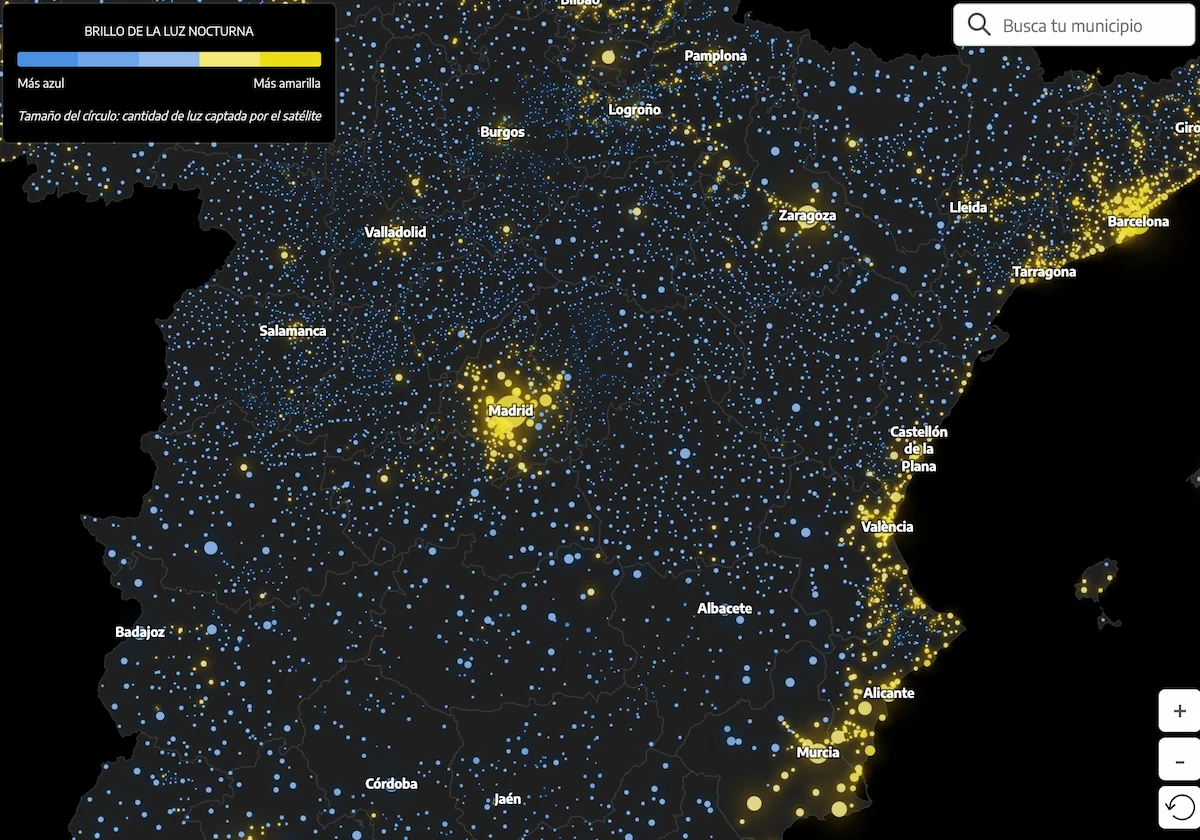
Entre farolas, LED azules y urbanismo con vocación de estadio, quedan pocos oasis realmente oscuros

La costumbre de dar vueltas en sentido contrario al reloj parece bastante humana, aunque su origen siga escondido.

Entre pipetas, GPUs y algo de IA ha logrado leer 3.000 millones de bases en casa con cobertura 30×. C.S.I. doméstico, aunque caro.
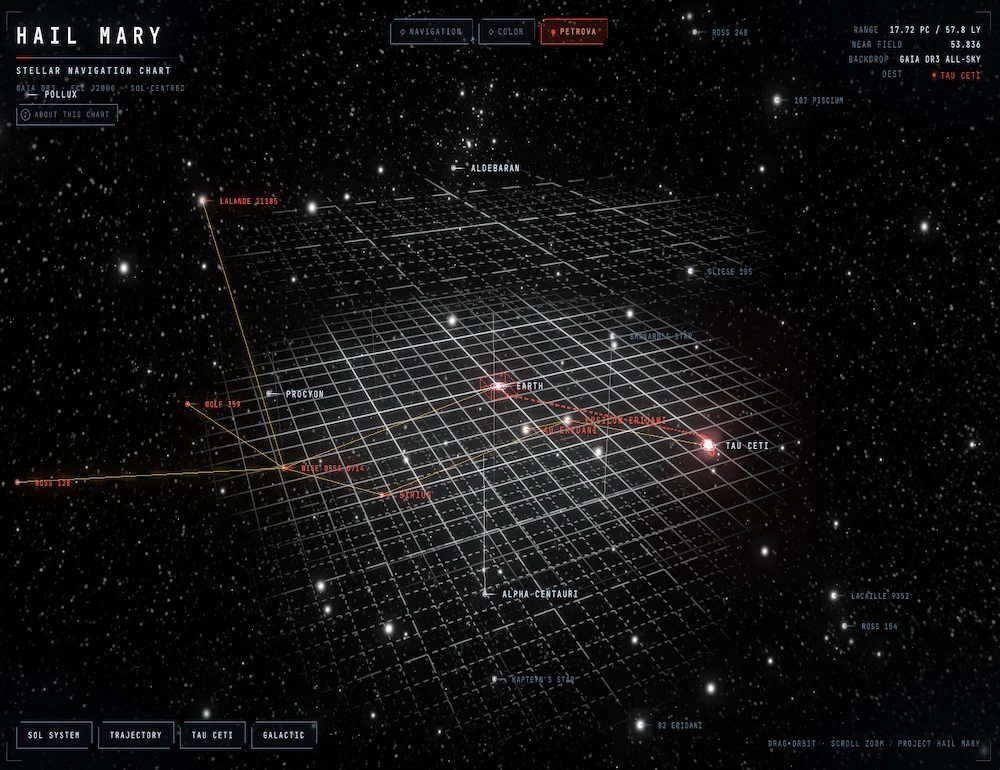
Un viaje intergaláctico gracias a los datos de GAIA DR3. Ojalá hubiera GPS y wifi en el espacio.

Tardará un mes en alcanzar su órbita de trabajo y está previsto que empiece a recoger datos en julio.

La gente prefiere seguir a un extraño por los andenes antes que usar el cerebro para leer las señales de salida.

Lleva en camino desde octubre de 2023 y no llegará a su destino hasta el verano de 2029.

Seis décadas y media de un invento tan molón que la ciencia ficción lo imaginó como un rayo mortal y acabó dentro de un lector de discos y cables de fibra.
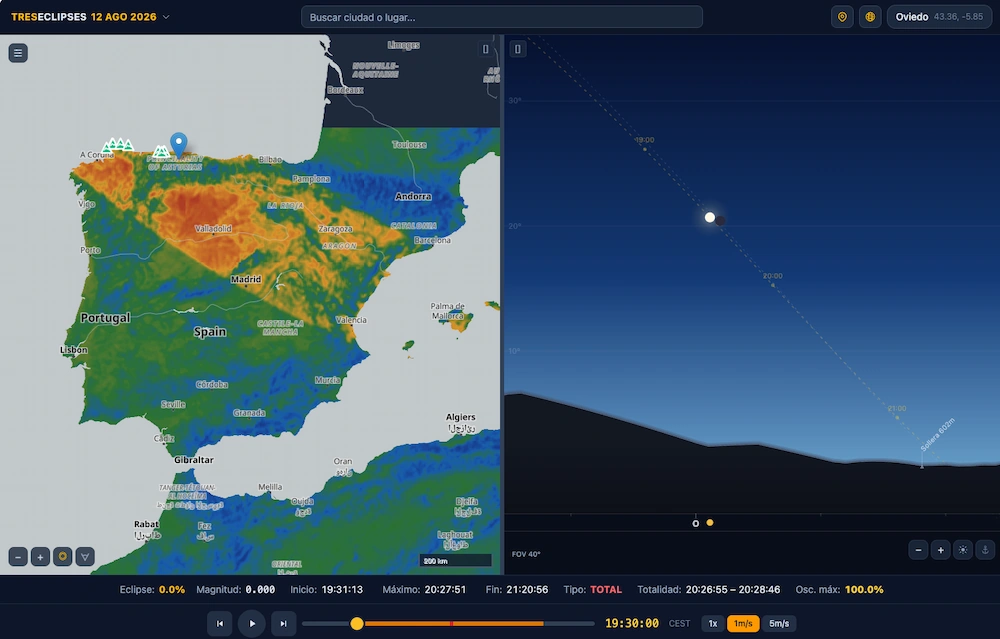
Una aplicación para ver lo que se verá.

Es ya la edición número 30 de esta jornada de celebración de la ciencia.

Nacer sin visión obliga al cerebro a reorganizarse para oír y recordar, dejando cero tiempo para alucinar.

Más allá de la fama y reconocimiento hay suculentos premios.

Hay oportunidades del 25 de abril al 4 de mayo para hacer la comprobación.
El GPS: ese artefacto que convierte la velocidad de la luz en la excusa perfecta para llegar tarde, gracias a Einstein.

Quizás sería el momento de retomar la petición a la UE de que los productos homeopáticos dejen de ser considerados medicamentos.

Esta sonda y su gemela son las que más lejos han llegado de la Tierra.

Es el cuarto cohete que está previsto que ponga en camino la misión; a ver si a la cuarta va la vencida.

Toca ahora buscar la forma de revitalizar el proyecto.

Ni la fruta fermenta en el estómago ni necesitas beber 2 litros de agua al día. La ciencia de la nutrición desmiente estas y otras patrañas alimentarias.

Habrá que espras unas horas e incluso días para que el ancho de banda disponible permita recibir imágenes en alta resolución.

Serán algo menos de cinco horas de actividad frenética a bordo de la cápsula Orión Integrity.

Tampoco verán un eclipse de Sol, aunque lo hayas oído por ahí.

De templo de ideas a feria del humo.

Una tabla limpia que convierte los 118 elementos en algo consultable, visual y hasta entretenido.

Este resultado amplía las capacidades de defensa planetaria de la humanidad, que falta nos hace.

Es un texto ágil y entretenido que engancha desde el principio.

El traslado a Tabakalera impedirá que siga funcionando igual.

La física ya prueba el «reparto por carretera»: 92 antiprotones en 20 minutos de viaje en un camión tuneado para que nada estalle con mal gusto.

Serán eventos que muevan a miles de personas, así que es más que conveniente prepararse con tiempo, en especial si tienes que desplazarte.

El medicamento de moda ayuda con la diabetes y la obesidad, pero no obra milagros: reduce el apetito, pero tiene riesgos y exige control.
Lo que antes dormía en cajones de museo ahora está al alcance de cualquiera.

El clima político en el país, y más en concreto la forma de tratar a algunos visitantes, ha llevado a tomar esta decisión.

Esperan que ayuden a entender mejor la evolución de las ideas científicas del sabio italiano.

Tenemos que esforzarnos más en esto.

Mil dólares, un millón y ordenador que jamás falla: un problema paradójico que enfrenta a la razón, la filosofía y la codicia.

Del Sáhara a Teruel, la ciencia reúne huesos, plumas y paciencia para contar qué eran aquellas bestias y qué color tenían.

Tal y como están las cosas es prácticamente seguro que las muestras que ha tomado no llegarán nunca a la Tierra.

Un robot de 4 m con brazo de 5 m moverá 2,3 t y montará 20.000 piezas con más de 30 herramientas, 24/6 durante 2 años.

Un experimento para jugar con autómatas celulares unidimensionales, cambiando las reglas «a ver qué sucede».

Una demo interactiva explica cómo nacen los estruendosos estampidos que producen los amores militares.

Al filtrar accidentes y desgracias varias, los datos analizados por los científicos elevan la heredabilidad de la longevidad a más del 50%.

Una búsqueda casual en el momento oportuno la localizó entre un montón de fotografías a subasta.

Los datos que obtenga se incorporarán a los modelos meteorológicos con los que se elaboran las predicciones y también los avisos de riesgos inmediatos.

La humanidad se coloca a 85 segundos simbólicos del fin un mundo con bombas atómicas, crisis climática, IA rebelde y amenazas de bioseguridad. O todo junto.

Entre mapas viejos y geodesia fina, ya se sabe definitivamente dónde se montó el observatorio del eclipse de 1860.

Un interesante recorrido por los resultados más recientes de la neurociencia.

Es una no-noticia que resurge año tras año por estas fechas.

Vivió 271 días con el órgano del animal antes de que hubiera que extirpárselo.
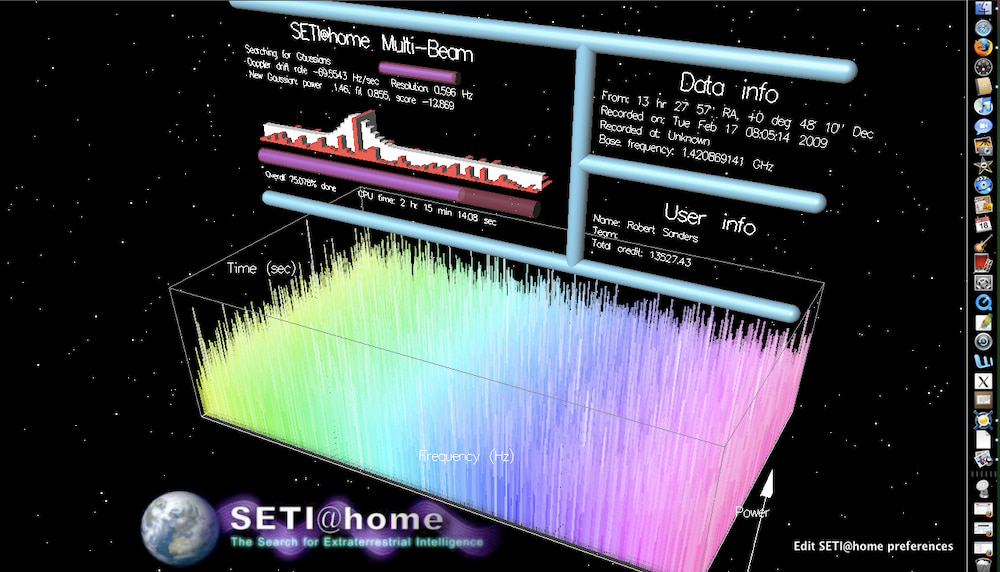
El proyecto dejó ciencia ciudadana a escala planetaria y muchas lecciones aprendidas. El resultado: 100 señales que aún se hacen las «interesantes».

Tres nuevos conjuntos se unen a la línea de colaboraciones entre ambas.

China tiene ahora todas las papeletas para convertirse en el primer país que lleve a cabo una misión de ese tipo.

La Lab-Cola es un clon casi perfecto de la Coca-Cola, que igual su sabor con aceites esenciales y mucha ciencia.

Cuatro lecturas que no tienen desperdicio.

¿Retardo en las videollamadas? No es solo molesto; también destroza la confianza. Y pensar que solo arruinaba las pelis…
-Alvy.jpg)
El resumen del año: el Museo de Historia de la Computación como paraíso retro, un nuevo protocolo SETI que ni Mulder y Scully podrían ignorar y mucho más

Las gotas de agua no son lágrimas redondeadas. Las pequeñas son esferas; las grandes, aplanadas e inestables, se dividen al caer.

Es una misión conjunta de la ESA y la NASA que estudia el Sol.

En la lucha por la eficiencia energética, el ser humano se lleva el oro, pero con un poco de ayuda.

Es una historia de más de 200 años que recorre el mundo a lo largo y a lo ancho en búsqueda de respuestas que no siempre están disponibles.

En abril debería ser declarado oficialmente en servicio.

Se unirá en breve a su gemelo, el 6A, para dar continuidad a una toma de datos que se está haciendo de forma ininterrumpida desde 1993.

La fóvea, o cómo asombrar a tu cerebro con estrellas giratorias. Nn es magia, es ciencia.

Hay otras once más para ver con el tema general la ciencia del futuro.

Es el cuarto de esta familia que es lanzado.
Ha superado en más del doble la anterior marca para una operación de este tipo.

LaTeX: donde los valientes transcriben la tesis de Hawking mientras los mortales nos perdemos entre símbolos griegos.

¿ECM, déjà vus y casas encantadas? No hay magia, solo un cerebro que se cree todo un Spielberg en modo paranormal.

La IAA renovó el protocolo SETI: prohibido responder a extraterrestres hasta que la ONU dé luz verde.

Aún falta mucho para que se pueda aplicar la técnica de forma rutinaria, pero es un avance.

Ideal para detectar el hidrógeno galáctico y demostrar que el cartón sirve para algo más que para montar cajas.

La gravedad no es tan rápida como pensaba Newton. La Tierra necesita 8 minutos tras la desaparición del Sol para darse cuenta de que ya no está ahí.

Cómo revivir la edad dorada de Investigación y Ciencia: descargando esas joyas de la divulgación científica y matemática

Un fin de semana donde la ciencia se pone su capa de superheroina y sale a pasear por diez comunidades con 200 actividades para todos.

Su destino es el punto de Lagrange L1 del sistema Sol-Tierra.

No hay ningún estudio científico en todo el mundo que permita hacer tal afirmación.
Para reír pero también para reflexionar.

Cada segundo que pasa perdemos de vista para siempre miles de estrellas.
Por ahora es una terapia experimental pero gracias a las técnicas de edición genética empieza a dar resultados antes imposibles.

Desde 1947, los microondas han pasado de ser un lujo a una necesidad. Todo gracias al magnetrón, héroe anónimo de la cocina moderna.

El Wi-Fi se apunta a la medicina: un sistema para medir los latidos cardiacos con un error de solo 0,5 latidos por minuto.

Usar ChatGPT para escribir: una dieta de neuronas tan efectiva como zamparse una tarta entera para adelgazar.

Un sistema decodifica pensamientos internos, pero al hardware le falta un hervor. Con contraseña mental para activarlo, eso sí.

Está disponible para su desscarga gratuita en formato PDF, aunque también se puede adquirir en formato árboles muertos.

Aún falta mucho para que sea una operación viable para mantener a alguien con vida.

Westworld y la IA: de la ciencia ficción a la realidad. Las máquinas podrían alcanzar la autoconsciencia, pero aún son simples entindades robóticas.

Pesaje celular: la obsesión científica llega al mundo microscópico con precisión femtogramal.

La luz no es un imán para insectos, es como un hacker que sabotea su brújula interna, haciendo que vuelen como si estuvieran borrachos.
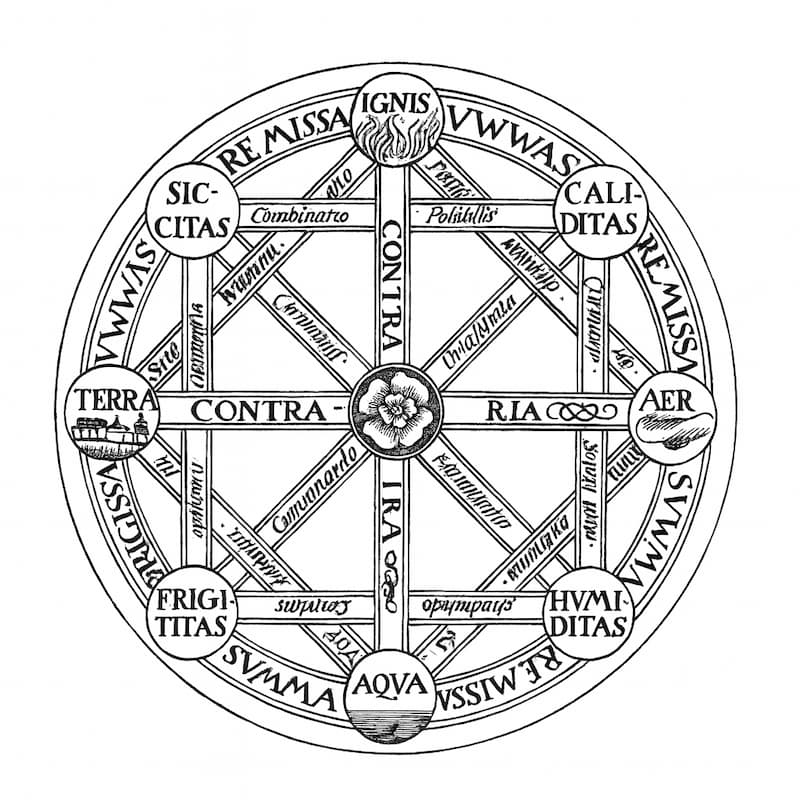
Leibniz soñó con un alfabeto del pensamiento en 1666. Quería mecanizar la razón, pero admitió que su idea no era para tanto.

Con más tecnología casi que la NASA, unos científicos argentinos descubren fauna oceánica propia de otros planetas en las profundidades frente al Mar del Plata.

magia de los imanes radica en los electrones alineados. El espín y el momento magnético son caprichos cuánticos sin explicación.

El equipo de la misión está teniendo problemas para poner en marcha uno de los dos.

Del pique entre Márkov y Nekrasov a la IA moderna: cómo una idea de 1906 cambió el mundo, incluyendo el PageRank de Google.
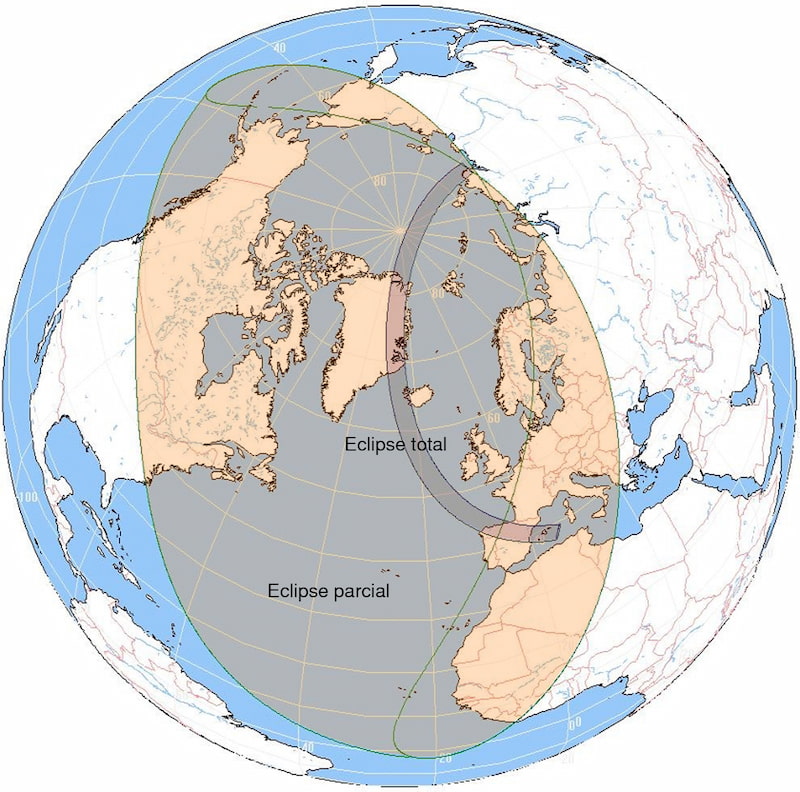
Próximos eclipses en España: planificar las vacaciones de 2026 a 2028 nunca fue tan astronómicamente importante.

Con un coste de 1.500 millones de dólares es el satélite de observación terrestre más caro jamás lanzado.
Los Estados Unidos ya han autorizado su uso, y se están tramitando las pertinentes solicitudes en otros países.

Miles de barriles radiactivos en el Atlántico. La misión NODSSUM estudia sus riesgos ecológicos y el dilema acerca de su recuperación.

La nueva obra de Hofstadter, «Ambigrammia», desafía a la creatividad con ambigramas y reflexiones sobre lo que llama «descubrimentalidad».
En realidad un par de años después de su publicación ya había quedado bastante desacreditado, pero entonces no cumplía los criterios para que la revista se retractara.

Ese importe no es suficiente pero puede servir de acicate para que otros países que participan en el proyecto pongan lo que falta.
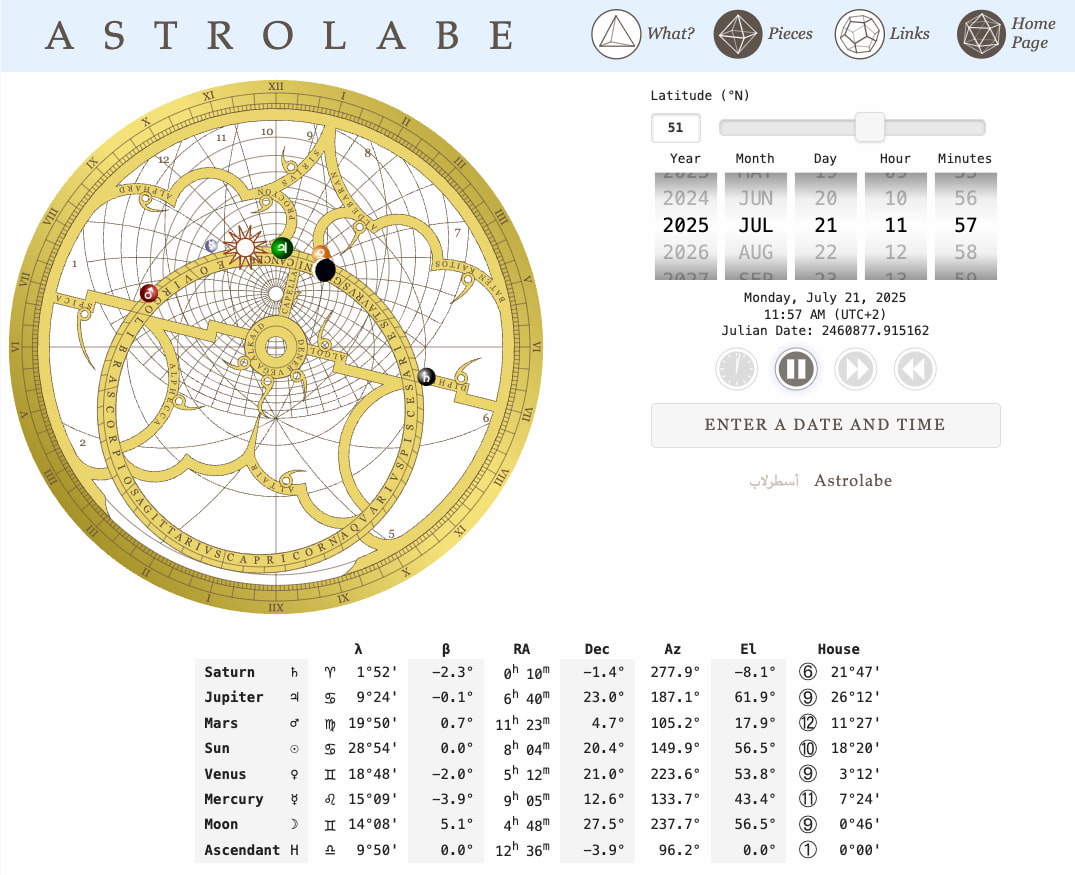
El astrolabio: el iPhone de la antigüedad para astrólogos y astrónomos, la mejor forma de mirar a las estrellas, y no necesitaba wi-fi.

Está aún en su fase inicial de pruebas pero los resultados ya son prometedores.
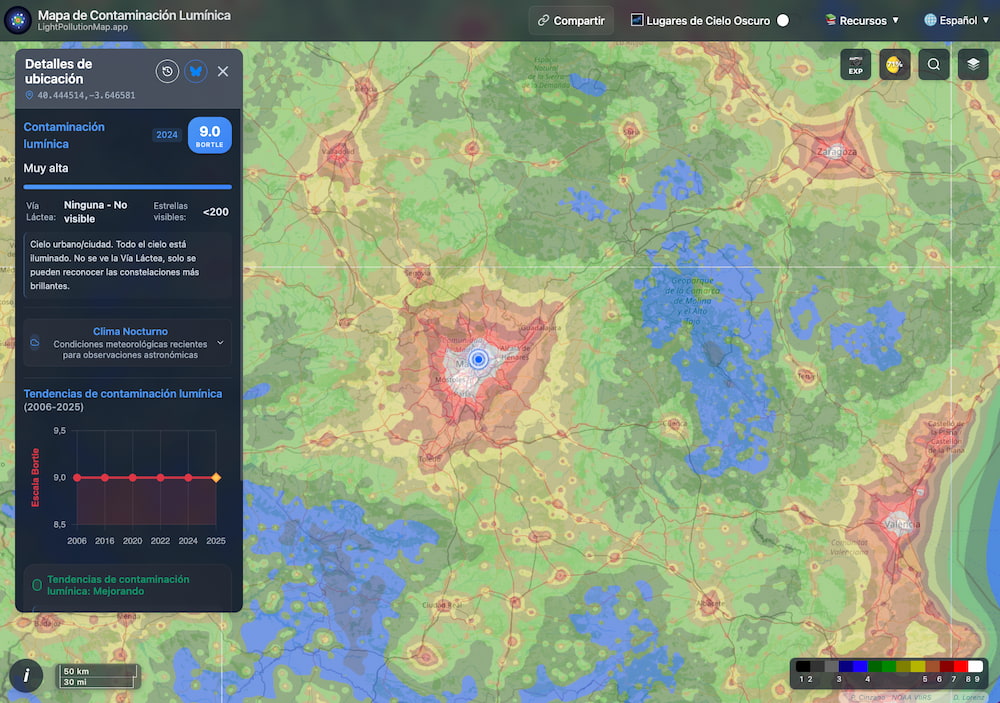
Los mapas de contaminación lumínica son el Tinder de la astronomía: efímeros. LightPollutionMap.app promete durar más que otros.

Algo similar es bastante impensable hoy en día.

Por ahora está previsto que la misión siga activa mientras le quede combustible de maniobra.

Su futuro está en el aire debido a los recortes que la administración Trump quiere imponer al presupuesto de la NASA.
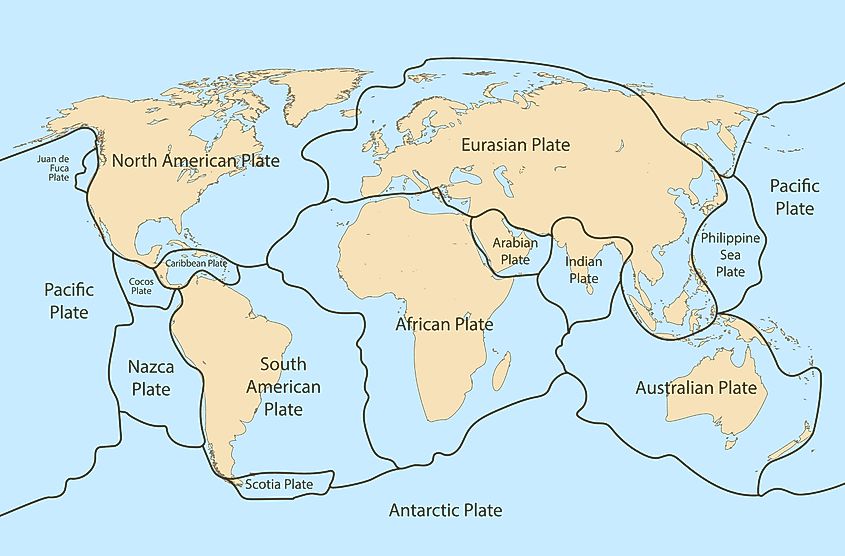
La geografía es como el Risk: nadie se pone de acuerdo en cuántos continentes hay, pero las risas están aseguradas.

Pasará a una distancia mínima de la Tierra de 240 millones de kilómetros, con lo que no supone ninguna amenaza.

Ayudará con la predicción en tiempo real de fenómenos atmosféricos extremos.

Cierra una trilogía dedicada a hacer llegar la ciencia a todos los públicos.

Seguirá orbitando el Sol durante los próximos millones de años, en una misión extendida mientras le quede combustible de maniobra.

Estará dos semanas en la Estación Espacial Internacional llevando a cabo hasta trece experimentos y demostraciones de tecnología.

La Tierra girará más rápido en julio y agosto de 2025. Los científicos están confundidos, porque que ni los modelos atmosféricos ni los oceánicos explican el misterio.

Incluyen unos 10.000 millones de galaxias y unos 2.100 asteroides antes desconocidos.

San Juan Coruña 2011 - Cuenta conmigo CC por Dani Vázquez Hoy lo oiremos y lo leeremos repetido montones de veces, tanto a amigos, familiares, y conocidos como en los medios de comunicación, como por ejemplo aquí, y pasa año tras año…...

Permitirá entender mejor cómo se crean las eyecciones de masa solar y probar nuevos sistemas de orientación y posicionamiento para futuras misiones.

Su órbita en el futuro, que cada vez irá teniendo más inclinación, le permitirá ver los dos polos con más detalle.
Dos días de charlas sobre ciencia, tecnología y humanidades para el público en general y una mañana dedicada a los más pequeños.

Su proximidad a Elon Musk y su insuficiente alineamiento con la causa MAGA parecen haber sido los dos factores fundamentales que han terminado con sus opciones.

La agencia espacial china tiene programadas sendas misiones más a Marte y a Júpiter para lanzarlas antes de que termine esta década.

Ramón Noguera revela cómo los sesgos nos manejan más que nuestras propias decisiones. El libre albedrío es relativo, y la psicología lo sabe.

Un láser de 3 petavatios que hace que encender el vacío parezca un paseo por el capo mientras se causan estragos en la física extrema.

También se estableció la definición del kilogramo, pero por lo que sea no se incluyó en el nombre de la convención.

Ser deportista podría no ser la pócima mágica contra la muerte. Puede haber factores no analizados que estén escondidos por ahí.

De los misterios de los agujeros negros a la hipótesis de Riemann: retos ideales para quienes disfrutan de la desesperación en la matemática y la física.

Resulta que el Universo no es tan eterno como se pensaba, con un Gran Final que podría llegar en solo unos 10^78 años.

El NIST-F4 redefine la precisión temporal: no se desajusta ni un segundo en 100 millones de años. Ideal para maniáticos de la puntualidad.

La alquimia moderna convierte plomo en oro, pero a 67.200 millones de euros el gramo, mejor buscar metales en la playa.

Algunas herramientas para poder observar el cielo utilizando tu móvil, tablet u ordenador.

El ADN podría caber en un CD-ROM, pero con tanta compresión la humanidad parecería más una lata de sardinas que un milagro de la naturaleza.

Tendrá aún que negociarlo en el congreso y el senado pero hasta ahora no ha tenido mucha oposición en nada.

El sábado 10 de mayo se presenta lleno de actividades para aprender y disfrutar.
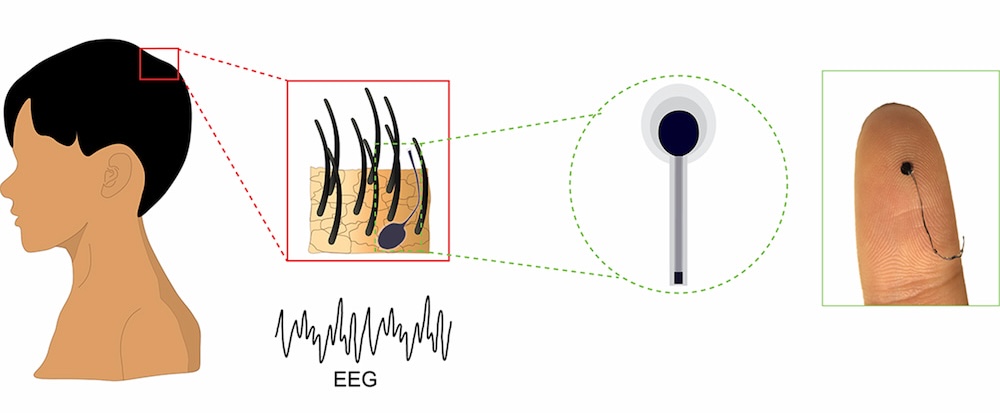
Un EEG tamaño cabello humano: una innovación que monitoriza el cerebro sin dramas capilares.

Es un paso fundamental e imprescindible de cara a su entrada en servicio.
El Deutsches Museum fue el encargado de estrenar en público el primer proyector después de cerca de dos años de pruebas.

Dispone de un radar que permitirá obtener un perfil más detallado que nunca de la cobertura forestal de nuestro planeta.

Ha servido como un ensayo general para las fugaces visitas a sus objetivos que llevará a cabo durante los doce años que se prevé que dure la misión

Han sido necesarios cerca de treinta años de desarrollo para tenerlos listos.

Hay ocho categorías en los premios, seis de ellas con una dotación económica de 4.000 euros cada una.
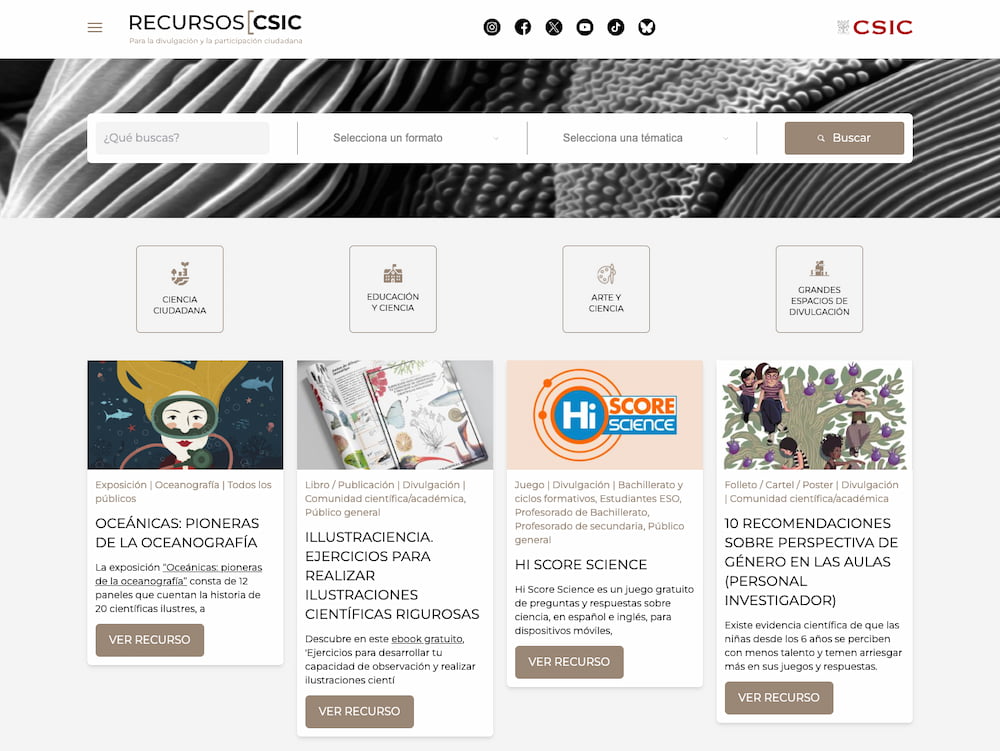
El CSIC lanza una innovadora web de recursos científicos educativos, incluyendo apps, arte y ciencia en una plataforma moderna y fácil de navegar.

Observacones con el Telescopio Espacial James Webb indican la posible presencia de una molécula relacionada con la vida en la Tierra pero que puede tener otros orígenes.

Tiene el puesto prácticamente garantizado gracias al apoyo del presidente Trump y de Elon Musk.
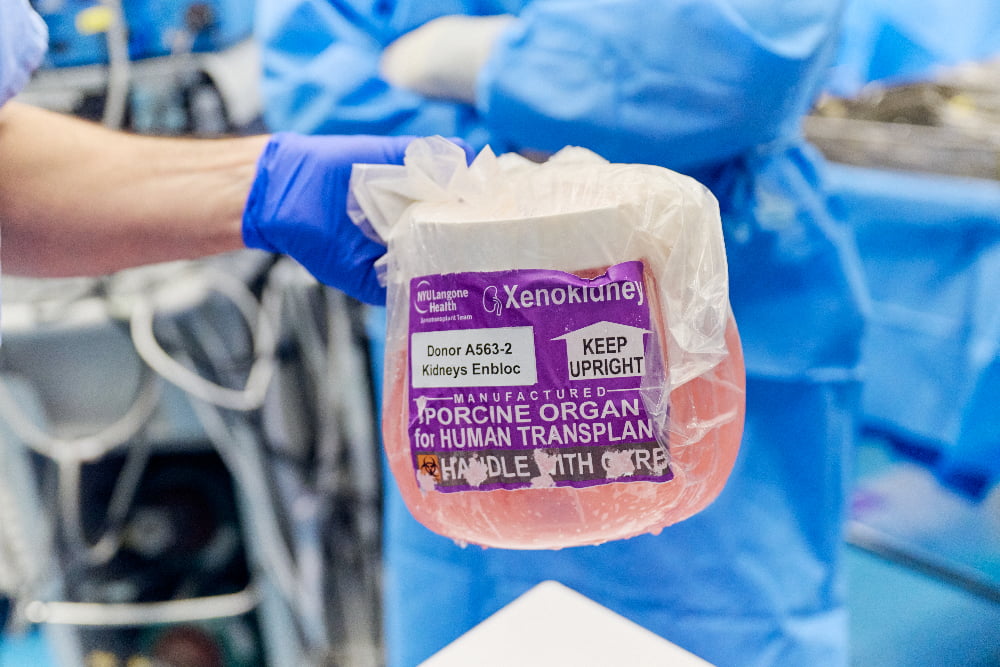
La receptora ha optado por volver a la diálisis después de que su cuerpo empezara a rechazar el órgano.

El legado de la misión son los teras de datos que deja detrás, que seguirán produciendo trabajos científicos durante años.

Puede servir de práctica de observación para los eclipses totales de 2026, 2027, y el parcial de 2028.

El cerebro infantil codifica recuerdos, pero luego los pierde como quien olvida dónde dejó las llaves del coche.

Una app que combina juegos y IA para verificar si la memoria empieza a deteriorarse. Disponible para tabletas Android.

La misión tiene una duración inicial prevista de seis años a lo largo de la cual producirá unos 100 GB de datos al día que serán catalogados con la ayuda de una IA.

Teorías y conceptos en psicología que han gozado de una inmerecida popularidad hasta que la ciencia ha terminado por determinar que no eran más que mitos.

El gravitón podría tener masa, cuestionando la gravedad que actúa hasta el infinito y explicando la expansión del universo.

Uno estudiara la historia del universo; los otros la región más externa de la atmósfera del Sol.

Son las sondas que más lejos han llegado de la historia.

Le quedan aún algo más de cinco años de viaje.

Nuevas observaciones descartan que sea un peligro.

Olvídate de los dados trucados: este lanzamiento de una moneda cuántica es tan aleatorio que ni el universo sabe con anticipación qué saldrá.

Lo que empezó como una inspección rutinaria… Terminó con un año y medio de reparaciones. A veces, «mirar por si acaso» es la mejor estrategia de seguridad.
Ser atravesado por un agujero negro primordial no sería un problema… Salvo por la onda de choque, que te haría papilla.

Las seleccionadas serán incluidas en el programa de la jornada, que se celebrará en mayo en Bilbao.

Pueden aliviar la falta crónica de órganos a la que es enfrentan estos pacientes.

El «Proyecto pelícano» prometía misiles dirigidos por palomas condicionadas. No funcionó, pero seguro que fue todo un espectáculo.

Faltan aún muchos datos como para tener que preocuparnos definitivamente.

Muchas observaciones y estudios previos, pero refinados y rematados por Hubble y Humason, llevaron a esta conclusión.
Este tipo de intervenciones permiten atisbar una vía para terminar con la escasez crónica de órganos para trasplantar

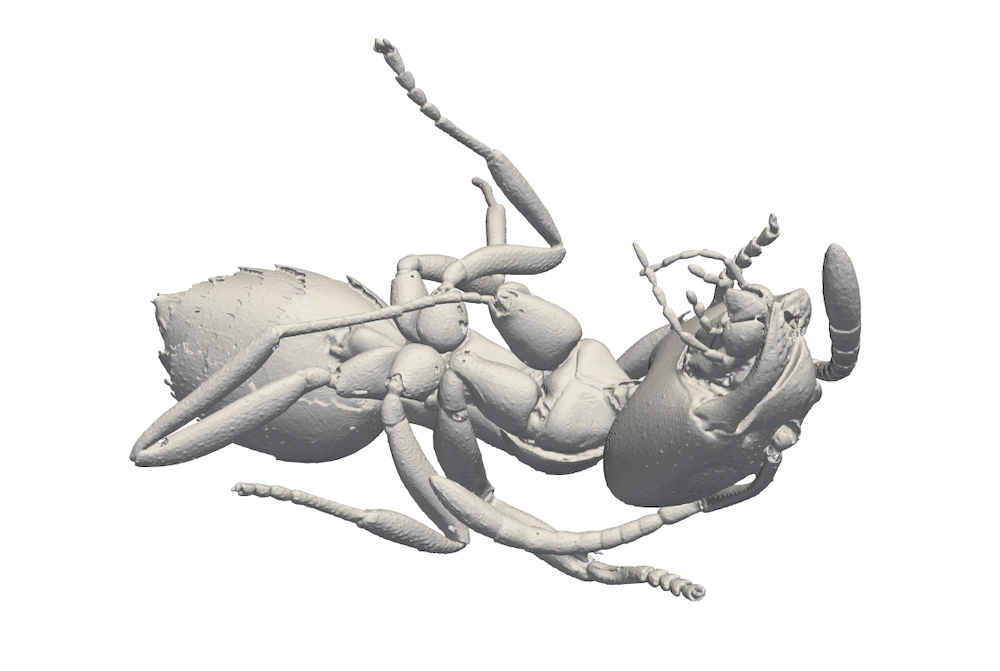
Contabilizar hormigas resulta ridículamente complejo, pero resulta que su masa supera a la de los grandes vertebrados.

La humanidad ya tiene su copia de seguridad en cristal de silicio. Ahora solo falta que alguien del futuro sepa cómo restaurarla.

Ella y su equipo médico están explorando territorio nuevo

Una galaxia, 200 millones de estrellas y un archivo gigantesco: Andrómeda como nunca antes se había visto, gracias a los trabajos de una década del telescopio Hubble.
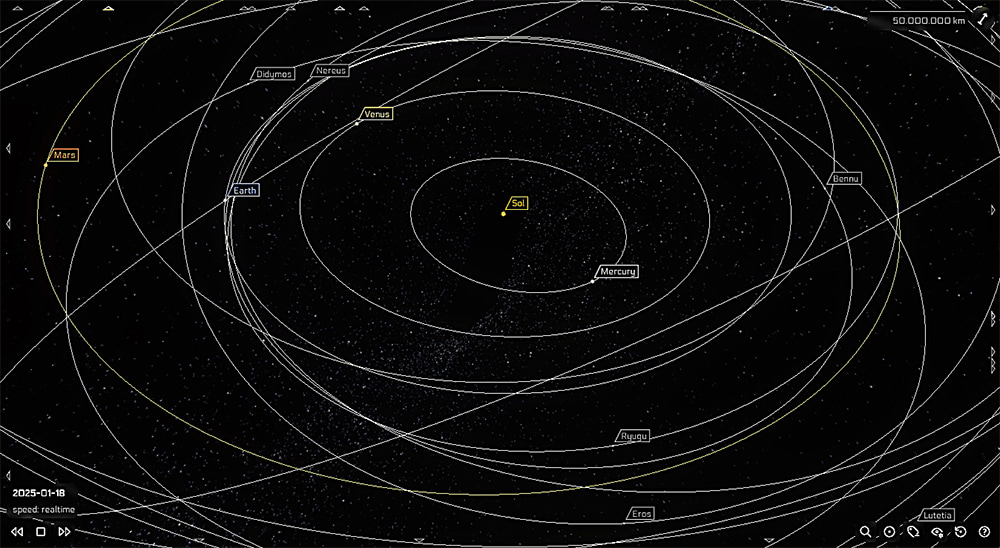
Esta herramienta visual del Sistema Solar permite explorar en 3D datos de objetos celestes.

Es con toda probabilidad la primera vez que queda registrada tal cosa.

Las eventuales reparaciones prometen ser costosas y prolongadas en el tiempo, lo que pone en duda su supervivencia.
El agotamiento de su combustible de maniobra obliga a poner fin a su misión, que en cualquier caso ha durado más del doble de lo previsto.
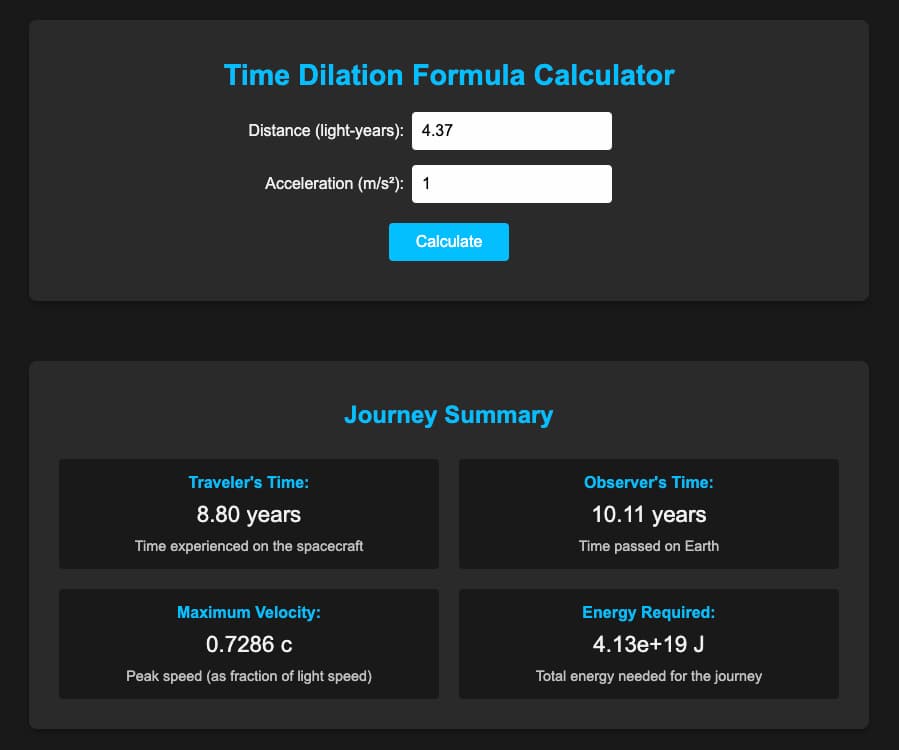
Alcanzar incluso las estrellas más cercanas implica velocidades extremas y consumir el equivalente a 397 millones de camiones cisterna llenos de gasolina, entre otras dificultades.
Son una interna y otra privada, con costes entre 5.800 y 7.700 millones de dólares, para ser lanzadas sobre 2030.

Hace un siglo revolucionó la astronomía y nuestra visión del mundo.

Si todo va bien hará otros cuatro a lo largo de 2025

Un eficaz escudo térmico, un sistema de refrigeración por agua y la velocidad son clave.

La evolución parece haber dejado al cerebro con un ancho de banda de tortuga, haciendo que la multitarea sea un desafío casi épico.
Con un impresionante 99,9% de eficacia, el nuevo tratamiento inyectable se perfila como un gran aliado en la lucha contra el VIH.
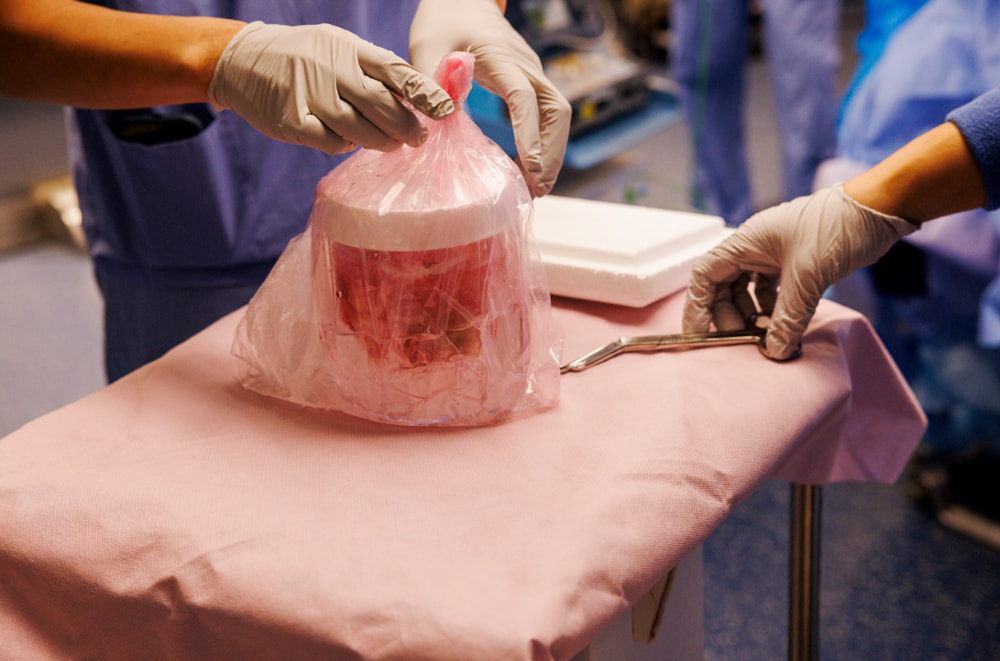
El cerdo como salvavidas: tercer trasplante con éxito de riñón porcino modificado genéticamente.

Con 3 telescopios y 58 espejos, el XMM-Newton explora el universo en rayos X.

Mercury in motion... One of the #BepiColombo selfie-cameras captured Mercury today as the spacecraft rushed by the planet at almost 3 km per second.This time-lapse of unprocessed images was captured during 10:26-11:18 UTC today (11:26-12:18 CET), between 53700 and 48000 km… pic.twitter.com/NPlnLCBOr3—...
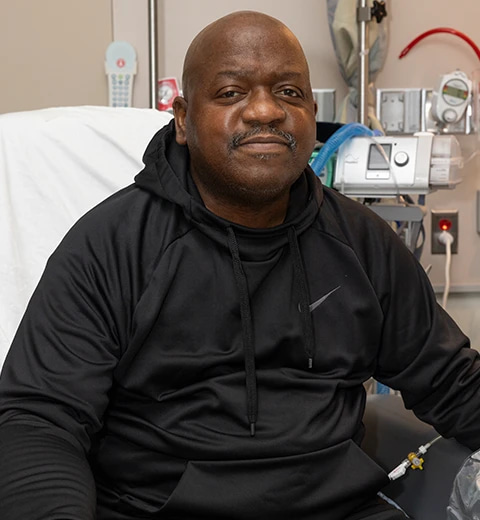
En marzo de este año Richard Slayman se convertía en el primer paciente en recibir el trasplante de un riñón de cerdo. Todo fue bien con el trasplante, hasta el punto de que apenas dos semanas después de la operación recibía el...

Nuevas imágenes del Sol tomadas por la Solar Orbiter muestran detalles del astro rey a máxima resolución.

El mensaje de arecibo puesto «bonito» en forma de mapa de bits – SETI Institute Hoy se cumplen 50 años del envío del mensaje de Arecibo. Así que ya ha pasado una milésima parte del tiempo necesario para que nos contesten. Suponiendo...

El Evento Laschamp sucedió hace unos 42.000 años, momento en el que el campo magnético de la Tierra se debilitó hasta el 5 por ciento de su fuerza actual. Ahora unos científicos de la Universidad Técnica de Dinamarca y del Centro...
Impresión artística de la Voyager 1 en el espacio – NASA/JPL La NASA no se lo ha dicho a nadie pero lleva una semana sin contacto con la Voyager 1. Lo sabemos gracias al ojo avizor de Bernard Netherclift, que el pasado...
Falcon Heavy lifts off from pad 39A in Florida for the 11th time! pic.twitter.com/tcZu1LOOOm— SpaceX (@SpaceX) October 14, 2024 Hace unas horas un Falcon Heavy despegaba de la plataforma 39A del Centro Espacial Kennedy para lanzar la sonda Europa Clipper de la...

I think we could all use some good news right now, so here you go: Bright comet Tsuchinshan-ATLAS will become visible in the evening sky starting tomorrow night.Clear view to the west essential. Sharp eye highly recommended. Pointers at the link.https://t.co/KggJD46Cmp pic.twitter.com/WywCfQipyO—...

We have a mission!!#HeraMission's solar arrays have deployed and its batteries are charging. The satellite is in good health and the first commands have been confirmed on board. pic.twitter.com/ChckwCmNw9— ESA Operations (@esaoperations) October 7, 2024 Aunque la meteorología no era la más...

Ayer hacia las 12:18 se detectó una llamarada solar muy poderosa que ha quedado clasificada como X9,0 y que forma parte del ciclo solar actual, que comenzó en diciembre de 2019 (suelen durar entre 11 y 12 años). Curiosidad: el ciclo...

Me he encontrado en Vidas Ajenas con esta estupenda entrevista a un magnífico científico, José Ignacio Latorre, un físico cuántico, investigador, divulgador científico y (ex)catedrático universitario –dejó el puesto para dedicarse a «hacer cosas», porque le apetecía más– cuya forma de...
Septiembre otra vez, con lo que toca disfrutar con el fallo de los Premios Ig Nobel de 2024, esos que celebran aquellas investigaciones con títulos y descripciones hilarantes pero que si e fijas un poco sí que tienen sentido. Las investigaciones agraciadas...

A bordo de tu curiosidad: Un viaje por las preguntas y retos de la ciencia actual. Por Carlos Briones. Ilustraciones de Kim Amate. Editorial Crítica (8 de mayo de 2024). 336 páginas. Si hay unos libros que de pequeño haya leído una...

Rompiendo barreras: Mi vida dedicada a la ciencia. Por Katalin Karikó.GeoPlaneta (4 de septiembre de 2024). 331 páginas. Traducción de Begoña Olga Merino Gómez. Ya está disponible en español la autobiografía de Katalin Karikó, la investigadora que durante muchos años tuvo que...

He perdido probablemente demasiado tiempo probando cómo de azul –o verde– es lo que yo considero azul en distintos dispositivos, condiciones de iluminación y horas en Is My Blue Your Blue? para comprobar que, al menos soy consistente en mis resultados y...

EC Henry se ha dedicado a modelar algunas naves de Star Wars para examinar y comparar su coeficiente de resistencia, un valor asociado con la aerodinámica de las naves que da una idea de lo capaz, veloz y maniobrable que puede...

Impresión artística de JUICE sobrevolando la Tierra – ESA Las próximas horas son cruciales para la misión JUICE de la Agencia Espacial Europea (ESA) porque va a ejecutar un sobrevuelo de la Luna y la Tierra que le ayudará a modificar su...

Impresión artística de NEOWISE en órbita – NASA/JPL-Caltech Esta pasada noche la NASA ha enviado el comando para que apagara sus radios, lo que significa el final de la misión del telescopio espacial NEOWISE. Reentrará en la atmósfera en los próximos meses,...

Hoy hace diez años que la misión Rosetta de la Agencia Espacial Europea (ESA) entró en órbita alrededor del cometa 67P. Para ser exactos del cometa 67P/Churyumov-Gerasimenko. A falta de un Apolo XI yo la he comparado en muchas ocasiones con...

Epsilon Indi Ab visto por el instrumento MIRI – ESA/Webb, NASA, CSA, STScI, E. Matthews (Max Planck Institute for Astronomy) Hace unos días la ESA y la NASA presentaban la primera imagen de un planeta extrasolar conseguida por el Telescopio espacial James...

Impresión artística de Chandra en el espacio – NASA/SAO/CXC Se me había pasado pero el pasado 23 de julio se cumplieron 25 años de la puesta en órbita del observatorio espacial de rayos X Chandra por parte del transbordador espacial Columbia para...
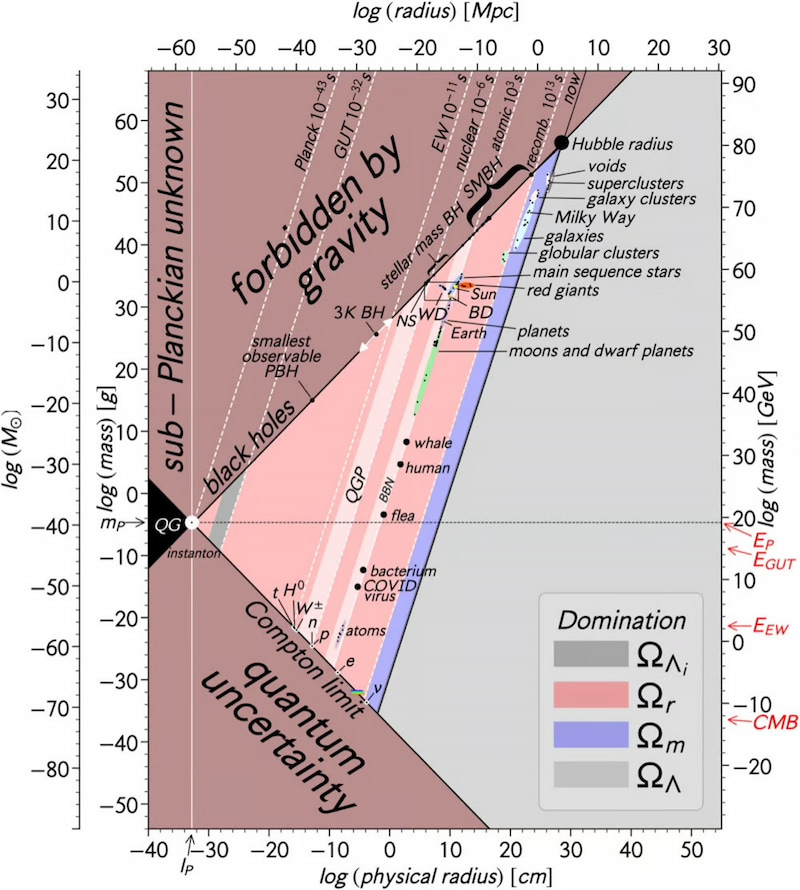
Este interesante diagrama procede del trabajo All objects and some questions («Todos los objetos y algunas preguntas») y la verdad es que sirve para despertar ciertas preguntas mientras por otro lado permite aprender algo más sobre los objetos que nos rodean...

Las manchas de leopardo y vetas de olivino en Chevaya Falls – NASA/JPL-Caltech/MSSS Hace unos días el Laboratorio de Propulsión a Chorro de la NASA publicaba una nota en la que informaba de que Perseverance ha encontrado una roca que muestra algunos...
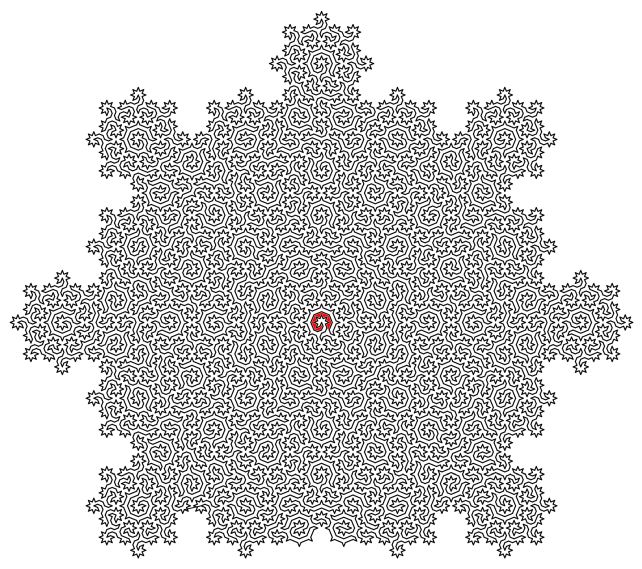
¿Eres capaz de encontrar la salida al laberinto? En su trabajo Ciclos hamiltonianos en teselaciones de Ammann-Beenker unos físicos y matemáticos de la Universidad de Bristol han encontrado algo que puede usarse como base para crear «el laberinto más difícil del mundo»....

Impresión artística de VIPER sobre la superficie de la Luna – Centro de Investigación Ames En un anuncio que ha pillado a casi todo el mundo por sorpresa la NASA ha comunicado que cancela el rover VIPER después de haberse dejado unos...

Europa Clipper con el satélite que le da nombre y Júpiter al fondo – NASA/JPL-Caltech La NASA estaba preparando todo para el lanzamiento de la sonda Europa Clipper rumbo a la luna del mismo nombre de Júpiter el próximo mes de octubre....
Un corazón para la señora Pisano – Joe Carrotta / NYU Langone Health El centro Langone Health de la Universidad de Nueva York acaba de hacer pública la muerte de Lisa Pisano, la mujer que el pasado mes de abril recibió un...

Un cerebro lleno de palabras: Descubre cómo influye tu diccionario mental en lo que piensas y sientes. Por Mamen Horno Chéliz. Plataforma Editorial (14 de febrero de 2024). 184 páginas. Desde que puedo recordar me ha fascinado la relación entre el lenguaje...
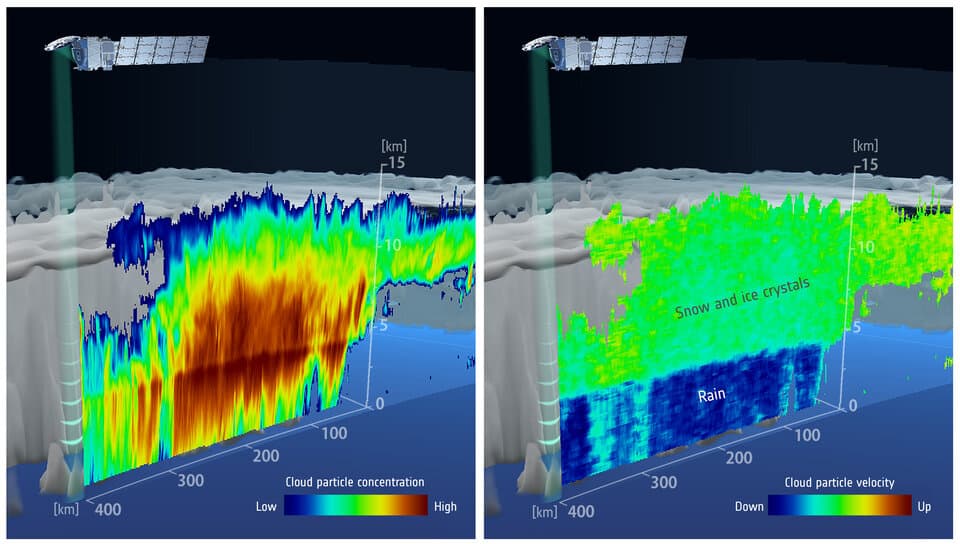
Primera imagen del radar de perfilado de nubes del satélite EarthCARE – JAXA/NICT/ESA Menos de un mes después de su lanzamiento el satélite medioambiental EarthCARE ha enviado ya su primera imagen. En concreto se trata de una del interior de una nube...

La cápsula de muestras antes de ser abierta – CNSA Nos quedaba por saber el dato de cuánto pesaban las muestras que la misión china Chang'e ha traído del lado oculto de la Luna. Pero ya lo tenemos: han sido dos kilos...

En este vídeo Adam Savage, nuestro cazador de mitos favorito, prueba en primera persona el Pillbot, un «endoscopio en forma de cápsula, motorizado e inalámbrico». En otras palabras: es un robot-cámara-cápsula experimental que por su tamaño es tragable (pesa 3 gramos),...

Hace unos minutos la cápsula con muestras del lado oculto de la Luna de la misión china Chang'e 6 aterrizaba sin problemas en la zona designada de la provincia de Sichuan, poniendo fin con éxito a la misión, que en total...

Impresión artística de la sonda camino de vuelta – CNSA No ha habido ninguna confirmación oficial al respecto pero observaciones de radio y mediante telescopios por parte de aficionados han confirmado que la sonda china Chang'e 6 ya viene rumbo a la...

Esta mañana a las 9:00, hora peninsular española (UTC +2) un cohete Larga Marcha 2C despegaba del cosmódromo de Sichang para poner en órbita el observatorio franco-chino de explosiones de rayos gamma SVOM. Lo dejó en una órbita circular de 625...

Aristóteles dijo un montón de cosas que estaban mal. Galileo y Newton deshicieron el entuerto. Luego Einstein volvió a liarla. Ahora, básicamente lo tenemos todo resuelto, excepto lo pequeño, lo grande, lo caliente, lo frío, lo rápido, lo pesado, lo oscuro,...
Impresión artística de la Voyager 1 en el espacio – NASA/JPL El pasado mes de noviembre un fallo en un chip de memoria dejó a la Voyager 1 incapaz de enviar datos ni telemetría a la Tierra. Pero desde hace unos días...

Ed Stone con un modelo de las Voyager en 2022, año de su jubilación. De Stone, no de las sondas, que siguen a lo suyo dándolo todo – JPL Acaba de hacerse pública la noticia de la muerte de Ed Stone, quien...

Los Supertacañones han hecho público el programa provisional de Naukas Bilbao 2024. Como viene siendo habitual en los últimos años se celebra de jueves a domingo, en concreto los días 19, 20, 21 y 22 de septiembre en el Palacio Euskalduna. En...

La Administración Nacional del Espacio China (CNSA) ha confirmado que hace un par de horas el módulo de ascenso de la misión Chang'e 6 se ha acoplado correctamente con el orbitador y le ha transferido las muestras tomadas en el lado...

Esta pasada madrugada el módulo de ascenso de la misión china Chang'e 6 despegaba de la superficie de la Luna con las muestras que ha recogido el brazo robot del aterrizador. Unos seis minutos después la cápsula con las muestras entraba...
Un corazón para la señora Pisano – Joe Carrotta / NYU Langone Health Se me había pasado la noticia del trasplante de un riñón de cerdo genéticamente modificado a Lisa Pisano, una paciente que no podía optar a un trasplante tradicional. Pero...

Esta pasada noche el aterrizador de la misión china Chang'e 6 se posaba sin problemas en la superficie de la Luna para tomar muestras de su lado oculto. En concreto ha aterrizado en la Cuenca Aitken, donde todo parece indicar que...

SLIM fotografiado por el rover LEV-2, cuyas ruedas se ven en primer plano a ambos lados de la parte inferior de la imagen – JAXA Esta semana se daban las condiciones de iluminación necesarias en el cráter Shioli de la Luna como...

Separation complete: #EarthCARE is alone in space for the first time.The satellite will now automatically deploy its solar array and begin transmitting telemetry.Next up: the all-important ‘acquisition of signal’ from Hartebeesthoek ground station in South Africa in approx.… pic.twitter.com/2UQDDzn9RP— ESA Operations (@esaoperations)...

Quien más, quien menos, todos los hemos preguntado alguna vez si funciona el «truco» de cambiar los precios redondos por otros más bajos acabados en decimales: anunciar 9,99 en vez de 10 euros, poner 199,95 en vez de 200… Si los...

El buen profesor Neil deGrasse Tyson también se ha apuntado a la noble costumbre de hacer listas y deja en su videoblog de StarTalk Plus la racionalización sobre cuáles son sus películas de ciencia-ficción favoritas. La enumeración no tiene ni orden...

Este espectacular vídeo 360° ha sido creado por el Centro Goddard de Vuelos Espaciales de la NASA y es una fiel simulación para entender lo que sucede al aproximarse a un agujero negro y caer en su interior. Digo «fiel» por...

Mosaico de las imágenes presentadas hoy – ESA/Euclid/Euclid Consortium/NASA et al. La Agencia Espacial Europea (ESA) acaba de anunciar la publicación de los primeros datos del telescopio espacial Euclid. Junto a ellos vienen unas cuantas imágenes nuevas. Y quince trabajos científicos que...

Impresión artística de la Voyager 1 en el espacio – NASA/JPL Según informaba la NASA hace unas horas la Voyager 1 vuelve a enviar datos de dos de sus instrumentos por primera vez desde noviembre de 2023. En concreto son el Subsistema...
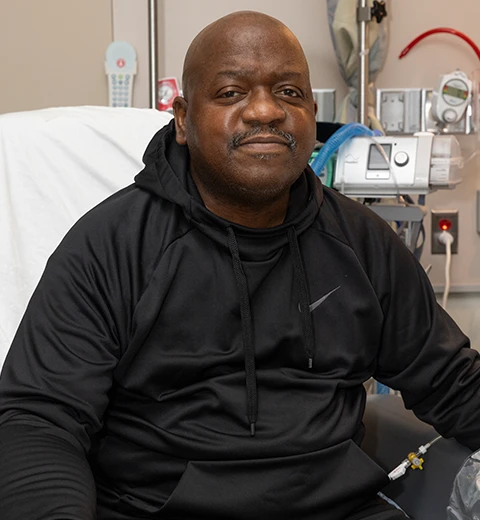
Acaba de hacerse pública la muerte de Richard «Rick» Slayman, el paciente estadounidense que hace apenas un par de meses se convertía en la primera persona del mundo en recibir el trasplante de un riñón de cerdo. Había sido trasplantado el pasado...

Esta pasada madrugada he vivido uno de los momentos más emocionantes desde que hago fotos. He podido capturar el arco de la Vía Láctea y una aurora boreal juntas desde la cumbre de Tenerife.Un sueño hecho realidad. Espero que la disfrutéis tanto...

Según un reciente experimento, en un milímetro cúbico de tejido cerebral humano hay ni más ni menos que 57.000 células individuales, 230 milímetros de vasos sanguíneos y 150 millones de sinapsis, que son los nodos a través de los cuales se comunican...

Chang'e 6 probe‘s 53-day journey continues after performing the first near-moon braking procedure on Wednesday (May 8th).What's next? Here's a short video showing what will take place before the Chang'e 6 probe lands on the far side of the moon.#ChangE6 #Queqiao2 pic.twitter.com/ZGG9jDKdUt—...

Decidido. La ciencia de la vida sin libre albedrío. Por Robert Sapolsky. Capitán Swing Libros (25 de marzo de 2024). 707 páginas. Sapolsky es un defensor acérrimo de la idea de que no existe el libre albedrío. Es una postura opuesta a...

Despegue de la misión – Administración Espacial Nacional China (CNSA) Tras un lanzamiento sin problemas y su inyección en una trayectoria de transferencia lunar la misión china Chang'e 6 ya va camino de la Luna para traer muestras de su lado oculto....

El cohete que va a lanzar la misión listo en su plataforma – Administración Espacial Nacional China (CNSA) Todo está aparentemente listo en el centro de lanzamientos espaciales de Wenchang para el de la misión china Chang'e 6 para traer muestras del...

Otro año más llega el Día de la Ciencia en la Calle. En su edición de 2024, que es ya la número XXVIII, tendrá lugar, como es tradición, en el Parque de Santa Margarita el sábado 4 de mayo de 11...

Lego sigue con sus esfuerzos para apartarnos de nuestros duramente ganados euros. En este caso con una Vía Láctea formada por 3.091 piezas. Por supuesto se trata de una representación artística de la pinta que creemos que puede tener nuestra galaxia...

La superficie de la Luna vista por SLIM al abrir los ojos a su cuarto día lunar – JAXA Lo del aterrizador japonés SLIM, de Smart Lander for Investigating Moon, Aterrizador inteligente para investigación lunar, es sorprendente: ha sobrevivido a su tercera...
Como cada año, y ya van unos cuantos, los Museos Científicos Coruñeses, en los que trabajo en el MundoReal™, han convocado los Prismas Casa de las Ciencias a la Divulgación. La de 2024 es la XXXVII Convocatoria. Ahí es nada. La...

La NASA acaba de anunciar que ha dado el visto bueno para seguir adelante con el desarrollo del dron Dragonfly con el objetivo de lanzarlo rumbo a a Titán en julio de 2028… O al menos para intentarlo. Dragonfly es, para...

Ingenuity a la derecha de la imagen sobre las dunas en las que quedará para siempre y el aspa rota de su rotor a la izquierda del centro de la imagen – NASA/JPL-Caltech/LANL/CNES/CNRS El pasado 25 de enero la NASA daba por...
Me había apuntado ver cómo le iba a Richard «Rick» Slayman con su riñón de cerdo modificado genéticamente para aproximadamente un mes después de recibir el trasplante. Pero llego ya tarde: el señor Slayman fue dado de alta el pasado el pasado...

La Agencia Espacial Europea (ESA) acaba de publicar la noticia de que un grupo de astrónomas y astrónomos han encontrado gracias al telescopio espacial Gaia el que pasa a ser el agujero negro estelar más pesado de la Vía Láctea, nuestra...
Impresión artística de los distintos elementos de la misión en la configuración propuesta en 2022, que ya no es válida - NASA Bill Nelson, el administrador de la NASA, y Nicky Fox la administradora adjunta para la Dirección de misiones científicas, acaban...
Impresión artística de la Voyager 1 en el espacio – NASA/JPL Aún no hay un comunicado oficial al respecto pero según una de las personas que trabaja en la estación de Canberra de la Red de Espacio Profundo (DSN) de la NASA...

Neuronas para la emoción: Cómo la neurociencia comienza a descifrar los circuitos de tus emociones. Por Xurxo Mariño. Shackleton Books (19 de junio de 2023). 231 páginas. Creo que hasta que leí este libro utilizaba las palabras emociones y sentimientos de manera...

Impresión artística de alguien de la tripulación de la misión Artemisa III colocando los instrumentos sobre la superficie de la Luna – NASA Aunque aún faltan años para su lanzamiento la NASA ha seleccionado los tres primeros instrumentos científicos que la misión...

¿Cómo definir el tiempo? ¿Existe realmente? ¿Cómo lo interpretaron Aristóteles, Newton o Einstein? Este vídeo, que forma parte de una trilogía, hace un repaso histórico preciso, aportando matices y detalles que hacen más fácil entender la cuestión. Además, profundiza en la...

Impresión artística del terreno en las proximidades el polo sur de Encélado y los géiseres que salen de sus grietas – ESA/Science Office La Agencia Espacial Europea (ESA) acaba de hacer público el estudio con el que buscaba escoger el objetivo de...

Imagen más reciente enviada por SLIM – JAXA De nuevo el aterrizador japonés SLIM ha sorprendido a propios y extraños y ha sobrevivido a su segunda noche en la Luna y desde hace unas horas está de nuevo en contacto con el...

Impresión artística de Euclid en el espacio – ESA Se confirman las primeras impresiones adelantadas hace unos días: la ESA ha conseguido restaurar la vista del telescopio espacial Euclid al evaporar el hielo depositado en sus ópticas. El problema de que es...
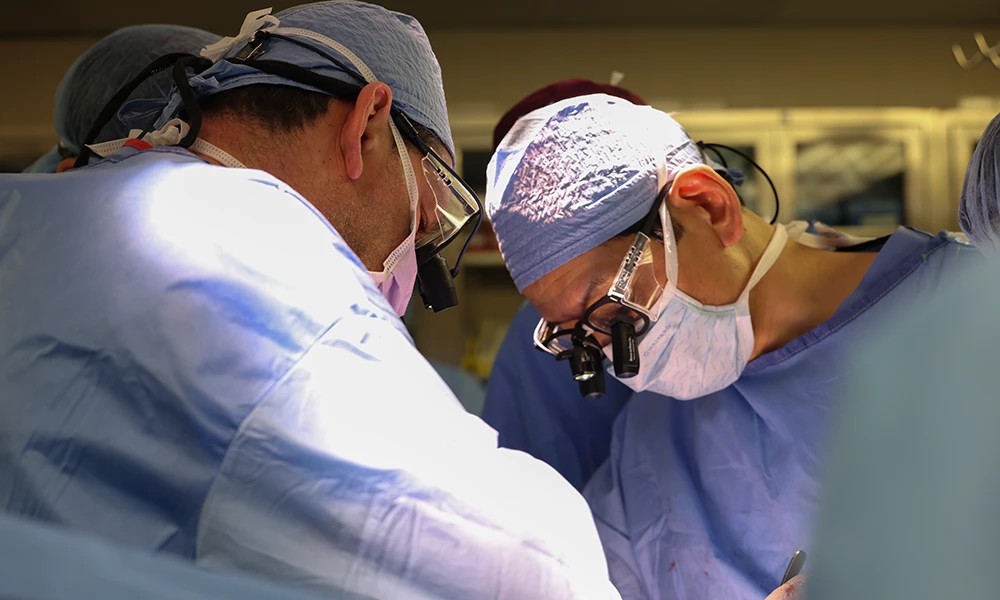
Cirujanos del MGH durante la operación – MGH Hace unos días el Hospital General de Massachusetts (MGH) anunciaba el trasplante de un riñón de cerdo modificado genéticamente a un paciente de 62 años con enfermedad renal terminal. Es la primera vez que...
Impresión artística de Euclid en el espacio – ESA La Agencia Espacial Europea (ESA) se ha encontrado con problemas causadas por el depósito de hielo en las ópticas del telescopio espacial Euclid, que apenas acaba de comenzar su misión hace dos meses....

El canal de YouTube del Museo Americano de Historia Natural tiene muchas maravillas y esta diría que es una de ellas. Es una visualización de todo el Universo conocido en 360°, al estilo de Potencias de 10, es decir, alejándose de...

No se puede negar que programadores y científicos tengan un fino sentido del humor. Un perfecto ejemplo sería este paquete/extensión creado por Hanno Rein y Patrick Bideault que sirve para añadir marcas de tazas de café a los documentos generados con...
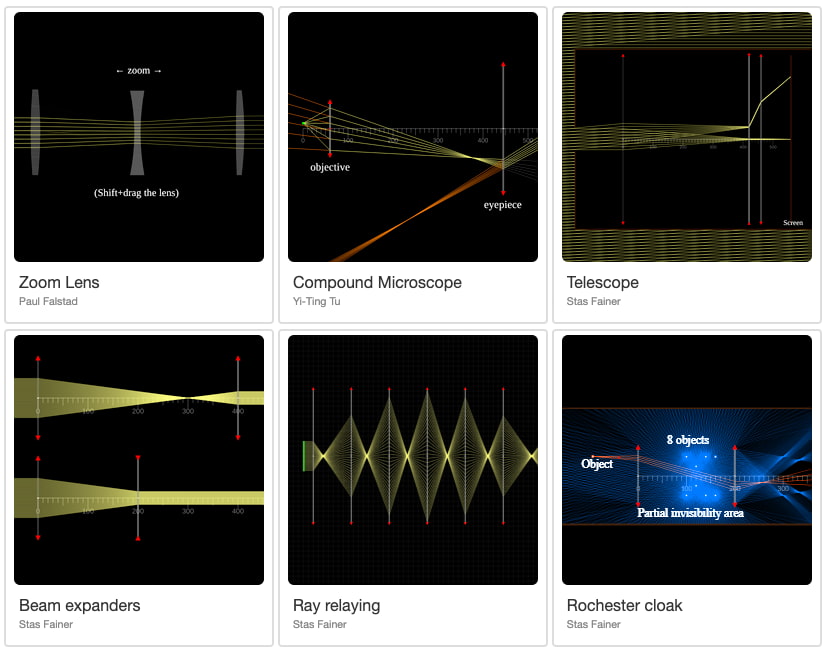
Es realmente impresionante la cantidad de herramientas y opciones de este Simulador óptico, en el que se puede «dibujar» con rayos de luz y diversos objetos con un gran realismo físico y matemático en 2-D. Es obra de Yi-Ting Yu y...

Había leído alguna vez sobre este tema palomar, pero verlo en acción es mucho más impresionante. Son unas prácticas llevadas a cabo por el profesor de psicología de la Universidad de Sevilla Santiago Berjumea quien junto sus alumnos, hace ahora una...

La Agencia Japonesa de Exploración Aeroespacial (JAXA) acaba de comunicar que el telescopio espacial de rayos X XRISM (se pronuncia «crism») ha superado su fase de puesta en marcha y que con ello empieza su misión. Esta tiene como objetivo estudiar...

Una pausa en la edición de 2023 – Íñigo Sierra/ISO100 Foto Tras el éxito, aunque esté mal que yo lo diga, de la edición del año pasado, la Cátedra de Cultura Científica de la Universidad del País Vasco decidió repetir. Así que...

La cápsula por fin en Tierra – Varda Space Industries El 12 de junio de 2023 un Falcon 9 de SpaceX lanzó con éxito la misión compartida Transporter 8. Una de sus cargar útiles era el satélite W-Series 1, fabricado por Rocket...

Hace unos días, en concreto el pasado 14 de febrero, el telescopio espacial Euclid de la Agencia Espacial Europea empezaba su misión y se ponía a recoger datos. A lo largo de los próximos seis años, Euclid observará miles de millones...

Los 212,6 gramos de Bennu que OSIRIS-REx ha traído a la Tierra – NASA/Erika Blumenfeld & Joseph Aebersold La NASA por fin ha conseguido pasar las muestras del asteroide Bennu que estaban en el interior del TAGSAM, el instrumento que las recogió,...

Este cruce entre el tren de la bruja y un experimento de científico loco consiste básicamente en una cinta transportadora que mueve muestras de calcita por un túnel de irradiación de electrones a toda potencia, 3 MeV y 50 mA. Al...

El problema de los tres cuerpos es más difícil de lo que parece. Aplicable a la mecánica celeste, consiste en calcular las posiciones y velocidades de tres cuerpos sometidos a atracción gravitacional mutua partiendo de unas posiciones y velocidades dadas. Como...

Esta curiosa app creada por Matt Webb se llama Galactic Compass y es, como su propio nombre indica, una brújula galáctica. Y si acaso hay algún sitio interesante al que «apuntar» con ella este sería el centro de nuestra galaxia, la...

Joaquin Phoenix y familia con sus gorritos en Señales (2002) de M. Night Shyamalan Llegué hasta esta vieja página del foro de Física de StackExchange donde alguien se preguntaba si los gorritos de papel de aluminio bloqueaban realmente algo. Siendo un sitio...

Dmytry Lavrov creó hace tiempo este Simulador de nave espacial relativista con el que se puede experimentar cómo sería un viaje a velocidades cercanas a la luz. Lo interesante es que hay «datos de telemetría» que permiten entender mejor lo que...
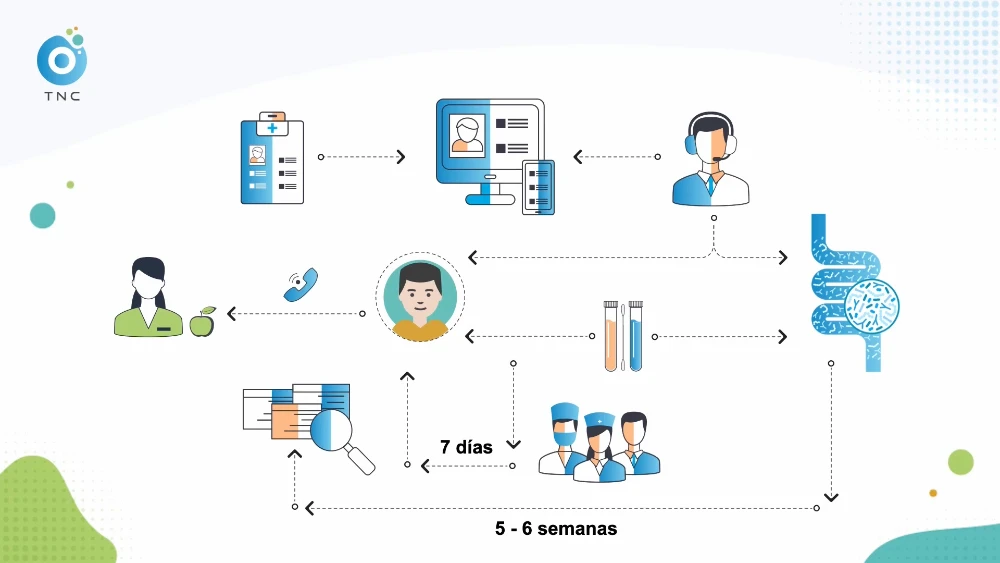
Esquema de los distintos pasos del proceso de definición de la dieta personalizada – TNC terapia Hablar de dieta y cáncer es un tema peliagudo, en especial por las muchas sandeces que han dicho en los últimos años algunas personas al respecto....
SLIM fotografiado por el rover LEV-2, cuyas ruedas se ven en primer plano a ambos lados de la parte inferior de la imagen – JAXA No había muchas esperanzas pero ha habido suerte y ayer por la noche –hora peninsular española– la...

Impresión muy artística de LISA (arriba) y otra no tan artística de EnVision. (abajo) – ESA La Agencia Espacial Europea (ESA) acaba de anunciar que ha adoptado el observatorio espacial de ondas gravitacionales LISA y la sonda para estudiar Venus EnVision. En...

Hasta hace no mucho esto sonaría a ciencia ficción. Pero según se puede leer en Gene Therapy Allows an 11-Year-Old Boy to Hear for the First Time la terapia génica ha curado la sordera congénita de Aissam Dam, un niño de once...

Las muestras «tímidas« por fin al descubierto – NASA/Erika Blumenfeld y Joseph Aebersold EL pasado 24 de septiembre la cápsula con muestras del asteroide Bennu que la misión Osiris-REX de la NASA traía de vuelta a casa tras algo más de siete...

Andaba buscando algo decente sobre el origen de la aleatoriedad en la mecánica cuántica cuando me encontré este antiguo vídeo de Jade Tan-Holmes en Up and Atom, uno de los canales más divulgativos, tranquilos, de buen rollo y nada sobreactuados sobre...
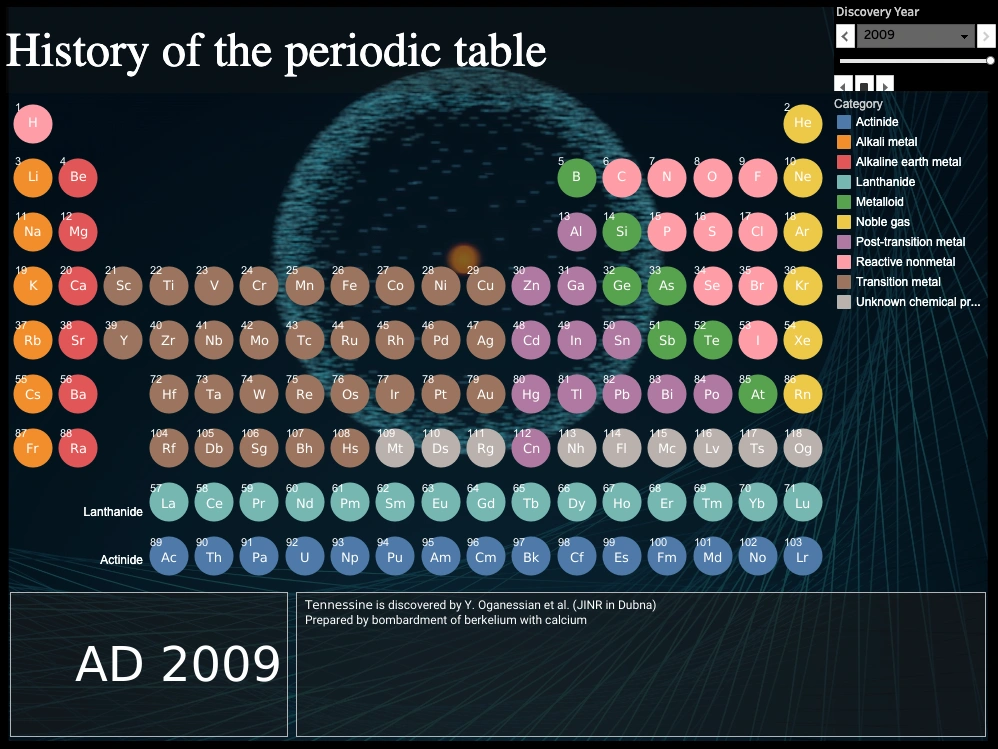
La Historia de la tabla periódica es básicamente una tabla interactiva en la que haciendo clics sobre los elementos puedes ver el año (o época) en que fueron descubiertos y algunos datos más sobre ellos. Alternativamente, puedes utilizar el calendario de...

Neftali Hernández, parte del equipo de conservación de muestras OSIRIS-REx, coloca en su sitio una de las herramientas desarrolladas específicamente para abrir el contenedor de muestras – NASA/Robert Markowitz El 24 de septiembre de 2023 la cápsula que contiene las muestras del...
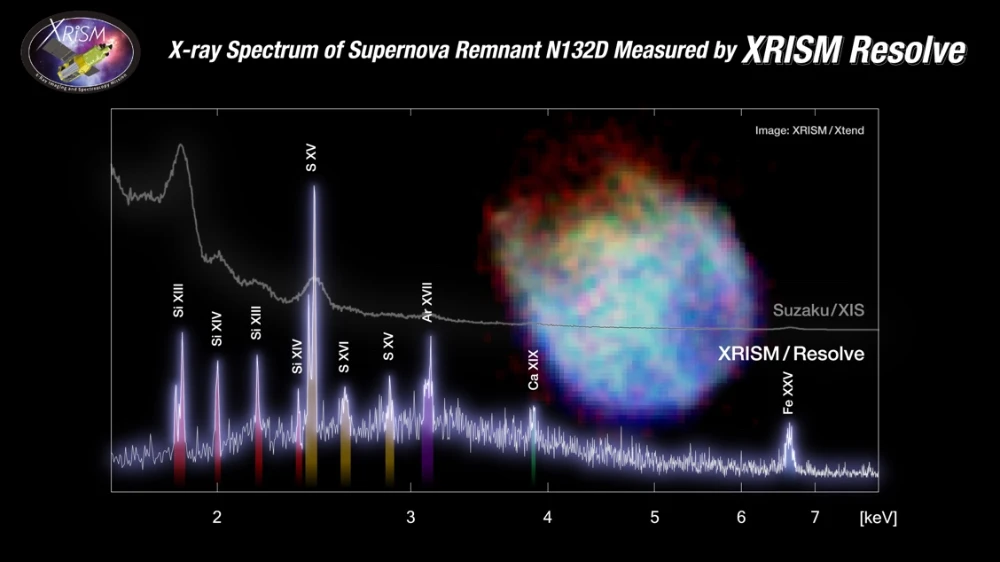
La Agencia Japonesa de Exploración Aeroespacial (JAXA) ha publicado las primeras imágenes obtenidas por el telescopio espacial de rayos X XRISM (se pronuncia «crism»), lanzado el pasado 7 de septiembre. Tal y como se puede ver en el vídeo de arriba...

Hace unas horas un cohete chino Larga Marcha 2C ha lanzado la sonda Einstein para el estudio de fuentes de rayos X cósmicas desde el Centro de Lanzamiento de Satélites de Xichang. La ha colocado, tal y como estaba previsto, en...

Impresión muy artística de Aditya-L1 observando el Sol desde el punto de Lagrange L1 - ISRO Los Reyes Magos le han traído un magnífico regalo a la Agencia India de Investigación Espacial (ISRO) con la correcta inserción del observatorio solar Aditya-L1 en...

La interpretación de los muchos mundosde la mecánica cuántica Según la interpretación de los muchos mundos (Many Worlds), probablemente haya montones de universos ahí fuera. Es una de las ideas sobre el multiverso en ciencia y filosofía. En esos mundos el...
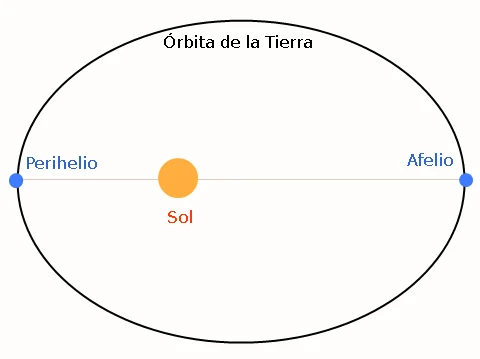
Afelio y perihelio Todos los años en los primeros días de enero la Tierra pasa por el perihelio de su órbita, el punto de esta en el que está a menor distancia del Sol. Es algo que sucede entre el 2 y...

Juno a 2.500 kilómetros de distancia – NASA JPL / Southwest Research Institute / Kevin M. Gill El pasado 30 de diciembre la sonda Juno de la NASA hizo el sobrevuelo más cercano de Ío, la luna de Júpiter, en los últimos...

Despegue de la misión – ISRO A la 4:40, hora peninsular española (UTC +1) del 1 de enero de 2024 India inauguraba los lanzamientos espaciales del año con la puesta en órbita del observatorio de rayos X XSpoSat. El lanzamiento corrió a...

Puesta de Sol del 21 de diciembre de 2015 en A Coruña El 21 de diciembre –aunque puede adelantarse o retrasarse un día– se produce el solsticio de diciembre, que en el hemisferio norte marca el principio del invierno astronómico, mientras que...

Breaking Through: My Life in Science. Por Katalin Karikó. Crown (10 de octubre de 2023). 336 páginas. Cuando el 2 de octubre de 2023 el Instituto Karolinska anunció la concesión del Premio Nobel de Medicina a Kasalin Karikó y Drew Weissman por...

El ELT visto desde el aire a principios de diciembre de 2023 – ESO/G. Vecchia Esta semana recibí una nota de prensa que dice que los primeros 18 segmentos del espejo principal del Telescopio Extremadamente Grande (Extremely Large Telescope, ELT) del Observatorio...

Primates al este del Edén: El organismo humano a la luz de su evolución. Por Juan Ignacio Pérez. Editorial Crítica (15 de noviembre de 2023). 368 páginas. La evolución nos ha hecho monos desnudos en el sentido de que tenemos mucho menos...

Esta visita virtual, sencilla pero encantadora, a la casa del físico y matemático James Clerk Maxwell (1831-1879), destaca por su simplicidad. Si no tienes previsto visitar Edimburgo y realizar recorridos históricos, al menos podrás verla «como si estuvieras allí». No es...

En este vídeo nuestra física teórica favorita Sabine Hossenfelder explica de forma divulgativa qué hay detrás de un nuevo trabajo que cuestiona una vieja idea: que en el interior de cada agujero negro haya una singularidad. Siempre se ha dicho que...

Primeras imágenes del Sol captadas por el observatorio Aditya-L1 – ISRO La Agencia India de Investigación Espacial (ISRO por sus siglas en inglés) acaba de hacer públicas las primeras imágenes obtenidas por el observatorio espacial solar Aditya-L1. Se trata de imágenes del...

Impresión artística de la Voyager 1 en el espacio intergaláctico – NASA-JPL/Caltech Según cuenta la NASA en Engineers Working to Resolve Issue With Voyager 1 Computer la Voyager 1 lleva días sin transmitir datos de sus instrumentos ni de telemetría. Lógicamente, están...

El cometa Halley fotografiado desde la Tierra durante su visita de 1986 – NASA/W. Liller - NSSDC's Photo Gallery (NASA) A la hora en la que se publica esta anotación, las 2:01 de la mañana, hora peninsular española (UTC +1) del 9...

La cápsula en tierra junto con el paracaídas principal – NASA/Keegan Barber El pasado 24 de septiembre la cápsula de la sonda OSIRIS-REx aterrizaba en el desierto de Utah con muestras del asteroide Bennu. No había visto nada raro en la maniobra...

El viernes 1 de diciembre un Falcon 9 despegaba del Complejo de lanzamiento espacial 4 de la Base de la Fuerza Aérea de Vandenberg en California para poner en órbita el satélite espía surcoreano Project EO/IR Sat 1. Pero como el...

Aunque es un dato que a mí aún me sorprende hace menos de un siglo que sabemos a ciencia cierta que en el universo hay otras galaxias distintas a la Vía Láctea. Esas galaxias, como la nuestra, están repletas de estrellas...
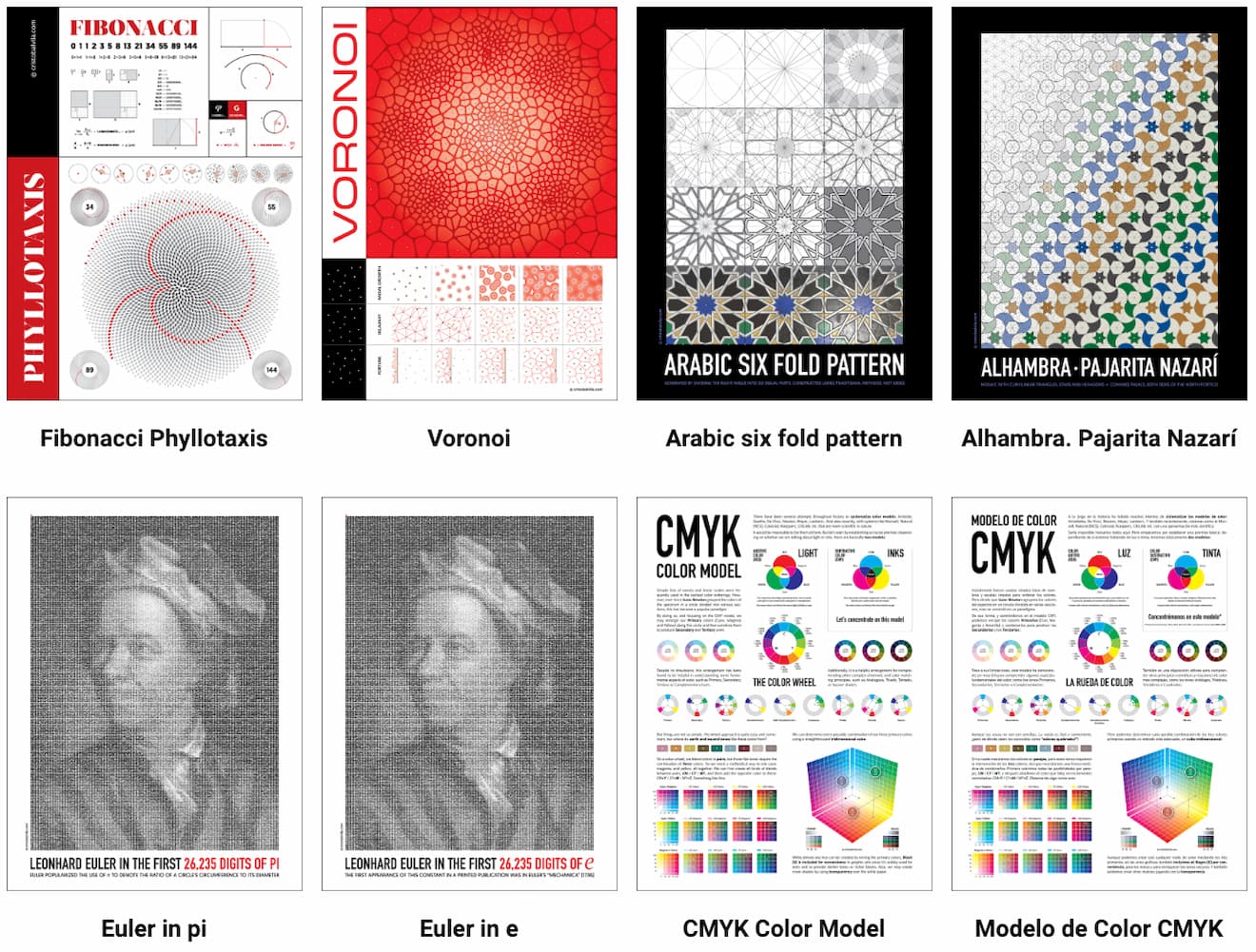
Nuestro admirado Cristóbal Vila de Etérea Estudios anunció sus láminas y pósteres, unas preciosas ilustraciones sobre sus pasiones: la ciencia y el grafismo, con toques e inspiraciones matemáticas como trasfondo. Con títulos como Fibonacci Phyllotaxis, Pajarita Nazarí o Euler en pi...

En este debate sobre la Biología del libre albedrío el gran Robert Sapolsky se enfrenta –pero muy amablemente– con Kevin Mitchell, en una conversación tranquila y relajada; nada de youtube chirriante. Sapolsky defiende como es lógico su idea de que nuestro...
Después de unas cuantas semanas diciendo que «launching soon» por fin está en línea NASA+, la plataforma de contenidos en streaming de la NASA. Está disponible de forma gratuita a través de las apps de la agencia para Android e iOS, para...
Impresión artística de los distintos elementos de la misión en la configuración propuesta en 2022 - NASA A finales de septiembre un comité de revisión independiente (Independent Review Board, IRB) analizó los planes de la NASA y la ESA para llevar a...

Dinkinesh y familia fotografiados desde unos 1.600 kilómetros de distancia – NASA/Goddard/SwRI/Johns Hopkins APL Hace unos días las primeras imágenes que recibimos de la sonda Lucy de la NASA tras su sobrevuelo del asteroide Dinkinesh revelaron que lo acompaña otro asteroide que...

La Agencia Espacial Europea (ESA) acaba de presentar las primeras imágenes obtenidas por el telescopio espacial Euclid. El telescopio está aún en fase de prueba pero las imágenes ya son representativas de las que capturará cuando entre oficialmente en servicio a...

Dinkinesh y su luna vistos por Lucy – NASA/Goddard/SwRI/Johns Hopkins APL/NOAO El 1 de noviembre de 2023 la sonda Lucy de la NASA hizo un sobrevuelo del asteroide Dinkinesh. Las primeras imágenes recibidas han dado la sorpresa de que Dinkinesh es un...
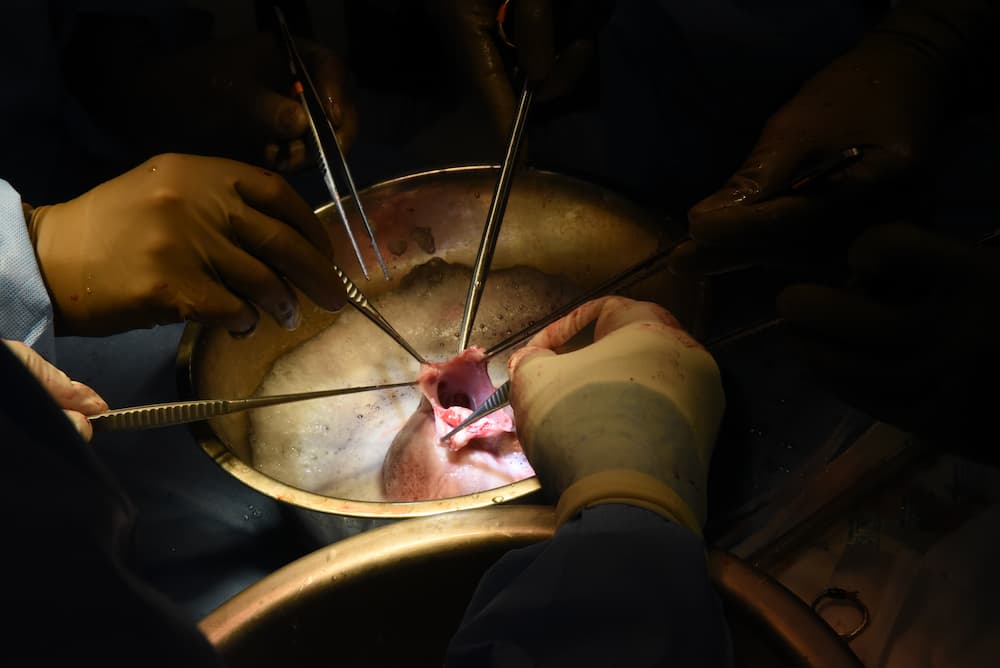
El corazón del cerdo durante los preparativos para el trasplante – UMMS Lawrence Faucette, la segunda persona en la historia en recibir el trasplante del corazón de un cerdo, ha fallecido apenas seis semanas después de la operación. Según el Centro Médico...

Esta tarde a las 17:54 la sonda Lucy de la NASA ha hecho su máxima aproximación al asteroide Dinkinesh. La distancia mínima que los separó fue de 425 kilómetros. La velocidad de la sonda era de 16.200 kilómetros por hora. El...

Tapa del TAGSAM con sus tornillos – NASA/Erika Blumenfeld & Joseph Aebersold El pasado 24 de septiembre la cápsula que contiene las muestras del asteroide Bennu que recogió la sonda OSIRIS-REx aterrizaba sin problemas en el desierto de Utah. De allí fue...

Este vídeo rescatado por los archivos de la BBC muestra a Peter Mansfield (1933-2017), el inventor del escáner de resonancia magnética (RMI), haciendo de conejillo de indias en la primera prueba del aparato de RMI en el que habían montado el...

Me sorprendió encontrarme con un artículo del Wall Street Journal en el que se dan bastantes detalles sobre un test de 50 tipos de cáncer «a partir de una sola gota de sangre» llamado Galleri (véase: This $1,000 Test Finds Signs...

Impresión artística del dispensador de satélites del Vega en órbita – Arianespace [Léase esta anotación escuchando Alive and Kicking de Simple Minds] En las últimas horas ha saltado la noticia de que dos de los satélites puestos en órbita en el lanzamiento...

Un Falcon Heavy de SpaceX acaba de lanzar, por fin, la misión Psyche de la NASA rumbo al asteroide del mismo nombre. El lanzamiento llega con un año de retraso porque en 2022 el software de a bordo no estaba listo...
Esto es lo que veía Euclid durante los peores momentos – ESA La Agencia Espacial Europea (ESA) y los contratistas del observatorio espacial Euclid han conseguido solucionar el problema con el sistema de guiado fino (FGS) del observatorio que hacía que a...
El corazón del cerdo durante los preparativos para el trasplante – UMMS El pasado 20 de septiembre Lawrence Faucette se convirtió en la segunda persona de la historia en recibir el trasplante del corazón de un cerdo. En el momento de escribir...

Aunque ya hemos recibido algunas imágenes de prueba que prometen resultados espectaculares la Agencia Espacial Europea (ESA) se ha visto obligada a prolongar la puesta en marcha del observatorio espacial Euclid a causa de tres problemas. Estos son que el sensor...

BREAKING NEWSThe 2023 #NobelPrize in Physiology or Medicine has been awarded to Katalin Karikó and Drew Weissman for their discoveries concerning nucleoside base modifications that enabled the development of effective mRNA vaccines against COVID-19. pic.twitter.com/Y62uJDlNMj— The Nobel Prize (@NobelPrize) October 2, 2023...

Aerogeneradores en el Parque Eólico Thorntonbank; costa de Westende, Bélgica (CC) Lieven Esta foto de Lieven, un arquitecto belga que además de aficionado a la fotografía es experto en lenguaje klingon (!), es tal vez la más sencilla y visual demostración visual...

We've spotted the #OSIRISREx capsule on the ground, the parachute has separated, and the helicopters are arriving at the site. We're ready to recover that sample! pic.twitter.com/ZmPyb8fyrR— NASA Solar System (@NASASolarSystem) September 24, 2023 [Anotación en actualización] El aterrizaje esta tarde de...

La Agencia India de Investigación Espacial (ISRO) calculaba que entre ayer y hoy las condiciones de iluminación en el entorno del cráter Manzinus U, dónde están el rover Pragyan y el aterrizador Vikram de la misión Chadrayaan 3, podrían haberles permitido...

Diccionario del asombro. Una historia de la ciencia a través de las palabras. Por Antonio Martínez Ron. Gráficos por Carlos el rojo. Editorial Crítica (20 de septiembre de 2023). 376 páginas. El más reciente libro de Aberron tiene su origen en su...

Este pasado fin de semana se ha celebrado en el Palacio Euskalduna de Bilbao el evento de divulgación científica Naukas Bilbao 2023. En él, a lo largo de dos días, pudimos disfrutar de casi 60 charlas de 10 minutos sobre temas...

La espera ha sido larga pero por fin ha tenido lugar la 33 ceremonia de entrega de los Premios Ig Nobel. Ya sabes, esos premios que celebran aquellas investigaciones con títulos y descripciones hilarantes pero tampoco tan descabelladas si te fijas un...

Los océanos cubren aproximadamente el 70 por ciento de la superficie de la Tierra. Cerca del 97 por ciento de toda el agua del planeta es salada. Si se pudiera extraer toda esa sal del océano y distribuirla de manera uniforme...

Despegue de la misión – MHI Launch Services Después de tener que cancelar un primer intento el pasado 28 de agosto por la presencia de vientos demasiado fuertes en altura hace unas horas un cohete H-2A despegaba del espaciopuerto de Tanegashima y...

Hacia 1854, Londres fue el epicentro de una devastadora epidemia de cólera. Por aquel entonces un médico llamado John Snow decidió investigar la causa real de la rápida propagación de la enfermedad. A diferencia de muchos de sus contemporáneos, Snow no...

Chandrayaan-3 Mission:Vikram soft-landed on , again!Vikram Lander exceeded its mission objectives. It successfully underwent a hop experiment.On command, it fired the engines, elevated itself by about 40 cm as expected and landed safely at a distance of 30 – 40 cm away.…...

Pragyan en el momento de pisar la Luna – ISRO El rover Pragyan y el aterrizador Vikram de la misión Chandrayaan-3, funcionan con la electricidad que producen sus paneles solares. Y como está a punto de anochecer sobre su zona de aterrizaje...

Esta imagen que hizo las rondas de internet hace algún tiempo es una ilusión visual de lo más curiosa. Si miras la foto, muestra claramente un excursionista caminando por la nieve hacia unos árboles. Pero si la miras de nuevo, tranquilamente,...

Un cohete PSLV-XL lanzado desde el Centro Espacial Satish Dhawan ha puesto en órbita hace unas horas el observatorio solar Aditya-L1. Es la primera vez que la India lanza una misión de este tipo. El cohete ha dejado el observatorio en...

Si todo va según lo previsto el próximo día 24 la cápsula de la sonda OSIRIS-REx que contiene muestras del asteroide Bennu aterrizará en el Campo de pruebas de Utah descendiendo suavemente colgada de un paracaídas. Recientemente el equipo de la...

Vi que en The Guardian hablaban de El imperio de los chimpancés (Chimp Empire, 2023, Netflix) como si fuera «Succession, pero con simios» y lo describían como «una historia de traición, conflicto y luchas de poder». Así que como solo eran...
Beyond Borders, Across Moonscapes:India's Majesty knows no bounds!. Once more, co-traveller Pragyan captures Vikram in a Snap! This iconic snap was taken today around 11 am IST from about 15 m.The data from the NavCams is processed by SAC/ISRO, Ahmedabad. pic.twitter.com/n0yvXenfdm— ISRO...

Aunque está incompleto, me gustó la idea tras Many Tiny Things (Muchas cosas pequeñas) porque como interactivo físico resulta especialmente sencillo, entretenido e incluso diría que con un punto gozoso. Es un tutorial a medio acabar, pero lo que puede verse...

La Royal Society ha publicado en su canal este didáctico vídeo que enseña cómo es la Tierra por dentro, viajando desde su superficie hasta el centro, viajando visualmente en tan solo tres minutos, con una «nave perforadora» que se asemeja tanto...

Psych: The Story of the Human Mind. Por Paul Bloom. Ecco (28 de febrero de 2023).464 páginas. Basado en un curso de introducción a la psicología que el autor lleva años impartiendo en la Universidad de Yale este libro cuenta lo que...

Cristales de LK-99 obtenidos en el Instituto Max Planck de Investigación del Estado Sólido – Pascal Puphal Una de las noticias de ciencia de las que más se ha hablado este verano ha sido el anuncio de que el compuesto bautizado como...

El físico de armas nucleares Greg Spriggs analiza en este vídeo para Insider el realismo de las explosiones nucleares en el cine. Las únicas películas que se salvan de casi una decena son dos de Christopher Nolan: Oppenheimer y Batman: el...

Viajes interestelares. Historia de las sondas Voyager. Por Pedro León. Guadalmazán (11 julio de 2023). 430 páginas. En el momento de publicar esta anotación la sonda Voyager 1 está a algo más de 24.000 millones de kilómetros de la Tierra mientras que...

Today is the final collapse of the Arecibo Observatory. In 2020, it lost its iconic 305-meter dish. Now, all the remaining instruments and computers will be closing down. Only a few people would be left there to transition to an educational center...
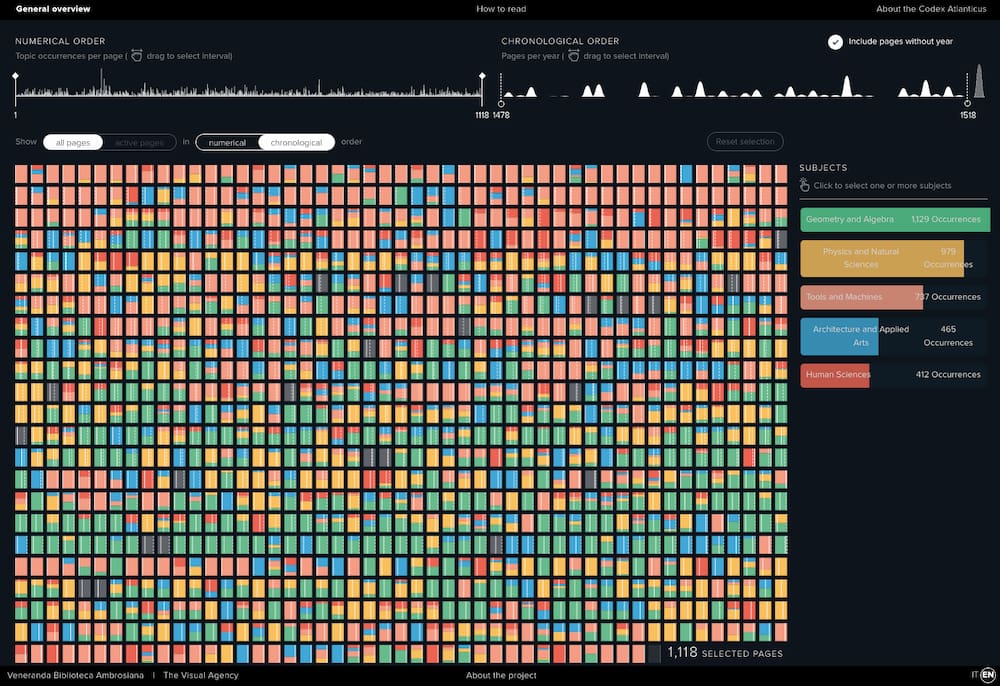
El Codex Atlanticus es un proyecto sobre la exploración visual de la mayor colección que existe de trabajos y dibujos originales de Leonardo da Vinci. Es una aplicación interactiva que permite obtener una visión general pero también detallada de todos los...

Tras un mes de viaje después de su lanzamiento el telescopio espacial Euclid de la Agencia Espacial Europea llegaba hace unos días a su destino en el punto de Lagrange L2 del sistema Sol-Tierra. Es un punto situado a 1,5 millones...
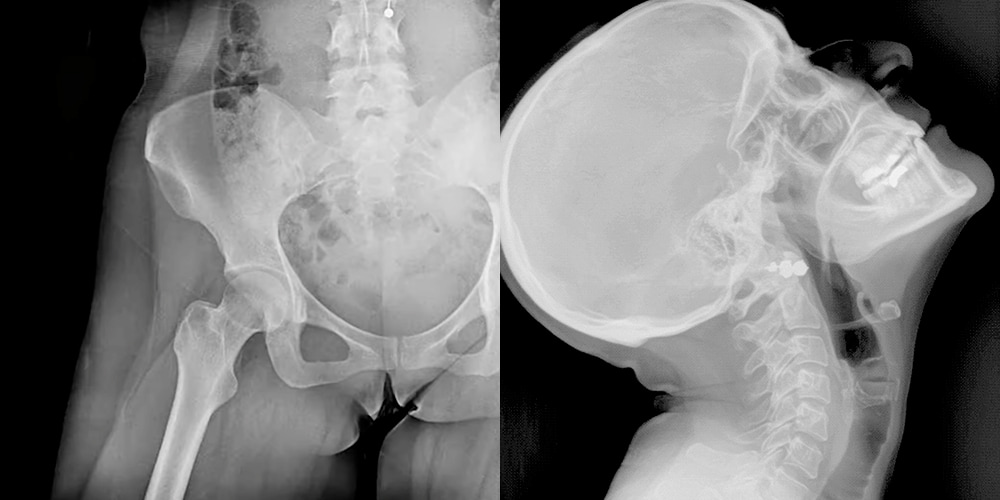
Siempre me he preguntado por qué las radiografías son estáticas y por qué no sería más práctico observarlas en movimiento, como en una película; darían más información de lo que sucede dentro de nuestros cuerpos. Lo cierto es que esa técnica...

Se está hablando bastante del anuncio de un grupo de científicos de Corea del Sur que dicen haber conseguido un material superconductor a temperatura y presión ambiente, lo que es una gran noticia porque los que conocemos sólo funcionan como tales a...

Impresión artística de WD 1856 b y su estrella – NASA/Centro de vuelo espacial Goddard El planeta extrasolar WD 1856 b, descubierto en 2020, tiene una peculiaridad que llama la atención: es siete veces más grande que su estrella, WD 1856. Eso...
Impresión artística de los distintos elementos de la misión en su configuración actual ya en Marte - NASA Todavía no es definitivo porque aún tienen que negociarlo con el Congreso, pero por su parte el senado de los Estados Unidos, en su...

La guardería estelar de Rho Ophiuci – NASA/ESA/CSA/STSc/K. Pontoppidan (STScI). Procesamiento de imágenes: A. Pagan (STScI) Hace unas horas la NASA, la Agencia Espacial Europea (ESA) y la Agencia Espacial Canadiense (CSA) han publicado una espectacular imagen para celebrar el primer año...

En 2020 el telescopio espacial TESS de la NASA, junto con observaciones hechas por el instrumento HARPS de la Agencia Espacial Europea (ESA) instalado en el Observatorio Europeo Austral en Chile permitieron descubrir y confirmar la características de LTT9779 b. Es...
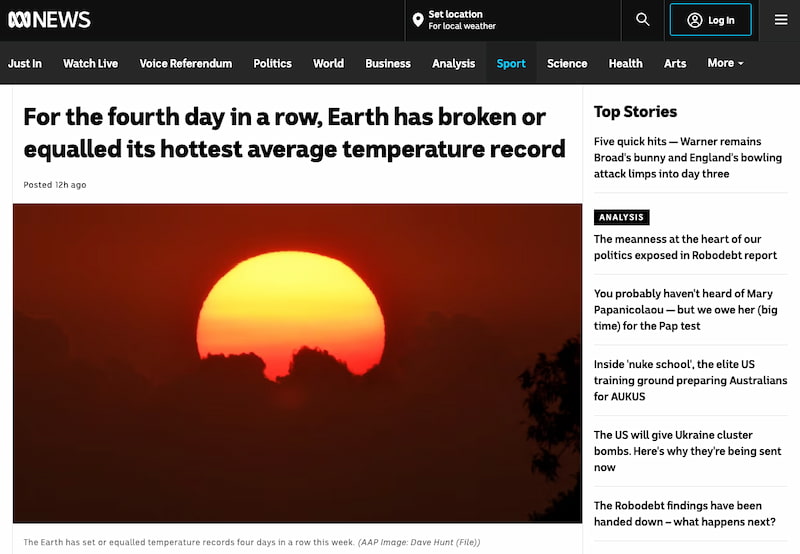
Las noticias lo dicen bien claro: Por cuarto día seguido la Tierra vuelve a romper el récord de temperatura más cálida de todos los tiempos. En concreto este pálido punto azul marcó ayer una temperatura planetaria de 17,23°C, superando los 17,18°C...

De izquierda a derecha y de arriba a abajo: Júpiter, Saturno, Urano y Neptuno Con una imagen recién publicada de Saturno el telescopio espacial James Webb ya tiene a los cuatro gigantes gaseosos del Sistema Solar en su colección, pues se une...

A pesar de haber superado por segunda vez los 10.000 votos necesarios para ser considerado al final el modelo en Lego del telescopio espacial James Webb (JWST) tampoco ha sido escogido por la empresa para convertirse en un producto comercial. Pero...

La Agencia Espacial Europea (ESA) acaba de publicar las primeras imágenes captadas por el detector de rayos del primer satélite Meteosat de tercera generación (MTG). Conocido como Lightning Imager (LI), está compuesto por cuatro cámaras que permiten detectar tormentas 24 horas...

Deployment of @ESA’s Euclid confirmed pic.twitter.com/JSX43KXaSn— SpaceX (@SpaceX) July 1, 2023 Un cohete Falcon 9 de SpaceX acaba de lanzar con éxito el telescopio espacial Euclid de la Agencia Espacial Europea (ESA). El lanzamiento estaba previsto originalmente en un Soyuz ST, la...

Todo está listo en el Complejo de lanzamiento 40 de Cabo Cañaveral para el lanzamiento del telescopio espacial Euclid de la Agencia Espacial Europea (ESA). Está previsto para las 17:11, hora peninsular española (UTC +2), del 1 de julio a bordo...

Alguna vez te habrá pasado que piensas en hacer algo en otra habitación, te levantas, cruzas la puerta y ¡zas! acabas de olvidar qué es lo que ibas a hacer. Se llama efecto puerta, como ya explicó Wicho por aquí hace...

Ya tenemos programa provisional para Naukas Bilbao 2023. Se celebrará del 14 al 17 de septiembre en el Palacio Euskalduna. Conserva el esquema estrenado en 2017 y recuperado tras la pandemia que incluye tres eventos relacionados: Jueves 14: Naukas PRO. Centros de...

Impresión artística con estrellas, agujeros negros y nebulosas dispuestos sobre una cuadrícula que representa el tejido del espacio-tiempo. Las ondulaciones de este tejido son las ondas gravitacionales – Colaboración NANOGrav/Aurore Simonet La noticia científica de la semana, aunque un tanto esotérica, es...

El avión cohete VSS Unity de Virgin Galactic acaba de completar con éxito el primer vuelo comercial de la empresa, bautizado como Galactic01. Es también el primer vuelo dedicado a la investigación científica. Iban a bordo el coronel Walter Villadei de...

Cúmulo de galaxias M92 / ESA/Hubble, NASA, Gilles Chapdelaine Como muestra de lo extraño que sigue siendo el Universo y lo que minuciosamente que se va descubriendo, teorizando e interpretando sobre él, un par de noticias de carácter cosmológico que vi pasar...

Creo que casi todo el mundo que me conoce diría que soy, como se suele decir, de ciencias. Pero también creo que quien me conoce mejor diría que tampoco encajo de todo en esa etiqueta. Y que sin ser de letras,...

El arte de la estadística. Cómo aprender de los datos. Por David Spiegelhalter. Capitán Swing (15 de mayo de 2023). 427 páginas. Traducción de Francisco Herreros. El pasado 3 de junio el diario El Mundo llevaba en su portada una noticia titulada...

Este curioso trabajo titulado Comunicación con inteligencias extraterrestres, medio secreto, medio «sólo para uso oficial» de la NSA estadounidense fue desclasificado por el puro paso de los años. Es curioso verlo con perspectiva, porque parece que inspiró a muchos científicos, además...
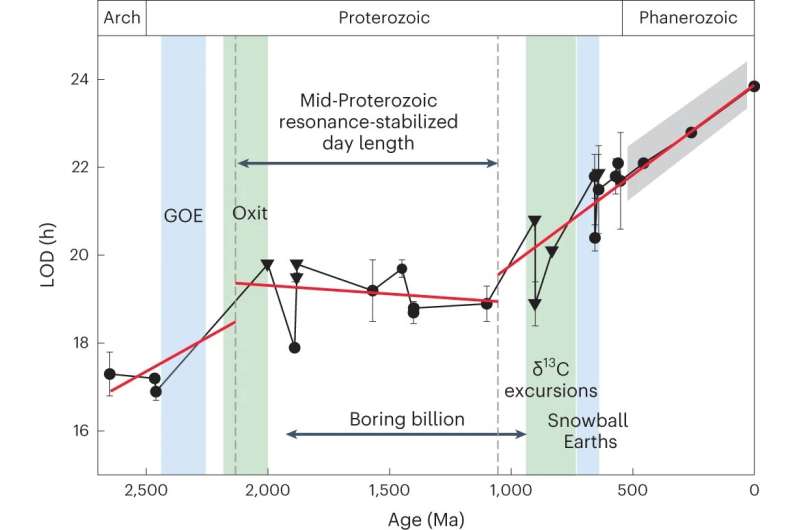
Los días actuales tienen una duración de 24 horas –más o menos– pero no siempre fue así. Según datos recopilados por los científicos y un análisis estadístico relativo a lo que sucedió en la Tierra en el más distante pasado, hace...

Hasta el próximo 11 de julio se puede ver en RTVE Play Isaac Asimov, mensaje al futuro, un pseudo-documental en el que se puede tener ocasión de ver al genio divulgador de la ciencia y el maestro de la ciencia-ficción en su...

El telescopio espacial James Webb es un ejemplo magnífico de esa sinergia – NASA La mezcla entre ciencia e ingeniería es esencial. Puedes hacer la ciencia, pero la parte fundamental es hacer la práctica, y tener esta combinación entre ambas es algo...

Life Beyond Us: An Original Anthology of SF Stories and Science Essays. Editada por Julie Nováková, Lucas K. Law y Susan Forest. Laksa Media Groups Inc. e Instituto Europeo de Astrobiología (22 de abril de 2023). 582 páginas. Inglés. Tenemos un pequeño...
Al parecer se ha observado un curioso fenómeno entre las personas mayores que padecen demencia senil que tiene que ver con una súbita recuperación o lucidez poco antes del momento de morir. Los científicos creen que esa lucidez terminal puede deberse...

Hoy se cumplen 20 años del lanzamiento de la Mars Express de la Agencia Espacial Europea (ESA) rumbo a Marte el 2 de junio de 2003. Llegó a su destino el 25 de diciembre de ese mismo año. Y aunque estaba...

Impresión artística de JUICE totalmente desplegada – ESA A finales de la semana pasada la sonda JUICE de la Agencia Espacial Europea (ESA) completaba su proceso de despliegue tras su lanzamiento. En concreto los últimos elementos en colocarse en posición fueron las...

Esta pasada madrugada un cohete Electrón de Rocket Lab despegaba desde sus instalaciones en Nueva Zelanda para la misión Coming to a Storm Near You. A bordo iban los dos últimos satélites de la constelación TROPICS de la NASA, que fueron...

Ya es oficial: el 1 de junio sale el set Lego 42158 con el que podrás montar el rover Perseverance de la NASA junto, cómo no, con su intrépido compañero el helicóptero Ingenuity. Son 1.132 piezas de la serie LEGO Technic...

Este este breve pero intenso vídeo del cazador de tornados Reed Timmer y su equipo Team Dominator se puede disfrutar de lo que él llama una «interceptación de Tornado» de libro, la mejor que ha hecho, en su humilde opinión. El...

Josie nos escribió para contarnos que lanzaron The Solar System Flipbook Collection, unos minilibros «cinemágicos» animados de esos en los que pasas las páginas con el dedo para ver cómo se mueven las imágenes. La colección limitada, que ya ha cosechado...

Saturno y sus algunas de sus lunas más grandes en un fotomontaje de imágenes tomadas por las sondas Voyager. Dione está al frente; Mimas, Tetis y están a la derecha, Encélado y Rea fuera de los anillos de Saturno a la izquierda,...

El Catálogo de rocas y polvo de la Luna de las Misiones Apolo de la NASA es una pequeña maravilla que han recuperado en un artículo de Beautiful Public Data junto con algunas cifras y anécdotas. Básicamente contiene información detallada de...

Después de varios aplazamientos debidos a una meteorología poco cooperativa esta pasada noche Rocket Lab ha lanzado con éxito la misión Rocket Like a Hurricane. A bordo del cohete Electrón iban dos de los satélites de la constelación TROPICS de la...

Debe ser rara la sensación de dedicar tu vida a la ciencia para ver cómo en pleno siglo XXI vuelven a circular con fuerza entre ciertos individuos un tanto descerebrados/conspiranoicos las teorías de la conspiración de las estelas químicas (chemtrails) más...

Se acaban de dar a conocer las primeras y muy espectaculares imágenes del satélite meteorológico MTG-I1 con unas fotografías de Europa desde una órbita a unos 36.000 km sobre la Tierra donde se pueden ver –y comparar– los progresos en tecnología...

Este próximo sábado, 6 de mayo, tendrá lugar el XXVII Día de la Ciencia en la Calle. En él 49 centros educativos de A Coruña, Arteixo, Arzúa, As Pontes, Betanzos, Cambre, Carral, Cerceda, Coristanco, Culleredo, Miño, Oleiros, Ortigueira, Outes, Poio, Pontedeume,...

Ayer, 30 de abril de 2023, fue el último día de operaciones del satélite Aeolus de la Agencia Espacial Europea (ESA). Lanzado el 23 de agosto de 2018 su objetivo era medir la velocidad del viento entre la superficie y los...

#ESAJuice deployment status update: our 16 m-long ice-penetrating RIME antenna is not yet fully deployed as planned. Work is ongoing to resolve an issue currently preventing it from being released from its mounting bracket.Details https://t.co/AIr13dQzMw pic.twitter.com/ABC2Ok8DXj— ESA's Juice mission (@ESA_JUICE) April 28,...
Todo lo que queda: Lo que la ciencia forense nos enseña sobre la naturaleza humana. Por Sue Black. Ediciones Paidós (17 de mayo de 2023). 384 páginas. Creo que no hace falta saber mucho de tecnología para suponer, acertadamente, que esos zooms...

Lanzamiento de SOHO el 2 de diciembre de 1995 – ESA/NASA En esta casa somos muy «fanses» de los números redondos. Así que nos ha encantado descubrir que el Solar and Heliospheric Observatory, Observatorio solar y heliosférico, mucho más conocido como SOHO,...
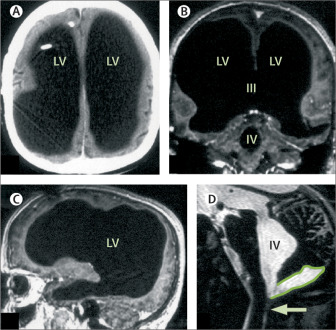
Siempre se ha dicho que lo de que «usamos solamente un 10% de nuestro cerebro» es una tontería pseudocientífica fuente de una mala interpretación de una cita, pero lo que sucedió con un paciente del Dr. Lionel Feuillet al respecto fue más...

Con el despliegue de los paneles solares, que desde las 15:33, hora penincular española (UTC +2), están en posición y generando electricidad, ya se puede decir que el lanzamiento de la sonda JUICE de la Agencia Espacial Europea rumbo a Júpiter...

Juice y su cohete en la plataforma de lanzamiento – ESA-CNES-ArianeSpace / Optique vidéo du CSG - S. Martin Todo está listo en el espaciopuerto de Kourou para el segundo intento de lanzamiento de la sonda Juice de la Agencia Espacial Europea...

Mosaico conmemorativo de las 50 órbitas de Juno – NASA Hace unos días la sonda Juno de la NASA completaba su órbita número 50 alrededor de Júpiter. La agencia lo ha celebrado publicando un mosaico que recoge otras tantas imágenes, una por...

Historia del futuro: Utopías y distopías después de la pandemia. Por Pablo Francescutti. Editorial Comares (28 de diciembre de 2021). 198 páginas. Desde unas fracciones infinitesimales de segundo después del Big Bang –la ciencia no es capaz de asegurar lo que pasó...

El pasado 6 de abril la doctora Makenzie Lystrup tomaba posesión de su cargo como directora del Centro de vuelo espacial Goddard de la NASA. Es la primera mujer que lo va a dirigir en los 65 años que han transcurrido desde...

La lira desafinada de Pitágoras – Cómo la música inspiró a la ciencia para entender el mundo. Por Almudena Martín Castro. HarperCollins Ibérica S.A. (18 de mayo de 2022). 360 páginas. En la Grecia clásica Pitágoras y sus seguidores descubrieron, entre otras...

Los Prismas posando para una foto en el Aquarium Finisterrae – mc2 Los Museos Científicos Coruñeses, en los que trabajo en el MundoReal™, acaban de poner en marcha la convocatoria de los Prismas Casa de las Ciencias a la Divulgación de 2023....

La Fundación Española para la Ciencia y la Tecnología (FECYT) acaba de publicar los resultados de la Encuesta de percepción social de la ciencia en España 2022. Es un estudio que se viene haciendo cada dos años desde 2002. El estudio cubre...

A principios del año pasado todo estaba listo para iniciar la campaña de lanzamiento del rover Rosalind Franklin de la Agencia Espacial Europea (ESA) rumbo a Marte. Pero la invasión rusa de Ucrania dio con todo al traste y obligó a...

Aunque su nombramiento se había producido en diciembre desde el pasado 1 de marzo de 2023 Carole Mundell es la nueva directora de ciencia de la Agencia Espacial Europea (ESA). Asume también la dirección del Centro Europeo de Astronomía Espacial (ESAC). Según...

Efecto de la lente gravitacional en cúmulo RX J2129. Imagen: ESA/Webb, NASA & CSA, P. Kelly Esta foto resulta impactante cuando te das cuenta de la grandeza de lo que estás viendo: tres imágenes de la misma galaxia en la misma toma,...
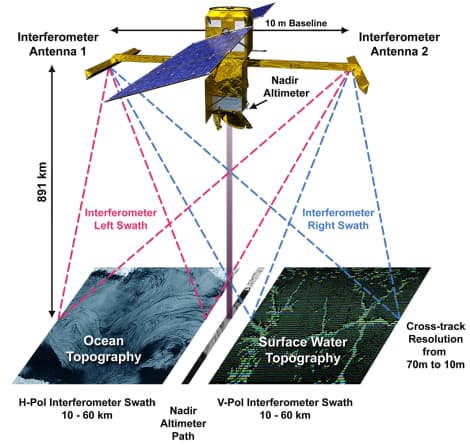
Impresión artística de SWOT en órbita - NASA Según se puede leer en el blog de la misión KaRIN, el instrumento principal del satélite medioambiental SWOT, ha fallado durante las primeras fases de su puesta en marcha y calibración. En concreto ha...

La NASA acaba de anunciar que, con efecto inmediato, Nicola Fox pasa a ser la directora de ciencia de la agencia. Sustituye en el puesto a Thomas Zurbuchen, que el año pasado decidió dejar el puesto tras seis años al frente de...

Cúmulo de Pandora, fotografía de NASA, ESA, CSA, I. Labbe (Swinburne University of Technology) y R. Bezanson (University of Pittsburgh) / Imagen Procesada por Alyssa Pagan (STScI). La NASA ha dado a conocer esta nueva imagen del cúmulo de Pandora obtenida con...

En este vídeo de Nova, de la PBS, se explica en menos tres minutos cómo funciona un astrolabio islámico, un invento que se usó durante siglos –se conoce desde el siglo II a. C.– para calcular, entre otras cosas, la hora...

La sombra de Hayabusa 2 a 30 metros de altura mientras sube tras la primera toma de muestras – JAXA Hace poco se cumplían dos años de la llegada a la Tierra de la cápsula con las muestras del asteroide Ryugu que...

JUICE tras ser sacada de su contenedor de transporte. En la foto está tumbada de lado, con su lado superior apuntando hacia la izquierda de la imagen. En esta orientación se ven los paneles solares, plegados, arriba y abajo – ESA/CNES/Arianespace/Optique vidéo...

Con motivo de la celebración del Día Internacional de la Mujer y la Niña en la Ciencia reproducimos aquí el artículo que la Cátedra de Cultura Científica de la Universidad del País Vasco ha publicado al respecto. El 11F es, sin...

Inferior. Por Angela Saini. Círculo de Tiza (2ª edición, 1 de noviembre de 2017). 270 páginas. Traducción de Alejandra Chaparro. En 2011, mientras estaba en plena promoción de su libro Geek Nation, la autora tuvo que enfrentarse con un «señoro» que, al...

La idea detrás de lo que hacen en GravityLab es tan sencilla como aparentemente fácil de llevar a cabo: proporcionar hasta 180 segundos de microgravedad (ingravidez o cero-G) para realizar experimentos científicos. Ese entorno se consigue dejando caer una cápsula con...

Selfie de Perseverance con el décimo tubo de muestras. Si abres la imagen en grande seguramente serás capaz de ver el tubo número 9 – NASA/JPL-Caltech El décimo tubo de muestras sobre la superficie de Marte visto por la cámara Watson del...

Estuve leyendo en un artículo de Nature sobre lo complicado que es responder a la pregunta ¿Qué hora es en la Luna? cuando se necesita saber el dato exacto. Pero exacto, exacto. Y es que, claro, si en la Tierra ya...
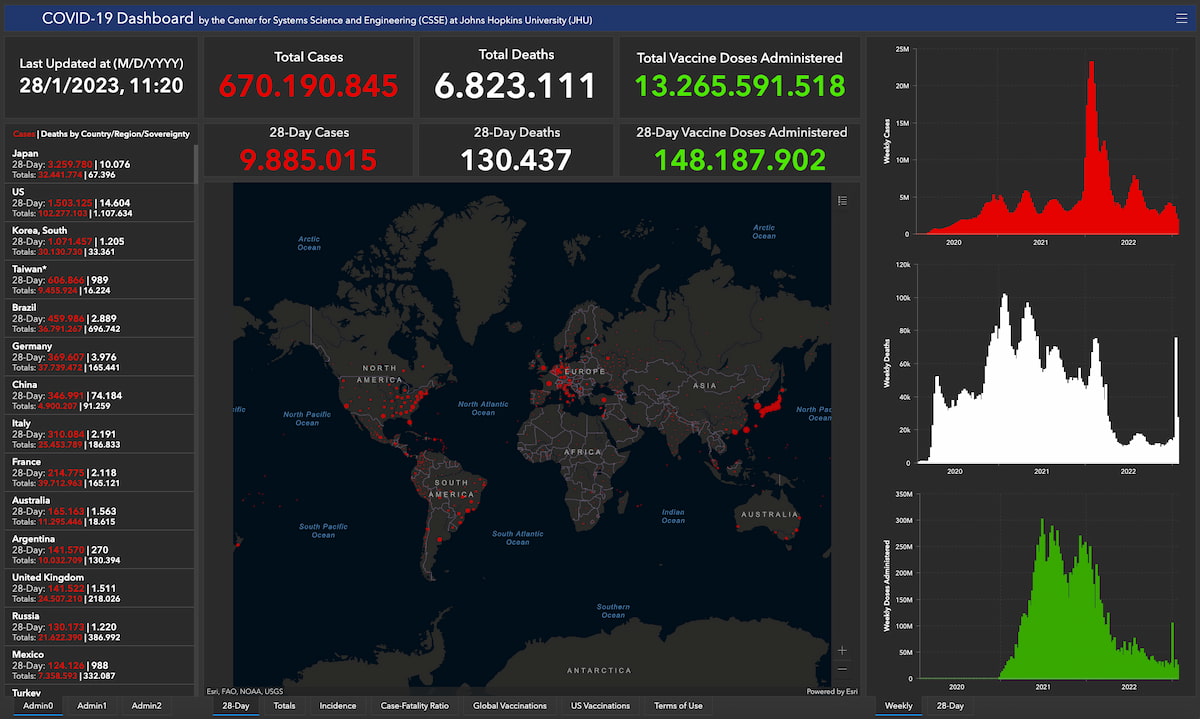
28 de enero de 2020 28 de enero de 2021 / año 2020 28 de enero de 2022 / año 2021 28 de enero de 2023 / año 2022 Tal día como hoy, hace exactamente tres años, publicábamos en Microsiervos la primera...

Al mirar este mapa algunas de las «calles verdes» en la visión periférica parecen trazar curvas. Pero al comprobarlo con más cuidado mirando directamente, se ve que son rectas… y entonces esas mismas curvas parecen moverse y aparecer en otros sitios. En...
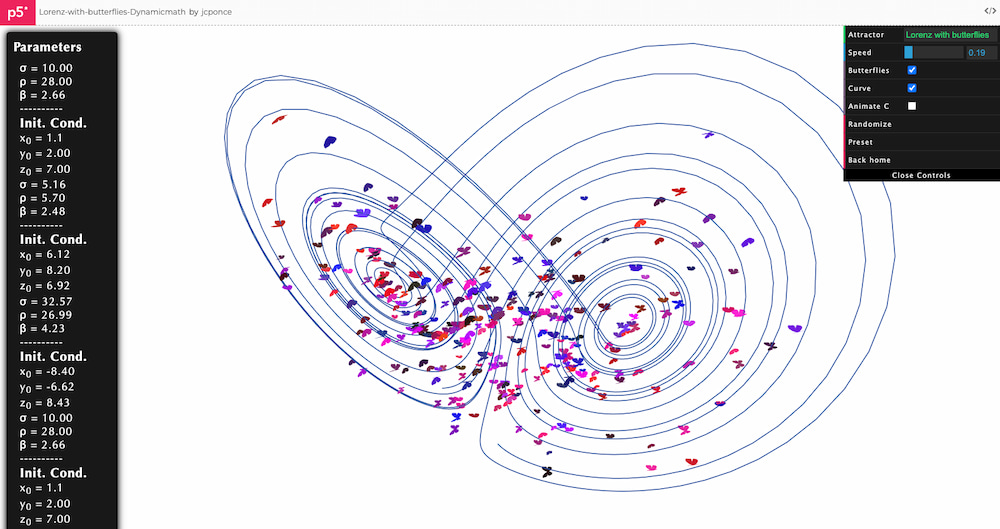
Mariposas revoloteando el atractor de Lorenz, que a su vez tiene forma de mariposa. ¿Se puede pedir algo más? Pues Juan Carlos Ponce tiene en su web esta preciosa página sobre Atractores extraños donde se puede ver su dinámico y caótico...
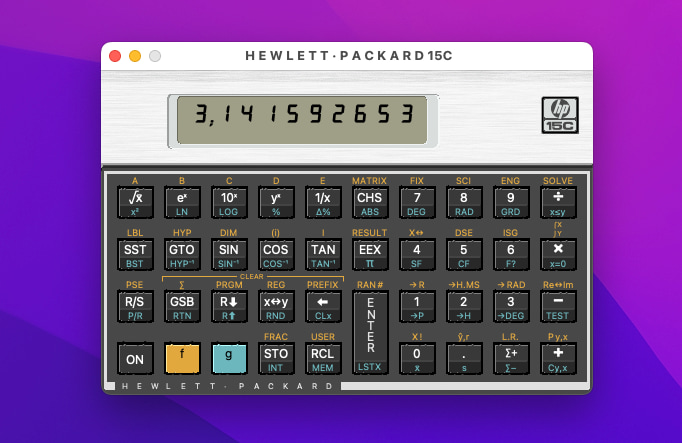
Desde el departamento de simuladores míticos y viejunos nos llega este Simulador de Calculadora HP-15C, en forma de aplicación para Windows, Mac y Linux. Este modelo, que recordarán los más viejos del lugar que sean «de ciencias», era el tope de...

Momento de la instalación de la placa – ESA/M.Pedoussaut Hoy he tenido la oportunidad de ver la sonda JUICE en persona, así como la de asistir a la dedicación e instalación de la placa en homenaje a Galileo que monta. A falta...

Llevo unos meses trabajando, junto con un equipo estupendo, en la organización de Género y Comunicación de la Ciencia. Se trata de la primera jornada de ámbito estatal destinada debatir la realidad de la perspectiva de género en el ámbito de la...
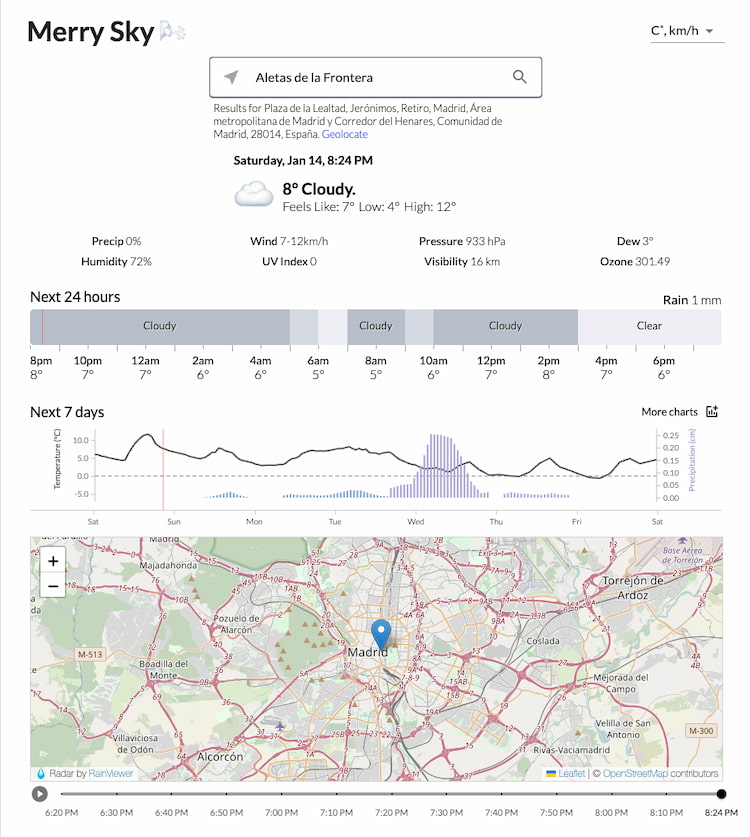
¡Ah, el tiempo atmosférico, esa gran afición oculta –o no tanto– de más gente de lo que que parece! Merry Sky permite ver la previsión del tiempo en tu zona es completamente automático: no hay ventanas que te pidan registrarte, ni...
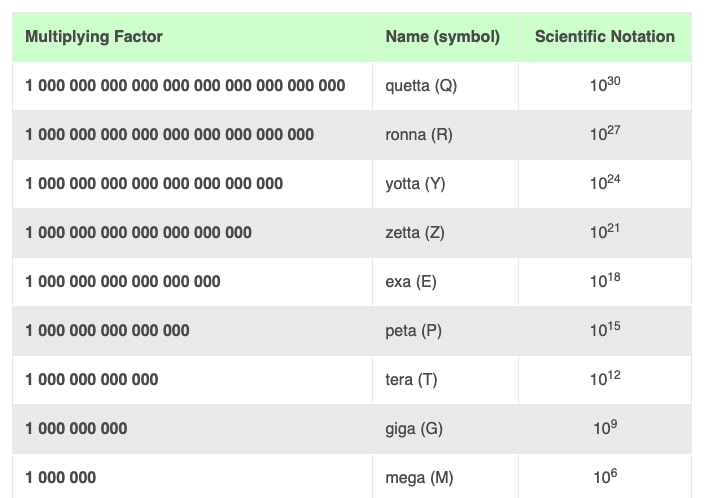
No me había yo enterado todavía de que a finales de año se añadieron nuevos prefijos al Sistema Internacional, en concreto ronna (1027), quetta (1030) y sus inversos ronto (10-27) quecto (10-30). No se añadía ninguno más allá del yotta desde...

Impresión artística de LHS 475 b y su estrella – NASA, ESA, CSA, Leah Hustak (STScI) Un estudio recién publicado confirma la detección del primer planeta extrasolar por parte del telescopio espacial James Webb. Denominado LHS 475 b, el planeta es rocoso...
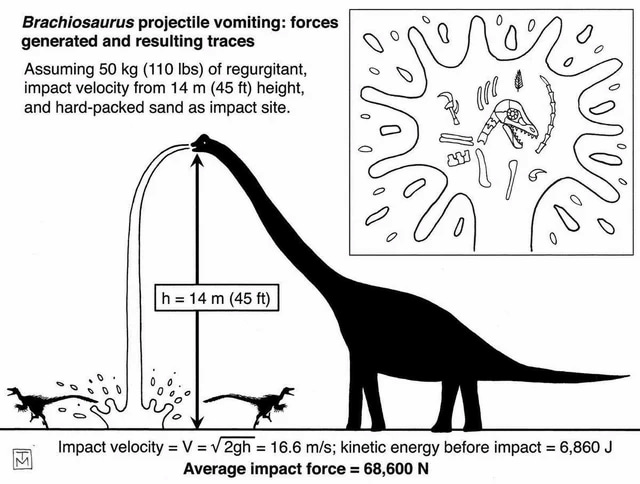
¡Puaaagggggg! En el libro Dinosaurs Without Bones (Dinosaurios sin huesos) de Anthony J. Martin hay un divertido y asqueroso cálculo sobre la fuerza generada por la pota/vómito/devuelto/emesis de un braquiosaurio. Debido a la altura y cantidad serían algo así como 68.000...

Derek de Veritasium tiene un vídeo de «visitas a laboratorios» que tanto nos gustan por aquí; en concreto uno de los del Instituto Nacional de Estándares y Tecnología (NIST) de los Estados Unidos, donde se miden las masas y fuerzas más...
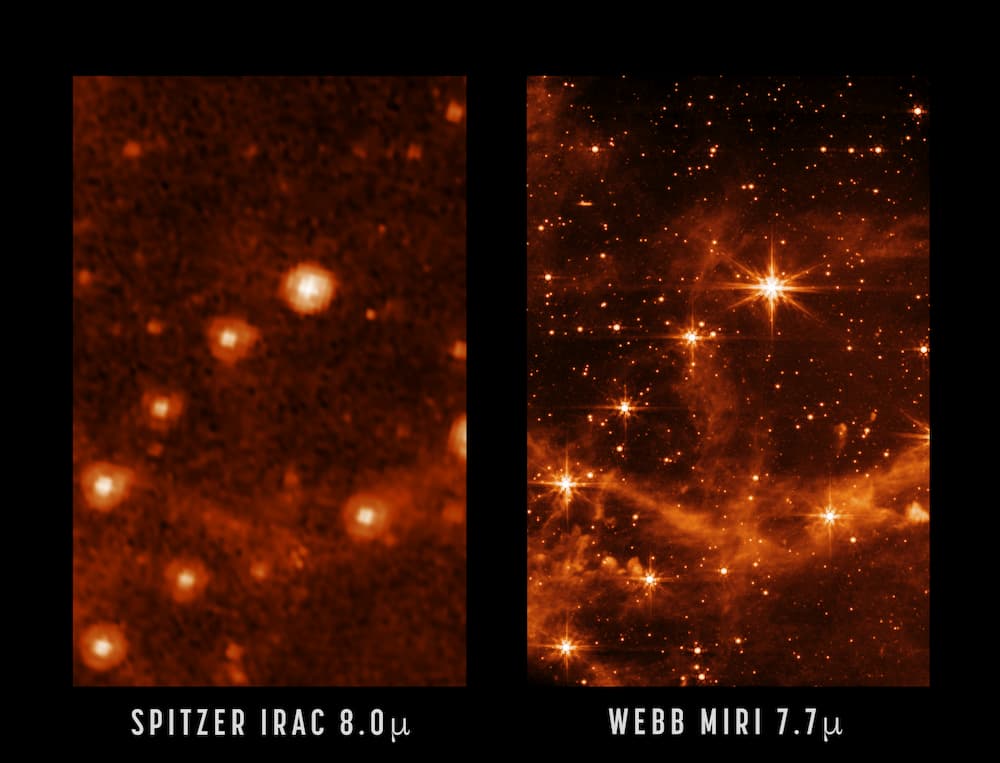
Se acerca el final de año y llega el momento de las recopilaciones. Así que hemos desempolvado algunos datos de la página de estadísticas para ver qué fue lo más popular del año pasado en Microsiervos. Estas son las cinco anotaciones más...

El primer tubo de muestras sobre la superficie de Marte visto por la cámara Watson del rover. La imagen sirve no sólo para ver que en efecto el tubo está sobre el suelo de Marte sino también para comprobar que no ha...

My power’s really low, so this may be the last image I can send. Don’t worry about me though: my time here has been both productive and serene. If I can keep talking to my mission team, I will – but I’ll...
Me he encontrado a través de los insondables RTs de Twitter con CaixaForum+, una plataforma de vídeo que no tengo ni idea de cuándo se ha lanzado pero que tiene pintaza: contiene cerca de mil documentales sobre cultura, ciencia y artes,...
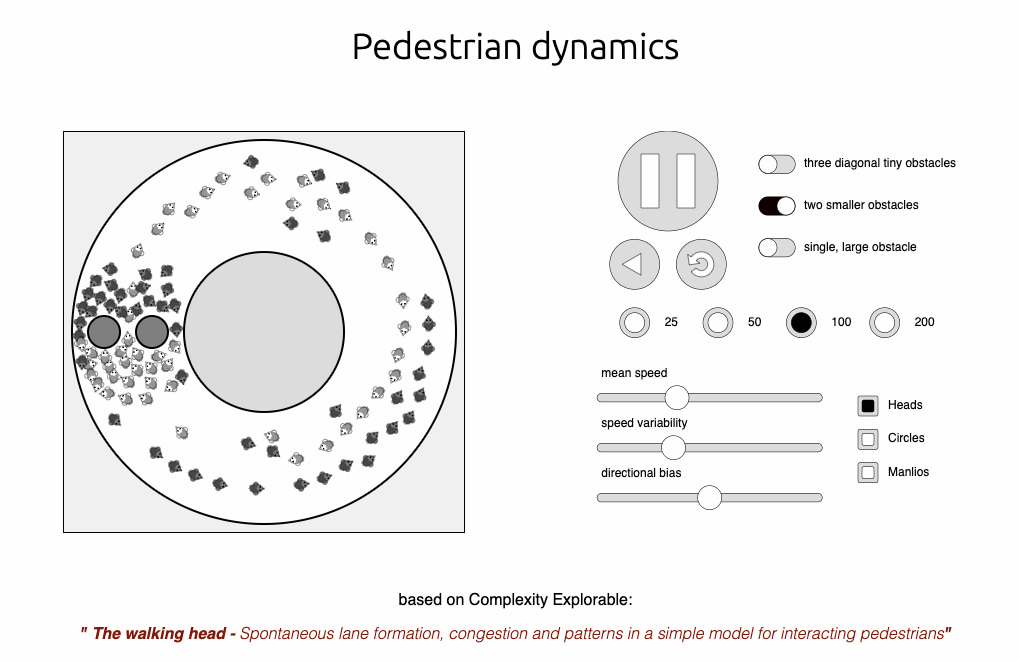
Bajo el título de The walking head (algo así como «cabeza andadora») hay un trabajo de simulación de esos que siempre resulta entretenido mirar. En este caso es una simulación del movimiento de peatones por la calle, poniendo énfasis en lo...

La broca para recogida de regolito de Perseverance montada en el cabezal de su taladro – NASA/JPL-Caltech/ASU Perseverance, el rover de la NASA que recorre el cráter Jezero en Marte, acaba de obtener su primera muestra de regolito marciano. Para ello ha...

Una pasada del BlueWalker 3 sobre el observatorio de Kitt Peak – KPNO/NOIRLab/IAU/SKAO/NSF/AURA/R. Sparks Tal y como era de suponer debido a su antena de 64 metros cuadrados el satélite BlueWalker 3 de AST SpaceMobile, que tiene como objetivo ofrecer cobertura de...

NASA, ESA, CSA, STScI, J. DePasquale (STScI), A. Pagan (STScI), A. M. Koekemoer (STScI) Aquí tenemos una tercera imagen de los Pilares de la creación vistos por el telescopio espacial James Webb. Combina las imágenes ya publicadas con anterioridad conseguidas por la...
Además de su impresionante nombre, Galáctica es un experimento consistente en una IA entrenada para ayudar a responder preguntas sobre ciencia, escribir código sobre cuestiones científicas, analizar la literatura científica y mucho más. Resuelve el clásico problema de la sobrecarga de...

La manera en que funciona nuestro cerebro nos permite llevar a cabo dos o más tareas a la vez, la conocida multitarea (multitasking), un término muy propio de la informática, en lo que las máquinas son geniales. Pero la ciencia tiene...

Impresión artística de la sonda Psyche en órbita alrededor del asteroide Psyche – NASA/JPL-Caltech La sonda Psyche de la NASA tenía que haber sido lanzada este año, como muy tarde a principios de octubre. Pero como no estuvo lista a tiempo lo...
Estaba viendo una charla sobre el perfil criminológico de los delincuentes en el ámbito empresarial cuando han mencionado DarkFactor.org, una web en la que se puede obtener una evaluación sobre lo que llaman el Factor D o «Factor oscuro» de la...

Los admiradores de Nikola Tesla están de enhorabuena: la Fundación La Caixa ha organizado un ciclo de divulgación científica bajo el título El futuro es de Tesla dentro de la exposición Nikola Tesla: el genio de la electridad moderna en la...

Utilizando diferentes simulaciones para visualizar altas velocidades, Benjamin Granville muestra en forma de vídeo lo curioso que «se vería» al viajar a la velocidad de la luz alrededor de la Tierra. También tiene otros vídeos interesantes de Mach 1 (la velocidad...

Los Pilares de la creación vistos a través del instrumento MIRI – NASA, ESA, CSA, STScI, J. DePasquale (STScI), A. Pagan (STScI) Hace unos días teníamos la oportunidad de ver la icónica imagen de los Pilares de la creación a través del...

Impresión artística de Rosalind Franklin y Kazachock recién aterrizados en Marte, algo que ya nunca veremos – ESA/Roscosmos El Consejo de la Agencia Espacial Europea (ESA), en su última reunión, recién celebrada, ha decidido pedir a los ministros del ramo, que se...

Hace poco estuve viendo Science Fiction: Voyage to the Edge of Imagination, una magnífica y muy interesante exposición sobre ciencia ficción que el Museo de Ciencias de Londres inauguró a principios de este mes. Si te pilla por allí –y te...
Cuando el radiotelescopio de Arecibo en Puerto Rico resultó destruido en diciembre de 2020 después de caer sobre su antena la plataforma de instrumentos se pusieron en marcha algunas iniciativas que pedían su reconstrucción. Pero en una nota publicada hace unos...

Los pilares de la creación, versión Webb – NASA, ESA, CSA, STScI; J. DePasquale, A. Koekemoer, A. Pagan (STScI) Si hay una imagen icónica en la historia de la astronomía en general y de la del Telescopio espacial Hubble en particular es...

NASA’s #LucyMission completed its 1st Earth Gravity Assist, passing just 220 miles/350 km above Earth’s surface!In 2 years, Lucy will return for a 2nd gravity assist, which will let it reach the main asteroid belt & observe asteroid Donaldjohanson. https://t.co/rOFSJXtk9D pic.twitter.com/fpB8wUiLHZ— NASA...

Impresión artística del observatorio en órbita Un cohete Larga Marcha 2D ponía en órbita hace unos días el observatorio solar espacial chino ASO-S, también conocido como Kuafu-1. ASOS-S viene de Advanced Space-based Observatory - Solar, Observatorio solar espacial avanzado; Kuafu, por su...

Aunque este verano aún estaba publicando lo que denominaban fotos recientes de la misión resulta que desde abril la Agencia India de Investigación Espacial (ISRO) no tiene contacto con la Mars Orbiter Mission (MOM), también conocida como Mangalyaan. Así que en un...

Este pasado fin de semana he podido ver –más o menos– la exposición AI: More than Human, que explora la relación entre los seres humanos y la tecnología y la inteligencia artificial así como los más recientes avances tanto creativos como...

El Hubble en la bodega de carga del Atlantis, listo para las tareas de mantenimiento que iba a acometer la tripulación de la misión STS-125 – NASA En mayo de 2009 el transbordador espacial Atlantis y su tripulación llevaba a cabo la...
Early this morning, @NASAJuno flew by Europa, returning our first closeup view since the Galileo spacecraft in 2001. Europa, with its ocean under its icy surface, is the target of @EuropaClipper, which will arrive at the beginning of the next decade to...

En estos instantes el telescopio aerotransportado SOFIA hace su último vuelo como instrumento científico. SOFIA, de Stratospheric Observatory For Infrared Astronomy, Observatorio estratosférico para la astronomía infrarroja no es ni más ni menos que un telescopio de 2,5 metros montado en...

En este vídeo del Videomuseo de la Ciencia (VMoS) japonés se puede experimentar, sin salir de casa, cómo es moverse a velocidades entre cero y la velocidad de la luz y lo que se vería a nuestro alrededor, comparando las velocidades...

Júpiter visto por el Hubble en junio de 2019. Por mucho que te esfuerces esta noche no lo verás así ni remotamente – NASA, ESA, A. Simon (Goddard Space Flight Center), y M.H. Wong (Universidad de California, Berkeley) Júpiter y Saturno suelen...

What do you think happens to the ping pong ball when I try to sink it in water? Find out! #MissionMinerva #bouyancy #SpaceTok @esa @esaspaceflight @Space_Station pic.twitter.com/dtxW8AOtlS— Samantha Cristoforetti (@AstroSamantha) September 24, 2022 Este vídeo grabado por Samantha Cristoforetti en la Estación...
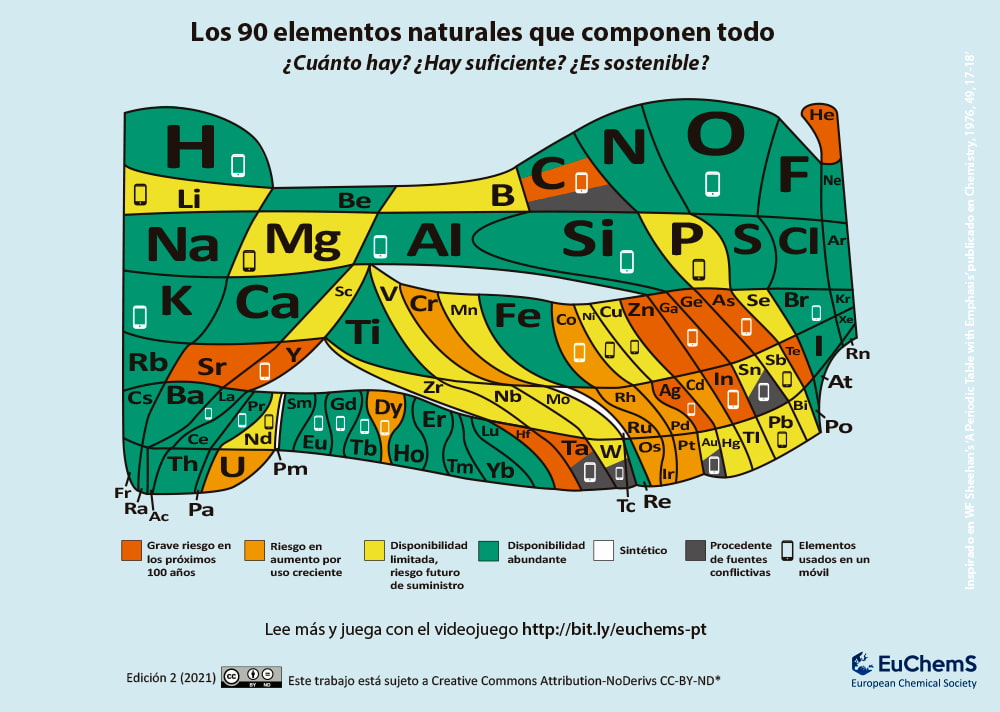
La Sociedad Química Europea publicó en 2019 una curiosa tabla periódica que fue posteriormente actualizada a la versión de 2021 que se ve en esta página. En ella aparecen los 90 elementos químicos naturales que componen básicamente todas las cosas que...

En julio de 2021 el AFOL Tonysmuncle, que además es astrónomo, propuso un Telescopio espacial James Webb de Lego a la escala de los minifig. Su propuesta alcanzó los 10.000 votos necesarios para que la empresa lo considerara como uno de...

Hasta hace unos minutos nunca había oído hablar de las gotas del príncipe Ruperto. O al menos que yo recuerde. Se crean dejando caer vidrio fundido en agua fría. Eso crea unas gotas con forma de renacuajo, con una cola larga...
Temperaturas umbrales de definición de ola de calor en función del percentil 95 de las series de temperaturas máximas diarias en el periodo junio-septiembre - Julio Díaz, Ferran Ballester y Rogelio López-Vélez Hace unos días me contaron que en A Coruña es...
El lupus eritematoso sistémico (LES) es una enfermedad autoinmune incurable que afecta prácticamente cualquier órgano del cuerpo, aunque hay tratamientos contra sus síntomas. Pero si se confirman los resultados publicados en el estudio Anti-CD19 CAR T cell therapy for refractory systemic lupus...

Este fin de semana he estado en Naukas Bilbao 2022. Han sido unas 50 charlas y similares sobre montones de temas distintos relacionados sobre todo, pero no exclusivamente, con la ciencia y la tecnología. Las puedes ver todas en la web...
Anoche se celebró la 32 ceremonia de entrega de los Premios Ig Nobel. Esos que premian aquellas investigaciones con títulos y descripciones hilarantes. Aunque a poco que te pares a darles una vuelta, tampoco tan descabelladas. Así que sin más rollos, aquí...

Impresión artística de la Solar Orbiter sobrevolando Venus – ESA A las 3:36, hora peninsular española (UTC +2), de ayer, domingo 4 de septiembre de 2022, la Solar Orbiter de la Agencia Espacial Europea (ESA) completaba sin problemas su tercer sobrevuelo de...

Acaba de fallecer Frank D. Drake a los 92 años. Ha dado la noticia su hija Nadia. Drake es el autor de la conocida ecuación que lleva su apellido. Es una estimación de cuántas civilizaciones extraterrestres pueden existir en un momento dado...

El núcleo de M74 – ESA/Webb, NASA & CSA, J. Lee y el equipo PHANGS-JWST. Gracias a J. Schmidt Después de años y años de retraso de su lanzamiento y seis meses de infarto después de él mientras se configuraba para funcionar...

¿Cómo sabes que eres una persona que ha vivido su vida, y no un cerebro recién formado, lleno de recuerdos artificiales, que sufre una alucinación momentánea de una realidad que no existe? Este curioso vídeo de Fabio Pacucci para TED Education...

En este artículo de la National Library of Medicine unos investigadores explican cómo decidieron examinar hasta qué medida afectaba la aleatoriedad (o falta de ella) de algunos generadores de números aleatorios (RNGs) a las simulaciones de Monte Carlo, un método utilizado...

Vi una referencia a un trabajo de unos investigadores del departamento de Inteligencia Artificial aplicada a la medicina de la Universidad de Cambridge que publicaron un trabajo en el que explicaban cómo dieron con un método para seleccionar los pacientes que...

La noticia apocalíptica del día que sin embargo mencionan solo así como de pasada en las noticias es que el agua de lluvia ya no es potable en ningún lugar del mundo debido a los agentes químicos perjudiciales para la salud...
Impresión artística de la estructura de algunas proteínas - AlphaFold Hace un año AlphaFold publicaba una base de datos que incluía la estructura prevista de cerca de un millón de proteínas. Eso incluía todas las proteínas humanas y alguna que otra más....
Impresión artística de los distintos elementos de la misión ya en Marte - NASA La NASA y la Agencia Espacial Europea (ESA) acaban de presentar una arquitectura simplificada para la misión de retorno de muestras de Marte. En ella han eliminando el...

Los siempre espectaculares vídeos de MetaBall Studios son una forma rápida y directa de entender órdenes de magnitud muy grandes, ya sea en distancias gigantescas, tamaños desmesurados o fuerzas desencadenadas. En esta ocasión Álvaro Gracia, con datos científicos de Ignacio Ferrin,...

Prototipo del brazo durante sus pruebas – Leonardo/Maxon/GMV/ OHB Italia/ SAB Aerospace s.r.o Después de una fase de estudio y prototipado la Agencia Espacial Europea (ESA) acaba de anunciar que la empresa italiana Leonardo diseñará el brazo del rover europeo que recogerá...

Primer campo profundo del Webb – NASA, ESA, CSA y STScI Esta pasada noche el presidente Biden presentaba, con más de una hora de retraso sobre la hora prevista como cualquier estrella del rock, la primera imagen del telescopio espacial James Webb....

Después de un parón de cuatro años, la tercera y mejorada versión del Gran Colisionador de Hadrones (LHC por su siglas en inglés) acaba de empezar a «acer la cencia», provocando colisiones de partículas a 13,6 teraelectronvoltios (TeV) y recogiendo los...
Aunque por aquí somos muy fans del dilema del tranvía desde hace más de una década, cierto es que tuvo su resurgir con la popularización de las IAs en los coches (pseudo)autónomos, donde ya había vidas en juego bajo el control...
Tanto el sonido como la luz son rápidos, muy rápidos. Pero es difícil hacerse exactamente una idea de cuán rápidos son a menos que se utilicen algunas comparaciones o se contemple el asunto desde una perspectiva un poco diferente. Justamente eso...

La consciencia nos parece algo único. Sin embargo, ese reconocimiento natural de la propia existencia parece claro que no es único del homo sapiens: muchos animales exhiben las mismas propiedades que nosotros. Por si eso fuera poco, ahora comenzamos a explorar...

Esto es lo típico que parece obvio cuando lo dices pero seguramente nunca se te habría ocurrido; al menos a mi. Christoph Schiller lo explica en una presentación [PDF] y un artículo titulado Fuerza máxima: un límite y principio de la...

SHOTS HAVE BEEN FIRED. I REPEAT, SHOTS HAVE BEEN FIRED.In a seminar to Nanjing University, Sun Zezhou, program chief of Chinese Mars mission Tianwen-1, has reported on the Chinese Mars Sample Return mission.TL;DR: Landing on Earth in July 2031, 2 years BEFORE...

Este extraño y absurdo proyecto se llama Exaluminal y tiene una función tan interesante como fútil: avisarte de la inminente destrucción de la Tierra si ha estallado una supernova y sus fotones, neutrones y otras partículas se dirigen hacia la Tierra....

Ahora que empieza la época de los festivales musicales de verano, andamos por el 93% de la población vacunada contra la covid y se comienza a debatir sobre la conveniencia de una cuarta dosis de refuerzo es el mejor momento para...
Esta semana el observatorio espacial Gaia de la Agencia Espacial Europea (ESA) ha publicado su tercer conjunto de datos. Incluye información nueva y mejorada de casi dos mil millones de estrellas de nuestra galaxia que mejora la de los conjuntos de...

Ya tenemos programa provisional para Naukas Bilbao 2022. Tendrá lugar del 15 al 18 de septiembre en el Palacio Euskalduna. Repite el esquema estrenado en 2017 y recuperado en 2021 tras el parón impuesto por la pandemia que incluye tres eventos relacionados:...

La NASA ha perdido dos satélites de la misión TROPICS para el estudio de huracanes a causa del enésimo fallo de un Rocket 3 de Astra. El lanzamiento tuvo lugar el 12 de junio de 2022. En los primeros minutos todo...

Los males de la ciencia. Por Juan Ignacio Pérez y Joaquín Sevilla Moróder. Next Door Publishers S.L. (23 de marzo de 2022). 288 páginas. La ciencia y su derivada práctica, la tecnología, son sin duda dos de las más importantes herramientas de...

Before losing more solar energy, I took some time to take in my surroundings and snapped my final selfie before I rest my arm and camera permanently in the stowed position. More on my final months ahead: https://t.co/eATDXbOlx2 pic.twitter.com/q7gso8NSjv— NASA InSight (@NASAInSight)...

Cuando hace unos días hablábamos de la imagen de Sagitario A* (Sgr A*), el agujero negro que está en el centro de la Vía Láctea presentada por el Event Horizon Telescope (EHT, Telescopio del Horizonte de Sucesos). Y decíamos que era...

A esta visita guiada al Laboratorio de Fabricación Avanzada de los Lawrence Livermore la denominan tour, y permite ver en poco más de cuatro minutos lo que se cuece en sus instalaciones. Es lo que yo llamo, con cariño, una «visita...

Kurzgesagt ha plasmado en un ejercicio de humildad cósmica las complicaciones de definir dónde nos parece estar, dónde en realidad estamos y cómo nos movemos por el universo. El viaje, resumido en 8 minutos de vídeo, comienza delante de nuestros ojos,...

Imagen del agujero negro Sagitario A*, en el centro de la Vía Láctea – EHT El Event Horizon Telescope (EHT, Telescopio del Horizonte de Sucesos) acaba de presentar la primera imagen de Sagitario A* (Sgr A*), el agujero negro que está en...
IRAC vs MIRI (clic para ver en grande) – NASA/JPL-Caltech; NASA/ESA/CSA/STScI Terminado su enfoque, al telescopio espacial James Webb aún le quedan un par de meses de ajustes y pruebas antes de entrar en servicio. Pero las imágenes del instrumento MIRI, aún...

Este vídeo que publicó el CERN hace tiempo es una especie de recorrido al estilo Potencias de diez hacia lo más pequeño, un zoom al revés, un macro superpotente. Comienza a escala humana y desciende de un orden de magnitud a...

Ahora que está todo el mundo revolucionado con los temas de espías, nos llega desde el mundillo de la red eléctrica un vídeo sobre una curiosa técnica que desveló Tom Scott hace tiempo acerca de «cómo atrapar criminales mediante el ruido...

Tras el parón impuesto por la pandemia este próximo sábado 7 de mayo de 2022 vuelve el Día de la Ciencia en la Calle al Parque de Santa Margarita en A Coruña. 35 centros de A Coruña, Arteixo, Betanzos, Cambre, Carral, Coristanco,...

Intentar predecir el futuro es una desalentadora y peligrosa tarea, porque el profeta se enfrenta invariablemente a dos «opciones trampa». Si sus predicciones suenan razonables, puede estar seguro de que en veinte o, a lo sumo, cincuenta años, el progreso de...
Esta preciosa y apetecible tabla periódica del espectro de los elementos es una idea de Field Tested Systems que la tiene disponible en su web como póster, camiseta, taza, funda de móvil y no se cuántos formatos más. En las camisetas...

Urano visto por la Voyager 2 – NASA/JPL Con el objetivo de asegurarse de que tiene sus prioridades alineadas con las de la comunidad científica la NASA le pide cada diez años a las Academias Nacionales de Ciencia, de Ingeniería y de...

Benn Jordan explica estupendamente en este vídeo no sólo por qué 194 dB es el sonido más fuerte que puede existir sino también montón de cosas relacionadas con el asunto, que van desde lo absurdo de la pregunta ¿Cuál es el...

Collider Detector del Fermilab – Agencia SINC Trabajando con datos obtenidos hace más de 10 años en el acelerador Tevatrón del Fermilab la colaboración científica Collider Detector at Fermilab acaba de publicar un trabajo que afirma que el bosón W es más...

El 21 de noviembre de 2020 la Agencia Espacial Europea lanzaba el satélite medioambiental Sentinel 6 «Michael Freilich» a bordo de un Falcon 9. Desde hoy sus mediciones se convierten en la referencia a la hora de determinar el nivel del...
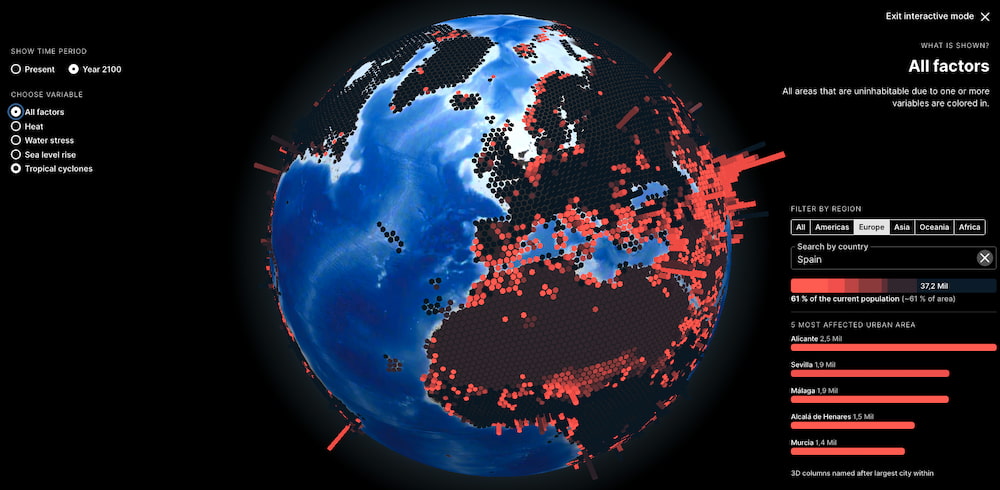
El diario alemán Berliner Morgenpost tiene este interesante Mapa de las zonas inhabitables de la Tierra en 2100 que básicamente muestra el futuro que se nos viene encima debido a la emergencia climática, región por región. Estas predicciones se corresponden con...
Los Prismas posando para una foto en el Aquarium Finisterrae – mc2 Los Museos Científicos Coruñeses, en los que por si aún no lo sabes trabajo en el MundoReal™, acaban de poner en marcha la convocatoria de los Prismas Casa de las...

En este vídeo a cámara superlenta (6.000 fotogramas por segundo) se ve el resultado de un experimento puntual que Kyle Gilroy y sus colegas llevaron a cabo para comprobar el tiempo de reacción de una mosca común. Y aunque se utiliza...

Eärendel es el punto indicado por la flecha roja – NASA, ESA, B. Welch (JHU), D. Coe (STScI), A. Pagan (STScI) La noticia astronómica de las últimas horas es la publicación de un trabajo en el que se afirma que el telescopio...
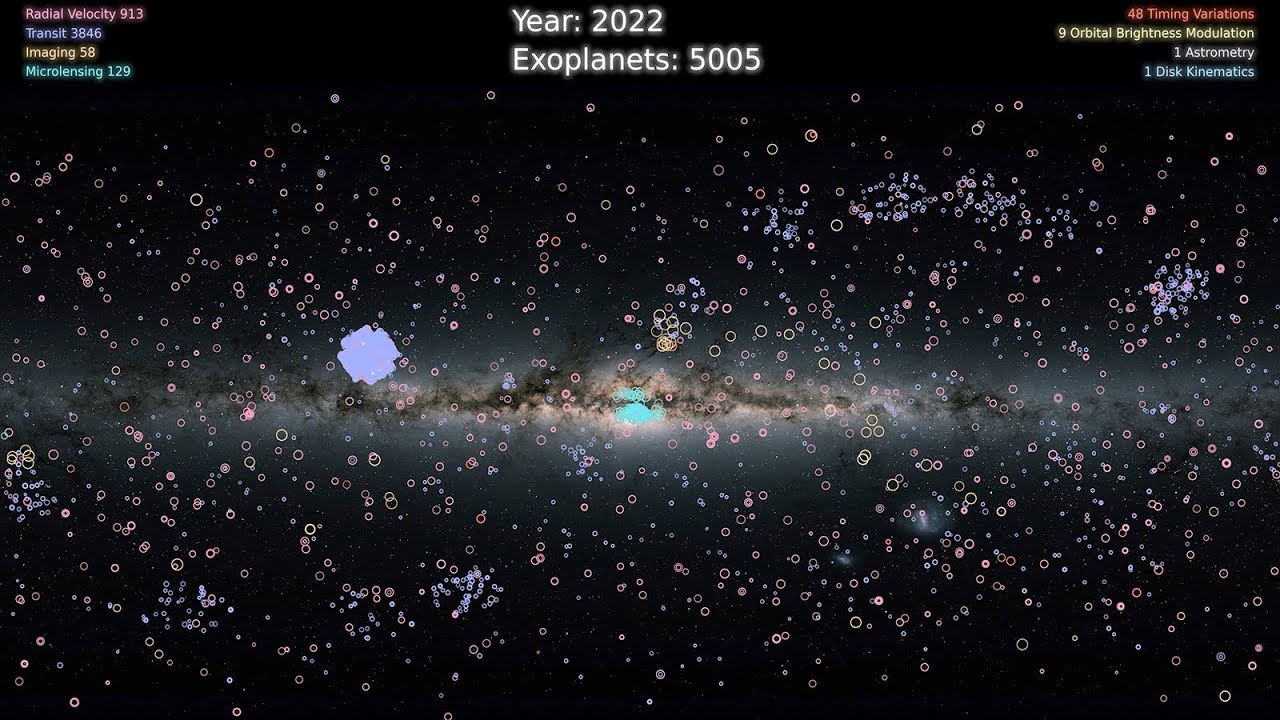
Hace apenas unos días la NASA anunciaba que la lista de planetas extrasolares que tenemos localizados ya pasaba de los 5.000. En la sonificación 5,000 Exoplanets: Listen to the Sounds of Discovery (360 Video) se puede ver –y escuchar, claro– en...

El Sol visto por la Solar Orbiter el 7 de marzo de 2022 - ESA & NASA/Solar Orbiter/EUI team; Data processing: E. Kraaikamp (ROB) El pasado 7 de marzo de 2022 el Extreme Ultraviolet Imager (EUI, Cámara de ultravioleta extremo) de la...

Ya en el siglo XVI Giordano Bruno estaba convencido de que tenía que haber planetas en órbita alrededor de otras estrellas. Pero no fue hasta 1992 cuando pudimos confirmar que su intuición, que a todas luces lo parecía, era correcta. Tres...

Sean Holloway ha creado estas espectaculares visualizaciones en ray tracing de agujeros negros según la relatividad general. Un trabajo a medio camino entre el arte, la ciencia y la programación. Traducido a lenguaje poco comprensible significa que se ha utilizado la...
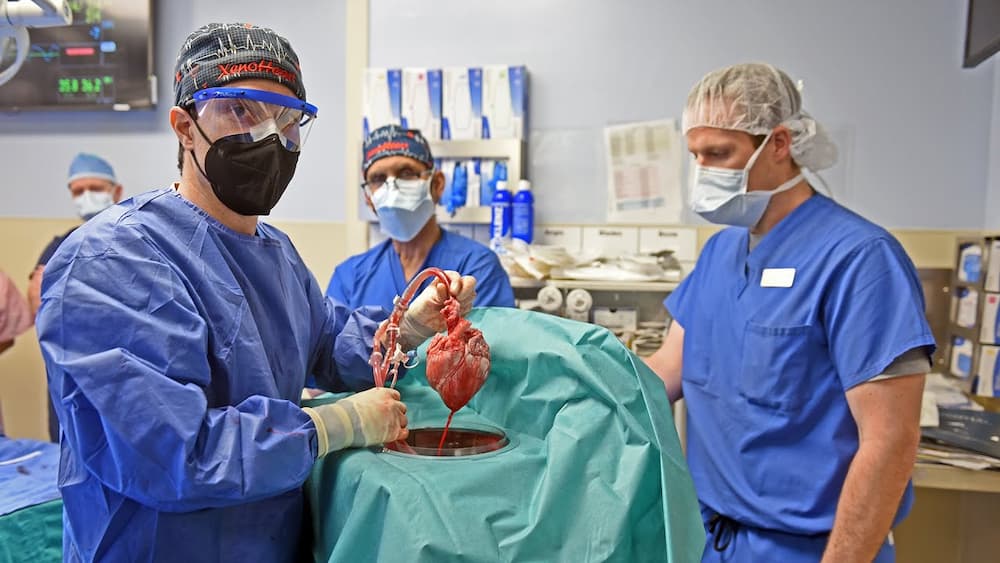
El corazón del cerdo ya listo para el trasplante – UMMS David Bennett, el paciente que a principios de este año se convertía en la primera persona en recibir un trasplante de corazón de cerdo, ha fallecido. Según la nota de prensa...
A través de un retuit me he enterado de la existencia del Diccionario de Siglas Médicas de la Sociedad Española de Documentación Médica(SEDOM). Es básicamente un gigantesco glosario de abreviaturas, acrónimos y siglas de esas que se mencionan en los informes...

Tenía por ahí guardado un enlace a este trabajo sobre una inyección de «nanoantenas» para dotar de visión infrarroja a los mamíferos, un invento propio de «científicos locos» que es tal como suena. Se publicó en la revista Cell, aunque no...

Estos vídeos tan elegantes y tranquilizadores provienen del canal Cosas hechas de cartón, donde como su nombre indica se pueden ver diversos «inventos» y chismes construidos básicamente con cartón, pegamento, hilos, canicas, imanes y poco más. Pero… ¿Quién dijo que con...

Hace unos días se cumplía un año de la llegada del rover Perseverance de la NASA a Marte junto con su compañero de viaje el helicóptero Ingenuity. A lo largo de este año Perseverance ha estado haciendo cosas de rovers, igual...

Con motivo de la celebración del Día Internacional de la Mujer y la Niña en la Ciencia reproducimos aquí el artículo que la Cátedra de Cultura Científica de la Universidad del País Vasco ha publicado al respecto. El 11F es, sin...

Impresión artística de Próxima d (con permiso del Astrónomo Indignado) – ESO/L. Calçada Un equipo internacional de investigadores e investigadoras ha localizado un posible nuevo planeta alrededor de Próxima Centauri, la estrella más cercana al Sol, a tan sólo cuatro años luz...

Despegue del MAV – NASA JPL Caltech Ya sabíamos que Airbus se va a encargar de diseñar –y probablemente construir– el rover que va a recoger las muestras que está tomando ahora mismo Perseverance en Marte y también la nave que las...

Con todas las reservas porque por ahora la muestra es de tres personas pero lo que se puede leer en New implant offers promise for the paralyzed es impresionante. El artículo habla de unos nuevos implantes, junto con un sistema informático...
Foto por Johannes Plenio en Unsplash Hace unos días la Organización Meteorológica Mundial (OMM) publicaba el artículo WMO certifies two megaflash lightning records en el que hace oficiales dos récords para sendos rayos: uno de longitud y otro de duración. Así, en...

No es que vayamos a poder hacer mucho si alguna vez descubrimos que un asteroide va a chocar contra la Tierra, aunque estamos empezando a hacer pruebas. Pero para poder hacer algo es necesario que lo descubramos con la suficiente antelación....

This rock almost looked surprised that I was coming back! Thankfully, I was able to collect another sample here to replace the one I discarded earlier. This may be one of the oldest rocks I sample, so it could help us understand...

Doug Olson – Universidad de Pensilvania Ayer se publicó el artículo Decade-long leukaemia remissions with persistence of CD4+ CAR T cells. En él se menciona a Doug Olson, que en 2010, y tras haber agotado todas las demás opciones, fue uno de...

No conocía el trabajo de Craig Beals, pero parece de lo más interesante. Es ciencia divertida, en forma de experimentos, vídeos y todo tipo de actividades propias de «científico loco». En este antiguo vídeo, por ejemplo, puede verse cómo es la...

Como ya hemos comentado en varias ocasiones el telescopio espacial James Webb va a pasarse su vida útil en órbita alrededor del punto de Lagrange L2 del sistema Sol – Tierra y apuntando siempre en dirección contraria al Sol con la...
Impresión artística de un páncreas con cáncer – CSIC Una baza fundamental en la lucha contra el cáncer en cualquiera de sus formas es la detección precoz, lo que no siempre es fácil. Pero un equipo co-liderado por investigadores del CSIC ha...
28 de enero de 2020 28 de enero de 2021 28 de enero de 2022 Tal día como hoy, hace exactamente dos años, publicábamos en Microsiervos la primera anotación en la que hablábamos de la incidencia del coronavirus (2019-nCoV) en todo el...

El Calendario científico escolar es una iniciativa del Instituto de Ganadería de Montaña (IGM) del centro mixto del Consejo Superior de Investigaciones Científicas (CSIC). Como desde hace tres años, se puede descargar y usar en clases o en casa: El Calendario...

A veces la suerte tiene mucho que ver en la ciencia, igual que en otros ámbitos. Y fue precisamente una cuestión de suerte la que hizo que la Solar Orbiter de la Agencia Espacial Europea cruzara por casualidad la cola del...
Me había apuntado mirar un par de semanas después de dar la noticia qué tal le iba a David Bennett Sr. la primera persona de la historia en recibir trasplantado el corazón de un cerdo. Y la buena noticia para él, su...

El Consejo de Ciencia y Seguridad de los Científicos Atómicos entre los que hay 13 premios Nobel, ha publicado que el Reloj del Apocalipsis se mantiene a 100 segundos antes de la medianoche tras ver el panorama de 2021 – y...
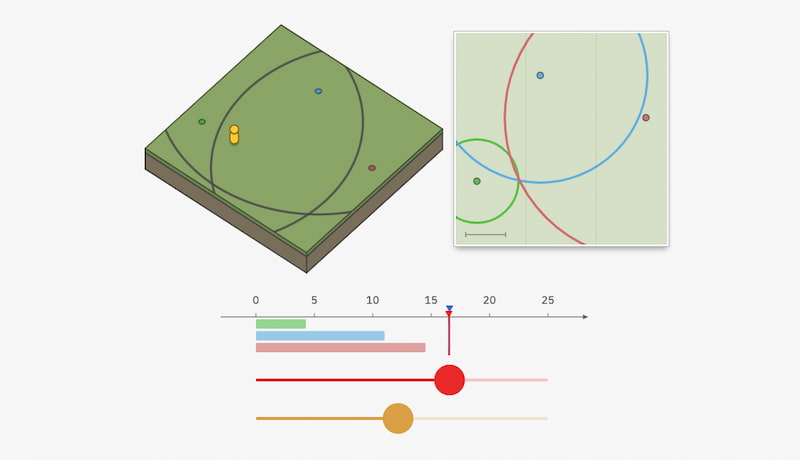
GPS, de Bartosz Ciechanowski es el nuevo artículo interactivo de este creador californiano especializado en la divulgación sobre física, matemáticas e ingeniería. Básicamente describe paso a paso cada uno de los componentes que hacen funcionar el Sistema de Posicionamiento Global y...

La BBC, el divulgador británico Brian Cox y The Open University montaron hace poco esta nueva versión que recrea el clásico Potencias de diez, el minidocumental de Charles y Ray Eames de 1977 que se popularizara al emitirse por televisión en...
Non é sen tempo, que decimos en mi tierra. Pero por fin Twitter permite denunciar tuits específicamente por difundir información falsa sobre salud. Antes era complicado hacerlo porque realmente no había una categoría para hacerlo y había que ponerlos en el epígrafe...

A través de un artículo de BBC Future titulado The forgotten medieval habit of «two sleeps» («El olvidado hábito medieval del dormir dos veces») estuve leyendo algunas curiosidades sobre las diversas modalidades de sueño. Porque aunque todo el mundo tiene claro...

Los guijarros atascados en el carrusel de toma de muestras de Perseverance – NASA/JPL-Caltech/MSSS El pasado 29 de diciembre de 2021, al intentar almacenar la séptima muestra que tomó en Marte, el rover Perseverance de la NASA detectó un problema. Así que,...

Un mes después de su lanzamiento el observatorio espacial de rayos X IXPE de la NASA acaba de terminar su fase de puesta en marcha y ya está realizando observaciones. Aunque aún quedan por calibrar sus instrumentos de a bordo, para...
El corazón del cerdo ya listo para el trasplante – UMMS No sé cuánto tiempo hace que leí por primera vez acerca de xenotrasplantes, la posibilidad de hacer trasplantes de órganos entre especies, en concreto de animales a seres humanos para evitar...

Cosmicómic por Amedeo Baldi y Rossano Piccioni. Traducción de Julia Osuna Aguilar. Salamandra Graphic (3 de junio de 2021). 152 páginas. Español. Me ha gustado mucho este cómic que cuenta cómo llegamos a formular la teoría del Big Bang. Me parece que...

Despegue del Webb – ESA/CNES/Arianespace La misión del Telescopio Espacial James Webb es contar la historia del universo, desde unos pocos latidos después de su radiante y explosivo nacimiento, pasando por el discurrir de las eras cósmicas, hasta ahora, cuando los humanos...
De promedio, el cerebro consume más o menos el 20 por ciento de la energía del total del cuerpo humano. Curiosamente, este porcentaje no varía mucho por el hecho de «concentrarse y pensar» o por no estar haciendo «nada», por ejemplo...

El pasado mes de abril la Parker Solar Probe (PSP) de la NASA se convirtió en la primera sonda espacial de la historia en meterse en la atmósfera del Sol. Este vídeo recién publicado recoge cómo el instrumento WISPR (Wide-field Imager...

Si no me fallan las búsquedas la primera vez que mencioné el futuro lanzamiento del telescopio espacial James Webb en el blog fue en febrero de 2004. Entonces se hablaba de 2011 ó 2012. No sé cuántas veces he ido sacando...

Desde hoy mismo está disponible el primer capítulo de Universo Curioso, el primer podcast en español de la NASA. Es un capítulo dedicado al cada vez más próximo lanzamiento del Telescopio Espacial James Webb, ahora mismo previsto para no antes del...
La NASA acaba de confirmar que los datos recogidos por la la Parker Solar Probe (PSP) en su octava aproximación al Sol indican que el 28 de abril de 2021 la sonda cruzó el límite entre el espacio y la atmósfera...

Deployment of IXPE confirmed pic.twitter.com/Gqx52tUf2O— SpaceX (@SpaceX) December 9, 2021 Esta mañana un Falcon 9 de SpaceX ha lanzado el observatorio espacial de rayos X IXPE para la NASA. El observatorio está en su órbita y ahora toca el periodo de puesta...

El Webb durante los preparativos para el lanzamiento en el espaciopuerto de Kourou – ESA Una gran noticia por parte del blog del Telescopio Espacial James Webb. Según se puede leer en Testing Confirms Webb Telescope on Track for Targeted Dec. 22...
No hay nada más relevante en la vida de un ciudadano que la ciencia que salva vidas.– Patricia Fernández de Lis, autora de El año de la ciencia,en los actos de entrega de los Prismas a la Divulgación 2021de los Museos...

Internet hace que la gente se crea más inteligente de lo que es. Es un fenómeno que recuerda un poco al efecto Dunning-Kruger, solo que es medible de otra forma y atribuible a otras causas: En la actual era digital, las personas...

El Webb durante los preparativos para el lanzamiento en el espaciopuerto de Kourou – ESA/CNES/Arianespace/P. Piron Un accidente en el procesado del telescopio espacial James Webb en el que se soltó inesperadamente una cinta de sujección mientras lo iban a fijar en...

En este vídeo de Cerebrotes la bioquímica y doctora en neurociencia Clara García explica la hipótesis del mundo justo. También conocida como «creencia en un mundo justo» se trata de una falacia muy arraigada que hace pensar a la gente que...

Estuve estos días investigando sobre las cámaras oscuras como instrumentos para la copia de imágenes, a raíz de ver el maravilloso documental Tim’s Vermeer (2013) y uno de los vídeos que encontré es este de National Geographic que aunque tiene una...
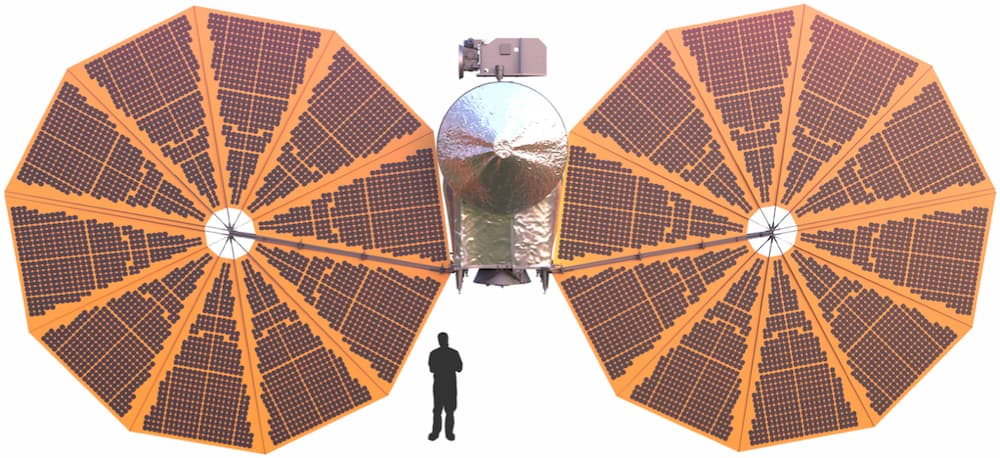
Esquema de Lucy con los paneles solares y la plataforma de instrumentos, en la parte superior de la sonda, encima de la antena, desplegados, con una persona para dar escala – Southwest Research Institute El pasado 16 de octubre de 2021 la...
ClimateArchive.org es una bonita visualización interactiva de los últimos 540 millones de años y todas sus eras, desde la paleozoica a la cenozoica, cuando los continentes se situaron en sus posiciones actuales. Es una estupenda «máquina del tiempo» para repasar en...

Impresión artística de la Mars Odyssey en órbita alrededor de Marte – NSA/JPL El 24 de octubre de 2001 la sonda Mars Odyssey de la NASA entraba en órbita alrededor de Marte para una misión con una duración prevista de 32 meses....

Desde que hace más de 500 años Martín Lutero se agarrara un cabreo monumental y clavara sus Noventa y cinco tesis en la puerta de la puerta de las iglesias de Wittenberg a modo de manifiesto de declaraciones o propuesta de debate...

CHASE antes de ser preparado para el lanzamiento – Corporación de Ciencia y Tecnología Aeroespacial de China El pasado 14 de octubre de 2021 China lanzaba el observatorio solar CHASE/Xihe, su primer observatorio solar. CHASE viene de Chinese Hydrogen Alpha Solar Explorer,...

Impresión artística de Lucy sobrevolando un asteroide troyano – Southwest Research Institute Hace unas horas un cohete Atlas 5 lanzaba la sonda Lucy de la NASA en un camino que durará doce años en el que visitará seis asteroides troyanos de Júpiter...

El Webb a su llegada a Kourou – ESA/CNES/Arienespace/Optique vidéo du CSG Desde hace unas horas el telescopio espacial James Webb está en las instalaciones del Espaciopuerto de Kourou en la Guayana Francesa desde el que, si todo va bien será lanzado...
Aunque no tiene una gran eficacia la Organización Mundial de la Salud (OMS) acaba de decidir recomendar una vacuna contra la malaria por primera vez en la historia. Se trata de una vacuna que actúa contra el Plasmodium falciparum, el más mortal...

El JWST en configuración de lanzamiento en la sala limpia de Northrop Grumman en California – Northrop Grumman A la chita callando el telescopio espacial James Webb (JWST) ha iniciado su camino hacia el espaciopuerto de Kourou en la Guayana Francesa para...
La entropía de un agujero negro es tan grande que toda la información de Google –hace años se calculó que unos 10 exabytes– podría almacenarse en un agujero negro de radio 10-24 milímetros (un yoctómetro o una cuatrillonésima parte de un metro)....

En la noche del viernes 24 de septiembre de 2021 cientos de actividades en más de 360 localidades repartidas por 29 países de toda Europa marcarán la edición de este año de la Noche europea de las personas investigadoras. La idea...

Vista desde la cabina del Falcon 20 de la DLR durante los vuelos de calibración – Thomas Marwick/DLR Lanzado el 23 de agosto de 2018, el satélite medioambiental Aeolus está demostrando ser un gran éxito a la hora de medir la velocidad...

Los agujeros dejados en Rochette por las dos primeras tomas de muestras con éxito de Perseverance – NASA/JPL-Caltech/ASU Tras el fracaso del primer intento de toma de muestras por parte del rover Perseverance de la NASA en Marte el equipo de la...
Otro año más, y con esta van 31 ediciones, ya tenemos los ganadores de los Premios Ig Nobel. Ya sabéis, los que premian aquellas investigaciones con títulos y descripciones hilarantes pero no por ello menos ciertas. Y a menudo, si las piensas...

Aunque desde hace unos días ya está listo para su traslado al Centro Espacial de Kourou la Agencia Espacial Europea (ESA) y la NASA han anunciado que el lanzamietno del elescopio Espacial James Webb se va a retrasar hasta el 18...

La muestra dentro de la broca – NASA/JPL-Caltech/ASU La NASA acaba de informar de que el tubo de muestras con el número 266 de los que llevó el rover Perseverance a Marte está ya correctamente almacenado en las tripas del rover. Así...

Allá por 2019 Casio sacó una gama de calculadoras científicas cuya carcasa estaba ilustrada por científicas relevantes de la historia. La idea era mostrarles a las niñas referentes fuertes femeninos en el campo de la ciencia, tecnología, ingeniería y matemáticas que les...

El JWST de Lego propuesto por tonysmyuncle James Webb Space Telescope (JWST) es una propuesta de tonysmyuncle para que Lego saque un Telescopio espacial James Webb. Está a la escala de los minifig, como se puede ver en la foto. E igual...
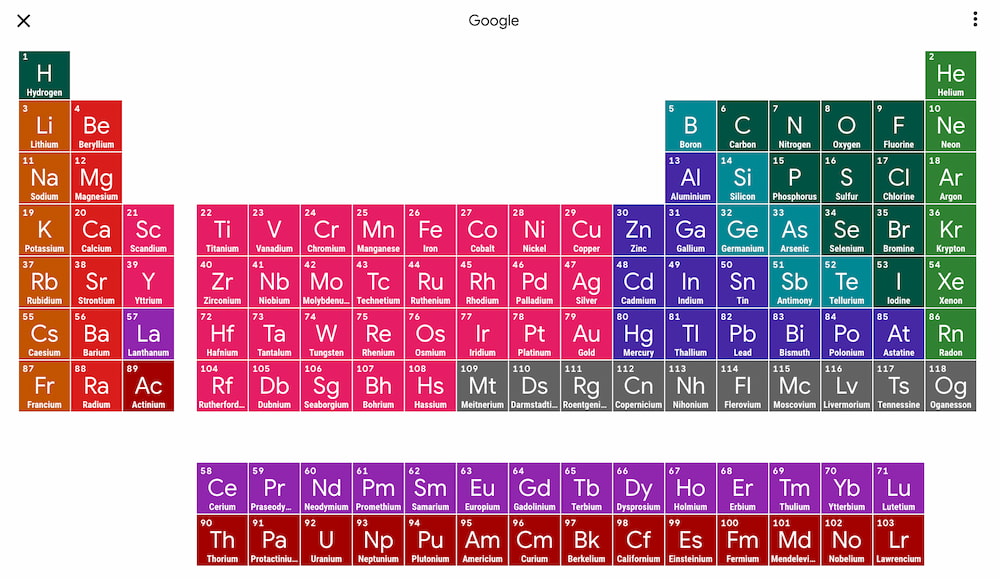
Esta tabla periódica de los elementos de Google, departamento de «experimentos» es una elegante representación de los elementos químicos, que no está mal tener guardada en los marcadores favoritos por si hay que consultar algo en plan rápido. Entre otros detalles...

Agujero dejado por la primera toma de muestras de Perseverance – NASA/JPL-Caltech El 6 de agosto de 2021 el rover Perseverance llevó a cabo su primera toma de muestras en Marte. O más bien su primer intento de toma de muestras, porque...

La gente de Ant Lab ha grabado unos espectaculares vídeos a cámara superlenta –porque a cámara superlenta todo es mejor– con siete polillas despegando y alzando el vuelo. Son una extraña mezcla de imágenes entre irreales y espectaculares, que podrían pasar...
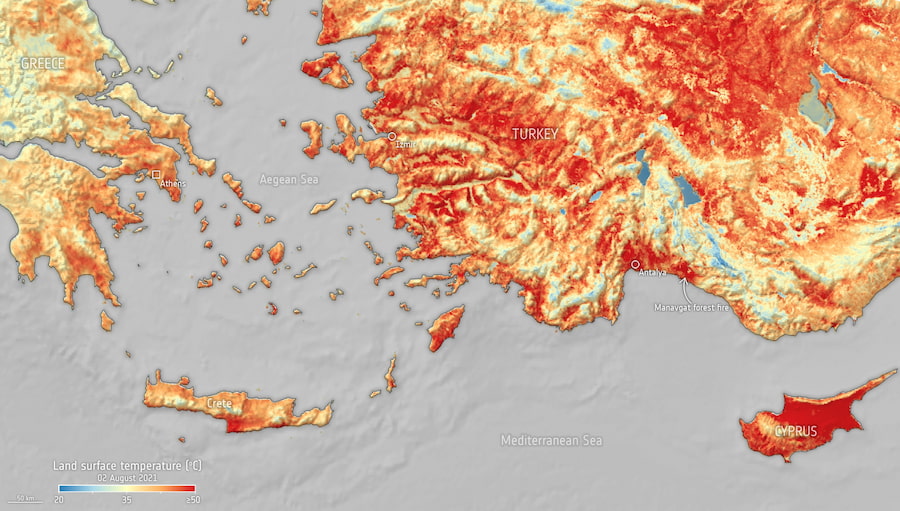
Grecia, Turquía y Chipre alcanzando récords de temperatura en superficieImagen (CC) ESA /Copernicus Sentinel-3 Cuando te llega un boletín de la Agencia Espacial Europea con el título «El Mediterráneo continúa cocinándose» muy bien no suena. La nota hace referencia a los récords...

Pedro Machado es un artista brasileño que tiene en su portfolio de animaciones 3-D este curioso Super Zoom que comienza con un escritorio, una hoja de papel y un bolígrafo y se adentra pasito a pasito hasta el interior de los...

La teoría del caos es una de esas cuestiones matemático-físicas que es mucho más fácil «ver para entender» que leer páginas y páginas sobre el tema. Lo interesante es que además puede visualizarse de muchas formas y ni siquiera hay que...
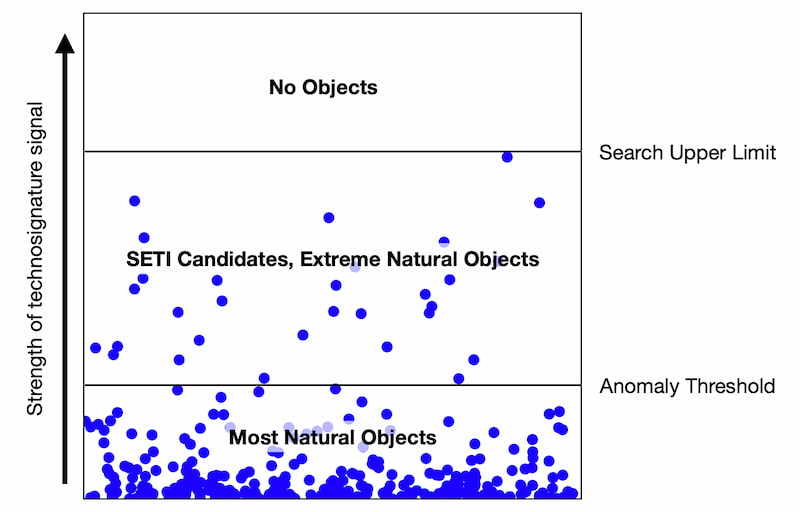
Bajo el interesante y prometedor título Estrategias y consejos para la búsqueda de inteligencia extraterrestre se puede encontrar un trabajo del profesor de astrofísica y astronomía Jason T. Wright donde se repasa el estado actual de la cuestión con un pequeño...

La ciencia de los campeones: Deporte, triunfo y revolución científica por José Manuel López Nicolás. Editorial Planeta (16 junio 2021). 384 páginas. Hoy, que acaban de comenzar los Juegos Olímpicos de 2020 aunque sea julio de 2021, es un día perfecto...
DeepMind, la empresa subsidiaria de Google conocida por haber escrito AlphaGo, el programa que fue capaz de ganar al go al campeón mundial de este juego, acaba de publicar junto con el Laboratorio Europeo de Biología Molecular (EMBL) una enorme base de...

Igual que sabemos desde hace años que existen planetas extrasolares situados alrededor de estrellas que no son nuestro Sol era de suponer que algunos de ellos tuvieran lunas a su alrededor. Y de hecho tenemos datos que sugieren que hemos detectado...

El vídeo Pulsar music tiene ya algún tiempo pero se me había pasado. Es una sonificación de datos recogidos por el telescopio espacial de rayos X Spektr-R del programa RadioAstron. En ella se hace corresponder la frecuencia de distintos púlsares con...
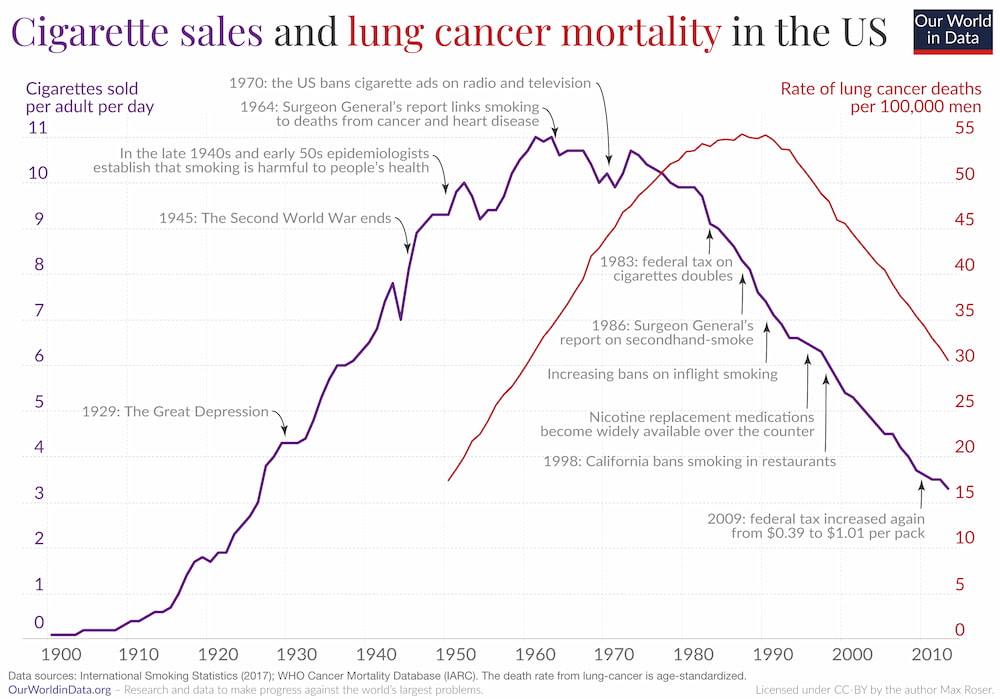
Venta de cigarrillos y mortalidad por cáncer de pulmón en los Estados Unidos. Datos: OMS/SMI/OurWorldInData.org Está haciendo las rondas esta interesante gráfica que correlaciona la venta de cigarrillos con la mortalidad por cáncer de pulmón en Estados Unidos durante las últimas décadas....

Una gran noticia: el procedimiento para activar el hardware de reserva del ordenador que controla los instrumentos del telescopio espacial Hubble ha funcionado a la perfección y el venerable telescopio vuelve a estar en funcionamiento. Ha estado parado algo más de...

Leyendo hace un tiempo sobre la deriva continental y la tectónica de placas me sorprendí al saber que era una ciencia que aunque fue propuesta hace ya casi un siglo por el geofísico Alfred Wegener no fue comúnmente aceptada hasta 1960...
En este vídeo de la Doctora Jessica So enseña a su hijo a practicar una duodenopancreatectomía (o procedimiento de Whipple), una operación quirúrgica sobre varios órganos que se realiza para retirar tumores del páncreas y los órganos cercanos. Lo interesante es...
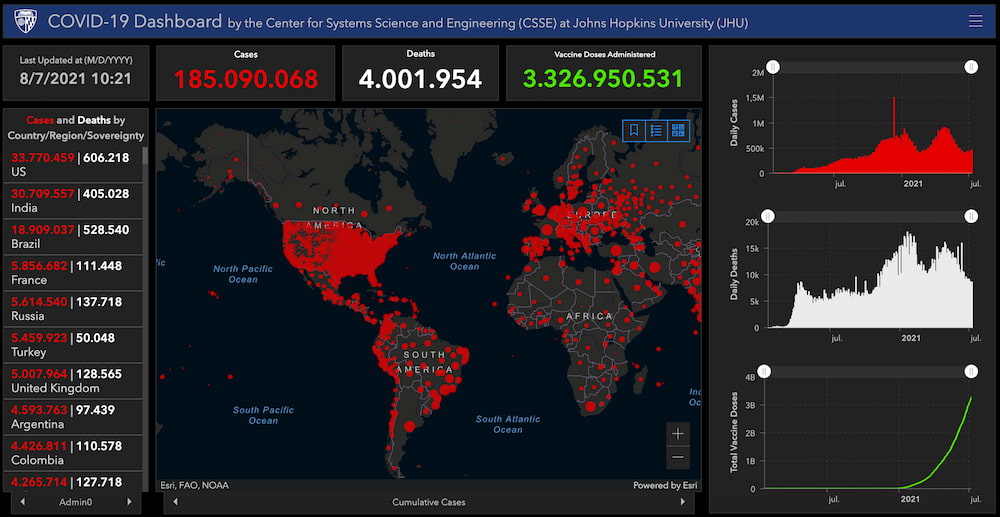
8 de julio de 2021 Estaba repasando el panel de la John Hopkins con el que en enero de 2020 comenzamos a visualizar la pandemia del coronavirus SARS‑CoV‑2, porque vi pasar que se acaban de superar los 4 millones de muertes debidas...

Cuando las temperaturas se desmadran más allá de lo razonable y rondan los 50°C suceden cosas un poco apocalípticas como esta: los pueblos arden y la gente se ve obligada a huir y abandonar sus posesiones que acaban destruidas sin remisión....

Este divertido clip que vuelve a hacer las rondas estos días fue una idea de Josh Darnit. El «reto» consiste en escribir las instrucciones exactas para hacer un sandwich. Y muestra cómo algo supuestamente sencillo puede convertirse en algo tan complicado...

El 5 de enero de 2020 el detector situado en Louisiana del Advanced LIGO y el detector Advanced Virgo en Italia detectaron un tren de ondas gravitacionales que se ha confirmado que fueron producidas en los instantes finales en los que...

Impresión artística del SKA. Esta imagen combina fotos de equipos reales que ya están instalados en ambos sitios con impresiones artísticas de las futuras antenas del SKA. Desde la izquierda: una impresión artística de las futuras antenas del SKA se funde con...

En la Universidad de Cornell (Estados Unidos) han conseguido batir un récord de resolución atómica al recrear imágenes con el equivalente a un zoom de 100 millones de aumentos, triplicando las mejores que se habían obteniendo hasta el momento mediante microscopios...

El blues de los agujeros negros y otras canciones del espacio exterior por Janna Levin. Capitán Swing 2021. 251 páginas. En la madrugada del 14 de septiembre de 2015, aún durante su fase de puesta a punto, y en lo que...
La NASA sigue intentando averiguar qué pasa con el Hubble, más en concreto con el ordenador que controla sus instrumentos científicos. Un fallo en él tiene parado el telescopio desde el pasado 13 de junio. En principio parecía que el fallo estaba...

Despliegue del Hubble el 24 de abril de 1990 – NASA El telescopio espacial Hubble lleva parado desde el pasado 13 de junio mientras la NASA intenta dar con el origen del fallo que hizo que se detuviera el ordenador que controla...
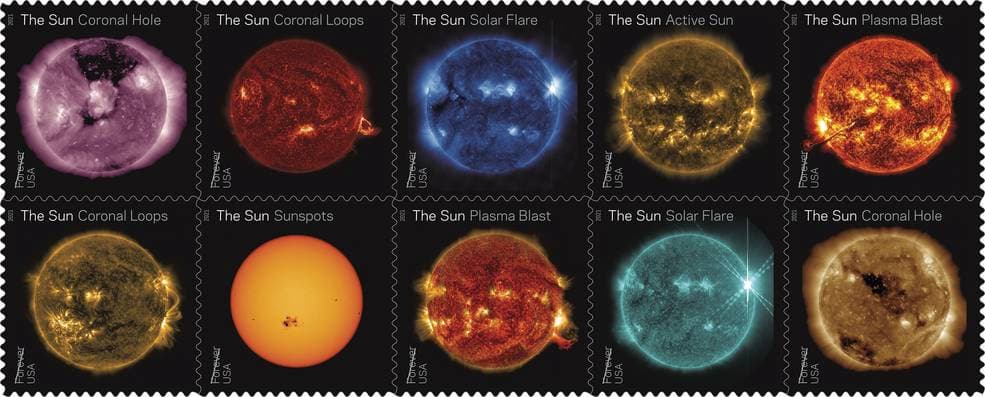
La serie de diez sellos – U.S. Postal Service El Servicio Postal de los Estados Unidos (USPS) acaba de presentar una serie de diez sellos que conmemoran el décimo aniversario del lanzamiento y entrada en servicio del Solar Dynamics Observatory (SDO), un...

AVISO GENÉRICO DE PELIGRO: NIÑOS Y NIÑAS, NO HAGÁIS ESTO EN CASA. Entre otras cosas, porque no tenéis los materiales y porque montar todo es un lío de narices, pero también porque la instensidad de la corriente mata y 1.000 amperios...

Nobel Run es un juego de construcción de mazos de cartas –de esos en los que tienes que ir consiguiendo cartas con ciertas características– que intenta explicar cómo funcionan la investigación y la ciencia. El objetivo: conseguir un Nobel. Con ayuda...
Después de la suspensión de la edición de 2020 debido a la pandemia Naukas Bilbao vuelve a la carga y ya tiene programa provisional para la edición de 2021, que además es su décima edición. Tendrá lugar los días 23, 24, 25...

Imagen alegórica de los tres grandes temas escogidos – ESA Después de escuchar las sugerencias de la comunidad científica la Agencia Espacial Europea acaba de anunciar cuales van a ser los temas principales para las misiones más ambiciosas de su programa Voyage...

La semana pasada, cuando la NASA anunciaba que había escogido seguir adelante con el desarrollo de las misiones Davinci+ y Veritas para visitar Venus ya mencionábamos que la Agencia Espacial Europea (ESA) podía decidir hacer lo propio con la misión EnVision....

La prestigiosa revista Scientific American tiene en su canal de YouTube una nueva serie de minidocumentales bajo el nombre Decoded («Decodificado»). El formato es bastante curioso, porque limita las explicaciones temáticas a entre tres y cinco minutos, sólo se emplean animaciones...
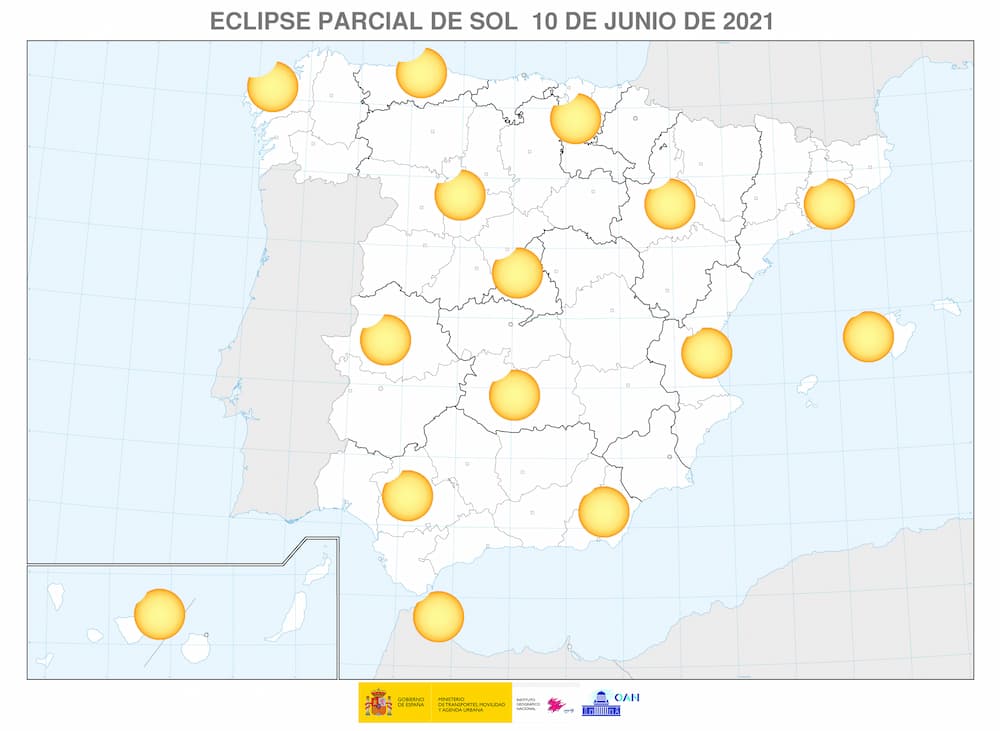
Trayectoria del eclipse – NASA Mañana, 10 de junio de 2021, se producirá un eclipse solar. Será un eclipse anular porque la Luna está demasiado lejos de la Tierra en su órbita como para que su tamaño aparente tape el Sol del...

Ganimedes por la JunoCam el 7 de junio de 2021 – NASA/JPL-Caltech/SwRI/MSSS A última hora de la tarde del 7 de junio de 2021 la sonda Juno de la NASA pasó a tan sólo 1.038 kilómetros de la superficie de Ganimedes, la...

Venus en una imagen compuesta creada con datos obtenidos por las misiones Magallanes y Pioneer 13 – NASA La NASA por fin ha anunciado la selección final de su más reciente ronda de misiones del programa Discovery. Las agraciadas han sido Davinci+...
Vacunas es el genérico nombre de un podcast-documental de la gente de El extraordinario, que explica en seis episodios (~6h) todo lo que hay que saber sobre las vacunas: qué son, cómo funcionan, cómo se descubrieron y mil y un detalles...

FAST visto desde el aire - Observatorio Astronómico Nacional de China/Academia China de las Ciencias El proyecto Galactic Plane Pulsar Snapshot (GPPS, Sondeo de púlsares en el plano galáctico) que se está ejecutando en el radiotelescopio chino FAST desde principios de 2020...
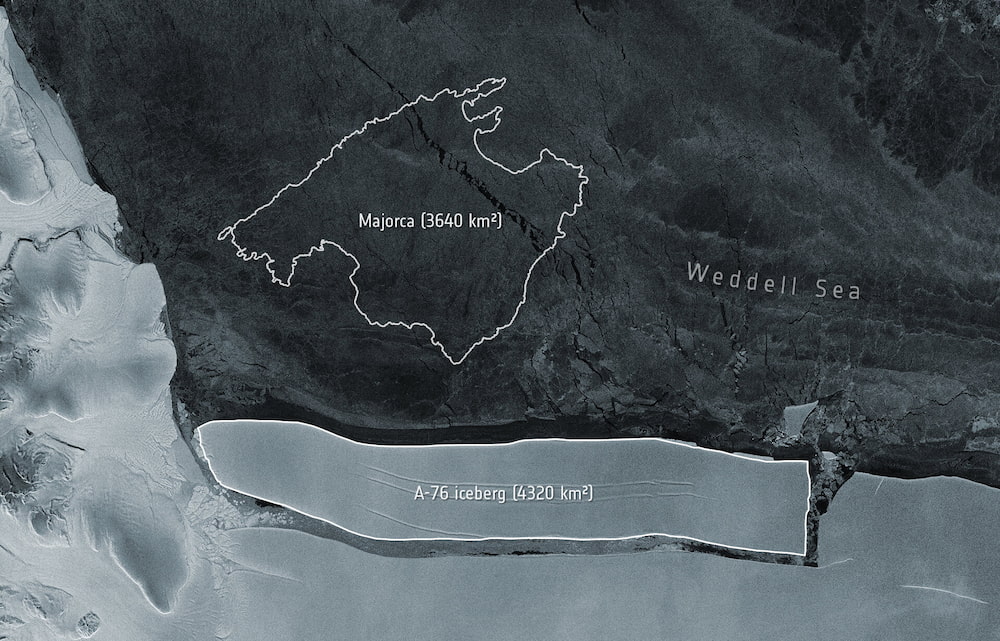
Iceberg A-76 el 16 de mayo. Con datos de Copernicus Sentinel, procesados por la ESA La Agencia Espacial Europea ha publicado una fotografía del iceberg A-76, el más grande del mundo en la actualidad, con una superficie de 4.320 km² (un rectángulo...

El año pasado la pandemia obligó a cancelar Pint of Science. Pero, convenientemente adaptado a la realidad que estamos viviendo, ya está a aquí Pint of Science 2021. La gran diferencia es que este año será un evento virtual y en el...

Mission navigation has received confirmation of burn cutoff. #OSIRISREx is headed home with a souvenir of rocks and dusts from a 4.5-billion-year-old asteroid! #ToBennuAndBack pic.twitter.com/BmaK1dkPDB— NASA Solar System (@NASASolarSystem) May 10, 2021 Después de algo más de dos años en órbita alrededor...

El año pasado la pandemia nos obligó a suspender la edición presencial de Ciencia en Redes 2020. Y aunque luego celebramos una edición en línea echábamos en falta el poder vernos cara a cara. Por eso nos alegra mucho poder decir...

Como seguramente ya sabéis quienes nos leéis, nuestro humilde blog surgió como un entretenimiento allá por 2003 para hablar sobre todo lo que nos encontrábamos por ahí al navegar por Internet: asuntos de ciencia y tecnología, gadgets, historia de la informática,...
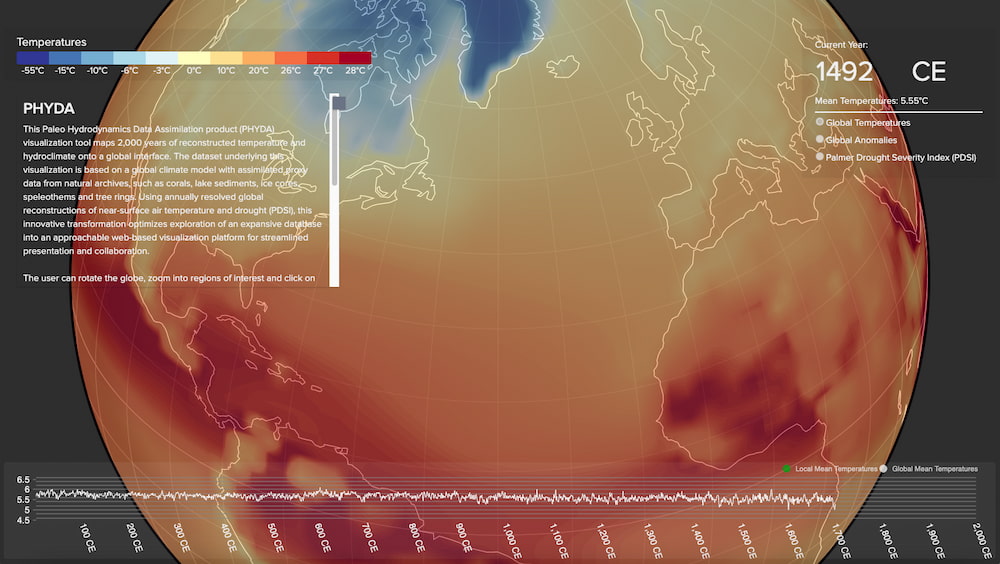
Este mapa interactivo llamado PHYDA [nota: los datos son muchos y tardan en descargarse, hay un indicador en la parte inferior] responde al acrónimo Paleo Hydrodynamics Data Assimilation product. Básicamente permite consultar cómo eran las temperaturas en la Tierra en cualquier...

¿Quién dijo pandemia? Los Museos Científicos Coruñeses, en los que trabajo en el MundoReal™, acaba de poner en marcha la convocatoria de los Prismas Casa de las Ciencias a la Divulgación de 2021. Las modalidades de esta edición son Vídeo, al mejor...

Con ustedes, el experimento de Thomas Young de la doble rendija, aquel de ¿onda o corpúsculo? Seguramente que de la generación Z para arriba lo entiendan mucho mejor así – al menos lo que es el concepto. ¿Veremos esta explicación en...

Información meteorológica desde el cráter Jezero – NASA/JPL-Caltech/CAB(CSIC-INTA) La NASA acaba de poner en marcha la página Latest Weather at Jezero Crater. En ella se puede ver la información meteorológica correspondiente al cráter Jezero de Marte. Es dónde están el rover Perseverance...

A veces creo que hay vida en otros planetas y a veces pienso que no. En cualquiera de los dos casos, la conclusión es asombrosa. – Arthur C. Clarke ¿Estamos solos? En busca de otras vidas en el Cosmos. Por Carlos Briones....
FAST ya terminado - Observatorio Astronómico Nacional de China/Academia China de las Ciencias El Observatorio Astronómico Nacional de China acaba de empezar a recibir propuestas para que equipos de otros países puedan utilizar el radiotelescopio FAST, que lleva en funcionamiento desde 2016,...
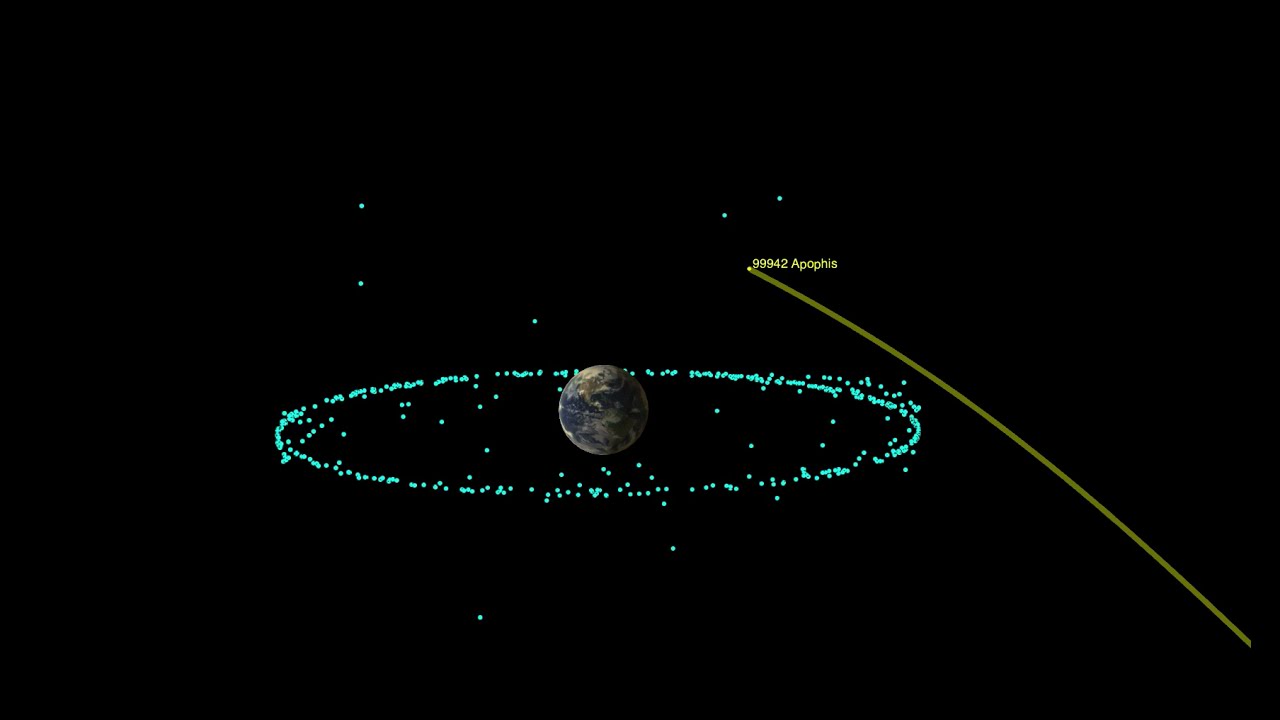
Desde su descubrimiento en diciembre de 2004 el asteroide (99942) Apofis ha venido asomándose periódicamente a los titulares por si iba a chocar (o más bien no) contra la Tierra. Pero las últimas mediciones de su órbita llevadas a cabo desde...

Impresión artística de Hope en órbita alrededor de Marte – MBRSC Se ha cumplido otro hito importante en la misión de la sonda Hope de los Emiratos Árabes Unidos: ya está en su órbita de trabajo prevista alrededor de Marte. Esto es...

Galaxia M106 / NGC 4258 – Imagen: KPNO/NOIRLab/NSF/AURA / PI: M.T. Patterson (New Mexico State University); procesamiento de imagen: T.A. Rector (University of Alaska Anchorage), M. Zamani y D. de Martin Esta espectacular foto de la Galaxia espiral Messier 106 (NGC 4258)...

Vista del agujero negro supermasivo M87 en luz polarizada – EHT Collaboration El equipo internacional que hay detrás del Event Horizon Telescope (EHT, telescopio del horizonte de sucesos) acaba de presentar una nueva imagen del agujero negro supermasivo que hay en la...

Timelapse de la erupción #FagradalsfjallHelicópteros y curiosos de acercan para ver el espectáculoVia @RUVfrettir pic.twitter.com/DlgRexpPd4— IGEO (CSIC-UCM) (@IGeociencias) March 20, 2021 Hace unos días entró en erupción el volcán islandés Fagradalsfjall. Millones de personas que trabajan en medios informativos de todo el...

El núcleo del Halley visto por la Halley Multicolour Camera (HMC) de la sonda Giotto – ESA/MPAe Lindau En la noche del 13 al 14 de marzo de 1986 la sonda Giotto de la Agencia Espacial Europea se aproximó hasta una distancia...
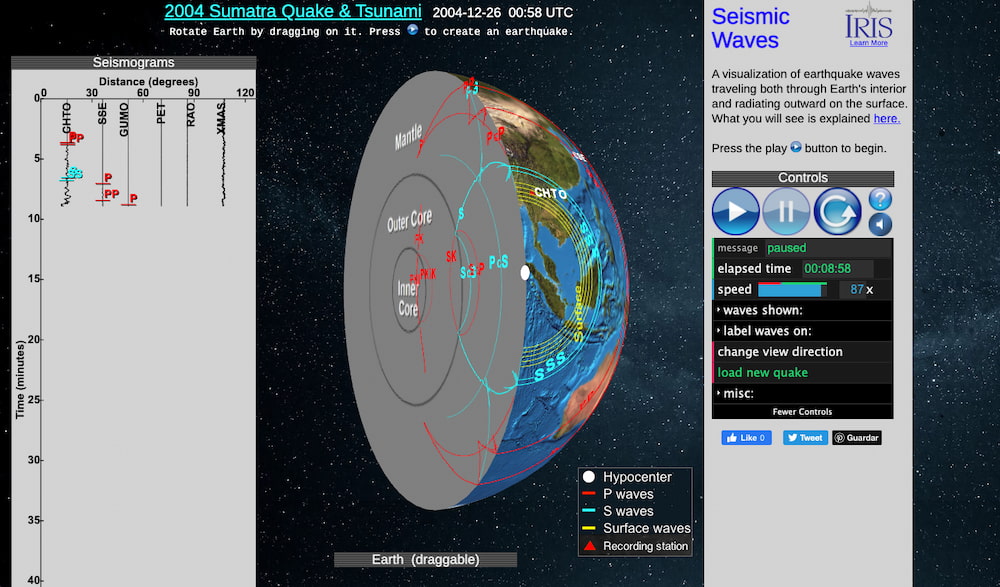
No imaginaba yo que las ondas sísmicas de los grandes terremotos pueden atravesar la Tierra de lado a lado hasta dejarse sentir en las antípodas. Naturalmente, había visto muchas veces cómo los sensores de todo el mundo registran incluso los terremotos...

Ya se ha lanzado en pruebas beta el Internet Archive Scholar (Archivo de Internet Académico) gracias a los esfuerzos del equipazo multidisciplinar de Archive.org y diversas organizaciones y entidades que trabajan en el acceso abierto. Está disponible en varios idiomas, incluyendo...

El Monte Olimpo visto por EXI – Hope Mars Mission/EXI El equipo de la sonda Hope de los Emiratos Árabes unidos acaba de publicar tres imágenes que permiten hacernos una idea de cómo ven Marte los tres instrumentos que van a bordo...
Estos días me enteré de que el Instituto de Tecnología de Massachussetts (M.I.T.) ofrece abierto con acceso completo, público y gratuito todas sus revistas académicas. Están disponibles a través de MIT Press Journals. El caso es que aunque alguien lo comentó...

Primeras huellas de Perseverance sobre Marte – NASA/JPL-Caltech Dos semanas después de su llegada a Marte el rover Perseverance de la NASA ha empezado a moverse. Como «primeros pasos» ha avanzado cuatro metros en la dirección en la que había quedado tras...

En la página 360-view: Eye conditions simulan cómo se ve el mundo «con otros ojos»: cada fotografía pasa por un filtro que simula diversas afecciones de la visión humana. Es un poco eso de «ponerse en lugar de otro» pero con...
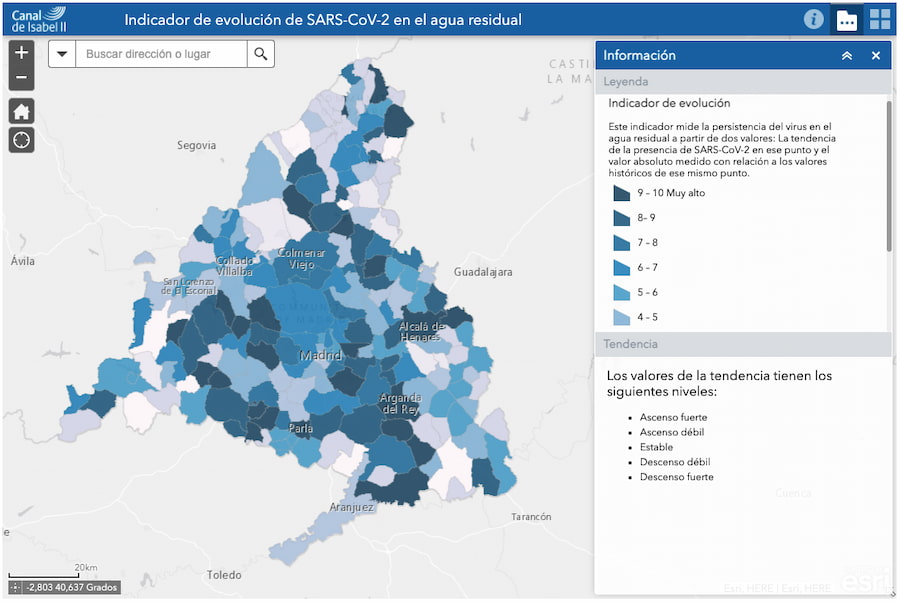
El Mapa del sistema VIGÍA del Canal de Isabel II de la Comunidad de Madrid y otros como el CovidBens de algunos municipios de A Coruña están demostrando ser una importante herramienta científica en la lucha contra la Covid-19. ¿Cómo sirven...

Impresión artística de Tianwen–1 reconociendo la superficie marciana – Corporación de Ciencia y Tecnología Aeroespacial de China (CASC) Tras su maniobra de inserción orbital la misión china Tianwen–1 ha ejecutado varias maniobras de frenado extra para poder entrar en su órbita inicial...

Cuidado que aquí viene Sabine Hossenfelder repartiendo estopa a diestro y siniestro. En el vídeo habla de la hipótesis del universo como simulación, una de nuestras favoritas entre las cosmologías extravagantes, que viene a decir –resumo rápido y seguramente mal– que...

Iceberger es el entretenimiento tonto del día: puedes dibujar un iceberg con el dedo y ver cómo flotaría. El iceberg se comporta según las leyes físicas en una simulación 2D bastante realista. Dice Joshua Tauberer, su creador, que se inspiró en...

Pandemia o no Ciencia Clip 2021 Acaba de ponerse en marcha. A partir de hoy mismo, 15 de febrero, se abre el plazo de presentación de vídeos para esta sexta edición del concurso. Está abierto a alumnas y alumnos de la...

Primera foto de Marte enviada por la sonda Hope – Hope Mars Mission/EXI Esta es la primera foto capturada por la sonda Hope de los Emiratos Árabes Unidos tras su llegada a Marte. Fue obtenida desde una altitud de 24.700 kilómetros por...

Bill es sabio. Y como hace cinco años predijo que no estaríamos preparados para la próxima pandemia (2015) y acertó de pleno, Derek de Veritasium le ha hecho una minientrevista realmente interesante y ultracondensada, donde cada frase es una perla de...

Con motivo de la celebración del Día Internacional de la Mujer y la Niña en la Ciencia la Cátedra de Cultura Científica de la Universidad del País Vasco ha publicado un vídeo sobre la vida de June Almeida junto con un...

Impresión muy artística de los componentes de la misión – Wan, W.X., Wang, C., Li, C.L. et al. China’s first mission to Mars. Nat Astron 4, 721 (2020) Dos de tres para las misiones enviadas hacia Marte en el verano de 2020:...

Impresión artística de Hope en órbita alrededor de Marte – MBRSC La maniobra de inserción orbital de la sonda Hope de los Emiratos Árabes Unidos (EAU) se ha desarrollado sin ningún tipo de problema y ya está en órbita alrededor de Marte....

La parte óptica del JWST a su llegada al aeropuerto de Los Ángeles a bordo de un C-5 Galaxy – NASA Si no hay más retrasos –que ya veremos– el Telescopio Espacial James Webb (JWST) será finalmente lanzado el 31 de octubre...

28 de enero de 2020 28 de enero de 2021 Tal día como hoy, hace exactamente un año, publicábamos en Microsiervos la primera anotación en la que hablábamos de la incidencia del coronavirus (2019-nCoV) en todo el mundo. Era el famoso panel...
A raíz de la serie de terremotos que vienen sacudiendo Granada en los últimos días, especialmente la zona de Santa Fe, Rodolfo y Jorge nos comentaron en Twitter algunos detalles recogidos en la página de Hechos y mitos acerca de los...
Impresión artística de Juno en órbita alrededor de Júpiter. En el extremo de uno de sus paneles solares se ve el magnetómetro, uno de los nueve instrumentos que lleva a bordo – NASA/JPL-Caltech/SwRI Dado que Juno sigue funcionando bien y recogiendo valiosos...
Impresión artística de InSight en Marte. Frente a ella, a la izquierda, el sismógrafo; a la derecha en sensor de temperatura – NASA/JPL-Caltech Hace unas semanas la NASA anunciaba la extensión de la misión de la sonda InSight en Marte hasta diciembre...

El equipo del Museo de la Ciencia de Londres lleva tiempo digitalizando toda su impresionante colección de objetos y libros y liberándolos para que cualquiera lo pueda ver online. Algunos son más populares que otros y reciben miles de visitas diarias...

No es que sea una gran sorpresa pero la NASA y la Administración Nacional Oceánica y Atmosférica (NOAA) confirman que 2020 fue uno de los años más cálidos de la historia desde que tenemos datos. De hecho los datos brutos indican...
Alguien se preguntó hace tiempo si se podría cocinar un pollo a hostia limpia, una idea basada en un principio científico: Si la energía cinética se convierte en energía térmica… ¿Cuán rápido habría que abofetear a un pollo para cocinarlo a...

¿Que si me da miedo qué? Con todo lo que yo he pasado… Los que aún tengan dudas, que se vacunen, es por el bien de todos. –Pepita Paleo, 80 años, primera vacunada contra la covid en Asturias...

El observatorio bajo la Vía Láctea en tiempos mejores – Universidad Central de Florida Aunque la Fundación Nacional para la Ciencia (NSF) estadounidense ya había anunciado que lo iban a desmantelar la caída de la plataforma de instrumentos del radiotelescopio de Arecibo...
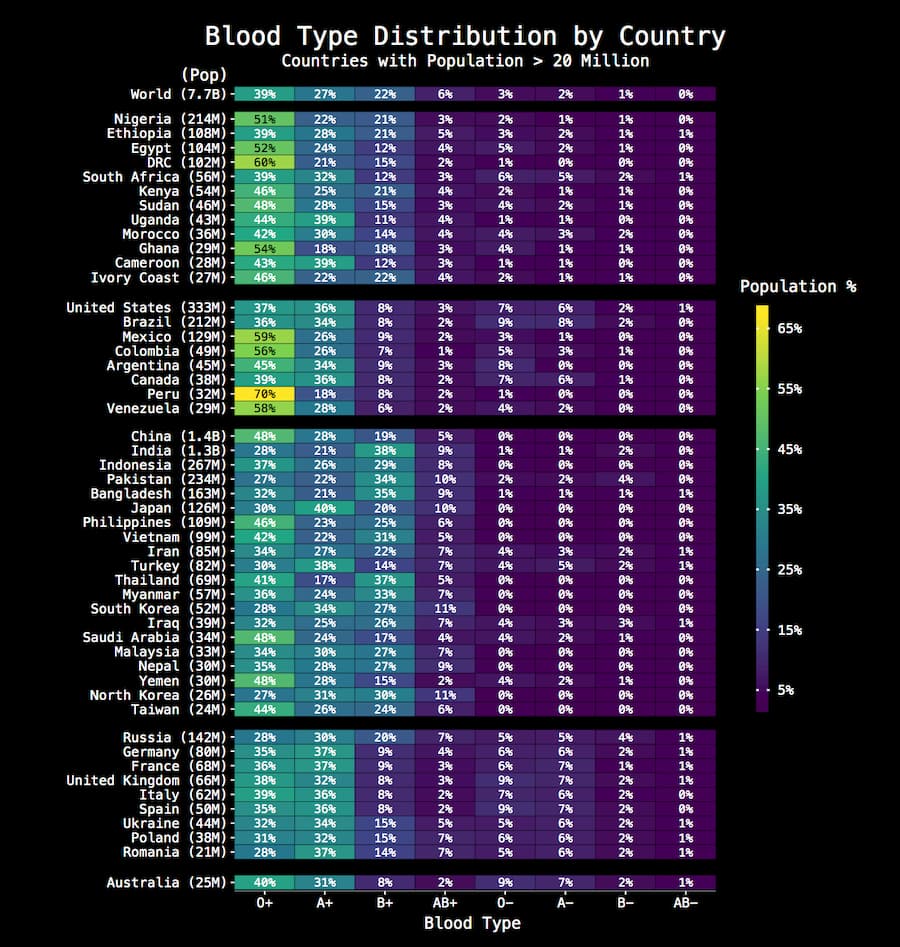
Esta curiosa gráfica de la distribución de los tipos de sangre por países permite ver cuáles son los más prevalentes en general y también país por país. Lo ha creado TakeASecond para subirlo a Reddit, a partir de los datos de...

La Solar Orbiter de la Agencia Espacial Europea (ESA) acaba de llevar a cabo sin problemas su primer sobrevuelo de Venus. Sucedió a las 13:39, hora peninsular española (UTC +1) del 27 de diciembre de 2020. Como la distancia a la...

Principio del código – Organización Mundial de la Salud Justo hoy, que comienza en Europa la campaña de vacunación contra la covid–19 con la vacuna desarrollada por BioNTech/Pfizer, me parece más que interesante la lectura del artículo Ingeniería inversa de la vacuna...
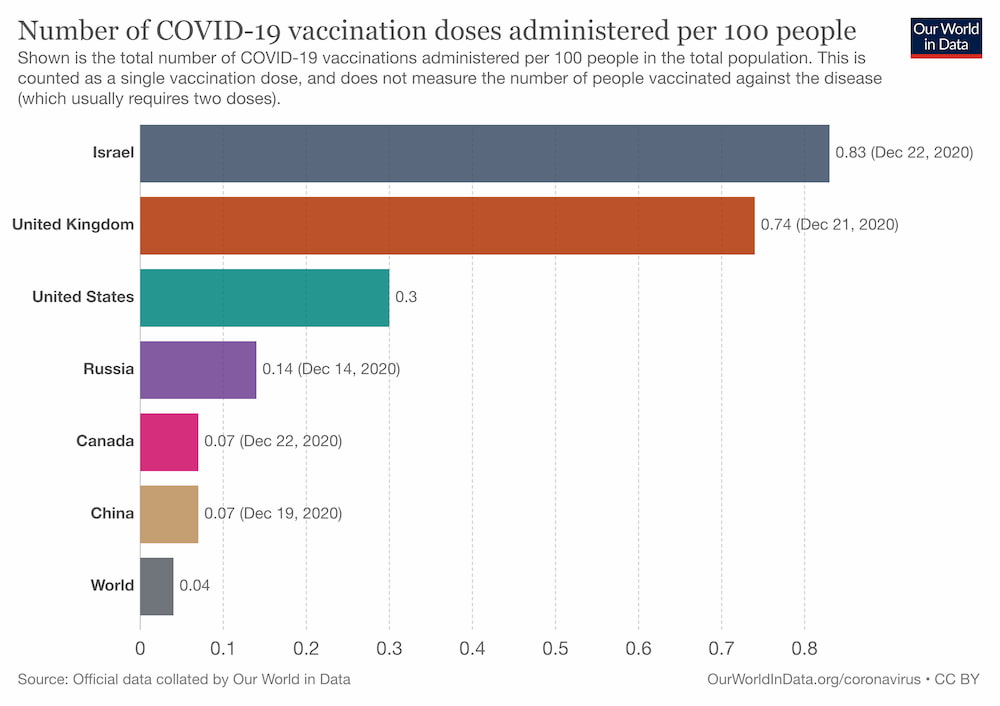
Está gráfica de OurWorld In Data muestra el porcentaje de dosis de vacunas de la Covid-19 administradas en cada país. Cuanto más arriba y mayor sea el porcentaje de un país, mejor. La fuente son los mejores datos oficiales proporcionados por...

La ChETEC Action ha dado a conocer un calendario para el año 2021 que conmemora a las científicas que hicieron la astrofísica nuclear. Está disponible en 26 idiomas, incluyendo el castellano, y se puede descargar, disfrutar, imprimir y divulgar aquí: Calendario...

¡Fácilmente! Tal y como dice nuestra profesora alemana de Física favorita –la entrañable Sabine Hossenfelder– lo mejor es que ni siquiera tienes por qué saber alemán. Letra a letra, fonema a fonema, las palabras se vuelven fáciles y this pasa a...

El Telescopio Espacial James Webb con su parasol desplegado – NASA/Chris Gunn En una prueba importante de cara a su lanzamiento la NASA y Northrop Grumman –el contratista principal del proyecto– han podido comprobar que el parasol del Telescopio Espacial James Webb...
En Universe Forecast se hace una increíble lista de predicciones para el futuro basadas en lo que la ciencia sabe ahora mismo. Comienza en el año 2061 de nuestra era y llegan hasta el año 1030 que es un momento inconcebiblemente...

Gran conjunción de Júpiter (abajo) y Saturno (arriba) de diciembre de 2020 – NASA/Bill Ingalls En la tarde del 21 de diciembre de 2020 Júpiter y Saturno parecerán estar tan cerca en el cielo como no lo han estado en los últimos...

The return capsule of China's Chang'e-5 probe has landed on Earth, bringing back the country's first samples collected from the moon. It marks a successful conclusion of China's current three-step lunar exploration program. #ChangE5 #LunarProbe pic.twitter.com/pezivtpsh9— China Xinhua News (@XHNews) December 16,...

Cámara A de muestras de Hayabusa 2 ya abierta - JAXA No sólo la cápsula que las contenía tenía que llegar de una pieza al suelo, lo que así sucedió el pasado 6 de diciembre de 2020, sino que además había que...

Impresión artística de la Venera 7 sobre la superficie de Venus – Roscosmos Hoy se cumplen 50 años del aterrizaje de la sonda Venera 7 sobre la superficie de Venus. Fue la primera vez que una sonda se posó sobre la superficie...

Animales ejemplares. Por Juan Ignacio «Iñako» Pérez y Yolanda González. Next Door Publishers 2020. 288 páginas. Aristóteles decía que la naturaleza aborrece el vacío, aunque esa frase que resume su pensamiento es de François Rabelais. Hoy sabemos que eso no es cierto....

The orbiter-returner combination of China's Chang'e-5 lunar probe conducted its second orbital maneuver on Sunday and entered the moon-Earth transfer orbit. #ChangE5 #LunarProbe pic.twitter.com/hzUTeBeoy2— China Xinhua News (@XHNews) December 13, 2020 La sonda china Chang'e 5 acaba de emprender su camino de...

Después de las pruebas hechas con el IXV y de que Thales Alenia Space se encargara de su diseño previo la Agencia Espacial Europea (ESA) acaba de encargar la construcción del Space Rider, su futuro avión espacial reutilizable. Correrá a cargo...

Uno de los satélites GECAM – Academia China de las Ciencias Esta pasada noche un cohete Larga Marcha 11 ponía en órbita los dos satélites de la misión GECAM, Gravitational Wave High-energy Electromagnetic Counterpart All-sky Monitor, Monitor de cielo completo de contrapartes...

Esta tabla periódica 3D con visualización interactiva permite explorar la tabla de los elementos viéndolos resaltados según ciertas propiedades. Es algo sumamente sencillo que se puede hacer manejándola con el ratón (o el dedo); al hacer clic aparecen además los detalles...

Chang'e 5 rendezvous, first robotic lunar docking, sample capsule transfer to return capsule. :CNSA/CLEPhttps://t.co/xP7FULCtp4 pic.twitter.com/of5JCfjQrB— LaunchStuff (@LaunchStuff) December 6, 2020 La misión china Chang'e 5 sigue avanzando incansablemente de cara a su objetivo de traer dos kilos de muestras de la Luna...

Dominic Walliman de Domain of Science, al que recordamos por trabajos gráficos como los pósters de la física, las matemáticas o la informática, ha publicado este vídeo en su canal acerca de su último trabajo: el póster de los posibles escenarios...

La cápsula y su paracaídas ya en tierra - JAXA Prácticamente seis años justos después del lanzamiento de la misión –tuvo lugar el 3 de diciembre de 2014– la cápsula de muestras de la sonda japonesa Hayabusa 2 aterrizaba esta pasada noche...
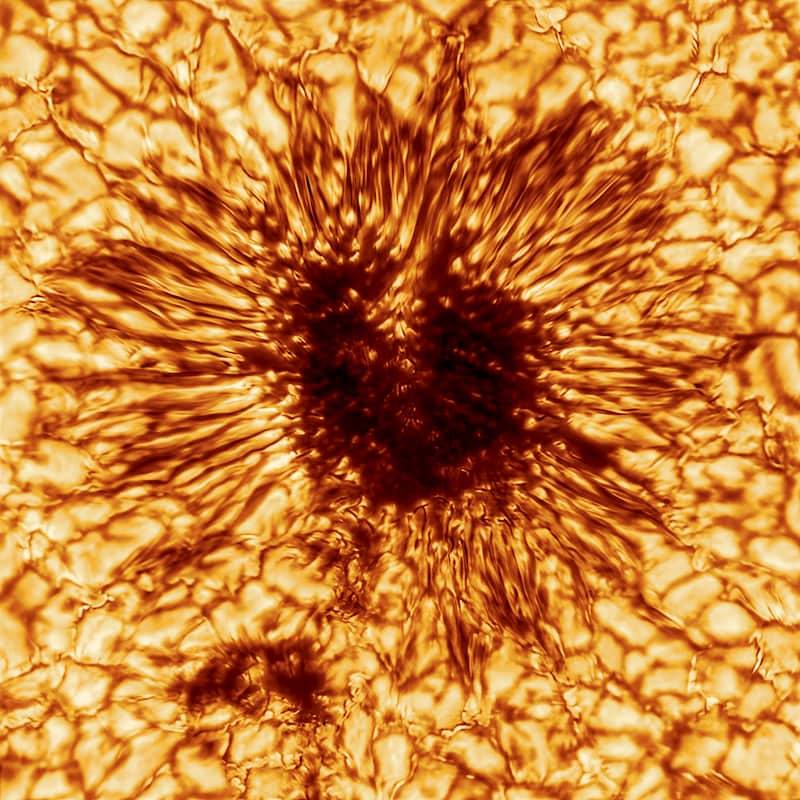
Mancha solar captada por el telescopio Solar Daniel K. Inouye el 28 de enero de 2020 – NSO/AURA/NSF La de arriba, con una resolución de 20 kilómetros por pixel, es la imagen de una mancha solar de más resolución que hayamos captado...

Chang'e 5 ascent module launch from the surface of Luna.CNSA/CLEPℹ:https://t.co/UdTzMHemHD pic.twitter.com/1rPHvoUk2Q— LaunchStuff (@LaunchStuff) December 3, 2020 La ambiciosa misión china Chang'e 5 para traer a tierra muestras de la Luna ha dado otro importante paso adelante con el despegue de su cápsula...

Ha querido la casualidad que hubiera un dron revisando el estado del radiotelescopio de Arecibo cuando se rompieron los cables de soporte de la plataforma de instrumentos. Así que el momento quedó grabado en vídeo que acaba de hacer público la...

Lanzamiento del SOHO – ESA/NASA Hoy se cumplen 25 años del lanzamiento del observatorio espacial SOHO, una misión conjunta de la Agencia Espacial Europea (ESA) y de la NASA. Tiene como objetivos estudiar las capas externas del Sol (cromosfera, región de transición...

El aterrizador de la misión china Chang'e 5 ha conseguido tomar muestras de la superficie de la Luna con su brazo robot y otras más hasta una profundidad de dos metros con su taladro. Están todas selladas ya en la cápsula...

Fantastic footage of the Chang'e-5 descent and landing released. Great view of the horizon there are clear phases of deceleration, the spacecraft going vertical, coarse hazard avoidance, hovering and then the landing. [CNSA/CLEP] https://t.co/q6i9Nxeg2d pic.twitter.com/HvGwClRGG4— Andrew Jones (@AJ_FI) December 2, 2020 Tras...

Ayer fue la última vez que visite esta belleza de lugar. Lamentablemente agonizaba. Aquí imágenes de ayer y hoy. pic.twitter.com/jWuAwtUc1s— Deborah Martorell (@DeborahTiempo) December 1, 2020 Según se puede ver en tuits de Deborah Martorell la plataforma de instrumentos de 900 toneladas...

En este pequeño vídeo de Deep Look, una miniserie de vídeos en 4K producida por KQED para la PBS se explican algunas curiosidades sobre porqué es tan complicado cazar una mosca con la mano o incluso con un matamoscas: Sus ojos...

Impresión artística de Chang'e 5 en órbita lunar – Proyecto de exploración lunar de China Tras algo menos de cinco días de viaje después de su lanzamiento el pasado 23 de noviembre la sonda china Chang'e 5 entraba en órbita alrededor de...

Después de cerca de una década de desarrollo y tres años extra de espera mientras no estaba listo el cohete necesario China acaba de lanzar la misión Chang'e 5 rumbo a la Luna. Su objetivo es traer de vuelta dos kilos...

Un Falcon 9 de SpaceX lanzaba sin problemas en la tarde del 21 de noviembre de 2020 el satélite medioambiental Sentinel 6 Michael Freilich. Se trata de una misión desarrollada en colaboración entre la Agencia Espacial Europea (ESA), la Uunión Europea,...

El radiotelescopio de 305 metros de Arecibo en noviembre de 2020 - Universidad de Florida Central En una decisión que no era para nada la esperada la Fundación Nacional para la Ciencia de los Estados Unidos (NSF) acaba de anunciar el cierre...

Impresión artística del Lunojod 1 en la Luna - Roscosmos Tras su lanzamiento el 10 de noviembre de 1970 el rover soviético Lunojod 1 se posaba sobre la superficie de la Luna a bordo de su plataforma de aterrizaje Luna 17 a...

Habrá que ver cómo acaba esto. De momento tal y como muestra esta gráfica de un artículo publicado en The Economist parece claro que la comunidad científica y los gobiernos de diversos países no se entienden demasiado bien. Los datos completos...

Vuelo sobre Júpiter resume en cinco minutos algo menos de horas de la máxima aproximación al planeta de la sonda Juno de la NASA su órbita número 27 al ritmo de un tema compuesto específicamente por Vangelis. Durante ese perijove la...

El cable roto - Universidad de Florida Central Apenas unos días antes de que llegara el equipo que se iba a encargar de hacer unas reparaciones de emergencia por la rotura de un cable de soporte el pasado 10 de agosto se...

Aunque el rover Perseverance de la NASA está equipado para estudiar in situ las muestras que recoja en Marte un objetivo importante de la misión es poder traer algunas muestras a la Tierra. Airbus ha sido seleccionada para construir la nave...

I’ve officially closed the Sample Return Capsule! The sample of Bennu is sealed inside and ready for our voyage back to Earth. The SRC will touch down in the Utah desert on Sep. 24, 2023. Thanks, everyone, for being a part of...

Yesterday, the OSIRIS-REx team received images of the spacecraft’s sample collector head brimming with regolith. So much sample was collected that some of it is actually slowly escaping the sampling head. More details: https://t.co/ufUXdotgsO pic.twitter.com/2wINd1Tk2g— NASA's OSIRIS-REx (@OSIRISREx) October 23, 2020 En...

