión publicitaria en las calles...

Interesante esta charla de Kevin Kelly, visionario y fundador de Wired, en TED: Predicting the next 5,000 days of the web [inglés, 20 min.] sobre el futuro de la Web, donde abunda en algunas de las ideas que ha desarrollado en...
Descubrí varios impresionantes trabajos de Jonathan Harris en una de sus charlas TED, The Art of Collecting Stories donde explica en primera persona el transfondo de algunos de sus proyectos, medio artísticos, medio tecnológicos, todos ellos absolutamente brillantes. Impresionante es la...
Wordle [Java] es una preciosa aplicación web que construye nubes de palabras à la Web 2.0 a partir de textos elegidos por el usuario. Una vez analizado el texto (donde se eliminan las «palabras cortas habituales» automáticamente), el usuario puede variar a...
Typosquat24.com es un curioso sitio que te indica al momento los dominios «similares» al tuyo, pero con erratas, que están «aparcados» – generalmente registrados por especuladores de dominios, cybersquatters (ciberocupas) y otras faunas sin demasiados escrúpulos. Es una técnica denominada en inglés...
Al cierre de la bolsa a día de ayer, Apple superó en valor a Google (en cuanto a capitalización bursátil se refiere, que es lo que suele utilizarse para comparar esto). O más bien habría que decir «vuelve a valer más...
Vía Neatorama descubrí que Erik Rasmussen publicó algo sobre ambigramas en dominios de Internet, esto es, dominios que se pueden leer igual si se giran 180 grados. Tienen la limitación de que la parte final debe corresponderse con un dominio que realmente...
¡Fácilmente! Los amantes de los juegos de ingenio bien saben que el clásico problema de los siete puentes de Königsberg no tenía solución, pero es que las cosas han cambiado: el sitio ahora se llama Kaliningrado, los puentes fueron destruidos y reconstruidos,...
Creía haberlo visto todo en Internet, ¡pero me equivoqué de nuevo! Existe algo llamado IKEAfans que es una especie de IKEApedia donde hay un montón de cosas: 50.000 hilos de debate en los foros por un lado y especialmente los manuales...
Mix Turtle es un sencillo buscador en el que escribes el nombre de una canción o artista y al instante puedes hacer clic sobre los resultados para oir la música, todo ello gratis y así de fácil. El buscador funciona bastante...
En Unicode Graphic Domains investigaron quién está detrás de algunos de los nuevos «dominios Unicode», esos sitios web con nombres pseudo-gráficos como www.♥.com que tienen su gracia aunque en realidad acaban convertidos a algo más mundano equivalente como xn--g6h.com al navegar por...
Proposed new tag: IMG fue el título del mensaje enviado por Marc Andreessen (el que fuera uno de los autores del primer navegador web, Mosaic y cofundador de la otrora todopoderosa Netscape), para proponer la forma de incorporar imágenes en los documentos...
Por Nacho Palou -
22 JUL 2008
Una cuna del saber como el M.I.T. genera una cantidad de material audivisual impresionante cada año, de modo que ahora han decidido abrir al público MIT TechTV, algo medio YouTube medio archivo de televisión donde pueden encontrarse todos los materiales publicados...
{ Nota: Esta anotación habla de un proyecto relacionado con Strands, que es una de las empresas en que participo como consejero. Ver Full Disclosure } Esta semana se anunció oficialmente el servicio de finanzas personales BBVA Tú Cuentas que ha sido...
Esta mañana estuvimos en la presentación de Blinko, una nueva red social pensada especialmente para móviles que por ahora está en beta cerrada, en la que pudimos escuchar una charla de David Weinberger, uno de los autores de The Cluetrain Manifesto, sobre...
Aunque -afortunadamente- los favicon (ese pequeño icono que aparece arriba en la barra de direcciones del navegador, junto a la dirección web de la página) en versión animada no han tenido mucho éxito -y parecía que no había mucho más que innovar...
Por Nacho Palou -
16 JUL 2008
La noticia dice que Industria prohibirá los servicios de banda ancha que no garanticen el 80%, de modo que queden prohibidas aquellas ofertas de conexión de «alta velocidad» que no garanticen al menos el 80% de lo prometido (digamos, 16 Mbps para...

Detalle de un depósito de gas en el puerto de Barcelona. A la derecha con las nuevas imágenes. Buenas noticias: algunas de las principales ciudades del litoral catalán, y toda la línea de costa entre Barcelona y Palamós, han recibido una actualización...
Por Nacho Palou -
14 JUL 2008
7 funcionalidades ocultas de Firefox 3, o al menos tal vez algunas de ellas son desconocidas por muchos. Aunque precisamente el truco de duplicar una pestaña con todo su historial de navegación, que no conocía y puede ser interesante, de momento no...
Por Nacho Palou -
12 JUL 2008
Estupenda noticia: Google Sightseeing, uno de los mejores sitios donde descubrir curiosidades del mundo a través de Google Maps, está disponible en español. También hoy se anuncia la incorporación de otros dos idiomas, alemán y holandés, que vienen a sumarse al...
Por Nacho Palou -
9 JUL 2008
Twitter siempre cayéndose, cayéndose, cayéndose... Twitter está saturado(como le pasó a Friendster y todo el mundo lo abandonó por Myspace) The State of the Web - Summer 2008...
Por Nacho Palou -
8 JUL 2008
Me reí bastante leyendo en cgredan el chiste wikipédico- friki titulado En la cultura popular procedente del siempre genial xkcd. No pude evitar recordar que el otro día me di cuenta de que la entrada sobre el Condensador de Fluzo en la...
Esta tarde el Comité de Mercado Interno y Protección del Consumidor (IMCO) de la Unión europea se reúne para votar el Paquete de Telecomunicaciones. Entre las más de 800 enmiendas que ha recibido este Paquete van tres, propuestas por el europarlamentario británico...
La verdadera historia del Error 404. ¡Uy, perdón! La verdadera historia del Error 404. Una historia clásica que aunque tiene cierto tiempo conviene releer. Actualización (21 de diciembre de 2020) – Irónicamente la página original de NeoTeo desapareció, pero quedó guardada en...
Es toda una alegría leer que absuelven de un delito de pornografía infantil al administrador de Forocoches.com. A. M. N. había sido acusado por el fiscal de «facilitar la producción, venta, difusión o exhibición por cualquier medio de material pornográfico en cuya...
10 Free MS Word Alternatives You Can Use Today recopila una decena de programas para edición de textos compatibles con el formato .doc de Microsoft Word. La selección incluye programas para instalar en el ordenador (como OpenOffice o Neo Office) o que...
Por Nacho Palou -
25 JUN 2008
Genial respuesta de Julio Alonso para los correos basura en Le informamos... Ante un correo no solicitado como Yamaytel, S.L. Le informamos que su dirección de correo electrónico ha pasado a formar parte de nuestros ficheros electrónicos, mediante los cuales, en alguna...
Si la semana pasada era Jeremy Zawodny, el evangelista tecnológico de Yahoo!, el que anunciaba su marcha de la empresa, y esta semana se sabía que Caterina Fake y Stewart Butterfield, los fundadores de Flickr, habían decidido dejar Yahoo!, hoy mismo se...
¡Entrañable! Yahoo va a añadir un par de dominios nuevos de correo a su servicio Yahoo Mail: ymail.com y rocketmail.com. A partir de mañana día 20 de junio se pueden abrir nuevos buzones sobre esos dominios en la página de Correo Yahoo...
Ya está disponible para descarga Skype 4 beta para Windows, la nueva versión del popular software de comunicaciones a través de Internet. En esta versión dicen que se han concentrado en mejorar las videollamadas, que funcionan a pantalla completa, y la...

Aspecto de los servidores de Archive.org en 2007 – Foto (CC) MysteryBee O’Reilly publica una extensa entrevista con el responsable de tecnología de Archive.org, uno de los proyectos más apasionantes de todo la Internet y su «repositorio histórico» de facto. Se titula...
Hoy a partir de las 19:00, hora de España (GMT +2), estará disponible para su descarga la versión definitiva de Firefox 3 y la Fundación Mozilla se ha planteado celebrarlo estableciendo un récord de descargas en 24 horas tal y como cuentan...
Toochr es una idea tan sencilla como elegante: un directorio web «editado por humanos» de sitios, servicios web optimizados y aplicaicones para iPhone y iPod Touch. Basta con comenzar a navegar por www.toochr.com desde la pantalla del iPod Touch/iPhone para descubrir...
En el capítulo 4.815.162.342 del culebrón internetero de esta primavera Yahoo! rompe sus negociaciones con Microsoft ya que ahora es la empresa de Redmond la que no está interesada en comprar a Yahoo! después de haber retomado el tema a mediados del...
La Campus Party Valencia, que se celebrará este año del 28 de julio al 3 de agosto, contará con un área dedicada a los blogs, llamada CampusBlog de cuya organización son responsables los conocidos blogueros Pixel y Dixel. El otro día...
La Voz de Galicia me pidió un pequeño artículo de opinión sobre la concesión a Google del premio Príncipe de Asturias de Comunicación y Humanidades de 2008 que publicaron con el título Fronteras económicas e ideológicasy que reproduzco aquí: Aún como usuario...
Sekaidokei es una forma visual y sencilla de ver la hora local en diferentes lugares del mundo: basta pasar el ratón por encima. Como bonus, la zona de «sombra» permite saber de un vistazo dónde es de día y dónde de...
Emerging Applications of P2P Technologies es un Wiki donde se puede participar incluyendo en las diversas categorías ejemplos y explicaciones de usos legítimos de las tecnologías P2P. En la lista hay todas esas cosas y alguna más: Distribución de películas de alquiler...
A falta de analizar la demanda a fondo para poder comentarla David Bravo reproduce en Caso Napster a la Española: reclaman a desarrollador de software P2P 13 millones de euros la nota de prensa que MP2P Technologies ha distribuido al respecto. Los...
En la sentencia del Juzgado de Instrucción Número 4 de Cartagena recogida en Caso Elitedivx: proporcionar enlaces P2P no es delito el juez ordena el sobreseimiento de caso contra los responsables del sitio eliteDivX. No soy abogado y a lo mejor meto...
Clic para ir a YouTube a ver el vídeo. Ya se pueden ver algunos vídeos de prueba / demo (Interactive card trick, My 22nd Skydive) de una nueva funcionalidad de YouTube que permitirá añadir notas de texto incluso interactivas en los vídeos...
Por Nacho Palou -
4 JUN 2008
Después de las sentencias contra los responsables de la Frikipedia y Alasbarricadas a causa de contenidos creados por terceros publicados en sus respectivas webs es preocupante leer esto en El País: El fiscal pide más de 5 años al administrador de una...
Desde el lunes de esta semana muchos medios están haciéndose eco de una nota de prensa que han recogido al menos la Agencia EFE y Europa Press que refleja los resultados de un supuesto informe del Observatorio de Internet Francesc Canals titulado...
De una línea de Twitter (en rojo) a Wired y Cinco Días. Antonio Delgado analizó las relaciones y el flujo principal de referencias y enlaces entre blogs y medios que publicaron, citando sus fuentes, acerca del supuesto descubrimiento de un microsite de...
Por Nacho Palou -
3 JUN 2008
Si eres de los que consultan el correo vía telnet y haces tus copias de seguridad como un verdadero hombre, disfrutarás utilizando Google a través de goosh.org, el shell no-oficial de Google....
Por Nacho Palou -
2 JUN 2008
(Nota: Esta anotación habla de Strands, que es una de las empresas en que participo como consejero. Ver Full Disclosure.) El otro día se enseñó la nueva versión beta de Strands a unos cuantos bloggers españoles, aprovechando que las nuevas oficinas en...
Cuando un proyecto tiene éxito lo habitual es que le salgan muchos «padres» que quieran apuntarse algún tanto a raíz de su intervención en el proyecto en cuestión. En el caso de Internet, nadie duda que aquel proyecto para compartir ordenadores ha...
Aunque la versión de Safari que incluyen el iPod Touch y el iPhone es probablemente uno de los mejores navegadores disponibles para cualquier dispositivo móvil una de sus limitaciones más obvias es que no soporta Flash. Esto hace que algunos sitios no...
Tag Galaxy [Flash] es una forma curiosa y visualmente interesante de navegar por las fotografías que la gente ha compartido y marcado con tags (etiquetas) en el popular servicio de fotografías Flickr. Para comenzar el «viaje interestelar» basta escribir un tag, como...
Está completamente en inglés, pero merece la pena leerlo con todo detalle, porque es tronchante: The Internet FAQ from 2085, las «preguntas frecuentes» que se harán dentro de ochenta años sobre la Red de Redes, incluyendo gemas como… P: ¿Qué era eso...
Una «carta de efectos acongojantes» de la Fundación Anti Piratería ha provocado el cierre de Wikisubtitles por parte de smalleye, su administrador, a la espera de lo que le puedan recomendar los abogados al respecto, tal y como cuenta él mismo en...
No creo que sorprenda a nadie, pero tras decidir retirar su oferta de compra por Yahoo! hace un par de semanas, ahora acaba de saberse que Microsoft reabre las conversaciones con Yahoo! para alcanzar una alianza. En esta ocasión no se trataría...
Digsby resultará útiles a quienes sean muy aficionados a chatear y a las redes sociales, cuantas más mejor. Es un programita que se descarga gratis y sirve para agrupar en un solo sitio las cuentas de mensajería de Yahoo, ICQ, AOL/AIM, Google...
Hoy de celebra en varios países el Día de Internet, pero por o general de una forma muy institucional y teniendo muy poco en cuenta o nada a los usuarios. Así, nos vemos spameados por empresas e instituciones que nos cuentan sus...
Tom Castro, un lector del blog, nos envió una captura de pantalla de una curiosa formación geográfica visible en las imágenes aéreas de Sigpac (Sistema de Información Geográfica del Ministerio de Agricultura y Pesca, similar a Google Maps), para preguntar si sabíamos...
Por Nacho Palou -
16 MAY 2008
Seguro que soy el último en enterarme, pero… Acabo de descubrir que pulsando la tecla Escape mientras se está viendo cualquier página web con el navegador Firefox, se detienen los GIF animados. Tal vez a alguien más le sirva el atajo/truco/solución al...
El que para mi es sin duda el mejor client de BitTorrent para Mac acaba de actualizarse: Transmission 1.2. Funciona sobre Mac OS X 10.4.11 pero recomiendan 10.5; también hay algunas versiones Linux. Los cambios de esta actualización «relevante» incluyen: Soporte...
Secuencia de la cadena FOX el 11 de septiembre de 2001 con el momento en que se interrume la programación y se inicia el informativo especial (ver como vídeo). La organización sin ánimo de lucro Internet Archive mantiene una enorme colección de...
Por Nacho Palou -
10 MAY 2008
TimeTube permite crear cronologías o líneas de tiempo (timelines) de vídeos de YouTube; escribiendo una o varias palabras clave, como por ejemplo enjuto muestra los vídeos que coinciden ordenador por orden cronlógico en un gráfico interactivo que permite modificar el nivel...
Por Nacho Palou -
9 MAY 2008
Vía Vida de un Consultor desde las Termópilas....
Así que es genial ver 15 grandes ejemplos de tipografía web que demuestran este hecho. Mis favoritos entre esos 15 serían: Seed Conference Hell Yeah Dude Information Architects The DECK § Cosas Sencillas...
Una semana después de que se terminara el ultimatum dado por Microsoft a Yahoo! para aceptar su oferta de compra la operación se ha venido finalmente abajo fundamentalmente porque las dos empresas no fueron capaces de ponerse de acuerdo en el precio....
Se denomina apnea del correo electrónico a un cambio en la frecuencia de respiración mientras se mira el correo electrónico, por ejemplo contener la respiración mientras se elige en el buzón de entrada qué email leer y contestar. El término lo acuñó...
Hoy acaban las tres semanas de plazo que Microsoft daba a Yahoo! para aceptar su oferta de compra o bien atenerse a las consecuencias de no hacerlo. Yahoo! ha empleado este tiempo en mantener contactos con otros grupos y empresas que pudieran...
Lista según Google: Mucha gente cree que… … el matrimonio es una obligación … Paul McCartney falleció en 1966 … Malí será la próxima Cuba … el ciclismo de montaña es como ir a un parque y dar varias vueltas … el...
La herramienta online FontStruct además de ser bastante chula permite hacer algo tan genial como construir tipografías. La aplicación funciona directamente en el navegador web. Para la construcción de fuentes se utilizan piezas o figuras preestablecidas, como bloques de construcción, que...
Por Nacho Palou -
23 ABR 2008
Adobe TV (requiere Flash, en inglés) es un repositorio de vídeos divulgativos, a modo de tutoriales y explicaciones visuales, con los productos de Adobe Creative Suite 3 como protagonistas. Aunque lleva poco tiempo online los contenidos van creciendo cada día —se...
Por Nacho Palou -
21 ABR 2008
Para qué vas a molestarte en predecir el clima si es mucho más práctico y divertido predecir el tráfico de las ciudades, como cuentan en LifeHacker. Esto es lo que hace ya en algunos lugares Google Maps. A ver si hay suerte...
El curioso a la par que utilísimo sitio TimeAndDate.com tiene un contador personalizado. Si pones una fecha futura puedes a continuación guardar esa URL «personalizada» para consultar cuantos días, horas, minutos o segundos quedan hasta entonces. Por ejemplo, ahora mismo quedan 5.756...
Amanece en la Puerta de Alcalá (Madrid).Arriba el nuevo control horario que modifica la iluminación entre día y noche. Ya es posible descargar la versión versión 4.3 beta de Google Earth. No hay grandes cambios respecto a la versión actual (para eso...
Por Nacho Palou -
16 ABR 2008
Después de la carta abierta en la que este pasado fin de semana Microsoft amenazaba con comprar directamente a los accionistas de Yahoo! las participaciones necesarias de la empresa como para hacerse con el control de esta, el consejo de administración de...
Cuando Yahoo! rechazó la oferta de compra que Microsoft le hizo el pasado 1 de febrero desde Redmond no se mostraron nada contentos con esa negativa y ya advirtieron que seguirían buscando fórmulas para llevar adelante la operación. Ahora, dado que desde...
Desde hoy se puede hacer un seguimiento del relevo de la antorcha olímpica tanto en Google Maps como en Google Earth. La antorcha, que hoy está en Estambul, pasará por múltiples lugares, incluyendo un punto a 8.300 metros de altura del...
Por Nacho Palou -
4 ABR 2008
Al parecer Google se indexó a sí mismo el 31 de enero de 2001. Y años después indexó a Google.es, el 15 de octubre de 2003. Estas fechas tan curiosas se le ocurrió mirarlas a Marqus tras leer Cómo saber cuando fue...
En unas pruebas de usabilidad se pidió a cierto número de personas que buscaran algo en Google. No se trataba de encontrar nada en concreto, sino de ver si eran capaces de llegar hasta Google y realizar una consulta (búsqueda). Esta prueba...
¿No resulta irónico, incluso poético en cierto modo, que la primera búsqueda para SEO en Google en español de como primer resultado a la SEO / Birdlife, Sociedad Española de Ornitología en vez de a cualquiera de las empresas que se dedican...
DownForEveryOneOrJustMe.com apropiado nombre para este útil servicio, que comprueba si una web está realmente caída o se está produciendo el inquietante efecto ¿seré yo, señor, seré yo? A ver… Ah, vale. Funciona. Nestor nos envió este útil enlace y además se...
¿Qué es más irónico? Que en el Día de la Libertad de Expresión en Internet (que era hoy) la UNESCO retire su patrocinio porque no quiere verse involucrada en las denuncias que hace Reporteros Sin Fronteras, O que de paso, en el...
FriendFeedFeed se antoja a simple vista como la solución definitiva para manejarse en el creciente número de servicios de redes sociales, agregadores sociales, servicios sociales y xyz sociales: un agregador que agrega a todos los agregadores. Absolutamente genial… si no fuera...
Aurelio nos recomendó que probásemos la extensión Taboo para Firefox. La he instalado esta mañana y ya se ha convertido en imprescindible (así, del tirón) porque se ajusta perfectamente a mi forma de procrastinar la lecturas de anotaciones o páginas o para...
Por Nacho Palou -
11 MAR 2008
Notengoenie.com es un servicio web minimalista de Korochi que resultara util para quienes se encuentren ante la dificil tarea de teclear con enies y acentos en un teclado sin enies ni acentos. Como funciona? Basta ir a esa pagina web para copiar-y-pegar....
«Una serie de tubos» :-) que llevan Internet por dentro en One Wilshire.Foto (CC) Xeni Jardin The World’s Densest Meet-Me Room es como titula Wired a esta lección de anatomía, un viaje al lugar donde más interconexiones entre proveedores de Internet hay...
De momento lo único que realmente me gusta de Firefox 3 (pero me gusta bastante y no me suena haber visto comentado por ahí) es la reinterpretación de la clásica opción de incrementar o reducir texto de la página (Ver >...
Por Nacho Palou -
4 MAR 2008
Mapping the Internet: Domains Names & Nameservers de Matthew Zook es un archivo KML para Google Earth que geoposiciona los TLD (Top Level Domain, la "extensiones" de los dominios que dependen del país que los otorga o del destino de uso...
Por Nacho Palou -
3 MAR 2008
Este Mapamundi de las Redes Sociales en castellano [ver la imagen ampliada, JPEG] es una traducción de Pancho de OpciónWeb a partir de la infografía publicada por Le Monde recientemente en Des audiences différentes selon les continents, a su vez con...
En septiembre de 2006 José Manuel L. H. fue absuelto en el juicio al que lo llevaron distintas entidades de gestión de derechos de autor por descargar música, películas y juegos de Internet y compartirlos a través de redes P2P con otros...
Una historia de alojamiento web: si se compara lo que puede comprar el mismo dinero ahora que hace diez años, resulta que hoy en día se puede tener unas 443 veces más capacidad de transferencia y unas 1.115 veces más de almacenamiento...
LinkBuch podría calificarse como «todo un avance en acortadores de direcciones tipo TinyURL». Es un miniservicio que permite enviar varias URLs a la vez convirtiéndolas en una URL mucho más corta, del tipo linkbun.ch/xyz. Basta teclear todas las URLs a la vez...
Reddit, el popular servicio de recomendacion de enlaces / noticias de forma personalizada ya está en español. La versión hispana consta de dos partes: el servicio web en sí por un lado y los contenidos en español por otro, donde el...
Horadio de Gran Ímpetu ha publicado una lista de lo que considera que son las Razones comunes para el fracaso de un sitio web. En el original están todas detalladas, la lista rápida es esta: Ausencia de objetivos bien definidos Falta de...
La mayor desventaja de usar las betas de Firefox 3 es, en mi opinión, el que al arrancar desactiva las extensiones que estuvieran instaladas en la versión 2.x y como por lo general estas todavía no están actualizadas para trabajar con Firefox...
Hay una forma rápida y fácil de pedirle a Alexa que actualice la captura de pantalla (miniatura o thumbnail) que tiene de un sitio web determinado y que se muestra junto a su ficha. Basta ir a la ficha de detalles de...
150 es el Número de Dunbar, una cifra con significado social formulada por el antropólogo Robin Dunbar. Su teoría dice que 150 es, más o menos, el número máximo de personas que en un grupo pueden mantener una relación social estable, en...
Según se puede leer en Yahoo rejects Microsoft bid se confirman los rumores y filtraciones que este pasado sábado ya afirmaban que la junta directiva de Yahoo! se disponía a decir que no a la oferta de Microsoft de adquirir la empresa....
Según cuenta Bloomberg en Yahoo to Reject $44.6 Billion Microsoft Bid, WSJ Says (Update2) el consejo de dirección de Yahoo! parece estar dispuesto a rechazar la oferta de Microsoft de comprar la empresa. La posición oficial de la Yahoo! es que están...
Ya está disponible la versión en español de Facebook, el popular servicio para estar en contacto con los amigos y conocidos, una de las mayores redes sociales de todo Internet. Se puede elegir el idioma preferido en Facebook > account >...
Primero fueron dos casi a la vez, luego tres, cuatro y hasta cinco los cables submarinos de Internet que están experimentando problemas. En la anotación Fourth Undersea Cable Failure in Middle East de Bruce Schenier se comenta que esto ya empieza a...
En La Voz de Galicia me pidieron un pequeño artículo de opinión sobre la oferta de de Microsoft para comprar Yahoo! que publicaron junto con el título «Como un muerto guiando aun ciego». Aprovecho para repescar aquí el texto y enlazarlo adecuadamente,...
El vídeo más corto en YouTube: 0 segundos. El vídeo más largo en YouTube: 42 horas. (Dosis friki de Tudosis.)...
LaListaWIP es un nuevo sitio web en formato lista/ránking que recopila la información sobre referencias en Internet a miles de personas, generalmente protagonistas de la actualidad. En base a todas esas referencias a sus nombres, que recogen unos bots de sitios...
Ismael El-Qudsi, que por si no lo sabes trabaja en Microsoft España, confirma en su anotación Propuesta de Microsoft para comprar Yahoo la noticia tecnológica del día, la oferta no solicitada de Microsoft de adquirir Yahoo! por 44.600 millones de dólares, lo...
Las entidades de gestión de derechos de autor siguen empeñadas en criminalizar el intercambio de archivos mediante redes P2P y en perseguir a sus usuarios, aún a pesar de que una vez tras otra se encuentran con que la ley dice que...
Amazon anunciaba ayer en Amazon to Begin International Rollout of Amazon MP3 in 2008 que a lo largo de este año empezará a ofrecer descargas de música en formato mp3 sin sistemas DRM a nivel internacional a través de su servicio Amazon...
Cuando hace un par de días recibimos la nota de prensa sobre la iniciativa de Televisión Española y YouTube para recoger las preguntas de los ciudadanos en vídeo en el canal Elecciones Generales '08 y luego trasladárselas a los políticos correspondientes para...
Tal y como se dio a conocer hace algunos días y ha circulado por ahí, SETI@home está buscando nuevos voluntarios. Este popular proyecto fue uno de los primeros en popularizar la idea de computación distribuida: la utilizacion de un gran número de...
Sun ha comprado MySQL por 1.000 millones de dólares. Lo cuenta el CEO de Sun Microsystems en su blog. MySQL es uno de los sistemas de gestión de bases de datos relacionales más populares del mundo, desarrollado como software libre. También es...
Nirewiki es una nueva plataforma para crear múltiples Wikis. En cierto modo sería como un MediaWiki pero co la posibilidad de crear varios Wikis a la vez con una base común (como hacen WordPress µ o Movable Type Enterprise para los blogs)....
Hoy he estrenado el año con Isidoro Valerio en Voces de Galicia hablando un rato de la conferencia inaugural de Bill Gates en el CES en la que este confirmaba que en julio deja Microsoft para dedicar su tiempo a la Fundación...
Según cuenta Reuters en Sony BMG to drop copy protection for downloads se confirman los rumores de que Sony empezará a vender música en formato mp3 sin sistemas DRM a través de Internet -aunque por ahora serán sólo 37 álbumes- en los...
Yahoo España ha organizado un concurso para ver cuál de todas estas es la Web Española Revelación de 2007 según la opinión del público. Hay 40 proyectos nominados, sitios de orientación y temática muy variada, algunos proyectos personales, otros totalmente profesionales: 11870...
Como actualización de la lista de Buscadores de Torrents que funcionan que publicamos hace casi un año, esta es la lista de los diez sitios más populares de 2007, sacada de Top 10 Most Popular Torrent Sites of 2007: Mininova, uno de...
AOL ha anunciado que abandonará el desasrrollo del navegador Netscape el próximo 1 de febrero de 2008, recomendando a quienes quieran un buen navegador que usen Firefox. Se pone así fin a una lenta agonía: el gigante compró a Netscape en...
Después de meses de rumores y de trabajo hoy se ha lanzado al público soitu.es, el nuevo proyecto de Gumersindo Lafuente, quien fuera director de la edición digital de El Mundo. Como todo lanzamiento en Internet que se precie y que haya...
La semana pasada, harto de versiones cada vez peores de Firefox 2, al menos bajo Mac OS X Leopard, y en especial de la actualización 2.0.0.11 del navegador, que es poco menos que insufrible, pensé que poco podía perder probando Firefox 3...
Hace poco descubrí que para escribir «al cuadrado», algo como m² digamos, se podía usar la entidad HTML ² en vez del clásico <sup>2</sup>. Aparentemente, m² y m2 deberían ser lo mismo, pero no. Según cómo se interprete el HTML, los navegadores...
Son las cinco palabras más buscadas en Google. Con permiso de Britney, ha de suponerse....
Mapas visuales que intentan captar la complejidad de Internet dentro de las vastas colecciones de VisualComplexity.com. (Visto en El mundo de los mapas.) Enlaces en el MundoReal™, otra forma de ver los libros. Complejidad Visual, algo más sobre este proyecto....
Como ya hemos comentado en varias ocasiones en los últimos meses el Proyecto de ley de Medidas de Impulso de la Sociedad de la Información, más conocido como LISI, está en plena tramitación parlamentaria. Es una ley que a todos los usuarios...
Adaptado de The Truth de Sean Bonner (Nos reveló la verdad Boing Boing.) – Esta anotación, licenciada como Creative Commons Reconocimiento-No comercial-Compartir bajo la misma licencia 2.0 Genérica....
Interesante la idea de Google Chart API, pensado como una herramienta para desarrolladores y webmasters, aunque es tan simple que casi, casi, podría usarla un niño de cuatro años.
Supuestamente, fue un chat real… Broma de quitarse el sombrero: JimBob2814: bueno, pues ya he probado el Superman 64 JimBob2814: sí, sí que lo es. Rawlsaur: ¿Es realmente tan malo como dicen? Rawlsaur: ... JimBob2814: no, es sólo que eres predecible Rawlsaur:...
¡Ah, tantas cosas nuevas en Internet y tan poco sitio y tiempo para contarlas! De modo que a partir de ahora los Microsiervos las estamos recopilando aquí: titulares rápidos y directos, con pequeños comentarios que pueden leerse en cinco segundos: i Microsiervos...
(Nota: Esta anotación habla de MyStrands, que es una de las empresas en que participo como consejero. Ver Full Disclosure.) Hoy ha sido un gran día para uno de los proyectos en los que tengo el honor de participar. El Grupo BBVA...
Texto de la etiqueta: “Este ordenador es un servidor ¡NO APAGAR!” Este NeXTcube de Berners-Lee fue el primer servidor web. Se utilizó también para programar el primer navegador web, llamado precisamente WorldWideWeb, en 1990. En la Navidad de aquel año, Berners-Lee...
Por Nacho Palou -
3 DIC 2007
Datos extraídos por blojer el otro día, sobre MySpace: El perfil del usuario medio de MySpace EspañaEn cuatro líneas. En estos momentos, Foro de España:Subforo de Ligues: 4.003 temas, 40.028 publicacionesSubforo de Ciencia: 89 temas, 538 publicaciones...
En estas fechas se tramita en el parlamento español la Ley de Impulso a la Sociedad de la Información, más conocida como LISI, que será la ley que una vez que entre en vigor determinará como va a ser Internet en España...
EveryScape es una especie de Google Maps avanzado, con fotos de las calles en cierto modo animadas, como en realidad virtual envolvente, de modo que se pueden recorrer con el ratón o en el modo «piloto automático». También se puede entrar...
Convirtiendo en nube de spam las palabras del correo basura. (Vía-gra PuntoGeek Credit Card.)...
Los dominios de primer nivel de Internet más consultados. (ICANN) Es bueno ser Rey, pero es mejor ser root en un Root Server. De ese modo es como cuentan en el blog de la ICANN que han obtenido este gráfico. Con una...
El terreno en Granada y sus alrededores en Google Maps. Google Maps ahora incorpora una nueva opción en la pestaña de arriba a la derecha que permite ver una especie de capa de «terreno», con montañas y otros accidentes geográficos, parecida a...
24 hours of Flickr fue una experiencia realizada por el popular servicio de almacenamiento de fotografías (nuestro favorito por cierto) que ahora han editado como libro; la gente de Yahoo/Flickr nos envió un ejemplar amablemente. Es una recopilación de fotografías de...
Hace ya unos días que vio la luz Flickr Places (accesible desde el menú Explorar), descrito como “una página de Flickr para cada lugar del mundo”. Su planteamiento básico es tan simple como reunir en una única página (del tipo página de...
Por Nacho Palou -
26 NOV 2007
Cada minuto se suben 8 horas de vídeo a YouTube. En total el servicio tiene almacenados unos 50 millones de vídeos. A ese ritmo, ya es imposible que nadie pudiera ver todo el material que se sube al servicio en «tiempo real»....
Nota: La explicación original de esta anotación es errónea. Ver al final. Después de haberlo visto pasar en algún lado hace tiempo como «truco para evitar el correo basura» he podido comprobar esta curiosidad de las direcciones de GMail. El servicio está...
Unas notas rápidas de la conferencia de Shel Israel, la persona que en sus propias palabras presentó PowerPoint al mundo, ilustrada con viñetas de Hugh MacLeod de gapingvoid. Shel Israel en EBE07 Le dio por ir preguntando a gente de todo el...
Módem USB Huawei E272 Vodafone. Vodafone nos ha prestado otro de sus módems USB 3G para probar, en este caso el Huawei E272. Se trata de un modelo desarrollado específicamente para Vodafone por Huawei Technologies, por lo que a diferencia del...
Uno de los clásicos de la blogosfera española, Bitacoras.com, vuelve con nuevos bríos, convertida en una empresa con un grupo inversor detrás que apoya el proyecto con los recursos económicos, técnicos y humanos necesarios. Historia visual de Bitácoras.com por Jasp El antiguo...
Para quienes quieran vivir «livin' la vida loca» ya está disponible para descarga Firefox 3 Beta 1, una versión recomendada solo para desarrolladores y aquellos que quieran hacer de conejillos de indias. De hecho desde Mozilla se pide que enlacemos con Firefox...
Hoy he vuelto a estar en Voces de Galicia con Isidoro Valerio y Marcus Fernández para hablar del tema del comercio electrónico a raíz del Estudio sobre comercio electrónico B2C 2007 [PDF 460 KB] de Red.es. Junto con otros invitados que participaron...
Si este próximo fin de semana no vas a estar en Evento Blog España a lo mejor te apetece pasarte por Jornada Albedrío: Por una Cultura Libre, organizada con el objeto de «debatir sobre el libre flujo de la información, que está...
Aprovechando que David Sifry anda estos días por España Luz Fernández lo entrevista para El País en "Cualquier intento de controlar la blogosfera llega demasiado tarde", una entrevista en la que entre otras cosas reconoce algunas de sus últimas equivocaciones a la...
La idea de Kroonos es sencilla: un sitio en el que la gente puede intercambiar favores y tiempo. Algunos pueden conseguir lecciones de inglés a cambio de ofrecer cursos de mecánica, y cosas así. La experiencia de todos combinada en forma...
La autodenominada «televisión mutante» ADNStream estrena nuevo player. En esencia sirve para ver vídeos y votarlos, también se pueden «incrustar» en cualquier blog o web, o guardar listas de favoritos – ahora está lleno de iconcitos para hacer esto más fácil....
La Wikipedia en español supera los 300.000 artículos, alcanzando otro hito simbólico. Aunque no esté my claro qué es exactamente lo que motiva a quienes los escriben lo cierto es que sigue creciendo. La versión en español está entre las diez Wikipedias...
Esto sí que sería un avance de verdad: Poder FTPear a la tarjeta SIM de los teléfonos móviles. Situación: llegas a la oficina, tienes el Bluetooth activado y con cualquier cliente de FTP puedes subirte, sin cables, lo que necesites para llevar...
Si la semana pasada enlazábamos con la anotación de Carlos Almeida sobre la aprobación en el Congreso de la LISI, la Ley de Medidas de Impulso de la Sociedad de la Información, y sus dudas sobre la forma en la que está...
La realidad: cientos de Root Servers en más de 130 ubicaciones en todo el mundo. Imagen de Patrik Fältström Interesante este apunte: There are not 13 root servers que desmitifica la leyenda de que en Internet sólo hay 13 Root Servers o...
El 99,9% de los pings que recibe el buscador de weblogs Technorati son spam: weblogs falsos, granjas de enlaces y sitios que roban textos a otros intentando «avisar» de que han «publicado nuevos contenidos», aunque en realidad son basura con la que...
Qué dice la Wikipedia sobre la Wikipedia es un buen ejemplo de autorreferencia, la entrada Wikipedia en la Wikipedia. xxxxxLa Esquizopedia despareció, pero quedó su rastro en Archive.org....
Hoy estuve de invitado en la sección La Red del programa Voces de Galicia de Radio Voz que dirige Isidoro Valerio y aprovechando que estamos en la Semana de la Ciencia propuse a la audiencia cuatro enlaces para estar al tanto de...
El próximo jueves, 15 de Noviembre de 2007 a las 17:00 el IEEE hay organizada una Conferencia de David Sifry de Technorati, Será en el Aula Magna (Edificio A) de la Escuela Técnica Superior de Ingenieros de Telecomunicación en la Universidad...
En febrero de 2006 la Frikipedia se veía obligada a cerrar a instancias de una demanda interpuesta por la SGAE contra sus responsables en la que se solicitaba el «cierre de la página» y el pago de 12.000 euros en concepto de...
Aunque las licencias Creative Commons están muy de moda en realidad hay un cierto debate sobre su validez y sobre si es adecuado usarlas, y todos conocemos ejemplos de casos en los que estas licencias se las han saltado a la torera....
TwiterPoster, una visualización de los usuarios de Twitter en función del número de sus «seguidores» (followers), agrupados por país (España), región (Europa) o El Mundo Mundial. (Vía su creador Metaperdomo; TwiterPoster se lanzó hace unos días en varios idiomas.) La Curva de...
The Hole Trick explica en términos llanos cómo en un mundo informático lleno de cortafuegos (firewalls) en el sistema operativo, en la oficina, en los proveedores de Internet, las aplicaciones P2P (peer-to-peer) de telefonía por Internet pueden funcionar. Si lo piensas, cuando...
Es bastante fácil extrapolar cómo continúa la evolución para los años 2006 y 2007. (Vía Digg.)...
Por Nacho Palou -
5 NOV 2007
QEDWiki es la herramienta de IBM para programadores que quieran crear mashups, con toques de wiki. En la página hay tantos acrónimos raros que para entenderlo es mejor ver el vídeos de demostración de su web. En cierto modo es parecido a...
Don’t Click Here: The Art of Hyperlinking es un excelente artículo de Coding Horror con muy buenos y sabios consejos sobre cómo hiperenlazar en la web. Se puede leer al completo traducido al castellano como Evitando el «click aquí»: el arte de...
Carlos Almeida nos pasa el aviso de que la semana pasada, justo antes del puente, el congreso aprobaba la Ley de Medidas de Impulso de la Sociedad de la Información, más conocida como LISI, en la que nos jugamos algunos aspectos muy...
Íñigo se percató de que en la nueva modalidad que admite la eñe en los dominios de Internet, la codificación para españa.com es xn--espaa-rta.com Curiosa coincidencia y momento ¡Esto es Espararrrrtaaaaa! de 300....
La librería Amazon ha añadido una pequeña funcionalidad a su extraordinaria sección Search Inside (que permite leer y buscar en el contenido completo de los libros a través del navegador). Se llama Text Stats y es una recopilación estadística sobre las...
ASCII Browser: Navegar + la Web + en ASCII. (VIASCII Digg.)...
What Motivates Wikipedians es un trabajo que ha publicado Oded Nov en Communications of the ACM, que resume Andy Oram parra O’Reilly Radar. Este sería mi resumen de ese resumen: qué motiva a la gente que participa creando, apliando y corrigiendo artículos...
Al hilo de la anotación Leyes mordaza y el futuro que les espera de JJ Merelo sobre la ley que pretende someter a los blogs en Italia a una serie de controles draconianos de la que hablaba Beppe Grillo hace unos días...
pForm es un generador de formularios en HTML. Considerada la Siberia de diseñadores, programadores y htmleros, la codificación en HTML de estas indispensables páginas web recobra una nueva luz gracias a este servicio gratuito: permite generarlos de forma visual en cuestión...
No lo decimos nosotros, claro, sino Javier Rojo, el presidente del Senado, quien según cuenta Cararias 7 en El presidente del Senado español alerta del desprestigio por informaciones no veraces en Internet se descolgó con perlas como estas en la clausura del...
Asistentes a la pasada edición de Copyfight (Foto: Pixel y Dixel) La edición de este año de Copyfight 2007 tendrá lugar en Girona, en el Centre Cultural la Mercè entre los días 8 y 10 de noviembre. Exposiciones, seminarios y charlas sobre...
El Museo Nacional del Prado ha rediseñado su web. Javier, que ha trabajado en el proyecto, nos ha contado que se ha intentado dar más importancia a los contenidos con un diseño más claro. A mi personalmente me parece ciertamente elegante...
Según cuenta Lourdes Muñoz de Santamaría en La LISI aprobada en comisión. Unanimidad en banda ancha y restricción de contenidos la ley en cuestión fue aprobada el pasado martes en la comisión de industria del Congreso con los votos favorables de todos...
Predictify es un curiosísimo nuevo servicio que utiliza algunas ideas de la sabiduría de las masas para adivinar el futuro, una especie de «mercado de predicciones». En forma medio de juego, medio real, organiza preguntas y respuestas que la gente envía, sobre...
El vídeo SMS [YouTube 1:22] parece patrocinado por el Comité Contra las Faltas Voluntarias y el Lenguaje SMS, y tiene toda la razón del mundo (aunque le falte un espacio detrás de una coma): (Twitteado por bolg… a ver si al final...
Si los usuarios de Internet en España estamos, o deberíamos estar, preocupados por la Ley de Medidas de Impulso de la Sociedad de la Información, también conocida como LISI, en la que nos jugamos unas cuantas cosas importantes respecto al futuro de...
Cuando Jack Bauer necesita mirar fotos aéreas en territorios hostiles como Tanzania recurre al Botón Secreto de Google Earth, que le que permite conmutar entre el modo normal y el modo «Alta Resolución para Agentes de la CTU»: Se ven hasta los...
Flash Earth sobre Barcelona: junto a la plaza, la Torre Agbar Flash Earth es una grácil interfaz gráfica vía web que muestra las imágenes por satélite de diversos proveedores (está basada obviamente en Flash, así que +1 al uso apropiado de esta...
Acaba de abrirse el plazo de inscripción para el Ciclo de conferencias IMAD 2.0, que organizado por el Consorcio RIBA del Ayuntamiento de Palma de Mallorca y dirigido principalmente al público universitario pretende acercar a este «la visión de las TIC como...
Flickr Related Tag Browser: simplemente hay que teclear una palabra etiqueta para ver una índice de miniaturas y etiquetas relacionadas con la escrita. (Vía Digg.) Bonus: Tiltviewer, visualizador de imágenes de Flickr en 3D....
Por Nacho Palou -
23 OCT 2007
En breve Flickr integrará el editor de fotografías online Picnik que comentamos por aquí hace un tiempo y que tanto nos gustó. Lo cuentan en el blog de Picnik: Flickr + Picnik = Awesome. (Vía Error500.) Flickr + Mapas: una forma fácil...
Por Nacho Palou -
22 OCT 2007
Vodafone Mobile Connect Módem USB HSPA/3G/EDGE/GPRS. Hace unas semanas Vodafone nos prestó su nuevo módem USB HSPA, así que después de haber hecho las pruebas pertinentes, este es nuestro análisis de su funcionamiento bajo Mac OS X. El kit El equipo...
Jesús Javier Pérez y Javier Barrera me invitaron de nuevo a participar en Enredados, la Radio de la Blogosfera Andaluza, en este caso para hablar de cómo la tecnología y más en concreto Internet han cambiado nuestra relación con la música, en...
Cinco errores de las plataformas de compra online son cinco grandes realidades captadas por SigT que cualquiera que navegue y compre de vez en cuando habrá sufrido más de n veces: Formularios que dependen de tecnologías no del todo compatibles Pedir registro...
Emezeta Rank se autodefine como «un nuevo sistema para estimar el éxito y/o popularidad que tiene tu página web, blog o sitio de Internet» y es un servicio para comprobar webs. Es el hijo del Ránking Emezeta (que por desgracia no...
Microsoft Live Maps (también conocido como Live Search Maps o Virtual Earth) ya dispone de imágenes a vista de pájaro de algunas zonas de Madrid capital y Barcelona. Este tipo de vista muestra la ciudad con perspectiva aérea además de la vista...
Por Nacho Palou -
19 OCT 2007
La Ley de Medidas de Impulso de la Sociedad de la Información, AKA LISI, que lleva ya tiempo dando vueltas por los despachos ministeriales a ver si de una vez por todas se alcanza un acuerdo en su redacción definitiva, acaba de...
Alguien tan histérico que incluso se compró un dominio… d-e-f-i-n-i-t-e-l-y.com Actualización : Parece que la expresión talibánica mediante curiosos d-o-m-i-n-i-o-s se va a convertir en moda… ti-nunca-lleva-tilde.com (¡Gracias CambioYCorto y TheOm3ga!) «Pilotless Drone!» el lector furioso que se quejaba de una redundancia....
Cuando en abril del año pasado se lanzó una gran operación policial contra las redes de intercambio de enlaces P2P, la que en su momento se calificó como una operación sin precedentes en Europa, muchos dijimos que no era más que un...
Para aquellos que se sienten superados por el crecimiento de sus colecciones de libros, películas, CDs de música y similares las recomendaciones del artículo Aplicaciones online para catalogar libros, discos y películas pueden estar bien. Se citan varios sitios útiles para catalogar...
Una entrevista de Nick Wingfield con Steve Jobs en The Wall Street Journal, Apple Reduces Prices on iTunes Songs Without Anti-Copying Software, confirma el rumor que esta misma tarde habían publicado en Ars Technica acerca de una bajada de precios de las...
Nada detiene a los chicos del proyecto Google Street View. Ni siquiera un cruce con varios coches estrellados, incluyendo un Range Rover “ruedas arriba” y un Audi Q7 bastante perjudicado. Cada día más imágenes cotidianas en Google Street View. (Vía Google Sightseeing.)...
Por Nacho Palou -
16 OCT 2007
ScienceHack es un sitio con aspecto webdosceriano que se dedica a recopilar vídeos de diversas fuentes, todos ellos relacionados con temas científicos y tecnológicos. Se clasifican por categorías y se etiquetan, de modo que son fáciles de encontrar. Según dicen, su...
GhItlh'a'!!! una enclopedia con honor, en la que la nota de aviso importante «por favor añadan el código {{Hov leng}} para referirse al universo de ficción de Star Trek» resulta ligeramente… redundante… por decir algo. Con casi cien artículos, la Wikipedia en...
De la Comarca a Mordor en un par de clics, con la tecnología del siglo XXI. La Tierra Media con Google Maps es una recreación modernizada de los mapas de Tolkien, por donde andan y andan y andan los personajes de...
LANDER - Un mapa de Internet codificado con colores, que muestra a qué zona corresponde cada una de las direcciones IP. Imagen (C) ISC/Information Sciences Institute Internet gets first full census for 25 years es un artículo de NewsScientist que explica cómo...
Rob Malda on Ten Years of Slashdot en Network Performance Daily es una bonita entrevista a CmdrTaco (en la vida real: Rob Malda), el creador de Slashdot, con motivo del décimo aniversario del «sitio de noticias para nerds, lo que de verdad...
Ian Rogers, Vice Presidente de Yahoo! Music dio una charla hace un par de días a unos cuantos ejecutivos de la industria discográfica dentro de las jornadas Digital Music Forum West, en concreto en la mesa The State of the Digital Union,...
More than 100 Web 2.0 Online Generators es, como su propio nombre indica, una lista de cien aplicaciones web tipo “generadores de botones / paletas de colores / gráficos / logos /texturas / fondos / CSS / favicons / esquinas redondeadas /...
Por Nacho Palou -
8 OCT 2007
Del departamento «es que nos encantan las listas», una lista con los peores errores empresariales en Internet, D’oh! The Biggest Internet Mistakes Ever, que como todas estas listas puede ser muy subjetiva y estar abierta a múltiples matices: AOL se fusiona con...
iPhoney es una pequeña aplicación que se supone emula cómo se ven las páginas web en el teléfono de Apple y en los nuevos iPod Touch. De ese modo podrías comprobar cómo se verá tu página en estos dispositivos —aunque no esperes...
Por Nacho Palou -
3 OCT 2007
Esta mañana he sido invitado a participar en Voces de Galicia, el programa de Radio Voz que dirige Isidoro Valerio, para hablar acerca de phishing, estafas y otros temas similares en Internet. Voces de Galicia se emite de 11:00 a 13:30, y...
Desde hoy Joost, el servicio de vídeo bajo demanda a través de Internet que tanto está dando que hablar en los últimos meses y que ya habíamos podido probar hace algún tiempo, está abierto al público sin necesidad de invitaciones, así que...
La Beca Alzado: 4.000 euros para el mejor proyecto o idea puede ser una buena forma de empezar para aquellos que tengan una gran idea o un proyecto interesante pero necesiten un empujoncito. De momento han llegado diez ideas y todavía se...
Planeta Web 2.0: Inteligencia colectiva o medios fast food es otro nuevo libro sobre el fenómeno Web 2.0, escrito por Cristóbal Cobo y Hugo Pardo. Se puede descargar y leer completo de forma gratuita porque está publicado con una licencia Creative Commons....
Tras anunciarlo en mayo, Amazon ha lanzado hoy Amazon MP3 en beta, una tienda de música en línea con más de dos millones de canciones de 180.000 artistas de más de 20.000 sellos, tanto independientes como de los grandes, incluyendo EMI Music...
Cómo utilizar la Wikipedia sólo con el teclado, poderosos atajos para Firefox y Explorer, Windows y Mac, para navegar como por arte de magia de unos sitios a otros de la popular enciclopedia. (Vía TuFunción, traducido de Micro Persuasion.) 18 atajos de...
Problema tonto del día: ¿Cuál es el número natural más bajo que nunca ha sido usado en la World Wide Web y que no aparece en Google? Google indica que el número 1 aparece en las páginas de la World Wide Web...
Ya hemos hablado bastantes veces de lo importante que nos parece que se mantenga el concepto de la neutralidad de Internet, de tal modo que los proveedores de acceso traten por igual todo el tráfico que circule por sus líneas, sin establecer...
Ayer por la tarde se hacía pública la sentencia del juicio por la demanda interpuesta por Ramoncín contra Alasbarricadas.org por unos comentarios dejados en este sitio por un tercero y que Ramoncín encontraba ofensivos contra su honor, y como ya «twitteó» en...
El 19 de septiembre de 1982 a las 11:44, hora de la costa este de los Estados Unidos, las 17:44 hora de España, Scott Fahlman proponía en medio de una serie de mensajes medio en serio y medio en broma el uso...
Según cuenta Hispalinux en Existe una mayoría clara en el parlamento que apuesta por Internet banda ancha como servicio universal y sin censura previa el polémico y tan traído y llevado artículo 17 bis de la Ley de Medidas de Impulso a...
Hace unos días la cadena NBC decidía retirar sus programas de televisión de la iTunes Store, no porque se vendieran mal, ya que de hecho suponían como un tercio de las ventas de vídeos en la iTunes Store, sino porque quería aumentar...
Una animación en Flash de El País que explica la trama de espionaje entre trama McLaren y Ferrari. Protagonizada por simpáticos personajes de Lego, además de ser bastante ingeniosa, la animación explica concisa y claramente el entuerto que de momento le ha...
Por Nacho Palou -
14 SEP 2007
Alex nos envía una foto que hizo este sábado en Barcelona de una de las furgonetas de Tele Atlas, una de las empresas que proporcionan las imágenes que vemos en Google Maps o Google Earth, furgoneta que por la pinta de los...
Who Owns What v2.0, de WebbMediaGroup es una sencilla vista de pájaro del panorama Web 2.0 internacional que ya ha sido acaparado por «los grandes»: (Vía Twitter.)...
Dopplr está ya lanzado en beta de forma masiva. Se trata de un servicio «web 2.0» estilo Twitter (¿qué estás haciendo ahora?) pero para gente que viaja a menudo (¿dónde estás ahora?) Básicamente le dices a Dopplr dónde vives, dónde vas...
Uno de los culebrones de este año está siendo el polémico artículo 17 Bis de la Ley de Impulso a la Sociedad de la Información (LISI), artículo que daría potestad a las «autoridades competentes» para solicitar la retirada de contenidos de Internet...
Jessica de Mister Wong me recordó que han puesto en marcha un concurso para cambiar su logotipo, en el que pueden participar los «artista de los píxeles» de cualquier país. Mr Wong es un servicio de marcadores sociales sobre el que comenté...
Visto en Pulso Digital, donde haciendo clic se puede ver el horror con todo detalle....
Un par de meses después de la primera beta pública de Movable Type 4.0 ya está disponible la versión final. Según comenta Anil Dash se trata de una versión completamente rediseñada tanto interna y externamente. MT 4 incluye un montón de novedades...
Por Nacho Palou -
16 AGO 2007
¡Nunca se sabe cuándo se va a necesitar uno! En la web del servicio Quantum Random Bit Generator se ofrece un generador de bits aleatorios realmente aleatorios y no pseudoaleatorios como suelen ser los generados por ordenador. La fuente aleatoria se llama...
Los códigos HTML que ofrecen YouTube y Google Video para «incrustar/insertar» los vídeos (embed) en otras páginas web no validan XHTML. Aunque validar en XHTML esté a veces sobrevalorado, no viene mal que las páginas con vídeos incrustados validen también correctamente. Además...
Siempre me ha parecido absolutamente incomprensible que la actividad empresarial en España, con la excepción del turismo y hostelería, se pare cada mes de agosto, con empresas que cierran todo o buena parte del mes, pero lo que no esperaba encontrarme de...
Todos los vídeos de YouTube tienen un código único al estilo SIvp8xmvAyc. Son combinaciones únicas al azar de once letras y números que, de seguir así, algún día se agotarían, como las matrículas. En ¿Cuántos vídeos caben en Youtube? hacen un repaso...
The Strangest Sights in Google Earth, una recopilación de algunos de los lugares, objetos y momentos más raros y curiosos que pueden econtrarse hasta ahora en Google Earh: barcos y camiones accidentados; elefantes corriendo por la sabana africana; figuras gigantes o un...
Por Nacho Palou -
30 JUL 2007
Cuenta la leyenda que en los tiempos prehistóricos de Yahoo los responsables de sección recibían un aviso de correo cuando alguna de sus páginas web superaba los 50 KB de tamaño: un robot se encargaba de revisar la navegación y de alertar...
Craig Newmark, de Craigslist, un extenso y completo perfil del que para muchos (me incluyo) es uno de los héroes de la Internet actual, fundador de Graigslist, el popular sitio de anuncios clasificados que ha roto moldes por su planteamiento y su...
Este bonito mapa que parece podría pasar por el del Metro de Madrid en 2019 es en realidad el Web Trend Map 2007. Se trata de un trabajo de Information Architects Japan que incluye los doscientos sitios web más populares de...
The Open Library es un nuevo proyecto, medio a lo Wikipedia medio a lo Proyecto Gutemberg, realmente ambicioso: su intención es ofrecer toda la información existente de todos los libros del mundo, ya sean físicos o digitales, estén a la venta o...
Esto es probablemente lo más cercano que estaremos la mayoría de dar un paseo por el interior de la Estación Espacial Internacional que orbita la tierra a más de 330 kilómetros de altura: ISS Interactive Reference Guide (inglés, requiere Flash). El interactivo...
Por Nacho Palou -
22 JUL 2007
«Ya sé que voy a ir al infierno» es el titular de una genial entrevista de ComputerWorld Australia donde un spammer «retirado» (no en el sentido bladerunneriano, sino en el económico) cuenta algunas de sus tácticas y cómo es la vida cotidiana...
AJAX, ASP, ASP, AVS, AWS, CGI, CMYK, CNAME, CPC, CPM, CRAP, CRON, CRUD, CSC, CSRF, CSS, CTR, CVS, DBMS, DHTML, DNS, DOM, DTD, FAQ, FLA, FTP, GIF, GUI, HTML, HTTP, HTTPS, ICANN, IIS, IP, JPEG, JS/, JSP, MID, PHP, PNG, PPC, PR,...
Actuando de una forma absolutamente consecuente con la parte del título del curso sobre Periodismo social, comunicación y nuevas tecnologías que habla de nuevas tecnologías Servimedia ha grabado y colgado en Internet todas las sesiones del mismo: Lunes 9 de julio de...
Unas notas sobre la conferencia de Dan Gillmor, 2.0 La red que gobierna, en el curso sobre Periodismo social, comunicación y nuevas tecnologías. 1. Evolución en los medios Cambios, democratización de los medios en el sentido de la participación. Herramientas para todos,...
WikiMindMap es otra forma de navegar la Wikipedia, visualmente, enlazando conceptos automáticamente, mediante la técnica de visualización de los mapas mentales. Son como un resumen destilado de lo más importante de cada artículo, y se puede ir saltando de idea a...
Difunde Firefox ha puesto en marcha Internet y Firefox: Encuesta para recopilar algo de información por parte de usuarios de Firefox sobre el entorno tecnológico y de divulgación de Internet en los países de habla hispana (principalmente España, México y Argentina)....
Depende. La Comisión multa a Telefónica con 151 millones de euros por dificultar la competencia en ADSL. Suena a mucho, pero se puede ver de otra forma: si Telefónica tiene hoy en día unos cuatro millones de clientes de ADSL en España,...
Joost de Valk ha creado la interesante y práctica Google Web Search Parameters Cheat Sheet [PDF, 100 ] una chuleta que resume qué significa y para qué se usa cada uno de los parámetros que se ve en las URLs del buscador...
Google Image Ripper es un poderoso por no decir poderosísimo buscador de imágenes. Lo que hace básicamente es lanzar a Google Images una consulta y enlazar directamente a las imágenes de los resultados. Pero no muestra las clásicos miniaturas, sino las imágenes...
La imagen de arriba (pulsa par ampliar) intenta comparar a escala el tamaño del Sol (etiquetado como “The Sun”, en la imagen) y el tamaño ampliamente aceptado para la estrella VY Canis Majoris, una estrella hipergigante roja con un radio estimado...
Por Nacho Palou -
2 JUL 2007
La entrada #779320 del siempre hilarante Bash.org define el concepto “Web 2.0” en dos frases. Tu haces todo el trabajo.Ellos se quedan la pasta. (Vía del.icio.us/popular.) Python... en la QDB....
Por Nacho Palou -
2 JUL 2007
Se publicó por fin la versión 3 de la GNU General Public License, una de las licencias de software libre pioneras y más populares del panorama actual, madurada tras más de quince años desde que se publicara la versión 2 (GPL v2)...
Random live webcams from the Net es una colección agrupada de cámaras web accesibles directamente desde Internet. Suelen estar instaladas en lugares públicos, aunque a veces la gente las ha instalado tal cual y no saben que sus feeds de vídeo...
Slapvid es una idea ingeniosa como solución para arreglar parte de los problemas de atención generados por ese ente del mal y amo de las pérdidas de tiempo de hoy en día llamado YouTube. Lo que hace es agrupar en un...
Inside the Intenet Archive es un antiguo pero no por ello menos interesante artículo sobre las interioridades de The Internet Archive (más conocido como Archive.org) – a veces llamado «la Biblioteca de Alejandría de la Web» o también «la mayor colección de...
Pownce es como Twitter. Es del inventor de Digg. Requiere invitación o apuntarse por correo a la cola, pepsi-cola. (Vía un tercio de la blogosfera.) (Otro tercio habla del iPhone.) (Y el otro tercio de los AdSense con esquinas redondeadas.)...
Sclipo [actualización: cambió de nombre a UnComo] es un sitio al que la gente envía vídeos con el objetivo de compartir conocimientos. Esto abarca campos extensos y variados del saber humano, tales como Cómo hacer chapas (botones), Cómo hacer un bizcocho,...
Parece que los razonamientos de Julio Alonso y sus abogados sobre su derecho a exponer su opinión sobre el Google bombing que hacía que la SGAE apareciera en primer lugar a la hora de buscar «ladrones» en el buscador no han sido...
Estuve probando hace algunas semanas el curioso Mr. Wong, que es una herramienta de marcadores sociales (social bookmarking) al estilo del conocido del.icio.us pero «en esteroides», que dicen los anglosajones. El diseño es más vistoso, las opciones algo más amplias y está...
Dentro del ecosistema de Netvibes los “universos” son páginas especializadas que suman información relacionada con un tema concreto de una o más fuentes que dispongan de feeds RSS. Un par de ejemplos serían los universos dedicados a Moby y Evanescence entre...
Por Nacho Palou -
25 JUN 2007
Antipodes Map emplea ingeniosamente los mapas de Google Maps para mostrar un lugar que tú elijas y el mapa totalmente preciso de su antípoda: el punto diametralmente opuesto en el globo terrestre. Aunque sabía que las antípodas de Madrid están en la...
Zattoo sirve para ver la tele en directo desde el ordenador, siempre que tengas una conexión decente a Internet. Basta registrarse, descarga el programa, y elegir el canal que quieres ver. Así de simple. Es la tele de siempre pero que puedes...
Estuve probando StumbleUpon mientras miraba cosas sobre sistemas de recomendaciones sociales y descubrimiento de «cosas nuevas» – y me pareció realmente entretenido. Se trata de una barrita que se instala en el navegador (Firefox o Explorer) y añade una serie de botones...
(Nota: Esta anotación habla de MyStrands, que es una de las empresas en que participo. Ver Full Disclosure.) Hace un rato se ha anunciado oficialmente que MyStrands ha conseguido 25 millones de dólares en financiación de Antonio Asensio, emprendedor, propietario y vicepresidente...
En la anotación Novedades en YouTube de Bitelia se comentan dos pequeñas novedades del popular sitio para publicar vídeos en Internet. La primera es la versión m.youtube.com que está pensada para el acceso a través de teléfonos y otros dispositivos móviles. La...
Si eres usuario de Mi Yahoo desdee hoy puedes optar por utilizar la nueva versión totalmente renovada actualizando tu cuenta o creando una nueva. Una vez actualizado es posible volver a la versión anterior (o actual), así que a probarla sin...
Por Nacho Palou -
15 JUN 2007
El próximo jueves 21 de junio Adobe organiza la Adobe Live 2007 un evento dirigido a profesionales de la industria gráifca, el desarrollo web, la publicidad, el vídeo y la fotografía digital. Este año el gran protagonista es el producto de Adobe...
Por Nacho Palou -
14 JUN 2007
Por si todavía queda alguien que no se haya enterado, tal y como prometió Stewart Butterfield, uno de los fundadores de Flickr, cuando estuvo en Madrid el pasado mes de noviembre en el Seminario Web 2.0 de Yahoo!, desde hoy Flickr, nuestro...
Pingdom Full Page Test es una herramienta que imita la forma en que los navegadores web cargan las páginas y mide cada uno de los objetos cronometrando el tiempo que tardan en transmitirse por Internet «realmente». De este modo se obtiene un...
(Nota: Esta anotación habla de FON, que es una de las empresas en las que participo. Ver Full Disclosure.) Martín Varsavsky ha hecho públicas algunas novedades sobre FON acerca de las cuales hay más información en la web oficial que ha sido...
Desde hoy el servicio de blogs de Six Apart Vox está disponible en español. Además del propio servicio, las páginas de ayuda y demás textos la localización se extiende a la comunidad que es la parte esencial del servicio, de modo...
Por Nacho Palou -
11 JUN 2007
PrimeraPlana.net es una página de recursos para periodistas en forma de página con enlaces. La portada contiene ni más ni menos que 1.105 enlaces directos, perfectamente clasificados por temas: Prensa de España, Confidenciales, Periodismo, Diccionarios, Mapas, Trnasportes, Agencias, Traductores, Cultura, Revistas, Geopolítica,...
Omnipelagos es un juguete para la Wikipedia que busca la relación entre definiciones/conceptos, un poco al estilo del juego de los seis grados de separación de Kevin Bacon. Por poner un ejemplo: puede encontrar la relación entre Leonardo da Vinci y Blogger...
S.Technorati.com parece mucho más práctico que la portada habitual de Technorati.com gracias a su simplicidad. (Vía OJOBuscador.) Actualización – Años después, el servicio desapareció pasando a dormir el sueño de los justos. Relacionado: WTF!? Technorati WTF, promoción de noticias interesantes. Tres años...
Ya está disponible la descarga de MovableType 4 en versión beta gratuita —beta auténtica publicada con objeto de recoger las sugerencias, mejoras y comentarios en general de los usuarios que deseen probarla, no es una beta a la 2.0, de modo que...
Por Nacho Palou -
5 JUN 2007
Si ya antes, desde el cielo Google, había pillado a nudistas tomando el sol en playas o azoteas o gente haciendo pis al aire libre, la cosa se vuelve aún más cercana (y menos anónima) con la función Street View. La función...
Por Nacho Palou -
1 JUN 2007
Un par de aplicaciones de calidad que pueden resultarte útiles si circulas habitualmente en coche Radar de 8000vueltas.com es un directorio de radares, controles y puntos negros de las carreteras nacionales. Aunque los radades móvil y los controles de alcoholemia no se...
Por Nacho Palou -
30 MAY 2007
Traducción rápida y resumen de 19 Things NOT To Do When Building a Website, de Josiah Cole —con quien no podría estar más de acuerdo excepto porque en su artículo utiliza incorrectamente palabras en mayúsculas para enfatizar. Nunca cambies el tamaño de...
Por Nacho Palou -
25 MAY 2007
Redescubriendo los clásicos, gracias a una pegatina vista por ahí: La Voz de la Experiencia: Cadena del W.C. es una reconversión a la era Internet de la mítica Radiocadena del Water, una «emisora libre» que se popularizó a principio de los 80...
David Troy ha creado dos de los mashups más adictivos de los últimos tiempos con flickrvision, que te permite ir viendo en qué lugares del mundo están hechas las fotos que se van subiendo a Flickr, y con twittervision, que te permite...
Pues eso, que feliz Día de Internet 2007, aún a pesar de que La OCU dice que España sigue siendo un país caro para los internautas, que además no siempre pueden acogerse a las mejores ofertas pues según el lugar en el...
¿Adónde van a parar los 180 mil millones de kilovatios de energía equivalente que llegan cada segundo desde el Sol? Earth Guide (en inglés) es un bonita aplicación online con diagramas y animaciones para mostrar y explicar de forma principalmente visual...
Por Nacho Palou -
17 MAY 2007
Flickrvision muestra sobre el mapa el lugar geográfico de las imágenes de que se están enviando a Flickr en ese momento. (Vía Neatorama.)...
Por Nacho Palou -
14 MAY 2007
La nueva versión de la característica de Flickr “View as slideshow” supone un avance importante respecto a la anterior principalmente porque muestra las fotos de gatos a tamaño grande y sobre fondo negro en toda la página, ¡bien! (Vía Flickr Blog.)...
Por Nacho Palou -
8 MAY 2007
El Hotmail «de siempre» se llama ahora Windows Live Hotmail oficialmente, es la nueva versión del correo gratuito de Microsoft con novedades en todas estas áreas: 2 GB de espacio para los mensajes Mejoras en seguridad Diseño e interfaz renovados Más rápido...
Tal y como cuenta Martín Varsavsky en su blog, el sábado día 12 de mayo va a organizar un evento con emprendedores del mundo de la tecnología en Menorca, aprovechando la presencia de algunos conocidos emprendedores que también participarán en el Innovate...
Ya se puede consultar el programa definitivo de las IV Jornadas sobre bitácoras y medios de comunicación, en las que el hilo conductor será el fenómeno de la larga cola. Las jornadas se celebran los próximos 10 y 11 de mayo en...
Carlos Almeida nos escribe para recordarnos que esta semana el Parlamento Europeo votaba una nueva propuesta de la Directiva sobre medidas penales destinadas a garantizar la defensa de los derechos de propiedad intelectual, y que contra todo pronóstico por una vez los...
Distribución mundial de diversos «activos» de Internet (direcciones IP): un 56% están en Norteamérica, un 22% en Europa. Esta representación visual de Internet en el mundo ha sido titulada Internet World Map 2007 y muestra cómo está distribuida Internet en todo...
Recopilando datos de distintas fuentes, Breathing Earth es una simulación del ritmo real de los nacimientos y defunciones que se producen en el mundo, además de contabilizar el volumen de las emisiones contaminantes de CO2 que se arrojan a la atmósfera...
Por Nacho Palou -
23 ABR 2007
Este Mapa Visual de la Web 2.0 es uno de los trabajos en que hemos colaborado en los últimos meses los dos microsiervos que trabajamos en Internality. Forma parte de una obra principal mayor, el libro La Web 2.0, publicado por...
En versiones online [requiere Flash] y salvapantallas para Mac y Windows: Polar Clock v2. (Vía Information Aesthetics.)...
Por Nacho Palou -
21 ABR 2007
Lo del artículo 17bis de la Ley de Impulso de la Sociedad de la Información se parece cada vez más a una película de la serie Viernes 13, en la que Jason parecía morir una vez tras otra para luego reaparecer aún...
No sé cuánto de nuevo es este pequeño pero importante avance en Flickr que no conocía y que permite elegir que el álbum de fotos utilice una estructura de página a elegir entre seis disponibles. Debe ser bastante nueva porque no la...
Por Nacho Palou -
19 ABR 2007
Retrato robot del asesino de la productividad. El original es Trapped in an Infinite Loop de Wellington Grey, quien muy amablemente nos ha permitido traducirlo y reproducirlo aquí....
Por Nacho Palou -
13 ABR 2007
A pesar de que ayer nos alegrábamos de la desaparición del artículo 17 bis del borrador de la LISI, artículo que conferiría a la SGAE y entidades similares el poder de decidir sobre qué puede publicarse en Internet, parece ser que en...
La semana pasada Google dio un nuevo paso en su PDM con la posibilidad de crear mapas personalizados, a los que se accede desde una pestaña llamada Mis mapas en Google Maps siempre que tengas una cuenta con Google. Los he...
Según cuenta El Mundo, Desaparece de la reforma de la Ley de Internet el polémico artículo 17 bis que tanto dio que hablar estos días, aunque habrá que ver qué forma tiene el texto definitivo de la Ley de Impulso de la...
Nuestro amigo Ferreira acaba de lanzar un servicio online para cantar karaoke llamado Red Karaoke, donde hay canciones gratis con la melodía y la letra sincronizada listas para utilizar. También es posible subir ficheros .kar y dejar grabadas las canciones cantadas para...
Por Nacho Palou -
11 ABR 2007
Hace algunas semanas la gente de Google nos adelantó que estaban preparando el Google Developer Day que ya se ha hecho público: es una jornada de un día completo a nivel mundial que en España se celebrará en Madrid, bajo el título...
Hace años que me explicaron aquello de que no se puede ser «juez y parte» cuando las opiniones o posturas de varias personas, entidades, o grupos de cualquier tipo están en liza y hay que emitir algún tipo de veredicto al respecto....
Pedro nos escribe para comentarnos que acaba de publicar ColorIURIS | Una aportación independiente a la cultura libre, un libro gratuito en formato PDF [1,5 MB] sobre «la problemática actual de los derechos de autor y derechos conexos en el entorno digital»....
DejaVu.org es un «emulador» para recordar los viejos tiempos de la WWW y cómo se veían y funcionaban los primeros navegadores (incluyendo Lynx, NCSA Mosaic, Netscape) y también una cronología de su historia. La página What's New? que se ve aquí...
A dot for every second in the day es un reloj visual, en el que cada píxel simboliza un segundo, de modo que un día completo de 60 × 60 × 24 = 86.400 segundos tiene otros tantos píxeles. La imagen se...
Yo me enteré porque estoy suscrito al blog de Flickr y allí lo contaron en Introducing Filters hace un par de semanas, pero aunque supuse que iban a enviar un correo a todo el mundo avisando del cambio, no han hecho tal...
YMMV, que se decía antiguamente (Your Mileage May Vary, en referencia a que con la misma gasolina coches parecidos e incluso iguales pueden recorrer distancias distintas dependiendo de factores incontrolables). ¿A qué velocidad te mueves en en Internet? es un interesante artículo...
La sección Moving Image Archive de Archive.org es un recurso fantástico que almacena a día de hoy 61.028 películas, definición que abarca «imágenes en movimiento» de todo tipo, desde largometrajes tradicionales que están libres de derechos a documentales, animaciones por ordenador y...
40. Cruzar el Atlántico a nado 5.572 km. ¿Acaso me ha visto cara de lemming? (¡Hey, al menos te avisa de las carreteras con peajes ya que no del riesgo de tiburones en el océano!) (Vía Reddit.) Google Maps y Google Earth...
Por Nacho Palou -
29 MAR 2007
Literalmente: Yahoo! Mail goes to infinity and beyond es el anuncio oficial de Yahoo acerca de que a partir de mayo los usuarios de Yahoo Mail tendrán buzones de correo de tamaño ilimitado. La excusa es el décimo aniversario de Yahoo Mail,...
En Twitter y la gestión del tiempo en Terremoto.net me encontré de casualidad la Curva Asintótica de Twitter que define gráficamente el «fenómeno Twitter»: Si el tiempo entre interrupciones llega a cero, estamos jodidos. Como esta mañana les contaba a unos amigos...
Ya ha arrancado la edición de este año del concurso HazRuido.com que es una competición de márketing viral que incluye una categoría de «Mejor marketing viral» y otra de «Posicionamiento en Google». HazRuido.com – Se trata de un reto intelectual para determinar...
Creo que no sorprendió a nadie que las reuniones entre las entidades gestoras de derechos de autor y los fabricantes de dispositivos electrónicos cuyos productos se verán gravados por el nuevo canon digital terminaran sin ningún tipo de acuerdo. Lo que ya...
Hace algún tiempo publicamos una serie de consejos para acelerar torrents que basados en la velocidad de tu conexión y algunas otras cosas más te permitían ajustar las cosas para que las descargas fueran más rápidas. No era nada excesivamente complicado, pero...
Este gráfico es parte de un estudio del proyecto SPIRE del JISC (Reino Unido), una encuesta acerca del uso de servicios y aplicaciones Internet estilo Web 2.0. Tal y como cuentan los autores en Some real data on Web 2.0 use participaron...
Bajo el lema «Sólo webs de calidad», Jubeo.es es un nuevo directorio / buscador en español con la intención mantener un contenido «limpio» según sus propios criterios de calidad: sitios sin pop-ups molestos, sin pornografía, sin casinos, sin descargas ilegales, sin spam,...
Si no te gusta que tu carpeta predefinida de descargas se llene con cientos de archivos de todo tipo mezclados, Download Sort es una extensión para Firefox te evitará tener que especificar a mano dónde quieres descargar algunos de esos archivos o...
Hoy y mañana se está celebrando el Congreso OJObuscador 2.0, es una conferencia dedicada a los buscadores de Internet, especialmente a sus secretos, cómo funcionan, las fórmulas de optimización (más conocidas como SEO) y también al márketing para buscadores y todo ese...
Aunque en 24 Jack Bauer se mueve en coche por la ciudad de Los Ángeles como si no hubiera nadie más en el mundo —incluso aunque (spoiler) haya habido una explosión nuclear en un barrio de la ciudad y la gente huya...
Por Nacho Palou -
6 MAR 2007
Sencillo pero informativo: How the WebOS Evolves? es una infografía que abarca desde la era del PC a los «Agentes Personales Inteligentes» de más allá de la era de Blade Runner. Como extiende la cronología hasta el año 2030 da juego para...
Igual que Alvy, ya hace algún tiempo que vengo usando los feeds RSS de Mininova y sitios similares como Dime A Dozen o U2Torrents para ver qué aparece en estos sitios y decidir qué me interesa descargar, pero eso hace que a...
Aunque mi impresión es que en la mayoría de las ocasiones la gente no les hace ni caso a estas licencias en lugar de respetarlas y tampoco está muy claro que sean válidas en todas partes, lo que ha creado encendidas polémicas,...
Word Source, albergada en el simpático dominio fácil de recordar word.sc, es un diccionario de definiciones y sinónimos en inglés, del estilo de Dictionary.com pero más a lo Web 2.0, con componentes «sociales», donde se pueden añadir fotos y tags a las...
Virtual Globe es una aplicación para visualizar el globo terrestre en tres dimensiones, combinando datos de elevación con imágenes aéres y de satélite. Es muy similar a Google Earth, tanto por la forma de funcionar (las imágenes y datos topográficos se descargan...
Por Nacho Palou -
24 FEB 2007
SpamBlog es un interesante blog en castellano sobre el universo del correo basura y todas sus variantes, como el spam a través de enlaces o los negocios que hay detrás del spam. Actualización (23 de febrero de 2021) – El blog dejó...
Llega uno de los lanzamientos más esperados de la temporada, 11870.com con lo cual se descubre por fin de qué va la cosa: 11870.com ya está online – Sirve para que la gente descubra, recuerde y comparta empresas y negocios. Pero la...
Hace unos años parte de los usuarios de Internet españoles organizaron un google bombing contra la SGAE de tal modo que si introducías la palabra «ladrones» en el cuadro de búsquedas de Google y pulsabas el botón «Voy a tener suerte» terminabas...
Page2RSS es un servicio que revisa los contenidos de páginas web «tradicionales» y genera un feed RSS cuando hay cambios. De ese modo que si estás acostumbrado a seguir lo que pasa en tus webs favoritas con un agregador web resulta mucho...
Llevaba algún tiempo apuntado en el programa de beta testers de Joost, antes conocido como The Venice Project, esperando a que saliera una versión para Mac OS para poder probarla, lo que por fin ocurrió este fin de semana con la publicación...
The SimCam es un simulador que emula el funcionamiento de máquinas fotográficas (de película y digital indistintamente). Su utilidad radica en lo sencillo que hace comprender y entender conceptos de técnicas fotográficas acerca de cómo funcionan los distintos controles de apertura y...
Por Nacho Palou -
18 FEB 2007
MetaGlossary es un híbrido entre glosario y diccionario a la vez. Utiliza las definiciones que hay en la web sobre diversas palabras para mostrar rápidamente el significado de un término o de un acrónimo. La clasificación de los resultados es temática y...
El Museum of Modern Betas recoge una “exposición” de 50 aplicaciones o servicios web anticipadas pero no funcionales o no del todo —es decir, aquellas que ya se han dado a conocer o anunciado de algún modo pero en las cuales de...
Por Nacho Palou -
14 FEB 2007
Michael Calore publica en Gallery: Best Firefox Add-Ons las que él considera las mejores diez extensiones para Firefox: DownThemAll!, un gestor y acelerador de descargas que permite, por ejemplo, descargar todas las fotos enlazadas desde una página de miniaturas. Fotofox, para poner...
25 Signals of Crap es un mensaje en uno de los foros de WebmasterWorld acerca de las señales inequívocas de que un sitio web es de mala calidad, título que podría traducirse como «25 señales de que un sitio web es patatero»...
Algoritmos de Google: El Page Rank es una larga y detallada explicación matemática de una de las partes más importantes del funcionamiento interno del buscador Google. El estupendo blog The Smoke Sellers ha preparado esta página en castellano a partir de...
No había tenido hasta hoy que usar servicios de estos para «enviar ficheros gigantes», pero me surgió un problema con unas fotos enormes que no era muy práctico enviar por correo y aproveché para probarlos. RapidShare y MegaUpload sirven para enviar y...
Google ha abierto al público general en España su servicio de correo web gratuito, GMail de modo que cualquier persona puede abrirse una cuenta sin necesidad de «invitaciones personales» de otros usuarios, como venía siendo necesario hasta ahora desde hace casi tres...
En el micrositio Virtual Lens Plant [requiere Flash, en inglés] se explica el proceso completo de fabricación de las lentes utilizadas en objetivos fotográficos. El proceso comienza con los materiales vitrificantes en bruto de los cuales se obtiene el vidrio y sigue...
Por Nacho Palou -
5 FEB 2007
He aquí cómo entender visualmente lo que es la Web 2.0, en menos de cinco minutos. Cuando en el vídeo se habla de «la Máquina» es una referencia al mítico artículo We Are the Web de Kevin Kelly en Wired, que...
He sido lo suficientemente procrastinador como para no buscar por mi mismo la solución al tema, pero a través de ALT1040 acabo de descubrir que para desactivar esas vistas previas de sitios web que hace Snap en una ventanita flotante cuando pasas...
Estamos probando la nueva versión beta del sistema de medición de tráfico para sitios web llamado Reinvigorate. Tal vez te suene el nombre (como Re_invigorate) porque hace justamente un par de años fue un servicio muy popular y era muy utilizado por...
Por Nacho Palou -
30 ENE 2007
Anagrams: Hall of Fame es una sección del legendario Internet Anagram Server que recopila los mejores anagramas de todos los tiempos, en este caso en inglés. Un anagrama es una palabra o serie de palabras cuyas letras se recombinan para formar otra...
Tras un tiempo trabajando en línea en su redacción para poder contar con las opiniones del mayor número posible de personas y no sólo de los que estuvimos en el Evento Blog España en Sevilla, Luis nos avisa de que acaba de...
El FromLostToTheRiverismo de hoy llega de la mano de la web de American Express España, donde el enlace que aparece al final de las páginas de cuentas es… La Cima de Pantalla = Top of the Screen Albahaca a la fuga, ¡corre,...
Me encantó el reportaje de EPS este fin de semana sobre Google y la gente que trabaja allí: Planeta Google. Incluye algunos detalles interesantes y no muy conocidos acerca de los llamados googlers y también de sus proyectos. Por ejemplo, Louis Monier,...
Luistxo cuenta en ¿Toda España en detalle en Google Maps? que muchas zonas de los mapas de España de Google Maps (también Google Earth) están mejorando de resolución. En la conocida Puerta del Sol de Madrid se puede ver hasta gente, detalles...
Un poco de historia reciente de la informática: cómo un programador de Microsoft inventó la API de XMLHTTP, la incorporó en Explorer 5 y cómo luego pasaría a estandarizarse y convertirse en uno de los pilares técnicos de la Web 2.0 y...
La sentencia se puede recurrir, pero por ahora la SGAE gana el primer asalto a la Frikipedia:Los hechos son que (por fin) ha habido una sentencia en el caso de la SGAE y Pedro Farré contra la Frikipedia, la cual me condena...
Palabras tan raras como estas que apenas es posible pronunciar molan: intercrastinación, definida por un lector de Lifehacker como la variante internetera de la procrastinación: El asunto es así: termino una tarea, actualizo mi «lista de cosas por hacer», reviso la lista...
Las estaba pasando canutas para etiquetar correctamente mis fotos de Praga que estoy subiendo poco a poco a Flickr por culpa de todos los signos diacríticos que se usan en checo (y sí, ya se que a Flickr le da igual, pero...
Mapa ilustrativo de los agujeros negros que existen en Internet producidos por países que prohíben, limitan o restringen a sus ciudadanos el uso y el acceso libre. (Vía information aesthetics.)...
Por Nacho Palou -
12 ENE 2007
He programando con mis rudimentarios conocimientos un pequeño experimento técnico sobre geolocalización de direcciones IP. Básicamente intenta distinguir con el menor código posible, de una forma «ligera» (ni siquiera requiere base de datos) si un visitante de una web llega desde España...
Existen muchos sistemas para geolocalizar direcciones de Internet, es decir convertir las direcciones IP numéricas del tipo 108.42.23.16 en datos localizables sobre un mapa, como por ejemplo el país de origen, el nombre de una ciudad o incluso unas coordenadas. IPligence Community...
Descubrí hoy, con algo de retraso, una gran idea y una buena implementación: los clusters de etiquetas en Flickr (el el popular servicio para almacenar fotografías). Estas páginas agrupan ideas similares a las etiquetas (tags) elegidas para las fotos públicas, de modo...
Hoy vino el técnico de Telefónica a instalarme en casa un Dúo ADSL 3 Megas porque aprovechando una promo y las vacaciones me he pasado de 1 Mbps a 3 Mbps por prácticamente el mismo precio al mes (un euro más, e...
Este Mapa de Internet: el espacio IPv4 de XKCD es un curioso mapa de Internet: emplea un «mapeado fractal» y está dibujado a mano, al estilo de los mapas geográficos. Las direcciones IP son números del tipo 66.249.65.6 que se asignan...
El sitio CSS10 del Consorcio W3 celebra el décimo aniversario de las hojas de estilo CSS, el mecanismo que da estructura, colores y en general buen aspecto a las páginas web independientemente (al menos en teoría) del medio utilizado o de las...
Por Nacho Palou -
20 DIC 2006
El mes pasado, en la mesa redonda sobre Blogs y Ética del Encuentro Blog España, Pedro comentaba su preocupación ante la posibilidad de que las empresas empezaran a enviar cartas tipo cease and desist a bloggers u otros sitios de Internet con...
La dirección de correo con el dominio alfabéticamente más largo tiene 63 letras, el tamaño máximo posible para los dominios de segundo nivel.
Tal y como habían anunciado los organizadores, ya está en funcionamiento el wiki para trabajar en la redacción del ‘Manifiesto Blog España’. Tienes hasta el 15 de diciembre para aportar tus sugerencias; a partir de ahí toca unificar las propuestas y pulir...
Aprovechando que en las últimas semanas he tenido que viajar bastante he aprovechado para probar uno de los módem USB 3G de Vodafone que nos prestaron y ver cómo funciona bajo Mac OS X, aunque salvo el apartado de instalación todo lo...
Desde hace un par de meses Adobe ofrece una serie de cursos y seminarios online vía web utilizando su tecnología Adobe Connect. Los seminarios retransmitidos en directo, permiten la asistencia de los oyentes desde cualquier lugar, vía web en la ventana del...
Por Nacho Palou -
4 DIC 2006
El mundo de los servicios de respuestas comparado en Can you drink water from an Air Conditioner? Google says no, Yahoo says yes (¿Puede beberse el agua sobrante de un aparato de aire acondicionado? Google dice ‘no’, Yahoo dice ‘sí’) según las...
Por Nacho Palou -
1 DIC 2006
En Kottke: del.icio.us will eat itself:Gente que ha guardado a gente que ha guardado a gente que ha guardado a gente que ha guardado a gente que ha guardado a gente que ha guardado a gente que ha guardado a gente que...
Por Nacho Palou -
30 NOV 2006
Enrique Dans comentaba hace un par de días en el Seminario Web 2.0 de Yahoo! como la inmensa mayoría de las empresas no sabe cómo reaccionar ante el hecho de que ahora los usuarios podamos escribir lo que opinamos de ellas o...
Aprovechando que Yahoo España traía ayer a Madrid a Stewart Butterfield y Joshua Schachter, los fundadores de dos de los servicios que más utilizamos a diario, para participar en el Seminario Web 2.0, y que luego íbamos a hacer una «cumbre Pixocierva»,...
¡...en 10 minutos! Ese es el tiempo de vida que duran en el servicio de correo web gratuito 10 Minute Mail una dirección de correo electrónico, el buzón y todo lo contenido. El servicio genera una dirección de correo electrónico tipo
[email protected]...
Por Nacho Palou -
29 NOV 2006
Ayer el sistema de bitácoras personales WordPress.com pasó de 500.000 blogs creados y el servicio de fotos Flickr pasó de 300 millones de fotos almacenadas....
Uno de los temas que surgió el sábado pasado en la mesa sobre Blogs y ética del EBE fue el peligro de que en algún momento las grandes empresas -y las no tan grandes- se den cuenta de que por su tamaño...
Por fin he podido ponerme con las notas que tomé durante la mesa Hai un galego na Rede de las jornadas Enredad@s que se celebraron del jueves al sábado pasado en Santiago de Compostela. Todos los errores que pueda haber son culpa...
Ayer la acción de Google cerró a 495,05 dólares, y llegó por unos instantes a los 499,85 dólares. Hoy el símbolo GOOG (Google) podría alcanzar el hito de los 500 dólares por acción en el mercado bursátil NASDAQ, el tecnológico de Estados...
Conferencia de Juan VarelaDespués de dejar un margen de tiempo razonable para que la gente se vaya incorporando tras el Beers & Blogs de anoche Juan Varela nos habla de su visión no ya de los blogs, de los que se declara...
Comienza con cierto retraso -parece ser que el programa social espontáneo del evento funciona de maravilla- la segunda jornada de Evento Blog España, con la mesa de emprendedores. Mesa de emprendedores (1ª parte)Antonio Ayala, profesor, nos cuenta que ve los blogs como...
Hoy se cumplía la segunda etapa del Tour Microsiervo 2006 con mi participación en la mesa redonda Hay un galego na rede en las jornadas Enredad@s. Moderó María Yáñez, y contamos nuestras experiencias y opiniones sobre Internet y Galicia, por orden de...
OctaGate SiteTimer es una muy buena utilidad para webmasters que todo creador de páginas web debería tener siempre a mano para hacer chequeos periódicos. Básicamente calcula el tiempo de transmisión una páginas web, con sólo indicarle la URL, fijándose en cada uno...
Si te interesa el desarrollo web basado en la plataforma Ruby on Rails tal vez te interesa la primera Conferencia Rails Hispana con sesiones y ponencias variadas (incluyendo introductorias a Ruby) de la mano de los mejores expertos de aquí y participantes...
Por Nacho Palou -
15 NOV 2006
«Geosaludos» desde el aire: GeoGreeting compone la palabra que escribas con símiles de caracteres formados por estructuras y edificios (sólo casi todos de EE.UU.) fotografíados desde el aire en Google Maps.El resultado puedes compartirlo como saludo-presentación enviando la URL resultante. (Vía Neatorama.)...
Por Nacho Palou -
15 NOV 2006
Estuvimos comiendo con un amigo de Vodafone que nos invitó a probar el Módem USB Mobile Connect de banda ancha 3G. La tecnología 3G / GPRS viene a ser para los teléfonos móviles lo que el ADSL es a los teléfonos fijos:...
Por Nacho Palou -
14 NOV 2006
TecFan es un buen ejemplo de cómo crear algo sencillo y práctico usando la tecnología Google Co-Op que hace fácil aquello de «crea tu propio buscador». Esta web argentina emplea Google para encontrar contenidos en un conjunto de sitios seleccionados por editores...
Google Maps España y Panoramio organizan conjuntamente el concurso de fotos de lugares geoposicionada en el sitio web Panoramio, el álbum de fotos online que permite marcar geográficamente, sobre un mapa, el lugar donde se han hecho las fotografías. De modo que...
Por Nacho Palou -
13 NOV 2006
Nos hemos dado cuenta un poco por casualidad (buscando las entradas de una de las bitácoras alojadas allí, que ahora mismo parecen parcialmente missing in action) que Barrapunto acaba de completar el rediseño que empezó hace unos meses, y nos da la...
Dominios '.es' gratis durante el mes de noviembre — Varios agentes registradores de dominios regalarán direcciones '.es' de forma gratuita durante el mes de noviembrecon motivo de la celebración de la feria tecnológica SIMO en Madrid.No se incluye servicio de DNS (necesario...
Por Nacho Palou -
2 NOV 2006
Cuando Google anunció que compraba YouTube muchos vaticinaron que a partir de ahí empezarían a lloverles las demandas por temas de derechos de propiedad intelectual para intentar aprovecharse del poderío económico de Google, pero curiosamente quien los ha denunciado ha sido una...
Todavía tienes hasta el día 11 de este mes para emitir tus votos en The BOBs - Best of the blogs 2006 y así, además de apoyar a tus blogs favoritos, poder participar en el sorteo del iPod de quinta generación reservado...
El otro día comentaba con alguien sobre cómo medir algunas cuestiones de efectividad en sitios web, en las interfaces de usuario, campañas publicitarias y demás. Eso me recordó una clásica historia sobre cómo Amazon, la tienda gigante de Internet, rediseña a veces...
Las Naciones Unidas celebran estos días el Internet Governance Forum en Atenas, una reunión en la que hablan del futuro de Internet en la que, curiosamente, falló la conexión a Internet: United Nations "Internet" Summit held sans internet. ¿Ironía? ¿Un caso de...
Un problema de interfaz de la nueva versión del navegador web Firefox 2 es que antes las pestañas tenían el botón de cierre en la misma posición, a la derecha de la pantalla, mientras que ahora tienen un botón en cada pestaña....
Los datos audiencias de un sitio web, o los beneficios de una empresa cualquiera en general, siempre dependen de cómo se midan y se «expliquen». Los expertos emplean a veces KPIs: Key Performance Index o Índices Clave de Rendimiento. Puedes simplemente calcular...
Este truco que ví pasar en Lifehacker me ha emocionado porque en ocasiones me sucede que sin querer cierro alguna pestaña de Firefox. Pero ahora pulsando Ctrl+Mayúsculas+T (Windows) o Comando+Mayúsculas+T (Mac) recupero la pestaña cerrada por error. También ayuda a reducir...
Por Nacho Palou -
26 OCT 2006
Víctor, que escribe en LaPapelera.org nos escribió para contarnos con alegría que su compañero de blog en Genbeta, Óscar (su blog personal es SferaZero) acaba de publicar con Anaya Multimedia un libro en papel: Manual Imprescindible Mozilla Firefox 2.0. Tiene unas 450...
Gracias al atajo publicado por el Dr. Wasabi hemos podido descargar la versión 2.0 final del navegador Firefox (sin variaciones respecto a la última RC3) con unas horas de adelanto respecto a la fecha de lanzamiento oficial que es mañana 24 octubre....
Por Nacho Palou -
23 OCT 2006
En lo que parece ser el día de las «versiones 2 definitivas», también llega hasta nuestras pantallas Skype 2 para Mac OS X con la famosa videoconferencia integrada. Esto garantiza horas y horas de diversión haciendo el ganso mientras simulas que te...
Tagzania y CodeSyntax han preparado una serie de fenomenales modelos arquitectónicos en 3D para colocar directamente en el programa Google Earth. Basta descargar los archivos con los modelos y el programa mostrará los edificios como objetos tridimensionales, con su tamaño adecuado y...
Por Nacho Palou -
23 OCT 2006
Simple y brillante: dead.licious 1.0 [OS X] comprueba los enlaces que tienes guardados en tu cuenta de del.icio.us indicando los que siguen siendo válidos y funcionan y los que no —y en este caso muestra la opción de eliminarlos. La comprobación puede...
Por Nacho Palou -
19 OCT 2006
Ya hay programa de Enredad@s, Xornadas sobre mocidade e internet, unas jornadas sobre jóvenes e Internet que organiza el Consello da Xuventude de Galicia del 16 al 18 de noviembre en Santiago de Compostela con el objetivo de «hacer una reflexión y...
Internet Explorer 7 para Windows, la nueva versión del navegador web más usado del mundo, ya se puede descargar desde la web de Microsoft, así que los amantes del riesgo pueden pasar un día entretenido. Los requerimientos son pocos: tener instalado Windows...
Una gráfica como ésta indica la frecuencia con que GoogleBot, el robot de Google, pasa a visitar tu sitio web. Es una de las novedades de Google Webmaster Tools (Herramientas para webmasters, anteriormente: Google SiteMaps) para que los webmasters examinen cómo se...
Con el navegador web Firefox 2 a punto de estar en versión definitiva, la Fundación Mozilla ha abierto un Wiki (un espacio público en págians web que cualquiera puede editar) donde admiten sugerencias para Firefox 3, en plan brainstorming (en inglés). Como...
Excelente el análisis en el comentario editorial del Financial Times sobre la adquisición de YouTube por parte de Google: Google grabs videos and legal uncertainty ($). Lo tradujo y publicó ayer El País resumiendo todo lo verdaderamente relavente en dos párrafos (aunque...
Cristina descubrió YaCy, que es un buscador distribuido basado en tecnología P2P, que describe en plan sencillo así: YaCy un buscador P2P. La idea es que la «comunidad» navega con el buscador instalado en su ordenador. Mientras navega va indizando e intercambiando...
Convert HTML to Javascript Include Source es una página que puede resultar útil para programadores de páginas web. Lo que hace es que convierte un trozo de código HTML cualquiera a una función document.write de Javascript que se puede incluir a su...
Reverse IP/Domain Lookup es un servicio de consulta bastante útil que permite saber qué dominios están alojados en el mismo servidor o en la misma dirección IP. Basta teclear el nombre o el dominio. La explicación técnica «sencilla» es que básicamente cada...
Ahora mismo da un error, pero en el centro de prensa de Google se puede ver el enlace Google To Acquire YouTube for $1.65 Billion in Stock*, que traducido quiere decir que Google va a adquirir YouTube por 1.650 millones de dólares...
Estos son tres tags de fotos sobre algunos de mis hobbies a los que me gusta estar suscrito en Flickr mediante sus feeds RSS, para ir viendo fotos que la gente va haciendo y clasificando con esas etiquetas. Suelen tener imágenes curiosas...
Según cuenta el Wall Street Journal, en una noticia que comenta El Mundo en Google negocia la compra de YouTube por unos 1.600 millones de dólares, Google y YouTube estarían en negociaciones para que la primera adquiera a la segunda por un...
En la Sociedad Bitchun de la novela de ciencia ficción Down and Out in the Magic Kingdom (traducida como Tocando fondo) lo personajes tienen whuffie, una especie de karma digital universal que reciben o pierden en función de cómo les percibe su...
(Nota: Esta anotación habla de FON, que es una de las empresas en las que participo. Ver Full Disclosure.) Alberto nos mandó hace unos días unas foneras para probar, dado que salieron a la venta hace unas semanas. Ayer que visité FON...
Acaba de hacerse público el blog de Evento Blog España , también conocido como EBE06, una convocatoria que pretende convertirse en un fenómeno similar a lo que respresenta Les Blogs en Francia. Tendrá lugar en Sevilla los días 17, 18 y 19...
Visto en un correo real de eBay, hoy: 1. Pulsa el vínculo que aparece a continuación. Si no ocurre nada al pulsarlo (o si usas AOL), copia y pega el vínculo en la barra de direcciones de tu navegador de Web. ¡Ah,...
Como cada 29 de septiembre, la LSPM cumple años. Esta vez es toda una década, un tiempo casi infinito en Internet. Digamos que en «años-perro» de esos que valen ×7, esa lista de correo debería estar ya jubilada, pero mírala, ahí sigue....
La vieja interfaz, que no era gran cosa, ha sido retirada. Buen comienzo. La nueva versión de Google Reader es mucho más agradabe, fácil de usar y parecida a GMail, el popular correo web al que tanta gente está acostumbrada. Para quien...
WikiLoc es un mashup con Google Maps que sirve para compartir rutas campestres y waypoints GPS en general. Ha sido la aplicación ganadora del Concurso Google Maps que se ha celebrado durante los pasados meses. Los usuarios pueden guardar sus rutas y...
Ya está disponible la versión RC 1 de Firefox 2 para aquellos a los que les gusta vivir en el filo de la navaja (y cortarse de vez en cuando): Mozilla Firefox 2 Release Candidate 1 Available for Testing. Se puede descargar...
Post Expression es un servicio que sirve para enviar mensajes de correo después de morir. Esto incluye correos (ejem) «multimedia». Como suele suceder con este tipo de sitios tan «especiales», lo mejor es el tagline, algunos iconos y la descripción de...
Si utilizas las últimas versiones de Movable Type para gestionar tu blog o cualquier otro tipo de sitio te interesa instalar el parche de seguridad publicado ayer tarde: Movable Type 3.33/MT Enteprise 1.03 patches. De momento no dan muchos detalles del problema...
Por Nacho Palou -
27 SEP 2006
Tim O'Reilly, el de los O'Reilly de toda la vida, estará por aquí en breve. Es uno de los héroes de mi lista de héroes de Internet, también conocido como padre del término «Web 2.0» y sobre todo sus colecciones de libros...
Los que tengan una cuenta de pago «Pro» en el servicio de fotos Flickr pueden pedirse gratis diez tarjetas de visita Minicards de Moo, en papel, fruto un acuerdo entre ambos servicios. Las tarjetas se crean a partir de las fotos de...
Hace tiempo que contamos por aquí algo sobre los avances en el sector del los autobuses urbanos cuando descubrimos lo de los SMS y autobuses en las paradas de Madrid, que te permiten saber cuándo va a llegar el autobús enviando un...
¿Cuántos datos tiene almacenados Google? Tal vez no sea exacto, pero dicen que tras ver una presentación de Google alguien dijo que dijeron que… 850 TeraBytes - Google Search (el buscador)220 TeraBytes - Google Analytics (estadísticas)70 TeraBytes - Google Earth (mapas por...
YouTube, el conocido sitio para compartir vídeos, acaba de anunciar un acuerdo con Warner Music mediante el que podrá utilizar legalmente contenidos propiedad de esta a cambio de una parte de sus ingresos por publicidad: YouTube in 'landmark' music deal. Así, vídeos...
Breathing Earth es un mapa que muestra en tiempo real una simulación a partir de datos demográficos disponibles en Wikipedia y The World Factbook con datos tan dispares como muertes y nacimiento que se producen en el mundo y las emisiones de...
Por Nacho Palou -
14 SEP 2006
Cuando este verano los políticos estadounidenses estaban discutiendo acerca de la neutralidad de Internet comentábamos que aunque pudiera parecer «cosa de los americanos» ese debate podía presentarse pronto en otros países cuando las telecos se dieran cuenta de que ahí podían tener...
Una juez absuelve a J.M. en el juicio al que lo llevaron distintas entidades por descargar material audiovisual de Internet, además de ofrecerlo e intercambiarlo con otros usuarios mediante chats. Dado que siempre lo hizo sin ningún ánimo de lucro, la sentencia...
Sacado de El Ejecutivo prepara una ley que prevé más control en el acceso a contenidos internacionales en la Red:El Gobierno podrá impedir el acceso desde España a servicios o contenidos internacionales cuya interrupción o retirada haya decidido un órgano competente, cuando...
¡Es bueno ser .com! O .net, o .org… o cualquier otra cosa que no sea «.es». Tal y como se ha publicado en varios sitios y nos ha contado mucha gente por correo, esta tarde ha habido varias horas de «corte» en...
Flickr ha conseguido un avance importante en su servicio de fotografías añadiendo la opción de geolicalizar las fotos directamente sobre los mapas, tal y como cuentan en su blog: Great shot - where'd you take that?. Aunque la palabra «geolocalizar» (geotagging) suene...