El pasado día 21 de octubre de 2020 la sonda Osiris-REX de la NASA llevó a cabo el primer intento de toma de muestras de un asteroide en la historia de la agencia. La telemetría recibida de la sonda parecía indicar...
Después de casi dos años de estudios del asteroide Bennu y de un par de ensayos la sonda OSIRIS-REx de la NASA está lista para intentar tomar una muestra de 60 gramos del asteroide para traerla a casa. El intento tendrá...

Este «invento» de Brian Edwards Kahrs es un monopatín sobre el cual va un cubo de fregona a modo de asiento. Entonces se sujeta un paraguas sobre el que actúa el aire que suelta un soplahojas. Pero si te parece que...

Bajo el suelo - NASA/JPL-Caltech Pues parece que aquello de que «el que la sigue la consigue» se va a cumplir en el caso del «topo» de la sonda InSight de la NASA. Y es que el equipo del instrumento por fin...
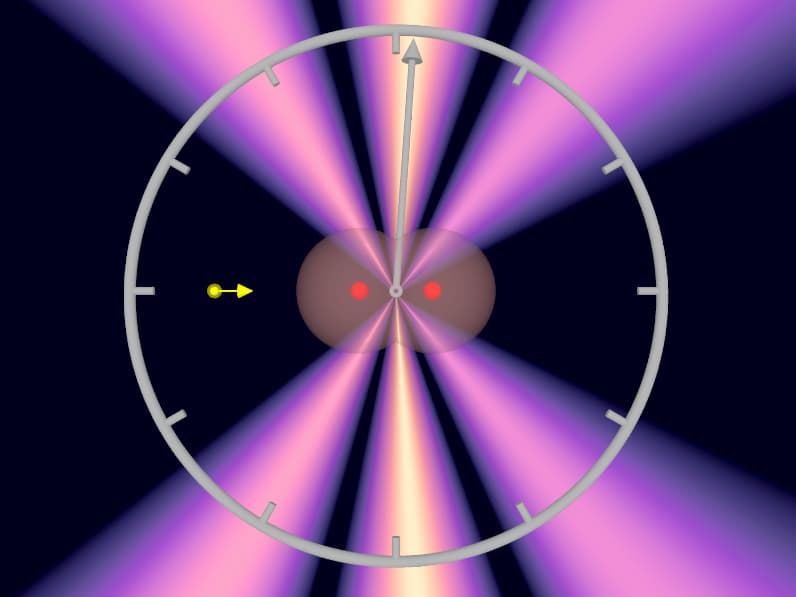
Unos científicos de la Universidad Goethe de Frankfurt han conseguido medir un instante tran breve como el que tarda la luz en atravesar una molécula. Dicen que es un nuevo récord mundial: Zeptoseconds: New world record in short time measurement. El...

Here it is! Beautiful #Venus as we made closest approach today! Watch how we swing by the planet from day to nightside during #BepiColomboVenusFlyby https://t.co/0AVrP2zKoy #ExploreFarther pic.twitter.com/nASSN35Y8U— Bepi (@ESA_Bepi) October 15, 2020 Lanzada el 20 de octubre de 2018 la misión BepiColombo...
Impresión artística del lanzamiento del JWST en un Ariane 5 – ESA/D. Ducros Una serie de pruebas en las instalaciones de Northrop Grumman en California ha permitido comprobar que el telescopio espacial James Webb puede sobrevivir a su lanzamiento. Lo que obviamente...

El mal sin cura de la Costa da Morte, SCA36. Por Manuel Rey. Libros.com 2019. 15,20€ en papel; 3,79€ para Kindle. 154 páginas. A partir de 1992 el neurólogo Manuel Arias empezó a ver en su consulta de Santiago de Compostela una...

El planeta extrasolar Matusalén – NASA y G. Bacon (STScI) Hace unos días un grupo de científicos de la Universidad de Cornell liderado por Rosanne Di Stefano publicaba un estudio en el que afirman haber descubierto el primer candidato a planeta extragaláctico,...

Un año más tenemos aquí los premios Ig Nobel. Otorgados los editores de Annals of Improbable Research las categorías de cada año dependen de los estudios o noticias que se hayan publicado. Y sin más rollo, los Ig Nobel de 2020...

Este vídeo de Scientific American recopila fragmentos de los mejores vídeos del concurso Nikon Small World in Motion 2020. Son trabajos presentados por científicos y fotógrafos que combinan con arte el mundo de lo sumamente pequeño con la estética fotográfica en...

Impresión muy artística del planeta Pi – NASA Ames/JPL-Caltech / T. Pyle, MIT Aunque la misión del telescopio espacial Kepler terminó en octubre de 2018 una vez exprimido hasta el límite su combustible los datos que recogió a lo largo de su...
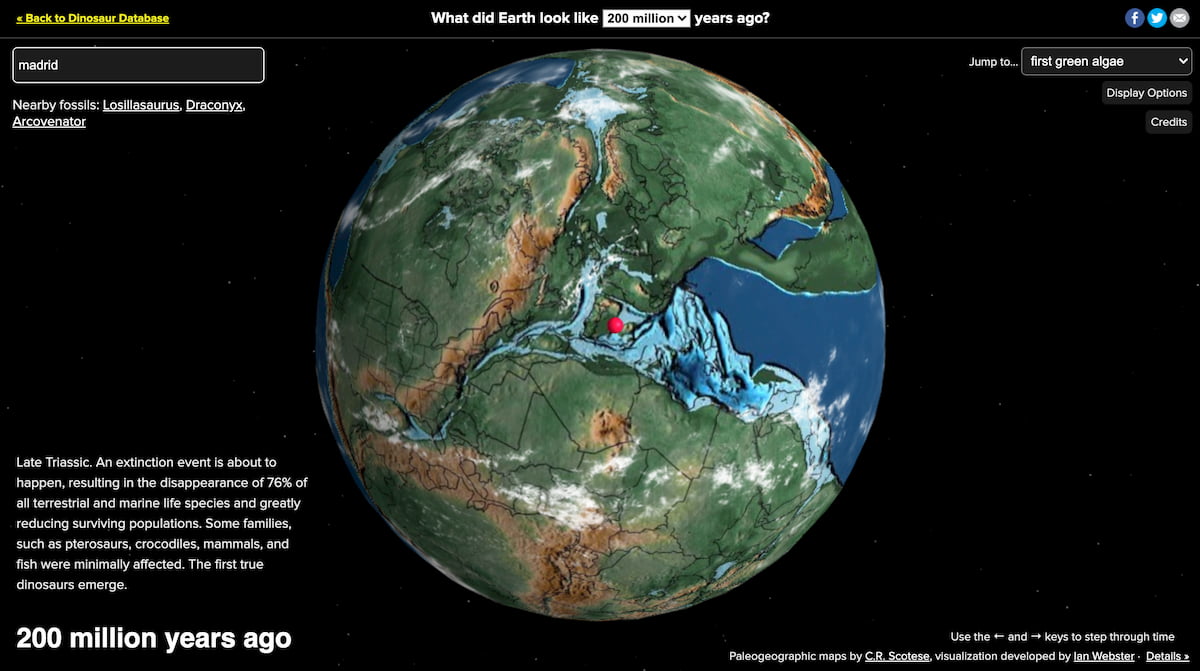
Ancient Earth es un curioso invento de la gente de la impresionante The Dinosaur Database. Es un globo terráqueo donde se puede buscar cualquier lugar actual y ver cómo era hace millones de años, en la época de los dinosaurios y...

Óscar Menéndez y sus colegas de Lab Sonoro me han liado para hacer un podcast. A mis años. Lo hemos bautizado La Senda: La senda del pensamiento es el nombre del camino que bordeaba la casa de Charles Darwin y que el...

We are not claiming we found life on Venus – Greaves, J.S., Richards, A.M.S., Bains, W. et al. Hoy se ha hablado mucho en los medios del fosfano (o fosfina en su denominación antigua) porque ha sido descubierto en la atmósfera de...

Tras décadas de esfuerzo el 25 de agosto de 2020 África fue por fin declarada como libre de polio. Algo que, sin desmerecer los esfuerzos de personas y organizaciones de todo el mundo que se han volcado en ello, hubiera sido...

Plato dañado - Universidad de Florida Central El radiotelescopio de Arecibo ha sufrido daños por la rotura de un cable de soporte. El que ha fallado es uno de los cables de 7,5 centímetros que soporta la plataforma que hay sobre el...

Lanzado en 2010 el satélite CryoSat-2 de la Agencia Espacial Europea (ESA) lleva desde entonces estudiando la capa de hielo que cubre los polos y la variación en su grosor. Lanzado en 2018 el ICESat–2 de la NASA hace lo propio....
Decía un viejo chiste que probablemente algo no funciona cuando tarda menos en llegarte a casa una pizza encargada por teléfono que una ambulancia tras llamar a urgencias. La pandemia del coronavirus y la Covid-19 ha destapado muchos puntos débiles de...

Con diez milisegundos de adelanto sobre la hora prevista un cohete Atlas V despegaba de Cabo Cañaveral para lanzar el rover Perseverance de la NASA hacia Marte a las 13:50, hora peninsular española, del 30 de julio de 2020. La maniobra,...

Impresión artística del lanzamiento de Perseverance – NASA/JPL-Caltech El lanzamiento de Perseverance hacia Marte ha pasado su Flight Readiness Review (FRR), así que la NASA ha confirmado el 30 de julio como fecha del lanzamiento de la misión. O al menos del...

Un cohete Larga Marcha 5 ha lanzado la misión china Tianwen 1 hacia Marte. El lanzamiento se produjo desde el Centro de Lanzamiento de Satélites de Wenchang a primera hora del miércoles 23 de julio. Su llegada al planeta rojo está...

Tras dos aplazamientos debidos a la mala meteorología la sonda Hope (Esperanza, Al Amal en Árabe) de los Emiratos Árabes Unidos (EAU) viaja ya hacia Marte. Aún desplazándose a 120.000 kilómetros por hora Hope necesitará unos siete meses para recorrer los...
Impresión artística del lanzamiento del JWST en un Ariane 5 – ESA/D. Ducros Van ya tantos retrasos que casi no es noticia. Pero la NASA ha confirmado que aplaza el lanzamiento del telescopio espacial James Webb al 31 de octubre de 2021....

La Agencia Espacial europea acaba de hacer públicas las primeras imágenes obtenidas por la Solar Orbiter. Tomadas durante el primer perihelio de la misión –la parte mas cercana al Sol de una órbita– a unos 77 millones de kilómetros, más o...

Neowise fotografiado al atardecer desde Logroño – MeteoSojuela Desde esta semana la posición del cometa C/2020 F3 (Neowise) respecto a la Tierra hace que sea posible verlo también al anochecer en España. Así que ya no hay que pegarse madrugones para intentar...
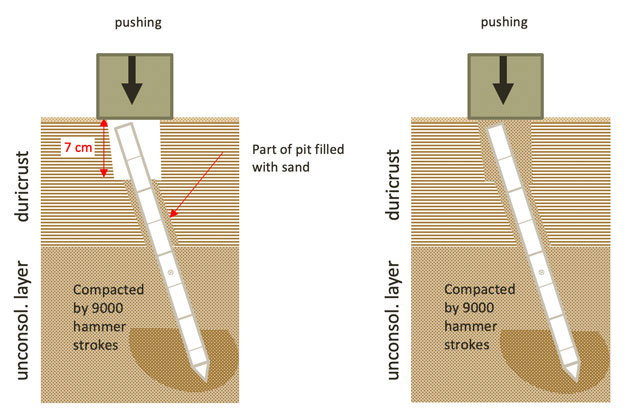
Esquema del nuevo plan - DLR Según cuenta Tilman Spohn, el investigador principal del «topo» de la sonda InSight de la NASA, en una actualización publicada 7 de julio de 2020 el instrumento está bajo el suelo pero no avanza. De hecho...

El Cometa Neowise fotografiado por Aleix Roig - http://astrocat.info Descubierto a finales de marzo de 2020 por el telescopio espacial Neowise de la NASA el cometa C/2020 F3 (Neowise) tenía el potencial de ser visible a simple vista. Pero para ello tenía...

Estuve repasando algunas versiones del famoso experimento de la doble rendija que planteó Thomas Young en 1801 para discernir si la luz era un corpúsculo o una onda, dando lugar a la teoría de la naturaleza ondulatoria de la luz… que...

El programa Copérnico (Copernicus) de observación terrestre que gestiona la Agencia Espacial Europea (ESA) la Unión Europea constaba hasta ahora de seis misiones Sentinel (Centinela). Algunas en satélites dedicados, otras como instrumentos a bordo de otros satélites. Pero entre 2025 y...

En esta interesante clase magistral de Hugh Hunt en el aula principal de la Royal Institution se exploran unas cuantas cosas interesantes –que mucha gente encontrará nuevas, además de fascinantes– acerca de «cómo giran las cosas». Tiene parte de juego, de...

Lanzado en febrero de 2010 el Solar Dynamics Observatory (SDO) es un observatorio espacial de la NASA que se dedica única y exclusivamente a mirar el Sol para que podamos estudiar su actividad. Con sus tres instrumentos obtiene una imagen de...
En esta página creada con la herramienta para visualización de datos abiertos de epidemiología genómica Microreact pueden verse las 47.000 secuenciaciones completos del virus de la Covid-19 (SARS-CoV-2) que se conocen hasta el momento. Estos virus son el resultado de las...

Sample Fetch rover en primer plano con el Sample Retrieval Lander detrás – NASA JPL Caltech Desde hace años la comunidad científica sueña con que alguna misión pueda traer muestras tomadas en Marte de vuelta a la Tierra. Y puede que por...

El mapa fantasma. Por Steven Johnson. Traducción de Cristina Mbarichi Lumu. Editorial Capitán Swing 2020. 15,57€ (papel). 8,54€ (mobi). 270 páginas. A principios de septiembre de 1854 un brote de cólera empezó a matar a decenas y decenas de personas en Londres....

El cielo en rayos X visto por eROSITA – Jeremy Sanders, Hermann Brunner y el equipo eSASS (MPE); Eugene Churazov, Marat Gilfanov (en representación de IKI) El equipo de eROSITA, de extended ROentgen Survey with an Imaging Telescope Array, que es el...

El 15 de junio de 2020 la sonda Solar Orbiter de la Agencia Espacial Europea alcanzaba la distancia mínima al Sol –perihelio– de su primera órbita. El acercamiento fue hasta unos 77 millones de kilómetros, aproximadamente la mitad de la distancia...
Tal día como hoy de hace 25 años Robert Nemiroff y Jerry Bonell, ambos empleados de la NASA, empezaron a publicar a diario una imagen relacionada con el universo. Conocida como Astronomy Picture of the Day (APOD), imagen de astronomía diaria,...

Prueba de extensión de la torre del James Webb – Northrop Grumman Falta todavía un anuncio oficial pero Thomas Zurbuchen, el director de los programas científicos de la NASA acaba de confirmar que el lanzamiento del telescopio espacial James Webb (JWST) sufrirá...

Editada por Julie Novakova en colaboración con el Instituto Europeo de Astrobiología Strangest of All es una colección de relatos de ciencia ficción que tienen como tema común la astrobiología. Incluye historias de G. David Nordley, Geoffrey Landis, Gregory Benford, Tobias S....

After several assists from my robotic arm, the mole appears to be underground. It’s been a real challenge troubleshooting from millions of miles away. We still need to see if the mole can dig on its own. More from our @DLR_en partners:...

El cometa ATLAS despachurrándose - NASA, ESA, D. Jewitt (UCLA), Q. Ye (University of Maryland) Cuando lanzamos una sonda espacial hacia otro astro su trayectoria se calcula con años de antelación. Y más si la trayectoria va a usar la asistencia gravitatoria...

Technovelgy es una web estilo retroviejuno que recopila noticias relacionadas con ideas e inventos surgidas de la ciencia ficción. Un campo fértil, como es fácil imaginar. Pero lo mejor es que lo tienen todo es que esa gigantesca colección está organizada...

En este programa de la televisión finlandesa un científico loco llamado Janne propuso hacer una prueba «bastante estúpida, pero interesante»: ver cuánto podrían cargar las baterías de un coche eléctrico 9 ciclistas pedaleando con todas sus fuerzas durante 20 minutos. El...

Pocos días después del que hubiera sido su 95º cumpleaños la NASA acaba de anunciar que a partir de ahora el telescopio espacial WFIRST se llama telescopio espacial Nancy Grace Roman (NGRST). Nancy Grace Roman fue la primera jefa de astronomía...

La ciencia evoluciona y rectifica. La pseudociencia, sin embargo, nunca falla: tiene un remedio estúpido que vale para cualquier cosa. Por eso la ciencia cura en cuanto puede, y la pseudociencia no cura nunca.– José Antonio López Guerreroen El País...

En esta pieza de Seeker se exploran algunos asuntos interesantes, en particular por qué el tiempo parece fluir en una sola dirección. Pero lejos de irse a las generalidades de la entropía y la Segunda ley de la termodinámica y todo...

Últimamente los lanzamientos espaciales –es rara la semana en la que no hay al menos uno– están empezando a parecer rutinarios. Pero distan de serlo. Hay un montón de pasos que hay que dar correctamente para que todo salga bien. Y...

COVID–19 o no desde los Museos Científicos Coruñeses, en los que trabajo en el MundoReal™, acabamos de lanzar la convocatoria de los Prismas Casa de las Ciencias a la Divulgación de 2020. Las modalidades de esta edición son Vídeo. Nuevos medios (web,...
La ciencia ficción sirve para plantearnos mucho antes de que sucedan qué futuros puede haber y entonces decidir.– Gemma Marfany Nadalen la charla El papel del conocimiento experto...

Tapestry of Blazing Starbirth muestra la nebulosa gigante NGC 2014 y su vecina NGC 2020. Juntas forman parte de una vasta región de formación de estrellas en la Gran Nube de Magallanes, una galaxia satélite de la Vía Láctea, situada a unos...
James O'Donoghue ha hecho otro de sos vídeos suyos que tanto nos gustan. En How Earth looks from the Moon / how the Moon looks from Earth, during April 2020 se puede ver cómo se ve la Tierra desde la Luna...
Datos de demografía y hogar – Nuria Oliver, Xavier Barber, Kirsten Roomp, Kristof Roomp Además de las consecuencias obvias y directas de personas que han enfermado y fallecido o se han curado por la COVID–19 hay toda una serie de efectos colaterales...

En Burger King regalan hamburguesas a los estudiantes capaces de resolver ecuaciones como esta; a quienes se saben el nombre de ciertas moléculas químicas o demuestran conocimientos en otros campos, usando la app oficial. Es una campaña pensada para jóvenes entre...
En la web del CERN, más concretamente del ATLAS, puede encontrarse esta pequeña maravilla: El libro para colorear del Experimento ATLAS. Son unas plantillas para imprimir en blanco y negro para que las coloreen los niños y niñas entre 5 y...

Nuestra mente nos engaña: Sesgos y errores cognitivos que todos cometemos. Por helena Matute. Shackleton Books, 2019. 8,54€. 160 páginas. Nuestra mente –y nuestro cerebro, en realidad; en opinión de la autora no tiene sentido hablar de la una sin el otro–...
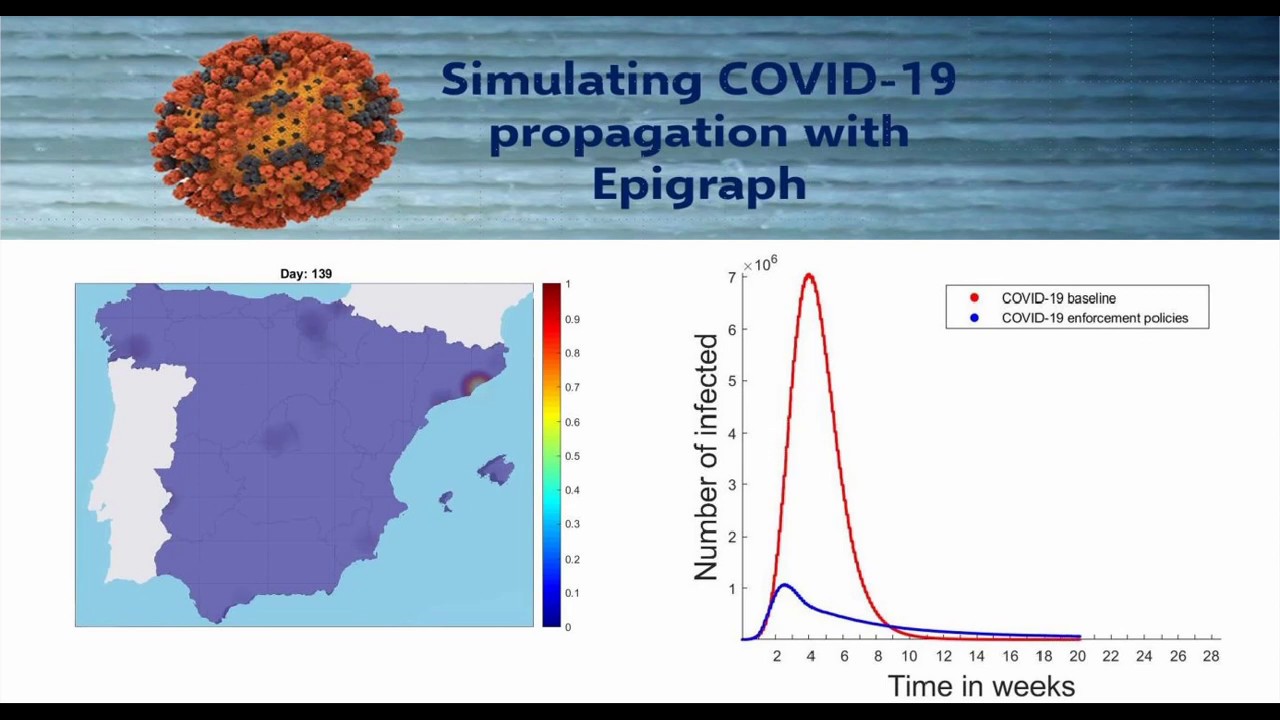
Esta animación muestra cómo es la propagación en España de la COVID-19 bajo un mismo modelo y dos escenarios diferentes: con confinamiento y sin él. Lo interesante es que usaron datos reales sobre cómo se produce esa propagación: datos del censo,...

Sala principal de control del ESOC – ESA Aunque la Agencia Espacial Europea (ESA) ya había tomado medidas para contener la pandemia de COVID-19 haciendo que la mayor parte de su personal trabajara desde casa hace unos días una de las personas...

Impresión artística de Cheops en órbita – ESA / ATG medialab Terminada la fase inicial de pruebas en órbita, que comenzó el 7 de enero de 2020, la Agencia Espacial europea y Airbus han declarado el telescopio espacial Cheops listo para empezar...

Sala de control del ESOC Con el objetivo de proteger mejor del coronavirus a las personas que trabajan en el Centro de Control de Operaciones Espaciales (ESOC) de Darmstadt la Agencia Espacial Europea (ESA) ha tomado la decisión de poner en modo...

Con eso de que todo el mundo anda con más tiempo libre que de costumbre en estos días extraños, me llamó Martín Expósito para ver qué tal andaba todo y proponerme aprovechar para grabar un episodio de Los Crononautas. Así que ni...

Las dos partes del Telescopio Espacial James Webb por fin ensambladas en junio de 2019 – NASA/Chris Gunn Era un poco una cuestión de tiempo pero el trabajo en el Telescopio Espacial James Webb (JWST) también se ha visto afectado por el...

En este vídeo de Mark Rober que es casi literalmente «para niños de cuatro años» se llevan a cabo algunos experimentos con niños de primaria para mostrar cómo en un entorno normal y corriente –una oficina o un hogar no son...
La forma en que se difunden el aire y las partículas (incluyendo virus) que tenemos en los pulmones y la boca al toser varía dependiendo de cómo lo hagamos y qué medidas protectoras tomemos. Este vídeo de la Bauhaus-Universität Weimar muestra...

Aunque normalmente les lleva entre 1.000 y 1.200 horas de trabajo y entre seis y doce meses preparar cada uno de sus vídeos la gente de Kurzgesagt ha hecho un enorme esfuerzo y ya tienen un vídeo sobre el SARS-CoV-2, el...

Impresión artística de WSP–76b - ESO/M. Kornmesser Uno de los principales objetivos de la astronomía en lo que se refiere a la búsqueda de planetas extrasolares es encontrar un gemelo de la Tierra. Eso nos permitiría afirmar que en algún otro sitio...
Matemáticos de la Universidad Rovira i Virgili han preparado estos mapas con los datos disponibles acerca del riesgo de propagación del coronavirus COVID-19 en los municipios españoles. El mapa utiliza datos del Instituto Nacional de Estadística y muestra la fracción de...
Esta simulación de coronavirus que han preparado en el Washington Post [ya traducida al castellano] es una forma gráfica fácil de entender de cómo se extienden fenómenos como el COVID-19 con gran rapidez y cómo se puede «aplanar la curva». Eso...

Este vídeo de Minute Earth nos recuerda lo complicado que son a veces cosas aparentemente sencillas. Como delimitar exactamente dónde empieza un océano y acaba otro en nuestro planeta. Algo que podemos hacer –mal que bien– con los países y continentes,...

Alexander Mather, un estudiante de 13 años de Virginia, fue el que propuso el nombre Perseverance (Perseverancia) para el rover hasta hace unos minutos conocido como Mars 2020. El ensayo con el que acompañó su propuesta dice: Curiosity (Curiosidad). InSight (Conocimiento)....

Impresión artística del WFIRST – NASA A mediados de 2012 la NASA se encontró en posesión de un regalo medio envenenado que le hizo la NRO (National Reconnaissance Office, Agencia nacional de reconocimiento). Se trataba de dos telescopios espaciales de 2,4 metros...

Mi japonés (creo) es más bien limitado, así que no sé qué líquido utilizan en este vídeo. Pero lo que está claro es que tiene el mismo índice de refracción que la canica con la que arrancan la reacción en cadena...
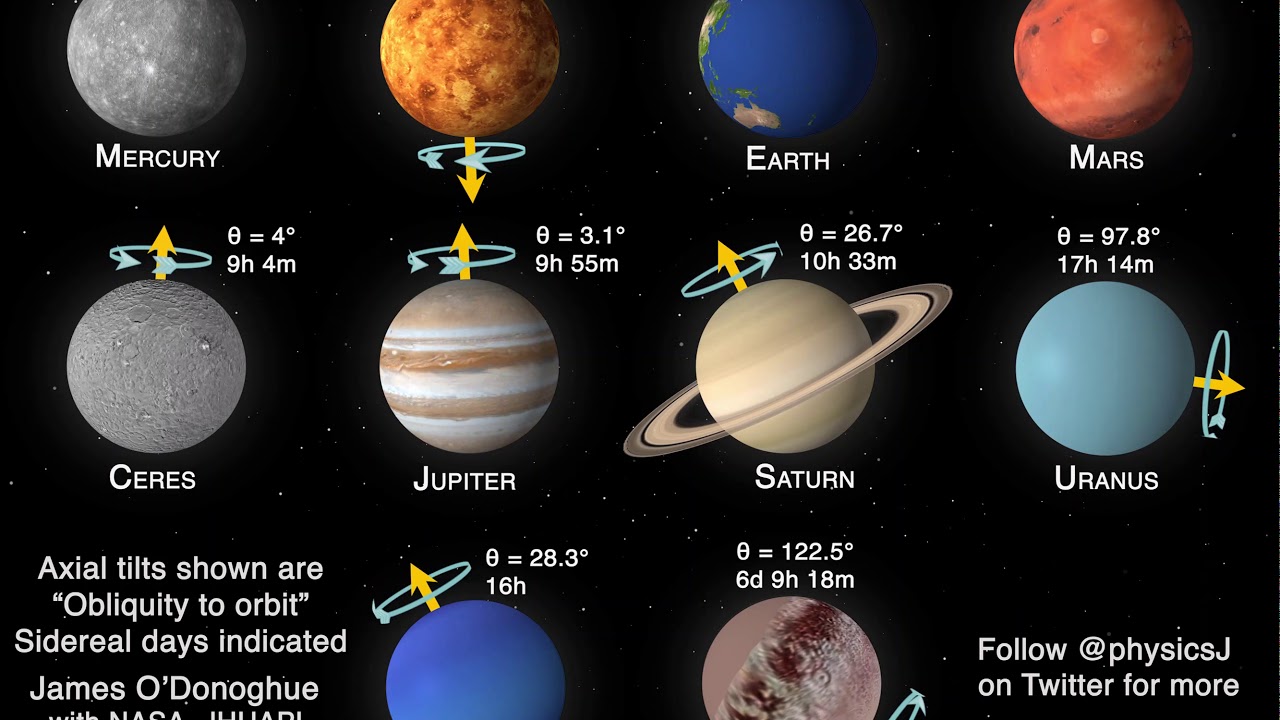
The eight planets and two dwarf planets… es otra de esas animaciones creadas por James O'Donoghue, un científico planetario que trabaja para la Agencia Japonesa de Exploración Aeorespacial (JAXA), que tanto nos gustan. En este caso compara la velocidad de rotación,...

El AMS-02 – NASA Entre noviembre de 2019 y enero de 2020 Andrew Morgan de la NASA y Luca Parmitano llevaron a cabo cuatro paseos espaciales para reparar el Espectrómetro Magnético Alfa (AMS, siendo estrictos AMS-02). Es un instrumento que está instalado...

La Smithsonian Institution, que se compone entre otras cosas de 19 museos, un zoológico y un complejo de investigación y educación acaba de lanzar la iniciativa Smithsonian Open Access. Se trata una plataforma donde están todos sus contenidos digitalizados, en en...

My robotic mole has had a hard time getting underground, so I’m going to try something we never thought we’d do: giving it a push with my robotic arm while it hammers. This will take several weeks, as the @NASAJPL/@DLR_en team works...

Siempre he dicho que una de las formas más sencillas de enganchar a una persona a la astronomía es llevarla a ver la Luna. Mejor cuando no hay luna llena porque entonces la iluminación del Sol es demasiado plana. Pero en...

En la Breakthrough Listen Initiative ya se pueden descargar cerca de 2 petabytes de datos capturados por el proyecto SETI de Berkeley como parte de la búsqueda de señales de vida inteligente en el universo. Quien tenga paciencia y una buena...

En esta pieza que el Musen Americano de Historia Natural hizo en conmemoración del 150º aniversario del nacimiento de Charles Hayden (1870-1937) y cuenta la historia de los planetearios, aunque un poco centrada en los de Estados Unidos. Hayden era hombre...
En la Universidad de Toronto un equipo de neurocientíficos está investigando cómo reconstruir imágenes visuales a partir de la actividad cerebral. En otras palabras, sería algo así como «ver lo que ven otras personas». Para ello utilizan el clásico gorrito-de-piscina-ridículo lleno...

Me gustó bastante esta charla del físico Sean Carroll en la Universidad de Cambridge por varias razones, pero principalmente porque es reciente y está muy actualizada; tiene un nivel adecuadamente divulgativo y se centra en explicar lo que no sabemos y...

Impresión muy artística del sistema solar - NASA La NASA acaba de anunciar cuatro nuevas misiones finalistas para los próximos lanzamientos del Programa Discovery. Estas son, por orden alfabético. Los enlaces van a Eureka, el blog de Daniel Marín: DAVINCI+ (Deep Atmosphere...

Pale Blue Dot Revisited - NASA/JPL-Caltech En 1990, el equipo de las misiones Voyager decidió apagar las cámaras de la Voyager 1 para conservar la energía porque la sonda, igual que la Voyager 2, ya no iba a pasar lo suficientemente cerca...

Hace unas semanas estuve viendo unos cuantos vídeos de las charlas de física para todos los públicos que el físico Javier García imparte el centro cívico Aula 141 de Barcelona. (Impagable labor la suya y la del centro, por cierto). Entre...

Hay tantas noticias de ciencia al cabo del año que es imposible enterarse de todas; tan siquiera es posible acordarse de todas aquellas que vemos pasar o incluso de las que escribimos. Por eso los anuarios que publica la agencia SINC son...
Primera imagen obtenida por el telescopio espacial Cheops - ESA/Airbus/CHEOPS Mission Consortium Después de haberle enviado la orden para abrir la tapa de su objetivo –que en realidad es un telescopio Ritchey-Chrétien de 30 cm de apertura y 1,2 m de longitud–...

Despegue del Solar Orbiter - ESA Tal y como estaba programado el Solar Orbiter de la Agencia Espacial Europea ESA) y la NASA despegaba rumbo al Sol a bordo de un cohete Atlas V a las 5:03 del 10 de febrero de...

Todo está listo para el lanzamiento del Solar Orbiter de la Agencia Espacial Europea (ESA) y la NASA rumbo al Sol desde el Complejo de lanzamiento 41 de Cabo Cañaveral. Si todo va según lo previsto el lanzamiento se producirá en...

The Mars Atlas es un proyecto para editar un atlas de nuestro vecino en el sistema solar con 218 detallados mapas de su superficie. Incluye también una historia de la exploración de Marte, un índice alfabético con los más de 2.000...

Con este vídeo de presentación comienza Polar Lab, un juego educativo interactivo de la PBS (la cadena de televisión pública estadounidense) creado por sus Nova Labs y esponsorizado por la Fundación Nacional para la Ciencia. Se trata de una forma entretenida...
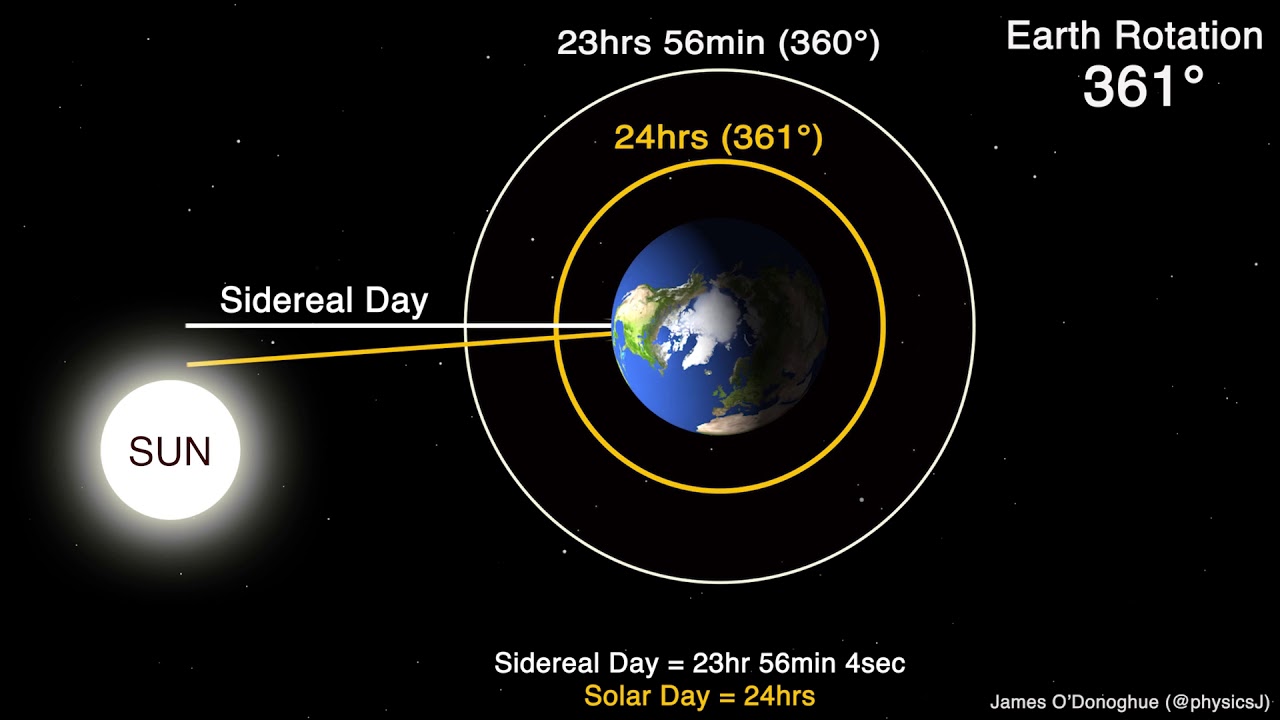
Esta animación del James O'Donoghue que trabaja en la JAXA explica gráficamente por qué hay cierta diferencia entre la duración del día solar y el día sideral. Lo que llamamos día solar medio son 24 horas exactas, que es lo que...

Con los tests genéticos cada vez más baratos cada vez se realizan más pruebas a todo tipo tanto de personas para cuestiones médicas como reproductivas, de investigación o incluso para resolver crímenes. A día de hoy a más o menos la...

Cada dos años desde 2002 la la Fundación Española para la Ciencia y la Tecnología (FECYT) hace la Encuesta de percepción social de la ciencia, cuyos resultados publica luego para que cualquier persona interesada pueda echarles un ojo. La última realizada hasta...
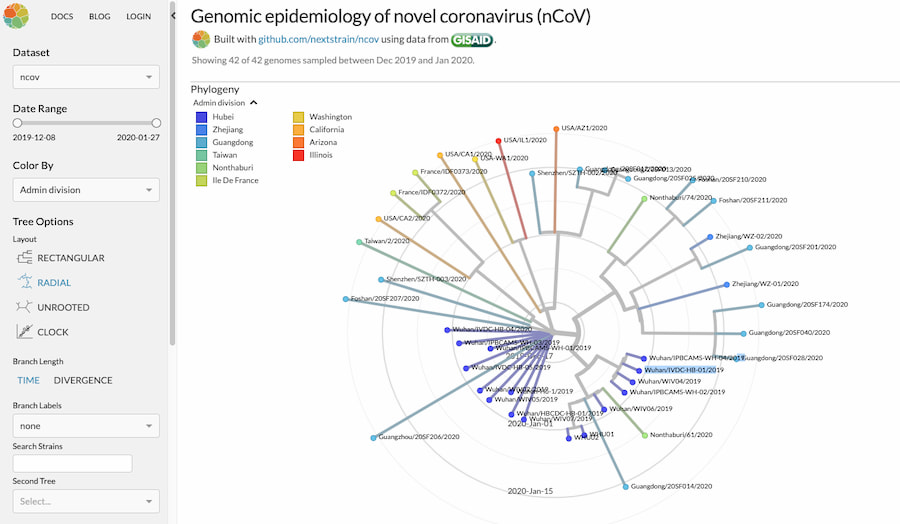
En Nextstrain, un proyecto que ofrece código y datos abiertos con fines científicos han preparado esta visualización de la epidemiología genómica del coronavirus, técnicamente conocido como nCoV-2019. Lo que se ve es básicamente la evolución en tiempo real de las diversas...

Lanzado el 25 de agosto de 2003 el telescopio espacial Spitzer es uno de los cuatro Grandes Observatorios de la NASA junto con el telescopio espacial Hubble, el observatorio de rayos gamma Compton y el observatorio de rayos X Chandra. Su...
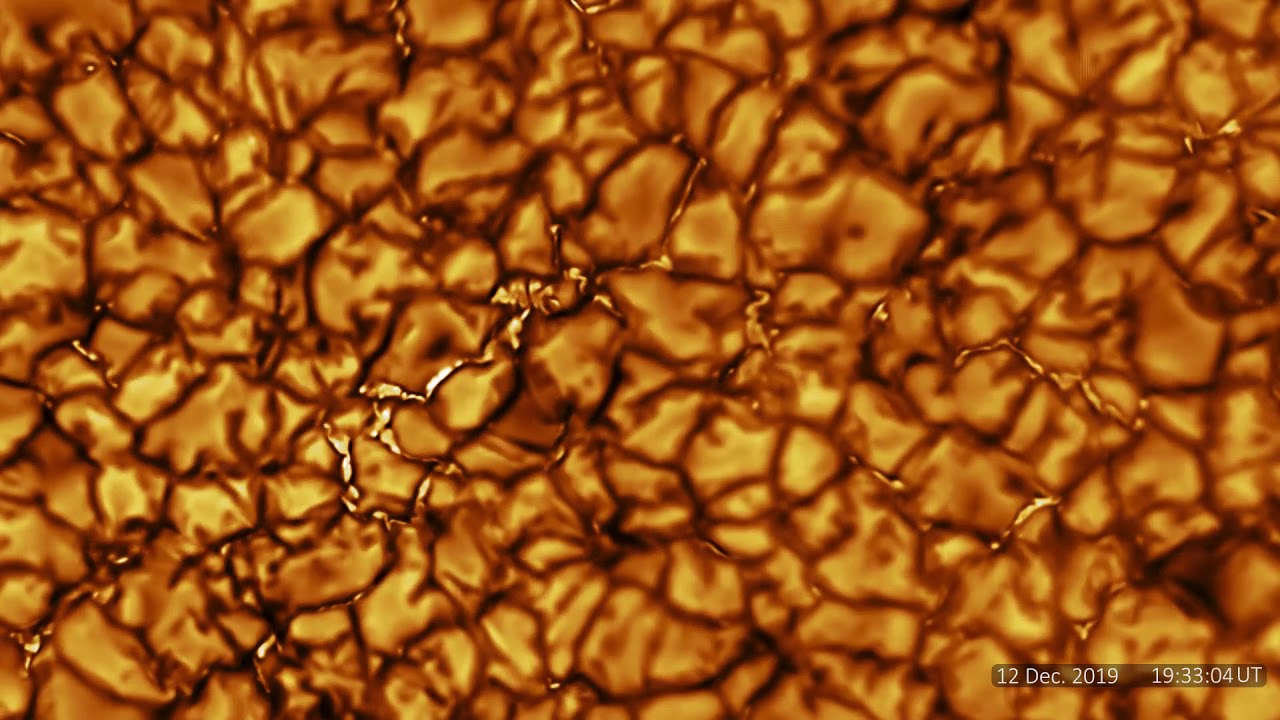
Este es el increíble aspecto que tiene nuestro Sol visto muy, muy ampliado. De hecho las imágenes, de hace unas semanas, están tomadas con cinco veces más resolución que lo máximo que habíamos podido captar hasta desde la Tierra. Es la...

Este vídeo de Will Schoder es una especie de reseña y análisis calmado de uno de los libros de Douglas Hofstadter, en concreto de I Am a Strange Loop (Yo soy un extraño bucle en castellano, editado por Metatemas). Es un...
Al igual que las ballenas, los delfines o los pájaros, las vacas también tienen emiten sonidos únicos y personalizados, sus mugidos, lo que permite distinguir a unos individuos de otros en una vacada. Alexandra Green, que es una científica de la...
Las dos partes del Telescopio Espacial James Webb por fin ensambladas en junio de 2019 – NASA/Chris Gunn Sorprendiendo aproximadamente a nadie el último informe del interventor general de Estados Unidos sobre la situación del telescopio espacial James Webb dice que lo...

Cheops con la tapa abierta – ESA / ATG medialab Esta mañana a las 7:38, hora peninsular española, se envió desde el Instituto Nacional de Técnica Aeroespacial (INTA) en Madrid el comando al telescopio espacial CHEOPS para que abriera la tapa de...
En la revista del American Institute of Physics se publicó hace unos meses un curioso trabajo titulado The mass-energy-information equivalence principle (AIP Advances). Tal y como cuentan es una proposición de «teoría comprobable» que sugiere que la información tiene masa y...
Ya hay un mapeado en tiempo real de los casos del coronavirus de Wuhan (2019-nCoV) en todo el mundo. Es una especie de dashboard o pantalla principal con los datos más relevantes, tomados de diversas fuentes fiables. {Nota: la página funciona...

The Guardian tiene este artículo titulado Has physicist’s gravity theory solved ‘impossible’ dark energy riddle? –con un título quizá un poco exagerado– acerca del trabajo de Claudia de Rham, una física teórica del Imperial College. Sus estudios sobre la gravedad le...

Andrew Morgan trabajando en el AMS - NASA Tras un paseo espacial de seis horas y 16 minutos Andrew Morgan de la NASA y Luca Parmitano de la Agencia Espacial Europea (ESA) terminaron la reparación del Espectrómetro Magnético Alfa (AMS). El instrumento,...

Seguro que has visto muchas vez el atractor de Lorenz como uno de los ejemplos de la teoría del caos y de cómo en ciertas ecuaciones se observa un comportamiento caótico simplemente porque cualquier pequeña diferencia en los valores iniciales hace...

En Science News han publicado este curioso vídeo microscópico a escala nanométrica en el que se puede ver cómo unos investigadores de la Universidad de Nottingham han captado cómo dos átomos de renio hacen una curiosa danza separándose y volviéndose a...

Nos ha escrito Carolina para decirnos que hace cosa de un año se ha relanzado la versión en español del canal de Veritasium. La idea es sacar un vídeo doblado a la semana, salvo en casos muy puntuales como el del...
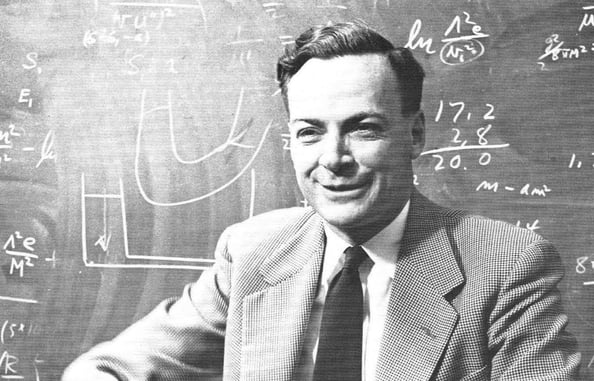
Estoy repasando en YouTube las míticas siete conferencias que impartió el no menos legendario, divertido y siempre didáctico Richard Feynman en 1964 en la Universidad de Cornell, tituladas The Character of Physical Law. Entre las muchas perlas, anécdotas y risas del...

Es sabido que Brian May, uno de los componentes del mítico grupo musical Queen, es también doctor en astrofísica. Pero lo más más curioso es que aunque el gran guitarrista y compositor se licenció en 1968 y comenzó su tesis de...
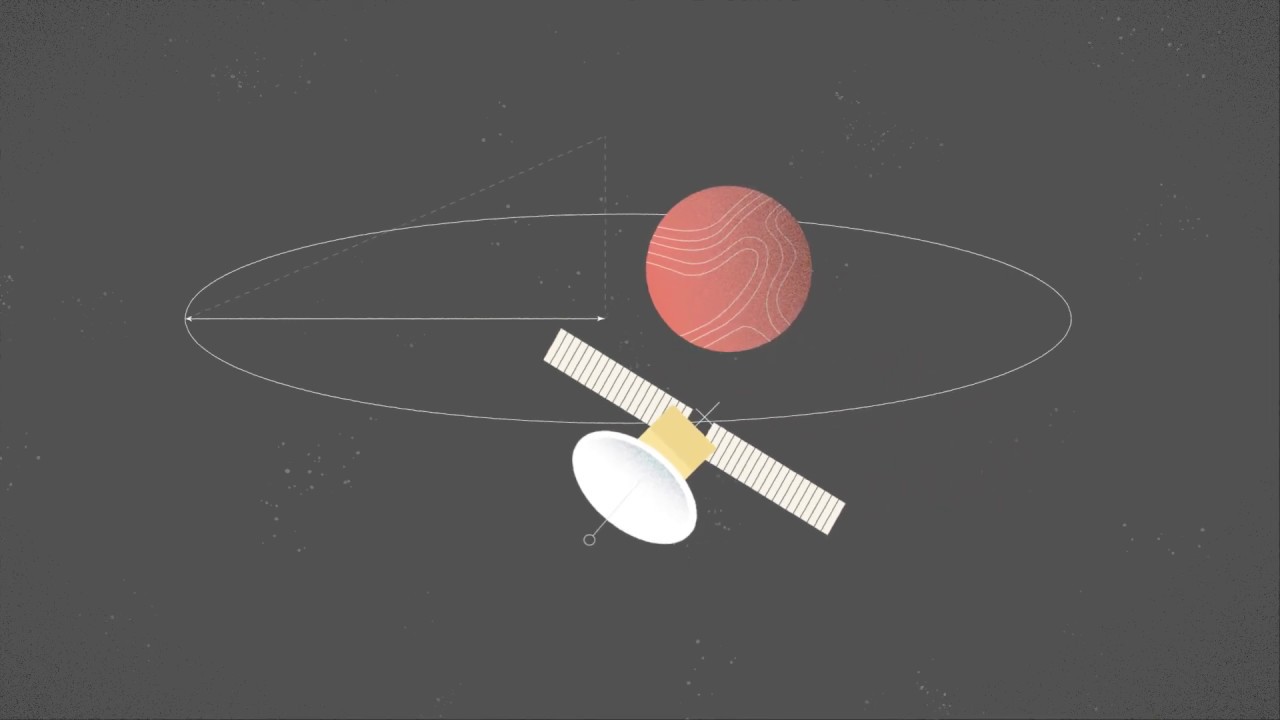
Todo está en marcha para que Ciencia Clip 2020 abra el plazo de recepción de vídeos, así que ya estáis tardando en preparar el vuestro. ¿Que qué es Ciencia Clip? Ciencia Clip es un concurso de vídeos de divulgación de ciencia...

El Large Synoptic Survey Telescope (LSST), o Gran Telescopio para Rastreos Sinópticos, en construcción en Cerro Pachón, en Chile, tiene como objetivo producir la imagen más profunda y amplia del universo. Ni más ni menos que 500 petabytes de imágenes y...

La Dragon 19 recién «pescada» - SpaceX Tras casi un mes atracada en la Estación Espacial Internacional la cápsula de carga Dragon 19 terminaba su misión al amerizar frente a la costa de California el 7 de enero de 2020. Trae a...

Tim Dodd, más conocido como Everyday Astronaut, ha hecho una encuesta entre sus seguidores en diversas plataformas. Y tras cocinar los resultados según su criterio, ya que a fin de cuentas el canal es suyo, estos son los mejores momentos de...
Desde hace unas semanas el Instituto de Astrofísica de Canarias está publicando vídeos en los que personas que viven en La Palma apoyan la construcción del Telescopio de Treinta Metros (TMT) en la isla. Obviamente el IAC no va a publicar...

A las 3:26, hora peninsular española, del 3 de enero de 2019 la misión china Chang'e 4 se posaba en el cráter Von Kármán, que a su vez está en la Cuenca Aitken, la segunda mayor estructura del sistema solar causada por...

A finales de 2018 el científico chino He Jiankui se hizo mundialmente famoso tras anunciar que había liderado un equipo que habría propiciado el nacimiento de dos bebés en China cuyo ADN habría sido modificado utilizando la técnica Crispr-Cas9. Al principio el...

Esta preciosidad se llama Deep Sea; es una gigantesca infografía vertical de Neal Agarwal que recorre las profundidades del mar desde la superficie donde se encuentran los primeros seres vivos hasta cientos de metros más abajo, donde apenas llega la luz,...

Todo comienza con una simple pregunta acerca de «qué es eso que se siente cuando dos imanes se repelen». A partir de ahí la búsqueda de un porqué se vuelve más y más enrevesada a medida que el físico Richard Feynman...

Jaralee Metcalf es una profesora que planteó en su escuela de primaria un experimento con rebanadas de pan de molde para estudiar los efectos de la suciedad en las manos sobre los alimentos. Está inspirado en un experimento que encontró en...

Impresión artística de la separación de Cheops de su lanzador - Arianespace Un cohete Soyuz con una etapa superior Fregat despegaba a las 9:54, hora peninsular española, del 17 de diciembre de 2019 para poner en órbita la misión Cheops (CHaracterising ExOPlanet...

Gemínidas y Luna llena – Juan Carlos Casado (TWAN) Como todos los meses de diciembre llega el pico de máxima actividad de la lluvia de estrellas de las Gemínidas. Este año se prevé que ocurra a las 20:00, hora peninsular española del...
En el verano de 2017 los Estados Unidos aprobaban el uso de una terapia genética que prometía convertirse en una importante arma más en la lucha contra el cáncer. En el caso concreto contra la leucemia infantil. Y acabamos de saber que...

El 10 de diciembre de 1999 un cohete Ariane 5 ponía en órbita el observatorio espacial de rayos X bautizado como XMM-Newton. Inicialmente la misión tenía financiación para dos años de funcionamiento aunque se esperaba que el telescopio pudiera funcionar durante...

Desde Newton a Lorenz, el caos muestra cómo el presente afecta el futuro.

La física Sabine Hossenfelder, investigadora en el Frankfurt Institute for Advanced Studies ha publicado en su blog Back Reaction un interesante artículo acerca de cuán científico es el principio antrópico. Va acompañado de un tranquilo vídeo en su canal de YouTube,...

Luca Parmitano con la nueva unidad de refrigeración / NASA Durante el tercer paseo espacial dedicado a la reparación del Espectrómetro Magnético Alfa (AMS) los astronautas Luca Parmitano y Andrew Morgan consiguieron instalar en su sitio la nueva unidad de refrigeración así...

Según cuentan en Japan Times, Toshiba ha desarrollado una tecnología para detectar 13 tipos de cáncer con una precisión del 99% a partir de una sola gota de sangre (las cifras de sentitividad 90-99% / selectividad 95-99% varían según las fuentes)....
Derek Muller de Veritasium plantea en este vídeo tres problemas de física recreativa de esos que todo el mundo más o menos conoce pero cuya explicación «desafía aparentemente a las leyes de la física». Y ese desafío consiste en que de...

En este vídeo de la Universidad de York explican cómo en el departamento de psicología han estado haciendo experimentos con unas máscaras de silicona hiperrealistas. Son tan reales, tan reales, que cuando se hacen pruebas con grupos de gente voluntaria para...

La Vía Láctea vista desde el Murchison Widefield Array, con las frecuencias más bajas en rojo, las frecuencias medias en verde y las más altas en azul. Foto: N. Hurley-Walker (ICRAR/Curtin) / Equipo GLEAM Bonita imagen captada por el Murchison Widefield Array,...
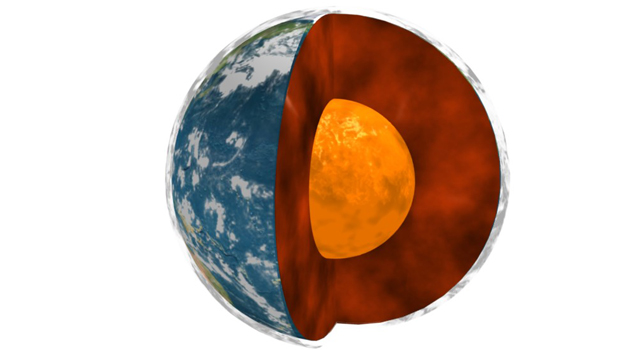
En un trabajo titulado The young center of the Earth [arXiv] tres científicos daneses desarrollan una explicación tan curiosa y llamativa como didáctica sobre el fenómeno de la dilatación temporal en la relatividad de Einstein. Sabemos que el tiempo transcurre más...

El AMS-02 en el exterior de la EEI – NASA El Espectrómetro Magnético Alfa es un detector de partículas desarrollado por 500 científicos de 56 instituciones de 16 países que está montado en el exterior de la Estación Espacial Internacional desde mayo...

Esta de arriba es la última foto del asteroide Ryugu tomada por la cámara de navegación de la sonda Hayabusa 2 de la Agencia Japonesa de Exploración Aeroespacial antes de empezar el camino de regreso a la Tierra. En su cámara...
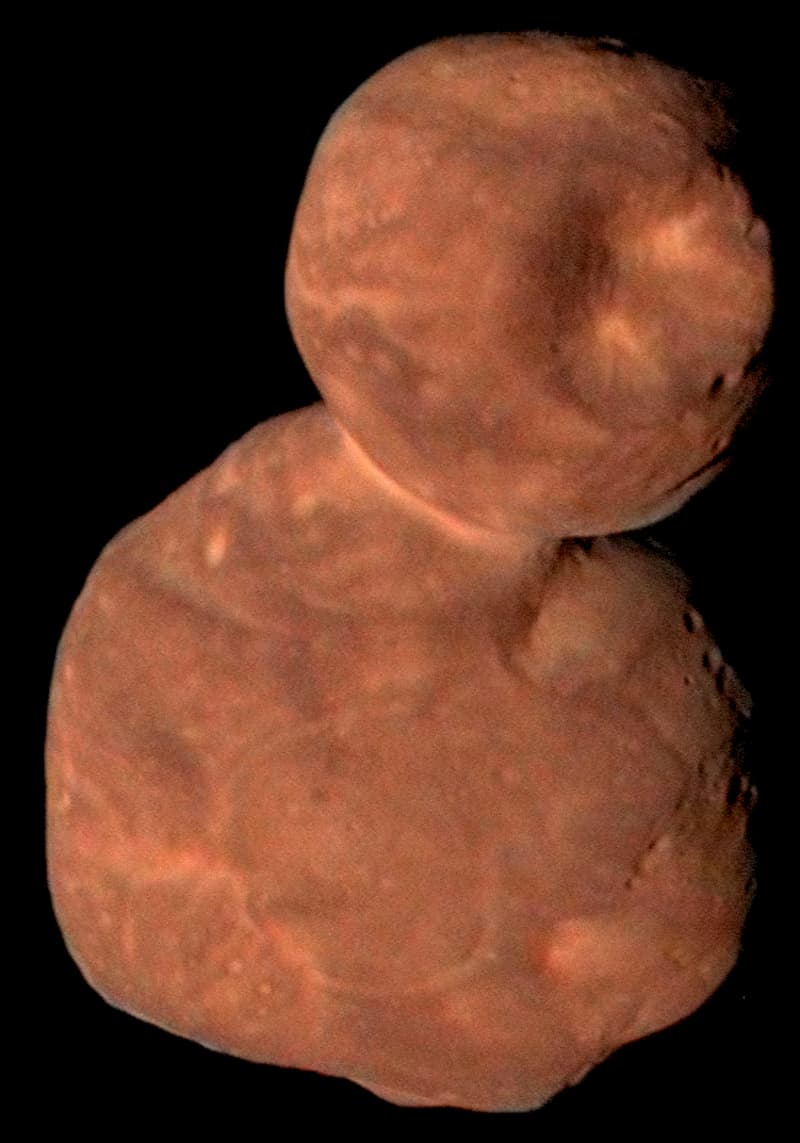
Cuando el 1 de enero de 2019 la sonda New Horizons de la NASA sobrevoló el objeto del Cinturón de Kuiper conocido oficialmente como 2014 MU69 la agencia llevaba ya un tiempo utilizando el apodo Ultima Thule para referirse a él...

En esta conferencia de la Royal Institution el mago y psicólogo Gustav Kuhn repasa y explica cómo funciona nuestro cerebro cuando vemos juegos de magia. Esto incluye qué sucede en el aspecto visual, qué datos científicos sumamente interesantes conocemos al respecto...

Hay conferencias que aburren a las ovejas y clases que hacen que el alumnado se adormezca sin remisión. pero esto no siempre es por la falta de interés de los temas o porque la gente llega a clase sin haber dormido...

En 2016 la enana marrón 2MASS J23062928-0502285 se hizo repentinamente famosa después de que el telescopio belga Trappist, instalado Observatorio Europeo Austral en Chile y operado por control remoto desde Lieja, descubriera tres planetas en órbita alrededor de ella. Era la...
El tres en raya cuántico es una ingeniosa variante del clásico juego para niños llevado al mundo de la física cuántica. Lo más interesante es que el juego captura la esencia de la física cuántica: la superposición, el entrelazamiento y el...

Mars continues to surprise us. While digging this weekend the mole backed about halfway out of the ground. Preliminary assessment points to unexpected soil properties as the main reason. Team looking at next steps. #SaveTheMole #Teamwork pic.twitter.com/UURvU8VTwZ— NASA InSight (@NASAInSight) October 27,...

A la gente carnívora a la que le gustan los filetes de carne «muy poco hecha, casi mugiendo» quizá les soprenda saber que la «sangre roja» de esos filetes casi crudos no es sangre, es mioglobina. La mioglobina es una proteína...

Impresión artística del Spektr-RG en el espacio Lanzado el pasado 13 de julio de 2019 el observatorio de rayos X ruso-alemán Spektr-RG acaba de alcanzar el punto de Lagrange L2 del sistema Tierra–Sol, que es desde dónde llevará a cabo su misión,...

Luis Peña ha propuesto un modelo del telescopio espacial Hubble en Lego Ideas, la web en la que aficionados de todo el mundo pueden sugerir construcciones para que el fabricante las saque al mercado como productos. Con unas 1.000 piezas está...

Joaquín Sevilla es físico. De ahí su interés en cómo funciona el mundo que nos rodea. Pero Joaquín conserva la curiosidad de un niño, lo que le permite encontrar cosas de las que maravillarse en un posavasos sucio, preguntarse por qué...

El 12 de octubre de 2019 el telescopio espacial Hubble se pasó siete horas observando el cometa interestelar 2I/Borisov mientras estaba a una distancia de unos 420 millones de kilómetros de la Tierra. Al seguirlo para mantenerlo en su campo visual...

La Universitat de Barcelona publicó hace unos años una interesante serie de vídeos bajo el tema Ciencia Animada dedicada a la divulgación científica. Se explica para empezar el método científico con animaciones, muñecos y unos pocos carteles; no hay narración, sólo...

With an assist from my robotic arm, the mole is digging again! We are just starting this new campaign, and are hopeful we can continue to dig. #Mars #Teamwork pic.twitter.com/Wkj7OhVG2y— NASA InSight (@NASAInSight) October 15, 2019 Después de seis meses sin moverse...

Después de más de dos años de retrasos la NASA por fin ha conseguido poner el órbita el satélite ICON el pasado 11 de octubre. Su nombre viene de Ionospheric Connection Explorer, Explorador de la Conexión Inonosférica; su misión es estudiar...

Aprovecho este vídeo de Seeker que me ha parecido una muy buena explicación de la cuestión para anotar algunos enlaces acerca de un asunto que lleva unos días revoloteando: el trabajo que investigadores de Google y la NASA han llevado a...
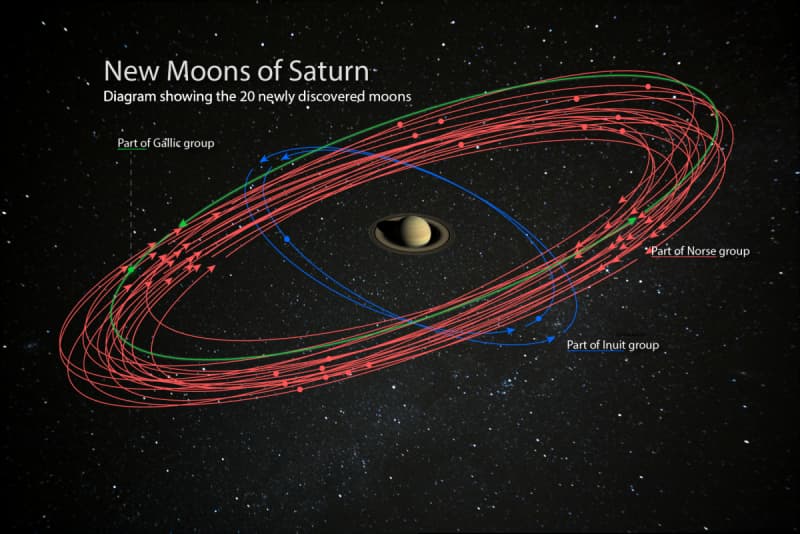
Órbitas de las nuevas lunas - Imagen del planeta por NASA/JPL-Caltech/Space Science Institute. Estrellas por Paolo Sartorio/Shutterstock Un equipo de científicos del Instituto Carnegie, de la Universidad de California y de la Universidad de Hawaii han anunciado el descubrimiento de 20 nuevas...

El HP3, de Heat Flow and Physical Properties Package, o Paquete de Flujo de Calor y Propiedades Físicas, también conocido como el topo, es uno de los dos instrumentos principales de la sonda InSight de la NASA. Estaba diseñado para introducirse...

Michael Stevens, más conocido por Vsauce, preparó hace tiempo una serie documental para YouTube Premium acerca de la mente y el comportamiento humano desde el punto de vista científico. Y tal y como ha anunciado ahora va a ser completamente gratis...

Desde hace años Daniel viene publicando en su blog una serie de anotaciones que explican la relación entre distintas mitologías y la ciencia, el por qué de los nombres escogidos para nuevos descubrimientos e invenciones. Del mito al laboratorio recoge esa...

Casi todos los animales son bilaterales.– Tracy Thomson En BioEssays han publicado un trabajo de Tracy J. Thomson titulado Three‐Legged Locomotion and the Constraints on Limb Number: Why Tripeds Don’t Have a Leg to Stand On acerca del movimiento con tres...

Impresión artística de 2I Borisov - NASA Descubierto a finales de agosto de 2019 por el astrónomo aficionado Gennadiy Borisov el Centro de Planetas Menores por fin ha confirmado que el cometa Borisov es un objeto interestelar. Así que tras pasar por...

Equivocarse al teclear muestra cómo la memoria implícita coordina nuestros movimientos sin que pensemos en ellos.

James de The Action Lab enseña en este vídeo algunos de los efectos, trucos y chorradas que se pueden hacer con un imán gigante de neodimio cuando se le acercan de diversas formas mil pequeñas bolitas de neodimio también imantadas. Los...

El virus del Ébola por Luke Jerram Hace poco tuve la oportunidad e visitar Micropia, el único museo del mundo –al menos según ellos– dedicado a los microbios. Una de sus secciones está dedicada a algunas de las enfermedades que provocan. Y...

Un equipo de ingenieros del MIT han desarrollado lo que llaman «el material más negro existente hasta la fecha», más negro que el Pantone Black, más negro que el alma de un spammer, más negro que la negrura misma y que...

Estos veinte minutos de entrevista con el profesor de informática y experto en computación cuántica Scott Aaronson son muy densos y dan para muchos temas. Lanza muchas preguntas –que es lo interesante– especialmente sobre el tema de la consciencia en las...
CONCISE es un proyecto de investigación de dos años formado por nueve instituciones de cinco países europeos que tiene como objetivo conocer el papel que desempeña la comunicación científica en el origen de las creencias, percepciones y conocimientos sobre temas científicos de...

Un momento de la ceremonia de entrega / AIR Suenan a broma pero no lo son; son investigaciones serias que quizás algún día sirvan para algo más que echarnos unas risas. Y los premios Ig Nobel de 2019, otorgados los editores de...

Los aficionados a los audiolibros (o los vídeolibros en este caso) encontrarán curiosa y relajante esta susurrante lectura del primer libro de los Principia de Isaac Newton, apropiadamente a la luz de las velas y con ambientación de la época (se...
Las dos partes del Telescopio Espacial James Webb ya ensambladas – NASA/Chris Gunn En otro importante paso adelante de cara a su lanzamiento las dos partes del Telescopio Espacial James Webb acaban de ser ensambladas en las instalaciones de Northrop Grumman en...
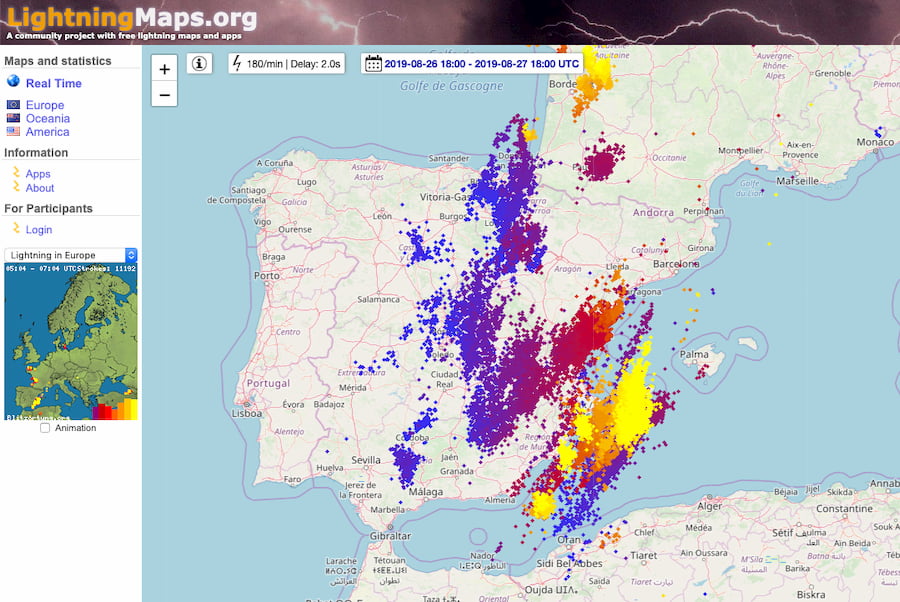
LightningMaps combina los datos públicos de diversas estaciones de observación para generar un mapa en tiempo real que indica dónde están cayendo los rayos de las tormentas a medida que se producen. En esas estaciones, gestionadas por aficionados, se emplea una...
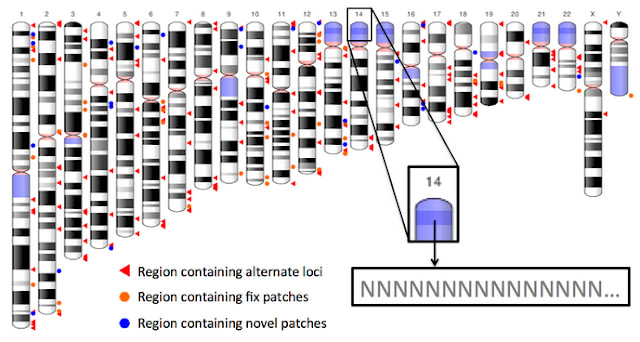
Se calcula que el genoma humano almacenado en los cromosomas contiene con bastante certeza unos 3.200 millones de pares de bases de ADN (3.200.000 kb, 3.200 Mb o 3,2 gigabases). Pero cuando se lee la secuencia no siempre se hace de...
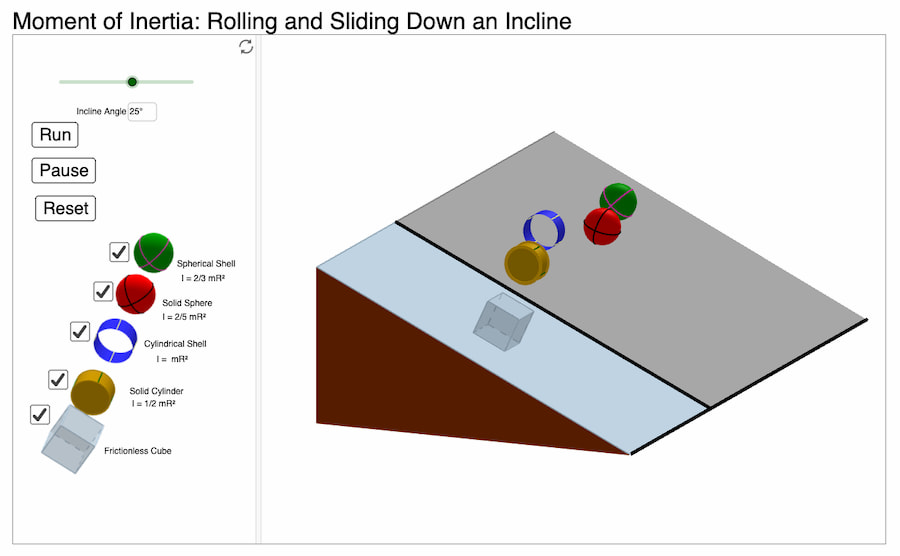
Esta página de oPhysics tienen un curioso simulador del momento de inercia de objetos rondando en un plano inclinado. Hay cinco objetos dispuestos para caer; la cuestión es cuál llegará primero abajo… Y no es fácil adivinar –ni calcular– en qué...
En este vídeo de Sekker dan cuenta del artículo publicado en Nature por unos investigadores del Centro de Investigación de IBM Almadén en California que han conseguido por primera vez una imagen de resonancia magnética de un átomo individual. Esto no...
La forma en la que las matemáticas resuelven los problemas del MundoReal™ suele pasar por crear «modelos» con los que realizamos cálculos partiendo de ciertas suposiciones. Mejorando esos modelos con nuevos detalles y variables esas soluciones tienen en cuenta más factores...

En este paseo virtual del canal PBS Space Time se puede ver cómo es el exterior y algunas de las instalaciones del radiotelescopio de Arecibo, que lleva ya algo más de 55 años en funcionamiento. Se ve un poco mejor y...

Perseidas en el ORM con los telescopios MAGIC durante la noche del 11 al 12 de agosto de 2016 - Daniel López/IAC Como todos los meses de agosto la Tierra está atravesando los restos dejados atrás por el cometa Swift-Tuttle. La entrada...

Un estudio publicado por empleados de un par de empresas del campo de la salud y de Apple muestra algunas ideas sobre cómo los dispositivos que llevamos todo el día encima, como teléfonos y relojes inteligentes, tabletas y demás, podrían usarse...
.jpg)
El cielo sobre los Himalayas (Nepal) (CC) Anton Yankovyi Esta magnífica foto de Anton Yankovyi que encontré en Wikimedia Commons muestra los efectos de la rotación de la tierra en una fotografía de larga exposición en la que el centro de los...

Frankenbook, editado por PubPub es la versión web, libre y completa, de Frankenstein: Annotated for Scientists, Engineers, and Creators of All Kinds editado por MIT Press, un libro de Guston, Finn, Robert y otros autores basado en la novela de Mary...

El diseñador Christian Stangl y el compositor Wolfgang Stangl han creado este vídeo que recoge en cosa de tres minutos la misión de Rosetta y Philae al cometa 67P Churyumov-Gerasimenko. Fue la primera misión de la historia en orbitar un cometa....
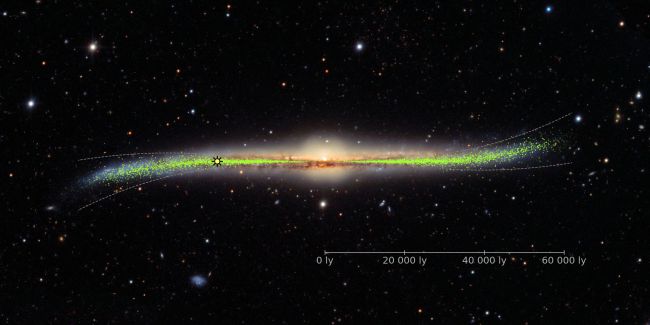
En un artículo en Science un equipo de astrónomos encabezado por Dorota Skowron explica cómo ha utilizado la luz de las cefeidas (estrellas variables) para realizar un mapa de nuestra Vía Láctea en 3-D, con el curioso resultado de que su...

En este episodio de Elements –una de las series de Seeker– Maren Hunsberger resume con eficacia y su clásico estilo tranquilo y didáctico qué es la teoría del caos y algunos de los asuntos relacionados, de los que también hemos hablado...

Estos Planetary Blocks triunfaron en Kickstarter con cerca de 1.000 pedidos son una serie de bloques de madera decorados con planetas, planetas enanos y lunas, además del Sol. En total son 20 cuerpos celestes con datos acerca de sus tamaños, órbitas...

¿Recuerdas el famoso test de empatía al que los Blade Runner someten a humanos y replicantes para distinguirlos, buscando indicios de respuestas físicas emocionales controlando los tiempos de reacción? Pues leyendo un curioso artículo de Nautilus (The Science Behind “Blade Runner”’s...

En este vídeo del Ames Research Center de la NASA se explica qué es el Ión hidruro de helio (HeH+), una curiosa molécula que se conoce desde 1925 y que se suponía que debía existir en la naturaleza en el espacio...

Este curioso montaje lo han llamado Ondas pendulares de Lego y es una propuesta de Lego Ideas. Consiste en ocho péndulos en los que se ha calculado perfectamente su periodo, ajustando la longitud de la cuerda. El primero oscila 60 veces...

Los seres humanos tenemos unos tiempos de reacción ante los estímulos más o menos fijos y relativamente lentos: unos 200-250 milisegundos. Esto es lo que tardamos en decidir hacer algo y que la orden del cerebro llegue a los músculos, tal...

Liam Mcmulkin, sordo de nacimiento, ha desarrollado unos 100 nuevos signos científicos para la lengua de signos inglesa (según los idiomas los signos varían). Como estudiante le resultaba incómodo asistir a conferencias y clases aunque hubiera un intérprete de signos, básicamente...

Entre el 16 y el 24 de julio de 1994 los 21 fragmentos del cometa Shoemaker-Levy 9 impactaron contra la atmósfera de Júpiter. Como había sido descubierto a tiempo científicos de todo el mundo –y la sonda Galileo– pudieron seguir en...

Como manda la mecánica celeste dos semanas después de un eclipse de Sol se produce un eclipse de Luna. Así que entre las 22:02, hora peninsular española, del 16 de julio de 2019 y la 1:00 del día 17 se podrá...

Un cohete Protón-M está listo en el Complejo de lanzamiento 81 del Cosmódromo de Baikonur para poner el órbita el observatorio ruso-alemán de rayos X Spektr-RG. El lanzamiento está programado para las 14:30:57, hora peninsular española y se podrá seguir a...

La superficie de Ryugu y el tubo de toma de muestras de Hayabusa 2 cuatro segundos después del contacto – JAXA El equipo de la sonda Hayabusa 2 de la Agencia Japonesa de Exploración Aeroespacial (JAXA) se ha apuntado otro éxito hoy...
Hace unos días la Comisión de la Transparencia de la Alta Autoridad para la Salud (HAS) francesa emitía su informe definitivo acerca de la homeopatía. Para sorpresa de aproximadamente nadie decía que su efectividad no ha podido ser demostrada, por lo...

Impresión artíctica Hayabusa 2 tomando muestras en el cráter que ha creado, aunque ahora sabemos que esto no va a ser exactamente así – Akihiro Ikeshita/JAXA Tras estudiar los datos e imágenes obtenidas de la superficie del asteroide Ryugu después de haber...

Hoy es uno de esos días en los que Internet amanece llena de fotos del eclipse del día anterior. Pero creo que de todas las que he visto hasta ahora las que más me han gustado son las que tomó el...

Behold the mole! Now with the support structure out of the way, my team has a view of the mole’s position. Read more on the plans to keep moving forward (and downward): https://t.co/9DmF5OANlO pic.twitter.com/mMthA5jrZ6— NASA InSight (@NASAInSight) July 1, 2019 Aunque hace...

Trayectoria del eclipse del 2 de julio de 2019 – NASA Faltan pocas horas para que se produzca el eclipse total de Sol del 2 de julio de 2019. La totalidad será visible desde Chile y Argentina. Será visible como un eclipse...

Si todo va según lo previsto los técnicos de la Agencia India de Investigación Espacial (ISRO) habrán terminado hoy, 28 de junio de 2019, la integración de los tres módulos de la misión Chandrayaan-2. Los módulos son el aterrizador Vikram, l...
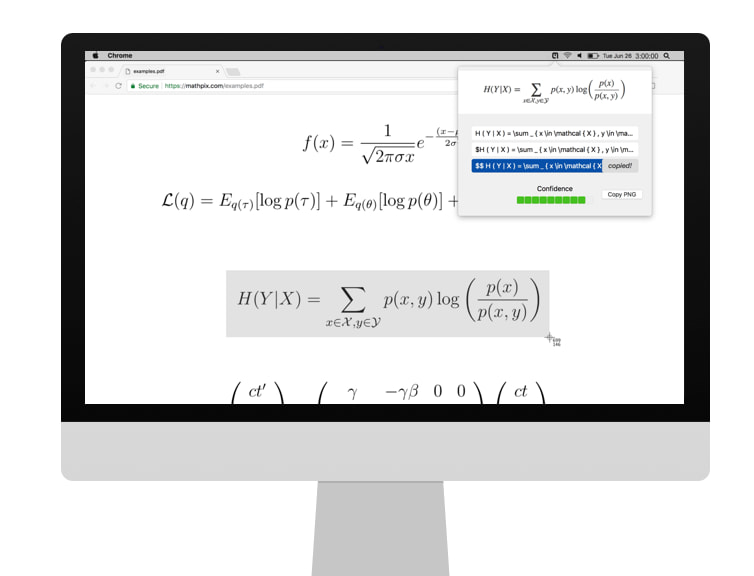
Mathpix [Mac OS, Windows, Linux] es una utilidad que sirve para convertir las ecuaciones que se ven en pantalla en código LaTeX, el lenguaje / sistema de composición de textos que todo el mundo utiliza para los trabajos científicos. Utilizarlo es...

No se esperaba la decisión hasta el mes que viene pero la NASA ya ha anunciado que la próxima misión del programa New Frontiers va a ser Dragonfly. Dragonfly es un «dron» con ocho rotores que tiene como misión estudiar Titán,...

En este didáctico vídeo de Steve Mould acerca de los cristales de cuarzo y su frecuencia de 32.768 hertzios en los relojes se pueden aprender unas cuantas cosas, entre ellas: El funcionamiento básico de algunos relojes mecánicos, incluyendo la necesidad de...

Ya tenemos el programa provisional de Naukas Bilbao 2019 que este año, cómo no, tiene un póster que está en la Luna. Conserva el formato estrenado en 2017 que incluye en realidad tres eventos relacionados: Jueves 19 de septiembre: Naukas Pro,...

Nos escribieron desde La venganza de Hipatia para contarnos que están realizando el segundo cuestionario de un estudio sobre creencias y percepciones sociales. Se trata de investigadores de la Universidad de Valencia, la Universidad de Cambridge y la Universidad de Bristol,...

Tras un tiempo en silencio el astrónomo indignado no ha podido resistirlo más y vuelve a la carga desde su escondrijo en los sótanos del Instituto de Astrofísica de Andalucía. En diez nuevos vídeos promete no dejar títere con cabeza, siempre...
Lanzado el 25 de agosto de 2003 el telescopio espacial Spitzer fue el último de los grandes observatorios de la NASA en ser lanzado, tras el telescopio espacial Hubble (1990), el Observatorio de Rayos Gamma Compton (1991) y el Observatorio Chandra...

Aterrizaje del Altantis tras la misión STS-125 – NASA Hace unos días se cumplían diez años del final de la cuarta y última misión de mantenimiento del telescopio espacial Hubble. Durante ella la tripulación del Atlantis instaló nuevas cámaras en el telescopio,...
Esta superchuleta matemática llamada All-in-one Mathematics Cheat Sheet [v2.6, PDF] de Alex Spartalis es una recopilación que ha requerido varios años de paciente trabajo y que se puede descargar para guardar por ahí porque contiene la típica información que nunca sabes...

Todas las líneas son igual de sinuosas, pero algunas parecen líneas rectas en zig-zag. Kohske Takahashi ha publicado esta imagen en un trabajo sobre algo que ha denominado «ilusión de la ceguera a la curvatura» (Curvature Blindness Illusion). Hay que mirarlo...
La cuenta de Instagram de Yuri Kovalenok está dedicada sus apuntes de física. Pero caligrafiados e ilustrados con un estilo particular y elegante que los convierten en pequeñas obras de arte: desde las explicaciones del movimiento circular a la Ley de...

You can do this already with a ZIP code. https://t.co/sVfNmDSQTo— Luther M. Siler (@nfinitefreetime) 5 de abril de 2018 Esto ya puede hacerse sabiendo el código postal. El artículo de Technology Review donde se habla de que por 50 dólares puedes «predecir»...

Nuestra admirada Ada Lovelace, la primera programadora de la historia, aunque mucho más allá de eso fue la primera persona en darse cuenta de los enormes cambios sociales que podían traer los ordenadores, busca hacerse un hueco en la Colección Científicos....

Imagen por ordenador que recrea el Gran K – Greg L No recuerdo exactamente la definición de kilogramo que estudié en el colegio. Pero era parecida a esta, sacada de la Wikipedia: «su patrón se define como la masa que tiene el...

El físico por la Universidad de Zaragoza Iñaki Echeverría, que actualmente se está doctorando en la Universidad de Navarra, ha ganado Famelab España 2019 con Déjame salir. Es un monólogo en el que nos intenta convencer, como dice la sabiduría popular,...
Hace unas semanas las agencias espaciales NASA y ESA, junto con la FEMA (emergencias) y quien se quisiera apuntar participaron en una simulación estilo «juegos de guerra» en la que el protagonista era un asteroide que iba a impactar contra la...
Esta pieza de Vox Media es muy entretenida porque combina todo un mito cultural como es Franskenstein, de Mary Shelley, con experimentos con electricidad y «apaños» médicos que hoy nos parecen un poco cafres, de cuando no se sabía muy bien...

The Planets es una nueva serie documental de la BBC Earth narrada por el físico Brian Cox, a quien ya conocemos y admiramos por sus excelentes trabajos divulgativos como Wonders of the Solar System (2010) Wonders of the Universe (2011) y...

Unos científicos de la Universidad de Newcastle (Reino Unido), han hecho una serie de experimentos para comprobar si, como mucha gente piensa, los objetos «humanizados» nos hacen ser más sociales. En concreto pusieron ojitos saltones en las huchas de donaciones de...
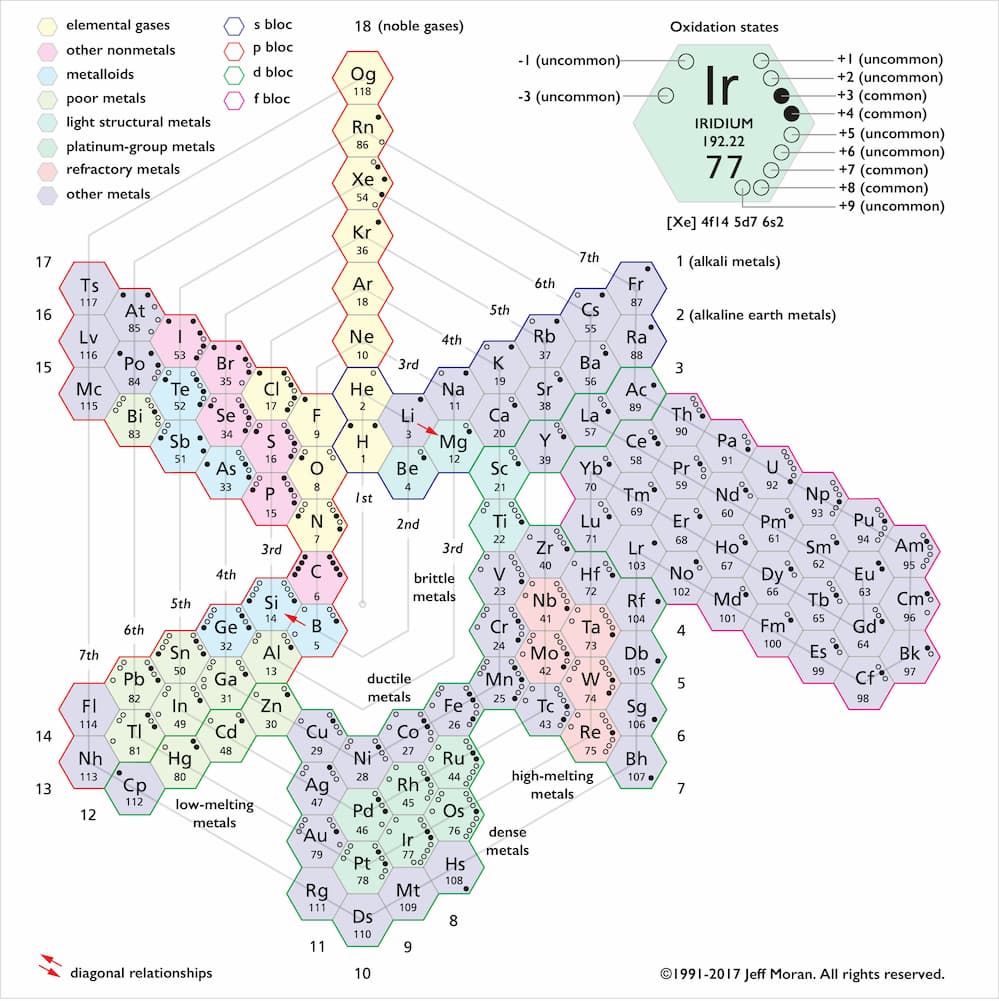
The Internet Database of Periodic Tables es una de esas maravillosas bases de datos gigantescas que recopila recursos sacados de dios sabe dónde para conformar un archivo masivo de las tablas periódicas en todas sus variantes. Las hay tanto formales como...

El sábado 4 de mayo de 2019 el Día de la Ciencia en la Calle vuelve al Parque de Santa Margarita. En su XXIV edición, y como es habitual, cientos de estudiantes y profesores de decenas de centros educativos, así como...

El último Consejo de Ministros del Gobierno de España antes de las elecciones generales del 28 de abril de 2019 ha aprobado un aumento del techo de la participación española en los programas espaciales de la Agencia Espacial Europea en el periodo...

En LiveScience dan una explicación a la imagen viral que está haciendo las rondas por internet como meme: una especie de foto en la que aparecen muchas cosas pero es imposible reconocer ninguna como un objeto concreto. Básicamente, es imposible nombrar...

Los Museos Científicos Coruñeses, en los que trabajo en el MundoReal™, junto con Naukas y el Campus Innova de la Universidade da Coruña, organizan mc2 presenta: Naukas Coruña 2019. Tendrá lugar el sábado 8 de junio en el teatro Rosalía Castro...

El agujero negro de M87 – NSF Después de años de trabajo el Event Horizon Telescope ha presentado la primera imagen de un agujero negro que hemos conseguido jamás. Aunque siendo estrictos nada –por definición– puede escapar de un agujero negro, así...
En un trabajo titulado Review of borophene and its potential applications del que da cuenta el MIT Technology Review se habla del borofeno, un alótropo cristalino del boro, básicamente otra forma de disponer de forma estable los átomos de boro, de...

Momento del disparo del instrumento SCI de Hayabusa 2 La sonda Hayabusa 2 de la Agencia Japonesa de Exploración Aeroespacial (JAXA) está lista para empezar con una de las operaciones más ambiciosas de su misión. La idea es hacerle un cráter nuevo...

En la Universidad de Bandeis tienen este curioso Laboratorio de Orientación Especial Ashton Graybiel. Es básicamente una habitación gigante que da vueltas. Si te pones en su interior –como ha tenido la suerte de hacer Tom Scott– puedes experimentar con sensaciones...

Microsoft y la Universidad de Washington están investigando y realizando demostraciones de un sistema automático para almacenar y recuperar datos en moléculas «fabricadas» con ADN. En un trabajo publicado en Nature Scientific Reports se explica en detalle sobre el proceso (Demonstration...

En este vídeo de Wired de la serie Almost Impossible («Casi imposible») examinan lo complicado que resulta en baloncesto mejorar los porcentajes de tiros libres más allá de cierto punto. En la NBA el promedio es del 70 por ciento y...

Me ha encantado este segmento de los Cazadores de Mitos en Science Channel donde intentan comprobar si –como en las películas– sería posible montar una barricada inexpugnable detrás de una puerta con lo que haya a mano, básicamente muebles diversos y...

Los placebos son medicina de mentirijillas que se utilizan en los ensayos clínicos principalmente para comprobar la efectividad de los medicamentos de verdad. Van desde el «sana, sana, curita de rana» a píldoras de todos los colores y tamaños, pero sin ningún...

Seba Naranjo hace cosas con papel, especialmente «dinosaurios y otros bichos fabulosos». En su Instagram @Naranjazo hay unas magníficas fotos de muchos de ellos que, ante todo, son «anatómicamente correctos», como dice. Artesanía con el papel en su máxima expresión. Está...

Es sabido que a falta de un «premio Nobel de matemáticas» el equivalente más cercano es el Premio Abel, que entrega la Academia Noruega de Ciencias y Letras cada año. En esta edición de 2019 la ganadora ha sido Karen Uhlenbeck,...

Se abre el telón y aparecen un matemático, siete colaboradores y una cómica. ¿Cómo se llama el programa? ¡@orbitalaika_tve! Los lunes a las 22h, no te pierdas la 5º temporada del show científico en @la2_tve. ¡Estreno el 18 de marzo!➡️https://t.co/EWVX6nflEe pic.twitter.com/61h0Ss222n— Órbita...

Convocados por el Círculo Escéptico y patrocinados por la Universidad de A Coruña acaban de nacer los Premios Isabel Zendal: El Premio Isabel Zendal tiene como objetivo fomentar la práctica del escepticismo en la educación secundaria. Entendemos el escepticismo como el uso...
Un reciente trabajo recién publicado de investigadores del Instituto de Física y Tecnología de Moscú esta dando lugar a grandes y espectaculares titulares del tipo «El sueño cumplido de viajar al pasado» (Diario Vasco) o «Físicos hacen retroceder el tiempo usando...
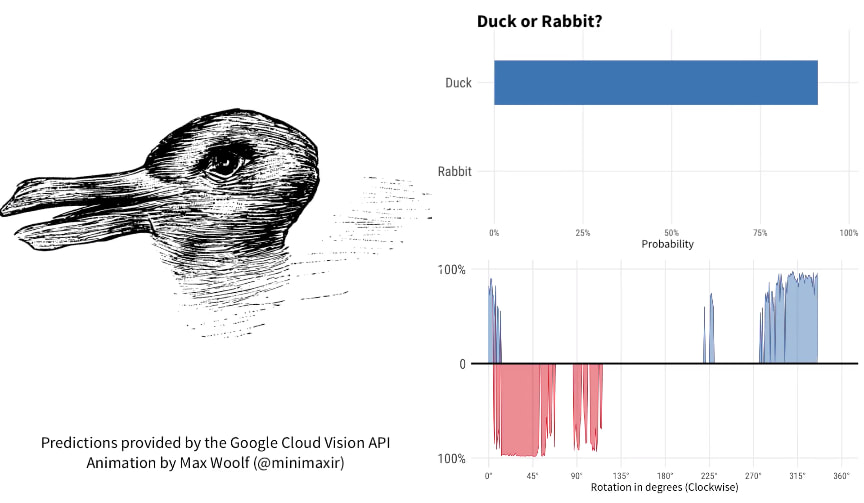
A Minimaxir de reddit se le ocurrió pasar la famosa y más que clásica ilusión óptica del patoconejo por el filtro de la API Cloud Vision de Google, un potente algoritmo de clasificación de imágenes se utiliza para todo tipo de...

Yuliya Klochan, una estudiante de matemáticas del M.I.T. explica en Science Out Loud qué son los fractales, cómo se construyen algunos de ellos y por qué resultan tan fascinantes, a la par que útiles. Entre otros utiliza el copo de nieve...

En el Museo de Ciencias de Londres tienen una edición original de la tabla periódica de Mendeléyev, que justamente cumple 150 años hoy 6 de marzo (la original se publicó en 1869). Recordemos que la Asamblea General de las Naciones Unidas...

Cunmpliendo con un compromiso adquirido al poco tiempo de entrar en el Gobierno por el Ministro de Ciencia, Innovación y Universidades de España hoy se ha lanzado #coNprueba, que es la marca que engloba las acciones frente a las pseudociencias y...

Close-ups from the Kuiper Belt! #NewHorizons has sent home its sharpest images from the #UltimaThule flyby, revealing new details about the farthest object ever explored by spacecraft. https://t.co/vKTWJPUFEG pic.twitter.com/MDvUzW8dL7— NASA New Horizons (@NASANewHorizons) 22 de febrero de 2019 Aunque aún falta más...
A 30 metros de altura y subiendo – JAXA Esta imagen, captada por la sonda Hayabusa 2 de la Agencia Japonesa de Exploración Aeroespacial (JAXA) a unos 30 metros de altura mientras subía tras haber tocado la superficie del asteroide Ryugu con...
Galaxy Quest, propuesta por el equipo Pillars of creation, formado por Almudena Martín, Jose Luis Martin-Oar y Juan Martinez, Rosa Narváez y Iñaki Úcar, ha sido la aplicación ganadora de la categoría Mejor uso de la ciencia del hackatón Space Apps...
Que el valor del número pi (π) se conoce desde la antigüedad –al menos desde el año 1800 o incluso 2000 a. C.–es un hecho cierto. Por suerte también han llegado hasta nosotros los métodos que hace miles de años se...

The gang’s all here: my seismometer, its cover, and now the heat flow probe! It’s no easy task to set up such sensitive instruments on the surface of another world. Together we’ll unlock some of #Mars’ deep secrets. pic.twitter.com/77nGAaBi6L— NASA InSight (@NASAInSight)...

Harun Mehmedinovic y Gavin Heffernan tienen esta curiosa peliculita rodada sorprendentemente con permiso en un paraje único. Forma parte de la serie de fotografías y películas del Proyecto Skyglow acerca de los cielos nocturnos y los efectos de la contaminación lumínica...

Una teoría propone que la consciencia es la forma imperfecta que tiene el cerebro de interpretar su propia actividad.– Michael Graziano En este vídeo de Ted-ED Michael Graziano explora qué es la consciencia humana según algunas teorías predominantes en varios campos...

BREAKING 2014 MU69 (nicknamed #UltimaThule), is not, as it turns out, quite so round as initially anticipated. Images from @NASANewHorizons confirm the highly unusual, flatter shape of the #KBO: https://t.co/yaAZx8XQqO pic.twitter.com/JQlLiL9Hxq— Johns Hopkins APL (@JHUAPL) 8 de febrero de 2019 Las primera...

La ciencia y la igualdad de género son fundamentales para el desarrollo sostenible. Aún así, las mujeres siguen encontrando obstáculos en el campo de la ciencia: menos del 30% de investigadores científicos en el mundo son mujeres. Hacer frente a algunos...

Con una cámara de alta velocidad y un sencillo montaje la gente de Magnetic Games ha publicado este vídeo en el que puede verse cómo la «arena magnética» interactúa con un imán en diversas tomas y movimientos. Lo que se adivina...
No es fácil encontrar los factores primos de algunos números; ni siquiera saber si son primos o compuestos a simple vita. Hacer esos cálculos mentalmente¹ es un problema bastante complejo. Sin embargo hay algunos trucos que si se conocen ayudan a...

Este sistema graba los datos de todos los componentes y le dice al ordenador principal de la Estación Espacial que «no está ardiendo» una vez por segundo, porque es muy importante no estar ardiendo en el espacio (…) Perdonadme que insista...

Ya está en marcha la cuarta edición de Ciencia Clip, el concurso de vídeos de divulgación de ciencia para estudiantes de la ESO, Bachillerato y del ciclo básico y medio de FP. Su objetivo es «fomentar el interés por la ciencia...

Like a flying saucer, the protective dome of the SEIS seismometer of the @NASAInSight probe has gently landed on the Martian surface. pic.twitter.com/2DdcIaPuSf— SEIS (@InSight_IPGP) 2 de febrero de 2019 Con la instalación del Escudo térmico y contra el viento (Wind and...
El Solar Orbiter, la misión de la Agencia Espacial Europea con destino al Sol, ha dado un importante paso adelante con el fin de las pruebas térmicas del modelo de vuelo. El prototipo de modelo de vuelo, o proto flight model...

Si esto en vez de ser una animación 3D fuera una película sería muy antigua: unos 13.000 millones de años, cuando el joven Universo tenía «tan solo» unos 400 millones de años de antigüedad. Las simulaciones astrofísicas renacentistas son los cálculos...

Advertencia: Este experimento ser considerada peligroso dado que el mercurio es altamente tóxico y debe ser manejado con sumo cuidado (tema aparte sería cómo conseguirlo, que no es fácil). Al ser absorbido por la piel y tremendamente tóxico sólo se debe...

Statistics Done Wrong de Alex Reinhart es una recopilación de todas esas cosas que se hacen mal cuando se trabaja con estadísticas, especialmente cuando se trabaja con datos científicos. Lo cual es importante porque hace que malas interpretaciones lleven a conclusiones...
Lanzado el 19 de abril de 2018 el observatorio espacial TESS de la NASA tiene como único objetivo en la vida descubrir planetas extrasolares de esos que están en órbita alrededor de otras estrellas. Para ello mira fijamente el cielo con...

Con el lema Evolucionando en la divulgación del conocimiento la VII edición del Congreso de Comunicación Social de la Ciencia se celebrará del 9 al 11 de octubre de 2019 en el Campus del Hospital del Rey de la Universidad de Burgos....
Tirando de API, canales RSS y similares el autor de Astropical consigue mostrar un montón de información para espaciotrastornados en una sola web, que aunque funciona en móviles es mejor en ordenadores o tablets. No es necesario registrarse para usarla pero...
Just 161 days after launching from Florida, our #ParkerSolarProbe recently completed its first orbit of the Sun, reaching the point in its orbit farthest from our star. The @NASASun probe is now preparing for its next solar flyby in April 2019: https://t.co/NcDLMNlZl1...

¿Alguna vez te ha pasado eso de que entras en una habitación de tu casa o en una dependencia de tu trabajo y no recuerdas por qué ibas allí por mucho que te esfuerces? Esto se asocia a un fenómeno conocido...

Materiales del experimento – R. Möller / C. S. Cockell En algún lugar de la Universidad de Edimburgo hay una caja de roble que contiene 400 viales de cristal sellados –bueno, ahora alguno menos– que a su vez contienen esporas desecadas de...

Confirmed Separation of the LSA on SEIS during mission sol 61. We can now look forward to deployment of the WTS and science @InSight_IPGP @InSight_IPGP @CNES @troyleehudson pic.twitter.com/yxVrtXID5v— Paul Hammond (@PaulHammond51) 28 de enero de 2019 Les ha costado casi cuatro semanas...

Se me había quedado un tanto traspapelado –hace dos meses de ello– mencionar la presentación de la 9ª edición de la Encuesta de percepción social de la ciencia de la Fundación Española para la Ciencia y la Tecnología (FECYT). Pero aquí queda...

Saturno y sus anillos – NASA / JPL-Caltech / SSI / Ian Regan Me ha sorprendido descubrir de la mano de Phil Plait en su blog Bad Astronomy que acabemos de conocer el periodo de rotación de Saturno, es decir cuánto dura...

Las Naciones Unidas han designado 2019 como el Año internacional de la tabla periódica para conmemorar el 150 aniversario de su descubrimiento. Y si tienes alguien cerca del ramo de la química esta tabla periódica con muestras reales de buena parte...

Universe (1960) es un documental de Roman Kroitor y Colin que rodaron siendo parte de la segunda unidad de la National Film Board de Canadá. Ahora ha sido restaurado y está disponible en YouTube a buena calidad, con estupendo sonido y...

NEW: #UltimaThule, now in higher-res! Both lobes now show many intriguing light & dark patterns of unknown origin, which may reveal clues about how it was assembled during the formation of the #solarsystem! @NASANewHorizons https://t.co/KK3T8ZFt3u pic.twitter.com/ULsF6atWUH— Johns Hopkins APL (@JHUAPL) 24 de...

En España nunca se ha hecho un macroestudio serio y enfocado a dilucidar la cantidad real de fallecidos a causa de las pseudoterapias. Pero mientras las administraciones públicas competentes se deciden a hacerlo la Asociación para Proteger al Enfermo de Terapias Pseudocientíficas...

Un equipo del NCAR (National Center for Atmospheric Research) estadounidense ha creado esta espectacular simulación para estudiar el comportamiento de las llamaradas solares cubriendo todas sus fases en un solo modelo: la acumulación de energía a unos diez mil kilómetros bajo...

En 2016 la NASA solicitó nuevas propuestas de misiones para el programa New Frontiers, el mismo que nos ha dado la New Horizons, Juno u Osiris-Rex. De las 12 propuestas recibidas en abril de 2017 la agencia se ha quedado con...

Desde Kronecker Wallis nos avisaron de la existencia de su proyecto Discovering the History of Astronomy en Kickstarter, una preciosa colección de seis volúmenes con los trabajos de Copérnico, Brahe, Kepler y Galileo en edición de lujo: De revolutionibus orbium coelestium...
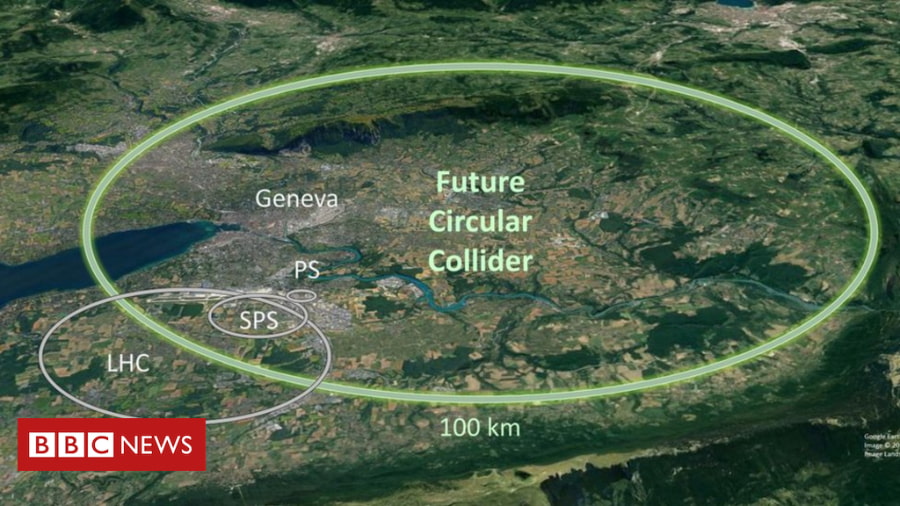
Estos días BBC News y otros medios han publicado sobre un posible sucesor del Gran Colisionador de Hadrones que tantas alegrías ha dado al mundo de la ciencia. Sería otro acelerador de partículas más grande que los actuales y llamado –de...

Esta curiosa demostración matemática está relacionada con los diagramas de Voronoi consiste en colocar pegotes de pintura en un cristal plano y acto seguido aplastarlos con otro cristal de modo que se expandan, definiendo regiones que quedan delimitadas por el contacto...

James O' Donoghue de la NASA ha preparado algunas animaciones a escala en las que se pueden apreciar las distancias y la velocidad de la luz cuando viaja entre tres objetos celestes: la Tierra, la Luna y Marte. En la primera...

Como un experimento vale más que mil cuñaos en The Action Lab se pusieron de nuevo en acción para comprobar qué es lo que sucede al volar un dron en miniatura en el interior de un ascensor. Así que se fueron...

En 3Blue1Brown tienen este curioso problema matemático consistente en contar las veces que rebotan dos objetos que chocan en «condiciones ideales». Se pueden imaginar como dos bloques sobre un plano junto a una pared: no hay rozamiento, la elasticidad es perfecta,...

Es difícil encontrar artículos más superlativos que vasto, enorme y gigantesco para esta lista recopilatoria –sin usar el manido y en este caso inapropiado casi infinito– pero es que con casi tres horas y media de duración en la que en...

Simulación del eclipse por Tom Ruen – CC BY-SA 4.0 El lunes 21 de enero de 2019 a las 3:35, hora peninsular española, comienza un eclipse total de Luna que termina a las 8:44 y que será visible en su totalidad desde...
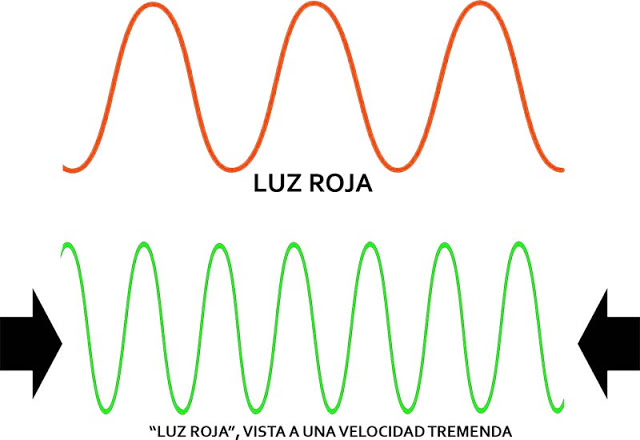
Cuando te mueves muy rápido, un concepto relativista llamado contracción de Lorentz provoca que las cosas que te rodean parezcan comprimirse en la dirección de tu movimiento, una especie de «efecto Doppler relativista». A velocidades cercanas a la de la luz...

En septiembre de 1998 Víctor Ruiz se embarcó en la aventura de publicar Astronomía Digital, una revista de difusión libre. Astronomía Digital se convertía así en la primera publicación electrónica de distribución gratuita en español orientada a la astronomía aficionada. Víctor iba...

Ultima Thule en rotación - NASA/JHUAPL/SwRI El equipo de la New Horizons ha dado hoy una nueva rueda de prensa en la que contaron alguna cosa más que han podido averiguar de un primer análisis de los datos que ya han recibido...

Escuché hablar de la app Universe Splitter (iOS, 2,29€) en una conferencia sobre la aleatoriedad intrínseca en la física cuántica; me encantó la idea por rebuscada y porque da para pensar un poco, así que he ido a buscarla y ahí...
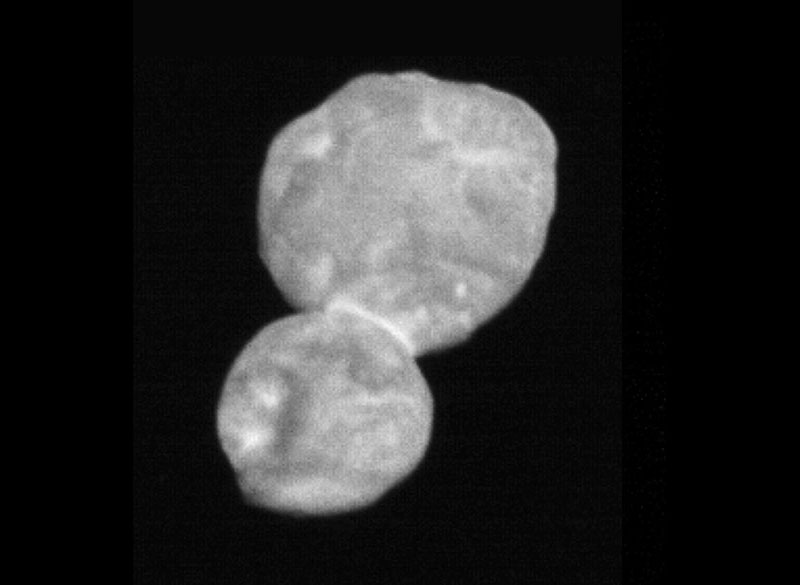
Impresión artística de New Horizons en Ultima Thule – NASA/JHUAPL/SwRI/Steve Gribben Desde primeras horas de la tarde del día 1 de enero de 2019, hora peninsular española, sabíamos que la sonda New Horizons de la NASA había superado sin problemas a su...

Ya sabíamos que a pesar de lo que dicen las leyendas los imanes superpotentes no afectan al hierro que tenemos en la sangre, que son solo unos 4 gramos en todo el cuerpo. Pero la cuestión es… ¿Cuán intenso ha de ser...

La increíble mujer invisible es una charla de Lorena Fernandez en la que habla de las muchas mujeres que a lo largo de la historia han llevado a cabo trabajos o investigaciones extraordinarias. Especialmente en el campo de la ciencia y...

La flexibilidad de los ratoncitos, como la de muchos otros animales (incluyendo pulpos y cucharachas, por mencionar algunos) es legendaria. Matthias Wandel se proposo comprobarlo rigurosamente y por eso creo este laberinto en Lego con una puertas mecánica controlada por ordenador...
En VirtualiTeach han dedicado un enorme trabajo a recopilar vídeos 360° educativos sobre tipo de materias. Se trata de una organización sin ánimo de lucro dedicada a promover el uso de la Realidad Virtual y la Realidad Aumentada en educación, así...
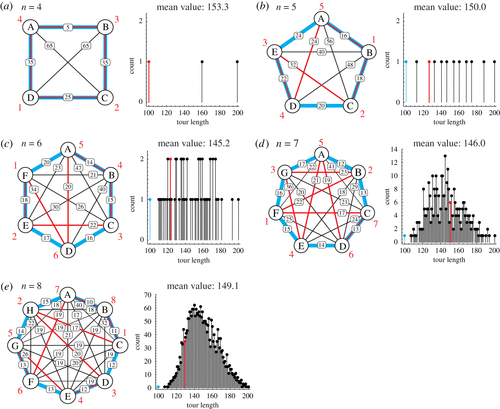
Este curioso vídeo muestra algo parecido a una ameba resolviendo el Problema del viajante (TSP) de forma sorprendentemente más «eficiente» –comillas obligatorias– que algunos algoritmos conocidos hasta la fecha. Este clásico problema matemático consiste básicamente en «encontrar la ruta más corta...

La RAE ha anunciado la actualización de este año de la versión en línea del Diccionario de la lengua española con 2.451 modificaciones, entre las que destacan la incorporación de meme, selfi (de selfie), baipasear (de bypass) o retroalimentación. En otras...

El Papá Noel de las matemáticas se ha adelantado este año unos días cuando el Proyecto GIMPS (Great Internet Mersenne Prime Search) ha anunciado el descubrimiento el 21 de diciembre del mayor número primo conocido hasta la fecha, un primo de Mersenne...

Estoy revisando algunos vídeos de conferencias del Instituto de Física Teórica (CSIC + UAM) y me llamaron especialmente la atención los del ciclo Los límites de la Física Fundamental de hace unos años. Este en concreto tiene una conferencia del profesor...

In case you missed it, here’s one for the history books: for the first time ever, I’ve placed a seismometer on the surface of #Mars! Once it’s all set up, I can start listening for marsquakes. More: https://t.co/GYNO4txPPi pic.twitter.com/vUkedVMcTX— NASA InSight (@NASAInSight)...

En este vídeo Bill Gates en persona muestra cómo funciona el Codescopio, una herramienta que no deja ser una tableta táctil gigante que sirve para leer de forma interactiva el Código Leicester, el único manuscrito de Leonardo da Vinci que está...
Es difícil dibujar un chiliágono regular con precisión en una pantalla pixelada: parece un círculo(abajo, contorno ampliado). Imagen: Cmprince (CC) Wikimedia Commons Me encontré así de repente con una referencia a un polígono regular interesante, que bien podría pasar a engrosar las...

Este instructivo vídeo muestra cómo ha sido el descubrimiento de 105 elementos químicos en los últimos 300 años. Antes de eso no se sabría gran cosa sobre el tema, así que añadidos a los otros 13 que se conocían de la...

El proyecto IllustrisTNG genera simulaciones cosmológicas de la formación de galaxias, algo que denominan simulaciones magnetohidrodinámicas, con la idea de arrojar algo de luz a los procesos mediante los que se crean y evolucionan estas estructuras en el universo. En su...

Unos recientes trabajos de investigadores de la Universidad de Waterloo han confirmado algo que en cierto modo más o menos se conocía –en especial entre los aficionados a los métodos mnemotécnicos– pero ahora ha sido comprobado experimentalmente. Tal y como se...
En Maths around the Clock la profesora de matemáticas Antonella Perucca ha recopilado algunos relojes que utilizan una numeración matemática inusual, aunque correcta. Eso sí, hacen pensar un poco antes de decidirse a dar la hora correcta, y algunos son realmente...

Las leyes de la física actuales parecen indicar que el negocio del turismo temporal no es una buena inversión.– José L. F. Barbón, físicoInstituto de Física Teórica de Madrid Desde luego no es tan fácil como ir a la tienda y...

¿Con cuántos puntos se puede definir adecuadamente una figura humana? Esta curiosa obra escultórico-mecánica llamada Estudio para quince puntos parece indicar que 15 pueden ser suficientes. Se puede ver lo más llamativo a partir de 00:32. Los pequeños brazos mecánicos dela...
Cliff Pickover explicaba con esta imagen de Jaime Michelle la interesante relación entre el número áureo y el pentagrama que dice que produce cierto gustito: el hecho de que la razón entre el segmento rojo y el verde, al igual que...

En esta minipresentación TEDx el siempre espectacular profesor Andrew Szydlo realiza 25 experimentos sobre química en tiempo récord: 15 minutos. Algunos son muy conocidos, como el agua que «cambia de color» o diversos usos del nitrógeno líquido, pero otros no tanto....

¿Cómo cambian los seres vivos con el paso del tiempo? ¿Por qué algunas mutaciones son importantes y otras no? ¿Qué sucede con las poblaciones vistas como conjuntos? Desde los tiempos de Darwin la ciencia nos ha enseñado que la selección natural...

A las 4:13 del 8 de diciembre de 1993, hora peninsular española, comenzaba uno de los paseos espaciales más importantes para la historia de la astronomía, el cuarto de la primera misión de mantenimiento del Telescopio espacial Hubble. El objetivo era...

Clarissa Grandi ofrece en su colorida, geométrica y muy recomendable web Artful Maths toda una serie de Lecciones de arte matemático con materiales tanto para profesores como estudiantes. Cubren distintos temas a cual más interesante (y colorido), a saber: Objetos imposibles...

El Centro Nacional de Estudios Espaciales (CNES), responsable principal del sismógrafo del aterrizador InSight de la NASA, ha confirmado que las pruebas iniciales confirman que tras el lanzamiento, el viaje y al aterrizaje de la misión el instrumento está en perfectas...

En enero de 2016 los astrónomos Konstantin Batygin y Mike Brown publicaron un artículo en el que exponen su teoría de que debe existir un noveno planeta en el sistema solar. Se trataría de un planeta con un tamaño similar al...

Las buenas noticias son que es bastante improbable que algún objeto del espacio exterior impacte contra la Tierra. Así que estamos seguros. Por ahora.– Gema Parreño Gema Parreño protagoniza este vídeo de Google en el que explica que se dedica a...

Encontré en Futility Closet una referencia a la integral de Borwein, que había visto mencionar alguna en otros sitios. Se trata de una integral (o serie de integrales) muy curiosa y con una propiedad un tanto desconcertante: cuando se van añadiendo...

Un año más el certamen de monólogos científicos FameLab España abre el plazo de inscripción. Para participar basta con que seas mayor de edad, tengas la nacionalidad española o residas en España, y que curses estudios o ejerzas cualquier actividad profesional...

En una rueda de prensa en la que ha habido más bien poca información concreta la NASA ha anunciado el nombre de las nueve empresas que ha escogido –de las 31 que se presentaron– para que puedan participar en el programa...

Stephen Cognetta llevo a cabo hace tiempo un curioso experimento personal relativo a la repetición (o reiteración, o incluso recursividad podríamos decir) de fotografías de fotografías. Su idea era tan intrigante como los resultados de un estudio de la Universidad de...

En un trabajo titulado Design and characterization of electrons in a fractal geometry (Nature) unos científicos encabezados por el físico Sander Kempkes explican cómo han construido con material atómico un triángulo de Sierpinski a base de electrones individuales. Su objetivo es...

En lo que califican como un descubrimiento inesperado un equipo de científicos de la NASA ha descubierto un gigantesco cráter procedente de un impacto de meteorito bajo el hielo de Groenlandia, en el llamado Glacial Hiawatha. A grandes rasgos el cráter...
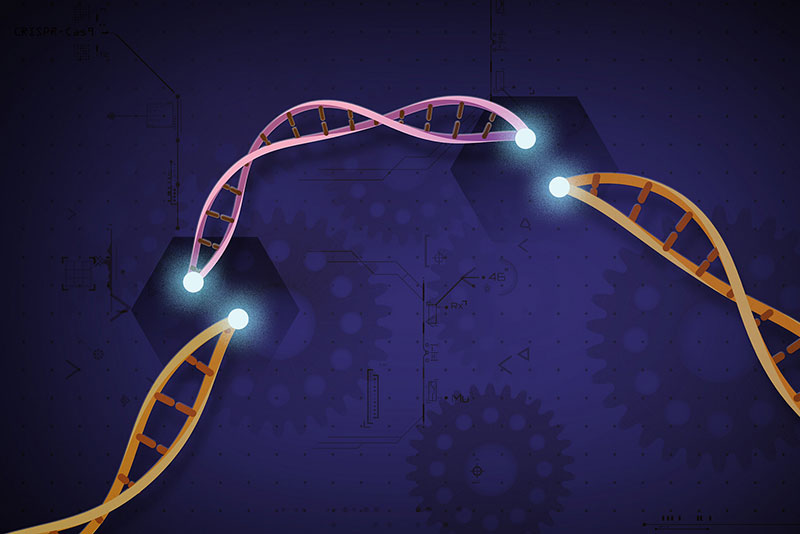
Ayer la noticia científica del día fue el supuesto nacimiento de dos bebés en China cuyo ADN habría sido modificado utilizando la técnica Crispr-Cas9. La historia viene básicamente de la exclusiva Chinese scientists are creating CRISPR babies del MIT Technology Review...

En Divulgacción, la Asociación Gallega de Comunicación de Cultura Científica y Tecnológica, llevamos algún tiempo colaborando con el programa Hoy por Hoy Vigo. Se trata de una sección semanal presentada por Mauro Picatoste en la que los socios, que nos turnamos...
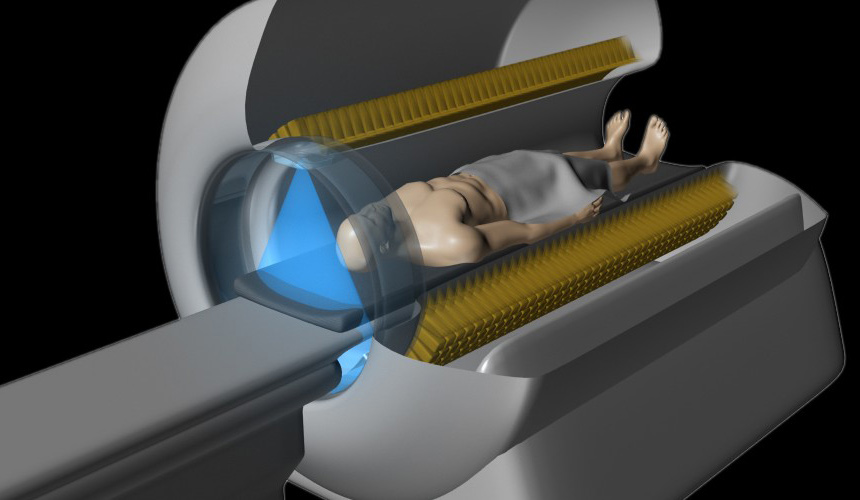
El primer escáner capaz de escanear un cuerpo humano completo se llama Explorer y produce estas espectaculares imágenes tridimensionales en apenas 20 o 30 segundos, 40 veces más rápido que los tomógrafos convencionales. Según el equipo multidisciplinar que ha desarrollado Explorer,...
Por Nacho Palou -
20 NOV 2018

Organizado por los Museos Científicos Coruñeses, en los que trabajo en el MundoReal™, con la colaboración del Círculo Escéptico, llega el ciclo de conferencias Mes Escéptico 2018. La idea, como siempre, es aportar un punto de vista crítico sobre diferentes temas de...

La NASA acaba de anunciar que el rover Mars 2020 y el pequeño helicóptero que lo acompañará aterrizarán en el cráter Jezero el día 18 de febrero de 2021 –un martes– si despega al principio de la ventana de lanzamiento, que...
¿Cuál de los dos rectángulos tiene mayor área? Mikael Sundqvist planteó este ingenioso problema sobre rectángulos como homenaje a las recreaciones matemáticas que el gran Ed Southall deja caer de cuándo en cuándo en @SolveMyMaths. Es de ese tipo de acertijos...

Marty Jopson se autocalifica como geek de la ciencia y aunque tenga poco que ver con la botánica y la biología –su especialidades– nos enseña en este vídeo de la Royal Institution la física tras el poderoso y sonoro chasquido del...

Una excusa enarbolada una y mil veces por la organización –vaga– de eventos de ciencia y tecnología para justificar la escasa –o nula– presencia de mujeres en este tipo de eventos es aquella de que no las encuentran. Pero ahora esa...

¡Ozú, qué caló! – en los pasillos del tokamak experimental Unos científicos chinos han batido el récord de altas temperaturas utilizando el Experimental Advanced Superconducting Tokamak (EAST), un reactor de fusión al que han llevado al límite: 100.000.000°C. Comparativamente en el...

El Gobierno de España acaba de presentar el Plan para la Protección de la Salud frente a las Pseudoterapias [PDF], desarrollado por los ministerios de Sanidad, Consumo y Bienestar Social y el de Ciencia, Innovación y Universidades. El plan prevé varias acciones...
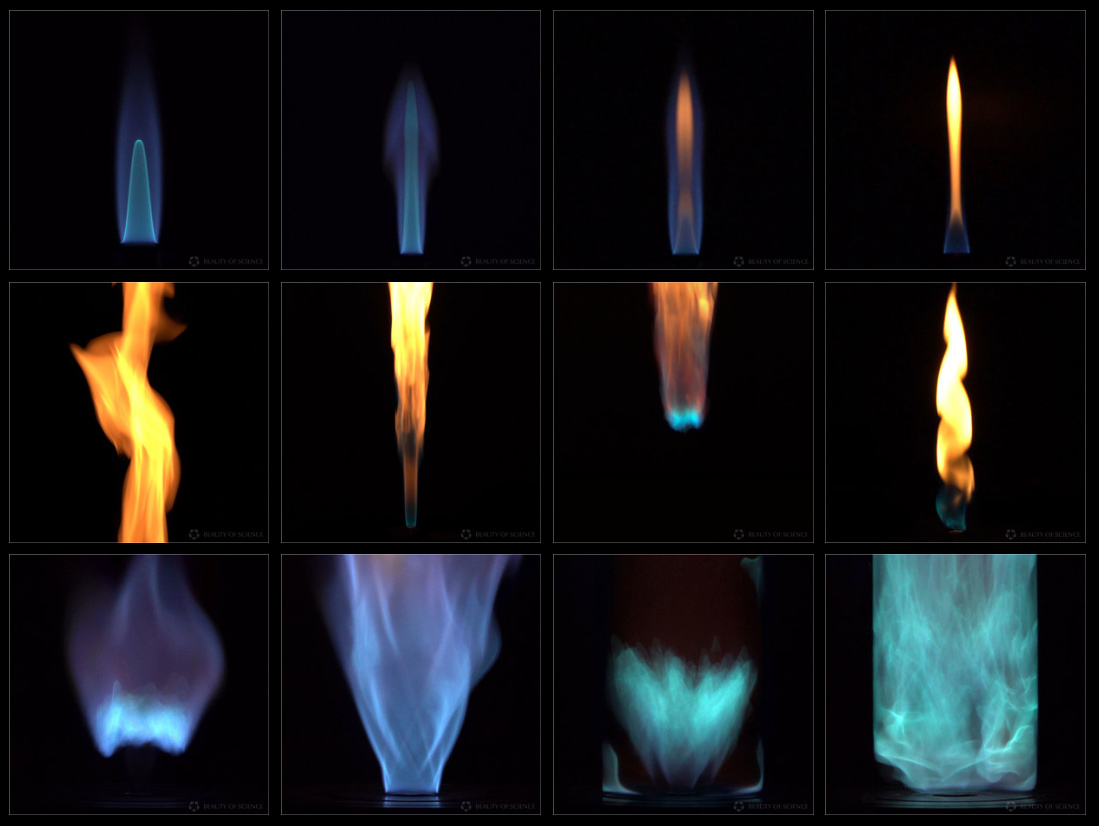
En el Laboratorio de Combustión de la Shanghai Jiao Tong University el profesor Fei Qi y su equipo se dedican al estudio de las llamas y el proceso de combustión. Esto les permite grabar imágenes como las del vídeo, que resultan...

A falta del horno de un piedra a 330° que al parecer es imprescindible para hornear una pizza de forma adecuada, físicos italianos han determinado la fórmula para cocinar pizza en un horno convencional. El resultado debería ser, en teoría, lo...
Por Nacho Palou -
8 NOV 2018

Este estupendo vídeo de TED-Ed explica algunos detalles teóricos y prácticos de la Ley de gravitación universal, esa fuerza –desde los tiempos de Einstein mejor entendida como una deformación del espacio-tiempo– que afecta a todos los objetos con masa. Es algo...
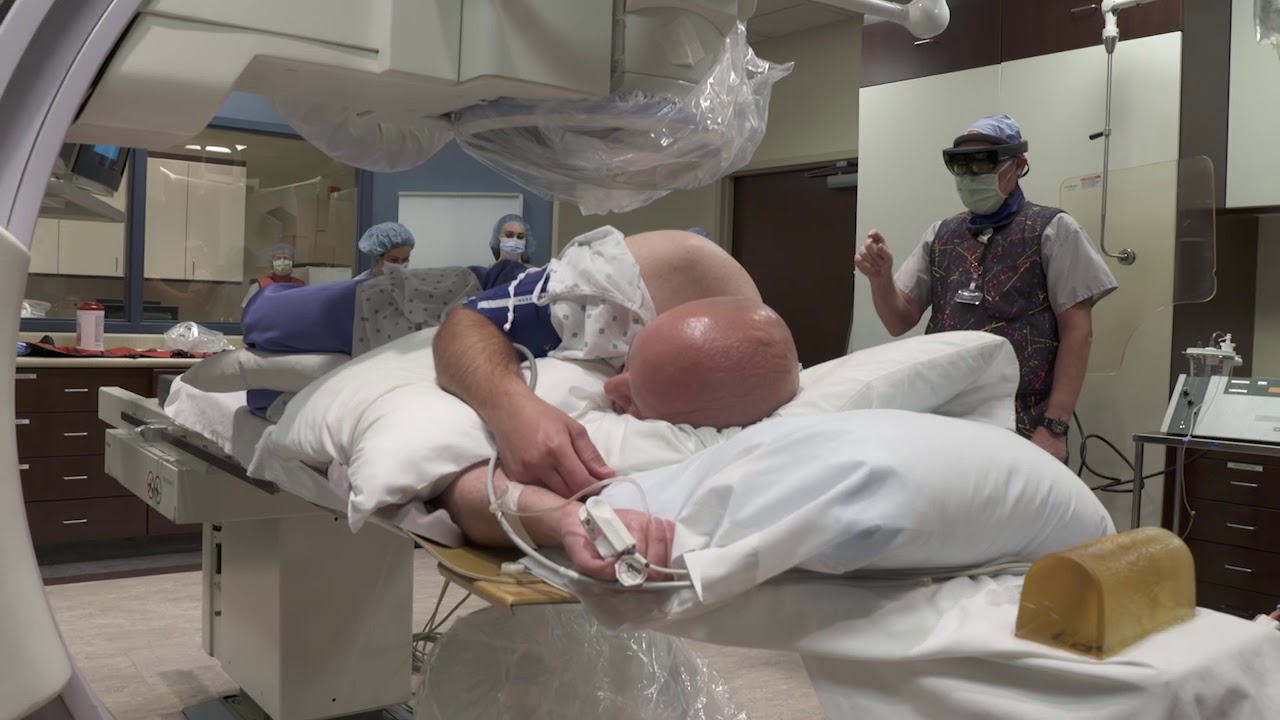
Este sistema llamado OpenSight de la empresa Novarad está basado en las HoloLens de Microsoft sirve para mostrar a los cirujanos el «interior» de los pacientes superponiendo imágenes obtenidas mediante rayos x y escáneres a los que se añadan las imágenes...
Niveles de ozono sobre el polo sur en noviembre de 2018. Los colores púrpura y azul son donde hay menos ozono, y los amarillos y rojos son donde hay más ozono. Imagen: NASA / Ozone Hole Watch. A principios de año la...
Por Nacho Palou -
6 NOV 2018

En este vídeo de Science Channel explican que el anticongelante de coche (extremadamente tóxico, por cierto) se puede «paradójicamente» congelar si se hace bajar su temperatura lo suficiente. En condiciones normales de presión y temperatura ambiente, o incluso a varios grados...
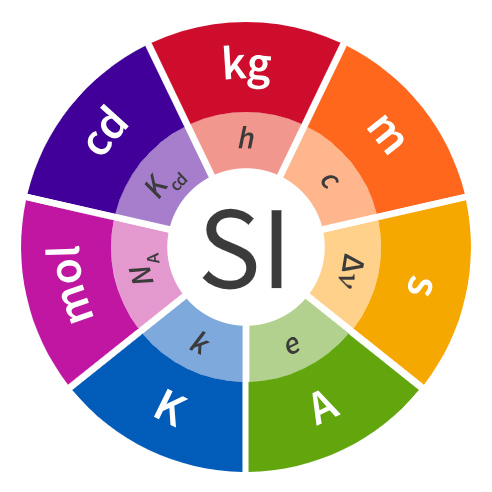
Haz clic para ir la página del NIST y explorar las unidades del SI y las constantes universales El NIST (Instituto Nacional de Estándares y Tecnología estadounidense) tiene esta interesante infografía interactiva sobre las constantes del Sistema Internacional de Unidades. Haciendo clic...

Si hoy mismo descubriéramos un asteroide en rumbo de colisión con la Tierra de esos que pueden hacernos mucha pupita lo cierto es que no podríamos hacer nada para evitar ese impacto. Pero casi peor que eso es que lo más...

La sonda Dawn de la NASA no se comunicó con el control de la misión en sendas sesiones programadas para los días 31 de octubre y 1 de noviembre. Eliminadas otras posibilidades el equipo de la misión ha llegado a la...

En lo que parece poner fin a un proceso legal que lleva en marcha desde 2011 el Tribunal supremo de Hawaii acaba de fallar por mayoría que el permiso de construcción del Telescopio de treinta metros (Thirty Meter Telescope, TMT), que...

Tras haber exprimido hasta la última gota de combustible que llevaba a bordo a la NASA no le ha quedado más remedio que dar por finalizada la misión del observatorio espacial Kepler, tal y como puede leerse en NASA Retires Kepler...
El Boletín Oficial del Estado del 30 de octubre de 2018 publica la lista de los 2.008 productos homeopáticos –me niego a llamarlos medicinas aunque la Unión Europea diga que lo son– que han solicitado su regularización en España. A partir...
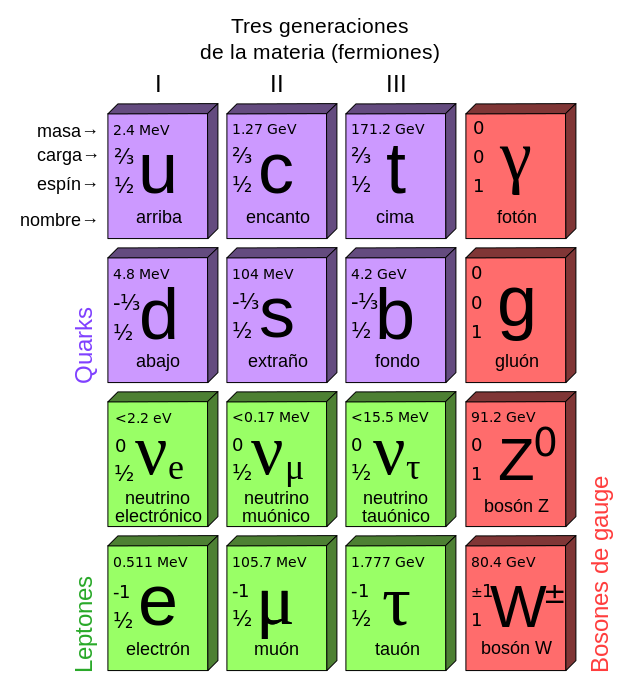
El modelo estándar de la física de partículas es, hasta ahora, la mejor forma que tenemos de explicar el universo si exceptuamos la fuerza de la gravedad, pues la relatividad general de Einstein no encaja ni con calzador con él. Pero a...

Tras el tercer lanzamiento del Advanced Supersonic Parachute Inflation Research Experiment, o Experimento Avanzado de Inflado de Paracaídas Supersónicos, la NASA ha certificado para ser utilizado en Marte el paracaídas que utilizará con el rover Mars 2020. Aspire es una especie...

Tras conseguir poner en funcionamiento un giroscopio que había fallado por el viejo, universal, y casi infalible método de apagarlo, encenderlo y sacudirlo un poco, el telescopio espacial Hubble vuelve a estar «aciendo la cencia». En concreto a las 8:10, hora...

En los últimos días hemos sabido que la Generalitat de Catalunya ha impuesto tres multas a Dolça Revolució, la asociación que promueve las ideas de Josep Pàmies acerca de las bondades del MMS y otros productos de más que dudosa efectividad –cuando...

En esta pequeña gran superproducción del Museo Americano de Historia Natural la astrofísica Jackie Faherty enseña a gente de todas las edades diversas visualizaciones, fotografías y animaciones 3D de la Vía Láctea. Muchas de estas visualizaciones provienen de los datos del...

He querido traer este ejemplo de una serie de vídeos preciosa que muestra el trabajo de los curadores del Museo Británico. Que conste que yo no era precisamente un fan del término curador: al parecer no está siquiera contemplado en el...

En este montaje de Sam y Nico del estudio Corridor Digital se utilizan efectos especiales a lo bestia para mostrar una versión a escala del universo, más concretamente a 1:190.000.000. Es bastante diferente a otros vídeos similares en los que lo...

Este objeto llamado Objeto tríplemente ambiguo es obra de Kokichi Sugihara (Japón) y ha ganado el premio del concurso Best Illusion of the Year Contest 2018. La ilusión es realmente buena y confunde bastante entender lo que está sucediendo al mirar...

Estos vasos matemáticos son representaciones decorativas de π, e, el número áureo y la raíz cuadrada de 2 sobre vasos de cristal. No están todos los que son, pero al menos sí cuatro de los más interesantes que se pueden encontrar...

Desde principios de 2018 la NASA está como jugando al ratón y al gato con el observatorio espacial Kepler: su combustible está a punto de acabarse, con lo que la agencia tendrá que decidir cuando lo apaga, aunque al mismo tiempo...

Este vídeo de Yenji Jem recorre cómo sería el crecimiento exponencial de una hoja de papel doblada sobre sí misma una y otra vez. Recordemos que el récord del mundo en doblado de una hoja de papel son 13 dobleces; a...

Esta es la segunda versión de Cosmic Eye (2011/2018), un viaje cósmico en el MundoReal™ desde la cotidianeidad de una escena que parte de una sonrisa en el Googleplex de Silicon Valley a lo más grande e inimaginable… Y vuelta hasta...

El viernes 5 de octubre de 2018 falló el tercero de los seis giroscopios que el telescopio espacial Hubble utiliza para detectar movimientos en cualquiera de sus ejes y así contrarrestarlo para mantenerse perfectamente estable durante sus observaciones. Con el fallo...

Las palabras elegidas por los participantes: más grande = más veces.Los colores indican cercanía en la clasificación por categorías Unos investigadores han hecho algo ingenioso: reducir el Test de Turing a una prueba de una sola palabra, por lo que la prueba...

Con los campos magnéticos a partir de 1.000 teslas se abren posibilidades… interesantes.– Shojiro Takeyama, físico Lo que se ve en la imagen es el momento clave en la que 4 millones de amperios alimentan un generador llamado MegaGauss que tiene...

Desde principios de 2018 la NASA está intentando sacar todo el partido posible del observatorio espacial Kepler antes de que se le termine el combustible. Pero cada vez le cuesta más. En julio ya lo tuvo que poner en hibernación ante...

Se acerca otro momento crucial de la misión de la sonda Hayabusa 2 con el despliegue de MASCOT, el rover diseñado por el DRL, el Centro Aeroespacial Alemán, y el CNES, el Centro Nacional de Estudios Espaciales francés. MASCOT, de Mobile...

La mitad telescopio a su llegada a Northrop Grumman - NASA/Chris Gunn Desde febrero de 2018 las dos mitades del Telescopio Espacial James Webb están en las instalaciones de Northrop Grumman en California para sus pruebas finales y para ser ensambladas de...

Este simpático planetario portátil es una idea que se le ocurrió a Jessie Christiansen, investigadora del Caltech y que llevó a cabo con ayuda de Jeff Rich de los Observatorios Carnegie. Básicamente se trata de un planetario semi-esférico transportable que se...

Aunque hace algo más de un año que tuvimos que despedirnos de ella la sonda Cassini/Huygens, un proyecto conjunto de la Agencia Espacial Europea y de la NASA, aún sigue produciendo nuevos descubrimientos. Y es seguro que lo seguirá haciendo durante...
El programa de satélites artificiales Earth Explorer –Explorador de la Tierra– de la Agencia Espacial Europea tiene como objetivo cubrir las necesidades de la comunidad científica para entender nuestro planeta y su funcionamiento como sistema. Como esas necesidades van avanzando según...

Hoy se presentó finalmente «una sencilla prueba» de la Hipótesis de Riemann, planteada por el célebre matemático en 1859 y que sigue trayendo de cabeza a la comunidad, con incontables demostraciones erróneas que año tras año van apareciendo en busca de...

Lanzado el 18 de abril de 2018 el observatorio espacial TESS comenzó su misión de detectar planetas extrasolares el 25 de julio tras una fase inicial fase de pruebas y calibración. Y menos de dos meses después del inicio de su...
Este vídeo de Randy Dobson explica perfectamente y con gráficos animados qué son los puntos de Lagrange o puntos L. Se trata de cinco puntos específicos que hay en los sistemas orbitales de dos objetos (por ejemplo el sistema Sol-Tierra) en...

El escenario que han utilizado los astronautas italianos del Instituto Nacional de Astrofísica (INAF) que han probado este invento llamado ScanMars ha sido el desierto de Dhofar en Omán – un recóndito lugar que se parece algo a Marte por sus...
Cada vez que aparezca un número primo, gira a la derecha.– Timothy Egan Esta caminata por los números primos sobre una cuadrícula en el plano es una idea de Timothy Egan inspirada en la espiral de Ulam y más concretamente en...

Según se puede leer en New planet could be Spock’s home world, astronomers say un grupo de astrónomos ha descubierto un planeta en órbita alrededor de 40 Eridani A. El trabajo en el que se informa del descubrimiento está en Arxiv.org....

Lanzado el 18 de abril de 2018, el observatorio espacial TESS tiene como misión encontrar planetas extrasolares. Para ello se pasará dos años observando el cielo, uno dedicado al hemisferio norte y otro al hemisferio sur con sus cuatro cámaras. Cada...

Lanzado el 7 de marzo de 2009 para una misión de tres años y medio el observatorio espacial Kepler no sólo la cumplió con creces sino que los miembros de su equipo encontraron la forma de seguir utilizándolo aún después de...

Me encontré en Numberphile con un vídeo explicativo de la curiosidad aquella que comentamos hace tiempo acerca de que todo número natural es la suma de tres números capicúas – algo para lo que consiguieron una brillante demostración Javier Cilleruelo, Florian...

Nunca he sido muy fan del triángulo de Pascal, pero hay que reconocer que este vídeo de Wajdi Mohamed Ratemi explicando algunas de sus propiedades e intríngulis es soberbio. Y además lo resume todo en cuatro minutos. El triángulo de Pascal...

Carlos Pazos de Mola Saber y Radio Skylab nos hizo llegar un par de ejemplares de sus nuevos libros infantiles para acercar la ciencia a la infancia. Son los que inauguran una colección llamada Futuros Genios en los que el propio...

Un año más, como vienen haciendo desde 1991, los editores de Annals of Improbable Research han hecho su selección de aquellas investigaciones reales pero con descripciones hilarantes, así que aquí están los ganadores de las 10 categorías de los premios Ig...

Sí, la herencia genética es la que determina las aptitudes de un individuo, pero es la experiencia la que las habilita. En otras palabras, sin genética no hay nada, pero sin estímulos no hay construcción cerebral posible.– María José Mas,neuropediatra Con...

#Aeolus' laser system emits short powerful pulses of ultraviolet light down to Earth. The telescope aboard the satellite collects the light backscattered from the air molecules, dust and water droplets, explains @Leonardo__Space rep at the European launch event @esaoperations pic.twitter.com/JxgCzxutc8— ESA EarthObservation...

Jim H. Simons (1938–) es un matemático del MIT y Berkeley que hace tiempo llegó al nivel de lo que los americanos llaman billonario; su fortuna se calcula en 2018 en unos 20.000 millones de dólares (puesto #24 del mundo según...

Después de unos meses de verano más cálidos de lo habitual (especialmente en las regiones más septentrionales) las perspectivas para los próximos años no son nada buenas incluso aunque el incremento de la temperatura no sea de más de un par...
Por Nacho Palou -
10 SEP 2018

El famoso historiador y divulgador de la ciencia y la tecnología James Burke protagonizó en 1978 este plano en su aclamada miniserie Conexiones para la BBC, concretamente en el episodio 8 (Eat, Drink and Be Merry). Hay quien lo ha denominado...

Tal y como contaba un usuario llamado Monroe en un foro, el titanio se oxida en diferentes colores cuando lo atraviesa una corriente eléctrica – pero el color exacto depende del voltaje. Este curioso fenómeno lo explican en WikiHow para enseñar...

Las buenas gentes de Principia han pergeñado otra idea genial: una colección de cromos que reúne 156 de las científicas y científicos más importantes de la historia. La extraordinaria liga de la ciencia los reúne en 12 equipos –Pioneras, Biología, Física,...

Prime Climb (La escalada de los primos) es un juego de mesa educativo creado por Math for Love que consiguió su financiación colectiva allá por 2014. Lo que más llama la atención es que se desarrolla en una espiral de números...
Lanzado el 10 de diciembre de 1999 el observatorio espacial de rayos X bautizado como XMM-Newton se convierte desde hoy, 6 de septiembre de 2018, en la misión más longeva de la Agencia Espacial Europea al superar los 6.842 días que...
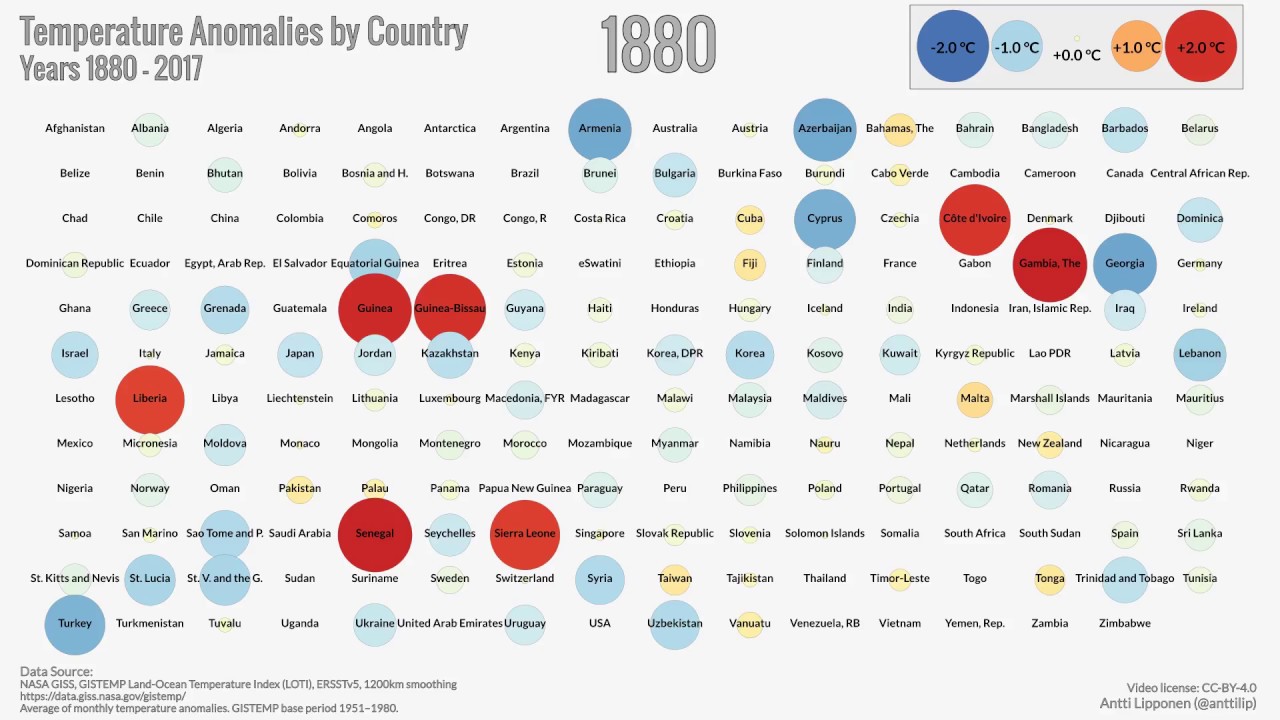
Esta animación muestra los más de 190 territorios y países del mundo junto con las anomalías a modo de diferencias de temperatura anuales en cada uno de ellos: azul = más frío, rojo = más caliente. Los datos están recopilados del...

Para averiguar cuál fue la década más prolífica para la ciencia Carlos de Bits and Science se revisó año por año las entradas de la Wikipedia del tipo 19xx in Science buscando términos como «descubrimiento», «publicación» y similares. Básicamente es un...
En este vídeo animado del Museo Americano de Historia Natural se muestra la posición relativa de la eclíptica del Sistema Solar respecto al plano en el que orbitan las estrellas alrededor de la Vía Láctea. No coinciden, ni mucho menos. Aunque...
Según cuenta Le parisien en Remboursement de l’homéopathie: des réponses attendues en février el gobierno de Emmanuel Macron, a través de su ministra de sanidad, ha pedido a la Comisión de transparencia de la Haute Autorité de Santé, Alta Autoridad de...
Según el modelo estándar de la física de partículas más o menos en el 60% de las ocasiones el bosón de Higgs decae –se convierte– en un par de quarks fondo. Es un resultado un poco esotérico para los que somos legos...

En este vídeo de The Action Lab se simula cómo veríamos en nuestro mundo de 3 dimensiones una bola o hiperesfera de 4 dimensiones. La explicación y la secuencia –con unos efectos especiales muy básicos pero correctos– recuerda a la llegada...
Esta visualización de la NASA representa los aerosoles presentes en la atmósfera el 23 de agosto de 2018, "algunos de los cuales pueden causar serios problemas en tierra." "Ese día enormes columnas de humo se desplazaron sobre América del Norte y...
Por Nacho Palou -
28 AGO 2018

No sé si será la primera vez, pero desde luego que es muy notable la aparición de una publicación científica sobre el software utilizado para una película de ciencia ficción. Se titula Gravitational Lensing by Spinning Black Holes in Astrophysics, and...

En este vídeo de las Infinite Series (serie que por degracia ya terminó) Kelsey Houston-Edwards explica algunas cosas sobre las supertareas que son una forma un tanto filosófica –más que nada porque son imposibles en la práctica– de presentar una solución...

El 25 de agosto de 2003 un cohete Delta II despegaba desde el Complejo de lanzamiento 17 de Cabo Cañaveral para poner el órbita el telescopio espacial Spitzer de la NASA, aunque el Spitzer no entró oficialmente en servicio hasta el...
Hoy sabemos, sin lugar a dudas, que los seres humanos tenemos 46 cromosomas. Pero durante algo mas de 30 años años creímos que teníamos 48. El origen de este error está en el recuento que hizo el zoólogo estadounidense Theophilus Painter...

Ian Stewart es un gran matemático y divulgador, alguno de cuyos libros, como Annotated Flatland o What Shape is a Snowflake? (¿Cuál es la forma de un copo de nieve?) son una auténtica maravilla. Entre sus temas favoritos están los fractales,...

Cliff Pickover mencionó este magnífico número como la respuesta ideal a «cuando te piden un número primo grande y tienes prisa»: 12345678910987654321 Dice que lo vió pasar por una de las lista de la OEIS, más concretamente la «lista de números que...

Qué mejor que un vídeo de Numberphile en este caso con el profesor David Eisenbud para repasar la famosa Conjetura de Goldbach que viene a decir que Todo número par mayor que 2 puede escribirse como suma de dos números primos....

Hace algún tiempo, en una de esas sobremesas que se prolongan hasta la hora de la cena y más allá, Xurxo nos preguntó a los presentes cómo creíamos que unos extraterrestres en órbita alrededor de la Tierra podían hacer para distinguir...

Demoledor primer párrafo de la nota de prensa Measles cases hit record high in the European Region de la Organización Mundial de la Salud: Más de 41.000 niños y adultos de la región europea de la OMS han contraído el sarampión...

Estudiando mediante un ingenioso sistema de seguimiento automatizado el comportamiento de las colonias de hormigas coloradas cuando excavan sus túneles, un grupo de investigadores de la Georgia Tech indagan cómo entrenar robots con la misma estrategia de trabajo en grupo. El...

Este Simulador de Origami es un proyecto de Amanda Ghassaei y es realmente brillante: pocas veces se consigue tal flexibilidad y comodidad en la visualización de figuras 3D tan complejas como pueden llegar a ser los origamis de la tradición japonesa....

La idea de un libro con dígitos aleatorios es de una inutilidad obvia, pero su existencia a la vez implica que debe tener cierta utilidad, o nadie se hubiera molestado en publicarlo.– Chris Staecker, matemático Spoiler: el libro acaba con …49188....
The Parker #SolarProbe mission & launch teams today concluded a successful Launch Readiness Review. There are no technical issues being worked at this time. Teams are proceeding for liftoff on Sat, Aug. 11, @ 3:33 am ET on @ulalaunch Delta IV Heavy...

Polyhedra Viewer es un visor de poliedros: «objetos matemáticos de caras planas y volumen finito». Y aunque los poliedros regulares y los cinco sólidos platónicos (tetraedro, cubo, octaedro, dodecaedro e icosaedro) son los más conocidos, lo cierto es que hay infinidad...

I made this animation of the most recent images on JAXA's website from Hayabusa2's wide angle camera (ONC-W1) taken during its current Gravity Measurement Ops. Clip contains images received up to 2018-08-06 23:23 UTC (I'll update as they post more images). #ryugu(Images:...

Un condensado de Bose-Einstein –y que me perdonen los físicos presentes– es un estado de la materia la mar de curioso en el que un montón de bosones en estado gaseoso a temperaturas muy próximas al cero absoluto se comportan como...

Como todos los años entre julio y agosto la Tierra está atravesando la parte de su órbita en la que se cruza con los restos dejados atrás por el cometa Swift-Tuttle. La entrada en la atmósfera a gran velocidad de estas...

En Motherboard, Planet at Risk of Heading Towards Apocalyptic, Irreversible ‘Hothouse Earth’ State, Este verano la gente ha estado sufriendo y muriendo a causa de las olas de calor y de incendios forestales en muchas partes del mundo. Los últimos tres...
Por Nacho Palou -
7 AGO 2018

Utilizando el radiotelescopio VLA (Very Large Array) astrónomos han localizado un objeto de masa planetaria más allá de nuestro Sistema Solar que es 12,7 veces más masivo que Júpiter, que presente una campo magnético "sorprendentemente potente" y que viaja errante por...
Por Nacho Palou -
7 AGO 2018

En la École polytechnique fédérale de Lausanne (Suiza) trabajan en estas simulaciones de la nieve en sus diferentes estados para estudiar qué es lo que sucede antes y durante las avalanchas. Debido a que la nieve se comporta a veces como...
Hemos sido los seres humanos los que hemos dado nombre a las estrellas del cielo y dibujado imaginarias figuras y constelaciones con ellas. Pero acostumbrados a las denominaciones de la cultura occidental olvidamos que esas líneas que forman animales, personajes mitológicos...

En un trabajo publicado en Nature un equipo multidisciplinar de los campos de las matemáticas, la biología y la física –dirigido por Luisma Escudero de la Universidad de Sevilla– ha descrito unas nuevas formas geométricas que sirven como modelo a las...

Ya está el listo que todo lo sabe de Sexo (Álfred López, 2018). Nuestro amigo Alfred de YELQTLS nos envió muy amablemente un ejemplar de su nuevo libro tan pronto como se publicó hace unos meses (aunque no lo he podido...

Este vídeo de Business Insider muestra algunas frutas y vegetales en estado salvaje, antes de que empezáramos a adaptarlos a nuestros gustos y necesidades mediante crianza selectiva o cruces, lo que no deja de ser una forma basta de manipulación genética....

Profes, id tomando nota, que la Agencia Espacial Europea propone Los detectives climáticos como proyecto escolar para alumnos de entre 8 y 15 años en este curso que empieza: Comenzará a principios de octubre de 2018 y se desarrollará a lo...

Ha tardado un poco más de lo previsto inicialmente –la NASA había hablado de unos 60 días después del lanzamiento– pero el pasado 27 de julio de 2018 la agencia anunciaba que el observatorio TESS ya está recogiendo datos. TESS, de...

Hace unos días se hacía pública la Declaración sobre la pseudociencia [PDF] del Comité de ética de la investigación y la docencia de la Universidade da Coruña, declaración aprobada por el Consejo de gobierno de la universidad. En ella la UDC deja...

La hipótesis de Sapir-Whorf (aunque no fue escrita ni por Sapir ni por Whorf, quienes de hecho nunca publicaron nada juntos) viene a decir que la estructura de un lenguaje modifica la forma en la que quienes lo hablan perciben el...

El vídeo How a single-celled organism almost wiped out life on Earth, de Anusuya Willis y con subtítulos en español, es una interesante y accesible explicación a los que se conoce como la Gran Oxidación (o la catástrofe de Oxígeno) que...
Por Nacho Palou -
30 JUL 2018

Además de un eclipse total de Luna hoy se da otra curiosidad astronómica, pues Marte está en oposición. Esto quiere decir que el Sol, la Tierra y Marte están en línea recta, algo que ocurre cada 779,96 días, cuando nuestro planeta...

Lo del agua en Marte es un poco como lo de Pedro y el lobo. Ha sido encontrada ya tantas veces que hasta hay una imagen que se usa como broma al respecto, imagen que incluso llegó a ser Imagen Astronómica...

El 19 de octubre de 2017 Robert Weryk descubrió lo que resultó ser el primer asteroide –o más probablemente el primer cometa– que vemos pasar por el sistema solar que viene del espacio interestelar. Pero lo descubrió ya un poco tarde...

Investigadores de la universidad de Harvard han desarrollado un modelo tridimensional a escala de un ventrículo izquierdo de corazón humano. El tejido cardiaco está montado sobre una estructura de nanofibras gelatinosas y de poliéster biodegradable en el cual se han añadido...
Por Nacho Palou -
24 JUL 2018
El viernes 27 de julio de 2018 tendrá lugar un eclipse de Luna total cuyo máximo estará centrado en el Océano Índico. Será visible en su totalidad desde el este de África y desde Asia central. En Europa podremos verlo a...
Científicos de la Universidad de Purdue han creado lo que llaman el objeto en rotación más rápido del mundo. Es tan pequeño que en realidad se trata de unas nanopartículas de silicio dando vueltas mediante levitación magnética, en lo que denominan...

El hexafloruro de azufre (SF6) es un gas inerte y no tóxico con una densidad cinco veces mayor que la del aire, lo que de algún modo asemeja su comportamiento al de un líquido y permite que en él flote un...
Por Nacho Palou -
23 JUL 2018

Lo astrónomos han anunciado el descubrimiento de 12 nuevas lunas de Júpiter, que se unen a las otras 53 ya reconocidas oficialmente, y que entre las que ya son «oficiales» y las que probablemente lo sean pronto ya totalizan unas 79....

Un año más Naukas Bilbao vuelve a su cita para acercar temas de ciencia y tecnología a cualquier persona que esté interesada en un programa que abarca cuatro días de actividades. Comienza el jueves 13 de septiembre con Naukas Pro, en el...

Aunque es, con diferencia, la estrella que nos parece más grande de todas las que alcanzamos a ver el Sol, nuestro Sol, no es más que una enana amarilla normalita del todo. Y este vídeo, que muestra cómo se verían otras...

La compañía MARS Bioimaging ha mostrado "la primera radiografía 3D en color del interior de un cuerpo humano" tomada con una escáner espectral denominado "escáner espectral de rayos X MARS". El escáner utiliza tecnología desarrollada por el CERN para el chip...
Por Nacho Palou -
16 JUL 2018

En esta visita guiada al Laboratorio del Reactor Nuclear del MIT, situado en pleno centro de Cambridge (Massachusetts), en la calle paralela al campus de la afamada universidad tecnológica, es ciertamente peculiar. Se trata de un reactor nuclear universitario, el más...
La ministra de sanidad, Carmen Montón, ha comparecido hoy ante la Comisión de Sanidad del Congreso de los Diputados para informar de las que van a ser sus líneas de actuación al frente de su departamento. Una de las cosas de...
Eyewire es un juego y a la vez una investigación científica en crowdsourcing, muy al estilo de FoldIt (relacionado con el doblamiento de proteínas). Básicamente consiste en trazar la posición en 3-D de las neuronas del cerebro, una por una. Cuando...

Roland Meertens ha ideado un método para pintar cuadros con colores usando números primos. Y la verdad es que el resultado –y el método– es la mar de interesante. Además en su web está el código para hacerlo y para comprobar...

Durante el gran final de la sonda Cassini —destruyéndose en la atmósfera de Saturno en septiembre de 2017— la sonda grabó esta especie de conversación entre el planeta Saturno y su luna Encélado. Lo que Cassini detectó entonces fueron ondas electromagnéticas...
Por Nacho Palou -
11 JUL 2018
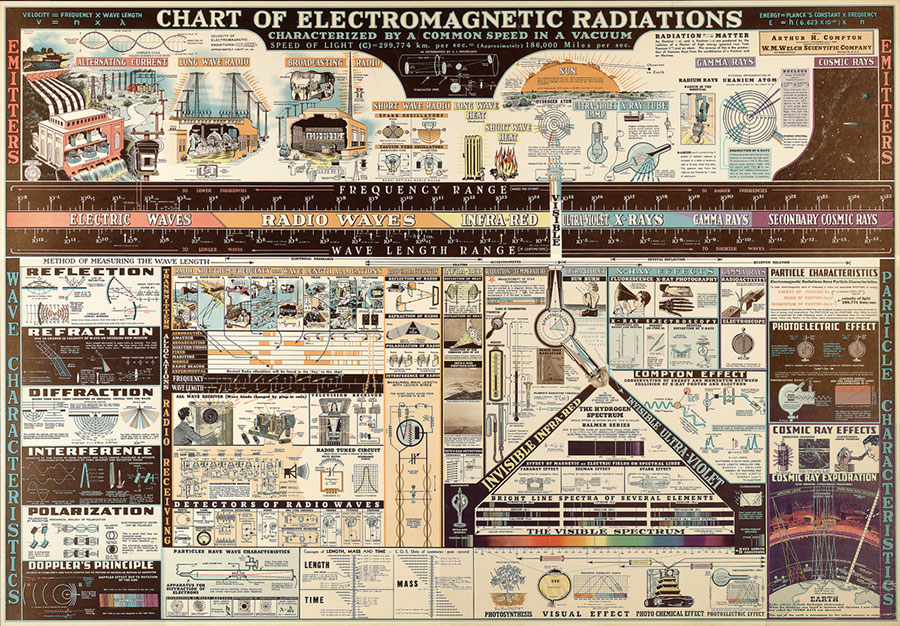
A través de un tuit del @OperadorNuclear llegué a este impresionante póster de las radiaciones electromagnéticas que data de 1944. Es un trabajo divulgativo que hizo en aquella época la W.M Welch Scientific Company (con dibujos de E. Borrone) y que...
Asgard nos avisó de la existencia del thaMographe –que podríamos traducir como taMógrafo– un invento geométrico-matemático que sustituye de una sola vez al compás, el transportador de ángulos, la regla y la escuadra, los instrumentos básicos de geometría del colegio. El...

El pasado 2 de junio una cámara de seguridad (vídeo de arriba) grabó la entrada en la atmósfera terrestre del asteroide ZLAF9B2, que tenía entre 3 y 5 metros de diámetro. El asteroide no se detecto hasta unas ocho horas antes...
Por Nacho Palou -
10 JUL 2018

El vídeo (acelerado), grabado por un equipo de científicos de la Universidad de Nueva York, recoge el momento de la rotura de un glaciar de seis kilómetros en Groenlandia. Este fenómeno es considerado como uno de los mayores contribuyente al aumento...
Por Nacho Palou -
10 JUL 2018

En los países desarrollados le hemos perdido el miedo a enfermedades como el sarampión porque gracias a las vacunas las tenemos bajo control. Y con ello hemos olvidado sus posibles complicaciones, que en el caso del sarampión van mucho más allá...

El satélite medioambiental Aeolus de la Agencia Espacial Europea, que ha cruzado el Atlántico desde Francia en barco en lugar de viajar en avión para proteger su instrumento de posibles cambios repentinos de presión que lo afectarían, está ya en el...
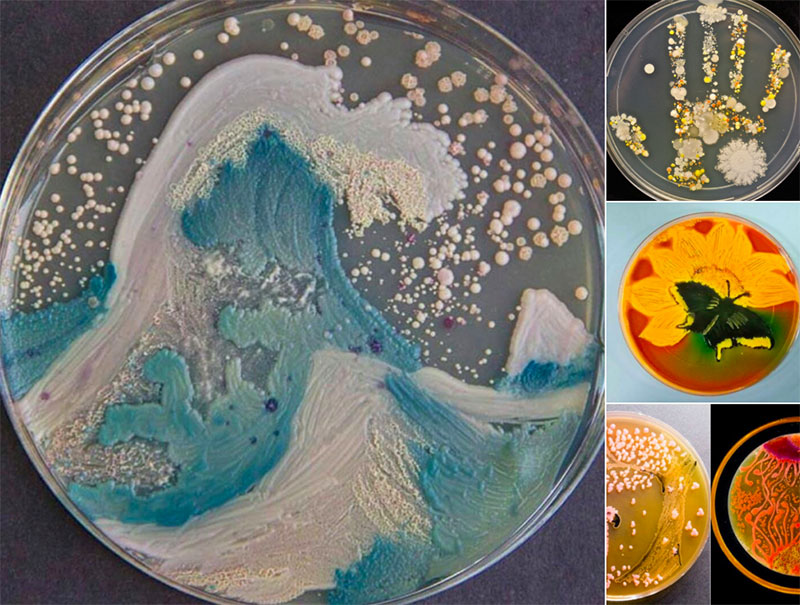
Puede sonar a broma pero la Sociedad Americana de Microbiología lleva varios años convocando Agar Art, un concurso en el que artistas de todo el mundo participan con imágenes creadas con microbios sobre una base de agar-agar en placas de Petri....

Pero, a ver… ¿esos «ordenadores cuánticos» van a ayudarme a hacer los deberes? Wired tiene una estupenda sección titulada 5 Levels en la que profesionales de diferentes áreas explican en cinco niveles de dificultad un concepto a cinco personas diferentes: niños,...
En Inverse, Heat Maps Reveal Record-Breaking Temperatures Across the Globe Ciudades de todo el hemisferio norte viven estos días temperaturas excepcionalmente altas con récords en Norteamérica, Europa, Oriente Medio y Asia occidental. Además de los efectos a largo plazo que estas...
Por Nacho Palou -
6 JUL 2018

El método es un poco retorcido, estilo Rube Goldberg, e incluso necesitas encender fuego para encender fuego. De hecho es necesario utilizar un fuego más potente que el fuego que se consigue encender. Pero, hey, el resultado cumple lo que promete:...
Por Nacho Palou -
5 JUL 2018

Los documentalistas del Lawrence Livermore National Laboratory acaban de subir nuevas versiones remasterizadas de más de 200 películas de explosiones atómicas de sus archivos. Unos documentos gráficos la mar de interesantes, tan espectaculares como estremecedores – y al mismo tiempo importantes...

Airbus ha terminado de ensamblar el observatorio espacial Cheops, lo que básicamente consiste en unir su carga útil –en este caso un telescopio Ritchey-Chrétien de 30 cm de apertura y 1,2 m de longitud– con el bus de la nave, la...

Este año, aprovechando que Aberron tenía libro recién publicado, hemos aprovechado para hablar con una librería de A Coruña y le hemos pedido que trajera unos cuantos libros relacionados con las charlas de mc2 presenta: Naukas Coruña 2018, que estaba dedicado...

Aunque sólo está en inglés, este vídeo de The Action Lab explica de forma bastante accesible conceptos como la masa relativista aparente que hace posible que la luz pueda empujar objetos a pesar de que se supone que la luz no...
Por Nacho Palou -
2 JUL 2018

El instrumento Sphere empleado por el VLT (Very Large Telescope del ESO) ha capturado esta imagen en la que se puede ver un planeta formándose de una nube de polvo alrededor de una estrella joven — en un disco de transición,...
Por Nacho Palou -
2 JUL 2018

La actividad del volcán Kīlauea, especialmente desde mediados del pasado mes de mayo, ha provocado el hundimiento del cráter Halemaumau, que ahora se encuentra unos 400 metros más por debajo del suelo de la caldera. El cráter no sólo se ha...
Por Nacho Palou -
30 JUN 2018

Una de las cosas que hizo la sonda Cassini durante su misión fue confirmar que Encélado, uno de los satélites Saturno, expulsa choros de agua y vapor de agua al espacio por unas grietas en su cubierta de hielo próximas a...

El 19 de octubre de 2017 Robert Weryk, trabajando con observaciones hechas por el telescopio Pan-STARRS, descubría el primer visitante interestelar que hayamos visto jamás, aunque con toda seguridad no es el primero que pasa por nuestra esquinita del cosmos. Bautizado...

Pues poco ha tardado la NASA en volver a retrasar el lanzamiento del Telescopio espacial James Webb. Ya no va a ser mayo de 2020, como había anunciado en marzo de este mismo año, sino que ahora será, si no se...

En este vídeo de Wired el analista profesional de la policía científica Matthew Steiner repasa qué hay de realidad y qué de ficción en algunas icónicas escenas «estilo C.S.I.» de películas y series de todas las épocas. El veredicto es por...

La junta directiva de la Organización del Square Kilometre Array acaba de aprobar la solicitud de adhesión de España, que se convierte así en el decimoprimer país en unirse al proyecto, en el que ya estaban Australia, Canadá, China, Italia, India,...
Vi pasar por Twitter esta igualdad, que a simple vista resulta un tanto peculiar e incluso sorprendente: Con la calculadora se puede comprobar que efectivamente sqrt(2+2/3) = 1,6329… y 2*sqrt(2/3) = 1,6329… (Ojo: el primer valor es una fracción mixta). Es un...
OpenDrop es un proyecto de GaudiLabs sobre «biología digital» con muchas ramificaciones, pero la más vistosa es quizá el OpenDrop V3, una plataforma de microfluidos en las que se pueden manipular mediante software las muestras haciendo que se desplacen en una...

El concepto de ahora: ¿es igual para todo el mundo? Ludwig Boltzmann, Einstein, la flecha del tiempo, la entropía, la teoría cuántica, la gravedad cuántica en bucle… El pasado está fijado, pero ¿y el futuro? ¿Por qué recordamos el pasado pero...

Con permiso de nuestros admirados @PlanetarioMad y @Pamplonetario hay que reconocer que en Shangái están construyendo un pedazo planetario como un señor Sol: 38.000 metros cuadrados que harán de él la mayor instalación de divulgación astronómica de este tipo del mundo....

Imágenes de radiotelescopio de una estrella destruida por un agujero negro supermasivo en el par de galaxias Arp 299. El chorro son partículas que se mueven hacia afuera del agujero negro. Astrónomos del Instituto de Astrofísica de Andalucía han podido observar, por...
Por Nacho Palou -
15 JUN 2018

Nuestro admirado profesor loco el Dr. Bagely explica en este episodio de Periodic Videos algunas cosas sobre una máquina de «aparente» movimiento perpetuo que construyó David Jones «Daedalus» hacia 1980 y que le regaló hace unos años. Es básicamente una rueda...

Cubo Rubik + Balón Telstar a partir de 01:00:00 Ayer grabamos el último podcast de la temporada de Los Crononautas #S02E28. Como recordaba Martín Expósito, en total han sido 28 programas, 56 horas de podcast y más de 200.000 descargas, que quedan...

El modelo que Adidas presentó como balón de fútbol de la Copa del Mundo Rusia 2018 de fútbol se llama Telstar 18. Se trata de un diseño renovado del clásico Telstar (1968) y encierra unas cuantas curiosidades geométricas y tecnológicas. La...

En los años de 1970 los científicos detectaron un inesperado aumentado temporal de la temperatura en el subsuelo de la Luna a través de unos sensores dejados en el satélite durante las misiones Apolo 15 (1971) y Apolo 17 (1972). Los...
Por Nacho Palou -
11 JUN 2018

En la madrugada del 5 de julio de 2016 la sonda Juno de la NASA efectuaba sin problemas la maniobra de inserción orbital que la colocó en órbita alrededor de Júpiter. Esta maniobra la dejó en una órbita de captura inicial...
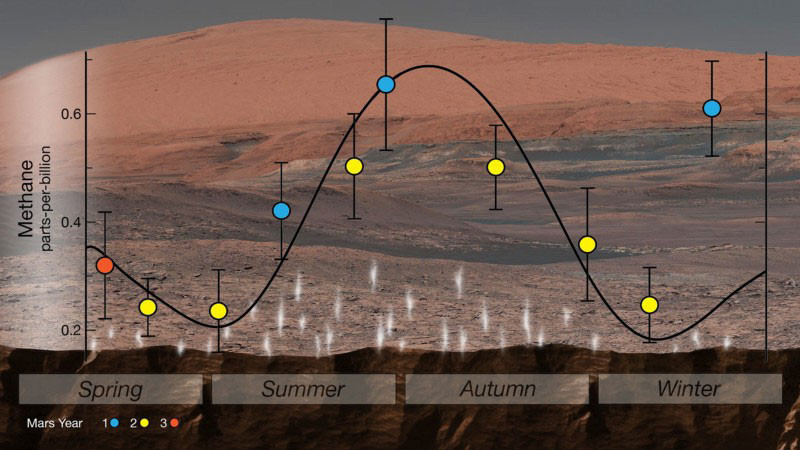
La NASA lo ha vuelto a hacer –aunque con menos exageración que en ocasiones anteriores, todo hay que decirlo– al presentar los resultados de los dos últimos trabajos publicados con datos obtenidos por el rover marciano Curiosity. De NASA Finds Ancient...

Los investigadores del experimento ATLAS del CERN han anunciado la observación de la «producción de quarks top asociados con el bosón de Higgs» con una gran significancia estadística. Es un resultado muy importante y esperado del segundo ciclo de funcionamiento (Run...

En Curiosity, What Does Water Taste Like? Science Finally Has an Answer Sorprendentemente se sabe muy poco sobre cómo se detecta el agua en la boca, especialmente cuando se compara con lo que se sabe sobre cómo se determinan otros sabores...
Por Nacho Palou -
6 JUN 2018
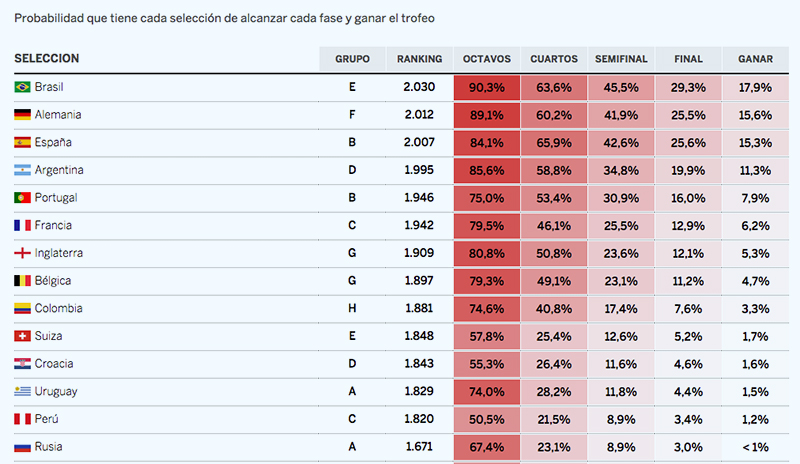
Kiko Llaneras ha explicado algunas cosas muy interesantes desde el punto de vista matemático y de programación sobre el modelo de predicción del mundial de fútbol Rusia 2018 que han preparado para El País, del cual hay también una metodología detallada....

Me crucé con estos curiosos vídeos sobre los puntos muertos en las pistas de tenis; aunque algo viejunos son bastante interesantes. ¿De qué estamos hablando? De algo que sucede a veces en algunas canchas de tenis y que no es tan...

Como ya hicieron hace unos años con un CD, en esta ocasión le toca el turno a un disco de vinilo de la vieja escuela: The Slow Mo Guys han grabado a alta velocidad cómo el disco se destruye en “aproximadamente...
Por Nacho Palou -
5 JUN 2018

El asteroide ZLAF9B2, con un tamaño de entre 3 y 5 metros de diámetro, se detectó ayer 2 de junio apenas unas horas antes de su aproximación a la Tierra. Poco más de una hora después de su descubrimiento los cálculos...
Por Nacho Palou -
3 JUN 2018

La sonda Dawn de la NASA lleva en órbita alrededor de Ceres desde marzo de 2015 y dado que sigue funcionando perfectamente la agencia ha extendido la misión en dos ocasiones. La última de estas extensiones fue anunciada en octubre de...

Advertencia: Lo primero que hay que decir es que este experimento podría ser considerado bastante cafre teniendo en cuenta que el mercurio es altamente tóxico y debe ser manejado con sumo cuidado (tema aparte sería cómo conseguirlo, que no es fácil)....
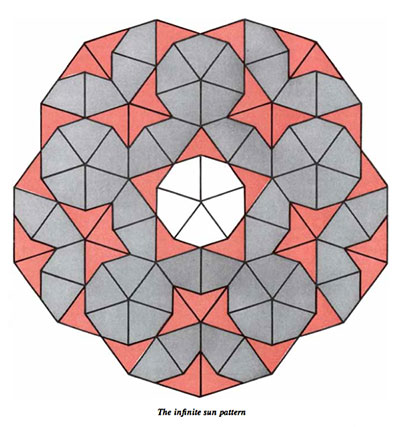
Aunque como bien dicen en Scientific American hace ya ni más ni menos que 30 años de la aparición del último de ellos, cada uno de los Los diez mejores artículos que publicó Martin Gardner en la columna Mathematical Games («Juegos...

El vídeo El universo en un grano de polvo, de Michael Marder, desgrana los componentes habituales que forman el polvo doméstico. Esto incluye desde las habitualmente mencionadas células de piel (humana y de animales) hasta partículas procedentes del espacio exterior, Cada...
Por Nacho Palou -
29 MAY 2018

El artículo de Business Insider Each year the US government asks 10 simple questions to test the public's knowledge of science. Can you correctly answer them all? recopila las diez preguntas que cada cierto tiempo lanza la National Science Foundation de...
Por Nacho Palou -
28 MAY 2018

En este vídeo de nuestra admirada matemática Hannah Fry para Numberphile se explica y muestra empíricamente cómo funciona la percepción de la magnitud de los estímulos físicos –dicen que también en cuanto a «percepción mental»– en los seres humanos, tam bién...

El monólogo Preguntas y catástrofes, que explica cómo preguntas sin aparente importancia han dado lugar a nuevas ramas de la ciencia, ha sido el ganador del certamen de monólogos científicos FameLab España 2018. Como ganador de la edición española su autor,...
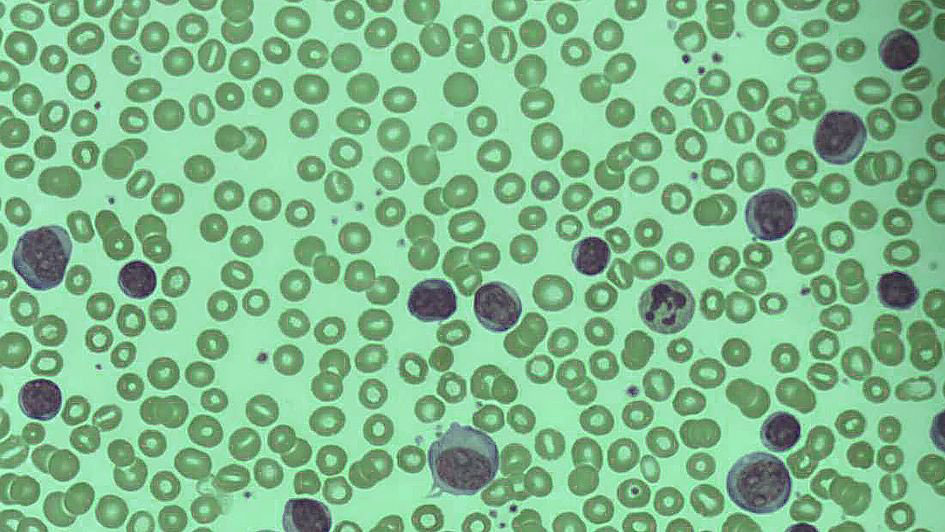
Estos días se está hablando bastante del trabajo A causal mechanism for childhood acute lymphoblastic leukaemia publicado por el profesor Mel Greaves del Institute of Cancer Research de Londres. Tal y como lo está vendiendo la institución parece que Greaves ha...

El EmDrive es un motor ideado por el ingeniero británico Roger Shawyer que básicamente consiste en un microondas acoplado a un cono metálico completamente cerrado que, de alguna manera, es capaz de producir empuje por el lado más grande del cono...

Artist's animation of the #GRACEFO separation... pic.twitter.com/F2QTLEnB2H— NASA Earth (@NASAEarth) 22 de mayo de 2018 Tras su lanzamiento a bordo de un Falcon 9 los dos satélites de la misión Grace-FO ya están en órbita y en comunicación con el control de...
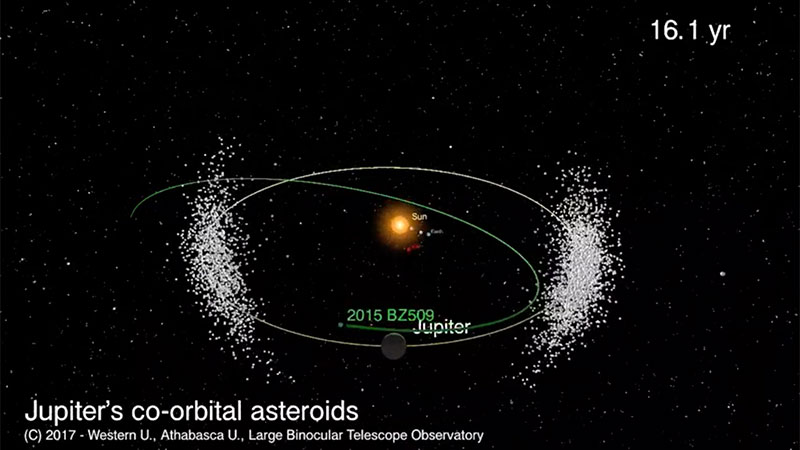
Ayer mismo se publicaba el trabajo An interstellar origin for Jupiter’s retrograde co-orbital asteroid de la astrónoma Fathi Namouni y de la estadística Helena Morais. El abstract dice: El asteroide (514107) 2015 BZ509 fue descubierto recientemente en la región co-orbital de...
Se ha publicado un interesante trabajo acerca de cómo almacena y procesa nuestro cerebro la información: si de forma discreta o continua. Se puede leer completo aquí: Is Information in the Brain Represented in Continuous or Discrete Form? Los autores explican...

Este vídeo de Arjan van der Meij es una magnífica representación del famosísimo tablero de ajedrez con arroz para explicar el crecimiento exponencial. Lo que hace es convertir en algo físico la conocida historia/cuento del problema de los granos de arroz...

Squared Away es un simpático sketch inspirado literalmente en una viñeta de nuestro siempre admirado Gary Larson, el autor de The Far Side – probablemente el mejor modo de hacer humor absurdo con la ciencia y la naturaleza que se haya...

El Journal of High Energy Physics ha publicado el que es el último trabajo escrito por Stephen Hawking junto con Thomas Hertog, enviado una semana antes de falleciera. Se titula A smooth exit from eternal inflation? (¿Una salida suave a la inflación...

Este vídeo de Kurzgesagt habla de unos bichos que cada día se calcula que terminan con el 40% de las bacterias que hay en los océanos. Unos bichos que suman, de largo, más ejemplares que todas las demás formas de vida...

Como bien titula el vídeo de Magnetic Games, esto es como ver a Iron Man enfundarse en su traje. Básicamente todo obedece a las leyes de la física y a los pequeños pero poderosos imanes colocándose sobre las líneas magnéticas de...

La receta para este experimento titulado simplemente The Cannon Project incluye diversas cantidades de pólvora fina con las que se carga un viejo cañón en el que se prende una mecha. Tan primitivo como efectivo. Los preparativos están bien, pero el...

Impulsada por los Museos Científicos – Ayuntamiento de A Coruña y Naukas la jornada de divulgación Naukas Coruña 2018 ya tiene fecha y programa provisional pero tirando a muy definitivo. Bajo el título Grandes viajes, aunque entendiendo viaje en un sentido...

¿Para qué nos sirve conocer nuestro lugar en el universo? Puede que la respuesta sea para todo.– Neil deGrasse Tyson Neil deGrasse Tyson y Ann Druyan vuelven en una nueva temporada de Cosmos, anunciada para 2019, titulada Mundos posibles, en la...

En mi grupo de amigos más íntimos aún se recuerda aquella tarde en la playa hace algunos lustros en la que terminé explicándole a mi hijo –que tendría unos 5 ó 6 años en aquel entonces– el ciclo del agua para...

A principios de 2017 un grupo de aficionados a las auroras boreales de Alberta, en Canadá, descubrió en algunas de sus fotos una banda entre verdosa y púrpura de varios cientos o incluso miles de kilómetros que no sabían muy bien...

Con todos ustedes La noche es necesaria, un vídeo que en clave de humor trata un tema la mar de serio como es el que hayamos echado la oscuridad de nuestras vidas y las consecuencias que eso tiene sobre nuestra salud....
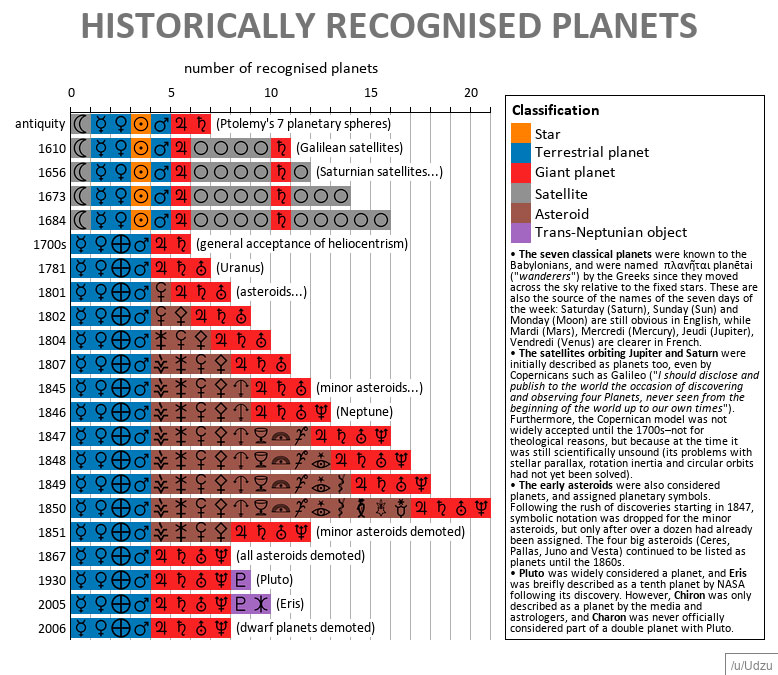
Esta imagen de Udzu muestra los planetas reconocidos históricamente como «oficiales», que es una forma laxa de referirse a «los que eran conocidos como planetas», «los que la mayor parte de la gente consideraba planetas» o finalmente «los reconocidos oficialmente como...

La construcción del Telescopio Extremadamente Grande del Observatorio Austral Europeo avanza adecuadamente y después de preparar el terreno ya se ha empezado trabajar en los cimientos de la cúpula y del espejo principal. En estas imágenes el círculo externo es el...

La época en la que vivimos será recordada para siempre como la era en la que los humanos emergimos de la cuna que es nuestro planeta para convertirnos en una especie con un lugar en el espacio. El 14 de julio...

La Agencia Espacial Europea ha seleccionado tres finalistas de entre las 25 propuestas que manejaba para ocupar el hueco de la quinta misión de tamaño medio del programa Cosmic Vision. Las misiones que han pasado la criba son la misión a...
¿Sientes curiosidad por el cosmos? ¿Te intriga el tema de la evolución? ¿O, simplemente, quieres saber por qué la cerveza sabe así de bien? Muchas de tus preguntas tienen respuestas, y Pint of Science trae a las mentes más brillantes para dártelas....

Según resume la Wikipedia, en 1991 el detector de rayos cósmicos Fly’s Eye de la Universidad de Utah detectó un rayo cósmico de ultra-alta energía al que llamaron partícula Oh-My-God (literalmente: ¡Oh Dios mío!) Se calculó su energía y para sorpresa...

Estamos en una de las dos épocas del año en las que la Tierra atraviesa el resto de partículas dejadas atrás por el cometa Halley en sus visitas periódicas al Sol de hace cientos de años –en la actualidad su órbita...
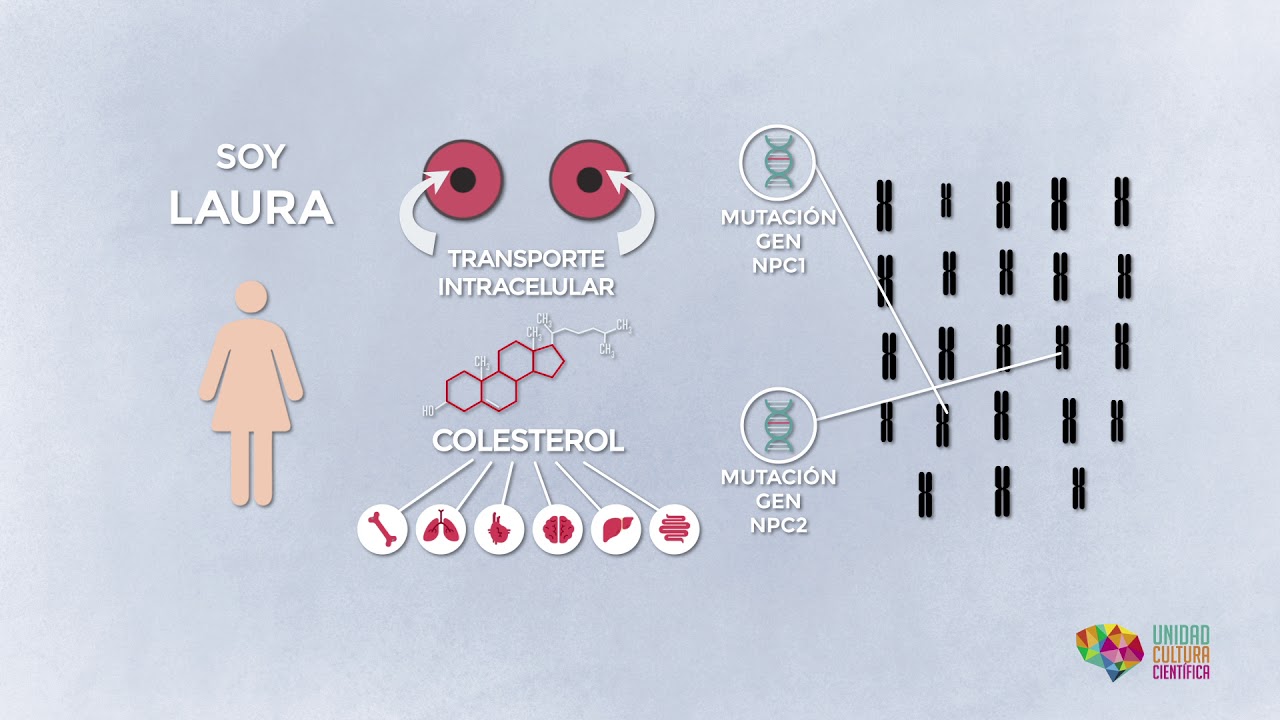
Las enfermedades raras, aquellas que afectan a menos de 5 de cada 10.000 habitantes, tienen mucha tela, pero este vídeo de tres minutos de la serie Ciencia en Corto de la Universidad de Murcia es una buena introducción. Según la OMS,...

Ya hace algún tiempo que se vienen haciendo pruebas en las que se usan datos obtenidos por satélite para intentar dar alertas tempranas de la aparición de epidemias. Por supuesto ningún satélite puede detectar los bichos que las causan, pero sí...

¿Cual es tu objetivo? ¿Tener razón o hacer cambiar de opinión a la gente? […] Porque si sólo quieres tener razón puedes irte de listillo y reírte de la gente. Entonces tendrás razón acerca de la ciencia pero tendrás razón en...

En Technology Review tienen un artículo que cuenta cómo unos neurocientíficos de la Universidad de Yale que han conseguido «reanimar» los cerebros de unos cerditos decapitados para mantenerlos con vida 36 horas. La inquietante investigación –que inevitablemente da un poco de...

Launch preparations are underway for New Shepard’s 8th test flight, as we continue our progress toward human spaceflight. Currently targeting Sunday 4/29 with launch window opening up at 830am CDT. Livestream info to come. @BlueOrigin #GradatimFerociter pic.twitter.com/zAYpAGWB8C— Jeff Bezos (@JeffBezos) 27 de...

En este vídeo de SciFri se muestra cómo es el «Huracán en una caja» que utiliza el Profesor Brian Haus, un investigador de la Universidad de Miami que estudia los huracanes y tormentas. Se trata de un «laboratorio» en forma de...

La Agencia Espacial Europea acaba de publicar el segundo catálogo de datos obtenidos por el observatorio espacial Gaia. Contiene datos de casi 1.700 millones de estrellas de la Vía Láctea, nuestra galaxia. Estos datos incluyen posiciones, indicadores de distancia y movimientos...
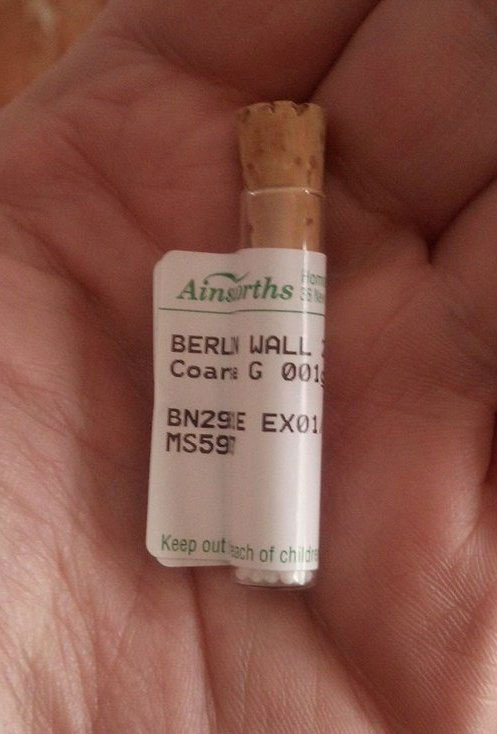
Cuando me preguntan por qué insisto en criticar la homeopatía, la astrología, las seudociencias… («¡Deja que la gente haga lo que quiera!»), siempre recuerdo esta frase de Montesquieu: «Instruid a los incautos y acabaréis con los bribones».– Xosé Castro En una reciente...

Aunque ahora lo damos por hecho gracias a sistemas como el GPS durante la mayor parte de nuestra historia como exploradores no dispusimos de una forma fiable de calcular la longitud de un lugar, cuán al este o al oeste de otro...

El experimento LIGO, que es el primero que nos ha permitido detectar las ondas gravitacionales, es extremadamente preciso. Tanto que es capaz de detectar una variación en la longitud de sus brazos equivalente al ancho de un átomo frente a la...

La misión Chang'e-4 del programa espacial chino, que será la primera de la historia en aterrizar en el lado oculto –que no oscuro– de la Luna tiene reservado un espacio para un experimento propuesto por estudiantes. De las más de 200...

Causada por las partículas dejadas atrás por el cometa C/1861 G1 Thatcher las Líridas –llamadas así porque parecen venir de la constelación de la Lira– son una de las lluvias de estrellas de las que tenemos constancia desde hace más tiempo,...

Vox tiene este interesante vídeo-documental acerca de la relación entre el calentamiento global –especialmente en el Ártico– y los cambios meterológicos que se están sufriendo en todas partes del mundo. Esto se traduce en situaciones tanto de calor extremo como de...

El segundo intento ha sido el bueno y el observatorio espacial TESS de la NASA ya está en órbita tras ser lanzado por un Falcon 9 FT de SpaceX. El lanzamiento se produjo a las 00:51:31 del 19 de abril de...

Todo está listo en el Complejo de Lanzamiento 40 de Cabo Cañaveral para que un Falcon 9 ponga en órbita TESS, el nuevo observatorio espacial de la NASA. Es el primer lanzamiento de SpaceX para una misión científica de la NASA...
Alex Gurvich tiene esta estupenda simulación acerca de la de formación de las galaxias que preparó como parte de su trabajo de investigación. Cada tic del reloj cósmico es un millón de años – y transcurren a gran velocidad. Son tres...

Lanzado en la cápsula de carga Dragon 14 el ASIM, de Atmosphere-Space Interactions Monitor o Monitor de Intercacciones entre la Atmósfera y el Espacio de la Agencia Espacial Europea ya ha quedado instalado en el exterior del laboratorio Columbus de la...

Escucha "Ciencia y tecnología (12/04/18)" en Play SER Hoy he aprovechado mi espacio quincenal en Hoy por hoy A Coruña para hablar con Mayte Gonzáles Trillo de algo que me fascina desde que conozco su existencia, la sinestesia. La sinestesia es una...

Damian Kulash de grupo OK Go explica en esta pieza algunos de los secretos matemáticos y de planificación que hay detrás de sus vídeos. Es algo que siempre tienen que llevar a cabo con mucha precisión pero que tuvieron que controlar...

Con el sugerente título de Experimentally generated randomness certified by the impossibility of superluminal signals un artículo publicado en Nature ($) describe un nuevo sistema que utiliza mediciones cuánticas para generar números aleatorios «certificados». En otras palabras: tienen la garantía de...
En el día internacional de la homeopatía, nada mejor que estrenar Sugarfree, un buscador que te permite localizar farmacias en las que ni se vende ni se publicita homeopatía. Sí, los farmacéuticos son libres de vender esos productos –aunque en mi...

La Taza de 7 colores es un ejemplo del Teorema de los 4 colores aplicado a la superficie de un objeto tridimensional. El enunciado original de este teorema matemático dice así: Cualquier mapa geográfico se puede colorear con cuatro colores diferentes...

¿Cuáles son los últimos diez dígitos de este número? La pregunta procede de uno de los retos Ponder This de IBM. Como puede imaginarse resolverlo no es trivial – sobre todo porque no valen trucos como usar Wolfram Alpha, que aquí...

Este vídeo se corresponde con el primer modelo 3D de copos de nieve derritiéndose en la atmósfera. Desarrollado por el científico Jussi Leinonen, del Jet Propulsion Laboratory de la NASA, el modelo se ha completado a partir de un nuevo estudio...
Por Nacho Palou -
5 ABR 2018

En teoría cualquier objeto que tenga masa podría convertirse en un agujero negro si toda su materia se comprimiese a un tamaño determinado (supuestamente) por el llamado radio de Schwarzschild. Al alcanzar ese tamaño el objeto se volverá denso de narices...
Por Nacho Palou -
3 ABR 2018
Por lo que sabemos hasta ahora la teoría de la tectónica de placas (que explica el movimiento de los continentes en la Tierra y también algunos de sus terremotos) no es aplicable a Marte. “Un planeta fósil” en el cual en...
Por Nacho Palou -
3 ABR 2018

Por lo general la ciencia exige trabajar muy duro para obtener resultados. Pero a veces se dan casualidades que llevan a descubrimientos inesperados. How science works: fail fail fail fail fail fail fail fail fail succeed fail fail fail fail fail...
A la gente le encanta la ciencia hasta que le dice aquello que no quiere oír.— Jennifer Ouellette(vía Susanna Kohler y Daniel Fischer)...

Sorprendiendo aproximadamente a nadie la NASA acaba de anunciar que el lanzamiento del telescopio Espacial James Webb se retrasa de nuevo. A mayo de 2020 como muy pronto, lo que supone un año más respecto a la última fecha anunciada. Esa...

Estamos dando los últimos toques al programa de la edición de 2018 de mc2 presenta: Naukas Coruña, para la que ya tenemos fecha y que en breve anunciaremos. Pero mientras tanto estos son los vídeos de las charlas de mc2 presenta:...

Se me había pasado este demoledor comunicado de la Sociedad Española de Oftalmología, que ya tiene unos meses, sobre los productos que vende Reticare basándose en el miedo a los daños que según ellos causa la «luz tóxica emitida por ciertos smartphones»...

Por segundo año consecutivo el astrónomo Ian P. Griffin, director del museo Otago en Dunedin, Nueva Zelanda, ha organizado por segundo año consecutivo un vuelo charter bautizado como Flight to the lights para ir a la caza de una aurora austral....

What? My DNA changed by 7%! Who knew? I just learned about it in this article. This could be good news! I no longer have to call @ShuttleCDRKelly my identical twin brother anymore. https://t.co/6idMFtu7l5— Scott Kelly (@StationCDRKelly) 10 de marzo de 2018...

Ariel, de Atmospheric Remote‐sensing Infrared Exoplanet Large‐survey, o Análisis Atmosférico Remoto de gran tamaño de Exoplanetas en el Infrarrojo ha sido escogida por la Agencia Espacial Europea como su próxima misión de tamaño medio del programa Cosmic Vision 2015-2015. Dotado de un...

Uno de los proyectos más recientes de la Unidad de Cultura Científica e Innovación de la Universidad de Murcia es Ciencia en Corto, una serie de vídeos de animación en los que abordarán diversos aspectos de la ciencia. El primero de...

Esta animación muestra sobre unas bonitas imágenes aéreas el funcionamiento de los aceleradores de partículas del Fermilab –nombre coloquial del Laboratorio Nacional Fermi– que se construyó en 1967 en Illinois (Estados Unidos) hace ya la friolera de más de 50 años....

Esto es divertido e instructivo a la vez; el reto es ver quién multiplica más rápido dos parejas de dos números de tres cifras y los suma. Los alumnos pueden utilizar calculadora; quien plantea la prueba no. Alguien de la clase...

¡Lo perdemos, lo perdemos!– una de las frases que nunca se escuchanen una sala de operaciones En este vídeo de Wired, Annie Onishi, cirujana en la Universidad de Columbia desvela la realidad tras algunos de los topicazos de las películas y...

Ilustración que representa un planeta similar a Júpiter vagando por el espacio, sin una estrella madre. Los astrónomos creen que los planetas errantes superan en número a las estrellas. Imagen: NASA/JPL-Caltech. En Forbes, un fascinante artículo del astrofísico Ethan Siegel: Space Is...
Por Nacho Palou -
14 MAR 2018

En mecánica cuántica suelen suceder cosas muy raras y calcular algunas de ellas en términos «cotidianos» para hacerse una idea de lo que eso significa es divertido – tal y como ha hecho Sophia Nasr (@AstroPartiGirl) en un hilo de Twitter...

Para celebrar hoy el día de pi (14 de marzo, 3/14 en notación anglosajona) he aquí una historia relativamente poco conocida de las primeras menciones que se tienen de π, concretamente del antiguo Egipto. Aunque no con su nombre actual, se...

El gran enemigo del conocimiento no es la ignorancia, sino la ilusión de conocimiento.— Stephen Hawking En 1963 a Stephen Hawking le diagnosticaron esclerosis lateral amiotrófica cuando tenía 21 años y le dieron dos años de vida. No sólo desafió ese...

Sí, existe un Real Hospital Homeopático de Londres, aunque desde 2010 se llama Real Hospital de Londres para Medicina Integrada, supongo que para disimular un poco. Pero según se puede leer en NHS homeopathy ending in London desde el próximo 3 de...

Fotografía: Joan Montanya / Universidad politécnica de Cataluña. Los rayos generalmente no suponen un problema para los aviones, menos aun desde que en 1963 la FAA reguló las medidas de protección contra rayos que debían llevar los aviones. Entre esas medias se...
Por Nacho Palou -
12 MAR 2018
Larry M. Silverberg y Chau Tran desarrollaron hace veinte años un sistema de simulación informática para calcular cuál era la forma óptima de lanzar un tiro libre: posición inicial (dependiendo de la altura de quien lanza), ángulo, fuerza/velocidad, efecto de rotación...

La Oregon Health & Science University ha publicado un artículo sobre el desarrollo de un corazón artificial permamente en el que llevan tiempo trabajando y que podría reemplazar el corazón dañado de cualquier persona a partir de los 10 años. No...

A finales de octubre de 2017 el asteroide A/2017 U1, más tarde bautizado como 'Oumuamua, dio bastante que hablar cuando los astrónomos se dieron cuenta de que venía de fuera del sistema solar y de que además no se iba a...

Me encontré con esta reedición modernizada de los Elementos de Euclides, el tratado de geometría que como es bien sabido es uno de los libros de texto más populares de la historia – además de uno de los más editados en...
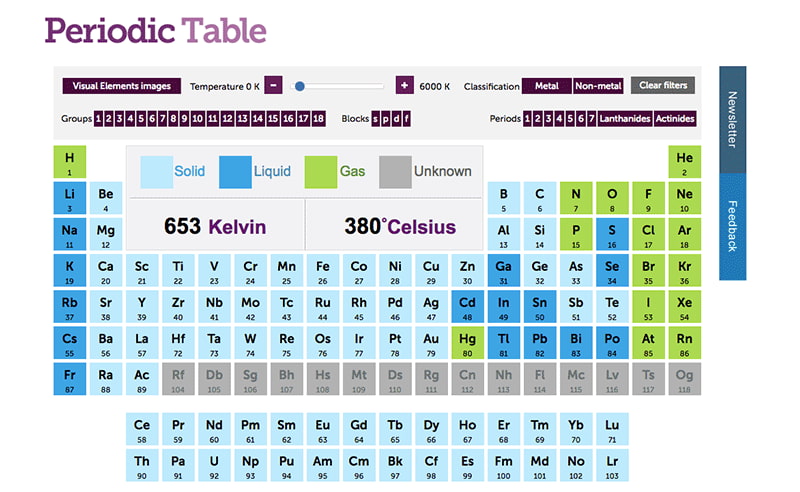
Esta Tabla Periódica de la RSC tiene como característica interesante que muestra los elementos químicos en diversos colores a medida que se va haciendo variar la temperatura. Azul claro, oscuro y verde simbolizan sólido, líquido y gaseoso respectivamente – también hay...

Como siempre me ha pasado no sé lo que es que las palabras no te sepan La sinestesia es una condición neurológica que hace que las personas que la tienen –explicado grosso modo– tengan los cinco sentidos tradicionales (tenemos más sentidos,...

En un motor de iones se carga eléctricamente un gas, habitualmente xenón, lo que lo convierte en un ión, un átomo o molécula con carga eléctrica. Esos átomos cargados eléctricamente se aceleran al pasar a través de unas rejillas metálicas también...

Desde los Museos Científicos Coruñeses, en los que trabajo en el MundoReal™, acabamos de lanzar la convocatoria de los Prismas Casa de las Ciencias a la Divulgación de 2018. Las modalidades son Vídeo. Web / Redes sociales. Texto inédito. Artículo periodístico. Radio....

En 2014 comenzó la construcción del Telescopio de Treinta Metros en el Mauna Kea en Hawaii con todos los permisos pertinentes, pero desde entonces diversos recursos y contra recursos la han tenido parada más tiempo que activa. De hecho la Corte Suprema...

En diversas revistas científicas se está hablando sobre un trabajo publicado por unos científicos de hospitales de Berlín y Cincinnati que llevan tiempo dedicándose a grabar con electrodos la actividad cerebral de algunos pacientes exactamente en el momento de la muerte....

Aunque en un primer vistazo podrían parecer floreros de diseño Hiuni y Stellina –que también me recuerda a TARS– son dos telescopios digitales –no tienen visor sino que un sensor fotográfico manda la imagen capturada a un móvil, ordenador o tablet–...

Nuestro cerebro es lo que nos hace ser quienes somos y buena parte de lo que somos. Se calcula que contiene unos 85.000 millones de neuronas, que son un montón de neuronas….Pero según las estimaciones más recientes y aparentemente más fiables esa...

Nuestra sociedad depende de la ciencia y la tecnología hasta límites de los que muchas veces no somos conscientes. Y aunque lo seamos se producen tal cantidad de noticias y avances al cabo del año que es imposible mantenerse al día. Pero...

¿Alguna vez os habéis preguntado de dónde viene el mito de que los transgénicos inducen la formación de tumores malignos, o sea, cáncer? Yo te lo cuento, y al final te pongo muchos papers y muchas cosas de esas científicas para que...

Weather Machine de Matt McCorkle es una web que hay que oír para disfrutar ya que es una sonificación –el uso de audio para presentar información– de los datos meteorológicos de tu ciudad o de aquella que le digas. Temperatura, humedad, cantidad...

En el verano de 2016 Próxima Centauri, la estrella más cercana a la Tierra –aparte del Sol, claro– dio que hablar por el descubrimiento de un planeta que da vueltas alrededor de ella, lo que lo convierte en el planeta extrasolar...
Un asunto genera debate científico cuando lo discuten montones de científicos, no cuando lo debate el público, la prensa o los políticos.– Neil deGrasse Tyson...
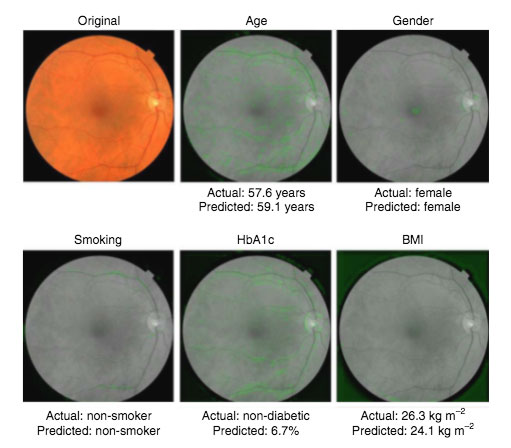
En Nature se ha publicado un trabajo sobre un método para detectar ciertas enfermedades y síntomas mediante inteligencia artificial a partir de las fotografías del fondo de ojo de los pacientes. Esto permite no sólo un diagnóstico más preciso de ciertas...

Ya le quedan pocos días pero si estás en Madrid o te toca pasar por allí y te da tiempo recomiendo encarecidamente una visita a Marte, la conquista de un sueño, una exposición que se puede ver en la Fundación Telefónica...

Lo que se ve en el vídeo es un imán que se sostiene “en el aire” sobre el campo magnético producido por un superconductor (efecto Meissner. Esta receta científica incluye añadir unas gotas de ferrofluido, líquido magnetizado con nanopartículas. El líquido...
Por Nacho Palou -
23 FEB 2018
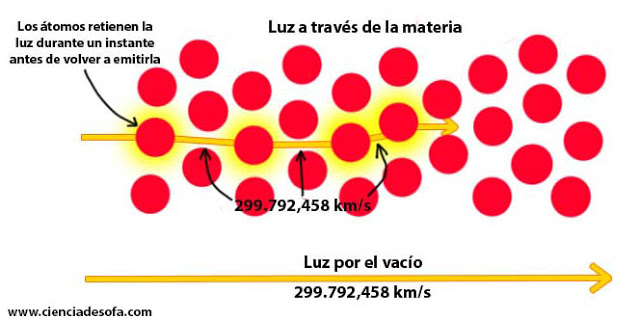
En Ciencia de Sofá han publicado este estupendo artículo titulado ¿Por qué la velocidad de la luz es la que es? donde se va un poco más allá de la explicación tradicional de por qué la luz es exactamente 299.792.458 metros...
Malas noticias desde la Organización Mundial de la Salud: Europa observa un aumento del 400% en casos de sarampión en 2017 comparado con el año anterior (en inglés por ahora). La enfermedad afectó a 21.315 personas en 2017, causando 35 muertes, frente...

La semana pasada supimos que Josep Pàmies pretendía impartir sendas charlas en A Coruña y Vigo. La primera en uno de los salones de actos del hotel Attica21 y la segunda en el salón de actos del Colegio Hogar. En cuanto...

Buenas noticias para los fans de los vídeos didácticos sobre matemáticas: nos han escrito para contarnos que Pedro Pardo y Jesús Montes (matemáticos, Jesús pone la voz) y Grant Sanderson (creador de 3Blue1Brown, el canal de «matemáticas animadas») llevan tiempo trabajando...

Paul Alexander tenía seis años cuando enfermó de polio en 1952. Al cabo de cinco días lo había perdido todo, como él mismo dice, pues ya no se podía mover, andar y ni tan siquiera respirar, ya que su diafragma dejó...

Este pequeño gadget llamado MinION es un secuenciador de ADN, que no necesita de ningún complicado laboratorio, pesa unos pocos gramos, cabe en un bolsillo y se conecta a cualquier ordenador a través de un puerto USB 3. Puede usarse para...

La foto Single Atom in an Ion Trap por David Nadlinger acaba de ganar el concurso de fotografía científica del Consejo de Investigación en Ingeniería y Ciencias Físicas del Reino Unido. En ella se ve un átomo de estroncio atrapado en...

Seguro que estas «noticias» te suenan: Petición de sangre del tipo AB para un niño con leucemia ingresado en el hospital La Fe de Valencia. Tanto se ha compartido este mensaje, que el hospital se vio obligado a emitir un comunicado...

Ya está en marcha la tercera edición de Ciencia Clip, el concurso de vídeos divulgativos de ciencia para estudiantes de la ESO, Bachillerato y del ciclo básico y medio de FP. Su objetivo es «fomentar el interés por la ciencia y...

En este experimento The Action Lab coloca un dron que pesa 21 gramos dentro de una caja que a su vez está puesta sobre una balanza. Con el medidor de la balanza a cero al quitar el dron la balanza indica...
Por Nacho Palou -
13 FEB 2018
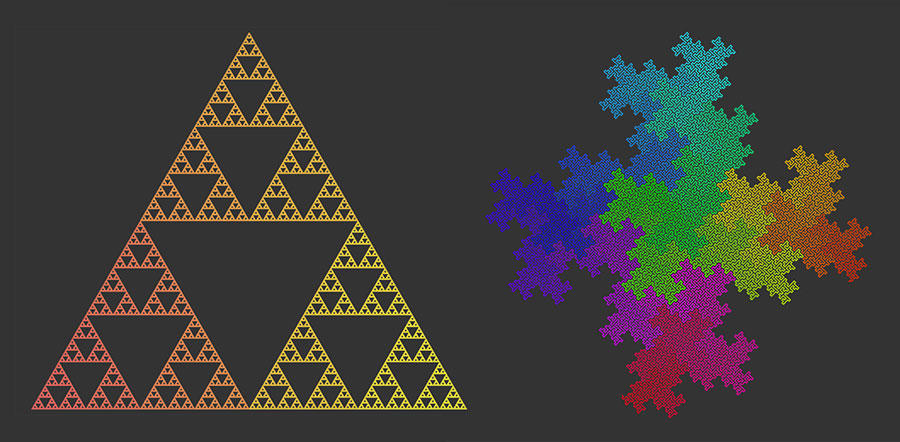
Fractality es un explorador web que funciona directamente desde el navegador, no hace falta descargar software y es multiplataforma Se comporta como un programa de diseño de fractales, en el que basta ir dibujando sobre una rejilla y definir algunas reglas...

El 7 de febrero de 2008 el transbordador espacial Atlantis despegaba en la misión STS-122, que tenía como objetivo principal llevar el laboratorio Columbus de la Agencia Espacial Europea a la Estación Espacial Internacional y dejarlo allí instalado. Tras un lanzamiento...

La revista Nature ha publicado un estudio científico acerca de «los efectos de la meditación», algo que en sus diversas variantes es más popular hoy en día como mindfulness. La versión abreviada es que no hay evidencias de que sirva para...
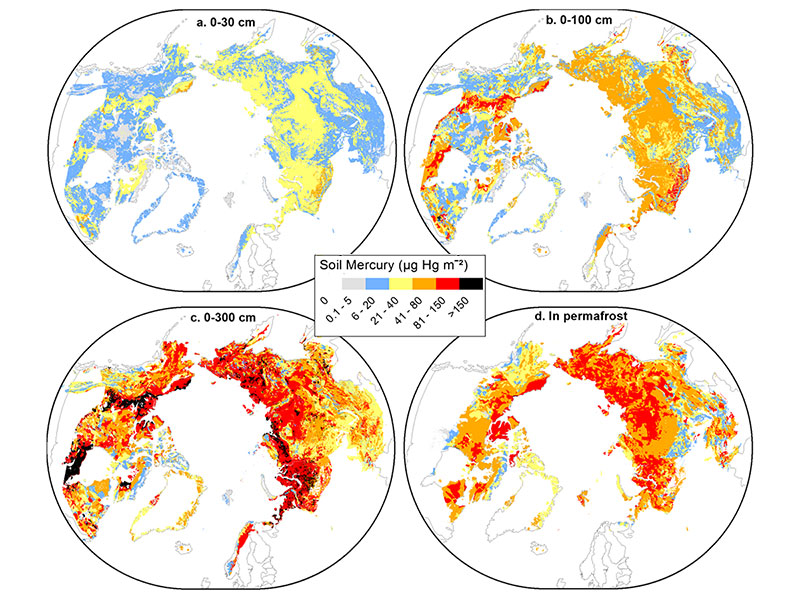
Mapa de la concentración de mercurio (μg Hg/m²) en el permafrost del Hemisferio NorteImagen: Paul F. Schuster et at. / Geophysical Research Letters / AGU Científicos del Servicio Geológico de los Estados Unidos han calculado la cantidad de mercurio que hay enterrada...
Este mapa soviético de la Luna data de 1979, una fecha relativamente reciente si tenemos en cuenta que los primeros mapas dibujados a través de telescopio datan de 1609. Figura como Composite map: Полная карта Луны (Polnaia karta Luny) en la...
83 años, enfermedad de Alzheimer moderada Azuquahe Pérez Hernández dice acerca del test del reloj: …es una prueba fácil de aplicar e interpretar que nos sirve para detectar el deterioro cognitivo que se produce en muchas enfermedades neurológicas y psiquiátricas. Es independiente...

Unos investigadores del MIT han desarrollado un método para utilizar piezas de Lego en experimentos con microfluidos, una especie de plataforma de laboratorio suficientemente flexible y fiable como para realizar ciertos trabajos de forma rápida y barata. Sí, Legos de los...

A menudo se pone a la inmensa variedad de especies presentes en Burgess Shale, un conocido yacimiento de fósiles situado en la Columbia Británica, en Canadá, como ejemplo de la explosión cámbrica, un fenómeno que provocó la aparición de numerosas especies...

Entre las 10:51 y las 16:08 UTC del 31 de enero de 2018 se produce un eclipse de Luna que, si haces caso de lo que se puede ver por ahí, va a ser un eclipse de superluna azul rojo sangre....

Este vídeo recoge las siete imágenes seleccionadas en el certamen de fotografía científica Fotciencia 15, una iniciativa de ámbito nacional que se propone acercar la ciencia a la ciudadanía a través de fotografías que abordan cuestiones científicas con un enfoque artístico...

Autotratamiento infructuoso de un caso de ”bloqueo del escritor” (en PDF) es un artículo academémico escrito por el psicólogo Dennis Upper. Se publicó en 1974, en la revista Journal of Applied Behavior Analysis. Se trata de un artículo humorístico (“humor de...
Por Nacho Palou -
25 ENE 2018
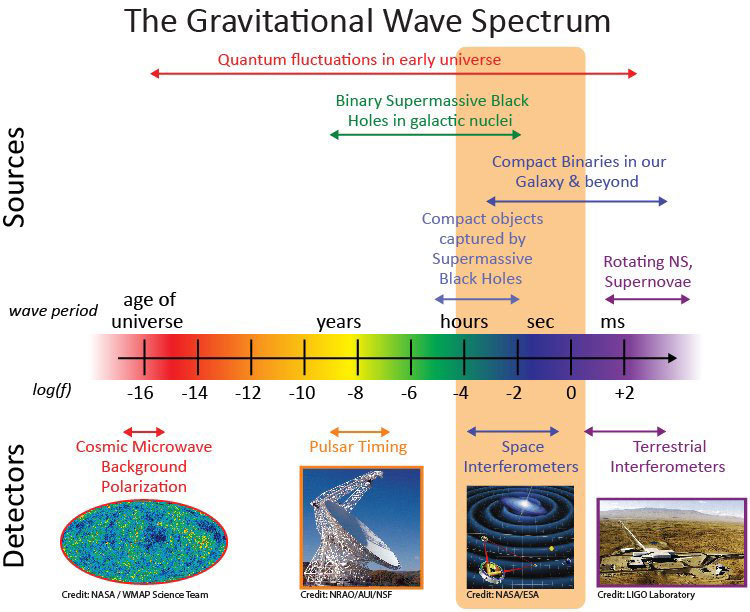
Uno de los avances científicos más importantes de los últimos años ha sido, sin duda, el que hayamos podido comprobar que las ondas gravitacionales, predichas por la teoría de la relatividad general de Einstein, existen. El que hayamos aprendido a observarlas...

Si todo va según lo previsto la NASA lanzará la Parker Solar Probe rumbo al Sol en una ventana que va del del 31 de julio al 19 de agosto de 2018. Pero antes de eso hay que comprobar que es...

Animales imaginarios que salen del cerebro al torrente sanguíneo y se comen los tumores. Telereiki. Metástasis que se curan con conversaciones con terapeutas especializados en bineuroemoción. Canciones que detienen un cáncer pero sólo si las escuchas desde un CD grabado a...
’Oumuamua, el primer visitante interestelar en pasar por nuestro sistema solar del que tenemos constancia, resultó tener una forma bastante peculiar. Según Karen Meech, del Instituto de Astronomía, Hawái, EE.UU., que dirigió un equipo que lo observó con varios telescopios: Oumuamua...

#URGENTE | #CONFIRMADO El Asteroide AJ129 2002, cambio curso y velocidad hacia la tierra y la @NASA hoy lo catalogo "potencialmente peligroso". Dato importante, llegaria el 4 de Febrero. pic.twitter.com/C03YNCfwVw— Big Data Noticias (@bigdatanoticias) 18 de enero de 2018 Odio los «tituláridos»...

Hay básicamente cinco razones por las que calcular trillones de dígitos de π es útil, según Tipping Point Math: Para hacer cálculos científicos y de ingeniería con precisión Para ver «hasta dónde podemos llegar» (ejercicio de superación) Para confirmar la integridad...

La forma de los huevos de lechuza, talégalo maleo y arao – una gran variedad En un artículo de Nature escrito por Sarah Crespi y con unas estupendas visualizaciones de Jia You se explican algunas cuestiones realmente curiosas sobre la forma de...

En 2017 el equipo del observatorio espacial Kepler decidió hacer públicos los datos que reciben tan pronto como están disponibles para que cualquiera pueda analizarlos y trabajar con ellos. Y según se puede leer en Multi-planet System Found Through Crowdsourcing por...
Ciertamente no faltarán pioneros humanos cuando hayamos dominado el arte de volar… Mientras tanto, prepararemos, para los valientes viajeros del cielo, mapas de los cuerpos celestes".– Johannes Kepler Con nuestros instrumentos cada vez más sensibles y con la ayuda de algoritmos...

En este vídeo de hace un par de días de π a un grupo de estudiantes del MIT que andaban por los pasillos les plantearon el reto de escribir en una tablilla tantos dígitos de π como supieran de memoria. Uno...

Según investigadores de la universidad de Purdue, cuando los bebés gatean su movimiento por el suelo, especialmente cuando gatean en alfombras, levantan grandes cantidades de suciedad, células de la piel, bacterias, polen y esporas de hongos y las inhalan en sus...
Por Nacho Palou -
11 ENE 2018

La empresa alemana Schott acaba de terminar la fabricación de la base de los seis primeros segmentos individuales de los 798 que formarán el espejo principal del Telescopio Extremadamente Grande (ELT) del Observatorio Europeo Austral. Estas bases están fabricadas en un...

Dicen los supersticiosos que encontrar un trébol de cuatro hojas trae buena suerte. Dado que se sabe que hay más o menos un trébol de cuatro hojas de cada 10.000 y que caben unos 200 tréboles por cada 60 cm² tan...
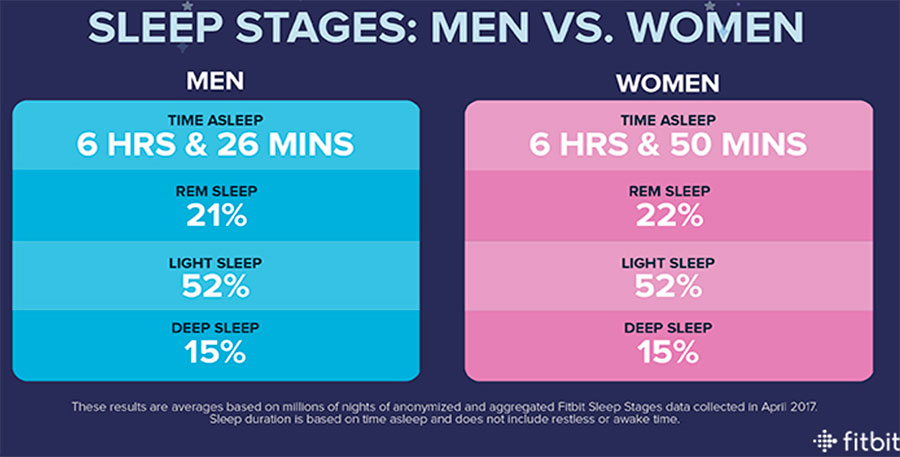
Gracias al análisis de 6.000 millones de noches de sueño cuyos datos proceden de las populares «pulseras de actividad» Fitbit se ha podido realizar una detallada revisión sobre las costumbres del sueño de un enorme número de personas. El Big Data...

… Total, que las piernas de la señora estaban aplastadas bajo una grúa gigantesca de 900 kilos de peso. Bien, supongo que sabréis que en un caso de emergencia de repente te viene como una fuerza sobrehumana… ¿Eh? Esto me bastó...
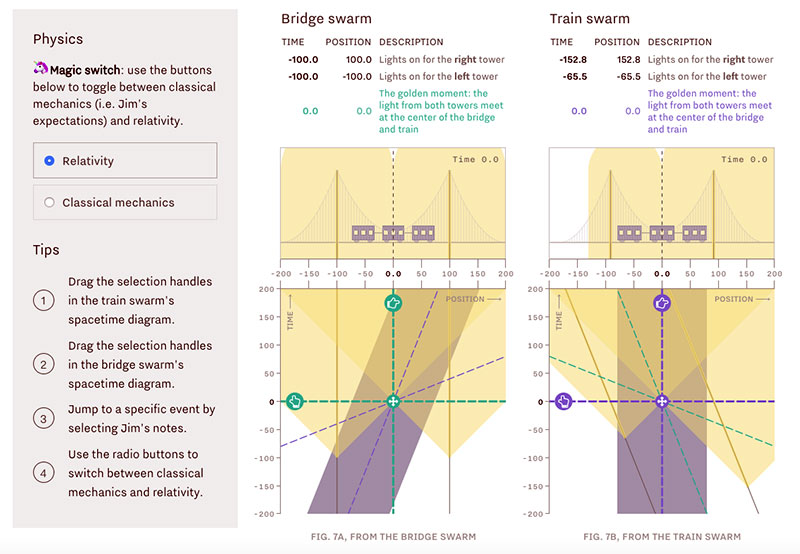
Utilizando una herramienta de visualización para datos y modelos llamada Lucify, Juho Ojala ha preparado un larguísimo artículo titulado Inside Einstein’s head que incluye diversas gráficas interactivas aceca de los experimentos mentales de Albert Einstein y el espaciotiempo relativista. Versión moderna,...

277.232.917-1 es el mayor número primo descubierto hasta hoy. Es el 50º número primo de Mersenne al tener la forma 2n-1 (siendo n también primo). Su longitud es de 23.249.425 dígitos; empieza por 4 y acaba en 1. El anterior mayor...

Beber agua no tratada (raw water) es una de las últimas tontandencias del “postureo pseudo-hippie”, en línea con la de beber leche de vaca cruda o despreciar las vacunas y la medicina científica. O más bien la tendencia es vender agua...
Por Nacho Palou -
5 ENE 2018

Además del curioso efecto que se produce cuando se deja caer ferrofluido sobre un imán —y que se aprecia con detalle gracias a la grabación de alta velocidad, a 1000 fotogramas por segundo— el efecto sirve para explicar visualmente la espaguetización...
Por Nacho Palou -
5 ENE 2018
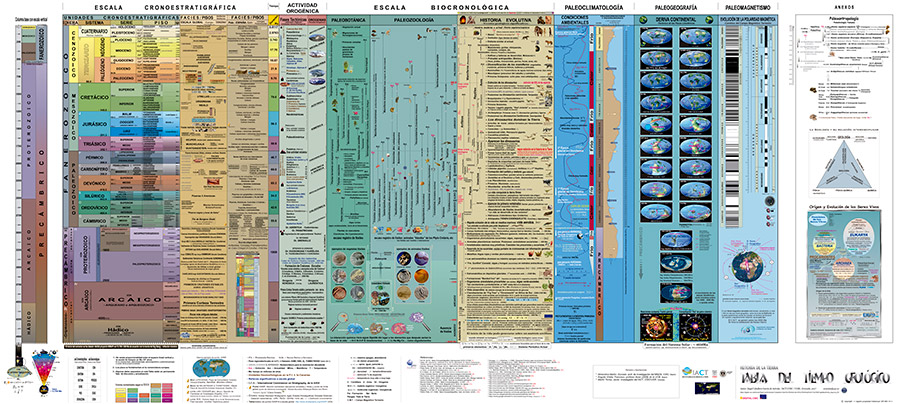
Esta Tabla del Tiempo Geológico es un trabajo de divulgación obra de Ángel Caballero y está editada por el Instituto Andaluz de Ciencias de la Tierra (IACT). Es básicamente una visualización del tiempo geológico en sus diferentes facetas, que cubre desde...

Ahora que la gripe está haciendo estragos viene muy a cuento este vídeo TED de Marco A. Sotomayor en el que se explica, con subtítulos en español, por qué nos encontramos mal cuando estamos enfermos: por qué los músculos comienzan a...
Por Nacho Palou -
4 ENE 2018

Hay una diferencia fundamental: los charlatanes lo saben todo. Son infalibles, mientras que los científicos y los divulgadores a veces te dicen «no sé, no te lo puedo explicar». Es más fácil decir que uno lo sabe todo que señalar los...

Los seres humanos nos hemos puesto de acuerdo en una especie de alucinación colectiva estándar y vemos más o menos lo mismo. Esto nos permite ser una sociedad con referentes universales.– Rodolfo Llinás,neurocientífico Desde tiempos inmemoriales sabemos que hay animales con...

Esta materia oscura es tan importante para nuestra comprensión del tamaño, forma y destino final del universo que su búsqueda probablemente dominará la Astronomía en las próximas décadas.– Vera Rubin en 1978 Cuando en 1970 Vera Rubin comenzó a observar la...
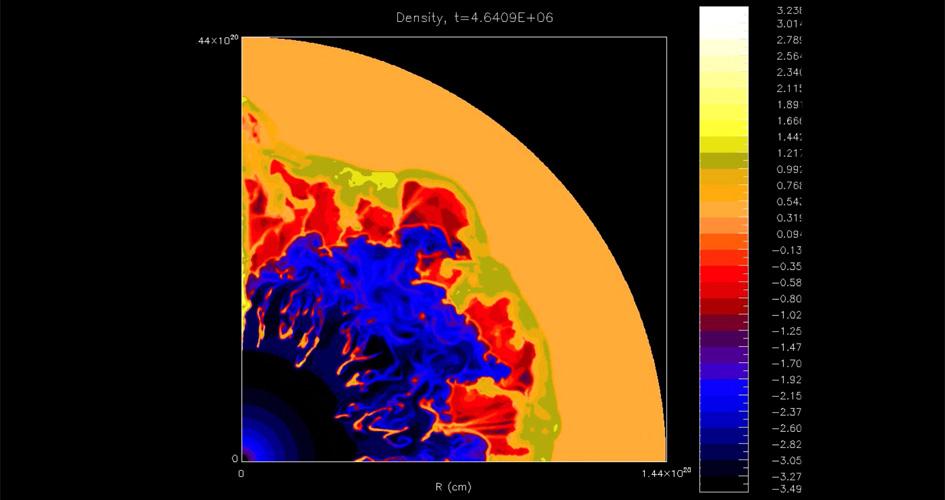
La simulación muestra cómo se forman burbujas a partir de los intensos vientos estelares de una estrella muy masiva en el transcurso de millones de años. Según investigadores de la universidad de Chicago nuestro sistema solar podría tener su origen en una...
Por Nacho Palou -
27 DIC 2017

Una esfera de Hoberman es una estructura plegable que se asemeja a una cúpula geodésica con ingeniosos mecanismos de unión entre sus piezas. Además de un gran juguete resulta ser un utensilio bastante colorido y espectacular con el que explicar la...
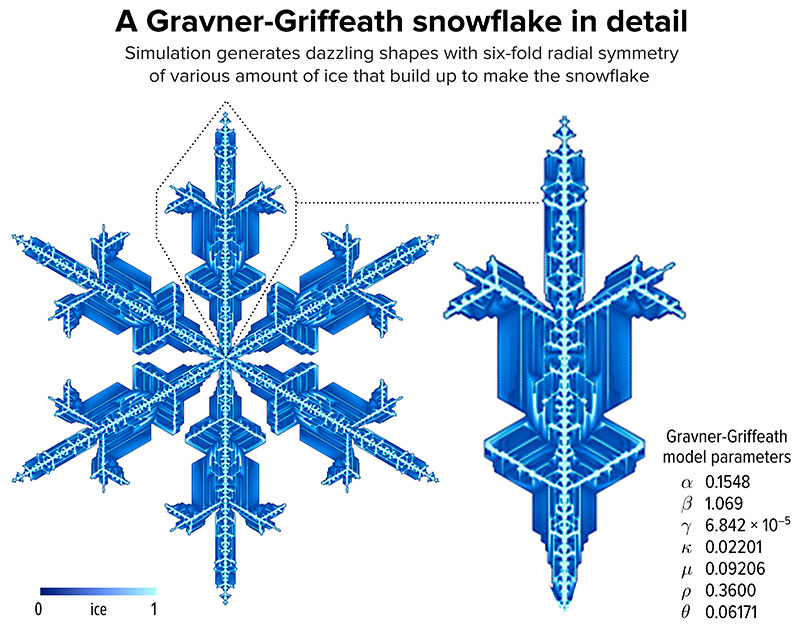
Krzywinski y Lever publicaron un precioso y bastante complejo artículo en Scientific American acerca de la creación de copos de nieve mediante modelos matemáticos. In Silico Flurries describe cómo utilizar un modelo que hace crecer estos intrincadas maravillas de la naturaleza...

Ensayo nuclear con la bomba Small Boy, parte de la Operación Sunbeam (1962) / Wikimedia / EE.UU. Anda circulando un trabajo de Keith Meyers, un economista de la Universidad de Arizona en el que se plantea cómo a causa de los efectos...

En Vielecke und Vielflache, Theorie und Geschichte (Polígonos y poliedros: teoría e historia) el matemático Max Brücker (1860-1934) documentó de forma gráfica cientos de curiosos poliedros regulares e irregulares, incluyendo sus tipos, nombres y clasificación. Ese libro en alemán –que data...

Todos conocemos la función factorial de un entero y su simpática expresión con forma de exclamación (n!) que básicamente consiste en multiplicar todos los enteros entre 1 y el número en cuestión. El cálculo de factoriales suele producir valores enteros bastante...

Aunque los materiales sintéticos que se reparan aplicando calor no son una novedad, la característica por la que destaca este material desarrollado por investigadores de la universidad de Tokio es que se autorrepara a temperatura ambiente. Tanto si se ha producido...
Por Nacho Palou -
23 DIC 2017
Don Lincoln es un físico y divulgador que entre otras muchas cosas ha participado en el TED (Los ladrillos que componen el Cosmos) y TED-Ed (La materia oscura y la velocidad de las estrellas) y cuyos vídeos divulgativos aparecen habitualmente en...
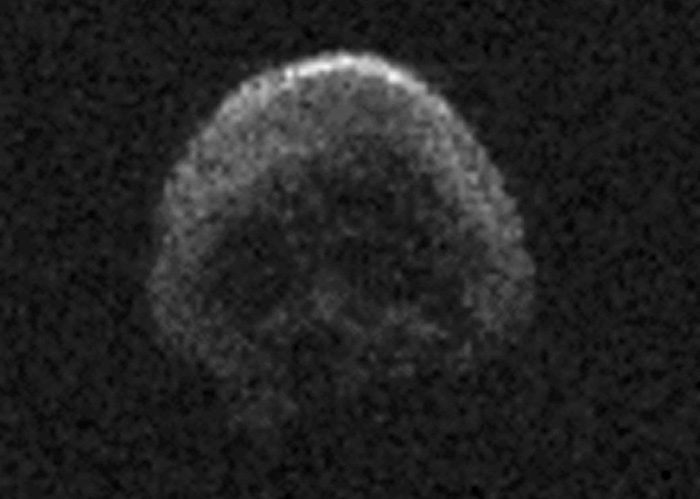
Ilustración del asteroide 2015 TB145 o “de Halloween”, que bajo determinadas condiciones de iluminación recuerda a una calavera. Imagen (cc) José Antonio Peñas / SINC. El asteroide 2015 TB145 se descubrió en 2015 y es conocido también como el “asteroide de Halloween”...
Por Nacho Palou -
22 DIC 2017

Impresión artística de los agujeros negros cuya fusión produjo esta segunda señal En un sistema binario la frecuencia de las ondas gravitacionales es el doble de la frecuencia a la que giran ambos objetos. Así que cuando Ligo ve una señal de...
La física cuántica es complicada, y la computación cuántica ya no veas. Por suerte para ayudar a entender algunas de las ideas y conceptos hay explicaciones tan interesantes y entretenidas como la de The Quantum Game (El juego cuántico). Se trata...

Suceden cosas raras cuando se meten uvas en el microondas, según vi por ahí. Así que me fui a esa fuente de sabiduría moderna llamada YouTube donde para mi sorpresa me encontré con un montón de vídeos de gente «haciendo pruebas»...

La cámara de guiado del observatorio Chandra de rayos X, formada básicamente por un telescopio Ritchey-Chrétien de 11,2 centímetros con un parasol de 2,5 metros de largo y 40 centímetros de diámetro, es tan precisa que si mirara un coche situado...

En Gizmodo, How Physicists Recycled WWII Ships and Artillery to Unlock the Mysteries of the Universe, A mediados de la década de los años de 1990 los físicos necesitaban toneladas de un metal lo suficientemente fuerte como para soportar los poderosos...
Por Nacho Palou -
19 DIC 2017

Antonio y Zerjillo se fueron en la madrugada del 14 de diciembre a la Carretera del Purche, en Sierra Nevada, con la idea de observar y fotografiar las Gemínidas, que en esa noche estaban próximas a su máximo previsto de actividad....

Al parecer hasta ahora no se entendía con precisión científica cuál era el proceso que fragmentaba y hacía explotar un meteoroide que entraba en la atmósfera terrestre. Se sabía que el fenómeno estaba relacionado y con el calor y la presión...
Por Nacho Palou -
18 DIC 2017
Si hace poco el Hubble ilustraba cómo queda una galaxia (NGC 4490) después de haber sido arrollada por otra galaxia en esta ocasión la imagen corresponde a NGC 5256, cuya extraña estructura se debe al hecho de que no es una...
Por Nacho Palou -
15 DIC 2017
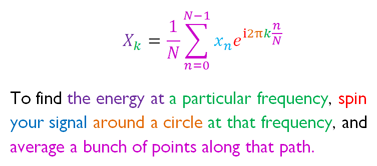
Kalid se topó con una vieja representación de una fórmula y le pareció una gran idea lo de las fórmulas coloreadas: asignar un color a cada término de una ecuación de modo que luego se puedan explicar en una frase –también...

Como todos los meses de diciembre la Tierra está atravesando la parte de su órbita en la que están los restos del asteroide (3200) Faetón, lo que provoca la lluvia de estrellas de las Gemínidas. La actividad de las Gemínidas suele...

Unos investigadores de la Universidad de Navarra han publicado un trabajo en el que analizan lo les sucede a 25.000 dados cuando se agitan al azar. El resultado es una ordenación bastante curiosa en forma de círculos concéntricos. Para que esto...

Aunque se parece mucho al comportamiento de los fluidos no newtonianos –esos que cuando les metes un guantazo se solidifican– el proceso que hace que la arena que llena este jacuzzi se comporte como un líquido es muy difernte. Se trata...

En pocos días termina la tercera misión de Paolo Nespoli, uno de los astronautas de la Agencia Espacial Europea, bautizada como VITA, de vitalidad, innovación, tecnología y habilidad (que en inglés no lleva hache); además en italiano significa vida, en referencia...
Ephemeris es un pequeño y precioso proyecto cuyo objetivo era representar en una sola imagen la posición real y la trayectoria de todas las sondas espaciales que hemos lanzado desde el planeta Tierra en 1962, cuando despegó la Mariner 2. Los...

En este vídeo de Veritasium, de hace algunos años, Derek Muller recorre —medidor de radiación en mano— algunos de los lugares conocidos en los que uno se expone a las mayores dosis de radiación ionizante. Entre los lugares evidentes: Chernóbil, Fukushima,...
Por Nacho Palou -
7 DIC 2017

Pi in the Sky es una amena y educativa revista sobre matemáticas del Pacific Institute for the Mathematical Sciences que puede leerse online al completo (en PDF). Está dirigida tanto a estudiantes de secundaria como a profesores, llena de temas interesantes...

En orden de menos a más tóxicas (aunque lo de «menos» es un poco relativo): Plomo (se dice que causó la caída del imperio romano) Tetrodotoxina (veneno del Pez globo) Arsénico (curiosamente presente en ciertas formas de vida) Estricnina (un pesticida...

The Conversartion cuenta en Turning hurricanes into music: Can listening to storms help us understand them better? el trabajo de investigadores, meteorólogos y músicos, que trabajan para sonificar las dinámicas de las tormentas. Esto es, para convertir en sonido o en...
Por Nacho Palou -
5 DIC 2017

Si estudias o trabajas en ciencia y te sientes capaz de contar lo que haces en tres minutos de tal forma que cualquiera pueda entenderlo anímate a apuntarte a la edición española de 2018 de Famelab. Ojo que el monólogo no...

El Mundo Lab publica hoy un especial multimedia tituado El mejor remedio para su salud en el que da un buen repaso a las pseudoterapias y a quienes las practican. El objetivo de este especial es hacer una advertencia sobre salud...

Esta pequeña maravilla se llama Brainfilling Curves: a Fractal Bestiary y es un libro de Jeffrey Ventrella sobre fractales, en especial las curvas que rellenan el el plano – una actividad muy escheriana. En Fractal Curves se puede ver la taxonomía...
Tras llevar a cabo un estudio sobre la efectividad de algunos tratamientos el National Health Service, el equivalente británico a la Seguridad Social, publicó un informe [PDF] en el que recomienda a sus médicos no recetar más tratamientos con homeopatía a sus...
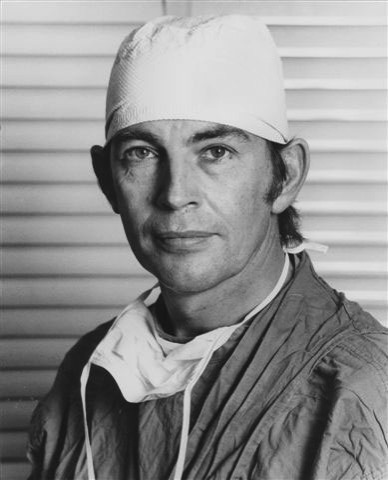
El 3 de diciembre de 1967 el cirujano Christiaan Barnard y su equipo llevaban a cabo el primer trasplante de corazón a un ser humano de la historia. El receptor, Louis Washkansky, sobrevivió 18 días a la operación hasta morir víctima de...

De un diario cualquiera de estos días: La madrugada del domingo (3 de diciembre) al lunes (4 de diciembre) aparecerá en el cielo la única superluna de 2017. Se trata de una luna llena en su perigeo, el punto más cercano...
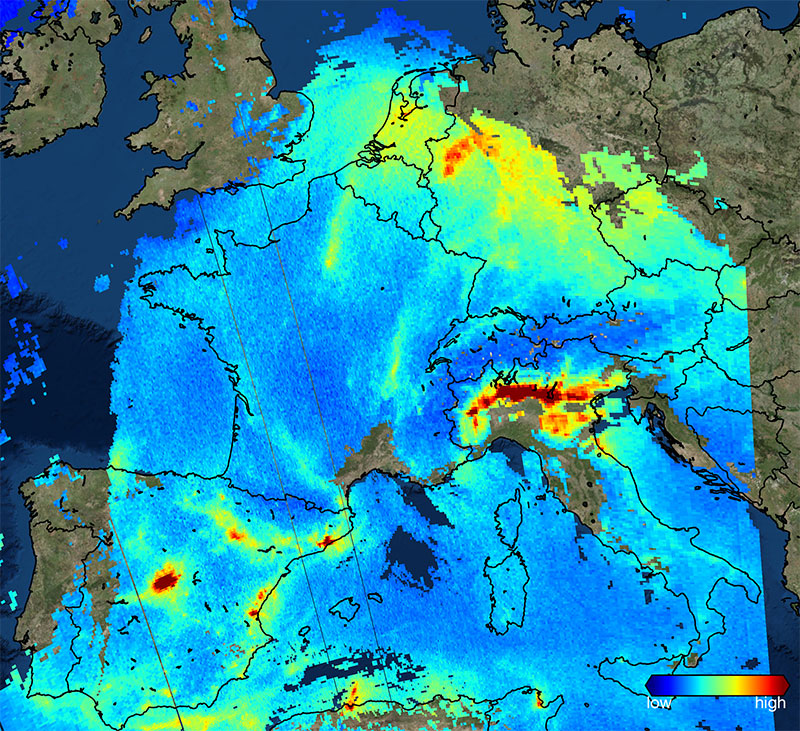
Aunque aún está en su fase de puesta en marcha la Agencia Espacial Europea ha presentado ya los primeros resultados obtenidos por el instrumento Tropomi del satélite medioambiental Sentinel 5P. Tropomi (TROPOspheric Monitoring Instrument) es un espectrómetro sensible a los rayos...

En biología celular las vesículas son unas estructuras de las células que almacenan, transportan o digieren productos y residuos. Ahora un equipo combinado de investigadores del MIT y otras universidades ha desarrollado una novedosa forma de analizar mediante ondas sonoras la...

En 2131 cuando llegó Rama estábamos preparados y el comandante Norton y su tripulación de la Endeavour fueron a explorarla. En 2017 cuando llegó ’Oumuamua nos pilló con el culo al aire y lo único que hemos podido hacer ha sido...
El equipo de Abel Méndez en el Planetary Habitability Laboratory de la Universidad de Puerto Rico han creado la Tabla periódica de los planetas extrasolares, que reúne los 3.700 reconocidos hasta ahora, aunque esta cifra depende de cómo los cuentes. Está...

En el montaje-videoclip The Nature of Sound - Symphony of Science algunos científicos y músicos famosos combinan sus voces para explicar lo que es la naturaleza del sonido y la música – y cómo las vibraciones que atraviesan el aire pueden...
Bassel El Mabsout tiene este curiosísimo artículo sobre los politopos regulares que son básicamente figuras geométricas con un alto grado de simetría. Estos objetos matemáticos pueden existir en diversas dimensiones. Una de sus características es que tengan caras planas; por eso...
El National Health Service –la seguridad social británica– pide a las personas que tengan fiebre alta, los ojos llorosos, irritados y enrojecidos, tos, dolor generalizado, y erupciones cutáneas rojizas-amarronadas que se queden en casa y llamen a su médico. Según la...
Robert Munafo es un apasionado de los grandes números, lo que algunos llaman un googlólogo (que proviene del término googol, uno de esos números descomunales inventados para hacer alucinar al personal). Por aquí hemos mencionado alguna vez alguno de sus ingeniosos problemas...

Nuestra admirada Vi Hart ha publicado este nuevo vídeo sobre construcción de hexaflexágonos explicando algunas de las formas de prepararlos, recortarlos e ilustrarlos. Sólo se necesita cartulina, tijeras y algo de pegamento. Dado que son unos objetos relativamente sencillos se pueden...

Cinco minutos bastan para metaculturizarse aprendiendo con un vídeo de Ted-Ed sobre el Efecto Dunning-Kruger, un curioso sesgo cognitivo que podría resumirse en que los individuos incompetentes tienden a sobreestimar sus propias habilidades. En terminología popular moderna podríamos llamarlo también el...

«No creo en la ciencia. Construiré un cohete para demostrarlo.» La ciencia no es un buffet libre donde puedes coger lo que te gusta y renegar de lo que no te interesa o cuando no te conviene. Por ejemplo, usar internet (¡ciencia!)...
Por Nacho Palou -
22 NOV 2017

Apenas un par de días antes del fin de su misión la sonda Cassini hizo 80 fotos con su cámara gran angular para componer con ellas un último retrato completo de Saturno, el planeta que se había convertido en su hogar....

La NASA ha completado otro paso más de cara al lanzamiento del telescopio espacial James Webb –ahora previsto ya para primavera de 2019– con la finalización de las pruebas de frío en la Cámara A del Centro Espacial Johnson. Y es...

Las líneas de ladera recurrentes son las bandas oscuras que se ven en esta imagen, cuya escala vertical está exagerada 1,5 veces - NASA/JPL/University of Arizona En septiembre de 2015 la NASA anunciaba que tenía datos para poder afirmar que las líneas...
’Oumuamua, el primer visitante interestelar en pasar por nuestro sistema solar del que tenemos constancia, viaja a 95.000 kilómetros por hora. Y para cuando lo detectamos y nos dimos cuenta de lo que era ya había pasado por el punto más...

Melissa McCracken tiene sinestesia, esa condición neurológica que hace que los sentidos funcionen entrelazados, de tal forma que, en su caso, escucha la música como colores. Dependiendo del género la ve de una forma u otra: La música expresiva como el...
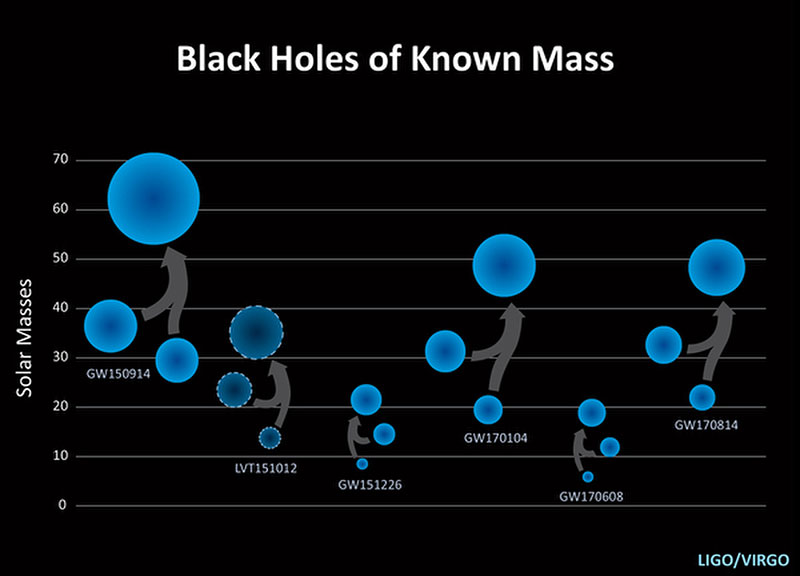
Según se puede leer en LIGO and Virgo announce the detection of a black hole binary merger from June 8, 2017 el detector de ondas gravitacionales LIGO detectó una nueva señal proveniente de la fusión de dos agujeros negros el 8...

Uno de los objetivos de la actual junta directiva de la sociación Española de Comunicación Científica, de la que soy miembro, era el de recuperar el Congreso de Comunicación Social de la Ciencia, cuya última edición fue la de Pamplona en 2010....

En este vídeo se pueden ver algunos experimentos para entender lo que sucede cuando se hace volar un dron en el interior de un coche. ¿Seguirá el dron el movimiento del coche? ¿Permanecerá estacionario? ¿Respecto al coche o respecto al suelo?...

El 14 de noviembre de 2017 Ollie Taylor estaba preparándose para hacer una foto nocturna en el paso Passo Falzarego, en los Dolomitas, cuando tuvo la enorme suerte de capturar el paso de un bólido que fue visto por un montón...

Administrad bien el planeta. Segundo aviso.– Ripple, Wolf y 15.370 científicos más de 184 países Estas son las 13 medidas para evitar el desastre climático que plantean 15.000 científicos, recogidas por CleanTechnica y procedentes de lo que se denominado, probablemente con...

Esta magnífica simulación que acaba de ver la luz en canal NASA Goddard muestra el estado de la atmósfera durante 2017. Más específicamente permite ver los huracanes y sobre todo los diferentes aerosoles: el agua marina pulverizada, el humo de los...

La Administración de Alimentos y Medicamentos, más conocida como FDA, el organismo estadounidense que se encarga, entre otras cosas, de la regulación de los medicamentos en el país, acaba de dar el visto bueno a la primera píldora capaz de avisar...

Un cúmulo de circunstancias desafortunadas y de malas decisiones destrozaron en órbita el telescopio espacial Hitomi apenas 38 días después de haber sido lanzado, cuando aún estaba en la fase de calibración de sus sistemas e instrumentos. Eso dio al traste con...

Tecnología para el sueño de la inmortalidad a partir de 01:03:00 Este verano me contactó por Twitter Martín Expósito de Los Crononautas. Conocía su trayectoria desde hace años, cuando empezó en La rosa de los vientos de Onda Cero Radio, donde tenía...

Con datos recibidos de la sonda Voyager 1, lanzada en 1977 y actualmente viajando a 17.043 km/h por el espacio interestelar –literalmente, más allá de donde Cristo dio las tres voces– Domenico Vicinanza y Genevieve Williams, de la Universidad Anglia Ruskin...
Lanzado el 25 de agosto de 2003 el telescopio espacial Spitzer aún mantiene uno de sus instrumentos en funcionamiento –los otros dos ya no funcionan al haberse agotado el helio líquido que los mantenía refrigerados, aunque duró más de lo previsto–...

Uniendo dos de los campos más curiosos de las matemáticas y la teoría de la información, los números primos y los autómatas celulares, este trabajo de tres científicos japoneses muestra cómo construir los generadores más pequeños posibles de números primos con...

Esto sería WTF si no fuera porque es pura ciencia. Unos científicos de Cambridge han entrenado a una oveja para reconocer la cara de Barack Obama (y también de Emma Watson) utilizando el método tan tradicional como viejo método de la...
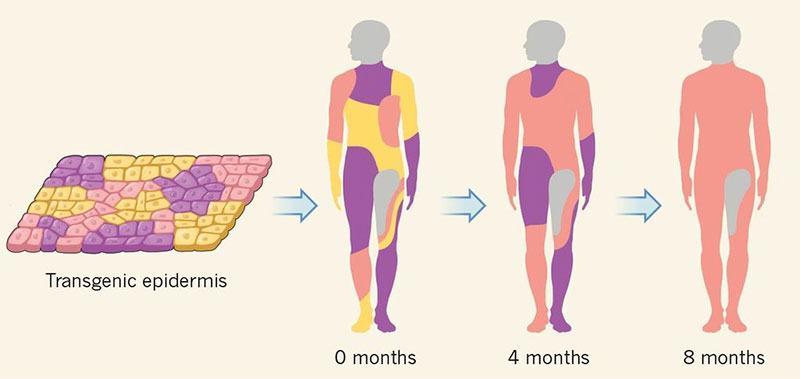
La terapia génica, que consiste en modificar el genoma de un individuo, en principio para repararlo, es polémica porque igual que para hacer el bien se podría utilizar para hacer el mal, aunque eso es algo común a cualquier herramienta. Sin...

Hace poco un artículo de Forbes hablaba del final del telescopio espacial Hubble, que si nadie lo remedia terminará incinerándose en la atmósfera en algún momento de los próximos 10, 15 o 20 años. Pero en realidad esto no tiene por...

Me ha encantado Rainbow on the Rings, una imagen de los anillos de Saturno capturada por nuestra añorada Cassini el 12 de junio de 2007. Se ve una especie de arcoiris en ellos… Aunque en realidad no estaba allí. O al...

Pepe Cervera escribía hace unos días acerca de Mary Somerville, una mujer extraordinaria que rompió con las convenciones de su época y a finales del siglo XVII y principios del XVIII se dedicó a las matemáticas, la física y la astronomía....

Esta cosa es la “concepción artística” de una enana marrón, un objeto que tiene más masa y es más caliente que los planetas más grandes y más calientes, pero cuya masa a la vez es insuficiente para hacer que se “encienda” como...
Por Nacho Palou -
8 NOV 2017

Los Museos Científicos Coruñeses, en los que trabajo en el MundoReal™, y el Círculo escéptico han organizado el Mes escéptico 2017, un ciclo de conferencias en el que se intenta aportar un punto de vista crítico sobre diferentes temas de actualidad abordados...

La ciencia es bella y es por esa belleza que debemos trabajar en ella, y quizás, algún día, un descubrimiento científico como el radio, puede ser un descubrimiento que beneficie a toda la humanidad.– Marie CurieDiscurso de aceptación del Premio Nobel...

Me ha parecido muy interesante lo que plantea Reshma Saujani en esta charla (hay subtítulos en castellano) acerca del motivo por el que las mujeres «huyen» de las carreras relacionadas con la ciencia, tecnología, ingeniería o matemáticas. Según ella, y en...

Espejos principales - Giant Magellan Telescope Organization Con siete espejos de 8,4 metros de diámetro que actuarán como un único espejo de 24,5 metros el Gran Telescopio Magallanes es uno de los mayores telescopios terrestres en construcción. Pero por supuesto fabricar esos...
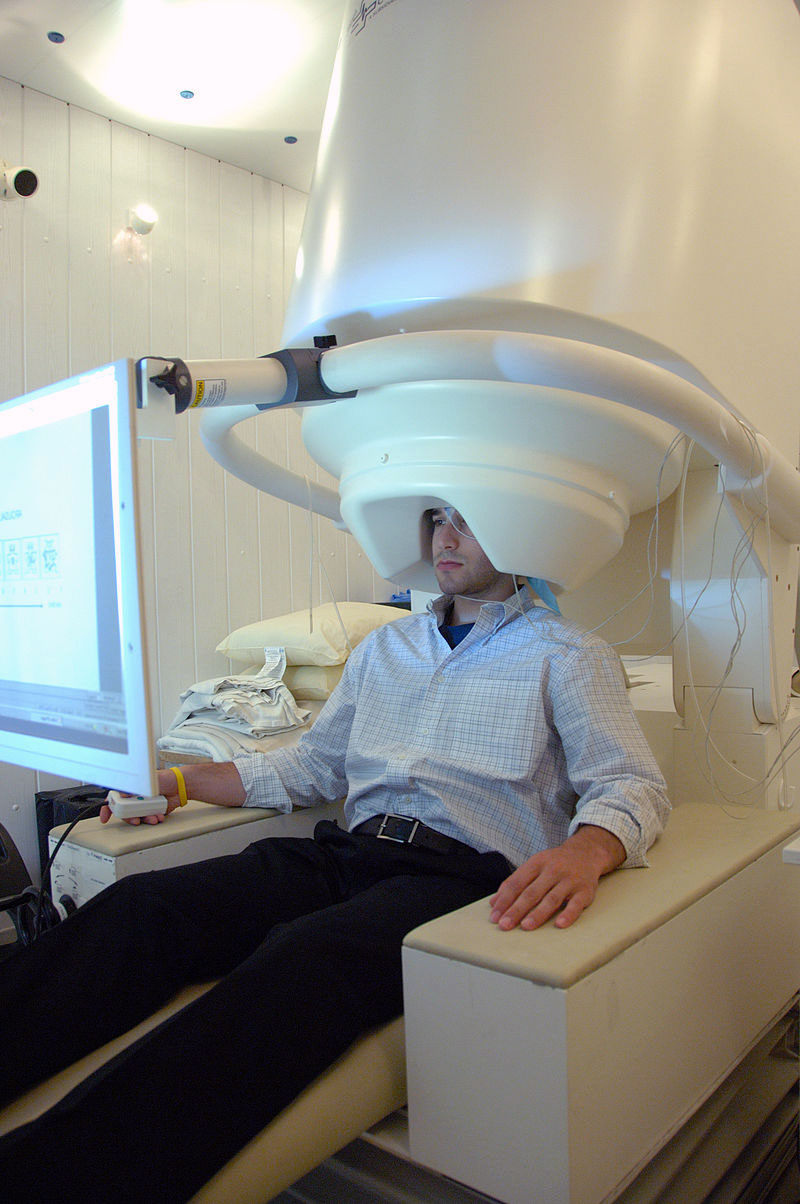
El electroencefalograma (EEG) es una herramienta muy utilizada por los neurólogos para el diagnóstico de la epilepsia y otro tipo de procesos que alteran el funcionamiento normal del cerebro. Pero tiene el problema de que las señales eléctricas que recoge han de...
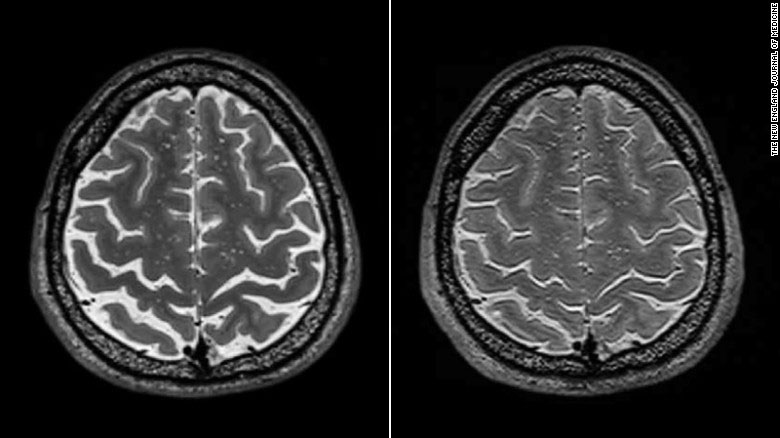
Aunque parece un poco contraintuitivo un estudio con 34 astronautas indica que estar en caída libre comprime su cerebro, tal y como se puede leer en Effects of Spaceflight on Astronaut Brain Structure as Indicated on MRI [PDF]. La causa principal...
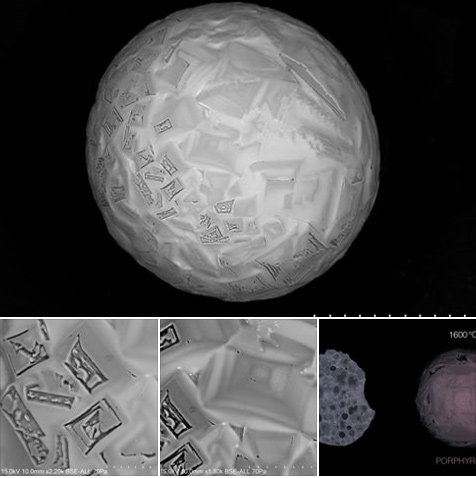
El Project Stardust de Jon Larsen es una ingente colección de micrometeoritos. Su tamaño varía entre la fracción de milímetro y los dos milímetros y quiere incorporar en ella los micrometeoritos recolectados por una red de voluntarios a escala mundial. A...
Por Nacho Palou -
6 NOV 2017

Una de las iniciativas del programa Horizonte 2020 de la Unión Europea es la creación de la European Open Science Cloud, la Nube Europea de Ciencia Abierta. Sus principios se pueden leer en la EOSC Declaration [PDF] pero básicamente se resumen en...