La primera vez que los Microsiervos nos reunimos en el MundoReal™ para algo que no fuera una de nuestras cumbres microsiervas fue cuando Javier Sánchez y sus colaboradores nos invitaron a participar en Internet@Mano, el programa sobre Internet que hacían para...
Servidores DNS es una recopilación de ADSLAyuda.com con todos los DNS de los proveedores de Internet de España. La lista se mantiene actualizada e incluye tiempos de respuesta de cada servidor. Viene bien tener la página a mano si andas cambiando mucho...
Wikipedia: Dios La concepción más común de Dios es la de ser supremo y omnisciente, aunque existen otras definiciones.… La definicion más común de Dios es la de ser Chuck Norris, aunque existen otras definiciones paganas menos aceptadas.… La concepción más común...
Cuando estuve hablando de YouTube en Plató Abierto la gran pregunta que nos hacíamos era cuál iba a ser el modelo de negocio que le permitiera sobrevivir, ya que parecía bastante obvio que los ingresos que pueda conseguir por la publicidad contextual...
Historia de los Buscadores: de 1993 a 2006 es un documento preparado por la gente de OJObuscador que recorre la curiosa historia de los buscadores de contenido en Internet desde 1993, al poco del nacimiento de la World Wide Web. Aunque mucha...
No se puede decir que no se lo hayan pensado, pero Google al fin ha sacado una nueva beta de Blogger, sólo tres añitos y medio o así desde que lo compraron. Hace tiempo que en Microsiervos dejamos de usarlo, pero los...
Algunas fotos (pocas) de elementos e instalaciones que participan en la tarea de hacer que Internet funcione:What the Internet really looks like – Corre la cortina en Internet y encontrarás poderosos generadores diésel, enormes conmutadores y gruesos tubos ocupando grandes superficies en...
Por Nacho Palou -
9 AGO 2006
Una de esas cosas que no sirven para nada pero molan: WEB2DNA Art Project representa la estructura de un sitio web gráficamente como si se tratase del ADN humano.(Vía Neatorama.)...
Por Nacho Palou -
8 AGO 2006
El spam es un auténtico coñazo, pero el proyecto Spam Plants de Alex Dragulescu intenta sacar algo bonito de él analizando el contenido de lotes de esos mensajes y convirtiéndolos en una especie de plantas generadas por ordenador, aunque a mi me...
No se si los datos que dan en The 1% Rule: Charting citizen participation son suficientes como para probarla, pero visto lo visto no me parece descabellada:Está empezando a hablarse de una regla que sugiere que si pones a 100 personas en...
Mercè Molist acaba de publicar en versión libre y original dos artículos que en su momento escribió para un par de revistas en los que trata del tema de las redes P2P, su situación legal, quienes están de cada lado, etc, explicado...
Hoy, tres semanas después de su publicación en el Boletín Oficial del Estado, entra en vigor la nueva Ley de Propiedad Intelectual, aprobada por unanimidad por nuestros representantes políticos aún a pesar de que va de manera bastante evidente en contra de...
Parece como si Nitrozac y Snaggy hubieran visto Plató Abierto ayer, ya que la viñeta de hoy de Joy of Tech, The Great Mistery of YouTube, dice:Hemos reunido las mejores mentes del planeta para ayudar a resolver uno de los grandes misterios...
Firefox Cheat Sheet, recopilación de las combinaciones de teclas y atajos de teclado y de ratón para manejar Firefox. Incluye algunos trucos extras e información sobre la configuración del navegador. «Chuleta» para Google«Chuleta» para Movable Type...
Por Nacho Palou -
26 JUL 2006
Ahora mismo Hasta hace un rato al acceder a Netscape.com aparece un bonito mensaje (captura de pantalla). Y a continuación un afectuoso saludo para los usuarios de Digg.com. Un usuario algo forrest de Digg se jacta de ser el autor aprovechando una...
Por Nacho Palou -
26 JUL 2006
Cada vez que se hace una lista sobre el uso de Internet y tecnologías similares España suele quedar a la cola cuando se trata de algo bueno, aunque escala puestos rápidamente cuando la lista trata un tema chungo, como por ejemplo el...
<Cobra> so i was watching a pr0n <Thunder> wait <Thunder> why u guys always say pr0n instead of porn ?? Thunder has been kicked by Guardian (No porn on this channel !) <Cobra> ... <Cobra> so i was watching a pr0nEn la...
Por Nacho Palou -
24 JUL 2006
El mes pasado AOL relanzaba Netscape como una especie de sitio social de noticias al estilo Digg o similares, pero según se puede leer en Huge Red Flag at Netscape los usuarios no acaban de entender ni aceptar el cambio, así que...
El nuevo servicio de Six Apart llamado Vox es una reinterpretación de las conocidas herramientas de blogs de la casa (TypePad, Movable Type y LiveJournal) y es fruto de relaciones carnales entre los conceptos «para todos los públicos» y «comunidad de usuarios»...
Por Nacho Palou -
19 JUL 2006
Después de casi dar por perdida la batalla contra el spam decidí buscar algún software adicional para Mac OS X que resultara más inteligente que los filtros del Apple Mail, que definitivamente funcionan fatal y con el tiempo se vuelven tontos y...
BBS: The Documentary. DVD (2005). Jason Scott. Inglés. (Subtítulos en inglés). 40 dólares (pack 3 DVDs). Licenciado como Creative Commons, descargable en torrents y disponible en YouTube. Hace tiempo descubrí esta pequeña joya de documental y tras leer sobre ella y...
¡Barcospotting! Sailwx es un sistema para conocer la posición en tiempo real de barcos grandes y pequeños, como cargueros y petroleros, pero también yates y cruceros, a través de la web: Además del mapa general, se pueden buscar barcos por nombre o...
Hoy se celebró la segunda y última jornada del I Encuentro Nacional de Internautas en León, en la que la ausencia de grandes empresas en las mesas redondas hizo que estas fueran bastante más interesantes que ayer, rivalizando en interés con las...
Enrique me recordó hoy que me había enviado la actualización de la viñeta en la que se cuenta aquello de que en Internet nadie sabe que eres un perro: «con tanta cookie, web bugs y compañía, el chiste ya no es en...
Manel nos habló de Opentrad que es un traductor entre castellano, catalán, gallego y euskera. Cubre varias de las combinaciones o pares de lenguas aunque el castellano parece ser la lengua «central». También se incluyen pares de lenguas para las que hasta...
Hasta ahora Wikipedia utilizaba la tecnología de feeds RSS de forma muy limitada. Ahora han añadido feeds RSS individuales para todas y cada una las 1.250.000 entradas que existen, de modo que cualquiera se puede suscribir a un artículo e ir viendo...
Tras un intenso día de presentaciones y, sobre todo, de encuentros cara a cara con un montón de gente, aquí van mis impresiones sobre la primera jornada del I Encuentro Nacional de Internautas. La primera es que si en el folleto del...
Nuestro experto en seguridad favorito, Bruce Schneier resume en unos pocos párrafos perfectamente el gran reto al que se están enfrentando Google y otras empresas de Internet cuyo negocio es básicamente la publicidad (AdWords, AdSense y similares) frente al grave problema del...
Cuando Wired (la revista) nació, a principios de los 90, todavía no existía la Web. Luego pasaron años hablando de Internet y el ciberespacio, bajo la paradójica situación de que ni ellos mismos tenían web – de hecho fueron bastante criticados por...
Nota: Ver actualizaciones importantes al final de la anotación. Bitacle es una página de inicio estilo Netvibes que está disponible tanto en castellano como en inglés. Sirve para colocar en un mismo lugar fuentes RSS de weblogs y periódicos, fotos de Flickr...
Ahora mismo estoy de camino hacia León, donde mañana y pasado mañana asistiré al I Encuentro Nacional de Internautas, AKA ENI 2006, que se celebra en el Parador de León. Aparte de ver qué cuenta la gente por allí, mañana al mediodía...
Zoooooooom! – Desde ahora el doble clic sobre los mapas de Google Maps además de centrar supone hacer zoom en lugar de únicamente centrar el mapa en pantalla. Doble clic con el botón derecho aleja el zoom un nivel –en los Mac...
Por Nacho Palou -
12 JUL 2006
Aunque en la página principal de Firefox todavía no dice nada, desde este fin de semana ya se puede descargar la beta 1 de Firefox 2.0, por ahora sólo en inglés:Para Linux.Para Mac OS X.Para Windows.Recuerda que es una beta, con lo...
Nunca creí que Kyle McDonald fuera a conseguir su objetivo de conseguir una casa a partir de sucesivos trueques a partir de un simple clip rojo de papel, pero así ha sido, y en menos de un año, gracias a estos objetos:...
The Degree Confluence Project es uno de esos proyectos curiosos que parte de la idea de hacer confluir geografía y matemáticas de una forma peculiar: El proyecto consiste en visitar físicamente cada una de las intersecciones de latitud y longitud con números...
Para conmemorar el 35 aniversario del Proyecto Gutenberg se está celebrando hasta el 4 de agosto la World eBook Fair, en la que hay a disposición de todo el mundo más de 330.000 eBooks gratuitos en formato PDF en más de 100...
El jueves y el viernes de la semana que viene, 13 y 14 de julio, se celebra en León el I Encuentro Nacional de Internautas, organizado por la Asociación de Internautas con el patrocinio de INTECO. Se trata de un encuentro abierto...
A menudo, cuando se habla de que en Internet es muy fácil hacerse pasar por alguien que no eres o de que no hay manera de saber si quien está del otro lado es quien dice ser se cita una viñeta de...
Después de que la Cámara de Representantes decidiera no incorporar ningún tipo de legislación en la COPE Act que prohiba a las telecos discriminar el trato que dan a los contenidos de Internet según sus propios intereses -básicamente comerciales- la esperanza era...
La revolución de los blogs. José Luis Orihuela. La esfera de los libros, 2006. ISBN: 8497344987. Español. Blog del autor: eCuaderno.com. Si escribes un blog es casi seguro que más de una vez te habrán preguntado qué es eso de los blogs;...
Amazon ofrece desde hace años (¿desde siempre?) un servicio de avisos por correo electrónico sobre temas que pueden ser de tu interés, pero la verdad es que funciona, al menos en mi experiencia, muy mal y pasa mucho tiempo sin que envíen...
Trabber es un buscador de vuelos baratos que busca y compara precios de billetes de avión proporcionados por 22 agencias y sitios web de viajes, simultáneamente. Basta elegir origen, destino y fechas, y Trabber se encarga del resto en unos segundos. Siendo...
Se ha lanzado estos días una versión mejorada de Google Sitemaps, el servicio de Google para webmasters que permite definir un mapa público de un sitio web para que el buscador encuentre mejor las páginas y sepa qué es importante o qué...
Desde el departamento «Se está cayendo el cielo»:The Golden Age of the Internet –Cada nueva tecnología que afecta profundamente a la Sociedad tiene una edad de oro en la que se es muy permisivo con ella. La pornografía en Internet simboliza esa...
Por Nacho Palou -
22 JUN 2006
Lista de lo que en Google se considera lo más importante de la vida: Lo más importante de la vida… … no es ganar dinero… es el amor… es asegurar tu propio «espacio de seguridad»… es la ópera… es la final de...
Tim Berners-Lee explica en Net Neutrality: This is serious lo que entiende por Neutralidad de la Red para aquellos que se empeñan en decir que los que la defendemos lo que pedimos en realidad es que sea gratis:Si pago para conectarme a...
A finales de abril y principios de mayo se produjeron unos cuantos anuncios de productoras de televisión y cine y discográficas que empezaban a experimentar con descargas por Internet de música y programas de televisión, ya fuera mediante webs y reproductores propios,...
Acabo de recibir un ejemplar del último libro de José Luis Orihuela, La Revolución de los Blogs. De la contraportada:Los weblogs, blogs, cuadernos de bitácora o simplemente bitácoras son los sitios web personales que están poniendo la Red al alcance de todo...
Los webmasters de phpBB están de enhorabuena. Se acaba de anunciar phpBB 3.0 en versión beta, también conocida como Olympus, una revisión importante del popular sistema de foros que tantas comunidades ha creado a lo largo y ancho de Internet. Entre las...
StatCounter, el popular servicio de «estadísticas web» hizo algunos cambios estos últimos días y ha incluido una nueva función que permite descargar los logs de las últimas visitas en formato texto o Excel, para procesarlos con otras aplicaciones. El tamaño del log...
Héctor se curró una traducción muy completa de Step-by-Step: How to Get BILLIONS of Pages Indexed by Google que ha titulado Cómo obtener billones de páginas indexadas en Google. Es la curiosa historia de una web que en menos de tres semanas...
Tras su encontronazo legal con la SGAE, la Frikipedia está (más o menos) de vuelta: AVISO TELA DE GORDO: Esta web no está "abierta", está en pruebas mientras dura el lío con la SGAE, ni siquiera sabemos qué va a pasar al...
Hace unos años Netscape era el navegador y su nombre era casi sinónimo de la web; fue protagonista de la salida a bolsa más espectaculares de todos los tiempos… y luego cayó víctima de la guerra de los navegadores -y de versiones...