Las buenas noticias: según la NASA el agujero de la capa de ozono alcanzó su máxima extensión anual el pasado 11 de septiembre, quedándose en algo menos de 20 millones de kilómetros cuadrados — unas dos veces el tamaño el continente...
Por Nacho Palou -
6 NOV 2017

Este pequeño vídeo de TED-Ed explica algunas curiosidades sobre los símbolos matemáticos, algo que usamos todos los días y que conocemos desde pequeñitos y que surgieron hace siglos de la necesidad de abreviar explicaciones demasiado largas. Uno de los primeros símbolos...
Uno de los problemas que más preocupan a los médicos de todo el mundo es la resistencia a los antibióticos que están desarrollando las bacterias. Esto, unido a que hace literalmente décadas que no descubrimos nuevos antibióticos, hace que en la...

Está haciendo las rondas esta imagen, que es de una captura de pantalla del boletín semanal del 3 de octubre [PDF] del sistema de vigilancia sobre sarampión y rubeola que funciona en Italia bajo los auspicios del Centro nacional para la prevención...

La insuficiencia cardíaca sucede cuando el corazón no es capaz de bombear la cantidad de sangre que necesita el cuerpo. Para compensarlo el corazón hace un esfuerzo mayor, crece en tamaño y bombea con más fuerza aumentando la presión. Pero esto...
Por Nacho Palou -
2 NOV 2017

Este trabajo de @Flerlagekr titulado simplemente The Beauty of π es una colección de visualizaciones geométricas y coloridas con el número π como inspiración. Haciendo clic sobre ellas (bajo el título) se van cargando y mostrando en todo su esplendor –...
El último estudio del gobierno portugués acerca de la inmunidad de la población frente a ciertas enfermedades, Inquérito Serológico Nacional (ISN) 2015-2016, ha desvelado que la inmunidad al sarampión está por debajo del 95%. Esta es una mala noticia porque el...

Me ha parecido curioso lo que cuenta la Agencia Espacial Europea en AMT4SentinelFRM: comparing measurements with measurements acerca de cómo se calibran los resultados obtenidos por los instrumentos que van a bordo del satélite medioambiental Sentinel 3. El Sentinel 3 está...

Los clavos dorados, golden spike en inglés –aunque no tienen que ser de oro ni en forma de clavo– son unos indicadores que marcan una sección estratotipo y punto de límite global, o GSSP en inglés. Las GSSP son secciones estratigráficas...

La caja de Lego bautizada como Women of NASA, nacida de una propuesta de 20tauri, sale a la venta el 1 de noviembre de 2017, y tiene pinta de ser de esas que se agotan en cero coma nada, así que...

El pasado 25 de febrero se celebraba en el teatro Rosalía Castro de A Coruña la jornada Naukas Coruña 2017 – la vida, el universo y todo lo demás, organizada por el Ayuntamiento de A Coruña y Naukas con la colaboración de...

Si alguna vez la expresión «adelantado a su tiempo» se pudo aplicar a alguien es a nuestro admirado Nikola Tesla, genio asombroso, visionario e inteligente como pocos que fue sin embargo un personaje misterioso y oscuro, controvertido e incapaz de obtener...

El gobierno de Australia, dentro de una revisión que está haciendo del funcionamiento del sistema de seguros privados de salud, acaba de anunciar que desde el 1 de abril de 2019 las aseguradoras no podrán incluir dentro de su cobertura [PDF]...

Una de las preguntas que más a menudo recibe Brainac75 –un aficionado a la ciencia danés– en su canal dedicado a los imanes es cuánto afecta la fuerza magnética de los imanes al hierro que tenemos en la sangre. A la...

Al igual que el otoño pasado, está circulando de nuevo el curioso vídeo de Nicholas Port (de profesión trapecista) en el que a cámara lenta se puede comprobar experimentalmente cómo actúa la inercia sobre las hojas secas caídas sobre una red...

Este compendio astronómico que guarda el Museo Británico tiene el aspecto y tamaño de lo que podría pasar por un auténtico smartphone del pasado – y aunque no servía para hablar un mandar tuits ni mensajes por WhatsApp sí que incluía...

Una idea tan simple como resultona: un reloj de los elementos químicos, en el que las horas se han sustituido por los elementos cuyo peso atómico es equivalente al número de deben representar (tanto en versión 12 horas como su extensión...

En Minute Physics han dedicado un vídeo a clasificar y desgranar los diferentes tipos de viajes en el tiempo que se suelen dar en la ficción, no tanto desde el punto de vista técnico de la física o las máquinas que...

Estas psicodélicas y coloridas gafas de cartón pueden parecer un poco pasadas de moda, pero su utilidad va más allá de la parte estética: con sólo hacerse un selfie permiten detectar la ictericia o «exceso de bilirrubina» en la sangre, algo...

Muchas veces los grandes conceptos matemáticos se explican mejor con rompecabezas; encontrar la solución lleva a desarrollar herramientas, fórmulas o métodos de razonamiento que luego sirven para aplicar en otras áreas. Este problema de los clavos y la cuerda es un...

He aquí un hecho curioso de la teoría de números; algo aparentemente trivial y con título autoexplicativo: todo número natural es la suma de 49 números capicúas. (Incluyendo el 0). [Actualización: ver la nota final.] Pero demostrarlo no es tan trivial...
En este delicioso episodio de Sixty Symbols la astrofísica Becky Smethurst utiliza el alfabeto de luces de la pared de Stranger Things para elucubrar una teoría física alocada acerca de si podría ser posible transmitir mensajes entre dos universos mediante un...
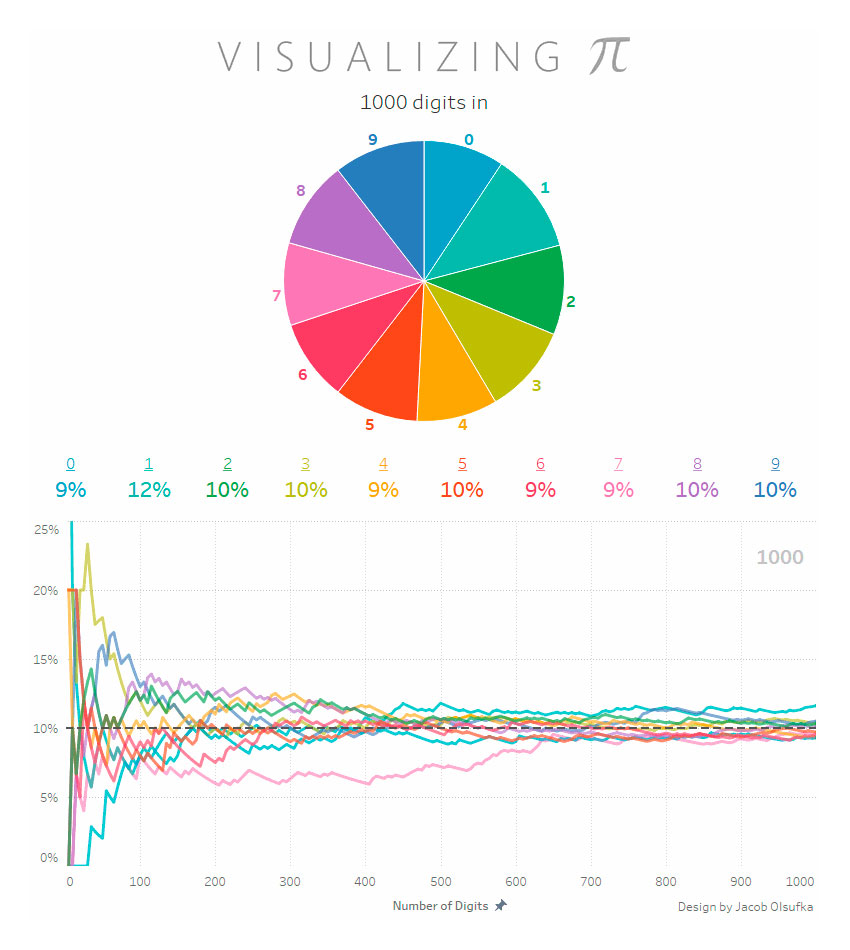
Visualizing π [clic y esperar para ver el GIF en movimiento] es una animación de Jacob Olsufka donde se muestra de forma gráfica la convergencia de los dígitos de π hacia una distribución uniforme a medida que se desarrollan sus primeros...

Cliff Stoll enfrentó a varias decenas de alumnos a este curioso problema: les entregó una hoja de papel y una regla y les pidió que calcularan su área –en unidades del sistema métrico– y explicaran cómo lo habían hecho. Ni uno...

Todos hemos jugado al tres en raya alguna vez. De hecho es durante una temporada uno de los juegos favoritos de los más pequeños, al menos hasta que se dan cuenta que cuando se aprende cierta estrategia es un juego que...

Simplemente no puedo dejar de observar si pienso que uno nunca sabe cuando la naturaleza nos mostrará algo sorprendente.– Hisako Koyama. La historia de Hisako Koyama es cuando menos sorprendente porque tenía todos los boletos para haber sido una abnegada mujer japonesa más...

Según investigadores del instituto Max Planck y de la universidad Uppsala, en Suecia, el temor (que llega a convertirse en aversión o pánico) a las arañas o las serpientes es algo innato y no algo que se adquiere o aprende: “Hasta...
Por Nacho Palou -
23 OCT 2017

La Tierra está pasando por la parte de su órbita que atraviesa los restos dejados atrás por el cometa Halley, con lo que estamos en la época del año en la que se puede ver la lluvia de estrellas de las...
El dibujo de Juan Valderrama que documentó una llamarada solar de luz blanca en 1886. Aunque hasta ahora habían pasado desapercibida, las observaciones realizadas por Juan Valderrama y Aguilar en 1886, desde Madrid, documentaron hace más de un siglo una inusual llamarada...
Por Nacho Palou -
20 OCT 2017

Envisioning Chemistry es un proyecto de Beauty of Science y la Sociedad química china que tiene dos objetivos principales: por un lado, hacer vídeos sobre reacciones químicas para dejar alucinada a la gente; por otro servir como recurso a los profesores...

El depósito de combustible de un cohete Delta 2 convertido en 250 kg de basura espacial que cayó en 1997 en algún lugar del estado de Texas. Hace no mucho comentábamos por aquí que según Heiner Klinkrad, director de la Space Debris...
Por Nacho Palou -
20 OCT 2017

Por fin se ha confirmado lo que adelantaba Craig T. Wheeler en un «inocente» tuit hace unos meses: telescopios de todo el mundo –y algunos en el espacio– han podido observar por primera vez en todo el espectro electromagnético –incluyendo la...

Haumea, o más correctamente (136108) Haumea, es un planeta enano que se encuentra más allá de la órbita de Neptuno, en el cinturón de Kuiper. También sabemos que tiene dos lunas, Hiʻiaka y Namaka, y que su órbita alrededor del Sol...

Cada día el calor del sol evapora grandes cantidades de agua en embalses y lagos, incluso en campos de cultivo, un fenómeno natural difícil de evitar. Sin embargo, según investigadores de la universidad de Columbia, la evaporación de agua puede proporcionar...
Por Nacho Palou -
10 OCT 2017
Un trabajo de biólogos moleculares de la Universidad Autónoma de Madrid (UAM) publicado en Neurobiology of Disease revela la presencia de distintos tipos de hongos en varias partes del sistema nervioso central de pacientes diagnosticados con esclerosis lateral amiotrófica. En concreto el...

Pulsa en la imagen para verla completa. Lifesaving Innovations (vía HumanProgress.org) es un gráfico de Medigo que muestra visualmente el número de vidas que han salvado diferentes innovaciones a lo largo de los últimos años. En la agricultura, la medicina, la nutrición,...
Por Nacho Palou -
9 OCT 2017
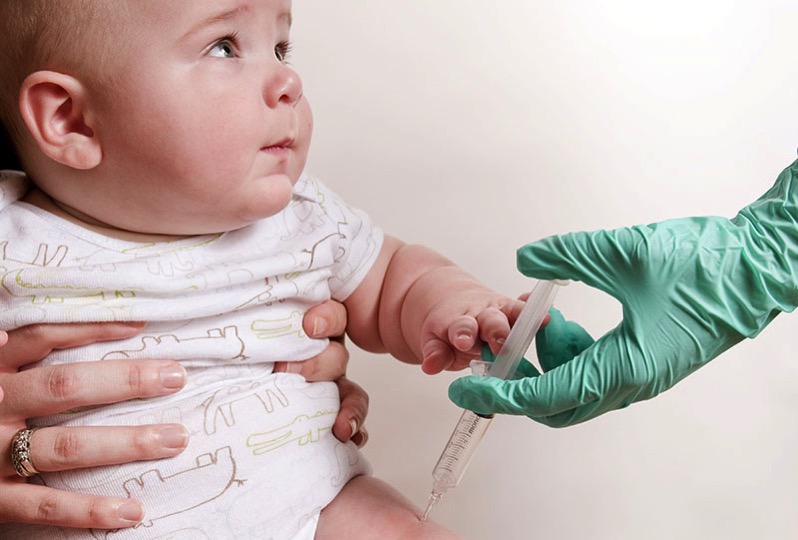
El Ministerio de Salud de Nueva Zelanda acaba de anunciar que el sarampión y la rubeola han sido oficialmente eliminados del país. Es un resultado avalado por la Organización Mundial de la Salud. Esto quiere decir que no se han originado...

A veces vas a hacer un cocido y te sale una fabada, es lo que tiene la ciencia.– Francis Mojica. En los últimos años se ha hablado mucho de Michelle Charpentier y Jennifer Doudna como creadoras del método de edición de ADN conocido...
La Agencia Espacial Europea está haciendo las últimas comprobaciones de la Solar Orbiter, la sonda que tiene previsto enviar rumbo al Sol en octubre de 2018. El objetivo de la misión es estudiar cómo el Sol genera y «controla» la heliosfera,...

En una decisión que no sorprende aproximadamente a nadie el premio Nobel de física 2017 ha sido otorgado a Rainer Weiss, Barry C. Barish y a Kip S. Thorne por «sus contribuciones decisivas al detector LIGO y la observación de ondas gravitacionales»....

La junta estatal que concede los permisos de construcción en Hawaii ha aprobado por 5 votos a favor y 2 en contra conceder el permiso para construir el Thirty Meter Telescope en el Mauna Kea, permiso que había sido suspendido por...

Hubble Focus: Our Amazing Solar System es un nuevo libro publicado por el equipo del telescopio espacial Hubble. Incluye una impresionante colección de imágenes de alta resolución y videos interactivos obtenidos por el telescopio espacial y otras sondas, con capítulos que cubren...
El EASAC, el Comité Científico Asesor de las Academias Europeas, formado por las academias de ciencias nacionales de los países miembros de la Unión Europea, acaba de publicar el informe Homeopathic products and practices: assessing the evidence and ensuring consistency in regulating...
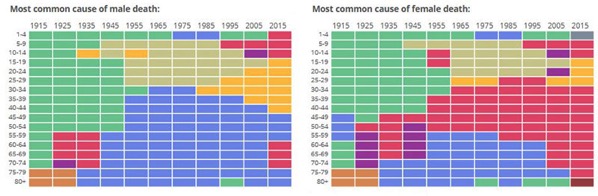
La Office for National Statistics, que es la versión británica del Instituto Nacional de Estadística, acaba de publicar un interactivo titulado Causes of death over 100 years que recoge las causas principales de muerte década a década de 1915 a 2015....

Lanzada el 8 de septiembre de 2016 la sonda Osiris-REx de la NASA tiene como objetivo tomar muestras del asteroide Bennu y traerlas de vuelta a la Tierra para 2023. Pero para poder alcanzar a Bennu sin tener que sacrificar peso...

La Antártida es el desierto más grande del planeta: prácticamente no llueve nunca, está despoblado y apenas alberga vida vegetal o animal. La ausencia de vida vegetal o animal significa que a los científicos que pasan largas temporadas allí hay que...
Por Nacho Palou -
22 SEP 2017

Este problema matemático sobre cómo repartir algo «con justicia» se refiere a las particiones equitativas de una tarta, pero puede aplicarse a muchas otras situaciones. Tiene un poco de teoría de juegos, un poco de lógica y un poco de matemáticas...

En los últimos días se está hablando de Link Space, una empresa china que pretende desarrollar un cohete para lanzamientos orbitales con una primera etapa reutilizable, al estilo de SpaceX, aunque con unas capacidades y dimensiones menos ambiciosas. El New Line...

Se nos habían despistado un poco los IgNobel 2017, esos premios que reconocen aquellos avances científicos que parecen broma pero que no lo son. Los ganadores de este año han sido: Física: Marc-Antoine Fardin, por utilizar la dinámica de fluidos para investigar...

Un asteroide híbrido llamado 288P es el primer y por ahora único caso conocido que combina dos tipos de asteroides poco comunes: asteroides binarios (en el cual dos asteroides orbitan el uno con el otro) y asteroides con actividad y características...
Por Nacho Palou -
21 SEP 2017

Me ha parecido muy interesante el artículo Your mind will never be uploaded to a computer del filófofo Jesús Zamora Bonilla en el que aborda la idea tan popular en la ciencia ficción y entre algunos iluminados de que en el futuro...

Este vídeo de Amber L. Stuver en TED-Ed es una explicación sencilla y comprensible, aunque en inglés (con subtítulos), de qué son las ondas gravitacionales. Aunque no es el primer vídeo que trata de dar un explicación accesible este en mi...
Por Nacho Palou -
19 SEP 2017

Dianna de Physics Girl lleva a cabo este pequeño experimento de microgravedad que implica caída libre, fuego, y una GoPro. La finalidad es dar respuesta a la pregunta de ¿qué sucede si se deja caer una vela encendida dentro de una...
Por Nacho Palou -
19 SEP 2017

El FAST, de Telescopio esférico de quinientos metros de apertura, situado en un apartado lugar de la provincia china de Guizhou, es el radiotelescopio de una sola antena más grande del mundo, puesto que ha quitado al de Arecibo. Sólo le...

Acabamos de decir adiós a la sonda Cassini. Pero apenas cuatro día antes la sonda New Horizons salía de cinco meses de hibernación para iniciar una campaña de observación en el cinturón de Kuiper que durará hasta diciembre. Durante esta campaña...

El principal legado de la misión Cassini/Huygens son los 653 GB de datos que ha transmitido a la Tierra durante los trece años de su misión. De ellos han salido ya 3.948 artículos científicos, aunque con toda seguridad en los próximos años...

Cuando un objeto sólido avanza por un líquido el arrastre, las fuerzas hidrodinámicas, se oponen a su avance ejerciendo una fuerza opuesta a la dirección del objeto. Es por este efecto que el agua detiene una bala. Ahora investigadores de la...
Por Nacho Palou -
14 SEP 2017

Aunque por lo general se piensa en Cassini/Huygens como una misión a Saturno en realidad las lunas del planeta también formaban una parte muy importante de la misión, como deja bien claro la existencia de Huygens, el aterrizador que dejamos en...

El 25 de diciembre de 2004, tras viajar hasta Saturno a lomos de la sonda Cassini, la sonda Huygens se separaba de ella para emprender la última parte de su viaje de siete años rumbo a Titán. Y así, después de...
El 11 de septiembre de 2017 el telescopio espacial Hubble completaba su órbita 150.000 desde su lanzamiento el 25 de abril de 1990 y el próximo 27 de septiembre de 2017 cumplirá su día número 10.000 en órbita. Aproximadamente un 60%...

Este dispositivo del tamaño de un llavero, todavía en fase de prototipo, es capaz de detectar a analizar muestras de alimentos y detectar la presencia de cinco tipos de alérgenos. El proceso de análisis tarda algo menos de diez minutos en...
Por Nacho Palou -
11 SEP 2017

Cassini Mission Overview es un resumen de la misión de la sonda Cassini que te puedes descargar para imprimir como póster que incluye los datos fundamentales de ésta, a la que le queda menos de una semana. En él se pueden...

Desde el CSIC nos enviaron muy amablemente un ejemplar de Mecánica cuántica (2015), un libro del profesor Salvador Miret-Artés acerca del mundo subyacente que forma nuestro universo. Cubre desde cuestiones acerca de partículas, ondas y campos hasta las mediciones y la...

Respuesta corta: mueres. La respuesta más larga la dan en el vídeo What Happens If We Bring the Sun to Earth?, con subtítulos en español. Y como la ciencia a veces es gallega la respuesta larga de lo que sucedería tiene mucho...
Por Nacho Palou -
8 SEP 2017

Las ondas sobre la superficie del agua son un buen ejemplo de combinación de movimiento transversal y longitudinal. Cada una de las partículas se mueve en círculos, tal y como puede verse en la animación. El radio de esos círculos disminuye...
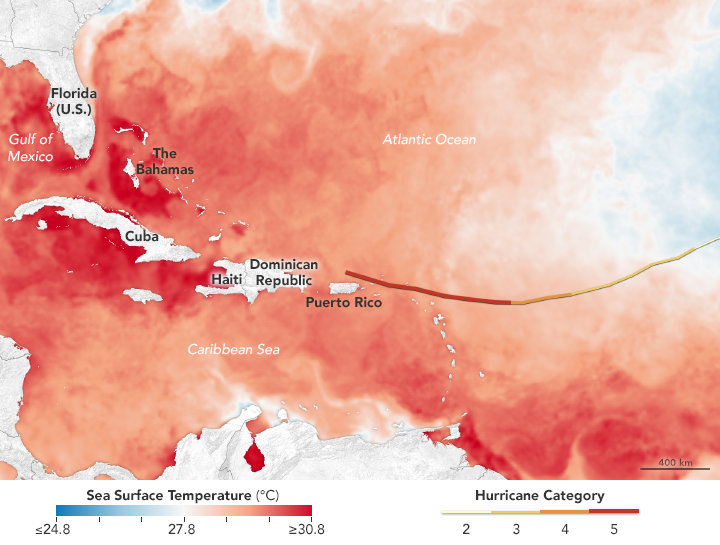
El mapa muestra las temperaturas de la superficie del mar en el Océano Atlántico, el Mar Caribe y el Golfo de México el pasado 5 de septiembre de 2017. Los datos fueron obtenidos desde los satélites Suomi NPP, MTSAT, Meteosat y...
Por Nacho Palou -
8 SEP 2017

Si tienes un máster o doctorado, o experiencia equivalente relevante en el campo de las Artes (Clásico, Contemporáneo, Moderno), Historia del Arte, Arte y Diseño, Multimedia, o equivalente y dominas el inglés hablado y escrito y tienes o estás dispuesto a...
La medicina científica no lo cura todo. La medicina alternativa no cura nada.– Luis Alfonso Gámez El recién publicado estudio Use of Alternative Medicine for Cancer and Its Impact on Survival analiza el riesgo de muerte para pacientes con cáncer de...

Organizado por la Escuela de Máster y Doctorado el Concurso Científico-Literario de la Universidad de La Rioja, dirigido a estudiantes de 3º y 4º de ESO y de Bachillerato, estuvo basado en su cuarta edición en la novela Relámpagos de Juan Echenoz,...
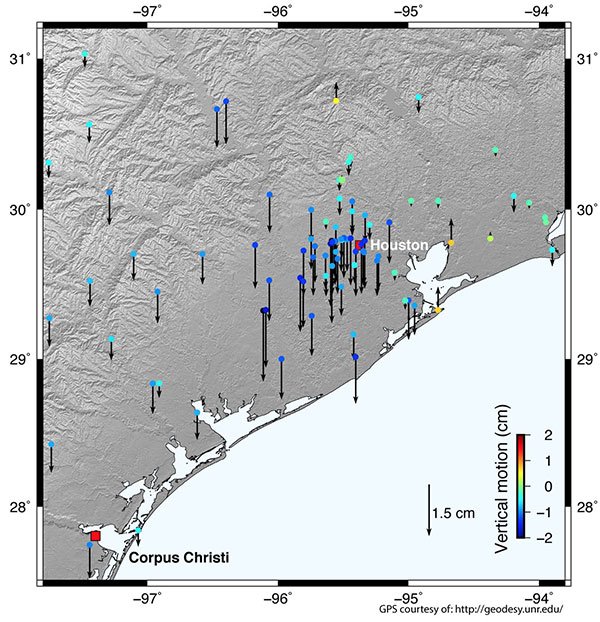
Chris Milliner, un científico que estudia los terremotos en el Jet Propulsion Laboratory de la NASA mostró en Twitter estos datos de GPS sobre el área de Houston. Las flechas indican desplazamiento en la altitud de cada punto. Los datos proceden...

El Gran Colisionador de Hadrones es uno de los instrumentos más complejos que hayamos construido jamás, sino el más complejo. Y aunque en la actualidad funciona a la perfección ya hace algún tiempo que están en marcha los planes para hacerlo...

Tal y como estaba previsto el asteroide (3122) Florence paso «rozándonos» sin ningún tipo de consecuencias a siete millones de kilómetros el 1 de septiembre de 2017. Los astrónomos aprovecharon la oportunidad para estudiarlo, en especial usando observaciones mediante radar que han...

Esta mañana hacia las 11.30 hora peninsular (09.30 GMT) se han detectado dos llamaradas solares significativas. Una de ellas la han clasificado X2,2 y la otra, que alcanzó máximos tres horas después, como X9,3. La llamarada X9,3 es la más potente...
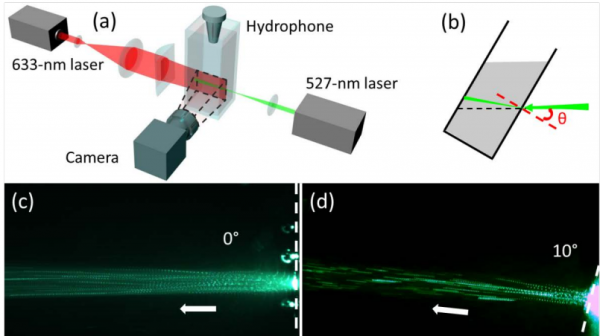
En MIT Technology Review, Engineers Turn a Laser Beam into a Stream of Liquid Jiming Bao de la Universidad de Houston en Texas y sus colegas de laboratorio aseguran haber descubierto un proceso completamente nuevo de optofluídica que hace posible utilizar...
Por Nacho Palou -
6 SEP 2017
![imagen]()
A eso de las 14:00 del 1 de septiembre de 2017, hora peninsular española, el asteroide (3122) Florence se acercará a la Tierra más de lo que lo ha hecho desde 1890 y más de lo que lo hará hasta más...
Uno de los trucos –el principal, diría yo– que usa el cáncer para hacernos tanto daño es que engaña a nuestro sistema inmune, que permanece impasible frente a la presencia de todas esas células chungas a la que debería estar atacando...

Entre 1885 y 1927 el Observatorio del Harvard College empleó a un buen número de mujeres, a las que se les conoce como las computadoras de Harvard cuyo trabajo era estudiar las placas de vidrio en las que se tomaban las...

A Cassini-Huygens, la misión conjunta de la Agencia Espacial Europea y la NASA a Saturno le quedan poco más de dos semanas de vida, pues está previsto que termine el 15 de septiembre de 2017 a las 12:44 hora peninsular española....

En Texas están sufriendo los efectos del huracán Harvey, aunque afortunadamente ha bajado a categoría 1 tras tocar tierra. Pero los meteorólogos han advertido en varias ocasiones que no es tanto el viento como la cantidad de agua que trae consigo...

Space Odyssey es el atractivo y apropiado nombre para un videojuego que buscaba πK dólares en Kickstarter (314.159 exactamente) y ya ha superado los 350.000 para su producción. Demostrando una vez más que la financiación colectiva funciona más que bien en...

Ya tiene algún tiempo, pero no había visto The Science of Awkwardness de Vsauce, un vídeo que trata de lo que sabe la ciencia sobre el arte de sentirse socialmente incómodo. Olvidarte del nombre de alguien (o en mi caso incluso...

Vi pasar por Twitter este vídeo de Neil deGrasse Tyson haciendo girar un peculiar artefacto de esos que «parece desafiar las leyes de la física». Buscando por ahí encontré que se llama peonza celta y un vídeo del entrañable Tim de...

En la zona de Altafulla y Torredembarra, en la Costa Dorada de Tarragona, un equipo de naturalistas y buceadores ha instalado biotopos marinos: unas pequeñas estructuras artificiales que sirven como «hogar» para algas, esponjas, invertebrados como las medusas y todo tipo...

El astrónomo J. Craig Wheeler de la Universidad de Texas en Austin la lió un tanto parda hace unos días con un tuit. En él viene a decir que el detector de ondas gravitacionales LIGO ha detectado una nueva señal pero que...

Con motivo del eclipse solar de hace un par de días Google organizó la Eclipse Megamovie 2017, una grabación en alta resolución del fenómeno que va acompañada de imágenes tomadas por los voluntarios que se apuntaron al proyecto. Por supuesto que...
Por Nacho Palou -
23 AGO 2017

Un nanosegundo luz es una unidad de distancia, aunque con una particularidad: utiliza una unidad de tiempo muy pequeña (el nanosegundo) multiplicada por una velocidad muy grande en términos humanos (la de la luz). En este sentido es similar al año...

El 30 de junio de 1973 se produjo un eclipse total de Sol que alcanzó su máximo en el área de Agadez, en Níger. Allí el máximo del eclipse alcanzó los 7 minutos y 4 segundos, tan sólo 283 segundos menos...
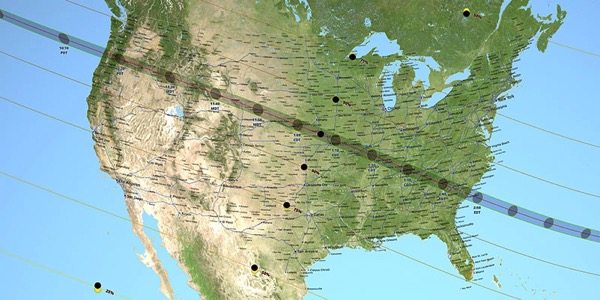
Entre las 17:46:48 y las 23:04:19, hora peninsular española, de hoy, 21 de agosto de 2017, se produce un eclipse total de Sol que atraviesa los Estados Unidos de costa a cosa. Aparte del espectáculo natural que supone es una magnífica...

El profesor Cliff Stoll explica en este vídeo de Numberphile la solución a un problema clásico: calcular en qué momentos exactos se solapan las manecillas de un reloj al cabo de una vuelta completa a partir de las 12:00. A las...

Aunque el mejor sitio para ver el eclipse de Sol del 21 de agosto de 2017 es sin lugar a dudas la parte continental de los Estados Unidos en el noroeste de Europa también podremos disfrutarlo durante un rato durante la...
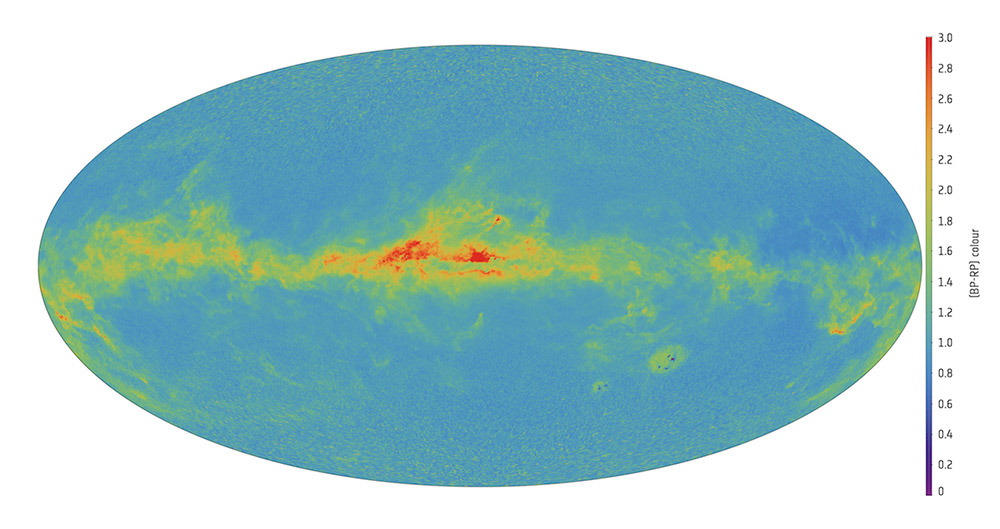
Mapa preliminar del cieloImagen: ESA/Gaia/DPAC/CU5/CU8/DPCIF. De Angeli, D.W. Evans, M. Riello, M. Fouesneau, R. Andrae, C.A.L. Bailer-Jones Estos días se ha dado a conocer un adelanto con la publicación de la versión preliminar del mapa del cielo con millones de estrellas que...

En otro paso más en la pelea porque la homeopatía ocupe el lugar que le corresponde la Comisión Federal de Comercio de los Estados Unidos ha decidido que los productos homeopáticos tienen que decir claramente en el envase que no funcionan....

Este precioso minirreportaje de Emic Films y Fabián Tejada cuenta la historia de Wanda Díaz-Merced, una astrofísica de Puerto Rico que estudia los misterios del universo simplemente escuchándolo. Todo esto aderezado con maravillas imágenes del cosmos y del radiotelescopio de Arecibo...
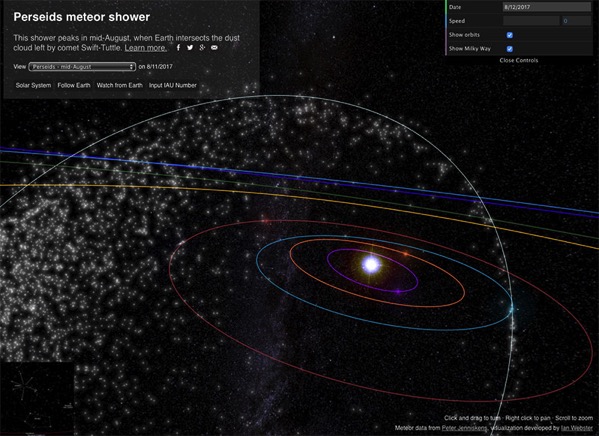
Me ha encantado Meteor showers, un sitio web que permite explorar las lluvias de estrellas reconocidas por la Unión Astronómica Internacional, que son en total 112. Ofrece una vista general del sistema solar que se puede mover haciendo clic y moviendo...
Como todos los años por estas fechas la Tierra está recorriendo la parte de su órbita que se cruza con los restos del cometa Swift/Tuttle. Cuando estas partículas se precipitan en la atmósfera a miles de kilómetros por hora se convierten...
Unicodeit.net es una útil herramienta para todos aquellos que tengan que bregar con expresiones matemáticas en documentos de todo tipo. LaTeX es la herramienta más popular para editar documentación de tipo técnico y científico. Y Unicode el estándar de codificación de...

Rod Bogart hizo esta fotografía desde la planta 26 del edificio Grace y construyó con ella un diagrama de Voronoi de gente en el Byrant Park. Los diagramas de Voronoi son una partición del plano en regiones según la distancia euclidiana...

En este vídeo con toques viejunos un joven Richard Dawkins explica en un programa de televisión paso a paso la evolución del ojo, uno de nuestros órganos sensoriales más importantes. Es sin duda uno de sus ejemplos favoritos, tratado en muchos...

Este instructivo vídeo de TED explica cuándo es seguro beber agua (aunque no de una forma tan práctica como cabría esperarse). En cualquier caso es más interesante como recurso sobre cómo funciona la potabilización del agua a escala industrial e incluye...

El 20 de febrero de 1824 William Buckland publicó los primeros datos acerca del Megalosaurus, un animal carnívoro de gran tamaño del que tenía parte de una mandíbula inferior, algunas vértebras, fragmentos de una pelvis, una escápula y de sus miembros...

A las 20:20:27 del 7 de agosto de 2017, hora peninsular española, se produce el máximo del segundo y último eclipse de Luna del año, que en este caso es parcial, ya que la Tierra no la llega a tapar por completo....

Riding dirty... getting wiser. See the top discoveries in the time it took to get so dusty. Five years on Mars: https://t.co/Ift2BPekDg pic.twitter.com/XXKbOsCFpH— Curiosity Rover (@MarsCuriosity) 4 de agosto de 2017 En sus cinco años en Marte desde que aterrizara allí el...

Temperature anomalies arranged by country 1900 - 2016. #dataviz #climate #climatechange #globalwarming Download: https://t.co/JnaU0tKDlc pic.twitter.com/w3yjmddpOe— Antti Lipponen (@anttilip) 1 de agosto de 2017 Usando datos de la NASA, Antti Lipponen ha creado este gráfico en el que se ve año a año...

La NASA ha montado un par de telescopios especiales en dos reactores para «perseguir» el eclipse que será visible en norteamérica el 21 de agosto. Los aviones volarán a 50.000 pies durante todo el tiempo posible para captar imágenes que ayuden...

Aunque asociamos los fósiles con los museos o con excavaciones científicas en sitios remotos en realidad es posible encontrarlos en las ciudades, escondidos en algunas rocas ornamentales. Tienen que ser rocas sedimentarias como la caliza o, especialmente la arenisca o el...

Un electrón gira alrededor del núcleo de un átomo a una velocidad equivalente a unos 1.000 km/s. El principio de incertidumbre de Heisenberg viene a decir –de forma simplificada– que es imposible conocer su posición y su velocidad a la vez de...

Estos días se cumplen 50 años del descubrimiento de PSR B1919+21, el primer púlsar que detectamos jamás, aunque entonces no sabíamos qué era ni teníamos nombre para él. Un púlsar es una estrella de neutrones o una enana blanca que gira muy...
Un grupo de científicos de Corea del Sur, China y los Estados Unidos acaban de publicar un estudio acerca de la posibilidad de utilizar la técnica de manipulación genética Crispr-Cas9 en embriones humanos. Crispr-Cas9 es una técnica que está dando mucho que...

No sabía de la existencia de los arcoíris de fuego, también conocidos como arcos circunhorizontales, aunque me he enterado de su existencia gracias a unas fotos supuestamente sacadas por un piloto que andan haciendo las rondas por los grupos de Whatsapp....

「切り餅」The inset appears to move. pic.twitter.com/YbZm4RpfEP— Akiyoshi Kitaoka (@AkiyoshiKitaoka) 24 de julio de 2017 Hemos mencionado en unas cuantas ocasiones a Akiyoshi Kitaoka, un profesor del departamento de Psicología de la Ritsumeikan University en Kyoto (Japón) especializado en percepción visual e ilusiones...

Ahora que sabemos que las ondas gravitacionales existen, tal y como había predicho Einstein hace más de cien años, una de las cosas que quieren hacer los astrónomos es intentar captar los fenómenos que las producen en luz visible. GOTO, de...

Nos hicieron llegar del CSIC un ejemplar de Los números trascendentes (2013), un libro de Javier Fresán y Juanjo Rué que se adentra en la teoría de números y el papel que los números trascendentes juegan en ella. La historia de...

Hasta hace poco creía que tanto tungsteno como wolframio eran nombres válidos para el elemento número 74 de la tabla periódica. Pero resulta que desde la edición de 2005 del Libro rojo de la Unión Internacional de Química Pura y Aplicada...

La Cátedra de Cultura Científica de la UPV/EHU, junto con la Diputación Foral de Bizkaia y el concurso y apoyo de otras entidades,, han organizado Bizkaia Zienztia Plaza, diez días de eventos relacionados con la ciencia y la divulgación. Por orden de...

A principios de 2016 Konstantin Batygin y Mike Brown –el mismo cuyo equipo descubrió Éride, el planeta enano que hizo perder su categoría de planeta a Plutón– proponían la existencia de un noveno planeta –otro, no Plutón– en el sistema solar....
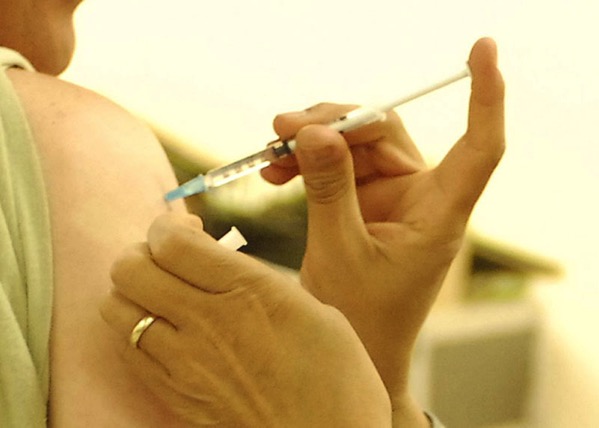
Desde el 1 de enero de 2016 está en vigor en Australia una norma que dice que si un niño no tiene sus vacunas al día sin justificación médica sus padres no pueden recibir ciertos beneficios fiscales. Y según se puede...
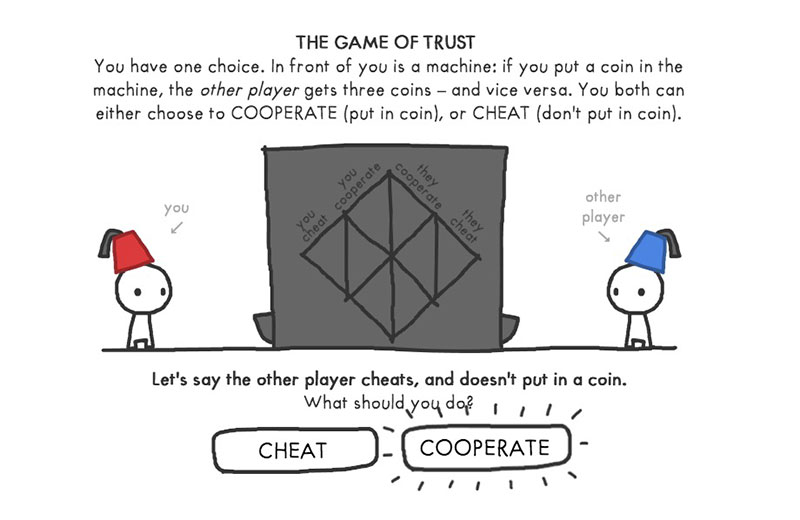
The Evolution of Trust de Nicky Case es un entretenido interactivo que explica algunos aspectos de la teoría de juegos utilizando una historia y permitiendo jugar a una variante del dilema del prisionero. Más concretamente se explora el dilema del prisionero...
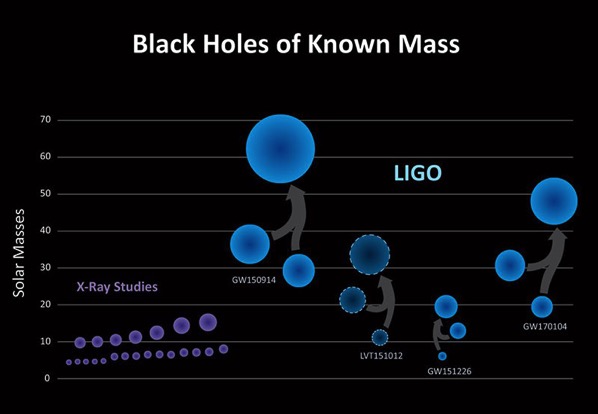
He escrito ya en unas cuantas ocasiones que la detección de ondas gravitacionales por parte del experimento LIGO es como si de repente hubiéramos ganado un sentido extra con el que observar el universo, y creo que este gráfico lo expresa...
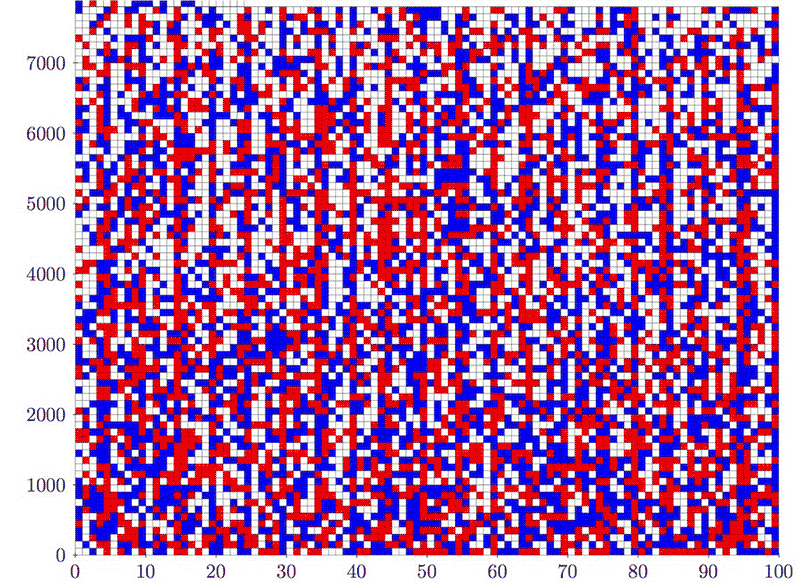
Heule, Kullmann y Marek son tres matemáticos que han resuelto con uno de los superordenadores de la Universidad de Texas uno de los problemas que desde hace décadas ha estado eludiendo a los expertos de los números: una cuestión combinatoria sobre...

EBLM J0555-57Ab y Saturno. A la izquierda de todo Júpiter; a la derecha de todo TRAPPIST-1 El tamaño es importante, al menos en lo que a la estrellas se refiere. Y en el caso de EBLM J0555-57Ab lo es porque es la...
El Telescopio de Treinta Metros, o TMT por sus siglas en inglés de Thirty Meter Telescope, es uno de los mayores telescopios en construcción en el mundo. Pero su construcción lleva parada desde finales de 2016 a causa de las protestas...

Según un reciente estudio un alto porcentaje de los datos científicos recogidos en trabajos de todo tipo está perdido, principalmente porque se guardaron en formatos que hoy no se pueden recuperar: disquetes ilegibles, archivos de papel que se han perdido o deteriorado,...

#LAST COMMAND sent #LISAPathfinder now fully passivated & shut down on a heliocentric disposal orbit #Eom— ESA Operations (@esaoperations) 18 de julio de 2017 Tras ejecutar los comandos para vaciar sus depósitos de combustible y desactivar su sistema eléctrico la sonda LISA...

Este Abecedario científico [en alta resolución y PSD en Google Drive] condensa de la A a la Z las más importantes figuras de la ciencia de todos los tiempos. «Una tarea titánica», como dice Pedro Cifuentes, el profesor que lo ha...

The Mechanical Universe es un documental de 1985 en 52 capítulos. Producido por el Caltech como parte de un proyecto sin ánimo de lucro es toda una joya de la «época de Cosmos», con look viejuno, muchas fotografías, animaciones y buena...

Hace unas semanas semanas en Warped Perception encendieron un cohete de carcasa transparente —construido en un tubo de vidrio— que dejaba ver su funcionamiento, cómo el combustible sólido se quemaba en su interior produciendo el chorro de gases de alta presión...
Por Nacho Palou -
19 JUL 2017

Impresión artística del encuentro de la New Horizons con un objeto del cinturón de Kuiper - NASA/JHUAPL/SwRI/Alex Parker Tras completar con éxito su misión de explorar Plutón, al que sobrevoló el 14 de julio de 2015, la sonda New Horizons de la...

En los últimos días muchos medios han dado bola a los resultados de dos estudios que sugieren que beber café alarga la vida, con cuñados confirmando en televisión que eso era así, tal cual. Al menos algún entrevistado por este asunto...
Por Nacho Palou -
17 JUL 2017

En Phys.org, Live-in grandparents helped human ancestors get a safer night's sleep, Un estudio llevado a cabo entre un grupo de cazadores-recolectores modernos de Tanzania considera que, para quienes viven en grupo, la existencia de diferencias en los patrones de sueño...
Por Nacho Palou -
17 JUL 2017

En 10 Surprising Mathematical Facts Sean Li hace un repaso a algunas de las cuestiones matemáticas que más nos sorprenden por su carácter paradójico, alejado de la intuición o misterioso – que de todo hay. He aquí un repaso rápido (y...

Fotograma del GIF original / Fotograma del GIF recuperado de la E. coli generaciones después En la ciencia esto de «probar a hacer cosas, simplemente porque se puede» lleva a demostraciones realmente curiosas, como las de los científicos que han editado el...

Charlie Deck de BigBlueBoo ha creado este Explorador fractal que hace buen uso de la potencia de los navegadores actuales para crear una visualización de fractales totalmente interactiva y extremadamente fina y ágil. Al arrancar se puede ver el conjunto de...
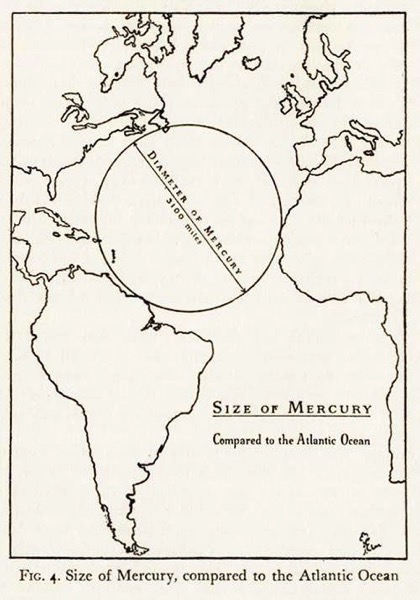
Desde la polémica expulsión de Plutón de la familia de planetas del sistema solar Mercurio pasó a ser no sólo el planeta más cercano al Sol sino también el más pequeño de la familia, con un diámetro de 4879,4 kilómetros. Es...

Investigadores del centro ETH de Zúrich han desarrollado el primer corazón flexible enteramente artificial que late igual que su equivalente natural y que más adelante puede servir como sustituto temporal. “Sustituto temporal” porque este corazón de silicona únicamente dura, por ahora,...
Por Nacho Palou -
14 JUL 2017

El 10 de julio de 2017 la sonda Juno de la NASA sobrevoló la Gran Mancha Roja de Júpiter a unos 9.000 kilómetros de altura sobre las nubes del planeta. Es lo más cerca que nos hemos acercado a ella nunca....
Este gráfico de The Washington Post muestra todos los eclipses solares que se producirán a lo largo de tu vida. Para configurarlo hay que introducir la fecha de nacimiento y arrastrar el globo terráqueo para dar con tu ubicación geográfica. Un...
Por Nacho Palou -
12 JUL 2017

Habíamos visto hasta ahora cómo algunos discos superconductores se desplazan en un circuito mediante el fenómeno conocido como flux pinning, un fenómeno bastante asombroso aunque cada vez más habitual. Se necesitan los materiales cerámicos adecuados, incluyendo una pieza superconductora de «tipo...
Kathryn Hess es una matemática de la École Polytechnique Fédérale de Lausanne (EPFL) que ha estado trabajando en un proyecto junto con el equipo Blue Brain para investigar qué es lo que sucede exactamente en el interior de nuestro cerebro cuando...

Esta imagen de Jotero muestra una banda de Möbius con estructura de esponja de Menger, lo cual la confiere propiedades bastante curiosas, por no decir paradójicas. Por un lado es una cinta que tiene una sola cara y un solo borde...

Aunque la creencia general es que los ojos se ponen rojos después de pasar un rato en el agua de las piscina debido al cloro, según este vídeo de SciShow, la verdadera causa es algo más asquerosa: el cloro tiene parte...
Por Nacho Palou -
7 JUL 2017

RELIVE the landing of NASA's Mars Pathfinder spacecraft on the red planet, which occurred 20 years ago today. pic.twitter.com/TlErOqLqte— Spaceflight Now (@SpaceflightNow) 5 de julio de 2017 El 4 de julio de 1997 aterrizaban sanos y salvos en Marte la sonda Mars...

En Wired, How Scientists Preserved a 440-Pound Blue Whale Heart, Extraer. Hacen falta hasta diez personas para abrir la ballena en canal y secciones hasta llegar al corazón Dilatar. Sin sangre el corazón de la ballena se aplasta. Tamponar las válculas...
Por Nacho Palou -
4 JUL 2017

Recientemente la NASA ha aprobado que del sistema de protección contra asteroides conocido como Dart (Double-Asteroid Redirection Test) pase a la siguiente fase de desarrollo, al diseño preliminar. El sistema está basado en la técnica del impactador cinético, que esencialmente consiste...
Por Nacho Palou -
4 JUL 2017

Plocan, la Plataforma Oceánica de Canarias, es un es un consorcio público que tiene como objetivo construir, equipar y operar un conjunto de infraestructuras marinas para la investigación en el campo de las ciencias y tecnologías marinas. Situada en la costa...

En esta interesantísima entrevista que ha mantenido Numberphile con Robbert Dijkgraaf, un físico matemático –que no un matemático físico– se habla de la eterna relación entre matemáticas y física, dos campos del conocimiento humano con los que pretendemos entender el universo,...
El gobierno australiano acaba de publicar una primera versión preliminar del documento titulado Review of Pharmacy Remuneration and Regulation [PDF 4,4 MB], un documento en el que se examina el funcionamiento y el marco regulatorio de las farmacias en el país que...

Un tokamak es un dispositivo de confinamiento magnético diseñado para contener el plasma durante una reacción de fusión termonuclear. Su nombre procede del ruso тороидальная камера с магнитными катушками («cámara toroidal con bobinas magnéticas») que básicamente describe su geometría: la de...
Sin la ciencia y la tecnología no seríamos quienes somos, aunque muchas veces no somos conscientes de cuanto dependemos de ellas. Pero quizás no estamos sabiendo transmitir el mensaje. Sobre esto, me parece muy recomendable leer El gran malentendido de la...
Mientras PLATO entra en su fase de diseño y construcción hay otra misión de la Agencia Espacial Europea relacionada con planetas extrasolares que avanza hacia su lanzamiento. Se trata de Cheops, de CHaracterising ExOPlanets Satellite, o Satélite para la Caracterización de...

Wired Muscle es un inquietante a la par que interesante proyecto de los investigadores Jun Nishida y Kenji Suzuki de la Universidad de Tsukuba en colaboración con Shunichi Kasahara del laboratorio de ciencias de la computación de Sony, que interconecta los...
Por Nacho Palou -
27 JUN 2017
La confirmación de la existencia de las ondas gravitacionales, previstas por Albert Einstein en su teoría de la relavitidad general allá por 1915, en uno de los grandes logros científicos de los últimos años, ya que nos abren una nueva ventana...

Hace algunos años algunos de los investigadores del Gran Colisionador de Hadrones hicieron un vídeo en el que parodiaban la canción Collide cantándola desde el punto de vista de un protón que estuviera en su interior. El resultado fue LHC "Collide"...

Además de dar el visto bueno a LISA la Agencia Espacial Europea ha decidido adoptar la misión PLATO. PLATO, de Planetary Transits and Oscillations of stars, o Tránsitos Planetarios y Oscilaciones estelares, tiene como objetivo principal buscar tránsitos planetarios observando hasta un...

El 21 de agosto de 2017 se producirá un eclipse de Sol que atravesará los Estados Unidos de la costa oeste a la costa este. Millones de personas lo seguirán, incluidas muchas que llegarán de otros países si en la aduana de...

En The Fibonacci Collection hay toda una recopilación de curiosos relojes geométricamente interesantes: los hay que tienen como diseño la espiral de Fibonacci, otros la espiral de Arquímedes, hipérboles, fracciones o la proporción áurea. En esta versión a medida que el...

Después de haber sido sometido con éxito a las pruebas de vibración y sonido que buscaban asegurarse de que podría sobrevivir a su lanzamiento el sistema óptico del Telescopio Espacial James Webb está ya en el Centro Espacial Johnson de la...

Tal y como era de prever la Agencia Espacial Europea ha seleccionado la misión LISA como L3, la tercera misión de la clase L de su programa de investigación Visión Cósmica. Las misiones L son las más grandes y ambiciosas de...

A mí me sorprende más que la gente se convierta en una cosa o la otra. Todos los niños son científicos y todos los niños son artistas. Todos leen. ¿Cómo es que dejamos de lado cosas tan importantes como esas? Esa...

En Buyer Beware: Antimicrobial Products Can Do More Harm Than Good, un grupo de 200 científicos avisan sobre la necesidad de dejar de utilizar jabones antibacterianos y desinfectantes. Por un lado porque no hay evidencia científica de que estos compuestos prevengan...
Por Nacho Palou -
21 JUN 2017
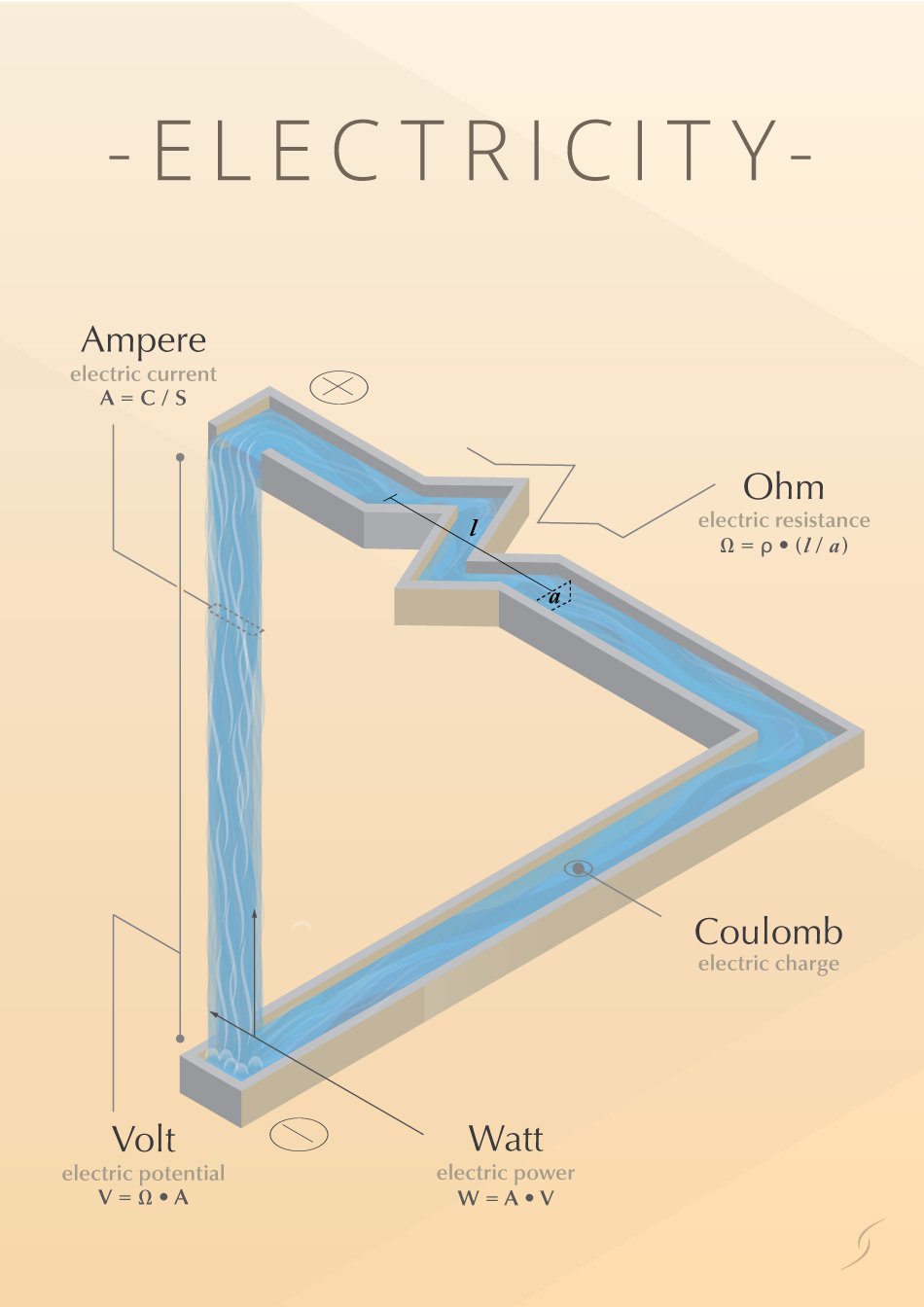
Las analogías son peligrosas, porque aunque ayudan a entender los conceptos no son exactamente lo mismo y pueden llevar a confusión, pero esta tiene el plus de utilizar una obra del genial M.C. Escher (su famosa Cascada) para explicar la electricidad...
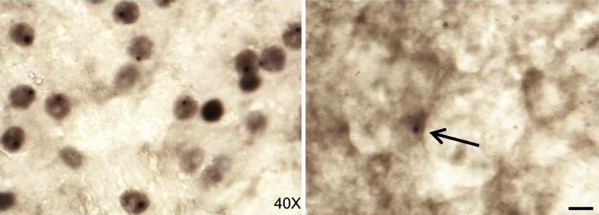
Acumulaciones de proteínas entes y después del tratamiento Antes que nada: faltan años para que esto pueda aplicarse en humanos, si es que alguna vez puede hacerse. Pero es una noticia muy esperanzadora lo que ha conseguido hacer un equipo de científicos...

Types of Nuclear Radiation es un vídeo del Fermilab en el que explican los distintos tipos de radiación, diferenciando la radiación nuclear -o ionizante-, que es la que nos puede hacer pupita, de la radiación electromagnética. La radiación nuclear se divide...

Durante casi cinco años el rover Curiosity ha estado explorando el fondo del cráter Gale, en Marte. Pero si retrocediéramos atrás en el tiempo lo suficiente no sería posible explorar el cráter Gale con un rover, haría falta un submarino. En...
Por Nacho Palou -
19 JUN 2017

Desde el departamento de ironías,... Según Phys.org, el equipo científico del rompehielos canadiense de investigación CCGS Amundsen ha tenido que cancelar la primera etapa de su expedición de 2017 debido a complicaciones causadas por el calentamiento global. El servicio de guardacostas cede...
Por Nacho Palou -
19 JUN 2017

Además de imágenes preciosas la sonda Juno de la NASA está enviando un montón de información a los científicos de la misión, que ya se van encontrando con algunas sorpresas, aún a pesar de que no está en la órbita prevista:...
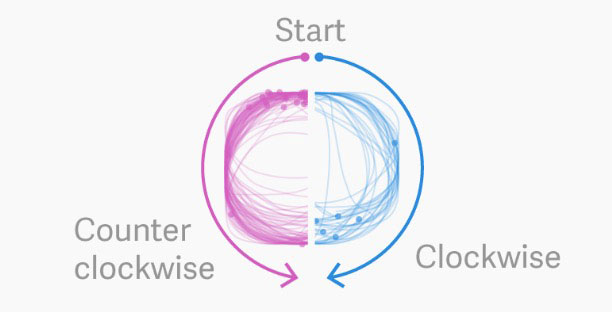
Es fácil pensar que no hay muchas formas de dibujar un círculo: o en sentido de las manecillas del reloj o en sentido contrario a las manecillas del reloj. Aunque, bueno, también se puede empezar por arriba o por abajo. O...

Corta pero interesante intervención de Elena Campos-Sánchez, presidenta de la Asociación para Proteger a los Enfermos de la Terapias Pseudocientíficas (APETP), en Late Motiv de Buenafuente. En ella hablan de los riesgos de las pseudoterapias, de la responsabilidad que supone que...
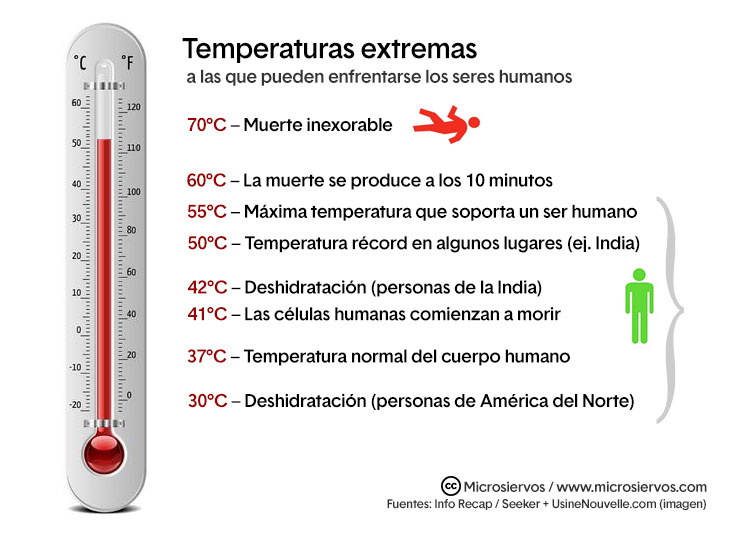
En estos días de ola de calor me preguntaba cuánto tiempo podría soportar una persona en plena calle, bajo el sol abrasador y un calor extremo (más de 40° o 45°, pero… ¿50°? ¿60°? ¿70°?) La pregunta es complicada de responder...

Un cohete Larga Marcha 4 ha puesto en órbita el telescopio espacial chino Hard X-ray Modulation Telescope, de Telescopio de Modulación de Rayos X Duros, también conocido como Insight. Como su propio nombre indica es un telescopio de rayos x que...
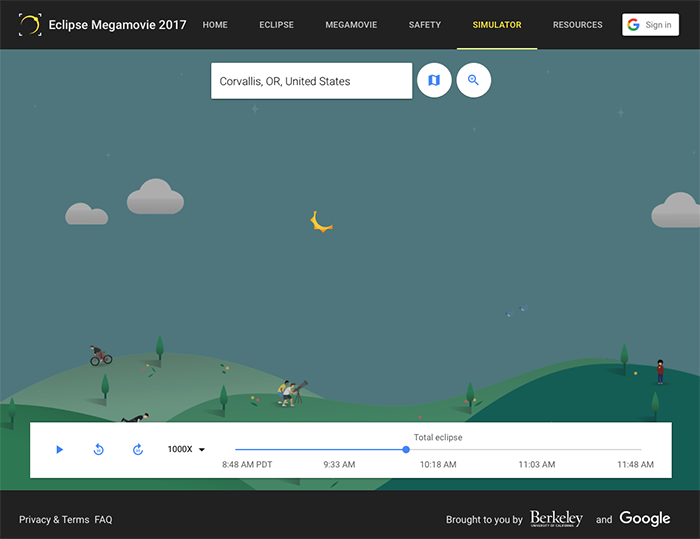
Desde este lado del mundo nos tendremos que conformar con ver el eclipse total de Sol en este simulador desarrollado por Google y la Universidad de Berkeley, que anticipa cómo y cuándo será visible el fenómeno (o más bien, no visible...
Por Nacho Palou -
15 JUN 2017

Una de las cosas que viajaba a bordo de la cápsula de carga Dragon SpX-11 es el Neutron star Interior Composition Explorer, o NICER, de Explorador de la Composición Interior de las Estrellas de Neutrones. Se trata de un telescopio de...
Júpiter LIV, antes conocida como S/2016 J 1, y Júpiter LIX, antes conocida como S/2017 J 1, son las dos adiciones mas recientes a la colección de lunas de Júpiter, que ya acumula un total de 69. La primera está a...

Bueno, en realidad no se han llevado el premio las ondas gravitacionales, cuya existencia previó Albert Einstein en su teoría de la relatividad, sino que se lo han concedido a los físicos estadounidenses Rainer Weiss y Kip S. Thorne y a...
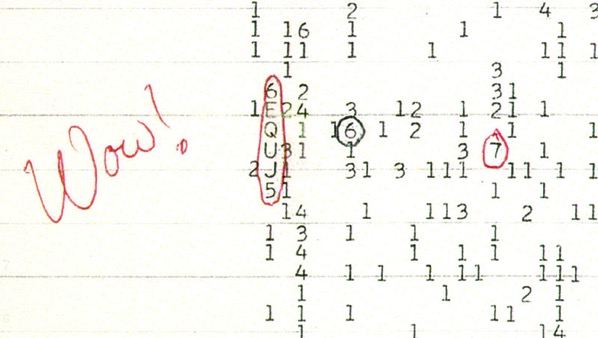
El 15 de agosto de 1977 el radiotelescopio de Big Ear detectaba una señal de radio extraordinariamente fuerte que días más tarde fue etiquetada por Jerry R. Ehman con un Wow! del que obtiene su nombre. Pero pesar de todos los...

En África entierran a los niños, en Europa enterramos a los ancianos.– Ignacio López-Goñi La mejora en las condiciones sanitarias, el acceso al agua potable, y las campañas masivas de vacunación hacen que hoy en día vivamos más y mejor que...

Según cuenta el Observatorio Europeo Austral (más conocido como ESO) en Renaming the E-ELT el Telescopio Europeo Extremadamente Grande, o E-ELT, por sus siglas en inglés, cambia de nombre. La nota de prensa dice que Telescopio Europeo Extremadamente Grande era un...

Desde que tenemos Google e Internet los médicos se encuentran con que muchos pacientes llegan a la consulta ya diagnosticados (por ellos mismos) y que en realidad es como si fueran a verlos para obtener una segunda opinión. Fernando Fabiani da...

Cerca de 60 charlas de 10 minutos que cubren prácticamente cualquier tema de ciencia en el que puedas pensar. Además, como son tan cortas –y lo de los tiempos se lleva a rajatabla– si una no te interesa mucho, lo que sería...
Hoy, 9 de junio de 2017, se produce la luna llena más pequeña –desde nuestro punto de vista– de todo el año. Una microluna. O una miniluna. Y sin embargo los medios no están dando –ni de lejos– la lata que...

Todos (bueno, más o menos) sabemos que Albert Einstein ganó un Nobel en física… pero lo que mucha gente no sabe es que no fue por su teoría de la relatividad sino por explicar el efecto fotoeléctrico, una explicación que puso...

Entre mayo y junio de 2016 un grupo de astrónomos detectó una fluctuación de aproximadamente un 0,5 por ciento en la luz que nos llega de la estrella KELT-9 usando el telescopio KELT-Norte. Esta disminución, que se repetía cada día y...

Transformative Appetite es un proyecto del Tangible Media Group, en el MIT Media Lab en un intento por desarrollar comida que cambia de forma, de estructuras 2D a 3D, cuando se cocinan, mediante la interacción hidromórfica. Este proceso de transformación puede...
Por Nacho Palou -
9 JUN 2017

Aunque lavarse las manos con agua caliente puede ser más agradable y facilitar eliminar determinado tipo de sociedad (grasas, adhesivos o pinturas) a efectos de higiene la temperatura del agua es irrelevante según un estudio de la universidad pública Rutgers de...
Por Nacho Palou -
9 JUN 2017
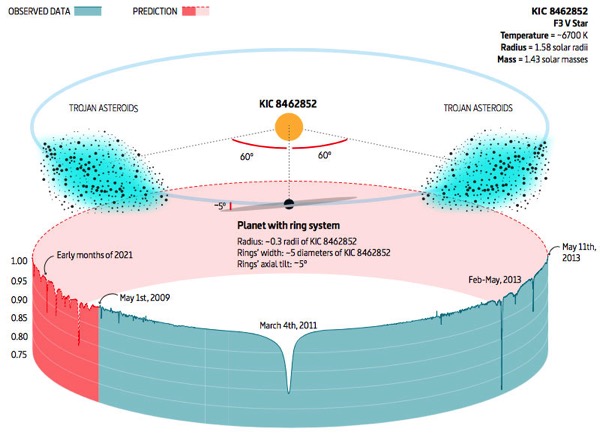
En 2015 la estrella llamada KIC 8462852 se hizo instantáneamente famosa cuando tras estudiar los datos obtenidos de ella por el telescopio espacial Kepler, decididamente raros, algunos científicos sugirieron que podían tener su origen en que estuviera rodeada por una esfera de...

Este vídeo de The Royal Institution muestra unos cuantos juegos científicos sobre propiocepción que se pueden hacer en una clase, con niños o si consigues convencerlo con los colegas de la oficina – son para todas las edades. La propiocepción es...
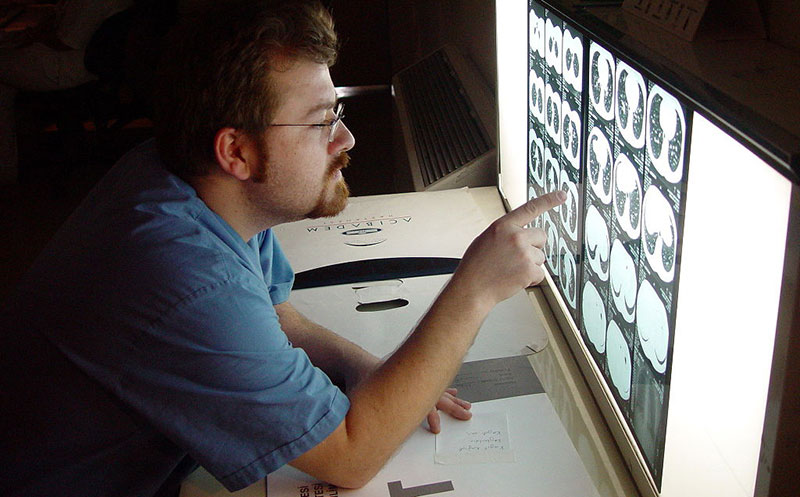
Los algoritmos de aprendizaje automático que examinan gigantescas colecciones de imágenes procedentes de pruebas de radiología ya son capaces de estimar la longevidad con la misma precisión que sus equivalentes humanos, los expertos en diversas especialidades que habitualmente diagnostican el estado...

El canal TED-ed, siempre tan educativo como interesante, añade su granito de arena –o más bien, otro clavo al ataúd– sobre las máquinas de movimiento perpetuo, de las que tantas veces hemos hablado por aquí. ¡En esta casa obedecemos las leyes...

Resulta que Kirai se encontró en un paseo por el barrio de Shinagawa, en Tokio con el libro con el número pi. Más concretamente, un libro que contiene pi, más exactamente un millón de dígitos decimales de π. Cuenta que el...
Decía hace unos días Rosa Montero en Consumidores engañados y cautivos (las negritas son mías): Yo, que tengo cuatro tornillos en la columna vertebral, dejé de tomar trigo y centeno hace algunos meses y la espalda ha mejorado radicalmente. Mi traumatólogo,...

No es sin tiempo, pero la Real Academia Nacional de Farmacia ha publicado un informe titulado Posición de la Real Academia Nacional de Farmacia en relación con la situación actual de los medicamentos homeopáticos [PDF 242 KB] en el que hace...

Predichas por Einstein en su teoría de la relatividad general las ondas gravitacionales son producto de algunos de los sucesos más enormemente cataclísimicos del universo, como por ejemplo la colisión de dos agujeros negros. Son sucesos tan violentos, que generan tanta...

¿Comprobar si has dejado bien cerrado el gas antes de salir de casa, una y otra vez? ¿Lavarte las manos a cada rato porque está todo lleno de gérmenes? ¿Organizar cualquier estantería de libros alfabéticamente por autor porque así es como...
Una sociedad científicamente informada es sinónimo de una sociedad más culta y por lo tanto, más libre y más capaz de tomar correctamente decisiones con alto componente científico-técnico y menos susceptible de manipulación por intereses de otros grupos de presión, por legítimos...

Aunque ya llevaban tiempo preparando el terreno el 26 de mayo de 2017 tuvo lugar la ceremonia de colocación de la primera piedra del Telescopio Europeo Extremadamente Grande o Extremely Large Telescope del Observatorio Europeo Austral. Esto marca el comienzo de...

En Veritasium visitan la balanza del Instituto Nacional de Estándares y Tecnología (NIST), una agencia del gobierno de EE UU dedicada a la ciencia de las mediciones. La balanza cuenta con una pesa capaz de medir hasta 1.000.000 de libras de...
Por Nacho Palou -
29 MAY 2017

Pedro Daniel Pajares, estudiante de Matemáticas en la Universidad de Extremadura en Badajoz, se ha impuesto en el concurso de monólogos científicos Famelab España 2017 con Una bola peluda para atraerlos a todos, un monólogo en el que explica la importancia...

Después de meses de trabajo para hacer un programa lo más atractivo posible éste es el programa definitivo (o al menos la intención del comité organizador es que lo sea) del VI Congreso de Comunicación Social de la Ciencia. Organizado por la...

La doctora Natasha Hurley-Walker explica en la charla Seeing the sky with radio eyes de TEDxPerth por qué es tan importante que seamos capaces de mirar el universo no sólo en el espectro de la luz visible, pues es una ventana...
El recientemente creado Observatorio OMC contra las Pseudociencias, Pseudoterapias, Intrusismo y Sectas Sanitarias va a presentar una denuncia ante la Fiscalía General del Estado en la que están incluidas cerca de un centenar de páginas web. Son webs que, según Jerónimo...

Siempre es agradable oír a un profesor de física y cosmólogo decir «no tenemos npi de cómo funciona esto», y más si es Sean Carroll, un gran divulgador de la ciencia – ahí están su The Big Picture o Desde la...

Con las debidas precauciones y un par de placas de material acrílico transparente puede fabricarse esta superficie llamada Ferrocell sobre la que cuando se colocan y mueven imanes de cualquier tipo permite una visualización directa de los campos magnéticos resultantes. Además...

Según explican investigadores de la NASA en NASA's Van Allen Probes Spot Man-Made Barrier Shrouding Earth, la actividad humana ha producido una barrera artificial alrededor de la Tierra que tiene su origen en la emisión terrestre de frecuencias de radio de...
Por Nacho Palou -
19 MAY 2017

En Life Nogging han dedicado un rato a explicar algunos de los trabajos científicos que se han realizado respecto a las experiencias cercanas a la muerte (ECM o NDE en inglés). [Por cierto que es el típico caso en el que...
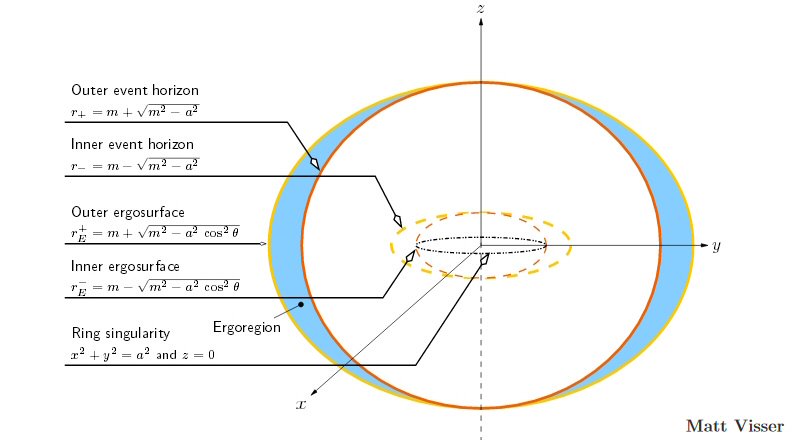
Roy Kerr es un matemático neozelandés entre cuyos logros relacionados con la astrofísica y la relatividad general está haber encontrado una solución «tan bella como exacta» de las ecuaciones de campo de Einstein con implicaciones acerca los viajes temporales que pudieran...

Como preparación para someter a los humanos, los robots han comenzado por controlar las tortugas. En el vídeo no es que se vea gran cosa, pero según New Scientist lo que aparece moviéndose por ahí es una tortuga que carga a...
Por Nacho Palou -
17 MAY 2017
Para q no haya dudas: Consejo Científico (SSCC) del colegio, decidió suprimir secciones colegiales de disciplinas sin evidencia científica— Icomem (@Icomem_Oficial) 15 de mayo de 2017 El Icomem, el colegio de médicos de Madrid, ha tomado la decisión de disolver sus secciones...

Genius (2017) es una serie-documental de National Geographic acerca de la vida y obra de Albert Einstein, uno de los mayores genios científicos del siglo XX y de todos los tiempos – y si no el más grande al menos el...

En este vídeo de Tech Insider el profesor Brian Greene –conocido físico téorico y divulgador de la Universidad de Columbia– explica que no hay nada en la teoría de cuerdas que impida que existan varias dimensiones del tiempo. Y, básicamente, si...
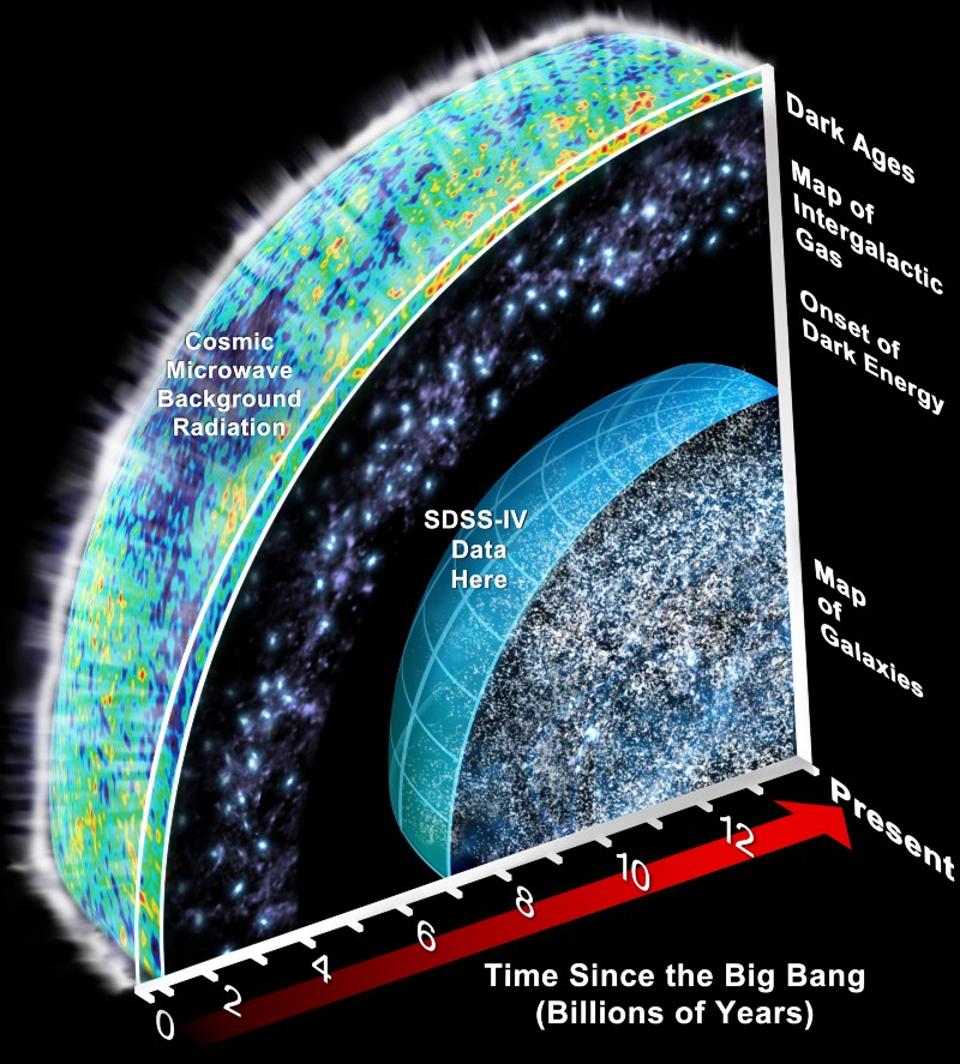
Ethan Siegel responde en su sección de Forbes a esta curiosa pregunta sobre cómo son exactamente los confines de nuestro universo observable. La respuesta completa está llena de detalles: How Far Is The Edge Of The Universe From The Farthest Galaxy?...

La ministra de Sanidad, Dolors Montserrat, en respuesta de una pregunta del diputado Francisco Igea acerca de qué hace el Gobierno para evitar los daños que causan la pseudoterapias, ha animado a pacientes y sociedad a implicarse «activamente en la denuncia de...
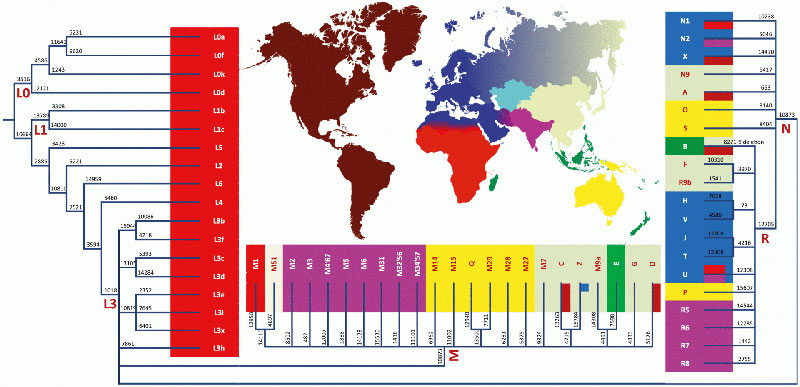
Haplogrupos de ADN mitocondrial humano / Wikimedia En un viejo número de Science Dialy tienen un buen artículo sobre genética y uno de los «personajes históricos» más curiosos de los que se pueda hablar, la Eva mitocondrial o «primigenia»: ‘Mitochondrial Eve’: Mother...

En la fila de arriba la imagen (letra) que se está mirando. En la parte inferior la reconstrucción de la imagen (letra) obtenida de la actividad cerebral. La imagen de arriba corresponde al proceso hecho por un algoritmo desarrollado por investigadores chinos...
Por Nacho Palou -
9 MAY 2017

La BBC condensa en 60 minutos la vida del Premio Nobel de Física y genio Richard Feynman: física cuántica, guerra nuclear y el desastre del Challenger… con bongos para aliviar las ecuaciones más complicadas.
Como decían por ahí, la proverbial ardilla podría cruzar España de evento en evento de Pint of Science España 2017. ¿Sientes curiosidad por el cosmos? ¿Te intriga el tema de la evolución? ¿O, simplemente, quieres saber por qué la cerveza sabe así...

En una semana arranca en CaixaForum Sevilla la sexta edición de Ciencia en Redes con este programón (aunque esté mal que yo lo diga): 09:30 Recogida de acreditaciones 10:00 Inauguración Moisés Roiz, director de CaixaForum Sevilla. Ignacio Fernández Bayo, vicepresidente de...

El spinner se ha convertido en uno de los juguetes de moda en los patios de los colegios: se trata de un sencillo artilugio giratorio con rodamientos, que se puede hacer girar fácilmente y que dura y dura y dura… entre...

El sábado 6 de mayo de 2017 el Día de la Ciencia en la Calle vuelve al Parque de Santa Margarita. En su XXII edición, y como es haitual, cientos de estudiantes y profesores de 36 centros educativos, así como miembros...

Los técnicos de Orbital ATK –la misma empresa que fabrica las cápsulas de carga Cygnus– está dando los últimos toques a TESS, el nuevo observatorio espacial para buscar planetas extrasolares de la NASA. TESS, de Transiting Exoplanet Survey Satellite, o Satélite...

James Wong: La leche sin tratar causa 840 veces más enfermedades que la pasteurizada. A ver si el tal Pasteur iba a tener razón…Jorg Mardian: Noticias sensacionalistas y estudios sesgados. Me pregunto cómo nadie sobrevivía antes de que llegara la sociedad...
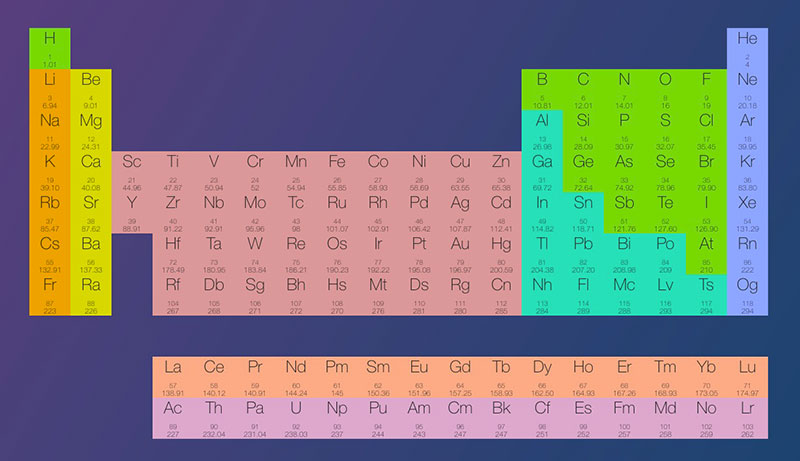
PeriodicStats.com es una tabla periódica minimalista. Y en Helvetica Ultralight. (Vía Boing Boing.)...

Le Voyage dans la Lune (Viaje a la Luna) fue uno de los primeros cortometrajes de Georges Méliès. En 1902 el pionero francés ya había rodado más de veinte pequeñas piezas cuando se embarcó en esta superproducción de algo más de...

Según cuenta NasaSpaceflight todo avanza para el primer lanzamiento de un cohete Falcon Heavy, que podría tener lugar en el verano de 2017. Un Falcon Heavy consiste de, grosso modo, tres Falcon 9 Heavy colocados lado a a lado que despegan...

De nuevo un tribunal italiano dicta una sentencia que va contra toda la evidencia científica en cuanto al uso de móviles: Un tribunal italiano concede una pensión vitalicia a un trabajador que tuvo un tumor por usar mucho el móvil. El Tribunal...
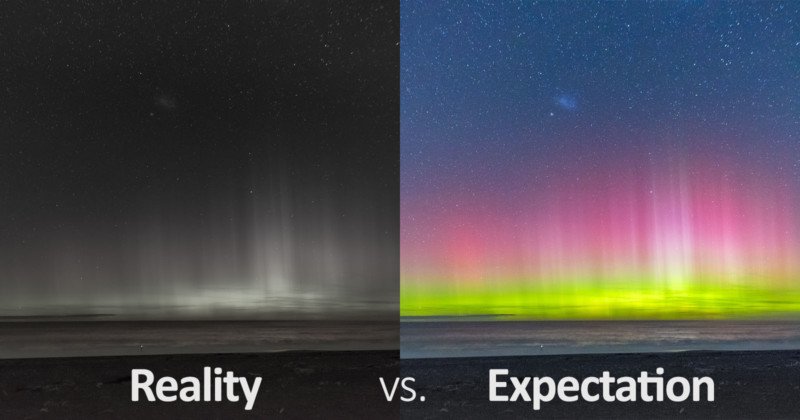
Tal y como explican en Aurora Photos: Reality vs. Expectation (PetaPixel) lo que realmente a través de nuestros ojos los humanos cuando tenemos delante el fenómeno natural de las auroras polares poco se parece a lo que solemos ver en fotografías...

Un reciente informe del interventor general de la NASA advierte del peligro que corre la agencia de quedarse sin trajes para paseos espaciales. Los trajes que utilizan los astronautas de la agencia en la actualidad son los denominados Unidad de Movilidad...

John Edmark es un matemático que se dedica a la construcción y búsqueda de estructuras geométricas «con comportamientos inusuales». En sus diseños hay mucho de matemáticas y bastante de «magia» y propiedades rarunas: espirales, ciclos infinitos, piezas que se despliegan… Nada...

Los clicks de Playmobil, versión científicos

La cadena de dígitos 79873884 aparece en el número π (pi) exactamente a partir 79873884ª posición decimal. Es bastante curioso pero… ¡alguna vez tenía que suceder! ¿O no? [Fuente: Cliff Pickover / Imagen David Reimann]...

Este ingenio de Giaco Whatever es un disco levitador que ha denominado cariñosamente Flying Fidget Spinner. Básicamente consiste en dos imanes que se repelen para contrarrestar la fuerza de la gravedad. ¿Simple, no? Pero para que funcione el imán de arriba...

En los últimos años cada vez es más habitual ver desfibriladores automáticos (o semiautomáticos) en lugares públicos. La idea, dejando aparte normativas que regulan quien puede usarlos y quien no, es que puedan ser utilizados para socorrer a personas en parada...

Si se cumplen los plazos previstos en 2022 la Agencia Espacial Europea lanzará la sonda Juice rumbo a Júpiter con el objetivo de estudiar Ganímedes, Calisto y Europa, tres lunas del planeta que por lo que sabemos albergan una cantidad significativa...

Desarrollada por Emmanuelle Charpentier y Jennifer Doudna, la técnica de edición de ADN Crispr-Cas9 promete facilitar grandes avances en el campo de la genética. Pero también se dice que como es tan fácil y barata podría caer en las manos equivocadas...

Nuestros políticos viven de espaldas a la ciencia, porque no gusta lo que no se conoce. Obama y Blair tenían un asesor científico conocido, pero ¿donde está el asesor científico de Rajoy? Pasar del ladrillo a la neurona no es algo gratuito....

Un vestido de tabla periódica estilo años 50 en Etsy. Algodón 100%. Atención al detallito de la foto de los frascos con muestras. La descripción está en engrish y dice que requiere añadir unas enaguas y el cinturón – además de...

Este vídeo educativo de Electric Experiments muestra lo que sucede cuando se vierte mercurio entre dos discos de aluminio (la base es de madera). Al aplicar corriente eléctrica al aluminio se genera un campo magnético que hace que el mercurio comience...

Para vestidos originales este que se vende en Esty bajo el nombre Espacio‑tiempo, con un diseño de auténtico modelo matemático: el espacio‑tiempo atravesado por un agujero de gusano. En cuanto a colores han utilizado azul oscuro / eléctrico y amarillo, pero...

Desde hace unos días está viva la web de Martian Moons Exploration, la misión de la JAXA, la Agencia Japonesa de Exploración Aeroespacial que pretende traer a la Tierra muestras de Fobos, una de las dos lunas de Marte. Para ello...

La Fundación Española para la Ciencia y la Tecnología acaba de presentar su 8ª Encuesta de percepción social de la ciencia. Es una encuesta que se viene realizando cada dos años desde 2002. Para mí el dato más esperanzador es el...

Aquellos que no quedan disgustados la primera vez que se inician en la mecánica cuántica seguramente es porque la entendieron. Niels Bohr Suspended In Language: Niels Bohr’s Life, Discoveries, And The Century He Shaped. Esta biografía en formato cómic (más de...

Gracias al uso de un dron los investigadores de la Universidad Pública de Oregon han logrado grabar el momento en el que una enorme ballena azul se alimenta engullendo krill. Ya el año pasado miembros de la Universidad Tecnológica de Auckland,...
Por Nacho Palou -
19 ABR 2017
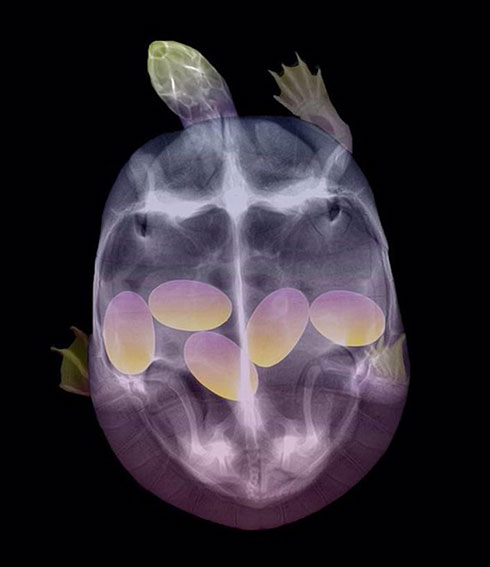
Estas interesantes radiografías de animales preñados muestran el aspecto del proceso de gestación en el vientre de las madres de diversas especies, desde las tortugas a los monos, los gatos o las serpientes. Las crías pueden tener aspecto de fetos en...
Geoff de Artificial Philosophy encontró un original entretenimiento a modo de proyecto el que trabajar programando un poco a la vez que indagando en las profundidades de π, la constante matemática con infinitos decimales en la que (se cree, pero no...

Copos de nieve gemelos, copias perfectas unos de otros. El investigador Ken Libbrecht cultiva copos de nieve para descubrir si realmente cada copo de nieve es único, y después de aplicar su método para hacer crecer copos de nieve en el...
Por Nacho Palou -
17 ABR 2017
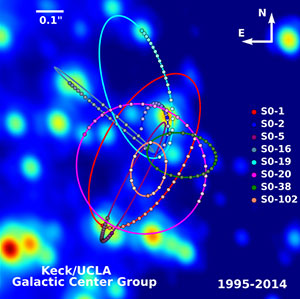
Esta animación del UCLA Galactic Center Group es toda una labor de paciencia y detalle: muestra cómo ciertas estrellas a las que se sigue la pista de forma muy precisa con varios telescopios desde hace veinte años orbitan alrededor del Centro...

James Maynard nos pone al día con el estado de la conjetura de los números primos gemelos, que viene a decir en versión resumida algo tan fácil de entender pero tan difícil de demostrar como que Hay un número infinito de...
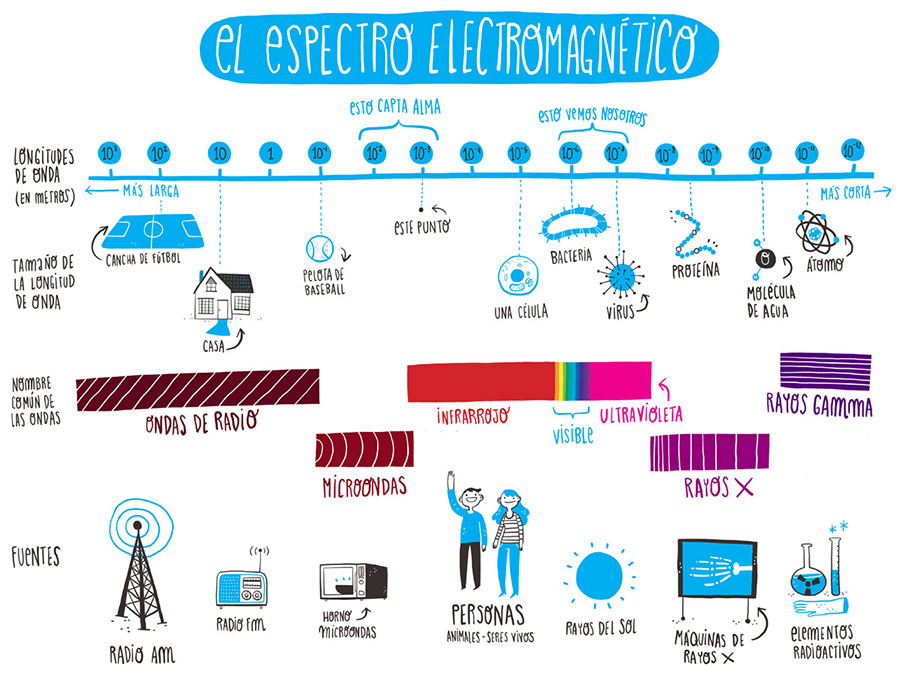
Me encontré en el twitter del observatorio @ALMA (Atacama Large Milimeter/submilimeter Array) esta versión de el espectro electromagnético explicado para niños que está al alcance de todos los públicos. Es como la versión aquella de xkcd (el espectro electromagnético completo) o...
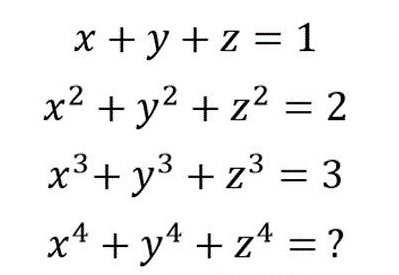
Lo vi en el Twitter de @eylen. La solución es un único número, que reemplaza a la interrogación....
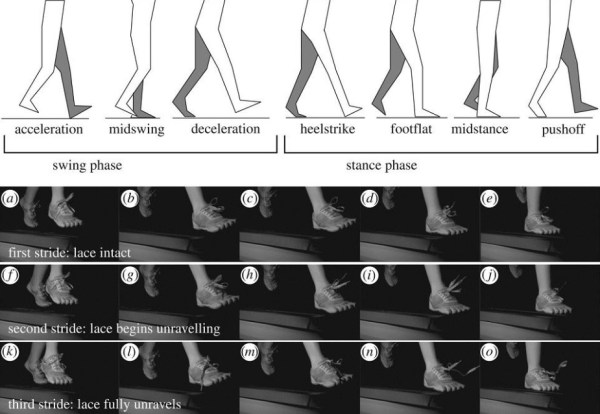
En Nature, Unravelling why shoelace knots fail, Los investigadores esperaban que los nudos se deshicieran lentamente. Pero en las imágenes a cámara lenta tomadas de los cordones de un corredor sobre una cinta de andar demostraron que los nudos se deshacían...
Por Nacho Palou -
14 ABR 2017
Self Reflected es una obra de arte que intenta hacernos reflexionar acerca del kilo y pico de materia gris que hay dentro de nuestros cráneos y que nos hace ser quienes somos; su funcionamiento es uno de los grandes misterios a...

El generador de este laboratorio de la electricidad puede alcanzar hasta dos millones de voltios, así que a Tom Scott se le ocurrió que sería buena idea usarlo para comprobar qué sucede si un rayo impacta contra un dron comercial normal...

Estas curiosas imágenes integran figuras humanas reducidas al sistema circulatorio en entornos urbanos. Forman parte de una colección digital titulada Humans After All que combina las fotografías de Jan Kriwol y los humanoides de venas y arterias generados por ordenador por...
Por Nacho Palou -
10 ABR 2017

#HomeopatiaGratis en #Burgos (Paseo de la Isla) #BurgosMola pic.twitter.com/9Qo7mnjUqS— Azucena Santillán (@Ebevidencia) 10 de abril de 2017 Los seguidores de las enseñanzas de Samuel Hahnemann, padre de la homeopatía, han decidido proclamar el 10 de abril, día de su nacimiento allá por...

Tal Danino es un biólogo de Columbia que además de estudiar las bacterias las fotografía de diversas y bellas formas – una suerte de espantosa belleza a veces. En un proyecto llamado Microuniverso que realizó entre 2015 y 2016 utilizó diversas...

Synlight es un sol artificial que, cuando se pone en marcha, puede fundir cualquier cosa que se ponga por delante, incluyendo el acero. Desarrollado en el centro aeroespacial alemán DLR, este panel de 149 lámparas de xenon produce 10.000 veces la...
Por Nacho Palou -
9 ABR 2017

Esta mesa redonda de casi dos horas se grabó el año pasado en el Museo Americano de Historia Natural. [Tiene buenos subtítulos en inglés]. Se trata del Isaac Asimov Memorial Debate, que reúne cada año a expertos de diversas disciplinas para...

Armado con datos obtenidos en autopsias de hombres realizadas en los 40 y los 50 del siglo XX el arqueólogo James Cole, de la Universidad de Brighton, ha calculado que un hombre adulto* aporta unas 126.000 calorías, tal y como se puede...

Un tuit de Toni Calvo me ha recordado que hoy se cumplen 25 años de la muerte de Isaac Asimov: 25 años de la muerte de Isaac Asimov. Para quienes escribíamos de ciencia sus libros eran la wikipedia antes de la Wikipedia....
Las rutas metabólicas es una imagen que muestra el camino que siguen las reacciones químicas en el interior de las células. Tendrás que darle al zoom varias veces para llegar a algo legible. Junta millones y millones de células en las...

Este avión teledirigido construido por Peter Sripol con dos cubos de pollo del KFC aprovecha el efecto Magnus para volar. Este efecto establece que un objeto en rotación (sea una pelota o un cubo para pollo frito) crea un remolino de...
Por Nacho Palou -
6 ABR 2017

El Comité Científico Asesor en Radiofrecuencias y Salud (CCARS) ha presentado el Informe sobre Radiofrecuencias y Salud 2016, que actualiza el documento previo publicado en 2013. En él se recogen, actualizan y analizan las evidencias científicas sobre la materia correspondientes al período...
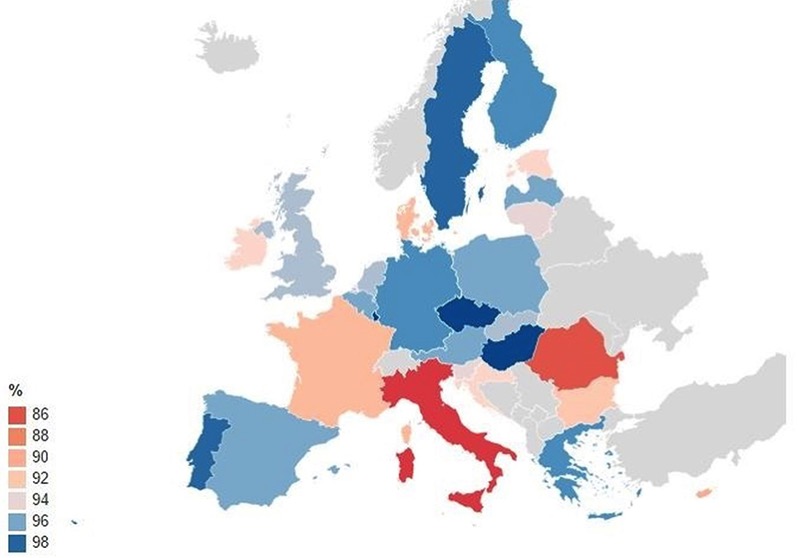
Inmunidad de grupo frente al sarampión en Europa. Por debajo del 95% la posibilidad de una epidemia aumenta – Datos de World Bank Open Data / creado con Datawrapper - vía El Español Lo cuenta Rocío P. Benavente en Sarampión en Europa:...

Julio Basulto, nutricionista*, no ha venido a hacer amigos con esta charla de TEDxAlcoi titulada ¿Es sana esa «copita de vino» diaria?. Y quien dice copita de vino dice una cervecita, unas galletitas, el jamoncito… La respuesta es que no lo...
Robert Schwarz hizo What does the sun do at the Pole !?, un time-lapse del Sol, que recoge su movimiento en el cielo del polo sur entre el 8 y el 13 de marzo de 2017. Se ve perfectamente como el...

La síntesis aditiva de color –lo del RGB a lo que nos tienen acostumbrados los ordenadores y el Photoshop– explicada con humor en apenas cinco minutos en una de las semifinales de FameLab España 2017, un monólogo que le ha valido...

En ciertas condiciones atmosféricas el vapor de agua presente en el escape de los motores de los aviones se puede condensar, con lo que se convierte en esas estelas blancas que todos hemos visto mil veces. Pero con la reciente publicación...

Todo el mundo se hace una idea de más o menos qué es un agujero negro, pero los detalles no son tan fáciles de comprender. Por aquí hemos hablado alguna vez de que hay un montón de cosas que la gente...

«Papá, si no lo ven, ¿cómo saben que está ahí?» fue la inocente pregunta de Laura, la hija de Antonio, que le embarcó en la aventura de escribir El ojo desnudo, el libro que es necesario para dar respuesta cumplida a la...

Cada minuto la atmósfera de la Tierra pierde 180 kilos de hidrógeno y 3 de helio, así como cantidades menores de oxígeno y nitrógeno. Es un fenómeno conocido como escape atmosférico, provocado por las estrellas, en este caso por el Sol,...

Un año más está abierta la convocatoria de los Prismas de Bronce a los mejores trabajos de divulgación científica de los Museos Científicos Coruñeses, en los que trabajo en el MundoReal™, que en 2017 celebran su XXX convocatoria. En esta XXX Convocatoria...

Encontré vía @AmuseChimp este viejo vídeo BBC Earth, que resulta ser un revival de la clásica prueba de memoria con números. El test consiste simplemente en ir pulsando sobre los números que aparecen en la pantalla por orden. La dificultad es...

Una de las muchas sorpresas que nos dejó la breve visita de la sonda New Horizons a Plutón fue la de descubrir que su atmósfera tiene una serie de capas azules. Los científicos creen que están formadas por una niebla fotoquímica...

Henry Segerman junto con Vi Hart, Andrea Hawksley and Sabetta Matsumoto han estado trabajando sobre esta realidad virtual no euclidiana. Se trata de un montaje que consiste en unas gafas de realidad virtual en el que el software no utiliza geometría...
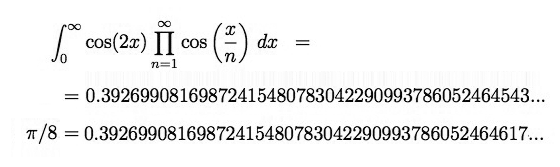
Encontré gracias a un tuit de @Pickover una referencia a esta curiosísima aproximación a pi. Si se calcula la integral el resultado parece ser π dividido por 8 (0,392…) Pero en realidad el número resultante sólo coincide con el valor auténtico...
Marte tuvo una vez anillos y es probable que vuelva a tenerlos en el futuro. Eso dice una teoría presentada por investigadores de la Purdue University descrita en un estudio publicado en la revista Nature Geoscience. El artículo sugiere que las...
Por Nacho Palou -
22 MAR 2017

Cada uno de nosotros comenzamos a existir así. Parece una imagen generada por ordenador, pero no lo es. El vídeo del fotógrafo Francis Chee recoge la secuencia de imágenes de la división celular del óvulo de una rana. En total, los...
Por Nacho Palou -
22 MAR 2017

Han transcurrido unos 13.700 millones de años, pero parece que fue ayer cuando el Bing Bang dio comienzo a todo – literalmente. Ha sido todo un viaje que resume Desde el Big Bang a la humanidad: La formación del universo comienza...
Pocas cosas pueden hacer que estos alumnos del IES El Calero de Telde (Gran Canaria) aprendan mejor lo que es el trabajo de un astrónomo: Dos grupos de segundo de ESO del IES El Calero, en Telde (Gran Canaria), han descubierto,...

Numberphile ha publicado un vídeo sobre uno de los mejores problemas matemáticos de la historia, el favorito de muchos aficionados. Se trata de una cuestión topológica tan simple que cualquier niño pequeño puede entenderla. Se trata del Mapa de los cuatro...

A las 10:28 UTC del 20 de marzo de 2017 –una hora más en España peninsular– se producía el equinoccio de marzo, que marca el principio de la primavera en el hemisferio norte y del otoño en el hemisferio sur. El...

Teletransporte. Moléculas. Átomos. Partículas. Mecánica cuántica. Paradojas. Qubits. Entrelazamiento cuántico. El gato de Schrödinger. Estados. Existencia. Con todos estos elementos animados adecuadamente Minuto de Física hace comprensible algo tremendamente complejo – aunque, la verdad, requiere mucha atención, paciencia y algo más...
Imagen NDVI de la isla de Noirmoultier Ojo, espaciotrastornados, gente a quienes os gusten los mapas, o a los que os encante curiosear por Google Maps o Google Earth… El programa Copérnico de la Agencia Espacial Europea (ESA) y la Unión Europea...

Brindisi en el visible Apenas había pasado una semana de su lanzamiento cuando el satélite medioambiental Sentinel-2B de la Agencia Espacial Europea estaba ya capturando sus primeras imágenes y enviándolas a tierra, aunque le quedan aún unos tres meses de pruebas antes...

Como ya decía don Sebastián a finales del siglo XIX «hoy las ciencias adelantan que es una barbaridad», y es algo que sigue plenamente vigente, así que resulta my difícil mantenerse al día. El Anuario SINC, que se edita desde 2010, es...

Carlos nos ha escrito para hablarnos de My Leaf, una aplicación que acaban de lanzar dirigida a aquellas personas que sufren de alguna de las denominadas enfermedades raras. Hay entre 5.000 y 7.000, la gran mayoría de origen genético, y son aquellas...

Los que llevéis algún tiempo leyéndome sabéis que reniego de la división entre ciencias y letras que hay en nuestro sistema educativo y que por tanto está incorporada a nuestra sociedad –o puede que sea al revés–. Así que muero de envidia...

Eyes on the elements es un póster al estilo test de Snellen donde las letras originales que se utilizan para medir la agudeza visual han sido reemplazadas por elementos químicos, ordenados según su abundancia en el universo. Esto es un poco...
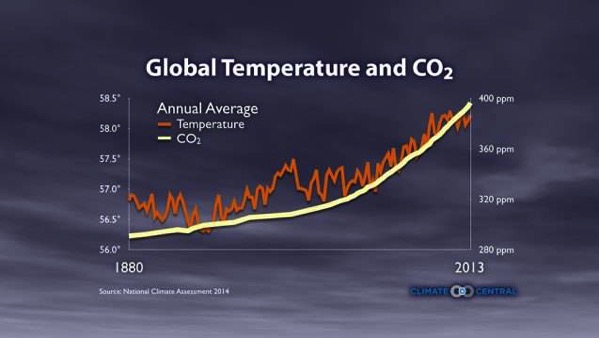
En Phys.org, The science of carbon dioxide and climate, La concentración de gases causantes del efecto invernadero, medido en partes por millón de dióxido de carbono (CO2), se ha incrementado de forma notable desde el inicio de la revolución industrial, el...
Por Nacho Palou -
14 MAR 2017

Como cada 14 de marzo (3/14 en anglosajón) hoy es el día de pi. Este año es un tanto especial porque diversas organizaciones, entre ellas la Real Sociedad Matemática Española, la Consejería de Economía y Conocimiento (CEC) de la Junta de...
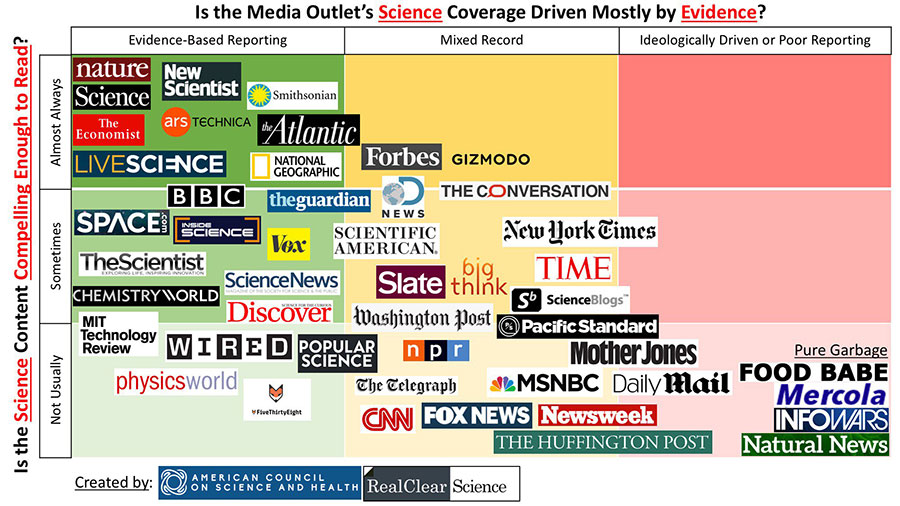
En el eje vertical (Y) cuán atractivo es el contenido científico de cara a leerlo; en el eje horizontal (X), si esa cobertura se hace en base a pruebas científicas o no o no. Cuanto más arriba y a la izquierda,...
Esta absolutamente espectacular animación es una «comparación de tamaños» de Reigarw Comparisons, que abarca desde las más pequeñas partículas subatómicas al universo completo. Es para tomárselo con calma porque sus diez minutos contienen una ingente cantidad de información; aunque el uso...

Existe un Centro Internacional de la Patata (CIP), sí. Está en Lima (Perú) y desde 1971 investiga y desarrolla soluciones sostenibles a problemas globales relacionados con el hambre, la pobreza y el cambio climático. Y desde hace unas semanas el CIP...
Por Nacho Palou -
13 MAR 2017

Encontre por Twitter una versión de este vídeo de BBC Earth en el que se ve a un cuervo resolviendo un complicado problema, una tarea asombrosa se mire como se mire. [El «espectáculo» empieza en 01:03.] Para conseguir su premio el...
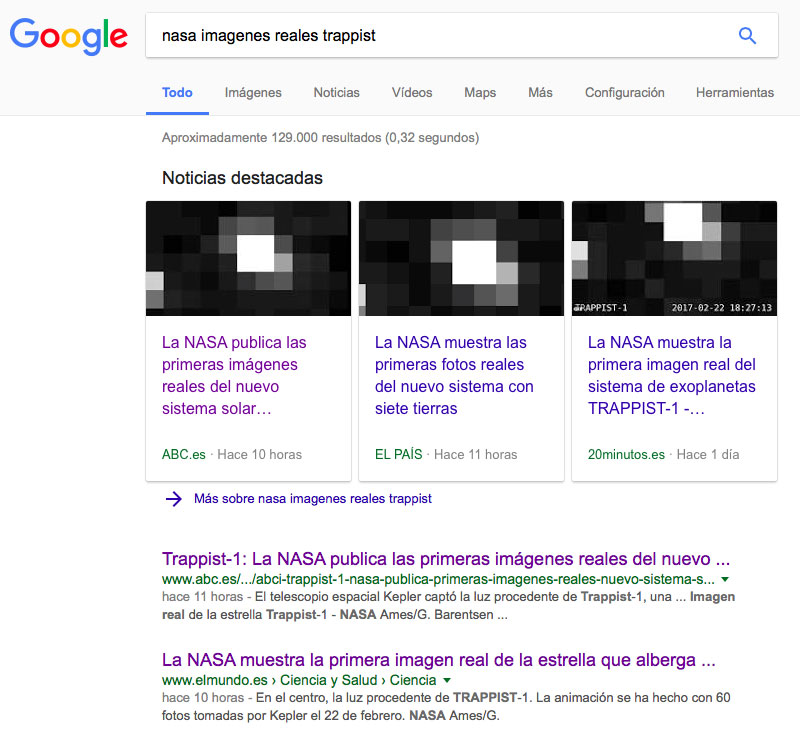
La NASA ha publicado estas imágenes de Trappist-1 en Light From An Ultra-Cool Neighbor. Son imágenes obtenidas por el telescopio Kepler de la ya famosa estrella con siete planetas de tamaño similar a la tierra en órbita a su alrededor. Se...

El cometa Halley en 1986 – NASA/W. Liller Probablemente el cometa Halley sea el famoso de los cometas. Pero sin embargo no lleva el nombre de su descubridor. De hecho no sabemos quién fue el primero en observarlo.El cometa Halley, oficialmente...

Este vídeo es uno de los muchísimos que hay con zooms animados a algún remoto lugar del conjunto de Mandelbrot utilizando software especializado y mucha paciencia. No creo que sea el récord absoluto (porque es de 2014) pero sí que me...

Los anillos de Urano vistos por la Voyager 2 – NASA/JPL El 10 de marzo de 1977 los astrónomos James L. Elliot, Edward W. Dunham, y Douglas J. Mink se proponían estudiar la atmósfera de Urano gracias a la ocultación de la...

David Reimann tiene esta curiosa imagen de π en espiral, otra forma curiosa de ver la infinitud de los decimales de la redonda constante. (Vía Cliff Pickover.) Más visualizaciones de pi, a cuál más bonita: Una curiosa visualización de π y...

Según un estudio experimental, el trastorno obsesivo-compulsivo (TOC; OCD en inglés) podría estar causado por la incapacidad de algunas personas para diferenciar entre situaciones seguras y situaciones de riesgo. Ejemplos típicos de TOC son «rituales» como comprobar varias veces si el gas...
Lo mejor de ambos mundos en esta obra sobre matemáticas para la informática, una magna obra de Lehman (Google), Thomson Leighton (MIT/Akamai) y Meyer (MIT). Disponible tanto en formato libro/PDF como en formato curso OpenCourseWare del Instituto de Tecnología de Massachusetts....

Me han encantado las imágenes de la serie Mujeres que cambiaron la ciencia. Y el mundo. de Hydrogene, disponibles en varios formatos (pósteres, fundas para teléfono y portátil, pegatinas, cuadernos…). Como ella misma dice: …el foco primario de mi portfolio ha...
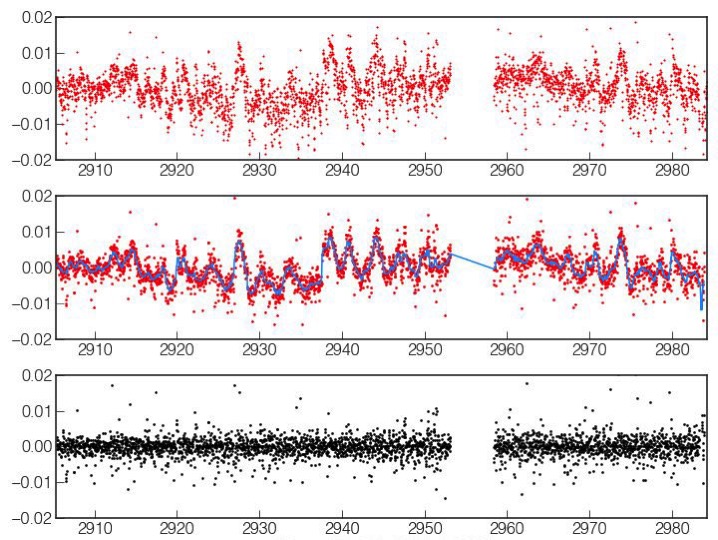
La NASA acaba de hacer públicos los datos que ha obtenido su telescopio espacial Kepler de la estrella Trappist-1 entre el 15 de diciembre de 2016 y el 4 de marzo de 2017, aunque con un hueco de cinco días causado...

En Hydraulic Press Action se han tomado la molestia de ver qué pasa cuando expones una extremidad –en este caso un brazo– o tu estómago al vacío para que no tengamos que hacerlo los demás. En el caso del brazo empieza...
Karl Sims tiene una página a la antigua usanza explica de forma sencilla y visualmente qué son y cómo se construyen los conjuntos de Julia y de Mandelbrot, dos de los fractales más conocidos e íntimamente relacionados. Los detalles en Understanding...

Sabemos que Saturno tiene anillos desde que en en 1659 Christiaan Huygens los identificara como tales –Galileo los había observado en 1610 pero la baja potencia de su telescopio no le había permitido dilucidar lo que eran–. William Herschel observó los anillos...

Para comprobar “cuánta destrucción es capaz de causar un dardo Nerf“, Giaco Whatever construye un cañón de aire comprimido con el cual dispara uno de esos proyectiles a una gran velocidad. En el vídeo no se indica qué velocidad alcanza el...
Por Nacho Palou -
6 MAR 2017

Todos los objetos esféricos del sistema solar de menos de 10.000 km de diámetro – Montaje por Emily Lakdawalla. Datos de NASA / JPL, JHUAPL/SwRI, SSI, y UCLA / MPS / DLR / IDA, procesados por Gordan Ugarkovic, Ted Stryk, Bjorn Jonsson,...

Impresión artística de Akatsuki en órbit alrededor de Venus Según cuenta la Agencia Japonesa de Exploración Aeroespacial en Two cameras on Akatsuki pause observations las cámaras de infrarrojos de 1 y 2 micrómetros de la sonda Akatsuki, que está en órbita alrededor...

El NASA's Software Catalog es un catálogo de programas de software desarrollados y utilizados por la agencia espacial. Las aplicaciones cubren una gran cantidad de disciplinas técnicas y científicas: aeronáutica, astronáutica, electrónica, comunicaciones, procesado de datos, sistemas de propulsión, materiales, etc. En...
Por Nacho Palou -
6 MAR 2017
Una ecuación tiene la misma solución en Israel y en Teherán. La ciencia es un lenguaje internacional, no entiende de religión, de política, de nacionalidades… si creamos un nuevo medicamento no curará solo a los judíos, curará a todos en este planeta....
Desde que conozco su existencia me ha fascinado el fenómeno de la sinestesia. La sinestesia es un fenómeno que hace que las personas que la tienen perciban curiosos cruces entre sus sentidos, de tal forma que los sonidos pueden evocar sabores,...
Hace algo más de una semana me alertaron de que Josep Pàmies iba a dar dos charlas en A Coruña, una en un centro cívico del ayuntamiento y otra en el paraninfo de la universidad. Cualquiera de las dos opciones me...

Descubierto en abril de 1900 en un pecio a 45 metros de profundidad en la isla griega de Anticitera el mecanismo de Anticitera, como se le conoce, es uno de los objetos más fascinantes del pasado. Fabricado hace unos 2100 años...

Un curso visual e interactivo queexplica probabilidad y estadística con monedas, dados y distribuciones.

Me he encontrado el curso Introduction to Critical Thinking de Wireless Philosophy, que en 32 vídeos, todos ellos de menos de 10 minutos, y muchos de incluso menos de cinco minutos, intenta explicar qué es el pensamiento crítico, una herramienta que...

Según se puede leer (y ver) en LEGO Ideas Second 2016 Review Results la propuesta de 20tauri bautizada como Women of NASA ha sido escogida por nuestro fabricante de ladrillos preferido para convertirlo en un producto «de verdad». Incluye a Margaret...

La expresión publish or perish (publica o perece) es de sobra conocida en el ámbito científico. Quiere expresar la importancia que tienen las publicaciones en los currículos del personal investigador. En ciencia no basta con hacer observaciones, obtener unos resultados y...

Este vídeo de Timelapse Vision muestra con un aumento considerable la yema de un dedo y sus glándulas sudoríparas en acción: auténticos goterones de sudor que van aumentado de tamaño y surgiendo de los dedos. Pese a lo sencillez del montaje...
Como os adelantaba hace unos meses, y tras varios años sin que se celebrara, este año vuelve el Congreso de Comunicación Social de la Ciencia. Bajo el lema «Cultura y Ciencia. Viejos retos, nuevos medios», su sexta edición se celebrará en la...

Juno con su motor en primer plano El 5 de julio de 2016 la sonda Juno de la NASA entraba en órbita alrededor de Júpiter. La idea era que describiera dos órbitas de captura, con una altitud mínima de 4150 kilómetros sobre...

El mago de los problemas lógicos que nos enseñó con acertijos fascinantes e historias llenas de imaginación (y pura lógica).

El vídeo capta diversos impactos de meteoritos contra la superficie de la Luna “y otros eventos” detectados desde el Automated Lunar and Meteor Observatory (Alamo). El Alamo emplea telescopios terrestres para observar zonas parciales del satélite con el fin de “determinar...
Por Nacho Palou -
15 FEB 2017

Alex Rosenthal y George Zaidan prepararon esta original animación TED titulada El caso de los fractales desaparecidos, donde el detective Manny Brot se enfrenta a tres enigmas matemáticos, cuyas soluciones le llevarán al mundo de los fractales y la autosemejanza. Por...

En la Asociación Española de Comunicación Científica, de cuya junta directiva soy miembro, llevamos ya meses preparando Ciencia en Redes 2017, que este año se muda a Sevilla. Así, la sexta edición de esta jornada para periodistas, investigadores, comunicadores, museógrafos e instituciones...

Ríos, mares, selvas, desiertos, montañas, llanuras… En The Earth: 4K Extended Edition encontrarás todo tipo de paisajes vistos Estación Espacial Internacional. Pero lo que seguro que no encontrarás son fronteras, una de las primeras cosas que todos los astronautas con los...
#StopPseudociencias Desde las 9 de la mañana del 13 de febrero de 2017, hora peninsular española, y hasta las 9 de la tarde, está en marcha la campaña #StopPseudociencias, que tiene como objetivo emplazar al ministerio de Sanidad, Asuntos Sociales e Igualdad...

Ya está en marcha la segunda edición de Ciencia Clip, el concurso de vídeos divulgativos de ciencia para estudiantes de la ESO, Bachillerato y del ciclo básico y medio de FP. El formato y el tema del vídeo, que debe tener...

What if NASA had the US Military's Budget? es un vídeo en el que el autor se pregunta qué pasaría si la NASA, que tiene un presupuesto anual de 18.500 millones de dólares, tuviera los 600.000 millones de dólares de los...

En la actualidad, las mujeres y las niñas encuentran barreras de muchos tipos, a veces muy sutiles, que dificultan su presencia en la ciencia, algo que se hace patente en la elección de los estudios por parte de las niñas, en especial...

Según los expertos publicitarios de los Clio Awards que saben mucho de estas cosas, este anuncio de Einstein inspirándose con música de Lady Gaga al violín fue el mejor de la larga lista de los que desfilaron por el mayor escaparate...

En un artículo del New York Times se da cuenta de un par de trabajos publicados en Science acerca de cuál es el propósito de dormir The Purpose of Sleep? To Forget, Scientists Say: Hay quien dice que dormir es una...

Devin de Make Anything construyó este doble péndulo con algunas piezas impresas en 3D y restos de monopatines. El resultado es un gigantesco péndulo doble, en el que uno de los péndulos cuelga del otro. A pesar de ser un mecanismo...

Ron Rivest en persona –lo cual siempre es agradable– explica en este vídeo de Numberphile unas cuantas cosas sobre el RSA-129, un número de 129 dígitos decimales (y 426 bits) que usaron como un reto criptográfico que tardó 17 años en...

En The Telegraph, Scientists brewing up plan to make beer on the Moon, Investigadores de la universidad de California están diseñado un recipiente para fermentar cerveza en la Luna que esperan sea transportada por una nave espacial India que despegará a...
Por Nacho Palou -
2 FEB 2017

Un “truco de científico” permite grabar la onda de choque simulada que deja tras de sí un haz de luz que viaja “más rápido” que la luz. Cuando un objeto, caso de un avión, supera la velocidad del sonido su desplazamiento a...
Por Nacho Palou -
2 FEB 2017
Este Mapa de las matemáticas de Dominic Walliman intenta cubrir todos los campos de las matemáticas, agrupándolos por campos de estudio, orígenes y similitudes. Como la historia de los números comienza con el hecho de «contar» también hay un poco de...

Steve Mould explica en este vídeo cómo hacer algunos simpáticos experimentos con rotuladores borrables y agua, dibujando con ellos en platos o superficies metálicas y añadiendo agua. El efecto resultante es que se puede ver cómo un «muñeco de palo» se...
Este simulador de líquidos utilizando autómatas celulares es una forma de mostrar cómo actúan este tipo de creaciones matemáticas que tienen «comportamientos complejos a partir de reglas simples». Su creador es JGallant y está programado en Unity. Utiliza dos tipos de...
El Cognitive Bias Codex es una recopilación de 188 sesgos cognitivos en forma de elegante póster. Básicamente reune los más conocidos efectos de predisposición o prejuicio que tenemos grabados a fuego en el cerebro los seres humanos y de los que...
Derek de Veritasium explica en este vídeo cómo funciona un cuadricóptero de levitación magnética – un trasto grande y pesado que flota sobre una placa de cobre gracias a cuatro imanes permanentes que giran a gran velocidad. El artilugio, al que...
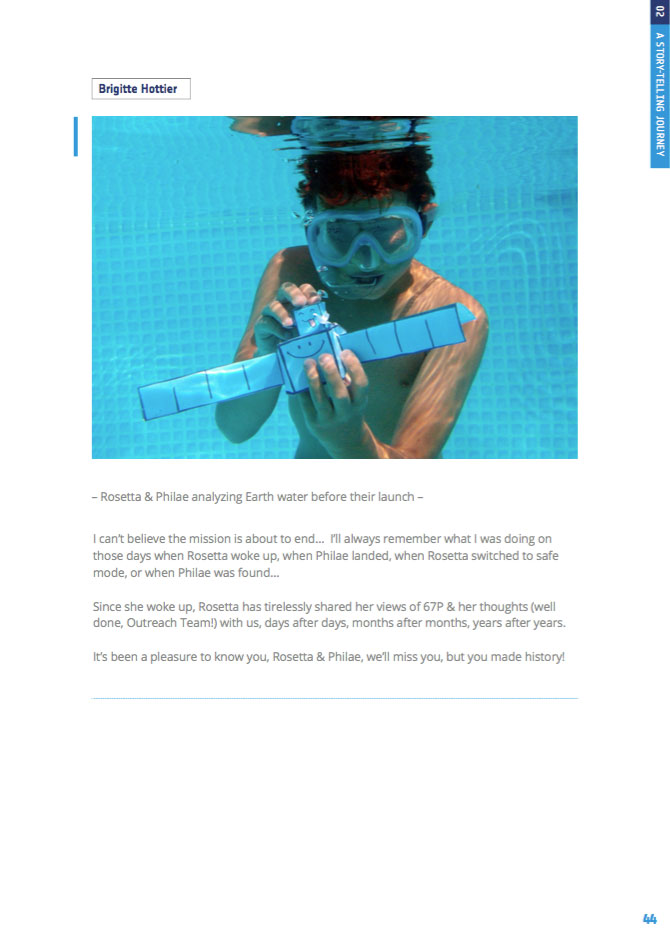
Aparte de muchos meses de datos acerca del cometa 67P-Churyumov/Gerasimenko que los científicos aún pasarán años analizando la misión Rosetta de la Agencia Espacial Europea es una de las que más interés ha despertado entre el público en los últimos años. Su...

El estudio de los microfluidos examina el comportamiento de los fluidos a microescala, al desplazarse y fluir por conductos diminutos, medidos en micras. También estudia la forma en que se mezclan unos nanolíquidos con otros, y la manera en que pueden...
Por Nacho Palou -
30 ENE 2017

Lightning Strikes: Timeless Lessons in Creativity from Nikola Tesla es una biografía sobre Tesla de John F. Wasik que cuenta la vida y obra del genial inventor y visionario. Según cuentan en la trasera cubre no sólo los datos que todos...

En este vídeo 3Blue1Brown titulado Los fractales no son autosemejantes se profundiza sobre algunas ideas relativas a los siempre interesantes fractales y la idea que casi todo el mundo tiene de que «son formas autosemejantes». Porque no todo es siempre como...

Este vídeo es una introducción a los programas de observación de la Tierra de la Agencia Espacial Europea pero se aplica a todos aquellos satélites artificiales que monitorizan nuestro planeta, sean de la agencia que sean. Nos permiten obtener datos acerca...

En NewScientist, Brainwaves could act as your password – but not if you’re drunk, Las ondas cerebrales son uno de los diversos indicadores biométricos que pueden servir como como alternativa a las contraseñas. La idea es que una persona pueda demostrar...
Por Nacho Palou -
27 ENE 2017

Este vídeo de Quantum Fracture explica de forma muy didáctica algunos métodos para calcular el valor de π, la más famosa de las constantes matemáticas. De cada método se da una explicación y algunas aproximaciones. Y también hay código fuente para...

Son tiempos difíciles para la rebelión…– Star Wars, episodio V Un grupo de empleados descontentos de la NASA han creado RogueNASA, una cuenta no-oficial de carácter rebelde en el que irán publicando datos y hechos científicos sin tener que pasar por...
Socratic [iOS] es una app cuya finalidad es resolver los deberes de los estudiantes – lo cual incluye ecuaciones algebraicas, historia, inglés, economía y otras. Y además es gratis. Al igual que otras «calculadoras» similares como Photomath o Mathpix basta apuntar...
El juego del caos es una curiosa forma de generar fractales. Todo comienza por elegir al azar un punto de una figura geométrica, por ejemplo un triángulo. Entonces se elige uno de los tres vértices también al azar y se calcula...
Como nos va la marcha, y después del éxito de Naukas Coruña neurociencia, en el que llenamos el teatro Rosalía Castro de A Coruña de personas dispuestas a emplear un sábado en que les hablaran de ciencia, y por tanto de cultura,...

¿Hay alguien ahí fuera? Este vídeo de Wendover repasa algunas de las cuestiones relativas a lo que se suele conocer como primer contacto con una civilización extraterrestre. Cubre muchas áreas y lo interesante es que plantea más preguntas de las que...

En este vídeo Michael de Vsauce repasa los detalles de la física que gobierna los giroscopios utilizando tanto un pequeño giróscopo como los que se pueden comprar en cualquier juguetería o tienda (ej. Tedco, en Amazon). En el vídeo se enseñan...

Este vídeo reúne toda una colección de motores homopolares, algo que hemos calificado alguna vez como los motores eléctricos más simples del mundo. Se pueden construir en casa muy fácilmente; básicamente se necesitan imanes de neodimio, pilas AA y cable eléctrico...

Frank Kovac decidió construirse un planetario a base de perseverancia e ingenuidad:, de modo que pasó 10 años fabricando una cúpula y pintando 5.000 estrellas en ella con pintura fosforescente («¡brilla en la oscuridad!»)– además de un ingenioso mecanismo para que...

Este trabajo de unos estudiantes del Columbus College of Art & Design consistía en ilustrar los elementos de la tabla periódica con animaciones de 6 segundos por elemento químico. Con una música de acción apropiada parece más una batalla épica que...

Cariñosamente la llaman papelfugadora. Este invento surgido de la universidad de Stanford es una solución de baja tecnología a las costosas centrifugadoras que se usan en los laboratorios. Nacida de una idea de los juguetes infantiles es capaz de realizar pruebas...

Un par de artículos / entrevistas sobre Yitang Zhang, el matemático que hace unos años realizó una importante demostración sobre los primos gemelos, acotando en parte una de las más famosas conjeturas para las que todavía no se conoce una demostración,...

Si lo tuyo es la ciencia, ingeniería o matemáticas y eres capaz de contar lo que haces en un monólogo tres minutos de manera que enganche aún estás a tiempo de participar en el certamen de monólogos científicos FameLab España 2017....
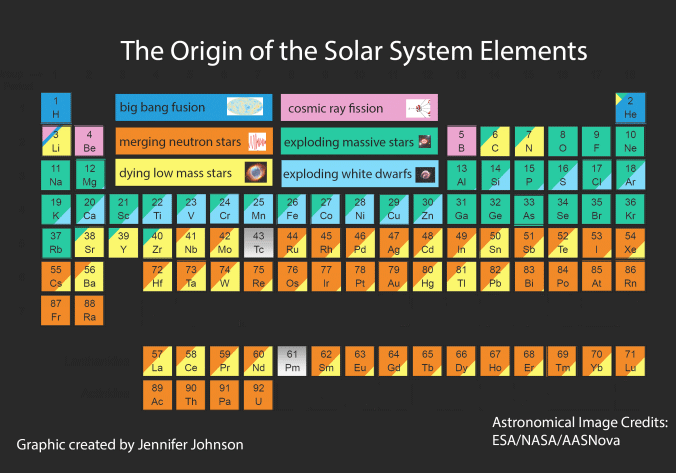
En el blog del SDSS, un proyecto de investigación de la NASA, han publicado esta tabla de los elementos según su origen que actualiza otras similares de 2008 y 2013. Esta versión permite conocer de un vistazo la procedencia de cada...

Según cuentan la NASA y el semanario The Week una gigantesca plataforma de hielo de la Antártida, conocida como barrera de hielo Larsen C está a punto de desprenderse y sería raro que no lo hiciera en los próximos meses. Su...

Como nos recuerda Karl Smallwod de Today I Found Out, todo aquel que haya experimentado ese gran momento de dolor instantáneo que se produce al pisar piezas de Lego con los pies descalzos sabrá que es «sólo comparable a que te...
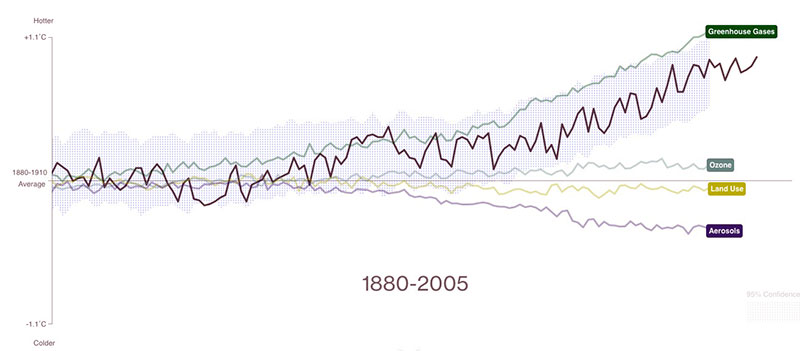
Bloomberg tiene en su web esta curiosa infografía interactiva titulada What’s Really Warming the World? que desglosa paso a paso las posibles causas del calentamiento global en relación con diversas causas naturales y producidas por los seres humanos – en una...

En este vídeo de PBS Infinite Series Kelsey Houston-Edwards nos explica lo que sucede cuando se utilizan formas distintas de medir la distancia euclidiana (que es a la que estamos acostumbrados) y donde los valores de la constante π varían entre...

Si te muerde una serpiente venenosa la única duda es si morirás en cuestión de horas, minutos, si la muerte será lenta y dolorosa o rápida, casi instantánea. Para evitar este problemilla al que se enfrentan casi un millón de personas...

Labracadabra son una serie de vídeos, seis por ahora, desarrollados por científicos de General Electric (GE) para mostrar «la magia de la ciencia». En cada uno de ellos se explica cómo hacer, paso a paso, diferentes experimentos sencillos y fáciles de...
Por Nacho Palou -
3 ENE 2017

El mercurio es el único metal que se mantiene líquido a temperatura y presión ambiente. En estado líquido sus átomos tienen suficiente energía térmica para vencer los vínculos metálicos que confinan a la mayoría de los metales a su estado sólido...
Por Nacho Palou -
2 ENE 2017

En diciembre de 2015 la Unión Astronómica Internacional anunció que la estrella mu Arae pasaba a llamarse Cervantes, y que los cuatro planetas que sabemos que orbitan a su alrededor recibían el nombre de Quijote, Dulcinea, Rocinante y Sancho en lugar...

Público, conferenciantes y organizadores tras Naukas Coruña neurociencia El sábado 11 de junio de 2016, con Víctor Grande a los mandos, los Museos Científicos Coruñeses, en los que trabajo en el MundoReal™, y la plataforma de comunicación científica Naukas, con la que...

Cinco libros de ciencia de otros tantos amigos que he leído este año y que me parecen todos y cada uno de ellos absolutamente recomendables: ¿Quién robó el cerebro de JFK?: tiempos bélicos y neurociencia, de José Ramón Alonso. Reseñado en...
Juno con su motor en primer plano El pasado 11 de diciembre la sonda Juno de la NASA pasaba por su tercer perijove, la parte más cercana a Júpiter de su órbita, en el que llegó a acercarse a un mínimo de...
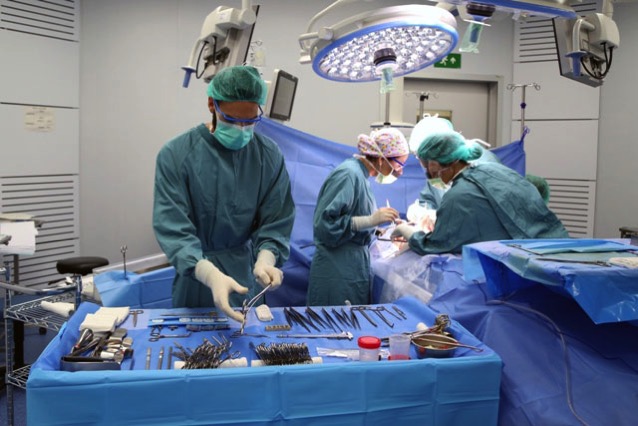
Acaba de hacerse público que el pasado mes de noviembre de 2016 el hospital Vall d'Hebron hizo 10 trasplantes en sólo 24 horas, lo que representa un récord en su programa de trasplantes. Nueve receptores, cuatro de ellos niños de entre...

La matemática Kelsey Houston-Edwards explica en este vídeo de PBS Infinite Series algunas cuestiones interesantes sobre el realismo y el antirrealismo en las matemáticas aprovechando los números primos, la conjetura de Goldbach y la definición del número π. El caso es...
Isotope [Android] es una preciosa app para Android con todos los elementos químicos de la tabla periódica bellamente presentados: fotografías (de un 70% más o menos, y subiendo), animaciones, detalles químicos… La versión gratuita de la app permite hacer una idea...

Einstein publicó sobre teoría de la relatividad en 1905 y 1915 (primero sobre la relatividad especial y luego sobre la relatividad general). Por eso esa película de 1923 tiene un encanto especial: es de la época en la que el cine...
Todo el mundo ha oído hablar del ruido blanco, que suele asociarse con los (antiguos) canales de televisión o radio analógicos en los que no había emisión y los receptores simplemente chisporroteaban al azar. También se da en otros fenómenos físicos,...

Faye Flam arroja algo de luz sobre una famosa cuestión que enlaza conceptos tan sutiles como la «inteligencia» y «el éxito económico», que suele enunciarse popularmente como: «si eres tan listo, ¿por qué no eres rico?» Este auténtico cierra-bocazas tiene algo de...

Esta materia oscura es tan importante para nuestra comprensión del tamaño, forma y destino final del universo que su búsqueda probablemente dominará la Astronomía en las próximas décadas.– Vera Rubin en 1978(vía Los Mundos de Brana) Otra persona que se ha llevado...

Me ha encantado este vídeo de Vsauce en el que he redescubierto la ley de Zipf, que ya habíamos mencionado brevemente en esta casa hace algún tiempo pero de la que no me acordaba, y que recibe su nombre del lingüista...
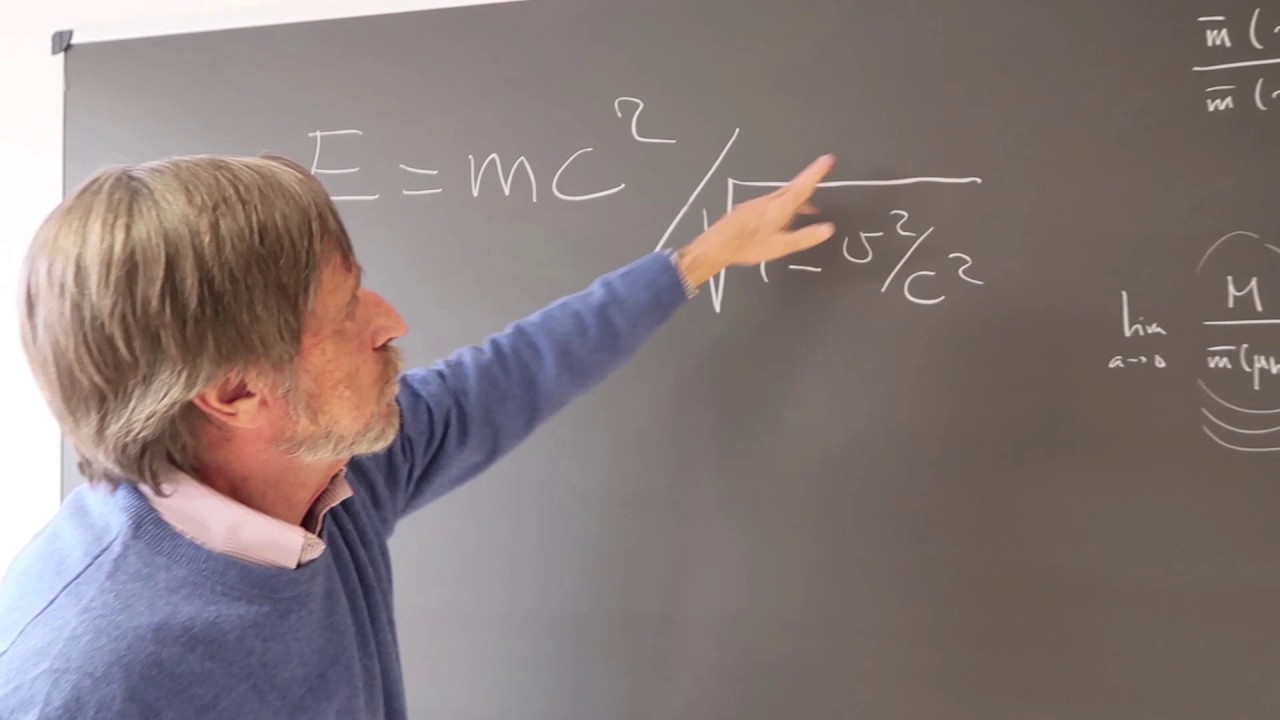
Desde el Instituto de Física Teórica nos llega este didáctico vídeo de Álvaro de Rújula, físico teórico del CERN, que resuelve una cuestión muy interesante sobre una de las ecuaciones más famosas de la física que quien más, quien menos, se...

Atracción digital, de Antonio Luis Martínez Cano, es la fotografía ganadora del certamen de fotografía científica Fotciencia 14: Nuestra vida cotidiana está rodeada de fenómenos físicos, solo es cuestión de observarlos adecuadamente a través de un objetivo para descubrir en ellos...
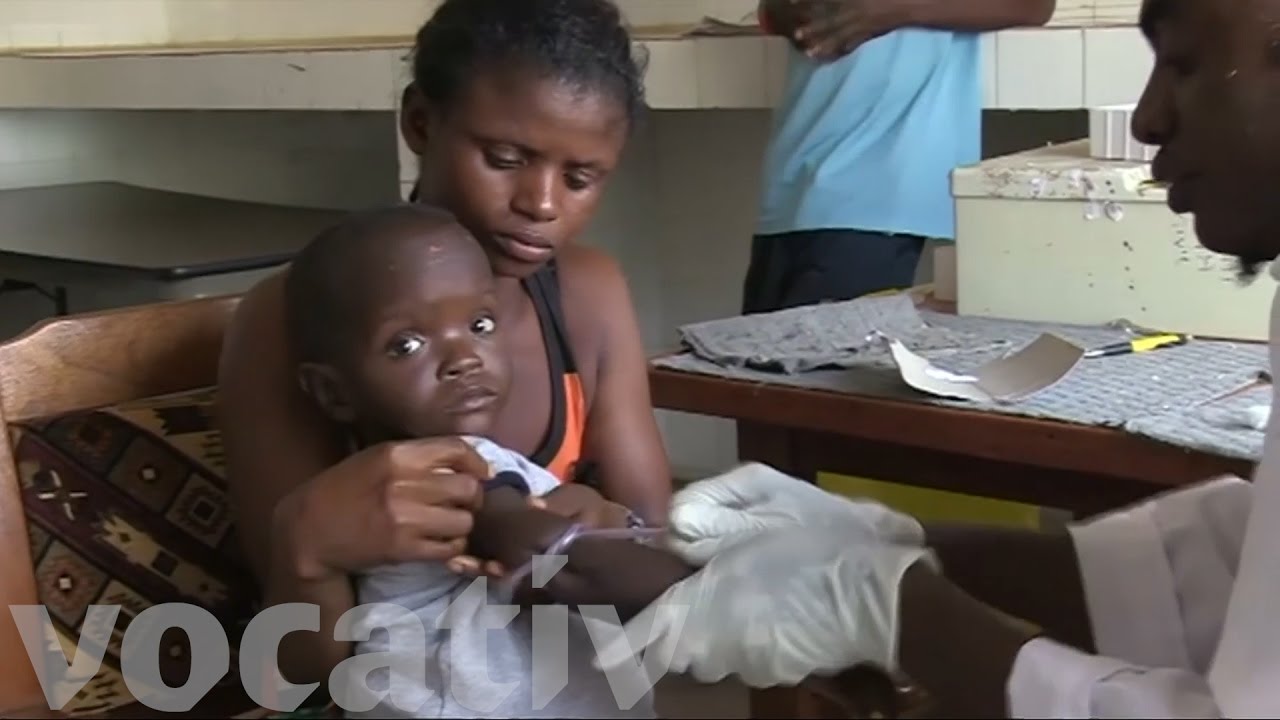
La OMS lleva desde 2015 realizando las pruebas definitivas de una vacuna llamada rVSV-Zebov («la vacuna contra el Ébola) en Guinea, con 5.837 personas primero y hasta 11.000 después. El éxito en la efectividad de la vacuna ha sido tan rotundo...

Tras el desastre del terremoto + maremoto de Japón que afectó a la central nuclear de Fukushima los científicos tomaron muestras sobre el terreno para vigilar el estado de la contaminación radioactiva. De modo que en 2015 capturaron un salmón (al...

En este blog nos gustan muchas veces más las preguntas que las respuestas, de modo que ahí van unas cuantas las que responde en esta especie de preguntas y respuestas [con subtítulos en inglés] Sean Carroll, el un cosmólogo del Caltech...

Las advertencias del divulgador siguen vigente: una sociedad tecnológica que no entiende de ciencia no tiene futuro. Cuánta razón tenía.

En Futurity, World’s lakes would cover land with 4 feet of water, Utilizando datos recientes obtenidos con satélites, los investigadores obtuvieron medidas precisas de la elevación sobre la superficie de la tierra, datos que se relacionaron después con miles de registros...
Por Nacho Palou -
20 DIC 2016
Este vídeo de la Royal Institution [subtítulos en castellano e inglés] la química Valeska Ting explica el principio cero de la termodinámica (a veces llamado «ley cero») que es quizá el menos conocido de las cuatro (para mucha gente, tan solo...

En la tradicional selección anual de Brain Pickings se pueden encontrar muchos de los mejores libros de divulgación científica de este año, de un nivel que los sitúa al alcance de cualquiera – no solo de los más expertos en las diversas...

En dos minutos este vídeo de la Royal Institution explica qué es la entropía: lo que más comúnmente conocemos como desorden. Algo difícil de definir pero intuitivo de captar. Algo que según dice la segunda ley de la termodinámica –que en...

alienígena1. adj. extranjero. Apl. a pers., u. t. c. s.2. adj. extraterrestre (‖ supuestamente venido desde el espacio exterior). U. t. c. s. Una divertida charla –tacos incluídos, luego no digáis que no avisamos– de Antonio Pérez Verde en el Ignite...

Un cohete Pegasus XL, lanzado desde el Stargazer de Orbital ATK, puso en órbita los ocho satélites de la misión Cygnss de la NASA el 16 de diciembre de 2016. El Cyclone Global Navigation Satellite System, o Sistema Satélite de Navegación...

Dígito viene del latín digitus (dedo) de modo que cuando levantamos uno, dos más dedos para indicar una cifra no estamos haciendo otra cosa que señalar dígitos para formar un número. La respuesta a la pregunta está en el vídeo y...

Con las mediciones de dióxido de carbono (CO2) y los datos obtenidos por el satélite de la NASA Orbiting Carbon Observatory-2 (OCO-2) la agencia espacial ha realizado esta visualización tridimensional que revela con detalle la presencia, incrementos y disminuciones y movimiento...
Por Nacho Palou -
15 DIC 2016

Los medios no siempre dan con el tono adecuado a la hora de contar las noticias relacionadas con la ciencia, y la astronomía no es ninguna excepción. Es frecuente, por ejemplo, que las noticias sobre planetas extrasolares vayan acompañadas de imágenes...

Casos como el de Nadia Nerea, en el que un padre sin escrúpulos se ha aprovechado de la relajación de estándares del periodismo para engañar a muchos –el caso ha saltado por los aires en los últimos días pero el padre de...
¿Qué misteriosas fuerzas […] establecen, en fin, esos ósculos protoplásmicos, las articulaciones intercelulares, que parecen constituir el éxtasis final de una épica historia de amor?– Santiago Ramón y Cajal,padre de la doctrina de la neurona,en Recuerdos de mi vida...

Según cuenta la televisión china CCTV un equipo de científicos e ingenieros de la Academia China de Ingeniería lleva tiempo trabajando con una bio-impresora 3D para crear vasos sanguíneos artificiales. De momento algunas de estas creaciones artificiales se han implantado a...

En Visions of Harmony: Inspired by NASA’s Mission Juno el investigador principal de la misión Juno de la NASA y varios músicos reflexionan acerca de la relación entre música y ciencia; acerca la curiosidad, una característica tan humana, que se expresa...
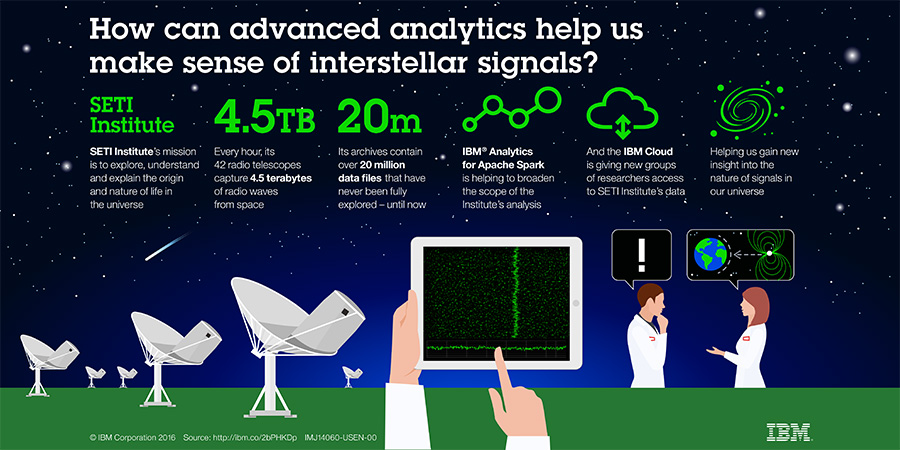
IBM ha publicado un pequeño estudio de caso titulado SETI Institute: expanding the parameters of the search for extra-terrestrial intelligence with advanced analytics en el que explica la tecnología de la marca que se está utilizando para actualizar el trabajo del...

Este experimento microscópico está inspirado en el clásico videojuego PacMan. Recrea el videojuego a escala microscópica: en total el laberinto mide menos de un milímetro de diámetro. El laberinto lo ocupan microorganismos. Los unicelulares, más pequeños y de color gris, hacen...
Por Nacho Palou -
7 DIC 2016

Esta tabla periódica 3D de Instructables recupera el primer diseño de tabla periódica de 1862 de Alexandre-Émile Béguyer de Chancourtois. (La que utilizamos actualmente, la de Mendeléyev, data de 1869). Chancourtois colocó los elementos químicos en un cilindro, de modo que...
Dominic Walliman explica en The Map of Physics, un vídeo de poco más de ocho minutos, los campos en los que se divide la física, convenientemente situados en un mapa para que sea más fácil ver cómo se relacionan unos con...

{ADVERTENCIA: ¡Peligro de muerte mortífera mortal! Los experimentos de este vídeo no están muy detallados, pero los componentes que se manejan son muy peligrosos y nadie en sus cabales querría recibir un premio Darwin por hacer el ganso con altas tensiones...

Este vídeo muestra de forma un tanto exagerada, desconcertante y en cierto modo melódica los botes y rebotes de unos potentes imanes de neodimio grabados a 4.000 fotogramas por segundo (unas 160 veces respecto a la velocidad real). Lo que va...

La astronauta Karen Nyberg experimentando con la Microgravity Science Glovebox. Foto: NASA Robert Frost, ingeniero y controlador de vuelo de la NASA, respondió a esta pregunta al alimón entre Quora y Forbes. Y es que si se piensa un poco, ciertamente no...

En órbita alrededor de Saturno desde el 1 de julio de 2004 la sonda Cassini comienza hoy, 30 de noviembre de 2016, la última fase de su misión. Cumplidos con creces los objetivos de la misión la programación de estas órbitas...
Público, conferenciantes y organizadores tras NaukasCoruña neurociencia Como Naukas Coruña Neurociencia funcionó rematadamente bien –aunque esté mal que yo lo diga– y nos va la marcha durante la clausura del evento los organizadores nos comprometimos a repetir la experiencia. Y ya os...

Aunque el aterrizador Schiaparelli no lo consiguió el orbitador de la misión ExoMars 2016 de la Agencia Espacial Europea no tuvo mayor problema en colocarse en órbita alrededor de Marte el pasado 19 de octubre de 2016. Desde entonces los responsables...

«Tal vez en la serie Westworld un androide como Maeve da el pego, pero no colaría en la vida real.» Por ahora. En Berkeley News, It takes less than a second to tell humans from androids, Los humanos son capaces de distinguir...
Por Nacho Palou -
29 NOV 2016

De momento se trata de un prototipo de Adidas: unas zapatillas de deporte biodegradables que una vez desechadas desaparecen en 36 horas. Las zapatillas están fabricadas con un material nuevo llamado Biosteel (creado por la compañía alemana AMSilk), una de cuyas...
Por Nacho Palou -
29 NOV 2016

El ingeniero que ayudó a electrificar el siglo XX y a inspirar lo inalámbrico, con cierta fama de «loco», no muy lejos de la genialidad.
Una de las cosas más sorprendentes que dicen la física cuántica –y no son pocas– es que dos partículas entrelazadas son capaces de «comunicarse» entre ellas de tal forma que cuando realizamos mediciones sobre una de ellas la otra es capaz...
Muchas melodías y sonidos tienen algo de fractales, pero en The Sound Of Mandelbrot Set Antonio (que también escribe en Fronkonstin) explica algunos de sus experimentos con el conjunto de Mandelbrot para convertirlo en notas musicales. Los resultados pueden oírse en...
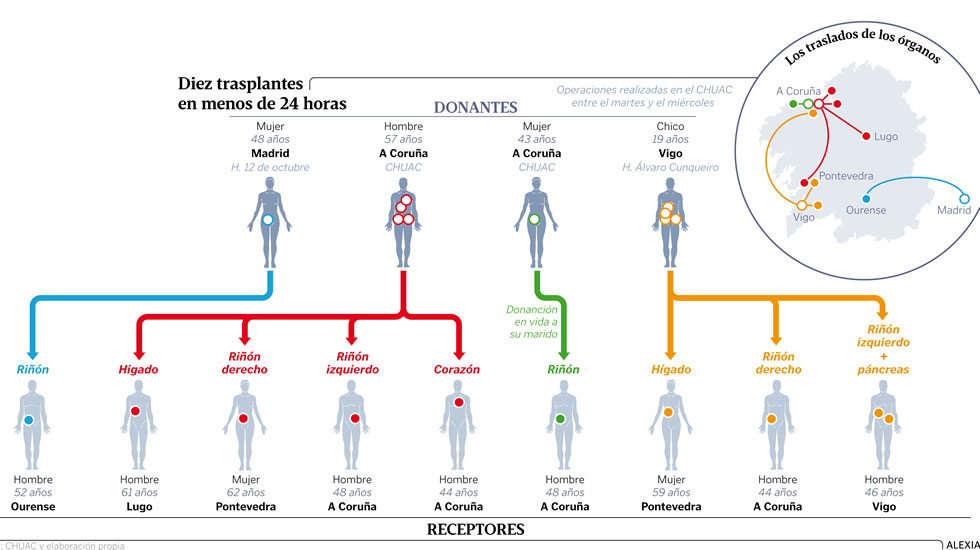
Cuatro donantes en A Coruña, Madrid y Vigo, uno de ellos una mujer que dona en vida un riñó a su marido, han permitido que en el Complexo Hospitalario Universitario de A Coruña (Chuac) se hayan levado a cabo diez trasplantes...
D3-force [código en Github] es un simulador de fuerzas entre partículas que utiliza un método denominado integración de Verlet para calcular los valores de la simulación – que no deja de ser una versión «simplificicada» de la realidad y cuya simplficación...

Lo cierto es que π se lleva toda la gloria cuando se habla de números interesantes en la matemática, pero el número e comparte muchas de sus características: es un número irracional, trascendente y no sigue ningún patrón. Pero nada de...

Este vídeo de Skunk Bear, un programa de divulgación científica de la NPR (la radio pública estadounidense), nos muestra de la mano de Adam Cole la historia del planeta tierra utilizando la metáfora del «campo de fútbol» como representación de los...

Novae, una visión estética y científica de una supernova, Durante la explosión de una estrella, tal vez causada por un colapso gravitacional, su luminosidad pueden aumentar hasta en 20 magnitudes. Esto sucede durante las últimas fases de la evolución estelar de...
Por Nacho Palou -
22 NOV 2016

Tras varios años «desaparecido en combate» el Congreso de Comunicación Social de la Ciencia vuelve a la carga. Su sexta edición se celebrará en la sede del Rectorado de la Universidad de Córdoba los días 23, 24 y 25 de noviembre de...

Si tienes media horita, échale un ojo a esta edición de Informe en V. Bajo las estrellas habla de lo que es un cielo oscuro de verdad y de lo que supone la contaminación lumínica. Cuenta también cómo funciona un planetario...

Encontré gracias a @pickover este vídeo bastante asombroso (y viejo) de Phillip Bradbury que muestra a un gigantesco autómata del juego de la vida emulando el juego de la vida. Había oído hablar de algunas estructuras de este tipo hace años,...
Casi superluna vs. meñique Hoy es el día. Llega la superluna más grande desde hace 68 años. Lo que quiere decir que la luna llena se producirá en el momento en el que nuestro satélite se encuentre en el punto de su...

Esta selección proviene de Goodreads; habiendo leído más o menos la mitad tan solo puedo concordar con ella. Es una lista ideal para quien quiera descubrir, aprender y maravillarse con las matemáticas: Los libros más populares de matemáticas 1. Gödel, Escher, Bach:...

Colgante diseñado por Cristina Romero para The Rosetta Legacy Poco antes del fin de la misión Rosetta la Agencia Espacial Europea lanzó una iniciativa llamada The Rosetta Legacy, El legado de Rosetta, en el que quería recoger testimonios acerca de pensamientos, sentimientos...

Por alguna razón ha resurgido este vídeo de Welch Labs que es en realidad el primero de una serie de trece que dedicaron a los números imaginarios. Lo más espectacular del primer vídeo es sin duda es la visualización sobre el...
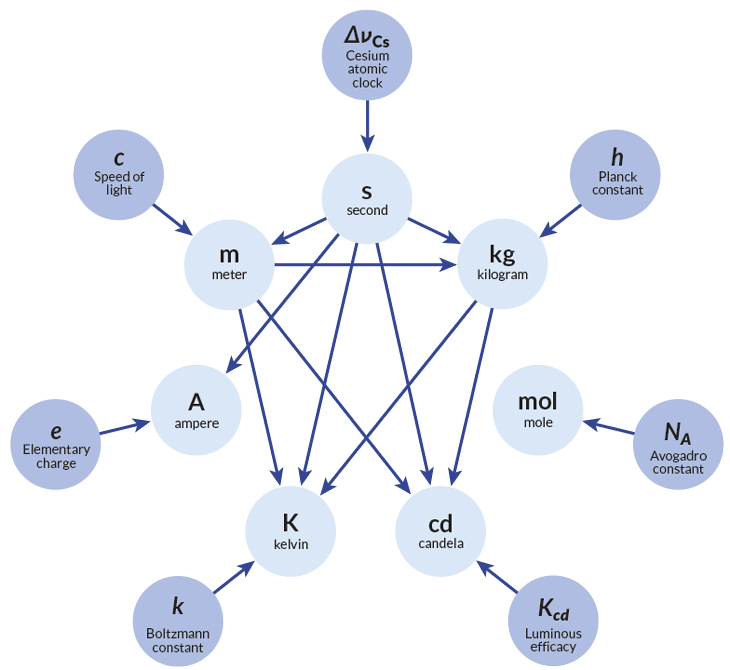
Las siete constantes que en el Sistema Internacional de Unidades definen las magnitudes físicas básicas (longitud, masa, tiempo…) se «actualizarán» a partir de 2018 para fijar aún más sus valores y de paso redefinir cuál es su relación de cara a...

Una de las tareas de la comunicación de la ciencia es ayudar a los ciudadanos a tomar decisiones y a tener espíritu crítico.- Xurxo Mariño. Tras el éxito de la primera edición en los Museos Científicos Coruñeses, en los que trabajo en el...

Descubrir los secretos del universo, transformar la comprensión de la ciencia y desentrañar los secretos de las estrellas con en planteamiento filosófico e innovador que lo situaron entre los más grandes hombres de la ciencia de todos los tiempos… para acabar...
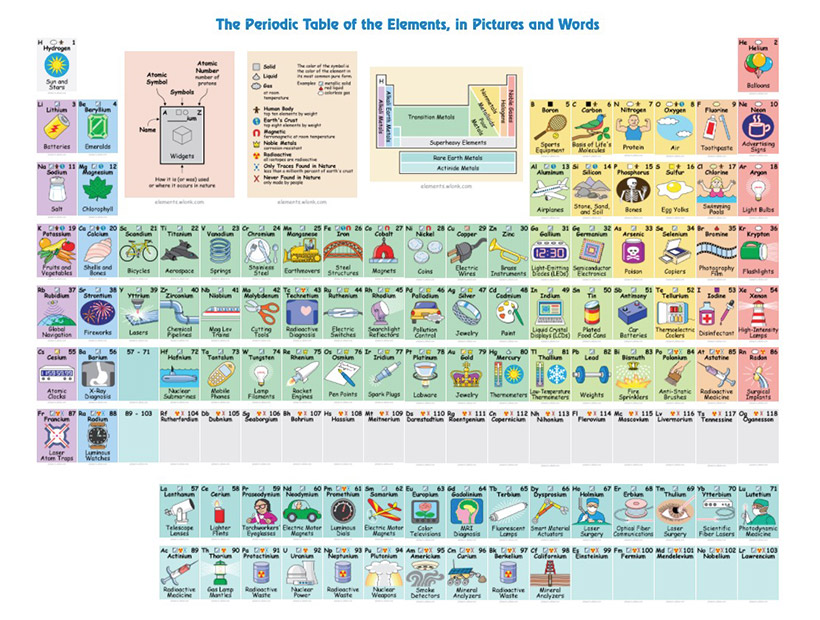
Mendeléyev asentiría orgulloso. Esta tabla periódica de los elementos con dibujos de Keith Enevoldsen muestra con palabras y objetos cotidianos para qué se usa cada uno de los elementos químicos que conocemos: desde el litio de las baterías al helio de...

En 2033 una misión internacional lanza a seis astronautas con destino a Marte. Pero durante el aterrizaje un fallo en el módulo de descenso hace que aterricen a más de 100 kilómetros de su punto de destino en el que los...

Nicholas Buer tiene este espectacular vídeo de La Palma, que no me resisto a dar a conocer aunque ya llevo un tiempo saturado de vídeos de belleza infinita, auroras y noches mágicas. Pero es que el protagonista es el cielo nocturno...

Hacer vibrar gotas sobre un altavoz en una placa de Petri en la que hay una fina capa de aceite de silicona permite obtener una visualización de las ondas y partículas de la mecánica cuántica que, aunque no sean lo mismo...

Super Luna y micro Luna por Catalin Paduraru – APOD 8/9/2014 Está haciendo las rondas la noticia que afirma que el próximo 14 de noviembre de 2016 podremos ver la superluna más grande de los últimos 68 años y que no volverá...

Uno de los mayores proyectos en marcha el campo de la astronomía es la construcción del Telescopio de Treinta Metros, o TMT por sus siglas en inglés de Thirty Meter Telescope. Formado por 492 espejos hexagonales de 1,4 metros sería el...

Uno de los problemas de la ciencia en la actualidad es que vive bajo la presión del «publica o perece», un esquema de cosas en el que vales tanto como los artículos que publicas. Esto lleva a que a menudo los...

El vídeo de Veritasium (con subtítulos en inglés) es una buena explicación —usando barritas de caramelo y cacahuetes, y también chocolate— sobre la soldadura en frío y su impacto en las misiones espaciales debido al vacío en el espacio, La soldadura...
Por Nacho Palou -
31 OCT 2016

El radiotelescopio de Green Bank, en Virginia (Estados Unidos) se dedicará al SETI Tal y como cuentan en BBC News un proyecto llamado The Breakthrough Listen Project (vale, suena un poco a Alan Parson’s Project) dedicará unos 100 millones de dólares a...

Después de entrar en modo seguro el pasado 19 de octubre de 2016 cuando su software de control detectó un error la sonda Juno de la NASA vuelve a estar completamente operativa. El modo seguro de una sonda espacial se activa...

Aparte de que demos o no por válido 42 como el sentido de la vida, el universo y todo lo demás hay otro punto de vista que es el que explica este vídeo animado de Minuto de Física, uno de nuestros...

En 1916 se creaba en la Residencia de Estudiantes de Madrid el Laboratorio de Fisiología de la Junta para Ampliación de Estudios, dirigido por el Dr. Juan Negrín, laboratorio que durante los siguientes veinte años sería una pieza fundamental en la formación...

El 24 de octubre de 2001 la sonda Mars Odyssey de la NASA entraba en órbita alrededor de Marte para una misión con una duración prevista de 32 meses, aunque en el momento de publicar esta anotación acaba de cumplir los...

¡Ay, si Descartes levantara la cabeza! He aquí una situación tan cotidiana como irritante, que mejor mirar desde la óptica del humor, protagonizada por Marta Flich y Ángel Martín en Solocomedia, con un guión de José Antonio Pérez. Mmm… Pues a...

El 14 de julio de 2015 a las 13:57:49, hora peninsular de España, la sonda New Horizons de la NASA llevó a cabo su sobrevuelo de Plutón, recogiendo durante los días previos y posteriores tantos datos como pudo acerca del ex–planeta...

El 19 de octubre de 2016, cuando estaba a unas 13 horas de su máxima aproximación al planeta en su segunda órbita alrededor de Júpiter, la sonda Juno de la NASA entró en modo seguro. El modo seguro de una sonda...

Los periodistas presentes en la rueda de prensa al respecto han tenido que sacárselo con sacacorchos en la sesión de preguntas, pero al final la los representantes de la Agencia Espacial Europea presentes han tenido que reconocer que no saben aún...

Mark McCaughrean, asesor científico del Centro Europeo de Investigación y Tecnología Espacial (ESTEC), nos cuenta en este vídeo qué tipo de cosas podemos aprender de misiones como Rosetta o ExoMars, que más allá de buscar vida en otros lugares del sistema...

Desarrollado por un equipo financiado por la agencia Darpa (Defense Advanced Research Projects Agency), investigadores de la universidad de Pittsburgh y del Pittsburgh Medical Center han desarrollado un brazo robótico controlado con el cerebro que que proporciona sentido del tacto al...
Por Nacho Palou -
17 OCT 2016

La innovación ha mejorado nuestras vidas en el último siglo. Desde la electricidad a los coches; desde la medicina a los aviones, la innovación hace que el mundo sea mejor. Bill Gates enAccelerating Innovation with Leadership El amigo Bill cree que...
Por Nacho Palou -
17 OCT 2016
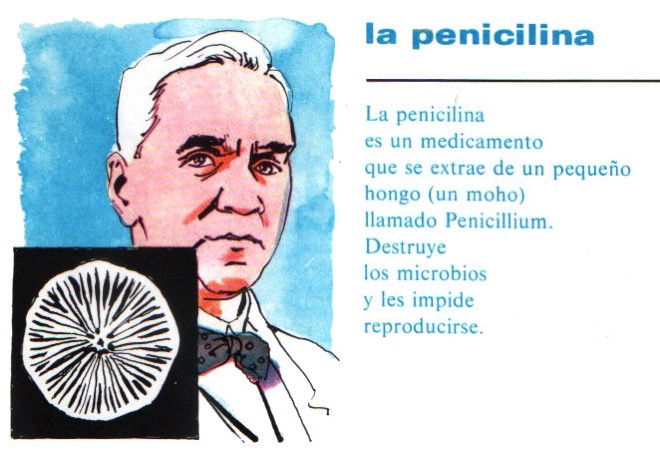
Todos –bueno, muchos– hemos oído contar la historia de cómo Alexander Fleming descubrió la penicilina. Según la historia «oficial» a la vuelta de unas vacaciones Fleming descubrió que algunas placas de Petri en las que estaba cultivando un estafilococo se habían contaminado...

El universo podría contener diez veces más galaxias de lo que se creía hasta ahora, según dicen en Science. En vez de unos 200.000 millones podría haber 2 billones de estas gigantescas estructuras en las cuales a su vez hay millones...

Me ha llamado la atención una noticia que he visto en varios medios estos días en la que hacían referencia a una carta, que no estudio, publicada en Nature que según las noticias en cuestión afirma que el ser humano no...

Tan importante como las leyes de la física, la relatividad y la mecánica hay un concepto subyacente la física, la computación e incluso la filosofía: la causalidad. Las causas van antes que los efectos. Y punto.

Por ahora sólo han publicado dos vídeos, este de arriba dedicado a Borges y a la memoria, con la aparición estelar de A. R. Luria y su paciente S, y este otro sobre Poe y el universo, pero los dos me...
En este mix malintencionado de los clásicos problemas lógico-matemáticos-filosóficos se combinan el dilema del prisionero y el dilema del tranvía, de modo que si conoces ambos y te pones a pensar… te puede acabar explotando la cabeza: Un tranvía en el...
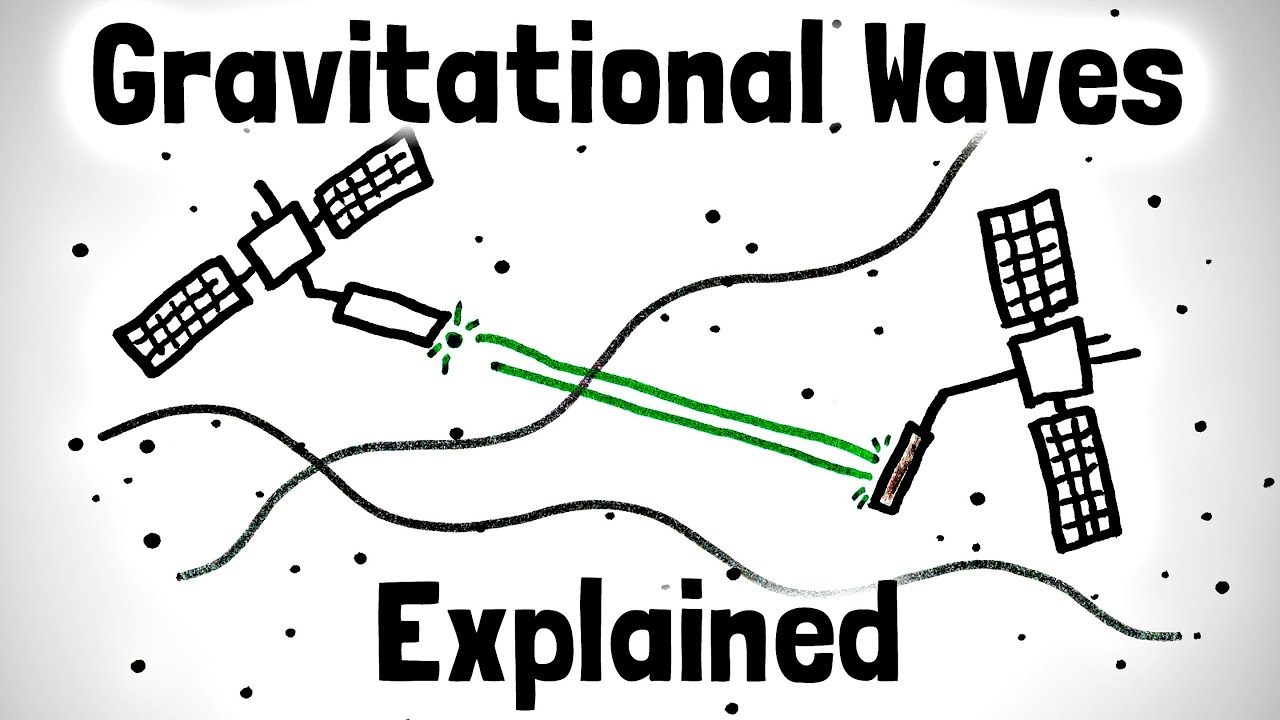
Ayesha publicó este vídeo explicativo a modo de Guía rápida de las ondas gravitacionales, esas curiosas oscilaciones en el espacio–tiempo que inundan los confines del universo. Las ondas gravitacionales acarrean los registros de los más apocalípticos eventos que hayan sucedido al...

El legado principal de la misión Rosetta es sin duda la enorme cantidad de datos que ha recogido acerca del cometa 67P/Churyumov-Gerasimenko y los que recogió sobre los asteroides Lutetia y Steins mientras iba para allá. Pero sin duda es también...
Me ha encantado Tree of Life Explorer, la versión interactiva de The Tree of Life. En ella se pueden explorar las relaciones entre una multitud de seres vivos y el ser humano. Para ello basta con hacer clic en cualquiera de...

Dianna Cowern, más conocida como Physics Girl y Jabril de SEFD Science, «el idiota que se hace demasiadas preguntas» ponen a prueba cinco trucos de magia física y a continuación explican el porqué de cada uno de ellos. Aunque el vídeo...
Por Nacho Palou -
5 OCT 2016

Eso me hacía preguntarme cada tarde por el sentido de la existencia, asombrarme de la fugacidad y fragilidad del ser humano, darle vueltas, con Leibniz, a por qué existe algo (el universo) en vez de no existir nada. Es donde comencé con...

La investigación que surgió en la barra de un bar llevada a cabo por científicos de la Universidad Carlos III de Madrid, en 2013, explica por qué se desborda una cerveza al golpear una botella con otra —la clásica broma del...
Por Nacho Palou -
4 OCT 2016
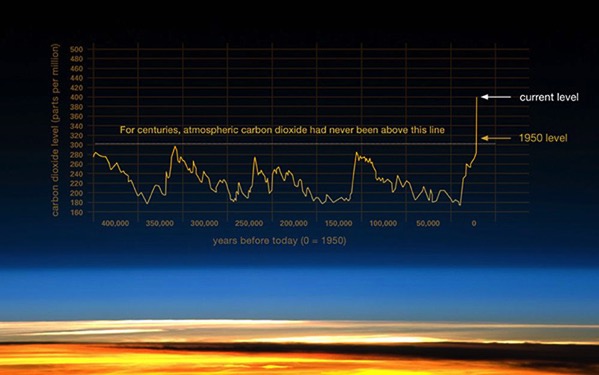
Mi recomendador de contenidos ya ha captado la ironía del ser humano, y hoy me sirve casi seguidos estos dos artículos, La inmortalidad tiene fecha: 2050, La titánica lucha contra enfermedades como el cáncer pertenecerán al pasado. Semejante predicción no puede...
Por Nacho Palou -
4 OCT 2016

Reykjavik a oscuras por dadigud Hace unos días, ante la previsión de que esa noche iba a haber una espectacular aurora boreal, las autoridades de Reykjavik, la capital de Islandia, decidieron que apagarían las luces de las calles entre las 22 y...

Mucho se ha escrito sobre la naturaleza del paso del tiempo, esa «dirección» o «flecha del tiempo», algo que no está apenas presente en las ecuaciones de la física, como si el hecho de que las cosas sucedieran «hacia el futuro»...

Por aquí hemos hablado alguna vez de las máquinas de Von Neumann, una idea sumamente interesante planeada hacia 1948-49 por uno de los matemáticos pioneros de la historia de la informática: John von Neumann. Este vídeo de TED-ed es un estupendo...

Hoy, 30 de septiembre de 2016, es el día en el que la Agencia Espacial Europea pone fin a la misión Rosetta, una de las más ambiciosas y de mejores resultados de los últimos años. El gran final de la misión...
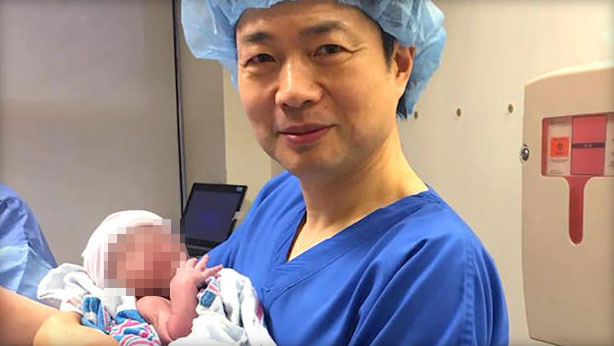
En New Scientist se habla de una nueva técnica que ha permitido que nazca un bebé con ADN de tres personas diferentes. Padre, madre y… donante. El objetivo era evitar que el bebé naciera con el síndrome de Leigh, un trastorno...

Impresión artística de los chorros de vapor de agua de Europa – NASA, ESA, y G. Bacon (STScI) Ya en 2012 el telescopio espacial Hubble parecía haber detectado unos chorros de vapor de agua saliendo del hemisferio sur de Europa, una de...

Lo mejor de este vídeo de Nature es que dura solo dos minutos; suficiente para que el físico Serge Haroche (Nobel 2012) explique en un lenguaje accesible al común de los mortales cómo se manipulan los fotones de forma individual en...
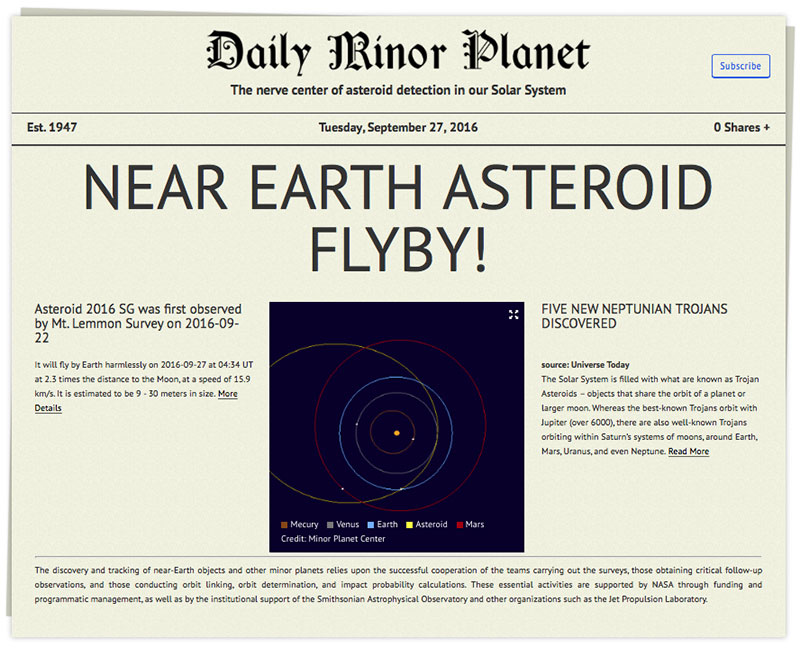
El sistema solar está llenito de asteroides y otros objetos que andan dando vueltas por ahí. Muchos de ellos se acercan a la Tierra, aunque aún no sabemos de ninguno que represente un peligro real para nosotros, a pesar de lo...
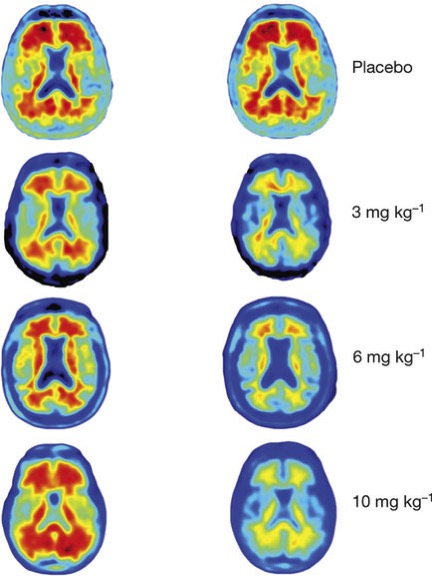
Del departamento de noticias muy esperanzadoras pero que hay que tomar con toda la precaución del mundo llega la historia que se puede leer en Are we close to find a treatment for Alzheimer´s disease? acerca de un medicamento que podría servir...

La app de meteorología Dark Sky comenzó como un proyecto de financiación colectiva. Cuando salió en 2013 se consideró como la mejor app de meteorología para móviles de todos los tiempos, a pesar de sus limitadas funciones y disponibilidad de entonces...
Por Nacho Palou -
26 SEP 2016

Great Big Story nos cuenta esta vez cómo a mediados de los años 60 se hablaba del Big Bang como una teoría bastante plausible en especial por los análisis y cálculos de Edwin Hubble (con datos de Henrietta Leavitt y otras...

Por aquí hemos hablado más de una vez de la curva de Hilbert y otras similares gracias a uno de los vídeos de Vi Hart; son formas relativamente simples en cuanto a su aspecto y construcción que evolucionan para rellenar el...
FAST ya terminado Uno de los paneles del FAST durante su instalación Con unos días de adelanto sobre el calendario previsto, ya que su entrada en funcionamiento estaba planeada para el 30 de septiembre de 2016, China acaba de poner en marcha...
Homeopatía contra la gripe… WTF!!! A pesar de que hay mil y un estudios que afirman sin lugar a dudas que la homeopatía no tiene ninguna eficacia más allá del efecto placebo es un producto –que no medicamento– que se pueden encontrar...

Lanzada el 2 de marzo de 2004 con el objetivo de colocarse en órbita alrededor del núcleo del cometa 67P-Churyumov/Gerasimenko para acompañarlo en su periplo hacia el Sol y de depositar un aterrizador sobre él la misión Rosetta de la Agencia...

Gavin de Tinkerings construyó este explorador de autómatas celulares, una máquina física y muy visual para ver en funcionamiento los autómatas celulares 1D más básicos. En su pantalla cada línea es un «momento» en la evolución de las «células»; la máquina...
Va a haber que ir ahorrando para intentar conseguir esta maravilla: El disco dorado de las Voyager: edición 40º aniversario. Una especie de copia «remasterizada» de los discos dorados originales que iban tanto en la Voyager 1 como en la Voyager...

Otro año más la gente del Instituto de Investigaciones Improbables ha presentado su selección de los mejores logros científicos que primero te hacen reír y luego pensar. Los ganadores de los premios Ig Nobel de 2016 han sido: Reproducción (Egipto): Ahmed Shafik,...
El pasado 8 de septiembre de 2016 la NASA lanzaba la misión Osiris-Rex rumbo al asteroide Bennu. Llegará allí en agosto de 2018 tras un encuentro con la Tierra en septiembre de 2017 que le permitirá ganar velocidad y modificar la...

A menudo nos encontramos con noticias que hablan de resultados de estudios médicos que nos dejan con cierta inquietud porque éstos se comunican con un titular lo más espectacular posible que prácticamente nunca recoge los matices del estudio. Por ello la Asociación...

Lanzado el 19 de diciembre de 2013 el telescopio espacial Gaia de la Agencia Espacial Europea tiene como misión realizar el mapa más detallado hasta la fecha de nuestro vecindario cósmico. Para ello estudiará algo más de 1000 millones de estrellas...

El vídeo corresponde a la prueba de encendido de un propulsor complementario del cohete SLS de la NASA. Tuvo lugar a finales del mes de junio pasado. El motor de prueba se encendió con éxito, expulsando gases a más de 3300°...
Por Nacho Palou -
16 SEP 2016
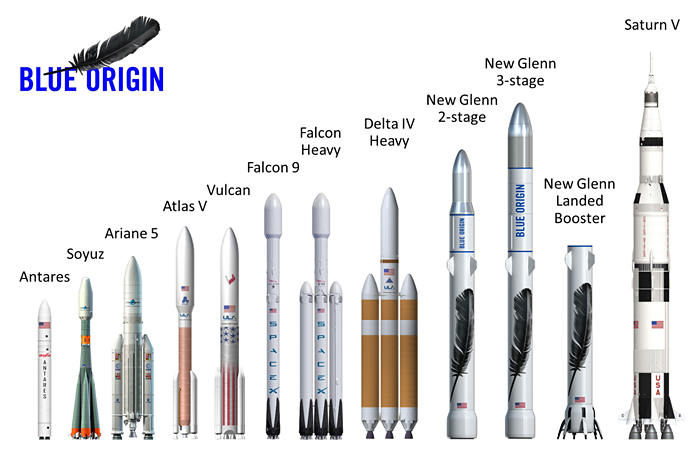
Dependiendo de la configuración de 2 o de 3 fases el cohete New Glenn alcanzará los 82 o los 95 metros de altura. El «landed booster» es la parte reutilizable que vuelve a tierra. El Saturno V medía 110 metros de altura...
Por Nacho Palou -
13 SEP 2016

En esta ilusión óptica hay doce puntos negros, pero nuestros ojos son incapaces de verlos todos a la vez. Se conoce como Ilusión de la extinción, de Ninio. No soy experto en el tema, pero creo que la explicación tiene que...

Este vídeo de la Harvard Medical School muestra un «experimento creativo» mediante el cual se puede ver a simple vista cómo las bacterias evolucionan y se vuelven resistentes a los antibióticos, algo que desde hace tiempo lleva convirtiéndose en un verdadero...

Muchos alimentos vienen en envoltorios de plástico, lo que produce un montón de desechos y de basura. Y ni siquiera es la forma óptima de envolver alimentos. Un grupo de investigadores ha desarrollado una lámina transparente hecha con proteínas obtenidas de...
Por Nacho Palou -
8 SEP 2016
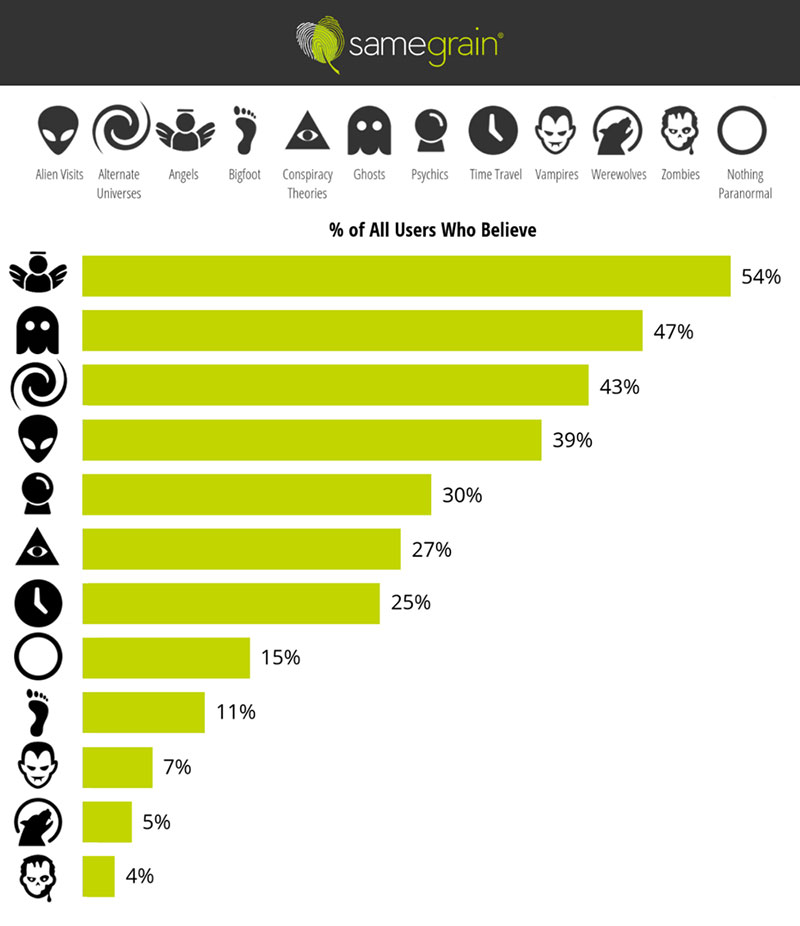
¿En qué cosas raras cree la gente que «cree cosas»? En SameGrain se publicó una serie de anotaciones de Jonathan Seale que examinan los perfiles de todas esas personas que tienen «creencias» en lo paranormal, misterioso y esotérico: We Want to...

El método de la «mano en garra» es la forma «correcta» de coger la taza de café, según la ciencia En A Study on the Coffee Spilling Phenomena in the Low Impulse Regime el investigador coreano Jiwon Han afirma haber determinado cuál...
Por Nacho Palou -
6 SEP 2016

Philae sobre 67P – Imagen principal y de Philae: ESA/Rosetta/MPS for OSIRIS Team MPS/UPD/LAM/IAA/SSO/INTA/UPM/DASP/IDA; imagen de 67P: ESA/Rosetta/NavCam – CC BY-SA IGO 3.0 Con poco más de tres semanas restantes en su misión y con todos los objetivos científicos de ésta cubiertos...

Este vídeo educativo de TED-ed explica la historia del problema de los puentes de Königsberg y cómo los intentos de genios matemáticos como Euler por resolverlo dieron lugar a la «geometría de la posición», ahora conocida como «teoría de grafos». Es...

¿Son todas las lágrimas iguales? ¿Cambian su forma dependiendo de cuál sea su origen? ¿Son las lágrimas de cebolla diferentes de las del dolor, el las del pesar de nuestros sentimientos o a las que nos protegen frente a una fuerte...

«Este es un experimento potencial y extremadamente peligroso que no deberías probar por tu cuenta porque como toques el metal te puede a soltar un zurriagazo que no veas». Así comienza todo buen vídeo de científicos locos, niños. Así que obedeced....

En una noche clara y con un cielo realmente oscuro seríamos capaces de ver unas 3000 estrellas a simple vista. Pero eso es algo que muy pocos hemos llegado a ver alguna vez, ya que en las ciudades la contaminación lumínica...

La Dragon 9 a su partida de la EEI Un amerizaje a 525 kilómetros al oeste de Baja California a las 15:47 UTC del 26 de agosto de 2016 ponía fin a la misión de la cápsula de carga Dragon SpX–9...

El canal de Kurzgesagt está lleno de vídeos interesantes, pero ahora que se está hablando tanto de Próxima b me ha parecido especialmente interesante rescatar The Last Star in the Universe, uno acerca de las enanas rojas. Próxima b es un...

Anda haciendo las rondas una noticia sobre la detección de una posible señal alienígena desde la estrella conocida como HD 16459 por parte del radiotelescopio ruso Ratan-600. Pero, según cuentan en "Baffling" "signal" "from HD 164595" is probably none of the above,...
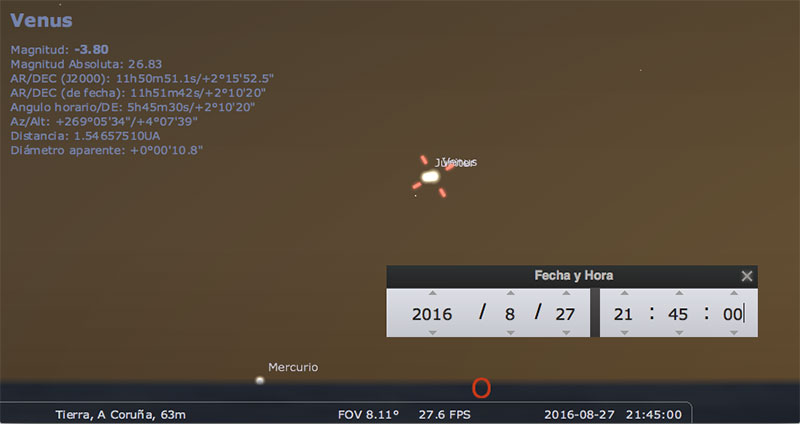
Venus y Júpiter el 27 de agosto de 2016 – Stellarium El mes de agosto de 2016 está siendo una buena oportunidad para disfrutar de la vista de Venus, Mercurio, Júpiter, Marte y Saturno al atardecer. Pero el atardecer del 27 de...

En la primera parte de este fragmento de conversación entre dos grandes divulgadores, el astrónomo Neil deGrasse Tyson y el etólogo Richard Dawkins sobre matemáticas, lógica y cómo nuestros cerebros parecen estar «cableados» para cierto tipo de conocimientos pero no tanto...
Impresión artística de la superficie de Próxima b Uno de los objetivos de la búsqueda de planetas extrasolares es encontrar uno similar a la Tierra, y según se puede leer en Se descubre un planeta en la zona habitable que rodea a...

Utilizando nuevas técnicas de análisis un grupo de científicos del Joint Genome Institute del Departamento de Energía de EEUU ha logrado encontrar más de 125000 secuencias virales parciales desconocidas en 3042 muestras tomadas por todo el mundo, tal y como se puede...

Un vídeo en 360º de los buttes de Murray, así llamados en honor a Bruce C. Murray, director del Laboratorio de Propulsión a Chorro y co-fundador de la Sociedad Planetaria, formado a partir de imágenes tomadas por Curiosity el 5 de...

Si ahora hasta los libros tienen tráilers el nuevo disco de Vangelis titulado Rosetta, inspirado por la misión homónima al cometa 67P/Churyumov-Gerasimenko de la Agencia Espacial Europea, no va a ser menos Sale a la venta el 23 de septiembre de...
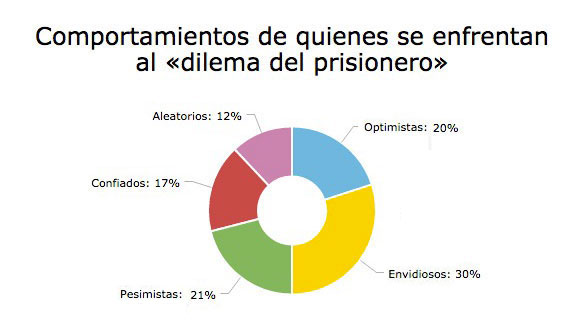
Un trabajo titulado Humans display a reduced set of consistent behavioral phenotypes in dyadic games explica cómo en el conocido dilema del prisionero los protagonistas pueden englobarse en cuatro grupos básicos. El dilema del prisionero es una situación en la que...
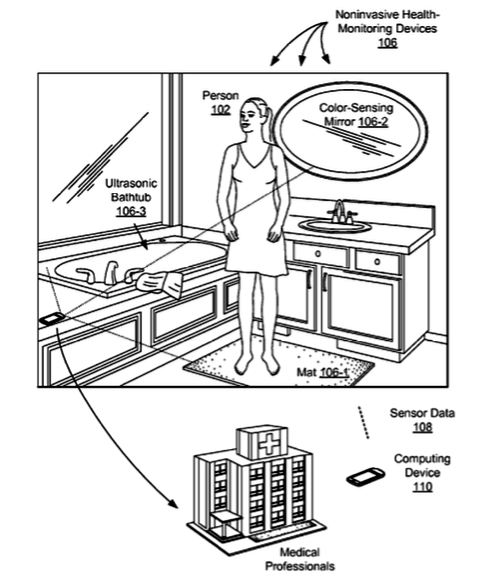
El «Google Bathroom» es una idea «a futuro» que apenas pasa del boceto, pero que ya está en la oficina de patentes. Plantea aprovechar el equipamiento del cuarto de baño que se utiliza a diario para monitorizar la salud, principalmente en...
Por Nacho Palou -
16 AGO 2016

Cinco planetas a la vista en el atardecer de agosto de 2016 - Imagen generada con Stellarium En estos días, y si estás en una latitud en la que se ponga el Sol, puedes ver cinco planetas en el cielo si miras...
Lo cuenta Juan Ignacio Pérez en Beber alcohol produce cáncer: un metaestudio cuyos resultados han sido publicados recientemente confirma que el consumo de alcohol es capaz de producir cáncer de bucofaringe, laringe, esófago, hígado, colon, recto y mama. No lo sugiere, lo...

Uno entre un millón. Millonésima. 1 ppm. 1/1000000. 0,000001. Hay muchas formas de expresar esta idea, pero es tan sencilla como dividir 1 entre un 1.000.000; imaginar un millón de cosas y pensar cuánto supone una de ellas frente a las...
Polio Vaccination | Egypt: vacunación contra la polio en Egipto - CC CDC Global En el verano de 2015 hablábamos de como hacía un año que no aparecían nuevos casos de poliomelitis en África, lo que acercaba al continente a poder ser...

Me ha encantado esta charla TED de Manuel Lima en la que habla de como la representación del conocimiento ha ido pasando con el tiempo de árboles con ramas perfectamente definidas sin conexiones entre ellas a redes en las que casi...

Nuestro sistema solar comparado con el agujero negro central del Cúmulo de Phoenix Situado a unos 5700 millones de años luz de nuestra Vía Láctea el Cúmulo de Phoenix es una de las estructuras más grandes que hemos descubierto hasta ahora en...

Las medallas de oro olímpicas que se entregan en Río 2016 no son de oro. Químicamente son tan solo 1,2% de oro y 98,8% de plata (de un 99,9% y un 92,5% de pureza, respectivamente). Las de plata sí que son...

La Aether 3D Bioprinter es un impresora 3D capaz de imprimir materia orgánica inyectando los compuestos mediante jeringas. El vídeo corresponde a un prototipo inicial que explora la idea de imprimir hueso y tendón utilizando una impresora con varios materiales simultáneamente,...
Por Nacho Palou -
14 AGO 2016

Con un sencillo ejercicio presentado estupendamente como el acto de lanzar 78 monedas intentando obtener «cara» en todas Josh Worth explica unas cuantas cosas sobre la probabilidad de existencia de otras formas de vida extraterrestres en algún otro lugar del universo....
Científicos de la universidad pública de Iowa han desarrollado una batería eléctrica que cuando se agota, se disuelve en agua y desaparece sin dejar rastro visible. El primer prototipo mide unos pocos milímetros y proporciona 2,5 voltios. Se trata de un...
Por Nacho Palou -
12 AGO 2016

Una cucharada de nitrógeno líquido patinando sobre gasolina, alcohol isopropílico y agua. Curioso....
Por Nacho Palou -
11 AGO 2016

El profesor de matemáticas Jeff Miller tiene en su web esta espectacular colección de Imágenes de grandes matemáticos en sellos de correos, acompañados de muchas de sus fórmulas y diagramas geométricos. La página en sí no es gran cosa visualmente, muy...

Estoy seguro de que en el estómago el espectáculo no es tan fascinante. Vía The Loop....
Por Nacho Palou -
10 AGO 2016

La Vía Láctea, Marte, Saturno, Antares y una estrella fugaz vistos desde O Grove, Galicia – Pietro Francia Como todos los meses de agosto llega la lluvia de estrellas de las Perseidas, que este año tiene su pico de actividad en las...

Wanda Diaz Merced es astrofísica, aunque durante un tiempo creyó que su carrera profesional había terminado tras perder la vista, lo que le impedía analizar los gráficos o las imágenes que producían los instrumentos con los que trabajaba. Pero lejos de...
Una respuesta simple a un mensaje elemental es un proyecto para recopilar opiniones de personas de todo el mundo acerca de una pregunta, ¿Cómo modelarán el futuro nuestras interacciones ambientales actuales? Hoy nos hallamos situados en un periodo teóricamente conocido como...
Hace tiempo que presentamos por aquí en qué consiste la conjetura de Collatz, un problema matemático que hasta un niño de primaria puede entender pero que lleva casi un siglo volviendo locos a los matemáticos: Piensa un número cualquiera, que sea...
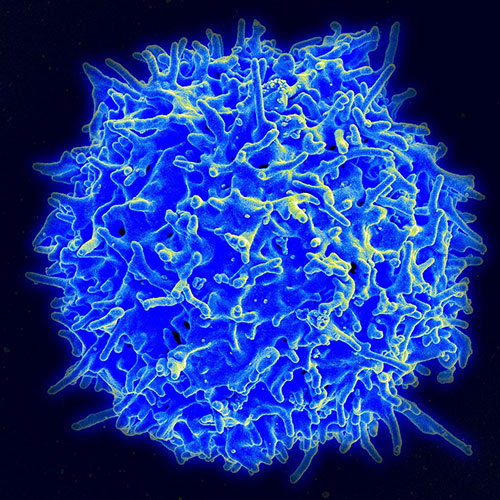
Desarrollado por Emmanuelle Charpentier y Jennifer Doudna, Crispr –más exactamente Crispr/Cas9– es un método de edición de ADN extraordinariamente potente que, no en vano, les ha servido a sus creadoras para hacerse con el Premio Princesa de Asturias de Investigación Científica y...

Pues depende. Según como se mire la pregunta puede no tener sentido; si se refiere al día sidéreo que es lo que tarda un cuerpo celeste en dar una vuelta sobre sí mismo en relación con otras estrellas estaríamos hablando del...

Como parte del esfuerzo de concienciar a los padres de la importancia de las vacunas desde el 1 de enero de 2016 está en vigor en Australia una norma que dice que si un niño no tiene sus vacunas al día...

Estos días ha sido noticia una sentencia del Tribunal Superior de Justicia de Madrid que reconoce la incapacidad permanente total para ejercer su profesión a Ricardo de Francisco, un ingeniero de telecomunicaciones que, según la sentencia, sufre electrosensibilidad. Vaya por delante...

El CERN, la Organización Europea para la Investigación Nuclear, aparece en TripAdvisor desde 2012, y en este momento ocupa el número uno en las listas de las 24 visitas y 28 museos de Ginebra. También tiene el Certificado de Excelencia de...

The Backyard Scientist la vuelve a liar parda usando termita para fundir metal a más de 2000° para ver qué sucede cuando se coloca cerca del metal fundido un poderoso imán de neodimio. El vídeo es entretenido y siempre está bien...
Por Nacho Palou -
3 AGO 2016

¿Dejarías que el «piloto automático» de un Tesla llevara el coche sin prestarle atención? ¿Te subirías a un coche autónomo como los de Google? ¿Y a un avión sin pilotos manejado sólo por su piloto automático? ¿O a un dron ambulancia?¿Conoces...

En una sociedad que depende de la ciencia y la tecnología tanto como la nuestra es fundamental estar bien informado para poder tomar decisiones con conocimiento de causa. Pero sin rebuscar mucho es fácil ver «reportajes» sobre electrosensibilidad en un informativo en...

Lanzado el 17 de febrero de 2016, el observatorio espacial de rayos X Hitomi de la Agencia Japonesa de Exploración Aeroespacial resultaba destruido en órbita apenas un mes después mientras aún estaba en su periodo inicial de pruebas. Su pérdida fue...
Hace tiempo que Brant Yorgey tuvo la genial idea de plantear unos algoritmos para crear diagramas de factorización de los números naturales. Básicamente se toma un número natural para ubicar en un plano tantos puntos como indique. Se descompone previamente el...
28 años de sol sin protección En el hemisferio norte estamos en pleno verano, lo que para muchos es sinónimo de días de sol y playa. Aunque hay que tener mucho cuidadito con el sol todo el año, so pena de acabar...

He estado viendo los vídeos de IAC Investiga, una serie de piezas de 10–12 minutos en las que el Instituto de Astrofísica de Canarias explica sus principales líneas de investigación: Física Solar Sistemas Planetarios Galaxias Cosmología y astropartículas Estrellas y medio...

Rosetta, el nuevo disco de Vangelis en honor a la misión homónima al cometa 67P/Churyumov-Gerasimenko de la Agencia Espacial Europea, sale a la venta el 23 de septiembre de 2016. Los títulos de los temas que contiene son Origins (Arrival) Starstuff...

Connor Flood ha sido el encargado de un proyecto apasionante en las tripas de Wolfram Alpha, ese poco conocido «motor de conocimiento» con aspecto de buscador pero que cuenta con gigantescas bases de datos estructuradas y con el cerebro de Mathematica,...
GroupET10 Aliens – CC Interdimensional Guardians En If we ever came across aliens, would we be able to understand them? se preguntan si llegaríamos a ser capaces de comunicarnos con unos alienígenas en el caso de que alguna vez nos encontráramos con...
Después de que no se haya registrado ningún caso de sarampión en Brasil en un año la Organización Panamericana de la Salud, afiliada a la Organización Mundial de la Salud, ha declarado interrumpida la transmisión de la enfermedad en ese país....

Philae durante su descenso hacia 67P Dentro de la campaña para optimizar el uso de la energía que producen sus paneles solares según se va alejando del Sol los responsables de la misión dieron la orden a Rosetta de apagar la radio...
Women of NASA es la propuesta de 20tauri para que Lego saque al mercado un conjunto que homenajea a cinco mujeres importantes en la historia de la NASA: Margaret Hamilton, quien escribió el software de a bordo de las misiones Apolo....
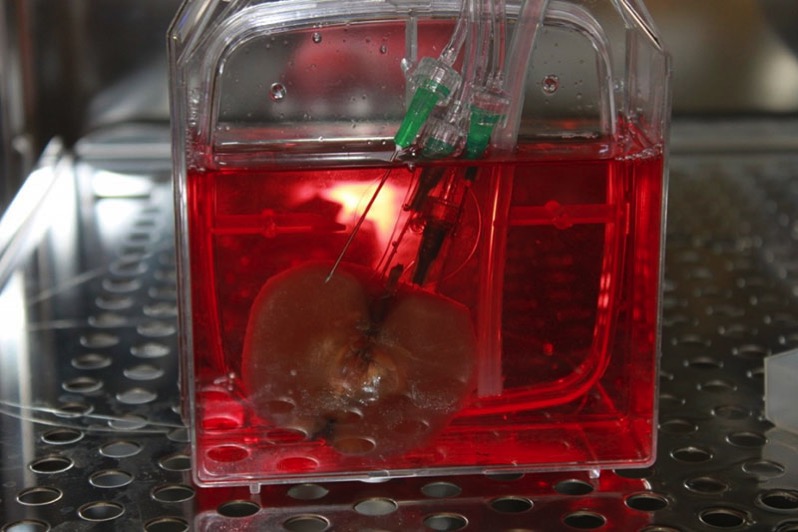
Hace años que científicos de todo el mundo están trabajando en crear órganos a partir de estructuras en 3D que luego pueblan con células madre, como por ejemplo hicieron en la universidad de Minesotta. Allí consiguieron que un corazón del que...

Exoplanetas potencialmente habitables ordenados por su Índice de Similitud con la Tierra, mayo de 2016 – PHL @ UPR Arecibo Desde que somos capaces de encontrar planetas más allá de nuestro sistema solar hemos encontrado algunos que van mucho más allá de...

Independientemente de que Plutón ya no sea considerado un planeta el telescopio del Observatorio Lowell que Clyde Tombaugh utilizó para descubrirlo nos ayudó también a descubrir y empezar a entender la parte del sistema solar en la que se encuentra éste....

Ma'at en el modelo 3D en línea de 67P La Agencia Espacial Europea ha decidido que el 30 de septiembre de 2016 la sonda Rosetta, ahora mismo en órbita alrededor del núcleo del cometa 67P/Churyumov–Gerasimenko, aterrizarará en Ma'at, una zona del lóbulo...

Estas curiosas y extrañas burbujas gigantes de metano surgen bajo tierra y se quedan ahí… ¡Boing, boing! Las descubrieron científicos del Environmental Research Centre en la isla de Belyy en la Península de Yamal, en las gélidas tierras del norte de...

Lanzada en febrero de 2015 a bordo del Deep Space Climate Observatory, la cámara EPIC de la NASA está todo el rato mirando hacia la Tierra desde un punto situado a unos 1,5 millones de kilómetros de esta en dirección al...

Carl Sagan es una de las personas que más admiramos en esta casa tanto por su faceta de escéptico convencido como por la de divulgador. Por eso me ha llamado mucho la atención una frase suya que me he encontrado en...
Hace mucho que los científicos tienen claro que la corteza cerebral se divide en distintas zonas, muchas de ellas con una función más o menos definida, aunque gracias a la plasticidad neuronal estas funciones pueden ser adoptadas por otras zonas si...

Preparar una charla en formato Ignite –5 minutos y 20 diapositivas que van pasando de forma automática cada 15 segundos– es todo un desafío, y más si eres Jose «Scientia». Pero aún así se las ha apañado para incluir en Estamos...

Aunque soy «de ciencias» odio cada vez más profundamente esa distinción, artificial y errónea, entre ser de ciencias o ser de letras; es algo que me horroriza. Por eso me ha encantado esta charla de Miriam Albusac Jorge, del Departamento de...

Serán algo más de 50 charlas sobre ciencia de diez minutos contados de duración, pero de los temas más variados, así que no te da tiempo a aburrirte si una trata sobre algo que no te interesa demasiado. Habrá también entrevistas al...

A las 11:53 UTC del 20 de julio de 1976 el aterrizador de la misión Viking 1 de la NASA tomaba tierra en Chryse Planitia, convirtiéndose en la primera sonda en sobrevivir al aterrizaje en el planeta rojo. La habían precedido...

Un precioso ensayo con fotografías del Museo Kuygens de Hofwijck, un lugar muy especial cuya historia merece la pena ser contada. Fue el hogar del astrónomo Christiaan Huygens y se utilizó como escenario histórico en Cosmos, de Carl Sagan.

Tras dos intentos fallidos parece que por fin tendremos dos micrófonos en Marte en 2020. El primero de estos intentos fallidos lo llevamos a cabo con el Mars Polar Lander, que se estrelló en 1998; el otro fue con el Phoenix Mars...

Los científicos sacan los trapos sucios de la ciencia: siete problemas desde la financiación hasta el estrés estudiantil.

Plutón en 1930 en las placas fotográficas en las que lo descubrió Clyde w. Tombaugh: es el pequeño punto al que apunta la flecha Plutón en 2015 visto por la sonda New Horizons a 800 000 kilómetros de distancia Tras un viaje de...

Júpiter y tres de sus lunas– NASA/JPL-Caltech/SwRI/MSSS Esta es la primera imagen enviada a la Tierra por la JunoCam de la sonda Juno de la NASA tras haber entrado en órbita alrededor de Júpiter y haberse acercado en el proceso hasta sólo...

El sonido de este vídeo se corresponde a las señales de radio emitidas por las auroras de Saturno recogidas por el instrumento Radio and Plasma Wave Science de la sonda Cassini, convenientemente hechas audibles dividiendo su frecuencia por 44. También están...

¿Por qué si la Tierra está en la parte de su órbita más lejana del Sol en el hemisferio norte estamos en verano? ¿No debería ser al revés? ¿Por qué los días más calurosos del verano van con un poco de...

Para esas horas de asueto veraniegas, tres de los libros de ciencia que más me han gustado en los últimos tiempos: El escritor que no sabía leer y otras historias de la neurociencia, por José Ramón Alonso, acerca de cómo funciona...
Un breve vistazo en 360º por fuera y por dentro a la sonda Juno de la NASA, la segunda que ponemos en órbita alrededor de Júpiter. El vídeo incluye subtítulos en inglés que Google no traduce mal del todo para ver...

Desde hace muchos años las industrias alimentaria y cosmética han estado mintiendo descaradamente al ciudadano con el único objetivo de enriquecerse. Si a esto se une que como herramienta de engaño […] utilizan la ciencia, uno de los mayores valores que...

Impresión artística del encuentro de la New Horizons con un objeto del cinturón de Kuiper - NASA/JHUAPL/SwRI/Alex Parker Cada vez hacemos mejor las sondas espaciales, tanto por los avances en materiales y electrónica como porque de fallos anteriores vamos aprendiendo como mejorar...

Tratar de comprender cómo es lo que nos rodea es la única forma de empezar a entender todo lo demás, incluso a sabiendas de que ese todo es inalcanzable. Es bello vivir con preguntas. Si la ciencia me hubiese dado respuestas...

Stephen Pakbaz se ha currado una impresionante reproducción en Lego de la sonda Juno de la NASA, recién entrada en órbita alrededor de Júpiter. En Prototype LEGO Juno están las fotos; en LEGO Set MOC-1363 - Juno están las instrucciones detalladas,...
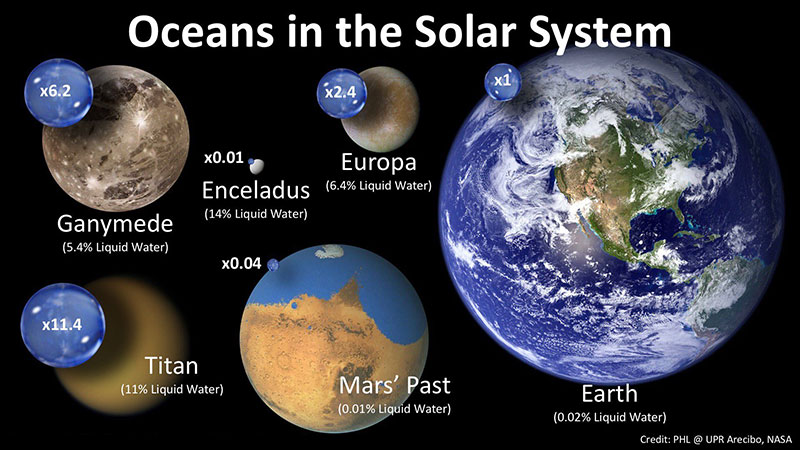
Océanos en el Sistema Solar: en el círculo azul la cantidad de agua libre respecto a la Tierra; entre paréntesis el porcentaje que representa – PHL @ UPL Arecibo, NASA Solemos decir que la Tierra no hace mucho honor a su nombre...

Carl Sagan decía que la astronomía era una lección de humildad, y en los casi 25 años que llevamos observando planetas extrasolares esto parece cada vez más cierto. Si nuestra esquina del universo nos parecía representativa de algo poco a poco...

En Quora el astrofísico Hossam Aly explicó algunas cosas interesantes sobre los agujeros negros. Pueden leerse con más detalle y ecuaciones aquí: An Astrophysicist Debunks 3 Popular Misconceptions About Black Holes. Estas son esas tres creencias erróneas: Las galaxias orbitan alrededor...

Este meme infográfico-inspirador-científico que encontré en The Meta Picture hace tiempo y que podría titularse Para pensar acerca las maravillas del universo me pareció uno de los más ingeniosos que he visto al respecto. Básicamente porque todos los hechos que menciona...

La nochevieja de este año 2016 se insertará un segundo intercalar como ya ha sucedido en años anteriores.

Hace unos días fue noticia una carta firmada por más de 100 premios Nobel que insta a Greenpeace y a sus seguidores a «abandonar su campaña contra los OMGs en general, y contra el arroz dorado en particular.» La carta dice...

El equipo de la sonda Juno de la NASA está de celebración, ya que en la madrugada del 5 de julio de 2016 esta conseguía ejecutar a la perfección la maniobra de inserción orbital que tenía que dejarla en órbita alrededor...
Entre el 20 y el 22 de Julio de 2016 se celebrará el I simposio internacional Julio Palacios, co–organizado por la Fundación Ramón Areces, la Cátedra Julio Palacios del CSIC y la Universidade da Coruña. El Simposium, en la línea del trabajo...
Todo está listo para que a las 2:30 UTC del 5 de julio de 2016 la sonda Juno de la NASA empiece la maniobra de inserción orbital que tiene como objetivo colocarla en órbita alrededor de Júpiter tras un viaje de...

Este vídeo del equipo Force India de Fórmula 1, capta los movimientos de los ojos del piloto Nico Hulkenberg mediante un dispositivo de seguimiento ocular. A semejantes velocidades y con fuertes y constantes movimientos externos, aceleraciones y deceleraciones, el ojo de...
Por Nacho Palou -
4 JUL 2016

Aunque depende mucho de cada uno y de las circunstancias, es muy habitual y sabido que la primera noche de hotel o «fuera de casa» suele resultar poco cómoda y se duerme como a medio gas. Conocido como el efecto «primera...
Por Nacho Palou -
4 JUL 2016
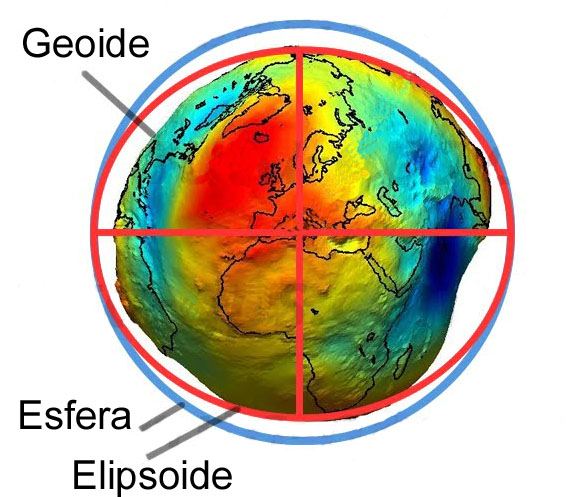
Aunque a mucha gente le extraña, el planeta Tierra no es una esfera perfecta. Está más bien «una esfera achatada por los polos», con zonas más altas y bajas correspondientes tanto con su forma general como por los relieves de las...

Mediante grabaciones de vídeo utilizando rayos X, científicos de la École polytechnique fédérale de Lausanne (EPFL, en Suiza) han desarrollado un robot que imita con una «exactitud sin precedentes» el caminar de una salamandra. En total el robot utiliza 27 motores...
Por Nacho Palou -
30 JUN 2016

Impresión artística de LISA Pathfinder tras la separación del módulo de propulsión tras llegar a su órbita de trabajo - ESA Lanzada el 3 de diciembre de 2015, la misión Lisa Pathfinder tenía como misión determinar si tenemos la tecnología necesaria para...

La hipnosis de carretera es un curioso «estado mental» que hace que una persona que conduce un coche o un camión durante mucho tiempo o a largas distancias reaccione a todos los estímulos y eventos externos «correctamente» pero sin recordar luego haberlo hecho conscientemente.
Los próximos 4, 5 y 6 de julio de 2016 varios divulgadores científicos tomaremos parte como profesores en la segunda edición del curso de verano de la Universidad de Burgos titulado Ciencia, Pseudociencia y Pensamiento Mágico en Tiempos de Incertidumbre.. Los objetivos...

Hay millones y millones de galaxias ahí fuera, pero entender de dónde vienen exactamente es complicado. Este vídeo de Minuto de Física intenta arrojar algo de luz sobre el asunto. Empezando por la definición de «galaxia» que no está del todo...

En el videoblog de ciencia Skunk Bear de la NPR respondieron a una pregunta que recibieron: ¿Cuán viejo es nuestro cuerpo realmente? No se refiere por supuesto a la edad legal, ni siquiera a la edad aparente que prefieren cierta gente...

La epigenética es el proceso mediante el cual el ADN interactúa con moléculas externas que activan y desactivan los genes de un ser vivo y que son debidas principalmente al ambiente en que se encuentran más que por la herencia genética....

El mayor avance del conocimiento es aportar conocimiento, pero todavía más aportar ignorancia, transformar la ignorancia inconsciente en consciente, que es la clave del descubrimiento.– Pedro Miguel Etxenike en el vídeo del5º aniversario de la Cátedra de Cultura Científica de la...

Matt O’Dowd explica en este vídeo de PBS Space Time qué son las constantes de Planck y su relación con el resto del mundo cuántico. Básicamente estas constantes son la escala más pequeña que puede medirse en el mundo de la...

Como parte de las lecturas de verano estuve revisando algunos artículos que tenía por ahí aparcados. The Evolutionary Argument Against Reality de Amanda Gefter en Quanta Magazine es uno especialmente interesante y provocador sobre las cuestiones de la percepción, la realidad...
Según la Universidad Tecnológica de Auckland, en Nueva Zelanda, se trata de la primera ver que un dron permite ver con detalle cómo se alimenta el rorcual de Bryde, «uno de los cetáceos menos conocidos y más inusuales de los rorcuales»...
Por Nacho Palou -
21 JUN 2016
Una de las peores cosas que puede pasar a bordo de una nave espacial tripulada es un incendio. De hecho se considera como la emergencia más peligrosa a la que tendrían que enfrentarse los astronautas de a Estación Espacial Internacional. Pero...
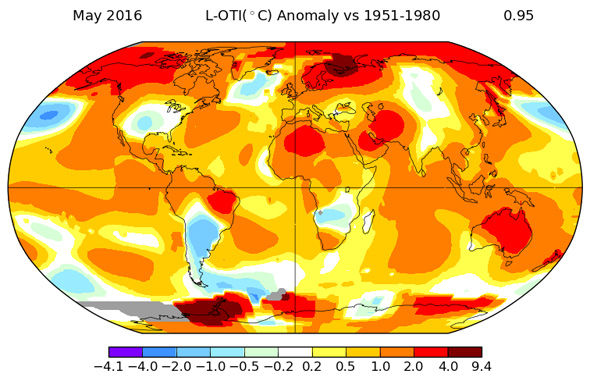
Phil Plait en Slate, March … I Mean April… I Mean May 2016 Is the Sixth … I Mean Seventh… I Mean Eighth Temperature Record-Breaking Month in a Row, Octubre, noviembre, diciembre. Enero, febrero, marzo, abril y ahora mayo. Por sexto...
Por Nacho Palou -
20 JUN 2016
El 30 de diciembre de 2015 la Unión Internacional de Química Pura y Aplicada confirmaba el hallazgo, y por tanto su inclusión en la tabla periódica, de cuatro nuevos elementos, elementos que ocupan los puestos 113, 115, 117 y 118 de esta....

La Soyuz TMA–19M durante su descenso – NASA/Bill Ingalls ¡Aterrizaje! – NASA/Bill Ingalls El aterrizaje de la Soyuz TMA–19M en Kazajistán a las 9:15 UTC del 18 de junio de 2016 ponía fin a la misión Principia del astronauta Tim Peake de...

Qué se aprende en este vídeo: La ciencia es increíble. Beber agua es saludable para las personas. Los pilotos tienen estupendas vistas desde sus oficinas. Quizá este vídeo debería haberse titulado más apropiadamente Aceleración vs. Gravedad o Potencia vs. Gravedad pero...
Impresión artística de los agujeros negros cuya fusión produjo esta segunda señal Los científicos que trabajan en el detector LIGO, junto con sus colegas del detector Virgo, han anunciado que el pasado 26 de diciembre de 2015 observaron un segundo «paquete» de...

Manuel es un doctor en bioquímica –ficticio pero desgraciadamente basado en hechos reales– que tras un tiempo en paro ha encontrado trabajo como camarero y que intenta explicar en este vídeo por qué aunque la economía vuelva a estar creciendo eso...

Que te roben el equipo unos monos. Que se te fundan los zapatos sobre la lava de un volcán. Quedarte pegado a un cocodrilo… Todo eso y más son los #fieldworkfail compartidos por científicos de todo el mundo en Twitter y...

Todo esto es una forma extrema de explicar cómo funciona el electromagnetismo.– Joe / Arc Attack A una gloriosa velocidad de 11.000 fotogramas por segundo es fácil apreciar la belleza de una explosión electromagnética capaz de partir una lata de aluminio...
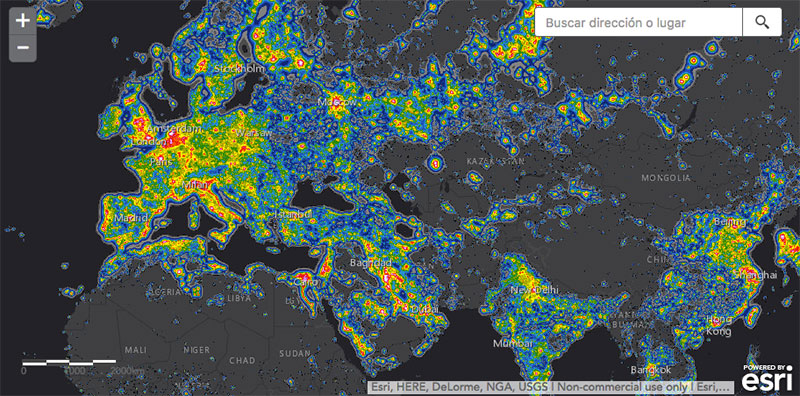
En esta nueva versión del Atlas del Brillo Artificial del Cielo se pueden ver los efectos de la contaminación lumínica en todo nuestro planeta, con datos actualizados de este año y un nuevo visualizador bastante rápido y fluido. Es un trabajo...

Uno de los clásicos de la divulgación científica divertida más apreciados por nuestros lectores ha reaparecido así de repente en YouTube. (…) El excéntrico profesor Beakman responde a preguntas populares e inusuales de su público haciendo demostraciones prácticas con sus ayudantes...
Esta visualización interactiva de π y sus «amigos» es distinta de otras a las que estamos acostumbrados y muy curiosa. Al principio tan solo encontré la referencia y como puedes toquetear los puntos de colores y desplegar el menú superior y...

¡Mira, mamá, estoy andando!– Álvaro,maravillado El Consejo Superior de Investigaciones Científicas (CSIC) ha presentado hoy el primer exoesqueleto del mundo dirigido a niños con enfermedades neuromusculares y que está siendo probado en niños con atrofia muscular espinal, una enfermedad degenerativa que...

La Agencia Espacial Europea acaba de hacer públicos los primeros resultados de la misión Lisa Pathfinder, diseñada para probar las tecnologías necesarias para crear un observatorio espacial capaz de detectar ondas gravitacionales y estos son espectaculares: tal y como se puede...
Según cuentan en Fast Co., Microsoft Is Teaching Your Plants To Talk Back, el proyecto Florence podría tener implicaciones increíbles para el futuro de la agricultura. Helene Steiner «artista residente» en el programa de investigación Studio 99 de Microsoft, trabaja para...
Por Nacho Palou -
6 JUN 2016

A las 7:00 UTC del 3 de junio de 2016 Saturno estaba en oposición, lo que quiere decir que el Sol, la Tierra y él formaban una línea recta, con nuestro planeta situado entre el Sol y Saturno, que desde nuestro punto...

Está haciendo las rondas un vídeo titulado You are two que habla de los síntomas que aparecen en algunas personas que han sido sometidas a una callosotomía. Estos síntomas van desde que una mano no sepa lo que está haciendo la...

Anda por ahí haciendo las rondas un estudio titulado Report of Partial findings from the National Toxicology Program Carcinogenesis Studies of Cell Phone Radiofrequency Radiation in Hsd: Sprague Dawley® SD rats (Whole Body Exposure) acerca de los efectos de las ondas de...
Y quien dice la homeopatía, que pasa por momentos bajos, dice cualquier otra pseudociencia: El reiki, la bioneuroemoción, las flores de Bach, la astrología, el biomagnetismo… Es muy preocupante el auge de las pseudociencias, entendiéndose estas como aquellas afirmaciones, creencias o...

AsapScience describe en este vídeo lo que sabe la ciencia sobre la transformación física que están realizando los móviles sobre nosotros, o más bien «nosotros mismos sobre nuestros cuerpos y mentes» por algunas malas costumbres: Curvar la espalda para mirar el...
Hace unos años tuve la oportunidad de realizar un vuelo en «gravedad cero» en uno de esos aviones que usan las agencias espaciales para entrenar a sus astronautas lo que es la caída libre, una experiencia absolutamente increíble. Xavi Fonseca me...

Ya hemos descubierto miles de exoplanetas y el número crece día a día. En esta web de Nadieh Bremer se pueden ver cientos de ellos girando alrededor de un sol imaginario y «respetando las leyes de la física», en particular la...
No lo había visto pasar en su momento, pero me encanta esta recopilación de vídeos de la #6secondscience fair, una iniciativa de GE que animaba a la gente a hacer vines que demostraran algún concepto científico en 6 segundos. Una forma...
Un desasosegante vídeo –tiene subtítulos en español– del siempre interesante canal de Youtube Kurzgesagt en el que explican las tres principales formas en las que los científicos creen que puede acabar el universo. Según de la cantidad de energía oscura que...
Aprovechando que el núcleo del cometa 67P/Churyumov-Gerasimenko está cada vez mas lejos del Sol, con lo que su actividad es cada vez más reducida, los responsables de la misión Rosetta están aprovechando para acercarla lo más posible al núcleo para obtener...
La cosmóloga Janna Levin, autora de Black Hole Blues and Other Songs from Outer Space, explica en esta charla como aunque hasta ahora hemos estudiado el universo fundamentalmente mediante imágenes, ya sean en el espectro visible o en cualquier otra parte...
El vídeo grabado por el profesor Ningyu Liu capta a cámara lenta, a 7000 fotogramas por segundo, una tormenta eléctrica. Lo que capta el vídeo es, primero, el descenso de las partículas con cargas negativas que bajan desde la nube hasta...
Por Nacho Palou -
30 MAY 2016
El espectrómetro Rosina fue el que realizó el descubrimiento Uno de los últimos resultados publicados por los científicos de la misión Rosetta revelan la detección del aminoácido glicina, así como de algunas moléculas precursoras que lo pueden formar, y también de fósforo...
Este vídeo de Life Noggin se plantea si un humano moderno sería capaz de sobrevivir en el Pleistoceno, una época en la que, para empezar, se dieron la mayoría de las glaciaciones, que hacían que la temperatura media de la Tierra...
Este vídeo, recién publicado por la NASA, incluye todas las imágenes de más alta resolución captadas por la sonda New Horizons al sobrevolar Plutón el 14 de julio de 2015, aunque ya hace tiempo que venimos sorprendiéndonos con las imágenes que...
Tal y como habíamos solicitado la Universidade de A Coruña reconocerá un crédito de libre elección por la asistencia a Naukas Coruña Neurociencia. Así que aunque la asistencia sigue siendo gratuita tendremos que llevar un control de esta para quien haya solicitado...
Este es el vídeo (acelerado) del retorno al espaciopuerto autónomo flotante Of Course I Still Love You de la primera etapa del Falcon 9 FT de SpaceX que puso en órbita el satélite de telecomunicaciones Thaicom 8. El Thaicom 8 tiene...
Álvaro, que trabaja como investigador en la Escuela de Farmacia de la University College de Londres, nos ha escrito para contarnos sobre un nuevo avance en los medicamentos 3D, en este caso la impresión de parches anti–acné. Tal y como se puede...
David Casas nos avisó del lanzamiento de La esfera de Boltzmann, su primera novela corta, de unas 140 páginas, que mezcla física futurista con unos personajes muy creíbles y una narración fluida. El relato está contado desde el punto de vista...
Intermedios de reacción a la vista Los químicos tienen razonablemente claro qué pasa cuando mezclas ciertos productos en ciertas cantidades y condiciones para provocar una reacción química y obtener un resultado final. Pero durante la reacción aparecen y desaparecen unos intermedios de...
Me ha gustado este vídeo –ya, ya, no hace falta que me digáis que soy un friki– acerca de cómo ha evolucionado la visualización de los resultados de los experimentos llevados a cabo en los aceleradores de partículas que los físicos...
Con mucho cuidadito y tras haber hecho varias simulaciones por ordenador y pruebas con un modelo los técnicos del Centro Goddard de la NASA han acoplado sin problemas el conjunto de instrumentos del telescopio espacial James Webb al telescopio propiamente dicho,...
#FoundThem Este trabajo publicado en ArXiv y firmado por un equipo de la Escuela de Física y Astronomía de la Universidad de St. Andrews (Reino Unido) es uno de esos documentos por los que merece la pena amar la ciencia y amar...
Supongamos un planeta Tierra esférico de densidad uniforme. Supongamos que se hace un agujero de polo a polo que pasa exactamente por el centro. Y supongamos que en ese agujero se hace el vacío antes de saltar a su interior. ¿Cuánto...
The Making of me and you es un curioso interactivo de la BBC en la que si le dices tu fecha de nacimiento, sexo, peso y altura puedes averiguar un montón de detalles acerca de tu cuerpo. Detalles como lo que...
Víctor nos ha escrito para ponernos en la pista de este vídeo en el que se ven varios tipos de hongos creciendo en time lapse al ritmo del tema de Juego de tronos, lo que lo hace bastante adecuado, ya que...
A la hora de extirpar un tumor cerebral una de las cosas que más influye en la posible recuperación del paciente es que la resección de este sea tan completa como sea posible, aunque los neurocirujanos se ven limitados cuando el...
La máquina Jller selecciona y ordena las piedras que encuentra esparcidas en su plataforma colándolas de forma organizada y según su edad geológica, Los cantos proceden del lecho del río Jller, en Alemania, que da nombre a la máquina y son...
Por Nacho Palou -
24 MAY 2016
Aquí el amigo CrazyRussianHacker decide emular a nuestra oriunda la socorrista torpe y hacer un experimento pero con conocimiento de causa: arrojar unos 15 kilos de hielo seco a una piscina. El hielo seco es lo que se utiliza en espectáculos...
Tal y como muestra la infografía How Long Animals Live, procedente de The Duration of Life in Animals de S.S. flower, La mayor parte de los animales viven menos que nosotros los seres humanos: pequeños mamíferos como los conejos, ardillas o...
Marte casi en oposición en 2016 con una resolucuón de 30 kilómetros por pixel – NASA, ESA, the Hubble Heritage Team (STScI/AURA), J. Bell (ASU), and M. Wolff (Space Science Institute) A las 11:10 UTC del 22 de mayo de 2016 el...
Esta es «la historia de un número que no siempre fue un número». De hecho según se mire hay quien dice que no es exactamente un número, quizá un concepto. Se puede sumar, restar y multiplicar un número por cero, pero...
James Beacham de la Universidad de Ohio State y el CERN explica en este vídeo de Simmetry Magazine por qué sentimos los objetos como sólidos a pesar de que en su mayor parte «están vacíos». Se refiere a que se suele...
El astrofísico Borja Tosar y el periodista científico Xavi Fonseca vuelven a la carga con su Espoiler científico, en este caso centrando su atención en el universo de Star Wars para hablar de cosas como los planetas que aparecen en la saga,...
«Encontrar meteoritos es más fácil que sobrellevar el clima de la Antártida». Y es que el trabajo de Constantine Tsang no es nada fácil, tal y como nos enseña Great Bit Story. Se pasaron dos meses recorriendo la Antártida en busca...
Bueno, en realidad son una naranja y media y un limón, pero les sirven a Javier Armentia y a Joaquín Sevilla para explicar por qué se producen las mareas en un par de minutos. El vídeo forma parte del canal de...
Ya está abierta la convocatoria de 2016 de los Prismas de Bronce a los mejores trabajos de divulgación científica de los Museos Científicos Coruñeses, en los que trabajo en el MundoReal™. En esta XIX Convocatoria las modalidades son: Vídeo. Web / Redes...
El Buddhabrot es tan solo una técnica de visualización de algo parecido al conjunto de Mandelbrot, uno de los fractales más conocidos. Aquí puede verse en todo su esplendor a 4K (aunque también a menores resoluciones es bonito) y acompañado de...
Es un poco la pescadilla que se muerde la cola, porque es imposible demostrar que no son malos para la salud, pero toda la evidencia científica disponible hasta ahora dice que no hay nada que pruebe que los alimentos transgénicos sean malos...
Aunque no están todas porque hay muchos, esta lista no está nada mal, sobre todo porque algunas no son tan obvias como podría parecer o ni siquiera se conocen popularmente. Las ha recogido Mental Floss en 8 Words you Might not Know...
Clic en la imagen para la versión animada No somos muy de poner gif en esta casa, pero Spiralling global temperatures se ha ganado su puesto porque deja ver de forma muy clarita que el cambio climático está ahí: representa la evolución...
En 2015 el festival Pint of Science llegaba a España con sesiones programadas en ocho ciudades, pero como la idea de llevarse la ciencia a los bares nos pareció tan buena, en 2016 Pint of Science España vuelve con sesiones programadas en...
Un resumen en 90 segundos de la información básica de la que disponemos del virus Zika, un virus que en la mayoría de los casos tan siquiera causa síntomas a los infectados, y que en la inmensa mayoría de los que...
En MinutoDeFísica (Minute Physics) dedican un clip a explicar una interpretación poco común de la paradoja del abuelo en los viajes temporales al pasado. Todo el mundo la ha visto en acción en películas como Terminator, Regreso al futuro o El...
Entropía (Kippel) por Tamara Feijoo Cid – Vía Dimetilsulfuro El arte ha avanzado gracias a la ciencia, y la ciencia, gracias al arte, ha descubierto nuevos recodos en su deriva sobre los que investigar y maravillarse. La ciencia ha dotado al arte...

Coincidió que en esta entrevista en plena calle una explosión hiciera volar por los aires una tapa de alcantarilla, un suceso poco habitual pero que sucede de vez en cuando – a veces con resultados desastrosos. Aquí la causa fueron un...
La bióloga Alba Aguión Tarrío se ha impuesto en la final del certamen de monólogos científicos FameLab España 2016. Su monólogo La inteligencia del hormiguero habla del asombroso mundo de la organización de las hormigas, no de El Hormiguero, que seguro...
Planetas extrasolares para dar y tomar Según se puede leer en NASA's Kepler Mission Announces Largest Collection of Planets Ever Discovered una nueva herramienta estadística aplicada a los datos obtenidos por el telescopio espacial Kepler ha permitido añadir 1284 planetas extrasolares a...
Derek de Veritasium se ha dado un rulo por la Bóveda Global de Semillas Svalbard, uno de los lugares más post-apocalípticos pero aun así reales que podemos encontrar en nuestro planeta: La Bóveda Global de Semillas Svalbard está construida como un...
Este vídeo de Explanimator, un canal de New Scientist, explica qué es la información y aborda cuestiones como si existe o no existe independientemente de que alguien la esté observando, la paradoja del demonio de Maxwell y la presencia al respecto...
A pesar de constituir una parte tan importante de nuestro organismo, el microbioma es uno de los grandes desconocidos de nuestra biología. Hasta ahora no ha sido estudiado en profundidad y su influencia en la fisiología y funciones de nuestro cuerpo...
El Sol, Mercurio y la EEI por Thierry Legault Hay unos tropecientosmil millones de trillones de imágenes del tránsito de Mercurio del 9 de mayo de 2016 en la red, pero creo que de todas las que he podido ver hasta ahora...
Mantenimiento en el LHC Según se puede leer en The 2016 physics season starts at the LHC el Gran Colisionador de Hadrones está ya listo para comenzar con su temporada de trabajo de 2016. El pasado 14 de diciembre de 2015 el...
Esto no es una bola de discoteca, aunque ciertamente lo parece, sino el satélite artificial Lageos de la NASA, una esfera de aluminio y latón de 60 centímetros de diámetro cubierta de 426 retrorreflectores de esquina, lanzado el 4 de mayo...
Técnicos inspeccionando el espejo del James Webb – Chris Gunn El impresionante espejo principal del Telescopio Espacial James Webb, formado por 18 espejos hexagonales, tiene un diámetro de 6,5 metros, lo que le confiere una superficie útil de 25 metros cuadrados.Estos espejos...
Hace unos días vi pasar un tuit en el que salen unas zapatillas decoradas con la tabla periódica, y aunque no he sido capaz de localizar esas mismas zapas sí he dado con las de Periodic Table Shoes de GetDigital. Están...
Probablemente la mejor opción para disfrutar del tránsito de Mercurio de 9 de mayo de 2016 sea acercarte a alguna de las sesiones de observación públicas que se están organizando por todas partes. Pero si no puedes ira a ninguna y te...
En NewScientist, Robotic surgeon could stitch you up after removing your appendix, Por vez primera un robot ha completado con éxito un operación sobre tejido blando vivo sin asistencia humana. Los cirujanos que han desarrollado el robot confían en que dentro...
Por Nacho Palou -
6 MAY 2016
Si este fin de semana estás por A Coruña una propuesta muy interesante es que te pases por el Parque de Santa Margarita, donde se celebra la XXI edición del Día de la Ciencia en la Calle. El sábado 7 de mayo...
Representación del tránsito en horario UTC – Imagen del Sol en Halfa – Daniel López/IAC El próximo 9 de mayo de 2016 se producirá un tránsito de Mercurio frente al Sol, algo que si bien no es exactamente raro sólo sucede unas...

David (¡gracias!) nos recomendó echar un vistazo a la página Notebooks of S. Ramanujan, donde se reproducen en tres grandes PDF otros tantos volúmenes con los trabajos del famoso matemático autodidacta. Ahora que va a tener un revival gracias a la...
Hace poco más de veinte años parecía bastante razonable suponer que con todo lo grande que es el universo nuestro Sol no iba a ser la única estrella a cuyo alrededor orbitaran planetas, pero no teníamos pruebas de la existencia de...
Un grupo de científicos de la Universidad de California en Berkley han metido a siete voluntarios en una máquina de resonancia magnética funcional mientras les hacían oír hasta dos horas de historias de un programa de radio, lo que supone que...
Este vídeo del Departamento de Física y Astronomía de la Universidad de Utah tiene ya un tiempo, pero me pareció increíblemente didáctico. Muestra cómo se puede atrapar la luz de un láser en un chorro de agua y se puede hacer...
Existen majestuosos bichos como esta medusa en la fosa de las Marianas, en el océano Pacífico. Este ejemplar se grabó hace poco a unos 3.700 metros de profundidad – un lugar tan profundo, oscuro y sobre el que el agua ejerce...
En este vídeo de Filmmaker IQ John Hess explica todo lo que hay detrás de los CGI o imágenes generadas por ordenador principalmente en el cine. Como sabiamente dice en el fondo todo son matemáticas aplicadas a las coordenadas de los...
Esta película protagonizada por Dev Patel es una biopic escrita y dirigida por Matthew Brown acerca de Srinivasa Ramanujan (1887-1920), una de las figuras más misteriosas y enigmáticas de las matemáticas. Muy al estilo de Una mente maravillosa, muestra cómo el...
Marte por Camille Flammarion en 1884 Intentando encontrar algo más de información sobre Fritz Kerner–Marilaun he dado con Historical Globes of the Red Planet, una página en la que el autor recoge referencias a los globos marcianos producidos comercialmente antes de la...
La gran duda es si la comadreja adquirirá los superpoderes del LHC o si el LHC adquirirá los de la comadreja. – Seth Zenz, astrofísico que trabaja en el LHC A medio camino del WTF: según cuentan en Weasel Apparently Shuts Down...
La ciencia es una empresa cooperativa que une generaciones. Es el paso del testigo de profesor a estudiante a profesor. Una comunidad de mentes que viene desde el pasado y que apunta hacia las estrellas. – Neil deGrasse Tyson, astrofísico Nanoinyectores que...
SAM, de Sample Analysis at Mars, Análisis de Muestras en Marte, es uno de los instrumentos del rover Curiosity, que lleva desde el 6 de agosto de 2012 explorando Marte; de hecho SAM representa más de la mitad de la carga útil...
Una de las presentaciones llevadas a cabo durante la celebración de Ciencia en Redes 2016, un encuentro en el que se de debate sobre todos y cada uno de las campos donde el mundo de la ciencia y los científicos pueden...
Según se puede leer en su último comunicado al respecto la Agencia Japonesa de Exploración Aeroespacial da oficialmente por perdido el telescopio espacial de rayos X Hitomi; dicen también que lo que harán será intentar entender qué pasó para, al menos aprender...
En su programa del 10 de marzo de 2014 Steve Colbert le preguntó a Neil deGrasse Tyson qué le habría sorprendido más a Carl Sagan desde su muerte en 1996. La respuesta es contundente y, por desgracia, todavía válida: Creo que lo...
Los técnicos del Centro Espacial Goddard de la NASA han tenido una semana ocupada retirando las tapas de los 18 espejos hexagonales que forman el espejo primario del telescopio espacial James Webb. Estos espejos están fabricados en berilio y recubiertos de...
Marte por Fritz Kerner–Marilaun Aunque Fritz Kerner-Marilaun estudió medicina según los deseos de su padre a él lo que le interesaban eran las matemáticas, la geología, la pintura y los idiomas. Así que terminó siendo conocido como paleoclimatólogo y paleogeógrafo y...
Impresión artística del encuentro de la New Horizons con un objeto del cinturón de Kuiper - NASA/JHUAPL/SwRI/Alex Parker Cuando el 14 de julio de 2015 la sonda New Horizons pasó por el sistema formado por Plutón y sus lunas lo hizo zumbando...
Jim nos ha escrito para hablarnos de Fieldwork Fail, un blog en el que ilustra las hilarantes (casi siempre) desventuras de científicos que la lían parda cuando están de trabajo de campo. Está en inglés, pero en la anotación Desatinos en...
En este vídeo Tom Scott explica un tanto por encima cómo son las instalaciones de un reactor de fusión, más concretamente el JET del Centro Culham de Energía de Fusión. Para ser un lugar en el que se alcanzan durante breves...
El próximo 9 de mayo de 2016 se produce un tránsito de Mercurio frente al Sol que mucha gente de todo el mundo intentará observar. Nosotros diremos, como siempre, que nunca mires al Sol directamente para intentar verlo, y mucho menos...
Esta comparación sobre terremotos es tan impactante como acongojante; comienza con terremotos de los que todos hemos oído hablar para irlos «situando en contexto» junto a otros más grandes. Aquí el concepto del tamaño del terremoto se refiere a la escala...
Hace unos días he descubierto el documental web Lunar Exploration – así lo llama la Agencia Espacial Europea– y me ha parecido impresionante. Cuenta la historia de la Luna y lo que hemos ido aprendiendo de ella tanto mediante observaciones como...
Según se puede leer en Kepler Recovered and Returned to the K2 Mission el telescopio espacial Kepler vuelve a estar en servicio desde las 15:30 UTC del 22 de abril de 2016. Esto quiere decir que está listo para ponerse a...
Para quien quiera sentirse un poco más insignificante los cosmólogos del Center for Complex Network Research han recreado en esta visualización cómo es lo que han dado en denominar «la gran telaraña cósmica» (cosmic web). El concepto de visualización del universo...
Procedentes de los restos del cometa C/1861 G1 Thatcher, la lluvia de estrellas de las Líridas tiene lugar cada año aproximadamente entre el 16 y el 25 de abril, cuando la Tierra recorre la parte de su órbita en la que...
{Voz de presentador de documental} «Queridos trabajadores, protéjanse de las radiaciones mediante estos sensores con forma de lápiz…» Era otra época, pero es que cuando se comenzó a trabajar con productos radioactivos toda precaución era poca. Mediante un protocolo para comprobar...
Después de unos meses de pausa Javier Armentia y Joaquín Sevilla vuelven a la carga con los vídeos de Ciencia en el Bar, un proyecto promovido por la Universidad Pública de Navarra, financiado por la FECYT, y con la colaboración del...
Otro impresionante vídeo de Roman Tkachenko realizado con datos tomados por la sonda New Horizons de la NASA a su paso por Plutón el 14 de julio de 2015. En este caso combina imágenes de la superficie del ex–planeta tomadas por...
¿Puede la exposición a una estrella como nuestro Sol darle superpoderes a un alienígena nacido a la luz de otra estrella? ¿Cómo reaccionaríamos si ahora mismo llegaran unos extraterrestres a vernos? ¿Se puede hacer retroceder el tiempo haciendo girar la Tierra del...
A mediados del siglo XIX Charles Darwin incluía una frase en el último párrafo de su libro El origen de las especies en la que dice que probablemente todas las formas de vida que existen en el mudo provienen de una...
Comprimidos de PAS (izquierda) y paracetamol (derecha) impresos mediante estereolitografía La impresión en 3D está cada vez más metida en nuestras vidas, y uno de los campos en los que está habiendo avances más interesantes es en el de la medicina, tanto...
Ondas, poleas, sonido, caída libre, ley de Bernoulli, tiempo, velocidad, fricción, centro de gravedad, poleas, trayectorias, movimiento giroscópico, momento rotacional, tensión superficial, presión sanguínea, universo, refracción de la luz, astronomía, planetas, flujo turbulento, impulso, tercera ley de Newton, órbitas, energía solar,...
La JAXA, la Agencia Japonesa de Exploración Aeroespacial, tiene más ya claro qué es lo que pasó para que el telescopio espacial de rayos X Hitomi terminara roto en varios fragmentos y dando tumbos sin control el pasado 26 de marzo de...
Investigadores de la Universidad de Rice (Estados Unidos) han descubierto que los campos de fuerza que emite una bobina de Tesla hacen que los nanotubos de carbono se ensamblen formando largas hebras. Aunque lo han llamado Teslaforesis ni siquiera el propio...
En Better Explained tienen esta preciosa mini-lección sobre cómo apreciar el cálculo: el área de un círculo. El círculo puede «diseccionarse» en una serie de anillos infinitamente pequeños; tendrán longitudes que variarán entre 0 y la el círculo máximo (que sabemos...
Las enanas marrones tipo Y son un tipo de estrellas fallidas extremadamente frías, tanto que podríamos tocar algunas de ellas sin morir calcinados ni tan siquiera quemarnos, ya que su temperatura está por debajo de los 100 °C. Los astrónomos sospechaban desde...
Proofs without Words II (Roger B. Nelsen, 2000) es la segunda parte del estupendo Proofs without Words (1997) que contiene páginas y páginas de pruebas geométricas «sin palabras», fáciles de entender con tan solo verlas. Valga como ejemplo esta bonita explicación...
Encontrar las venas en las que pinchar con la aguja para realizar una analítica, transfusión o similar es a veces un poco complicado, especialmente entre personas de edad avanzada, cuando ya se ha pinchado al paciente varias veces o debido –aunque...
Los virus representados en Virus trading cards están animados y diseñados como cromos de estrellas deportivas o cartas de Magic. Están el Dengue, el Adenovirus Tipo 5, el Clorela y el Tipo 16 del HPV (papiloma humano). Es la típica colección...
Muy curioso este truco para cuadrados de números terminados en cinco (mentalmente). Puede verse en el recuadro, y funciona así: Los dos últimos dígitos siempre son 25. Los anteriores son el producto del valor del primer dígito multiplicado por la que...
Todos los vídeos, imágenes, mails y demás información digital procedente de más de 600 móviles (unos 10 000 GB) pueden almacenarse en esa mancha borrosa de ADN que apenas se ve al fondo del tubo de ensayo. Fotografía: Tara Brown / Universidad...
Por Nacho Palou -
12 ABR 2016
El 11 de abril de 2006 la sonda Venus Express de la Agencia Espacial Europea llevaba a cabo con éxito la maniobra de inserción orbital que permitió que la gravedad de Venus la capturara. Esta maniobra ponía el punto final a...
Láser de 22W utilizado en el Very Large Telescopio, en Chile. Un conjunto de láseres similares se podrían utilizar para alterar el rastro dejado por el tránsito de un planeta con el propósito de difundir o de ocultar su presencia. Imagen: ESO...
Por Nacho Palou -
11 ABR 2016
El origen de la vida es uno de los grandes misterios sin resolver a los que nos enfrentamos. En este vídeo Carlos Briones, científico titular del CSIC en el Dpto. de Evolución Molecular del Centro de Astrobiología (CSIC-INTA, asociado al NASA...
Por ahora no hay muchos detalles, pero según se puede leer en Mission Manager Update: Kepler spacecraft in emergency mode el telescopio espacial Kepler está en modo de emergencia. El modo de emergencia es el más básico en el que puede...
Hitomi dando tumbos el 2 de abril de 2016 La Agencia Japonesa de Exploración Aeroespacial ha dado una rueda de prensa con información actualizada acerca del estado del observatorio espacial de rayos X Hitomi, con el que no tienen contacto desde el...
Es más probable salvarse de la explosión de una granada tirándose al suelo que lanzándose bajo el agua, si acaso es que hay agua cerca. La razón nos la enseñan Mark Rober y Kevin «The Backyard Scientist» en este vídeo de...
Están en el MoMA de Nueva York; técnicamente las esferas de Hoberman son (…) estructuras que se asemejan a una cúpula geodésica, pero que son capaces de plegarse hasta ocupar un tamaño mucho menor que el original, gracias a la acción...
El director Ric Burns está dando los últimos toques a un documental sobre Oliver Sacks, y como parte de la promoción hace unos días presentaba este pequeño clip, en el que Sacks habla de figuras que influyeron mucho en él como...
La sonda Akatsuki de la Agencia Japonesa de Exploración Aeroespacial tenía que haber entrado en órbita alrededor de Venus el 7 de diciembre de 2010, pero un fallo de su motor principal hizo que se pasara de largo. Sin embargo el...
Esta es la ocultación de Venus por parte de la Luna grabada en la mañana del 6 de abril de 2016 por el astrofísico y divulgador Alfred Rosenberg y el astrofotógrafo Daniel López con un telescopio de 20 centímetros de apertura...
En una de las escenas de Star Wars: El imperio contraataca Han Solo decide meter al Halcón Milenario en medio de un campo de asteroides para escapar de los cazas Tie que los persiguen, ya que no funciona la «velocidad luz»....
El hierro que hace que mi sangre sea roja se creó en el instante en el que murió una estrella.– Michelle Thaller Michelle Thaller, la directora asociada de comunicación científica de la NASA, habla en esta charla del ciclo de vida de...
Hace unos meses Konstantin Batygin y Mike Brown presentaron la hipótesis de la existencia de un noveno planeta en el sistema solar, ya descontado el hecho de que Plutón no lo es, basándose en ciertas características de las órbitas de algunos cuerpos...
En una ocasión le preguntaron a Richard Feynman, físico, cual sería el fragmento de conocimiento más importante que podríamos dejar a generaciones venideras en el caso de que un cataclismo fuera a destruir todo el conocimiento científico. Su respuesta le encantará...
Chronos es como se llama el sistema desarrollado por el equipo del profesor Dina Katab, del Computer Science and Artificial Intelligence Laboratory del MIT, que es capaz de determinar la posición de los usuarios con una precisión de «decenas de centímetro»....
Por Nacho Palou -
4 ABR 2016
El núcleo de 67P a contraluz el 27 de marzo de 2016ESA/Rosetta/NAVCAM – CC BY-SA IGO 3.0 La misión Rosetta de la Agencia Espacial Europea es una de los mayores éxitos de la exploración espacial de los últimos años, pues ha...
El pasado 26 de marzo de 2016 la Agencia Japonesa de Exploración Aeroespacial, JAXA, perdía el contacto con Hitomi, su telescopio de rayos x lazado el 17 de febrero de 2016 y que aún estaba en fase de calibración. Las primeras observaciones...
Impresión artística de HD 1885 Ab, otro planeta con tres soles Situado a unos 680 años luz de la Tierra, KELT-4Ab es un planeta en cuyo cielo no sólo se pueden ver dos sino tres soles, dejando en mantillas a Tatooine (el...
La técnica de edición de ADN que han desarrollado Emmanuelle Charpentier y Jennifer Doudna, conocida como Crispr-Cas9, es tan potente que, por ejemplo, permite eliminar el ADN de un virus VIH que ya esté metido dentro de una célula humana; es,...
En 2015 la Agencia Espacial Europea organizó una campaña para recoger dibujos de niños y adolescentes de entre 8 y 14 de los países miembros de la ESA o de sus estados asociados para decorar dos placas del telescopio espacial Cheops,...
Uno de los mayores misterios a los que nos enfrentamos es el de nuestro origen, y por ende del de la vida en nuestro planeta y el del Universo. ¿Quiénes somos? ¿De dónde venimos? ¿A dónde vamos? ¿Estamos solos en la galaxia...
Lo que se ve en el vídeo es un prototipo de brazo protésico robotizado, no implantado, del cual el paciente puede mover individualmente cada dedo pensando en cuál de ellos quiere mover y cómo. Según los investigadores del Johns Hopkins se...
Por Nacho Palou -
31 MAR 2016
Carl Sagan on Extraterrestrials es la transcripción de una entrevista para radio grabada el 4 de octubre de 1985 pero recientemente desenterrada en unos archivos que nos deja oír hablar a Carl Sagan de extraterrestres y de como proyectamos en ellos...
En Nautilus, Top 10 Design Flaws in the Human Body, Los griegos estaban obsesionados con un cuerpo humano matemáticamente perfecto. Pero desafortunadamente para cualquiera que persiga ese ideal no fuimos diseñados por Pigmalión, el escultor mítico que talló a la mujer perfecta,...
Por Nacho Palou -
30 MAR 2016
Soy muy fan de las clases de microbiología que Ignacio López–Goñi da a través de Twitter com la etiqueta #microMOOC y que luego recopila en Storify; un montón de información interesante y relevante en píldoras de 140 caracteres con sus correspondientes ilustraciones...
En 4K, para uso y disfrute de todos los espaciotrastornados del mundo, un time lapse del proceso de integración de la Trace Gas Orbiter y el aterrizador Schiaparelli, el traslado del Protón M que los lanzó a la plataforma de lanzamiento,...
Lo asteroides son la forma que tiene la naturaleza de preguntarnos eso de…¿Qué, cómo va ese programa espacial? – Neil deGrasse Tyson, astrónomo El 17 de marzo de 2016 algo chocó contra Júpiter; algo lo suficientemente grande como para que dos aficionados...
El plástico biodegradable es en realidad más bien poco biodegradable y una botella de agua que se tire por ahí seguirá por ahí incluso tanto como mil años después. Al enterarse de eso el estudiante de diseño Ari Jónsson sintió la...
Por Nacho Palou -
29 MAR 2016
En CoDesign, The Harvard Library That Protects The World's Rarest Colors, Hoy en día, cualquier color imaginable está al alcance de cualquiera. Puedes obtener muestras de pintura en la ferretería del barrio, hojear pantoneras y juguetear con el selector de colores...
Por Nacho Palou -
29 MAR 2016
La misión Hope –Esperanza– de los Emiratos Árabes Unidos con destino a Marte utilizará un lanzador H-IIA de la Agencia Japonesa de Exploración aeroespacial, tal y como se puede leer en United Arab Emirates ‘Hope’ Mars Mission picks Japan’s H-IIA Launch...
Las pocas noticias nuevas que hay tras la pérdida de comunicaciones con el telescopio espacial de rayos X Hitomi de la Agencia Japonesa de exploración Aeroespacial no son precisamente halagüeñas. Por un lado el Joint Space Operations Center de los Estados...
Desde el Sol hasta Plutón, con los añadidos de la Luna y Miranda, el conjunto de rocas del sistema solar de pebbleplush puede hacer las delicias de cualquier espaciotrastornado, tenga la edad que tenga. Son doce cojines/almohadas por un poco menos de...
El infinito es un concepto difícil; ya hemos hablado de él en más ocasiones: Por ejemplo, el conjunto de los números naturales (1, 2, 3, 4, 5…) es infinito, y parece más o menos razonable pensar que el conjunto de los...
Tal y como se puede leer –más o menos– en Communication failure of X-ray Astronomy Satellite “Hitomi” la Agencia Japonesa de Exploración Aeroespacial, JAXA, ha perdido el contacto con su observatorio espacial de rayos X. Hitomi, que en japonés quiere decir...
Electromagnetic Leak por Abstruse Goose Este gráfico recoge lo que podrían estar viendo si por el universo adelante existieran civilizaciones con la capacidad tecnológica, las ganas y, a menudo, el humor –que a ver si va a ser sólo cosa de los...
Tras diez días en el espacio la combinación Trace Gas Orbiter/Schiaparelli de la misión ExoMars 2016 de la Agencia Espacial Europea está funcionando perfectamente, tal y como se puede leer en ExoMars performing flawlessly. Las pruebas iniciales de los sistemas de energía,...
Mapa sinóptico de las amplias variaciones en la tasa de los zurdos a lo largo de los últimos diez millones de años (Fuente: The history and geography of human handedness.) En FiveThirtyEight, Why Am I Right-Handed?, La respuesta corta es que eres...
Por Nacho Palou -
22 MAR 2016
Encontrar el cerebro de Einstein fue una experiencia casi religiosa– Steven Levy Literalmente (!) En esta charla TED el afamado Steven Levy cuenta el que seguramente fue su momento cumbre como periodista: investigar qué fue del cerebro de Einstein –cuyo cuerpo...
Aunque los cohetes son una cosa espectacular lo cierto es que son muy poco eficientes: un Ariane 5 ECA como el que se utilizará para lanzar el telescopio espacial James Webb tiene una masa al lanzamiento de 770 toneladas para una...
The art of AIM es un delicioso vídeo que cuenta la historia de esta misión espacial dibujada en arena por Didi Rodan. AIM forma parte de la misión AIDA, de Asteroid Impact & Deflection Assessment, Misión de Análisis de Impacto y...
Diagrama de las estaciones: a la izquierda la Tierra en el solsticio de verano del hemisferio norte; a la derecha, en el solsticio de verano del hemisferio sur, es decir, en invierno en el hemisferio norte; en medio, los dos equinoccios –...
Canyval-X – NASA/Brittany Klein Cuando pensamos en un telescopio normalmente nos viene a la cabeza la imagen de un tubo más o menos largo que contiene unas lentes, pero en realidad el tubo no es necesario. Ya en el siglo XVII se...
Con ustedes, un crack. El crack de las matemáticas. El tipo que demostró lo que miles de matemáticos intentaron en vano durante siglos: la demostración del último teorema de Fermat. Lo explica con más detalle Gaussianos: Andrew Wiles, premio Abel 2016....
Uniendo una serie de imanes circulares con un agujero en el centro, con forma de arandelas o de toroides, al colocar un dardo en el centro del agujero éste sale zumbando y directo contra la diana. Para que funcione el invento...
Por Nacho Palou -
17 MAR 2016

Descubrí el canal de Explanimator con este vídeo, que trata de explicar por qué vivimos en un espacio de tres dimensiones. La respuesta es casi más metafísica que física y acaba siendo un poco circular: vivimos en un universo cuyo espacio...
Los números primos se «repelen» (…) Según un trabajo publicado por dos matemáticos de Stanford hay pruebas tanto teóricas como numéricas de que los números primos «repelen» a otros posibles números primos que terminan en el mismo dígito: esto implica que...
Con tan sólo un kilo y medio de peso, el cerebro es la estructura más compleja y maravillosa del universo. En él residen nuestro pasado, presente y futuro.– José Ramón Alonso El cerebro es lo que hace de cada uno de nosotros...
Hoy es 14 de marzo, el día de pi. Y el año pasado por estas fechas se dijo que fue el mejor día de pi del siglo porque las cifras de mes-día-año (que es como lo hacen los anglosajones) coincidían con...
Lo más divertido de esta simulación de fluidos «pixelizada» con piezas de Lego es que no solo el líquido no es real –como es bastante obvio– sino que las piezas de lego tampoco lo son: son otra simulación «física» llevada a...
Todo está listo en el cosmódromo de Baikonur para el lanzamiento de la primera parte de la misión ExoMars de la Agencia Espacial Europea, en este caso el del orbitador Trace Gas Orbiter y del aterrizador Schiaparelli. El lanzamiento se podrá...
Nick Berry tiene en DataGenetics la que tal vez sea la más completa página dedicada al «juego de los barquitos»: Batalla naval. En este popular juego de estrategia infantil los jugadores colocan sus barcos, de distintos tamaños, sobre una rejilla de...
Pobrecita la homeopatía, que últimamente le dan desde todas partes… También en Vía V. Debate sobre Homeopatía en Vía V es un magnífico ejemplo de periodismo bien hecho; un programa de televisión convertido en servicio público, nada de esa lamentable equidistancia...
Exoplanetas potencialmente habitables conocidos en marzo de 2016 - PHL @ UPR Arecibo Casi no pasa una semana sin que se anuncie el descubrimiento de algún nuevo planeta extrasolar, muchos de ellos claramente hostiles para la vida tal y como la conocemos....
Lanzada el 12 de agosto de 2005, a las 21:24 UTC del 10 de marzo de 2006 la sonda Mars Reconnaissance Orbiter de la NASA iniciaba la maniobra para colocarse en órbita alrededor de Marte. Terminada a las 21:51, la MRO...
Los médicos dicen que una de las causas del auge del movimiento anti vacunas es que ya no nos acordamos de cuando los entierros más numerosos eran los infantiles; que ya no nos acordamos de los efectos de muchas enfermedades que...
Una de las ventajas de tener unos cuantos satélites artificiales en órbita geoestacionaria es que nos permiten disfrutar de los eclipses de Sol desde un punto de vista diferente, como se puede ver en el vídeo de arriba. Incluye imágenes tomadas...
La esfera problemática del SEIS es la del centro de la imagen – CNES Un fallo en el instrumento SEIS, de Seismic Experiment for Interior Structure, o Experimento Sísmico para Estructura Interior, obligó a finales de 2015 a que la NASA pospusiera...
Hace unos días Boiron, esa empresa que está forrada a base de vender azúcar a precio de sangre de unicornio (o casi), quizás espoleada por la cancelación –no sin tiempo– del master en homeopatía de la Universidad de Barcelona, enviaba una convocatoria...
The chart of cosmic exploration es un póster de aproximadamente 1 metro por 69 centímetros que hará las delicias de cualquier espaciotrastornado que conozcas y al que aún le quede sitio en la pared para colgarlo. Incluye todas las sondas lanzadas...
Este es el típico avance tencológico-científico cuyo título simplemente mola porque nos recuerda que vivimos en el Futuro: una empresa llamada Veritas Genetics ofrece secuenciar el genoma completo de cualquier individuo por unos 1000 dólares y enviar los resultados a una app...

CGP Grey preparó un vídeo titulado The Trouble with Transporters donde divagando sobre los transportadores de Star Trek lanza más preguntas de las que responde respecto a cómo funcionan, qué hacen «realmente» y cómo afectan a las personas estas máquinas. Justo...
A las 1:58:19 UTC del 9 de marzo de 2016 se producirá el máximo de un eclipse de Sol, pero sucederá cuando la sombra de la Luna esté en medio del Pacífico, así que pocas personas alcanzarán a verlo, aunque muchas...
La permisividad que hay con las terapias alternativas a algunas personas ya les ha costado la vida. – Mariano Collantesen TEDxUPValència Un día de 2008 Mariano Collantes y su compañero Fernando Cervera montaron una web en la que hablaban de las virtudes...
Everything Is Crumbling (Todo se desmorona) en Slate: Una influyente teoría psicológica, confirmada por cientos de experimentos y citada por 3000 trabajos académicos ha quedado desacreditada. ¿Cómo pueden haber estado equivocados tantos científicos? (…) El experimento de los psicólogos Roy Baumeister y...
En este experimento de Steve Mould se utilizan granos de cuscús normal y corriente sobre una gran placa flexible llamada placa de Chladni, que al hacerse vibrar con un arco musical genera curiosas formas geométricas. En el efecto físico en cuestión...
Tal y como nos recuerdan en esta página con una animación GIF de un hipercubo 4D esta imagen de Paul Micarelli resulta muy interesante como forma de entender cómo «funcionan» otras dimensiones por analogía con las «sombras que proyectan»: La sombra...
Un triángulo rectángulo tiene una hipotenusa de 10 unidades y la altura de esa hipotenusa es de 6 unidades. ¿Cuál es el área del triángulo? Este problema geométrico parece fácil y de hecho la ecuación que define la solución es casi...
Los cañones ecuatoriales de Caronte – NASA/JHUAPL/SwRI Una de las cosas más evidentes que se puede ver en las fotos de Caronte, la luna más grande de Plutón, que ha enviado la sonda New Horizons de la NASA es que su superficie...
El Google Lunar XPrize es la competición que ofrece el mayor premio de todos los tiempos: 30 millones de dólares para quien consiga colocar un robot en la superficie de la luna — uno que sea capaz de recorrer al menos...
Por Nacho Palou -
3 MAR 2016
Lo asteroides son la forma que tiene la naturaleza de preguntarnos eso de…¿Qué, cómo va ese programa espacial? – Neil deGrasse Tyson, astrónomo Si ahora mismo descubriéramos un asteroide en rumbo de colisión con la Tierra estaríamos prácticamente indefensos, ya que no...
Un cometa en 1300 del libro de los milagros de Augsburgo Los cometas más importantes (Lámina nº 1) en Astronomy (1875) Me ha encantado la recopilación de ilustraciones de cometas que hay en Flowers of the Sky; va de la representación del...
Tercer Milenio –nada que ver con el Cuarto– es el suplemento de ciencia decano de la prensa escrita española; se viene publicando con el Heraldo de Aragón desde 1993. Así que ya le tocaba ir estrenando una versión en línea que dará...
El aterrizaje en Kazajistán de la Soyuz TMA-18M a las 4:26 UTC del 2 de marzo de 2016 con Scott Kelly, Mikhail Kornienko y Sergei Volkov marcaba el fin de la primera misión de un año de los dos primeros en...
Hablaba Javier Armentia hace unos días de El Auge De Las Pseudociencias a raíz de una conferencia que le invitaron a dar en el Grupo de Investigación, Ciencia, Razón y Fe (CRYF) de la Universidad de Navarra. De su anotación entresaco...
A Drage Josevski le diagnosticaron un tumor en sus dos primeras vértebras, justo las que unen el cráneo con la columna vertebral y nos permiten mover la cabeza. De no habérselo extirpado el cordoma se habría ido extendiendo hasta afectar a...
La gente de Astroblog se ha pasado por las oficinas del radiotelescopio ALMA en Santiago de Chile para grabar un podcast en el que el astrónomo Juan Cortés habla del proceso de instalación de las antenas, cómo se mide la distancia...
¡Oh Dios mío, está lleno de estrellas! – David Bowman en2001: Una odisea del espacio Cuando Stanley Kubrik puso esa mítica frase en los labios de Dave Bowman tras ver el interior del monolito no podía saber, aunque sí intuir, que había...
Impresión artística de 55 Cancri e – ESA/Hubble, M. Kornmesser Según se puede leer en First Detection of Super-Earth Atmosphere un grupo de astrónomos de la University College de Londres han podido analizar por primera vez la atmósfera de una supertierra. Para...
La fusión nuclear se considera una forma de generación de energía limpia, inagotable y segura. Por desgracia no es fácil domeñarla y que sea práctica: todavía se gasta en generarla más energía de la que se produce (mal negocio) y es...

Supercámara lenta y supermacro. Otra forma de ver lo que sucede a nuestro alrededor un día de nevada cualquiera: la fantástica geometría de los copos de nieve como colosales estructuras fractales, con sus naturales movimientos guiados por la ley de la...
En los Museos Científicos Coruñeses, en los que trabajo en el MundoReal™, estamos de estreno, en este caso con un nuevo programa de planetario. En las alas de la noche es un documental para planetarios sobre las migraciones de las aves...
Este vídeo del proyecto Atlasgal (APEX Telescope Large Area Survey of the Galaxy) del Observatorio Europeo del Sur es sencillamente sobrecogedor: el montaje más nítido del plano galáctico visible desde nuestro pequeño planeta. Las imágenes tienen resolución 4K y cubren 140...
Facebook también tiene un departamento de investigación con un blog donde publica eventualmente diversas curiosidades que van descubriendo y avances que realizan. Una de ellas tiene que ver con la famosa teoría de los seis grados de separación, algo que como...
Los giroscopios me siguen pareciendo unos artilugios fascinantes, así que me ha encantado ver al astronauta Tim Peake mostrando cómo se comporta un giroscopio en caída libre a bordo de la Estación Espacial Internacional , comparando qué sucede cuando está en...
Los «vídeos 360» ya son tan corrientes que están alcanzando su punto de saturación, pero me gustó el uso creativo que le dan en este documental del mítico David Attenborough: «moviéndose» con una pequeña plataforma por un escenario animado nos cuenta...
Este simpático vídeo de Minute Physics pone los puntos sobre las íes respecto al movimiento de rotación de la Tierra y los aviones que vuelan de un lugar hacia otro. Especialmente respecto a esa gran cuestión que todo el mundo se...
Llámense patatas Pringles o llámense paraboloides hiperbólicos su forma es exactamente la misma: la de una «silla de montar». Algunas de las curiosidades de esta peculiar forma es que se pueden apilar perfectamente pese a su curvo aspecto; el otro es...
Un time–lapse fotografiado por Tim Peake desde la Estación Espacial Internacional en el que una aurora parece querer huir del Sol naciente, aunque en realidad es el movimiento de la Estación, que se desplaza a unos 28000 kilómetros por hora, dando...
Un cohete H-IIA lanzaba a las 8:45 GTM del 17 de febrero de 2016 el observatorio espacial Astro–H, que, como es costumbre de la JAXA, la Agencia Japonesa de Exploración Aeroespacial, fue bautizado una vez en órbita. Su nombre es Hitomi,...
Un cohete Rockot lanzado a las 17:57:40 UTC del 16 de febrero de 2016 desde el cosmódromo de Plesetsk en el norte de Rusia ponía en órbita el satélite medioambiental Sentinel-3A. Últimas pruebas antes del lanzamiento – ESA Impresión artística del...
Ciencia en Redes 2016, una jornada para periodistas, investigadores, comunicadores, museógrafos e instituciones y empresas dedicadas a la ciencia y el I+D+i, tendrá lugar el jueves 28 de abril de 2016 en La Casa Encendida, en Madrid. Como en años anteriores una...
Lo mejor y lo peor de nosotros reside en nuestro cerebro: ahí está nuestra capacidad de entrega, de sacrificio, ahí están los circuitos que nos animan a hacer el bien e incluso nos hacen superar nuestras reglas biológicas para ser capaces...
Visions of the Future es la colección de pósteres de turismo espacial del famoso Jet Populsion Laboratory de la NASA, colección que ya incluye 14 destinos que van desde nuestro sistema solar hasta varios planetas extrasolares. Ceres, última oportunidad de coger...
He aquí una recopilación de Reddit y MetaFilter sobre algunos hechos matemáticos curiosos e interesantes –fascinantes podríamos decir– que no son por lo general muy conocidos pero que molan. Los he hiperenlazado para quien quiera indagar respecto a ellos: El x% de...
Según se puede leer en Philae se enfrenta a la eterna hibernación la Agencia Espacial Europea considera que las posibilidades de recuperar el contacto con el aterrizador de la misión Rosetta son ya prácticamente nulas, por lo que dejarán de enviarle...

Planetary suite es un óleo que Steve Gildea pintó en 1992 en el que hay nueve paneles que representan a los –entonce– nueve planetas del sistema solar, aunque en 1992 sólo podíamos suponer qué pinta tenía Plutón, por lo que el...
En Minute Physics dedicaron un vídeo a explicar por qué el cemento no se «seca» para endurecerse, o lo inapropiado que resulta el término secar. El asunto está en la diferencia entre los materiales que se endurecen cuando pierden agua pero...
Señoras y señores, hemos detectado ondas gravitacionales. ¡Lo hemos conseguido! Esta frase, pronunciada por David Reitze, el director del experimento LIGO, es histórica porque nos abre una nueva ventana al universo, aparte de que con toda seguridad traerá con ella toda...
{Lo interesante empieza en 06:15, si quieres ahorrarte el relleno.} Las pelotas de ping-pong son tan ligeras, tan ligeras que aunque durante un partido alguien remate con todas sus fuerzas es prácticamente imposible que te hagan realmente daño aunque impacten contra...
En la Asociación Española de Comunicación Científica, de cuya junta directiva soy miembro, llevamos ya meses preparando Ciencia en Redes 2016. La quinta edición de esta jornada para periodistas, investigadores, comunicadores, museógrafos e instituciones y empresas dedicadas a la ciencia y el...
Tras un viaje de unos 4900 millones de kilómetros de siete años y medio de duración la sonda Dawn de la NASA llegaba al planeta enano Ceres el viernes 6 de marzo de 2015 aproximadamente a las 13:36 UTC. Tras ajustar...
Una de las decisiones más polémicas de Ana Mato durante su mandato al frente del Ministerio de Sanidad fue la de cambiar el calendario de vacunación y dejar de administrar la vacuna de la varicela a los bebés a los 12 meses,...
Mars Express HRSC - Tharsis Region: volcanes en Marte, en primer plano el Monte Olimpo – ESA / DLR / FU Berlin / Justin Cowart Curiosity MastCam - Sol 1099: Curiosity mirando hacia los buttes Murray – NASA / JPL /...
Màrius se ha entretenido en descargarse las fotos de la cámara panorámica del rover chino Yutu publicadas por la Administración Espacial Nacional China y montar con ellas este vídeo, que permite recorrer la superficie de la Luna junto con él. La...
A la gente de Insvisible Creature le pidieron que diseñaran unos pósteres para el calendario de 2016 del Jet Propulsion Laboratory y crearon estos tres. Tal y como cuentan en en New Work: Visions Of The Future for NASA estos homenajean,...
La misión Lisa Pathfinder de la Agencia Espacial Europea es una misión preparatoria para intentar detectarlas en el espacio; hay rumores de que el el experimento LIGO podría haberlas detectado ya… Pero, ¿qué son las ondas gravitacionales y por qué nos...
Gripe aviar, SARS, Ébola… Ahora le llega el turno al zika, que la Organización Mundial de la Salud acaba de declarar emergencia mundial. El zika es un virus cuya infección es leve; de hecho el 75% de los infectados ni presentan síntomas,...
En The Guardian, A sigh's not just a sigh - it's a fundamental life-sustaining reflex, Según explican los investigadores en la revista Nature, dos pequeños grupos de células nerviosas en el tallo del cerebro —la región que se encarga de la respiración,...
Por Nacho Palou -
9 FEB 2016
En Quartz, This solar innovation by a Swedish artist uses surprisingly simple technology to save lives, En 2005 la diseñadora sueca Petra Wadström no tenía conocimientos de ingeniería ni sabía mucho acerca de la energía solar. Pero viendo la cantidad de...
Por Nacho Palou -
8 FEB 2016
En Details, Science Is Just Not That Into Your Fitbit, Investigadores de la Universidad de Lancaster, de la Universidad en Brístol y de la Universidad pública en Nottingham, no están entre aquellos que harán cola para comprar el nuevo y estiloso...
Por Nacho Palou -
6 FEB 2016
El gen egoista (Richard Dawkins, 1976) se considera una de las obras científicas más influyentes de las últimas décadas y ahora cumple 40 años. Por eso es tremendamente interesante la lectura de In retrospect: The selfish gene, de Matt Ridley, que...
Los icebergs de Plutón en color – NASA/HUAPL/SwRI/Roman Tkachenko Los científicos están cada vez más convencidos de que lo que en principio parecían montañas en la Planicie Sputnik en realidad son enormes bloques de hielo de agua flotando en un hielo formado...
El brazo robot en acción – NASA/Chris Gunn Usando un brazo robot capaz de moverlos con la precisión necesaria de fracciones de milímetro los técnicos del Centro Espacial Goddard de la NASA acaban de terminar la instalación de los 18 espejos que...
El vídeo A Year of Weather 2015 está compuesto a partir de las imágenes de los satélites meteorológicos Eumesat, NOAA y JMA. Muestra los sucesos y los cambios meteorológicos atmosféricos que se produjeron por todo el planeta a lo largo de...
Por Nacho Palou -
4 FEB 2016
Hoy es el Día Mundial concra el Cáncer, la causa de la muerte del diez por ciento de la población menor de 75 años en nuestros días en España. Y eso es un número enorme de gente. Los cánceres más mortíferos...
La profesora Hanna Fry nos explica en este vídeo algunas cuestiones acerca de las matemáticas de las probabilidades de los sucesos improbables, concretamente eventos como sufrir ataques terroristas, que-te-caiga-un-rayo-encima o que te muerda un tiburón. El trabajo completo que publicó y...
Maqueta del módulo de ciencia de la Luna 9. Su diámetro real era de 58 centímetros y pesaba 99 kg – 2008 IPMS Nats Models Tras ser lanzada el 31 de enero de 1966 a bordo de un cohete Molniya-M desde el...
La inmensa mayoría de los microorganismos son «gente» muy buena: gracias a ellos es posible la vida en el planeta, son la base de la biotecnología, limpian nuestros desechos y tienen funciones relevantes en la industria alimentaria. Pero es verdad que...
Un número primo que al dividirlo por 4 deje de resto 1 (por ejemplo, 41) siempre se puede expresar como la suma de dos cuadrados. Por ejemplo: 41 = 16 + 25 = 4² + 5². [Fuente:2radical3 vía Interesting Mathematics vía Gregory...
Adrian Brightmoore ha tenido la pericia de construir este El atractor de Lorenz en Minecraft. Popularizado por James Gleick junto con otras visualizaciones de la teoría del caos tras la publicación de Caos: la creación de una ciencia (1988), esta construcción...
En Gear Patrol, Why Space Is Making a Comeback, sobre el resurgir de la fascinación por el espacio en los últimos años que se expresa en el cine, con un montón de películas sobre este tema estrenadas en los últimos años...
Por Nacho Palou -
2 FEB 2016
Chang'e 3 en la superficie de la Luna – Chinese Academy of Sciences / China National Space Administration / The Science and Application Center for Moon and Deepspace Exploration / Emily Lakdawalla La sonda china Chang'e 3 aterrizó (y sí, se puede...
En BBC Earth publicaron un vídeo con un «experimento» en el que se grababa a una persona en plena ola de frío helador escocés mientras perdía calor corporal al quitarse prendas de ropa paulatinamente. Para la prueba se utilizó una «cámara...
El rover marciano Curiosity ha compartido en su página de Facebook una imagen de vídeo en la que capta todo lo que hay a su alrededor, 360° que incluyen el paisaje marciano y la propia sonda. Técnicamente no es la mejor...
Por Nacho Palou -
1 FEB 2016
Destinado a estudiantes de educación secundaria, Ciencia Clip es un concurso de vídeos divulgativos de ciencia que tiene como premios un robot, un viaje a Naukas Bilbao 2016 o una visita al CERN. Pueden participar estudiantes de la ESO, Bachillerato y...
Sé curioso, no temas equivocarte, mira los problemas como un reto y recuerda que tu imaginación es un arma muy poderosa.- Principia Kids T1E1 Desde el principio de su aventura la gente de Principia tenía una sección en su web dedicada...
Aparte de estar cada vez más cerca de hacer que aterrizar la primera etapa de un cohete tras su lanzamiento se vuelva algo habitual, SpaceX sigue adelante con su programa de pruebas para certificar la Dragon V2, su cápsula tripulada, para...
Deuteranopia o ceguera para el color verdeProtanopia o ceguera para el color rojoTritanopia o ceguera para el color azu A raíz de la anotación acerca de que las mujeres ven más colores que los hombres (sí, y tiene una base biológica) estuve...
Uno de los problemas que tienen los satélites que están en órbita baja terrestre es que durante la mayor parte del tiempo no están en contacto con estaciones terrestres a las que poder transmitir los datos que han recogido o desde...
En Slate, Don’t Walk on Escalators. It’s Faster if Everyone Stands, Un estudio de la Universidad de Greenwich en 2011 detectó que, de promedio, alrededor del 75 por ciento de los usuarios del metro permanecían quietos en las escaleras mecánicas, mientras...
Por Nacho Palou -
27 ENE 2016
Zero-G Fish Bowl, o así es el contenido de una pecera en microgravedad o en estado de caída libre: el agua y el pez no están en el espacio sino en una torre de caída que es básicamente un artilugio como...
Por Nacho Palou -
27 ENE 2016

[Lo bueno empieza en la marca de tiempo 12:52.] Andreas Wahl es un físico que con un par ha realizado el famoso experimento de la bala-en-el-agua disparando hacia su cuerpo un rifle de gran calibre sumergido en una piscina. Y tal...
Gran recomendación desde ¡Es la guerra!: La batalla del agua pesada (2015) – Se trata de la miniserie noruega de sólo seis episodios, que narra la Operación Gunnerside, cuyo objetivo era sabotear el proyecto atómico de la Alemania nazi (…) Aunque...
Impresión artística de LISA Pathfinder tras la separación del módulo de propulsión tras llegar a su órbita de trabajo - ESA Lanzada el 3 de diciembre de 2015, la nave LISA Pathfinder de la Agencia Espacial Europea ya está en su órbita...
Una de las ventajas de que la NASA vaya haciendo públicas las imágenes que capturó la sonda New Horizons a su paso por Plutón es que puede venir gente con el talento de Roman Tkachenko y hacer vídeos como este, en...
PIA00032: Uranus in True and False Color, Urano a 18 millones de kilómetros el 17 de enero de 1986 – NASA/JPL El 24 de enero de 1986 la sonda Voyager 2 de la NASA pasó a tan sólo 81500 kilómetros de la...
Este cohete New Shepard de Blue Origin acaba de convertirse en el primer cohete en volar dos veces al espacio con su vuelo del 22 de enero de 2016, que sigue a su vuelo del 23 de noviembre de 2015. En...
Anda haciendo las rondas una noticia que afirma que David Bowie tiene una constelación a su nombre como homenaje póstumo. Se trata de una iniciativa de la emisora de radio Studio Brussels y de un grupo de astrónomos belgas del Observatorio...
United Launch Alliance es una empresa en la que participan Boeing y Lockheed Martin a la que sobre la NASA y el gobierno de los Estados Unidos contratan lanzamientos de satélites artificiales y sondas espaciales. Según la masa de la carga...
El astronauta Scott Kelly, que lleva como un millón de años en la estación espacial, se entretiene jugando consigo mismo al pimpón usando dos raquetas hechas con material que repele el agua y tiene un recubrimiento deslizante y usando un sorbo...
Por Nacho Palou -
22 ENE 2016
Tal y como la conocemos ahora, la ciencia no ha existido desde siempre. Aunque en la antigüedad Aristóteles e Hipatia ya hacían investigaciones sobre el mundo natural, es en la Edad Media cuando Alhazén y Roger Bacon proponen que, para lograr...
Los astrónomos y espaciotrastornados de todo el mundo están como niños con zapatos nuevos con un trabajo de Konstantin Batygin y Mike Brown en el que hablan de la posible existencia de un planeta que se convertiría en el noveno planeta...
En 50 años quizá oigamos a la gente decir: «mira esa pobre persona, tiene que permanecer inconsciente ocho horas al día». En Motherboard explican cómo puede ser a medio plazo un futuro ligeramente distópico en el que parte de la humanidad pueda...
No está mal rescatar esta charla de hace unos años de James Hansen en TED, titulada ¿Por qué tengo que hablar del cambio climático?, que ahora ha seleccionado United Explanations como una de las mejores charlas sobre desarrollo global en este...
A pesar de que el título está en inglés este vídeo divulgativo sobre física está en castellano – lo cual siempre viene bien. Forma parte del Proyecto So Close y nos ha llegado de parte de un grupo de jóvenes investigadores...
En la EPFL suiza han montado una instalación artística llamada Sol.id que combina un poco de arte con diseño mediante ordenador e ingeniería. El resultado es que los rayos del sol se reflejan en varias placas metálicas para homenajear a cuatro...
Con el lanzamiento del satélite Irnss–1E a bordo de un cohete PSLVC la India tiene ya en órbita cinco de los siete satélites que formarán el Indian Regional Navigation Satellite System, o Sistema de Navegación Regional Indio, su equivalente al GPS...
Imagen generada con Stellarium Desde el amanecer del 20 de enero de 2016 hasta finales de febrero, nubes mediante, es posible ver a la vez en el cielo a primera hora del día a Mercurio, Venus, Marte, Júpiter y Saturno. Son los...
Definir la ciencia es muy complicado (…) Un filósofo de la ciencia diría algo como el conocimiento racional, sistemático, exacto, verificable y falible sobre la realidad (…) Por ejemplo, ¿las matemáticas son una ciencia? Sí, la mayoría de los filósofos de...
Los ordenadores del Proyecto GIMPS (Great Internet Mersenne Prime Search) han descubierto el mayor número primo conocido hasta la fecha, un primo de Mersenne de la forma M = 2n - 1 en el que n también es primo. El número en...
Automóvil en tanto se mueve por sí mismo, si bien es cierto que su utilidad es nula más allá del juego, la diversión o la enseñanza. Porque en realidad el automóvil del vídeo, vía Make:, es un motor homopolar construido con...
Por Nacho Palou -
18 ENE 2016
Falta aún algún tiempo para que veamos órganos funcionales impresos en 3D que se puedan implantar en una persona para tratar una dolencia o reparar algún daño. Pero tal y como cuenta Nieves Cubo en Imprimiendo piel humana, una charla de...
Lo tuiteaba recientemente el astronauta Scott Kelly: hay vida extraterrestre — aunque esa vida extraterrestre es por ahora una zinnia, una planta con flor típica sobre todo de la zona central del continente americano. La zinnia era hasta ahora notable por...
Por Nacho Palou -
18 ENE 2016
SpaceX decidió utilizar el lanzamiento del satélite medioambiental Jason–3 para intentar, por tercera vez, recuperar la primera etapa de un cohete Falcon 9 tras su lanzamiento haciéndola aterrizar en una plataforma flotante. No lo consiguieron porque una de las cuatro patas...
Blue Monday – Se Anuncia Oficialmente El Día Más Deprimente de Enero: el 22 de enero es el día más deprimente del calendario para a mayoría de los británicos de acuerdo a una sencilla fórmula desarrollada para Sky Travel. Teniendo en...
Impresión artística del Jason–3 en órbita – CNES Un cohete Falcon 9 v1.1 de SpaceX ha puesto hoy en órbita el satélite Jason–3, un proyecto conjunto de los Estados Unidos y la Unión Europea. Jason–3 tiene como objetivo medir la altura de...
El Falcon9 que lanzará al Jason3 – NASA Todo está listo en la Base Vandenberg de la Fuerza Aérea en California para el lanzamiento del satélite Jason–3 en un cohete Falcon 9 v1.1 de la empresa SpaceX a las 18:42:18 UTC del...
You’re All Just Jealous of My Jetpack de Tom Gauld (2013) es un pequeño librito que recopila las viñetas y tiras cómicas de este artista, que suele publicar en The Times. Humor británico fino, fino: con un toque científico, tecnológico, literario...
Impresión artística de Juno en órbita alrededor de Júpiter. En el extremo de uno de sus paneles solares se ve el magnetómetro, uno de los nueve instrumentos que lleva a bordo Lanzada el 5 de agosto de 2011, la sonda Juno de...
Ubicación de la unidad a reparar Una burbuja de agua en el casco de Tim Kopra hizo que desde el control de la misión dieran la orden de poner fin al paseo espacial que estaba llevando a cabo en el exterior de...
Impresión artística de la Dream Chaser Cargo System atracada en la EEI La NASA acaba de anunciar la firma de un nuevo contrato para llevar a cabo al menos 18 lanzamientos de carga a la Estación Espacial Internacinal en el periodo comprendido...
Víctima de las purgas estalinistas de los años treinta, Sergei Pávlovich Koroliov sobrevivió a su internamiento en un gulag en Kolymá, al este de Siberia, para convertirse en una pieza fundamental del programa espacial soviético. El primer satélite artificial, el Sputnik; el...
Si te dedicas a la ciencia, ingeniería o matemáticas y eres capaz de contar lo que haces en tres minutos de manera divertida aún estás a tiempo de participar en el certamen de monólogos científicos FameLab España 2016. Tienes hasta el...
Una de las patas de Philae sobre 67P Según cuenta el Deutsches Zentrum für Luft- und Raumfahrt e.V., el Centro Aeroespacial Alemán, vía Twitter el aterrizador Philae no ha dado señales de vida desde que el domingo 10 de enero de 2016...
Un posible iceberg de hielo sucio en Plutón – NASA/JHUAPL/SwRI Cuantos más datos vamos recibiendo y analizando del sobrevuelo de Plutón por la sonda New Horizons de la NASA más sorprendente resulta este mundo helado: la última e intrigante posibilidad es que...
Ya circulaba por ahí alguna versión de este vídeo, que montado a partir de imágenes de los lanzamientos de las misiones STS–117 y STS–127 de los transbordadores espaciales de la NASA, muestra el viaje de los propulsores de combustible sólido, o...
Aparte de combustible para maniobrar las sondas espaciales tienen otra necesidad básica: electricidad para mantener en funcionamiento sus sistemas de a bordo, y en el caso de las que llevan motores de iones, también para hacer funcionar estos. En el caso...
A finales de enero de 2016 el cometa 67P-Churyumov/Gerasimenko estará a más de 300 millones de kilómetros del Sol, con lo que la temperatura de Philae caerá por debajo de los –51ºC, lo que impediría definitivamente su activación. Por eso hoy,...
Con tan sólo un kilo y medio de peso, el cerebro es la estructura más compleja y maravillosa del universo. En él residen nuestro pasado, presente y futuro. El escritor que no sabía leer y otras historias de la Neurociencia, por...
Me encontré en Crononautas con esta explicación sobre las paradojas de los viajes en el tiempo desarrollada por el físico y cosmólogo Ígor Dmítrievich Nóvikov en los años 80 que se conoce como El principio de autoconsistencia de Novikov. La idea...
Heliocentrism and Geocentrism es una animación donde puede verse lo elegante y simple que resulta el modelo heliocéntrico («el Sol situado en el centro del Sistema solar») frente a lo extrañamente complejo que resultaba el geocéntrico («la Tierra en el centro»)....
Earthrise 2015 – NASA/Goddard/Arizona State University Una de las fotografías más famosas de la historia de la exploración espacial es la conocida como Earthrise, Salida de la Tierra, tomada por William Anders durante la misión Apolo 8 aproximadamente las 16:40 UTC del...
No lo vi pasar en su momento por Kickstarter, pero con la financiación más que conseguida, aún estás a tiempo de hacerte con Apollo: The Panoramas. Se trata de un libro que, a partir de las fotos hechas por los astronautas...
Esta imagen circular llena de estrellas, galaxias y nubes de gas contiene, aunque sea en pequeñito, todo el universo observable. ¿El truco? Está creado en lo que se denomina geometría hiperbólica: a medida que un punto se aleja del centro, es...

Los colores según los hombres y las mujeres por McLarenX;es una traducción de Color Wheel de Doghouse Diaries Turquesa viejo. Gris Marengo. Blanco roto. Rosa palo… Aunque esta ilustración está creada en clave de humor resulta que, más allá de que ya...
Muy al hilo del Premio Luis Freire de Investigación Científica en la Escuela de los Museos Científicos Coruñeses, una charla de César Hadada, profesor de la Harbour School de Hong Kong en la que explica cómo ha enseñado a sus alumnos...
¿Es verdad que la luz da luna pone verdes las patatas? ¿Qué distancia pueden dispersar las semillas los carnívoros? ¿El color de los alimentos que toman los caracoles influye, o determina, el color de la caca que depositan? ¿A qué velocidad se...
En diciembre de 2015 la empresa SpaceX hacía historia al conseguir hacer aterrizar la primera etapa de un cohete Falcon 9 tras un lanzamiento orbital. Pero no sólo la hicieron aterrizar, sino que tal y como comentaba Elon Musk, el dueño...
Como una especie de regalo de reyes anticipado el pasado 30 de diciembre de 2015 la Unión Internacional de Química Pura y Aplicada confirmaba el hallazgo, y por tanto su inclusión en la tabla periódica, de cuatro nuevos elementos, tal y...
A modo de revisión del año pasado y de anticipación de 2016 la revista Edge ha preguntado a 197 científicos y pensadores por las noticias más importantes del año, más concretamente, «Cuál considera que ha sido la noticia más interesante? ¿Y...
Fractal Lab es un proyecto perpetuo que desde 2011 permite renderizar imágenes fractales con increíble detalle, directamente en el navegador. Siguiendo la máxima de los sistemas no lineales, en los que una mínima diferencia en los parámetros de entrada puede producir...
Leland Melvin es un astronauta que explica en este vídeo algunos de los cambios que ha experimentado en «gravedad cero» y que son propios de las largas estancias en el espacio. Entre ellos, estos cuatro: Te vuelves algo más alto: entre...
Perihelio 2015 por Paco Bellido: 152.093.626 km en el afelio el 4 de julio de 2014, 147.095.995 km en el perihelio de 2015. Recuerda que nunca debes mirar al Sol sin la protección adecuada, y menos si es a través de algún...
El gráfico completo de Timeline of the Universe ocupa unos 23.000 píxeles en vertical, lo cual serían «unos 23 pantallazos» –así a ojo– de modo que si quieres verlo con todo detalle te pasarás un buen rato haciendo scroll. La cronología...
En Flowing Data recopilaron su selección anual de los mejores proyectos de visualización de datos del año. Puede verse un resumen de ellos aquí: 10 Best Data Visualization Projects of 2015. Cada uno es bastante distinto del anterior y de todos...
Ya hemos comentando aquí que los seres humanos no somos muy buenos en ciertas técnicas matemáticas (calcular probabilidades, entender los grandes números o el crecimiento exponencial). Pues bien: tampoco somos muy buenos generando secuencias de números al azar. Dos minutos bastan...
El cáncer de corazón no es algo de lo que se oiga hablar muy a menudo debido a que prácticamente no existe.¿Por qué es tan inusual que se produzca un tumor en el corazon?Las células cancerígenas obtienen su poder de su...
Por Nacho Palou -
26 DIC 2015
La idea de esta habitación es del artista Julian Hoeber; la idea es bastante sencilla: construir la «casa» deliberadamente inclinada, así como sus elementos: sus paredes que se tocan en ángulos de 90 grados, hay una silla, un espejo… La principal...
Última luna de 2015 por Javier Martínez Morán Si en la noche de la Navidad de 2015 miras al cielo verás que hay Luna llena, algo que no pasaba desde 1977 y que no sucederá de nuevo hasta 2034 y que no...

Pi en una espiral con cada dígito de un color / Martin Krzywinski Un paseo aleatorio creado con los dígitos de pi en base 4 / Franciso Aragón et al Aprovechando el Día de Pi en The Guardian publicaron el año pasado...
A las 10:27 UTC del 23 de diciembre de 2015 la nave de carga Progress MS-01 atracaba de forma automática en el módulo Pirs de la Estación Espacial Internacional tras dos días de pruebas en órbita que fueron utilizados para comprobar...
Técnicos trabajando en el InSight Un fallo en uno de los dos instrumentos principales del aterrizador ha obligado a la NASA a posponer el lanzamiento de la misión InSight, con lo que se perderá la ventana de lanzamiento de la primavera de...
La web Goldilocks muestra de forma interactiva los datos y la información procedente del Planetary Habitability Laboratory y en concreto de su Catálogo de Exoplanetas Habitables. De hecho, el término Goldilocks se refiere en astrobiología precisamente a los planetas extrasolares que...
Por Nacho Palou -
22 DIC 2015

Tras varios intentos la empresa de Elon Musk ha conseguido recuperar por fin la primera etapa de uno de sus cohetes.
El universo que podemos observar es apenas un cinco por ciento del total de masa y energía que este contiene; el resto está formado por un 26,8 por ciento de materia oscura y un 68,3 por ciento de energía oscura. Citando...
Lanzada por un cohete Soyuz 2-1A la primera cápsula de carga Progress MS despegaba el 21 de diciembre de 2015 a las 8:44 UTC rumbo a la Estación Espacial Internacional. Las Progress MS son la generación mas reciente de estas veteranas...
Hace unos años desde Proyecto Sandía propusieron que el 20 de diciembre se celebrara el Día Mundial del Escepticismo, pues es la fecha del fallecimiento de Carl Sagan, uno de los más grandes divulgadores científicos y defensores del pensamiento crítico. En los...
Máquinas que «crean energía», que «no se detienen nunca», «ruedas desequilibradas»… Son como el crecepelo mágico de la física. Un montón de ideas locas que llevan siglos perpetuándose –irónicamente– en busca del movimiento infinito. Son máquinas que supuestamente se mueven, de...
Partida de la Progress M-28M A las 7:35 UTC del 19 de diciembre de 2015 la cápsula de carga Progress M-28M desatracaba del módulo Pirs de la Estación Espacial Internacional para hacer una reentrada rápida sobre el océano Pacífico a las 11:28...
Impresión artística de Adriana y Liene tras la separación" Un cohete Soyuz 2-1B lanzado desde el puerto espacial de Kourou ponía en órbita los satélites 11 y 12 del sistema de posicionamiento global Galileo tras un lanzamiento perfecto a las 11:51 UTC...
Una fotografía tomada a partir de la huella de una niña de 6 años tras posar su mano sobre una placa de petri que contenía medio de cultivo e incubada a 28ºC durante dos días es la ganadora del primer premio...

Los científicos franceses más famosos de la historia han tenido simbólicamente que asistir a… esto Realmente es un fraude, una farsa. Es una gilipollez que digan «tenemos el objetivo de bajar las temperaturas 2°C e intentaremos hacerlo un poquito mejor cada cinco...
El Shell Ocean Discovery XPrize (sí: de «perforo-las-profundidades-del-océano-en-busca-de-petróleo Shell») es un nuevo reto para iniciativas privadas capaces de investigar la profundidad de los océanos en condiciones límite. Se suele decir que el océano es la parte más grande e interesante sin...
Despegue de la Soyuz TMA-19M – NASA/Joel Kowsky. Más fotos del lanzamiento y los preparativos en Expedition 46 Un lanzamiento perfecto de la Soyuz TMA-19M con Yuri Malenchenko, Tim Kopra y Tim Peake a bordo a las 11:03 UTC del 15 de...
La Gemini 7 vista desde la Gemini 6 – NASA Aunque la Unión Soviética ya había tenido dos naves en órbita al mismo tiempo fue la NASA la que el 15 de diciembre de 1965 a las 19:33 consiguió llevar a cabo...
Ya es oficial; según se puede leer en Final Results of NameExoWorlds Public Vote Released la estrella antes conocida como mu Arae pasará a llamarse Cervantes, mientras que Edasich b, también conocida como iota Draconis b, pasará a llamarse Hypatia. Además,...
Desde el departamento de nuestros amigos los gérmenes llega esta simpática y deliciosa peliculita animada sobre un germen codicioso y lo que sucede en el pequeño e invisible de mundo estas criaturitas «tímidas y amigables, que se ayudan unas a otras»...
Una charla de Javier García Martínez, el director del Laboratorio de Nanotecnología Molecular de la Universidad de Alicante, en TEDxPuraVida acerca de la nanotecnología, acerca de cómo está cambiando nuestras vidas, centrada especialmente en el campo de la energía, con algunos...
Es un poco muy lamentable que con todo el material que tienen este sea el vídeo que la NASA ha escogido para anunciar que a partir de hoy abre el plazo para recibir solicitudes para ser astronauta, pero es lo que...
Jack de Vsauce3 (que es uno de los canales en que se ha dividido el imperio Vsauce) trata en este vídeo sobre las paradojas en los viajes en el tiempo, con explicaciones fáciles de entender [y con buenos subtítulos en castellano]...
La Soyuz TMA-19M siendo erigida en la plataforma de lanzamiento Todo está listo en el cosmódromo de Baikonur para el lanzamiento de la Soyuz TMA-19M, previsto para el martes 15 de diciembre de 2015 a las 11:03 UTC. A bordo de ella...
Por lo general no le damos mayor importancia al horóscopo que sale en la inmensa mayoría de los diarios, pero hay gente que se lo toma en serio a pesar de que lo que dice no es más que una serie de...
Dos astronautas en el módulo lunar por Chet Jezierski,parte de la colección Eyewitness to Space La NASA documenta sus programas hasta la extenuación –aunque luego pueda perder cosas– y cada lanzamiento es fotografiado por montones de cámaras. Pero como dice la frase...
Provocadas cuando la Tierra atraviesa la órbita del del asteroide (3200) Faetón y sus restos se precipitan en la atmósfera, la lluvia de estrellas de las Gemínidas es, por lo general, una de las más espectaculares del año. En 2015 el pico...
Winner of SOHO's Birthday Image Contest El pasado 2 de diciembre se cumplían 20 años del lanzamiento del Solar and Heliospheric Observatory, o SOHO, un observatorio espacial de la Agencia Espacial Europea y la NASA que tiene como misión estudiar el Sol....
The Flavor Connection es un gráfico interactivo de Sientific American que explora las conexiones entre alimentos que tienen en común compuestos que dan sabor, basado en el trabajo Flavor network and the principles of food pairing. Cada uno de los puntos...
OSIRIS Image of the Day del 11 de diciembre de 2015, obtenida a 103,337 km del núcleo de 67P La cámara Osiris, de Sistema remoto de imágenes ópticas, espectroscópicas y de infrarrojos, es la cámara de más resolución de las que lleva...
Antes de que acabe el 2015, año en que Marty McFly y Doc llegan al futuro desde 1985, Borja Tosar y Xavi Fonseca se encargarán de dar un repaso a cómo creíamos que sería el futuro y a como ha resultado ser...
La TMA-17M tras su separación de la EEI – Vía @Volkov_ISS La TMA-17M durante su partida – Vía @StationCDRKelly La cápsula espacial tripulada Soyuz TMA-17M aterrizaba a las 13:15 UTC del 11 de diciembre de 2015 en Kazajistán con Oleg Kononenko, Kimiya...
«La ciencia ha hablado». Según un trabajo publicado por un equipo de la universidad de Binghamton (Reino Unido), los mensajes que acaban con un punto final, a diferencia del resto, son vistos por los destinatarios como menos sinceros. Según parece esto...
La Deke Slayton II lista para su captura El miércoles 9 de diciembre de 2015 a las 11:19 UTC la cápsula de carga Cygnus CRS OA-4, bautizada como Deke Slayton II, quedaba acoplada al módulo Unity de la Estación Espacial Internacional tras...
La cámara desarrollada por investigadores de las universidades Heriot-Watt y de Edimburgo puede captar los objetos que quedan ocultos al otro lado de una esquina, fuera de la vista. Sin embargo la cámara no captura la luz reflejada por el objeto,...
Por Nacho Palou -
10 DIC 2015
Lo cuenta la JAXA, el equivalente japonés a la NASA, en Venus Climate Orbiter «Akatsuki» Inserted Into Venus' Orbit: tras la maniobra del pasado 7 de diciembre de 2015 la sonda está en órbita alrededor de Venus. Akatsuki, también conocida como...
Según se puede leer en Japan to stay in space station project through 2024 el primer ministro japonés Shinzo Abe ha confirmado que Japón también se apunta a mantener la Estación Espacial Internacional, que recientemente ha cumplido 15 años permanentemente tripulada,...
Han tardado un poco más de lo previsto, pero por fin Bloostar tiene en línea el vídeo completo de presentación de su sistema de lanzamiento de nano y micro satélites. A diferencia de otras empresas que usan cohetes lanzados desde aviones...
Entre el 7 y el 19 de diciembre de 1972 tuvo lugar la misión Apolo 17, la última del programa Apolo de la NASA, la última –esperemos que hasta el momento– en la que un ser humano pisó otro astro distinto...
Recopilados por Paloma M. Arraiza, AKA @tolloder: La Puerta de los Tres Cerrojos de Sonia Fernández-Vidal. Quantic Love de Sonia Fernández-Vidal. ¿Qué pasaría si...? de Randall Munroe; los microsiervos reseñamos hace algún tiempo. Por amor a la Física de Walter Lewin....
The Mountainous Shoreline of Sputnik Planum: La orilla que separa las montañas al-Idrisi y Sputnik Planum – NASA/JHUAPL/SwRI Sueño que algún día alguien virará a estribor en un mar en otro mundo.- #µrelato de @Multimaniaco La sonda New Horizons de la NASA...
En El Diario han preparado un artículo y una infografía que recoge de forma resumida la posición de cada uno de los partidos políticos respecto a los temas energéticos relevantes en nuestro país. Desde qué pasa con las centrales nucleares hasta...
Impresión artística de Akatsuki frenando para entrar en órbita El 7 de diciembre de 2010 la sonda Akatsuki (Amanecer) de la JAXA, la Agencia Japonesa de Exploración Aeropespacial, tenía que haber entrado en órbita alrededor de Venus, pero un fallo de su...
Aunque vivimos bañados en radiaciones electromagnéticas de todo tipo que van desde las señales de las emisoras de radio y televisión a las del Sol, en los últimos tiempos se ha desarrollado un miedo especial al wifi y a la telefonía móvil....
Después de tres intentos de lanzamiento cancelados por culpa de la meteorología esta noche a las 21:44:57 UTC la cápsula de carga SS Deke Slayton II despegaba rumbo a la Estación Espacial Internacional con 3513 kilos de equipos y suministros a...
El 4 de diciembre de 1965 a las 19:30:03 un cohete Titan II GLV despegaba del Complejo de Lanzamiento 19 de la Estación de la Fuerza Aérea de Cabo Cañaveral con Frank Borman y James A. Lovell a bordo de la...
Este vídeo del histórico aterrizaje del cohete New Shepard hace unas semanas es toda una gozada: 400 miembros del equipo de Blue Origin siguen con toda emoción, en pantallas gigantes, el aterrizaje en vertical del impresionante chisme. Tan simpático resulta ver...
Uno de los principales problemas de la enfermedad de Alzheimer es que aunque conocemos demasiado bien sus consecuencias no tenemos ni idea de su origen, con lo que dar con tratamientos efectivos para ella, y no digamos ya curarla, ha sido...
Aunque se parecen mucho a las imágenes astronómicas que produce el Hubble, por ejemplo, en realidad lo que se ve en este delicioso vídeo son gotas de tinta luminiscente dejadas caer en un recipiente con agua iluminado con luz negra. Están...
El espacio-tiempo es un concepto matemático para describir la realidad del mundo físico que nos rodea. Por eso es más que interesante revisar What Is Spacetime, Really? del científico, genio hiperactivo Stephen Wolfram, creador entre otras cosas del software Mathematica. En...
Tras un lanzamiento perfecto a las 4:04 UTC del 3 de diciembre de 2015 a bordo de un cohete Vega el satélite Lisa Pathfinder de la Agencia Espacial Europea se separaba de este a las 5:49, quedando en órbita alrededor de...
El Bloomberg Carbon Clock. Aunque los niveles de concentración de partículas de CO2 en la atmósfera se reduce anualmente entre los meses de mayo y octubre debido a que la vegetación del hemisferio norte absorbe carbono del aire, la tendencia en...
Por Nacho Palou -
3 DIC 2015
Hoy, 2 de diciembre de 2015, se cumplen veinte años del lanzamiento del Solar and Heliospheric Observatory a bordo de un cohete Atlas II, aunque no entró en servicio hasta mayo de 1996. SOHO es una misión conjunta de la Agencia...
Moss Power es un blog dedicado al bio diseño y al musgo. Más concretamente al modo en el que las plantas terrestres briofitas pueden integrarse y aprovecharse para obtener electricidad verde de verded. Un ejemplo es el Moss FM de Fabienne...
Por Nacho Palou -
1 DIC 2015
En Addressing 4 billion People In Three Words, Si no te pueden localizar, no existes. Y el 75 por ciento de la población mundial, unos 4000 millones de personas, no tienen una dirección física. Todas esas personas sin dirección no pueden...
Por Nacho Palou -
1 DIC 2015
Los medios están llenos de anuncios de productos como el Actimel Pro-Vital que dice tener «L. Casei, Ginseng y además vitaminas que ayudan a tu vitalidad física y mental» y de otros que dicen llevar Coenzima Q10, que parece servir para todo,...
Este vídeo-homenaje titulado simplemente Apollo es además de bonito un perfecto ejemplo del efecto paralaje, una técnica para simular «profundidad 3D» a partir de imágenes planas 2D convencionales, en lo que se conoce popularmente como Efecto 2,5D. La técnica consiste básicamente...
Me ha parecido interesantísimo Tengo 34 años y hace tres me diagnosticaron autismo, un texto de una persona que durante la mayor parte de su vida, como indica en el título, ha ignorado que tenía un Trastorno del Espectro del Autismo, que...
Traducido de 12 bogus arguments about homeopathy de Edzard Ernst: Si hablas con los defensores de la homeopatía acabarás por oír afirmaciones que son falsas o engañosas; de hecho las oyes con tal regularidad que podrías empezar a dudar de la verdad....
Un vídeo de la Agencia Espacial Europea que explica cómo funciona el sistema óptico de la misión LISA Pathfinder, en el que un láser tiene que detectar los movimientos de dos cubos metálicos en caída libre separados por 38 centímetros. LISA...
En Motherboard publican un ensayo sobre cómo afectan diferentes tipos de drogas a la coordinación motora fina que es la que usamos a la hora de teclear frente al ordenador. Esto podría compararse con otras actividades que requieren prestar atención y...
El 25 de noviembre de 1915, en una conferencia en la Academia Prusiana de Ciencias, Albert Einstein presentaba en público por primera vez las ecuaciones que forman su teoría de la relatividad general. Con ella conseguía encajar la fuerza de la...
Desde la década de 1920 disponemos de una vacuna para la tuberculosis, la llamada BCG o Bacillus de Calmette y Guérin, aunque esta vacuna tiene el problema de que aunque es muy efectiva en los niños, apenas lo es en adolescentes y...
Ya hemos hablado más veces de la serendipia, esos descubrimientos que se producen cuando en realidad se está trabajando en otra cosa, y en este caso es el turno de un posible avance en el tratamiento de la infertilidad masculina cuando se...
Pues a la chita callando Jeff Bezos le ha ganado la carrera a Elon Musk para recuperar un cohete tras su lanzamiento. Como se puede ver en este vídeo el 23 de noviembre de 2015 cohete New Shepard de la empresa...
Los próximos 25 y 26 de noviembre de 2015 se celebrarán en la Facultad de Comunicación de la Universidad Pontificia de Salamanca las II Jornadas Comunicar Ciencia 2015. Su objetivo es «unir el mundo de la comunicación y el de la ciencia...
Llega el turno de Interstellar en Spoiler científico, el ciclo de conferencias sobre ciencia en el cine organizado por los Museos Científicos Coruñeses, en los que trabajo. El martes 24 de noviembre, en Domus, a las 19:30, el astrofísico Borja Tosar y...
En Cnet, Six Million Dollar Plant: Scientists grow cyborg roses, Investigadores del Laboratorio de Electrónica Orgánica de la Universidad de Linköping, en Suecia, ha logrado cultivar rosas con circuitos electrónicos integrado en su sistema circulatorio (...) el equipo, dirigido por el...
Por Nacho Palou -
23 NOV 2015
La identidad de Euler se considera la más bella y notable de las matemáticas, algo así como la Miss Universo de las fórmulas. e π i +1 = 0 Dicen que es así porque incluye cinco de las constantes más importantes...
Supuestas medicinas «milenarias» como el reiki que se venden como terapias complementarios a otros tratamientos cuando no como sustitutos de estas y que se ofrecen en hospitales públicos. Señores como Josep Pàmies que se dedican a crear miedo, duda y confusión sobre...
A simple vista no vemos los planetas del sistema solar más que como puntos de luz, y eso los que podemos ver sin ayuda de telescopio. Estos puntos son a veces más brillantes y a veces menos, dependiendo de la distancia...
Three things Rosetta taught us about Comet 67P es un vídeo de Nature que habla de tres cosas que Rosetta y Philae nos han permitido averiguar acerca del cometa 67P/Churyumov-Gerasimenko: El origen de su forma de «patito de goma», debido a...
Comienza el encapsulado – ESA–Manuel Pedoussaut, 2015 Unido ya al módulo de propulsión, que a su vez ya ha sido cargado de combustible, y retirados todos los remove before flight como las tapas de las toberas del sistema de maniobra y los...
Unos 20 minutos deberían ser suficientes para montar las piezas prefabricadas del Volta Flyer sin necesidad de usar herramientas ni pegamento y dejarlo listo para volar. El Volta Flyer es un pequeño avión de 42 centímetros de envergadura que vuela gracias a...
Instalar a propósito un componente con siete agujeros en una nave espacial tripulada no parece muy buena idea por aquello de mantener en su interior la atmósfera que permite a los astronautas respirar y esas cosas. Pero la Cúpula de la...
Leónidas de 1999 por Juan Carlos Casado – Vía APOD Como cada mes de noviembre la Tierra está atravesando la parte de su órbita que se cruza con la del cometa 55P/Tempel-Tuttle, cuyos restos, al caer en la atmósfera e incinerarse se...
El Skylab fotografiado por su última tripulación al partir de vuelta a casa Lanzada el 16 de noviembre de 1973 a la 14:01:23 UTC la tripulación de la misión Skylab 4 fue la última en ocupar la primera estación espacial estadounidense, y...
Hace unos días estuve en la presentación de Bloostar, el sistema de lanzamiento de nano y micro satélites de zero2infinity. Su idea es utilizar un globo lanzado desde una plataforma flotante para elevar el cohete hasta una altitud de unos 25...
Imagen CC por _Tasmo Me ha parecido muy interesante el artículo ¿Qué hay en una voz? de Michele Catanzaro, Astrid Viciano, Philipp Hummel y Elisabetta Tola en el que se analiza el uso y abuso de las pruebas de voz en los...
En Popular Mechanics, [ojo, artículo de 13 MB] The Asteroid Hunters, Cada noche se queman en la atmósfera terrestre pequeños trozos de roca procedentes del espacio. Los llamamos estrellas fugaces. Por lo general no son más grandes que un pelota de...
Por Nacho Palou -
13 NOV 2015
En la Asociación Española de Comunicación Científica, de la que soy miembro, estamos preparando Ciencia en Redes 2016, un evento destinado a periodistas, investigadores, comunicadores, museógrafos e instituciones y empresas dedicadas a la ciencia y el I+D+i. Aparte de las charlas de...
1. Morir.2. Enterrarse en caca de murciélago. * * * En National Geographic, Want to Be a Fossil? Try Burial in Guano, Restos del perezoso Shasta fosilizado en guano. Fotografía: Brian Switek. Gracias a un perezoso espectacular sabemos que enterrarse en guano...
Por Nacho Palou -
13 NOV 2015
Un grupo de músicos, diseñadores y programadores, trabajando con el Observatorio Astronómico Nacional de Japón, han creado ALMA Music Box, un ejercicio a medio camino entre el arte y la ciencia. En éste datos obtenidos en 2011 por el radiotelescopio ALMA...
Al explorar, la seguridad no es lo más importante. Al explorar lo más importante es ir.- Wayne Hale,responsable de los transbordadores espacialesde la NASA de 2005 a 2010. Hoy, 12 de noviembre de 2015, se cumple un año de uno de...

Las botellas de Klein son un tipo de objeto tridimensional realmente curioso, que tienen una sola cara y un solo lado. Si nunca has oído el término… ¿Puedes imaginar una? Es como una botella de cuello largo que se retuerce y...
Vivimos en una época en la que tenemos una facilidad de acceso antes inimaginable a una cantidad de información que jamás habríamos pensado, aunque a veces parece que no es suficiente. Así, nos encontramos con empresarios con pocos escrúpulos como Josep Pàmies...
Biopsia cerebral – Wikipedia/Dake~commonswiki Una de las herramientas fundamentales con las que cuentan los médicos a la hora de tratar un cáncer es la biopsia. Con una biopsia se extrae una muestra del tejido tumoral, y su análisis permite determinar si el...
Los considero mis amigos, así que puede que quede mal que lo diga así, pero Manuel Herrador y Xurxo Mariño han estado brillantes hablando de pseudociencias en Vía V. La reciente y polémica gira de Josep Pàmies por Galicia, bioconstrucción desvirtuada,...
El depósito de combustible de un cohete Delta 2 convertido 250 kg de basura espacial que cayó en 1997 en algún lugar del estado de Texas. El 13 de noviembre, en un par de días, está previsto que caiga a tierra un...
Por Nacho Palou -
11 NOV 2015
Minute Physics y XKCD como estrella invitada prepararon esta simpática animación sobre cómo son los viajes al espacio. Pero lo divertido no son solo los muñecos y el peculiar humor de los guionistas: es que además lo han narrado empleando solo...
En Motherboard, Researchers Threatened a Robot With a Knife to See If Humans Cared, sobre un peculiar experimento llevado a cabo por investigadores de la Universidad Tecnológica de Toyohashi, en Japón, con el fin de averiguar cuál es la reacción empática...
Por Nacho Palou -
10 NOV 2015
Investigadores de la Universidad de Donghua, en Shanghai, han desarrollado este papel que se pliega y se despliega cuando recibe luz o calor, caso de recibir una ligera radiación infrarroja. Lo interesante del asunto es que la manera en que se pliega...
Por Nacho Palou -
10 NOV 2015
En el MIT trabajan desde hace un par de años en el uso de redes inalámbricas, caso del wifi, con el fin de revelar si hay alguien al otro lado de una pared e incluso para medir el ritmo cardíaco a...
Por Nacho Palou -
9 NOV 2015
«Hola, soy Xingzhe y probablemente me recordarán como ‘el potro’ de sus clases de gimnasia en el colegio» Xingzhe es el robot cuadrúpedo que recientemente se ha hecho con el récord como el robot que más lejos ha llegado caminando de...
Por Nacho Palou -
6 NOV 2015
Las personas no somos más que comida recolocada. ¿Qué es la consciencia? Simplemente matemáticas.– Max TegmarkFísico En esta provocadora charla TED el físico Max Tegmark explica un punto de vista claro y directo, sin paños calientes, una de las grandes preguntas...
En New Scientist, 3D printed teeth to keep your mouth free of bacteria, Los investigadores integraron sales de amonio cuaternario en resina utilizada para la impresión 3D (…) y usaron la mezcla en una impresora 3D con la que fabricaron piezas...
Por Nacho Palou -
3 NOV 2015
La EEI en 2011 vista desde el Endeavour A las 9:21:03 UTC del 2 de noviembre de 2000 la Soyuz TM-31, con Yuri Gidzenko, Sergei Krikalev y William Shepherd a bordo, atracaba en la Estación Espacial Internacional, marcando el principio de la...
Hasta ahora tan solo era un invento teórico, pero este experimento que combina dos de las leyes más importantes de la física –con permiso de las de la termodinámica– demuestra que todo es posible: aprovechar esa explosión de energía paradójica que...
El último sábado de cada mes se puede asistir en el Planetario de los Museos Científicos Coruñeses, donde trabajo en el MundoReal™, a una sesión especial en la que cualquier aficionado al tema puede profundizar en sus conocimientos astronómicos y aprender...
Descubierto el 10 de octubre de 2015, el asteroide 2015 TB145 pasará hoy, 31 de octubre de 2015, a 286 000 kilómetros de la Luna a las 11:00 UTC, y luego, a las 17:01 UTC, a 486 000 kilómetros de la Tierra....
Alfa Centauri Bb, ¿el planeta fantasma? Hace unos días, con el motivo del centenario del descubrimiento de Próxima Centauri, la estrella más próxima a la Tierra, hablábamos también de Alfa Centauri Bb el planeta extrasolar más próximo a nosotros. Alfa Centauri Bb...
El espectrómetro Rosina fue el que realizó el descubrimiento La Agencia Espacial Europea acaba anunciar que la sonda Rosetta ha detectado oxígeno molecular en el núcleo del cometa 67P-Churyumov/Gerasimenko, alrededor del que lleva más de un año orbitando. Ya había detectado vapor...
Entre noviembre de 2002, cuando fue detectado por primera vez, y julio de 2003, cuando fue declarado contenido por la Organización Mundial de la Salud, el síndrome respiratorio agudo grave, más conocido por SARS, sus siglas en inglés, infectó a cerca de...
Impresión artística de la Voyager 1 Lanzada en 1977, el objetivo de la sonda Voyager 1 era estudiar Júpiter, Saturno, y Titán, unos objetivos para los que tenía que durar aproximadamente tres años y tres meses. La Voyager 1 pasó al lado...
Las visualizaciones sobre las probabilidades y causas de de la muerte son uno de esos temas un tanto oscuros que por aquí nos atraen como las flores a las abejas, de modo que aplaudimos este gráfico interactivo de la gente de...
No es tan poderoso como el del USS Enterprise o el de los superdestructores imperiales pero ahí está: lo que eufemísticamente llaman los científicos «haz tractor» –todo depende de cómo lo definas– al alcance de quien pueda pagar los materiales y...
El vídeo The Drill we sent to Mars de Smarter Every Day está dedicado al taladro del vehículo marciano Curiosity, el instrumento utilizado para perforar y tomar muestras de las rocas y el suelo marciano. Taladro aparte, lo mejor del vídeo...
Por Nacho Palou -
29 OCT 2015
Durante mi charla fui alcanzado por un cuarto creciente de Venus, pero la cosa se saldó sin consecuencias – Foto por Xurxo Mariño. Más fotos en Crónica fotográfica comentada de Naukas Bilbao 2015. Mi charla en Naukas Bilbao 2015 fue acerca de...
Star Stuff (The Story of Carl Sagan) es un delicioso vídeo de Ratimir Rakuljic que en un poco menos de diez minutos resume la actitud ante la vida y el universo de nuestro admirado Carl Sagan; tiene subtítulos en español. Ah,...
Este es un problema en el que hay que considerar varios factores y tener claro cómo «funciona» y cómo se aplica el principio de Arquímedes. Se puede resolver tanto de forma experimental (con un barreño y un barquito de juguete) como...
Ayer asistí a la primera de las charlas del ciclo Spoiler Científico que han organizado los Museos Científicos Coruñeses, donde trabajo en el MundoReal™. La «víctima» de esta primera charla fue Marte (The Martian), que Borja Tosar y Xavi Fonseca se...
Un montón de hormigas en grupo forman una suerte de material activo que se comporta a la vez como un líquido y como un sólido — pudiendo fluir, cambiar de forma o construir estructuras sólidas dependiendo del entorno o de la...
Por Nacho Palou -
28 OCT 2015
Cuanto más sabemos de Encélado, la luna de Saturno, más intrigante nos resulta, en especial desde que sabemos que bajo su superficie helada se esconde un océano global y, probablemente, actividad hidrotermal, es decir, química en la que intervienen rocas y...
La distribución animada de los dígitos de pi es una película que acaba como debe acabar: con una distribución perfectamente equilibrada de los diez dígitos que aparecen en la expresión decimal de π con un porcentaje de apariciones del 10% para...
Alguien en la cuenta oficial en Twitter de la @Policia (Policía Nacional) la ha liado parda en un absurdo intento de curar la «adicción» a los móviles e internet al asociarlos al insomnio y la «contaminación invisible» de los teléfonos móviles...
A menudo se critica el dinero que se gasta en los programas espaciales sin caer en la cuenta lo importante que el espacio es en nuestra vida cotidiana gracias a los satélites de comunicaciones o los sistemas de posicionamiento como el...
Para los frikis del espacio y de la informática, este documental de los años 60 sobre el Apollo Guidance Computer, el ordenador que llevó a las misiones Apolo a la Luna y de vuelta a la Tierra con mucha menos potencia...
Alpha Centauri Durante cinco años científicos de la Universidad Ruhr de Bochum han estado fotografiando la Vía Láctea desde el desierto de Atacama a la caza de objetos con brillo variable, trabajo que les ha llevado a dar con más de 50...
La suma del área de los triángulos verdes y suma del área de los cuadrados rojos parece igual. De hecho podría ser igual – pero no lo es: hay una diferencia de menos del uno por ciento. ¿Cuál de las dos...
Aún no se ha publicado el informe actualizado de la Agencia Internacional para la Investigación del Cáncer (IARC) de la Organización Mundial de la Salud que relaciona el consumo de carne procesada y de carne roja con el cáncer; por ahora...
Los Museos Científicos Coruñeses, en los que trabajo en el MundoReal™, estrenan mañana un nuevo ciclo de conferencias titulado Spoiler científico en el que hablaremos de la ciencia en el cine. La primera película en ser destripada será Marte (The Martian), el...
Oliver Sacks menciona en su biografía varias veces a Alexander Luria, un neuropsicólogo y médico ruso, alguien a quien empezó a seguir como estudiante de medicina, con quien más tarde comenzó a tener contacto profesional, y alguien con el que acabaría...
Si tienes un navegador con Java activado puedes darte una vuelta por Your age on other worlds, una página del Exploratorium de San Francisco que te permite calcular tu edad en los otros planetas del sistema solar, Plutón incluido. Cuanto más...
Este fin de semana, en la madrugada del próximo domingo 25 de octubre a las 3:00 volverán a ser las 2:00. Este fin de semana llegará el día más horrible del año, el más triste y deprimente... el aciago día del cambio...
Foto de familia de las lunas de Plutón, con una parte de Caronte, con 1212 kilómetros de radio, en la parte inferior. Nix e Hidra, por su parte, tienen unos 40 kilómetros de radio, mientras que Cerbero y Estigia se quedan en...
Desde el departamento de vídeos culturizadores nos llega hoy ¿Qué es la luz?, una infografía animada de In a Nutshell (antes Kurzgesagt) La luz es la cantidad de energía más pequeña que se puede transportar: un fotón, una partícula elemental sin...
Una de las cosas que hizo la NASA durante las fechas previas a la llegada de la sonda New Horizons a Plutón fue enseñarnos que aunque el ex–planeta iba a estar a unos 5000 millones de kilómetros de este cuando la...
Todos sabemos que en invierno es temporada de gripe, pero a pesar de la creencia popular, no es el frío en sí mismo el que nos hace coger la gripe, aunque sí es cierto que el mal tiempo puede ayudar. Por...
La próxima vez que se vaya a producir un eclipse, ya sea de Sol o de Luna, y comiences a oír predicciones apocalípticas, pásale el enlace a este tuit a quien te las haga llegar; es todo lo que necesitan saber...
Orion and possible Orionid meteor (CC) Mike Lewinski Ya está aquí otra lluvia de estrellas de la que disfrutar si las nubes te lo permiten: las Oriónidas, causadas por los restos del cometa Halley, alcanzarán su pico de actividad para 2015 en...
Desde el pasado 16 de octubre, al superar el total acumulado de 382 días en el espacio de Mike Fincke, el astronauta de la NASA Scott Kelly tiene el récord de tiempo en el espacio para un astronauta estadounidense, tal y...
El Deep Space Climate Observatory, también conocido como DSCOVR, de la Administración Nacional Oceánica y Atmosférica de los Estados Unidos, tiene como misión principal medir el viento solar desde el punto de Lagrange L1, a un millón y medio de kilómetros...
Lanzada el 13 de marzo de 2015 la Magnetospheric Multiscale Mission de la NASA tiene como objetivo estudiar la magnetosfera terrestre. Pero tiene la peculiaridad de que está formada por cuatro satélites idénticos que vuelan en formación. En concreto vuelan formando...
El gráfico Common MythConceptions de Information is Beautiful clasifica más de sesenta creencias muy populares y habituales que en realidad son inexactas o falsas, o simples mitos. Algunos ejemplos: en la lengua no hay distintas zonas para distinguir los sabores —dulce,...
Por Nacho Palou -
19 OCT 2015
Los robots también se fostian a base de bien al sortear obstáculos, saltar, subir escaleras o al sentarse en una silla; igual que las personas, excepto porque los robots caen ‘a saco’, como un peso muerto: «se desploman como si les...
Por Nacho Palou -
19 OCT 2015
La Sociedad Española de Bioquímica y Biología Molecular acaba de lanzar el concurso de divulgación científica Cuéntaselo a tus padres. Está dirigido a estudiantes universitarios de grado en las áreas de conocimiento de Bioquímica, Biología Molecular y Celular, Biomedicina, Farmacia, Biotecnología,...
Se cogen unas imágenes de Júpiter tomadas por el telescopio espacial Hubble, se mapean en una esfera, y… ¡Wow! La idea es usar el Hubble para estudiar Júpiter, Urano, Neptuno y Saturno cada año y así poder comparar las observaciones para...
TL;DR: por culpa de la atmósfera, que aunque le viene muy bien a los astrónomos para respirar y seguir vivos y seguir astronomeando, para su trabajo es un verdadero coñazo, ya que evita que puedan ver un montón de cosas interesantes....
Harrisonicus ha estado jugando con el archivo de fotos del programa Apolo de la NASA y ha montado Apollo Missions, un curioso timelapse que, a partir del lanzamiento del Apolo 10, incluye imágenes al menos de las misiones Apolo 12 y...
Peter Norvig, ex-Google, explica en un extenso artículo con código en Python cómo crear simulaciones para entender algunos de los problemas y paradojas clásicas de la matemática probabilística. En concreto emplea ejemplos con dados, fechas de nacimiento, cuestiones sobre el nacimiento...
Anda dando vueltas por ahí un artículo titulado The Most Mysterious Star in Our Galaxy que habla de la estrella KIC 8462852, y las da más que nada porque tiene un destacado que dice Parecía el tipo de cosa que uno pensaría...
Lovelace & Babbage: Ada Lovelace, Charles Babbage, y la máquina analítica en Lego Desde hace algunos años el segundo martes de octubre es el día de Ada Lovelace, que en 2015 cae en el 13 de octubre. Por lo general se considera...
I'm a scientist es una actividad en la que científicos y estudiantes interactúan en la red mediante chats de texto en los que los científicos responden a las preguntas de los chavales, tanto sobre sus investigaciones como sobre su día a...
El neurólogo Kenneth Miller escribe en Will You Ever Be Able to Upload Your Brain? acerca de si alguna vez seremos capaces de crear modelos biológicos, electrónicos, informáticos, o en el soporte que sea, que nos permitan replicar un cerebro humano de...
La estrella más próxima a la Tierra es Próxima Centauri, una de las tres estrellas que forman el sistema Alfa Centauri. Pero es una estrella tan poco brillante que no se puede ver a simple vista, así que cuando miramos al cielo...
Cuando Neil Armstrong y Buzz Aldrin estaban recogiendo todo en el módulo lunar para preparar las cosas para la vuelta a casa tras su paseo por la superficie de la Luna durante la misión Apolo 11, Aldrin encontró en el suelo la...
Después de nueve años y medio y casi 5000 millones de kilómetros de viaje la sonda New Horizons llegó a Plutón 96 segundos antes de lo previsto cuando se planificaba la misión a principios de los 2000 [Fuente: Alan Stern, investigador principal...
Si te sobran 9 millones de litros de agua puedes utilizarlos como en este generador de olas llamado Delta Flume. Un mecanismo hidráulico de 10 metros de altura mueve el agua guiado por unos sensores de alta precisión para conseguir la...
New Horizons Finds Blue Skies and Water Ice on Pluto: imagen tomada por la cámara Ralph de la New Horizons con filtros azul, rojo, e infrarrojo cercano, procesada para darle la apariencia que tendría para los ojos de un ser humano –...
Dracónidas de 2011 – Pere Soler Según las previsiones el máximo de actividad de la lluvia de estrellas de las Dracónidas de 2015 se producirá en la noche del 8 al 9 de octubre de 2015, con un máximo estimado de entre...
Vorágine de satélites en el cielo estrellado: aparecen como puntos, no como estrellas en «movimiento» Nunca había pensado en este detalle, pero me pareció buenísimo: tal y como cuentan en PetaPixel si haces una foto del cielo estrellado de esas en las...
La gente de la Fundación John Templeton produjo este documental titulado 4,850 Feet Below sobre una mina de oro abandonada en Dakota del Sur en la que un equipo de astrofísicos dedican sus esfuerzos científicos a la búsqueda de materia oscura....
Si te van los juegos de tablero, la exploración espacial, y sabes inglés, puede que te interese Xtronaut, que ya tiene la financiación asegurada en Kickstarter. El objetivo es intentar completar misiones espaciales –necesitarás completar más de una con éxito para ganar...
NASA/JPL/University of Arizona En HiRISE and “The Martian” se recopilan imágenes obtenidas por la sonda Mars Reconnaissance Orbiter de la NASA que muestran con detalle, en alta resolución, las zonas del MarteReal™ que aparecen en la película —y antes las novela, los...
Por Nacho Palou -
7 OCT 2015
Principia Kids es una versión para niños de la revista de ciencia en formato papel Principia, sin duda una de las mejores –y más elegantes, todo hay que decirlo– iniciativas divulgativas del año, por la que ya apostamos en su día....
Si estos días miras hacia el este a primera hora de la mañana, mejor cuando ya no se ven las estrellas pero aún no se ha hecho de día del todo, verás dos puntos de luz que no tienen pérdida. El de...
Anda la NASA diciendo por ahí que hoy, 6 de octubre de 2015, se cumplen 20 años del descubrimiento del primer planeta extrasolar, refiriéndose al descubrimiento de 51 Pegasi b. Pero en realidad 51 Pegasi b es el primer planeta extrasolar descubierto...
Impresión artística de Hayabusa 2 viajando rumbo a su destino Lanzada el 3 de diciembre de 2014, la sonda Hayabusa 2 de la Agencia Japonesa de Exploración Aeroespacial (JAXA) tiene como misión estudiar el asteroide antes llamado 1999 JU3, tomar muestras de...
545 puntitos y contando Stuart Lowe se ha entretenido en buscar los lugares de nacimiento de las 545 personas que han volado a más de 100 kilómetros de altura, la línea de Kármán, que tradicionalmente se considera el límite del espacio, y...
El método científico, proceso habitual: Observación Inducción (hacerse preguntas) Hipótesis (plantear posibles explicaciones) Experimentación Demostración o refutación (extraer conclusiones) Tesis o teoría científica (explicar los resultados) La verdad es que se ve poco. En La ciencia y sus demonios: ¿Por qué no...
Es-pec-ta-cu-lar: Fractalism es una combinación de dos de nuestras obsesiones favoritas: los fractales matemáticos y las tipografías. Es un viaje peculiarmente vertiginoso por un alfabeto pixelado en el que las aes están compuestas de bes que a su vez están compuestas...
Waving goodbye – Serge Meunier Dentro de unos 7500 millones de años, probablemente mucho después de que haya desaparecido nuestro descendiente más remoto, en especial si no somos capaces de salir nunca de la Tierra, el Sol habrá agotado su combustible y...
Un par de imágenes del detector Atlas dan idea de su tamaño, en especial cuando consigues ver las personas para hacerte una idea de la escala – ATLAS Experiment © 2014 CERN El Gran Colisionador de Hadrones del CERN es probablemente...
No es algo que se haga todos los días, pero cada vez es más frecuente que se use la Estación Espacial Internacional como plataforma de lanzamiento de CubeSats que viajan hasta ella a bordo de alguna de las naves de carga...
El polímero desarrollado por Julia Kornfield del Instituto Tecnológico de California reduce la posibilidad de que el combustible arda de forma accidental, tras el un impacto de un avión, por ejemplo. En el vídeo la mitad superior corresponde a un depósito...
Por Nacho Palou -
5 OCT 2015
Tras el éxito de la primera temporada, vuelve Cómete el Museo al Museo Nacional de Ciencias Naturales en Madrid. Se trata de una actividad para grupos reducidos, con un mínimo de 20 personas –han de ser mayores de 18 años– y un...
Con presupuestos de más de 100 millones de dólares cada una si se dedicara lo que ha costado producir Insterestelar (165 millones de dólares) + Gravity (100 millones) + The Martian (otros 100 millones) se podrían enviar cinco misiones orbitales reales...
Nunca lo había pensado, pero cuando un arquero apunta hacia su objetivo el mismo arco impide que la flecha pueda salir directamente disparada hacia él, y sin embargo, un arquero medianamente competente es capaz de acertar. Es lo que se denomina...
Hace ya algún tiempo de su publicación, así que algunas de las misiones a las que hace referencia como activas ya han terminado, como por ejemplo las naves de carga ATV, pero El efecto ESA es un interesante repaso a la...
Presentado por Javier Sardá, hoy comienza ADN Max, un nuevo programa semanal dedicado a la ciencia en que tambien tendrán cabida humor, tecnología, magia, y entretenimiento. Para ello Sardá contará con colaboradores como Pablo Jáuregui, el redactor jefe de ciencia en...
Desde las 22:52 UTC del 1 de octubre de 2015 la cápsula de carga Progress M-29M está acoplada a la esclusa trasera del módulo Zvezda de Estación Espacial Internacional, con un nuevo envío de suministros en su compartimento presurizado y en...
Es bien sabido que por aquí no somos muy de GIFs y que se pueden contar con los dedos de una mano las veces en que los hemos usado, pero esta imagen del nombre de Kepler y la elipse de las...
¡Cuidado, espaciotrastornados! La NASA ha subido a Project Apollo Archive todas, absolutamente todas, las fotos tomadas por los astronautas del programa Apolo durante sus misiones. Tanto las que ya conocemos como las que nunca se publicaron porque la NASA escogió publicar...
Caronte en color exagerado para poner de relieve las distintas texturas de su superficie. La imagen fue capturada por la cámara MVIC de la New Horizons el 14 de julio de 2015; se pueden ver detalles de hasta 2,8 kilómetros por pixel...

La probabilidad de ser zurdo según lo sean los padres o no:Si ambos padres son diestros es el 10% pero si ambos son zurdos llega hasta el 25%El porcentaje normal en la población es del 10-15% desde tiempos prehistóricos Me quedé muy...
Concepción artística de la misión Psyche De un total de 27 candidaturas presentadas, estas son las cinco misiones que la NASA ha escogido como finalistas para su próxima misión Discovery, un tipo de misiones limitadas a un coste de 500 millones de...
Ser autor de una novela de éxito tiene sus ventajas: Andy Weir, el autor de El marciano, le pidió al equipo de la HiRISE, la cámara de la Mars Reconnaissance Orbiter de la NASA, que fotografiara la zona de Acialia Planitia...
Tenía por ahí perdido el enlace al proyecto de Luis PG para convencer a Lego de que produzca el módulo luna, el módulo de comando, y el módulo de servicio de la misión Apolo 11, la que nos llevó a poner...
Las ya famosas líneas de ladera recurrentes en Marte El anuncio de la NASA del pasado lunes de que había encontrado (de nuevo) agua en Marte, o pruebas bastante fuertes de que en ciertas condiciones en algunas zonas el subsuelo puede humedecerse...
Una de las primeras sorpresas que nos dio la sonda Rosetta según se iba acercando al núcleo del cometa 67P/Churyumov-Gerasimenko, su objetivo, fue que la forma de este recuerda a la de un patito de goma, aunque a mí a veces,...
Más de cien años después de utilizarlos para tomar las notas que le permitieron ganar un Nobel en 1903 y otro en 1911 los cuadernos y papeles de Marie Curie siguen siendo radiactivos y lo seguirán siendo por al menos otros...
El HTV-5 fue liberado a las 15:20 UTC del 28 de septiembre de 2015 - Via NASA Johnson Con una reentrada controlada en la atmósfera a las 20:31 UTC del 29 la cápsula de carga Kounotori 5 –o HTV 5– de la...
Manu Arregi aportando datos científicos que indican que Bilbao es el fucking center of the universe - Foto por Xurxo Mariño. Más fotos en Crónica fotográfica comentada de Naukas Bilbao 2015. A veces tenemos problemas para comprender las distancias en el mundo...
Imágenes infrarrojas de M42, nebulosa de Orión. NASA. En Adobe Conversations, How Photoshop Helps NASA Reveal the Unseeable, [Para obtener las imágenes en color] básicamente cojo la información de las imágenes en escala de grises correspondientes a distintas partes del espectro infrarrojo...
Por Nacho Palou -
29 SEP 2015
Lanzamiento del Astrosat - ISRO Un cohete PSLV-C30 ponía en órbita el 28 de septiembre de 2015 el observatorio espacial Astrosat, el primero de estas características lanzado por la ISRO, la agencia espacial india. Lleva cinco instrumentos a bordo que le permitirán...
Aprovechando el 468 aniversario del nacimiento de Cervantes, Forges nos recuerda la iniciativa para bautizar como Cervantes la estrella µ (mu) Arae: En un lugar de la constelación Ara, en torno a una estrella sin un nombre propio, sólo conocida por...
Eclipse04 por Paco Bellido. Los tonos turquesa de la parte inferior izquierda de la imagen central son debidos a la dispersión de la luz causada por el ozono atmosférico El eclipse total de superluna de esta pasada noche no defraudó a los...
Las líneas de ladera recurrentes son las bandas oscuras que se ven en esta imagen, cuya escala vertical está exagerada 1,5 veces - NASA/JPL/University of Arizona El agua es indispensable para la vida tal y como la conocemos, así que encontrarla más...
El vídeo de arriba —vía Holy Kaw aunque es viejuno— permite ver cómo con una cámara de niebla se pueden ver las trazas que dejan las partículas emitidas por algunos minerales de uranio tales como la torbernita, uraninita o betafita. La...
Por Nacho Palou -
28 SEP 2015
Hielo en la superficie de 67P - ESA/Rosetta/VIRTIS/INAF-IAPS/OBS DE PARIS-LESIA/DLR; M.C. De Sanctis et al (2015); Comet: ESA/Rosetta/NavCam – CC BY-SA IGO 3.0 El equipo de científicos del instrumento VIRTIS (Espectrómetro Térmico en el Visible y en el Infrarrojo) de la sonda...
La basura espacial son los miles de objetos que hay en órbita y de los que no tenemos control: satélites artificiales que ya no funcionan, etapas de los cohetes usados para ponerlos en órbita, restos de colisiones, y otros objetos que...
Infografía por Manuela Mariño Para Marga Muñoz, vicepresidenta del Colegio de Farmacéuticos de A Coruña, hay una serie de cosas básicas que deberíamos saber de los medicamentos que nos llevamos a casa. A saber: Qué es (por ejemplo, un antibiótico). Para qué...
Jose, lanzando preguntas y llenando la ISS y nuestras mentes de flores y ciencia - Foto por Xurxo Mariño. Más fotos en Crónica fotográfica comentada de Naukas Bilbao 2015. El hombre que comerá flores en la ISS, a cargo de José Manuel...
Simulación del eclipse visto desde España por el Observatorio Astronómico Nacional En la noche del 27 al 28 de septiembre de 2015 hay un eclipse total de Luna que comienza a las 00:11:47 y termina a las 5:22:27 UTC; el eclipse máximo...
Se calcula que en la Tierra hay algo menos de 1400 millones de kilómetros cúbicos de agua, de los que aproximadamente un 96,5 por ciento es agua salada.Y aunque cambia de estado continuamente en el ciclo de agua la cantidad total de...
Michael de Vsauce explora en uno de sus vídeos educativos las formas en las que la humanidad puede enviar mensajes al lejano futuro y a remotos lugares: cápsulas del tiempo, mensajes de radio y sondas espaciales. Muchas de estas iniciativas ya...
Una nueva remesa de impresionantes imágenes de Plutón –más aún que las de la semana pasada– por cortesía de la New Horizons: The Rich Color Variations of Pluto - NASA/JHUAPL/SwRI Plutón en color visto por la cámara MVIC. Esta imagen combina imágenes...
Me ha gustado mucho este vídeo de la serie Ciencia Express de la Cátedra de Cultura Científica de la UPV/EHU que en apenas un par de minutos explica lo que son los transgénicos, por qué son de interés, y, como despedida,...
El 1974 Bill Kaysing escribió, y más tarde publicó por sus propios medios, el libro We never went to the Moon, en el que defiende que los alunizajes del programa Apolo nunca tuvieron lugar y que en realidad las imágenes que...
Hace unos años en los Museos Científicos Coruñeses, donde trabajo en el MundoReal™, tuvimos la suerte de disfrutar de una conferencia de Susumu Tonegawa, premio Nobel de medicina en 1987 por el descubrimiento del mecanismo que permite al sistema inmune producir anticuerpos...
Hoy se cumple un año de la entrada en órbita alrededor de Marte de la sonda oficialmente conocida como Mars Orbiter Mission de la ISRO, la Agencia Espacial India, lo que fue todo un logro, ya que se convirtió en la...
Natalia y Manolo dándolo todo - Foto por Xurxo Mariño.Más fotos en Crónica fotográfica comentada de Naukas Bilbao 2015. ¿Astronomía en el espectro visible? ¿Qué me dices de los infrarrojos? ¿Y qué hay de la radioastronomía? ¿Amas los telescopios? Natalia Ruiz Zelmanovitch...
La Tierra vista por el instrumento SEVIRI del Meteosat-10 a las 6:00 UTC del 23 de septiembre de 2015 - Eumetsat A las 8:22 UTC del 23 de septiembre de 2015 se producía el equinoccio de otoño en el hemisferio norte, y...
Con un montón de actividades como exposiciones, debates, charlas, talleres, demostraciones gastronómicas y mucho más en numerosos puntos de la ciudad hoy arranca el festival Mar de Mares en A Coruña, aunque este año incorpora también una exposición en el Museo do...
Aunque su estreno estaba inicialmente previsto para el pasado domingo, en el mismo hueco que la primera temporada, al final los responsables de programación de La 2 han optado por colocar la segunda temporada de Órbita Laika los miércoles a las...
Aitor disparando balas de brócoli - Foto por Xurxo Mariño.Más fotos en Crónica fotográfica comentada de Naukas Bilbao 2015. ¿Qué te parecería si te dijeran que el colesterol en los alimentos no es tan malo como nos han dicho durante años? ¿O...
No había visto este vídeo hecho por el CNES en el que, con datos de las cámaras de a bordo y ROMAP, el instrumento diseñado para medir el campo magnético del núcleo de 67P, se reconstruye la trayectoria de Philae en...
Mars Trek, una herramienta recién estrenada por la NASA, permite pasearse por Marte casi igual que uno lo haría por la Tierra usando Google Maps y ver imágenes y analizar datos de nuestro vecino. Los controles son los habituales, aunque además...
En el anuncio de Actimel de Danone, Según los expertos para convertir un propósito en un hábito hay que repetirlo durante 21 días. Y aunque es verdad que se trata de un anuncio, tampoco está de más tener en cuenta que: a)...
Por Nacho Palou -
22 SEP 2015
Open tree of life Todos los seres vivos que hay en día en nuestro planeta descienden de Luca, el último antepasado común universal. El árbol de la vida que acaba de publicar la Universidad de Durham –o más bien un primer borrador...
Bill Nye (the Science Guy) explica cómo se las apañará nuestro cerebro para «procesar toda la información resultante cuando todo esté conectado a Internet». Y lo explica utilizando emojis — el «lenguaje de las cosas». De modo que aunque se podría...
Por Nacho Palou -
22 SEP 2015
Antena de 35 metros de Nueva Norcia - ESA/S. Marti Igual que la NASA, la Agencia Espacial Europea tiene su propia red de estaciones en tierra para comunicarse y controlar sus satélites y sondas espaciales. Conocida como Estrack, está formada por diez...

En un episodio de StarTalk, el podcast de Neil deGrasse Tyson, el mismísimo Edward Snowden aportó un granito de arena al mundo de la astronomía mencionando una posible explicación a la paradoja de Fermi. Enunciada de forma llana viene a preguntarse:...
Chile earthquake on the radar - Copernicus Sentinel data (2015)/ESA SEOM INSARAP study PPO.labs/NORUT Una de las ventajas del radar que lleva a bordo el satélite medioambiental Sentinel-1A, aparte de que puede «ver» de día y de noche y con cualquier meteorología,...
67P por Damian Peach el 17 de septiembre de 2015: se distinge perfectamente su coma alrededor del núcleo y su cola - Vía @IAmComet67P A partir del 23 de septiembre de 2015, con la llegada del otoño en el hemisferio norte de...
Khader siguió la estela de la gente de Bellerby nos envió este vídeo de Planetenkugel-Manufaktur, un artesano de la fabricación de «globos planetarios» lo cual quiere decir que no se limita al Planeta Tierra sino también a otros como Marte, el...
Imagen Bryce Vickmark, Phys.org. Las máquinas de resonancia magnética son capaces de obtener imágenes del interior del cuerpo humano; permite por ejemplo observar los tejidos blandos y órganos como el corazón o el cerebro. A partir de las imágenes obtenidas por resonancia...
Por Nacho Palou -
21 SEP 2015
Luis hablando de memoria de los distintos tipos de memoria - Foto por Xurxo Mariño.Más fotos en Crónica fotográfica comentada de Naukas Bilbao 2015. Somos, fundamentalmente, nuestras memorias, como las consecuencias de la enfermedad de Alzheimer nos recuerdan. Pero incluso cuando nuestra...
Un puesto de avanzada de exploradores humanos en Marte, imaginado por un artista / NASA ¡Que se joda la Tierra! ¿A quién le importa la Tierra? (…) Debemos llegar a otros planetas para asegurar la supervivencia de la humanidad ante cualquier evento...

Laurie Santos resucita en forma de vídeo un viejo «experimento psicológico» relacionado con la contabilidad mental del que ya hablamos por aquí hace años, el de las entradas de cine compradas y perdidas. El planteamiento cambia ligeramente, pero la idea subyacente...
To Scale: The Solar System es un vídeo en el que un grupo de amigos montan un sistema solar a escala en el que la Tierra está representado por una canica nos ha llegado como por varios cienes de sitios, y...
Closer Look: Majestic Mountains and Frozen Plains - NASA/JHUAPL/SwRI Tomada 15 minutos después de la aproximación máxima de la New Horizons a Plutón el 14 de julio de 2015 esta imagen capta la superficie del planeta casi al atardecer desde el punto...
¿En qué sentido «existen» los números, si es que acaso existen? ¿Estaban ahí y simplemente los descubrimos? ¿Existirían independientemente de si pensáramos en ellos? ¿Son como Sherlock Holmes, que solo existe en la ficción pero todo el mundo lo conoce y...
Naia durante su charla - Foto por Xurxo Mariño.Más fotos en Crónica fotográfica comentada de Naukas Bilbao 2015. Uno de los grandes logros de los sistemas sanitarios es el del cribado mamográfico al que se somete a las mujeres cada dos años...
Airport seating (cc) James Lee En Quartz, Danish researchers have an enraging proposal to speed up queues: Serve the last person first, El problema de «el primero en llegar es el primero en ser atendido» es que incentiva a la gente a...
Por Nacho Palou -
18 SEP 2015
El estudio Consequences of Erudite Vernacular Utilized Irrespective of Necessity: Problems with Using Long Words Needlessly, hace precisamente referencia —con sana ironía— a la ciencia por la cual cuando se utilizan palabras más complejas y largas con intención de sonar más culto...
Por Nacho Palou -
18 SEP 2015
Por fin ha llegado uno de los momentos del año que con más ansiaviva esperamos, el de la entrega de los premios Ig Nobel, aquellos mediante los que el Instituto de Investigaciones Improbables saca a la luz logros científicos que primero te...
En este vídeo Vi Hart se pierde en los frondosos árboles del infinito intentando encontrar una forma de escribir todos los números, algo que le lleva a elucubrar sobre los infinitos contables, incontables y muchos de esos conceptos que le encantaban...
Este vídeo es un nuevo trabajo de Roman Tkachenko con las últimas imágenes de Tombaugh Regio en Plutón recibidas de la sonda New Horizons de la NASA. Simula un sobrevuelo de la zona, un sobrevuelo que en realidad no hemos hecho...
Impresión artística de una cápsula Orión en órbita Según lo que se puede leer en NASA Completes Key Milestone for Orion Spacecraft in Support of Journey to Mars la cápsula tripulada Orión de la NASA acaba de pasar un importante paso en...
La EEI frente a Júpiter Hemos publicado fotos de tránsitos de la Estación Espacial Internacional frente a la Luna y frente al Sol, pero nunca habíamos publicado una de un tránsito frente a Júpiter… Porque nunca antes se había hecho una. La...
El próximo 28 de septiembre de 2015 a las 00:11:47 UTC comienza un eclipse total de Luna que será visible desde buena parte del planeta. Visibilidad del eclipse - F. Espenak / NASA La peculiaridad de este es que esa noche...
Sergio durante su charla - Foto por Xurxo Mariño.Más fotos en Crónica fotográfica comentada de Naukas Bilbao 2015. A lo largo de la vida de un europeo este consume 40 cerdos, cuatro vacas, cuatro terneras y 1000 pollos para alimentarse. Durante esa...
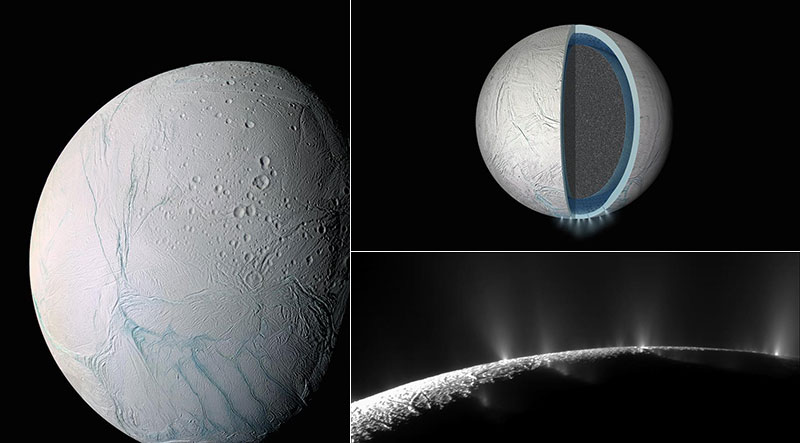
Una de las primeras sorpresas, ya en 2005, que nos dio la sonda Cassini cuando empezó a estudiar Saturno y sus lunas fue la de que Encélado podría estar expulsando al espacio chorros de partículas heladas desde su polo sur. La...
La asociación de divulgación científica Hablando de Ciencia está organizando, por tercer año consecutivo, Desgranando Ciencia. Desgranando Ciencia es un evento de divulgación de «Dos semanas en las que la ciencia será protagonista mediante espectáculos en la calle, jornadas de más...
El Solar Dynamics Observatory de la NASA está siempre mirando al Sol para estudiarlo en distintas longitudes de onda. Para ello está en una órbita circular geosíncrona de 35 789 kilómetros de altitud en una longitud de 102 grados oeste y...
Un equipo de médicos del Hospital Universitario de Salamanca dirigido por los doctores José Aranda, Marcelo Jimenez, y Gonzalo Varela, acaba de convertirse en el primero del mundo en implantar una prótesis impresa en 3D a un paciente de 54 años...
Deborah durante su charla - Foto por Xurxo Mariño.Más fotos en Crónica fotográfica comentada de Naukas Bilbao 2015. Aunque soy de esa parte de la población a la que se le califica como «de ciencias», esta es una etiqueta de la que...
Financiado y producido por espaciotrastornados de todo el mundo, Moonscape es un documental de más de tres horas y cuarto de duración que recoge, convenientemente restauradas y mejoradas con técnicas de procesado actuales, todas las imágenes y vídeos disponibles del primer...
Aterrizaje de la Soyuz TMA-16M A las 00:51 del pasado 12 de septiembre la Soyuz TMA-16M aterrizaba en Kazajistán con Gennady Padalka, Aidyn Aimbetov, y Andreas Mogensen a bordo, poniendo fin a la misión Iriss de la Agencia Espacial Europea. Durante los...
Women in Science es un juego de cartas creado por Anouk Charles y Benoît Fries después de darse cuenta de lo que les costaba poner ejemplos a su hija de mujeres científicas a la hora de intentar proponerle más alternativas en...
{Esta anotación no es apta para gente con fobia a los gérmenes. Misofóbicos abstenerse.} En Travelmath contrataron a un microbiólogo para examinar 26 muestras de 5 aeropuertos y 4 aviones y obtener un cálculo rápido de cuáles eran los lugares más...
El 7 de septiembre de 2015 el astronauta de la Agencia Espacial Europea Andreas Mogensen intentaba por primera vez el control de un rover y su brazo robot desde una nave espacial en órbita en una especie de ensayo para cuando...
Bajo el lema Ciencia más allá de la ficción y moderado por el astronauta belga Andrè Kuipers el próximo 11 de noviembre se celebra el primer TEDxESA, en que científicos, ingenieros, emprendedores, astronautas, gestores y artistas hablarán del espacio, la Tierra...
Los ansiosos pueden adelantar hasta 00:28. Hoy en día hay tantas cámaras a nuestro alrededor que hasta los meteoros se graban por doquier, hasta en alta definición – en este caso con una dashcam. De este que pasó por Bangkok (Tailandia)...
Scott Kelly: Un saludo a mis amigos que vienen en la #Soyuz @Astro_Andreas y @Volkov_ISS y al cosmonauta kazajo A. Aimbetov al que aún no conozcoSergey Volkov: Gracias!!! Hola desde el módulo de al lado! Todos hemos hecho esto de enviarle un...
Salvo los Lunojod soviéticos todos los rovers y aterrizadores que hemos colocado sobre la superficie de otros astros han funcionado o bien de forma autónoma o bien preprogramados para realizar una serie de tareas cada día. El principal motivo para esto...

Dicen que Hypernom es «como un Pac-Man en 4D» (para que se entienda) aunque en realidad es un explorador de objetos 4D en un entorno de realidad virtual o, técnicamente, un juego de orientación en S^3. Sí: hay pastillas que comer...
Plutón a contraluz desde unos dos millones de kilómetros, una de las últimas imágenes enviadas por la New Horizons hasta ahora - NASA/JHUAPL/SwRI Aparte de las imágenes y datos enviados en los primeros días después de su sobrevuelo de Plutón la sonda...
impresión artística de una CST-100 Starliner en órbita Se acabó referirse a la cápsula tripulada que está desarrollando Boeing sólo como CST-100, de Crew Space Transportation 100, Transporte Espacial de Tripulaciones 100: a partir de ahora se llama Starliner, tal y como...
A las 10:15 GMT del 4 de septiembre de 2015 se abrieron las escotillas entre la Soyuz TMA-18M y la Estación Espacial Internacional, con lo que esta pasó a tener nueve tripulantes, entre ellos Andreas Mogensen, el astronauta danés de la...
Tras un lanzamiento perfecto por parte de un cohete Soyuz FG la cápsula tripulada Soyuz TMA-18M está en órbita con Sergey Volkov, Andreas Mogensen, y Aidyn Aimbetov a bordo, rumbo a la Estación Espacial Internacional. Se trata del décimo lanzamiento de...
Nunca antes había visto este dibujo, hecho por Alexei Leonov mientras daba vueltas alrededor de la Tierra en la Vosjod 2, la misma nave desde la que hizo el primer paseo espacial de la historia y que casi le cuesta la...
Impresión artística del encuentro de la New Horizons con un objeto del cinturón de Kuiper - NASA/JHUAPL/SwRI/Alex Parker Tal y como se puede leer en NASA’s New Horizons Team Selects Potential Kuiper Belt Flyby Target y como estaba casi cantado la NASA...
Compite con dragones variados y una especie de bollito de pasta de soja, pero Hipatia de Alejandría podría tener su propio planeta. En concreto se trata de Iota Draconis b, un planeta con 2803,3 veces la masa de la Tierra situado en...
Uno de los riesgos más grandes a los que se enfrentan los astronautas es el de los efectos de los rayos cósmicos galácticos y de las partículas más energéticas del viento solar sobre su cuerpo. Mientras estamos en la Tierra esta...
Impresión artística de CHEOPS - C. Carreau La Agencia Espacial Europea está en plena construcción del telescopio espacial CHEOPS, de CHaracterising ExOPlanets Satellite, satélite de caracterización de planetas extrasolares, cuya misión es examinar planetas extrasolares ya conocidos. En concreto su misión principal...
Desde hace unos meses sabíamos, él mismo lo sabía, que este momento era inevitable: en la mañana del 30 de agosto de 2015 Oliver Sacks perdía su batalla contra el cáncer y moría en su casa de Manhattan a los 82...
La semana que viene tienen prevista su llegada a la Estación Espacial Internacional Sergei Volkov, Andreas Mogensen y Aidyn Aimbetov a bordo de la Soyuz TMA-18M. Esa nave será la que utilicen Mikhail Kornienko y Scott Kelly para volver a tierra...
Venus visto en radar de 12,6 centímetros el 13 de agosto de 2015 desde el Observatorio de Arecibo - Smithsonian/NASA GFSC/Arecibo Observatory/NAIC Uno de los principales problemas a los que se enfrentan los científicos a la hora de estudiar Venus es que...
Uno de cada tres científicos admite realizar algún tipo de malas prácticas y uno de cada 50 admite falsificar o inventar resultados Los científicos son humanos, y por tanto en un momento dado pueden decidir «torcer» un poco los resultados de un...
La cápsula tripulada Orión de la NASA ha superado otro importante paso para su primer vuelo tripulado. En este caso, lanzada desde un C-17 a 35000 pies de altura, unos 12000 metros, los ingenieros de la agencia prepararon todo para que...
Otro vídeo cortesía de Roman Tkachenko basado en mapas generados por Björn Jónsson. En este caso se ve a Caronte en órbita alrededor de Plutón… Aunque en realidad si te fijas bien verás que Plutón no se queda en el centro...
La presentación del Slide de Lexus, el «patín volador», «patinete mágico» o aerodeslizador –como prefieras llamarlo– fue bastante espectacular, y en la propia web explicaban cómo funciona mediante un sistema de imanes superconductores, raíles y otros truquis. Ahora en otro vídeo...
La Fundación B612 tiene como objetivo mejorar nuestra capacidad para proteger a la Tierra de los posibles impactos de asteroides destructores. Eventos que son tan altísimamente improbables como potencialmente apocalípticos – y si no, que pregunten a los dinosaurios. No sería...
El Ateneo Navarro, con la colaboración del Gobierno de Navarra, MECNA, la Fundación Cajanavarra y el Planetario de Pamplona, organiza el curso Frente a las pseudociencias. Las sesiones tendrán lugar en la sala Ibn'Ezra del Planetario de Pamplona del 7 al 10...
Impresión artística de LISA Pathfinder tras la separación del módulo de propulsión - ESA Una de las predicciones de la teoría general de la relatividad es la existencia de ondas gravitacionales, que transportan energía en forma de radiación gravitacional. Según las predicciones...
Tal y como estaba previsto la cápsula de carga Kounotori 5 fue capturada por el brazo robot de la Estación Espacial Internacional y acoplada a esta a las 14:02 UTC del 24 agosto de 2015. A bordo van 6057 kilos de...
Algo que nunca habíamos visto antes hasta que la New Horizons pasó por allí: Plutón dando una vuelta completa sobre sí mismo, lo que sucede cada 153 horas, unos 6,4 días terrestres: Y otra de las cosas que nunca habíamos visto antes,...
En A Children’s Picture-book Introduction to Quantum Field Theory Brian Skinner hace el ejercicio de intentar explicar algo de teoría cuántica de campos «como para niños de cinco años», es decir con dibujitos y explicaciones fáciles. Para mi que es un...
Este es desde hace años uno de mis trucos científicos favoritos: utilizar el cráneo como antena amplificadora y abrir el coche a distancias sorprendentemente grandes. Ahora la gente del Science Channel le dedicó un segmento con una demostración de un canadiense...
S65-50774: Lanzamiento de la Gemini V - NASA Hoy a las 13:59:59 UTC del 21 de agosto de 2015 se cumplen 50 años del lanzamiento de la misión Gemini V; el amerizaje se produjo en el Pacífico el 29 de julio a...
Un vídeo de buena definición grabado en la Estación Espacial Internacional permite ver con detalle el efecto Dzahanibekov que alguna vez hemos comentado por aquí y que sigue resultando asombroso cada vez que aparece: Este efecto lo observó por primera vez...
Y hablando de marcianos, aquí tenemos unos cuantos selfies que Curiosity se hizo mientras estudiaba una roca bautizada como Buckskin con su taladro. Estas fotos están formadas por varias imágenes tomadas por la cámara MAHLI de su brazo convenientemente procesadas para...
Impressions of Baikonur - a cosmic place es un vídeo de la Agencia Espacial Europea en la que varios espaciotrastornados comentan sus impresiones de un viaje a Baikonur para ver un lanzamiento, en concreto el de la Soyuz TMA-09M con Fiodor...
Está muy bien lo de la energía geotérmica, pero lo de que la farmacia «saludable» de Mairena del Aljarafe sea «el primer establecimiento sanitario descontaminado electromagnéticamente» ya chirría bastante más. Por lo visto tienen un sistema de apantallamiento de sus muros...
Un cohete H-IIB ha sido el encargado de poner en órbita el quinto vehículo de transferencia H-II, o HTV, de la Agencia Japonesa de Exploración Aeroespacial, con rumbo a la Estación Espacial Internacional. Con 10 metros de largo por aproximadamente cuatro...
Aunque de apariencia normal, la bicicleta que aparece en este vídeo de Smarter Every Day [con subtítulos en español] tiene una particularidad: la rueda gira en el sentido opuesto al giro del manillar. Tal y como se explica en el vídeo,...
Por Nacho Palou -
19 AGO 2015
Impresión artística de Insight en Marte - NASA/JPL-Caltech El InSight, de Interior Exploration using Seismic Investigations, Geodesy and Heat Transport, en español, Exploración Interior utilizando Investigaciones Sísmicas, Geodesia y Transmisión de Calor, es un aterrizador que la NASA tiene previsto lanzar hacia...
Por lo visto Jaume Padrós, presidente del Colegio Oficial de Médicos de Barcelona, dice que propondrá «sanciones e incluso la suspensión del ejercicio de los facultativos que desaconsejen las vacunas», siempre que medie una denuncia, tal y como aclaraba más tarde Jaume...
En esta charla TED el filósofo Jim Holt intenta arrojar algo de luz sobre la que es probablemente la cuestión más transcendental que se pueda concebir: ¿por qué existe algo en vez de nada? Una pregunta que se remonta –en esa...
En la sección Nutrición de El País: Cómo responder al típico que dice que la leche es mala: Incluyendo contraargumentos para rebatir: “La mayoría de la población mundial no puede beber leche” “Los lácteos tienen mucha grasa saturada” “La leche está llena...
La Mars Orbiter Mission, también conocida como Mangalyaan, de la Agencia Espacial India, tiene como objetivo estudiar la atmósfera y la superficie del planeta durante entre seis y diez meses, según ande de combustible y según se comporten los sistemas de...
Hoy, 15 de agosto de 2015, se cumplen 150 años de la muerte de Ignacio Felipe Semmelweis, internado en un sanatorio mental y prácticamente olvidado. Sin embargo millones de madres de todo el mundo le deben la vida. Nacido en 1818,...
En Ars Qubica se exploran los patrones geométricos de la belleza, o incluso podría decirse que la belleza de los patrones geométricos: son detalladas secuencias enlazadas por suaves transiciones y música que combinan las matemáticas de la geometría con el arte...
Perseids 2015 por Andrés Nieto AKA Porras @anieto2KPerseids Meteor Shower 2015: 130 exposiciones a lo largo e una hora por nothing-but-photographyPerseidas 2015 por NASA Goddard En mi esquina del mundo lo de ver las Perseidas de 2015 en su noche de máxima...
Hoy hace un mes que la sonda New Horizons de la NASA pasó zumbando por Plutón. Aún quedan meses de descarga de datos, pero esto es un resumen de lo que llevamos aprendido hasta ahora: Plutón tiene un diámetro de 2370...
EMSR130: Inundaciones en Birmania. Este mapa permite separar el río Irrawadi y sus afluentes, en azul oscuro, de las zonas inundadas, en azul claro, lo que permite estimar tanto la superficie de terreno afectado como ver qué rutas se pueden seguir para...
67P una hora antes de su perihelio visto por Rosetta - ESA/Rosetta/NAVCAM – CC BY-SA IGO 3.0 67P a las 11:29 UTC del 12 de agosto de 2015 visto desde la Tierra - SEN/Damian Peach A las 2:03 GMT del 13 de...
Al no existir una red mundial de sensores de contaminación lumínica la tarea de crear un mapa mundial de esta era prácticamente una misión imposible. Pero el proyecto Cities at Night de la Universidad Complutense de Madrid, en España, y el...
Polio Vaccination | Egypt: vacunación contra la polio en Egipto - CC CDC Global Se enfrentan todavía a desafíos como que las acciones de Al-Shabaab y Boko Haram impidan la llegada de las vacunas a todos los niños que hay que vacunar,...
La primera Perseida cazada por @astroemporda en 2015 Si quieres saber todo y más sobre las Perseidas, la que probablemente es la lluvia de estrellas más popular del año, aunque no la más intensa, en el Pamplonetario se lo ha currado con...
Impresión artística de Kepler-453b - Mark A. Garlick Durante mucho tiempo Tatooine fue el planeta en el que vivía Luke Skywalker cuando lo conocimos, un planeta en el que se pueden disfrutar de atardeceres con dos soles poniéndose al tiempo. Luego se...
Sistema Cervantes La Unión Astronómica Internacional ha abierto –por fin– un proceso internacional para recibir propuestas y votar cómo se llamarán 20 nuevos sistemas planetarios que se han descubierto estos últimos años. El Planetario de Pamplona (España), con el apoyo de la...
Mario Rodríguez era un estudiante de físicas de veinte años al que le diagnosticaron una leucemia. La quimio y un trasplante podían haberlo salvado. O no, pues hemos avanzado mucho en la lucha contra el cáncer, pero aún queda mucho que...
En realidad se tardan como seis horas desde el lanzamiento de una Soyuz hasta que esta se acoplam con la Estación Espacial Internacional, pero gracias a la magia de los time lapse aquí tenemos el proceso resumido en unos 90 segundos....
La Luna y PlutónJúpiter y la Luna. Sí, la Luna estáEl Sol y Júpiter Puedes encontrar los datos de su radio en la Wikipedia sin mayor problema, pero poder comparar visualmente los tamaños de los planetas del sistema solar, más Plutón y...
Ya hemos hablado por aquí alguna vez de lo impresionante que es el cielo oscuro en el Teide, aunque las Canarias en general tienen algunos de los mejores cielos para levantar la mirada por la noche y maravillarse con el universo...
Una galaxia en distintas longitudes de onda - ICRAR/GAMA y ESO Tenemos bastante claro que el universo nació hace unos 13700 millones de años con el Big Bang. Entonces se creó toda la energía, y a partir de parte de ella la...
Feet Up es el primer tema de Space Sessions: Songs From a Tin Can, el disco de Chris Hadfield, que sale a la venta el próximo 9 de octubre de 2015. Habrá que darle –o no– una oportunidad al resto de...
Tres planetas, una luna, y montones de estrellas - NASA Va con retraso porque en su momento no la había visto pasar, pero aquí queda enlazada una foto hecha por Scott Kelly desde la Estación Espacial Internacional en la que se ven...
Deberíamos dejar de referirnos a la homeopatía o la astrología como pseudociencias y empezar a llamarlas «timo socialmente aceptado».- @BolliStuff(Vía RT de @Karlos346)....
Impresión artística de COS-B en órbita - ESA El 9 de agosto de 1975 un cohete Thor Delta 2913 ponía en órbita del COS-B, el primer satélite artificial de la Agencia Espacial Europea… Aunque este aniversario tiene un poco de trampa, ya...
Suele decirse del ajedrez que es tan complejo que el número de posibles partidas es mayor que el número de átomos en el universo. En este vídeo de Numberphile se examinan esas cifras y cómo se ha llegado a ellas. El...
La Agencia Japonesa de Exploración Aeroespacial confirma que según la telemetría recibida de la sonda Akatsuki esta ha realizado correctamente las maniobras necesarias para que su órbita se cruce con la de Venus el próximo 7 de diciembre de 2015, tal...
Me encanta la crueldad con la que algunos descalifican a la ciencia cuando dicen «¿Ciencia? ¿La misma ciencia que no sabe de qué está hecho el 85% del universo?» A mi me parece un touché en toda regla, tengo que admitirlo....
Hoy hace tres años de la llegada de Curiosity a Marte en una maniobra de descenso bautizada como los siete minutos de terror. Para celebrarlo la NASA ha hecho pública una web llamada Experience Curiosity que permite conducir a Curiosity por...
Puede que no estén todos los eventos espaciotrastornados del mundo, pero Space Agenda es un punto de partida para no perderte nada de lo que se cuece. Aparte de por fecha puedes filtrar por tipo de evento (charla, congreso, curso, simposio…)...
Clic para ver en grande Después de 10 años, 5 meses y 4 días de viaje por el sistema solar la sonda Rosetta de la Agencia Espacial Europea entraba en órbita alrededor de su objetivo, el cometa 67P/Churyumov-Gerasimenko, en la mañana del...
NASA/NOAA Aunque la misión principal del Deep Space Climate Observatory, también conocido como DSCOVR, de la Administración Nacional Oceánica y Atmosférica de los Estados Unidos, es medir el viento solar desde el punto de Lagrange L1, a un millón y medio de...
MSG-4 SEVIRI First image Tras su lanzamiento el pasado 26 de julio el cuarto satélite medioambiental Meteosat de segunda generación, o MSG-4, está siendo probado y calibrado en órbita, aunque una vez que termine este periodo de pruebas y alcance su órbita...
Spritam impreso en 3D - Aprecia Pharmaceuticals Creí que tardaríamos un poco más en verlos, pero según cuentan en FDA approves the first 3D printed drug product [PDF 196 KB] la empresa estadounidense Aprecia ha obtenido ya la autorización para comercializar un...

Si estás aburrido estas tardes de verano después de ver las noticias te habrás cruzado con Ciencia para aficionados, título políticamente correcto de Science of Stupid, un producción de National Geographic que tiene buenas dosis de ciencia seria, recreativa y –siempre,...
Visitantes durante el día de puertas abiertas de 2014 / ESA-Sergi Ferreté Aymerich El domingo 4 de octubre de 2015, coincidiendo con el 58 aniversario del lanzamiento del Sputnik, el Centro Europeo de Investigación y Tecnología Espacial, también conocido como ESTEC, celebra...
Nunca había visto este detalle; a cámara lenta se aprecia mucho mejor. Los iris tiemblan como flanes cuando se mueven los ojos; de hecho todo el movimiento resulta muy acuoso y menos sólido de lo que cabría esperar – algo de...
Impresión artística de HD 219134b - NASA/JPL-Caltech Con el continuo goteo de nuevos planetas extrasolares cuya existencia vamos confirmando los récords en este campo suelen durar poco. Pero por ahora HD 219134b es el planeta rocoso más cercano a la Tierra que...
Una distancia adecuada al sol, tener un núcleo magnético que genera un campo magnético que nos protege de lo peor del viento solar y de los rayos cósmicos, una atmósfera que impide que la Tierra sea demasiado fría, agua y oxígeno...
STS114-S-017: Lanzamiento del Discovery en la misión STS-114 / NASA El 26 de julio de 2005 el transbordador espacial Discovery despegaba en la misión STS-114, la primera misión de vuelta al vuelo de los transbordadores espaciales de la NASA tras el desastre...
A Oliver Sacks le diagnosticaron un cáncer terminal a principios de 2015. Lo contaba en De mi propia vida, una reflexión digna de leer. Ahora vuelve sobre el tema con Mi tabla periódica: […] Y ahora, en este punto crítico, cuando la...
Aún no está ni en su órbita final ni terminado de calibrar, pero el satélite medioambiental Sentinel-2A del sistema Copérnico de la Unión Europea ya está empezando a demostrar de lo que es capaz. Como muestra, estas tres imágenes, sacadas de Primeras...
Souare Sekouba, miembro del equipo de ensayos clínicos, toma la temperatura a uno de los voluntarios usando un termómetro infrarrojo - OMS Seguimos sin tener una cura para el Ébola, pero los resultados de las vacunas experimentales que se están probando en...
HitchBot no lo ha conseguido: apenas dos semanas después de comenzar su periplo estadounidense, en el que pretendía llegar de Salem, Massachusetts, a San Francisco, su cuerpo ha sido destrozado en Filadelfia. Los responsables del proyecto no piensan buscar al culpable...
Con los Sentinel-1A y Sentinel-2A del sistema Copérnico de la Agencia Espacial Europea y de la Unión Europea ya en órbita ahora es el turno del Sentinel-3A, cuyo lanzamiento está previsto para octubre de 2015. El Sentinel-3A medirá el nivel del...
La costa de Titán – Tyler Nordgren Sueño que algún día alguien virará a estribor en un mar en otro mundo.- #µrelato de @multimaniaco. ¡Tantos pósters chulos, no hay pared suficiente! En este caso es la serie de pósters planetarios de Tyler...
Africa and Europe from a Million Miles Away - NASA El Deep Space Climate Observatory, también conocido como DSCOVR, de la Administración Nacional Oceánica y Atmosférica de los Estados Unidos, tiene como misión principal medir el viento solar desde el punto de...
«Puedo mirar por un telescopio sin cerrar un ojo. Así que creo que sé un poquito de ciencia» «Soy como Galileo para la gente que no quiere recordar cómo se deletrea Galileo» En Fake Science se han entretenido en ponerle citas «macarras»...
Eclipse de Luna Azul: Luna azul y eclipsada del 31 de diciembre de 2009 - Jean Paul Roux El tiempo medio entre dos lunas llenas consecutivas es de 29,5 días, mientras que en el calendario gregoriano que usamos en la mayoría de...
Si te gustó la baraja de naipes de la ciencia probablemente te encantarán estas otras, llamadas simplemente EduStacks. Hay una versión matemática absolutamente preciosa y otra de astronomía que tampoco está mal. Esta idea consiguió en su momento financiación en IndieGoGo...
Nadie duda de que la cosa de la financiación para ciencia está muy malita, así que la Fecyt, la Fundación española para la Ciencia y la Tecnología, ha puesto en marcha Precipita, una plataforma de financiación colectiva para proyectos científicos. ¿Qué...
Paolo Nespoli durante la misión Esperia - NASA Si todo va según lo previsto, Paolo Nespoli, el astronauta europeo de nacionalidad italiana, llevará a cabo su tercera misión a partir de mayo de 2017. Tal y como se puede leer en Third...
Es una pena que no hagan envíos internacionales, porque por 500 yenes, menos de 4 euros, en Village Vanguard te puedes hacer con un fragmento de la cofia protectora del cohete H-IIB que el 21 de julio de 2012 lanzó la...
La gente de Chop Shop ha conseguido ya financiación para su segunda serie de pósters dedicados a sondas espaciales, que en este caso estarán dedicados a la New Horizons, Rosetta y Philae, y a Galileo, aunque el diseño de este último...
Sí, la respuesta a la tercera pregunta es incorrecta, o como poco, demasiado simplificada, y sobra un mil en las cuentas de millones de años de los dinosaurios, pero aún así… ¿Sabes más de ciencia que un niño de primaria? Las...
Todo es 4: si en inglés eliges cualquier palabra y cuentas sus letras, y luego cuentas las letras del número resultante, y luego cuentas las letras del número resultante… y así sucesivamente, siempre acabas en 4. Lo explicó gráficamente Ramiro Gómez...
Aunque la probabilidad de que alguna vez algún ser vivo llegue a encontrarlos y a ser capaz de reproducirlos las dos sondas Voyager de la NASA llevan a bordo sendos discos dorados, que no de oro, en los que hay grabados...

La Science Deck es una preciosa baraja de naipes en la que el tema general son motivos científicos: las figuras son los grandes personajes de la ciencia –Einstein, Curie, Tesla, Lovelace, Mendeleiev) y el resto descubrimientos, inventos o componentes de teorías...
El EmDrive es una propuesta del ingeniero británico Roger Shawyer que básicamente dice –simplificando un poco, vale– que si acoplas un microondas a un cono metálico completamente cerrado este se convierte en un motor capaz de producir empuje por el lado...
El aspecto del radiotelescopio FAST cuando esté acabado en 2016 Circulan este día bastantes noticias sobre la construcción del FAST, un gigantesco radiotelescopio chino que hemos venido siguiendo por aquí, cuyo nombre viene del acrónimo Five hundred meter Aperture Spherical Telescope (Telescopio...
The Astrobiological Periodic Table es una versión de la tabla periódica diseñada por Charles Cockell en la que se pueden ver la procedencia de los elementos en cuanto a qué proceso los produce y su uso biológico. Procedencia, arriba a la...
@Maxkleiner dibujó esta curiosa teoría que explicaría por qué el tiempo parece pasar más rápido cuanto más envejeces; lo mejor es sin duda la representación visual e interactiva a la que puedes acceder con un clic y moviendo un poco el...
El interior del laboratorio Columbus En realidad aún faltan los módulos del segmento ruso, que serán añadidos más adelante, pero en International Space Station panoramic tour se puede dar un paseo en 3D por el interior de la Estación Espacial Internacional. La...
Mapa de Plutón con nombres - clic para ver en grandeMapa de Caronte con nombres - clic para ver en grande Todavía no son oficiales, pero ahora que ya tenemos unas cuantas imágenes de Plutón y Caronte en las que podemos distinguir...
Los avances en la lucha contra el cáncer pueden parecer muy lentos, en especial cuando te toca uno muy de cerca, pero esta ilustración, que recoge la evolución de los índices de supervivencia a 10 años a distintos tipos de cáncer...
En Truth Theory crearon un resumen fácil de entender de cómo reacciona tu cuerpo a la ingestión de una lata de Coca-Cola: 330 ml del precioso líquido, a todas luces inocente, refrescante y que todo el mundo ha probado alguna vez…...
Como se suele decir, no están todas las que son, pero son todas las que están, y la lista podría ser otra, pero estas son 27 mujeres que jugaron un papel fundamental en la historia de la investigación científica que ha...
Una delta acuarida por Jimmy Westlake - Vía NASA Procedentes del cometa 96P/Machholz –o eso creemos– se prevé que en la noche del 28 al 29 de julio de 2015 la lluvia de estrellas de las delta acuáridas alcance su máximo de...
Ya está convocado el primer TEDxESA bajo el tema Ciencia más allá de la ficción: Lo que ayer parecía imposible, es realidad hoy. Los sueños se convierten en ideas. Las ideas se convierten en conceptos. Y los conceptos se desarrollan como...
New Horizons Discovers Flowing Ices on Pluto - NASA/JHUAPL/SwRI Plutón ha vuelto a sorprendernos, en este caso con lo que parecen ser flujos de hielo en su superficie, algo parecido a los glaciares en la Tierra. En esta imagen de la cámara...
Ricardo nos escribió para contarnos esta divertida historia. Resulta que como regalo para un amiguete matemático‑científico diseñó una camiseta de John Ellis, el físico del CERN que trabaja con aceleradores de partículas. La subió a Neatoshop, donde se puso a la...
Dylan Selterman es un profesor de la Universidad de Maryland que se ha hecho popular por incluir en el examen final que presenta a sus alumnos una especie de «pregunta trampa» para conseguir puntos extra. La pregunta, convertida en viral de Internet,...
La gente de Moby Motion ha preparado estos vídeos a alta definición y 60 FPS como demostraciones de simulaciones físicas realistas: son básicamente torres de palitos que caen por la fuerza de la gravedad cuando otros objetos colisionan con ellas. Quizá...
Cuando ILC Dover, más conocida por su marca comercial Playtex, fabricó los trajes de los astronautas del programa Apolo su objetivo era que estos los protegieran adecuadamente durante el desarrollo de sus misiones. Nadie pensó en la necesidad de conservarlos para...
En La Sociedad planetaria tienen un estupendo artículo dedicado a la asistencia gravitacional que es el tipo de maniobra que utilizan las sondas espaciales para ahorrar energía dejándose atraer por grandes cuerpos astronómicos (normalmente planetas y lunas) para luego salir lanzadas...
Representación artística de Kepler-452b y la Tierra, aunque en realidad no sabemos si Kepler-452b tiene continentes y océanos - NASA/Ames/JPL-Caltech/T. Pyle El equipo de la misión Kepler de la NASA presentó ayer un nuevo planeta extrasolar, Kepler Kepler-452b, situado a unos 1...
Apollo Mission Patches es una animación en 3D de cada uno de los parches de las doce misiones del programa Apolo de la NASA. Está hecha con el motor de renderizado Octane en Cinema 4D; el behind the musgo de cómo...
Lanzada el 3 de diciembre de 2014, la sonda Hayabusa 2 de la Agencia Japonesa de Exploración Aeroespacial (JAXA) tiene como misión estudiar el asteroide 1999 JU3, tomar muestras de su superficie, y traerlas de vuelta a la Tierra. Pero como...
Foto: @FragileOasis ¿Qué nos falta por saber? Más de lo que nos faltaba hace 50 años. El conocimiento científico es como una isla y ahí está todo lo que sabemos. El océano es lo que no sabemos; y no podemos preguntarle al...
Lanzamiento de la Soyuz TMA-17MLa Soyuz TMA-17M en la plataforma de lanzamiento Tras un lanzamiento sin problemas a bordo de la Soyuz TMA-17M, Oleg Kononenko, Kjell Lindgren y Kimiya Yui se unían en la madrugada del 23 de julio de 2015 a...
NASA’s New Horizons Finds Second Mountain Range in Pluto’s ‘Heart’ - NASA/JHUAPL/SWRI La New Horizons ha encontrado una segunda cadena de montañas en otra de las fotos que ya ha enviado. Esta nueva imagen muestra tres terrenos bien diferentes: una zona oscura...
Aprovechando la infografía The Locations Of Every Lunar Landing y tirando de la Wikipedia, un repaso a todas las misiones espaciales que hemos conseguido colocar en la superficie de la Luna con más o menos éxito, un total de veinte por...
El pasado 29 de junio de 2015 el Falcon 9 que tenía que haber puesto en órbita la cápsula de carga Dragon CRS-7 reventaba dos minutos y 19 segundos después de haber despegado, provocando la pérdida de la cápsula. SpaceX suspendió...
New Horizons Captures Two of Pluto's Smaller Moons - NASA/JHUAPL/SWRI La NASA ya había publicado imágenes de Nix e Hidra obtenidas por la sonda New Horizons durante su sobrevuelo de Plutón, pero estas tienen más resolución, y en el caso de Nix...
La New Horizons en Eyes on the solar system Una semana después de su sobrevuelo de Plutón la sonda New Horizons se encuentra ya a más de ocho millones de kilómetros de este, rumbo al cinturón de Kuiper. Desde el día 19...
Welcome to a comet - Philae en la superficie de 67P - ESA/Rosetta/Philae/CIVA Desde que el 13 de junio de 2015 el centro de control de la Agencia Espacial Europea en Darmstadt recibiera señales de que Philae ha salido de su hibernación...
Una colaboración de Minute Physics y Neil DeGrasse Tyson: A Brief History of Everything. Un vídeo que pide a gritos unos subtítulos en español que cuenta la historia de todo desde el principio del universo hasta nosotros, así que lo mismo...
Impresión de un comprimido mediante capas de un polímero impregnado en el principio activo - Álvaro Goyanes Que la impresión en 3D va a revolucionar muchas cosas parece bastante claro, pero lo que no había pensado es que esta revolución pudiera extenderse...
Estas son las montañas de Plutón en 3D y 360 grados vía fotoclinometría, que es la técnica que permite convertir una imagen en 2D a 3D usando las sombras y la dirección como puntos de referencia para el cálculo. Casi dan...
Ya van unas cuantas veces que nos escriben mencionando Kerbal Space Program, un simulador que permite construir naves, sondas, rovers, y estaciones espaciales, pero con la salvedad de que la simulación incluye su comportamiento aerodinámico y la mecánica orbital correspondiente, de...
Hace un tiempo publicamos una anotación en la que salía un time lapse con imágenes de la Tierra vista desde la Estación Espacial Internacional a ritmo de Yann Tiersen. Pero resulta que nos hemos enterado de que el vídeo en cuestión...
Una nueva dosis de imágenes y datos para plutonófilos, cortesía de la New Horizons y de su sobrevuelo de Plutón. Homing in on Nix, Pluto's Small Satellite - NASA/JHUAPL/SWRI En el caso de Nix, tenemos un primer vistazo desde una distancia de...
Impresión artística de Akatsuki en órbit alrededor de Venus Lanzada en 2010, la sonda Akatsuki (Amanecer) de la la JAXA, la Agencia Japonesa de Exploración Aeroespacial, tenía que haber entrado en órbita alrededor de Venus el 7 de diciembre de ese mismo...
New Horizons Close-Up of Charon’s ‘Mountain in a Moat’ - NASA-JHUAPL-SwRI La NASA sigue publicando imágenes capturadas por la sonda New Horizons durante su sobrevuelo de Plutón. En este caso se trata de una foto de detalle de un área de Caronte...
Este curioso planteamiento de Kurz Gesagt en In a Nutshell parte de una idea un tanto alocada que necesita que dejes llevar tu imaginación para luego desarrollarla – da hasta para una clase de física. ¿Qué sucedería si de repente una...
De toda la vida –bueno, desde que sabemos que existe– a los estudiantes de medicina se les ha dicho que no hay conexión entre el cerebro y el sistema linfático, pero dos recientes estudios independientes parecen demostrar que esto en realidad...
La Fundación Zaragoza Ciudad del Conocimiento, en colaboración con el Ayuntamiento de Zaragoza, organiza la tercera edición de las Jornadas de Divulgación Innovadora D+I, que «son un foro profesional en el que reflexionar sobre los más novedosos caminos, enfoques y formatos para...
Por el efecto Magnus balones y pelotas realizan movimientos imposibles, como se puede comprobar de forma exagerada en este vídeo en el que lanzan desde lo alto de una presa un balón que está girando, Un objeto en rotación crea un...
Por Nacho Palou -
16 JUL 2015
Esta pasad noche un cohete Ariane 5 colocaba en órbita el satélite meteorológico Meteosat MSG-4, que será aparcado en órbita durante al menos dos años y medio, listo para actuar como sustituto de los otros tres Meteosat de segunda generación ya...
The Icy Mountains of Pluto - NASA-JHUAPL-SwRI Charon’s Surprising Youthful and Varied Terrain - NASA-JHUAPL-SwRI Hydra Emerges from the Shadows - NASA-JHUAPL-SwRI Ya tenemos las tres primeras imágenes enviadas por la sonda New Horizons tras su sobrevuelo de Plutón. Los protagonistas de...
The not-planets: Montaje por Emily Lakdawalla. La Luna: Gari Arrillaga. Otros datos: NASA/JPL/JHUAPL/SwRI/UCLA/MPS/IDA. Procesado por Ted Stryk, Gordan Ugarkovic, Emily Lakdawalla, y Jason Perry - CC BY-NC-SA 3.0 ES - Clic en la imagen para ver el original [4,5 MB] Según la...
Los Museos Científicos Coruñeses del Ayuntamiento de A Coruña, en los que trabajo en el MundoReal™, convocan un año más sus Prismas de Bronce a los mejores trabajos de divulgación científica. En esta XXVIII Convocatoria las modalidades son: Vídeo. Web / Redes...
Liberando la tensión en el control de la misión- NASA/Bill Ingalls Cuando a las 11:57:49 UTC del 14 de julio celebrábamos el sobrevuelo de Plutón por parte de la sonda New Horizons en realidad estábamos haciendo un acto de fe. Un acto...
First close-up image of Mars, from the Mariner 4 spacecraft No parece gran cosa, y mucho menos comparada con la calidad de las imágenes a las que nos tienen acostumbrados las sondas y rovers que en la actualidad tenemos en servicio por...
Imagen por Ben Gross Da igual que la Unión Astronómica Internacional decidiera relegar a Plutón a la categoría de planeta enano en 2006… 85 años después del descubrimiento de Plutón, 58 años después del inicio de la era espacial, y gracias a...
Plutón en 1930 en las placas fotográficas en las que lo descubrió Clyde w. Tombaugh: es el pequeño punto al que apunta la flecha Plutón en 2015 visto por la sonda New Horizons a 800 000 kilómetros de distancia Si todo ha...
Foto (cc) Ghostly Cualquiera que haya que tenido que pasar por el dentista o que se haya hecho una herida que requiriera unos puntos, por no hablar de otras ocasiones más graves, estará enormemente agradecido de que exista la anestesia. Aunque se...
Falta justo un día para que la sonda New Horizons haga su máxima aproximación a Plutón, que se producirá a las 11:49:57 UTC del 14 de julio, el momento álgido de un viaje empezado hace más de nueve años. Será la...
Cuando la NASA retiró del servicio sus transbordadores espaciales en 2011 se quedó sin ninguna nave tripulada capaz de poner sus astronautas en órbita. Por ello desde entonces tienen que comprar plazas en las cápsulas Soyuz rusas para hacer llegar sus...
Del departamento de enlaces traspapelados, un estudio publicado en The Journal of The American Medical Association sobre 95 727 niños titulado Autism Occurrence by MMR Vaccine Status Among US Children With Older Siblings With and Without Autism (Ocurrencia de autismo a causa...
New Horizons’ Last Portrait of Pluto’s Puzzling Spots - NASA/JHUAPL/SWRI La sonda New Horizons de la NASA pasará a las 11:49:57 UTC de este martes 15 de julio de 2015 a tan sólo 12 500 kilómetros de la superficie de Plutón, pero...
Puede que Plutón ya no sea un planeta, pero no por ello los mapas de su superficie que nos va a permitir confeccionar la sonda New Horizons van a quedarse sin nombres. Estas son las categorías de nombres que el Instituto...
A las 16:34 UTC del 7 de julio de 2015 la sonda New Horizons de la NASA ha comenzado a ejecutar la secuencia de comandos diseñada para su sobrevuelo de Plutón, tal y como se puede leer en NASA's New Horizons...
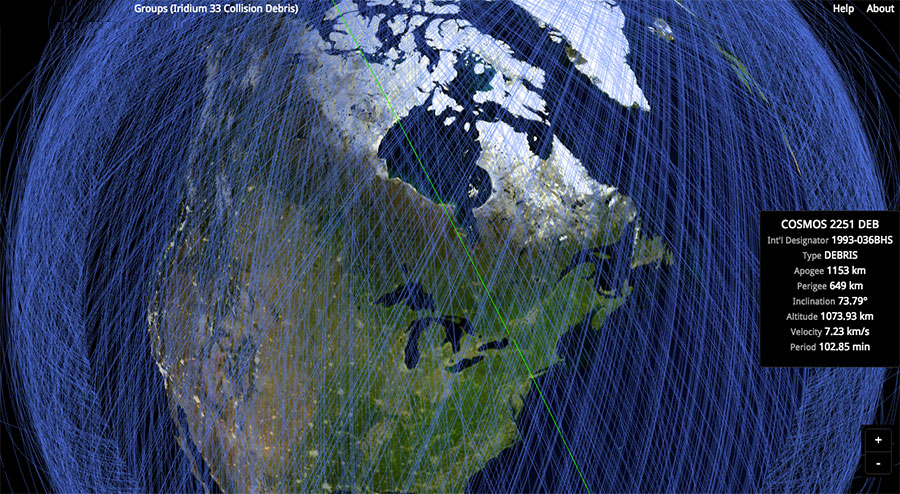
Stuff in Space es un genial nombre para esta espectacular visualización de satélites y otros objetos orbitando la Tierra en tiempo real. Están tanto los satélites artificiales como los restos de basura espacial que nos rodea y que los científicos intentan...
El pasado mes de mayo de 2015 el cuentakilómetros de Opportunity, el rover marciano de la NASA, pasaba de los 42,195 kilómetros, la distancia de un maratón, sólo que recorrido sobre la superficie de Marte a lo largo de once años....
El sarampión había sido declarado eliminado en los Estados Unidos en el año 2000, pero en los últimos años la enfermedad ha vuelto a repuntar en el país gracias al movimiento antivacunas y a personas que vienen infectadas de fuera del...
Según se puede leer en NASA’s New Horizons Plans July 7 Return to Normal Science Operations el equipo de la New Horizons ya ha identificado la causa del fallo que la dejo en modo seguro el pasado 4 de julio. Afortunadamente...
Cliff Stoll es uno de los adorables «profesores locos» de Numberphile, un apasionado de las botellas de Klein. ¿Qué son? Si conoces la banda de Möbius (que tiene una sola cara y un solo lado) es fácil entender lo curioso de...
Ingenieros de la Escuela Politécnica Federal de Lausanne (Suiza) han diseñado para un proyecto llamado CleanSpace One un satélite capaz de «comer basura espacial» atrapándola con una red en sus fauces. Como Pac-Man pero orbitando la Tierra y deshaciéndose de minisatélites...
La M-28M llegando a la EEI A las 7:11 UTC del 5 de julio de 2015 la cápsula de carga Progress M-28M atracaba en el módulo Pirs de la Estación Espacial Internacional, poniendo fin a una racha de tres lanzamientos fallidos consecutivos...
Impresión artística de la New Horizons llegando a Plutón - NASA/JHU APL/SwRI/Steve Gribben Tal y como se puede leer en New Horizons Team Responds to Spacecraft Anomaly la NASA perdió comunicación con la sonda New Horizons a última hora de la tarde...
Hay quien ha calificado a How Not to Be Wrong (2015) de Jordan Ellenberg como «el Freakonomics de las matemáticas» y bien que podría considerarse así. Es un libro divulgativo sobre las matemáticas cotidianas, que puede venir bien tanto a los...
Detectando la actividad neuronal, las señales eléctricas del cerebro, es posible controlar dispositivos y aparatos, desde ordenadores a cuadricópteros y hasta hacer explotar sandías con la mente. También los implantes neuroglógicos permiten controlar brazos robot y prótesis para pacientes con amputaciones....
Por Nacho Palou -
3 JUL 2015
NASA/Johns Hopkins University Applied Physics Laboratory/Southwest Research Institute/Thomas Appéré En esta casa no somos nada de poner gif animados, pero creo que este bien merece una excepción: es Plutón visto por la sonda New Horizons a lo largo de uno de sus...
Montaje de @ShuttleAlmanac Tras un lanzamiento perfecto la cápsula de carga Progress M-28M ya está en órbita, con sus paneles solares y antenas de comunicación y guiado desplegados, y lista para emprender su camino a la Estación Espacial Internacional, tal y como...
Ciencia clandestina es una iniciativa de la Universidad de Córdoba y la Fecyt que tiene como objeto crear seis murales pintados por un grafitero local dedicados a otros tantos personajes históricos de la ciencia que en su momento no consiguieron el...
La Progress M-28M en la plataforma de lanzamiento sobre el cohete Soyuz 2-1A que la pondrá en órbita - RSC Energia Roscosmos cree haber identificado el problema que causó la pérdida de la Progress M-27M el pasado mes de mayo, así que...
Salvo algún ajuste de trayectoria de última hora la sonda New Horizons de la NASA pasará a 12 500 kilómetros de la superficie de Plutón dentro de dos semanas exactas, el 14 de julio de 2015 a las 11:49:57 UTC. Bueno,...
Desde el 28 de junio de 2015 Gennadi Padalka es la persona que más tiempo acumula de permanencia en el espacio. Ese día alcanzó su día número 804 en órbita, y para cuando termine su misión actual en la Estación Espacial Internacional...
Impresión artística del Sentinel2A en órbita - ESA/ATG medialab Ni una semana ha tardado el satélite Sentinel-2A del sistema Copérnico de la Unión Europea en empezar a transmitir imágenes después de su lanzamiento, tal y como se puede leer en Sentinel-2 delivers...
30 junio 23:59:5930 junio 23:59:60 1 julio 00:00:00 Mañana 30 de junio el día durará 24 horas y un segundo, aunque no habrá que tocar los relojes para nada, simplemente disfrutar de la curiosa circunstancia exactamente a medianoche. Se añadirá lo que...
Dos minutos y 19 segundos después de un lanzamiento en apariencia perfecto el Falcon 9 que tenía que haber puesto en órbita la cápsula de carga Dragon CRS-7 reventaba, en apariencia por un fallo estructural en la segunda etapa, aunque la...
Brain Games tiene unos estupendos documentales donde se estudia la ciencia del comportamiento del cerebro humano, algunos de los cuales hemos comentado más de una vez por aquí. Un estupendo ejemplo es este segmento sobre cómo actúan los celos en nuestro...
A principios de este mes nos sobresaltaba la noticia del primer caso de difteria en España en 28 años. Según la Asociación Española de Pediatría: La difteria es una enfermedad respiratoria contagiosa, con frecuencia mortal, debida a la infección por una...
Lo que sucede cuando se vierte lava sobre el hielo es que la alta temperatura de ésta hace que el hielo se sublime — es decir, que el hielo sólido se convierte instantáneamente en vapor, sin pasar por el estado líquido;...
Por Nacho Palou -
26 JUN 2015
Que sí, que nos gustan los vídeos hechos con imágenes tomadas desde la Estación Espacial Internacional más que un caramelo a un niño… Pero Mundo ilimitado tiene la ventaja añadida de que lleva etiquetas en español, que vienen bien para saber...
Foto: Fernando Rey Daluz Si has mirado al cielo estos días hacia el oeste al anochecer y las nubes no andaban por medio habrás visto dos puntos muy brillantes en el cielo que llaman la atención. Son Venus y Júpiter, que están...
¿Qué hacer con una sonda espacial cuando esta funciona perfectamente y se va acercando el fin de su misión? Pues echar cuentas a ver si sale a cuento seguir utilizándola y en ese caso prolongar su misión, que es lo que...
Otro lanzamiento perfecto para un cohete Vega de la Agencia Espacial Europea ha dejado en órbita esta pasada noche al satélite medioambiental Sentinel-2A. El Sentinel-2A está en comunicación con el equipo de control, su panel solar desplegado, y sus sistemas funcionan...
Triple Crescents - NASA/JPL-Caltech/Space Science Institute Aún nos falta un poquito para poder verlo en persona, pero mientras tanto tenemos a la Cassini para que sea nuestros ojos en Saturno y que nos muestre cosas como esta, Titán, Mimas y Rea en...
Sesenta y pico charlas de diez minutos sobre ciencia pero de temas de lo más variados, así que si una te aburre, no tienes más que esperar a la siguiente, tres entrevistas de media hora, dos monólogos de The Big Van Theory,...
Imagen: The Washington Post. Fuente: Water Resources Research. En The Washington Post, New NASA data show how the world is running out of water, Los principales acuíferos del mundo —agua subterránea de la que dependen cientos de millones de personas— se agotan...
Por Nacho Palou -
22 JUN 2015
Todo está listo en el Puerto espacial de Kourou para el lanzamiento del satélite medioambiental Sentinel-2A, el segundo del programa Copérinico de la Agencia Espacial Europea y de la Unión Europea. La misión del Sentinel-2A es obtener imágenes de alta resolución...
Este curioso e hipnótico cubo de GeoBender tiene movimientos bastante asombrosos, además de que sus patrones son también interesantes – más concretamente, fractales. Pero a diferencia de los hexaflexágonos que son casi triviales de construir el GeoBender emplea 12 pirámides individuales...
Los miembros del consorcio encargado de su construcción aprobaron hace unos días el principio de las obras para la construcción del Telescopio Gigante de Magallanes, tal y como se puede leer en Giant Magellan Telescope’s international partners approve start of construction...
La resolución de los nuevos vídeos grabados desde la Estación Espacial Internacional tienen tal calidad de ampliación óptica y resolución que puede verse hasta el tráfico en movimiento. Debido al desplazamiento relativo de la Tierra y la EEI incluso la perspectiva...
Este vídeo viejuno que demuestra a las bravas los efectos de la resonancia y la «vibración forzada» con varillas y pesos a modo de péndulos invertidos. Como los péndulos del mismo color tienen la misma longitud al vibrar uno de ellos...

En este segmento de vídeo de Hacking the Universe del siempre altamente recomendable Science Channel el profesor Brian Cox explica cómo Galileo confirmó que vivimos en un sistema solar heliocéntrico, algo que ya anticipara Nicolás Copérnico en su De Revolutionibus Orbium...
Alex Soloviev nos avisó de la puesta en la red de Endless Gravity, un espectacular vídeo sobre criaturas marinas. Lo más interesante es que a pesar de lo fantasmagóricas y extrañas que se ven las criaturas del fondo del mar no...
Study Participant Receives NIAID/GSK Candidate Ebola Vaccine: la primera voluntaria de las pruebas de fase I de la vacuna ChAd3-ZEBOV siendo inoculada - Foto CC NIAID El hecho de que en algunos países ya se haya controlado la epidemia y que hace...
Expedition 42/43 #ISS Interactive Map - Sam's Pictures permite recorrer la Estación Espacial Internacional gracias a las fotos que Sam Cristoforetti fue tuiteando durante su estancia a bordo como miembro de las Expediciones 42 y 43 a esta. Cada círculo de...
El vídeo muestra a cámara lenta cómo un cuchillo superhidrofóbico corta una simple gota de agua por la mitad. En otras palabras, que en parte explican la dificultad y belleza del asunto: la hoja del cuchillo es repelente al agua y...
REMS, la estación meteorológica de Curiosity, ha sido construida en España Hasta ahora España es el único gran país europeo que no tiene una agencia espacial como tal y las competencias al respecto se reparten, con la organización actual, entre seis ministerios....
«Es irónico que Baikonur, el lugar donde las lanzaderas nacieron y desde donde debían despegar hacia la inmensidad del cosmos, sea ahora su tumba y la cripta que las mantiene encerradas.» —Ralph Mirebs En estas fotografías de Ralph Mirebs no se puede...
Por Nacho Palou -
15 JUN 2015
El Airbus 320 utiliza ampliamente materiales compuestos en partes de su estructura. Fotografía (cc) Wicho. En The Independent, Self-healing technology one step closer after scientists produce aircraft wings which fix themselves, Un equipo de investigadores británicos ha logrado producir unas alas de...
Por Nacho Palou -
15 JUN 2015
Trevor Mahlmann El pasado 9 de junio Trevor Mahlmann iba a volar de Nueva York a Chicago en un avión que salía a las 9 de la noche. Tal y como cuenta en International Space Station from 40,000ft se le ocurrió pensar...
A las 22:28 del 13 de junio de 2015, hora central europea, volvieron a recibirse paquetes de datos provenientes de Philae, el aterrizador de la misión Rosetta, tal y como se puede leer en Rosetta's lander Philae wakes up from hibernation....
Este triángulo de Sierpinski animado es una auténtica maravilla capaz de hipnotizar a cualquiera. ¿Cómo de grande llega a ser el triángulo? ¿Por qué no se acaba nunca? ¿De dónde proceden los diferentes componentes de tan curiosa forma geométrica? El GIF...
Impresión artística de Hayabusa en las cercanías de Itokawa - JAXA El 13 de junio de 2010 llegaba de vuelta a tierra el contenedor de toma de muestras de la sonda Hayabusa de la Agencia Japonesa de Exploración Aeroespacial. Lanzada el 9...
Todos –menos los conspiranoicos lunares– sabemos que los Estados Unidos ganaron la carrera espacial cuando el 20 de julio de 1969 el Apolo 11 aterrizó en la Luna, pero es bastante menos conocida la historia del programa N1-L3, el equivalente soviético...
Investigadores de la Universidad Carlos III de Madrid han desarrollado lo que se podría considerar el Prius de las avionetas, un sistema de propulsión híbrido que combina un motor convencional con un motor eléctrico, Nuevo sistema eléctrico de propulsión para mejorar...
Por Nacho Palou -
12 JUN 2015
¡Valar Morghulis! {Y aviso de spoilers de paso.} El universo de ficción de la exitosa saga de Juego de tronos / Canción de hielo y fuego tiene su propia consistencia; en este vídeo no se exploran precisamente las semajanzas con nuestra...

{Esto es tan peligroso como suena, así que cuidadín – busca la supervisión de un adulto… Un adulto responsable.} ¿Cómo resistirse a una propuesta así? Yago de I Can’t Believe it’s Science demuestra cómo convertir un Super Soaker veraniego, concebido para...
Apurando al límite los seis meses que puede permanecer en órbita la Soyuz TMA-15M aterrizaba a las 13:44 UTC del 11 de junio de 2015 en Kazajistán con Anton Shkaplerov, Terry Virts y Samantha Cristoforetti a bordo, tal y como se...
Hoy me tocó explicar didácticamente la evolución biológica como parte de una charleta sobre «cómo funciona el mundo y el universo» en la que quienes no creemos en ningún Dios se lo explicamos y otras personas que sí – o que...
Medicina sin engaños: Todo lo que necesitas saber sobre los peligros de la medicina alternativa. J. M. Mulet. Ediciones Destino, 368 páginas. En poco más de un siglo nuestra esperanza de vida se ha doblado gracias a los avances y universalización...
A menudo se esgrime que no tiene efectos secundarios -no tiene ninguno, de hecho- pero según un estudio de D. M. Shaw, de la Universidad de Glasgow, la homeopatía dista de ser inocua: Puede evitar que el paciente busque un tratamiento efectivo....
A Samantha Cristoforetti le quedan dos noches de dormir en la Estación Espacial Internacional antes de volver a tierra, pero en este vídeo nos lleva de visita a su camarote en el módulo Harmony de la Estación, un cubículo de unos...
Mediodía en Plutón (impresión artística) - NASA/Southwest Research Institute/Alex Parker Plutón está muy, muy lejos. A la sonda New Horizons, a pesar de viajar a unos 14,5 kilómetros por segundo, unos 52 000 kilómetros por hora, le habrá costado algo más de...
Análisis realizados a 57 personas del entorno del niño que está hospitalizado con difteria en el Hospital de la Vall D'Hebron han revelado que ocho niños son portadores de la bacteria que provoca esta enfermedad. Afortunadamente los ocho niños infectados sí...
Aproximadamente cada 26 meses Marte se coloca al otro lado del Sol visto desde la Tierra; es lo que los astrónomos llaman estar en conjunción. Durante este tiempo comunicarse con las sondas y rovers que por allí tenemos es extremadamente complicado,...
Una lista –naturalmente, incompleta– de las cosas que según Chris Anderson de TED todavía no sabemos. Importante de recordar porque a veces los humanos somos muy cuñaos y vamos de listos y en realidad hay tantas y tantas cosas que no...
Si el pasado jueves Sam Cristoforetti se hacía con el récord de la misión espacial más larga de cualquier astronauta de la ESA, desde el sábado 6 de junio a las 14:21 UTC tiene también el récord de la misión espacial...
En Scientists Develop the First Biolimb, a Lab-Grown Rat Arm, Científicos del Hospital General de Massachusetts, han logrado desarrollar por completo en un laboratorio la extremidad de una rata, un antebrazo completo. Se trata de la primera bioextremidad en el mundo,...
Por Nacho Palou -
7 JUN 2015
Mucha confianza debe tener este profesor para realizar una demostración así en mitad de una clase; y muy aterrorizados se habrán quedado algunos alumnos… Lo cual, visto por el lado bueno, les servirá para recordar esa lección para siempre: ¡Es ciencia!...
Si has visitado alguna vez la Alhambra de Granada, una mezquita o cualquier otro edificio de la cultura islámica habrás observado –tal vez hasta el punto de maravillarte– una serie de intrincados y repetitivos diseños con una intrigante geometría matemática subyacente....
Desde las 17:27, hora central europea, del 4 de junio de 2015, Samantha Cristoforetti es la astronauta de la Agencia Espacial Europea más tiempo ha pasado seguido en el espacio. Le quita el récord a André Kuipers, que en 2012 estuvo...
Los organizadores le han cogido el gustillo al asunto, así que los próximos 12 y 13 de junio de 2015 se celebra Ciencia JotDown 2015 en el salón de actos de la EtSI de informática de Sevilla. El programa incluye charlas...
Este este corto divulgativo TED se explica cómo se calcula el tiempo que la luz de Sol tarda en llegar hasta nosotros. Porque no necesita únicamente los 8 minutos que tarda en recorrer la de distancia entre el Sol y la...

Space Time es una producción divulgativa de la PBS en la que se exploran conceptos científicos complicados de una manera aparentemente sencilla. Al verlos no hay que olvidar que es un contenido para todos los públicos, en un formato visual y...
Este vídeo, en el que varios médicos insisten en que las vacunas funcionan, son seguras, y en que vacunemos a nuestros hijos, está grabado en clave de humor… Pero trata de algo muy, muy serio. Ojo, que hay un espoiler muy...
Sala de control del LHC - CMS/CERN. Más imágenes en Start of run2 physics at the Large Hadron Collider Construido bajo el suelo a las afueras de Ginebra, el Gran Colisionador de Hadrones –simplificando mucho– consta de dos grandes anillos de 27...
Great Images In NASA: Ed White performs first U.S. spacewalk Hoy se cumplen 50 años del lanzamiento de la misión Gemini 4, durante la cual Edward H. White llevó a cabo el primer paseo espacial de la NASA. Aunque tuvieron problemas a...
Fotografía (cc) Girl receiving oral polio vaccine Un niño de 6 años con difteria está ingresado en estado crítico en el Hospital de la Vall d'Hebron. Se trata del primer caso de difteria en España en 28 años, tal y como se...
Como está previsto la sonda Rosetta de la Agencia Espacial Europea sigue en órbita alrededor del núcleo del cometa 67P/Churyumov-Gersaimenko, a donde llegó el 6 de agosto de 2014, mientras este se aproxima al perihelio, el punto de su órbita más...
En Supercompressor, 12 Things You Can Do With Coca-Cola Besides Drink It, una recopilación de doce cosas para las que sirve la Coca-Cola además de para beberla. Resumiendo: Limpiar manchas de sangre Eliminar el óxido Quitar la grasa de la sartén...
Por Nacho Palou -
1 JUN 2015
Las bioquímicas Emmanuelle Charpentier y Jennifer Doudna se han llevado el Premio Princesa de Asturias de Investigación Científica y Técnica por la técnica de edición de ADN que han desarrollado, conocida como CRISPR-Cas9, una técnica mucho más precisa y económica que...
La sonda Rosetta de la Agencia Espacial Europea sigue acercándose al Sol en compañía del cometa 67P/Churyumov-Gerasimenko. Es la primera vez en la historia que ponemos una sonda en órbita alrededor del núcleo de un cometa, y también la primera vez...
Thank you, anonymous donor por Brian en Flickr Aunque hoy en día es un procedimiento habitual que salva muchas vidas hace poco más de cien años que las transfusiones de sangre dejaron de ser una lotería y un procedimiento casi desesperado gracias...
Edward Felten, profesor de Princeton y nuevo Director adjunto de tecnología de la Casa Blanca, planteó el otro día este problema lógico en su blog: Alice y Bob juegan a un juego. Son compañeros de equipo, de modo que ganan o pierden...
MalMath [Android] es una calculadora en forma de app que resuelve ecuaciones pero las explica paso a paso. Incluye detalles, gráficas y hasta un «generador de problemas» para practicar, con varios niveles de dificultad. Dicen que es una herramienta ideal «para...
Y así, amigos espaciotrastornados, es cómo se ve la llegada al módulo Poisk de la Estación Espacial Internacional de una cápsula Soyuz tripulada desde el interior de esta. La Soyuz en cuestión es la TMA-16M, a bordo de la cual iban...
La escasa presencia de mujeres en las carreras tecnológicas y de ciencias es algo muy preocupante, así que toda iniciativa para mejorar eso es bienvenida. En este caso se trata del II Campus Tecnológico para Chicas de la UGR en el...
La lengua de las matemáticas y otros relatos exactos. Fernando Álvarez, Óscar Martín y Cristobal Pareja. Ed. Catarata, Universidad Complutense. 130 páginas. Los autores de este libro nos hicieron llegar muy amablemente un ejemplar que he podido devorar en unos pocos...
Lanzamiento de la Progress M-27M - RKK Energía Hoy, 26 de mayo de 2015, estaba previsto que se lanzara la Soyuz TMA-17M con Oleg Kononenko, Kimiya Yui, y Kjell N. Lindgren rumbo a la Estación Espacial Internacional para convertirse en miembros de...
Mola que en la Agencia Espacial Europea se tomen las cosas con sentido del humor. Esta es Samantha Cristoforetti celebrando el Día de la toalla desde la EEI: De la Guía del Autoestopista Galáctico de Douglas Adams: Esta es la historia...
El pasado 15 de abril, durante su 956 día en Marte, el rover Curiosity tomó una serie de fotos del Sol poniéndose desde el cráter Gale. Glen Nagle cogió los fotogramas en cuestión y reconstruyó los intermedios para hacer este vídeo...
Fotografía (cc) Fonda Low Vision En New Scientist, 6 surprising ways to improve your eyesight, Conforme más sabemos acerca de los ojos, surgen formas nuevas de preservar o de mejorar la vista, desde cambiar la dieta a utilizar pantallas que se adaptan,...
Por Nacho Palou -
25 MAY 2015
(Los primeros segundos del vídeo incluyen imágenesde la intervención en el cerebro del paciente.) En Controlling a Robotic Arm with a Patient's Intentions, Implantando una neuroprótesis en una parte del cerebro que controla no los movimientos musculares, sino directamente la intención de...
Por Nacho Palou -
25 MAY 2015
El vídeo, con subtítulos en español, Eye vs. camera, de Michael Mauser, explica cómo funciona el ojo humano —«el resultado de cientos de millones de años de coevolución con el cerebro»—, el porqué de las ilusiones ópticas —«en realidad vemos con...
Por Nacho Palou -
25 MAY 2015
Francisco ha cogido el vídeo homenaje de Chin Li Zhi a Un punto azul pálido que publicábamos hace unos días y le ha añadido el audio de la narración que hizo en castellano el mítico doblador José María del Río para...
El inefable James Randi, mago, excéptico, y azote de todos los que se dedican a intentar engañar a los demás haciendo de medium y cosas así, explica en estos 15 minutos escasos cómo funciona la homeopatía. Spoiler: no funciona, no más...
Este problema dista de ser trivial; solo digo eso. Como meme recurrente lleva semanas dando vueltas por la red; probablemente es aún más antiguo y reaparece de vez en cuando («Un problema de matemáticas para niños vietnamitas de ocho años…»). El...

Menudo pedazo de halo acaba de aparecer en el cielo de Madrid este mediodía. Y es que cuando te mandan un mensaje que dice «Abre la ventana que el Sol está haciendo cosas raras» solo puede ser a) un eclipse, b)...
Nuestra admirada Physics Girl dedica cinco minutos muy educativos a explicar cómo se las ingenian los físicos para «ver» objetos cada vez más pequeños. El viaje comienza con objetos tan pequeños como las células del cuerpo, las motas de polvo o...
Principia es una publicación online divulgativa sobre ciencia totalmente gratuita y en castellano; la han calificado como «heredera de la mítica Journal of Feelsynapsis», lo cual ya debería desplegar las orejas-radar a cualquier persona interesada en la ciencia. En su web...
Las baterías son un triunfo de la ciencia.– Adam Jacobson Este vídeo comienza con historias de hace siglos, casi en el año 1800: la «guerra» entre Volta y Galvani, el proceso de oxidación y reducción y materiales como el cobre y...
Grabado por el biólogo y fotógrafo Anand Varma el vídeo muestra como time-lapse el proceso de formación y nacimiento de las abejas desde que el huevo eclosiona y surgen las larvas que comienzan a alimentarse con jalea real en sus celdas...
Por Nacho Palou -
22 MAY 2015
La Estación Espacial Internacional da vueltas alrededor de la Tierra a unos 28 000 kilómetros por hora, lo que hace que cada día describa 16 órbitas alrededor de ella, una cada 90 minutos. En numerosas ocasiones hemos dicho que eso lleva...
NOTA: Este proyecto estuvo activo durante algún tiempo pero ya está descontinuado y la app no funciona. Hace unos meses lanzamos la versión para iOS y ahora por fin ha visto la luz Microsiervos Quiz para Android en Google Play. Era...
Dos personas están en un gran estadio lleno de gente, se separan y se pierden. Quieren encontrarse la una a la otra, pero no han acordado nada de antemano; la única forma que tienen de localizarse es deambular buscándose. Tal vez...
Un nuevo vídeo para acompañar uno de los textos más populares de Carl Sagan, Un punto azul pálido: Desde este punto de vista lejano, la Tierra puede no parecer de ningún interés particular. Pero, para nosotros, es diferente. Mira ese punto.Eso...
Apenas son 30 segundos, pero ahí queda una pasada de la Estación Espacial Internacional sobre las Canarias y la Península Ibérica por la noche. Ponlo en pantalla grande, a ver si eres capaz de encontrarte o de reconocer las ciudades que...
Nearest Approaches of Asteroids to the Earth, una inforgrafía de 2013 ya, recoge los asteroides potencialmente peligrosos que en los próximos 200 años van a pasar a menos distancia de la Tierra de la que separa a la Luna de esta....
Ya hemos hablado aquí en alguna ocasión de las solarigrafías, esas imágenes que se obtienen exponiendo papel fotográfico durante mucho tiempo –hasta seis meses– que capturan la trayectoria del Sol por el cielo. Pero no hay como tener un físico como...
El vídeo —con subtítulos en español— What's the difference between accuracy and precision? de Matt Anticole explica la diferencia entre dos términos que a menudo se intercambian, pero que no significan lo mismo, sobre todo cuando se aplican a cuestiones científicas,...
Por Nacho Palou -
18 MAY 2015
Ahora mismo tenemos cinco sondas espaciales activas en órbita alrededor de Marte, más una sexta que aunque ya no funciona sigue estando ahí. Son, por orden de llegada: 2001: La Mars Odyssey de la NASA. 2003: La Mars Express de la...
En la primera ecuación: «14 veces algo más la constante 15 es igual a la constante 71»Era la forma de la época de expresar que 14x + 15 = 71 allá por el siglo XVI Aunque hay símbolos matemáticos que usamos todos...
El NASA's Software Catalog es un amplio catálogo de productos de software y desarrollos con un amplio espectro de aplicaciones técnicas de todos los colores, desde cómo lanzar un cohete a procesar datos o imágenes obtenidas por instrumentos a bordo del...
Por Nacho Palou -
17 MAY 2015
¿Cuáles son los motivos por los que, a simple vista, algunas estrellas parecen «titilar» más que otras? (Pregunta de FryPan). Si miramos al cielo nocturno en una noche clara libre de contaminación lumínica veremos que algunas estrellas centellean más que otras....
Si te gusta jugar al Monopoly y quieres mejorar tu juego utilizando fundamentos puramente matemáticos puedes echar un vistazo a este vídeo de Business Insider, que viene a ser una versión animada de los consejos de Erik Arneson publicados hace años...
Luciano Pavarotti no estaba gordo… ¡Luciano Pavarotti era un visionario! Álvaro Morales Molina de la Universidad de Alcalá se ha llevado el primer premio de Famelab España 2015 con este monólogo en el que explica las características de las células madre....
En Scientists forecast weather on planets outside our solar system, que traducido libremente viene a ser algo así como «Los meteorólogos nunca aciertan con el tiempo que va a hacer en la Tierra durante la Semana Santa, pero saben qué tiempo hace...
Por Nacho Palou -
15 MAY 2015
¿Sientes curiosidad por el cosmos? ¿Te intriga el tema de la evolución? ¿O, simplemente, quieres saber por qué la cerveza sabe así de bien? Muchas de tus preguntas tienen respuestas, y Pint of Science trae a las mentes más brillantes para dártelas....
Michael de Vsauce nos cuenta algunas historias raras, raras, sobre gente a la que le da por contar números: el récord del mundo está en contar de 1 a 1 000 000 sin parar, para lo cual el recordman tardó más...

The Light Of Other Suns es un trabajo de Rhys Taylor en el que podemos ver qué pinta tendría nuestro sistema solar si sustituyéramos el Sol por otras estrellas y como se verían estas desde los distintos planetas de este, aunque...
Serene Saturn: otra impresionante imagen de Saturno por cortesía de la sonda Cassini, una misión conjunta de la NASA, la Agencia Espacial Europea, y la Agencia Espacial Italiana. Tomada el 4 de febrero de 2015 a una distancia de unos 2,5...
En una serie de imágenes tomadas por la cámara LORRI de la sonda New Horizons entre el 25 de abril y el 1 de mayo de 2015, convenientemente procesadas para eliminar el brillo de Plutón y de Caronte, ya se pueden...
El vídeo How to unboil an egg de Eleanor Nelsen, con subtítulos en español, explica cómo es el proceso de deshervir un huevo duro, cocido, y para devolverlo a su estado anterior, crudo —algo que se consiguió hacer por vez primera...
Por Nacho Palou -
13 MAY 2015
Un grupo de investigadores del CNIO, el Centro Nacional de Investigaciones Oncológicas, ha dado un prometedor paso en la lucha contra el cáncer de pulmón, el que más muertes provoca en el mundo, tal y como se puede leer en Científicos del...
No sabría muy bien cómo definir este… póster… altar… homenaje… a la figura de Carl Sagan, pero tiene de todo: desde una sonda Voyager a una navaja de Occam, un pastel π y dodecaedros, estrellas y un hipercubo, además del punto...

AEON publicó un largo artículo titulado Natural Police hablando de corrupción y teoría de juegos: su planteamiento, estrategias, las ventajas de la cooperación y cuestiones como el dilema del prisionero y otras de las que hemos hablado muchas veces por aquí. También...
En una demostración práctica del principio de Bernoulli en este vídeo nos enseñan cómo lograr un resultado bastante espectacular haciendo levitar un destornillador. El truqui consiste en ir probando poco a poco hasta encontrar la distancia y el ángulo adecuados para...
Philippe Chrétien buscó financiación colectiva para fabricar una idea, el Reloj Fibonacci, y ya hay miles de personas interesadas que han multiplicado por 20 sus expectativas. Este reloj sirve incluso como lámpara, aunque básicamente es un artilugio para marcar el paso...
A causa de la complejidad de la enfermedad, Paqui debe acudir a diversos especialistas: reumatología, psiquiatría, neurología, oftalmología y clínica del dolor. ¿Qué es el Lupus? es un reportaje fotográfico conmovedor y necesario de la fotoperiodista Elisa Bernal sobre esta enfermedad del...
Por Nacho Palou -
10 MAY 2015
Impresión artística de la reentrada vía Spaceflight 101 - Imagen: AGI Según el Comando Estratégico de los Estados Unidos la cápsula de carga Progress M-27M, que llevaba fuera de control desde su fallido lanzamiento del pasado 28 de abril, reentró en la...
Bautizada como Emirates Mars Mission tiene como objetivo hacer una caracterización completa de la atmósfera y el clima marcianos, la primera vez que se hará tal cosa según los responsables de la misión. Los datos que obtengan, calculan que más de...
Un aumento del flujo solar está precipitando el final de la cápsula de carga Progress M-27M, que lleva fuera de control desde su entrada en órbita el pasado 28 de abril. Este aumento ha hecho que el apogeo y el perigeo de...
Lo dice la Organización Panamericana de la Salud: La región de las Américas es la primera en el mundo en ser declarada libre de rubéola. Aunque no es una enfermedad especialmente grave para los niños, la rubeola sí puede tener consecuencias...
El pasado 5 de mayo de 2015 se produjo una erupción solar que alcanzó un pico de potencia medido como X2,7 ya el 6 de mayo. Las erupciones de categoría X son las más poderosas de todas, superando a las A,...
Hace unas horas SpaceX daba un importante paso en el desarrollo de la versión tripulada de su cápsula Dragon al probar por primera vez el sistema de escape de esta. Esto es lo que se ve en el vídeo, segundo arriba,...
Impresión artística de VHS 1256b - Gabriel Pérez (SMM, IAC) En la actualidad tenemos localizados cerca de 1 900 planetas extrasolares, planetas en órbita alrededor de otras estrellas. La mayoría de ellos, de todos modos, están tan lejos que no tenemos forma...
Si este próximo fin de semana estás por A Coruña, en el Parque de Santa Margarita se celebra la XX edición del Día de la Ciencia en la Calle. El sábado 9 de mayo de 2015, de 11 a 19 horas, alumnos...
Se cogen dos de los gráficos usados en la presentación del bosón de Higgs en el auditorio del CERN, se les deja en manos de un físico aficionado a la música heavy que los masajee un poco… Y el resultado es...
Roscosmos, la agencia espacial rusa, da desde hace unos días por perdida la cápsula de carga Progress M-27M que quedó fuera de control poco después de su lanzamiento, así que ahora sólo queda por ver cuándo y dónde cae. Según los...
El 18 de marzo de 1965 Alekséi Leónov se convertía en el primer astronauta en dar un paseo espacial al salir de la esclusa inflable de la cápsula Vosjod 2 a las 8:34:51 UTC. El tiempo de los primeros trata de...
Composición a color de los Pilares de la Creación con datos de MUSE Los pilares de la creación, unas enormes columnas de gas situadas en la Nebulosa del Águila, a unos 7 000 años luz de la tierra, es una de las...
En esta charla TED el neurocientífico Greg Gage realiza una demostración de salón sobre cómo captar con unos sensores las señales que el cerebro de una voluntaria envía a los músculos de la mano –en forma de descargas eléctricas– para lanzar...
Impresión artística de la Messenger en órbita alrededor de Mercurio - NASA Según las últimas estimaciones sobre su órbita hoy a las 19:26:02 UTC la sonda Messenger de la NASA se estrellará sobre la superficie de Mercurio a unos 14 000 kilómetros...
Aún necesitan de mucho procesado extra para que se pueda apreciar, pero en estas imágenes, tomadas entre el 12 y el 18 de abril por la cámara LORRI de la New Horizons, cuando estaba aún a unos 100 millones de kilómetros...
Jeff Bezos, además de fundar esa empresa bautizada como Amazon, anda también metido en el negocio del turismo espacial. Para ello su empresa Blue Origin está trabajando en un cohete reutilizable de despegue y aterrizaje vertical que lleva una cápsula tripulada...
Bariónica, de Desiré de Palacio, es el vídeo ganador de la categoría absoluta del concurso Ode to Hubble, que invitaba a personas de todo el mundo a crear vídeos que homenajearan al telescopio espacial Hubble con motivo del 25 aniversario de...
Comet Churyumov Gerasimenko in Crescent es la Imagen Astronómica del Día de la NASA de hoy, una foto en color falso del núcleo del cometa 67P/Churyumov-Gerasimenko en cuarto creciente tomada por la sonda Rosetta de la Agencia Espacial Europea, que lleva...
Ninguno de los intentos por comunicarse con la Progress M-27M llevados a cabo hoy han dado fruto, por lo que esta sigue dando tumbos en una órbita que la llevará a desintegrarse en la atmósfera en menos de una semana si...
En estas galería de fotos de Bored Panda los aficionados de las matemáticas pueden encontrar un poco de todo: simetría, fractales, númberos de Fibonacci y estructuras que parecen surgidas de procesos de autómatas artificiales. Están todas recopiladas en 20+ Photos Of...
El vídeo muestra un modelo de cómo orbitan la Tierra los satélites del sistema GPS (Sistema de Posicionamiento Global) que están en funcionamiento actualmente y cuyas señales emplean los navegadores GPS para calcular nuestra posición exacta sobre el globo terráqueo. Mucha...
Self Portrait (cc) Verónica Aguilar En Mental Floss, How Chewing Gum Prevents Songs From Getting Stuck in Your Head, No está claro por qué a veces se nos quedan metidas canciones en la cabeza, pero lo más probable es que sea debido...
Por Nacho Palou -
29 ABR 2015

National Geographic le ha dedicado una pieza a la Mars Desert Research Station, uno de esos proyectos al filo de la delgada línea roja que separa la investigación seria del pajamentalismo. Situada en el desierto de Utah es una iniciativa de...

Inspirados por este antiguo vídeo se han realizado diversas comprobaciones de la técnica del «rebote de las pilas», incluyendo este vídeo que han publicado en Chemistry World UK de la Royal Society of Chemistry, donde se puede apreciar mejor el efecto:...
Lanzamiento de la Progress M-27M A las 7:09:50 UTC de esta mañana un cohete Soyuz-2-1A ponía en órbita la cápsula de carga Progress M-27M, que lleva a bordo 2 357 kilos de suministros para la Estación Espacial Internacional. Si todo hubiera ido...
En Scientists create the sensation of invisibility, sobre el experimento llevado a cabo por neurocientíficos suecos cuyo estudio se puede leer en Illusory ownership of an invisible body reduces autonomic and subjective social anxiety responses, El voluntario utiliza unas gafas de...
Por Nacho Palou -
28 ABR 2015
Cualquier cosa es mala en exceso e incluso la cafeína del café y otras bebidas puede serlo; insomnio, irritabilidad, dolores de cabeza… Pero el riesgo exacto puede calcularse fácilmente, como nos recuerda I can programming con el «lenguaje natural» de Wolfram...
Agua, energías renovables y CO2 son los ingredientes del combustible diésel sintético de Audi. En Gizmag, Audi just created diesel fuel from air and water, El producto base se denomina ‘petróleo azul’. El proceso comienza utilizando electricidad procedente de fuentes renovables —...
Por Nacho Palou -
27 ABR 2015
¿Qué se vería en un escáner cerebral si el sujeto dentro de la máquina se pone a pensar en las letras de su próxima jugada sobre un tablero de Scrabble? El caso es que en Scientific American David Z. Hambrick examinó...
Hay distintos catálogos, así que el número de ellos cuya existencia hemos podido confirmar depende un poco de cual mires, pero según el Laboratorio de Habitabilidad Planetaria de la Universidad de Puerto Rico, esta es la distribución de los 1894 planetas...
Se acaban de cumplir 25 años de la puesta en órbita del telescopio Espacial Hubble, una misión conjunta de la NASA y de la Agencia Espacial Europea que a pesar de no empezar con buen pie en estos años nos ha...
En Fast Co., The Self-Driving Car Revolution's Unintended Consequence: Lots Of Puking Passengers, Según este informe, entre el 6 y el 10 por ciento de los adultos padecerán cinetosis —con náuseas, mareos, vómitos y demás a bordo de un coche autónomo,...
Por Nacho Palou -
26 ABR 2015
No estaba yo al tanto de que Edwin Schrödinger, el famoso físico que tanto contribuyó en las teorías de la mecánica cuánta, es para algunos injustamente considerado un científico cruel con los animales. Y todo por su famoso experimento mental con...
Es bien conocido que la temperatura corporal «normal» de los seres humanos está en algún punto entre los 36 °C y los 37 °C, décima arriba décima abajo, y que a partir de 38 °C se considera fiebre – aunque el punto...
Aunque miope en su lanzamiento hace hoy 25 años, el telescopio espacial Hubble, una misión conjunta de la NASA y de la Agencia Espacial Europea, es una de las misiones espaciales que más han contribuido al avance de la ciencia con...
Sismómetro — Este dispositivo podía detectar terremotos tan distantes que nadie cercano los sentía siquiera. Era un dispositivo en forma de jarrón con varias cabezas en bronce de dragones, cada una con una bola de bronce en su boca; alrededor del...
Por Nacho Palou -
24 ABR 2015
En ThinkGeek, Brain Specimen Coasters Ahora mismo en tu cerebro miles de millones de neuronas trabajan como locas para que existas y en este momento muchas de ellas están dedicadas a la lectura de estas palabras. Piensa en todas las áreas...
Por Nacho Palou -
24 ABR 2015
En El País: Un 25% de los españoles cree que el Sol gira alrededor de la Tierra. Así, sin paños calientes. (...) Un 30% de los españoles cree que los humanos convivieron con los dinosaurios --en línea con la serie de dibujos...
Jennifer Golbeck ha detectado que la Ley de Benford -tan fascinante como carente de «sentido común»- también se aplica a las redes sociales y que eso puede tener interesantes aplicaciones prácticas. Puede leerse el trabajo completo en Arxiv: Benford's Law Applies...
Entre la tarde del 22 de abril de 2015 a las 16:00 UTC y las 3:00 de la madrugada del 23 se espera el pico máximo de actividad de la lluvia de estrellas de las Líridas de este año, con una...
{Aviso: leer este artículo completo puede hacerte estallar la cabeza.} Matrix. El cerebro en una cubeta. Descartes, Platón y sus disquisiciones filosóficas. La Holocubierta de Star Trek. Los Sims. El cerebro humano. La teoría computacional de la mente. La capacidad de...
Plutón está a una enorme distancia del Sol, por lo que no sabemos demasiadas cosas acerca de él. Pero una de las que sí sabemos desde hace algún tiempo que su superficie es rojiza, como deja ver la imagen de arriba,...
Esta imagen de las fallas de Piquing, en la provincia de Sinkiang en el noroeste de China, se ha hecho con el título de Tournament Earth de 2015 de la NASA. En ella se pueden ver perfectamente el resultado de dos...
Estamos seguros de que hay vida extraterrestre en algún lugar del universo. El universo es vasto. Que haya vida extraterrestre no es una «cuestión de creerlo». Solo que hay que examinar las pruebas. Y las pruebas nos muestran que el universo...
¡Un país bastante lento! —replicó la Reina—. Lo que es aquí, como ves, hace falta correr todo cuanto una pueda para permanecer en el mismo sitio. Si se quiere llegar a otra parte hay que correr por lo menos dos veces...
4K x 4K Real time Aurora Substorm es una grabación que realizó Kwon O Chul el pasado 16 de marzo en Yellowknife, Canadá, en la que se ve un cielo completamente cubierto por una aurora boreal durante una tormenta geomagnética. Y...
Radiotelescopio del Very Large Array en New Mexico — Foto: NRAO. Aunque los robot-cortacésped que recorren por sí mismos el jardín cortando el césped no son un novedad, sí lo es cómo el fabricante iRobot quiere evolucionar la forma en que funcionan....
Por Nacho Palou -
18 ABR 2015
Uno de los objetivos de SpaceX, la empresa aeroespacial de Elon Musk, es desarrollar un cohete cuya primera etapa sea reutilizable. La idea es que en lugar de dejar que esta se pierda en el fondo del mar se pueda recuperar...
Despegue de la Dragon CRS-6 Con algunos meses de retraso sobre las previsiones iniciales la ISSPresso, que es como una Nespresso, pero preparada para funcionar en la Estación Espacial Internacional, va rumbo a esta a bordo de la cápsula de carga Dragon...
Andasol, un complejo de almacenamiento térmico de energía solar, entre 1987 y 2013 Images of Change es una galería de imágenes de la NASA, la mayoría obtenidas mediante satélites, en la que se puede ver cómo distintos lugares de nuestro planeta han...
Todo comenzó cuando me crucé con este meme, que puede entenderse entre divertido, entrañable e incluso un poco triste: «Si alguna vez te sientes solo…… nunca olvides que Curiosity está programadopara cantarse a sí mismo Cumpleaños Feliz una vez al año» Una...
La sinestesia es una curiosa combinación mental automática de varios sentidos y percepciones, como pueden ser la vista y el oído, o el gusto y la vista. En cierto modo es como un «superpoder» de cerebros superconectados: hay personas que pueden...
Sketchnoting Detail — Mike Rohde Al menos en lo que se refiere a recordar conceptos después de haber estado tomando notas. En Fast Company, How Typing Is Destroying Your Memory, La investigadora Pam Mueller de la Universidad de Princeton realizó tres estudios...
Por Nacho Palou -
15 ABR 2015
Antes de reproducir este vídeo, intenta responder estas preguntas: ¿Cuántas mujeres científicas españolas conoces? ¿Qué porcentaje de premios científicos crees que se conceden a las mujeres? De los 132 premios Nobel de ciencias que hay, ¿cuántos crees que se han concedido...
Esta semana se está celebrando la cuarta Conferencia de Defensa Planetaria, que aunque suena mucho a ciencia ficción en realidad está dedicada a estudiar la amenaza que suponen los asteroides para la Tierra y, en especial, para los que vivimos en ella....
Alguien se ha molestado en calcularlo: Una persona de peso medio (70 Kg) tiene aproximadamente unos 7 × 1027 átomos en su cuerpo. Eso es un 7 seguido de 27 ceros (7 000 000.000 000 000 000 000 000 000). Por...
El Solar Dynamics Observatory de la NASA lleva desde 2010 observando el Sol en distintas longitudes de onda para que los científicos puedan estudiar los distintos procesos que tienen lugar en nuestra estrella. Para ello lleva a bordo dos instrumentos, el...
Habíamos visto cámaras GoPro en situaciones cuando menos comprometidas, pero la que se llevó con él el astronauta Terry Virts durante dos recientes paseos espaciales probablemente se lleve la palma. En el que está incrustado arriba se ve en primer plano...
Imgen: ACS Nano, Phys.org. El efecto triboeléctrico es aquel por el que se produce electricidad cuando dos materiales entran en contacto, y es el que investigadores del Georgia Institute of Technology están aprovechando para desarrollar vidrio capaz de producir electricidad que puede...
Por Nacho Palou -
13 ABR 2015
Por ahora estas son las mejores imágenes que tenemos de Plutón, tomadas por el telescopio espacial Hubble entre junio de 2002 y junio de 2003. Puede que no parezcan gran cosa, pero hay que tener que cuando se tomaron Plutón estaba...
Una de las decisiones más polémicas de Ana Mato durante su tiempo como ministra de sanidad del Gobierno de España fue la de cambiar el calendario de vacunación y dejar de administrar la vacuna de la varicela a los bebés a...
Si tienes un telescopio y eres medianamente competente usándolo puedes echarle una mano a la Agencia Espacial Europea observando con él el cometa 67P/Churyumov-Gerasimenko, Chury para los amigos. Chury es el cometa alrededor del cual está en órbita la sonda Rosetta de...
El año pasado, cuando la NASA anunció las empresas privadas que había escogido para contratar lanzamientos de astronautas causó un poco de sorpresa que quedara fuera la Dream Chaser de Sierra Nevada Corporation. Un motivo es que la Dream Chaser es...
Ellen Stofan, científica jefe de la NASA, en Phys.org, We'll find alien life in 10 to 20 years, Creo que vamos a encontrar fuertes evidencias de que existe vida más allá de la Tierra durante la próxima década y pruebas definitivas...
Por Nacho Palou -
9 ABR 2015
Desde el pasado fin de semana, y tras dos años de actualización y mantenimiento, ya vuelven a circular haces de partículas por el Gran Colisionador de Hadrones, o LHC por sus siglas en inglés. Estos dos años de trabajo han sido...
Descubierto entre 1900 y 1901 en los restos de un naufragio en las proximidades de la isla de Anticitera el mecanismo de Anticitera lleva desde entonces siendo un misterio, aunque poco a poco, con mucho trabajo, se ha ido desvelando parte...
Moon Phases es una instalación interactiva fabricada con Arduino, botones circulares, una linterna, una pequeña maqueta de la Luna y muy buen estilo. Basta elegir la fecha para que la máquina coloque la Luna en posición; la lámpara led se encarga...
Ya, en realidad vale cualquier palo, pero tiene mucha más gracia si usas un palo-selfie para medir el radio de la Tierra, imitando a Eratóstenes en el siglo III a. C. Lo cuenta con mucha gracia Javier Santaolalla, uno de los...
Visibilidad del eclipse, vía NASA Este próximo sábado, 4 de abril de 2015, se produce un eclipse total de Luna. Pero dado que el máximo se produce a las 12:00:14 UTC a los que vivimos en Europa nos viene un poco mal...
La hipotética estación espacial rusa PPOI Con los programas espaciales pasa un poco como con la educación, que cada vez que hay un cambio de gobierno hay que meterles mano, o al menos esa parece la norma en España, así que es...
Astronomer's Paradise, un vídeo de Cristhoph Malin y Babak Tafreshi para ver a pantalla completa, a oscuras a ser posible, y con el volumen alto, para comprender, si es que no lo tienes claro ya, por qué todo el mundo debería...
En The Washington Post, When it comes to putting out fire, GMU students show it’s all about that bass, Las ondas sonoras crean ondas de presión en el aire que desplazan parte del oxígeno. A la frecuencia correcta las ondas de...
Por Nacho Palou -
31 MAR 2015
Se calculan más o menos así: Si tú tienes 4 lápices y yo tengo 7 manzanas, ¿cuantas tortitas caben en el tejado? Púrpura, porque los alienígenas no llevan sombreros. Mientras tanto, hay que recordar que imágenes como la de la derecha, de...
Aunque Opportunity, el rover marciano de la NASA, es capaz de moverse a una velocidad de hasta 124 metros por hora, esto sólo se da cuando se mueve a lo largo de un trayecto preprogramado enviado desde el control de la...
Aunque el código genético de nuestras células es el que es y no cambia durante nuestras vidas, salvo mutaciones, la epigenética lleva un tiempo estudiando como factores externos pueden influir en como se expresan los genes de nuestro ADN, un poco...
En Dentists will soon be able to 3D print you a new tooth in minutes, sobre cómo la aplicación de esta tecnología de impresión 3D más rápida desarrollada recientemente por la empresa Carbon3D --que multiplica por 100 la velocidad de impresión...
Por Nacho Palou -
30 MAR 2015
Los seis tripulantes de la EEI Esta pasada madrugada a las 3:33 UTC se abría la escotilla que conecta la Soyuz TMA-16M con la Estación Espacial Internacional, con lo que esta vuelve a tener seis tripulantes tras el retorno el pasado día...
Manuel González García, del Instituto de Ciencia de Materiales, ha conseguido una plaza en la final de Famelab España 2015 con esta brillante Copla de las estrellas. ¿Quién ha dicho que ciencia y humor están reñidos? La final, con presentación pública...
En Vox Media, ¿Qué sucede cuando se chascan los nudillos? ¿es perjudicial para las articulaciones?, Básicamente se comprime el gas acumulado en el líquido sinovial —el fluido viscoso que lubrica las articulaciones, caso de los dedos— que explota de forma parecida...
Por Nacho Palou -
26 MAR 2015
The Slow Mo Guys graban en el vídeo CD Shattering at 170,000 fps! cómo un disco compacto girando a 23.000 vueltas por minuto se deshace en miles de pedazos debido a las fuerzas del giro. La velocidad de grabación hacia el...
Por Nacho Palou -
26 MAR 2015
Marathon Valley Es cierto que ha tardado la friolera de once años y dos meses, pero el cuentakilómetros de Opportunity acaba de superar los 42,195 kilómetros, la distancia de una maratón, solo que en este caso recorridos sobre la superficie de Marte,...
Spaceprob.es –por fin un dominio .es sirve para algo– es un sitio web que incluye información acerca de todas las sondas espaciales activas que tenemos por ahí averiguando cosas acerca del sistema solar. Incluye un pequeño resumen de cada una y...
Javier Armentia y Joaquín Sevilla vuelven al bar para explicarnos como mirar a las estrellas desde puntos opuestos de la órbita de la Tierra nos permite conocer la distancia a la que están de nosotros. Para ello se mide el movimiento...
La ESA busca propuestas para objetivos que pueda fotografiar la Cámara de Monitorización Visual, o VMC, de la Mars Express entre los días 25 y 27 de mayo. La VMC no es propiamente uno de los instrumentos científicos de la Mars...
Si tienes diez minutos para ver este vídeo y luego un rato para meditar, quizá te resulte interesante echarle un vistazo. Es una disquisición de Richard Holton del M.I.Y acerca de la cuestión filosófica del libre albedrío: El problema filosófico del...
La buena gente de Minute Physics ha dedicado una de sus piezas a explicar el problema de las mezclas y difuminados de color en las imágenes digitales. Esto hace que al combinar colores en aplicaciones fotográficas el resultado sean unas zonas...
Ya sabemos que el principito vive en el asteroide B612, pero dejando ese pequeño detalle aparte, esta sudadera en la que salen él y la rosa en el núcleo del cometa 67P/Churyumov-Gerasimenko tocará el corazoncito de cualquier espaciotrastornado con un mínimo...
Fases del eclipse visto desde A Coruña - Observatorio Astronómico Nacional Mañana, 20 de marzo de 2015, se producirá un eclipse de Sol que sólo podrán disfrutar como total los que estén en las islas Faroe o las islas Svalbard en lo...
Según cuentan en Yahoo Beauty una empresa llamada Strōma Medical ha perfeccionado un método para convertir los ojos castaños en ojos azules. Dice su principal investigador científico: Bajo cada ojo castaño hay un ojo azul. La única diferencia es que los...
Ángel Gómez Roldán comentaba en Twitter que esta pasada noche ha sido una de las más impresionantes de los últimos años en cuanto a auroras polares, en este caso auroras boreales, ya que estaba en Islandia como etapa previa en su...
Por aquí nunca nos hemos creído nada del proyecto de Mars One de enviar una misión tripulada sólo de ida a Marte. Pero lo que cuenta Elmo Keep en Mars One Finalist Explains Exactly How It‘s Ripping Off Supporters gracias a...
Con unas dimensiones de 157,58 km el asteroide (804) Hispania, uno de los cientos de miles que forman parte del cinturón de asteroides, no es especialmente relevante. Pero tiene la peculiaridad de haber sido el primer asteroide descubierto desde España, en...
Hoy 14 de marzo, que se escribiría 14/3 pero los anglosajones prefieren como 3/14, se produce la coincidencia del calendario con los dígitos decimales del número π, de modo que los amantes de los números y las matemáticas celebran el día...
Observa este vídeo con mucha atención para descubrir lo que está sucediendo; se trata de comprobar tu capacidad de atención – más o menos. Son solo 60 segundos. (No tiene susto ni nada de eso.) Al cabo de un rato notarás...
Cuando Philae aterrizó en el núcleo del cometa 67P/Churyumov-Gerasimenko el pasado 12 de noviembre de 2014 este se hallaba a unos 510 millones de kilómetros del Sol. Hoy, cuatro meses después, 67P está a unos 317 millones de kilómetros del Sol,...
Dentro de una semana se producirá el eclipse de Sol del 20 de marzo de 2015 que será total para quien lo pueda ver desde el Ártico, lo que quiere decir básicamente desde las islas Faroe y Svalbard, que son las...
Seguro que hay un motivo razonable para que alguien grabara con una Photron Fastcam SA-X un globo explotando debajo del agua a 36 000 cuadros por segundo, pero bastaría con decir que lo hizo porque mola. Más sobre globos haciendo cosas...
En NewScientist, Liquid metal brings shape-shifting robot a step closer, Sayonara, baby. El T-1000, el robot que cambia de forma en la película Terminator 2, está un poco más cerca de ser real gracias a una aleación de metal líquido capaz...
Por Nacho Palou -
12 MAR 2015
Después de nueve años y casi dos meses de camino la sonda New Horizons de la NASA ya está más cerca de este que la distancia media de la Tierra al Sol. Esta distancia es lo que se conoce como una...
Dicen que las imágenes de CERN’s Unknow Photo Archive son fotos de los «inicios del CERN» (la Organización Europea para la Investigación Nuclear, y donde incidentalmente nació la Web). Al no disponer de más fuentes tampoco se puede asegurar cuál es...
Philae es el aterrizador de la sonda Rosetta de la Agencia Espacial Europea, que el pasado 12 de noviembre de 2014 nos permitió tocar el núcleo de un cometa por primera vez. Por ahora duerme sobre 67P-Churyumov-Gerasimenko, tras llevar a cabo...
Impresión artística de Gliese 581d - Wikipedia Dentro de los planetas extrasolares Gliese 581d, situado –o no– a unos 20 años luz de la Tierra, tiene una cierta relevancia porque fue el primer planeta extrasolar «parecido» al nuestro situado en la zona...
Ceres a 48 000 kilómetros de distancia / Foto: NASA Tras un viaje de uno 4 900 millones de kilómetros de siete años y medio de duración la sonda Dawn de la NASA era capturada por la gravedad del planeta enano Ceres...
El gato más famoso de la Física es el hilo conductor de esta breve historia animada divulgativa sobre mecánica cuántica, que pretende explicar el clásico experimento mental de Schrödinger de forma muy breve y enseñar algunas de sus connotaciones; por ejemplo...
En Gizmag, Concordia – science at the edge of the world, La estación polar Concordia es el asentamiento humano más aislado e inhóspito, y para llegar hasta ella hay que viajar más lejos y durante más tiempo que para alcanzar la...
Por Nacho Palou -
6 MAR 2015
Pluton y la Tierra, a la misma resolución En Exploring Space, Plutón y la Tierra representados a la misma resolución, o en otras palabras: «cómo se vería la Tierra con la misma calidad con la que estamos viendo las fotos de Plutón...

Richard Feynman fue tan famoso como profesor de Física y premio Nobel como en su papel de divulgador y conferenciante; si lo llamaban El Gran Explicador sería por algo. podríamos decir que fue el Carl Sagan o el Neil deGrasse de...
Esta semana un cohete Falcon 9 ponía en órbita dos satélites de comunicaciones, uno de Eutelsat y otro de Asia Broadcast Satellite. Son satélites destinados a funcionar en órbita geoestacionaria, y como tales no tienen mucho que destacar, aunque en realidad...
Mirando DRB me crucé con esta foto [zoom a alta resolución] de un dispositivo llamado nanoinyector que se utiliza para manipulación genética. Lo que se ve en la foto es una esfera de latex que simula ser una célula/cigoto; el mecanismo...
Antonio Pérez Verde ha empezado una sección sobre «astrotrastornados» en la revista Astronomía, y como dice que yo soy la primera persona a la que recuerda haber oído decir el término, la ha empezado conmigo y con esta minientrevista: Definición de Astrotrastornado:...
Más simple, imposible: Conceptos matemáticos minimalistas....
Dianna a.k.a. Physics Girl (habrá que suscribirse) demuestra en este vídeo los efectos de la transferencia de momento lineal entre varios objetos, en este caso pelotas de de golf, béisbol y un balón de baloncesto. Al soltarlos individualmente, rebotan contra el...

En este vídeo explican cómo para grabar estas espectaculares imágenes del volcán del cráter Marum, en el volcán-isla Ambryn, tuvieron que sacrificar dos drones con sus respectivas cámaras en la caldera del volcán. Los drones sobrevolaron en varias ocasiones los 12...
The Large Hadron Collider es una propuesta para que Lego fabrique y ponga a la venta un Gran Colisionador de Hadrones. Pero claro, no mide 27 kilómetros de largo, sino que es una versión simplificada y estilizada de lo que es...
El Sentinel-2A montado en su banco de pruebas. Mide 3,4×1,8×2,35 metros Esta semana he tenido la oportunidad de ver el satélite artificial Sentinel-2A de la Agencia Espacial Europea en el Centro de Pruebas Espaciales de IABG en Munich, donde fue terminado de...
La órbita de Plutón tiene 248 años y medio, aproximadamente, algo que ya nos cuesta un poco entender a la escala de las vidas humanas; estos son algunos de los hechos que han ocurrido durante su órbita actual, y mientras esperamos...
Para espaciotrastornados: Spacefarers es un póster de 1,2 metros × 55 centímetros en el que salen todos los seres humanos a los que se les puede considerar astronautas, actualizado hasta la Expedición 45/46 a la Estación Espacial Internacional, cuyos últimos miembros...
Dramatis personae: CDR: Thomas Stafford, el comandante de la misión Apolo 10. CMP: John Young, el piloto del módulo de mando. LMP: Gene Cernan, piloto del módulo lunar. Aquí huele a muerto... Las risas: CDR Oh - ¿Quién ha sido? CMP...
Distant Horizons, una imagen creada por Mike Malaska y Michiel Straathof, recoge imágenes de todos los astros en los que hemos conseguido posar sondas o naves espaciales, además de la Tierra, que, para los despistados, es donde vivimos. De izquierda a...
Evolución de los casos de rubeola en los Estados Unidos tras la introducción de la vacuna en 1969 Muy reveladores los gráficos que se pueden ver en Battling Infectious Diseases in the 20th Century: The Impact of Vaccines acerca del impacto de...
Erradicar, eliminar y controlar son cosas bien distintas, como bien se encarga de explicar la exposición del Museo de Historia Natural. Erradicar es librar al mundo entero de un mal; eliminar supone acabar con la enfermedad en determinados países; controlar es evitar...
Benn Blatt dedicó algún tiempo a completar unos cálculos sobre las diferentes jugadas de bolos, buscando en especial aclarar cuál es la más difícil en la práctica; en concreto estamos hablando de la «segunda tirada» tras haber dejado algunos bolos en...
Tenemos nuevo episodio en el canal de vídeo de Ciencia en el bar: ¿Cuánto se tarda en cocer una patata? Pues como casi todo, depende, en este caso de que la almidón –que lo la albúmina– de la patata se gelifique....
Súper Luna y micro Luna de 2012, APOD del 8 de septiembre de 2014; fotos de Catalin Paduraru Por lo general se considera que hay una superluna cuando la Luna llena se produce a una distancia de menos de 360.000 kilómetros de...
Me gustan los problemas, una charla de TEDxYouth@Murcia en la que José Ángel Murcia, más conocido por estos pagos como @tocamates, nos explica qué fue lo que le enganchó de las matemáticas. Y, ¡oh sopresa!, no fueron precisamente las clases de...
La conjunción vista desde A Coruña a las 20:00 locales del 20 de febrero de 2015 - imagen generada con Stellarium El viernes 20 de febrero de 2015, o puede que ya el 21, según donde vivas, pues por ejemplo en Buenos...
Una demostración doméstica de que el desorden en el universo no para de crecer, tal y como dice la segunda ley de la termodinámica, ley que en esta casa obedecemos respetuosamente. Como si en este universo en el que nos ha...
Un Soyuz U fue el encargado del lanzamiento A las 16:57 UTC, poco más de seis horas y cuatro órbitas después de su lanzamiento, la nave de carga Progress M-26M, o Progress 58 según la terminología que usa la NASA, atracaba de...
La Asociación Española de Comunicación Científica, de la que soy miembro, organiza por cuarto año consecutivo la jornada Ciencia en Redes, que se celebrará el próximo 28 de mayo de 2015 en La Casa Encendida, en Madrid. Como siempre, aspiramos a contar...
La zona de Imhotep, en el lóbulo grande del núcleo de 67P, a 8,9 kilómetros de la superficie; la escala es de 0,76 metros por pixel en el original - ESA/Rosetta/NAVCAM – CC BY-SA IGO 3.0 El pasado 14 de febrero de...
En el programa What Could Possibly Go Wrong de Science Channel construyeron recientemente un «rayo de la muerte» que utiliza únicamente la energía solar y que es capaz de fundir el metal de un montón de monedas apiladas, como si fueran...
Por Nacho Palou -
16 FEB 2015
Que sí, que nos gustan más los timelapses desde la Estación Espacial Internacional que un caramelo a un niño… ISS Timelapse - Europe City Lights, un par de pasadas de la Estación Espacial Internacional sobre Europa durante la noche del 24...
El ATV 5 se desintegra en la atmósfera A las 19:04, hora central europea, del 15 de febrero de 2015 el último carguero espacial de la serie ATV de la Agencia Espacial Europea se desintegraba según lo previsto, poniendo fin no solo...
Hoy se cumplen 25 años desde que el 14 de febrero de 1990 la sonda Voyager 1 apuntara su cámara hacia el interior del sistema solar y en 60 cuadros individuales luego montados como un mosaico tomara este Retrato de Familia...
La sonda Rosetta de la Agencia Espacial Europea lleva en órbita alrededor del núcleo del cometa 67P/Churyumov-Gerasimenko desde el 6 de agosto de 2014. Esta órbita no es siempre la misma para poder cubrir distintas zonas del núcleo tanto con sus...
Todos –o al menos los espaciotrastornados– tenemos en mente las fotos oficiales de los astronautas con su mono de vuelo, a veces su casco, posando frente a un sobrio fondo azul, quizás con la bandera de su país… Pero desde hace...
El Solar Dynamics Observatory, un observatorio espacial dedicado a observar el Sol en distintas longitudes de onda acaba de cumplir cinco años en órbita y la NASA ha publicado este par de vídeos para conmemorarlo, tal y como se puede leer...
Lanzamiento del DSCOVR Tras un par de aplazamientos al fin esta pasada noche un Falcon 9 de de SpaceX ponía en órbita el Deep Space Climate Observatory, también conocido como DSCOVR, de la Administración Nacional Oceánica y Atmosférica de los Estados Unidos....
Ah, la ciencia, esa dama que trabaja incansable para encontrar la verdad y desentrañar los misterios más profundos del Universo, como por qué el maíz explota y sale volando al convertirse en palomitas. En The Guardian, Scientists now know why popcorns...
Por Nacho Palou -
12 FEB 2015
Sol 15-02-11 13-22TU: Filamento solar de febrero de 2015 por Paco Bellido Cuando se produce una prominencia solar y desde nuestra perspectiva en la Tierra la vemos desde arriba esta recibe el nombre de filamento solar; es un poco como cuando los...
El Vehículo Experimental Intermedio de la Agencia Espacial Europea, Intermediate Experimental Vehicle, más conocido como IXV, ha llevado hoy a cabo con éxito su misión, tal y como se puede leer en El vehículo experimental de la ESA, IXV, concluye con...
Cometwatch 6 february - El núcleo del cometa 67P se va poniendo las pilas - ESA/Rosetta/NAVCAM – CC BY-SA IGO 3.0 Esta es una imagen del núcleo del cometa 67P/Churyumov-Gerasimenko tomada por la cámara de navegación de la sonda Rosetta el pasado...
En The Atlantic, Why Is Google Making Human Skin? Google fabrica piel humana sintética como parte de los desarrollos médicos y científicos que se llevan a cabo en la división Google X. Uno de esos desarrollos se refiere a una pulsera...
Por Nacho Palou -
11 FEB 2015
Terraformed Mars, por Quanto Terraforming, Hypothetical Continents and Oceans, La terraformación de otros planetas es un tema habitual en libros y películas de ciencia-ficción; los humanos tienen que dejar la Tierra y habitar otros mundos, pero primero tienen que hacer que sean...
Por Nacho Palou -
11 FEB 2015
Todo está listo en el espaciopuerto de Kourou para el lanzamiento del IXV, el Intermediate Experimental Vehicle, el Vehículo Experimental Intermedio de la Agencia Espacial Europea, a bordo de un cohete Vega. Técnicos de la ESA preparando el IXV para su...
Amerizaje de la Dragon CRS-5 - Vía @ElonMusk Un suave amerizaje a 440 kilómetros de la costa de California a las 0:44 UTC de esta pasada noche ponía fin a la quinta misión regular de una cápsula de carga Dragon a la...
Agua versus homeopatía, CC Mola Saber Más visiones en clave de humor sobre la homeopatía, aunque sea un tema muy serio: Lotería y homeopatía, Homeopatía de urgencias y No seas bobo: consume homeopatía genérica y ahorra un pastón. La homeopatía no funciona...
Impresión artística de las enanas blancas en el centro de Henize 2-428 - ESO/L. Calçada Serendipia, según la Wikipedia: «es un descubrimiento o un hallazgo afortunado e inesperado que se produce cuando se está buscando otra cosa distinta.» Un equipo de astrónomos...
Jupiter Triple-Moon Conjunction - Conjunción de tres de las lunas galileanas en enero de 2015, APOD del 6 de febrero de 2015 Júpiter tiene, que sepamos, 67 lunas, 51 de ellas de menos de 10 kilómetros de diámetro. Pero hay cuatro bastante...
Desde hace millones de años desde la Tierra solo podemos ver un lado de la Luna porque nuestro planeta y su satélite rotan de forma síncrona, de tal forma que a la Luna le lleva el mismo tiempo dar la vuelta...
Shuttle in Mate-Demate Device being Loaded onto SCA-747 - Side View: El Atlantis siendo acoplado al NASA 911 - NASA/Jim Ross Aunque los transbordadores espaciales de la NASA despegaron en todas sus misiones del Centro Espacial Kennedy en algunas ocasiones las condiciones...
Un nuevo vídeo de Ciencia en el bar, en este caso explicando cómo de grande es la Tierra y los tamaños relativos de la Tierra y la Luna y sus órbitas y la de los satélites geoestacionarios usando copas de cóctel,...
All Alone in the Night, un time lapse Para ver a pantalla completa, con las luces bajadas o apagadas, y con el volumen alto. Ciudades iluminadas por la noche, grandes extensiones deshabitadas, tormentas, auroras polares… La belleza de nuestro planeta por...
Hoy es en cumpleaños de Konstantin Feoktistov, cosmonauta soviético e ingeniero espacial. Nacido en 1926 y fallecido en 2009, Feotsikov fue el primer civil en participar en una misión espacial; también fue el único cosmonauta de la Unión Soviética que no era...
En The Whasington Post, How much sleep do you need? An expert panel releases its recommendations, El exceso y la carencia de sueño están asociadas con un incremento de la mortalidad y tiene diversos efectos negativos en la salud (...) la...
Por Nacho Palou -
6 FEB 2015
Plutón, en el centro de la imagen, y Caronte el 27 de enero de 2015 - NASA/APL/Southwest Research Institute Coincidiendo con el cumpleaños de Clyde W. Tombaugh, el descubridor de Plutón, el planeta que ya no es un planeta, la NASA ha...
Contenedor con parte de las cenizas de Clyde W. Tombaugh a bordo de la New Horizons - JHU/APL La sonda New Horizons de la NASA, que el próximo 14 de julio pasará por las inmediaciones de Plutón, lleva a bordo nueve objetos...

Con esta estupenda animación de M. Beilicke (FieldViz) puede entenderse cómo funciona un motor trifásico: tres electroimanes situados en círculo y separados 120 grados rodean a un imán permanente. Haciendo fluir la corriente eléctrica de forma «ordenada» (alterna) el campo magnético...
El campo de vista de Bicep2 superpuesto a los datos de Plack - ESA/Planck Collaboration. Acknowledgment: M.-A. Miville-Deschênes, CNRS – Institut d’Astrophysique Spatiale, Université Paris-XI, Orsay, France Una de las noticias más importantes en el campo de la ciencia del año pasado...
En el programa número 8 de Órbita Laika pudimos ver a Clara Grima hablando de fluidos no newtonianos, aquellos que cuando reciben un impacto fuerte y rápido reaccionan convirtiéndose casi en un sólido. En Do you know which Dessert is Bulletproof?...
En LifeHacker, How Long to Nap for the Biggest Brain Benefits Para un impulso de energía, los expertos dicen que una siesta de 10 a 20 minutos es suficiente. Para reforzar la memoria cognitiva una siesta de 60 minutos puede ser...
Por Nacho Palou -
3 FEB 2015
Si conectas las ronchas se lee «Mis padres son idiotas» - Emily Flake en The New Yorker En 2014 se ha batido el récord de casos de sarampión en los Estados Unidos desde 1994, aún cuando desde 2000 se consideraba erradicada la...
PIA12627: Petite Pair Beyond Rings es una de esas impresionantes imágenes que nos envía la sonda Cassini que casi le paran el corazón a uno. En este caso las protagonistas son Pandora, a la izquierda, una luna de 81 kilómetros de...
Han pasado ya más de once años desde que Pedro Duque estuvo en la Estación Espacial Internacional durante la misión Cervantes, y en todo este tiempo se le han añadido el módulo Harmony, los laboratorios Columbus y Kibo, los módulos Poisk,...
Kanilj ha captado en este sketch la esencia de la cuestión en toda su profundidad: Así son todas las clases de matemáticas. (Vía Geeks are Sexy.)...
(Disponible en HD y con subtítulos en español en el menú configuración del vídeo) El ojo humano es un mecanismo increíble, capaz de detectar desde unos pocos fotones hasta la luz solar directa o cambiar el enfoque desde la pantalla que...
Por Nacho Palou -
2 FEB 2015
Riding Light de Alphonse Swinehart es un viaje en el que el espectador cabalga literalemente sobre un fotón de luz en tiempo real, partiendo del Sol y llegando hasta las profundidades de nuestro Sistema Solar – más o menos. El viaje...
Casos de sarampión en los Estados Unidos desde 2001 - Elaborado por el Washington Post con datos de los Centros para el Control y la Prevención de Enfermedades No es ninguna sorpresa porque en mayo de 2014 ya se habían detectado más...
Planetary suite por Steve Gildea es un óleo en el que se ven los nueve planetas del sistema solar –vale, vale, ya sé que ahora son ocho, pero esta obra es anterior a la democión de Plutón– y que se puede...
Impresión artística de SMAP en órbita La NASA ha puesto hoy en órbita un nuevo satélite artificial de observación de la Tierra, el SMAP, de Soil Moisture Active Passive, Humedad del Suelo Activo Pasivo, que tiene como misión medir el nivel de...
El pasado 26 de enero el asteroide 2004 BL86 pasó cerquita de la Tierra, a tan sólo 1,2 millones de kilómetros, lo que la NASA aprovechó para estudiarlo mediante radar con la antena de 70 metros de la Red del Espacio...
Del canal de vídeo de Roscosmos, la agencia espacial rusa, este vídeo que muestra como se vería el cielo si cambiáramos el Sol por otras estrellas como Alfa Centauri, Sirio, Arturo, Vega, y la Polaris, más conocida como la Estrella Polar....
Hemos dicho mil veces aquello de «niños, no intentéis esto en casa», de modo que casi se me hace raro recomendar el canal Do Try This At Home del centro de ciencia At-Bristol. Son pequeños vídeos que proponen experimentos que se...
La impresora 3D de la EEI en la caja de guantes del módulo Columbus - NASA / Made in Space Por ahora es poco más que un experimento, una demostración tecnológica, pero según se puede leer en 3D Printing In Space: Four...

Impresión artística de J1407B – Ron Miller/Universidad de Rochester Ya sabíamos de la existencia del sistema de anillos alrededor de J1407B, aunque no tenemos muy claro si J1407B es un planeta gigante o una enana marrón. Pero, tal y como se puede...

Hannah Fry de Numberphile nos explica gráficamente cómo unos matemáticos pusieron a un montón de chinos –literalmente, a 360 de ellos– a jugar 300 rondas de Piedra, Papel, Tijeras por parejas, ni más ni menos que 54.000 enfrentamientos, para observar las...
Esta noche pasa por las proximidades de la Tierra –siendo esto 1,2 millones de kilómetros, unas tres veces más lejos que la Luna– el asteroide 2004 BL86, un asteroide de aproximadamente medio kilómetro de ancho, tal y como se puede leer...
Hoy se cumplen once años del aterrizaje –sí, se puede aterrizar en Marte– del rover Opportunity de la NASA en un cráter en lo que NASA lo llamó un hoyo en uno interplanetario Con el tiempo el lugar de aterrizaje fue...
Grieta en Anuket Aunque la Agencia Espacial Europea venía publicando con regularidad imágenes de 67P/Churyumov-Gerasimenko, el cometa alrededor del que está en órbita la sonda Rosetta, estas provenían de la cámara de navegación de la sonda. Pero, al fin, han publicado unas...
Super-strong neodymium magnets destroying everyday items in slow motion: Una manzana, un iPhone viejuno, unas chuches, un brik de zumo… Todo ello espectacularmente aplastado a cámara lenta con dos imanes de neodimio. Niños, no intentéis esto en casa, ¡dejadlo en manos...

Los científicos y el Reloj del Jucio Final en «Watchmen» (Zack Snyder, 2009) El Reloj del Apocalipsis esta ahora más cerca de la medianoche (más conocida como ¡boom!) dado que los científicos que lo gestionan lo han adelantado un poco hasta las...
Sagitarius Airborne Launch System - Celestia Aerospace En los últimos años los satélites artificiales en miniatura basados en el estándar Cubesat se han convertido en una alternativa muy interesante para instituciones y empresas que quieren colocar experimentos en el espacio a un...
Tras el terremoto de Los Ángeles de 1994, que dejó buena parte de la ciudad a oscuras, la policía recibió numerosas llamadas de ciudadanos preocupados por una curiosa nube plateada que veían en el cielo. Se trataba de la Vía Láctea,...
En It's okay to be smart explican en There's No Such Thing As Cold que no existe el frío. Todos lo hemos sentido, pero el frío como tal no existe, aunque en estos días de invierno y temporal suene raro: no...
Cuando este invento de la Universidad de Rochester se haga realidad ni el traje de Aquaman estará más seco: se trata de un nuevo metal que repele el agua gracias a su nanoestructura, creada especialmente con un láser de alta intensidad....
Educación 3.0 acaba de publicar esta lista de 15 películas basadas en las matemáticas con la idea de que ver películas en las que los conceptos matemáticos son de alguna manera los protagonistas puede ayudar a desarrollar un interés y la...
Los átomos son tan pequeños, tan pequeños, que en en el ancho de un cabello humano caben unos 500.000 átomos de carbono. Decían que si hubiera que transmitir una sola idea sobre nuestro universo a una generación futura en la que...
Imagen 100 millones del AIA - NASA/SDO/AIA/LMSAL Lanzado el 11 de febrero de 2010, el objetivo del Solar Dynamics Observatory es estudiar el Sol y ver cómo influye en la Tierra y en el espacio que la rodea. Para ello observa continuamente...
Hay quien podría opinar que merecería la pena comprar un TV 4K solo para ver esto. Se trata de un montaje titulado Gigapixels of Andromeda [4K] que utiliza las imágenes de la NASA recientemente dadas a conocer de la galaxia M-31,...
La sonda New Horizons de la NASA está ahora mismo a unos 4.850 millones de kilómetros de la Tierra, a unos 200 millones de kilómetros de su destino, Plutón, a donde llegará el próximo 14 de julio tras algo más de nueve...
Mikael Hvidtfeldt Christensen de Syntopia explica en un excelente artículo titulado Path Tracing 3D Fractals algunas cuestiones y ejemplos sobre la técnica del ray-tracing o trazado de rayos para generar imágenes por ordenador empleando fractales a modo de ejemplo. Entre las...
La Beagle 2 en Marte - HiRISE/NASA/JPL/Parker/Leicester El día de Navidad de 2003 la Agencia Espacial Europea esperaba ansiosa el momento del aterrizaje de la sonda Beagle 2 en Marte… Aunque pasaron las horas, los días, las semanas, y los meses sin...
Clic en las fotos para ir a los originales El 10 de enero de 2015 SpaceX lanzaba la quinta cápsula de carga Dragon rumbo a la Estación Espacial Internacional. El lanzamiento fue realizado sin problemas y de hecho la Dragon ya lleva...
La NASA ha iniciado hoy, 15 de enero de 2015, la fase de aproximación a Plutón de la sonda New Horizons, lanzada el 19 de enero de 2006, y es que faltan seis meses para que el próximo 14 de julio...
Petricor es el nombre que recibe el “olor a lluvia”, y su composición es compleja; es la suma de decenas de sustancias, incluyendo la geosmina producida por las bacterias que hay en la tierra. La teoría es que la caída de...
Por Nacho Palou -
15 ENE 2015
Para quienes no conozcan la espiral de Ulam y los «misteriosos» patrones de números primos ahí dejo un vídeo viejuno que encontré de pasada, donde puede observarse el impactante fenómeno con claridad y elegancia (a partir de 01:20). Allá por 1963...
A las 21:05 hora central europea Barry Wilmore, el comandante de la Estación, y Terry Virts volvían a entrar en el segmento estadounidense de la EEI protegidos por máscaras para analizar el aire en distintos compartimentos de la Estación y confirmar...
Telescopios del NGTS Los doce telescopios del NGTS, Next-Generation Transit Survey, Nueva Generación en el Sondeo de Tránsitos, acaban de recibir su primera luz en el Observatorio Europeo Austral, según se puede leer en Nuevos telescopios para «cazar» exoplanetas en Paranal. Son...
Hoy se cumplen diez años del aterrizaje de la sonda Huygens en Titán, una de las lunas de Saturno. Huygens viajó hasta allí a lomos de la sonda Cassini, y después de siete años de viaje rumbo a Saturno y otros...
Entrenamiento para fugas de amoníaco Este mañana a las 10:00 hora central europea una alarma que indicaba una posible fuga de amoníaco en el segmento estadounidense de la Estación Espacial Internacional provocó la evacuación de este y el sellado de la esclusa...
Mientras preparaba un proyecto para una productora Lucas Green pensó que tenía que ser relativamente sencillo preparar imágenes muy atractivas tirando del enorme banco de imágenes de la NASA. El resultado es Space suite, este vídeo que nos lleva de paseo...
Aunque los campos magnéticos apenas tienen efectos perceptibles para los cuerpos de los seres humanos, ¿hay alguna densidad de flujo magnético que pudiera resultar dañina para las personas? Veamos: el campo magnético de la Tierra apenas tiene de 30 a 60 µT...

Julian Melchiorri es un estudiante del curso de Ingeniería, Diseño e Innovación del Royal College of Art que ha creado lo que dice ser la primera «hoja de planta artificial». Está fabricada con cloropastos y proteínas de la seda, y resulta...
La Dragon CRS-5 capturada por el brazo robot de la Estación Espacial Internacional - vía @AntonAstrey Hoy a las 13:54 UTC la quinta cápsula de carga Dragon enviada a la Estación Espacial Internacional quedaba atracada en el módulo Harmony de esta, lista...
El Revolution CT es un escáner médico de tomografía axial computarizada (TAC) desarrollado por GE que recientemente ha comenzado a funcionar en el Hospital West Kendall de Florida. La máquina utiliza un haz concentrado de rayos x que obtiene imágenes por...
Por Nacho Palou -
12 ENE 2015
Solar Eclipse Finder te permite saber cuando va a haber o ha habido eclipses solares totales y anulares entre 1601 y 2200. Para usarlo solo tienes que hacer zoom en el mapa hasta localizar la ciudad que te interesa y hacer...
Un grupo de matemáticos de la Universidad de Alberta han dado con un un algoritmo imbatible al póker (variante Texas Hold'em) como se puede leer en Science (Texas Hold 'em poker solved by computer), Scientific American (Game Theorists Crack Poker), Spectrum...
Comet C/2014 Q2 (Lovejoy) - CC Joseph Morgan Aunque ya ha pasado el momento de su máxima aproximación a la Tierra estas dos semanas son las mejores para intentar observar el cometa Lovejoy C/2014 Q2 antes de que el brillo de la...
Secuencia del lanzamiento - NASA/SpaceX Esta mañana a las 10:47 hora central europea un cohete Falcon 9 de SpaceX lanzaba la cápsula de carga Dragon CRS-5 hacia la Estación Espacial Internacional. Con la Dragon en la órbita correcta, sus paneles solares desplegados,...
Relájate en Kepler-16b, la tierra de los dos soles, donde tu sombra siempre tiene compañía En la NASA a veces se pasan de serios, pero los carteles turísticos de planetas extrasolares como Kepler-16b y sus dos soles, HD 40307g y masa ocho...
El cielo paso a paso es una nueva exposición en La Casa de las Ciencias, uno de los Museos Científicos Coruñeses, en los que trabajo en el MundoReal™, sobre la técnica del time lapse, un método muy eficaz para ver procesos...
En el primer episodio de 2015 de Ciencia en el bar Javier Armentia y Joaquín Sevilla nos explican ¿Por qué sabe diferente cocido que a la parrilla?. En resumen: tres mecanismos distintos de transmisión del calor alcanzan distintas temperaturas y provocan...
GMB Akash — Crossing the Waterways in Bangladesh The Art of Saving a Life es una iniciativa de la «Bill & Melinda Gates Foundation» que defiende las vacunas como uno de los mayores avances de la humanidad, Las vacunas salvan millones de...
Por Nacho Palou -
8 ENE 2015
El purificador de aire sin filtro de la NASA se utilizaba a bordo de los transbordadores espaciales para limpiar la atmósfera de la nave, de ahí su precio elevado. A diferencia de los purificadores de aire convencionales éste carece del filtro...
Por Nacho Palou -
8 ENE 2015

(Nota: Este anotación es la aportación de un lector de Microsiervos. Por Fernando García Muestras de los compuestos. Las siglas PE y PP corresponden al polietileno y al polipropileno, respectivamente. A mayor numeración, mayor concentración de carbono. Se puede notar la diferencia...
La máquina Omniprocessor (¡gran nombre!) es capaz de obtener agua potable y electricidad a partir de aguas residuales. Desechos humanos. Pis y caca. Y Bill Gates no tiene problema en beberse un vaso del agua que produce esa máquina: «sabe igual...
Por Nacho Palou -
8 ENE 2015
De todos los objetos que podemos ver en el cielo por la noche Andrómeda, también conocida como M-31, es el único que no pertenece a la Vía Láctea, nuestra propia galaxia. La imagen, disponible en Andromeda in HD, muestra 100 millones...
Tras varios aplazamientos SpaceX está lista para lanzar su quinta cápsula de carga Cygnus rumbo a la Estación Espacial Internacional el sábado 10 de enero de 2015. Esta cápsula, conocida como SpaceX CRS-5 está previsto que entregue 2.317 de suministros, provisiones...
En abril de este año el telescopio espacial Hubble cumplirá 25 años en órbita, y para comenzar a celebrarlo acaban de publicar una nueva versión de una de sus imágenes más conocidas, la de los Pilares de la Creación. Los Pilares...
π4 + π5 ≈ e6 (con un 0,000005% de margen de error) Una relación increíble que descubrimos gracias a @Pickover, aunque el descubrimiento original parece haber sido de D. Wilson. Hay más de estos, tanto o incluso más sorprendentes, en la listas...
Impresión artística de Eris y Disnomia - vía Wikipedia Hoy se cumplen diez años desde que los astrónomos Michael E. Brown, ahora conocido como @PlutoKiller, Chad A. Trujillo y David Lincoln Rabinowitz descubrieran el planeta enano Eris desde el Observatorio del Monte...
Costumbres estadísticamente reprobables por Morán en Eh, tío Como tras el sorteo del Niño la inmensa mayoría seguiremos teniendo más o menos el mismo dinero que antes de su celebración, y ahora que ya está todo el pescado vendido, es un buen...
De los 100.000 millones de galaxias que hay en el universo observable, alguna tenía que ser la más grande. De momento esta es la que bate todos los récords: la galaxia elíptica IC 1101, una bestia supermasiva 50 veces mayor en...
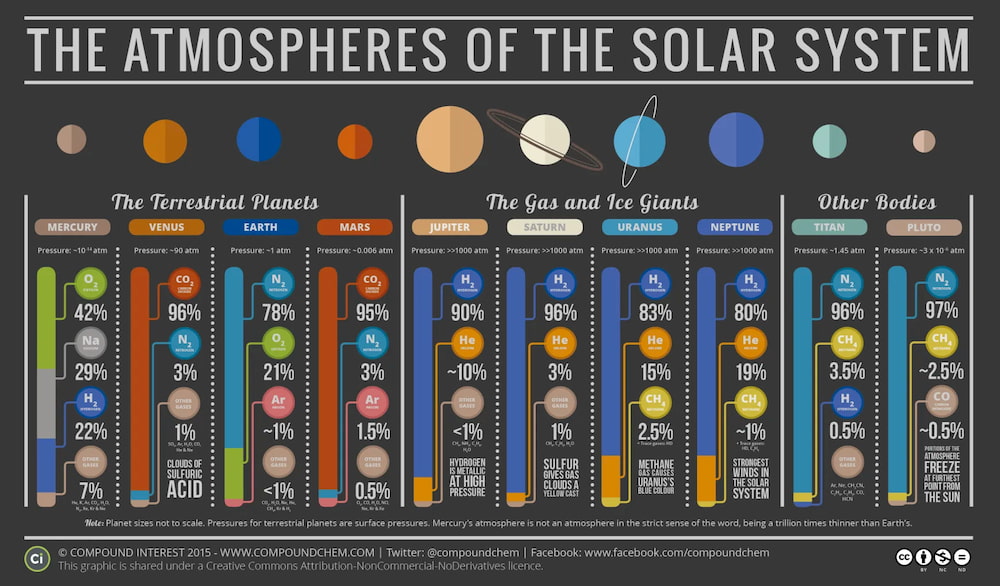
Esta bonita infografía sobre las atmósferas del sistema solar [que también puede verse ampliada] muestra cómo son los planetas de nuestro sistema solar en cuanto a su atmósfera, tanto los terrestres como los gigantes gaseosos. Además de indicar los componentes principales...
Perihelio 2015 por Paco Bellido: 152.093.626 km en el afelio el 4 de julio de 2014, 147.095.995 km en el perihelio de 2015 Recuerda que nunca debes mirar al Sol sin la protección adecuada, y menos si es a través de algún...

En esta breve charla TED Martin Hanczyc habla de la diferencia entre lo que se suele considerar vivo (animales, plantas, células) y lo que no (minerales, compuestos químicos, etc): The line between life and not-life. Sobre si están vivos o no,...
Quadrantid meteor, 4:04am por Mike Lewinski Las cuadrántidas son la primera lluvia de estrellas del año, aunque normalmente el máximo de actividad, muy corto, es difícil de observar porque se produce de día, al menos para los que vivimos en España. Pero...
El mes pasado la NASA llevaba a cabo con éxito el Exploration Flight Test 1, el primer vuelo de pruebas de la cápsula tripulada Orión, aunque en este caso no iba tripulada. Su objetivo era comprobar el funcionamiento del escudo térmico...
Que le den morcillas a tus «medidas de seguridad del laboratorio»¡Quiero superpoderes! ¿Y qué buen científico no querría una camiseta como esta? (Vía The Meta Picture.)...
Tras pasar 166 días en órbita observando y fotografiando la Tierra desde la Estación Espacial Internacional (ISS), el astronauta Alexander Gerst ha reunido 12.500 imágenes en este “timelapse” que se puede en resolución 4K baja y que muestra amaneceres y atardeceres,...
Por Nacho Palou -
30 DIC 2014
Que hay más bacterias en tu boca que personas hay en la tierra, que el aire que sale de tu nariz puede alcanzar los 160 km/h, que tus pies pueden producir hasta medio litro de sudor al día o que tus...
Por Nacho Palou -
29 DIC 2014
En nuestros cuerpos hay más bacterias que células humanas. De hecho, el 90 por ciento de las células de una persona son microbios del estilo del E. coli. Debido a ello, resulta que el 99 por ciento de los genes funcionales de...
Mucha gente es consciente de que si doblas un espagueti crudo normal y corriente por las puntas, arqueándolo hasta que se fracture, el resultado es que siempre se rompe en al menos tres trozos, no en simplemente dos como cabría esperar....
Esta infografía animada es fruto de una colaboración especial de la gente de Kurzgesagt y de Wait but Why. Es una especie de repaso a nuestra historia al completo y a la de la vida en la tierra en general, un...
Esta interesante simulación de un doble péndulo creado en Python está realmente lograda y resulta muy instructiva. Un doble péndulo no es más que un péndulo simple del que cuelga otro péndulo y sobre el que influyen la gravedad y otras...
Terence Tao y otros cuatro matemáticos llevan años intentando probar una de las conjeturas de Paul Erdős relativas a los números primos. Recientemente han anunciado un avance que dicen será uno de los más importantes en los últimos 76 años, tal...
Urano es el planeta más lejano del que una persona podría llegar a ver una órbita completa alrededor del Sol, pues esta dura 84 años.Desde su descubrimiento en 1846 Neptuno ha terminado una sola de sus órbitas de 168 años, en...
Jishai recopiló todos los datos sobre la genética de diversos animales para crear una sencilla gráfica de barras en la que se indica en qué porcentaje los seres humanos somos parecidos a otros animales. Nuestro «primo» más cercano es como cabría...
Rosetta y Philae son sin duda la misión espacial más importante de 2014, pero es una misión que comenzó a gestarse en 1993. Manual para Misiones espaciales en cinco fases es un interesante vídeo del Instituto de Astrofísica de Andalucía acerca...
Javier Armentia y Joaquín Sevilla vuelven a la carga con sus vídeos de Ciencia en el bar, en esta ocasión preguntándose ¿Cuál es el objeto más lejano del Universo? y explicándonos como una lente gravitatoria nos ha permitido ver MACS1149-JD, de...
El GSLV Mk. III durante su lanzamiento - ISRO La Agencia India de Investigación Espacial, la ISRO, ha probado hoy con éxito un nuevo cohete destinado a colocar satélites en órbita geoestacionaria y de paso ha llevado a cabo la primera prueba...
Impresión artística de la Venus Express en la atmósfera de Venus - ESA Desde finales de noviembre la Agencia Espacial Europea está teniendo enormes dificultades a la hora de comunicarse con la sonda Venus Express, probablemente porque esta haya agotado ya su...
Aún falta para que este tipo de prótesis puedan estar al alcance de todo el mundo que las necesite, pero es impresionante ver a Les Baugh controlar dos brazos protésicos usando unos sensores que leen señales de los músculos de su...
Curiosity ha detectado el metano con su instrumento SAM, visto aquí durante su instalación en el rover - NASA No es la primera vez que detectamos metano en Marte; de hecho se había hecho tanto con telescopios terrestres como con instrumentos a...
Estas son las imágenes ganadoras de Fotciencia 12, convocado por la Fundación Española para la Ciencia y la Tecnología (FECYT) y el Consejo Superior de Investigaciones Científicas (CSIC). Su objetivo es «acercar la ciencia y la tecnología a los ciudadanos mediante...
Los seres vivos evitan caer en el desorden y el equilibrio.– Erwin Schrödinger Wait But Why ha preparado esta animación documental (perfectamente subtitulada en castellano) en la que se adentran en algunas cuestiones sobre qué es la vida e incluso se...
¿Eres de los que consumen productos homeopáticos? Pues hazte un favor y pide un genérico, que por menos de un euro tiene los mismos efectos que los más de 2000 euritos el kilo en los que salen más o menos las...
El pasado 15 de noviembre a las 16:57, agotadas ya sus baterías tras 60 horas de frenética actividad sobre la superficie del núcleo del cometa 67P/Churyumov-Gerasimenko la sonda Philae de la Agencia Espacial Europea lanzaba su último tuit. Su último tuit...
Geminid Fireball: Una gemínida de 2012 por Jimmy Westlake - vía NASA Aunque el pico de actividad máxima estaba previsto para la noche del 13 al 14 de diciembre, aún es posible ver las gemínidas de este año, ya que están activas...
En The Guardian, Neil Sloane: the man who loved only integer sequences, un ensayo-celebración sobre el 50º aniversario de la famosa Enciclopedia Online de Secuencias de enteros (OEIS) donde Neil J. A. Sloane (que ahora tiene 75 años) recopila secuencias de...
Hay que echarle un par de narices: Como el autismo es provocado en gran manera por la gran condensación de metales pesados como el mercurio, que desestructuran el agua, crearemos un agua estructurada bioinformada con el código de adn original y añadiremos...
Don Pettit, uno de nuestros astronautas favoritos de todos los tiempos, habla en From Above acerca de las espectaculares fotografías que hacen él y sus compañeros cuando están a bordo de la Estación Espacial Internacional, qué se puede ver, lo que...
Los que vivimos en una ciudad a menudo olvidamos lo que es un cielo estrellado de verdad, ya que poco a poco hemos ido perdiendo la oscuridad. Pero podemos hacernos una idea de lo que es gracias a Blackout City, un...

¡Ajá, lo sabía! Tom Scott recurre a «ciencia de la buena» para demostrar que esos numeritos que tienen los diales de las tostadores no indican en realidad «minutos» como se suelen pensar (y cuentan por ahí en Internet, ese nido de...
Desde hace tiempo los geólogos tienen bastante claro que el mineral más abundante en la Tierra es la estatita piroxeno con fórmula MgSiO3, un tipo de perovskita. Pero se encuentra sobre todo en el manto inferior de la Tierra, que se...
Diez + uno tuits de José Luis Ferreira, @JL_Ferr: La ciencia es una manera más acercarse a la realidad, la tuya es tan válida como cualquier otra. La ciencia no lo sabe todo, así que por qué no va a ser cierta...
Auspiciado por la Fundación Española para la Ciencia y la Tecnología (FECYT), en colaboración con Wikimedia España, el fin de semana del 13 y 14 de diciembre de 2014 tendrá lugar en seis museos de la ciencia de España un Wikimaratón Científico...
Vi Hart y Nicki Case han escrito este post-jugable a modo de cuento que explica cómo «elecciones inocentes pueden hacer el mundo algo peor»: La parábola de los polígonos, una especie de historia con moraleja y meditación asociadas respecto a cómo...
Ando estos días enganchado a The Knick (de Steven Soderburgh), una serie de diez episodios producida por Cinemax y protagonizada por Clive Owen que se podría resumir de muchas formas, pero por abreviar: Un Dr. House en el Nueva York de...
New Horizons pasando por las proximidades de Plutón Casi nueve años después de su lanzamiento y tras haber pasado buena parte de ese tiempo en hibernación para conservar los sistemas de a bordo La sonda New Horizons de la NASA ha salido...
Con 24 horas de retraso sobre lo previsto debido a varios problemas encadenados la primera cápsula tripulada Orión de la NASA ha superado hoy el denominado Exploration Flight Test 1. Durante este se probaron los sistemas principales de la nave, incluyendo...
El vídeo muestra una haz de luz rebotando en un espejo. Está grabada con una cámara que capta, sin necesidad de flash ni luces estroboscópicas, 100.000 millones de fotogramas por segundo. En Motherboard, The Fastest Camera Ever Created Will Be Used...
Por Nacho Palou -
5 DIC 2014

… ¿O de hecho sí lo es? Michael de Vsauce explica en un nuevo vídeo qué pasaría si la Tierra fuera plana pero circular: aparte de «caernos por el borde» la gente que viviera en el centro haría una vida normal,...
Este próximo domingo 7 de diciembre a las 23:00 se estrena en La 2 de TVE Órbita Laika, un late show de divulgación científica. Sí, has leído bien, un late show de divulgación científica, que además por supuesto tiene cuenta en...
Esta pasada madrugada la Agencia Japonesa de Exploración Aroespacial lanzaba una nueva misión para traer muestras de vuelta de un asteroide. He escrito una pieza sobre esta misión para rtve.es llamada La sonda japonesa Hayabusa 2, lista para emprender su camino...
Según cuenta The Telegraph, el famoso biólogo James Watson va a subastar su medalla del premio Nobel porque –tal y como cuenta Joe Hanson en It's Okay To Be Smart– el científico admite que se ha convertido en una «no-persona» sobre...
Si trabajas en ciencia, ingeniería o matemáticas y eres capaz de contarlo en tres minutos y de manera divertida, eres un candidato ideal para participar certamen de monólogos científicos FameLab España 2015. Aquí tienes las bases, que debes respetar, y unos...
Igual todos es un poco exagerado, por aquello de los satélites espía y tal, pero en This is every active satellite orbiting earth se pueden ver los satélites artificiales en activo que están incluidos en la UCS Satellite Database, una base...
Es difícil afirmar hasta dónde llegaba la capacidad mental y de abstracción de Kurt Gödel (1906-1978). Lo único que podemos afirmar con certeza es que estaba un poco más allá de la de los concursantes de Gandía Shore. Calificado como uno...
Del departamento de enlaces traspapelados, este fotón de la Tierra vista desde más allá del lado oculto de la Luna por la sonda china Chang’e 5T1. Perfecta como fondo de escritorio; se puede descargar a 2048×2048 pixeles en Unmanned Spaceflight La...
David Schneider escribió en Spectrum acerca de su Detector casero de exoplanetas, versión bricolaje algo tan simple como grandioso a nada que lo pienses un poco. Es un montaje que permite utilizar una cámara fotográfica normalita, ni siquiera profesional, para tomar...
Una jeringuilla, un poco de agua de un charco, un láser… Y Javier Armentia y Joaquín Sevilla nos dan respuesta a la pregunta ¿hay vida en una gota de agua? en el vídeo más reciente de Ciencia en el Bar. El...
png 1,7 MB - clic para ver a tamaño real En Reddit, Human Spaceflight (everything is to scale), un gráfico con todos los vehículos espaciales tripulados de la historia, incluyendo la Estación Espacial Internacional, a la misma escala. Allí por el medio,...
Todavía no se ha determinado la causa del fallo del lanzamiento del cohete Antares el pasado 28 de octubre de 2014 con la cápsula de carga Cygnus 3 a bordo rumbo a la Estación Espacial Internacional, aunque todo apunta al fallo...
Celestial buddies es una colección de peluches que incluye el Sol, los ocho planetas, y un cometa. Cada uno de ellos está hecho con distintos materiales y colores que se adaptan a las características de cada uno de ellos. Traen también una...
El cáncer es una enfermedad muy chunga que a casi todo el mundo toca directa o indirectamente, y hace mucho que defiendo que hay que tener mucho cuidado con como se cuentan las cosas. Por ejemplo, titular Una vacuna prueba en un...
Con todas sus ventajas materiales, la vida sedentaria nos ha dejado un poso de inquietud, de insatisfacción. Incluso tras cuatrocientas generaciones en pueblos y ciudades, no hemos olvidado. El camino abierto sigue llamándonos quedamente, como una canción de infancia ya casi...
NASA Reducir al máximo el peso de las naves espaciales durante el despegue desde la tierra es uno de las premisas de cara a viajes espaciales de larga duración en los que hay que cargar los vehículos hasta los topes, caso de...
Por Nacho Palou -
28 NOV 2014
En el vídeo What Happens When You Eat Too Much, Reactions se explica de forma sencilla y muy comprensible —aunque esté en inglés, se pueden activar subtítulos— la reacción del cuerpo humano ante un atracón de comida y cuando se supera...
Por Nacho Palou -
28 NOV 2014
AL igual que la selección que hizo Brain Pickings, CultureLab y New Scientist han publicado una selección de diez libros sobre ciencia que no solo son recomendables sino que además pueden darte ideas para regalos (o auto-regalos). 1. Does Santa Exist?...
Ahora que llega el final de año también lo hacen nuestras listas, ese subgénero del que somos fans, de modo que puedes irte adelantando -o ir lanzando los pedidos a la tienda- por ejemplo con esta selección de Brain Pickings sobre...
Despegue de la Soyuz TMA-15M - NASA/Aubrey Gemignani Esta pasada madrugada a las 5:00 UTC se abrían las escotillas que comunican la Soyuz TMA-15M y la Estación Espacial Internacional, con lo que la Expedición 42 a esta ya está completa con sus...
Mediante una curiosa técnica óptica esta lente permite «ver el aire» y apreciar los detalles gracias a un montaje de su flujo y movimiento gracias a una cámara de vídeo y una lente de telescopio. Más detalles en la Universidad de...
Acabo de darme la que probablemente ha sido la ducha más larga de mi vida. ¡Gran sabiduría por parte de los rusos al dejarle tiempo más que suficiente en el horario! #SinPrisasEnElDíaDelLanzamiento Hace unas horas Sam Cristoforetti lanzaba este tuit en el...
Si todo va según lo previsto esta noche a las 21:01 UTC la Soyuz TMA-15M despegará del cosmódromo de Baikonur rumbo a la Estación Espacial Internacional con Anton Shkaplerov, Samantha Cristoforetti, y Terry W. Virts a bordo. Unas seis horas después...
Kvy de Mola Saber nos escribió para contarnos que había estado trabajando en esta infografía titulada Evolución estelar para todos los públicos [zoom] ¿Y nuestro Sol? Está clasificado como una enana amarilla; en la imagen la pequeña estrella amarilla que hay...
Si eres de los afortunados que ya dispone de un televisor o pantalla 4K podrás disfrutar de imágenes de nuestro planeta como nunca se han visto. Se trata de un vídeo de la agencia especial rusa, del Centro de Investigación para...
Me encantan las ilustraciones que intentan hacernos ver lo ridículamente pequeña que es la Tierra como esta en la que está en el centro de los anillos de Saturno. El diámetro ecuatorial de la Tierra es de 12 742 kilómetros, mientras...
Los diez instrumentos de Philae explicados en otros tantos tuits Lo cuenta la DLR, la Agencia Espacial Alemana, en Churyumov-Gerasimenko – hard ice and organic molecules: el instrumento COSAC de Rosetta ha detectado moléculas orgánicas en la «atmósfera» del núcleo del cometa...
Rockets 3D Collection, cohetes en 3D por @Veiderdar; de izquierda a derecha son el SLS Bloque II de Carga, el SLS Bloque I tripulado, el Ares I-X, el Falcon 9 Heavy, el H-IIB, el Ariane 5 ECA, y el Vega. Al...
Welcome to a comet: una de las patas de Philae sobre la superficie del núcleo de 67P - ESA/Rosetta/Philae/CIVA Pedro Simón en El Mundo, escribe en La parábola de Leonov sobre Philae, Rosetta, y alguna que otra misión espacial más: Obviemos que...
Esta pasada noche, a las 1:36 el Centro Europeo de Operaciones Espaciales de la Agencia Espacial Europea recibía las últimas comunicaciones con Philae, que desde anoche está en hibernación sobre el núcleo del cometa 67P, tal y como se puede leer...
Dado que el lugar en el que ha quedado Philae sobre la superficie del núcleo del cometa 67P recibe mucha menos luz del Sol de la que sería necesaria para recargar las baterías los responsables de la misión han decidido intentar...
Primera panorámica desde 67P con el instrumento CIVA - ESA/Rosetta/Philae/CIVA Primero las buenas noticias: Philae sigue activo y en comunicación con el control de la misión, posado sobre la superficie del núcleo del cometa 67P. De hecho siguió comunicándose también con Rosetta...
Hoy hemos hecho historia: hemos colocado una sonda en el núcleo de un cometa que se mueve a 66.000 kilómetros por hora a 500 millones de kilómetros de la Tierra tras más de diez años de viaje y 6500 millones de...
Philae emprende su camino visto por la cámara Osiris de Rosetta - ESA/Rosetta/MPS for OSIRIS Team MPS/UPD/LAM/IAA/SSO/INTA/UPM/DASP/IDA Hoy a las 10:03 se recibía en el Centro Europeo de Operaciones Espaciales de la Agencia Espacial Europea en Darmstadt la señal que confirma que...
Esta featurette de Interestelar (Christopher Nolan, 2014) explica algunos de los detalles científicos sobre los que se trabajó durante la creación del guión y los efectos visuales de la película de ciencia-ficción del momento. Pero pese a todo lo que veáis...
Si todo va según lo previsto en el momento en el que Cron publique esta anotación en Microsiervos faltarán exactamente 24 horas para que en el Centro Europeo de Operaciones Espaciales de la Agencia Espacial Europea se reciba la confirmación de...
Junto con la perrita Laika y el gato de Shrödinger el requetefamoso y popular perro de Pávlov (más bien: perros, porque eran varios) es probablemente uno de los animales más famosos de la historia de la ciencia. Mediante la técnica de...
La animación está formada por más de 17.000 imágenes (72 GB de datos) tomadas en las últimas semanas por el Solar Dynamics Observatory. En ella se puede ver la mancha solar AR 2192, la mayor de los últimos 20 años. La...
Por Nacho Palou -
11 NOV 2014
Expedition 41 Soyuz TMA-13M Landing: La Soyuz TMA-13M tras su aterrizaje - NASA/Bill Ingalls Tras 165 días en la Estación Espacial Internacional el astronauta de la Agencia Espacial Europea Alexander Gerst tomaba tierra junto con sus compañeros Maxim Suraev y Reid Wiseman...
Llevaba algún tiempo dándole vueltas a hacerme donante de médula ósea, pero tenía la idea aparcada porque entendía que tenía que desplazarme, en mi caso, a Santiago de Compostela para que me hicieran la toma de muestras pertinente, y estaba esperando...
La disculpa oficial es estudiar los efectos de la tensión superficial sobre el agua cuando esta se encuentra en caída libre… Pero Steve Swanson, Reid Wiseman y Alexander Gerst se lo pasan pipa metiendo una GoPro dentro de la bola de...
Inside the ISS - 18,000 M.P.H. with Reid Wiseman: Del ATV-5, atracado en el módulo Zvezda de la Estación Espacial Internacional, al Nodo 2, en la parte frontal de la Estación Espacial Internacional, con Reid Wiseman en menos de dos minutos....
Specular Spectacular - NASA/JPL-Caltech/University of Arizona/University of Idaho Los últimos diez o quince años están siendo una especie de época dorada para la investigación espacial, pues cada vez tenemos más y más sondas repartidas por el sistema solar recogiendo datos de todo...
Un nuevo vídeo de Ciencia en el Bar en el que Javier Armentia y Joaquín Sevilla explican qué es la materia oscura usando un café con leche. El canal de vídeos de Ciencia en el bar es un proyecto promovido por...
Si todo va bien el próximo miércoles 12 de noviembre a las 15:30 UTC el módulo Philae de la sonda Rosetta de la Agencia Espacial Europea aterrizará en el núcleo del cometa 67P/Churyumov-Gerasimenko. Este vídeo recién publicado por la Agencia Espacial...
En la tienda de homeopatía: – Serán 89 dólares con 75 céntimos.– Quédate el cambio Homeopathy = infinity monies!, homeopatía = dinero infinito por Tracey Moody. (Héctor lo encontró vía Fabio.com.ar). Homeopatía de urgencias y Terrorismo homeopático, otras dos visiones en clave...
Unos días antes de dejar su mando al frente de la Estación Espacial Internacional el astronauta canadiense Chris Hadfield grabó la versión de Space Oddity de David Bowie que se puede ver aquí arriba. Tenía todos los permisos pertinentes, pero el...
Todos hemos visto imágenes de meteorología extrema tomadas desde el espacio. Pero ninguno es como este vídeo del Estudio de Visualización Científica de la NASA. Utilizando datos reales, esta simulación muestra el movimiento de las nubes a lo largo de siete...
Por Nacho Palou -
4 NOV 2014
Desde los tiempos de Galileo sabemos que dos objetos en caída libre ideal (sin rozamiento, en el vacío) llegarán al suelo al mismo tiempo. Y es que aunque suene increíble hasta el siglo XVI la gente intuía que el tiempo de...
SS2 en el momento del accidente - Foto Kenneth Brown Aunque en un principio el motor era el componente que más sospechas levantaba como causante del accidente del SpaceShipTwo que el viernes 31 de octubre de 2014 le costó la vida a...
Armado con una aplicación web llamada I ♥ ∆ que permite convertir imágenes en imágenes formadas por polígonos que ajustan su forma y color en función de la imagen original, aunque de una forma que permite jugar mucho con los resultados...
El primer SpaceShipTwo de Virgin Galactic, la nave espacial que parecía más avanzada de cara a realizar los primeros vuelos turísticos al espacio, se ha estrellado hoy durante un vuelo de prueba. Restos del SpaceShipTwo Se trataba del vuelo libre número...
Las ratas de laboratorio tontas, tontas, no son. Para reconfirmarlo unos científicos del Howard Hughes Medical Institute han realizando algunos experimentos acerca de sus habilidades en en juegos no tan sencillos como los habituales de queso y laberintos. El resultado viene...
Aún tardarán en tiempo en conocerse los motivos pero anoche, apenas seis segundos después de despegar de la plataforma de lanzamiento de las Instalaciones de Vuelo Wallops de la ANSA el cohete Antares de Orbital Sciences que tenía que poner en...
Lanzar un cohete, aunque a estas alturas nos parezca casi rutinario, dista de serlo. Todos los sistemas de a bordo tienen que funcionar correctamente, así como los sistemas de soporte en tierra en la plataforma de lanzamiento y en el control...
El espacio huele a ropa mojada y la Luna huele a pólvora y recientemente investigadores europeos han concluido que los cometas huelen mal, El “perfume” del cometa 67P/C-G — Considerando las partículas detectadas por la sonda Rosetta los cometas apestan. «Si...
Por Nacho Palou -
28 OCT 2014
Plane, Clouds, Moon, Spots, Sun es la foto de Doyle Slifer que es la Imagen Astronómica del Día del 27 de octubre de 2014 y recoge el eclipse parcial de Sol del 23 de octubre de 2014. En ella sale una...
El agua, clave para la vida en la Tierra. Y no sabemos a ciencia cierta de donde viene. Rosetta, la primera misión diseñada para seguir un cometa y estudiar, entre otras cosas, el origen del agua, pues aunque parezca increíble no...
La zona activa AR 2192 en luz blanca por Paco Bellido - foto tomada el 23 de octubre de 2014 Esta de aquí arriba es la mancha AR 2192, la más grande registrada en el ciclo solar 24, que se supone que...
¡Eh, que es ciencia! Se trata de una una simulación del DEM Research Group que permite predecir cómo se dañarán docena y pico de peras metidas en una caja –no sabemos si variedad de agua o conferencia– durante su transporte, debido...
Partial Solar Eclipse of October 23 - Fred Espenak / NASA Si vives en el extremo este de Siberia o prácticamente en cualquier lugar de los Canadá y los Estados Unidos salvo Hawai y Nueva Inglaterra, hoy, 23 de octubre de 2014,...
La gente de Numberphile se entretuvo en imprimir un millón de decimales de π en papel. Tuvieron que irse con unos cuantos voluntarios a una pista de aeropuerto cerrada donde extendieron el papel en toda su longitud: 1.693 metros en total....
Foto: NASA Kate Greene, una de las mujeres participantes en el experimento de la NASA HI-SEAS (que simula en la Tierra un viaje de larga duración al planeta Marte) escribe Slate, Durante cuatro meses estuve confinada en una cúpula geodésica instalada en...
Por Nacho Palou -
22 OCT 2014
OCR + software matemático = solución En mis tiempos no había esto, pero la verdad es que Photomath mola y es todo un avance de los tiempos. Ideal para vagos, estudiantes que no quieran hacer los deberes o gente de letras...
Matusalén, el planeta extrasolar más antiguo que conocemos Resumido de The Strangest Alien Planets, algunos de los planetas extrasolares más curiosos que hemos encontrado. Kepler-10c, una mega Tierra, de 2,3 veces su tamaño y 17 veces su masa. Kepler-10b, el planeta extrasolar...
Ébola: ¿una nueva pandemia?, otro genial vídeo vía Ignacio López-Goñi, el autor de microBIO. Por si no quieres pararte a verlo, aunque deberías: «El Ébola se transmite de persona a persona a través del contacto directo con el cuerpo o fluidos...
Orión y una oriónida Como todos los años por esta época la Tierra está atravesando una de las zonas del sistema solar en la que están los restos que el cometa Halley va dejando a su paso, lo que da lugar a...
Si memorizas la línea correspondiente con tu signo –obviando que Ofiuco lleva mucho tiempo descuadrando las cosas— con este horóscopo no necesitarás ninguno más en toda tu vida. Palabrita. (Vía Manolo Elmas)....
Jota - ESA/Rosetta/MPS for OSIRIS Team MPS/UPD/LAM/IAA/SSO/INTA/UPM/DASP/IDA El punto del núcleo del cometa 67P/Churyumov-Gerasimenko en el que va a intentar aterrizar la sonda Philae el próximo 12 de noviembre tiene por ahora el prosaico nombre J, lo que no quiere decir más...
El temor en los tiempos del ébola, una muy recomendable conferencia a cargo de Guillermo Quindós, catedrático de Microbiología en la UPV/EHU, para adquirir conocimientos básicos sobre el ébola. La impartió dentro del ciclo de conferencias Zientziateka, organizado por la Cátedra...
Javier Armentia y Joaquín Sevilla vuelven a la carga con los vídeos de Ciencia en el bar, y en este tercer episodio nos explican por qué los atardeceres son rojos usando un par de copas de agua, un folio, una linterna,...

La física gana otra vez: 95 km/h contra -95 km/h, y la pelota aterriza como si se hubiera soltado de la mano. Aplausos para Newton.
Ya es oficial, La ESA da el visto bueno al intento de aterrizaje de Philae en el cometa 67P el próximo 12 de noviembre. Lo he contado para rtve.es en el enlace anterior, y espero poder contarlo en directo desde el...
Bea por Xurxo Mariño Una de las principales críticas que tuvo siempre Naukas Bilbao fue la reducida cantidad de mujeres que daban charlas en el evento. Bea Sevilla, AKA @feminoacid, que se estrenaba como ponente en Naukas Bilbao 2014, estaba intrigada por...
Mission selfie from 16 km: Rosetta y Philae a 16 km de 67P/C-G - ESA/Rosetta/Philae/CIVA Esta es una imagen compuesta por otras dos, una con un tiempo de exposición más corto para captar los detalles del núcleo del cometa 67P/Churyumov-Gerasimenko, y otra...
Nicolas García ha creado este pequeño experimento de Google Chrome llamado Anomalías en las temperaturas que muestra en un precioso globo terráqueo interactivo los datos de la NASA sobre el calentamiento global. Experimento: Anomalías en las temperaturas [Chrome] Se pueden seleccionar...
Two-Planet Perspective from Lunar Orbit - NASA/GSFC/Arizona State University (clic en la imagen para ver en grande y comprobar que Marte no es cuadrado) Con un poco de planificación y unas cuantas pruebas previas para ajustar los tiempos de exposición se pueden...
All Saturn V Launches At Once recoge los doce lanzamientos del programa Apolo más el extra del laboratorio espacial Skylab en un solo vídeo; todos ellos a cargo de cohetes Saturno V, los más potentes jamás fabricados. Hay otro vídeo similar...
Hubble Ultra Deep Field - NASA, ESA, S. Beckwith (STScI) and the HUDF Team El Campo Ultra Profundo del Hubble es una de las imágenes más conocidas obtenidas por el telescopio espacial Hubble. Contiene unas 10.000 galaxias, cada una de ellas con...
Pues eso, que casi cada hueso del cuerpo humano, o al menos los principales, con sus nombres en una ilustración. Están en inglés pero en la mayoría de los casos son muy parecidos sino iguales. (@Fisicalimite vía @CSIC). Industriepalast: el Hombre...
Angel R. López-Sánchez trabajó durante algún tiempo como astrónomo de soporte del Telescopio Anglo-Australiano (AAT por sus siglas en inglés, Anglo-Australian Telescope), y aprovechó sus ratos libres para ir creando este espectacular time-lapse del cielo austral sobre este. En sus propias...
Teide 1 y otros objetos - vía caosyciencia Aunque las teorías que manejaban los astrofísicos sobre el nacimiento y evolución de las estrellas ya contemplaban su existencia no fue sino hasta 1995 cuando se pudo observar la primera enana marrón. Esta primera...
En el Washington Post han preparado una Simulación de cómo se produce la difusión de enfermedades infecciosas, incluyendo infecciones víricas como el ébola, la gripe y otras tan comunes conocidas como la rubeola, el sarampión o la tos ferina. En la...
Visibilidad del eclipse - Feed Espenak/NASA Mañana se produce un eclipse total de Luna que alcanza su punto máximo a las 07:45:40 UTC, lo que quiere decir que ni desde España ni de hecho desde la mayor parte de Europa ni toda...
La semana del 4 al 10 de octubre de cada año ha sido declarada por la ONU como la Semana Mundial del Espacio; es la celebración internacional de la ciencia y la tecnología del espacio como contribución para la mejora de la...
Plutón y Caronte vistors por la New Horizons. La imagen de la derecha los muestra dentro de sendos círculos para ayudar a localizarlos: Plutón es el del centro, Caronte el que está arriba a la izquierda de este Anda por ahí circulando...
Anda por ahí haciendo las rondas de Internet esta imagen. Dice ser una imagen real de un bacteriófago T4, un virus, tomada con un microscopio electrónico. Pero precisamente por haber sido tomada con un microscopio electrónico como poco esta imagen tendría...
Virus del Ébola Me sorprendió mucho este titular, La OMS admite que las vacunas contra la enfermedad no estarán hasta marzo como muy pronto, porque uno de los grandes problemas del ébola es que no hay vacuna conocida. Así que tras preguntarles...
Itziar Laka - Foto por Xurxo Mariño Empecemos con un pequeño ejercicio. En unos 10 segundos cuenta cuantas F hay en este texto. Puedes hacer trampa y dedicarle más tiempo, pero entonces no tiene gracia: Finished files are the result of years...
Con una versión para el hemisferio norte y otra para el hemisferio sur en el canal de La costa de las estrellas cada mes publican vídeos que muestran las efemérides astronómicas más significativas para ambos hemisferios celestes. (Vía mi amiga Amalia)....
Sergio Pérez Acebrón es un investigador del German Cancer Research Center (Heidelberg, Alemania) que dio una charla muy interesante en el reciente evento Naukas sobre ese tema tan controvertido y de actualidad: el aborto. La charla es de tan solo diez...
Esta es una imagen de nuestro vecino del sistema solar tomada por la sonda Mars Orbiter Mission de la India casi desde la parte de su órbita más alejada del planeta, en concreto a 74 500 kilómetros de este; el punto...
Según ha anunciado la Agencia Espacial Europea en La misión Rosetta aterrizará sobre el cometa el 12 de noviembre será el próximo 12 de noviembre de 2014 y no el 11 como se venía pensando hasta ahora cuando Philae intente posarse...
Ya está disponible el segundo capítulo de Ciencia en el bar, en el que Javier Armentia y Joaquín Sevilla explican ¿por qué se empañan las gafas? Ciencia en el bar es un proyecto promovido por la Universidad Pública de Navarra, financiado...
Este mapa de las emisiones de carbono The Guardian representa el tamaño de los países según la cantidad de CO2 que emiten anualmente a la atmósfera. La configuración del mapa cambia para representar de igual modo también la distribución de la...
Por Nacho Palou -
24 SEP 2014
The Physics of Space Battles cuestiona la posibilidad de que puedan tener lugar en el EspacioReal™ las batallas a las que nos tiene acostumbrados la ciencia ficción en general y la Guerra de las Galaxias en particular. ¿Por qué viajo con...
Por Nacho Palou -
24 SEP 2014
Se puede seguir a esta sonda en Twitter como @MarsOrbiter Apenas unos días después de la MAVEN de la NASA esta pasada noche la India conseguía poner en órbita alrededor de Marte su primera sonda interplanetaria, lo que convierte a ISRO, la...
Si todo va según lo previsto y hay un poco de suerte el próximo 11 de noviembre Philae, el aterrizador de la sonda Rosetta, tomará contacto con el núcleo del cometa 67P/Churyumov-Gerasimenko, algo que será la primera vez que suceda en...
Esta madrugada a las 4:29 hora peninsular, comienza el otoño, que este año durará 89 días y 20 horas y terminará el 22 de diciembre con la entrada del invierno, tal y como se puede leer en Inicio astronómico del otoño...
Tal y como se puede leer en ¡Construye tu propio E-ELT con piezas de LEGO! gracias al trabajo del astrónomo holandés Frans Snik ahora cualquiera puede construirse su propia versión del E-ELT en Lego. Eso sí, es un proyecto con una...
La imágenes de este vídeo pueden no ser aptas para todo el mundo, aunque los subtítulos automáticos son casi peores. 25 Strangest Things Found In An X-Ray recoge las 25 cosas más extrañas que se pueden ver en unos rayos X,...
Impresión artística de MAVEN en órbita alrededor de Marte Tras llevar a cabo con éxito esta pasada noche la delicada maniobra de inserción orbital la sonda MAVEN de la NASA está ya en órbita alrededor de Marte después de un viaje de...
Tras una cancelación ayer porque las condiciones meteorológicas no permitían en lanzamiento un cohete Falcon 9 de SpaceX ha puesto en órbita la cuarta cápsula de carga Dragon con destino a la Estación Espacial Internacional. La CRS-4/Dragon SpX-4 lleva a bordo...
¡Y a mitad de precio, Santa Madonna! Un curioso experimento que consiste en arrojar sobre un globo inflable peludo de esos que venden en los bazares un poco de nitrógeno líquido. El resultado es divertido y un poco sorprendente; lo interesante...
La profesora de matemáticas Zvezdelina Stankova explica para Numberphile el problema geométrico de los tres triángulos que consiste en averiguar cuál es la suma de tres ángulos que se forman en una construcción que comienza con tres cuadrados unidos. El problema...
Ya tenemos aquí el cuadro de honor de 2014 de los premios Ig Nobel, aquellos mediante los que el Instituto de Investigaciones Improbables saca a la luz logros científicos que primero te hacen reír y luego pensar. Física: Kiyoshi Mabuchi, Kensei Tanaka,...
Visualize Pi es un fotoblog genial en el que se cuenta un proyecto que consiste en visualizar el número pi en forma de pósteres y murales callejeros de todas las formas y colores. Básicamente los voluntarios eligen el diseño que van...
Todos los días vivimos milagros. O vemos, escuchamos y leemos cosas que nos lo parecen. ¿Pero lo son realmente? ¿Cómo se explica que sueñe con alguien al que no he visto en años y, pocas horas después, reciba noticias de esa...
Con la inauguración a las 19:30 de las exposiciones Skeleton Sea y Spill arranca hoy en A Coruña la primera edición del Festival Marea Alta, un encuentro artístico, educativo y lúdico de celebración y preservación del mar que tiene como objetivo convertirse...
Jota - ESA/Rosetta/MPS for OSIRIS Team MPS/UPD/LAM/IAA/SSO/INTA/UPM/DASP/IDA Aún no tiene nombre –aunque habrá un concurso para ponérselo– pero desde hoy sabemos que Philae, el aterrizador de la sonda Rosetta, se posará sobre el punto por ahora conocido como J de los cinco...
Cmglee ha plasmado en esta educativa infografía los tamaños de los principales espejos de los telescopios, desde los más pequeños y antiguos de hace dos siglos (Observatorio Yerkes, 1893) al futuro Telescopio Europeo Extremadamente Grande (E-ELT) previsto para 2022 y que...
Rosetta and Philae snap selfie at comet: Rosetta, Philae, un panel solar, y el núcleo de 67P/Churyumov-Gerasimenko - ESA/Rosetta/Philae/CIVA Tomada el pasado 7 de septiembre, en esta foto se ve el núcleo del cometa 67P/Churyumov-Gerasimenko, que es el objetivo de la misión...
It’s Payback Time es un corto que recoge la destrucción de una civilización a manos de una misteriosa sustancia azul… Y sólo puedo decir que ojalá. Forma parte de una campaña para recoger fondos para la lucha contra en cáncer en...
Stephen Hawking está este mes de visita por nuestro país para participar en el Festival Starmus de Tenerife. Una de sus frases en las entrevistas recientes ha sido esta: Ahora mismo no sé todavía por qué existe el Universo. Aunque a simple...
Unos astrónomos han mapeado los supercúmulos de galaxias y les han asignado diversos nombres para hacerlos más fáciles de recordar, más «amables» y diferenciarlos unos de otros. Entre ellos está el nuestro, de modo que a partir de ahora deberíamos escribir...
Algo por aquí, algo por allá: pi, vía Visualizing Math....
Pues eso, que ya hay programa para Naukas Bilbao 2014 y pinta muy bien, como por otra parte ya es habitual.En tan solo dos semanas, el próximo 26 de septiembre, arranca en en paraninfo de la UPV en Bilbao una de las...
La TMA-12M a su partida de la EEI - NASA Aleksandr Skvortsov, Oleg Artemyev y Steve Swanson volvían ayer de la Estación Espacial Internacional a bordo de la Soyuz TMA-12M, que aterrizaba a las 2:23 UTC en Kazajistán, tal y como se...
Para ir desfogando al final de la semana, Nuestra Tierra - Our Earth, un vídeo montado por Fede Castro con fotos tomadas por los tripulantes de la Estación Espacial Internacional aprovechando que estás están disponibles para su uso en la Earth...
Earth images from Alexander Gerst in 4K, un precioso time lapse montado con imágenes tomadas por Alexander Gerst, el astronauta de la Agencia Espacial Europea que está a bordo de la Estación Espacial Internacional llevando a cabo la misión bautizada como...
67P el 5 de septiembre de 2014 - ESA/Rosetta/MPS for OSIRIS Team MPS/UPD/LAM/IAA/SSO/INTA/UPM/DASP/IDA Cualquiera podría imaginarse a Bruce Willis y su equipo en Armageddon aproximándose a su objetivo viendo esta imagen, pero la gran diferencia es que esta imagen es real. Es...
Son dieciséis bolas de jugar a los bolos: cuelgan como péndulos de una estructura de madera de unos seis metros; en la parte de abajo parece haber unas pequeñas piezas metálicas que emiten los sonidos. Las longitudes de los péndulos están...
Súper Luna y micro Luna de 2012, APOD del 8 de septiembre de 2014; fotos de Catalin Paduraru Hoy se volverá a hablar de súper Lunas, y si te suena a repetido es porque es la tercera súper Luna consecutiva de 2014,...
Las mentes inquietas de Juan Ignacio Pérez y sus secuaces de la Cátedra de Cultura Científica de la Universidad del País Vasco han puesto un nuevo invento para seguir adelante con su empeño de ayudar en todo lo posible con la...
Lo hemos dicho mil veces, y o diremos mil veces más, en especial ante el auge de los movimientos antivacunas en los últimos años. En este caso mediante este vídeo de Ignacio López-Goñi, el autor de microBIO, Las vacunas funcionan. Hay...
Hay muchos tópicos sobre el espacio exterior, los planetas y la física relacionada que han calado profundamente en nuestra sociedad debido a películas, libros y series de televisión. Pero no todos son ciertos; de hecho algunos de los más espectaculares resultan...