Estos días se hizo público Google Earth 4, una nueva versión beta del software de visualización de imágenes y mapas de Google. Está disponible para Mac OS como binario universal, también para Windows y para Linux, otra de las novedades. La interfaz...
Una serie de empresas que compartían ISP con The Pirate Bay cuyos servidores fueron también confiscados por la policía en la operación dirigida contra el conocido sitio de intercambio de torrents han anunciado que planean pedir compensaciones económicas al estado sueco de...
Desde ayer ya se están activando las primeras cuentas de la versión beta de Feeds 2.0, un agregador web de feeds RSS con algunas cuestiones interesantes a la hora de mostrar el contenido de los feeds. Feeds 2.0 incluye un «motor de...
Por Nacho Palou -
15 JUN 2006
Dos nuevas betas recién salidas del horno para jugar:Por un lado, la primera beta de Flock, el navegador basado en Mozilla que integra el acceso a sitios como de.icio.us, Flickr y Photobucket, un lector de feeds RSS, y que además sirve como...
El congreso de los Estados Unidos lleva ya algún tiempo dándole vueltas a la Communications Opportunity, Promotion and Enhancement Act of 2006, una ley que pretende modificar ciertos aspectos de la Telecommunications Act of 1996, otra ley que si bien pretendía favorecer...
Ahí van algunos servicios más que creo que son recientes (¡o tal vez no!) y que descubrí hace poco y se pueden ver en dos minutos para entender de qué van y si te resultan útiles: MyBlog, estilo Bogger, para crear blogs.MyVideo,...
Desde la sección Podcasts del iTunes Music Store (PC y Mac, gratuito) es posible suscribirse gratis a los videocasts y podcats (vídeo y audio en diferido) que las cadenas Canal+ y Cuatro están publicando con motivo del Mundial de Alemania 2006. Aunque...
Por Nacho Palou -
13 JUN 2006
The World's Largest Band (que parece parecía haber vuelto a la vida después de varios días no disponible por exceso de tráfico –va sólo a ratos) es una aplicación online que convierte cualquier página web en una interpretación musical en formato MIDIThe...
Por Nacho Palou -
8 JUN 2006
No creo que sorprenda a nadie, salvo a los instigadores de la operación en la que la policía sueca cerró The Pirate Bay (y probablemente a estos tampoco) pero sólo tres días después de la citada operación el conocido sitio de intercambio...
Estuve probando un poco Wridea (en versión beta, claro), un bonito y sencillo servicio web donde volcar la ideas que a uno se le ocurren de vez en cuando –aunque normalmente esto sucede cuando se está lejos de un ordenador. El objeto...
Por Nacho Palou -
6 JUN 2006
Vía GarrafaBlog estuve echándole un vistazo a la sección de El Tiempo en Terra y es cierto que resulta extraña la forma y el lenguaje que utiliza para indicar la meteorología, con expresiones ambiguas y extrañas como por ejemplo:Parcialmente soleado y confortableMayormente...
Por Nacho Palou -
5 JUN 2006
Netvibes Ecosystem es una especie de «ecosistema/biblioteca» alrededor de Netvibes, uno de esos nuevos servicios que permiten crear fácilmente una página de inicio personalizada y agregar diversas cosas, como recientemente módulos de Digg o de eBay, además de los clásicos feeds, fotos,...
CCHits es un sitio tipo digg pero en lugar de enviarse, votarse y comentarse noticias se hace eso mismo pero con canciones con licencia Creative Commons. El pequeño icono a la izquierda de cada uno de los títulos inicia la reproducción de...
Por Nacho Palou -
3 JUN 2006
Hoy en Ciberpaís, David Sifry, fundador de Technorati: "Yo soy el editor del siglo XXI". (Vía La Huella Digital.)...
La policía sueca ha clausurado hoy The Pirate Bay, el conocido sitio de intercambio de torrents, tal y como puede leerse en la nota que hay ahora mismo en su web, aún a pesar de que su supuesta ilegalidad está a debate....
La utilidad del servicio web Krunch es enorme y su uso simple como el mecanismo de un chupete: se trata de un servicio web al que le envías uno o varios archivos desde el navegador y te devuelve uno comprimido en formato...
Por Nacho Palou -
30 MAY 2006
Ya hace algún tiempo que se viene oyendo el «run-run» de que si hay o no una nueva burbuja hinchándose alrededor del fenómeno Web 2.0 -aún cuando para muchos tan siquiera está clara su definición- y cada vez se oyen más noticias...
Telewiki, el proyecto para «crear la primera enciclopedia catódica de España» lleva ya en marcha unos días; el anuncio de su creación está en [TV] TeleWiki, enciclopedia de televisión. Como en otros wikis puedes echar una mano escribiendo los artículos que te...
Paul Stamatiou hace una selección de los siete mejores grupos de Flickr para «techies» en Top 7 Techie Flickr Groups en la que seguro que encuentras más de uno que te guste (si es que no eres ya miembro de alguno de...
Ayer por la mañana Julio contaba en Technorati, Edelman ¿y el español qué? que estas dos empresas habían alcanzado un acuerdo para lanzar locales de Technorati en alemán, coreano, italiano, francés y chino, e igual que él, mi primera reacción fue un...
WikiMapia es una web creada como un servicio mashup de Google Maps con Wikis, un poco al estilo de Tagzania y otros similares, aunque cada uno de ellos tiene un estilo diferente. WikiMapia permite marcar y añadir tags y textos a zonas...
PBwiki es un sistema de gestión de contenidos tipo Wiki, páginas donde diversos usuarios pueden editar a la vez de forma colaborativa, como la corchera de la pared de cualquier punto de reunión social. Me encantó su diseño y velocidad, y es...
RocketBoom contaba hoy la historia de ThanksNo.com que es una mini-página web con cuyo sencillo nombre/dirección web puedes contestar al típico amigo imbécil y/o graciosillo que no deja de enviarte correos encadenados. (Todos tenemos amigos imbéciles de esos, generalmente gente cariñosa e...
En Concurso de Google Maps España se pueden encontrar las bases de un concurso que empieza ahora, que consiste en crear aplicaciones empleando la versión española de Google Maps. Esto ya se anunció en el congreso OJObuscador hace algunas semanas. Estas son...
Protopage es otra de esas páginas de inicio personalizadas donde hay paneles y puedes configurar noticias e información útil para leer de un vistazo. Al estilo de Netvibes y unos cuantos otros similares, pero con un aspecto formidable. Se puede usar con...
A finales de la semana pasada salió la segunda alfa de Firefox 2, llamada Bon Echo, así que aproveché para descargarla y utilizarlo como navegador durante este fin de semana para ver cómo iba. Para ser una alfa, resultó ser muy estable,...
No sé si esto es viejo, o nuevo, o mediopensionista, ni cómo se llama el servicio… pero me pareció curioso y útil a la vez: http://www.google.com/gwt/n?u=URL Como por ejemplo: Microsiervos. Escribiendo una URL al final de esa dirección la página se adapta...
Disponible la versión 1.5 final de Infoscape, el notificador de actualizaciones en feeds RSS que recientemente comentamos por aquí. Conviene instalar la actualización en tanto añade varias mejoras y corrige algunos bugs de la versión anterior, aunque de momento sigue estando sólo...
Por Nacho Palou -
22 MAY 2006
Hoy se cumplen cinco años de la puesta en marcha de la versión en español de la Wikipedia, tiempo a lo largo del cual ha acumulado algo más de 119.000 artículos. Un buen regalo de cumpleaños podría ser apuntarse a la iniciativa...

Hoy en día la palabra spam significa para casi todo el mundo correo basura, pero en realidad es la marca de una gama de embutidos fabricados por Hormel Foods. Lo de identificar la marca en cuestión con algo que se repite...
Lo comentaron en del.icio.us / blog pero no me percaté del anuncio y me he enterado vía Emily Chang: si guardas el enlace de una imagen de Flickr en del.icio.us se adjunta una minuatura de ésta.La idea viene porque según han notado...
Por Nacho Palou -
19 MAY 2006
Nuestro sitio de fotos preferido, Flickr, ha dejado de ser beta y ya es gamma, con nuevas navegación y búsquedas, y con un organizador muy mejorado. Los detalles en Alpha... Beta... Gamma! (Vía Moonsadow y Pixel y Dixel.) h4ppier photos para Flickr,...
Imposible no mencionarlo: herramientas, metales, tornillos, tubos, rodamientos y demás elementos de material industrial y científico y (más) chismes de todo tipo en Amazon Industrial & Scientific. Los gastos de envío de una caja llena de bolas de acero deben ser gloriosos....
Por Nacho Palou -
17 MAY 2006
10 Things You Might Not Know About Google, entre otras:2. Google también fue beta4. Sus fundadores no se caían bien al principio.5. Tiene 16 blogs oficiales6. Se autocensura en algunos países7. Dejó de contabilizar el tamaño de su índice(Vía The J-Walk Blog.)...
Por Nacho Palou -
17 MAY 2006
(Nota: Esta anotación habla de FON, que es una de las empresas en las que participo. Ver Full Disclosure.) Hoy 17 de mayo es el Día de Internet, también conocido como «Día Mundial de la Sociedad de la Información» y hay cientos...
No es que no lo hayamos dicho por aquí unas cuantas veces ya, es que el propio Fiscal General del Estado deja claro en una circular del 5 de mayo [PDF 588 KB] que el intercambio de archivos vía redes P2P no...
Crear la entrada en la Wikipedia de nuestro santo patrón, el novelista Douglas Coupland ha sido mi aportación a la iniciativa Wikiesx2. Como ya contamos hace algunos días, el objetivo es duplicar el número de entradas que hay en la versión en...
La extensión TinyUrl Creator para Firefox incorpora la función del servicio web TinyURL directamente en el menú contextual del navegador. Más cómodo imposible.
Por Nacho Palou -
13 MAY 2006
Isma me pasó unos enlaces de sitios nuevos que hacen cosas. BittyFoldMesRssTambién llegaron por diversas vías: Sabro.usWikilearningListamaticÚltimamente hay tantos que es imposible seguirlos todos....
Atlas es una aplicación web tipo Google Maps, con las vistas aéreas y callejero habituales pero que en alguna zonas (pocas y sólo en usa) tiene una función llamada «Bird's Eye» que muestra unas imágenes francamente chulas en las que incluso es...
Por Nacho Palou -
12 MAY 2006
Google Trends es el último invento de los laboratorios Google. Escribes un término y te muestra una gráfica de «tendencias». La tendencia indica cuántas veces la gente ha buscado ese término en Google, o cuántas veces aparece el término en las noticias...
Livesearch es un nuevo servicio de AlltheWeb, un buscador que en tiempos remotos pretendió competir con Google y que ahora forma parte de Yahoo. Livesearch es un servicio realmente curioso: permite ver qué frases de búsqueda está empleando la gente para las...
Emilio nos invitó amablemente a probar la aplicación infoscape (blog) que está desarrollando en sus ratos libres. Aunque por aquí utilizamos ordenadores Macintosh también hay algún PC con Windows disponible para pruebas y comprobaciones y en uno de ellos instalé la versión...
Por Nacho Palou -
10 MAY 2006
No es una lista exhaustiva ni mucho menos, pero esta colección de noticias de los últimos días hace pensar que lo mismo los grandes estudios se están empezando a dar cuenta de que realmente tienen que renovar su modelo de negocio: La...
Apunti es un sencillo servicio de correo para enviar mensajes «al futuro». Puedes enviártelos a ti mismo o a otras personas. Eliges la fecha y el mensaje se envía cuando corresponde. Al parecer la gente lo está usando para todo tipo de...
Si el módulo de proceso por lotes de Flickr estuviera bien hecho, haría lo que hace h4ppier photos, un organizador para tus fotos de Flickr realmente potente que te permite hacer selecciones bajo multitud de criterios y luego hacer cambios en bloque...
La iniciativa Wikiesx2 tiene como objetivo duplicar el número de entradas que hay en la versión en español de la Wikipedia. «La lista de artículos que la Wikipedia en español debiera tener basada en la lista de artículos que debe tener toda...
Por Nacho Palou -
9 MAY 2006
Nacho y yo estamos en el Congreso OJOBuscador 2006 a ver si aprendemos algo. Hay un montón gente (unas doscientas personas) y por suerte también hay Wi-Fi gratis así que igual vamos publicando algunas cosillas según oigamos. • Ricado Baeza-Yates de Yahoo...
… Carros de alfalfa estallando más allá de la puerta de Tanhauser. … Excursiones llenas de niños sin amigos. … Teclear la URL en la caja de Google. … Attack ships on fire off the shoulder of Orion (la original de...
Free Network Visible Network es un curioso proyecto del Mixed Reality Lab de una técnica que se suele denominar «realidad aumentada»: Free Network Visible Network – Es un sistema de visualización de datos en realidad aumentada que permite ver, flotando en el...
Wikocracia: tal vez, la expresión definitiva de la democracia. Si no te gusta la Ley, puedes reescribirla. De hecho, cualquiera puede reescribirla, una y otra vez. Es un Wiki. Han cargado este sistema experimental con la Constitución de los Estados Unidos de...

Según el calendario geek, tal día como hoy, un 5 de mayo pero de 1974, Vinton Cerf y Bob Kahn publicaron el artículo A Protocol for Packet Network Communication en el ejemplar número 5 del volumen 22 de IEEE Transcactions on...
La particularidad del buscador PodZinger es que permite encontrar palabras dentro del archivo de audio de un podcast y video podcasts. Existe desde hace no mucho tiempo y desde principios de este mes permite realizar las búsquedas en español. Al realizar un...
Por Nacho Palou -
5 MAY 2006
Ya hemos enlazado en alguna ocasión con Airliners.net, un sitio en el que hay montones de impresionantes fotos de aviones, pero en el que el idioma «oficial» es el inglés; ahora, desde hace un par de meses, los «aerotranstornados» que hablamos español...
Para variar, un artículo que habla bien de los hackers, titulado precisamente ¿Qué tenemos que agradecer a los hackers? Unas pistas: videojuegos, música generada por ordenador, el ordenador personal, una «cosilla» llamada Internet… (Vía Port 666.) The New Hacker's Dictionary, Third Edition;...
Desde abril estamos probando el seguimiento de estadísticas web de Microsiervos con Google Analytics que es el nombre que Google dio al antiguo Urchin Web Analytics, tras adquirir la compañía. Tuvimos la suerte de que nuestro amigo David que trabaja en Google...
José Carlos publicó en ComicPublicidad una interesante reflexión en Márketing Viral ¿Nos dejamos contagiar? relativa a las campañas de márketing viral que circulan por Internet y de las que últimamente ha habido varios ejemplos muy conocidos: (…) Cuando contemplé el video, el...
Cuando titulé Internet, mentiras y descargas de archivos a la anotación sobre la supuesta detención de 15 personas y la clausura de 17 páginas web por facilitar el intercambio de archivos no imaginaba hasta que punto lo de las mentiras jugaba un...
Para los aficionados a los vídeos de Internet, Javi Moya ha lanzado VideoDownloader 1.0 para Firefox, una extensión para el popular navegador de su utilidad web del mismo nombre, VideoDownloader. Tanto la versión para Firefox como la página web del mismo nombre...
Una lista de diversas «máquinas»: La Máquina del Tiempo (novela de H.G. Wells) La Máquina de Turing (matemáticas/informática) La Máquina de Vapor (física) La Máquina Enigma (matemáticas/criptografía) La Máquina Inventora (tecnología) La Máquina Java (informática) La Máquina Térmica (física) La Máquina de...
Sencillo: Vibmarks. La popularidad mata a la relevancia.(Vía Loogic.com.)...
Llevo un par de semanas probando FlickrExport (Mac OS X) y la verdad es que va muy bien aunque presenta cierta inestabilidad a veces. También Flickr se sigue atascando a veces mientras subes fotos, pero bueno. Creo que definitivamente es de lo...
Ya están abiertos: Google Maps España, con sus mapas vectoriales, paradas de metro, cálculo de recorridos óptimos y todas esas cosillas. Esto añade una nueva dimensión al los populares mapas que en España hasta ahora sólo estaban disponibles con fotos de satélite....
Otro de cifras: Estadísticas mundiales de InternetEstadísticas mundiales con el número de usuarios en más de 240 países y regiones del mundo [...] para conocer el potencial de los mercados mundiales. Incluye información por país y región, la población actual y la...
Por Nacho Palou -
25 ABR 2006
Google Cheat Sheets [descargar PDF, ~100 KB.], una guía rápida con lo operadores y comandos para realizar búsquedas en Google. También permite localizar los distintos servicios y herramientas disponibles e incluye algo de información irrelevante sobre la compañía. (Vía Proletarium.) «Chuleta» para...
Por Nacho Palou -
24 ABR 2006
Robots.txt Validator and Testing es una sencilla herramienta para comprobar que el contenido del archivo robots.txt de una web se ajusta al Protocolo de Exclusión de Robots. Ese archivo lo instalan algunos webmasters, y sirve para decirle a Google y a otros...
¡Nuevo Fresqui! Desde hoy Fresqui ya está en beta, lo cual sirve como recordatorio de que hasta ahora sólo disfrutábamos de la versión «alfa» de este interesante servicio de promoción de noticias estilo Digg, pero orientado al mundillo de la tecnología, la...
Una de las muchas utilidades de TimeAndDate.com que viene bien tener a mano es esta página que sirve para calcular el número de días entre dos fechas. ¿Qué hora es en…? para calcular en diferentes ciudades...
Una lista de diversos «efectos»: El Efecto Invernadero (climatología) El Efecto Fotoeléctrico (física) El Efecto Doppler (física) El Efecto 2000 (Y2K, problema informático) El Efecto Mariposa (física) El Efecto Slashdot (Internet) El Efecto Barrapunto (Internet) El Efecto Cloux (los disparos en el...
Sofá Naranja informa de un nuevo e importante elemento de XHTML: Un nuevo elemento XHTML: <CWT/> – Es un hecho demostrado de la vida profesional de cualquiera que trabaje con clientes el que, antes o después, tendrás que producir algo con lo...
Flickr es la mejor herramienta de Internet para compartir fotos -o al menos es nuestra herramienta favorita- y no sólo por sus características sino también gracias a su naturaleza abierta, que permite que casi cualquiera pueda montar servicios basados en Flickr. The...
Si repetir una mentira el suficiente número de veces la hiciera cierta esta desde luego tendría que serlo [lista extraída y editada del comentario titulado Corta y Pega en Barrapunto; la mayoría de estas fuentes se limitan a reproducir las notas de...
Si hay alguien que debe tener una cierta idea de por dónde pueden ir los tiros con esto de la web es precisamente quien la inventó, Sir Tim Berners-Lee, quien hace unos días impartió una conferencia al respecto en el Oxford Internet...
Una gran verdad en The Surprising Truth About Ugly Websites (La sorprendente verdad sobre los sitios web feos), comentado Slashdot: Esta es una de las razones por la que los sitios web feos pueden ser exitosos: la falta de profesionalismo y de...
Hoy volvieron a spammear el Wiki de Microsiervos. De vez en cuando sufre diversos tipos de vandalismo pero por suerte se corrige rápido. Es lo bueno de los wikis: bien el propietario o cualquier usuario pueden «revertir» cambios vandálicos en cuestión de...
Navegar por la colección de fotos de alguien en Flickr es un tanto pesado si pretendes hacerlo a través de las páginas de fotos de esta persona -las que salen cuando vas haciendo clic en los enlaces que aparecen tras Pages en...
¡Pronto Google dará horóscopos! Ayer lanzaron Google Finance que es como el Yahoo Finance de toda la vida, combinado con noticias y todo eso. Tiene bonitos los gráficos interactivos en Flash sobre las cotizaciones. La gracia del asunto es que el año...
Es una lástima que la calidad de imagen y sonido no sean mejores, pero en cualquier caso el documental de 1972 Computer Networks: The Heralds of Resource Sharing no tiene desperdicio. En él pioneros de Internet como J. C. R. Licklider,...
Brent Simmons acaba de anunciar la beta pública de NetNewsWire 2.1b16 para Mac OS X. Es la primera beta de la esperada versión 2.1. NetNewsWire del que he hablado más de una vez es mi agregador de feeds RSS favorito: es muy...
iXen nos ha escrito para contarnos que ha creado esta sencilla página [Actualización – ya no existe] que te dice la posición de una palabra en Google para un dominio de Internet, algo así como El dominio microsiervos.com aparece en Google cuando...
Ya se han publicado los resultados provisionales del concurso HazRuido.com, la competición de márketing viral organizada por Alianzo y Dirson que se lleva celebrando desde principios de año. Casi todos los ganadores de las distintas categorías están ya claros, aunque para el...
Ta-Da Lists ya la hemos comentado por aquí antes: es una aplicación web rápida y sencilla de usar que sirve para gestionar listas del tipo «cosas pendientes de hacer» y similares. Y ahora además es posible acceder a esas listas y manejarlas...
Por Nacho Palou -
13 MAR 2006
Google acaba de extender su PDM a Marte con Google Mars, fruto de una colaboración con investigadores de la NASA de la Arizona State University: Incluye como imágenes base:Mapas de altura codificados por color obtenidos por el Mars Orbiter Laser Altimeter del...
Hoy va de retro la cosa: así era la página web de Microsoft entre 1994 y 1995.Ya entonces servía casi 125.000 páginas cada día y fue alabada por Bill Gates porque resultaba más útil para encontrar información que la red corporativa interna....
Por Nacho Palou -
10 MAR 2006
Podquerón es el podcast del Grupo de Usuarios Macintosh de Málaga y la Costa del Sol (GUM/Málaga). Está dedicado a «las novedades en torno al Mac, Internet y el mundo de la tecnología y los gadgets». Después del «episodio piloto» (Podquerón...
Por Nacho Palou -
10 MAR 2006
Esto es más viejo que yo que sé... pero hoy tuve que hacerlo para la web de un proyecto y no conseguía encontrarlo fácilmente, así que tal vez a alguien le venga bien la página y la explicación. Google Free es el...
Con el anuncio de que Wikipedia en español alcanza los 100.000 artículos queda un poquito menos para alcanzar el millón de artículos que recientemente superó la Wikipedia en inglés. ¡Ánimo! La edición de Wikipedia en español comenzó en mayo de 2001 y...

Feed Your Reader es una extensión para Firefox que modifica el comportamiento del botón RSS (el que hay en la barra de direcciones) para que tenga utilidad (¡aleluya!) si en vez de Firefox utilizas un lector «agregador» de feeds RSS externo. Lo...
Convocatoria para el jueves 6 de abril en la Universidad de Deusto (Bilbao), bien para asistir, bien para presentar algo interesante. Blogak 2.0 es una jornada sobre la Web 2.0 en las que se pretenden tratar temas como los blogs, los wikis,...
Si llevas escrito «r34lly» en tu camiseta te gustará utilizar Google h4x0r para realizar tus búsquedas. Todo sobre esta versión de Google está explicado aquí: 411 480|_|+ 600613 (lo creas o no ahí dice «All about Google» ;-) En Pipes Network Clog...
Por Nacho Palou -
6 MAR 2006
Nunca hubiera imaginado que había tantos, pero tal vez es que nadie se molestó siquiera en comprobarlo, y resulta que son más de la mitad del diccionario: 43.226 dominios – De las ochenta y pico mil palabras que hay en el diccionario,...
SEOtester es una recopilación de algunas herramientas sencillas para consultar datos sobre SEO relativos a cualquier sitio web. El servicio está disponible en inglés y castellano y es totalmente gratuito. Incluye en una única página, en estilo ajaxiano bastante cómodo y rápido,...
Dave Winer anunció el borrador de la especificación OPML 2.0 (Outline Processor Markup Language – Lenguaje de Marcas para Procesar Esquemas). OPML es algo de lo que puede que se hable mucho este año y el que viene, como sucedió con el...
Un artículo sobre la estación de tren de Jordanhill en Glasgow se ha convertido en el artículo 1.000.000 de la versión inglesa de la Wikipedia, poco menos de un año después de pasar la barrera de los 500.000 artículos. Los comunicados de...
Al menos en opinión de Neil Holloway, el responsable de Microsoft para la zona EMEA, quien al hablar del nuevo motor de búsqueda que piensan presentar en seis meses en los Estados Unidos y Gran Bretaña y poco después en otros países...
¡La realidad supera nuevamente a la ficción! Utopiq nos avisa de que el CCFVLS del que hablamos hace unos días ya existe realmente, y tiene su hogar en la Web: CCFVLS: (La imagen oficial es un poco más light, pero esta que...
Javier de OJOBuscador nos envió amablemente una invitación para el Congreso OJOBuscador 2006 que se celebrará el 4 de mayo [cambio de fecha] 9 de mayo de 2006 en Madrid. El Congreso es un día completo y el programa preliminar ya se...
ispalo nos pasa un enlace a la noticia que publica El Mundo acerca de una investigación en marcha contra Telefónica por haber abusado de su posición dominante en el mercado de la banda ancha: Bruselas presenta cargos contra Telefónica por abuso de...
He estado probando Democracy que es una mezcla entre un player de QuickTime y un agregador como NetNewsWire, de hecho hasta la interfaz es muy parecida. Está bastante bien y es agradable porque consigue un punto de comodidad a la hora de...
Otra pieza más para el arsenal de betas de Google y su PDM, Google Page Creator:100 Mb de hosting gratuito.Editor WYSIWYG, con soporte para arrastrar y soltar imágenes.41 plantillas predefinidas.Número de columnas personalizable…Como dicen en MetaFilter, ¿es esto Geocities 2.0? (Vía Pixel...
Paul Beelen acaba de publicar Publicidad 2.0, un interesante trabajo sobre los cambios de la publicidad en la renovada Internet de la actualidad, así como sobre nuevas relaciones entre empresas e internautas, realmente divulgativo. Trata muchos temas como los weblogs, los...
Technorati, que es como el Google del mundo de los weblogs, acaba de lanzar Technorati Favorites que es otra forma de llamar a su agregador de feeds RSS. Básicamente se trata de un servicio que permite crear una lista de suscripciones de...
Tras su aprobación por el Parlamento europeo a mediados de diciembre de 2005 la directiva sobre retención de datos superaba hoy su último trámite de aprobación al recibir el visto bueno del consejo de ministros de Justicia e Interior de la Unión...
Nacho y yo estuvimos probando eXternalTest por invitación de Enrique. Se trata de un servicio web gratuito que sirve para monitorizar tus páginas web desde distintos servidores. Simplemente te registras con tus datos y le indicas qué sitios web (dominios) quieres monitorizar....
Apareció por la oficina una caja de Amazon con algunos libros en inglés. Eran de un viejo pedido que por extrañas circunstancias me llegó repetido. Al parecer en alguna oficina de correos se equivocaron: mi caja le llegó a un tío de...
Me encontré esto en un foro y me hizo gracia, hay quien lo usa como firma o como respuesta a otros mensajes: He buscado un poco en Google y parece que el CCFVLS no existe, aunque diría que sin duda aunque fuera...
Un comité del Senado y Congreso norteamericanos estuvo estudiando esta semana si la actuación de las grandes empresas de Internet estadounidenses en China, como los recientes casos de la censura aceptada por Google en sus contenidos para China o el que Yahoo...
Ya se puede ir probando la versión alpha pública de la edición dedicada a la tecnología y la ciencia de Fresqui.com en tec.Fresqui.com. Si conoces digg reconocerás enseguida la mecánica del site. Fresqui.com viene a ser un servicio similar pero en castellano...
Por Nacho Palou -
17 FEB 2006
Tenía pendiente escribir algo genérico sobre los memes desde el punto de vista de fenómenos de la «promoción viral» o «márketing viral», pero el otro día José Luis Orihuela publicó Memes: los virus de la mente que es algo muy completito: Meme...
Después del fiasco del DRM de Sony/BMG, ahora resulta que también hay DVDs en el mercado que, igual que los discos de audio de Sony/BMG, llevan sistemas DRM que instalan un rootkit que compromete la seguridad del ordenador en el que los...
El efecto es muy divertido, porque va traduciendo de forma instantánea mientras tecleas: AJAX Translator. Está programando utilizando técnicas AJAX. (Vía TecnoCHICA.)...
Llevaba algún tiempo comentándose, y por fin la Asociación de Internautas confirma que Telefónica está desactivando progresivamente el proxy-caché que tantos quebraderos de cabeza dio a más de uno en su momento; se supone que en marzo estará completamente desactivado: El éxito...
Algún día me gustaría ver cómo funciona el proceso mediante el que Amazon convierte los pedidos en línea en los paquetes que luego llegan a casa, pero por ahora en artículo Inside Newegg: They give us a Tour and you a Prize...

Ya está disponible Camino 1.0, un navegador de código abierto basado en Mozilla, igual que Firefox, pero en el caso de Camino especialmente pensado para usuarios de Macintosh. Es una aplicación universal, es decir, que corre tanto en Macintosh con procesador PowerPC...
Dejando aparte los problemas que pueda tener con su tienda de vídeos, Google sigue adelante con su PDM y estos días también eran noticia:La integración de gmail y gtalk.Gmail for your domain, la opción de ofrecer Gmail a los usuarios de cualquier...
Hace algún tiempo hablábamos de las prisas de Google, y entre otras cosas mencionábamos los problemas que supone que los vídeos que vende con DRM sólo se puedan reproducir, al menos por ahora, bajo Windows. Hoy Cory insiste en el tema del...
El año pasado se celebró el 25 de octubre, pero este año el Día de Internet se adelanta al 17 de mayo, con lo que ya están convocados los premios díadeinternet 2006 y ya se pueden ir presentando candidaturas. Igual que el...
Como cuentan en este hilo de un foro [actualización: ya no existe] si se te ocurre un buen nombre de dominio a veces es mejor no buscarlo. Algunos sitios web que facilitan las búsquedas en el servicio WHOIS luego registran ellos mismos...
Un «troll» de Internet es el que siente placer al sembrar discordia en Internet. Intenta iniciar discusiones y ofender a la gente (…) La única manera de tratar con trolls es limitar su reacción a recordar a los demás que no respondan...
Se me ocurrió la soberana chorrada de preparar una extensión o plugin para hacer búsquedas directamente en Microsiervos con la opción de búsqueda integrada en Firefox. El buscador de Movable Type (la herramienta de publicación que utilizamos en Microsiervos) no es especialmente...
Por Nacho Palou -
11 FEB 2006
¡Por fin! Ahora Netvibes funciona en el navegador Safari:Netvibes on Safari – Netvibes funciona ahora en [Safari,] Opera 9 beta, Opera 8, Firefox e Internet Explorer. Esta actualización incluye un montón de nuevas funcionalidades que iremos viendo esta semana.Una noticia excelente. del.icio.us...
Por Nacho Palou -
9 FEB 2006
Videbomb es el enésimo sitio de publicación colectiva tipo Digg pero esta vez decidado a videoclips, que se pueden votar o a los que puedes suscribirte por RSS para ver los más populares – también se pueden subir allí nuevos vídeos...
Mientras se celebra el décimo aniversario de la Declaración de Independencia del Ciberespacio los políticos de Washington están debatiendo si es necesario crear leyes que aseguren la neutralidad de Internet o no. Esto, que suena a raro, es debido a que algunas...
Una nota en Barrapunto me ha recordado que se cumplen 10 años de la Declaración de Independencia del Ciberespacio. Esta declaración fue presentada por John Perry Barlow de la EFF en Davos (Suiza) en 1996. El original en inglés puede leerse aquí:...
Jaime nos escribió anoche para comentarnos que tras leer nuestra anotación acerca del cierre de la Frikipedia a causa de una demanda de la SGAE se dio una vuelta por la web de la Sociedad y que allí descubrió una cosa la...
El sábado nos avisaron por correo de que la SGAE había provocado el cierre de la Frikipedia mediante una denuncia, pero no quisimos hablar del tema hasta habernos podido poner en contacto con su responsable, lo que finalmente hicimos entre ayer y...
Los responsables del sitio web de BMW para Alemania decidieron seguir los consejos de algún «optimizador de búsquedas» e incluir texto oculto en sus páginas para mejorar su colocación y PageRank en Google… Pero Google se dio cuenta y en consecuencia ha...
Martin Varsasvky acaba de anunciar que varios de los gigantes de Internet invierten 18 millones de euros en FON. El objetivo de FON es crear redes Wi-Fi ciudadanas en las que compartir el acceso a Internet entre todos permite tener conexión a...
Eventtos es un nuevo servicio web realmente curioso e interesante. [Actualización: dejó de existir hace tiempo] – Es un de blog colaborativo en el que cualquiera puede escribir para anunciar un evento (una reunión, conferencia, curso, acto, charla, quedada, concierto). Funciona...
Google nos trata muy bien, así que nuestras anotaciones suelen salir bastante bien colocadas en las búsquedas que hace la gente, por lo que a esta alturas estamos acostumbrados a recibir correos prácticamente a diario en los que se nos pide consejo...
Eduardo nos escribió hace unos días para comentarnos que Planeta DeAgostini, basándose en que es propietaria de Ediciones Deusto, quiere quitarle mediante una denuncia ante la WIPO el dominio deusto.com que tiene registrado desde 1997, y que ahora mismo está suspendido, en...
Misma búsqueda, distintos resultadosBúsqueda de tiananmen desde el MundoReal™Búsqueda de tiananmen desde Yupilandia.(Enviado por Guillermo.) Actualizado: por acumulación de «pendientes de leer» me uno a la ronda de actualizaciones respecto a este caso de uso de Google. En Pixel y Dixel y...
Por Nacho Palou -
1 FEB 2006
Nueva beta de Internet Explorer 7, pública y disponible para que cualquier usuario de Windows XP pueda descargarlo y probarlo: Internet Explorer 7: Beta 2 Preview. También hay una pequeña presentación de las nuevas características del navegador, Tour of new features, que...
Por Nacho Palou -
1 FEB 2006
Otra frase genial de Pedro Farré, el abogado de la SGAE, en «Las fiestas tienen que pagar por los derechos de autor»:-¿Qué piensa del «Copy left»? (movimiento que propugna la libre circulación de ideas)-Es un movimiento alentado por intereses oscuros. Hay quien...
Cada vez entiendo menos a los políticos cuando se meten en temas de tecnología… o quizás es que los políticos nunca han entendido mucho de esta y por eso meten las patas continuamente con sus iniciativas tecnológicas. Según cuenta La Voz de...
No es la primera vez que se oye este rumor, pero Kevin Burton lo ve esta vez lo suficientemente claro como para hablar de que la operación sería por un importe de unos 30 millones de dólares y que podría hacerse pública...
Se ve que a Uxio le gustó la imagen aquella de «me siento vigilado» y le inspiró tres síntomas para detectar si eres esclavo de Google y la Wikipedia, y nos lo mandó por correo: Primer síntoma: Buscar sólo con Google (ni...
¡Qué bueno! InstantDomainSearch.com es un buscador de dominios instantáneo. A medida que vas tecleando nombres o lo que se te ocurre te dice si el dominio de Internet .com/net/org correspondiente está registrado o libre. El primer dominio .com libre con las cifras...
Si hace unos días Google ganaba puntos por negarse a facilitar datos de las búsquedas que hacen sus usuarios al gobierno de los Estados Unidos, hoy pierde unos cuantos al haber cedido a las presiones del gobierno chino y anunciar el lanzamiento...
Algunas impresiones de jasp después de probar un poco Internet Explorer 7:Microsoft Internet Explorer 7, (o cómo he sido infiel a Firefox) – IE ha aprendido, pero lo ha hecho copiando. No hay más que echar un pequeños vistazo a la estructura...
Por Nacho Palou -
24 ENE 2006
NetNewsWire es nuestro lector de canales RSS preferido, y no dejamos de recomendarlo como una herramienta estupenda para estar al tanto de las noticias que te interesan con un mínimo de esfuerzo y sin la necesidad de acudir a un agregador en...
Alex Tew, quien pretendía hacerse rico vendiendo píxeles en su página, podría enfrentarse pronto a una demanda por incumplimiento de contrato. Eliger Kliger, el propietario de milliondollarweightloss.com, ganó la semana pasada la subasta por el último hueco que quedaba libre en la...
Se las está pidiendo el gobierno de los EE.UU. «para evitar que los menores tengan acceso a la pornografía» Google se enfrenta al Gobierno de EE UU al negarse a revelar las búsquedas de sus usuarios –Google se niega a cumplir una...
Por Nacho Palou -
20 ENE 2006