Esta curiosa foto-anuncio vía parislemon afirma que «posiblemente las locomotoras lleven pronto su propio reactor nuclear» aunque también apunta algo más cercano a la realidad de hoy en día: «… o quizá utilicen electricidad generada en estaciones eléctricas nucleares» (cauta idea)....
Montado por Christoph Malin, el timelapse The ESO Observatories: Atacama Transitions and Landscapes under the Southern Sky es otro producto de la Ultra High Definition Expedition del Observatorio Europeo Austral. Ver un cielo oscuro de verdad es una experiencia que nadie...
En inglés subtitulado en español —activando los subtítulos, Your Brain On Coffee, sobre cómo funciona la cafeina y qué efectos que tiene sobre el cerebro y el cuerpo, y por qué resulta ligeramente adictivo. Al parecer aquellos que beben café descafeinado...
Por Nacho Palou -
3 SEP 2014
Philae aterrizando Bueno, en realidad será Philae el que aterrice sobre el núcleo del cometa 67P/Churyumov-Gerasimenko, en principio el próximo 11 de noviembre, aunque la fecha está todavía por confirmar, igual que la elección del lugar de aterrizaje definitivo. Pero mientas...
Ian Regan cogió la imagen PIA18278: Ring King, recientemente añadida a los archivos públicos de la misión Cassini-Huygens, y con un poco de habilidad la convirtió en esta espectacular y preciosa imagen. En ella se ve el hexágono del polo norte...
Lo explica Greg Foot en Why does your voice sound different on a recording?, pero por si quieres ahorrarte los subtítulos automáticos traducidos por Skynet Google, aquí va un resumen. Al oír nuestra propia voz el sonido que percibimos como vibraciones...
Además de sus tareas como astronautas Alexander Gerst, Reid Wiseman, Max Surayev y Oleg Artemyev publican casi a diario fotos de la Tierra en Twitter en sus cuentas, @Astro_Alex, @astro_reid, @Msuraev, y @OlegMKS. Dave MacLean las ha ido recopilando y están...
El problema matemático del viajante (en inglés: Travelling Salesman Problem, TSP) es un clásico en el mundo de los algoritmos: encontrar la ruta más corta posible que visite cada ciudad una sola vez en un mapa, regresando a la ciudad de...
Florian Born y David Friedrich de la Universidad de las Artes de Berlín han creado esta delicia de trasto que llama Mechanical Pi en homenaje a William Shanks. Este matemático calculó allá por 1873 ni más ni menos que 707 dígitos...

Tal y como aprendimos en Planilandia, vivir en un mundo 2D es complicado; y descubrir el 3D puede ser un shock para sus habitantes, algo impactante dado que les resulta casi imposible comprender lo que están viendo y sintiendo. Por poner...
Un vídeo de cómo es sobrevolar una aurora desde órbita en la Estación Espacial Internacional, cortesía de los miembros de la Expedición 40 a esta. No están mal las vistas que tienen. (Vía @Astro_Alex)....

El efecto Shepard (o escala de Shepard / tono de Shepard) consiste en escuchar el sonido de unas notas que van «subiendo y subiendo» en la escala. Pero aunque parecen no dejar de ir subiendo, octava por octava, en realidad si...

El medio de transporte más seguro no es el avión, sino el ascensor. Desde Slate y el departamento de «nunca sabes cuándo puedes necesitar este conocimiento del mundo moderno, así que ahí queda» nos llega hoy un recordatorio: Según las estadísticas,...
Como hay gente pa tó alguien se entretuvo en crear este vídeo de más de cuatro horas y media en el que básicamente se escucha el disco de marcado de un teléfono clásico escribiendo el número π dígito a dígito (3,1415926…)...
Con la llegada del ATV-5 Georges Lemaître a la Estación Espacial Internacional el miércoles 13 de agosto de 2014, y hasta la partida de la Cygnus 2 Janice Voss el viernes 15 los cinco puertos de atraque de esta estaban todos...
Con toques de Una mente maravillosa + historia romántica en noviembre llegará «La teoría del Todo», una película biográfica sobre Stephen Hawking, el físico, cosmólogo y divulgador científico. Aunque no sea una superproducción de Hollywood, a sus 72 años parece un...
A Spaceship for All es un «experimento con el navegador Chrome» que permite aprender cosas sobre la ISEE-3, una sonda enviada para explorar el Sol que se abandonó oficialmente en 1997 pero con la que los aficionados han logrado contactar para...
Este gráfico sobre las dosis letales de productos químicos cotidianos incluye el agua, la cafeína y el alcohol. Haciendo bueno aquello de que «cualquier cosa en exceso es mala» la traducción química es que morirás si eres capaz de beber esto...
Una perseida de 2013 @Starfest2013 Un año más las Perseidas, las lágrimas de San Lorenzo, vienen a dar su espectáculo, aunque lo más correcto sería decir que es la Tierra la que atraviesa una vez más la órbita del cometa 109P/Swift-Tuttle, de...
Baikonur Cosmodrome Launchpad es una propuesta del usuario XCLD para conseguir que Lego fabrique de serie un modelo de la mítica plataforma de lanzamiento desde la que Yuri Gagarin despegó en su misión el 12 de abril de 1961 para convertirse...
El núcleo de 67P el pasado 3 de agosto de 2014 Después de 10 años, 5 meses y 4 días la sonda Rosetta de la Agencia Espacial Europea entraba en órbita esta mañana alrededor de su objetivo, el cometa 67P/Churyumov-Gerasimenko. Rosetta y...
El proyecto Mechaneu parte de la idea de construir pequeños objetos a modo de juguetes con movimientos complejos– pero en modelos de una sola pieza que puedan imprimirse con las actuales impresoras 3D caseras. Los resultados deben funcionar de forma suave...
Gaia Tal y como se puede leer en Gaia ya está lista para entrar en acción el telescopio espacial Gaia de la Agencia Espacial Europea ha terminado su fase de pruebas y calibración y está listo para empezar su misión científica. Esta,...
Aunque el ácido clorhídrico (agua fuerte) utilizado en el vídeo es bastante más corrosivo que los jugos gástricos del estómago —que contienen un 3% de ácido clorhídrico— más o menos así es como acaba una hamburguesa durante el proceso de digestión...
Por Nacho Palou -
31 JUL 2014
El TinyTesla Kit es una bobina Tesla que cabe en la palma de la mano, pero que no por ello deja de ser muy chula y hace cosas de bobinas y jugar a ser un “maestro electrificador”, produciendo arcos eléctricos, dando...
Por Nacho Palou -
31 JUL 2014
Algunas de las más bellas e importantes ecuaciones de la física y las matemáticas presentadas con elegancia y estilo de la mano de Like a Physicist. (Vía Visualizing Math + Sink Her Ship + The Grand Staircase.)...
Si todo va según lo previsto el próximo jueves 6 de agosto de 2014, tras un viaje por el espacio de más de 10 años, la sonda Rosetta de la Agencia Espacial Europea entrará en órbita alrededor de su objetivo, el...
Más o menos todos sabemos que la velocidad de la luz es de unos 300.000 kilómetros por segundo, pero… ¿cuál es la velocidad de la oscuridad? Según cómo lo mires –nunca mejor dicho– la velocidad de una sombra podría ser, o...
Según se puede leer en NASA’s Long-Lived Mars Opportunity Rover Sets Off-World Driving Record el pasado día 26 el podómetro de Opportunity, que lleva recorriendo la superficie de Marte desde enero de 2004, pasó de los 40,25 kilómetros, lo que le...
Los chicos de ThinkTwiceShow grabaron en cámara oculta una encuesta muy divertida –al estilo Gomaespuma de antaño– en la que se pedía a la gente firmar para detener los experimentos con gatos al estilo Schrödinger. Sí, el gato más famoso de...
¿Ves esa pequeña mancha verde, marrón y amarilla a la izquierda de la Gran Mancha Roja de Júpiter? Pues son los Estados Unidos, Canadá, y México a la misma escala que esta, una de las ilustraciones que hay en Astronomy: The...
Crazy Circle Illusion!, otro de esos geniales vídeos de brusspup, en el que parece que ocho bolas blancas parecen estar girando dentro de otra bola más grande cuando el realidad se mueven en línea recta. Y es que nuestro cerebro a...
Ya habíamos hablado aquí de los autorretratos que se hacen los astronautas, que desde luego molan mucho, antes de que se empezara a poner de moda lo de los selfies, aunque ya puestos Buzz Aldrin reclamaba recientemente la autoría del primer...
50 satélites en órbitas geosincrónicas entrando y saliendo de la sombra de la Tierra, grabados en vídeo como pequeños puntos luminosos (flashes y flares) y también con un montaje que permite «seguir su rastro» a través del cielo. No vi este...
Teniendo en cuenta que el cuerpo humano pierde cada día un millón de células epidérmicas, ¿por qué los tatuajes permanecen indefinidamente?, Cada vez que la aguja del tatuador penetra en la piel causa una herida provocando que se inicie el proceso...
Por Nacho Palou -
24 JUL 2014
«¿O? ¿No querrás decir más bien ‘y’…?» Schrödinger tuiteando con su madre acerca del gato que le dejó a cuidar… Y otros grandes momentos de la ciencia si Twitter hubiera existido en aquellas épocas. Pitágoras, Darwin, Edison (vs. Tesla)… Están casi todos....

Desconocía la existencia de Cosmic zoom, un corto de Eva Szasz encargado por la National Film Board de Canadá que igual que Powers of Ten se basa en el ensayo Cosmic View: The Universe in 40 Jumps de Kees Boeke para...
The Air We Breathe es un pequeño examen sorpresa que pone a prueba tus conocimientos sobre la atmósfera con diez preguntas relacionadas con la contaminación, el comportamiento y el estudio del aire del planeta. Es parte de la iniciativa Climate Change:...
Por Nacho Palou -
23 JUL 2014
Para los astronautas es fundamental hacer ejercicio para reducir al mínimo los efectos perniciosos de estar varios meses en caída libre Uno de los problemas que tiene vivir en la Estación Espacial Internacional, como ya hemos comentado por aquí en alguna ocasión,...
Uno de esos vídeos creisis de Taras Kul, que tiene un montón más publicados en Crazy Russian Hacker. Relacionado: Experimentando en plan casero con hielo seco («Russian style»)....
Por Nacho Palou -
22 JUL 2014
Vaya por delante que el espacio es algo extremadamente enorme, así que seguro que huele a cosas distintas según donde lo huelas, si es que no mueres en el intento; en este caso Reid Wiseman se refiere al olor que había...
Tal y como estaba previsto esta tarde la segunda cápsula de carga Cygnus de Orbital Sciences, bautizada como Janice Voss, llegaba a la Estación Espacial Internacional, cuyos tripulantes la capturaron con el brazo robot de la Estación para acoplarla al módulo...
Crisis mediante o no, los Museos Científicos Coruñeses del Ayuntamiento de A Coruña, en los que trabajo en el MundoReal™, convocan de nuevo sus Prismas de Bronce a los mejores trabajos de divulgación científica. En esta XXVII Convocatoria las categorías son: Vídeo....
Supermoon por Heny Weiland La noche del pasado sábado coincidió que la Luna pasaba por su perigeo, el punto más cercano de su órbita alrededor de la Tierra, cuando además estaba en fase de luna llena, lo que se ha venido a...
Dentro de unos días tendré la oportunidad de conocer en persona la versión más reciente de Asimo, el robot humanoide de Honda, así que me he estado documentando un poco acerca del tema, y uno de los recursos más interesantes que...
Algo estamos haciendo muy mal cuando, por los motivos que sean, las mujeres pierden el interés por la ciencia y la tecnología según van creciendo o, como poco, deciden dedicarse a otros campos. Según el informe She figures de la Unión...
Lanzamiento del Angará 1.2 PP - Denis Yefremov No ha sido sin tiempo, pues lleva en desarrollo veinte años, pero por fin Rusia realizó un primer lanzamiento de prueba de un cohete Angará, que entre otras cosas en los próximos años será...
Después de algo más de diez años de viaje y unos 6 700 millones de kilómetros recorridos la sonda Rosetta y su aterrizador Philae están ya muy cerca de su destino, el cometa 67P/Churyumov-Gerasimenko. De hecho está previsto que el próximo...
David de NatGeo visitó un laboratorio en el que fabrican agua ultrapura: agua a la que se le ha eliminado absolutamente todos los productos minerales que no sean oxígeno o hidrógeno (H2O). En cierto modo es como el agua destilada, que...
Aún a pesar de que un informe encargado en su momento por el Ministerio de Sanidad concluía que el principal efecto de la homeopatía es placebo este ha decidido poner en marcha un proceso para regular unos 19 000 productos homeopáticos....
Gliese 581g por Lynette Cook vía NASA Salvo en el caso de unos pocos planetas extrasolares que hemos podido observar directamente la inmensa mayoría de ellos han sido localizados mediante métodos indirectos. Los dos más populares son el de los tránsitos y...
Mejor ver el vídeo antes de continuar. ¿Cuál es la historia? . . . Casi todo el mundo que ve este vídeo de NatGeo lo interpreta de la misma manera: un triángulo grande y abusón molesta a un pequeño circulito, que...
Wicho siempre comenta cómo impresionaba el transbordador espacial «en persona» por su gigantesco tamaño – y el ruido del despegue. Pero pongamos si se ponen las cosas en perspectiva… La bestia de la derecha es el Transbordador SLS, que está todavía...
Aparte de ser muy grande, al menos a escala humana, tal y como nos demostraban desde Ciencia en el bar con el vídeo del sistema solar en el encierro de Pamplona, el sistema solar está muy vacío. Tanto que todos los...
M42: Live View Optical Zoom es un precioso vídeo que nos va acercando a la nebulosa de Orión, una zona en la que están naciendo estrellas ahora mismo. Está grabado desde Sierra Nevada con una Canon 5D Mark II, una Canon...
A veces las cosas más fáciles puede tener explicaciones muy complejas: aquí el buen profesor Roger Bowley explica «cómo funciona» un columpio y el fenómeno de la resonancia paramétrica para conseguir impulso en un columpio autopropulsado – el columpio de cuerdas...
Pues eso, que ya hay programa provisional para Naukas Bilbao 2014 y pinta muy bien, como por otra parte ya es habitual. Respetando el formato que tan bien ha funcionado en las ediciones anteriores son 60 charlas de 10 minutos –y son...
El espacio, SIN el espacio Otra genialidad de XKCD, la superficie de los objetos sólidos del sistema solar representada en un mapa. Los de la Tierra salimos ganando, aunque con un poco de trampa, ya que en realidad algo así como las...
Ahora que llegan los Sanfermines Javier Armentia y Joaquín Sevilla estrenan el canal de YouTube de Ciencia en el bar con El sistema solar en el encierro de Pamplona, un vídeo en el que explican la escala del sistema solar usando...
Rocket Launch: Foto de larga exposición del lanzamiento - Stephen Kelly Sullivan Cinco años después de que el Orbiting Carbon Observatory original se perdiera en su lanzamiento, y con un día de retraso sobre lo previsto debido a un fallo del sistema...
Brotes de enfermedades evitables mediante vacunas desde 2008 El estudio Safety of Vaccines Used for Routine Immunization in the United States [PDF 4,8 MB] analiza los resultados de otros 166 estudios realizados con grupos de control sobre los posibles efectos de las...
PIA03883: Impresión artística de la inserción orbital de la sonda Cassini-Huygens en la noche del 30 de junio al 1 de julio de 2004 - NASA/JPL Hoy se cumplen 10 años de la entrada en órbita alrededor de Saturno de la sonda...

La energía ni se crea ni se destruye – pero la demanda global no deja de aumentar. ¿De dónde viene esa energía y a dónde va? A guide to the energy of the Earth es una «lección animada» de Joshua M....
Este vídeo es un anuncio de Verizon, pero lo que dice no sólo se aplica en los Estados Unidos, sino que probablemente aún es peor en otros sitios: si a los 10 años el 66 por ciento de las niñas dicen...
Hace tiempo que no poníamos un vídeo de estos de la Tierra vista desde la Estación Espacial Internacional, pero eso de que las imágenes que toman los astronautas estén libremente disponibles es lo que tiene, que la gente hace cosas preciosas...
Impresión artística de Athena - Javier Garcia Nombela-art-eres.net/Volker Springel(MPA)/IRAP A finales de 2013 la ESA ya había anunciado que la misión L2 dentro de su programa de investigación Visión Cósmica sería una que estudiara el universo invisible, en concreto en el espectro...
Esta es una representación de como el Gran Colisionador de Hadrones «ve» al bosón de Higgs descomponiéndose en fotones En julio de 2012 los científicos de los experimentos ATLAS y CMS del Gran Colisionador de Hadrones anunciaban el haber descubierto «una partícula...
Misiones a los planetas exteriores - HistoricSpacecraft.com (clic en la imagen para ver a tamaño completo) Una comparación que se hace a menudo entre la sonda Cassini, que lleva desde julio de 2004 en órbita alrededor de Saturno, para explicar su tamaño...

Fue un cambio que nadie vio venir: la idea de que podríamos tomar un libro, una pintura o una canción y enviarla a través de hilos, cables o incluso el aire hasta el otro lado del mundo – de modo que...
Doha desde el espacio Apenas 12 horas después de su lanzamiento el satélite español de observación terrestre Deimos 2 ya estaba captando sus primeras imágenes, que Elecnor-Deimos, la empresa que lo fabricó, acaba de publicar. Queda aún terminar de calibrar las cámaras,...
La verdad es que tiene todo el sentido del mundo lo que se puede leer en Airliners Become Weathermen as Sensors Upend Forecasting: Southwest y UPS comparten información de velocidad del viento, temperatura y humedad que recogen algunos de sus aviones...
Impresión artística del Corot en órbita Aunque en julio de 2013 la ESA tuvo que dar por finalizada su misión al no poder volver a poner en funcionamiento el segundo de sus ordenadores de a bordo, lo que le impedía obtener datos...
Impresión artística de Gliese 832 c por Efrain Morales Rivera de la Sociedad Astronómica del Caribe; la imagen de Gliese 832 es real Según cuenta el Planetary Habitability Laboratory, el Laboratorio de Habitabilidad Planetaria, en A Nearby Super-Earth with the Right Temperature...
Si quieres echar una mano a los astrónomos a añadir más asteroides a la colección de cerca de 650.000 –y contando– que ya tenemos fichados en Asteroid Zoo tienes una herramienta que sirve para ello. Verás secuencias de cuatro imágenes del...
Una de las cosas que hace más atractiva la misión de Curiosity es la cantidad de imágenes que la NASA publica de esta, incluidos los selfies del rover. Justin Maki explica en Curiosity Rover Report (June 13, 2013): Curiosity's Cameras vídeo...
Aunque la EEI tiene el tamaño aproximado de un campo de fútbol –por muy imprecisa que sea esa medida– el espacio personal del que disponen sus tripulantes no es que sea muy grande. Cada uno de los seis duerme y guarda...
El 24 de abril de 2014 se cumplirán los 25 años del lanzamiento del telescopio espacial Hubble a bordo del transbordador espacial Discovery, aunque no fue liberado en órbita hasta el día siguiente. Para conmemorar esto Gabriel Russo ha propuesto la...
Selfie de Curiosity por su primer cumpleaños marciano Curiosity cumple hoy 678 días en Marte, o lo que es lo mismo, un año marciano completo sobre la superficie de nuestro vecino tras aquel espectacular y emocionante aterrizaje del 6 de agosto de...
Al parecer se debe a la coincidencia de varios motivos, Why Does Everyone Look Hotter in Sunglasses? — Ponte unas gafas de sol y voilà —¡simetría al instante! Las gafas oscuras ocultan cualquier asimetría en torno a los ojos, y según los...
Por Nacho Palou -
24 JUN 2014

Los espejos curvos, como este gigantesco espejo cóncavo que tienen en el Exploratorium de San Francisco, tienen curiosas e intrigantes propiedades. En este caso el espejo mide casi tres metros; al aproximarse a él se forma una «imagen perfecta» aunque está...
Adam Lore publicó hace tiempo en Noiless Chatter un artículo puntualizador un tanto crítico con Gizmodo acerca de unas desavenencias periodístico-divulgativas con los poliedros como tema de fondo. La historia en sí no me pareció muy relevante, pero el artículo es...
«El zumo de granadas POM Wonderful afirma tener superpoderes» Hace unos días aparecía en Scientia un vídeo de John Oliver, quien cada día nos gusta más, dándole caña a los fabricantes de alimentos y bebidas, en este caso estadounidenses, por las auténticas...
TL;DR: no merece mucho la pena. El vídeo Should You Hover Or Cover The Toilet Seat? se refiere a uno de esos grandes dilemas relacionados con el cuarto de baño: ¿debería cubrir con papel la tapa del váter antes de sentarme...
Por Nacho Palou -
23 JUN 2014
Los monoides son estructuras algebraicas con operaciones binarias que… bla bla bla… ¡Pf! ¡No hay quien lo entienda! Pero en Visualizing Math encontraron un ejemplo estupendo de explicarlos sin tanto tecnicismo – algo recomendable solo para quienes se dediquen a la...
Domenico Vicinanza, uno de los empleados de Géant, la red de ordenadores que conecta las redes europeas de investigación y educación, es doctor en física y músico. Así que armado con datos de los contadores de protones de la Voyager 1...

George Cantor asentiría orgulloso ante las explicaciones de su discípula Vi Hart, en una explicación genial, sencilla y muy gráfica sobre los infinitos: qué tipos de infinitos hay, cómo se puede demostrar matemáticamente que algunos infinitos son más grandes que otros...

Una playa en verano – Wicho Hoy a las 10:51 UTC se produce el solsticio de junio de 2014. Es el momento del año en el que el Sol alcanza su mayor altura aparente en el cielo con respecto al ecuador para...
A Vincent Brady le dio por pensar cómo veríamos el cielo nocturno si en lugar de tener los dos ojos muy próximos y a ambos lados de la nariz como los tenemos fuéramos capaces de ver 360 grados alrededor de nosotros....
Aunque cuando esté en funcionamiento será un instrumento extremadamente preciso ayer comenzaba la preparación de la plataforma de 300×150 metros en la que será instalado el Telescopio Europeo Extremadamente Grande con la primera de una serie de voladuras controladas que tienen...
New York to London Milky Way es la Imagen Astronómica del Día de la NASA del pasado 14 de junio, en la que se puede ver la Vía Láctea fotografiada desde un Boeing 747 por Alessandro Merga en un vuelo entre...
Annalee Newitz publica en 10 Scientific Ideas That Scientists Wish You Would Stop Misusing una lista de los diez conceptos científicos que en opinión de algunos cientfícos peor usamos los que no nos dedicamos a la ciencia. Claro que probablemente le pase...
Mientras desde el Ministerio de Educación reducen las horas dedicadas a la asignatura de Tecnología, otra sonda amateur construida por alumnos de los tres colegios de Oñati en una colaboración entre el Gazteleku de Oñati, Ilatargi Astronomia Taldea, el grupo de...
En 1979 la sonda Voyager 1, en su aproximación a Júpiter, envió unas 19.000 fotos que se usaron, entre muchas otras cosas, para crear esta pequeña película: En el invierno de 2013/2014 un grupo de siete astrónomos aficionados suecos decidieron reconstruir...
Un vídeo que explicativo de Michael Stevens que complementa la anotación ¿Qué pasaría si la Tierra dejara de girar? que sacamos por aquí hace ya algún tiempo. En el vídeo se puede ver de forma más o menos visual —simulada, claro—...
Por Nacho Palou -
17 JUN 2014
Hace poco Alexander Gerst se quejaba de que el único café disponible en la Estación Espacial Internacional es café instantáneo, aunque eso cambiará a partir del próximo mes de noviembre. Cuando Samantha Cristoforetti despegue rumbo a la EEI su cápsula Soyuz...
En New Scientist, Massive 'ocean' discovered towards Earth's core, sobre la teoría de que en el manto terrestre hay tres veces más agua que en los océanos según un estudio reciente, El agua estaría atrapada dentro de un tipo de roca llamada...
Por Nacho Palou -
16 JUN 2014
Clasificando manchas solares A veces los científicos se encuentran con que tienen tal volumen de datos a su disposición que no son capaces de procesarlos adecuadamente o con que no tienen las herramientas necesarias para ello. En el caso de Sunspotter la...
Impresión artística del choque entre Tea y la Tierra - NASA Del departamento de «no me da la vida para más», algunos resultados recientemente publicados de estudios que nos permiten saber unas cuantas cosas más acerca de la Luna: Por una parte,...
Durante un tiempo la Unión Soviética estuvo desarrollando un transbordador espacial conocido como Burán, muy similar al de la NASA, aunque en ciertos aspectos más avanzado. Sin embargo el fin de la Unión Soviética significó también el fin del programa, quedando...
El vídeo del Ames Research Center de la NASA corresponde al estudio de la aerodinámica del balón oficial del Mundial de Fútbol, el Adidas Brazuca, Aunque la NASA no participa del negocio de diseñar balones de fútbol, se trata de una...
Por Nacho Palou -
13 JUN 2014
La editorial Taschen nos envió un ejemplar de reseña de su libro recopilatorio del trabajo del médico y artista Fritz Kahn (1888–1968) un artista cuyos trabajos gráficos marcó una época aunque ha pasado ligeramente desapercibido desde el siglo pasado. Perseguido por...
4,5 grados, original en 4.5 degrees 4,5 grados celsius parecen poca cosa, pero tal y como lo plantea Randall Munroe son todo un mundo....
La Progress M-21M desatracando - Foto vía @OlegMKS A las 17:17 UTC del 9 de junio de 2014 comenzaba la reentrada en la atmósfera de la cápsula de carga Progress M-21M para poner fin a su misión, actuando como camión de la...
Scott Manley actualiza de vez en cuando su estupenda animación en la que se muestran los asteroides de nuestro sistema solar orbitando alrededor del Sol, «apareciendo» en el año en que fueron descubiertos. Los círculos más grandes son los planetas (Mercurio,...
La lámpara del vídeo es un prototipo funcional, al menos en parte, de un dispositivo impreso que se ensambla por sí mismo. De la impresora sale una lámina con múltiples capas. Una de esas capas está formada de polímeros que al...
Por Nacho Palou -
9 JUN 2014
Soyuz TMA-13M liftoff, un time lapse cortesía de la ESA en la que se ve cómo se traslada el cohete ya ensamblado en el MIK, el equivalente ruso al Edificio de Ensamblado de Vehículos de la NASA, a la plataforma de...
Vi Hart garabatea al tiempo que explica cuántos tipos de infinitos existen y cuáles han sido sus definiciones con el paso del tiempo en las diferentes áreas del conocimiento. También habla de los ℵ (aleph) y de posibles respuestas a ¿cuán...
Hace apenas unas horas el experimento OPALS, Optical Payload for Lasercomm Science, un sistema diseñado para proporcionar comunicaciones de banda ancha vía láser, realizaba su primera transmisión desde la Estación Espacial Internacional. Como no podía ser de otro modo, se trata...
Las ruedas de reacción del Kepler son los cilindros negros que se ven en la imagen; funcionan como giróscopos - Ball Aerospace Cuando en mayo de 2013 falló la segunda de las ruedas de reacción que permitían mantenerlo estable en el espacio,...
Flu jab, foto CC por NHSE La noticia está en un montón de sitios, por ejemplo: La varicela repunta en España tras el bloqueo de la vacuna en las farmacias. Los datos indican que en lo que va de año se han...
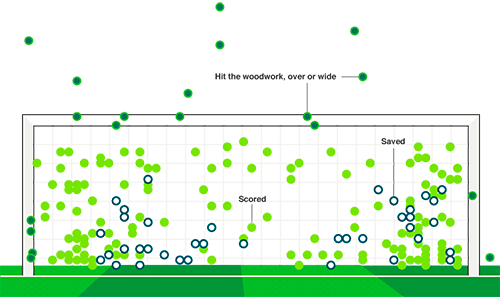
204 penaltis lanzados en las Copas del Mundo y el mejor estilo es… a lo Panenka (!)
Hubble Ultra Deep Field 2014, también conocido como Ultraviolet Coverage of the Hubble Ultra Deep Field o UVUDF Los 24 años en servicio del telescopio espacial Hubble han permitido ir acumulando observaciones del mismo fragmento del cielo en distintas longitudes de onda...
¿Debería una persona tocar 200.000 voltios? ¿Aunque esté bien aislada? Mucha gente no lo haría ni de broma, pero no todo depende del voltaje, sino también de la intensidad de la corriente. Este profesor del Jefferson Lab utiliza precisamente los efectos...
eso1417a: Anillo de polvo alrededor de la estrella HR 4796A El instrumento Spectro-Polarimetric High-contrast Exoplanet REsearch, de búsqueda de exoplanetas con espectro-polarimetría de alto contraste, ya está instalado y funcionando en Melipal, el tercer telescopio de los cuatro que forman el Very...
He tenido la oportunidad de vivitar el B/O Ramón Margalef, que junto con su gemelo el Ángeles Alvariño forman lo más moderno de la flota del Instituto Español de Oceanografía, que por cierto este año cumple 100 años, y aunque en...
Impresión artística de Kepler-10c Ya conocíamos la existencia del planeta extrasolar Kepler-10c desde 2011, cuando se confirmó su detección gracias al telescopio espacial Kepler de la NASA. En aquel momento se lo calificó inicialmente como un minineptuno de unas 2,3 veces el...

Un tipo encargó a un abogado registrar la marca π. (pi) para hostigar a pequeñas empresas que usan el símbolo matemático.
Impresión artística de la ISEE3-ICE Lanzada en agosto de 1978, la sonda International Sun/Earth Explorer 3, Explorador Internacional del Sol/Tierra 3, tenía como objetivo estudiar la interacción entre el viento solar y el campo magnético terrestre. Terminada su misión original, la NASA...
Astronaut vandalism por XKCD El espacio, la frontera final, y tal… Pero sólo está a 62 millas de altitud, o lo que son lo mismo, 100 kilómetros, donde está la línea de Kármán, la que marca el punto al que una aeronave...
The elements according to relative abundance [jeg 3038×2014 pixeles, 1,6 MB] Esta tabla, creada por el profesor William F. Sheehan allá por 1976 describe la proporción de los distintos elementos químicos en la corteza de nuestro planeta; en Abundance of elements in...
Scott Sheppard tuvo mucha suerte de que el rayo que le cayó encima mientras se dedicaba a cazar tormentas en Dakota del Sur sólo le dejara el brazo un tanto dolorido. Según cuentan en Man Films Being Struck By Lightning el...
Se pueden tranmisir datos desde la Luna a 622 megabits por segundo de bajada y 20 mbps de subida

El 97 por ciento de los científicos sostiene que el cambio climático es un hecho.
Imagen de síntesis del futuro E-ELT. Hay un coche aparcado delante para dar una idea de la escala - Swinburne Astronomy Productions/ESO Con un presupuesto de unos 950 millones de euros el Telescopio Europeo Extremadamente Grande (E-ELT) es el telescopio de nueva...
Número de casos de sarampión en los EEUU Aunque el sarampión se considera erradicado en el país desde 2000 este año –del que sólo llevamos cinco meses, ojo– se han visto más casos de sarampión en los Estados Unidos que en cualquier...
Aunque se habían barajado varios nombres como DragonRider o Dragon 2 al final la primera nave tripulada de SpaceX se llamará Dragon V2. Basada en la cápsula Dragon que en la actualidad se usa para hacer envíos de carga a la...
Esta noche el astronauta de la Agencia Espacial Europea Alexander Gerst ha dormido por primera vez en caída libre, aunque tal y como nos contaba Paolo Nespoli cuando estuvo en Madrid aún necesitará unas semanas para aclimatarse de todo, ya que...
Despegue de la TMA-13M - NASA/Joel Kowsky Ayer a las 21:57, hora peninsular de España, despegaba la Soyuz TMA-13M con Maksim Surayev, Reid Wiseman, y Alexander Gerst a bordo rumbo a la Estación Espacial Internacional. Tras un lanzamiento de libro la cápsula...

Un vídeo divulgativo sobre cosmología relacionado con la expansión del universo y la inflación cósmica.
La Deep Space Network, la Red del Espacio Profundo, la red de antenas que la NASA tiene alrededor del mundo para comunicarse con sus naves espaciales y con las de otras agencias cumple este año 50. La idea, en su momento,...
El Saturno V fue el cohete utilizado por la NASA para el programa Apolo a partir de 1966, con un total de trece lanzamientos si se incluye el del laboratorio espacial Skylab. En este vídeo se pueden ver sincronizados esos trece...
La Progress desde dentro, mirando hacia la escotilla: racks y racks para almacenar la cargaDon Pettit en la escotilla a través de la que se accede a la Progress fotografiado desde el interior de esta No me extrañaría que Daniel Marín tuviera...
Uno de los ítems que iban incluidos en la carga de la cápsula de carga Dragon CRS-3 era un experimento conocido como Veggie en el que, por primera vez, se cultivará comida a bordo de la Estación Espacial Internacional, en concreto...
Dextre, que es el manipulador preciso del brazo robot de la Estación Espacial Internacional, consiguió el pasado fin de semana ser el primer robot en repararse a si mismo en el espacio. Lo que hizo fue retirar una de las cámaras...
Seguro que has oído algunos de ellos sino todos, pero son todos falsos, si no no serían mitos: El cáncer es una enfermedad moderna creada por el hombre. Existen «super alimentos» que previenen el cáncer. Las dietas ácidas causan cáncer. El cáncer...
Malcolm Park (North York Astronomical Association) Camelopardalids and ISS es la Foto Astronómica del Día de la NASA y aunque mola mucho sólo recoge tres de las Camelopardálidas que en la noche del pasado viernes algunas predicciones decían que podían alcanzar una...
Del departamento de «niños, no intentéis esto en casa», aunque supongo que nadie tiene una fuente de lava en casa, esto es lo que pasa cuando dejas unas latas de Coca Cola en el camino de la lava procedente de un...
Si todo va según lo previsto Alexander Gerst despegará el próximo 28 de mayo rumbo a la Estación Espacial Internacional a bordo de la Soyuz TMA-13M para incorporarse a la Expedición 40 a la EEI. Una vez allí, tal y como...
Camelopardalidas El cometa 209P/LINEAR, descubierto el 3 de febrero de 2004, tiene un periodo de cinco años y el próximo 6 de mayo pasará por el perihelio de la órbita actual. Pero por todo lo que sabemos lleva cientos, miles, o incluso...
El universo en un minuto: diez preguntas clave de astronomía y cosmología es una colección de vídeos producidos por Conec y la Sociedad Española de Astronomía que intenta responder a diez cuestiones básicas sobre el universo en el que vivimos: ¿Existen...
Lo hemos dicho una y mil veces: no vacunar a los niños es una salvajada, no sólo por los tuyos sino también por los de los demás porque cuantos menos vacunados haya más baja la inmunidad de grupo. Este vídeo de...
El 14 de diciembre de 1972, a eso de las 5:40 UTC, Eugene «Gene» Cernan entraba en el Challenger, el módulo lunar del Apolo 17, convirtiéndose así en el último hombre en haber pisado la Luna, título que aún ostenta más...
The Dynamic Ebbinghaus, en la que aunque parezca otra cosa el círculo central no cambia de tamaño, es la ilusión óptica ganadora del concurso de mejores ilusiones ópticas del año. Las diez finalistas se pueden ver en 2014 Finalists, y son...
La antena de Holmdel en 1962. Hoy en día ha sido declarada monumento nacional – NASA El 20 de mayo de 1964, mientras trabajaban en poner en marcha su receptor más sensible hasta la fecha, Arno Penzias y Robert Wilson detectaron lo...
Va en la categoría de humor, pero que conste que la combinación Quimiofobia + ignorancia es más bien para llorar. (@GaboTuitero vía RT de @elnocturno)....
Tras algo más de ocho años en órbita alrededor de Venus a la Venus Express se le está agotando el combustible que le permite mantener su órbita polar de 66 000 × 250 kilómetros sobre nuestro vecino, así que la ESA...
Hace unos años Andrew Wakefield se inventó, por sus propios intereses económicos un «estudio» que relacionaba la aplicación de la vacuna triple vírica (sarampión, paperas y rubeola) con la aparición de autismo en los niños vacunados con esta. Él mismo, de hecho,...
(Vía Campana de Gauss)....
A veces los astros se alinean de tal modo que uno pasa por delante del otro ocultándolo; esto pasó hace unos días con la Luna y Saturno, que a eso de las 10:55 UTC se metió detrás de esta, quedando oculto...
La Dragon CRS-3 a punto de ser liberada por el brazo robot de la Estación Espacial Internacional Con un amerizaje a las 19:05 UTC a unos 500 kilómetros al oeste de Baja California terminaba la misión de la tercera cápsula de carga...
Dextre en la EEI He escrito un montón de veces acerca de Dextre, el Special Purpose Dexterous Manipulator, o el brazo robot habilidoso de la Estación Espacial Internacional. Instalado en 2008, está diseñado para ser capaz de manipular objetos en el exterior...
La Gran Mancha Roja de Júpiter, una tormenta que lleva activa, que sepamos, al menos desde 1645, cuando fue vista por primera vez por Giovanni Cassini, lleva varios años haciéndose más pequeña, tal y como se puede ver en este vídeo....
Ricardo Moure, con su monólogo acerca de los adipocitos y el efecto de la grasa sobre nuestro cuerpo, se ha proclamado ganador de Famelab España 2014. Se enfrentará a los ganadores de otros países en Famelab International en el Festival de...
La semana pasada tuvimos la suerte de tener a Paolo Nespoli, el astronauta de la Agencia Espacial Europea, en Madrid durante dos días y pico. La disculpa era que venía a dar una charla a Ciencia en Redes 3, aunque aprovechando su...
Un Atlas V lanzando el satélite espía NROL-67 Era sólo una cuestión de tiempo que después de que los Estados Unidos anunciaran la suspensión de la mayoría de sus actividades conjuntas con Rusia en lo que se refiere a programas espaciales a...
Herschel y Planck fueron lanzados por un Ariane 5-ECA Aunque sus misiones ya han terminado al agotarse el refrigerante necesario para el funcionamiento de sus instrumentos, he pensado aprovechar el quinto aniversario del lanzamiento de los observatorios espaciales Herschel y Planck para...
Impresión artística de Rosetta y Philae en las cercanías del cometa 67P/Churyumov-Gerasimenko - ESA–C. Carreau/ATG medialab Tras casi diez años de camino, incluyendo algo más de dos y medio en hibernación, la sonda Rosetta de la Agencia Espacial Europea despertaba el pasado...
La TMA-11M tras el aterrizaje mientras se aproximan un helicóptero y diversos vehículos todo terreno - NASA/Bill Ingalls Esta pasada noche, a las 1:58 UTC, la Soyuz TMA-11M tomaba tierra en las estepas de Kazajistán, trayendo de vuelta a Mikhail Tyurin, Rick...
Aunque todavía no hay un gran número de dispositivos en los que verlo –y los que hay no los regalan precisamente con las cajas de cereales– el Observatorio Europeo Austral ha decidido que va a ofrecer sus vídeos en 4K. Lo...
Clic en la imagen para el original a 1000×1104 pixeles Anda haciendo las rondas estos días esta bonita foto de Fobos, una de las lunas de Marte, fotografiada por la Cámara Estéreo en Alta Resolución de la sonda Mars Express de la...
En azul, las películas en las que sale Nicolas Cage; en rojo los accidentes de helicóptero con víctimas mortales. La correlación es de -0,827811, bastante buena Spurious Correlations es un blog en el que se demuestra que si torturas los datos lo...
Antes de darle al play, ¿volverá el boomerang a las manos de Takao Doi después de que lo lance en la Estación Espacial Internacional? a) Sí b) No c) No sé d) Lo que diga la rubia . . . Pues...
Una de las fotos más conocidas de las tomadas por los astronautas del programa Apolo es sin lugar a dudas la conocida como Earthrise, en la que se ve la Tierra amaneciendo en la Luna el 24 de diciembre de 1968...
Sirva este vídeo como homenaje a Michael Stevens de Vsauce, uno de nuestros personajes favoritos y del que aprendemos todo tipo de cuestiones sobre ciencia gracias a su videoblog. Además de eso puede venir bien a todos aquellos que se dedican...
Las células madre son, por decirlo así, como los comodines del cuerpo humano, ya que son capaces de convertirse en cualquier otro tipo de célula del cuerpo. La importancia de las investigaciones con este tipo de células reside en que se...
Este aviso llega un poco tarde por causas ajenas a mi voluntad, como suele decirse, pero si hoy estás por A Coruña y te apetece pasar un día verdaderamente entretenido, pásate por el XIX Día de la Ciencia en la Calle. Se...

Todo un personaje John Stapp. Coronel de las fuerzas aéreas norteamericanas, se pasó los años 40 y 50 sirviendo de conejillo de indias sobre los efectos de las fuerzas G – que es la forma en la que se suele medir...
Tecnología punta fácil de entender. (Vía The Meta Picture.)...
Este vídeo del Proyecto Ilustris es una simulación cosmológica del desarrollo de nuestro universo en sus 13.800 millones de años de existencia: nubes de gas, estrellas, agujeros negros… Ha sido creado combinando la potencia de superordenadores de varios países; en total...
En Mars Panorama - Curiosity rover: Martian solar day 613 hay una foto panorámica interactiva compuesta por 138 imágenes tomadas por la cámara del mástil de Curiosity que tiene un objetivo de 34 milímetros en la que se puede ver tanto...
Vistoso efecto, grabado en la exposición del Museo de la Ciencia de Valencia. «Tan obvio como extraño resulta verlo», como bien dicen al pie del vídeo. Especialmente cuando se mueve rápido....
En este time-lapse se puede ver como los técnicos de la Agencia Espacial Europea cargan el quinto vehículo de transferencia automatizado o ATV de la agencia, bautizado como Georges Lemaître, cuyo lanzamiento rumbo a la Estación Espacial Internacional está previsto para...
Aprovechando que Paolo Nespoli estará en Madrid para participar en Ciencia en Redes III y la buena voluntad tanto del propio Paolo como de la Agencia Espacial Europea y que en La casa encendida nos han cedido el espacio hemos conseguido organizar...
Posición de Juno a principios de mayo de 2014 Si 2014 es el año de la sonda Rosetta de la Agencia Espacial Europea, que nos permitirá tocar por primera vez el núcleo de un cometa, y 2015 el de la New Horizons,...
El eclipse cazado por el Proba 2 He esperado algunos días para ver si aparecía alguna imagen de la totalidad del eclipse anular de Sol del pasado 29 de abril, que sólo se podía ver desde la Antártida, pero se ve que...
Algunas de las Eta Acuáridas de 2013 cazadas por el All Sky Camera Network de la NASA La Tierra atraviesa estos días una de las regiones del sistema solar en la que el cometa Halley deja sus restos cuando se acerca al...
El telescopio Celestron NexStar Evolution se conecta por wifi al móvil o al tablet de modo que basta con tocar en la pantalla, utilizando la aplicación de Celestron para iOS y Android, qué parte del cielo o qué cuerpo u objeto...
Por Nacho Palou -
5 MAY 2014
SpaceX sigue adelante con su empeño de crear cohetes reutilizables, lo que permitirá abaratar los costes de los lanzamientos, y para ello está llevando a cabo pruebas con una plataforma de pruebas conocida como F9R. Si en su primer vuelo esta...
Ser científica es tan emocionante, creativo e interesante como ser artista.– Mayim Bialik, doctora en neurociencia,AKA Blossom AKA Amy Farrah Fowler,en Secret Life of Scientists and Engineers;en español en Por amor a la ciencia...
Beta Pictoris b Científicos de la Universidad de Leiden y del Instituto para la Investigación Espacial de los Países Bajos (SRON) han podido medir por primera vez el periodo de rotación de un planeta extrasolar. Se trata de Beta Pictoris b, un...
Recreational Mathematics Magazine es una revista electrónica publicada por la asociación portuguesa Ludus y el Centro Interuniversitario de Historia de las Ciencias y la Tecnología. Se publica en inglés un par de veces al año y tiene todo el aspecto y el...
Instrumentos de Rosetta Si todo va según lo previsto, y todo apunta a que será así, la Agencia Espacial Europea terminará esta semana de poner en marcha los instrumentos de la sonda Rosetta, que tiene previsto acompañar al cometa 67P/Churyumov-Gerasimenko en su...
Alicia Watkins vende en Etsy virus, microbios y gérmenes en punto de cruz que se pueden comprar ya hechos o en forma de patrones para hacerlos tú mismo si eres lo suficientemente manitas. Molan. (this isn't happiness™ vía Colossal). Entrañables cabroncetes...
The tenth watch, esperando a la décima gota En 1927 Thomas Parnell calentó un poco de brea y la colocó en un embudo cuya base cortó en 1930 a la espera de que empezaran a caer gotas con la idea de estudiar...
La explosión de la bomba atómica sobre Hiroshima liberó una energía de unos 15 kilotones. La de la explosión de Tunguska hace un siglo, unos 10 o 15 megatones (10.000 a 15.000 kilotones) y arrasó 2.000 kilómetros cuadrados de bosque siberiano....
¿Cuánta gente muere cada año debido a diversos animales? ¿Es el tiburón? ¿Quizá el ser humano? ¡No! El animal más mortífero del mundo es el mosquito, tal y como explica BillG en su blog, en la que ha llamado semana-anti-mosquitos....
Como puede verse por la descripción del –por otro lado muy apetecible– Infinitesimal: How a Dangerous Mathematical Theory Shaped the Modern World, hoy en día o exageras, dramatizas y utilizas la palabra ÉPICO o no vendes un colín: La épica batalla...
Annular Solar Eclipse of April 29 - Fred Espenak / NASA El martes 29 de abril de 2014 a las 5:57:35 UTC comienza un eclipse de Sol que alcanza su máximo a las 6:03:25 y que termina a las 6:09:36. De todos...
Tom Hands ha usado los datos del Open Exoplanet Catalogue para hacer este vídeo en el que se ven los exoplanetas de ese catálogo que orbitan una sola estrella ordenados por el tamaño de esta. Es importante verlo a pantalla completa...
La sonda Cassini-Huygens, lanzada en 1997, es la sonda interplanetaria más grande jamás construida. El próximo 1 de julio de 2014 se cumplirán 10 años de su inserción orbital alrededor de Saturno, donde lleva desde entonces obteniendo datos e imágenes sorprendentes,...
Del 24 al 30 de abril de 2014 la Organización Mundial de la Salud promueve la Semana Mundial de la Inmunización para «promover uno de los instrumentos más potentes con que cuenta la humanidad en relación con la salud». Y es que...
De izquierda a derecha y de atrás hacia adelante: Júpiter, Saturno, Urano, Neptuno, la Tierra, Venus, Marte y Mercurio La Tierra nos parece grandota porque vivimos sobre ella y los demás planetas están muy lejos, pero en realidad es la quinta de...
Pete Conrad y la Surveyor 3 Aunque algunas han enviado muestras de vuelta a la Tierra lo habitual es que la última vez que un ser humano toca una sonda planetaria es cuando esta es encapsulada en su cohete lanzador. La única...
Interior del transportador del cohete Vega Durante 2012 y 2013 el fotógrafo Edgar Martins recorrió con su cámara analógica de 10×8 pulgadas unas 20 instalaciones de la Agencia Espacial Europea y otras entidades asociadas en Alemania, España, Francia, la Guinea Francesa, Kazajistán,...
Se supone que la idea es enseñarnos como en General Electric someten los nuevos materiales en los que trabajan a distintas pruebas para comprobar su idoneidad para distintos usos… Pero para mi que en realidad es que los científicos de GE...
¿Que hay que salir a cambiar un ordenador estropeado en el exterior de la Estación Espacial Internacional? Pues se sale, pero de paso uno aprovecha para hacerse un autorretrato de esos que molan cantidad, como ha hecho Rick Mastracchio hoy. Se...
Clic para ver en otros tamaños Aunque aún le faltan meses para emprender su misión mientras se acaban de comprobar los sistemas de a bordo y de calibrar sus instrumentos el satélite Sentinel-1A de la Agencia Espacial Europea ya ha enviado sus...
Nos están envenenando y esterilizando con todas las «movidas artificiales» que nos hacen comer con los alimentos y que nos apelmazan el esperma. Menos mal que las «cocretas» se salvan. Porque… ¿Sabemos lo que comemos? Dani y Fiti es una webserie...
En la cultura globalizada, la autoayuda es ya un gran negocio editorial y un timo a escala planetaria (…) Su última cara es el coaching ¡Cuídense de los coaches! Recuerden que soluciones rápidas y de bajo coste a nuestros problemas no suelen...
Paneles de Opportunity enero y marzo de 2014 A diferencia de Curiosity, que lleva su propio generador térmico de radioisótopos para producir electricidad, Opportunity depende de sus paneles solares para obtener la energía que le permite funcionar durante el día y cargar...
Lyrid Meteor No. 1, una de las Líridas de 2013 por Mike Lewinski Las Líridas son una de las lluvias de estrellas de las que tenemos constancia desde hace más tiempo, en este caso desde hace unos 2600 años. Las causan las...
Intenta resolver este ejercicio mental / problema de física recreativa antes de mirar el vídeo que grabaron en Smart Every Day: Si hay un globo de helio en equilibro dentro de un coche cerrado, sujeto por su cuerda, y arrancas para...
A pesar de algunos problemas con las comunicaciones que se cortaban a ratos y de un perno que se resistía a entrar en su sitio la cápsula de carga Dragon CRS3 está ya firmemente sujeta en el módulo Harmony de la...
Visualizing Math es un estupendo tumbleblog que muestra un montón de curiosidades matemáticas, especialmente geométricas, encontradas en todas partes de Internet. Merece la pena echarle un vistazo si te gustas estas cosas raras. ¿Sabías que puedes hacer una elipse doblando un...
He aquí un vídeo de hace tiempo de lo que fue el primer vuelo de pruebas del Falcon 9 reutilizable (de ahí la «R») que ayer amerizó suavemente sobre el mar tras lanzar una cápsula hacia la Estación Espacial Internacional, aterrizando...
La Progress M-22M a su llegada a la EEI el 5 de febrero de 2014 Tras dejar 2370 kilos de carga en la Estación Espacial Internacional que incluyen 1244 kilos de suministros varios, 420 de agua, 50 de oxígeno y 656 de...
Lanzamiento de la Dragon CRS3. Se ven tres de las cuatro patas de la priemra etapa plegadas contra esta - Walter Scriptunas II Tras un primer intento cancelado el pasado lunes por una fuga en una de las vávlulas del sistema de...
Lanzada en septiembre de 2013 la sonda LADEE, de Lunar Atmosphere and Dust Environment Explorer, Explorador de la Atmósfera Lunar y del Entorno de Polvo, tenía como objetivo estudiar la tenue atmósfera de la Luna, que en realidad es lo que...
Impresión artística de Kepler-186f Aunque lleva fuera de servicio desde mayo de 2013 el telescopio espacial Kepler recogió tal cantidad de datos durante su misión que el análisis de estos aún proporciona nuevas sorpresas. En este caso, tal y como se puede...
La DSN comunicándose con la Voyager 2 vía la antena de 43 metros de Camberra La Deep Space Network, la Red del Espacio Profundo, es el conjunto de antenas que usa la NASA para comunicarse con las sondas que tiene repartidas por...
Cosmos: una odisea del espacio-tiempo (2014) es un remake del mítico documental de Carl Sagan de los años 80 que acercó el amor y la pasión por la ciencia a gentes de todas las edades. Esta nueva versión el mismo objetivo....
Fases del eclipse por David Dickinson Para los que no pudimos ver el eclipse de Luna de esta pasada madrugada, Internet viene al rescate con montones y montones de fotos. La de arriba es de las que recoge Universe Today en Seeing...
Prometeo - NASA/JPL/Space Science Institute Los avances en ciencia son, cada vez más, fruto de mucho trabajo y esfuerzo, aunque a veces aún se producen por casualidad. Esto fue lo que sucedió el 15 de abril de 2013 cuando la sonda Cassini...
Ciclo solar 23 - SOHO (ESA & NASA) En 1826 Samuel Heinrich Schwabe, convencido de que existía un planeta entre el Sol y Mercurio, se puso a observar el Sol siempre que estaba despejado con la idea de localizar este hipotético planeta...
Regiones de Voronoi de los aeropuertos españoles World Airports Voronoi es una visualización hecha por Jason Davies en la que el mundo está dividido en las regiones de Vonornoi correspondientes a los aeropuertos que tienen servicios regulares. Un diagrama de de Voronoi...
Millones de años de evolución han hecho que nuestros cuerpos estén preparados para permanecer de forma constante bajo los efectos de la gravedad terrestre, por lo que los astronautas que pasan periodos prolongados de tiempo en caída libre dentro de una...
Visibilidad del eclipse - Fred Espenak (NASA GSFC) En la madrugada y primeras horas de la mañana del 15 de abril de 2014 se produce el primer eclipse total de Luna de los dos que va a haber en 2014. El eclipse...
El pasado 6 de abril Paul Williams volaba de Londres a Nueva York cuando se dio cuenta de que se veía una aurora boreal, así que se puso a hacer fotos con un tiempo de exposición de dos segundos. Unas cuantas...
Foto de archivo de la Progress M-18M a su llegada a la EEI Como os podéis imaginar los tripulantes de la Estación Espacial Internacional no pueden salir a hacer la compra y, al menos por ahora, Amazon todavía no reparte hasta allí...
Wil Wheaton, quien interpretaba a Wesley Crusher en Star Trek: La Nueva Generación, le da una contestación de quitarse el sombrero a una niña que le pregunta si de pequeño le llamaban empollón (nerd). (Vía @Roberto_Pastor). Neil Armstrong acerca de lo...
Como cualquier lista esta es matizable y probablemente cada uno de nosotros haría una ligeramente distinta. Pero para Jose A. Pérez, probablemente más conocido como @mimesacojea, y unos cuantos miembros de Naukas que le echaron una mano para elaborarla, estos son Diez...
El nombre del juego Super Planet Crash, de Stefano Meschiari, ya anticipa la dificultad que supone construir un sistema solar, con sus planetas y alguna que otra estrella por ahí dando vueltas y sin que se estrellen —nunca mejor dicho— entre...
Por Nacho Palou -
10 ABR 2014
El sonido se transmite a través del aire y otros medios a más de 300 metros por segundo. No podemos verlo, pero esta curiosa técnica fotográfica permite hacernos una buena idea de cómo es o «cómo se vería». Es el conocido...
¿Tú sabías que los tomates tienen genes? Pues Dani y Fiti no lo tienen tan claro. Más acerca de la ingeniería genética en «La aplicación de las nuevas tecnologías en agricultura» por Pere Puigdomènec y en «Las plantas transgénicas y los...
Neil Armstrong, el primer hombre en pisar la Luna, hace un alegato en Neil Armstrong on Being a Nerd acerca de lo que significa ser un ingeniero empollón, un «nerd». Pon la traducción automática de los subtítulos al español si el...
El vídeo está en inglés; activa los subtítulos y la traducción automática si quieres, no lo hace mal Si, como sugiere la NASA en La oposición de Marte, piensas en la Tierra y en Marte como dos atletas que corren por una...
Trailing the Canaries es la imagen ganadora del concurso Tournament Earth de 2014 del Earth Observatory de la NASA en la que usuarios de Internet han ido votando entre 32 imágenes la mejor del año. En esta imagen da la impresión...
Hasta ahora se manejaba el cálculo de que una nave que viajara a otro sistema solar podía salir de la Tierra con entre 150 y 180 peregrinos cuyos descendientes, dos mil años —entre 60 y 80 generaciones— después, podrían colonizarlo «siempre...
Por Nacho Palou -
7 ABR 2014

Fresh Tiger Stripes on Saturn's Enceladus, APOD del 6 de abril de 2014: Las tiras de tigre de Encélado, de donde salen los chorros de gas detectados por la sonda Cassini - Cassini Imaging Team, SSI, JPL, ESA, NASA En enero de...
Este es el lanzamiento del satélite medioambiental de la Agencia Espacial Europea Sentinel-1A grabado por cámaras montadas en la etapa Fregat del Soyuz que lo puso en órbita. Se ve perfectamente la separación de los propulsores de combustible sólido, de la...
Flores para Algernon, de Daniel Keyes, en la que a un deficiente mental se le somete a un tratamiento que lo dota de una enorme inteligencia, es una de las mejores novelas que he leído jamás. A Flores para Algernon se la...
Ahora que el #TiramisúDeWicho es mundialmente famoso mi próximo desafío va a ser aprender a hacer pasteles planetarios como estos que describen en Spherical Concentric Layer Cake Tutorial… Claro que me parece que la parte final, la que no sale en...
El lanzamiento con éxito anoche del satélite Sentinel-1A de la Agencia Espacial Europea marca el principio de la puesta en marcha de la iniciativa Copérnico de la ESA y de la Unión Europea. Copérnico es una red de vigilancia medioambiental que...
Una consecuencia imprevista de la crisis en Ucrania es que el gobierno de los Estados Unidos, además de otras medidas, ha decidido suspender todo tipo de colaboración entre la NASA y Rusia salvo casos muy puntuales, tal y como se ha sabido...
Una superpermutación mínima es la cadena de símbolos de longitud en mínima en la que aparecen todas las permutaciones de esos símbolos en algún punto de la cadena. Por ejemplo con los números 1, 2 y 3 sería 123121321 porque cualquier cadena...
Falta una nota oficial de la NASA sobre el tema, pero ya está circulando por ahí un correo de Michael F. O'Brien, el director asociado de la agencia para relaciones internacionales que dice: Dada la continuada violación por parte de Rusia de...
Impresión artística del GPM Core Observatory en órbita El GPM Core Observatory, una misión conjunta de la Agencia Japonesa de Exploración Aeroespacial, la NASA, y otras agencias espaciales, es un observatorio espacial que tiene como objetivo medir las precipitaciones en todo el...
A determinada temperatura --según de qué líquido se trate-- variando la presión se puede cambiar el estado de un líquido entre líquido, sólido y gaseoso. Se trata del Punto triple; un efecto tan chulo como su propio nombre, El punto triple...
Por Nacho Palou -
2 ABR 2014
Según cuentan, una nanopartícula atrapada mediante luz láser es capaz de violar temporalmente la segunda ley de la termodinámica, algo que debería ser imposible – al menos a escalas de tiempo y longitud humanas. Esto sugiere que tal vez haya que revisar...
La TMA-12M en su aproximación final a la EEI Con un par de días de retraso sobre lo previsto la Soyuz TMA-12M atracaba de forma automática en el módulo Poisk de la Estación Espacial Internacional a las 00:53 del viernes 28 de...
Ya hemos hablado en varias ocasiones de SOFIA,el Observatorio Estratosférico para la Astronomía Infrarroja, que no es ni más ni menos que un telescopio refractor de 2,5 metros montado en un Boeing 747SP convenientemente modificado. SOFIA en vuelo con la puerta...
El proceso de puesta en marcha de los instrumentos de la sonda Rosetta de la Agencia Espacial Europea, comenzado el pasado 17 de marzo, incluía hoy el de la activación de Philae, el aterrizador que en noviembre de este año, si...

Como en Internet hay gente pa tó, el autor de este trabajo se entretuvo en crear este vídeo educativo, no solo como demostración de que era posible hacer algo aparentemente tan complicado como explicar detalles sobre la física de la velocidad...

Wacław Sierpiński aprobaría esta página: The Sierpinski Triangle Page to End Most Sierpinski Triangle Pages™, tan exhaustiva como definitiva y bella. La elegancia de los fractales en su máxima expresión, combinada con grandes dosis de algoritmos y programación para hacerlas posibles....
The Valentina Project, que recibe su nombre de la cosmonauta soviética Valentina Tereshkova, arrancó a finales de 2013 con el objetivo de ensalzar las contribuciones de las mujeres en los campos de la ciencia, tecnología, ingeniería y matemáticas, o STEM por sus...
Foto de larga exposición del lanzamiento - Más en Expedition 39 Ayer a las 22:17, hora de España, la Soyuz TMA-12M despegaba rumbo a la Estación Espacial Internacional con Aleksandr Skvortsov, Oleg Artemyev, y Steven Swanson a bordo para que se unieran...
Impresión artística de Chariklo y sus anillos Durante años la ciencia ficción nos ha traído ideas e imágenes de un universo espectacular que poco a poco la realidad va dejando en paños menores. Así, hoy sabemos que hay galaxias activas en cuyos...
Nuestros dos futbolistas preferidos vuelven a la carga, en esta ocasión discutiendo sobre el fin del universo y del tiempo, un complot de los fabricantes de relojes sin duda alguna. Más detalles en Del espacio y el tiempo (I), (II) y...
En Phys.org, Can you drive fast enough to avoid being clocked by speed cameras? Cualquier conductor puede evitar que le cacen los radares de carretera — lo único que tiene que hacer es respetar los límites de velocidad.Pero estos estudiantes de física...
Por Nacho Palou -
25 MAR 2014
En esa señal en el cielo podemos discernir nuestro origen: alguna vez fuimos luz. Luego fuimos fluctuaciones en la temperatura que se convirtieron en estrellas… Galaxias, materia… Y vida Durante los últimos días se ha escrito mucho, hasta nosotros nos hemos atrevido,...
Absorción de las distintas longitudes de onda según la altura Como ya hemos comentado en alguna ocasión a los astrónomos la atmósfera les viene muy bien para respirar, pero al mismo tiempo les hace la puñeta porque absorbe algunas de las longitudes...

Los equinoccios son el momento del año cuando el eje de la Tierra, en el viaje de esta alrededor del Sol, alcanza tal posición respecto a este que el día y la noche duran prácticamente lo mismo. Se suele decir que...
Tras un retraso de un día causado por la meteorología esta pasada noche un Ariane 5 ECA ponía en órbita los satélites Astra 5B y Amazonas 4A, tal y como se puede leer en Ariane 5’s second launch of 2014. El...
Hace unos días una niña de tres años residente en Treviño moría por una sepsis causada por de una varicela. Y curiosamente la discusión se está centrando en quién tenía que haber enviado una ambulancia a recogerla y en qué momento, aunque...
El cometa Churyumov-Gerasimenko, visto el 28 de febrero de 2014 Se me había quedado medio traspapelada esta foto del cometa 67P/Churyumov-Gerasimenko tomada por el telescopio VLT del Observatorio Europeo Austral (ESO) en Chile a finales de febrero. 67P/Churyumov-Gerasimenko, también conocido como Kevin...
Derek de Veritasium explicó hace tiempo en este vídeo cómo funciona el efecto de precesión giroscópica, algo que le sigue sorprendiendo poderosamente tanto a él como a los que vemos vídeos de esto cada vez que alguien experimenta con ello. La...
Los detalles son… complicados. Comprender de verdad el significado de las observaciones del telescopio Bicep2 solo está probablemente al alcance de un puñado de físicos, pero hacerse una idea como mero mortal requiere poco menos de dos minutos, gracias a este...
Brotes de enfermedades evitables mediante vacunas desde 2008 En 1998 el médico inglés Andrew Wakefield, aunque desde entonces le han retirado la licencia -y poco me parece- se inventó que la vacuna triple vírica podía causar autismo, unos resutlados que nadie más...
El telescopio Bicep2 al anochecer - Vía BICEP2 2014 Release Image Gallery La ciencia avanza un poquito cada día, pero a veces, como ocurrió el pasado lunes, da un salto adelante importante. Si se confirman los resultados publicados por el telescopio Bicep2...
Nueve maneras de amanecer en el Sistema Solar Aunque desde la Tierra vemos al Sol razonablemente grande es porque estamos bastante cerca de él. Pero en realidad es una estrella normalita del todo que en cuanto empiezas a alejarte cada vez cuesta...
Molaría que domináramos la fusión nuclear como fuente de energía y que esta no estuviera permanentemente a veinte años vista. O que tuviéramos instalada la potencia suficiente de energías renovables para satisfacer nuestras necesidades… Pero mientas tanto la viñeta Log Scale...
Somos estrellas, polvo de estrellas.– Carl Sagan Y la tipografía en que está escrito este pensamiento parece ser Trooper Roman Bold, según investigaron por ahí hace tiempo. Es la que se utiliza en el libro y la serie Cosmos original (1980)....
Como cada 14 de marzo (3/14 en anglosajón) hoy es el día de pi. En este vídeo Vi Hart aprovecha para despotricar un poco sobre pi con fina ironía; explicando por qué «pi no es para tanto»: No es «infinito»: 3...
Koichi Wakata preparando el lanzamiento de unos CubeSat en el laboratorio Kibo la EEI Tras cuatro vuelos en los transbordadores espaciales de la NASA y una estadía anterior en la Estación Espacial Internacional, Koichi Wakata se convertía el pasado 10 de marzo...
La onda P300 (en negro) aparece cuando el sujeto reacciona ante un estímulo relevante Sabiendo que los polígrafos, más conocidos como máquinas de la verdad, no son admitidos como prueba en un juicio, me ha llamado bastante la atención toda la bola...
Nuestros dos futbolistas preferidos vuelven a la carga, en esta ocasión discutiendo sobre el cambio climático. Dani y Fiti es una webserie de la Cátedra de Cultura Científica de la UPV con guiones de José Antonio Pérez, también conocido como @mimesacojea....
If the Moon were only 1 pixel es una página web que puedes desplazar y desplazar y desplazar y desplazar y desplazar y desplazar y desplazar y desplazar y desplazar y desplazar y desplazar y desplazar y desplazar y desplazar y...
TL;DR unos 7 megapíxeles + 1 megapíxel extra para el fondo. Vsauce, uno de nuestros videoblogueros divulgadores favoritos, se pregunta en este vídeo por la comparación entre la visión humana y las cámaras fotográficas, en concreto qué resolución tendrían nuestros ojos...
Toda una vida dedicada a la astronomía galáctica, la evolución estelar y la comología; enseñando, divulgando y publicando trabajos y casi nadie te conoce… Y de repente te haces famosillo en Internet hace dos años, presentas una serie de televisión y… Desde...
Tras su estreno en los Estados Unidos Cosmos: a spacetime odyssey llega esta noche a España con la emisión simultánea del primer capítulo a las 23:00 en los canales National Geographic Channel, FOX, FOX Crime, Nat Geo Wild y Viajar. El...
El Cielo de Canarias / Canary sky - Tenerife por Daniel López en Vimeo. Todo el mundo relaciona a Tenerife con el turismo de sol y playa, aunque algunos van más allá de esto y se dan una vuelta por su...
Luis Alfonso Gámez prepara su enésimo suicidio homeopático con Sedatif PC, y como siempre, sobrevive. Algo falla en esto. Me recordó mucho al capítulo correspondiente de Escépticos, algo que de hecho estaba avisado. Así que me parece muy recomendable el programa El...
De las mentes de @aberron e @irreductible, y con el apoyo de la Cátedra de Cultura Científica de la UPV y la Fundación Euskampus, está a punto de ver la luz Catástrofe Ultravioleta. Catástrofe Ultravioleta será un podcast en el que...
Chelyabinsk Meteor Flash: el Metorito de Cheliábinsk de febrero de 2013 fotografiado por Marat Ametvaleev como Imagen Astronómica del Día del 24 de febrero de 2013 Bueno, lo de zumbando es una licencia poética, porque como todo el mundo sabe, en el...
Space Race es un interactivo de la BBC que permite recorrer el sistema solar desde la superficie de la Tierra hasta alcanzar la heliopausa desplazándote por una página web. Solo que si al principio del viaje la escala es de 1...
El Proyecto Morpheus tiene como protagonista principal un vehículo de despegue y aterrizaje en vertical en el que la NASA está probando diversos tipos de combustible, sistemas de dirección, guiado y demás. El prototipo pesa una tonelada y la idea es...
La revista de alumnos de la Universidad de California en Berkeley publicó un artículo titulado Sculpting Geometry acerca del trabajo de Carlo Séquin, uno de sus profesores de la escuela de ingeniería. Sus trabajos artístico son una mezcla de arte y...
Este es un recorte de la parte central de la imagen publicada en El Rover Opportunity el día de San Valentín de 2014. Tomada por la HiRISE, la cámara más potente de la Mars Reconnaissance Orbiter, muestra a Opportunity, el longevo...
Aunque estoy seguro de que no hay nada como verlas en directo, la Agencia Espacial Canadiense ofrece la posibilidad de ver auroras boreales desde la comodidad de tu navegador gracias a AuroraMAX. AuroraMAX es un telescopio con un ángulo de visión...
Hoy es el Día de las Enfermedades Raras, aquellas que afectan a una parte muy pequeña de la población. Por su rareza la mayoría de nosotros no conocemos a nadie que sufra una, pero si tienes una hora, ver Raras pero...
El 26 de febrero de 2014 se pudo ver una bonita conjunción de Venus con la Luna casi nueva –febrero de 2014 es, por cierto, un mes sin luna nueva– que en algunos sitios incluso terminó por convertirse en una ocultación...
Aunque lleva fuera de servicio desde mayo de 2013 durante su misión el Kepler, un telescopio espacial diseñado para encontrar planetas fuera de nuestro sistema solar, recogió tal cantidad de datos que aún están siendo analizados. Y la NASA acaba de anunciar...

Michael de Vsauce explica para Mental Floss los 15 errores más comunes en las ilustraciones y visualizaciones científicas que siempre hemos visto en libros y revistas. Las hay bastante evidentes como las antiguas imágenes de animales (¡ey! no había fotografía), «leyendas»...
Desde hace años la ciencia ficción propone cohetes capaces de despegar y aterrizar en vertical, a menudo con patas que los estabilicen. Pero si SpaceX se sale con la suya esto pronto podría dejar de ser ficción. Despúes de las pruebas...
En The Atlantic recogen que según un estudio de la Universidad de Plymouth University, jugar al Tetris reduce el «mono» asociado a adicciones como el tabaco, el alcoholismo o el comer en exceso. La idea es básicamente engañar al cerebro distrayéndolo...
Tal y como se puede leer en First Moments of a Solar Flare in Different Wavelengths of Light el 25 de febrero de 2014 a las 00:35 UTC el Solar Dynamics Observatory conseguía captar los primeros momentos de una erupción solar...
Foto estereoscópica del telescopio Sheepshanks tomada por Piazzi Smyth en el Teide Sir Isaac Newton escribía en su libro Opticks de 1704 que no se pueden construir telescopios a los que no afecte la atmósfera y que lo único que se puede...
Se me había pasado, pero desde hace cosa de un par de meses ya tenemos ganadores de Fotciencia 11. Fotciencia es el concurso de fotografía científica convocado por la Fundación Española para la Ciencia y la Tecnología (FECYT) y el Consejo...
Después de haberlo hecho sobre la teoría de la evolución hoy a Dani y Fiti se les pasa por la cabeza hablar de los clones. Clones de ovejas, seres humanos, futbolistas, y de lo que haga falta, aunque curiosamente no salen...
La idea del minimuseo de Hans Fex ha sido todo un éxito: pretendía recaudar unos 40.000 dólares y lleva casi 600.000 – a este paso superará el millón. Está como proyecto en KickStarter y todavía le quedan varias semanas antes de...
La semana pasada tuve el honor de impartir la charla de clausura de la ceremonia de entrega del concurso Tesis en 3 Minutos de la Universidad Pública de Navarra. Este concurso, que tiene categorías para tesis, trabajos de fin de máster...
Snowtime es un vídeo en time lapse de Vyacheslav Ivanov sobre el proceso de formación de los copos de nieve que es simplemente hipnotizante. En The Science of Snowflakes hay una explicación de cómo se forman y sobre si es cierto...
Las galaxias activas son aquellas que, como nuestra propia Vía Láctea, tienen un enorme agujero negro en su centro alrededor del que casi siempre se forma un disco de acreción de materia que va cayendo en este, aunque casi la mitad...
La Ciencia en Big Bang es un proyecto de Muy Interesante, la FECYT, TNT y Albireo con Miguel Angel Sabadell al frente y en colaboración con la Obra Social la Caixa que aprovecha ciertos momentos de The Big Bang Theory para...
Si el primer escalón es así, el segundo así, el tercero así y en el 43º hay 3.784 puntos azules, ¿Cuál es la fórmula de la secuencia? En Visual Patterns hay 140 problemas de este tipo, ordenados por dificultad, desde lo...
Esta es la medida más precisa de la masa del electrón que se haya obtenido nunca; es trece veces más precisa que la que se usaba hasta ahora. El valor exacto es 0,000548579909067(14)(9)(2) «donde los números entre paréntesis corresponden respectivamente a la...
Poner a un astronauta en órbita no es precisamente barato, y un paseo espacial es además una actividad arriesgada, por lo que antes de salir del espacio han practicado una y otra vez los paseos espaciales, del orden de unas siete...
Lo más bonito de estas explicaciones matemáticas es cuando la zona de los valores obtenidos en el «experimento» («Actual») van coincidendo lenta pero inexorablemente con los valores esperados («Expected») de forma milimétricamente precisa. La visualización es de Victor Power y muestras...
Los secretos de Nikola Tesla [castellano/inglés, iOS, 2,69€] es una app para iPad que puede entenderse como una biografía interactiva. Contiene información sobre el famoso ‘inventor del siglo XX’ y locuciones que van narrado su vida y sus inventos. Una forma...
La rampa de Gagarin en los años 70 El primer Sputnik, Laika, Gagarin, los primeros grandes éxitos soviéticos en la carrera espacial, fueron lanzados desde la que hoy en día se conoce como rampa número 5 o PU-5 o Puskovaia Ustanovka, instalación...
Parafraseando a Mark Twain, parece que las noticias sobre la muerte del rover lunar chino Yutu han sido un tanto exageradas, ya que aunque con un poco de retraso sobre el horario previsto al final este se despertó y desde el...
Muchos no veríamos en esta foto más que un posavasos sucio y una taza de café, pero Joaquín Sevilla ha sido capaz de que esta imagen le sirva como pie para hablar de capilaridad, cromatografía, anillos del café, menisco y anamorfosis....
Los detalles son más bien parcos, pero tras sufrir algún tipo de fallo mecánico el pasado 25 de enero y no poder restablecer la comunicación con él el lunes 11 de febrero, pasada la última noche lunar, China ha dado por...
No conocía Experiment.com (anteriormente: Microryza), que se lanzó hace casi un año. Es básicamente un Kickstarter para proyectos científicos. Grupos de científicos plantean allí abiertamente experimentos e investigaciones que quieren llevar a cabo y la gente puede realizar donaciones para sacarlos...
Dani y Fiti son dos personajes que, de la mano de la Cátedra de Cultura Científica de la UPV, y con guión de José Antonio Pérez, más conocido quizás como @mimesacojea, vienen a hablarnos de ciencia. En concreto en este primer...
De los creadores de Necomimi, orejas de gato que reaccionan a las emociones, el accesorio Neurocam «detecta las emociones» del usuario y a la vez controla la cámara del móvil, la cual empezará a grabar cuando detecta por las ondas cerebrales...
Por Nacho Palou -
11 FEB 2014
En el vídeo se puede ver cómo un disco de material conductor enfriado con nitrógeno líquido se vuelve superconductor (conduce la electricidad sin ofrecer resistencia eléctrica y repele campos magnéticos débiles) con lo que basta darle un ligero empujón para que...
Por Nacho Palou -
10 FEB 2014
Si la misión de Rosetta y Philae es la misión espacial de 2014 y principios de 2015, en julio del año que viene la New Horizons de la NASA llegará a Plutón, al que llegará a aproximarse hasta un mínimo de...
En realidad llegará a a la vez a 180 países en 48 idiomas tan solo un día después de su estreno en los Estados Unidos. En España el primer capítulo de Cosmos: a spacetime odyssey podrá ser visto a la vez...
Tal día como hoy hace 30 años Bruce McCandless II se convertía en el primer astronauta en realizar un paseo espacial sin estar sujeto por ninguna línea de seguridad a su nave. Durante el primer paseo espacial programado para la misión...
El punto brillante que se ve en esta imagen como a un tercio de la parte superior y hacia la izquierda es la Tierra fotografiada con la cámara izquierda de la Mastcam de Curiosity el pasado 31 de enero unos 80...
Aunque su uso no está muy extendido desde hace años existen manos protésicas que pueden abrir y cerrar los dedos leyendo las señales que les llegan de los músculos del brazo. Su mayor problema, precio aparte, es que los usuarios no...
Aunque la mayoría de la gente no lo sabe la Estación Espacial Internacional es perfectamente visible a simple vista desde la mayor parte de la Tierra, con lo que aproximadamente un 90 por ciento de la población mundial puede verla siempre...
Mira el vídeo. Esa incapacidad de tu cerebro para darse cuenta de que los ojos y la boca del tipo del vídeo están al revés es lo que se conoce como efecto Thatcher porque se usaba una foto de ella para...
Creciente de Luna, el primer cachito de Luna que podemos ver tras la Luna nueva y que marca el principio del mes en algunos calendarios - NASA/Goddard Space Flight Center Scientific Visualization Studio El calendario gregoriano, que es el estándar de facto...
(Niños: no intentéis esto en casa y bla bla bla…) En SparkFun explican con todo lujo de detalles lo que sucede cuando chupas los polos de una pila de 9 voltios: esa extraña sensación de cosquilleo entre divertida y curiosa: electricidad...
En cierto modo, e irónicamente, «nada más lejos de la realidad». El artículo se titula Perfectly centered break of a perfectly aligned pool ball rack y proviene de Physics Stack Exchange cruzado de Mat Stack Exchange y Math Overflow. La cuestión...
Cuando el 14 de octubre de 2012 Felix Baumgartner saltó desde un globo a 31.333 metros de altitud para establecer tres nuevos récords su traje llevaba siete cámaras Hero2 de GoPro. GoPro: Red Bull Stratos - The Full Story es el...
Uno de los más grandes misterios a los que nos enfrentamos es el del funcionamiento de nuestro cerebro. Este vídeo explica como un equipo de Harvard está creando modelos en 3D de todas y cada una de las conexiones de los...
Paso a paso, despacito (más de lo que hubiera sido deseable), y con buena letra, se monta uno una Estación Espacial Internacional, aunque el primer módulo haya sido lanzado al espacio en 1998 y aún falten algunos módulos más por subir....
Las expectativas son enormes –y el recuerdo del Cosmos original muy poderoso– así que el batacazo puede ser morrocotudo, pero el próximo 9 de marzo comenzaremos a salir de dudas acerca de si la actualización de Cosmos merece la pena. Cosmos:...
Otro momento de entretenimiento ofrecido por el efecto Leidenfrost, vía Laughing Squid....
Por Nacho Palou -
30 ENE 2014
Earth es una visualización de las condiciones meteorológicas pronosticadas por superordenadores a partir de modelos numéricos. Los datos se actualizan cada tres horas y se puede configurar para que muestre los vientos, lluvias, la presión atmosférica, la nubosidad o las temperaturas....
Por Nacho Palou -
30 ENE 2014
1/9998 = 0,0001 0002 0004 0008 0016 0032 0064 0128 0256 0512 1024 2048 4096… Más en Wolfram Alpha: 1/9998. El patrón de los números de cuatro dígitos como potencias de 2 se mantiene durante 52 digitos. Al parecer esta división «funciona»...
Dentro del programa de desarrollo de naves espaciales tripuladas por parte de empresas privadas que está teniendo lugar en los Estados Unidos la única que realmente parece una nave espacial tripulada es la Dream Chaser de Sierra Nevada Corporation. Se basa...
Autorretrato de Opportunity en enero de 2014 Hace años que su rueda frontal derecha dejó de funcionar, por lo que desde entonces tiene que moverse por Marte marcha atrás. Su brazo robot muestra síntomas de artritis, por lo que también hace tiempo...
Autorretrato de Buzz Aldrin durante la misión Gemini 12 Ya hemos dicho muchas veces que los autorretratos de astronautas son de lo mejorcito que hay por ahí, con permiso de los de los pilotos de caza. Karen Nyberg en la Estación Espacial...
Aunque Nature cita textualmente a Stephen Hawking diciendo «los agujeros negros no existen» la realidad es un poco distinta. El célebre astrofísico ha meditado y publicado un trabajo en el que revisa lo que sabemos sobre los agujeros negros, incluyendo como nueva...
¿Insectos voladores con una envergadura de 70 centímetros? ¿Artrópodos de 2,5 metros de largo y 500 kilos de peso? ¿Una serpiente de 15 metros de largo y uno de diámetro? ¿Bicharracos voladores con una envergadura de 16 metros? World's 10 Biggest...
Vizual Statistix / Seth Kadish. Dependiendo de en qué parte del planeta se encuentre uno el movimiento circular debido a la rotación de la Tierra sobre su eje es mayor o menor. En el ecuador esta velocidad es de unos 1600 km/h...
Por Nacho Palou -
27 ENE 2014
Todos los que tenemos una cierta edad tenemos esta imagen grabada en nuestras retinas. Se corresponde con la destrucción del Challenger el 28 de enero de 1986 durante el lanzamiento de la misión STS-51-L. Pero en realidad esta no es la...
Anomalías de temperatura en 2013 Según la Administración Nacional Oceánica y Atmosférica de los Estados Unidos 2013 fue el año más caliente desde que se empezaron a llevar estos registros, allá por 1880, posición en la que empata con 2003, tal y...
«Los humanos ya no nacemos, Neo… Se nos cultiva» ¡Ding! Un chip convierte el latido del corazón en energía renovable. De momento dicen que «extrae suficiente electricidad de los órganos como para alimentar un marcapasos». Pronto seremos seres AAAA....
El pasado lunes, mientras esperábamos que la sonda Rosetta de la Agencia Espacial Europea llamara a casa tras 31 meses de hibernación en el espacio profundo comentamos en varias ocasiones que todo estaba preparado en el Centro Europeo de Operaciones Espaciales,...
Un plátano es un plátano a pesar de que debajo se incluya toda su detallada composición química. Disponibles también como pósteres. (Vía Principia Marsupia.)...
En este caso –curiosamente– nada sale mal. Hay otro vídeo con una dramatización similar aquí. Tan apropiado para una clase de química como para una escapada a lo Gandalf....

1950-2013. Después de eso, no sabemos. Esta visualización proviene del Instituto de Estudios Espaciales Goddard de la NASA que se dedica a analizar las temperaturas de nuestro planeta, entre otras muchas cosas, en especial el calentamiento global. En su web se...
Ese pico es la señal de Rosetta, destacando claramente sobre el ruido Fueron momentos de tensión según se acercaba el final de la primera ventana posible de comunicaciones, y probablemente nunca la pantalla de un analizador de espectros despertó tanta atención. Pero...
Top 10 de las causas de muerte en 1900 y ahora en los 2000 Este gráfico forma parte de un trabajo llamado The Burden of Disease and the Changing Task of Medicine, donde se comparan las causas de la muerte en los...
Una buena ocasión para recordar las particularidades de los fluidos no-newtonianos....
Por Nacho Palou -
17 ENE 2014
Dentro de una semana, a las 10:00 UTC del 20 de enero de 2014, la sonda Rosetta de la Agencia Espacial Europea está programada para salir del estado de hibernación en el que lleva desde el 8 de junio de 2011....

La cinetosis es marearse debido al movimiento, normalmente durante los viajes en coche, barco o avión. Quien más, quien menos, lo ha experimentado alguna vez – para algunos es una auténtica pesadilla. Técnicamente es diferente de un «mareo» o «vértigo» aunque...
La Asociación Española de Comunicación Científica, de la que soy miembro, organiza por tercer año consecutivo la jornada Ciencia en Redes, que se celebrará el próximo 8 de mayo en La Casa Encendida, en Madrid. La idea es, un año más, contar...
Preciosa infografía diseñada por la gente de Future (BBC) sobre las temperaturas de diversos lugares y momentos de nuestro universo para explicar la diferencia entre el frío y el calor más extremo posibles: Absolute zero to ‘absolute hot. La temperatura teórica...
La G. Gordon Fullerton a punto de ser acoplada a la EEI Tras una primera misión de prueba en octubre de 2013 la primera cápsula de carga Cygnus en un lanzamiento regular era capturada por el brazo robot de la Estación Espacial...
Virgin Galactic comienza el año con un nuevo vuelo de prueba de su SpaceShipTwo en el que un encendido de su motor cohete lo llevó a 71.000 pies de altura con una velocidad máxima de Mach 1,4 antes de aterrizar más...
Si el efecto de la levitación magnética por sí impresiona, a cámara lenta… el doble. En este vídeo de la Universidad de Bath se puede observa claramente y con todo detalle cómo actúan los superconductores a muy baja temperatura sobre un...
Aunque por ahora el radiotelescopio de Arecibo con sus 305 metros de diámetro es el más grande del mundo de su tipo allá por septiembre de 2016 perderá su puesto cuando China inaugure en FAST, el Five hundred meter Aperture Spherical...
Aunque el Sol se mostró un tanto vago en lo que debía haber sido el pico de actividad del ciclo solar 24 hace un par de días soltó un par de chupinazos en nuestra dirección, como si se estuviera desperezando para...
Gaia A eso de las 21:30 UTC del 7 de enero de 2013 el telescopio espacial Gaia de la Agencia Espacial Europea terminaba su maniobra de inserción orbital en el punto de Lagrange L2 en el que si todo va bien pasará...
Curiosity en Lego - Stephen Pakbaz. Más fotos en Mars Science Laboratory En 2013 Stephen Pakbaz propuso un modelo de Curiosity a Cuusoo, el sitio web en el que aficionados de todo el mundo pueden sugerir ideas de modelos que creen que...
Casi un cuarto de siglo después de que la Voyager 1 tomara la fotografía de la Tierra ahora conocida como Un punto azul pálido esta y el texto escrito por Carl Sagan que la acompaña siguen siendo fuente de inspiración para...
Timeline of the far future es un gráfico en el que se especula sobre lo que podría ir sucediendo en el planeta, a la humanidad y en los cielos a lo largo de los próximos miles, decenas de miles y hasta...
Por Nacho Palou -
7 ENE 2014
Cosas divertidas que se pueden grabar a 2.500 fps, como suelen hacer Guv y Dan «The Slow Mo Guys». El primero es un material superhidrofóbico que repele los líquidos (a partir de 02:00); el segundo es un ejemplo de lo que...
James Grime de Numberphile hace un repaso en este vídeo a diversas formas de visualizar el número π que circulan por ahí en forma de trabajos académicos, imágenes de Internet y vídeos… Es una labor peculiar entre la ciencia y el...
Hay toda una serie de consideraciones que hacen que esto sea imposible, entre otras cosas que la Luna estaría muy dentro del límite de Roche, y las mareas serían una cosa terrorífica, pero esta es la pinta que tendría la Luna...
Quadrantid-2, una cuadrántida de 2013 por Rocky Raybell Las Cuadrántidas con la primera lluvia de estrellas del año, y tienen la peculiaridad de que su máximo de actividad apenas dura unas horas, no como en el caso de otras lluvias de estrellas...
Uno de mis objetivos para este año es viajar muy al norte para poder ver en persona una aurora boreal antes de que pase del todo este máximo solar que tampoco es que haya sido muy activo. Paco Bellido lo hizo...
Sendos resúmenes del año que acaba por parte de la Agencia Espacial Europea y de la NASA:...
En un estudio sobre la sensibilidad social de los perros los investigadores utilizaron un robot de «telepresencia» para reemplazar a un ser humano y observar su comportamiento. El resultado: la relación no era ciertamente la misma, pero no había gran diferencia....
Tras 31 meses en hibernación la sonda Rosetta de la Agencia Espacial Europea está programada para despertar el próximo 20 de enero a las 10 de la mañana UTC, a unos 673 millones de kilómetros del Sol. Y es que tras...
Solarigrafía tomada en Weilheim, Alemania, por Bob Fosbury Recientemente me han preguntado en un par de ocasiones si el Sol sale también por el este en el hemisferio sur, y la respuesta corta es que sí. La respuesta un poco más...
Impresión artística de la Mars Express El 25 de diciembre de 2003 en la Agencia Espacial Europea había un motivo extra para celebrar la Navidad con la llegada con éxito de la sonda Mars Express a Marte; lo conté para RTVE.es en...
En 1742 Celsius situó los 0 ºC en el punto de ebullición y los 100 ºC en el punto de congelación. Sí, sí, lo ha leído bien. La escala era invertida respecto a la actual para que no aparecieran temperaturas negativas en...
Lo que comenzó como un WTF cuando hace unos días me encontré con unos filtros Reticare que, según dicen, protegen de la «luz tóxica», ha estado a punto de convertirse en una nueva demostración del efecto Streisand. Y es que tal...
Mastracchio moviendo la bomba con la ayuda del brazo robot de la Estación; esta mide 175×127×91 centímetros y pesa unos 354 kilos - NASA TV Aunque el conector rápido M3 de las líneas de amoníaco, el mismo que en 2010 trajo de...
Saturno visto desde arriba por Gordan Ugarkovic Como todos los años, Phil Plait ha hecho su selección de las mejores imágenes astronómicas del año, que en 2013 son 27 imágenes que incluyen un vídeo y un gif animado, así como enlaces a...
Hoy hace 45 años la tripulación del Apolo 8, formada por Frank Borman, James Lovell y William Anders, tomaba esta foto de nuestro planeta desde la Luna, la primera imagen de la Tierra desde más allá de la órbita terrestre, y...

En diez minutos el profesor Edward Frenkel explica con lápiz y papel no sólo cómo funciona el espionaje de la NSA a nivel matemático; también es una excelente introducción en un estilo rápido y sencillo de entender de lo que son...
La unidad estropeada ya fuera de su sitio Aunque en 2010 una reparación similar se complicó de mala manera, de tal forma que hubo que realizar tres paseos espaciales en lugar de las dos inicialmente previstas, hoy Mike Hopkins y Rick Mastracchio...
Ya habíamos hablado acerca de como el Solar Dynamics Observatory usa varios filtros para obtener imágenes de los distintos procesos que ocurren en el Sol… Cómo ve el Sol el SDO Pero en el vídeo Jewel Box Sun se aprecia esto...
Esta mañana a las 10:12, hora de España, el telescopio espacial Gaia de la Agencia Espacial Europea despegaba del puerto espacial de Kourou a bordo de un cohete Soyuz ST-B que 42 minutos después la dejaba en la órbita de transferencia...
En How Global Warming Works hay versiones algo más largas, a elegir. En cualquiera de las versiones se pueden activar los subtítulos en inglés en el reproductor de YouTube. O ya puestos y si lo prefieres esta otra es la explicación...
Por Nacho Palou -
19 DIC 2013
El universo es un holograma vs. El universo no es un holograma...
Hopkins y Mastracchio preparando los trajes espaciales Aunque desde el control de la misión estaban trabajando en un parche de software para controlar la temperatura del bucle de refrigeración externo A del segmento estadounidense de la Estación Espacial Internacional en el que...
En Boing Boing comentan que al parecer pudiera haber una razón científica para que odiemos los vídeos en vertical: vendría a decir que el campo de visión de nuestros ojos, según se puede leer en trabajos científicos [imagen de la derecha],...
We saw it burn up from the Falklands at about 9.20pm last night. Came from the South breaking up into bits. pic.twitter.com/54DwAiTI0k— Bill Chater (@Cheds23) noviembre 11, 2013Fin de la sonda GOCE de la ESA Pues tienen razón en Wired con lo...
A raíz de que al gobierno se le han cruzado los cables y dicen que va a «adecuar la legislación» para regularizar los productos homeopáticos para su venta en farmacias, como si fueran «medicinas», ayer ese gran personaje de El Intermedio...
En El Correo le han pedido a Mauricio-José Schwarz que haga una lista de libros que regalar estas navidades para gente interesada en la ciencia, lista que hasta donde yo sé no está en línea, así que aquí va: La partícula...
Tras posar con éxito la sonda Chang'e 3 sobre la superficie de la Luna a las 13:11 UTC del 14 de diciembre de 2013 China se apuntó otro gran éxito con el despliegue de Yutu, el rover que esta portaba a...
Impresión artística del aterriaje A las 13:11 UTC del 14 de diciembre de 2013 China se unió al grupo de naciones que han sido capaces de colocar una sonda en la superficie de la Luna de una sola pieza, formado a partir...
Situación del módulo que contiene la válvula que está fallando Desde el miércoles 12 de diciembre el segmento estadounidense de la Estación Espacial Internacional está operando con uno sólo de sus dos circuitos de refrigeración externos, todo parece indicar que por el...
Geminid spiral, una foto de las Gemínidas de 2012 - CC Jason Jenkins Aunque aún queda alguna otra lluvia de estrellas que llega un poco más tarde las Gemínidas son la última gran lluvia de estrellas del año, con una predicción de...
La supernova de Nathan Gray es el punto luminoso que se ve arriba a la izquierda de PGC 61330; imagen por David J. Lane A principios de noviembre de 2013 Nathan Gray descubría una posible supernova en la galaxia PGC 61330, situada...
Andan las cosas estos días un poco revueltas en España con el asunto de la homeopatía, esa superchería inventada por Samuel Hahnemann en el siglo XVIII y que algunos quieren hacer pasar como medicina, porque el gobierno ha puesto en marcha...
En 12 Obvious Things Confirmed By Science, en Mental Floss, hay más detalles y se incluyen enlaces a los estudios científicos que confirman estos hechos que ya sospechábamos, incluyendo que: En realidad tu gato pasa de ti Los hombres se fijan en...
Por Nacho Palou -
9 DIC 2013
Despliegue del Hubble el 25 de abril de 1990 desde la bodega del Discovery - NASA/IMAX Lanzado el 24 de abril de 1990, el telescopio espacial Hubble prometía resultados espectaculares con su espejo primario de 2,4 metros y su órbita a 593...
In my crew quarters on station. 3'x3'x6.3' I barely fit but it is home. I have my sleeping bag and computer and pics pic.twitter.com/pOeBHPF1nG— Rick Mastracchio (@AstroRM) diciembre 2, 2013 Según cuenta Rich Mastracchio apenas cabe en su camarote de la Estación...
Foto de larga exposición del lanzamiento Tras verse obligados a cancelar dos intentos de lanzamiento anteriores el 3 de diciembre de 2013 SpaceX conseguía llevar a cabo su primer lanzamiento de un satélite a órbita geoestacionaria usando su cohete Falcon 9 v1.1,...
Prime Explorer es una herramienta para jugar gráficamente con los 62.500 primeros números primos; 2, 3, 5, 7, 11… todos aquellos que son divisibles únicamente por sí mismos o por la unidad. Estos números aparecen en blanco sobre un fondo gris...
If #science is @MerriamWebster's #WOTY, and @OED's is #selfie, then science selfies win, right? pic.twitter.com/ZQ4X7iA8Vt— Curiosity Rover (@MarsCuriosity) diciembre 5, 2013 Pues tiene razón Curiosity: si ciencia es la palabra del año del Merriam Webster y selfie es la del Diccionario Oxford,...
The World Outside My Window - Time Lapse of Earth from the ISS (4K) es otro de esos increíbles vídeos con imágenes de nuestro planeta tomadas desde la Estación Espacial Internacional, aunque en este caso la intención es que el hardware...
The Dark Side of the Moon explained in ten seconds — que no es que la luna tenga un lado oscuro, sino que hay una parte de su superficie que desde la tierra no podemos ver porque la luna tarda en...
Por Nacho Palou -
4 DIC 2013
Uno de los grandes logros de Einstein fue explicar que el concepto de gravedad como «fuerza» era una ilusión: en realidad la gravedad deforma el espacio (más exactamente: el espacio-tiempo) haciendo que sea el propio espacio el que «empuja» unos objetos...
Luca Parmitano, con 166 días a bordo de la Estación Espacial Internacional, fue el astronauta protagonista de la misión Volare de la Agencia Espacial Europea, la quinta de larga duración a la EEI. From launch to landing: Luca's Volare mission la...
NASA Investigating the Life of Comet ISON: ISON en el coronógrafo LASCO 3 de SOHO; la imagen central es del Solar Dynamics Observatory Aunque el cometa C/2012 S1 (ISON) pareció retomar fuerzas después de haber pasado por el perihelio de su órbita,...
Distant Horizons - Different Surfaces es una composición hecha por Mike Malaska en la que se ven las superficies de cinco mundos que hemos visitado, además del nuestro. De izquierda a derecha son el asteroide Itokawa, visitado por la sonda Hayabusa,...
3D Heart Models Help Save Children’s Lives, Justin Ryan es un artista convertido en ingeniero biomédico que utiliza su habilidad para hacer un modelo tridimensional del corazón de un niño que necesita cirugía [...] el modelo es una réplica exacta del...
Por Nacho Palou -
2 DIC 2013
La tercera sonda china con destino a la Luna despegó a las 17:30 UTC del 1 de diciembre de 2013 a bordo de un cohete Larga Marcha. Si todo va según lo previsto será la primera sonda china en aterrizar en...
Impresión artística de la MOM en órbita alrededor de Marte Lanzada el 4 de noviembre de 2013, la Mars Orbiter Mission de la Agencia India de Investigación Espacial acaba de emprender su viaje camino a Marte, a donde llegará el 21 de...
Parece que el nuevo sistema de guiado automático Kurs-NA que se estaba probando en la Progress M-21M necesita algún refinamiento más, pues aunque el miércoles 27 todas las pruebas realizadas dieron los resultados correctos en su aproximación final el viernes 29...
Por aquí se accede a las cestas del sistema de evacuación de la plataforma 39A Todo espaciotrastornado que se precie tiene que hacer una visita al Centro Espacial Kennedy, aunque sólo sea para ver la plataforma 39A, desde la que despegaron el...
Atención niños: algo divertido pero peligroso a la vez, que tiene que ver con fuego, latas a altísimas temperatura, frío radical e implosiones – que son como explosiones pero «al revés». Se trata de un vídeo de calidad explicando cómo producir...
Las primeras impresiones eran muy malas, pues no sólo el brillo del cometa ISON había ido perdiendo intensidad según se acercaba al Sol, sino que el Solar Dynamics Observatory de la NASA no lograba verlo saliendo por el otro lado. Así...
ISS - 15th Year Anniversary Highlights Video es un vídeo creado con motivo del decimoquinto cumpleaños de la Estación Espacial Internacional en el que se pueden ver astronautas haciendo el ganso, astronautas haciendo ciencia, lo que incluye extraerse sangre, o trabajando...
Hoy a las 18:25 UTC el cometa ISON pasará por el perihelio de su órbita, el punto de esta más cercano al Sol. Si hay suerte y sobrevive a este momento, puede convertirse en todo un espectáculo en el cielo del...

Lanzamiento de la STS-9 El 28 de noviembre de 1983 Ulf Merbold se convertía en el primer astronauta europeo en volar al espacio, en concreto a bordo del transbordador espacial Columbia en la misión STS-9. Merbold se convertía también de ese modo...
The Soyuz launch sequence explained, basado en material que la Agencia Espacial Europea usa para entrenar a sus astronautas, explica cómo es el lanzamiento de una Soyuz, incluyendo qué pasa si hay algún problema, hasta que esta está en órbita, se...
No habían pasado tres días desde su lanzamiento cuando la Agencia Espacial Europea declaraba superada con éxito la primera fase de la misión de los tres satélites Swarm. Durante esta se desplegaron los mástiles de sus magnetómetros y se activaron tanto...
La Progress M-21M en la plataforma de lanzamiento Tras un lanzamiento perfecto a bordo de un cohete Soyuz U a las 20:53 UTC del 25 de noviembre de 2013 la nave de carga Progress M-21M va rumbo hacia la Estación Espacial Internacional,...
Impresión artística de LADEE en órbita alrededor de la Luna - NASA Ames / Dana Berry Tal y como se puede leer en LADEE Project Manager Update: Commissioning Complete desde el pasado día 20 de noviembre la sonda LADEE de la NASA...
One fresh tomato for dinner makes us happy in space. It came up with us on Soyuz TMA-11M two weeks ago. pic.twitter.com/40INkQqq3n— Koichi Wakata (@Astro_Wakata) noviembre 22, 2013 A veces son las cosas más sencillas las que más nos alegran el día,...
Este Dnepr lanzado desde Dombarovsky ha puesto en órbita 29 CubeSats Esta semana han sido puestos en órbita ni más ni menos que un total de 61 CubeSats, cuatro de ellos desde la Estación Espacial Internacional y el resto en dos lanzamientos...
Si trabajas en ciencia, ingeniería o matemáticas y eres capaz de contarlo en tres minutos y de manera divertida, reúnes las condiciones necesarias para apuntarte al certamen de monólogos científicos FameLab. Aquí tienes las bases, que debes respetar, y unos consejos,...
La Tierra vista por la MOM La Mars Orbiter Mission, con destino a Marte, es la primera misión interplanenataria de la Agencia India de Investigación Espacial. Fue colocada en órbita terrestre el 4 de noviembre de 2013 para comprobar el funcionamiento de...
Impresión artística de Gaia en servicio Cuando faltaba poco menos de un mes para el lanzamiento del telescopio espacial Gaia de la Agencia Espacial Europea esta anunció que este quedaba pospuesto sine die, aunque a los pocos días anunciaba que la nueva...
Secuencia de ensamblado de la EEI Aunque quizás sería más correcto usar el 2 de noviembre como fecha de su cumpleaños, ya que fue tal día del año 2000 cuando recibió sus primeros tripulantes, las agencias que participar en el programa han...
El programa de conservación de la Biosfera (IGBP), Globaia y la Fundación de las Naciones Unidas han preparado esta visualización que muestra el estado de salud de nuestro planeta a partir de los datos científicos recabados por sensores, sondas y documentos...
ISS 2013.10.08 - La Estación Espacial Internacional vista desde tierra Ver la Estación Espacial Internacional desde tierra como un punto brillante que se mueve por el cielo es sencillo, sólo hay que saber hacia donde mirar gracias a sitios como Spot The...
Tras un lanzamiento perfecto a cargo de una primera etapa Atlas V y una segunda Centaur la sonda MAVEN de la NASA viaja ya rumbo a Marte, aunque el cierre de la administración de los Estados Unidos estuvo a punto de...

Esta absolutamente cautivadora y tierna joya documental sobre Benoît Mandelbrot, padre de los fractales es capaz de condensar en unas pocas frases y cuatro meros minutos toda una ciencia, un arte y un concepto que todavía mantienen fascinada a físicos, matemáticos...
Vista aérea del rariotelescopio de Arecibo - H. Schweiker/WIYN y NOAO/AURA/NSF Popularizado por películas como Goldeneye o Contact, y de indudable utilidad científica, el radiotelescopio de Arecibo acaba de superar el hito del medio siglo en funcionamiento, tal y como he contado...
Impresión artística del Burán durante su primer vuelo - Vadim Lukashevich/www.buran.ru El pasado 15 de noviembre se cumplían 25 años del primer y único vuelo del Burán, el que debía haber sido el transbordador espacial soviético. Daniel Marín, que sabe todo lo...
El gran Mónico: La insólita aventura de un ingeniero manchego en tiempos de crisis. Manuel Lozano Leyva. Mónico Sánchez Moreno nació el 4 de mayo de 1880 en Piedrabuena, un municipio de Ciudad Real, al menos en la actualidad, en el...
Las Leónidas por la NASA En esta época del año la órbita de la Tierra recorre la parte de su órbita que se cruza con la del cometa Tempel-Tuttle, cuyos restos se convierten en la lluvia de estrellas de las Leónidas al...
La Vía Láctea ahorra (arriba) y hace 11.000 millones de años (abajo) - NASA/ESA Igual que no podemos ver el pasado de la Tierra tampoco podemos ver el pasado de la Vía Láctea porque estamos en ella. Pero dado que sí podemos...
Los que quieran ponerle cara a las manos que trazan los garabatos matemáticos más famosos de Internet lo tienen fácil: con todos ustedes… Vi Hart, cuyos vídeos por aquí hemos publicado más de una y más de dos y más de...
Our pilot Simon Wijker caught this great shot of the Soyuz TMA-09M returning to Earth carrying the Olympic torch @esa pic.twitter.com/u9z2wnnYIP— British Airways (@British_Airways) November 13, 2013 La NASA y Roscosmos envían siempre a fotógrafos a cubrir los aterrizajes de las Soyuz...
Soyuz undocking, reentry and landing explained es un vídeo de unos veinte minutos de duración basado en las lecciones que se le dan a los astronautas de la Agencia Espacial Europea sobre el proceso de retorno de la Estación Espacial Internacional...
Saturno y la Tierra, julio de 2013 - NASA/JPL-Caltech/SSI El pasado 19 de julio la sonda Cassini, como en otras ocasiones, pasaba por detrás de Saturno y le hizo unas cuantas fotos. Pero a diferencia de otras ocasiones las posiciones de Cassini,...
Por fin he tenido tiempo de ver Telescope, un corto de ciencia ficción ambientado en el año 2138 en el que el protagonista, un arqueólogo cósmico, viaja más rápido que la luz alejándose cada vez más de nuestro planeta, desprovisto ya...
Luca Parmitano, el astronauta de la Agencia Espacial Europea, acaba de volver de su misión en la Estación Espacial Internacional. Esta es la última anotación que publicó en su blog antes de emprender el camino de vuelta, titulada Wind, sand and stars...
La órbita objetivo era la verde En una nota de prensa un tanto confusa que casi parece traducida con un traductor automático la Agencia India de Investigación Espacial ha comunicado que la cuarta, y en principio última, maniobra de aumento de apogeo...
We saw it burn up from the Falklands at about 9.20pm last night. Came from the South breaking up into bits. pic.twitter.com/54DwAiTI0k— Bill Chater (@Cheds23) November 11, 2013 No había nada organizado formalmente porque la reentrada del satélite GOCE dependía de muchos...
El pasado 9 de noviembre, fecha de su nacimiento en 1934, se celebraba el Día de Carl Sagan, como viene sucediendo desde 2009. Dentro de los múltiples actos y homenajes que se le hicieron al astrónomo, astrofísico, cosmólogo, escritor y divulgador...
La TMA-09M momentos antes de tomar tierra - NASA/Carla Cioffi - más en Expedition 37 (landing only) Esta noche a las 2:49 UTC la Soyuz TMA-09M tomaba tierra todo lo suavemente que una Soyuz es capaz de tomar tierra en Kazajistán trayendo...
Hurricane? Cyclone? Typhoon? Here's the difference — ¿Huracán, tifón o ciclón? Son lo mismo, ciclones tropicales. Pero se llaman de distinta manera según en qué parte del mundo se produzca la tormenta. Huracán se utiliza en el Atlántico, mar Caribe y...
Por Nacho Palou -
11 NOV 2013
Nueve en la EEI: en la primera fila, de izquierda a derecha, Karen Nyberg, Fyodor Yurchikhin, y Luca Parmitano; en la del medio Michael Hopkins, Oleg Kotov ,y Sergey Ryazanskiy; detrás del todo Rick Mastracchio, Koichi Wakata, y Mikhail Tyurin, los recién...
Impresión artística de satélite GOCE en órbita - ESA Tras quedarse sin combustible a mediados del mes de octubre el satélite GOCE de la Agencia Espacial Europea, que se ha encargado de hacer el mapa más detallado del que disponemos de la...
Usando modelos en 3D y texturas de la NASA Shane Gehlert ha creado este vídeo, I need some space, en el que nos lleva de visita por el sistema solar, incluyendo en el paseo alguna de las naves que tenemos dando...
En estos momentos Oleg Kotov y Sergey Ryazanskiy están llevando un paseo espacial en el exterior de la Estación Espacial Internacional durante el que se han pasado la antorcha olímpica de los juegos de Sochi 2014 uno a otro, un relevo...
Postal de Curiosity en el sol 409 - clic para ver en grande, que es como hay que verla - NASA/JPL-Caltech/Damia Bouic Aprovechando que las fotos que envía Curiosity desde Marte están disponibles en Internet para quien quiera usarlas Damia Bouic hace...
Hace años explicamos por aquí hablando de la física del columpio autopropulsado que los giros de 360 son imposibles en los columpios convencionales (de cuerdas o cadenas) pero perfectamente posibles en los de «cables» metálicos fijos. Este vídeo un poco jackass...
La supernova de Nathan Gray es el punto luminoso que se ve arriba a la izquierda de PGC 61330 Falta aún la confirmación oficialísima, aunque todo parece indicar que es sólo una formalidad, para que Nathan Gray pueda decir que ha descubierto...
En una decisión no exenta de polémica las cápsulas Soyuz fueron diseñadas originalmente para que sus tripulantes no usaran traje espacial, de tal forma que había sitio para tres en lugar de para dos. Pero tras la muerte por asfixia de...
Restos del Albert Einstein durante la reentrada Los Vehículos de Transferencia Automatizados de la Agencia Espacial Europea están pensados para terminar su misión mediante una reentrada controlada en la atmósfera en la que no solo se destruye la nave sino la carga...
Situado en una órbita geoestacionaria a 35.786 kilómetros sobre África el Meteosat-10 estaba en una posición ideal para capturar el eclipse híbrido de Sol del 3 de noviembre de 2013 desde el espacio, tal y como se ve en Solar Eclipse...
Tras un lanzamiento perfecto desde el Centro Espacial Satish Dhawan la sonda Mars Orbiter Mission de la Agencia India de Investigación Espacial (ISRO) está ya en órbita alrededor de la Tierra. Una serie de encendidos de su motor le irán haciendo...

Utilizando un peculiar «generador de círculos», Simon Singh como invitado de Numberphile nos explica algunas curiosidades matemáticas sobre Los Simpson, comenzando por que solo tienen cuatro dedos, como casi todos los dibujos animados desde la era Disney, aunque su universo utiliza...
La foto ya tiene unos añitos, pues es del 29 de julio de 2011, pero la misión Cassini-Huygens acaba de publicarla y lo cierto es que no tiene desperdicio. En Quintet of moons se pueden ver cinco lunas de Saturno, que...
Hay montones y montones de imágenes del último eclipse solar de 2013; estas son algunas de las que me han ido llamando la atención: Total Solar Eclipse 2013 El eclipse visto desde un Falcon 900B a 43.000 pies de altura y a...
El ATV-4 a su aprtida de la Estación Espacial Internacional El Albert Einstein, el cuarto ATV de la ESA, ha terminado hoy su misión con una reentrada controlada sobre el océano Pacífico en la que no sólo se ha destruido la nave...
El próximo 7 de noviembre Rick Mastracchio, Koichi Wakata y Mikhail Tyurin llegarán a la Estación Espacial Internacional a bordo de la Soyuz TMA-11M, con lo que pasará a haber tres Soyuz atracadas a la Estación y nueve tripulantes a bordo....
Una costurera de ILC Dover trabajando en uno de los trajes del programa Apolo No hubiera imaginado ni en un millón de años que los trajes que utilizaron Neil Armstrong y Buzz Aldrin para su paseo por la superficie de la Luna...
Total Solar Eclipse of November 3 - Fred Espenak / NASA El domingo 3 de noviembre de 2013 a las 10:04:34 UTC comienza el último eclipse del año, que es un eclipse híbrido de Sol. Al ser híbrido comenzará como un eclipse...
La sonda de la NASA New Horizons, que viaja rumbo a Plutón y el cinturón de Kuiper, lo hace tan rápido que podría recorrer los aproximadamente 4.000 kilómetros que separan Los Ángeles de Nueva York en cuatro minutos. Esto es el doble...
Concepción artística de Kepler-78b y su estrella Hace unos días, hablando de como la cuenta de planetas extrasolares está ya rondando los 1.000, comentaba que una de las cosas que nos han enseñado es que hay que revisar los modelos que manejamos...
En inglés con subtítulos (menú subtítulos en el reproductor de YouTube), tres técnicas para viajar en el tiempo fácilmente (y tres técnicas más complicadas), 3 Simple Ways to Time Travel (& 3 Complicated Ones), En el espacio-tiempo cuándo más rápido te...
Por Nacho Palou -
30 OCT 2013
Probando la primera Orion - Lockheed Martin Tal y como se puede leer en NASA's Orion Spacecraft Comes to Life la semana pasada la primera cápsula tripulada Orión de la NASA fue encendida. Es la primera vez que la NASA estrena una...
En la Agencia Especial Europea se han marcado este bonito vídeo grabado con imágenes de la Mars Express [mejor ver en HD, pantalla gigante y a tutiplén]. Combina las imágenes de alta resolución con los datos topográficos que se han ido...
Con motivo de la celebración de la Semana de las Ciencias de la Tierra de 2013 la NASA ha publicado Mapping Our World, una web en la que se pueden ver hasta 25 conjuntos de datos distintos recogidos por doce de...
José Mª Fernández, químico, investigador, alineando un láser de Argón ionizado utilizado como fuente de excitación de un espectrómetro Raman de alta sensibilidad dedicado al estudio de moléculas en fase gaseosa. Laboratorio de Fluidodinámica Molecular. Instituto de Estructura de la Materia. Estaría...
Todo el mundo sabe que hay millones y millones de células en un cuerpo humano, debido a su ínfimo tamaño, hasta ahora pero según a quién preguntaras podías obtener una respuesta de entre 5.000 millones y 200 billones – unas cifras muy...
Por si acaso estuvieras en la coyuntura de tener que decidir si estudiar física u otras ramas del saber te vendrá bien ver este vídeo, donde Shixie, de la escuela de diseño de Rhode Island, explica la relación entre la física...
SOFIA, el Stratospheric Observatory For Infrared Astronomy, es un telescopio verdaderamente peculiar porque va montado en un Boeing 747SP modificado para servirle de plataforma a unos 12 kilómetros de altura. Allí arriba está por encima de la mayor parte del vapor...
Aunque Virgin Galactic promete llevar a sus pasajeros a más de 100 kilómetros de altura, lo que los convertirá oficialmente en astronautas al sobrepasar la línea de Kármán, la fase de ingravidez en el espacio apenas durará unos minutos. Igual que...
Cena de domingo en la EEI Unos enlaces que me he ido encontrando estos días acerca de lo que supone vivir en la EEI: A day on the International Space Station, en el que Luca Parmitano cuenta como es un día cualquiera...
Aunque el vuelo y la aproximación se realizaron sin problema alguno la Dream Chaser de Sierra Nevada sufrió un accidente al aterrizar tras su primer vuelo libre cuando la pata izquierda del tren de aterrizaje no se extendió, tal y como...
Pensado para niños entre 3 y 7 años, Numblers es un juego didáctico para familiarizar a los más pequeños con los números. Tan solo hace falta un poco de papel, imprimir varias hojas que incluyen el tablero, las piezas y las...
La tabla periódica de los planetas extrasolares según los datos del Planetary Habitability Laboratory, que a 22 de octubre de 2013 contaba 1.010 confirmados Depende de a quién le preguntes, porque por ejemplo la NASA no añade un planeta extrasolar –un planeta...
Las matemáticas, considerándolas estrictamente, proporcionan no solo la verdad, sino también una belleza suprema; una belleza fría y austera, sin la magnificencia engañosa de la pintura o la música.– Bertrand Russell Las matemáticas son bellas. Y la física. Y la química....

La obsesión por entender el pensamiento humano hizo surgir un clásico con el que Douglas Hofstadter ganó un Pulitzer y provocó debates incendiarios en el mundillo tecnológico.
El parasol de Gaia durante las pruebas de despliegue A menos de un mes de la fecha de lanzamiento prevista la Agencia Espacial Europea ha descubierto que dos de los transpondedores que monta el observatorio espacial Gaia y que forman parte del...
Traducido y resumido de Carl Sagan's 5 Greatest Contributions to Science: Cosmos; un viaje personal, una serie que si no has visto ya estás tardando. Hizo que muchos nos enamoráramos de lo asombroso que es el universo y que además entendiéramos que...
En Apollo Lunar Landings Multiscreen se puede ver lo que veían los pilotos de los módulos lunares de las misiones Apolo 11, 12, 14, 15, 16 y 17 mientras aterrizaban, convenientemente sincronizado con el audio correspondiente. Los vídeos están girados aproximadamente...
We have lost the signal from #Cygnus. Reentry accomplished. Represents the official completion of our COTS program with @NASA partners— Orbital Sciences (@OrbitalSciences) October 23, 2013 Tras 35 días, 3 horas, 18 minutos y 27 segundos la primera cápsula de carga Cygnus...
El transmisor láser del LLCD va montado en el exterior de la LADEE de forma que puede pivotar para apuntar a la Tierra La sonda LADEE de la NASA tiene como misión principal estudiar la extremadamente tenue atmósfera de la Luna, que...
Esta es la galaxia más lejana conocida hastas la fecha. Su nombre de catálogo es Z8-GND-5296 y la ha descubierto un equipo de la Universidad de Texas y la A&M. Tiene a los astrónomos totalmente emocionados: está a unos 30.000 millones...
Esta versión de Gravity científicamente correcta de Eduardo Salles lo clava en cuatro viñetas, y además no contiene spoilers si has visto los trailers. No te pierdas tampoco la parodia en 8 bits de Gravity. Y es que yo, como espaciotrastornado,...
So long, and thanks for all the hydrazine...— ESA Planck (@Planck) October 23, 2013 Agotado el refrigerante que permitía funcionar a sus instrumentos ya hace unos meses, la Agencia Espacial Europea procedió a colocar el observatorio espacial Planck en una órbita de...
En el altamente recomendable blog de visualizaciones científicas esquemat.es, una demostración tan gráfica como intuitiva de que los ángulos de un triángulo siempre suman 180 grados, inspirada en una explicación de Learn at Mathematics Realm. Y tienen muchas más. {Nota para...
Hoy Google homenajea a André Jacques Garnerin en el 216 aniversario del primer salto en paracaídas fehacientemente documentado. Pero hay un personaje en la historia, muy anterior a Garnerin y bastante desconocido, del que se dice que podría haber sido el inventor...
El vídeo Shape oscillation of a levitated drop in an acoustic field muestra como es posible mantener en el aire una gota de agua usando ultrasonidos, cambiar su forma al variar la frecuencia de estos, haciendo que coincidan con los armónicos...
Este minivídeo de TED Ed explica por qué las moléculas tienen la forma que tienen: la cuestión implica a las cargas de sus partículas y la geometría de los átomos que componen la molécula: físicamente se encuentran abocados a maximizar la...
Chelyabinsk Meteor Flash: el Metorito de Cheliábinsk, que nos dio un buen susto, fotografiado por Marat Ametvaleev como Imagen Astronómica del Día del 24 de febrero de 2013 Algunos titulares de estos días respecto a 2013 TV135, un asteroide descubierto el pasado...

Stan Lee es un todo un figura. En una de sus apariciones en un programa de la PBS llamado Superheroes: A never ending Battle reconoció con su jocosidad habitual que de ciencia no sabe mucho y que no aunque Spiderman y...
Orión y una oriónida Cada año la Tierra atraviesa en su órbita alrededor del Sol la trayectoria del cometa Halley, allá por abril-mayo, y ahora, entre octubre y noviembre. Estos dos encuentros dan lugar a otras tantas lluvias de estrellas, las Eta...
Saturno por Gordan Ugarkovic - Haz clic para ver la imagen a tamaño completo, no tiene desperdicio De la descripción de Phil Plait en Saturn As You’ve Never Seen It Before: Se puede ver la tormenta hexagonal del polo norte, los restos...
Gabriela Tavares y Aldo Faisal publicaron un sesudo trabajo con el impactante título de Scaling-Laws of Human Broadcast Communication Enable Distinction between Human, Corporate and Robot Twitter Users que Jack Schofield tuvo a bien resumir extrayendo este excelente gráfico. Básicamente trataban...
Luca Parmitano se encargó ayer de anunciar el equipo ganador del concurso de robótica espacial Volare de la Agencia Espacial Europea, que resultó ser el equipo TecnoRoisTres del Centro Público Plurilingüe de Os Dices en La Coruña, España. El equipo está formado...
Visibilidad del eclipse - Vía NASA Durante la noche del 18 al 19 de octubre de 2013 se producirá el último eclipse de Luna del año, aunque en este caso se trata de un eclipse penumbral, así que no se notará demasiado,...
Dos partes de agua por cada parte de fécula de maíz (Maicena) y ¡a disfrutar como enanos! El comportamiento de los fluidos no-newtonianos sigue siendo asombroso se mire como se mire: un fluido que parece comportarse distinto si tomas contacto con...
Ya habíamos publicado un time-lapse del traslado del transbordador espacial Endeavour al Centro de Ciencias de California, donde desde noviembre de 2012 está expuesto al público. Pero este es mucho más completo, ya que arranca con la instalación del Endeavour a...
Pipas, de Manuela Moreno, el corto ganador de los premios al mejor Guión y a la mejor dirección en la XI Edición del Notodofilmfest. Aunque parezca de risa en realidad no lo es tanto. (Vía @FECYT_ciencia)....
Zombies vs. animals? The living dead wouldn't stand a chance, o cómo la naturaleza acabaría con un Apocalipsis zombi rápida y salvajemente. Para disfrutar del horror zombi hay que dejar de lado algunas reglas de la ciencia. De hecho, asumiendo que los...
Por Nacho Palou -
15 OCT 2013
«Volunteer Duty» Psychology Testing, foto CC por Chris Hope Tras escuchar una pieza compuesta para un cuarteto de cuerda basada en las señales de radio que llegan del espacio a Josef Parvizi, un neurólogo de música de la Universidad de Stanford, se...
Roscosmos lleva ya algún tiempo hablando de buscar un sustituto a las venerables Soyuz tripuladas, y en diciembre pasado presentaba el diseño externo de la Pilotiruemyi Transportny Korabl Novogo Pokoleniya o PTK NP, la «nave de transporte pilotada de nueva generación». Desde...

Pues tal y como cuentan en What Color Is The Sun? (está subtitulado en inglés, pero puedes activar la traducción automática, que no lo hace mal) depende de con qué ojos lo mires y a través de qué atmósfera lo filtres....
Un nuevo avance para el Grasshopper de SpaceX, en este caso alcanzar los 744 metros de altura, la mayor que ha conseguido hasta ahora. 744 metros no son muchos para un cohete al uso, aunque supera en más de dos veces...
Pero, ¿qué clase de brujería es esta? Nada que no pueda explicar la ciencia: es simplemente una versión superlativa del ya conocido pero siempre sorprendente efecto de aparente levedad de los imanes megapotentes debido a la Ley de Lenz y las...
El personal del CERN celebra la confirmación de los resultados acerca del descubrimiento del bosón de Higgs Cuando se anunció la concesión del Nobel de Física de 2013 a François Englert y Peter Higgs «por el descubrimiento teórico de un mecanismo que...
El efecto del vídeo es común en líquidos viscosos que fluyen en caída, que chorran, y que parecen rotar durante en el aire formando al llegar al suelo algo parecido a una cuerda enrollada. El comportamiento no lineal de un fluido...
Por Nacho Palou -
11 OCT 2013
El 24 de mayo de 1962 Scott Carpenter se convirtió en el segundo astronauta de la NASA en orbitar la Tierra, y en el cuarto en salir al espacio, en la misión Mercury Atlas 7. Aunque no estuvo exenta de problemas,...
Estas figuras de Lego construidas en aluminio y que representan a Júpiter, su esposa Juno, y a Galileo Galilei, viajan a bordo de la Juno Aunque fue lanzada hace un poco más de dos años la sonda Juno de la NASA acaba...
Hoy termina la Semana Mundial del Espacio, que este año se ha celebrado bajo el lema Explorando Marte, descubriendo la Tierra, con varios cientos de actos celebrados en unos 70 países de todo el mundo. Pedro Duque y la Agencia Espacial...
Este mapa de ciudades afectadas por el cambio de temperaturas global indica la fecha aproximada en que diversos lugares del globo sufrirán las consecuencias del cambio climático sobre el que la comunidad científica lleva años avisando – en forma de subidas...
La gente de TestTube hace en este vídeo una visita guiada al Chabot Space & Science Center de California para explicar algunas de las cuestiones básicas sobre astrofotografía: qué tipo de telescopios se usan, cómo son las cámaras de larga exposición...

Aunque el vídeo está disponible en la web de la EITB y subí la presentación a Slideshare, este es el texto de la charla de 10 minutos que di en Naukas 13. Está basada en una que le vi dar a Jaap...
Observe el termómetro. Si la temperatura marcada baja aproximadamente 30 grados Celsius, ¿cuál sería la temperatura en grados Celsius (o C)? Esta es una de las preguntas de la famosa prueba PIAAC que en España realizaron 6.055 individuos de entre 16...
El agujero negro más pequeño posible tiene una masa de unos 21 microgramos (eso son 0,000021 gramos) más o menos lo mismo que una mota de polvo. Pero para ser un agujero negro de verdad tendría que estar comprimido en una esfera...
Técnicos del centro Kennedy trabajando en la MAVEN - Foto vía Ken Kremer / Universe Today Hoy se cumple una semana del cierre de la administración de los Estados Unidos a causa de la falta de acuerdo entre demócratas y republicanos para...
El bosón de Higgs en tres minutos y medio - subtítulos por El Profe de Física La verdad es que estaba cantado, así que no ha sorprendido a nadie que la Real Academia Sueca de las Ciencias haya dado el Premio Nobel...
Representación artística de Kepler-7b, a la izquierda, y Júpiter Aunque hace mucho que todo lo que íbamos aprendiendo del universo indicaba que tenían que existir planetas más allá de nuestro sistema solar no fue sino hasta hace veinte años cuando aprendimos a...
Un mes después de su lanzamiento, mes que ha utilizado para trazar tres órbitas alrededor de la Tierra cada vez más elípticas que le han permitido ir ganando velocidad, la sonda LADEE está desde esta mañana en órbita alrededor de la...
Helmet View from Astronaut Mike Fossum Ya habíamos sacado por aquí este autorretrato de Mike Fossum durante la misión STS-135 de la NASA como ejemplo de fotos que sólo un astronauta puede hacer. En Best Ever Astronaut ‘Selfies’ hay unos cuantos más...
4942 Munroe A propuesta de Lewis Hulbert y Jordan Zhu, dos lectores habituales de XKCD, esa tira cómica sobre romance, sarcasmo, mates y lenguaje que tanto nos ha hecho reír y pensar, el asteroide antes conocido como (4942) 1987 DU6 ahora se...

La gente de Sixty Simbols entrevistó al profesor Mike Merrifield para que les explicara cómo funciona la transmisión de información especialmente en el caso de la fibra óptica. La charla es un tanto técnica y está en inglés [los subtítulos automáticos...
Con el inminente estreno de Gravity estos días se habla mucho de astronautas perdidos en el espacio. En What Happens If An Astronaut Floats Off In Space? cuentan que si bien nunca se ha perdido uno las normas indican que siempre han...
100 toneladas de antena a lomos de Otto He escrito un artículo para RTVE.es acerca de como con la entrega por parte del consorcio europeo AEM de la antena número 25 de las que se había comprometido a poner Europa el...
Esta es la primera impresora 3D que irá al espacio Según se puede leer en Made in Space and NASA to send first 3D printer into space todo avanza adecuadamente para que en 2014 la Estación Espacial Internacional reciba una impresora en...
Jeffrey Kluger de Time Magazine recopila fallos técnicos de la película Gravity en Gravity Fact Check: What the Season’s Big Movie Gets Wrong. Algunos son tan técnicos que es imposible que los detecte la mayoría del público. Otros como los sonidos...
Por Nacho Palou -
2 OCT 2013
¿5 kW? Póngame tres o cuatro, con fundas a juego. Y un par de esos bonitos trajes ya de paso. Esta pequeña bestia es un láser de 5 kilovatios acoplado en el cuerpo de un rifle. Se utiliza para lo que...
Un pequeño resumen en vídeo de la primera llegada de una cápsula Cygnus de Orbital Sciences a la Estación Espacial Internacional. Se trata de su primera misión de pruebas de esta cápsula, pero si todo va bien en diciembre otra Cygnus...
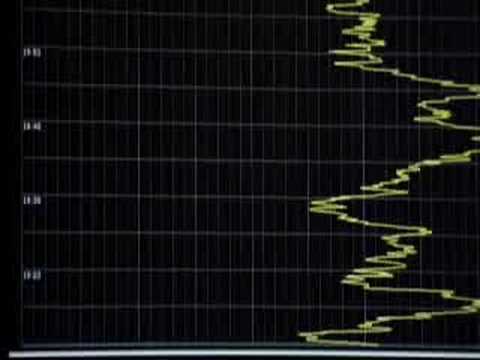
3.000 millones de vatios durante 5 minutos: es un fenómeno único que se produce en el sistema eléctrico de Gran Bretaña y que coincide, por supuesto, con la hora del té y con la emisión de los programas de televisión de...
www.nasa.gov cerrado Debido a la falta de acuerdo entre los políticos del partido demócrata y del partido republicano el Gobierno de los Estados Unidos está cerrado desde las 12 de la noche del 1 de octubre. Entre otros muchos departamentos esto incluye...

Leonov durante su paseo espacial El 18 de marzo de 1965 el cosmonauta soviético Alekséi Leónov se convertía en el primer ser humano en llevar a cabo un paseo espacial al permanecer durante 12 minutos y nueve segundos en el exterior de...
Ciencia en primera persona es un proyecto de Euskampus, el Campus de Excelencia Internacional de la Universidad del País Vasco, que busca acercar al público lo que hacen cuatro investigadores –por ahora– en su vida profesional, contar lo que les llevó...
CapturaAcoplamiento Tras un retraso debido a un problema de compatibilidad con los datos que recibía de la Estación Espacial Internacional y luego para no interferir con la llegada de la Soyuz TMA-10M la cápsula Cygnus fue capturada finalmente esta mañana por el...
El cometa al cometa 9P/Tempel un minuto después del impacto de la Deep Impact He publicado en RTVE.es un artículo acerca de como ocho años, ocho meses, una semana y un día después de ser lanzada, y tras haber desempeñado dos misiones...
Esos mismos motores F1 –u otros iguales– que los Jeff Bezos sacó recientemente del fondo del Atlántico y que sirvieron para lanzar las naves del programa Apolo grabados en el banco de pruebas en Dolby 5.1 y desde distintos ángulos. Mejor...
Foto de familia con los recién llegados en primera fila Oleg Kotov, Sergey Ryazanski y Michael S. Hopkins están desde esta pasada madrugada a bordo de la EEI como parte de la Expedición 37 a esta. He contado para RTVE.es quienes son...
Capas de sedimentos en Nili Fossae Hemos hablado montones de veces de la HiRISE, la High Resolution Imaging Science Experiment de la Mars Reconnaissance Orbiter, que es la cámara con más resolución que jamás hayamos enviado a dar vueltas alrededor de Marte....
El 25 de junio de 1997 los responsables de Roscosmos decidieron llevar a cabo una prueba de atraque manual de una nave Progress de carga en la estación espacial Mir con el objetivo de ver si era posible abaratar el coste...
Desde siempre hemos visualizado los cromosomas tal cual se ven con el microscopio, como una especie de pares de segmentos con aspecto de «X» y diversas formas. Ahora los científicos del Instituto Babraham/BBSCR y la Universidad de Cambridge y el Instituto...
… ¿Y si vas con los ojos vendados? Este experimento consiste en llevar a alguien a un gran parque, una gran playa o un lugar parecido y taparle los ojos, pidiéndole que camine en línea recta. Al poco se observa que...
En esta pieza del Idea Channel de la PBS el divulgador Mike Rugnetta plantea algunos de los puntos de vista sobre una de las cuestiones más profundas de la filosofía de la ciencia: ¿existen las matemáticas realmente? Aunque usamos los números...
La sonda espacial Voyager 1 ya está oficialmente en el espacio interestelar desde hace algún tiempo, aunque técnicamente no haya «salido» del Sistema Solar. Si quieres despedirte de ella de forma apropiada puedes salir cualquier noche estrellada y mirar al cielo...
Otra genialidad de Tim Blais, el autor de Bohemian Gravity, y su A Capella Science, que se me había pasado en su momento: En este caso el tema es el descubrimiento del bosón de Higgs en el Gran Colisionador de Hadrones al...
La gente de Astra explica en este vídeo cómo la gravedad mantiene «atrapados» a los satélites que orbitan la tierra. El vídeo es parte de una miniserie llamada cómo funcionan los satélites que es bastante divulgativa y entretenida de ver. (Vía...
Revolucionar la física concebiendo la mecánica cuántica pero que años después tu imagen aparezca #2 en Google enterrada junto a decenas más de un personaje de ficción asociado con la metanfetamina. ¡Qué jodienda! Al menos se trata de Breaking Bad y...
Antares Cygnus Cargo Resupply (201309180012HQ): Próxima parada, la Estación Espacial Internacional Una discrepancia entre los sistemas de navegación de a bordo de la Estación Espacial Internacional y de la cápsula de carga Cygnus de Orbital Sciences que hacía que esta rechazara algunos...
¿Cómo es el centro de proceso de datos del CERN donde están alojado el Gran Colisionador de Hadrones y otros cientos de proyectos científicos y tecnológicos? La gente de Computerphile tuvo acceso al interior de ese datacenter y nos explica todas...
El viernes 27 y el sábado 28 de septiembre de 2013 se celebra en el paraninfo de la UPV/EHU la tercera edición de Naukas Bilbao, el evento antes conocido como Amazings Bilbao. Son más de 40 charlas de diez minutos –y en...
Guiding light to the stars por Mark Gee Esta impresionante foto de Mark Gee de la Vía Láctea y el faro de Cabo Palliser de la Isla Norte de Nueva Zelanda es la ganadora de la edición de 2013 del concurso Astronomy...
La Tierra vista por la sonda Kaguya mientras esta sobrevolaba el polo sur de la Luna La Planetary Society tiene una bonita recopilación de imágenes de la Tierra tomada por diversas sondas espaciales no destinadas a estudiarla pero que la vieron desde...
Antares Cygnus Cargo Resupply (201309180012HQ): Próxima parada, la Estación Espacial Internacional Tras un lanzamiento perfecto a lomos de un cohete Antares la cápsula Cygnus de Orbital Sciences tiene que pasar once pruebas antes de poder ser acoplada a la Estación Espacial Internacional...
Euclides, padre de la geometría Minimal Posters - Five Great Mathematicians And Their Contributions es un trabajo de Hydrogene que resume a Newton, Euler, Euclides, Gauss y Pitágoras y sus contribuciones a las matemáticas en otros tantos pósters. Lástima que no haya...
Este vídeo, Voyager Captures Sounds of Interstellar Space, publicado por el JPL reproduce dos momentos, el primero de octubre a noviembre de 2012 y el segundo de abril a mayo de 2013 en los que el instrumento de medición de plasma...
Fabricadas con galio puro al 99,998%, estas cucharas parecen igual que las «de verdad», suenan igual que las de verdad y tienen un peso parecido a las de verdad, con la diferencia de que al frotarlas con el calorcillo se pueden...
Dado que la Luna está en rotación síncrona con la Tierra a causa del acoplamiento de marea siempre vemos la misma cara de nuestro satélite. De hecho no fue sino hasta el 7 de octubre de 1969 cuando pudimos ver la...
Este vídeo de Philipp Dettmer explica la teoría de la evolución en poco más de diez minutos y de forma muy gráfica. [Se pueden activar los subtítulos en inglés, están bastante bien]. Entre otras cosas explica cómo los protozoos llegaron a...
No creo que ni los físicos presentes en la sala entiendan todo lo que menciona Tim Blais en A Capella Science - Bohemian Gravity!, pero no cabe duda de que tiene un curro impresionante… Aparte de ser un vídeo la mar...
Una llamarada de tamaño mediano del pasado mes de mayo / NASA Goddard No sabía que este tipo de sucesos pudiera determinarse con tanta precisión pero según cuentan en Smithsonian Magazine el campo magnético del Sol va a invertirse «de forma inminente»....

En un universo como el nuestro que está en continua expansión… ¿Nos «expandimos» también las personas, los objetos y las partículas subatómicas? ¿Es esa expansión como hacer un gigantesco zoom aunque en realidad el tamaño relativo de las cosas no cambia?...
La NASA ha publicado una estupenda recreación de cómo fue la trayectoria del bólido de Cheliábinsk, el impacto de hace unos meses en Rusia que resultó ser el más importante desde el de Tunguska de 1908 – todo un impacto cósmico...
No llega a ser un 1 en la escala de cielo oscuro de Bortle, pero el cielo nocturno del Salar de Bonneville se le aproxima, y es un recordatorio de lo que supone la pérdida de la oscuridad. Night Sky Panorama-Bonneville...
Luna, 13 de abril de 2011 Hace unos días Raúl me escribió pidiéndome alguna recomendación para ir iniciando a su hijo en el mundo de la astronomía y esto fue lo que se me ocurrió recomendarle; lo cuento aquí por si a...
Despegue del primer Epsilon La Agencia Japonesa de Exploración Aeroespacial ha puesto hoy en órbita un nuevo telescopio espacial con un lanzamiento perfecto a bordo del nuevo cohete Epsilon, poniendo fin a un proceso iniciado en 2007 para crear un cohete que...
Nico Disseldorp ha completado su último proyecto, que ha llamado Fractal Machine. Se trata de una herramienta interactiva para jugar creando fractales directamente con el navegador. Basta ir pulsando los botones y moviendo los reguladores para crear diversas formas y examinar...
Un año más el Instituto de Investigaciones Improbables ha entregado sus premios Ig Nobel, aquellos que según ellos mismos dicen se otorgan a aquellos logros que primero te hacen reír y luego pensar. Así, los de 2013 han sido otorgados en estas...
Impresión artística de la Voyager1 saliendo de la heliosfera Después de años diciendo que sí y luego que no uno ya no sabe si tomarse muy en serio los repetidos anuncios de la NASA de que la Voyager 1 ha abandonado el...
Bonito texto este de Sergio Toporek en el documental Beware of Images que republicaron en el Lunar Science Institute de la NASA. Me quedo con: Considera que puedes ver menos del 1 por ciento del espectro electromagnético y escuchar menos del 1%...
Impresión artística del núcleo de la Vía Láctea visto de lado Hace bastante que sabemos que en el núcleo de la Vía Láctea hay miles y miles de estrellas –unos 10.000 millones– acumuladas en un espacio relativamente pequeño de miles de años...
La sonda MAVEN de la NASA comenzó su fase ATLO, de Assembly, Test, and Launch Operations, Operaciones de Ensamblado, Pruebas y Lanzamiento, el 11 de septiembre de 2011. El 2 de agosto de 2013 fue enviada al Centro Espacial Kennedy para...
Expedition 36 Soyuz TMA-08M Landing (201309110001HQ): Los motores de la Soyuz TMA-08M terminando de frenarla justo antes de aterrizar - NASA/Bill Ingalls - Más fotos en el álbum Expedition 36 Tras 166 días a bordo de la Estación Espacial Internacional Pavel Vinogradov,...
Esta es una pequeña joyita de hace tiempo titulada To Infinity And Beyond (2010) que trata sobre nuestra peculiar relación con el infinito, la forma de entenderlo y algunas de las ideas básicas relacionadas con él. ¿Existe realmente? ¿Es tan solo una...
El Macizo Tamu Estos días se ha hablado bastante del Macizo Tamu, un enorme volcán –afortunadamente inactivo desde hace unos 140 millones de años– de unos 650 kilómetros de diámetro situado a unos 1.600 kilómetros el este de Japón y cuyo tamaño...
Ya comentamos el trailer hace tiempo, hoy se ha estrenado Traveling Salesman, una producción indie con aspecto de peli de espías a lo Sneakers sobre qué sucedería si qué sucedería si P = NP....
Me he encontrado esta impresionante ilusión óptica –que demuestra una vez más lo fáciles que somos de engañar– gracias a Phil Plait, que en Is This Asteroid Apocalypse Viral TV Ad Fact or Fake? analiza si lo de la entrevista de...
Aunque no sepamos como se llama, casi todos hemos visto el efecto Leidenfrost en acción. Es el que se produce cuando una o varias gotas, normalmente de agua pero puede ser cualquier líquido volátil, caen sobre una superficie caliente, normalmente una...
LADEE empieza su viaje - Ben Cooper / LaunchPhotography.com Aunque las ruedas de reacción, que sirven para mantenerla estabilizada, dieron u pequeño susto al no arrancar correctamente tras el lanzamiento, situación que ya se ha corregido, la sonda LADEE de la NASA...
frameborder="0" allowfullscreen>Mars' Moon Phobos Eclipses the Sun, as Seen by Curiosity Ya decíamos que había más fotogramas del eclipse anular de Sol causado por Fobos en Marte el pasado 17 de agosto que los tres que publicamos hace unos días, y ahora...
Hoy se ha producido el segundo vuelo con motor de SpaceShipTwo, que fue soltado de su avión nodriza a 46.000 pies (unos 15 kilómetros de altura) sobre el desierto de Mojave. Inmediatamente tras la separación Dave Mackay, el piloto, puso en...
El brazo robot de la EEI fue el encargado de desacoplar el HVT 4 de la Estación - Foto vía @AstroKarenN Con los 5.400 kilogramos de carga útil que llevaba a bordo ya a buen recaudo en la Estación Espacial Internacional, 3.900...
Un par de interesantes lecturas recomendadas para espaciotrastornados. Una es A view of the Earth, en la que Mike Massimino cuenta lo que sentía durante el paseo espacial en el que tenían que cambiar la fuente de alimentación del Space Telescope Imaging...
Un problema importante con el que se enfrentan los médicos al tratar a sus pacientes es que, al menos según la Organización Mundial de la Salud, la mitad de ellos no siguen el tratamiento de la forma prescrita. Pero si lo que...
Neurociencia para Julia. Xurxo Mariño, @xurxomar. Editorial Laetoli 2012, 224 páginas. Uno de los grandes misterios a los que nos enfrentamos es el del funcionamiento de nuestro cerebro, que entre otras muchas cosas hace surgir nuestro yo cada día cuando nos...
Las sondas Voyager llevan a bordo lo mejor que se podía permitir la NASA en cuanto a tecnología a finales de los 70, aunque claro, las cosas han cambiado un poco desde entones.Sus cámaras eran unos tubos vidicon de sulfuro de selenio...
El físico Enrico Fermi, además de su contribución al desarrollo de la primera boma atómica, era conocido por su afición a plantear problemas que en principio parecían irresolubles pero que a fuerza de irlos descomponiendo en otros más simple a menudo era...
NASA Mars Rover Views Eclipse of the Sun by Phobos Aunque el Sol se ve más pequeño desde Marte que desde la Tierra su luna más grande, Fobos, apenas mide 22,5 kilómetros de diámetro, por lo que aunque pase por delante del...
Durante los seis últimos años la misión IceBridge de la NASA ha estado explorando la capa de hielo que cubre ambos polos de nuestro planeta y Groenlandia. Este vídeo recoge algunas impresionantes tomas del Ático y de Groenlandia recogidas por las...
Los vehículos de transferencia automatizados de la Agencia Espacial Europea tienen tres depósitos en los que pueden llevar dos tipos de gases distintos. Esto es así porque los depósitos 2 y 3 están conectados entre ellos, mientras que el 1 es totalmente...
Eye Sci es un juego que esconde en una imagen ampliable pistas para localizar a 50 científicos de toda la historia… Lo que no es fácil del todo y probablemente acabará por volverte un poco loco. Algunas de las pistas son...
Berlín desde el espacio por la noche Aunque ya no falta mucho para que se cumpla un cuarto de siglo de la caída del muro de Berlín y desde el suelo cada vez quedan menos diferencias entre Berlín del este y Berlín...
Esto es bastante extraño y el vídeo no es nada espectacular, pero aquí queda: Un investigador controla los movimiento de su colega con la primera interfaz entre cerebros humanos, Utilizando un detector de los impulsos eléctricos del cerebro y un estimulador...
Por Nacho Palou -
28 AGO 2013
El Lunar Landing Research Facility en uso por la noche Todos los espaciotrastornados hemos visto montones y montones de fotos del programa Apolo, pero Mark Wilson se ha dado un paseo por los archivos de la NASA para sacar 50 imágenes poco...
En Minute Physics han dedicado un microepisodio muy aclarativo con sus muñecos y garabatos habituales a explicar cómo el Big Bang no tuvo lugar exactamente en el «centro del universo», «lugar» en el que nosotros tampoco estamos porque todo depende del...
Vi que @medicorazon recomendaba este Atlas de mortalidad en España y me pareció razón suficiente para echarle un vistazo. Aunque los datos no están muy actualizados (son de 1984 a 2004) tienen además del valor estadístico, médico y científico algunas curiosidades...
Una de las genialidades de Newton fue darse cuenta de que no era necesario aplicar una fuerza a un cuerpo para que se mantuviera permanentemente en movimiento; del mismo modo, tampoco empezará a moverse a menos que actúe una fuerza externa...
Este artículo se publicó originalmente en Sin vuelta de hoja, un blog de MásMóvil con el objetivo de contar cosas sensatas y relajantes relacionadas con la tecnología y la ciencia. Hace tiempo se publicó en diversos medios la historia de una...
Apolo 11, Estación 5 Durante sus paseos por la superficie de la Luna los doce astronautas del Programa Apolo que aterrizaron allí tomaron miles de fotos usando las cámaras Hasselblad que llevaban para ello y que aún están allí. En Apollo Surface...

Otro genial vídeo de muñecos de Minute Physics, que a pesar del título original apenas habla de religión sino más bien de cosmología y del Bing Bang que probablemente no debería llamarse Big Bang. Ni el universo era infinitalmente pequeño como...
Michael Chung asegura que tuvo mucha suerte cuando hace unas semanas pudo grabar la explosión de un meteoro durante la lluvia de Perseidas de agosto [en 00:37 exactamente) – como es bien sabido esas «estrellas fugaces» se conocen técnicamente con ese...
A raíz de la anotación sobre Universo 25 Frank Lester nos escribió para hablarnos de Los renos de la isla de San Mateo. En 1944 el Servicio de Guardacostas de los Estados Unidos puso en marcha una estación del sistema de navegación...
Aunque Curiosity es una misión de la NASA otros países han colaborado con ella en la construcción de algunos de sus instrumentos. Es el caso, por ejemplo con el Rover Environmental Monitoring Station, la estación meteorológica del river, construida en España por...
Esta no es más que la esquina superior de un gráfico que explica en forma de mapa de metro lo principal de la fisiología del cuerpo humano. En su forma original, incluida en el libro «Bases fisiológicas de la práctica médica»...
Factura del remolque del Odissey Cuando el 14 de abril de 1970 explotó un tanque de oxígeno número 2 del módulo de servicio del Apolo 13 los responsables de la misión tuvieron que improvisar un plan para traer de vuelta a sus...
La Voyager 2 finalmente estará a un día luz de la Tierra en algún momento a finales de 2035, 58 años después de su lanzamiento. La Voyager 1, que va un poco más rápido, alcanzará esa distancia a principios de 2027, un...
Estos días los astrónomos andan un tanto revolucionados por la aparición de una nova en el cielo, que primero llamaron PNV J20233073+2046041 y tras un poco de observación y confirmación se ha quedado con Nova Delphini 2013 . Está en la...
La cabina de SOFIA durante el vuelo de vuelta a su base - Foto vía @SOFIATelescope Una de las ventajas de tener un telescopio montado en un avión es que te lo puedes llevar allá a donde quieras hacer una campaña de...
Siguiendo con su proyecto para desarrollar cohetes reutilizables capaces de volver a su plataforma de lanzamiento tras el despegue –o a otra que les quede más a mano– la gente de SpaceX acaba de hacer un vuelo de prueba con el...
El físico Phil Moriarty de la Universidad de Nottingham explica en este vídeo algunas de las cuestiones filosóficas tras el planteamiento de que nuestro universo fuera en realidad una gigantesca simulación, una especie de mundo tipo Matrix o alguna forma de...
De las naves tripuladas en desarrollo en la actualidad el Dream Chaser de Sierra Nevada es el que más pinta de nave espacial tiene, con mucho parecido, salvando el tamaño, con los transbordadores espaciales que usaba la NASA. Igual que estas...
Perseid Meteors over Ancient Bristlecone Pine, las Perseidas de 2013 fotografiadas por Kenneth Brandon A los que nos tocó nublado no nos queda más que contentarnos con ver fotos que otros hayan podido hacer de las Perseidas de 2013, como por ejemplo...
El Tumblr de Chris Hadfield encontré este curioso montaje que muestra cuál es la distancia hasta la que una persona de altura media puede ver mirando hacia la línea del horizonte. La gracia del asunto es que depende de en qué...
Órbitas de los PHAs conocidos Orbits of Potentially Hazardous Asteroids , Órbitas de los asteroides potencialmente peligrosos, recoge en una imagen las órbitas de más de 1.000 asteroides de los que consideramos potencialmente peligrosos, aquellos que miden más de 140 metros de...

Hoy se celebra el aniversario del nacimiento de Erwin Rudolf Josef Alexander Schrödinger, más conocido por… su gato. El célebre físico austríaco nacido en 1887 nos dejó como legado un montón de trabajos relevantes y trascendentales, además del que probablemente es...

Aquí puede verse cómo crear nitrógeno sólido a partir de nitrógeno líquido. La cuestión es ¿cómo enfrías algo qua ya está tan sumamente frío? El truco es usar una curiosa propiedad de estos elementos: a medida que se hace disminuir la...
Una perseida madrgugadora vía @Starfest2013 En agosto acuden a su cita anual las Perseidas, también conocidas como las lágrimas de San Lorenzo, la lluvia de meteoros que produce más estrellas fugaces de todas las que se pueden ver a lo largo del...
Este artículo se publicó originalmente en Sin vuelta de hoja, un blog de MásMóvil donde colaboramos semanalmente con el objetivo de contar cosas sensatas y relajantes relacionadas con la tecnología y la ciencia. ¿Hasta dónde llega la practicidad del teórico mundo...

El otro día alguien preguntó en Twitter por el número más grande que jamás haya existido, y además de mencionar algunos de los más famosos yo recomendé el número de Graham, una poderosa bestia matemática donde las haya. Ahora @Minid nos...
El Kounotori 4 con sus 5.400 kilogramos de carga ya está en la Estación Espacial Internacional, tras haber sido lanzado el pasado 3 de agosto y realizar una aproximación sin problemas. Aproximación Paparazzis espaciales… Cualquier diría que con tanto entrenamiento alguien habría...

Simplemente delicioso. Podríamos subtitularlo Planilandia versión TED. Otra forma de ver el famoso romance en muchas dimensiones. (Vía Geeks Are Sexy.)...
Este vídeo, que explica los componentes de un cohete Soyuz FG de los que se usan para lanzar las cápsulas tripuladas Soyuz TMA y el proceso de lanzamiento de este es parte del material que usaron los astronautas del grupo de...
Hemos comentado unas cuantas veces que las estaciones en nuestro planeta tienen bastante menos que ver con la distancia que separa a la Tierra del Sol, que cambia en unos 5 millones de kilómetros entre el punto en el que están...

Como viene sucediendo aproximadamente cada 11 años desde que tenemos datos sobre él el campo magnético del Sol está cambiando, con lo que el polo norte pasará a estar en lo que es el polo sur y viceversa, tal y como...
Aunque da la impresión de que la trompa de un mosquito tiene que ser rígida para poder perforar la piel de sus víctimas en este vídeo se ve perfectamente lo flexible que es mientras busca un vaso sanguíneo del que sorber...
INTEGRAL en iSat Aunque Heavens-Above sigue ahí para contarnos cuando se puede ver según qué satélites desde cualquier punto del planeta el Interactive Satellite Viewer de la NASA permite seguirlos en órbita viendo los datos de su altura y velocidad en tiempo...
Estaba buscando información acerca de Susana Martínez Conde, una de las autoras de Los engaños de la mente: Cómo los trucos de magia desvelan el funcionamiento del cerebro cuando me encontré con este vídeo en el que explica cómo funcionan algunos...
Wired nos iustra con un vídeo acerca de el maravilloso mundo de las cerillas; esos pequeños objetos cotidianos tan aparentemente inocentes pero tan revolucionarios a la vez....
JuanPablo nos planteó un curioso problema: Así como existe el día de la tierra, el día del programador, etcétera. Debería existir el día de los que no tienen día. El problema es que si los que no tienen día lo celebran, tendrían...
Hoy hace un año que a las 7:17 de la mañana, hora de España, Curiosity aterrizaba en Marte tras una de las maniobras más increíbles y apasionantes de los últimos años en la historia de la investigación espacial. En lo que...
La Tierra, la luminiscencia nocturna de la atmósfera, la Luna, el Sol… Recién llegada desde la Estación Espacial Internacional, Sunrise and moonrise, una de esas fotos de @AstroKarenN que molan todo. Actualización: Phil Plait, el @BadAstronomer, se ha dado cuenta de...
La Agencia Japonesa de Exploración Aeroespecial lanzó la pasada noche su cuarto vehículo de transferencia automatizado H-II con rumbo a la Estación Espacial Internacional: Launch Result of H-II Transfer Vehicle "KOUNOTORI4" (HTV4) by H-IIB Launch Vehicle No. 4. El Kounotori 4...
Asistentes al primer Space Tweetup 60 afortunados tuiteros espaciotrastornados pudimos participar el 18 de septiembre de 2011 en el primer SpaceTweetup organizado por la ESA y el DLR en Colonia. Durante un día pudimos ver las tripas del telescopio aerotrasportado SOFIA, entrar...
A todos nos ha tocado ordenar una colección de revistas, libros, discos, un mazo de cartas, etc. Cuando son pocos da más o menos igual el método que sigas para ordenarlos, aunque cuando el número de cosas a ordenar crece sí...
Algunas de las antenas de ALMA vistas desde el aire No era una tarea sencilla, porque a 5.200 metros de altura y 3 grados bajo cero las condiciones atmosféricas quedaban muy fuera de las recomendadas para el hexacóptero que usaron. Pero aligerando...
Los trajes espaciales son en realidad como una pequeña nave espacial que tiene que mantener con vida a su ocupante en condiciones extremas de temperatura y presión, a la vez que le permite la suficiente movilidad como para que pueda llevar...
Todavía no se sabe el motivo por el que el traje espacial de Luca Parmitano sufrió una fuga de agua el pasado 16 de julio que obligó a abortar el paseo espacial que estaban llevando a cabo, y de hecho la Progress...
El archivador de anillas. El lápiz. El plástico de burbujas. La tirita. La cremallera. El clip. la cinta adhesiva. El velcro. El taco de pared. El mosquetón. El paraguas. El portalatas. El tetrabrik. La goma elástica. La pinza para tender. El sacacorchos....
Impresión artística de HD 189733b pasando frente a HD 189733a. El recuadro contiene la imagen en rayos X de la estrella en el centro, la enana blanca que la acompaña a la derecha, y otro objeto que pertenece a otro sistema solar...
Fibonacci's Spiral, por Arvin Rahimzadeh En esta fotografía de Arvin Rahimzadeh de una pelota de tenis mojada (que vi pasar por Colossal) se pueden ver las espirales que surgen de forma natural alrededor de ésta mientras rota sobre sí misma. La imagen...
Por Nacho Palou -
31 JUL 2013
De una forma tenaz China está avanzando en su programa espacial, que recientemente acaba de terminar su misión tripulada más larga, y que incluye objetivos tan ambiciosos como tener su propia estación espacial o colocar un taikonauta sobre la superficie de...
Hace unos días The Alan Parsons Project actuaba en Roma, y tras enterarse de que Eye in the Sky es la canción favorita del astronauta italiano Luca Parmitano el mismo Alan Parsons no dudó en dedicarle la canción: Alan Parsons' "Eye...
Un año más, y con este ya van veintiseis, los Museos Científicos Coruñeses, en los que trabajo en el MundoReal™, han convocado los Prismas Casa de las Ciencias a la Divulgación. La gran novedad de este año es que la FECYT se...
PIA08235: Candle in the Dark - Contraluz en Saturno La Imagen Astronómica del Día de la NASA de hoy viene del baúl de los recuerdos digital de la sonda Cassini, pues es una imagen tomada por su cámara de campo estrecho el...
Stargazing: una Delta Cuadrántida de 2011 por Pat Kight Aunque se las puede ver desde mediados de julio y hasta finales de agosto se prevé que el máximo de actividad de las Delta Acuáridas de 2013 ocurra en la noche del 29...
Este de ahí arriba es el Soyuz-U que hace unos días lanzó la nave de carga Progress M-20M hacia la Estación Espacial Internacional. En el momento del lanzamiento un Soyuz-U pesa 313.000 kilos, al que en este caso hay que sumar...
La Progress M-20M poco antes de atracar - Fotos del lanzamiento en Soyuz-U - Progress M-20M Launch Photos Tras su lanzamiento a la 20:45 UTC del 28 de julio de 2013 y gracias a utilizar la trayectoria rápida de cuatro órbitas la...
El Cielo de La Palma es un impresionante trabajo de Daniel López para disfrutar a pantalla completa y con los altavoces puestos. Pero además el título menciona el astroturismo, algo que no dudo en recomendar y que va mucho más allá...
Primera imagen del IRIS, a la izquierda, comparada con una imagen de la misma zona tomada por el Solar Dynamics Observatory - NASA/SDO/IRIS La NASA ya ha publicado la primera imagen obtenida por el telescopio espacial IRIS, el Espectrógrafo de Imágenes de...
El Alphasat I-XL, recién lanzado por un Ariane 5 ECA, sería un satélite de comunicaciones más de no ser porque es el primero que está basado en la plataforma Alphabus con la que la ESA espera hacerse un hueco en el...
Bueno, más que pararlo, Bill Nye explica en Could We Stop An Asteroid? algunas ideas que podrían permitirnos variar su velocidad en una diezmillonésima, lo que evitaría que chocara contra la Tierra. Una opción es hacer chocar con él un cohete;...

¡Apréndelos! Y estarás más cerca de los secretos del cosmos. Vía Gaussianos, un breve vídeo que reune a los diez números más importantes en las matemáticas y la física. Nadie dijo que fuera fácil recordarlos todos, pero estaría bien al menos...
Los astronautas de la NASA Randy Bresnik y Serena Auñón, con sus trajes ACES puestos, probaron hace unos días el diseño interior de la cápsula CST-100 de Boeing, lo que gracias a las fotos y vídeos que se publicaron después ha...
En 1968 el etólogo John B. Calhoun metió en un entorno en el que no les faltaba de nada, salvo espacio en cuanto la población creciera, a cuatro pares de ratones, que en cuanto comenzaron a sentirse cómodos en su nuevo entorno...
El 19 de julio de 2013, aprovechando que la sonda Cassini de la Agencia Espacial Europea y la NASA pasaba por la parte de atrás de Saturno visto desde el Sol, el equipo de la misión la programó para tomar una serie...
Viñeta de Alex Gregory publicada en The New Yorker y traducida por @OmaCroga A pesar de lo que se dice a menudo de que en el pasado vivíamos vidas más sencillas y con menos preocupaciones la entrada El pasado era una mierda,...
(Voz de documental antiguo) «Y esto, jóvenes amigos, es lo que llamamos un cerebro mecánico capaz de ayudar a los ingenieros aeroespaciales en los más difíciles cálculos». Y es que al mismo tiempo que los primeros ordenadores (fuera cual fuera el...
Un experimento científico logra crear una ola congelada en el tiempo -- Científicos de la Universidad Carlos III de Madrid (UC3M) y de la Universidad de California en San Diego (UCSD) han recreado en el laboratorio una ola de tubo estática,...
Por Nacho Palou -
23 JUL 2013
¿Cuántos decimales de pi son necesarios para realizar cálculos prácticos? Aunque los decimales del redondo número son infinitos no hace falta conocer muchos de ellos para usar la constante matemática de forma práctica: la NASA se conforma con 15 o 16 para...

Karen Chong explica con mucho salero la relación entre música y matemáticas, las escalas, las notas y algunos que otros secretillos que pasan desapercibidos para el común de los mortales. Lo ha titulado Cómo resolver una canción con matemáticas y más...
Earth and Moon from Cassini:La Tierra y la Luna vistas por la Cassini Esta es una versión no oficial de la foto que la sonda Cassini tomó el viernes 19 de julio de 2013 de la Tierra y la Luna desde una...
¡Alabado sea el FSM! Efectivamente: esta es la secuela de la mítica serie documental Cosmos: un viaje personal de Carl Sagan, de la que la Fox ha dejado ver un prometedor trailer en la Comic-Con. Llega con un par de años...
Martin Kryzwinski ha utilizado el conocido software de visualización Circos con los decimales de pi, la proporción áurea y e como datos de entrada. El resultado es tan aleatorio como cabría esperar, pero a la vez muy bello. La numerología es...

Ya han recaudado dinero suficiente para desarrollar este concepto que es justo lo que se ve: un material que cambia de color si la bebida tiene drogas. Se supone que puede incorporarse en vasos, cubiertos o pajitas de plástico. No está...
Niños, no intentéis esto en casa porque el tiocianato de mercurio (II) es muy tóxico, aunque mole kilos cuando arde y pudiera servir como efectos especiales de una película de ciencia ficción/terror de serie z (o así). Pero si queréis intentarlo,...
En estos mismos instantes la sonda Cassini está fotografiando la Tierra desde unos 1.200 millones de kilómetros. Es un homenaje a a la imagen tomada por la Voyager 1 el 14 de febrero de 1990 y bautizada como Punto Azul Pálido...
Cámara de combustión del motor 5 del Apolo 11 - Bezos Expeditions Cuando Jeff Bezos y su equipo sacaron del fondo del Atlántico los componentes de un par de motores F1 de los Saturno V del programa Apolo no había certeza respecto...
En la Universidad de Queensland están llevando a cabo desde 1927 un experimento, conocido como el experimento de la gota de brea, para estudiar el comportamiento de la brea, que aunque nos parece un sólido es un líquido muy viscoso, de...
El inicio es más o menos previsible, pero a partir de 00:35… Suceden cosas. Cosas horribles. (Vía Colossal + The Awesomer donde lo califican de … )...
La Tierra vista desde la Cassini gracias al Solar System Simulator del JPL Aprovechando que estos días la sonda Cassini pasará por la cara de Saturno opuesta al Sol el equipo de la misión ha programado la toma de una serie de...
1 kilómetro y mirando adelante Ha pasado casi un año desde su aterrizaje en Marte pero por fin Curiosity ha superado la barrera –psicológica, obviamente– de un kilómetro recorrido sobre la superficie de nuestro vecino, tal y como se puede leer en...
Como decían en @ShuttleAlmanac acerca de la fuga de agua en el casco del traje espacial de Luca Parmitano, «imagina que tienes la cabeza metida en una pecera esférica con medio litro de agua pegado a tu cara, orejas, y nariz....
Karen Nyberg se apresura a ayudar a Luca a quitarse el casco El paseo espacial que tenían que haber llevado a cabo Chris Cassidy y Luca Parmitano hoy para realizar distintas tareas en el exterior de la EEI tuvo que ser cancelado...
Después de ver cómo Karen N. Nyberg se lava la melena en la Estación Espacial Internacional ya decíamos que Luca Parmitano había optado por otro tipo de solución a este problema… Y así es cómo se lava él el pelo: Inside...
La nueva luna de Neptuno Descubierta por Mark Showalter del Instituto SETI el pasado 1 de julio en unas fotos de Neptuno tomadas por el telescopio espacial Hubble, y confirmada su presencia en otras imágenes tomadas entre 2004 y 2009, con S/2004...
Resulta que si haces una comparación directa, Rusia con sus 17 millones de kilómetros cuadrados es prácticamente igual de grande en cuanto a superficie que Plutón, el planetoide –hasta hace unos años, «planeta»– de los confines remotos de nuestro Sistema Solar. [Fuente:...
El premio AHS Sikorsky se estableció en 1980 para premiar el desarrollo de un artilugio volador propulsado por la fuerza humana. Los requisitos básicos eran que debía mantener el vuelo durante más de un minuto y alcanzar los tres metros de...
Por Nacho Palou -
15 JUL 2013
Plutón y Caronte vistors por la New Horizons. La imagen de la derecha los muestra dentro de sendos círculos para ayudar a localizarlos: Plutón es el del centro, Caronte el que está arriba a la izquierda de este Aunque aún faltan dos...
En ocasiones se diría que tienen vida propia. En realidad buscan las formas óptimas a partir de la cantidad de jabón existente, según se tocan unas con otras. Una geometría física que resulta tan interesante de investigar para los matemáticos como...
Las lunas mayores del sistema solar agrupadas por el planeta alrededor del que orbitan En el sistema solar hay 18 ó 19 lunas, según las cuentes, que son lo suficientemente grandes como para que su gravedad las haga redondas. La duda de...
Impresión artística de HD 189733b HD 189733b es un planeta extrasolar que está a unos 63 años luz de la Tierra y se ha convertido en el primero del que hemos podido averiguar su color. Tal y como se puede leer en...
Pues igual que en tierra, con agua y champú, aunque en este caso se trate de un champú que se supone que no tiene que ser aclarado al terminar y haya que extender tanto el agua como el champú a mano...
El astronauta italiano de la Agencia Espacial Europea y Chris Cassidy llevaron a cabo un paseo espacial de seis horas de duración para mantenimiento y mejora de la Estación Espacial Internacional. He escrito una pieza sobre él y las tareas llevadas...
Mars rover 2020 Lanzar una misión a Marte no es algo que se haga de un día para otro, así que la NASA ya está trabajando en definir qué va a hacer el rover que quiere enviar allí en 2020. Una cosa...
Según cuenta Anatoly Zak en Culprit found el fallo en el lanzamiento del Protón-M que el pasado 2 de julio tenía que haber puesto en órbita tres satélites del sistema Glonass tiene un origen bastante tonto ya que por lo visto...
Aún quedan muchos detalles que pulir de aquí a que vuele el primer Ariane 6, pero los ministros del ramo han decidido ya la que será la configuración básica del Ariane 6, que tendrá como objetivo poder poner en órbita de transferencia...

La prueba es sencilla: capturar al vuelo un billete o una regla de madera según se deja caer entre los dedos por efecto de la gravedad. Básicamente mide el tiempo de reacción, pero tal y como explican los entendidos del Gazzay...
La gente de SpaceX sigue trabajando en la tecnología necesaria para que cuando se lanza un cohete con la ayuda de propulsores auxiliares estos puedan volver por sus propios medios a la base sin que tengan que caer en el océano...
Impresión artística del Corot en órbita El fallo definitivo de sus dos ordenadores de a bordo impide que el Corot pueda seguir realizando observaciones, por lo que la Agencia Espacial Europea ha decidido dar por finalizada su misión. He escrito una pieza...
Por ahora sólo es un diseño conceptual, pero Cortex es una idea de Jake Evill que podría sustituir las escayolas de toda la vida que nos ponen cuando nos rompemos un hueso por una estructura de nylon impresa en 3D que...
Nos lo cuenta Daniel Marín con todo lujo de detalles en Cinco mitos de la carrera espacial que no son exactamente tal y como nos los han contado pero en un resumen rápido: El Sputnik no fue el primer objeto fabricado por...
Jamie y Adam comprueban cuán difícil es ponerse un traje espacial en las mismas condiciones de entrenamiento que utilizan los astronautas «de verdad» – que será más complicado todavía en gravedad cero, suponemos. Tal y como explican, este tipo de trajes...
Si pones un termómetro en la oscuridad en el espacio, sin nada alrededor, para medir su temperatura, primero tendría que enfriarse. Esto podría llevarle mucho tiempo porque el espacio es muy mal conductor térmico.Una vez que se hubiera enfriado, marcaría 2,7 kelvin,...
Why are blue whales so enormous? es una simpática y amena charla TED de Asha de Vos que explica el porqué del enorme tamaño de las ballenas entre otras curiosidades de estos mamíferos, que pueden llegar a medir 33 metros y...
Por Nacho Palou -
3 JUL 2013
Plutón y sus lunas Descubiertas por el Hubble en 2011 y en 2012 respectivamente la cuarta y la quinta lunas de Plutón, antes conocidas con los imaginativos nombres de P4 y P5 ya tienen nombre, tal y como puede leerse en Names...
Gracias a todo lo que hemos ido avanzando en el conocimiento de nuestro universo una de las cosas que hemos aprendido es que este está formado en hasta un 95 por ciento de materia y energía que no podemos –o al...
El Protón-M que esta pasada noche tenía que haber puesto en órbita tres satélites del sistema de posicionamiento global ruso Glonass –el equivalente al GPS estadounidense o al Galileo europeo– perdió el control apenas unos segundos después de despegar de la...
Aunque tenemos observaciones de las manchas solares documentadas desde el siglo XVII gracias a Galileo y luego al trabajo de Samuel Heinrich Schwabe y Rudolf Wolf no podemos predecir exactamente, al menos no aún, cuando el Sol va a alcanzar uno...
Pocas cosas tan gozosas debe haber en el mundo como poder tocar esta esfera perfectamente redonda y perfectamente lisa, aunque sea con guantes de laboratorio. Es tan esférica tan esférica que si se ampliara mágicamente al tamaño de la Tierra, la...
Lanzados en noviembre de 1970 y en enero de 1973 los Lunojod 1 y 2 fueron dos rover soviéticos que recorrieron 10 y 37 kilómetros sobre la superficie de la Luna. De hecho el Lunojod 2 tiene todavía, 40 años después,...
Impresión artística del GALEX en órbita Lanzado el 28 de abril de 2003 por un cohete Pegasus XL, igual que el IRIS hace apenas unos días, el GALEX era un telescopio para observar galaxias en el ultravioleta. La duración inicial prevista de...
En The Periodic Table of National pride, un trabajo de @JamieBGall, se pueden ver los elementos químicos y el pais en el que fueron descubiertos. A ojo hubiera apostado por los Estados Unidos como país que más elementos ha descubierto, pero...
Una Soyuz en Lego Para quien tenga la paciencia –y sobre todo las piezas– la galería legorealspace de John M. Knight propone hasta 21 construcciones de naves espaciales para realizar con Lego. (Vía @Brigitte_Ba). Lego fabricará un modelo del Curiosity, y con...
Desde hoy se puede visitar el nuevo pabellón dedicado al transbordador espacial Atlantis en el Complejo de Visitantes del Centro Espacial Kennedy, en el que se le puede ver como si estuviera en órbita, con las puertas de la bodega de carga...
Steve Mould explica y demuestra en este vídeo a cámara lenta un efecto de física muy curioso conocido como el collar de Newton. En él una cadena de bolitas metálicas va cayendo libremente de forma un tanto sorprendente respecto a lo...
Por si a alguien le quedaba alguna duda, la Tierra en toda su redondez vista a través de las ventanas de la Cúpula de la Estación Espacial Internacional, por cortesía de @astro_luca....
Otro de esos impresionantes vídeos hechos con imágenes tomadas por los tripulantes de la Estación Espacial Internacional, disponibles para cualquiera que quiera usarlas en The Gateway to Astronaut Photography of Earth. Este, titulado Time-Lapse | Earth, es un montaje de Bruce...
Pues nos lo explica José Miguel Viñas, AKA @Divulgameteo, en este vídeo de la Revista del Aficionado a la Meteorología. Como extra bonus además nos explica también que en realidad el cielo debería ser violeta. Salvo que vivas en Galicia, claro,...
Hace apenas unas horas el Stargazer, el Lockheed L-1011 de Orbital Sciences, lanzaba desde unos 39.000 pies de altura un cohete Pegasus a bordo del que viajaba IRIS, el nuevo observatorio solar de la NASA. Apenas veinte minutos después de un...
Aunque el segmento estadounidense de la Estación Espacial Internacional lleva ya unos años terminado Rusia tiene previsto enviar hasta cuatro módulos más a la Estación. El primero de ellos, bautizado como Nauka (ciencia) tiene previsto su lanzamiento para principios de 2014, pero...
Un MiG-15UTI similar a aquel en el que se estrellaron Gagarin y Seryogin - Foto por Denis Lyaskovskiy El 27 de marzo de 1968 Yuri Gagarin, el primer hombre en salir al espacio, moría al estrellarse el MiG-15UTI en el que estaba...
La Shenzhou 10 fue arrastrada varios metros por su paracaídas, que no de desinfló al aterrizar a causa del fuerte viento reinante La quinta misión espacial tripulada china terminaba a las 0:07 UTC del 26 de junio de 2013 con el aterrizaje...
Con la relativa facilidad con la que aparecen nuevos planetas extrasolares en la actualidad a veces es necesario salirse un poco de la norma para que el descubrimiento de alguno nuevo llame un poco la atención, como ha pasado con Gliese 667C....
Transit of Tiangong1 Chinese space station and Shenzhou-10 module por Thierry Legault Otra de esas fotazas de Thierry Legault, en este caso con la Shenzhou-10 atracada al Tiangong-11 pasando frente al Sol. La Tiangong-1 es la parte izquierda de la H que...
Interior del túnel que alberga el LHC En el Gran Colisionador de Hadrones dos haces de partículas circulan en sentido contrario por sendos anillos de 27 kilómetros de longitud prácticamente a la velocidad de la luz. Pero para que el LHC pueda...
Dentro de la famosa torre (CC) Éole Wind @ Flickr Kuriositas tiene una preciosa recopilación de fotografías inusuales de la torre Eiffel, bien por su perspectiva exterior o interior o por el uso del color u otros recursos. Desde luego unas tomas...
Las imágenes del espacio nos ponen en contacto con la grandeza del universo y hacen saltar la chispa de la curiosidad en nosotros sobre lo que habrá ahí fuera esperándonos una vez emprendamos camino a las estrellas. Este precioso documental de...
Curiosity en Rocknest 850 cuadros tomados por la Narrow Angle Camera, la cámara de Curiosity que lleva un objetivo de 100 milímetros, 21 con la Medium Angle Camera, la cámara que lleva un 34 milímetros, y otros 25 en blanco y negro...
ISS Progress 51 Cargo Craft: La M-19M a su partida de la EEI. Se aprecia la antena 2ASF-VKA del sistema de guiado KURS doblada tras no haberse desplegado correctamente antes del atraque - NASA Un frenado con sus motores iniciado a las...
La animación Particles 01: The Higgs Boson de James Sutton es una explicación sencilla y visual para entender qué es el bosón de Higgs —o qué sería dentro de la teoría física que considera su existencia, el modelo estándar de física...
Por Nacho Palou -
19 JUN 2013

Sally Ride a bordo del Challenger en 1983 La imagen del día de la NASA, First American Woman in Space, homenajea el trigésimo aniversario del lanzamiento de la misión STS-7 de la agencia, en la que Sally Ride, viajando a bordo del...
Charles Bolden, el director de la NASA, ha presentado ante el Comité para Usos Pacíficos del Espacio Exterior de las Naciones Unidas la Asteroid Initiative, el próximo gran desafío en el que está trabajando su agencia. Esta Iniciativa Asteroides tiene dos ejes...
Establecidas las pertinentes conexiones eléctricas y de datos entre la Estación Espacial Internacional y el ATV-4 Albert Einstein, comprobada que la unión entre ambas naves es estanca, y limipiada la atmósfera del interior de este de posibles partículas que se pudieran...
Desde el departamento de Todo por la Ciencia: En The Atlantic, Confirmed: 1-Billion-Year-Old Water Tastes 'Terrible', El agua encontrada ha estado atrapada a 2,5 km bajo la superficie de la Tierra durante mucho tiempo. ¿Durante cuánto? Según los análisis los científicos creen...
Por Nacho Palou -
18 JUN 2013
Diseñada para traer de vuelta a la Tierra muestras del asteroide (25143) Itokawa la misión de la sonda Hayabusa fue de esas en las que casi todo lo que podía ir mal salió mal, ya fuera por falta de previsión o por...
Su misión científica había acabado ya el 29 de abril cuando, agotado el helio líquido que mantenía sus instrumentos cerca del cero absoluto, ya era imposible continuar con sus observaciones de los objetos más lejanos y fríos del universo en las...
Tras un proceso de selección que ha durado un año y medio la NASA ha anunciado sus candidatos a astronauta de 2013, escogidos de entre más de 6.100 personas que se presentaron. Según se puede leer en NASA Selects 2013 Astronaut Candidate...

F=ma. Measuring body mass in space: hang on tight, release a known spring force, measure acceleration, calculate mass. Esta de aquí arriba es Karen N. Nyberg pesándose a bordo de la Estación Espacial Internacional. Claro que pesándose puede ser un término no...
(En inglés con subtítulos en inglés o traducción automática de subtítulos) Un divertido y a la vez inútil ejercicio teórico sobre qué pasaría si Superman te diese un puñetazo en la cara. Eso sí, en este ejercicio se respeta aquello de que...
Por Nacho Palou -
17 JUN 2013
Curiosity en Lego - Stephen Pakbaz. Más fotos en Mars Science Laboratory En 2008 Lego lanzó un sitio llamado Cuusoo –que viene a querer decir deseo o imaginación en japonés– en el que aficionados de todo el mundo pueden proponer ideas de...
Aquí Chaika, veo el horizonte como una línea azul. Es la Tierra. ¡Es hermosa! Hola, universo.- Valentina Tereshkova, 16 de junio de 1963 El 16 de junio de 1963 a las 9:29:52 UTC Valentina Tehreshkova despegaba de la plataforma de lanzamiento...
El ATV-4 Albert Einstein de la Agencia Espacial Europea está atracado en el módulo Zvezda de la Estación Espacial Internacional desde las 14:07 GMT. A pesar de que cabía la posibilidad de que la nave de carga Progress M-19M hubiera dañado...
Con lo mal parada que está saliendo la ciencia en los últimos tiempos con todo esto de la crisis económica siempre es bienvenida una noticia como que la Sociedad Max Planck para la Promoción de las Ciencias se haya llevado un Príncipe...
El Tiangong-1 a través del mecanismo de atraque de la Shenzhou-10 - foto vía @shuttlealmanac No es que desde China hayan dado demasiada información, quizás porque la misión es un poco más de los mismo que la anterior, pero desde esta mañana...
Nuestro admirado divulgador matemático Adrián Paenza participó hace algunos años en el TEDxJoven@RiodelaPlata y Luis nos ha hecho llegar ahora un enlace con el vídeo completo. Algunas referencias que hemos publicado por aquí sobre este periodista y matemático incluyen el curioso...
El Sol está haciéndose poco a poco cada vez más brillante. Se hace un 10% más luminoso cada mil millones de años.[Fuente: @NASA_SDO]...
SpeechJammer es un artilugio que hace algo así como «alterar artificialmente el habla devolviendo la voz del orador con retardo». La capacidad de hablar se ve afectada cuando el orador recibe sus propias declaraciones con una demora de unos pocos cientos...
Por Nacho Palou -
12 JUN 2013
John Howell ha creado estos efectos ópticos caseros como demostración de algunas ideas y dispositivos en los que está trabajando: sistemas de «camuflaje» o «capas de invisibilidad». Lo bueno es el efecto, totalmente sorprendente; también que las capas en cuestión están...
Si este vídeo formara parte de una película de ciencia ficción igual diríamos que a los de los efectos especiales se les había ido la mano, pero en realidad ha sido rodado en el MundoReal™. Se trata del proceso de formación...
Imagen de archivo de la Progress M-17M partiendo de la ISS Después de apenas un mes y medio atracada en el módulo Zvezda de la Estación Espacial Internacional los muelles del sistema de atraque separaban a la Progress M-19M de este a...
En IO9 publicaron 8 Great Philosophical Questions That We’ll Never Solve, que básicamenre recopila algunas de las grandes cuestiones para la humanidad: ¿Por qué hay algo en vez de nada? ¿Es real el Universo? ¿Tenemos libre albedrío? ¿Existe Dios? ¿Hay vida después...
Tal y como estaba previsto Nie Haisheng, Zhang Xiaoguang y Wang Yaping han despegado a las 9:38 UTC del 11 de junio de 2013 a bordo de la Shenzhou-10 rumbo al Tiangong-1. Se trata de la quinta misión espacial tripulada China,...
Un señor con pintas de científico loco nos enseña a cámara lenta lo que sucede cuando se arrojan trozos de carbón ardiendo en una cubeta con oxígeno líquido. Es uno de los muchos y recomendables vídeos de Periodic Videos. [Los subtítulos...
Placa metálica + sal + generador de tonos = ¡formas geométricas! ¡Tesla asentiría orgulloso! Este curioso experimento muestra lo que sucede cuando se varía poco a poco la frecuencia de un sonido que impacta en una placa metálica: los granos de...
El ATV-4 sobre Leiden vía @Marco_Langbroek; imagen compuesta por ocho imágenes individuales - Más fotos del lanzamiento en Liftoff ATV-4 Otro lanzamiento perfecto para la historia de Arianespace colocó en órbita al ATV-4 Albert Einstein prácticamente a la medianoche del 5 al...
Una predicción de Ovation para auroras boreales Depende fundamentalmente de la actividad solar, y siempre hay más probabilidades de verlas cuando más al norte o más al sur vivas, pero a veces las auroras polares llegan bastante más al sur o al...
El carenado protector del ATV-4 a punto de ser instalado La cuenta atrás para el lanzamiento del ATV-4 Albert Einstein desde el Puerto Espacial de Kourou con rumbo a la Estación Espacial Internacional, previsto para las 21:52 UTC del 5 de junio...
Cualquier diría que tras gastar miles de millones de dólares –y da igual que sean de entonces que de ahora, siguen siendo miles de millones– y de arriesgar la vida de sus astronautas, tres de los cuales fallecieron, la NASA habría sido...
Como hemos recordado muchas veces, Gattaca ya casi está aquí: hoy en día hay análisis genéticos avanzados, baratos y casi al momento. Los puedes pedir en las farmacias o incluso por Internet. Por unos cientos de euros te desvelan a qué enfermedades...

Muchos inventos han cambiando el mundo, y no es extraño que a veces lo hayan hecho por pura casualidad. Algunos se descubrieron tras invenciones fallidas (que visto lo visto no lo fueron tanto), otros debido a rocambolescas historias casi difíciles de...
Apenas llevan una semana viviendo a bordo de la Estación Espacial Internacional, pero Karen N. Nyberg y Luca Parmitano están tuiteando su experiencia todos los días, lo que es muy de agradecer, aunque tengan el precedente de Chris Hadfield contra el...
Una gloriosa coronación: casquete de hielo en el polo norte de Marte La Agencia Espacial Europea está celebrando el décimo lanzamiento de la Mars Express, que se produjo el 2 de junio de 2003 a las 17:45 UTC a lomos de un...
Según aparece explicado en muchos sitios, el récord de velocidad del viento más rápido jamás registrado en nuestro planeta es de 372 kilómetros por hora (231 millas por hora), alcanzado en el Monte Washington de New Hampshire (Estados Unidos) allá por...
Si andas por los alrededores del CERN desde hoy dispones de una nueva forma de visitar el Gran Colisionador de Hadrones. Passeport Big Bang aúna la ciencia con el ejercicio físico, ya que propone un recorrido en bicicleta alrededor del anillo del...
Un viaje a las estrellas a través de diagramas estelares antiguos, reciclados y animados con buen gusto y herramientas modernas; de paso acompañados con la peculiar música de Björk (Frosti)....
EL próximo 29 de junio está prevista la inauguración del nuevo pabellón que alberga al Atlantis en el Complejo de Visitantes del Centro Espacial Kennedy. Impresión artística del edificio que albergará el Atlantis En él estará expuesto como si estuviera en...
Toda la superficie de Mercurio - NASA/Johns Hopkins University Applied Physics Laboratory/Carnegie Institution of Washington La NASA acaba de hacer pública la imagen que recoge toda la superficie de Mercurio a la luz del Sol después de que la Messenger consiguiera la...
It's official! NASA's Dr. Michael Freilich and Colleen Hartman sign #Landsat 8 over to USGS's Suzette Kimball and Frank Kelly.— NASA Landsat Program (@NASA_Landsat) 30 de mayo de 2013 Con al traspaso del control de la misión por parte de la NASA...
A las 20:59 UTC del 31 de mayo de 2013 el asteroide (285263) 1998 QE2 pasará a «tan sólo» 5,8 millones de kilómetros de la Tierra, su aproximación más cercana durante lo que queda de este siglo, tal y como se...
Luca Parmitano entrando en la Estación Espacial Internacional - ESA Con la llegada de Luca Parmitano a la Estación Espacial Internacional a bordo de la Soyuz TMA-09M comienza la quinta misión de larga duración de la Agencia Espacial Europea a la ISS,...
4764 kilómetros de error - Not bad Si GeoGuessr, el juego en el que hay que adivinar a qué lugar pertenecen las imágenes de Street View que aparecen, te pareció complicado y a ratos desesperante, lo de Where on the Blue Marble?...
Entonces sopló y sopló y la casa derribó....
Por Nacho Palou -
30 MAY 2013
Tras un lanzamiento perfecto, y siguiendo una trayectoria rápida de cuatro órbitas, la Soyuz TMA-09M llevó a Fyodor Yurchikhin, de Roscosmos, a Karen L. Nyberg, de la NASA, y a Luca Parmitano, de la ESA, a la Estación Espacial Internacional, donde...
El jurado del Premio Príncipe de Asturias de Investigación Científica y Técnica 2013 ha concedido este galardón a Peter Higgs, François Englert por la formulación teórica y al CERN por la confirmación experimental de la existencia del bosón de Higgs. Esta partícula,...
Endulzando una cámara de combustión Los operarios del Cosmosphere and Space Center de Kansas están ya trabajando en el proceso de conservación de los componentes de los dos motores F1 que usaban las primeras etapas de los Saturno V del programa Apolo...
En The New York Times, Is Google Glass Dangerous? Es una limitación evidente del cerebro humano: no podemos mirar hacia otro sitio al que nos estamos dirigiendo durante más de unos pocos segundos sin desviarnos. Y el tiempo que dedicamos a mirar...
Por Nacho Palou -
28 MAY 2013
Jabi Luengo nos ha escrito para hablarnos del lanzamiento de la sonda estratosférica Izar Galaktik III, que el pasado 24 de abril alcanzaba los 28.000 metros de altura tras su lanzamiento desde la Estación Automática de Radiosondeo de Euskalmet en Gautegiz-Arteaga....
Una aurora austral en Saturno captada por el Hubble Se me había pasado comentar la publicación de sendos libros gratuitos en la plataforma iBooks de Apple dedicados a los telescopios espaciales Hubble y James Webb, con montones de fotos y vídeos de...
La TMA-09M sobre su lanzador (vía @Romain_CHARLES) - Más fotos en Expedition 36 La Soyuz TMA-09M ya está preparada en el cosmódromo de Baikonur para su lanzamiento el próximo martes 28 de mayo rumbo a la Estación Espacial Internacional. A bordo irán...
Gathering Of Venus, Jupiter and Mercury on May 25, 2013: Venus está abajo, Mercurio a la derecha y Júpiter a la izquierda- vía @EclipseMaps Estos días, si miras al cielo hacia el noroeste un poco después de la puesta del Sol y...
El 25 de mayo de 2008 la sonda Phoenix de la NASA se convertía en el primer vehículo espacial en aterrizar en una de las zonas polares de Marte, en concreto en el ártico marciano. Su objetivo era averiguar si, como...
El Very Large Telescope de ESO celebra 15 años de éxitos: IC 2944 vista por el VLT Hoy se cumplen 15 años desde que el primer Telescopio Unitario de los cuatro que forman el Very Large Telescope del Observatorio Europeo Austral celebrara...
Eclipse de Luna de mayo de 2014 - Fred Espenak / NASA GSFC Esta pasada madrugada se producía un eclipse penumbral de Luna que habrá pasado desapercibido para casi todo el mundo porque era prácticamente invisible, pues la Luna apenas tocaba la...
Mercurio en color gracias a la Cámada Gran Angular de la sonda MESSENGER de la NASA. En blanco o azul claro los cráteres y los fragmentos eyectados de estos sobre la superficie, en azul y azul oscuro el material «base» de...
Aprovechando que todas las imágenes que envía Curiosity desde Marte están libremente disponibles en Internet Karl Sanford ha creado un time lapse de los 281 soles que llevaba el rover en Marte desde su llegada allí el 8 de agosto de...
Los Teslianos pasaron hoy por Twitter una carismática foto de nuestro admirado Nikola Tesla, en la que ve al gran inventor en su laboratorio de Colorado Spring, medio escondido, en pequeñito, con lo que bien podría ser una pícara sonrisa. Pero...
Según la Unión Europea una enfermedad rara es aquella que afecta a menos de 5 de cada 10.000 individuos, pero dado que existen más de 5.000 de estas enfermedades la OMS estima que aproximadamente el 7% de la población se ve...
Kepler-76b en Exoplanet Exoplanet, una aplicación escrita por Hanno Rein, un astrofísico, y disponible para iPhone e iPad, es una magnífica opción para mantenerte al día de todas las novedades sobre planetas extrasolares que se producen casi cada semana. Incluye una base...
Distances Driven on Other Worlds - Karle Tate/Space.com Desde el pasado 15 de mayo de 2013 Opportunity se ha hecho con la plaza del segundo vehículo que más distancia ha recorrido sobre la superficie de otro mundo que no sea la Tierra,...
Un telescopio construido para demostrar la viabilidad de Kepler - NASA Con el fallo de una segunda rueda de reacción el telescopio espacial Kepler a mediados de mayo de 2013 ya no puede seguir buscando planetas extrasolares, la misión para la que...
Las fotos que salen en este vídeo son las que han ganado y recibido menciones honoríficas en los distintos apartados del concurso Earth & Sky 2013, organizado por The World At Night. Un requisito imprescindible para participar en el concurso era...
Una viñeta de Alex Gregory publicada en The New Yorker y traducida por @OmaCroga, muy a cuento después del programa de Salvados titulado «¿Qué comemos?» y sobre la que deberían reflexionar aquellos que se empeñan en defender la bondad de los...
SL4-143-4706: El Skylab fotografiado desde el Apolo SL 4 - NASA Casi se me pasa el 40 aniversario del lanzamiento del Skylab, la primera –y única– estación espacial estadounidense, que a diferencia de la Estación Espacial Internacional no fue ensamblada en órbita...
Impresión artística del Kepler en órbita - NASA Hacía meses que venía dando problemas, pero según se puede leer en Kepler Mission Manager Update, al final ha fallado un segundo giroscopio en el telescopio espacial Kepler de la NASA. Los volantes de...
Through the night of May 13/14 Herschel's thrusters fired for over 7 hours to put it into a non-return trajectory outside the Earth's orbit.— ESA Herschel (@ESAHerschel) 14 de mayo de 2013 Durante la noche del 14 al 15 de mayo de...
Primera erupción solar de clase X de 2013 - NASA/SDO Aunque las predicciones iniciales apuntaban a que el pico máximo de actividad del actual ciclo solar ocurriría a principios o mediados de 2013 lo cierto es que el Sol se ha mostrado...
Según publican en Discovery y Nature: '‘Junk’ DNA Mystery Solved: It's Not Needed. En otras palabras: el famoso misterio sobre para qué sirve el ADN basura que hay en la mayoría de los seres vivos pero no codifica nada –aunque supone más...
Eduardo Sáenz de Cabezón Irigaray, de la Universidad de La Rioja, ha ganado la final de Famelab España con este monólogo sobre teoremas y amor, con el que representará a España en la final internacional de Famelab en el Festival de...
Expedition 35 Landing (201305140003HQ): La TMA-07M momentos antes de aterrizar - NASA/Carla Cioffi. Más fotos en Expedition 35 (Landing Only) La misión de 146 días de Roman Romanenko, Chris Hadfield y Tom Marshburn terminaba a las 2:31 UTC del martes 14 de...
Por aquí ya mostrado nuestro escepticismo cuando se empezó a hablar de Mars One calificándolo de irrealizable; tampoco nos convenció mucho lo de que la cosa se plantee como una especie de reality. De hecho tampoco nos creemos los planes de...

Titánica obra de ingeniería, el proyecto Biosfera 2 tuvo una historia la mar de curiosa. ¡Ay, si hubieran existido los blogs y Twitter en aquella época! Habría molado. Este vídeo procedente de The Avant Garde Diaries es un relato de lo...
Bolid.es representa la caída de casi 35.000 meteoroides, principalmente de los 1045 de ellos de los cuales se tiene constancia que fueron vistos durante su entrada en la atmósfera. La mayoría de los cuerpos encontrados y observados se concentran en Europa,...
Por Nacho Palou -
13 MAY 2013
Un apretón de manos entre Chris Hafvield y Pavel Vinogradov marcó el traslado del mando Tal y como estaba previsto Chris Hadfield ha cedido su puesto como comandante de la Estación Espacial Internacional a Pavel Vinogradov, ya que está previsto que Hadfield...
Cassidy y Marshburn saliendo de la esclusa Quest - NASA Aún cuando es uno de los tipos de paseos espaciales de contingencia para los que todos los tripulantes de la Estación Espacial Internacional se entrenan ello no quita mérito ninguno al trabajo...
Este artículo se publicó originalmente en Trend It Up, un blog de Sony Mobile donde colaboramos con anotaciones sobre el mundo de las tendencias combinadas de la tecnología, el diseño y las artes. En un precioso trabajo divulgativo de Brad Goodspeed...
Eclipse parcial desde Sydney por Ángel R. López-Sánchez A final Ángel «Lobo Rayado» no se pudo resistir y sacó la cámara, un objetivo de 250 milímetros, y un filtro solar e hizo esta foto del eclipse anular del 10 de mayo de...
Una fuga de amoníaco en uno de los circuitos de refrigeración de la Estación Espacial Internacional ha obligado a desactivar uno de sus paneles solares. Aunque la situación no supone peligro alguno para la tripulación o para la nave sí es...
Un niño ciego tocando la Luna El que más el que menos se ha quedado embobado mirando al cielo por la noche, disfrutando del espectáculo que la Luna, los planetas y las estrellas nos ofrecen. Pero claro, es un espectáculo visual, aún...
Annular Solar Eclipse of May 10 - Fred Espenak / NASA A los microsiervos y a la inmensa mayoría de nuestros lectores nos pilla un poco a desmano, pero el 9 de mayo de 2013 a las 21:25:10 comienza un eclipse anular...
¿Qué sucedería si se resolviera el problema más difícil del mundo? Vale que el tema no tiene para el común de los mortales la espectacularidad de Iron Man 3, el carisma de Star Trek o la acción de Los vengadores, y...
Remote camera view of Vega VV02 liftoff: Despegue del Vega VV02 Desde las 4:06 de la madrugada del martes 7 de mayo de 2013 el cohete Vega de la Agencia Espacial Europea cuenta ya con su segundo lanzamiento con éxito, en el...
Earth, Moon, and Jupiter, as Seen From Mars - clic para ver la imagen completa en la que también sale Júpiter El 8 de mayo de 2003 a las 13:00 UTC la NASA aprovechó que se producía una alineación entre la Tierra...
Foto del panel solar agujereado - NASA En una de las múltiples fotos que hace Chris Hadfield en la Estación Espacial Internacional apareció una sorpresa en la forma de un pequeño agujero en uno de los paneles solares de esta. Según la...
Impresión artística de como quedarán el Explorer y el NASA 905 - Space Center Houston Cuando la NASA anunció a donde iban a ir sus transbordadores espaciales una vez que fueran dados de baja del servicio activo en Houston se lo tomaron...
Este vídeo explica el transfondo del proyecto Alya Red, que fue elegido mejor vídeo científico del 2012 por la National Science Foundation norteamericana y la revista Science. En él se explica cómo se crean los modelos con los que se simula...
John Mainstone, el cuidador actual del experimento, se perdió la caída de la gota de 2000, y con 78 años de edad no querría perdérselo esta vez El profesor Thomas Parnell inició en 1927 un experimento científico que todavía está en curso...
En Brilliant.org hay problemas matemáticos muchos de los cuales son casi recreaciones y cálculos mentales, pero podrían servir para las pruebas un test de inteligencia o incluso para exámenes de alguna asignatura. Entre otros hay problemas con números primos; reconocimiento de...
HereIsToday.com es una demostración práctica de que el dónde es tan importante como el cuándo, o que a veces (¿quizá siempre?) ambos conceptos son intercambiables. Basta expresar el momento actual como una gráfica de barras en la que, a diversas escalas,...
Este artículo se publicó originalmente en Sin vuelta de hoja, un blog de MásMóvil donde colaboramos semanalmente con el objetivo de contar cosas sensatas y relajantes relacionadas con la tecnología y la ciencia. Perder el tiempo en la cola del supermercado...
Al astrofísico Rhys Taylor le pareció muy mal que si buscas en Google comparaciones de los tamaños de distintas galaxias lo que te encuentras es más la comparación del tamaño de distintos teléfonos móviles. Así que un sábado se dedicó a buscar...
El laboratorio en el que Tesla y Westinghouse trabajaron en el desarrollo de la corriente alterna Del cuadro El alquimista de David Teniers el Joven a unas fotos del ENIAC en la Universidad de Pensilvania, Incredible Pictures of Early Science Labs es...
Algunas de las Eta Acuáridas de 2013 cazadas por el All Sky Camera Network de la NASA Aunque en cometa Halley sólo pasa por nuestro sistema solar aproximadamente cada 76 años nos ha dejado un par de recuerdos en forma de lluvias...
A Supercell Thunderstorm Cloud Over Montana es una espectacular imagen –hay que verla en grande para apreciarla realmente– de una supercelda, una tormenta en rotación que puede alcanzar varios kilómetros de diámetro y que es el tipo de tormenta con más...
En mis tiempos al profe de física –un gran tipo– lo teníamos desesperao en clase, todo lo contrario que aquí el amigo Andrew Vanden Heuvel, un conocido profesor y divulgador que se dedica a dar clases por Internet para gente que...
Smartphone Photos From Orbit Aprovechando en lanzamiento de prueba de un cohete Antares y una cápsula Cygnus simulada el pasado 21 de abril se ponían también en órbita tres CubeSats que llevaban en su interior otros tantos teléfonos móviles. El objetivo de...
Aproimadamente cada 26 meses la Tierra y Marte se colocan en lados opuestos del Sol, lo que hace que sea sino imposible sí poco recomendable intentar comunicarse con la flotilla de sondas y rovers que tenemos dando vueltas por allí. No...
Impresión artística de la MAVEN en órbita alrededor de Marte Si todo va según lo previsto el próximo 18 de noviembre la NASA lanzará la sonda MAVEN con destino a Marte para estudiar su atmósfera y, quizás, ayudar a averiguar por qué...
Cady Coleman, de la NASA, a la izquierda a bordo de la Soyuz TMA-20 Con la retirada del servicio de los transbordadores espaciales los Estados Unidos no sólo se quedaron sin la enorme capacidad de carga de estos sino que también se...
El simulador de carga de la Cygnus en el momento de su separación de su lanzador Orbital Sciences es la segunda empresa con la que la NASA ha contratado el lanzamiento de cápsulas de carga con destino a la Estación Espacial Internacional...
La galaxia de Andrómeda vista por el Herschel, en color falso, por supuesto, ya que el Herschel «veía» en el infrarrojo y en longitudes de onda submilimétricas El telescopio espacial Herschel diseñado para observar desde el espacio algunos de los objetos más...

La han titulado A boy and his atom y aunque artísticamente no sea gran cosa es literalmente la película más pequeña del mundo – récord Guiness oficial incluido. Cada fotograma de la animación se creó y fotografió en los laboratorios de...
Recorte del original; clic para ver completo Alguien debe espiarme en la NASA, porque justo estaba empezando a preparar una charla sobre las misiones activas o venideras de exploración del sistema solar y van y publican Humanity Explores the Solar System, una...
La que aspira a ser la primer nave desarrollada con capital privado en llegar al espacio, el VSS Enterprise, llevó a cabo hoy su vuelo de prueba número 27, en el que se encendió su motor cohete por primera vez. El...
Chris Hadfield está llevando a nuevos extremos el concepto de tuitear desde la Estación Espacial Internacional, ya que no solo tuitea y envía fotos a diario, disculpándose cuando puede tuitear poco, sino que hace poco se dio cuenta de que un cierto...
Las ecuaciones de Maxwell, por poner un ejemplo, nos permiten explicar cómo se trasmite la información para la televisión, Internet y los teléfonos, cuánto tarda en llegar la luz de las estrellas, cuál es la base del funcionamiento de las neuronas o...
Impresión artística de Kepler-61B Con la confirmación de que el candidato a planeta conocido como KOI 1361.01 realmente existe, y rebautizado como Kepler-61b, este se convierte en el décimo planeta extrasolar o exoplaneta potencialmente habitable que conocemos. Como siempre lo de potencialmente...
Luna eclipsada y avión por Philip Corneille – FRAS (Bégica) Aunque no prometía gran cosa, ya que en el momento de máximo eclipse apenas un 1,5 por ciento de la superficie lunar iba a estar en la sombra producida por la Tierra,...
Uno de los brazos del KMOS - ESO La lista de telescopios que hay en Gallery: The Seven Most Incredible Telescopes In Existence es un tanto optimista pues algunos de los que incluye todavía están siendo construidos, y como cualquier lista es...
Qué simpáticas fotos estas de la Universidad de Cornell en las que unos estudiantes de veterinaria practican la reanimación de emergencia con un entrañable y peludo perro… que en realidad es un perro robótico, eso sí. Los llaman simplemente robo-pets. Además...
Saturn and some of its moons. From left to right Titan, Rhea, Dione, Enceladus, Saturn and Thetys. twitter.com/lrargerich/sta…— Luis Argerich (@lrargerich) 28 de abril de 2013 Durante la noche del 28 al 29 de abril de 2013 Saturno se coloca a la...
Además del problema para el funcionamiento del sistema de guiado KURS que suponía que la antena 2ASF-VKA no se hubiera desplegado existía una cierta preocupación de que esta en su posición plegada interfiriera en el funcionamiento del mecanismo de acople de...
Iberian Peninsula, otra foto de la esquinita del mundo en la que vivimos los microsiervos, por cortesía de los miembros de la Expedición 35 a la Estación Espacial Internacional. Por lo que cuenta la NASA, es una de las pocas imágenes...
Aunque la inauguración del nuevo edificio que lo aloja en el Complejo de Visitantes del Centro Espacial Kennedy no se inaugurará hasta el próximo 29 de junio ya circula por ahí esta foto del Atlantis instalado en él, justo cuando los...
Diseñado para poder obtener imágenes que sirvan para ayudar a los que tienen que tomar decisiones sobre temas de medio ambiente en países en desarrollo, la NASA acaba de poner en línea la galería de imágenes del ISERV. Se trata de...
Todos somos iguales, pero también un poco diferentes: se ha calculado que el 10 por ciento de la gente es zurda, el 8 por ciento tiene ojos azules y el 1 por ciento es pelirroja. Pero hay otras mutaciones y rasgos...
Impresión artística del púlsar PSR J0348+0432 y su compañera enana blanca Aún para tratarse ser un púlsar PSR J0348+0432 es un objeto peculiar. Se trata de una estrella de neutrones que gira 25 veces por segundo sobre si misma y que con...
Algunas galaxias tienen un ritmo de creación de estrellas nuevas muy superior al normal, un proceso enormemente energético que desde hace tiempo sabíamos que afecta a toda la galaxia en el que se está produciendo. En concreto lo que sucede es que...
Visibilidad del eclipse - Fred Espenak, NASA GSFC Esta tarde/noche se puede ver un eclipse parcial de Luna visible desde Europa, parte de Asia y África, aunque incluso en el momento de mayor intensidad apenas un 1,5 por ciento de la superficie...
Este vídeo recoge el paso –tránsito, tal y como se denomina en astronomía– de la Estación Espacial Internacional frente al Sol el 20 de abril de 2013 a las 17:35:32, y aparte de la ISS se ve la región activa 1726...
Un cohete Soyuz-U se encargaba de lanzar la nave de suministros Progress M-19M rumbo a la Estación Espacial Internacional a las 10:12 UTC de hoy, 24 de abril de 2013, insertándola en su órbita inicial prevista de 193,5 por 247,2 kilómetros...
Han pasado por mis feeds un par de fotazas de la Vía Láctea que me han hecho acordarme, una vez más, de lo que supone la pérdida de la oscuridad a la que nos hemos visto abocados en los últimos tiempos. Esta...
Según ScienceNow, unos científicos franceses han realizado unos interesantes estudios sobre la consciencia y memoria en el cerebro de los bebés. Gracias a esto han determinado mediante comparación con los patrones de señales cerebrales de adultos que los primeros signos de memoria...
Una paciente inyectándose insulina Probablemente todos conocemos a alguien que padece diabetes, e incluso a alguien que por ello tiene que inyectarse insulina, algo a lo que hoy en día no le damos mayor importancia porque su disponibilidad es algo que damos...
The Russian Progress 49 - NASA Tras partir de la Estación Espacial Internacional el pasado 15 de abril la Progress M-17M terminaba su misión el domingo 21 con una reentrada controlada en la atmósfera que causó su destrucción, tal y como estaba...
Como sigan recortando en ciencia, la tierra volverá a ser plana.— simpulso (@simpulso) 7 de febrero de 2013 De La política científica española necesita un giro de ciento ochenta grados, una traducción de Natalia Ruiz Zelmanovitch del editorial de Nature de mayo...
El cometa ISON captado por el Hubble - NASA, ESA, J.-Y. Li (Planetary Science Institute), and the Hubble Comet ISON Imaging Science Team Descubierto en septiembre de 2012 por la International Scientific Optical Network (ISON), o Red Científica Óptica Internacional, el cometa...
NASA/SDO/AIA/S. Wiessinger La imagen de arriba combina otras 25 tomadas por el Solar Dynamics Observatory de la NASA entre el 16 de abril de 2012 y el 15 de abril de 2013. Tal y como se puede leer en Three Years of...

Un equipo del CERN ha preparado esta pieza divulgativa sobre cómo se procesan los datos generados por el Gran Colisionador de Hadrones (LHC) cada día. Los datos hablan por si solo: se trata de capturar información sobre 600 millones de colisiones...
Lyrid Meteor Shower: Al menos cuatro de las Líridas de 2007 - Imagen CC por Phillip Chee Si vives en España y no está nublado ni hay demasiada contaminación lumínica durante la noche del 22 al 23 de abril de 2013 puedes...
Elements - Experiments in Character Design comenzó como el trabajo de fin de carrera Kaycie D. en el que diseñó los personajes de los 72 primeros elementos químicos, serie que luego completó hasta llegar a los 112 conocidos en noviembre de...
La nebulosa Cabeza de Caballo en el infrarrojo, arriba, y en luz visible, abajo - NASA, ESA, and the Hubble Heritage Team (AURA/STScI); ESO Todos los años, para celebrar el cumpleaños del Hubble, la ESO y la NASA publican una imagen especial,...
Representación artística de Kepler-62f, que es la estrella de esta nueva hornada de exoplanetas La NASA acaba de hacer público que dos nuevos estudios de los datos obtenidos por el observatorio espacial Kepler, diseñado para localizar planetas extrasolares, acaban de identificar otros...
Hugh Everett asentiría orgulloso creo yo ante esta explicación en un vídeo de tres minutos de su hipótesis de los universos paralelos para explicar la mecánica cuántica. Tal y como se explica en la Wikipedia, En esta interpretación cada evento involucra...
¿Cuanto tiempo hace que no ves la Vía Láctea? Seguro que bastante, ya que la contaminación lumínica nos está robando la posibilidad de ver el cielo nocturno tal y como se merece. La pérdida de la oscuridad es un documental sobre...
Correcto Y en este vídeo la demostración—vía Explorer, Así que en el espacio nadie puede oir tus gritos y encima al parecer puedes morir ahogado con tus propias lágrimas....
Por Nacho Palou -
17 ABR 2013
El Antares A-ONE en su plataforma de lanzamiento - Brea Reeves / NASA Wallops Flight Facility Tras la retirada del servicio de los transbordadores espaciales la NASA contrató a SpaceX y a Orbital Sciences para que se encargaran de llevar suministros a...
Anda circulando por ahí una noticia que habla de un riñón «artificial» de rata fabricado en un laboratorio que una vez trasplantado a una rata fue capaz de filtrar su sangre y producir orina, aunque de forma menos eficaz que un...
La primera edición de Famelab España, el certamen para divulgar ciencia con risas y monólogos, ya tiene finalistas. Miguel Abril Martí, de Instituto de Astrofísica de Andalucía (CSIC), Daniel García Jiménez de la Universidad Pompeu Fabra, Helena González Burón del Institut...
No tenía ni idea de que existía esto… … pero obviamente que al lector RSS va directo; al parecer han publicado ya seis números – voy a bajar algunos a ver qué tal por dentro. Geek está disponible tanto en papel como...
Una interesante charla de José Manuel López Nicolás, el autor de Scientia, en TEDx Murcia en la que explica qué hay de cierto (spoiler: más bien poco) en los claims de muchos de los alimentos que podemos comprar en el supermercado....
Tom Whyntie, un físico del CERN, explica en este vídeo de TED-Ed qué sabemos de cómo comenzó nuestro universo y por qué necesitamos máquinas como el Gran Colisionador de Hadrones para avanzar en este conocimiento. Hay subtítulos en español. Ya sabes,...
Este cartel de Jess Bradley recopila a todos los perros que participaron desde el lado soviético de la carrera espacial; toda una preciosidad: Soviet Space Dogs. Aunque Laika es la que ha quedado en la memoria colectiva como ejemplo del sacrificio...
Modelo del aterrizador de la Mars 3 en el museo del Monumento a los Conquistadores del Espacio de Moscú El 2 de diciembre de 1971 la sonda soviética Mars 3, a pesar de haber sufrido una pérdida importante de combustible, entró en...
Los algo más de cuatro millones de personas que han nacido gracias a las técnicas de las que fue pionero, sus familiares, y los que apreciamos lo que ha hecho por millones de personas que de otra forma no habrían podido tener...
El Planck en las instalaciones de la ESA durante su preparación para el lanzamiento Lanzado para estudiar la radiación de fondo de microondas, la huella del Big Bang, al observatorio espacial Planck le quedan apenas unos meses de servicio, aunque ha durado...
Parece ser que estos días se está celebrando la World Homeopathy Awareness Week, algo así como la Semana Mundial de Apreciación de la Homeopatía, creada por lo visto para que la gente de todo el mundo tome conciencia de lo que...
Aunque el Espectrómetro Magnético Alfa 02 o AMS-02 estuvo a punto de quedarse en tierra porque tras el desastre del transbordador espacial Columbia en 2003 simplemente se había quedado sin sitio en las misiones programadas de estos, la NASA al final...

Padre + Madre = Probabilidad del color de ojos resultante Esta estupenda tabla me pareció muy ingeniosa porque resume en unos cuantos iconos las probabilidades respecto al color de ojos de los hijos según sean los colores de ojos de los padres...
No soy muy de coches, pero cada vez que veo que sale en la televisión el anuncio de Audi que se pregunta para qué sirve la tecnología si no es para emocionar porque casi sale un fragmento minúsculo de uno de...
Estaba un día el Integral de la Agencia Espacial Europea haciendo sus cositas en el espacio cuando detectó, por casualidad, ya que no estaba mirando para allí, un subidón de rayos x.
En Co.Exist, Forget Fukushima, Nuclear Power Has Saved 1.8 Million Lives, Dos investigadores de la NASA han calculado que 4.900 personas murieron entre 1971 y 2009 debido a la energía nuclear (principalmente por accidentes laborales y escapes radiactivos) pero también afirman que...
Por Nacho Palou -
10 ABR 2013
Esta imagen del volcán submarino de El Hierro capturada en color real por por el satélite Earth Observing-1 de la NASA y que fue imagen del día del Observatorio de La Tierra de la NASA el 16 de febrero de 2012...

En 5 segundos sin oxígeno, el hidrógeno se libera, las células estallan y el planeta pierde presión: un día normal, claro.
En The New Yorker, The Nocebo Effect: How We Worry Ourselves Sick, Las víctimas del síndrome del wifi afirman que las emisiones de radio de las comunicaciones móviles causan dolor de cabeza, náuseas, cansancio, hormigueos, dificultad para concentrarse y problemas gastrointestinales, entre...
Por Nacho Palou -
8 ABR 2013
La VKA23 o M-48 de 1959 Cualquier espaciotrastornado que se precie sabe, más o menos, la historia de la Burán, la lanzadera espacial soviética que podía haber superado al transbordador espacial de la NASA. Pero resulta que en la URSS ya estaba...
Sí, otro vídeo montado con fotos tomadas por los tripulantes de la Estación Espacial Internacional, pero con tormentas, ciudades iluminadas por la noche en contraste con desiertos oscuros, auroras polares, y la belleza de esa nave espacial a la que llamamos...
How Far is it to Mars? es una brillante represetación gráfica —usando píxeles como unidad de referencia— de la enorme distancia que nos separa de Marte, destino previso para la década de 2030 y que requiere unos 150 días de viaje...
Por Nacho Palou -
4 ABR 2013
Welcome Aboard! Pavel Vinogradov, Aleksandr Misurkin y Chris Cassidy a su llegada a la Estación Espacial Internacional El pasado viernes a primera hora de la madrugada llegaban a bordo de la ISS los tres miembros del complemento de la Expedición 35, llevando...
Me encontré con este vídeo que profundiza en cómo un ingeniero nerd y gafotas de 26 años salvó el culo a los astronautas de la misión Apolo 12 acordándose de dónde estaba un botón del que la mayoría de los especialistas...
Apollo 11 In 100 Seconds es un bonito homenaje de Spacecraft Films que resume en 100 segundos la misión del Apolo 11, la primera que puso a unos seres humanos sobre un astro distinto a la Tierra. (Vía zemiorka)....
Representación artística de la Pioneer 11 en el espacio En 1980 algunos científicos que trabajaban con los datos de las sondas Pioneer 10 y 11 se dieron cuenta de que estas estaban frenando algo más despacio de lo previsto por la ley...
Confusión y pánico, para empezar: exactamente a los 8 minutos nos veríamos en total oscuridad; eso es lo que tarda la luz del Sol en llegar a nosotros – curiosamente, Júpiter continuaría reflejando la luz solar durante unos 30 minutos. Los...
Por lo visto existen unas 400 ciudades en el mundo con una población igual o superior a un millón de habitantes. En High-Res Images of Cities at Night (from ISS) ven unas cuantas de ellas fotografiadas por la noche desde la...

Nature ha publicado este vídeo de una nanopartícula en la que cada uno de los puntitos que puede verse –si se relaja el concepto «ver»– es un átomo individual. Es un trabajo de científico de UCLA que se está utilizxando para...
Mars Gigapixel Panorama - Curiosity rover: Martian solar days 136-149 en Out of this World Por si a alguien no le parecen suficientes las imágenes que envía Curiosity y que están disponibles prácticamente en tiempo real Andrew Bodrov ha montado este espectacular...
Esta es sólo una pequeña parte del diagrama de Venn de la charlatanería y el irraciocinio; haz clic en la imagen o en el enlace para verlo entero. Es una traducción de The Venn Diagram of Irrational Nonsense de @Crispian_Jago. (Vía...
Ever nos escribió para contarnos que está trabajando con Henry Reich en la producción de una versión en español de MinutePhysics, esas pequeñas joyas que ya hemos sacado por aquí en unas cuantas ocasiones, y que esperan llegar a poner al...
Expedition 35 Soyuz Rollout (201303260022HQ): La Soyuz TMA-08M en la plataforma de lanzamiento - NASA. Más fotos en Expedition 35 y en Soyuz TMA-08M - Soyuz FG Rollout Pavel Vinogradov, Aleksandr Misurkin y Chris Cassidy despegarán esta noche a bordo de la...
Dos veces al año, una entre el 20 y el 21 de marzo, y otra entre el 22 y 23 de septiembre, el Sol alcanza el cenit justo sobre el plano del Ecuador, momento en el que los dos hemisferios reciben...
Un vídeo de BuzzFeed inspirado en esta colección de imágenes de comida representando 200 Calorias. Es curioso ver por ejemplo que —en lo que a la ingesta pura y dura de calorías se refiere (sin considerar grasas ni otra cosas)— aporta...
Por Nacho Palou -
27 MAR 2013
La ciencia no tiene ni idea de cómo emerge la mente consciente.– Xurxo MariñoEn La Voz de Galicia...
Voyager 1 por XKCD No había visto la ilustración de XKCD sobre el enésimo anuncio de que la Voyager 1 había salido del sistema solar, algo que la NASA desmintió rápidamente, pero que coincide bastante con lo que dije al ver la...
And I'm back in the game! I've resumed science investigations on Mars [status report] go.nasa.gov/16UhCRi— Curiosity Rover (@MarsCuriosity) 25 de marzo de 2013 Tras una serie de problemas con sus ordenadores de a bordo Curiosity por fin vuelve a estar completamente operativo,...
La Dragon CRS-2 segundos antes del amerizaje - SpaceX #Dragon is on the recovery boat, cargo is safe and sound. All heading home to California.— SpaceX (@SpaceX) 26 de marzo de 2013 Hoy a las 16:34 UTC terminaba la misión de la...
Primera imagen del Landsat 8 - USGS/NASA Earth Observatory Aunque no será formalmente el Landsat 8 hasta que la NASA termine de probar y calibrar los instrumentos de a bordo y ceda su control al Servicio Geológico de los Estados Unidos, el...
Creado en el año 2000, el National Recording Registry, el Registro Nacional de Grabaciones, es una colección de sonidos que «son cultural, histórica o estéticamente importantes, y/o informan o reflejan la vida en los Estados Unidos». Lleva desde 2002 recogiéndolos, y...
Cójase una erupción solar clase M1, espérense un par de días a que la eyección de masa coronal que produce llegue a la Tierra, plántese una cámara con un objetivo de ojo de pez… Y si sabes lo que haces puede...
El superordenador Cray XE6 Grace Hopper del NERSC El Planck, con cuyos datos se acaba de hacer pública la imagen más detallada y antigua de nuestro universo, genera unas 10.000 mediciones por segundo. Además, es necesario separar esas mediciones del ruido y...
Aunque hace años que no uso despertador me ha parecido interesante esta explicación sobre el uso de la opción posponer alarma --botón snooze en los despertadores. Al parecer su utilización habitual puede hacer que te levantes más cansado que levantándote de...
Por Nacho Palou -
22 MAR 2013
La radiación de fondo de microondas vista por el Planck, con las anomalías detectadas por este resaltadas - ESA and the Planck Collaboration. Clic para ver en grande Durante sus primeros cientos de miles de años de existencia el universo no era...
K.P. Kaiser se ha construido un chisme con Arduino que sirve para medir la frecuencia cardíaca durante ciertas actividades, como pueden ser meditar o navegar por la web. Tal y como dicen en Hack-a-day que es donde lo vi, lo curioso...
Tobera de un F-1 - Bezos Expeditions El caso de espaciotrastorno de Jeff Bezos, el fundador de Amazon, es especialmente fuerte, pues además de haber fundado Blue Origin, una empresa dedicada a desarrollar tecnologías que permitan el acceso al espacio con un...
Safety Dance: Team diagnosed software issue that prompted weekend safe mode. Back to science in a few days go.nasa.gov/109o4kq— Curiosity Rover (@MarsCuriosity) 18 de marzo de 2013 No bien acababa el equipo de Curiosity de recuperar el ordenador A de a bordo,...
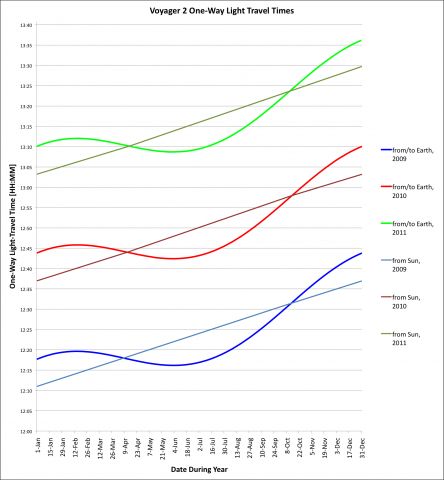
Según la época del año, entre febrero y junio la distancia de la sonda Voyager hasta la Tierra disminuye un poco cada día.
En Minute Physics intentaron ayudarnos a visualizar cómo son de grandes los 93.000 millones de años luz que se calcula que tiene de diámetro el universo observable. Como la medida comparativa habitual para estas cosas, el campo de fútbol, resultaba un...
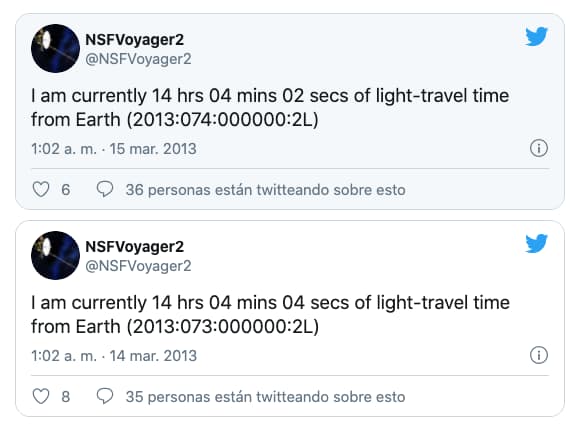
Estaba el otro día revisando los datos de la sonda Voyager 2 que la NASA vuelca en una simpática cuenta de Twitter según se reciben cuando algo extraño me pareció entrever. Estos son los datos del día 15 de marzo y antes...
Podría tratarse del título de una película de Disney, pero en realidad Daniel Marín nos recuerda que además de Laika y la multitud de monos que los Estados Unidos y la Unión Soviética lanzaron al espacio, con mejor o peor fortuna, fueron...
Este artículo se publicó originalmente en Trend It Up, un blog de Sony Mobile donde colaboramos con anotaciones sobre el mundo de las tendencias combinadas de la tecnología, el diseño y las artes. La relación entre matemáticas y música es tremendamente...
Aproximación al espacio disponible en la nave - Inspiration Mars Uno de los grandes desafíos de Inspiration Mars, la que pretende ser la primera misión tripulada a Marte, es encontrar dos personas que sean capaces de soportarse durante 502 días en un...
Como cada 14 de marzo (3/14 en anglosajón) hoy es el día de pi. Uno de nuestros números favoritos, si no el que más: redondo, abarcador de todos los demás (o casi), encarnación de la aleatoriedad (cuasi)perfecta y constante matemática idolatrada...
El efecto es realmente curioso: emitir una onda sinusoidal a 24 Hz al tiempo que se graba a 24 fotogramas por segundo. El resultado ya lo habíamos visto en experimentos similares, aunque un poco diferentes: aunque el chorro cae normalmente con...
La mano robot es tan sensible que permite teclear en el ordenador, repartir naipes, pelar verduras, atar zapatos y que el paciente pueda vestirse por sí mismo. La mano tipo Terminator se mueve como una extremidad humana real [incluso hace algún...
Por Nacho Palou -
13 MAR 2013
Creo que pocos podremos poner en práctica los trucos y consejos que da Don Pettit en este vídeo acerca de cómo hacer fotografías en y desde la Estación Espacial Internacional, pero aún así, e incluso aunque no entiendas ni papa de...
Supongo que son los peligros de intentar dar las novedades de una rueda de prensa de la NASA desde un noticiario de televisión en directo, pero acabo de ver estupefacto como en la Sexta anunciaban que Curiosity había encontrado señales de vida...
Seguro que hay muchos más, pero de momento Dave MacLean del Centro de Servicios Geográficos de los Estados Unidos ha recopilado en una web unas cuantas imágenes tomadas desde la Estación Espacial Internacional y las ha ubicado sobre el mapa: Nuestro...
Rhea 'Rev 183' Raw Preview #1 - NASA/JPL-Caltech/SSI Aunque la Cassini sigue funcionando espectacularmente bien a pesar de llevar casi nueve años en órbita alrededor de Saturno, habiendo excedido con creces su misión primaria, cumplida el 30 de marzo de 2008, hay...
Antes de ayer éramos bichejos de este estilo, como quien dice. Hay un montón de estos microorganismos fotografiados y en vídeo en PlanktonChronicles.org: renacuajos, micro-medusas, embriones… Tan pequeños y tan bellos a la vez....
Toda una flotilla de cargueros espaciales se encarga de llevar suministros a la Estación Espacial Internacional; en Orbital Delivery hay una infografía en la que salen todos los que están en activo, y la Cygnus de Orbital Sciences Corp, aún en...
Construido con el panel tipo lente Fresnel de un viejo televisor proyector de 50 pulgadas, el Rayo de la Muerte de Grant Thompson puede producir un punto de concentración solar de más de 1000 grados, suficiente para derretir monedas, incendiar madera,...
Por Nacho Palou -
11 MAR 2013
Física de EGB convertida en entretenimiento, perfecta para entretener —y enseñar— a los más pequeños: The Flying Bag, vía Mental Floss....
Por Nacho Palou -
11 MAR 2013
La sonda New Horizons producirá más de 140 gigas de datos en los aproximadamente seis meses que pasará estudiando Plutón en 2015, aunque necesitará más de un año para enviarlos a la Tierra comprimidos sin pérdida. Es una velocidad equivalente a...
Además de la primera cápsula de carga desarrollada por una empresa privada que lleva suministros a la Estación Espacial Internacional SpaceX intenta también desarrollar una versión reutilizable de sus lanzadores, para lo que está probando las tecnologías en el Grasshopper (saltamontes)....
La vida en la Tierra es captada a través de la tecnología de un satélite. Este detecta cualquier incidencia que se produce en el Planeta, inundaciones, incendios, movimientos de las corrientes oceánicas y cuánta nieve ha caído o caerá durante la...
Hace tiempo que no poníamos una foto de las que hace la Cassini, pero esta merece mucho la pena: ese punto brillante que se ve entre los anillos de Saturno no es un fallo de la foto ni un pixel muerto...
Además del compartimento presurizado en el que viaja la carga a la que acceden los tripulantes de la Estación Espacial Intenacional desde el interior de esta las cápsulas Dragon tienen una especie de maletero abierto al espacio de 14 metros cúbicos...
De izquierda a derecha, todos a la misma escala: Mercurio, Venus, la Tierra y la Luna, Marte, Júpiter, Saturno, Urano, Neptuno, y los planetas enanos Plutón, Haumea, Makemake y Eris, aunque en honor a la verdad, falta Ceres, que es un...

Space Frontiers, de J R Eyerman para la revista Life, es una bonita mini-galería de imágenes de la NASA, incluyendo esta que muestra cómo los ingenieros colaboraban a principios de los 60 cuando eso de los ordenadores para trabajo en grupo...
El marcianito del Hubble - NASA y ESA Bueno, vale, no se trata de un marcianito de los de Space Invaders ni de ninguna película de ciencia ficción de serie B ni Z sino de unas galaxias muy, muy lejanas que a...
Thanks for the well wishes! I'm out of "safe mode" and expect to resume full operations next week. go.nasa.gov/Vws8Lb— Curiosity Rover (@MarsCuriosity) March 5, 2013 Un fallo en la memoria flash del ordenador A de Curiosity obligó a los responsables de la...
La gravedad nos mantiene a todos con los pies en el suelo. Pero debido a que la Tierra gira sobre su propio eje también nos vemos «expulsados» por la fuerza centrífuga en sentido contrario, hacia el exterior del planeta. Si la Tierra...
Chelyabinsk Meteor Flash: el Metorito de Cheliábinsk fotografiado por Marat Ametvaleev como Imagen Astronómica del Día del 24 de febrero de 2013 Nuevos análisis de la trayectoria calculada para el meteorito de Cheliábinsk a partir de las imágenes captadas por cientos de...
Este montaje de una cuerda girando grácilmente gracias a dos motores forma parte de una colección seleccionada por Douglas Repetto y Stefan Hutzler para el museo de Dublín, donde hay muchas más cosas que giran, vibran oscilan y se mueven de...

Seguro que este no lo conoces, ¡hay que verlo hasta el final! Según cuentan en Steve Spangler Science la ciencia que hay detrás de este el sorprendente efecto consiste en una combinación de electricidad estática y fricción. Cargando negativamente el globo...
El resultado se puede ve en el vídeo: una preciosa erosión fractal. Se trata de un curioso experimento de Melanie Hoff que aquí se muestra acelerado, y en cuyos dibujos influyen las vetas de la madera, sus direcciones y las capas...
La Dragon CRS-2 sobre África durante su aproximación - NASA A pesar del susto que dieron los motores cuando no se encendieron tras su separación de la segunda fase del Falcon 9 que la lanzó la Dragon CRS-2 llegó hoy a la...

Unos amigos lanzaron un globo de helio a la estratosfera desde la ciudad de Vigo. El ingenio iba equipado con una cámara GoPro que es la que grabó las imágenes; también llevaba un par de GPS: el primero enviaba la posición...
#Dragon is GO for approach to station early Sunday AM! Grapple targeting 6:00A ET/3:00A PT. Updates here and spacex.com/webcast— SpaceX (@SpaceX) 2 de marzo de 2013 Solucionados los problemas con los motores de la Dragon CRS-2, ajustada su órbita para aproximarse a...
Autorretrato panorámico de Curiosity, APOD del 22 de febrero de 2013. Clic para ver entero. Un fallo en el ordenador A de Curiosity a la hora de escribir datos en su memoria flash ha obligado a los responsables de la misión a...
El lanzamiento de la CRS-2/SpX-2 visto desde la Estación Espacial Internacional El Falcon 9 encargado de lanzar la Dragon CRS-2 funcionó a la perfección, dejándola en una órbita de 199 por 321 kilómetros apenas transcurridos 10 minutos desde el despegue, a diferencia...
Un tanto complicada de escribir en su representación como ecuaciones paramétricas… Pero Wolfram Alpha siempre está ahí al rescate para trazar el resultado: La curva de Zoidberg. (Vía Proof.)...
Protoplaneta alrededor de HD100546 Según cuentan desde el Observatorio Europeo Austral en ¿El nacimiento de un planeta gigante? la imagen de arriba es la primera que se ha obtenido jamás de un protoplaneta, aunque en realidad aún falta por confirmarlo. Se trata...
Prueba de motores del Falcon 9 que lanzará la Dragon CRS-2 Tras las últimas comprobaciones SpaceX tiene la autorización de la NASA para lanzar la segunda misión regular de una cápsula Dragon de carga, oficialmente la SpaceX CRS-2, rumbo a la Estación...
Somos lo suficientemente inteligentes y tenemos un programa espacial. No tenemos por qué extinguirnos por un asteroide. Tenemos más posibilidades de las que tuvieron los dinosaurios. En Vice, La última misión submarina de la NASA para salvar la Tierra es un...
Por Nacho Palou -
28 FEB 2013
Representación artística de la nave de Inspiration Mars rodeando Marte Dennis Tito ha revelado hoy los detalles de lo que él considera el próximo gran desafío para los Estados Unidos, que no es otra cosa que enviar a un matrimonio en una...
Fire on Space Station - the alarms just rang, we reacted as-trained, used sensors to sniff behind suspect panels, false alarm. Good thing.— Chris Hadfield (@Cmdr_Hadfield) February 27, 2013 Los tripulantes de la Estación Espacial Internacional se llevaron hoy un buen susto...
Chelyabinsk Meteor Flash: el Metorito de Cheliábinsk fotografiado por Marat Ametvaleev como Imagen Astronómica del Día del 24 de febrero de 2013 Aunque el meteorito de Cheliábinsk pilló a todo el mundo por sorpresa los datos registrados por la red de detectores...
Aunque no se han encontrado restos arqueológicos que lo confirmen, Cádiz es la ciudad occidental de cuya fundación hay referencias más antiguas. Estas referencias sitúan la fundación de la ciudad entre los siglos XIII y XI a. C., con lo que...
Zapped, Martian Rock: Marcas de la ChemCam - NASA/JPL-Caltech/MSSS/Honeybee Robotics/LANL/CNES Una de las fotos publicadas recientemente por la NASA deja ver los agujeros que la ChemCam de Curiosity ha dejado en la roca llamada Wernecke mientras los responsables de la misión buscaban...
Una de las ventajas de estar en la Estación Espacial Internacional es que ves amanecer entre 16 y 18 veces al día y que puedes hacer fotacas como esta… Claro que a cambio tienes que beberte tu propia orina (y la...
Es grandísimo. Y se expande. ¿Es el universo observable lo mismo que el resto del Universo? ¿Tiene centro? ¿Es infinito? Si miramos al cielo podemos ver luz que llega desde 13.800 millones de años luz de distancia, procedente incluso de objetos...
Después del desastre del Columbia cada lanzamiento de un transbordador espacial pasó a ser filmado por más de 125 cámaras que desde todos los ángulos obtenían imágenes para su análisis para detectar posibles problemas como el que provocó la destrucción del...
He aquí un tatuaje con un mensaje de profundidad cósmica, el clásico Somos polvo de estrellas (I am star stuff) reconstruido a base de un esquema de aminoácidos y moléculas. (…) La impresión de “infinito” que nos produce mirar al firmamento...
Orbital Sciences Corporation es una de las empresas con las que la NASA ha contratado el lanzamiento de suministros a la Estación Espacial Internacional para sustituir, aunque sólo sea parcialmente, la capacidad perdida con la retirada de los transbordadores espaciales. En concreto...
Chelyabinsk Meteor Flash: el Metorito de Cheliábinsk fotografiado por Marat Ametvaleev como Imagen Astronómica del Día del 24 de febrero de 2013 Tenemos montones de imágenes en vídeo del meteorito de Cheliábinsk gracias a la muy extendida costumbre que hay en Rusia...
Impresión artística de Kepler 37-B - ESO/L. Calçada Las observaciones del Kepler han permitido confirmar la existencia de Kepler-37b, un planeta extrasolar en órbita alrededor de una estrella en la constelación de Lyra situada a unos 210 años luz de la Tierra....
Se calcula que cada día caen sobre la Tierra unas cien toneladas de material procedente del espacio. La inmensa mayoría de este se quema en la atmósfera. Pero tal y como nos recordó el meteorito hace unos días en Cheliábinsk, a...
La pala de recogida de muestras de Curiosity mide unos 4,5 centímetros de ancho - NASA/JPL-Caltech/MSSS Ese polvo grisáceo que se ve en la pala del brazo de Curiosity es la primera muestra de roca perforada recogida por este, lo que por...
Bueno, vale, en realidad no es fuego sino que son gases del interior del Sol a tal temperatura que pierden sus electrones y se ionizan, condición en la que las líneas del campo magnético del Sol lo atraen con más fuerza...
Los cálculos más recientes de la Agencia Espacial Europea estiman que el meteorito que cayó sobre Cheliábinsk el 15 de febrero tenía una masa de entre 7.000 y 10.000 toneladas y un diámetro de unos 17 metros, y que estalló en...
Aunque pasó por aquí mismito en términos cósmicos el asteroide 2012 DA14 no es que sea muy grande, así que aparte de ser imposible de seguir a simple vista, tampoco es que haya dejado imágenes muy espectaculares. De todos modos, me quedo...
Good Morning, Earth! Today we transition the Space Station's main computers to a new software load. Nothing could possibly go wrong.— Chris Hadfield (@Cmdr_Hadfield) 19 de febrero de 2013 Es una actualización de software, ¿qué podría fallar? Ayer una actualización del software...
Name That Space Rock, de Tim Lillis. Cometa -- un trozo de hielo y roca que procede de los confines más remotos del Sistema Solar. Asteroide -- una roca en órbita, generalmente entre Marte y Júpiter. Meteoroide -- más grande que un...
Por Nacho Palou -
19 FEB 2013
Philip Bump se ha entretenido en crear una imagen de 1726 × 1666 píxeles que contiene todos los dígitos del mayor número primo de Merssene que se ha descubierto: una bestia de más de 17 millones de dígitos. Lo ha apañado...
Los trajes espaciales no son meras ropas. Son una complicada mezcla de telas, máquinas y arquitectura, para proporcionar protección a nuestro frágil cuerpo humano una vez se aventura fuera de la atmósfera. En Motherboard –que forma parte de Vice– han producido...

En Minute Physics resumen en un vídeo de unos minutos una de las más grandes preguntas que pueden plantearse: ¿qué es el Universo? Porque resulta que está el universo observable, el Universo (con mayúscula) que contiene cosas y fenómenos que no...
2012 DA14 6 hours before closest approach, el asteroide visto desde Australia 6 horas antes de su aproximación máxima Si las nubes te lo permiten y vives en un lugar desde el que se pueda seguir su trayectoria, puedes intentar ver el...
La razón por la que en mi Twitter privado mantenga solo a unos 140 o 150 amigos como máximo es –como algunos sagazmente observaron– porque ese es el número de Dunbar, sobre el que he hablado esta semana en Sin Vuelta de...

Según se puede ver en decenas de vídeos captados por cámaras de esas que es habitual llevar en el salpicadero en Rusia un meteorito acaba de caer allí sobre los Urales, en concreto en la zona de Cheliábinsk. Los informes iniciales...
Después de seis meses en la Estación Espacial Internacional un astronauta habrá envejecido 0,007 segundos menos que los que estamos en la Tierra. [Fuente: Ed's Musings From Space vía @ISS_Research y @ageekmom.]...
App de la Messenger en el iPad El 18 de marzo de 2011 la Messenger se convirtió en la primera sonda en entrar en órbita alrededor de Mercurio, con el objetivo de determinar con precisión la composición de Mercurio, incluyendo la de...
A William Utermohlen le diagnosticaron la enfermedad de Alzheimer en 1995, y siendo pintor decidió afrontar el diagnóstico haciendo una serie de autorretratos mientras fuera capaz. Algunas de esas imágenes, que produjo hasta el año 2000, se pueden ver en la...

Si tu peso en la Tierra fuera 100 loquesea en estos otros astros del sistema solar pesarías: Eso sí, tu masa sería la misma. En Your Weight on Other Worlds puedes poner tu peso en las unidades que quiera y te...
Utilizando el mismo formato visual que le sirvió para el salto a la fama en una charla TED –disponible públicamente en Gapminder.org– el doctor Hans Rosling examina los avances en la erradicación de la mortalidad infantil en las últimas décadas. De...
Los colores del SDO – NASA/SDO/Goddard Space Flight Center Como dice el refrán, todo depende del color del cristal con que lo mires, lo cual es también cierto cuando se trata de mirar al Sol. El mosaico de arriba se corresponde con...
Clic para ver en grande (575×2.064 pixeles) 50 Years of Human Spaceflight es otra de esas infografías chulas de Space.com que te puedes comprar en forma de póster grande (30×76 cm) y muy grande (45×183). Pero lo que la hace más interesante...
Paul Sorenson, físico: Donde yo trabajo hacemos chocar entre sí cosas pequeñas para romperlas en cosas aún más pequeñas y así hasta que obtenemos la cosa más pequeña que sea posible. De este modo sabemos de qué está hecha la materia. Y...
Por Nacho Palou -
11 FEB 2013

Somos 7.000 millones de humanos, pero competimos con 10.000 millones de murciélagos y trillones de bacterias. Éxito relativo.
Este vídeo muestra una simulación del paso del asteroide 2012 DA14 cerca de la Tierra el próximo viernes-sábado 15-16 de febrero de 2013. Dicen que será el mayor acercamiento que ha visto nuestro planeta de un objeto de ese tamaño (unos...
Hace unos días se cumplían los seis meses del espectacular y complicado aterrizaje de Curiosity en Marte. Este vídeo mezcla imágenes de personas que estaban siguiéndolo en distintos lugares con animaciones por ordenador e imágenes reales obtenidas por el propio Curiosity...
Estos días se está hablando bastante de 2012 DA14, un asteroide de unos 50 metros de ancho que aunque se aproximará hasta unos 27.680 kilómetros de la Tierra, menos distancia de aquella a la que orbitan los satélites geoestacionarios, no chocará...
Primer taladro en una roca de Marte. El agujero tiene un diámetro de 1,6 centímetros - NASA / JPL-Caltech / MSSS Después de probar el percutor de su taladro hace unos días el equipo de Curiosity ha llevado a cabo también su...
De la nieve en las cumbres de las montañas al mar y de nuevo a las nubes pasando por ríos y lagos: el ciclo del agua en una foto de Nueva Zelanda tomada por @AstroMarshburn....
Ciudades iluminadas, mares de nubes, relámpagos, auroras multicolor, la luminiscencia nocturna de la atmósfera… Orbit es para ver en HD y alucinar con la belleza de nuestro mundo. La edición del vídeo es de Brian Tomlinson, las imágenes de la NASA,...
Felix Baumgartner iniciando el salto Falta todavía que la Federación Aeronáutica Internacional se pronuncie sobre la solicitud presentada por el equipo de Red Bull Stratos sobre los récords de velocidad vertical máxima sin usar paracaídas guía, altura de salto, y caída libre...
Del departamento de conocimientos que nunca sabes cuando te van a venir bien, y de nuevo por cortesía de Chris Hadfield, en este caso respondiendo a preguntas de estudiantes. Aunque… Spoiler: con agua y jabón, por sorprendente que parezca. (Vía @poliukGV)....
Primera perforación de Curiosity en la roca conocida como John Klein - NASA/JPL-Caltech/MSSS/Ken Kremer/Marco Di Lorenzo Entre el 31 de enero y el 2 de febrero de 2013 Curiosity ha dado otro importante paso en su misión, que ha sido el de...
¿Puedes adivinarlo antes de ver el final del vídeo? La explicación científica de este profesor de la Universidad de Purdue ocupa los primeros minutos, empezando por el ejemplo subsónico para luego pasar a velocidades de más de 340 metros por segundo...
En Instituto de Sistemas Aeroespaciales de la Universidad Técnica de Braunchsweig calcula que en los algo menos de 55 años de la era espacial que habían transcurrido cuando publicaron este vídeo hemos dejado unos 150 millones de objetos de más de...
Dale al play y mira fijamente la cruz que sale en el vídeo. ¿Has reconocido a alguien? ¿Te han parecido tan siquiera normales las caras que salen? Vuelve a mirar el vídeo, pero esta vez fíjate en las caras que salen...
En Space.com venden un poster, aquí recortado, en versiones de 30×76 y 45×183 centímetros en los que se pueden ver los transbordadores espaciales de la NASA de arriba a abajo, sus interiores, sus plataformas de lanzamiento, etc. Claro que también se...
Uno de los tripulantes del transbordador espacial Columbia en su última misión era Ilan Ramon, el hasta ahora único astronauta israelí de la historia. Entre los varios ítems personales que llevó a bordo en el viaje había uno muy especial, una...
¿Qué pasaría si cogiéramos una Cessna 172 y, tras cambiar su motor por uno eléctrico alimentado por baterías de iones de litio*, porque como recordaréis un motor de explosión no puede funcionar en el vacío, nos la lleváramos a volar por...
Esta frase cortada por la mitad de Rick Husband fue la última transmisión recibida en el control de la misión el 1 de febrero de 2003 a las 13:59:32 UTC desde el transbordador espacial Columbia antes de que este se desintegrara...
El otro día Chris Hadfield nos mostraba un cóctel de frutos secos en el espacio. Pero la verdad es que echándole un ojo a la galería de fotos de comida para astronautas que hay en Gallery: Half a century of space food...
Una preciosa animación narrada por Jerry Carr, que fue comandante del SkyLab y pasó más de 2.000 horas en el espacio, sobre la vida de los astronautas: esa profesión que probablemente tiene el mayor ratio entre lo que los niños querrían...
Cada vez es más normal que los satélites y sondas espaciales duren más de lo previsto inicialmente y que haya que retirarlos del servicio porque se quedan sin combustible. Por eso cada vez parece más atractiva la posibilidad de poder volver...
Water Bubble in Space, un retrato de Kevin Ford, el comandante de la Expedición 34 a la Estación Espacial Internacional, refractado en una esfera de agua flotando en caída libre en la ISS. El agua toma esta forma cuando está en...
Impresión artística del Kepler en órbita - NASA El telescopio espacial Kepler, cuya misión es cazar planetas extrasolares, hace esto «mirando» fijamente a una zona de la Vía Láctea situada entre las constelaciones del Cisne y Lyra, midiendo variaciones en la intensidad...
Le falta una musica épica, aunque todo se andará, pero en From Night to Day to Night Again, este time lapse creado por los tripulantes de la Expedición 34 se ve como la Estación Espacial Internacional hace dos órbitas desde el...
De NASA: Reaching for New Heights, por orden y salvo error u omisión: Aterrizaje de Curiosity en Marte; aún se me ponen los pelos de punta viendo a la gente del control de la misión celebrándolo. 40 aniversario del programa Landsat....
Clic para ver en grande Pues que queréis que os diga, siempre mola ver la esquinita del punto azul pálido en la que uno vive desde el espacio, en este caso por cortesía de los chicos de Fragile Oasis. (Vía @DigitalMeteo)....
Se ha dicho que la astronomía es una experiencia de humildad y formadora del carácter. En mi opinión, no hay quizá mejor demostración de la locura de la soberbia humana que esta distante imagen……de nuestro minúsculo mundo. No sé cuantas veces puedo...
Vaya chollo sería a la hora de irse de copas si lo de la memoria del agua funcionara como canta David R.Valeiras en La memoria del agua y como dicen los que defienden la homeopatía que hace. (Gracias por la pista,...

Más allá de los juegos de palabras y las consideraciones metafísicas, lógicas y semánticas, se pueden aprender algunas cosas interesantes analizando lo que dice la física sobre lo que hay detrás de la tradicional paradoja: ¿Qué pasaría si una fuerza imparablechocara...

Aunque parezca increíble, si consigues ajustar bien la velocidad de la «silla de montar» la pelota encuentra un curioso equilibro y puede mantenerse horas girando y girando sin caerse. Técnicamente la forma que tiene la silla se llama algo así como...
Distances Driven on Other Worlds - Karle Tate/Space.com Aunque las sondas y naves espaciales que hemos enviado por ahí desde el principio de la era espacial llevan recorridos literalmente miles de millones de kilómetros por el espacio en realidad llevamos muy poquito...
A lo largo de su carrera Boris Chertok estuvo profundamente involucrado en el desarrollo del programa espacial soviético, en el que llegó a ocupar el puesto de ayudante de Sergey Korolev. Por eso sus memorias se consideran una de las fuentes fundamentales,...
Este sistema solar dibujado por un niño de 11 ó 12 años se aproxima mucho al modelo que maneja mucha gente: Y eso que en realidad está bastante bien, ya que se cruzan las órbitas de Neptuno y Plutón y hasta incluye...
(Con subtítulos en español) El título de esta anotación es la máxima del grupo de especialistas y entusiastas que forman el grupo Copenhagen Suborbitals que se dedica a construir cohetes. Un trabajo -y unos logros- documentados en el emocionante reportaje Espacio exterior...
Por Nacho Palou -
24 ENE 2013
Disco con mensajes de buena voluntad del Apolo 11 - NASA Además de los varios instrumentos científicos y las varias toneladas de hardware abandonado, Hasselblad incluida, que dejaron allí los astronautas del Apolo 11 estos dejaron sobre la superficie de la Luna...
Owen Phairis tiene una obsesión: los planetarios. De modo que desde hace tiempo ha ido adquiriendo, clasificando y manteniendo todos los que ha podido encontrar para su particular Museo de los Planetarios. El resultado es la mayor colección del planetarios del...
Synesthesia por *PeaceMakerGirl Este artículo se publicó originalmente en Cooking Ideas, un blog de Vodafone donde colaboramos semanalmente con el objetivo de crear historias que «alimenten la mente de ideas». Hace algún tiempo tuve la oportunidad de acudir a una charla de...
Conjunción navideña: conjunción de la Luna y Júpiter en diciembre de 2012 por Paco Bellido La pasada noche del 21 al 22 de enero de 2013 Júpiter y la Luna se aproximaron hasta 29 minutos de arco uno de la otra, la...
Una de las misiones espaciales más emocionantes de los últimos años fue el aterrizaje de la sonda Huygens en la superficie de Titán, no tanto por la cantidad de datos que esta obtuvo durante el descenso y los 90 minutos que...
Conjunción de Venus y Júpiter, imagen ganadora de la categoría gente y espacio de 2012, por Laurent Laveder El Real Observatorio de Greenwich, junto con la revista Sky at Night, han abierto la convocatoria para el concurso de Astrofotógrafo del Año de...
Así veían nuestro sistema los geocéntricos: Ptolomeo, Heráclides… y así los heliocéntricos: Aristasco, Copérnico, Tycho Brahe, Galileo y Kepler: Se llama simplemente Orrery y es un pequeño planetario a modo de animación con datos reales procedentes de la NASA. Estaba concebido como...
Phases of the Moon en el iPhone La gente de Universe Today acaba de sacar una versión nueva de su aplicación Phases of the Moon que aparte de la información sobre la fase lunar, distancia a la que está de la Tierra,...
Cuando vi pasar la noticia que titulada Esperanzadores resultados en la primera vacuna preventiva contra el Alzheimer saltaron todas mis alarmas, en especial cuando llegué a la parte que dice que ha sido probada en animales transgénicos. Y en efecto, esto es...
The Tracks of Curiosity: las huellas de Curiosity - NASA/JPL/University of Arizona. Clic para ver la imagen entera Una vez más la cámara HiRISE (High-Resolution Imaging Science Experiment, Experimento Científico de Imágenes de Alta Resolución) de la Mars Reconnaissance Orbiter de la...

We Need More Rain (CC) Andy Melton Andamos estos días con varias ciclogénesis explosivas encadenadas a vueltas, y estas traen con ellas viento y lluvia, que a menudo se mide en litros por metro cuadrado, una unidad que en principio parece un...
Medice cura te ipsum. Resultan curiosos los datos de un estudio de la Universidad Johns Hopkins en el que se trabaja desde hace décadas y en el que se pregunta a los médicos acerca de qué tratamientos aceptarían para salvar sus...
Impresión artística del MPCV en servicio en una posible misión a un asteroide - ESA Tal y como se esperaba la NASA y la ESA han confirmado que van a trabajar juntas en el desarrollo de la futura nave espacial tripulada de...
Luz desde la oscuridad: Lupus 3 visto por el MPG/ESO - ESO/F. Comeron Las estrellas nacen en las nubes de polvo que flotan en el espacio a medida que estas se van contrayendo por efecto de la gravedad, lo que hace que...
Michael Good en el brazo robot y Mike Massimino metido en sus tripas durante uno de los paseos espaciales de la misión STS-125 al Hubble Tras la puesta a punto llevada a cabo en 2009 durante la misión STS-125 del transbordador espacial...
Técnicos de la ESA dentro el ATV-4 - ESA/Arianespace/CNES/Optique Video du CSG | Más fotos en ATV-4 cargo loading Los técnicos de la Agencia Espacial Europea han comenzado ya a estibar la carga que viajará en el interior del compartimento presurizado del...
El Sol es grande, muy grande, tanto que a pesar de que se desplaza a una velocidad de aproximadamente 300.000 kilómetros por segundo la luz que llega a la Tierra desde sus bordes tarda aproximadamente dos segundos más en llegar aquí...
Los astrónomos están detectando cada vez más planetas extrasolares, o al menos candidatos a serlo, tal y como contábamos hace unos días en la anotación Nueva cosecha de planetas extrasolares. Y también están empezando a detectar cometas extrasolares, pero lo que no...
100,000 Stars es una visualización interactiva de nuestro vecindario estelar con, para ser exactos, datos de 119.617 estrellas, claro que en el caso de distancias cósmicas lo de vecindario siempre es relativo. Si te acercas lo suficiente, 87 de estas estrellas...
asteroid (99942 Apophis) missed earth by 38 lunar distances: diameter 270 m, velocity 4.09 km/s, energy ~62 megatons. j.mp/V1z8OR— Asteroids and Comets (@AsteroidMisses) enero 9, 2013 Esta semana Apofis, el asteroide que en 2004 nos dio un susto, o más bien unos...
Mientras esperamos a que se haga de día en el lugar en el que terminaron su misión estrellándose contra la superficie de la Luna, la NASA publica este vídeo con las últimas imágenes tomadas por las MoonKAM de las sondas Grail....
Estos últimos días han venido calentitos en cuanto a noticias sobre planetas extrasolares, aquellos que están en órbita alrededor de otras estrellas. Por un lado la NASA ha anunciado que el análisis de las observaciones del telescopio Kepler ha detectado 461 nuevos...
Se comercializan ojos biónicos de alta resolución (6/4). China reclama la posesión de la Luna (5/1). Muchos vuelos comerciales tienen lugar sin pilotos (3/1). Existe un gobierno mundial (8/1). La singularidad ha ocurrido (8/1). Hay al menos un edificio de más...
Bueno, por ahora sólo a un trozo de una roca llamada Ekwir_1, pero por algún lado hay que empezar: First Use of Mars Rover Curiosity's Dust Removal Tool: Ekwir_1 antes y después de pasarle el polvo - NASA/JPL-Caltech/MSSS Esto es fundamental para...
Respondiendo a una pregunta que unos cuantos lectores han planteado en Twitter a raíz del vídeo del aerografito... Si el aerografito tiene menor densidad que el aire, ¿por qué no sale volando? Ahí va la que creo es la respuesta correcta:...
Valores medios de Índice de Masa Corporal en el mundoVerde: normal | Naranja: sobrepeso | Rojo: obeso Me han parecido muy curiosos los resultados del estudio The Global Burden of Disease Study 2010, La carga global de enfermedad 2010, que comenta Juan...
Este vídeo muestra un sencillo experimento con el aerografito, un interesante material que tiene el vulgar aspecto de una pelusa o espuma gris pero que es sólido y a la vez más ligero que el aire. Si un metro cúbico de...
Todos aceptamos que la Tierra es redonda, pero no es tan fácil explicar cómo demostrar que la Tierra es redonda. Así que en el vídeo hay diez buenas razones al respecto. No es que vayan a servir para convencer a algunos...
Volcanoes look dramatic at dawn. They startled me when I spotted them through the lens. twitter.com/Cmdr_Hadfield/…— Chris Hadfield (@Cmdr_Hadfield) enero 6, 2013 Chris Hadfield apenas lleva unas semanas a bordo de la Estación Espacial Internacional, pero en este tiempo ya se las...
Asterank en acción Cuando pensamos en el sistema solar solemos quedarnos en el Sol, los planetas, sin entrar en si incluimos a Plutón o no, la Luna, y puede que alguna luna que otra. Pero en realidad el sistema solar contiene muchísimos...
El Gran Cañón photoshopeado por Travis Odgers Estaba intentando encontrar la fuente original de esta foto –y reconozco que al principio pensaba que estaría tomada desde la Estación Espacial Internacional– pero en realidad parece ser una imagen tomada desde un avión a...
Quadrantid meteor shower: January 4, 2012, una de las cuadrántidas de 2012 por Donovan Shortey Apenas ha comenzado el año y ya tenemos la primera lluvia de estrellas fugaces, las Cuadrántidas, cuyo pico de actividad se espera para la noche del 3...
iss034e009895: La Tierra, la Luna, y la Soyuz TMA-07M - NASA Con esto de las celebraciones de fin de año no había visto esta foto tomada por Kevin Ford desde la Estación Espacial Internacional de la aproximación de la Soyuz TMA-07M en...
Este artículo se publicó originalmente en Cooking Ideas, un blog de Vodafone donde colaboramos semanalmente con el objetivo de crear historias que «alimenten la mente de ideas». Imagina que estás un día cualquiera leyendo a tus colegas en Twitter o repasando...
He aquí otra demostración del famoso efecto péndulo que sincroniza los objetos que están en contacto a través de la misma superficie. Es la misma idea que en el no menos curioso experimento de los metrónomos, solo que con luces oscilantes....
Es un pequeño paso para un hombre, pero un gran salto para la humanidad. Durante muchos años se ha debatido si la frase que pronunció Neil Armstrong tras poner pisar la Luna era «that's one small step for a man…» o...
Tras Maravillas del sistema solar y Maravillas del universo Brian Cox y la BBC vuelven a la carga con Wonders of Life, que se estrena en unos días y que tiene toda la pinta de ir a ser tan impresionante como...
Una región activa que viene hacia nosotros - NASA/SDO El Sol ha tenido manchas solares todos los días en 2012. ¡Máximo solar, allá vamos! [Vía @NASA_SDO.]...
Impresión artística de la PTK-NP en el espacio En un primer vistazo se parece mucho a la Orion de la NASA, pero en realidad se trata de la PTK-NP, la nave que RKK Energia ha diseñado como potencial sustituta de las Soyuz....
En este año de 13 lunas llenas Rafael Defavari ha aprovechado la última de ellas para realizar este vídeo de la ocultación de Júpiter tal y como se vio desde Brasil. Está acelerado 5 veces, y recortado, ya que Júpiter permaneció...
Velocidad. Presión. Sustentación. Principio de Bernoulli. Mecánica de fluidos. Una preciosa demostración del poder de la ciencia y la ingeniería acerca de cómo se elevan los aviones. La cuestión es que hay que realizar el experimento con total precisión para evitar...
*Con todo el respeto a quienes se dedican a la venta ambulante y anuncian a voces su mercancía. Aquí hablamos de los que venden productos y tratamientos milagrosos, también conocidos como magufos. Traducido y resumido de How to become a charlatan: Encuentra...
¿Y por qué? . . . Aleatoridad no es lo mismo que uniformidad. Y resulta que del mismo modo que nos cuesta mucho generar mentalmente una serie de valores realmente aleatorios, los seres humanos no somos demasiado buenos juzgando la aleatoriedad....
Nuestra admirada Vi Hart nos trae este estupendo entretenimiento navideño-matemático: cómo crear recortables con simetrías similares a las de los copos de nieve, las estrellas y otros objetos similares. (Vía Gaussianos.) Serpientes en la clase de matemáticas Garabateando en clase de...
El Grasshopper de SpaceX (en castellano: Saltamontes) es un pedazo pepino de 12 pisos de altura, concebido con la idea de que pueda recuperarse tras su utilización. Este es su primer vuelo de prueba, en el que se ve cómo se...
Lo demás, migajas. Aunque la composición de nuestro planeta no sea exactamente así y esté lleno de compuestos químicos raros, esto es lo que se desprendería así a primera vista de un somero análisis a la tabla de los elementos según...
Esta animación es una simulación de la colisión entre dos galaxias: la Vía Láctea y la galaxia de Andrómeda, acelerada para que permita se pueda ver algo comprensible para nosotros. El original se grabó a una «velocidad simulada» de 10.000 años...
La Soyuz TMA-07M y sus tripulantes terminaron su viaje a la Estación Espacial Internacional con el atraque de la nave a las 14:09 UTC del 21 de diciembre de 2012 en el módulo Rassvet de esta. Con ello la Expedición 34,...
Bailarina - Juan Manuel Maroto Romo ¿Has hecho «bailar» alguna vez una peonza? ¿Sabes por qué no se cae mientras está girando? Seguro que muchas personas han jugado en su infancia a «bailar» la peonza, pero pocas de ellas son las que...
Z-1 La NASA acaba de dar por terminadas las pruebas del Z-1, un prototipo de traje espacial que espera que sirva para diseñar el que usarán sus futuros astronautas en la Luna o en la superficie de un asteroide. Uno de los...
Sí, caca. De astronauta. En algún sitio tenían que dejar las deposiciones que habían hecho durante el viaje desde la Tierra hasta la Luna. Otros objetos que dejaron por ahí tirados: herramientas, cámaras de fotos y vídeo, botas lunares, toallas usadas,...
Por Nacho Palou -
20 DIC 2012
El cometa Lovejoy sobre el VLT - Gabriel Brammer/European Southern Observatory Como ya viene siendo tradición Phil Plait, más conocido como @BadAstronomer, ha publicado su selección de las mejores imágenes astronómicas del año, que se pueden disfrutar en The Best Astronomy Images...
Nada más práctico que una comprobación empírica de cómo los ojos ven una cosa y el cerebro interpreta lo que le da lo real gana. En algún sitio leí que se cree que estas ilusiones visuales son tan efectivas porque lo...
Vídeo del traslado de la TMA-07M a la plataforma de lanzamiento. Fotos en Soyuz TMA-07M/Expedition 34/35 - Soyuz Rollout Todo está preparado en el cosmódromo de Baikonur para el lanzamiento de la Soyuz TMA-07M rumbo a la Estación Espacial Internacional. Viajarán en...
A Splendor Seldom Seen: Saturno en verde a contraluz - NASA/JPL-Caltech/SSI El equipo que procesa las imágenes de la sonda Cassini acaba de publicar esta espectacular imagen de Saturno sacada a contraluz desde un lugar unos 19 grados por debajo del plano...
Los ministros correspondientes de los 20 países miembros de la Agencia Espacial Europea, junto con Canadá, que es estado cooperante de la Agencia desde 1979, se reunieron hace unas semanas para organizar los planes de la agencia y fijar sus presupuestos...
Si todo va según lo previsto esta noche a las 23:28 hora de España (UTC +1) y con apenas 20 segundos de diferencia entre ella las sondas GRAIL de la NASA se estrellarán contra la pared de un cráter cercano al...
Las gemínidas sobre el observatorio de Paranal - Stéphane Guisard Observando las gemínidas con estilo en una fuente termal del Mar Muerto - Menahem Kahana / AFP - Getty Images Como era de suponer fotógrafos de todo el mundo han estado pendientes...
Double Halo Lunar 2 APOD (NASA) - Dani Caxete En las noches frías en las que hay nubes altas y delgadas (cirros) es posible ver un halo que rodea la Luna que se forma cuando la luz se ve refractada por los...
Estoy en la superficie. Y, mientras doy el último paso del hombre desde la superficie, de vuelta a casa por algún tiempo –que creemos no muy lejano en el futuro– tan sólo me gustaría [decir] lo que creo que recogerá la...
Geminid::T-18 (348/365) - Gemínidas de 2009 por Dr. Rawhead - CC by-nc-sa Estamos en la época del año en la que se pueden ver las Gemínidas, las estrellas fugaces procedentes de los restos del asteroide (3200) Faetón. El máximo de este año...
Earthquakes since 1898 - clic para versión a 3.410×2.058 Se cogen los datos de magnitud de todos los terremotos registrados en la base de datos del Advanced National Seismic System del Servicio Geológico de los Estados Unidos, se plantan encima de una...
Neptuno se descubrió en el año 1846. Como debido al tamaño de su órbita necesita 165 años para dar una vuelta completa al Sol, no fue hasta el año pasado cuando completó una órbita entera desde que fue descubierto. [Fuente: Nature vía...
Inspirada por las imágenes disponibles en The Visible Human Project® y con mucha habilidad Lisa Nilsson ha reproducido unas cuantas de esas imágenes usando tiras de papel enrolladas y plegadas para darles forma. Forman la parte de su trabajo denominada Tissue...
Júpter e Io el 24 de julio de 1996 - J. Spencer, Lowell Observatory, y NASA Además de todo lo que nos ha permitido averiguar acerca del universo en el que vivimos el telescopio espacial Hubble nos ha proporcionado algunas de las...
Primera imagen de la Tierra desde el espacio - Ejército de los EE. UU. Aunque con 105 kilómetros de altura máxima superó por poco la línea de Kármán, esta imagen tomada por una cámara de cine de 35 mm que iba a...
En este precioso y reciente vídeo sobre las fases de la luna y la libración pueden apreciarse algunos de los movimientos que hace la Luna observada desde la superficie de la Tierra. Más en concreto la libración, que es peculiar oscilación...
Despegue del Apolo 17 el 7 de diciembre de 1972 - NASA Hoy se cumplen 40 años desde la última vez que unos seres humanos fueron más allá de la órbita terrestre baja. Demasiado tiempo.– @schierholz...
Los físicos e informáticos llevan tiempo trabajando con la supercomputadora Mira para recrear la historia de nuestro universo con cierto nivel de detalle dentro de las posibilidades de este tipo de modelos matemáticos y la potencia del hardware y el software...
Menos mal que sólo cuatro de ellos están disponibles en formato electrónico, porque si no... Los engaños de la mente, de Susana Martínez-Conde. [versión Kindle.] Este libro le hará más inteligente, de John Brockman. [versión Kindle.] Feynman, de Jim Ottaviani y...
La nebulosa de Carina vista por el VST - ESO/VPHAS+ Consortium/Cambridge Astronomical Survey Unit Aunque las primeras imágenes ya se habían publicado en junio de 2012 hoy se ha producido la inauguración oficial del Telescopio de Rastreo del Very Large Telescope del...
Fueron necesarias 312 órbitas del satélite Suomi NPP de la NASA a lo largo de 9 días de abril y 13 días de octubre de 2012 para poder fotografiar toda la superficie de la Tierra por la noche con la calidad...
Trazos de estrellas sobre el telescopio de 3,6 metros que en la actualidad alberga el HARPS, una de las imágenes incluidas en Europe to the stars El Observatorio Europeo Austral celebra este año su 50 aniversario, y entre otras cosas ha publicado...
Ya lo dice el vídeo: «si trabajas en ciencia, ingeniería o matemáticas y puedes hablar de lo que haces de una forma divertida y que todo el mundo te entienda…» ¡Pues ya estás tardando en apuntarte grabar un vídeo de tres...
La Torre de Lego de Praga Hay por lo visto una especie de competición para ver quién es capaz de construir la torre de piezas de Lego más alta, récord que ahora mismo tiene una torre de piezas de Lego de 32,5...
El último avance matemático en formas de embarcar a los pasajeros en los aviones va mucho más allá de hacerlo por filas o separándolos por pares e impares: consiste en analizar su agilidad y «velocidad máxima personal» en función del equipaje...