Cuando Flickr está de mantenimiento, ponen una página diciendo que «Flickr está recibiendo un masaje». Hay otra divertida en Bloglines, con un fontanero. Hoy me apareció la página de «mantenimiento» de YouTube, que también es muy graciosa. Desde luego, se les...
Intentando buscar algo en la revista TIME Canadá pulsé Search y me salió esto: Es la página de Netscape (Canadá). Ha sido como un momento Retro de los 90, tiempos en los que Netscape rulaba la tierra y todo aquello, con el...
No es ningún secreto que Google tiene un plan para dominar el mundo trocito a trocito, pero… ¿está dándose demasiada prisa últimamente con sus lanzamientos? Por un lado, Google Analytics «murió» de éxito a los pocos días de su lanzamiento y hace...
Me queda pendiente probarlo más a fondo pero me ha gustado la idea porque está en mi lista de «Aplicaciones Atómicas»: formArchitect (vía populicious) es una aplicación web para crear formularios web de forma más o menos visual y cómoda, sin tener...
Por Nacho Palou -
17 ENE 2006
Según cuenta el programador de Mozilla Josh Aas en en el artículo Firefox for Intel Macs planned for March si todo va bien está previsto que en marzo esté disponible el navegador Firefox nativo para los Mac con procesador Intel, a falta...
Por Nacho Palou -
16 ENE 2006
Si eres usuario de del.icio.us y de Netvibes te encantará esto: Netvibes welcome to the delicious module. El nuevo módulo accede a la cuenta de del.icio.us indicando el usuario y la contraseña e inserta en la página de Netvibes los últimos favoritos...
Por Nacho Palou -
16 ENE 2006
¡Felicidades Wikipedia! Wikipedia cumple cinco años – Un 15 de Enero de 2001 se pone en marcha la Wikipedia, la cual fue creada como una alternativa a Nupedia, un proyecto en algunos aspectos similar y también fundado por Jimmy Wales. Se empezó...
Martín y el equipo de FON (proyecto en el que como hemos comentado más de una vez Nacho y yo andamos metidos) han anunciado una campaña para llevar Wi-Fi a sitios públicos elegidos por los usuarios, la idea es instalar puntos de...
Explica PJorge: La muerte de Barrapunto – En realidad, Jeremy Zawodny predice para 2006 el comienzo de la muerte de Slashdot, pero supongo que sus argumentos se aplican igual de bien a Barrapunto. Básicamente, se refiere a la estratificación entre «editores» y...
No sé si será el primer día que sucede esto, pero Google vale hoy en bolsa más que IBM (133.000 frente a 130.000 millones de dólares de capitalización bursátil, que es como suelen medirse estas cosas). Google también vale ya aproximadamente la...
Se publicó la tradicional lista de Top #25 Influyentes de Internet en España de este año, que la verdad es que no parece cambiar demasiado de un año a otro. José R. en Mi Primera Bitácora se dio cuenta de que la...
AllPeers es una extensión para Firefox que promete ya que permitirá el intercambio de archivos de forma descentralizada, tipo P2P/Bittorrent directamente desde el navegador.AllPeers Is The FireFox «Killer App» - AllPeers permite compartir cualquier archivo de tu ordenador con una o más...
Por Nacho Palou -
4 ENE 2006
No me cansaré de recomendar NetNewsWire, el agregador de feeds RSS más potente que existe para Mac OS X. Vale cada dólar que pagas y más. Hoy conseguí configurar y que ¡por fin! funcionara la sincronización entre ordenadores, que es una función...
¿Pensando en ganar dinero en Internet montando una web, un blog, algo Web 2.0? De los fallos también se aprende (y lo narra kuro5hin, que es todo un clásico): My $25,000 Lesson - Hace un año más o menos decidí dejar mi...
Como suele decirse, yo no habría sabido explicarlo mejor, así que dejaré que sea Dan Gillmor quien lo haga: Proof that Some People are Idiots - Reuters: El estudiante que tuvo la idea de la web del millón de dólares se hace...
En algún momento van a empezar a surgir preguntas sobre por qué estamos rechazando tanto dinero. Esta frase es de Jimmy Wales, fundador de Wikipedia, la enciclopedia libre. Tal vez la presión publicitaria se esté haciendo cada día mayor, o tal vez...
Con un par de imágenes es suficiente. (Matthew Thomas vía Halón Disparado.)...
En Google Acquisitions está la lista de todas las empresas que ha ido comprando Google, imprescindible si quieres intentar averiguar cómo Google planea dominar el mundo. (Vía Pixel y Dixel.)...
Tenía guardados un par de enlaces para comentar tras los fastos navideños sobre el tema de la música en línea, pero Enrique se me ha adelantado con uno de ellos en Panorama de la música online en el 2005, que cubre lo...
La marca que más ha crecido en Internet en los últimos doce meses es Apple, casi un 60% respecto a noviembre de 2004. Se suponía que Apple principalmente fabrica ordenadores y software y algunos gadgets y vende algo de música por Internet...
Por Nacho Palou -
27 DIC 2005
Lo contaron la semana pasada en distintos sitios: Internet Explorer adoptará el icono que utiliza Firefox para indicar los Feed RSS. Si ya utilizas Firefox éste icono es el que aparece arriba en la barra de direcciones donde aparece la URL de...
Por Nacho Palou -
26 DIC 2005
Este texto lo escribí hace ya más de cinco años, lo mandé a algún foro o se publicó en algún sitio - y me parece que sigue siendo bastante válido hoy en día. He aprovechado para renovarlo un poco, aunque el panorama...
Google Modules es un directorio «no-oficales» de módulos (pequeñas aplicaciones) que sirven para aumentar las funcionalidades de la página de inicio personalizada. Google Modules tiene algo más contenido y se actualiza con más frecuencia que el directorio de módulos de Google....
Por Nacho Palou -
26 DIC 2005
Una supuesta compra de Opera por parte de Microsoft aún no confirmada pero que empieza a oirse por todas partesMicrosoft Buys Out Opera — En una reciente conversación con uno de nuestras fuentes internas en Microsoft reveló que ésta ha comprado Opera...
Por Nacho Palou -
23 DIC 2005
Y al tercer día también, qué cosasKinja Upgrade — Creemos que esta versión de Kinja es mucho mejor y seguiremos mejorándola. Nos habíamos quedado descolgados y hemos necesitado tres días para mejorarlo y añadirle nuevas funcionalidades.Kinja surgió en abril de 2004 y...
Por Nacho Palou -
22 DIC 2005
Esta es la época del año en la que Google, Yahoo! y compañía suelen publicar lo que más busca la gente en Internet con resúmenes como el 2005 Google Year-End Zeitgeist, los Yahoo! 2005 Top Searches, los Web's Most Wanted 2005 de...
Debe ser una impresión mía la de que cada día recibo más correo basura, porque por lo que cuentan en FTC says federal spam law has worked la Comisión Federal de Comunicaciones de los Estados Unidos opina que la ley de 2003...
En Google: resumen del año 2005 recopila y ordena cronológicamente los hechos más destacados de Google durante el año....
Por Nacho Palou -
21 DIC 2005
La Wikipedia gana peso en Google, siendo uno de los términos que más renombre ha ganado en 2005, aún a pesar de las últimas críticas recibidas. Precisamente este veritiginoso aumento de popularidad desencadenó la necesidad de imponer algunas restricciones en la Wikipedia....
Por Nacho Palou -
21 DIC 2005
Alguans nuevas medidas contra el vandalismo en la Wikipedia: Más restricciones en la Wikipedia - Acaba de publicarse en Slashdot un nuevo cambio en las políticas de la Wikipedia, las páginas semi-protegidas. Se aplicará fundamentalmente a páginas sujetas a contínuo vandalismo, y...
La página de Microsoft Internet Explorer 5 for Mac cuenta que la empresa dejará de dar soporte para IE para Macintosh el 31 de diciembre de 2005 y que dejará de distribuirlo a través de Mactopia, su sitio web dedicado a sus...
Clic, clic, del.icio.us, clic: del.icio.us is down for emergency maintenance. we'll be back as soon possible¿Efecto de la fiesta de adquisición? ;-) Actualización: pues más que un hipo realmente era una emergencia tras un fallo eléctrico total, ya lleva casi 24 horas...
A mediados de 1985 Juan Riera, Juan Viñas, Juan Quemada, Joaquín Seoane y Fernando Fournón ponían en marcha en la Escuela Superior de Ingenieros de Telecomunicaciones de la Universidad Politécnica de Madrid la primera conexión a Internet en España al montar el...
Es genial lo de que los blogueros vayan a charlas y conferencias porque luego van y escriben perlas como ésta: Uno de los puntos débiles de Google es que busca en internet. Por muy depurado que esté su algoritmo, si el contenido...
El artíclo Qué es la Web 2.0, de Tim O'Reilly, en castellano en CanalPDA: El concepto de «Web 2.0» nació durante una sesión conjunta de O'Reilly y MediaLive Internacional para la preparación de conferencias. Dale Dougherty, pionero de la web y vicepresidente...
Una de las críticas más habituales de los detractores de la Wikipedia es el hecho de que pueda ser editada por cualquiera -o casi por cualquiera desde hace poco- y utilizan este hecho como argumento para poner en duda su fiabilidad. Estas...
El invitado de esta semana en NerdTV es Douglas Engelbart, el hombre que inventó en ratón y uno de los que más influyó en que la forma habitual de entenderse hoy en día con los ordenadores sea mediante interfaces WIMP. Como siempre...
Google Safe Browsing es una extensón para Firefox [1.5] que trata de combatir el phising:[La] extensión para Firefox avisa cuando detecta que la página web que estás visitando está pidiendo información personal o bancaria con falsas pretensiones.(Vía populicio.us.) Actualización: en Two Things...
Por Nacho Palou -
15 DIC 2005
Se acabó aquello de que para poner tus llamadas telefónicas bajo vigilancia haga falta la orden de un juez. Miguel nos avisa de que ha sido aprobada la directiva de retención de datos, que además, imagino que para ir en sintonía con...
Si tienes un Macintosh con un procesador PowerPC G4 o PowerPC G5, BeatnikPad ofrece versiones optimizadas de Firefox 1.5 para cada uno de esos procesadores:G4-optimized Firefox 1.5 released.G5-optimized Firefox 1.5 released. Actualización: Alex nos pasa un enlace a Dopar Firefox, una anotación...
Alianzo y Dirson han puesto en marcha HazRuido.com que es una competición de márketing viral: HazRuido.com - Un concurso para saber quién es capaz de hacer más ruido en Internet en el menor tiempo posible. Se, se trata de premiar a aquel...
¿Se puede «comprar» una copia de la Web completa? Bueno, no te la podrás llevar en disquetes pero sí acceder a ella. Alexa que es una compañía propiedad de Amazon ha anunciado algo interesante. En Announcing the Alexa Web Search Platform Beta...
Interesantes datos sobre Flickr, nuestro servicio de fotos favorito: Los numeros de Flickr - Realmente, Yahoo! hizo la mejor compra desde el día que los rostros pálidos compraron la isla de Manhattan, y a las pruebas me remito: Flickr tiene ya ni...
Xyle scope una aplicación (OS X) que destripa las páginas web que visitas mostrándolas a la izquierda como un navegador web normal (el motor de visualización es Safari) y a la vez mostrando a la derecha todos los detalles sobre cómo está...
Por Nacho Palou -
12 DIC 2005
Me invitaron a participar en esta mesa redonda el próximo Viernes 16 a las 10.00, básicamente para contar allí lo de los búhos Ad-Free Blog (blogs libres de publicidad) y para explicar mi opinión sobre la publicidad y los weblogs. Al final...

Espectacular revelación: Un espejo gigante refleja la luz solar en el lado que está a oscuras de la Tierra, lo cual sirve para que la gente se mantenga despierta por la noche, de modo que así pueden utilizar Google todavía más. Y...
Otro más en el saco, Yahoo! sigue adelante con su PDM y se compra del.icio.us. Lo cuenta Joshua Schachter en y.ah.oo! (Vía Enrique Dans.) Yahoo compra Flickr....
Divertido hilo de comentarios en Firefox-logo in deep space! de digg.com en el que la foto de la estrella V838 enviado por el Hubble recuerda al logo de Firefox (girándola convenientemente).Aunque todo es cuestión de interpretaciones.El Monstruo Espagueti Volador ha hablado: ¡usa...
Por Nacho Palou -
9 DIC 2005
Algunos servicios web que he curioseado estos últimos días un poco por encima por falta de tiempo... ClipMarks, una extensión para los navegadores Firefox e Internet Explorer. Otro intento de solucionar el habitual problema que surge cuando se quiere conservar algo visto...
Por Nacho Palou -
9 DIC 2005
Wikitravel es un «proyecto para crear una guía mundial de viajes gratuita, completa, actualizada y fiable» en plan wiki, con lo que los propios usuarios son los que crean y editan el contenido de esta. Si te gusta viajar, un sitio así...
Aunque desde principios de este año Roxio ya distribuía una versión con Toast 7 Titanium, DivX.com acaba de publicar una versión de DivX 6 para Mac OS X que te puedes descargar sin necesidad de comprar Toast, DivX 6 for Mac. Esta...
Cuando se trabaja en proyectos informáticos hay un valor conocido como el uptime o tiempo que un ordenador (o sistema, o sitio web en general) ha estado funcionando sin interrupciones. No estoy del todo seguro de cuál es la traducción más...
Casi mes y medio después de que se hiciera público el fiasco del sistema DRM de Sony la empresa por fin ha sacado un desinstalador en condiciones que sustituye al anterior desinstalador que funcionaba a través de una página web y que...
Este tipo de sitios estilo Digg tienen la ventaja de que al suscribirte a sus feeds, si están bien construidos, a veces descubres enlaces interesantes por el simple hecho de que son «populares»: Populicias.com es una web de noticias de tecnología en...
Al menos para los editores del New Oxford American Dictionary, podcast es la palabra del año 2005 en los Estados Unidos, por delante de palabras como gripe aviar, reggaeton o incluso sudoku. Los detalles, en 'Podcast' Is the Word of the Year....
El lema de la Wikipedia es «the free encyclopedia that anyone can edit», pero al parecer eso va a cambiar a partir del lunes que viene, pues por lo visto Jimmy Wales, su fundador, está decidido a que a partir de entonces...
Todo un clásico, disponible en castellano: El artículo Trolls de Internet de Timothy Campbell es sumamente interesante para cualquier internauta, incluso de los que se limitan a navegar de vez en cuando o a escribir unas líneas en su blog personal. Leerlo...
Unos consejos para acelerar la descarga de torrents, traducidos de Speed up your torrents:Limita la velocidad de tu cliente bittorrent a aproximadamente un 80% de la velocidad máxima de subida de tu conexión. Puedes creerte lo que te dice tu proveedor en...
Tras obtener la aprobación de sus respectivas juntas de accionistas y los correspondientes permisos y vistos buenos de las agencias gubernamentales implicadas en el proceso Adobe anunciaba esta semana en Adobe's Acquisition of Macromedia Expected to Close on December 3, 2005 que...
En Fimoculous están recopilando en Lists: 2005 listas de todo tipo relativas a 2005: música, libros, coches, juguetes más peligrosos, descubrimientos científicos... El año pasado llegaron a recopilar unas 550 listas en Lists: 2004. (Vía MetaFilter.)...
Desde la página Try Ruby! puedes probar de forma interactiva y totalmente indolora el lenguaje de programación Ruby. Simplemente siguiendo las instrucciones de las 20 lecciones que permiten directamente sin tener que instalar ni saber nada al respecto, toquetearlo directamente y juguetear...
Por Nacho Palou -
2 DIC 2005
Ya está disponible la versión definitiva de Firefox 1.5....
Web 2.0 Checklist, lista de requisitos que debe cumplir tu sitio web para ser Web 2.0. Aunque no tengas muy claro qué es eso de Web 2.0, lo reconocerás si encuentras un sitio web que cumple al menos la mitad de estos...
Por Nacho Palou -
29 NOV 2005
Albert nos pasa un enlace a RSS en su iPod, para Mac y Windows, un artículo que cuenta como pasar feeds RSS y algún tipo que otro más de datos a un iPod de 3ª, 4ª o 5ª generación. Música, conferencias, vídeos,...
El desastre de los dominios .es no deja de sorprender casi a diario. En este caso, Lanetro olvidó renovar a tiempo el dominio lanetro.es, con lo que este quedó libre, cosa de la que se dio cuenta T. P., quién solicitó este...
Durante unos días tuve que trabajar en una oficina en el que no había conexión a Internet instalada, lo que supuso una oportunidad excelente de probar la tarjeta PCMCIA UMTS/3G de Movistar en el MundoReal™. Como ya conté en su momento, Movistar...
Sin duda a los lectores de microsiervos les gustará saltar un rato por las páginas de la Frikipedia: Frikipedia - Este es un compendio extremadamente serio de todo el conocimiento humano (Vía ¿Está usted de broma, Sr SPIN?) Actualización: el sitio fue...
del.icio.us estrena un bonito rediseño, delicioso. El mismo ambiente de siempre pero mejorado. Viva el espacio blanco. Nuevo también No había visto y me gusta el acceso a etiquetas que ahora pueden escribirse directamente arriba en la cabecera de la página, en...
Por Nacho Palou -
22 NOV 2005
Nunca fue más cierto aquello de que en Internet nadie sabe que eres un perro ;-) El fraude de las empresas de citas online - Match.com y el servicio de relaciones personales de Yahoo están en la picota. Un grupo de usuarios...
Me recuerda el chiste del que quería hacer una copia de seguridad de Internet en un disquete. Descarga la Wikipedia entera- Ya puedes descargar completamente el contenido de cualquier proyecto de la WikiMedia, entre ellos la Wikipedia, claro (...) Los backups son...
David Sifry cuenta en Technorati Performance Improvement Update lo contento y orgulloso que está de los equipos de ingeniería y de operaciones de Technorati y de cómo se lo han currado para mejorar el funcionamiento del servicio, con una disponibilidad del 100%...
No es que Google sea una empresa desconocida que cuando lanza un servicio este vaya a pasar desapercibido, así que no deja de ser sorprendente que Google se haya visto obligada a limitar el registro en Google Analytics:Google Analytics has experienced extremely...
Simple Sharing Extensions (SSE) el RSS convertido en flujo de datos bidireccionalFrequently Asked Questions for Simple Sharing Extensions (SSE) -- Por ejemplo, el SSE podría utilizarse para compartir tu agenda de trabajo con tu mujer. Si tu calendario se publicase en un...
Por Nacho Palou -
21 NOV 2005
Algunas extensiones para Firefox mencionadas en la presentación Web Development with Firefox: Rapid Web Development and Testing with Mozilla Firefox, en la que Leslie Franke explica cómo aprovechar los navegadores tipo Mozilla en el desarrollo web, que me han parecido especialmente interesantes:...
Por Nacho Palou -
21 NOV 2005
Firefox 1.5 RC3 ya está disponible para descarga. Si utilizas alguna versión 1.5 anterior a la RC3 Firefox se actualiza automáticamente (como ha sido mi caso) y simplemente tienes que permitir el reinicio del navegador para disfrutarla. También está disponible en español...
Por Nacho Palou -
18 NOV 2005
Las acciones de Google superaron ayer por primera vez los 400 dólares, cerrando a 403,45 dólares por acción, con lo que la empresa sigue su imparable ascensión y deja atrás a otras grandes compañías como Coca-Cola o Cisco en valor de mercado;...
Un par de aplicaciones en Google Maps. Para ver qué hora es en cualquier parte del mundo: Time for everything and everyone.Y el tiempo meteorológico: Weather around the World. (Vía demian0311 en SuprGlu.)...
Por Nacho Palou -
17 NOV 2005
Curioso servicio de búsquedas fruto de una noche loca entre un motor de búsquedas y un wiki: Swicki es un buscador personalizable tipo RollyoWhat is a swicki?—Swicki es una herramienta de búsquedas que permite crear buscadores específicamente enfocados a temas concretos de...
Por Nacho Palou -
16 NOV 2005
A estas horas ya está por toda la web, pero por si todavía no te has enterado, Google sigue adelante con su PDM con Google Base: Lanzado definitivamente 'Google Base' (en beta, claro). Explicado en pocas palabras, Google Base es algo así...
Firefox me acaba de avisar de que está disponible para descarga Firefox 1.5 Release Candidate 2, que según las Mozilla Firefox 1.5 Release Notes parece que sólo incluye correcciones en el sistema de actualizaciones automáticas....
Martín Varsavsky está recorriendo Europa promocionando Fon, y durante su estancia en Suecia tuvo la oportunidad de probar una conexión a Internet de 1 Gbps, tal y como cuenta en Labs2. Y no, no me he equivocado, se trata de 1 gigabit...
Google parece seguir dispuesta a no dejar un sólo palo sin tocar en lo que se refiere a Internet, y hoy mismo anunciaba Google Analytics, un sistema de estadísticas para páginas web basado en Urchin (que ya lleva directamente al nuevo servicio),...
Del departamento de hola-soy-tonto-toma-mi-número-de-VISA-y-tímame: Alerta de phising con el buscador de Google — En Websense nos avisan de un nuevo caso de phising (páginas web falsas que pretenden engañarnos), esta vez utilizando la página principal del buscador de Google. Se afirma que...
Me ha gustado la pequeña aplicación para OS X RSS Menu que coloca un minilector de feeds en el menú superior a modo de acceso super-rápido a unos cuantos feeds imprescindibles. (Vía RSS Haciendo facil lo simple.)...
Por Nacho Palou -
6 NOV 2005
Buena pregunta directa: Si Google no fuera gratis, ¿pagarías cinco dólares al mes por poder usarlo?(Vía Signal vs. Noise.)...
Cuentan los periódicos que el gobierno aprobó hoy el Plan Avanza 2006-2010 para el desarrollo de la Sociedad de la Información: El Gobierno aprueba un nuevo plan para impulsar Internet, El Gobierno aprueba el Plan Avanza. Con una inversión prevista de más...
Todo el mundo sabe escribir unas palabras en el cuadro de búsqueda de Google, y la mayor parte de las veces esto le basta para encontrar rápidamente lo que busca, pero en ocasiones la cosa se complica un poco, por lo que...
En una página web que contiene el Sistema Solar a una escala en la que cada píxel de la pantalla equivale a unos 1.000 kilómetros Plutón (o, ese píxel muerto) estaría (si no me equivoco) a unos 6 millones de píxeles del...
Por Nacho Palou -
2 NOV 2005
Mi copia de Firefox todavía no ha dicho ni «mú» al respecto, pero desde esta mañana ya está disponible Firefox 1.5 RC 1, una nueva versión algo menos beta que la anterior y más cercana a lo que debería ser la versión...
¡Qué bueno! Ahora resulta comodísimo reproducir archivos de audio MP3 enlazados desde el gestor de favoritos del.icio.us. Para escucharlos basta con pulsar el pequeño icono con forma de flecha que aparece ahora a la izquierda de los enlaces de audio. Lo dicho,...
Por Nacho Palou -
2 NOV 2005
Me pareció interesante esta nota de David Weinberger sobre la Wikipedia, se titula Wikipedia's long tail y habla un poco de la situación de la enciclopedia libre. Explica que, como es de esperar, probablemente el efecto larga cola hace que haya muchísimos...
Realmente curioso: Email kills concentration more than pot - La revista Discover Magazine cita un estudio en el que a dos grupos de personas se les hicieron pruebas de inteligencia (CI). Uno de los grupos estaba bajo la influencia de la marihuana...
A diferencia de lo que ocurre con la Oficin@ Movistar 3G y los Macintosh, que no soporta el uso de tarjetas PCMCIA bajo Mac OS X, Vodafone menciona específicamente en su web que sus tarjetas Vodafone Mobile Connect 3G funcionan con Mac...
En mi trabajo del MundoReal™ ya hace algún tiempo que somos los suficientes como para que casi todas las semanas haya alguien de viaje o en algún sitio con conectividad reducida o inexistente, por lo que llevaba algún tiempo queriendo probar una...
Hoy se han celebrado varios cientos de actos con motivo del Día de Internet, y entre ellos ha estado la entrega de los Premios del Día de Internet, cuyos ganadores han resultado ser:Mejor evento: Guadalinfo. Junta de Andalucía, Diputaciones Provinciales y Ayuntamientos....
Estoy probando un poco Blummy, una especie de «agregador de bookmarklets» a modo de ventana flotante que puede desplegarse sobre cualquier página web conteniendo todos los scripts de atajo típicos para interactuar con aplicaciones web: añadir una página en del.icio.us, ver el...
Por Nacho Palou -
25 OCT 2005
Me entero por Enrique Dans de que El País ha publicado un especial dedicado al Día de Internet en su web dividido en varios apartados que tocan distintos aspectos de la red. Aunque quizás un poco demasiado breve, la parte dedicada a...
Aunque aquí en España de momento no se ha notado el efecto, he leído en Boing Boing que dos de los backbones de Internet (proveedores de comunicaciones, también conocidos Tier One, básicamente ISPs que interconectan a otros ISPs) están con serios problemas....
Flock, el nuevo navegador basado en Gecko que comentábamos hace unos días ya está disponible para descarga en versión beta (versión 0.4.8, unos 10MB). Luis nos avisaba de que en Dobleclic.org ya hay una pequeña reseña y Alex también lo cuenta desde...
Por Nacho Palou -
21 OCT 2005
Unos cuantos artículos y entrevistas de estos días que se me van acumulando sin poder echarles nada más que un ojo pero que parecen tener buena pinta:David Bravo, en El País, sobre la creación de Comisión Antipitarería gubernamental y sobre el borrador...
Firefox ha superado hoy los cien millones de descargas, algo menos de seis meses después de haber superado los cincuenta millones de descargas: 100,000,000 DOWNLOADS! (Vía Slashdot.) Relacionado: 50 millones de descargas de Firefox....
Hoy han sido anunciadas las ternas finalistas de los Premios del Día de Internet, premios que se entregarán el próximo martes día 25 en el Senado. Estábamos entre los diez candidatos finales del del apartado Mejor Webloger o Periodista Digital, pero no...
Aunque sea escrito y enviado desde el ordenador del trabajo, desde hace algún tiempo ya hay una sentencia que dice que el correo electrónico de los trabajadores es privado. Ahora, una nueva sentencia de la Audiencia Provincial de Madrid dice que no...
Pepe cuenta excelentemente este tipo de cosas, su análisis es como siembre breve y certero, de modo que conviene leerlo completo (y seguir los enlaces), esto es sólo un pequeño resumen: Internet y la pinza mortal - El mes que viene Internet...
En realidad no estamos muy seguros de si es hoy o fue ayer, porque la información no coincide entre la web y los correos que hemos recibido, pero por lo visto hoy es el último día para participar en la votación de...
Ya tenemos la lista de los diez principales errores a la hora de diseñar weblogs según Jakob Nielsen en Weblog Usability: The Top Ten Design Mistakes. Chewie los ha resumido y traducido en Jakob Nielsen sobre usabilidad en blogs, así que copio,...
Hace algún tiempo publicamos un truco para acelerar Firefox que funciona bien, pero que implica trastear con el fichero de configuración, operación no muy complicada pero que puede no ser del gusto de todo el mundo. Si quieres probar el truco en...
Yahoo ha incorporado el contenido de los weblogs a su Yahoo News Search, de modo que va a sumar a su buscador de noticias el contenido de la blogosfera, lo cual es un formato curioso. En esto se diferencia de Google Blog...
Curioso. LiveMarks permite ir viendo en tiempo real (van apareciendo a la derecha) los enlaces que se van añadiendo al gestor de favoritos del.icio.us. El último experimento que ví que era similar a este mostraba en tiempo real todas las modificaciones que...
Por Nacho Palou -
11 OCT 2005
La CNN publicó hace unos días A convicted hacker debunks some myths, una entrevista con Kevin Mitnick, el famoso cracker/hacker (según opiniones), en la que reconoce que él mismo tiene la culpa de todos sus problemas legales y su paso por la...
Movable Type, nuestro sistema de publicación actual cumple hoy cuatro años, tal y como cuenta Jay Allen en Movable Type Turns Four. Uses el sistema que uses para publicar un blog, parece claro que estos sistemas han hecho que por fin para...
Aunque de momento es vaporware aquí hay algunas capturas de pantalla de Flock, un navegador web basado en Gecko (como Firefox) del que se lleva oyendo hablar desde hace algún tiempo pero que todavía no está disponible para descarga (ops, el «modo...
Por Nacho Palou -
10 OCT 2005
Stowe Boyd es un internauta y empresario amante de los numeritos, que se ha pasado un rato analizando los últimos ocho años de correo electrónico de su vida y ha extraído algunos datos curiosos. En 2004 recibió unos 14.000 correos en total,...
Deep Thoughts at Web 2.0 es un artículo sobre el contenido de una de las ponencias en la Conferencia Web 2.0 en las que participó la gente de Bloglines (ahora Ask Jeeves). Tienen un curioso estudio sobre los datos de su servicio,...
En la conferencia Web 2.0 se ha anunciado hoy el más esperado agregador de feeds RSS de la temporada: Google Reader, que llega para acabar con Bloglines y cualquier otra forma de vida inferior del universo RSS. El PDM de Google avanza...
Llegó la primera ronda de donaciones a Creative Commons, al estilo de las organizadas por Wikipedia de vez en cuando. En CC quieren recaudar 250.000 dólares para empezar: Creative Commons solicita ayuda - Por primera vez la organización en defensa del «copyleft»...
Disponible la versión beta 2 de Firefox 1.5, más o menos un mes después de la versión beta 1. Dada la «inestabilidad» de la actual 1.0.7 sobre Mac OS X tampoco se pierde nada probando esta versión beta. De hecho en todo...
Por Nacho Palou -
7 OCT 2005
El próximo día 25 de octubre se celebra el Día de Internet, era algo que teníamos apuntado en el Calendario Geek para que no se nos olvidara. Tal y como cuentan en el FAQ sobre el Día de Internet: Es una jornada...
Como recuerda Eneko este que viene es fin de semana de Fórmula 1 en Japón. Aunque a la temporada de F1 le quedan (¡literalmente!) dos telediarios me enteré tarde pero aún a tiempo vía Eneko y Algo que hacer que a través...
Por Nacho Palou -
6 OCT 2005
Domain Hacks es un servicio buenísimo: pones una palabra que te guste, que puede ser una marca o tu nombre, o el de tu empresa, o el de un servicio que estás creando o algo así, y te muestra posibles dominios sobre...
Del mismo modo que Internet y los buscadores como Google, Yahoo o cualquier otro han puesto al alcance de cualquiera cantidades ingentes de información, Internet también ha puesto al alcance de cualquiera la posibilidad de publicar lo que quiera a un coste...
Lo siento, no sé cómo habrán hecho el estudio pero «va a ser que no», Víctor que encontró la noticia tampoco se lo cree.ComScore: La mitad de los internautas españoles conocen los blogs - Según la encuesta, entre un 7 y un...
Víctor recopila en el blog del evento WebDosBeta diversos enlaces con información y definiciones del concepto «Web 2.0». Sobre qué es y también lo que no es Web 2.0Ajax, RSS, etc.Listas de funcionalidadesCapital riesgoContratar, contratar y contratar más«Modo invisible»Betas públicasFormatos «propietarios»Cualquier cosa...
Por Nacho Palou -
5 OCT 2005
He pasado un rato divertido con MapBuilder, una herramienta vía web que sirve para crear los típicos mapas de GoogleMaps en los que hay cosas marcadas e información relacionada con la marca. En el caso del mapa de prueba he marcado en...
Por Nacho Palou -
5 OCT 2005
Estar bien colocados en los resultados de Google está muy bien y mola todo, pero uno de los efectos colaterales de esto es que a menudo aparecen comentarios de gente que claramente no tiene ni idea de dónde ha ido a dar...
Tal como suena: La Wikipedia tiene una sección dedicada a corregir los errores de la Enciclopedia Británica. Y ya hay más de 42 correcciones. Por poner un ejemplo: al definir los números reales se habla de los límites de los conjuntos que...
Jakob Nielsen acaba de publicar su lista de este año de los diez peores errores en el diseño de webs en Top Ten Web Design Mistakes of 2005. Traduzco y resumo:Problemas de legibilidad con tipos de letra demasiado pequeños, de tamaño fijo,...
Curioso engendro: una especie de gestor de contenidos personal (no para publicar) que funciona online; hay que instalarlo en un servidor con PHP pero no necesita base de datos. Tiene cierto aire a sistema operativo y permitiría la instalación de aplicaciones adicionales...
Por Nacho Palou -
1 OCT 2005
¡Hmmmm! ¡Iconos y Futurama en la misma frase!: Futurama Vol. 1(Vía r00lz.) FamFamFam: iconos gratis total¡Favicons!Iconos: la historiaIconos, enlaces a sitios y colecciones de iconos.GUIdebook, un bonito sitio que reúne iconos y otros elementos de interfaces gráficos.Futurama TaglinesCuriosidades matemáticas en Futurama...
Por Nacho Palou -
30 SEP 2005
JJ explica por qué septiembre es como una avalancha de novatos despistados: Septiembre eterno - Septiembre es (...) cuando tradicionalmente la gente vuelve al instituto o la universidad. Antiguamente, eso significaba tener por primera vez contacto con la Internet, y empezar a...
La LSPM (Lista de Soluciones Planeta Mac) es ya todo un clásico en el círculo de los mackeros españoles. Es una lista de correo que funciona a modo de comunidad Macintosh o MUG. Hoy la LSPM está de celebración, y no muchos...
Este nuevo buscador es curioso, se llama Rollyo y está en beta. Es como un Google pero donde tú puedes personalizar en qué sitios quieres que busque. Digamos que es como añadir la función site:xyz.com a una búsqueda de Google, para limitar...
Las Diez conclusiones a las que ha llegado Google a lo largo de sus recién cumplidos siete añosLo más importante es pensar en el usuario.Es mejor especializarse en algo y hacerlo realmente bien.La velocidad es un valor seguro.La democracia en la web...
Por Nacho Palou -
29 SEP 2005
Uno de los artículos que más me gustó de la revista Wired de septiembre es On the Internet, Nobody Knows You're a Bot. Cuenta cómo expertos en software y juegos, más específicamente poker online, diseñan bots (robots) que juegan en las salas...
Se ha dado a conocer un nuevo ránking llamado PubSub LinkRanks Top 1000 basado en todo tipo de fuentes RSS (feeds) que incluye tanto a weblogs como otro tipo de fuentes de información (periódicos, tiendas, servicios web), según algo llamado LinkRank que...
Igual esto ya es viejo y habrá salido en un montón de sitios pero no lo había visto hasta ahora y me ha hecho gracia:La imagen de la izquierda corresponde a la dirección/coordenadas de las oficinas de Apple vistas con Virtual Earth,...
Por Nacho Palou -
27 SEP 2005
A lo mejor alguien me puede sacar de la duda sobre si esto es algo útil para la sociedad o en realidad algo tan absurdo como realmente parece a simple vista (igual es que mi desconocimiento del tema me hace parecer que...
Si usas el correo de Gogole, GMail habrás visto que en la portada dice que no hace falta que borres nada, porque el tamaño de buzón crece y crece. ¿Cuánto almacenamiento tendrás realmente en el futuro? ¡Jasp lo ha calculado! El tamaño...
WebDosBeta tendrá lugar dentro de un mes en Madrid: Six Apart, el Instituto de Empresa y eConozco organizan WebDosBeta, una jornada sobre blogs, sindicación, podcasts, AJAX, APIs, redes sociales, folksonomías, internet móvil... (añada su «buzzword» preferido™). Se celebrará el lunes 24 de...
Estratega ha recopilado en una lista de listas, recopilaciones, al estilo de «Los 10 mejores... xyz» de esas que tanto me gustan. (Son un fan de cualquier tipo de listas). Estas son las listas que se mencionan: Los 10 peores productos (digitales)...
Una útil recopilación de trucos y técnicas con CSS que han aparecido dispersas por ahí recientemente: CSS Techniques Roundup, 20 CSS Tips & Tricks. También a través de la etiqueta CSS en del.icio.us se pueden encontrar un montón de tutoriales y sitios...
Por Nacho Palou -
23 SEP 2005
¡Cuánto geek! Sobre todo entre los primeros veinte puestos (unos seis u ocho, dependiendo de cómo midas su geekez). Esto sin duda es parte del PDM. He marcado los definitivamente geeks en negrita, aunque seguro que falta alguno. Debajo del puesto 20...
¡Cuánta razón! Merece la pena dejarlo por aquí a modo de recordatorioSpecial: Lifehacker's guide to weblog comments — Dejar un comentario en el blog de alguien es como entrar en su sala de estar y unirse a una conversación [...] Los buenos...
Por Nacho Palou -
22 SEP 2005
Copy URL+ es una extensión bastante útil para bloggers y gente que está todo el día mandando por correo o chat URLs de páginas webs. Lo que hace es añadir una opción de menú contextual a Firefox para copiar con el botón...

El otro día hablando del e-mail, de los teléfonos y los faxes nos acordamos del Télex. Recuerdo cuando era niño jugar con las enormes tiras amarillas de papel perforado, muy estrecho, que luego se convertían en mensajes, y que servían para...
Convocatoria interesante. Añadida al Calendario Geek de octubre: Bajo el lema «Libertad en Construcción Permanente» la sexta edición del Hackmeeting se celebrará este año en el recinto ferial de Mercadal (Menorca) durante los días 21, 22 y 23 de Octubre. El hackmeeting...
Esa pregunta se hace Nacho Escolar: ¿Cuánto pagan por estafar a tus lectores? - Corto y pego de un correo tipo que me acaba de llegar de una empresa que quiere comprar publicidad en mi blog: «(…) Tenemos un nuevo formato de...
Una nueva serie de artículos sobre tecnología e inteligencia, interesantes: Is the internet making us more intelligent? - CNET ha publicado el primero de los artículos en una serie acerca de si las nuevas tecnologías nos están volviendo más inteligentes: Intelligence in...
Qué bueno, por fin encontré la Página de inicio de la WWW: Para nostálgicos - El otro día,navegando, me encontré por casualidad con 2 «joyas». La primera es es una de las primeras paginas del CERN, posiblemente de las primeras paginas de...
Si hace apenas tres semanas Opera celebraba el décimo cumpleaños de su navegador regalando licencias para su uso, ahora han decidido hacerlo gratuito, lo que puede estar muy bien de cara a ganar cuota de mercado y esas cosas... pero a ver...
Con la conexión segura (cifrada) de Google del servicio llamado Google Secure Access se garantizan conexiones a Internet más seguras partiendo de un planteamiento bastante básico: un programa cliente necesario que hay que instalar en el ordenador (y que de momento sólo...
Por Nacho Palou -
20 SEP 2005
Estuvimos probando un poco Netvibes.com, un servicio gratuito que ha salido recientemente similar a Start.com. Resulta muy útil para configurar en un rato y con un par de clics una página de inicio personalizada que contenga feeds favoritos, notas de texto, información...
Por Nacho Palou -
19 SEP 2005
Instrucciones para instalar un Portable Firefox multiplataforma con todos tus favoritos, historial, etc, de tal forma que pueda ser utilizado en cualquier tipo de dispositivo removible como memorias USB, discos zip o incluso CD-ROMs tanto bajo Mac OS X como bajo Windows,...
¡23 años! Tal día como hoy, un 19 de septiembre de 1982, Scott Fahlman, del departamento de informática de la universidad Carnegie Mellon, utilizó por primera vez el smiley :-) en un correo electrónico. Esa secuencia se convertiría en un icono universal...
Si alguna vez te preguntaste qué pasará con todo tu correo electrónico cuando estés muerto, esta parece que es la respuesta, al menos en Estados Unidos (en otros países puede variar): Un juez sentencia que las cuentas de correo electrónico no mueran...
Hay un montón de caracteres especiales que están disponibles para mostrarse en todas las páginas web, sistemas de contenidos y navegadores. Con ellos se escribe mucho más bonito, más exacto, más elegante. También es ligeramente más trabajoso, pero sin duda merece la...
CSS Table Gallery es una colección de distintos atributos CSS para dar estilo a tablas HTML. Los distintos estilos se van aplicando a la tabla que contiene la lista de estilos para ver «en vivo» como quedan cada una de las opciones...
Por Nacho Palou -
16 SEP 2005
El plug-in para Firefox ScreenGrab sirve para hacer una captura en imagen de una página web completa. «Completa» significa una única imagen en formato .png que contiene el documento / página web en su totalidad, incluyendo las partes que quedan fuera de...
Por Nacho Palou -
16 SEP 2005
La linguística no es mi especialidad, lo de la doble negación a veces suena extraño, etc. pero lo que viene a continuación es bastante fácil de entendener creo yo. Bill Gates en una entrevista contesta a una pregunta haciendo referencia al famoso...
En Internet a 200 Mbps Eneko cuenta algunas cosillas interesantes sobre los tests de velocidad de conexión y nos descubre Speakeasy que parece algo más moderno y desde luego más atractivo: Entre las diferentes pruebas que he realizado, el test de velocidad...
¡Ah! Esa gran verdad: El 79% de los responsables informáticos cree que los empleados son «peligrosos» - Un estudio ha revelado que el 79% de los responsables informáticos cree que los empleados ponen en peligro a sus empresas al no hacer un...
Scott Berkun, que trabajó en el diseño del interfaz de usuario de Microsoft Explorer de las versiones 1 a la 5, se ha pasado a Firefox, y ha escrito una lista en Why I switched to Firefox con los cinco motivos que...
La revista Wired de Agosto pasado titulaba 10 Años que Cambinaron el Mundo, conmemorando salida a bolsa de Netscape, hito que marcó un época. Kevin Kelly, uno de los primeros editores de la revista, repasa en un We Are The Web esos...
Ya tienes un motivo más para andar con una PDA, Treo, o similar encima, pues con Wikipedia PDA puedes llevar en ella los contenidos de la Wikipedia en español y consultarlos aunque no estés conectado a nada. Está disponible en tres versiones,...
Yo no habría sabido explicarlo mejor, lo vi en Enlaces externos: P: ¿Para qué sirve el hipertexto en Internet? R: Básicamente para leer textos (también se pueden obtener otros elementos multimedia) y navegar gracias a los hiperenlaces que éstos contienen. Bien, respuesta...
Otro paso más del PDM de Google, la búsqueda de blogs de Google. Este es el primer punto del FAQ:¿En qué consiste la Búsqueda de blogs?Blog Search es la tecnología desarrollada por Google específica para blogs. Google cree firmemente en el fenómeno...
Ayer hacia las 22.00 hora de Madrid el servidor de Microsiervos cayó en una especie de agujero negro. Tras las primeras alertas y comprobaciones, nos dimos cuenta de que en realidad todo Media Temple, nuestra empresa de alojamiento, había caído. Cientos de...
La BBC confirma la noticia de que eBay adquiere Skype por 2.600 millones de dólares, la mitad en efectivo y la mitad en acciones, con el objetivo de crear «un motor de comercio electrónico y comunicaciones sin parangón»: eBay to buy Skype...
Autoexplicativo: Publicidad poco ética - Busquen en Google «trucos para ganar en los casinos». La Red está infectada: Más de 200.000 resultados. Abran ahora unas cuantas de esas webs al azar... ¿notan algo extraño? Todas, aunque con diferente aspecto y forma, explican...
Ya se puede descargar la beta 1 de la versión 1.5 de Firefox, que es la próxima versión «de referencia» de este navegador, aunque por ahora sólo está en inglés: Firefox 1.5 Beta 1 release notes. Entre otras cosas incluye actualizaciones automáticas,...
Google sigue adelante con su PDM y hoy mismo ha anunciado oficialmente que Vint Cerf, universalmente reconocido como uno de los padres de Internet, se une a la empresa como «Chief Internet Evangelist»: Cerf's up at Google. Si le dejan, seguro que...
Durante el verano Yahoo anunció el Yahoo Site Explorer, que a día de hoy sigue en un limbo beta y no está todavía disponible. Pero mientras tanto la sección Yahoo Submit Your Site además de las típicas páginas sueltas que quieres «dar...
Parece que los rumores se van confirmando y que pronto llegará el inminente anuncio oficial de que eBay ha comprado Skype. En algunos sitios serios como Financial Times se habla ya de 5.000 millones de dólares. En otros no menos serios como...
(Vía Demasiada Cafeína.)...
Por Nacho Palou -
8 SEP 2005
En teoría podrías hacerte con un millón de dólares vendiendo un millón de píxeles de una página web cada uno a un dólar:The pixels you buy will be displayed on the homepage permanently. The homepage will not change [...] I want it...
Por Nacho Palou -
7 SEP 2005
¿Qué estabas haciendo el 7 de septiembre de 1998? (pregunta estilo JFK ;-) Hoy Google cumple 7 años - La fecha oficial del nacimiento de Google es el 7 de septiembre de 1998. El dominio google.com había sido registrado un año antes,...
Esto sí que puede ser realmente revolucionario para muchos negocios. Por fin se cumplen las promesas de los 90: Micropagos - (...) Llevamos literalmente años, casi desde los albores del comercio electrónico, hablando de micropagos. Sin embargo, nunca ha llegado a haber...
A finales de este mes tendré la suerte de irme unos días al sur, invitado por JJ de la Universidad de Granada para impartir una parte del curso titulado Curso de Arquitectura de la Información, Construcción Avanzada de Sitios Web, 2ª Edición....
En mi trabajo del MundoReal™, los Museos Científicos Coruñeses, hasta ahora hemos estado utilizando el viejo método de «pásaselo al webmaster» para gestionar y actualizar nuestra web, pero ya hace tiempo que se nos viene quedando corto, así que estamos buscando un...
Death by Caffeine calcula en función del peso corporal el número de latas de refrescos con cafeína (Coca-Cola, Pepsi, RedBull…) que hay que beberse de una sentada para que la cantidad ingerida sea mortalAunque es imposible beber esa cantidad de líquido (~43...
Por Nacho Palou -
5 SEP 2005
La página Most Popular Firefox Extensions recopila las extensiones más populares para el navegador Firefox, indicando cuantos miles de personas se las han descargado. En esa misma página también hay una lista con las extensiones más nuevas para ir viendo las novedades...
Techorati sigue siendo uno de nuestros servicios favoritos. Últimamente está bastante roto aunque lo están arreglado. Añadieron hace poco algunas cosas nuevas pero no muy relevantes como Technorati Blogs que es un directorio. El caso es que leí en Scripting.com que ahora...
Hoy se cumplen diez años de la puesta en marcha de AuctionWeb por parte de Pierre Omidyar, aunque seguro que te suena más como eBay. En estos años eBay se ha convertido, junto con Amazon y pocas otras más, en una de...
Víctor de La papelera me invitó amablemente al Festival de Blogs: Publicidad en la Red que es una especie de nuevo «formato» que está siendo promovido por Manuel de Mangas Verdes. En inglés son más conocidos como Carnivals. Víctor sabía que por...
Con la aparición de Google Maps han surgido montones de sitios que recopilan sitios importantes y/o interesantes de todo el mundo organizados por categorías como por ejemplo Google GlobeTrotting o Google Sightseeing, y ahora hay también uno en español y centrado en...
Teniendo en cuenta lo de que Technorati está un poco pocho no está mal mirar alternativas, como por otro lado sugería ALT1040. Diario Gratis ha recopilado algunos: Buscadores de Feeds - Un listado sacado de OjoBuscador: Bloglines, BlogPulse, Daypop, Feedster, Findory, Gigablast,...
Una entrevista al maestro siembre es bienvenida, sobre todo si además se han tomado la molestia de traducirla al castellano. Es larguísima pero muy interesante: Entrevista a Jakob Nielsen - A través de un mensaje de Paula Maciel a la lista de...
Opera Software ASA está celebrando el décimo cumpleaños del navegador Opera con la Opera 10-year online anniversary party, y lo curioso es que en vez de recibir regalos los hacen, pues dan códigos de registro gratis «mientras dure la fiesta». (Vía Slashdot.)...
Un buen resumen sobre qué es el software social y cómo encajan muchas de los sistemas y servicios de este tipo que están de moda en la actualidad: Qué es el software social - Nos preguntan un día sí y otro también...
En otro paso importante del proceso, los accionistas de Adobe y Macromedia han aprobado la compra de la segunda por parte de la primera, aunque ahora le estén llamando fusión a operación: Adobe, Macromedia Shareholders Give Merger High Five. Ahora sólo queda...
Las siguientes anotaciones son muy buenas, y mejor aún los comentarios - de lo mejorcito que he leído últimamente. Tal vez sea el mejor hilo temático del año. No son del todo recientes, pero es que las vi tarde. Durante las vacaciones...
Existe todo un curioso mundo dedicado a la ingeniería inversa para «adivinar cómo funciona el PageRank de Google» haciendo exprimentos empíricos. Uno de los factores más importante de todo lo relacionado con Google suele ser el posicionamiento de las palabras clave. Si...
En el comentario número 42 a la anotación El verdadero origen de Internet, lo que es totalmente adecuado porque como todo el mundo sabe 42 es la respuesta al sentido de la vida, el universo y todo lo demás, lucia pregunta quién...
Todavía no hay anuncio oficial, que se espera para hoy, pero todo el mundo está hablando ya de Google Talk, un nuevo servicio de mensajería instantánea y voz sobre IP de Google, como por ejemplo en Google Talk Review o en I'm...
Editar un wiki, como por ejemplo el Calendario Geek de Microsiervos, no es demasiado complicado, pero exige aprenderse unas cuantas etiquetas y saber dónde colocarlas, aunque esto podría cambiar pronto y ser todavía más fácil con Wikiwyg, una librería JavaScript de código...
Para los que están «cansados de la publicidad en Internet» acaba de lanzarse una especie de nueva versión de AdBlock llamada AdBlock Plus para Firefox: Después de Adblock, Adblock Plus - Adblock, la famosa extensión para el navegador Firefox que permite eliminar...
Igual he sido el último en enterarme, pero no me suena haberlo visto comentado por ahí. Desde hace algunos días me parece que Google.com ha cambiado el formato de los enlaces de los resultados. Antes buscabas cualquier cosa, como por ejemplo imdb...
Marc Lawson habla con Tim Berners-Lee sobre la web en Berners-Lee on the read/write web, una entrevista para la BBC2 en la que, entre otras cosas, el creador de la web dice que los blogs se parecen mucho a su concepto original...
Hoy se cumplen diez años de la salida a bolsa (IPO) de Netscape Communications, que fue una de las primeras de la ahora conocida como «burbuja de las .com» en la que los inversores empezaron a valorar las posibilidades futuras de las...
Seguro que en estas fechas a más de uno se le ha pasado por la cabeza la cuestión de qué llevarse de viaje; la solución, The Universal Packing List....
Esta mañana salíamos de viaje con unos amigos y la ocasión me sirvió para comprobar un par de cosas curiosas acerca del sistema de «check-in online» de Iberia que el domingo por la noche se negaba a funcionar. Por un lado, aunque...
Estoy intentando hacer la facturación en línea de un vuelo que tengo este martes a las 9:45 de la mañana, lo que en teoría puede hacerse desde 36 hasta 2 horas antes de la salida del vuelo, pero por el motivo que...

Actualización (2023) – El wiki hace años que ya no existe, así que se han quitado los enlaces dado que no funcionan. El Calendario Geek del Wiki ya tiene 56 entradas, la mayoría escritas por lectores del Wiki de Microsiervos. Eso supone...
Esto es una consulta que lanzamos a otros webmasters que puedan estar en una situación similar, porque ya nos estamos volviendo locos. Ayer tuvimos un rato de inestabilidad en el servidor web de Microsiervos hacia las 22.00-23.30 hora de Madrid. El síntoma...
Desde la Campus Party: Servidor montado en la Campus... ¡a descargar! - En mi «clan» (grupo de usuarios) de la Campus Party hemos montado un servidor para que todo el mundo (incluso desde el «mundo exterior») pueda descargar lo que tenemos. En...
Podría ser que en Rusia no acaben de encajar del todo bien que alguien les llene el ordenador de correo basuraRussian spammer murdered — El conocido «spammer» ruso Vardan Kushnir fue encontrado muerto a golpes el pasado domingo en su apartamento. Sus...
Por Nacho Palou -
27 JUL 2005
Cuando la BBC Radio 3 organizó The Beethoven Experience, durante la cual emitió la obra completa de Beethoven en algo menos de una semana, también puso a disposición de cualquiera que quisiera bajárselas sus 9 sinfonías en formato mp3, y para sorpresa...
Había pensado estar desconectado durante las vacaciones, pero en previsión de un acontecimiento del que estamos pendientes en mi trabajo en el MundoReal™ al final he decidido que va a ser mejor que tenga alguna forma de conectarme a Internet durante ese...
Desde el programa Google Earth es posible guardar en un archivo diversa información relativa a una localización o vista concreta, de modo que además de poder volver en cualquier momento al mismo punto también es posible (y esto es lo divertido) compartir...
Por Nacho Palou -
22 JUL 2005
Logo RIP es un tributo a logotipos que han pasado a mejor vida en los últimos años —aunque sólo hay algunos ejemplos procedentes del libro que se promociona (y se vende) en el sitio. Algunos de mis favoritos: el «gusano» de la...
Por Nacho Palou -
22 JUL 2005
Después de todas las aventuras para usar UMTS en la playa al final acabé usando bastante cómodamente el GPRS normal y corriente de mi Nokia 6600 conectado a un iMac, que me cuesta menos y me da una velocidad razonable. Usar el...
Un nuevo servicio que suena interesante... Tags y mapas: Tagzania combina el software social, las folksonomias, a través de las etiquetas que los propios usuarios van adjudicando a las diferentes localizaciones o lugares, y los mapas de Google Maps. Si se quiere,...
Esta historia es interesante: cookies, publicidad, márketing. Al parecer las cookies están perdiendo su efectividad. Bueno, no es el Fin del Mundo™, pero casi. Al menos para algunos. Net Marketers Worried as Cookies Lose Effectiveness - Según un artículo titulado Expertos del...
Estamos registrando este curioso dato en las estadísticas de búsqueda de nuestro web desde hace semanas, y antes probablemente era igual pero no lo teníamos tan controlado como ahora. Si no fuera porque existe la posibilidad de que sea cierto y porque...
Hordas de estafadores que se dedicaban a los timos nigerianos, también conocidos como 419 (ese es el código telefónico de Nigeria) (el artículo del código penal nigeriano aplicable a este delito - gracias Julio) están en el calabozo. Supuestamente ya no recibirás...
Para celebrar el primer aterrizaje de un hombre en la Luna hace ahora 36 años Google ha preparado Google Moon, la versión lunar de Google Maps.Es una pena que las imágenes no tienen detalle suficiente como para ver los restos de los...
Por Nacho Palou -
20 JUL 2005
Mi amigo Pedro me cuenta queLos grandes vienen por Gijón en noviembre al Encuentro Internacional de Accesibilidad, Usabilidad y Estándares Web. El evento reunirá a los máximos expertos internacionales en accesibilidad, usabilidad y estándares web como Jakob Nielsen, Jeffrey Zeldman, Steven Pemberton,...
Por Nacho Palou -
20 JUL 2005
Fernando cazó una muy buena metedura de pata en El País: ¿Son los medios de comunicación necesarios? - Reza un titular en El País: Un estudio sostiene que más del 70 por ciento de españoles no considera necesario Internet. Y también se...
A VC (un Venture Capitalist en Nueva York) es un blog más o menos popular que sirve varios miles de páginas al día a un público algo selecto, diría yo. Eso son más visitas/páginas que las que tienen la mayoría de los...
Enrique dice que los bits quieren ser libres; yo diría que hasta los átomos quieren ser libres: Harry Potter and the half-blood prince YA en la red. Y antes de que nadie lo pregunte, ni lo he descargado ni se dónde se...
22 preguntas frecuentes sobre preguntas frecuentes es un buen artículo de Alzado.org sobre los documentos FAQ. Por supuesto, un FAQ sobre FAQs debe incluir al menos una pregunta circular: ¿Para qué sirven las preguntas frecuentes?...
¡Wow! ¡Error Un 403 en Gooogle! Es la primera vez que lo veo ahí. En todos estos años sólo he visto a Google caído un par de veces, y en realidad esto no quiere decir que está caído, sino prohibiendo el acceso...
José Luis nos escribe para recordarnos que estos días también cumple diez años el formato mp3 y que ha escrito un artículo al respecto en su Glosario de Tecnología Informática. Como tiene problemas con su proveedor de acceso y por lo visto...
dave g. nos pasa un enlace a la grabación que hizo de la conferencia de Cory Doctorow en CopyFight, evento al que desafortunadamente al final ninguno de nosotros ha podido asistir. Se trata de tres archivos QuickTime con una duración total de...
Everything Bad Is Good for You. How Today's Popular Culture Is Actually Making Us Smarter. Steven Johnson. Riverhead Hardcover, 5 de mayo de 2005. ISBN: 1573223077. Inglés. [ver similares] Desde hace años la «cultura popular» viene manteniendo que los juegos de ordenador,...
Hoy se cumplen diez años de la entrada en funcionamiento de Amazon.com, empresa que imagino que a estas alturas no necesita presentación para nadie. Quedan lejos los tiempos en los que Jeff Bezos se dedicaba a empaquetar los pedidos de libros, que...
Algo raro ha pasado con ONLAE.com que se supone que era el dominio de la La Organización Nacional de Loterías y Apuestas del Estado. Ahora aparece este mensaje: This directNIC Free Hosting account has been terminated due to a violation of the...
¡Cuántos recuerdos de una vida anterior! Terra sale de bolsa. - La empresa Terra salió a bolsa el día 17 de Noviembre del año 1999 a un precio por acción de 11,81 Euros, la demanda de sus acciones fue tan grande que...

Una entrevista con el cofundador de la Wikipedia: obra colectiva, orgullo individual.
Encontré SearchStatus buscando por ahí. Es una extensión para Firefox y Mozilla que muestra en la parte inferior de la ventana el contador de PageRank de Google y el Ranking Alexa de la página por la que estás navegando. También tiene un...
Incorporaré a esta anotación los textos sobre este tema que encuentre por ahí. Estos días seguro que va a haber muchos. El titular de El País de hoy a cuatro columnas ya es bastate acongojante: La UE acuerda medidas de control de...
Estos días he estado transfiriendo un dominio de Network Solutions a otro lado. De hecho es el viejo hiperespacio.com que los más viejos del lugar recordarán porque era el hogar de este blog. Mi primer dominio. Lo compré en 1998 y andaba...
El servicio de favoritos Del.icio.us ya tiene soporte para la etiqueta (tag) denominada for: de forma oficial. Hasta ahora había gente usándolo para enviarse recomendaciones. Ponías tag:pepito al subir algo y pepito seguramente lo leería si lo habíais acordado de antemano -...
Parecía que en el sótano de Flickr había trabajando un chino con una vía de bromuro que filtraba todas las imágenes enviadas, pero está visto que no es así y que el servicio no es tan casto como algunos creíamos. Algunas imágenes...
Por Nacho Palou -
11 JUL 2005
Phyneas nos envía el enlace a Planetarium, un planetario bastante chulo hecho en Flash, de modo que se puede utilizar directamente desde el navegador. Es bastante preciso y funciona en tiempo real en función de la fecha y hora del ordenador o...
Por Nacho Palou -
9 JUL 2005
¡Qué bueno! Luis me mandó por correo un vídeo procedente del año 2014, un documental del Museo de Historia de los Medios titulado EPIC 2014 [Act: ya no funciona]. Cuenta mediante imágenes y una narración en inglés cómo han ido las...
Sven Jaschan, el joven alemán que en mayo del año pasado se confesó autor del gusano Sasser que puso fuera de servicio a miles de ordenadores en todo el muno, acaba de ser condenado a 21 meses de cárcel y 30 horas...
Leído en Cinco Días:El titular de Industria, José Montilla, señaló que el nuevo documento [nacional de identidad] digital «acelerará el desarrollo de la sociedad de la información», ya que los ciudadanos españoles podrán acreditar electrónicamente y con seguridad su identidad personal a...
Por Nacho Palou -
8 JUL 2005
Impresionante cómo puede cambiar el aspecto de las ciudades a vista de satélite, en especial el caso de Sharm ElSheik, por donde estuvimos hace un par de años buceando un poco, que pasan de la nada al todoOtros casos como los de...
Por Nacho Palou -
8 JUL 2005
Ya disponible: Google Toolbar para Firefox. ¡A probarla! Lo mejor de todo es que funciona tanto en Windows y Linux como (por fin) en Mac OS X. También hay otras extensiones de Google para Firefox y un enlace a la Googlebar desarrollada...
Si el último modelo de ordenador superchulo con todo lo que hayas podido soñas en Estados Unidos cuesta 3.995,95 dólares, ¿cuánto es eso en euros? Ahora Google realiza conversiones de moneda usando frases como estas: 3999,95 dollars in euros. Y por si...
Curiosos datos:RSS Aggregators: Some Statistics - Brian Livingston ha publicado unas intrigantes estadísticas (RSS Readers: Narrowing Down Your Choices) sobre programas agregadores RSS y cuál se utiliza más. Todos aquellos editores que sindican sus contenidos encontrarán esto interesante.Hay varias listas; una de...
Interesante convocatoria para este próximo fin de semana: Jornadas Telemáticas 2005 en el Kaslab - Un año más, los días 8, 9 y 10 de Julio, tendrán lugar en el C.S. Seco las Jornadas Telemáticas del Kaslab (Hacklab de Vallekas). En esta...
Gmaps Pedometer mide la distancia entre dos o más puntos marcados sobre el callejero o sobre las imágenes aéreas de Google Maps.Para convertir el resultado que devuelve en millas se puede utilizar por ejemplo este Conversor de Millas a Kilómetros. He hecho...
Por Nacho Palou -
6 JUL 2005
Este fin de semana largo de cuatro días he tenido ocasión de probar con cierta intensidad Imagenio, la televisión por ADSL (IPTV) de Telefónica, que aunque todavía tiene algunos peros me ha sorprendido muy gratamente y ha resultado ser mucho mejor de...
Por Nacho Palou -
5 JUL 2005
Copia este libro, de nuestro admirado paisano David Bravo es un libro publicado con una licencia de Creative Commons (…) Es un placer ofrecer este libro desde Elástico, gracias al ancho de banda financiado por los generosos fondos del Berkman Center for...
Ya se conoce algo más sobre el nuevo projecto de Doug Kaye creador del espléndido ITConversations - archivos audio de cientos de entrevistas y conferencias sobre Tecnología. Doug lo ha explicado de forma muy clara y sencilla en su blog: es una...
Viene bien tener una de estas estas a mano: Num Sum, una hoja de cálculo tipo Excel como servicio Web, que funciona simplemente desde el navegador - y abrir una cuenta es gratis. Como no podía ser menos (las modas son las...
Mi amiga Cartulain me escribió para contarme que cuando quería ver algunas páginas web que le enviaban por correo electrónico desde el ordenador de su empresa le salía un mensaje extraño: Burst Technology's WebFilter The Requested web page is categorized as ChatLe...
Recording Your Podcast, cómo utilizar GarageBand, el programa de composición musical incluido en iLife, para hacer podcasting. Yo de esto no tengo mucha idea (ejem, ninguna) pero recortaría todas las cifras de duración que indica la receta de Apple a la mitad....
Por Nacho Palou -
30 JUN 2005
La «otra Internet» - Hoy estuve en Tertulia Digital, la verdad es que hacia muchos meses que no iba, pero no me he perdido nada. Ha sido más bien lamentable, patético, irreal... El título del debate era «Debat sobre el Estat d’...
El último experimento de software social de The Robot Co-op, la gente que creó 43 Things, se llama 43 Places[A] way to share stories about great places in your city and around the world.De modo que permite indicar los sitios a los...
Por Nacho Palou -
29 JUN 2005
Me encanta cuando se analizan los datos de forma tan... fácil de entender: eBay, the 9th nation in the World? - 135 millones de personas usan eBay en todo el Mundo. Si fueran un país, serían la novena mayor nación (si esa...
Google Earth, el programa antes conocido como Keyhole, ahora es gratuito (ya no hay versión de prueba limitada) aunque las opciones más poderosas se quedan para las versiones de pago (Plus y Pro) o como extras con coste adicional para la versión...
Por Nacho Palou -
28 JUN 2005
Un compañero mío ha tenido problemas para conectarse a la red Wi-Fi de la sala VIP de Iberia del Aeropuerto de Barajas en las últimas ocasiones en las que ha intentado usarla. Su ordenador es un PowerBook G4 con Mac OS X...
Google cotizó ayer en bolsa a más de 300 dólares la acción. Llevaba semanas a punto de pasar esa barrera «psicológica», como dirían los «analistos». En el noble deporte del Bowling un «300» es una partida perfecta, hay que hacer ni más...
La Corte Suprema de los Estados Unidos ha fallado hoy en el caso MGM Studios, Inc. v. Grokster, Ltd., y lo ha hecho en favor de MGM y los otros 27 estudios que se habían personado en el caso. Las reacciones por...
Aunque hemos dicho en muchas ocasiones que nuestro sitio favorito para compartir fotos es Flickr, hay muchas más opciones, incluyendo sitios que además permiten imprimir esas fotos, y en CNET analizan más de cuarenta de ellos en Online digital photo printing and...
Otra aplicación que mejora el uso del servicio del.icio.us, especialmente en lo que se refiere a buscar y encontrar páginas cuando se tiene una cantidad considerable de enlaces no siempre del todo bien organizados.del.icio.us direc.tor se instala como un bookmarklet de modo...
Por Nacho Palou -
27 JUN 2005
Yummy! (ojo, versión alfa) es un «directorio social de documentos PDF» en el que se puede crear una biblioteca personal de documentos PDF guardándolos y etiquetándolos igual que se hace en del.icio.us con enlaces y favoritos. Hay archivos PDF de todo tipo...
Por Nacho Palou -
27 JUN 2005
Estar en la playa sin conexión (apenas) hace que se te ocurran ideas estúpidas, como esta: ¿Por qué Telefónica no pone un router Wi-Fi en cada cabina de teléfonos y cobra por ese acceso algo razonable? Cabitel, creo que se llama filial...
En algún comentario sobre la Wikipedia en español me pareció entender algo así como que históricamente se había producido una especie de fork o «desdoblamiento de caminos» en su desarrollo (en la inglesa hay varios), pero no llegé a investigarlo más. ¿Alguien...
Esta semana, algo más de ocho años después de los hechos juzgados, ha salido la sentencia sobre el caso de la web del «Jamón y el vino»: Cárcel para los responsables de El vino y el jamón y detenido el legendario cracker...
Hoy 2/3 de los Microsiervos hemos asisitido al fallo de los VII Premios Favoritos de Expansión.com. Estábamos nominados al mejor blog tecnológico o de negocios, galardón que se ha llevado Genbeta de la empresa Weblogs SL, ¡enhorabuena a ellos y al resto...
Por Nacho Palou -
23 JUN 2005
Mmmm... que buena pinta y qué buena excusa para volver a Barcelona dentro de un mes: Copyfight: Lawrence Lessig / John Perry Barlow / Cory Doctorow / Jimmy Wales, Wikipedia / Downhill Battle / Illegal Art / David Bravo / Carlos Sánchez...
David nos visitó hace algunas semanas en la oficina. Es un tipo genial que trabajó con Nacho y conmigo en Ya.com durante varios años. Es uno de mis marketoides favoritos: tiene un gran sentido común, los pies en la tierra y es...
Entre el 24 y 26 de junio se celebrará en Internet el Mid Summer Eve Web Festival organizado desde Tenerife.Un festival virtual sobre las nuevas tendencias en arte, tecnología, comunicación, código y software libre, nuevos medios de comunicación, licencias de autor...Para asistir...
Por Nacho Palou -
22 JUN 2005
Google Maps ya tiene fotos satélite de otras zonas del planeta incluyendo «trozos» de España y ciudades casi completas como Madrid o Barcelona aunque de momento todavía no permite buscar por direcciones.(Vía Google Sightseeing.) Más sobre las marcas en Google Maps«Marcas misteriosas»...
Por Nacho Palou -
21 JUN 2005
Yo estoy encantado con los 2 megas que R me acaba de «regalar», pero Jazztel ha anunciado que antes del mes de octubre pretende ofrecer conexiones de 20 megas a sus abonados, poniéndose a la cabeza del mercado: Los proveedores de ADSL...
Al menos el bug detectado el mes pasado sobre que Netscape podía «romper» IExplorer ha quedado solucionado por parte de Netscape: Netscape 8 update for XML rendering....
Por Nacho Palou -
20 JUN 2005
A principio de julio podría empezar a funcionar una cadena de televisión por Internet que emitiría ACTLab TV usando tecnología P2P para la transmisión de datos en sustitución del habitual streaming desde el servidor emisor. El funcionamiento es similar al de BitTorrent...
Por Nacho Palou -
20 JUN 2005
Este artículo fue publicado originalmente el 7 de diciembre de 1997 en el periódico El Ideal Gallego; en esta revisión me he limitado a añadir algunos enlaces....
La Astronomy Picture of the Day, una cita obligada para los aficionados a la astronomía, cumple hoy diez años. (Vía El Lobo Rayado.) APOD Grabber: astronomía en tu escritorio, una utilidad para colocar automáticamente la APOD en el escritorio de tu Mac...
Al hilo de la frase de hoy, Guide to Flaming:Los flameos son una de las maldiciones de Internet - ¿y aún así cuántas personas que hayan tomado parte alguna vez en una discusión pueden decir que nunca han «flameado» a nadie -...
Operating System Sucks-Rules-O-Meter hace búsquedas periódicas en Altavista en las que cuenta cuantas veces aparece el nombre de un sistema operativo unido a la palabra «rocks» (mola) o «sucks» (no mola) y hace un gráfico con los resultados. El más popular en...
Google Maps Wallpapers & Power-of-ten animation es una sencilla aplicación web que permite obtener imágenes de hasta 2048 x 1536 píxeles de las imágenes satélite/aéreas de Google Maps de la zona indicada o de localizaciones predeterminadas obtenidas de Google Sightseeing. Para tamaños...
Por Nacho Palou -
7 JUN 2005
Ya no hace falta salir de casa para hacer turismo: de la mano de Alex, James y Olly Google Sightseeing te enseña los lugares más conocidos del mundo a través de las imágenes de Google Maps. (Vía Gadgetopia.)...
En el suplemento Ariadna de El Mundo de hoy domingo cuentan en una nota titulada Vendo «Jedi» con experiencia cómo hay gente que vende objetos y jugadores virtuales a cambio de dinero real, en juegos de rol multijugador masivos: El máximo vendedor...
The Unofficial Web Applications List recopila y clasifica un montón de aplicaciones web clasificadas por temas: diseño, educación, juegos, correo, programación... Incluye muchos servicios ampliamente conocidos y otros muchos que merece la pena conocer....
Por Nacho Palou -
5 JUN 2005
LastInfoo es un servicio recién lanzado, un agregador de fuentes RSS temático, en el que puedes ver todas las anotaciones en bitácoras y foros de la Internet en castellano sobre un tema determinado: un personaje, un producto, una tendencia, ciertas palabras clave....
Suena bien, un poco tipo Why Not?. Habrá que probarlo: Khef es una aplicación web para tormentas de ideas en Internet. Es una web desde la que puedes crear y guardar una idea, que estará disponible para que tú y los demás...
Un articulo poco técnico sobre la infraestructura que mantiene en funcionamiento la web de BBC News, una web que llega a alcanzar en sus días pico más de 4 millones de usuarios y 50 millones de impresiones de página: The BBC News...
Google Sitemaps es un experimento en beta de Google que permite a los webmasters enviar mapas completos de sus sitios webs para que Google los indexe mejor. Los mapas son simplemente una lista con todas las URLs, bien en XML o en...
En ocasiones veo paquetes de Amazon. Hoy. Y en abril. Y en febrero. Cinco señales de que Amazon triunfa, cálculos sobre una servilleta Amazon, paquetes con sonrisas, descubrimiendo de este «efecto»...
Similar al Mapa de la Blogosfera Hispana que se había currado Alvy, The FlickrVerse es una imagen hecha por GustavoG que dibuja las relaciones entre 2.367 usuarios de Flickr. Localicé rápidamente y a simple vista a Enrique Dans, fernand0, pjorge, mini-d, Manu...
Sólo han tardado un poco más de dos años, pero la edición digital de El País vuelve por fin a ser gratis. Según dicen en ELPAIS.es para todos La edición digital de EL PAíS inicia hoy una nueva etapa. Todos los usuarios...
Este artículo es otro de los que escribí hace años para El Ideal Gallego como parte una serie más o menos regular que pretendía ir contando a los lectores qué era eso de Internet de lo que se empezaba a hablar tanto...
Momento histórico: Google (GOOG) está rozando ya los 300 dólares por acción. Hace una semana hizo un máximo histórico de 264 dólares, hoy ya marca 292,47, más de un 10% de subida en cinco días de cotización. En estos momentos la capitalización...
Customer Intelligence. El poder de conocer al cliente. La economía de la atención. Por Andreas Weigend, Chief Scientist de MusicStrands. Organizada por EmpresaDigitala.net y SPRI. 27 de mayo de 2005. Museo Guggenheim, Bilbao. Imágenes de la Conferencia en Flickr. Audio completo de...
¿Qué se puede hacer con una rana muerta que no sea sopa? Por ejemplo, un servidor web: Frog with Implanted WebserverLa rana está suspendida en un cubo de cristal relleno de formaldehído y tiene un cable ethernet conectado por el abdomen al...
Por Nacho Palou -
1 JUN 2005
Bueno, digan lo que digan los los anuncios, los periódicos, revistas, etc. sobre el UMTS y la «tercera generación» de móviles/Internet, etc. la situación real es un poco patética. Contaré mi experiencia al respecto. Llega el verano y como tanta gente me...
Keyhole ha sido adquirido por Google y ahora se llama Google Earth. Hace poco que añadieron imágenes de satélite de España además del resto del mundo, lo cual lo hacía más interesante. Ahora a los usuarios registrados nos han mandado por...
Si todavía estás estudiando y te gusta programar Google anuncia el programa Summer of Code para estudiantes de todo el mundo que deseen colaborar con alguna de las organizaciones seleccionadas en el desarrollo de programas de código abiertoGoogle's latest open source initiatives...
Por Nacho Palou -
31 MAY 2005
Con un montón de fotos, pequeños ejemplo de código y bastantes enlaces, A Computer Geek's History of the Internet, una historia de Internet desde el punto de vista de un geek.Not the complete history but just the cool stuff. The Internet history...
Abraldes cierra Feedmanía este 15 de junio. «A pesar de todo el dinero, tiempo y esfuerzo perdidos, tenía que intentarlo :)»....
Al instalar el nuevo Netscape 8 puede suceder (como ha sido mi caso con un Windows XP) que Internet Explorer deje de visualizar documentos XML —como los feeds RSS. En IEBlog cuentan la solución en dos pasos y el primero de ellos...
Por Nacho Palou -
26 MAY 2005
Foxylicious — Una extensión para Firefox que sincroniza los favoritos guardados en del.icio.us y los favoritos del navegador. del.icio.us Cómo hacer un backup de Del.icio.us Del.icio.us loader...
Por Nacho Palou -
26 MAY 2005
El navegador web Firefox 1.1 ya está descargable en versión alfa: Firefox 1.1 (Alpha 1 RC): Deer Park - La fundación Mozilla acaba de publicar una pre-alpha de la que será la nueva versión de Mozilla Firefox. La nueva versión, 1.1, de...
Hace ya algunos días que All Consuming volvió de entre las tinieblas (había sido crackeado por algún idiota). Es un sitio en el que puedes apuntar los libros que estás leyendo, los discos que escuchas, las películas que has visto, etc. El...
Wikimania 2005 será la primera Conferencia Internacional de Wikimedia y tendrá lugar Fráncfort (Alemania) entre los días 4 y 8 de agosto.El programa incluirá una gran variedad de presentaciones, grupos de trabajo y tutoriales, orientados a nuevos participantes así como a veteranos...
Por Nacho Palou -
24 MAY 2005
Hoy me llevé una alegría al abrir el buzón del portal y ver una tarjeta de mi operadora de cable que me anuncia que en junio mi acceso a Internet va a aumentar de ancho de banda y pasará de ser un...
Google (GOOG) cotiza en bolsa hoy a un nuevo récord histórico de 264 dólares por acción. Su capitalización bursátil («lo grande que és la empresa») que es con lo que los entendidos comparan unas empresas con otras, es mayor, incluso bastante mayor...
Bonitos mapas de Internet, y bonito proyecto: DIMES [Distributed Internet MEasurements & Simulations] es un proyecto de investigación distribuido (parecido a la filosofía de proyectos como SETI@Home) que tiene como fin estudiar la estructura y topología de la Internet, con ayuda de...
¡Qué bueno! Una forma más rápida de añadir favoritos y tags en del.icio.us, increíble que se más útil que el bookmarklet post-to-delicious, pero cierto: La mayoría de la gente que usamos el gestor de favoritos / comunidad online del.icio.us, solemos tener un...
En la Universidad Politécnica de Valencia es posible mantener cualquier opción política, siempre que no ponga en solfa la propiedad intelectual. Defender, por ejemplo, que las redes de intercambio de ficheros P2P tienen aplicaciones legales al parecer no es aceptable. Y si...
El viernes de la semana que viene estaré todo el día en Bilbao, asistiendo a esta conferencia: Customer Intelligence. El poder de conocer al cliente: El próximo día 27 de mayo tendrá lugar en el auditorio del museo Guggenheim de Bilbao la...
Si tienes una dirección web (URL) de esas larguísimas que se «cortan» al enviarlas por correo, puedes usar un servicio como Doiop, que te permite cambiarla por otra más corta tipo doiop.com/xyz. La diferencia de este servicio con otros como TinyURL es...
Estos señores de la SGAE se salen:Pedro Farré, abogado que representaba a la SGAE en la IV Jornada de Periodismo Digital, celebrado en Madrid, ha declarado que "igual que se necesita una licencia para conducir, tendrá que haber una identificación necesaria para...
Aunque al hacer una página web siempre es conveniente comprobar que se visualiza correctamente en el mayor número de navegadores (y sus distintas versiones y plataformas) no siempre es posible ni cómodo disponer de múltiples instalaciones de todos ellos. Y aquí es...
Por Nacho Palou -
18 MAY 2005
CSS Optimiser ayuda a reducir el tamaño de las hojas de estilo (CSS) sin alterar el resultado final —aunque según el contenido y complejidad de la hoja habrá que usar ciertas opciones con más o menos cuidado— al eliminar buena parte del...
Por Nacho Palou -
18 MAY 2005
Lo que faltaba: más y más basura que se une a la existente, ahora en los servicios de telefonía de voz por IP... Combating Spam - Spam is back in the news, and it has a new name. This time it's voice-over-IP...
Hace tiempo que compré la versión Pro, ahora que ya tiene fotos de España (en realidad, de todo el planeta), es infinitamete más útil. Keyhole (propiedad de Google) ha anunciado que ya tienen una base de datos con el scanneo de imágenes...
Lo más sorprendente es que con la cantidad de años de retraso que lleva Internet Explorer 7 (cuatro o cinco ya) ahora se esté decidiendo esto:Yes, IE7 has tabs [...] we made the wrong decision here initially, and we're making the right...
Por Nacho Palou -
16 MAY 2005
MusicStrands ya está en español: Musicstrands es un servicio el cual puedes compartir tus listas de reproducción de audio, visitar las de los demás usuarios, votar sus listas y hasta comprar canciones en tiendas online. Además, según tus gustos, te recomiendan otra...
Adivina qué empresa de tres letras es propietaria del lunes, el día favorito de todos trabajadores del mundo, siguiendo el enlace a Monday.com. - Escuchando... I Don't Like Mondays de The Boomtown Rats....
Debido al espectacular aumento del spam (correo basura) durante los últimos años, es altamente recomendable desde hace ya tiempo no publicar nunca una dirección de correo en una página web. El problema es que a veces es necesario hacerlo, porque hay que...