Más claro, agua. Y nunca mejor dicho. Si Pitágoras no conocía esta visualización de su famoso teorema, seguro que hubiera asentido orgulloso. Es curioso que a pesar de su antigüedad todavía sorprendan algunas de sus consecuencias, como ya contamos en su...
La gravedad que la Tierra ejerce sobre un astronauta en órbita es un 90% de la que ejerce en su superficie. Pero están en caída libre, así que parece que no es ninguna. [Fuente: un #BAFact de @BadAsronomer]...
Capturado en una secuencia de fotografías con un objetivo ojo de pez (que abarca la totalidad del cielo), el vídeo Leonid and Zodiacal Light de Stephane Vetter recoge el paso de las Leónidas de hace un par de semanas, la Vía...
Por Nacho Palou -
4 DIC 2012
Lugar de toma de las primeras muestras - NASA/JPL-Caltech/MSSS. Clic en la imagen para la versión anotada (en inglés) Después de todo el revuelo organizado por unas declaraciones sacadas de contexto de John Grotzinger, el investigador principal de la misión, la presentación...
¿Cuánto vale tu cuerpo?, ¿Cuál es el valor de un cuerpo humano considerando únicamente la cotización de los elementos químicos que lo componen? Si de alguna forma pudiésemos extraer de un cuerpo humano todos sus componentes elementales -oxígeno, carbono, hidrógeno, calcio, fósforo,...
Por Nacho Palou -
3 DIC 2012
Desde hace años en la NASA tienen medianamente claro que Internet, los blogs, y las redes sociales son una estupenda herramienta para hacer llegar su trabajo al público en general sin tener de pasar por el filtro de los medios tradicionales,...
La Tierra como arte, versión PDF Con imágenes de la Tierra tomadas por los satélites Landsat 5 y 7, Terra, Aqua, y Earth Observing-1 (EO-1) de la NASA, el libro Earth as Art es uno de esos que sin duda aún merece...
Aprovechando que @papacabreao me ha metido en la lista de Ateillos materialistas, aprovecho para rescatar este segmento del capítulo 10 de Cosmos en el que Carl Sagan habla de dioses, el universo, y los seres humanos. Si no te suena Cosmos,...
Desde hace bastante años años los astrónomos piensan que podría existir agua helada en los cráteres de los polos de Mercurio en los que nunca da la luz del Sol. Esta idea se vio reforzada en 1991 cuando tras enviar señales de...
Un equipo rumano-australiano lanzó el pasado 13 de noviembre un globo con una cámara para tomar imágenes del eclipse total de Sol, imágenes que están resumidas en este vídeo. El Eclipser 1 alcanzó una altura máxima de uno 37.000 metros, aunque...
Tranquilos que nadie ha estado haciendo un time-lapse fotográfico de tal magnitud, no había tarjetas de memoria de tanta capacidad. Este vídeo de AsapScience es una recreación animada con plastilina de una historia que tiene 4.500 millones de años de antigüedad:...
[…] Le enseñamos todo lo que sabemos, hicimos todo lo que pudimos por él. Pero ahora tiene que encontrar su propio camino.Lo vemos en las fotos que toma de si mismo, pero nunca lo tocaremos de nuevo ni tampoco podremos arreglarlo...
Super Moon vs. Micro Moon - Catalin Paduraru La órbita de la Luna alrededor de la Tierra es elíptica, por lo que no siempre está a la misma distancia de la Tierra. Además, debido a diversas perturbaciones a las que está sometida,...
Estas son las instrucciones para montar el Gran Colisoinador de Hadrones en versión Ikea, al menos para los chicos de College Humor, que en If Ikea Made Instructions for Everything tienen instrucciones para unas cuantas cosas más. Igual si hubieran seguido...
ADN en Domus Según cuenta la BBC en Leicester scientists print human genome in 130 books científicos de la Universidad de Leicester han impreso el genoma de un ser humano en 130 libros para dar una idea de la cantidad de información...
Neil deGrasse Tyson responde a esta pregunta en este vídeo de MinutePhysics. La respuesta (ojo, spoiler): está seguro en un 99,9999% de que no. Claro que ya decía esto Baruch Spinoza allá por el siglo XVII: Todos los prejuicios que intento...
Las condiciones de nuestra separación serán estas: lavarás, plancharás y ordenarás mi ropa; me traerás la comida regularmente tres veces al día a mi habitación; limpiarás mi cama y mi despacho y especialmente no tocarás nada de mi escritorio.Aparte de eso olvídate...
Cuando miramos a alguien por primera vez la mayoría echamos un primer vistazo hacia la zona central de la cara y un poco por debajo de la altura de los ojos, según determina este estudio. Es algo que hacemos de forma automática,...
Por Nacho Palou -
27 NOV 2012
El NASA 905 partiendo de Dryden rumbo a Houston - NASA/Carla Thomas Aunque la NASA había anunciado que el Shuttle Carrier Aircraft conocido como NASA 905 iba a ser utilizado como fuente de piezas de repuesto para SOFIA, el telescopio aerotransportado, igual...
Aprovechando que el segmento central de los 91 que conforman el espejo del Gran Telescopio Sudafricano estaba retirado por mantenimiento Bruno Letarte montó una Olympus PEN E-3P con un objetivo Panasonic de 20 mm justo debajo del hueco que quedaba y...

Pocos entretenimientos matemáticos hay como el Juego de la vida, ese sistema de autómatas celulares de absoluta simpleza y a la vez increíble complejidad creado por John H. Conway en 1970. Ahora Stephan Rafler ha creado SmoothLife, una interesante «generalización» que...
Nebula 12 de Micasa Lab parece una lámpara de techo, pero es una estación meteorológica que representa físicamente en tu salón la previsión del tiempo: si está nublado produce nubes más o menos intensas; si hace sol se ilumina con diferentes...
Por Nacho Palou -
27 NOV 2012
La distribución de Alexander - periodictable.com Cuando estudié la tabla periódica usábamos la típica distribución en filas y columnas diseñada por Alfred Werner sobre la ordenación establecida por Dmitri Mendeléyev. Pero por lo visto hay otras formas de ver la tabla periódica,...
Leyendo sobre esta botella que utiliza nanotecnología para rellenarse de agua por sí misma —obteniéndola de la humedad del aire— recordé este truco para obtener agua líquida de las hojas de los árboles. El método no es tan sofisticado ni refinado...
Por Nacho Palou -
23 NOV 2012
El pasado 18 de noviembre, justo unas horas antes de partir de vuelta a tierra en la Soyuz TMA-05M, Suni Williams grabó Departing Space Station Commander Provides Tour of Orbital Laboratory, un tour guiado de la Estación Espacial Internacional en el...
Sobre la homeopatía y otras terapias no científicas En lugar de mirar hacia otro lado y hacer caja, como muchas otras farmacias lamentablemente hacen, en la Farmacia Rialto de Madrid le entregan a sus clientes el folleto que está reproducido el principio...
Pues se ha liado parda con las declaraciones de John Grotzinger, el investigador principal de Curiosity, publicadas en Big News From Mars? Rover Scientists Mum For Now. En esa historia Grotzinger menciona los datos que están obteniendo de SAM, el instrumento de...
Hace unos días enlazábamos con la anotación en la que Ángel López-Sánzhez, contaba sus aventuras persiguiendo el eclipse solar del 13 de noviembre por Australia adelante. Y ahora que ha tenido tiempo de procesarlo, aquí está el timelapse montado con las...
Soyuz Re-Entry: Reentrada de la Soyuz TMA-05M Viendo esta foto de la reentrada en la atmósfera de la Soyuz TMA-05M al final de la Expedición 33 a la Estación Espacial Internacional es fácilmente comprensible que los astronautas que han volado en ellas...
Este peculiar fondo marino con submarinos esconde tras el simpático decorado de color un PET (tomógrafo por emisión de positrones) de los usados habitualmente en medicina nuclear. Así los niños no se asustan al entrar dentro de un gran aparato gris,...
Lo mejor este cohete llamado New Shepard no es que despegue, cosa que hoy en día hace casi cualquier cohete construido con un poco de habilidad, sino que puede aterrizar también en vertical al cabo de un rato (00:50 en el...
Percentiles de temperatura de enero a octubre de 2012 - NOAA Octubre de 2012 fue el 332º mes consecutivo con una temperatura media global por encima de la media del siglo XX, lo que visto de otra forma quiere decir que si...
¿Qué hace que una empresa sea revolucionaria? Que sus innovaciones obliguen a otras empresas a cambiar de rumbo. Y estás son las 50 empresas revolucionarias en 2012, según los editores del MIT Technology Review....
Por Nacho Palou -
21 NOV 2012
What is littleBits? por littleBits en Vimeo. Ayah Bdeir cree que todo el mundo debería saber cómo funcionan las tripas electrónicas que dan vida a muchos de los gadgets que usamos hoy en día. Para eso ha desarrollado littleBits, una colección de...
Bodega del FFT - Jason Paur/Wired Cuando el gobierno de los Estados Unidos decidió retirar del servicio la flota de transbordadores espaciales de la NASA decidió que los transbordadores que quedaban en activo serían cedidos a distintos museos del país. Así, el...
La vista desde 31,8 km de altura - bloon. Más fotos en Microbloon Flight Zero2Infinity, la empresa con sede en Barcelona que quiere acercarnos un poco más al espacio con su proyecto Bloon de globos estratosféricos tripulados, está un paso más cerca...
El proyecto de globo estratosférico Bloon propone que, cuando esté en marcha en 2014, cualquier persona lo suficientemente interesada (el billete exige varias decenas de miles de euros de interés) pueda ascender en globo hasta 'casi' las estrellas. Bueno, hasta unos...
Por Nacho Palou -
20 NOV 2012
IBM va a simular 10.000 millones de neuronas y sus 100.000 millones de conexiones sinápticas en lo que denominan la mayor simulación del cerebro humano hasta la fecha – aunque el invento dista mucho de ser un cerebro humano completo, ya...
Este artículo se publicó originalmente en Cooking Ideas, un blog de Vodafone donde colaboramos semanalmente con el objetivo de crear historias que «alimenten la mente de ideas». Si este es el organigrama del plan general, no quiero ni pensar en el...
Recorte del panorama de Stu Atkinson Gracias a la política de la NASA –y de su investigador principal, que es quien decide en última instancia en estos casos– en lo que se refiere a la misión de Curiosity de publicar en Internet...
Impresión artística del COROT en órbita - CNES / D. Ducros El COROT, del francés COnvection ROtation et Transits planétaires, y COnvección, ROtación y Transitos planetarios en español, es el «cazador de exoplanetas» de la Agencia Espacial Francesa y de la Agencia...
Una noticia de la Agencia EFE distribuida a principios de este mes afirmaba que «Dos mellizos de siete años con autismo han logrado en apenas dos semanas, gracias a una terapia, romper la "coraza de cristal" que les mantenía aislados del...
El aterrizaje a la 1:56 UTC de esta noche la Soyuz TMA-05M a unos 85 kilómetros al nor-noroeste de Arkalyk en Kazajistán con Yuri Malenchenko, Suni Williams y Aki Hoshide a bordo marcó el final de la Expedición 33 a la...
Te hayas vacunado o no, hayas pasado ya la gripe de este año o estés esperando su incómodo ataque, puedes colaborar con la ciencia participando en GripeNet.es. La idea básicamente consiste en rellenar un perfil personal y luego pequeños informes semanales (en...
Clic para ver la colección completa Heroes of Science Action Figures es una colección de figuras de acción de 30 científicos que han estado vivos en algún momento del siglo XX creada por *datazoid. Menos mal que son sólo producto del uso...
Gigapan del cockpit del NASA 905 - Jon Brack/National Geographic Mauro nos ha escrito para pasarnos un par de enlaces a dos GigaPan del interior del NASA 905, uno de la cabina y otro de la cabina de pasajeros, prácticamente vacía para...
Investigadores han convertido la actividad mental en música, y suena increíblemente parecida a una improvisación de jazz con piano. El traductor cerebro-a-sonido convierte las variaciones eléctricas del cebrero en el tono de la notas y la circulación sanguínea en su intensidad....
Por Nacho Palou -
16 NOV 2012
2009 Leonid Meteor: Una excepcional captura de las Leonidas de 2009 - Foto CC por Ed Sweeney Las Leónidas acuden estos días un año más a su cita anual con la Tierra, o más bien la Tierra vuelve a recorrer la parte...
Desde los Google Labs llega otro experiento de estos que combinan fuerza bruta y elegancia: 100.000 estrellas. Es una representación visual de nuestro vecindario cósmico, muy resultona sobre todo vista a pantalla completa en una pantalla gigante. S esas 100.000 estrellas...
El visor OneZoom es una estupenda herramienta para manejar grandes conjunto de datos clasificados. En visualización fractal de todos los mamíferos del reino animal, en la que se puede ir profundizando e investigando con el ratón, es un perfecto ejemplo. Como...
Impresión artística del Kepler en órbita - NASA El telescopio espacial Kepler, el cazador de exoplanetas de la NASA que ha localizado más de 2.300 candidatos y 105 confirmados, ha dado comienzo hoy a su misión extendida. Exoplanetas candidatos. En azul los...
Salida del Sol, ya con el eclipse comenzado, tras las montañas al este del lugar de observación a 50 km al sur de Lakeland, Queensland - Ángel R. López-Sánchez (Australian Astronomical Observatory / Macquarie University, Agrupación Astronómica de Córdoba / Red Andaluza...
Trayectoria del eclipse - Fred Espenak / NASA Esta noche tiene lugar un eclipse de Sol, que alcanzará su totalidad entre las 20:35:08 y las 23:48:24 UTC (una hora más en España), recorriendo unos 14.500 kilómetros en total. Pero sólo será visible...
Stanford creates touch-sensitive, conductive, infinitely-self-healing synthetic skin, Investigadores de la Universidad de Stanford han desarrollado la primera piel sintética, de plástico, que es conductora de electricidad, sensible al tacto (distingue cambios de presión y temperatura) y capaz de auto repararse repetidamente...
Por Nacho Palou -
13 NOV 2012
Desde el departamento Sonaba mejor por el título, Hacia un manto de invisibilidad "perfecto" -- Científicos han logrado por primera vez hacer que un objeto sea completamente invisible a las microondas [...] En términos simples, «la idea es controlar la luz que...
Por Nacho Palou -
12 NOV 2012
Aunque a simple vista el Sol parece siempre el mismo, en realidad su actividad sigue unos ciclos de actividad de aproximadamente 11 años, descubiertos en 1843 Samuel Heinrich Schwabe, tras 17 años de observaciones de las manchas solares. Se suele decir...
A mi me habían metido la idea desde la secundaria […] que las matemáticas se acababan y que el cálculo ya era lo máximo. Y llegas y te das cuenta que no y que apenas están abriendo la puerta y que...
Esta curiosa instalación del Museo Randall de San Francisco se llama Windswept; consiste básicamente en 500 flechas muy ligeras que se mueven según la dirección del viento, algo tan bello y relajante como científicamente interesante. Es evidente su parecido con las...
Candilazo en La Coruña Ayer, sin saber que ese fenómeno se llama así, presencié un candilazo, como luego me dijo Emilio Rey, @digitalmeteo, que se denomina. Es el fenómeno que se da cuando hay nubes altas al atardecer en los pocos minutos...
Lo que comenzó a principios del curso 2011-2012 como el desafío de un profesor de Tecnología a sus alumnos para ver cómo se podría comprobar que la Tierra es redonda terminó el pasado 12 de mayo con el lanzamiento de Limasat....
Ya tenemos el primer autorretrato oficial de Curiosity en Marte, tomado por la cámara de alta resolución de su brazo robot: High-Resolution Self-Portrait by Curiosity Rover Arm Camera. En el enlace anterior está disponible a más resolución, hasta 5.463×7.595 pixeles, y...
Habíamos mencionado en varias ocasiones las imágenes en alta definición que tomó la sonda japonesa Kaguya mientras orbitaba la Luna en las que se veía salir la Tierra desde esta, pero acabo de darme cuenta de que nunca habíamos puesto el...

He aquí la famosa receta del pastel de manzana de Carl Sagan [también en versión imprimible] que nuestro divulgador científico favorito comenzaba con Para cocinar un pastel de manzana desde cero primero necesitas un Universo. Importante: el Universo puede estar a...

Si eres como la mayoría de la humanidad cuando mires la imagen que hay al principio de esta anotación te parecerá que hay unos puntos negros en las intersecciones de las líneas grises. Pero en cuanto intentes mirarlos, estos desaparecerán, porque...

Este artículo se publicó originalmente en Cooking Ideas, un blog de Vodafone donde colaboramos semanalmente. Las pantallas táctiles capacitivas —las que funcionan por contacto, sin necesidad de hacer presión— se basan en la propiedad del cuerpo humano para conducir la electricidad....
Por Nacho Palou -
7 NOV 2012
The Final Journey of Space Shuttle Atlantis por Kyle Kappmeier en Vimeo. El pasado 2 de noviembre el transbordador espacial Atlantis fue trasladado al edificio en el que será expuesto al público a partir de julio de 2013 en el Complejo...
Como muchos sabéis y pone en mi biografía microsierva en el MundoReal™ trabajo en los Museos Científicos Coruñeses, donde desde hace 25 años se convocan los Prismas Casa de las Ciencias a la Divulgación, unos premios que aunque esté mal que yo...
Para conmemorar el 12º aniversario de ocupación permanente de la Estación Espacial Internacional la NASA ha lanzado un servicio llamado Spot The Station que te permite recibir alertas por correo electrónico –e incluso por SMS si vives en los Estados Unidos– de...
A Toy Train in Space por Ron Fugelseth en Vimeo. Con una altura máxima en su viaje de unos 32,5 kilómetros no es técnicamente cierto que Stanley, el tren de juguete del hijo de Ron, haya llegado al espacio, pero esto...
A Slower Speed of Light [Windows, Mac] es un juego diseñado por el MIT Game Lab para hacer que la Relatividad sea menos rara de lo que le parece a mucha gente que es. Si esto se puede conseguir jugando… ¿Por...
Hormigón con bacterias productoras de calcita / TU Delft En BBC News, vía Dvice, Hormigón con bacterias — El hormigón presenta un problema importante ya que tiende a agrietarse, lo que hace que se filtren químicos y agua con efectos corrosivos. [En...
Por Nacho Palou -
5 NOV 2012
Imagen ganadora por Jennifer Peters y Michael Taylor Un año más Nikon ha anunciado los ganadores de su concurso Nikon Small World de fotografía microscópica, a medio camino entre la fotografía y la ciencia. La imagen ganadora es de la barrera hematoencefálica,...
En I fucking love Science: el universo frente a lo que sabemos de él. (¡Gracias Ana por la pista!)...
Está previsto que el transbordador espacial Atlantis abandone hoy por última vez el Edificio de Ensamblado de Vehículos rumbo al Complejo de Visitantes del Centro Kennedy, donde se está construyendo el edificio en el que será expuesto al público a partir...
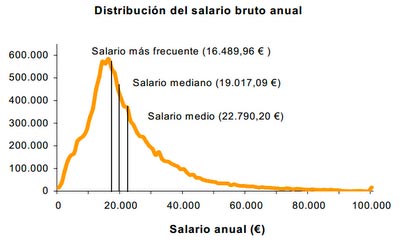
Esta explicación matemática de lo que son la media, la mediana y la moda aplicadas a los salarios españoles es tan ilustrativa como fácil de entender. Estaría bien que quienes escriben sobre el tema o quienes lo utilizan en los debates...
Autorretrato de Curiosity - @mars_stu No me digáis que no ha salido mono en esta foto, compuesta por otras 55 tomadas por la cámara MAHLI, Mars Hand Lens Imager, la que está en el extremo del brazo robot del Curiosity. Claro que...
Imagen generada con Stellarium Si a lo largo de la noche del 1 al 2 de noviembre de 2012 buscas la Luna, suponiendo que las nubes te permitan verla, podrás ver un punto brillante muy cerca de ella, que dependiendo de la...
Con un ligero adelanto sobre el horario previsto de las 13:40 UTC el carguero Progress M-17M atracaba a las 13:33 en el módulo Zvezda de la Estación Espacial Internacional con 2.397 de carga útil, que se divide en 683 kg de...
Resultados del primer análisis del CheMin - NASA/JPL-Caltech/Ames El equipo de Curiosity ha superado otro hito en su misión con el análisis de la primera muestra de suelo marciano, obtenida el pasado 15 de octubre y analizada el 17 con el instrumento...
Aunque se titule Our Story in 1 Minute este vídeo de melodysheep en realidad dura más bien minuto y medio, 90 segundos en los que se recorren los aproximadamente 13.700 millones de años de historia de nuestro planeta y de nuestra...
La M-17M en la plataforma de lanzamiento - Energia. Más fotos en Progress M-17M - Rollout. El carguero espacial Progress M-17M está ya en la plataforma de lanzamiento desde la está previsto que un Soyuz-U lo ponga en órbita mañana a las...
Si no fuera porque mi escepcitismo me lo impide, diría que alguien en Houston le ha echado el mal de ojo a los del museo Intrepid de Nueva York, que se ha hecho con uno de los transbordadores espaciales mientras que...
Este artículo se publicó originalmente en Cooking Ideas, un blog de Vodafone donde colaboramos semanalmente con el objetivo de crear historias que «alimenten la mente de ideas». A muchos seres humanos no les gana a cabezones nadie. Una buena muestra de...
Dragon in its Nest: La Dragon ya en el barco que la llevará a puerto - SpaceX Un limpio amerizaje a las 19:22 UTC del 28 de octubre de 2012 a unos cientos de kilómetros al oeste de la costa de Baja...
Casi todo el mundo conoce la famosa ecuación E=mc². En Minute Physics han aprovechado para explicar, con su habitual claridad meridiana, lo que hay más allá de esa ecuación. En particular, se adentran en el concepto de equivalencia entre masa y...
Space.com: Paintball Players vs. The Asteroid Apocalypse?, vía SlashGear. Sung Wook Paek, estudiante graduado en el MIT, cree que se puede alterar la trayectoria de un asteroide en curso contra la tierra salpicándolo con pintura brillante. De modo que los fotones...
Por Nacho Palou -
29 OCT 2012
Los niños pequeños tienen la curiosa forma de esconderse tapándose los ojos. Cuando se tapan los ojos los niños se sienten invisibles. El porqué exacto no se sabe, aunque algunos estudios indican que la mayor parte de los niños son conscientes de...
Por Nacho Palou -
29 OCT 2012
Está a punto de terminar la primera misión regular de una cápsula Dragon de SpaceX a la Estación Espacial Internacional, a la que llevó carga, y de la que se trae carga de vuelta. En SpaceX–Dragon Spacecraft hay un panorama navegable...
Todavía no se sabe muy bien por qué, pero resulta que las pelirrojas necesitan un 20 por ciento más de anestesia que el resto de personas para que la sustancia les haga efecto cuando están sobre una mesa de operaciones.Al principio los...
«Un impactante estudio científico demuestra que los estudios científicos con resultados impactantes suelen ser falsos» Vía Boing Boing y Los Angeles Times. El impactante estudio está aquí: Empirical Evaluation of Very Large Treatment Effects of Medical Interventions ($)....
La Estación Espacial Internacional vuelve a tener seis tripulantes desde las 15:08 UTC cuando se abrió la compuerta de la Soyuz TMA-06M que llevaba a bordo a Oleg Novitskiy y Evgeny Tarelkin de Roscosmos y Kevin Ford de la NASA. Expedition...
European Southern Observatory (ESO) Con una imagen de 9.000 Megapíxeles (9 Gigapíxeles) tomada con el telescopio VISTA de la ESO, situado al norte de Chile, un equipo de astrónomos ha creado el mayor catálogo de estrellas cercanas al núcleo de la Vía...
Por Nacho Palou -
25 OCT 2012
Ross Hilbert creó estas preciosas Ventanas fractales de tonos Escherescos con su generador de fractales, el Fractal Science Kit [Windows]. Aunque el resultado para el común de los mortales son unas curiosas ventanas infinitas encadenadas, matemáticamente se trata de un «conjunto...
Más o menos. Cassete philips (cc) raulrodlin En New Scientist, Cassette tapes are the future of big data storage. Aunque los discos duros han sido tradicionalmente la bestia de carga del almacenamiento masivo, próximamente podrían ser sustituidos por un nuevo tipo de...
Por Nacho Palou -
24 OCT 2012
Estaba convencido de que las escenas de CSI y series similares en las que sale un forense realizando una autopsia virtual del interfecto en cuestión eran licencias de los guionistas, AKA fantasmadas, pero parece ser que no lo son tanto. Al parecer,...
Expedition 33 Soyuz Launch (201210230007HQ): Miembros de la prensa fotografían el despegue - NASA/Bill Ingalls. Más fotos en Expedition 33. Tal y como estaba programado la Soyuz TMA-06M despegó esta mañana a las 10:51 UTC rumbo a la Estación Espacial Internacional con...
Divulgar ciencia no tiene por qué ser serio y aburrido, como demuestra esta iniciativa de la Unidad de Cultura Científica de Instituto de Astrofísica de Andalucía (IAA-CSIC), en la que Henrietta S. Leavitt y su alter ego Erasmus Cefeido tienen como...
Todo está listo en el cosmódromo de Baikonur para el lanzamiento de la Soyuz TMA-06M a la Estación Espacial Internacional a las 10:51 UTC (dos horas más en España) del 23 de octubre de 2012. A bordo viajarán tres nuevos miembros...
Orionid: Orión y una Oriónida - Foto CC por Steve Ryan Como con cualquier otra lluvia de estrellas ya hace días que se pueden ver las Oriónidas, pero se espera que la noche del 20 al 21 de octubre presenten su máximo...
ISS Startrails - TRONized por Christoph Malin en Vimeo. El autor de este vídeo utilizó las imágenes disponibles The Gateway to Astronaut Photography of Earth de una forma peculiar, apilándolas en lugar de poner una tras otra, por lo que las estrellas...
A Innocente Marcolini se le diagnosticó en 2002 un tumor en el nervio trigémino izquierdo, algo que él asocia a haber usado durante años el teléfono móvil unas seis horas al día prácticamente a diario. Así que decidió acudir a los tribunales...
Unos científicos han diseñado un medicamento que dicen puede eliminar los malos recuerdos de una persona mientras duerme. De momento lo han probado en ratoncillos, haciéndoles olvidar los miedos asociados a experimentos realizados durante el día. La cosa funciona así: se les...
Impresion artística de Alfa Centauri Bb Que los planetas extrasolares son abundantes está quedando cada vez más claro gracias a la velocidad a la que se confirma la detección de nuevos planetas, cuyo número ya pasa de 800, con un par de...
Trasladar el transbordador espacial Endeavour desde el aeropuerto de Los Angeles al Centro de Ciencias de California, donde quedará expuesto al público, fue una tarea delicada que necesitó de mucha coordinación y del uso de un vehículo especial capaz de maniobrar...
Mirror Inspection: Técnicos de la NASA inspeccionan uno de los espejos del JWST - NASA/Chris Gunn El Centro Espacial Goddard de la NASA ha recibido ya los espejos del telescopio Espacial James Webb, el que está llamado a ser sucesor del Hubble....
Mientras Felix Baumgartner se preparaba para romper la barrera del sonido en su salto estratosférico, otro récord que quizá sea a la postre tan histórico como los de su hazaña también se batió otro en las redes: el del número de personas...
Baumgartner abandonando la cápsula Dejadme que os diga - cuando estás en lo más alto del mundo te vuelves muy humilde. Dejas de pensar en romper récords, no piensas en conseguir datos científicos - lo único que quieres es volver vivo. Falta...
La cuenta atrás está en marcha otra vez para el salto de Felix Baumgartner en el que pretende establecer nuevos récords en las categorías de vuelo en globo tripulado más alto, con 36.000 metros de altitud, salto en paracaídas desde la...
Solar Walk 2.0 [iPad, 0,99€] es una bastante renovada versión de la herramienta interactiva para explorar el Sistema Solar que comentamos hace tiempo por aquí. Es como darse un paseo de forma relajada y gráfica, con un montón de información acerca...
Despegue del Soyuz VS03 - ESA–S. Corvaja, 2012 Un lanzador Soyuz ST-B puso ayer en órbita los satélites Galileo FM-3 y FM-4 del sistema de posicionamiento Galileo, el equivalente europeo al GPS estadounidense o al Glonass ruso: Continúa el despliegue de la...
Gloria fotografiada por Xurxo Mariño Literalmente. Xurxo Mariño ha podido fotografiar una gloria mientras su avión iba a aterrizar en Londres. Una gloria puede observarse cuando vas en una ventanilla que está del lado opuesto al Sol, hay nubes cerca del avión,...
Shuttle Endeavour Crossing - NASA/Bill Ingalls En Los Angeles, cuna de Hollywood, deben de estar curados de espantos, pero seguro que aún así encontrarse al transbordador espacial Endeavour circulando por la calle detrás de una señal de Shuttle xing tiene que ser...
Digna del mismísimo Tesla, que asentiría orgulloso, esta especie de «barbacoa» –como la conocen cariñosamente en el Palais de la Découverte de Paris– es capaz de hacer levitar un disco de aluminio de un kilo de peso como si tal cosa....
Aunque inicialmente estaba previsto que fuera hoy cuando los tripulantes de la Estación Espacial Internacional entraran en la cápsula Dragon CRS-1 que les lleva una nueva carga de suministros al final entraron en ella ayer a las 17:40 UTC. Esto fue...
Algunos de los pacientes de Justo Gonzalo Justo Gonzalo era un neurólogo español que durante la guerra civil española empezó a tratar a heridos en la cabeza, lo que desafortunadamente es una de las mejores formas de estudiar el cerebro. Después de...
Esa fue la frase que usó Sunita Williams, la actual comandante de la Estación Espacial Internacional, tras acoplar la cápsula Dragon CRS-1 en el módulo Harmony de la Estación a las 13:03 UTC utilizando el brazo robot de esta: Dragon Berthed to...
La lección divulgativa de hoy es una de las mejores y más curiosas que he visto últimamente. Procede del excelente trabajo de Vsauce y describe la relación entre las fuerzas que ejerce la luz (o las sombras) en los objetos cotidianos,...
Paul Broun, miembro de la Cámara de Representantes de Estados Unidos de los Estados Unidos por Georgia, en un reciente banquete: Esta es una idea que probablemente no habéis considerado. El astrónomo Edwin Hubble, quien descubrió la expansión del universo, formaba parte...
Cuando un transbordador espacial no aterrizaba en el Centro Kennedy al final de una misión tenía que ser transportado de vuelta allí a lomos de uno de los Shuttle Carrier Aircraft, los dos Boeing 747 modificados que tenía la NASA para...
Tras varios años de preparación de los equipos necesarios y las pruebas pertinentes todo parece listo para que hoy Felix Baumgartner y el equipo de Red Bull Stratos lleven por fin a cabo el salto en paracaídas con el que pretenden...
Domenico Vicinanza, físico de partículas y compositor, ha cogido los datos en los que los científicos del LHC han encontrado evidencias más que fuertes de la existencia del bosón de Higgs y los ha convertido en esta pieza musical. Como explica...
Lanzamiento de la Dragon CRS-1 - Ben Cooper/LaunchPhotography.com A pesar de que las previsiones meteorológicas de los días anteriores sólo daban un 60 por ciento de posibilidades de que se pudiera proceder con el lanzamiento al final estas mejoraron hasta el 80...
Muchos años los premios Nobel de medicina son otorgados por trabajos tan especializados que es muy complicado entender de qué tratan. Pero no este año, ya que el Nobel de medicina ha sido otorgado a John B. Gurdon y Shinya Yamanaka por...
Tres CubeSAT emprenden su camino - NASA El pasado día 4, el mismo día que se cumplían 55 años del lanzamiento del Sputnik, se lanzaron cinco CubeSAT desde la Estación Espacial Internacional usando el Small Satellite Orbital Deployer. Se trata de un...
Draconid Meteors Over Spain, APOD del 19 de octubre de 2011 - Juan Carlos Casado (TWAN) No se prevé que alcancen ni de lejos la intensidad del año pasado, pero las Dracónidas alcanzarán su máxima actividad para este año el 8 de...
Después de sus dos vuelos de pruebas y certificación todo está listo en el complejo de lanzamiento 40 de Cabo Cañaveral para que esta noche se lleve a cabo el primer lanzamiento de una cápsula Dragon de carga en su primer...
Salidos de las mentes inquietas de Xurxo Mariño y Vicente de Souza los Discurshows no son una charla ni un discurso, ni tampoco son teatro ni un show, sino un poco de todo, y pretenden acercar temas relacionados con la ciencia y...
Situado en un lugar remoto de Australia, a 700 kilómetros al norte de Perth, en una zona en la que en una superficie similar a la de los Países Bajos hay censadas 16 personas, hoy se ha inaugurado el interferómetro ASKAP,...
eso1238a: La Nebulosa del Casco de Thor (NGC 2359) por el VLT - ESO/Brigitte Bailleul La celebración del 50 aniversario del Observatorio Europeo Austral incluía la observación de la Nebulosa del Casco de Thor (NGC 2359) usando el Very Large Telescope del...
Un letrero dice así: Si compra este producto junto con otra persona más obtendrá 1.000 dólares de regalo. Un hombre pobre lee el letrero y le sugiere la transacción a un hombre rico que pasa por ahí. El producto cuesta 50 dólares....
El ATV-3 al partir de la ISS - ESA/NASA El Edoardo Amaldi, el tercer carguero espacial de la Agencia Espacial Europea, terminaba su misión la madrugada del pasado miércoles cuando a las 3:28:31 se precipitaba en la atmósfera para desintegrarse. Rastro de...
El Observatorio Europeo Austral celebra mañana, 5 de octubre de 2012, su 50 aniversario con una serie de actos bautizados como «Un día en la vida de ESO». Los telescopios del VLT - ESO/G.Hüdepohl (atacamaphoto.com) Comenzarán con la retransmisión en directo de...
Omega, el parámetro de densidad determina cual será el destino de nuestro universo Esta cifra, obtenida gracias a nuevas observaciones realizadas con el telescopio espacial Spitzer, es el nuevo valor de la constante de Hubble, con un margen de error del 3...
¡Estoy indignado! No porque @MarsCuriosity use foursquare –todo lo contrario, llevo años diciendo que me parece brillante el uso que la NASA está haciendo de las redes sociales– sino porque me parece increíble que le vayan a dar la alcaldía de...

Simulación numérica de los gases alrededor del agujero negro de M87 - Avery E. Broderick (University of Waterloo/Perimeter Institute) Aunque a estas alturas hay montones de observaciones y datos que confirman que los agujeros negros efectivamente existen lo cierto es que nunca...
Aki Hoshide y Yuri Malenchenko en el módulo Zvezda de la ISS - NASA En la actualidad los tripulantes de la Estación Espacial Internacional permanecen en esta por periodos de unos seis meses de duración, pero todo parece estar listo para que...
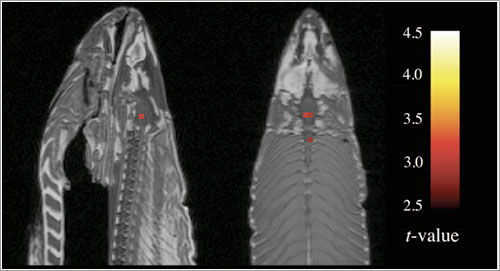
El salmón zombie Hace poco Craig Bennett, Abigail Baird, Michael Miller, y George Wolford ganaban el premio Ig Nobel 2012 de neurociencia por demostrar que los investigadores, usando instrumentos complicados y estadísticas simples, pueden ver actividad cerebral significativa en cualquier sitio, incluso...
4737 × 2985810 + 1 es primo Este nuevo número primo lo ha calculado John Perretta, un profesor de informática del Broward College. Tiene casi 300.000 dígitos y para calcularlo tuvo que programar un «superordenador casero» con 3.076 procesadores construido por él...
Impresión artística del aterrizaje de una misión de retorno de muestras en Marte No cabe ninguna duda de que la NASA se ha marcado un importante tanto con la llegada de Curiosity a Marte. Pero más allá de las sondas de bajo...
Desde el departamento Naturaleza que Acongoja, Parasitic Wasps: Alien on Earth -- Las avispas parasitoides (Parasitica) insertan sus huevos dentro de una oruga, donde se dearrollan durante 14 días. Los embriones mantienen paralizada a la oruga mediante un virus en su ADN...
Por Nacho Palou -
2 OCT 2012
Primeros datos del instrumento MHS, que mide la humedad en la atmósfera. Cuanto más hacia el rojo, menos humedad - Eumetsat El proceso de puesta en producción del MetOp-B, el satélite más nuevo de la Organización Europea para la Explotación de Satélites...
R.: Con un puntero láser convencional el efecto sería… ninguno.P.: ¿Y utilizando el láser más potente que tenemos?R.: Entonces convertiríamos la atmósfera en plasma que calcinaría al instante la superficie de la Tierra, matándonos a todos. Laser Pointer en XKCD/What if?, vía...
Por Nacho Palou -
2 OCT 2012
Cualquier mapa geográfico puede ser coloreado con cuatro colores diferentes, de forma que no haya regiones adyacentes con el mismo color. ¡Cuidado que engancha! Si quieres comprobar si el teorema de los cuatro colores es cierto, nada más fácil que jugar...
Cepillo de dientes tuneado como herramienta espacial - NASA/ESA La exploración del espacio exige una cuidadosa preparación, ya que no vale aquello de «voy a bajar el súper que me olvidé de comprar naranjas». Pero aún así hay veces en que toda...
Terminada la campaña iniciada por Matthew Inman de The Oatmeal para reunir fondos con el fin de construir el Museo Tesla en los laboratorios de Wanderclyffe actualmente abandonados, la suma final supera los 2,2 millones de dólares: 1,3 millones obtenidos en...
Por Nacho Palou -
1 OCT 2012
Este vídeo recoge la espectacular erupción solar del 31 de agosto de 2012 según la vieron diversos instrumentos a bordo de los observatorios Solar Dynamics Observatory y STEREO de la NASA y del SOHO de la NASA y la ESA. Esta...
Carson, Ride, Hopper, Franklin, Goodall y –mi favorita– Curie, todas en formato póster minimalista: seis científicas que cambiaron la Ciencia. Cortesía de Hydrogene. (Vía Fuck Yeah Math.)...
Aviso: hipnotizante. En esta versión vitaminada y mineralizada del experimento de los cinco metrónomos alguien el Laboratorio Ikeguchi de Japón se entretuvo en ver qué sucedía si utilizaba 32 metrónomos a la vez. La magia de esta sincronicidad se debe, aunque...
Sensores para alertar de fugas de aire La formación de los astronautas dura varios años, durante los que estudian los sistemas de sus naves y practican los procedimientos a aplicar en cada caso hasta la saciedad, reciben entrenamiento de supervivencia por si...
Recorte de la zona central del Hubbe XDF - NASA/ESA. Clic en la imagen para verla entera y a varios tamaños. La ESA y la NASA acaban de publicar una nueva imagen profunda del espacio obtenida por el Hubble, en este caso...
La aplicación para iPad NMHMC Harvey Collection (7,99€), publicada por el National Museum of Health and Medicine Chicago, Permite a cualquier persona examinar el cerebro del Nobel en Física Albert Einstein como si estuviera mirándolo con un microscopio. Son imágenes en...
Por Nacho Palou -
26 SEP 2012
Ya hemos hablado en unas cuantas ocasiones de que si el espacio representa para la mayoría de nosotros lo inexplorado es porque muchas veces no nos acordamos de que en realidad hay una gran parte de nuestro planeta que aún no...
Aunque hay tratamientos que consiguen en mayor o menor medida ralentizar –que no detener– el avance de la enfermedad hoy por hoy la enfermedad de Alzheimer no tiene cura. Los médicos y científicos que lo investigan creen que uno de los...
Este artículo se publicó originalmente en Cooking Ideas, un blog de Vodafone donde colaboramos semanalmente. Eric Selby, uno de los usuarios de las gafas Argus II En las últimas semanas se está hablando bastante de un par de «ojos biónicos» que pronto...
Endeavour lands at LAX - NASA/Matt Hedges El aeropuerto internacional de Los Angeles recibió ayer uno de los tráficos más peculiares de toda su historia con la llegada del transbordador espacial Endeavour a lomos del NASA905, uno de los dos Boeing 747...
Un año más la gente de los Annals of Improbable Research nos traen unas risas con los premios Ig Nobel 2012, otorgados a los estudios y trabajos serios que menos lo parecen: Premio de psicología a Anita Eerland, Rolf Zwaan, y Tulio...
Esta impresionante foto de Martin Pugh de la galaxia M51, también conocida como la Galaxia Remolino, es la ganadora absoluta del concurso Astronomy Photographer of the Year organizado por el Real Observatorio de Greenwich y la revista Sky at Night. Los...

Tras los preparativos… suceden cosas interesantes. Eso sí, hay que esperar hasta 03:40 - 03:50 más o menos....
KSC-2012-5425: el Endeavour, el SCA, y los aviones de apoyo - NASA/Alan Ault Tras dos días de retraso debido al mal tiempo esta mañana, poco después de amanecer en Florida, el Shuttle Carrier Aircraft conocido como NASA 905 despegaba del Centro Espacial...
The Earth can sing! Listen to its 'chorus' — ¿Qué causa esto? Esta ondas de radio [sonoras al ser captadas por las sondas RBSP de la NASA] son emitidas por las partículas energéticas que se encuentran en la magnetosfera, un fenómeno...
Por Nacho Palou -
19 SEP 2012
Lanzamiento del MetOp-B / EUMETSAT Tras un lanzamiento perfecto el MetOp-B, el nuevo satélite meteorológico de la Agencia Espacial Europea, está en órbita a 810 kilómetros de altura, recorriendo la Tierra de polo a polo cada 101 minutos: Lanzado con éxito el...
Santiago nos escribió para contarnos cómo creó un adaptación de este precioso diagrama de Venn de 7 conjuntos: Cada conjunto va asociado a un color. Los 7 colores están tomados equiangularmente del círculo de matiz (hue). Los 27-1 = 127 subconjuntos...
Expedition 32 Landing. Más fotos en 210120917 Expedition 32 (landing only) Tal y como estaba previsto a las 2:53 UTC de esta pasada noche la Soyuz TMA-04M con Gennady Padalka, Sergei Revin y Joe Acaba a bordo tomaba tierra al norte de...
Soyuz and Metop-B rolled out to launch pad: el MetOp-B y su lanzador en la plataforma de lanzamiento. Más fotos en Metop-B launch campaign Si todo va según lo previsto esta tarde a las 16:28 UTC un Soyuz ST con una segunda...
iss032e025666: Los astronautas realizan una prueba de estanqueidad de sus trajes espaciales a bordo de la Soyuz TMA-04M antes de volver a tierra Tras cuatro meses en el espacio Gennady Padalka, Sergei Revin y Joe Acaba están listos para volver esta noche...
En un laboratorio hay encontrado una forma de utilizar la levitación mediante ondas acústicas con dos altavoces a 22 KHz para mantener estables en el aire pequeñas gota de líquido. Además de bastante curioso e hipnotizante puede tener ciertas aplicaciones médicas:...
Portrait of ASPX on Mars: el espectrómetro de rayos X por radiación alfa, conocido como ASPX, en el extremo del brazo de Curiosity Con un solo sol de retraso sobre los planes previstos los técnicos de la misión han acabado de comprobar...

… ¡Cosas realmente extrañas! Para empezar te chocarías contra las paredes debido al efecto Coriolis. Pero si consiguieras evitar este «problemilla» alcanzarías la nada despreciable velocidad de 35.000 Km/h al atravesar el centro… donde surgiría el (¡ejem!) problemilla de evitar achicharrarse...
Endeavour a lomos del SCA NASA 905 Desde hace un par de horas el transbordador espacial Endeavour está ya colocado a lomos del NASA 905, el avión que lo va a llevar en su último vuelo con destino a Los Ángeles, donde...
El Kounotori 3 atracado en la ISS. Se ve claramente la carga de su modulo no presurizado, que va abierto al espacio Esta mañana aproximadamente a las 5:30 UTC el tercer carguero espacial H-II de la Agencia Japonesa de Exploración Aeroespacial terminaba...
Desde el departamento de ciencia recreativa llega hoy este vídeo demostrativo de cómo los líquidos son apilables según su densidad. No se mezclan e incluso se puede conseguir una artística combinación de diversas tonalidades. Se puede hacer por ejemplo combinando sirope...
NumberSimulation.com es una curiosa representación animada de los números primos en una espiral. Llegamos a ella gracias a una pista de Víctor que lo vio en Creative JS. En la imagen, los números naturales (1, 2, 3…) parten del centro hacia...
HeartMate II Roberto Martín Asenjo y José Manuel Montero Cabezas nos escribieron desde el departamento de Cardiología del Hospital 12 de Octubre de Madrid para ponernos en la pista del caso de Pedro, que es la primera persona a la que se...
¿Cómo funciona el cerebro humano? ¿Por qué los olores despiertan tantos recuerdos? ¿Cuánto tiempo transcurre desde que se forma un pensamiento hasta que se transforma en palabras? ¿Es diferente el cerebro de las personas tímidas? ¿Por qué cometemos lapsus? ¿Cómo tomamos decisiones?...
Uno de los calibradores fotográficos de Curiosity. Foto: NASA / JPL … aún habiendo llegado a Marte por nuestra cuenta. Ese es uno de los «mensajes» que hemos enviado al planeta rojo: en una de las imágenes que he visto pasar...
En esta dirección hay un feed RSS con las últimas imágenes en bruto que van llegando desde el Mars Science Laboratory, en diversas calidades: http://mars.open-notify.org/feeds/msl-all-feed-nothumb.xml Además de para epatarse, tiene gran utilidad para quejarse de los anacronismos de la vida moderna,...

Un experimento sobre hipoxia muestra cómo la falta de oxígeno aturde la mente y plantea su uso en ejecuciones menos dolorosas.
Una preciosa infografía interactiva de Future (BBC) que muestra de forma gráfica cómo funciona la ecuación de Drake de la que hablábamos el otro día por aquí: ¿Cuántos mundos habitables existen? Los valores de cada variable de la ecuación se pueden...
Dado que la mayoría de vosotros no vais a poder ir a la Estación Espacial Internacional este vídeo en el que André Kuipers la recorre de una punta a otra pasando por los camarotes, los baños, el ATV-3, las Soyuz, que...
… al menos lo haría con estilo. Esta bella e impresionante eyección coronal de masa solar a una velocidad de 1.400 kilómetros por segundo se produjo hace unos días, el 31 de agosto. Aunque los materiales no salieron en dirección a...
El truco está en la aplicación en un patrón de nanoperforaciones en la superficie de una «lente plana ultrafina», formada por una lámina de silicio y un recubrimiento de oro de unos poco nanómetros de grosor, que cambian la dirección de la...
Por Nacho Palou -
4 SEP 2012
Los Museos Científicos Coruñeses, en los que trabajo en el MundoReal™, han convocado un año más sus Premios Prismas «Casa de las Ciencias» a la Divulgación. Este año, además, es una ocasión especial, pues cumplen sus bodas de plata, algo que en...

El otro día contaba en otro blog que los móviles perpetuos son una de mis «imposibilidades» favoritas; en este vídeo han recopilado muchos de esos diseños y se puede ver cómo (hipotéticamente) funcionarían o, más bien, cómo no funcionan todos estos...

Ya habíamos visto antes el descenso de Curiosity a su llegada a Marte, pero ahora un aficionado se ha entretenido en arreglar aquella película, grabada originalmente a 4 fotogramas por segundo, mejorándola a 25 fotogramas por segundo. El resultado es mucho...
Data visualization: Tweets sent about Neil Armstrong 08/25/2012-08/27/2012 es un vídeo montado por Nicolas Belmonte, @philogb, que se encarga de hacer viualizaciones de datos en Twitter, en el que se recogen los 1.600.000 tuits que mencionan a Neil Armstrong en las...
Jakub Halik con las baterías de su corazón artificial en el regazo Después de que le detectaran un tumor maligno en el corazón al bombero checo Jakub Halik le quedaban pocas opciones, pues las medicinas necesarias para suprimir el rechazo tras un...
Es tan redondo que según los investigadores que lo llevan observando durante se trata del objeto natural más redondo que se conoce. Más redondo incluso de lo que predecían los modelos informáticos. La afirmación no es trivial porque debido a las...
Por Nacho Palou -
28 AGO 2012
Este vídeo educativo TED-Ed es una buena explicación de cómo funciona la Ecuación de Drake, una forma de estimar un tanto a ojímetro cuál es la probabilidad de que exista vida extraterrestre en algún lugar del universo. Lo más interesante de...
Corazón artificial «clásico» Este artículo se publicó originalmente en Cooking Ideas, un blog de Vodafone donde colaboramos semanalmente. Hace años que los trasplantes de corazón han dejado de ser noticia ya que se llevan a cabo con éxito varios miles al año....
Cuando los fluidos viajan a través de tubos pueden producir un curioso efecto de «aspiración» que lleva el nombre de Giovanni Battista Venturi, su descubridor. Esto se debe factores como la la presión, la velocidad y el efecto Bernoulli, que también...
Si se puede crear lava en un laboratorio… ¿Por qué no hacerlo y ver cómo se comporta? Consistencia, viscosidad, porosidad, duración del flujo, volumen, estructura, cambios de temperatura… Un sinfín de parámetros que explorar. Lo hicieron en la Universidad de Siracusa....
Una visualización compacta y simple de entender: Los planetas del Sistema Solar a escala. (Vía Geekdad.)...

En este vídeo divulgativo de AsapSCIENCE Mitchell Moffit y Gregory Brown recopilan algunos datos más o menos conocidos y avalados por la ciencia relacionados con las dietas de adelgazamiento: la endocrinología del apetito, el papel de las protenías, el apetito y...
Venecia vista por el Pleiades 1 del CNES francés Aparte de saber más de sus propias naves que muchos empleados de la ESA, la NASA, o Roscosmos y contárnoslo en Eureka, Daniel Marín tiene un tumblr llamado Astroperlas en el que va...
Para la inmensa mayoría de nosotros un sonido es un sonido, un sabor es un sabor, o un color es un color, pero para aquellos que tienen sinestesia un sonido puede provocar un sabor, los números tener color debido a su...

Hace unos días surgía en una conversación el viejo asunto de que si en el hemisferio norte el agua gira en los desagües en distinto sentido que en el hemisferio sur por culpa del efecto Coriolis. Es algo que supuestamente se...
Mars One es un proyecto para la colonización de Marte por parte de la iniciativa privada para 2023. Aunque llegar al planeta rojo «en persona» sería el sueño de muchos, tal hazaña está todavía muy lejos de la tecnología aeroespacial actual....
Fmri fMRI del movimiento de una mano Este artículo se publicó originalmente en Cooking Ideas, un blog de Vodafone donde colaboramos semanalmente. No hace mucho Sir Robin Murray, un reconocido psiquiatra británico, decía que nunca seremos capaces de entender el cerebro, ya...
Además de sus tareas oficiales Don Pettit dedicaba parte de su tiempo libre en la Estación Espacial Internacional a grabar vídeos en los que realizaba experimentos que sólo se pueden realizar en microgravedad, al final de los que plantea una pregunta...
A propuesta de la gente The Oatmeal, más conocidos por sus tiras y libros cómicos, se ha puesto en marcha una iniciativa de financiación colectiva para comprar los terrenos en los que Nikola Tesla tuvo su laboratorio y construir un museo...

Según los datos de Online Satellite Calculations de los ~13.000 satélites que hay orbitando la Tierra solo están funcionando realmente unos 3.500: el resto están clasificados como basura espacial, lo cual empieza a ser un problema. Antes que eso, otros ~20.000...
Cyborg: Progress - Foto CC por pasukaru76 Este artículo se publicó originalmente en Cooking Ideas, un blog de Vodafone donde colaboramos semanalmente. Hace unos días alguien me decía, de broma, por supuesto, que es medio ciborg porque lleva un marcapasos, pero me...
Siempre he dicho que es muy importante no tomarse demasiado en serio a uno mismo para mentener la perspectiva de las cosas; los chicos de la NASA lo clavan en We're NASA and We Know It (Mars Curiosity), un vídeo en...
Heather Archuletta se ha pegado el curro de colocar en un mapa las instalaciones de todas las agencias espaciales del mundo: Pillow Astronaut: Map of Worldwide Space Agencies. Son un total de 198 y reconozco que a pesar de mi espaciotrastorno...
En 3.1415926535897932384626… se puede navegar por una representación visual de los cuatro primeros millones de dígitos de Pi, en los que cada uno lleva asociado un color y está representado por un pixel. Hasta ahora hay calculados 10 billones de decimales...
NASNASA/JPL-Caltech/University of Arizona Curiosity in Exaggerated Color es una nueva imagen de Curiosity obtenida por la Mars Reconnaissance Orbiter en la que se ve el más nuevo rover de la NASA en Aeolis Palus, la planicie marciana a los pies de Aeolis...
Checking out the Rover Deck in Full Resolution - NASA/JPL-Caltech Desde que aterrizó en Marte Curiosity no ha parado de tomar fotos, cual turista japonés desatado, y es difícil quedarse con una, aunque quizás mi preferida sea esta. Compuesta a partir de...
El astronauta Don Petit nos hace una demo de cómo funcionan los yo-yos en la Estación Espacial Internacional. Parecen un poco «a cámara lenta» pero en realidad todo se debe al efecto de la ingravidez....
Ciudades iluminadas por la noche, rayos, auroras, estrellas, la Vía Láctea… Earth Illuminated: ISS Time-lapse Photography es otro espectacular vídeo construido con fotografías disponibles en The Gateway to Astronaut Photography of Earth. Ya sabéis, para ver a pantalla completa, con las...
Tras conseguir llenar el salón de actos del Paraninfo de la UPV/EHU un viernes y un sábado era de esperar que los chicos de Amazings insistieran, así que ya tenemos programa y fechas para Amazings Bilbao 2012. Se celebrará el viernes 28...
Una introducción visual muy fácil de entender al concepto de la infinitud y la teoría de conjuntos en matemásticas, donde apreciar matices tan aparentemente paradójicos y contrarios a la intuición como que existen tantos números enteros (1, 2, 3…) como números...
Primera imagen de la Tierra adquirida por el Meteosat 10 el 7 de agosto de 2012 a las 9:45 UTC- Eumetsat Esta es la primera imagen del globo terrestre enviada a tierra por el Meteosat 10, el tercer satélite Meteosat de segunda...
Perseid Meteors over Stanmer Church - Foto CC por Dominic Alves Si esto es la Tierra y estamos en agosto esto quiere decir que nuestro planeta se acerca en su órbita una vez más a los restos del cometa 109P/Swift-Tuttle, de donde...
Esta calculadora es la delicia de los profesores de ingeniería: se llama QAMA (Quick Approximate Mental Arithmetic) y sólo te da la respuesta exacta cuando tú también piensas e introduces una aproximación razonable. Digamos que si quieres obtener 4.815 multiplicado por...
Recorte de un fotograma de MARDI. Clic para ver en tamaño completo. Cuando sacamos el vídeo del descenso de Curiosity en Marte tomado por la cámara MARDI ya avisamos de que eran imágenes previas en baja resolución y que habría que esperar...
Scene of a Martian Landing es una imagen obtenida por la Mars Reconnaissance Orbiter unas 24 horas después del aterrizaje de Curiosity en Marte en la que se ven todos los componentes de esta. El escudo térmico (heatshield), que fue lo...
¿Cómo? ¿Otra anotación sobre Curiosity en Microsiervos? ¡Ja! ¡Y lo que os queda! Curiosity's Descent es un vídeo montado con 297 fotogramas en baja resolución tomados por la MARDI, la MSL Mars Descent Imager, una cámara que apuntaba hacia abajo y...
… Que en el fondo es lo que todos haríamos si pudiéramos disfrutar de la ingravidez en la Estación Espacial Internacional, que es donde están grabados estos curiosos experimentos....
NASA's Mars Science Laboratory Image: Curiosity fotografiada por la HiRISE de la MRO - NASA/JPL-Caltech Los chicos de la Mars Reconnaissance Orbiter se están ganando el puesto de «sondaspotters» marcianos a pulso. Si en 2008 cazaron a la Phoenix en su descenso...
No photo or it didn't happen? Well lookee here, I'm casting a shadow on the ground in Mars' Gale crater #MSL twitter.com/MarsCuriosity/…— Curiosity Rover (@MarsCuriosity) agosto 6, 2012 La sombra de Curiosity fotografiada por una de sus hazcams traseras - JPL/NASA Los...
Right now, I'm closer to Mars than the moon is to Earth. 28 hours to landing!— Curiosity Rover (@MarsCuriosity) agosto 5, 2012 Quedan doce horas para la hora en la que, si todo va según lo previsto, en la Tierra recibamos confirmación...
Lanzamiento del VA208 - ESA/CNES/Arianespace/Optique Video du CSG Un Ariane 5 ECA que despegó ayer a las 22:54 hora central europea del espaciopuerto europeo en Kourou se convirtió en el 50º lanzamiento con éxito consecutivo de un cohete Ariane 5, lo que...
Tras ser lanzada desde el cosmódromo de Baikonur el 1 de agosto a las 19:35 UTC la nave de carga Progress M-16M atracaba en el módulo Pirs de la Estación Espacial Internacional el 2 de agosto a la 1:18 UTC. Si...
Un bosón de Higgs con 126 GeV con 5,9 sigmas Cuando el pasado 4 de julio los científicos de los experimentos ATLAS y CMS del Gran Colisionador de Hadrones anunciaban el haber descubierto «una partícula compatible con las características del bosón de...

Como dice @aberron, La cámara de los recuerdos perdidos es una especie de spin-off de El mal del cerebro que trata de un grupo de personas con amnesia severa y un experimento que está llevando a cabo el Centro Estatal de...
Ya hemos mencionado en varias ocasiones el arriesgado método de aterrizaje que va a utilizar Curiosity en su llegada a Marte, prevista para el próximo lunes a las 5:31 UTC, pero no está de más recordarlo en este vídeo narrado por...
Septiembre promete ser un mes interesante para los espaciotrastornados europeos, ya que además del segundo SpaceTweetup de la DLR y la ESA se va a celebrar la primera edición de SpaceUp Europe. Se trata de una desconferencia en la que no hay...
Model del rover ExoMars que se pudo ver en año pasado en el Pabellón Espacial de ILA - ESA/M. Pedoussaut La DLR, la Agencia Espacial Alemana, y la ESA han convocado su segundo SpaceTweetup conjunto, que en esta ocasión se celebrará en...
A principios de este mes Amazings.es cumplía dos años, así que para celebrarlo nos proponen una lista de los 10 artículos más leídos de su segundo año, material que puede servir para aprovechar mejor el fin de semana: 10 cosas sobre física...
El Kounotori 3 capturado por el brazo robot de la ISS - NASA Desde hoy a las 14:34 GMT el vehículo de carga H-II bautizado como Kounotori 3 de la Agencia Japonesa de Exploración Aeroespacial está atracado al módulo Harmony de la...
Felix Baumgartner en el momento de saltar - Jay Nemeth/Red Bull Content Pool Tras dos intentos que hubo que cancelar por culpa del viento y la lluvia Felix Baumgartner ha podido realizar en Nuevo México su último salto de prueba antes del...
El rosa oscuro representa la extensión de hielo fundido en superficie en Groenlandia el 8 (izquierda) y el 12 de julio (derecha) Varios medios de comunicación se han hecho eco hoy de una nota enviada por EFE que dice que Groenlandia perdió...
Sally Ride en la cabina del Challenger durante su primera misión en junio de 1983 - NASA Veterana de las misiones STS-7 y STS-41-G, miembro de las comisiones que estudiaron los accidentes del Challenger y del Columbia, y miembro también del comité...
El Patrón de los Números Primos es un curioso experimento de Jason Davies que permite explorar el lugar que ocupan los números primos en el conjunto de los números naturales pinchando, arrastrando, y haciendo zoom. Los primos son aquellos que sólo...
Views of the Sky es una sencilla visualización 3-D del cielo estrellado y las constelaciones, a partir de datos extraídos de la Wikipedia, usando JavaScript + HTML (canvas). Los lo envió Santiago para compartirlo con todos. Elegante y bonito....
La desecación del mar de Aral, uno de los vídeos sacados de imágenes de los LandSat que Google ha incorporado a su Earth Engine La NASA y el Departamento del Interior de los Estados Unidos celebran hoy el lanzamiento en 1972 del...
View from the ISS at Night por Knate Myers en Vimeo. Una de las ventajas que tiene el que la NASA ponga en The Gateway to Astronaut Photography of Earth las imágenes que toman los astronautas que viven a bordo de la...
Desde esta madrugada a las 2:06:18 UTC el tercer carguero espacial H-II de la Agencia Japonesa de Exploración Aeroespacial, JAXA, viaja rumbo a la Estación Espacial Internacional, a la que lleva un total de 4.600 kilogramos de materiales y suministros repartidos...

Space Shuttle: The complete missions: un homenaje de Nature a estas naves Hoy se cumple un año del aterrizaje del Atlantis al final de la misión STS-135 de la flota de transbordadores espaciales de la NASA, la que ponía final a...
La Operación Plumbbomb fue una serie de pruebas nucleares llevadas a cabo por los Estados Unidos entre mayo y octubre de 1957 en el emplazamiento de pruebas de Nevada. La prueba denominada John, del 19 de julio, consistió en la detonación...
La NASA ha reunido en First Planetary Images las primeras imágenes que sus sondas fueron sacando de los distintos planetas del sistema solar desde más o menos cerca. Incluyen a Plutón porque en el momento de tomar la imagen incluida en...
Esto es una portada de Modern Electrics de 1912 una revista con una misión divulgativa para la época: explicar qué era eso de la electricidad y para qué servía – como el Muy Interesante o el Quo que hoy en día...
Don Pettit y las cámaras de la ISS - NASA Ahora que Don Pettit está de vuelta de su última estancia en la Estación Espacial Internacional imagino que echará de menos estar todo el día en caída libre y esas cosas, pero...
Esta mañana a las 4:51 GMT la Soyuz TMA-05M en la que viajaban Yuri Malenchenko, de Roscosmos, Sunita Williams de la NASA, y Akihiko Hoshide, de la Agencia Japonesa de Exploración Aeroespacial, quedaba atracada en el módulo Rassvet de la Estación...
Ocultación de Júpiter del 15 de julio de 2012 por Thiery Legault La maravillosa meteo que hemos tenido en mi esquina del mundo estas últimas semanas ha hecho que se me pasara por completo la ocultación de Júpiter por la Luna que...
Esta madrugada a las 2:40:03 UTC la Soyuz TMA-05M despegaba de la Rampa Número 5, también conocida como la Rampa de Gagarin, del cosmódromo de Baikonur rumbo a la Estación Espacial Internacional. Un poco menos de nueve minutos más tarde, tras...
La Soyuz TMA-05M en la plataforma; en primer plano una de las zanjas para conducir las llamas del lanzamiento - NASA/Carla Cioffi. Más fotos en Expedition 32. La Soyuz TMA-05M y todos los equipos de tierra del cosmódromo de Baikonur están listos...
Optimización en la cocción de los alimentos, gracias a la geometría de la hélice. Resultado: salchichas mejor asadas y más crujientes… ¡ñam!...
Pirate McDonaldsMcMoon Hemos mencionado varias veces el Lunar Orbiter Image Recovery Project, el proyecto puesto en marcha en 2008 para recuperar las imágenes de las sondas Lunar Orbiter de la NASA de los años 60 y procesarlas con tecnologías modernas… Pero igual...
Unos científicos locos han disparado simultáneamente los 192 haces del láser más poderoso del mundo para ver qué pasaba, utilizando una potencia combinada de 500.000.000.000.000 watios (500 billones en español; 500 trillons anglosajones). El objetivo era un pequeño blanco circular de...
En noviembre de 1953 los miembros del Politburó se reúnen para decidir acerca del futuro del programa nuclear soviético, y en concreto para tomar decisiones acerca del misil intercontinental que todos tienen claro que la URSS tiene que construir para mantenerse a...
El LauncherOne de Virgin Galactic No contentos con tener muchas posibilidades de convertirse en la primera empresa en llevar viajeros de pago al espacio, aunque por ahora se a 100.000 dólares el billete, Virgin Galactic acaba de anunciar que también está en...
Cada vez es más raro que te den de comer en un avión, al menos sin pagar, y la verdad es que tampoco es algo que echemos tanto de menos porque todos sabemos que la comida a bordo sabe como sabe,...
El curioso vehículo Blackbird propulsado por viento. Foto de Rick Cavallaro, en Wired El vehículo Blackbird se desplaza más rápido que la velocidad del viento que utiliza para moverse. Algo que, de entrada, suena imposible o al menos "contrario a la intuición"....
Por Nacho Palou -
12 JUL 2012
NuSTAR's First View of High-Energy X-ray Universe, Primera imagen del NuSTAR - NASA/JPL-Caltech Se me había pasado que la NASA ha publicado la primera imagen del telescopio espacial de rayos X NuSTAR. El NuSTAR no es ni por asomo el primer telescopio...
Plutón y sus cinco lunas - NASA, ESA, and M. Showalter (SETI Institute) Estaba el Hubble echándole un vistazo a Plutón y a sus lunas por aquello de que cuando llegue allí la sonda New Horizons llegue allí en 2015 no se...
Una sola gota de esta víbora de Russell (víbora de cadena o serpiente de las tijeras) basta para solidificar la sangre que el experto deja caer sobre el envase de pruebas en cuestión de segundos [01:00]. ¡Ooouch! Y es que, según...
Técnicos de AT&T haciendo pruebas con el Teslstar 1 Hoy se cumplen 50 años del lanzamiento del Telstar 1, el primer satélite artificial activo de comunicaciones. Con una masa de 77 kilogramos un un tamaño de 87,6 centímetros, límites marcados por la...
Lado izquierdo de la sala limpia del Edificio 29 El próximo gran telescopio de la NASA, el Telescopio Espacial James Webb, está siendo montado en la sala limpia del Edificio 29 del Centro de vuelo espacial Goddard de la agencia. El proceso...
La Orión EFT-1 siendo descargada en el KSC - NASA Desde hace unos días la primera cápsula Orión de la NASA que volará al espacio está en el Centro Espacial Kennedy, aunque aún queda mucho trabajo por hacer en ella: NASA'S Orión...
(@yelsp vía RT de @JoseM_SGP)....
Los resultados sugieren fuertemente que hemos encontrado la partícula de Higgs, la partícula que da masa a las otras partículas. Si su desintegración y otras interacciones son las que esperamos, será una fuerte evidencia a favor del modelo estándar de la...
Aunque Opportunity pasó su quinto invierno marciano sin moverse, convenientemente aparcado en una ligera pendiente que hacía que sus paneles solares aprovecharan en la medida de lo posible la luz que llegaba del Sol, eso no quiere decir que estuviera inactivo....
Joe Kittinger posee desde el 16 de agosto de 1960 el récord de altura en salto con paracaídas con 31.300 metros. Saltó desde el Excelsior III, un globo de helio, dentro del programa Manhigh de la Fuerza Aérea de los Estados...
Imagen de microscopio electrónico de barrido de la GFAJ-1 - Science / AAAS En diciembre de 2010 la NASA anunció a bombo y platillo un estudio sobre unas bacterias extremófilas conocidas como GFAJ-1 que viven en el lago Mono de California que...
En el momento en el que se publica esta anotación hace exactamente un año que estaba viviendo una de las experiencias más alucinantes –e irrepetible en este caso– de mi vida, ver en directo el lanzamiento del transbordador espacial Atlantis. Se...

Este Zoom al centro de la galaxia es una aventura visual muy al estilo de Potencias de 10: un vertiginoso viaje hacia el centro de nuestra galaxia, comenzando por la constelación de Sagitario y pasando por grandes nubes de gas hasta...
Todos estos datos que hemos recopilado con gran fiabilidad corresponden a una partícula compatible con el bosón de Higgs. En un seminario impartido desde el CERN se han anunciado las novedades sobre la búsqueda del bosón de Higgs, que básicamente confirman...
Mañana a las 9 de la mañana, hora central europea, desde el CERN se van a comunicar los nuevos resultados de los que disponen tras analizar los datos obtenidos por los experimentos ATLAS y CMS del Gran Colisionador de Hadrones durante el...
Esto podría definirse como dar una clase con clase. Y echarle imaginación a lo que de otra forma sería una charla convencional sobre números imaginarios. Aunque algunos de los «trucos» están un poco vistos, aquí el profe ciertamente se lo ha...
Estos diseños de Cut n Paste son recortables en vinilo que se pueden pegar directamente en la pared, para decorar la casa con la elegancia propia de la ciencia más seria – o casi. Hay varios diseños a cual más intrigante...
¿Que hubiera pasado si Nikola Tesla se las hubiera apañado para viajar en el tiempo y se hubiera hecho con la tecnología necesaria para dejar grabados unos cuantos Teslablogs en VHS? Pues a eso precisamente es a lo que ha decidido...
La TMA-04M justo en el momento del aterrizaje - NASA/Bill Ingalls. Más fotos en Expedition 31 (landing only). Esta mañana las 8:14 UTC tomaba tierra en Kazajistán la Soyuz TMA-03M en la que regresaban a tierra Oleg Kononenko de Roscosmos, la agencia...
Este time-lapse sobre formación de tormentas está grabado en a última hora de la tarde; muestra cómo se juntan y crecen las nubes hasta formar una buena «fiesta», que comienza con unas cuantas sacudidadas en forma de rayos y truenos. No...
Aunque su cápsula quedó patas arriba tras el aterrizaje, Jing Haipeng, Liu Wang y Liu Yang regresaron sanos y salvos esta pasada madrugada a las 2:05 UTC a la Tierra tras completar con éxito su misión de 13 días: China's Shenzhou-9...
Un precioso vídeo de la serie de Veritasium sobre Slinky, el famoso muelle espiral, en cámara super-lenta y con música de Kevin McLeod. Realmente precioso, aparte de las estupendas explicaciones sobre la ciencia tras su curioso comportamiento físico. (Vía A Cool...
El domingo pasado China superó otro de los objetivos de la misión de la Shenzhou 9, que consistía en realizar un atraque manual de esta con el módulo Tiangong 1, que es el que se está utilizando como base para desarrollar...
Puede que en origen un estallido de rayos gamma sí produzca sonido, pero ya sabemos que a pesar de que en las películas queda muy bien –e incluso en los vídeos de la NASA– en el espacio no hay sonido. Además,...
Kern el gnomo en el LHC. Sí, es relevante ;-) Uno de los objetivos principales del Gran Colisionador de Hadrones del CERN es poder determinar si el bosón de Higgs existe o no, algo que es extremadamente importante pues es la partícula...
Así de complicado va a ser el descenso del Curiosity cuando llegue a Marte dentro de unas semanas. El objetivo es el Crater Gale de Marte, junto a una gigantesca montaña a más de 6 kilómetros de altura. El aterrizaje* debería...
Ayer, mientras la selección española machacaba inmisericordemente a la francesa en los cuartos de final de la Eurocopa, RTVE emitía en Informe Semanal una mini biografía sobre Nikola Tesla, que probablemente tuvo audiencia cero, pero que podemos recuperar ahora mismo gracias...
Nunca pensé que publicaría un vídeo sobre cómo hacer punto en este blog, pero si se trata de tejer una banda de Möbius, la cosa cambia, claro. Proviene de Tejiendo Perú. Si te fijas, las bufandas en cuestión tienen un solo...
The Ecliptic Plane, Imagen Astonómica del Día del 14 de octubre de 2000 En esta imagen, tomada por la sonda Clementine, se pueden ver de izquierda a derecha a Mercurio, Marte, Saturno, el Sol, y la Luna, casi perfectamente alineados en el...
¿Que cómo de grande eran los transbordadores espaciales comparados con las Soyuz o el SpaceShipOne? Pues Invader Xan se ha currado esta imagen en la que se ven un montón de naves espaciales reales a la misma escala para poder comparar...
¿De verdad que desde la Unión Europea creen que van a animar a las mujeres a dedicarse a la ciencia con un vídeo como este? Casi, casi lo saco en WTF? Y no, no es un fake: la campaña tiene su...
Venus Transits the Midnight Sun: El sol de medianoche y el tránsito de Venus por Babak Tafreshi Esta pasada madrugada se produjo el solsticio de junio, que marca el principio del verano en el hemisferio norte y la noche más corta del...
Arctic Marble - NASA / GSFC / Suomi NPP White Marble - Arctic View es una toma un tanto diferente de nuestro planeta: es la primera vez que se ha montado la típica foto planetaria exactamente sobre el Polo norte, haciendo que...

Hace unos días una compañera me pidió que le confirmara si era cierto aquello que se dice de que los aviones vuelan porque la forma del ala hace que el aire que pasa por la parte de arriba del esta vaya...
Esta mañana a las 6:07 UTC la cápsula Shenzhou 9, lanzada el pasado sábado, atracó en el módulo Tiangong 1, tal y como se puede leer en China's first manned space docking successful. La maniobra fue realizada en modo automático, aunque...

Φ se convierte en un hit musical, demostrando que hasta los números irracionales pueden tener más ritmo que tú en la pista de baile.
El Meteosat, el primero de los cuales sería lanzado en 1977, en el boletín número 1, de junio de 1975 Desde su fundación en mayo de 1975 para aglutinar las funciones de la Organización Europea para la Investigación Espacial (ESRO) y la...
Una gota de lluvia de 5 mm de diámetro que cae desde una nube a 1.800 metros de altitud tarda en llegar al suelo unos 4 minutos y medio. Esto se debe por un lado a su forma, peso y a la...
Hoy a las 10:37 UTC un cohete Larga March 2F/G despegaba de la plataforma de lanzamiento 921 del Centro de Lanzamiento de Satélites de Jiuquan en China con tres tripulantes a bordo. Su misión es acoplar su cápsula Shenzhou-9 con el...
Por si había pocas celebraciones -así, en general- llega una nueva, sin duda la más interesante para nuestros lectores y sus respectivas versiones 2.0 también conocidas como mini-,o descendencia o, más popularmente, hijos: el Día de los padres geeks, los apasionados...
Intenta adivinarlo antes de ver el vídeo – aunque la imagen estática de YouTube ya da una pequeña pista. Tiene su gracia. Es un vídeo del Bermuda Institute of Ocean Sciences (BIOS), del año pasado. Lo vi pasar vía Cynical-C....
Impresión artística del NuSTAR en órbita - NASA/JPL-Caltech Esta tarde un cohete Pegasus XL de Orbital Sciences Corporation ha puesto en órbita el más nuevo telescopio espacial de la NASA, el NuSTAR. El NuSTAR, de Nuclear Spectroscopic Telescope Array, Matriz de Telescopios...
Localizan una galaxia situada a unos 13.200 millones de años-luz. Está tan lejos, tan lejos que debió empezar a formarse al poco de crearse el universo observable, cuando tenía tan solo ~500 millones de añitos (480 para ser más exactos, según los...
Uno de los riesgos que corre cualquier nave espacial es la de chocar con algún otro objeto en el espacio, justo lo que le ocurrió el 10 de junio a la Estación Espacial Internacional, cuando un micrometeorito chocó con la ventana 2...
Una de las características que tienen las cápsulas Soyuz para que sus tripulantes vayan más cómodos y protegidos es la de usar fundas personalizadas para cada uno de ellos para el asiento que ocupan. En el vídeo insertado arriba se ve...
La Imagen Astronómica del Día de hoy es A Venus Transit Music Video from SDO, un vídeo del tránsito de Venus de la semana pasada compuesto por imágenes tomadas por el Solar Dynamics Observatory en distintas longitudes de órbita, al son...
Un educativo vídeo sobre cómo somos capaces de medir el universo y los métodos que usamos para medir la distancia a la que están de nosotros los objetos que observamos en este: El paralaje, que compara la posición de una estrella...
SPACE ODYSSEY por Chilefixers en Vimeo. Space Odyssey: Voyage To The Planets (BBC, 2004). Se trata de un falso documental que narra el viaje de seis años por el sistema solar de la nave Prometeus en una misión conjunta de la...
Enterprise a punto de tomar contacto con la cubierta del Intrepid - collectSPACE.com / Ben Cooper / Robert Z. Pearlman Desde el pasado miércoles por la tarde el transbordador espacial Enterprise está sobre la cubierta del portaaviones Intrepid después de haber completado...
Dale, que pasas… ¡Ooops! - Dennis Jenkins Tras llegar al aeropuerto John Fitzgerald Kennedy de Nueva York a finales de abril este domingo pasado el transbordador espacial Enterprise comenzaba la última parte de su viaje hasta el Museo Mar-Aire-Espacio del Intrepid montado...
Hace unos días 80 tuiteros participaron en un SpaceTweetup con André Kuipers, un acto organizado por la Agencia Espacial Europea en el que diez de ellos tuvieron la oportunidad de plantearle otras tantas preguntas en directo al astronauta de la ESA...

La lección divulgativa de hoy sobre ciencia y tecnología es de diez minutos –pero altamente interesantes y recomendable, probablemente lo más interesante que aprenderás hoy. Viene de la mano de Vsauce y está dedicada a las superestructuras de gran altura que...
Tránsito de Venus de 2004 -NASA Cuando un astro pasa frente a otro desde el punto de vista del que los está observando se produce lo que los astrónomos denominan un tránsito. En el caso de la Tierra esto es lo que...
MagicTile es una excelente recopilación de imágenes topológicas relacionadas con el mundo del Cubo de Rubik y sus infinitas variantes.: más piezas, diversas formas, colores… Algunos son rompecabezas completamente análogos –matemáticamente hablando– mientras otros son fundamentalmente distintos. En el vídeo se...
En DNA drawing with an old twist (Nature) se describe cómo crear complejas estructuras de ADN para «escribir» letras, números y otros signos e iconos en escalas minúsculas. (Vía Not Exactly Rocket Science.)...
La aplicación para iPad Leonardo da Vinci: Anatomy [iTunes, 10,99 €] recopila 268 páginas de notas y dibujos en alta resolución que Leonardo realizó durante sus estudios de la anatomía humana y de algunos animales. La resolución de las imágenes y...
Por Nacho Palou -
1 JUN 2012

En el glaciar argentino de Upsala captaron este precioso fenómeno que suele producirse por el deshielo en los icebergs, aunque es raro que coincida que haya un tipo con una cámara grabándolo. Relacionado: Un desprendimiento de tamaño histórico en el glaciar...
La Dragon C2 a la espera de ser recogida - SpaceX Tras 9 días y 8 horas la cápsula Dragon que llevaba a cabo la misión COTS 2 amerizaba esta tarde a las 15:42 UTC –dos minutos antes de lo previsto– a...
WhiteKnightTwo y SpaceShipTwo sobre la pista de at Spaceport America en Nuevo Mexico - Virgin Galactic La Administración Federal de Aviación de los Estados Unidos ha dado permiso a Virgin Galactic para realizar vuelos suborbitales con SpaceShipTwo, la nave con la que...
La Dragon tras su captura por el Canadarm2 el pasado día 25 - NASA Tras el cierre de escotillas ayer hoy está previsto que hoy vuelva a tierra la cápsula Dragon C2 de SpaceX que lleva desde la semana pasada atracada a...
Primera imagen recuperada por el LOIRP - NASA/LOIRP Entre 1966 y 1967 la NASA envió a la Luna cinco sondas de la serie Lunar Orbiter con el objetivo de obtener datos e imágenes de nuestro satélite para escoger los sitios en los...
No, ni me he olvidado de aquello de la concordancia de géneros ni es que en Microsiervos nos hayamos pasado al género de fantasía, pero en efecto desde el pasado viernes la cápsula Dragon C2 está atracada en el módulo Harmony de...
Procedimientos de retirada y mantenimiento de posición - NASA Hoy puede ser un día importante para la NASA, que podría ver como su apuesta por la iniciativa privada para llevar suministros a la Estación Espacial Internacional da sus frutos con la llegada...
iss031e067328: La Dragon aproximándose a la ISS - NASA Hasta ahora todo está saliendo a pedir de boca en la misión de la Dragon C2 que tiene como objetivo que esta sea capturada pro el brazo robot de la Estación Espacial Internacional...
¿Que quién es Scott Carpenter? Pues la demostración de que el que da primero da dos veces: Carpenter fue el segundo astronauta de la NASA en realizar un vuelo orbital, tal día como hoy hace 50 años, en la misión Mercury...
Patricia Fernández de Lis y alguno de sus secuaces de la sección de ciencia del desaparecido diario Público anuncian su vuelta con Materia, «una nueva web de noticias de ciencia, medio ambiente, salud y tecnología, que estará online en el verano...
Opportunity's Selfie es una foto recién publicada por la NASA del paisaje que veía Opportunity si miraba hacia el este a través del cráter Endeavour desde el sitio en el que pasó el invierno marciano. Está tomada con la cámara panorámica...
Cuando se produce un eclipse de Sol es porque la Luna se interpone entre el Sol y la Tierra, tapando la luz del primero, dejando a oscuras o en penumbra aquellas zonas de la Tierra sobre las que cae la sombra...
¡Ah!, el misterioso ketchup sobre el que escribía por aquí -hace 10 años (¿tanto?)- parece que tiene los días contados en su oposición a fluir suavemente de la botella: Investigadores del MIT han desarrollado LiquiGlide, un recubrimiento "súper resbaladizo" no tóxico...
Por Nacho Palou -
23 MAY 2012
Dragon Fire: momentos después del lanzamiento - NASA/Alan Ault Hoy a las 7:44:38 UTC se ha dado un importante paso de cara a que la iniciativa privada se haga un hueco en el espacio con el lanzamiento de la cápsula Dragon en...
8 Years Around Saturn es un bonito homenaje de Nahum Méndez Chazarra (@nchazarra) a la sonda Cassini. El próximo 1 de julio la Cassini cumplirá ocho años en órbita alrededor de Saturno maravillándonos con las increíbles imágenes que nos envía y...
En la web del Centro de Tecnología Edison tienen esta detallada cronología de la invención y desarrollo de la corriente alterna, la electricidad que llega a nuestros hogares hoy en día, incluyendo a todos los pioneros que intervinieron en su descubrimiento...
Un comportamiento raro y curioso de investigar experimentalmente: cómo interactúa un huevo duro con el líquido en el que está bañado mientras gira sobre su propio eje, explorado con cámaras de alta velocidad. Curiosidades de la mecánica de fluidos. +1 para...
Prueba de motores del Falcon 9 el pasado 30 de abril - NASA (clic para ampliar) Tras sustituir la válvula estropeada que provocó el exceso de presión que hizo que los sistema automáticos cancelaran el lanzamiento del pasado sábado en T -0,5...
2012 Annular Eclipse: El eclipse de Sol visible a través de los huecos que quedan entre las hojas de un árbol, huecos que actúan como cámaras estenopeicas en miniatura Cuando la Luna se interpone entre el Sol y la Tierra se produce...
Sala de control de SpaceX - SpaceXEquipos para controlar el atraque de la Dragon en la Cúpula de la ISS - NASA Sólo la meteorología parece ser un problema de cara al lanzamiento esta mañana a las 8:55 UTC , las 10:55...
Divertido e interesante a la vez, este trabajo recopilado por Amitabh Chandra hace años y comentado en el New York Times ha sido reconvertido en una representación visual más apropiada: ¿Cuán común es tu cumpleaños? También existe como pequeño interactivo: How...
Hoy a las 4:35:56 UTC, 152 segundos antes de lo previsto, pero aún así dentro de la ventana de ±3 minutos prevista, la Soyuz TMA-04M con Gennady Padalka, Joe Acaba y Sergei Revin a bordo, atracaba en el módulo Poisk de...
Otra joya por cortesía de las imágenes del satélite Elektro-L, en este caso de media Tierra al completo vista desde 36.000 kilómetros de altura. El Electro-L en realidad toma imágenes fijas, pero James Drake es quien se ha tomado la molestia...
Este experimento con dominós permite entender cómo se producen las reacciones en cadena: es el famoso efecto dominó ejemplificado un poco a lo bestia, digamos. En este caso hay 13 piezas de dominó y como puede verse cada una puede tumbar...
En 1979 cayó la sexta gota de brea del experimento iniciado en 1927. Hay diversos tipos de brea, y probablemente alguna vez has salido de la playa con un pegote de este residuo pegado en el pie. Como sea, se trata de...
Por Nacho Palou -
16 MAY 2012
Tal y como estaba previsto esta pasada noche a las 3:01 UTC la Soyuz TMA-04M despegaba rumbo a la Estación Espacial Internacional con Gennady Padalka, Sergei Revin y Joe Acaba a bordo. Este próximo jueves los tres se unirán a Oleg...
Edison estaba comercializando su sistema de corriente continua cuando Tesla vio las grandes posibilidades de la corriente alterna (…) ¿Y qué es lo que hizo Edison en aquella famosa «guerra de las corrientes»? Pues resulta que, en su vecindario, las familias empezaron...
Pues con mucho cuidado y con un «peazo» de grúa, aunque hubiera estado bien que a pesar de la crisis se hubieran gastado unos céntimos en un nivel para que la cámara no les quedara torcida al grabar un vídeo de...
Expedition 31 Soyuz Rocket Rollout: La TMA-04M y el lanzador Soyuz FG durante su traslado a la plataforma de lanzamiento - NASA/Bill Ingalls. Más fotos en Expedition 31 Todo está listo en el cosmódromo de Baikonur para el lanzamiento de la Soyuz...
El Endeavour apagado para siempre - NASA/Ben Smegelsky La verdad es que hace muchos meses que no era una nave espacial viable porque le han ido retirando subsistemas y componentes que o bien serán –hipotéticamente– reutilizados en otras naves que podían ser...
La escala del universo. Clic para ver la imagen completa de 6.910×864 píxeles. Dada la escala del mundo en el que nos movemos los seres humanos nos vemos fácilmente sobrepasados por las distancias de las que se habla en cuanto comenzamos a...

Este clásico de la psicología del comportamiento, más conocido como el experimento de los marshmallows consiste en hacerle una proposición a un niño pequeño: Aquí tienes una nube de azucar. Puedes comértela ahora o puedes esperar. Si resistes sin comértela, entonces...
Dale al HD 1080p y a pantalla completa, merece la pena. En esta combinación de fotos fijas a modo de time-lapse, cada pixel representa un kilómetro cuadrado de nuestro planeta, más o menos. Hay más detalles sobre las fotos en Planet...
Calendario maya de Xultún - William Saturno y David Stuart Lo sentimos si tenías pensado celebrar el fin del mundo este próximo mes de diciembre, pero un calendario maya encontrado en Xultún, en la actual Guatemala, incluye cálculos sobre los ciclos ceremoniales...
Cercanía con la ciencia y conocimiento científico “están asociados de forma tal que a mayor cercanía, mayor conocimiento» (…) el nivel de cercanía con la ciencia mide el grado de interés que muestran los ciudadanos por las noticias relacionadas con los...
La cápsula Liberty No hay como escribir una anotación sobre las empresas estadounidenses que están desarrollando naves espaciales tripuladas como para que salga otra dispuesta a hacer lo propio. En este caso se trata del proyecto Liberty, de la empresa estadounidense ATK...
Dusty Mars Rover's Self Portrait es la imagen del día de la NASA del pasado 22 de marzo, en la que se puede ver un autorretrato de Opportunity tomado el 21 de diciembre de 2011. Tras pasar casi cinco meses parado en...

Un experimento con una hoja de papel revela que 45 dobleces son suficientes para alcanzar la Luna. Crecimiento exponencial en acción.
Impresión artística del Envisat en órbita - ESA Tras perder el contacto con él el pasado 8 de abril, la Agencia Espacial Europea acaba de anunciar que declara el fin de la misión Envisat. Teniendo en cuenta que estaba diseñado para durar...
Tal y como están las cosas en la NASA pasarán muchos años antes de que esta agencia vuelva a tener una nave tripulada propia, pero precisamente esto hace que unas cuantas empresas privadas estén trabajando en el desarrollo de sus propias naves...

El problema del viajante es un clásico de las matemáticas y la teoría de la computación: consiste en encontrar la ruta óptima para visitar varias ciudades, recorriendo la menor distancia posible, sin repetir el paso por ninguna de ellas. El problema...
Esta impresionante imagen es la región activa 1476 del Sol empezando a asomarse desde el otro lado de este fotografiada el 5 de mayo por Alan Friedman, cuyas fotos ya hemos sacado aquí en unas cuantas ocasiones. Se trata de una...
Si alguien todavía sigue indagando el porqué de las «misteriosas» líneas de Nazca, que recuerde esto: a veces la gente hace cosas raras simplemente porque puede. Ese es el caso de Simon Beck, que gusta de crear en la nieve gigantescas...
Como parte de la exposición Ilusionismo, ¿magia o ciencia? de la Fundación «La Caixa» habrá hasta el 19 de junio en Zaragoza un montón de ilusiones ópticas y juegos científicos, incluyendo una habitación de Ames, similar a la del documental Brain...
Puede resultar extraño encontrar en la Wikipedia –donde tanta información precisa hay sobre hechos– que también haya una lista de todo lo que va a suceder, pero ahí está. Más exactamente, hay tres cronologías del futuro a cual más interesante: Timeline...

El vídeo relajante de este viernes llega de la mano de Lost Lander, a recomendación de Mike. Su montaje es «una canción casi tan hipnotizante como el vídeo musical en sí, donde se ve cómo van conectando y evolucionando los números...
Las Buckybolas son pequeñas bolitas magnéticas que se venden como juguetes; sirven para construir esculturas artísticas y también como puro entretenimiento. También hay quien se lo trabaja un poco más y con la ayuda de una pila convencional es capaz de...
La animación en vídeo Welcome to the Anthropocene (existe también una versión narrada, en inglés) realizado por Globaïa para la conferencia científica Planet Under Pressure es una visualización de las huella dejada por la actividad humana sobre la Tierra, El término...
Por Nacho Palou -
30 ABR 2012
Shuttle Enterprise Flight To New York - NASA/Bill Ingalls Aunque estaba previsto que el traslado se hubiera realizado e pasado lunes la meteorología no permitió que el NASA905 trasladara al Enterprise desde Washington a Nueva York hasta hoy. Tras las correspondientes pasadas...
Expedition 30 Landing - NASA/Carla Cioffi. Más fotos en Expedition 30 (landing only). Tras desatracar de la Estación Espacial Internacional a las 8:18 UTC la Soyuz TMA-22 aterrizaba a las 11:45 en Kazajistán, en uno de los aterrizajes más precisos de una...
Los sensores que conformarán los «ojos» del Large Synoptic Survey Telescope tendrán una resolución total equivalente a unos 3.200 megapíxeles (3,2 Gpx), cientos de veces más que las cámaras convencionales. El tamaño de la bestia no será tampoco desdeñable, como se...
Un diseño homenaje a la gente que se dedica a calcular millones de dígitos de π. Cada color, un dígito. Así a simple vista no se aprecia –aparentemente– ningún patrón reconocible....
¡Con mucho cuidado! Y de tres formas distintas, tal y como explican en este resumido vídeo de 60 segundos procedente del Laboratorio de Propulsión a Chorro de la NASA. El tercer método es el que utilizará Curiosity tan pronto llegue allí....

En este vídeo de VertikalDesign se ha combinado una antiquísima película de 1930 de Ralph Steiner con música electrónica/industrial moderna (3 Liquid Hz de Little Boy), reemplazando la música clásica del original. Un resultado genial para un vídeo de esos que...
En este curioso vídeo que Brusspup ha colgado en YouTube puede ver el efecto producido por las cámaras de vídeo al grabar a una velocidad de cuadros determinada una escena perfectamente «sincronizada». El asunto está en hacer pasar el agua por...
Muchos llevábamos meses –años en realidad– esperando esta noticia, pero por fin es oficial ya que el próximo 4 de mayo se inaugurará la sede en La Coruña del Museo Nacional de Ciencia y Tecnología. La inauguración se hará con seis salas...
Con los Estados Unidos y Rusia dándole muchas vueltas a sus programas espaciales, la Agencia Espacial Europea trae una buena noticia con el anuncio de su próxima gran misión espacial. Se trata de la misión JUICE (de Jupiter Icy Moons Explorer), aunque...
Tras la persecución entre Batman y el Espantapájaros, el Señor de la Noche desciende durante 1,5 segundos en caída controlada, alcanzando 15 m/s de velocidad en el momento del impacto. Lo ha calculado e ilustrado convenientemente Shahed Syed, ecuaciones incluidas: La...
Space Shuttle Discovery leaving @NASA_Kennedy for the last time yesterday He visto un montón de fotos y vídeos del último vuelo del Discovery entre el Centro Kennedy y el aeropuerto de Washington, pero creo que esta, con diferencia, es la que más...
Space Shuttle Discovery leaving @NASA_Kennedy for the last time Esta mañana el transbordador espacial Discovery dejaba para siempre el Centro Espacial Kennedy despegando a lomos del Shuttle Carrier Aircraft NASA 905 de la pista en la que tantas veces aterrizó al término...

The Solar System: Explore Your Backyard es una aplicación para Windows que con casi toda seguridad conseguirá financiar su desarrollo en unos días: es una increíble visualización de nuestro planeta y «los alrededores» – que si uno tiene algo de visión...
Recién llegada del Solar Dynamics Observatory, Amazing Hi-Def CME, es una foto de eyección de masa coronal del Sol, que vino acompañado de una erupción solar de clase M1.7. Está disponible también en vídeo aquí. Las erupciones solares se clasifican en...
Coma Niddy se marca en este vídeo una de las explicaciones no sé si más divulgativas pero desde luego más musicales y raperas de la teoría de cuerdas que se han visto hasta el momento. Aprovechando la coyuntura, unas breves explicaciones...
Impresion artística de la Dragon C2 en las proximidades de la ISS - SpaceX" Con la retirada de los transbordadores espaciales de la NASA la Estación Espacial Internacional se quedó sin su principal medio de transporte de suministros. Desde entonces se han...
KSC-2012-2246: El Discovery ya colocado sobre el SCA - NASA/Tim Jacobs El viento impidió ayer colocar al Discovery a lomos del Shuttle Carrier Aricraft que lo tiene que llevar a Washington, pues mover más de 70 toneladas de transbordador con la precisión...
Uno de los problemas de la retirada del servicio de los transbordadores espaciales de la NASA es que la Estación Espacial Internacional se quedó sin su principal medio de transporte, tanto de astronautas, como de suministros o de piezas. Y pocas imágenes...
No lo había visto en su momento, pero el año pasado la Asamblea General de las Naciones Unidas declaraba el 12 de abril el Día Internacional de los Vuelos Espaciales Tripulados. Ese día «se conmemorará cada año a nivel internacional el principio...

Este artículo se publicó originalmente en Cooking Ideas, un blog de Vodafone donde colaboramos semanalmente con el objetivo de crear historias que «alimenten la mente de ideas». Hace poco una compañía llamada Ion Torrent anunció un nuevo avance en chips para...
Las distancias en cuanto salimos de la Tierra comienzan enseguida a hacerse enormes, tanto que nos cuesta hacernos una idea de ellas. En OMG SPACE hay una representación del sistema solar que partiendo del Sol llega hasta la heliosfera, que en...
Geostationary satellites in the Swiss Alps por Michael Kunze en Vimeo. Si miras este vídeo con un poco de atención verás que hay una serie de estrellas que no se mueven, pero es que no son estrellas sino satélites artificiales en órbita...
Shuttle Carrier Aircraft Arrives at Kennedy Space Center: El NASA905 en el Centro Kennedy - NASA/Kim Shiflett El transbordador espacial Discovery ya está listo para viajar al Centro Steven F. Udvar-Hazy, el anexo del Museo Nacional del Aire y el Espacio que...
La Agencia Espacial Europea convoca un nuevo SpaceTweetup, en este caso con Andre Kuipers. Se celebrará el 29 de mayo en el Centro Europeo de Investigación y Tecnología Espacial (ESTEC) de la ESA en Noordwijk, en los Países Bajos. Para participar hay...
En Titanic 3-D el fondo estrellado es por fin correcto, gracias a un astrofísico Algunos enlaces más que están publicándose con motivo del centenario de la tragedia del Titanic: El capitán Bernoulli la lía parda de nuevo (Física de película) - Una...
Un día en Mercurio dura 1409 horas aproximadamente. Lo mismo que un lunes en la tierra.– @200bares(Vía Oído en Twitter)...
En este vídeo bastante viejuno puede observarse algo conocido como efecto Dzhanibekov. Consiste en que objetos asimétricos que giran sobre sí mismos en situaciones de ingravidez, de repente cambian bruscamente 180 grados el sentido del giro, dándose la vuelta «sin razón...
Las cosas han cambiado bastante desde que lo único que los astronautas tenían para comer a bordo de sus naves eran cubitos liofilizados de lo que antes habían sido comidas normales o la versión de estos en forma de una especie...
Aparte de llevar suministros a la Estación Espacial Internacional una de las funciones de los cargueros espaciales de la Agencia Espacial Europea es subir a órbita de la Estación Espacial Internacional, que puede decaer una media de unos cien metros por día....
Explorando las delicias de los números, formas y colores con un bonito trabajo de Stefanie Posavec: Multiplication Waterfall, una representación de la aritmética básica con la que jugar, entretenerse o hacerse un póster. (Vía Co.Design.)...
Sky Gazers por Babak Tafreshi en Vimeo. Este vídeo es un homenaje de Babak Tafreshi, astrónomo, periodista y director de The World at Night, en el Mes Global de la Astronomía, a todas las personas que en todo el mundo nos podemos...
Impresión artística de Curiosity en el espacio. La parte circular de la izquierda es la etapa de crucero, que lleva los motores y sistemas de navegación; Curiosity viaja dentro del escudo térmico con forma de cono que se ve a la derecha...
Convencida del enorme potencial de las llamadas herramientas 2.0 la Asociación Española de Comunicación Científica –de la que soy miembro– convoca Ciencia en Redes, un evento destinado a periodistas, investigadores, comunicadores, museógrafos e instituciones y empresas dedicadas a la ciencia y el...
Esta foto, Edoardo Amaldi Arrives At The International Space Station, es doblemente acojonante. Por un lado, podría pertenecer a cualquier película de ciencia ficción, pero ha sido tomada esta pasada noche por Don Pettit en el MundoReal™, aunque a bordo de...
Brian Cox's Wonders of the Universe (iPad, 5,49€) es una fenomenal aplicación sobre el Universo conocido, desde las partículas subatómicas a los agujeros negros, pasando por cuestiones como su origen, el tiempo o las fuerzas que lo gobiernan. Los distintos temas...
Por Nacho Palou -
29 MAR 2012
Esta pasada noche, a las 22:31:17 GMT, con un minuto y medio de adelanto sobre el horario previsto, y a una altura de 389,2 kilómetros, el ATV-3 de la Agencia Espacial Europea llegaba a la Estación Espacial Internacional, tomando contacto con...
Plataforma de lanzamiento 39b desmontada - NASA/Jim Grossmann Decommissioning the Space Shuttles es una magnífica galería de fotos que se han currado en The Atlantic con fotos oficiales de la NASA que retrata el proceso de retirada del servicio de los transbordadores...
ATV-CC during ATV-3 docking 28 March 2012: la sala de control del CNES Todo está listo en el centro de control de la Agencia Espacial Europea en el CNES de Toulouse para la llegada del tercer carguero espacial de la Agencia, el...
... Concretamente unos cuantos miles de millones de ellas en cada una de las 200.000 galaxias que ha captado esta foto del telescopio chileno VISTA, y que pueden verse como diminutos puntitos azulados y blancos. Desde el siguiente enlace se puede...
Luna, Júpiter, Venus y surferos por Pablo Becerra Tal y como nos recuerda Pablo, esta tarde –y ayer, pero ya no llegamos sin usar el condensador de fluzo– hay la oportunidad de pillar a la Luna, Venus y Júpiter bastante próximos en...
El popular director y productor de cine ha demostrado ser no solo un gran artista sino que también es un tío con un par capaz de entrar con fuerza en nuestra lista de «héroes favoritos con los huevos forrados de plomo»:...
No soy muy fan de las fotos de estelas de aviones en las que no se distingue el avión, pero creo que con esta en concreto haré una excepción: ha sido tomada por André Kuipers desde la Estación Espacial Internacional. De...
Esta próxima madrugada experimentaremos el desplazamiento temporal de la primavera, uno de nuestros días favoritos por excelencia. En 2012 cae en 25 de marzo porque como el cambio es siempre el último domingo de marzo y el próximo sábado es 31, el...
Dorothy Cheng y Sara Ma en la categoría de 14 a 16 años y Amr Mohamed en la de 17 a 18 años han sido los ganadores del concurso YouTube Space Lab. El objetivo del concurso era seleccionar dos experimentos propuestos por...
>Liftoff of Ariane 5 VA205 with ATV-3: Lanzamiento ATV-3 / ESA - S. Corvaja Tal y como estaba previsto esta pasada madrugada el tercer vehículo de transferencia automatizado de la ESA, bautizado como Edoardo Amaldi, despegó rumbo a la Estación Espacial Internacional...
Una simple caja de cartón bien, bien cerrada a la que se le aprietan los laterales con cierta fuerza es suficiente para generar un vórtice o flujo turbulento que sale disparado hacia cualquier objetivo enclenque, en este caso una ligera pirámide...
Ariane 5 flight VA205 and ATV Edoardo Amaldi ready for launch, el ATV3 en la plataforma sobre su lanzador - ESA - S. Corvaja Esta próxima madrugada, a las 5:34, está previsto el lanzamiento del tercer carguero espacial rumbo a la ISS...
Dusty Mars Rover's Self Portrait es la imagen del día de la NASA de hoy, en la que se puede ver un autorretrato de Opportunity tomado el pasado 21 de diciembre. Como se puede ver, está cubierto de polvo, en especial...
Sunspots and Solar Flares es una imagen de la región activa 1429 del Sol, la misma que hemos mencionado varias veces ya en el último par de semanas, poco antes de desaparecer por el otro lado del Sol. La 1429 ha...
Este vídeo, creado por el Estudio de Visualización Científica del Centro de vuelo espacial Goddard, muestra una aproximación de cómo se vería la Luna desde la Tierra durante todas y cada una de las horas de 2012. Es una aproximación porque,...
Hoy a las 5:14 UTC el Sol se ha situado en el plano del ecuador terrestre, lo que para entendernos quiere decir que ha comenzado la primavera en el hemisferio norte y el otoño en el hemisferio sur. Es el día del...
¿Existe el azar? ¿Y la causalidad? ¿Y si todo es determinista, qué es el azar? ¿No sería el indeterminismo prueba de nuestro desconocimiento? ¿Cómo afecta esto al determinismo? ¿Es la física cuántica no determinista? ¿Son los sucesos probabilísticos no deterministas? ¿Qué es...
Para celebrar los 1.000 días en órbita lunar la LRO la NASA ha publicado este vídeo, en el que nos llevan de paseo por algunos de los lugares más especiales de nuestro satélite. Combina imágenes reales de la cámara de ángulo...
Las corrientes de los océanos, a partir de datos de todas las zonas del globo, condensadas en una relajante animación HD 1080p con música de fondo. Para disfrutar y relajarse un rato. (Vía @PepeCerezo.)...
Las partículas expulsadas en una eyección de masa coronal no producen sonido, pero Robert Alexander, un estudiante de la Universidad de Michigan y estudiante de posgrado en la NASA, que se especializa en buscar formas de explorar datos científicos en formas...
Flight over Enceladus por Bjorn Jonsson en Vimeo. Este vídeo no contiene imágenes reales sino que están construidas a partir de datos de elevación reales de Encélado obtenidos por la sonda Cassini, con lo que el modelo en 3D es muy real....
Felix Baumgartner ascendió en globo a 22 kilómetros de altura para desde ahí iniciar una caída libre que duró casi 4 minutos y durante la que alcanzo una velocidad de 586 km por hora. En total tardo más de 8 minutos en...
Por Nacho Palou -
16 MAR 2012
Puedo entender perfectamente la necesidad de conseguir ingresos extra mediante el alquiler de salas de centros de ciencia, y más en los tiempos de crisis que corren, pero eso no me parece que justifique de ningún modo el mirar hacia otro lado...

Cuando hablo acerca del lanzamiento del Atlantis, que pude vivir en directo gracias a un TweetUp de la NASA, siempre destaco el impresionante sonido del despegue, en especial el sonido restallante que se aprecia con especial fuerza a partir del segundo...
Recién llegada de la Estación Espacial Internacional, y por cortesía de los miembros de la Expedición 30 a esta, una foto con con una Soyuz, una Progress, y una aurora polar. La Soyuz, que está en primer término, es la TMA-03M,...
Angry Sun Erupting es una foto tomada por Alan Friedman en la que se ve la mancha solar denominada AR 1429, que en los últimos días ha causado algunas espectaculares erupciones solares. Está filtrada para captar las longitudes de onda correspondientes...
Dueling Banjos on musical Tesla Coils no es el típico vídeo que recomendaría escuchar con el volumen a tope, o de hecho tan siquiera con el volumen muy alto, pero… ¡Hey, que son dos bobinas de Tesla tocando duelo de banjos!...
Apollo 11: 'A Stark Beauty All Its Own' Se me había pasado esta nueva imagen tomada por la Lunar Reconnaissance Orbiter de la Base Tranquilidad, el lugar en el que aterrizó el Apolo 11 cuando llegó a la Luna. No es la...
Ayer hablábamos de los efectos de las tormentas solares que las eyecciones de masa coronal del Sol pueden causar cuando alcanzan la Tierra y de las manchas solares que las causan. Según la intensidad en rayos de estas -se clasifican como A,...
Estamos acostumbrados a pensar en las estrellas como cosas muy grandes, y eso que el Sol, nuestra estrella particular, no es especialmente grande, y mucho menos si la comparamos con otras estrellas cuyo tamaño conocemos o intuimos, como se ve en...
Aunque le costó desperezarse, el Sol está demostrando en los últimos meses su poderío y el ciclo solar 24, cuyo máximo se espera a principios o mediados de 2013, ya nos ha proporcionado unas cuantas erupciones solares espectaculares. Estas pueden causar...
¿Estrellas al atardecer? - Imagen creada con Stellarium Si has echado un ojo al cielo estos días al atardecer seguro que no has podido evitar darte cuenta de que hay un par de estrellas que brillan mucho más que las demás y...
Un día más, André Kuipers, @astro_Andre, sigue regalándonos la vista con sus fotos desde la Estación Espacial Internacional, en este caso con una tomada cuando la ISS estaba a punto de pasar sobre una aurora austral entre la Antártida y Australia....
Se puede seguir el rastro de los átomos que forman el cuerpo humano […] hasta las estrellas… El universo está dentro de nosotros. A ver si llega pronto esa actualización de Cosmos. (Reddit vía Amazings)....
No todo en la vida de un tripulante de la Estación Espacial Internacional va a ser realizar experimentos científicos, tareas de mantenimiento, y hacer ejercicio para contrarrestar la pérdida de masa ósea que ocurre en órbita, y si no que se...
Three Generations of Rovers with Crouching Engineers: Los rover marcianos de la NASA - NASA/JPL-Caltech En estos momentos viaja hacia Marte el Mars Science Laboratory, bautizado como Curiosity, que es el rover más grande y equipado lanzado nunca por la NASA. Es...
¿Que un astronauta puede hacer una foto de la Vía Láctea desde una estación espacial en órbita y colgarla en cuestión de minutos sino de segundos en un sitio de Internet al que me puedo conectar desde mi ordenador o desde...
La información: historia y realidad (en inglés: The Information: A History, a Theory, a Flood). Bits. Canales. Códigos. Compresión. Lógica. Einstein. Gödel. Turing. Shannon. Dawkins. Física. Hawking. Espistemología. Pokemons. Criptografía. Un libro divulgativo sobre la teoría de la información cuyo autor...
ESA's ATV Jules Verne: El Jules Verne llegando a la ISS - ESA Tras tener que retrasar el lanzamiento el ATV-3 Edoardo Amaldi, destinado a la Estación Espacial Internacional, la Agencia Espacial Europea ha anunciado hoy que este se producirá –si no...
Tras conseguir editar un primer número de su revista, los chicos de Amazings le han cogido el gustillo y vuelven a la carga y van a por el número 2. Como con el número 1 la idea es editarla mediante crowdfunding en...
Todos vivimos 80 milisegundos en el pasado, concretamente. Tiene que ver con lo que tarda nuestro cerebro en recibir y procesar la señales que se reciben en el cerebro desde distintas partes del cuerpo a través de los sentidos. Estos cinco...
Marte en la oposición de 2012. Imagen creada con Stellarium. Si estos días has mirado hacia el este al atardecer habrás visto un punto rojizo o anaranjado, según lo mires o lo veas, que seguro que te habrá llamado la atención, porque...
El ATV-2 Johannes Kepler llegando a la ISS - ESA No explican el motivo, pero según se puede leer en Aplazado el lanzamiento del ATV-3 la Agencia Espacial Europea ha tomado la decisión de posponer el lanzamiento del Edoardo Amaldi rumbo a...
Todos hemos visto fotos de trazos de estrellas, que por cierto es una forma sencilla de iniciarse en la fotografía astronómica, pero esta es bastante especial, pues está hecha desde la Estación Espacial Internacional por Don Pettit. La exposición es de...
Como es bien sabido, el diario Público cerró y dejó de existir en los quioscos en su formato árbol muerto hace una semana. Llevaba publicándose desde 2007. Mientras los empleados intentaban llegar un acuerdo con la empresa editora para salvar el...
Cuando la NASA tomó la decisión de retirar del servicio su flota de transbordadores espaciales no sólo se quedó sin la capacidad de poner astronautas en órbita, sino que se quedó también sin la principal vía de enviar suministros a la Estación...
Aunque We Are the Explorers no deja de ser un vídeo promocional de la NASA, en mi opinión la última frase lo clava en cuanto a por qué es importante no sólo la investigación espacial sino cualquier tipo de exploración e...
El ATV-2 Johannes Kepler en la ISS - ESA La Agencia Espacial Europea ha convocado un SpaceTweetup, una reunión de tuiteros, para seguir en directo el atraque en la Estación Espacial Internacional del tercer Vehículo de Transferencia Automatizado (ATV) que va a...
Atardecer en HD 209458 b por Frédéric Pont Desde que hace unos años suponíamos que tienen que existir planetas en órbita alrededor de otras estrellas, los llamados planetas extrasolares, las cosas han cambiado mucho, y ya tenemos comprobado la existencia de al...
No la tabla sino la mesa, que además de servir para comer contiene también una muestra representativa de casi todos los elementos recogidos por la tabla mesa periódica de los ídem, incluyendo balas de plata en el cajón 47. § Gizmodo....
Por Nacho Palou -
23 FEB 2012

Laura y María explican en qué consiste el experimento que han diseñado, sobre qué sucede cuando se mezclan agua, jabón y aceite en condiciones de microgravedad. La idea es grabarlo con una cámara de alta resolución y comprobar si desaparecen algunos...
VLT (Very Large Telescope) HD Timelapse Footage es otra de esas increíbles piezas de Stephane Guisard y José Francisco Salgado, editada en este caso por Nicolás Bustos, que a los que nos encanta mirar al cielo no hacen sino convencernos de...
Construction Begins on Atlantis' Permanent Home: Impresión artística del futuro edificio para el Atlantis - NASA/PGAV Destinations for Delaware North Parks & Resorts Cuando la NASA pidió candidatos dispuestos a hacerse con sus transbordadores espaciales una vez retirados del servicio una de...
Cielo de febrero en el hemisferio norte Es gratis, y lo puedes ver todos los días, siempre que las nubes, la niebla, o similares colaboren, pero si quieres saber qué es lo que estas viendo en el cielo, o lo que se...
Thread of Life (1960) es una antiquísimo documental divulgativo sobre cómo funciona la herencia genética en los seres humanos: qué son los genes, el ADN y cómo se transmite la información de una generación a otra – al menos lo que...
Imaginario - Foto de Alin Petrus Fotomat es un blog que recoge una imagen cada día que enlaza con un concepto matemático, «porque la vida está llena de mates.» Ojo, no confundir con Fotomaf, que también va de imágenes y de cacharros...
El 13 de junio de 2010, tras un periplo de algo más de siete años, tres más de lo previsto, la sonda espacial Hayabusa de la Agencia Espacial de Explorción Aeroespacial (JAXA) se convertía en la primera de la historia en traer...
S62-00303: John Glenn en órbita a bordo de la Friendship 7 - NASA Hoy se cumplen 50 años desde que John Glenn se convirtiera en el primer astronauta de la NASA en entrar en órbita, lo que lo convierte en el primer...
Sipirit's Journey es un sitio web montado por la NASA y el Laboratorio de Propulsiñon a Chorro que permite recorrer a voluntad el camino seguido por Spirit durante sus algo más de seis años de actividad en Marte, hasta que el...
El Discovery a lomos del N905NA en 2005 [JPEG a 3.000×2.382 pixeles 2,2 MB] Si todo va según lo previsto, dentro de dos meses exactos e transbordador espacial Discovery será instalado en su lugar del Centro Steven F. Udvar-Hazy, el anexo del...
Último aterrizaje del NASA 911 - NASA/Tony Landis (jpeg a 4.587×3.058, 2MB) Aunque tienen forma de avión y eran capaces de planear a la vuelta de sus misiones, los transbordadores espaciales no podían trasladarse de un lugar a otro por sus propios...
Un CubeSat de una U sin sus cubiertas - Foto cc Svobodat El cohete Vega lanzado el pasado lunes por la Agencia Espacial Europea llevaba a bordo siete CubeSats diseñados por otras tantas universidades europeas. Se trata de unos pequeños satélites artificiales...
- No trabaja bien con otras personas- No da crédito a los demás de forma apropiada… Esta evaluación de rendimiento en la página de Peter Norvig (experto en IA y director de investigación de Google) muestra lo que podría haber escrito...
La mano de Robonaut 2 por André Kuipers Aunque lleva a bordo de la Estación Espacial Internacional desde febrero de 2011, cuando fue lanzado a bordo del Discovery en la misión STS-133, Robonaut 2 todavía no ha empezado a trabajar, aunque entre...
Liftoff of Vega VV01: VV01 se eleva sobre la plataforma de lanzamiento un segundo después del encendido de la primera etapa - ESA Hoy a las 11:00 despegaba desde Puerto Espacial Europeo en Kourou en la Guayana Francesa, y con una puntualidad...
Elizabeth, Charles y Jacob demostrando que la ropa de laboratorio mola This is what a scientist looks like es un blog dedicado a intentar desmontar la imagen estereotipada que muchos tienen de que los científicos son unos señores aburridos que van siempre...
Posiciones de Urano y Venus a las 19:57:01 del 11 de febrero de 2012 - imagen creada con Stellarium Aprovechando que hoy es sábado, si las nubes te lo permiten y tienes unos prismáticos a mano sal un rato antes de que...
¿Quieres darte una vueltecita por el universo, en un tiempo razonable y entre las escalas de lo más inimaginablemente grande y lo infinitesimalmente pequeño? Prueba The Scale of the Universe 2, segunda parte de un interactivo similar que hace tiempo estuvo...
Clic para ver en grande (png 1,2 MB) Aunque parezca el FSM pintado por alguien bajo la influencia de alguna sustancia alucinógena esta imagen en realidad es una representación de cómo reacciona la magnetosfera terrestre cuando se produce una tormenta solar. La...
Trasteando por el Flickr de Gordan Ugarkovic, el autor de Enceladus Backlit by Saturn, la Imagen Astronómica del Día en la que se ve a Encélado retroiluminado por Saturno, me encontré esta otra de Encélado iluminado a la vez por el...

Este sistema conceptual llamado Mirracle, de la Technische Universität München, utiliza la realidad virtual para crear un efecto de «espejo mágico» o de «rayos X virtuales» bastante resultón: tras calcular la posición de la persona y sus movimientos puede situar imágenes...
Mi chino es más bien limitado, pero aún así no he tenido demasiados problemas para moverme por este mapa de la Luna a 7 metros por pixel que acaba de hacer público la Administración Espacial Nacional China. Está hecho a partir...

Por sorprendente que pueda parecer la ciencia no ha sido capaz de explicar todavía por qué las cosas tienen masa y, por tanto, pesan cuando la gravedad tira de ellas. Pero dentro del modelo estándar de la física de partículas, que...
La computación cuántica… Es posible vs. es imposible Scott Aaronson del M.I.T se ha apostado 100.000 dólares de su propio bolsillo a que la computación cuántica escalable es posible, una idea que está enfrentada a la de una «minoría pequeña pero ruidosa»...
Muchos dábamos por hecho que el genoma humano había sido secuenciado ya hace años al completo. No en vano se dedicaron décadas de investigación e ingentes cantidades de dinero hasta lograr esa primera secuencia «completa»: unos 2.700 millones de dólares más...
Titulado Signal to Noise tenemos este estupendo montaje medio time-lapse, medio efectos animados, de Douglas Koke con las antenas del radiotelescopio VLA (Very Large Array) de protagonistas. Situado en Socorro, Nuevo México, es el mismo lugar que se usó como escenario...

Tras el éxito que ha alcanzado la versión 2.0 de la «canica azul» –que es como llama la NASA a la la tradicional foto de nuestro planeta azul al completo– han publicado otra versión todavía con más resolución y tomada desde...
Cero Plazas por Felix G. en Vimeo. Que si lo del ladrillo no ha funcionado y hay que buscar otras formas de activar la economía y tal… Pues con 600 millones menos de presupuesto para I+D+i, y sin previsión de plazas de...
Impresión artística de la sonda en órbita de Marte - Roscosmos/IKI En lugar de estar en estos momentos rumbo a Marte, los restos de la sonda rusa Fobos-Grunt, que tenía como misión estudiar Fobos, una de las lunas del planeta, y traer...
Queso en la ISS - ESA/NASA Siendo André Kuipers, @astro_Andre, holandés, era casi inevitable que nos enseñara en una foto las porciones de queso que la Progress M-14M recién llegada a la Estación Espacial Internacional llevaba a bordo, entre otras muchas cosas....
Este artículo se publicó originalmente en Cooking Ideas, un blog de Vodafone donde colaboramos semanalmente con el objetivo de crear historias que «alimenten la mente de ideas». Los más duchos en números están acostumbrado a usar «cálculos de servilleta» para computar...
Esta aurora boreal sobre Ivujivik, el pueblo más al norte de la provincia de Quebec, en Canadá, fue tomada la noche del 27 de enero de 2012 por Sylvain Serre. En January 2012 Aurora Gallery Spaceweather.com tiene unas cuantas imágenes de...
Con un minuto de adelanto sobre el horario previsto esta noche la nave de carga Progress M-14M atracaba a las 00:07 UTC en el módulo Pirs de la Estación Espacial Internacional. A bordo van: 539 kg de combustible para trasvasar al...
Sencillamente precioso. Un vídeo del cosmólogo Andrew Pontzen. (Vía Bad Astronomy Blog.)...
¿Puedes ver Orión saliendo sobre el horizonte de la Tierra en esta foto tomada por André Kuipers desde la Estación Espacial Internacional? Kuipers, @astro_Andre, es un astronauta de la Agencia Espacial Europea que está a bordo de la ISS en la...
Esta pasada noche fue lanzada la nave Progress M-14M (también conocida como Progress 46) rumbo a la Estación Espacial Internacional, con 2,9 toneladas de suministros a bordo, que consisten en: 539 kg de combustible para trasvasar al módulo Zvezdá. 250 kg...
Lights Over Lapland Photo Expedition video of CME impact on 1-24-2012 por Lights Over Lapland en Vimeo. Este vídeo es un time-lapse creado por la gente de Lights Over Lapland que resume tres horas de una aurora boreal que se produjo el...
Estas son las vistas de las que disfruta Opportunity desde el lugar en el que va a pasar el invierno marciano Hoy se cumplen ocho años de la llegada a Marte del Mars Exploration Rover B, más conocido como Opportunity, durante los...
Una imagen de 64 millones de píxeles vale más que mil palabras: Most Amazing High Definition Image of Earth - Blue Marble 2012. Tomada hace un par de semanas y cortesía como es habitual de NASA/NOAA/GSFC/Suomi NPP/VIIRS/Norman Kuring. (Vía FayerWayer.)...
El sarampión mata, sobre todo a niños pequeños; es capaz de desencadenar una infección tan grave que destroza el cerebro. Aunque la Organización Mundial de la Salud esperaba haber erradicado el sarampión de Europa en 2010 la triste realidad es que muy...
Round Triangles (Triángulos redondos) otro de esos deliciosos mini vídeos de la gente de Minute Physics, donde se explican cosas sobre los objetos redondos y sobre otros que no son redondos pero casi, casi, podrían considerarse como tales. El Premio Nobel...
Past Night es una imagen tomada con luz visible por la cámara de campo estrecho de la sonda Cassini en su pasada por Dione, una de las lunas de Saturno, en la que Mimas, otra de las lunas del planeta, se...
La eyección vista por el satélite GOES - NOAA Hoy, a eso de las 4 UTC, la mancha solar 1402 llegó a su pico de actividad, produciendo una eyección de masa coronal que apunta hacia la Tierra. No es de la categoría...
Esta es la órbita de reentrada en la que la mayoría de las predicciones, pero no todas, coincidían (vía Zarya) Hoy hace una semana que Roscosmos, otras agencias espaciales, y los espaciotrastornados del mundo estábamos siguiendo la reentrada de la sonda rusa...

He aquí un maravilloso vídeo que muestra lo que sucede cuando un fluido viscoso (sirope) se deja caer de forma uniforme sobre una cinta transportadora mientras baja lentamente de velocidad. El resultado es una simpática secuencia de comportamiento no lineal con...
The Milky Way and Storms over Africa es otro de esos vídeos hechos desde la Estación Espacial Internacional que te dejan boquiabierto durante un rato aún a pesar de que este sólo dura veinte segundos. Está montado con fotografías tomadas por...
La radiación de fondo de microondas, que ahora sabemos que está presente en todo el universo, es como si fuera el resto del Big Bang, la enorme explosión que por todo lo que sabemos dio le dio origen. Aunque su existencia fue...
Por cortesía del Laboratorio de Bajas Temperaturas de la Universidad de Ithaca, una pastilla superconductora dando vueltas sobre un circuito de imanes, impulsada por los motores de un coche de juguete: Es una manifestación de un fenómeno conocido como flux pinning (¿anclaje...
En 1995 el telescopio espacial Hubble tomó una de las imágenes más famosas de la astronomía, la conocida como los Pilares de la Creación, situados en la Nebulosa del Águila, a 6.500 años luz de la Tierra: Los Pilares de la creación...
Los 28 alumnos de la clase de Nina DiMauro en la escuela elemental Emily Dickinson de Bozeman, Montana, han ganado el concurso organizado por la NASA para poner nombre a las sondas GRAIL, Montana Students Pick Winning Names for Moon Craft. Ebb...
No estamos acostumbrados a las escalas de distancia astronómicas; tan siquiera a las de nuestro sistema solar, como queda claro con Astronomical, un trabajo de Mishka Henner que lo representa mediante 12 volúmenes de 506 páginas en los que el ancho...
IBM ha conseguido reducir a 12 átomos los necesarios para almacenar 1 bit (en cualquier de sus dos estados, "1" ó "0"). La cantidad de átomos utilizados repercute directamente en el tamaño físico de la memoria y por tanto permite guardar...
Por Nacho Palou -
16 ENE 2012
Mark Powell, uno de los informáticos del Laboratorio de Propulsion a Chorro de la NASA, acaba de publicar la aplicación Mars Images, disponible tanto para iOS como para Android, una aplicación que permite ver en el móvil las imágenes enviadas a...
Órbita de la Phobos-Grunt Según las últimas previsiones la reentrada en la atmósfera de la sonda rusa Phobos-Grunt podría ocurrir sobre las 18:30 UTC, aunque estas tienen un margen de error de varias horas debido a los múltiples factores que influyen en...
Todo parece indicar que a la sonda espacial rusa Fobos-Grunt, varada en órbita desde el pasado 26 de noviembre, le quedan poco más de 24 horas antes de precipitarse sobre la Tierra y ser destruida durante la reentrada. El objetivo de la...

Durante años se pensó que no se podía dobla un papel por la mitad más de siete u ocho veces, hasta que en 2002 Britney Gallivan, una estudiante de instituto, encontró la forma de calcular cuantas veces se puede doblar por...
Los hoteles japoneses Rihga Royal Hotels ofrecen a sus clientes una tentación a la que ningún aficionado a la astronomía podría resistirse, un sistema solar de chocolate con un Mercurio con sabor a mango, Venus de crema de limón, la Tierra...
Cyanide & Happiness #2665, traducción por El Guindilla, ligeramente NSFW. (Vía Yoriento). Homeopatía de urgencias y Terrorismo homeopático, que ya se que no es lo mismo que los remedios herbales ni exactamente como para tomársela de broma....
Pasta Geometries, un interactivo del New York Times basado en el libro Pasta by Design de George L. Legrende. Toda una demostración de que la trigonometría, el número π y las ecuaciones están más cerca de los linguine de lo que...
Hace menos de veinte años no teníamos confirmación experimental de que los planetas extrasolares existieran, aunque suponíamos que tenía que ser así. Desde entonces, la lista de planetas extrasolares cuya existencia está confirmada no para de crecer, con 716 confirmados hasta el...
Impresión artística de Curiosity en su fase de crucero - NASA/JPL-Caltech Según se puede leer en Spacecraft Completes Biggest Maneuver la primera y fundamental maniobra de ajuste de la trayectoria de Curiosity, el rover más grande y completo de la historia de...
Lanzamiento de Curiosity el pasado 26 de noviembre - Justin Ray, vía @Camilla_SDO Hoy a medianoche el Mars Science Laboratory, más conocido como Curiosity, va a realizar una maniobra de corrección de su trayectoria que por fin lo pondrá camino a Marte....
¿Y tú me lo preguntas? La vida es… ∵ ∴ Estas tres palabras son las que con más frecuencia aparecen en una selección de unas 300 definiciones de lo que es «vida» recopiladas por el biólogo Radu Popa en trabajos científicos de...
S65-30427_G04-H: Ed Whte en el primer paseo espacial de la NASA durante la misión Gemini IV - NASA/JSC/Arizona State University Aunque fue el programa Apolo el que representó el culmen de la popularidad de la NASA, nunca habría podido alcanzar su objetivo...
Apollo 11 Lunar Landing Visualization, 1969 (2011) por Yanni Loukissas en Vimeo. Este es un trabajo del Laboratorio de Automatización, Robótica y Sociedad del MIT sobr el descenso del módulo lunar Apolo 11 en el que se pueden ver las comunicaciones entre...
In the shadow of the Moon (En la sombra de la Luna) es un documental sobre el programa Apolo con testimonios de diez de los veinticuatro astronautas que estuvieron en la superficie de la Luna o en órbita alrededor de esta,...
Earth Observations, tomada desde la Cúpula de la Estación Espacial Internacional, es la Imagen del Día de la NASA de hoy, en la que se puede ver el sitio desde el que los astronautas que la ocupan toman muchas de las...
It Was 40 Years Ago Today: El presidente Nixon y el director de la NASA, el Dr. James C. Fletcher, con una maqueta del STS - NASA Tal día como hoy hace 40 años Richard Nixon anunciaba que los Estados Unidos iban...
Como comentábamos el otro día, el principio del año no coincide por poco con el perihelio de la órbita de la Tierra alrededor del Sol, por cosas de los romanos. Las fechas son aproximadas, cambian cada año En su lugar, el perihelio,...
2011 Quadrantid Meteor (cc) Ed Sweeney Esta noche a las 7:20 UTC está previsto que se produzca el pico de actividad de las Cuadrántidas, la primera lluvia de estrellas del año, que aunque viene de la dirección de la constelación del Boyero...
GRAIL & The Moon en Eyes on the Solar System Durante Nochevieja y el día de Año Nuevo el equipo de la misión GRAIL de la NASA tuvo que trabajar porque sus sondas gemelas llegaban a la Luna y había que realizar...
History of Life - Department of Geoscience. University of Wisconsin-Madison Lo que conocemos y aventuramos sobre el origen y evolución de la vida en el planeta Tierra presentado en forma de reloj de 24 horas. En esta representación, a lo largo de...
Por Nacho Palou -
2 ENE 2012
Un curioso proyecto que arranca hoy en Twitter, @Tierra366d, que tiene como objetivo contar la historia de la Tierra comprimida en la duración de un año bisiesto, con lo que cada segundo que pasa avanza 150 años en la historia del planeta:...
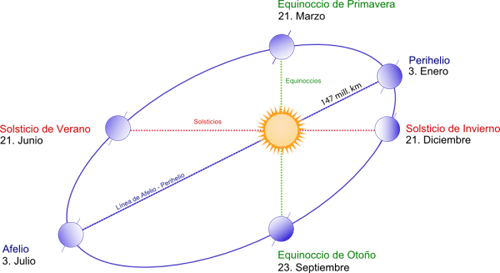
Aunque a la vista de este gráfico podría parecer que el principio de año marca el paso de la Tierra por el perihelio de su órbita, el principio del año del calendario gregoriano, que es el que se usa de manera oficial...
Impresión artística de las sondas en funcionamiento - NASA Mientras por aquí nos preparamos para despedir el año, en la NASA hay un equipo al que le ha tocado trabajar, ya que entre esta noche y mañana las sondas de la misión...

Tan solo una de cada 10.000 personas tienen esta capacidad casi sobrehumana: el denominado oído absoluto (en inglés, perfect pitch). Básicamente consiste en la habilidad para identificar una nota musical sin ningún tipo de referencia externa, e incluso cantarla – lo...
20 Hz por Semiconductor en Vimeo. Cuando un eyección de masa coronal se produce apuntando a la Tierra a los pocos días las partículas procedentes de esta llegan a nuestro planeta. Esto causa las llamadas tormentas geomagnéticas, que se manifiestan con auroras...
Del departamento de enlaces traspapelados, llegan las imágenes premiadas este año en Fotciencia, el certamen de fotografía científica convocado por el Consejo Superior de Investigaciones Científicas (CSIC) y la Fundación Española para la Ciencia y la Tecnología (FECYT), que va ya...
Lovejoy C/2011 W3 por Colin Legg (vía Universe Today) El Cometa Lovejoy C/2011 W3, descubierto el pasado 27 de de noviembre de 2011 por el astrónomo aficionado Terry Lovejoy, pertenece a la categoría de los rasantes del Sol de de Kreutz, que...
Cielo de Madrid a las 18:45 recreado con Stellarium Esta tarde, a partir de aproximadamente las 18:00 en España (UTC +1), se podrán ver la Luna y Venus muy cerca en el cielo, con sólo mirar hacia el suroeste, y a no...
Un hipercubo es el equivalente a un cubo en cuatro dimensiones; también se llama teseracto y en la página del enlace se puede ver una excelente animación «tridimensional» de «cómo es» – aunque paradójicamente si lo piensas en realidad lo que...
Iberian Peninsula at Night La Imagen del Día del Earth Observatory de la NASA de hoy es una bonita foto de la península iberica tomada el pasado día 4 de diciembre desde la Estación Espacial Internacional por uno de los miembros...
La Soyuz TMA-03M desde la ISSLa ISS desde la Soyuz TMA-03M Con tres minutos de adelanto sobre el horario previsto la Soyuz TMA-03M, lanzada el pasado miércoles, se acopló con la Estación Espacial Internacional esta tarde a las 16:19 hora de España...
Si después de verlo todavía no entiendes qué son y cómo «funcionan» los neutrinos… ¡que te traigan a un niño de cuatro años! (Groucho Marx dixit). [Recordatorio: clic en el icono CC para los subtítulos.] Y, como bonus, cameo de nuestro...
Hoy a las 17:28 un técnico de la NASA apagaba para siempre el Atlantis, mi transbordador, que está siendo preparado dentro del Orbiter Processing Facility 2 para ser expuesto en el Complejo de Visitantes del Centro Espacial Kennedy a partir de...
La TMA-03M en la plataforma de lanzamiento / ESA - S. Corvaja Todo está listo en el cosmódromo de Baikonur para el lanzamiento de la Soyuz TMA-03M rumbo a la Estación Espacial Internacional. En ella viajarán Oleg Kononenko de Roscosmos, André Kuipers...
Desde hace un par de años, por iniciativa del blog argentino Proyecto Sandía, el 20 de diciembre, aniversario de la muerte de Carl Sagan, que como buen divulgador científico también era escéptico, se celebra el Día del escepticismo. Así que este año...
Carl Sagan, 9/11/1934 - 20/12/1996, in memoriam Hoy se cumplen quince años de la muerte de Carl Sagan, uno de los más conocidos divulgadores científicos de los últimos años, que nos hizo ver a muchos que es posible explicar cosas complicadas de...
El pasado día 16, tras cerrar las puertas de su bodega de carga, los técnicos de la NASA apagaron el transbordador espacial Discovery por última vez: NASA Terminates Power, Locks Cargo Doors on Retiring Shuttle Discovery. Todas las fotos NASA/Kim Shiflett Esto...
Al año apenas le quedan quince días, así que estamos en plena época de listas de los mejores loquesea del año. Y un año más, como viene haciendo desde 2006, Phil Plait, AKA @BadAstronomer, hace su selección de las mejores imágenes astronómicas...
Una selección de fotos y vídeos tomados por aquellos que tuvieron la suerte de estar en uno de los sitios en los que era visible el eclipse total de Luna del pasado día 10 y a los que la meteorología no...
El plan que está desarrollando la NASA para obtener muestras de cometas que viajan por el sistema solar a velocidades de hasta 240.000 km/h es simple, al menos sobre el papel: acercarse con una sonda y, cual buque ballenero, disparar un...
Por Nacho Palou -
15 DIC 2011
Aunque parezca mentira, pues es algo que experimentamos a diario, la ciencia aún no tiene una explicación de por qué las cosas tienen masa. Para entendernos, y que me perdonen los físicos, no sabemos por qué pesan las cosas; de hecho tampoco...
Fleeting Light: The High Desert and the Geminid Meteor Shower, las Gemínidas de 2010 en el desierto de California por Henry Jun Wah Lee en Vimeo. Aunque ya llevan unos días siendo visibles –si las nubes lo permiten– se prevé que esta...
Siendo hoy martes y 13, qué mejor ocasión para recuperar el episodio de Escépticos dedicado a las supersticiones: Es sólo uno de los trece episodios de una serie que ha demostrado que otra televisión es posible, en la que el pensamiento crítico...
Llevo unas semanas probando SkySafari 3 en mi iPhone, una aplicación con una base de datos que contiene 120.000 estrellas, 220 de los más conocidos cúmulos estelares, nebulosas y galaxias, los objetos del sistema solar, etc. Esto lo hace más que suficiente...
El sábado 10 de diciembre de 2011 se producirá el segundo eclipse total de Luna del año, que será visible total o parcialmente desde buena parte del mundo, quedando sólo excluidas Sudamérica, una parte de Centroamérica, el oeste de África, y la...
Algunas cifras en una infografía animada sobre los satélites que se han lanzado al espacio en las últimas décadas. El satélite número mil se puso en órbita a finales de los 60, pero hasta principios de los 80 no llegamos a...
Ahora Google muestra gráficas de ecuaciones matemáticas cuando identifica que un término de búsqueda es una ecuación. Basta teclearlas en la caja de búsqueda. (Vía Wwwhat's new?)...
Una esponja de Menger es una curva fractal que tiene una superficie infinita al mismo tiempo que contiene un volumen cero. Se construye dividiendo cada una de las caras de un cubo en nueve cubos, eliminando el cubo central de cada yba...
CRONUS4: Una de las pantallas de monitorización de los sistemas informáticos y de comunicaciones de la ISS Para personas con espaciotrastorno severo ISS Live permite cotillear en timpo real el funcionamiento de los sistemas de la Estación Espacial Interdnacional en tiempo real...
Hace tiempo una empresa aeroespacial llamada MDA propuso esta curiosa idea consistente en estaciones de recarga y mantenimiento de satélites, algo así como una especie de «talleres-gasolineras en el espacio». La idea sería duplicar o triplicarla vida útil de los ingenios...
Clic para ver en grande (recomendable) Arriba, a la derecha, dejando un rastro de aire ionizado, la Soyuz TMA-02M está reentrando en la atmósfera el pasado día 22 para llevar de vuelta a casa a Mike Fossum, @AstroAggie, Satoshi Furukawa y Sergei...
Aquí está la recopilación anual de ciencia recreativa de Richard Wiseman, en forma de diez juegos/trucos sorprendentes y divertidos. en un solo vídeo de unos pocos minutos...
Hace unos días saltaba la noticia del descubrimiento de un compuesto, bautizado como PD 404,182, capaz de matar el virus del VIH al actuar sobre su cápsula, «disolviéndolo», como quien dice: PD 404,182 is a virucidal small molecule that disrupts hepatitis C...
STS-135 Postflight Image Gallery: las tripulaciones de la STS-1 y STS-135 - NASA Photo/Houston Chronicle, Smiley N. Pool A principios de mes la NASA hacía públicas unas cuantas imágenes en las que salen las tripulaciones de las misiones STS-1 y de la...

The Open University tiene un montón de estupendos vídeos educativos en su canal de YouTube; entre ellos este titulado Aventuras del pensamiento en 60 segundos donde se explican en simpáticos clips animados algunos de los clásicos entre los clásicos de las...
Lanzamiento del MSL, AKA Curiosity - Justin Ray, vía @Camilla_SDO Tras un lanzamiento de libro el Mars Science Laboratory, más conocido como Curiosity, viaja desde primeras horas de esta tarde rumbo a Marte, a donde está previsto que llegue el 5 de...
Rollout de Curiosity a su plataforma de lanzamiento - NASA/Scott Andrews Todo está listo en Cabo Cañaveral para el lanzamiento en un Atlas V del Mars Science Laboratory, bautizado como Curiosity, rumbo a Marte hoy a las 16:02 hora de España (UTC...
The protoplanetary disc around Beta Pictoris: el disco protoplanetario de Beta Pictoris por Rolf Olsen Beta Pictoris, la segunda estrella más brillante de la constelación de Pictor, está a 63,4 años luz de la Tierra, y desde 1984 sabemos que a su...
Anoche la Agencia Espacial Europea consiguió ponerse en contacto con la sonda espacial rusa Fobos-Grunt, que lleva dos semanas varada en órbita terrestre cuando debería estar de camino a Marte: Una antena de la ESA consigue contactar con la misión rusa a...
Time Lapse From Space - Literally. The Journey Home. por Fragile Oasis en Vimeo. Aunque parezca increíble, Ron Garan (@astro_Ron) hizo la primera prueba de crear un time lapse unas seis semanas antes de volver a Tierra al final de su misión...
La cápsula momentos después del aterrizaje rodeada de vehículos de apoyo - NASA Esta madrugada a las 3:27, hora de España (UTC +1), aterrizaba en Kazajistán la Soyuz TMA-02M en la que Mike Fossum, @AstroAggie, Satoshi Furukawa y Sergei Volkov regresaban a...
Un ingeniero llamado Greg Lyeh tiene como proyecto personal construir dos bobinas Tesla de más de 30 metros de altura, con las que se podrían producir gigantescos rayos de electricidad que atravesarían un campo de fútbol de lado a lado. La...
Investigadores de la Universidad Rovira i Virgili (URV) pueden conocer el voto de un juez del Tribunal Supremo de EE.UU. a partir de las decisiones que tomen los otros ocho miembros del tribunal con una probabilidad de éxito del 83%. El...
Este curioso artilugio con forma de nave-pepino de Star Wars está instalado cerca de la estación de McMurdo - sí, esa en la que están todos los cajeros automáticos del continente helado. Cualquier persona de la base puede acercarse, bajar por...
La Shenzhou-8 tras el aterrizaje Con el retorno en perfectas condiciones de la cápsula de la tripulación de la Shenzhou-8 el programa espacial chino ha completado con éxito su primera misión destinada a establecer una estación espacial propia. En este caso la...
Leonids (cc) RG Photo Esta noche se prevé que ocurra el pico máximo de actividad de las Leónidas de este año, con una tasa estimada de hasta 15 estrellas fugaces por hora, aunque la Luna puede dificultar su observación. Las Leónidas están...
Soyuz Docks to ISS A primera hora de esta mañana Anton Shkaplerov, Anatoly Ivanishin, y Dan Burbank llegaban a la Estación Espacial Internacional a bordo de la Soyuz TMA-22, lanzada el pasado lunes, volviendo a poner –aunque sólo por unos días– la...
Helmet View from Astronaut Mike Fossum: Mike Fossum durante la misión STS-135 - NASA Pus voy a tener que darles la razón a @thatgirlallie y a @jasonkeene: este autorretrato de Mike Fossum durante la estancia del Atlantis en la Estación Espacial Internacional...
La Tierra, el Sol, Rigel y VY Canis Majoris (de unos ~2.000 radios solares) a escala. Ultrainsignificante se queda corto para describir nuestro pequeño hogar dentro del gigantesco Cosmos. (Vía Neil deGrasse Tyson.)...
Después del primer acoplamiento llevado a cabo el pasado día 2 el programa espacial chino consiguió hoy llevar a cabo el segundo acoplamiento de dos naves de su programa espacial: China completes 2nd Docking to Space Lab and sets Path to Manned...
Los 5 años, 3 meses, y 27 días de Spirit en Marte resumidos en poco menos de tres minutos en el vídeo Mars Rover Spirit's Entire Journey on Mars - Time Lapse gracias a 3.418 imágenes de su cámara de navegación...
Esta madrugada a las 5:14, hora de España (UTC +1), Rusia lanzaba la cápsula Soyuz TMA-22 rumbo a la Estacion Espacial Internacional. Al loro con la mascota de la tripulación ;-) Se trata de la primera misión tripulada desde el lanzamiento del...
Una de las cosas que nos comentó Douglas Wheelock (@astro_Wheels) a los que tuvimos la oportunidad de participar en el TweetUp que organizó la NASA con el motivo del lanzamiento del Atlantis en la última misión de los transbordadores espaciales fue el...
En el documental The Joy of Stats recrearon una de las charlas-TED más populares de todos los tiempos, ni más ni menos que Hans Rosling’s 200 Countries, una de las más famosas presentaciones del simpático gurú de las estadísticas, que explica...
Según se puede leer en NASA JSC Solicitation: Exploration Flight Test 1, la NASA quiere añadir un lanzamiento de prueba de la cápsula Orion (o en la terminología oficial actual de la NASA Multi-Purpose Crew Vehicle) a principios de 2014 al contrato...
Región activa 1339 por Alan Friedman La misma imagen de la región activa 1339 con la Tierra añadida para dar una idea de escala Región activa 1339 por César Cantú, apenas una manchita en el SolTres imágenes de la región activa 1339...
Si hoy es 9 de noviembre de 2011 y puedo escribir esta anotación es porque, una vez más, ha quedado bastante claro que los científicos tienen controlado esto de la dinámica de los objetos que se mueven por el espacio y que...
Aunque la primera fase de su lanzamiento anoche transcurrió sin problemas y la sonda alcanzó su órbita inicial, la Fobos-Grunt se ha quedado en esta, sin partir con destino a Marte, como tenía que haber ocurrido: Un fallo impide que la estación...
Rusia acaba de lanzar con éxito la sonda Fobos-Grunt, su primera sonda interplanetaria desde el fallido lanzamiento de la Mars 96, que tan siquiera llegó a alcanzar la órbita terrestre al fallar su cohete lanzador. Igual que la Mars 96, la...
Como todos los anteriores, el octavo capítulo de Escépticos, en esta ocasión dedicado a la homeopatía, no tiene desperdicio, y cualquiera que consuma este tipo de productos debería verlo. Para los que no nos creemos nada de la homeopatía, es un...
YU55 «visto» por el radiotelescopio de Arecibo - NASA/Cornell/Arecibo Mañana por la noche, en concreto a las 00:28 hora de España (UTC +1), el asteroide YU55 pasará a «solo» 325.000 kilómetros de la Tierra, lo que en efecto es más cerca de...
Un poco más de dos minutos y medio del cielo austral sobre el Telescopio Anglo-Australiano situado en Coonabarabran, Nueva Gales del Sur, Australia, a ser posible para ver en alta definición y con las luce apagadas. Luego, no te pierdas la...
Aunque lleva desde marzo a bordo de la Estación Espacial Internacional, cuando el Discovery lo llevó allí en su última misión, no fue sino hasta esta semana cuando los ingenieros que lo controlan le enviaron los primeros comandos a Robonaut 2...
Tras 520 días encerrados en su «nave» instalada en el Instituto Ruso para Problemas Biomédicos (IBMP), en las afueras de Moscú, los siete «tripulantes» de la MARS500 ponían hoy fin a su misión simulada, tal y como se puede leer en ¡Bienvenidos...
Esta canción me levanta en ánimo cada vez que estoy triste, con una reacción en cadena de sonrisas… (zsgalarza99) Como demostración práctica de que cualquier cosa no solo es mejor aderezada con violines o sables láser, sino que cantada a coro...
La nave Shenzhou 8, lanzada el pasado lunes por la noche, consiguió hoy un importantísimo hito dentro del programa espacial chino al establecer contacto a las 18:29 hora de España (GMT +2) con el módulo Tiangong-1 cuando ambas naves sobrevolaban China a...
Lanzamiento de la Shenzhou 8 Esta pasada noche China daba el segundo paso en su plan para poner en servicio una estación espacial con el lanzamiento de la Shenzhou 8. La Shenzhou es una cápsula con capacidad para tres tripulantes, y es...
No es habitual que el lanzamiento de un carguero espacial genere especial interés, tan siquiera entre los que nos apasiona la investigación espacial. DJSC2011-E-204584: Despegue de la Progress M-13M - NASA Pero el lanzamiento hoy de la Progress M-13M era especial por...
La Agencia Espacial Europea acaba de publicar este vídeo, en el que se ve en acción la primera ley de Newton, o la ley de la inercia, que dice que «Todo cuerpo persevera en su estado de reposo o movimiento uniforme y...
Teoría. Incertidumbre. Error. Sesgo. Valores. Manipulación. Anomalía… ¿Por qué es tan importante la labor de los buenos divulgadores científicos? Porque una cosa es lo que los científicos dicen y otra lo que el público piensa. «Teoría»: Para el público: especulación, corazonada,...
El día más deprimente del año, en el que las tardes se hacen más cortas y las noches comienzan a tornarse interminablemente más largas, ya está aquí: el día del cambio de horario de invierno. Excepto para los más dormilones, que duermen...
He perdido la cuenta de la cantidad de estudios que he visto pasar que no han conseguido establecer una relación entre el uso de teléfonos móviles y el cáncer, con lo que el hecho de que tampoco lo haga el estudio del...
Liftoff of flight VS01 - ESA/CNES/ARIANESPACE - S. Corvaja, 2011 Hoy a las 12:30, tras un retraso de 24 horas sobre lo inicialmente previsto por un problema con uno de los equipos de tierra, el cohete Soyuz VS01 despegaba de la plataforma...
Ondas Pendulares y movimientos armónicos, una demo que dicen es un clásico entre los clásicos, en este caso desde la web de demostraciones científicas de Harvard. (Vía The Kinds Should See This.)...
Espectacular como pocos, el efecto Meissner produce un curioso comportamiento en los campos magnéticos, que incluyen un «efecto de levitación» bastante espectacular. Este otro vídeo contiene explicaciones más detalladas: Y esta es la página del grupo especializado en superconductividad que se...
El equipo que ha desarrollado el MVA-B, el candidato español a convertirse en vacuna contra el Sida, ha obtenido un gran éxito con su primer ensayo clínico de Fase I. En este se ha demostrado que la vacuna es altamente eficiente, que...
NASA's Great Observatories Celebrate International Year of Astronomy: Centro de la Vía Láctea - NASA, ESA, SSC, CXC, y STScI Esta imagen se corresponde al centro de nuestra galaxia, la Vía Láctea, con un campo de vista de medio grado, similar al...
Adam Reiss, Saul Perlmutter y Brian P. Schmidt descubrieron la aceleración de la expansión del universo, y por ello han recibido el Nobel de Física de este año. Como casi todas las teorías cosmológicas, es un poco complicadilla de entender en...
Two fer the price of one: las Dracónidas de 2009 por Scott Butner Mañana, 8 de octubre de 2011, está previsto que alrededor de las 22 horas (hora de España, UTC +2) la lluvia de meteoros de las Dracónidas alcance un máximo...
Me encontré esta alucinante foto en un tuit de @Astro_Ron, Ron Garan, aunque en realidad es una foto que tomó Mike Fossum, @Astro_Aggie. El original está en The Gateway to Astronaut Photography of Earth, de donde se puede descargar a 4.256×2.832...

En este vídeo se explica qué son las sustancias placebo pero también está lleno detalles sobre los estudios que se han llevado a cabo con ellas y sus curiosos efectos. Por resumir para quien no lo sepa: los placebos son «medicina...
Este artículo se publicó originalmente en Cooking Ideas, un blog de Vodafone donde colaboramos semanalmente. Uno de los grandes problemas de la investigación espacial es que a menudo es difícil comunicar sus logros al público, lo que unido a la impresión de...
Llegó la época, y me tocó tener un par de charletas con las amigas sobre este tema recurrente: «cuidado con no coger frío que luego vienen los resfriados y la gripe». ¿Se puede defender que el frío no sea realmente el «reponsable»...
genera… Es endiabladamente enrevesado, pero alguien se ha entretenido en programar una visualización del conjunto de Mandelbrot en Python (ofuscado), de modo que el código de arriba, con ese formato tan curioso, genera la imagen de abajo: toda una delicia recursiva...
A menudo se acusa a la ciencia y la tecnología de ser algo frío, basado en datos, análisis y teorías… Pero dudo que nadie pueda ver este vídeo de una chica sorda* de nacimiento a la que acaban de activarle un implante...
La densidad del tungsteno (otro nombre para el wolframio) es de 19.250 kilogramos por metro cúbico, casi igual que la del oro, que es de 19.300 Kg/m³. Por esta razón, y porque es muy difícil distinguir un material de otro «al peso»,...
Me pareció curioso este dato de Science Daily: Millisecond Memory: ‘Teleportation’ of Rats Sheds Light On How the Memory Is Organized. Básicamente explica algunas investigaciones publicadas en Nature a partir de las que un equipo de científicos creen que la memoria y...
Un año más tenemos con nosotros los premios Ig Nobel, aquellos que se dan a aquellos logros que primero hacen que la gente se ría y luego piense, y que este año han sido otorgados en las categorías de: Fisiología: para Anna...
Esta tarde China ha lanzado con éxito el módulo Tiangong-1, un laboratorio espacial que será el banco de pruebas para la construcción de su futura estación espacial. El Tiangong-1 es relativamente pequeño, con un diámetro máximo de 3,35 metros, una longitud...
Cultivo celular de pruebas - CSIC El anuncio de ayer del Consejo Superior de Investigaciones Científicas del éxito del ensayo clínico en fase I de la vacuna MVA-B contra el virus de la inmunodeficiencia humana desarrollada en España tiene todas las...

Una preciosa selección de relojes astronómicos, en fotos realizada por la gente de Kuriositas. {Foto: Prazsky orloj (CC) George M. Groutas}...
Seguro que tienes o has tenido alguno por casa, y si no es así puedes encontrarlo en cualquier juguetería. Detrás de los movimientos del Slinky hay más ciencia de la que parece. Y no es que solo el pequeño muelle parezca...
Escépticos: trailer por Jose A. Pérez en Vimeo. Tras el éxito del estreno del piloto ¿Fuimos a la Luna? y de que con ello la ETB encargara una temporada completa de Escépticos, hoy por fin comienza la emisión de la primera temporada...
No, si al final los del Proyecto Brainstorm va a resultar que eran unos visionarios… Resulta que unos científicos han conseguido reconstruir experiencias visuales a partir de la actividad cerebral. En el laboratorio, al sujeto a modo de conejillo de indias...
La sonda Dawn de la NASA, lanzada el 27 de septiembre de 2007, tiene como ibjetivo visitar Vesta y Ceres, los dos cuerpos más grandes del cinturón de asteroides de nuestro sistema solar. El pasado 16 de julio entró en órbita alrededor...
yesterday2221 se ha tomado el trabajo de descargarse toda una serie de imágenes de The Gateway to Astronaut Photography of Earth y montar este time lapse en el que se ve lo que pueden ver los tripulantes de la Estación Espacial...
Treinta charlas –breves, de 10 minutos cada una– a cargo de otros tantos colaboradores de Amazings, entre los que nos encontramos, son motivo más que suficiente para acercarte si puedes el viernes 23 de septiembre y el sábado 24 al Paraninfo de...
Expedition 28 Floats Past the Moon - NASA/Bill Ingalls La Soyuz TMA-21 «Yuri Gagarin» aterrizó ayer en la proximidades de Zhezkazgan, en Kazajistán, trayendo de vuelta de la Estación Espacial Internacional a Andrey Borisenko, comandante de la Expedición 28, y a los...
Lo mejor es ser forever alone porque ni te enteras. Este corto infoanimado, llamado Contagion, está promovido por TakePart, que forma parte de una red de sitios web y organizaciones para concienciar a la gente de cosas importantes, como en este...
Si en alguna ocasión sientes que los líquidos expuestos de tu cuerpo como saliva, lágrimas o las mucosa de la garganta, entran en ebullición sólo con el contacto de tu propio cuerpo entonces es que has sobrepasado el límite de Armstrong. El...
Por Nacho Palou -
12 SEP 2011
GRAIL Heads to the Moon: el cohete Delta II Heavy que se encargó del lanzamiento de las sondas GRAIL segundos después de su despegue - NASA/Darrell McCall Un par de días más tarde de lo previsto inicialmente, hoy a las 15:08:52 hora...
Sendos fragmentos de tela y madera del Wright Flyer fueron depositados en la superficie de la Luna por la tripulación del Apolo 11, la primera misión tripulada en llegar a la Luna [Fuente: kit de prensa de la exhibición The Wright...
GRAIL on the Pad: El lanzador, listo para hacer su trabajo - NASA/JPL-Caltech/United Launch Alliance, Thom Baur Si todo va según lo previsto, la NASA enviará hoy a las 14:37 hora de España (UTC +2) las sondas casi gemelas de la misión...
Según una encuesta informal por parte de un profesor de matemáticas que vi mencionada en @algebrafact, respondida y votada por la comunidad de MathOverflow, las diez ideas matemáticas que más han influido en el curso de la historia bien podrían ser...

Impresión artística de los restos de una sonda sobre la superficie de Venus Una presión atmosférica de 92 atmósferas y una temperatura media de 464 grados Celsius hacen que la superficie de Venus no sea precisamente un lugar amigable para las naves...
La Lunar Reconnaissance Orbiter de la NASA, que ya había enviado imágenes de la superficie de la Luna en las que se ven los lugares de aterrizaje –y sí, se puede aterrizar en la Luna– de las misiones Apolo 11, 14, 15,...
Tránsito de la ISS frente al Sol por Danikxt Una vez enganchado a ver los pasos de la Estación Espacial Internacional por dónde vives, es posible que te pique el gusanillo y que el siguiente paso del «espaciotrastorno» sea intentar fotografiar un...
Adiós a la productividad de este lunes. La aplicación web Eyes on the Solar System de la NASA permite recorrer el Sistema Solar en 3D libremente, en cualquier dirección y ver modelos tridimensionales de los numerosos objetos que contiene (desde el...
Por Nacho Palou -
5 SEP 2011
Un diseño de Clarkie: I Love Science, vía Un Mundo Libre....
El pasado mes de julio tuve la oportunidad de ver el lanzamiento del Atlantis en la última misión de los transbordadores espaciales de la NASA en directo gracias a que conseguí una plaza en el TweetUp organizado por la agencia con motivo...
S119-E-009793: La Estación Espacial Internacional con todos sus paneles solares Desde que en marzo de 2009 los tripulantes de la misión STS-119 de la NASA instalaran el último juego de paneles solares en la Estación Espacial Internacional esta es el segundo objeto...
El carguero espacial Progress 44, lanzado ayer a las 17:00 hora española (UTC +2), que llevaba 2,9 toneladas de comida, combustible, y otros suministros rumbo a la Estación Espacial Internacional, se estrelló poco después del despegue en la región de Altai: Progress...

La radiación no se ve ni se oye. Así que para poder «ponerle cara» lo que lo que han hecho la KSU, la organización de seguridad sueca, y el DJ Axel Boman es asignar una nota a cada cambio posible en...
El gran número de sensores y sismógrafos desplegados como parte del proyecto Earthscope revelan el movimiento de las ondas producidas por el terremoto de 5,9 que se localizó ayer a 1000 metros de profundidad bajo el estado de Virginia. En la...
Por Nacho Palou -
24 AGO 2011
Parece ser que como casi es obligatorio en verano hay circulando por ahí noticias que un nuevo cometa va a suponer el fin del mundo y cosas como que sirve de camuflaje a una flota de naves extraterrestres, etc… Órbita del cometa...
Tras tres años de viaje desde que saliera del cráter Victoria, el rover Opportunity de la NASA llegó la semana pasada al borde del cráter Endeavour en Marte: NASA Mars Rover Arrives At New Site On Martian Surface. Endeavour Crater in Context:...
Otro excelente trabajo divulgativo de la gente de Sixty Symbols que explica lo que hay detrás del funcionamiento de los sistemas caóticos, especialmente su sensibilidad a las condiciones iniciales. Tan solo se necesitan una mesa de billar, un péndulo o una...
Para los que no hemos podido echar ni un vistazo a las Perseidas de 2011 por el motivo que sea, Ron Garan nos regala una foto de una de ellas tomada desde un punto de vista privilegiado, la Estación Espacial Internacional....
Aunque llevan activas desde el pasado 17 de julio y se podrán ver hasta el 24 de agosto, las Perseidas de 2011, también conocidas como las lágrimas de San Lorenzo, alcanzarán su máximo en la noche del 12 al 13 de agosto....

The Golden Ration Project necesita medio minuto de tu tiempo para completar un test de tipo A/B eligiendo formas. Es una suerte de experimento geométrico y social para comprobar cuánto de «divina proporción» tiene la razon áurea, y si realmente es tan...
A esto le llamo yo divulgación científica: Los insectos no mueren en los microondas en Maldita Ciencia, incluyendo detalles técnicos y explicaciones sobre cómo funcionan esos misteriosos pero cotidianos aparatos dignos de Tesla que todos tenemos en nuestros hogares, con el bonus...
Hace algunas horas ha habido otra gigantesca llamarada solar [en el enlace hay un vídeo del Solar Dynamics Observatory, en ultravioleta extremo] bastante más potente que las llamaradas del Sol de los últimos días que a su vez fueron calificadas ya...
No es un fake, ni tampoco una máquina de antigravedad como dice de cachondeo el protagonista del vídeo: son potentísimos imanes de neodimio atravesando un tubo de cobre. El efecto físico que se produce mientras descienden se debe a la ley...
¿Ocean's 12? No, Atlantis 125 Aunque todos hemos visto las fotos oficiales de los astronautas de la NASA, desde hace algún tiempo existe la costumbre de que al terminar de hacerse las fotos «serias» se hagan una foto mucho más divertida e...

Si te pones a dibujar líneas sin levantar el lápiz del papel y lo haces de forma recursiva puedes acabar rellenando el plano con dibujos que no varíen según la escala a la que se miren, creando motivos artísticos o cubriendo...
Aurora boreal en Kiel por Jan Haltenhof Aurora boreal en Burgum por Peter Elzinga Uno de los efectos que puede tener una erupción solar es la de la aparición de auroras polares en latitudes en las que estas no son del todo...
Tal y como cuenta el New York Times, la Fox ha encargado a National Geographic 13 episodios a modo de remake de Cosmos: un viaje personal, la obra de divulgación definitiva de Carl Sagan. En la nueva serie participarán Seth MacFarlane...
La ubicación de los aseos en bares y restaurantes y el origen de nuestro universo nunca tuvieron tanto en común… En fin, es que me hizo gracia el errorcillo de traducción de left por «izquierda» (en vez de por «restos») de...
Esta imagen del 4 de agosto es la tercera erupción solar en tres días, calificada por la NASA de tamaño tirando a «bastante grande» o lo que es lo mismo de clase M9,3 (aunque todavía hay otra clase llamada X que...
Si las condiciones meteorológicas lo permiten –y por ahora todo parece indicar que sí a pesar de que la tormenta tropical Emily podría estar dirigiéndose hacia Florida– hoy a las 17:34, hora de España (GMT +2), está previsto el lanzamiento de la...
Tal y como cuentan en Futility Closet, resulta que la secuencia de Fibonacci se puede usar fácilmente para convertir de kilómetros a millas. Esto es porque casualmente la conversión entre millas y kilómetros se hace multiplicando por 1,60934... que es un...
Una de las consecuencias de estar a bordo de la Estación Espacial Internacional es que al dar esta 16 vueltas alrededor de la Tierra cada día desde allí se pueden ver otras tantas puestas y salidas de Sol y y de...
Estos días circulaba por ahí una ecuación que genera el logo de Batman (tal vez debiéramos decir mas técnicamente el isotipo del Justiciero de Ghotam). El caso es que había incluso quien dudaba de que fuera cierta… ¡Ah, hombres de poca...
AS15-85-11471: David R. Scott, comandante de la misión, sentado en el LRV del Apolo 5 Hoy se cumplen 40 años de la utilización por primera vez del Lunar Roving Vehicle, el buggy eléctrico que permitió a los astronautas de las misiones Apolo...
Estos días ha muerto Robert Ettinger, el padre de la criónica, esa idea / movimiento social con tintes científicos –aunque bastante cuestionada– que propone que la gente sea congelada tras su muerte cerebral confiando en que años o siglos después pueden ser...
Desde el departamento de cuestiones profundas llega Existence: Why is there a universe? en New Scientist. Es una de mis cuestiones existenciales favoritas; en su momento yo la escuché como ¿Por qué existe algo en vez de nada? Ideal para meditar durante...
Lanzada hace casi 34 años, la sonda Voyager 1, que aún no ha salido del sistema solar, ha recorrido en todo este tiempo sólo 16 horas 14 minutos 18 segundos luz, unos 17.350 millones de kilómetros. La estrella más próxima, Próxima Centauri,...
Bonita alfombra fractal de Samuel Monier, correspondiente a una alfombra de Sierpinski coloreada: una extraña bestia que no tiene ni una ni dos dimensiones, sino más bien 1,8928…. Para complicar un poco más las cosas, en el concepto original de la...
En Popular Science explican la que parece la solución definitiva a la anomalía de las sondas Pioneer, uno de los grandes problemas de la ciencia actual que se había ganado un espacio entre las 13 cosas que no encajan según las...
Inflight Science. Brian Clegg. Icon Books, 2011. Edición Kindle, 256 páginas en papel. Inglés.Viajar en avión es todo un triunfo de la ciencia y la ingeniería, y de hecho cada vez que nos subimos a un avión estamos aprovechándonos de un...
Space Shuttle: The complete missions es un bonito homenaje a los transbordadores espaciales creado por Adam Rutherford del Guardian en el que se recogen los 135 lanzamientos de su carrera, recién terminada. Tal y como cuenta en Space shuttles united -...
Esta mañana, a las 11:57 hora de España, UTC +2, el transbordador espacial Atlantis tomaba tierra en la pista del centro espacial Kennedy tras pasar trece días en el espacio llevando a cabo la misión STS-135: The Voyage Home: Atlantis tomando tierra...
La meteorología esta mañana en Florida es perfecta para la vuelta a casa del Atlantis tras haber completado su última misión, la última misión de los transbordadores espaciales de la NASA. Atlantis está también en perfectas condiciones desde el punto de vista...
La NASA y la ESA acaban de hacer pública esta imagen, en la que se puede ver a S/2011 P1, también conocida como P4, la cuarta luna de Plutón: NASA's Hubble Discovers Another Moon Around Pluto Esta cuarta luna tiene un diámetro...
El Espectrómetro Magnético Alpha es un sofisticado detector de partículas fruto de la colaboración de 16 países, 56 instituciones, y 600 físicos repartidos por tres continentes distintos. Está diseñado para detectar partículas como antihelio, neutralinos, o strangelets, lo que se espera que...
Esta pasada noche, a las 1:28, el Atlantis desatracó de la Estación Espacial Internacional, poniendo fin a ocho días, 15 horas y 21 minutos de operaciones conjuntas. El Atlantis alejándose de la ISS - NASA TV Durante ellas los tripulantes del Atlantis...
Este modelo a escala 1:24 de la sonda Juno, que será lanzada el próximo mes de agosto con destino a Júpiter, es sólo uno de los muchos que se pueden descargar de forma gratuita de la galería de modelos de The Lower...
Hay en marcha una Campaña de concienciación sobre el autismo sin mitos ni usos peyorativos con diversas acciones en marcha, incluyendo el grupo de Facebook Acciones contra los mitos del autismo. Esto es debido a que cada vez se utiliza con...
Dependiendo de si se toma en cuenta el centro de masas del sistema solar o el centro del Sol como punto de referencia o bien ayer, 11 de julio de 2011, u hoy, 12 de julio, respectivamente, Neptuno habrá completado su primera...
Tras un lanzamiento sin mayores problemas y de emplear unas 48 horas como es habitual en igualar órbitas con la Estación Espacial Internacional el Atlantis atracó allí a las 17:07 del domingo, y las escotillas entre ambas naves se abrieron a las...
Si no llevo mal la cuenta, tenemos que irnos a la quinta para encontrar una que no hayamos enlazado o mencionado antes en Microsiervos, pero en The 20 most-watched TEDTalks (so far) está la lista de las veinte charlas TED más...
A pesar de que las previsiones meteorológicas daban sólo un 30% de posibilidades de que el Atlantis pudiera despegar hoy en su última misión, un porcentaje que a tenor de lo que llovió la noche anterior a muchos nos parecía incluso optimista....
Aunque cayeron un par de fuertes rayos cerca del Atlantis durante la tormenta que ayer al mediodía descargó sobre el Centro Espacial Kenenedy, ninguno de los dos afectó a la nave ni a ninguno de los sistemas asociados, con lo que todo...
Hay que mirar fijamente al punto blanco del centro: se apreciará que los círculos cambian de color. Pero cuando comienzan a moverse y rotar, dejan de cambiar aunque en realidad siguen cambiando. Basta que se queden quietos de nuevo para verse...
En plena cuenta atrás para el lanzamiento del Atlantis en la misión STS-135, la última del programa de transbordadores espaciales de la NASA, la mayor preocupación es la meteorología: Launch Weather Forecast Remains 30 Percent "Go" for Friday. Atlantis en la plataforma...
La tipografía "Dyslexie" básicamente acentúa las diferencias entre unas y otras letras. Así reduce las posibilidades de confundir unas con otras, especialmente las que son parecidas entre sí e incluso aunque se giren mentalmente. Según la Universidad de Twente, en los...
Por Nacho Palou -
6 JUL 2011
Hoy a las 19:00 hora de España (UTC +2) comenzó la cuenta atrás del lanzamiento del Atlantis en la misión STS-135 de la NASA, la última misión de la flota de transbordadores espaciales. Aunque el reloj de la cuenta atrás comienza en...
Cójanse las fotos que hizo Paolo Nespoli del Endeavour atracado a la Estación Espacial Internacional, añádasele una dosis de Zoomify, y… Adiós a la productividad durante un buen rato si visitas TerraZoom: ISS and Endeavour. (Vía Universe Today). Nuevo archivo fotográfico...
Desde el Departamento de Sugerencias de Lectura para el Verano, la Editorial Turner acaba de editar, por primera vez en español, Yo y la energía (19,90 €), con textos autobiográficos de (el gran) Nikola Tesla en español. Hace unos años ya pasó...
Por Nacho Palou -
4 JUL 2011
Desde el estupendo Grey’s Blog llega Coffee: Greatest Addiction Ever, un minidocumental divulgativo sobre nuestra adorada C8H10N4O2: la cafeína así como sus efectos y las curiosas circunstancias que la rodean en nuestro mundo. Son unos cinco minutos de culturización concentrada cual...
Preciosa esta composición musical con τ como protagonista. Pero… ¿Qué es τ? Para quien no haya oído todavía hablar de tau, simplemente simplemente remitirle al artículo del Cuaderno de Ciencias de Maikelnai: ¿Es el número pi incorrecto? Donde se explica que...
Ahora que el programa de los transbordadores espaciales llega a su final, está saliendo a la luz un montón de información muy interesante sobre ellos, como por ejemplo Birth of Atlantis, una galería de fotos de la construcción del Atlantis en la...
Una camiseta con un geométrico mensaje, a la venta en W+K Studio; me recordó a la bella tipografía matemática ROKE1984, aunque es ligeramente distinta....
Hoy se llevó a cabo la última Flight Readiness Review de la historia del programa de transbordadores espaciales de la NASA, la reunión en la que se repasan todos los puntos necesarios para dar la autorización a un lanzamiento. Momento en el...
Versión camiseta del Omnomnomagóno, informalmente juguetona....
Se me había pasado por completo que el Telescopio de Rastreo del VLT (VST, VLT Survey Telescope), instalado en el Observatorio Paranal del Observatorio Europeo del Sur en Chile, ya esta en funcionamiento, tal y como se puede leer en Primeras imágenes...
Walter Scriptunas II (@wscriptunas) es un fotógrafo freelance que está pasando este verano cubriendo el final del programa de los transbordadores espaciales, y hace unos días tuvo la oportunidad de entrar en el transbordador espacial Discovery y fotografiar su cabina y bodega...
Curiosity, el próximo rover marciano de la NASA, ya está montado y probado, con lo que los técnicos del Laboratorio de Propulsion a Chorro lo han empaquetado para enviarlo al Centro Espacial Kennedy: Building Curiosity: Packing for Florida Allí será montado en...
Operación Suelo Lunar es otro proyecto DIY que por cuatro duros (o más bien rublos en este caso) ha enviado una sonda a las alturas. El objetivo era fotografiar el eclipse de Luna del pasado día 15, y ni más ni...
Anoche, con una destrucción controlada en la atmósfera en una zona del Pacífico sur a unos 2.500 kilómetros al este de Nueva Zelanda, 6.000 kilómetros al oeste de Chile, y 2.500 kilómetros al sur de la Polinesia Francesa, terminaba la misión del...
Los chicos de la C.H.A.S.A. (CHAminade Space Agency) han vuelto a lanzar una de sus sondas estratosféricas low cost, pero en este caso calculando la hora de lanzamiento para que esta pudiera filmar el amanecer: Distintos problemas técnicos de esos de los...
Originalmente, el «algorismo» significaba la utilización de guarismos indios/arábigos para el sistema de numeración decimal. Actualmente, el algoritmo es un conjunto de reglas predefinido para realizar diversas actividades en matemáticas y programación. [Fuente: Sangakoo.]...
Mr. Gorsky se ha hecho con una pequeña joya que le gustará a los aficionados a la historia de la investigación espacial, un catálogo acerca de la estación espacial de Fresnedillas editado por el Centro de vuelo espacial Goddard. Equipos de comunicaciones...
El estupendo blog de divulgación y popularización de la ciencia Amazings ha anunciado hoy que también se publicará como revista próximamente , en cuanto completen el crowdfunding planeado con aportaciones por adelantado de los lectores. El presupuesto inicial para el primer número...
El Ford Nucleón fue un modelo a escala de 1958 que materializaba la idea de un turismo propulsado por un pequeño reactor nuclear que hacía funcionar un motor de vapor, de forma similar a como funcionan los submarinos o portaaviones nucleares....
Por Nacho Palou -
17 JUN 2011
Atlantis' Final Roll to Pad: a su llegada a la plataforma de lanzamiento el pasado 1 de junio - NASA/Terry Zaperach Dado que el lanzamiento del Discovery en la misión STS-133 tuvo que ser retrasado para reparar unas grietas que se habían...
Lunas (CC) Dzilam Unas cuantas fotos del eclipse total de Luna de anoche hechas por aquellos que estuvieron en un sitio en el que las nubes no le impidieron verlo :S Lunar Eclipse Images from Around the World; June 15, 2011 en...
En Japón, el Museo Nacional de Ciencias Emergentes e Innovación, cuenta con una pantalla esférica de unos seis metros de diámetro y compuesta por más de 10.000 paneles OLED, en la que se se puede ver como "se ve nuestro bello...
Por Nacho Palou -
16 JUN 2011
El Estudio de Visualización Científica del Centro de vuelo espacial Goddard ha creado esta animación que muestra cómo se ve la Luna desde la Tierra a lo largo de este año: One Year of the Moon in 2.5 Minutes La gracia del...
Mañana, 15 de junio de 2011, se produce el primer eclipse total de Luna de los dos que tendrán lugar este año: Total Lunar Eclipse of June 15. Se trata de un eclipse que en su fase de totalidad durará 100 minutos,...
Desde hace ya algún tiempo la NASA está muy activa en Twitter, y una de las cosas que viene organizando de vez en cuando son los NASA Tweetups vía @NASATweetup, en los que reúne a un grupo de usuarios de Twitter para...
The Sun Unleashed, APOD del 11 de junio de 2011 Esta es la foto de la erupción solar del 7 de julio que hace unos días sacábamos en vídeo. La erupción en si no es que haya sido de las más potentes,...
Cuando las últimas misiones programadas de la flota de transbordadores espaciales de la NASA eran la STS-133 y la STS-134 la agencia lanzó la iniciativa bautizada Face in Space mediante la que cualquiera podía enviar una foto suya y su nombre -o...
Red Carpet Rolled Out at Space Station La Estación Espacial Internacional ya vuelve a tener una tripulación completa con la llegada de Mike Fossum, Sergei Volkov, y Satoshi Furukawa a esta a bordo de la Soyuz TMA-02M/27S, en la que se han...
La NASA está dando los últimos toques -y con cierta prisa- a Curiosity, su próximo rover con destino a Marte. La prisa viene de que en noviembre se abre una ventana de lanzamiento para aprovechar la aproximación de la Tierra y Marte,...
Para acompañar a las fotos que hizo @astro_paolo de la Estación Espacial Internacional con el Endeavour atracado, tenemos este vídeo, tomado también desde la Soyuz TMA-20. La Estación fue rotada para ofrecer distintos ángulos a Nespoli, por lo que se pueden...

7 de junio de 2011: un compañero de trabajo le envía un correo a uno de los científicos de la NASA que trabaja en The Sun Today avisándole de un evento único hasta el momento: A Spectacular Event – A Filament/Prominence...
Me llamó poderosamente la atención descubrir la explicación del físico David Dilworth acerca de que la Unión Astronómica Internacional no tiene una definición para «Big Bang». Me pareció algo tan chocante como si la ONU no tuviera una definición de «país»… ¡Oh,...
Esta pasada noche Mike Fossum de la NASA, el cosmonauta ruso Sergei Volkov, y Satoshi Furukawa, de la Agencia Japones de Exploración Aeroespacial, despegaron en la Soyuz TMA-02M/27S con rumbo a la Estación Espacial Internacional. Fossum and Crewmates Liftoff for Station Está...
The International Space Station and the Docked Space Shuttle Endeavour Por increíble que parezca, desde que se comenzó a construir la Estación Espacial Internacional nunca se había dado la ocasión de poder hacer fotos de esta con un transbordador espacial atracado, al...
Cassini mission de cabbas en Vimeo. La sonda Cassini no lleva ninguna cámara de vídeo a bordo, pero con gran paciencia y un montón de trabajo Chris Abbas de Digital Kitchen ha montado esta película a partir de las fotografías que hemos...
Quizás la Organización Mundial de la Salud no fue muy hábil a la hora de comunicar los resultados del análisis que hizo su panel de 31 expertos sobre la posible asociación entre el uso de teléfonos móviles y el cáncer, lo que...
Mientras el Endeavour volvía a casa esta mañana al final de su última misión, la NASA estaba transportando el Atlantis a la plataforma de lanzamiento, para la que será también su última misión y la última del programa de los transbordadores espaciales...
Endeavour's Last Homecoming: El Endeavour en su último aterrizaje - NASA/Bill Ingalls [Más imágenes en la galería de imágenes de la misión] Esta mañana, a las 8:35:36 hora de España (UTC +2), las ruedas del transbordador espacial Endeavour se detenían para poner...
What an Astronaut's Camera Sees son siete minutos de las espectaculares vistas de las que disfrutan los astronautas cuando están en órbita, convenientemente rotulados y narrados por Justin Wilkinson. Mejor en 1080p y a pantalla completa, claro. Por supuesto que no...
El Endeavour y la ISS frente al Sol, fotografiados desde la frontera entre Madrid y Guadalajar a las 15:30:52,60 del 23 de mayo de 2011 Hemos mencionado el excepcional trabajo de Thierry Legault a la hora de capturar tránsitos de la ISS...
Terminadas sus tareas en el exterior de la Estación Espacial Internacional y transferidos todos los materiales y suministros entre ambas naves, el Endeavour partió en la noche del domingo al lunes de la ISS por última vez. Como es habitual, dio una...
Last Panorama of the Spirit Rover on Mars es una imagen creada por Ken Kremer y Marco De Lorenzo en la que se ve una panorámica de la zona bautizada como Home Plate, que es donde Spirit quedó atrapado en abril...
Hemos visto montones de vídeos en los que se aprecia el movimiento aparente de las estrellas en el cielo nocturno mientras la Tierra gira sobre si misma, pero este es diferente porque mantiene las estrellas inmóviles de tal forma que el...

Tras el éxito del programa piloto de Escépticos la ETB encargó una temporada completa, que tendremos que esperar a septiembre para ver, pero podemos ir haciendo boca con este teaser… En mi caso, y con lo que me ha contado Luis...
Mientras esperamos a que se hagan públicas las fotos que tomó Paolo Nespoli desde la Soyuz TMA-20 al emprender el viaje de regreso desde la Estación Espacial Internacional, tendremos que contentarnos con estas que ha hecho hoy Gregory E. Chamitoff durante el...
Lo cierto es que es la decisión lógica visto que Spirit lleva más de un año sin dar señales de vida, pero eso no hace menos doloroso el que la NASA haya hecho oficial su decisión de abandonar los intentos por restablecer...
La tripulación del Endeavour en la misión STS-134 no se ha estado precisamente quieta en los últimos cinco días, lo cual es por otra parte de esperar teniendo en cuenta la cantidad de dinero que cuesta cada una de estas misiones. Así,...
Return to Earth: La Soyuz TMA-20 aterrizando - NASA/Bill Ingalls El aterrizaje de la Soyuz TMA-20 al sureste de la ciudad de Zhezkazgan en Kazajistán con Cady Coleman de la NASA, Paolo Nespoli de la ESA, y Dmitry Kondratyev, quien fue el...
Io: The Prometheus Plume, APOD del 23 de mayo de 2011 - Galileo Project, JPL, NASA Hace ya años que la sonda Galileo, terminada su misión, se precipitó en la atmósfera de Júpiter, de hecho pocos meses después de que Microsiervos naciera...
KSC-2011-3734: El Endeavour visto muy de cerca durante su lanzamiento en la misión STS-134. Tan de cerca que cualquiera que intentara hacer esta foto en persona moriría carbonizado por las llamas y/o reducido a pulpa por la enorme potencia del sonido §...
Andrew Feustel y Greg Chamitoff han llevado a cabo el primer paseo espacial de la misión STS-134, aunque hubo que recortarlo en unos 10 minutos debido a un fallo en el sensor de CO2 del traje de Chamitoff. Not Your Typical 9-to-5:...
Möbius Pasta aglio e olio, de Steve Kass, una curiosa combinación entre pasta italiana y uno de los objetos más matemáticamente curiosos que se pueden encontrar por ahí: la banda de Möbius, que solo tiene un lado y un borde. Lo...
Con mucho cuidado, porque aunque los 6.700 kilogramos del Espectrómetro Magnético Alpha no pesen en caída libre aún tienen una inercia considerable, Andrew Feustel y Roberto Vittori usaron el brazo robot del Endeavour para sacarlo de la bodega de carga de este...

SkySurvey es una fotografía de 5.000 megapíxeles (5 Gpx) compuesta a partir de 37.440 fotos individuales, que muestra el cielo nocturno en todo su detalle y esplendor, a pantalla completa, 360 grados y un zoom casi infinito. Ideal para quienes vivimos...
El primer día completo en el espacio del Endeavour y su tripulación en la última misión de la nave comenzó al ritmo de Beautiful day, de U2, dedicada al comandante Mark Kelly. The Mission Begins: Mark Kelly en plena faena al poco...

Este entretenido vídeo muestra en diez minutos –y de forma muy divulgativa– cómo funcionan los dados no-transitivos, un «paradójico» juego de azar en el que se utilizan tres dados con sus caras marcadas con números del 1 al 6, pero de...
En SFGate cuentan que EE UU ha propuesto a la Organización Mundial de la Salud y la ONU que no se destruyan las 450 muestras que todavía existen de virus de la viruela. A pesar de que esta enfermedad letal fue erradicada...
Hace un par de días algo más de 70 personas que trabajamos en museos de ciencia y/o que nos dedicamos a la comunicación científica nos reunimos en Madrid para el Curso de redes sociales para museos y planetarios. Creo que todos los...
Atlantis' Final Rollover: el transbordador sobre su transporte, rumbo al VAB - NASA/Jack Pfaller Justo un días después de haber lanzado al Endeavour en su última misión, la NASA ha trasladado al Atlantis de su hangar al Edificio de Ensamblado de Vehículos,...
Endeavour's Final Flight: El Endeavour despegando en su última misión Un lanzamiento de libro puso al Endevour y su tripulación en órbita en ocho minutos y medio, donde dedicaron las primeras horas de la misión STS-134 a preparar su nave para esta....
Por fin el Endeavour ha podido despegar en la que será su última misión, llevando el Espectrómetro Magnético Alfa a la Estación Espacial Internacional, así como varias toneladas de carga entre suministros y piezas de repuesto. Como en todos los lanzamientos, y...
Todo está en marcha en el Centro Espacial Kennedy para el intento de lanzamiento del Endeavour y su tripulación en la misión STS-134 hoy a las 14:56, hora de España (UTC +2). El Endeavour en la plataforma de lanzamiento - NASA/Frankie Martin...
Lo han llamado, apropiadamente, Tricorder X PRIZE, y el reto consiste en desarrollar un aparato –se parezca o al del Dr. McCoy o no– que diagnostique mejor o igual de bien que un panel de médicos colegiados. Lo que viene siendo...
Lightning Over Brazil es una foto obtenida desde la Estación Espacial Internacional por Paolo Nespoli, el astronauta de la Agencia Espacial Europea, en la que se ve como los rayos iluminan las nubes que cubren Brasil la noche. A Paolo, que...

El proceso que lleva a la formación de un ser humano a partir de un óvulo más un espermatozoide es ciertamente impresionante, pero nunca había visto algo como esto: Se trata de una animación creada a partir de escaneos de embriones...
Tras sustituir la Unidad de Control de Carga 2 (LCA-2) que falló en el intento de lanzamiento del Endeavour del pasado 29 de abril en la misión STS-134, los responsables de la NASA dieron el visto bueno para intentarlo de nuevo el...
Estos días, y hasta fin de mes, si miras hacia el este una media hora antes del amanecer, podrás ver muy juntos a Marte, Júpiter, Venus y Mercurio, tanto como no lo han estado desde hace 160 años, tal y como se...
Universe Sandbox es un simulador interactivo para Windows, en el que los ingredientes son estrellas, planetas y un toque de gravedad. El resultado es que se puede «jugar» a crear sistemas solares y ver los efectos de modificar sus masas y...
Shadow of a Martian Robot: La sombra de Oportunity en Marte - Mars Exploration Rover Mission, JPL, NASA La Imagen Astronómica del Día de hoy es de la sombra de Opportunity -y dos de sus ruedas- en el cráter Endurance, mientras va...
Los responsables de la agencia han decidido darse más tiempo para terminar las reparaciones y comprobar que todo está bien a bordo del Endeavour, con lo que han fijado el lanzamiento para no antes del lunes 16 de mayo a las 14:56,...
James Randi estuvo esta semana en la isla de San Simón, muy cerquita de Vigo, participando en NeuroMagic 2011. Se trataba de una convención de magos y neurocientíficos que tenían como objetivo estudiar los engaños de la mente, durante la que aberron...
Ya habíamos visto alguna demo parecida, y el vídeo es un tanto viejuno, pero no deja de ser espectacular: en esta ocasión los científicos meten en una urna 136 pelotas de ping-pong en frágil equilibrio sujetas en tensión en trampas para...
50 Years Ago: Freedom 7 Flies - NASA Hoy a las 14:34:14 UTC se cumplen 50 años del lanzamiento de Alan Shepard a bordo de la cápsula Freedom 7, impulsada por el cohete Mercury Redstone 3, convirtiéndose en el segundo ser humano...
Tras reunirse ayer para evaluar la situación los responsables de la NASA han decidido retrasar el lanzamiento de la misión STS-134 al menos hasta el 10 de mayo. Esto es debido a las tareas necesarias para reemplazar la Unidad de Control de...
Este es uno de los educativos y entretenidos vídeos del «ingeniero irreverente» Bill Hammack, más conocido como EngineerGuy. En esta ocasión explica la teoría de colas y cómo la aplicó Agner Erlang a las primigenias centralitas telefónicas, así como sus efectos,...
En la NASA existe una tradición que viene ya desde los tiempos del programa Apolo que consiste en despertar a los astronautas que están en órbita con una canción. Esta canción la escogen normalmente familiares, amigos, y compañeros de los astronautas, pero...
Cuando ya piensas que después de los iconos de iPhone o las letras de Scrabble nada más podría adaptarse al formato «complemento de sofá», llegan estos mullidos y adorables cojines con forma de distribuciones estadísticas que incluyen a toda la familia...
Las comprobaciones y pruebas llevadas a cabo desde el viernes no han permitido solucionar el problema que provocó la cancelación de este. El problema parece radicar en un componente denominado aft load control assembly-2 (ALCA-2), que es una caja de interruptores que...
Tras llegar a la plataforma de lanzamiento, la estructura rotativa de servicio (Rotating Service Structure) es acoplada a los transbordadores espaciales con el doble objetivo de protegerlos de la intemperie y de dar acceso a estos. De hecho, para el intento de...
Hace años recuerdo haber leído, aunque probablemente en la colección Joyas Literarias Juveniles de Bruguera, la novela El rayo verde de Julio Verne. No recuerdo muy bien es el argumento de la novela, pero lo que sí es cierto es que el...
Endeavour at the Pad: El Endeavour bajo una tormenta en la madrugada del 29 de abril - NASA/Bill Ingalls Aunque todo parecía ir sobre ruedas desde el punto de vista técnico para el lanzamiento del Endeavour ayer en la misión STS-134 un...
Todo está listo en el Centro Espacial Kennedy para el lanzamiento del Endeavour en la misión STS-134. El Endeavour sobre la plataforma de lanzamiento - NASA Tras solucionar un pequeño problema con el sistema de maniobra orbital esta misma mañana, ahora mismo...
La Tierra completa su órbita alrededor del Sol más o menos en 365,25 días (demostración). Newton y Kepler esbozan una sonrisa al fondo de la sala....
La complicada situación económica por la que pasa el Radio Observatorio de Hat Creek, que se ha ido quedando sin financiación, ha obligado a poner en hibernación el Allen Telescope Array (ATA), tal y como explica Tom Pierson, el director del Instituto...
El 21 de abril de 2010 la NASA revelaba las primeras imágenes obtenidas por el Solar Dynamics Observatory, un observatorio que tiene como objetivo estudiar detalladamente el campo magnético del Sol, como se genera, qué estructuras presenta, y como se libera su...
Goodyear, conocida marca de neumáticos, es quien fabrica buena parte del plástico neutro que sirve como base gomosa para las 560.000 toneladas de goma de mascar que se consumen cada año en todo el mundo, el acetato de polivinilo o PVA. El...
Por Nacho Palou -
25 ABR 2011
¿What is Reality? es un programa de Horizon emitido por la BBC a principios de este año, que explora algunas ideas relacionadas con el concepto de realidad. Aparecen en él un montón de físicos, que en breves entrevistas intentan explicar algo...
En el colegio nos enseñan que la Tierra es redonda, en el sentido de que es esférica, y normalmente nos quedamos con esa idea, que para el día a día es más que suficiente. Pero hace tiempo que sabemos que en realidad...
Tras las pertinentes pruebas y ensayos los responsables de la NASA han dado el visto bueno para el lanzamiento del Endeavour en la misión STS-134 el próximo viernes 29 de abril a las 20:47 hora de España (UTC +2): NASA Sets Launch...
Un clásico: Tree of Life, unas 3.000 especies perfectamente ubicadas según la secuenciación de su ARNr, en un gigantesco PDF que se puede descargar para imrpimir. Un trabajo que literalmente coloca a cada forma de vida en su sitio. Nuestra especie...
Aunque no estarían fuera de lugar en una película de ciencia ficción, estas imágenes son parte de los efectos visuales creados por la empresa Burrell Durrant Hifle para Maravillas del universo, por lo que en realidad representan cosas que se pueden...
Aunque es posible hacer unos pinitos en la observación astronómica desde casa con telescopios no muy caros, si un astrónomo profesional te ayuda en esos primeros pasos, seguro que todo va mucho mejor. Esta es la idea detrás de la iniciativa que...
Esta Colonia flotante tripulada en Venus es una de las múltiples ilustraciones, deliciosamente ingenuas en muchos casos, que se pueden ver en scienceillustration. Se observa una cierta fijación con las aeronaves y otros vehículos propulsados mediante energía atómica, y por en...
Aunque los modelos y teorías que manejamos en la actualidad sobre cómo funciona nuestro universo funcionan razonablemente bien, hace tiempo que científicos de todo el mundo están a la caza de la materia oscura (que no debe ser confundida con la energía...
Aunque los tripulantes del Atlantis en la misión STS-125 hicieron un magnífico trabajo de puesta al día del telescopio espacial Hubble, dejándolo en muchos aspectos mejor que cuando fue lanzado, es inevitable que con el tiempo sus componentes vayan fallando. A pesar...
Cuando una persona recibe una transfusión de sangre… ¿Hay en su cuerpo células con distinto ADN? Depende un poco del tipo de transfusión (se necesita que tenga células, lo cual es poco habitual) y de cuánto tiempo haya transcurrido, pero a veces...
Lo que cuenta es interesante, pero ni siquiera hace falta entenderlo, porque te quedas directamente hipnotizado con las imágenes a los pocos segundos. Es otro de los vídeos de la saga de Vi Hart garabateando en clase, geometría y topología para...
Las normas de la Federación Aeronáutica Internacional que estaban vigentes cuando Yuri Gagarin realizó su vuelo al espacio especificaban claramente que para certificar un vuelo espacial como tal el piloto de una nave tenía que despegar y aterrizar con ella.El problema era...

Las flautas en gravedad cero –técnicamente, en «caída libre»– suenan exactamente igual que en Tierra, tal y como comprobó empíricamente la astronauta Cady Coleman el otro día en la Estación Espacial Internacional. En Brucknerite cuentan más sobre otros instrumentos que la...
La gente de xRez Studio tiene algo llamado «fotografía panorámica a resolución extrema» que combinado con «hemos hecho una visita al dispositivo óptico más grande del mundo con 192 de los más poderosos láseres» se antoja ciertamente una combinación irresistible. El...
Siempre me ha fascinado el arte del soplado del vidrio, por lo que no he podido menos que quedarme embelesado con este corto vídeo sobre Kiva Ford, que fabrica instrumentos a medida para que los químicos hagan sus cositas: Kiva también tiene...
El Discovery siendo preparado para su retiro - NASA. Más fotos en Discovery heads into retirement Tal y como estaba previsto, la NASA ha hecho pública su decisión acerca de los lugares en los que descansaran sus transbordadores espaciales ahora que se...
Además del 50 aniversario del primer vuelo espacial de un ser humano, hoy se cumplen también 30 años del lanzamiento del primer transbordador espacial. Lanzamiento del Columbia en la misión STS-1 - NASA A las 12:00:03 UTC del 12 de abril de...
First Orbit es una recreación en tiempo real del primer vuelo de Yuri Gagarin, que incluye fundamentalmente imágenes tomadas desde la Estación Espacial Internacional combinadas con algunas originales de aquel histórico 12 de abril de 1961, junto con el audio original...
Con una idea original extraída de Hervir un Oso, de Jonathan Millán y Miguel Noguera, en Mediavida hicieron hace tiempo una genial reflexión sobre los desplazamientos y paradojas temporales en la popular serie de televisión Cuéntame, que titularon Cuéntame cómo pasó...
Hay una leyenda urbana muy extendida que dice que tras los primeros vuelos espaciales tripulados la NASA se dio cuenta de que los bolígrafos normales no funcionaban en el espacio y que entonces procedió a diseñar uno que sí lo hiciera, gastándose...
La Tierra y la Luna se encuentran en lo que se denomina acoplamiento de marea, de tal forma que la Luna siempre muestra la misma cara hacia la Tierra precisamente porque debido a este acoplamiento tarda lo mismo en girar sobre si...
Se ha batido el récord de doblar un papel de punta a punta, con 13 dobleces. Más apropiadamente deberíamos decir que el récord anterior ha sido doblegado: quedó marcado allá por 2002 con un total de 12 dobleces y lo tenía...
La vista desde arriba - NASA The View from Up Top (La vista desde arriba) es la Imagen del Día la NASA de hoy, en la que puede verse un sistema de bajas presiones en el norte del Océano Pacífico. Fue hecha...
Esta ilustración, de autor desconocido, seguro que os sacará una sonrisa a los geeks de las matemáticas que nos leeis. Los demás, no nos lo tengáis muy en cuenta ;-) (Llegó mediante varias funciones de transferencia sucesivas desde In web we...
Aleksandr Samokutyayev, Andrei Samokutyayev, y Ronald J. Garan están ya a bordo de la Estación Espacial Internacional, donde atracó la Soyuz TMA-21M en la que viajaban esta pasada noche a la 1:09 hora de España, UTC +2. Con la apertura de...
La NASA acaba de publicar este vídeo que muestra cómo llegará, si todo va bien, el Mars Science Laboratory, bautizado como Curiosity, a Marte: En él se ve perfectamente el nuevo método que se va a utilizar para el aterrizaje (y sí,...
Todo el mundo recordará que unas semanas después de los ataques del 11-S en EE UU se vivió otro pánico social cuando comenzaron a aparecer sobres enviados por correo postal infectados con ántrax, una bacteria letal cuyas esporas se consideran armas biológicas....
Estamos ya bastante acostumbrados a ver espectaculares imágenes de otros planetas y cuerpos de nuestro sistema solar captadas por todas las sondas que tenemos por ahí, nuestros ojos en el sistema solar, pero la Tierra también tiene su gracia cuando estos...
¿Qué pasa cuando tienes un telescopio espacial mirando todo el rato para el Sol y la Tierra se interpone parcialmente entre ambos? Pues que tu mandíbula hace «clonc» contra el suelo al ver imágenes como esta: SDO Sees Spring Eclipse - NASA/GSFC/SDO...
El lanzamiento del carguero espacial Progress 42P rumbo a la Estación Espacial Internacional el próximo 27 de abril ha llevado a la NASA a tomar la decisión de posponer el lanzamiento del Endeavour hasta el día 29 de este mes: NASA Retargets...
¡No! es el póster oficial de la misión STS-134 de la NASA, que otra cosa no se yo, pero de publicity entienden un rato… Dan ganas de hacerse astronauta solo para que te hagan una foto de estudio de estas en...
Esta pasada noche, a las 00:18:20, hora de España (UTC +2), la Soyuz TMA-21 despegaba a lomos de un lanzador Soyuz FG (sí, es un poco lío que los rusos llamen igual a la cápsula que a su cohete lanzador) con destino...
Se ve que no sólo en España las cosas de palacio van despacio, pero al fin hoy, un año después de que se constituyera por ley, la UK Space Agency, la Agencia Espacial del Reino Unido, empieza a funcionar al 100%. Se...
Tras desatracar de la Estación Espacial Internacional el pasado lunes el vehículo de transferencia H-II de la Agencia Espacial de Exploración Aeroespacial bautizado como Kounotori 2 se ha consumido sobre el Pacífico central esta madrugada en su reentrada en a atmósfera, poniendo...
Hace un par de días que el Departamento de Educación y Comunicación Pública (ePOD) del Observatorio Austral Europeo (ESO) y la Agencia Espacial Europea (ESA) han lanzado ni más ni menos que tres aplicaciones para que los aficionados a la astronomía podamos...
First Image Ever Obtained from Mercury Orbit - NASA/Johns Hopkins University Applied Physics Laboratory/Carnegie Institution of Washington Esta es la primera imagen tomada por la sonda Messenger después de entrar en órbita alrededor de Mercurio el pasado 18 de marzo. En concreto...
La formación acerca de la salud es un tema que está contemplado en el currículum de la enseñanza obligatoria en España (primaria y secundaria), ya sea en forma de contenidos específicos en ciertas asignaturas o bien como contenido complementario en otras asignaturas...

Wonders of the Universe, una miniserie documental de la BBC, es una especie de continuación del estupendo y divulgativo Wonders of the Solar System emitido el año pasado. Protagonizado por el profesor Brian Cox, «el nuevo Carl Sagan», Wonders of the...
Con el aterrizaje de su cápsula de muestras en el desierto de Utah en enero de 2006 la sonda Stardust culminaba con éxito su misión. El objetivo de esta era recoger partículas de la coma del cometa Wild 2 y traerlas de...
Composición de como podría estar Spirit atascado en Marte - NASA/Stu Atkinson Ya se ha cumplido un año desde que Spirit se comunicara por última vez con el control de la misión desde Troy, el lugar en el que permanece atrapado sobre...
Sabía que a pesar de que los astronautas hacen ejercicio asiduamente mientras están en el espacio al final de sus misiones, cuando vuelven a tierra tras varios meses en caída libre, necesitan de un periodo de adaptación para volver a acostumbrarse a...
Aunque existen grabaciones de audio de los 108 minutos que duró el primer vuelo al espacio de un ser humano, no hay ninguna imagen tomada desde la Vostok 1 que nos pueda dar una idea de lo que vio Yuri Gagarin aquel...

He aquí el tráiler de una serie de la BBC4 titulada Everything and Nothing sobre la naturaleza física del espacio y la materia. Es interesante cómo una mini-explosión que parece el disparo de un petardo de las fiestas acaba siendo cosmológicamente...
Como parte de la Geek Week, una especie de semana de la ciencia celebrada en la Universidad de Utah, la multitud pudo disfrutar de un curioso experimento científico: el lanzamiento de 20.000 pelotas de goma de colores desde un helicóptero en...
Todo un detalle para conmemorar los casi 30 años de servicio de estas naves. En Kennedy Employees Form Human Shuttle hay una foto de la figura que formaron. (Vía @NASAKenndy)....
Esta pasada noche a las 2:45 el Centro de Operaciones de la misión Messenger de la NASA comenzó a recibir los datos que indicaban que la sonda del mismo nombre había ejecutado a la perfección la maniobra de inserción orbital programada en...
El Discovery se aproxima a la ISS en la misión STS-133 - NASA For Discovery, a farewell spin es una recopilación de 45 imágenes en homenaje al transbordador espacial Discovery, que acaba de completar con éxito la última misión de su carrera....
Después de seis años y medio en el espacio, 15 órbitas alrededor del Sol en las que ha recorrido 7.840 millones de kilómetros y durante las que se ha acercado un vez a la Tierra, dos a Venus, y tres a Mercurio...
Por fin han publicado el esperado vídeo de la charla de Deb Roy en TED: The birth of a word. Lo que hizo este investigador del M.I.T. fue grabar una decena de videocámaras a su hijo, unas 8 o 10 horas...
En medio de vientos de 30 nudos y sobre una capa de nieve que llegaba a la altura del tobillo, la Soyuz TMA-01M aterrizó sin problemas -aunque de lado- esta mañana a las 8:54 hora de España (UTC +1) a unos 80...
En Birmingham Science City hicieron un experimento para ver cómo de despistados andan los residentes del Reino Unido respecto a lo que todavía es ciencia ficción y lo que ya no lo es, cuyos resultados publican en Time to turn on the...
Kinect-Controlled Tesla Coils: The Evil Genius Simulator. ¿Dónde sino en una Maker Faire, en este caso Maker Faire UK 2011, se pueden controlar un par de bobinas Tesla con un Kinect convertido así en un Simulador de Genios Malignos? Pues eso....
Como cada 14 de marzo (3/14 en anglosajón) hoy es el día de pi, así que ahí va una pequeña diversión conmemorativa: Michael John Blake muestra cómo se puede escuchar π en forma de notas musicales en este vídeo: What Pi...
Desde ayer el Endeavour está en la plataforma de lanzamiento 39A del Centro Espacial Kennedy, donde los técnicos de la NASA ya trabajan en prepararlo para su última misión, la STS-134. EL Endeavour en la plataforma de lanzamiento - NASA/Jack Pfaller. [Original...
Con las palabras «Por última vez Discovery, ruedas paradas» el comandante Steve Lindsey ponía fin a las 17:58:14 del 9 de marzo de 2011 a la misión STS-133 de la NASA, la número 39 del Discovery, la última del más veterano de...
Dentro de los preparativos para su lanzamiento rumbo a la Estación Espacial Internacional en la misión STS-134 el Endeavour, ya acoplado a su depósito de combustible y los propulsores de combustible sólido, será trasladado hoy a la plataforma de lanzamiento 39A del...
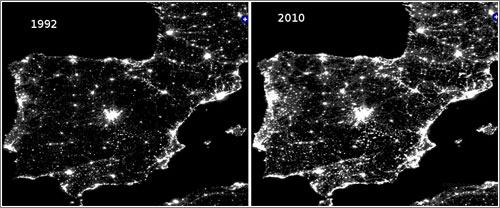
Estas imágenes de satélite de la NASA recopiladas desde 1992 hastas hoy muestran con claridad el problema de la contaminación lumínica en España y cómo las luces nocturas de ciudades y carreteras engullen la noche, deteriorando la oscuridad y recordándonos a...
Fractal Lab es como tener un fractal en las manos con una lupa infinita y un montón de pinturas; una herramienta impresionante para la exploración de fractales matemáticos. Funciona a través del navegador; sólo hace falta instalar la última versión de...
Cuando las misiones STS-133 a cargo del Discovery y la STS-134 a cargo del Endeavour eran las dos únicas que quedaban en el programa de los transbordadores espaciales de la NASA la agencia lanzó la iniciativa bautizada Face in Space mediante la...
Eyes on the Earth es una genial aplicación interactiva de la NASA para observar cómo trabajan los satélites de observación que rodean la Tierra, vigilando datos tales como las emisiones de CO2, las temperatura o los niveles del mar a cada...
El primero de los dos días extra añadidos a la misión STS-133 fue utilizado, como estaba previsto, fundamentalmente para echar una mano en ir descargando y preparando el módulo Leonardo para su funcionamiento, aunque por la tarde Steve Bowen y Alvin Drew...
En este reloj de los irracionales no aparecen horas exactas sino sólo aquellas que se corresponden –aprox.– con algunos números irracionales más o menos conocidos. Muy apropiado ahora que se cumplen 250 años de la demostración de la irracionalidad de π....
Terminados con éxito los dos paseos espaciales de la misión e instalado en su ubicación definitiva en la Estación Espacial Internacional el módulo Leonardo, reconvertido de módulo de carga a módulo permanente de la ISS, la tripulación del Discovery dedicó la mañana...
Tal vez no haya ninguna aplicación práctica en el hecho de que Pi sea irracional. Pero, dado que podemos saberlo, sería intolerable no conocer ese hecho. – E.C. Titchmarsh Tal día como hoy, pero de hace 250 años, un matemático llamado Johann...
Steve Bowen y Alvin Drew, con la ayuda de Nicole Stott desde el interior, llevaron a cabo un montón de tareas en el exterior de la Estación Espacial Internacional durante las 6 horas y 14 minutos del segundo y último paseo espacial...
La Estación Espacial Internacional cuenta desde ayer con casi 70 metros cúbicos más de espacio de almacenamiento con la instalación en el punto de atraque que apunta hacia la Tierra del módulo Unity del módulo Leonardo, reconvertido de contenedor de carga a...
El Endeavour entrando en el VAB - Alan Walters - awaltersphoto.com. Original y más imágenes en Endeavour Rolls to Vehicle Assembly Building for Final Flight Después de haber sido revisado y preparado para la misión STS-134 en el hangar correspondiente, oficialmente conocido...
Steve Bowen y Al Drew fueron los que tuvieron más trabajo durante el quinto día de la misión, ya que les tocó llevar a cabo el primer paseo espacial de esta. A Good Day for a Spacewalk - NASA. Alvin Dren a...
Beyond Southern Rhea - NASA/JPL/Space Science Institute Otra impresionante imagen por cortesía de la sonda Cassini, en este caso Dione «posada» sobre los anillos de Saturno, con el polo sur de Rea en la parte superior de la imagen. Como sucede con...
¿Cuánto se ahorrará realmente con la medida de reducción de velocidad en autopistas y autovías de 120 Km/h a 110 Km/h? ¿Y cómo puede un problema que parece de matemáticas básicas arrojar tantas respuestas distintas según quién lo analice? Los factores son...
Las tripulaciones del Discovery y de la Estación Espacial Internacional utilizaron la mayor parte del domingo en pasar equipos y suministros de una nave a otra, aunque también estuvieron revisando los procedimientos a utilizar en el primer paseo espacial de la misión...
Tras meses de retrasos el transbordador espacial Discovery inició la semana pasada su última misión, la STS-133. El vídeo de arriba capta el momento del despegue visto desde un avión que pasaba "cerca" de la base de lanzamiento en su vuelo...
Por Nacho Palou -
28 FEB 2011
Desde ayer a las 20:14, hora de España (UTC +1), el Discovery está atracado en el módulo Harmony de la Estación Espacial Internacional, aunque las escotillas entre ambas naves no se abrieron hasta las 22:16, una vez que se hubieron realizado las...
Tras despertar al son de Through Heaven's Eyes por Brian Stokes Mitchell la tripulación del Discovery tuvo como actividad principal del día inspeccionar el estado de los bordes de ataque de las alas y del morro de su nave con el Orbiter...
Nadie lo diría viendo este vídeo, pero tanto la Estación Espacial Internacional como el ATV Johannes Kepler se están moviendo a unos 28.000 kilómetros por hora mientras el Johannes Kepler atraca de forma totalmente automática en el módulo Zvezda de la Estación:...
Anoche, tras casi seis meses de retraso sobre las primeras previsiones y seis intentos de lanzamiento previos, el Discovery y su tripulación despegaban al fin en la misión STS-133 de la NASA: Todo indica que ha sido un lanzamiento sin problemas, pero...
Oh, ¿puede haber un metal más divertido que el Galio –que no sea el Mercurio? El galio es un metal blando, grisáceo en estado líquido y plateado brillante al solidificar [...] que funde a temperaturas cercanas a la de la ambiente...
Por Nacho Palou -
25 FEB 2011
Con la retirada de la Estructura Rotatoria de Servicio a primera hora de esta mañana comenzaba el día del -esperemos- lanzamiento del Discovery en la misión STS-133 de la NASA. Ready for launch - NASA/Bill Ingalls. La estructura de servicio, que se...
Esta tarde a las 16:45 está prevista la llegada del Vehículo Automatizado de Transferencia Johannes Kepler de la Agencia Espacial Europea a la Estación Espacial Internacional, lo que se podrá seguir en directo a través de la web de la ESA a...
Todos los que nos gusta la astronomía babeamos con imágenes como esta de la galaxia NGC3982 publicada en Hubblesite: Face-on Spiral Galaxy NGC 3982 - NASA, ESA, and the Hubble Heritage Team (STScI/AURA) - A. Riess (STScI) Pero lo que normalmente no...
El año pasado la Organización Mundial de la Salud (OMS) se gastó 30 millones de euros para que medio centenar de investigadores indagaran en la relación entre el uso de teléfonos móviles y el riesgo de desarrollar tumores cerebrales. El resultado fue...
Por Nacho Palou -
23 FEB 2011
Cada vez que veo un vídeo de estos no puedo evitar pensar en lo que nos perdemos los que vivimos en las ciudades cada noche que no podemos salir de ellas a echarle un vistazo al cielo: ALMA Time-lapse sequences - June...
A las 21:00 de esta noche ha arrancado la cuenta atrás para el lanzamiento del Discovery en la misión STS-133 de la NASA el próximo jueves 24 de febrero de 2011 a las 21:50 hora de España (UTC +1). STS-133 Crew Arrives...
A la izquierda el mecanismo quirúrgico articulado similar a una culebra; a la derecha (b) se ven los controladores y mecanismos que lo manejan / Howie Choset. The Robotics Institute, Carnegie Mellon University. Cardio Arm es el nombre de este inquietante artilugio...
Por Nacho Palou -
21 FEB 2011
Al menos si amas las matemáticas: La identidad de Euler grabada para siempre, con las constantes más importantes y enigmáticas relacionadas entre sí «de una forma totalmente inesperada», como decía el matemático Euler, su descubridor. (Vía Proof.) _____Actualización (marzo de 2017)...
A Tale of Two Twins es algo así como una explicación de la relatividad especial para niños grandes: comienza con una especie de cuento y sigue con una explicación más detallada de todo lo que sucede a los famosos gemelos de...
En este vídeo se puede ver como se produce la erupción solar del día de San Valentín -el destello brillante que se ve en el segundo 5 un poco hacia abajo y hacia la derecha del centro del Sol- y la...
Después de llevar a cabo la Flight Readiness Review, que es una reunión en la que los responsables del programa, los ingenieros y representantes de todas las subcontratas analizan el estado de la nave, los equipos de apoyo, y del personal involucrado,...
Anunciado el 13 de septiembre de 2007, el Google Lunar X PRIZE ofrece un primer premio de 20 millones de dólares al primer equipo que sea capaz de hacer aterrizar una sonda en la superficie de la Luna, conseguir que avance 500...
Si todo va según lo previsto, exactamente dentro de un mes la sonda MESSENGER de la NASA (MErcury Surface, Space ENvironment, GEochemistry and Ranging - Medición de Superficie, Ambiente Espacial, y Geoquímica de Mercurio) entrará en órbita alrededor de Mercurio. Pero antes...
Olá con la nueva versión de Google Public Data Explorer surjan muchos Hans Rosling que hagan más fácil entender el mundo en que vivimos. No en vano se trata de una herramienta basada en Gapminder, cuya tecnología adquirió Google hace años,...
La imagen astronómica del día nos llega hoy por cortesía del Solar Dynamics Observatory, que desde su lanzamiento hace ahora un año viene sorprendiéndonos con las espectaculares imágenes del Sol que envía. En esta, bautizada como X-Class Flare, se puede ver...
Con un día de retraso sobre lo inicialmente previsto el segundo Vehículo de Transferencia Automatizado de la Agencia Espacial Europea, bautizado como Johannes Kepler, despegó anoche rumbo a la Estación Espacial Internacional con 6.600 kilogramos de suministros a bordo para esta....
Juan Diego nos pasó un enlace a Google Earth fractals, una deliciosa página de Paul Bourke que recopila imágenes de la Tierra, vista «desde las alturas», en que se observan formas con un toque decididamente fractal. Cada imagen lleva vinculado su...
Dado que los tripulantes de la Estación Espacial Internacional lo tienen un poco complicado para ir a hacer la compra lo que hacen las distintas naciones que participan en el programa es enviársela periódicamente a bordo de distintas naves. Aparte de en...
Como el enormemente complejo sistema que es, la producción de energía del Sol no es constante, y cambia a lo largo del tiempo de forma periódica. Probablemente el ciclo solar de 11 años descubierto por Samuel Heinrich Schwabe y cuyos mínimos y...
La tecnología actual no nos permite enviar una misión tripulada a Marte, tanto desde el punto de vista del coste, que ninguna nación o grupo de naciones quiere asumir, como desde el punto de vista técnico, pues ya nos resulta bastante difícil...
Todos los ordenadores convencionales del mundo, juntos, podrían almacenar unos 295 exabytes comprimidos de forma óptima y ejecutar unos 6,4 billones de MIPS (millones de instrucciones por segundo). Pero aun así –y salvando el abismo que diferencia a las máquinas de los...
El intento de lanzamiento de la misión el pasado 5 de noviembre -el quinto ya- tuvo que ser cancelado porque se detectó una fuga de hidrógeno gaseoso en el Ground Umbilical Carrier Plate. Ubicación del GUCP en el tanque de combustibleDetalle de...
Víctor ya me lo había chivado hace unos días, pero hoy por fin se ha hecho pública la existencia de una aplicación para iPhone y similares para Portal To The Universe. Portal To The Universe es uno de los proyectos pilares del...

Butterfly Curves es un entretenimiento de la gente de Subblue, que permite dibujar «mariposas» y curvas parecidas a las del espirógrafo variando los diversos parámetros de forma interactiva. Bonus: de la misma gente, un vídeo de un fractal que ha estado...
Mark Kelly, el comandante de la misión STS-134 de la NASA, es el marido de la congresista Gabrielle Giffords, quien recibió un disparo en la cabeza en el tiroteo de Tucson del 8 de enero de 2011. Para poder estar junto a...
Out in the Cold (CC) Tuchodi @ Flickr En Curiositas publicaron una bella anotación con estupendas fotos de aficionados de todo el mundo con el precioso e intrigante termómetro de Galileo como protagonista, un curioso artilugio inventado en el siglo XVI y...

Esta es la que más me gustó de las que encontré [había otras pero desparecieron con el paso del tiempo]: Φ Golden Ratio Calculator ofrece los datos pero como parte de una secuencia de números en proporción áurea alrededor del indicado, de...
Julia Map es un experimento matemático que ha montado alguien que trabaja en Google, relativo a la visualización de fractales tales como el Conjunto de Julia, el de Mandelbrot y otros usando la API de Google Maps y HTML5 para su...
El periodo sinódico de la Luna es de unos 29,5 días de promedio; más exactamente: 29,530589. Eso quiere decir entre otras cosas que entre una luna llena y la siguiente transcurren unos 29 días y medio. Como el mes de febrero...
Lanzado en marzo de 2009, Kepler es un satélite de la NASA diseñado para detectar exoplanetas. Para ello «mira» fijamente una zona de la Vía Láctea situada entre las constelaciones del Cisne y Lyra, utilizando el método de los tránsitos para detectarlos....
El ciclón tropical Yasi cerca de AustraliaFoto: NASA / GSFC / Jeff Schmaltz / MODIS El nombre de este espectacular ciclón tropical es «Yasi», y se dirige hacia Queensland (Australia) con un inmenso poder destructivo –categoría 5, la máxima– que atemoriza a...
Terminadas las reparaciones y modificaciones necesarias en el tanque de combustible del Discovery, este ha vuelto a ser trasladado hoy a la plataforma de lanzamiento 39A en un lento paseo de unas siete horas. Discovery Returns to the Launch Pad: La estructura...
El amanecer del 18 de agosto de 2010 captado por el lanzamiento Sunrise Soar II Creo que el primer proyecto de este estilo que vi fue el de los chicos de Meteotek08, ya en 2008, pero desde entonces ha habido más gente...
Tal y como estaba previsto la Progress M-09M quedó atracada a las 3:39 (hora de España, UTC +1) en el módulo Pirs de la Estación Espacial Internacional, como se puede ver en este vídeo: Lleva a bordo unos 870 kilogramos de combustible...

150 decimales de π, cantados por Danny Perich. La musiquilla está muy bien, pero la probable normalidad de pi hace que la carencia de estribillo resulte… extraña, cuando menos. Si tienes algún número favorito, y dado que todos los números están...
Esto es lo que pasa cuando los grajos vuelan demasiado bajo, comienzan a usar la tuneladora e incluso consideran presentarse al casting de El Núcleo 2: que hasta las pompas de jabón se congelan. El experimento recreativo lo llevaron a cabo...
A la tripulación de la Estación Espacial Internacional se le acumula el trabajo estos días, pues al vehículo de transferencia H-II de la Agencia Japonesa de Investigación Aeroespacial recién llegado allí se le unirá esta próxima madrugada la Progress M-09M lanzada ayer...
Desde la cuenta de Twitter de Paolo Nespoli, @astro_paolo: HTV-2, we are ready for you! Cady Coleman, @astro_cady, y Paolo Nespoli listos para recibir al segundo vehículo de transferencia H-II que llega a la ISS en la Cúpula MCC-Houston: “Station, you have...
El astronauta caído por Paul Van Hoeydonck La Tierra es la cuna de la humanidad, pero no se puede estar para siempre en la cuna.– Konstantín Tsiolkovski,pionero de la astronáutica Desde que el 4 de abril de 1961 Yuri Gagarin se convirtiera...
La inminente retirada de los transbordadores espaciales de la NASA va a dejar a la Estación Espacial Internacional sin su principal sistema de transporte, ya que la relativamente enorme capacidad de carga de estas naves las convertía en las más eficaces a...
Si no lo hubiera leído en la descripción que hace Emily Lakdawalla de este vídeo en Animation of Phobos rotating from recent Mars Express flyby images, creo que jamás habría imaginado que está hecho a partir de cinco imágenes captadas por...
Esta mañana, a las 6:05 hora de España (UTC +1), se cumplieron siete años de la llegada de Opportunity a Marte, tres semanas después que su gemelo Spirit. Artist's Concept of Rover on Mars: Representación artística de Opportunity en Marte - NASA/JPL...
M78 for ESO Processing contest por Igor Chekalin Esta imagen de la nebulosa M87 en Orión ha sido la ganadora del concurso para hallar los tesoros ocultos del Observatorio Austral Europeo en el que se pedía a los aficionados que exploraran los...
Los interesados en la ciencia, el universo y los maravillosos misterios de la física encontrarán interesante hacerse con los DVD de El universo de Stephen Hawking, una miniserie documental de la PBS en tres partes que tiene al eminente físico como estrella....
La órbita de la Mars Express de la Agencia Espacial Europea la lleva a pasar muy cerca de Fobos, una de las lunas de Marte, periódicamente. Uno de estos encuentros cercanos ha tenido lugar el pasado 9 de enero, cuando la sonda...
No es realmente una sorpresa porque el presidente Obama ya había firmado una orden al respecto el año pasado, pero la NASA le ha puesto por fin fecha a la misión STS-135 de la flota de transbordadores espaciales, lo que contamos para...
En el mismo día, y no es broma: Científicos italianos dicen haber logrado la fusión fría y, en otras noticias, P=NP, según un matemático ruso. ¿Alguien presentó por casualidad un inversor de entropía o un condensador de fluzo, ya de paso?...
La NASA ha confirmado que Tim Kopra se rompió una cadera tras una caída de bicicleta el pasado fin de semana, por lo que en principio le será imposible tomar parte en la misión STS-133 si esta finalmente despega en febrero. Kopra...

A pesar de lo que podría parecer, una gota de nitrógeno líquido ultra-frío no se desintegra instantáneamente al tocar una sartén. Eso es debido al conocido efecto Leidenfrost. Básicamente al contactar con la sartén se forma una finísima capa de vapor...
Como era de suponer, la inspección detallada a la que los técnicos de la NASA han sometido al tanque de combustible del Discovery tras haberlo llevado de vuelta al Edificio de Ensamblado de Vehículos encontró hasta cuatro grietas más en los nervios...
Hace unos días de hizo pública la imagen en color del cielo más grande de la que disponemos, la Sloan Digital Sky Survey-III. Formada a partir de millones de imágenes de 2,8 megapíxeles, la imagen completa tiene más de un billón de...

Vale, Energy & Dynamic Braking es un vídeo promocional sobre una tecnología de General Electric para recuperar la energía de las locomotoras que fabrican cuando estas frenan, pero no me diréis que no mola ver objetos chocando entre si a cámara...

Vi Hart, una matemática que vive en Long Island, tiene toda una serie de geniales vídeos titulada garabatos matemáticos donde se explora el mundo de la matemática con algo tan aparentemente trivial como son los dibujitos que mucha gente se pone...
Como prácticamente cualquier otro avance médico, técnico o científico de la historia de la humanidad las vacunas han tenido detractores desde siempre. En los últimos años estos basaban buena parte de su posición anti-vacunas en un estudio del doctor Andrew Wakefield publicado...
Hinode Observes Annular Solar Eclipse [Video] Me sigo quedando con la foto de Thierry Legault en la que se ven la Estación Espacial Internacional, la Luna, y el Sol como la más chula que he visto del pasado eclipse, pero este...
Televisión Española estrena mañana a las 13:40 Maravillas del sistema solar, una de las mejores series que he visto en los últimos años: Ver vídeo: Wonders of the Solar System - Trailer - BBC TwoWonders of the Solar System - Trailer -...
El mismo método que utilizó en 1930 Clyde Tombaugh para encontrar Plutón, que fue el de comparar imágenes de la misma porción del cielo tomadas con cierta separación en el tiempo, en su caso dos semanas, sigue siendo utilizado hoy en día....
Cuando Thierry Legault dijo que se iba a ir de viaje para hacer fotos del eclipse de hoy ya supuse que no nos iba a defraudar, pero lo de esta imagen es absolutamente a-lu-ci-nan-te: Transit of the ISS during the solar eclipse...
Imagen original: The Road Less Traveled - NASA Hoy hace siete años que Spirit, el primero de los rovers de la misión Mars Exploration Rover de la NASA, llegaba a Marte. El criterio de éxito de la misión era que este se...

Vale, en efecto conozco personalmente a José A. Pérez y a Luis Alfonso Gámez, las cabezas pensantes detrás de Escépticos, y al segundo incluso lo considero amigo ;-) Pero eso no tiene nada que ver con que el piloto de Escépticos,...
Cady Coleman y Dmitry Kondratyev en el interior de la Soyuz TMA-20 / Roscosmos Me han llamado mucho la atención las imágenes que Dmitry Kondratyev ha publicado del interior de la Soyuz TMA-20 en su blog (en ruso, me temo), imágenes en...
Este año va a haber cuatro eclipses de Sol, todos ellos parciales, y dos lunares, ambos totales. El primero de los solares, que tendrá lugar el día 4 de enero, será el único que será visible desde España. Este eclipse comienza a...
Thierry Legault nos sorprende de nuevo con una de sus espectaculares imágenes astronómicas, en este caso con un tránsito de la Estación Espacial Internacional por delante de la Luna fotografiado el pasado 20 de diciembre a las 21:34 UTC. La ISS...
Mientras la NASA analiza los resultados de las pruebas realizadas al depósito de combustible del Discovery para ver si se puede mantener la fecha de lanzamiento prevista -ya tras varios retrasos- del 3 de febrero de 2011, sus técnicos siguen adelante con...
Estos días, entre copita de champán y pedacito de turrón, Luis Alfonso Gámez y José A. Pérez andan dando los últimos toques al programa piloto de Escépticos, un programa que a juzgar por lo que se puede ver en la promo, hace...
Crater Tsiolkovsky - NASA Aunque la imagen más famosa de la misión Apolo 8 es sin duda el amanecer terrestre visto desde la Luna, sus tripulantes fueron tomaron un buen número de fotografías del lado oculto de esta, lado que fueron las...
Discovery de vuelta al VAB - NASA/Frank Michaux [jpeg 3.000×1.970 5,2 MB] Ojo a las dos personas que se ven al pie del Discovery, ayudan a darse una idea del tamaño de este Desde esta pasada noche el Discovery está de vuelta...
Discovery and the Lunar Eclipse - NASA/Kim Shiflett Como espaciotrastornado, no puedo dejar de destacar esta imagen de la NASA en la que se ve al transbordador espacial Discovery en la plataforma de lanzamiento 39A del Centro Espacial Kennedy durante el eclipse...
El traje lunar de Alan Shepard en la misión Apolo 14 - NYT/Roland H. Cunningham/Mark Avino Esta chulísima imagen -y hay que verla en grande para apreciarla como se merece- es una radiografía del traje que utilizó Alan Shepard durante sus dos...
Esta noche entre el 20 y el 21 de diciembre se producirá un «espectáculo astronómico increíble» en algunas partes del mundo, según cuentan Space.com y varios sitios dedicados a la astronomía. Todo se debe a una curiosa conjunción de acontecimientos astronómicos....
Hoy a las 21:12, hora de España (UTC +1) está prevista la llegada de la Soyuz-TMA20 con Dmitri Kondratyev de Roscosmos, Catherine Coleman de la NASA, y Paolo Nespoli de la ESA, a la Estación Espacial Internacional. Unas tres horas después, tras...
Esta tarde saltó la noticia de que durante aproximadamente tres horas, el control de la misión perdió el contacto con la Soyuz TMA-20, lo que naturalmente causó bastante alarma. En especial porque si perder las comunicaciones con una nave espacial ya es...
Geminids over Kitt Peak por David A. Harvey, APOD del 16 de diciembre de 2010 No he tenido mucha -más bien ninguna- suerte a la hora de ver las gemínidas de este año desde mi esquina del mundo, aunque Venus se ve...
Con 3.340 días de servicio desde que entró en órbita alrededor de Marte el 24 de octubre de 2001, la sonda Mars Odyssey es desde hoy la que más tiempo ha permanecido en servicio en el planeta rojo: Odyssey Orbiter Nears Martian...
La TMA-20 en la plataforma de lanzamiento - ESA - S. Corvaja, 2010 [jpeg 2.329×3.500 pixeles - 991 KB] Todo está listo en el cosmódromo de Baikonur para el lanzamiento de la Soyuz TMA-20. A bordo viajarán Dmitri Kondratyev de Roscosmos, Catherine...
Este artículo se publicó originalmente en Cooking Ideas, un blog de Vodafone donde colaboramos semanalmente con el objetivo de crear historias que «alimenten la mente de ideas». Ser científico debe ser tan apasionante como aburrido, a juzgar por las «creaciones locas»...
Estamos en diciembre, se acaba el año, y no sólo el año, sino también una década, con lo que en estos días aparecerá cienes y cienes de listas con los mejores loquesea del año o incluso de la década. Así que dejadme...
La NASA está pendiente de poder realizar la carga del depósito de combustible del Discovery programada para comprobar las reparaciones realizadas en las grietas encontradas en este, pero aunque tenían pensado hacerla el día 15 el frío que está haciendo estos días...
A diferencia de los transbordadores espaciales, que son ensamblados ya en su posición de lanzamiento y trasladados así a la plataforma a bordo de su crawler, las cápsulas Soyuz rusas y sus cohetes lanzadores son ensambladas y trasladadas a la plataforma en...
Todos los espaciotrastornados hemos visto multitud de lanzamientos de los transbordadores espaciales, pero normalmente sólo desde el punto de vista de las cámaras que se usan para imágenes documentales. Este vídeo, compilado y comentado por Matt Melis y Kevin Burke, muestra...
Su pico de actividad se prevé para mañana martes a las 11 UTC, por lo que esta noche, la del 13 al 14 de diciembre, será probablemente la mejor para observar las gemínidas de este año. Meteor in the Desert Sky por...
Scott Kelly, el actual comandante de la Expedición 26 a la Estación Espacial Internacional, nos enseña en este vídeo cómo es su reducido y espartano camarote a bordo de esta. Está en inglés, pero la función de traducción automática de subtítulos...
Hace unos días hablábamos de una espectacular prominencia solar captada por el Solar Dynamics Observatory, la misma que se puede ver en este vídeo: También mencionábamos que su tamaño era de unos 700.000 kilómetros, lo que deja a la Tierra en ridículo,...
Como dice Phil Plait, un vídeo para disfrutar a pantalla completa y a 1080p: Se trata de otra de las virguerías de Stéphane Guisard, en este caso un time-lapse tomado la noche del pasado día 5 con un ojo de pez en...
La agencia espacial japonesa ha fracasado, al menos de momento, en su segundo intento de colocar una sonda en órbita alrededor de un planeta del sistema solar. En este caso, la sonda Akatsuki, que tenía como objetivo estudiar Venus durante dos años,...
Miércoles 8 de diciembre de 2010, 17:30 En estos momentos, y tras un lanzamiento perfecto a bordo de un cohete Falcon 9 de la misma empresa, la primera cápsula Dragon de SpaceX está en órbita alrededor de la Tierra. Esta cápsula está...
El Solar Dynamics Observatory, que cada día envía 1,5 terabytes de datos desde su privilegiada posición para observar el Sol, se está convirtiendo rápidamente en uno de mis favoritos por espectaculares imágenes como esta, captada esta misma tarde: SDO 20101206 174957 2048...
El recorrido de Spirit si hubiera partido de la Puerta del Sol en Madrid BBC Dimensions es un curioso sitio en el que puedes comparar el tamaño de ciertos lugares, eventos y cosas con la zona en la que vives. Para ello...
Los responsables de la NASA han anunciado hoy que aunque las reparaciones en el depósito de combustible del Discovery ya están terminadas necesitan más tiempo para comprobar qué causó las grietas que aparecieron en este y en qué forma podrían afectar a...
Hace tiempo que sabemos que los puntos de luz que vemos en el cielo son otras estrellas como nuestro Sol o, en muchos casos, galaxias como nuestra Vía Láctea en las que hay miles de millones de estrellas. De hecho, un estudio...
Uno de los principales problemas que tienen los astrónomos es que la atmósfera de nuestro planeta, que nos protege de forma muy efectiva contra todo tipo de radiaciones dañinas, impide también realizar observaciones en esas longitudes de onda. Para evitar esto una...
Todo un clásico que salió a raíz de unos comentarios entre @Joaquin_Sevilla y @Xurxomar acerca de si el lenguaje que hablas define tu forma de pensar y de que, por ejemplo, si hablas ruso tu mente será más rápida a la...
Los técnicos del Laboratorio de Propulsión a Chorro llevan ya algún tiempo trabajando en el ensamblado final del Mars Science Laboratory, bautizado como Curiosity, el próximo rover que la NASA tiene previsto enviar a Marte en septiembre de 2011, aunque no...
El Ground Umbilical Carrier Plate y los componentes asociados, por los que se elimina a la atmósfera el hidrógeno gaseoso que se pueda escapar durante el llenado del tanque de combustible, ya está comprobado y reparado. Técnicos de la NASA trabajando en...
Este ha sido un buen año para para el Gran Colisionador de Hadrones, que lejos de terminar con el universo ha ido obteniendo ya sus primeros resultados, al tiempo que los técnicos y científicos que lo usan van aprendiendo mejor cómo...
Mechanical Calculating Device por sicsnewton El artilugio que se puede ver sobre estas líneas es uno de las aproximadamente 5.000 calculadoras mecánicas bautizadas como The Millionaire que se vendieron entre 1893 y 1935. La característica más importante de este dispositivo es que...
Estamos más que acostumbrados a ver las imágenes que envían las sondas espaciales de los objetivos de sus misiones, pero en Five amazing engineering camera videos from Chang'E 2 se pueden ver cinco vídeos de la segunda sonda lunar china, la...
Home from Above, Imagen Astronómica del Día del 15 de noviembre de 2010 - Expedition 24 Crew, NASA Tracy Caldwell Dyson, miembro de la Expedición 24 a la Estación Espacial Internacional hasta finales del pasado mes de septiembre, aprovecha un momento libre...
Aunque los técnicos del centro espacial Kennedy ya han reparado el refuerzo del depósito de combustible en el que aparecieron dos grietas de unos 22 centímetros de longitud retirando el fragmento dañado y soldando en su sitio una pieza con el doble...

Lanzada el 9 de mayo de 2003 con el objetivo de tomar muestras del asteroide Itokawa, la historia de la sonda Hayabusa es una demostración de que Murphy tenía más razón que un santo al decir que si algo puede ir mal,...
No era algo inesperado, pero tras haber encontrado hace unos días dos grietas en uno de los refuerzos metálicos del tanque de combustible del Discovery para la misión STS-133 los técnicos de la NASA encontraron otra, más pequeña, en uno de los...
Aunque arriesgada, la apuesta de la Xunta de Galicia por Conexións, un programa de divulgación sobre los últimos avances en el conocimiento, la tecnología, la investigación y la innovación en Galicia cuya primera temporada se comenzó a emitir el pasado mes de...
Aunque el pasado día 5 se canceló el lanzamiento del Discovery en la misión STS-133 al ser detectada una fuga de hidrógeno en el punto en el Ground Umbilical Carrier Plate, el punto en el que una tubería diseñada para llevarse cualquier...
La sonda CHASAT II es fruto de un proyecto llevado a cabo durante el curso pasado en el Colegio Mayor Universitario Chaminade para construir una sonda casera que el pasado mes de abril llegaba a la estratosfera: La sonda en si, con...
NGC 4452: An Extremely Thin Galaxy - ESA, Hubble, NASA Esta es una imagen tomada por el telescopio espacial Hubble de la galaxia NGC 4452, perteneciente al Cúmulo de Virgo, situado a unos 59 millones de años luz, y que contiene unas...
Aunque en realidad dura dos semanas, ya que se prolonga hasta el próximo 21 de noviembre, hoy comienza la Semana de la Ciencia 2010, durante la que se celebran numerosos actos de todo tipo a lo largo y ancho del país en...
Elige tu terapia alternativa (clic para ver completo) Hace algún tiempo habíamos mencionado ya el diagrama de flujo de la terapias alternativas hecho por Crispian Jago, pero ahora mola más porque está disponible en español gracias a la traducción de FerFrias. (Vía...
La sonda Deep Impact de la NASA tenía como misión principal visitar el comenta Tempel 1 y lanzar contra él un proyectil para poder estudiar mejor su composición, misión que completó el 4 de julio de 2005. Pero como la sonda seguía...
La acumulación de cancelaciones en el lanzamiento del Discovery en la misión STS-133 va para récord, pues hoy mismo se producía la quinta, en este caso por una fuga de hidrógeno en el Ground Umbilical Carrier Plate. Ubicación del GUCP en el...
Satisfechos con que el problema con la unidad de control de backup de uno de los motores principales del Discovery, causante del último aplazamiento, ha sido resuelto, los responsables de la misión han decidido empezar con los preparativos para el lanzamiento de...
Las tripulaciones de la Estación Espacial Internacional han consumido unas 22.000 comidas desde la Expedición 1 en 2000. Hacen falta unas cuatro toneladas de suministros, entre los que se incluye la comida, cada seis meses para una tripulación de tres astronautas. [Fuente:...
A veces da la impresión de que el Discovery se resiste a despegar en la STS-133, la que será su última misión pues con este ya van tres retrasos de su lanzamiento. Los dos primeros tuvieron lugar a causa de sendas fugas...
La homeopatía no es una medicina milenaria, no funciona más allá del efecto placebo, y aunque en efecto no tiene efectos negativos de por si, ya que lo único de lo que están hechos los «medicamentos» homeopáticos es de agua, sí es...
Estados Unidos ahora quiere que los genes no sean patentables, tal y como cuentan en Fayerwayer. Es todo un giro en la controversia sobre las patentes genéticas en Estados Unidos: El Departamento de Justicia de Estados Unidos ha presentado un escrito en...
Las reparaciones necesarias en el módulo derecho del sistema de maniobra orbital del Discovery ya están completadas. Los módulos OMS, igual que los motores principales de los transbordadores, son intercambiables - NASA/Kim Shiflett, vía The Flame Trench Pero han acumulado un poco...
Dos nuevas fugas detectadas en el módulo derecho del sistema de maniobra orbital, pero distintas a la que fue reparada la semana pasada, han obligado a la NASA a posponer en lanzamiento del Discovery en la misión STS-133. Discovery Lifted Toward High...

(…) La Universidad juega un papel muy importante ante el avance que en la sociedad contemporánea están teniendo determinadas corrientes anticientíficas y antirracionales, que pueden suponer un significativo retroceso hacia el oscurantismo y la superstición, algo que se encuentra en el...
Es como el Cid Campeador, que todavía gana batallas después de muerto: El rover atrapado en Marte halla evidencias de agua filtrada bajo sus ruedas. Alucinante. Spirit y Opportunity en el buscador de Microsiervos....
Unpopular Science son una serie de ilustraciones de Cristoph Neiman que intentan explicar algunas de las leyes físicas que se aplican a nuestras vidas cotidianas en clave de humor. Me pareció buenísima la de la nevera para explicar la ley de...
S132-E-012208: La Estación Espacial Internacional en su configuración actual, tras la visita del Atlantis en la misión STS-132 en mayo de 2010 No coincide realmente con nada porque hasta el próximo día 2 de noviembre no se cumplen realmente los diez años...
Tras comprobar a su satisfacción que la fuga de propelente en uno de los motores de maniobra orbital ha sido correctamente reparada y que todos los demás componentes de la nave funcionan correctamente, así como los sistemas de soporte y que el...
Me encontré en DrGEN una cita atribuida a Richard Dawkins que dice: Según una encuesta de Gallup, el 44 por ciento de los norteamericanos cree que el mundo tiene menos de 10.000 años de edad. Se trata de un error descomunal que...
Los usuarios «de a pie» de foursquare vamos a tener cuando menos complicado poder conseguir la insignia de NASA Explorer con la que se ha hecho hoy Douglas Wheelock al hacer check-in allí arriba: One small step for man, one giant check-in...
Un poco WTF resulta esta entrada donde explican un trabajo publicado por dos veterinarios en 1987 sobre la caída de gatos desde las alturas. Los científicos querían analizar si los simpáticos felinos realmente tienen la extraordinaria habilidad de «sobrevivir a caídas...
Los técnicos de la agencia están intentando arreglar una pequeña fuga de propelentes que se ha detectado en uno de los módulos de maniobra orbital del Discovery, aunque esperan poder hacerlo con la nave en la plataforma. Payload to Pad: El Discovery...
Sun and Moon recoge la primera vez que la Luna se interpuso entre el Sol y el Solar Dynamics Observatory, en lo que se corresponde a un eclipse parcial de Sol desde el punto de vista del SDO, en órbita a...
«Los recortes en Ciencia son un suicidio económico» Parece que España no es el único país en el que se utilizan tijeras para recortar los presupuestos de Ciencia, investigación y desarrollo. Esta foto es de una manifestación en Londres por el...

Durante la mayor parte de mi vida, una de las personas más asombradas por mi trabajo he sido yo mismo. Hace un par de días que sucedió, pero hoy se ha sabido que ha muerto Benoît Mandelbrot, quien nos descubrió el conjunto...
Esta semana la última misión del Discovery dio otro importante paso adelante con la realización del Terminal Countdown Demonstration Test. Durante el TCDT se llevan a cabo todos los pasos necesarios para llevar a cabo el lanzamiento, y de hecho se para...
Hace unos días Óscar Menéndez se tomó en vivo y en directo en A2, el programa de televisión que dirige, 36 de las 40 pastillas de una caja de tranquilizantes, tal y como cuenta en Me suicidé ayer. Con un tranquilizante de...
No lo tengo todavía, pero después de ver fotos como estas: Hormiga y microchip - Science Photo Library / BarcroftMicrochip sin hormiga - Science Photo Library / Barcroft Tiene toda la pinta de que más bien temprano que tarde acabaré comprando Microcosmos:...
Estos días se ha hablado mucho de Gliese 581g. Gliese 581g por Lynette Cook vía NASA Se supone que se trata de un exoplaneta en el que supuestamente se podrían dar las condiciones para que hubiera agua líquida en su superficie (nótense...
Un paciente sin identificar del centro Shepherd de rehabilitación y de investigación de lesiones de la médula espinal y del cerebro de Atlanta que ha sufrido una lesión en la médula espinal hace menos de dos semanas se ha convertido en el...
Como estaba previsto, Aleksandr Kaleri, Oleg Skripochka y Scott J. Kelly llegaron ayer a la Estación Espacial Internacional, en la que entraron a las 5:09 de la madrugada, tras realizar las comprobaciones pertinentes de la estanqueidad de la unión de la Soyuz...
El pasado mes de febrero la administración Obama anunciaba una serie de nuevos objetivos para la NASA, aunque dado que estos cambios no contaban con el apoyo de todos los miembros del partido demócrata, lo que le impidió utilizar la mayoría de...

Módulo lunar tripulado soviético La galería Secret Department of the Moscow Aviation Institute de English Russia incluye unas cuantas fotografías tomadas en lo que dicen que es un departamento secreto del Instituto de Aviación de Moscú en la que, entre otras cosas,...
Del departamento de niños-no-intentéis-esto-en-casa-nidecoña, un vídeo en el que se puede ver a cámara lenta que pasa cuando le pegas un martillazo a una gota de nitroglicerina. Aún ralentizado 600 veces, la detonación es increíblemente rápida. (Vía Boing Boing)....
Seis minutos de paseo por algunas de las 61 lunas de Saturno que conocemos hasta ahora y sus curiosidades, que nos hacen preguntarnos cosas. Las imágenes, como casi es obligado, las pone la sonda Cassini, una de nuestras favoritas. La música...
Construye tu propio reloj de sol vertical de papel. Todo lo que hay que hacer es 1) visitar la página web, 2) buscar la dirección en Google Maps del lugar en que vas a situarlo, 3) marcar la pared elegida del...

Homemade Spacecraft es una preciosa y bastante detallada historia de cómo un grupo de amigos envió un globo de helio más allá de la estrosfera y consiguió recuperarlo junto con la grabación completa del viaje… incluyendo imágenes de una preciosa Tierra...
Soyuz Liftoff in Kazakhstan - NASA/Carla Cioffi Esta pasada noche, a la 1:01 hora de España (UTC +2) despegó del cosmódromo de Baikonur la Soyuz TMA-01M, que lleva a bordo Aleksandr Kaleri, Oleg Skripochka y Scott J. Kelly, quienes a partir del...
Cuando el 19 de julio de 1969 Neil Armstrong y «Buzz» Aldrin se convirtieron en los primeros seres humanos en llegar a la Luna la señal de vídeo que procedía de las cámaras que iban a bordo del Eagle no era compatible...
Panorama de 360 grados del cielo del hemisferio sur - ESO/H. H. Heyer No hay mucho más que explicar: En Top 100 Images están las cien mejores imágenes producidas por el Observatorio Austral Europeo según el criterio de los miembros de su...
Desde hace un par de semanas se está hablando mucho de Gliese 581g, un planeta extrasolar del que los científicos creen que podría tener la condiciones necesarias para que en su superficie exista agua en estado líquido. La noticia es relevante porque,...
Este artículo se publicó originalmente en Cooking Ideas, un blog de Vodafone donde colaboramos semanalmente con el objetivo de crear historias que «alimenten la mente de ideas». Cuando apenas acababa de cumplir los treinta años un trombo causo daños masivos en el...
Io in True Color, APOD del 3/10/2010 - Galileo Project, JPL, NASA Hace algo más de siete años que terminó la misión de la sonda Galileo, cuando esta, agotado su combustible de maniobra, y tras 14 años de servicio, se hundía...
El Observatorio Austral Europeo convoca un concurso para re-descubrir sus fondos que consiste en re-procesar datos disponibles en su archivo para crear nuevas imágenes. Las condiciones son pocas: No se puede presentar una imagen que ya haya sido publicada antes por el...
Ya se ha hecho pública la lista de los premios Ig Nobel 2010, los premios que reconocen cada año desde hace ya veinte aquellas investigaciones que aunque suenan a coña marinera, son reales: Ingeniería: Karina Acevedo-Whitehouse y Agnes Rocha-Gosselin de la Zoological...
Desde el descubrimiento de Gamma Cephei Ab en 1988, aunque este descubrimiento no fue confirmado hasta 2002, cada vez somos mejores encontrando planetas extrasolares. De hecho, de los cerca de 500 que conocemos en la actualidad, 285 han sido descubiertos desde 2007....
Este año el otoño empieza esta madrugada a las 4:09 UTC, y coincide casi con la Luna de Cosecha, que es como se conoce a la luna llena más próxima al principio del otoño, una coincidencia que no se da desde el...

Recordatorio: todos morimos. DeathRiskTakings.com [Actualización: ese sitio web ya no existe; en toda una ironía cósmica, ha muerto, así que lo que se ve aquí es una versión archivada por Archive.org], de la Carnegie Mellon, es una calculadora sobre la «probabilidad...
KSC-2010-4733: El Discovery y la estructura rotatoria de servicio - NASA/Jack Pfaller Esta pasada noche el Discovery ha hecho el recorrido desde el Edificio de Ensamblado de Vehículos a la plataforma de lanzamiento 39A, desde dónde está previsto que despegue el próximo...
/iframe> ¡Va el tío y acierta! (...) Y en el año 2000, gracias a los satélites y las nuevas posibilidades de las comunicaciones, la gente podrá hacer negocios desde cualquier lugar: no tendrán que desplazarse para ir a trabajar a la oficina,...
Tenemos a la Luna aquí al lado, en especial en términos de distancias astronómicas, y aunque la podemos ver casi todos los días de nuestra vida, ¿realmente la miramos? Mañana por la noche se celebra la primera Noche Internacional de Observación Lunar,...
La Tierra y la Luna fotografiadas desde la ISS el 4 de septiembre de 2010 Hace algún tiempo montamos un Safari fotográfico por el Sistema Solar con la APOD a partir de imágenes publicadas como imagen astronómica del día de la NASA;...
Parece que los récords relacionados con el buceo en las profundidades de π en busca de más y más dígitos se están calentando: un investigador de Yahoo llamado Nicholas Sze ha calculado el dígito binario que ocupa la posición 2.000 billonésima...
KSC-2010-4622: El Discovery siendo levantado dentro del VAB - NASA/JAck Pfaller Desde hace unos días los técnicos de la NASA están trabajando en el interior del Vehicle Assembly Building, el edificio de una planta más alto del mundo, en ensamblado del...
Agus Martínez Llobet le hizo esta tabla periódica de magdalenas a Johnny G. Halife por su cumpleaños… ¡Todo un detallazo geek! El juego de las 100 magdalenas, otro uso la mar de geek de estos dulces....
4*-/%>:+:i.1e6 es un programa escrito en el lenguaje de programación J que calcula π con una precisión de cinco decimales. tiene su mérito porque sólo usa 14 caracteres/bytes. La circular constante también se puede calcular con un programa de 52 bytes en...
π en forma de collar, una bonita aproximación de cien decimales, obra de RGB-laboratory. (¡Gracias, Walter!)...
Time Lapse from Space - Earth es un bonito vídeo grabado por Don Pettit desde la Estación Espacial Internacional que recoge una vuelta a la Tierra, algo en lo que esta emplea unos 90 minutos, en apenas medio minuto. (Lo Facebookeo...
Los 553.355 litros de oxígeno líquido y 1.497.440 de hidrógeno líquido que hay en el tanque externo, más los 499.000 kilogramos de combustible que lleva cada uno de los propulsores sólidos de un transbordador espacial, hacen que cuando una de estas naves...
… nadie hace caso de los estudios científicos (De la colección de Scientific Studies (CC); ¡Gracias, David!)...

Haciendo el ganso en gravedad cero. Más fotos en el álbum Gravedad 0 en Flickr Tras toda una vida atrapado por la gravedad terrestre, volar en gravedad cero supone toda una experiencia que te descubre un montón de nuevas sensaciones, ya que...

Preciosa esta charla de Tom Wujec en TED en la que explica cómo funciona el astrolabio, un antiguo instrumento que actuaba a modo de reloj y para localizar las estrellas y la latitud, además de las diversas efemérides. Tom Wujec demos...
En este Modern Science Map pueden encontrarse todas las figuras relevantes de los últimos 500 años ubicadas convenientemente como si fueran paradas de las líneas del Metro. Es un trabajo de Crispian Jago. (Vía Bad Astronomy Blog.)...
Hombre, poder, se puede. Lo que pasa es que muy rentable no es. En este curioso artículo titulado Gold from the Sea? publicado en 1934 en Modern Mechanix se especula precisamente con esa posibilidad, a partir de un proceso similar al...