En Craigslist el lema es «hacer el bien haciendo el bien”: cero publicidad, cero gráficos y cero prisa por cobrar.
Si te gusta la astronomía pero la climatología no te es propicia, o si simplemente prefieres ver las estrellas sin abandonar el calor del hogar, por no hablar del dinero que te puede costar un buen telescopio, SLOOH te permite comprar tiempo...
La página indispensable para días de aburrimiento: Random Google Page. Hace exactamente lo que dice su nombre: te lleva al azar a una página cualquiera de la World Wide Web entre las 8.000 millones que Google tiene indexadas. Lo cual se resumen...
Un off-topic sobre otro off-topic en uno de los comentarios de un post anterior llevó a cierto debate sobre los feeds RSS con textos completos, sólo con titular, o recortados. Aun a riesgo de no ser entendido, afirmé que todos los que...
Sin problemas de javascripts desmelenados ni nada parecido, aunque también sin imágenes, la primera página web publicada: 9101 -- /News. (Vía Gadgetopia.)...
Greasemonkey parece un invento realmente poderoso. Es una extensión para Firefox que te permite programar y añadir DHTML («scripts de usuario» digamos) a cualquier página web que visites, para cambiar su comportamiento. Por ejemplo, puedes poner enlaces allí donde no los hay,...
En realidad esta fuente no es tan fea pero se la acaba cogiendo manía porque se abusa de ella, se utiliza demasiado y sobre todo se utiliza mal: The World's Ugliest Font....
Por Nacho Palou -
10 MAY 2005
Si usas el agregador de feeds NetNewsWire para Mac OS X (mi favorito) y quieres bloquear la publicidad de Google que ha empezado a aparecer en algunos feeds RSS, puedes usar este truco: Blocking Ads in NetNewsWire Feeds. El truco es bastante...
Google Web Accelerator recuerda a esos inventos que se hicieron tan populares hace algunos años y con los que se suponía que se navegaba más blanco rápido.Google Web Accelerator is an application that uses the power of Google's global computer network to...
Por Nacho Palou -
5 MAY 2005
Y también se carga su web. No de forma tan espectacular, pero desde hace unos días no hay manera de buscar vuelos en la web de Spanair ni con Explorer, ni con Firefox, ni con Safari bajo Mac OS 10.4 Tiger. El...
Backpack es otro servicio de 37signals de planteamiento muy similar al conocido Basecamp pero pensado más a organizar la VidaReal™ que a la gestión de proyectos profesionales. Para esto se sirve de las herramientas habituales: listas de cosas, listas To-Do, notas, archivos,...
Por Nacho Palou -
4 MAY 2005
«Echábamos de menos los anuncios aquellos de las cámaras espías X-10». Y podremos jugar todos otra vez al «acierta al mono y gana un iPod» (Vía FuckedGoogle.com y CMSwire.)...
Esta mañana descubrí con tristeza el cambio de diseño y a la vez destrozo de usabilidad en Yahoo News Photos: ya no se puede hacer Comando+Clic (Control+Clic) para abrir las imágenes en pestañas nuevas desde la portada en que salen las fotos...
Odialas o ámalas, las 40 empresas líderes en tecnología e innovación para Wired en The Wired 40. En el número uno, Apple; entre las que se quedaron fuera por los pelos, Inditex....
En el O'Reilly Radar, el magnífico Tim O'Reilly se explaya en un artículo titulado Ten (No, Eleven) Years of Internet Advertising con un buen repaso a algunos números de la primera década de anuncios en Internet, a raíz de un informa publicado...
Así era Internet o, más bien, lo que había en vez de Internet, en los años 80: Textfiles.com. Textos. En ASCII. En monitores de fósforo verde. Guardados en los BBS de la era pre-internet. Así eran las cosas. textfiles.com_ Ahora puedes pasarte...
A eso de las seis de la tarde de hoy (hora de España) Firefox superó la marca de los 50 millones de descargas. Lo cuentan en Blazing a trail to 50,000,000 y desde allí enlazan con Firefox Counter, un contador desarrollado por...
¿Puedes estar delante de una página web sin hacer clic en algún sitio? Compruébalo: dontclick.it...
Por Nacho Palou -
29 ABR 2005
No parece especialmente útil, pero amaztype es un buscador para libros a la venta en Amazon que desde luego muestra los resultados de una forma espectacular: (Gracias, Iñigo.)...
XtraGoogle (que no es de Google) muestra en una única página las opciones de búsqueda que ofrece Google --noticias, películas, froogle, citas, imágenes, grupos de noticias,......
Por Nacho Palou -
29 ABR 2005
Desde PDFonline es posible convertir documentos PDF a páginas HTML o documentos a formato PDF. Basta con subir el archivo y dar una dirección de correo electrónico donde recibir el resultado. Lo probé con un PDF de 1,9 MB (el tamaño máximo...
Por Nacho Palou -
28 ABR 2005
A raíz de todo el asunto este de la publicidad molesta hasta en la sopa, leyendo un comentario de Víctor me animó a probar Adblock, que no conocía. Adblock es una extensión para Firefox que bloquea y elimina toda la publicidad mientras...
En varios blogs se comenta ya lo de que habrá publicidad Google AdSense en los RSS, en inglés Google AdSense in RSS. Eso será si cada cual quiere. En realidad en muchos sitios están explicando mal la noticia: ya existían formatos publicitarios...
Podscope es un buscador que localiza palabras dentro del audio de archivos de podcasting o audiobooks - archivos de audio «hablado». Tal vez convierte el audio en texto «entendiéndolo» o tal vez alguien ha hecho previamente la transcripción completa. En cualquier caso,...
Si utilizas el gestor de proyectos Basecamp seguramente encontrarás muy útil la extensión Basecode para Firefox.Basecode is a simple to use Firefox browser extension designed to give easy access to the hidden formatting options available when posting messages and comments in Basecamp....
Por Nacho Palou -
25 ABR 2005
Esto suena interesante y además es gratis asistir - la cita es dentro de dos viernes por la tarde: I Microcongreso sobre estándares web, RubyOnRails, podcasting, y buzzwords en general: El próximo viernes 6 de mayo tendrá lugar en Madrid el I...
Leído en ¿Usuarios o personas?: Si te empeñas en llamar a la gente como «usuarios» (o «clientes») al final no son ni personas, y acaban siendo todos imbéciles. (De una entrevista a Donald Norman.)Desde que leí Cluetrain mi me sucede lo mismo:...
Imagino que la historia que cuenta Lance Fortnow en Does a book exist if nobody reads it? acerca de un estudiante que al no encontrar información sobre un tema en Google pensó que en realidad no existía es un caso aislado:Student: I...
Llegó hoy una nota de Flickr por mail: como ya dijeron que tras ser adquiridos por Yahoo harían algunos regalitos y mejoras en el servicio a nivel de precios y características, ahora a todos los usuarios que en su día pagamos una...
Nacho ya escribió acerca del tema hace más de un año en www. obsoleto, y en QueWeb! tienen montado un especial al respecto, to www or not to www, pero no hay manera, sigue habiendo sitios y sitios que no funcionan con...
A mi, al menos, la noticia me ha pillado totalmente por sorpresa: Adobe compra Macromedia por 2.623 millones. Nota oficial de Adobe: Adobe to acquire Macromedia. Es quizás demasiado pronto para especular con qué puede significar esto, pero me da que como...
A irra e ismmma de QueWeb! les ha salido un imitador en inglés: Sites That SuckEveryone thinks they’re a designer. Everyone thinks that the spinning logo will finally look cool again on their site. Just because Microsoft builds a HTML editor into...
Lo cuenta Evan en Gmail adds feed reading: There's a new feature in Gmail called Web Clips, which displays little headlines above your inbox or message and is fed via, um, feeds (...) You can add your own feeds and/or choose from...
Yahoo Buzz muestra las 20 búsquedas más populares en general en Yahoo (en inglés) en las clásicas columnas leaders y movers, que equivalen a los «más buscados» y «con más movimiento últimamente» (términos «de moda»). No es una página nueva, pero hoy...
Un par de servicios más de tipo software social que vienen en forma de pozo de los deseos virtual: añade tu objetos de deseo, etiquétalos e incluye el enlace de dónde encontrarlos.grat.uito.usMetaWishlist Un poco verdes, ningún concepto nuevo y una estética más...
Por Nacho Palou -
14 ABR 2005
Buzztracker muestra de forma gráfica la proporción y relación entre países y ciudades del mundo que se mencionan en los titulares de Google News (en la versión en inglés) y el porcentaje que representan dentro del total de noticias. Además del...
Por Nacho Palou -
13 ABR 2005
Una forma ingeniosa de resolver un problema: hacerle una foto y pregunta en Flickr: How do I change this light bulb? Con un poco de suerte otros usuarios conocen la solución y problema resuelto. (Vía Jeremy Zawodny's linkblog.)...
Por Nacho Palou -
8 ABR 2005
Dado que el ciclo de este año de las Reith Lectures se llama Triumph of Tech, me parece absolutamente adecuado que las estén distribuyendo vía podcasting. iPodder 2.0 (el limón)....
Mola, no sabía que existe una versión de Flickr para el móvil.12. Can I access my Flickr photos via my cameraphone's web browser? Yes, you can. Just visit http://flickr.com/mob/ to access your photos, and read recent comments. Como cuentan en su FAQ...
Por Nacho Palou -
8 ABR 2005
La Wikimedia Foundation acaba de anunciar que ha alcanzado un acuerdo con Yahoo! Search mediante el que esta empresa dedicará hardware y recursos para dar soporte a la Wikipedia: Wikimedia Foundation Announces Corporate Support of Wikipedia from Yahoo! Search; Helps Allow the...
Hoy se cumple un mes desde que recibí un correo electrónico de Iberia anunciándome el estreno de su nueva web ¡¡ BIENVENIDOS A LA NUEVA IBERIA.COM !!Es un placer para nosotros anunciarle que en breves días lanzaremos la nueva iberia.com. Una web...
Nuestro colega David se animó a probar el navegador FirefoxI think Mozilla has made me a more complete human being... How did I ever survive without it??!!¡Aaaamén!...
Por Nacho Palou -
6 ABR 2005
Stuart Mudie propone una variante de Googlewhaking en Flickr a la que ha llamado Flickrwhacking. La idea es encotrar dos tags que devuelvan una sola foto, lo que puede ser más o menos fácil con las propias:mero españa, que también funciona en...
Si estás preguntándote cuál de los distintos formatos en liza se convertirá en el sucesor del DVD, Robert Capps se plantea en Discs Are So Dead que el futuro de la distribución de películas y otros contenidos en vídeo no pasa por...
Jeff Dean de Google habla de lo que supone poder ofrecer unas búsquedas de calidad en Google: A Behind-the-Scenes Look, un programa de la televisión de la Universidad de Washington. (Vía Slashdot.)...
El API de Flickr y la gente que lo aprovecha son una fuente continua de aplicaciones sorprendentes. Cuando buscas cualquier etiqueta (tag) en Flickr Related Tag Browser éste carga todas las etiquetas relacionadas y las últimas 36 fotos con esa etiqueta. Para...
Ranchero Software acaba de montar un par de páginas de recursos adicionales para dos de nuestras aplicaciones de cabecera, NetNewsWire (lector/agregador de feeds RSS/XML) y MarsEdit (editor de blogs): NetNewsWire resources y MarsEdit resources. (Vía The Unofficial Apple Weblog.)...
Links-Rotos.com es la típica utilidad sencilla pero que resuelve muchos problemas: es un robot (araña) validador de enlaces. Puedes ir a esa web, teclear el nombre del website que quieras comprobar y te hará un repaso rápido (aunque limitado) a todos los...
Quizás un poco excesivamente académico, y además en inglés, pero The Lifecycle of Memes no está mal del todo. Si no sabes lo que es un meme, la Wikipedia lo define....
Total y absolutamente inútil, pero Netdisaster sirve para echarte unas risas:(Vía Gadgetopia)...
Elías es un fan de Microsiervos que nos ha escrito para comentar algo que hace tiempo me daba vueltas por la cabeza, y que él ha descrito de forma bastante realista: Gracias a vosotros, entre otros, he conocido Flickr y me he...
Lleva casi un año sin actualizarla, pero Larry Kestembaum llegó a reunir 540 ejemplos de correos nigerianos de esos que te prometen fortunas a cambio de sólo un poquito de ayuda en Nigerian Fraud Email Gallery, ordenados por fecha, remitente e importe...
Basándome en el mini-tutorial 6600, T-Mobile and Mac :-) añadí una conexión en el PowerBook con Mac OS X 10.3 que me permite tener acceso a Internet desde cualquier sitio donde haya cobertura GPRS (aka «en toda España» [fuente]) a través de...
Por Nacho Palou -
22 MAR 2005
Poniendo fin a semanas de rumores, Caterina Fake confirma en el blog de Flickr que Yahoo finalmente los ha comprado: Yahoo actually does acquire Flickr... Lo cual no deja de ser curioso teniendo en cuenta que Stewart Butterfield, uno de los co-fundadores...

A modo de recordatorio histórico, algo que escribí en 1996 y que ha estado en la Red desde entonces. En 2003 lo actualicé mínimamente dado que incluso las definiciones originales habían cambiado en los últimos años. De vez en cuando se reedita...
Amazon no deja de sorprender: ahora está analizando los textos de su enorme catálogo de libros y junto al título muestra las denominadas SIPs: Statistically Improbable Phrases (Frases Estadísticamente Improbables). Por ejemplo para Cluetrain Manifesto muestra networked markets y market conversation; para...
Una primera versión de este artículo se escribirió originalmente en 1996 - hace ya casi diez años. Iba a formar parte de un libro que en realidad nunca se terminó, ni publicó. Se puede acceder a la versión completa original mediante la...
...no lo arregles. Hace unos días Iberia puso en funcionamiento una nueva versión de su web que es el ejemplo perfecto del título de esta anotación, pues si bien antes no era una web espectacular, también es cierto que funcionaba correctamente, pero...
Lo que todo el mundo estaba esperando: una utilidad web llamada Del.icio.us loader que sirve para que exportes todos tus favoritos de Firefox a un fichero y luego los subas de una sola vez a tu cuenta de del.icio.us. Los favoritos exportados...
La Wikipedia, por definición, es un esfuerzo colectivo, pero hay algunas personas que dedican más trabajo que nadie a mantenerla, y Wired ha entrevistado a unos cuantos de los que más trabajan en la versión en inglés en Wiki Becomes a Way...
Nadie, claro, pero sí es cierto que hay una serie de organismos que son fundamentales para su funcionamiento: A Concise Guide to the Major Internet Bodies. (Vía Slashdot.)...
Buenísima idea... Online Poker Googlebomb:Enlaza a este artículo de la Wikipedia con las palabras: Online Poker — Este es otro esfuerzo para desalentar a los blogspammers.(Vía ALT1040.)...
La primera imagen publicada en la web, allá por 1992, LHC: The First Band on the Web, y la historia de la primera webcam (que además era útil), la famosa Trojan Room Cofee Machine. [vía Slashdot]...
Por fin: Baquía en RSS con un feed de todo el site y también feeds por secciones. Además, hace poco renovaron bastante toda la web: Baquía, Knowledge Center. Lo malo: todavía no han entendido que los feeds hay que publicarlos completos para...
En Slashdot cuentan en 100,000 Domains Sold for $164 Million que una empresa ha pagado 164 millones de dólares por Name Development Ltd, la típica empresa oscurilla cuyo negocio consiste en mostrar publicidad en unos 100.000 dominios de su propiedad aprovechándose de...
La idea es divertida. Desde MailToTheFuture.com puedes enviarte correo a tí mismo o a cualquier otra persona... en una fecha futura. Es como un webmail, pero lleva añadido el campo «Fecha/Hora» para programar el envío. Las aplicaciones son infinitas y futurísticas, como...
Un divertido 'gadget' para Flickr: flickr graph. Escribe tu nombre de usuario de Flickr a la derecha y pulsa 'start'. Lo sé, lo sé --esto ya lo habíamos publicado......
Por Nacho Palou -
18 FEB 2005
Se ha anunciado que The New York Times ha adquirido About.com y al parecer han pagado 410 millones de dólares en efectivo, lo cual no está nada mal. Anteriormente ya habia cambiado de propietario alguna vez. About.com es uno de esos servicios...
En On the Trail of the Long Tail, un artículo publicado en el blog corporativo Yahoo Search Blog se hace un buen repaso al fenómeno social y de mercado de la Larga Cola, que ya hemos comentado varias veces por aquí. The...
Han tardado casi un año más que Boeing, pero en Airbus también se han dado cuenta de que el dinero protege a los aviones de las interferencias: Presentan un sistema para usar móviles y ordenadores en aviones. Eso sí, Airbus ha aprovechado...
El otro día alguien lo comentó y al verlo en Inessential lo volví a recordar: RSS 1.1. En otras palabras, ya hay gente trabajando en la especificación RSS 1.1: RDF Site Summary, que todavía está abierta a comentarios. El número de versión...
El pasado miércoles 9 de febrero se celebró la puesta de largo de MusicStrands bajo el título Exploración y Descubrimiento de Música: Oportunidades en la era de la Música digital. El lugar elegido fue el aula del IIAA-CSIC, en el campus de...
En Slate, The Typo Millionaires (Los millonarios de las erratas), cuenta la sórdida historia de uno de los timos más viejos de Internet. Incluyendo algunos datos curiosos como Algunos estudios estiman que entre un diez y un veinte por ciento de las...
Cory de Boing Boing nos recuerda que hoy es el cumpleaños de Flickr. Parece que existe hace un siglo y que hayan sacado veinte versiones en este tiempo, pero Flickr es mucho más reciente que todo eso. Resulta que hoy Diego también...
¿Cómo puede ser el URL de la sección de sociedad (por ejemplo) de la edición en línea de El Ideal Gallego tenga URLs largas como churros?
Estoy en Barcelona porque esta tarde es la puesta de largo de MusicStrands, un servicio para explorar, descubrir y organizar música que se lanzó silenciosamente en versión beta el pasado lunes. (Ver full disclosure al pie de esta nota: soy parte del...
Richard Koman entrevista al CEO de Flickr para O'Reilly Network: Stewart Butterfield on Flickr. [vía Kottke]...
Russell tiene toda la razón al escribir en A9: Never been done before? que los de A9 (Amazon) han exagerando y de mala manera al afirmar que su Yellow Pages on A9 «nunca antes se había hecho». Efectivamente, QDQ en España con...
Una versión algo más ruda del STFW para cuando te preguntan algo que se averigua en cinco segundos usando Google: Just Fucking Google It.Someone thinks you are an idiot because you were too stupid to check Google before asking a question. They...
El planteamiento original es de Tom Foremski en Is this a Google atom bomb? A $100m mystery treasure hunt through Google Adwords...?, lo vi en Google.Dirson.com y me ha parecido un ejercicio hipotético tremendamente ingenioso. Literalmente: A billionaire has arranged to give...
Hay gente para todo y con todo tipo de aficiones, como queda patente en Unusual Museums of the Internet: desde coches de juguete a aisladores eléctricos, pasando por perchas, linternas, mecheros, o casi cualquier otra cosa que se te pueda ocurrir. [vía...
Ya terminado el periodo de pruebas, Microsoft lanza formalmente su buscador en Internet 'MSN Search' en 25 países. ¿Sucederá algo parecido a la guerra de los navegadores y se saldrá Microsoft una vez más con la suya? Aunque sólo sea por la...
Aunque normalmente utilizo MarsEdit como editor de blogs (usando MovableType) hoy estuve probando ecto que es muy similar y funciona igual de bien aunque es algo más poderoso en algunos aspectos. Una de las mayores ventajas de ecto sobre MarsEdit es...
Por Nacho Palou -
25 ENE 2005
El otro día fui a la oficina de Correos de mi barrio a recoger un paquete de Amazon con un pedido de tres o cuatro libros medio urgentes que tenía pendientes. Siempre que voy veo paquetes con sonrisas, y esta vez decidí...
Este año me he propuesto hacerme con el certificado de usuario de la FNMT, necesario para poder presentar la declaración de Hacienda a través de Internet, pero en el proceso me he encontrado con algo que está a medio camino entre un...
Para los que gustan de utilizar listas tipo To-Do, aka "listas de cosas pendientes de hacer" Ta-Da Lists es una aplicación web realmente rápida y sencilla de usar que sirve precisamente para gestionar este tipo de listas. Tiene el encanto de Basecamp...
Por Nacho Palou -
20 ENE 2005
Si te dedicas al desrrollo web te puede interesar especialmente la extensión para FireFox y Mozilla Web Developer (0.9.2, Mac, PC) de Chris Pederick que incluye múltiples opciones para validar, ver información sobre páginas y el servidor que las contiene, cambiar hojas...
Por Nacho Palou -
20 ENE 2005
Interesante iniciativa de Google: Preventing comment spam. Básicamente consiste en que si se añade el la etiqueta rel=“nofollow” a cualquier enlace, Google no lo seguirá ni lo considerará un «voto» para el PageRank de la página destino. A raíz de esto, Six...
Hace unos días Alvy comentaba lo bien pensado que está MarsEdit, pues es capaz de recuperar tu trabajo no guardado en el caso de un cuelgue o de que se vaya la luz, pero en eso no es sino la excepción que...
Acabo de ver que Technorati ha lanzado Technorati Tags, de modo que va a ser interesante empezar a usar etiquetas como rel=tag en los enlaces href para marcar los contenidos y que este invento se vuelva algo realmente grande. Los tags se...
En Abordaje.net cuentan cómo han pedido nuevos RSS por encargo, de modo que ahora aunque no existían, ahora existen: Cadena Ser Noticias [RSS] Estos feeds RSS a medida...
Cuentan los periódicos de por aquí que Un vigués patenta un buscador para competir con GoogleUn investigador gallego crea un sistema universal de búsqueda en Internet Lo que me recuerda mucho a los chicos de Comintper. ¿Alguien se acuerda de ellos todavía?...
Para meditar sobre tu existencia en Internet como persona, empresa, sobre tus proyectos, el uso del software social, los enlaces, los contenidos en abierto o en cerrado, etc. Estar en Internet es, en definitiva, vivir en comunidad, y ser el vecino usurero...
Ciertamente esto da una sensación extraña entre diversión y miedo. Utilizando estas búsqueda en Google salen cientos de URLs que apuntan a cámaras de seguridad que puedes ver desde tu navegador. Nota: no todas las cámaras funcionan, tal vez únicamente la mitad......
Como viene haciendo desde hace algunos años, Google ha publicado un resumen de las búsquedas más populares del año que acaba de terminar: 2004 Year-End Google Zeitgeist. También hay versiones internacionales; esta es la española. ¿Será así realmente como vemos el mundo...
The Dream Machine. J. C. R. Licklider and the Revolution That Made Computing Personal. M. Mitchell Waldrop. Penguin Books, agosto de 2002. Inglés. Aunque J. C. R. Licklider no es el autor directo de ninguno de los avances fundamentales en el campo...
En Periodistas 21 avanzan algo sobre el gran Concurso de Blogs que será organizado por 20 Minutos, el mayor diario gratuito de España, durante 2005. En esta ocasión me ha tocado participar como miembro del jurado. Todavía se están decidiendo las categorías...
Virtual Apple es un emulador en línea de un Apple II que cuenta con unas 1100 imágenes de disco con software para esta máquina al que se accede mediante un emulador escrito en Active X... por lo que sólo funciona con Internet...
En los últimos meses el proveedor de hosting donde actualmente tenemos hospedado Microsiervos nos está causando más dolores de cabeza que otra cosa, así que tal vez ha llegado el momento de cambiar a otro. Y puestos a cambiar estaría bien contar...
Por Nacho Palou -
16 DIC 2004
Vía Forever Geek, la lista con los 100 dominios .com más antiguos de Internet, que todavía están en uso: 1. SYMBOLICS.COM 2. BBN.COM 3. THINK.COM 4. MCC.COM 5. DEC.COM 6. NORTHROP.COM 7. XEROX.COM 8. SRI.COM 9. HP.COM 10. BELLCORE.COM Viejas glorias en...
Manuti habla sobre las Comillas tipográficas con CSS, diferenciando entres las comillas tipográficas latinas « » y las comillas Doctor Maligno o anglosajonas “ ” que no son las mismas que las comillas verticales " " (que son más bien el símbolo...
Tintachina cuenta el resultado de los premios BOBs. Los Microsiervos nos quedamos sin premio esta vez, aunque estuvimos compitiendo entre los 10 mejores. ¡Felicidades a los agraciados! Ganadores de los BOBs: Ya se conocen los ganadores del premio del jurado de los...
El artículo Secrets of Firefox 1.0 muestra algunos curiosos y útiles secretos de Firefox 1.0. Y si utilizas este navegador también te puede interesar la página Best Firefox Extensions....
Por Nacho Palou -
9 DIC 2004
Chris Locke (a.k.a. Rageboy) explica en Amazon hypercites que se encontró hace poco en Amazon con hipercitas, una nueva funcionalidad por la que algunos libros de Amazon muestran enlaces a los libros citados en su contenido y también a los que citan...
Bloglines ya está disponible en español, además de en otros seis idiomas: francés, alemán, chino, japonés, portugués y el original en inglés. También han explicado que ya tienen 200 millones de artículos (posts) indexados. Parece que todos los agregadores RSS, como ya...
Feedmanía y Ferca Network se han aliado para mejorar el servicio en unos nuevos servidores. Feedmanía es un agregador RSS en castellano, gratuito y sin publicidad, que ya lleva seis meses funcionando. El primer cambio tras este anuncio es que las cuentas...
Concretamente, un 42%. Delirios de un informático se ha dado cuenta de que matemáticamente no puede ser verdad todo lo que se publica sobre que ciertos porcentajes del tráfico de Internet son spam, P2P, etc. A saber: "Los correos electrónicos no solicitados...
Después de un par de años durante los que no ha sido posible registrarse en Metafilter (necesario para postear o comentar) vuelve a ser posible... pero previa donación de 5 dólares.Due to the bursting size of the community, its use of resources,...
Por Nacho Palou -
18 NOV 2004
10×10 es un sitio experimental realmente curioso: una forma gráfica de ver el "ahora". Básicamente, 10×10 recoge información de las noticias de actualidad de la Web, busca imágenes equivalentes según el contexto y monta un mosaico. THIS IS NOW -- Every hour,...
Reuters informa al final de la noticia Acciones a tomar en cuenta en Wall Street 16/11/04 de que hoy termina el periodo de restricción que impedía a los empleados y primeros inversores de Google vender 39 millones acciones en su poder, lo...
Abraldes acaba de anunciar el lanzamiento de iFavoritos en versión alfa. iFavoritos es un gestor de favoritos online bastado en tags (palabras clave), feeds RSS y cuentas públicas; como el popular del.icio.us pero en castellano. Este servicio gratuito permite almacenar vuestros favoritos...
Si las versiones 0.x y la PR ya han sido buenas, Firefox 1.0, que acaba de ser publicado hoy mismo, tiene que ser la bomba. Firefox 1.0 empowers you to browse faster, more safely and more efficiently than with any other browser.Si...
Es anecdótico frente al número de spammers que hay, y la sentencia probablemente va a ser recurrida, pero Jeremy Jaynes acaba de ser condenado a nueve años de cárcel en Virginia por estafar a gente a través del spam, como se puede...
Cuando recibimos la convocatoria de The BOBs decidimos no presentar nuestra candidatura porque por una parte nos parecía un tanto presuntuoso y por otra no creíamos encajar del todo en la definición utilizada por la organización para la categoría en la que...
Hoy he visto en el listado de referrers que alguien llegaba a Microsiervos a través de Google al realizar la búsquedaactores de los años 60 americanos muertosy no pude evitar acordarme del Dead People Server, una base de datos de celebridades en...
Pensaba que era solo yo:Important Update - Rolex for $150 !! Italian Rolex at throw away prices You said once you like Rolex Rolex, Cartier, Frank Mueller, Bretling for sale Order Rolex or other Swiss watches online No Compromise Wear only ROLEX...
El pasado 2 de septiembre publiqué un post titulado Hoy NO es el cumpleaños de Internet en el que argumentaba que los que decían que ese día Internet cumplía 35 años se estaban adelantando casi dos meses con la fecha de la...
Simplemente comentar que con el tema este de la publicidad en los weblogs siguen Chris Pirillo (que se gana la vida con esto) que cuenta su punto de vista en Opinions are like… (haciendo el viejo chiste de que Las opiniones son...
MacRumors lleva todo el día recopilando información en New iTMS Localizations Tuesday? acerca de paises en los que Apple podría anunciar disponibilidad de iTMS mañana:Suiza Austria Irlanda Canada España Noruega Finlandia Países Bajos Suecia Japón Italia Bélgica Polonia Nueva Zelanda Dinamarca MéjicoMéxicoLlegan...
Estos días estuvimos comentando muchos aspectos de la publicidad en los weblogs (a partir de esta historia de JJ). Ahora es Jason, uno de los creadores de Weblogs, Inc (una red de weblogs temáticos) quien responde a la idea de Marc Carter...
¡Ríos de blancos en la Web! Antipixel explica en Unjustified [archive.org, el original desapareció], algo que debería ser obvio para cualquier diseñador de páginas web: los textos no se «justifican» en la web. Por desgracia son muchos los diseñadores novatos que cometen...
Tengo que recomendar ESTRATEgA.com [atom], un excelente weblog que descubrí hace una semana a través de un enlace de Merodeando. El autor (que se hace llamar Sr. Martínez) desarrolla su carta de intenciones publicando todos los días notas interesantes sobre estrategia de...
Interesante hilo de comentarios a raiz de una anotación de JJ sobre la publicidad en los weblogs, con una gran mayoría a favor de poner anuncios de texto tipo AdSense en su blog… y conmigo, pues… en contra. Hasta ahora se ha...
Usa Firefox y difunde Firefox. Así de simple....
Abrió sus puertas Bitadir, un directorio de weblogs donde los usuarios pueden registrarse y añadir bitácoras de forma clasificada, hacer pings, y donde también hay foros y noticias sobre el mundillo de los weblogs. Es una iniciativa de Ferca Network que también...
No sabemos quien es Asturias, pero nos ha postulado para The BOBs - Best of the Blogs en las categorías de Mejor Weblog y Mejor Innovación. Probablemente no tenemos nada que hacer en ninguna de esas dos categorías, pero gracias de todos...
En Don't get me wrong, I really like BBC News Online Stef Magdalinski dice que aunque BBC News le parece una excelente fuente de noticias, en su opinión tiene un fallo importante, que es la reticencia que demuestran a la hora de...
Loïc Le Meur comenta una actualización a uno de los datos más impresionantes (y menos conocidos, diría yo) de las empresas de Internet a nivel mundial: "430.000 personas en todo el mundo viven de los beneficios que obtienen en eBay." El último...
... dijo un empleado de Microsoft en su weblog: Resulta que ahora tengo GMail, la Toolbar de Google, la Deskbar de Google y Google Desktop. Para buscar en la ayuda de MSDN uso Google. En casa, todos mis ordenadores tienen Google como...
Hoy mi amigo Jon me recomendó probar Clusty que es un nuevo buscador que está en versión beta y que funciona un poco como Google y los demás motores de búsqueda, y de hecho creo que combina varias fuentes de datos, pero...
Google SMS permite hacer consultas al buscador desde el móvil y recibir los resultados en un mensaje corto de texto. De momento está en beta sólo disponible en EE.UU. Dirson cuenta un poco el tipo de información que se puede obtener a...
Por Nacho Palou -
8 OCT 2004
Anoche se celebró la fiesta de aniversario de Google España, a la que acudió también bastante gente de Google Europa. Parece que fue ayer, pero ya hace un año que abrieron oficialmente su oficina en Madrid. Aunque Sergei Brin y Larry Page...
elgooG es un auténtico mirror de Google....
Bruce Schneier, uno de los gurús de la seguridad en Internet, acaba de estrenar blog: Schneier on Security. (Vía BoingBoing.)...
Evan Williams (aka Evhead) deja Google. Y Blogger, claro....
Por Nacho Palou -
5 OCT 2004
El efecto Slashdot se produce cuando el popular sitio Slashdot envía un montón de tráfico a sitios de Internet más o menos humildes provocando su muerte por éxito —que sea imposible acceder a ellos. Para combatir este efecto la idea de Mirrordot...
Por Nacho Palou -
4 OCT 2004

Por resumir un caso complejo: Oracle lleva tiempo queriendo comprar PeopleSoft mediante una OPA hostil, y el caso está todavía en los tribunales. En realidad es Larry Ellison, Presidente de Oracle, quien se ha "emperrado" en hacer esa operación. En cualquier caso,...
Una de las múltiples razones para cambiarse a Mozilla Firefox es que la ventana de búsquedas puede personalizarse para añadir otros motores (engines) entre los que se encuentran varias versiones de Google (Google Web, Google Images, Google News en varios idiomas --...
Logicola ha conseguido algo difícil: explicar en una brillante anotación un tema supuesamente complejo como son las APIs y los Web Services. Lo puedes leer en Bloglines API: Algunas Malas Respuestas A Buenas Preguntas: ¿Qué es un webservice? Con la mayoría de...
Puede que te sea de ayuda tener algunas de estas excusas a mano, Top 11 Reasons Why You Just Saw Porn on My Computer Screen. Por ejemplo:11. Estoy cogiendo nombres de personas por las que deberíamos rezar esta semana. 5. Sólo estoy...
Por Nacho Palou -
30 SEP 2004
Aunque a estas alturas a nadie se le escapa que Tim Berners-Lee cambió el mundo cuando inventó la web, su idea original iba más allá, y en esta entrevista en Technology Review explica como su idea de la Web Semántica podría por...
En la portada de Amazon se anuncia un descuento del 1,57079632679% para los que hagan sus compras a través de su nuevo buscador A9: Bueno, 1,57% no es mucho pero ciertamente es mejor que eπi+1. En esta página explican el porqué del...
En una sala de chat: <Sonium> someone speak python here? <lucky> HHHHHSSSSSHSSS <lucky> SSSSS <Sonium> the programming language Esta es una de las últimas (y muy graciosas) estupideces / chistes que se pueden encontrar entre los miles de citas de la QDB...
Según Sloppy emailing is bad for business (The Register), estos son los siete pecados capitales de los trabajadores europeos al usar el correo electrónico: 1. Ignorar el correo 2. Usar incorrectamente el "enviar a todos" 3. Demostrar falta de tacto 4. Descuidar...
Después de utilizarlo un tiempo, CSSEdit (Mac OS X) es sin duda el editor CSS que más me gusta: sencillo, completo, rápido y eficaz –incluso previsualizando, y también es bonito y barato, unos 20€. StyleMaster (Mac OS X y Windows) es ligeramente...
Por Nacho Palou -
16 SEP 2004
La gente de Bitácoras.com acaba de estrenar un ranking en el que aparecen las 500 bitácoras más populares / influyentes de la blogosfera en castellano. El criterio para ordenar por popularidad las casi 10.000 bitácoras que se han registrado durante el primer...
Los &%$&%/!& de Domain Registry of America volvieron a enviarme spam en papel. Esta gentuza se dedica a hurgar en las bases de datos del WHOIS y luego envía cartas en papel no solicitadas con "apariencia oficial" como esta Se supone que...
Ayer recibí un correo electrónico no solicitado (un spam, vaya) de Galirede, una empresa de esas que se dedican a gestionar y diseñar webs y todo tipo de servicios multimedia. No iba a hacele ni caso, pero como el mensaje incluía un...
Derek publica una lista de sus atajos de teclado favoritos para Firefox que está realmente bien, y seguro que si usas Firefox muchos no los conoces y te van a permitir ahorrar tiempo. Por ejemplo, Control+0 (Control y el número 0 a...
¿Por qué extraño motivo cuando te vas a registrar como cliente en la web de El Corte Inglés si contestas que ya tienes su tarjeta de compra te vuelven a pedir los datos que ya tienen? ¿Tanto les costaba tirar de bases...
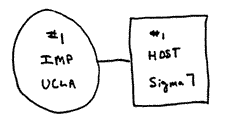
Aunque algunos sitios comentan que Internet cumple hoy 35 años, yo diría que como poco se adelantan en casi dos meses a la fecha real. Lo que ocurrió el 2 de septiembre de 1969 fue que Truett Thach conectó con éxito el...
Aparte de por lo bien que lo pasé cuando estuve allí en diciembre pasado, por los increíbles precios que ofrece Bredbandsbolaget para sus conexiones de banda ancha: 10 Mbit/s: 399 coronas/mes ≈ 44 €/mes 24 Mbit/s: 449 coronas/mes ≈ 49 €/mes100 Mbit/s: 595 coronas/mes...
Tras meses de espera tras el anuncio de su IPO, las acciones de Google cotizan en bolsa desde hoy. Aunque esta IPO es de las más esperadas en los últimos años, algunos analistas han enfriado un poco las espectativas debido al método...
How the Web was Born: The Story of the World Wide Web. James Gillies, Robert Cailliau. Oxford University Press, 15 de enero de 2000. Inglés. Al principio este libro parece uno de tantos acerca de Internet, ya que empieza haablando de los...
RSSCalendar genera un feed RSS con el contenido de tu agenda (diaria, semanal o mensual), de modo que puedes compartirla con quien quieras o simplemente consultarla vía RSS desde tu lector de feeds favorito....
Por Nacho Palou -
4 AGO 2004
Si los derechos de Propiedad Intelectual no se protegen, la red de redes desaparecerá porque no tendrá contenidos.Entiendo que este señor tenga que decir este tipo de cosas por trabajar donde trabaja, y hay que reconocerle que tuvo valor para decirlo en...
Uno de los temas recurrentes en Microsiervos es el de la patochez generalizada que parece afectar a las iniciativas empresariales españolas en Internet, pero algunos usuarios tampoco se quedan cortos: por lo visto cinco individuos roban un escudo de los que adornan...
Hace algún tiempo se puso en marcha un concurso de posicionamiento en Google similar al del telendro cuyo objetivo era colocarse como primer resultado al buscar nigritude ultramarine. Pues bien, el concurso ha terminado hace unos días y en lugar de ganar...
Una buena idea bien ejecutadaCopyscape encuentra copias de tus contenidos en la Web. Puedes utilizar Copyscape para identificar sitios que han copiado tu contenido sin permiso. Copyscape también muestra quién está citando tu sitio. Simplemente escribe la URL donde están tus contenidos...
Por Nacho Palou -
13 JUL 2004
Hace unas semanas Carlo Zottmann, «Gossip» lanzó una propuesta interesante: crearía bajo petición feeds RSS por 2 euros a partir de cualquier página web HTML. Me enteré vía Boing Boing, y al leer su propuesta opiné exactamente lo mismo que dijeron en...
Un vistazo al contenido de los mensajes basura tipo "Buy Viagra" revela cómo los spammers intentan saltarse los filtros antispam escribiendo el nombre de la famosa píldora azul de todas las maneras posibles. Pues bien, alguien por ahí se ha propuesto conocer...
Por Nacho Palou -
12 JUL 2004
Mis compañeros de equipo de Ya.com encargados del buscador han lanzado estos días una nueva página para estadísticos y aficionados a las búsquedas y el cotilleo llamada Búsquedas Populares donde se recoge una especie de resumen de lo más buscado por la...
Supongo que a estas alturas ya debería estar acostumbrado, pero hace unos días comprobé una vez más que lo del comercio electrónico en España sigue siendo una especie de coña marinera. Estaba buscando algún viaje para este verano cuando di con un...
Según cuenta El Ideal Gallego de hoy, durante la IV edición de la Semana Internacional de las TICJosé Antonio Mañas, catedrático de Ingeniería de Sistemas Telemáticos de la Politécnica de Madrid, explicó ayer que más del 60 por ciento del correo electrónico...
Howard Carmack, aka «Buffalo Spammer», ha sido condenado a entre 3 y medio y siete años de cárcel, dependiendo de su comportamiento en prisión, aunque en realidad no ha sido condenado por enviar millones y millones de correos basura -hasta 825 millones...
No Soy Superwoman da en el clavo al describir en a mí me daría vergüenza una situación desgracidamente bastante típica: que el peor spam es el correo de los imbéciles: Alguien a quien has conocido de forma superficial por Internet, tiene tu...
Aprovechando que GoogleGroups 2 ofrece un feed Atom de cada grupo de usenet (newsgroups) hemos reunido más de 200 grupos de noticias de Usenet-es en Feedmanía. Si eres usuario registrado de Feedmanía puedes añadir directamente los que te interese seguir a tu...
Por Nacho Palou -
27 MAY 2004
Una romántica (y práctica) aplicación:BugMeNot.com was created as a mechanism to quickly bypass the login of web sites that require compulsory registration and/or the collection of personal/demographic information (such as the New York Times)....
Por Nacho Palou -
26 MAY 2004
Estaba hoy registrándome en TypeKey cuando me encontré por enésima vez con un estúpido problema de usabilidad que persigue a muchos sitios web donde hay registro de usuarios... esa famosa cajita Teclea el código que se lee en la imagen para que...
Tengo el gusto de presentar el proyecto que he venido co-desarrollado en los últimos meses junto a mi buen amigo Abraldes con quien ya antes he compartido muchos años de trabajo en distintas empresas y que se ha volcado en este proyecto...
Por Nacho Palou -
18 MAY 2004
El lenguaje de Internet para la creación de documentos electrónicos más conocido es el HTML, que es con el que se define la estructura y contenido de una página web. Consta de una serie de etiquetas (markups) predefinidas que permiten construir...
Por Nacho Palou -
18 MAY 2004
Otro par de ejemplos de la maravilla que es la distribución de contenidos mediante feeds XML (especialmente en el formato Atom).Google habilita feeds Atom en los Grupos de noticias, de modo que cada grupo de noticias de usenet se puede consultar desde...
Por Nacho Palou -
13 MAY 2004
SearchGuild y DarkBlue han organizado un concurso de posicionamiento en Google muy similar al del telendro, aunque hay que estar registrado en SearchGuild para poder participar. El término de la búsqueda es nigritude ultramarine, está en marcha desde el pasado 7 de...
Meg Whitman, CEO de eBay, una de las pocas empresas que no sólo ha sobrevivido al colapso de las .com sino que ha crecido más allá de cualquier espectativa razonable, habla con Michael Grebb acerca del presente y futuro de su empresa...
La agencia de noticias Reuters proporciona desde hoy sus titulares de noticias en formato RSS.Reuters news and television is now available through the Reuters RSS service. With Reuters RSS you can take Reuters world class news and television headlines, free of charge,...
Por Nacho Palou -
7 MAY 2004
Hace tiempo que se esperaba, y por fin hoy la SEC ha aceptado la documentación presentada por Google para su IPO, lo que representa su pronta salida a bolsa. Más información en Slashdot, CNN y Associated Press....
The Abusive Hosts Blocking List ha hecho público un comunicado en el que anuncia que está bloqueando el tráfico SMTP (correo electrónico saliente) de prácticamente todas las direcciones IP de Telefónica debido a la enorme y creciente cantidad de spam que proviene...
Steve Gillmor publica una entrevista con Sergey Brin en eWeek acerca de Gmail en la que hablan del futuro del proyecto y comentan algunas sugerencias de Gillmor y características que piensan irle añadiendo al servicio como acceso vía POP, cifrado del correo,...
Sus autores definen del.icio.us como un «gestor social de favoritos», aunque su planteamiento es mucho más sencillo que su descripción. del.icio.us permite disponer de una cuenta personal en la que se pueden ir salvando los enlaces de interés que se encuentran navegando...
Por Nacho Palou -
23 ABR 2004

Este artículo, igual que el del verdadero origen de Internet, fue publicado originalmente en el periódico El Ideal Gallego; más tarde se publicó como especial en la web de iWorld, la revista de Internet de IDG -donde ya no está disponible- y...
Ev ha anunciado que Google ha abierto en pruebas GMail para algunos usuarios registrados de Blogger. Se puede acceder al nuevo servicio de correo GMail desde la portada de Blogger si tienes una cuenta «activa» en Blogger. Como dice Ev, si vas...
Leo en La Voz de Galicia de hoy: Una empresa coruñesa, Comintper (Compañía de Internet Personal) ha lanzado un servicio que ofrece un espacio de almacenamiento ilimitado on line y de forma gratuita. De esta forma, se adelanta al proyecto ideado por...
Lo más interesante del nuevo buscador A9.com (Amazon + Google) es que puedes identificarte con la misma cuenta (nombre y contraseña) que tengas en Amazon. Esto hace que la función Search History que muestra un histórico de búsquedas (algo que ni siquiera...
Igual que muchas otras compañías aéreas Iberia ofrece la opción de utilizar el billete electrónico (Ciberticket) en las compras por Internet, lo que supone un pequeño ahorro en el precio de éste y más agilidad en los trámites en el aeropuerto, pero...
A algún descerebrado de NetworkSolutions no se le ha ocurrido otras cosa que vender renovaciones de dominio por 100 años --aunque realmente son renovaciones continuas y automática del máximo posible (10 años) hasta cubrir ese período en total. Cuando el dominio esté...
Por Nacho Palou -
28 MAR 2004
Boeing ha hecho un descubrimiento sorprendente: el dinero protege los sistemas de vuelo de los aviones de las dañinas interferencias de las redes WiFi. A partir de abril los pasajeros de varios vuelos internacionales de Lufthansa con origen en Alemania podrán tener...
Aunque por lo visto lo podría ser más: Al menos según el frikitest de Fundación Friki, en el que he obtenido una puntuación de 29 sobre 42:Dejémonos de rodeos, eres un friqui y ya lo sabías.[vía lista de correo del canal de...
Hace algún tiempo hablábamos de lo rentable que les sale el negocio a los spammers, lo que implica que hay muy pocas posibilidades -o más bien ninguna- de que éste desaparezca. Pero, ¿quién hace rentable esta actividad? Pues tipos como éste, al...
Periódicos, weblogs, listas de correos, foros, mensajes de amigos... «Voy en tren todas las mañanas (...) Curiosamente, muchos pasajeros solemos subirnos siempre al mismo vagón, por costumbre tal vez. Yo, por ejemplo, siempre subo al tercer vagón. Y, por tanto, muchos nos...
¿Te has planteado alguna vez en cuál de las tiendas de Amazon puede ser más barato hacer un pedido? Calcularlo a mano puede ser bastante pesado, pero ahora gracias a Pricenoia puedes comparar precios automáticamente entre todas las tiendas de Amazon y...
Doc Searls y David Weinberger, dos de los autores de The Cluetrain Manifesto, resumen lo que no es Internet en diez puntos. Hay una traducción al español, también disponible en formato PDF....
Mozilla Firebird cambia su nombre por el de Mozilla Firefox con la versión 0.8 presentada hoy. Firefox está disponible para Windows, Linux y Mac OS X. En Geek Style cuentan cómo modificar la configuración original del programa para hacerlo más rápido en...
Por Nacho Palou -
9 FEB 2004
¿Cuánto valen los datos personales que entregamos más o menos alegremente a distintas empresas? Una iniciativa realiza estudios al respecto y dispone de una calculadora que sirve para conocer, al menos en teoría y en EE.UU., el valor monetario equivalente «regalado» a...
Por Nacho Palou -
6 FEB 2004

Los verdaderos creadores de Internet / Foto: Clark Quinn, Boston, Massachusetts Este artículo fue publicado originalmente el 1 de diciembre de 1996 en el periódico El Ideal Gallego dentro de una serie de artículos que me valdría ser finalista de la primera...
Y en su empresa se lo toman de coña. Escribe old fart (algo así como vejete o viejo cascarrabias) en el recuadro de búsquedas de Amazon.com y fíjate en el curioso resultado de la búsqueda. [vía Joho the Blog] Actualización 29-1-2004: Ya...
Google acaba de publicar un curioso resumen sobre los más de 55.000 millones de búsquedas realizadas el año pasado por sus usuarios organizado en distintas categorías y paises, en lo que dicen que podría ser un vistazo al mundo a través de...
Según una encuesta realizada por Goldman, Sachs & Co., Harris Interactive, y Nielsen/NetRatings [informe en formato PDF, 64 KB] en el periodo comprendido entre el 1 de noviembre y el 12 de diciembre las ventas en línea alcanzaron los 13.000 millones de...
The Faces in Front of the Monitors recoge una colección de fotografías de muchos de los personajes más conocidos de la historia de Internet y de los ordenadores. [vía Slashdot]...
Ya está disponible la versión final de FeedDemon, uno de los mejores lectores de feeds RSS disponibles para PC/Windows. La última versión RC, la 4, dejará de ser válida a finales de este mes, aunque existe una versión de prueba. FeedDemon tiene...
Por Nacho Palou -
19 DIC 2003
Cuenta el artículo El Gobierno da luz verde al servicio Imagenio de Telefónica [La Gaceta de los Negocios] que finalmente, después de casi un año, Telefónica ha conseguido los permisos para comercializar su producto de televisión por banda ancha, el cual la...
Por Nacho Palou -
16 DIC 2003
Existen muchos casos de dominios o URL en los que la omisión del subdominio "www" tiene como resultado un error de destino, de servidor o página, en lugar de mostrar el contenido correcto como sí sucede al incluir "www" en la dirección...
Por Nacho Palou -
11 DIC 2003
Adaptarse a Internet: Mitos y realidades sobre los aspectos psicológicos de la red. Helena Matute. La Voz de Galicia, 2003. 84-9757-115-0. En la presentación de este libro la autora comentó como uno de los motivos fundamentales que le llevaron a escribir este...
En The Opte Project tienen en marcha un proyecto para poder realizar un mapa (quizás representación visual sería una descripción más adecuada) diario de Internet que según dicen podría ser utilizado paraModeling the Internet, analyzing wasted IP space, IP space distribution, detecting...
Desde luego Spain is different. Mientras en el resto del mundo se van aprobando leyes cada vez más restrictivas y duras frente al spam el gobierno español aprueba una modificación de la LSSI mediante la Ley General de Telecomunicaciones que entra hoy...
Acaba de llegarme, muy oportunamente para estos días de perros, el Blogger Hoodie cortesía de los chicos de Blogger/Google ahora que BloggerPro ha desaparecido. Un detalle muy enrrollado del que mola todo: es bonito, cómodo, práctico-a-la-par-que-elegante y muy geek -¡gracias!...
Por Nacho Palou -
28 OCT 2003
Desde hoy al buscar por una o varias palabras en Amazon además de rastrarse títulos y autores como hasta ahora la búsqueda se efectúa también en los 33 millones de páginas correspondientes a los 120.000 volúmenes de su catálogo. Search Inside the...
Por Nacho Palou -
23 OCT 2003
Eric Parke, un ciudadano de California, ha denunciado a la RIAA a causa de la oferta de amnistía que ha hecho a los usuarios de redes P2P, pues considera que es una oferta fraudulenta y engañosa. Parke argumenta que «-está diseñada para...
Hoy ha sido el primer día del encuentro Net.es3, que reune a gente del mundo de las ONG y del software libre, de las punto-coms y de Internet en general. Había unos 60 ó 70 30 ó 40 asistentes en el Palacio...
Lo explica a la perfección Perogrullo, a raíz del debate que se ha montado por quienes consideran (como PeriodistaDigital.com) que hay que defender la justicia, la libertad y blah blah blah haciendo un copiar-y-pegar de medios informativos de pago como El País...
El próximo martes 14 de octubre a las 9.30 estoy invitado a participar en una de las mesas redondas de Net.es3: Jornadas Net.es3 Dedicadas a explorar el potencial de las tecnologías de la información en el ámbito del movimiento del voluntariado y...
El enésimo intento para desarrollar y popularizar la voz sobre IP (VoIP) se llama Skype y viene de la mano de los creadores de KaZaA que han aprovechado tecnología P2P similar a la empleada en el conocido sistema de intercambio de ficheros....
Por Nacho Palou -
18 SEP 2003
A ver si alguien puede confirmarme si puede acceder al WHOIS de RIPE desde un ADSL que pase por los proxys de Telefónica -- puede dejarlo en un comentario a esta anotación. Me da la impresión de que no funciona hace semanas...
Ahora que me he aficionando a los feeds RSS gracias a NetNewsWire he podido comprobar que algo así como el 70 o el 80 por ciento de los blogs y páginas de noticias tienen sus feeds RSS/XML para sindicación, lo cual está...
Hoy hace cinco años que Google se instaló en sus primeras oficinas. En este tiempo (una enormidad en téminos de Internet) ha pasado de tener 4 empleados y de responder a unas 10.000 búsquedas al día a contar con más de 1.000...
[Vía Scripting News] una buena noticia para los usuarios de My.Yahoo. La gente de Library Stuff comenta que ya se puede añadir un nuevo módulo, denominado Blogs, a la portada de My Yahoo. Al igual que con los de noticias, allí puedes...
Hoy he probado NetNewsWire, del que había oído hablar en círculos mackeros como NoticiasMac y que es realmente una herramienta estupenda. • NetNewsWire [Mac OS X, $39,95, demo de 30 días.] Es un lector/agregador de feeds RSS/XML como los que hay en...
Amazon: Get Big Fast. Robert Spector (2002). Aprovechando el lema que inventaron a medias entre Jezz Bezos y los bancos de inversión, Spector describe en Get Big Fast la historia de Amazon y Jeff Bezos de forma una tanto aséptica. El libro...

El libro Burbuja (.es) con el subtítulo Auge y caída de las empresas de Internet en España (Miguel Ángel Patiño, 2003) recopila algunos de los capítulos más relevantes o interesantes (a juicio del autor) de los ocurridos en el transcurso de tiempo...
Por Nacho Palou -
14 AGO 2003
Wicho escribió el otro día sobre las barreras al comercio electrónico en España explicando algunos puntos interesantes, aunque sin dar nombres (yo añadí algunos en los comentarios). En algún otro lugar, alguien preguntó hace tiempo qué tal le iría a Amazon con...
Leo en la prensa de hoy una noticia acerca de un estudio de las Cámaras de Comercio que dice que El 70 por ciento de las empresas españolas considera que el miedo de los consumidores a efectuar compras a través de Internet...
Si alguna vez te has preguntado si existe alguna posibilidad de que los spammers dejen su actividad por falta de negocio, vete perdiendo toda esperanza. Un reciente fallo de seguridad de una de las webs de Amazing Internet Products, una empresa que...
La mejor definición del término geek, palabra que se usa tanto en inglés como en castellano (aunque en nuestro idioma apenas es conocida fuera de los propios círculos geeks) es la de Jon Katz, autor de Geeks: How Two Lost Boys Rode...
A estas alturas he recibido todo tipo de mensajes basura (spam), desde los de amables caballeros nigerianos dispuestos a compartir sus fortunas conmigo sólo con que les ayude un poquito con cierto asunto monetario hasta aquellos que me ofrecen agrandar / mejorar...
Tomando como base la cifra que maneja la EFF de que 60 millones de norteamericanos usan las redes P2P Michaela Stephens ha calculado que la RIAA necesitaría la friolera de 2.191,78 años para presentar una denuncia contra todos y cada uno de...
Una buena razón para dedicarle algo de tiempo a aprender a buscar en Internet: Ley de Suitt: cuanto mejor seas buscando información en la Web, menos información tendrás que almacenar en tu cerebro. (Vía Halley's Comment.)...
Muy recomendable el artículo de Ignacio Escolar titulado ¿Susto o Muerte? relativo a la reciente denuncia contra usuarios españoles de programas P2P. Las empresas de software, Javier Ribas mediante, han anunciado que van a denunciar a 95.000 internautas, nada menos, por piratear...
La afirmación final de este párrafo de este mensaje en InternalMemos.com no sería tan graciosa si no fuera porque lo firma quien lo firma… (…) Like almost everyone, I receive a lot of spam every day, much of it offering to help...
Algunas cosillas interesantes que encontré por ahí estos días: Flash Mobs Take Manhattan, hackeo social Dominios expirados, correos y contraseñas en Kriptópolis El manuscrito Voynich también en Kriptópolis Tio Gilito y la acumulación de capital en Efimera.org (¡gran blog!) Las cosas de...
Una demostración de que en eBay se puede hacer dinero de la Nada, concretamente 14,50 dólares tras 14 pujas en una semana. Nothing for sale – I am legitimately trying to sell nothing. It is hard to describe nothing but I can...
La publicidad contextual, de texto, sindicada, etc. (se le pusieron muchos nombres) de Google, sobre la que ya se habló, comentó y sobre la que se lanzaron muchas hipótesis hace dos meses tiene finalmente nombre: AdSense. Según Sergey Brin: Google Adense mejora...
Vía 7bytes, información sobre BookCrossing, una interesante iniciativa que incluso comentaron en televisión el fin de semana (junto a lo del virus BugBear): Un proyecto muy interesante para compartir y leer libros entre todos. Es una idea que consiste en registrar un...
Se acaba de anunciar hace unos minutos que la CNMV ha suspendido la cotización de Terra-Lycos. La razón: Telefónica ha anunciado una OPA de exclusión sobre Terra-Lycos. Lo cual traducido al lenguaje de los mortales quiere decir que Telefónica (que era propietaria...
Ya está en el aire la segunda beta de Plaf, el nuevo buscador que comenté el otro día. Ahora tiene pestañas para buscar fotos, videos y MP3, además de la tradicional búsqueda web y la de noticias en castellano. Me han contado...
En Missing the blog-clog point, Phil reflexiona sobre el verdadero sentido de que los blogs sean relevantes para Google. En especial, sobre la gente que buscando se encuentran a sí mismos enlazados «muy arriba» por relevancia, respecto a algunas frases de búsqueda...
Se acaba de lanzar en versión beta Plaf.com: un nuevo buscador, sencillo y muy muy rápido, que hemos creado en la empresa para la que trabajo (Ya.com). Pruébalo y si tienes un rato nos cuentas qué te parece. Plaf es un buscador...
Dicen los libros de historia que existió la denominada «burbuja de las puntocom», que llegó la crisis en 2000 y que todo se desinfló y blah blah blah. Y a pesar de todo, ahora mismo, en mayo de 2003, la puntocom eBay...
Vía Dive into mark, siete palabras en cinco líneas de HTML que cuelgan Internet Explorer para Windows –aunque esté actualizado con todos los parches habidos y por haber– así como Outlook y cualquier otro software que lleve el motor HTML de Microsoft...
No se si alguien se dio cuenta ya de esto. En las páginas de Slashdot hace tiempo que aparece publicidad de texto (sólo a veces - prueba a hacer reloads). Es decir: en vez de un banner gráfico convencional, en la cabecera...
El vecino cabrón monopoliza el ADSL, llevando la creatividad ibérica a nuevos niveles de ilegalidad. La familia, esa gran desconocida.
WhatTheFont es una de esas cosas chulas que se encuentran por ahí—por casualidad y normalmente cuando no se necesitan. En plan rápido es un sistema de reconocimiento de tipografías que funciona más o menos así a) ves una tipografía por ahí o...
Por Nacho Palou -
10 ABR 2003
Pregunta Técnica: Si una publicidad en Internet dice algo así como: La melodía de tu móvil está anticuada ¿Quieres cambiarla? [ Sí ] [ No] « Tu fondo de escritorio es muy SOSO ¿Quieres cambiarlo? [ Sí ] [ No] » Tenemos...
El otro día un compañero de trabajo nos forwardeó a un pequeño grupo de personas un mensaje comenzándolo con PVI, en vez de utilizar el habitual acrónimo inglés FYI. Supongo que esa persona no usará el verbo «forwardear», sino más bien algo...
Si la próxima vez que recibes un correo encadenado, sea un hoax, un aviso falso de virus, un timo, un correo de la suerte encadenado, una falsa petición de ayuda para niños enfermos / perdidos, la leyenda urbana de turno, etc. te...
La Online Publishers Association ha publicado una nota de prensa en la que se habla de lo que ha ingresado la industria de los contenidos de pago en Internet. NEW YORK, March 4, 2003 - The Online Publishers Association today released its...
Resulta que me encontré una lista de los más comentados por los bloggeros de donde a su vez salté a la portada de All Consuming, donde luego encontré una página que describía los libros sobre los que había escrito en las páginas...
Poco a poco, poco a poco... te dan un certificado al pasar de las 2.500 unidades de trabajo en SETI@home. Estas son las estadísticas de los últimos años donando tiempo de CPU: Name alvy Results Received 2,502 Total CPU Time 3.848 years...
El libro Homepage Usability, 50 Websites Deconstructed, de Jakob Nielsen y Marie Tahir [disponible en español con el título Usabilidad de páginas de inicio. Análisis de 50 sitios web] repasa y analiza 50 sitios web, elegidos por su popularidad en Internet y/o...
Por Nacho Palou -
3 MAR 2003
El otro día tuve que leer un buzón POP3 de correo electrónico utilizando Telnet, porque estaba atascado por un extraño exceso de mensajes (que para colmo eran 100% spam). Por suerte encontré una página muy explicativa (ya no existe, pero prueba: Correo...
Creo que ur.ru es el único dominio palíndromo de toda Internet que funciona de verdad y que no te redirige a otro dominio distinto. A saber de qué trata, porque está en ruso... pero tiene pinta de correo web. La escasez de...
A modo de actualización: No he podido resistirme a comentar algunas curiosidades más del tema, como por ejemplo que Dave tiene esta apuesta casi ganada; algunas de las primeras visiones de la gente del mundillo; la teoría sobre que Google está intentando...
Ahí va mi granito de arena sobre la compra de Pyra Labs (el nombre formal de la empresa creadora de Blogger) por parte de Google. La primera noticia del acuerdo la publicó Dan Gillmor en su blog (ver Google Buys Pyra: Blogging...
Si tienes registrado algún dominio gTLD tipo .com, .net o .org, o dominios con extensión .biz o .info tal vez hayas recibido alguna vez una carta "en papel" remitida por Domain Registry of America/Europe/Canada [DRoA]. En ella te notifican la próxima caducidad...
Por Nacho Palou -
15 FEB 2003
<abogado del diablo> Sarta de estupideces leídas en diversos foros (news españolas, ibrujula, aih, bandaancha y otros) sobre el famoso proxy-caché de Telefónica. He omitido los nombres para proteger a los inocentes - también he intentado corregir las faltas de ortografía para...
De modo que por curiosidad se me ha ocurrido preguntar por nacho en Register.com y como está cogido en casi todas sus extensiones TLD (.com, .net, .org,...) el sistema hace sus propias sugerencias derivadas de tal palabra, del estilo: tortilla-chip, cornchips, tortillachip,...
Por Nacho Palou -
20 ENE 2003
Parecerá una idiotez, pero en varios sitios he leído que la gente no encuentra cómo dar un alta de su web en Google. Esto no hace falta teóricamente nada más que una vez en la vida (cuando estrenas página, doiminio, etc) porque...
Desde principios de enero, Telefónica (de España) está instalado un servicio de proxy/caché en su Red IP, que afecta a todos los usuarios de ADSL españoles, incluyendo a los de proveedores como la propia Telefónica, Terra, Ya.com, Wanadoo y otros. Este tipo...
Según Robert Braden, Internet celebró su vigésimo cumpleaños el día de Año Nuevo [1 de enero de 2003], al considerar que su origen lógico se remonta al 1 de enero de 1983, fecha en la que oficialmente ARPAnet cambió del protocolo utilizado...
Por Nacho Palou -
7 ENE 2003
La columna Alertbox del 23 de diciembre en UseIt recopila los que son para Jakob Nielsen los 10 principales y más comunes (o peores) errores de diseño web a lo largo del 2002, los que confunden al usuario, dificultan su vida web...
Por Nacho Palou -
27 DIC 2002
Una visión cyberpunk de Amazon dentro de unos 20 años... ¡no te pierdas los detalles! Cortesía de los zyberpunks de Kamita.com...
Según cuenta este artículo de Independent OnLine en Francia han decidido aceptar y adoptar el neologismo arobase como traducción del at referido al símbolo arroba cuando es parte de las direcciones de correo electrónico, aparentemente tomando como origen la propia palabra arroba...
Por Nacho Palou -
10 DIC 2002
Resulta que he empezado a leer sobre MyWay.com y he decidido echarle un vistazo rápido — una visita realmente rápida porque en quince minutos puedes hacer de todo: navegarlo, enterarte de lo que es y registrarte (e incluso personalizarlo un poco). Se...
Aquí va una versión simplificada del JavaScript que David sugería para poner la dirección de correo electrónico sin ponerla, es decir, sin que esté disponible para las arañas. <script language="JavaScript"> function email() { document.location = 'mailto:'+'nombre'+'@'+'servidor.com'; } </script> y luego en lugar...
Por Nacho Palou -
2 DIC 2002
Si hace unos días era Asereje.org/biz etc. hoy resulta que sube a las listas de éxitos la página de PeriodistaDigital.com, que con un peso de 660 kilobytes (250 KB de HTML —te cagas— y 410 en imágenes... ahí es nada) desbanca al...
Esta historia es real (doy fé) y está escrita en el año 1997. [Entre corchetes he puesto algunas aclaraciones]. Podría titularse Como ponerse de acuerdo «a la española». La historia proviene de una lista de correo que existía entonces que se llamaba...
Hace un par de días llegó hasta mi buzón un mensaje del autor de la página Noticias de Google en español, la cual ha resultado ser una de esas páginas que me encantan conocer y que da gusto visitar, tanto por su...
Por Nacho Palou -
13 NOV 2002
Comentario de Alberto Lozano en una entrevista de Faq-Mac, contestando sobre esa ya clásica pregunta: el futuro del «todo gratis» en Internet. ¿Internet gratis? Es un problema de pura aritmética: Si algo es gratis y a alguien le cuesta dinero, la gratuidad...
En las últimas páginas por las que he navegado he leído he dado con algunas nuevas definiciones para viejos conceptos, que creo que pueden ser muy válidas. Por ejemplo, en Searching for a Definition of Spam de Paul Soltoff hay una definición...
Me bajé ayer Pop-up Zapper Lite, que es un shareware para Macintosh que te elimina los pop-ups publicitarios mientras navegas - esas ventanitas que se abren sin que tú quieras. Funciona bien y hace un divertido ruidito zap! como si estuviera matando...
De modo que existe un Simulador de Internet muy ingenioso que permite experimentar en primera persona, y de una manera muy fiel a como es en verdad, la experiencia de utilizar Internet en la actualidad—pero sin necesidad de navegar realmente....
Por Nacho Palou -
28 OCT 2002
Estaba pensando que si el 90% de los internautas no fueran tan rematadamente idiotas en el manejo de sus ordenadores, sabrían que con dos clics puedes poner cualquier fondo de pantalla en Windows y por tanto no exisitiría la basura publicitaria de...
Ahí va un pequeño truco para incrementar (sin compartir) el nivel de participación (Participation Level) de Kazaa Lite. Por lo que sé al respecto (que no es mucho) hay al menos un par de formas distintas a esta de hacerlo. Con esta...
Por Nacho Palou -
12 OCT 2002
Ya tiene tiempo y es bastante conocida, pero aún resulta divertido utilizar la Wayback Machine de The Internet Archive para buscar una copia de páginas antiguas o para navegar por portales o sitios de empresas desaparecidas o adaptadas a las nuevas circunstancias...
Por Nacho Palou -
30 SEP 2002
Encontré esto hoy en un blog: es una versión «extendida» del famoso mailto: de HTML (tal vez ya la conocías, pero yo no la había visto hasta ahora). Esta curiosa variante permite añadir, además de la dirección de correo, el «nombre real»...
Hiperespacio es un término que describe el número total de ubicaciones individuales y todas sus interconexiones en un entorno hipertextual, por ejemplo en la World Wide Web. Otra connotación es el sentido percibido por cada persona de esta totalidad potencialmente confusa. Si...
Cuentan en Slashdot que un ejercicio de arqueología informática rescata de una copia de seguridad en cinta el que se considera fue el primer smiley, el emoticono que se viene utilizando desde hace ya veinte años. Los emoticonos se usan para plasmar...
Por Nacho Palou -
13 SEP 2002
The Victorian Internet: The Remarkable Story of the Telegraph and the Nineteenth Century's On-Line Pioneers. Tom Standage. 1999. Resulta increíble encontrar tantas similitudes entre la invención del telégrafo y la Internet actual. El libro, que resulta increíblemente ameno y entretenido, no...
El famoso pirao que iba a cortarse los pies en directo (CutOffMyFeet.com) vuelve a recular (lo imaginábamos) alegando excusas como en las veces anteriores (aun así, la gente está pagando por las entradas para el evento en directo vía webcam). Dice que...
Uno de los pocos dominios legales de una letra (el resto está reservado por la ICANN), ha sido vendido a Nissan, para su nuevo coche, el Future Z, como puede verse en Z.com....
De modo que hice otro de esos tests para Geeks y me salió esto (bastante preciso por cierto) You are 32% geek - You are a geek liaison, which means you go both ways. You can hang out with normal people or...
Una buena iniciativa de esas con las que hay que colaborar por el bien de la red: RFC-es.org, los documentos de «petición de recomendaciones» (Request For Comments) que acaban convirtiéndose en los estándares de la Red....
Todo un clásico, el Código Geek de Robert A. Hayden, ahora con una versión en Codificador de GeekCode y otra de Decodificador de GeekCode. Mi código geek a día de hoy es este: -----BEGIN GEEK CODE BLOCK----- Version: 3.1 GIT d-- s:+...
Desde luego, con cosas como WebPlayer que permiten oir una página web (transformada en música) hay que volver a preguntarse en qué diablos está la gente pensando todo el día. Como suceden con estas cosas: sencillamente, mola....
Una curiosa iniciativa visual a modo de diccionario / tesauro tridimensional: Visual Thesaurus que resulta interesante explorar....
La mayoría están escritos por empleados descontentos, por sindicados, o simplemente por gente con ganas de tocar las pelotas. Es lo que tiene Internet, que da a todos la misma capacidad de hacer oir su voz. De modo que si quieres saber...
Si aún no la has probado, Mozilla es uno de los navegadores más completos y avanzados que puedes encontrar. Cumple con la mayoría de los estándares actuales, funciona realmente bien, es de código libre y está disponible en versiones 1.0 final y...
Por Nacho Palou -
3 JUL 2002
Ha comenzado la tercera edición del concurso organizado por the5k.org para elegir las mejores páginas web presentadas que pesen 5KB o menos. Y se pueden encontrar maravillas como Ownlog, creada por el genial Joaquin Bernal de Earful, que nunca no deja de...
Por Nacho Palou -
28 JUN 2002
Esto sí que es un Invento (con mayúsculas), SpamNet, de los creadores de Napster. Sirve para tener un sistema P2P instalado sobre tu programa de correo y «democráticamente» decidir si lo que te llega es spam (correo basura) o correo aceptable. No...
Ya puedes hacer de Spielberg con DFILM, una especie de generador de películas en Flash donde personalizas escenario, personajes y las cosas que van diciendo, y luego puedes enviar las películas como postal a tus amigos....
Si siempre has querido saber qué busca la gente en Internet, Ask Jeeves (uno de los buscadores populares en EE.UU., al que se le hacen preguntas con frases en vez de por palabras) ha puesto online Ask Jeeves: Interesting Queries (Consultas Interesantes),...
Qué es, cómo se inventó, cómo funciona, quiénes han pasado a formar parte de la historia: Living Internet....