Bonito time-lapse de la lluvia de meteoritos de hace un par de semanas, las Perseidas que llegan en verano cada año, en este caso fotografiado en el Parque Nacional Joshua Tree de Estados Unidos. Su autor es Henry Jun Wah Lee,...
Esta animación muestra los asteroides que se han ido descubriendo en nuestro Sistema Solar desde 1980 hasta la actualidad. Recordatorio: la Tierra es el tercer planeta desde el Sol. En verde aparecen los asteroides normales y corrientes; los rojos son los...
Según nos contó Petrus en un correo, al parecer alguien se entretuvo en hacer un estudio del tamaño del campo de fútbol de Oliver y Benji y ahora circula en forma de meme aunque es un poco viejuno (2008) aunque por aquí...
Desde el departamento de pa’ habernos matao nanosegundos después del Big Bang llega… El inflatón, la partícula madre del universo. Y como IANC mejor traduzco un resumen rápido del New Scientist, que si suena a chino es porque la cosmología es así:...
Este Juego de la vida interactivo es una creación de Leo Villareal, y está expuesto en el Museo de Arte de San José, California. La mesa consiste en una serie de placas con circuitos, que siguen la lógica de los autómatas...
Saturn V Launch Views - High Speed Cams 480p En un Chrevrolet Corvette C3, el coche preferido de los astronautas del programa Apolo, en estado de marcha y completamente cargado de combustible, el 96 por ciento de su masa la representaba el...
Como todos los meses de agosto, la Tierra está atravesando los restos que deja en el espacio la cola del cometa 109P/Swift-Tuttle, lo que provoca la lluvia de meteoros conocida como las Lágrimas de San Lorenzo o Perseidas, precisamente porque este santo...
Todos asociamos los lanzamientos de los transbordadores espaciales a una enorme nube de humo que se forma alrededor de la plataforma de lanzamiento, como por ejemplo en esta foto... Atlantis despegando en la misión STS-132 - NASA. Original y más fotos en...
Cuando el 25 de mayo de 1961 John F. Kennedy anunció públicamente ante el Congreso el objetivo de poner un astronauta sobre la superficie de la Luna y traerlo de vuelta a casa sano y salvo antes de que finalizara la década...
Tenemos nuevo récord del mundo relacionado con π: Alexander J. Yee y Shigeru Kondo han calculado 5 billones de dígitos de la redonda constante, tal y como cuentan en 5 Trillion Digits of Pi. Esto casi duplica al récord anterior, que...
Aunque nosotros no lo percibamos porque nos movemos con ella -y ya dijo un tal Einstein que todo es relativo- la Tierra, en su movimiento de rotación, se mueve a unos 1.700 kilómetros por hora en el ecuador, velocidad que baja a...
Este artículo se publicó originalmente en Cooking Ideas, un blog de Vodafone donde colaboramos semanalmente con el objetivo de crear historias que «alimenten la mente de ideas». Explosión nuclear a 59 km de altura Hay un relato breve de Isaac Asimov, más...
Una de las cargas más peculiares que va a ir a bordo del Discovery en la misión STS-133 es un robot bautizado como Robonaut 2, o R2 para abreviar, diseñado como un proyecto conjunto de la NASA y General Motors. [jpeg a...
Recomendación: televisor gigante, pantalla completa, HD, luces apagadas, audio envolvente y caja de palomitas... Es un flipante y vertiginoso viaje animado al interior de un fractal de estilo Mandelbrot, creado por Krzysztof Marczak con el software Mandelbulber. La música es Crystal...
Hay una fina línea que separa la ciencia de la paja mental. Las pseudociencias pretenden usar y estar cerca de la ciencia para parecer «serias»; a veces la ciencia parece más bien ciencia-ficción y en general suele ser muy entretido leer...
Desde la revista Quo nos pidieron a unos cuantos bloggers que escogiéramos nuestros misterios de la ciencia preferidos para un especial sobre precisamente los grandes misterios de la ciencia aún por resolver. Los míos fueron: ¿Existe algún resquicio en la teoría de...
El Ampersand de Möbius: Es un signo et y a la vez una superficie de una sola cara y un solo borde, una banda de Möbius. (Vía Proof)....
Unas cuantas imágenes de distintos alimentos obtenidas mediante resonancia magnética nuclear: RMI de comidas por DrGEN en Vimeo. En Inside insides, que es de dónde salen estas imágenes, hay más, pero en forma de gif animados… Quedáis avisados ;-) Radiology Art, el...
Estamos acostumbrados a que el Sol domine nuestro cielo, a verlo como el objeto más grande de este, pero en realidad es una estrella de un tamaño normalito, como demuestra esta imagen, que lo comprara con unas cuantas estrellas más de las...
Seth Lloyd del MIT, autor del recomendable Programming the Universe sobre computación cuántica, ha publicado un trabajo donde plantea una curiosa teoría sobre los viajes en el tiempo. Entre otras cosas, tiene la propiedad de evitar las malditas paradojas temporales como «del...
Chromoscope es una web con imágenes astronómicas de nuestro universo tomadas en diferentes longitudes de onda, preparadas de modo que se puedan comparar fácilmente moviendo unos botones, haciendo zoom y moviéndose por ahí «a lo Google Maps». (Agradecimientos a Ignasi y...
Tuve la inmensa suerte de tener a Juan Carlos Medal Cabezas, Jaitos para todo el mundo, como profesor de ciencias hace ya unos cuantos años, cuando aún existía aquello de la EGB. Jaitos y sus compañeros en Santa María del Mar se...
En binario por ejemplo empieza por 11,0010010000… En hexadecimal es 3,243F6A8885A30… y así sucesivamente.
A mediados de la década de los 70 en el mundo existían dos grandes bloques profundamente enfrentados que, entre otras cosas, poseían unos arsenales nucleares capaces de acaba varias veces con la humanidad entera. Por eso, el que el 17 de julio...
Gracias a los esfuerzos de EC-JPR y de Emtochka, en colaboración con el autor, ya está disponible Homeopatía (un cómic de Darryl Cunningham), la versión traducida al español de Homeopathy. Explica qué es y qué no es la homeopatía y las...
Solar Walk 1.4 para iOS 4 / iPad. Vito Technology. 2,39€ [App Store]. Esta aplicación diseñada específicamente para iPad no es exactamente un planetario, sino más bien un entretenimiento para darse un paseito por nuestro vecindario del sistema solar de forma...
Curioso el efecto que explica este artículo: La posición de los ojos predice el número que tienes en mente. Al parecer tomaron un grupo de sujetos y les pidieron que pensaran números al azar entre el 1 y al 30. Grabando en...
Según se puede leer en Small Solar Power Sail Demonstrator 'IKAROS' Confirmation of Photon Acceleration la Agencia Japonesa de Exploración Espacial ha podido confirmar mediante mediciones de radar doppler, que es capaz de medir la velocidad de un objeto, que el efecto...
Foto del eclipse por Stéphane Guisard, Imagen Astronómica del Día del 14 de julio de 2010 La Isla de Pascua era uno de los mejores -y pocos- sitios para observar el eclipse total de Sol del pasado domingo 11 de julio, por...
Otro de los didácticos vídeos que Don Pettit grabó durante su estancia en la Estación Espacial Internacional, en este caso demostrando como es posible beber un café en caída libre sin que este quede flotando en forma de burbujas si usas un...
Y no sólo figuradamente tras haber ganado el Mundial, sino en el sentido más literal: 9 de julio de 2010, 10:15 AM, 33 kilómetros sobre Igualada: La Roja en la estratosfera [jpeg original 4.000×3.000 puntos - 8,2 MB] El pasado día 9,...
La sonda Rosetta de la Agencia Espacial Europea tenía ayer una importante cita en su viaje con destino al cometa 67P/Churyumov-Gerasimenko a donde no llegará hasta 2014. Se trataba de un encuentro con el asteroide (21) Lutetia, descubierto el 15 de noviembre...
Simpático artículo el titulado Until Cryonics Do Us Part en el Ney York Times [requiere registro, gratuito], que cuenta los efectos colaterales que sufren las familias en las que uno de sus miembros elige buscar la inmortalidad mediante la criogénesis: las parejas...
Mañana a partir de las 20:15:15 hora de España (UTC +2) se produce un eclipse total de Sol en el que la sombra de la Luna correspondiente a la zona de totalidad caerá sobre el sur del Pacífico, con lo que prácticamente...
Cada vez hay más y más aplicaciones de realidad aumentada gracias a los móviles cada vez más potentes de los que disponemos, permanentemente conectados a Internet, aunque la mayoría de ellas están pensadas para ofrecer información actual sobre restaurantes, cajeros automáticos, puntos...
La sonda Rosetta de la Agencia Espacial Europea lleva desde el 2 de marzo de 2004 navegando por el espacio en una complicada trayectoria que la llevará a encontrarse con su objetivo, el cometa 67P/Churyumov-Gerasimenko en 2014, sobre cuya superficie depositará un...
La NASA lleva ya un tiempo trabajando en su próxima misión a la superficie de Marte, el Mars Science Laboratory, bautizado como Curiosity. Next Mars Rover Sports a Set of New Wheels: Técnicos del Jet Propulsion Laboratory instalando las ruedas - NASA/JPL-Caltech...
Esta preciosa serie de ampliaciones de un copo de nieve en la Wikipedia [clic, clic para zoom en la imagen original de alta resolución], del Departamento de Investigación Agrícola no es nueva (2007), pero no por ello deja de ser encantadoramente...
Después de varios meses de darle vueltas a una idea surgida en EBE 09 el sábado pasado Miguel Artime, Antonio Martínez Ron y Javier Peláez presentaban su proyecto Amazings.es en el ESET Foro Internet Meeting Point. Quizás por sus nombres no acabes...
El matemático John Napier estaba convencido de que el mundo se acabaría entre 1688 y 1700; por ello publicó un libro crítico contra el catolicismo en el que explicaba su teoría de que el Papa era el Anticristo y algunas otras cosas...
Buscando y preparando las tecnoimágenes de la semana pasada me encontré con esta impresionante imagen ultravioleta del Sol expulsando chorros de plasma del Goddard Space Flight Center de la NASA (aquí se puede ver ampliada). Aparte de su belleza intrínseca, lo...
El pasado 13 de junio la sonda Hayabusa de la Agencia Japonesa de Exploración Aeroespacial regresaba a casa tras siete años en el espacio después de que todo tipo de problemas previstos e imprevistos hubieran hecho temer en más de una ocasión...
Fotografía: Johnson Space Center / NASA Espectacular fotografía de una aurora austral sobre el sur del Océano Índico tomada desde la Estación Espacial Internacional. Aurora Australis From Space - Las auroras ocurren cuando partículas cargadas procedentes del Sol colisionan con las capas...
Por Nacho Palou -
24 JUN 2010
Un equipo de astrónomos de la Universidad de Sheffield, partiendo de imágenes de los bucles coronales que emite la atmósfera del Sol, han traducido las vibraciones que se observan en ellos en sonidos, y esto es lo que han llamado, de forma...
Diego Urbina, uno de los «tripulantes» del proyecto Mars 500, que tiene como objetivo simular las condiciones a las que tendrían que enfrentarse unos astronautas que viajaran en una misión tripulada a Marte, hace una visita guiada por las instalaciones en...
Aurora austral por Douglas Wheelock Soichi Noguchi, que nos tenía enganchados a las fotos que enviaba vía Twitter desde la Estación Espacial Internacional, y que está de vuelta en tierra desde el pasado 2 de junio, ya tiene sucesor en Douglas Wheelock....
El astrolabio de Simeon De Witt, en el Museo de Historia Americana del Smithsonian. Un pequeño mapa estelar creado en 1780 por Simeon De Witt, que muestra los cielos vistos desde Nueva Jersey, junto con todo tipo de datos astronómicos y...
Un mapa que muestra las líneas de flujo magnético en unas nanopartículas de níquel, obtenido por el Brookhaven National Laboratory. (Vía Proof + Science is Beauty.)...
Interesante todo lo que cuenta Migui en Primeras evidencias de que los procesos cuánticos generan números verdaderamente aleatorios, una traducción libre de First Evidence That Quantum Processes Generate Truly Random Numbers de Cristian Calude (Universidad de Auckland de Nueva Zelanda) donde se...
Otra genialidad de Abstruse Goose, vía Proof. Esto es lo que los extraterrestres en otros planetas verían de nuestra TV Qué hubiera pasado en Star Wars de haber sido R2-D2 un producto de HP...
Imagen cortesía de Jacques Descloitres y Ana Pinheiro, MODIS Rapid Response Team, NASA GSFC. Algunos de los países participantes en el Mundial de Fútbol 2010 vistos por la NASA, Spain – Representación de las mediciones de temperatura de la superficie terrestre obtenidas...
Por Nacho Palou -
17 JUN 2010
Esta pasada noche despegaron del cosmódromo de Baikonur los astronautas de la NASA Doug Wheelock y Shannon Walker y el cosmonauta Fyodor Yurchikhin a bordo de la Soyuz TMA-19, tal y como se puede leer en New Space Station Crew Members Launch...
A estas alturas quedan muy pocas dudas de que en el pasado existió agua en estado líquido sobre la superficie de Marte. Pero en el artículo titulado Ancient ocean on Mars supported by global distribution of deltas and valleys de Nature Geoscience...
Imagen: NASA. Espectacular imagen tomada desde la Estación Espacial Internacional en un atardecer sobre el Océano Índico. En la imagen se aprecian las distintas capas que forman la atmósfera terrestre. La troposfera que se muestra naranja es la más densa -representa el...
Por Nacho Palou -
15 JUN 2010
Curiosa unidad de medida alternativa a la par que comprensible, La dosis equivalente a un plátano es un concepto utilizado ocasionalmente por los defensores de la energía nuclear para comparar los riesgos que supone la exposición la radiación en comparación con la...
Por Nacho Palou -
15 JUN 2010
¡La ciencia! Hace que el mundo sea mejor, y puede que además también lo salve.– Phil Plait...
Tras una reentrada de libro que la colocó justo en el sitio previsto, la Agencia Japonesa de Exploración Aeroespacial ha recuperado ya la cápsula de muestras de la sonda Hayabusa, una vez obtenida la autorización de los ancianos aborígenes, ya que la...
Esta tarde a eso de las 16:00 hora de España (UTC +2) se espera que haga su reentrada en la atmósfera la cápsula de muestras de la sonda Hayabusa de la Agencia Japonesa de Investigación Aeroespacial, poniendo fin a un poco más...
Tal y como cuentan en Singularity Hub y en otros sitios (véase Genetic Testing Mix-up at 23andMe, Another Blow to the Industry) alguien en los laboratorios del servicio de pruebas genéticas 23andMe la lió parda al equivocarse con las bandejas donde se...
Desde hace tiempo se viene especulando con la posibilidad de que una vela solar sea capaz de servir de método gratuito de impulsión de una nave espacial. La vela solar funcionaría gracias a la combinación de los efectos sobre ella de la...
Versión traducida especialmente para Fogonazos por Luke Surl, su autor. El original en inglés está en The Homeopathic Webcomic y tiene un huevo de pascua que aquí puede ser difícil de apreciar, así que vete a buscarlo. (La culpa de todo...
Algo que dice que ninguno de los que escribimos Microsiervos ni de los que lo leéis tenemos muchas posibilidades de conseguir una plaza a bordo del Discovery en la misión STS-133 ni del Atlantis en la STS-134… Así que en su lugar...
Wonders of the Solar System BBC 2010. Presentada por Brian Cox. El Profesor Brian Cox, además de trabajar en el Gran Colisionador de Hadrones, uno de los sitios más increíbles en la actualidad para un físico, se ha pasado varios meses...
La atmósfera, aunque generalmente les viene bien a los astrónomos para respirar, es una fuente de problemas para ellos a la hora de realizar ciertas observaciones ya que causa distorsiones e impide hacer otras porque absorbe ciertos tipos de radiación, como por...
Creo que es artificial… De la mejor calidad, un producto superior… Sí, aquí está el número de serie…– Blade Runner (1982) Craig Venter y su equipo han incluido una especie de mensaje secreto, «huevo de pascua» o marca de agua en la...
Mientras no dispongamos de un sistema de propulsión más eficaz que los cohetes actuales una misión tripulada a Marte tendrá una duración mínima de aproximadamente año y medio entre ir, esperar allí el tiempo necesario para que la Tierra y Marte volvieran...
Expedition 23 Returns to Earth - NASA/Bill Ingalls Esta pasada madrugada a las 5:25 hora de España (UTC +2) Oleg Kotov, T.J. Creamer y Soichi Noguchi aterrizaban a bordo de la Soyuz TMA-17 al este de Dzhezkazgan, en Kazajistán, poniendo fin a...
Viejuno pero curioso e interesante: si se ponen dos latas de Coca-Cola –una normal y otra light– en un recipiente con agua, la primera se hundirá como una piedra, mientras que la segunda flotará, El azúcar es mucho más denso que...
Por Nacho Palou -
31 MAY 2010
Desde Gaussianos, un reto: construir un poliedro de Császár y enviar una foto. Este curioso objeto geométrico tiene la particularidad de ser no convexo y de que no tiene diagonales (como los tetraedros): tiene 7 vértices, 21 aristas y 14 caras...
Vivo y muerto a la vez es un simpático diseño sobre el estado del gato más famoso de la física. Lo envió Tito Eliatron al altamente recomendable blog El espejo lúdico....
Desde su puesta en marcha el Gran Colisionador de Hadrones, en lugar de acabar con el universo, está proporcionando ya cantidades ingentes de información que físicos de todo el mundo usarán a lo largo de los próximos años para intentar entender mejor...
¡Fácilmente! Desde luego es que hay matemáticas definitivamente encantadoras: Cómo dibujar un elefante con cuatro números complejos. Una historia de John von Neumann, Enrico Fermi y Freeman Dyson recuperada ahora con una explicación completa por el siempre recomendable blog La ciencia de...
Star-forming galaxies like grains of sand - ESA & SPIRE Consortium & HerMES consortia Esta imagen, captada por el instrumento SPIRE del observatorio espacial Herschel de la Agencia Espacial Europea dentro del programa Herschel Multi-tiered Extragalactic Survey (HerMES) para estudiar el origen...
Tras recibir ayer el visto bueno por parte del equipo de apoyo en tierra respecto al estado del escudo de protección térmica del Atlantis todo está listo a bordo para intentar el aterrizaje hoy a las 14:48 hora de España (UTC +2)....
Un día relajado a bordo del Atlantis, si se puede utilizar este adjetivo al referirse a una misión espacial, durante el que los tripulantes fueron preparando las cosas para su vuelta a tierra. Mike Good y Steve Bowen terminaron de guardar los...
El color del fondo de este párrafo es más o menos del mismo color, casi blanco, que se podría considerar presenta el Sol cuando se mira desde el espacio, sin la dispersión de la luz causada por la atmósfera terrestre. (Claro que...
Por Nacho Palou -
25 MAY 2010
Cuando la NASA lanzó la Phoenix Mars Lander sabía que por el lugar escogido para su aterrizaje sus días estaban contados, ya que la llegada del invierno marciano hacía inevitable que fuera a quedar cubierta de hielo al estar tan cerca del...
Curiosas figuras con estructura de polígonos y poliedros formadas cuando un chorro de agua golpea en una pequeña superficie circular horizontal; las formas se ven alteradas dependiendo de la velocidad y viscosidad del líquido: Fluid Polygons and Poluhedra, vía Make....
Por Nacho Palou -
24 MAY 2010
No soy biólogo, pero el anuncio de la semana pasada de que un equipo de investigadores estadounidenses había creado vida sintética capaz de reproducirse por si misma, tal y como titula Wired en Scientists Create First Self-Replicating Synthetic Life me pareció cuando...
El octavo día de la misión STS-132 tuvo como principal actividad el tercer paseo espacial de esta a cargo de Mike Good y Garrett Reisman. Durante este dieron por finalizada la segunda de las dos tareas prioritarias de la misión al terminar...
¡Oh! Martin Gardner, uno de los maestros de los juegos matemáticos, la divulgación científica y el escepticismo, ha muerto a los 95 años. Aprendimos tantas cosas de él... :-(...
Este pasado martes Opportunity superó el récord de duración de las misiones en la superficie de Marte, hasta entonces en posesión del Viking 1, también de la NASA, que funcionó durante seis años y 116 días: NASA's Mars Rovers Set Longevity Record...
Los tripulantes del Atlantis y de la Estación Espacial Internacional, tras comprobar que no había fugas, abrieron las escotillas entre esta última y el módulo Rassvet instalado durante el quinto día de la misión, a las 12:52 hora de España (UTC +2)....
Proof es un precioso blog minimalista dedicado a imágenes matemáticas, detrás de las cuales se esconde toda una historia: una demostración, una teoría, cálculos complejos o el planteamiento de un problema. Cada imagen va acompañada de una pequeña descripción y los...
Docked at the Station: El Atlantis atracado en la ISS. Foto tomada durante el primer paseo espacial de la misión. Más imágenes en STS-132 Flight Day 6 Gallery. Segundo paseo espacial de la misión a cargo de Steve Bowen y Michael Good,...
Space Shuttle: The Time-Lapse Movie, el cómo se hizo Miles de fotografías tomadas por los fotógrafos Scott Andrews, Stan Jirman y Philip Scott Andrews de Air & Space, la revista bimestral del Museo Nacional del Aire y el Espacio, han dado como...
La Estación Espacial Internacional cuenta con un nuevo módulo después de que Garrett Reisman utilizara el brazo robot de esta en su sitio al primer intento, con una precisión tal que apenas quedaba un milímetro libre a cada lado de la sonda...
Original a 4.000×4.000 pixeles - 2,8 MB No es la primera vez que Thierry Legault nos deja asombrados con una de sus imágenes de un tránsito de alguna nave espacial frente al Sol como la imagen de hoy, que muestra al Atlantis...
Steve Bowen y Garrett Reisman completaron el primer paseo espacial de la misión STS-132 de la NASA en 7 horas y 25 minutos, casi una hora más de lo previsto inicialmente. Reisman's Self-Portrait: Autorretrato de Reisman usando el visor de su casco....
Para malabarismos matemáticos raros, nadie mejor que la gente de Futility Closet y sus lectores. Uno de ellos (Robin) les envió estas aproximaciones a π y e obtenidas en operaciones aritméticas sencillas donde participan todos los dígitos del 1 al 9 (además...
Tras realizar la rendezvous pitch maneuver con el objetivo de que los tripulantes de la Estación Espacial Internacional pudieran fotografiar la parte inferior del Atlantis este quedó atracado en la ISS a las 16:28 hora de España (UTC +2) sobre el Pacífico...
Atlantis sobre las Canarias por Astro_Soichi Ya está, Soichi Noguchi lo ha vuelto a hacer con otra de sus impresionantes fotos desde la Estación Espacial Internacional, en este caso del Atlantis a poco de atracar en la ISS, con las Canarias al...
Ver vídeo: The Elements ebook for iPad The Elements ebook for iPad [9:56] Si los libros del futuro van a ser como este, casi apetece volver al cole! Es la versión para ipad de The Photographic Periodic Table of the Elements....
Tras un lanzamiento de libro seguido por unas 39.000 personas en directo desde el Centro Espacial Kennedy -se nota que quedan pocos lanzamientos de transbordadores espaciales- los tripulantes del Atlantis en la misión STS-132 dedicaron su segundo día en órbita a revisar...
Arnaud Chéritat del Instituto de Matemáticas de Toulouse tiene un montón de preciosas imágenes matemáticas en su web, incluyendo estos dos fractales del tipo conjuntos de Julia dibujados sobre la superficie de una esfera, como si se estuvieran besando, con un...

Quedan dos horas y media para que el transbordador espacial Atlantis despegue en la que en principio va a ser su última misión a las 20:20 hora de España (UTC +2). Los seis astronautas están ya firmemente sujetos a sus asientos mientras...

Desde tiempos inmemoriales el hombre ha intentado domeñar al azar. Si el destino estaba escrito en los dados ¿por qué no leerlo con antelación? Y si no está escrito, ¿podríamos con nuestro libre albedrío influenciarlo a nuestro favor? Cuando además hay...
Esta mañana arranca en Madrid el congreso Media For Science Forum, en el que durante dos días más de 250 personas nos reunimos para debatir la habitualmente complicada relación entre ciencia, medios y periodismo. Yo estaré por ahí los dos días e...

Este vídeo muestra en acción la ilusión óptica Impossible Motion “Magnet-Like Slopes” [PDF 53 KB] de Kokichi Sugihara, la ganadora de la edición de 2010 de Best Illusion of the Year Contest, el concurso de la mejor ilusión óptica del año....
Ciencia al cubo. Por qué los elefantes saben contar. América Valenzuela. Temas de hoy, 2010. 280 páginas. ISBN 9788484608585. La ciencia ocupa, por lo general y por desgracia, un espacio muy poco destacado en los medios de comunicación generalistas, con lo...
Pablo Motos y dos de sus compañeros de El Hormiguero consiguen colarle a la revista Más Allá unas fotos falsas de un OVNI, y lo cuentan en este vídeo, lo cual da para unas risas: Ver vídeo: El Hormiguero - Engaño a...
The Scale of the Universe es una infografía interactiva al estilo de Potencias de 10, con la que descubrir desde lo más grande a lo más pequeño de nuestro universo simplemente moviendo el ratón. Relacionado: Cosmic view, el libro que inspiró...

El próximo domingo 9 de mayo a las 15:20 la Televisión de Galicia estrena Conexións, un programa de divulgación sobre los últimos avances en el conocimiento, la tecnología, la investigación y la innovación en Galicia producido por Adivina Producciones. Yo tengo...
Sunrise at Launch Pad 39A: Atlantis en la plataforma de lanzamiento - NASA/Jack Pfaller La NASA ha confirmado que todo está listo para el lanzamiento del Atlantis en la misión STS-132 el próximo viernes 14 de mayo a las 20:20 hora de...
Este sábado 8 de mayo se celebra en el Parque de Santa Margarita de La Coruña el XV Día de la Ciencia en la Calle, organizado por la Asociación de Amigos de la Casa de las Ciencias y los Museos Científicos Coruñeses,...
Si lanzas un montón de D4s en un recipiente, dejando que se coloquen al azar, se puede «rellenar» con una efectividad del ~76%, que es algo mejor que si colocaras esferas perfectamente ordenadas como en las cajas del supermercado, cuya efectividad...
Comparando la organización de los sistemas que controlan los procesos que tienen lugar en un organismo vivo y en un ordenador, investigadores de la Universidad de Yale tratan de explicar por qué los ordenadores tienden a funcionar mal más a menudo que...
Por Nacho Palou -
4 MAY 2010
No, no se trata de un cuadro impresionista sino de licor café visto muy de cerca (y sospecho que con luz polarizada). Es una de las imágenes que se pueden ver en la galería de imágenes microscópicas de bebidas recogidas en...
No creo que sea necesario decir que no creo ni remotamente en las supuestas cualidades beneficiosas de las pulseras Power Balance y productos derivados , aquellos que se supone que logran un «aumento del equilibrio, la fuerza, flexibilidad, resistencia, enfoque, coordinación y...
Después del desastre del Columbia el gobierno de los Estados Unidos ordenó a la NASA restringir el número de misiones de sus transbordadores espaciales al mínimo imprescindible para completar su aportación a la construcción de la Estación Espacial Internacional para luego proceder...
Con un presupuesto de unos 950 millones de euros el Telescopio Europeo Extremadamente Grande (E-ELT) es el telescopio de nueva generación que el Observatorio Europeo del Sur planea tener en funcionamiento para 2018. Imagen de síntesis del futuro E-ELT. Hay un coche...
Se ha montado un cierto revuelo con la detección de la llamada «Partícula Belleza» en el Gran Colisionador de Hadrones, compuesta por un antiquark fondo y un quark arriba, tal y como se puede leer en 21 April 2010: First reconstructed Beauty...
Ver vídeo: HUBBLE: Window to the Universe HUBBLE: Window to the Universe [~16 min.] Un documental acerca de los veinte años de servicio del Hubble, repasados en poco más de un cuarto de hora por algunos de los científicos que trabajan con...
El ciclo de la vida de la medusa Turritopsis nutricula no tiene que ver con el tuyo ni con el mío, ya que puede considerarse biológicamente inmortal. Es el único caso conocido de un metazoo [animal] capaz de volver a un estado...
Por Nacho Palou -
26 ABR 2010

Esto es tan altamente viejuno que data de 1987, pero mola. Se llama cámara de levitación acústica y fue diseñada para un experimento de la NASA. El cubo es de plexigás y contiene tres potentes altavoces que emiten una onda sonora...
STScI-2010-13: Esta es la imagen que el equipo del Hubble ha escogido para celebrar su vigésimo aniversario, en la que se pueden ver unos pilares de gas de tres años luz de altura que esconden una guardería estelar en la nebulosa Carina,...
Ya se han realizado varios trasplantes parciales de cara en el mundo en los que lo trasplantado eran los tejidos blandos de la cara como piel, tendones, músculos, etc. Pero en el Hospital Universitario Vall d'Hebron de Barcelona han dado hoy los...
Atlantis rumbo a la plataforma - Alan Walters (awaltersphoto.com) for Universe Today Tras ser pospuesto en varias ocasiones a causa del mal tiempo, esta mañana el transbordador espacial Atlantis recorrió por última vez el camino entre el edificio de ensamblado de vehículos...
Los murciélagos son los únicos mamíferos voladores que existen y son mucho más comunes de lo que creemos. Más de una quinta parte de los mamíferos del planeta son murciélagos, y existen cerca de mil especies. [Fuente: Ciencia al cubo]....
Con dos días de retraso sobre lo previsto inicialmente el Discovery y su tripulación aterrizaron hoy en la pista 33 del Centro Espacial Kennedy a las 15:08, hora de España (UTC +2), poniendo fin a la misión STS-131 de la NASA. Discovery's...
El gráfico de la derecha es una infografía de Information is Beautiful. Planes or Volcano? representa el balance en las emisiones de CO2 ahora que buena parte de los vuelos están cancelados en Europa por la nube de cenizas. Los triángulos rojos...
Por Nacho Palou -
19 ABR 2010
Hoy se cumplen 40 años del retorno a tierra, sanos y salvos, de los tripulantes del Apolo 13 después de que una explosión los dejara prácticamente sin oxígeno y sin electricidad en el módulo de comando algo más de dos días de...
La velocidad de rotación de Venus sobre su eje es tan lenta que tarda más en girar sobre si mismo que alrededor del Sol, con lo que se podría decir que allí un día dura más que un año. [Fuente: Wonders of...
Aurora Australis, NASA/JSC La imagen de arriba muestra una aurora polar (austral, cerca del polo sur) fotografiada por astronautas a bordo de la Estación Espacial Internacional (ISS), a 356 km sobre el Océano Índico. Es una de las casi cuarenta espectaculares imágenes...
Por Nacho Palou -
15 ABR 2010
Podría considerarse que esta tabla periódica de las tablas periódicas es el culmen de todas las tablas de «elementos» tanto reales como imaginarios y divertidos: cada elemento apunta en realidad a otra tabla completa. Hay desde tablas con variantes de los...
La teoría que creemos que explica la formación de los planetas asume -simplificando un poco- que nacen en una nube de gas que rodea una estrella joven, nube que gira con la estrella, por lo que los planetas giran alrededor de esta...
Si el universo fuera infinito y hubiera infinita materia en él, repartida más o menos como la conocemos en nuestra región, se producirían curiosas y en cierto modo muy extrañas situaciones. Aunque algunas regiones estarían muy lejos de nosotros y nunca llegaríamos...
Las tareas de transferencia de carga entre el Discovery, el módulo logístico Leonardo, y la Estación Espacial Internacional siguieron su curso durante estos días, sólo interrumpidas momentáneamente el día 10 de abril por la mañana cuando saltó una alarma de incendio que...
Spain coast, otra de esas magníficas fotos que envía Soichi Noguchi desde a Estación Espacial Internacional, en la que en este caso se ven España y una de las cápsulas Soyuz TMA que permanecen permanentemente atracadas a la ISS por si...
Por cortesía del observatorio SOHO, las últimas horas de un comenta que este fin de semana se acercó demasiado al Sol y al que nunca se vio aparecer por el otro lado: Por supuesto no es la primera vez que pasa esto,...
Los amantes de las geometrías «poco habituales» apreciarán Conformal Models of the Hyperbolic Geometry, una deliciosa presentacion de Vladimir Bulatov sobre cómo se comportan las figuras y otros elementos geométricos en la geometría hiperbólica. Es una especie de powerpoint que se...
Stephanie Wilson y Naoko Yamazaki utilizaron el brazo robot de la Estación Espacial Internacional para retirar el módulo logístico Leonardo de la bodega de carga del Discovery y dejarlo enganchado a esta a las 6:24 del jueves 8 de abril (hora de...
El 12 de abril de 1961 Yuri Gagarin se convertía en el primer ser humano en salir al espacio a bordo de la Vostok 1. El 12 de abril de 1981, en el vigésimo aniversario de la histórica misión de Gagarin, John...
Después de un lanzamiento al primer intento y los ocho minutos y medio de ascenso hasta entrar en órbita la tripulación del Discovery se dedicó a preparar la nave para su estancia en el espacio durante la misión STS-131. Ver vídeo: Discovery...
Esta tarde, a las 15:57 hora española (UTC +2), está previsto el despegue del CryoSat-2 a bordo de un cohete ruso Dnepr desde el Cosmódromo de Baikonur. Imagen de síntesis de como debería ocurrir la separación del CryoSat-2 y el cohete lanzador...
Gráfico: Information Is Beautiful Snake Oil?, scientific evidence for popular dietary supplements es un interesante gráfico de Information Is Beautiful que representa de forma visual algunos de los más populares suplementos alimenticios asociados a determinados beneficios. Las pompas del gráfico están situadas...
Por Nacho Palou -
7 ABR 2010
Extraído de la intervención de Ramón Núñez Centella en el Senado sobre Cultura científica durante la Reunión de Presidentes de Comisiones de Ciencia e Innovación de los Parlamentos Nacionales de los Estados miembros de la Unión Europea y del Parlamento Europeo celebrada...
Sin ningún problema técnico a la vista y con una previsión meteorológica favorable en un 80 por ciento todo está listo en el Centro Espacial Kennedy para el lanzamiento del Discovery en la misión STS-131 de la NASA. El Discovery con la...
Una de las consecuencias de vivir en la Estación Espacial Internacional es que a la velocidad que esta orbita alrededor de la Tierra -aproximadamente cada 90 minutos- cada día se pueden llegar a ver hasta 18 salidas y puestas de Sol y...
Primera colisión a 7 TeV detectada en el LHC Ayer a eso de las 13:06 según la nota de prensa oficial, o a eso las 12:58 según el blog del experimento ATLAS, se produjo la detección de la primera colisión de haces...
Después de un mes dedicado a realizar pruebas de los sistemas de guiado de los haces de protones y de los sistemas de protección de los instrumentos del Gran Colisionador de Hadrones del CERN, está previsto que hoy se intente llevar a...
Preparing Discovery for Flight: El contenedor con la carga de la misión siendo izado a su lugar - NASA/Amanda Diller Aunque durante algunos días hubo serias sospechas de que podría ser necesario cambiar el módulo trasero derecho de motores de maniobra orbital,...
Los Museos Científicos Coruñeses, que es donde trabajo en el MundoReal™, han convocado el concurso de vídeo amateur «La ciencia en mi vida» sobre el impacto de la ciencia en nuestra vida en el que se pretende explorar nuevas formas de mejorar...
Hoy se celebra el Tercer Día Europeo de la homeopatía, organizado por las «asociaciones europeas de pacientes, doctores, practicantes, farmecéuticos e industria en el campo de la medicina complementaria en Europa». Además, se celebra en un edificio del Parlamento Europeo, lo que...
En español la expresión «cuando las ranas críen pelo» se utiliza para referirse a algo que no va a pasar nunca… Pero resulta que existe una especie de rana que tiene pelo. Se trata de la apropiadamente llamada rana peluda, o Trichobatrachus...
Aterrizaje de la Soyuz TMA-16 Esta mañaba a las 12:24 hora de España la nave Soyuz TMA-16 aterrizaba en las proximidades de la ciudad kazaja de Arkalyk trayendo de vuelta al comandante de la Expedición 22 a la Estación Espacial Internacional, Jeff...
Una de las frases míticas de Star Trek es la que a menudo le dice el señor Spock al capitán Kirk cuando se encuentran con una forma de vida alienígena en los viajes del Enterprise, que dice poco más o menos «es...
Estructuras de polvo a 500 años luz del Sol - ESA/HFI Consortium/IRAS La zona más clara en tono rosa-blanco de esta imagen se corresponde con el plano de la Vía Láctea, en el que el polvo está a una temperatura apenas unas...
Raúl (¡gracias!) nos hizo llegar esto precioso y emocionante vídeo titulado Nature by Numbers, de Cristóbal Vila, que recoge algunas de las más conocidas relaciones entre la naturaleza y los números. La sección la teoría detrás de la película explica y...
Por Nacho Palou -
17 MAR 2010
Aunque en el espacio no se transmite ningún sonido, a pesar de lo que nos quieren hacer creer casi todas las películas y series, el espectro electromagnético sí está lleno de ruido y señales en prácticamente cualquier banda. Unas son periódicas como...
La sonda Mars Express de la Agencia Espacial Europea está en una órbita polar muy elíptica sobre Marte que la acerca a Fobos cada cinco meses, siendo la única nave allí presente que se acerca lo suficiente a esta luna como para...
Esta ilustración de Michael Paukner muestra la trayectoria de todos los eclipses solares totales que se van a producir de aquí a 2025 (e incluye los que se han producido desde 2001): Total Solar Eclipse Paths por Michael Paukner En Europa está...
Candor Chasma animation using HiRISE DTM Candor Chasma animation using HiRISE DTM [4:50] Otra impresionante animación creada a partir de los datos obtenidos por el radar de mapeado del terreno de la cámara HiRISE de la sonda Mars Reconaissance Orbiter. El punto...
Snapshot of the International Space Station - DLR La imagen del día de la NASA de hoy es una obtenida hace casi dos años por el satélite TerraSAR-X del Centro Aeroespacial Alemán cuando la Estación Espacial Internacional pasó por su campo de...
Además de que según simulaciones informáticas el terremoto de Chile podría haber alterado el eje de la tierra y acortado la duración de los días en 1,26 microsegundos, también podría haber desplazado la posición de varias ciudades, Chile Earthquake Moved Entire City...
Por Nacho Palou -
9 MAR 2010
Uno de los pósteros con los que el CERN celebra el Día Internacional de la Mujer. El CERN (Conseil Européen pour la Recherche Nucléaire, Organización Europea para la Investigación Nuclear), el organismo responsable del Gran Colisionador de Hadrones (LHC), celebra el Día...
Por Nacho Palou -
8 MAR 2010

Wonders of the Solar System es una serie de cinco capítulos de la BBC en la que Brian Cox recorre el planeta para explicar como las leyes de la naturaleza han creado diversas maravillas naturales a lo largo y ancho del...
El transbordador espacial Discovery recorrió esta pasada noche el camino que separa el Edificio de Ensamblado de Vehículos y la plataforma de lanzamiento 39A del Centro Espacial Kennedy, de donde en principio ya no se moverá hasta que despegue en la...
My Solar System es un juego/simulador creado por la Universidad de Colorado en Boulder que permite toquetear los parámetros de un sistema solar de hasta cuatro cuerpos y que da una idea de lo complicado que debe ser el trabajo del FSM:...
Window to the world - NASA. Nicholas Patrick dando los últimos toques a la Cúpula durante la misión STS-130 de la agencia. Sin duda una ventana con vistas espectaculares...
Aunque las condiciones meteorológicas a primera hora estaban bajo mínimos para el aterrizaje del Endeavour, al final estas mejoraron lo suficiente como para que pudiera tomar tierra a la primera ocasión, aterrizando a las 4:21:32 de esta madrugada, poniendo fin a la...
Para los próximos 10 al 12 de marzo está prevista la celebración en Pamplona del V Congreso de Comunicación Social de la Ciencia, que tendrá su sede en el Palacio de Congresos Baluarte. Yo he sido amablemente invitado a participar en la...
Con la comprobación de los sistemas de control realizada por el comandante George Zamka y el piloto Terry Virts y con todo guardado en su sitio todo está listo a bordo del Endeavour para su vuelta a tierra a expensas de que...

Calisto, Io y Ganímedes proyectando su sombra sobre Júpiter en marzo de 2004. Todo un espectáculo por cortesía del telescopio espacial Hubble: (Vía cgr v2.0)....
El Endeavour y su tripulación en la misión STS-130 de la NASA dejaron la Estación Espacial Internacional cuando el comandante George Zamka y el piloto Terry Virts desatracaron ambas naves a la 1:54 de la noche (hora de España, UTC +1). Tras...
Con el traslado de muestras científicas que tienen que permanecer refrigeradas al Endeavour, la ceremonia de despedida, y el cierre de escotillas entre este y la Estación Espacial Internacional a las 9:08 de la mañana, hora de España, terminaron las operaciones conjuntas...
Después de mantener una conversación con el presidente Barack Obama los astronautas de la misión STS-130 y de la Estación Espacial Internacional dedicaron el grueso de sus actividades de este día extra a instalar equipos en el módulo Tranquility y en la...
Diseñado por Blake Dumesnil, un ingeniero de cámaras de Hamilton Sundstrand que trabaja en el Centro Espacial Johnson en Houston, este es el emblema que tanto el jurado como la votación popular han escogido mediante un concurso para marcar el final...
Un investigador de la Universidad de Burgos, Pedro Fuertes, ha descubierto que las moléculas de azufre y nitrógeno manipuladas son estupendos sensores del mercurio y el cianuro, gracias a sondas cromogénicas que se alteran ante estos potentes contaminantes. El investigador descubrió este...
Por Esther -
18 FEB 2010
Tercer paseo espacial de la misión STS-130 en el que Robert Behnken y Nicholas Patrick quitaron las protecciones y bloqueos que llevaban las ventanas de la Cúpula durante el lanzamiento para que Terry Virts pudiera ir abriéndolas una a una hasta que...
Tras el correspondiente periodo de pruebas y calibración después de su lanzamiento a mediados de diciembre de 2009 el telescopio espacial WISE comenzó con su misión, que tiene como objetivo realizar el mapa más detallado del universo en infrarrojo hasta la fecha,...
¡Que se haga la luz! Las ventanas de la Cúpula se abren hacia el desierto del Sahara. Impagable.– Soichi Noguchidesde la Estación Espacial Internacional vía Twitter...
Robert Behnken y Nicholas Patrick usaron el brazo robot de la Estación Espacial Internacional para mover el adaptador de acoplamiento presurizado 3 de su ubicación en el módulo Harmony a su posición definitiva en el extremo del módulo Tranquility, justo donde viajó...
La Cúpula de camino a su sitio - NASA. Original y más imágenes en STS-130 Flight Day 8 Gallery La Cúpula ya está colocada en su lugar definitivo en la Estación Espacial Internacional, en la parte que mira a la tierra del...
Mimas "Rev 126" Flyby Raw Preview #1 - NASA/JPL/Space Science Institute Esta espectacular imagen de la Estrella de la Muerte Mimas es una de las que ha conseguido la sonda Cassini en su reciente visita a esta luna de Saturno el pasado...
Robert Behnken y Nicholas Patrick terminaron con éxito el segundo paseo espacial de la misión STS-130, durante el cual conectaron el sistema de refrigeración de Tranquility al de la Estación Espacial Internacional, prepararon la Cúpula para su traslado a su ubicación definitiva,...
Extremes por PeterMain muestra a una escala correcta los puntos más altos y bajos de la Tierra y Marte, los montes Everest y Olimpo y la fosa de las Marianas y la llanura de Hellas Planitia respectivamente. (cgr v2.0 vía Irreductible)....
Tras abrir las escotillas que dan acceso a Tranquility y entrar allí con gafas y mascarillas por si hubiera partículas en suspensión tras el lanzamiento George Zamka, Terry Virts, Stephen Robinson, Kay Hire y Soichi Noguchi se dedicaron a ir instalando equipos...
HD Fractals es una web donde pueden verse animaciones del conjunto de Mandelbrot con una nivel de detalle y ampliación increíblemente alto. Tan alto, tan alto, que este que han publicado explora las profundidades del famoso fractal a nivel de e.214...
Shuttle Silhouette, en la que se ve al Endeavour en su aproximación a la Estación Espacial Internacional durante la misión STS-130, fue la imagen del día de la NASA del 12 de febrero de 2010. Puede que en efecto esté un...
El primer paseo espacial de la misión STS-130 se llevó a cabo sin ningún tipo de problema, hasta el punto de que Bob Behnken y Nick Patrick pudieron realizar algunas tareas por adelantado que estaban previstas para los paseos siguientes. Tras salir...
Una de las tareas prioritarias del primer día de operaciones conjuntas de las tripulaciones del Endeavour en la misión STS-130 de la NASA y de la Estación Espacial Internacional fue la instalación de las piezas de recambio del sistema de reciclado de...
La aplicación DssBH (Distortion of the stellar sky by a Schwarzschild black hole, para Windows y Linux) simula cómo se vería el espacio entorno a un agujero negro de Schwarzschild, la región simétrica y esférica contenida dentro de los límites de...
Por Nacho Palou -
12 FEB 2010
SDO Launches - Pat Corkery/United Launch Alliance El viento que ayer impidió el lanzamiento del Solar Dynamics Observatory no hizo acto de presencia hoy, con lo que el observatorio solar despegó a lomos de un Atlas V desde el Complejo de Lanzamiento...
El Endeavour atracó en la Estación Espacial Internacional después de realizar la rendezvous pitch maneuver, que es la maniobra mediante la que le muestra la panza a la tripulación de la ISS para que esta pueda fotografiarla con el objetivo de poder...
La constelación de Orión es una de las más sencillas de identificar, en la que lo que a simple vista parece una estrella en su «espada» es en realidad M42, la nebulosa de Orión, que está a unos 1.350 años luz de...
El 40 por ciento de probabilidades de que el tiempo no colaborara esta tarde con el lanzamiento del Solar Dynamics Observatory se hicieron efectivas y los vientos reinantes en altura, que excedían el límite permitido, impidieron realizarlo. La NASA volverá a intentarlo...
Después de despertarse al ritmo de Give Me Your Eyes por Brandon Heath, dedicada al piloto Terry Virts, el único novato en el espacio de la misión, la tripulación del Endeavour dedicó el segundo día de la misión STS-130 a las actividades...
Con su traslado a lomos del cohete Atlas V que lo tiene que poner en órbita al Complejo de Lanzamiento 41 del Centro Espacial Kennedy todo está listo para que mañana a las 16:26 sea lanzado el Solar Dynamics Observatory. Traslado del...
Poco después de entrar en órbita la tripulación del Endeavour se puso a configurarlo para su estancia en el espacio. Para ello abrieron las compuertas de la bodega de carga y activaron los radiadores allí instalados, lo que permite disipar el calor...
El ultra preciso reloj Quantum-Logic podría convertirse en la referencia en lo que a medir el tiempo se refiere: mantiene la hora con un segundo de precisión cada 3.700 millones de años. Esto es 100.000 veces más precisión de la que ofrecen...
Por Nacho Palou -
9 FEB 2010
Spectacular Launch! El Endeavour ilumina las nubes sobre la plataforma de lanzamiento 39A del Centro Espacial Kenendy en Florida - NASA/Ben Cooper Aunque las nubes siguieron planteando dudas acerca de la posibilidad de lanzar hoy o no al final la capa de...
Aunque todo estaba funcionando perfectamente en lo que se refiere a la nave y sus sistemas de apoyo, el tiempo empeoró bastante respecto a las previsiones iniciales y en las últimas horas previas al lanzamiento una capan de nubes bajas estuvo haciendo...
Poised to Fly: El Endeavour listo para el lanzamiento - NASA/Troy Cryder La retracción de la estructura de servicio que da acceso a los transbordadores espaciales cuando están en la plataforma de lanzamiento, iniciada esta tarde a las 13:58 hora de España...
ISS desde la ISS, foto de @Astro_Jose Imágenes como la de arriba se pueden ver pasar por Twitter enviadas directamente por los usuarios este servicio @Astro_Jose y @Astro_Soichi, que han formado o forman parte de la tripulación de la Estación Espacial Internacional....
Por Nacho Palou -
5 FEB 2010
P/2010 A2 visto por el Hubble - NASA, ESA, and D. Jewitt (University of California, Los Angeles) P/2010 A2 fue desubierto el 6 de enero de este año por el Lincoln Near-Earth Asteroid Research, y clasificado y bautizado en un primer momento...
Durante la campaña electoral Barack Obama no había hablado apenas de qué pensaba hacer respecto a la NASA en casod e ganar las elecciones, y después de ser elegido tampoco había mucha información al respecto, salvo la puesta en marcha de comité...
A finales del pasado mes de abril el suelo sobre el que rodaba Spirit cedió y sus ruedas se hundieron en una capa de sulfato de hierro (III) en la que permanece atrapado desde entonces. Rock garden: Spirit quedó atrapado en la...

Nuestro sistema inmune en acción, en este caso un neutrófilo, que es un tipo de glóbulo blanco, a la caza de una bacteria de Staphylococcus aureus a la que persigue hasta que fagocita. Los neutrófilos son de los primeros en llegar...
Fractales, caos, proyecciones, autómatas celulares, mecánica de fluidos, representaciones matemáticas… más de 3.000 imágenes sobre todos estos temas componen la colección de Jean-François Colonna llamada A Virtual Space-Time Travel Machine. Aunque la mayor parte parezcan influenciadas por el LSD que alguien...
La primavera pasada saltaron todas las alarmas ante la aparición de un brote de gripe porcina, luego rebautizada como gripe nueva, y más tarde como gripe A, en México que según nos decían podía ser peligrosísima y extremadamente contagiosa. First look: Swine...
Aunque los tripulantes de la ISS disponían ya de acceso a correo electrónico, telefonía sobre IP, y videoconferencias con algunas limitaciones, hasta ahora no tenían acceso a la web. Pero desde esta misma semana, gracias a una actualización de software recién instalada...
Excepto entre 1940 y 1970, desde 1880 se observa un ascenso en la temperatura media de la superficie terrestre de 0,8°C. Según las mediciones de la NASA, se considera que el año 2009 ha sido el segundo año más caluroso de los...
Por Nacho Palou -
22 ENE 2010
Por mucho que avance el turismo espacial en los próximos años es poco probable que lo haga tanto como para que no ya nosotros sino tan siquiera nuestros nietos puedan irse de vacaciones a Marte y volver con unas estupendas fotos… Pero...
El artículo de National Geographic, Within One Cubic Foot va acompañado de un ejercicio visual que indaga sobre cuántos organismos caben en un cubo lleno de tierra o de mar. Para obtener respuesta, el fotógrafo David Liittschwager utilizó una estructura metálica...
Por Nacho Palou -
19 ENE 2010
Los astronautas de la misión STS-125 de la NASA, aparte de dejar al Hubble en mejores condiciones que cuando salió de fábrica, llevaron una cámara IMAX para filmarlo todo, y ya hay trailer de la película: Ver vídeo: IMAX Hubble 3D IMAX...
Cuando se diseñó la misión de la Phoenix Mars Lander sus responsables ya sabían que por muy bien que funcionara la sonda la misión tenía los días contados, a diferencia, por ejemplo, de Spirit y Opportunity, que aunque estaban diseñados para durar...
La cortina de baño Pi que venden en Think Geek contiene unos 4.600 decimales, lo cual es más que suficiente para mantenerse entretenido mientras uno se ducha y repasarlos mentalmente para que siempre estén frescos. Me hizo mucha gracia cómo lo...
El Reloj del Juicio Final marca 6 minutos para la medianoche… y teniendo en cuenta que la medianoche es el Fin del mundo, seguimos apañaos. Esta idea, promovida por los científicos en 1947 utiliza un simbólico reloj como indicativo de lo...
Esta madrugada, a partir de la 5:14 UTC (una hora más tarde en España), comienza el primer eclipse solar del año, que además, dado que ocurre cuando la Luna está cerca de su apogeo -la distancia máxima que alcanza de la Tierra-...
Este pedazo de cámara del tamaño de un Mini que está siendo construida en el Fermilab tiene 74 sensores CCD que suman un total de 570 megapíxeles, lo que la hace una de las de más resolución jamás construidas. Se trata...
… lo fliparía con esta colección de tablas periódicas, de las más variadas formas, cada cual con un punto interesante sobre cómo está construida. (Vía Sopa de Ciencias.)...
En un artículo publicado en Investigación y Ciencia dos expertos en energías renovables tienen un plan: construir millones de aerogeneradores y plantas solares para que el consumo energético del planeta Tierra al completo sea autosuficiente y respetuoso con la naturaleza hacia 2030....
Me regalaron el libro Misión: la Luna de Rod Pyle, publicado en español por la editorial Susaeta / Tikal que, aunque a priori es un libro más sobre la llegada del hombre a la Luna, contiene un ingrediente extra que lo hace...
Por Nacho Palou -
11 ENE 2010
Una recopilación de vídeos sobre ingenios mecánicos publicados en el libro How round is your circle? Where engineering and mathematics meet de by John Bryant and Chris Sangwin que parece altamente recomendable....
Esta semana la NASA transportó el transbordador espacial Endeavour a la plataforma de lanzamiento, desde donde está previsto que despegue el próximo 7 de febrero a las 10:39 (hora de España, UTC +1) rumbo a la Estación Espacial Internacional en la misión...
Fabrice Bellard ha anunciado un nuevo récord en el cálculo de π al calcular 2.699.999.990.000 decimales. El asunto tiene mérito porque lo hizo con un ordenador casero que cuesta menos de 2.000 euros. El tiempo de cálculo fueron 103 días, pero como...
La NASA acaba de hacer pública la primera imagen recibida del telescopio espacial WISE, todavía en fase de calibración tras su lanzamiento a mediados del pasado mes de diciembre: WISE 'First-Light' Image - NASA/JPL-Caltech/UCLA La imagen, que cubre un área de unas...
Si todo va según lo previsto en septiembre de este año el transbordador espacial Discovery llevará a cabo la misión STS-133 de la NASA, que será la última de la flota de transbordadores de la agencia. Con este motivo hace unos meses...
Eclipse de Luna azul por Jean Paul Roux La imagen astronómica del día de la NASA del pasado día 2 es esta preciosa foto de la Luna del 31 de diciembre de 2009 con un trocito en sombra a causa del eclipse...
Concepción artística de Spirit en Marte - Maas Digital LLC para la Universidad de Cornell y NASA/JPL Esta madrugada se han cumplido seis años desde que Spirit aterrizara en el cráter Gusev en Marte en lo que estaba planeado como una misión...

En estos últimos ías hemos mencionado en varias ocasiones el uso de ópticas adaptativas por parte de los telescopios terrestres para mejorar la calidad de las observaciones que pueden hacer; en este vídeo se ve como el telescopio Gemini Norte usa...
Atomium / Foto (CC) O Palsson El Atomium de Bruselas es una impresionante construcción de más de cien metros de altura llena de curiosidades interesantes. Entre otras está que representa un patron de átomos de hierro ampliados unas 165.000.000.000 veces, lo cual...
Esta Noche: Una Luna Azul por Vic Winter (ICSTARS) / APOD Dado que los meses del calendario gregoriano, que es el que usamos en la mayoría de los países occidentales, tienen una duración media de 30,5 días, y que el tiempo medio...
A pesar de todos los avances tecnológicos que nos permiten construir telescopios cada vez más grandes y/o efectivos, en especial gracias a las ópticas adaptativas y las ópticas activas, hay un enemigo contra el que los astrónomos poco pueden hacer, la atmósfera...
La expedición científica Tara recoge muestras para conocer mejor los microorganismos marinos Imagen: Tara Expeditions Dos expediciones científicas surcan los mares y océanos del mundo para recoger muestras y secuenciar el genoma de los microorganismos marinos. Son la forma de vida más...
Por Esther -
29 DIC 2009
Al tenor de la anotación ¿Qué ve una persona ciega? Carlos ha tenido la amabilidad de compartir esto con nosotros: «Una tía de mi madre es ciega de nacimiento: Le falta el nervio óptico, es decir, no es problema de conos, retina,...
CollectSPACE tiene una recopilación de las insignias de las misiones de los transbordadores espaciales de la NASA. Son los propios astronautas y miembros de las misiones los que diseñan los emblemas, que luego pasan una preselección antes de ser «oficiales». Según...
No se si nunca he pensado realmente mucho en el tema, pero creo que siempre había asumido, aún a pesar de saber que hay distintos grados de ceguera, que una persona ciega «ve» en negro, como cuando cerramos los ojos en la...
Son sólo diez preguntas en inglés, que se pueden responder en unos minutos a ver qué tal anda ese lóbulo trivial en relación con los temas científicos del año: The 2009 New Scientist Trivia Quiz. Pista: lo que está -240°C en...
Con todo el montón de imágenes chulas que salieron la semana pasada se me había pasado que también se hicieron públicas las primeras imágenes del telescopio VISTA (Visible and Infrared Survey Telescope for Astronomy, Telescopio de Rastreo en lo Visible e Infrarrojo...
El Polo Norte Magnético no sólo no está en la misma posición que el Polo Norte geográfico sino que además se mueve bastante: unos 10 kilómetros por año, pero además hasta unos 80 kilómetros cada día. Esto se debe a los irregulares...
A todos nos han contado en algún momento dado en el colegio que los números no se acaban nunca, que son infinitos, aunque normalmente se nos escapa lo que esto quiere decir realmente y muchas de sus curiosas implicaciones. Por ejemplo, el...

Una conocida ilusión óptica que en este vídeo gana mucho al ver como van desapareciendo los elementos que la causan y que, una vez más, hacen que nuestro cerebro nos engañe: (Vía Fogonazos). Relacionado: La ilusión óptica altamente desconcertante de los...

Este vídeo realizado por el American Museum of Natural History de Nueva York en colaboración con el Rubin Museum of Art es como una versión actualizada del mítico Powers of Ten en la que se va viendo el universo conocido a...
Medusa Porpita Porpita (unos 2 cm de diámtro) de David Liittschwager, National Geographic. Fotografías de la espectacular microfauna de los océanos, tomadas por el fotógrafo David Liittschwager. Se pueden ver más fotografías en David Liittschwager - Marine Micro Fauna (8 pics) y...
Por Nacho Palou -
17 DIC 2009
Con un espejo de 3,5 metros de diámetro el telescopio espacial Herschel de la Agencia Espacial Europea es el más grande y de los telescopios espaciales, más incluso que el Hubble con sus 2,4 metros de diámtero. También es con diferencia el...
Hubble's Festive View of a Grand Star-Forming Region - NASA, ESA, and F. Paresce (INAF-IASF, Bologna, Italy), R. O'Connell (University of Virginia, Charlottesville), and the Wide Field Camera 3 Science Oversight Committee Esta impresionante imagen tomada por el telescopio espacial Hubble muestra...

Hoy se han presentado en el Planetario de la Casa de las Ciencias las primeras secuencias de video fulldome (a cúpula completa) del Observatorio del Roque de los Muchachos y del interior de algunos de los telescopios que allí se encuentran. Este,...
Desde esta misma mañana Steorn, la empresa irlandesa que lleva años afirmando haber conseguido diseñar una tecnología que «…genera una energía gratuita, limpia y constante», está haciendo una (otra) demostración pública del Orbo, su producto que Pretendido móvil perpétuo (izquierda); Orbo de...
Tras más de diez años de desarrollo la NASA ha lanzado hoy a las 15:09 (hora de España, UTC +1) el telescopio espacial Wide-Field Infrared Survey Explorer (WISE), destinado a realizar un mapa completo del cielo en el infrarrojo, aunque aún le...
Diagrama de cómo se "imprime" una arteria humana con células humanas colocadas sobre una base de hidrogel. Imagen Organovo. Durante el próximo año estarán disponibles para investigación las primeras bioimpresoras comerciales, capaces de fabricar órganos y tejidos humanos a partir de un...
Por Nacho Palou -
14 DIC 2009
Electroforesis en gel en galletas por Ms. Humble Aunque Ms. Humble se dedica a la antropología biológica en la actualidad ha hecho una pausa en su carrera para ejercer como madre, pero con frecuentes escapadas a la cocina para hacer un poco...
Comenzando por la clásica y siempre necesaria simplificación del estilo supongamos un coche plano y perfectamente rectangular… parece ser que un matemático ha creado la fórmula perfecta para estacionar un coche. Pues si tiene lo que hay que tener, que venga...
Aunque casi todos los copos de nieve tienen intrincadas formas hexagonales, algunos son triangulares. De hecho no hay una razón física que "prohíba" que un copo de nieve pueda tener otras formas, como rombos, trapecios o incluso que fueran irregulares. En...

Funcionar, funciona, y más sencillo de construir, imposible. Eso sí, para que en el montaje de este móvil perpetuo que da vueltas se respete la Primera ley de la termodinámica –como debe ser en todas las casas honradas– hay que dejar...
Estos pastelillos que componen la tabla periódica cocinados por Katherine y su hermana –una nerd de la química– debieron tener mucho éxito en la fiesta de cumpleaños para la que fueron concebidos. Con total precisión cada pastelillo tiene su color de...
El proceso de puesta en marcha del Gran Colisionador de Hadrones, una vez superada la grave avería del año pasado que lo dejó un año fuera de juego, está progresando sin sobresaltos, tanto que esta pasada noche se ha conseguido acelerar sus...
Ver vídeo: Zero gravity silly but cool experimentsZero gravity silly but cool experiments [2:52] Algunos experimentos del sábado por la mañana más del astronauta Don Pettit, en este caso con globos de agua en caída libre en la Estación Espacial Internacional. En...
Cables de 12.500 amperios del LEP (detrás) y del LHC (delante) - Foto (CC) por Rama Esta foto es parte de los objetos exhibidos en Micrososm, un centro de ciencia que tiene como objetivo divulgar el trabajo que se realiza en el...
No pasa en todas las misiones ni mucho menos, pero tras haber despegado en el primer intento, el Atlantis y su tripulación tomaban tierra hoy a las 15:44:23 (hora de España, UTC +1), también en la primera oportunidad que tenían para aterrizar....
Trampa para arcoíris. Fuente: Experimental Observation of the Trapped Rainbow, V.N. Smolyaninova et. al. Según NewScientis, investigadores han conseguido atrapar por primera vez un arcoíris (Rainbow trapped for the first time) lo cual, aunque no deja ninguna imagen espectacular, no deja de...
Por Nacho Palou -
27 NOV 2009
Atlantis ya tiene el visto bueno para volver a casa, con lo que su tripulación dedicó parte del que está previsto que haya sido su último día completo en órbita en la misión STS-129 a ir recogiendo las cosas y preparando la...
Después de permanecer atracado en ella durante 6 días, 17 horas y 2 minutos el transbordador espacial Atlantis se desacopló de la Estación Espacial Internacional ayer a las 10:53 (hora de España, UTC +1), comenzando así la última fase de la misión...
En el último día de operaciones conjuntas, poco después de hacerse la foto de familia de ambas tripulaciones a media tarde, Frank De Winne transfirió el comando de la Estación Espacial Internacional a Jeffrey Williams, pues que está previsto que De Winne...
A pesar de haber empezado el paseo espacial con más de una hora de retraso al salirse de su sitio una válvula de suministro de agua para beber en el casco de Robert Satcher, lo que le obligó a quitarse el caso...
Apenas tres días después de haber puesto de nuevo en funcionamiento el Gran Colisionador de Hadrones del CERN y de conseguir mantener haces en circulación dentro de sus dos anillos, ayer se producían las primeras colisiones (voluntarias) de partículas en el LHC,...
Edición original de El origen de las especies Hoy se cumplen 150 años de la publicación en Londres de El origen de las especies, la obra en la que Charles Darwin sintetizó sus años de observaciones a bordo del Beagle y décadas...
El Sol y la Tierra vistos desde la ISS - NASA. Más fotos en STS-129 Flight Day 7 Gallery. La tripulación del Atlantis disfrutó de medio día libre durante su séptimo día en órbita en la misión STS-129, día que además comenzó...
Ahí en el CERN, entre las migas del bocadillo de calamares y esto, deberían hablar seriamente con los del departamento de limpieza, Colisión “beam-gas” or “beam-wall” en CMS – El sábado por la tarde se registró en CMS [el detector] este curioso...
Por Nacho Palou -
23 NOV 2009
Repasando enlaces que se me quedaron pendientes hay un par de espectaculares imágenes que no hay que dejar pasar. Una de ellas es esta imagen del centro de la Vía Láctea hecha combinando imágenes tomadas por el telescopio Espacial Hubble en luz...
Sólo se puede controlar aquello que es conocido. Hay que conocer el riesgo para poderlo controlar Es la máxima del Centro de estudios de riesgo tecnológico de la Universidad Politécnica de Catalunya (UPC). De siete líneas de investigación, dos se dedican a...
Por Esther -
23 NOV 2009
Mike Foreman y Randy Bresnik dieron buena cuenta del segundo paseo espacial de la misión STS-129 ayer, terminando no solo las tareas previstas para este sino adelantando también algunas que estaba programadas para el tercer paseo espacial de la misión. Foreman en...
Big Think publicó una interesante anotación titulada Slouching Toward Gattaca? donde habla de una nueva ley estadounidense que entra en funcionamiento estos días, dirigida a evitar la discriminación a partir de la información genética de los individuos. Esto básicamente quiere decir que...
La tripulación del Atlantis fue despertada media hora más tarde de lo previsto inicialmente para que recuperaran en parte el sueño perdido durante la noche cuando saltaron las alarmas de despresurización de la Estación Espacial Internacional una media hora después de que...
Harald Kraft se curró The Big Bang Theory Intro Frame by Frame extrayendo los 109 fotogramas de la secuencia ultrarrápida de la cabecera de The Big Bang Theory e intentando completar las imágenes con datos sobre lo que muestran. Como dice...
Anoche, tras un parón de algo más de un año causado por una avería provocada por un cortocircuito que a su vez provocó una fuga de helio al haber dañado las conducciones de este el Gran Colisonador de Hadrones del CERN volvió...
El paseo espacial a cargo de los especialistas de la misión Mike Foreman y Robert Satcher, durante el que realizaron diversas tareas de instalación de componentes y cables de la Estación Espacial Internacional así como de mantenimiento de su brazo robot fue...
Ver vídeo: The Rings of the Earth The Rings of the Earth [3 min.] {Hd} Aunque no está del todo claro cuán científicamente correcta sería esta recreación –diría que bastante– es en cualquier caso preciosa: una simulación animada con 3Ds Max de...
La fotomicrografía de arriba, tomada por Alvaro E. Migotto de la Universidad de São Paulo, muestra el tentáculo de la medusa Physalia physalis o fragata portuguesa como un delicado collar de perlas, cada una de unas 300 micras de diámetro, con...
Por Nacho Palou -
20 NOV 2009
El Atlantis atracó en el módulo Harmony de la Estación Espacial Internacional a las 17:51 de la tarde del miércoles (hora de España, UTC +1) tras realizar la maniobra denominada R-bar Pitch Maneuver que sirve para que los tripulantes de la ISS...
Como es habitual tras cada lanzamiento una de las primeras tareas de la tripulación del Atlantis en la misión STS-129 fue la de realizar una inspección del estado del escudo de protección térmica de la nave utilizando el Orbiter Boom Sensor Sytem....
Me pareció muy interesante este vídeo del proyecto Sixty Symbols de la Universidad de Nottingham en el que explican de forma divulgativa qué es el radio de Schwarzschild. Básicamente es el radio de un agujero negro. Su fórmula es bastante simple,...
Como todos los años en estas fechas el recorrido de la Tierra en su órbita alrededor del Sol la lleva a atravesar la zona del Sistema Solar que recorre el cometa Tempel-Tuttle en sus visitas a este, lo que provoca que por...
El Atlantis en la plataforma de lanzamiento a primera hora de la mañana - NASA/Troy Cryder [jpeg a 3.000×2.286 pixeles 3,8 MB] Con la tripulación firmemente sujeta en sus asientos, la escotilla de la nave cerrada, la meteorología dentro de los parámetros...
Altamente educativa e impactante resulta esta representación visual animada del tamaño de los planetas y las estrellas. Si nuestro Sol ya es una auténtica enormidad comparada con la minúscula Tierra, qué decir del resto de estrellas que le ganan por mucho:...
En The Unravelling of the Real 3D Daniel White describe cómo ha generado unas increíbles imágenes fractales que son bastante similares al conjunto de Mandelbrot pero en tres dimensiones. Su trabajo consistió durante los dos últimos años en reconvertir las fórmulas...
Hubble's amazing rescue. PBS/Nova 2009. Una de las discusiones más recurrentes en el campo de la investigación es el de si es conveniente o tan siquiera necesario enviar seres humanos al espacio, en especial teniendo en cuenta los resultados espectaculares que...
El rover marciano Spirit lleva prácticamente cinco meses atascado en un banco de arena, y aunque en todo este tiempo sus responsables han estado estudiando y ensayando distintas estrategias para poder sacarlo del apuro no ha sido sino hasta el pasado día...
El proyecto SpaceDiver en el que participa la compañía OrbitalOutfitters –dedicada al desarrollo y construcción de materiales para utilizar en el espacio– pretende construir un traje que permita saltar, como poco, desde 36.500 metros de altura. El récord lo tiene actualmente...
Por Nacho Palou -
11 NOV 2009
Una semana antes del lanzamiento previsto de su misión los tripulantes de los transbordadores espaciales de la NASA inician su periodo de cuarentena en las Instalaciones de Cuarentena de Astronautas [PDF 176 KB] del Centro Espacial Johnson, momento a partir del que...
A pesar de las apariencias, esta imagen no recoge un experimento de repostería fallido sino de una de las magníficas imágenes de Marte tomadas por la cámara HiRISE de la sonda Mars Reconnaissance Orbiter de la NASA que The Big Picture...
A New Theory of Awesomeness and Miracles es un fascinante artículo que proviene de una conferencia de Jaime Bridle sobre juegos y estrategia, en el que se describe la construcción de MENACE, una increíble «máquina» ideada por el profesor Donald Michie,...
Baguette Dropped From Bird's Beak Shuts Down The Large Hadron Collider (Really) cuenta que al parecer el pan que dejó caer un pájaro hizo necesario parar del Gran Colisionador de Hadrones (LHC), ahora conocida como el Gran Colisionador de Panes. Poco más...
Por Nacho Palou -
6 NOV 2009
Me he estado riendo un rato con Encubrimiento de La Pulga Snob; para un vistazo más serio sobre el tema recomiendo Los ovnis ¡vaya timo! (ALT1040 vía Otháner Kasiyas)....
¡Qué bueno! Unos científicos han analizado ciertos isótopos de carbono y nitrógeno en los restos de los esqueletos de unos leones africanos realmente especiales: supuestamente, alguna de esas bestias se zampó a más de cien personas, según informaciones de la época. Fue...
La caída de las hojas de los árboles de hoja caduca con la llegada del otoño no está causada sólo por el viento. Es más bien el árbol el que las echa de sus ramas una vez que ya no son útiles...
Por Nacho Palou -
2 NOV 2009
Representación del SMOS en órbita / Imagen: ESA - AOES Medialab Esta madrugada se ha puesto en órbita el satélite de la Agencia Espacial Europea SMOS (Soil Moisture and Ocean Salinity), cuya misión es obtener información sobre la humedad del suelo y...
Por Nacho Palou -
2 NOV 2009
Beige, café manchado, castaño claro, marfil, amarillo tirando a marrón, color carne… Como ampliamente explican en El Sofista, éste sería el color medio del universo si se mezclaran todos los colores de los cielos. Es el resultado de promediar el color...
Cell Size and Scale, del departamento de genética de la Universidad de Utah, es un interactivo que te deja con la boca abierta a nada que muevas el ratón sobre el deslizador para hacer zoom. Al estilo de Powers of Ten...
A diferencia de lo que la gente suele creer, los agujeros negros no siempre son objetos sólidos. Hay algunos tan grandes, tan grandes, que son muy poco densos, como el que hay en el centro de nuestra galaxia. Ese tipo de agujeros...
Utilizando un cable de fibra óptica, originalmente diseñado para monitorizar pozos de petróleo, investigadores de la Universidad de Nevada pueden medir la temperatura del interior de la tierra con el que probablemente podría considerarse el termómetro más grande del mundo: mide casi...
Por Nacho Palou -
29 OCT 2009
En New Scientist: Robots cirujanos que van a su aire en el laboratorio de patología – Ponerle en las manos a un robot autónomo un escalpelo es demasiado arriesgado… Pero basta reemplazar al paciente por un cadáver para ver cómo de cómodo...
Sencillamente espectacular: los efectos de la tensión superficial en gotas de agua que caen sobre agua. No me cansaría de verlas. (Vía Aquí estuve ayer.)...
LaInformación.com ha publicado un gráfico interactivo que muestra las emisiones de CO2 -considerado uno de los principales gases causantes del efecto invernadero- por países: emisiones totales, en relación al Producto Interior Bruto (PIB, o riqueza del país) y per cápita, en...
Por Nacho Palou -
28 OCT 2009
A principios de 2004 un equipo de científicos del Corea del Sur dirigido por Hwang Woo-suk anunciaba haber conseguido por primera vez en la historia la clonación con éxito de embriones humanos y el haber obtenido células madre de ellos, y en...
Tras una parada de algo más de un año causada por una fuga de helio líquido en el sector 3-4 del LHC, entre los experimentos ALICE y CMS, causada a su vez por un cortocircuito que dañó las conducciones de helio del...
No lo hace: How does your body digest a cigarette? - el problema con los cigarrillos es que el cuerpo no digiere muchos de los más de 4.000 productos químicos que contienen, incluyendo benceno, plomo, níquel, arsénico, cadmio, acetona, butano... (Vía Guy...
Por Nacho Palou -
26 OCT 2009
Embracing the Wide Sky: A Tour Across the Horizons of the Mind. Por Daniel Tammet. Free Press, 6 de enero de 2009. Inglés. 305 páginas. Susumu Tonegawa recibió el premio Nobel de medicina de 1987 por haber descubierto como nuestro sistema...
El mapa The Impact of a global temperature rise of 4º, realizado por el Museo de la Ciencia de Londres, muestra -basado en modelos climáticos- el impacto que tendría el aumento en 4 grados de la temperatura media del planeta. Este...
Por Nacho Palou -
23 OCT 2009
Dentro de las actividades que se están celebrando en todo el mundo con motivo de la celebración del Año Internacional de la Astronomía 2009 mañana están a punto de comenzar Las Noches de Galileo. Estas tienen como objetivo mostrar a todo aquel...
Missions to Mars por Bryan Christie Roberto nos pasó un enlace a esta imagen sin más datos, pero tirando de Google y del nombre del diseñador he descubierto que forma parte de un interesante especial de IEEE Spectrum, la revista del Instituto...
(…) Daniel Tammet pudo recitar las 22.514 cifras de π en una exhibición con fines benéficos el el 14 de marzo de 2004 (día de π, naturalmente). Se limitó a mirar el paisaje que formaban los dígitos, según se desplazaban ante...
Batsehba Grossman aplica la misma técnica que se utiliza para hacer esos souvenirs que reproducen la torre Eiffel, el Golden Gate, o la atracción turística de turno como una serie de burbujitas dentro de un bloque de cristal a la creación de...
Me encantó esta teoría conspiranoica que encontré en un ensayo de la sección de Ciencia del New York Times, titulada The Collider, the Particle and a Theory About Fate. Basicamente viene a contar que se han oído algunas propuestas realmente extrañas acerca...
¿Qué sucede cuando conectas dos globos, uno muy inflado y otro poco inflado? Contrariamente a lo que tiende a indicar la intuición, el aire del globo poco inflado se transfiere al globo más inflado, haciéndolo más grande. He tenido que ir...
50 Years of Space Exploration muestra hasta donde ha llegado la exploración espacial de la humanidad en los últimos 50 años. El gráfico no está a escala, pero es elegante representación de todos los sitios a los que hemos ido, cuántas...
Hacia las 13.30 horas oficial español (GMT +2) está previsto el impacto de la sonda LCROSS contra la superficie de la luna, que se podrá ver en directo por NASA TV. Actualización: ¡Crash! Fotos y más datos en Moonlanding.es....
Por Nacho Palou -
9 OCT 2009
Representación gráfica de la sección superior del cohete Atlas en rumbo de colisión con la Luna. Detrás la sonda LCROSS observará el impacto, y cuatro minutos después terminará igual. Imagen NASA En un ejemplo más de si no lo consigues, prueba con...
Por Nacho Palou -
8 OCT 2009
Desde hace tiempo los astrónomos sospechaban que el que Jápeto tenga una mitad clara y otra oscura tiene que ver con material que se desprende de Febe, otra luna de Saturno que gira en el sentido contrario a la primera, material que...
Cuando José Luis Rodríguez Zapatero no era más que candidato a la presidencia de España prometió duplicar en una sola legislatura el gasto en investigación y desarrollo, hablando a menudo de la necesidad de una reconversión de la economía del país a...
Chus nos recordó que aún no habíamos puesto este vídeo que al parecer montó un admirador de Cosmos. Es un videoclip musical con escenas de la serie, en el que con gran habilidad consigue que Carl Sagan cante la canción junto...
Estos días, mirando cerca del horizonte hacia el norte - noreste, a última hora de la tarde y primera de la noche (hemisferio norte), se puede ver una fantástica luna casi llena. Mañana 4 de octubre es la luna llena más próxima...
Por Nacho Palou -
3 OCT 2009
Ya tenemos una nueva edición de los premios Ig Nobel, los galardones que la revista Annals of Improbable Research concede anualmente a aquellas investigaciones que aunque son serias tienen temáticas o títulos que no pueden por menos que poner una sonrisa en...
Dentro de las múltiples actividades y proyectos que en todo el mundo se están llevando a cabo dentro del Año Internacional de la Astronomía 2009 el Observatorio Europeo Austral ya están en línea las tres imágenes que componen el proyecto GigaGalaxy Zoom....
¿Has extraído alguna vez ADN de un kiwi? ¿Sabes como Darwin desarrolló su teoría de la evolución? ¿Quieres crear tu propio fósil? Y… ¿para qué sirve, en definitiva, la ciencia? Si este próximo sábado 3 de octubre estás por Barcelona y o...
Aunque en el espacio la fuente de energía más utilizada es la procedente del sol –que es captada por paneles solares montados en sondas, satélites o en la Estación Espacial– ésta no es apropiada para todas las misiones. Por ejemplo, no sirve...
Por Nacho Palou -
29 SEP 2009
M45 por Arran Hill Wired recoge en Reader Photo Gallery: Awesome DIY Astronomy unas cuantas impresionantes imágenes astronómicas hechas con equipos «de andar por casas» enviadas por sus lectores que son como para quitarse el sombrero. Trazos de estrellas, una iniciación fácil...
Varios proyectos de investigación podrían devolver la vista a ciertos casos de pacientes ciegos o con problemas de visión. No será algo aplicable en todos los casos, ni tampoco algo disponible inmediatamente, pero son avances técnicamente interesantes y esperanzadores. Uno de ellos,...
Por Nacho Palou -
28 SEP 2009
Hace algunos meses Eugenio Manuel de Ciencia en el XXI me hizo llegar muy amablemente una invitación para participar en las Jornadas Blogs & Ciencia 2009 que tendrán lugar este próximo viernes 2 y sábado 3 en Cosmocaixa Alcobendas (Madrid) [PDF]. Es...
Este bonito brillo azulado se llama radiación de Cherenkov y en esta imagen en concreto procede de un reactor nuclear usado en investigaciones en Idaho, el ATR. Lektu y Fernando nos enviaron sendos correos mencionándola, a raíz de la anotación del...
Inside Bill Moorier's head Hace unos días a Bill Moorier su médico le mandó hacerse una resonancia para descartar un par de patologías, y con los datos obtenidos de la prueba se montó esta página en la que se puede ver el...
Con mega-camiones y mucha paciencia, ¡fácilmente! En Wired Science explican estupendamente y con bonitas fotos la construcción del Observatorio ALMA en Atacama, Chile. La primera antena ya ha sido instalada. Quedan otras 65 más....
Curioso: con menos de un par de cientos de muestras de ADN tomadas a voluntarios residentes en el barrio de Astoria, en Nueva York, ha sido posible dibujar un mapa que recoge las principales rutas seguidas por los antepasados que poblaron...
Por Nacho Palou -
24 SEP 2009

Elaborado con datos disponibles públicamente procedentes de la cámara HiRISE, la más potente a bordo de la sonda Mars Reconnaissace Orbiter, este es un vídeo elaborado por Doug Ellison de Unmanned Spaceflight.com en homenaje a los años -ya van camino de...
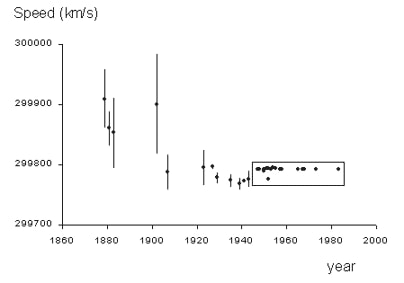
La velocidad de la luz en el vacío es de 299.792.458 metros por segundo. Exactamente. Cuando te enseñan en el colegio se redondea a 300.000 kilómetros por segundo, que es un valor bastante cercano y más fácil de recordar. Siempre me...
Ya está, ya no hace falta seguir buscando el mecanismo mediante el que se originó el Big Bang que según creemos dio lugar a nuestro universo: No juguemos a ser Dios Mientras tanto, nuestro LHC podría empezar a producir sus primeras colisiones...
The Rite of Spring - NASA/JPL/Space Science Institute La sonda Cassini lleva ya años asombrándonos con las imágenes que nos envía desde Saturno, pero yo diría que esta es una de las más impresionantes que hemos podido ver hasta la fecha, aunque...
Io - Galileo Project, JPL, NASA Fantastic Photos of our Solar System es una galería recién publicada por el Instituto Smithsoniano que recoge algunas de las más impresionantes imágenes que más de 20 sondas nos han ido enviando desde todos los confines...
Esta semana la NASA anunció que superada la fase de pruebas y calibración de sus instrumentos y realizado un último ajuste que la deja en una órbita polar de algo menos de 50 kilómetros de altura la sonda Lunar Reconnaissance Orbiter está...
Aunque el número de exoplanetas no para de crecer y crecer la inmensa mayoría de ellos son gigantes gaseosos del estilo de Júpiter y Saturno o incluso mucho más grandes que estos. Pero a principios de este año el equipo del observatorio...
La radiación cósmica de microondas es una forma de radicación electromagnética que llena todo el universo y que sólo es visible mediante radiotelescopios. Su estudio es extremadamente importante, ya que cualquier modelo que pretenda explicar el origen de nuestro universo tiene que...
El tesla es la unidad en que se mide la densidad del flujo magnético, nombrada así en honor de nuestro apreciado Nikola Tesla. Hay algunas unidades del Sistema Internacional que son más o menos «cercanas» en cuanto a su magnitud a...
El Planetario de Madrid ha inaugurado una exposición permanente dedicada a las misiones desarrolladas por la Agencia Espacial Europea (ESA). Durante el mes de septiembre varios expertos de la agencia darán cuatro de conferencias sobre la exploración europea del espacio, las misiones...
Por Nacho Palou -
16 SEP 2009
La Universidad de Vigo ha desarrollado una boya inteligente capaz de monitorizar, de forma autónoma y en tiempo real, distintos parámetros del agua del mar, como pueden ser la salinidad, temperatura, transparencia, oxigenación o la contaminación. Los resultados de la mediciones se...
Por Nacho Palou -
16 SEP 2009
Encontré este artículo de Los Ángeles Times de hace un par de años, que hacía referencia a un estudio publicado entonces, acerca de cómo la especie humana continúa evolucionando y de cómo se ha detectado que lo hace a ritmos superiores a...
Por Nacho Palou -
16 SEP 2009
La imagen de arriba, publicada en First Detailed Photos of Atoms y tomada por investigadores del Instituto de Física y Tecnología de Kharkov , en Ucrania, muestra la nube de electrones que forma parte de un átomo de carbono. Es la...
Por Nacho Palou -
15 SEP 2009
Restros de orina en el cielo nocturno. Imagen de Abe Megahed. Esta estela luminosa, capturada en el cielo nocturno por el observador Abe Megahed el pasado miércoles, es en realidad... orina. Su origen está en el transbordador Discovery, que se desacopló el...
Por Nacho Palou -
14 SEP 2009

The Golden Ratio: The Story of phi, the World's Most Astonishing Number. Mario Livio. Broadway Books. Inglés. 2003. En castellano: La proporción áurea: la historia de Phi, el número más sorprendente del mundo. Editorial Ariel (2006). Este libro sobre Φ, el...
Esta genial representación de Abstruse Goose medio en broma medio en serio se titula Electromagnetic Leak: cuanto más cerca del pequeño punto azul que es la Tierra, más recientes las emisiones. El autor parece haberse centrado en las series ignorando la...

Glass Microbiology: Viruela, HIV, y una futura mutación A Luke Jerram le preocupan cosas como saber cuanta gente puede pensar que los virus tienen vivos colores en el MundoReal™ o qué puede suponer representar un virus en un color o en otro,...
Una de las primeras cosas que hizo Barack Obama al asumir la presidencia de los Estados Unidos fue crear un comité de expertos independientes al que pidió un informe sobre el estado del programa espacial tripulado de la NASA y su situación...
Tras varios meses calibrando y comprobando los instrumentos del telescopio espacial Hubble, tanto los nuevos como los reparados por la tripulación de la espectacular misión STS-125 de la NASA, hoy se han presentado en público las primeras imágenes obtenidas de cuatro de...
La órbita de la Tierra pasa hoy por el mismo plano que los anillos de Saturno, con lo que estos, observados desde nuestro punto de vista, parecen desaparecer, como se puede ver en esta animación construida por el astrónomo aficionado Alan Friedman...
Momento_tampax: «¿A qué suena la superficie de la Luna?» Moonbell es una curiosa aplicación online (requiere Java), que permite escuchar la topografía de la Luna. Utilizando los datos obtenidos por el altímetro láser del orbitador lunar japonés Kaguya, convierte las variaciones de...
Por Nacho Palou -
4 SEP 2009
Mientras se discute si aplazar o no el comienzo de las clases, a quien incluir en los grupos de riesgo para vacunar y se echan cuentas del número de dosis de vacunas y antivirales que van acaparando los gobiernos, me parecen muy...
How science reporting works por Saturday Morning Breakfast CerealHemos destruido el diez por ciento de las células cancerígenas de la cola de una rata de laboratorio-Curado el cáncer Afortunadamente hay excepciones, pero en muchos casos esto es lamentablemente cierto. (Vía ">Boing Boing)....
Precioso estudio de Hoefler / Frere-Jones, expertos en tipografía, en el que analizaron lo que ocuparía escrito en papel el 45º número primo de Mersenne, que expresado en la forma abreviada es 243112609-1 pero completo son más de 12 millones de...
"Tinta" de nanopartículas capaces de capturar la energía solar.Imagen: Cockrell School of Engineering, The University of Texas at Austin Es un concepto aún en desarrollo y más que futurista, pero suena interesante: células fotovoltaicas compuestas de nanopartículas que forman una especie de...
Por Nacho Palou -
27 AGO 2009

Una genial parodia de lo que pasaría si en el servicio de urgencias de un hospital se hiciera uso de la homeopatía y otras pseudomedicinas para tratar a los pacientes. (Vía La Torre de Hércules). Relacionado: ¿Qué es la homeopatía? Homeopatía...
Auque la invención del telescopio se atribuye generalmente a Hans Lippershey en 1608, o al menos el registro de la primera solicitud de patente para su fabricación, sería Galileo, quien construyó su primer telescopio en 1609, uno de los primeros en demostrar...
Si tienes curiosidad por saber cuántas personas hay ahora mismo en el espacio, lo puedes consultar aquí: How Many People Are In Space Right Now? En el momento de escribir esto hay seis, todos ellos en la Estación Espacial Internacional (ISS), de...
Por Nacho Palou -
24 AGO 2009
Tomograma coloreado de una oreja humana. Imagen Kai-hung Fung / Barcroft Media / Mail Online. Imágenes tomadas con un tomógrafo por el radiólogo Kai-hung Fung, que une ciencia y arte para obtener sorprendentes imágenes del cuerpo humano: Body art: Real parts of...
Por Nacho Palou -
24 AGO 2009
La sonda Lunar Reconnaissance Orbiter de la NASA utiliza un sistema de comunicación en la llamada Banda K para transmitir datos a la Tierra a 800 Mbps 100 Mbps. A través de esa conexión la NASA recibe en tierra unos 461 GB...
La sonda Stardust, en su encuentro con el cometa Wild 2 en 2004, capturó entre muchas partículas, sobre todo minerales, glicina, uno de los aminoácidos que utilizan los seres vivos para formar proteínas, siendo la primera vez que se detecta un aminoácido...
Por Nacho Palou -
19 AGO 2009
Burbujas de metano ascendiendo a la superficie desde el suelo oceánico del Ártico. Imagen: BBC News. Hace más o menos un año investigadores rusos afirmaban tener pruebas de que se estaba liberando metano desde los fondos marinos del Ártico, fenómeno que se...
Por Nacho Palou -
19 AGO 2009
Rubor. Risa. Vello púbico. Adolescencia. Sueños. Altruismo. Arte. Superstición. Besos. Hurgarse la nariz. Son diez cosas que seguimos sin entender sobre los humanos, «incógnitas evolutivas» de las que no está del todo clara su función/explicación, sobre las que hablaron en New Scientist....
Quienes estén en Vitoria-Gasteiz estos días están de suerte: Con la imagen, la palabra y el sonido les presentamos la trayectoria y toda la genialidad del gran inventor Nikola Tesla. La complejidad de los acontecimientos históricos que acompañan la trayectoria de...
Se ha batido un nuevo récord histórico relacionado con π al calcularse 2,5 billones de decimales en 73 horas y 36 minutos. Esto es más del doble de los decimales que hasta ahora ostentaban el récord (para el que se necesitaron 600...
Análisis de las Paradojas del Viaje en el Tiempo es la continuación de Los Problemas Filosóficos del Viaje en el Tiempo, dos artículos de El Cedazo, lectura obligada para quienes se sientan apasionados por el tema o quieran introducirse en él y...
Lo de arriba es el discreto aterrizaje sobre la tundra siberiana de la nave rusa Soyuz TMA-11 el 19 de abril de 2008, que acabó en el suelo a 475 km de distancia de su punto objetivo. La TMA-11 realizó una...
Por Nacho Palou -
14 AGO 2009
Imagen del National Air and Space Museum. Estos días, en 1960, se lanzó al espacio el primero de los satélites-globo del proyecto Echo, los primeros satélites pasivos de telecomunicaciones. Retomando una anotación al respecto de hace alguno años (“Satelloons”, satélites inflables), los...
Por Nacho Palou -
13 AGO 2009

Un vídeo para disfrutar en HD, pantalla gigante y a ser posible con la sala a oscuras. Es un paseo en 3-D por una de las fotos más impactantes de nuestro Universo que nunca se haya conseguido, el Campo Ultra Profundo...
Dentro de las actividades que se están llevando a cabo con motivo del Año Internacional de la Astronomía 2009 hoy se celebra la Tercera Fiesta de Estrellas en numerosas localidades de toda España para observar las lágrimas de San Lorenzo. Las lágrimas...
Domo Vredefort. Imagen: NASA. Galería de imágenes en los que se pueden ver las lo que queda de las cicatrices dejadas por antiguos impactos de asteroides contra la superficie de la Tierra. El de arriba es el Vredefort Dome en Suráfrica, “probablemente...
Por Nacho Palou -
12 AGO 2009
Imponente y grande como una nevera familiar, este chisme se llama Heliscope Single Molecule Sequencer (HSMS) y es un invento de Stephen Quake, un ingeniero de Stanford, que fundó para Helicos BioSciences. Sirve para secuenciar el genoma humano. El HSMS puede...
El cielo en la medianoche del 12 al 13 de agosto de 2009 (centro peninsular) representado con Neave Planetarium. La Sociedad de Observadores de Meteoros y Cometas de España (SOMYCE) ha publicado una Guía de Observación de las Perseidas 2009 [PDF, 2,1...
Por Nacho Palou -
11 AGO 2009
El 26º número primo, multiplicado por 26, da como resultado 2626. Una de tantas curiosidades sobre los números primos....
Punching through the F Ring (NASA Cassini Saturn Mission Images) - NASA/JPL/Space Science Institute No soy astrónomo ni físico, pero Phil Plait, que sí es astrónomo, y si lo entiendo bien, cuenta en Like the fist of an angry god, que fue...
La luna vista desde el Galileoscope por Marcos López Todavía estoy esperando que lleguen mis Galileoscopios, pero ver la imagen que ha conseguido Marcos haciéndole una foto al ocular del telescopio con una cámara compacta de 8 megapíxeles hace que aún me...
La Convención Marco de las Naciones Unidas sobre el Cambio Climático (CMNUCC o UNFCCC por sus siglas en inglés), que desde hace un decenio a agrupa a la mayoría de los países, trabaja en el desarrollo de medidas para combatir el...
Por Nacho Palou -
5 AGO 2009
Not As Far As You Think (No tan lejos como crees) por Aled Lewis Por sugerencia de José «JamSession» Millares vía Twitter, una camiseta para tomarse un poco a cachondeo a los que defienden la conspiración lunar, aunque ha tenido tanto éxito...
Por cortesía de Producciones Irreductibles, un vídeo con la selección de las 25 imágenes astronómicas preferidas de Javi Peláez, el editor de La Aldea Irreductible: La Aldea Irreductible - Top 25 Astronomía por Aldea Irreductible en Vimeo. Se trata de imágenes de...
Hay que verlo y oirlo para creerlo, es imposible no esbozar una sonrisa. Divulgación de la Ciencia en estado puro. El protagonista, Bobby McFerrin es el autor de la universalmente conocida canción Don't Worry, Be Happy. (¡Gracias Javier por la pista!)...
El pasado 18 de noviembre durante el primer paseo espacial de la misión STS-126 de la NASA a la astronauta Heidemarie Stefanyshyn-Piper se le escapó una bolsa de herramientas mientras intentaba limpiarla después de que una de las pistolas de grasa que...
La conspiración lunar ¡Vaya timo! por Eugenio Fernández Aguilar. Laetoli, 2009. ISBN 9788492422142. La celebración de 40 aniversario de la llegada del hombre a la Luna ha hecho que se haya rememorado esta hazaña en montones de actos, programas especiales, publicaciones,...
Durante la misión Apolo 14 el astronauta Stuart Roosa llevó consigo una bolsita con 500 semillas de árboles proporcionadas por Stan Krugman, director de Investigación Genética del Servicio Forestal de EE UU. Hoy los árboles han crecido en la Tierra sin problemas,...
Miembros del JPL probando maniobras para tratar de liberar el Spirit.Imagen: NASA/JPL-Caltech. Free Spirit: NASA Recreates Mars Surface to Liberate Rover, galería de imágenes de cómo ingenieros del JPL recrean la zona de la superficie de Marte en la que el rover...
Por Nacho Palou -
29 JUL 2009
Aunque todavía está en pleno proceso de calibración tras la espectacular y exitosa misión de mantenimiento y reparación realizada el pasado mes de mayo por el transbordador espacial Atlantis y su tripulación, los responsables del telescopio espacial Hubble han entendido que el...
Parece que hoy es el día oficial de las noticias que me habrían interesado pero que de alguna manera se me escaparon, como es en este caso la inclusión de la Luna en Google Earth 5, justo coincidiendo con el 40 aniversario...
Hoy ha tenido lugar el eclipse total de Sol más largo de este siglo, con una duración de la totalidad de 6 minutos y 39 segundos, que no será superado por ningún otro hasta el 13 de junio de 2132, con lo...
Impacto sobre Júpiter por Anthony Wesley Se hace ciencia en base a mucho trabajo, pero de vez en cuando la casualidad también se asoma, y esto es lo que le pasó hace un par de días a Anthony Wesley cuando pudo observar...

00:15 Tras un descenso en el que el ordenador de a bordo del módulo lunar Eagle dio un susto de muerte a los controladores de la misión y a sus tripulantes con una serie de alarmas de tipo 1201 y 1202 que...
El NASA Apollo 11 Owners' Workshop Manual de Haynes es todo lo que necesitas para llegar a la Luna con un módulo lunar a bordo de un Saturno V, planear sobre el satélite, caminar sobre la superficie polvorienta y conocer el...
Por Nacho Palou -
20 JUL 2009
Esta madrugada a las 5:11:55, hora de España (UTC +2), el Apolo 11 alcanzó el punto en el espacio en el que la NASA considera que está más influido por el campo gravitatorio de la Luna que por el de la Tierra,...
Neil Armstrong, Edwin «Buzz» Aldrin y Michael Collins siguen su viaje a bordo del Columbia, el módulo de mando del Apolo 11, rumbo a la Luna con el objetivo de que los dos primeros se conviertan en los primeros seres humanos en...
No servirá de nada en absoluto de cara a convencer a aquellos que están empeñados en que el hombre nunca llegó a la Luna y que todo es un montaje/conspiración, pero la NASA acaba de presentar unas imágenes tomadas por la Lunar...
WebUrbanist recoge en Stroke of Genius: Abilities Borne of Brain Damage los casos de diez personas que tras sufrir daños en el cerebro bien por un traumatismo, bien por una enfermedad, o bien por un accidente cerebrovascular, desarrollaron unas capacidades artísticas que...
La respuesta a la pregunta de si se llega más rápido simplemente caminando o haciéndolo además subido en una cinta transportadora como las que hay en los aeropuertos o pasillos de metro ya tiene respuesta «científica»: ir por encima de la...
Con el lanzamiento del Endeavour en la misión STS-127 ha salido al espacio la persona número 500 desde que Yuri Gagarin iniciara la cuenta el 12 de abril de 1961.Cuatro de los tripulantes de la misión están en su primea misión, con...
Día de rutina, si se puede decir tal cosa de una misión histórica como esta, en el que a las 18:16, hora de España (GMT +2), el Apolo 11 pasó el punto medio de su recorrido hacia la Luna, ejecutando sin problemas...
El nuevo elemento de la tabla periódica, que ocupa el número 112, que fue «creado en laboratorio» ha sido finalmente llamado Copernicio (Copernicum) en honor a Nicolás Copérnico, el astrónomo que formuló la teoría de que el Sol era el centro del...
Tal y como estaba anunciado la NASA ha presentado hoy versiones restauradas de las escenas más relevantes del paseo espacial de Neil Armstrong y Buzz Aldrin cuando hace cuarenta años pisaron la Luna durante la misión Apolo 11, escenas que están disponibles...
Sala de lanzamiento - NASA A falta de una hora para las 15:32, momento previsto de lanzamiento de la misión Apolo 11 que tiene como objetivo colocar a un ser humano por primera vez en la Luna, todos los sistemas funcionan correctamente...
No lo dicen abiertamente, pero según se puede leer en NASA Holds Briefing to Release Restored Apollo 11 Moonwalk Video la agencia va a presentar este próximo jueves «imágenes en vídeo muy mejoradas de la transmisión en directo del paseo espacial del...
Tras haber comprobado en unos ensayos llevados a cabo en 2004 que implantar un sensor en el cortex motor -la zona de la corteza cerebral que se encarga de controlar lo movimientos- de pacientes con parálisis les permitía controlar cosas como el...
Al parecer si una cartera perdida lleva en su interior fotos de bebé la probabilidad de que sea devuelta a su dueño se multiplica por más de cinco respecto a una cartera que no lleve fotos. Frente al 15 por ciento que...
Según cuenta la Agencia Espacial Europea en Las primeras imágenes de Herschel auguran un futuro brillante ya se han recibido en tierra imágenes de los tres instrumentos a bordo del observatorio espacial Herschel de la agencia. PACS incorpora una cámara y un...
Hace 153 años nacía Nikola Tesla; Google ha cambiado su logo a una poderosa e impactante bobina Tesla en plena acción en un entrañable homenaje al «hombre que inventó el Siglo XX». (¡Gracias Miguelo y Zarce por el aviso!) Tablero de...
Con 1 palo y 5 ladrillos se pueden hacer mil cosas. Un sencillo y original mnemónico para los diez primeros decimales de pi. Es una de las técnicas para Ejercitar la memoria de un interesante artículo de Consumer....
La NASA acaba de hacer públicas las primeras imágenes recibidas de la sonda Lunar Reconnaissance Orbiter después de que esta activara sus cámaras el pasado día 30: Superficie de la Luna por la LRO - NASA/Goddard Space Flight Center/Arizona State University Esta...
Sixty Symbols es otro proyecto del periodista científico Brady Haran, el mismo de la Tabla Periódica en Vídeo, en el que en este caso se explicarán sesenta conceptos del entorno de la física y de la astronomía a partir de otros...
Debido a las limitaciones de la tecnología de la época cuando hace casi cuarenta años Neil Armstrong y Buzz Aldrin se conviertieron en los primeros seres humanos en pisar la Luna la NASA utilizó una solución bastante pedestre para retransmitir a todo...
George W. Hart se dedica a explorar la relación entre la geometría de figuras en dos y tres dimensiones, lo llama Construcciones geométricas de papel que «encajan unas con otras». Consisten en una idea muy simple: copias y copias de una...
La Halobacterium NRC-1 es el organismo conocido más resistente a la radiación, capaz de soportar unos 18.000 dosis de radiación -bastan 10 para matar a una persona. Esto duplica la marca establecida por la D. radiodurans, descubierta en los años 50...
Por Nacho Palou -
29 JUN 2009
En Trucos para psicotécnicos se explican algunas técnicas de cálculo mental rápido con números. Hay desde cosas sencillas como darse cuenta de que dividir por 5 es como dividir por 10 y luego multiplicar por 2 a otras más complicadillas como...
Si has visto el vídeo en el que Kate McAlpine AKA Alpine Kat explica el funcionamiento del Gran Colisionador de Hadrones al ritmo de rap Ver vídeoLarge Hadron Rap [4:49, disponible en HQ] Y piensas que no solo mola sino que puedes...
La órbita de la Luna alrededor del Sol tiene forma de hélice: una especie de «espiral tridimensional», debido a que la órbita de la Luna alrededor de la Tierra no está exactamente en el mismo plano que el Sol y la...
En agosto de 2006 la empresa irlandesa Steorn se descolgaba con el anuncio de que había conseguido diseñar una tecnología que «…genera una energía gratuita, limpia y constante» sobre la que que afirmaban en su propia web que: La tecnología presenta un...
La Agencia Espacial Europea hizo pública hace unos días la primera imagen tomada por el telescopio Herschel, que aún está en su periodo de pruebas y calibración: Primera imagen del Herschel. Se trata de una imagen de M51 compuesta por tres tomadas...
Sala de control del LHC durante la inyección del primer haz de partículas en este /AP-Spiegel OnLine La puesta en marcha del Gran Colisionador de Hadrones empieza a parecerse a la construcción del monasterio de El Escorial -en España se suelen comparar...

La Agencia Japonesa de Exploración Aeroespacial ha publicado al fin las últimas imágenes y vídeo tomados por la sonda Kaguya el pasado 10 de junio cuando terminó su misión con un impacto controlado sobre la superficie de la Luna con el...

Nacido a las 25 semanas de gestación y con apenas medio kilogramo de peso ni el doctor que atendía el parto ni su madre pensaron que Derek Paravicini sobreviviría al parto, pero de hecho sí lo hizo, aunque la terapia a...
Células de la bactería Herminiimonas glaciei, recientemente revivida. Imagen: The Society for General Microbiology La bacteria, bautizada como Herminiimonas glaciei, fue encontrada en el hielo a tres kilómetros de profundidad bajo el hielo de un glaciar de Groenlandia, donde se calcula llevaba...
Por Nacho Palou -
16 JUN 2009
FLOTA es una curiosa «lámpara que levita» que utiliza dos tecnologías: la levitación magnética y la inducción electromagnética. Es una creación de los alumnos de disñeo industrial Marc Fabra y Adrià GM con la colaboración de Diego Villuendas del UBXLAB Magnetisme...
En el reciente evento Maker Faire de inventores piraos y científicos locos, al que nos hubiera encantado asistir, la gente de Omega Recoil enseñó cómo recrearon algunos de los experimentos de Nikola Tesla, en una exhibición mitad espectáculo, mitad «investigación». En...
El otro día le cayó encima un meteorito a un chaval Alemán; por suerte sólo le hirió en la mano, pero al impactar contra el suelo dejó un pequeño cráter de casi medio metro de diámetro. Hay más detalles en Meteorite Strikes...
Ya se confirmó oficialmente que el pasado mes de abril se encontró el 47º primo de Mersenne, un número de la forma M = 2n - 1 en el que n también es primo. El número en cuestión es el 242.643.801-1 y...
Científicos alemanes han conseguido que finalmente se incluya el elemento número 112 en la tabla periódica. Se trata un elemento químico superpesado que a falta de un nombre (tienen el privilegio de elegirlo) se llama ununbium, que en Latín se traduce...
Hoy a las 20:25 hora de España (UTC +2) la sonda Kaguya de la Agencia Japonesa de Exploración Aeroespacial (JAXA) terminará su misión con un impacto controlado contra la superficie de la Luna, cerca del cráter Gill en su hemisferio sur, tal...
Desde que nació me suscribí a Atrapados en el tiempo, que no es sino el blog de los meteorólogos de TVE. Hoy 40 de mayo (día en que toca quitarse el sayo) publicaron esta joyita sobre la relación entre las ciencias físicas...
Lanzada el 3 de agosto de 2004 con destino a Mercurio, la sonda MESSENGER de la NASA no llegará allí hasta el 18 de marzo de 2011. Esto es así porque la única forma que conocemos de enviarla hacia este planeta y...
La investigación con células madre, por su capacidad de convertirse en cualquier otra célula de nuestro cuerpo, es uno de los campos más prometedores de la medicina actual. Gracias a ella, por ejemplo, se han llevado a cabo estudios en los que...

Gotas de agua como nunca antes las has visto, tres preciosos vídeos sobre algo tan simple como la caída de una gota sobre una superficie acuosa. Algo que se convierte en un espectáculo casi mágico merced al vídeo proyectado a cámara...
Una de las grandes contribuciones que ha hecho la investigación espacial a nuestro mundo es la posibilidad de conocerlo mejor gracias a la multitud de satélites artificiales que hemos puesto en órbita para mirar hacia ella con distintos instrumentos. Esto normalmente es...
Con motivo del 40 aniversario de la llegada del Apolo XI a la Luna, radioaficionados y voluntarios de todo el mundo están organizando el proyecto Echoes of Apollo, World Moon Bounce Day (Día mundial de rebotes en la Luna). La idea es...
Por Nacho Palou -
4 JUN 2009
Una visualización de la Ley De Benford / Daniel A. Becker Random Walk es un impresionante y detallado trabajo de representación visual del azar en muchas de sus apariciones en el mundo de la matemática y la física. Es un trabajo de...
Visualizador de exoplanetas que utiliza Google Earth en el navegador (requiere plugin), incluye algo de información sobre lo poco que se sabe de los exoplanetas o planetas fuer del Sistema Solar y se adorna de una interfaz estilo pantallas de la...
Por Nacho Palou -
4 JUN 2009
Resumo y traduzco de 15 Scientific Discoveries that Developed the Modern World: El desarrollo de la prevención y tratamientos para las enfermedades infecciosas, que nos ha proporcionado vidas más largas y saludables para disfrutar de los frutos de los avances científicos y...
Spirit Encounters Soft Ground on Mars es la Imagen Astronómica del Día de ayer en la que se puede ver la situación en la que se encuentra Spirit desde finales del mes de abril, cuando se quedó atascado en un suelo...
El agujero en la capa de ozono sobre la Ántartida entre 1979 y 2008; la secuencia completa año a año puede verse en Antarctic Ozone Hole. El Ozone Processing Team de la NASA lleva desde los años ochenta del siglo pasado vigilando...
Por Nacho Palou -
2 JUN 2009
A menudo se argumenta que se gasta un montón de dinero en programas espaciales cuando ese dinero podría ser dedicado a otras cosas más provechosas, aunque conviene no olvidar lo mucho que le debemos a los distintos programas espaciales, no sólo en...
¿Podría el Monte Olimpo albergar vida? es una traducción de New Theory: Olympus Mons Could Harbor Water, Life on Mars, un artículo de Universe Today que se publicó hace unos meses y que mencionamos de pasada por aquí, donde se habla...
Spirit, uno de los rovers marcianos de la NASA, lleva ya unas semanas inmovilizado porque sus ruedas están medio hundidas en un suelo especialmente blando, con lo que los responsables de la misión se están pensando muy detenidamente qué hacer para no...
Mars Science Laboratory, a partir de ahora Curiosity - NASA El próximo rover marciano de la NASA, hasta ahora conocido como Mars Science Laboratory, se llamará a partir de ahora Curiosity, un nombre propuesto por Clara Ma, una niña de 12 años...
Dani nos ha pasado el enlace a este entrañable vídeo en el que una niña de cinco años cuenta como es vivir con su hermano autista. Relacionado: Brain Man en español, un más que recomendable documental sobre Daniel Tammet, una persona...
Misterios a la luz de la ciencia. Varios autores; coordinado por Luis Alfonso Gámez. Universidad del País Vasco. ISBN: 9788498600810. Español. A diario vemos como las pseudociencias gozan cada vez de más atención en los medios de comunicación, con brujas, adivinos, tarots,...

El astronauta Donald Pettit fue miembro de la Expedición 6 a la Estación Espacial Internacional, donde estuvo viviendo entre noviembre de 2002 y mayo de 2003, y durante este periodo aprovechó sus ratos libres de los sábados por la mañana para...
El Hubble flota en libertad, Imagen Astronómica del Día, 25 de mayo de 2009 El telescopio espacial Hubble es el protagonista de la Imagen Astronómica del Día de hoy, justo el día después de que el transbordador espacial Atlantis ">tomara tierra en...
La de arriba es una de las dos marcas circulares detectadas en la superficie helada del Lago Baikal uno de los lagos más antiguos (se calcula que tiene entre 25 y 30 millones de años), de los más grandes y el...
Por Nacho Palou -
25 MAY 2009
Al parecer la conocida Fórmula de Euler, para muchos la «fórmula matemática más bella del mundo» ei π + 1 = 0 puede visualizarse gráficamente así: lo cual, como dicen en IAmNotMakingThisUp: Math, que es donde lo vi, «da para una bonita...

El Hubble elevándose fuera de la bodega de carga del Atlantis tras su suelta - NASA TV Esta misma tarde, a las 14:57, y tras comprobar que su tapa se había abierto al recibir la orden, la especialista de la misión Megan...
Este fin de semana del 23 y 24 de mayo se celebra en Madrid el “Finde Científico”, la I Fiesta de la Ciencia y la Tecnología en Madrid, organizado por el Museo Nacional de Ciencia y Tecnología. Aunque me temo de que...
Por Nacho Palou -
19 MAY 2009
William Castleman es el autor de este impresionante vídeo que utiliza la técnica de time-lapse o «secuencia de vídeo acelerada» para comprimir en 50 segundos toda una noche de fotografías de larga exposición. Lo que hizo fue apuntar al cielo nocturno...
The Difference por Randall MunroeA la izquierda, una persona normal, que piensa «supongo que no debería hacer eso»; a la derecha un científico que piensa «Me pregunto si pasa todas las veces» mientras se dispone a activar la palanca de nuevo. Simplemente...
The Reason Project es una organización sin ánimo de lucro … dedicada a difundir el conocimiento científico y los valores seculares de la sociedad. Una fundación basada en el talento de destacados pensadores creativos en un amplio rango de disciplinas y...
Jorge nos envió esta curiosa página que encontró en la hemeroteca de La Vanguardia (1933) donde hay una breve noticia de agencia sobre Nikola Tesla y uno de sus descubrimientos de la época: La energía cósmica. Un viento que puede revolucionar el...
Ya hemos mencionado en unas cuantas ocasiones las TED Talks y reseñado unas cuantas de ellas, todas muy recomendables y no demasaido largas, aunque el problema es que están en inglés. Pero ahora, gracias al TED Open Translation Project, estas charlas...
Por fin se abrió el esperado Wolfram Alpha, la última criatura de Wolfram Research, la empresa más conocida por su revolucionario software Mathematica. Wolfram Alpha no es un nuevo Google, ni acabará con Google. Que no cunda el pánico. Wolfram Alpha...
Tránsito del Atlantis y del Hubble frente al Sol Thierry Legault consiguió tomar esta espectacular imagen del tránsito del transbordador espacial Atlantis y del telescopio espacial Hubble el pasado miércoles 13 de mayo a las 18:17 hora de España (UTC +2), algo...
La aplicación Google Sky Map (de momento está en inglés) para Android es el programa de planetario definitivo. Aunque hay muchos y muy buenos programas de este tippo para ordenadores y móviles, el de Sky Map establece una nueva forma de funcionar...
Por Nacho Palou -
14 MAY 2009
Resto desprendido durante el ascenso - NASA TV Un fragmento desprendido durante el despegue del Atlantis en la misión STS-125 de la NASA ha dañado el escudo térmico de la nave, aunque en principio todo parece indicar que no se trata de...
El transbordador espacial Atlantis y su tripulación despegaron esta tarde con puntualidad absoluta a las 20:01 rumbo al telescopio espacial Hubble en una misión de once días que tiene como objetivo realizar tareas de mantenimiento y mejora en este para dejarlo...
Si todo va según lo previsto esta tarde a las 20:01 hora de España el transbordador espacial Atlantis despegará rumbo al telescopio espacial Hubble para realizar toda una serie de tareas de mantenimiento que lo dejarán mejor que cuando fue puesto en...
A dos días del lanzamiento - NASA/Bill Ingalls En el Centro Espacial Kennedy todo está listo para lanzar al Atlantis con rumbo al telescopio espacial Hubble el próximo lunes a las 20:01 hora de España (UTC +2). Lo contamos en Atlantis/STS-125: A...
The Humble Telescope es una escultura interactiva del estudio ENESS, que pretende llevar las maravillas del espacio a lugares como las ciudades donde la contaminación lumínica impide disfrutar de la vista de las estrellas. En su interior hay una simulación 3-D...
La administración de Barack Obama acaba de encargar una evaluación externa del programa espacial tripulado de la NASA en la que se echará un vistazo a: El proyecto Constelación, que tiene como objetivo sustituir los transbordadores espaciales por los cohetes Ares y...
Hoy, de 11 de la mañana a 7 de la tarde, se celebra en el Parque de Santa Margarita en La Coruña en XIV Día de la Ciencia en la Calle, en el que alrededor de 1.000 estudiantes y profesores de 26...
Hacía tiempo que nuestros amiguitos los números primos no hacían su aparición por aquí, pero este artículo en Ciencia Kanija titulado Nuevo patrón encontrado en los números primos (original en inglés: New Pattern Found in Prime Numbers en PhysOrg) permite a...
Agaporomorphus colberti Cuando la NASA pidió a la gente que le ayudara a escoger el nombre del Nodo 3 de la Estación Espacial Internacional el cómico Stephen Colbert puso en marcha una campaña para que sus seguidores votaran por ponerle su apellido...
Combinar los datos obtenidos de la observación de estrellas variables cefeidas en distintas galaxias con los obtenidos de la observación se supernovas en esas mismas galaxias ha permitido afinar con más precisión que nunca el ritmo de expansión del universo, que resulta...
La esclusa en la que atracan los transbordadores espaciales cuando visitan la ISS La NASA, en colaboración con el equipo de ">Virtual Earth de Microsoft, acaba de presentar una colección de fotografías en 3D del exterior y del interior de la Estación...
Build an Atom es una preciosa forma de visualizar cómo son los átomos y cómo van creciendo y organizándose los electrones en las órbitas según se van haciendo más y más complejos. En la imagen, el átomo de Kriptón, un elemento...
Durante la próxima misión de mantenimiento al telescopio espacial Hubble su cámara principal, cuyo lanzamiento está previsto para la semana que viene, la Cámara Planetaria y de Gran Angular 2, responsable de muchas imágenes espectaculares, será sustituida por una versión más moderna...
El NIF usa flashes de alta potencia para realimentar los láseres - Dave Bullock/Wired.com Wired tiene una galería de fotos con sus correspondientes explicaciones de la National Ignition Facility, la instalación que alberga el láser más poderoso del mundo, con una potencia...
Tras ver las fotos de Fibonacci en La Barceloneta un par de lectores nos enviaron estas fotos de la secuencia numérica en una fábrica en Turku, Finlandia. Estas dos son de Shirokuroneko. y Murdock que también estuvo allí no encontró las...
Uno de los grandes proyectos de Nikola Tesla, “padre olvidado de la tecnología moderna” e “inventor del Siglo XX”, era transmitir energía a través de las ondas de radio y no sólo información como él mismo ya había logrado hacer (aunque...
Por Nacho Palou -
6 MAY 2009
First look: Swine Flu Virus Revealed Esta es la primera imagen publicada del virus responsable de la gripe (porcina, nueva, o A) que se está extendiendo por todo el mundo en las últimas semanas. La obtuvo el Centro de Control de Enfermedades...
La nueva gripe en la Wikiteca de mc2 En los Museos Científicos Coruñeses, que es donde trabajo en el MundoReal™, hemos desarrollado y recopilado una serie de recursos para intentar ayudar a seguir todo lo que se está diciendo y lo que...
Xavi se topó con la sucesión de Fibonacci en La Barceloneta y nos envió un correo con algunas fotos. Está en el Passeig Joan de Borbó en la zona del puerto, donde los fines de semana se instala el mercadillo de...
Un pequeño pero interesante vídeo con dos preciosos detalles: 00:18 – el Sol se sitúa detrás de la Tierra, espectacular es poco 00:45 – la Luna hace su tránsito por detrás de nuestro planeta Bonus: momento conspiranoico del vídeo: En 00:20...
Ahora que se habla tanto de ellos a causa de la gripe porcina, nueva gripe, o gripe A, o como quiera que se llame hoy, en Come the pandemic, the drugs do work se pueden ver datos de diferentes estudios realizados sobre...

Olga nos pasó un enlace a AstroCappella, la página de un grupo de astrofísicos y profesores que cantan a cappella sobre temas de astronomía, con letras «rigurosas y divertidas». Tienen un montón de canciones y vídeos en su sección multimedia, incluyendo...
La web de la Fundación Educativa James Randi tiene en sus páginas un pequeño tesoro, la Enciclopedia de los fraudes, hoaxes, lo oculto y lo sobrenatural donde se pueden encontrar, organizadas de la A a la Z, descripciones breves de muchas pseudociencias,...
Siete segundos «mágicos» en los que la gravedad parece disminuir su fuerza en el interior de un tubo. Se trata del efecto de la Ley de Lenz que ya vimos hace tiempo en otro vídeo muy llamativo, en aquel caso utilizando...
Good Old Girls [YouTube 4:30, disponible en HD] Steve Hammond, uno de los Embajadores del Sistema Solar de la NASA, ha montado este vídeo para conmemorar los cinco años que Spirit y Opportunity llevan trabajando en Marte, sobrepasando las expectativas más optimistas...
Aunque hace años que las autoridades recomiendan vacunarse contra la gripe al menos a ciertos grupos de personas que pueden verse más afectados por la enfermedad el reciente brote de gripe porcina en México ha puesto el asunto de nuevo de actualidad....
Impresión artística del Atlantis y el Hubble durante la próxima misión de mantenimiento - ESA/Hubble Todo está prácticamente listo para que en un par de semanas se lance la cuarta y última misión de mantenimiento al telescopio espacial Hubble, durante la que...
Estaba oyendo en la tele a la corresponsal de TVE en México informar sobre un terremoto de magnitud 5,6 en México y me recordó que leí sobre un detalle que trae de cabeza a los expertos en el tema en el...
Simon Kochen y John H. Conway, el matemático que popularizó el «juego de la vida» y nos iluminó sobre recreaciones numéricas, publicaron The Strong Free Will Theorem [PDF, 135 KB] en Notices of the AMS. Se trata de un curioso trabajo...
El equipo del Lunar Orbiter Image Recovery Project presentaba hace unos días una versión mejorada, pero todavía sin acabar de procesar, de la que en su momento se llamó «la imagen del siglo». Imagen restaurada del interior del cráter Copérnico - NASA/LOIRP...
Potencias de diez (Powers of ten) es un conocido documental de 1977 dirigido y escrito por Charles y Ray Eames para IBM en el que se intentan describir las escalas del universo en un viaje que nos va alejando del punto...

LightSith nos envió un correo preguntando por qué una persona que está a punto de perder el equilibrio -por ejemplo, al borde de una piscina- tiende a girar sin cesar los brazos, en vez de buscar compensar el peso del cuerpo...
¡Señoras! ¡Señoras! No estoy interesado en el romance sino en la CIENCIA. ¡Contrólense! Tesla, el científico célibe. Unas viñetas de K. Beaton, que consiguió encontrarle un punto de humor a la vida del genio....
Imanes: nada tan sorprendente y divertido que poner en manos de un geek. Esta lista de «truquis» incluye cómo poner a dormir los Mac portátiles acercándoles un iman al sensor de la tapa, convertir objetos cotidianos en imanes de nevera, construir un...
Aunque haya habido largas temporadas durante las que no pasó nada nuevo, resumir los 13.700 millones de años de historia de nuestro universo tiene su mérito, así que no le tendremos en cuenta a rvr que se haya pasado en unas cuantas...
Los resultados de la votación de los mayores logros de la NASA (en la tierra) reflejan un poco lo importante que es para el público que los estudios científicos tengan aplicaciones prácticas “tangibles” –como lo son el uso del GPS o conocer...
Por Nacho Palou -
22 ABR 2009
Predicciones sobre el calentamiento global, APOD del 21 de Abril de 2009 La Imagen Astronómica del Día de hoy nos recuerda que aunque nadie esté seguro de cuanto, todo parece indicar que la temperatura de nuestro planeta subirá unos cuantos grados de...
Mimas sobre Saturno - NASA/JPL/SSI The Big Picture recoge en Cassini's continued mission una galería de 24 impresionantes imágenes de Saturno y sus lunas enviadas por la sonda Cassini, que desde el 1 de julio de 2008, y tras acabar su exitosa...
Endeavour y Atlantis en sus plataformas de lanzamiento - NASA/Dimitri Gerondidakis Estos días se pueden ver dos transbordadores espaciales en sendas plataformas de lanzamiento al mismo tiempo, previsiblemente por última vez durante la carrera de estas naves, mientras el Atlantis está listo...
Agujero de la capa de ozono sobre la Antártida. Sept. 2008. Fuente: Earth Observatory, NASA.Hasta mañana se puede votar cuál es el mayor logro de la NASA en sus vías de investigación dedicadas al planeta Tierra. Se pueden votar un máximo de...
Por Nacho Palou -
20 ABR 2009
Dos siglos después del nacimiento de Charles Darwin y 150 años después de la publicación de su libro El origen de las especies la evolución es noticia y ocupa páginas y tiempo en los medios de comunicación: ¿Volverían las especies a evolucionar...
El misterio detrás de estos curiosos rollos de nieve, Nieve enrollada cerca de Lewiston - Fotografía de Tim Tevebaugh. desvelado en Fogonazos, El misterio de los rollos de nieve – se trata de un fenómeno natural bien documentado y conocido como rollo...
Por Nacho Palou -
18 ABR 2009
La NASA acaba de publicar las primeras imágenes del «cazador de planetas» Kepler tras su lanzamiento el pasado 7 de marzo: NASA's Kepler Captures First Views of Planet-Hunting Territory Kepler Eyes Cluster and Known Planet - NASA/Ames/JPL-Caltech Esta imagen muestra el campo...
El Pasapalabra Científico 2009 es una reedición del pasapalabra Científico del año pasado: cinco «roscos» de preguntas y respuestas de la A a la Z relacionadas con el mundo de la ciencia, para jugar en clase o con los amigos. Se pueden...
La Agencia Espacial Europea acaba de publicar unas imágenes obtenidas a partir de los datos obtenidos por los radares a bordo del Envisat de la ESA y los COSMO-SkyMed de la Agencia Espacial Italiana en los que se puede apreciar cómo se...
Una curiosa transformación de un «ocho» de plastilina ensartado en una barra, que se aprovecha de las peculiares características topológicas del objeto para solucionar un problema aparentemente imposible: pasar de tener un aro ensartado a tener los dos. (Vía Cgredan v8.0.)...
Desde hace tiempo se viene hablando de que el uso de células madre podría permitir desarrollar nuevos tratamientos para enfermedades como la diabetes, y según se puede leer en La restauración del sistema inmunitario podría combatir la diabetes los resultados de un...
El Earth Observatory (Observatorio Terrestre) de la NASA cumple diez años. Su objetivo desde que se puso en marcha en abril de 1999 es "compartir con el público las imágenes, historias y descubrimientos sobre el clima y el medio ambiente que...
Por Nacho Palou -
15 ABR 2009
Eyes on the Earth 3D es un sitio web de la NASA en colaboración con el Laboratorio de Propulsión a Chorro y el Instituto Tecnológico de California en el que se pueden seguir dentro de un entorno 3D que se maneja...
El altímetro del sistema PARIS puede seguir a la vez múltiples señales (líneas rojas), mientras que los altímetros convencionales siguen sólo una señal en cada pasada (línea amarilla). Imagen cortesía de ESA. Me pareció muy ingenioso leer en Satnav reflection technology for...
Por Nacho Palou -
15 ABR 2009
La teoría generalmente más aceptada sobre el origen de la Luna, aunque hay algunos hechos que no puede explicar, conocida como la teoría del Gran Impacto, es que hace unos 4.533 millones de años un planeta de un tamaño similar al de...
Ilustración de cómo quedará Tranquility una vez instalado en la Estación Al final ni los fans de Firefly ni los de Stephen Colbert hemos conseguido salirnos con la nuestra y el Nodo 3 de la Estación Espacial Internacional no se llamará ni...
Berlín ha prohibido hoy el cultivo de maíz genéticamente modificado del tipo MON810, el único que es legal en la Unión Europea. Con Alemania son ya cinco los países europeos (los otros cuatro son Francia, Grecia, Austria, Hungría y Luxemburgo) que aplican...
Por Nacho Palou -
14 ABR 2009
La red ChloroGIN monitoriza el nivel mundial diario de clorofila ChloroGIN es una red mundial para medir el nivel diario de clorofila en los mares, según las estimaciones de varios satélites. Los datos obtenidos permiten conocer mejor el comportamiento de los océanos...
Por Esther -
14 ABR 2009
Es azar, no lo llames telepatía es una anotación que preparó Eugenio junto con un grupo de alumnos: trabajaron para entender el factor del azar en la baraja Zener, mediante un análisis estadístico. La conclusión del análisis es que los parapsicólogos...
Animación con los movimientos verticales del volcán Etna. Imagen: ESA. A modo de pulsaciones, el monte del volcán Etna asciende y desciende verticalmente varios centímetros a lo largo de los años. La animación disponible en 15 years of satellite data over Mt....
Por Nacho Palou -
9 ABR 2009
Esta demo del efecto giroscópico en una rueda de bicicleta procedente del departamento de Física del M.I.T no es novedoso pero está muy conseguido. Se hace girar una rueda, cuyo eje cuelga libremente de una cuerda normal y corriente y luego...
La cámara HiRISE (High-Resolution Imaging Science Experiment, Experimento Científico de Imágenes de Alta Resolución) es la más potente de las instaladas a bordo de la sonda Mars Reconnaissance Orbiter de la NASA -de hecho es la cámara más potente que se ha...
Heavens Above ofrece de forma bastante sencilla información sobre lo que se puede ver en el cielo nocturno en un momento dado, desde un lugar concreto, lo cual incluye la Estación Espacial Internacional, satélites de comunicaciones y observación o incluso la famosa...
Este Nuevo Gran Mapa Mental de las Matemáticas [zoom, GIF] hace bueno aquello de «tantas cosas por aprender y tan poco tiempo…» (Vía Ciencia en el XXI.)...
Bruno Sánchez-Andrade Nuño et al. (IAG & MPS, Alemania) Solemos pensar en el Sol como una bola amarilla uniforme que está en el cielo, pero en realidad su superficie no es lisa y está cubierta de los denominados gránulos que suelen tener...
Iniciado en 2001 y terminado en 2005, acaban de ser presentados los resultados de la 6dF Galaxy Survey, un proyecto que tenía como objetivo medir la distancia a más de 100.000 galaxias y realizar un mapa de parte del universo tal y...
Tal y como estaba previsto, se acaba de hacer pública la imagen del trío de galaxias Arp274 que el público votó como objetivo del telescopio espacial Hubble para las 100 horas de astronomía, que se están celebrando ahora mismo en todo el...
Aunque hemos mencionado a James Randi, azote de magufos y defensores de lo paranormal, nunca habíamos hablado de los Premios Pigasus (Pigasus Awards) que otorga la James Randi Educational Foundation. Anunciados el 1 de abril de cada año -es el equivalente anglosajón...
Cómo enseñar matemáticas con un cañón de bolas: la simpática experiencia educativa del IS Valsequillo, en Gran Canaria, donde los jóvenes aprenden «mates» disparando pelotas a una canasta, pero con fundamento. Lo llaman Cannonbasket....
Man on the Moon: Harrison Schmitt en la superficie de la Luna durante la misión Apolo 17; foto hecha por Gene Cernan - NASA Robert Nemiroff, quien junto con Jerry Bonnell lleva publicando la Imagen Astronómica del Día desde el 16 de...
Este bosque de arena parece tanto una cosa como la otra, debido a la naturaleza fractal de las caprichosas formas de los surcos de arena de la playa, en este caso cerca de Santoña. La foto y la anotación son de...
Mañana arranca la celebración en todo el mundo de las 100 horas de astronomía, uno de los proyectos pilares del Año Internacional de la Astronomía 2009. La idea es aprovechar estos cuatro días para realizar todo tipo de actividades, incluyendo observaciones del...
Genciencia publicó un par de anotaciones realmente curiosas acerca de números muy, muy, muy grandes y números muy, muy, muy pequeños. Entre los grandes está el gúgol (10100) y el gúgolplex (10gúgol); entre los pequeños que describen fenómenos «reales» está el tiempo...
Con potencia como para simular la energía liberada en una explosión nuclear, el láser más poderoso del mundo está a la espera de ser probado. En la noticia de Wired cuentan que está compuesto de 192 haces que se disparan de...
Uno de los mayores problemas a la hora de enviar una misión tripulada a Marte, más allá de los obvios desafíos técnicos de la misión y de las consideraciones de si merece la vista desde un punto de vista económico, en especial...
Exoplanet.eu es una enciclopedia de planetas extrasolares: en su catálogo hay ya más de 344 planetas detectados más allá de nuestro Sistema Solar; no podemos llegar todavía a ellos, pero más les vale a las generaciones venideras (aunque tienen 5.000 millones de...
Átomo de carbono de una molécula de azúcar del ADN humano. Nanoreisen (disponible en español) es “un viaje virtual al descubrimiento del micro y del nano cosmos”: comienza a escala humana normal y llega a valores de femtómetros, 10-15 metros (un...
Por Nacho Palou -
29 MAR 2009
El Discovery tomando tierra - NASA [más fotos en los archivos de la misión] Tras casi dos semanas en el espacio durante las que realizó 202 órbitas a la Tierra y recorrió algo más de 9,5 millones de kilómetros el Discovery tomaba...
La ISS con sus cuatro juegos de paneles solares - NASA [más fotos en los archivos de la misión] Ya tenemos imágenes de la Estación Espacial Internacional con sus cuatro juegos de paneles solares instalados, capaces de producir hasta 120 kilovatios de...
Con el lanzamiento hoy de la Expedición 19 a la Estación Espacial Internacional, compuesta por el comandante Gennady Padalka, el ingeniero de vuelo Michael Barratt el turista espacial Charles Simonyi, hay en estos momentos 13 personas en el espacio al sumarse a...
La Agencia Espacial Europea ha declarado hace unos días al satélite GOCE listo para comenzar la fase principal de su misión tras comprobar que los sistemas de guiado funcionan correctamente gracias a los datos recibidos del sistema de seguimiento satélite a satélite,...
El Atlantis entrando al VAB - Foto vía Damaris B. Sarria La vuelta del Atlantis al Edificio de Ensamblado de Vehículos marca el arranque de un nuevo intento -esperemos que definitivo- de lanzar la cuarta misión de mantenimiento al telescopio espacial Hubble,...
PIA10588: Tormenta azul en Saturno - NASA/JPL/Space Science Institute La NASA y Microsoft acaban de anunciar que WorldWide Telescope, el telescopio virtual de la segunda, incorporará más de 100 terabytes de imágenes procedentes del Planetary Data System de la agencia, un repositorio...
Mars Science Laboratory - NASA Además de poder enviar tu nombre a la NASA para que viaje a Marte en un chip que irá dentro del Mars Science Laboratory, cuyo lanzamiento está previsto para el último trimestre de 2011, está también en...
Academic Earth es un vasto almacén de sabiduría: una recopilación de clases y conferencias de las más prestigiosas universidades, profesores y expertos en todo tipo de disciplinas, desde astronomía a religión, pasando por informática, historia, física, filosofía, biología o medicina. Está...
¡Puntos geeks! Send Your Name to Mars es una página donde escribir tu nombre para que sea enviado en una misión de la NASA a Marte en 2011, la del Mars Science Laboratory . Es gratis y cualquiera puede participar; el sitio...
La Tierra fotografiada por la sonda Meteotek08El equipo Meteotek08: De izquierda a derecha Jordi Fanals, Gerard Marull, Martí Gasull, Jaume Puigmiquel y Sergi Saballs. En primer plano, su sonda. The Big Picture le dedica la galería de 28 imágenes Scenes from 30,000...
Hoy se cumplen veinte años de la celebración de la rueda de prensa en la que los químicos Stanley Pons y Martin Fleischmann anunciaban al mundo que habían conseguido producir una reacción de fusión fría a temperatura ambiente, unos resultados que se...
Con el despliegue de su cuarto y último juego de paneles solares la Estación Espacial Internacional es desde ayer el segundo objeto más brillante del cielo nocturno, sólo por detrás de la Luna. Este cuarto juego de paneles solares ha sido instalado...

Estuve leyendo algunas cosas sobre qué ocurre cuando dormimos y qué sucede cuando soñamos, algo que nos ocupa una parte importante de cada día. Había visto por ahí algunas referencias a cosas raras que ocurren debido a la privación de sueño,...
Tenóforo por Martin George/QVMAG Aunque parezca una medusa el animal de la fotografía es en realidad un tenóforo, un grupo de animales similares a estas pero que en lugar de picar a sus presas las capturan gracias a unas células que producen...
Microsoft WorldWide Telescope en la web Microsoft acaba de anunciar un cliente web en versión alfa para su WorldWide Telescope, con el que se puede acceder a la mayoría de las funciones de la citada aplicación sin necesidad de instalar nada salvo...
La Estación Espacial Internacional y el Discovery fotografiados desde el Centro Astronómico de Yebes (Guadalajara), con la Osa Mayor como fondo y la antena de 40 m del observatorio en primer planoDetalle de la foto anterior Juan Luis Cano nos ha enviado...
La Tierra fotografiada por la sonda Meteotek08 La imagen que abre esta ilustración podría venir de los archivos multimedia de la Agencia Espacial Europea, la NASA, o cualquier otra agencia aeroespacial del mundo, y aunque en ese caso quizás tendría algo más...
El Discovery en su aproximación final a la ISS - NASA [más imágenes en los archivos de la misión] Apenas hace unos minutos que el transbordador espacial Discovery ha atracado en el módulo Harmony de la Estación Espacial Internacional donde permanecerá durante...
Closeup of Quadruple Saturn Moon Transit - NASA, ESA, Hubble Heritage Team / M.H. Wong (STScI/UC Berkeley) y C. Go (Philippines) Es cierto que Saturno tiene lunas para dar y tomar (61 según la última cuenta, y cualquier día la sonda Cassini...
Koichi Wakata, astronaura japonés que llegará hoy a la Estación Espacial, permanecerá algo más de tres meses en ella... sin cambiarse prácticamente de ropa. No es que esté condenado a convertirse en el apestado del grupo –que podría suceder– sino que a...
Por Nacho Palou -
17 MAR 2009
La ISS sobre Madrid el 15 de marzo de 2009 por David Montes y Jaime Zamorano En los álbumes 2009_03_15_ISS y 2009_03_16_ISS se pueden ver algunas fotos y animaciones realizadas por David Montes y Jaime Zamorano del Departamento de Astrofísica de la...
El poderío de los láseres no tiene parangón: esta vez los científicos están planeando usarlos cual rayo de la muerte contra las plagas de mosquitos. En pruebas de laboratorio han conseguido un sistema de sensores que detecta su presencia, apunta el láser...
Giroscopio de la sonda Gravity Probe B. Imagen: Don Harley. La particularidad del objeto de arriba es que se trata del la esfera más perfectamente redonda nunca antes construida. Fabricada en cuarzo y recubierta de una finísima capa de niobio, tiene el...
Por Nacho Palou -
16 MAR 2009
Los seres humanos tenemos entre 100.000 y 150.000 pelos en la cabeza (yo concretamente… más bien no). La forma de comprobarlo está explicada en Ciencia Infinita: es un experimento que han titulado pelos cabezones [PDF, 770 KB] que consiste en construir...

El satélite GOCE en órbita - ESA Si no hay ningún cambio de planes o problema de última hora esta tarde a las 15:21 hora de España (UTC +1) la Agencia Espacial Europea lanzará el satélite artificial GOCE (Gravity field and steady-state...
Desde hoy hasta el 28 de marzo está en marcha la edición de este año de GLOBE at night, una iniciativa en la que gente cualquier habitante los 110 países de la iniciativa GLOBE puede participar para intentar establecer cómo de grave...
Con más de un mes de retraso sobre la fecha inicialmente prevista esta noche al fin ha sido lanzado el transbordador espacial Discovery rumbo a la Estación Espacial Internacional en la misión STS-119 de la NASA. Como es habitual, haremos un...
La NASA anunció esta semana que se puede ver vídeo en directo desde la Estación Espacial Internacional, aunque con ciertas limitaciones. Por un lado, dado el limitado ancho de banda disponible, sólo se verá mientras la tripulación esté durmiendo, pues la NASA...

Una opción para hacerse con un telescopio de bajo coste que parece que cualquiera podría construirse sin necesidad de ser McGyver… Y para los menos manitas, siempre nos queda el Galileoscope. (Gracias, Rafa.) Relacionado: Cómo elegir un telescopio, con varios precios...
¡Feliz mes 3 día 14! … más conocido como día de π: el redondo número, abarcador de todos los demás (o casi), encarnación de la aleatoriedad (cuasi)perfecta y constante matemática favorita de los lectores de Microsiervos como demostró sin lugar a...
Google ha anunciado hoy tres nuevas funciones en el apartado dedicado a Marte de Google Earth: Por un lado, hay una nueva capa con mapas históricos al estilo de los que hicieron Giovanni Schiaparelli, Percival Lowell a finales del siglo XIX y...
La Estación Espacial Internacional en su configuración actual - NASA A partir de hoy y hasta finales de mayo la Estación Espacial Internacional podrá ser observada a simple vista desde España en varias ocasiones al atardecer, e incluso, si se produce el...
Tal y como cuentan hoy las noticias, El primer niño seleccionado genéticamente en España ha curado a su hermano. La historia es que los padres tenían ya un hijo con una enfermedad congénita que podría ser curada sólo con un transplante de...
Extremo de un cabello humano (izquierda), papila gustativa de la lengua, los clásicos glóbulos rojos –que siempre impresionan. 15 Beautiful Microscopic Images from Inside the Human Body, imágenes tomadas en su mayoría con un microscopio electrónico de barrido (SEM, por sus siglas...
Por Nacho Palou -
12 MAR 2009
Esta tarde se vivieron unos momentos intensos cuando la tripulación de la Estacion Espacial Itnernacional se vio obligada a ocupar la cápsula Soyuz de emergencia ante el riesgo de choque con un fragmento de basura espacial. Los detalles en La Estación Espacial...
Uno de los proyectos estrella del Año Internacional de la Astronomía tenía como objetivo diseñar y poner en producción y en venta un telescopio asequible para que el mayor número posible de personas pudiera adquirirlo y utilizarlo como introducción al apasionante mundo...
Los avances en las técnicas para la detección de planetas extrasolares nos han permitido pasar en los últimos años de la certeza razonable de que estos tenían que existir a tener pruebas inequívocas de su existencia, e incluso a fotografiarlos, de tal...
Wired entrevista al sociólogo y transhumanista James Hughes acerca de la clínica de fertilidad americana que ofrecía niños «a la carta» donde se examinan algunos ejemplos de lo que ya ha sucedido y puede suceder en el futuro: Designer Babies: A Right...
Tal y como se esperaba el presidente Barack Obama firmó hoy la orden ejecutiva que levanta la prohibición de financiar investigaciones con células madre en los Estados Unidos con dinero federal: Obama reverses Bush-era stem cell policy. Para los científicos que trabajan...
Este artículo en The Economist refiere a un trabajo de unos científicos en el New Journal of Physics que dicen haber confirmado la paradoja de Hardy de la observación cuántica directa, la cual tiene que ver con lo que sucede cuando no...
Carrera corta por La pulga snob (Vía Cambalache.)...
El programa de televisión NASA EDGE">EDGE de la NASA, que se dedica a acercar al público tecnologías y proyectos en desarrollo en distintas instalaciones de la agencia por todo el país, lanza hoy mismo una especie de competición para escoger la mejor...
Colonia de células madre embrionarias humanas Lo prometió durante su campaña, y parece que va a cumplir lo prometido, ya que según cuenta la BBC en Obama 'to reverse stem cell ban' el presidente Barack Obama podría firmar este mismo lunes una...
Kepler en órbita - NASA Esta madrugada ha sido lanzada desde la plataforma de lanzamiento 17B de Cabo Cañaveral la misión Kepler de la NASA, que tiene como objetivo la detección de planetas extrasolares, de los que hasta la fecha conocemos 342,...
El estado de Illinois ha restituido al plutoide Plutón su antigua clasificación como planeta dentro del Sistema Solar, por considerar «injusta» su degradación. La razón de fondo parece ser más bien que Clyde Tombaugh, que nació en una granja de ese estado,...
Vela solar desplegada NanoSail-D. Una breve historia sobre las velas solares cuenta que fue Johannes Kepler quien, hace 400 años, sugirió, inspirado por la cola de los cometas, que sería posible viajar por el espacio en artefactos impulsados por velas. Y que...
Por Nacho Palou -
7 MAR 2009

Mr. George, también conocido como SuperMagnetMan, hace una demostración de lo cuidadoso que hay que ser al manejar imanes de neodimio (en realidad de Nd2Fe14B), los más poderosos imanes permanentes que se fabrican: Él mismo los maneja con guantes, ya que...
Con un interfaz que cualquiera que haya usado Google Maps podrá usar sin ningún tipo de problema, Iceman Photoscan es un proyecto que permite echar un vistazo a través de Internet a Ötzi, el hombre de hielo, con una resolución y detalle...
La sonda de la NASA Cassini captó una nueva luna en el anillo G de Saturno. Imagen: NASA/JPL/Space Science Institute. Hasta ahora el anillo G de Saturno era el único en el que no constaba que tuviera una luna, es uno de...
Por Nacho Palou -
6 MAR 2009
La BBC habla en Bionic eye gives blind man sight del caso de un invidente británico de 73 años, sólo identificado como Ron, que es uno de los tres pacientes en el Reino Unido que están tomando parte en una prueba experimental...
Recreación de cómo será el telescopio una vez terminado.Imagen cortesía de LSST. Internet-Observatory to Provide Movie-like Window on Universe – El LSST pondrá cada noche terabytes de datos en manos de cualquiera que quiera explorar las imágenes. El telescopio de 8,4 metros...
Por Nacho Palou -
5 MAR 2009
Estaba viendo en el telediario de La Primera la noticia de que una clínica de EE.UU. ofrece niños a la carta: se trata del Los Angeles Infertility Center. Al parecer han tenido que suspender su oferta de selección del sexo del niño,...
Según cuenta el estudio Lip-Reading Aids Word Recognition Most in Moderate Noise: A Bayesian Explanation Using High-Dimensional Feature Space aunque no seamos conscientes de ello todos somos capaces de leer los labios con mayor o menos habilidad, por lo que si miramos...
Eclipses luminarium, de Cyprian Leowitz, “describe los eclipses de Sol y Luna ocurridos entre 1554 to 1600 con Viena como punto de observación.”...
Por Nacho Palou -
4 MAR 2009
La votación para escoger el objeto que el telescopio espacial Hubble va a fotografiar para el evento 100 Horas de Astronomía ha terminado, y el objeto ganador ha resultado ser el par de galaxias en interacción Arp 274, con un total de...
Las células madre, con su capacidad de convertirse en cualquier otra célula de nuestro cuerpo, son uno de los campos de investigación más prometedores de los últimos años, aunque también uno de los que más polémica han generado a su alrededor. Colonia...
Acaban de cumplirse 25 años del lanzamiento del Landsat 5, un satélite fotográfico lanzado el 1 de marzo de 1984 que a estas alturas ha superado con creces su esperanza de vida prevista de cinco años. De hecho, es el único de...
Recreación de la misión Phobos-Grunt cerca de Fobos. Fotograma del vídeo Project Phobos-Grunt (YouTube, 10:39, ruso) Mientras un grupo de seleccionados por la Agencia Espacial Europea se prepara para simular una misión completa a Marte en una instalación espacial en Moscú, los...
Por Nacho Palou -
2 MAR 2009
Aunque ya hace unos días que el cometa Lulin pasó por el punto de su órbita más cercano a la Tierra, Rafael Benavides nos recuerda en Previsiones para el Lulin en Marzo que durante todo este mes aún podrá observarse con relativa...
Algunos de mis compañeros de trabajo en los Museos Científicos Coruñeses, con la colaboración de JRMora y de A Fortiori Editorial, se han liado la manta a la cabeza y han puesto en marcha la Colección Ciencia Infinita, que será una serie...
¡Bonita foto! Pues tiene más mérito de lo que parece: la consiguió hacer Jean-Sébastien Busque desde un globo «casero» que se elevó hasta 90.000 pies de altura (28 kilómetros) ni más ni menos, casi llegando al límite de la estratosfera. Esta...
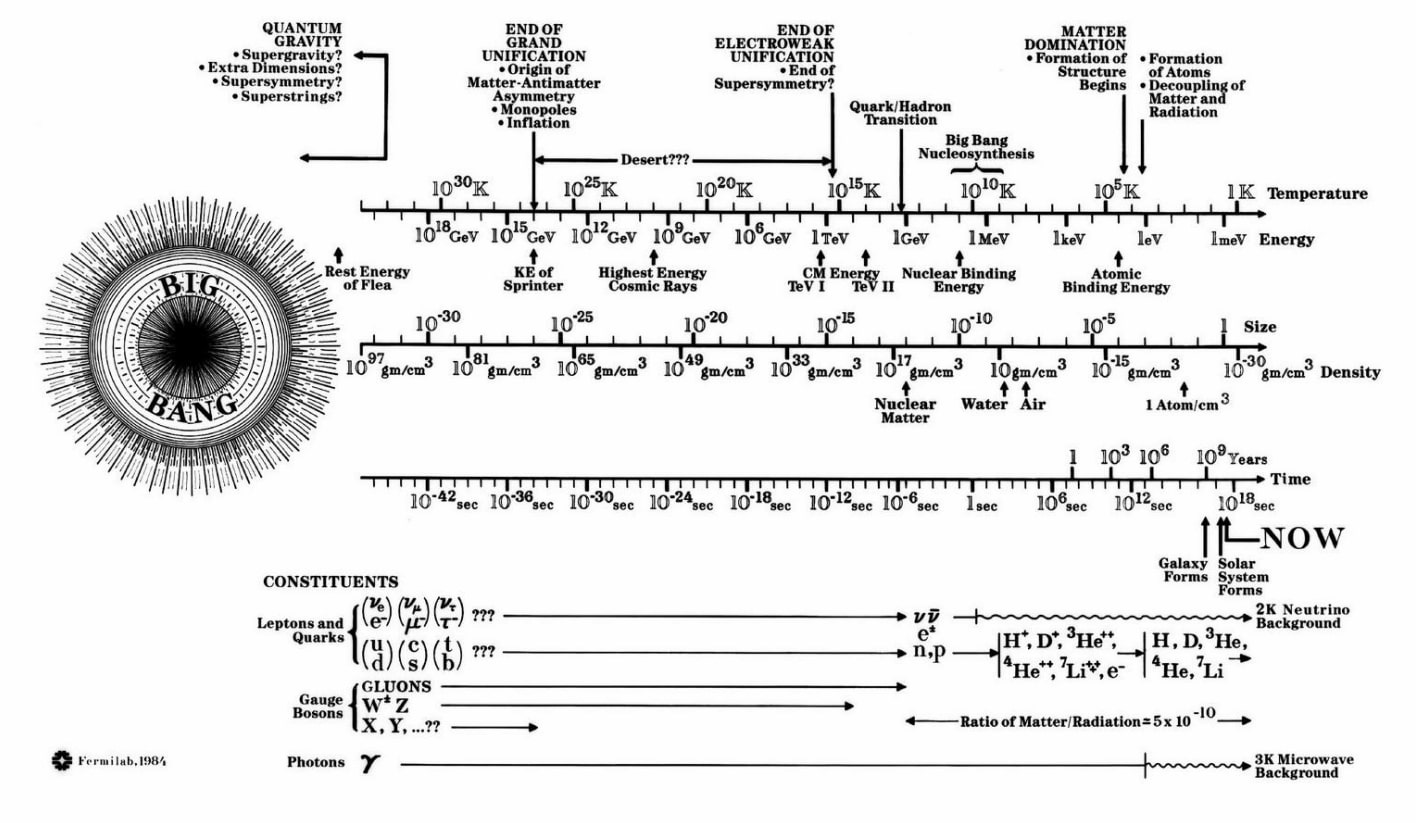
Esta imagen del Fermilab, que data del 1984, resume en varias líneas la Cronología del Universo [PDF], en términos de su temperatura, densidad, el tiempo transcurrido y otros factores. Obsérvese que la escala no es lineal sino logarítmica; esto es especialmente...
La NASA ha lanzado hoy el Orbiting Carbon Observatory, un satélite destinado a medir el comportamiento del CO2 en la atmósfera, aunque en lanzamiento ha fallado y el satélite se ha precipitado al agua en algún lugar próximo a la Antártida....
“Restos” de la supernova del año 1006 en muestras de hielo milenario.Fuente: An Antarctic ice core recording both supernovae and solar cycles. Me entusiasmó leer la anotación Evidence of Supernovae Found in Ice Core Sample, en la que se cuenta cómo hielo...
Por Nacho Palou -
24 FEB 2009
Dos imágenes condensan en el Atlas del conocimiento humano miles de años de historia; un proyecto que Tall&Cute completó el año pasado (y que yo tenía por ahí traspapelado entre el correo viejo). En él se pueden ver los factores e...
Michael De Volder, John Hart / Universidad de Michigan / Materials Research Society. Galleries – The World's Smallest Puzzles recopila en forma de trivial algunas de las mejores imágenes presentadas al concurso “Ciencia como Arte” de la Materials Research Society. La imagen...
Por Nacho Palou -
24 FEB 2009
El cometa Lulin fotografiado por el astrónomo aficionado Jack Newton Como ya comentábamos hace unos días, esta noche se producirá la máxima aproximación a la Tierra del cometa C/2007 N3, también conocido como cometa Lulin cuando pase a «sólo» 0,41 UA de...
Corona formada cuando la luz de la Luna se dispersa por las gotas de agua que forman la nube. El sitio Atmospheric Optics, dedicado a recopilar y explicar los distintos efectos ópticos que se producen en la atmósfera, tiene una sección tipo...
Por Nacho Palou -
23 FEB 2009
Ver vídeoBad astronomer: Why Science is Important [YouTube 4:43] Phil Plait, el autor de Bad Astronomy Blog, explica en este vídeo por qué piensa que la ciencia es importante, y aunque lo explica en más detalle, el resumen es que para él...
2143/22 ≅ π4 Visto de otra forma: la raíz cuadrada de la raíz cuadrada de 2143/22 es igual a 3,14159265… el número π con una precisión de ocho decimales. Esta ecuación salió de la genial mente de Srinivasa Ramanujan, como tantas otras....

Qué simpático este viejuno vídeo del Real-life µ-Tetris (es de 2002) en el que unos científicos metieron 42 microesferas de vidrio de 1 µm (micrómetro: una milésima de milímetro) y las guiaron mediante un láser y un ordenador en lo que...

No conocía este chisme llamado Tubo de Rubens que es un curioso y al clásico experimento que incluye combinar un tubo al que se hacen agujeros con con propano, fuego y algo de música, para visualizar el sonido en forma de...
La Tierra situada delante del Sol, vista por la sonda Kaguya en órbita lunar. Imagen:(C) JAXA/NHK La sonda lunar Kaguya tomó la imagen de arriba el pasado día 10 de febrero, justo cunado la Tierra se coloca delante del Sol, cubriéndola parcialmente...
Por Nacho Palou -
20 FEB 2009
Imagen GFZ Postdam. Eso de ahí arriba con forma de patata es un modelo global del campo gravitatorio de la Tierra (al fondo se oyen las risas de Fobos y Deimos). Ésta fuerza no es exactamente la misma en todos los puntos...
Por Nacho Palou -
19 FEB 2009
Una píldora podría borrar los malos recuerdos: una de esas noticias sobre fármacos que siempre hay que tomarse con cierta cautela, aunque el original se publicó en Nature Neuroscience. A saber cuándo estará disponible, pero en principio dicen que podría ser algo...
El magenta, que parecía ser un color pero decían que no era un color vuelve a existir: Yes, Virgina, there is a magenta reaparición estelar cortesía de Ars Technica. Lo cierto es que no existe ningún color realmente más allá de nuestra...
Punset, el entrañable Yoda de la divulgación científica, acierta en la diana con un artículo sobre las metáforas. ;-)...
El magenta no es color del espectro visible para los humanos: ¿Así que dónde demonios está el magenta? Como bien explica el artículo de Liz Elliott el magenta es un color compuesto por dos longitudes de onda: una de la zona del...
Al parecer la revista Health publicó (no encontré cuando) una lista realizada con un panel de expertos en drogas. Se les pidió que valoraran dos factores: la facilidad con la que la gente se vuelve adicta y lo difícil que les resulta...
Concepción artística de Spirit en Marte - Maas Digital LLC para la Universidad de Cornell y NASA/JPL Desde que Spirit y Opportunity llegaron a Marte el objetivo de los equipos que los gestionan ha sido siempre aprovechar al máximo sus posibilidades y...
Charles Darwin por J. M. Cameron en 1869 Como todos los 12 de febrero desde hace años hoy se celebra el Día de Darwin en coincidencia con la fecha del nacimiento de Charles Robert Darwin, pero este año es en cierto modo...
Complicadas pero bellas igualdades dentro de un grupo muy curioso de los que se podrían llamar números autogenerados. (Vía Ciencia en el XXI.)...
Mi «yo» como «Homo erectus», hace 1,8 millones de años. Devolve Me modifica tu imagen actual para adaptarla al look que se llevaba hace hasta 3,7 millones de años. Basta con subir una fotografía tipo carnet, aplicar la máscara de cara (haciendo...
Por Nacho Palou -
12 FEB 2009
Vista del detector CMS del LHC (2007). Foto © Maximilien Brice / CERN A finales del pasado mes de septiembre una fuga de helio líquido causada por un cortocircuito obligó a parar el apenas arrancado Gran Colisionador de Hadrones, y aunque al...
Las colas del cometa Lulin, Imagen Astronómica del Día del 7-2-2009 Descubierto por el estudiante de 19 años Quanzhi Ye de la Universidad Sun Yat-sen en unas imágenes tomadas por Chi Sheng Lin con un telescopio de 16 pulgadas en el Observatorio...
En 2002 un grupo de investigadores se dedicó a pedir a más de un millón de personas por las calles de Francia que les enseñaran las monedas que llevaban encima. Contaron meticulosamente cuántas monedas eran «euros franceses» frente a las acuñados...
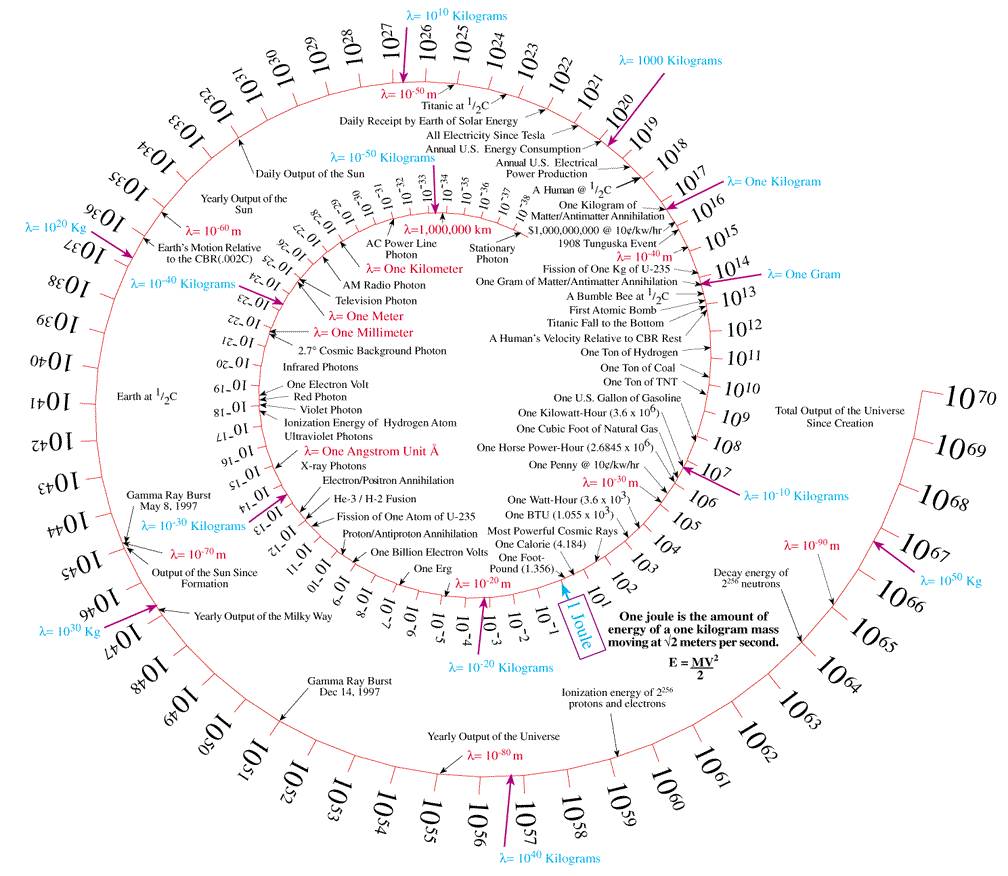
Este interesante gráfico en espiral muestra diferentes niveles de energía que varían entre 10-34 julios (la energía de un fotón) y 1070 julios (la energía total estimada para todo el universo observable). No está muy claro el origen del gráfico porque...
La medida del Radio de la Tierra cuenta una interesante iniciativa promovida con motivo del actual Año Internacional de la Astronomía que consistirá en medir el radio de la tierra mediante cálculos relativos a la sombra proyectada por algunos gnomones en diversos...
Esta semana la NASA conmemora los aniversarios de los tres peores accidentes de su historia, que se saldaron con la muerte de un total de 17 astronautas; los recordamos en la anotación Termina una semana de tristes aniversarios para la NASA...
Dentro de los actos que por todo el mundo se están llevando a cabo para conmemorar el Año Internacional de la Astronomía, y dentro del evento 100 Horas de Astronomía, desde el Space Telescope Science Institute, que es la institución encargada de...
La Agencia de Noticias para la Difusión de la Ciencia y la Tecnología tiene un canal de vídeos en YouTube en el que unas marionetas -las Ciencionetas- realizan con la ayuda de unas manos unos sencillos experimentos que se pueden hacer en...
Ene este curioso árbol matemático cada rama se divide en diversos tipos de fórmulas relacionadas entre sí y los diversos campos que abarca la más exacta de las ciencias. (Vía² Ciencia en el XXI.)...
Dos desarrollos interesantes para Google Earth en HeyWhatsThat, vía Google Earth Blog. Eclipses – animaciones de los eclipses de sol del pasado 26 de enero y del próximo 21 de julio, que será total y visible desde el Pacífico Sur. La...
Por Nacho Palou -
29 ENE 2009
Digamos que no es tan elegante como E=mc², pero es que explicar cómo «funciona» un botijo puede ser más complicado que desentrañár los entresijos de la matería y energía del universo, por lo que se ve. A través de Enchufa2 me...
Datos geofísicos obtenidos desde el aire permiten "ver" el Lago Vostok a través de la capa de 4 km de hielo que lo cubre (A la derecha representadop en azul; rocas en marrón). Imagen de Michael Studinger / Subglacial Lakes and...
Por Nacho Palou -
27 ENE 2009
10² + 11² + 12² = 13² + 14² Curiosidad que se encontró Pepf en NUM63R5, ¡gracias por enviarlo! Bonus: el resultado son los días del año, así que es fácil de recordar....
Un mapa de la Luna de 1969 en el que se puede hacer zoom hasta alcanzar bastante detalle. Está en la web de la colección de mapas de National Geographic. (Vía lunar: Kottke.)...
Unas interesantes reflexiones sobre conductas, refuerzos castigos, experimentos con ratones y el uso que las personas hacemos de los servicios Internet, procedente de una presentación sobre «sistemas de descubrimiento que enganchan», en el blog de Jesús Encinar: El email, como las tragaperras,...
Eclipse anular: el Anillo de Fuego - Fotografía de Dennis L. Mammana (TWAN) del eclipse anular de sol de enero de 1992 En estos momentos está teniendo lugar un eclipse anular de Sol que se puede ver en un corredor de unos...
Panorámica Bonestell desde Marte - Mars Exploration Rover Mission, Cornell, JPL, NASA Spirit y Opportunity, cinco años explorando Marte: Hoy se cumplen cinco años de la llegada a Marte del rover Opportunity, que se unía allí a su gemelo Spirit. Hablamos un...
Discovery/STS-119: Completado el ensayo general, otro importante paso para el lanzamiento de la próxima misión de la flota de transbordadores espaciales de la NASA que estamos siguiendo en Avión Microsiervos, nuestro blog de aeronaútica y tecnología aeroespacial....

No creo que haga falta avisar de que niños, no intentéis esto en casa porque no es tan habitual tener tan a mano un equipo de tomografía por resonancia magnética como, digamos, una batidora, pero por si acaso… En esta demostración...
Me pareció muy interesante leer algunas de las cosas que publicó El Tamiz bajo el título ¿Por qué se producen más catarros y gripes durante el invierno? al que llegué a través de Enchufa2. En estos días invernales, en que quien más...
Discovery/STS-119: En la plataforma de lanzamiento, continúa nuestra cobertura habitual sobre las misiones de los transbordadores espaciales, en esta ocasión en nuestro blog de aeronaútica y tecnología aeroespacial, Avión Microsiervos....
Milky Way Transit Authority por Samuel Arbesman Este es un bonito mapa en el que el autor ha intentado representar la Vía Láctea de tal modo que cada brazo de esta se corresponde con una línea y en el que los objetos...
Faro nuclear abandonado en la costa rusa en English Russia. La anotación Abandoned Russian Polar Nuclear Lighthouses (Faros nucleares abandonados en el ártico ruso), ilustra con varias fotos el estado de deterioro de uno de las decenas de faros con generadores...
Por Nacho Palou -
12 ENE 2009
Discovery/STS-119: Primeros pasos, la primera anotación sobre la próxima misión del transbordador espacial Discovery que se lanzará el próximo 12 de febrero. Desde Microsiervos seguiremos, como de costumbre, el día a día de la misión en nuestro blog de aeronaútica y...

Este precioso vídeo es una recopilación de las fotografías aéreas de Héctor Garrido en las marismas atlánticas andaluzas, que el mes que viene se publicarán en un libro. En la web Armonía fractal pueden verse todas ellas junto con la ubicación...
Toys from Trash es una enorme colección de proyectos prácticos de ciencia y juguetes construidos con objetos convencionales, de los que habitualmente se encuentran por casa. Hay ejercicios de astronomía, matemáticas, física, electricidad y magnetismo, audio, estructuras, fuerzas, biología, algo de magia,...
Por Nacho Palou -
10 ENE 2009
A menudo es muy difícil que apreciemos la belleza y lo extraordinario de las cosas que vemos a diario, y si hay algo lleno de cosas maravillosas y alucinantes que veamos todos los días -si las nubes lo permiten- es el...
La ASAAF en colaboración con la AAM, AstroHenares y el Observatorio de la UCM ha organizado una concentración popular de telescopios y astrónomos en la tarde-noche del próximo sábado, 10 de enero, en la Plaza Mayor de Madrid (a las 18:00). La...
Frankenstein (1931) Una de las curiosas anécdotas de Nikola Tesla que se cuenta en Wizard: The Life and Times of Nikola Tesla es que en los años 30 colaboró con Paramount Pictures para crear toda la parafernalia eléctrica que utilizaba el doctor...
Ordenados de menor a mayor, encabezan la lista: 0, ϕ, e, π, 5 y luego viene el resto, algo más… complicados.

En una de las conferencias de TED titulada Why Things Sync Up?, magistralmente planteada por Steven Strogatz, se mostró este interesante vídeo donde se aprecia con claridad el problema que tuvo el famoso Puente del Milenio de Londres el mismo día...
Esta bonita imagen es de algo no tan bonito: las modificaciones que hay en los cromosomas de las células cancerígenas. Al parecer el ADN de estas células enfermas se mezcla y unos trozos se reinsertan en otros de forma caótica, degradando...
Interesante la charla de Dan Gilbert en TED (2005) que se titula Exploring the frontiers of happiness (Explorando las fronteras de la felicidad), donde a partir del concepto de valor esperado o «esperanza matemática» popularizado y adecuadamente definido por Daniel Bernoulli...
La sucesión de Fibonacci es una conocida serie de números naturales que empieza por 0, 1… y en la que cada siguiente elemento es la suma de los dos anteriores. Empieza así: 0, 1, 1, 2, 3, 5, 8, 13, 21, 34,...

Hipnotizantes imágenes a cámara lenta captadas haciendo vibrar una gota de agua. Si crees que te podrías pasar horas mirando algo así también existe una versión larga en DVD de dos horas de duración: Wasserklangbilder. (¡Gracias por el enlace, Ángel!) Actualización...
Un millón de dígitos de π reunidos en la misma página....
Zulú llevando unas gafas adaptables de Josh Silver. La idea de las lentes adaptables, desarrollada por el profesor Josh Silver, ahora retirado, de la Universidad de Oxford, consiste en desarrollar unas gafas que cada persona pueda ajustar a sus necesidades de corrección...
Por Nacho Palou -
23 DIC 2008
1, 12, 123, 1234… Esta secuencia tan simple es el primer ejemplo de las Secuencias de números consecutivos, una de las tal vez poco conocidas pero fascinantes entradas de MathWorld, la enciclopedia de las matemáticas. Vista así, esa secuencia de números enteros...
Curiosa simulación de los efectos del posible futuro choque entre la Vía Láctea (nuestra galaxia) y la galaxia de Andrómeda, que se acercan en rumbo de colisión la una a la otra a unos 300 kilómetros por segundo. De tener lugar...
Un par de científicos de la Universidad de Indiana publicaron en el British Medical Journal sobre algunos mitos y creencias populares que se dedicaron a investigar y desmontar. El resumen está publicado en The Guardian: Scientists debunk myths y muy resumidos son...
En los 50 años de carrera espacial no sólo hemos conseguido visitar todos los planetas del Sistema Solar* y muchas de sus lunas con diversas sondas espaciales, sino que en este tiempo, y como es lógico, las capacidades de los instrumentos de...
Esta foto captada por la cámara HiRISE de la Mars Reconnaissance Orbiter titulada avalanchas en Marte y de la que ya explicó por aquí Wicho en su día es una de las 10 mejores fotos de astronomía de 2008 según Phil...
En esta paradoja fractal explicada por pseudópodo y basada en la curiosa figura de la Curva de Gosper se aprecia una de las curiosas propiedades de los fractales: aunque la superficie de las siete islas de color que cubren el plano...
Sex, de Catherine Chalmers. Si no tienes mucho reparo, Catherine Chalmers ha fotografiado, con todo detalle y en modo macro, el proceso completo desde el cortejo y la copula hasta que la Mantis religiosa hembra se zampa literalmente al macho que la...
Por Nacho Palou -
15 DIC 2008
Según nuestro conocimiento del universo fue mejorando y aumentando tuvimos que aceptar no sólo que la Tierra no es el centro del universo, sino también que tampoco lo es el Sol, y que de hecho nuestra estrella no es más que una...
El mal tiempo reinante en Florida el pasado 30 de noviembre llevó a los responsables de la misión STS-126 a tomar la decisión de que el transbordador tomara tierra en el Dryden Flight Research Center en la Base de la Fuerza Aérea...
Todos los ejemplares de Popular Science en Google Books, un impresionante archivo para descubrir esta fascinante revista, que se publica desde 1870 o buscar cualquier artículo histórico, ahora disponible en forma de hemeroteca digital. Como complemento para quien sea capaz de...
¡Avances en sistemas lectores de mentes! Al parecer unos científicos japoneses de los ATR Computational Neuroscience Laboratories han conseguido desarrollar una nueva tecnología de análisis cerebral digna de película de ciencia ficción. El sistema permite reconstruir las imágenes que nuestro cerebro...
De forma bastante similar a lo que sucede con la sin duda fascinante espiral de Ulam, resulta que si se numera una espiral así (de modo que los cuadrados perfectos 1, 4, 9, 16... queden alineados) emergen ciertos patrones si se «mira...
878 / 323 = 2,718266... Esta es la mejor aproximación al número e utilizando una fracción de números enteros por debajo de 1.000: ofrece cuatro dígitos de precisión. En cierto modo se parece a la conocida 355/113 que está asombrosamente cerca de...
¿Qué lado del papel aluminio se debe usar para envolver los alimentos, el mate o el brillante? Resulta que es indiferente, según los propios fabricantes. (Vía, El listo que todo lo sabe.)...
«Bota, bota, mi universo rebota». Me encantó la teoría en la que trabaja Martin Bojowald, que es el artículo de portada del Investigación y Ciencia de diciembre. En inglés puede leer completo aquí: Big Bang or Big Bounce?: New Theory on...
The Amazing Show, starring James Randi es un curioso podcast dentro de iTricks, una interesante web sobre magia e ilusionismo. De periodicidad variable, hay publicados ya 14 episodios. A veces se publica uno al mes y hay meses con tres o...
Efecto Doppler relativista / John Walker Excelente anotación la que que se publicó en La Singularidad Desnuda sobre los Efectos ópticos de la relatividad especial y lo que sucede cuando uno se mueve a velocidades próximas a la de la luz. En...
Condiciones meteorológicas adversas durante el día de hoy y unas previsiones poco favorables para mañana han llevado a los responsables de la misión a tomar la decisión de optar por tomar tierra en el Dryden Flight Research Center en la Base de...
Desde el control de la misión se dio el visto bueno al escudo de protección térmica del Endeavour para su vuelta a tierra, con lo que tras la comprobación satisfactoria por parte de la tripulación de las superficies de control de la...
El Endeavour ya está camino de vuelta hacia el Centro Espacial Kennedy, donde tiene previsto aterrizar mañana domingo si las condiciones meteorológicas lo permiten. Partió de la Estación Espacial Internacional a las 15:47 (UTC +1) y, tras dar una vuelta a su...
Igor Ostrovsky es un desarrollador de Microsoft que trabaja en computación en paralelo; escribió una interesante anotación titulada Numbers that cannot be computed donde describe un fenómeno curioso, los números que no son computables. El asunto dista de ser trivial, pero allí...
Las tripulaciones del Endeavour y de la Estación Espacial Internacional disfrutaron de la mañana libre en el día de Acción de Gracias antes de compartir una comida especial para celebrar el día. Comida de Acción de Gracias. Sólo falta añadir agua -...
El úlltimo día completo del Endeavour y su tripulación en la Estación Espacial Internacional durante la misión STS-126 fue dedicado básicamente a recogerlo todo. Así, acabaron de guardar las últimas cosas en el módulo logístico Leonardo, que vuelve a tierra con unos...
James Newman trabaja en la conexión de los módulos Zarya y Unity en diciembre de 1988 durante la misión STS-88 - NASA Atlantis durante la misión STS-98 visto desde la ISS - NASA Con motivo del reciente décimo aniversario del comienzo de...
Metro de la ciencia de Muy Interesante, estación Albert Einstein McrLnx nos pasa el enlace a El gran metro de la ciencia, una preciosa infografía de José Antonio Peñas para Muy Interesante en la que partiendo de los griegos se sigue la...
Mientras las tripulaciones del Endeavour y de la Estación Espacial Internacional trabajaban para acabar de cargar en el módulo logístico Leonardo todo el material que van a traer en él de vuelta a tierra y así poder cerrarlo para luego colocarlo de...
Después de cuatro paseos espaciales que suman algo más de 26 horas y media de actividad total los doce rodamientos de la Junta Solar Rotativa de estribor de la Estación Espacial Internacional han sido finalmente cambiados por otros nuevos y todo el...
¿Deberíamos resucitar un neandertal si pudiéramos? se preguntan en Slate. Aunque Esta historia tenga un poco tintes de Parque Jurásico, podría no estar tan lejos de la realidad como parece. Cada día parece más cercana la posibilidad de recrear especies extintas; la...
Mientras el resto de la tripulación del Endeavour disfrutaba de cuatro horas libres Mike Fincke, el comandante de la ISS, y Don Pettit, que decidió echarle una mano con la tarea, consiguieron por fin solventar el problema que hacía que el Procesador...
Fractals: Hunting the hidden dimension (Michael Schwarz y Bill Jersey, 2008. NOVA / PBS). Un excelente y altamente recomendable documental sobre el fascinante mundo de los fractales. De una calidad de producción inigualable, explora gráficamente lo que son y cuál es...
El tercer paseo espacial de la misión sirvió a Heide Stefanyshyn-Piper y Steve Bowen para seguir limpiando la Junta Solar Rotativa de estribor y cambiar otros cinco de sus rodamientos, con lo que sólo queda uno para cambiar, que será sustituido por...
Otro día de relativa calma en el Endeavour y la Estación Espacial Internacional entre paseos espaciales en el que las tripulaciones siguieron adelante con las tareas de transferencia de equipos y suministros entre ambas naves, aunque también aprovecharon para montar y comprobar...
ø π ∑ ≈ ∞ Una gran recopilación de Símbolos matemáticos: qué son, cómo se leen, cómo se usan y un ejemplo. Sería todavía mejor si estuviera en castellano, pero algo es algo. Actualización (12 de noviembre de 2022) – La anotación...
Heide Stefanyshyn-Piper y Shane Kimbrough llevaron a cabo ayer el segundo paseo espacial de la misión STS-126 en el que de nuevo el objetivo principal fue intentar arreglar la Junta Solar Rotativa de estribor, que lleva meses dando problemas. Shane Kimbrough durante...
Como es habitual en las misiones de los transbordadores espaciales a un día de paseo espacial en la misión STS-126 le siguió un día de «descanso» en el que los astronautas se centraron en tareas a realizar a bordo de la Estación...
Carabela portuguesa encallada en Tarifa © Angel FebreroEl I Concurso de Fotografía de Divulgación Científica, Tecnológica y Medioambiental organizado por la Universidad Carlos III de Madrid y Fnac Parquesur tiene como objetivo concienciar sobre cómo aplicar estas disciplinas al cuidado del medio...
Por Nacho Palou -
19 NOV 2008
Primer paseo espacial de la misión STS-126 a cargo de Heide Stefanyshyn-Piper y Steve Bowen, quienes aparte de retirar un tanque de nitrógeno vacío de una de las plataformas externas de almacenamiento de la Estación Espacial Internacional y guardarlo en la bodega...
Representantes de las empresas premiadas en las distintas categorías con José Pardina (tercero por la derecha), director de la revista Muy Interesante. La semana pasada fuimos amablemente invitados a la entrega de los Premios Muy Interesante a la Innovación en una gala...
Por Nacho Palou -
18 NOV 2008
El módulo logístico Leonardo fue trasladado de la bodega de carga del Endeavour y conectado al módulo Harmony de la Estación Espacial Internacional, con lo que sus tripulaciones comenzaron a descargar los algo más de 7.000 kilos de suministros y equipos que...
...Visto desde el cielo, NASA Earth Observatory, Fires in California Incendios del sur de California desde el satélite Aqua de la NASA. ...Y visto desde la tierra en The Big Picture, California wildfires (yet again) The Big Pcture, Boston.com, David McNew/Getty Images...
Por Nacho Palou -
17 NOV 2008
La primera imagen de la Tierra vista desde la Luna fue transmitida el 23 de agosto de 1966 desde el Lunar Orbiter I a la estación espacial de Robledo de Chavela, en Madrid. A la derecha la versión original, a la izquierda...
Por Nacho Palou -
17 NOV 2008
El Endeavour quedó atracado en la Estación Espacial Internacional a las 22:01 del domingo, hora de España (UTC +1), después de que su comandante realizara la maniobra que permitió a Mike Fincke y Greg Chamitoff fotografiar la panza de este desde la...
La Luna y Saturno – Doug Murray, Palm Beach Gardens, Florida, (EE UU) 30 de noviembre de 2001. Ver en grande. Fotografía tomada por Doug Murray, durante en el encuentro planetario entre la Luna y Saturno en noviembre de 2001, en la...
Por Nacho Palou -
17 NOV 2008
La Tierra vista desde el Endeavour - NASAMás imágenes en STS-126 Flight Day 2 Gallery De camino a la Estación Espacial Internacional la tripulación del Endeavour terminó la inspección inicial del escudo térmico de la nave utilizando el Orbiter Boom Sensor System,...
En este caso en la vasta colección de camisetas π de CafePress....
Tras un lanzamiento sin problemas a la 1:55:31 de esta madrugada (UTC +1) el Endeavour está ya en órbita y rumbo a la Estación Espacial Internacional, a donde tiene previsto llegar el próximo lunes. Separación del tanque principal - NASA/KSC Bodega de...
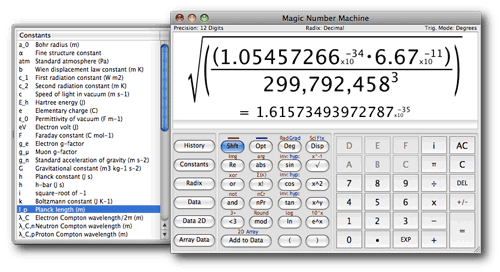
Con tan amenazador aspecto, ha de ser descagarda de inmediato: Magic Number Machine, sólo para Mac OS X. Quien use Windows habrá de esperar a la Calculadora de Windows 7 para poder saborear algo con 25 dígitos de precisión y tantos...
Era algo con lo que se contaba desde que se concibió la misión, era algo que en las últimas semanas se veía como algo ya muy próximo, y finalmente anoche la sonda Mars Phoenix Lander de la NASA se despedía de sus...

Esta preciosa cronología del universo (NASA/WMAP Science Team) condensa unos 13.700 millones de años desde el Big Bang hasta la actualidad, intentando aproximar lo que sería su tamaño en las diversas épocas (incluyendo la inflación cósmica, para algunos un tanto controvertida)....
No hace falta instalar nada para flipar un poco sumergiéndose en este psicodélico Neave Fractal: un viaje por el Conjunto de Mandelbrot directamente desde el navegador. Como bien dice la página «el zoom no es infinito porque hasta los ordenadores tienen...
Curiosa herramienta esta Tabla periódica de los elementos en las que al mover la barra que aparece se van coloreando los diferentes elementos, indicando su estado y cuándo son sólidos, líquidos o gases. Por un lado, es interesante el conocido comportamiento...
32 Nearby Stars es una representación espacial de 32 estrellas cercanas al Sol, situadas a no más de 14 años luz del Sistema Solar –cada recuadro representa un año luz. Con el ratón se puede rotar el plano, también colocándolo sobre...
Por Nacho Palou -
3 NOV 2008
El Mathcaching es parecido al Geocaching, pero en vez de tener que localizar un premio oculto físicamente algún lugar mediante sus coordenadas terrestres hay que encontrarlo en una página web determinada, parte de cuya dirección (URL) está formada por la solución...
Diseño del frontal aerodinámico del tren bala japonés (foto: JR Central Railway Technology) inspirado por la forma del pico de aves como el Martín pescador (foto: Sitio Web del Monasterio de Piedra) ¿Por qué malgastar tiempo y recursos en soluciones tecnológicas peores...
Por Esther -
3 NOV 2008
Visto uno, vistos todos (o casi), pero no deja de ser divertido a la vez que impactante echar un vistazo de vez en cuando a algunos de estos zooms animados sobre el Conjunto de Mandelbrot, esa prodigiosa bestia matemática que descubriera...

Le pusieron unos colores que hacen que parezca más bien «la Tierra en LSD», pero en realidad se trata simplemente de un completo mapa de las anomalías magnéticas de nuestro planeta, donde las zonas rojas indican las mayores «desviaciones» y las...
Este Solar System Visualizer [Flash] es una forma rápida y bonita de echar un vistazo de forma interactiva a nuestro sistema solar «animado», moviéndose con un zoom o utilizando el menú para saltar de planeta en planeta. Recomendable: echar un vistazo...
Desde el siempre recomendable Bad Astronomy llega esta recopilación de detalles curiosos sobre los agujeros negros, titulada Ten things you don’t know about black holes No es su masa, es su tamaño lo que los hace poderosos No son infinitamente pequeños Son...
Arp 147 fotografiada por el Hubble - NASA, ESA and M. Livio (STScI) Llevaba toda esta semana pendiente de que se confirmara si el Telescopio Espacial Hubble volvía a estar en marcha tras el fallo del componente que procesa los datos recogidos...
Se ha puesto de moda denigrar los ordenadores del pasado con frases como «volamos a la Luna con menos potencia de cálculo de la que tengo en mi reloj» o «¿puedes creer que todo el programa Apolo cabía en solo 36K de...
4! + 0! + 5! + 8! + 5! = 40585 (Vía Ciencia en el XXI, desde Futility Closet)...

Tal vez sean los cinco minutos con los que más aprendas hoy, así que atento a todas las técnicas para la fabricación de globos terráqueos: cómo se imprimen los dibujos, se les da relieve, se transforman en semi-esferas a partir de...
Selective Memory en Science News explica cómo dos equipos de científicos han conseguido borrar de forma selectiva de la memoria ciertos recuerdos traumáticos de un ratón. ¡Ya estamos un pasito más cerca de la máquina de Eternal Sunshine of the Spotless Mind!...
El polo sur de Encélado en color falso - NASA/JPL-Caltech Otra espectacular recopilación de imágenes de The Big Picture , en este caso de fotografías de Encélado, una de las lunas de Saturno, tomadas por la sonda Cassini a lo largo de...
Después de que en las dos últimas ocasiones en las que tripulantes de la Estación Espacial Internacional volvieron a tierra a bordo de una cápsula Soyuz TMA los aterrizajes se produjeran a cientos de kilómetros del punto previsto se detectó que esto...
Después de que la NASA decidiera posponer la misión de mantenimiento al Hubble hasta principios de 2009 para poder incluir en ella la sustitución de un componente que ahora mismo hace que el telescopio espacial no pueda enviar a tierra los datos...

Hace algún tiempo reseñábamos Brain Man, un interesante documental de Channel Five sobre Daniel Tammet, una persona que sufre el síndrome de Asperger y que, entre otras cosas, tiene unas asombrosas capacidades en cuanto a la manipulación de números y el...
Me encantó la actuación de Arthur Benjamin en TED (2005) que se titula Lightning calculation and other «Mathemagic» (Cálculos ultrarrapidos y otra «matemagia») donde hace algunas demostraciones impresionantes de cálculos mentales, entre ellos resolver «al vuelo» cuadrados de números de tres,...
Este cuadro muestra la diferencia entre el ancho de banda o capacidad de transmisión de datos «real» de nuestros sentidos al cerebro, frente al ancho de banda de nuestra percepción consciente. Esto último es algo tan bajo como un bit por...

Teresa nos pasó el enlace a The Periodic Table of Videos, una colección de vídeos grabados por un grupo de la Universidad de Nottingham liderado por el profesor Martyn Poliakoff y el periodista científico Brady Haran que habla de todos y...
Tras la decisión de postergar la misión STS-125 de mantenimiento del telescopio espacial Hubble hasta que se pueda preparar un repuesto para el componente que ha fallado en él y que en estos momentos le impide enviar a tierra los datos que...
¿Te mojas más o te mojas menos si corres bajo la lluvia? El artículo Por qué correr bajo la lluvia SÍ merece la pena empieza casi, casi, como el famoso chiste del físico, el matemático, el ingeniero y la vaca: Vamos...
Hace algún tiempo estuve buscando sin suerte por las redes P2P el documental de la serie Megaestructuras de National Geographic dedicado a la construcción del Gran Colisonador de Hadrones, así que cuando vi que Aberron lo había encontrado en YouTube me faltó...
Estuve revisando la charla que dio a principios de año Garrett Lisi en TED que se titula A beautiful new theory of everything y que se ha publicado estos días en vídeo. Este científico combina tres cosas en su vida: el...
Según se puede leer en Hubble update: Looking good so far y en High hopes for healed Hubble la puesta en marcha del «Lado B» del sistema estropeado en el telescopio espacial Hubble que le impide enviar a tierra los datos que...
El telescopio espacial Hubble lleva desde el último fin de semana de septiembre parado sin poder transmitir datos de sus instrumentos de a bordo a causa de un fallo en los componentes electrónicos que se encargan de prepararlos, algo así como si...
Aparentemente no satisfecho con las reacciones que sus artículos a favor del creacionismo y criticando el método científico han creado, Juan Manuel de Prada la emprendía este pasado domingo contra los escépticos en Incrédulos. Pero en realidad hace trampa, y mucha, porque...
Desde hace más de diez años la NASA publica la Astronomy Picture of the Day , también disponible en español como Imagen Astronómica del Día , una web en la que cada día se destaca una imagen relacionada con la astronomía acompañada...
En La Singularidad desnuda explican este curioso mapa logarítmico de nuestro universo: A Map of the Universe, a colación de otra historia sobre una viñeta similar de Xkcd, ambos absolutamente preciosos. Aquí se analiza cómo podría realizarse un mapa a escala...

Galaxia de Andrómeda / Foto (CC) David (Deddy) Dayag Una de las cosas que no conocía y me encantó descubrir leyendo la primera parte de Faster Than the Speed of Light fue algo sobre el tamaño aparente de las galaxias. Como es...
Este vídeo demuestra varias cosas: lo primero, la habilidad que tiene el chef (Kin Jing Mark) para preparar pasta en forma de fideos manualmente. Por otro lado, y no menos interesante, el poderío de la potenciación, que con 12 dobleces repetidos...
El ingente volumen de datos para analizar que generará el inmenso Gran Colisionador de Hadrones (LHC) se calcula en unos 15 petabytes al año (eso son unos 15.000 terabytes). Para procesar esa vasta cantidad de información se ha tenido que recurrir a...
Arte visual a partir de la matemática intrínseca de la música, creada por Glenn Marshall con Processing, un lenguaje de programación open source que suelen emplear los artistas que trabajan con imágenes, animación y entornos interactivos especialmente visuales. (~~ FlowingData ~~)...
Ya están aquí los Premios IgNobel de 2008, entregados anoche por la revista Annals of Improbable Research en una gala en el Teatro Sanders de Harvard. Algunas de las mejores de este año son: Medicina: Dan Ariely, de la Universidad Duke, EEUU,...

Ingenioso híbrido de camiseta-chuleta de matemáticas con unas cuantas formulas que siempre viene bien tener a mano, y que como bonus también pueden salvar al compañero que se siente detrás. Se vende vendía a través de Amazon; también en encarnaciones de...
¡Planetas a la vista! por Mike Salway (IceInSpace), Imagen Astronómica del Día del 30 de septiembre de 2008 En esta foto pueden verse los cuatro planetas rocosos del Sistema Solar. El punto más brillante y alto en la foto es Venus, el...
Aunque su acta de creación fue firmada por el presidente Eisenhower el 29 de julio de 1958, hoy se cumplen 50 años de la entrada en funcionamiento oficial de la NASA. La agencia tiene ya desde hace algún tiempo un sitio especial...
¿Has extraído alguna vez ADN de un tomate? ¿Sabes qué aspecto tiene una proteína? ¿Qué hará la levadura si le tocas las narices? Y... ¿para qué sirve, en definitiva, la ciencia? Por iniciativa del grupo Science Meets Society , un grupo de...
Cuando el domingo pasado empecé a leer el artículo Creacionismo de Juan Manuel de Prada en XLSemanal lo hice suponiendo que sería un artículo contra el creacionismo, aunque para sorpresa mía (o no) en realidad lo defiende... Pero como se dice en...
Durante la noche del sábado al domingo pasados un componente crítico del telescopio espacial Hubble, en concreto el que se encarga de procesar los datos recogidos por sus diversos instrumentos y de enviarlos a tierra, falló, haciendo que los ordenadores de a...
Mi láser lidar ha detectado nieve cayendo desde el cielo. Se evapora antes de llegar al suelo, pero puede que más tarde llegue hasta abajo. La Phoenix Mars Lander cuenta que ha detectado nieve de agua en Marte usando su LIDAR, un...
Windows on Earth es un simulador que permite observar la superficie de la Tierra como si se mirase a través de alguna de las ventanas de la Estación Espacial Internacional (ISS), a 360 kilómetros de altura. Funciona directamente en el navegador;...
Por Nacho Palou -
29 SEP 2008

A la cuarta fue la vencida y anoche por fin SpaceX consiguió poner en órbita uno de sus cohetes Falcon 1, tal y como cuentan en SpaceX successfully launches Falcon 1 to orbit. Falcon 1 despegando © 2008 Space Exploration Technologies Corp....

Estoy indagando desde hace tiempo sobre el origami, el arte japonés de la papiroflexia, a raiz de una apasionante presentación de Robert Lang en TED, que me dejó totalmente impactado por los avances en «origamis modernos» que allí explicó que ha...
Esta tarde, con una reentrada controlada sobre el Pacífico que se iniciará a las 15:30 hora de España (GMT +2), termina la misión del Vehículo de Transferencia Automatizado Julio Verne de la Agencia Espacial Europea, el primero de su tipo en ser...
The Big Picture publicó algunas fotografías impresionantes del cosmódromo ruso de Baikonur, la base desde donde Rusia suele lanzar sus misiones espaciales. Merece la pena echarle un vistazo a algunas de las bestias mecánicas que por allí han circulado. (Lo ví...
Tal y como estaba previsto esta mañana Zhai Zhigang, uno de los tres tripulantes de la nave Shenzhou 7, se convirtió en el primer astronauta chino en realizar un paseo espacial, paseo que duró unos 15 minutos: Taikonaut Zhai's small step historical...
Me entero un poco tarde de la convocatoria de este año, ya que se celebra hoy mismo, pero desde 2005 se viene celebrando La Noche de los Investigadores, un acontecimiento que se celebrará en 30 países y más de 150 ciudades europeas...
El pasado viernes se producía una fuga de helio líquido en el Gran Colisionador de Hadrones en el sector 3-4, entre los instrumentos Alice y CMS, probablemente causada por un cortocircuito que a su vez habría dañado las conducciones de helio. Sala...
Me encantó cuando la leí en el libro de Taleb en Los Cisnes Negros, así que no me resisto a publicarla ahora que la he reencontrado por casualidad en un blog: La paradoja del pavo – Un pavo es alimentado durante mil...
1RSX J160929.1-210524 y su planeta / Gemini Observatory La estrella se parece a nuestro Sol y tiene un nombre tan raro como 1RSX J160929.1-210524. Está a unos 500 años luz de la Tierra. El planeta acompañante tiene unas 8 veces la masa...
Una fuga del helio líquido que se utiliza para mantener los imanes del Gran Colisionador de Hadrones a 1,9 kelvin hizo que ayer la temperatura de aproximadamente cien de estos situados en el sector 3-4, entre los instrumentos Alice y CMS, subiera...
El transbordador espacial Endeavour está desde este mediodía en la plataforma de lanzamiento 39B del Centro Espacial Kennedy, en principio para ser preparado para la misión STS-126, pero listo para ser preparado en diez días para el lanzamiento de la misión STS-400...
A punto de celebrarse los 400 de la, hasta ahora supuesta, invención de telescopio por el holandés en 1608, un estudioso avala la teoría de que el telescopio se inventó en Gerona y no en Holanda. Lo habría hecho el óptico catalán...
Por Nacho Palou -
19 SEP 2008
Plétora de Piñatas 15-9-2008 - Mauro Entrialgo/Público.esSeñor taxista: Percibo que circula usted a una velocidad próxima a la de la luz… Mientras mantiene el aire acondicionado a una temperatura cercana al cero absoluto. Perdone mi pregunta pero, ¿no estará usted intentando colisionar...
Ignasi de PS3GRID-GPUGRID nos escribió para contarnos que están reclutando voluntarios para unirse a su red de computación distribuida. Esta red tiene la particularidad de que utiliza la potencia «sobrante» de las consolas PlayStation3 de Sony y de las tarjetas gráficas Nvidia...

La gracia del artilugio no está en cómo oscila, sino en que delata la rotaión de la Tierra.

El Telescopio de Herschel: su base mide unos 12 metros de diámetro Una de las más impresionantes instalaciones que tuvimos la suerte de ver en nuestra visita al Observatorio Astronómico de Madrid fue el Telescopio de Herschel de 25 pies de longitud,...

Tuvimos el otro día la oportunidad de disfrutar de una «jornada astronómica» organizada por la gente de ACTA y hacer una visita al Observatorio Astronómico de Madrid y al Planetario de Madrid, así como asistir a algunas interesantes conferencias; aprovechamos para hacer...
Aunque será el Discovery el transbordador que lleve a cabo la cuarta misión de mantenimiento al telescopio espacial Hubble las normas de la NASA exigen que para esta misión esté listo para su lanzamiento un segundo transbordador en caso de que el...
"Ver todo el universo conocido", el botón más chulo nunca antes visto en una aplicación Flash. El proyecto 4D2U (requiere Flash, en inglés y japonés), desarrollado por el Observatorio Astronómico de Japón, contiene en la ventana del navegador la jerarquía de todo...
Por Nacho Palou -
12 SEP 2008
Para cotillear un rato en LHC Compact Muon Solenoid Experiment Webcams se pueden ver, a través de una webcam y en directo, las instalaciones del Gran Colisionador de Hadrones y sus alrededores. (Vía UX Magazine.) Sobreviví al experimento del LHCGran Colisionador de...
Por Nacho Palou -
11 SEP 2008
I Survived the Large Hadron Collider Experiment por MadSciStuff.com Voy a pedir una ya mismo, antes de que se acabe el universo ;-) Actualización [Alvy]: Otra también muy graciosa de Neatorama: ¡Hurra! ¡Sin agujeros negros! ¡Viva la Ciencia!Yo sobreviví al Gran Colisionador...
Tras ver a 3,14 en un café de Bélgica y conocedores de que a mi me tira mucho la circular constante, unos cuantos lectores del blog nos han enviado otras apariciones de π en diversas situaciones reales que les resultaron cercanas, algunas...
Hoy, entre las 9 y las 10 de la mañana, se producirá un importante paso para la puesta en marcha definitiva del Gran Colisionador de Hadrones, el acelerador de partículas más grande y potente del mundo, con la inyección de los primeros...
Si alguna vez acabamos destruyendo el mundo, la última voz en oirse probablemente sería la de un experto diciendo que «eso no puede suceder».– Peter Ustinov, escritor y actor(… Let’s Roll!)bonus track: fin del mundo versión Donnie Darko...
La Agencia Espacial Europea ha publicado las primeras imágenes del encuentro del pasado viernes de la sonda Rosetta con el asteroide 2867 Šteins en El asteroide Steins, un diamante en el espacio contemplado por la nave Rosetta, de la ESA. Steins visto...

Me pareció curiosísima esta charla de Ron Eglash en TED titulada Fractales Africanos (2007). Su investigación como matemático se centra en un área llamada etnomatemáticas; estuvo durante muchos años buscando desde una avioneta imágenes fractales, cuando veía una, bajaba a explorar...
El otro día se anunciaba el probable 45º primo de Mersenne y antes de que siquiera haya terminado la comprobación se ha anunciado que otro ordenador ha encontrardo el que podría se el 46º, que también se está comprobando. Es un poco...
Rosetta y Šteins - ESA, imagen por C.Carreau Hoy se produce la máxima aproximación de la sonda Rosetta de la Agencia Espacial Europea al asteroide 2867 Šteins, con estas operaciones programadas según se puede leer en Agenda del sobrevuelo de la nave...
El transbordador espacial Atlantis está desde hace apenas unas horas en la plataforma de lanzamiento 39A del Centro Espacial Kennedy, listo para ser lanzado en la misión de mantenimiento al telescopio espacial Hubble el próximo 8 de octubre. Atlantis camino de la...
Me pareció brillante esta idea para un cuadro: la sin duda más famosa imagen de Albert Einstein construida a base de dados, en alusión a su recordada, descontextualizada, malinterpretada pero en cualquier caso inmortal frase. Esto lo encontré en Ciencia en el...
Con esta preciosa fórmula 3-D de Jürgen Köller la gente de Neatorama se ha hecho unas camisetas chulas que venden en su tienda por 10 dólares: I Love Math. El bonus nerd es que las hay también de biología, química y...
Durante este verano Luis Alfonso Gámez estuvo publicando una serie de artículos en El Correo en los que día a día iba explicando la verdad detrás de 42 supuestos misterios de dentro y fuera de este mundo, misterios que van desde la...
Con motivo del inminente encuentro de la sonda Rosetta con el asteroide Šteins la Agencia Espacial Europea ha relanzado Rosetta Blog (hay también feeds RSS por categorías) como una fuente no oficial de información para el público en general sobre este. La...
Desde cómo funciona a la importancia de encontrar el bosón de Higgs, pasando por qué hacen los distintos instrumentos que forman parte de él y qué preguntas esperan responder los científicos al ponerlo en marcha, es sorprendente la cantidad de cosas...
Esta preciosa creación llamada Blue Cells es una interpretación en Flash del basada en los célebres autómatas celulares del Juego de la Vida de Conway. Ha sido creado por Grant Robinson, quien también tiene otra versión más colorida llamada Heatmap. Las...

Algunas ideas sobre la geometría de las torres de Gaudí, con toques fractales, en Figures for «Gaudí’s strange geometry, un análisis visual de Cameron Browne....
Después de casi un año en su interior Opportunity recorría el pasado jueves los últimos 6,8 metros que le quedaban para salir del cráter Victoria usando como camino las mismas rodadas que había creado al entrar en él el 12 de septiembre...

Esta breve charla de la física Patricia Burchat en TED es una de las más amenas y explicativas que haya visto nunca sobre la composición del Universo, donde explica la diferencia entre la materia «convencional» de la materia oscura y la...
El proyecto GIMPS ha anunciado que el pasado día 23 de agosto encontró un número que podría ser el 45º primo de Mersenne. Ahora están llevando a cabo la comprobación, un penoso cálculo que no estará terminado hasta mediados de septiembre. En...
Square-Hole Drill in Three Dimensions es una demostración animada en 3-D de cómo trazar un cuadrado con un mecanismo que combina piezas circulares y el curioso Triángulo de Reuleaux: uno de los lados tiene un movimiento completamente circular mientras que con...
Tal y como había anunciado hace unos días la NASA ha presentado la primera imagen pública del telescopio espacial GLAST, obtenida tras unas 95 horas de observación: First Light! Se trata de una panorámica de todo el cielo en la que la...
El pasado viernes el transbordador espacial Atlantis fue llevado del Orbiter Processing Facility, el edificio en el que se revisan estas naves entre misiones, al Vehicle Assembly Building, donde durante el fin de semana se unió al tanque principal de combustible y...
Algunas fórmulas matemáticas en las que aparece el número i (la raíz cuadrada de -1, un número denominado imaginario) tienen como resultado números bastante poco imaginarios; algunos incluso son enteros, aunque suele distar de ser trivial el cálculo preciso. La fórmula matemática...
Si tienes algo de tiempo libre, un terreno amplio detrás del jardín y unos cuantos miles de millones de euros tal vez te apetezca construir un superacelerador de partículas para jugar a los científicos locos. The CERN Large Hadron Collider: Accelerator,...
Del departamento de Cosas Interesantes que Pasaron Mientras Estaba de Vacaciones, los reponsables del telescopio espacial Hubble celebraban su cien milésima órbita en algo más de 18 años de servicio con esta espectacular imagen del cúmulo estelar NGC 2074: Hubble Unveils Colorful...
Este interesante mapa, publicado en un artículo de Current Biology y explicado en The genetic map of Europe (New York Times) muestra las relaciones entre las ligeras diferencias genéticas de 23 poblaciones europeas que participaron en un estudio. El mapa de...
La juventud de un ser no se mide por los años que tiene, sino por la curiosidad que almacena.– Salvador Paniker(Vía La Huella Digital)...
Los primos permutables son números como 919 ó 311, en los que podrías colocar sus dígitos en cualquier orden y el resultado seguiría siendo un número primo. La lista de los primos permutables no es muy larga, empieza algo bastante obvio como...
La teoría del todo: El origen y destino del universo. Stephen W. Hawking. Editorial Debate, 2007. 128 páginas, español. ISBN: 9788483067529. En inglés: The Theory of Everything: The Origin and Fate of the Universe. Este libro recoge la transcripción de siete...
A través de Tecnología Obsoleta he descubierto este gráfico que según comentan es uno de los grandes clásicos de la ilustración científica. Se llama The Geologic Time Spiral y muestra visualmente cómo entender la «senda del tiempo» de nuestro planeta a...
El Gran Colisionador de Hadrones ya tiene fecha oficial de puesta en marcha, que será el próximo 10 de septiembre salvo causas de fuerza mayor: CERN announces start-up date for LHC. Vista del detector CMS del LHD (2007). Foto © Maximilien Brice...
Lanzada el 2 de marzo de 2004 por un Ariane 5 la sonda Rosetta de la Agencia Espacial Europea tiene como objetivo encontrarse con el cometa 67P/Churyumov-Gerasimenko en 2014 y estudiarlo mediante los instrumentos que lleva a bordo, así como mediante el...
Un resumen de todas las misiones que le quedan a la flota de transbordadores espaciales de la NASA desde ahora hasta que sea retirada del servicio activo, sacado de NASA Sets Launch Dates for Remaining Space Shuttle Missions y de la Wikipedia:...
Vista del detector CMS del LHD (2007). Foto © Maximilien Brice / CERN Boston.com ha publicado una espectacular galería fotográfica del Gran Colisionador de Hadrones, que ya está prácticamente listo: Large Hadron Collider nearly ready. Seamos francos: vistas las fotos, así tal...
Desde España no puede verse, pero desde estos webcasts que ha recopilado Javier Armentia en Eclipse a la Europea, sí. Empieza a las 11:41 hora peninsular, hasta las 13:45. Shelios para la Universidad Politénica de Madrid - desde Novosibirsk, Siberia.NASA Sun-Earth...
En plan telegráfico porque estoy de viaje, más información esta noche: Hasta ahora teníamos evidencias indirectas de la presencia de agua en Marte gracias a observaciones realizadas por sondas en órbita alrededor del planeta y, en especial, por unos fragmentos expuestos por...

Ruth Jarman y Joe Gerhardt, que firman sus trabajos como Semiconductor, tomaron una serie de imágenes del Sol en distintas bandas espectrales obtenidas por diferentes sondas espaciales y las montaron como una secuencia de imágenes en el vídeo Brilliant Noise en...
The Genographic Project, en español El Projecto Genográfico es una interesante inciativa de National Geographic que consiste en investigar la pregunta ¿De dónde venimos realmente? mediante los análisis de ADN de miles y miles de personas, buscando rastros de sus antecesores...
Un físico de General Electric se dio cuenta hace unos 70 años de que así, en general, Los números suelen empezar por «1». Con el tiempo a aquello se llamó Ley de Benford (o Ley del Primer Dígito) en su honor,...
Este transbordador espacial Burán soviético parece que acabó en un desguace, según unas fotos que alguien envió al siempre interesante sitio de curiosidades English Russia: Where Do Shuttles Go? Su único vuelo, que ni siquiera fue tripulado, fue allá por 1988....
Hoy he recibido un ejemplar de Misterios a la luz de la ciencia por cortesía de Luis Alfonso Gámez, su editor. De la tapa trasera: ¿Por qué atraen tanto a la gente los extraterrestres, los monstruos, la comunicación con los espíritus, las...
President Eisenhower Presents NASA Commissions: Aunque la NASA comenzó a funcionar oficialmente el 1 de octubre de 1958 con el objetivo de realizar investigaciones civiles en el campo de la aeronáutica y de los vuelos espaciales, hoy se cumplen 50 años de...
Después de darle muchas vueltas al tema y de probar varias formas de hacerlo el brazo robot de la sonda Phoenix Mars Lander de la NASA consiguió finalmente hacerse con una muestra de suelo helado para someterlo a análisis en uno de...
Como es bien sabido las simpáticas abejas utilizan sus «bailes» y movimientos para indicar las distancias a sus objetivos, pero al parecer según las diferentes familias de abejas (hay nueve en todo el planeta) lo hacen de un modo u otro. En...
Richard Branson y Burt Rutan hicieron esta mañana la presentación pública del Virgin Mothership, antes conocido como White Knight Two, el avión nodriza que llevará los SpaceShipTwo de Virgin Galactic hasta una altitud de 50.000 pies antes de soltarlos para que estos...

Otro vídeo de esos que debí perderme y me encontré por casualidad, esta vez a través de Ciencia en el XXI. Es un mini-documental titulado Pulpos: Suave inteligencia (2007), toda una demostración visual de cómo actúan estos curiosos animales: La inteligencia...
Después de casi 50 años de funcionamiento la NASA tiene una enorme e interesantísima colección de fotografías y vídeos en sus fondos, que además, dado el carácter público de la agencia, están disponibles para cualquiera que las quiera utilizar sin ánimo de...
Un curioso artículo en Scientific American explicando desde un punto de vista real por qué un superhéroe como Batman podría existir en el MundoReal™. Why Batman Could Exist--But Not for Long (Por qué Batman podría existir --aunque no por mucho tiempo -...
Por Nacho Palou -
21 JUL 2008
Preguntándose qué hay de cierto o de leyenda en el dicho aquel de que una imagen vale más que mil palabras, José Muelas decidió darle una vuelta: partió de ciertas premisas y de las bases de la Teoría de la Información de...
Una cuna del saber como el M.I.T. genera una cantidad de material audivisual impresionante cada año, de modo que ahora han decidido abrir al público MIT TechTV, algo medio YouTube medio archivo de televisión donde pueden encontrarse todos los materiales publicados...
En más del 40 por ciento de la superficie terrestre se producen vientos de más de 6 metros por segundo, mucha de ella correspondiente a zonas que no se están explotando. Actualmente menos de una décima del 1 por ciento de...
Por Nacho Palou -
17 JUL 2008
Dos de los instrumentos más importantes que lleva a bordo la Phoenix Mars Lander de la NASA son sus cámaras, pues son imprescindibles para que los controladores de la misión sepan qué está haciendo la sonda y qué está pasando a su...
He aquí otro vídeo de nuestras intervenciones en Solo ante el peligro, el late night de Paramount Comedy presentado por Juan Solo. En esta ocasión Wicho cuenta algo sobre La vida de los astronautas en el espacio. Esta anotación publicada hace...
Como por ejemplo, Nikola Tesla como protagonista de un billete de 10 millardos (!) de dinares yugoslavos de 1993. Recopilados en Physicists of the 20th Century on Banknotes [PDF, 5 MB] que publicó la revista The SPS Observer del año pasado. También...
¡Ah! Ahora que llega el buen tiempo y la época de playa y piscina, qué mejor que recordar un clásico entre los clásicos que investigado y rescatado por El Listo que Todo lo Sabe: ¿Es cierto que si te bañas o haces...
En los antiguos archivos de El Acertijo (número 6, pág 15), Rodolfo Kurchan enunciaba este curioso problema: Con los nueve dígitos del 1 al 9, sin repetirlos, intentar armar una fracción que se aproxime lo más posible a pi: 3,1415926… Entre las...
A Modern-Day Sangaku es una preciosa galería fotográfica que muestra cómo en 2006 George Hart y un montón de ayudantes construyeron este impresionante objeto geométrico de más de dos metros de diámetro. La estructura se construyó con 75 módulos que eran...
Con prisas porque en unos minutos salgo de viaje, nuevos análisis de muestras de origen volcánico traídas de la Luna durante el programa Apollo revelan que hace unos 3.000 millones de años había agua en nuestro satélite que no provenía del impacto...
El pasado mes de abril la cápsula Soyuz-TMA en la que Peggy Whitson, Yi So-yeon y Yuri Malenchenko volvían al Tierra después de su estancia en la Estación Espacial Internacional aterrizó a unos 420 kilómetros del punto previsto. Durante cerca de media...
La galaxia espiral NGC 5907. Foto © R Jay GaBany Que un astrónomo profesional haya calificado esta fotografía como una de las más asombrosas que ha visto en su vida es un buen aval para una imagen impactante: El fantasma de una...
Después de disfrutar de un fin de semana relajado por aquello de la celebración del 4 de julio al equipo de la Mars Phoenix Lander le espera una semana crucial para la misión en la que intentarán analizar una muestra de suelo...
Ver este vídeo [YouTube, 7 seg.] escuchando bien lo que pronuncia el protagonista. Reproducir de nuevo el vídeo, pero cerrando los ojos, o mirando a otro lado y esta vez escuchar atentamente lo que pronuncia el protagonista. (!!!) Este extraño efecto...
Agustín me avisó por correo electrónico de que Li Xian-Jin ha publicado una demostración de la Hipotesís de Riemann en arXiv.org: A proof of the Riemann hypothesis [PDF v2, 40 págs.] Resumen - Aplicando el análisis de Fourier en campos numéricos, se...
Estas partículas subatómicas tan monas de The Particle Zoo son muñequitos que se venden a unos diez dólares cada una. Además de sueltas, también se venden agrupadas por afinidad, están rellenas de material apropiadamente ligero o pesado según sea cada una...
Puesta en órbita en octubre de 1990 por el transbordador espacial Discovery en la misión STS-41 la sonda Ulysses es un proyecto conjunto de la Agencia Espacial Europea y de la NASA para estudiar el Sol desde fuera del plano de la...
Ejemplos: Quark – Es la cosa más pequeña que puedas encontrarte en este asqueroso mundo. Un quark tiene un aspecto similar a un Lacasito chupado visto a un millón de kilómetros. Principio de incertidumbre – Este principio viene a decir que no...

Hoy, tras cuatro años en órbita alrededor de Saturno, termina de manera oficial la misión principal de la sonda Cassini de la NASA: Cassini to Earth: 'Mission Accomplished, But New Questions Await!'. PIA03883: Impresión artística de la inserción orbital de la sonda...

Árboles caídos en la zona afectada por el evento fotografiados por la segunda expedición de Leonid Kulik en 1927 Hoy se cumplen cien años de la explosión de origen desconocido que arrasó una zona de 50 kilómetros de diámetro en Tunguska, una...
Con prisas mientras BlogAsturias 2008 está a punto de empezar, un par de enlaces sobre los resultados recién anunciados por el equipo de la Phoenix Mars Lander que indican que el suelo marciano tiene los nutrientes necesarios como para que se pudieran...
El proceso de inscripción en la selección de astronautas que está llevando a cabo la Agencia Espacial Europea ya está cerrado y ahora de los miles de solicitudes la agencia se quedará con entre 700 y 1.000 para pasar a la siguiente...
Del twitter de la Mars Phoenix Lander: ¿Listos para una celebración? Bueno, pues preparaos: Tenemos HIELO!!!!! Sí, HIELO, *HIELO DE AGUA* en Marte! El mejor día!! Más información en Bright Chunks At Phoenix Lander's Mars Site Must Have Been Ice, donde se...
Bucles descubrió a través del programa divulgativo Alterados por Pi una interesante referencia a los dados no transitivos. Son dados con puntuaciones diseñadas especialmente de modo que tienen la siguiente curiosa propiedad, por ejemplo estos dados de Efron propuestos por Bradley Efron:...
No está muy claro si ha sido por todas las sacudidas que se le han dado con el vibrador del filtro que hay a la entrada del horno número 4 del Thermal Evolved Gas Analyzer (TEGA), el instrumento de la Phoenix Mars...
Antonio nos escribió para contarnos que el otro día con motivo del partido de fútbol de la selección España hicieron la tradicional «porra» de apuestas entre los amigos. Pero llevaron el juego a un nuevo metanivel: Hicimos la tradicional porra, pero luego...
Un aterrizaje de libro marcó el final de una misión también de libro en el que el transbordador espacial Discovery y su tripulación colocaron en órbita el componente principal del Kibō de la Agencia Japonesa de Exploración Aeroespacial y acoplaron a este...
El Discovery y su tripulación ya tienen permiso para volver a casa después de que los datos e imágenes tomadas con el Orbiter Boom Sensor System durante el día 12 de la misión hayan confirmado que el escudo de protección térmica de...
Impact Calculador de Down 2 Earth es, literalmente, una calculadora donde eliges los datos precisos del «pedazo piedro» que quieres que choque contra la Tierra y te calcula cuán vasta sería la destrucción de su impacto. El original está en inglés pero...
Aunque casi el 85% de los bosques originales de España han desaparecido, entre 1990 y 2005 la recuperación se ha incrementado en más de un 30%. Utilizando datos de fuentes como la FAO (Organización de las Naciones Unidas para la Agricultura y...
Por Nacho Palou -
13 JUN 2008
Este ha sido un día prácticamente de descanso para la tripulación del Discovery mientras preparan su vuelta a tierra, prevista en principio para mañana sábado a las 17:15, hora de España (GMT +2). Dentro de estos preparativos las dos tareas principales del...
El Discovery y su tripulación partieron ayer de la Estación Espacial Internacional a las 13:42 hora de España (GMT +2). El Discovery fotografiado desde la ISS poco después de su partida - NASA. Más imágenes en STS-124 Flight Day 12 Gallery Tras...
How long could you survive in the vacuum of space? es un test de seis preguntas en inglés que se rellena en cero coma y que permite descubrir algunas curiosidades sobre cuánto tiempo puede sobrevivir una persona en el vacío del...
Cuando en agosto de 2006 la XXVI Asamblea General de la Asociación Astronómica Internacional decidió que Plutón dejaba de ser un planeta aprobaba una resolución que decía Resolución 6ALa UAI además resuelve que:Plutón es un planeta enano según la definición anterior y...
Tras tres intentos anteriores cancelados por distintos motivos esta tarde a las 18:05 hora de España (GMT +2) un cohete Delta II ponía por fin en órbita el Gamma-ray Large Area Space Telescope, Telescopio Espacial de Rayos Gamma de Gran Área, más...
Poco que contar del último día del Discovery y su tripulación en la Estación Espacial Internacional en la misión STS-124 de la NASA, en especial porque disfrutaron de un par de horas libres durante la mañana antes de despedirse de los tripulantes...
Con las pruebas finales del brazo robot del laboratorio Kibō de la Agencia Japonesa de Exploración Aeroespacial y la apertura de la esclusa que comunica con su módulo logístico los astronautas Akihiko Hoshide y Karen Nyberg daban por completados los objetivos principales...
Científicos made in Spain por Manel Fontdevila. Por desgracia no es al 100% en clave de humor. (Vía davidgp.com.) Actualización: Juan Varela entrevista a Cristina Garmendia, la ministra española de Ciencia e Innovación, en Preocupados por la ciencia....
El tema de The Mickey Mouse Club sirvió para iniciar las actividades del día, edurante el que tuvo lugar el tercer y último paseo espacial de la misión, a cargo, como los dos anteriores de Mike Fossum y Ron Garan. Greg Chamitoff...
Los ingenieros y científicos que trabajan en el control de la Phoenix Mars Lander están intentando determinar por qué nada de la muestra que el brazo de la nave dejó sobre una de las entradas del Thermal Evolved Gas Analyzer (TEGA), el...
Día relativamente relajado en órbita durante el que Akihiko Hoshide y Karen Nyberg liberaron el brazo robot del laboratorio Kibō de su mecanismo de frenado para moverlo a la posición en la que Mike Fossum y Ron Garan procederán a quitarle las...
Hoy descubrí a través de una selección de blogs de El País un weblog de esos que te enganchan por interesante y buen estilo de «blogueo», algo apreciable con solo echar un vistazo a sus últimas anotaciones. Se trata de Apuntes...
La cuenta atrás para la puesta en marcha del LHC (más conocido como Gran Colisionador de Hadrones) es todo un hito científico histórico, tanto que algunos zumbaos piensan que puede provocar el «fin del Universo» y denunciaron hace meses al CERN...
Greg Chamitoff y Karen Nyberg se encargaron de trasladar el módulo logístico del laboratorio Kibō, que es así como su trastero, desde su posición temporal en el módulo Harmony de la Estación Espacial Internacional, donde lo había dejado la tripulación del Endeavour...
Segundo paseo espacial de la misión, de nuevo a cargo de Mike Fossum y Ron Garan. El objetivo principal de este paseo era preparar el laboratorio Kibō para su entrada en funcionamiento, en concreto instalando un par de cámaras en su exterior...
Parece que a pesar de los temores del responsable ruso de misiones espaciales humanas, Vladimir Soloviev, la Estación Espacial Internacional no va a tener que ser evacuada ya que Oleg Kononenko consiguió reparar el retrete de la ISS con las piezas de...
Después de que Mike Fossum y Ron Garan terminaran de prepararlo para su traslado de la bodega de carga del Discovery a su ubicación en la Estación Espacial Internacional el laboratorio Kibō de la Agencia Japonesa de Exploración Aeroespacial ya está en...
El transbordador espacial Discovery, con el comandante Mark Kelly a los mandos, atracaba ayer en la Estación Espacial Internacional a las 20:03 hora de España (GMT +2), con nueve minutos de retraso sobre el horario previsto. El Discovery atracado a la ISS...
La sonda Phoenix Mars Lander, tras un pequeño susto con una parte de la funda de su brazo robot que parecía no querer desprenderse de su sitio y dejarlo moverse con total libertad, ha tomado ya su primera muestra de suelo marciano,...
Cuando Dean Kamen presentó al mundo el Segway fue una especie de anticlímax a causa de la tremenda expectación que se había formado al respecto, pero visto el vídeo de lo que es capaz de hacer el brazo biónico que su...
Mientras el Discovery sigue su persecución de la Estación Espacial Internacional para igualar su órbita y velocidad y poder acoplarse con ella mañana lunes su tripulación realizó una primera inspección del escudo térmico de la nave usando el brazo robot de esta...
Cuenta atrás detenida en T-9, 22:45 hora de España: El reloj de la cuenta atrás para el lanzamiento del transbordador espacial Discovery en la misión STS-124 de la NASA está parado en T-9, la última parada antes del lanzamiento, tal y como...
El número de enteros positivos menores o iguales que 666 que son primos relativos con 666 es 6 × 6 × 6. Por otro lado resulta que 666 = 6 + 6 + 6 + 6³ + 6³ + 6³. Estas y...
Interesante Scientists move a step closer to mind-reading en The Guardian donde cuentan un reciente experimento sobre lectura de la mente, llevado a cabo en la Carnegie Mellon. Después de entrenar a un ordenador con escáneres del cerebro de unos voluntarios (a...
Prehistoric Calculus: Discovering Pi es una anotación del siempre recomendable sitio sobre matemáticas Better Explained donde se narra cómo a lo largo de los tiempos diversos matemáticos fueron aproximando el valor de π de forma cada vez más y más exacta....
Aunque la cuenta atrás lleva en marcha desde el miércoles 28 de mayo por la noche, los responsables de la NASA daban ayer la autorización definitiva para el lanzamiento tras revisar todos los parámetros de la misión, y el estado de la...
Un fallo en una de las radios a bordo de la Mars Reconnaissance Orbiter, que se apagó por un motivo que no ha sido determinado, impidió a los controladores de la Phoenix enviarle el martes los comandos necesarios para que comenzara a...
Hace un par de horas que ha arrancado la cuenta atrás para el lanzamiento del Discovery en la misión STS-124 de la NASA, cuyo despegue está previsto para el sábado 31 de mayo a las 23:02 hora de España (GMT +2). La...
La Asociación de Amigos de la Casa de las Ciencias convoca la I Edición de la Muestra Internacional de Ciencia y Cine, un certamen que «quiere ser un referente internacional en el ámbito del documentalismo científico, y aspira a ser el gran...
El columpio de Heidi, cuyas colosales dimensiones mirábamos asombrados los niños de los 70 en la ya clásica apertura de cada episodio [YouTube] tiene según puede calcularse una longitud de l = 20,25 metros tal y como explican en el hilo del...
El domingo por la noche el descenso de la sonda Phoenix de la NASA a la superficie de Marte estaba siendo vigilado por otras tres sondas en órbita para recopilar todos los datos posibles sobre este. La Mars Odyssey de la NASA...
Al final todo fue casi por el libro y la sonda Phoenix de la NASA está ya perfectamente instalada en las proximidades del polo norte de Marte y enviando sus primeras fotos: NASA's Phoenix Spacecraft Reports Good Health After Mars Landing. Aspecto...
355/113 es una muy buena aproximación del número π con seis decimales, pero no fue utilizada hasta 1573 por Valentinus Otho. La sencillez de esa fracción le confiere cierto toque de elegancia, si bien se sabe que matemáticos como Aryabhatta conocían con...
Quedan poco más de tres horas para que la sonda Phoenix de la NASA inicie la fase de aterrizaje en las cercanías del polo norte de Marte que, si todo va según lo previsto, pondrá fin a su viaje de 670 millones...
Durante su estancia en la Estación Espacial Internacional como miembro de la Expedición 6 entre finales de 2002 y principios de 2003 el astronauta Donald Pettit se dedicó, entre otras muchas cosas, a tomar fotografías de diversas ciudades de todo el mundo...
Esta es mi gente. Inventos y anécdotas de 46 mentes prodigiosas. Ramón Núñez Centella. Le pourquoi pas 2007. ISBN: 978-84-935631-0-3. 256 páginas De Pitágoras a Severo Ochoa este libro va recogiendo las principales aportaciones científicas de cada uno de los personajes...
El Met Office británico ha desarrollado una capa de datos para Google Earth con una representación animada de la evolución de la temperatura global para los próximos cien años (Archivo KML, 6KB). Hay que tener en cuenta que se trata de...
Por Nacho Palou -
22 MAY 2008
Desde hoy mismo y hasta el día 23 de mayo la órbita de la Estación Espacial Internacional es tal que la llevará a pasar sobre Europa y los Estados Unidos perfectamente iluminada por el Sol entre dos y cuatro veces por noche...
El anuncio por parte de la NASA del descubrimiento de la supernova G1.9+0 me pilló de viaje en Granada en las V Jornadas sobre Bitácoras y Medios de Comunicación por lo que no pude seguir el tema muy de cerca, así que...
No sólo Einstein publicó uno de sus grandes a lo que podría considerarse la temprana edad de sólo 26 años; según nos cuenta Gabriel… Dirac, el cual se dice que ha sido igual de importante que Einstein, hizo su gran formulación de...
Una supernova, en concreto la supernova más joven de nuestra galaxia, con sólo 140 años de antigüedad, lo que en términos cósmicos es nada: Chandra Uncovers Youngest Supernova in Our Galaxy. La anterior se calcula que ocurrió en 1680, basándonos en el...
Últimas aportaciones con ideas de lo nos va a contar la NASA esta tarde (ver La misteriosa sorpresa de la NASA para ver de qué va el asunto y las otras propuestas de los microlectores): Xals se apunta también a la ya...
El miércoles de esta semana la NASA anunciaba en la nota de prensa NASA to Announce Success of Long Galactic Hunt que el miércoles 14 de mayo a las 17:00, hora de España (GMT +2), dará una rueda de prensa en la...
Si tomamos como buena la cifra calculada por hombrelobo de que los SMS cuestan en España unos 1.123 euros el MB y teniendo en cuenta que la NASA cifra en $17,33 dólares (unos 11 euros al cambio actual) el coste de recibir...
10! segundos = 42 días exactos 10! = 10 × 9 × 8 × 7 × 6 × 5 × 4 × 3 × 2 × 1 = 3628800 362800 / (60 × 60 × 24) = 42 Tal y como apreció...
En Virtual Reality Could Explain the Fermi Paradox se hace una referencia Where Are They?, un artículo de Technology Review sobre el tema de las inteligencias extraterrestres (y la aparente inexistencia de ellas, a pesar de que llevamos años buscándolas). La Paradoja...
Eneko que comparte nuestra afición por el número 42 nos envió esta curiosa historia que reproduzco tal cual porque me pareció curiosísima: Resulta que si hicieras un tunel de un lado a otro de la tierra cruzando por el centro y te...
Fiel a su cita de todos los años, y patrocinado una vez más por Caixanova, mañana se celebra de 11 de la mañana a 7 de la tarde en el Parque de Santa Margarita de La Coruña (España) el XIII Día de...
Estaba leyendo Sampling is tricky sobre las dificultades de encontrar a veces una buena muestra estadística, con un simpático ejemplo llamado La demostración del peso de los caramelos, o la carencia de sabiduría de las multitudes: Básicamente, tienes una bolsa con un...
Sabía que cuando se lanza un cohete al espacio este lleva a bordo unas cargas explosivas que se pueden activar desde tierra que aseguran su destrucción si por cualquier motivo se pierde el control sobre él y así evitar que pueda causar...
Estado en el que estaba el disco duro Seagate de 400 MB que iba a bordo del Columbia y cuyos datos ahora han sido recuperados. Fotos NASA. Más de cinco años después del accidente del Transbordador Espacial Columbia, ingenieros de la NASA...
Por Nacho Palou -
8 MAY 2008
Ayer charlábamos sobre el tema de las demostraciones de cierto tipo de hechos, creo que charlando sobre el ya clásico y controvertido Argumento de la Simulación. Eso me recordó aquel asunto que se conoce como la prueba diabólica de un hecho negativo,...
El Episodio 5: Polvo Lunar y Cinta Adhesiva de las Crónicas de Apolo que publica reguarlamente el sitio Ciencia @ NASA cuenta una anécdota ocurrida durante el paseo lunar de los astronautas del Apolo XVII. Foto NASA Los astronautas Gene Cernan y...
Por Nacho Palou -
7 MAY 2008
Fotografía de Carlos Gutierrez/UPI/Landov Tras unos 9.000 años de inactividad, el volcán Chaitén comenzó a tener actividad el pasado dos de mayo. Desde entonces se ha forzado la evación de miles de personas de la región. Además de provocar la expulsión de...
Por Nacho Palou -
7 MAY 2008
Mathematics Version 2.12: What’s New muestra qué sucedería con la Matemática si se pudiera actualizar como el software, de modo que se arreglaran algunos bugs mejorándola de versión en versión, incluyendo entre otros estos que me hicieron reir bastante: Matemática: actualización a...
Se denomina apnea del correo electrónico a un cambio en la frecuencia de respiración mientras se mira el correo electrónico, por ejemplo contener la respiración mientras se elige en el buzón de entrada qué email leer y contestar. El término lo acuñó...
Total primary energy supply: Land area requirements -- Cubriendo con sistemas de producción de energía con origen solar las áreas cubiertas por los puntos negros (en la imagen superior) se obtendrían 18 TW, algo más de toda la cantidad de energía...
Por Nacho Palou -
29 ABR 2008
Hoy se cumplen 18 años del lanzamiento del telescopio espacial Hubble y para celebrar su mayoría de edad la ESA y la NASA han publicado una colección de 59 imágenes de galaxias en colisión y cuatro vídeos que las acompañan: Galaxies gone...
Esta tarde a las 19 horas en el Centro Social Universitario de la Universidad de Murcia: Presentación del libro "Abriendo los ojos a otra realidad" y conferencia "Los OVNIS y el cambio climático global". El título del libro ya resulta medianamente sospechoso,...
En el Día del Libro, los libros que cambiaron la vida de 17 científicos, adaptado y resumido de Life-changing books: Recommendations from 17 leading scientists: Steve Jones, geneticista: En la noche y entre los hielos / Farthest North, la odisea del Fram...
Resulta que partiendo del número de siete cifras 1.741.725 Si se suman todos sus dígitos elevados a la séptima potencia. 17 + 77 + 47 + 17 + 77 + 27 + 57 = 1.741.725 Es una curiosidad del libro Matemática, ¿dónde...
Esta semana arrancaban en el hospital Jackson Memorial de los Estados Unidos las primeras pruebas clínicas en las que se intenta comprobar si los efectos reparadores que se han observado al injertar células madre en tejidos dañados de animales de laboratorio son...
Imagino que la noticia que dice que Un niño de 13 años demuestra que la NASA erró al calcular la probabilidad de colisión del «Apophis» con la Tierra en 2029, en la que se comenta como este niño ha demostrado que si...
Dado el magnífico estado en el que se encuentra la sonda Cassini tras casi cuatro años en órbita alrededor de Saturno y más de diez años después de su lanzamiento, y sobre todo, dados los magníficos resultados científicos que ha obtenido y...
Estos días nos han llegado varias copias de un PowerPoint en el que se pueden ver varias fotografías del proceso de preparación de un transbordador espacial para su lanzamiento, fotos que también se pueden ver en Space Shuttle Processing: Rarely seen by...
Mmmmmm… Galletitas fractales cocinadas por científicos locos. (Vía Ned Batchelder's blog mmm.) Fractal de plastilina, también basado en el Triángulo de Sierpinski....
Basado en el diseño del SpaceShipOne con el que Scaled Composites consiguió ganar los 10 millones de dólares del ANSARI X Prize, el primero de los cinco SpaceShipTwo con los que Virgin Galactic pretende lanzar la industria del turismo espacial comercial está...
Simple y bello: los números enteros del 1 al 100, representados como sus factores primos. En horizontal están los números correlativos y en vertical sus factores primos. La diagonal de abajo representa los números que no tienen divisores: los números primos...
Uno de los argumentos esgrimidos por aquellos que creen que el cambio climático no tiene nada o poco que ver con las actividades de los seres humanos es la teoría del científico danés Henrik Svensmark que relaciona los rayos cósmicos con la...
Tuvimos ocasión de asistir a la exposición Bodies The Exhibition a la que nos invitaron amablemente. Bodies es un “homenaje a la maravilla que es el cuerpo humano” representado por individuos reales cuyos cadáveres se han preservado para que se pueda...
Por Nacho Palou -
7 ABR 2008
Juanpi nos avisó de que en una charla del TED que ofreció Stephen Hawking desde Cambridge, la famosa respuesta al sentido de la vida, el Universo y todo lo demás, podía verse en la pizarra que tenía detrás, confirmando lo que se...
(Nota: Esta anotación menciona a GMV, una de las empresas que se anuncia en Microsiervos.) Después de la prueba de aproximación del pasado lunes en la que el Vehículo de Transferencia Automatizado de la Agencia Espacial Europea llegó a situarse a 12...
Aunque las vistas desde allí arriba quitan la respiración a cualquiera, vivir en el espacio supone una serie de compromisos en lo cotidiano que resultan cuando menos curiosos, como por ejemplo que: No hay manera de conseguir pizza decente en el espacio,...
Estos son algunos documentales que vi recientemente y me parecieron recomendables, me los encontré mirando por ahí recopilaciones de programas similares, en concreto la lista de Horizon, la magnífica serie de la BBC: Most of our Universe is Missing (2006) – Una...
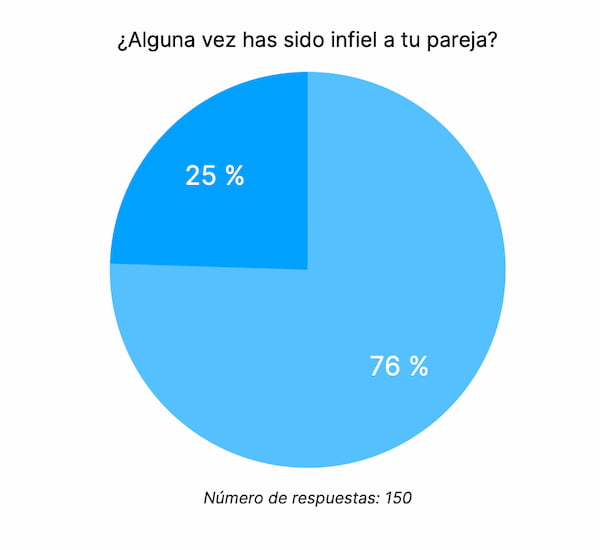
Cuando preguntamos el mes pasado por pura curiosidad a los lectores habituales acerca de su nivel de inglés Gonzo me escribió para comentame si no creía que era el tipo de cuestión en la gente tendería a exagerar. Efectivamente en algunas...
Ritmos circadianos es un detallado artículo en tres partes que me envió Pseudópodo a raíz de lo de si el cambio de hora afecta a las personas negativamemente por los trastornos en el sueño y otras actividades rutinarias. El ensayo tiene muchos...
Una breve grabación de audio, de apenas diez segundos, de la canción “Au Clair de la Lune” recientemete hallada en París, se ha convertido en la grabación de audio más antigua que se conoce: según los investigadores fue realizada en 1860 utilizando...
Por Nacho Palou -
28 MAR 2008
Después de tener que realizar una órbita más debido a que las condiciones meteorológicas estaban bajo mínimos para la primera oportunidad de aterrizar las ruedas del Endeavour se detenían a las 1:40:41 (hora de España, GMT +1) de esta noche, tras haber...
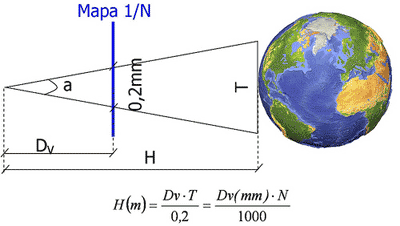
¿A qué altura estaríamos situados si estuvieramos viendo la Tierra realmente tan lejos como lo que se ve en un mapa colgado de la pared? Esta es La cuestión Kimerling, una pregunta que se hizo el profesor Kimerling y que explicó...
~ 600 ml Medio cerebro humano ~ 600 ml Suficiente plutonio como para una bomba ~ 500 ml Células de tu cuerpo que mueren cada día ~ 400 ml Cuarta parte del sistema inmunitario humano ~ 300 ml Suficiente vino para...
La tripulación del Endeavour dedicó el día a los preparativos necesarios para el aterrizaje, que básicamente consistieron en recoger y almacenar cosas, probar los sistemas de control y motores de la nave, así como el plegado de la antena de banda Ku...
Gondwana habría sido el supercontiente que se cree resultó de la separación de la Pangea en dos partes: la norte llamada Laurasia y la sur, que recibe el nombre de la región de Gond en la actual India. Con la rotura...
Por Nacho Palou -
25 MAR 2008
Fin de la estancia del Endeavour y su tripulación en la Estación Espacial Internacional durante la misión STS-123, estancia que ha durado 11 días, 20 horas, y 36 minutos. La maniobra de desatraque se vio retrasada en unos 30 minutos porque uno...
Último día completo del Endeavour y su tripulación en la Estación Espacial Internacional en la misión STS-123 que ha sido dedicado principalmente al descanso de las tripulaciones de este y de la ISS. Los astronautas del Endeavour tuvieron la mañana libre y...
… sobreimpreso sobre un campo de fútbol. La mancha azul grande es el módulo lunar. En la imagen original de la NASA se puede ver a qué corresponde cada detalle del paseo del mítico paseo de la misión Apolo 11: En...
Este interesante número se llama el Número de Lines por Gleen T. Lines, un profesor de la Universidad de Oslo en Noruega, quien llamó la atención sobre el en 2005. Tiene la siguiente propiedad cuando se consideran la mitad de sus dígitos,...
Quinto y último paseo espacial de la misión STS-123 a cargo de Robert Behnken y Michael Foreman. Las principales tareas llevadas a cabo durante las 6 horas y 2 minutos que duró este fueron dejar el Orbiter Boom Sensor System, el conjunto...
El gran tamaño del Módulo Presurizado del laboratorio Kibō hace que en la bodega de carga del Discovery, que lo pondrá en órbita en la misión STS-124 junto con su Sistema Remoto Manipulador, el brazo robot del laboratorio, no quede sitio para...
Bob Behnken y Michael Foreman llevaron a cabo el cuarto paseo espacial de la misión STS-123 en el que aunque se realizaron algunas tareas de mantenimiento y de preparación final del módulo Harmony para la llegada del componente principal del Kibō a...
Las tripulaciones del Endeavour y de la Estación Espacial Internacional gozaron de un día de merecido descanso en esta larga misión, con la mañana libre, y apenas unas entrevistas y llamadas telefónicas por la tarde con diferentes medios de comunicación y el...
Un día relativamente tranquilo en órbita tras el paseo espacial del día anterior en el que Richard Linnehan y Robert Behnken terminaron de montar Dextre, el nuevo brazo robot de la Estación Espacial Internacional. El nuevo módulo de la ISS, el Japanese...
Dextre ya tiene ojos y un bolsillo en el que guardar sus herramientas cuando no las esté utilizando por cortesía de Richard Linnehan y Robert Behnken, quienes se las instalaron durante el tercer paseo espacial de la misión STS-123. Esquema de Dextre....
Llegó el momento de comprobar el trabajo de ensamblado de Dextre, el nuevo brazo robot de la Estación Espacial Internacional, realizado en los dos primeros paseos espaciales de la misión STS-123, para lo que tanto desde el control de la misión en...

Aquí tenemos a Carl Sagan explicando Planilandia, el mundo en dos dimensiones narrado por Edwin Abbot en su novela del mismo título: Flatland: A Romance in Many Dimensions. El vídeo está en inglés pero es fácil de entender y sirve para...
La mañana del 10 de diciembre de 1996 la neuroanatomista Jill Bolte Taylor, que trabajaba en el estudio de las diferencias que puede haber entre un cerebro sano y aquel de personas a las que le ha sido diagnosticada una esquizofrenia...
A pesar de que Michael Foreman y Richard Linnehan se encontraron con algunas dificultades a la hora de liberar uno de los brazos de Dextre del contenedor en el que había sido enviado, hasta el punto de tener que utilizar una palanqueta...
Buenas noticias desde la Estación Espacial Internacional y el Endeavour respecto a Dextre, el nuevo brazo robot de la Estación que la tripulación de la misión STS-123 de la NASA está ensamblando. Rick Linnehan trabajando en el ensamblado de Dextre. Más imágenes...
Primer paseo espacial de la misión STS-123, a cargo del ingeniero de vuelo Garrett Reisman y del especialista de la misión Richard Linnehan, en el que las cosas no salieron exactamente como estaban previstas. La primera parte del paseo fue dedicada a...
El Endeavour atracó ayer en la Estación Espacial Internacional a las 4:49 de la madrugada (hora de España, GMT +1) mientras ambos sobrevolaban Singapur a unas 200 millas de altura después de realizar una «voltereta» para que la tripulación de la ISS...
Con motivo de la celebración del día de pi, que es hoy, nos escribieron desde la Escuela Técnica Superior de Ingeniéría Informática de la Universidad de la Laguna en Tenerife para contarnos cómo lo van a celebrar, de una forma un tanto...
Jornada de preparativos en la misión STS-123 de la NASA para la llegada del Endeavour y su tripulación a la Estación Espacial Internacional y de comprobación del estado del escudo térmico de la nave. El Experiment Logistics Module de Kibo en la...
El hecho de que el lanzamiento de la misión STS-123 se haya producido a las 2:28 de la noche y el que su tripulación tenga que adaptarse al horario de la Estación Espacial Internacional, que se rige por la Hora Zulu, han...
Martes 11 de marzo de 2008, 7:45 Tras un despegue por el libro y sin ningún problema aparente, al menos a primera vista, el Endeavour ya está en órbita y rumbo a la Estación Espacial Internacional. Lanzamiento del Endeavour en la misión...
Handbuch der Anatomie der Tiere für Künstler (Atlas de Anatomía Animal para Artistas) es una colección de precisas y preciosas ilustraciones anatómicas de diferentes animales (caballo, oveja, vaca, perro, león y cabra) que proceden de los trabajos realizadas por los veterinarios...
Por Nacho Palou -
10 MAR 2008
Siempre me intrigó si un imán mantiene su poder de atracción (campo magnético) de forma permanente, por siempre jamás. Recuerdo que fue una de las primeras preguntas que le hice a mi profesor de física. Un día nos llevó al museo de...
Esta madrugada, a las 5:03 hora de España (GMT +1), despegaba desde el Puerto Espacial de Kourou, en la Guayana Francesa, el primer Vehículo de Transferencia Automatizado de la Agencia Espacial Europea con destino a la Estación Espacial Internacional. Comparativa de tamaños...
Aunque en las misiones espaciales todo está -o debería estarlo- planificado casi hasta el milímetro para asegurar en la medida de lo posible el éxito de estas a veces la suerte se alía con los responsables de la misión para obtener resultados...
Extraños y curiosos donde los haya: Números irracionales cebra, como por ejemplo y para ver por qué se llaman así y la tan curiosa forma en que se pueden visualizar sus dígitos hay que seguir el enlace: cientos y cientos de dígitos...
Dangerous Knowledge BBC Four. David Malone (2007). Inglés. 90 minutos. Esteban me recomendó este documental que, dividido en dos entregas de 45 minutos, explora a modo de homenaje las vidas de cuatro científicos: Cantor, Gödel, Turing y Boltzmann. Las vidas de...
Bad Astronomy: Misconceptions and Misuses Revealed, from Astrology to the Moon Landing Hoax. Philip C. Plait. John Wiley & Sons, 14 de Marzo de 2002. ISBN: 0471409766. 288 páginas. Inglés. Antes de que Bad Astronomy Blog se convirtiera en un blog...
Tomadas justo antes de que se forme el habitual (y su lado aburrido) hongo nuclear. Imagen de 1952 tomada 1 ms después de la detonación de un bomba nuclear sobre una torre para pruebas. Las imágenes siguientes muestran el desarrollo de una...
Por Nacho Palou -
29 FEB 2008
Por si no tuviéramos suficiente con asomarnos a la intimidad de la vida privada de los electrones gracias a la técnica desarrollada en la Universidad de Lund que permite fotografiar electrones en movimiento, la universidad de Cornell anunciaba hace unos días la...
Prometo dejar de dar la lata con el eclipse total de Luna de la semana pasada, pero no podría dejar de enlazar con Eclipse totale de Lune, un vídeo en time-lapse creado por Yves Boisjoly que nos recomienda cgredan: Eclipse totale de...
La situación es bastante corriente: cuando alguien va con el coche por un lugar desconocido y se pierde, apagar la radio o la música parece un gesto natural para concentrarse en encontrar pistas sobre por dónde seguir. ¿Es que acaso se interfieren...
El reciente anuncio por parte del equipo de Kathrin Plath y William Lowry de la Universidad de California de que han conseguido obtener células de piel adulta humana para convertirlas en células madre embrionarias, unido a los resultados similares obtenidos por los...
El Atlas del Espacio para Google Earth se inició con motivo de la convocatoria del Wirefly X PRIZE Cup de 2006, y actualmente reúne y posiciona todo tipo de información relacionada con el espacio: centros espaciales, asociaciones astronómicas, museos, bases de lanzamiento...
Por Nacho Palou -
25 FEB 2008
No esperes ver nada espectacular pero el concepto mola por sí mismo: Electron filmed for first time ever (Electrón grabado por primera vez en vídeo). Hasta ahora había sido imposible fotografiar electrones ya que su extremada velocidad producía imágenes borrosas. No había...
Por Nacho Palou -
25 FEB 2008
Una de las ventajas de los eclipses de Luna es que, al contrario de lo que sucede con los de Sol, su observación no entraña riesgo alguno más allá del frío que se pueda pasar al salir por la noche a verlos,...
Qué maravilla de simulador de objetos y leyes físicas en 2-D. Lo ha creado Emil Ernerfeldt, un estudiante sueco y se llama Phun (juego de palabras con fun, «divertido»). Incluye gravedad, fluidos y un montón de opciones para crear pequeños mundos...
Recuerda que si las condiciones meteorológicas lo permiten esta noche se podrá ver el que será el último eclipse total de Luna visible desde España hasta 2015. Eclipse del 21 de febrero de 2008 por Paco Bellido.Esquemas para otros horarios disponibles en...
15:08:08 > Se detienen las ruedas, la misión STS-122 ha terminado para el Atlantis y su tripulación tras recorrer 9,8 millones de kilómetros en 12 días, 18 horas, 21 minutos y 50 segundos. Por su parte, la Estación Espacial Internacional tiene un...
Comprobados todos los sistemas de a bordo necesarios para la reentrada y que el escudo de protección térmica de la nave no tiene ningún problema la tripulación del Atlantis dedicó el día a preparar la nave para su aterrizaje, guardando todas las...
El Atlantis dejó la Estación Espacial Internacional a las 10:24, hora de España, para comenzar su camino de vuelta a casa, aunque antes el piloto Alan Poindexter maniobró la nave en una vuelta alrededor de la ISS para poder fotografiar esta tras...
Grandes cifras: El láser más intenso del Universo que bate récords ha sido puesto en marcha en la Universidad de Michigan. Tiene una intensidad de 2 × 1022 vatios por centímetro cuadrado (eso son veinte mil trillones de vatios) y es cien...
Terminada su parte en la instalación y puesta en marcha del laboratorio espacial Columbus y el transbordo de carga entre ambas naves la tripulación del Atlantis se despidió de la tripulación de la Estación Espacial Internacional a media tarde y a las...
No se puede cuadrar un círculo, esto es, dibujar un cuadrado, utilizando únicamente regla y compás, que tenga la misma superficie que un círculo determinado. Es uno de los más clásicos problemas irresolubles de la geometría y las matemáticas. Pero sí que...
Bonito gráfico que recoge la aceptación que tiene entre la población general la Teoría de la Evolución en diversos países del mundo. Los datos indican: Azul, creen que es verdad; Rojo, creen que es falsa. Marrón, no están seguros. Los datos son...
Esta semana podremos disfrutar, si las nubes no lo impiden, por segundo año consecutivo de un eclipse de Luna que será visible desde el oeste de Asia, Africa, el oeste de Europa, la mayor parte de Norteamérica, y América del Sur. Ocurrirá...
Último día completo de operaciones conjuntas para las tripulaciones del Atlantis y de la Estación Espacial Internacional en la misión STS-122 de la NASA en el que los diez astronautas siguieron adelante con la puesta en marcha del laboratorio Columbus sin encontrar...
Este vídeo filmado en el departamento de Física de la Universidad de Nuevo México muestra lo que se conoce como Flujo Laminar [YouTube, 2 min.] Es más o menos lo contrario del flujo con turbulencias tan típico en la naturaleza, un...
Absolute Zero: The story of harnessing of cold and the race to reach the lowest temperature possible. NOVA/PBS. David Dugan (2008). Inglés. 120 minutos. Basado en el libro Absolute Zero and the Conquest of Cold de Tom Shachtman. Me cruce con...
Rex Walheim y Stanley Love se encargaron de llevar a cabo el tercer paseo espacial de la misión STS-122, durante el que, con la ayuda de Leland Melvin a los mandos del Canadarm2 y la coordinación de Alan Poindexter, instalaron dos módulos...
El reciente anuncio por parte del equipo de Kathrin Plath y William Lowry de la Universidad de California de que han conseguido obtener células de piel adulta humana para convertirlas en células madre embrionarias, unido a los resultados similares obtenidos por los...
Día relajado para las tripulaciones del Atlantis y de la Estación Espacial Internacional en el que tras seguir con las tareas de puesta en marcha del Columbus por la mañana la actividad fundamental del resto del día fue atender a varios medios...
A Sense of Scale es un interactivo de NOVA/PBS asociado al doccumental Absolute Zero que permite jugar con el ratón sobre una escala de temperaturas, para hacerse una idea de lo que que hay más frío y más caliente en el...
Otro día curiosamente rutinario en la misión STS-122 durante el cual Rex Walheim y Hans Schlegel llevaron a cabo el segundo paseo espacial de la misión en el que sustituyeron un depósito de nitrógeno del sistema de refrigeración del laboratorio Columbus por...
Una vez comprobado que no había fugas de ningún tipo en la unión del laboratorio Columbus con el módulo Harmony de la Estación Espacial Internacional los astronautas de la Agencia Espacial Europea Leopold Eyharts y Hans Schlegel abrieron las compuertas del laboratorio...
Tras un paseo espacial de casi ocho horas a cargo de Stanley Love y Rex Walheim el laboratorio Columbus de la Agencia Espacial Europea ya está instalado en su ubicación definitiva en la Estación Espacial Internacional. Vista del interior del Columbus ya...
El tener que posponer el primer paseo espacial de la misión a causa de la condición médica sin especificar que afecta a Hans Schlegel ha hecho que el cuarto día de la misión haya sido prácticamente un día de impasse en el...
El Atlantis y su tripulación llegaron sin novedad a la Estación Espacial Internacional, donde el transbordador quedó atracado a las 18:17 del sábado, hora de España, en el tercer día de la misión. Columbus en la bodega de carga del Atlantis fotografiado...
Una Verdad Incómoda (An Inconvenient Truth, 2006). Davis Guggenheim. Web oficial: ClimateCrisis.net. El documental de Al Gore sobre el calentamiento global y el cambio climático es un documento impresionante, con algunas escenas realmente gráficas y cifras espeluznantes sobre lo que está...
Día rutinario -si se puede usar esa palabra al hablar de una misión espacial- a bordo del Atlantis mientras se dirige a su cita con la Estación Espacial Internacional. La tarea más importante del día fue inspeccionar el escudo de protección térmica...
20:53 > Tras un lanzamiento de libro el Atlantis está en órbita, camino de la Estación Espacial Internacional, a donde llegará el sábado con el laboratorio espacial Columbus de la ESA en su bodega de carga. 20:45 > El Atlantis despega con...
Desde este lunes por la tarde está en marcha el reloj de la tercera cuenta atrás para el lanzamiento del transbordador espacial Atlantis en la misión STS-122 de la NASA a la Estación Espacial Internacional, tras dos cancelaciones anteriores a principios de...

En todos los libros de texto que hablan de probabilidad se utilizan siempre dados, monedas y urnas con bolas para poner ejemplos de objetos que proporcionan una forma teórica de ver el azar y las probabilidades de los sucesos. En estos...
Erica Walker y Raza M. Syed de la Northeastern University se han dedicado a hacer un estudio matemático-físico acerca de si el tigre siberiano del zoo de San Francisco fue capaz de saltar una valla de cuatro metros de altura situada tras...

El primer Explorador: Lanzamiento del Explorer 1 en un cohete Juno I el 1 de febrero de 1958 a las 3:48 UTC Tal y como recuerda la Imagen Astronómica del Día El primer Explorador, hoy 1 de febrero -o el 31 de...
Un equipo de investigadores del Observatorio Astronómico Ramón María Aller de la Universidade de Santiago de Compostela, del Special Astrophysical Observatory de Rusia, del Instituto Max Planck de Alemania, y del Grupo de Mecánica Espacial de la Universidad de Zaragoza, publica en...
Leí esta mañana que los científicos habían descubierto un método para revertir… nosequé....
Cuarto Milenio por El Listo Nuevo enigma para Iker Jiménez: ¿Dónde estarán los lectores de «El País» desaparecidos?Yo es que lo leía asiduamente creyendo que era un diario serio y racional, pero empezaron a sacar libro-DVDs de exorcismo, brujería y avistamientos de...
Un vídeo y el análisis de gente que estuvo allí además de diversas personas interesadas en el tema parecen indicar que el récord mundial de memorización de dígitos de Pi: 150.000 decimales no fue tal, sino más bien un despropósito, incluyendo que...
No tenía pensado escribir sobre el tema de la supuesta figura humanoide que algunos dicen haber encontrado en una de las imágenes enviadas por Spirit desde Marte: ¿Hay un hombre en esta foto? [imagen original, 39,2 MB] Pero dado que ha salido...

¿Si encierras dos velas o más velas dentro de una campana de aire, en donde se consumirá el oxígeno poco a poco, cuál se apagará primero: la vela más alta o más baja? Hay que contestar mentalmente antes de ver el...
Guía del cielo. Edición 2008 Óscar Blanco, Julio Casal, Óscar Sánchez y Borja Tosar. Le pourquoi-pas 2007. ISBN: 978-84-935631-2-7. 64 páginas. Escrita por cuatro miembros de la Agrupación Astronómica Io, esta guía arranca con un apartado inicial en el que se intenta...
La humanidad lleva décadas debatiéndose ante el dilema de si esperar al autobús o echar a andar, esas veces que da la impresión de que el transporte públicco no va a llegar nunca. ¿Es mejor esperar o andar? ¿Cuánto tiempo esperar?...
Aunque ya hay referencias a autotrasplantes de piel realizados con éxito en el siglo II antes de Cristo y a alotrasplantes de este mismo tejido en la segunda mitad del siglo XVI, de los que ninguno funcionó por culpa del rechazo del...
Imagen: Centre International de Recherche sur l'Environnement et le Développement and Ecole Nationale de la Météorologie, Météo-France. El mapa superior muestra la posición geográfica que equivale al clima que tendrán varias capitales europeas en el año 2071 debido al incremento de temperaturas,...
Por Nacho Palou -
25 ENE 2008
Entrenando catorce horas al día, Jaime García (un colombiano que vive en Brunete) ha recitado 150.000 dígitos de π en la Facultad de Matemáticas de la Universidad Complutense de Madrid, batiendo el anterior récord del mundo (100.000 dígitos) de Akira Haraguchi estuvo...
Con el título Cent llibres de ciència [PDF 6,3 MB] la Generalitat de Catalunya ha publicado una recomendable guía de lectura que recoge todo tipo de títulos sobre el conocimiento científico, incluyendo temas como la astronomía, la biomedicina, botánica, informática, ecología, evolución,...
Si te interesa la ciencia y la tecnología que hay detrás de la energía eólica, el sitio de Windpower es una de las mejores fuentes de información disponibles en español (aunque el sitio pertenece a la Asociación Danesa de la Industria...
Por Nacho Palou -
24 ENE 2008
Virgin Galactic, la empresa de Richard Branson que tiene como objetivo popularizar el turismo espacial por ahora al «módico» precio de 200.000 dólares por pasajero, ha revelado hoy el diseño final de la nave en la que viajarán sus pasajeros: Virgin unveils...
La semana pasada la Agencia Espacial Europea (ESA) firmaba el contrato industrial para la construcción de BepiColombo, la sonda espacial que la agencia prevé enviar con rumbo a Mercurio en agosto o septiembre de 2013, en lo que se convertirá en la...
Absolutamente brillante la viñeta de xkcd de hoy, The Data So Far (Los Datos Hasta Ahora): Afirmaciones sobre poderes sobrenaturales:(izda) Confirmadas experimentalmente(dcha) Refutadas experimentalmente { Esta anotación está licenciada bajo Creative Commons (CC) } Ciencia vs Fe, un diagrama de flujo de...
Anomalías en las temperaturas de 2007 relativas a los promedios 1951-1980.Cuando más rojo/oscuro, mayor ha sido la desviación hacia temperaturas más altas. Fuente: GIIS/NASA Según un reciente informe del Goddard Institute for Space Studies de la NASA, titulado 2007 Was Tied as...
El 3 de agosto de 2004 la NASA lanzaba al espacio con destino a Mercurio, a donde no está previsto que llegue hasta el 18 de marzo de 2011, la sonda MESSENGER (MErcury Surface, Space ENvironment, GEochemistry and Ranging - Medición de...
Tal y como se dio a conocer hace algunos días y ha circulado por ahí, SETI@home está buscando nuevos voluntarios. Este popular proyecto fue uno de los primeros en popularizar la idea de computación distribuida: la utilizacion de un gran número de...
A la izquierda una referencia de material negro, el “nuevo material más negro” y otra muestra de referencia de carbono vítreo. Foto Reuters. Investigadores de la Universidad Rice en Houston afirman haber conseguido un material de color negro que es más negro...
Por Nacho Palou -
16 ENE 2008
3300 / 0,123 = 26829, 26829 26829 26829… Curiosa división (¡Gracias por el envío, luipermom!) Actualización: Rafael también vio que 2988 / 11111 da como resultado 0, 26892 26892 … y además 26892 se lee igual girándolo....
Durante este año 2008, este es el indicador que marcará el punto exacto en el que se encuentra el Polo Sur Geográfico. Indicador del Polo Sur Geográfico 2008. Foto de Peter Rejcek / National Science Foundation. El Polo Sur Geográfico se refiere...
Por Nacho Palou -
15 ENE 2008
Suena a ciencia ficción, y aún estamos a años de que esta técnica se pueda aplicar en seres humanos -si es que alguna vez llega a poderse- pero en cualquier caso lo que se puede leer en Researchers create a new heart...
Aunque la NASA había mencionado la posibilidad de que el Atlantis estuviera listo para su lanzamiento en la misión STS-122 el próximo 24 de enero al final no va a ser posible tener listas a tiempo las modificaciones que se están realizando...
Esta semana la NASA daba los detalles de la misión STS-125 de la flota de transbordadores espaciales de la agencia que será llevada a cabo por el Atlantis y que tiene como fin realizar tareas de mantenimiento en el Telescopio Espacial Hubble;...
MARS-500 (Marte 500) es un experimento ruso que lleva varios años en marcha y que pretende recrear las condiciones de un viaje espacial a Marte, aislando a varios voluntarios durante 500 días en una nave-simulador de unos 400 metros cuadrados. Este viaje...
Esta foto tiene un poco de trampa porque en realidad es un montaje de dos imágenes enviadas por la sonda New Horizons en su camino a Plutón, a donde no está previsto que llegue hasta julio de 2015, pero me parece absolutamente...
El Polo Inaccesible es un punto geográfico que se encuentra, de algún modo, en medio de ninguna parte. Existen polos inaccesibles en el Polo Norte, en el Polo Sur, en el océano y en tierra firme. Tanto en el Polo Norte como...
Por Nacho Palou -
8 ENE 2008
1+1 no es 2, o por qué el MundoReal™ no es como las matemáticas....
El suplemento El País Semanal dedica esta semana un reportaje a los Fraudes científicos montados con más o menos malicia por sus autores, en general científicos más preocupados por la codicia de ser aclamados o escribir su nombre en los libros de...
Por Nacho Palou -
7 ENE 2008
Periodic Spiral es otra forma de ver la tabla periódica de los elementos químicos, más «lógica y fresca» según algunos expertos. Moviendo el ratón y jugando con las diversas opciones pueden aprenderse detalles sobre cada uno de los elementos. [Shockwave.] (¡Gracias,...
Hoy se cumplen cuatro años de la llegada de Spirit a Marte, el primero de los rovers marcianos de la NASA de la misión Mars Exploration Rovers, que se posó en lo que luego sería bautizado como Columbia Memorial Station. Teniendo en...
Ya hay una nueva fecha para el próximo intento de lanzamiento del transbordador espacial Atlantis en la misión STS-122 de la NASA a la Estación Espacial Internacional, el 24 de enero de 2007: Space Shuttle Work Out Sensor System Plan, La NASA...
En ausencia de la sensatez, sí: la lengua puede quedarse pegada en un metal helado —igual que un dedo en la superficie de un congelador antiguo o en un cubito de hielo. Will Your Tongue Really Stick to a Frozen Flagpole? —...
Por Nacho Palou -
2 ENE 2008
Desde Tall & Cute nos escribió Sergio para contarnos que ha publicado 10 consejos para escribir sobre ciencia en tu blog, una lista excelente de buenos consejos: Cita la fuente original Asegurate de que la fuente es fiable Revisa cuales son los...
What have you changed your mind about? es un artículo de la revista Edge que recoge la respuesta que dieron a esta pregunta un grupo de intelectuales de élite, demostrando así su humildad. El lema del comienzo me encantó: Cuando al pensar...

La Rosa de los Vientos: el programa que demuestra que la pseudociencia puede ser entretenida y la historia menos aburrida que en el cole.
Una forma entretenida de repasar los nombres de las lunas de algunos los planetas del sistema solar es este pequeño juego en Flash: Selected Moons of the Solar System Quiz, donde hay imágenes de todas ellas a escala, junto a la...
La NASA ha anunciado hoy que no sabe cuanto tiempo necesitará para reparar el conector al que se le atribuyen los fallos de lectura de los sensores de nivel bajo de combustible del depósito principal del Atlantis con el que va a...
Estaa colección de tatuajes con motivos científicos está a medio camino del WTF y del contenido científico, así que tras meditarlo profundamente se queda en Microsiervos, que no es ni una cosa ni otra ;-) Science Tattoos de Carl Zimmer (Originalmente en...
La NASA ha anunciado recientemente que ha escogido Altair como nombre de su nuevo [aterrizador lunar | alunizador], el que tendrá como misión llevar hasta cuatro astronautas a la Luna dentro del Proyecto Constelación: NASA Chooses "Altair" as Name for Astronauts' Lunar...
La madre del astronauta Dan Tani falleció recientemente en un accidente de coche. El problema era cómo darle la mala noticia, dado que se encontraba en ese momento trabajando... en la Estación Espacial Internacional, donde todavía le quedaba un mes de trabajo....

Este vídeo de BBC4, Superfluid explica visualmente la superfluidez que es lo que les sucede a ciertos líquidos, como el Helio-3 y el Helio-4 cuando se enfrían a temperaturas cercanas al cero absoluto (-273°C). En ese punto de frío extremo lo...
El listado de las pseudociencias es extenso; encontré este en la Wikipedia: Alquimia Astrología Cerealogía Creacionismo y Diseño inteligente Criptozoología Dianética Fisiognomía Flores de Bach Frenología Grafología Homeopatía Negacionismo del Holocausto Numerología Parapsicología Piramidología Programación neurolingüística Psicoanálisis Radiestesia Ufología La definición rápida...
Después de que varios fallos en los sensores de nivel bajo de combustible evitaran el lanzamiento del transbordador espacial Atlantis en la misión STS-122 de la NASA los pasados 6 y 9 de diciembre ayer se procedió a un llenado de prueba...
El escritor británico Arthur C. Clarke, uno de los más famosos autores de ciencia ficción de todos los tiempos, cumple hoy 90 años. Como en mi opinión ya le sucediera en su momento a Isaac Asimov, en los últimos años la calidad...
Curioso: 1² + 2² + 3² + … + 24² = 70² Isabel de God Plays Dice ha comprobado todas las sumas de la secuencia de los primeros n números naturales al cuadrado hasta 1.000.000 para ver si alguna otra daba como...
La página UDF SkyWalker v1.0 permite recorrer la imagen Ultra Deep Field, la mirada más profunda hecha por el hombre al Universo. Para ver en grande las partes de la foto, como si estuvieras mirando desde el mismo Hubble como quien...
Por Nacho Palou -
15 DIC 2007
Los responsables del programa de transbordadores espaciales de la NASA han anunciado que el próximo intento de lanzamiento del Atlantis en la misión STS-122 queda fijado para el 10 de enero en lugar de para el día 2 como se había anunciado...
The Room Illusion es uno de los más asombrosos e impactantes fragmentos del maravilloso y altamente recomendable documental Brain Story (2000). Es una ilusión óptica de las mejores que haya visto nunca. No hay trucos digitales ni de post-producción: es una...
Does time slow in crisis? explica un curioso experimento recretativo en el que se intenta comprobar empíricamente si en situaciones de tensión o crisis las personas pueden ver las cosas en tiempo-bala como le sucedía a Neo en Matrix. No sé si...
Conflusions tiene una imagen en movimiento de un hipercubo o tesseracto, que es la denominación de un cubo en cuatro dimensiones (4-D), algo tan difícil de visualizar que nuestros limitados cerebros acostumbrados a la tridimensionalidad apenas pueden abarcarlo; a un ser plano...
El equipo de voluntarios que cada día traduce la Imagen Astronómica del Día de la NASA (APOD) al español para Observatorio se había marcado como objetivo traducir al español el archivo completo de más de 4.500 imágenes acumuladas durante los 12 años...
La lluvia de meteoros Gemínidas de 2007 alcanzará su máximo el próximo viernes 14 de diciembre. La particularidad de las Gemínidas es que, a diferencia de las lluvias de meteoros habituales, sus destellos no están producidos por partículas desprendidas de un cometa,...
Por Nacho Palou -
11 DIC 2007
Los sensores de corte de ignición de los motores principales en caso de que el nivel de combustible baje demasiado han sido de nuevo responsables de la cancelación de este segundo intento de lanzamiento de la misión STS-122 de la NASA, lanzamiento...
Leyendo Decoding the Universe me encontré con un curioso experimento mental acerca de la teoría de la Relatividad llamado Spear-in-the-Barn, del que no hallé más referencias. Por suerte Lektu y JarFil me enviaron algunos enlaces, porque resulta que también se conoce por...
Dicen que Claude Shannon, el padre de la Teoría de la Información, tenía en su despacho un juguete en forma de caja que construyó a partir de una idea de Marvin Minsky. Lo llamaba La Máquina Definitiva. La máquina definitiva tenía el...
Los sensores de nivel bajo de combustible en el depósito principal del transbordador espacial Atlantis siguen dando problemas, y ya no son dos los que fallan, sino que un tercero ha empezado a hacer también cosas raras mientras se vaciaba el depósito....
En lo relativo a la captura de datos para SETI, el proyecto de búsqueda de inteligencia extraterrestre mediante observación de señales electromagnéticas, el nuevo Allen Telescope Array es tan sumamente poderoso que, cuando esté plenamente operativo, ocho días de captura de datos...
La NASA ha anunciado que el lanzamiento del transbordador espacial Atlantis en la misión STS-122 queda pospuesto al menos hasta el sábado 8 de diciembre a las 21:43, hora de España (UTC +1). El primer intento de lanzamiento tuvo que ser cancelado...

La Ecuación de Drake, que como tantas cosas descubrí en Cosmos de Carl Sagan, es una fórmula que sirve para estimar la cantidad de civilizacions que puede haber en la Vía Láctea, nuestra galaxia. La fórmula original es y aunque aperente...
Cómo crear una escultura plástica algoríticamente iterativa o, dicho en términos más humanos, un fractal de plastilina, con el bello aspecto del Triángulo de Sierpinski. La idea es sencilla e ingeniosa: sólo hace falta plastilina (o algún material similar) de dos...
Apenas hace unos minutos se ha abortado el lanzamiento del transbordador espacial Atlantis es en la misión STS-122 de la NASA que tiene como objetivo colocar en órbita el laboratorio o Columbus de la ESA e instalarlo en la Estación Espacial Internacional....
Antenas del Allen Telescope Array. Foto © SETI Institute. El Allen Telescope Array (ATA), anteriormente conocido como One Hectare Telescope (1hT) es una de los más prometedores proyectos relacionados con SETI, el proyecto de búsqueda de vida extraterrestre inteligente. Situado a unos...
Backroom Boys: The Secret Return of the British Boffin Francis Spufford. Faber and Faber, 2 de septiembre de 2004. ISBN: 0571214975. Inglés. [No hay edición en español] Los backroom boys a los que se refiere el título son los científicos e ingenieros...
Traducción-resumen-adaptación de Why explore space? de Bad Astronomy Blog, previously on c Microsiervos: Los satélites artificiales han revolucionado nuestro mundo en casi cualquier aspecto que te puedas plantear. Los satélites meteorológicos nos permiten seguir el desarrollo de los huracanes y avisar con...
Decoding the Universe: How the New Science of Information Is Explaining Everything in the Cosmos, from Our Brains to Black Holes. Charles Seife. Inglés. 298 páginas. Apasionante este libro que desarrolla muchas de las ideas de la Teoría de la Información...
El Laboratorio Nacional Los Alamos se ganó se puesto en la historia como sede del Proyecto Manhattan, que fue el que permitió a los aliados desarrollar la bomba atómica durante la Segunda Guerra Mundial. Desde entonces es uno de los dos laboratorios,...
La llegada de Neil Armstrong y Buzz Aldrin a la Luna el 21 de julio de 1969 a bordo del Apolo 11 fue una de las retransmisiones televisivas más vistas de la historia de la televisión, seguida en directo por millones de...
La Editorial Sirio acaba de sacar al mercado Nacido en un día azul, la traducción al español de Born on a blue day, la muy recomandable autobiografía de Daniel Tammet. Daniel Tammet sufre de síndrome de Asperger, una forma de autismo, y...
Love Earth es un nuevo portal (¡ha dicho portal! – bueno: es lo que pone en la nota que nos han enviado) dedicado a la naturaleza de nuestro planeta. Es la página de la película Tierra realizada a partir del documental...
Como parte del precioso artículo Siete genios (y una rama completa de la ciencia) que nunca ganaron el Nobel se comenta el curioso hecho de que no exista el Premio Nobel de Matemáticas. Una leyenda urbana sostiene que Alfred Nobel, el inventor...
Campos de invernaderos en Almería. Foto: NASA/Visible Earth Campos de cosechas en Almería, miles de hectáreas cubiertas de plásticos, que pueden verse fácilmente desde el espacio, como una gran mancha blanca, debido a su alta reflectividad. La fecha indica la situación de...
Más conocido como «el satélite ese que siempre mencionaba el Hombre del Tiempo», el Meteosat comenzó su andadura por el espacio enviando esta foto de nuestro planeta. (¡Gracias, Mezvan!)...
Hoy las ciencias avanzan que es una barbaridad: Prensador eléctrico de latas de aluminio D-Wave at MIT NASA dips into bargain basement with new satellite A Hazy Future for a ‘Jewel’ of Space Instruments Embrionarias Y Epiteliales Top 20 most bizarre experiments...
¡Nunca se sabe cuándo se va a necesitar escapar de un cubo gigante lleno de habitaciones llenas de trampas mortales, con números extraños grabados en las puertas! Para no acabar como los protagonistas de Cube, MalaCiencia ha recopilado en la anotación...
Actualmente se cuentan en el catálogo de exoplanetas 221 planetas situados fuera del Sistema solar. El catálogo recoge planetas y cuerpos-tipo-planeta extrasolares que orbitan estrellas más o menos cercanas —teniendo en cuenta en astronomía el concepto de “cercano” adquiere una nueva dimensión...
Por Nacho Palou -
20 NOV 2007

Este vídeo muestra cómo construir con papel este sorprendente objeto, que está entre la curiosidad topológica y la magia de lo cotidiano. Esta cinta (o banda) tiene una sola cara y un solo borde; pueden hacerse un par de experimientos muy...
Aunque en su momento lo de la «Teoría Unificada sobre las Leyes del Universo propuesta por un Surfista» nos pareció bastante WTF lo cierto es que se le está dando cierta cancha, porque Garrett Lisi además de surfero es también un respestable...
Al parecer visualizamos nuestros recuerdos durante el sueño hasta siete vez más deprisa de lo normal, como a cámara rápida. El hipocampo y el córtex cerebral son capaces de hacer esto cuando dormimos porque el cerebro no está «entretenido» procesando lo que...
El calendario de la NASA Occupational Health -que debe ser algo así como el departamento médico de la agencia- para 2008 incluye dos fotografías tomadas por sendos aficionados españoles, el cordobés Francisco Bellido, y el donostiarra Juan Carlos Casado. Sus fotos son...
Crayon Physics es un juego todavía en desarrollo, aunque existe un prototipo que se puede probar. Funciona sobre TabletPC y convierte «mágicamente» los dibujos en objetos físicos que respetan las leyes de la física, principalmente la gravedad y luego las colisiones...
Nos enviaron esta foto que llevaba alguien ayer en una fiesta de la Facultad de Ciencias en Valladolid. «El Gato cuyo estado está en modo Wanted» se podría decir. Lo que es la vida: de protagonizar un experimento imaginario a camiseta...
Mientras la NASA ultima los preparativos para el lanzamiento de la misión STS-122 el próximo 6 de diciembre los miembros de la Expedición 16 a la Estación Espacial Internacional han completado ya su parte con la colocación en su lugar definitivo del...
Phytoplankton Bloom off Namibia. La mancha azul y verde de la izquierda es fitoplancton floreciendo frente a las costas del desierto de Namibia (derecha). La imagen a alta resolución resulta simplemente espectacular (ojo, son 2,55 MB de archivo). Está tomada a...
Por Nacho Palou -
16 NOV 2007
No se puede comprobar a simple vista ya que ahora mismo está a unas dos unidades astronómicas de la Tierra y alejándose, pero el cometa 17P/Holmes es en estos momentos el objeto más grande del Sistema Solar, más grande incluso que el...
Preparar una misión espacial no es algo que se haga de un momento para otro, por lo que la Agencia Espacial Europea ya lleva algún tiempo pensando en las misiones que lanzará al espacio en la década que va de 2015 a...
Una impresionante imagen de la Tierra saliendo en la Luna tomada en formato HDTV por la sonda Kaguya/Selene de la Agencia Espacial Japonesa: La Tierra vista desde la Luna © JAXA/NHK Los datos de la toma, la imagen a su resolución completa...
Cuando estuve ayer en Voces de Galicia se quedó en el tintero por falta de tiempo el hablar del coloquio que Javier Armentia dirigirá sobre el telescopio espacial Hubble el próximo viernes en Domus (calle Santa Teresa 1, 15002, La Coruña). El...
Hoy estuve de invitado en la sección La Red del programa Voces de Galicia de Radio Voz que dirige Isidoro Valerio y aprovechando que estamos en la Semana de la Ciencia propuse a la audiencia cuatro enlaces para estar al tanto de...
El transbordador espacial Atlantis está en la plataforma de lanzamiento 39A del Centro Espacial Kennedy desde este sábado, listo para los útimos preparativos para el lanzamiento de la misión STS-122. El Atlantis en la plataforma de lanzamiento - NASA/Kim Shiflett(Alta resolución, 2014×3000...
Nuestra civilización está condenada. Probablemente eso no es lo primero que quisieras leer al abrir este libro, pero es verdad. La humanidad -y toda la vida del Universo- va a ser completamente barrida. No importa cuán avanzada se desarrolle nuestra civilización, no...
A logarithmic image transformation es un artículo que explica las transformaciones matemáticas que M.C. Escher aplicó a su trabajo Galería de Grabados (1956), una de sus obras «autorreferentes» más impactantes. Estas transformaciones divididas en tres fases de logaritmos, rotaciones + escalas...

Potències de 10 [YouTube, 5:30 min., catalán] es un remake del popular documental Powers of Ten, emitido por el programa científico Dígits. Fue creado por la productora catalana Lavinia TV, de modo que, apropiadamente, el viaje por el universo comienza en...
3D IFS fractal: Menger Sponge Zoom [YouTube, 20 seg.] es un zoom entre 1 y 1.150.000 de una esponja de Menger (el famoso cubo con agujeros construido con cubos con agujeros con cubos con agujeros…) La animación está hecha con un...
The Riemann Hypothesis: The Greatest Unsolved Problem in Mathematics. Karl Sabbagh. 2002. Inglés. Sigo leyendo cosas interesantes sobre la Hipótesis de Riemann, ese bello y profundo problema matemático rodeado de historias increíbles de los expertos que han trabajado en todos sus...
Why is the number one not prime? recoge las cuatro explicaciones más relevantes sobre por qué el número 1 no es primo, o en otras palabras, por qué la secuencia de los números primos empieza por 2, 3, 5, 7, 11… dejando...
Alex nos envió su apunte Polimedia: de repografía al USB que cuenta un montón de cosas sobre Polimedia, una herramienta que se usa en la UPV y que consiste en una grabación del profesor exponiendo diversos contenidos de cada curso. Está previsto...
La «pobre víctima» es el puntito rojo, los otros son sus… «amigos». Según un estudio matemático realizado por unos físicos, la extensión y velocidad de propagación de un cotilleo depende de cuántos amigos tenga la víctima del rumor. A veces hay que...
Science in Silico muestra cómo las simulaciones por ordenador y las diversas formas de visualizar datos han revolucionado las formas de ver algunas cosas. Incluye algunas descripciones de los fractales y también explicaciones sobre cómo los científicos pueden simular experimentos que...
El Discovery y su tripulación ya están en casa tras un aterrizaje de libro esta tarde a las 19:01, hora de España, tras 15 días en el espacio y tras dar 238 vueltas a la Tierra por un total de cerca de...
La Sucesión de Farey es una de esas curiosidades matemáticas a la vez llenas de belleza y fáciles de entender que casualmente descubrió un no-matemático, John Farey, en 1928. La idea es tomar un número natural (ej. n = 3) y empiezar...
El Océano de las Tormentas, cerca del polo norte de la Luna © JAXA World’s First Image Taking of the Moon by HDTV es un montaje de la JAXA (la agencia espacial japonesa) y NHK, la televisión pública, con nuestro viejo satélite...
Último día de comprobaciones en órbita para asegurarse de que todo está listo para la maniobra de reentrada del Discovery, que en principio comenzará a las 17:59 (hora de España, GMT +1) con el encendido de los motores principales de la nave...
La palabra clave de esto es desalentador. (Vía Novedades Científicas.) Actualización: El título original de la anotación era Vídeo: El deshielo del Ártico, desde 1979 hasta nuestros días (tal y como mencionaba Novedades Científicas), pero snipfer (¡gracias!) nos escribió acerca de...
The Story of π es un precioso vídeo divulgativo que explica visualmente por qué el área de un círculo es π r² y otras curiosidades sobre el número pi. Su autor es el matemático Tom M. Apostol quien trabaja en teoría...
Después de casi once días atracado en la Estación Espacial Internacional el Discovery se desconectaba de esta ayer a las 11:32 hora de España (GMT +1) para primero dar una vuelta a su alrededor a una distancia de unos 125 metros con...
Hasta hace unos días el cometa 17P/Holmes era prácticamente un desconocido fuera del mundo de los astrónomos y de los aficionados a la astronomía porque aunque visita nuestro sistema solar cada siete años su magnitud es tan baja que normalmente sólo se...
Con la transferencia de los últimos kilogramos de carga entre el Discovery y la Estación Espacial Internacional se dieron por concluidas las tareas de la tripulación de la misión STS-120 de la NASA a la ISS, con lo que a las 21:03...
Los detallados preparativos para el cuarto paseo espacial de la misión STS-120 que se llevaron a cabo durante el jueves y el viernes han dado los frutos deseados, ya que Scott Parazynski consiguió reparar la sección B4 del panel solar del segmento...
El gran matemático Leonhard Euler descubrió el resultado de una famosa serie infinita de sumas, la de los inversos de los cuadrados de los números enteros positivos (1/12 + 1/22 + 1/32 ...), también conocida como Problema de Basilea. Aunque tiene infinitos...
Haciendo esto resulta que El área de un círculo de radio 5 es la misma que la suma de las áreas de dos círculo de radios 4 y 3. Como cuentan allí, esto se puede aplicar a otras fórmulas que tengan otros...
Otro día de preparativos para el complicado paseo espacial que espera a Scott Parazynski, en el que intentará reparar la sección 4B del panel solar del segmento P6 de la Estación Espacial Internacional, panel en el que apareció una raja durante su...
El mayor número primo conocido cuyos dígitos contienen más ceros es el 134088 × 1015036 +1. Puede leerse como 134088000... seguido de más de 15.000 ceros y después acabado en un 1. Si se escribiera en formato libro ocuparía ocho páginas: todas...
El número 2 no existe El 2 es el único número primo que es par Pero hay infinitos números primos Por tanto la probabilidad de que un número primo dado sea par sería 1 dividido por infinito, es decir, cero Por tanto,...
Las tripulaciones del Discovery y de la Estación Espacial Internacional pasaron el día preparando las herramientas con las que Scott Parazynski intentará reparar la sección 4B del panel solar del segmento P6 que se rajó durante su despliegue el pasado martes. Para...
Cuando se extraen células del cuerpo humano éstas comienzan a morir lenta e inexorablemente, normalmente antes de que lleguen a completar cincuenta divisiones. Las células no pueden sobrevivir sin el soporte vital que proporciona el cuerpo y tampoco pueden prolongarse artificialmente porque...
Por Nacho Palou -
2 NOV 2007
Traducidas por Maikelnai de Death special: How does it feel to die?, el especial sobre la muerte de New Scientist, diez formas de morir: De un ataque al corazón. Ahogado. Desangrado. En un incendio. Decapitado. Electrocutado. Por caída desde altura. Ahorcado. Por...
La sección 4B del panel solar del segmento P6 que se rajó durante su despliegue el pasado martes se ha convertido en la preocupación principal de los responsables de la misión, con lo que la inspección de la Junta Solar Rotatoria (SARJ)...
A pesar de que el paseo espacial de Scott Parazynski y Douglas H. Wheelock era a priori uno de los considerados complicados la instalación del segmento P6 de la Estación Espacial Internacional en su ubicación definitiva en el extremo de babor de...
Tal y como cuenta Karl Sabbag en su excelente libro sobre un de los grandes problemas de las matemáticas, The Riemann Hypothesis: The Greatest Unsolved Problem in Mathematics el mayor número primo cuyos dígitos son todos unos y ceros tiene 5856 dígitos:...
Ayer fue un día de relativo descanso para las tripulaciones del Discovery en la misión STS-120 de la NASA y de la Expedición 16 a la Estación Espacial Internacional tras el paseo espacial del domingo. La principal actividad del día fue acercar...
El sexto día de la misión STS-120 tuvo como protagonistas principales a Scott Parazynski y Daniel M. Tani, quienes llevaron a cabo el segundo paseo espacial de la misión. En 6 horas y 33 minutos Parazynski y Tani terminaron de desconectar el...
Bonito número primo, lleno de simetrías: es capicúa (se lee igual de izquierda a derecha que de derecha a izquierda), es un ambigrama (se ve igual si se gira 180 grados) y tiene simetría especular (se lee igual frente a un espejo)....
La Estación Espacial Internacional tiene 75 metros cúbicos más de espacio desde las 14:24 del 27 de octubre de 2007, hora de España (GMT +2), momento en el que Peggy Whitson, la comandante de la ISS, y el especialista de la misión...
Los especialistas de la misión Scott Parazynski y Doug Wheelock aprovecharon el primer día completo del Discovery atracado en la Estación Espacial Internacional para llevar a cabo el primero de los cinco paseos espaciales previstos en la misión STS-120. La primera tarea...
Huracanes: guía animada explica de forma visual cómo se producen los huracanes. (Vía Ya está el listo que todo lo sabe.)...
Por Nacho Palou -
27 OCT 2007
La página que verifica si un número es primo o no. Permite probar números entre 0 y [bastante más de] 1.000.000.000. Nunca se sabe cuándo se va a poder necesitar… Por ejemplo para comprobar si tu número de teléfono o tu DNI...
Después de realizar la Rendezvous Pitch Maneuver, que consiste en dar una vuelta con el transbordador antes de llegar a la Estación Espacial Internacional para que este pueda ser fotografiado por la tripulación de la ISS con el objeto de detectar cualquier...
Guide to Mathematics and Mathematicians on The Simpsons recopila, una por una, todas las referencias matemáticas que alguna vez han aparecido en episodios de los Simpson. Hay otras recopilaciones similares y muchos enlaces más en Simpsonsmath.com. (¡Mosquis! ¡Gracias Javier!)...
A pesar de que el color de luz visible que emite el Sol -nuestro Sol- con más fuerza es el verde la suma de los colores que emite hace que esta luz sea blanca... Pero nadie sabe a ciencia cierta por qué...
Como es habitual en todas las misiones de los transbordadores espaciales desde que estos han vuelto al servicio tras el desastre del Columbia de 2003 la tripulación del Discovery en la misión STS-120 ha pasado su primer día en órbita comprobando el...
La máquina de Turing (2,3) de dos estados y tres colores.Se ha demostrado que es de tipo «Universal» El premio sobre una pequeña Maquina de Turing (2,3) ofrecido por Stephen Wolfram ya tiene ganador oficial: Alex Smith, un estudiante de veinte años...
El principio antrópico cosmológico viene a decir, en su versión simplificada, que El mundo es necesariamente como es porque hay seres humanos que se preguntan por qué es así. o, como dijo Stephen Hawking, Vemos el universo en la forma que es...
A pesar de que las predicciones meteorológicas cifraban hasta en un 60% las posibilidades de que hubiera que aplazar el lanzamiento del transbordador espacial Discovery en la misión STS-120 de la NASA este despegaba esta tarde a la hora prevista en un...
A petición popular, una recopilación sobre anotaciones entrañables que se han publicado estos días sobre Juan Antonio Cebrián, periodista, locutor de radio, escritor y divulgador que falleció súbitamente el pasado día 20 de octubre de un ataque al corazón. El programa La...
Desde hace años Jamie Zawinski (AKA jwz) viene proporcionando un feed RSS no oficial de la Astronomy Picture of the Day de la NASA porque por increíble que parezca la APOD no lo tenía, pero hoy me he dado cuenta de que...
¡Nunca se sabe en qué segundo exacto del día se va a necesitar la hora factorizada! Eso es lo que hace Factor Clock, tomando los dígitos de la hora y eliminando el separador : entre horas, minutos y segundos, como por ejemplo...
Se puede considerar que es el tornado artificial más poderoso hecho por el hombre. Está instalado en el Mercedes-Benz Museum y se crea con 144 pequeñas turbinas que después de siete minutos funcionando simultáneamente causan un tornado que mide casi 35...
Por Nacho Palou -
20 OCT 2007
Reglas de Cálculo es un sitio dedicado a las entrañables calculadoras mecánicas del pasado, principal instrumento de ingenieros, físicos y matemáticos en décadas pasadas, hasta que fueron ofuscadas por la llegada de la calculadoras electrónicas. Era el gadget geek por excelencia de...
Aunque pueda parecer un paisaje lunar, este campo de cráteres está en la Tierra. Y fue construido por el hombre. Ver en Google Maps. Cerca de Flagstaff, en Arizona (EE UU), existe una versión terrestre de la superficie lunar. Se construyó unos...
Por Nacho Palou -
18 OCT 2007
A pesar de que en los últimos días una serie de ingenieros habían expresado sus dudas acerca de si seguir adelante con el lanzamiento del transbordador espacial Discovery la semana que viene al haber detectado un desgaste excesivo en tres de los...
Las personas negras son menos inteligentes ha dicho James Watson. Es sin duda el WTF del día, sobre todo porque el protagonista de tan desafortunado comentario no es otro que uno de los descubridores del ADN (el material en que están codificados...
La NASA acaba de anunciar que ha aprobado la que es ya la quinta extensión de la misión para los rovers marcianos Spirit y Opportunity, que llevan ya casi cuatro años en la superficie de Marte: NASA Extends Operations for Its Long-Lived...
Cómo saber fácilmente si un número es divisible por 7, ¡nunca se sabe cuándo puede viene venir bien hacer este cálculo mentalmente! La prueba del siete – Se multiplica la última cifra del número por dos y el resultado se resta al...
Hoy se cumplen diez años del lanzamiento de la sonda espacial Cassini-Huygens, una misión conjunta de la NASA, la Agencia Espacial Europea y la Agencia Espacial Italiana. Como en muchas otras ocasiones es el Jet Propulsion Laboratory quien lleva el control de...
ScienceHack es un sitio con aspecto webdosceriano que se dedica a recopilar vídeos de diversas fuentes, todos ellos relacionados con temas científicos y tecnológicos. Se clasifican por categorías y se etiquetan, de modo que son fáciles de encontrar. Según dicen, su...
Preparando en Thrust SSC en el desierto de Nevada. Foto de ThrustSSC.com El 13 de octubre de 1997 el Thrust SuperSonic Car (SSC) rompió la barrera del sonido rodando en el desierto de Black Rock, en Nevada. Construido especialmente para la ocasión,...
Por Nacho Palou -
15 OCT 2007
El Mensaje de Arecibo es un mensaje de radio que fue enviado hacia el cúmulo de estrellas M13 en 1974 por el radiotelescopio de Arecibo con el fin de informar al universo que hay vida inteligente en la Tierra (...) Fue diseñado...
La edición de Informe Semanal del sábado 6 de octubre de 2007 incluyó un reportaje titulado Pensar en Español [Necesita Flash, 10 min. aprox.] sobre la Quincena Pensar en Español, que reúne en Madrid a representantes de diversos organismos e instituciones del...
Imagen del National Air and Space Museum. Los satélites-globo del proyecto Echo comenzaron a desarrollarse a mediados de la década de los años 50 del siglo pasado. Medían más 30 metros de diámetro (la altura de un edificio de 10 plantas) y...
Por Nacho Palou -
11 OCT 2007
… visualmente: IANAM, así que ignoro si es una «demostración» estricta y válida y todo eso (parece que sí), pero me pareció preciosa y no la conocía. Proviene de una bonita recopilación llamada Math Gems. En la Wikipedia hay otras demostraciones y...
Es un poco largo y falto de enlaces porque está escrito para una revista de esas que se publican en formato árboles muertos, pero aún así Más Allá De La Telebasura: Las Pseudociencias es un interesante repaso de Javier Armentia a cómo...
Imagen ganadora de la edición de 2007. Embrión de ratón de 18,5 días a 17 aumentos. Imagen Gloria Kwon. Nikon's Small World es un concurso internacional en el que se premian las imágenes más curiosas o hermosas tomadas a la luz del...
Por Nacho Palou -
8 OCT 2007
Anoche se celebró la gala de entrega de los premios Ig Nobel 2007, aquellos galardones que se otorgan a aquellas investigaciones que aunque son serias tienen temáticas o títulos que no pueden por menos que poner una sonrisa en nuestras caras. En...
Tal día como hoy hace 50 años, a las 22:28:34 hora de Moscú (GMT +3), un cohete R-7 Semyorka modificado despegaba desde el campo de lanzamientos de Tyuratam, hoy conocido como Cosmódromo de Baikonur, llevando a bordo el Sputnik 1, que...
El accidente en la planta de Chernóbil ocurrido en 1986 tiene el triste honor de ser el accidente nuclear más grave. También convirtió los alrededores de la central en uno de los diez lugares más contaminados del mundo —y lo seguirá siendo...
Por Nacho Palou -
4 OCT 2007
Brain Story. Narrado por Susan Greenfield. 2000. Inglés. Miniserie (6 episodios de 50 minutos). Libro de la autora: Brain Story: Why Do We Think and Feel as We Do? (Por qué pensamos y sentimos como lo hacemos?) El estudio del cerebro...
Fotograma de vídeo grabado en formato de alta definición (HDTV) desde el espacio por la sonda Kaguya. La sonda lunar Kaguya enviada el pasado día 14 de septiembre por la agencia espacial japonesa (JAXA) tomó por primera vez imágenes de vídeo de...
Por Nacho Palou -
4 OCT 2007
Hace ya tiempo que Virgin Galactic tiene planes de construir un espaciopuerto en Nuevo México. Recientemente la firma Foster + Partners junto con URS Corp. han ganado el concurso internacional organizado con el objetivo de llevar a cabo el proyecto del...
Por Nacho Palou -
4 OCT 2007
El 73939133 es un número primo que tiene la curiosa propiedad de que quitando dígitos por la derecha los números resultantes también son primos: 7393913, 739391 … 739, 73, 7. Como la pirámide de números primos que funciona con los dígitos de...
10 Easy Arithmetic Tricks explica cómo conseguir algunos superpoderes aritméticos, de esos que nunca se sabe cuándo los vas a necesitar. Están excelentemente explicados con ejemplos y de forma sencilla. El primero, por ejemplo, es Cómo multiplicar por 11 un número de...
Brain Man (Channel Five, 2005) [Google Vídeo, 43 min., inglés; también disponible en las redes P2P] Al acabar de leer Born on a blue day me quedé con las ganas de ver Brain Man, el documental que realizó Channel Five sobre...
A pesar de haber tenido que realizar modificaciones en el depósito principal de combustible para evitar en la medida de lo posible los desprendimientos de espuma aislante y de haber tenido que realizar una reparación de última hora en la pata derecha...
Un estudio realizado por un equipo de la Universidad de Oxford dirigido por David Deutsch sugiere que la teoría de los universos paralelos múltiples propuesta por primera vez en 1950 por el físico Hugh Everett podría explicar ciertos aspectos de la mecánica...
Los técnicos de la NASA se han dado bastante prisa a la hora de reparar la pata derecha del tren de aterrizaje principal del transbordador espacial Discovery, en la que una de sus juntas de goma perdía fluido hidráulico al ritmo de...
Foto: NASA/JPL/Cornell/Texas A&M. You are here: Earth as seen from Mars es la primera foto de la Tierra vista desde otro planeta. Fue tomada por la sonda Spirit tras 63 días de exploración en Marte, hace ya años. En cierto modo, muestra...
Tanto la carencia como el exceso de sueño doblan las probabilidades de morir. Tener hábitos de sueño extraños (especialmente, dormir poco) ya sonaba algo chungo, pero no imaginaba que pudiera ser tan mortal. El estudio es de la Universidad de Warwick y...
Maikelnai nos cuenta en 10 cosas que hubieras preferido no saber de tu cuerpo algunos detallitos sobre nosotros mismos que igual hubiéramos preferido seguir ignorando, como por ejemplo cuanto suda un pie cada día o cuantos litros de orina producimos a lo...
Dentro de la apretada agenda de misiones que le queda a la flota de transbordadores espaciales de la NASA para tener terminada la construcción de la Estación Espacial Internacional para cuando llegue 2010, la fecha prevista de retirada de los transbordadores, la...
Hace unos días Elías nos escribía para recomendarnos Hubblecast , un podcast en vídeo con noticias e imágenes del telescopio espacial Hubble de la ESA / NASA. Son vídeos cortos, de unos cinco minutos de duración, en los que se van explicando...
Google y la X PRIZE Foundation acaban de dar a conocer los primeros detalles del Google Lunar X PRIZE, el próximo desafío destinado a promocionar la investigación espacial de bajo coste por iniciativa privada. Aquellos que quieran optar al premio tienen que...
Otra colección más de enlaces que se van quedando en el tintero, en este caso fundamentalmente sobre cosas de la NASA y sus misiones espaciales: NASA issues repair plan on shuttle tanks: Tras la reciente misión STS-118 del Endeavour la NASA se...
Jeannine Mosely posando con su esponja de Menger.El «cubo fractal» mide 140 cm de lado y pesa 70 kg. Con un poco de habilidad y 66.048 tarjetas de visita es posible construir un gigantesco cubo fractal como el de la imagen. Tiene...
Perpetual Futility: Una breve historia de la búsqueda del movimiento perpetuo es un excelente ensayo sobre cómo a lo largo de los siglos los seres humanos han intentado crear máquinas de movimiento perpétuo. Las primeras máquinas conocidas y documentadas datan del...

Júpiter fotografiado por la Voyager 1 - Foto: PIA01384, NASA Hoy se cumplen 30 años del lanzamiento de la sonda espacial Voyager 1 desde Cabo Cañaveral a lomos de un cohete Titan IIIE, que desde entonces, y junto con la Voyager 2,...
A principios del año pasado mencionamos la existencia de Imagen Astronómica del Día, una iniciativa para traducir al español la conocidísima APOD de la NASA, aunque iba con cierto retraso respecto al original. Ahora Alex nos escribe para contarnos que este verano...
Rememorando un clásico: La extraña igualdad entre un número periódico puro (0,9999999…), que repite de forma infinita todas sus cifras decimales, y un número entero (1) , que está muy, muy cerca… 0,999… = x multiplicando por 10 a ambos lados9,999… =...
En el mundo de los pi-primos, cada dígito de π es un potencial protagonista. Pero no todos tienen el carisma para ser primo.
Algunas fórmulas matemáticas que podrían clasificarse de aparentemente normalitas y fáciles de entender dan como resultado números casi enteros: valores numéricos que curiosamente están muy cerca de ser enteros pero por poco, poco, poco, no lo son. Estos son los ejemplos que...
Imagino que más medio en serio que medio en broma la constante de aparcamiento de Rényi indica algunas cosas curiosas sobre cuantos coches caben aparcados en línea en una calle. El número mágico es 0,74759792025341… que equivale a la densidad media:...
Una anécdota medio matemática, medio informática, extraída también de The Music of the Primes, el libro Marcus du Sautoy. A principios de los 70, los matemáticos Zagier y Bombardi hicieron una apuesta relativa a la hipótesis de Riemann en la que ambos...
Google Earth 4.2 es una actualización significativa del popular programa de Google para explorar el planeta con imágenes aéreas y de satélite. Tal y como cuentan en Google Earth 4.2: novedades ahora se puede mirar al cielo y utilizar el programa también...
Esta tarde a las 18:33:20 (hora de España, GMT +2) el transbordador espacial Endeavour se detenía por completo en la pista 15 del Centro Espacial Kennedy, poniendo fin a la misión STS-118 de la NASA tras 13 días en el espacio y...
Importante: ver actualización al final Hasta la NASA se equivoca con su datos y a veces las consecuencias son insospechadas. El famoso bug del «efecto 2000» que se produjo al cambiar de 1999 a 2000 afectó a los datos climáticos en bruto...
El Endeavour y su tripulación están en una especie de carrera contra el huracán Dean para intentar aterrizar en el Centro Espacial Kennedy antes de que los efectos de Dean puedan hacerlo imposible, y para ello desde el control de la misión...
The Music of the Primes: Searching to Solve the Greatest Mystery in Mathematics. Marcus du Sautoy, 2003. En castellano: La música de los números primos (Editorial Acantilado). Este libro es un recorrido por la vida de algunos de los más grandes...
La tripulación del Endeavour dedicó la mayor parte del jueves y del viernes (días 9 y 10 de la misión) a prepararse para el paseo espacial del sábado, que según la decisión que estaban pendientes de tomar los responsables de la misión...
Si durante el segundo paseo espacial de la misión el traje espacial de Rick Mastracchio dio un susto a todo el mundo al dar un aviso de niveles altos de CO2, aunque luego resulto ser una falsa alarma, este mismo traje fue...
Durante estos días la tripulación del Endeavour ha seguido adelante con las tareas de construcción y mantenimiento de la Estación Espacial Internacional, en concreto:Instalando el segmento S5 (Estribor 5) del armazón principal de la ISS, con lo que este mide ahora unos...
Desde que en julio de 1965 la sonda Mariner 4 de la NASA se pasara por las proximidades de Marte enviando de vuelta 21 imágenes de nuestro vecino hemos ido acumulando una importante cantidad de imágenes de este que nos han permitido...
El transbordador espacial Endeavour entró en órbita ayer preparándose para dirigirse a su destino: la Estación Espacial Internacional (EEI). Durante el primer día los astronautas aprovecharon para acostumbrarse a estar en el espacio y a las condiciones de ingravidez. El primer problema...
Una observación de estrellas y meteoros en Hokkaido, Japón, en una fotografía de larga exposición. (CC) Daita. Lluvia de Estellas: Perseidas 2007 es la página de la comunidad Astrowiki desde donde se está promoviendo la observación del fénomeno astronómico del verano. Este...
En unas horas está previsto el lanzamiento del transbordador espacial Endeavour en la misión STS-118 de la NASA con destino a la Estación Espacial Internacional. Está previsto para las 18:36 hora local del Centro Espacial Kennedy, que equivale a las 00:35 de...
Born on a blue day Daniel Tammet. Hodder Paperback, 22 de febero de 2007. ISBN: 0340899751. Inglés. Daniel Tammet, el autor de este libro, sufre del síndrome de Asperger, aunque no fue diagnosticado hasta los 25 años, y como sucede en otros...
Pirámides de números primos encontradas en Futility Closet. Partiendo del 7 y añadiendo «convenientemente» números dígitos por la izquierda... 7 37 137 9137 29137 629137 7629137 67629137 567629137 6567629137 16567629137 216567629137 6216567629137 46216567629137 646216567629137 2646216567629137 12646216567629137 312646216567629137 6312646216567629137 86312646216567629137 686312646216567629137 7686312646216567629137 57686312646216567629137...

Gene Cernan comprobando el Rover Lunar, en la misión Apollo 17 Aunque ya había muchas fotografías en la web de la NASA ahora la Arizona State University ha comenzado a escanear y publicar los archivos fotográficos completos que llevaban casi 40 años...
Este vídeo en cinco partes es un documental de BBC Horizons sobre algunas ideas científicas alrededor de la construcción del Large Hadron Collider (en la Wikipedia en español: Gran Colisionador de Hadrones), el más caro y complejo instrumento científico jamás creado...
Esta noche, a las dos de la madrugada, se puso finalmente en marcha la cuenta atrás para el lanzamiento del transbordador espacial Endeavour en la misión STS-118, lanzamiento previsto para la 1:35 0:35 de la madrugada del jueves 9 de agosto, hora...
Jesús Javier Pérez me invitó a participar en una edición especial de Enredados, la Radio de la Blogosfera Andaluza, sobre la reciente sentencia condenatoria contra Luis Alfonso Gámez a instancias de la denuncia de J. J. Benítez. En ella Luis Rull leyó...
El lanzamiento del transbordador espacial Endeavour en la misión STS-118 de la NASA ha sido pospuesto 24 horas para permitir al equipo completar los trabajos preparatorios antes del lanzamiento. De este modo el lanzamiento desde el Centro Espacial Kennedy tendrá lugar próximo...

Bonita película del estilo de Cosmic View y Powers of Ten. [35 min.; dividida en YouTube en cuatro partes]. Originalmente concebida para salas IMAX es del año 1996 y está narrada por Morgan Freeman. (¡Gracias, Eduardo!) Actualización (5 de agosto de...
Poco antes del mediodía de hoy la sonda espacial Phoenix de la NASA despegaba desde Cabo Cañaveral rumbo a Marte, donde está previsto que llegue el 25 de mayo de 2008. El objetivo de esta sonda es posarse en las proximidades de...
Klondike Solitaire Online, para jugar vía web al «Solitario». El popular Solitario incluido en las versiones modernas de Windows es una de las muchas versiones de este tipo de juegos de cartas y se llamaba originalmente Klondike, en inglés Patience o también...
Cosmic View: The Universe in 40 Jumps es un libro de 1957 que recuerda muchísimo al más moderno Potencias de 10 de Philip and Phylis Morrison (popularizado por IBM, Cosmos y Scientific American). Las páginas de Cosmic View incluyen ilustraciones en...
Aunque siempre se dice que el Sol sale por el este y se pone por el oeste en realidad, debido a la inclinación del eje de rotación de la Tierra y al movimiento de traslación de esta alrededor del Sol, esto sólo...
Una ballena azul comparada con un submarinista y un delfin.Ilustración de T. Bjornstad. La ballena azul (Balaenoptera musculus) es el mayor mamífero del reino animal. Hacia 1930 se midieron ejemplares de más de 30 metros y 190 toneladas de peso, aunque los...
Luis Alfonso Gámez, uno de los más férreos críticos de J. J. Benítez, ha perdido una demanda que interpuso este contra él por, en opinión del juez Jairo Ávarez-Uria Franco, del Juzgado de Primera Instancia Nº 5 de Getxo, haber vulnerado su...
The End of Everything es una entretenido ejercicio de especulaciones sobre cómo y cuándo podría terminar todo: la Humanidad, la vida, el Sol y el planeta Tierra, el Sistema Solar, la Vía Láctea, la materia... el fin de todo en el Universo,...
Por Nacho Palou -
31 JUL 2007
Todos los vídeos de YouTube tienen un código único al estilo SIvp8xmvAyc. Son combinaciones únicas al azar de once letras y números que, de seguir así, algún día se agotarían, como las matrículas. En ¿Cuántos vídeos caben en Youtube? hacen un repaso...
Al parecer las acusaciones de que se permitió volar a astronautas bajo los efectos del alcohol que comentábamos el viernes están contenidas en dos informes realizados por la NASA, uno a nivel interno y otro a cargo de un comité independiente, que...
Hoy debería de haber sido un día relajado, incluso feliz, para los responsables de la NASA, ya que según se puede leer en NASA Gives 'Go' for Shuttle Endeavour Launch on Aug. 7 el transbordador espacial Endeavour recibía ayer el visto bueno...
Al principio de la carrera espacial la Unión Soviética parecía imparable, haciéndose con un éxito tras otro, como el de colocar el primer satélite artificial en órbita (el Sputnik 1 el 4 de octubre de 1957), el primer hombre en el espacio...
La imagen superior fue tomada ayer 25 de julio por el satélite Aqua de la NASA. Cada punto rojo representa un incendio sobre le que puede verse el penacho de humo blanco que se suman a la fina capa de humo...
Por Nacho Palou -
26 JUL 2007
En el asunto del calentamiento global las emisiones de CO2 a la atmósfera son una parte crítica del problema. Entre esas emisiones están las producidas por los coches, aviones y fábricas, pero también está el no menos desdeñable problema de todo el...
Y eso aún sin haber puesto el pie sobre el planeta. El rover lunar (210 Kg) es uno de los objetos artificiales abandonados. Se calcula que actualmente hay 8.053 kilos de material terrestre sobre la superficie de Marte. Excepto los pequeños rover...
Por Nacho Palou -
23 JUL 2007
Esto es probablemente lo más cercano que estaremos la mayoría de dar un paseo por el interior de la Estación Espacial Internacional que orbita la tierra a más de 330 kilómetros de altura: ISS Interactive Reference Guide (inglés, requiere Flash). El interactivo...
Por Nacho Palou -
22 JUL 2007

Atención a este increíble viaje fractal: si el último fotograma tuviera el tamaño de la pantalla de tu ordenador, el tamaño del conjunto original al principio de la secuencia sería más grande que todo el Universo conocido. Hay una explicación en...
El otro día vi de casualidad una reposición de Redes, el programa titulado Estamos Programados, donde se entre entrevistaba a Malcom Gladwell respecto a los temas de su libro Blink! (también en castellano: Inteligencia Intuitiva). En la parte final participaban también Óscar...
Esta medianoche el Gran Telescopio Canarias abrirá por primera vez sus ojos para echar un vistazo al firmamento, en concreto apuntando a la Estrella Polar: El Gran Telescopio CANARIAS observa su Primera Luz; el acto pude seguirse en línea y en directo...
Tras un parón de casi cinco años el transbordador espacial Endeavour llegaba esta pasada madrugada a la plataforma de lanzamiento 39A del Centro Espacial Kennedy para los últimos preparativos para el lanzamiento de la misión STS-118 de la NASA, que tiene como...
The Prime Game describe un pequeño juego con un resultado profundamente extraño y curioso a la vez, que tiene que ver con los números primos: Pídele a un amigo que escriba un número primo. Apuesta a que puedes tachar cero o más...
Tras completar con éxito sus respectivas misiones, la NASA se encontró con que tenía en órbita dos sondas en perfecto estado de funcionamiento, la Deep Impact y la Stardust, así que tras realizar los estudios y cálculos pertinentes acaba de anunciar nuevas...
Un reciente vuelo de inspección ha podido constatar que el lago Témpanos, de cuya desaparición hablábamos hace nos días, está volviendo a llenarse, aunque no está claro si alcanzará la profundidad que tenía antes ni si será capaz de conservar el agua...
An Introduction to the fascinating patterns of Visual Math es una excelente galería de diversos tipos de imágenes matemáticas que van desde los sólidos y la geometría vectorial a fractales de diversos tipos, incluyendo los fractales en la naturaleza, la geometría...
Hace unos meses la empresa irlandesa Steorn anunció a bombo y platillo un avance revolucionario en el campo de la obtención de energía, revolucionario hasta el punto de que prometían energía gratuita e ilimitada, aunque ello pareciera contravenir las leyes físicas de...
Tras un vuelo con varias escalas a lo ancho de los Estados Unidos el Atlantis aterrizaba hoy en el centro espacial John F. Kennedy a lomos de uno de los Shuttle Carrier Aircraft de la NASA procedente de la Base de la...
La imagen de arriba (pulsa par ampliar) intenta comparar a escala el tamaño del Sol (etiquetado como “The Sun”, en la imagen) y el tamaño ampliamente aceptado para la estrella VY Canis Majoris, una estrella hipergigante roja con un radio estimado...
Por Nacho Palou -
2 JUL 2007
Nunca se sabe cuándo va a necesitar uno una lista como esta ni para qué, pero en Lists of Primes at the Prime Pages hay varias en distintos formatos para descargar, especialmente útiles en formatos de texto, ZIP y PDF. También hay...

Almost Gone – (CC) Anna (Flickr: bcmom) Durante todo este fin de semana hay Luna llena. Tal y como cuentan en Space.com estará muy baja en el horizonte, de hecho la vez que más baja estará en todo el año en el...
The Sun/Moon Calculator es una calculadora de horarios de salidas y puestas del sol, también de luna. Basta introducir el lugar y otros datos como la zona horaria, si se está en el «horario de verano» (por lo del cambio de hora)...
Series como C.S.I. nos han familiarizado con los análisis de ADN, mediante los cuales es posible identificar cualquier resto biológico encontrado en una escena del crimen siempre que haya alguna muestra con la que compararlo debido a que la composición de los...
El tiempo no es constante en nuestra memoria: se expande y se contrae y los recuerdos se concentran en períodos concretos. A este hecho se le llama efecto reminiscencia... Una pequeña treta de la memoria que hace la mayoría de los...
La meteorología ha vuelto a impedir que el Atlantis tome hoy tierra en el centro espacial John F. Kennedy en Florida, pero sin embargo lo hará en la Base de la Fuerza Aérea de Edwards en aproximadamente tres cuartos de hora, a...
La presencia de tormentas en las proximidades de la pista de aterrizaje de transbordadores espaciales del Centro Espacial Kennedy en Florida ha hecho que en las dos oportunidades que el Atlantis tenía hoy para aterrizar la meteorología estuviera bajo mínimos, con lo...
Tras revisar las nuevas imágenes del escudo térmico del Atlantis tomadas por su tripulación tras la separación de la Estación Espacial Internacional y revisar también las fotos tomadas por John «Danny» Olivas durante la reparación de la manta de protección cuya esquina...
Este fue un día de escasa actividad a bordo del Atlantis, en especial comparado con los anteriores, en el que tras desatracar de la Estación Espacial Internacional el piloto Lee Archambault rodeó esta a una distancia de unos 150 metros para que...
El descubrimiento de 2003 UB313, ahora conocido oficialmente como Eris, y antes más conocido como Xena, marcó el principio del fin del status de Plutón como planeta después de haberse comprobado que Eris es más grande que Plutón, con lo que o...
Liberia, Myanmar y… los Estados Unidos de América. Tal y como cuenta la Wikipedia sobre el Sistema Métrico todos los demás países del mundo han seguido un proceso de metrificación, que se inició en Francia en 1790, de modo ahora mismo...
Ayer fue una especie de ensayo general de los resultados de la misión STS-117 de la NASA, ensayo que comenzó al son de Redeemer [mp3 1008 KB] por Nicole C. Mullen, canción dedicada al especialista de la misión Patrick Forrester. Por un...
Los especialistas de la misión Pat Forrester y Steve Swanson llevaron a cabo ayer el último paseo espacial de la misión STS-117 en el que no sólo terminaron con todas las tareas programadas para esta misión, sino que además tuvieron tiempo para...
El tema Fight Song [mp3 484 KB] de la Pep Band de la Universidad de Texas en El Paso, dedicada al especialista de la misión John «Danny» Olivas marcó el principio de una jornada tranquila para la tripulación del Atlantis en la...
Algo así: un continente con ríos y grandes lagos, tal y como cuentan en La Antártida, sin hielo: Las imagen (también en alta resolución) proviene del informe Exploration of Antarctic Subglacial Aquatic Environments: Environmental and Scientific Stewardship de la National Science Foundation....
El octavo día en órbita de la tripulación del Atlantis en la misión STS-117 de la NASA comenzó al ritmo de la canción Radar Love [mp3 748 KB] de Golden Earring, dedicada al especialista de la misión Steve Swanson, y resultó ser...
Aunque el día comenzó de forma oficial para la tripulación del Atlantis con la canción Indescribable de Chris Tomlin dedicada al especialista de la misión Pat Forrester, en realidad a esas alturas los astronautas llevaban ya más de una hora despiertos a...
El sexto día en el espacio de la tripulación del Atlantis en la misión STS-117 arrancó al ritmo de Questions 67 and 68 de Chicago, dedicada al piloto Lee Archambault. Además de las típicas transferencias de carga a y de la Estación...
The Kevin & Kell Horoscope © Bill HolbrookAries: Haz lo que te apetezca. La astrología es un engaño.Tauro: Sí, no es más que un mito.Geminis: La posición de las estrellas no tiene ninguna influencia en tu vida.El horóscopo completo está en The...
El Gigantoraptor Erlianensis es como dicen en Pharyngula «una versión de pesadilla de la gallina Caponata» (Big Bird) de más de 1.400 kilos, ocho metros de largo y unos cinco de altura, que se cree que vivió su mejor momento a...
Después de las maniobras realizadas por Jim Reilly y John «Danny» Olivas durante el primer paseo espacial de la misión STS-117 el quinto día en órbita fue utilizado para extender los paneles solares del segmento S3/S4, lo que empezaron a hacer desde...
La actividad principal del día fue la de empezar a trabajar en la activación del segmento S3/S4 de la Estación Espacial Internacional durante el paseo espacial de 6 horas y 15 minutos de duración que llevaron a cabo Jim Reilly y John...
También titulable como «avances en la protección de patentes relativas a organismos modificados genéticamente», DNA-based watermarks using the DNA-Crypt algorithm es un trabajo de investigación que explora una curiosa idea: incorporar pequeñas mutaciones en las secuencias del ADN de los organismos, a...
La canción Riding the Sky, compuesta e interpretada por los empleados del Centro Espacial Johnson David Kelldorf y Brad Loveall y dedicada al especialista de la misión Clayton Anderson fue el tema que sirvió para despertar a la tripulación del transbordador espacial...
Como ya es norma desde que los transbordadores espaciales volvieron al servicio tras la pérdida del Columbia en 2003 la actividad más importante del primer día completo de la misión STS-117 fue la de inspeccionar a fondo el escudo térmico de la...
Aunque a menos de una hora del momento previsto para el lanzamiento de la misión STS-117 de la NASA la meteorología en los sitios alternativos de aterrizaje en Istres, Francia, y Zaragoza, España, estaba bajo mínimos, lo que hacía peligrar el lanzamiento,...
Cuando se produce la fecundación de un óvulo por un espermatozoide convirtiéndose ambos en un cigoto esa célula tiene una característica que la hace muy especial, que es la capacidad de convertirse en cualquier otra célula de las que forman el feto...
Investigadores del MIT situados entre la fuente de energía inalámbrica (bobina izquierda) y la bombilla de 60 W (a la derecha) situada a unos dos metros de distancia y que recibe la energía de manera inalámbrica. Tras los recientes avances en energía...
Por Nacho Palou -
8 JUN 2007
Comprobando con hechos lo que hay de realidad tras ciertos mitos: Convierten festival de rock en experimento humano (saltando en nombre de la ciencia) – ¿Qué pasaría si 1.300 millones de chinos saltasen a la vez? Hummm… pues nada en realidad. Esa...
Al las 3 de esta madrugada, hora de España (GMT +2), comenzó la cuenta atrás para el lanzamiento del transbordador espacial Atlantis en la misión STS-117 de la NASA, misión que tiene como objetivo poner en órbita e instalar el segmento S3/S4...
Journey of Mankind es una animación gráfica (en inglés) que representa el viaje por el planeta que ha seguido el hombre moderno durante los últimos 160.000 años. Basándose en los estudios del ADN Mitocondrial (mtADN) y del Cromosoma Y, para seguir...
Por Nacho Palou -
5 JUN 2007
¡Récord! El número (19249 × 213018586)+1 es primo. Tiene 3.918.990 cifras y ha aparecido como una nueva solución al problema de Sierpinski. Ese número es el más grande que no es un número primo de Mersenne: de los de ese estilo, el...
La APOD de hoy, A Hole in Mars, muestra una mancha negra en la ladera del volcán Arsia Mons en los Montes de Tharsis en Marte que tiene toda la pinta de que podría ser la entrada a una cueva o sistema...
Desde hace ya un par de años los científicos que trabajan en el campo de la percepción visual vienen realizando un congreso en el que, aparte de hablar de estos temas, se falla el concurso de la mejor ilusión visual del año,...
Una vez más Spirit ha encontrado evidencias que tienden a confirmar que en el pasado Marte tenía mucha más agua que hoy en día, aunque en este caso ha sido un descubrimiento realizado prácticamente por casualidad: Mars Rover Spirit Unearths Surprise Evidence...
Darwin Correspondence Project es una archivo de cinco mil cartas originales de Charles Darwin, que intercambió con más de dos mil personas, que se pueden consultar en la Web. Hay un archivo de escáneres de las cartas y reseñas biográficas de la...
¿Adónde van a parar los 180 mil millones de kilovatios de energía equivalente que llegan cada segundo desde el Sol? Earth Guide (en inglés) es un bonita aplicación online con diagramas y animaciones para mostrar y explicar de forma principalmente visual...
Por Nacho Palou -
17 MAY 2007
Uno de las grandes incógnitas a las que se enfrenta la ciencia desde hace algún tiempo es que la cantidad de materia que vemos en el universo es insuficiente para explicar y justificar los efectos gravitacionales que observamos; de hecho, con la...
Esta máquina de Turing tiene dos estados y tres colores.¿Es universal o no? La demostración se paga a 25.000 dólares Seguramente ni el propio Stephen Wolfram ni su equipo han podido resolver este problema durante los últimos años, de modo que ahora...
Atmospheric Optics recopila imágenes de los distintos efectos ópticos que pueden producir en la atmósfera elementos como gotas de agua, rayos del sol, cristales de hielo, nubes, sombras... Está clasificados según el tipo y elemento causante e incluye una breve y...
Por Nacho Palou -
16 MAY 2007
Una vez que los seres humanos aceptamos que ni la Tierra ni el Sol eran el centro del universo y que todos esos puntitos de luz que vemos por la noche en el cielo son soles o colecciones de soles como el...
Senses Challenge [Flash, inglés, ~10 min.] Son veinte preguntas rápidas sobre los sentidos y la percepción del cerebro. Hay cuestiones sobre casi todos los sentidos, aunque la mayor parte son visuales y se limitan a interactuar con el ordenador en preguntas...
La ESA ha presentado GlobCover, el más detallado mapa global de la Tierra hasta la fecha, montado con más de 40 terabytes de información fotográfica procedente de la instrumentación MERIS del satélite Envisat. El mapa completo necesitó de 1561 órbitas entre...
El cerebro humano tiene un nivel de complejidad tremendo, pero es algo que podríamos llegar a entender y manejar prácticamente en su totalidad. Una de las formas de verlo es que el «diseño» del cerebro humano está descrito en unos 20 megabytes...
El observatorio espacial de rayos-X Chandra, junto con otra serie de telescopios ópticos terrestres, ha localizado la supernova más grande de la que se tiene constancia. Bautizada como SN 2006gy, podría corresponderse con la explosión de una estrella de las más grandes...
El poderoso y mastodóntico Airbus A380 consume el equivalente a tres litros de gasolina a los cien kilómetros… pero por persona transportada. En este avión pueden viajar entre 555 y 850 pasajeros según las configuraciones y cómo se reparta entre turista y...
Ayer fallecía en un hospital de California a los 84 años de edad el ex-astronauta Wally Schirra, uno de los siete astronautas del programa Mercury, y el único que voló en los tres primeros programas tripulados de la NASA: Veteran Astronaut Walter...
El telescopio espacial COROT del CNES en el que también participa la ESA lleva apenas dos meses en funcionamiento pero ya ha localizado su primer planeta extrasolar, que es uno de los objetivos de su misión: COROT discovers its first exoplanet and...
Hace un par de meses la sonda New Horizons de la NASA utilizó la gravedad de Júpiter para dar un acelerón en su viaje con destino a Plutón y sus lunas y para no desaprovechar la oportunidad estuvo tomando imágenes y adquiriendo...
Ya hemos comentado en alguna ocasión como gracias a todas las sondas espaciales que hemos enviado a lo largo y ancho de nuestro Sistema Solar a menudo parece que sabemos más de esos remotos rincones del espacio que del enorme porcentaje de...
Tal y como cabría esperar de este experimento, suena bastante aleatorio: Solo de Piano con los mil primeros dígitos decimales de Pi. Cada nota se corresponde a un dígito diferente, primero suenan unas escalas de prueba y entonces comienza la música de...
Con cierta frecuencia recibimos correos en los que se menciona a Vladimir Ilyushin como primer hombre en el espacio en lugar de Yuri Gagarin, quien por lo visto en realidad ni siquiera habría llegado a volar y habría sido presentado el lugar...
Del departamento de cosas-extrañas-que-suceden-en-física-cuántica llega este curioso apunte, que en realidad no sabemos si existe o no (al menos hasta que alguien lo «observe»): La física cuántica le dice adios a la realidad [Maikelnai’s Blog] – Físicos austriacos afirman haber realizado un...
El artículo de Wired de hace casi diez años The Future Ruins of the Nuclear Age cuenta la curiosa historia del físico Anatoli Bugorski, quien a finales de los 70 fue atravesado por el haz de partículas de un acelerador lineal. El...
Por Nacho Palou -
26 ABR 2007
A estas alturas habrás oído y/o leído la noticia en montones de sitios, pero por si acaso todavía no te has enterado o quieres profundizar más en el tema, astrónomos europeos han anunciado el descubrimiento de un planeta extrasolar similar a la...
Bueno, en realidad es el Sol en tres dimensiones, y deberías ver la imagen con unas gafas de esas rojas y azules, ya que la Astronomy Picture of the Day de hoy es una de las primeras imágenes en 3D del Sol...
Con motivo de la celebración ayer del Día Mundial de la Tierra los Museos Científicos Coruñeses editaron un tríptico sobre el cambio climático para el que hace algún tiempo te propusimos que plantearas aquellas preguntas que más pudieran interesarte. La monografía se...
Bueno, no es seguro, pero sí «casi seguro». Contiene 109.297 unos. Un repunit es cualquier número que consista únicamente del dígito 1 repetido varias veces. Esa palabra es la abreviatura de repeated unit, «unidad repetida», así que en español podría usarse «unirep»,...
Hoy en el telediario daban una noticia acerca de un compuesto basado en ciertas algas unicelulares y desarrollado entre investigadores de la Universidad de Alicante y una empresa española que podría convertirse en una alternativa viable al petróleo y estar en las...
Tal y como se sospechaba desde hace ya algún tiempo, el equipo que investiga la pérdida de la sonda Mars Global Surveyor de la NASA ha confirmado este pasado viernes que un error de programación fue el que puso en marcha la...
Tal día como hoy en 1961 Yuri Gagarin se convirtió en el primer ser humano en abandonar la Tierra y en viajar al espacio, lo que hizo a bordo de la Vostok 1. El 12 de abril también marca la fecha del...
Momento nostálgico total, hoy he encontrado la ilustración del Sistema Peryódico del doctor Gonzales de la Otonomic Yunibersiti que circulaba como fotocopia entre los estudiantes de mi época, época que se puede situar viendo el Est'año en la imagen completa y gracias...
Floods in Spain — Las lluvias primaverales hicieron crecer el río Ebro inundando 10.000 hectáreas de cultivos y causando más de 30 millones de euros en pérdidas. Las imágenes fueron tomadas por el satélite de la NASA Terra el 8 de...
Por Nacho Palou -
10 ABR 2007
Los bancos de sangre sufren una escasez crónica de stock que lleva a que en ciertas épocas del año, como por ejemplo en Semana Santa, no sea raro que haya que posponer operaciones programadas para atender a las urgencias por falta de...
(Original es de 1 MB y 11.060 píxeles de largo: All (known) Bodies in the Solar System Larger than 200 Miles in Diameter.) El Sol es el más grande con 1.390.000 km y el asteroide Davida el menor de los registrados,...
Por Nacho Palou -
30 MAR 2007
Sky Map es un simulador de planetario al completo, directamente en el navegador con solo teclear www.sky-map.org. La interfaz recuerda a la de Google Maps… En cierto modo es lo mismo pero mirando hacia arriba. Puedes moverte con el ratón, buscar...
Cuando hace casi treinta años las sondas Voyager pasaron por las cercanías de Saturno detectaron una extraña tormenta de forma hexagonal centrada casi exactamente sobre el polo norte del planeta, y la sonda Cassini acaba de enviarnos nuevas imágenes de ella, en...
Interesantes colecciones de fotografías (aunque algunas coinciden) de cómo se monta un transbordador espacial para su lanzamiento, desde la llegada del depósito principal de combustible en la barcaza Pegasus, hasta el lanzamiento, pasando por todas las etapas intermedias de acoplamiento de los...
Todos estamos acostumbrados a ver esas enormes masas de agua que conocemos como nubes pasar por encima de nuestras cabezas (el vapor de agua es sólo un pequeño porcentaje de su composición). Algunos incluso vivimos buena parte del año bajo cielos cubiertos...
… y además es imposible.(π) La cuadratura del círculo, una cuestión milenaria descrita con maestría en Juegos de Ingenio por Claudio H. Sánchez. Actualización (27 de marzo de 2021) – El blog original desapareció, pero quedó el contenido en Archive.org....
La tabla periódica del Miracle of Science. Foto: Ezraball En el Miracle of Science, un bar/restaurante situado en Cambridge, Massachusetts, cerca del MIT, el menú tiene forma de tabla periódica y está dibujado en una gran pizarra. Cuna de geeks, no podía...
Dado el interés que está despertando el tema del cambio climático, los Museos Científicos Coruñeses están elaborando una nueva Monografía de Comunicación Científica sobre el tema. Como en anteriores ocasiones, la idea es recoger las preguntas más frecuentes y/o interesantes del público...
Hace tiempo que no hablamos de ellos, pero Spirit y Opportunity, los rovers marcianos de la NASA, siguen en activo y gozando de un estado de salud envidiable después de más de 1.100 días en Marte, cuando estaban pensados para durar 90...
La sonda Hayabusa (halcón peregrino), lanzada por la agencia espacial japonesa el 9 de mayo de 2003 con el objetivo de posarse en el asteroide Itokawa en noviembre de 2005, tomar muestras y volver a la Tierra en julio de 2007, probablemente...
Como todos los años, y tal y como indica nuestro calendario geek hoy 14 de marzo (mes 3, día 14) se celebra el día de Pi. En el mundo anglosajón, el 14 de marzo se escribe como 3/14, que se «parece» al...
Hasta hace un rato estaba razonablemente convencido de que las danzas de la lluvia de los pieles roja no eran muy efectivas a la hora de provocar lluvia, pero sin embargo creía que lo de lanzar sales de plata, hielo seco, o...
El diario El Mundo publicaba ayer domingo una encuesta acompañada de un par de columnas de opinión, bajo el título ¿Es necesario construir más centrales nucleares en España? (€) (enlace que por desgracia requiere registro). Cuatro de cada cinco internautas que contestaron...
Pale Blue Dot es un breve videoclip musical casero montado con fotografías de dominio público a modo de homenaje al famoso punto azul pálido y a Carl Sagan y su mujer Anne Druyan. Tuvimos éxito en tomar esta fotografía, y al...
La sonda Cassini de la Agencia Espacial Europea y la NASA ha pasado los últimos meses modificando su órbita alrededor de Saturno para elevarla respecto al plano de los anillos del planeta y así poderlo ver desde arriba, algo que desde la...
Los seres humanos somos máquinas de identificar patrones, diríase que especialmente brillantes identificando rostros humanos, sobre todo si son de algún modo familiares o conocidos. ¿Reconoces a alguien en esta foto?...Una de cada cuatro personas puede identificar a este «Napoleón» de tan...
Me ha hecho gracia el artículo The Teflon myth and other `inventions' from NASA del Chicago Tribune en el que se habla de como se atribuye a la NASA la invención de unas cuantas cosas que en realidad son producto de desarrollos...
El matemático es el individuo que, al ver el papel que tienen el dinero, la sexualidad y el poder en la fabricación de famosos, prefiere dedicarse a los números, los gráficos y la lógica.– John Allen PaulosEsta y otras 1.500 citas se...
Después de leer nuestra anotación sobre círculos máximos y rutas aéreas y como los mapas distorsionan nuestra visión del mundo Diego estuvo un rato trasteando con el Great Circle Mapper y nos envió esta, en sus propias palabras, curiosa pero inútil imagen...
La metamemoria es una de las características del funcionamiento del cerebro humano y es parte de la metacognición. Es algo bastante autorreferente: «la facultad de tener conocimiento de nuestra propia capacidad memorística.» Dicho en palabras menos técnicas, «tener algo en la punta...
Actualización (Wicho): Pues nada, por aquí al final sólo pudimos ver el eclipse a trocitos entre las nubes, pero por supuesto hay montones de imágenes por ahí, y por enlazar unas cuantas:Eclipse de luna, de Mauro A. Fuentes, un bonito montaje con...
Si en tu rinconcito del mundo el cielo no está cubierto de nubes, como parece que nos va a tocar a todos los que vivimos en la mitad norte de España a tenor de la imagen de satélite que acaba de mostrar...
Un depósito de combustible de un transbordador espacial saliendo de la barcaza Pegasus – NASA Todos hemos visto al transbordador espacial ya listo para salir al espacio moviéndose a lomos del transportador de la NASA, transportador que por cierto usa un sistema...
Igual que hizo la sonda Rosetta de la ESA el pasado domingo con Marte, ayer la sonda New Horizons de la NASA, lanzada hace algo más de un año, pasó por las cercanías de Júpiter, entendido esto en términos cósmicos ya que...
Según el Smithsonian National Zoological Park (Animal Records) y el Top 10 de animales mortíferos de Live Science, el animal más mortífero [sin contar al ser humano] es el mosquito Anopheles que al poder ser portador y transmisor de la malaria o...
Por Nacho Palou -
28 FEB 2007
Cuando el 28 de enero de 1986 el depósito principal del transbordador espacial Challenger reventó a los 73 segundos de haber despegado en la misión STS-51-L desintegrándolo y enviando a su tripulación a una muerte segura una de las siete personas que...
La sonda espacial Rosetta, lanzada por la Agencia Espacial Europea el 2 de marzo de 2004, pasó ayer por las proximidades de Marte en una de las maniobras más delicadas de su complejo «plan de vuelo» que utiliza la gravedad del planeta...
Falta ya menos de una semana para el eclipse total de luna que tendrá lugar en la noche del 3 al 4 de marzo y que será visible desde buena parte del mundo si la climatología acompaña. Si te quieres ir haciendo...
Virtual Globe es una aplicación para visualizar el globo terrestre en tres dimensiones, combinando datos de elevación con imágenes aéres y de satélite. Es muy similar a Google Earth, tanto por la forma de funcionar (las imágenes y datos topográficos se descargan...
Por Nacho Palou -
24 FEB 2007
A traves del O'Reilly Radar llegué a una página de la que habíamos hablado alguna vez por aquí, que ilustra una buena forma de ver una clásica paradoja. Casi todos los números tienen algo de especial: el único primo par (2), el...
Sencillamente genial:(Wellington Grey, traducción de El Retorno de los Charlatanes.)...
Luis C. nos había avisado de esto ya hace unos meses, pero su mensaje se me quedó despistado por ahí en los buzones de Eudora y olvidé comentar el tema en su momento, aunque visto el resultado de las protestas al respecto...
Ask Dr. Math es una sección del Math Forum de la Universidad Drexel donde un montón de matemáticos responden desde hace años a todo tipo de preguntas de la gente sobre el mundo de los números. Entre las Preguntas Frecuentes sobre Matemáticas...
Estos días son una buena ocasión para recordar a Nicolás Copérnico, considerado el padre de la astronomía moderna: ayer 19 de febrero se cumplieron 534 años de su nacimiento en 1473 en Torun (Polonia). Copérnico desarrolló el primer modelo matemático heliocéntrico del...
Por Nacho Palou -
20 FEB 2007
Es la cuarta vez en ocho años que se cambian los contenidos relativos a la enseñanza de las ciencias en Kansas, pero tras las elecciones celebradas en año pasado en la que los miembros más conservadores del Consejo de Educación de Kansas...
El próximo 3 de marzo se producirá un eclipse lunar total que se podrá ver total o parcialmente desde prácticamente todo el mundo, y en España tenemos la suerte de que estamos dentro de la zona en la que se puede ver...
He terminado de actualizar la anotación acerca del Sistema de Computación Cuántica Orion, la computadora cuántica que D-Wave presentó el otro día. Ahora que ha pasado el ruido mediático y tras hacer el seguimiento a decenas y decenas de enlaces y noticias...
El 13 de febrero de 1965 el satélite meteorológico TIROS IX (Television Infrared Observation Satellite, Satélite de Observación por Infrarrojos) permitió componer la primera imagen meteorológica que mostraba de una vez el estado del tiempo de todo el planeta. La imagen es...
Por Nacho Palou -
13 FEB 2007
La cámara principal de la sonda Mars Reconnaissance Orbiter, conocida como HiRISE, y que ya ha enviado de vuelta a la Tierra imágenes tan espectaculares como esta en la que se ver al rover Opportunity en las proximidades del cráter Victoria, está...
Sin palabras me he quedado al leer sobre el sistema de computación cuántica llamado Orion que la compañía canadiense D-Wave presentará la semana que viene al público. La descripción técnica está llena de términos que asombran a la vez que asustan un...
Nuestro contacto en el CNES nos avisa que el telescopio COROT comenzó ayer a las 13:30 TU (una hora más en España) la fase científica de su misión al entrar en el modo de observación. Tal y como él comenta, «Se puede...
Mini-biografía de Kurt Gödel en La Singularidad Desnuda: La mente más maravillosa del siglo XX – El lógico más brillante desde Aristóteles, muy posiblemente la mente más preclara del siglo XX, y sin ningún género de dudas una de las personas que...
¿Este asteroide acabará con nuestro planeta? tituló el artículo principal de la sección Manual de Curiosos del Mazagine de El Mundo [el artículo completo no está disponible] del 21 de enero. Tal y como lo explican recuerda al «destructor total» de Armageddon,...
El sábado por la tarde, hora de España, se produjo un cortocircuito en la electrónica de la Advanced Camera for Surveys, la cámara principal del Telescopio Espacial Hubble, que ha dejado fuera de servicio y sin muchas esperanzas de recuperarlos dos de...
Hoy se cumplen 40 años del fallecimiento de Virgil «Gus» Grissom, Ed White y Roger Chaffee en el incendio durante un ensayo de la cápsula de mando que por aquel entonces se conocía como AS-204, aunque meses después, y a petición de...
La ESA acaba de hacer pública la primera imagen obtenida por el observatorio espacial COROT, un proyecto del CNES con la colaboración de la ESA, obtenida tras la apertura de su tapa protectora en la noche del 17 al 18 de este...
En Russian Space Centre del blog English Russia se pueden ver un montón de fotografías de un centro de entrenamiento espacial ruso cercano a Moscú donde se preparan los astronautas y turistas espaciales. En las instalaciones además viven los miembros de la...
Por Nacho Palou -
25 ENE 2007
Traducidos de The Most Popular Myths in Science por Maikelnai y publicados en Los 20 mitos más populares de la ciencia (parte I) y Los 20 mitos más populares de la ciencia (parte II), una lista elaborada a partir de las votaciones...
Impresionantes revelaciones sobre lo que la industria del tabaco está haciendo con sus productos para seguir teniendo «clientes»; las oí ayer también en el telediario de la noche: Las tabaqueras de EE UU aumentaron un 11% en ocho años el nivel de...
Dos nuevos primos gemelos de récord: 2003663613 × 2195000-1 y 2003663613 × 2195000+1Encontrados por Eric Vautier, de Francia. Véase en Twin Prime Search. Por otro lado, Jaroslaw Wroblewski descubrió que la secuencia 468395662504823 + 45872132836530 kgenera números primos para cualquier valor de...
List of holy grails en la Wikipedia [actualización: ya no existe; versión de archivo] es una lista de lo que popularmente se conoce por la expresión «santos griales» en distintos campos de la ciencia y el conocimiento, es decir Objetivos que son...
Mientras un cohete asciende a través de la atmósfera terrestre, se ve sujeto a un intenso calentamiento aerodinámico, causado por la fricción del aire contra la frágil piel del vehículo en aceleración. En lugar de arriesgarse a que el calor pudiera agujerear...
Roving Mars. Spirit, Opportunity, and the Exploration of the Red Planet. Steve Squyres. Hyperion, 3 de agosto de 2005. ISBN: 1401301495. Inglés. [No hay edición en español] Al principio de este libro el autor cuenta como siendo todavía estudiante unversitario llegó a...
Mientras esperamos a que Steorn nos cuente algún detalle más de su sistema para generar energía gratuita, en España no queremos ser menos: Una empresa gallega financia un invento para ahorrar energía, aunque como es habitual en este caso la cosa tiene...
El equipo encargado de gestionar la flota de transbordadores espaciales de la NASA y sus vuelos acaba de hacer pública una nueva versión de su manifiesto en el que se puede ver que será el Atlantis el que realice la misión de...
La NASA todavía lo considera un resultado preliminar, pero el consenso parece ir en la dirección de que una actualización fallida del software de a bordo habría causado la pérdida de la sonda Mars Global Surveyor: NASA Decides That A Software Error...
Tras el parón procrastinatorio navideño, la correspondiente lista de enlaces sobre ciencia e investigación espacial mínimamente ordenados y brevemente comentados: Resúmenes de 2006: La astronomía en 2006, una traducción de un artículo de NewScientistSpace en el blog de la Sociedad Española de...
Colosal y preciosa construcción: AquaDom, el mayor acuario cilíndrico del mundo – El acuario cilíndrico más grande del mundo se encuentra en el vestíbulo del Hotel Radisson de Berlín, y constituye un auténtico espectáculo para los ojos. Con sus más de 25...
No es una lista exhaustiva, y le faltan enlaces para poder profundizar en los puntos que incluye -aunque Google o tu buscador favorito siempre pueden ayudarte en eso- pero Maikelnai publicaba hace unos días una lista de 50 cosas que aprendimos en...
Perdida entre los fastos navideños se me ha colado la publicación de las primeras imágenes de las sondas STEREO, lanzadas a finales de octubre para estudiar el Sol a la vez desde dos posiciones distintas en el espacio: Imagen captada por el...
Esta es la lista de canciones que desde el control de tierra utilizaron durante la recién terminada misión STS-116 del transbordador espacial Discovery para despertar cada día a su tripulación, en una costumbre que se remonta a los tiempos del programa Gemini:...

Henrietta Leavitt (1868-1921) descifró el cosmos desde un puesto de ayudante, mientras sus superiores recogían premios y ella sólo silencio.
Actualización 23:33: Ruedas paradas, comienza el proceso de asegurar el transbordador para que los astronautas puedan salir de él y en unas horas comenzar a disfrutar de unas merecidas vacaciones. Tiempo total de la misión: 12 días, 20 horas, 45 minutos y...
Ayer fue otro día de preparativos para el aterrizaje en el que la tripulación del Discovery siguió preparando todo para la toma de tierra a la vez que el piloto y el comandante practicaban simulaciones del aterrizaje. Desde el control de la...
Igual que hiciera el año pasado, Tammy Plotner ha preparado una guía para observar el cielo durante 2007 en la que en lugar de decirte todo lo que se puede ver cada día, lo que por otro lado puedes averiguar fácilmente con...
La actividad principal del día para la tripulación del Discovery fue preparar la nave para su aterrizaje, previsto para este viernes a las 21:56 hora de España (GMT +2). Para ello la tripulación recogió todos los elementos sueltos de a bordo para...
En el número de diciembre de Investigación y Ciencia el profesor Ralph Hollis publicaba el artículo Robots Monobola donde podían verse algunos avances en movilidad de robots. Lo que lleva años investigando es la forma de emplear una única y enorme bola...
Hoy se cumplen diez años de la prematura muerte de Carl Sagan, uno de los más conocidos divulgadores científicos de los últimos años. Creo que yo ya era «de ciencias» cuando pusieron Cosmos en la televisión -aunque en realidad odio la dicotomía...
Una vez cumplidos todos los objetivos de la misión, y con un día de retraso sobre lo previsto para acomodar el paseo espacial extra que el lunes permitió recoger por completo uno de los paneles solares del segmento P6 de la Estación...
Si Lidl no mintiera a sus clientes igual que hacen otras empresas y tuviera realmente el Meade ETX-70 (AKA LIDLscopio) de oferta en las tiendas en las que dice tenerlo probablemente ya habría uno en mi casa o de camino a ella...
Bob Curbeam, Christer Fuglesang, y sus compañeros a bordo del Discovery y de la Estación Espacial Internacional consiguieron finalmente plegar por completo y dejar bloqueado en su posición de almacenamiento el panel solar del segmento P6 que sólo se había retraído en...
Los astronautas del Discovery y de la Estación Espacial Internacional disfrutaron ayer de otro día relativamente tranquilo dedicado principalmente a mover suministros y carga del Discovery a la ISS y viceversa mientras los controladores de la misión preparan los detalles del paseo...
Bob Curbeam y Sunita Williams terminaron ayer con la reconfiguración del sistema eléctrico de la Estación Espacial Internacional al pasar los canales 1 y 4 de este a su configuración definitiva, lo que deja a la estación lista para la instalación de...
Un par de noticias de esta semana sobre observaciones astronómicas que se me han ido quedado pendientes pero que han sido cubiertas por Javier Armentia y Astroseti:El OSPAN (Optical Solar Patrol Network - Red de Patrulla Solar en el Óptico) fotografiaba lo...
Ayer fue un día relativamente relajado para las tripulaciones del Discovery y de la Estación Espacial Internacional en el que la principal tarea consistió en seguir pasando carga y suministros entre ambas naves. Ambas tripulaciones dedicaron también algún tiempo a atender a...
Aunque se consideraba como una de las partes más peliagudas de la misión STS-116 Bob Curbeam y Christer Fuglesang reconfiguraron ayer los canales dos y tres del sistema eléctrico de la Estación Espacial Internacional para dejarlos en su estado definitivo, ya que...
El día de ayer fue un tanto más complicado de lo previsto, ya que tras seis años en el espacio los paneles solares del segmento P6 de la Estación Espacial Internacional parecían no querer plegarse y hubo que enviar hasta 45 veces...
La mejor lluvia de estrellas del año comenzará esta noche — Durante la noche del 13 al 14 de diciembre tendrá lugar la lluvia de estrellas fugaces Gemínidas, la más espectacular del año. Las Gemínidas son una lluvia de estrellas llamativa, recomendable...
Por Nacho Palou -
13 DIC 2006
Tras el paseo espacial de Bob Curbeam y Christer Fuglesang de ayer la Estación Espacial Internacional ya tiene instalado el segmento P5 que el Discovery llevaba como carga principal en esta misión. Curbeam y Fuglesang estuvieron de EVA durante 6 horas y...
El transbordador espacial Discovery atracó en la Estación Espacial Internacional anoche a las 23:05 hora de España (GMT +1) tras girar sobre si mismo para que la tripulación de la ISS pudiera fotografiar su parte inferior para poder analizar el estado del...
Tras su despegue el sábado a última hora de la tarde (madrugada en España) la tripulación del transbordador espacial Discovery pasó su primer día en órbita preparando y comprobando el sistema de atraque con la Estación Espacial Internacional, así como los trajes...
En estos momentos se está produciendo el segundo intento de lanzamiento del transbordador espacial Discovery en la misión STS-116 de la NASA con destino a la Estación Espacial Internacional. Está previsto a las 2:47 de la madrugada del domingo día 10 de...
A lo mejor alguna vez algún ser humano llega a ver esto en directo, pero mientras tanto Spirit nos ha enviado hace ya algunos meses una foto de una puesta de Sol desde Marte: Sunset on Mars. (Vía Mentiras Piadosas.)...
A doce horas del momento previsto para el lanzamiento del transbordador espacial Discovery en la misión STS-116 de la NASA con destino a la Estación Espacial Internacional la principal preocupación de los responsables de la agencia es el tiempo, que de unas...
Estamos prácticamente seguros de que en el pasado remoto hubo agua líquida en la superficie de Marte y sabemos que en la actualidad hay hielo tanto en sus polos como en su superficie, porque así nos lo ha confirmado las sondas que...
No es raro oír de vez en cuando que nuevos estudios revelan que ciertas cosas que se supone que son malas para nuestro organismo en realidad no lo son tanto si se consumen o usan con moderación; Maikelnai recoge en ¿Pero eso...
El número (21127239+2563620+1)/ 5 tiene 339.333 dígitos y probablemente es primo, pero no se sabe seguro todavía. Lo ha descubierto Borys Jaworski y encabeza la lista de Primos Probables. En esa lista aparecen un montón de números de los que no sabe...
Como paso intermedio en su objetivo de llegar a Marte la NASA ha decidido que en lugar de realizar misiones puntuales como las del programa Apollo la mejor forma de preparar esa eventual llegada del hombre a Marte es conseguir tener una...
Gracias a Gaussianos me he enterado de algunas cosas sobre los últimos récords de «recitar el número π de memoria», a los que venía haciendo un seguimiento últimamente. Al parecer el récord de Akira Haraguchi que recitó recientemente 100.000 dígitos de Pi...
Esta madrugada, a las 5, hora de España (GMT +1), acaba de arrancar la cuenta atrás para el lanzamiento del transbordador espacial Discovery en la misión STS-116, que tiene como objetivos principales terminar con la instalación eléctrica de la Estación Espacial Internacional...
Una de las noticias del día era la publicación de un estudio en el que por fin parece que se desvela la función del mecanismo de Antiquitera, un dispositivo fabricado hace unos 2.100 años y encontrado en 1900 por unos pescadores de...
El equipo a cargo de la cámara HiRISE de la Mars Reconnaissance Orbiter está publicando imágenes absoultamente espectaculares en el HiRISE Operations Center, como por ejemplo esta de Cerberus Fossae, en la que cada pixel representa unos 55 centímetros, aunque aquí está...
Los responsables de la NASA han dado el visto bueno de forma unánime al lanzamiento del transbordador espacial Discovery en la misión STS-116: It's Official: Discovery is 'Go' for Launch on Dec. 7. Está previsto que este lanzamiento se produzca el próximo...
Tras perder a principios de mes el contacto con la sonda Mars Global Surveyor la NASA intentó fotografiarla a finales de la semana pasada con la Mars Reconnaissance Orbiter, pero o bien la MGS no está donde se supone que tiene que...
Un par de historias de los percances que sufren los astrónomos en sus observaciones con telescopios: Varado en una playa interestelar: el poder de la informática, por David Barrado y Navascués, y El Nordic Optical Telescope y la salida de emergencia por...
¡Hey, esto no lo enseñaban a hacer en Bricomanía!Teen goes nuclear: He creates fusion in his Oakland Township home — En el sótano de la casa de sus padres Thiago aprovecha su pasión y sus conocimientos por la física para investigar y...
Por Nacho Palou -
21 NOV 2006
Tal y como han ido las cosas hasta hora no es descabellado suponer que la sonda Cassini podrá terminar con éxito su misión actual en julio de 2008, por lo que es más que probable que se aprueben una o dos extensiones...
Ya sabíamos que en la atmósfera de Saturno hay fuertes vientos en direcciones alternantes que son los que causan esas bandas horizontales que vemos; lo que no sabíamos es que en Saturno también hay al menos un huracán sobre el polo sur...
Después de que Marte saliera de la fase de oposición en la que el Sol impedía las comunicaciones entre la Tierra y el planeta rojo la buena noticia es que los dos rovers marcianos de la NASA, Spirit y Opportunity, están listos...
El transbordador espacial Discovery fue trasladado ayer a la plataforma de lanzamiento 39B del Centro Espacial Kennedy para terminar de ser preparado para el lanzamiento de la misión STS-116: Discovery Rolls to Launch Pad 39B. El objetivo de la misión es poner...
The First Photo From Space — Las fotografías, granulosas y en blanco y negro, se tomaron a una altitud de 65 millas (104,60 kilómetros) con una cámara de cine de 35 mm. montada sobre un misil V2 lanzado desde el Base de...
Por Nacho Palou -
10 NOV 2006
Con lo que nos gustan las ilusiones ópticas a los microciervos… Optical Illusions , un blog dedicado a las ilusiones ópticas. Me hizo especial ilusión encontrarme en él con ECVP Waves, una ilusión diseñada por Akiyoshi Kitaoka para el ECVP 2005, un...

Una entrevista a Martin Gardner, el gran divulgador de las matemáticas y los rompecabezas lógicos. Recuerda décadas de juegos matemáticos y su lado cazamagufos, con un poco de ambigramas con simetrías e inversiones.
Al parecer el sábado pasado en el telediario del mediodía de Telecinco el clip de los «reporteros» estuvo dedicado a presentarUn «método científico» llamado neodiseño humano, que aplicando avanzados cálculos cuánticos permite realizar un «mapa» del carácter de un determinado ser humano,...
La próxima misión del transbordador espacial Discovery, la STS-116, tiene previsto su despegue para el 7 de diciembre y una duración estimada de 12 días, pero si por algún motivo hubiera que retrasar el lanzamiento más allá del 17 o el 18...
Tras alcanzar su órbita definitiva sobre el terminador terrestre, lo que le permitirá la observación continua del Sol durante meses, la sonda Hinode (Amanecer), antes conocida como Solar-B, estará durante este mes en una fase de pruebas en la que se está...
Mike Griffin acaba de decirlo, van a añadir una misión de mantenimiento al telescopio espacial Hubble a la lista de misiones de los transbordadores espaciales antes de retirarlos: NASA Approves Mission and Names Crew for Return to Hubble. La sala de prensa...
Desde 2003 la revista Popular Science publica cada años un listado con los diez peores trabajos en el campo de la ciencia, y los de este año son: Inspector de estiércol. Recolector de orina de orangután. Superintendente de zona caliente en la...
Tal y como había anunciado Mike Griffin en la rueda de prensa inmediatamente posterior al regreso del transbordador espacial Atlantis de la misión STS-115 a la Estación Espacial Internacional, responsables de la NASA se reunieron ayer -Griffin había hablado de finales de...
Su misión original estaba prevista para 90 soles (días marcianos, de 24 horas, 39 minutos, y 35 segundos), pero hoy mismo Spirit ha cumplido los 1.000 soles en Marte y contando. Para celebrarlo, la NASA ha publicado un panorama que Spirit ha...
Después de varios retrasos a lo largo de este año por motivos técnicos, esta noche la NASA por fin puso en órbita las sondas STEREO, un par de sondas destinadas a estudiar las erupciones solares durante una misión con una duración prevista...
Aquellas personas que son incapaces de reconocer las caras de otras personas, incluso las de sus propias parejas o hijos, sufren de prosopagnosia, una condición mental de la que se desconoce su origen, aunque en ocasiones está claramente causada por una lesión...
Scott Adams, más conocido por ser el autor de las tiras cómicas de Dilbert sufre desde hace un par de años dos curiosas enfermedades cerebrales. Por un lado, distonía focal que le impide dibujar a mano, y por otro disfonía espasmódica que...
Coloreando los dígitos de π con un color distinto para cada uno de sus valores decimales, en base 10. La verdad es que se sigue viendo… bastante… alteatorio. Actualización: Del mismo autor unos días después llega… Pi, redondo, en colores. El círculo...
El 3608528850368400786036725 es un número extraordinario porque es polidivisible. Si lo divides por 25, que es su número de cifras, el resultado da exacto. Si le quitas la última cifra por la derecha, también divisible por 24. Lo mismo quitando la siguiente...
El nombre es por ahora un tanto optimista, ya que en estos momentos sólo tienen disponible aproximadamente la mitad del material que esperan tener en línea en 2009 cuando esté todo digitalizado, pero The Complete Work of Charles Darwin aspira a convertirse...
¿Quién puso nombre a las constelaciones? ¿Cuántas hay? ¿Las ven igual todas las culturas? ¿Existirán para siempre? La entrada Historias de constelaciones del Cuaderno de bitácora estelar contesta esas y alguna otra pregunta más en una introducción corta pero recomendable a las...
Los últimos datos recibidos desde el telescopio espacial Hubble confirman que la Advanced Camera for Surveys, su cámara principal, vuelve a funcionar correctamente tras el corte de alimentación que sufrió a finales del mes pasado: Hubble's ACS Is Back In Action. El...
¿Cuánto tiempo tardarían nuestras huellas en desaparecer? Inmediatamente: La mayoría de las especies en peligro empezarían a recuperarse. 24-48 horas: La contaminación lumínica se acabaría. 3 meses: La polución atmosférica (nitrógeno y óxidos de azufre) se va reduciendo. En 10 años: Desaparecería...
Hoy en día conocemos un millón de millones de millones de dígitos decimales del número π (Pi). Hay gente que incluso se sabe miles y miles de memoria. Pero históricamente no siempre se conocieron tantos decimales. Estas son algunas de las aproximaciones...
ei π + 1 = 0 Debido a su aparente simplicididad se la considera a menudo la fórmula matemática más bella del mundo, una variante de la Fórmula de Euler, que implica a las constantes matemáticas más enigmáticas e importantes, «de una...
Hace unos días hablábamos de la HiRISE, la potente cámara que lleva a bordo la Mars Reconnaisscance Orbiter, y la foto The Opportunity rover at "Victoria Crater" es una prueba asombrosa de sus capacidades. En ella se ve el cráter Victoria, al...
Hace un par de años a Harriet Hall, una escéptica norteamericana, se le ocurrió que podía dedicar parte de su tiempo libre a acudir a las reuniones que un grupo de personas de su zona que se hace llamar Mingling of the...
Alejandro resumió en Discriminación alfabética el curioso error matemático en que (increíblemente) todavía se cae en muchas situaciones cuando se realizan sorteos que implican a un gran número de personas: el «sorteo alfabético». Normalmente se elige una letra (o dos) del bombo,...
Los estadounidenses arrasaron este año con los premios Nobel, pero los Premios Ig® Nobel 2006 han quedado considerablemente más repartidos. La lista, traducida de The 2006 Ig Nobel Prize Winners, es esta, y verdaderamente hace honor a su lema de premiar «aquellos...
La luna llena de esta noche es la más cercana al equinoccio de otoño. También es conocida como «luna de la cosecha» porque antiguamente permitía a los agricultores que recogían sus cultivos en esta época del año (en el hemisferio norte) disponer...
Por Nacho Palou -
6 OCT 2006
Lo de la cámara grabando me hizo especial gracia: Akira bate su propio récord – Akira Haraguchi ha batido su propio récord. Este japonés tenía el récord de decimales de π (Pi) recitados de memoria con 83.431 decimales. Ahora ha aumentado esa...
Arrugas en el tiempo. George Smoot y Keay Davidson. Plaza & Janés Editores, S.A. 1994. ISBN: 8401240689. Español. Original en inglés: Wrinkles in time: The Imprint of Creation La concesión del premio Nobel de física de este año a John C. Mather...
Una vez alcanzada su órbita definitiva, la sonda Mars Reconaissance Orbiter está a punto de empezar la fase principal de su misión en cuanto todos los instrumentos de a bordo hayan sido comprobados y colocados en su configuración de trabajo. Uno de...
En una anotación de hace cuatro años ya conté la curiosa historia de una de las más famosas frases de la historia de la humanidad, Este es un pequeño paso para … el hombre… pronunciada por Neil Armstrong nada más pisar la...
Leo con cierto asombro que, según un reciente estudio, más del cuarenta por ciento de las clínicas de fertilidad estadounidenses permiten hoy en día a los padres elegir el sexo del futuro niño, La noticia completa está en What's Next In Health....
Una FOD me tiene estos días bastante hecho polvo e identificado con los pacientes de House, pero aprovechando un rato en el que la combinación de antibióticos y antitérmicos ha devuelto mi temperatura corporal a límites más o menos normales, aquí van...
The atheist es una excelente entrevista de Salon a Richard Dawkins, biólogo y divulgador, profesor en Oxford. Además de controvertido «evolucionista» (su obra más conocida, El Gen Egoísta, plantea aquello de que los seres humanos no somos más que «máquinas de supervivencia,...
La NASA acaba de anunciar en NASA Mars Spacecraft Gear Up for Extra Work que acaba de aprobar nuevas extensiones de las misiones de los rovers marcianos, Spirit y Opportunity, así como de las sondas Mars Global Surveyor y Mars Odissey. Contando...
He aquí un bonito trailer sobre Between the Folds, un documental de Green Fuse Films acerca de cómo puede utilizarse el Origami como herramienta para enseñar la geometría en la escuela. Está en inglés e incluye algunas frases y mini-entrevistas preciosas,...
Después del desastre del Columbia, de la inversión multimillonaria en mejorar la seguridad de los transbordadores que quedan en servicio, y de las dos misiones de vuelta al vuelo llevadas a cabo por el Discovery (STS-114 y STS-121), la NASA necesitaba que...
Tras intentarlo en varias ocasiones desde abril de 2004 al fin las condiciones atmosféricas permitieron a la sonda Mars Express de la ESA fotografiar la región de Cidonia en la superficie de Marte, región en la que está la famosa «cara» que...
Esta es la lista de canciones que desde control de la misión utilizaron para despertar a la tripulación del Atlantis durante la recién terminada misión STS-115: Moon River, interpretada por Audrey Hepburn, para el comandante Brent Jett a petición de su mujer...
12:22: Las ruedas se paran tras un viaje de 4,9 millones de millas; la tripulación tardará aún unos 45 minutos en salir de la nave mientras realizan los procedimientos de dejarla «segura». 12:21: ¡Contacto! Atlantis y la tripulación de la misión STS-115...
Tras una primera inspección del Atlantis con las cámaras del brazo robot de la bodega de carga y un posterior análisis más detallado con el Orbiter Boom Sensor System, el conjunto de instrumentos que se maneja con el citado brazo robot diseñado...
Los responsables de la misión decidieron añadir un día más a la misión debido al mal tiempo reinante en Florida y, sobre todo, a un resto sin identificar que las cámaras de vídeo a bordo detectaron flotando cerca del Atlantis. La tripulación...
El escudo térmico del Atlantis fue sometido a una nueva inspección usando el Orbiter Boom Sensor System, el aguilón de unos 15 metros de largo que se coloca en el extremo del brazo robot de la bodega de carga y que lleva...
Tras casi seis días conectados, el transbordador espacial Atlantis dejó por fin la Estación Espacial Internacional, en la que el nuevo segmento P3/4 y sus paneles solares son el recordatorio del éxito de esta misión hasta este momento, un éxito que además...
Anousheh Ansari, una de los Ansari detrás del Ansari X PRIZE, acaba de despegar esta madrugada a bordo de la misión Soyuz TMA-9 rumbo a la Estación Espacial Internacional, conviertiéndose así en la primera turista espacial de la historia: Despega la primera...
La tripulación del Atlantis tuvo la mañana del sábado libre para relajarse un poco tras la intensa semana de actividad que llevan con tres paseos espaciales en cuatro días para dejar el segmento P3/4 de la Estación Espacial Internacional listo para su...
Tercer y último paseo espacial de la misión STS-115 de la NASA, de nuevo a cargo de Heidemarie Stefanyshyn-Piper y Joe Tanner, para instalar un radiador en el nuevo segmento de paneles solares extendido el día anterior que se utilizará para refrigerar...
Una vez solucionado el problema detectado ayer con la junta rotatoria que permite orientar a voluntad los paneles solares montados en el recién instalado segmento P3/4 de la Estación Espacial Internacional, problema que resultó ser de software, desde el control de la...
Un día después de recibir su número oficial en la lista del Minor Planet Center 2003 UB313, conocido hasta ahora informalmente como Xena, recibía el nombre oficial de Eris (o Éride); su luna recibe el nombre de Disnomia. IAU Numbers Pluto as...
De nuevo la actividad principal del día fue un paseo espacial, en este caso a cargo de Dan Burbank y Steve McLean, quienes a lo largo de algo más de siete horas siguieron preparando el segmento P3/4 de la Estación Espacial Internacional...
Estas noticias hay que tomarlas con todas las reservas del mundo porque aún falta hacer estudios completos al respecto y tratar de entender qué es lo que pasa realmente, pero aunque sólo sea por los casos en los que ya han funcionado,...
Los especialistas de la misión Joe Tanner y Heidemarie Stefanyshyn-Piper completaron ayer el primer paseo espacial de la misión STS-115 en el que prepararon el segmento P3/4, que había sido colocado previamente en su sitio con el Canadarm 2 de la ISS,...
Como consecuencia de su pérdida de status como planeta decidida en la reciente XXVI Asamblea General de la Unión Astronómica Internacional, Plutón es ahora el asteroide número 134.340 del registro del Minor Planet Center, y sus compañeros Caronte, Nix e Hidra serán...
A raíz de la anotación del vídeo 12 horas en el Canal de Panamá un lector preguntaba por la necesidad de utilizar esclusas para que los barcos a pasar de un océano si en teoría ambos océanos estaban al mismo nivel y...
Por Nacho Palou -
12 SEP 2006
En la que ha sido descrito como una maniobra perfecta, el Atlantis atracó ayer a las 12:48, hora de España (GMT + 2), en la Estación Espacial Internacional tras dar una voltereta, conocida oficialmente como Rotational Pitch Maneuver, que permitió a la...
Durante el segundo día de la misión STS-115, el primero completo que pasan en órbita, el Atlantis siguió acercándose a la Estación Espacial Internacional, a dónde tiene previsto llegar hoy, lunes 11 de septiembre, a las 12:46 hora de España (GMT +...
Una Breve Historia de Casi Todo. Bill Bryson. RBA Editores. ISBN: 84-7871-175-9. Castellano. Aunque Wicho ya reseñó hace un par de años la versión original, A Short History of Nearly Everything, no quería dejar de volver a recomendarlo con una nota...
Uno de los más apasionantes temas relacionados con los números primos: La espiral de Ulam – El aburrimiento puede ser padre de curiosos descubrimientos. Allá por 1963, el matemático polaco, nacionalizado estadounidense, Stanislaw Marcin Ulam, se encontraba en un congreso científico (…)...
A menos que los responsables de la agencia decidan no respetar la norma fijada después del desastre del Columbia de que los lanzamientos de los transbordadores espaciales tienen que efectuarse de día para poder fotografiarlos y filmarlos exhaustivamente para detectar posibles desprendimientos...
Actualización 16:54 Los directores de la misión acaban de anunciar que van a ir por el libro y que finalmente aplazan el lanzamiento hasta mañana para ver si al vaciar y llenar de nuevo el tanque el sensor de nivel bajo de...

Tal vez el título de The Most Beautiful Periodic Table Poster in the World sea un poco pretencioso, pero desde luego que es bonita. Es una Tabla Periódica de todos los elementos químicos hasta el 103 (Lawrencio) construida a base de...
Wayne Hale está contando ahora mismo en NASA TV (00:05) que siguen analizando el problema de esta mañana con la celda de combustible 1 del Atlantis, que resulta ser un tipo de problema que nunca había ocurrido, por lo que están bastante...
Aunque como se puede leer en White House says new stem cell method "encouraging" al principio hasta la misma Casa Blanca encontró interesante el método anunciado por Advanced Cell Technology que permitiría obtener células madre embrionarias a partir de una sola célula,...
A doce horas para la hora prevista de lanzamiento del transbordador espacial Atlantis en la misión STS-115 de la NASA para retomar la construcción de la Estación Espacial Internacional todos los sistemas funcionan correctamente y la única preocupación es la meteorología, pues...
Sharpest Manmade Thing, una tan espectacular como curiosa foto convenientemente coloreada del objeto más puntiagudo de todo el reino de los objetos puntiagudos: la punta de una aguja vista a nivel atómico –tal vez te apetezca contar el número de átomos que...
Por Nacho Palou -
5 SEP 2006
Y van 44. Sería el récord de la lista y llegaría casi un año después de que se calculara el 43º que fue en diciembre del año pasado. Un número de Mersenne es un número de la forma M = 2n -...
Tras el retraso causado por la caída de un rayo en la plataforma de lanzamiento y la posterior interrupción causada por la tormenta tropical Ernesto la cuenta atrás para el lanzamiento del transbordador espacial Atlantis en la misión STS-115 de la NASA...
Mañana por la mañana, a eso de las 7:43 hora de España (GMT +2), la sonda SMART-1 de la ESA se estrellará con la superficie de la Luna, poniendo fin a una misión de casi tres años que ha servido de demostración...
Las matemáticas de la cooperación humana es un extenso trabajo sobre uno de mis temas favoritos: la «cooperación» en matemáticas y teoría de juegos y cómo su estudio puede tener consecuencias prácticas en el MundoReal™ o incluso en el plano personal y...
Desde que salió el comunicado de prensa en el que la empresa irlandesa Steorn afirma haber conseguido diseñar una tecnología que «…genera una energía gratuita, limpia y constante» ya hemos recibido varios correos preguntándonos nuestra opinión al respecto. Pues bien, dado que...
La NASA acaba de hacer público que será Lockheed Martin la empresa que construya el Orion, el nuevo vehículo espacial tripulado de la agencia que llevará a los astronautas de vuelta a la Luna y más tarde a Marte y que debe...
Hispaciencia es un nuevo proyecto sin ánimo de lucro que ha nacido a inciativa de varios blogueros con la intención de agrupar y potenciar los blogs sobre Ciencia de habla hispana. La idea es hacerlo no en forma de «agregador pasivo» que...
Según cuenta la NASA en Atlantis Weathers the Storm la lanzadera espacial Atlantis superó sin problemas el paso de la tormenta tropical (a ratos huracán) Ernesto por Florida, bien protegida por la Rotating Service Structure, que en la foto de la derecha...
La mal llamada teoría del Diseño Inteligente defiende que algunas de las cosas que existen en el universo y en la naturaleza son tan complicadas que la teoría de la evolución no puede explicarlas y que tienen que haber sido diseñadas por...
Interesante reflexión, apropiada para el BlogDay: ¿Son los blogs académicos una nueva forma de comunicación científica? – Un artículo en la revista Nature, Science in the web age: Joint efforts comenta dos nuevas formas mediante las cuales los científicos pueden comunicar su...
Al principio pensamos que se trataba de la típica metedura de pata en la que un artículo confunde a astrónomos con astrólogos, pero después de «googlear» los nombres que salen en Controversia entre los astrólogos por la exclusión de Plutón resulta que...
¿Has mirado alguna vez de qué están hechos los palitos de pescado congelados? Pues vete a la nevera y echa un vistazo a la caja de nuevo, a ver qué encuentras. Debido a la sobreexplotación de especies marinas, su composición ha ido...
El huracán/tormenta tropical Ernesto parece haberse desviado hacia el oeste abandonando Florida, de modo que el Kennedy Space Center ha quedado fuera de la zona de mayor peligro. Esta es la razón por la que la NASA ha decidido volver a llevar...
¡Ingeniería casera con materiales atípicos! El motor eléctrico más simple es una explicación en castellano que nos envió Javi, con fotos sobre cómo construir paso-a-paso un motor que funciona con una pequeña pila normal y corriente, un tornillo, un trozo de cable...
Mucha gente nos ha escrito estos días sobre asunto matemático de la Conjetura (ahora Teorema) de Poincaré, la compleja y larga (pero finalmente correcta) demostración de Grigori Perelman y su sorprendente reacción al no aceptar la Medalla Fields, que se considera el...
Los responsables de la NASA han decidido darse un día más para inspeccionar el Atlantis después de que un rayo lo alcanzara el pasado viernes [vídeo Real | Windows] en la plataforma de lanzamiento. La principal preocupación son los propulsores de combustible...
Se ha anunciado el aplazamiento 24 horas del lanzamiento del transbordador espacial Atlantis debido a las malas condiciones meteorológicas. Hasta ahora había un 60% de probabilidads de luz verde pero el clima no permite actualmente el lanzamiento desde el Centro Espacial Kennedy,...
Ayer comenzaba la cuenta atrás para el lanzamiento del transbordador espacial Atlantis en la misión STS-115 de la NASA, una misión que estaba planeada originalmente para principios de 2003 y que se vio retrasada por el desastre del Columbia en febrero de...
La XXVI Asamblea General de la Asociación Astronómica Internacional ha aprobado esta tarde la Resolución 5a, que dice:Resolución de la UAI: Definición de un Planeta en el Sistema Solar Las observaciones actuales están cambiando nuestra forma de entender los sistemas planetarios, y...
Según se puede leer en el último número de la revista Nature un grupo de científicos estadounidenses han conseguido crear líneas de células madre embrionarias sin necesidad de destruir embriones en el proceso, lo que es una de las principales objeciones que...
Hace mucho tiempo que los astrónomos se dieron cuenta de que los efectos gravitacionales que podemos observar en el universo no se pueden explicar con la materia que vemos, ya que esta es a todas luces insuficiente para provocarlos. Una de las...
Roman Numerals and Arithmetic es un artículo en el que el autor explica algunas cosas interesantes sobre la aritmética con «números romanos», especialmente lo difícil que resulta (o resultaba) trabajar con ellos, algo que pone en evidencia su carencia de practicidad. El...
Como dice Luis Alfonso Gámez, será cosa de que en verano escasean las noticias, pero me parece que dar pábulo a los que dicen que los aterrizajes en la Luna son un montaje es pasarse varios pueblos: Antena 3 TV dice que...
Por lo visto no todos los asistentes a la XXVI Asamblea General de la UAI están muy convencidos de que la propuesta que se hizo pública este miércoles para definir qué es un planeta y qué no lo es sea demasiado buena....
Finalmente, ante la casi certeza de que los tornillos con los que ha volado durante los últimos 20 años son demasiado cortos, la NASA ha decidido reemplazar dos de los tornillos que sujetan la antena de comunicaciones de banda Ku que está...
La respuesta no es tan simple como pudiera parecer a primera vista. Imaginemos que la estamos observando desde un satélite y tomamos medidas. Si ahora la recorremos a pie, ¿saldría la misma distancia? ¿Y si la recorriera una bacteria? Desde el satélite...
La NASA acaba de anunciar que el transbordador espacial Atlantis despegará el próximo 27 de agosto a las 22:30 GMT (con lo que en España serán en realidad las 00:30 del 28 de agosto) para llevar a cabo la misión STS-115 de...
El cerebro social. Michael S. Gazzaniga. Alianza Editorial 1993. ISBN 8420606464. Español. A raíz de la anotación vivir con medio cerebro sobre pacientes sometidos a hemisferectomías Jorge nos recomendó este libro, así que lo encargué y me lo llevé de vacaciones. En...

Me faltó tiempo para ir a mi juguetería favorita a buscar giroscopios o peonzas, y cuando llego me encuentro... ¡Ni más ni menos que el mismísimo Levitron! Así que junto con otros juguetitos ya está en la oficina. Este es un...
Hace unos días tuve la oportunidad de visitar las famosas Cuevas del Drach (Cuevas del Dragón) en Mallorca, y aunque las cuevas en si son un sitio impresionante, lo cierto es que el planteamiento de la visita me dejó absolutamente decepcionado. Tal...
Todavía no es oficial porque aún tiene que ser ratificada por la XXVI Asamblea General de la UAI que como comentábamos el lunes se está celebrando estos días en Praga en una votación que tendrá lugar el próximo 24 de agosto, pero...

Descubriendo los secretos de los giroscopios, unos fascinantes artilugios mecánicos que abarcan desde los juguetes hasta los más avanzados instrumentos, incluyendo historias sobre «teorías de antigravedad».
Hoy comenzó en Praga la Asamblea General de la Unión Astronómica Internacional, asamblea de la que, entre otras cosas, se espera que salga una definición clara de lo que se considera un planeta y lo que no lo es, lo que debería...
The Missing Body Parts of 10 Famous People cuenta las historias de algunas partes del cuerpo «perdidas» de diez personajes históricos más o menos famosos, desde la mano de San Francisco Javier a los huesos de John Wilkes (el asesino de Linconl)...
Top Ten Weirdest Cosmologies es una recopilación interesante de New Scientist sobre las diez teorías cosmológicas más extrañas que se manejan en la actualidad como respuesta a «cómo es este Universo en el que existimos». Este es un pequeño resumen que...
Enigmático Ramanujan es una breve y preciosa descripción de una de las figuras más misteriosas de las matemáticas, el hindú Srinivasa Ramanujan (1887-1920), quien con su auténtica «mente maravillosa» desarrollaba fórmulas casi imposibles que relacionaban unos números con otros. Una de ellas...
El astrofísico norteamericano James Van Allen murió ayer a la edad de 91 años. La contribución más conocida de Van Allen fue el descubrimiento en 1958 de los cinturones de radiación, ahora conocidos como cinturones Van Allen, que rodean la Tierra. Tambén...
Por Nacho Palou -
10 AGO 2006
Este año la observación de las Perseidas o Lágrimas de San Lorenzo se verá obstaculizada por una Luna llena al 87% durante los días de máxima actividad de la lluvia, los días 12 y 13 de agosto –también pueden observarse los días...
Por Nacho Palou -
10 AGO 2006
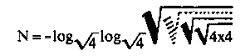
La coincidencia de «Los cuatro cuatros» explica cómo obtener todos los números del cero al diez utilizando siempre cuatro números cuatro y diversas operaciones matemáticas básicas. Por ejemplo 7 = (44/4)-4. Es curioso que en el libro original del que está extraída...
Un bonito y sencillo experimento para calcular la velocidad de la luz en casa: Microondas, regaliz y la velocidad de la luz. Me recuerda muchísimo al método SCIS, que se utilizaba en mi colegio cuando hacía EGB, en el que mediante sencillas...
Hace algún tiempo circuló por la blogosfera el enlace a unas imágenes creadas en 3DMax que mostraban el tamaño relativo del Sol y algunos planetas y lunas de nuestro Sistema Solar, pero dado que las imágenes parecían haber sido pasadas manualmente a...
El transbordador espacial Atlantis ya está camino de la plataforma de lanzamiento 39B trasladado desde Vehicle Assembly Building donde se le acoplaron el depósito externo y los dos cohetes de combustible sólido. Una vez en la plataforma se añadirá la carga útil...
Por Nacho Palou -
2 AGO 2006
Aunque con varios meses de retraso sobre lo previsto, esta tarde a las 20:00, hora de España, comienza a funcionar el proyecto Stardust@Home, que utilizando la potencia de cálculo donada todos aquellos que quieran participar en el proyecto se pondrá a buscar...
The Hundred Greatest Theorems lista los mejores cien teoremas matemáticos de la historia, basándose en las referencias que aparecen en literatura, la calidad de la prueba y lo inesperado del resultado. Algunos llevan enlaces a las demostraciones y sus descubridores. Encabeza la...

The five-hundred-dollar twenty dollar bill, and other negotiated pleasures (El billete de 20 dólares que valía 500, y otros placeres negociados) es un antiguo pero entretenido artículo sobre una curiosa «paradoja» matemática que se produce si se cambian las reglas de una...
El transbordador espacial Atlantis fue trasladado hoy del Orbiter Processing Facility -el hangar de las lanzaderas espaciales- al Vehicle Assembly Building, donde será unido al depósito principal de combustible y a los cohetes de combustible sólido en preparación para el lanzamiento de...
Si la semana pasada George W. Bush vetaba una ley que habría permitido que en los Estados Unidos mejoraran las condiciones para la investigación con células madre, hoy se ha sabido que, aunque por los pelos, la Unión Europea seguirá financiando este...
Llevaba algún tiempo pendiente de que saliera alguna imagen de las manchas rojas de Júpiter tras su encuentro del pasado 4 de julio, y hoy por fin he dado con una tomada por el Observatorio Gemini de Hawai el pasado 13 de...
La órbita típica de una lanzadera espacial está a unas 300 millas de altura, y desde allí las vistas son espectaculares. Alan Taylor ha recogido las que él considera las 125 mejores imágenes tomadas desde esa órbita por astronautas o cámaras automáticas,...
Este reloj de agua del Museo de los Niños de Indianápolis tiene ocho metros de altura y muestra la hora rellenando poco a poco con 260 litros de agua coloreada unas vasijas numeradas. Consta de un «mecanismo de relojería» líquido, construido tras...
Hoy se cumplen 30 años del aterrizaje de la sonda Viking 1 de la NASA en Marte, convirtiéndose en la primera sonda espacial en conseguir posarse suavemente sobre la superficie de otro planeta y enviar datos e imágenes de vuelta a la...
Estos días algunos nos habéis escrito para recordarnos que hoy es el World Jump Day, en el que está previsto que a las 11:39:13 GMT 600 millones de personas salten de forma sincronizada con el objeto de modificar la órbita de la...
Wakai se encontró este reloj de pared geek en Florida. Marca todas las horas pero utiliza siempre tres números nueve con diversas operaciones matemáticas como suma, división, raíz cuadrada, factorial, etc. para representar los números del 1 al 12. Sólo se necesita...
Otra preciosa galería de imágenes científicas, Biomedical Image Awards 2006 muestra las formas y patrones de las estructuras microscópicas de los seres vivos de forma espectacular. Más allá de su interés científico, ya que todas han sido obtenidas en el marco de...
El presidente Bush ha frenado hoy un proyecto de ley que pretendía eliminar la prohibición de utilizar fondos públicos para la investigación con células madre en los Estados Unidos: Bush estrena su derecho a veto para frenar la investigación con células embrionarias....
Un mini-FAQ que no lo parece sobre astronomía en forma de Conversaciones astronómicas con el peluquero:Carlos: Ah, supongo que desde los microscopios de Canarias podéis ver la Luna con musho detalle.Ángel: Bueno, la verdad es que no solemos observar demasiado la Luna...
ICM 2006 Benoit Mandelbrot Fractal Art Contest es la página oficial del concurso de arte fractal que lleva el nombre de Benoît Mandelbrot, el «padre de la criatura» sin cuyo trabajo no conoceríamos estas extrañas maravillas matemáticas que también aparecen en la...
Existe la tradición de que durante las misiones de las lanzaderas espaciales la tripulación es despertada cada día con una canción escogida por alguien en Tierra, ya sea de la familia, del control de la misión, alguien de la NASA, etc… Hemos...
Si todo va según lo previsto el Discovery tomará tierra hoy a las 15:14 en el Shuttle Landing Facility del Centro Espacial Kennedy. Para que esto suceda la tripulación encenderá los motores de la nave a las 14:07 para sacarla de su...
Esto son los primeros 1024 dígitos de Pi en hexadecimal, convertidos en notas musicales MIDI: A song of Pi [descargable como Pi MIDI track en formato .MID, 8 KB] Cada dígito se escucha como una nota distinta. Tiene una duración de 4...
La tripulación del Discovery dedicó su último día previsto en órbita a preparar el aterrizaje,que debería producirse hoy lunes a las 15:14, y para el que recibieron el visto bueno final a la hora de la comida. Todos colaboraron en asegurarse de...
Tras desatracar de la Estación Espacial Internacional a las 12:08 del sábado el Discovery se encuentra en estos momentos a unas 46 millas de la ISS, a la espera de que desde control de la misión sean terminadas de analizar las últimas...
Tras haberse asegurado de que toda la carga estaba correctamente almacenada en el módulo de carga Leonardo en días anteriores de la misión, este fue finalmente desactivado y transferido a la bodega de carga del Discovery a media tarde del viernes. Las...
¡Lucha mental! Física en Murcia está haciendo un seguimiento de la 37ª Olimpiada Internacional de Física que se está celebrando estos días en Singapur y acaba en un par de días. También se puede leer sobre el evento en la Web oficial:...
20 Things You Didn't Know About… Sleep de la revista Discover incluye hechos tan curiosos como que ya se sabe científicamente que el famoso sistema de «contar ovejas» para dormirse carece de efectividad («la actividad matemática es tan aburrida que es inevitable...
Nacho me pasó un enlace a Pi cantado que es exactamente eso: una canción pegadiza de unas chicas cantando los dígitos de π (pi) en inglés, sobre una melodía bastante simpática y en cierto modo «electrónica». No será la canción del verano,...
Imagining the Tenth Dimension es un libro y a la vez una web con una interesante animación infográfica que explica (en inglés) cómo se puede pensar en «como sería un universo con diez dimensiones». Teniendo en cuenta que los seres humanos estamos...
A lo largo de su vida, un corazón humano bombea tanta sangre como para llenar 100 piscinas.Un rayo alcanza una temperatura mayor que la de la superficie del sol. Un feto femenino de 5 meses de edad posee siete millones de óvulos...
Por Nacho Palou -
14 JUL 2006
No hay mucho que contar de este décimo día en órbita del Discovery y su tripulación, ya que después de tres paseos espaciales y de varios días pasando suministros de y desde la Estación Espacial Internacional les tocaba el día libre. La...
Según publica la revista Nature en Top five science blogs, serían estos: Pharyngula The Panda’s Tumb Real Climate Cosmic Variance The Scientific Activist Estos blogs en inglés están extraidos del Ranking de Technorati y ocupan diversos puestos entre los 3.500 primeros blogs...
La actividad principal del día fue el tercer paseo espacial de Mike Fossum y Piers Sellers, durante el cual aprovecharon para ensayar técnicas de detección de averías y de reparación del escudo térmico de las lanzaderas espaciales. Para ello filmaron imágenes de...
Probablemente describir cualquier actividad relacionada con la investigación espacial como rutinaria no es muy adecuado, pero la misión STS-121 de la NASA está tomando todo el cariz de convertirse en una misión de rutina de la flota de lanzaderas espaciales, a pesar...
Otro día tranquilo para las tripulaciones del Discovery y de la Estación Espacial Internacional, y más desde que desde el control de la misión anunciaran que el escudo térmico de la lanzadera espacial parece estar en perfectas condiciones para el regreso a...
Hoy lunes 10 de julio se celebra el 150 aniversario del nacimiento de Nikola Tesla (Никола Тесла), uno de los más importantes inventores de la historia. Tesla dominó disciplinas tales como la física, las matemáticas y la electricidad y es considerado el...
Por Nacho Palou -
10 JUL 2006
Un día tranquilo en órbita, dedicado básicamente a seguir con el transvase de los suministros que el Discovery lleva para la Estación Espacial Internacional a esta. En total son algo más de 4 toneladas, repartidas entre el módulo de carga Leonardo y...
Fíjate bien en esta foto: ¿Cuál de las dos piezas es más grande? La de abajo, ¿no? Pues aunque parezca increíble en realidad ambas piezas tienen el mismo tamaño. Échale un vistazo a este vídeo para comprobarlo: Se trata de una ilusión...
El paseo espacial de Mike Fossum y Piers Sellers fue la principal actividad del quinto día en el espacio del Discovery y su tripulación. La primera tarea que acometieron fue instalar un bloqueo en la cuchilla de seguridad del cableado que queda...
Nick's Mathematical Puzzles es una interesante colección de puzzles y problemas matemáticos para pasar el rato. Algunos como el número #3 (Los dos lógicos) o el #4 (El cinturón ecuatorial) son unos clásicos, con una solución totalmente sorprendente. Otros como el #50...
Al parecer ya hay un caso confirmado de un ave muerta por gripe aviaria en España: El Gobierno pide tranquilidad ante el primer caso de gripe aviar en España. Se trata de un somormujo que apareció muerto el pasado miércoles en el...
Las tripulaciones del Discovery y de la Estación Espacial Internacional dedicaron el cuarto día de la misión fundamentalmente a ir transfiriendo carga del módulo Leonardo a la ISS una vez que este fue trasladado de la bodega de carga del transbordador a...
La vida de los números es una exposición que no me quiero perder. Lleva abierta más de un mes en la Biblioteca Nacional (Madrid) y permanecerá hasta el próximo 10 de septiembre de 2006. La entrada es gratuita y hay horarios detallados...
El Discovery terminó ayer su viaje hacia la Estación espacial Internacional al atracar con ella a las 16:52 sin ningún problema [vídeo del momento del atraque en formato Real]. Justo antes de atracar el comandante Steve Lindsey tomó los mandos de la...
La principal ocupación de la tripulación del Discovery durante su segundo día en el espacio fue la de examinar cuidadosamente el estado de la nave con el Orbiter Boom Sensor System, un conjunto de instrumentos que se manipula con el Canadarm, el...
La sábana santa ¡vaya timo! Félix Ares. Editorial Laetoli y Sociedad para el Avance del Pensamiento Crítico 2006. ISBN: 8493486221. Español. Blog del autor: ciencia 15 . Este es el tercer y último libro por ahora de la colección ¡Vaya timo! y...
Con el Discovery ya en órbita la NASA se declara muy satisfecha del comportamiento del depósito externo de combustible de la lanzadera espacial, pues aunque se desprendieron algunos trozos de espuma aislante el análisis preliminar de las fotografías tomadas durante el ascenso...
Martes, 4 de julio de 2006, 8:38, 12 horas para el lanzamiento, cuenta atrás en T -6 horas: Tras los dos intentos fallidos del sábado y del domingo y el susto de la grieta aparecida en la espuma aislante del depósito externo...
La mayoría de las ilusiones ópticas sólo duran unos segundos, pero la que se describe y puede probar en The McCollough Effect - An On-line Science Exhibit se sale de la norma porque sus efectos pueden durar literalmente horas. Lo único que...
Las nubes han dejado de ser la principal preocupación de la NASA para el lanzamiento del transbordador espacial Discovery para pasar a un remoto segundo plano tras haber sido detectada una grieta en la espuma aislante que recubre el depósito externo de...
Con las consecuencias catastróficas que puede tener un accidente cerebrovascular en el que sólo una parte del cerebro se ve afectada resulta sorprendente que hay personas que no sólo viven sino que pueden llevar una vida bastante normal tras sufrir una hemisferectomía....
Quedan cinco horas para el lanzamiento (domingo, 2 de julio de 2006, 21:26, hora peninsular española): Tras la cancelación ayer del primer intento de lanzamiento del Discovery, el clima sigue siendo el principal problema para que el lanzamiento se produzca hoy, las...
Increíble, pero existe: Hollywood Math and Science Film Consulting – Somos una empresa que garantiza que todos los detalles técnicos y jerga de los guiones de sus películas suenen creíbles, ya sean de temas matemáticos, científicos o médicos. Nos encargamos de que...
Los ingenieros de la NASA han conseguido poner en marcha de nuevo la cámara principal del Telescopio Espacial Hubble tras pasarla junto con otros dos instrumentos a una fuente de alimentación de respaldo: Hubble Camera is Back Online. Tras las pruebas pertinentes...
12 horas para el lanzamiento (1 de julio de 2006, 9:49): Ya en el día del lanzamiento la única preocupación, al menos a nivel oficial desde dentro de la NASA, es el clima, al que aún le dan un 60% de posibilidades...
Test Blindness Color es una prueba de daltonismo pero al revés. Las personas con visión normal no verán nada especial en las dos imágenes que se muestran, únicamente colores. Pero los daltónicos deberían poder ver instantáneamente unas figuras que hay ocultas ocultas...
El transbordador espacial Discovery está en la plataforma de lanzamiento 39B listo para despegar en la misión STS-121 de la NASA, la segunda de un transbordador tras el desastre del Columbia en 2003. Los objetivos básicos de esta misión de 12 días...
Esta mañana llegó al Centro Espacial John F. Kennedy la tripulación del transbordador espacial Discovery para la misión STS-121 de la NASA, que si todo va según lo previsto despegará el próximo sábado 1 de julio a las 21:49 hora de España:...

Esta ilusión óptica que causa una alucinación visual es bastante curiosa. Tienes que mirar el vídeo a pantalla completa durante un rato para adaptar la vista. Dura poco más de 90 segundos. Es un patrón en movimiento con musiquilla trance de fondo....
Mientras el juicio en el que se le acusa de fraude y malversación de fondos públicos y de violar las leyes sobre bioética del país sigue su curso, el abogado de Hwang Woo-suk acaba de anunciar que su representado va a abrir...
Celestia es un simulador espacial, una especie de planetario avanzado con el que se pueden ver y admirar las estrellas y los planetas, pero también viajar más allá de la superficie de nuestro planeta, algo que es la limitación típica de otros...
La cámara principal del Telescopio Espacial Hubble lleva desde este lunes sin funcionar, aunque los responsables de este tienen esperanzas de poder ponerla en marcha de nuevo pronto: Hubble’s main camera stops working. En estos momentos sus sospechas se centran en un...
La verdad es que con tanto bombo como se le dio al tema de la gripe aviaria hace unos meses me parece sorprendente que la noticia de que la OMS admite el primer contagio de la gripe aviar entre humanos esté pasando...
El anuncio el sábado por parte de la NASA de que iba a seguir adelante con un lanzamiento del transbordador espacial Discovery en la misión STS-121 previsto para el próximo 1 de julio a pesar del voto en contra de Christopher Scolese...

Conway: el genio que hizo que los nerds perdieran horas estudiando patrones simples y complejos.
Revisando el artículo del año pasado Trece cosas que no tienen sentido referidas a «misterios de la ciencia» me sorprendió no recordar haber oído nada sobre la anomalía de las sondas Pioneer 10 y 11 (en inglés: Pioneer Anomaly). Estas sondas fueron...
Como siempre que se habla de resultados de laboratorio hay que tomar esta noticia con un cierto grado de precaución, ya que estos no siempre se traducen en aplicaciones prácticas, pero según cuenta La Voz de Galicia en Científicos de EE.UU. devuelven...
Hydrogen Atom Scale Model – el diámetro de un átomo de hidrógeno es la 10 millonésima parte de un milímetro. El protón que contiene en el centro es cientos de miles de veces más pequeño, y el electrón que gira alrededor de...
Por Nacho Palou -
22 JUN 2006
No estoy siguiendo el mundia de fútbol con mucho interés -más bien con ninguno, en realidad- pero por lo visto estos días ha circulado por ahí una supuesta profecía de Nostradamus que dice tal queCuando el sexto mes de 2006 finalice, el...
La Unión Astronómica Internacional acaba de poner nombre a las dos nuevas lunas de Plutón cuya existencia confirmó el Telescopio Espacial Hubble en febrero de este año: Pluto’s new moons named Hydra and Nix. Así, S/2005 P 1 pasa a llamarse Hidra,...
Hoy comienza en Seúl el juicio contra Hwang Woo-suk, el científico acusado de fraude y malversación de fondos públicos y de violar las leyes sobre bioética del país: S Korea cloning expert on trial. Si resulta condenado se enfrenta a una pena...
Tenía muchas dudas de que fueran a decir nada, pero así como de pasada y como quien no quiere la cosa, en la edición de esta noche de Cuarto Milenio Iker Jiménez acaba de darle las gracias a todos los amigos que...
Tal y como estaba previsto la NASA anunció ayer la fecha para el lanzamiento del transbordador espacial Discovery en la misión STS-121, y tal y como se preveía, la fecha escogida es el próximo 1 de julio, justo el día en el...
Ciertamente, el número 142.857 tiene algunas características un tanto peculiares....
Como parte de la preparación de todos los lanzamientos de los transbordadores espaciales de la NASA se hace un simulacro de lanzamiento que se cancela apenas unos segundos antes de terminar la cuenta atrás, y hoy ha tenido lugar el de la...
El 8 de septiembre de 2004 la sonda Genesis debía haber descendido suavemente colgada de unos paracaídas sobre el desierto de Utah para que un helicóptero la pescara en el aire y así evitar contaminar las muestras de partículas de viento solar...
Con un día de retraso sobre lo previsto debido a la presencia en la zona de la tormenta tropical Alberto la tripulación que volará a bordo del transbordador espacial Discovery en la misión STS-121 ha llegado hoy al Kennedy Space Center para...
Parece que de un tiempo a esta parte y aunque no se sabe muy bien cómo ni porqué la famosa capa de ozono, que dio una nueva dimensión a la expresión «se está cayendo el cielo», se va recuperando por algunas zonas...
Por Nacho Palou -
13 JUN 2006
Me encantó este reportaje del domingo pasado: El cambio climático abre el Ártico, que incluye algunos detalles bastante impactantes: El Polo Norte siente ya con fuerza el imparable calentamiento del planeta, una terrible amenaza a la supervivencia de la especie humana de...
Tengo por costumbre no ver Cuarto Milenio, el programa de que hace Iker Jiménez en Cuatro, pero he de reconocer que me gustaría haber visto al menos la parte en la que en el programa de ayer daban a conocer la historia...
Lemelson-MIT: Inventon Dimension es una web del MIT sobre inventos e inventores, con algunos juegos y preguntas de trivial, recursos para educadores, el Inventor de la Semana, muchos enlaces para descubrir más cosas y bastante información sobre el mundo de los inventos....
Lektu, friki de los volcanes, nos envió una referencia a Volcano World, que es un sitio con un montón de fotos y de información sobre estos espectaculares fenómenos de la naturaleza. Hay una lista de FAQs / Preguntas Frecuentes sobre volcanes donde...
Un año más la Universidad de Princeton ha escogido las mejores imágenes y, por primera vez también vídeos y sonidos, producidos por sus empleados durante el año y las publica en Art of Science Competition / 2006 online gallery: Todas estas imágenes,...
Según se puede leer en Shuttle fuel tank fit for flight la NASA acaba de anunciar que los cambios realizados en el tanque principal de combustible del transbordador espacial Discovery para intentar minimizar los desprendimientos de espuma aislante le permiten soportar sin...
Según cuenta la NASA en Huge Storms Converge las dos grandes tormentas rojas de Júpiter, la Gran Mancha Roja y Red Jr., se encuentran en un rumbo que las llevará a rozarse el próximo 4 de julio. No es la primera vez...
Esto es una de esas cosas curiosas sobre cómo funciona el cerebro humano, y puedo asegurar que funciona porque lo probé hace años, y fue muy divertido: Sueños lúcidos – El sueño lúcido consiste en, durante un sueño, adquirir consciencia de que...
Estaba calificado como «el mayor enigma matemático del siglo XX»: La Conjetura de Poincaré (más en inglés: Poincaré Conjecture). La conjetura parece haber sido resuelta, aunque con estos temas tan matemáticamente avanzados ya se sabe: se puede tardar tanto en confirmar que...
¡Destrucción, destrucción masiva! ¿Acaso podría suceder otra cosa? Asteroid Impact es una preciosa simulación documental en vídeo sobre qué sucedería si un meteorito gigantesco estilo «destructor total» colisionara con la tierra, un posible Fin del Mundo realmente espectacular. Resultan especialmente impresionantes...
Aunque hay algunas discrepancias en la comunidad científica acerca de dónde termina nuestro sistema solar, las sondas Voyager están aproximándose al límite de este y en los próximos años saldrán definitivamente de él. El doctor Ed Stone del California Institute of Technology,...
Los ovnis ¡vaya timo! Ricardo Campo. Editorial Laetoli y Sociedad para el Avance del Pensamiento Crítico 2006. ISBN: 8493486213. Español. Blog del autor: mihteriohdelasiensia . El segundo libro de la colección ¡vaya timo! está dedicado al fenómeno de los ovnis, esos aparatos...
Month in Space es una bonita y a menudo espectacular sección de Space News de MSNBC que mes a mes recopila las mejores imágenes relacionadas con la investigación espacial. Ayuda si sabes inglés, pero no es imprescindible para quedarse alucinado con muchas...
What is special about this number es una enorme lista en la que está explicado qué tiene de «especial» cada número concreto. Algunos a veces son incluso «únicos» en ciertos aspectos. Incluye casi todos los números del 0 al 500 (y números...
Una buena introducción: El mundillo fractal – Un fractal es un objeto que tiene alguna de las siguientes características: Posee detalles a todas las escalas (si lo ampliamos, no se simplifica), no se puede describir ni local ni globalmente con la geometría...
El creacionismo ¡vaya timo! Ernesto Carmena. Editorial Laetoli y Sociedad para el Avance del Pensamiento Crítico 2006. ISBN: 8493486205. Español. Pues sí, ya han caído en mis manos los tres primeros libros de la colección ¡Vaya timo!, y ya he tenido tiempo...
El transbordador espacial Discovery ya está en la plataforma de lanzamiento 39B, lo que como siempre da lugar a una foto preciosa: Puedes descargarte esta foto en alta resolución de aquí [JPEG 884 KB]; la galería de fotos del traslado está en...
La NASA planea trasladar al transbordador espacial Discovery del Vehicle Assembly Building, al que llegó el viernes pasado, a la plataforma de lanzamiento 39B a partir de las seis de esta tarde, hora española. Lo hará cargado en el enorme Crawler-Transporter -a...
En su libro Blink! (traducido como inteligencia intuitiva) el divulgador Malcolm Gladwell explica una de las características de la mente humana y la percepción que más me han intrigado últimamente. Se trata del efecto denominado «bullet-time» o «dilatación temporal» que muchas personas...
A pesar del fiasco de la sonda Beagle 2 la ESA sigue teniendo como uno de sus objetivos conseguir colocar una sonda sobre la superficie Marte, y el próximo intentó será el de la misión ExoMars, que si todo va según lo...
Views of the Earth es una colección de «fotos de satélite» de todo el planeta Tierra, generadas de forma artificial (técnicas de gráficos 3-D) a partir de datos de fuentes de información gratuitas. Las imágenes se componen y muestran desde ubicaciones en...
Microsimulation of road traffic es un sencillo e interesante simulador de tráfico en carretera, con el que se puede ver fácilmente por qué se forman los atascos, y por qué algunos se forman y desaparecen incluso sin causa aparente. Se pueden variar...
Tras casi nueve meses en el Orbiter Processing Facility el transbordador espacial Discovery fue llevado este mediodía al Vehicle Assembly Building, donde será unido al depósito principal de combustible y a los motores cohete con la idea de que todo el conjunto...
Tras meses de investigación los tribunales surcoreanos procesan por fraude al falso pionero de la clonación, a quien acusan de haber malversado 3 millones de dólares y de haber dirigido la manipulación de los datos de los estudios publicados en 2004 y...
Comentando acerca de Drowned Alive, de David Blaine surgió el tema del «líquido ese que salía en Abyss en el cual era posible respirar» y sobre el que recuerdo haber leído hace años en un número de Selecciones Reader's Digest de mi...
Por Nacho Palou -
12 MAY 2006
A poco que hayas leído la prensa estos días o que hayas visto los telediarios te habrás topado con la noticia de las excavaciones que acaban de comenzar unos arqueólogos con la intención de averiguar si bajo una colina próxima a la...
Si viste el reportaje de la BBC Cuatro maneras de acabar con el mundo que emitió el canal Cuatro el domingo pasado seguramente te interesa la anotación de MalaCiencia Cuatro maneras de acabar con el mundo: Mini agujeros negros y los comentarios...
Por Nacho Palou -
11 MAY 2006
No recuerdo cómo di con él, pero Ciencia de bolsillo lleva ya algún tiempo en mi lista de feeds, aunque me gustaría que Ambros lo actualizara más a menudo. Él mismo define su blog comoUna página para explicar la ciencia que se...
12-Qubits Reached in Quantum Information Quest cuenta que los científicos ya han logrado realizar cálculos computacionales con 12 qubits. Los qubits son parecidos a los bits, son como los «átomos de información» que se manejan en computación cuántica, la unidad mínima de...
Tras la maniobra de inserción orbital del pasado 11 de abril la sonda Venus Express de la ESA alcanzaba este fin de semana su órbita definitiva, desde la que desarrollará su misión científica: Venus Express has reached final orbit. Se trata de...
Space Colony Art from the 1970s: colección de interpretaciones artísticas de las colonias espaciales según los diseños de estudios dirigidos por la NASA en los años 70. Una colonia debería poder albergar a unos 10.000 habitantes.(Vía Populicious | Make:)...
Por Nacho Palou -
9 MAY 2006
Ya no es la primera vez que algún científico del Vaticano se expresa claramente en contra del creacionismo, pero cuantos más lo hagan y más claramente lo digan, mejor. El último en hacerlo ha sido el jesuita y astrónomo del Vaticano Guy...
Al ángulo que forman el norte geográfico y el norte magnético, medido desde un punto concreto de la Tierra, se le llama declinación magnética y ha sido un valor primordial en la navegación durante mucho tiempo (…) La declinación magnética cambia a...
El Sr. Pez comenta que este viernes se presenta una nueva colección de libros elaborada por la Editorial Laetoli en colaboración con la Sociedad para el Avance del Pensamiento Crítico que bajo el nombre ¡Vaya timo! va a ir tratando esas historias...
La ESA acaba de publicar unos vídeos del descenso de la sonda Huygens en Titán el pasado 14 de enero de 2005 en los que se comprimen horas de datos de los instrumentos y cámaras de la sonda en unos minutos: Landing...
Mañana, como todos los primeros sábados de mayo desde hace ya algunos años, la Asociación de Amigos de la Casa de las Ciencias y los Museos Científicos Coruñeses celebran el Día de la Ciencia en la Calle, que este año cumple 11...
Supongo -espero- que a estas alturas no quede nadie que crea que Uri Geller realmente doblaba cucharas con el poder de su mente, pero por si acaso, en Spoon-bending How Uri Geller really does it! hay un vídeo y unas cuantas capturas...
Miguel de Astroseti nos escribió para contarnos que se abrió hace poco una sección sobre Matemáticas, que incluye una serie de artículos y biografías. Estos son los primeros títulos: Biografía de Leonardo da Vinci Biografía de Mary Somerville Historia del cero Historia...
Desde que empezó a funcionar la NASA ha ido produciendo cantidades ingentes de imágenes que en buena parte, dado el carácter público de la agencia, están disponibles para cualquiera que las quiera utilizar sin ánimo de lucro. El problema es que a...
Tal día como hoy en 1990 el transbordador espacial Discovery ponía en órbita el telescopio Espacial Hubble, haciendo realidad una idea nacida allá por 1946. En estos momentos el Hubble necesita cada vez más desesperadamente una misión de mantenimiento que permite reparar...
La sonda Mars Express de la ESA se ha pasado un año marciano (687 días de por aquí) elaborando un detallado mapa geológico de la superficie de Marte gracias al OMEGA, uno de los instrumentos que lleva a bordo, y con estos...
La historia oficial de la cosmonáutica rusa dice que la Soyuz 2 fue una nave no tripulada que se puso en órbita con el objetivo de que la Soyuz 3 se acoplara con ella, aunque Georgi Beregovoi, el tripulante de esta última,...
Tenía la impresión de que la negativa de la ESA de tomar parte en el desarrollo del transbordador espacial ruso Cliper había supuesto un parón indefinido en el proyecto, pero Anatoli Perminov, el director de Roskosmos, la Agencia Federal Espacial, anunciaba hace...
Tal día como hoy, hace 25 años, John Young y Robert Crippen despegaban a bordo del transbordador espacial Columbia en la misión STS-1, la primera de este tipo de naves, misión en la que se dedicaron principalmente a comprobar el funcionamiento de...
En unas horas la sonda Venus Express llega a su destino y se enfrentará a una maniobra de inserción orbital similar a la de la Mars Reconaissance Orbiter en la que encenderá su motor durante 50 minutos para frenar su velocidad lo...
Robert L. Park ha publicado en The Seven Warning Signs of Bogus Science una lista de siete síntomas que pueden querer decir que una noticia científica tiene en realidad más de pseudociencia que de otra cosa:El autor acude directamente a los medios,...
Una de esas maravillas que interrelaciona el mundo de la naturaleza con las matemáticas: Cómo encontrar la sucesión de Fibonacci en los girasoles y las margaritas: 1, 1, 2, 3, 5, 8, 13, 21, 34… y ya es primavera. Cada número es...
O al menos eso es lo que afirma la Conferencia Episcopal según se puede leer en La Iglesia dice que producir personas en el laboratorio es tratarlas como cosas pues según dicen:La reproducción humana artificial, aunque se tilde generalmente de asistida y...
Hala, a rehacer el modelo del universo otra vez. En el artículo Light shed on mysterious particle (BBC) se describe uno de los que puede ser más importantes avances científicos de la física: los neutrinos tienen masa. Este hecho ya está confirmado...
Esta semana se presentó en Santiago de Compostela el proyecto de construcción del superordenador «Finis Terrae», una máquina que cuando esté terminada al «módico» precio de 60 millones de euros contará con 18 terabytes de memoria y unos 2.500 procesadores. Según cuenta...
Alguien pensó que era buena idea gastar dos millones y medio de dólares en demostrar científicamente si rezar ayuda o no ayuda a los pacientes enfermos. El dinero lo puso la fundación Templeton Foundation, que estudia la relación entre ciencia y religión....
Salva nos pasa un enlace a Cassini's View of Jupiter's South Pole, la imagen que Universe Today escogió como imagen del día hace un par de días, que aunque no es nueva desde luego presenta a Júpiter desde una perspectiva poco habitual,...
Hoy a partir de las 11.00 de la mañana (UTC +2) el Sol se verá parcialmente tapado por la Luna durante una dos horas. En España no será excesivamente vistoso y de momento, al menos en Madrid, el cielo se presenta más...
Por Nacho Palou -
29 MAR 2006
La Astronomy Picture of the Day de hoy es una animación donde se representan varios objetos de tamaño respetable que andaban próximos a la Tierra (a menos de 20 millones de kilómetros) en su ruta alrededor del Sol durante enero y febrero...
Por Nacho Palou -
28 MAR 2006

¿Telepatía? No, un truco bien trabajado. Actualización (22 de marzo de 2023) – El vídeo original desapareció, pero encontramos este otro de Penn & Teller que está igual de bien. Relacionado: Telequinesis y el inefable James Randi; atención a los comentarios....
Eduardo Punset lleva ya unas semanas publicando artículos en El Semanal XL bajo la forma de respuestas a preguntas de los lectores, y en el número de este pasado fin de semana trata el tema de la clonación a raíz de la...
En uno de esos curiosos momentos de conjunción cósmica universal, un par de matemáticos han descubierto que el número 42 realmente podría ser la respuesta al sentido de la vida, el Universo y todo lo demás como ya anticipó la Guía del...
Recordatorio del próximo eclipse solar:Eclipse parcial de Sol el próximo miércoles 29 – El miércoles el Sol, la Luna y la Tierra se alinearán por este orden en el espacio, en un espectáculo que, aunque en algunas zonas se percibirá como un...
Por Nacho Palou -
27 MAR 2006
Según el artículo The Silent Speaker un grupo de científicos de la NASA ha conseguido interpretar las señales del pensamiento relacionadas con el habla mediante unos electrodos conectados en la laringe de una persona. Funciona más o menos así: cuando uno está...
Tras meses de retrasos y tres intentos cancelados Space X intentaba ayer por fin el primer lanzamiento del Falcon 1, su cohete parcialmente reutilizable diseñado para poner en órbita baja cargas de hasta unos 600 kilos. En este primer intento transportaba el...
La NASA ha hecho pública hoy la primera imagen enviada por la sonda Mars Reconaissance Orbiter, tomada con cámara High Resolution Imaging Science Experiment (HiRISE) de a bordo: Está tomada desde una altura de 2.489 kilómetros y su tamaño es de 20.000...
Según cuenta La Voz de Galicia en La OMS rebaja la alerta ante una posible pandemia de la gripe aviar entre seres humanos la Organización Mundial de la Salud dice ahora queEl virus H5N1 de la gripe aviaria, que ha matado a...
En Marte se acerca el invierno, y con sus paneles solares cada vez más cubiertos de polvo, lo que reduce su efectividad a la hora de cargar las baterías, los rovers de la Mars Exploration Rover Mission de la NASA, más conocidos...
Apenas unos días después de que el gobierno de Corea del Sur retirara su licencia de investigador a Hwang Woo-suk la Universidad Nacional de Seúl ha anunciado hoy su despido, lo que supone que su finiquito se reducirá a la mitad y...
El ministerio de salud de Corea del Sur retiró esta semana su licencia de investigador a Hwang Woo-suk, principal sospechoso del fraude de los resultados sobre clonación celular en ese país, aunque lo curioso es que lo han hecho basándose en un...
Full Moon and Lunar Effects es un viejo pero siempre interesante de releer artículo de The Skeptic’s Dictionary sobre un tema que roza la frontera entre el folklore, la leyenda urbana, lo paranormal y la ciencia. Es un asunto que si sacas...
Postal Experiments es un artículo sobre la exploración de los límites en el sistema postal (de Estados Unidos) llevándolo hasta lo inimaginable. El autor cuenta cómo intentaron enviar experimentalmente, a veces con éxito, a veces sin tanto éxito, globos inflados, billetes de...
La sonda Genesis tenía que haber devuelto partículas de viento solar capturadas en el espacio a Tierra para su análisis en septiembre de 2004, pero un fallo a la hora de montar los sensores de deceleración que tenían que haber disparado los...
MalaCiencia publicó una divertida anotación sobre la Ciencia en Espacio: 1999. Como siempre que se analiza una película o serie de ciencia ficción hay muchas lagunas, y estas son las más divertidas de la legendaria serie: Espacio: 1999 – ¿A qué velocidad...
Al final los problemas con los sensores del nivel de combustible en el depósito principal que va a ser utilizado en la próxima misión del transbordador espacial Discovery han obligado a la NASA a posponer su lanzamiento hasta julio, ya que se...
¿Quién puede nombrar el mayor número? es un artículo dividido en ocho anotaciones, que ha sido publicado por Tío Petros durante las últimas semanas, traducido por Jorge Alonso. El original está en inglés, Who Can Name the Bigger Number? y es de...
¡Feliz día de Pi! Tal y como indica el calendario geek, hoy 14 de marzo (mes 3, día 14) se celebra el día de Pi. En el mundo anglosajón, el 14 de marzo se escribe como 3/14, que es el valor de...
Después de buscar un poco en Google Mars resulta que las imágenes no tienen resolución suficiente como para permitir ver directamente en la superficie las famosas caras de Marte que parecían verse en las fotografías tomadas por las sondas Mars Global Surveyor...
Por Nacho Palou -
13 MAR 2006
Google acaba de extender su PDM a Marte con Google Mars, fruto de una colaboración con investigadores de la NASA de la Arizona State University: Incluye como imágenes base:Mapas de altura codificados por color obtenidos por el Mars Orbiter Laser Altimeter del...
Serendipia es una palabra todavía no aceptada en el diccionario de la Real Academia que se refiere a aquellos descubrimientos que se realizan gracias a una combinación de accidente y sagacidad, y esta es sin duda la palabra que habría que usar...
Game Theory (Teoría de Juegos) de la Stanford Encyclopedia of Philosophy es un excelente documento divulgativo sobre esta interesante rama de las mátemáticas, que tiene un montón de ramificaciones a otras áreas del concimiento: La Teoría de Juegos es el estudio de...
23:25: ¡Bingo! La MRO está en órbita alrededor de Marte. A las 23:30 la NASA emitirá un informe sobre el estado de la sonda, pero todo parece indicar que todos los sistemas están funcionando perfectamente. 23:16: La Deep Space Network acaba de...
Esta noche, a partir de las 22:24 hora de España, la sonda Mars Reconaissance Orbiter de la NASA comienza su maniobra de inserción orbital. Para ello disparará su motor durante 27 minutos, lo que debería frenarla lo suficiente como para que la...
La NASA acaba de anunciar que después de analizar algunas imágenes enviadas por la sonda Cassini de Encélado, una de las lunas de Saturno, piensan que el modelo que mejor podría explicarlas es la existencia de agua en estado líquido a pocos...
La agencia espacial japonesa anunciaba esta semana que ha conseguido restablecer contacto parcial con la sonda Hayabusa tras perder contacto con ella en diciembre y que esto les ha permitido hacer una evaluación de su estado actual. Esta sonda tenía como misión...
Según cuenta la BBC en Una familia al centro de la evolución algunos miembros de una familia que vive en una remota región de Turquía que se ven obligados a caminar a cuatro patas «pueden ofrecer información valiosa sobre la evolución humana»;...
Una de las características más conocidas y que más llama la atención de Júpiter es la Gran Mancha Roja que hay en su hemisferio sur, mancha que en realidad es un anticiclón con un diámetro de unos 25.000 kilómetros -aproximadamente el doble...
Por primera vez desde que se destapara el escándalo de la falsificación de los resultados obtenidos sobre clonación de células madre en Corea del Sur el máximo responsable del equipo está siendo sometido a interrogatorio por los fiscales encargados del caso. Hwang...
La NASA, tras pactarlo con las otras agencias espaciales involucradas, acaba de hacer público un nuevo plan de construcción para poder tener terminada y en servicio la Estación Espacial Internacional para cuando en 2010 sea retirada del servicio la flota de transbordadores...
Inside the Brain: An Interactive Tour es una excelente página de divulgación sobre cómo funciona el cerebro y qué está sucedediendo exactamente cuando una persona padece la enfermedad de Alzheimer. Son 16 imágenes interactivas con explicaciones que permiten aprender algo más sobre...
Hace unas semanas el Hubble nos proporcionaba una impresionante foto de Orión a 384 megapíxeles y ahora acaba de hacer lo propio con la galaxia M101, aunque en este caso a «sólo» 192 megapíxeles, Photo - heic0602: Largest ever Hubble galaxy portrait...
La NASA tiene planeado realizar la segunda misión de vuelta al vuelo de los transbordadores espaciales el próximo mes de mayo, conocida como STS-121, durante una ventana de lanzamiento que va del 10 al 23 de ese mes, pero hay toda una...

¡Aja! Ayer revisando esa gran película geek que es Pi, fe en el Caos me di cuenta de que en el título hay un grave error/bug. En la película el número π aparece como: 3,1415926526312453… cuando π en realidad es 3,1415926535897932…...
A partir del próximo sábado 4 de marzo LIDL vuelve a poner a la venta por 139 euros el telescopio Meade ETX-70 del que hablábamos en diciembre. Como decíamos entonces, no es que se trate de un aparato sofisticadísimo, pero sí...
Pi Phone Number Search Engine [por desgracia desapareció, aunque existe The Pi Search Page que es similar] es una página que busca cualquier número que le indiques, especialmente números de teléfono, dentro de los deciminales de π (Pi). La búsqueda se realiza...
Tras perder el Cryosat a causa de un fallo del cohete que lo tenía que haber puesto en órbita el pasado mes de octubre la ESA acaba de publicar en ESA confirms CryoSat recovery mission que va a construir un reemplazo. El...
Hace unos meses la NASA, pendiente del resultado de nuevas observaciones, anunciaba que creía haber detectado dos nuevos satélites de Plutón, al que hasta ahora sólo se le conocía uno, Caronte. Ayer mismo la agencia confirmaba la existencia de S/2005 P 1...
La Asociación Americana para el Avance de la Ciencia es una organización internacional que tiene como objetivo «el avance de la ciencia y la innovación alrededor del mundo para el beneficio de todas las personas», para lo que tiene múltiples programas de...
Un core dump en miniatura con unos enlaces que se me han ido acumulando estos días y que de otro modo acabaré por no poner:Japan launches space telescope, el lanzamiento de la sonda Astro-F, que lleva un telescopio de infrarrojos para localizar...
Ya tiene unos añitos, pero como a escala cósmica nueve años no son nada, The Wiki History of the Universe in 200 Words or Less, que cuenta la historia del universo en menos de 200 palabras con cada una de ellas enlazada...
Si tienes problemas con el inglés para seguir las descripciones que acompañan a la Astronomy Picture of the Day de la NASA en Imagen Astronómica del Día la encontrarás traducida al español, aunque va con cierto retraso respecto al original. (Gracias, Javier.)...
La NASA anunció este viernes que el transbordador espacial Atlantis, que tiene previsto realizar cinco misiones de aquí a 2008 y que luego iba a ser sometido a una profunda operación de renovación, será en realidad retirado del servicio cuando acabe esas...
La ministra de sanidad advertía el verano pasado que quería que el consejo de ministros aprobara una nueva ley de reproducción asistida menos restrictiva que la que actualmente está en vigor y que esperaba tenerla lista para finales de 2005 o principios...
Tenía pendiente escribir algo genérico sobre los memes desde el punto de vista de fenómenos de la «promoción viral» o «márketing viral», pero el otro día José Luis Orihuela publicó Memes: los virus de la mente que es algo muy completito: Meme...

Geekismo extremo: Música para los fractales de Mandelbrot: Dedicado al fractal único y primigenio, dedicado al Conjunto de Mandelbrot (en la imagen un detalle). El freakomúsico Jonathan Coulton le ha dedicado esta canción, en formato MP3: Mandelbrot Set. La letra es alucinante...
Cumpliendo por fin una vieja reivindicación de los astrofísicos españoles, la Ministra de Educación y Ciencia, María José San Segundo y la directora del European Southern Observatory, Catherine Cesarsky, firmaban ayer por fin el acuerdo para el ingreso de España en el...
Sara Martín publica hoy en La Razón el artículo Darwin cede un puesto al Diseño Inteligente en el que una vez más se recurre a la falacia de intentar hacer ver que el la evolución sea una teoría le resta credibilidad:No todo...
Mientras la investigación acerca de sus prácticas y anuncios fraudulentos sobre éxitos en la clonación de células que nunca tuvieron lugar sigue adelante, la universidad de Seúl ha suspendido de empleo y sueldo a Hwang-Woo Suk y seis de sus colaboradores. En...
La Voz de Galicia publica hoy una pequeña entrevista con Adriana Aquino, no Andrea como dice el periódico, responsable del departamento de educación del American Museum of Natural History de Nueva York acerca de Darwin, la evolución y el diseño inteligente y...
La NASA acaba de presentar su presupuesto para este año y los científicos no están nada contentos, ya que se sacrifican o reducen varios proyectos en aras del deseo de la administración Bush de volver a la Luna y de la necesidad...
Buen nombre para un reloj atómico:La Estación Espacial Internacional a la hora atómica de Pharao – Este singular instrumento debe medir el tiempo con una exactitud y una estabilidad inigualadas: el reloj no perderá más que 1 segundito cada 300 millones de...
Por Nacho Palou -
9 FEB 2006
Earth View es una forma de visualización que simula, en «tiempo real», cómo se vería la Tierra desde la posición del Sol en el momento exacto en que mires la imagen, utilizando fotos de satélite. También puedes hacer lo mismo con la...
La Astronomy Picture Of the Day de hoy es una impresión artística de 2003 UB313 dibujada por Thierry Lombry. UB 313 es un objeto que orbita el Sol al doble de sitancia que Plutón cuya existencia fue hecha pública el año pasado...
Tenía aparcado por ahí el artículo NASA Chief Backs Agency Openness del New York Times en el que se habla de las injerencias de los responsables de prensa con poca o ninguna formación científica colocados por la Casa Blanca en la NASA...
El FBI está dirigiendo una investigación sobre numerosas protestas que dicen que el Inspector General de la NASA, Robert W. Cobb, dejó de investigar fallos de seguridad y que además tomaba represalias contra aquellos que intentaban llamar la atención sobre ellas. La...
Por lo visto el polvo lunar huele «a pólvora usada». Es un olor fuerte, «como si alguien acabase de efecturar un disparo». Tampoco tiene mal sabor y tiene un tacto suave como la nueve en polvo, aunque extrañamente áspera. «Es algo alucinante»...
Por Nacho Palou -
3 FEB 2006
Científicos del Centro de Control y Prevención de Enfermedades y de la Universidad de Purdue acaban de anunciar que han desarrollado una vacuna contra el virus H5N1 que produce la gripe aviar de la que tanto se viene hablando recientemente, vacuna que...
Durante el mes pasado se cumplieron los primeros nueve meses de Mike Griffin al frente de la NASA, lo que aprovechó el Orlando Sentinel para entrevistarlo, entrevista cuya transcripción está en Mike Griffin After Nine Months. Entre otras cosas, en ella Griffin...
Uno de los grandes desafíos de la física actual es encontrar una teoría unificada que permita conciliar las dos teorías que manejamos para explicar el funcionamiento de las cosas a nivel macroscópico y a nivel microscópico, la teoría de la relatividad y...
Tom de Mind Hacks se pregunta si existe realmente una «ciencia de la publicidad» o algo similar, y se propone escribir durante el próximo mes sobre todo lo que vaya descubriendo al respecto, además de que en marzo modera una mesa redonda...
Masterfill nos pasa un enlace a Stardust Capsule Reentry Movie, dónde se puede ver un pequeño vídeo de la reentrada en la atmósfera terrestre de la sonda Stardust el pasado 15 de enero tomado desde el Airborne Laboratory de la NASA, un...
Un par de enlaces que he encontrado estos días sobre gente con problemas de memoria, un tema que siempre me ha interesado mucho, pues al fin y al cabo no seríamos nada sin nuestros recuerdos:Una reseña de Memory's Ghost, un libro sobre...
¿Qué haces para explicarle a tus hijos porque al vivir en Alaska hay tantas horas de luz en verano y tan pocas en invierno? Pues construir una esfera armilar con Lego, por supuesto, como hizo Tom Johnson: El modelo no intenta ser...
Jay Barbree, el actual corresponsal de NBC News en Cabo Cañaveral, lleva años cubriendo el programa espacial norteamericano, y acaba de publicar una versión actualizada de su relato del desastre del Challenger publicado originalmente en enero de 1997, dividido en ocho partes...
Esto sí que me ha sorprendido: Cory Doctorow cuenta en Boing Boing que los números suelen comenzar más frecuentemente por «1» que por cualquier otro dígito. Así como suena. Una teoría matemática llamada Ley de Benford predice que en un conjunto...
Lo cierto es que se me había pasado por completo porque ya casi ha dejado de ser noticia que sigan funcionando, pero este martes Opportunity cumplía dos años en funcionamiento sobre la superficie de Marte, uniéndose a su gemela Spirit, que ya...
El Challenger desintegrándose – AmericanMustache Hoy se cumplen veinte años del desastre del transbordador espacial Challenger. Muchos recuerdan haber visto en directo como explotaba la nave a los 73 segundos de vuelo, terminando inmediatamente con las vidas de los siete astronautas que...
Ildefonso Hernández-Aguado, presidente de la Sociedad Española de Epidemiología, dictó ayer una conferencia sobre la gripe aviaria en Domus, en La Coruña, en la que intentó dejar bien claro que aunque es muy importante estar preparado para lo que pueda pasar la...
La BBC emitió hoy el programa A war on science de la serie Horizon, programa que trataba sobre los intentos de incluir el Diseño Inteligente en el currículum de la enseñanza de ciencias en los Estados Unidos, y se les ocurrió hacer...
Heber Rizzo traduce en Diseño inteligente: ¿ciencia mala o no-ciencia? un artículo original de Uriah Kriegel, profesor de filosofía en la Universidad de Arizona, que explica por qué el Diseño Inteligente no es ciencia aunque sus defensores quieran hacer ver que lo...
Ya lo he enlazado en alguna ocasión, pero El retorno de los charlatanes de Mauricio-José Schwarz es un estupendo blog para seguir las andanzas de magufos y fauna similar. A menudo sus anotaciones son más largas de lo que es habitual en...
El estudio epidemiológico más grande realizado hasta la fecha no ha conseguido demostrar relación alguna entre el uso de teléfonos móviles y los tumores cerebrales, según se puede leer en Un nuevo estudio descarta la relación entre cáncer y móviles o, con...
Alvy escribía hace unos meses en lo que tus ojos no ven tu cerebro lo completa acerca de los movimientos sacádicos oculares, que son unos movimientos involuntarios que hacemos continuamente con los ojos sin darnos cuenta durante los que no vemos, aunque...
Tras varios retrasos debidos a nubes bajas que impedían el seguimiento del lanzamiento la sonda New Horizons, con destino a Plutón, despegó finalmente a las 20:00 hora de España para emprender un viaje que le llevará aproximadamente nueve años. Aplazado por segunda...
Scott Sandford, uno de los astrofísicos encargados de la recuperación y apertura de la SRC de la sonda Stardust envió ayer un correo electrónico a otros colegas de la NASA en el que les explica un poco por encima como fue el...
Imagino que no servirá de nada, porque los defensores del Diseño Inteligente son, y nunca mejor dicho que en este caso, más papistas que el Papa, pero este martes L'Osservatore Romano, el diario oficial de la Santa Sede [por Dios, que contraten...
Si ayer fueron vientos por encima del límite aceptable para el lanzamiento hoy ha sido otro fenómeno meteorológico, en este caso fuertes tormentas sobre la zona de Baltimore y Washington, el que ha obligado a suspender de nuevo el lanzamiento de la...
La sonda New Horizons, la primera misión espacial con destino a Plutón y el cinturón de Kuiper, está lista para su lanzamiento, que si todo va según lo previsto se producirá tarde a las 19:24 hora de España. La NASA tiene una...
La Astronomy Picture of the Day es una página muy popular entre los aficionados a la astronomía en la que la NASAPublica cada día una imagen o fotografía diferentes de nuestro fascinante universo junto con una breve explicación escrita por un astrónomo...
Carl Sagan escribía hace un cuarto de siglo en Cosmos:El dinero gastado en la exploración espacial, gracias al empleo técnico y al estímulo que supone para la alta tecnología, tiene un efecto multiplicador sobre la economía. Un estudio sugiere que por cada...
Actualización 13:10: La cápsula ya está en el Michael Army Airfield. Allí será cargada en un camión para llevarla a una sala estéril dónde será abierta, proceso que puede llevar unos días. De allí el aerogel con las partículas será transportado por...
En poco menos de 24 horas, si todo va bien, la sonda Stardust habrá completado su misión de traer de vuelta a la Tierra muestras tomadas de la coma del cometa Wild 2 y del espacio tras un viaje de 7 años...
Hwang Woo-suk, el científico surcoreano responsable de todo el follón de los resultados falsificados sobre clonación de células madre, pidió ayer disculpas en su primera aparición pública después de que el panel de científicos que estudió sus resultados desacreditara completamente su trabajo,...
Esto es lo que se dice «hacer una buena foto»: Hubble Panoramic View of Orion Nebula Reveals Thousands of Stars - En una de las imágenes astronómicas más detalladas nunca antes producida, el Telescopio Espacial Hubble de la NASA hizo una captura...
Por Nacho Palou -
12 ENE 2006
Astroseti acaba de publicar Los 10 experimentos de ciencia más bonitos, una traducción de Science's 10 Most Beautiful Experiments, que a su vez se basa en el artículo de George Johnson Here They Are, Science's 10 Most Beautiful Experiments [$] publicado en...
La NASA, la ESA y el STscI acaban de anunciar que gracias al telescopio espacial Hubble han podido fotografiar por primera vez la segunda de las compañeras de la Estrella Polar, que aunque a simple vista se ve como una sola estrella...
Trabajar en el espacio, o de hecho por encima de los 19 kilómetros de altura, exige, entre otras cosas, que los seres humanos se lleven consigo un entorno en el que poder sobrevivir a la falta de atmósfera respirable, mantener una presión...
Si te gusta la astronomía y te manejas con el inglés aquí va un buen regalo de reyes del sitio Universe Today: El libro What's Up 2006 - 365 Days of Skywatching gratuito para descargar en formato PDF (unos 14MB entero, disponible...
Por Nacho Palou -
9 ENE 2006
Resulta que hubo algunos supervivientes al accidente del transbordador espacial Columbia Catástrofe del Columbia, hubo supervivientes - Minúsculos gusanos de laboratorio, que se guardaban en unas cánulas especiales de aluminio, a bordo de la malograda lanzadera espacial Columbia, sobrevivieron tras salir despedidas...
Por Nacho Palou -
5 ENE 2006
Vía Tempus Fugit (aka «el blog que se llama como mi disco duro») llegué a MalaCiencia un blog sobre «disparates, barbaridades y patadas a la ciencia, en noticias, películas o incluso en el saber general». Las últimas anotaciones son muy adecuadas para...
Por Nacho Palou -
4 ENE 2006
Hwang Woo-suk, el científico surcoreano cuyos resultados sobre clonación celular han sido recientemente desacreditados sigue defendiéndolos a capa y espada, aunque a esta alturas ya recurre a teorías conspiratorias, según cuenta Reuters en Disgraced S.Korean scientist stands by study. El artículo cuenta...
Para repasar el efecto que se produce cuando un cuerpo alcanza y supera la velocidad del sonido: La barrera del sonido en Curioso Pero Inútil. Incluye algunas fotos y vídeos espectaculares.(Vía email.)...
Por Nacho Palou -
30 DIC 2005
Ayer fue lanzado desde el centro espacial ruso de Baikonur el primer satélite del futuro sistema de posicionamiento Galileo, desarrollado por la Unión Europea con la colaboración de China con la idea de que se convierta en una alternativa de uso civil...
Se confirma lo peor respecto a las investigaciones sobre clonación de células madre en Corea del Sur, pues los resultados de los experimentos en los que el doctor Hwang Woo-suk afirmaba haber obtenido células madre a medida de hasta 11 donantes han...
Una de las ventajas del método científico es que en virtud de nuevos experimentos y observaciones es posible formular nuevas teorías que mejoren o sustituyan a las anteriores, como viene sucediendo en el campo de la biología con el Diseño Inteligente frente...
No es que haya sido formulada el otro día ni nada parecido, pero en un año en el que ha tenido que luchar a brazo partido contra el Diseño Inteligente, la revista Nature ha escogido a la teoría de la evolución como...
Aunque las evidencias halladas hasta ahora por los rovers marcianos de la NASA habían sido interpretadas como sugerencias de que en el pasado de Marte puede haber existido agua en estado líquido, lo que es uno de los requisitos para la vida...
En mayo de este año el equipo del doctor Hwang Woo-suk de la Universidad Nacional de Seúl asombraba al mundo al anunciar que habían conseguido clonar células madre adaptadas a la identidad genética de distintos donantes, lo que abría un montón de...
La NASA acaba de anunciar que el telescopio espacial Hubble acaba de descubrir dos nuevos anillos alrededor de Urano, el más grande de ellos del doble de diámetro del anillo más grande que se le conocía al planeta hasta ahora. Además, ya...
Apasionante caso el de Kim Peek a.k.a. Rain Man: Estudian a "Rain Man" para desvelar los secretos de la mente - Su verdadero nombre es Kim Peek y recuerda de memoria 9.000 libros. Le llevó poco más de una hora leer La...
Muy en consonancia con uno de los temas que se tratarán en la edición de esta noche de Redes, un juez en Filadelfia acaba de meterle un buen varapalo a los defensores del Diseño Inteligente, sentenciando que su enseñanza en el distrito...
La edición de esta noche de Redes, titulada ¿Aún creyendo cosas extrañas?, que como siempre sale a la cómoda hora de la 1:15 de la madrugada, estará dedicada al escepticismo y al pensamiento crítico. La entrevista que se emite durante el programa...
Está por confirmar cuál es, pero casi seguro que será válido (y récord): Probable hallazgo del 43º primo Mersenne - Este tipo de número está relacionado con los denominados números perfectos, que ya fueron estudiados por los griegos, sobre todo por Euclides....
Desde que la conozco he asociado la marca LIDL con ofertas de productos alimentarios de nombre inverosímil a precios bajísimos, pero desde hace poco me tiene sorprendido con algunas de las cosas que se pueden comprar por allí -al menos mientras duren...
La resupuesta corta sería «poco más de un megapixel». La respuesta larga es mucho más interesante, porque no es tan fácil de comparar el ojo humano con una cámara digital. Está explicada en cuatro posts en forma de serie: ¿Cuántos megapixels tienen...
Los responsables de la misión Hayabusa, la sonda espacial japonesa que tenía que conseguir muestras del asteroide Itokawa y traerlas de vuelta a la Tierra, ya dan prácticamente por hecho que la sonda no podrá emprender el camino de vuelta este mes...
Transcripción completa de una entrevista de Eduardo Punset a Jeff Hawkins en Redes de TVE. La verdad es que me la perdí, pero es genial que al menos esté en la web. Construyendo la realidad - Jeff Hawkins, creador de la agenda...
Virgin Galactic anunció hoy que planea construir un espaciopuerto en Nuevo México en el que invertirá 225 millones de dólares desde el que despegaran sus vuelos comerciales al espacio: Virgin Spaceport to Be Built in N.M.. También confirmó que ya hay 38.000...
Está visto que el nivel de estulticia de la gente -o su afán de notoriedad a cualquier costa- alcanzan límites insospechados: Space Cadets es un reality show que ahora mismo está en marcha en el que han convencido a tres participantes de...
Los problemas de la NASA con la flota de transbordadores espaciales no acaban, y mientras se plantea volver a introducir cambios en el diseño del tanque externo (NASA finds cracks in shuttle tank foam, NASA contemplating changes to shuttle tank) e investiga...
Tras una reunión de los correspondientes ministros de los países miembros de la ESA su director ha anunciado que la agencia dispone de un presupuesto de 8.255 millones de euros para los próximos años, dinero que será empleado fundamentalmente en:Iniciar el programa...
Lo de la sonda Hayabusa es peor que un culebrón de esos de la televisión. Tras haber perdido en el espacio a Minerva, el robot que transportaba y que tenía que haber tomado muestras de temepratura y fotografías en distintos lugares del...
En Fimoculous están recopilando en Lists: 2005 listas de todo tipo relativas a 2005: música, libros, coches, juguetes más peligrosos, descubrimientos científicos... El año pasado llegaron a recopilar unas 550 listas en Lists: 2004. (Vía MetaFilter.)...
Beyond Einstein es un webcast de 12 horas de duración en el que participan los más importantes centros de investigación en física del mundo y que arranca hoy a las 12 de la mañana, hora central europea. Tratará, por supuesto, de la...
Tal y como preveían los modelos que manejaban los científicos, y siguiendo con su cadena de estupendos resultados, la sonda Mars Express ha detectado depósitos de hielo bajo la superficie de Marte utilizando el MARSIS; los detalles están en el artículo Radar...
Si hay algún programa espacial reciente que sea un ejemplo claro de la ley de Murphy en acción, este es el de la sonda espacial Hayabusa (Halcón) de la JAXA. Después de estropearse dos de sus giróscopos estabilizadores, con lo que le...
Un curioso efecto óptico que me apunto intentar ver (¡y fotografiar!) la próxima vez que viaje en avión explicado en Los Cielos del Día de Acción de GraciasEn el lado opuesto al Sol, el punto principal para observar es la gloria. Se...
Por Nacho Palou -
28 NOV 2005
La BBC cuenta en Probe 'gathers asteroid material' que al fin, después de tantos problemas y tribulaciones, la sonda Hayabusa (Halcón) de la JAXA consiguió posarse ayer en el asteroide Itokawa durante unos segundos y tomar unas muestras del material que lo...
Según cuentan en Evolving into a tricky exhibit y en No corporate sponsors for Darwin exhibition el American Museum of Natural History no ha conseguido que ni una sola empresa patrocinara una nueva exposición sobre Darwinporque las empresas americanas se muestran especialmente...
Me da que a estas alturas la JAXA debe estar casi deseando no haber lanzado la sonda Hayabusa, cuya misión era aterrizar en el asteroide Itokawa, tomar unas muestras y devolverlas a la Tierra, pues a la cadena de fallos, tanto mecánicos...
A raíz del estreno de Cuarto Milenio la Sociedad para el Avance del Pensamiento Crítico está promoviendo el Manifiesto por la cultura veraz, al que puede adherirse cualquiera que lo estime oportuno. Me quedo con este párrafo:En estos programas habría que recordar...
A la JAXA le están creciendo los enanos con la misión de la sonda Hayabusa al asteroide Itokawa, cuyo objetivo es aterrizar en éste, tomar unas muestras y volver con ellas a la Tierra. Primero, se le estropean dos de los tres...
El Congreso de los Estados Unidos acaba de aprobar el presupuesto de la NASA para el año fiscal 2006, que empezó el pasado 1 de octubre. Son casi 16.500 millones de dólares que incluyen todo lo que la agencia pidió para ir...
Lo he leído en El día más largo de BlockPocket, es una enlace a The Leap Second [ya no existe, ver Leap Second como alternativa] donde se explica que efectivamente el último minuto de este año 2005 tendrá 61 segundos en vez...
La semana pasada estuve tan liado que hasta anoche no tuve tiempo ni de sintonizar Cuatro en el canal adecuado de las televisiones de casa, y cuando al final lo hice, voy y me encuentro con Iker Jiménez y Cuarto Milenio. ¿Es...
Mediante una combinación de mala suerte y falta de previsión la Agencia para la Exploración Espacial de Japón ha perdido en el espacio al Minerva (Micro/Nano Experimental Robot Vehicle for Asteroid), un pequeño robot que iba a bordo de la sonda Hayabusa,...
No conocía esta historia, pero ya está en mi lista de Clásicos: ¿El infierno es endotérmico o exotérmico? - Un profesor un poco cachondo de Termodinámica había preparado un examen para sus alumnos. Este tenía una sola pregunta: «¿Es el Infierno exotérmico...
Tras varios meses dándole vueltas al tema el Consejo de Educación de Kansas finalmente aprobó ayer por seis votos frente a cuatro nuevas normas para la enseñanza de ciencias que ponen en duda la teoría de la evolución, lo que es sin...
Tras un retraso de algo más de tres semanas debido a que se contaminó con aislante del cohete que iba lanzarla, lo que obligó a hacerle una limpieza a fondo, está previsto que por fin la sonda Venus Express de la ESA...
Aprovechando que el otro día Marte estaba, como quien dice, a la vuelta de la esquina, el Hubble le tiró una foto, que como es habitual en lo que hace ese cacharrito, es espectacular, en especial por la tormenta de polvo de...
Pasa con poca frecuencia, pero a veces la iglesia me sorprende positivamente, como en el caso de unas declaraciones del cardenal Paul Poupard, quien dirige en Consejo Potificio para la Cultura, que el pasado jueves dijo que los creyentes deben tener en...
En una página web que contiene el Sistema Solar a una escala en la que cada píxel de la pantalla equivale a unos 1.000 kilómetros Plutón (o, ese píxel muerto) estaría (si no me equivoco) a unos 6 millones de píxeles del...
Por Nacho Palou -
2 NOV 2005
Los Museos Científicos Coruñeses, en colaboración con Caixanova, acaban de publicar una Monografía de Comunicación Científica sobre la gripe aviar [PDF 2,1 MB] que mediante veinte preguntas y respuestas pretende dar respuesta a las inquietudes que se han venido generando sobre esta...
No tenía absolutamente ninguna intención de mencionar lo de la nueva infanta por aquí, aunque estuve a punto de publicar una anotación el pasado lunes protestando porque una de las primeras informaciones aparecidas sobre el ella, al menos en La Voz de...
La NASA anunciaba ayer que el telescopio espacial Hubble, que a pesar de los pesares sigue trabajando como un campeón, podría haber descubierto que Plutón no tiene una sóla luna, Caronte, como creíamos hasta ahora, sino que podría tener otras dos: Hubble...
Popular Science hace todos los años una lista de los peores trabajos en el campo de la ciencia; los de este año, resumidos de The Worst Jobs in Science, son: Rata humana de laboratorio.Inspector de estiércol.Profesor de biología en Kansas, estado en...
No lo había visto comentado por ningún sitio hasta hoy, pero por lo visto el satélite SSETI Express, diseñado por estudiantes de nueve países y puesto en órbita el pasado jueves, lleva desde el viernes en reposo debido a un fallo eléctrico...
Aunque no llegará a acercarse tanto como en 2003, la noche del sábado al domingo Marte alcanzará su última gran oposición en el presente ciclo y se situará a «sólo» unos 69,3 millones de kilómetros de la Tierra y muy alto en...
Varias noticias relacionadas con la investigación espacial:Por un lado, los rovers marcianos, de los que hacía tiempo que no hablábamos, siguen dando guerra mucho después de lo previsto, pues su misión original era de 90 días y sin embargo aún funcionan casi...
Recordatorio: entre los días del 7 al 20 de noviembre se celebra en Madrid la Semana de la Ciencia[T]oda la ciencia y la tecnología realizada en la Comunidad de Madrid desde el mundo de la biología molecular hasta las últimas investigaciones en...
Por Nacho Palou -
26 OCT 2005
A menudo se cuestionan las inversiones en investigación científica y se acusa a la ciencia y/o los científicos de estar desconectados del MundoReal™, pero creo que no hay más que pensar en cómo eran las cosas hace por ejemplo cincuenta años para...
La ARP Sociedad para el Avance del Pensamiento Crítico acaba de estrenar bitácora hace unos días, la bitacorARP , un lugar dónde estar al tanto de sus novedades y actividades, así como de «magufadas» y atentados similares contra el sentido común, como...
Si alguna vez te has preguntado qué es lo que hace Alexx cuando le toca realizar la autopsia a alguna de las víctimas de CSI: Miami, o lo que hacen los forenses en el MundoReal™, en Interactive Autopsy [Flash] lo puedes ver....
La sonda Cassini lleva ya algo más de un año en órbita alrededor de Saturno enviando montones y montones de datos, y por si eso fuera poco de vez en cuando envía además imágenes que quitan el hipo, como esta: Llamada Ringsinde...
Insértense aquí todos los disclaimers que sean oportunos teniendo en cuenta que no soy biólogo y tal y tal, pero salvo por el hecho de que se va acercando a Europa, que me aspen si entiendo el pollo que se está montando...
A pesar del gran potencial que ofrecen las células madre de cara al tratamiento de enfermedades como el Parkinson o la diabetes, o incluso a más largo plazo para la regeneración de tejidos y a lo mejor órganos enteros, es un campo...
En mayo de este año Antonio Bru se hizo un lugar en todos los medios de comunicación al anunciar que había descubierto un nuevo tratamiento del cáncer que habría curado incluso a enfermos desahuciados. El problema es que Bru es físico y...
Fei Junlong y Nie Haisheng, los tripulantes de la segunda misión espacial tripulada China ya están de nuevo el tierra después de que la Shenzou VI, la nave en la que han pasado los últimos cinco días en órbita, haya tomado tierra...
Nikon lleva desde 1974 premiando los mejores trabajos en microfotografía relacionados con las ciencias naturales y la investigación biológica y de materiales en una competición llamada Nikon Small World. Los ganadores de este año están en The 2005 Winners y son treinta...
Wayne Hale, el director del programa de transbordadores espaciales de la NASA, acaba de hacer unas declaraciones recogidas por Reuters en NASA aims for May for next shuttle launch en las que plantea como factible la posibilidad de un lanzamiento del transbordador...
¿Cuánto tardarán en llegar al cien por cien? Un 20% de los genes humanos han sido patentados - National Geographic News anticipa hoy los resultados de un informe (que publicará la semana próxima Science, titulado One-Fifth of Human Genes Have Been Patented)...
La NASA quiere poner en marcha dos nuevos premios similares al Ansari X Prize en colaboración con la X Prize Foundation; la nota de prensa está en NASA's Centennial Challenges Collaborates With Foundation. Uno de ellos, el Suborbital Payload Challenge, se lo...
Sin duda alguna una de las imágenes más famosas e impactantes de las generadas por la investigación espacial es la que tomaron los astronautas del Apollo 17 el 7 de diciembre de 1972, que es la que está aquí a la derecha....
Tal y como estaba previsto esta madrugada se produjo el lanzamiento de la segunda misión espacial tripulada china a bordo de la nave Shenzou VI, como se puede leer en China lanza con éxito su segunda misión espacial tripulada. Los tripulantes son...
La CNSA ha confirmado que planea realizar el lanzamiento de la misión Shenzhou VI a primera hora de la mañana del miércoles, lo que supondría que el lanzamiento tendrá lugar sobre la 1 o las 2 de la madrugada, hora peninsular de...
Unos cuantos enlaces a galerías de imágenes que se me han ido acumulando por ahí, sin ningún orden en particular: Abandoned, edificios e instalaciones industriales y científicas de distinto tipo abandonados a lo largo y ancho de la antigua Unión Soviética, vía...
La Agencia Espacial Europea ha confirmado en CryoSat Mission lost due to launch failure la pérdida del satélite CryoSat, cuyo objetivo era medir durante tres años el espesor del hielo en los casquetes y océanos polares. Parece ser que el satélite y...
liferfe nos ha pasado el enlace a una fotografía tomada con exposiciones múltiples del eclipse anular del pasado día 3 que ha sido publicada como Astronomy Picture Of the Day del 7 de octubre: Eclipse anular 2005 en directo.Diez años de APOD....
Estamos en es época del año en la que se anuncian los ganadores de las distintas categorías de los Premios Nobel, y seguro que a poco que hayas abierto un periódico o visto la tele ya te has ido enterando de algunos....
Desde hoy hay un motivo más para visitar el Smithsonian National Air and Space Museum, pues SpaceShipOne está expuesto desde hoy en la galería Milestones of flight. SS1 fue la nave con la que Scaled Composites consiguió ganar en octubre del año...
Peter H. Diamandis, el hombre que puso en marcha el Ansari X Prize, acaba de anunciar la creación y puesta en marcha de la Rocket Racing League, una competición de aviones cohete para...inspirar a personas de todas las edades a mirar de...
17:30: También hay fotos con la etiqueta «eclipse anular», que fue la que propuso rvr en Barrapunto. [Alvy]: Ahí van algunas de las fotillos que hicimos en el Planetario de Madrid: Más en Flickr: Alvy: Eclipse Anular; Nacho: Eclipse Anular; Todos:...
¡No habrá nubes el lunes! Al menos eso es lo que dicen las previsiones. En la zona de Madrid y Levante estará despejado aunque en Galicia y zona centro y norte puede estar un poco nuboso. A ver si hay suerte y...

Esta misma semana se cumplieron cien años de la publicación por parte de Albert Einstein del artículo titulado «¿Depende la inercia de un cuerpo de su contenido de energía?» en el que incluía una fórmula que relaciona la masa y la...
Visions of Science es un concurso de imágenes relacionadas con la ciencia que patrocinan Novartis y The Daily Telegraph cuyos ganadores en la edición de este año acaban de ser anunciados en Winners 2005. La idea del concurso es fomentar la discusión...
Eva es una cabeza que habla, estilo Futurama. Se puede ver en un vídeo, Eva: Biomimetic Robot Hanson [MPEG, 18 MB] de la NASA, en la web de un departamento de biométrica con un nombre muy largo y extraño. Podría pasar por...
Bonita colección de sellos acerca de matemáticos y su trabajo: Images of Mathematicians on Postage Stamps. (Vía Cambalache 3.14.)...
A estas alturas ya no es novedad que alguien diga que los transbordadores espaciales o la Estación Espacial Internacional han sido un fiasco, pero el que también lo esté diciendo Mike Griffin, el máximo responsable de la NASA, resulta cuando menos chocante....
Quedan cuatro días, es el próximo lunes:Eclipse anular de Sol: Entrevista con Javier Armentia - Infoastro.com publica su primer podcast. Se trata de una entrevista realizada por Víctor R. Ruiz a Javier Armentia, director del Planetario de Pamplona, en el que hablan...
También conocida como La Cola de la Bestia. PD: abstenerse de chistes obvios en los comentarios... Que os estoy viendo ;-)...
Empezando así: «Gödel, Chomsky y Heisenberg entran en un bar...» sólo puede ser un muy buen chiste. Al menos para linguistas y lógicos, claro ;-)...
Otra cita para ver el eclipse del 3 de octubre si estás en Madrid: El eclipse anular desde Madrid - La Asociación Astronómica de la Complutense de Madrid organizará la observación pública en el campus de la UCM: «Desde el Jardín botánico...
Una nueva serie de artículos sobre tecnología e inteligencia, interesantes: Is the internet making us more intelligent? - CNET ha publicado el primero de los artículos en una serie acerca de si las nuevas tecnologías nos están volviendo más inteligentes: Intelligence in...
Según estaba previsto la NASA presentó hoy en público su plan para volver a la Luna, tal y como recogen, por ejemplo, El País en la NASA enviará cuatro astronautas a la Luna en 2018 o El Mundo en la NASA presenta...
Aunque suene a broma, la comisión que estudió el accidente del transbordador espacial Columbia ha llegado a la conclusión de que, entre otros múltiples factores, el uso de PowerPoint para presentar información sobre la que basar decisiones de vida o muerte en...
Bueno, he estado investigando un poquillo lo del eclipse de dentro de dos semanas que atravesará buena parte de España, especialmente porque pasa por mi ciudad, y hoy casualmente la sección Madrid de El País publica un artículo titulado Madrid será la...
He visto McDonalds con más medidas de seguridad que algunos de estos «laboratorios de bioterrorismo».Eso dice Richard Ebright, microbiólogo de la Rutgers University, en referencia a los laboratorios de investigación de bioterrorismo en Estados Unidos, después de que se hayan escapado de...
Faltan poco más de dos semanas para el 3 de octubre, día del eclipse anular de Sol 2005 que podrá verse desde buena parte de España, así que si tienes interés en verlo ya va siendo hora de que te pongas en...
La NASA acaba de presentar a los responsables de la Casa Blanca su plan para volver a poner astronautas sobre la superficie de la Luna en 2018, lo que implica una inversión de 100.000 millones de dólares durante los próximos 12 años;...
Ciertas enfermedades de origen genético se transmiten mediante el ADN mitocondrial que todos hemos heredado de nuestras madres, ADN que se halla presente en el exterior del núcleo de los embriones, y hasta ahora nada se podía hacer para evitarlo, aunque esto...
Realmente, un título total y absolutamente redundante: Astrología para tontos(Vía Pjorge, vía Skeptico)...
Boing Boing publica algo sobre los efectos de la destrucción tecnológica que ha causado el huracán Katrina, especialmente infraestructura de las compañías telefónicas del golfo en la zona sur de los Estados Unidos. Esto obviamente afectará a muchas más cosas, porque estar...
Las imágenes del Dartmouth Electron Microscope Facility son espectaculares, en especial las de la exhibición Micromondi que realizó el Museo de Ciencias de Trieste. He visto películas de ciencia ficción en las que los alienígenas tienen pintas menos raras. (Vía ...hmmm...)...
Boing Boing le ha dedicado casi todo el agosto, se llama Flying Spaghetti Monster (FSM) o también Pastafarismo y es realmente tronchante: El espagueti volador - Lo que comenzó siendo una broma entre amigos se ha convertido, gracias a Internet, en un...
Con un día de diferencia salen estas dos noticias:Mobile phone cancer link rejected (esta no la he visto en los medios españoles, ¿alguien tiene un enlace?).Los médicos austriacos advierten de que los móviles pueden dañar la salud a largo plazo. Enésima ronda...
No tenía ni idea de este dato, que oí comentar a un meteorólogo en el telediario de la Primera mientras hablaban del ciclón Katrina, pero resulta que un ciclón, un huracán y un tifón son la misma cosa, sólo que cambia de...
A mi el asunto de la homeopatía siempre me sonó a cuento chino, y repasando noticias atrasadas de estos días veo que un estudio publicado en The Lancet, una de las revistas de medicina más prestigiosas del mundo, dice que en efecto...
Supernatural selection es una inteligente animación, en especial la viñeta final, sobre el Diseño Inteligente. Ojo, está en inglés. (Vía pjorge.)...
Will White¬horn, el presidente de Virgin Galactic, ha asegurado en unas declaraciones para Flight International que si el servicio suborbital que pretenden ofrecer con SpaceShipTwo tiene éxito, desarrollarán SpaceShipThree para entrar en órbita: SpaceShipThree poised to follow if SS2 succeeds. Teniendo en...
Uno de los campos más prometedores en la investigación científica actual es el de las células madre, que podría suponer una revolución en el tratamiento de todo tipo de enfermedades o incluso podría permitir la creación de órganos a medida para transplantes...
Con un día de retraso sobre las previsiones iniciales -esta misión parece la de los eternos retrasos- el transbordador espacial Discovery ha vuelto al Kennedy Space Center a lomos del Shuttle Carrier Aircraft, un Boeing 747 modificado para servir como transporte de...
Leí en el especial de verano de la revista Muy Interesante (del que he reseñado algunas curiosidades) que la pregunta ¿Cuántos planetas hay en el Sistema Solar? no tiene actualmente una buena respuesta porque, según la revista, la Unión Astrónomica Internacional no...
Serguéi Krikalev, quien está al mando de la undécima expedición en la Estación Espacial Internacional (ISS), acaba de convertirse en el nuevo poseedor del récord de permanencia en el espacio con un total acumulado de 747 días y 14 horas en varias...
Aún cuando la NASA decidió la suspensión de los vuelos de los transbordadores espaciales al día siguiente del lanzamiento del Discovery a causa del desprendimiento de espuma aislante del depósito externo de combustible, a finales de la semana pasada anunciaban de forma...
Con un par de días de retraso sobre lo previsto la NASA ha puesto hoy en camino la sonda Mars Reconnaissance Orbiter, que llegará al planeta rojo en marzo de 2006. Durante su misión, que se prevé que tenga una duración de...
Actualización 14:12: ¡Contacto! Tras catorce días en el espacio y más de nueve millones de kilómetros recorridos la tripulación, sus familias y la NASA ya pueden respirar tranquilos. Actualización 14:08: La comandante Collins ya tiene la nave bajo control manual para el...
Actualización 22:30: La NASA ha hecho públicas las horas disponibles para intentar aterrizar mañana:Kennedy Space Center: 9:07 GMT y 10:43 GMTEdwards Air Force Base, California: 12:12 GMT y 13:47 GMT.White Sands Test Facility, Nuevo Méjico: 10:39 GMT y 12:13 GMTLas predicciones indican...
Una vez comprobado que los mecanismos de control de vuelo de la nave funcionan correctamente la comandante Collins y el piloto James Kelly están ensayando el aterrizaje mediante un simulador, pero poco más hay que hacer en este día para la tripulación...
El transbordador espacial Discovery está de camino a casa, tras haberse separado de la Estación Espacial Internacional esta mañana. Si todo va bien debería tomar tierra el próximo lunes a las 8:46 GMT en el Kennedy Space Center, aunque cabe la posibilidad...
La tripulación del Discovery está llevando a cabo las últimas tareas de su misión y se prepara para abandonar la Estación Espacial Internacional; igual que dejaron suministros nuevos en la ISS, ahora se llevan cosas que ya no son necesarias a bordo...
Forges y los problemas de la NASA con el Discovery en El País: (Vía jlprieto.) STS-114: día ocho....
Water on Mars, Astronomy Picture of the Day del 1 de abril de 2005. (Gracias, Raúl.) Diez años de APOD.Imagen Astronómica del día....
Más acarreo de materiales entre el Discovery y la Estación Espacial Internacional, y una buena noticia para variar, pues tras ponderar realizar un segundo paseo espacial extra para repararlo, la NASA ha decidido que el trozo de aislante térmico perforado cerca de...
En la NASA lo han llamado «un paseo espacial histórico» y dicen que desde ahora formará parte de los libros de texto. Lo cierto es que Steve Robinson se ha pasado seis horas en actividad extravehicular, reparando algunas de las losetas térmicas...
El momento «estelar» del día fue la conversación que mantuvo el presidente George W. Bush con la tripulación del Discovery, en la que les comunicó lo orgullosos que se sienten de ellos y sus deseos de que vuelvan sanos y salvos, para...
Soichi Noguchi y Stephen Robinson llevaron hoy a cabo el segundo de los paseos espaciales previstos, en esta ocasión para sustituir un giróscopo estropeado de la Estación Espacial Internacional, con lo que esta vuelve a disponer de su dotación completa de cuatro...
Cuando la Academia de Ciencias de París encargó a Alexis Bouvard revisar las posiciones exactas de los planetas este descubrió que la órbita de Urano presentaba anomalías que hacían que su órbita no se correspondiera exactamente con lo que predecía la ley...
Rupert Sheldrake es un controvertido científico que explica en Do physical constants fluctuate? algo sobre las constantes de la Física y si son tan constantes como deberían serlo. Es un repaso interesante: Tal y como su nombre implica, se supone que las...
Las tripulaciones del Discovery y de la Estación Espacial Internacional han pasado hoy la mayor parte del día moviendo suministros del transbordador a la estación a mayores de los que ya estaban previstos en previsión de que pueda pasar bastante tiempo antes...
La actividad principal durante la jornada de ayer fue un paseo espacial de casi siete horas llevado a cabo por Soichi Noguchi y Stephen Robinson durante el que inspeccionaron el estado del exterior del Discovery, ensayaron métodos de reparación de las losetas...
Una preciosa imagen del lago de agua congelada encontrado recientemente en Marte y fotografiado por la sonda Mars Express.Los científicos creen que el agua puede estar presente allí [congelada] durante todo el año. [Y] están seguros de que no se trata de...
Por Nacho Palou -
30 JUL 2005
Las tripulaciones del Discovery y de la Estación Espacial Internacional dedicaron el tercer día de la misión básicamente a mover las aproximadamente quince toneladas de suministros que llevaba la lanzadera para la ISS. También aprovecharon el día para volver a comprobar el...
El transbordador espacial Discovery ha atracado en la Estación Espacial Internacional tal y como estaba previsto; justo antes de atracar la comandante Collins puso el transbordador boca arriba para que los tripulantes de la ISS pudieran hacer fotos de su parte inferior...
Después de que durante el despegue del Discovery se desprendieran dos trozos del aislamiento del depósito principal de combustible la NASA ha anunciado que no realizará nuevos lanzamientos hasta que el problema haya sido corregido. Fue precisamente un fragmento de aislante desprendido...
Olalla Cernuda de El Mundo ha tenido la enorme suerte de hacer un vuelo en uno de esos aviones que se dedican a simular condiciones de gravedad cero y lo cuenta en Volando en gravedad cero. Y además le habrán pagado por...
La tripulación del Discovery ha dedicado su primer día en órbita fundamentalmente a repasar el estado del escudo térmico de la nave, utilizando el brazo robot del transbordador con una extensión diseñada especialmente para esta tarea para observar la zona de las...
Actualización 20:30: Hay cierta inquietud por una foto publicada en Spaceflight.now en la que parece apreciarse un objeto desprendiéndose de la nave, aunque La NASA no confirma el posible desprendimiento de un objeto del ´Discovery´. Actualización 16:50: El depósito principal de combustible...
Unas espectaculares nubes mammatus sobre el estado de Nebraska, Spectacular Mammatus CloudsEsta anotación se la dedico a JJ Merelo con el que comparto esta extraña afición por las nubes. JJ tiene algunas fotos de nubes entre propias y enviadas por lectores. Yo...
Por Nacho Palou -
26 JUL 2005
Mientras se acerca el segundo intento de lanzamiento del transbordador espacial Discovery sin tener del todo claro qué provocó el fallo del sensor de nivel bajo de combustible que obligó a la NASA a cancelar el lanzamiento del pasado día 13 la...
Hoy a las 16:00 GMT (dos horas más en España) empieza la cuenta atrás para el segundo intento de lanzamiento del transbordador espacial Discovery, con lo que habrá un montón de actividad en el Kennedy Space Center, ocasión ideal para probar el...
Aunque todavía no saben a ciencia cierta qué causó el fallo de un sensor de nivel bajo de combustible del tanque principal del transbordador espacial Discovery que obligó a cancelar el lanzamiento del pasado día 13, la NASA anunció anoche que lo...
Electric Universe. The Shocking True Story of Electricity. David Bodanis. Crown, 15 de febrero de 2005. ISBN: 1400045509. Inglés. De la misma forma que en E=mc2: A Biography of the World's Most Famous Equation David Bodanis cuenta la historia de la famosa...
La NASA ha anunciado hoy que el lanzamiento del Discovery no se producirá antes del 26 de julio, y esto siendo optimistas porque todavía no han dado con el fallo del sensor que obligó a suspender el lanzamiento el pasado día 13....
Mind Hacks. Tom Stafford, Matt Webb. Editado por O'Reilly. Noviembre 2004. ISBN: 0596007795. Inglés. Web oficial del libro: Mind Hacks. O'Reilly lleva algún tiempo explorando algo más allá de los libros tecnológicos y de referencia que son su especialidad. Se está adentrando...
La NASA ha decidido detener la cuenta atrás para el lanzamiento del Discovery -hasta ahora estaba en pausa- porque a pesar de que hay doce equipos trabajando en el tema desde el miércoles no han conseguido avanzar nada en la tarea de...
La teoría más aceptada sobre la formación de los planetas es que estos tienen su origen en nubes de polvo y gas que orbitan alrededor de una estrella, y esta misma teoría mantiene que debería ser muy difícil que se formaran planetas...
En la NASA andan como locos intentando aislar la causa del fallo del sensor de nivel de combustible que ayer obligó a cancelar el lanzamiento del transbordador espacial Discovery. El sensor en cuestión es uno de los cuatro que miden el nivel...
18:00: Aunque la meteorología se está poniendo cada vez peor y ahora mismo sólo le dan un 40% de posibilidades a que el lanzamiento del Discovery se efectúe hoy, la tripulación acaba de abandonar el edificio de Operaciones y se dirige a...
Esta noche, a menos de 24 horas del lanzamiento en el que la NASA se juega su credibilidad en su regreso al espacio con el «Discovery», una cubierta de plástico cuya misión es mantener limpias y protegidas las ventanas del transbordador se...
La cuenta atrás para el despegue de la misión STS-114 de la NASA, previsto para mañana a las 19:51 GMT (2 horas más en España), sigue adelante y seguro que será uno de los lanzamientos más seguidos de los últimos años, ya...
Pi in the Sky. Counting, Thinking and Being. John D. Barrow. Back Bay Books. 1992. ISBN 0316082597. Inglés. Tenía este libro en «la pila» y lo terminé hace poco. De hecho sólo ojeé rápidamente los últimos capítulos. Me costó cierto esfuerzo...
La ministra de Sanidad ha dicho hoy que su ministerio quiere que el consejo de ministros apruebe a finales de este año o como muy tarde a principios de 2006 la ley que permita la clonación terapéutica en España: Sanidad quiere Consejo...
A las seis de la tarde de ayer, hora de la costa este de los Estados Unidos, 2 de la mañana en España, comenzó la cuenta atrás para el lanzamiento del transbordador espacial Discovery en la misión STS-114. Un detalle curioso de...
Con un día de antelación sobre lo previsto para evitar problemas con los fuertes vientos y lluvias asociadas con el huracán Dennis la tripulación del Discovery voló ayer al Centro Espacial Kennedy, dónde hoy comienza la cuenta atrás del lanzamiento. En palabras...
Phyneas nos envía el enlace a Planetarium, un planetario bastante chulo hecho en Flash, de modo que se puede utilizar directamente desde el navegador. Es bastante preciso y funciona en tiempo real en función de la fecha y hora del ordenador o...
Por Nacho Palou -
9 JUL 2005
Ahora que la NASA tiene más o menos hechos los deberes de cara al lanzamiento del transbordador espacial Discovery el próximo miércoles 13 de julio, parece ser la naturaleza la que puede poner trabas al lanzamiento, ya que el huracán Dennis se...
Tras la alegría que supuso acertar con el impactador de la sonda Deep Impact en el cometa Tempel 1, uno de los objetivos fundamentales de la misión puede quedar sin cumplir, ya que debido a la gran cantidad de material que expulsó...
¿Podrías calcular mentalmente si es correcto que 9002 = 899 × 901 + 1? Un lector sin nombre nos envió esto: Seguro que no he inventado la pólvora ni mucho menos, pero chorreando con la hoja de cálculo descubrí una cosa: n2...
La humanidad sigue manipulando el «tiempo» a su antojo, qué bueno: Éste año tendrá un segundo más - El 2005 tendrá un segundo más para compensar el hecho que la tierra está girando más lento de lo normal. Esta es la primera...
Si en la NASA están comprensiblemente encantados con el éxito obtenido por la misión Deep Impact, en la ESA tienen en marcha la misión Rosetta, que tampoco es moco de pavo, pues su objetivo es depositar suavemente un módulo con instrumentación en...
El Ateneo Madrid XXI ha organizado una tertulia con el profesor Antonio Bru y el equipo médico del Ramón y Cajal, lo que puede ser una oportunidad para comprobar en vivo y en directo qué hay detrás de esta polémica: Entrada libre...
Esta madrugada a las 5:52 GMT el proyectil disparado por la sonda Deep Impact contra el cometa Tempel 1 alcanzará su objetivo mientras esta observa el proceso a una distancia prudencial, así que con un poco de suerte en unas horas sabremos...
La revista Science celebra este mes su 125 aniversario, y para ello, entre otras cosas, ha hecho una selección de 125 cuestiones en las que los científicos están trabajando, selección realizada con el criterio de que sean problemas para los que se...
El pasado 1 de julio se cumplió un año de la entrada en órbita alrededor de Saturno de la misión conjunta de la NASA y de la ESA Cassini-Huygens, que en este año no ha parado de ofrecer resultados espectaculares y momentos...
83,431 Recited Digits of Pi - Akira Haraguchi, de 59 años, Japón, batió el récord del mundo al recitar 83.431 dígitos del número Pi de memoria, para lo que necesitó más de trece horas. Superó por prácticamente el doble el anterior récord...
Ayer leí una reseña en Slashdot, Our Brains Don't Work Like Computers, sobre un trabajo publicado en Proceedings of the National Academy of Sciences por un psicolingüista de la Universidad de Cornell: New Cornell study suggests that mental processing is continuous, not...
Después de cuatro años debatiendo su ubicación los socios del proyecto ITER han decidido que Francia albergará el reactor que simulará la fusión nuclear del Sol. Además, para tener contentos a todos, la sede administrativa europea del proyecto estará en Barcelona, lo...
Ya hemos comentado en varias ocasiones que este es el Año Mundial de la Física, que conmemora el centenario del año más brillante de la carrera de Albert Einstein; hoy en concreto se cumplen cien años de la publicación de «Zur Elektrodynamik...
La NASA acaba de anunciar que salvo problemas imprevistos el lanzamiento del transbordador Discovery se producirá el próximo 13 de julio: Nasa unveils shuttle launch date. La NASA suspende tres; hace un par de días aún no estaba claro si el lanzamiento...
La Comisión Stafford-Covey, cuyo objetivo es supervisar de manera independiente si la NASA ha cumplido con las recomendaciones de la Columbia Accident Investigation Board, acaba de anunciar que la agencia todavía no ha cumplido con tres de las quince recomendaciones de la...
Murray Gell-Mann estuvo ayer en Vigo para impartir una conferencia sobre el pensamiento creativo de Albert Einstein en su juventud, y aunque dijo que estaba cansado y no tenía ganas de hablar con la prensa, finalmente los periodistas consiguieron que se decidiera...
En estos días Mercurio, Venus y Saturno están en conjuncion, es decir, que pueden verse «juntos» en una misma región del cielo. El momento será durante las primeras horas de la noche, juntos después de que el Sol haya desaparecido por el...
Por Nacho Palou -
27 JUN 2005
Al final el equipo del proyecto ha tenido que rendirse a la evidencia y reconocer que el segundo intento de lanzamiento de la vela solar Cosmos 1 ha fracasado, de nuevo a causa de un fallo del cohete lanzador Volna. Aún así,...
El telescopio espacial Hubble sigue sorprendiéndonos con las imágenes que capta; en este caso se trata de una nube de partículas de polvo que orbitan Fomalhaut, una estrella que está a 25 años luz del Sol, y que se parece sospechosamente al...
Si esta noche sales a mirar el cielo, la luna parecerá gigante, porque está muy baja en el horizonte; de hecho estará mas baja de lo que lo ha estado en los últimos dieciocho años. Lo curioso es que aunque está claro...
Las noticias sobre el lanzamiento de Cosmos 1 no parecen demasiado esperanzadoras, ya que no se reciben señales de la nave desde poco después del despegue. Hay información actualizada cada pocos minutos en el blog de la misión. Actualización 22 de junio...
Un equipo de científicos británicos acaba de anunciar que han desarrollado un proceso que les permite obtener espermatozoides y óvulos a partir de células madre embrionarias, lo que podría suponer una solución para personas con problemas de esterilidad: Crean óvulos y espermatozoides...
Con más de un año de retraso por los temores de los técnicos de que pudieran golpear la nave y afectarla, por fin están desplegados los dos mástiles del MARSIS, el instrumento de la sonda Mars Express diseñado para buscar agua enterrada...
Parece que esta vez sí se van a cumplir las previsiones de The Planetary Society y Cosmos Studios y que por fin mañana a las 19:46:09 UTC tendrá lugar el lanzamiento de Cosmos 1, que aspira a convertirse en la primera nave...
Por lo visto un grupo de científicos austríacos y estadounidenses han llegado a la conclusión de que sí se podría viajar hacia atrás en el tiempo y que las propias leyes que rigen la mecánica cuántica harían imposible que se dieran paradojas...
Maria Van der Hoeven, a la sazón Ministra de Educación de Holanda, dice que es una buena idea[...] que los jóvenes conozcan los distintos puntos de vista. Eso está claro en nuestros estándares educativos. Es parte de su desarrollo para la adultez...
Un equipo de científicos australianos acaba de anunciar que han encontrado la forma de producir células sanguíneas a partir de células madre, y que son capaces de hacer que éstas se conviertan en glóbulos blancos o glóbulos rojos a voluntad: Scientists make...
La Astronomy Picture of the Day, una cita obligada para los aficionados a la astronomía, cumple hoy diez años. (Vía El Lobo Rayado.) APOD Grabber: astronomía en tu escritorio, una utilidad para colocar automáticamente la APOD en el escritorio de tu Mac...
Nacho Escolar ha entrevistado para Telecinco a Antonio Bru, quien saltó a los medios de comunicación al anunciar una cura para ciertos tipos de cáncer el pasado 31 de mayo: Antonio Bru: "La Complutense apoyará mi investigación contra el cáncer" Curiosamente, hoy...
Aunque aquí la palabra clave es «similar», un grupo de científicos que ya llevan descubiertos algo más de 100 exoplanetas acaban de anunciar el descubrimiento de un planeta extrasolar rocoso de unas dos veces el diámetro de la Tierra y unas 7,5...
En mi trabajo del MundoReal™ estamos organizando el III Congreso Sobre la Comunicación Social de la Ciencia, que se celebrará en La Coruña, España, del 9 al 11 de noviembre de este año bajo el lema Sin Ciencia no hay Cultura, y...
Reuters cuenta en Panel sees no roadblocks to space shuttle launch que si bien a pesar de que aún no hace mucho había dudas de que el panel de expertos dirigido por los ex-astronautas Frank Stafford y Richard Covey que supervisa la...
Tras quedar atascado en una duna el pasado 26 de abril y tras varias semanas de delicadas maniobras este fin de semana el equipo que dirige a Opportunity ha conseguido liberarlo y por lo visto se encuentra ya en terreno firme:Mars rover...
Alejandra Rodríguez e Isabel Perancho publican El extraño caso del profesor Brú en el suplemento Salud de El Mundo:Su equipo lo integran familiares y amigos. Investigadores que han colaborado con él reniegan de sus experimentos con enfermos. La comunidad médica le acusa...
El Cosmódromo de Baikonur celebra hoy su 50 cumpleaños. Es el complejo de lanzamientos espaciales más antiguo del mundo, y desde allí fueron lanzadas todas las misiones que al principio de la carrera espacial pusieron a la extinta Unión Soviética muy por...
Acabo de llegar de una pequeña celebración en la que conmemoramos que la Casa de las Ciencias, germen y en la actualidad parte de los Museos Científicos Coruñeses, ha cumplido hoy veinte años. A nadie le extraña ya que un ayuntamiento decida...
La mayoría de la masa en un lanzamiento espacial consiste en los cohetes que ponen la carga útil en órbita y en el combustible que utilizan según va subiendo, cohetes que van siendo desechados durante el vuelo cuando quedan vacíos y se...
The Universe Map es un mapa del National Geographic Map Store que sitúa nuestro planeta en relación con el resto del universo del universo conocido utilizando cinco saltos de escala. Se puede ver el mapa en detalle utilizando el navegador que sale...
¿Te habrías imaginado alguna vez que si un paciente sufre una reacción adversa a un medicamento y se lo dice a su médico es más probable que le cambien el tratamiento que si no dice nada? ¿O que es peligroso poner los...
En la Universidad de Iowa han diseñado unos cuantos instrumentos que ha ido al espacio en distintas sondas espaciales, instrumentos capaces de detectar ondas radioeléctricas que luego se pueden convertir en sonido y que se pueden escuchar en Space Audio, incluido el...
En especial para los que recordamos la época de las BBS y nos vamos haciendo «viejos», 11 steps to a better brain, un artículo de New Scientist en el que cubren once formas de conservar e incluso mejorar el funcionamiento de tu...
Art of Science Competition recoge una bonita colección de imágenes surgidas de la investigación y la ciencia.Mi favorita es la imagen de la derecha que muestra unas hormigas marcadas con pintura de color para estudiar su comportamiento....
Por Nacho Palou -
26 MAY 2005
Un póster de Pi con 350.000+ dígitos, disponible en PDF por si te lo quieres imprimir gigante para la pared y también en código fuente: pi por si quieres calcularlos tu mismo. Existe otro parecido en forma de Camiseta Pi en ThinkGeek...
Si tienes curiosidad (¡y estómago!) con Visible Human Browsers puedes recorrer casi por completo un cuerpo humano diseccionado por capas en vista transversal, lateral y superior, seleccionando la zona casi al milímetro con la líneas rojas o las flechas del «navegador humano»...
Por Nacho Palou -
26 MAY 2005
Aunque ya en 2003 algunos científicos defendían la idea de que la Voyager 1 había salido del Sistema Solar, otros no lo tenían tan claro porque en realidad no sabemos muy bien dónde acaba éste, pero parece que ahora incluso los más...
Pues por lo visto porque funciona y nos da una ventaja sobre los que son menos hábiles haciéndolo; incluso cuando nos engañamos a nosotros mismos es a modo de ensayo para poder mentir y manipular mejor a los demás, al menos según...
The Planetary Society ha anunciado una vez más, y ya no es la primera ni la segunda, una fecha para el lanzamiento de Cosmos 1, su nave espacial impulsada por una vela solar, como la del Conde Dooku en El ataque de...
Los astrónomos tienen un nuevo método para detectar planetas extrasolares mediante el uso de lentes gravitatorias y el descubrimiento de un nuevo exoplaneta y la estrella que orbita a mucha más distancia que los anteriores para demostrar la validez del susodicho método....
Después de la alegría que dio Mike Griffin, el recién estrenado director de la NASA, a la comunidad científica internacional al anunciar que había dado órdenes de preparar la misión de mantenimiento al Hubble que su predecesor había cancelado para estupor de...
Los creacionistas no sólo están intentando poner patas arriba el sistema educativo en Kansas disfrazando el tema mediante el Diseño Inteligente, sino que además se están gastando 25 millones de dólares en un museo dedicado a difundir sus ideas en Cincinnati: Ministry...
Llevo meses intentando investigar un poco cuánto de ciencia hay en el psicoanálisis, pero no he sido muy bueno encontrando nada definitivo al respecto. No sé si en realidad lo hay, si es una pregunta estúpida o si es que nadie se...
Así es de grande el universo: 156.000 millones de años luz de diámetro, que equivalen a 1,4 trillones de kilómetros (un 1 seguido de 18 ceros) si mis cálculos no están mal. Y tiene 13.700 millones de años de antiguedad. Más información...
Como en muchas otras series o películas, en Futurama hay más de lo que parece a simple vista, como por ejemplo toda una serie de curiosidades matemáticas que puedes encontrar en la Indoblable Página de Bender Bending Rodríguez. Por cierto, en la...
El mismo equipo de científicos surcoreanos que hace poco más de un año conseguía clonar por primera vez embriones humanos y a partir de ellos obtener células madre acaba de anunciar que ahora son capaces de conseguir células madre embrionarias «a medida»,...
Esto de la escapada a Londres me ha dejado con varias noticias relacionadas con la investigación espacial acumuladas, así que aquí van en plan rápido: Después de semanas atascado en una duna, Opportunity ha conseguido retroceder unos centímetros desde el pasado viernes,...
El Hubble es sin duda más conocido, pero desde luego el telescopio espacial Spitzer tampoco se queda corto con imágenes como First Peek at Spitzer's Legacy: Mysterious Whirlpool Galaxy. (Vía El Lobo Rayado.)...
La CNN cuenta en Kansas looks at redefining science como por lo visto en Kansas no tienen suficiente con haber puesto de nuevo en tela de juicio la teoría de la evolución frente al diseño inteligente sino que además los defensores del...
Si te gusta la astronomía pero la climatología no te es propicia, o si simplemente prefieres ver las estrellas sin abandonar el calor del hogar, por no hablar del dinero que te puede costar un buen telescopio, SLOOH te permite comprar tiempo...
P: Si pudieras ser un animal, ¿qué animal serías?R: Ya eres un animal.(Douglas Coupland, Microsiervos) El Gen Egoísta: Las bases biológicas de nuestra conducta. Richard Dawkins. Salvat Ciencia. 1976, 1989. ISBN: 8434501783. Español. Título Original (inglés): The Selfish Gene. 408 páginas....
Ayer estaba terminado de releer El Gen Egoista de Richard Dawkins, en una edición reciente de Salvat (revisada). Haré una reseña completa al terminarlo, para la colección. Pero me llamó mucho la atención una frase impactante, que tiene que ver con un...
Entiendo que un redactor de cualquier medio, y probablemente menos si se trata de una agencia, no puede estar especializado en todo aquello sobre lo que le toca escribir, pero si simplemente se tomaran la molestia en comprobar las cosas -y supongo...
Dos de las sondas espaciales que están activas en Marte están teniendo problemas estos días. Por una parte, el rover Opportunity lleva desde el 26 de abril atascado sobre una duna de arena, aunque en la NASA han estado haciendo pruebas con...
Un año más la Asociación de Amigos de la Casa de las Ciencias y los Museos Científicos Coruñeses celebran el Día de la Ciencia en la Calle, que mañana alcanza su X edición, en el Parque de Santa Margarita en La Coruña....
Hoy comenzaba en Kansas el "juicio" acerca de lo que se debe enseñar a los niños de ese estado acerca del origen de la vida; en este caso se trata de los que defienden el Diseño Inteligente frente a la evolución:El estado...
Dentro de la preparación de cada misión de los transbordadores espaciales se incluye una simulación del lanzamiento que se aborta cuando faltan cinco segundos para que este se produzca, simulación que el Discovery y su tripulación acaban de realizar con éxito relativo,...
Las películas y series de ciencia ficción nos tienen tan acostumbrados a que las naves espaciales tengan unos ordenadores tan potentes que resulta cuando menos soprendente descubrir que la mayoría de los cohetes tienen menos potencia de cálculo que cualquier consola portátil...
Aprovechando la celebración del centenario de la publicación de la famosa fórmula E=mc2 Spiked ha preguntado a 250 científicos, divulgadores científicos y educadores qué hecho científico le enseñarían al mundo si tuvieran que escoger sólo uno y por qué escogerían ese y...
Aunque no hay nada decidido y todo depende de que la flota de transbordadores espaciales vuelva a entrar en servicio sin problemas, Mike Griffin, el nuevo director de la NASA, informó al congreso el jueves pasado de que ha dado órdenes a...
Finalmente parece que la NASA se va a ver obligada a retrasar la vuelta al servicio de los transbordadores espaciales al menos hasta julio:La NASA aplaza el vuelo del trasbordador Discovery.NASA to Delay U.S. Space Shuttle Launch. Shuttle launch delayed until July.Parece...

The Eudaemonic Pie: The bizarre true story of how a band of physicists and computer wizards took on Las Vegas. Thomas A.Bass. Houghton Mifflin. 1985. ISBN: 0395353351. Inglés. 330 páginas. Web sobre el libro, por Thomas A. Bass Este libro también...
Hoy se cumplen 15 años de la puesta en órbita del Telescopio Espacial Hubble, que en estos años ha tomado más de 700.000 imágenes, todas ellas de un gran valor científico, y muchas además absolutamente preciosas desde un punto de vista estético....
Tras el accidente del Columbia hace ahora algo más de dos años la comisión que se encargó de investigar sus causas redactó una lista de quince recomendaciones que la NASA debía cumplir antes de que la flota de lanzaderas pudiera volver al...
The Book of Prime Number Records. Paulo Ribenboim. Springer-Verlag. 1988. ISBN: 0387965734. (Inglés). 478 páginas. Este curioso libro presenta, como su título indica, los récords relativos a los números primos. Pero contiene mucho más: todas las preguntas frecuentes, respuestas y demostraciones de...
Hoy se ha sabido que la NASA está considerando retrasar la vuelta al servicio de los transbordadores espaciales al menos una semana porque los preparativos previos al lanzamiento del Discovery van con algo de retraso sobre lo previsto: Shuttle launch delay expected....
Hoy se cumplen 50 años del fallecimiento de Albert Einstein, uno de los mas brillantes científicos de todos los tiempos, cuya Teoría de la Relatividad puso en tela de juicio muchas de nuestras ideas sobre el mundo. Aparte de la bibliografía sobre...
Al mismo tiempo que la NASA prepara la lanzadera Discovery para volver a volar a mediados de mayo, está preparando a su compañera Atlantis por si es necesario montar una misión de rescate: The Mission NASA Hopes Won't Happen. Pero de tener...
Javier Armentia publica hoy Einstein en los libros, una bibliografía en español sobre el conocido físico, y me he permitido copiarla con enlaces a Casa del Libro; para las descripciones lee el artículo de Javier:Sobre la teoría de la relatividad especial y...
Según cuenta en New Scientist Sony patent takes first step towards real-life Matrix (también lo cuentan en Registran una patente para recrear mundos virtuales dentro del cerebro) una reciente patente de Sony se refiere a algo parecido a los chismes que utilizan...
Por Nacho Palou -
13 ABR 2005
Parece que no pasa una semana sin que la NASA reconsidere qué va a hacer con el Telescopio Espacial Hubble. Si hace poco anunciaba que la decisión definitiva era hacerlo caer controladamente sobre el océano, el que probablemente se convierta en breve...
What Do You Care What Other People Think?: Further Adventures of a Curious Character. Richard P. Feynman y Ralph Leighton. W. W. Norton & Company, enero de 2001. Inglés. [ver similares] [en español] Este es el segundo volumen de las memorias del...
A pesar del fiasco de la Beagle 2, es muy probable que la Agencia Espacial Europea envíe un rover a Marte con el objetivo de realizar análisis detallados del terreno y la biología del planeta, con la idea de complementar y no...
Con el futuro del Hubble más que en entredicho es interesante ver que los astrónomos no se arredran y están trabajando en una nueva generación de telescopios terrestres de gran tamaño y con ópticas adaptativas que podrían dejar al Hubble en mantillas:...
Blink. Malcolm Gladwell. Little Brown and Company. 11 de enero de 2005. Inglés. En español: Inteligencia Intuitiva. ¿Por qué las primeras impresiones son tan fuertes? ¿Por qué en muchos casos nos permiten llegar a conclusiones acertadas cuando en apariencia no tenemos información...
Dado que el ciclo de este año de las Reith Lectures se llama Triumph of Tech, me parece absolutamente adecuado que las estén distribuyendo vía podcasting. iPodder 2.0 (el limón)....
No todo van a ser malas noticias por parte de la NASA, que ayer mismo anunciaba que va a prolongar por tercera vez la misión de los rovers marcianos, en esta ocasión por un año y medio más: Durable Mars Rovers Sent...
Más contenido de calidad que te puedes bajar de Internet: Cyberf recomienda las Reith Lectures, unos seminarios que yo también me encontré hace tiempo y que son de lo más interesantes (nota: están en inglés): (...) Estas conferencias son excelentes. Las de...
No sólo van a por el Hubble. Confirmando rumores previos, la NASA dice que se está planteando cerrar el programa Voyager, que hoy por hoy sólo cuesta algo más de cuatro millones de dólares al año... lo que es algo así como...
Tras una evaluación intensiva durante la semana pasada de las opciones que hay respecto al Hubble, los responsables de la NASA han decidido que el único curso posible de acción es enviar un cohete que se acople al telescopio espacial para llevarlo...
La NASA acaba de confirmar que la sonda Deep Impact, que a principios del próximo mes de julio se aproximará a unos 500 kilómetros del cometa Tempel 1 para tomar imégenes de éste y lanzar un módulo que impactará sobre su superficie,...
El podcasting va ganando cada vez más adeptos, y hasta la NASA se apunta: A new "podcast" puts audio recordings of NASA science news articles into your pocket MP3 player. Por ahora sólo en inglés, aunque planean una versión en español en...
Los tiempos avanzan que es una barbaridad: Dos astronautas lanzan a mano un satélite desde la Estación Internacional....
Otra vez el Sr. Pez, esta vez con una interesante reflexión acerca de la ciencia ficción en Entre La Ciencia Y La Ficción....
Un comunicado de prensa del Fermilab anuncia la publicación de un estudio que da una explicación alternativa a la aceleración de la expansión del universo que no necesita de la existencia de la energía oscura para explicar ésta: Italian, US cosmologists present...
Un reciente estudio del que da cuenta Nature podría estar a punto de poner patas arriba una de las premisas básicas de nuestro conocimiento sobre la genética, pues aunque se supone que cada ser vivo recibe su información genética de sus progenitores...
Todos los números del 0 al 9.999 que tienen algo de especial (por esotérico que sea): What's Special About This Number? (Vía Grow-a-Brain.)...
New Scientist acaba de publicar un artículo sobre trece resultados observados experimentalmente que todavía no somos capaces de explicar, aunque como dice Vendell quizás podrían haberse saltado el último, ya que parece claro que aquella fusión fría de Pons y Fleischmann fue...
No, en serio: How to destroy the Earth.For the purposes of what I hope to be a technically and scientifically accurate document, I will define our goal thus: by any means necessary, to render the Earth into a form in which it...
Que el creacionismo gana terreno en los Estados Unidos ya no es novedad, pero la verdad es que me parece gravísimo que en algunos estados los creacionistas consigan que algunos centros de ciencia decidan no mostrar aquellos documentales IMAX en los que...
Olvídate de lo del Windsor: la gran conspiración del siglo es que nos están ocultando que Japeto, una de las lunas de de Saturno, es en realidad una nave espacial. Richard C. Hoagland defiende apasionadamente esta idea en A Moon With a...
Aunque en los últimos años los astrónomos creen haber descubierto un buen número de planetas extrasolares (o exoplanetas), hasta el punto de que ya casi no es noticia que aparezca uno nuevo, Angel comentaba hace unos días que el Observatorio Europeo del...
Tras el espectacular éxito de la misión Cassini-Huygens a Saturno y Titan, la Agencia Espacial Europea y la NASA están empezando a discutir una misión similar a Europa, la luna de Júpiter, aunque no sería lanzada antes de 2016: Europe tells US:...
Si ayer escribía acerca de Powers of Ten, la película creada para ayudar a comprender el tamaño relativo de las cosas, hoy leo que mañana se inaugura SpacedOut, una maqueta del sistema solar a escala 1:15.000.000 instalada en el Reino Unido que...
La American Astronomical Society ha hecho pública hoy una nota de prensa en la que defiende la importancia del Hubble y pide a la NASA que retome los planes iniciales de mantenimiento del telescopio espacial: AAS Calls Servicing Hubble Important for Astronomy,...
Powers of Ten es una película producida por Charles y Ray Eames en 1977 con el objeto de explorar el tamaño relativo de las cosas desde lo microscópico hasta lo más grande. Partiendo de un plano de un metro de ancho...
Nuestro cerebro es una cosa increíble, y hay numerosos casos de personas con habilidades que se salen de lo normal por un funcionamiento peculiar de su cerebro, como el caso de Elizabeth Sulston, una músico que toca la flauta y que sufre...
Hace un par de días mi hijo, que está en primero de Primaria, tuvo que estudiarse una hoja de uno de los libros que usan en clase porque al día siguiente se lo iban a preguntar. El tema era parte de «Conocimiento...
Un corto pero interesante artículo del Sr. Pez acerca de la memoria: La Memoria A Corto Plazo... Y un libro para añadir a «the pila». Por cierto, si estás en o pasas por La Coruña y te interesa el tema, date una...
Cuando me enseñaron lo que era un metro me contaron aquello de que era la longitud de una barra de platino iridiado guardada en la Oficina Internacional de Pesos y Medidas en París, que a su vez coincidía con la diezmillonésima parte...
Los rovers marcianos de la NASA llevan más de un año sorprendiendo a propios y extraños, tanto con lo que están durando en servicio como con los extraordinarios resultados científicos que están proporcionando; esta es una selección de las diez mejores imágenes...
The Soviet Exploration of Venus es una completísima web acerca de las sondas espaciales enviadas por la antigua URSS a Venus mantenida por Don P. Mitchell. Si te interesa el tema, merece la pena dedicarle un buen rato, pues allí encontrarás información...
La NASA ha anunciado que ha fijado el próximo 15 de mayo como fecha de lanzamiento de la lanzadera Discovery en la misión STS-114, con el objetivo principal de probar las nuevas medidas de seguridad adoptadas tras el desastre de la Columbia...
Impresionante, aunque lo de la Hamburgesa de Gómez suene a coña marinera: Hubble Heritage Image Gallery....
Hay que tomarse esta noticia con mucha precaución, pero Carol Stoker y Larry Lemke del Ames Research Center de la NASA dicen que han encontrado indicios de que podría haber vida en Marte en la actualidad: Report: Evidence for Mars life found....
Hoy sabemos que la misión del Apollo 11 fue un éxito y que los tres astronautas que lo tripulaban volvieron sanos y salvos, pero en el momento de lanzar la misión algunos no les daban más allá de un 50% de posibilidades...
The Wellcome Trust y la Biblioteca Nacional de Medicina de los Estados Unidos están trabajando en digitalizar los aproximadamente 11.000 ítems que forman parte del archivo personal del recientemente fallecido Francis Crick para que todo el mundo pueda tener acceso a ellos:...
Sabemos muy poco acerca del funcionamiento de nuestro cerebro y de nuestra mente, así que el caso de Daniel Tammet, un autista sabio que es capaz de explicar cómo "ve" los números y sus procesos mentales resulta realmente interesante por las pistas...
Tras el espectacular descenso de la sonda Huygens en Titán el mes pasado el único pero que se le podía poner a la misión fue la pérdida de datos sobre el viento en la atmósfera de la luna que se produjo por...
Astrónomos estadounidenses del Harvard-Smithsonian Center for Astrophysics han descubierto que la estrella SDSS J090745.0+24507, situada a unos 180.000 años luz de la Tierra, se escapa de la Vía Láctea a una velocidad de unos 2.400 2,4 millones de kilómetros por hora: El...
Como estaba previsto, tenemos un nuevo capítulo en el culebrón del Hubble: Nasa plans to bring down Hubble. Ayer, al presentar los presupuestos de la NASA de este año el interventor de la NASA dijo que sólo piden 93 millones de dólares...
Los ascensores son de mediados del siglo XIX, aunque parezcan más modernos. En Elevator History se puede aprender algo en cinco minutos sobre estos curiosos e indispensables aparatos de la vida moderna. Elisha Graves Otis (la «Otis» de los ascensores modernos, curiosamente...
Con resultados como este y quieren retirar al Hubble: Light Continues to Echo Three Years After Stellar Outburst....
Hace algunos días que tenía guardado el enlace a una noticia aparecida en la BBC sobre un estudio que apunta nuevas pistas sobre el posible origen de nuestro sistema solar, pero veo que el Sr. Pez se me ha adelantado, así que...
Ayer se cumplieron 19 años de la explosión del Challenger (misión STS 51-L de la NASA), una de las primeras lanzaderas espaciales. Command Post se pregunta ¿Hace 19 años, ¿dónde estabas tú? Controller: We will report, uh, more as we have information...
La PBS, productora de El Universo Elegante, una muy recomendable serie acerca de la teoría de cuerdas [Wikipedia: en español, en inglés], acaba de estrenar scienceNOW, un programa que se emitirá cada dos meses y que pretende seguir de cerca los desarrollos...
El próximo 3 de octubre se podrá ver un eclipse anular de sol desde buena parte de España y desde el Planetario de Pamplona ya están coordinando un proyecto de divulgación científica sobre el evento, igual que sucedió con el tránsito de...
El asunto de la hipotética reparación del Hubble [más info en la ESA y en la Wikipedia] parece el cuento de nunca acabar. Si hace unos días la empresa MacDonald, Dettwiler and Associates anunciaba que se había hecho con el contrato para...
Disponible en archive.org como Flight of Apollo 11 (The Eagle Has Landed) (1969) en formato MPEG4 y MPEG1 (VideoCD), se trata de un documental de treinta minutos de la NASA creado poco después de que el Apollo XI llegara a la Luna...
Una semana después de que la sonda Huygens alcanzara la superficie de Titán, los científicos que están estudiando los datos enviados por esta han dado una rueda de prensa esta mañana para ir presentando los resultados que van obteniendo, aunque piensan que...
rvr recuerda unos cuantos relatos, libros y películas en los que está presente Titán en Regreso a Titán, e incluye una referencia a entrada de José Carlos Canalda sobre esta luna el el glosario del Sitio de Ciencia-Ficción, que a su vez...
On Intelligence. Jeff Hawkins con Sandra Blakeslee. Times Books. Octubre 2004. Inglés. 272 páginas. Web oficial: OnIntelligence.org. Hace un mes que comenté por aquí la existencia de este libro (ver Jeff Hawkins sobre el cerebro humano y el interesante hilo de comentarios...
Aunque hace tiempo que circulaban rumores al respecto Jeff Bezos (sí, el Jeff Bezos de Amazon) ha dado por fin algunos detalles acerca de sus planes para llegar al espacio: Amazon founder unveils space center plans. Igual que han hecho Paul Allen...
El genoma fluido. Josep M. Casacuberta. La Voz de Galicia 2004. ISBN 84-9757-161-4. Este libro, ganador del premio a textos inéditos en la edición de 2003 de los Prismas de la Casa de las Ciencias a la Divulgación, explica de forma clara...
La Agencia Espacial Europea confirma que se ha detectado la portadora de la sonda Huygens mediante el Robert C. Byrd Green Bank Telescope: Radio astronomers confirm Huygens entry in the atmosphere of Titan. Esto quiere decir que la cubierta trasera de Huygens...
Estos últimos días han traído unas cuantas noticias interesantes en cuanto a la investigación espacial y a nuestro conocimiento del universo: Un equipo internacional de astrónomos ha identificado las tres estrellas más grandes conocidas: Three largest stars identified. Se trata de gigantes...
Aunque la NASA anunció hace algo menos de un año que cancelaba las misiones de mantenimiento previstas para el telescopio espacial Hubble, las protestas, opiniones contrarias a esta decisión, e iniciativas para salvar el Hubble alcanzaron tal magnitud que parecen haber hecho...
Aunque por aquí acabaremos hartos de lo del cuarto centenario de la publicación de El Quijote, resulta que 2005 ha sido declarado por la UNESCO Año Internacional de la Física. La UNESCO escogió este año porque marca el primer centenario desde que...
Yabu va a hacer un divertido experimento cuántico relacionado con la Loto, lo cuenta en El Gordo de Schrödinger. Tomamos un boleto de El Gordo de la Primitiva, rellenado al azar. Lo introducimos en una caja vacía en mi casa, y la...
Con todo el follón de la migración a MT se me pasó, pero ayer Spirit cumplió su primer año en Marte: NASA Rovers' Adventures on Mars Continue Spirit marks one year on Mars Martian explorer marks first year Durante este año, junto...
En el New York Times han publicado God (or Not), Physics and, of Course, Love: Scientists Take a Leap donde catorce científicos hablan sobre catorce cuestiones que creen que son ciertas pero sin que puedan demostrar que lo son: ¿Qué cree usted...
Hace algún tiempo descubrimos The Elegant Universe, un libro de Brian Greene que intenta explicar la teoría de cuerdas, y la serie de tres documentales que la televisión pública americana realizó basada en el, una serie que nos pareció muy buena. Por...
Igual que Science publicó su lista de las diez noticias más importantes de ciencia en 2004, Scientific American ha creado su lista de las doce historias científicas más importantes del año:Mars ExplorationResearchers Unveil New Form of MatterCloned Human Embryos Yield Stem CellsChemists...
El verano pasado tuve la oportunidad de fotografiar un bonito arco iris cerca de Avilés, en Asturias. Lo más curioso es que resultó ser un arco iris doble. (La calidad de la foto por desgracia no es gran cosa porque está hecha...
Burt Rutan empieza a desvelar algunos detalles del que será el sucesor de SpaceShipOne en este artículo de la BBC: Virgin soars towards new frontier. La nueva nave, diseñada según las especificaciones de Virgin Galactic, no sólo será mayor que su predecesora,...
En Seismic Monitor del consorcio IRIS se puede ver de forma muy gráfica cómo de enorme ha sido el reciente terremoto de 8,9 en la escala de Richter en la isla de Sumatra, que está entre los cinco más grandes del último...
Esta noche la sonda Huygens se separará de Cassini, a la que ha permanecido unida durante los últimos siete años mientras atravesaban el sistema solar con destino a Saturno, para comenzar su aproximación y descenso a Titán: Europa y EE.UU. inician en...
Además de las diversas pruebas que se han ido obteniendo este año de que en el pasado Marte tuvo agua líquida, lo cual ya se sospechaba, hoy se ha sabido que Marte guarda otras sorpresas. Científicos de la ESA han publicado un...
Science, la revista editada por la Asociación Americana por el Avance de la Ciencia, incluye en su número de diciembre una lista de las noticias de ciencia más importantes del año, lista encabezada por el descubrimiento de que"Alguna vez Marte fue cálido,...
Aunque a estas alturas ya quedan muy pocas dudas de que en el pasado existió agua en estado líquido en Marte, Spirit acaba de hallar una prueba más en la forma de un mineral llamado goethita: Spirit claims Mars water prize. Por...
Sí, este Jeff Hawkins es el mismo que creó Palm Computing. Su interés por los estudios sobre el funcionamiento del cerebro humano venían ya relatados en el libro Piloting Palm, y son sumamente interesantes: segun Hawkins, el cerebro funciona a base de...
GoldenPalace.com Space Program Powered by the da Vinci Project, que al menos según pregonaba el líder del proyecto Brian Feeney estaba a la cabeza de la carrera por hacerse con el Ansari X Prize, ha anunciado que tendrá que postponer su lanzamiento,...
Los medios de comunicación han ido recogiendo la noticia este fin de semana, por ejemplo: Las nuevas caras de Bélmez fueron falsificadas por unos 'cazafantasmas' en complicidad con el ayuntamiento (El Mundo).Varios colaboradores rompen con Pedro Amorós y avalan la tesis de...
Una de las cuestiones más importantes sin resolver en nuestro conocimiento de cómo evolucionó la vida en nuestro planeta es la del origen de las células con núcleo (eucariotas), que son aquellas de las que estamos formados nosotros, el resto de los...
El equipo detrás del diseño de Cosmos 1, que aspira a convertirse en la primera nave espacial impulsada por velas solares, ha anunciado recientemente que tienen como fecha prevista de lanzamiento el próximo 1 de marzo: Cosmos 1 Launchdate Set. Si todo...
La NASA ha conseguido batir hoy todos los récords de velocidad en lo que a vehículos impulsados por motores atmosféricos se refiere con el último vuelo del X-43A, que lanzado desde un B-52 alcanzó una velocidad de Mach 9,8 (unos 11.000 kilómetros...
Parece ser que la American Vacuum Society ha decidido que hoy es el centenario de la invención por parte de John Ambrose Fleming [biografía más extensa, en inglés] de la válvula termoinónica o de vacío, el primer dispositivo electrónico con una utilidad...
Tras más de un año de viaje la sonda SMART-1, la primera misión espacial europea con destino a la Luna, alcanzará hoy la primera de sus aproximaciones máximas a nuestro satélite en lo que marca el principio de un proceso de ajuste...
New Scientist publica una entrevista con Benoît Mandelbrot, el matemático que descubrió el conjunto que lleva su nombre e hizo que el término fractal se volviera casi de uso cotidiano: A fractal life (€). (Vía Boing Boing)....
Una vez alcanzado el límite del espacio, el próximo gran desafío es poner una nave en órbita: Rules Set for $50 Million 'America's Space Prize'. El que se quiera hacer con el America Space Prize ha de construir una nave espacial capaz...
La X Prize Foundation entregó ayer de forma oficial el cheque de 10 millones de dólares a Mojave Aerospace Ventures, el equipo que desarrolló SpaceShipOne, el vehículo que ganó el Ansari X Prize: Winners of X Prize get their reward. De los...
Del departamento «no recuerdo de dónde he sacado este enlace», una APOD en la que se aprecia la cantidad de estelas de vapor dejadas por aviones sobre el estado norteamericano de Georgia el 29 de enero de este año: Contrail Clutter over...
La semana que viene Carl Sagan, uno de los héroes de este blog, habría cumplido 70 años de no haber fallecido prematuramente víctima del cáncer. Con tal motivo, y coincidiendo con la celebración de la IV Semana de la Ciencia, el Ilustre...
Una pequeña colección de enlaces que se me van acumulando: Los datos obtenidos por la sonda Cassini-Huygens en su primer vistazo de cerca a Titán siguen dando que pensar a los científicos: NASA Scientists Find Surface of Titan 'Very Alien', Titan Photos...
En algo menos de una hora la sonda Cassini-Huygens se colocará a unos 1.200 kilómetros de Titán, la luna más grande de Saturno, en la aproximación más cercana jamás lograda por un ingenio espacial a esta luna: Cassini-Huygens makes first close approach...
Tras tres intentos fallidos, uno de los cuales costó la vida a 16 personas en agosto del año pasado, Brasil ha conseguido al fin poner en órbita su cohete VSB-30 el pasado sábado. La fuerza aérea brasileña espera vender sus lanzadores a...
Los nombres científicos de los organismos son fundamentales a la hora de especificar claramente de qué especie se está hablando, en especial en el caso de los peces, cuyo nombre común puede cambiar varias veces en pocos kilómetros, y nadie pensaría que...
OSXplanet es un software de escritorio "vivo" de Gabriel Otte para Mac OS X que descubrí a través de Dan Gillmor. Está basado en el open source Xplanet nativo de Linux/FreeBSD, también para Windows, que a su vez se está inspirado...
La sonda Genesis se estrelló hace un mes cuando no se le abrieron los paracaídas que ayudarían a que pudiera ser recogida por helicópteros. Al parecer debían abrirse cuando un sensor de deceleración detectara el frenado durante el descenso, de 30G a...
Un equipo de la Southampton University ganó el concurso de programación The Iterated Prisoner's Dilemma Competition, celebrado con motivo del 20º aniversario del Dilema del Prisionero, con una estrategia que superó a la clásica ganadora de toda la vida, tit-for-tat, considerada invencible....
Powers of ten (Potencias de diez), para conmemorar la famosa producción de los hermanos Eames: Hoy 10 de octubre se celebra el día de Powers of Ten Es una película divulgativa que data de 1977 y trata acerca del tamaño relativo...
El Jet Propulsion Laboratory ha anunciado que un fallo en los relés que controlan los motores de dirección de dos de las seis ruedas de Spirit les ha obligado a dejarlo parado mientras ven cómo solucionar el problema o qué alternativas hay...
Aunque en un primer momento publicaron que había muerto James Watson, BBC News acaba de rectificar la noticia para indicar que en realidad ha muerto Maurice Wilkins, quien recibió el premio Nobel de Fisiología y Medicina en 1962 junto con Watson y...
Hace unos días a un equipo de una televisión alemana que filmaba la carrera de Fórmula 1 de Bahrain le llegaron rumores de que había una lanzadera espacial rusa abandonada en el desierto, decicieron investigarlos y se encontraron con que los rumores...
¿Te has fijado alguna vez como en un retrato en el que el sujeto mira al frente parece que este te esté mirando a los ojos siempre que tú lo miras? Pues al parecer durante años ese fenómeno no tuvo explicación científica,...
Hoy por la tarde se producirá el segundo lanzamiento de SS1 para hacerse con el Ansari X Prize. Como en el lanzamiento X1, se puede acceder (o intentar acceder) a un webcast del lanzamiento desde la página principal de la X Prize...
El pasado día 30 de septiembre se han fallado los premios Ig® Nobel de 2004, cuyas categorías Noradrex se ha tomado la molestia de traducir:Medicina: El efecto de la música country en el suicidio. Física: Modos de coordinación en la dinámica multisegmento...
Todavía no hay confirmación oficial por parte de la X Prize Foundation, que no se pronunciará al respecto hasta haber analizado los datos de la instrumentación de a bordo, pero al parecer al menos dos lecturas de radar no oficiales indican que...
Hoy se cumplen 50 años de la entrada en vigor del acuerdo por el que se creó el CERN, lugar en el que se han producido numerosos avances científicos y en el que Tim Berners-Lee y Robert Cailliau inventaron la web....
Mañana a partir de las tres de la tarde, hora de España (las 6 de la mañana en la costa oeste de los Estados Unidos) se podrá seguir en directo a través de Internet el lanzamiento de SpaceShipOne en el primero de...
Richard Branson y Burt Rutan han anunciado hoy que Virgin Group, la empresa de Branson, ha alcanzado un acuerdo con Mojave Aerospace Ventures, la empresa financiada por Paul Allen que está detrás del diseño de SpaceShipOne, para que esta diseñe y construya...
Cuando apenas faltan algo más de 72 horas para que SpaceShipOne realice el primero de los vuelos con los que el equipo de Burt Rutan y Paul Allen intentará hacerse con el Ansari X Prize la BBC publica una entrevista con Rutan...
Una vez más, la NASA ha decidido extender la duración de la misión de Spirit y Opportunity en Marte. Tras los cinco meses adicionales añadidos en marzo a su misión original de 90 días y a la vista de los fenomenales resultados...
2M1207A en una imagen obtenida por el Very Large Telescope del ESO Un equipo de astrónomos acaba de anunciar que han tomado lo que podría ser la primera imagen de un exoplaneta usando el VLT del Observatorio Austral Europeo, una instalación que...
El grupo de científicos encargado de analizar las imágenes de la sonda Cassini-Huygens acaba de anunciar que han descubierto un nuevo anillo de Saturno -aunque todavía no está confirmado si da la vuelta completa al planeta- y una o incluso posiblemente dos...
Si todo funciona según está previsto esta tarde, a eso de las 18:15 (hora de España), un helicóptero recogerá sobre el desierto de Utah, en los Estados Unidos, el contenedor que trae las muestras de viento solar que la sonda Genesis ha...
Mind Wide Open: Your Brain and the Neuroscience of Everyday Life. Steven Johnson. Scribner, 10 de febrero de 2004. Inglés. [ver similares] En español: La mente de par en par: Nuestro cerebro y la neurociencia en la vida cotidiana. En unas recientes...
Wired publica hoy un artículo en el que comenta las reacciones que está desencadenando Brian Feeney -el líder de The GoldenPalace.com Space Project: Powered by the da Vinci Project- con su anuncio de que piensan llevar a cabo su primer lanzamiento para...
La sonda Cassini-Huygens acaba de descubrir dos nuevas lunas de Saturno, lo que eleva el número de estas a 33, aunque se cree que una de ellas ya había sido fotografiada por la sonda Voyager en 1981. Un equipo internacional de astrónomos...
Según se acerca el final del plazo previsto en las bases del Ansari X Prize para hacerse con el premio se van produciendo más y más noticias de los diferentes equipos en liza. Aquí va un pequeño resumen de las últimas:American Mojave...
Rubicón 1, el modelo a escala de Space Transport Corporation, uno de los equipos que intenta hacerse con el Ansari X Prize, se estrelló el domingo pasado durante un vuelo de prueba. El problema fue que uno de los motores de combustible...
Ha tardado, pero parece que por fin el próximo 28 de agosto saldrá a la venta Cosmos en DVD en España. Si lees este blog, imagino que la explicación sobra, pero por si acaso, Cosmos es una de las más grandes series...
Bonita imagen tomada por la sonda Cassini-Huygens de la luna de Saturno Mimas y titulada por NASA "That's No Space Station", aka "No, no es la Estrella de la Muerte". [vía Ned Batchelder]...
Por Nacho Palou -
3 AGO 2004
Francis Crick, quien junto a James Watson y con la muchas veces ignorada ayuda de Rosalind Franklin descubrió la estructura del ADN, falleció en la noche del pasado miércoles. Este descubrimiento, por el que recibió el premio Nobel de Fisiología y Medicina...
Tal y como se esperaba, American Mojave Aerospace Ventures -el equipo de Paul Allen, Burt Rutan y Scaled Composites- ha anunciado hoy oficialmente que el próximo 29 de septiembre realizará el primero de sus vuelos con el objetivo de hacerse con el...
La X Prize Foundation ha convocado a los medios de comunicación para un acto el próximo día 27 en el que se harán varios anuncios muy importantes. Probablemente se trate del anuncio oficial de las fechas de los vuelos que intentarán hacerse...
Aunque algunos insistan en que nunca sucedió y otros en que allí se encontró mucho más de lo que nos dicen, hoy hace 35 años que Neil Armstrong y Buzz Aldrin se convirtieron en los primeros seres humanos en pisar la Luna....
En una entrevista telefónica con Wired Burt Rutan afirma que ya han identificado el origen de los problemas que tuvieron durante el vuelo del pasado 21 de junio. Durante aquel vuelo SpaceShipOne tuvo un problema con el sistema de control que hizo...
Tras casi siete años de viaje por el Sistema Solar la sonda Cassini-Huygens realizará mañana a partir de las tres de la madrugada su maniobra de inserción orbital para, si todo va bien, comenzar su misión de cuatro años alrededor de Saturno...
Aunque de momento por aquí no se van a ver muchos copos de nieve no deja de resultar curioso e interesante echarle un vistazo al sitio snowcrystals.com, enteramente dedicado a los copos y cristales de nieve: qué son, de dónde vienen, cómo...
Por Nacho Palou -
29 JUN 2004
Parece ser que que el vuelo de ayer de SpaceShipOne no fue tan suave como pareció, pues hubo varios problemas que pudieron dar al traste con todo. Hubo problemas desde con el motor, que rindió menos de lo esperado e hizo que...
Ha llegado el momento de la verdad para Burt Rutan y su equipo. 16:15: Space.com está haciendo un seguimiento en directo aquí; MSNBC tiene un feed de video aquí, pero a ratos parece estar congestionado; la BBC tiene otro feed de video...
Esta vez, síEsa era la frase que coreaba el público que llevaba a Charles Lindbergh a hombros en el aeropuerto parisino de Le Bourget hace 77 años, justo después de que aterrizara tras su épico vuelo en solitario a través del Atlántico....
Una pequeña entrevista a Manolo Toharia en Aragón Digital:P.-A la amplia mayoría de los españoles no le interesa la ciencia ¿no? R.- No y la verdad es que conocer la Ciencia con mayúsculas no les sirve para nada. Lo que hay que...
Suicide by Pseudoscience es un estupendo artículo de Bruce Sterling acerca de las consecuencias de mezclar política y ciencia que no tiene desperdicio. Habla de la administración Bush y de cómo se está cargando la investigación científica en los Estados Unidos, pero...
Scaled Composites acaba de anunciar que el próximo 21 de junio intentará alcanzar los 100 kilómetros de altura con SpaceShipOne. Si tienen éxito, el piloto, todavía por decidir, que lleve la nave en ese vuelo se convertirá en el primer civil empleado...
El próximo día 8 de este mes se producirá un tránsito de Venus frente al Sol, lo que ocurre cuando este planeta se interpone exactamente entre la Tierra y el Sol. Es el primero que ocurre desde 1882, y representa una oportunidad...
Vía Slashdot llega la noticia del descubrimiento del número primo más grande hasta la fecha: 224.036.583-1, que es el 41º primo de Mersenne. Tiene más de siete millones de dígitos (un millón más que el anterior) y fue descubierto el 15 de...
Traduzco un post de Michael en Slashdot: There Are Infinitely Many Prime Twins: R. F. Arenstorf de la Vanderbilt University ha presentado una posible demostración en 38 páginas relativa a la conjetura de los primos gemelos utilizando métodos de la teoría de...
Un equipo de aficionados a los cohetes llamado Civilian Space eXploration Team ha anunciado que su tercer cohete, llamado GoFast, lanzado ayer desde el desierto de Nevada, ha alcanzado una altura superior a los 100 kilómetros, el límite oficial del espacio. Todavía...
Falta la confirmación por parte de Scaled Composites, que prefiere terminar con el análisis de los datos antes de hacerlos públicos, pero testigos del vuelo de esta mañana de White Knight y SpaceShipOne aseguran que el vehículo suborbital alcanzó una altura de...
Ayer se celebró en el Parque de Santa Margarita de La Coruña el IX Día de la Ciencia en la Calle, organizado por la Asociación de Amigos de la Casa de las Ciencias y los Museos Científicos Coruñeses. Resulta esperanzador ver cómo...
La X PRIZE Foundation ha anunciado que ha cambiado el nombre de la X PRIZE Competition a Ansari X PRIZE Competition a modo de reconocimiento del importante donativo recibido de los empresarios de origen iraní Anousheh y Amir Ansari. El ahora llamado...
En La vida de Mercredi, algunas «posibles advertencias en los envoltorios de algunos productos teniendo en cuenta las leyes físicas», incluyendo: ADVERTENCIA: Este producto deforma el espacio y el tiempo en sus inmediaciones. ADVERTENCIA: Algunas teorías mecanocuánticas sugieren que cuando el consumidor...
... o al menos, «sólo una interpretación». Vía Boing Boing se llega a un artículo de Kathryn Cramer titulado Quantum Mechanics: Not Just a Matter of Interpretationen el que se explica algo que puede ser bastante relevante para entender cómo funciona el...
El Astronomy Picture of the Day Calendar permite recorrer un calendario que muestra todas las fotos (una por día) publicadas por la NASA durante los últimos ocho años....
Por Nacho Palou -
22 ABR 2004
El artículo Catastrophe Calculator: Estimate Asteroid Impact Effects Online se refiere a un curioso simulador de los efectos que tendría el impacto de un cometa o asteroide contra la Tierra. El cálculo se efectúa según los parámetros que le demos correspondientes al...
Por Nacho Palou -
13 ABR 2004
La Conjetura de Kepler dice que la forma más eficaz de apilar naranjas es hacerlo en forma piramidal, de tal forma que las naranjas de cada capa -excepto las de la primera, claro- se introducen en los huecos de la capa inferior....
Tal y como se esperaba la NASA ha anunciado que ha extendido la misión de los rovers marcianos hasta los 250 soles (días marcianos), casi tres veces más de lo previsto originalmente. Spirit ya ha superado los 90 soles previstos en su...
Scaled Composites realizó ayer la segunda prueba en vuelo del motor de SpaceShipOne, en la que éste se encendió durante cuarenta segundos, dándole impulso suficiente para que alcanzara los 32 kilómetros de altura y una velocidad de Mach 2, y aunque todavía...
El pasado 1 de abril el Very Large Telescope del Observatorio Austral Europeo (ESO) cumplió cinco años en servicio, lo que celebran con esta selección de las veinte mejores imágenes que se han obtenido con él. Es impresionante la calidad de las...
Un artículo publicado ayer en el diario Independent anunciaba el descubrimiento de metano en la atmósfera de Marte por parte de dos equipos independientes de la ESA y de la NASA, lo que podría ser una noticia mucho más importante que la...
Casi tres años después de un primer intento que fracasó la NASA consiguió ayer alcanzar una velocidad siete veces superior a la del sonido con el avión no tripulado X-43. Con ésto no sólo han establecido un récord de velocidad, sino que...
...en Marte. Los científicos de la NASA hicieron público ayer que los datos enviados por Opportunity les permiten afirmar casi con toda seguridad que la zona en la que está ahora mismo el rover fue en el pasado la orilla de una...
Aunque los rovers Spirit y Opportunity estaban diseñados para permanecer en funcionamiento durante 90 días marcianos (soles) este artículo de la BBC comenta que todo indica que podrían llegar a durar unos 240 soles gracias a que los paneles solares que los...
Bellísimas imágenes en Our Earth as Art, con fotografías de los Landsat. Imágenes: NASA....
Casi tres meses después del vuelo en el que rompió la barrera del sonido y en el que sufrió ligeros desperfectos al aterrizar Scaled Composites ha vuelto a realizar un vuelo de prueba de SpaceShipOne sin encender el motor. El vuelo sirvió...
El artículo Scientists Examine Image of Mars Beagle 2 Lander recoge algunas de las posibilidades manejadas por los investigadores que tratan de averiguar cuál fue el destino final de la sonda europea Beagle 2. Para tratar resolver el misterio se está investigando...
Por Nacho Palou -
10 MAR 2004
Hoy se ha hecho pública una imagen obtenida por el Hubble que muestra las galaxias más jóvenes del universo jamás vistas, las primeras en aparecer cuando tras el Big Bang las primeras estrellas volvieron a calentar el universo. Llamada Hubble Ultra Deep...
Dos divertidos blogs que relatan las andanzas de las «hermanas» spiritrover [perfil] y opportunitygrrl [perfil] por la superficie de MarteTuesday, March 2nd, 2004, 2:26 pm nya-nyah, sis! I found water first! Go me! If you haven't heard from my sister, I'm sure...
Por Nacho Palou -
4 MAR 2004
Quizás con un poco de exceso de bombo y platillo la NASA nunció ayer en una rueda de prensa que los resultados obtenidos por Opportunity confirman que en el pasado hubo agua en estado líquido en Marte, lo cual es una condición...
Una de las noticias más comentadas del mes pasado fue la clonación de células humanas por parte de científicos surcoreanos. Como os adelantaba en su momento los Museos Científicos Coruñeses se pusieron rápidamente en marcha para elaborar una Monografía de Comunicación Científica...
Después de dos aplazamientos, uno debido a las condiciones meteorológicas, y otro debido a un problema técnico, esta mañana por fin ha sido lanzada la sonda Rosetta, que tiene como objetivo acercarse al cometa 67P/Churyumov-Gerasimenko en 2014 y depositar en su superficie...
Yahoo! España entrevista a Manuel Toharia acerca de Atlantia, el programa de divulgación científica que presenta en TVE en la madrugada del domingo al lunes. No está nada mal el dato de audiencia que da en la entrevista:¿Cree que su programa tiene...
Recordé al leer en Chicle «No podía perder esta oportunidad» que hoy es 29 de febrero, un día que sólo existe cada cuatro años. Hace poco un amigo me envió la página de las Preguntas Frecuentes sobre Calendarios donde se pueden encontrar...
En Habitablezone han creado un navegador para acceder rápidamente a todas las imágenes enviadas por Spirit y Opportunity, los rovers marcianos de la NASA, organizadas por cámara y Sol (día marciano). Ojo, que a mi no me ha funcionado ni con Microsoft...
Es una curiosa coincidencia que apenas unos días después de que la ESA haya dado oficialmente por perdida a la sonda Beagle 2 un arqueólogo británico haya anunciado que cree haber encontrado los restos del HMS Beagle, el barco en el que...
La noticia científica de hoy es sin duda que unos científicos surcoreanos han conseguido por primera vez en la historia clonar embriones humanos y que a partir de ellos han conseguido células madre. Estas células, con el tiempo, podrían llegar a ser...
Finalmente la Agencia Espacial Europea ha tenido que rendirse a la evidencia y admitir mediante este comunicado de prensa que la Beagle 2 ha resultado perdida. Como es normal en estos casos, se nombrará una comisión que intentará esclarecer los posibles motivos...
Anoche comenzó en Televisión Española la emisión de Atlantia, el programa de divulgación científica presentado por Manuel Toharia. En este primer programa el tema a tratar era la posible existencia de vida más allá de La Tierra, y la verdad es que...
Esta mañana Opportunity ha bajado de su plataforma de aterrizaje y por fin ha pisado la superficie de Marte, 24 horas antes de lo inicialmente planeado. Esta es la nota de prensa de la NASA, con un enlace a las imágenes y...
La revista Nature publica un artículo acerca de un experimento realizado en la universidad de Lübeck (Alemania) que parece confirmar que dormir ayuda a pensar mejor los problemas y resolverlos, lo que daría validez científica a la expresión «voy a consultarlo con...
Igual que he criticado a TVE por emitir Planeta Encantado (y no he sido el único) me parece justo felicitarla por el anuncio de la próxima emisión de Atlantia, un programa de divulgación científica presentado por Manuel Toharia que se emitirá a...
Si todo va según lo previsto esta madrugada a eso de las 5:05 UTC la sonda Opportunity, que forma junto con la Spirit la Mars Exploration Rover Mission de la NASA, se posará en Marte. Mientras tanto, Spirit sigue teniendo serios problemas...
Mientras la NASA sigue intentando recuperar el contacto con Spirit, la ESA acaba de confirmar en una rueda de prensa que la Mars Express ha detectado agua -en forma de hielo, naturalmente- en el polo sur de Marte, lo que supone un...
A pesar de que la Beagle 2 sigue sin dar señales de vida, su compañera de viaje, la Mars Express, está enviando unas estupendas imágenes de Marte, de las que la Agencia Espacial Europea ha escogido una a modo de aperitivo de...
Por fin la sonda Spirit ha abandonado su plataforma de aterrizaje y ya está directamente sobre la superficie de Marte. Esta mañana ha terminado la maniobra que le permitió bajarse de ésta evitando el airbag que podría haber entorpecido su salida por...
NASA ha publicado la primera actualización de la versión pública del programa Maestro, un software muy similar al utilizado por los científicos para operar las sondas de la misión Mars Express Rovers. Ahora viene acompañado con datos reales enviados por las sondas...
Por Nacho Palou -
8 ENE 2004
Hoy era el primer día en el que la Mars Express sobrevolaba el supuesto punto de aterrizaje de la Beagle 2 tras haber cambiado su órbita de inserción ecuatorial por una polar desde la que cumplirá su misión, y desde el control...
Después del fracaso de la sonda japonesa Nozomi y de la incertidumbre acerca del destino de la Beagle 2, esta próxima madrugada el Spirit intentará posarse en Marte para recorrer su superficie durante 90 días e intentar averiguar que papel puede haber...
Si todo va según lo previsto, la sonda Beagle 2 se posará en Marte en la madrugada del día de Navidad tras haberse separado del Mars Express este pasado fin de semana; aprovechando tal evento, os propongo unos cuantos enlaces sobre astronomía...
Mientras ayer se conmemoraba el centenario de la aviación en las colinas de Kitty Hawk, Scaled Composites realizó el primer encendido en vuelo del motor de SS1, la nave suborbital con la que pretende hacerse con el ">X Prize. Tras ser lanzado...
Hace años que la NASA publica la imagen astronómica del día acompañada de una breve explicación escrita por un astrónomo profesional en Astronomy Picture of the Day, pero si eres usuario de Macintosh, hay una pequeña utilidad donationware llamada APOD Grabber que...
La pasado 4 de diciembre tuvo lugar un nuevo vuelo de prueba de SS1 en el que además de realizar una serie de pruebas de maniobrabilidad y estabilidad con fuerzas de hasta 4g se llevó a cabo una prueba en frío de...
El otro día hablábamos de la página de los números primos y de que se había descubierto el mayor hasta la fecha, con unos 6,3 millones de dígitos. Casi al mismo tiempo se anunciaba la factorización del RSA-576, un número cuasi-primo de...
Luis Javier Capote Pérez, miembro de ARP - Sociedad para el Avance del Pensamiento Crítico, ha redactado un manifiesto acerca de Planeta Encantado al que se puede adherir quien lo desee en el que se denuncia cómo J. J. Benítezintenta presentar como...
En The Prime Pages se puede encontrar de todo sobre los números primos: Los primos más grandes, listas de números primos, métodos para comprobar la primalidad, lista histórica de los primos más grandes descubiertos en cada año, récords... en fin, toda una...
Mientras se acerca el 17 de diciembre, día que marca el centenario de la aviación, Scaled Composites ha llevado a cabo el sexto vuelo de prueba de SpaceShipOne (SS1) el pasado día 19, lo que representa dos vuelos de prueba en otras...
El Pamplonetario celebra estos días su décimo aniversario, motivo por el que se han reunido allí representantes de centros de ciencia de toda España, reunión que han aprovechado para firmar la Declaración de Pamplona, en la que se renueva la apuesta por...

E=mc²: La biografía de la ecuación más famosa del mundo. David Bodanis. Traducido por Juan María Madariaga López de Sa. Amat Editorial (4 de febrero de 2020). 307 páginas. Este libro ha sido todo un descubrimiento, uno de los mejores libros de...
El famoso Jet Propulsion Laboratory de la NASA acaba de hacer pública esta semana la imagen PIA04866: Cassini Jupiter Portrait, a la que se considera como mejor fotografía de Júpiter jamás tomada, y creo que razón no les falta, obtenida de datos...
Scaled Composites acaba de publicar los resultados del quinto vuelo de prueba de SpaceShipOne, la nave con la que pretende ganar el X Prize. Con un nuevo piloto a los mandos, la nave mostró de nuevo que las modificaciones hechas tras el...
Uno de los grandes desafíos -si no el mayor- de la ciencia actual es dar con una teoría unificada que explique las cuatro fuerzas fundamentales que gobiernan el funcionamiento básico de nuestro universo (fuerza de gravedad, electromagnética, nuclear fuerte y nuclear débil)...
Dedicarse a la ciencia tiene un halo de glamour que no siempre se corresponde con la realidad, ya que llegar a algún resultado útil requiere por lo general horas y horas de trabajo y dedicación, y en algunas ocasiones se trata de...
Scaled Composites sigue dando pasos adelante en su carrera por hacerse con el X Prize y el pasado 17 de octubre llevó a cabo el cuarto vuelo de prueba de SpaceShipOne para comprobar si las modificaciones hechas a la nave tras una...
Me ha parecido muy curiosa la historia que reproduce Javier Armentia en su blog acerca de como el propio Pedro Duque descubrió apenas unos días antes de despegar hacia la Estación Espacial Internacional que no es cierto que haya que utilizar bolígrafos...
Los enigmas del Cosmos. Vicente Aupí (2001). Este comentario de Etxe de hace unos días me hizo pensar en lo mucho que nos queda por aprender en general y acerca del universo en particular y me recordó este libro que ya leí...
Hoy a la 1:00 GMT se ha producido el lanzamiento primera misión espacial tripulada china, en el primer día de la ventana de lanzamiento que especificaba el gobierno chino en China's first manned spacecraft to blast off next week el pasado viernes....
Scaled Composites está dando muy poca publicidad a los vuelos de prueba que está llevando a cabo con el objeto de hacerse con el X Prize, que dará diez millones de dólares a la primera empresa privada que consiga llevar una nave...
Your Sky, un planetario interactivo vía web similar a Voyager o StarryNight (algo más limitado) pero muy rápido (nada de applets), lo suficientemente completo y con la ventaja de estar disponible desde cualquier ordenador -con conexión. Funciona bastante bien y se configura...
Por Nacho Palou -
6 OCT 2003
Ayer se anunciaron los ganadores de las diez categorías de los premios Ig® Nobel de 2003, entre ellos:• Ingeniería: John Paul Stapp, Edward A. Murphy, Jr., y George Nichols por formular en 1949 la famosa Ley de Murphy: «Si algo puede ir...
Si todo sale según lo previsto esta noche a partir de las 23:02 TU un cohete Ariane 5 lanzará la primera sonda espacial europea con destino a la Luna desde la Guayana. La misión científica de SMART-1 es realizar un completo mapa...
Esta tarde, a las 18:57 UTC, la sonda espacial Galileo se precipitará en las profundidades de la atmósfera de Júpiter, poniendo fin a una de las misiones espaciales de más éxito de los últimos años. Lanzada en 1989, Galileo realizó un largo...
Una de las primeras consecuencias de la asunción por parte de la NASA de las conclusiones del informe sobre el accidente del Columbia ha sido el anuncio de que acelerará el desarrollo del Orbital Space Plane, una pequeña nave espacial diseñada para...
El Asiento del Alma cuenta algunas cosas interesantes sobre uno de los mitos que más han circulado, sobre todo entre los promotores y creyentes en las pseudociencias: que las personas solamente usamos un 10 por ciento de nuestro cerebro: Esta afirmación pudo...
Hace poco han terminado las pruebas estáticas de los dos motores que Scaled Composites está considerando para propulsar su nave SpaceShipOne a la conquista del X Prize. Al parecer ambos han funcionado sin problemas durante el tiempo requerido, aunque no se han...
Esta noche sería la noche ideal para que los marcianos de La Guerra de los Mundos de H. G. Wells lanzaran sus naves a la conquista de la Tierra ya que ésta y Marte alcanzaron hoy su máxima aproximación en los últimos...
Al final se ha demostrado científicamente que la Gallina fue antes que el Huevo. La prueba empírica la da Alice Shirrell en el último número del siempre jocoso AIR (Annals of Improbable Research): Which Came First ? The Chicken Or the Egg?...
Dentro de una semana Marte estará tan cerca de la Tierra cómo no lo ha estado desde hace al menos 60.000 años, situándose a sólo 55.758.006 kilómetros de nuestro planeta, o lo que es lo mismo, a sólo 3 minutos y 6...
Alvy se preguntaba cómo se ponen en hora los relojes atómicos que sirven como referencia a otros relojes… y en lo que podría llegar a convertirse en una costumbre en Microsiervos, esta pregunta tiene una respuesta más complicada de lo que a...
El pasado 7 de agosto Scaled Composites llevó a cabo el primer vuelo independiente de SpaceShipOne, lo que los acerca un poco más a la posibilidad de ganar el X Prize. El SS1 fue llevado a una altura de 14.300 metros por...
Aprovechando que Albert Einstein ha sido hoy el protagonista de nuestra imagen del día, os recuerdo que desde hace algún tiempo se pueden consultar al fin en línea los más de 900 manuscritos de Einstein depositados en el Archivo Albert Einstein de...
Aunque la promesa de un acceso fácil y barato al espacio fue el principal argumento utilizado para vender el desarrollo de la lanzadera espacial lo cierto es que desde su primer vuelo el 12 de abril de 1981 hasta el momento actual...
Se ha descubierto una nueva partícula, el pentaquark. Lo cuentan en Behold the pentaquark. Se trata de cinco quarks en formación. El pentaquark ha aparecido tras treinta años de búsqueda. El descubrimiento del pentaquark, también connocido como un nuevo estado bariónico exótico,...
Cien a uno a que demostración simplificada del último teorema de Fermat es incorrecta: El alumno de la Facultad de Informática de la Universidad de Murcia Juan Manuel Dato Ruiz ha inscrito en el Registro de la Propiedad Intelectual la que asegura...
En Cuestión de escala, hasta en la Bolsa se hace referencia a este artículo de Nature: A theory of power-law distributions in financial market fluctuations [PDF] (Xavier Gabaix et al.) Es un estudio sobre las fluctuaciones del sistema financiero en diversos mercados,...
No sabía que fuera posible que exisitera un web oficial de una teoría (o teorías) de esas que enuncian los físicos teorícos, pero hela aquí: la web oficial de la Teoría de Cuerdas. Los textos son bastante amenos y divulgativos… pero desgraciadamente,...
Una académico londinense ha hecho algunos cálculos para explicar cómo sería la Película Perfecta: Según Clayton, el esquema de la película perfecta sería algo así como: 30 por ciento de acción, 17 por ciento comedia, 13 por ciento de el Bien contra...
Sucede una vez cada pocos años que Scientific American (publicada como Investigación y Ciencia en España) publica un «número perfecto» en el que todos los artículos son de lo más interesantes… incluso los de aquellas áreas que no conoces demasiado. El ejemplar...
Marisa E. Avogadro ha publicado un interesante artículo titulado «Las mujeres de la ciencia: Hipatía» a modo de mini-biografía de Hipatía de Alejandría: Fue ella quien inventó el planisferio, el idómetro, el destilador de agua, diseñó el astrolabio plano (empleado para medir...
En Una Conjetura Matemática Javier Armentia escribe largo, tendido y ameno, sobre la Conjetura de Poincaré y los Siete problemas del Milenio: Estas semanas los foros matemáticos vuelven a hervir con una noticia relativa a la conjetura de Poincaré. Un matemático ruso,...
Vía Mathpuzzle.com una elegante solución a un problema que se consideraba hasta ahora imposible de resolver: cómo doblar un papel por la mitad más de ocho veces, utilizando cualquier tipo y tamaño de papel. ¡Inténtalo! Resulta muy educativo por su sencillo planteamiento...
Un recordatorio importante: El moderno estudio del Caos comenzó en el decenio de 1960, con el desagradable hallazgo de que ecuaciones matemáticas muy simples podían modelar sistemas tan violentos como una cascada. Nimias diferencias de entrada llegaban a transformarse rápidamente en enormes...
En su weblog, el paleofreak asegura: He visto cosas que vosotros, primates, nunca creeríais...seguido de enlaces interesantes. Bonito blog. Apropiado homenaje....
Apareció esto en alt.sport.bowling [traduzco]: El otro día en SportsCenter dieron algunas estadísticas relacionadas con la «suerte» en los deportes. Por ejemplo, la probabilidad de hacer un «hoyo en uno» en golf es de 33.000 contra 1. En los bolos la probabilidad...
Poco a poco, poco a poco... te dan un certificado al pasar de las 2.500 unidades de trabajo en SETI@home. Estas son las estadísticas de los últimos años donando tiempo de CPU: Name alvy Results Received 2,502 Total CPU Time 3.848 years...
Y si hacemos caso a la leyenda entonces tendremos que pensar que en la tierra hay una perra menos y en el cielo una estrella más- Laika (Mecano, de su álbum Descanso Dominical) En efecto, la letra de la canción de Mecano...
La nave, que realizó su primer vuelo en 1981, ha sufrido un accidente en la maniobra de reentrada para tomar tierra en Texas con siete tripulantes a bordo. Noticia en CNN. Hace ahora 17 años (el 28 de enero de 1986) se...
Por Nacho Palou -
1 FEB 2003
Unas palabras del Profesor Doyne Farmer en el SFI, durante unas jornadas públicas de conferencias gratuitas, el IX Memorial Stanislaw Ulam: Conferencia Ulam II: Predicción Retroalimentación y Realidad: Si eres capaz de crear realidad, se hacer más difícil saber exactamente lo que...
Al parecer, Neil Armstrong [1930-] no se dió cuenta de que se había equivocado con la frase que debía pronunciar al poner el pie en la Luna hasta pasado cierto tiempo después de haber vuelto a la Tierra. Cuando los constructores del...
Hoy es el día del año que deja de funcionar el Horario de Verano (GMT +2) y volvemos a usar el horario convencional (GMT +1), de modo que atrasamos los relojes una hora y este domingo tiene 25 horas en vez de...
Es este: Dos cazadores están en el bosque cuando uno de ellos de repente cae al suelo. No parece que respire y tiene los ojos vidriosos, de modo que su amigo coge el teléfono móvil y llama al servicio de emergencias: -...
The Annotated Flatland: A Romance of Many Dimensions. Edwin Abbot, Ian Stewart. 2001. Se trata de una versión anotada del clásico Flatland: A Romance of Many Dimensions de Edwin Abbot Abbot (publicado en 1884). Ian Stewart, el autor de esta nueva...
Por un lado resulta que la velocidad de la luz podría haber descendido, como apunta Black hole theory suggests light is slowing (New Scientist) y por otro que se ha conseguido enviar señales a 4 veces la velocidad de la luz, según...
Como cada agosto, las Perseidas o Lágrimas de San Lorenzo llegan para ofrecer un espectáculo de estrellas fugaces en las claras y agradables noches de verano, cuando la Tierra atraviesa la órbita del cometa Swift-Tuttle. El periodo de este cometa, el tiempo...
Por Nacho Palou -
12 AGO 2002
Ayer comenté algo sobre problemas matemáticos abiertos, como el de demostrar si P=NP dentro de la teoría de complejidad computacional. Una lista de los clásicos es Mathematical Problems, by Professor David Hilbert, que data de 1900 y de la que todavía quedan...
Se ha publicado un artículo, titulado Primes is in P que demuestra que la primalidad de un número está dentro de P (es decir, dentro de las soluciones de problemas en tiempo polinomial, según las teorías de complejidad computacional). Lo cual está...
Velocidad de la sonda Voyager: Resulta que es exactamente de 3,6 UA por año. Sabiendo lo que es una Unidad Astronómica, el resultado es que la Voyager 1 viaja a 61.400 kilómetros por hora, o 17 kilómetros por segundo. Esto se refiere...
explica alguna de las tonterías más tontas que se pueden hacer con los números, como comprobar su popularidad durante años en los buscadores....
